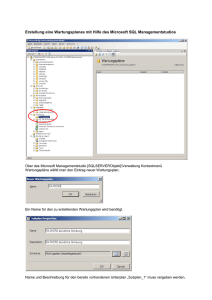
Fachhochschule Köln Campus Gummersbach Bachelorarbeit
Werbung

Fachhochschule Köln Campus Gummersbach Cologne University of Applied Siences Fakultät für Informatik und Ingenieurwissenschaften Bachelorarbeit Im Studiengang Wirtschaftsinformatik Etablierte Datenmodelle der NoSQL-Familie und ihre spezifischen Eigenschaften im Kontext von Cloud-Datenbanken 1. Prüferin/Betreuerin: 2. Prüferin: Prof. Dr. Birgit Bertelsmeier Prof. Dr. Heide Faeskorn-Woyke vorgelegt von: Mathias Frey Oberer Hengsbacher Weg 36b 57080 Siegen Matrikel-Nr.: 11053766 E-Mail: [email protected] Gummersbach, den 6. August 2010 Abstract Die relationalen Datenbankmanagementsysteme sind seit Mitte der 80er Jahre die vorherrschenden Systeme im Datenbanksegment. Diese Erfolgstory nähert sich womöglich jedoch ihrem Ende zu, da das Cloud Computing die IT-Landschaft in einen Wandel gebracht hat, der auch am Datenmanagement nicht vorbeigeht. Dynamische Skalierung, verteilte Systeme und riesige Datenmengen werden den Einsatzbereich der Datenbanken erweitern. Diese Arbeit stellt eingehend die neuen Herausforderungen vor, mit welchen die relationalen Datenbankmanagementsysteme, im Kontext der Cloud-Technologie, konfrontiert werden. Darüber hinaus werden die vier derzeit bekanntesten Typen der NoSQL-Datenmodelle und dazu jeweils ein Open-Source-Produkt beschrieben. Abschließend wird die Anwendung und Handhabung einer relationalen mit einer NoSQL-Datenbank in einem CRUD-Projekt verglichen. 2 Inhaltsverzeichnis Inhaltsverzeichnis...................................................................................................................3 1. Einleitung und Motivation ..................................................................................................4 2. Cloud Datenbanken...........................................................................................................6 2.1 RDBMS und die Anforderungen der Cloud-Technologie .............................................7 2.2 Das CAP-Theorem .....................................................................................................9 2.3 NoSQL......................................................................................................................11 2.3.1 Stärken und Schwächen der NoSQL-Datenbanken .............................................12 2.3.2 Datenbankskalierung ...........................................................................................13 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“..............................14 3. Gegenüberstellung etablierter NoSQL-Datenmodelle .......................................................16 3.1 Dokumentenorientiertes Datenmodell .......................................................................17 3.1.1 Eigenschaften dokumentenorientierter Datenmodelle ..........................................19 3.1.2 Apache CouchDB ................................................................................................19 3.2 Key-Value-orientiertes Datenmodell .........................................................................20 3.2.1 Eigenschaften Key-Value-orientierter Datenmodelle ............................................22 3.2.2 Redis ...................................................................................................................22 3.3 Spaltenorientiertes Datenmodell ...............................................................................24 3.3.1 Eigenschaften spaltenorientierter Datenmodelle ..................................................25 3.3.2 Cassandra ...........................................................................................................25 3.4 Graphorientiertes Datenmodell .................................................................................27 3.4.1 Eigenschaften graphorientierter Datenmodelle ....................................................28 3.4.2 Neo4j ...................................................................................................................28 3.5 Gesamtübersicht ......................................................................................................31 3.6 Fazit .........................................................................................................................32 4. Vergleich eines RDBMS mit einer NoSQL-Datenbank......................................................33 4.1 Oracle 11g in der Cloud ............................................................................................33 4.2 CRUD-Projekt mit Oracle Database 11g...................................................................34 4.3 CRUD-Projekt mit MongoDB ....................................................................................35 4.4 Gegenüberstellung von CouchDB und MongoDB .....................................................38 4.5 Fazit .........................................................................................................................41 5. Schlusswort......................................................................................................................43 6. Abkürzungsverzeichnis.....................................................................................................45 7. Literaturverzeichnis ..........................................................................................................47 3 1. Einleitung und Motivation Seit Mitte der 80er Jahre haben sich relationale Datenbankmanagementsysteme als die dominierenden etablieren können. Bereits in den Jahren zuvor haben sie viele der heute so genannten vorrelationalen Systeme, wie beispielsweise das Netzwerk-Datenbankmodell, das besonders in den 70er Jahren eine große Marktbedeutung hatte, verdrängt. In allen erdenklichen Unternehmens –und Wirtschaftsbereichen, in denen Datenbanken eingesetzt wurden, war das RDBMS das mit Abstand häufigste. In Anbetracht der Schnelllebigkeit der IT-Welt, die ständig mit neuen Innovationen, Veränderungen und technologischen Fortschritten aufwarten kann, stellen dreißig Jahre Dominanz eine beachtliche Leistung dar. Gegenwärtig jedoch befindet sich die IT in einem weiteren Wandel und dieser geht auch am Datenmanagement nicht vorbei. Das Cloud Computing ist der neue „Hype“ der IT-Welt, dem immer mehr Unternehmen folgen. Es birgt beträchtliche Potenziale, die jedoch nur abgerufen werden können, wenn alle Aspekte der Cloud-Plattform berücksichtigt werden. Einer dieser Aspekte ist die dynamische Skalierbarkeit oder die Fähigkeit Server nach Bedarf hinzuschalten zu können und Verarbeitungsprozesse oder Datenverwaltung auf diese zu verlagern bzw. auszuweiten (s. Kap. 2.3.2 Datenbankskalierung). Relationale Datenbankmanagementsysteme haben durch die Einhaltung des ACID-Transaktionskonzepts stets ein strenges und solides Datenmanagement sichergestellt. Dies kann sich nun im Zuge der Umstellung auf einen Cloud-Betrieb als unflexibel erweisen und wird in seiner bisherigen Form immer schwerer durchsetzbar sein (s. Kap. 2.1 RDBMS und die Anforderungen der Cloud-Technologie). Das Cloud-Computing-Konzept baut auf verteilten Systemen auf, für welche die Begriffe „Konsistenz“, „Verfügbarkeit“ und „Partitionstoleranz“ eine zentrale Rolle spielen (s. Kap. 2.2 Das CAP-Theorem). Diese sind jedoch erwiesenermaßen nicht gleichzeitig realisierbar, was wiederum das Aufkommen eines neuen Transaktionskonzepts und einer neuen Art von Datenbanken begünstigt hat (s. Kap. 2.3 NoSQL). Diese CloudDatenbanken sind speziell für den Betrieb in der gleichnamigen Umgebung entwickelt und ausgerichtet worden. Ihre Datenmodelle sind vielfältig (s. Kap. 3. Gegenüberstellung etablierter NoSQL-Datenmodelle) und weichen vom relationalen Tabellenmodell ab. Darüber hinaus erfolgt die Kommunikation nicht mehr über die, aus dem RDBMS bekannte Abfragesprache SQL, sondern über „gewöhnliche“ Programmiersprachen. Viele Unternehmen, insbesondere jene, die stark vom Internet abhängig sind, haben bereits eine Cloud-Datenbank mit einem NoSQL-Datenmodell übernommen. Die Überwiegende Anzahl der Datenbanken der NoSQL-Familie wird unter freier Lizenz vertrieben und kann gewöhnlich direkt von der Seite des Herstellers heruntergeladen werden. Ein weiterer Aspekt, auf welchen die rasche Verbreitung der NoSQL-Datenbanken zurück geführt werden kann, ist die relativ leichte Handhabung und der konzeptionell auf Einfachheit ausgelegte 4 Aufbau der Datenbanken. Dieser erlaubt auch weniger versierten Datenbankanwendern sich schnell zurecht finden zu können. In Anbetracht der schemafreien Struktur und der häufig sehr ausführlichen Dokumentation ist, unter Voraussetzung der Kenntnis der entsprechenden Programmiersprache, ein schneller Einstieg in die Materie möglich. Die Freiheiten, welche von den NoSQL-Datenbanken zur Verfügung gestellt werden, müssen jedoch mit einer größeren Sorgfalt seitens des Anwenders bei der Bearbeitung einhergehen, da viele absichernde Regulierungsmechanismen, wie sie das relationalen Datenmodell zur Verfügung stellt, nicht mehr vorhanden sind (s. Kap. 4. Vergleich verschiedener Datenbank). Diese Arbeit entstand vor dem Hintergrund des anhaltenden Cloud-Computing-„Hypes“ und seiner Auswirkungen auf die Datenverwaltung durch das etablierte relationale Datenmodell. Ihr Ziel ist die Untersuchung der vier NoSQL-Kern-Systeme (s. Kap. 3. Gegenüberstellung etablierter NoSQL-Datenmodelle) auf ihre konzeptionellen Unterschiede zum relationalen Datenmodell und deren Beurteilung im Hinblick eines Einsatzes in der Cloud-Umgebung. Der vorliegende Artikel setzt grundlegende Kenntnisse des Cloud Computing-Konzepts voraus. Zum besseren Verständnis empfiehlt der Autor daher die Lektüre von [Frey_2010]. 5 2. Cloud Datenbanken Viele etablierte Datenbanken, wie beispielsweise objektrelationale oder objektorientierte, besonders jedoch die relationalen Datenbanken haben zahlreiche Aufgaben in ebenso zahlreichen Bereichen wahrgenommen und tun das bis heute. Unternehmen und Institutionen aus den verschiedensten Forschungs –und Wirtschaftsbereichen sind auf eine klare, strukturierte und persistente Speicherung ihrer Daten angewiesen. Die IT-Landschaft hat bereits viele Innovationen kommen und gehen sehen. Genannt seien an dieser Stelle die E-Business Euphorie der 1990er Jahre, der dotcom-Boom 2000 oder auch das 2003 aufgekommene, neue Internetverständnis, welches unter dem Begriff „Web 2.0“ bekannt ist. Das Cloud Computing jedoch ist nach wie vor „im Kommen“ und hat bereits jetzt für weit reichende Veränderungen gesorgt. Industrie und Wirtschaft sind dem Trend gefolgt und umgestiegen. Mit dem vernetzten Cloud-Betrieb jedoch sind neue Herausforderungen einher gegangen, auf welche gerade im Datenmanagement reagiert werden muss (s. Kap. 2.1 RDBMS und die Anforderungen der Cloud-Technologie). Petabytes an Daten, die sich zudem auf verschiedenen Instanzen befinden, müssen verarbeitet und verwaltet werden während gleichzeitig eine permanente Verfügbarkeit und der Zugriff sichergestellt werden muss. Trotz dieser dezentralisierten Datenhaltung sollen Konsistenz und Verfügbarkeit gewahrt bleiben, aber das ist nicht ohne weiteres möglich (s. Kap. 2.2 Das CAP-Theorem). Die Umstellungen im Datenbankbereich sind groß, so dass man sich von manchen etablierten Schemata und Regeln verabschieden und neue wird annehmen müssen (s. Kap. 2.3.3 Funktionale Partitionierung und die ACID-Alternative). Viele Unternehmen, insbesondere jene, die stark vom Internet abhängig sind oder auf jenem basieren, haben kurzer Hand eigene Datenbanksysteme entwickelt, die speziell auf den firmeninternen Einsatzzweck zugeschnitten sind. Allerdings bringt die Freiheit eigene Entwicklungen zu nutzen, bedingt durch das gegenwärtige Fehlen von vorgeschriebenen Richtlinien oder Standards auch Nachteile bezüglich der Kompatibilität mit sich (s. Kap. 2.3 NoSQL). Die freie Verfügbarkeit der NoSQL-Datenbanken hat bereits jetzt sehr viele Unternehmen aus den verschiedensten Branchen zu einer Nutzung animiert. Allein die dokumentenorientierte NoSQL-Datenbank MongoDB wird von weit über 100 Unternehmen, unter denen sich auch namhafte Größen wie die New York Times oder Electronic Arts befinden, eingesetzt (s. Kap. 3.1 Dokumentenorientiertes Datenmodell und Kap. 4.3 CRUD-Projekt mit MongoDB).1 1 [Mong_2010] 6 2.1 RDBMS und die Anforderungen der Cloud-Technologie Aus der Unmenge der verschiedenen Datenmodelle, hat sich seit den 80er Jahren das relationale Datenmodell, sowie die dazugehörigen relationalen Datenbanken, zu dem marktbeherrschenden entwickelt. Bekannte Vertreter wie Oracle, IBM oder MySQL haben diese Entwicklung maßgeblich vorangetrieben. Jüngst jedoch, insbesondere seit dem Aufkommen des Cloud Computing-Hypes, haben sich die Fälle gehäuft, bei denen sich der Einsatz relationaler Datenbanken als schwierig herausgestellt hat. Vermehrt traten Defizite und Probleme in der Datenmodellierung, aber auch in der Skalierung über mehrere Maschinen und große Datenmengen, auf. Gegenwärtig kristallisieren sich zwei Tendenzen auf dem Datensektor heraus. Zum Einen der expotenzielle Zuwachs des Volumens, der von Nutzern, Systemen und Sensoren produzierten Datenmengen, sowie deren Konzentration auf verteilte Systeme (Amazon, Google und weitere Cloud-Systeme). Auf der anderen Seite ist eine steigende Abhängigkeit zu Daten aus verschiedenen Systemen bemerkbar, welche auf eine stetig wachsende Vernetzung und die daraus resultierende dezentralisierte Datenhaltung zurückzuführen ist. Letzterer Umstand wird insbesondere durch Techniken wie das Internet, Web 2.0 und soziale Netzwerke beschleunigt.2 Grundsätzlich gibt es in der Cloud die gleichen Möglichkeiten zur Datenspeicherung, wie in anderen On –oder Offlineumgebungen auch. Das heißt also entweder in Dateien oder in (meist relationalen) Datenbanken. Die Cloud birgt jedoch den Unterschied, dass die zu verwaltenden und zu speichernden Datenmengen um eine Beträchtliches größer sind. Das wiederum stellt neue Herausforderungen an die eingesetzte Hard –und Software, sowie die zugrunde liegenden Algorithmen. Als Beispiel sei an dieser Stelle das soziale Netzwerk Facebook.com erwähnt, dass Ende vergangenen Jahres rund 2,5 PB (!) an Daten speichern musste. Zudem beträgt der Datenzuwachs durchschnittlich etwa 15 TB am Tag. Diese Daten werden von ca. 400 Mio. Nutzern generiert und müssen permanent mit minimalen Antwortzeiten aufrufbar sein. Das Cloud Computing-Konzept zieht eine seiner Stärken aus der nahezu uneingeschränkten Verfügbarkeit der Ressourcen, sowie der starken, dezentralisierten Struktur. Mit der Dezentralisierung geht aber auch eine Verteilung der Daten auf verschiedene Rechner bzw. Standorte einher. Darüber hinaus enthält das Cloud Computing viele personalisierte Ressourcen und individualisierte Strukturen. Das bedeutet, dass sich Datenstrukturen verändern können und zwar auch