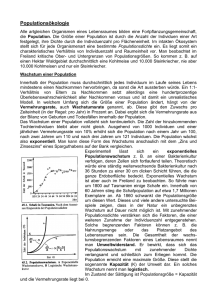
Einführung in Statistik - uni
Werbung

Einführung in Statistik Sven Mostböck 2011 Introduction to statistics -1- Teil 1 Part 1 Haarfarbe und Körpergröße sind nicht dasselbe. Hair color is not the same as body size. Die verschiedenen Arten von Daten und wie sie eine Population beschreiben. Understanding the different flavours of data and how to use them to describe a population. -2- Daten Data Mensch Human • Haarfarbe • hair color • Geschlecht • sex • Postleitzahl • zip code • Gesundheitszustand • health • Körpertemperatur • body temperature • Geburtsdatum • date of birth • Größe • size • Gewicht • weight • Alter • age -3- Daten Data Mensch • Haarfarbe • blond, schwarz, rot, brünett • Geschlecht • männlich, weiblich • Postleitzahl • 93047, 93053, etc nominale Daten Human • hair color • blonde, black, red, brunette • Sex • male, female • zip code • 93047, 93053, etc nominal data -4- Daten Data nominale Daten (Kategorien) nominal data (categories) • Reihenfolge bedeutungslos • order meaningless • rot – schwarz – blond • red – black – blonde • blond – rot – schwarz • blonde – red – black • Abstände bedeutungslos • distance meaningless • Rot ist nicht weiter weg von Schwarz als Blond • red is not farther apart from blonde than black • es gibt keinen Abstand zwischen Kategorien • there is no distance between categories • Verhältnisse bedeutungslos • Rot ist nicht doppelt so haarfarbig wie Schwarz • ratio meaningless • red is not double as much a hair color than red -5- Daten Data Mensch • Gesundheitszustand Human • health • schlecht – normal – sehr gut • bad – normal – good =0–1–2 =0–1–2 Kategorien in festgelegter Reihenfolge categories in defined order ordinale Daten ordinal data -6- Daten Data ordinale Daten (Score, Rang) ordinal data (score, rank) • Reihenfolge wichtig • order is important • schlecht – normal – gut • bad – normal – good • [gut – schlecht – normal] • [good – bad – normal] • Abstände bedeutungslos • Was ist der „Abstand“ zwischen schlecht und gut? • Verhältnisse bedeutungslos • distances meaningless • What is the “distance” between bad and good? • ratio meaningless • 2 x schlecht = normal? • 2 x bad = normal? • 3 x schlecht = gut? • 3 x bad = good? -7- Daten Data Mensch Human • Körpertemperatur • body temperature • °C • Geburtsdatum • Datum metrische Daten ohne natürlichem Nullpunkt • °C • date of birth • date metric data without a natural zero -8- Daten Data metrische Daten ohne natürlichem Nullpunkt metric data without natural zero • Reihenfolge wichtig • order is important • 37°C – 38°C – 39°C • Abstände wichtig • 37°C – 38°C – 39°C • distance is important • 38°C – 37°C = 37°C – 36°C • 38°C – 37°C = 37°C – 36°C • 14.07.11 – 12.07.11 = 10.06.08 – 08.06.08 • 14.07.11 – 12.07.11 = 10.06.08 – 08.06.08 • Verhältnisse bedeutungslos • ratio meaningless • 50°C ist nicht doppelt so heiß wie 25°C • 50°C is not double as hot as 25°C • Kann man Kalenderdaten multiplizieren? • Can you multiply calendar dates? -9- Daten Data Mensch Human • Größe – cm • size – cm • Körpergewicht – kg • weight – kg • Alter – Jahre • age – years metrische Daten mit natürlichem Nullpunkt metric data with natural zero - 10 - Daten Data metrische Daten mit natürlichem Nullpunkt metric data with natural zero • Reihenfolge wichtig • order is important • 5 kg – 6 kg – 7kg • Abstände wichtig • 5kg – 6 kg = 10 kg – 11 kg • Verhältnisse wichtig • 2 x 10 kg = 20 kg • 5 kg – 6 kg – 7kg • distance is important • 5kg – 6 kg = 10 kg – 11 kg • ratio is important • 2 x 10 kg = 20 kg - 11 - Daten Data Nominalskala categorical variable nominale Daten Rangskala ordinal variable ordinale Daten Intervallskala interval variable metrische Daten ohne Nullpunkt Verhältnisskala ratio variable metrische Daten mit Nullpunkt - 12 - Daten Nominalskala • Kategorien Farben Postleitzahlen Data categorical variable Rangskala ordinal variable Intervallskala interval variable Verhältnisskala ratio variable • categories, colors, zip codes - 13 - Daten Nominalskala Rangskala Data categorical variable • Film-Noten, Scores ordinal variable Intervallskala interval variable Verhältnisskala ratio variable • Movie marks, scores - 14 - Daten Data Nominalskala categorical variable Rangskala ordinal variable Intervallskala Verhältnisskala • Kalenderdaten, Temperatur in °C • willkürlicher 0-Wert interval variable • dates, temperature in °C • arbitrary 0 ratio variable - 15 - Daten Data Nominalskala categorical variable Rangskala ordinal variable Intervallskala interval variable Verhältnisskala • °K, m, kg • absolut definierter Nullwert ratio variable • °K, m, kg • 0 is defined in an absolute way - 16 - Population Gesamtheit der Subjekte, um die es geht Population Sum of all subjects of interest • Die Menschheit • Humanity • Die weibliche Menschheit • female humans • Die Studenten am Institut • at the institute - 17 - Population Population deskriptive Statistik descriptive statistics Beschreibende Analyse der Population Descriptive analysis of the population • Nominalskala (Haarfarbe) • categorical (hair color) • Rangskala (Klassifizierung der Gesundheit) • ordinal (state of health) • Verhältnisskala (Gewicht) • Ratio variables (weight) Zusammenfassung der Daten Mittelwert? Summary of the data average? - 18 - Population Population Mittelwert mean Mittelwert Mean = durchschnittlicher Wert = average value • bedeutungslos bei Nominalskala [durchschnittliche Haarfarbe] • meaningless for categorical variables [mean hair color] • bedeutungslos bei Rangskala [es gibt keine „Abstände“ in einer Rangskala] • meaningless for ordinal variables [there is no „distance“] • möglich bei Intervall- und Verhältnisskala • possible for interval and ratio variables - 19 - Population Population Mittelwert mean ? 8 unit 6 4 2 0 A B - 20 - Population Population Mittelwert mean 8 unit 6 4 2 8 0 A B A B 4 8 2 6 0 A B unit unit 6 4 2 0 - 21 - Population Population Mittelwert mean 8 unit 6 4 2 0 A Die Breite der Population muss mit dem Mittelwert angegeben werden. B The width of the population has to be given together with the mean. - 22 - Population Population Normalverteilung Gaussian distribution 0.5 frequency 0.4 0.3 0.2 0.1 0.0 -5 -4 -3 -2 -1 0 1 2 3 4 5 value Wenn viele unabhängige Faktoren ein Ergebnis gleich stark beeinflussen, dann verteilt sich das Ergebnis als Normalverteilung When many independent factors influence an observation equally, then the result will follow a normal distribution. - 23 - Population Population Normalverteilung Gaussian distribution Example 1x 150 n 100 50 11 .0 10 .5 10 .0 9. 5 9. 0 0 ml • 10 ml werden pipettiert • Die Pipette liefert zufällige Mengen zwischen 9.5 - 10.5 ml • 10 ml are pipetted • The pipette delivers random volumes between 9.5 – 10.5 ml Idee aus (1) Idea from (1) - 24 - Population Population Normalverteilung Gaussian distribution Example 2x 200 n 150 100 50 22 21 20 19 18 0 ml • 20 ml werden pipettiert indem 2 x 10 ml genommen werden • Die Pipette liefert zufällige Mengen zwischen 9.5 10.5 ml • Die Variationen beginnen einander auszugleichen es gibt mehr Möglichkeiten, 20 ml zu erreichen, als 19 ml zu erreichen • 20 ml are pipetted by taking 2 x 10 ml • The pipette delivers random volumes between 9.5 – 10.5 ml • The variations balance each other out there are more combinations to reach 20 ml than to reach 19 ml - 25 - Population Population Normalverteilung Gaussian distribution Example 2x 250 200 n 150 100 50 22 21 20 19 18 0 ml • 20 ml werden pipettiert indem 2 x 10 ml genommen werden • Die Pipette liefert zufällige Mengen zwischen 9.5 10.5 ml • Die Variationen beginnen einander auszugleichen es gibt mehr Möglichkeiten, 20 ml zu erreichen, als 19 ml zu erreichen • 20 ml are pipetted by taking 2 x 10 ml • The pipette delivers random volumes between 9.5 – 10.5 ml • The variations balance each other out there are more combinations to reach 20 ml than to reach 19 ml - 26 - Population Population Normalverteilung Gaussian distribution Example 10 x 250 200 n 150 100 50 10 4 10 2 10 0 98 96 0 ml • 100 ml werden pipettiert indem 10 x 10 ml genommen werden • Die Pipette liefert zufällige Mengen zwischen 9.5 10.5 ml • Die Variationen beginnen einander auszugleichen es gibt mehr Möglichkeiten, 100 ml zu erreichen, als 98 ml zu erreichen • 100 ml are pipetted by taking 10 x 10 ml • The pipette delivers random volumes between 9.5 – 10.5 ml • The variations balance each other out there are more combinations to reach 100 ml than to reach 98 ml - 27 - Population Population Normalverteilung Gaussian distribution Example 10 x 250 200 n 150 100 50 10 4 10 2 10 0 98 96 0 ml • 100 ml werden pipettiert indem 10 x 10 ml genommen werden • Die Pipette liefert zufällige Mengen zwischen 9.5 10.5 ml • Die Variationen beginnen einander auszugleichen es gibt mehr Möglichkeiten, 100 ml zu erreichen, als 98 ml zu erreichen • 100 ml are pipetted by taking 10 x 10 ml • The pipette delivers random volumes between 9.5 – 10.5 ml • The variations balance each other out there are more combinations to reach 100 ml than to reach 98 ml - 28 - Population Normalverteilung Gaussian distribution frequency Population value • Der Durchschnitt und die Standardabweichung σ bestimmen die normalverteilte Population. • Mean and standard deviation σ define the normally distributed population. - 29 - Population Population Normalverteilung Gaussian distribution σ = SD = positive Quadratwurzel der Varianz σ = SD = positive square root of the variance = Wurzel aus Mittelwert der quadrierten Abweichungen = square root of the mean of the squared deviations = ∑ ( x − x)² n = ∑ ( x − x)² n - 30 - Population Normalverteilung Gaussian distribution frequency Population σ value Durchschnitt ± σ = 66,27% aller Ereignisse mean ± σ = 66,27% of all events Durchschnitt ± 2σ = 95,45% aller Ereignisse mean ± 2σ = 95,45% of all events - 31 - Population Population Normalverteilung Gaussian distribution 8 unit 6 σ = SD 4 2 0 A B Durchschnitt ± σ = 66,27% aller Ereignisse mean ± σ = 66,27% of all events Durchschnitt ± 2σ = 95,45% aller Ereignisse mean ± 2σ = 95,45% of all events - 32 - Population Population Normalverteilung Gaussian distribution 8 unit 6 4 2 0 A • Der Durchschnitt und die Standardabweichung σ bestimmen die normalverteilte Population. B • Mean and standard deviation σ define the normally distributed population. - 33 - Population Population Normalverteilung Gaussian distribution 8 unit 6 4 2 0 A • Der Durchschnitt und die Standardabweichung σ bestimmen die normalverteilte Population. B • Mean and standard deviation σ define the normally distributed population. - 34 - Population Population Normalverteilung Gaussian distribution 15 unit 10 5 0 A B C - 35 - Population Population Normalverteilung Gaussian distribution 15 unit 10 5 0 A • Der Durchschnitt und die Standardabweichung σ können nicht-normalverteilte Populationen nicht beschreiben. B C • Mean and standard deviation σ cannot define nonnormally distributed populations. - 36 - Population Population Median median 15 unit 10 5 0 A • Der Median ist jener Wert, bei dem 50% der Ereignisse oberhalb und 50% unterhalb liegen. B C • The median is that value, where 50% of events are above and 50% are below. - 37 - Population Population Median median 8 unit 6 4 2 0 A B C D E 1 2 3 4 5 1 2 3 4 5 6 1 2 3 3 4 5 1 2 3 3 3 4 1 2 3 3 3 3 4 • Der Median ist jener Wert, bei dem 50% der Ereignisse oberhalb und 50% unterhalb liegen. • Bei einer ungeraden Anzahl an Ereignissen ist der Median ein realer Wert dieser Ereignisse. • Bei einer geraden Anzahl an Werten ist der Median der Mittelwert der beiden mittleren Ereignisse. • The median is that value, where 50% of events are above and 50% are below. • For an odd number of events, the median is a real value of these events. • For an even number of events, the median is the mean of the two middle events. - 38 - Population Population Median median 15 unit 10 5 0 A • Der Median ist jener Wert, bei dem 50% der Ereignisse oberhalb und 50% unterhalb liegen. • Bei einer ungeraden Anzahl an Ereignissen ist der Median ein realer Wert dieser Ereignisse. • Bei einer geraden Anzahl an Werten ist der Median der Mittelwert der beiden mittleren Ereignisse. B C • The median is that value, where 50% of events are above and 50% are below. • For an odd number of events, the median is a real value of these events. • For an even number of events, the median is the mean of the two middle events. - 39 - Population Population Median median 15 unit 10 5 0 A • Der Median alleine beschreibt die Population nicht ausreichend. • SD macht keinen Sinn; die SD ist ja die Abweichung vom Mittelwert. • Beim Median verwendet man Perzentile. B C • The median by itself does not describe a population properly. • SD is meaningless; after all, the SD is the deviation from the mean. • The percentiles are used in combination with the median. - 40 - Population Population Median - Perzentile median - percentile 15 10 unit Q75 Quartile Median 5 Q25 Quartile 0 A • Die Perzentile ist jener Wert, unterhalb dessen x% der Ereignisse liegen. • Der Median ist das 50% Perzentil. • Die Quartilen sind die 25% und 75% Perzentilen. • Verwendet werden gerne auch 10/90 und 5/95 Perzentile. B C • The percentile is the value, below which x% of the events lie. • The median is the 50% percentile. • The quartiles are the 25% and 75% percentile. • 10/90 and 5/95 percentiles are also widely used. - 41 - Population Population Box-Whiskers plot Box-Whiskers plot 15 P95 Percentile Q75 Quartile unit 10 Median 5 Q25 Quartile P05 Percentile 0 A B C - 42 - Population Population Box-Whiskers plot Box-Whiskers plot 15 unit 10 5 0 A Achtung: • Es gibt viele Möglichkeiten, einen Box-Whiskersplot