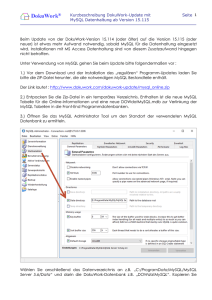
Open Source Datenbanken für analytische Systeme
Werbung

it-novum White Paper Februar 2011 Open Source Datenbanken für analytische Systeme im strukturierten Vergleich ©it-novum GmbH 2010 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Kurzfassung Datenbanksysteme für analytische Anwendungen unterliegen speziellen Anforderungen. In diesem Whitepaper evaluieren wir anhand eines Kriterienkatalogs die beiden Open Source-Datenbanksysteme MySQL und PostgreSQL hinsichtlich ihrer Einsatztauglichkeit für eine BI-Architektur und unterziehen sie einem Leistungstest. Fragen, Anmerkungen, Kritik Sie haben Fragen zum vorliegenden Whitepaper, Anmerkungen, Kritik? Dann schreiben Sie uns an [email protected]. Webinar Wir bieten regelmäßig Webinare zu Open Source-Datenbanken und weiteren BI-bezogenen Themen an. Bei Interesse schreiben Sie an [email protected]. © it-novum GmbH 2010 2 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Inhalt 1. Einleitung: Open Source Datenbanken für analytische Systeme 5 2. Definition der Anforderungen an Datenbanken im analytischen Einsatz ......................................................... 6 2.1. Herstellerbezogene Anforderungen .................................... 6 2.2. Produktbezogene Anforderungen ........................................8 2.3 Kriterienübersicht .................................................................. 20 3. Marktüberblick Open Source-Datenbanken ........................ 23 3.1 Weitere Auswahlkriterien ......................................................... 24 4. Die Teststellung: Performancetest mit dem Pentaho Analyzer ...................................................................26 5. Produktübersicht und -vergleich ............................................31 5.1 Evaluierung von MySQL ...........................................................31 Allgemeine Kriterien ....................................................................... 33 Systemanforderungen und Software-Anbindung...................... 35 Datenbankobjekte ........................................................................... 38 Unterstützung des SQL/OLAP-Standards .................................... 40 Performance und Skalierbarkeit ................................................... 41 Datenintegrität und -sicherheit ................................................... 46 Administration und Wartung....................................................... 48 Zukünftige Entwicklungen ............................................................50 5.2 Evaluierung von PostgreSQL ................................................. 52 Allgemeine Kriterien ....................................................................... 53 © it-novum GmbH 2010 3 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Systemanforderungen und Software-Anbindung...................... 55 Datenbankobjekte ........................................................................... 57 Unterstützung des SQL/OLAP-Standards .....................................59 Performance ..................................................................................... 61 Datenintegrität und -sicherheit ....................................................67 Administration / Wartung ............................................................ 69 Zukünftige Entwicklungen .............................................................71 6. MySQL und PostgreSQL im direkten Vergleich ................... 72 7. Sonderbetrachtung: Infobright ..............................................79 8. Fazit .............................................................................................. 81 Anhang: TestQueries ..................................................................... 83 Weiterführende Informationen /Links: ........................................ 85 Kontaktadressen ............................................................................. 86 © it-novum GmbH 2010 4 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 1. Einleitung: Open Source Datenbanken für analytische Systeme Innerhalb einer Business Intelligence-Architektur ist ein leistungsstarkes und sicheres Backend mindestens ebenso wichtig wie ein leicht zu bedienendes Frontend. Das gilt insbesondere, wenn man sich für einen klassischen Data Warehouse-Ansatz entscheidet, d.h. alle analyserelevanten Unternehmensdaten in ein zentrales Datenbanksystem geladen werden. Was muss ein solches Datenbanksystem können? Die Anforderungen an eine Datenbank im operativen Einsatz unterscheiden sich von denen an ein Data Warehouse. Datenbanken innerhalb operativer Systeme sind durch eine Vielzahl von Zugriffen durch eine große Zahl an Anwendern gekennzeichnet. Die Daten innerhalb eines solchen Systems ändern sich ständig und liegen in einem sehr hohen Detailgrad vor. Eine analytische Datenbank dagegen wird üblicherweise von einer deutlich geringeren Anzahl von Anwendern verwendet. Die Abfragen gegen ein solches System sind also weniger zahlreich, können aber wesentlich umfangreicher und komplexer sein. Die Daten in einer analytischen Datenbank liegen in speziellen, analyseorientierten Strukturen vor, zum Teil auch aggregiert. Vor diesem Hintergrund haben wir einen generischen Kriterienkatalog entwickelt, mit dem sich Datenbanken hinsichtlich ihres Einsatzes in einem BISzenario vergleichen lassen. Als Vergleichsobjekte haben wir nicht die klassischen Datenbanken, z.B. von Oracle oder Microsoft, herangezogen, sondern zwei Open Source-Systeme. MySQL und PostgreSQL sind die beiden bekanntesten Vertreter des Segments quelloffene Datenbanken. Um auch einen anderen Datenbankenansatz mit einzubeziehen, haben wir zusätzlich die spaltenbasierte Datenbank Infobright einem vergleichenden Test unterzogen. © it-novum GmbH 2010 5 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 2. Definition der Anforderungen an Datenbanken im analytischen Einsatz Die Anforderungen an ein Datenbanksystem (DBS) sind vielfältig und hängen vom Einsatzbereich ab. Bei unserem Vergleich liegt der Fokus auf Datenbanken, die sowohl eine solide Liste an Eigenschaften für einen dauerhaften Einsatz im Unternehmen (in größerem Umfang) bieten, nach Möglichkeit aber auch analytische Funktionen haben. Wir haben diese Aspekte daher in den Katalog der Anforderungen an die DBS mit aufgenommen. Außerdem gibt es bei Open Source-Software bestimmte Punkte, die für die Auswahl des Produktes wichtig sind (z.B. das Lizenzmodell). Bei unserer Recherche haben wir darüber hinaus weitere Kriterien ausgewählt. Daneben werden nicht nur an die DBS selber, sondern auch an die Hersteller gewisse Anforderungen gestellt. Eine Evaluierung von Open Source-Produkten muss daher auch einbeziehen, ob und inwiefern sie sich als „Enterprise-level Application“ eignen. Darunter verstehen wir den Einsatz der Software auf gesamter Unternehmensebene. Dazu gehört nicht nur eine sehr gute Funktionalität, sondern auch ein Hersteller, der strategisch gut positioniert ist und positive mittel- bis langfristige Zukunftsaussichten hat. 2.1. Herstellerbezogene Anforderungen Datenbanken bilden die Grundlage für viele Unternehmensanwendungen und sind essenziell für einen funktionierenden Geschäftsablauf. Die Datenbestände eines größeren Unternehmens können dabei bis weit in den Terabyte-Bereich gehen und komplexe Strukturen aufweisen, die speziell an die gewählte Datenbanklösung angepasst worden sind. Dementsprechend aufwendig ist eine Migration auf ein komplett neues DBS – die Festlegung auf ein DBS hat langfristigen Charakter. Daher ist es notwendig, sich vor der Wahl eines DBS auch eingehend über den Hersteller zu informieren. Bei Open Source Software ist besonders wichtig, weil nur in wenigen Fällen ein großer Hersteller hinter dem Produkt steht. Kleine Hersteller ohne feste Basis in vielen Unternehmen und mit kleiner Entwicklergemeinde können unter Umständen schnell vom Markt verschwinden. Auch kann man nie ausschließen, dass eine Firma mit einem gut laufenden Open Source-Projekt von einem großen proprietären Hersteller aufgekauft und für eigene Zwecke benutzt wird. © it-novum GmbH 2010 6 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Referenzkunden Ein guter Anhaltspunkt für die Verbreitung bzw. Käuferakzeptanz eines Produkts sind die Referenzkunden des Herstellers. Diese werden oft schon auf der Internetseite des Herstellers zur Schau gestellt. Dort finden sich oft auch (häufig eher oberflächliche) Aussagen darüber, in welchem Rahmen das DBS beim Kunden eingesetzt wird. Auch wenn sich damit noch keine genauen Aussagen über die Qualität des Produktes treffen lassen, so stellt doch eine Vielzahl namhafter Referenzkunden einen brauchbaren Anhaltspunkt für die Käuferakzeptanz dar. Produktstrategie Ein weiteres wichtiges Kriterium ist die Produktstrategie des Herstellers: Wo ist das Produkt im Vergleich mit dem Wettbewerb positioniert? In welchen Aspekten differenziert es sich von Konkurrenzprodukten (evtl. sogar von einem Produkt aus dem gleichen Unternehmen)? Positiv zu bewerten ist hier, wenn ein DBS über ein besonderes Leistungsmerkmal verfügt, mit dem es sich von den anderen DBS deutlich abhebt – das sog. Alleinstellungsmerkmal. Auch verschiedene Variationen eines Produktes sind Teil der Produktstrategie. Die Produktstrategie ist mittel- bis langfristig ausgelegt und deshalb von entscheidender Bedeutung für den Erfolg oder Misserfolg eines Produktes. Allerdings ist die Strategie oftmals von außen nur schwer zu beurteilen, wenn der Hersteller sie nicht publik macht. Herstelleraktivität / Produkt-Updates Der Softwaremarkt im Allgemeinen und Open Source-Software im Speziellen unterliegen einem raschen Wandel. Funktionalitäten, die zum Zeitpunkt einer Evaluierung noch nicht Bestandteil eines Produktes waren, können bereits im nächsten Update enthalten sein. Deshalb ist es wichtig, auch die Produkthistorie zu betrachten: In welchen Abständen werden kleinere und größere Updates bereit gestellt? Wie kompliziert ist die Installation dieser Updates? Hat das Aufspielen des Updates möglicherweise tiefgreifende Folgen für den Betrieb des DBS? Dabei sollte man sich aber im Klaren sein, dass es immer einen gewissen Aufwand mit sich bringt, wenn die neuen Funktionen auch sinnvoll genutzt werden sollen. Support Das Thema Support ist bei der Auswahl eines Anbieters immer ein (mit)entscheidendes Kriterium: Über welche Kanäle erhalte ich Hilfe nicht nur bei technischen, sondern auch bei nichttechnischen Fragen (E-Mail, Live Support System, Telefon, Fernwartung usw.)? Welche Konditionen beinhaltet der Support- © it-novum GmbH 2010 7 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Vertrag? Wichtig ist auch, welches der verschiedenen Supportmodelle des Herstellers am besten zu meinen Bedürfnissen passt. Einen bedeutenden Teil des Supports übernimmt bei Open Source-Projekten die Entwickler- und Anwendergemeinde. Hier ist entscheidend, wie aktiv die Community-Kanäle sind (Forum, Mailverteiler) und wie stark die Community in die Abläufe eines möglicherweise hinter dem Projekt stehenden Herstellers eingebunden ist. Dokumentation Datenbanksysteme bieten sehr umfangreiche Konfigurationsmöglichkeiten. Daher ist neben einem funktionierenden Support auch eine detaillierte Dokumentation wichtig. Diese kann bspw. aus Wikis, gebundenen Dokumenten oder Online-Handbüchern bestehen. 2.2. Produktbezogene Anforderungen Lizenzmodelle Bei der Verwendung von Open Source-Software spielt das verwendete Lizenzmodell eine wichtige Rolle. Derzeit gibt es vier Lizenzen, die am häufigsten für Open Source-Projekte eingesetzt werden. Sie sollen an dieser Stelle kurz vorgestellt werden. Die Lizenzen unterscheiden sich vor allem hinsichtlich der Einschränkungen für die Veränderung des Quellcodes und eine anschließende kommerzielle Nutzung in einer Closed Source-Anwendung. Bei manchen Lizenzen ist das streng untersagt, d.h. veränderter Open Source-Code muss ebenfalls unter eine Open Source-Lizenz gestellt werden und zwar dieselbe wie der Ausgangscode. Derartige Bestimmungen werden unter dem Begriff „Copyleft“ zusammengefasst. Andere Lizenzen haben ein nicht so strenges Copyleft und erlauben zumindest das Einbinden von unter Open Source stehenden Bibliotheken für eine Einbindung in proprietären Code. Die dritte Gruppe verzichtet gänzlich auf Copyleft, dort darf der gesamte Quellcode in proprietäre Software eingebunden werden. Die Berkeley Software Distribution License (BSD-Lizenz) wurde ursprünglich an der University of California, Berkeley, entwickelt. Sie erlaubt, Software unter ihrer Lizenz zu kopieren, verändern und zu verbreiten. Die BSD-Lizenz enthält kein Copyleft, weshalb Programme unter ihrer Lizenz interessant sind als Basis für © it-novum GmbH 2010 8 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 kommerzielle Weiterentwicklungen oder Lösungen. Weder muss der Quelltext des kommerziellen Programms offen gelegt noch das Programm selbst unter die BSD-Lizenz gestellt werden. Die Version 2.0 der Apache License wurde 2004 veröffentlicht und gegenüber der Vorgängerversion 1.1 stark erweitert. Wie auch die BSD-Lizenz enthält die Apache License kein Copyleft. Sie umfasst jedoch ein Copyright, d.h. bei der Verteilung von Software unter der Apache License muss eindeutig auf die verwendete Software und deren Abstammung vom Lizenzgeber hingewiesen werden. Daneben muss eine Kopie der Lizenz dem Paket Fall beiliegen, der Quelltext allerdings nicht. Die GNU General Public License (kurz GPL) ist die hauseigene Lizenz der Free Software Foundation und wird derzeit sowohl in Version 2 als auch Version 3 verwendet. Hauptsächlich ist aber Version 2 im Einsatz. Im Gegensatz zu den beiden vorgenannten Lizenzen enthält die GPL ein Copyleft, d.h. unter die GPL gestellte Software muss nach Veränderung wieder unter die GPL gestellt werden. Für die meisten kommerziellen Entwicklungen stellt das ein K.O.