gerade zur Laufzeit. Darüber hinaus sind Schemata zunehmend nicht mehr fix und selbst Datentypen können variieren. Hingegen müssen Daten bei traditionellen Datenbanken mit einem relationalen Datenmodell beispielsweise, in Tabellen abgelegt werden, die aus Spalten und Zeilen bestehen. Das Tabellenschema muss dafür vordefiniert werden, ebenso muss bei den zu verarbeitenden 2 [Neub_2010] 7 Daten eine strikte Schemakonformität zur Tabelle gewährleistet sein. Migrationszeiten steigen mit der Menge an Daten und komplexe Datenstrukturen häufen sich, was deren Abbildung erschwert. Die relative Starrheit ist daher ein weiteres Manko relationaler Datenbanksysteme im Hinblick auf den Einsatz in einem verteilten System wie der CloudUmgebung. Viele Hersteller haben zwar den Betrieb auf mehreren Servern vorgesehen, allerdings nur über interne, spezielle Kommunikationsprotokolle – dem Clustering. Dieses ist jedoch nur sehr begrenzt linear skalierbar und auf keinen Fall wurde es für einen Einsatz auf hunderten oder sogar tausenden Rechnern konzipiert. Hinzu kommt, dass die Befolgung der ACID-Eigenschaften und die Gewährleistung der Transaktionssicherheit zu kurzzeitigen Datensatzsperrungen führen. Diese wiederum können die Antwortzeiten insgesamt verlängern oder gar ein Dead-Lock hervorrufen. Eine über viele Server verteilte Datenbank arbeitet zudem noch mit umständlichen Mehrphasen-Commit-Protokollen, um die Konsistenz über alle Knoten sicherzustellen, was sich zusätzlich sehr negativ auf die Performanz im Gesamtsystem auswirkt. Nachteile dieser Art lassen sich prinzipiell auf Designentscheidungen zurückführen. Datenbankserver waren immer teure High-End-Maschinen bestehend aus hochqualitativer Hardware mit dem Ziel Fehler und Störungen möglichst vollständig auszuschließen. In Cloud-Rechenzentren kommt aber überwiegend preisgünstige Standardhardware zum Einsatz, ganz nach dem Prinzip „Masse statt Klasse“. Hardwarefehler oder Abstürze werden bewusst in Kauf genommen, da ein anderer beliebiger Server die Aufgabe des ausgefallenen Gerätes nahtlos übernehmen kann. Traditionelle DBMS können mit diesen Konditionen nur sehr schlecht umgehen, Transaktionsabbrüche oder gar fehlende Datenblöcke sind die Folge. Der Einsatz in der Cloud bedeutet insgesamt eine Verschiebung von der Komplexität hin zur Simplizität. Durch die Vernetzung und die gegenseitige „Überdeckung“ im Problemfall, ist die Transaktionssicherheit oftmals unnötig. Das Locking bremst zudem die Performanz und erschwert Replikationen. Hinzu kommt, dass Index-Updates sehr häufig „immediate“ sind und daher die Transaktion verzögern. Mehr Indizes erhöhen die Komplexität beispielsweise bei der Ausführung von Updates oder bei der Index-Auswahl für Queries. 3 Nicht unerheblich wirkt sich zudem die Virtualisierung aus, auf welcher das Cloud Computing zu einem beträchtlichen Teil basiert. Relationale Datenbanksysteme werden meist direkt auf normalen Server-Betriebssystemen, wie Windows oder Unix, betrieben. Virtuelle Maschinen, wie sie beim Cloud Computing gang und gäbe sind, verbergen aber die Komplexität sowie die zugrunde liegenden Mechanismen der CloudUmgebung vor dem DBMS.4 Die relationalen Datenbanksysteme können somit den, für den Cloud-Betrieb essenziellen, Anforderungen nicht mehr hinreichend genügen. Bezogen auf die Datenverwaltung vollführt sich in der Cloud-Umgebung ein Prioritätenwechsel. Die bisherige Daten –und Strukturkonformität, weicht einer Flexibilität und der Möglichkeit zu 3 4 [Wien_2010] [Meyer_2009] 8 Änderungen während des Betriebes. Generell lassen sich die spezifischen Anforderungen an eine Datenbank aus den konzeptionellen Stärken des Cloud Computings herleiten. Das Datenvolumen, das in der Cloud umgesetzt und verwaltet wird, muss auf mehrere Server, welche sich zudem noch auf verschiedenen Standorten weltweit befinden können, verteilt werden. Zugleich sollen Daten aber stets in der angeforderten Art und Menge zur Verfügung stehen und das noch möglichst ohne Geschwindigkeitseinbußen. Verfügbarkeit und Performanz gehören somit zu den primären Eigenschaften einer Datenbank für den Einsatz in der Cloud. Das Cloud Computing ist jedoch ein verteiltes System und als solches gibt es keine „zentrale“ Datenbank. Folglich muss auch Letztere die Fähigkeit besitzen Daten auf verteilten Servern verwalten zu können, weshalb die wichtigste Eigenschaft die Skalierbarkeit ist. Durch die Aufteilung (Partitionierung) der Daten lässt sich in einem verteilten System jedoch eine permanente Konsistenz der Daten nicht gewährleisten (s. Kap. 2.2 Das CAP-Theorem), was wiederum die Durchführung von ACID-konformen Transaktionen in ihrer bisherigen Form verhindert. Letzteres ist der Grund für das Aufkommen des BASE-Konzepts, das speziell in Cloud-Datenbanken zum Einsatz kommt (s. Kap. 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“).5 2.2 Das CAP-Theorem Im Juli 2000 stellte der Computerwissenschaftler und frühere Yahoo-Mitarbeiter Eric A. Brewer die CAP-Vermutung auf ([PODC_2000]). Zwei Jahre später veröffentlichten Seth Gilbert und Nancy Lynch vom MIT einen axiomatischen Beweis dieser Vermutung und etablierten diese somit zu einem Theorem ([CAP_2002]). Brewer, gegenwärtig Professor für Computerwissenschaft an der University of California in Berkeley, beschrieb das Theorem auf Grund von Forschungsergebnissen und Observierungen verteilter Systeme. CAP steht verkürzt für Consistency, Availability und Partition Tolerance. Das CAP-Theorem besagt, dass ein verteiltes System durch die drei fundamentalen Charakteristika Konsistenz, Verfügbarkeit und Partitionstoleranz, beschrieben wird und das es immer nur zwei dieser drei Charakteristika gleichzeitig erfüllen kann. Dies lässt sich mit zwei Beispielen anschaulich beschreiben: Das Online-Versandhaus Amazon möchte möglichst viele Kunden weltweit bedienen und betreibt daher ein weit verstreutes Netz an Servern. Amazon strebt folglich also eine hohe Verfügbarkeit an – muss aber dafür Einbußen bei der Konsistenz hinnehmen. Kauft A ein Buch in New York und B eins in Singapur und geschieht dies auf zwei verschiedenen Servern, sind die beiden Datenbanken nicht mehr synchron bzw. konsistent. Brewer beschreibt diesen Umstand als „eventually consistent“, da die Datenbanken später wieder synchronisiert werden. 5 [North_2010] 9 Ein großes Bankunternehmen besitzt ebenfalls viele Filialen und verteilte Server. Permanent werden Geldbeträge zwischen den Konten transferiert. Neben der Verfügbarkeit ist die Konsistenz in diesem Fall derart entscheidend, dass Einschnitte in der Distributivität vorgenommen werden. Die Bank zentralisiert diese Aktionen und steuert sie von einem einzigen Datenzentrum heraus. Die zentrale Datenbank ist durchgehend konsistent. Die „spätere Konsistenz“ wird im so genannten BASE-Konzept umgesetzt (s. Kap. 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“). Brewer definiert BASE als das andere Ende des Spektrums gegenüber ACID.6 Konsistenz (Consistency) Ein System, welches konsistent ist, arbeitet entweder ganz oder gar nicht. Gilbert und Lynch verwenden den Begriff „atomic“ (dt.: atomar, unteilbar) statt konsistent, was technisch gesehen mehr Sinn macht, da konsistent für das „c“ in ACID steht, den idealen Eigenschaften von Datenbanktransaktionen. Es bedeutet, dass Daten nie gegen bestimmte voreingestellte Beschränkungen (Constraints) verstoßen werden. Stellt man sich jedoch ein verteiltes System vor, welches darauf beschränkt wird, dass beispielsweise mehrfache Werte nicht für ein und den selben Datenteil erlaubt werden, wird das Problem offensichtlich. Verfügbarkeit (Availability) Verfügbarkeit bedeutet was es heißt – ein Dienst oder System ist verfügbar. Gilbert und Lynch meinten treffend, dass gerade die Verfügbarkeit jemanden genau dann im Stich lässt, wenn sie am meisten gebraucht wird. Internetseiten zum Beispiel brechen in Zeiten von erhöhtem Anfrageaufkommen zusammen, eben weil sie so stark frequentiert werden. Partitionstoleranz (Partition Tolerance) Wenn ein Programm oder eine Datenbank auf einem Rechner / Server betrieben wird, agiert dieser Rechner als eine Art atomarer Prozessor, in dem Sinne, dass er entweder funktioniert oder nicht (beispielsweise auf Grund eines Absturzes etc.). Beginnt man jedoch damit Daten und Logik auf verschiedene Rechner (auch Knoten) zu verteilen, besteht das Risiko, dass sich Partitionen formen. Als Beispiel sei eine Datenbank gegeben, die auf 100 Knoten betrieben wird, welche wiederum auf zwei Schränke verteilt sind. Nun wird die Verbindung zwischen diesen Schränken unterbrochen – die Datenbank ist damit partitioniert. Ist das System partitionstolerant, dann wird die Datenbank auch weiterhin Lese –und Schreiboperationen durchführen können. In Anbetracht der Art der Verteilungsfähigkeiten, die das Internet zur Verfügung stellt, sind temporäre Partitionen eine relativ gewöhnliche und häufige 6 [Dash_2010] 10 Erscheinung. Selbiges gilt auch für globale Unternehmen mit mehreren Datenzentren. 7 8 9 Gilbert und Lynch definieren die Partitionstoleranz nicht als die Eigenschaft einer verteilten Applikation, sondern als eine des Netzwerks, auf welchem die Applikation betrieben wird. Die Partitionstoleranz kann einem System also nicht nach belieben hinzugefügt werden. Liegt eine Partition in einem Netzwerk vor, verliert es entweder die Konsistenz (da nun auf beiden Seiten der Partition Updates erlaubt werden) oder die Verfügbarkeit (weil der defekte Bereich bis zur Fehlerbeseitigung abgeschaltet wird). Partitionstoleranz bedeutet ganz einfach die Entwicklung einer Bewältigungsstrategie, um zu entscheiden auf welche der beiden anderen Systemeigenschaften verzichtet werden soll. Dies ist die Kernaussage des CAP-Theorems.10 Relationale Datenbanksystem sind also, bezogen auf die drei Eigenschaften des CAPTheorems, primär auf strenge Konsistenz und Verfügbarkeit ausgelegt – „CA-Systeme“. In großen verteilten Systemen wie dem Cloud Computing, welches stark auf günstiger Hardware aufbaut und Ausfälle einkalkuliert werden, muss die Toleranz für Netzwerkpartitionen jederzeit gegeben sein. Folglich muss zwischen Konsistenz und Verfügbarkeit abgewogen werden.11 Tendenziell werden im Cloud Computing bei der Konsistenz Abstriche hingenommen um dafür eine höhere Verfügbarkeit zu erlangen und damit letzten Endes auch die Performanz zu steigern.12 Die meisten NoSQL-Datenbanken kommen mit diesen Abstrichen besser zurecht, da sie, im Gegensatz zu den relationalen Datenbanken, nicht an die Umsetzung der ACID-Eigenschaften gebunden werden – für sie gelten andere „Regeln“ (s. Kap. 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“). 2.3 NoSQL 1998 stellte der damalige IBM-Informatiker Carlo Strozzi eine nicht-relationale Datenbank vor, die speziell für den Einsatz im Betriebssystem Debian Linux entwickelt wurde. Abb. 1: NoSQL Logo Der Name dieser Datenbank war NoSQL. 2009 wurde der Begriff NoSQL („Not only SQL“) vom Rackspace-Mitarbeiter Eric Evans wieder verwendet und bezeichnet heute eine eigene Bewegung, die sich als eine Open-Source-Community versteht. Diese führt jährlich verschiedene Veranstaltungen und Treffen durch, auf welcher Meinungen, Tests und Diskussionen rund um den Bereich nichtrelationale Open Source Datenbanken, geäußert und durchgeführt werden.13 14 7 [CAP_2002] [Browne_2009] 9 [Gray_2009] 10 [Robi_2010] 11 [Mok_2009] 12 [Vogels_2008] 13 [Strozzi_2010] 8 11 2.3.1 Stärken und Schwächen der NoSQL-Datenbanken Das Angebot an NoSQL-Datenbanken hat sich rasant vervielfältigt und bietet mittlerweile eine Fülle von Datenbanklösungen mit unterschiedlichsten Datenmodellen, welche Daten auf verschiedene Weise handhaben. Von der Datenverwaltung in Form von Dokumenten, als Schlüssel-Wert-Paar bis hin zu einer grafischen Darstellungsweise steht dem Anwender ein breites Spektrum an Datenmodellen zur Auswahl (s. Kap. 3. Gegenüberstellung etablierter NoSQL-Datenmodelle). Die Entwicklung dieser Datenmodelle geht nicht zuletzt auch deshalb so schnell von statten, weil die NoSQL-Bewegung ein loser Zusammenschluss von Entwicklern und Interessenten ist, die keine festen Richtlinien oder bindende Normen vorgeben. Bisher sind keine Standardisierungsvorschriften für die NoSQL-Datenmodelle beschlossen oder herausgegeben worden. So kann praktisch Jeder, der das benötigte Wissen und die Kenntnisse besitzt, seine eigene NoSQL-Datenbank entwickeln, einsetzen oder weitergeben. Ein Beispiel für so einen Fall ist die Entwicklung von Redis (s. Kap. 3.2.2 Redis). Der daraus resultierende Nachteil ist, das jede NoSQL-Datenbank für sich einzigartig ist und es somit zu Komplikationen bei der Kompatibilität von Applikationen kommen kann, die nur für eine spezielle Datenbank geschrieben wurden. In einem solchen Fall ist auch der Open-Source-Aspekt keine Hilfe. Analysten gehen deshalb davon aus, dass sich NoSQLEntwickler in den kommenden Jahren unter anderem verstärkt auf die Ausarbeitung einer besseren Applikationskompatibilität zwischen den Datenmodellen konzentrieren werden.15 16 Die fehlende Standardisierung macht sich zudem auch im Bereich der Datensicherheit bemerkbar. Es wurden bisher keine einheitlichen Richtlinien aufgestellt, die vorgeben, welche und wie viele Möglichkeiten ein NoSQL-Datenmodell zur Verfügung stellen oder mit welchen Methoden und Mechanismen dieser Schutz gewährleistet werden soll. Zwar unterstützt jede Datenbank Sicherungsmaßnahmen wie beispielsweise das Backup für die Wiederherstellung nach einem Störfall, intern jedoch bestehen viele konzeptionelle Unterschiede. Die dokumentenorientierte Datenbank MongoDB zum Beispiel startet in einem so genannten Default-Modus, der keinerlei Einschränkungen für den Anwender beinhaltet. Das bedeutet es können nach belieben Datenbanken und Dokumente erstellt, verändert und wieder gelöscht werden. Selbiges gilt für das ebenfalls dokumentenorientierte System CouchDB. Beide bieten zwar die Möglichkeit Benutzergruppen mit unterschiedlichen Zugriffsrechten zu erstellen, allerdings erlauben diese keine Erstellung von Zugriffsbeschränkungen auf bestimmte Datenbankbereiche oder gar einzelne Dokumente. Diese Einstellungen muss der Anwender derzeit mit Hilfe von eigens programmierten 14 [Silicon_2010] [Kell_2010] 16 [Leav_2010] 15 12 Zugriffsroutinen verwirklichen.17 18 Ein Beispiel für das Fehlen jeglicher interner Sicherheitsmechanismen ist die Graphendatenbank Neo4j, deren Betrieb von einem „trusted environment“ (dt. vertraute Umgebung) ausgeht. Sämtliche Sicherheitsvorkehrungen, wie die auf der Internetpräsenz des Entwicklers vorgestellte access control list (ACL), müssen auf der Applikationsebene ausgeführt werden.19 Angemerkt sei an dieser Stelle, dass sich insbesondere die Open-Source-Datenbankprojekte nach wie vor in einer ständigen Entwicklungsphase befinden. Es ist somit nicht ausgeschlossen, dass zukünftig verbesserte Zugriffsbeschränkungen oder verfeinerte Rechtvergabesysteme installiert werden. Der gegenwärtigen Abwesendheit von Standards zum Trotz haben sämtliche NoSQLDatenbanken prinzipiell eine Gemeinsamkeit. Sie wurden primär vor dem Hintergrund entwickelt, dass sie bei der Verwaltung von immensen Datenmengen –und Größen eine hohe Performanz und Geschwindigkeit bereitstellen können. Auch die Tatsache, dass die stetig wachsenden Datenmengen langfristig Skalierungen der Datenbanken unumgänglich gemacht haben, wurde bei der Entwicklung der NoSQL-Datenbanken einbezogen (s. Kap. 2.3.2 Datenbankskalierung). 