Datenbanken Unit 5: Funktionale Abhängigkeit
Werbung

Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Datenbanken
Unit 5: Funktionale Abhängigkeit
Ronald Ortner
19. IV. 2016
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Outline
1
Organisatorisches
2
SQL
3
Funktionale Abhängigkeit
4
Anomalien
5
Datenbank Normalisierung
Zerlegung von Relationen
Ronald Ortner
Anomalien
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Organisatorisches
Heute Zwischentest in den UE.
Wissensüberprüfung zu JOINs nächste Woche.
Ronald Ortner
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
SQL – Häufige Fehler
Verwenden Sie NIE ein GROUP BY ohne entsprechende
Aggregatfunktion!
Für weitere häufige Fehler siehe Handout.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
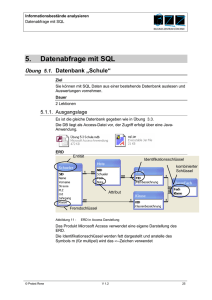
Datenbankdesign bisher:
zeichne Entitäten, Relationen, und Attribute in ein ER-Diagramm
leite aus dem ER-Diagramm ein Datenbankschema ab
Nun beschäftigen wir uns mit einem verfeinerten Zugang
(’Normalisierung’).
Die Grundlage dafür ist der Begriff der funktionalen Abhängigkeit.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Abstrakte Schemata und ihre Realisierung
Bisher waren wir ein wenig schlampig.
Im folgenden unterscheiden wir oft genauer zwischen
abstrakten relationalen Datenbankschemata
(' Tabellenstruktur ohne Daten)
Notation: R
Realisierungen R solcher Schemata
(' die Daten in den Tabellen)
Notation: R
Ronald Ortner
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Funktionale Abhängigkeit
Definition (funktionale Abhängigkeit)
Gegeben sei ein abstraktes relationales Datenbankschema R,
sowie (Mengen von) Attribute(n) α, β in R.
Wir sagen, dass β funktional abhängig (FD) von α ist, wenn für alle
Realisierungen R of R:
Immer wenn zwei Tupel (Zeilen) dieselben Werte für α haben, so
haben sie auch gleiche Werte für β.
Notation: α → β
Beispiele:
{ name} → { region, area, population, gdp} in cia
{ jahr, monat} → { tmin, tmax, gmin, sun, rain} in sowe
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Funktionale Abhängigkeit: Ein Beispiel
A
a4
a1
a1
a2
a3
Es gelten:
{A} → {B}
{A} → {C}
{C,D} → {B}
{B} 6→ {C}
Ronald Ortner
B
b2
b1
b1
b2
b2
C
c4
c1
c1
c3
c4
D
d3
d1
d2
d2
d3
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Überprüfen funktionaler Abhängigkeit
Das Überprüfen, ob eine FD α → β für eine Realisierung R gilt, ist
einfach:
Sortiere R nach α.
Überprüfe ob Tupel mit gleichen α-Werten auch gleiche β-Werte
haben.
[→ Aufwand fürs Sortieren: O(n log n) für n Zeilen]
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Triviale funktionale Abhängigkeiten
Eine FD heißt trivial, wenn sie in allen möglichen Realisierungen gilt.
Charakterisierung trivialer FDs
Jede triviale FD ist von der Form α → β mit β ⊆ α.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Schlüssel und funktionale Abhängigkeiten
FDs sind eine Verallgemeinerung des Schlüssel-Konzepts.
→ Schlüssel lassen sich über FDs definieren:
Definition (Superschlüssel)
Für ein abstraktes relationales Datenbankschema R ist α ⊆ R ein
Superschlüssel, wenn
α → R.
Trivialerweise bildent die Menge aller Attribute in R einen
Superschlüssel für R (weil R → R).