-Kriterium dar, da den entwickelnden Firmen wenig daran gelegen ist, dass ihr Quelltext veröffentlicht wird. Ebenfalls entwickelt von der Free Software Foundation, stellt die Lesser General Public LIcence (LGPL) eine geschäftsfreundlichere Variante der GPL dar. Sie verfügt, dass alle Programme, die lediglich extern unter der LGPL stehende Software nutzen (z.B. Programmbibliotheken), unter ihrer eigenen Lizenz bleiben. Die LGPL eignet sich folglich besonders für die Lizenzierung von Bibliotheken, die die Erstellung proprietärer Software erlauben sollen. Allerdings ist nur die Verlinkung dieser Bibliotheken erlaubt, nicht ihre direkte Einbindung in den Programmcode. In diesem Fall greift wieder das Copyleft und das betreffende Programm muss wieder unter die LGPL bzw. eine kompatible Lizenz (wie die GPL) gestellt werden. Plattform-Unterstützung Datenbanksysteme befinden sich technisch gesehen zwischen Anwendungssystemen und dem Betriebssystem. Die unterstützten Systeme spielen je nach Größe und Software-Struktur des jeweiligen Unternehmens eine kleinere oder größere Rolle. Ein wesentliches Kriterium ist daher die Unterstützung von 64-bit Betriebssystemen, da 32-bit Betriebssysteme nur maximal 4 Gigabyte Arbeitsspeicher adressieren können. Gerade bei analytischen Abfragen im Data Warehouse-Bereich fallen schnell sehr große Datenmengen an, die bei Erreichen der 4 GB-Grenze erst auf die Festplatte ausgelagert werden müssen. Die Folge ist häufig ein Flaschenhals, was die Leistung betrifft. © it-novum GmbH 2010 9 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Datenbank-Schnittstellen Datenbanksysteme müssen normalerweise mit mehreren Anwendungsprogrammen kommunizieren. Schnittstellen regeln dabei den Zugriff und den Datenaustausch mit der Datenbank. Gerade im Data WarehouseBereich existiert eine Vielzahl von Programmen, z.B. zur Abwicklung des ETLProzesses oder zur Realisierung analytischer Aufgabenstellungen, u.a. mit OLAPWürfeln. Da für spezielle Einsatzgebiete häufig eigene Anwendungen geschrieben werden, spielen Schnittstellen auch hier eine große Rolle. Zentrales Stichwort in diesem Kontext ist Offenheit: Das Programm muss nicht für jede Datenbankart eine eigene spezielle Schnittstelle enthalten. Deshalb gewinnen standardisierte und sprachunabhängige (d.h. nicht mehr an eine spezielle Programmiersprache gebundene) Schnittstellen immer mehr an Bedeutung (z.B. JDBC). Unterstützt das DBS diese Schnittstellen, stellt das einen erheblichen Vorteil gegenüber Insellösungen dar. Hier haben Open Source-Lösungen einen klaren Vorteil: Selbst wenn das DBS von sich aus wenige Schnittstellen zur Verfügung stellt, so gibt es häufig eine Lösung in Form eines Drittanbieterprodukts (das meistens von den Entwicklern der Anwendungsprogramme selbst stammt). Diese müssen nicht unbedingt kostenlos sein, dennoch ist allein die die Unterstützung von Drittsystemen ein wichtiges Kriterium bei der Entscheidung für ein DBS. Datenbanksprache Benutzer oder Anwendungsprogramme kommunizieren über die Datenbanksprache mit dem Datenbanksystem. Bei den relationalen DBS hat sich SQL als de facto-Standard durchgesetzt. In der mittlerweile drei Jahrzehnte umfassenden Entwicklung von SQL sind mehrere Standards entstanden, die von der Internationalen Organisation für Normung (ISO) verabschiedet wurden. Das ausschlaggebende Kriterium ist also nicht, ob das DBS SQL unterstützt, sondern welchen SQL-Standard es beherrscht (und ob vollständig oder nur teilweise). Unterstützung des OLAP-SQL-Standards Als SQL Mitte der 1970er Jahre entwickelt wurde, lag der Fokus auf der Verarbeitung operationaler Daten. Für eine komplexe Analyse von Daten, die nicht in Clientanwendungen umständlich durchgeführt werden soll, sondern direkt vom DBS unterstützt wird, war SQL ursprünglich nicht ausgelegt. Da dieses Anwendungsgebiet aber bereits Mitte der 90er Jahre immer gefragter wurde, entschloss sich das ISO-Gremium, SQL um analytische Funktionen zu erweitern. Diese Funktionen wurden 1999 von den führenden DBS-Herstellern mit Unterstützung von Client-Anbietern entwickelt und unter dem Namen SQL/OLAP © it-novum GmbH 2010 10 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 verabschiedet (zuerst als Anhang zu SQL99, später wurde es direkt in das Framework von SQL2003 aufgenommen). Relationale DBS beherrschen die in diesem Standard spezifizierten Konzepte, allerdings gibt es auch noch herstellerspezifische Implementierungen für analytische Funktionen. In diesem Rahmen betrachten wir nur die Funktionen im SQL-Standard. Die SQL/OLAP-Erweiterungen lassen sich in drei Teile gliedern: 1. Erweiterung des GROUP BY-Operators Bereits vor den SQL/OLAP-Erweiterungen gab es Funktionen, um sich aggregierte Informationen innerhalb einer Tabelle anzeigen zu lassen (z.B. den maximalen oder minimalen Wert über alle Zeilen). Diese Funktionen fassen mehrere Zeilen zu einer Ergebnismenge zusammen und geben nur noch diese aus. Ist es notwendig, die Werte dieser Funktionen nicht über den gesamten Tabellenbestand, sondern nur über bestimmte Gruppen von Tabellenzeilen zu bilden, wird die „GROUP BY“ Klausel verwendet. Mit der Erweiterung „ROLLUP“ der GROUP BY-Klausel lassen sich zusätzlich zu dieser Ergebnismenge auch noch sogenannte „Super-Aggregate“ ermitteln und ausgeben. Super-Aggregate sind Summen, die durch Aufaddierung nach einem Gruppierungsmerkmal entstehen. Sofern die Ausgabe aller möglichen Super-Aggregate für die Gruppierungsspalten erforderlich ist, verwendet man statt ROLLUP den Operator CUBE. Im Gegensatz zum ROLLUP-Operator ist hier die Reihenfolge der angegebenen Spalten nicht für das Ergebnis ausschlaggebend. Die Erweiterung “Grouping Sets” ist die vielseitigste der bisher aufgeführten. Sie generiert keine Super-Aggregate wie die beiden anderen Erweiterungen, sondern berechnet Gruppen in Bezug auf verschiedene Spaltengruppen in derselben Anfrage. Dadurch kann sie einerseits Ergebnisse generieren, die auch durch Verwendung von GROUP BY ROLLUP oder GROUP BY CUBE möglich wären, es sind allerdings auch andere Ausgaben durch eine feinere Gruppenauswahl möglich. 2. Fensterkonstrukte Eine wichtige Neuerung, die mit SQL/OLAP und im SQL 2003-Standard Einzug gehalten hat, sind die Fensterkonstrukte (auch Window-Konstrukte genannt). Ein Fenster (Window) spezifiziert eine benutzerdefinierte Menge von Reihen, auf die eine Funktion angewendet wird. Die Fenstergröße lässt © it-novum GmbH 2010 11 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 sich beliebig wählen, meist wird ausgehend von der aktuellen Reihe ein Reihenbereich definiert. Mit Hilfe dieser Konstrukte lassen sich beispielsweise kumulative Summen und laufende Durchschnitte innerhalb von spezifizierten Partitionen berechnen. Der SQL-Standard unterstützt zwei verschiedene Formen für die Definition von analytischen Funktionen: die explizite und die implizite Form (auch „in-line“-Form genannt). Bei der expliziten Form wird die Fensterfunktion am Ende der SELECT-Anweisung spezifiziert, die in-line-Form formuliert die Funktion bereits in der Projektion der Anfrage. Die Fensterfunktion besitzt drei verschiedene Subfunktionen, die allerdings nicht alle in einer Abfrage enthalten sein müssen: 1 Window Partitioning 2 Window Ordering 3 Window Framing 3. OLAP-Funktionen Obwohl sich die beschriebenen GROUP-BY Erweiterungen und die Fensterfunktionen für analytische Abfragen nutzen lassen, gibt es darüber hinaus seit dem SQL/OLAP Standard neue SQL-Funktionen, die sich speziell für diese Zwecke nutzen lassen. Eine Gruppe dieser neuen Funktionen sind die Rangfunktionen, sie geben für jede Reihe einer Partition einen Rang als Nummer aus. Der Standard enthält vier verschiedene Rangfunktionen: RANK, DENSE_RANK, PERCENT_RANK und CUME_DIST RANK. Letztere gibt dabei den Rang der aktuellen Reihe einer Partition als natürliche Zahl aus. Das Ergebnis ist die aktuelle Reihe plus Anzahl der Reihen innerhalb derselben Partition mit tatsächlich niedrigeren Sortierkriterien. Folglich haben Reihen mit gleichwertigen Sortierkriterien denselben Rang und der nächsthöhere Rang lässt eine entsprechende Lücke zum vorhergehenden (je nachdem wie viele gleichwertige Reihen es vorher gibt). Im Gegensatz dazu liefert DENSE_RANK im Falle mehrerer gleichwertiger Ränge beim aktuellen Rang nur den kleineren Rang plus 1. Dadurch entstehen bei den Werten von DENSE_RANK keine Lücken. PERCENT_RANK gibt den Rang ebenfalls anhand des Sortierkriteriums zurück, allerdings nicht einen ganzzahligen, sondern einen relativen Wert. Dieser berechnet sich anhand der Formel (RANK − 1)/(n − 1). © it-novum GmbH 2010 12 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 CUME_DIST ermittelt den relativen Rang einer Reihe innerhalb einer Partition. Hierfür wird die relative Anzahl von Reihen bestimmt, deren Rang kleiner gleich dem Rang der aktuellen Reihe ist. In einer Formel ausgedrückt berechnet sie sich wie folgt: (1/n) ∗ AnzahlderReihen <= x (wobei n die Anzahl der Reihen der Partition ist. Außerdem gibt es die Funktion ROW NUMBER, die jeder Reihe innerhalb einer Partition eine eindeutige Nummer zuweist. Für statistische Analysen wurden in den SQL-Standard statistische Funktionen aufgenommen. So berechnet die Funktion STDDEV_POP die Populations-Standardabweichung aller Werte des angegebenen Parameters für jede Reihe der Partition. Auf die gleiche Weise berechnet STDDEV_SAMP die Stichprobenabweichung. Weiterhin gibt es Funktionen zur Berechnung der Varianz sowie für die Regressions-und Korrelationsanalyse. Common Table Expressions Der SQL-Standard enthält allgemeine Tabellenausdrücke (Common Table Expressions, CTE) in zwei Varianten, nicht-rekursiv und rekursiv. CTE kann man sich am besten als abgeleitete Tabellen bzw. temporäre Views vorstellen, da CTE ebenso wie diese nur für die Dauer der Abfrage vorhanden sind. Der Hauptunterschied zu abgeleiteten Tabellen ist, dass eine CTE auf sich selbst verweisen kann. In diesem Fall wird von einer rekursiven CTE gesprochen. Rekursive CTE lassen sich beispielsweise für rekursive Abfragen nutzen. Nicht-rekursive CTE erlauben eine wesentlich vereinfachte Syntax, da sie nur einmal definiert werden müssen und anschließend mehrfach in derselben Abfrage auf sie verwiesen werden kann. Dadurch lassen sich normalerweise tief verschachtelte Abfragen vermeiden. Transaktionskontrolle Transaktionen bündeln mehrere Datenbankoperationen, die innerhalb eines Mehrbenutzersystems fehlerfrei und als Einheit ausgeführt werden sollen, ohne dass sie durch andere Transaktionen beeinflusst werden. Das Transaktionskonzept dient dazu, (teilweise unvermeidliche) Fehlersituationen zu beheben. Das ACID-Prinzip beschreibt die Eigenschaften, die Transaktionen haben sollen: © it-novum GmbH 2010 13 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Atomicity: Transaktion ist die kleinste, nicht weiter zerlegbare Einheit. Das bedeutet, dass sie entweder ganz oder gar nicht ausgeführt wird. Consistency: Die Datenbasis ist nach der Ausführung der Transaktion konsistent, ansonsten wird die Transaktion komplett zurückgesetzt (Rollback). Isolation: Parallel ausgeführte Transaktionen dürfen sich nicht gegenseitig beeinflussen. Jede Transaktion muss logisch so ausgeführt werden, als ob sie die einzig aktive auf dem DBS wäre. Durability: Die Wirkung einer erfolgreich abgeschlossenen Transaktion bleibt dauerhaft in der Datenbank erhalten. Views Ein Datenbankensystem muss sehr anpassungsfähig sein, damit es den individuellen Anforderungen verschiedener Benutzer und Benutzergruppen Rechnung tragen kann. Ein elementares Konzept zur Erfüllung dieser Forderung sind Sichten oder „Views“. Sie stellen eine virtuelle Relation bzw. virtuelle Tabelle dar, die über eine im DBS gespeicherte Abfrage definiert wird. Virtuell bedeutet in diesem Zusammenhang, dass die Tabellen nicht bei jedem Aufruf der Sicht jeweils neu erstellt werden, sondern lediglich neu berechnet. Vereinfacht ausgedrückt, sind also Sichten Aliase von Abfragen. Eine Sicht erfüllt hauptsächlich die Aufgabe, den Zugriff auf das oft sehr komplexe Datenbankschema (mit vielen Tabellen und Relationen zueinander) zu vereinfachen. Sichten implementieren auch eine Art Datenschutzmechanismus, da sie nur einen Ausschnitt des Gesamtmodells darstellen und manchen Nutzern daher bestimmte Daten verborgen bleiben. Als alleiniger Datenschutzmechanismus sind sie aber natürlich nicht geeignet – schließlich können die Nutzer an die Daten gelangen, wenn sie die Abfrage kennen, die hinter der Sicht steht. Sichten können nicht nur bestimmte Zeilen oder bestimmte Spalten aus einer Tabelle herausfiltern, sondern auch mehrere Tabellen miteinander verknüpfen oder Aggregationsfunktionen (MIN, MAX, Count etc.) anwenden. Neben Views, die lediglich den Zugriff auf andere Tabellen erlauben, nicht aber deren Veränderung, gibt es auch noch veränderbare Views. Sie erlauben eine Verwendung in Update-, Delete- und Insert-Anweisungen, um die zugrunde liegende Tabelle zu ändern. © it-novum GmbH 2010 14 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Eine relativ neue Abwandlung der Sichten sind die sogenannten „Materialized Views“. Im Gegensatz zu herkömmlichen Sichten werden Materialized Views tatsächlich und nicht nur virtuell abgespeichert. Dadurch kann man schneller auf sie zugreifen. Das ist gerade bei aufwändigen OLAP-Anwendungen ein klarer Vorteil, z.B. bei der Vorberechnung und Speicherung aggregierter Daten (Dimensions-/Fakttabellen). Materialized Views werden beispielsweise bei einem Update der Basistabellen aktualisiert, was zu einem hohen Aufwand führen kann. Denkbar sind auch log-basierte Updates oder Updates nach bestimmten Zeitintervallen. Zusammengefasst spricht es klar für ein Datenbanksystem, wenn es Materialized Views unterstützt. Skalierungsmöglichkeiten Skalierbarkeit ist die Fähigkeit einer Anwendung, ihre Leistung beizubehalten, wenn sie um ein bestimmtes Maß anwächst. Um das zu erreichen, muss die Anwendung in der Lage sein, ihre Kapazität (d.h. die Gesamtlast, die sie verarbeiten kann) bei Bedarf zu erhöhen. Es reicht deshalb nicht aus, dass ein Datenbanksystem die Fähigkeit zur Skalierung mitbringt, auch die benutzte Anwendung muss skalierbar sein! Das Konzept der Skalierbarkeit hängt eng mit der Fehlertoleranz (Failover) zusammen, da bei der Skalierung von vornherein eingeplant werden sollte, dass Komponenten teilweise ausfallen. Nachfolgend werden die gebräuchlichsten Methoden der Skalierung vorgestellt. • Replikation Als Replikation Speicherung werden von Daten in an der Datenverarbeitung verschiedenen die mehrfache Standorten und die Synchronisation der Datenquellen verstanden. Die Replikation erlaubt es also, einen oder mehrere Server als Slaves bzw. Repliken eines anderen Servers zu benutzen. Es existieren zwei unterschiedliche Arten der Replikation: Synchrone Replikation: Änderungen werden nicht nur auf dem Master, sondern zeitgleich auch auf allen Replikaten durchgeführt. Die Replikate sind damit zu jeder Zeit auf dem Stand des Masters. Die Umsetzung einer synchronen Replikation ist mit viel Aufwand verbunden. Asynchrone Replikation: Bei dieser Art der Replikation liegt eine Latenzzeit zwischen Änderungen auf dem Master und dem Replizierungsvorgang auf den Slaves. Folglich sind die Daten nur zum Zeitpunkt der Replikation synchronisiert. Die meisten DBS beherrschen heute die asynchrone Replikation. Die technischen Verfahren zur Umsetzung sind sehr komplex © it-novum GmbH 2010 15 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 und können von Hersteller zu Hersteller unterschiedlich sein. Replikation dient dabei nicht nur der Ausfallsicherung (Failover), sondern wird auch zur Steigerung der Performance eingesetzt. Gerade bei extrem vielen gleichzeitigen Leseabfragen ist es sinnvoll, sie über mehrere Server zu verteilen, um einen Lastausgleich zu schaffen. Selbstverständlich können (asynchron) replizierte DBS auch dazu genutzt werden, etwa neue Updates zu testen, bevor man sie im Produktivsystem einsetzt. Zu beachten ist, dass die Replikation die herkömmlichen Backup-Verfahren zur langfristigen und vor allem historisch vollständigen Sicherung nicht ersetzen kann, sondern sie lediglich unterstützt und ergänzt. Ungeachtet dessen stellt die Replikation eine wichtige Anforderung dar, die ein DBS erfüllen sollte. • Partitionierung / Sharding Mit Hilfe der Partitionierung ist es möglich, eine Datenbank (oder auch nur einzelne Datenbankelemente, wie z.B. Tabellen) in voneinander unabhängige Teile zu zerlegen und verteilt abzuspeichern. Bei einem verteilten DBS kann jede Partition auf mehrere Rechnerknoten zugreifen und die Benutzer des Rechnerknotens können lokale Transaktionen auf die Partition ausführen. Das führt in der Regel zu einer besseren Performance und Verfügbarkeit. Die Regeln der Partitionierung kann der Nutzer im Rahmen der Möglichkeiten des DBS selbst bestimmen (z.B. durch einen definierten Wertebereich verschiedener oder, Tabellenzeilen Hash-Funktionen). auf Die unterschiedlichen Speicherung physikalischen Partitionen wird als horizontale Partitionierung bezeichnet (Sharding), die Verteilung von Tabellenspalten auf verschiedene Partitionen als vertikale Partitionierung. Ausfallsicherung Ein DBS muss im Unternehmen stets verfügbar sein, deshalb werden Techniken wie die bereits beschriebene Replikation auf mehrere Server eingesetzt. Fällt ein Server aus, muss er entfernt und stattdessen ein anderer benutzt werden. Diesen Vorgang bezeichnet man als Ausfallsicherung oder Failover. Ein anderer Begriff in diesem Zusammenhang ist das “Failback”. Je nach Konfiguration der Replikation stellt es den Gegenschritt von Failover dar, also die Rückkehr zu einem Server, der ausgefallen war und nun repariert ist. Failover kann nicht nur bei einem Ausfall eingesetzt werden, sondern auch zum Ausgleichen von Lastspitzen. Lastausgleich und Failover hängen daher eng zusammen. Die Umsetzung des FailoverKonzeptes ist abhängig von der IT-Infrastruktur der jeweiligen Firma und den Möglichkeiten