2.3.2 Datenbankskalierung Prinzipiell gibt es zwei Strategien um Skalierungen zu verwirklichen. Die erste und einfachste ist die vertikale Skalierung, also die Übertragung von Applikationen und Daten auf einen größeren Rechner. Die vertikale Skalierung funktioniert für Daten einwandfrei, ist jedoch in vielerlei Hinsicht Einschränkungen unterworfen. Die offensichtlichste ist, dass über Kurz oder Lang die Kapazitäten selbst der größten Maschine dem Datenvolumen nicht mehr gewachsen sind. Die vertikale Skalierung ist zudem kostenintensiv, da sie Investitionen in größere Maschinen erfordert, um die steigende Zahl der Transaktionen bedienen zu können. Die horizontale Skalierung offeriert eine größere Flexibilität, ist dafür aber Abb. 2: Funk. Skalierung und Sharding wiederum komplexer, da das Hinzuziehen weiterer Server mit einem größeren Verwaltungsaufwand einhergeht.20 Horizontale Skalierung kann entlang zweier Richtungen erreicht werden. Zum einen durch die funktionale 17 [Secure_2010] [Ander_2010] S. 189 – 191, Kap. 22 19 [Vick_2010] 20 [WASC_2010] 18 13 Skalierung, die eine Gruppierung der Daten nach Funktionen beinhaltet und diese funktionalen Gruppen über Datenbanken verteilt. Zum zweiten erfolgt eine Aufteilung von Daten innerhalb funktionaler Bereiche über mehrere Datenbanken – dies wird auch als „sharding“ bezeichnet. Das Beispiel in Abbildung 2 zeigt, wie beide Ansätze zu gleich in der horizontalen Skalierung verwirklicht werden. Die funktionalen Bereiche User, Produkte und Transaktionen können auf separate Datenbanken verteilt werden. Zusätzlich wird aber auch jeder Bereich auf mehrere Datenbanken verteilt, was dem Transaktionsvolumen dienlich ist. Wie die Abbildung zeigt, können die funktionalen Bereiche unabhängig voneinander skaliert werden. Die funktionale Partitionierung (s. Kap. 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“) ist besonders dann empfehlenswert, wenn es darum gilt ein möglichst hohes Maß an Skalierbarkeit zu erreichen – eine grundlegende Anforderung für den Cloud-Einsatz.21 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“ Die Skalierbarkeit stellt bei nahezu allen großen Applikationen, besonders bei Webapplikationen, ein entscheidendes Problem dar. Hat die Nutzeranzahl ein hinreichend großes Maß erreicht, gerät jede Applikation zu einem Punkt, an welchem auch eine Aufrüstung des Datenbankservers die ansteigende Belastung nicht mehr kompensieren kann. Eine Skalierung kann zum Einen durch das Clustering ermöglicht werden. Es besteht jedoch auch die Option die Daten zu partitionieren, das bedeutet die Tabellen so weit zu isolieren, dass Gruppen von Daten jeweils auf einem eigenen Server liegen. Cluster aufzusetzen und zu betreiben ist jedoch sehr aufwändig und kostenintensiv. Des Weiteren reagiert es empfindlich auf Netzwerkstörungen. Darüber hinaus unterliegt es Einschränkungen, wenn beispielsweise eine Serverart oder Applikation das Clustering nicht unterstützt.22 23 Nicht unerheblich ist zudem die Tatsache, dass Transaktionen nach wie vor zu Locks auf Bereiche der Datenbank führen können, welche während der Transaktion nicht parallel bearbeitet werden können. Selbst wenn man, mit Hilfe von mehreren Servern pro Cluster, eine theoretisch beliebige Performanzsteigerung erreichen kann, sind, über Kurz oder Lang, Probleme auf Grund gelockter Datenbankbereiche unausweichlich, so dass die Server warten werden müssen, bis der Lock aufgehoben ist. Die funktionale Partitionierung besitzt diese Probleme zwar nicht, ermöglicht dafür aber keine ACID-konformen Transaktionen, da auf Grund der einsetzenden Verteilung keine permanente Konsistenz der Datenbank mehr aufrechterhalten werden kann (s. Kap. 2.2 Das CAP-Theorem). Das würde wiederum bedeuten, dass entweder die Applikation selber in der Lage sein muss die 21 [ACM_2008] [McGe_2002] 23 [Servs_2009] 22 14 Konsistenz der Datenbank sicherzustellen oder die Partitionierung müsste immer so gewählt werden, dass keine serverübergreifenden Transaktionen nötig wären – beides ist praktisch unmöglich. Hier greift ein neues Konzept ein, welches mit der Bezeichnung BASE abgekürzt wird: Basically Available, Soft State, Eventually Consistent. Es soll also eine grundsätzliche Verfügbarkeit sichergestellt werden, bei der zwar keine „feste“ („hard state“) permanente Konsistenz besteht, diese aber dafür zu einem späteren Zeitpunkt gewährleistet wird. Sie ist also fließend. Der zugrunde liegende Gedanke des Konzepts ist, das nicht alle Operationen in einer Transaktion durchgeführt werden sollen, sonder eine Message-Queue (dt. Nachrichtenschlange) zu verwenden. In einer Transaktion werden Änderungen an der ersten Tabelle durchgeführt und zugleich eine Nachricht in einen speziellen Table geschrieben. Unabhängig davon wird ein weiterer Prozess gestartet, der jenen speziellen Table anfragt und die Änderungen ausführt, die für gewöhnlich in der ersten Transaktion ausgeführt worden wären. Das Resultat ist eine erheblich gestiegene Skalierbarkeit, die allerdings – wenn auch nur temporär – auf Kosten der Konsistenz erkauft wird. Alle Operationen werden weiterhin in echten Transaktionen ausgeführt, so dass die Datenbank früher oder später tatsächlich wieder konsistent ist. Dies ist besonders dann vorteilhaft, wenn Aktionen aufgerufen werden, die bei verschiedenen Usern sowieso unterschiedlich aussehen. Wenn beispielsweise eine Nachricht in ein Forum geschrieben wird und sich erst dann auf weitere Server ausbreitet. Ein Beispiel an dieser Stelle wäre der NewsFeed von Facebook. Dieser weist zwar deutliche Latenzen auf, allerdings stellt dieser Umstand kein Problem dar, da die Nachrichten früher oder später auf jeden Fall ankommen und ihre Zustellung nicht zeitkritisch ist. In einem Fall könnten dennoch Probleme auftreten und zwar, wenn die Partitionierung ungünstig gewählt ist und der User die Inkonsistenz der Daten bemerkt, was sein Vertrauen in das System erschüttern kann. Dies war eine Zeit lang bei der Community-Plattform StudiVZ der Fall, als zum Teil Nachrichten, die man auf eine der Pinwände geschrieben hatte, erst merklich später beim verfassenden User sichtbar wurden. Wenn aber die Partitionierung die Konsistenz für den User garantiert und Latenzen nur während den Kommunikationen untereinander auftreten, ist dies sehr viel eher hinnehmbar, als ein System, welches die Leistungsfähigkeit seiner Datenbank sprengt und schlussendlich nicht mehr ansprechbar ist.24 24 [Patz_2009] 15 3. Gegenüberstellung etablierter NoSQL-Datenmodelle Die Konkurrenz des relationalen Datenbankmanagementsystems gestaltet sich sehr vielfältig und unterschiedlich. Allerdings sind auch konzeptionelle Gemeinsamkeiten feststellbar, da bei ihrer Entwicklung besonders viel Wert auf Eigenschaften wie Verfügbarkeit und Skalierbarkeit gelegt wurde. Darüber hinaus verzichten NoSQL-Datenbanken zum Teil vollständig auf schemaspezifische Vorgaben. Nicht unerheblich ist die Tatsache, dass sie sich leicht in Web-Standards wie beispielsweise REST und vor allem in Cloud-Technologien integrieren lassen.25 Zudem sind sie, auf Grund ihrer konzeptionellen Eigenschaften und ihrem strukturellen Aufbau, häufig auf den Einsatz in bestimmten Bereichen ausgelegt und auf diese spezialisiert. Der Überbegriff „NoSQL-Familie“ lässt auf eine weitere Eigenheit schließen: Alle Datenmodelle dieser Gruppe und ihre Implementierungen rücken von der bisher vorherrschenden Anfragesprache SQL ab. Damit einhergehend entfallen auch bekannte Operationen wie Joins oder diverse Gruppierungsfunktionen, mit denen in relationalen Datenmodellen verschiedene Abfragen formuliert werden konnten. Viele Datenbanken sind in bekannten Programmiersprachen, wie C, C++ oder Java, geschrieben worden. Sie werden über diverse Programmierschnittstellen (engl. APIs) angesprochen, wobei Letztere wiederum weitere Sprachen unterstützen, was den jeweiligen Entwicklern entgegenkommt. Ihre konzeptionellen Vorteile erreichen NoSQL-Datenbanken jedoch nur dadurch, dass einige Abstriche auf Gebieten wie der Datenintegrität oder den ACID-Regeln hingenommen werden müssen. Dennoch sind diese Datenmodelle derzeit sehr erfolgreich und nehmen in vielen, überwiegend internet-basierenden Applikationen, die verschiedensten Aufgaben war. Die stetig wachsende Zahl der Abnehmer, hier besonders Unternehmen, ist ein weiterer Indikator für die Attraktivität des Open-Source-Angebots.26 27 28 Gegenwärtig lassen sich knapp ein Dutzend verschiedene NoSQL-Datenbanken unterscheiden, die von der Community geführt werden. Diese Gruppe setzt sich zum Einen aus den so genannten NoSQL Kern-Systemen (Core NoSQL Systems) und zum Anderen aus den Soft-Systemen (Soft NoSQL Systems) zusammen. Letztere definieren sich dadurch, dass sie zwar nichtrelationale Lösungen darstellen, andererseits jedoch nicht Teil der ursprünglichen NoSQLDatenmodelle sind. Zu den Soft NoSQL-Systemen gehören unter anderem Objektdatenbanken (db4o [db4o_2010], Versant [Vrsnt_2010], Objectivity [Objct_2010]), Grid-Datenbanken (GigaSpaces [GigS_2010], Hazelcast [Hzlc_2010]) und XMLDatenbanken (Mark Logic Server [MLS_2010], EMC Documentum xDB [EMCD_2010], eXist 25 [CIO_2010] [Redis_2010] 27 [Mong_2010] 28 [CSCDB_2010] 26 16 [exst_2010]).29 Die Gruppe wird von den vier Kern-Typen, welche verschiedene Ansätze und Methoden der Datenverwaltung besitzen, dominiert. In diesem Kapitel werden diese Vertreter der NoSQL-Datenmodelle vorgestellt und beschrieben. Zudem werden, in einer tabellarischen Übersicht, ausgewählte, konzeptionelle Eigenschaften und Techniken des jeweiligen Datenmodells aufgeführt. Zu diesen Eigenschaften zählen die Realisierung und Höhe von Konsistenz, Skalierbarkeit und Performanz, die Informationsdarstellung, die Unterstützung sekundärer Indizes für präzise Abfragen, die Art des Schemas und Fähigkeit für den Multi-Server-Betrieb. An dieser Stelle muss explizit darauf hingewiesen werden, dass die verschiedenen NoSQL-Produkte, auch Datenmodell übergreifend, unterschiedliche Methoden und Techniken zur Sicherstellung der genannten Eigenschaften einsetzen. Resultierend daraus lässt sich nicht jeder Punkt mit einer eindeutigen Angabe belegen. Im Anschluss erfolgt jeweils die Kurzvorstellung einer Open-Source-Implementierungen zu dem betreffenden Datenmodell. Die erwähnten Eigenschaften lassen sich auf alle vier KernTypen anwenden, was deren Präsentation in einer Gesamtübersicht ermöglicht (s. Kap. 3.5 Gesamtübersicht). Statt den, aus dem relationalen Datenmodell bekannten, Tabellen, werden Daten hier in Dokumenten (s. Kap. 3.1 Dokumentenorientiertes Datenmodell) oder Spalten (s. Kap. 3.3 Spaltenorientiertes Datenmodell) organisiert. Neben relativ einfach gehaltenen Schlüssel-Wert-Strukturen (s. Kap. 3.2 Key-Value-orientiertes Datenmodell) haben sich auch grafische Modellierungsweisen (s. Kap. 3.4 Graphorientiertes Datenmodell) etabliert. Mit einer zusammenfassenden Schlussbetrachtung schließt das Kapitel ab (s. Kap. 3.6 Fazit). 3.1 Dokumentenorientiertes Datenmodell Unter dem Begriff dokumentorientiert versteht man prinzipiell, das sämtliche Daten, die in der Datenbank abgelegt werden, aus einer Reihe von Dokumenten bestehen. Jedes dieser Dokumente wiederum kann mehrere Felder und Werte enthalten. Darüber hinaus sind alle Dokumente voneinander unabhängig und es existiert auch kein Schema, an das sie gebunden sind. Unterschiede gibt es auch bezüglich der Identifizierung von Objekten. Es gibt keine Primär –oder Fremdschlüssel in dem Sinne, wie sie aus dem relationalen Datenbankmodell bekannt sind. Auch referentielle Integritäten entfallen bei der dokumentenorientierten Datenbank. Primärschlüssel werden im RDBMS automatisch inkrementiert oder durch eine Sequenz generiert. Das stellt die Einzigartigkeit innerhalb einer Tabelle oder Datenbank sicher. Sie können also in anderen Tabellen oder Datenbanken wieder auftauchen. Wird nun zum selben Zeitpunkt eine Update-Operation auf zwei Datenbanken in separaten Netzwerken durchgeführt, können diese die nächste eindeutige 29 [Nsql_2010] 17 ID nicht ermitteln.30 Solche Fälle sind in dokumentenorientierten Datenbanken nahezu ausgeschlossen, da jedem einzelnen Dokument eine einzigartige, mehrstellige ID generiert wird. Ist eine derartige Identifikation nicht vonnöten, kann die ID auch von einem Anwender oder Programm bestimmt werden. Der Aufbau eines Dokumentes ist nur von der, in dem Dokument abgelegten Information abhängig und völlig unabhängig vom Aufbau der anderen Dokumente. Alle Daten, Informationen sowie die Beschreibung, die ein bestimmtes Dokument betreffen, werden in jenem Dokument selbst abgelegt. Die Schemafreiheit dieses Datenmodells ist eine wichtige Eigenschaft. Bei einer relationalen Datenbank muss im Voraus genau überlegt sein, wie die Datenbank modelliert werden soll, bevor sie erstellt wird. Datentypen oder Feldlängen müssen von vorneherein festgelegt werden. In der relationalen Datenbank wird zum Beispiel definiert, dass ein Nachname den Typ Text besitzt und höchstens 20 Zeichen lang sein darf. Sollte hier eine Änderung vorgenommen werden, ist eine Anpassung des gesamten Datenbankdesigns notwendig. Nachträgliche Änderungen einer SQL-Datenbank, können zu einem wahren Alptraum für den betreffenden Administrator werden, da hier oftmals verschiedene Integritäten und Abhängigkeiten in Spiel kommen. Im dokumentenorientierten Datenmodell sind alle Dokumente autark, so gibt es keine redundanten NULL-Werte und es können jederzeit neue Felder in einem beliebigen Dokument definiert werden. Zur besseren Einteilung und Übersicht bieten einige dokumentenorientierte Datenbanken Gruppierungsfunktionen an. In MongoDB beispielsweise lassen sich Dokumente in Collections zusammenfassen (s. Abb. 3) Abb. 3: Die MongoDB-Collection „Artikel“ (u.) und ihr SQL-Pendant (o.) Man kann sich dieses Datenmodell als eine Sammlung von Papierdokumenten vorstellen. Es wäre völlig sinnlos auf einem Papier ein NULL-Feld anzulegen. Wenn beispielsweise eine Person keinen zweiten Vornamen hat, wäre es jedem Sinn abträglich „Max NULL 30 [Ecdb_2009] 18 Mustermann“ zu schreiben. Der Zweitname entfällt einfach, so dass nur noch Vor –und Nachname bestehen. Das selbe Prinzip gilt für ein Dokumentenorientiertes Datenmodell.31 3.1.1 Eigenschaften dokumentenorientierter Datenmodelle Dokumentenorientierte Datenmodelle Darstellung / Format der