zu gestalten. • Die Box ist eigentlich immer 25%-Median-75%. • Die Whiskers sind iA 10/90 oder 5/95. • Manchmal wird auch der Mittelwert eingetragen. • Das muss in der Figurenlegende angegeben werden! B C Warning: • There are many ways to design a box-whiskersplot. • The box is usually 25%-Median-75%. • The whiskers are usually either 10/90 or 5/95. • Sometimes the mean is shown as well. • All this has to be defined in the figure legend! - 43 - Teil 2 Part 2 Eine Schwalbe macht noch keinen Sommer. One swallow does not a summer make. Der Unterschied zwischen Stichprobe und Population. Insbesondere: der SEM ist nicht einfach eine Möglichkeit, kleine Fehlerbalken für die Abbildung zu bekommen. Understanding the difference of investigating a sample to investigating the whole population. Special focus: the SEM is not a way to get shorter error bars for the graph. - 44 - Population Unterschiede differences frequency Population value Sind diese Populationen unterschiedlich? Are these populations different? - 45 - Population Unterschiede differences frequency Population value Sind diese Populationen unterschiedlich? Are these populations different? - 46 - Population Unterschiede differences frequency Population value Sind diese Populationen unterschiedlich? Are these populations different? - 47 - Population Unterschiede differences frequency Population value Sind diese Populationen unterschiedlich? Are these populations different? - 48 - Population Population Unterschiede differences Wenn zwei Populationen nicht absolut identisch sind (in jeder Kleinigkeit), so sind sie verschieden. When two populations are not absolutely identical (in every aspect), they are different. - 49 - Population Population Unterschiede differences Wenn zwei Populationen nicht absolut identisch sind (in jeder Kleinigkeit), so sind sie verschieden. When two populations are not absolutely identical (in every aspect), they are different. • Die Populationen sind, was sie sind. • Nur ein einziger unterschiedlicher Wert unter 100 000 identischen Werten bedeutet, dass die Populationen unterschiedlich sind. • Ein statistischer Test auf Unterschiede ist bedeutungslos. • Populations are, what they are. • Just one different value between 100 000 identical values means, that the populations are different. • A statistical test for differences is meaningless. - 50 - Population Population Stichprobe Sample Aber wir können normalerweise nicht die gesamte Population untersuchen. But we usually can't examine the complete population. Daher nehmen wir zufällige Stichproben und ziehen Rückschlüsse auf die darunterliegende Population. Therefore we take random samples and draw conclusions about the underlying population. Um diese Rückschlüsse ziehen zu können, brauchen wir statistische Tests. To draw these conclusions, we need statistical tests. - 51 - Stichprobe Die Mäuse in dem Käfig des Experimentes Sample The mice in the cage of the experiment Unsere C57BL/6 Linie Our C57BL/6 line Alle C57BL/6 dieser Welt All C57BL/6 in the world Alle Mäuse dieser Welt All mice in the world Alle lebenden und noch kommende Menschen All living and still-to-come humans - 52 - Sample frequency Stichprobe value - 53 - Sample frequency Stichprobe value - 54 - Sample frequency Stichprobe value - 55 - Stichprobe Sample deskriptive Statistik descriptive statistics Mögliche Angaben Available Information Mittelwert, SD, SEM, CI • sinnvoll bei normalverteilten Populationen • die Population muß normalverteilt sein, nicht die Stichprobe • Nur bei Intervall- und Verhältnisskalen! Mean, SD, SEM, CI • Useful for normal distributed populations • The population should follow the normal distribution, not the sample • Only for interval and ratio variables! Median, Quartilen • Sinnvoll, wenn man die Verteilung der Population nicht kennt • Wichtig bei scores! Median, Quartiles • Useful, when the distribution of the population is not known • Important for scores! - 56 - Stichprobe Sample deskriptive Statistik descriptive statistics Was bedeutet das alles? What do they mean? Mittelwert, SD; Median, Quartilen Mean, SD; Median, Quartiles • Werden aufgrund der Stichprobe berechnet und geben uns also die genauen Werte der Stichprobe • Sollten uns eine Vorstellung der jeweiligen Werte der Population geben • Können, je nach Pech, stark von den wirklichen Werten der Population abweichen • Are calculated from the sample and give us the exact values of the samples • Should give us an idea about the values of the population • May, depending on your bad luck, vary wildly from the actual values of the population - 57 - Stichprobe Sample deskriptive Statistik descriptive statistics Sample 1 Sample 2 value - 58 - Stichprobe Sample deskriptive Statistik descriptive statistics Was bedeutet das alles? What do they mean? SEM SEM • Auch einfach als SE bekannt • Standardfehler des Mittelwertes • Gibt an, welchen Fehler der Mittelwert der Stichprobe im Vergleich zum Mittelwert der Population hat • Gibt eine Vorstellung, wie sehr der gesehene Mittelwert von dem eigentlichen Mittelwert abweicht • Also known as SE • Standard error of the mean • Defines the error of the mean of the sample with respect to the mean of the population • Ergibt sich mit: SEM = SD/√n • je größer die Stichprobe, desto wahrscheinlicher ist der gefundene Mittelwert korrekt • Calculated by: SEM = SD/√n • the larger the sample, the higher the probability, that the found mean is correct • Gives an idea about how far the found mean differs from the real mean - 59 - Stichprobe Sample deskriptive Statistik descriptive statistics ? ? Sample 1 Sample 2 value - 60 - Stichprobe Sample deskriptive Statistik descriptive statistics ?? Sample 1 Sample 2 value - 61 - Stichprobe Sample deskriptive Statistik descriptive statistics Was bedeutet das alles? What does that mean? • Stichproben sind zufällig aus der Population gezogen • Samples are randomly chosen from the population. • Daher können alle Rückschlüsse von den Stichproben nur eine gewisse Wahrscheinlichkeit haben. • Therefore, all conclusions based on samples have a certain probability. • Es können keine exakten Aussagen über die zugrundeliegende Population gemacht werden! • No exact statements about the population can be made! • Ab sofort dreht sich alles nur noch um die Wahrscheinlichkeit der Schlussfolgerungen! • From now on, everything here deals with the probabilities of our conclusions! - 62 - Stichprobe Sample deskriptive Statistik descriptive statistics Was bedeutet das alles? SEM • Mit welcher Wahrscheinlichkeit umfasst der Mittelwert der Stichprobe ± SEM den Mittelwert der Population? What do they mean? SEM • What is the probability, that the range of the mean of the sample ± SEM includes the mean of the population? sehr schwer zu sagen, da diese Wahrscheinlichkeit auch von n abhängt very difficult to calculate, as this probability additionally depends on n! besser den CI verwenden better use the CI - 63 - Stichprobe Sample deskriptive Statistik descriptive statistics Was bedeutet das alles? What do they mean? CI • Vertrauensbereich eines jeweiligen Wertes • Kann im Prinzip für alles berechnet werden • Üblich ist der CI des Mean CI • Confidence interval of a given value • Can be calculated for everything • Commonly, the CI of mean is used • Das 95% CI des Mean einer Stichprobe bedeutet, dass dieser Bereich mit 95% Wahrscheinlichkeit den Mittelwert der Population enthält. • The 95% CI of the mean of a sample means that the mean of the population falls within that range with a probability of 95%. Anders gesagt, in 1 von 20 Fällen enthält dieser Bereich den Mittelwert der Population nicht. In other words, in 1 of 20 cases, this range does not include the mean of the population. - 64 - Stichprobe Sample deskriptive Statistik descriptive statistics Was bedeutet das alles? What do they mean? CI • Berechnung: CI • Calculation: • • • • Am besten einfach vom Statistikprogramm ausgeben lassen. Let a statistics program do it for you. Ansonsten in Excel: CI = SEM*TINV(1-Wahrscheinl.; Freiheitsgrad) Freiheitsgrad = Stichprobengröße -1 In Excel: CI = SEM*TINV(1-probability; degrees of freedom) degrees of freedom = sample size -1 zB: Gewünscht ist der 95% CI 0.95 Wahrscheinlichkeit Gruppengröße n = 3 CI = SEM*TINV(0,05;2) CI = SEM*4,303 for example: Wanted is the 95% CI 0.95 probability Sample size n = 3 CI = SEM*TINV(0.05;2) CI = SEM*4.303 • • • • - 65 - Stichprobe Sample deskriptive Statistik descriptive statistics 6 unit 4 2 0 Scatter SD SEM 95% CI - 66 - Stichprobe Sample deskriptive Statistik descriptive statistics 4 4 unit 6 unit 6 2 2 0 0 Scatter SD SEM 95% CI Scatter SD SEM 95% CI - 67 - Stichprobe Sample deskriptive Statistik descriptive statistics 4 4 unit 6 unit 6 2 2 0 0 Scatter SD SEM 95% CI • SD wird nicht durch die Stichprobengröße verändert • SEM and CI werden kleiner mit größere Stichprobe der Mittelwertsbereich wird wahrscheinlicher Scatter SD SEM 95% CI • SD is not affected by sample size • SEM and CI get smaller with sample size the range of the mean gets more probable - 68 - Stichprobe Sample deskriptive Statistik descriptive statistics Zusammenfassung Summary SD • Breite der Stichprobe • Wird der SD der Population ähnlicher mit großer Stichprobe • „ähnlicher“ kann bedeuten, dass die SD sich vergrößert SD • Width of the sample • Comes closer to the SD of the population with large sample sizes „closer“ can mean, that the SD becomes larger SEM • Der Fehler des Stichproben-Mittelwertes im Vergleich zum Populations-Mittelwert • Wird kleiner mit größeren Stichproben SEM • The error of the sample-mean in comparison to the population-mean • Gets smaller with larger sample sizes 95% CI • Jener Bereich, der zu 95% Wahrscheinlichkeit den Mittelwert der Population beinhaltet • Wird kleiner mit größeren Stichproben 95% CI • The range, that includes the mean of the population with a 95% probability • Gets smaller with larger sample sizes - 69 - Stichprobe Sample Stichprobengröße sample size The influence of n on sample mean mean of replicates 150 pop mean 50 • Aus einer normalverteilten Population wurden je 100 x 2, 3, 5 oder 10 Werte gezogen • Von jeder Stichprobe wurde der Mittelwert berechnet und hier Idee aus (1) aufgetragen n= 10 n= 5 n= 3 n= 2 0 • From a normally distributed population, 100 samples of 2, 3, 5, or 10 values were taken • Of each sample, the mean was calculated and graphed Idea from (1) - 70 - Stichprobe Sample Stichprobengröße sample size The influence of n on SD 80 SD of replicates 60 40 pop SD 20 • Aus einer normalverteilten Population wurden je 100 x 2, 3, 5 oder 10 Werte gezogen • Von jeder Stichprobe wurde die Standardabweichung berechnet und hier aufgetragen Idee aus (1) n= 10 n= 5 n= 3 n= 2 0 • From a normally distributed population, 100 samples of 2, 3, 5, or 10 values were taken • Of each sample, the SD was calculated and graphed Idea from (1) - 71 - Stichprobe Sample deskriptive Statistik descriptive statistics Was sollte man verwenden? What should we use? SD • Wenn man die Stichprobe genau definieren will • Gibt Hinweis auf die SD der Stichprobe (wenn auch nur mit einer gewissen Wahrscheinlichkeit) SD • When you want to define the sample more precisely • Gives an idea about the SD of the population (though only with a certain probability) 95% CI • Wenn man definieren will, in welchem Bereich der Mittelwert der Population zu 95% liegt • Wenn also der Mittelwert wichtig ist, aber die SD eigentlich nicht so wichtig 95% CI • When you want to show, in what range the mean of the population lies to 95% probability • So when the mean is important, but the SD is not SEM • Eigentlich nur, wenn man kurze Fehlerbalken möchte und die Leser verwirren will • Aber wir wissen nun ja alle, wie man aufgrund des SEM auf SD und 95% CI rückrechnen kann … • ACHTUNG: immer die Stichprobengröße angeben, wenn man den SEM zeigt! SEM • Only if you want a short error bar and like to confuse the readers • But we all know now how to calculated the SD and 95% CI based on the SEM … • IMPORTANT: always give the sample size when using the SEM! - 72 - Stichprobe Sample Ausreißer Outlier 200 value = 150 100 50 0 value • Ist das ein Ausreißer? • Nein! Es ist ein Wert der Population. Damit muss man leben. group • Is this an outlier? • No! This is a value of the population. Live with it. - 73 - Stichprobe Sample Ausreißer Outliers Woher weiß man, dass ein Wert ein Ausreißer ist? How do you know that a value is an outlier? • Eine sehr schwere Frage • A very difficult question • Zuerst: gibt es einen Grund, weshalb dieser Wert ein Ausreißer sein könnte? (Pipettierfehler, etc). • First: is there a reason, why this particular value is an outlier? (pipetting errors, etc) • Das einfachste ist ein Wert, der außerhalb des biologisch oder technisch sinnvollen liegt Fehler in der Technik • The simplest case is a values that lies outside the biologically or technically reasonable Error in the method • Ein nur sehr hoher oder sehr niedriger Wert könnte einfach ein Wert am Rande der Normalverteilung sein. Solch ein Wert sollte in der Analyse verbleiben! • A value that is just quite high or low could simply be a value from the edge of the normal distribution. Such a value should remain in the analysis! • Man sollte die Ausreißer nicht händisch entfernen – dann betrügt man sich nur selber und nimmt jene Werte weg, die das erwünschte Ergebnis stören. • You should not remove outlier manually – usually you'll simply fool yourself and remove these values, that disturb the wanted result. • Benutze den „Grubbs Test“ auf www.graphpad.com/quickcalcs/Grubbs1.cfm • Use the „Grubbs' Test“ on www.graphpad.com/quickcalcs/Grubbs1.cfm - 74 - Stichprobe