innerhalb des DBS. © it-novum GmbH 2010 16 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Indizes Dieses Kriterium betrifft die physische Datenorganisation (Speicherung). Abfragen auf eine Datenbank benötigen häufig nur wenige Tupel einer Relation. Sofern die Datensätze ohne zusätzliche Informationen in den einzelnen Tabellen gespeichert wurden, werden die ausgewählten Spalten komplett (sequenziell) nach den zu erfüllenden Kriterien durchsucht. Dazu braucht man bei großen Tabellen sehr viel (unnötige) Zeit, weshalb man Indizes einsetzt. Ein Index besteht aus einer Sammlung von Zeigern auf eine oder mehrere Spalten in einer Tabelle. Die Indexstruktur ist dabei von der Datenstruktur unabhängig. Bei der Erstellung einer Tabelle, die einen Primärschlüssel enthält, wird automatisch für diese Spalte (oder Spalten bei einem zusammengesetzten Primärschlüssel) ein Index gesetzt. Er reicht je nach Komplexität der Tabelle aber nicht aus, weshalb weitere Indizes angelegt werden können. Die meisten DBS unterstützen auch zusammengesetzte Indizes, d.h. mehrere Spalten in einem Index. Es gibt verschiedene Arten von Indizes, die aber nicht alle von jedem DBS-Typ unterstützt werden. Zur Indexumsetzung gibt es unterschiedliche Methoden, nach denen die Indizes auch teilweise benannt sind (z.B. der B-Baum). Besondere Arten von Indizes stellen die beiden folgenden dar: • Bitmap-Index Bitmap-Indizes sind besonders für die Indizierung von multidimensionalen Daten geeignet, da sie gegenüber Bäumen unempfindlicher sind bei einer höheren Anzahl von Dimensionen. Beschränkt eine Anfrage die indizierten Dimensionen stark, kann der Bitmap-Index besonders effektiv sein. Diese Eigenschaften machen Bitmap-Indizes vor allem für den Einsatz in einem Data Warehouse interessant. Der Bitmap-Index speichert ein oder mehrere Attribute in Form eines Bitmusters und hilft daher sehr bei Spalten mit einer geringen Kardinalität (Anzahl der in dieser Spalte vorhandenen unterschiedlichen Werte). Für Spalten, in denen sich die Werte häufig ändern, ist er dagegen nicht geeignet, da der Änderungsaufwand höher ist als bei herkömmlichen Index-Techniken. • Volltext-Index Wie der Name bereits sagt, sind Volltext-Indizes dafür zuständig, das angegebene Dokument (bei Datenbanken eine Tabelle) vollständig nach den vom Benutzer eingegebenen Wörtern zu durchsuchen. Dieses Verfahren findet sich in vielen Programmen, vor allem im Bereich von Office-Software. © it-novum GmbH 2010 17 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Gespeicherte Prozeduren Eine gespeicherte Prozedur ist eine Menge von (SQL-) Anweisungen, die unter einem Namen auf dem Datenbankserver gespeichert werden kann. Die Clients müssen dadurch nicht immer wieder die jeweiligen Einzelanweisungen ausführen, sondern können direkt die gespeicherte Prozedur aufrufen. Neben der reinen Anfragesprache (meist SQL) können sie auch zusätzliche Befehle zur Ablaufsteuerung (z.B. Schleifen) und Auswertung von Bedingungen enthalten. Gespeicherte Prozeduren werden zum einen eingesetzt, um die Leistung zu erhöhen, da weniger Informationen zwischen Client und Server ausgetauscht werden müssen. Allerdings erhöhen sie die Belastung des Datenbankservers, was bei sehr vielen Clients und nur einem oder wenigen Datenbankservern zu Verzögerungen führen kann. Zum anderen sind sie aus Sicherheitsgründen in Gebrauch: Bei konsequenter Nutzung von gespeicherten Prozeduren haben Anwendungen und Benutzer keinen Direktzugriff auf die Datenbanktabellen. Das erleichtert die Protokollierung enorm und führt zu einer sichereren Umgebung, in der auch Angriffe von außen, z.B. durch SQL-Injections, erheblich erschwert werden. Trigger Ein Trigger ist ein benanntes Datenbankobjekt, das mit einer Tabelle verbunden ist. Er wird aktiviert, wenn für die Tabelle ein bestimmtes Ereignis eintritt, d.h., wenn auf dieser Tabelle eine Insert-, Delete- oder Update-Anweisung ausgeführt wird. Verwendung finden Trigger beispielsweise bei der Überprüfung von Werten, die in eine Tabelle eingefügt werden sollen. Dabei kann der Trigger so eingestellt werden, dass er entweder vor oder nach der auslösenden Anweisung aktiviert wird. Sperrverfahren (Locking) In einem Unternehmen greift eine Vielzahl von Personen auf Daten zu, im Extremfall sogar zur gleichen Zeit. Wenn der Zugriff nicht kontrolliert wird, kann es passieren, dass die Daten nicht mehr in einem konsistenten Zustand sind. Man spricht dann von einer Anomalie. Darunter fällt z.B. das Phänomen „lost update“: zwei Benutzer editieren zur gleichen Zeit eine Datei und die Änderungen des einen Benutzers werden von dem, der die Datei zuletzt abspeichert, überschrieben. Moderne DBMS verfügen über Methoden, um solche Anomalien zu verhindern (genannt “Locking”, worauf wir bei der Evaluierung näher eingehen). © it-novum GmbH 2010 18 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Datensicherheit Die Datensicherheit umfasst sowohl den Schutz vor Datenverlust als auch den Schutz vor unberechtigtem Zugriff. Um einen Datenverlust zu verhindern, kann das DBMS in regelmäßigen Abständen Backups anlegen, gegen unberechtigten Zugriff schützen Zugriffsrechte. Charakteristisch für Datenbanksysteme ist, dass Zugriffsrechte sehr flexibel für einzelne Benutzer bzw. Benutzergruppen vergeben werden können. So kann man beispielsweise einstellen, dass Nutzer A eine komplette Tabelle sehen kann, Nutzer B aber nur gewisse Teile / Attribute (z.B. in einer Personaltabelle nur Personalnummer und Name, nicht aber das Gehalt). Migrationsmöglichkeiten Soll ein altes DBS abgelöst und die Datenbestände weiter verwendet werden, müssen sie in das neue DBS migriert werden. Eine solche Migration erfordert in den meisten Fällen einen enormen Aufwand, sowohl finanziell als auch personell. Ein wichtiges Kriterium ist daher, inwieweit das DBS den Anwender bei einer Datenmigration unterstützt. © it-novum GmbH 2010 19 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 2.3 Kriterienübersicht In den folgenden Tabellen sind die Kriterien nach Themengebieten in Kriteriengruppen zusammengefasst und ihre Gewichtung bei der Bewertung der beiden DBS dargestellt. In der Untersuchung erhielten die Datenbanken zwei verschiedene Bewertungen: Einmal eine Punktanzahl und daraus abgeleitet den sogenannten Nutzwert. Der Nutzwert wird gebildet aus der Multiplikation der Punktanzahl mit dem Wert der Gewichtung. Beispiel: PostgreSQL hat von uns beim Kriterium „Dokumentation“ neun Punkte erhalten. Da das Kriterium „Dokumentation“ mit 20 Punkten bewertet ist, ergibt sich ein Nutzwert von 180 Punkten. Kriteriengruppe A: Allgemeine Kriterien Kriterium Gewichtung 1 Lizenz 15 2 Referenzkunden 15 3 Support 25 3.1 Hersteller-Support 3.2 Community-Support 3.2.1 Support-Kanäle 3.2.2 Qualität 0 25 12,5 12,5 4 Dokumentation 20 5 Produkt-Updates 25 Summe 100 Kriteriengruppe B: Systemanforderungen und Softwareanbindung: Kriterium Gewichtung 1 Unterstützte Betriebssysteme/ Architekturen 15 1.1 32-Bit 1.2 64-Bit 5 10 2 Beschränkungen 20 2.1 pro Datenbank 2.2 pro Tabelle 2.3 pro Spalte 2.4 pro Index 5 5 5 5 3 Unicode-Support 15 4 Datentypen 25 5 XML-Support 15 6 Schnittstellen 10 Summe © it-novum GmbH 2010 20 100 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Kriteriengruppe C: Datenbankobjekte Kriterium Gewichtung 1 Schemata 10 2 Views 40 2.1 nichtveränderbar 2.2 updateable 2.3 materialized 10 10 20 3 Stored Procedures / Functions 25 4 Trigger 25 Summe 100 Kriteriengruppe D: Unterstützung des SQL-OLAP-Standards / OLAPFunktionalitäten Kriterium Gewichtung 1 Erweiterung des Group-By-Operators 8,33 8,33 8,33 2 Fensterfunktionen 30 2.1 Partitioning 2.2 Ordering 2.3 Framing 10 10 10 3 OLAP-Funktionen 20 3.1 Rangfunktionen 3.2 Statistische Funktionen 10 10 4 Common Table Expressions 25 Summe © it-novum GmbH 2010 25 1.1 Group By Rollup 1.2 Group By Cube 1.3 Group By Grouping Sets 21 100 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Kriteriengruppe E: Performance Kriterium Gewichtung 1 Skalierbarkeit 40 1.1 Replikation 1.1.1 a) synchrone 1.2.1 b) asynchrone 1.2 Partitionierung 20 10 10 20 2 Indizes 25 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 10 10 5 3 SMP-Support 15 4 Multithreading 10 5 Parallel Query Processing 10 6 Performance-Messung 0 Summe 100 Kriteriengruppe F: Datensicherheit und Datenintegrität Kriterium Gewichtung 1 Skalierbarkeit 35 1.1 Replikation 1.2 Partitionierung 25 10 2 Indizes 40 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 10 10 20 3 SMP-Support 25 Summe 100 Kriteriengruppe G: Administration und Wartung Kriterium Gewichtung 1 Client- und Hilfsprogramme 2 Backup-Möglichkeiten 50 50 Summe © it-novum GmbH 2010 22 100 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 3. Marktüberblick Open Source-Datenbanken Im Bereich der Open Source-Datenbanksysteme gibt es eine fast unüberschaubare Anzahl von Projekten und Anbietern. Eine vollständige Übersicht zu erstellen scheint fast unmöglich, da sich der Markt beinahe wöchentlich verändert und ständig neue Projekte gestartet werden. Am besten illustriert das die Webseite SourceForge.net. Sie dient als zentraler Verwaltungsund Verteilungsort für alle Arten von Open Source-Programmen. Im Bereich Datenbanken listete SourceForge Ende Mai 2010 1.710 Einträge in der Kategorie ’Datenbankserver / Datenbank-Engines’. Diese Zahl beinhaltet allerdings auch Tools und Erweiterungen zu bestehenden Datenbankprojekten. „Echte“ Datenbankprojekte müsste man also manuell zählen. Für die Absicht dieses Whitepapers reicht jedoch die untenstehende Auflistung, die eine gute Übersicht der bekanntesten Open Source-DBS bietet und keinen Anspruch auf Vollständigkeit erhebt. Apache Cassandra Apache CouchDB Apache Derby Apache Xindice Berkeley DB BlackRay CSQL C-Store CUBRID Db40 Drizzle EnterpriseDB eXist Firebird GadflyB5 Gladius DB GNU SQL Server H2 HBase HSQLDB Infini DB Infobright CE Ingres InnoDB LucidDB MaxDB Mnesia Monet DB MongoDB MySQL Neo4j NeoDatis ODB Palo PostgreSQL Sedna SmallSQL SQLite Die meisten Produkte, die die Übersicht enthält, sind relationale DBS. Es gibt jedoch auch Ausnahmen. So sind beispielsweise Apache Xindice und eXist XMLDatenbanken, d.h. alle Datensätze gelangen per XML in die Datenbank und auch die Ausgabe findet im XML-Format statt. Als Abfragesprache einer XMLDatenbank kommen u.a. die vom W3C-Konsortium entwickelten Sprachen XPath sowie das darauf aufbauende XQuery zum Einsatz. Apache Xindice scheint nicht mehr bzw. wenn überhaupt sehr langsam weiterentwickelt zu werden – die letzte stabile Version wurde vor über drei Jahren veröffentlicht. eXist dagegen wird noch aktiv weiterentwickelt, der Projektfortschritt lässt sich auf Sourceforge verfolgen. Für unsere Evaluierung kommt allerdings auch eXist nicht in Betracht, © it-novum GmbH 2010 23 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 da es hauptsächlich im Bereich der Webapplikationen Verwendung findet und ein “herkömmliches” DBS keinesfalls ersetzen kann (und will). Palo nimmt in dieser Liste eine Sonderposition ein, denn es ist der einzige Open Source MOLAPServer bisher. Aufgrund der proprietären Abfragesprache und der nicht gegebenen Vergleichbarkeit zu anderen DBS haben wir uns aber gegen Palo entschieden. Beim Betrachten der Tabelle fällt auf, dass sie einige sogenannte “eingebettete” (embedded) Datenbankensysteme enthält. Embedded DBS sind in Anwendungen integriert und treten nach außen nicht sichtbar als DBS in Erscheinung (beispielsweise Apache Derby und SQLite). Trotzdem lassen sich einige dieser Systeme auch im “klassischen” Client/Server-Modus betreiben, sodass sie für die Auswertung in Betracht kämen. Ausschließlich eingebettet lauffähige DBS kommen jedoch von vornherein nicht in Frage, da wir nur selbständig lauffähige Datenbankensysteme testen wollen. 3.1 Weitere Auswahlkriterien Doch auch durch diese Festlegung bleiben noch zu viele Produkte übrig. Wir müssen daher weitere Kriterien anwenden. Das erste Kriterium ist der Verbreitungsgrad des jeweiligen DBS. Er lässt sich am besten anhand des Marktanteils bestimmen, den das Produkt besitzt. Gerade bei Open SourceProdukten ist das jedoch schwierig bis unmöglich, denn aktuelle und objektive Studien über die Marktanteile von Open Source DBMS existieren schlichtweg nicht. Wir versuchen daher, anhand von Downloadzahlen Rückschlüsse auf den Verbreitungsgrad der DBS zu ziehen. Auf Sourceforge existieren zwar Einträge zu den größten Projekten wie MySQL und PostgreSQL, jedoch gibt es keine validen Downloadzahlen (MySQL lässt sich beispielsweise von SourceForge gar nicht herunterladen). Außerdem laden viele Nutzer die populärsten Anwendungen direkt von den Herstellerseiten und gehen nicht den “Umweg” über ein Portal. MySQL schreibt von sich selbst, dass es das populärste Open Source DBMS der Welt sei mit 65.000 Downloads pro Tag und über 100 Millionen Downloads insgesamt. Inwieweit diese Zahlen aktuell sind und den Tatsachen entsprechen, kann nicht überprüft werden. Viele der anderen DBS-Projekte geben überhaupt keine Informationen zu den Downloadzahlen Preis. Deshalb wird als weiteres Indiz für den Verbreitungsgrad die Entwicklergemeinde herangezogen. Bei MySQL und PostgreSQL ist sie am größten ausgeprägt und den anderen oben aufgeführten Produkten in wichtigen Punkten wie Aktualität, Integration von Entwicklern und Anwendern sowie Struktur (in den Hilfeforen) überlegen. © it-novum GmbH 2010 24 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Als zweites Kriterium für die Vorauswahl der Software haben wir ihren Reifegrad ausgewählt. Dazu haben wir Referenzinstallationen herangezogen. Auch hier zeigt sich, dass die MySQL und PostgreSQL einen Vorsprung gegenüber der Konkurrenz haben. So können beide Projekte in fast allen Wirtschaftsbereichen namhafte Referenzkunden vorweisen. Da wir die vorgestellten Kriterien für wesentlich halten, ist die Evaluierung von MySQL und PostgreSQL aus unserer Sicht am vielversprechendsten. Der Trend im Data Warehouse-Bereich geht eindeutig hin zu anwendungsspezifischen DBS, genauer gesagt spaltenorientierten DBS. Sie weisen deutliche Geschwindigkeitsvorteile beim Laden von sehr großen Datenmengen sowie bei analytischen Abfragen auf. Belegt wird das durch eine Vielzahl neuer Projekte bzw. Produkte in diesem Bereich, z.B. InfiniDB, LucidDB, Infobright (nur die Community Edition ist Open Source). Je nach Wunsch können auch innerhalb des Data Warehouse zeilenorientierte DBS für alle anderen Aufgaben benutzt werden (oder etwa ein spaltenorientiertes DBS speziell für einen DataMart – die Möglichkeiten sind sehr vielfältig). Die meisten der spaltenorientierten DBS setzen auf bekannte DBS wie MySQL oder PostgreSQL auf und erweitern sie um Performance-Features wie erweitertes Multithreading, verbesserte Datenkompression und schnellere Abfrageoptimierer. Da wir dieser Entwicklung auch in dem vorliegenden Whitepaper Rechnung tragen wollen, haben wir Infobright stellvertretend für spaltenorientierte DBS in die Auswahl der zu bewertenden DBS genommen. Infobright setzt allerdings auf MySQL auf und ist gerade in der Community Version nicht als Konkurrenz- sondern als Komplementärprodukt zu sehen. Wir haben uns daher gegen eine vollständige Evaluierung von Infobright entschieden und unterziehen das DBS nach dem Test von MySQL und Postgre nur einer Sonderbetrachtung. © it-novum GmbH 2010 25 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 4. Die Teststellung: Performancetest mit dem Pentaho Analyzer Ziel unserer Auswertung ist es, die ausgewählten Datenbankensystemen u.a. auf ihre Eignung als Data Warehouse zu überprüfen. Wir haben sie daher an eine Business Intelligence-Software angebunden, die zum Zweck der Teststellung mit den Daten aus den DBS arbeitet. Sinnvollerweise haben wir dazu ebenfalls ein Open Source-Produkt ausgewählt, um exemplarisch zu zeigen, wie eine offene, anpassungsfähige und gleichzeitig kostengünstige Data Warehouse-Lösung aussehen kann. Dabei handelt es sich um die