Informationen Präzise Abfragen / Sek. Indizes Konsistenz (Methoden) MultiServerBetrieb Skalierbarkeit (Techniken) Performanz Schema Dokumente und Anhänge (oft BSON oder JSON) Präzise Abfragen möglich / Sek. Indizes werden unterstützt Mittel hoch (häufig Update-inplace oder MVCC) Betrieb auf mehreren Servern wird unterstützt Sehr hoch (oft über Replikation oder Sharding) I. d. R. Hoch (Abhängig von Konsistenzmethode u. tiefe der Abfragen – besonders bei WriteZugriffen Generell schemalos, oft zusätzl. unterstützende Gruppierungsfunktionen wie Collections oder Views 3.1.2 Apache CouchDB Im April 2005 kündigte Damian Katz, ein ehemaliger Senior Developer von Lotus Notes, in seinem Blog, die Entwicklung einer neuen Datenbank an. Er gab dem Projekt den Namen CouchDB, wobei Couch zugleich als Akronym für „Cluster Of Unreliable Commodity Hardware“ (dt. etwa. „Bündel von unzuverlässiger handelsüblicher Hardware) verstanden werden soll. Damit ist gemeint, dass CouchDB extrem skalierfähig, hoch verfügbar und zuverlässig ist und zwar auch dann, wenn das System auf einer Hardware betrieben wird, die von niederer Qualität ist und zu Ausfällen neigt. Ursprünglich ist CouchDB in C++ geschrieben worden, allerdings wechselte man im April 2008 auf die Programmiersprache Erlang, eine ehemalige hausinterne Sprache der Firma Ericsson. Eine Besonderheit der Sprache ist der größere Schwerpunkt im Bezug auf die Fehlertoleranz.32 Für den Anwender bedeutet dies jedoch, dass er für den Betrieb der Datenbank eine Erlang-Umgebung bereitstellen muss. Die dafür benötigten Programme lassen sich aber jederzeit aus dem 31 32 [Lenn_2009] S. 5 – 6, Kap. 1 [IBM_2009] 19 Internet beziehen. Entwickelt wurde CouchDB ursprünglich unter der Lizenz der Apache Software Foundation, einer freien Gemeinschaft von Entwicklern. Mittlerweile ist Katz jedoch zu IBM zurückgekehrt und darf dort die weitere Entwicklung, nun jedoch ohne jegliche Auflagen, leiten. Aktuell stellt CouchDB neben MongoDB (s. Kap. 4.1 ) einen der bekanntesten Vertreter aus der Reihe der dokumentenorientierten Datenmodelle dar. Beim Netzwerkprotokoll bedient sich CouchDB den verbreiteten Internetstandard http und verarbeitet Daten im JSON-Format, was insbesondere Web-Entwicklern sehr gelegen kommt. Passend dazu ist die Standardsprache für Anfragen JavaScript. Um die Anfragen strukturieren zu können, bietet CouchDB so genannte Views. Sie geben dem Nutzer eine bestimmte Sicht auf die Daten und können beispielsweise die Abfragen nach gewünschten Kriterien filtern. In komplexeren Fällen können Filteranfragen in Javascript definiert werden um die Ergebnismenge sukzessive auf eine überschaubare Größe zu reduzieren. Diese Methode ist auch unter der Bezeichnung Map/Reduce, einem Google-Patent, welches auch in der verteilten Datenbank BigTable angewandt wird33. Um die Konsistenz der Daten sicherzustellen, bedient sich CouchDB des MVCC-Prinzips.34 In der Datenbank werden also immer mehrere verschiedene Versionen eines Objektes bereitgehalten, die beispielsweise durch einen Zeitstempel oder fortlaufende Transaktionsnummern voneinander unterschieden werden. Jede Objektversion besitzt einen Zeitstempel vom Zeitpunkt des Schreibens durch eine Transaktion. Eine Transaktion Ti kann jeweils die aktuelle Version eines Objektes lesen, deren Zeitstempel kleiner ist als ZS(Ti), also die von der Transaktion geschrieben wurde. So wird sichergestellt, dass Transaktionen nie auf ein Datenobjekt warten müssen und ReadLocks werden ausgeschlossen.35 CouchDB wird derzeit von fast achtzig verschiedenen Quellen verwendet. Neben diversen Facebook Applikationen kommt es in mehreren Firmenwebsites zum Einsatz, unter welchen auch namhafte Größen wie beispielsweise jene der britischen Rundfunkanstalt BBC zu finden sind.36 3.2 Key-Value-orientiertes Datenmodell Mit der steigenden Popularität sozialer Medien und cloud-basierter Dienste, gewann auch das Key-Value-orientierte Datenmodell an Bedeutung. Für cloud-basierte Applikationen und Dienste, die eine internetbezogene Datenverwaltung voraussetzen, werden Key-ValueDatenbanken vermehrt ihren relationalen Pendants vorgezogen. Das Prinzip der Key-ValueStores ist sehr simpel. Ein bestimmter Schlüssel verweist auf einen Wert. In seiner einfachsten Form kann dieser wiederum eine beliebige Zeichenkette sein. Ähnlich einfach 33 [USPTO_2010] [From_2009] 35 [MVCC_2010] 36 [Cwiki_2010] 34 20 verhält es sich mit dem Schema des Key-Value-orientierten Datenmodells: Der Key ist ein String, der Wert ist ein BLOB, ansonsten liegt es ganz beim Anwender, wie er die Daten handhaben möchte. Es herrscht, wie in den meisten Datenmodellen aus der NoSQL-Welt, kein vordefiniertes Schema, aber der Benutzer selbst kann die Semantik definieren um die zu speichernden Daten nach seinen Gutdünken in der Datenbank abzulegen.37 Der Anwender bedient sich dazu einer Programmiersprache, die von einer zuvor gewählten API unterstützt wird. Besonders Open-Source-Produkte werden mit mehreren Programmierschnittstellen angeboten, um eine breite Palette an akzeptierten Programmiersprachen für die Kommunikation mit der Datenbank bereitzustellen. Im Key-Value-orientierten Datenmodell wird zudem auf sekundäre Indizes, wie beispielsweise Bitlisten-Indizes über Attribute verzichtet. Ebenso wenig werden Fremdschlüsselintegritäten gewahrt. Das bedeutet, dass ein Wert immer nur über einen bestimmten Schlüssel angesprochen werden kann. Dadurch wird das Datenmodell zwar simpler und häufig auch schneller, allerdings können sich Schwierigkeiten bei dem Versuch ergeben, komplexe Daten anzusprechen. Als Beispiel sei folgender Eintrag aus einer Benutzerliste gegeben: ID Name Alter eMail 12345 Thorger 30 [email protected] In einem relationalen Datenmodell wäre es möglich nach beliebigen „Spalten“ abzufragen. Bezogen auf ein Key-Value-Store, gestaltet sich das obige Beispiel hingegen etwas anders: 12345 ’Thorger, 30, [email protected]’ Im übertragenen Sinne „zeigt“ also ein Wert (ID) auf den kompletten Eintrag. Spezifische Abfragen, wie in diesem Fall, nach Name, Alter oder e-Mail-Adresse lassen sich hier nicht formulieren. Durch den Wegfall von Konsistenzerhaltungsmechanismen soll eine Effizienzsteigerung der Datenbank für Anwendungen mit vielen aber einfachen Daten bzw. Datentypen erreicht werden.38 Der Einsatz eines Key-Value-Stores eignet sich somit in den Fällen, in welchen die Verwaltung großer Datenmengen mit möglichst minimalen Geschwindigkeitseinbußen angestrebt wird und die Konsistenz kein entscheidender Faktor ist. Innerhalb der Key-Value-Stores werden zwei Untergruppen unterschieden. Zum einen die „in-memory“-Variante (auch in-cache-Variante), bei der die Daten primär im Hauptspeicher gelagert werden. Sie können mit schnellen Zugriffszeiten aufwarten und werden überwiegend für Applikationen eingesetzt, bei denen die Antwortzeiten ein ausschlaggebendes Kriterium darstellen. Die zweite Kategorie bilden die „on-disk“-Varianten, 37 38 [Heise_2010] [Brekle_2010] 21 bei welcher die Daten direkt auf einen persistenten Speicher, wie beispielsweise eine Festplatte, abgelegt werden. Der Vorteil des Key-Value-Datenmodells ist die Schlichtheit und Simplizität. Es ist sehr einfach eine Key-Value-orientierte Datenbank zu erstellen und ebenso leicht ist es sie zu skalieren. Auch hier wird dies über das Sharding oder die Replikationen verwirklicht. Auch ist es möglich eine sehr hohe Performanz zu erreichen, da Zugriffsmuster stark optimiert werden können. Mit der Entwicklung von Key-Value-Stores sollte beabsichtigt werden ein Datenmodell zu schaffen, dass für alltägliche (Web-)Anwendungen, wie Warenkorb –oder Lesezeichensysteme, effizient einsetzbar ist. Es ist für Applikationen gedacht, die keine beliebig komplexen Anfragen benötigen und schemafreie respektive nur leicht schematisierte Daten speichern. Im Fokus des Key-Value-Datenmodells liegt die Skalierbarkeit, hohe Verfügbarkeit, Partitionierung sowie extrem kurze Antwortzeiten. 39 Sehr häufig werden auch dokumentenorientierte Datenbanken als Key-Value-Datenbanken bezeichnet. Tatsächlich sind Erstere eine Abwandlung, da sie ebenfalls nach einem Schlüssel-Wert-Prinzip arbeiten. Der Vorteil hier ist jedoch, das man nicht nur darauf beschränkt wird nach Schlüsseln abzufragen, da dokumentenorientierte Datenbanken sekundäre Indizes und somit gründlichere Anfragemöglichkeiten bieten. 3.2.1 Eigenschaften Key-Value-orientierter Datenmodelle Key-Value-orientierte Datenmodelle Darstellung / Format der Informationen Präzise Abfragen / Sek. Indizes Konsistenz (Methoden) MultiServerBetrieb Skalierbarkeit (Techniken) Performanz Schema Sehr verschieden (häufig BLOB) I. d. R. keine I. d. R. schwach (inMemory, optimistic concurrency control) Betrieb auf mehreren Servern wird unterstützt Sehr hoch (oft über Replikation oder Sharding) Sehr hoch (Aufgrund der oft nicht vorhandenen Möglichkeiten für präzise Abfragen) Schemalos (Ausnahmen: z. Bsp.: Redis (Strings, Lists u. Sets) 3.2.2 Redis 39 [Bin_2010] S. 4, Kap. 1 22 Salvatore Sanfilippo, ein Programmierer von Webapplikationen und iPhone-Apps, begann im März 2009 mit der Entwicklung einer Datenbank, die speziell auf die Erfordernisse seiner beiden Unternehmen ausgerichtet sein sollte. Was als kleine nebenberufliche Tätigkeit gedacht war, wuchs schnell an und entwickelte sich rasch zu einem primären Projekt. Ursprünglich als hausinterne Lösung geplant, gab Sanfilippo Redis bereits nach wenigen Wochen als Open Source Software heraus. Redis fand erste Abnehmer und die Ansprüche der Nutzer wuchsen, so dass das Projekt weiter ausgebaut wurde. Sehr bald folgten die ersten Angebote von diversen Firmen und Sanfilippo ging zu VMware, einem USUnternehmen für Virtualisierungssoftware, deren großes Interesse von der Geschwindigkeit der Datenbank rührte.40 41 Mit 110000 Lese –und 81000 Schreibzugriffen in der Sekunde, gehört Redis in der Tat zu den derzeit schnellsten Datenbanken in dem Segment. Redis ist eine recht einfach gehaltene, auf Geschwindigkeit und Skalierbarkeit getrimmte, Key-Value Datenbank. Im Gegensatz zu vielen anderen Datenmodellen dieser Art, besitzt in Redis jeder Wert einen der vier folgenden Typen: - String Standardtyp, der alle möglichen Daten (Texte, Bilder, Videos usw.) enthalten kann. - List Eine List enthält mehrere Strings, die in der Reihenfolge ihrer Eingabe gespeichert werden. - Set Ein Set enthält eine unsortierte Sammlung von Lists. Doppelte Eintragungen sind nicht möglich, es wird ein neuer Set mit der entsprechenden Eintragung erstellt. - Sorted Set (seit v1.1) Ein Set, bei dem jedoch jede List einen Hashwert erhält und entsprechend sortiert wird. Das hat den Vorteil, dass, ähnlich wie bei sekundären Indizes, präzisere Abfragen nach Attributen von Lists und Sets möglich sind – einzig Attribute einzelner Strings lassen sich nicht abfragen. Die SQL-Relation „Artikel“ aus Abbildung 3 lässt sich in Redis als List darstellen, die die einzelnen Artikel als Strings beinhaltet (s. Abb. 4). Abb. 4: Abfrage aller 5 Artikel der Redis-List „Artikel“ (Index 0 – 4) 40 41 [Ablog_2009] [Pron_2010] 23 Eine weitere Besonderheit ist, das Redis die Daten im Hauptspeicher behält und im selben Moment persistent auf der Festplatte speichert – also „in-memory“ und „on-disk“ zugleich ist. Dem Anwender werden hier diverse Einstellungen angeboten. Beispielsweise kann man Redis so einstellen, dass alle 1000 Veränderungen ein Mal persistent gespeichert wird und/oder 60 Sekunden nach der letzten Änderung.42 Die bekanntesten Nutzer von Redis sind OKNOtizie, Italiens größtes Social-News-Portal und die britische Tageszeitung „The Gurdian“.43 VMware belässt Redis unter Open Source-Lizenz, eine Bedingung Sanfilippos, und plant die Datenbank in seine Cloud -und Virtualisierungstechnologien einzubinden.44 3.3 Spaltenorientiertes Datenmodell Unter dem Begriff der spaltenorientierten Datenbank (engl. Column-orientated database) versteht man zunächst die Art und Weise auf welcher die Daten auf dem eingesetzten persistenten Speichermedium, wie zum Beispiel einer Festplatte, abgelegt werden. In traditionellen Datenbanken werden dort immer alle Felder (Attribute) einer Tabellenzeile (Tupel) hintereinander abgelegt, weshalb eine solche Datenbank zutreffender Weise auch als zeilenorientiert bezeichnet wird.45 Für den Menschen stellt dies eine bequeme Sichtweise dar, denn sie passt zu der Art, wie der er selbst die Information speichert. Als Beispiel sie hier die Karteikarte genannt. Nimmt man jedoch an, dass jede Karteikarte einen Verkauf pro Vertriebsmitarbeiter belegt und man nun den Gesamtumsatz ermitteln möchte, so müsste man jede einzelne Karte durchsehen, den Verkaufsumsatz zum Gesamtergebnis hinzuaddieren und zur nächsten Karte übergehen. Selbstverständlich lässt sich eine SQLDatenbank in einem solchen Einsatzgebiet anwenden und optimieren, allerdings dauert dieser Vorgang länger, je mehr Daten zu verwalten sind. Zu bevorzugen wäre in einem solchen Fall die Möglichkeit, den jeweiligen Verkaufsumsatz eines Mitarbeiters auf einer Karte festzuhalten, diese aber zugleich auch auf einer Liste mit den Verkaufszahlen zu notieren. Um den Gesamtbetrag zu ermitteln, müsste man jetzt nur noch die Zahlen jener Liste zusammenrechnen. Dieses sehr schnelle Schema ist im Grunde das, was eine spaltenorientierte Datenbank ausmacht.46 Wenn eine hohe Performanz auch bei einer großen Anzahl an verschiedenen, simultan durchgeführten Anfragen gefordert wird, stoßen relationale Datenmodelle häufig an ihre Grenzen. Sie verwenden zusätzliche speicherintensive Indizes, um die Anfragen zu beschleunigen. Dies wird mit dem Laden unterschiedlicher Anfragen unhaltbar, auf Grund des damit einhergehenden wachsenden Bedarfes an Speicher und Rechenleistung zur Erhaltung und Verwaltung dieser Indizes. In 42 [Intro_2010] [Redis_2010] 44 [Pron_2010] 45 [GI_2010] 46 [Heise_2010] 43 24 spaltenorientierten Systemen werden Indizes vollkommen anders gestaltet. Sie sind primär dazu entwickelt worden um Daten zu speichern und dienen weniger als Referenzmechanismus, der auf einen anderen Speicherbereich mit der entsprechenden Datenzeile verweist. Resultierend daraus müssen nur die angefragten Spalten aus dem Speicher geholt werden. Spaltenorientierte Datenbanken kommen verstärkt in den Unternehmen zum Einsatz, in denen ein reger Gebrauch von analytischen Datenbanken gemacht wird. Sie dienen dort der Unterstützung des Berichtswesens, der Erstellung strategischer Analysen und vieler weiterer Aktivitäten im Bereich des Business Intelligence.47 3.3.1 Eigenschaften spaltenorientierter Datenmodelle Spaltenorientierte Datenmodelle Darstellung / Format der Informationen Präzise Abfragen / Sek. Indizes Konsistenz (Methoden) MultiServerBetrieb Skalierbarkeit (Techniken) Performanz Schema Spalten + Attribute (Rows) / oft JSON, BSON Präzise Abfragen möglich / Sek. Indizes werden unterstützt Mittel - Hoch (Variiert aufgrund des Einsatzes versch. Methoden u. a. MVCC) Betrieb auf mehreren Servern wird unterstützt Sehr hoch (oft über Replikation oder Sharding) I. d. R. Hoch (Abhängig von Konsistenzmethode u. Anzahl der Abfragen – besonders bei WriteZugriffen schemafrei 3.3.2 Cassandra Das Projekt Cassandra wurde im Juli 2008 auf Google Codes, einer Internetseite auf der Google Entwicklerwerkzeuge bereitstellt, veröffentlicht. Seit Februar diesen Jahres wird das Projekt von der ASF geleitet, die sich u. a. auch für CouchDB verantwortlich zeichnen.48 Cassandra gilt als Open-Source-Imitat von Googles hausinternem Datenbanksystem BigTable und war ursprünglich für den Einsatz im sozialen Netzwerk Facebook gedacht. 