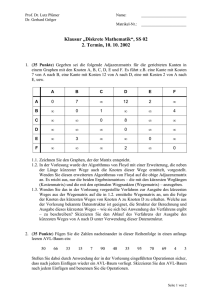
Parallele Algorithmen
Werbung

Parallele Algorithmen im Sommersemester 2016 - Dr. Oliver Schaudt - Universität zu Köln Mathematisches Institut 28. August 2016 Inhaltsverzeichnis Inhaltsverzeichnis 1 1 Einleitung & Grundbegriffe 1.1 Die Klasse N C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2 Elementare Techniken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3 Brents Gesetz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 3 3 5 2 Graphenalgorithmen 2.1 Kürzeste Wege . . . . . . . . . . 2.2 Zusammenhangskomponenten . 2.3 Minimale Spannbäume . . . . . 2.4 2-Zusammenhangskomponenten 2.5 Eulertouren . . . . . . . . . . . . 2.6 Maximale Matchings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 6 7 11 13 15 21 3 Paralleles Sortieren 24 3.1 Einfache Sortieralgorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 3.2 Sortieren in O (log n) bzw. Coles Algorithmus . . . . . . . . . . . . . . . . . . . 28 4 P-Vollständigkeit 4.1 Erzeugbarkeit ist P-vollständig . . . 4.2 Weitere P-vollständige Probleme . . 4.2.1 Auswertungsproblem (CVP) . 4.2.2 Tiefensuche (DFS) . . . . . . 4.2.3 Maximum Flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 35 38 38 39 41 Abbildungsverzeichnis 44 Liste der Algorithmen 45 Mitschrift der Vorlesung von Dario Antweiler. Keine Garantie auf Richtigkeit oder Vollständigkeit. Lob, Kritik, Kommentare an [email protected]. Lizensiert unter (CC BY-SA 4.0). Stand 28. August 2016. Verwendete Software: LaTeX, TikZ, yEd & Ipe = hier fehlt noch etwas 1 Einleitung & Grundbegriffe 11.04.16 VL01 Bemerkung. Fragen: • Welche algorithmischen Probleme lassen sich ”gut” parallelisieren? • Was bedeutet ”gut” genau? • Welche Probleme lassen dagegen nicht gut parallelisieren? Definition. Wir arbeiten mit dem P-RAM-Modell. Dabei teilen sich mehrere Prozessoren einen gemeinsamen Speicher. Die Prozessoren greifen in Konstantzeit auf beliebige Speicherstellen zu und führen elementare Operationen, wie z.B. Addition oder der Vergleich zweier Zahlen durch. Bemerkung. Wir gehen von Einheitskosten für diese Operation aus. Das Hauptprogramm gibt den Prozessoren Anweisungen. Diese führen die gleiche Anweisung gleichzeitig aus. Dabei greifen sie auf unterschiedliche Stellen im Speicher zu. Abbildung 1: Das P-RAM-Modell Definition. Innerhalb des P-RAM-Modells betrachten wir das SIMD-Modell (SingleInstruction-Multiple-Datastream). Bemerkung. Ein verallgemeinerter Pseudocode hat folgende Form: forall the x ∈ X in parallel do instruction (x) end Algorithmus 1 : Grundgerüst eines parallelen Algorithmus Dabei ist X typischerweise eine Liste oder ein Array z.B. von Zahlen. Die Anweisung instruction (x) wird für jedes x ∈ X von einem eigenen Prozessor ausgeführt. Das Hauptprogramm wartet auf die Beendigung aller Prozessoren, bevor es fortfährt. Wir gehen von einer ausreichend großen Anzahl Prozessoren aus. Definition. Es gilt folgende P-RAM-Modelle: • CREW (Concurrent-Read-Exclusive-Write) • EREW (Exclusive-Read-Exclusive-Write) • CRCW (Concurrent-Read-Concurrent-Write) 1 3 EINLEITUNG & GRUNDBEGRIFFE Im Folgenden betrachten wir das CREW-Modell. 9 9 8 9 9 7 3 7 8 4 8 2 5 1 2 Abbildung 2: Maximumsbestimmung mit einem Baum Fragen: • Wieviele Prozessoren haben wir benötigt? • Wieviele Schritte wurden ausgeführt? Dieser Algorithmus benötigt ⌈ n2 ⌉ viele Prozessoren, wenn das Array n Einträge hat. Also im Wesentlichen O (n) viele. Wir machen ⌈log n⌉ viele parallele Schritte, also O (log n) viele. Sei A das Array mit n = 2m vielen Einträgen. Sei B ein Array mit 2n vielen Plätzen mit B [n] = A [1] , B [n + 1] = A [2] , . . . , B [2n − 1] = A [n]. Am Ende ist das Maximum von A in B [1]. Pseudocode: for k = m − 1 bis 0 do for all j ∈ [2k , 2k+1 − 1] in parallel do B [j] ← max {B [2j] , B [2j + 1]} end end return B [1] Algorithmus 2 : Parallele Berechnung des Maximums in einem Array 1.1 Die Klasse N C Satz 1.1. Es gilt N C ⊆ P. Beweis. Jeder parallele Schritt lässt sich mit einem Prozessor in O (nO(1) ) vielen Schritten sequentiell bearbeiten. Wir haben nur O (logO(1) n) viele parallele Schritte. Insgesamt brauchen wir O (nO(1) ⋅ logO(1) n) = O (nO(1) ) viele sequentielle Schritte. Vermutung. N C ≠ P, dazu später mehr. 1.2 Elementare Techniken Verdoppeln Wenn wir ein Array von Zahlen gegeben haben, dann können wir effizient parallel ein Maximum bestimmen. Was passiert, wenn wir eine (verkettete) Liste gegeben haben? L ∶ L1 → L2 → ⋅ ⋅ ⋅ → Ln ⟲ 13.04.16 VL02 1 4 EINLEITUNG & GRUNDBEGRIFFE for all k ∈ [1, . . . , n] in parallel do succ (k) ← next (k) if succ (k) = k then dist (k) ← 0 else dist (k) ← 1 end end repeat ⌈log n⌉ times for all k ∈ [1, . . . , n] in parallel do if succ (k) ≠ succ (succ (k)) then dist (k) ← dist (k) + dist (succ (k)) succ (k) ← succ (succ (k)) end end end Algorithmus 3 : Paralleles Durchmustern einer (verketteten) Liste 1 1 1 1 0 2 2 2 1 0 4 3 2 1 0 Abbildung 3: Die Werte von dist und die Zeiger von SUCC zu Beginn und nach 1. bzw. 2 Schritt Sei next (k) der Nachfolgeindex von Lk in L. Algorithmus 3 bestimmt die Abstände der Einträge der Liste zum Ende, d.h. zu Ln . Wir brauchen O (n) viele Prozessoren und O (log n) Schritte, das Problem liegt also in N C. Anstatt dist können wir auch abstrakt einen Wert value (k) berechnen, mit einer Vorschrift unserer Wahl. Wir ersetzen dist (k) ← dist (k) + dist (succ (k)) durch value (k) ← value (k) ⊕ value (succ (k)) wobei ”⊕” eine beliebige binäre Verknüpfung ist. Zum Beispiel kann mit i⊕j ∶= max {i, j} und der Initialisierung von value (k) mit dem Wert des Eintrags im Listenelement das Maximum aller Zahlen im Array parallel berechnet werden. Diese Methode nennen wir verdoppeln. Dynamische Programmierung Im nächsten Beispiel benutzen wir dynamische Programmierung um einen effizienten parallelen Algorithmus zu bauen. Wir wollen Polynome der Form n p (x) = ∑ ai xi i=0 an einer Stelle x0 auswerten. Sei OBdA n = 2k − 1, ansonsten fülle mit Nullen auf. Schreibe p (x) = r (x) + x n−1 2 ⋅ s (x) 1 5 EINLEITUNG & GRUNDBEGRIFFE wobei r (x) und s (x) Polynome vom Grad 2k−1 −1 sind. Rekursiv berechnen wir r (x0 ) , s (x0 ) und dann p (x0 ). Zunächst berechnen wir sequentiell die Folge n−1 x0 , x20 , x40 , . . . , x0 2 in O (log n) vielen Schritten. Der Rekursionsbaum ist dann n+1 r (x0 ) + x0 2 · s (x0 ) n+1 ∗ r0 (x0 ) + x0 4 · s0 (x0 ) :: : :: n+1 x0 4 : s (x0 ) a0 + a1 x0 ∗ a0 a1 x0 Abbildung 4: Rekursionsbaum für die parallele Auswertung von Polynomen 1.3 Brents Gesetz Das optimale Verhältnis von der Anzahl der Prozessoren zur Laufzeit kann auch nachgelagert werden. Als Beispiel nehmen wir die Maximumsbestimmung in einem Array. Im ersten Schritt brauchen wir n2 viele Prozessoren, danach n4 , n8 ,usw. Nach kurzer Zeit sind also viele Prozessoren ”arbeitslos”. Angenommen wir haben p < n2 viele Prozessoren. Wir lassen jeden Prozessor ⌈ np ⌉ viele Einträge des Arrays sequentiell vergleichen. A = A1 , A2 , . . . , A⌈ n ⌉ , A⌈ n ⌉+1 , . . . , A2⋅⌈ n ⌉ , . . . , An p p p ´¹¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¸¹¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¶ ´¹¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹¸¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¶ p1 p2 Das kostet O ( np ) viele Schritte. Nach diesem Schritt haben wir ein Array der Länge p, welches wir mit Hilfe von p vielen Prozessoren in O (log p) vielen Schritten bearbeiten können. Insgesamt haben wir p Prozessoren gebraucht und machen O ( np + log p) viele Schritte. Für p = ⌈ logn n ⌉ ergibt sich eine Laufzeit von O (log n). Mit O ( logn n ) Prozessoren und einer Laufzeit von O (log n) werden O( n ⋅ log n) = O (n) log n viele einzelne Arbeitsschritte gemacht. Das ist optimal! Satz 1.2. Sei A ein paralleler Algorithmus mit Laufzeit t und sei m die Anzahl der Arbeitsschritte. Dann lässt sich A mit p Prozessoren in Zeit O ( m + t) implementieren. p Beweis. Sei mi die Anzahl der Arbeitsschritte, die im parallelen Schritt i gleichzeitig ausgeführt werden. Es gilt t ∑ mi = m i=0 In ⌈ mpi ⌉ Schritten simulieren wir Schritt i von A und es gilt t m mi +1= +t p p i=1 ∑ 18.04.16 VL03 2 6 GRAPHENALGORITHMEN Bemerkung. In der Praxis lassen sich die mi schwer abschätzen. Wir betrachten n = 2k Elemente in einer linearen Liste und die Methode des Verdoppelns. In jedem Schritt halbiert sich die Distanz eines Elements zum Ende der Liste. Insbesondere haben wir nach l Schritten alle Elemente der Distanz < 2l abgearbeitet. Im letzten Schritt bleiben die Elemente, die dist ≥ 2n−1 = n2 zum Ende haben übrig. Davon gibt es n2 viele. Insbesondere brauchen wir n log n Arbeitsschritte. D.h. eine Maximumsbestimmung im Array lässt sich ”einfach” optimal parallelisieren, in einer linearen Liste dagegen nicht. 2 Graphenalgorithmen 2.1 Kürzeste Wege Wir wollen den kürzesten Weg zwischen jedem Paar von Knoten eines Graphen finden (APSP, All-Pairs-Shortest-Paths). Eingabe: Adjazenzmatrix M mit Mij geben die Kosten der Kante von i nach j an, bzw. Mij = ∞, falls die Kante (i, j) nicht existiert. Wir setzen voraus, dass der Graph keine Kreise negativer Länge enthält, sonst sind die kürzeste Wege nicht wohldefiniert. 1 2 1 -3 2 3 3 ⎛0 M =⎜1 ⎝∞ ∞ 2⎞ 0 −3⎟ 3 0⎠ Abbildung 5: Ein Graph G und seine Adjazenzmatrix M Idee: Berechne Q (i, k, j) als die Länge des kürzesten Weges von i nach k + die Länge des kürzesten Weges von k nach j mit maximal 2l Kanten. Algorithmus 4. for all i, j ∈ [n] in parallel do M ′ (i, j) ← M (i, j) end repeat ⌈log n⌉ times for all i, k, j ∈ [n] in parallel do Q (i, k, j) = M ′ (i, k) + M ′ (k, j) end for all i, j ∈ [n] in parallel do M ′ (i, j) ← mink∈[n] Q (i, k, j) end end Algorithmus 4 : Parallele Berechnung kürzester Wege in einem Graphen Analyse: Die Initialisierung geht mit O (n2 ) Prozessoren in O (1) Zeit. Q kann mit O (n3 ) Prozessoren in Zeit O (1) berechnet werden. Eine Minimumsbildung geht mit O (n/ log n) Prozessoren in O (log n) Zeit. Wir müssen n2 viele Minima berechnen und benötigen dafür also insgesamt O (n3 / log n) viele Prozessoren und O (log n) Zeit. Daher ergibt sich: 2 GRAPHENALGORITHMEN 7 Satz 2.1. APSP geht mit O (n3 / log n) Prozessoren in Zeit O (log2 n). Insbesondere gilt APSP ∈ N C. Bemerkung. Der beste bekannte sequentielle Algorithmus braucht O (n3 ) Zeit (FloydWashall), insbesondere ist der obige Algorithmus nicht optimal. 