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Volle funktionale Abhängigkeit
Um Schlüssel von Superschlüsseln unterscheiden zu können, führen
wir den Begriff der vollen funktionalen Abhängigkeit ein:
Definition (volle funktionalen Abhängigkeit)
β ist voll funktional abhängig von α, wenn
1
α → β, und
2
α ist minimal, d.h. entfernt man irgendein Attribut A aus α, so
bricht die FD zusammen, d.h. α − A 6→ β.
Notation:
Ronald Ortner
α→β
˙
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Schlüssel und funktionale Abhängigkeiten II
Definition (Kandidatenschlüssel)
Für ein abstraktes relationales Datenbankschema R ist α ⊆ R ein
Kandidatenschlüssel, wenn
α→R.
˙
Ein Primärschlüssel ist ein beliebig gewählter Kandidatenschlüssel.
Es ist unwichtig, welcher gewählt wird.
Es ist aber wichtig, dass der gewählte Schlüssel durchgehend
verwendet wird (etwa als Fremdschlüssel in anderen Tabellen).
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Eigenschaften von FDs
Beispiel: Studierendentelefonbuch:
{[matrnr, name, strasse, plz, stadt, vorwahl, telnr]}
FDs:
{matrnr} → {name, strasse, plz, stadt}
{plz} → {vorwahl}
{matrnr} → {vorwahl}
Anmerkung: Die dritte Relation scheint aus den anderen beiden zu
folgen...
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Eigenschaften von FDs: Armstrong Axiome
Armstrong Axiome:
Reflexivität:
Wenn β ⊆ α, dann α → β.
Insbesondere gilt α → α.
Ronald Ortner
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Eigenschaften von FDs: Armstrong Axiome
Armstrong Axiome:
Reflexivität:
Wenn β ⊆ α, dann α → β.
Insbesondere gilt α → α.
Verstärkung:
Wenn α → β, dann auch αγ → βγ.
(Notation: αγ steht für α ∪ γ.)
Ronald Ortner
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Eigenschaften von FDs: Armstrong Axiome
Armstrong Axiome:
Reflexivität:
Wenn β ⊆ α, dann α → β.
Insbesondere gilt α → α.
Verstärkung:
Wenn α → β, dann auch αγ → βγ.
(Notation: αγ steht für α ∪ γ.)
Transitivität:
Wenn α → β und β → γ, dann auch α → γ.
Ronald Ortner
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Eigenschaften von FDs: Der Abschluss
Definition (Abschluss)
Sei R eine Relation und F eine Menge von FDs in R. Der Abschluss
F + von F ist die Menge aller FDs, die logisch aus den FDs in F folgen.
Korrektheit und Vollständigkeit der Armstrong Axiome
Alles, was aus F mithilfe der Armstrong Axiome abgeleitet werden
kann, ist in F + (Korrektheit).
Alle FDs in F + können aus F mithilfe der Armstrong Axiome
abgeleitet werden (Vollständikgkeit).
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Noch mehr Eigenschaften von FDs
Mithilfe der Armstrong Axiome können weiters folgende Eigenschaften
abgeleitet werden:
Vereinigung:
Wenn α → β und α → γ, dann α → βγ.
Dekompositionsregel:
Wenn α → βγ, dann α → β und α → γ.
Pseudotransitivität:
Wenn α → β und βγ → δ, dann auch αγ → δ.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Eigenschaften von FDs: Zurück zum Beispiel
Beispiel: Studierendentelefonbuch:
{[matrnr, name, strasse, plz, stadt, vorwahl, telnr]}
FDs:
{matrnr} → {name, strasse, plz, stadt}
{plz} → {vorwahl}
{matrnr} → {vorwahl}
Ableitung der dritten FD aus den anderen beiden:
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Eigenschaften von FDs: Zurück zum Beispiel
Beispiel: Studierendentelefonbuch:
{[matrnr, name, strasse, plz, stadt, vorwahl, telnr]}
FDs:
{matrnr} → {name, strasse, plz, stadt}
{plz} → {vorwahl}
{matrnr} → {vorwahl}
Ableitung der dritten FD aus den anderen beiden:
Durch (wiederholte) Zerlegung folgt aus (1):
{matrnr} → {plz}
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Eigenschaften von FDs: Zurück zum Beispiel
Beispiel: Studierendentelefonbuch:
{[matrnr, name, strasse, plz, stadt, vorwahl, telnr]}
FDs:
{matrnr} → {name, strasse, plz, stadt}
{plz} → {vorwahl}
{matrnr} → {vorwahl}
Ableitung der dritten FD aus den anderen beiden:
Durch (wiederholte) Zerlegung folgt aus (1):
{matrnr} → {plz}
Zusammen mit (2) folgt mit Transitivität (3).