47 48 [Loshin_2009] S. 1 – 3 [DBMS_2008] 25 In Anbetracht von Facebooks über 400 Mio. Nutzern, war Cassandra primär darauf ausgelegt große Datenmengen effizient verwalten zu können. Durch die schnell ansteigende Nutzeranzahl sanken die Reaktionszeiten. Vor allem die Suchläufe auf den auf MySQL basierenden Posteingängen, auf welchen täglich mehrere Mrd. Schreibzugriffe erfolgten, nahmen immer mehr Zeit in Anspruch.49 Cassandra wurde in der Programmiersprache Java geschrieben und nutzt eine Synthese aus bekannten und etablierten Techniken, wie Partitionierung und Replikation, um die benötigte hohe Skalierbarkeit und Verfügbarkeit sicherzustellen. 50 Die Replikation kann in ihrem Umfang beschränkt werden, beispielsweise auf Datenzentren oder Serverschränke. Die Knoten des Systems wissen stets wo sie sich physisch befinden, was sehr vorteilhaft sein kann, um Latenzen gering zu halten. Der Eintritt eines neuen Knotens beginnt mit dem Kopiervorgang von Daten eines bereits ausgelasteten Knotens, was mit dem Ergebnis resultiert, dass sich beide den Schlüsselbereich und damit einhergehend die Arbeit teilen. Eine Lese –oder Schreiboperation kann auf einem beliebigen Knoten stattfinden, da dieser die Anfrage anschließend an den oder die betreffenden Knoten weiterleitet. Gewährleistet wird dies durch die Ermittlung des betroffenen Schlüssels. Die Speicherung erfolgt sowohl auf der Festplatte als auch auf dem Hauptspeicher, auf welchem zumeist die aktuellen Daten oder Indizes abgelegt werden. Jede Spalte (Column) erhält ihre eigene ID, über welche sie angesprochen werden kann (s. Abb. 5). Abb. 5: Die „Artikel“-Relation als SuperColumn in Cassandra. Darunter die einzelne SubColumn ArtNr1 Mit einem, im Hintergrund betriebenen Prozess, werden sämtliche Speicherabbilder zusammenführt und daraus ein „Superindex“ erstellt. Aus diesem lässt sich herleiten in welchen Daten ein Schlüssel vorkommt. Im Falle einer Anfrage wird zuerst im Speicher nachgesehen, ob die angefragten Daten dort noch vorhanden sind, ist dies nicht mehr gegeben, so werden die Daten an Hand der entsprechenden Indizes von der Festplatte geladen.51 Gegenwärtig wird das System in vielen Unternehmen erfolgreich eingesetzt. Neben Facebook nutzen weitere bekannte Firmen wie Cisco, Twitter, Digg oder Rackspace die Open-Source-Datenbank.52 49 [Bin_2010] S. 14, Kap. 3.1 [Malik_2009] Kap. 1 51 [Bin_2010] S. 17 – 18, Kap. 3.4, 3.5 52 [Cass_2009] 50 26 3.4 Graphorientiertes Datenmodell Graphenorientierte Datenmodelle können dadurch definiert werden, dass Datenstrukturen als Graphen oder Generalisierungen modelliert werden und Datenmanipulationen mittels graphenorientierter Operationen und Typkonstruktoren dargestellt werden. Sie sind nicht an strikte Schemata gebunden und eignen sich deshalb auch zur Verwaltung von häufig variierenden Daten(-typen) und verändernden Strukturen. Diese Modelle kamen, zusammen mit den objektorientierten Datenmodellen, in den Achtzigern und Anfang der Neunziger Jahre auf. Ihr Einfluss verschwand allmählich mit dem Aufkommen anderen Datenmodelle, namentlich den geographischen, räumlichen sowie den semi-strukturierten Datenmodellen. In jüngster Zeit stieg jedoch der Wunsch nach der Verwaltung von Informationen in einem graphähnlichen Schema. Die Anwendungsbereiche sind sehr verschieden. Zu ihnen gehören beispielsweise Applikationen aus dem GIS-Sektor, in welchem Aufgaben zur Speicherung und Darstellung geographischer Daten übernommen werden. Auf der anderen Seite bestehen auch im medizintechnischen Bereich Einsatzmöglichkeiten, zum Beispiel bei der Visualisierung von chemischen oder biologischen Daten.53 so dass dieses Modell wieder an Relevanz gewann. Datenmodelle dieser Art werden bevorzugt in den Bereichen angewandt, in denen Informationen über die Dateninterkonnektivität –oder Topologie wichtiger oder ebenso wichtig ist, wie die Daten selbst. Daten und ihre Relationen untereinander sind hier für gewöhnlich gleichwertig. Die Einführung von Graphen als Modellierungswerkzeug birgt für diesen Daten mehrere Vorteile. Zum einen sind Graphenstrukturen für den Benutzer sichtbar und erlauben eine natürlichere Handhabung von Programmdaten. Sie bieten die Möglichkeit alle Informationen über eine Entität in einem Knoten zu behalten und auf diesen Knoten bezogene Informationen durch Kanten darzustellen. Darüber hinaus können Anfragen direkt auf die Graphstruktur bezogen werden. Zu den ressourcenintensivsten und kompliziertesten Dingen, welche in einer SQL-Datenbank gespeichert werden können, sind die Beziehungen zwischen verschiedenen Elementen. Als Beispiel sei hier das Geflecht der Freunde und Bekannten in einem sozialen Netzwerk genannt. Nicht selten sind, in einer SQL-Datenbank, mehrere Abfragen notwendig, um eine solche Beziehung zu durchlaufen. Beim graphorientierten Datenmodell hingegen, können spezifische Graphoperationen aus der Anfragesprachenalgebra angewandt werden, um zum Beispiel den kürzesten Pfad zu ermitteln oder die Determinierung bestimmter Subgraphen vor zunehmen. Explizite Graphen und Graphoperationen erlauben dem Anwender Anfragen mit einem hohen Abstraktionsgrad zu formulieren. Aus einer gewissen Sicht, ist dies das Gegenteil der Graphenmanipulation in deduktiven Datenbanken, in welchen häufig komplexe Regeln geschrieben werden müssen. Im graphenorientierten Datenmodell ist es möglich wichtige Anfragen zu formulieren, ohne 53 [Wneo_2010] 27 das Wissen über die vollständige Struktur zu besitzen. Graphendatenbanken können ihre Stärken bei der Darstellung von Elementen ausspielen, bei denen die Beziehungen zueinander im Fokus stehen. Selbstverständlich lassen sich auch Informationen in einer Graphendatenbank speichern, die keinen Beziehungsbezug haben, allerdings bliebe hier ab zu wägen, in wiefern dies sinnvoll ist.54 55 3.4.1 Eigenschaften graphorientierter Datenmodelle Graphorientierte Datenmodelle Darstellung / Format der Informationen Präzise Abfragen / Sek. Indizes Konsistenz (Methoden) MultiServerBetrieb Skalierbarkeit (Techniken) Performanz Schema Knoten u. Kanten (Anhängen diverser Dateiformate möglich) Präzise Abfragen möglich / Sek. Indizes werden unterstützt Hoch (MVCC, aber auch mittels Write-Locks Betrieb auf mehreren Servern wird unterstützt Sehr hoch (oft über Replikation oder Sharding) Sehr hoch (Oft auch bei hoher Serverzahl u. tiefen Abfragen) I. d. R. schemafrei 3.4.2 Neo4j Neo4j war ursprünglich als hausinterne Technologie des kleinen, im schwedischen Malmö beheimateten, Softwareunternehmens Windh Technologies gedacht. Windh entwickelt und verkauft Dienste aus dem ECM-Bereich für den öffentlichen Sektor und die Rüstungsindustrie. Als das relationale Datenbankmodell den Ansprüchen nicht mehr genügte, begann man an einer eigenen Lösung zu arbeiten.56 Der Start der ersten Beta-Version fand im November 2007 statt und im Februar diesen Jahres schließlich wurde die Veröffentlichung von Neo4j 1.0 bekannt gegeben.57 Derzeit gibt es noch kein standardisiertes Graphenmodell, jedoch lässt sich allgemein festhalten, dass Graphenmodelle Informationen in - Knoten (engl. Nodes), - Kanten (mit Richtung und Typ) und - Eigenschaften (für Knoten und Kanten) 54 [SGDB_2008] S. 4, Kap. 2.1, S. 5, Kap. 2.2 [Heise_2010] 56 [Neo_2010] 57 [Nblog_2010] 55 28 abbilden. Gerade RDBMS-Implementationen können rekursive Strukturen, wie Dateibäume, vernetzte Verhältnisse und soziale Relationen, sehr schwer performant abfragen. Jede Kante stellt zumindest einen Join auf der Ausführungsebene eines RDBMS dar, welcher wiederum eine Mengenoperation zwischen den Tupeln zweier Tabellen erfordert, was sich nachteilig auf die Geschwindigkeit auswirkt. Eine große Stärke der graphenorientierten Datenmodelle liegt daher in der Performanz.58 Die Graphorientierte Datenbank Neo4j wurde in Java geschrieben. Wie in vielen anderen Open-Source Datenbanken aus dem NoSQL-Bereich, werden aber auch hier noch weitere Programmiersprachen, wie beispielsweise Python, Scala, JRuby oder Clojure, mit Hilfe des Einsatzes entsprechender APIAPIs, unterstützt.59 Zudem hat Neo4j mit Neoclipse ein Subprojekt ins Leben gerufen mit dem Ziel, durch Plugins für die freie Entwicklungsumgebung Eclipse, eine Möglichkeit zur graphischen Datenbankmodellierung bereitzustellen (s. Abb. 5). Abb. 6: Graphendatenbank in „Reinform“ – die SQL-Relation „Artikel“ in Neoclipse Neo4j kann mit einer starken Skalierbarkeit und Performanz aufwarten, während es zugleich ohne Schwierigkeiten mehrere Milliarden(!) Knoten, Kanten und Eigenschaften verwaltet. Durch den geschickten Einsatz von Caches werden Leseleistungen von über 2000 58 59 [Peter_2010] [OpenS_2010] 29 Kantenschritten pro Millisekunde, was also etwa 2 Mio. Schritte pro Sekunde entspricht, erreicht. In einem Vergleich mit einem Netzwerk von 1000 Personen und dem „Freundemeiner-Freunde-Problem“, konnte Neo4j eine 1000fach höhere Geschwindigkeit gegenüber einem MySQL-Gegenstück erreichen. Der Unterschied steigt dabei expotenziell mit der Größe des Graphen. Die enormen Geschwindigkeiten können dadurch erzielt werden, das die Traversierung entlang der Kanten mit einer konstanten Geschwindigkeit erfolgt und das zudem noch unabhängig von der Größe des Graphen. Es müssen somit keine Einbußen bei größeren Setoperationen, wie beispielsweise in den RDBMS-Joins, hingenommen werden. Darüber hinaus lädt Neo4j nach dem so genannten „lazy“-Verfahren. Knoten und Relationen werden also nur dann eingelesen, wenn sie wirklich im ResultSet abgefragt werden. Dies wirkt sich zusätzlich optimierend auf die Performanz speziell bei großen und tiefen Traversierungen aus.60 60 [PNeu_2010] 30 3.5 Gesamtübersicht Dokumentenorient. Datenmodell Key-Valueorient. Datenmodell Spaltenorient. Datenmodell Graphenorient. Datenmodell Dokumente und Anhänge (oft BSON oder JSON) Sehr verschieden (häufig BLOB) Spalten + Attribute (Rows) / überwiegend JSON, BSON Knoten u. Kanten (Anhängen diverser Dateiformate möglich) Präzise Abfragen / Sek. Indizes Präzise Abfragen möglich / Sek. Indizes werden unterstützt In der Regel nicht Präzise Abfragen möglich / Sek. Indizes werden unterstützt Präzise Abfragen möglich / Sek. Indizes werden unterstützt Konsistenz (Methoden) Mittel – Hoch (häufig Update-in-place oder MVCC) I. d. R. schwach (in-Memory, optimistic concur-rency control) Mittel - Hoch (Variiert aufgrund des Einsatzes versch. Methoden u. a. MVCC) Hoch (oft MVCC, Neo4j bietet ACIDIntegrität aber mit Locking Betrieb auf Mehreren Servern wird unterstützt Betrieb auf mehreren Servern wird unterstützt Betrieb auf mehreren Servern wird unterstützt Betrieb auf mehreren Servern wird unterstützt Sehr hoch (Replikation, Sharding) Sehr hoch (Replikation, Sharding Sehr hoch (Replikation, Sharding Sehr hoch (Replikation, Sharding) Performanz I. d. R. Hoch (Abhängig von Konsistenzmethode sowie tiefe der Abfragen, besonders bei WriteZugriffen Sehr hoch (Aufgrund der oft nicht vorhandenen Möglichkeiten für präzise Abfragen) I. d. R. Hoch (Abhängig von Konsistenzmethode u. Anzahl der Abfragen – besonders bei Write-Zugriffen Sehr hoch (oft auch bei hoher Serverzahl u. tiefen Abfragen) Schema Generell schemafrei, oft zusätzl. unterstützende Gruppierungsfunktionen wie Collections oder Views schemafrei schemafrei Darstellung d. Informationen / Formate Multi-ServerBetrieb Skalierbarkeit (Techniken) Schemafrei bzw. flexibel 31 3.6 Fazit Die NoSQL-Bewegung präsentiert sich mit einem hohen Maß an Kreativität und einer Fülle an neuen Ideen und Entwicklungen, die Datenbanken sind der Beweis dafür. Zwar hat dieser Artikel nur die vier bekanntesten NoSQL-Datenmodelle vorgestellt, jedoch lässt sich eindeutig erkennen wie derzeit zahlreiche NoSQL-Storage-Systeme entstehen. So vielfältig die verschiedenen Datenmodelle sind, so unterschiedlich gestalten sich die Bereiche, in denen sie zum Einsatz kommen. Zum einen lässt sich eindeutig bestimmen, dass die Zeit der „Allround-Datenbank“, die für alle Einsatzbereiche und Segmente eingesetzt wurde, vorbei ist. Der Trend geht dahin, dass ein bestimmtes Datenmodell für ein bestimmtes Einsatzgebiet zuständig ist. Auf Grund der Tatsache, dass jedes Datenmodell seine individuelle Spezialisierung besitzt, lässt sich hier ein direkter Vergleich der verschiedenen Datenmodelle schwerlich umsetzten und bewerten. Die NoSQL-Datenbanken können ihre Stärken am effektivsten ausspielen, wenn sie für die Bewältigung der entsprechenden Aufgaben benutzt werden. Hier lassen sich zum einen beispielsweise der flexible Umgang mit variablen Daten nennen, was auf das dokumentenorientierte Datenmodell (s. Kap. 3.1 Dokumentenorientiertes Datenmodell) zutreffen würde. Die Abbildung von Beziehungen und Relationen träfe auf das graphenorientierte Datenmodell (s. Kap. 3.4 Graphorientiertes Datenmodell) zu und die simple Reduzierung der Datenbank auf einen Behälter für Schlüssel-Wert-Paare ist eine Stärke des Key-Value-orientierten Datenmodells (s. Kap. 3.2 Key-Value-orientiertes Datenmodell). Viele NoSQL-Datenbanken, wie beispielsweise CouchDB oder Cassandra, lockern die Konsistenzgarantien ein Wenig auf um dafür mit Vorteilen, wie zum Beispiel der Skalierbarkeit, aufwarten zu können. Andere wiederum, wie etwa die graphenorientierten Datenbankmodelle, sind auf die Speicherung spezieller Daten optimiert, die sich in einem relationalem Datenbanksystem nur mühsam abbilden lassen würden. Deutlich macht sich bei diesen Datenmodellen jedoch die fehlende Standardisierung bemerkbar und das bei den eingesetzten Mechanismen zur Bewältigung spezifischer Anforderungen, wie auch in der Bedienung. Zwar bietet jedes Produkt die Möglichkeit auf viele verschiedene Programmiersprachen zurückgreifen zu können, eine einheitliche Abfragesprache wie die SQL aus der relationalen Welt, ist jedoch nicht verfügbar. „Umsteiger“ aus der relationalen Welt werden sich zudem auch an das Fehlen von jeglichen vorgegebenen Schemata und Strukturen gewöhnen müssen. Relationen bietet keines der Datenmodelle, genauso wenig wie beispielsweise Joins für übergreifende Abfragen. Letztere müssen eigens in der jeweiligen Programmiersprache programmiert werden. Allen Datenmodellen der NoSQL-Familie jedoch gereicht zum Vorteil, dass sie Alternativen schaffen und den Datenbankmarkt dadurch neu beleben werden. 