Sample Experiment experiment Die Teilnehmer ziehen eine Stichprobe. The participates draw a sample. - 75 - Teil 3 Part 3 Ein * macht es nicht wahr. A * does not mean it is true. Der t-test: was ist ein „statistisch signifikanter Unterschied“? Wann kann der t-test verwendet werden? Understanding the t-test: what is a “statistical significant difference”? When can the t-test be used? - 76 - Stichprobe Sample Experiment experiment Population Population Histogram 60 100 40 0 15 0 0 10 0 20 0 50 50 n value 150 value Die Gesamtpopulation, aus der die Stichprobe stammt. The population that was used to get the sample. - 77 - Stichprobe Sample Experiment experiment Samples taken by audience Die Stichproben, die vom Publikum gezogen wurden. The samples taken by the audience. - 78 - Statistische Tests Statistical tests Das Problem: The problem: • Stichproben werden zufällig gezogen • Samples are picked randomly • Mittelwerte und SD zweier Stichproben werden selten exakt gleich sein • Mean and SD of two samples are rarely going to be exactly the same • Ist das nun wegen einer zufälligen Abweichung beim zufälligen Ziehen? • Is that based on a random variation when picking the samples? • Oder ist das weil die Stichproben von zwei unterschiedlichen Populationen stammen? • Or is that because the two samples come from two different populations? - 79 - Statistische Tests Statistical tests Statistische Tests beantworten folgende Frage: Statistical tests answer the following question: Wie hoch ist die Wahrscheinlichkeit, dass zwei getrennte Stichproben von Populationen mit dem gleichem Mittelwert stammen? What is the probability, that two separate samples come from the population with the same mean? - 80 - Statistische Tests Statistical tests t-test Student’s t-test p= 0.0285 8 unit 6 4 2 0 A Wie hoch ist die Wahrscheinlichkeit, dass zwei getrennte Stichproben von der gleichen Population stammen? B What is the probability, that two separate samples come from the same population? - 81 - Statistische Tests Statistical tests t-test Student’s t-test p= 0.0285 8 unit 6 4 2 0 A B Genauer gesagt: More precise: p ist die Wahrscheinlichkeit, dass zumindest dieser Mittelwertsunterschied gesehen werden kann, wenn Stichproben dieser Größe von zwei Populationen genommen werden, die eigentlich den gleichen Mittelwert haben. p is the probability that at least as large a difference in the mean of two samples of that size is seen when the underlying populations have in fact the same mean.(1) Mit einer Wahrscheinlichkeit von 2,85% kann zumindest dieser Unterschied in Mittelwerten von zwei Stichproben von Größe 10 auftreten, wenn die Populationen eigentlich den gleichen Mittelwert haben. With a probability of 2.85% at least that difference in the means of two samples of size 10 is seen, when the populations have actually the same mean. - 82 - Statistische Tests Statistical tests Student’s t-test t-test Genauer gesagt: More precise: p ist die Wahrscheinlichkeit, dass zumindest dieser Mittelwertsunterschied gesehen werden kann, wenn Stichproben dieser Größe von zwei Populationen genommen werden, die eigentlich den gleichen Mittelwert haben. p is the probability that at least as large a difference in the mean of two samples of that size is seen when the underlying populations have in fact the same mean. Mit einer Wahrscheinlichkeit von 2,85% kann zumindest dieser Unterschied in Mittelwerten von zwei Stichproben von Größe 10 auftreten, wenn die Populationen eigentlich den gleichen Mittelwert haben. With a probability of 2.85% at least that difference in the means of two samples of size 10 is seen, when the populations have actually the same mean. Es gibt eine 2,85% Wahrscheinlichkeit, dass man zumindest solch einen Unterschied sieht, obwohl die Populationen identisch sind. There is a 2.85% chance of observing a difference as large as observed even if the two population means are identical. Es gibt eine 2,85% Wahrscheinlichkeit, dass die Null-Hypothese korrekt ist. There is a 2.85% chance that the null hypothesis is true. Zufällige Stichproben von identischen Populationen würden in 97,15% aller Fälle zu geringeren Unterschieden und in 2,85% aller Fälle zu diesem oder höheren Unterschiede führen. Random sampling from identical populations would lead to a difference smaller than observed in 97.15% of experiments, and larger than observed in 2.85% of experiments. NICHT Es besteht eine 97,15% Wahrscheinlichkeit, dass der beobachtete Unterschied einen wirklichen Unterschied zwischen den Populationen widerspiegelt, und eine 2,85% Wahrscheinlichkeit, dass der Unterschied rein zufällig ist. NOT There is a 97.15% chance that the difference observed reflects a real difference between populations, and a 2.85% chance that the difference is due to chance. (1) - 83 - Statistische Tests Statistical tests Nullhypothese Null hypothesis Nullhypothese: Null hypothesis: • • Reihenfolge eines statistischen Tests 1. Zuerst definiert man eine Nullhypothese. Procedure of a statistical test 1. Diese Nullhypothese ist normalerweise „kein Unterschied“ [also das Gegenteil von dem, was einen eigentlich interessiert] First, define a null hypothesis. This null hypothesis is usually „no difference“ [the opposite of what you are interested in] 2. Man definiert nun einen Schwellenwert, ab dem man die Nullhypothese verwirft. 2. Define a threshold of rejecting the null hypothesis. 3. Der Test untersucht dann die Wahrscheinlichkeit, mit der die Nullhypothese korrekt ist. 3. The statistical test now evaluates the probability, that the null hypothesis is true. 4. Wenn diese Wahrscheinlichkeit niedriger ist als der Schwellenwert, so ist die Nullhypothese verworfen. 4. When this probability is lower than the threshold, reject the null hypothesis. - 84 - Statistische Tests Statistical tests Nullhypothese Null hypothesis Nullhypothese: Null hypothesis: • • Reihenfolge eines statistischen Tests: zB: Procedure of a statistical test: For example: • Nullhypothese: Die Population der Stichproben A und B haben die gleichen Mittelwerten. • Null hypothesis: The populations of samples A und B have the same mean. • Schwellenwert: 0.05 • threshold: 0.05 • t-test: p=0.0285 • t-test: p=0.0285 Mit einer Wahrscheinlichkeit von 0.0285 ist die Nullhypothese richtig. • 0.0285 < 0.05 Nullhypothese wird verworfen Der Unterschied ist statistisch signifikant. The null hypothesis is correct with a probability of 0.0285. • 0.0285 < 0.05 null hypothesis is rejected The difference is statistically significant. - 85 - Statistische Tests Statistical tests Nullhypothese Null hypothesis Nullhypothese: Null hypothesis: • „statistisch signifikant“ bedeutet: die Nullhypothese wird verworfen. Nicht mehr. • „statistical significant“ means: the null hypothesis is rejected. Nothing more. • Wenn p > Schwellenwert, so bedeutet das nicht, dass die Nullhypothese korrekt ist! • p > threshold does not mean that the null hypothesis is correct! Es bedeutet nur, dass die Nullhypothese nicht verworfen werden kann. • Der Schwellenwert ist von jedem selbst bestimmbar. Üblich sind 0.05. „Statistisch signifikant“ bedeutet NICHT • hoch • viel • wichtig • relevant It only means that the null hypothesis can't be rejected. • Everybody may select his own threshold. 0.05 is a common value. „Statistical significant“ DOES NOT mean • high • much • important • relevant - 86 - Statistische Tests Statistical tests p p Was bedeutet p nun? What does p mean? • Der beobachtete Effekt oder mehr tritt mit der Wahrscheinlichkeit p auf obwohl die Populationen den gleichen Mittelwert haben. • The observed effect or even more happens with a probability of p even though the populations have the same mean. • Bei kleinem p (p<threshold) kann folgendes sein: • For a small p (p<threshold) the following cases are possible: • The null hypothesis is still correct. A rare case has occurred. The probability for this is not defined by p, nut by the experimental layout. • Die Nullhypothese ist immer noch korrekt, es ist einfach ein seltener Zufall eingetreten. Die Wahrscheinlichkeit dafür ist nicht nur durch den p-Wert definiert, sondern auch durch das experimentelle Layout. • Die Nullhypothese ist falsch. Es besteht wirklich ein Unterschied zwischen den beiden Populationen. • Dieser Unterschied kann wichtig und interessant sein, oder biologisch komplett irrelevant. Der 95% CI des Unterschiedes kann helfen, diese Frage zu klären. Ist ein Unterschied in diesem Bereich wissenschaftlich interessant? • The null hypothesis is wrong. There is a factual difference between the means of the two populations. • This difference may be interesting and important, or biologically completely irrelevant. The 95% CI of the difference can help to decide that question. Is a difference that falls into that range scientifically - 87 interesting? Statistische Tests Statistical tests t-test Student’s t-test Was bedeutet p nun? What does p mean? • Der beobachtete Effekt oder mehr tritt mit der Wahrscheinlichkeit p auf obwohl die Populationen den gleichen Mittelwert haben. • The observed effect or even more happens with a probability of p even though the populations have the same mean. • Bei großen p (p>threshold) ist folgendes: • For a large p (p>threshold) consider the following: • Man kann nicht sagen, dass die Populationen Mittelwertsunterschiede haben. Man kann auch nicht sagen, dass die Mittelwerte gleich sind! • You can't say that the populations have a difference in their means. You can't either say that the means are the same! • Welchen Unterschied könnten die Mittelwerte haben? Dazu kann man sich wieder den 95% CI des Unterschiedes ansehen. • What difference may the means have? This can be estimated with the 95% CI of the difference. Wenn der 95% CI einen Bereich umfasst, der uninteressant ist, dann spielt es keine Rolle. Man kann beschließen, dass ein möglicher Effekt bei Gruppe B gleichgültig ist. If the 95% CI covers a range of values that is not of interest to you, it doesn't matter. You can decide that a possible effect in group B is not relevant. Wenn der 95% CI auch einen Wert umfasst, der von Interesse ist, dann kann man eigentlich gar nichts sicher aussagen. When the 95% CI covers a value that is of interest to you, you can't draw any conclusions any longer. - 88 - Statistische Tests Statistical tests t-test Student’s t-test Wann wird der t-test verwendet? When is the t-test used? 10 * value 8 6 4 2 tr ea tm en t pl ac eb o 0 groups • Vergleich von zwei Stichproben (aus normalverteilten Populationen) • Comparing to samples (from populations with Gaussian distribution) - 89 - Statistische Tests Statistical tests t-test t-test Wann wird der t-test verwendet? When is the t-test used? 15 * value 10 5 PS Su bs ta nc e A Su bs ta nc e B co nt ro lL po si ti ve ju st m ed iu m 0 groups • Vergleich von zwei Stichproben (aus normalverteilten Populationen) • Comparing to samples (from populations with Gaussian distribution) Wenn die anderen Gruppen nur technische Kontrollen sind When the other groups are just technical controls - 90 - Statistische Tests Statistical tests Paarung pairing unpaired 10 paired 10 p= 0.2252 p= 0.0212 8 4 4 2 2 0 0 • Paarung kann sein: • Das selbe Subjekt, vorher/nachher re at m en t en t Tr ea tm fo re be af te rt Tr be fo re re at m en t 6 ea tm en t 6 af te rt 8 • Pairing can be: • The same subject, before/after - 91 - Statistische Tests Statistical tests Paarung pairing unpaired age paired age 10 10 p= 0.2252 4 4 2 2 0 0 Tr ea t B en t Tr ea tm en t Tr ea tm • Paarung kann sein: • Das selbe Subjekt, vorher/nachher • Subjekte, die genau zusammenpassen • Alter, Gewicht, Wohnort Parameter, der das Subjekt definiert und möglicherweise Einfluss auf das Ergebnis hat zB transgene Mäuse unterschiedlichen Alters • Die Paarung muss vor dem Start des Experiments festgelegt werden! m en tA 6 A 6 Age 3 w 5 w 8 w 11w 15w 18w m en tB p= 0.0212 8 Tr ea t 8 • Pairing can be: • The same subject, before/after • Subjects, that match up • Age, weight, place of residency parameters, that define the subject and might have influence on the result for example transgenic mice of different age • The pairing has to be defined before the experiment is started! - 92 - Statistische Tests Verhältnis t-test Statistical tests Ratio t-test • Ein gepaarter t-test nutzt die Differenz der gepaarten Werte. • A paired t-test uses the difference of the paired values. • Das funktioniert gut, wenn die Differenz relativ stabil ist und nur die Grundlinie sich verschiebt (zB 1/3 und 3/5 als jeweils gepaarte Werte). • This works well when the difference of the values remains fairly stable and just the base line moves (for example 1/3 and 3/5 as respective paired values). • Es funktioniert schlecht, wenn die Differenz sich mit der Grundlinie verändert (zB 1/3 und 3/9). • It does not work good when the difference changes with the baseline (for example 1/3 and 3/9). • Eine mögliche Variante ist ein t-test auf das Verhältnis der beiden gepaarten Werte • A possible alternative is a t-test based on the ratio of the values - 93 - Statistische Tests Verhältnis t-test • Eine mögliche Variante ist ein t-test auf das Verhältnis der beiden gepaarten Werte: • Die Verhältnisse der Werte können nicht direkt genutzt werden für einen t-test, da das Verhältnis Control/Behandlung nicht den gleichen p liefert wie das Verhältnis Behandlung/Control • Statt dessen nimmt man den log der Verhältnisse • Das geht so: Statistical tests Ratio t-test • A possible alternative is a t-test based on the ratio of the values: • The ratios of the values can't be used directly for a t-test, as the ratios from Control/Treatment would give a different p than the ratios