Business Intelligence-Plattform Pentaho. Als Grundlage für die Tests wurden die DBS auf einem Server mit folgenden Spezifikationen installiert: Betriebssystem Windows Server 2003 R2 CPU Intel Core2Duo E6700 (2x 2,66 GHz) Arbeitsspeicher 4 Gigabyte Festplatte(n) 2x Western Digital Caviar Blue, 250 GB, 16 MB Cache, Raid 1 Die DBS können ohne Voreinstellungen auf diesem System installiert werden. Die Pentaho BI Suite ist vollständig in Java entwickelt und beinhaltet Komponenten für fast alle Anwendungsbereiche der Business Intelligence, darunter ETL, OLAP/ Reporting und Data Mining. Die Suite ist modular aufgebaut, sodass sich die einzelnen Module auch separat nutzen lassen. So kann beispielsweise das ETLTool (Pentaho Data Integration / PDI, früher Kettle) unabhängig von den anderen Modulen eingesetzt werden. Zudem lassen sich manche Module auch in andere Java-Anwendungen einbinden. Die Administration des BI-Suite-Servers wird über die sogenannte “Administration Console” im Web-Browser durchgeführt. Dort lassen sich auch die Datenbanken einbinden. Für die populärsten DBS bringt Pentaho bereits Konnektoren mit, die anderen DBS lassen sich per JDBC- oder ODBC-Treiber des jeweiligen Herstellers anbinden. Der modulare Aufbau der Suite führt dazu, dass die Administration Console keine globale Konfigurationsmöglichkeit für alle Tools der Suite bietet. Alle erforderlichen Einstellungen bezüglich der DBAnbindung kann man jedoch in den Client-Programmen vornehmen. Den Kern der OLAP-Funktionalität in Pentaho bildet der OLAP-Server Mondrian, der im Jahr 2001 als eigenständiges Open Source-Projekt begann und seit 2006 Teil von Pentaho ist. Mondrian ist (vereinfacht ausgedrückt) dafür zuständig, MDXQueries auszuführen, Daten von einer relationalen DB zu lesen und das Ergebnis in multidimensionaler Form auszugeben. Die Architektur von Mondrian besteht aus vier Schichten oder Layer: © it-novum GmbH 2010 26 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Abbildung 3: Architektur des Mondrian OLAP-Servers. Quelle: http://mondrian.pentaho.org/documentation/architecture.php 1. Presentation Layer: Visualisiert die Ausgabe für den Benutzer. Über diese Schicht kann der Benutzer mit Mondrian interagieren. Sie wird nicht von Mondrian selbst bereitgestellt, sondern durch Frontends anderer Hersteller. Diese lassen sich an Mondrian anbinden, darunter das ebenfalls unter Open Source-Lizenz stehende Web-Frontend jPivot für die Navigation über einen Webbrowser. Darüber hinaus ist die Anbindung an Mondrian u.a. durch XMLA und JOLAP möglich. 2. Dimension Layer: Diese Schicht parst, validiert und führt MDX-Queries aus. Die MDX Queries werden in mehreren Schritten generiert und ausgeführt: zuerst werden die Achsen (Dimensionen) des Würfels berechnet, danach die © it-novum GmbH 2010 27 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich einzelnen Zellen innerhalb der Achsen. Damit Februar 2011 nicht für jede Benutzerinteraktion das MDX-Query komplett neu berechnet werden muss, erlaubt ein sogenannter “Query Transformator” die Manipulation bestehender Queries. Für die Ausführung dieser Schritte ist es zwingend notwendig, dass vorher das relationale Datenbankmodell an das multidimensionale Modell angepasst wurde und diese Logik (d.h. die Zuordnung der einzelnen Dimensionen zur Fakttabelle) Mondrian mitgeteilt wurde. Das passiert über XML-Dateien, die alle notwendigen Informationen für Mondrian beinhalten. Pentaho liefert mit der Schema Workbench ein grafisches Tool, mit dem sich diese Dateien auf relativ einfache Weise erstellen lassen. In der Schema Workbench wird bereits festgelegt, auf welches DBS Mondrian später zugreifen wird. Nach Erstellung wird die XMLDatei dem BI-Server bekannt gegeben (publish). 3. Star Layer: In dieser Schicht werden bereits aggregierte Werte (z.B. die Marketingausgaben für ein bestimmtes Produkt zu einem bestimmten Zeitraum in einem bestimmten Land) im Speicher gehalten. Bei der nächsten Abfrage prüft Mondrian, ob er sie mit Werten aus dem Cache beantworten kann. Nur wenn die Prüfung negativ ausfällt, wird eine Abfrage an die zugrunde liegende Datenbank gesendet. 4. Storage Layer: Hier findet der Zugriff auf die zugrunde liegende Datenbank statt. Es macht aus Performancegründen Sinn, bereits voraggregierte Tabellen zu erstellen, auf die Mondrian zugreifen kann. Sonst kann es sein, dass die gesamte Faktentabelle gelesen werden muss. Die performanteste Variante wären Materialized Views, XML for Analysis, ein Standard für den Datenzugriff in analytischen Systemen, basiert u.a. auf SOAP, XML und http, Java Based OLAP interface, API auf Java-Basis für plattformunabhängigen Zugriff auf OLAP-Systeme sofern sie vom jeweiligen DBS unterstützt werden. Die Beispieldatenbank: World Class Movies Das Buch “Pentaho Solutions” (erschienen im Wiley-Verlag) enthält eine BeispielDatenbank, welche die Daten eines DVD-Verleihunternehmens enthält. Die im Buch enthaltenen Beispiele sowie die Datenbanken als MySQL-Dump lassen sich auf der Webseite des Verlags (http://eu.wiley.com/) herunterladen. Die Datenbank ist im beschriebenen Sternschema angeordnet und besteht aus verschiedenen Dimensionstabellen (z.B. für die Kunden, DVDs, Orte, Zeit) sowie vier Faktentabellen. Für die vorliegende Studie ist aber nur die Faktentabelle “fact_orders” von Relevanz. Sie beinhaltet 1,35 Millionen Datensätze, die © it-novum GmbH 2010 28 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Dimensionstabelle für die Kunden (“dim_customer”) Februar 2011 umfasst 145.000 Datensätze. Die Datenbanken, die wir testen wollen, haben wir an den Pentaho BI-Server über eine entsprechende Konfiguration in der Administration Console angebunden. Im Rahmen der Definition des Mondrian-Schemas wird in der zugehörigen Workbench der zugrundeliegende Datenbestand (die Datenbank) eingestellt, bevor es auf dem BI-Server publiziert wird. Das erlaubt es, den gleichen Cube mehrfach an den BI-Server mit verschiedenen darunterliegenden Datenbanken zu senden, was den Konfigurationsaufwand danach minimiert. Mondrian ist dann in der Lage, auf Grundlage der angegebenen DB die SQLStatements anzupassen (die Kennzeichnung von Werten und Bezeichnern betreffend). So kennzeichnet MySQL Werte teilweise mit einem doppelten Anführungsstrich (nicht ANSI-konform), wohingegen PostgreSQL einfache Anführungsstriche benutzt. Durch Parameter in der Konfigurationsdatei von Mondrian lässt sich das Logging sowohl der gesendeten SQL- als auch der MDX- Anweisungen einschalten. Verschiedene Operationen auf Basis des vorhandenen Würfels wurden ausgeführt, die Queries für die Messung wurden aus der Log-Datei ausgelesen und auf dem jeweiligen DBS direkt ausgeführt. Ergebnisse der Abfragemessung Bei einer Performance-Messung sollten unter anderem folgende Faktoren berücksichtigt werden: • das verwendete Betriebssystem • die Hardware • die Anzahl der (simulierten) Clientverbindungen • die Art der Anwendung (bspw. OLAP versus OLTP) • das Datenbankschema und die darauf simulierte Arbeitslast • das Datenvolumen und • Datenbankkonfiguration Die in der Tabelle dargestellten Ergebnisse haben wir erhalten, indem wir die Queries Q1 bis Q5 jeweils drei Mal nach Neustart des DBS ausgeführt haben (alle Queries sind im Anhang am Ende des Dokuments zu finden). Anschließend wurde der Mittelwert der Antwortzeiten gebildet. Alle Spalten in den SelectAnweisungen der Queries wurden aus Gründen der Vergleichbarkeit auf allen DBS indiziert (außer Infobright, da hier keine Index-Definitionen erlaubt sind). In den jeweiligen Konfigurationsdateien haben wir darauf geachtet, dass kein Query-Cache eingestellt war. Allerdings hält auch das Betriebssystem einige © it-novum GmbH 2010 29 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Daten im Cache. Unserer Kenntnis nach gibt es derzeit aber keinen Befehl, um den Cache in Windows zu leeren. MySQL (MyISAM) PostgreSQL Infobright Q1 39,296 34,265 2,001 Q2 17,359 6,901 2,250 Q3 2,591 2,016 2,281 Q4 23,422 5,172 6,157 Q5 7,907 8,453 1,969 Abbildung 4: Messergebnisse des Abfragetests Bei den Abfragen (auch bei denen, die hier nicht aufgelistet sind) konnten wir eine deutliche Tendenz feststellen: PostgreSQL schnitt durchwegs schneller ab als MySQL. Da es möglich ist, dass man mit einer anderen Hardwareausstattung andere Ergebnisse erzielt, muss man vorsichtig damit sein, die gewonnenen Daten auf alle Betriebssysteme und Hardwarekomponenten zu übertragen. Die Messung soll daher lediglich zur groben Orientierung dienen und fließt nicht in das Evaluationsergebnis ein. © it-novum GmbH 2010 30 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 5. Produktübersicht und -vergleich In diesem Kapitel beschreiben wir die drei untersuchten Datenbanken und ihr Abschneiden im Leistungstest. Die Tabelle enthält die Eckdaten von MySQL, PostgreSQL und Infobright: Hersteller MySQL AB PostgreSQL Infobright Evaluiertes Evaluierte Release- Produkt Version Datum Bemerkung MySQL Server PostgreSQL 5.1.46 April 2010 - 8.4.4 April 2010 - Infobright CE 3.3.2 Nicht betrachtet Nur Kurzbetrachtung 5.1 Evaluierung von MySQL MySQL ist ein relationales DBS und wurde 1994 von den Schweden David Axmark und Allan Larsson und dem Finnen Michael Widenius entwickelt. Es ist sowohl im Client-Server-Modus als auch eingebettet lauffähig. Das erste interne Release von MySQL datiert auf den 23. Mai 1995. Die drei Entwickler gründeten später das Unternehmen MySQL AB, das neben den Produkten auch Dienstleistungen für das Datenbanksystem anbietet. MySQL AB wurde im Februar 2008 von Sun Microsystems übernommen, Sun im Januar 2010 wiederum von der Oracle Corporation. Damit ist Oracle nun Träger des Projekts. Das Alleinstellungsmerkmal von MySQL sind die verschiedenen Speicher-Engines – manche von MySQL selbst entwickelt, andere von Drittanbietern. Die SpeicherEngines sind für verschiedene Einsatzzwecke konzipiert worden und machen MySQL sehr flexibel. Engines lassen sich in MySQL auch selbst erstellen. Für die verschiedenen Tabellen einer DB kann man auch unterschiedliche SpeicherEngines definieren. Durch den Befehl ENGINE=... gibt man bei der Erzeugung der Tabelle den zu verwendenden Speichermanager vor. MySQL enthält folgende Speicher-Engines: • MyISAM: Die Standard-Speicher-Engine von MySQL für nicht- transaktionssichere Tabellen. MyISAM-Tabellen können dafür Daten sehr schnell speichern und abrufen. © it-novum GmbH 2010 31 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich • Februar 2011 InnoDB: Engine für transaktionssichere Tabellen. InnoDB unterstützt COMMIT, ROLLBACK und Datenwiederherstellung. Für einen Mehrbenutzerbetrieb eignet sich sie besser als MyISAM, weil sie u.a. Zeilensperrungen ermöglicht (Features wie Zeilensperrung (engl. Row Level Locking), d.h. Schreibzugriffe in einer Transaktion bewirken eine Schreibsperre der betroffenen Datensätze für alle anderen Transaktionen. Erlaubt zudem die Erstellung von FremdschlüsselConstraints. • Memory: Speichert Tabelleninhalte im Hauptspeicher ab für sehr schnelle Reaktionszeiten. Bei einem Server-Neustart gehen die Inhalte natürlich verloren, dieTabellen selbst bestehen jedoch weiter, da ihre Definitionen auf der Festplatte gespeichert werden. • Merge: Sammlung mehrerer MyISAM-Tabellen, die dann als einziges Tabellenobjekt angesprochen werden können. Die zusammengefügten Tabellen müssen jedoch alle dieselben Spalten- und Indexdaten haben. • BDB: Bietet wie InnoDB Transaktionssicherheit, jedoch im Gegensatz zu dieser auch besondere Vorkehrungen im Falle eines Systemausfalls. • Archive: Geeignet für die Speicherung sehr großer Datenmengen bei möglichst niedrigem Speicherbedarf dank effizienter Kompressionsmethoden. Unterstützt keine Indizes und erlaubt nur Einfüge- und Leseoperationen. Bei der Installation von MySQL Server auf Windows-Rechnern wird bereits während der Installation ein Dialog angezeigt, der eine Bestimmung des Haupteinsatz-Zweckes des DBS erlaubt: • multifunktionales DBS: Aktivierung von MyISAM und InnoDB (Standard: InnoDB), gleichmäßige Verteilung der Serverressourcen auf beide Engines • transaktionales DBS: Aktivierung von MyISAM und InnoDB (Standard: InnoDB), Reservierung der überwiegenden Serverressourcen für InnoDB • nicht-transaktionales DBS: Vollständige Deaktivierung von InnoDB (Standard: MyISAM), Reservierung der gesamten Serverressourcen für MyISAM © it-novum GmbH 2010 32 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Allgemeine Kriterien Lizenz MySQL ist eine freie Software, die unter der General Public License (GPL) steht. Für die Einbettung in kommerzielle Applikationen ist das Produkt allerdings auch mit einer kommerziellen Lizenz erhältlich (MySQL Enterprise). Sie bietet im Gegensatz zur freien Version Gewährleistung und Hersteller-Support, der u.a. Beratungsleistungen und Unterstützung bei Problemlösungen mit festgelegten Reaktionszeiten umfasst. Des Weiteren umfasst sie zusätzliche Tools für Monitoring sowie Lösungen für Hochverfügbarkeit. Der Leistungsumfang der Enterprise-Version ist abhängig vom gewählten Modell, derzeit werden vier Leistungsstufen angeboten. Im Rahmen der Evaluierung kommt jedoch nur die freie Version zum Einsatz. Da die Community-Version von MySQL wegen der GPLLizenz mit einem Copyleft versehen ist, bekommt sie sieben Punkte. Referenzkunden MySQL wird in vielen Branchen eingesetzt und kann dementsprechend viele Referenzkunden vorweisen. So zählen z.B. im Bereich Softwaretechnologie Citrix, im Web/Web 2.0 unter anderem Wikipedia, Facebook, Google, Yahoo und Youtube und im Handel Sears zu den Kunden, um nur eine der Prominentesten zu nennen. Eine Übersicht über die größten Kunden, sortiert nach Branchen, kann auf der Herstellerseite eingesehen werden: http://www.mysql.com/customers/?origref=http://www.oracle.com/us/products /mysql/index.html. Die große Zahl an prominenten Kunden, die MySQL auch in sehr großem Maßstab einsetzen (Datenbanken im Terabyte-Bereich sind keine Seltenheit), führen zu einer Bewertung von 10 Punkten. Support Für die Community-Version des MySQL-Server wird naturgemäß kein HerstellerSupport gegeben. MySQL stellt allerdings eine ganze Reihe von Foren zur Verfügung, sowohl für Neueinsteiger als auch Fortgeschrittene. Durch die Einteilung in verschiedene Kategorien (z.B. Installation, Migration von anderen DBS, Performance) werden dort auf übersichtliche Weise alle Themenkomplexe rund um MySQL abgedeckt, sodass neue Nutzer nach kurzer Zeit einschätzen können, wo sie ihre Frage am besten einstellen. Die Anzahl der Beiträge in diesen Foren und die Antworthäufigkeit deuten auf eine hohe Aktivität der Community hin. Ein weiterer Kommunikationskanal bei MySQL sind Mailinglisten, bei denen der Nutzer nach der Anmeldung Beiträge als E-Mails bekommt. Der Nutzer kann auch © it-novum GmbH 2010 33 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fragen (und Antworten) an die Liste schicken. Eine Übersicht über die aktiven Listen gibt http://lists.mysql.com/. Außerdem ist es möglich, über den Internet Relay Chat (kurz IRC) in Kontakt mit anderen MySQL-Nutzern zu treten. Dazu dient der IRC-Channel #mysql, mit dem Chats mit einer beliebigen Anzahl von Teilnehmern möglich sind. Für die Enterprise-Edition von MySQL gibt es wie bereits beschrieben Hersteller-Support von Oracle. Da diese Version nicht zur Evaluierung steht, wird der Hersteller-Support aber nicht bewertet. Der Support durch die Community ist als sehr gut einzustufen, da MySQLAnwender über vielfältige Kommunikationskanäle Kontakt zu erfahrenen Benutzern aufnehmen können. Die Community von MySQL ist sehr groß, die Qualität der Antworten in den Foren nach stichprobenartigem Lesen sehr hoch. Aus diesen Gründen erhält MySQL im Bereich Support eine Bewertung von acht Punkten. Dokumentation Zu MySQL Server 5.1 existiert ein Referenzhandbuch, das man in vollem Umfang unter http://dev.mysql.com/doc/refman/5.1/en/index.html einsehen kann. Es ist auch in einer deutschen Übersetzung vorhanden, wobei wir