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Bestimmung funktional abhängiger Attribute
Gegeben: Attribute α, Menge F von FDs
+
Wollen: alle Attribute αF
, die von α funktional abhängig sind
Algorithmus:
+
Initialisiere αF
:= {α}, change:=true;
while (change) do{
change=false;
for each FD β → γ in F do{
if (β ⊆ α+ ) then{
+
+
αF
:= αF
∪ γ;
change=true;
}}}
Dieser Algorithmus kann dazu verwendet werden, um Superschlüssel
κ zu finden: Wenn κ+ = R, dann ist κ ein Superschlüssel von R.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Bestimmung funktional abhängiger Attribute
Beispiel:
Sei F = {C → DA, A → BC, E → ABC, F → BC, CD → BF }.
Berechne A+
F.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Bestimmung funktional abhängiger Attribute
Beispiel:
Sei F = {C → DA, A → BC, E → ABC, F → BC, CD → BF }.
Berechne A+
F.
A+
F = {A, B, C, D, F }
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Äquivalenz und kanonische Überdeckung
Definition (Äquivalenz)
Zwei Mengen F, G von FDs heißen äquivalent (F ≡ G), wenn
F + = G +.
Intuitiv: F, G sind äquivalent, wenn dieselben FDs ableitbar sind.
Problem: F + ist im allgemeinen recht groß und unstrukturiert.
Lösung: Wähle für jedes F ein spezielles G mit F ≡ G.
(So ein G heißt kanonische Überdeckung.)
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Kanonische Überdeckung
Definition (kanonische Überdeckung)
Sei F eine Menge von FDs. Fc heißt kanonische Überdeckung von F,
wenn
1
Fc ≡ F (d.h., Fc+ = F + )
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Kanonische Überdeckung
Definition (kanonische Überdeckung)
Sei F eine Menge von FDs. Fc heißt kanonische Überdeckung von F,
wenn
1
2
Fc ≡ F (d.h., Fc+ = F + )
In allen FDs α → β aus Fc enthalten weder α noch β redundante
Attribute, d.h.:
1
2
Ronald Ortner
für alle A in α: (Fc − {α → β}) ∪ {(α − A) → β} ≡
6 Fc
für alle B in β: (Fc − {α → β}) ∪ {α → (β − B)} ≡
6 Fc
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Kanonische Überdeckung
Definition (kanonische Überdeckung)
Sei F eine Menge von FDs. Fc heißt kanonische Überdeckung von F,
wenn
1
2
Fc ≡ F (d.h., Fc+ = F + )
In allen FDs α → β aus Fc enthalten weder α noch β redundante
Attribute, d.h.:
1
2
3
für alle A in α: (Fc − {α → β}) ∪ {(α − A) → β} ≡
6 Fc
für alle B in β: (Fc − {α → β}) ∪ {α → (β − B)} ≡
6 Fc
Für jede FD α → β in Fc gibt es keine andere FD der Form α → γ
in Fc .
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Kanonische Überdeckung
Definition (kanonische Überdeckung)
Sei F eine Menge von FDs. Fc heißt kanonische Überdeckung von F,
wenn
1
2
Fc ≡ F (d.h., Fc+ = F + )
In allen FDs α → β aus Fc enthalten weder α noch β redundante
Attribute, d.h.:
1
2
3
für alle A in α: (Fc − {α → β}) ∪ {(α − A) → β} ≡
6 Fc
für alle B in β: (Fc − {α → β}) ∪ {α → (β − B)} ≡
6 Fc
Für jede FD α → β in Fc gibt es keine andere FD der Form α → γ
in Fc .