from Treatment/Control. • Instead, we use the log of the ratios • This is how it's done: • Die Werte der Gruppen werden zu ihrem log transformiert: y=log(y) • The values of the groups are transformed to their log values: y=log(y) • Diese Werte werden dann einfach in einem paired t-test analysiert • These values are simply analyzed in a paired t-test • Die ausgegebenen Werte für durchschnittliche Differenz und 95% CI müssen dann noch anti-log behandelt werden (y= 10y). Dies sind dann das durchschnittliche Verhältnis der Werte zueinander sowie der 95% CI der Verhältnisse der Werte. • The printed values for mean difference and 95% CI then have to be transformed to their anti-log (y= 10y). These are then the mean ratio of the values and the 95% CI of the ratio of the values. - 94 - Statistische Tests Verhältnis t-test Statistical tests Ratio t-test Control Treated Difference Ratio 4,2 8,7 4,3 0,483 2,5 4,9 2,4 0,510 6,5 13,1 6,6 0,496 Log Control Log Treated 0,6232493 0,9395192 0,39794 0,6901961 0,8129134 1,117271 paired t-test p=0.065 paired t-test p=0.0005 Mean of differences: -0,3043 Mean of ratio = 10-0,3043 = 0,496 95% CI: -0,3341 to -0,2745 95% CI of the ratios: 10-0,3341 to 10-0,2745 = 0,463 – 0,531 (1) - 95 - Statistische Tests Statistical tests einseitig / zweiseitig one-tailed / two-tailed • Es wird untersucht, mit welcher Wahrscheinlichkeit die gesehene Differenz auftreten kann. • The statistical test assays the probability of an observed difference. • Die Wahrscheinlichkeit hängt davon ab, ob die Differenz in eine oder zwei Richtungen gehen kann. • This probability depends on whether a difference can take place in one or two directions. • Dabei geht es nicht darum, was man sieht, sondern darum, was passieren könnte (theoretisch). • Normalerweise sind Versuche two-tailed die Behandlung könnte den Effekt schwächen oder verstärken • Here, what is theoretically possible is important, not what is actually seen • One-tailed nur dann, wenn nur eine Richtung Sinn macht bzw. wissenschaftlich möglich ist. Diese Richtung muss man bereits vor dem Experiment definiert haben. immer zweiseitige Tests benutzen • Usually, experiments are two-tailed the treatment could increase or decrease the effect • Only use one-tailed when just one direction makes sense / is scientifically possible. Always use two-tailed - 96 - Statistische Tests Statistical tests t-test Student’s t-test Wann kann der t-test nicht verwendet werden? When can the t-test not be used? • Populationen sind nicht normalverteilt • Achtung: es geht um die Verteilung der Population, nicht der Stichprobe. Stichproben von weniger als 10 Einzelwerten sind sowieso nicht normalverteilt. Populations do not have a Gaussian distribution Note: the distribution of the population matters, not the distribution of the sample. Samples with less than 10 values rarely have a Gaussian distribution. - 97 - Statistische Tests Statistical tests t-test Student’s t-test Wann kann der t-test nicht verwendet werden? When can the t-test not be used? • Populationen haben nicht die gleiche Varianz • Populations do not have the same variance Wenn die Varianz (SD) der Populationen nicht gleich sind, sollte der normale t-test nicht verwendet werden. When the variances (SD) of the populations differ, the Student’s t-test should not be used. Verwende die Korrektur nach Welch Use the Welch’s correction Allerdings ist der t-test recht robust gegenüber ungleichen Varianzen. However, the test is fairly robust concerning unequal variances - 98 - Statistische Tests Statistical tests t-test Student’s t-test Wann kann der t-test nicht verwendet werden? When can the t-test not be used? • Die Daten sind nicht metrisch • The data are not metric Der t-test arbeitet mit Mittelwert und Varianzen. Diese Werte machen nur bei metrischen Daten Sinn. The t-test uses mean and variances. These properties are only usable with metric data. Der t-test kann bei ordinalen Daten (scores) nicht verwendet werden. The t-test can’t be used with ordinal data (scores). - 99 - Statistische Tests Statistical tests Wann macht eine statistische Analyse Sinn? When does a statistical analysis make sense? • Technische Replikate? • Technical replicates? Beispiel: Example: Milzzellen werden aus einer Maus gewonnen. Je 106 Zellen werden in 6 wells einer Kulturplatte eingesetzt. 3 wells erhalten Substanz A, 3 wells Substanz B. Nach 48h wird die Menge an TNF in jedem well getrennt bestimmt. Spleen cells are harvested from a mouse. 106 cells each are put into 6 wells of a culture plate. 3 wells receive substance A, 3 wells substance B. After 48h, the amount of TNF is determined for each well separately. Ein Vergleich der drei Einzelwerte ergibt eine statistisch signifikant höhere Menge an TNF in den wells, die mit Substanz B behandelt wurden. A comparison of the three single values reveals a statistically significant higher amount of TNF in the wells treated with substance B. Was bedeutet das nun? Die je drei Einzelwerte werden als Stichproben gesehen. Aber von welcher Gesamtpopulation? Alle Mäuse dieser Welt, oder nur eben jene eine Spendermaus. What does this mean? Each three single values are samples. But from what population? All mice of the world, or just that one donor mouse? Wäre es nicht besser, sechs Einzelmäuse zu verwenden? Wouldn’t it be better to use six separate mice? - 100 - Statistische Tests Statistical tests Wann macht eine statistische Analyse Sinn? When does a statistical analysis make sense? • Was ist das Ziel? • What is the purpose? Beispiel: Example: Ein Zoo hat drei Giraffen, die dünn und kränklich sind. Daher erhalten die Giraffen ein neues Futter. Nach einem Monat stellt man fest, dass sie an Gewicht zugenommen haben. A zoo has three giraffes, which are thin and sickly. They receive a new kind of food. After one month an increase in body weight is found. Sollte man hier eine statistische Analyse machen? Das Ziel der Gewichtszunahme wurde ja bereits erreicht. Oder möchte man eine Futterempfehlung aussprechen können? Should a statistical analysis be made? The increase in body weight was already achieved. Or do you want to make a general feeding recommendation? In anderen Worten: sind die drei Giraffen die Stichprobe, oder die Population? In other words: are the three giraffes the sample or the population? - 101 - Statistische Tests Statistical tests t-test t-test Beispielberechnung mit GraphPad Prism Exemplary analysis by GraphPad Prism - 102 - Statistische Tests Statistical tests t-test t-test Table Analyzed Column A vs Column B t-test/MW low vs high Unpaired t test P value P value summary Are means signif. different? (P < 0.05) One- or two-tailed P value? t, df How big is the difference? Mean ± SEM of column A Mean ± SEM of column B Difference between means 95% confidence interval R square 3,000 ± 0,4082 N=9 4,700 ± 0,4726 N=10 -1,700 ± 0,6314 -3,032 to -0,3678 0,2990 F test to compare variances F,DFn, Dfd P value P value summary Are variances significantly different? t ist das Ergebnis der eigentlichen Berechnung. Von t wird dann p ermittelt. Df = Freiheitsgrade, ein Teil der Berechnung. 0,0154 * Yes Two-tailed t=2,693 df=17 1,489, 9, 8 0,5858 ns No t is the result of the actual calculation. p is determined from t. Df = degrees of freedom, a part of the calculation. - 103 - Statistische Tests Statistical tests t-test t-test Table Analyzed Column A vs Column B Unpaired t test P value P value summary Are means signif. different? (P < 0.05) One- or two-tailed P value? t, df How big is the difference? Mean ± SEM of column A Mean ± SEM of column B Difference between means 95% confidence interval R square F test to compare variances F,DFn, Dfd P value P value summary Are variances significantly different? Zusammenfassung der Stichproben. t-test/MW low vs high 0,0154 * Yes Two-tailed t=2,693 df=17 3,000 ± 0,4082 N=9 4,700 ± 0,4726 N=10 -1,700 ± 0,6314 -3,032 to -0,3678 0,2990 1,489, 9, 8 0,5858 ns No Summary of the samples. - 104 - Statistische Tests Statistical tests t-test t-test Table Analyzed Column A vs Column B t-test/MW low vs high Unpaired t test P value P value summary Are means signif. different? (P < 0.05) One- or two-tailed P value? t, df How big is the difference? Mean ± SEM of column A Mean ± SEM of column B Difference between means 95% confidence interval R square 3,000 ± 0,4082 N=9 4,700 ± 0,4726 N=10 -1,700 ± 0,6314 -3,032 to -0,3678 0,2990 F test to compare variances F,DFn, Dfd P value P value summary Are variances significantly different? Der 95% CI der Differenz. Wichtig! Sind die Werte in diesem Bereich biologisch relevant? 0,0154 * Yes Two-tailed t=2,693 df=17 1,489, 9, 8 0,5858 ns No The 95% CI of the difference. Important! Are the values in that range biologically relevant? - 105 - Statistische Tests Statistical tests t-test t-test Table Analyzed Column A vs Column B t-test/MW low vs high Unpaired t test P value P value summary Are means signif. different? (P < 0.05) One- or two-tailed P value? t, df How big is the difference? Mean ± SEM of column A Mean ± SEM of column B Difference between means 95% confidence interval R square 3,000 ± 0,4082 N=9 4,700 ± 0,4726 N=10 -1,700 ± 0,6314 -3,032 to -0,3678 0,2990 F test to compare variances F,DFn, Dfd P value P value summary Are variances significantly different? Der Anteil der Wertstreuung, der auf den Unterschied der Durchschnitte zurückzuführen ist. Bei identen Durchschnitten ist R²=0, bei extrem unterschiedlichen Durchschnitten ist R² nahezu 1. Ist für uns nicht wichtig. 0,0154 * Yes Two-tailed t=2,693 df=17 1,489, 9, 8 0,5858 ns No The fraction of all variation of the samples due to the difference of the population means. When the means are equal, R² = 0, when the means are hugely different, R² is near 1. Not important for us. - 106 - Statistische Tests Statistical tests t-test t-test Table Analyzed Column A vs Column B t-test/MW low vs high Unpaired t test P value P value summary Are means signif. different? (P < 0.05) One- or two-tailed P value? t, df How big is the difference? Mean ± SEM of column A Mean ± SEM of column B Difference between means 95% confidence interval R square 3,000 ± 0,4082 N=9 4,700 ± 0,4726 N=10 -1,700 ± 0,6314 -3,032 to -0,3678 0,2990 F test to compare variances F,DFn, Dfd P value P value summary Are variances significantly different? Vergleich der Varianz der Stichprobe. • Nicht so wichtig für den t-test, da dieser relativ stabil ist gegenüber ungleichen Varianzen. • Man sollte nicht aufgrund diesen Wertes im Nachhinein beschließen, die Welch's correction anzuwenden. Solche Entscheidungen sollte man im Voraus treffen. • Wichtig: wenn die Varianz signifikant unterschiedlich ist, so ist hier vielleicht ein Effekt der Behandlung zu sehen! Auch wenn die Durchschnitte nicht signifikant unterschiedlich sind! 0,0154 * Yes Two-tailed t=2,693 df=17 1,489, 9, 8 0,5858 ns No Comparison of the variances of the samples • Not that relevant for the t-test, as the t-test is relatively stable in face of unequal variances. • One should not switch to use Welch's correction in retrospective based on this value. Such decisions should always be made upfront. • Important: when the variances really differ significantly, it might be an effect of the treatment! Even when the means do - 107 not differ significantly! Statistische Tests Statistical tests t-test t-test Table Analyzed Column A vs Column B Data 1 A vs B Paired t test P value P value summary Are means signif. different? (P < 0.05) One- or two-tailed P value? t, df Number of pairs How big is the difference? Mean of differences 95% confidence interval R square 0,0 -0,5147 to 0,5147 0,0 How effective was the pairing? Correlation coefficient (r) P Value (one tailed) P value summary Was the pairing significantly effective? Überprüfung der Paarung 1,0000 ns No Two-tailed t=0,0 df=15 16 0,9000 < 0,0001 *** Yes Control of the matching • Zuerst wird der Korrelationskoeffizient berechnet. • First the correlation coefficient is calculated • Dann wird p für folgende Frage berechnet: Wenn die zwei Gruppen komplett unabhängig sind (also Paarung keinen Sinn macht), was ist die Wahrscheinlichkeit das zufällige Werte zumindest diesen Korrelationskoeffizienten zeigen? • Then the p of the following question is calculated: If the two groups are not correlated at all (and matching is useless), what is the chance that randomly selected values would have at least such a correlation coefficient? - 108 - Teil 4 Part 4 Nicht jedes * bedeutet dasselbe. Not every * means the same. Der Unterschied zwischen t-test und Mann-Whitney test: Mann-Whitney ist nicht eine zweite Möglichkeit, wenn der t-test keine Signifikanz ergibt. The difference between t-test and Mann-Whitney test: Mann-Whitney is not a desperate second choice if the Student’s t-test didn’t give significance. - 109 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney Mann-Whitney: Mann-Whitney: • • • • • • • • Mann-Whitney Test Mann-Whitney U Test Mann-Whitney-Wilcoxon Test Wilcoxon Rank-Sum Test Mann-Whitney test Mann-Whitney U test Mann-Whitney-Wilcoxon test Wilcoxon rank-sum test Wilcoxon entwickelte den Test für gleiche Stichprobengrößen. Mann und Whitney entwickelten den Test weiter, unter anderem für ungleiche Stichprobengrößen. Wilcoxon developed the test for samples of the same size. Mann and Whitney expanded the test, amongst others for unequal sample sizes. Heutzutage wird (meines Wissens nach) immer die weiterentwickelte Form verwendet. To my knowledge, the expanded form is always used nowadays. - 110 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney Mann-Whitney: Mann-Whitney: • Basiert auf der Rangliste der Werte • Is based on ranked data • Das