2.2 Zusammenhangskomponenten Der nächste Algorithmus bestimmt die ZHK eines Graphen. Im sequentiellen Fall geht das in O (m + n). Das Problem bei der Parallelisierung: Tiefensuchbäume lassen sich (vermutlich) nicht effizient parallel berechnen! Dazu später mehr. Nehmen wir an, der Eingabegraph habe die n Knoten {1, . . . , n}. Wir haben als Eingabe die Adjazenzmatrix A von G gegeben, wobei A (i, j) ⇔ i, j sind benachbart in G, sonst A (i, j) = 0. Die Ausgabe ist ein Vektor C in n Dimensionen. Es gilt C (i) = C (j) ⇔ i, j liegen in der gleichen ZHK. Dabei ist C (i) = k genau dann, wenn k der numerisch kleinste Index in der ZHK von i ist. Zu Beginn setze C (i) = i für alle Knoten i. Der Algorithmus verschmilzt Knoten zu Pseudoknoten. Diese Pseudoknoten bilden eine Teilmenge der Knoten. Ist C (i) = j, dann sagen wir, dass j der Pseudoknoten zu i ist. 25.04.16 VL04 Abbildung 6: Graph G und Digraph D In jeder Iteration wird die Anzahl der Pseudoknoten innerhalb jeder ZHK halbiert. Der Algorithmus führt ⌈log n⌉ oft folgende Schritte durch. Wir benutzen einen n-dimensionalen Hilfsvektor T . for all i ∈ [n] in parallel do if ∃j ∈ [n] mit A (i, j) = 1 und C (i) ≠ C (j) then T (i) ← min {C (i) ∣ A (i, j) = 1, C (i) ≠ C (j)} else T (i) ← C (i) end end Algorithmus 5 : Berechnung der ZHK, Schritt 1 Betrachte den ger. Graphen D = ({1, . . . , n} , {(i, T (i)) ∣ 1 ≤ i ≤ n}) wie in Abbildung 7. Nach Schritt 2 gilt: • alle Nicht-Pseudoknoten i zeigen in D auf ihren Pseudoknoten C (i) • Jeder Pseudoknoten i zeigt auf den günstigsten ”benachbarten” Pseudoknoten j, d.h. es existieren k, l mit A (k, l) = 1 und C (k) = i, C (l) = j 27.04.16 VL05 2 8 GRAPHENALGORITHMEN Abbildung 7: Digraph D for all i ∈ [n] in parallel do if ∃j ∈ [n] mit C (j) = i und T (j) ≠ i then T (i) ← min {T (j) ∣ C (j) = i, T (j) ≠ i} else T (i) ← C (i) end end Algorithmus 6 : Berechnung der ZHK, Schritt 2 Definition. Eine schwache ZHK eines gerichteten Graphen ist eine ZHK im zugrundeliegenden ungerichteten Graphen. In jeder schwachen ZHK gibt es genau einen Kreis, da jeder Knoten genau einen Nachfolger hat. Dieser Kreis hat Länge 1 (Schlinge) oder 2 (antiparallele Kanten). Wichtig: Ein Kreis der Länge 1 existiert genau dann, wenn die gesamte ZHK, in der dieser Pseudoknoten liegt, in i zusammengefasst ist. In den Schritten 3-5 werden die Pseudoknoten einer jeden schwachen ZHK von D zu je einem einzigen Pseudoknoten verschmolzen: for all i ∈ [n] in parallel do B (i) ← T (i) end Algorithmus 7 : Berechnung der ZHK, Schritt 3 Im gerichteten Graphen D′ = ({1, . . . , n} , {(i, B (i)) ∣ 1 ≤ i ≤ n}) zeigt jeder Knoten auf einen Pseudoknoten aus dem Kreis seiner schwachen ZHK in D. Lemma 2.2. Der Algorithmus berechnet die ZHK des Eingabegraphen (bzw. den korrekten C-Vektor. Beweis. Alle Knoten mit demselben Pseudoknoten liegen in derselben ZHK des Eingangssystems. Wie vorher erklärt halbieren wir die Anzahl der Pseudoknoten in jeder ZHK, außer sie ist schon gleich 1. Daher besteht nach ⌈log n⌉ Schritten jede ZHK aus genau einem Pseudoknoten. Laufzeitanalyse Insgesamt haben wir ⌈log n⌉ viele Iterationen der Schritte 1-5. Schritt 4 besteht wiederum aus ⌈log n⌉ vielen Iterationen, also ist die Laufzeit Ω (log2 n). Wir wollen bei O (log2 n) vielen parallelen Schritten bleiben. Dazu müssen wir die Schritte 1 bzw 2 in O (log n) viel Zeit abarbeiten. Wir diskutieren Schritt 1, das implementieren wir so: 2 9 GRAPHENALGORITHMEN repeat ⌈log n⌉ times for all i ∈ [n] in parallel do B (i) ← B (B (i)) end end Algorithmus 8 : Berechnung der ZHK, Schritt 4 for all i ∈ [n] in parallel do C (i) ← min {B (i) , T (B (i))} end Algorithmus 9 : Berechnung der ZHK, Schritt 5 Schritt 1.1 implementieren wir so, dass je ⌈log n⌉ viele Paare (i, j), festes i, vom selbem Prozessor abgearbeitet werden. Schritt 1.2 können wir mit O (n ⋅ logn n ) vielen Prozessoren in O (log n) Schritten implementieren. Schritt 2 geht analog. Insgesamt im Algorithmus machen wir O (log2 n) viele 2 n Schritte und brauchen O ( log ) viele Prozessoren. Das ist gut. Es geht noch besser: n Satz 2.3. Wir können die ZHK eines Graphen mit O (n2 / log2 n) Prozessoren in O (log2 n) Zeit bestimmt werden. 2 2 n Beweis. Wir müssen von O ( log ) Prozessoren wieder auf O ( logn2 n ) viele Prozessoren. Nehn men wir an wir haben n−k viele Prozessoren. Angenommen wir verschmelzen Pseudoknoten (nach jedem Schritt 5 ) tatsächlich zu einem einzelnen Knoten und löschen die Pseudoknoten, welche eine ZHK umfassen. Später. Dann wird durch jede Iteration des Algorithmus die Anzahl der Knoten des Graphen halbiert. Nach k Schritten haben wir nk ≤ 2nk , wobei nk die Anzahl der Knoten nach Iteration k bezeichnet. Wir müssen nur 1 und 2 diskutie- ren, aber eigentlich nur 1 . Zur Minimumsbildung: In einem Array mit nk vielen Einträgen können wir das Maximum in ⎧ ⎪ ⎪⌈ nk ⌉ − 1 + ⌈log k⌉ k < ⌊ n2k ⌋ Tk = ⎨ k ⎪ ⌈log nk ⌉ k ≥ ⌊ n2k ⌋ ⎪ ⎩ vielen Schritten bestimmen, siehe Kapitel 1. Es gilt k ≥ ⌊ n2k ⌋, sobald k ≥ ⌈log n − log k⌉ =∶ t, weil nk ≤ 2nk ≤ k. Somit geht die Minimumsbildung summiert über alle Iterationen in T = ... = ... = O (log2 n) Wir müssen noch die Hausarbeit erledigen. Die aktuell relevanten Pseudoknoten müssen n nachgehalten werden. Dafür benutzen wir einen n-dimensionalen Vektore pseudo ∈ {0, 1} . Dabei soll gelten pseudo (i) = 1 ⇔ i ist ein Pseudoknoten, welcher keine ganze ZHK umfasst Zu Beginn ist pseudo (i) = 1 für alle Knoten i. Zu Beginn jeder Iteration sortieren wir die Knoten gemäß ihrem Pseudo-Wert absteigend. Das geht in O (log n) Schritten mit O (n) Prozessoren, das sehen wir später. Die ersten Stelle des sortierten Arrays enthalten die relevanten Pseudoknoten. Es sei P = {i ∶ pseudo (i) = 1}. Die Adjazenzmatrix modifizieren wir so, dass für je zwei Knoten i, j ∈ P gilt A (i, j) = 1 ⇔ ∃l, k mit C (l) = i, C (k) = j, (l, k) ∈ E 02.05.16 VL06 2 10 GRAPHENALGORITHMEN for all i, j, 1 ≤ i, j ≤ n in parallel do // Schritt 1.1 if A (i, j) = 1 und C (i) ≠ C (j); then Temp (i, j) ← C (i) else Temp (i, j) ← ∞ end end for all i ∈ [n] in parallel do // Schritt 1.2 Temp (i, 1) ← min {Temp (i, j) ∣ 1 ≤ j ≤ n} end for all i ∈ [n] in parallel do // Schritt 1.3 if Temp (i, 1) ≠ ∞; then T (i) ← Temp (i, 1) else T (i) ← C (i) end end Algorithmus 10 : Berechnung der ZHK, Nachbesserungen in Schritt 1 Schritt 1 & 2 werden dann zu for all i ∈ P in parallel do if ∃j ∈ P mit A (i, j) = 1 then T (i) ← min {j ∶ j ∈ P, A (i, j) = 1} else T (i) ← C (i) end pseudo (i) ← 0 end Die Schritte 3 bis 5 passen wir an, in dem wir ”forall vertices i” durch ”forall i ∈ P ” ersetzen. Am Ende der Iteration müssen wir 1. die Vektoren C und pseudo aktualisieren und 2. die Adjazenzmatrix aktualisieren Für ersteres setzen wir pseudo (i) auf 0, falls C (i) ≠ i. Die C-Werte der Knoten aus P sind nach Ende der Iteration korrekt. Für alle anderen Knoten j gilt möglicherweise C (C (j)) ≠ C (j), auf jeden Fall aber C (C (j)) = C (C (C (j))), also ist C (C (j)) der korrekte Pseudoknoten von j. P V nP Abbildung 8: Pseudoknoten P am Ende der Iteration und Knoten, welche nach der Iteration keine Pseudoknoten mehr sind 2 11 GRAPHENALGORITHMEN Wir setzen folgende Zeile ein: for all vertices i in parallel do C (i) ← C (C (i)) end Danach sind alle C-Werte aktuell. Zu letzterem: Wir machen for all i ∈ P in parallel do for all j ∈ P mit C (j) = j in parallel do A (i, j) ← max {A (i, k) , k ∈ P, C (k) = j} end end Danach gilt A (i, j) = 1 genau dann, wenn es einen Knoten k im Pseudoknoten j gibt mit A (i, k) = 1. Dann machen wir for all j ∈ P mit C (j) = j in parallel do for all i ∈ P mit C (i) = i in parallel do A (i, j) ← max {A (k, j) , k ∈ P, C (k) = i} end end Danach gilt A (i, j) = 1 genau dann, wenn A (k, j) = 1 für ein k mit C (k) = i. i k j Abbildung 9: blablabla Diese Schritte lassen sich, analog zu oben, in der gewünschten Komplexität implementieren. Damit ist auch die Hausarbeit erledigt. 2.3 Minimale Spannbäume Unser Algorithmus kann wesentlich mehr, als nur die ZHKs zu bestimmen. Zum Beispiel können wir einen kostenminimalen aufspannenden Wald bestimmen. Die Idee ist, den gerichteten Graphen D als ungerichteten Wald auf den Pseudoknoten zu verstehen und daraus rekursiv einen Spannbaum zu berechnen. Abbildung 10: Rekursive Berechnung eines Spannbaums 2 12 GRAPHENALGORITHMEN Wir müssen (a) die Kanten der schwachen ZHK von D identifizieren und (b) jeder dieser Kanten eine Kante aus dem Eingangsgraph zuordnen. Schritt (a) ist klar und für (b): i j i j Abbildung 11: (b) Wir merken uns im Zuge jeder Aktualisierung von A eine repräsentative Kante aus dem Eingangsgraphen als Stellvertreter. Die Kante merken wir uns im Eintrag A (i, j). Das kostet uns keine zusätzlichen Prozessoren oder Rechenschritte (bis auf Konstante). Auch die Kostenminimierung funktioniert ähnlich. Wir haben als Eingabe die symmetrische Matrix M ∈ Qn×n >0 der Kantengewichte des Graphen. Wir suchen einen Spannbaum mit minimalen Kosten. Dieses Problem lässt sich mittels folgender Modifikation des vorherigen SpannbaumAlgorithmus lösen. Anstatt des benachbarten Pseudoknoten mit dem numerisch kleinsten Index zu wählen, wählen wir den Pseudoknoten, welcher über die günstigste ausgehende Kante erreichbar ist. 7 9 3 Abbildung 12: Iteration in der Berechnung eines minimalen Spannbaums Nach Pertubation der Kantengewichte wissen wir, dass es keine Uneindeutigkeiten mehr gibt. Alternativ können wir Kantenindizes vergeben. Analog zum alten Algorithmus kann man zeigen, dass auf den relevanten schwachen ZHK von D nur Kreise der Länge 2 entstehen. Die Komplexität bleibt erhalten. Lemma 2.4. Der so berechnete Spannbaum hat minimale Kosten. Beweis. Angenommen die Annahme ist falsch. Dann sei k die erste Iteration, in der wir einen Fehler gemacht haben, es also keine Spannbaum minimaler Gesamtkosten gibt, welcher die bisher ausgewählten Kanten enthält. Die in der Iteration k hinzugefügten Kanten seien in der Menge Ek gesammelt. Ohne die Kanten aus Ek haben wir bisher einen Spannbaum innerhalb der Pseudoknoten aufgebaut. Diese sind insgesamt kostenminimal. Fügen wir die Kanten der Menge Ek sukzessive ein, dann vollziehen wir Schritte des Prim-Algorithmus. Dieser ist korrekt. Somit ist die Menge Ek korrekt. Das ist ein Widerspruch zur Annahme. 04.05.16 VL07 2 GRAPHENALGORITHMEN 13 Satz 2.5. Kostenoptimale Spannbäume lassen sich mit O (n2 / log2 n) vielen Prozessoren in O (log2 n) vielen Schritten berechnen. 