Anmerkung: Bedingung 3 kann durch wiederholte Zusammenfassung
von FDs α → β, α → γ to α → βγ erreicht werden.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung
Gegeben: Menge F of FDs
Wollen: kanonische Überdeckung Fc
Algorithmus:
1
Führe für jede FD α → β in F Linksreduktion aus:
Überprüfe für alle A in α, ob A redundant, d.h., β ⊆ (α − A)+
F.
In diesem Fall ersetze α → β durch (α − A) → β.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung
Gegeben: Menge F of FDs
Wollen: kanonische Überdeckung Fc
Algorithmus:
1
Führe für jede FD α → β in F Linksreduktion aus:
Überprüfe für alle A in α, ob A redundant, d.h., β ⊆ (α − A)+
F.
In diesem Fall ersetze α → β durch (α − A) → β.
2
Führe für jede FD α → β in F Rechtsreduktion aus:
Überprüfe für alle B in β, ob B redundant, d.h., B in
+
αF
−{α→β})∪{α→(β−B)} . In diesem Fall ersetze α → β durch
α → (β − B).
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung
Gegeben: Menge F of FDs
Wollen: kanonische Überdeckung Fc
Algorithmus:
1
Führe für jede FD α → β in F Linksreduktion aus:
Überprüfe für alle A in α, ob A redundant, d.h., β ⊆ (α − A)+
F.
In diesem Fall ersetze α → β durch (α − A) → β.
2
Führe für jede FD α → β in F Rechtsreduktion aus:
Überprüfe für alle B in β, ob B redundant, d.h., B in
+
αF
−{α→β})∪{α→(β−B)} . In diesem Fall ersetze α → β durch
α → (β − B).
3
Entferne FDs α → ∅ aus F. (Diese können in Schritt 2 entstehen.)
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung
Gegeben: Menge F of FDs
Wollen: kanonische Überdeckung Fc
Algorithmus:
1
Führe für jede FD α → β in F Linksreduktion aus:
Überprüfe für alle A in α, ob A redundant, d.h., β ⊆ (α − A)+
F.
In diesem Fall ersetze α → β durch (α − A) → β.
2
Führe für jede FD α → β in F Rechtsreduktion aus:
Überprüfe für alle B in β, ob B redundant, d.h., B in
+
αF
−{α→β})∪{α→(β−B)} . In diesem Fall ersetze α → β durch
α → (β − B).
3
Entferne FDs α → ∅ aus F. (Diese können in Schritt 2 entstehen.)
4
Fasse FDs α → β1 , α → β2 ,. . . , α → βk zusammen zu
α → β1 β2 . . . βk .
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung: Ein
Beispiel
Beispiel: F = {A → B, B → C, AB → C}
In Schritt 1 des Algorithmus ersetzen wir AB → C durch A → C,
da C in A+
F : C folgt aus A → B und B → C, wenn A gegeben.
Dann F = {A → B, B → C, A → C}.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung: Ein
Beispiel
Beispiel: F = {A → B, B → C, AB → C}
In Schritt 1 des Algorithmus ersetzen wir AB → C durch A → C,
da C in A+
F : C folgt aus A → B und B → C, wenn A gegeben.
Dann F = {A → B, B → C, A → C}.
In Schritt 2 ersetzen wir A → C durch A → ∅, da C redundant:
C in A+
{A→B,B→C,A→∅} .
Dann F = {A → B, B → C, A → ∅}.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung: Ein
Beispiel
Beispiel: F = {A → B, B → C, AB → C}
In Schritt 1 des Algorithmus ersetzen wir AB → C durch A → C,
da C in A+
F : C folgt aus A → B und B → C, wenn A gegeben.
Dann F = {A → B, B → C, A → C}.