heißt, die Werte werden in eine Rangliste umgewandelt, die danach für die Berechnung eingesetzt • That means, the data is converted into a ranked list that is later used for the calculations • Es werden also ordinale Daten verwendet, auch wenn die Ausgangsdaten metrisch sind. • Hence, ordinal data are used, even if the source data is metric. - 111 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney 8 t-test: p= 0.0032 Mann-Whitney: p= 0.0071 6 4 80 60 40 20 8 t-test: p= 0.2335 Mann-Whitney: p= 0.0071 6 4 2 2 Mann-Whitney ist stabil gegenüber Ausreißern hi gh lo w hi gh 0 lo w 0 Mann-Whitney is robust against outliers - 112 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney 5 t-test: p= 0.0132 Mann-Whitney: p= 0.0722 4 400 t-test: p= < 0.0001 Mann-Whitney: p= 0.0765 300 3 200 2 100 1 Mann-Whitney ist immer >0.05 wenn die Gruppengröße 3 oder kleiner ist! hi gh lo w hi gh 0 lo w 0 Mann-Whitney is always >0.05 when group size is 3 or less! - 113 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney 6 t-test: p= 0.0134 Mann-Whitney: p= 0.0396 4 2 Mann-Whitney funktioniert mit Gruppengrößen von vier oder mehr. hi gh lo w 0 Mann-Whitney works with group sizes of four or larger - 114 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney p=0.0283 150 score 100 50 0 control treatment • Der Mann-Whitney test vergleicht nicht einfach die Mediane. • The Mann-Whitney test doesn't really compare medians. • Der Mann-Whitney test vergleicht die Verteilung der Werte auf einer Rangliste. • The Mann-Whitney test compares the distributions of the values on a rank scale - 115 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney p=0.9090 400 score 300 200 100 ea tm en t tr co nt ro l 0 Der Mann-Whitney test überprüft nicht, ob die Samples von Populationen mit unterschiedlicher Verteilung kommen. The Mann-Whitney test does not analyze if the samples come from populations with different distributions. - 116 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney Mann-Whitney: Mann-Whitney: • Der P Wert beantwortet folgende Frage: Was ist die Wahrscheinlichkeit dass ein zufälliger Wert der Population mit dem höheren Median größer ist als ein zufälliger Wert der anderen Population? • The P value answers this question: What is the chance that a randomly selected value from the population with the larger median is greater than a randomly selected value from the other population? • Der Mann-Whitney test vergleicht die Summe der Ränge. Er vergleicht nicht die Mediane und nicht die Verteilungen. • The Mann-Whitney test compares sums of ranks - it does not compare medians and does not compare distributions. • Der Mann-Whitney test ist nur dann ein Vergleich der Mediane, wenn man annimmt dass die Verteilungen der beiden Populationen die gleiche Form haben, sogar wenn sie zueinander versetzt sind. Wenn man diese Annahme akzeptiert, dann erlaubt ein kleiner P Wert den Schluss, dass die Differenz der Mediane statistisch signifikant ist. • The Mann-Whitney test is a comparison of medians only when you assume that the distributions of the two populations have the same shape, even if they are shifted (have different medians). If you accept this assumption, then a small P value leads you to conclude that the difference between medians is statistically significant. (1) - 117 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney Welche Gründe gibt es, den MW einzusetzen? What reasons speak for the MW? • Die Grunddaten sind ordinal scores! • The data are ordinal scores! • Man weiß oder vermutet, dass die Populationen nicht normalverteilt sind • It is known or suspected that the populations do not follow a Gaussian distribution • Man vermeidet eine Aussage über die Verteilungsform der Population. Das bedeutet auch, dass man kein beschreibendes Model der Population hat. • A statement about the distribution of the population is avoided. This also means that there is no model describing the population. • Der Test ist stabil gegenüber Ausreißern • The test is robust when facing outliers. - 118 - Statistische Tests Statistical tests Mann-Whitney Mann-Whitney Welche Gründe sprechen gegen den MW? What reasons speak against the MW? • Für normalverteilte Populationen ergeben sich immer höhere p-Werte als mit dem t-test. • For populations following a Gaussian distribution, MW gives higher p-values than the t-test • Aber vor allem sagt er aus, dass die Population nicht als normalverteilt beschrieben werden kann (eine normalverteilte Population mit vielen Ausreißern ist auch nicht gut) • Above all, it states that the population does not follow a Gaussian distribution (a Gaussian population with many outliers isn’t great neither) • Damit machen alle Abbildungen mit Mittelwert und SD keinen Sinn mehr. Man müßte auf Median und Quartilen zurückgreifen. • All graphs with mean and SD don’t make sense any longer. Median and quartiles should be used. • De facto reduziert man seine metrischen Daten auf ordinale Daten. • De facto the metric data are reduced to ordinal data. - 119 - • Statistische Tests Statistical tests Friedman Friedman Der Friedman test ist der MW für gepaarte Daten • Friedman’s test is the MW for paired data - 120 - Statistische Tests Statistical tests überlappende Fehlerbalken overlapping error-bars t-test: p= 0.0154 Mann-Whitney: p= 0.0226 8 6 4 2 0 low • high SD SD Die SD definiert die Breite der Normalverteilung einer Population. Zwei Populationen können eine große SD haben und dennoch unterschiedlich sein. Die SD gibt keinen Hinweis ob p signifikant ist oder nicht. SEM • SEM 95% CI 95% CI The SD defines the width of the Gaussian distribution of a population. Two populations can have a large SD = a broad normal distribution and still be different. The SD does not give any clue whether p is significant or not. - 121 - Statistische Tests Statistical tests überlappende Fehlerbalken overlapping error-bars t-test: p= 0.0154 Mann-Whitney: p= 0.0226 8 6 4 2 0 low • high SD SD Der SEM definiert den Fehler des beobachteten Durchschnitts zum wahrscheinlichen Durchschnitt der Population. Wenn die SEM zweier Stichproben überlappen, kann p nicht signifikant sein. Wenn die SEM nicht überlappen, kann p signifikant sein oder nicht. SEM • SEM 95% CI 95% CI The SEM defines the error of the observed mean to the probable mean of the population. When the SEM of two samples overlap, p cannot be significant. However, when the SEM do not overlap, p can be significant or not. - 122 - Statistische Tests Statistical tests überlappende Fehlerbalken overlapping error-bars t-test: p= 0.0154 Mann-Whitney: p= 0.0226 8 6 4 2 0 low • high SD SD Der 95% CI definiert einen Bereich, der den Durchschnitt der Population zu 95% umfasst. Überlappende 95% CI sagen nicht aus über den p Wert. SEM • SEM 95% CI 95% CI The 95% CI defines a range that covers the mean of the populations in 95%. Overlapping 95% CI don't tell anything about the p value. - 123 - Statistische Tests Statistical tests Fishers exakter Test Fisher’s exact test • • Der t-test ist für normalverteilte metrische Daten • The t-test is used for metric data of Gaussian populations • Der MW ist für nicht-normalverteilte und ordinale Daten • The MW is for non-Gaussian populations and ordinal data • Was verwendet man für nominale Daten (Kategorien)? • What is used for nominal data (categories) Den exakten Test nach Fisher. The Fisher’s exact test. - 124 - Statistische Tests Statistical tests Fishers exakter Test Fisher’s exact test Example: Beispiel: Der Einfluss einer Substanz auf das Entstehen von Tumoren soll getestet werden. Dazu erhalten Mäuse eine Injektion mit Tumorzellen und werden danach behandelt: eine Gruppe von Mäusen mit der Testsubstanz A und eine andere Gruppe mit einer Kontrollsubstanz B. The impact of a substance on the emerge of tumors shall be tested. Mice receive a injection with tumor cells and are subsequently treated: one group with test substance A, the second group with control substance B. Nach fünf Wochen werden die Tiere palpiert und es wird notiert, welche Tiere einen oder mehrere Tumore haben. After five weeks, the animals are palpated and the animals that have one or more tumors are recorded. Substanz A, kein Tumor: Substanz A, Tumor: Substanz B, kein Tumor: Substanz B, Tumor: Substance A, no tumor: Substance A, tumor: Substance B, no tumor: Substance B, tumor: 14 36 27 23 14 36 27 23 - 125 - Statistische Tests Statistical tests Fishers exakter Test Fisher’s exact test Beispiel: Example: Kontingenztabelle: Contingency table: Kein Tumor Tumor Substanz A 14 36 Substanz B 27 23 no tumor tumor Substance A 14 36 Substance B 27 23 Exakter Test nach Fisher: Fisher’s exact test: p = 0,0142 p = 0.0142 - 126 - Statistische Tests Statistical tests Fishers exakter Test Fisher’s exact test • Bei hohen Fallzahlen (tausende) sollte der Chiquadrat test verwendet werden • For a large sample size (thousands), the chisquare test should be used • Chi-quadrat sollte bei kleinen Fallzahlen (unsere normalen Daten) nicht verwendet werden • Chi-square should not be used to small sample sizes (our usual data) • Wenn es mehr als zwei Gruppen oder zwei Kategorien gibt, kann man nur den Chi-quadrat test verwenden • With more than two categories or more than two groups, just the chi-square test can be used - 127 - Statistische Tests Statistical tests Fehler 1. Art Type I error • Der p Wert gibt die Wahrscheinlichkeit an, dass eine gefundene Differenz auftritt obwohl die Populationen den gleichen Durchschnitt haben. • The p value gives the chance that the observed difference is seen even though the populations have the same mean. • Der Wissenschaftler definiert einen Schwellenwert, ab dem er die Differenz „signifikant“ nennt. • Normalerweise 0.05 • Das heißt: in 5% der Fälle erklären wir die Differenz zu „signifikant“ obwohl die Differenz zufällig aufgetreten ist. • The scientist defines a threshold for declaring a difference „significant“. • Usually 0.05 • This means: in 5% of the experiments a difference is declared „significant“ although it is purely random Der Fehler 1. Art besagt die Wahrscheinlichkeit, dass wir eine Differenz fälschlich signifikant nennen. The type I error is the probability that a difference is falsely declared to be significant. Fehler 1. Art = α, normalerweise 0,05 Type I error = α, usually 0.05 - 128 - • Statistische Tests Statistical tests Fehler 2. Art Type II error Aber es gibt auch noch den umgekehrten Fall • But there is also the opposite case • Obwohl die Populationen unterschiedlich sind, bekommen wir mit den Stichproben ein p > Schwellenwert. • Even though the population means are different, we get a p > threshold from the samples. • Es werden unterschiedliche Populationen fälschlich als nicht-signifikant definiert. • Different populations are falsely declared to be not significant. Der Fehler 2. Art besagt die Wahrscheinlichkeit, dass wir unterschiedliche Populationen nicht als solche erkennen. The type II error is the probability that different populations are not discovered. Fehler 2. Art = β, normalerweise 0,20 Type II error = β, usually 0.20 - 129 - Teil 5 Part 5 Ein Experiment ist kein Glückspiel. An experiment is not a lottery. Das Problem der Mehrfachvergleiche: wenn man oft genug versucht, dann bekommt man Signifikanz – aber sie ist nutzlos. Der ANOVA ist die Rettung. The problem of multiple comparisons: if you look often enough, you will get significance. But it is useless. The ANOVA comes to the rescue. - 130 - Stichprobe Sample Experiment experiment Samples taken by audience Die Stichproben, die vom Publikum gezogen wurden. The samples taken by the audience. - 131 - Statistische Tests Statistical tests Fehler 1. Art Type I errors Der Fehler 1. Art sagt, dass in 5% der Fälle eine Signifikanz gefunden wird, obwohl die Mittelwerte der Populationen keinen Unterschied haben. • • Ein „Fall“ ist einfach ein Vergleich zweier Gruppen. • • A „case“ is simply a comparison of groups. • Wenn man also oft genug vergleicht, findet man schon irgendwo eine Signifikanz • Bei 13 Vergleichen gibt es eine 50:50 Chance, dass man ein falsches p<0.05 erhält. • When you compare often enough, you will find a significance somewhere • With 13 comparisons there is a 50:50 chance to find a wrong p<0.05. • • Solche Vergleiche summieren sich auf • Eine Kontrolle ohne LPS • 5 verschiedene Konzentrationen LPS • 15 Vergleiche • Such comparisons add up • One Control without LPS • 5 different concentrations of LPS • 15 comparisons • The type I error means that in 5% of the cases a significance is seen even though there is no difference between the mean of the populations. • - 132 - Stichprobe Sample Experiment experiment Samples taken by audience Die Stichproben, die vom Publikum gezogen wurden. The samples taken by the audience. - 133 - Stichprobe Sample Experiment experiment Example t-tests Die Stichproben, die vom Publikum gezogen wurden. The samples taken by the audience. - 134 - • Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons Es ist nicht zulässig, einfach nur zwei Gruppen aus dem Experiment miteinander zu vergleichen, weil man: • It is not allowed to simply compare two groups of the experiment with each other, because: • normalerweise nicht nur zwei Gruppen miteinander vergleicht, sondern mehrmals verschiedene zwei Gruppen miteinander – je nach der Figur, an der man gerade bastelt • • die Gruppen dann nach Interesse wählt. Man hat x Gruppen, bei den meisten sieht man irgendwie optisch nichts, aber Gruppe 4 schaut interessant aus, also macht man dort dann den t-test. • the groups are usually selected by ones interest. There are x groups and one doesn't really see anything in most of them, but group 4 