2.4 2-Zusammenhangskomponenten Als nächstes berechnen wir die 2-Zusammenhangskomponenten des Graphen G. Definition. Eine 2-ZHK ist eine inklusionsmaximale Knotenmenge U ⊆ V (G) mit folgender Eigenschaft: Zwischen je zwei Knoten u, v ∈ U existieren zwei Wege zwischen u und v, welche sich keinen inneren Knoten teilen. Abbildung 13: Ein Graph G und seine 2-ZHK Lemma 2.6. Zwei Kanten eines Graphen liegen in derselben 2-ZHK genau dann, wenn es einen Kreis durch beide Kanten gibt. Beweis. GT1. Idee: Kantendisjunkte u, v-Wege. Zuerst berechnen wir einen Spannbaum T von G in einem beliebigen Knoten r. Wir berechnen zu diesem Knoten die Präordnung von T . Abbildung 14: Ein gewurzelter Baum T und markiert der Teilbaum gewurzelt in u Diese Präordnung (=Tiefensuch-Struktur) lässt sich bei Bäumen effizient parallel berechnen. Wir wollen eine Graphen G′ konstruieren. Dafür reicht es aus, die Fundamentalkreise von G zu betrachten. Seien u, v ∈ V (G). Dann heißt v Nachfolger von u bzw. u ≤ v, wenn v im Teilbaum gewurzelt in u vorkommt. Zum Testen von ”u ≤ v” reicht es, zu fragen: • Gilt preorder (u) ≤ preorder (v) und • Gilt preorder (v) < preorder (u) + Anzahl Knoten im Teilbaum von u 09.05.16 VL08 2 14 GRAPHENALGORITHMEN Abbildung 15: Anwendung von Schritt 2 for all (u, v) ∈ E (G) ∖ E (T ) mit u ≤ v in parallel do // Regel 1 add ((u, v) , (v, father (v))) to G′ end for all (u, v) ∈ E (G) ∖ E (T ) mit u ≰ v, v ≰ u in parallel do // Regel 2 add ((u, v) , (u, father (u))) to G′ add ((u, v) , (v, father (v))) to G′ end for all (u, v) ∈ E (T ) , u ≤ v, u ≠ r, ∃ Kante e joining a desc. of v to a non-desc. of u in parallel do add ((u, v) , (u, father (u))) to G′ // Regel 3 end Algorithmus 11 : Parallele Berechnung von 2-Zusammenhangskomponenten Dabei ist preorder (v) die Präordnungszahl von v und die Anzahl der Knoten im Teilbaum von u können wir effizient parallel berechnen (vgl. Übung). Wir starten mit G′ = (E (G) , ∅) und fügen sukzessive Kanten gemäß Algorithmus 15 ein. Damit sind alle Fundamentalkreise abgedeckt. 3 3 3 3 3 1 3 3 3 2 2 3 Abbildung 16: Konstruktion des Graphen G′ Lemma 2.7. Sind zwei Kanten im selben Fundamentalkreis, dann liegen sie in der gleichen ZHK von G′ . Beweis. Übung. Idee: Zeige per Fallunterscheidung und Induktion, dass die Regeln der Konstruktion ausreichen. Lemma 2.8. Ist C ein Kreis in G und sind e ≠ f Kanten auf C (d.h. e, f liegen in der gleichen 2-ZHK), dann liegen e und f in der gleichen ZHK von G′ . 2 GRAPHENALGORITHMEN 15 Beweis. Sei C = C1 ⊕ ⋅ ⋅ ⋅ ⊕ Ck , wobei Ci Fundamentalkreise sind. Ist k minimal, dann gilt folgendes für alle i, j mit 1 ≤ i, j ≤ k: Es gibt Indizes r1 , . . . , rs mit r1 = i und rs = j so, dass Crt mit Crt+1 mindestens eine Kante gemeinsam hat. Nach Lemma 2.7 liegen alle Kanten eines Fundamentalkreises in der gleichen ZHK von G′ . Seien e ∈ E (Ci ) , f ∈ E (Cj ) und seien Cr1 , . . . , Crs wie oben gewählt. Alle Kanten von Crt liegen in der gleichen ZHK von G′ wie alle Kanten von Crt+1 , t = 1, . . . , s − 1. Damit liegen auch e, f in der gleichen ZHK von G′ . Mit Lemma 2.6 folgt, dass zwei Kanten aus der gleichen 2-ZHK von G in der gleichen ZHK von G′ liegen. Die Rückrichtung gilt ebenfalls: Lemma 2.9. Liegen zwei Kanten e, f von G in der gleichen ZHK von G′ , dann liegen e, f in der gleichen 2-ZHK von G. Beweis. Ist (g, h) ∈ E (G′ ), dann liegen g, h auf einem gemeinsamen Fundamentalkreis in G nach Konstruktion. Ist (e1 , . . . , ek ) ein Weg in G′ mit e1 = e und ek = f , dann liegen jeweils ei und ei+1 in der gleichen 2-ZHK von G, nach Lemma 2.6. Somit liegen alle Kanten aus {e1 , . . . , ek } in der gleichen 2-ZHK von G, da die Eigenschaft in der gleichen 2-ZHK zu liegen eine Äquivalenzrelation auf den Kanten ist. Satz 2.10. Die Berechnung der 2-ZHK eines Graphen ist in der Klasse N C. 2.5 Eulertouren Als nächstes zeigen wir, wie man Eulertouren berechnet. Dabei starten wir mit dem Fall gerichteter Graphen. Satz 2.11. Ein zusammenhängender gerichteter Graph hat eine Eulertour genau dann, wenn es in jedem Knoten gleich viele eingehende wie ausgehende Kanten gibt. Beweis. Graphentheorie I. Bemerkung. Die obige Bedingung lässt sich effizient parallel testen (ohne Beweis). Wir nehmen an, der Eingangsgraph G = (V, E) ist gerichtet und erfüllt die Bedingungen des Satzes. Wir nehmen an, dass die Kanten des Graphen in einem Array EDGE gespeichert sind. Jetzt sortieren wir EDGE auf zwei verschiedene Arten. EDGE sortieren wir gemäß folgender Ordnung: (i, j) < (k, l) wenn j < l oder j = l, i < k Das geht mit O (n) Prozessoren in O (log n) Schritte. Ähnlich definieren wir ein Array SUCC (Successor), welches aus EDGE durch Sortieren gemäß folgender Ordnung entsteht: (i, j) < (l, k) wenn i < l oder i = l, j < k EDGE und SUCC zusammen ergeben eine Partition von E in geschlossene gerichtete Kantenzüge. Definition. Ein geschlossener, gerichteter Kantenzug heißt Zykel. Für den Graphen aus Abbildung 17 ergibt sich: EDGE = [(2, 1) (4, 1) (3, 2) (7, 2) (1, 3) (6, 3) (3, 4) (5, 4) (1, 5) (6, 5) (2, 6) (4, 6) (5, 7)] SUCC = [(1, 3) (1, 5) (2, 1) (2, 6) (3, 2) (3, 4) (4, 1) (4, 6) (5, 4) (5, 7) (6, 3) (6, 5) (7, 2)] 11.05.16 VL09 2 16 GRAPHENALGORITHMEN 2 3 6 1 7 4 5 Abbildung 17: Ein eulerscher Graph G Das funktioniert immer! (→ Übung). Zum leichteren Zugriff speichern wir im Eintrag SUCC (i) einen Zeiger P (i) mit P (i) = j für das j, wo SUCC (i) = EDGE (j). Den Zeiger P können wir beim Sortieren von EDGE zu SUCC gewinnen. Nun haben wir den Graphen schon implizit in disjunkte Zykel zerlegt. Diese müssen wir nun geschickt zu einer Eulertour zusammensetzen. In Schritt 2 des Algorithmus konstruieren wir einen Hilfsgraphen G′ = (V ′ , E ′ ) mit V ′ = V ∪ {Zykel in der Partition von E}. Dazu repräsentieren wir jeden Zykel durch eine Kante daraus. Dies wird die lexikografisch kleinste Kante des Zykels sein. Im Beispiel wird der erste Zykel durch (1, 3) repräsentiert, der zweite durch (1, 5). Dazu definieren wir ein Array REP, wobei REP (i) die Kante ist, die den Zykel repräsentiert, auf dem die Kante EDGE (i) liegt. Im Beispiel ergibt sich REP = [(1, 3) (1, 5) (1, 3) (1, 5) (1, 3) (1, 5) (1, 5) (1, 5) (1, 5) (1, 5) (1, 5) (1, 5) (1, 5)] Das Array REP rechnen wir mittels Verdoppeln aus: for all i ∈ [m] in parallel do REP (i) ← SUCC (i) end repeat ⌈log m⌉ times for all i ∈ [m] in parallel do REP (i) ← min {REP (i) , REP (P (i))} P (i) ← P (P (i)) end end Algorithmus 12 : Berechnung von REP Dafür brauchen wir mit O (log m) Prozessoren O (log n) viele Schritte. Sei C die Menge der Kanten, die Zykel repräsentieren. Wir definieren G′ = (V ′ , E ′ ) als V ′ = V ∪ C und E ′ = {(u, c) ∶ u ∈ V, c ∈ C, Knoten u kommt im von C repräsentierten Zykel vor} Zur Konstruktion von G′ erstellen wir ein Array EDGE′ , welches die Kanten von E ′ enthält. Wir berechnen das Folgende, wobei (u, v) = EDGE (i): for all i ∈ [m] in parallel do EDGE′ (2i − 1) ← (u, REP (i)) EDGE′ (2i) ← (v, REP (i)) end Algorithmus 13 : Konstruktion von EDGE′ Dies geht mit O (m) Prozessoren in O (1) vielen Schritten. 23.05.16 VL10 2 17 GRAPHENALGORITHMEN 1 2 (1; 3) 3 4 5 6 7 (1; 5) Abbildung 18: Der Graph G′ zu G for all i ∈ {1, . . . , 2m − 1} in parallel do if EDGE′ (i) = EDGE′ (i + 1) then EDGE′ (i) ← ∞ end end Algorithmus 14 : Entfernung der Mehrfachkanten In EDGE′ kommen Kanten evtl. mehrfach vor. Um dies zu beheben, sortieren wir EDGE′ lexikografisch. Danach kommen Mehrfachkanten konsekutiv im Array vor. Wir überschreiben alle bis auf eine dieser Mehrfachkanten: Nach einer weiteren Sortierung enthalten die ersten Einträge von EDGE′ genau die Kanten aus E ′ in einfacher Ausfertigung. Sei EDGE′ (i) = (v, w) ∈ E ′ . Wir brauchen ein ”Zertifikat” für das Vorkommen des Knotens v aus dem durch w repräsentierten Zykel Zw . Dies soll eine Kante der Form (x, v) auf Zw sein. Eine solche Kante finden wir beim Erstellen von EDGE′ : Beispiel. CERTIFICATE (1, (1, 3)) ← (2, 1) CERTIFICATE (2, (1, 3)) ← (3, 2) Eine Wahl haben wir nur bei den Knoten 4, 5, 6 im Zykel zu (1, 5). Wir wählen CERTIFICATE (4, (1, 5)) ← (3, 4) CERTIFICATE (5, (1, 5)) ← (1, 5) CERTIFICATE (6, (1, 5)) ← (2, 6) Wir brauchen O (m) viele Prozessoren und O (log n) viel Zeit. In Schritt 3 des Algorithmus berechnen wir einen Spannbaum T von G′ . Das geht mit O (n′2 / log2 n′ ) vielen Prozessoren in O (log2 n′ ) vielen Schritten, wobei n′ = ∣V ′ ∣ = O (m + n). Dazu berechnen wir eine gerichteten Baum T ′ , wobei wir jede Kante von T durch ein Paar antiparallele Kanten ersetzen. Wir suchen eine spezielle Eulertour auf T ′ . Dazu berechnen wir in Schritt 4 einen ”Zykel” L auf den Kanten von G und T ′ gemeinsam. Der Zykel alterniert zwischen Wegen in T der Länge 2 und Wegen in G entlang den entsprechenden Zyklen in G. Sei w ∈ C und seien (v0 , w) , (v1 , w) , . . . , (vα−1 , w) die in T ′ nach w eingehenden Kanten. Es sei (iα , vα ) = CERTIFICATE (vα , w) für alle α ∈ {0, . . . , α − 1}. Wir fügen jetzt zu EDGE und SUCC die Kanten aus T ′ hinzu. Für jedes (vα , w) und (w, vα ) aus T ′ fügen wir einen entsprechenden Eintrag zu EDGE hinzu. Wir setzen SUCC (vα , w) ← (vα , jα ) 2 18 GRAPHENALGORITHMEN (iα ; vα ) (vα ; jα ) vα W Abbildung 19: und SUCC (iα , vα ) ← (w, vα ) Es bleiben die Einträge aus SUCC (w, vα ) zu bestimmen. Es seien (vα , w0 ) , . . . , (vα , wk−1 ) die in T ′ von vα ausgehenden Kanten. Dann setze SUCC (wi , vα ) ← (vα , wi+1(mod k) ) EDGE und SUCC zusammen definieren einen Zykel L auf den Kanten in E (T ′ ) ∪ E (G), wie gewünscht. Dieser ist wie folgt aufgebaut: Benutzt L eine Kante der Form (wi , vα ), dann folgt die Kante (vα , wi+1(mod k) ). Dann gehen wir entlang des Zykels wi+1 mod k weiter, wobei wir mit der Kante (vα , jα ) = SUCC (CERTIFICATE (vα , wi+1(mod k) )) starten. Wir laufen entlang wi+1 bis zu nächsten Kante der Form (iβ , vβ ). Dann gehen wir über (wi+1 , vβ ) zu vβ . Nachtrag: Benutzt L eine Kante der Form (wi , vα ), dann folgt die Kante (vα , wi+1(mod k) ). Dann geht es in wi+1(mod k) weiter, startend mit (vα , jα ). Sobald wir auf eine Kante der Form (iβ , vβ ) = CERTIFICATE (vβ , wi+1(mod k) ) treffen mit (vβ , wi+1(mod k) ) ∈ E (T ′ ), gehen wir zu vβ usw. 2 5 1 4 6 5 (1; 5) (1; 3) 7 2 3 3 4 6 Abbildung 20: G und T ′ zusammen Für jeden Knoten aus T ′ haben wir eine zyklische Ordnung auf den ausgehenden Kanten definiert. Für die Knoten aus V ist das klar: Nach