In Schritt 2 ersetzen wir A → C durch A → ∅, da C redundant:
C in A+
{A→B,B→C,A→∅} .
Dann F = {A → B, B → C, A → ∅}.
In Schritt 3 entfernen wir A → ∅.
Dann F = {A → B, B → C}.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Berechnung der kanonischen Überdeckung: Ein
Beispiel
Beispiel: F = {A → B, B → C, AB → C}
In Schritt 1 des Algorithmus ersetzen wir AB → C durch A → C,
da C in A+
F : C folgt aus A → B und B → C, wenn A gegeben.
Dann F = {A → B, B → C, A → C}.
In Schritt 2 ersetzen wir A → C durch A → ∅, da C redundant:
C in A+
{A→B,B→C,A→∅} .
Dann F = {A → B, B → C, A → ∅}.
In Schritt 3 entfernen wir A → ∅.
Dann F = {A → B, B → C}.
Schritt 4 lässt F unverändert, sodass die kanonische
Überdeckung Fc = {A → B, B → C}.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Anomalien in schlecht designten Datenbankschemata
Betrachten das folgende Datenbankschema zum Speichern von
Studenteninformation:
M_Nr
Name
Lva_Nr
Lva
Note
1335123
1335123
.
.
.
Franz Huber
Franz Huber
.
.
.
150420
150111
.
.
.
Datenbanken
IT I
.
.
.
2
4
.
.
.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Anomalien in schlecht designten Datenbankschemata
Betrachten das folgende Datenbankschema zum Speichern von
Studenteninformation:
M_Nr
Name
Lva_Nr
Lva
Note
1335123
1335123
.
.
.
Franz Huber
Franz Huber
.
.
.
150420
150111
.
.
.
Datenbanken
IT I
.
.
.
2
4
.
.
.
Das ist ein schlecht designtes Datenbankschema, weil ...
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Update-Anomalie
Das ist ein schlecht designtes Datenbankschema, weil ...
... wenn Studenteninformation aktualisiert wird, müssen mehrere
Zeilen geändert werden:
M_Nr
Name
Lva_Nr
Lva
Note
1335123
1335123
.
.
.
Franz Huber
Franz Huber
.
.
.
150420
150111
.
.
.
Datenbanken
IT I
.
.
.
2
4
.
.
.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Update-Anomalie
Das ist ein schlecht designtes Datenbankschema, weil ...
... wenn Studenteninformation aktualisiert wird, müssen mehrere
Zeilen geändert werden:
M_Nr
Name
Lva_Nr
Lva
Note
1335123
1335123
.
.
.
Adolf Huber
Adolf Huber
.
.
.
150420
150111
.
.
.
Datenbanken
IT I
.
.
.
2
4
.
.
.
fehleranfällig
schlechtere Performance bei Aktualisierungen
speichert redundante Information
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Einfüge-Anomalie
Das ist ein schlecht designtes Datenbankschema, weil ...
... wenn neue Studenteninformation eingefügt wird, ist keine
entsprechende Lehrveranstaltungsinformation verfügbar:
M_Nr
Name
Lva_Nr
Lva
Note
1335123
1335123
1635001
.
.
.
Franz Huber
Franz Huber
Anna Schmied
.
.
.
150420
150111
NULL
.
.
.
Datenbanken
IT I
NULL
.
.
.
2
4
NULL
.
.
.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Lösch-Anomalie
Das ist ein schlecht designtes Datenbankschema, weil ...
... wenn Informationen von Studenten gelöscht werden, gehen
Informationen über Lehrveranstaltungen verloren und umgekehrt:
M_Nr
Name
Lva_Nr
Lva
Note
1335123
1335123
.
.
.
Franz Huber
Franz Huber
.
.
.
150420
150111
.
.
.
Datenbanken
IT I
.
.
.
2
4
.
.
.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Lösch-Anomalie
Das ist ein schlecht designtes Datenbankschema, weil ...
... wenn Informationen von Studenten gelöscht werden, gehen
Informationen über Lehrveranstaltungen verloren und umgekehrt:
M_Nr
.