looks interesting and is used in the t-test. • Man betrügt sich dadurch nur selber. • You’ll just fool yourself. • You usually not simply compare two groups with each other, but various pairs of two groups with each other based on the figure one currently works at. • - 135 - • Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons Generell gilt: • Generally: • Man muss sich vor dem Experiment überlegen, welche statistische Auswertung man vornimmt. • You have to decide on the statistical analysis before the experiment is done. • Nachträgliches Ändern ist nicht erlaubt. • Retrospective changes are not permitted • Nicht weil die Mathematik „weiss“, ob man die Analyse ändert. • Not because the mathematic “knows” that the analysis is altered • Sondern um Selbstbetrug zu vermeiden. • But to prevent self deception • Man darf die Statistik ändern, wenn man erkennt, dass der statistische Test für die Daten methodisch falsch ist – zB dass eine Population als nicht normalverteilt erkannt wird. • The analysis can be altered if it becomes apparent that the statistical test is invalid for the data – for example because a population is found to be non-Gaussian. - 136 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons Was tun? What shall we do? • Es gibt spezielle statistische Tests für solche Mehrfachvergleiche. • There are special statistical tests for multiple comparisons. • Bei diesen Tests wird der Fehler 1. Art α angepasst, sodass er für das gesamte Experiment 0.05 ist – alle Vergleiche inkludiert. Zum Beispiel wird bei der Bonferroni Korrektur für jeden einzelnen Vergleich ein α' verwendet, das durch „α/Anzahl der Vergleiche“ berechnet wird. • Here, the Type I error α is adjusted, so that it is 0.05 for the whole experiment – including all comparisons. For example, the Bonferroni correction uses an α' for each comparison that is calculated by „α/Number of Comparisons“. • Durch die größere Datenmenge wird die Statistik genauer und kann mehr Freiheitsgrade ausnutzen, was das kleine α' ein wenig ausgleicht. • But the larger amount of data makes the statistical analysis more accurate and allows for more degrees of freedom, which balance the smaller α' a little. - 137 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons 150 100 50 Sind die Gruppen unterschiedlich? • Mögliche Analysen: • Einfaktorieller ANOVA Faktor: Behandlung Tr ea te d+ A nt ag on is t Tr ea te d C on tr ol 0 Are the groups different? • Possible calculations: • One-way ANOVA Factor: treatment - 138 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Beispielberechnung mit GraphPad Prism Exemplary analysis by GraphPad Prism - 139 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Table Analyzed One-way analysis of variance P value P value summary Are means signif. different? (P < 0.05) Number of groups F R square Bartlett's test for equal variances Bartlett's statistic (corrected) P value P value summary Do the variances differ signif. (P < 0.05) ANOVA Table Treatment (between columns) Residual (within columns) Total p-value beantwortet: „Wenn alle Populationen den gleichen Durchschnitt haben, was ist die Wahrscheinlichkeit, dass zufällige Stichproben zu Durchschnitte führen, die zumindest so weit entfernt sind, wie in diesem Experiment?“ One-way ANOVA data < 0,0001 *** Yes 3 22,57 0,7633 2,986 0,2247 ns No SS 4760 1476 6236 df 2 14 16 MS 2380 105,4 p-value answers: „If all populations have the same mean, what is the chance that random sampling would result in means at least as far apart as observed in this experiment?“ (1) - 140 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Table Analyzed One-way analysis of variance P value P value summary Are means signif. different? (P < 0.05) Number of groups F R square Bartlett's test for equal variances Bartlett's statistic (corrected) P value P value summary Do the variances differ signif. (P < 0.05) ANOVA Table Treatment (between columns) Residual (within columns) Total Das eigentliche Ergebnis, welches dann verwendet wird, um p zu ermitteln. One-way ANOVA data < 0,0001 *** Yes 3 22,57 0,7633 2,986 0,2247 ns No SS 4760 1476 6236 df 2 14 16 MS 2380 105,4 The actual result that is used to determine p. - 141 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Table Analyzed One-way analysis of variance P value P value summary Are means signif. different? (P < 0.05) Number of groups F R square Bartlett's test for equal variances Bartlett's statistic (corrected) P value P value summary Do the variances differ signif. (P < 0.05) ANOVA Table Treatment (between columns) Residual (within columns) Total Definiert die Stärke der Beziehung zwischen Gruppen-Zugehörigkeit und der Gruppenvariablen. Wird berechnet, indem die Variabilität der Gruppendurchschnitte mit der Variabilität innerhalb der Gruppen verglichen wird. Auch genannt η². One-way ANOVA data < 0,0001 *** Yes 3 22,57 0,7633 2,986 0,2247 ns No SS 4760 1476 6236 df 2 14 16 MS 2380 105,4 Quantifies the strength of the relationship between group membership and the variable. It is calculated by comparing the variability among group means with the variability within the groups. Also called η². - 142 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Table Analyzed One-way analysis of variance P value P value summary Are means signif. different? (P < 0.05) Number of groups F R square Bartlett's test for equal variances Bartlett's statistic (corrected) P value P value summary Do the variances differ signif. (P < 0.05) ANOVA Table Treatment (between columns) Residual (within columns) Total ANOVA geht davon aus, dass alle Gruppen die gleiche Varianz haben. Für Gruppengröße > 4 wird das hier überprüft. Sollte p<0.05 sein, so muss man nachdenken, ob man den ANOVA hier überhaupt nutzen kann. One-way ANOVA data < 0,0001 *** Yes 3 22,57 0,7633 2,986 0,2247 ns No SS 4760 1476 6236 df 2 14 16 MS 2380 105,4 ANOVA assumes that all groups have the same variance. This is tested here for groups of sizes > 4. If p<0.05, one has to consider if the ANOVA should be used here at all. - 143 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Table Analyzed One-way analysis of variance P value P value summary Are means signif. different? (P < 0.05) Number of groups F R square Bartlett's test for equal variances Bartlett's statistic (corrected) P value P value summary Do the variances differ signif. (P < 0.05) ANOVA Table Treatment (between columns) Residual (within columns) Total Die Daten, die genutzt werden um F zu berechnen. Es werden die • Varianzen der Gruppendurchschnitte zum Gesamtdurchschnitt (Treatment) mit den • Varianzen der Einzelpunkte zu dem jeweiligen Gruppendurchschnitt (Residual) dividiert. One-way ANOVA data < 0,0001 *** Yes 3 22,57 0,7633 2,986 0,2247 ns No SS 4760 1476 6236 df 2 14 16 MS 2380 105,4 The data used to calculate F. The • Variances of the group means to the overall mean (treatment) are divided by the • variances of the single values to their respective group mean. - 144 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA 150 100 50 Also was bedeutet der signifikante einfaktorielle ANOVA nun? • Irgendwo im Experiment ist ein signifikanter Unterschied. Tr ea te d+ A nt ag on is t Tr ea te d C on tr ol 0 What does the significant one-way ANOVA mean? • There is a significant difference in the experiment. - 145 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA 150 100 50 Tr ea te d+ A nt ag on is t Tr ea te d C on tr ol 0 Wo denn? Where? • Das berechnen die post-Tests. • This is calculated by the postTests. • Dies sind nun Mehrfachvergleiche. t-test ist nicht erlaubt, auch wenn der ANOVA signifikant war. • These are multiple comparisons. t-test is not appropriate, even though the ANOVA was significant. - 146 - Statistische Tests Statistical tests Post-Test post-test • Benutze Tukey, wenn alles mit allem verglichen werden soll. • Benutze „Bonferroni: Compare selected“ wenn gewisse Gruppen mit gewissen anderen verglichen werden sollen. • Benutze Dunnett, wenn alle Gruppen mit einer Kontrollgruppe verglichen werden sollen. • Benutze „test for linear trend“ wenn die Gruppen alle miteinander in Bezug stehen. Beispiel: alle Gruppen erhalten das selbe Agens, aber in einer Konzentrationsreihe. Die Reihe muss absteigend oder aufsteigend sein. • Verwende die anderen Tests nicht. • use Tukey, when all groups shall be com pared to all other columns. • use „Bonferroni: Compare selected“ when specific groups shall be compared to certain other groups. • use Dunnett, when all groups shall be compared to a single control group. • use „test for linear trend“ when the groups have some direct relationship with each other. For example: all groups receive the same substance, but in a concentration series. The series has to be either increasing or decreasing. • don't use the other tests. - 147 - Statistische Tests Statistical tests Post-Test post-test 150 100 50 Tukey's Multiple Comparison Test Tr ea te d+ A nt ag on is t Tr ea te d C on tr ol 0 Mean Diff, q Significant? P < 0,05? Summary 95% CI of diff Control vs Treated -38,33 8,719 Yes *** -54,61 to -22,06 Control vs Treated+Antagonist -3,500 0,8349 No ns -19,02 to 12,02 Treated vs Treated+Antagonist 34,83 7,923 Yes *** 18,56 to 51,11 - 148 - Statistische Tests Statistical tests gepaarter einfakt. ANOVA paired one-way ANOVA 150 100 50 Sind die Gruppen unterschiedlich? • Mögliche Analysen: • Einfaktorieller ANOVA Faktor: Behandlung 3 Tr ea tm en t 2 Tr ea tm en t 1 Tr ea tm en t C on tr ol 0 Are the groups different? • Possible calculations: • One-way ANOVA Factor: treatment - 149 - Statistische Tests Statistical tests gepaarter einfakt. ANOVA paired one-way ANOVA 150 100 Control 50 Treatment 2 Treatment 3 54,0 43,0 78,0 111,0 JM 23,0 34,0 65,0 99,0 HM 45,0 65,0 99,0 78,0 DR 54,0 77,0 79,0 90,0 PS 45,0 46,0 87,0 95,0 3 GS Tr ea tm en t 2 Tr ea tm en t 1 Tr ea tm en t C on tr ol 0 Treatment 1 Sind die Gruppen unterschiedlich? • die Daten sind paired • die gleichen Personen bekommen wiederholt Behandlung repeated-measures • unterschiedliche Personen werden nach Alter/Geschlecht/etc gepaired und erhalten dann unterschiedliche Behandlungen randomized block experiment • Jede Reihe ist eine getrennte Wiederholung des gleichen Experiments randomized block experiment Are the groups different? • the data are paired • the same subjects receive repeated treatments repeated-measures • different people are paired based on age/sex/etc and receive different treatments randomized block experiment • Each row is a separate repeat of the same experiment randomized block experiment - 150 - Statistische Tests Statistical tests gepaarter einfakt. ANOVA paired one-way ANOVA „test for linear trend“ ist oft nützlich hier. Die anderen tests sind nicht so hilfreich bei repeated-measures ANOVA. „test for linear trend“ is often useful here. The other tests are not that helpful with the repeated-measures ANOVA. - 151 - Statistische Tests Statistical tests Kruskal-Wallis, Post-test Kruskal-Wallis, post-test Kruskal-Wallis ist der nichtparametrische ANOVA. Der passende post-test ist der Dunns-Test. Kruskal-Wallis is the non-parametric ANOVA. The respective post-test is the Dunns-Test. - 152 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons A priori Tests – Geplante Vergleiche A priori tests – planned comparisons • Eine Möglichkeit, um das Problem des verringerten α abzuschwächen oder gar zu umgehen • An approach to ease or even eliminate the reduced α of multiple comparisons • Man entscheidet während der Planung des Experimentes (Bevor man auch nur eine Pipette angefaßt hat), welche Gruppen man letztlich miteinander vergleicht. • Already when planning the experiment it is decided which groups are compared – before one even touches the pipette • Dann macht man hinterher mit den Daten genau diese Vergleiche. Achtung: keinen Selbstbetrug durchführen! Egal wie die Daten aussehen und welche anderen Vergleiche nun interessanter wären. • After the experiment, exactly those comparisons are done with the data. Warning: don't fool yourself! No matter what the data look like and what other comparisons are more interesting now. • Dadurch kann man die Anzahl der Vergleiche niedrig halten das α verringert sich nicht so stark für die Einzelvergleiche. • This reduces the number of comparisons the α is not a strongly lowered for the single comparisons. - 153 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons A priori Tests – Geplante Vergleiche A priori tests – planned comparisons • Manche Statistiker sagen, man könne sogar einfach mit dem normalen α von 0.05 arbeiten. • Some statisticians claim that you can even work simply with the normal α of 0.05. • Ich bezweifle, dass man einfach schreiben kann „ich plane im Voraus, alle Gruppen mit allen Gruppen zu vergleichen“ und dann ein α von 0.05 verwenden darf. • I doubt that you can simply write „I plan in advance to compare each group to each other group“ and then use an α of 0.05. • Diese Gruppenvergleiche sollte man mit dem „Bonferroni: Compare selected“ durchführen, nicht einfach mit einem t-test. • These comparisons should be done with the „Bonferroni: Compare selected“, not just with a simply t-test. - 154 - Statistische Tests Statistical tests einfaktorieller ANOVA one-way ANOVA Wann verwendet man den einfaktoriellen ANOVA? When is the one-way ANOVA used? • Mehr als ein Vergleich – also im Allgemeinen wenn mehr als zwei Gruppen vorhanden sind, außer den technischen Kontrollen • More than one comparison– in general, when more than two groups exist (except for technical controls) • Ein Faktor, der die verschiedenen Gruppen definiert • One factor defines the groups - 155 - Teil 6 Part 6 Keine Zeit für alles. So