Definition ist SUCC (wi , vα ) = (vα , wi+1(k) ) Für die Knoten w aus C folgt auf das Einsteigen in den Zykel über (wα , wi+1(k)? ) das Aussteigen über (w, vβ ). Dadurch wird eine zyklische Ordnung auf den ausgehenden Kanten in T ′ definiert. Damit ist für jede Kante (v, w) bzw. (w, v) , v ∈ V, c ∈ C genau eine Kante 25.05.16 VL11 2 19 GRAPHENALGORITHMEN next (v, w) bzw. next (w, v) definiert, so wie in der Übung. Somit liefert L eine Eulertour auf T ′ ab, wie in der Übung bewiesen. In G läuft L eine Menge von Teilstücken von Zykeln ab; jeweils zwischen zwei Kanten vα , vβ . Dabei steigen wir jeweils mit der Kante (vα , jα ) ein und enden mit der Kante (iβ , vβ ). Da L eine Eulertour auf T ′ beschreibt geht L jedes Teilstück genau einmal ab. Somit beschreibt L auch auf G eine Eulertour. Schritt 4 geht offenbar effizient parallel. Im letzten Schritt 5 löschen wir die Kanten aus T ′ aus der Tour L. Dazu nutzen wir, dass Kanten aus T ′ in L immer die Form (w, v) , (v, w′ ) haben, wobei v ∈ C, w, w′ ∈ C. Wir berechnen repeat 2 times for all e ∈ EDGE in parallel do if SUCC (e) ∈ E (T ′ ) then SUCC (e) ← SUCC (SUCC (e)) end end end Algorithmus 15 : Schritt 5: Entfernen der Kanten aus T ′ in L Schritt 5 geht mit O (m) Prozessoren in O (1) Schritten und nun definiert das SUCCArray eine tournext-Funktion, also Satz 2.12. Die Berechnung von Eulertouren in gerichteten Graphen ist in N C. Jetzt zur ungerichteten Variante: Wir haben einen ungerichteten eulerschen Graphen G gegeben. Wir müssen eine Orientierung G′ berechnen, für die jeder Knoten genauso viele eingehende wie ausgehende Kanten hat. G G0 Abbildung 21: Eulersche Orientierung G′ von G Dann gilt: Jede Eulertour in G′ ist eine in G, aber nicht umgekehrt. Zunächst spalten wir die Kanten in G zu je zwei antiparallelen Kanten auf. Das gibt uns wieder ein EDGE-Array. Diesmal sortieren wir EDGE lexikografisch: (i, j) < (k, l) ⇔ i < k oder i = k, j < l Jede Kante (u, v) statten wir mit einem Label aus: (u, v0 ) , . . . , (u, vd−1 ) wobei u d-viele Nachfolger hat. Dann setzen wir ein Array SUCC auf: for all v und i ∈ {0, . . . , d (v) − 1} ungerade in parallel do SUCC (vi , v) ← (v, vi+1 mod d(v) ) SUCC (vi+1 mod d(v) , v) ← (v, vi ) end Algorithmus 16 : Initialisierung von SUCC 2 20 GRAPHENALGORITHMEN SUCC vi+1 vi v SUCC Abbildung 22: Konstruktion des Arrays SUCC Durch EDGE und SUCC sind wieder Zykel definiert. Dabei gibt es (ohne Beweis) zu jedem Zykel genau einen anderen Zykel, der umgekehrt läuft. Wir löschen je einen antiparallelen Zykel pro Paar. Dafür kopieren wir das EDGE-Array in ein Array ”REP”. Wir verdoppeln gemäß Algorithmus 21. repeat ⌈log m⌉ times for all i ∈ {1, . . . , 2m} in parallel do REP (i) ← min {REP (i) , REP (SUCC (i))} SUCC (i) ← SUCC (SUCC (i)) end end Algorithmus 17 : Berechnung von REP mit Verdoppeln Dabei ist min das lexikografische Minimum. Anschließend steht in REP(i) die lex. kleinste Kante aus dem Zykel, der die Kante EDGE(i) enthält. Dann löschen wir gemäß Algorithmus 22. for all e = (i, j) in parallel do if REP (i, j) > REP (j, i) then EDGE (i, j) ← ∞ end end Algorithmus 18 : Löschen von antiparallelen Zykeln Danach sind alle Kanten aus dem jeweils lex. größerem Zykel mit ∞ überschrieben. Sortieren und abschneiden nach dem m-ten Eintrag von EDGE liefert einen gerichteten Graphen mit der gewünschten Eigenschaft (eulersch). Jetzt können wir den Algorithmus für den gerichteten Fall anwenden. 30.05.16 VL12 2 GRAPHENALGORITHMEN 2.6 21 Maximale Matchings Definition. Ein Matching M in G ist eine Menge von Kanten, welche paarweise keinen gemeinsamen Knoten haben. Ein Matching heißt maximal, falls keine weitere Kante aus G hinzugefügt werden kann. Abbildung 23: Zwei (inklusions-)maximale Matchings Der Algorithmus besteht aus der logarithmisch oft iterierten Anwendung der Subroutine ’SPLIT’, welche auf der Berechnung von Eulertouren basiert. Sei G unser Eingabegraph. Wir bezeichnen mit Gi den Graphen vor Iteration i, also G1 = G. In der Iteration i wird ein Matching Mi von Gi berechnet. Es sei k die kleinste ganze Zahl mit 2k ≤ ∆ (G) ≤ 2k+1 +1. Die Knoten v mit Grad 2k ≤ d (v) ≤ 2k+1 + 1 nennen wir aktiv. Dieses k und die aktiven Knoten können wir effizient parallel bestimmen. Der Graph, auf den die j-te innere Iteration von SPLIT angewendet wird, nennen wir Gji . • In Schritt 1 von SPLIT berechnen wir d (v) für v ∈ V (Gji ), k, ∆ (G) und die Menge der aktiven Knoten. Dies geht effizient parallel • In Schritt 2 berechnen wir den Graphen Hij . Dieser entsteht aus Gji durch Löschen aller Kanten, die nicht zu einem aktiven Knoten inzident sind. In Hij gibt es womöglich Knoten mit ungeradem Grad. Davon gibt es aber gerade viele, nach dem Handschlaglemma. Wir verbinden diese mit einem neuen Knoten v. Im Anschluss haben alle Knoten geraden Grad • In Schritt 3 berechnen wir für jede Komponente von Hij eine Eulertour • In Schritt 4 des Algorithmus geben wir jeder Kante von Hij ein Label 0 oder 1. Dazu alternieren wir die Label entlang der Eulertour, startend mit Label 0 • In Schritt 5 löschen wir die Kanten mit Label 0 aus Gji . Ist Gji jetzt ein Matching, dann geben wir dies als Mi aus, sonst wende SPLIT auf Gj+1 ← Gji an. Das Labeln i machen wir mit Rangbestimmung in einer verketteten Liste Lemma 2.13. Nach höchstens 3 + ⌈log ∆ (Gi )⌉ vielen inneren Iterationen ist Mi gefunden. Beweis. Es sei 2k ≤ ∆ (G1i ) ≤ 2k+1 + 1, wobei k kleinstmöglich ist. Ist u ein aktiver Knoten in G1i , dann gilt dG1 (u) dG1 (u) ⌊ i ⌋ ≤ dG2i (u) ≤ ⌊ i ⌋+1 2 2 Also ist 2k−1 ≤ ∆ (G2i ) ≤ 2k + 1 und jeder Knoten, der in G1i aktiv war, ist es auch in G2i . Allgemein: aktive Knoten bleiben aktiv. Somit ist für j = ⌈log ∆ (Gi )⌉+1, dass 1 ≤ ∆ (Gji ) ≤ 3. Dies gilt, da 01.06.16 VL13 2 22 GRAPHENALGORITHMEN G11 : v H11 : v G21 : v G31 : M1 = f(1; 2) ; (5; 6) ; (8; 10) ; (11; 12)g Abbildung 24: Eine Iteration von SPLIT 1 2k+1−⌈log ∆(Gi )⌉+1 + 1 ≤ 2 ⋅ 2k ⋅ 2−⌈log ∆(Gi )⌉+1 + 1 ≤ 2 ⋅ ∆ (G11 ) ⋅ 2−⌈log ∆(Gi )⌉ + 1 ≤3 In höchstens zwei weiteren Iterationen sind wir fertig. Nach der Berechnung von Mi löschen wir Mi und alle inzidenten Kanten aus Gi . Dies gibt uns Gi+1 . Ist Gi+1 ohne Kanten, dann geben wir ⋃ij=1 Mj aus. Ansonsten wende SPLIT auf Gi+1 an. Sofern der Algorithmus terminiert, geben wir ein maximales Matching aus. Das zeigen wir im nächsten Lemma. Definition. Eine Knotenüberdeckung ist eine Teilmenge der Knoten, so dass jede Kante mindestens einen Knoten daraus enthält. 2 23 GRAPHENALGORITHMEN Abbildung 25: Ein maximales Matching für G Es bleibt zu zeigen, dass wir SPLIT nur logarithmisch oft anwenden. Ist Gi+1 nicht leer, dann existiert eine Knotenüberdeckung Ci+1 von Gi+1 mit ∣Ci+1 ∣ ≤ 2 ∣Ci ∣ 3 dabei ist C1 = V . Dann gilt: Es gibt ein j ≤ ⌈log3/2 V ⌉ für das Gj+1 leer ist. Wir folgern: Lemma 2.14. Nach der Anwendung von höchstens ⌈log3/2 ∣V ∣⌉ äußeren Iterationen ist ein maximales Matching gefunden. Beweis. Seien Ai die Knoten, welche in der Anwendung von SPLIT auf Gi aktiv werden. Dies ist eine Knotenüberdeckung von Gi . Andernfalls gäbe es eine Kante (x, y) mit x, y ∉ Ai . Dies ist ein Widerspruch, da x oder y spätestens bei ∆ (Gji ) ≤ 3 aktiv werden. Wir zeigen jetzt, dass (nach einer kleinen Modifikation) mindestens die Hälfte der Knoten aus Ai von Mi gematcht werden. Das bedeutet ∣Ai ∖ V (Mi )∣ ≤ ∣Ai ∣ 2 Wir greifen ein, sobald ∆ (Gji ) ≤ 3. Wenn wir statt der Menge der Kanten mit Label 0, die Kanten mit dem Label löschen, durch welches wir mehr Kanten übrig lassen, dann haben wir ∣Mi ∣ ≥ ∣E (Gji )∣ /2 Dies liegt daran, dass wir höchstens zwei Iterationen auf Gji anwenden. Wir sind fertig, wenn ∣E (Gji )∣ ≥ ∣Ai ∣, da ∣Mi ∣ ≥ ∣Ai ∣ /4 und diese Kanten aus Mi jeweils zwischen Knoten aus Ai verlaufen. 06.06.16 VL14 Satz 2.15. Die Berechnung von maximalen Matchings liegt in N C. 3 24 PARALLELES SORTIEREN 3 Paralleles Sortieren Gegeben ein Arra ’Key’ von n vielen Schlüsseln, z.B. ganze Zahlen. Wir wollen durch sukzessives Vertauschen der Werte erreichen, dass Key (i) ≤ Key (j) für 1 ≤ i ≤ j ≤ n Eine wichtige Anweisung ist compare-exchange(i, j) für i ≤ j. Dabei werden die Werte Key (i) und Key (j) getauscht, sofern Key (i) > Key (j). Das geht in O (1). Wegen des CREW-Modells können compare-exchange (i, j) und compare-exchange (j, k) nicht parallel angewendet werde. Aus dem Grundstudium wissen wir, das jeder Algorithmus Ω (n log n) viele Vergleiche machen muss. Mit O (n) vielen Prozessoren brauchen wir also im Worst-Case O (log n) viele Schritte. Wir entwickeln einen solchen Algorithmus, basierend auf merge-sort. 3.1 Einfache Sortieralgorithmen Die Algorithmen basieren auf dem Binärbaumprinzip. Der Baum hat die Tiefe O (log n). merge merge key(1) merge key(2) key(3) key(4) Abbildung 26: Aufrufbaum eines merge-Algorithmus Also ist die Gesamtlaufzeit des Algorithmus O (log n ⋅ Laufzeit von merge) Die effiziente Gestaltung von merge ist Thema dieses Kapitels. Odd-Even-Merge Der erste Algorithmus wendet maximal viele parallele compare-exchange Operationen an: odd-even-merge. Ist S ein Array von Schlüsseln, dann sei ODD (S) das Teilarray der Einträge von S mit ungeradem Index. Analog ist EVEN (S) definiert. Sind R und S zwei Arrays gleicher Länge, dann sei interleave (R, S) = (R (1) , S (S) , R (2) , S (2) , . . . ) Wir definieren die Operation odd-even(S): for all i ∈ {1, . . . , ⌊ ∣S∣−1 ⌋} in parallel do 2 compare-exchange (2i, 2i + 1) end Algorithmus 19 : odd-even (S) welche parallel Nachbarpaare vergleicht und ggf. vertauscht. Der erste Eintrag wird ausgelassen. 