32 4. Vergleich verschiedener Datenbanksysteme Dieses Kapitel soll dazu dienen, an Hand eines einfachen CRUD-Projektes die Funktionsweisen einer relationalen und einer NoSQL-Datenbank gegenüberzustellen und anschließend zu vergleichen. Stellvertretend für relationale Datenbanken soll an dieser Stelle der bisherige Marktführer Oracle61 mit dem gleichnamigen Produkt Oracle 11g für einen Vergleich herangezogen werden. Aus Ermangelung eines eindeutig bestimmbaren Marktführers aus der Reihe der NoSQL-Datenmodelle, mangels derzeit (Juli 2010) nicht vorhandener Marktanteilinformationen oder entsprechender Statistiken, hat sich der Autor dazu entschlossen die dokumentenorientierte Open-Source-Datenbank MongoDB für den Vergleich heranzuziehen. Als Grund sei hier auf die Referenzen der Datenbank hingewiesen, die gegenwärtig in über 100 Unternehmen, Magazinen und Projekten eingesetzt wird62. Dieser Wert wird, nach den Recherchen des Autors, aktuell von keiner anderen Datenbank aus der NoSQL-Sparte erreicht. Neben den, für die Durchführung der einzelnen Operationen des CRUD-Projekts, benötigten Befehlen, soll auch kurz auf die konzeptionellen Eigenheiten beider Datenmodelle, wie beispielsweise den Clients und Schemavorgaben, eingegangen werden. Inhalt des Projekts ist eine Artikeltabelle, die mit verschiedenen Werten und Datentypen gefüllt, bearbeitet und abschließend vollständig gelöscht wird (s. Kap. 4.2 CRUD-Projekt mit Oracle Database 11g und Kap. 4.3 CRUD-Projekt mit MongoDB). Auf Grund der häufigen Erwähnung der, ebenfalls dokumentorientierten NoSQL-Datenbank, CouchDB in dieser Arbeit, sollen der Vollständigkeit halber auch diese beiden Datenbanken verglichen und auf ihre konzeptionellen Unterschiede hin untersucht werden (s. Kap. 4.4 Gegenüberstellung von CouchDB und MongoDB). In einem anschließenden Resümee werden die gewonnenen Eindrücke zusammengefasst (s. Kap. 4.5 Fazit). 4.1 Oracle 11g in der Cloud Seit September 2008 begann Oracle damit seine Softwarepalette über die CloudInfrastruktur von Amazon (EC2) anzubieten. In diesem Angebot ist auch die relationale Datenbank Oracle 11g Standard Edition enthalten. Diese kommt, neben weiterer zusätzlicher Software, in einem Paket, dem so genannten Business Process Management (Oracle BPM). Das BPM wird als ein Amazon Machine Image (AMI) verfügbar gemacht, welches bereits vorkonfiguriert und ohne Installation nutzbar ist. Somit besitzt Oracle eine der ersten relationalen Datenbanken in einer Cloud-Umgebung. Allerdings unterliegt ihre Nutzung einigen Einschränkungen. Neben einer benötigten Softwarelizenz von Oracle, müssen 61 62 [Info_2008] [Mong_2010] 33 Nutzungsgebühren für die Inanspruchnahme der Cloud-Dienste von Amazon entrichtet werden. Darüber hinaus unterstützt EC2 (noch) keine Cluster, was die Skalierbarkeit der Datenbank somit stark begrenzt.63 64 65 4.2 CRUD-Projekt mit Oracle Database 11g 1977 gründete „Larry“ Ellison, zusammen mit den Mathematikern Bob Miner und Ed Oates, die Software Development Labs (SDL), in welcher die erste Version der Oracle-Datenbank entstand. Aus der SDL wurde zwei Jahre später die Relational Software Inc. (RSI) und 1983 benannte sich das Unternehmen, das mittlerweile die 3. Version der Datenbank veröffentlicht hatte, schließlich in Oracle um. Über die 80er und 90er Jahre hinweg, wuchs das Unternehmen an und erweiterte seine Angebotspalette sowie seine Unternehmenssparten kontinuierlich.66 Die Konkurrenz für Oracles Datenbank besteht unter anderem aus DB2 von IBM, SQL Server von Microsoft und verstärkt auftretende Opern-Source-Produkte. Die proprietäre Oracle Database 11g ist eine objektrelationale Datenbank und ihre Kommunikation erfolgt, nicht anders als bei ihren Vorgängern auch, über die etablierte Abfragesprache SQL. Als Client bietet sich der hauseigene SQL Developer an, da dieser lediglich eine Registrierung verlangt und ansonsten frei erhältlich ist. Darüber hinaus ist nach dem Download des Clients kein Installationsvorgang nötig – die EXE-Datei kann sofort ausgeführt werden. Einzige Vorraussetzung für den einwandfreien Betrieb des auf Java basierenden Clients, ist das vorhanden sein des Java Development Kits (JDK). Nachdem der Datenbanktreiber eingerichtet und die Verbindung hergestellt wurde, präsentiert sich die Benutzeroberfläche des SQL Developers in einem Design, welches dem Windows Explorer sehr ähnlich ist. Es bietet unter anderem ein spezielles Fenster für die Eingabe der SQLBefehle sowie, nach erfolgter Ausführung des Codes, ein Result-Fenster mit einer Ausgabe in tabellarischer Form. Mit dem „CREATE TABLE“-Befehl kann sogleich eine Tabelle erstellt werden. Oracle ist eine schemabasierte SQL-Datenbank, was bedeutet, dass die Tabellen bei der Erstellung in einer vordefinierten Struktur angelegt werden müssen. Die Datentypen der eingetragenen Werte, müssen also dem, in den Spalten festgelegten Typ, entsprechen, andernfalls wird die Transaktion abgebrochen und eine Fehlermeldung ausgegeben. Gefüllt wird die Tabelle mit dem „Insert“-Befehl, die Ausgabe erfolgt grundsätzlich über ein „Select“. Selbstverständlich erlaubt SQL die nachträgliche Änderung von Werten oder Datenstrukturen. Bewerkstelligt wird dies mit einem „Update“-Befehl. Ein „Delete“ löscht einzelne Zeilen aus der Tabelle, während die vollständige Tabelle mit dem „Drop“-Befehl aus der DDL, der Data Definition Language, gelöscht werden kann. 63 [Zdnet_2008] [Cptw_2008] 65 [OBPM_2010] 66 [O9i_2002] S. 4 – 12, Kap. 1 64 34 4.3 CRUD-Projekt mit MongoDB Die Computeranalysten und Wissenschaftler Dwight Merriman und Eliot Horowitz gründeten 2007 das Softwareunternehmen 10gen, das als Plattform gestaltet wurde, um Entwickler dabei zu unterstützen schnell und einfach komplexe und skalierbare Web-Applikationen zu entwickeln. Neben verschiedenen angebotenen Tools und Leistungen, wie beispielsweise Grid-Management und Applikationsserver, stellt die NoSQL-Datenbank MongoDB das derzeit bekanntestes Produkt der Firma dar und wird von vielen Unternehmen, insbesondere für Blogs und Cloud-Dienste, erfolgreich eingesetzt. Die frei verfügbare, dokumentenorientierte NoSQL-Datenbank MonoDB kann als Softwarepaket problemlos von der MongoDB-Webseite www.mongodb.org heruntergeladen werden. In der Downloadrubrik können die Binärdateien für Windows, die in einer gebündelten ZIP-Datei vorliegen, gefunden werden. Die derzeit (Stand Juni 2010) aktuellste Version der Datenbank ist v1.4.4. Sind die Dateien einmal an einem gewünschten Ort gespeichert und ausgepackt worden, ist der Installationsvorgang damit auch schon beendet. Das Paket besteht insgesamt aus drei Verzeichnissen, von denen nur das „bin“-Verzeichnis für die Anwendung interessant ist. Von den acht darin befindlichen ausführbaren EXEDateien, sind primär die Dateien Mongod und Mongo relevant. Bei der Ersten handelt es sich um den MongoDB-Datenbankprozess bzw. den Datenbankserver, der mit der zweiten Datei, dem Befehlszeilen-Shellclient angesprochen werden kann. Standardmäßig wird eine Verbindung mit einer Testdatenbank hergestellt. MongoDB nutzt im Wesentlichen die Javascript Object Notation (JSON) als Datennotation. Intern speichert MongoDB die Daten in BSON, einer binären Obermenge von JSON. Ist die Shell einmal gestartet, können sofort beliebige Funktionen oder Berechnungen mit Javascript eingegeben und ausgeführt werden. Die Kommunikation erfolgt derzeit über Kommandozeilenfenster, da eine GUI noch nicht verfügbar ist. Eine solche befindet sich in Planung und wird voraussichtlich erst in einer späteren Version der Datenbank verfügbar sein. Da MongoDB eine schemafreie Datenbank ist, gibt es keine Tabellen, wie sie aus dem relationalen Datenmodell bekannt sind. Um zusammenhängende Dokumente dennoch in einer einheitlichen Struktur unterbringen zu können, bietet MongoDB so genannte Collections an. Diese werden jedoch erst angelegt, wenn zumindest ein Dokument darin erstellt wurde. Die Collections können als ein Äquivalent zu den Tabellen eines RDBMS angesehen werden. Im dokumentenbasierten Ansatz können sie als „Ordner“ eingesetzt werden, um zusammenhängende Dokumente (Thema, Rubrik etc.) zu gruppieren und präzisere Abfragen zu ermöglichen. Beispielsweise ließe sich eine „Papierkorb“-Collection dazu nutzen, um, wie aus Microsofts Betriebssystem Windows bekannt, für den Löschvorgang bestimmte Dokumente zu speichern. Diese Funktion ist insofern interessant, als das MongoDB keine Undo-Fähigkeit besitzt, d.h. 35 gelöschte Dokumente nicht wieder hergestellt werden können. Die Befehle Insert, Update und Delete sind in MongoDB unter den Ausdrücken Insert, Save und Remove bekannt, führen jedoch meist die selben Funktionen aus. Wie bereits erwähnt, wird eine Collection erst erstellt, wenn ein Dokument angelegt wurde. Einen Create-Befehl kennt MongoDB dafür nicht, hier wird ebenfalls mit „Insert“ erstellt. Zur Veranschaulichung dient das folgende Syntaxbeispiel, in welchem ein Artikel mit mehreren Attributen in die Collection „Artikel“ eingefügt wird: > db.Artikel.insert( { „_id“ : 1, “ArtNr“ : 1, “Bez“ : “Tastatur“, “Preis“ : 10, “Bestand“ : 100} ); Es bietet sich an dieser Stelle an, dem eingefügten Dokument eine ID zu vergeben, da MongoDB ansonsten eine zufällige generiert. Diese ist jedoch häufig zwanzig oder mehr Zeichen lang, was der Übersichtlichkeit ein Wenig abträglich ist. Es lassen sich auf diese Weise beliebig viele und verschiedene Objekte hinzufügen, da die Schemafreiheit auch innerhalb der Collection besteht. Folgende Eingaben wären möglich und von MongoDB anstandslos akzeptiert: > db.Artikel.insert( { “ArtNr“ : 2, “Bez“ : “Maus“, “Preis“ : 5, “Bestand“ : 200, “_id“ : 2 } ); > db.Artikel.insert( { “_id“ : 3, “Bez“ : “Monitor“, “ArtNr“ : 3, “Preis“ : 100, “Bestand“ : 10 } ); > db.Artikel.insert( { “ArtNr“ : 4, “Bez“ : “Rechner“, “Preis“ : 200, “Bestand“ : 5 } ); Das Ergebnis dieser Eingaben kann mit dem Befehl „Find“ abgerufen werden: > db.Artikel.find() > {“_id“ : 1, “ArtNr“ : 1, “Bez“ : “Tastatur“, “Preis“ : 10, “Bestand“ : 100} > {“_id“ : 2, “ArtNr“ : 2, “Bez“ : “Maus“, “Preis“ : 5, “Bestand“ : 200} > {“_id“ : 3, “Bez“ : “Monitor“, “ArtNr“ : 3, “Preis“ : 100, “Bestand“ : 10} > {“_id“ : ObjectId(“4c500c5525460000000059f4“), “ArtNr“ : 4, “Bez“ : “Rechner“, “Preis“ : 200, “Bestand“ : 5} Der Unterstrich deklariert die ID als reservierte Bezeichnung von MongoDB. Sie wird unabhängig von der Eingabe an den Anfang gesetzt. Hingegen können die nachfolgenden Attribute beliebig versetzt und verändert werden, d.h. “ArtNr“ würde genauso akzeptiert werden wie beispielsweise “ArtikelNr“ usw. Die Objekt-ID stellt das Äquivalent zum PrimaryKey der SQL-Tabelle dar. Sie kann innerhalb der Collection nur einmal vergeben werden und ein Verstoß resultiert in der Ausgabe einer entsprechenden Fehlermeldung seitens der Shell. Im folgenden Beispiel werden nur die Informationen über Monitore aus der Collection abgerufen: 36 > db.Artikel.find( { “Bez“ : “Monitor“} ) > {“_id“ : 3, “Bez“ : “Monitor“, “ArtNr“ : 3, “Preis“ : 100, “Bestand“ : 10} Die Abfragen lassen sich mit Hilfe der Eingabe weiterer Bedingungen natürlich noch weiter präzisieren. Dazu stehen dem Anwender eine Reihe von Operatoren zur Verfügung. Diesen wird ein „$“ vorgesetzt, was so viel wie „ist enthalten in“ bedeutet. Auf Grund der Menge der Operatoren und Optionen, sowie der Tatsache, dass mit neuen Versionen von MongoDB meist auch neue Operatoren hinzukommen, soll hier nur eine Auswahl der Möglichkeiten präsentiert werden. Für ausführlichere Informationen verweist der Autor auf [Mquer_2010]. Um zu prüfen welche Artikel nicht mehr als 100€ kosten und von diesen zu gleich mehr als 10 Stück vorhanden sind, bietet sich die folgende Formulierung an: > db.Artikel.find( { “Preis“: { $lte: 100 }, “Bestand“: {$gt: 10} } ) Lte ist ein Konditionaloperator und bedeutet „less than or equal“ (dt. weniger als oder gleich). Analog dazu steht gt für „greater than“ (dt. größer als). Der $-Operator dient als Platzhalter für den zu prüfenden Wert, d.h. es wird in jedem Dokument auf diesen Wert eingegangen und mit dem angegebenen Wert (hier: 100 bzw. 10) verglichen. Das obige Beispiel lässt sich durch hinzufügen weiterer Bedingungen selbstverständlich entsprechend verfeinern. $in – prüfen, ob ein Wert oder Zeichen vorhanden ist (ähnlich „IN“ in SQL) $nin – prüfen, ob ein Wert oder Zeichen nicht vorhanden ist (ähnlich „NOT IN“ in SQL) Beide obigen Befehle eignen sich z.B. für eine Collection mit Posts oder Kommentaren, um nach bestimmten Werten, Wörtern oder Zeichen zu suchen. $or (ab v.1.5.1) – Entspricht logischem ODER > db.Artikel.find( { “Bez“ : “Monitor“, $or: [ {“Bestand“: 10}, {“Preis“: 100} ] } ) MongoDB bietet darüber hinaus noch zusätzliche Optionen, welche an die Abfragen angehängt werden können. Das Ergebnis des obigen Beispiels wird nun auf die ersten 10 Einträge begrenzt (limit(10)), sowie dem Preis nach absteigend sortiert (-1): > db.Artikel.find({ “Bez“ : “Monitor“, $or: [{“Bestand“: 10}, {“Preis“: 100} ] } ).sort({“Preis“: -1}). limit(10) 37 Neben der Erstellungsfunktion wird der Insert-Befehl zum hinzufügen eines Dokuments oder einer „Zeile“ bzw. einem Array benutzt. Der Save-Befehl ähnelt in der Syntax dem Insert und führt die selbe Aktion aus, wenn das zu ändernden Objekt ohne ID übergeben wird. Andernfalls wird nur die Änderung übernommen. Mit Save kann jedoch immer nur ein bestimmtes Objekt angesprochen werden. Um weitere Bedingungen einzufügen oder mehrere Datensätze zu verändern, ist der Update-Befehl anzuwenden. Auch hier sollen nur einige der Abfragemöglichkeiten aufgezeigt werden. Generell kann ein Update mit vier Parametern ausgeführt werden: db.collection.updage(criteria, objNew, upsert, multi). Criteria – Die Bedingung, die für ein Update erfüllt sein muss objNew – Das zumanipulierende Objekt upsert – Update falls schon vorhanden, einfügen (“Insert“), falls nicht multi – Wenn das Update für mehrere Objekte gelten soll auf Bei upsert und multi handelt es sich um boolsche Parameter, die entweder auf true oder false gesetzt werden können. Im folgenden Beispiel wird der Artikel „Monitor“ mit einem Peis von 50 gesetzt. Falls noch weitere Artikel mit dem selben Namen vorhanden sind, wird deren Preis ebenfalls auf den gleichen Wert gesetzt: > db.Artikel.update( { Bez : “Monitor“, { Bez: “Monitor“, Preis: 50 }, true, true } ) Auch hier lassen sich die Abfragen mit Hilfe diverser Operatoren ausweiten oder verfeinern. In [Aquer_2010] werden die Parameter und Operatoren eingehend erklärt. Der RemoveBefehl löscht das übergebene Objekt aus der Collection und kann mit den gleichen Parametern und Operatoren aufgerufen werden wie Find. Mit dem, auch in der SQL anzutreffenden, „Drop“ lässt sich die gesamte Collection löschen. Nach den Recherchen des Autors, sind die hier genannten Befehle nur innerhalb einer bestimmten Collection anwendbar. Operationen, die mehrere Collections betreffen, sollten jedoch über eigens programmierte Routinen erstellt werden können. 