many options, so little time. Der zweifaktorielle ANOVA und die multifaktorielle Forschung. The two-way ANOVA and multi-factor research. - 156 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons Welche Substanz hat einen Effekt? Which substance has an effect? Experiment: Experiment: • Zwei Substanzen sollen auf ihren Einfluss auf TNF Produktion getestet werden. Mäuse werden mit einer oder beiden Substanzen behandelt und danach TNF im Serum bestimmt. • Two substances shall be assayed for their influence on TNF production. Mice are treated with one or both substances and TNF in serum is determined. • Mögliche Analysen: • zweifaktorieller ANOVA Faktoren: A und B • Possible analysis: • two-way ANOVA Factors: A und B - 157 - Statistische Tests Statistical tests Zweifaktorieller ANOVA Two-way ANOVA Ergebnisse des zweifaktoriellen ANOVA Results of the two-way ANOVA • Beeinflusst der erste Faktor das Resultat? • Does the first factor influence the result? • Beeinflusst der zweite Faktor das Resultat? • Does the second factor influence the result? • Interagieren die beiden Faktoren? • Do the two factors interact? - 158 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons 4 0 ug/ml A 5 ug/ml A 10 ug/ml A TNF 3 2 1 Interaction ns Substance A ns Substance B ns 0 0 ug/ml B 5 ug/ml B 10 ug/ml B Welche Substanz hat einen Effekt? • keine Which substance has an effect? • none - 159 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons 6 0 ug/ml A 5 ug/ml A 10 ug/ml A TNF 4 2 Interaction ns Substance A ns Substance B * 0 0 ug/ml B 5 ug/ml B 10 ug/ml B Welche Substanz hat einen Effekt? • Substanz B Which substance has an effect? • Substance B - 160 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons 15 0 ug/ml A 5 ug/ml A 10 ug/ml A TNF 10 5 Interaction ns Substance A * Substance B * 0 0 ug/ml B 5 ug/ml B 10 ug/ml B Welche Substanz hat einen Effekt? • Substanzen A und B Which substance has an effect? • Substances A and B - 161 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons 30 0 ug/ml A 5 ug/ml A 10 ug/ml A TNF 20 10 Interaction * Substance A * Substance B * 0 0 ug/ml B 5 ug/ml B 10 ug/ml B Welche Substanz hat einen Effekt? Which substance has an effect? • Substanzen A und B • Substances A and B • A und B beeinflussen einander! Synergie! • A and B interact with each other! Synergy! - 162 - Statistische Tests Statistical tests Mehrfachvergleiche multiple comparisons IgG2a 1.0 0.5 0.0 1.5 rel. Elisa units OVA CLP + OVA 1.0 0.5 days Sind die Kurven unterschiedlich? • Mögliche Analysen: • Kurvenfläche • zweifaktorieller ANOVA Faktoren: Zeit und Gruppe 40 30 20 10 0 30 23 16 0.0 8 rel. Elisa units 1.5 days Are the curves different? • Possible calculations: • Area under the curve • Two-way ANOVA Factors: time and group - 163 - Statistische Tests Statistical tests Zweifaktorieller ANOVA Two-way ANOVA IgG2a OVA CLP + OVA 1.0 0.5 30 23 16 0.0 8 rel. Elisa units 1.5 days - 164 - Statistische Tests Statistical tests Zweifaktorieller ANOVA Two-way ANOVA IgG2a Matching by cols Source of Variation Interaction Time CLP Subjects (matching) P value summary ** *** * *** Significant? Yes Yes Yes Yes Source of Variation Interaction Time CLP Subjects (matching) Residual Df 3 3 1 8 24 Sum-of-squares 0,4941 0,9637 1,070 1,245 0,6529 Number of missing values 0.0 30 P value 0,0032 < 0,0001 0,0306 0,0004 0.5 23 % of total variation 11,17 21,78 24,17 28,1345 1.0 16 Source of Variation Interaction Time CLP Subjects (matching) OVA CLP + OVA 8 Two-way RM ANOVA rel. Elisa units 1.5 days Mean square 0,1647 0,3212 1,070 0,1556 0,02720 F 6,054 11,81 6,873 5,721 0 - 165 - Statistische Tests Statistical tests Zweifaktorieller ANOVA Two-way ANOVA 1.5 OVA CLP + OVA 1.0 0.5 30 23 16 0.0 8 Does CLP affect the result? (Are the curves different?) CLP accounts for 24.17% of the total variance (after adjusting for matching). F = 6.87. DFn=1 DFd=8 The P value = 0.0306 If CLP has no effect overall, there is a 3.1% chance of randomly observing an effect this big (or bigger) in an experiment of this size. The effect is considered significant. IgG2a rel. Elisa units Does Time have the same effect at all values of CLP? Interaction accounts for 11.17% of the total variance. F = 6.05. DFn=3 DFd=24 The P value = 0.0032 If there is no interaction overall, there is a 0.32% chance of randomly observing so much interaction in an experiment of this size. The interaction is considered very significant. Since the interaction is statistically significant, the P values that follow for the row and column effects are difficult to interpret. days Does Time affect the result? (Are the curves horizontal?) Time accounts for 21.78% of the total variance (after adjusting for matching). F = 11.81. DFn=3 DFd=24 The P value is <0.0001 If Time has no effect overall, there is a less than 0.01% chance of randomly observing an effect this big (or bigger) in an experiment of this size. The effect is considered extremely significant. Was the matching effective? F = 5.72. DFn=8 DFd=24 The P value = 0.0004 If matching were not effective overall, there is a 0.04% chance of randomly observing an effect this big (or bigger) in an experiment of this size. The effect is considered extremely significant. - 166 - Statistische Tests Statistical tests Kurvenfläche area under the curve 1.5 Area under the curve area under the curve 20 1.0 0.5 15 10 5 O VA C LP + O VA days 40 30 20 0 10 0 0.0 p= 0.0272 Kurvenfläche Area under the curve • Für jede Einzelkurve (jedes individuelle Tier/well) wird die Fläche berechnet. • Diese Flächen werden dann als normale Werte als zwei-Gruppen Vergleich mit t-test analysiert. • For every single curve (every individual animal/well) the area is calculated • These areas are then simply used as regular values for a two-group comparison with t-test. - 167 - Statistische Tests Statistical tests zweifaktorieller ANOVA two-way ANOVA Wann verwendet man den zweifaktoriellen ANOVA? When is the two-way ANOVA used? • Mehr als ein Vergleich – also im Allgemeinen wenn mehr als zwei Gruppen vorhanden sind, außer den technischen Kontrollen • More than one comparison– in general, when more than two groups exist (except for technical controls) • Zwei Faktor, der die verschiedenen Gruppen definiert • Two factors define the groups • Die Gruppen umfassen jede mögliche Kombination der beiden Faktoren • The groups encompass all possible combinations of the factors • Analyse von Interaktionen! • Analysis of interactions! - 168 - Statistische Tests Statistical tests zweifaktorieller ANOVA two-way ANOVA Wann verwendet man die Kurvenfläche? When is the area under the curve used? • Einer der beiden Faktoren ist keine Substanz, sondern ein genereller Faktor wie Zeit oder Konzentration • One of the factors is not a substance, but a general factor like time or concentration • Dieser Faktor ist im Prinzip unwichtig – das Wissen, dass Zeit eine Rolle spielt bei Tumorwachstum ist nicht relevant. • That factor is in principle not important – the knowledge that time plays a role in tumor growth is nor relevant • Die Einzelwerte des unwichtigen Faktors können gepaart werden – also zum Beispiel Einzeltiere, die über die Zeit hin beobachtet werden • The single values of the unimportant factor can be pared – for example single animals that are monitored over time - 169 - Statistische Tests Statistical tests mehr als zwei Faktoren more than two factors • Benötigen multifaktorielle Analysen • Require multi-factor analyses • Bitte einen Statistiker fragen, bevor man mit dem Experiment anfängt. • Please ask a statistician before starting the experiment • Nicht mich, ich verstehe das nicht • Not me, I don’t understand that - 170 - Teil 7 Part 7 n = 3, weil … ich immer drei verwende. n = 3, because … I always use three. Warum ist die Anzahl an Mäusen im Experiment wichtig? Woher weiß ich, wieviele Mäuse ich benutzen soll? Why does it matter, how many mice are used in an experiment? How do I know the number of mice I should use? - 171 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? - 172 - Statistische Tests Statistical tests Stichprobengröße sample size 2? Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? - 173 - Statistische Tests Statistical tests Stichprobengröße sample size 2? 4? Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? - 174 - Statistische Tests Statistical tests Stichprobengröße sample size 2? 4? Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? 9? How large has the sample to be to detect a difference in the population with a certain probability? - 175 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • • Man kann im Prinzip jeden Unterschied finden, wenn die Stichprobe groß genug ist In principle, every difference can be detected, when the sample size is large enough - 176 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • • Um die Stichprobengröße zu bestimmen, muss man die Normalverteilung der Populationen kennen. - Mean und SD To define the sample size, the Gaussian distribution of the populations need to be known. Mean and SD - 177 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • • • • Wir kennen Mean und SD nicht. Daher stellt man die Frage anders: Welche Unterschiede will ich finden können? • • Man berechnet die Gruppengröße, um eine gegebene Differenz finden zu können. Somit kann man kleinere Differenzen nicht finden, auch wenn sie existieren! Relevanter Unterschied / relevanter Effekt We don‘t know mean and SD So the question is asked differently: What difference do you want to be able to find? • You calculate the sample size to be able to find a given difference • Smaller differences can‘t be found, even when they exist! Relevant difference / relevant effect - 178 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • Möchte man einen Unterschied von 4 x, 2.5 x oder 1.5x finden? • Do you want to find a 4x, 2.5 x, or 1.2x difference? • Dies bestimmt, ob man 2, 4 oder 9 Subjekte pro Gruppe braucht. • This will determine, if you need 2, 4, or 9 subjects per group. - 179 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • • • • • • Die Möglichkeit, einen Unterschied zu finden heißt Teststärke Er ist definiert durch den Fehler 2. Art: die Wahrscheinlichkeit, dass ein bestehender Unterschied nicht gefunden wird. β Fehler Teststärke = 1- β Üblich ist ein β von 0.2, somit eine Teststärke von 0.80 Das heißt, in 20% der Fälle wird ein Unterschied der gewünschten Größe nicht gefunden, obwohl er existiert! • • • • The ability to find a difference is the power of a test It is defined by the Type II error: the probability of not finding a n existing difference. β error Power = 1-β Common is a β of 0.2, hence a power of 0.80 This means, that in 20% of the cases a difference of the wanted amount is not found, even though it exists! - 180 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • Aber da ist auch noch der Fehler 1. Art • But there still is the Type I error • Eine statistisch signifikanter Unterschied wird gefunden, obwohl die Populationen gleich sind α, normalerweise 0.05 • A statistical significant difference is found, even though the populations are the same α, usually 0.05 - 181 - Statistische Tests Statistical tests Stichprobengröße sample size Wie groß muss die Stichprobe sein, damit ein Unterschied in den Populationen mit einer gewissen Wahrscheinlichkeit erkannt wird? How large has the sample to be to detect a difference in the population with a certain probability? • • Bei gleicher Stichprobengröße gilt: Je kleiner α, desto größer β Unchanged sample sizes mean: the smaller α, the larger β • Wenn man sicher sein möchte, dass man zwei Populationen nicht fälschlich als „unterschiedlich“ definiert, dann erkennt man existierende Unterschiede schlechter. • When you want to make sure that you don‘t declare two populations as „different“ by mistake, it is more difficult to detect existing differences. • Die Erhöhung der Stichprobengröße ist die einzige Möglichkeit, beide Fehler niedrig zu halten. • The increase of the sample size is the only way to keep both errors low. - 182 - Statistische Tests Statistical tests Stichprobengröße sample size Beispiel: Example: Welche Gruppengröße ist nötig, um einen Unterschied zwischen zwei normalverteilten Populationen zu finden? What sample size is needed to find a difference between two populations with Gaussian distribution? Berechnung mit G*Power 3.1.2. Calculation with G*Power 3.1.2. - 183 - Stichprobengröße Sample size G*Power 3.1.2 G*Power 3.1.2 Select test - 184 - Stichprobengröße Sample size G*Power 3.1.2 G*Power 3.1.2 - 185 - Stichprobengröße Sample size G*Power 3.1.2 G*Power 3.1.2 Click - 186 - Stichprobengröße Sample size G*Power 3.1.2 G*Power 3.1.2 Enter mean and SD of the two populations. • earlier experiments • Literature data • Educated guess based on your scientific expertise - 187 - Stichprobengröße Sample size G*Power 3.1.2 G*Power 3.1.2 click - 188 - Stichprobengröße Sample size G*Power 3.1.2 G*Power 3.1.2 Sample size = 3 click - 189 - Stichprobengröße Sample size Annahme Educated guess „Wie bitte? Ich soll da einfach irgendwelche Annahmen reintippen?“ „Excuse me? I shall simply enter some estimates?“ Ja. Yes. Denn: Because: • Statistische Tests berechnet die Wahrscheinlichkeit, dass ein Unterschied zufällig auftrat • Statistical tests calculate the probability that a difference occurred randomly • Die Gruppengröße bestimmt, ob die Statistischen Tests dazu in der Lage ist, einen gewissen Unterschied zu finden • The sample size determines, if the statistical analysis is able to find a certain difference • Welcher Unterschied gefunden werden können soll, ist die Entscheidung des Wissenschaftlers. Die Entscheidung sollte gut überlegt werden, da sonst die gesamte Studie nutzlos werden könnte. Das kann kein Computerprogramm. • The difference that should be possible to be found is the decision of the scientist. This decision should be made carefully, as the whole study could become useless. No computer program can do that. - 190 - Stichprobengröße Sample size Annahme Educated guess „Und woher soll ich wissen, welcher Unterschied wichtig ist?