08.06.16 VL15 3 25 PARALLELES SORTIEREN Beispiel. odd-even (3, 2, 1, 4, 7, 9, 6, 8) = (3, 1, 2, 4, 7, 6, 9, 8) Die Operation join (R, S) ist definiert als join (R, S) ← odd-even (interleave (R, S)) wobei R, S zwei gleichlange Arrays sind. Wir brauchen für join O (1) viele parallele Schritte bei O (n) vielen Prozessoren. (n = ∣S∣ = ∣R∣) Jetzt können wir odd-even-merge (R, S) definieren. Dabei sind R, S gleichlang und vorsortiert. Wir verschmelzen R und S zum sortierten Array M : if ∣S∣ = ∣R∣ = 1 then M ← (R (1) , S (1)) compare-exchange (1, 2) else Modd ← odd-even-merge (odd (R) , odd (S)) Meven ← odd-even-merge (even (R) , even (S)) M ← join (Modd , Meven ) end Algorithmus 20 : odd-even-merge (R, S) Die Rekursion hat O (log n) Tiefe. Eventuell müssen wir das Eingabearray (des gesamten Algorithmus) auf eine Größe der Form 2k bringen. Beispiel. Seien R = (2, 6, 10, 15) , S = (3, 4, 5, 8). Dann ist odd (R) = (2, 10) , even (R) = (6, 15) , odd (S) = (3, 5) , even (S) = (4, 8). Außerdem Modd = (2, 3, 5, 10) , Meven = (4, 6, 8, 15). Dann gilt: M = join (Modd , Meven ) = odd-even (interleave (Modd , Meven )) = odd-even (2, 4, 3, 6, 5, 8, 10, 15) = (2, 3, 4, 5, 6, 8, 10, 15) Zum Beweis der Korrektheit nutzen wir folgendes Lemma. Danach können wir uns auf den Fall beschränken, in dem das Array 0/1-wertig ist. Lemma 3.1. Wenn jedes 0/1-wertige Array korrekt sortiert wird, dann auch jedes Z-wertige. Beweis. Sei f ∶ Z → Z eine monotone Funktion, d.h. f (z) ≤ f (z + 1) für alle z ∈ Z. Es gilt folgende Aussage: Wird ein Array A = (a1 , . . . , an ) von unserem Algorithmus zu B = (b1 , . . . , bn ) sortiert, dann wird das Array (f (a1 ) , . . . , f (an )) zu (f (b1 ) , . . . , f (bn )) sortiert. (→ Übung) Also gilt: Ist bi > bi+1 für ein i, dann ist f (bi ) ≥ f (bi+1 ). D.h. ist f (bi ) < f (bi+1 ), dann wurde auch f (a1 ) , . . . , f (an ) falsch sortiert. Wir setzen nun f ∶ Z → {0, 1} auf ⎧ ⎪ ⎪0 falls z ≤ bi+1 f (z) = ⎨ ⎪ 1 sonst ⎪ ⎩ Damit gilt f (bi ) = 1, aber f (bi+1 ) = 0, also wurde das 0/1-wertige Array (f (a1 ) , . . . , f (an )) fehlerhaft sortiert. Somit gilt: Wenn alle 0/1-wertigen Arrays korrekt sortiert werden, dann auch alle ganzzahligen. 3 26 PARALLELES SORTIEREN Das Lemma gilt offenbar nicht nur für den auf odd-even-merge basierenden Algorithmus, sondern für alle Sortieralgorithmen. Satz 3.2. Der Algorithmus odd-even-merge sortiert korrekt. Beweis. Nach Lemma 3.1 können wir uns auf 0/1-wertige Arrays beschränken. Zudem reicht es, die Korrektheit von odd-even-merge induktiv zu verifizieren. Seien 0/1-wertige Arrays R, S der Länge 2k = n gegeben. R, S seien vorsortiert, also von der Form R = 0 . . . 0 1 . . . 1 und S = 0 . . . 0 1 . . . 1 ²² ²² r n−r s n−s Ist k = 0, dann ist M offenbar korrekt sortiert. Sei also k ≥ 1 und off-even-merge korrekt für alle Paare von kürzeren Arrays der Länge 2i , 0 ≤ i ≤ k − 1. Somit werden Modd und Meven korrekt berechnet. Danach ist Modd = 0 . . . 0 1 . . . 1 und Meven = 0 . . . 0 1 . . . 1 ² ² ⌈ r2 ⌉+⌈ 2s ⌉ ⌊ r2 ⌋+⌊ 2s ⌋ Es sei δ = ⌈ 2r ⌉ + ⌈ 2s ⌉ − (⌊ 2r ⌋ + ⌊ 2s ⌋). Offenbar gilt δ ∈ {0, 1, 2}. 1. δ = 0. Es gilt interleave (Modd , Meven ) = (0o , 0e , . . . , 0o , 0e , 1o , 1e , . . . , 1o , 1e ) wobei 0o , 1o aus Modd und 1e , 0e aus Meven stammen. Da keine Vertauschungen durch odd-even stattfinden, ist M von der Form (0, . . . , 0, 1, . . . , 1), also korrekt sortiert. 2. δ = 1. Es gilt interleave (Modd , Meven ) = (0o , 0e , . . . , 0o , 0e , 0o , 1e , 1o , . . . , 1o , 1e ) Wieder ist M von der korrekten Form, da odd-even nicht vertauscht. 3. δ = 2. Es gilt interleave (Modd , Meven ) = (0o , 0e , . . . , 0e , 0o , 1e , 0o , 1e , . . . , 1o , 1e ) Wegen δ = 2 sind r, s beide ungerade, also ist r + s gerade. Somit wird Position r + s und r + s + 1 verglichen und vertauscht. Also ist M korrekt sortiert. Literatur: K.E. Batcher : Sorting Networks and their Applications. Proc. AFIPS Spring Joint Comput. Conf., Vol. 32, 307-314 (1968) Bitonic-Merge Das zweite Verfahren bitonic-merge funktioniert nach der gleichen Idee, d.h. maximal viele parallele compare-exchange Anwendungen. Das Verfahren kommt (in einer geschickten Implementierung) mit O (n/ log n) Prozessoren in O (log2 n) Laufzeit aus. Dies ist optimal! Das Verfahren basiert auf einer join-Operation, diese basiert wiederum auf der shuffle-Operation. Ist S ein Array gerader Länge n = 2k , dann ist shuffle (S): S1 ← (S (1) , S (2) , . . . , S ( n2 )) S2 ← (S ( n2 + 1) , S ( n2 + 2) , . . . , S (n)) S ← interleave (S1 , S2 ) Algorithmus 21 : shuffle (S) 13.06.16 VL16 3 27 PARALLELES SORTIEREN shuffle (S) for all i ∈ {1, . . . , n2 } in parallel do compare-exchange (2i − 1, 2i) end Algorithmus 22 : join (S) M ← R ∣ S −1 repeat log 2n times M ← join (M ) end return M Algorithmus 23 : bitonic-merge (R, S) Dies kann in O (1) Schritten bei O (n) Prozessoren berechnet werden. Das join (S) ist so definiert: Jetzt können wir bitonic-merge definieren. Seien R und S zwei vorsortierte Arrays der Länge n = 2k . Es sei S −1 das Array S in umgekehrter Reihenfolge und sei R ∣ S −1 die Konkatenation von R und S −1 . Das Array R ∣ S −1 ist monoton steigend bis zum n-ten Eintrag und fallend vom (n + 1)ten bis zum letzten Eintrag. Es ist also biton. Beispiel. Sei R = (1, 5, 9, 12) und S = (2, 3, 4, 11). Dann ist R ∣ S −1 = (1, 5, 9, 12, 11, 4, 3, 2) Wir wenden log ∣M ∣ = 3 Mal join an: shuffle (M ) = (1, 11, 5, 4, 9, 3, 12, 2) join (M ) = (1, 11, 4, 5, 3, 9, 2, 12) shuffle (M ) = (1, 3, 11, 9, 4, 2, 5, 12) join (M ) = (1, 3, 9, 11, 2, 4, 5, 12) shuffle (M ) = (1, 2, 3, 4, 9, 5, 11, 12) join (M ) = (1, 2, 3, 4, 5, 9, 11, 12) Die Anzahl der Iterationen ist fest, jede weitere Iteration verhindert die korrekte Sortierung. Warum genau log M viele Iterationen gebraucht werden, wird im 0/1-Fall deutlich: join (00001111) = (01010101) join (01010101) = (00110011) join (00110011) = (00001111) Der Korrektheitsbeweis wird auf die Übung verlagert. 3 28 PARALLELES SORTIEREN 3.2 Sortieren in O (log n) bzw. Coles Algorithmus Sind zwei sortierte Arrays R, S gegeben, dann wollen wir diese in Zeit O (1) verschmelzen zu merge (R, S). Dazu brauchen wir mehr Informationen über R, S, welche wir uns beim Aufbau des Binärbaums generieren. OBdA gilt: • das zu sortierende Array besteht aus ganzen Zahlen • keine zwei Zahlen daraus sind gleich Zur Berechnung von merge benutzen wir Sampler. Informell: Ein Array R ist ein Sampler für ein Array S, wenn die Einträge von R ”gleichmäßig” in dem Array merge (R, S) vorkommen. Formal: Definition. R ist ein Sampler für S, wenn für alle i, j gilt, dass zwischen dem i-ten und dem (i + j)-ten Wert aus −∞ ∣ R ∣ ∞ höchstens 2j + 1 viele Werte aus S liegen. Dabei sagen wir für x, y, z ∈ Z mit x < y ≤ z, dass y zwischen x und z liegt. Beispiel. R = (1, 8, 12) ist ein Sampler für S = (0, 1, 7, 9, 11), aber keiner für S = (0, 2, 7, 8, 10, 11, 12) Insbesondere liegen zwischen je zwei benachbarten Werten aus R höchstens drei Werte aus S. Nun können wir die merge-Operation definieren. Dafür sei R ein Sampler für die zu verschmelzenden Arrays S, T . Diese seien gleichlang und vorsortiert. Dann ist: for all i ∈ [∣R∣ + 1] in parallel do Si ← Array der Einträge aus S zwischen R (i − 1) und R (i) Ti ← Array der Einträge aus T zwischen R (i − 1) und R (i) Mi ← merge (Si , Ti ) end return M1 ∣ M2 ∣ . . . ∣ Mi+1 Algorithmus 24 : merge-with-help (S, T, R) Dabei sei R (0) = −∞ und R (∣R∣ + 1) = ∞. Als Schema: R (i) trennt jeweils S (i) von S (i + 1) und T (i) von T (i + 1). Beispiel. R = (5, 10, 12, 17) S = (1, 4, 6, 9, 11, 12, 13, 16, 19, 20) T = (2, 3, 7, 8, 10, 14, 15, 17, 18, 21) Dann gilt S1 = (1, 4) , S2 = (6, 9) , S3 = (11, 12) , S4 = (13, 16) , S5 = (19, 20) T1 = (2, 3) , T2 = (7, 8, 10) , T3 = ∅, T4 = (14, 15, 17) , T5 = (18, 21) M1 = (1, 2, 3, 4) , M2 = (6, 7, 8, 9, 10) , M3 = (11, 12) , M4 = (13, 14, 15, 16, 17) M5 = (18, 19, 20, 21) 15.06.16 VL17 3 PARALLELES SORTIEREN 29 Wir geben folgendes zurück (1, 2, 3, 4, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21) Wir wollen, dass merge-with-help in O (1) Schritten bei O (n) Prozessoren läuft. Zunächst klären wir die Berechnung der Si , Ti , Mi und von M1 ∣ . . . ∣ M∣R∣+1 . Dafür benutzen wir folgendes Hilfsarray: Sei R ein Array und x ∈ Z ein Schlüsselwert. Eventuell gilt x ∉ R. Definition. Wir definieren den Rang eines Elements in einem Array als rank (x, R) ∶= #Werte aus R, welche echt kleiner als x sind. Sind R, S zwei sortierte Arrays, dann sei das Array rank (R, S) definiert als rank (R, S) ∶= (rank (R [1] , S) , rank (R [2] , S) , . . . , rank (R [∣R∣] , S)) Die i-te Stelle von rank (R, S) ist also der Rang von R (i) in S. Über diese Hilfsarrays lässt sich merge-with-help realisieren. Lemma 3.3. Seien S, T, R wie vorausgesetzt. Dann lässt sich merge-with-help (S, T, R) in O (1) Schritten mit O (∣S∣ + ∣T ∣) Prozessoren realisieren, sofern rank (R, S) , rank (S, R) , rank (R, T ) und rank (T, R) gegeben sind. Beweis. Übung. Nun zeigen wir, wie wir die Sampler konstruieren. Für zwei sortierte Arrays R, S sei merge (R, S) die sortierte Verschmelzung von R und S. Lemma 3.4. Es sei R ein Sampler für R′ und S ein Sampler für S ′ , alle sortiert. Dann ist M = merge (R, S) ein Sampler für R′ und für S ′ . Beweis. Für alle i, j gibt es i′ , j ′ mit j ′ ≤ j, R (i′ ) ≤ M (i) und R (i′ + j ′ ) ≥ M (i + j). Somit liegen höchstens 2j ′ + 1 viele Werte aus R′ zwischen R (i′ ) und R (i′ + j ′ ). Also liegen höchstens 2j ′ + 1 ≤ 2j + 1 Werte R′ zwischen M (i) und M (i + j). Daher ist M ein Sampler für R′ , genauso für S ′ . Bemerkung. Unter den Voraussetzungen des Lemma gilt nicht unbedingt dass M ein Sampler für M ′ = merge (R′ , S ′ ) ist. Setze z.B. R = (2, 7) , R′ = (2, 5, 6, 7) , S = (1, 8) , S ′ = (1, 3, 4, 8) Dann gilt M = (1, 2, 7, 8) , M ′ = (1, 2, 3, 4, 5, 6, 7, 8) und M sampelt M ′ nicht. Lemma 3.5. Unter den Voraussetzungen gilt: Zwischen dem i-ten und dem (i + j)-ten Element aus (−∞ ∣ M ∣ ∞) liegen höchtens 2j + 4 Werte aus M ′ . 3 30 PARALLELES SORTIEREN Beweis. Sei M ′′ = −∞ ∣ M ∣ ∞, R′′ = −∞ ∣ R ∣ ∞ und S ′′ = −∞ ∣ S ∣ ∞. OBdA ist M ′′ (i) aus R′′ . Es seien r viele Werte des Teilarrays M ′′ (i) , . . . , M ′′ (i + j) aus R′′ , entsprechend sei s analog. 1. M ′′ (i + j) ist ein Wert aus R′′ . Da R ein Sampler für R′ ist, liegen höchstens 2 (r − 1)+1 viele Werte aus R′ zwischen M ′′ (i) und M ′′ (i + j). Wähle i′ maximal und darunter j ′ minimal so, dass S ′′ (i′ ) ≤ M ′′ (i) und S ′′ (i′ + j ′ ) ≥ M ′′ (i + j). Dann gilt j ′ ≤ s + 1, da im Teilarray M ′′ (i) , . . . , M ′′ (i + j) nur genau s viele Elemente aus S ′′ liegen. Somit liegen höchstens 2 (s + 1) + 1 viele Elemente aus S ′ zwischen S ′′ (i′ ) und S ′′ (i′ + j ′ ) und somit zwischen M ′′ (i) und M ′′ (i + j). Insgesamt höchstens 2 (r − 1) + 1 + 2 (s + 1) + 1 viele Werte aus M ′ zwischen M ′′ (i) und M ′′ (i + j). Wegen 2 (r − 1) + 1 + 2 (s + 1) + 1 = 2 (r + s) + 2 = 2j + 1 gilt die Behauptung. 2. 