.
.
Name
.
.
.
Lva_Nr
.
.
.
Lva
.
.
.
Note
.
.
.
Das passiert auch, wenn z.B. Informationen von “alten” Prüfungen
gelöscht werden.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Zerlegung von Relationen
Outline
1
Organisatorisches
2
SQL
3
Funktionale Abhängigkeit
4
Anomalien
5
Datenbank Normalisierung
Zerlegung von Relationen
Ronald Ortner
Anomalien
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Zerlegung von Relationen
Anomalien treten auf, wenn Informationen, die nicht
“zusammenpassen”, in eine Tabelle/Relation gesteckt werden.
Idee der Normalisierung:
Zerlege Relation R in kleinere Relationen R1 , . . . Rn .
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Zerlegung von Relationen
Anomalien treten auf, wenn Informationen, die nicht
“zusammenpassen”, in eine Tabelle/Relation gesteckt werden.
Idee der Normalisierung:
Zerlege Relation R in kleinere Relationen R1 , . . . Rn .
Dabei soll die Zerlegung gewisse Eigenschaften erfüllen:
Verlustfreiheit:
R kann aus R1 , . . . Rn rekonstruiert werden.
Erhaltung von FDs:
Die funktionalen Abhängigkeiten von R bleiben in R1 , . . . Rn
erhalten.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Verlustfreiheit
Betrachten Zerlegung von R in zwei Relationen R1 , R2 .
Um Verlustfreiheit zu haben, benötigen wir zumindest R = R1 ∪ R2 .
Darüber hinaus möchten wir:
Definition (Verlustfreiheit)
Die Zerlegung von R in R1 , R2 ist verlustfrei, wenn für Realisierungen
R von R (und für entsprechende Zerlegungen R1 , R2 ):
R ist der natürliche Join von R1 und R2 , d.h. R = R1 o
n R2 .
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Zerlegung von Relationen
Verlustfreiheit: Beispiel
Betrachten die folgende Relation/Tabelle:
Ronald Ortner
Gast
Gasthof
Bier
R.Ortner
F.Huber
R.Ortner
Gösserbräu
Zur Post
Zur Post
Gösser
Gösser
Murauer
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Zerlegung von Relationen
Verlustfreiheit: Beispiel
Betrachten die folgende Relation/Tabelle:
Gast
Gasthof
Bier
R.Ortner
F.Huber
R.Ortner
Gösserbräu
Zur Post
Zur Post
Gösser
Gösser
Murauer
Betrachten folgende Zerlegung:
Besucher: {[Gast, Gasthof]}
Getränke: {[Gast, Bier]}
Ronald Ortner
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Zerlegung von Relationen
Verlustfreiheit: Beispiel
Betrachten die folgende Relation/Tabelle:
Gast
Gasthof
Bier
R.Ortner
F.Huber
R.Ortner
Gösserbräu
Zur Post
Zur Post
Gösser
Gösser
Murauer
Besucher:
Ronald Ortner
Gast
Gasthof
R.Ortner
F.Huber
R.Ortner
Gösserbräu
Zur Post
Zur Post
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Zerlegung von Relationen
Verlustfreiheit: Beispiel
Betrachten die folgende Relation/Tabelle:
Gast
Gasthof
Bier
R.Ortner
F.Huber
R.Ortner
Gösserbräu
Zur Post
Zur Post
Gösser
Gösser
Murauer
Getränke:
Ronald Ortner
Gast
Bier
R.Ortner
F.Huber
R.Ortner
Gösser
Gösser
Murauer
Datenbank Normalisierung
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Verlustfreiheit: Beispiel
Der Join der beiden Relationen Besucher und Getränke enthält zwei
zusätzliche (falsche) Einträge:
Ronald Ortner
Gast
Gasthof
Bier
R.Ortner
R.Ortner
F.Huber
R.Ortner
R.Ortner
Gösserbräu
Gösserbräu
Zur Post
Zur Post
Zur Post
Gösser
Murauer
Gösser
Murauer
Gösser
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Verlustfreiheit: Beispiel
Der Join der beiden Relationen Besucher und Getränke enthält zwei
zusätzliche (falsche) Einträge:
Gast
Gasthof
Bier
R.Ortner
R.Ortner
F.Huber
R.Ortner
R.Ortner
Gösserbräu
Gösserbräu
Zur Post
Zur Post
Zur Post
Gösser
Murauer
Gösser
Murauer
Gösser
Diese Zerlegung ist nicht verlustfrei.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Ein Kriterium für Verlustfreiheit
Man kann ein Kriterium für Verlustfreiheit über funktionale
Abhängigkeiten(FDs) angeben:
Kriterium für Verlustfreiheit
Eine Zerlegung von R mit FDs F in R1 , R2 ist verlustlos, wenn
zumindest eine der beiden folgenden Bedingungen gilt:
(R1 ∩ R2 ) → R1 ist in F + ,
(R1 ∩ R2 ) → R2 ist in F + .