“ • Verständnis der Materie. Spielt es eine Rolle, ob ein Mensch einen 5% höheren Puls hat? Spielt es eine Rolle, dass er 50% höher ist? • Literatur Studien anderer Leute zeigen, dass Faktor X sich durch diese Behandlung zu 30% im Gewebe reduziert. Daher sollte meine Behandlung wohl auch eine 30% Reduktion erreichen. • Schlussfolgerungen Faktor X wird in 20% der Krebszellen exprimiert. Mein Faktor Y wird durch X induziert. Ich muss also Y in 20% der Zellen finden können. „And how shall I know which difference is important?“ • Understanding the topic Is it relevant if a human has a 5% higher pulse? Does it matter if it is 50% higher? • Literature Studies other people have shown that factor X is reduced by 30% in tissue by treatment. My treatment should better also reach 30% reduction. • Conclusions Factor X is expressed in 20% of tumor cells. My factor Y is induced by X. So I have to be able to find Y in 20% of the cells. - 191 - Stichprobengröße Sample size Annahme Educated guess „Und wenn ich mich irre?“ „What if I am wrong?“ • Aufgrund der erhobenen Daten kann dann ein neues Experiment gemacht werden, bei dem die Annahmen angepasst werden • Based on the achieved data, a new experiment with adjusted estimated can be performed „Also so ganz passt mir das nicht.“ „I don’t like the sound of that.“ • Unglücklicherweise geht es nicht anders. Man muss mit einer Annahme anfangen und sehen, wohin sie einen bringt. • Unfortunately there is no other way. You have to start with an estimate and see where you end up. - 192 - Stichprobengröße Sample size Häufigkeit Prevalence Beispiel: Example: Wie oft tritt eine gewisse Mutation in Menschen auf? How often does a certain mutation occur in humans? • Hier möchte man die Häufigkeit eines Parameters in der Population statistisch abgesichert feststellen. • The prevalence of a parameter in a population shall be determined in a statistically reliable way. • Die Frage ist also: Wie hoch ist die Wahrscheinlichkeit, dass der gefundene Wert in der Stichprobe dem „realen“ Wert entspricht? • The question is: how high is the probability that the found value is the “real” value? Was ist der 95% CI dieses Wertes? What is the 95% CI of that value? - 193 - Stichprobengröße Sample size Häufigkeit Prevalence Beispiel: Example: Wie oft tritt eine gewisse Mutation in Menschen auf? How often does a certain mutation occur in humans? Dazu zwei Fragen: Two questions: • welche Häufigkeit soll gefunden werden können? Die Häufigkeit beeinflusst die Anzahl der nötigen Probanden. • Wie breit darf der Bereich des 95% CI sein? 95% CI in nur 1% benötigt genauere Daten, also mehr Probanden, als 95% CI in 20% • What prevalence shall be found? The prevalence influences the number of test persons needed. • How big may the range of the 95% CI be? 95% CI in just 1% needs more data, so more test persons, than 95% in 20% - 194 - Stichprobengröße Sample size Häufigkeit Prevalence Beispiel: Example: Wie oft tritt eine gewisse Mutation in Menschen auf? How often does a certain mutation occur in humans? Berechnung: Calculation: Z P (1 − P ) n= 2 d 2 Z P (1 − P ) n= 2 d 2 Z: repräsentiert den CI 90% CI Z = 1,64 95% CI Z = 1,96 99% CI Z = 2,58 Z: represents the CI 90% CI Z = 1.64 95% CI Z = 1.96 99% CI Z = 2.58 P: erwartete Häufigkeit 20% tragen die Mutation 0,20 P: expected prevalence 20% carry the mutation 0.20 d: Präzision; 2d = Breite des CI Bereiches CI soll 10% umfassen d=0,05 d: precision; 2d = width of the CI range CI shall encompass 10% d=0.05 - 195 - Stichprobengröße Sample size Häufigkeit Prevalence Beispiel: Example: Wie oft tritt eine gewisse Mutation in Menschen auf? How often does a certain mutation occur in humans? Berechnung: Calculation: Z 2 P(1 − P ) n= d2 Z 2 P(1 − P ) n= d2 1,96 2 * 0,20(1 − 0,20) n= 0,052 1.96 2 * 0.20(1 − 0.20) n= 0.052 n = 245,86 = 246 n = 245.86 = 246 Man benötigt 246 Probanden um eine Mutation in der Bevölkerung festzustellen, deren Häufigkeit mit 95-prozentiger Wahrscheinlichkeit zwischen 15% und 25% liegt. 246 test persons are needed to find a mutation in the population, whose prevalence lies between 15% and 25% with a 95% probability. - 196 - Statistische Tests Statistical tests Extrem signifikant extremely significant *, **, *** *, **, *** • Gruppengröße in diesem Beispiel • α 0.05 3 • α 0.01 4 • α 0.001 5 • Sample size in this example • α 0.05 3 • α 0.01 4 • α 0.001 5 • Meine Meinung: • Man hat nur die nötige Gruppengröße, um die Signifikanz von α 0.05 zu berechnen. • Entweder, das p ist kleiner als 0.05, oder nicht. • Es macht keinen Sinn, nach dem Berechnen des p den α zu verringern und das Ergebnis „extrem signifikant“ zu nennen. • My opinion: • You only have the sample size to determine significance based on an α 0.05. • Either, p is smaller than 0.05, or not. • Meinung der einen Statistiker • Es gibt nur signifikant oder nicht signifikant • Meinung der anderen Statistiker • Man kann *, **, *** machen • Opinion of the one kind of statistician • There is only significant or not significant • Opinion of the other kind of statistician • You can use *, **, *** • It is not meaningful to adjust α after calculating p to call the result „extremely significant“. - 197 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Aufhören, wenn signifikant? Stop, when significant? • Beispiel: • Example: • • • • Mean 1 = 50, SD = 30 Mean 2 = 90, SD = 30 α=0.05, β = 0.20 Gruppengröße 10 • Weil es zuviele Tiere für einfaches Handling ist, macht man an erst einmal 5 Tiere, dann später die zweiten 5 Tiere. • Vor dem zweiten Teil des Experimentes analysiert man diese ersten Daten der ersten 5 Tiere. • Es wird ein signifikanter Unterschied gefunden! • Yippee? • • • • Mean 1 = 50, SD = 30 Mean 2 = 90, SD = 30 α=0.05, β = 0.20 Sample size 10 • Because these are too many animals for easy handling, you first sue 5 animals and plan to use the other five later. • Before you start the second part of the experiment, you analyze the data of the first 5 animals. • You find a statistical significant difference! • Yippee? - 198 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Samples taken by audience Die Stichproben, die vom Publikum gezogen wurden. The samples taken by the audience. - 199 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Samples taken by audience Die Stichproben, die vom Publikum gezogen wurden. The samples taken by the audience. - 200 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Aufhören, wenn signifikant? Stop, when significant? • Beispiel: • Example: • • • • Mean 1 = 50, SD = 30 Mean 2 = 90, SD = 30 α=0.05, β = 0.20 Gruppengröße 10 • • • • Mean 1 = 50, SD = 30 Mean 2 = 90, SD = 30 α=0.05, β = 0.20 Sample size 10 • Weil es zuviele Tiere für einfaches Handling ist, macht man an erst einmal 5 Tiere, dann später die zweiten 5 Tiere. • Vor dem zweiten Teil des Experimentes analysiert man diese ersten Daten der ersten 5 Tiere. • Es wird ein signifikanter Unterschied gefunden! • Yippee? • Nein • Because these are too many animals for easy handling, you first sue 5 animals and plan to use the other five later. • Before you start the second part of the experiment, you analyze the data of the first 5 animals. • You find a statistical significant difference! • Bei einer Gruppengröße von 5 ist die Teststärke nicht mehr gegeben. Man hat ein größeres α. • Hier: α=0.25 in 25% der Fälle wird eine falsche Signifikanz gefunden! [Sonst könnte man ja auch einfach mit n=1 oder n=2 arbeiten] • With a sample size of 5 the power of the test is not the same. You have a larger α. • Yippee? • No • Here: α=0.25 in 25% of the cases, a wrong significance is found! [Else, you could simply work with n=1 or n=2 and.] - 201 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Weitermachen, bis signifikant? Continue, until significant? • Beispiel: • Example: • • • • Mean 1 = 50, SD = 30 Mean 2 = 120, SD = 30 α=0.05, β = 0.20 Gruppengröße 3 • • • • Mean 1 = 50, SD = 30 Mean 2 = 120, SD = 30 α=0.05, β = 0.20 Sample size 3 • Das Experiment wird gemacht; p>0.05 • Aber man sieht einen Trend • Mehr Tiere würden das doch signifikant machen …. • Ja, durchaus. Vor allem, wenn man so lange weitermacht, bis man die Signifikanz endlich hat. • Selbstbetrug • The experiment is made; p>0.05 • But you see a trend • More animals would make that significant …. • Yes, sure. Especially, when you continue on until you finally reach significance • Das Problem: • Wann hört man auf? • Wenn man willkürlich in einem Experiment nun solange die Gruppengröße verändert, bis man das gewünschte Ergebnis erzielt, verfälscht man das Ergebnis. • The problem: • When do you stop? • When you arbitrarily increase the sample size in an experiment until you reach the wanted result, you tamper with the result. You fool yourself - 202 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance • • • • Statistician: "Oh, so you have already calculated the P value?" Surgeon: "Yes, I used multinomial logistic regression." Statistician: "Really? How did you come up with that?" Surgeon: "Well, I tried each analysis on the SPSS drop-down menus, and that was the one that gave the smallest P value” (1) • “Datenfolter” kommt vor, wenn Wissenschaftler auf der Suche nach Signifikanz ohne klaren Plan die Daten auf alle möglichen Arten analysieren. • Veränderte Definition des Ergebnisses • Andere Zeitskala • Kriterien werden verändert um Subjekte aus der Analyse zu entfernen • Willkürliches Picken von Ausreißern • Verschiedene Möglichkeiten, Daten zu Subgruppen zu arrangieren werden ausprobiert • Verschiedene statistische Tests werden ausprobiert. • “Data torture” occurs when investigators, without a clear plan, analyze their data in many ways, desperately seeking “statistical significance” • Change the definition of the outcome. • Use a different time scale. • Try different criteria for including or excluding a subject. • Arbitrarily decide which points to remove as outliers. • Try different ways to clump or separate subgroups. • Try different statistical tests. - 203 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Was man machen kann: What you can do: • Für Experimente, bei denen die Daten sequentiell Subjekt für Subjekt analysiert werden, gibt es spezielle statistische Verfahren. • For experimental setups where each subject is analyzed sequentially, special statistic methods exist. Wichtig für klinische Studien. This is important for clinical studies. - 204 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Was kann ich tun? What to do? • Wenn die Schätzungen der Experimentplanung nicht stimmen: Anpassen der Vorraussetzungen des Experimentes • When the estimates used for planning the experiments are shown to be wrong: Adjust the conditions of the experiment. • Anderen Fehler 2. Art festlegen • Define a different Type II error • Mean und SD an die effektiv gefundenen Werte anpassen • Adjust mean and SD of the group size calculation to the found values Dieses Experiment wird zu einem Pilotexperiment This experiment becomes a pilot study Eine neue benötigte Gruppengröße berechnen A new group size is calculated Ein neues Experiment mit dieser Gruppengröße durchführen und die neuen Daten analysieren. A new experiment is performed with the new group size and the new data are analyzed. NICHT mit den alten Daten des Pilotexperiments poolen! DO NOT pool the new data with the old data of the pilot experiment! - 205 - Statistische Tests Statistical tests Die Suche nach Signifikanz looking for significance Was kann ich tun? What to do? • Wenn die Schätzungen der Experimentplanung stimmen: • When the estimates used for planing the experiments are shown to be correct: Einen anderen Ansatz wählen. Pick another approach. Dasselbe Experiment noch einmal zu machen ist nicht korrekt – man beginnt die Signifikanz zu jagen. To repeat the experiment is not correct – you start to hunt for significance. Statt dessen kann man einen anderen Ansatz für ein neues Experiment wählen (knock-out Maus, andere Substanzen, etc) Instead, choose a different approach for a new experiment (knock-out mouse, other substance, etc) - 206 - The Experiment Das Experiment • Formuliere die Frage, die beantwortet werden soll. Es muss eine JA / NEIN Frage sein. • Define the question to answer. It has to be a YES/NO Question. • Bestimme den/die untersuchten Faktoren. Nicht mehr als zwei Faktoren in einem Experiment! • Define the assayed factors. Not more than two factors in one experiment! • Bestimme den/die gemessenen Parameter. Am besten nur einen Hauptgröße • Define the measured parameter. Best, just one main factor • Entscheide / bestimme den relevanten Unterschied. • Define the relevant difference. • Bestimme die interessanten Vergleiche • Define the comparisons to make. • Bestimme den statistischen Test • Define the statistical test used. • Berechne die Gruppengröße • Calculate the group size. • Mache das Experiment. • Perform the experiment. • Mache genau die statistische Auswertung, die vorher festgelegt wurde. • Perform the statistical test defined before. - 207 - Sources Quellen • (1) GraphPad Prism Statistics Guide. Harvey Motulsky • (1) GraphPad Prism Statistics Guide. Harvey Motulsky • (2) Biostatistik. Köhler-Schachtel-Voleske • (2) Biostatistik. Köhler-Schachtel-Voleske - 208 -