20.06.16 VL18 Definition. Sei R ein beliebiges Array. Das Array reduce (R) sei das Array, welches jedes vierte Element aus R enthält. Lemma 3.6. Unter den Voraussetzungen des vorherigen reduce (merge (R, S)) ist ein Sampler für reduce (merge (R′ , S ′ )). Lemmas gilt: Beweis. Sei T = reduce (merge (R, S)) und T ′ = reduce (merge (R′ , S ′ )). Zudem sei T ′′ = −∞ ∣ T ∣ ∞. Seien i, j so, dass 1 ≤ i < i + j ≤ ∣T ′′ ∣. In dem Teilarray T ′′ (i) bis T ′′ (i + j) liegen j + 1 Elemente, somit liegen zwischen T ′′ (i) und T ′′ (i + j) höchstens 4j + 1 viele Elemente aus M ′′ = −∞ ∣ merge (R, S) ∣ ∞, inklusive T ′′ (i) selber. Seien also i′ und j ′ so, dass M ′′ (i′ ) = T ′′ (i) und M ′′ (i′ + j ′ ) = T ′′ (i + j) Dann ist j ′ ≤ 4j. Nach Lemma 3.5 liegen zwischen M ′′ (i′ ) und M ′′ (i′ + j ′ ) höchstens 2j ′ + 4 ≤ 8j + 4 viele Werte aus M ′ = merge (R′ , S ′ ). Höchstens 2j + 1 viele dieser Werte kommen in T ′ vor. Somit ist T ein Sampler für T ′ . Wir beschreiben den Algorithmus zunächst ohne die Berechnung der rank (X, Y )-Arrays, d.h. wir nehmen an, dass wir merge-with-help in O (1) Schritten berechnen können. In jedem inneren Knoten des merge-Baums führen wir eine Reihe von merge-with-help und reduceOperationen aus. Die Aufgabe eines Knoten v ist das Sortieren der Schlüsselwerte unter v. Das Array dieser Schlüsselwerte sei mit listv bezeichnet. Jeder innere Knoten macht dies: Der linke Sohn u und der rechte Sohn w senden jeweils ein Array R bzw. S an v. Dabei ist R bzw. S ein sortiertes Array mit Werten aus listu bzw. listw . Zudem gilt ∣R∣ = ∣S∣. v berechnet daraus ein sortiertes Array T = merge (R, S). Dann gibt v das Array reduce (T ) an seinen Vater weiter. Genauer: Ab einem Zeitschritt erhält v die Arrays R1 , S1 , im nächsten Schritt 3 31 PARALLELES SORTIEREN v u a w b c d Abbildung 27: Schema im Aufruf-Baum mit listv = (a, b, c, d) R2 , S2 usw. Die Länge dieser Arrays verdoppelt sich in jedem Schritt. Als letzte Elemente dieses Datenstroms werden Rk und Sk zu v hochgeschickt, dabei ist ∣Rk ∣ = ∣listu ∣ = ∣Sk ∣ = ∣listw ∣ Dann ist Rk die Sortierung von listu und Sk die Sortierung von listw . Ist Ri und Si die Eingabe, dann berechnet v ein Array Ti und gibt dies an seinen Vater weiter. Genauer: Ab einem Zeitschritt erhält v die Arrays R1 und S1 . Im folgenden Schritt erhält v die Arrays R2 und S2 usw. Die Länge dieser Arrays verdoppelt sich in jedem Schritt. Als letzte Elemente dieses Datenstroms werden Rk und Sk zu v hochgeschickt, dabei ist ∣Rk ∣ = ∣listu ∣ und ∣Sk ∣ = ∣listw ∣. Dann ist Rk die Sortierung von listu und Sk die Sortierung von listw . Ist Ri und Si die Eingabe, dann berechnet v ein Array Ti und gibt dies an seinen Vater weiter. v berechnet valuev = merge-with-help (Ri , Si , valv ) • Ist i ≤ k, dann gibt v das Array Ti = reduce (valv ) an seinen Vater weiter • Ist i = k + 1, dann senden wir reduce′ (valv ) an den Vater von v, wobei reduce′ (valv ) jedes zweite Element aus valv enthält • Ist i = k + 2, dann senden wir Tk+2 = valv an den Vater von v hoch Die Arrays Ri und Si verdoppeln stets die Länge, ebenso die Ti . Nach Lemma 3.6 ist Ti ein Sampler für Ti+1 , da Ri ein Sampler für Ri+1 und Si ein Sampler für Si+1 ist. Diese Invariante gilt in jedem inneren Knoten des merge-Binärbaums. Definition. Ist ∣valv ∣ = ∣listv ∣, dann nennen wir v vollständig. Werden Ri , Si an einen Knoten v übergeben, wird in der nächsten Runde Ti an den Vater von v weitergegeben. Somit ist der Vater von v vollständig drei Schritte, nachdem v vollständig ist. Schematisch: input(v) input(f ather(v)) R1 , S 1 - R2 , S2 T1 ... ... Rk , S k Tk−1 Tk Tk+1 Tk+2 Die Blätter des merge-Baums sind nach der ersten Runde vollständig. Demnach ist die Wurzel des Baumes nach 3 ⋅ log n = O (log n) Schritten vollständig. Die verwendeten mergewith-help-Operationen laufen in O (1) Schritten. Dafür brauchen wir O (∣valv ∣) viele Prozessoren in jedem Knoten v, welcher noch nicht vollständig ist. Es gilt das Folgende: 22.06.16 VL19 3 32 PARALLELES SORTIEREN 1 T1 = ; valv = (7; 8) R1 = (7) 3 valv = (3; 5; 7; 8) S1 = (8) 4 T2 = (8) 2 R2 = (3; 7) T4 = (2; 4; 6; 8) S2 = (5; 8) 5 valv = (1; 2; 3; 4; 5; 6; 7; 8) R4 = ; S4 = ; T3 = (4; 8) valv = (1; 2; 3; 4; 5; 6; 7; 8) R3 = (1; 3; 4; 7) S3 = (2; 5; 6; 8) T5 = (1; 2; 3; 4; 5; 6; 7; 8) valv = (1; 2; 3; 4; 5; 6; 7; 8) R4 = ; S4 = ; Abbildung 28: Beispiel der Sortierung des Arrays (1, 3, 4, 7 ∣ 2, 5, 6, 8) durch den Algorithmus von Cole. Betrachtet wird der Input, aktuelle Wert und der Output des festen Knoten v. In Schritt 3 wird v vollständig. Lemma 3.7. Es reichen O (n) viele Prozessoren aus, da ∑ ∣valv ∣ = O (n) v unvollständig Beweis. Übung. Nun schauen wir uns merge-with-help nochmal genau an. Wir wissen aus der Invariante, dass Ri ein Sampler für Ri+1 (Si für Si+1 ) ist. Nach Lemma 3.4 ist valv = merge (Ri , Si ) ein Sampler für Ri+1 und Si+1 . Zur Ausführung von merge-with-help(Ri+1 , Si+1 , valv ) in O (1) brauchen wir noch die Ränge rank (valv , Ri+1 ) , rank (Ri+1 , valv ) , rank (valv , Si+1 ) , rank (Si+1 , valv ) Wir nehmen dazu an, dass wir für jedes berechnete Array X das Array rank (X, X) kennen. Lemma 3.8. Zu einem sortierten Array R kann der Rang rank [x, R] für ein Schlüsselwort x mit O (∣R∣) Prozessoren in O (1) Schritten berechnet werden. Gilt auch, wenn x ∉ R. Beweis. Wir setzen R′′ = (−∞ ∣ R ∣ ∞). Dann berechnen wir for all i ∈ [∣R∣ + 1] in parallel do if R′′ (i − 1) < x ≤ R′′ (i) then rank (x, R) ← i − 1 end end Algorithmus 25 : merge-with-help (S, T, R) Die if-Bedingung ist genau für ein i wahr, somit wird CREW nicht verletzt. 3 PARALLELES SORTIEREN 33 Lemma 3.9. Sind R, S sortierte Arrays und T = merge (R, S) mit R∩S = ∅, dann können die Arrays rank [R, S] und rank [S, R] mit O (∣T ∣) Prozessoren in O (1) Schritten bestimmt werden. Beweis. Nach der Grundannahme kennen wir rank [R, R], rank [S, S] und rank [T, T ]. Sei x ∈ R beliebig. Dann ist rank [x, S] = rank [x, T ] − rank [x, R] Somit können die Werte aus rank [R, S] in O (1) mit O (∣T ∣) Prozessoren berechnet werden. Analog für rank [S, R]. Lemma 3.10. Sind R, S, R′ , S ′ und M = merge (R, S) sortierte Arrays, wobei R für R′ und S für S ′ ein Sampler ist und kennen wir die Rangarrays rank [R′ , R] und rank [S ′ , S], dann können wir rank [R′ , M ], rank [S ′ , M ], rank [M, R′ ] und rank [M, S ′ ] in Zeit O (1) mit O (∣R′ ∣ + ∣S ′ ∣) vielen Prozessoren berechnen. Beweis. • rank [R′ , M ] , rank [S ′ , M ]: Dafür bestimmen wir die Teilarrays Ri′ . Dabei ist R1′ das Array der Werte aus R′ , welche zwischen −∞ und R (1) liegen. R2′ sind die Werte aus R′ , welche zwischen R (1) und R (2) usw. Das geht in O (1) Schritten mit O (∣R′ ∣) vielen Prozessoren, da wir rank [R, R′ ] kennen. (siehe Beweis von Lemma 3.3) Für jedes i mit 1 ≤ i ≤ ∣R∣+1 sei Mi das Arrays der Werte aus M , die zwischen R (i − 1) und R (i) liegen. Dabei lassen wir R (i) selber aus Mi raus. Zudem definieren wir R (0) = −∞ und R (∣R∣ + 1) = ∞. Somit ist jedes Mi eine Teilmenge aus S. Beachte: Mi lässt sich mit O (∣Mi ∣) vielen Prozessoren berechnen. Dafür benutzen wir rank [M, M ]. Nun berechnen wir: for all i ∈ [∣R∣ + 1] in parallel do for all x ∈ Ri′ compute rank[x, Mi ] rank [x, M ] ← rank [x, Mi ] + rank [R (i − 1) , M ] + 1 end end Algorithmus 26 : merge-with-help (S, T, R) Dies läuft in O (1), da wir rank [M, M ] kennen und rank [x, Mi ] nach Lemma 3.8 in O (1) Schritten mit O (∣Mi ∣) Prozessoren berechnen können. Da R ein Sampler für R′ ist, gilt zudem ∣Ri ∣ = O (1). Analog können wir rank [S ′ , M ] berechnen. • rank [R, R′ ] , rank [S, S ′ ]: Sei x ∈ R, sagen wir x = R (i). Wir berechnen zuerst y = ′ Ri+1 (1), dann rank [y, R′ ]. Letzteres geht in O (1), da wir rank [R′ , R′ ] kennen. Sei j = rank [y, R′ ]. Ist x = R′ (j), dann ist rank [x, R′ ] = rank [R′ (j) , R′ ] = j − 1 Andernfalls ist R′ (j) < x < y, also rank [x, R′ ] = j. Das geht in O (1) Schritten mit O (∣R′ ∣) vielen Prozessoren. Analog für rank [S, S ′ ]. Wir brauchen noch rank [R, S ′ ] und rank [S, R′ ]. Mittels Lemma 3.9 können wir rank [R, S] bzw. rank [S, R] ausrechnen. Zusammen mit rank [R, R′ ] bzw. rank [S, S ′ ] gibt uns das in O (1) Schritten rank [R, S ′ ] und rank [S, R′ ], da R ein Sampler für R′ und S ein Sampler für S ′ ist. Aus rank [R, R′ ] und rank [S, R′ ] können wir rank [M, R′ ] berechnen, da M = merge (R, S). Analog für rank [M, S ′ ]. 27.06.16 VL20 3 PARALLELES SORTIEREN 34 Abbildung 29: Ein primitives Sortiernetzwerk Als Invariante des Algorithmus erhalten wir uns folgendes: Zum Datenstrom Z1 , . . . , Zk wird stets rank [Zi+1 , Zi ] zeitgleich mit Zi+1 gesendet. Angenommen wir kennen (im Knoten v) rank [Ri+1 , Ri ] und rank [Si+1 , Si ]. Zur Berechnung von merge-with-help (Ri+1 , Si+1 , merge (Ri , Si )) benötigen wir, nach Lemma 3.3 die Arrays rank [Mi , Ri+1 ], rank [Mi , Si+1 ], rank [Ri+1 , Mi ] und rank [Si+1 , Mi ]. Nach den Invarianten können wir Lemma 3.10 auf R = Ri , S = Si , R′ = Ri+1 , S ′ = Si+1 anwenden. Wir erhalten in O (1) Schritten die gewünschten Rangarrays. Dafür brauchen wir O (∣R′ ∣ + ∣S ′ ∣) = O (∣valv ∣) viele Prozessoren. Aus rank [Ri+1 , Mi ] und rank [Si+1 , Mi ] können wir leicht rank [Ri+1 , reduce (Mi )] und rank [Si+1 , reduce (Mi )] errechnen. Daraus können wir rank [Mi+1 = merge (Ri+1 , Si+1 ) , reduce (Mi )] berechnen, also auch rank [reduce (Mi+1 ) , reduce (Mi )] = rank [Ti+1 , Ti ] und damit gilt die Invariante weiterhin. Satz 3.11. Ein Array mit n Einträgen können wir mit O (n) Prozessoren in O (log n) Schritten sortieren. Im Gegensatz zu diesem Algorithmus hängen die Positionen, die mit compare-exchange verglichen werden, bei den Algorithmen odd-even-merge und bitonic-merge nicht vom Input ab. Definition. Solche Algorithmen nennt man Sortiernetzwerke. Bemerkung. Es gibt Sortiernetzwerke, die eine Folge mit O (n) Prozessoren in O (log n) Schritten sortieren. Diese nutzen sogenannte Expander-Graphen. 