darauf hinweisen möchten, dass sie nicht zwangsläufig so aktuell wie das englische Original sein muss. Außerdem können auf der Entwicklungsseite noch weitere Leitfäden, z.B. zur Benutzung der MySQL Workbench (diese wird später betrachtet) und des Source-Codes, heruntergeladen werden. Die Dokumentation zu MySQL erhält die volle Punktzahl, da sie sowohl in Umfang als auch Verständlichkeit keine Wünsche offen lässt. Produkt-Updates Im Gegensatz zur Enterprise Edition werden für die Community-Version des MySQLServers keine Service Packs bereit gestellt. Dennoch wird auch weiterhin an der Community Edition gearbeitet. In circa einmonatigen Abständen wird eine neue (Minor-)Version zum Download angeboten. Die Änderungen sind im Anhang des Referenzhandbuchs als Zusammenstellung von Patches dokumentiert. Da größere Updates bzw. neue Major-Releases für die CommunityVersion bei MySQL einige Zeit brauchen, um veröffentlicht zu werden, erhält MySQL nur sieben Punkte. © it-novum GmbH 2010 34 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fazit: Allgemeine Kriterien Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Lizenz 15 7 105 2 Referenzkunden 15 10 150 3 Support 25 9 225 0 25 12,5 12,5 0 9 9 9 0 225 112,5 112,5 4 Dokumentation 20 10 200 5 Produkt-Updates 25 7 175 100 43 855 3.1 Hersteller-Support 3.2 Community-Support 3.2.1 Support-Kanäle 3.2.2 Qualität Summe Systemanforderungen und Software-Anbindung Unterstützte Betriebssysteme Der MySQL Community Server ist für viele Betriebssysteme verfügbar. Namentlich sind das Windows, Mac OS X, Linux-Distributionen (spezielle Versionen für SuSE Linux Enterprise Server und Red Hat Enterprise Linux), HP-UX, Sun Solaris, IBM AIX sowie FreeBSD. Dabei gibt es auch 64-Bit Versionen für die genannten Systeme. Aufgrund der breiten Unterstützung aller gängigen Betriebssysteme, sowohl für 32-Bit und 64-Bit, vergeben wir die volle Punktzahl. Beschränkungen In diesem Kontext beziehen wir “Beschränkungen” nicht auf funktionelle Unzulänglichkeiten, sondern auf die Restriktionen, die das DBS größenmäßig vorgibt. Hinsichtlich der Tabellengröße gibt es bei MySQL kaum nennenswerte Beschränkungen. Vielmehr wird in der Praxis das Betriebssystem die Größe vorgeben. MyISAM unterstützt eine maximale Tabellengröße von 65,56 Terabyte. InnoDB speichert Tabellen in sogenannten Tablespaces ab, wobei ein Tablespace aus mehreren Dateien bestehen kann. Die maximale Größe eines Tablespace beträgt 64 Gigabyte. Sofern die maximale Dateigröße des verwendeten Betriebssystems ein Problem darstellt, kann man es durch Verwendung der © it-novum GmbH 2010 35 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 beschriebenen Merge-Engine umgehen. Eine weitere Möglichkeit ist, bei schreibgeschützten MyISAM-Tabellen das Hilfsprogramm “myisampack” zu verwenden, das diese Tabellen um mindestens 50% komprimieren soll. Bei InnoDB-Tabellen kann der Tablespace so konfiguriert werden, dass er aus mehreren kleinen Dateien besteht. Die maximale Anzahl von Indizes hängt von der verwendeten Speicher-Engine ab. Eine MyISAM-Tabelle kann maximal 64 Indizes haben, diese Zahl lässt sich jedoch durch manuelle Konfiguration des Builds seit Version 5.1.4 auf 128 erhöhen. Ein Index darf dabei aus maximal 16 Spalten bestehen. Wegen den wenigen serverseitigen Beschränkungen und den Möglichkeiten, Betriebssystem-Beschränkungen mit MySQL zu umgehen, erhält MySQL in diesem Kriterium insgesamt 9,75 Punkte. Unicode-Support Mit UTF-8 unterstützt MySQL einen weit verbreiteten Unicode-Zeichensatz, der die Zeichen vieler unterschiedlicher Sprachen enthält. Bereits bei der Installation von MySQL erscheint ein Dialog für die Festlegung des Standardzeichensatzes. Mit der Wahl der Option “Best Support for Multilingualism” wird UTF-8 ausgewählt. Diese Option kann man selbstverständlich im Nachhinein noch verändern. Deshalb erhält MySQL bei diesem Kriterium die volle Punktzahl. Datentypen MySQL unterstützt eine Vielzahl numerischer und zeichenbasierter Datentypen sowie Typen für Datum und Zeit. Bei manchen Datentypen unterscheidet sich ihre Implementierung allerdings vom SQL-Standard. So werden die booleschen Datentypen BOOL und BOOLEAN bei MySQL zurzeit lediglich als Synonym für TINYINT(1) behandelt. Eine vollständige Verarbeitung boolescher Datentypen gemäß dem SQL-Standard ist für die Zukunft geplant. Wegen der ansonsten vollständigen Unterstützung vergeben wir neun Punkte. XML-Unterstützung Seit Version 5.1.5 unterstützt MySQL grundlegende XML-Funktionalitäten nach dem XPath-Standard, allerdings ist die Implementierung noch nicht abgeschlossen. Es ist möglich, die Ausgabe von Clientprogrammen (mysql und mysqldump) in einer XML-Formatierung zu erhalten. Dazu werden beide Programme mit der Variable -xml gestartet. Durch diese Option können bereits existierende Tabellen in ein XML-Format exportiert werden. Es existieren auch verschiedene Techniken für den Import von XML-Dateien. So kann z.B. die Funktion LOAD_FILE() benutzt werden, um ein XML-Dokument zu öffnen, seinen Inhalt in einen String zu konvertieren und ihn in eine Tabellenspalte in MySQL zu schreiben. Eine weitere Möglichkeit ist, einen XML-formatierten MySQL Dump per © it-novum GmbH 2010 36 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Stored Procedures in eine MySQL Tabelle zu importieren. Die dritte Variante betrifft nur MySQL 6.0. In dieser Version gibt es das Statement “Load XML”. Vereinfacht agiert es umgekehrt wie die XML-Ausgabe von mysqldump und soll so einen unkomplizierten Import ermöglichen. Trotz dieser Möglichkeiten, existiert noch kein nativer XML-Datentyp. Da der XML-Support noch weitgehend in der Entwicklung ist und erst Version 6 eine verbesserte Implementation enthält, erhält MySQL in diesem Bereich nur sechs Punkte. Schnittstellen Durch die Schnittstelle Connector/ODBC (MyODBC) liefert MySQL Konnektivität für Clientprogramme, die sich über ODBC mit MySQL verbinden möchten. Die Clients können dabei Clients unter Windows und Unix laufen. Daneben gibt es für JDBC eine Schnittstelle namens Connector/J, die ebenso wie MyODBC quelltext-offen ist. Eine dritte Schnittstelle ist Connector/NET. Damit lassen sich .NET-Applikationen unter Verwendung von MySQL-Datenbankverbindungen entwickeln. Der Connector/MXJ ermöglicht es, eine MySQL-DB als Zusatzparameter in der JDBC-Verbindungs-URL anzugeben. Beim ersten Verbindungsaufbau wird durch diesen Parameter die DB gestartet. Des Weiteren enthält MySQL APIs u.a. für C, C++, Perl, PHP und Python bzw. entsprechende Module. Aufgrund dieser umfassenden Schnittstellenunterstützung vergeben wir die volle Punktzahl. Fazit: Systemanforderungen und Softwareanbindung Kriterium Gewichtung 1 Unterstützte Betriebssysteme/ Architekturen 15 10 150 5 10 10 10 50 100 2 Beschränkungen 20 9,75 195 2.1 pro Datenbank 2.2 pro Tabelle 2.3 pro Spalte 2.4 pro Index 5 5 5 5 10 10 10 9 50 50 50 45 Unicode-Support Datentypen XML-Support Schnittstellen 15 25 15 10 10 9 6 10 150 225 90 100 100 54,75 910 1.1 32-Bit 1.2 64-Bit 3 4 5 6 Summe © it-novum GmbH 2010 Erfüllungsgrad Nutzwert 37 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Datenbankobjekte Schemata MySQL verwendet Schemata synonym zu Datenbanken – die Befehle CREATE DATABASE und CREATE SCHEMA führen zum selben Ergebnis. Eine Datenbank kann also nicht mehrere Schemata besitzen, Schemata sind de facto nicht implementiert. Für jede Datenbank legt MySQL einen Ordner an, in dem die Dateien der dazugehörigen Tabellen abgespeichert werden. Bei neueren Windows-Versionen werden diese aufgrund von Berechtigungsproblemen seit Version 5.1.24 nicht mehr im Programmverzeichnis von MySQL gespeichert, sondern im Anwendungsdatenverzeichnis von Windows, das sich typischerweise im Home-Verzeichnis des Benutzers befindet . Da Schemata nicht unterstützt werden, erhält MySQL hier keine Punkte. Views MySQL erlaubt die Erstellung sowohl gewöhnlicher (nicht veränderbarer) als auch veränderbarer Views. Eine einfache View wird wie folgt erstellt: CREATE VIEW db_name . view_name AS SELECT * FROM table_name ; Ohne Angabe der Datenbank (db_name) wird die View der Standarddatenbank (Standardschema) zugeordnet. Basistabellen und Views teilen sich denselben Namensraum, daher darf eine Datenbank keine Basistabelle und View gleichen Namens enthalten. Eine View kann aus diversen Arten von Select-Anweisungen erstellt werden. Sie kann dabei Basistabellen, andere Views, Joins, Unions und Unterabfragen verwenden. Es ist möglich, bei ihrer Erstellung durch Angabe eines Algorithmus die Verarbeitung der View von MySQL zu beeinflussen. Das ist eine Erweiterung des SQL-Standards durch MySQL. Dabei werden die Algorithmen MERGE und TEMPTABLE unterschieden: • MERGE: Der Text der Anweisung, in der die View benutzt wird, wird mit der View-Definition “verschmolzen”, d.h. Teile der View-Definitionen ersetzen entsprechende Teile der Anweisung. Dieser Algorithmus ist effizienter als der TEMPTABLE-Algorithmus und ermöglicht zudem veränderbare Views. • TEMPTABLE: Die Ergebnisse der View werden in eine temporäre Tabelle geladen, die dann zur Ausführung der Anweisung genutzt wird. TEMPTABLE erlaubt keine veränderbaren Views. Wenn kein Algorithmus bei Erstellung der View angegeben wird, entscheidet MySQL selbst, welchen es für passender hält. Für die Erstellung einer veränderbaren (updateable) View gilt die Einschränkung, dass eine eins-zu-eins- © it-novum GmbH 2010 38 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Beziehung zwischen den Zeilen der View und den Zeilen der zugrunde liegenden Tabelle bestehen muss. Daher darf eine solche View u.a. keine Aggregatfunktionen, Unterabfragen, Joins oder Unions enthalten, andernfalls wird sie unveränderbar. Die anfangs angesprochenen Materialized Views werden gegenwärtig nicht von MySQL unterstützt. Deshalb vergeben wir in der Kategorie “Views“ nur fünf Punkte. Stored Procedures / Stored Functions MySQL unterstützt gespeicherte Prozeduren und gespeicherte Funktionen unter Verwendung der SQL:2003 Standard-Syntax für gespeicherte Routinen. Die Implementierung ist jedoch noch nicht vollständig abgeschlossen. Gespeicherte Routinen sind immer einer bestimmten Datenbank zugeordnet. Allerdings kann man durch die explizite Angabe des Datenbanknamens auch eine gespeicherte Routine aufrufen, die nicht auf der aktuellen Datenbank liegt. Zu beachten ist, dass durch das Löschen einer Datenbank ihre gespeicherten Prozeduren und Funktionen ebenfalls gelöscht werden. MySQL erhält in diesem Bereich acht Punkte. Trigger MySQL unterstützt Trigger. Sie sind mit einer Tabelle verbunden. Es ist nicht möglich, Trigger mit einer als temporär definierten Tabelle oder einer View zu verbinden. Für die Erstellung eines Triggers auf der Tabelle ist in der evaluierten Version das Super-Recht erforderlich. Seit Version 5.1.6 genügt ein spezielles Recht (Trigger-Recht). Die drei Ereignisse (Events), die einen Trigger auslösen, sind Insert, Update und Delete. Die Ereignisse sind dabei nicht automatisch gleichzusetzen mit den gleichnamigen SQL-Anweisungen. So können z.B. neben einer Insert-Anweisung auch Load Data- und Replace-Anweisungen ein Insert-Ereignis sein, weil auch diese beiden Befehle Zeilen in eine Tabelle einfügen. MySQL beschränkt die Anzahl von Triggern insofern, als dass pro Tabelle nicht zwei Trigger dieselbe Aktionszeit (Einschaltung des Triggers entweder vor oder nach dem Ereignis) und dasselbe Trigger-Ereignis haben. Durch die solide Unterstützung von Trigger erhält MySQL die volle Punktzahl. © it-novum GmbH 2010 39 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fazit: Datenbankobjekte Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Schemata 2 Views 10 40 0 5 0 200 2.1 nichtveränderbar 2.2 updateable 2.3 materialized 10 10 20 10 10 0 100 100 0 3 Stored Procedures/ Functions 4 Trigger 25 8 200 25 10 250 100 43 650 Summe Unterstützung des SQL/OLAP-Standards Erweiterung des Group-By-Operators MySQL erlaubt seit Version 4.1 den Einsatz des Rollup-Operators. Die Syntax entspricht jedoch nicht dem SQL/OLAP-Standard. Anstatt des Aufrufs “Group By Rollup (Name/ n der Gruppierungsspalte/n)” wird bei MySQL der Bezeichner WITH ROLLUP nach Auflistung der Gruppierungsspalte/n angegeben. Die beiden anderen Erweiterungen CUBE und GROUPING SETS sind derzeit nicht in MySQL implementiert und müssen daher weiterhin über verschachtelte Abfragen realisiert werden. Daher erhält MySQL in dieser Kategorie 3,33 Punkte. Fensterfunktionen Fensterfunktionen (Window Functions) werden gegenwärtig nicht von MySQL unterstützt. Es ist zwar möglich, Tabellen zu partitionieren, das liefert jedoch nicht die Funktionalität des Window-Partitioning. Aus diesem Grund gibt es hier keine Punkte. Olap-Funktionen Rangfunktionen werden gegenwärtig nicht von MySQL unterstützt, statistische Funktionen teilweise seit Version 4 – dort waren einige allerdings nicht konform © it-novum GmbH 2010 40 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 zum SQL-Standard. Das hat sich mit Version 5 verbessert: Sie enthält die SQLkonforme Funktion STDDEV_POP, welche die Populationsstandardabweichung des angegebenen Ausdrucks berechnet. Außerdem enthält sie STDDEV_SAMP (Beispielstandardabweichung), VAR_POP (Populationsstandardvarianz) sowie VAR_SAMP (Beispielvarianz). Weitere statistische Funktionen, z.B. zur Korrelations- und Regressionsanalyse, besitzt MySQL derzeit nicht. Aufgrund der rudimentären Unterstützung von statistischen Funktionen und dem Mangel an Rangfunktionen vergeben wir nur 1,5 Punkte. Common Table Expressions / Rekursive Queries CTEs und rekursive Queries werden zum jetzigen Stand nicht von MySQL unterstützt. Aus diesem Grund vergeben wir null Punkte. Fazit: Unterstützung des SQL-OLAP-Standards / OLAP-Funktionalitäten Kriterium Gewichtung Erfüllungs- Nutzwert grad 1 Erweiterung des Group-By Operators 25 3,332 83,3 1.1 Group By Rollup 1.2 Group By Cube 1.3 Group By Grouping Sets 8,33 8,33 8,33 10 0 0 83,3 0 0 30 0 0 10 10 10 0 0 0 0 0 0 20 1,5 30 10 10 0 3 0 30 2 Fensterfunktionen 2.1 Partitioning 2.2 Ordering 2.3 Framing 3 OLAP-Funktionen 3.1 Rangfunktionen 3.2 Statistische Funktionen 4 Common Table Expressions Summe 25 0 0 100 17,832 113,3 Performance und Skalierbarkeit Die Performance von MySQL hängt wie bei jedem DBS von einer ganzen Reihe von Faktoren ab. Teilweise lassen sich die einzelnen Komponenten der DBS nicht einer bestimmten Funktion zuordnen. So kann beispielsweise die Replikation © it-novum GmbH 2010 41 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 gleichermaßen der Ausfallsicherheit als auch der Geschwindigkeitsoptimierung dienen, genauso wie Indizes sowohl ein Objekt der Datenbank als auch ein Geschwindigkeitsfeature darstellen. Ein wesentlicher Punkt bei MySQL ist die Wahl der verwendeten Speicher-Engine. Sie ist ein wesentlicher Faktor bei der Leistungsfähigkeit der Datenbank. Man sollte daher genau abwägen, ob die Anwendung tatsächlich Transaktionssicherheit benötigt, weil MyISAM in der Regel bei vielen Select- und Insertoperationen schneller ist als z.B. das ACIDkompatible InnoDB. Skalierbarkeit Die beiden bereits beschriebenen Techniken der horizontalen Skalierung, Replikation und Partitionierung funktionieren auch in MySQL. In der von uns untersuchten Version unterstützt MySQL lediglich die asynchrone Replikation. Mit MySQL Cluster hat MySQL allerdings ein Datenbanksystem im Portfolio, das als besonderes Merkmal die synchrone Replikation unterstützt. Wie MySQL ist es in einer freien und in einer kommerziellen Version erhältlich. Bei der asynchronen Replikation von MySQL kann man zwischen verschiedenen Konfigurationen auswählen: • Single-Master: Ein Master verteilt die Aktualisierungen auf mehrere Slaves • Erweitertes Single Master: Verkettung von Replikationsservern, indem Slaves als Master agieren. • Multi-Master: Das System verteilt alle Änderungen jeden Mitglieds an die jeweils anderen Mitglieder. Vorteil: Fällt ein Master aus, können die anderen Master die Datenbank weiterhin aktuell halten. Nachteil: Weil der Rechenaufwand und die Netzwerklast bei vielen Knoten enorm steigen, kommt es vermehrt zu Asynchronitätsproblemen (und den daraus resultierenden Folgeproblemen wie Inkonsistenz). MySQL selbst empfiehlt, keine Multi-Master-Replikation unterschiedliche Realisierungen zu der verwenden. Replikation: Es unterstützt zwei Anweisungsbasierte Replikation (“logische Replikation”) und zeilenbasierte Replikation. Der zugrunde liegende Vorgang ist bei beiden Arten derselbe: 1. Der Master zeichnet Änderungen an seinen Daten im Binärlog auf (diese Änderungen werden auch Binärlog-Events genannt). 