In unserem Beispiel gibt es nur die FD {Gast}→{Gasthof,Bier}, aber es
gelten weder {Gast}→{Gasthof} noch {Gast}→{Bier}.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Verlustfreiheit: Weiteres Beispiel
Betrachten folgende Relation:
Vater
.
.
.
Mutter
.
.
.
Kind
.
.
.
Die Zerlegung in Relationen
Väter: {[Vater, Kind]}
Mütter: {[Mutter, Kind]}
ist verlustlos, da beide FDs {Kind}→{Vater} und {Kind}→{Mutter}
gelten.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Erhaltung von Abhängigkeiten
Gegeben: Relation R mit FDs F und Zerlegung in R1 , . . . , Rn .
Im Prinzip können FDs auch dann überprüft werden, wenn diese durch
die Zerlegung ’auseinandergerissen’ werden:
Bilde Join der Realisierungen R1 , . . . Rn .
Überprüfe FDs.
Besser ist allerdings:
FDs können in den Relationen R1 , . . . , Rn überprüft werden.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Abhängigkeitserhaltung
D.h., wir hätten gerne:
Definition (Abhängigkeitserhaltung)
Gegeben sei eine Relation R mit FDs F und eine Zerlegung von R in
R1 , . . . , Rn , wobei jedes Ri die FDs Fi hat. Diese Zerlegung ist
abhängigkeitserhaltend, wenn
F ≡ (F1 ∪ . . . ∪ Fn ).
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Abhängigkeitserhaltung: Beispiel
Stadt
Bundesland
Strasse
PLZ
Bruck
Leoben
Bruck
Stmk
Stmk
NÖ
Mittergasse
Franz Josef Straße
Hauptstraße
8600
8700
2460
Wir nehmen an:
Es gibt keine zwei Städte mit gleichem Namen im gleichen
Bundesland.
Die PLZ ändert sich nicht innerhalb derselben Straße.
Verschiedene Städte haben unterschiedliche PLZ.
Städte gehören eindeutig zu einem Bundesland.
Ronald Ortner
Organisatorisches
SQL
Funktionale Abhängigkeit
Anomalien
Datenbank Normalisierung
Zerlegung von Relationen
Abhängigkeitserhaltung: Beispiel
Stadt
Bundesland
Straße
PLZ
Bruck
Leoben
Bruck
Stmk
Stmk
NÖ
Mittergasse
Franz Josef Straße
Hauptstraße
8600
8700
2460
Betrachten folgende Zerlegung:
Städte: {[PLZ, Stadt, Bundesland]}
Streets: {[PLZ, Straße]}
Diese Zerlegung ist verlustlos, da FD {PLZ}→{Stadt, Bundesland} gilt.
Allerdings, kann die FD {Stadt,Bundesland,Straße}→{PLZ} keiner der
neuen Relationen zugeordnet werden.
Diese Zerlegung ist nicht abhängigkeitserhaltend.
Ronald Ortner