4 P-VOLLSTÄNDIGKEIT 35 P-Vollständigkeit 4 Wir wissen schon, dass N C ⊆ P. Zudem glaubt man, dass folgende Vermutung gilt: Vermutung 4.1. N C ≠ P. Ähnlich wie bei der Vermutung P ≠ N P ist unklar, wie ein Beweis aussehen könnte. Wir wollen Probleme identifizieren, welche in P ∖ N C liegen, sofern die Vermutung gilt. Dafür brauchen wir einen geeigneten Reduktionsbegriff. Wir ziehen uns auf Entscheidungsprobleme zurück. Definition. Seien A, B zwei Entscheidungsprobleme aus P. Eine N C-Reduktion von A auf B ist eine Abbildung f mit folgenden Eigenschaften: 1. Ist x eine Instanz von Problem A, dann ist f (x) eine Instanz von B 2. x ist eine Ja-Instanz für A ⇔ f (x) ist eine Ja-Instanz für B 3. Es gibt einen Algorithmus, welcher f effizient parallel berechnet Dann gilt B ∈ N C ⇒ A ∈ N C. Definition. Ein Problem A ∈ P nennen wir P-vollständig, wenn es zu jedem Problem B ∈ P eine N C-Reduktion von B auf A gibt. Wir schreiben auch B ≤N C A wenn es eine N C-Reduktion von B auf A gibt. Es gilt: Ist A ein P-vollständiges Problem, dann gilt A ∈ N C genau dann, wenn N C = P. 4.1 Erzeugbarkeit ist P-vollständig Als ’erstes’ P-vollständiges Problem wählen wir das Erzeugbarkeits-Problem. Definition. Das Erzeugbarkeitsproblem besteht aus folgendem Input: • eine Grundmenge X und Y ⊆ X • ein binärer Operator ○ ∶ X × X → X (den wir in O (1) auswerten können) • ein ausgezeichnetes Element x ∈ X, das Zielelement Wir müssen entscheiden, ob wir x aus der Menge Y durch sukzessives Anwenden von ○ erhalten können. Wir sollen also entscheiden, ob x im Abschluss der Menge Y unter ○ ist. Zunächst zeigen wir, dass das Erzeugbarkeitsproblem in P liegt. Dies sieht man über folgenden Lösungsalgorithmus: Da ∣Z∣ , ∣Z ′ ∣ ≤ ∣X∣ und die while-Schleife höchstens ∣X∣ Mal durchlaufen wird, läuft der Algorithmus in O (∣X 3 ∣), also polynomiell. Somit liegt Erzeugbarkeit in P. Zur Vereinfachung führen wir das Problem 3-Erzeugbarkeit ein. Definition. Das 3-Erzeugbarkeitsproblem ist das Erzeugbarkeitsproblem wobei wir an- 04.07.16 VL21 4 P-VOLLSTÄNDIGKEIT 36 Z←Y Z ′ ← {r ○ s ∶ r, s ∈ Z} while Z ≠ Z ′ do Z ← Z′ Z ′ ← {r ○ s ∶ r, s ∈ Z} end return x ∈ Z? Algorithmus 27 : Lösungsalgorithmus für das Erzeugbarkeitsproblem statt dem binären Operator ○ ∶ X × X → X einen ternären Operator next ∶ X × X × X → X betrachten. Es gilt: Lemma 4.2. 3-Erzeugbarkeit ≤N C Erzeugbarkeit. Beweis. Übung. Nun sei A ∈ P. Wir wollen zeigen, dass A ≤N C 3-Erzeugbarkeit. Sei M eine Turingmaschine, welche A in Polynomialzeit entscheidet. Wir modellieren die Rechenschritte von M als ternären Operator next. Die Startmenge Y entspricht dem Input von M . Das Zielelement entspricht der akzeptierenden Konfiguration der Maschine M . Es gibt ein Polynom p, welches die Anzahl der Rechenschritte von M in Abhängigkeit von der Größe des Inputs n beschränkt. Demnach liest die Maschine auch nur höchstens p (n) viele Felder ein. Wir machen noch folgende Annahmen: • Auf der Stelle 0 und p (n) + 1 des Bands steht jeweils ein $ • Der Input steht an den Stellen 1 bis n • Am Ende der Rechnung schreibt M entweder 0 oder 1 auf Stelle 1 • Die Maschine überschreibt die $-Symbole nicht und wandert nie auf die Stellen −1 oder p (n) + 1 • Das Alphabet von M sei Γ = (◻, $, 0, 1) • Die Zustandsmenge von M sei Q. Dabei sei qs der Start- und qe der Endzustand Den Inhalt der Stelle i des Bands zum Zeitpunkt t bezeichnen wir mit B (i, t) ∈ Γ. Der Input ist also B (1, 0) ∣ B (2, 0) ∣ . . . ∣ B (n, 0) und B (0, 0) = B (p (n) + 1, 0) = $ Der Output der Maschine bzw. dessen Entscheidung ist B (1, p (n) + 1). Satz 4.3. Erzeugbarkeit ist P-vollständig. Beweis. Nach Lemma 4.2 reicht es zu zeigen, dass 3-Erzeugbarkeit P-vollständig ist. Wir simulieren die Schritte der Turingmaschine M , welches unser Problem A ∈ P löst, über die next-Operation. 06.07.16 VL22 4 P-VOLLSTÄNDIGKEIT 37 Bk−1;t Bk;t Bk+1;t α; ; β; q γ; ; ::: ::: β 0; ; Bk;t+1 Abbildung 30: Ein Beispiel einer Bewegung der Turingmaschine nach rechts Zu dem in einer Stelle gespeicherten Buchstaben merken wir uns auch den aktuellen Zustand. Diesen setzen wir auf ∅, falls der Lesekopf gerade nicht auf das betrachtete Feld schaut. Wir setzen also X = {0, . . . , p (n) + 1} × {0, . . . , p (n) + 1} × Γ × (Q ∪ {∅}) ® ´¹¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¸ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¶ ´¹¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¸ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¶ Alphabet ´¹¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¸ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¹ ¶ Ort Zeit Zustand Wir definieren next ∶ X × X × X → X wie folgt: next (a, b, c) = d ⇔ a = (k − 1, t, α, qa ) , b = (k, t, β, qb ) , c = (k + 1, t, γ, qc ) wobei mindestens zwei von qa , qb , qc gleich ∅ sind. Dazu soll d = (k, t + 1, δ, qd ) sein, wobei die Turingmaschine lokal aus a, b, c im nächsten Schritt d berechnen würde. Wir fügen ein Dummy-Element D ein, welchen den Wert von next zu den inkompatiblen Eingabewerten ist. Wir setzen Y wie folgt zu einer Inputmenge I: Y = {(i, 0, I (i) , ∅) ∶ i ∈ {2, . . . , n}} ∪ {(1, 0, I (1) , qs )} ∪ {(i, 0, ◻, ∅) ∶ i ∈ {n + 1, . . . , p (n)}} ∪ {(0, 0, $, ∅)} ∪ {(p (n) + 1, 0, $, ∅)} Zudem ist x = (1, p (n) + 1, 1, qe ) das Zielelement. Somit liegt x im Abschluss von Y unter next genau dann, wenn die Turingmaschine die Ausgabe true zum Input I berechnet. Es gilt 2 ∣X∣ , ∣Y ∣ ∈ O (p (n) ) 2 Es reichen also O (p (n) ) viele Prozessoren zur Berechnung der Menge aus. Die Berechnung 3 von next benötigt höchstens O (∣X∣ ) viele Prozessoren, also auch nur polynomiell viele. Das ganze geht in polylogarithmischer Zeit, also haben wir eine N C-Reduktion gefunden und damit A ≤N C 3-Erzeugbarkeit Bemerkung. Erzeugbarkeit liegt in N C, wenn der Operator ○ assoziativ ist, also a○(b ○ c) = (a ○ b) ○ c für alle a, b, c ∈ X. Dies sieht man leicht: Lässt sich x aus Y ableiten, dann gilt x = (((y1 ○ y2 ) ○ y3 ) ⋅ ⋅ ⋅ ○ yk ) für geeignete y1 , . . . , yk ∈ Y . Wir konstruieren einen Graphen G = (X, E). Dabei haben wir eine Kante (a, b), wenn es ein c ∈ Y gibt, mit a ○ c = b. Gibt es einen gerichteten Weg von einem y ∈ Y zu x, dann und nur dann ist x im Abschluss von Y . 4 P-VOLLSTÄNDIGKEIT 4.2 4.2.1 38 Weitere P-vollständige Probleme Auswertungsproblem (CVP) Definition. Das Auswertungsproblem (engl. Circuit-Value-Problem, CVP) fragt nach der Ausgabe eines Schaltkreises (d.h. DAG) bei gegebenen Input. Dabei bilden Knoten ohne Vorgänger den Input und Knoten ohne Nachfolger den Output. Jeder innere Knoten repräsentiert eine der logischen Verknüpfungen ∧, ∨ oder ¬. 1 1 1 _ ^ 1 : : _ ^ Abbildung 31: Ein Schaltkreis Definition. Ein Schaltkreis heißt monoton, falls alle inneren Knoten nur die Verknüpfungen ∧ oder ∨ enthalten. Satz 4.4. Das monotone Auswertungsproblem ist P-vollständig. Beweis. Die Idee ist, den Operator ○ durch ∧-Operatoren zu ersetzen. Für jedes Element v ∈ X ∖ Y bestimmen wir alle Paare (u1 , w1 ) , . . . , (uk , wk ) mit ui , wi ∈ X und ui ○ wi = v für alle i = 1, . . . , k. Wir definieren Fv = (u1 ∧ w1 ) ∨ (u2 ∧ w2 ) ∨ ⋅ ⋅ ⋅ ∨ (uk ∧ wk ) Dazu bestimmen wir einen Schaltkreis mit Input u1 , w1 , . . . , uk , wk und Output v. ^ ^ ^ _ _ Abbildung 32: Ein Gadget in der Konstruktion für das monotone Auswertungsproblem Diese Teile konkatenieren wir zu einem großen Schaltkreis S. Input sind die Knoten aus Y , Output ist x. Die Kreisfreiheit bekommen wir aus der Reduktion von oben, d.h. aus dem Beweis von Satz 4.3. 4 P-VOLLSTÄNDIGKEIT 4.2.2 39 Tiefensuche (DFS) In der ”sequentiellen Welt” ist die Tiefensuche (DFS) ein effizientes Verfahren, das in Graphenalgorithmen als Teilschritt benutzt wird. DFS berechnet die Funktion dfi ∶ V (G) → N wobei G ein gerichteter Graph ist wie folgt: counter ← 0 dfs (v0 ) , v0 ∈ V (G) procedure dfs(v) if dfi (v) is not assigned yet then counter++ dfi (v) ← counter for v → u ∈ E (G) do dfs (u) end end end Algorithmus 28 : Sequentielle Tiefensuche im gerichteten Graphen G Beachte: Die Reihenfolge, in der die Nachbarn besucht werden, muss fixiert werden, damit dfi eindeutig ist. Leider gilt selbst für dieses grundlegende Verfahren: Satz 4.5. DFS ist P-vollständig. Beweis. Wir reduzieren CVP auf DFS. OBdA (siehe Übung) können wir annehmen, dass V (C) topologisch sortiert ist, d.h. V (C) = {v1 , . . . , vn }, wobei C eine Instanz von CVP ist. Weiterhin beschränken wir die zulässigen Gatter auf • konstante 1-Input • x ⋅ y ∶= ¬ (x ∨ y) = (¬x) ∧ (¬y) Dies ist erlaubt, da 1 ⋅ 1 = 0, ¬x = x ⋅ 0, x ∨ y = (x ⋅ y) ⋅ 0 sowie x ∧ y = (x ⋅ 0) ⋅ (y ⋅ 0). Wir müssen einen gerichteten Graphen G konstruieren, sodass das Auswerten der CVP-Knoten einer Tiefensuche in G entspricht. G konstruieren wir als Vereinigung kantendisjunkter Teilgraphen mit Knotenmenge • first (v) , last (v) , s (v) , t (v) für alle v ∈ V (C) • e (v, u) für alle v → u ∈ E (C) • anonyme Hilfsknoten, lokal zu jedem Teilgraphen Beschrifte die Kanten v → u, welche von einem Knoten v ausgehen mit natürlichen Zahlen, welche die Reihenfolge angeben, in der die Nachbarn von v besucht werden. Fehlende Label entsprechen implizit einer 1. G besteht aus den folgenden Teilgraphen: a) Grundstruktur. Hier ist die topologische Sortierung relevant b) Struktur für jeden Input-Knoten v mit Kindern u1 , . . . , uk c) Struktur für jeden inneren Knoten v mit Eltern-Knoten w, w′ und Kindern u1 , . . . , uk Der Beweis des Satzes folgt aus dem nächsten Lemma. 08.07.16 VL23 4 P-VOLLSTÄNDIGKEIT f irst(v) last(v1 ) 40 s(v) e(w; v) f irst(v) 2 e(w0 ; v) 2 f irst(v2 ) ::: 2 s(v) 2 2 e(v; u1 ) e(v; u1 ) .. . 2 .. . last(vn−1 ) : : : f irst(vn ) last(v) .. . e(v; u2 ) ... e(v; uk ) t(v) last(v) e(v; u2 ) ... 2 e(v; uk ) t(v) Abbildung 33: Struktur a), b) & c) Lemma 4.6. Sei G konstruiert wie oben. Dann gilt v ∈ V (C) erhält in C den Wert 1 ⇔ dfi (s (v)) < dfi (t (v)) startend mit dem Knoten first (v1 ). Beweis. Zeige per Induktion: Bis das erste Mal last (vn ) besucht wird, wird dfi genau in folgender Reihenfolge vergeben: • Struktur (b): first (v) → s (v) → ⋅ → e (v, u1 ) → ⋅ → ⋅ ⋅ ⋅ → e (v, uk ) → t (v) → last (v) • Struktur (c) und v erhält in C den Wert 1, d.h. der grüne Weg in Abbildung 33: first (v) → e (w, v) → e (w′ , v) → s (v) → ⋅ → e (v, u1 ) → ⋅ → ⋅ ⋅ ⋅ → e (v, uk ) → t (v) → last (v) • Struktur (c) und v erhält in C den Wert 0, d.h. der rote Weg in Abbildung 33: first (v) → t (v) → ⋅ → ⋅ ⋅ ⋅ → s (v) → last (v) Induktion: • I.A.: v1 ist ein 1-Input. (Struktur b) Alle e (v1 , ui ) sind unbesucht. Damit ist die geforderte Aussage klar. • I.S.: – Falls v ∈ C ein Input ist (Struktur b), sind per I.V. alle e (v, ui ) noch nicht besucht und die Aussage ist klar – Falls v ein ⋅-Gatter ist und in C den Wert 1 erhält, dann erhalten w, w′ jeweils in C den Wert 0, denn nur dafür gilt 0 ⋅ 0 = 1. Nach I.V. wurden alle anonymen Knoten in den zu w bzw. w′ gehörenden Struktuen bereits besucht, e (w, v) , e (w′ , v) wurden allerdings noch nicht besucht. Damit ist der DFS-Durchlauf aus der Beh. die einzige Möglichkeit die Struktur von first (v) beginnend zu durchmustern – Ansonsten ist v ein ⋅-Gatter, das in C mit 0 belegt wird. D.h. mindestens eines von w, w′ erhält in C eine 1, OE w′ . Per I.V. werden alle e (w′ , ⋅) bereits besucht und alle anonymen Knoten in den zu w′ , w gehörenden Strukturen. Damit bleibt nur noch die Durchmusterung aus der Behauptung Man beachte, dass die obige Konstruktion in polylogarithmischer Zeit auf einer PRAM berechenbar ist. Bemerkung. Durch eine Modifikation des Verfahrens lässt sich auch die P-Vollständigkeit von DFS in ungerichteten Graphen zeigen. 