2. Der Slave kopiert die Binärlog-Events in sein Relay-Log. 3. Der Slave spielt die Änderungen im Relay-Log noch einmal ab und wendet damit die Änderungen auf seine eigenen Daten an. © it-novum GmbH 2010 42 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Bei der anweisungsbasierten Replikation, die es seit MySQL 3.23 gibt, wird die tatsächliche SQL-Abfrage noch einmal ausgeführt. Dieses System ist relativ leicht zu implementieren. Ein weiterer Vorteil ist, dass die Binärlog-Events sehr kompakt sind, sodass die Datenströme innerhalb des Netzwerks zwischen Master und Slaves klein bleiben. Allerdings hat dieses Verfahren auch Nachteile: Das Binärlog-Format von MySQL enthält nicht nur den Abfragetext, sondern auch Metadaten (z.B. Zeitstempel). Manche Anweisungen kann MySQL nicht korrekt replizieren, z.B. Abfragen mit der Funktion CURRENT_USER(). Genauso führen gespeicherte Routinen und Trigger bei der anweisungsbasierten Replikationen häufig zu Problemen. Demgegenüber schreibt der Master bei der zeilenbasierten Replikation alle Ereignisse, die angeben, wie einzelne Datensätze in der Tabelle geändert werden, in sein Binärlog. Dadurch kann jede Anweisung repliziert werden, das Binärlog wird allerdings auch sehr viel größer. MySQL empfiehlt die Verwendung einer möglichst neuen Version für Replikation, weil sie ständig weiter verbessert wird, sowie die Verwendung der gleichen Version auf Master und Slaves. Vor allem bei Versionen unter 5.1 kann es zu Inkompatibilitäten kommen, da das Binärlogformat erheblich verändert wurde. Seit Version 5.1 unterstützt MySQL die horizontale Partitionierung von Tabellen, die Implementierung ist allerdings noch nicht vollständig abgeschlossen. Die Datenzeilen werden dabei anhand einer Partitionierungsfunktion verschiedenen Partitionen zugeordnet, wobei eine Zeile nicht in mehreren Partitionen vorkommen darf. Die verfügbaren Varianten bei der Partitionierungsfunktion sind: • Range-Partitionierung (Bereichspartitionierung): Zuweisung der Zeilen an die Partitionen durch Prüfung, ob ihre Spaltenwerte in einen definierten Wertebereich fallen • List-Partitionierung (Listenpartitionierung): Ähnlich der Range- Partitionierung. Allerdings wird hier geprüft, ob ein Spaltenwert in einer von mehreren definierten Wertelisten (pro Partition eine Liste mit expliziten Werten) vorkommt. • Hash-Partitionierung: Möglichst gleichmäßige Verteilung der Datensätze auf die Partitionen durch das DBS mit Hilfe einer Hash-Funktion. Der Benutzer braucht sich also keine Gedanken über die Aufteilung der Partitionen machen, er gibt lediglich die Anzahl der Partitionen an. • Key-Partitionierung: Ähnlich der Hash-Partitionierung, allerdings dient hier der Primärschlüssel als Eingangsvariable für die Hashfunktion Der Partitionierungsschlüssel muss dabei immer eine Integer-Spalte oder ein Ausdruck sein, der einen Integer-Wert ergibt. © it-novum GmbH 2010 43 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 MySQL unterstützt daneben auch die Definition von Unterpartitionen, d.h. jede Partition kann noch weiter unterteilt werden. Als Unterpartitionen werden nur Hash- oder Keypartitionen akzeptiert. Jede Partition muss zudem dieselbe Anzahl von Unterpartitionen haben. Durch die Partitionierung verringert sich die Datenmenge, die ein Server untersuchen muss, was zu einer besseren Abfrageperformance führen kann. Die Partitionen können auch auf verschiedene physische Datenspeicher verteilt werden. Auch beim Löschen von vielen Zeilen können Partitionen sehr hilfreich sein, da durch das Löschen der Partition auch gleichzeitig alle in ihr enthaltenen Datensätze gelöscht werden. Zu beachten ist, dass partitionierte Tabellen, die mit einer Version vor 5.1.6 erstellt wurden, von einem Server der Version 5.1.6 und höher nicht mehr gelesen werden können. Das spätere Hinzufügen der Partitionierung durch ein ALTER TABLE funktioniert ebenfalls nur ab Version 5.1.6. Davor wird die Anweisung zwar akzeptiert, hat jedoch keinerlei Auswirkung. Partitionierte Tabellen unterstützen keine Fremdschlüssel (auch nicht bei InnoDB) und alle Partitionen und Unterpartitionen müssen dieselbe Engine verwenden (diese Beschränkung soll demnächst beseitigt werden). Vertikale Partitionierung (d.h. Verteilung von Tabellenspalten auf verschiedene physikalische Partitionen) wird nicht von MySQL unterstützt und es gibt derzeit auch keine Bestrebungen, sie zukünftig einzuführen. Insgesamt erhält MySQL von uns 6,5 Punkte – maßgeblich deshalb, weil eine synchrone Replizierung nur mit MySQL Cluster möglich ist. Indizes Indizes sind einerseits Objekte einer Datenbank, andererseits werden sie zur Steigerung der Performance eingesetzt. Die Implementierung von Indizes in MySQL hängt wie beschrieben von der verwendeten Speicher-Engine ab, wobei alle Engines mindestens 16 Spaltenindizes pro Tabelle erlauben. Die Erstellung von zusammengesetzten (d.h. mehrspaltigen) Indizes ist möglich. Außerdem unterstützt MySQL die Erstellung von Volltext-Indizes, allerdings nur für MyISAMTabellen und dort auch nur für Spalten der Datentypen Char, Varchar und Text. Ein Volltext-Index wird durch das Schlüsselwort FULLTEXT entweder bei der Tabellendefinition oder im Nachhinein mit CREATE INDEX erzeugt. Die Volltextsuche wird danach über die Funktion MATCH() ausgeführt. Die meisten Indizes sind in B-Bäumen gespeichert. Ausnahme ist die Memory-Engine, die auch Hash-Indizes unterstützt sowie Indizes auf raumbezogene Datentypen, die mit Hilfe von R-Bäumen indiziert werden. Zum gegenwärtigen Zeitpunkt unterstützt MySQL keine Bitmap-Indizes. Aus diesem Grund und aufgrund der fehlenden Volltext-Indizes in den meisten Speicher-Engines gibt es eine Punktzahl von fünf. © it-novum GmbH 2010 44 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Weitere Performance-Features MySQL ist multithreading-fähig und damit in der Lage, mehrere Prozessoren und Prozessorkerne zu unterstützen. Realisiert wird das über Kernel-Threads des jeweiligen Betriebssystems. Für jede Client-Verbindung auf den Server wird ein eigener Thread angelegt. Die Variable “max_connections” in der MySQLKonfigurationsdatei my.conf regelt folglich auch die Maximalanzahl der Threads auf dem MySQL-Server. Inwieweit MySQL allerdings von mehreren CPUs profitieren kann, hängt stark von der jeweiligen Systemarchitektur (Betriebssystem und Hardware) und der Last (die Art der Zugriffe auf das DBS) ab. Bei vielen Verbindungen, die auf getrennte Tabellen zugreifen, kann MySQL theoretisch mehrere CPUs gut einsetzen, da es wenig Blockierungen durch Locks gibt. Allerdings ist es nicht in der Lage, eine einzelne Abfrage parallel auf mehreren Kernen / CPUs ausführen zu lassen (außer in einem Cluster). Dieses Feature bieten von MySQL abgespaltene Produkte (Forks) wie InfiniDB. Für die Multiprozessor-Unterstützung (SMP) von MySQL vergeben wir acht, für das Multithreading zehn Punkte. Rückschlüsse aus der Performance-Messung Auch wenn die Messergebnisse von MySQL tendenziell schlechter sind als bei PostgreSQL, kann auch MySQL teilweise von den gesetzten Indizes profitieren. MySQL bietet in seiner Konfigurationsdatei my.ini einige Möglichkeiten der Performance-Verbesserung, allen voran natürlich der Query Cache, der für diese Tests deaktiviert war. In den Voreinstellungen wird er für Systeme optimiert, die wenig Leistung haben und/oder auf denen noch viele weitere Dienste außer dem MySQL-Server laufen. Fazit: Performance Kriterium 1 Skalierbarkeit 1.1 Replikation 1.1.1 a) synchrone 1.2.1 b) asynchrone 1.2 Partitionierung 2 Indizes 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 3 SMP-Support 4 Multithreading © it-novum GmbH 2010 Gewichtung Erfüllungsgrad Nutzwert 40 6,5 260 20 10 10 20 4 0 8 9 80 0 80 180 25 5,2 130 10 10 5 10 0 6 100 0 30 15 10 8 10 120 100 45 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich 5 Parallel Query Processing 6 Performance-Messung Summe Februar 2011 10 0 0 0 0 0 100 29,7 610 Datenintegrität und -sicherheit Transaktionen Die Transaktionsunterstützung von MySQL hängt wie beschrieben von der verwendeten Speicher-Engine ab. Die populärste MySQL-Speicherengine für Transaktionsunterstützung, InnoDB, ist voll ACID-kompatibel und implementiert alle vier Isolationsstufen des SQL-Standards. Die Standardisolationsebene von MySQL ist REPEATABLE_READ (die dritthöchste Isolationsebene, die bereits eine sehr hohe Nebenläufigkeit garantiert). InnoDB setzt sie auch als Standardeinstellung ein. Des Weiteren ist die Erstellung von Savepoints möglich, d.h. Stellen, an die bei einem Fehler innerhalb einer Transaktion zurückgesprungen werden kann. Ein Savepoint wird mit der Anweisung SAVEPOINT “savepointname” erstellt. Bei einem Fehler innerhalb der Transaktion geht MySQL mit der Anweisung ROLLBACK TO SAVEPOINT “savepointname” zu diesem gespeicherten Punkt zurück und führt die Transaktion problemlos fort. Für die sehr gut umgesetzte Transaktionsunterstützung erhält MySQL die volle Punktzahl. Locking und Nebenläufigkeit MySQL verfügt über Sperrverfahren auf Tabellenebene und Zeilenebene und unterstützt das Verfahren zur Erhöhung der Nebenläufigkeit (MVCC). Allerdings hängt auch hier wieder viel davon ab, welche Speicher-Engine zum Einsatz kommt. MyISAM unterstützt lediglich Sperrverfahren auf Tabellenebene, bietet jedoch auch eine Funktion für gleichzeitige Einfügevorgänge an. Diese lassen sich dadurch ausführen, ohne Abfragen zu blockieren. Sperrverfahren auf Tabellenebene bedeuten einerseits wenig Aufwand für die Erstellung, Prüfung und Freigabe der Locks (Locking-Overhead), andererseits garantieren sie wenig Nebenläufigkeit. Dagegen unterstützt InnoDB auch zeilenorientierte Sperrverfahren und MVCC, wobei letzteres mit den Isolationsebenen REPEATABLE READ und READ COMMITED funktioniert. Eine Übersicht über die LockingImplementierung der gebräuchlichsten Speicher-Engines von MySQL gibt folgende Tabelle: © it-novum GmbH 2010 46 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich LockingStrategie Concurrency Februar 2011 Overhead Engines tabellenorientiert niedrigste niedrigster zeilenorientiert zeilenorientiert, mit MVCC hoch höchster MyISAM, Merge, Memory NDB Cluster InnoDB, Falcon, PBXT, solidDB hoch höchste Für die Locking- und Nebenläufigkeitsstrategien geben wir 8,5 Punkte, da MVCC für Data Warehouse-relevante Speicherengines wie MyISAM und Memory nicht verfügbar ist. Benutzerrollen und Berechtigungskonzepte MySQL unterstützt keine Rollen oder Gruppen, verfügt allerdings über ein recht komplexes Sicherheits- und Berechtigungssystem, das man als Anfänger nur schwer durchschaut. Nutzer werden nicht nur anhand ihres Benutzernamens und des Passworts authentifiziert, sondern auch durch ihren Host, von dem aus sie die Verbindung herstellen. Das bedeutet in der Praxis, dass zwei gleichnamige Benutzernamen von Host A und von Host B den gleichen Benutzer darstellen können, dies aber nicht zwangsläufig müssen. Es können auch verschiedene Benutzer mit komplett anderen Passwörtern und Berechtigungen sein, das hängt allein von der Konfiguration der Benutzer-Accounts ab. Nachdem ein Account authentifiziert wurde (sich einloggen durfte), prüft MySQL, welche Berechtigungen er hat. Dabei gibt es zwei Arten von Berechtigungen: • Objektspezifische Berechtigungen: Sie gewähren den Zugriff auf bestimmte Objekte (z.B. auf Tabellen, Trigger und Views) • Globale Berechtigungen: Sie erlauben Funktionsaufrufe auf dem MySQLServer (z.B. um diesen herunterzufahren oder Abfragen anderer Benutzer anzuschauen) Die Berechtigungen werden in mehreren Tabellen abgespeichert (Grant-Tabellen), die den Kern der Sicherheitsmaßnahmen von MySQL darstellen. Es ist möglich, sie durch direkte Eingaben (INSERT, DELETE usw.) zu verändern. Das kann aber bei unerfahrenen Benutzern leicht zu einem unerwünschten Verhalten der Datenbank führen. Besser ist es, die Befehle GRANT und REVOKE zu verwenden. Beim GRANT-Befehl ist der entscheidende Punkt, dass gleichnamige Benutzer sich von jedem Host aus mit der Datenbank verbinden dürfen, wenn bei seiner Auslösung nicht explizit der Hostname mit angegeben wird. Die Berechtigungen für einen anderen Benutzer lassen sich mit folgendem Befehl anzeigen: © it-novum GmbH 2010 47 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 SHOW GRANTS For " user " " password " MySQL erlaubt auch die Erstellung eines sogenannten “Superuser” durch Vergabe der Berechtigung SUPER. Ein solcher User darf Operationen auf dem DBS ausführen, die anderen verwehrt bleiben, wie z.B. die Datenänderung auf einem schreibgeschützten Server. Ein weiteres Merkmal des Superuser ist, dass er sich auf die Datenbank verbinden darf, selbst wenn schon die maximale Verbindungsanzahl erreicht wurde und sich andere Clients nicht mehr verbinden dürfen. Das Berechtigungskonzept von MySQL ist als sicher einzustufen, das fehlende Rollenkonzept führt allerdings zu einem Punkteabzug, sodass MySQL für dieses Kriterium acht Punkte erhält. Fazit: Datensicherheit und Datenintegrität Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Skalierbarkeit 1.1 Replikation 1.2 Partitionierung 2 Indizes 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 3 SMP-Support Summe 35 10 350 25 10 10 10 250 100 40 8,5 340 10 10 20 10 10 7 100 100 140 25 8 200 100 26,5 890 Administration und Wartung Client- und Hilfsprogramme MySQL bietet ein kostenloses grafisches Tool zur Administration an, die MySQL Workbench. In der neuesten Version (5.2 RC) ersetzt es die beiden älteren Tools “MySQL Query Browser” und “MySQL Administrator”. Die Workbench bietet eine dreigeteilte Funktionalität: Zum einen lassen sich dort auf relativ einfache Art und Weise Datenbankobjekte verändern. Zum anderen können Enhanced-EntityRelationship-Modelle erstellt werden. Außerdem ist die Workbench der Ort, wo sich Serververwaltungsaufgaben durchführen lassen, d.h. Konfiguration des © it-novum GmbH 2010 48 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Servers, Benutzerverwaltung, Einsehen aktiver Verbindungen, Status- und Servervariablen. A Abbildung: MySQL Workbench 5.2 RC Im Programm selbst werden keine Hilfestellungen durch Tooltips o.