4.4 Gegenüberstellung von CouchDB und MongoDB Auf der einen Seiten weisen die NoSQL-Datenbanken CouchDB und MongoDB mehrere Gemeinsamkeiten auf. Beide gehören zur Gruppe der nicht-relationalen, dokumentenbasierten Datenbanken. Darüber hinaus sind sie zudem frei erhältliche Open-Source Produkte. Es gibt jedoch einige konzeptionelle Unterschiede in Bezug auf den Aufbau und die Umsetzung, welche die Datenbanken in bestimmten Einsatzbereichen besser bzw. 38 schlechter stellen. Im Folgenden sollen diese Unterschiede aufgelistet und beschrieben werden: Zugriffskontrolle und Updates Ein großer Unterschied zwischen den Datenbanken liegt in der Handhabung gleichzeitiger (konkurrierender) Zugriffe. CouchDB bedient sich zu diesem Zweck des MVCC-Verfahrens während MongoDB Updates sofort ausführt (Update-in-Place). MVCC (Multi Version Concurrency Control) ist sehr solide, kann aber keine 100%ige ACID-Integrität garantieren. Das Prinzip besteht darin, dass von jedem Dokument in CouchDB eine weitere Kopie (Version) existiert. Eine Transaktion T1 greift beispielsweise auf ein Dokument D lesend zu. Während dieser Zugriff noch andauert greift eine zweite Transaktion T2 auf das selbe Dokument zu allerdings schreibend. Während also T1 die erste Version ließt, ändert T2 zur gleichen Zeit die zweite Version des Dokumentes. Nach Abschluss des Updates ist jene zweite Version die „aktuelle“, so dass alle weiteren Zugriffe auf jene zweite Version erfolgen. Das bedeutet, dass die Datenbank für alle Konsistent ist, die nicht auf ein Dokument zugreifen, welches gerade geändert wird. Bei einem erneuten Zugriff sehen natürlich auch sie die Veränderungen. MVCC kommt völlig ohne Read-Locks aus und macht die Datenbank sicherer bei plötzlichen Störfällen (z.B. Stromausfall), da anschließend noch auf die letzte Version des Dokumentes zugegriffen werden kann. Auch ist dies für Offline-Datenbanken von Vorteil, die erst zu einem späteren Zeitpunkt synchronisiert werden. MongoDB wiederum benutzt das „Update-in-Place“-Verfahren, welches ohne Kopien oder Versionen der Daten auskommt. Letzteres ist somit zwar speichereffizienter, kann aber weder Write –noch ReadLocks ausschließen und ist zudem kritischer, wenn sich zum Zeitpunkt eines Updates eine Störung ereignet. Je nachdem wie lange die „Slaves“ benötigen, um ein Update durchzuführen ist „Update-in-Place“ fast ACID-konform. Horizontale Skalierung Beide Datenbanken lassen sich selbstverständlich horizontal skalieren. CouchDB wie MongoDB unterstützen zu diesem Zweck sowohl das Sharding als auch die Replikation. Bei Letzterer werden jedoch unterschiedliche Verfahren angewandt. Während CouchDB nach dem Master/Master-Verfahren repliziert, ist MongoDB auf die Master/Slave-Replikation ausgelegt. Das bedeutet, dass unter CouchDB auf jedem Server der Datenbank Lese –und Schreibzugriffe erfolgen können, wohingegen Änderungen bei MongoDB zuerst nur auf dem Mastergerät erfolgen und dann auf die Slave-Geräte weitergeleitet werden. Beide Replikationsarten haben ihre Vor –und Nachteile. In einer Master/Master (auch Multimaster)Replikation, kann jedes Gerät Updates auf der Datenbank durchführen, was das System stabiler gegenüber Ausfällen einzelner Geräte macht. Fällt der Master in der Master/Slave- 39 Repliaktion aus, muss dieser entweder wiederhergestellt werden oder ein Slavegerät übernimmt die Master-Eigenschaft. In beiden Fällen können auf der Datenbank, für den Zeitraum der Wiederherstellung, nur Lesezugriffe erfolgen. Der Nachteil beim MultimasterSystem ist, dass die Geräte meist asynchron konfiguriert sind, da jedes Gerät unabhängig Updates durchführen kann. Dadurch kann wiederum keine ACID-Konsistenz garantiert werden. Die Master/Slave-Replikation wird daher bevorzugt eingesetzt. Hier bestätigt der Master das Update und gibt dieses an alle „Slaves“ weiter. Objektspeicherung MongoDB speichert Objekte Collection-basiert (s. Kap. 4.3 CRUD-Projekt mit MongoDB). Solche oder ähnliche Gruppierungsfunktionen existieren in CouchDB (noch) nicht. Entwicklungssprache CouchDB wurde zuerst in C++ geschrieben. Während man bei MongoDB dabei geblieben ist, wechselten die Entwickler bei Apache auf die Sprache Erlang. Diese Sprache wurde, innerhalb der Firma Ericsson, primär für Anwendungen im Telekommunikationsbereich entwickelt. Bei der Entwicklung der Sprache gab es drei grundlegende Anforderungen: Die Sprache sollte Änderungen an Programmen auch während der Ausführung erlauben. Die Anwendungen mussten i. d. R. über Jahre hinweg fehlerfrei betrieben werden – im Störfall sollten sich Anwendungen daher nicht gegenseitig behindern. Zudem sollte ein, auf mehrere Rechner, verteilter Betrieb der Anwendungen möglich sein.67 Beide Hersteller bieten Programmierschnittstellen an, so dass sich Anwender bei der Kommunikation weder auf C++ noch auf Erlang festlegen müssen. Eine der Kernbotschaften der NoSQL-Bewegung ist, dass es keine Datenbank für alles mehr gibt. Dies gilt aber ebenso für NoSQL-Datenbanken untereinander. CouchDB ist nicht grundsätzlich besser als MongoDB und umgekehrt. Die Stärken können beide Datenbanken erst dann ausspielen, wenn sie unter entsprechenden Konditionen eingesetzt werden. MongoDB ist auf hohe Leistung und Geschwindigkeit zugeschnitten, was mehrere Benchmark-Tests und Vergleiche dargelegt haben.68 69 70 CouchDB kann dafür unter anderem in Szenarien mit häufigen, gleichzeitigen Zugriffen punkten. Ist die Datenbank häufig offline oder wird auf eine verteilte Master/Master-Replikation bestanden, bietet sich der Einsatz von CouchDB an. Ist dagegen hohe Performanz gefragt, beispielsweise bei der 67 [Erlng_2008] [Chap_2009] 69 [Brwn_2010] 70 [Bnch_2009] 68 40 schnellen Speicherung von Daten oder häufigen Zwischenspeicherungen von Daten aus anderen Quellen, würde MongoDB das Rennen machen.71 4.5 Fazit Der Vergleich hat verstärkt die Deutlichkeit zu Tage gefördert, wie sehr sich das relationale vom dokumentenorientierten Datenmodell unterscheidet. Beim Wortlaut des einen oder anderen Befehls, von denen einige auch die selbe Funktion besitzen, hören bereits sämtliche Gemeinsamkeiten auf. Für den versierten SQL-Anwender stellt besonders die schemafreie Struktur ein Novum dar, an welches er sich erste einmal wird gewöhnen müssen. Keine Tabellen, Spalten oder Zeilen, keine Primärschlüssel oder Fremdschlüsseleinschränkungen die es zu beachten gilt. Im umgekehrten Schluss bedeutet dies aber auch, dass bei der Erstellung beispielsweise einer Collection, also dem Tabellen-Äquivalent des dokumentenorientierten Datenmodells, die Reihenfolge der jeweiligen Eintragung eingehalten werden sollte. Wird die Eintragung nicht mit einer selbst definierten ID begonnen, sondern sofort mit der Artikelnummer zum Beispiel, stört das MongoDB überhaupt nicht. Es generiert per Zufall eine eigene ID und fügt diese einfach hinzu. Werden die Werte für „Preis“ und „Bezeichnung“ versehentlich vertauscht, ist das für MongoDB ebenfalls unerheblich – jeder Eintrag ist vom Typ JSON. Allgemein lässt sich festhalten, dass sich Datenbanken wie MongoDB gut für Anwendungen und Komponenten eignen, die Daten speichern müssen, die häufig verwendet werden und auf welche schnell zugegriffen werden muss. Websiteanalysen, Foren, Benutzereinstellungen sowie jedes System, in welchen Daten nicht vollständig strukturiert sind oder von der Struktur her flexibel sein müssen, bieten sich als Einsatzgebiet für MongoDB an. Das System aktualisiert Dokumente atomarisch, besitzt jedoch kein Transaktionskonzept, welches die Aktualisierung mehrerer Dokumente auf einmal abdeckt. Das heißt nicht, das MongoDB keine Dauerhaftigkeit verfügt, es bedeutet nur, dass eine MongoDB-Instanz einen Stromausfall weniger gut verkraftet als eine SQL Server-Instanz. In Systemen, in denen ACID-konforme Tranksaktionen erforderlich sind, sollten deshalb weiterhin relationale Datenbanken eingesetzt werden. Unternehmenswichtige Daten, wie beispielsweise Stammdaten, eignen sich nicht für die Speicherung in einer MongoDB-Instanz. Allenfalls für deren Replikation auf einem Webserver oder für die Zwischenspeicherung.72 Positiv fällt auf, wie überaus einfach der Einstieg in MongoDB ist – auch für Neulinge, die bisher eher auf dem SQL-Gebiet heimisch waren. Ein rudimentäres Verständnis einer der unterstützten Sprachen genügt bereits, um grundlegende Operationen auf dieser NoSQL-Datenbank durchführen zu können. Eine 71 72 [Merr_2010] [MSDN_2010] 41 ausführliche Dokumentation, Blogs und Foren zu verschiedenen Themen, Typen, Operationen und Funktionen der Datenbank, tragen das ihre zur Verständlichkeit bei. 42 5. Schlusswort Mit der Schemafreiheit, Dynamik, Skalierbarkeit und einem, von wenigen proprietären Umsetzungen abgesehen, freien Erwerb der NoSQL-Datenbanken, hat die gleichnamige Community definitiv eine Bresche in den Datenbankmarkt geschlagen und ihn belebt. Die NoSQL-Datenbanken können ihren relationalen Gegenparts, auf dem Cloud-Gebiet allein schon deshalb eine harte Konkurrenz bereiten, weil sie die benötigten Eigenschaften mitbringen, welche für den Einsatz in dieser Umgebung nötig sind (s. Kap. 2.1 RDBMS und die Anforderungen der Cloud-Technologie). Aber können sie die Vorherrschaft der traditionellen relationalen Datenbankmanagementsysteme beenden? Diese Frage kann eindeutig mit einem „Nein“ beantwortet werden, dem jedoch ein „aber“ folgen muss. Zum Einen ist die Verdrängung des relationalen Datenmodells nie die Intention der Community gewesen. NoSQL ist schließlich nicht die Abkürzung für „no“, sondern „not only“ SQL. Die neuen Datenmodelle sollen vielmehr als Alternativen verstanden werden, die in bestimmten Gebieten eingesetzt werden können, auf denen sie mehr Potenzial aufbieten als relationale Datenbanken dazu in der Lage sind. Und dies ist auch die Kernaussage der gegenwärtigen Entwicklung auf dem Datenbanksegment: Die Zeiten der „Eine-für-alles“-Datenbank sind vorbei. Der Trend geht dahin aus einer Vielzahl an Datenmodellen die optimale Lösung für ein Aufgabengebiet auszuwählen und das gilt auch für die verschiedenen NoSQLDatenbanken selbst (s. Kap. 3. Gegenüberstellung etablierter NoSQL-Datenmodelle). Google geht da mit gutem Beispiel voran. Der Internetgigant besitzt mit BigTable, eine der derzeit wohl ausgereiftesten NoSQL-Lösungen und betreibt doch seine Internetwerbeplattform „AdWords“ nach wie vor auf einer MySQL-Instanz. NoSQLDatenbanken werden durch die erwähnte Schemafreiheit sehr viel flexibler bei der Ablage von beliebigen Dokumenten sein. Sind genau strukturierte Tabelleninhalte von vorrangiger Bedeutung und müssen ACID-konforme Transaktionen eingehalten werden, besitzen NoSQL-Datenmodelle hier weniger gute Karten (s. Kap. 2.3.3 Funktionale Partitionierung und die ACID-Alternative „BASE“). Auf der anderen Seite sind relationale Datenbanken darauf ausgelegt auf einem zentralen Server betrieben zu werden, welcher zudem noch aus einer qualitativ hochwertigen Hardware zusammengestellt ist. Das Cloud Computing zieht eine seiner größten Stärken aber aus der Möglichkeit, Applikationen und Dienste immer und überall bereitstellen zu können. Dies wiederum setzt den Einsatz meist kleinerer einfacher Rechner und einer dezentralen Struktur voraus. Das bedeutet also, dass die Verteilung von Anfragen vermehrt an Bedeutung gewinnen wird. Die relationalen Systeme bieten an dieser Stelle zwar Cluster-Lösungen an, sind von ihrem Grunddesign her jedoch nicht dafür ausgelegt. Resultierend daraus kommt man, besonders bei neueren Webanwendungen, sogar mit jenen relationalen Clustern an ihre Grenzen. Neben verteilten Servern, spielen die 43 immensen Datenmengen eine entscheidende Rolle. Hier bieten die NoSQL-Datenbanken flexible Datenskalierungsmöglichkeiten (s. Kap. 2.3.2 Datenbankskalierung). Zum Anderen bringt diese Umstellung auch konzeptionelle Änderungen in Bezug auf die eingesetzte Hardware mit sich. Da sich die Maschinen nun gegenseitig unterstützen und die Eine im Störfall den Dienst der Anderen übernehmen kann, wird zwangläufig nicht mehr in gleicher Höhe in Qualitätshardware investiert. Ausfälle können nun eher in Kauf genommen werden und die Ausgaben werden minimiert. Auch auf diesem Gebiet tun sich relationale Datenbanksysteme, die zuvor stets auf High-End-Anlagen betrieben wurden, schwer. NoSQL-Datenbanken sind stark auf Schlichtheit und Simplizität getrimmt. Das gilt für die Handhabung als auf für ihren Funktionsumfang. Der Code von CouchDB beispielsweise ist etwa 13.000 Zeilen lang, der von MySQL liegt oberhalb der Million. Dafür sind CouchDB und Konsorten schnell eingerichtet und betriebsbereit. Schon die moderate Kenntnis einer der unterstützten Programmiersprachen reicht, um sogar einem absoluten Neuling grundlegende Befehle zu vermitteln (s. Kap. 4. Vergleich verschiedener Datenbank). Eine Sprachenvielfalt bieten relationale Datenmodelle zwar nicht, dafür können nahezu alle mit dem QuasiStandard SQL abgefragt und modelliert werden. Von Standards und Vereinheitlichungen sind wiederum die Datenmodelle der NoSQL-Familie weit entfernt. Verschiedene Ansätze und Methoden bei der Umsetzung von Eigenschaften, wie der Datenintegrität oder der Informationsdarstellung, bergen Kompatibilitätsprobleme oder eingeschränkte Portabilitätsmöglichkeiten. Im Grunde ist es mit den NoSQL-Datenmodellen ein Wenig wie mit dem Cloud Computing selbst: Beide werden definitiv neue Impulse geben bzw. haben dies schon getan, aber zugleich sind beide nur ein weiterer Schritt auf der Entwicklungsleiter der sich ständig im Wandel befindlichen Welt der IT. Viele der NoSQL-Lösungen werden zweifelsohne einen festen Platz in verschiednen hochskalierbaren Architekturen finden, doch gilt es stets neben den Möglichkeiten auch die Grenzen dieser Lösungen in Betracht zu ziehen, bevor man ihre Implementierung plant. 