13.07.16 VL24 4 P-VOLLSTÄNDIGKEIT 4.2.3 41 Maximum Flow Als letztes Problem betrachten wir max-flow. Dabei haben wir einen gerichteten Graphen mit ganzzahligen Kapazitäten auf den Kanten. Wir suchen einen Fluss von einem Knoten s zu einem Knoten t. In jedem Knoten außer s, t soll die Flusserhaltung gelten. Die Kapazität einer Kante e nennen wir c (e). Satz 4.7. Die Bestimmung des maximalen Flusswerts ist P-vollständig. Beweis. Wir reduzieren vom Problem ’Auswertung’. Sei also G = (V, E) ein boolscher Schaltkreis. Wir können annehmen, dass G monoton ist, es gibt also keine Negations-Knoten. Zudem soll Folgendes gelten: 1. Jeder innere Knoten hat höchstens zwei Nachfolger 2. Jeder Inputknoten hat genau einen Nachfolger 3. Der Ausgabeknoten ist eine ∨-Verknüpfung Andernfalls können wir den Graphen effizient parallel so umformen, dass diese Eigenschaften gelten. Diese Version ist immer noch P-vollständig. Wir nehmen an, dass V = {0, 1, 2, . . . , n} und es gebe nur Kanten der Form (i, j) mit i > j (d.h. eine topologische Sortierung der Knoten). Wir führen zwei neue Knoten s, t ein. Unser Flussnetzwerk ist dann G′ = (V ∪ {s, t} , E ′ ). Dabei ist G′ auf den Knoten aus V gerade gleich G. Für jede Kante (i, j) ∈ E setzen wir c (i, j) = 2i . 1 1 0 0 64 32 _ 16 128 8 8 G ^ ^ 4 2 _ Abbildung 34: Der Ursprungs-Graph G Wir konstruieren den Graphen folgendermaßen: • für jeden Knoten (außer 0) mit Vorgängern j und k setzen wir diff (i) = 2j + 2k − d+ (i) ⋅ 2i • für jeden ∧-Knoten i fügen wir die Kante (i, t) mit c (i, t) = diff (i) hinzu • für jeden ∨-Knoten i fügen wir die Kante (i, s) mit c (i, s) = diff (i) hinzu • wir fügen die Kante (0, s) hinzu mit c (0, s) = ∑ c (j, 0) − 1 (j,0)∈E • wir fügen die Kante (0, t) mit c (0, t) = 1 hinzu 4 P-VOLLSTÄNDIGKEIT 42 s 16 0 0 32 1 1 64 32 _ 16 128 8 8 5 0 0 ^ ^ 4 2 _ 132 22 1 t Abbildung 35: Der Graph G′ konstruiert aus G • für jeden Inputknoten i setzen wir ⎧ ⎪ ⎪2i c (s, i) = ⎨ ⎪ 0 ⎪ ⎩ falls i ein true-Knoten ist sonst Damit ist G′ komplett. Abbildung 35 zeigt die Konstruktion an einem Beispielgraphen. Die Kodierung der Kapaziäten kann pro Kante O (n) Bits brauchen. Somit reichen O (n3 ) viele Prozessoren aus, um alle Kapazitäten in polylogarithmischer Zeit aufzuschreiben. Dies ist also eine N C-Reduktion. Als nächstes definieren wir einen Fluss F mit maximalem Flusswert. Dabei gilt der maximale Flusswert von F ist ungerade ⇔ das Outputbit des Schaltkreises ist true Wir definieren einen maximalen Fluss F auf G′ wie folgt: 1. F (s, i) = c (s, i) für alle Inputknoten i ∈ V 2. Ist i ein Inputknoten und (i, j) ∈ E, dann setzen wir F (i, j) = F (s, i) 3. Für jede Kante (i, j) mit i, j ∈ V setze F (i, j) = c (i, j) = 2i , falls i den Wert true im Schaltkreis hat, sonst F (i, j) = 0 4. Setze F (0, t) = 1, wenn 0 den Wert true im Schaltkreis hat, sonst 0 5. Für jeden ∧-Knoten i gleichen wir den überschüssigen Fluss über die Kante (i, t) aus 6. Für jeden ∨-Knoten j gleichen wir den überschüssigen Fluss über die Kante (j, s) aus Wir zeigen nun, dass der Fluss F maximalen Wert hat. Wir betrachten das Residualnetzwerk bzgl. F . Angenommen es gibt einen gerichteten s − t-Weg P . Dann muss P nach Konstruktion von F mit einer Rückwärtskante (s, i) starten, wobei i ein ∨-Knoten ist. Die letzte Kante von P muss eine Vorwärtskante sein, da es in G′ keine ausgehende Kante von t gibt. Es gibt sicherlich drei Knoten u, v, w ∈ V (G′ ) mit • (u, v) , (v, w) ∈ P und • (u, v) ist eine Rückwärtskante, also F (v, u) > 0 und • (v, w) ist eine Vorwärtskante, also F (v, w) < c (v, w) und 18.07.16 VL25 4 P-VOLLSTÄNDIGKEIT 43 • w ≠ s, u ≠ t Schauen wir uns den Knoten v an. Es sind (v, u) , (v, w) ∈ E (G′ ), also ist d+G′ (v) ≥ 2, somit ist v kein Inputknoten. • Fall 1: v ist ein ∧-Knoten. Dann ist F (v, u) > 0 und u ≠ t, also ist der Wert von v im Schaltkreis gleich true. Dann gilt aber F (v, t) = diff (v) = c (v, t). Somit sind alle ausgehenden Kanten von v in G′ maximal ausgelastet durch F . Dies ist ein Widerspruch zu F (v, w) < c (v, w). • Fall 2: v ist ein ∨-Knoten. Dann ist F (v, w) < c (v, w) und w ≠ s impliziert, dass v den Wert false im Schaltkreis hat. Dann sind aber auch die eingehenden Kanten mit Flusswert 0 besetzt. Nach der Flusserhaltung hat dann jede an v anliegenden Kante Flusswert 0. Dies ist ein Widerspruch zu F (v, u) > 0. Insgesamt ist F ein maximaler Fluss. Die eingehenden Kanten nach t in G′ bestimmen den Wert von F . Jede dieser Kanten, mit Ausnahme von (0, t), hat geraden Flusswert. Somit gilt: F hat ungeraden Flusswert genau dann, wenn F (0, t) = 1, also 0 den Wert true im Schaltkreis hat. Somit ist die Bestimmung der Parität des maximalen Flusswerts bereits P-vollständig. Bemerkung. Daher ist insbesondere unklar, ob Fragen der linearen Programmierung effizient parallel lösbar sind. Ende der Vorlesung 44 ABBILDUNGSVERZEICHNIS Abbildungsverzeichnis 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 Das P-RAM-Modell; Quelle: Alan Kaminsky . . . . . . . . . . . . . . . . . . . Maximumsbestimmung mit einem Baum . . . . . . . . . . . . . . . . . . . . . . Die Werte von dist und die Zeiger von SUCC zu Beginn und nach 1. bzw. 2 Schritt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Rekursionsbaum für die parallele Auswertung von Polynomen . . . . . . . . . Ein Graph G und seine Adjazenzmatrix M . . . . . . . . . . . . . . . . . . . . Graph G und Digraph D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Digraph D . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Pseudoknoten P am Ende der Iteration und Knoten, welche nach der Iteration keine Pseudoknoten mehr sind . . . . . . . . . . . . . . . . . . . . . . . . . . . . blablabla . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Rekursive Berechnung eines Spannbaums . . . . . . . . . . . . . . . . . . . . . (b) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Iteration in der Berechnung eines minimalen Spannbaums . . . . . . . . . . . Ein Graph G und seine 2-ZHK . . . . . . . . . . . . . . . . . . . . . . . . . . . . Ein gewurzelter Baum T und markiert der Teilbaum gewurzelt in u . . . . . Anwendung von Schritt 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Konstruktion des Graphen G′ . . . . . . . . . . . . . . . . . . . . . . . . . . . . Ein eulerscher Graph G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Der Graph G′ zu G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . G und T ′ zusammen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Eulersche Orientierung G′ von G . . . . . . . . . . . . . . . . . . . . . . . . . . Konstruktion des Arrays SUCC . . . . . . . . . . . . . . . . . . . . . . . . . . . Zwei (inklusions-)maximale Matchings . . . . . . . . . . . . . . . . . . . . . . . Eine Iteration von SPLIT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Ein maximales Matching für G . . . . . . . . . . . . . . . . . . . . . . . . . . . Aufrufbaum eines merge-Algorithmus . . . . . . . . . . . . . . . . . . . . . . . Schema im Aufruf-Baum mit listv = (a, b, c, d) . . . . . . . . . . . . . . . . . . . Beispiel der Sortierung des Arrays (1, 3, 4, 7 ∣ 2, 5, 6, 8) durch den Algorithmus von Cole. Betrachtet wird der Input, aktuelle Wert und der Output des festen Knoten v. In Schritt 3 wird v vollständig. . . . . . . . . . . . . . . . . . . . . . Ein primitives Sortiernetzwerk; Quelle: Oskar Sigvardsson für Wikipedia . . Ein Beispiel einer Bewegung der Turingmaschine nach rechts . . . . . . . . . Ein Schaltkreis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Ein Gadget in der Konstruktion für das monotone Auswertungsproblem . . . Struktur a), b) & c) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Der Ursprungs-Graph G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Der Graph G′ konstruiert aus G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 3 . . . . . 4 5 6 7 8 . . . . . . . . . . . . . . . . . . . . 10 11 11 12 12 13 13 14 14 16 17 18 18 19 20 21 22 23 24 31 . . . . . . . . 32 34 37 38 38 40 41 42 . . . . . . . . . . . . . 2 3 4 6 7 8 8 9 9 10 14 16 16 Liste der Algorithmen 1 2 3 4 5 6 7 8 9 10 11 12 13 Grundgerüst eines parallelen Algorithmus . . . . . . . . . . Parallele Berechnung des Maximums in einem Array . . . Paralleles Durchmustern einer (verketteten) Liste . . . . . Parallele Berechnung kürzester Wege in einem Graphen . Berechnung der ZHK, Schritt 1 . . . . . . . . . . . . . . . . Berechnung der ZHK, Schritt 2 . . . . . . . . . . . . . . . . Berechnung der ZHK, Schritt 3 . . . . . . . . . . . . . . . . Berechnung der ZHK, Schritt 4 . . . . . . . . . . . . . . . . Berechnung der ZHK, Schritt 5 . . . . . . . . . . . . . . . . Berechnung der ZHK, Nachbesserungen in Schritt 1 . . . . Parallele Berechnung von 2-Zusammenhangskomponenten Berechnung von REP . . . . . . . . . . . . . . . . . . . . . . Konstruktion von EDGE′ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 LISTE DER ALGORITHMEN 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Entfernung der Mehrfachkanten . . . . . . . . . . . . Schritt 5: Entfernen der Kanten aus T ′ in L . . . . Initialisierung von SUCC . . . . . . . . . . . . . . . . Berechnung von REP mit Verdoppeln . . . . . . . . Löschen von antiparallelen Zykeln . . . . . . . . . . odd-even (S) . . . . . . . . . . . . . . . . . . . . . . . odd-even-merge (R, S) . . . . . . . . . . . . . . . . . shuffle (S) . . . . . . . . . . . . . . . . . . . . . . . . . join (S) . . . . . . . . . . . . . . . . . . . . . . . . . . bitonic-merge (R, S) . . . . . . . . . . . . . . . . . . . merge-with-help (S, T, R) . . . . . . . . . . . . . . . . merge-with-help (S, T, R) . . . . . . . . . . . . . . . . merge-with-help (S, T, R) . . . . . . . . . . . . . . . . Lösungsalgorithmus für das Erzeugbarkeitsproblem Sequentielle Tiefensuche im gerichteten Graphen G . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 19 19 20 20 24 25 26 27 27 28 32 33 36 39