ä. gegeben, auch nicht bei der Serverkonfiguration. Ein Anfänger tut sich folglich schwer. Er kann sich aber über die FAQs (http://wb.mysql.com/?page_id=7) informieren oder das Handbuch konsultieren: http://dev.mysql.com/doc/workbench/en/ Außer diesem grafischen Tool enthält MySQL eine Reihe weiterer Kommandozeilen-Tools, darunter: a. mysql: Tool zur Server-Administration b. mysqldump: Backup-Tool c. mysqlcheck: Tool für die Wartung von Tabellen (Überprüfung, Reparatur, Analyse und Optimierung) Die Clientprogramme von MySQL sind in ihrem Funktionsumfang als sehr gut einzustufen, allerdings bietet das ältere Tool “MySQL Administrator” einen besseren Bedienkomfort. Da der Administrator aber auch problemlos mit dem MySQL Server 5.1 funktioniert, gibt es dafür keinen Punktabzug, sondern die volle Punktzahl. © it-novum GmbH 2010 49 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Backup und Wiederherstellung Backup und Wiederherstellung sind zwei Schlüsselbegriffe für jeden Datenbankadministrator. Da das Thema sehr komplex ist, wollen wir an dieser Stelle nur kurz auf die unterschiedlichen Methoden zur Datenbankensicherung in MySQL und die mitgelieferten Werkzeuge eingehen. Zur Sicherung einer MySQLDatenbank kann man das gerade erwähnte Hilfsprogramm mysqldump verwenden. Es erstellt ein logisches Backup, das die Daten in einer Form enthält, die MySQL interpretieren kann (DDL- und DML-Anweisungen). Eine weitere Methode ist die Benutzung von mysqlhotcopy, einem mitgelieferten Perl-Scrip. Es sperrt die Tabellen der zu sichernden DB (Lesezugriffe sind weiterhin möglich) und kopiert sie mittels Betriebssystembefehle an einen anderen physischen Ort. Der Begriff hotcopy ist in diesem Zusammenhang etwas irreführend, da er gewöhnlich dafür steht, dass der Server keine Ausfallzeit hat. Durch die Schreibsperre auf die Tabellen ist das de facto aber doch der Fall. Für eine punktgenaue Wiederherstellung ist allerdings auch das Sichern der Binärlogs zwingend erforderlich. Die mitgelieferten Backup-Tools liefern die nötigen Funktionalitäten für eine kontinuierliche oder eine punktuelle Sicherung. OnlineBackups (Hot Copies) sind allerdings schwer realisierbar, daher bekommt MySQL von uns nur acht Punkte. Fazit: Administration und Wartung Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Client- und Hilfsprogramme 50 10 500 2 Backup-Möglichkeiten 50 8 400 100 18 900 Summe Zukünftige Entwicklungen „Falcon“ hieß die Speicher-Engine, die seit längerem entwickelt wurde, um die zukünftige Standard-Engine von MySQL zu werden. Oracle hat die Entwicklung nach der Übernahme von MySQL jedoch eingestellt. Nun soll InnoDB den Platz der Standard-Engine einnehmen (Hersteller Innobase wurde ebenfalls von Oracle übernommen) und kontinuierlich verbessert werden. MyISAM soll allerdings weiterhin unterstützt werden. Ein weiterer Punkt auf der Entwicklungsagenda ist © it-novum GmbH 2010 50 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 die einfache Migration zwischen Oracle- und MySQL-Datenbanken, außerdem sollen Features, die bisher nur Oracle 11G besaß, teilweise Einzug in MySQL halten. © it-novum GmbH 2010 51 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 5.2 Evaluierung von PostgreSQL PostgreSQL ist ein objektrelationales DBS, dessen Entwicklung auf die University of California in Berkeley (UCB) zurückgeh. Hier wurde zwischen 1977 und 1985 ein relationales Datenbanksystem unter dem Namen Ingres entwickelt. Der Sourcecode dieses Projektes wurde von der Firma Relational Technologies (später INGRES Inc.) aufgekauft und weiterentwickelt für kommerzielle Zwecke. Zwischen 1986 und 1994 wurde ein weiteres Produkt aus den Erfahrungen mit Ingres entwickelt: Postgres (post steht für lateinisch nach, also nach Ingres). Dieses Produkt wurde ebenfalls von einer kommerziellen Firma aufgekauft: Zuerst von Illustra und dann von Informix, wo es teilweise in den Informix Universal Server integriert wurde. Die Geschichte des heutigen PostgreSQL beginnt 1994 mit der Erweiterung des Codes von Postgre um einen SQL-Interpreter und der Veröffentlichung als Postgres95. Zwei Jahre später (1996) wurde mit der Weiterführung der Versionsnummern aus dem Berkeley-Projekt der Name in PostgreSQL geändert. Die Objektrelationalität unterscheidet PostgreSQL von anderen Datenbanken wie MySQL. PostgreSQL besitzt Klassen, Vererbung und Überladung von Funktionen als objektrelationale Merkmale. Die Instanzen (reale Objekte einer Klasse) haben eine systemweit eindeutige Objekt-ID (OID). Beispiel: Eine Tabelle stellt eine Klasse dar und jede Spalte in ihr ist eine eigene Instanz. Durch das Vererbungskonzept können Kindtabellen erstellt werden, die die Eigenschaften der Muttertabelle erben, aber zusätzlich noch weitere Eigenschaften haben können. Die Überladung von Funktionen ermöglicht die Mehrfachdefinierung einer Funktion mit gleichem Namen. Das PostgreSQL kann zur Laufzeit anhand der übergebenen Parameter an diese Funktion erkennen, welche der Funktionen verwendet werden soll. Eine weitere Besonderheit von PostgreSQL ist das Rule-System. Rules werden vom Benutzer erstellt und an die angegebene Klasse (z.B. eine Tabelle) angehängt. Sie sind dann in der Lage, eingehende Queries umzuschreiben und die modifizierten Queries an den Ausführungsplaner zu senden – anders als andere Regeln wie Trigger oder Stored Procedures. Rules werden u.a. für Updateable Views und Tabellenpartitionierung eingesetzt. © it-novum GmbH 2010 52 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Allgemeine Kriterien Lizenz PostgreSQL steht unter der Berkeley Software Distribution-Lizenz (BSD), die kein Copyleft beinhaltet. Der Code kann also ohne die Beschränkung, ihn nach Veränderung wieder veröffentlichen zu müssen, verändert werden. Dadurch ist PostgreSQL für die Entwicklung kommerzieller Anwendungen interessant und erhält zehn Punkte. Referenzkunden Auf der Webseite von PostgreSQL kann man eine Auswahl von Kunden aus verschiedenen Branchen einsehen – darunter BASF, Cisco, Juniper Networks und Apple, aber auch einige US-amerikanische Behörden und Open Source-Projekte wie Debian und Sourceforge. Aus den verschiedenen Branchen der Kunden (und den teilweise auf dieser Seite verfügbaren Fallstudien) lässt sich entnehmen, dass sich PostgreSQL für praktisch alle Einsatzzwecke nutzen lässt. In manchen Bereichen ist PostgreSQL nicht so stark vertreten wie MySQL, gerade im stark wachsenden Bereich Web/Web 2.0. Aus diesem Grund erhält PostgreSQL acht Punkte. Support Hersteller-Support gibt es für PostgreSQL nicht, weil PostgreSQL ein reines Community-Projekt ist, hinter dem kein kommerzielles Unternehmen steht. Sofern kommerzieller Support gewünscht ist und nicht auf die Dienstleistungen dritter Unternehmen zurückgegriffen werden soll, bietet sich die Verwendung von Postgres Plus an. Das DBS wird von der Enterprise DB Corporation vertrieben und baut auf PostgreSQL auf, erweitert es allerdings um einige Features wie Qualitätstests, erweiterte Tuning-Optionen und Kompatibilität zu Oracle. Support durch die Community gibt es durch die Foren, Mailinglisten, UserGruppen und den IRC. Im deutschsprachigen Raum gibt es mehrere Foren, einen Überblick vermittelt http://www.postgresql.de/info.whtml#forum. Da die üblichen Supportkanäle allesamt vorhanden sind, die Aktivität der Community dort allerdings nicht ganz so hoch ist wie bei MySQL, erhält PostgreSQL für das Kriterium Support 8,5 Punkte. Dokumentation Das komplette Referenzhandbuch zu PostgreSQL ist auf Englisch verfügbar, sowohl in einer Online-Version als auch in einer pdf-Version (auch für Releases älter als 8.4): http://www.postgresql.org/docs/manuals/. Eine deutsche Ausgabe © it-novum GmbH 2010 53 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 ist erhältlich, allerdings nicht auf dem neuesten Stand (2003). Außerdem gibt es eine Dokumentation in Form eines Wikis, das User-Dokumentationen, FAQs und Ratgeber zu vielen Bereichen von PostgreSQL umfasst: http://wiki.postgresql.org/wiki/Main_Page. Das englische Referenzhandbuch behandelt alle vorstellbaren Themen rund um PostgreSQL (auch werden dort die jeweils neuen Funktionen gut erklärt), für das Fehlen einer aktuellen deutschen Referenz gibt es allerdings einen Punktabzug und somit nur neun Punkte. Produkt-Updates / Neue Versionen Ähnlich MySQL wird bei PostgreSQL eine dreiteilige Versionsnummer verwendet. Die erste Zahl ändert sich dabei sehr selten, mit ihr wird kenntlich gemacht, dass gravierende Neuerungen oder Änderungen stattgefunden haben. Dagegen steht die zweite Zahl (in Verbindung mit der ersten) für ein Major-Release. Diese werden in unregelmäßigen Abständen veröffentlicht, meistens ist von einem Zeitabstand von circa einem Jahr auszugehen. Diese Releases werden bis zu fünf Jahre nach ihrer Veröffentlichung durch Patches weiter aktualisiert und als Minor-Release (die dritte Zahl in der Versionsnummer) zur Verfügung gestellt. Nach Ablauf dieser Zeit (End of Lifetime), kann es allerdings weiterhin vorkommen, dass kritische Bugfixes in den Sourcecode integriert werden. Die Versionspolitik von PostgreSQL ist daher als anwenderfreundlich einzustufen. Eine komplette Übersicht über den Versionssupport ist im Wiki von PostgreSQL zu finden. Seit März 2008 gibt es sogenannte “Commit Fests”, die in einem Dreimonatsrhythmus stattfinden. Während eines solchen Commit Fest richtet sich der Fokus der Entwickler-Community nicht auf die Programmierung, sondern auf die Bewertung und Gewichtung neuer Patches. Für neue Funktionen gibt es eine Art “Warteschlange” (Queue). Ein Patch wird erst dann als solcher angenommen, bis alle Funktionen in das CVS von PostgreSQL gewandert sind (oder endgültig abgelehnt wurden). Auf diese Weise will man einerseits die Übersichtlichkeit wahren, auf der anderen Seite beschleunigt man so die Entwicklung von PostgreSQL. Aufgrund des sehr strukturierten Vorgehens und der regelmäßig stattfindenden Commit Fests bewerten wir PostgreSQL im Bereich Dokumentation mit insgesamt neun Punkten. © it-novum GmbH 2010 54 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fazit: Allgemeine Kriterien Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Lizenz 15 10 150 2 Referenzkunden 15 8 120 3 Support 25 8,5 212,5 3.1 Hersteller-Support 3.2 Community-Support 3.2.1 Support-Kanäle 3.2.2 Qualität 0 25 12,5 12,5 0 8,5 9 8 0 212,5 112,5 100 4 Dokumentation 20 9 180 5 Produkt-Updates 25 9 225 100 46,5 887,5 Summe Systemanforderungen und Software-Anbindung Unterstützte Betriebssysteme PostgreSQL bringt Binärdistributionen für Linux, Mac OS, Solaris, Free BSD und Windows mit. Eine 64-Bit-Version ist bei PostgreSQL 8.4 nur für Linux erhältlich, die neue Version 9.0 enthält sie nun auch für Windows. Da dadurch 64-BitUnterstützung für alle wichtigen Betriebssysteme vorhanden ist, erhält PostgreSQL 10 Punkte. Beschränkungen des Datenbankensystems Hinsichtlich der Datenbankgröße gibt es bei PostgreSQL keine Beschränkung, eine Tabelle darf maximal 32 Terabyte groß sein. Eine Zeile darf 1,6 Terabyte nicht überschreiten, ein Feld nicht 1 Gigabyte. Die Zeilenanzahl sowie die Anzahl der Indizes pro Tabelle (hauptsächlich Quelltext) nicht limitiert, die maximale Spaltenanzahl richtet sich nach den verwendeten Datentypen (zwischen 250 und 1600 Spalten). Aufgrund der Tatsache, dass bei PostgreSQL die Limitierungen des Betriebssystems nicht so leicht zu umgehen sind wie bei MySQL, gibt es einen Punktabzug bei den Tabellen-Limits, sodass wir PostgreSQL in diesem Bereich mit 9,5 Punkte bewerten. Unicode-Support PostgreSQL unterstützt eine Vielzahl von Zeichensätzen, darunter auch den Unicode-Zeichensatz UTF-8. Zur Änderung der Lokalisierung ist es möglich, bei © it-novum GmbH 2010 55 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 der Initialisierung des Datenbank-Clusters (des Datenverzeichnisses) mit der Option “locale” Sprache und Land einzustellen. Ohne Angabe dieser Option wird die Regions- und Spracheinstellung des Betriebssystems übernommen. PostgreSQL erhält aufgrund der umfassenden Einstellungsmöglichkeiten zehn Punkte. Datentypen PostgreSQL unterstützt alle wichtigen Datentypen, darunter auch Sequenzen (Zähler, die tabellenunabhängig in festlegbaren Schritten vorwärts und rückwärts zählen) und zusammengesetzte Datentypen. Darüber hinaus kann man eigene Datentypen mit dem Befehl CREATE TYPE erstellen. Eine Besonderheit von PostgreSQL ist, dass eine Spalte auch als ein- oder mehrdimensionaler Arraytyp definiert werden kann, d.h. in einer Spalte lässt sich mehr als nur ein einzelner Wert speichern. Angesichts dieser vielfältigen Möglichkeiten bewerten wir PostgreSQL mit der vollen Punktzahl. XML-Unterstützung Mit dem XML-Datentyp hat man in PostgreSQL die Möglichkeit, komplette Dokumente oder nur Teile davon zu speichern und zu bearbeiten. Dabei werden die Eingaben auf eine korrekte XML-Syntax hin geprüft, ansonsten wird die Eingabe mit dem Hinweis auf eine inkorrekte Syntax abgelehnt. Außerdem kann man durch XPath-Definitionen in den Daten suchen. Die gefundenen Werte werden dann als Array ausgegeben. Des Weiteren lassen sich sowohl Tabellen und Queries als auch Cursors als XML-ausgeben. Insgesamt stufen wir den XMLSupport von PostgreSQL als solide ein und bewerten ihn mit acht Punkten. Schnittstellen Zur Anbindung von Java-Programmen unterstützt PostgreSQL den JDBCStandard. Downloadmöglichkeiten für aktuelle und ältere PostgreSQL-JDBCTreiber sowie einen Überblick der Versionskompatibilität einzelner Treiber gibt die Webseite http://jdbcpostgresql.org/download.html. Daneben wird der ODBCStandard unterstützt, den Treiber kann man auf http://www.postgresql.org/ftp/odbc/versions/ herunterladen. Darüber hinaus gibt es Schnittstellen für .Net, C, C++, PHP, Perl, TCL, ECPG, Python und Ruby. Da PostgreSQL Anbindemöglichkeiten für nahezu alle relevanten Programmiersprachen besitzt, bekommt das DBS von uns zehn Punkte. © it-novum GmbH 2010 56 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fazit: Systemanforderungen und Software-Anbindung Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Unterstützte Betriebssysteme/ Architekturen 15 8,67 130 5 10 10 10 50 100 2 Beschränkungen 20 9,5 190 2.1 pro Datenbank 2.2 pro Tabelle 2.3 pro Spalte 2.4 pro Index 5 5 5 5 10 8 10 10 50 40 50 50 Unicode-Support Datentypen XML-Support Schnittstellen 15 25 15 10 10 10 8 10 150 250 120 100 100 56,17 940 1.1 32-Bit 1.2 64-Bit 3 4 5 6 Summe Datenbankobjekte Schemata PostgreSQL unterstützt im Gegensatz zu MySQL Schemata: Innerhalb des Datenbank-Clusters kann es mehrere Datenbanken geben, die wiederum aus Schemata bestehen. In verschiedenen Schemata dürfen Objekte gleichen Namens existieren (beispielsweise zwei gleichnamige Tabellen). Der große Unterschied zwischen Datenbanken und Schemata ist, dass ein Client sich jeweils nur mit der Datenbank verbinden kann, die er in der Verbindungsanfrage angibt, dort dann aber Zugriff auf alle Objekte des Schemas hat (entsprechende Rechte vorausgesetzt). Die Verwendung von Schemata ermöglicht eine logischere Strukturierung der Datenbankobjekte. Außerdem lassen sich so Namenskollisionen verschiedener Objekte und Funktionen vermeiden, etwa wenn Anwendungen von Drittanbietern benutzt werden. Greift man häufig auf Schemata zurück und soll nicht jedes Mal der Schemaname vor den Tabellennamen geschrieben werden, hilft der Parameter search_path. Durch ihn lassen sich ein oder mehrere Schemata angeben, die der Reihe nach durchsucht werden. Das erste Schema in dieser Liste ist das aktuelle Schema, das für CREATE TABLES verwendet wird, sofern man kein Schema gibt. Der aktuelle Schema-Suchpfad lässt sich mit folgender Anweisung ermitteln: © it-novum GmbH 2010 57 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 SHOW search_path ; Um diesen Pfad zu ändern, wird folgende Anweisung verwendet: SET search_path TO ( schemaname1 , schemaname2 , usw . ) Wenn eine Tabelle gleichen Namens in mehreren der Schemata enthalten ist, wird die Tabelle desjenigen Schemas verwendet, in dem sie zuerst gefunden wird. Eine dauerhafte Einstellung des Schema-Suchpfades lässt sich in der Konfigurationsdatei postgresql.conf vornehmen. Der Suchpfad funktioniert in gleicher Weise auch für Datentypnamen, Funktionsnamen und Operatornamen. Aufgrund der Unterstützung von Schemata vergeben wir zehn Punkte. Views Views lassen sich in PostgreSQL mit den gleichen Anweisungen wie in MySQL erzeugen und löschen. PostgreSQL unterstützt ebenfalls geschachtelte Views, d.h. Sichten, die wiederum auf anderen Sichten basieren. Updateable Views können erzeugt werden, allerdings nur in Verbindung mit Rules, was die Definition einer View deutlich erschwert. Materialized Views an sich unterstützt PostgreSQL nicht. Sie lassen sich jedoch erstellen, allerdings bedeutet das etwas Aufwand. Unter Verwendung der prozeduralen Abfragesprache PL/pgSQL gibt es mit Hilfe von Triggern verschiedene Implementierungstechniken, die aber ein hohes Maß an technischem Verständnis und Detailwissen über die zugrunde liegenden Daten verlangen. Funktionierende Implementierungen lassen sich beispielsweise auf der Webseite von Jonathan Gardner (http://tech.jonathangardner.net/) nachlesen. PostgreSQL erhält in den