44 6. Abkürzungsverzeichnis ACID Atomicity Consistency Isolation Durability ACL Access Control List AMI Amazon Machine Image API Application Programming Interface ASF Apache Software Foundation AWS Amazon Web Services BASE Basically Available Soft State Eventually Consistent BBC British Broadcasting Corporation BLOB Binary Large Object BPM Business Process Management BSON Binary JSON CAP Consistency Availability Partition Tolerance CDN Content Delivery Network CRUD Create Read Update Delete DBMS Datenbankmanagementsystem DDL Data Definition Language EC2 Elastic Compute Cloud ECM Enterprise Content Management ERP Enterprise Ressource Planing GFS Google File System GUI Graphical User Interface IBM International Business Machines Corporation JDK Java Development Kit JSON Javascript Object Notation MIT Massachuesetts Institute of Technology MVCC Multiversion Concurrency Control NoSQL Not only SQL PB Petabyte (= 1000 Terrabyte) RDBMS Relational Database Management System REST Representational State Transfer RSI Relational Software Inc. SAP Aktiengesellschaft Systeme, Anwendungen und Produkte in der Datenverarbeitung SDL Software Development Labs SQL Structured Query Language 45 TB Terrabyte (= 1000 Gigabyte) 46 7. Literaturverzeichnis [Ablog_2009] Sanfilippo, S.: Reds, My New Open Source Project, antirez.com, 06. März 2009, http://antirez.com/post/Redis-my-new-open-sourceproject.html, besucht am 25. Juni [ACM_2008] Pritchett, D.: BASE: An Acid Alternative, queue.acm.org, 28.07.2008, http://queue.acm.org/detail.cfm?id=1394128, besucht am 16. Juni 2010 [Ander_2010] Anderson, J. C., Lehnardt, J., Slater, N.: CouchDB: The Definite Guide, O’Reilly Media Inc., USA 2010 [Aquer_2010] Steam, M.: Updating – MongoDB, mongodb.org, 05.08.2010, http://www.mongodb.org/display/DOCS/Updating, besucht am 6. August 2010 [Bin_2010] Bin, S.: Key Value Stores Dynamo und Cassandra, Seminararbeit Cloud Data Management, Universität Leipzig, 2010 [Bnch_2009] Chodorow, K.: CouchDB vs MongoDB Benchmark, snailinaturtleneck.com, 06.12.2009, http://www.snailinaturtleneck.com/blog/2009/06/29/couchdb-vsmongodb-benchmark/, besucht am 29. Juli 2010 [Brekle_2010] Brekle, J.: Key Value Stores, BigTable, Hadoop, CouchDB, Seminararbeit, Universität Leipzig, 2010 [Browne_2009] Browne, J.: Brewer’s CAP Theorem, julianbrowne.com, 11.01.2009, http://www.julianbrowne.com/article/viewer/brewers-cap-theorem, besucht am 13. Juni 2010 [Brwn_2010] Brown, B.: Did I mention #MongoDb is fast?!?! Way to go @mongodb, idiotsabound.com, 23.01.2010, http://www.idiotsabound.com/did-imention-mongodb-is-fast-way-to-go-mongo, besucht am 29. Juli 2010 [CAP_2002] Gilbert, S., Lynch, N.: Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web, ACM SIGACT News Vol. 47 33, Issue 2, June 2002, http://.www.lpd.epfl.ch/sgilbert/pubs/BrewersConjecture-SigAct.pdf, besucht am 13. Juni 2010 [Cass_2009] o. Autor: The Apache Cassandra Project, cassandra.apache.org, 2009, http://cassandra.apache.org/, besucht am 24. Juni 2010 [Chap_2009] Chapman, B.: Evaluating key- value and document stores for short read data, bcbio.wordpress.com, 10.05.2009, http://bcbio.wordpress.com/2009/05/10/evaluating-key-value-anddocument-stores-for-short-read-data/, besucht am 29. Juli 2010 [CIO_2010] Sarrel, M.: A Few Words About ‘NoSQL’ And Other Unstructed Databases, cioupdate.com, 28. April 2010, http://www.cioupdate.com/trends/article.php/3879191/A-Few-WordsAbout-NoSQL-and-Other-Unstructured-Databases.htm, besucht am 22. Juni 2010 [Cptw_2008] Kanaracus, C.: Oracle puts its 11g database in Amazon’s Cloud, computerworld.com, 22.09.2008, http://www.computerworld.com/s/article/9115291/Oracle_puts_its_11g_ database_in_Amazon_s_cloud, besucht am 29. Juli 2010 [Crunch_2008] Hendrickson, M.: Source: Google To Launch BigTable As Web Service, techcrunch.com, 04.04.2008, http://techcrunch.com/2008/04/04/source-google-to-launch-bigtable-asweb-service/, besucht am 17. Juni 2010 [CSCDB_2010] o. Autor: Case Studies – CouchDB: The NoSQL Document Database, couch.io, 2010, http://www.couch.io/case-studies, besucht am 26. Juli 2010 [Cwiki_2010] o. Autor: CouchDB In The Wild, wiki.apache.org, 17. Juni 2010, http://wiki.apache.org/couchdb/CouchDB_in_the_wild, besucht am 23. Juni 2010 48 [Dash_2010] Dash, J.: The CAP Theorem, cloudcomputing.sys-con.com, 19.05.2010, http://cloudcomputing.sys-con.com/node/1400253, besucht am 25. Juli 2010 [db4o_2010] o. Autor: db4o :: Java & .NET Object Database :: Open Source Object Database (OODB) :: Product Information, db4o.com, 30.07.2010, http://db4o.com/about/productinformation/, besucht am 30. Juli 2010 [DBMS_2008] o. Autor: Project Cassandra – Facebook’s open sourced quasi-DBMS, dbsms2.com, 21. Juli 2008, http://www.dbms2.com/2008/07/21/projectcassandra-facebook-open-sourced-quasi-dbms/, besucht am 24. Juni 2010 [Dynamo_2007] Vogels, W.: Amazon’s Dynamo, allthingsdistributed.com, 02.10.2007, http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html, besucht am 17. Juni 2010 [Ecdb_2009] Lennon, J.: Exploring CouchDB, ibm.com, 31.03.2009, http://www.ibm.com/developerworks/opensource/library/oscouchdb/index.html, besucht am 31. Juli 2010 [EMCD_2010] o. Autor: Product: EMC Documentum xDB, emc.com, 30.07.2010, http://www.emc.com/products/detail/software/documentum-xdb.htm, besucht am 30. Juli 2010 [Erlng_2008] o. Autor: Einführung in sequentielles Erlang, fh-wedel.de, 07.05.2008, http://www.fh-wedel.de/fileadmin/mitarbeiter/uh/Erlang1.htm#Was, besucht am 29. Juli 2010 [exst_2010] o. Autor: eXist-db Open Source Native XML Database, exist-db.org, 12.04.2010, http://exist-db.org/, besucht am 30. Juli 2010 [Frey_2010] Frey, M.: Chancen und Risiken des Cloud Computing, Praxisprojektausarbeitung, FH Köln Campus Gummersbach, April 2010 49 [From_2009] Frommel, O.: Dokumentzentrierte Datenbank CouchDB, adminmagazin.de, Januar 2009, http://www.adminmagazin.de/content/dokumentenzentrierte-datenbank-couchdb, besucht am 23. Juni 2010 [GI_2010] Bösswetter, D.: Spaltenorientierte Datenbanken, gi-ev.de, 9. Februar 2010, http://www.gi-ev.de/service/informatiklexikon/informatiklexikondetailansicht/meldung/spaltenorientierte-datenbanken-267.html, besucht am 21. Juni 2010 [GigS_2010] o. Autor: GigaSpaces.com | Application Server | Application Scalability | Data Grid | Cloud PaaS, gigaspaces.com, 30.07.2010, http://www.gigaspaces.com/, besucht am 30. Juli 2010 [Gray_2009] Gray, J.: Partition Tolerance, devblog.streamy.com, 24.08.2009, http://devblog.streamy.com/tag/partition-tolerance/, besucht am 25. Juli 2010 [Heise_2010] o. Autor.: NoSQL im Überblick, heise.de, 01. Juni 2010, http://www.heise.de/open/artikel/NoSQL-im-Ueberblick-1012483.html, besucht am 20. Juni 2010 [Hoff_2009] Hoff, T.: Drop ACID and think about Data, highscalability.com, 05.05.2009, http://highscalability.com/drop-acid-and-think-about-data, besucht am 16. Juni 2010 [Hzlc_2010] o. Autor: In-Memory Data Grid – Hazelcast – Home, hazelcast.com, 30.07.2010, http://www.hazelcast.com/, besucht am 30. Juli 2010 [IBM_2009] Lennon, J.: Exploring CouchDB, ibm.com, 31. März 2009, http://www.ibm.com/developerworks/opensource/library/oscouchdb/index.html#resources, besucht am 23. Juni 2010 [Info_2008] Babcock, C.: In Database Market, Oracle Gets Bigger, Others Hang On, informationweek.com, 25.04.2008, http://www.informationweek.com/news/software/database_apps/showA rticle.jhtml?articleID=207402230, besucht am 28. Juli 2010 50 [Intro_2010] Sanfilippo, S.: README – redis – Project Hosting on Google Code, code.google.com, 05. Dezember 2009, http://code.google.com/p/redis/wiki/README, besucht am 25. Juni 2010 [Kell_2010] Kellogg, D.: Six Thoughts on The NoSQL Movement, kellblog.com, 18.06.2010, http://www.kellblog.com/2010/06/18/six-thoughts-on-thenosql-movement/, besucht am 23. Juli 2010 [Leav_2010] Leavitt, N.: Will NoSQL Databases Live Up to Their Promise?, leavcom.com, 26.01.2010, http://www.leavcom.com/pdf/NoSQL.pdf, besucht am 23. Juli 2010 [Lenn_2009] Lennon, J.: Beginning CouchDB, Apress, USA Dez. 2009 [Loshin_2009] Loshin, D.: Gaining the Performance Edge Using a Column-Oriented Database Management System, sybase.de, 2009, http://www.sybase.de/detail?id=1063191, besucht am 21. Juni 2010 [Malik_2009] Laksham, A., Malik, P.: Cassandra – A Decentralized Structured Storage System, cs.cornell.edu, 2009, http://www.cs.cornell.edu/projects/ladis2009/papers/lakshmanladis2009.pdf, besucht am 24. Juni 2010 [McGe_2002] McGehee, B.: An Introduction to SQL Server Clustering, sql-serverperformance.com, 03.04.2002, http://www.sql-serverperformance.com/articles/clustering/clustering_intro_p1.aspx, besucht am 27. Juli 2010 [Meyer_2009] Meyer, M.: Datenbanken in der Cloud – Datastorage jenseits von SQL, Peritor Consulting, 25.11.2009, http://www.cloudconf.de/downloads/cloudconfclouddatenbankenmathia smeyerperitor.pdf, besucht am 11. Juni 2010 [Merr_2010] Merriman, D.: Comparing Mongo DB and Couch DB, mongodb.org, 23.04.2010, 51 http://www.mongodb.org/display/DOCS/Comparing+Mongo+DB+and+ Couch+DB, besucht am 29. Juli 2010 [MLS_2010] o. Autor: MarkLogic: The Leading XML Server, marklogic.com, 30.07.2010, http://www.marklogic.com/, besucht am 30. Juli 2010 [Mong_2010] Gill, M.: Production Deployments, mongodb.org, 26.07.2010, http://www.mongodb.org/display/DOCS/Production+Deployments, besucht am 29. Juni 2010 [Mok_2009] Mok, W.: Consistency and Availability Tradeoff for Distributed Systems, waimingmok.wordpress.com, 26.01.2009, http://waimingmok.wordpress.com/2009/01/26/consistency-andavailability-tradeoff-for-distributed-systems/, besucht am 25. Juli 2010 [Mquer_2010] Gill, M.: Querying – MongoDB, mongodb.org, 04.08.2010, http://www.mongodb.org/display/DOCS/Querying, besucht am 06. August 2010 [MSDN_2010] Neward, T.: Der Programmierer bei der Arbeit – In Richtung NoSQL mit MongoDB, msdn.microsoft.com, Mai 2010, http://msdn.microsoft.com/de-de/magazine/ee310029.aspx, besucht am 24. Juli 2010 [MVCC_2010] o. Autor: Advanced, h2database.com, 25.07.2010, http://www.h2database.com/html/advanced.html#mvcc, besucht am 28. Juli 2010 [Nblog_2010] o. Autor: Neo4j Blog, blog.neo4j.org, 16. Februar 2010, http://blog.neo4j.org/2010/02/top-10-ways-to-get-to-know-neo4j.html, besucht am 25. Juni 2010 [Neo_2010] o. Autor: Neo4j – About, neo4j.org, 16. Februar 2010, http://neo4j.org/about/, besucht am 25. Juni 2010 [Neub_2010] Neubauer P.: Graphendatenbanken, NoSQL und Neo4j, ITRepublik.de, März 2010, http://it- 52 republik.de/jaxenter/artikel/Graphendatenbanken-NoSQL-und-Neo4j2906.html, besucht am 11. Juni 2010 [North_2010] North, K.: The NoSQL Alternative, drdobbs.com, 21.05.2010, http://www.drdobbs.com/database/224900500;jsessionid=UYD2AXIKR KM4RQE1GHPSKHWATMY32JVN?pgno=1, besucht am 27. Juli 2010 [Nsql_2010] Prof. Dr. Edlich, S.: NoSQL Databases, nosql-databases.org. 29.07.2010, http://nosql-database.org/, besucht 30. Juli 2010 [O9i_2002] Abbey, M., Corey, M., Abramson, I.: Oracle 9i A Beginner’s Guide, McGraw-Hill Professional, USA 2002 [Objct_2010] o. Autor: Database and data management soloutions by Objectivity Inc., objectivity.com, 30.07.2010, http://www.objectivity.com/, besucht am 30. Juli 2010 [OBPM_2010] Palvankar, P.: BPM 11gR1 now Available on Amazon EC2 (Oracle BPM), blogs.oracle.com, 14.06.2010, http://blogs.oracle.com/bpm/2010/06/bpm_11gr1_now_available_on_a ma.html#comments, besucht am 29. Juli 2010 [OpenS_2010] Neubauer, P.: Neo4j – die High-Performance-Graphendatenbank, entwickler.de, März 2010, http://entwickler.de/zonen/portale/psecom,id,194,online,2919,p,0.html, besucht am 23. Juli 2010 [Patz_2009] Patzwaldt, K.: Basically Available, Soft state, Eventually consistent, patzwaldt.org, 11.03.2009, http://patzwaldt.org/karsten/post/33/basically-available--soft-state-eventually-consistent.html, besucht am 16. Juni 2010 [Peter_2010] Neubauer, P.: Graphendatenbanken, NoSQL und Neo4j, it-republik.de, März 2010, http://it-republik.de/jaxenter/artikel/GraphendatenbankenNoSQL-und-Neo4j-2908.html?print=1, besucht am 25. Juni 2010 53 [PNeu_2010] Neubauer, P.: Neo4j – die High-Performance-Graphendatenbank, itrepublik.de, März 2010, http://it-republik.de/jaxenter/artikel/Neo4j-%96die-High-Performance-Graphendatenbank-2919.html, besucht am 25. Juni 2010 [PODC_2000] Brewer, E. A.: Towards Robust Distributed Systems, cs.berkeley.edu, 19.07.2000, http://www.cs.berkeley.edu/~brewer/cs262b-2004/PODCkeynote.pdf, besucht am 25. Juli 2010 [Pron_2010] Pronschinske, M.: VMware Hires Key NoSQL Developer, architects.dzone.com, 15. März 2010, http://architects.dzone.com/articles/vmware-hires-key-nosql, besucht am 25. Juni 2010 [Redis_2010] o. Autor: redis – Project Hosting on Google Code, code.google.com, 2010, http://code.google.com/p/redis/, besucht am 25. Juni 2010 [Robi_2010] Robinson, H.: CAP Confusion: Problems with ‘partition tolerance’, cloudera.com, 26.04.2010, http://www.cloudera.com/blog/2010/04/capconfusion-problems-with-partition-tolerance/, besucht am 25. Juli 2010 [Secure_2010] Merriman, D.: Security and Authentication – MongoDB, mongodb.com, 01.07.2010, http://www.mongodb.org/display/DOCS/Security+and+Authentication, besucht am 24. Juli 2010 [Servs_2009] o. Autor: Pros and Cons of Server Clustering, serverschool.com, 15.08.2009, http://www.serverschool.com/cluster-servers/pros-andcons-of-server-clustering/, besucht am 27. Juli 2010 [SGDB_2008] Angles, R., Gutierrez C.: Survey of graph database models, ACM Computer Survey, Februar 2008, www.dcc.uchile.cl/~cgutierr/papers/surveyGDB.pdf, besucht am 20. Juni 2010 54 [Silicon_2010] Schindler, M.: NoSQL: Die schlanke Zukunft dicker Datenbanken, silicon.de, 15.02.2010, http://www.silicon.de/hardware/serverdesktops/0,39038998,41527418,00/nosql+die+schlanke+zukunft+dicke r+datenbanken.htm, besucht am 15. Juni 2010 [Strozzi_2010] Strozzi, C.: NoSQL – A Relational Database Management System, strozzi.it, 2010, http://www.strozzi.it/cgibin/CSA/tw7/I/en_US/nosql/Home%20Page, besucht am 15. Juni 2010 [TAZ_2010] o. Autor: Wendepunkt bei Amazon: Mehr Kaufhaus als Buchladen, taz.de, 23.04.2010, http://www.taz.de/1/netz/netzoekonomie/artikel/1/mehr-kaufhaus-alsbuchladen/, besucht am 17. Juni 2010 [USPTO_2010] o. Autor: United States Patent: 7650331, patft.uspto.gov, 19.01.2010, http://patft.uspto.gov/netacgi/nphParser?Sect1=PTO1&Sect2=HITOFF&d=PALL&p=1&u=/netahtml/PTO /srchnum.htm&r=1&f=G&l=50&s1=7,650,331.PN.&OS=PN/7,650,331& RS=PN/7,650,331, besucht am 3. August 2010 [Vick_2010] Vicknair, C., Macias, M., Zhao, Z., Nan, X., Chen, Y., Wilkins, D. : A Comparison of a Graph Database and a Relational Database, cs.olemiss.edu, 15. – 17.04.2010, http://cs.olemiss.edu/~ychen/publications/conference/vicknair_acmse1 0.pdf, besucht am 24. Juli 2010 [Vogels_2008] Vogels, W.: Eventually Consistent – Revisited, Allthingsdistributed.com, 23.12.2008, http://www.allthingsdistributed.com/2008/12/eventually_consistent.html, besucht am 13. Juni 2010 [Vrsnt_2010] o. Autor: Versant, Object Database, ODBMS, OODBMS, Data Management, High Performance, High Availability, High Scalability, versant.com, 30.07.2010, http://www.versant.com/, besucht am 30. Juli 2010 55 [WASC_2010] o. Autor: WebSphere Application Server-Cluster, publib.boulder.ibm.com, 29.07.2010, http://publib.boulder.ibm.com/infocenter/ramhelp/v7r2m0/index.jsp?topi c=/com.ibm.ram.installguide.doc/topics/c_clusters.html, besucht am 29. Juli 2010 [Wneo_2010] o. Autor: Neo4j In The Wild – Neo4j Wiki, wiki.neo4j.org, 13.07.2010, http://wiki.neo4j.org/content/Neo4j_In_The_Wild, besucht am 26. Juli 2010 [Wien_2010] Wienecke, S.: Relationale Cloud-DB, Universität Leipzig Institut für Informatik Abteilung Datenbanken, 30.03.2010, http://dbs.unileipzig.de/file/seminar_0910_wienecke_ausarbeitung.pdf, besucht am 11. Juni 2010 [Zdnet_2008] Dignan, L.: Amazon adds Oracle support to EC2, zdnet.com, 22.09.2008, http://www.zdnet.com/blog/btl/amazon-adds-oraclesupport-to-ec2/10122, besucht am 29. Juli 2010 56