Unterkriterien “Updateable Views” und “Materialized Views” Punktabzüge und bekommt daher insgesamt 6,5 Punkte. Stored Procedures / Stored Functions Stored Procedures werden unterstützt und vorzugsweise in PL/pgSQL geschrieben, allerdings sind auch Umsetzungen in anderen prozeduralen Sprachen möglich. Man erstellt sie in PostgreSQL durch den Befehl CREATE FUNCTION, daher der Begriff „Stored Functions“. Bis auf syntaktische Unterschiede aufgrund der prozeduralen Sprache sind sie genauso zu erstellen wie die Stored Procedures von MySQL. Wir bewerten PostgreSQL daher mit der vollen Punktzahl. © it-novum GmbH 2010 58 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Trigger Trigger werden unterstützt und können in den meisten prozeduralen Sprachen (z.B. PL/pgSQL, PL/Perl und PL/Python) sowie in C geschrieben werden. Um einen Trigger zu erstellen, muss vorher eine Trigger-Funktion mit CREATE FUNCTION erstellt werden, auf die das Trigger-Objekt zugreifen kann. Aufgrund der etwas komplizierteren Vorgehensweise als bei MySQL erhält PostgreSQL nur neun Punkte. Fazit: Datenbankobjekte Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Schemata 2 Views 2.1 nichtveränderbar 2.2 updateable 2.3 materialized 3 Stored Procedures / Functions 4 Trigger Summe 10 40 10 6,5 100 260 10 10 20 10 8 4 100 80 80 25 25 10 9 250 225 100 35,5 835 Unterstützung des SQL/OLAP-Standards Erweiterung des Group-By-Operators PostgreSQL unterstützt zum gegenwärtigen Zeitpunkt keine Erweiterungen durch ROLLUP, CUBE oder GROUPING SETS und erhält deswegen null Punkte. Fensterfunktionen Seit Version 8.4 unterstützt PostgreSQL Fensterfunktionen (Window Functions). Die Syntax ist konform zum SQL/OLAP-Standard. Windowing Functions arbeiten auf einer Art virtuellen Tabelle, die durch die FROM-Klausel bestimmt wird. Sofern in dieser auch noch WHERE-, GROUP BY- und HAVING- Klauseln angegeben wurden, reduziert sich die Tupelmenge, die eine Fensterfunktion betrachtet. Eine Abfrage kann somit zwar mehrere Fensterfunktionen enthalten, die die Daten auf verschiedene Art “slicen” (definiert über verschiedene OVERKlauseln), aber sie alle arbeiten auf dem gleichen Datenset. Zu beachten ist, dass der Window Frame durch die ORDER BY-Klausel mitbestimmt werden kann – fehlt sie, besteht der Standard-Window-Frame aus allen Zeilen der Partition. Die Implementierung der © it-novum GmbH 2010 59 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fensterfunktionen scheint an dieser Stelle noch nicht ganz abgeschlossen zu sein. Im Vergleich zum SQL-Standard (und zu kommerziellen Systemen wie Oracle DB) ist es nämlich nicht möglich, Befehle wie BETWEEN x PRECEDING AND y FOLLOWING anzugeben (sogenannte “sliding windows”, z.B. für laufende Durchschnittsberechnungen). Dafür ziehen wir Punkte ab, sodass PostgreSQL im Bereich Fensterfunktionen auf 8,33 Punkte kommt. Olap-Funktionen Außer den bekannten Aggregationsfunktionen integriert PostgreSQL eine Reihe spezieller (Fenster-)Funktionen, die sich für analytische Zwecke eignen. Dazu zählen die behandelten Rangfunktionen (rank, dense_rank, percent_rank, cume_dist, row_number). Eine komplette Übersicht der enthaltenen Funktionen gibt es im PostgreSQL-Referenzhandbuch. PostgreSQL hat inzwischen eine ganze Reihe von statistischen AggregatFunktionen gemäß dem SQL-Standard umgesetzt. Neben den bereits bei MySQL genannten Funktionen (z.B. für die Varianz) sind das u.a. Funktionen zur Berechnung der Kovarianz (covar_pop, covar_samp), des Korrelations- Koeffizienten (corr) und die Regressionsanalyse. Angesichts der kompletten Abdeckung von Rang- und Statistikfunktionen erhält PostgreSQL zehn Punkte. Common Table Expressions / Rekursive Queries Seit Version 8.4 sind Common Table Expressions in PostgreSQL integriert, dabei sind sowohl nichtrekursive als auch rekursive CTE möglich. Bei der Implementierung wurden die Vorgaben aus dem SQL-Standard eingehalten, sodass wir die volle Punktzahl vergeben. © it-novum GmbH 2010 60 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fazit: Unterstützung des SQL/OLAP-Standards, weitere OLAP-Funktionalitäten Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Erweiterung des Group-ByOperators 1.1 Group By Rollup 1.2 Group By Cube 1.3 Group By Grouping Sets 2 Fensterfunktionen 2.1 Partitioning 2.2 Ordering 2.3 Framing 3 OLAP-Funktionen 3.1 Rangfunktionen 3.2 Statistische Funktionen 4 Common Table Expressions Summe 25 0 0 8,33 8,33 8,33 0 0 0 0 0 0 30 8,33 250 10 10 10 10 10 5 100 100 50 20 10 200 10 10 10 10 100 100 25 10 250 100 28,33 700 Performance Skalierbarkeit PostgreSQL unterstützt die asynchrone Replikation. Das bekannteste System für asynchrone Replikation ist Slony-I, das ebenso wie PostgreSQL unter der liberalen BSD-Lizenz steht. Es arbeitet im Master/Slave-Verfahren, wobei der Master (bei PostgreSQL “Origin” genannt) der einzige Knoten des Slony-I-Clusters ist, der Änderungen an Datenbankobjekten vornehmen kann. Die Tabellen und Sequenzen werden in sogenannte “Sets” zusammengefasst, die die Slaves (“Subscriber” genannt) abonnieren können. Durch dieses System weiß der Master, an welche Slaves er bei Änderungen welche Sets verteilen muss. Realisiert wird die Replikation über slon-Prozesse, Trigger erfassen im Master die Änderungen. Diese Methode bietet den Vorteil, dass nur genau die Daten erfasst werden, die in die Datenbank geschrieben werden. Andererseits vergrößert sich dadurch die I/O-Last auf dem Master, da die Daten vom Trigger noch einmal zwischengespeichert werden müssen, bevor sie der slon-Prozess überträgt. Slony-I besitzt keine eingebaute Überwachung, dennoch ist eine FailoverFunktionalität möglich durch die Verbindung zu einem Heartbeat-Programm (z.B. das Linux High Availability Project http://linux-ha.org/wiki/Heartbeat). © it-novum GmbH 2010 61 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Außer Slony-I existieren noch weitere Möglichkeiten der Replikation. Eine sehr vielseitige Methode ist pgpool-II. Es handelt sich um eine Middleware zum Verbinden von Programmen zu einer PostgreSQL-Datenbank. Der Vorteil von pgpool-II ist, dass die Programme nicht jedes Mal eine Verbindungsanfrage an das DBS schicken müssen, sondern stattdessen mit pgpool-II kommunizieren, das den Programmen eine von mehreren bereits vorher (bei Programmstart von pgpool-II) geöffneten Verbindungen zuweist. Sobald die Anwendung beendet wird, kommt die weiterhin offene Verbindung zurück in den Connection Pool. Außerdem unterstützt pgpool-II die synchrone Replikation auf zwei oder mehr Server – allerdings auf SQL-Zeilenebene. Dadurch kann es nötig sein, bei einigen Programmen Anpassungen vorzunehmen, da die Ausführungsergebnisse sonst auf den verschiedenen DB-Instanzen unterschiedlich sein können. Eine weitere Anwendungsmöglichkeit ist das Zusammenspiel von pgpool-II und einer bestehenden Replikationslösung wie Slony-I. In dieser Kombination ist es möglich, dass lesende Abfragen zum Zwecke des Load Balancing an verschiedene Knoten im Cluster übertragen werden. In diesem Modus ist pgpool-II außerdem in der Lage, einen einzelnen Query bzw. die betroffenen Datensätze in mehrere Teile aufzusplitten, die dann gleichzeitig von mehreren Servern ausgeführt werden (Parallel Query Processing). Die Tatsache, dass PostgreSQL bei der Replikation auf Drittprogramme verweist, führt zu einem Punktabzug. Außerdem ist die synchrone Replikation u.U. nur mit erheblichem Aufwand möglich. PostgreSQL erhält im Unterkriterium “Replikation” daher nur sechs Punkte. PostgreSQL unterstützt die Partitionierung von Tabellen. Hier kommt wieder die Objektrelationalität von PostgreSQL zum Tragen, da sie das Anlegen vererbter Tabellen ermöglicht, die sich für eine Partitionierung nutzen lassen. Dabei wird zuerst die Basistabelle erstellt: create table sales (id int primary key not null , product_name text not null , sales_date timestamp not null default localtimestamp); Nun werden die vererbten (partitionierten) Tabellen angelegt: CREATE TABLE sales_2010_january ( CHECK (sales_date BETWEEN timestamp ’2010−01−01 ’ AND timestamp ’2010−01−31 ’ ) ) INHERITS( sales ); CREATE TABLE sales_2010_february ( CHECK (sales_date BETWEEN timestamp ’2010−02−01 ’ AND timestamp ’2010−02−29 ’ ) ) INHERITS( sales ); CREATE TABLE sales_2010_march ( CHECK (sales_date © it-novum GmbH 2010 62 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 BETWEEN timestamp ’2010−03−01 ’ AND timestamp ’2010−03−31 ’ ) ) INHERITS( sales ); Durch die CHECK-Bedingung wird sichergestellt, dass nur Daten aus dem jeweils angegebenen Monat in den Tabellen stehen. Führt man ein EXPLAIN SELECT auf die Basistabelle “sales” aus, werden alle vererbten Tabellen ebenfalls durchsucht, auch wenn z.B. nur ein Eintrag aus einer der vererbten Tabellen gesucht wird. Das ist in vielen Fällen zeitaufwändig und verfehlt den eigentlichen Zweck des Partitionierens. Ändern kann man dieses Verhalten mit dem Parameter constraint_exclusion. Er sorgt dafür, dass der Abfrageplaner in der Lage ist, nicht erfüllte Constraints auszuklammern. Standardmäßig ist der Befehl deaktiviert, er lässt sich mit dem Befehl SET CONSTRAINT_EXCLUSION TO ON aktivieren. Danach berücksichtigt PostgreSQL nur noch die Tabellen vom Abfrageplaner, die es aufgrund der Anfragebedingung benötigt. Von sich aus kann PostgreSQL Einträge von der Basistabelle nicht auf die vererbten Tabellen umlenken. Es gibt zwei Verfahren, diese Problematik zu lösen: 1. Rules: Mit ihnen kann man alle Inserts auf die Basistabelle direkt auf die vererbten Tabellen umleiten. Auf diese Art lassen sich auch Rules zum Ändern und Löschen von Datensätzen erstellen. 2. Trigger: Die etwas komplexere Variante ist die Erstellung von Stored Procedures, die mit Hilfe von Triggern ausgelöst werden. Beide Varianten haben Vor-und Nachteile. So muss man bei der Verwendung von Rules nicht erst einen Trigger aufrufen, was weniger Aufwand für das DBS bedeutet. Allerdings müssen bei diesem Verfahren bereits alle Tabellen und Rules bestehen. Bei Triggern kann man hingegen festlegen, dass fehlende Tabellen während der Abfrage erstellt werden. Zudem muss beim Löschen einer vererbten Tabelle die entsprechende Rule in der Basistabelle auch gelöscht werden, was bei Triggern nicht der Fall ist. Die recht komplizierte Vorgehensweise zur Erstellung von partitionierten Tabellen veranlasst uns dazu, PostgreSQL nur sieben Punkte zu verleihen. Insgesamt kommt es damit auf 6,5 Punkte beim Kriterium Skalierbarkeit. Indizes Derzeit sind vier verschiedene Indextypen in PostgreSQL implementiert: © it-novum GmbH 2010 63 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich • B-Tree-Index • Hash-Index • Generalized Inverted Index (GIN) • Generalized Search Tree (GiST) Februar 2011 Der B-Tree-Index ist der Standard-Index in PostgreSQL. Er wird verwendet, wenn kein anderer Indextyp explizit angegeben wird. B-Tree kann Anfragen bearbeiten, die die Operatoren <, <=, =, >= und > beinhalten, sowie darauf aufbauende Konstrukte wie BETWEEN und IN. Außerdem kann man mit ihm Anfragen mit IS NULL bearbeiten. Der Hash-Index verwendet eine Hash-Tabelle und kann nur Anfragen mit dem Operator = bearbeiten. Er bietet, soweit uns bekannt ist, keine Geschwindigkeitsvorteile gegenüber dem B-Tree-Index und sollte nur in Ausnahmefällen verwendet werden, u.a. weil er noch nicht so weit in PostgreSQL implementiert ist wie der B-Tree-Index. Der Generalized Inverted Index kehrt (invertiert) das Indexprinzip um. Er enthält eine Liste von Wertepaaren, die wiederum aus einem Schlüssel und einer Liste von mehreren Datensätzen bestehen, in denen der Schlüssel enthalten ist. Es lassen sich auch Werte mit mehreren Schlüsseln, z.B. Arrays, indizieren. Die Einsatzmöglichkeiten des Generalized Inverted Index sind vielfältig, oft wird er für die Volltextindizierung eingesetzt. Der Generalized Search Tree ist weniger ein eigener Indextyp, als vielmehr ein Tool zur Erstellung individueller Indextypen (z.B. in C). Er wird meist verwendet, wenn ein spezielles Modul das erforderlich macht (d.h. die anderen Indextypen nicht verwendet werden können). Auf dem GiST basiert die Volltextsuche in PostgreSQL (seit Version 8.3). Wie auch MySQL erlaubt PostgreSQL, einen Index über mehrere Spalten aufzubauen, allerdings nur in B-Tree und GiST-Indizes. Außerdem können partielle Indizes (Indizes über Teile einer Tabelle) angelegt werden. Das verringert den Platzbedarf des Index und macht ihn leistungsfähiger für Abfragen. Einen partiellen Index definiert man durch Angabe der WHERE-Klausel: CREATE INDEX idx_customer_key ON dim_customer(customer_key) WHERE customer_key < 1000; Der Index wird nur vom Ausführungsplaner benutzt, wenn die WHEREBedingung erfüllt ist. Folgende Abfrage würde dazu führen, dass er nicht benutzt wird: SELECT ∗ from dim_customer where customer_key = 1234; © it-novum GmbH 2010 64 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Die Erstellung von Bitmap-Indizes als solche wird von PostgreSQL nicht unterstützt. Allerdings verwendet PostgreSQL intern Bitmaps, um bei aufwendigen Anfragen mehrere Indizes nutzen zu können, die Ergebnisse als Bitmap zwischenzuspeichern und schließlich zu kombinieren (genannt Index Bitmap Scan). Das Anlegen von Indizes auf großen Tabellen kann sehr lange dauern (manchmal sogar Stunden oder Tage). Während dieser Zeit wird ein Schreib-Lock auf die zu indizierende Tabelle gelegt. Die Besonderheit bei PostgreSQL ist, dass man Indizes im laufenden Betrieb erzeugen kann, d.h. währenddessen können weitere Schreibvorgänge auf die Tabelle erfolgen. Der Befehl zum Erstellen eines Index in diesem Modus lautet CREATE INDEX CONCURRENTLY. Bei diesem Verfahren muss die Tabelle zweimal gelesen werden, deshalb dauert die Erstellung des Index in diesem Modus mindestens doppelt so lange wie das Anlegen. Alle Indizes eines Schemas oder einer Tabelle lassen sich in der (System-)View pg_indexes durch gewöhnliche Select-Anfragen anzeigen. Ob ein gesetzter Index tatsächlich in einer bestimmten Anfrage benutzt wird, lässt sich aus dem Ausführungsplan ersehen. Zu diesem Zweck stellt man der Anweisung noch das Schlüsselwort EXPLAIN voran (wie auch in MySQL). Sobald ein Index benutzt wird, zeigt das der Ausführungsplan mit “Index Scan using ’indexname’...” an. Zusätzlich lassen sich mit EXPLAIN ANALYZE auch noch die Ausführungszeiten jedes einzelnen Schrittes im Plan anzeigen. Da PostgreSQL keine Bitmap-Index-Erstellung unterstützt, vergeben wir hier nur fünf Punkte. Für das Kriterium Indizes erhält das DBS daher insgesamt acht Punkte. Weitere Performance-Eigenschaften PostgreSQL nutzt Multi-CPU-Systeme so, dass es für jede Client-Verbindung einen eigenen Prozess auf dem Server anlegt und dadurch die Connections auf verschiedene CPUs verteilen kann. Ab diesem Punkt kommunizieren der Client und der PG-Server nur über diesen Prozess miteinander, d.h. ohne Eingreifen des ursprünglichen -Prozesses. Da auch hier (wie bei MySQL) der Grad der Multi-CPUNutzung vom Einzelfall abhängig ist, erhält PostgreSQL acht Punkte. Multi-Threading unterstützt das DBS hingegen nicht, jede Verbindung zur Datenbank kann nur eine CPU gleichzeitig nutzen (0 Punkte). Auch Parallel Query Processing unterstützt PostgreSQL nicht – und erhält daher null Punkte. Erkenntnisse aus der Performance-Messung PostgreSQL profitiert von den gesetzten Indizes. Auf Basis einer Kostenrechnung entscheidet sein Abfrageoptimierer, welche Alternativen die “günstigsten” sind. © it-novum GmbH 2010 65 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Diese werden dann ausgewählt. Mithilfe des Befehls EXPLAIN ANALYZE lassen sich in PostgreSQL sowohl die einzelnen Schritte als auch deren Ausführungszeiten nachvollziehen. Die folgende Grafik zeigt den Ausführungsplan für das Query Q1: Abbildung: Ausführungsplan für das Query Q1 Fazit: Performance Kriterium Gewichtung Erfüllungsgrad Nutzwert 40 6,5 260 20 10 10 20 6 4 8 7 120 40 80 140 1 Skalierbarkeit 1.1 Replikation 1.1.1 a) synchrone 1.2.1 b) asynchrone 1.2 Partitionierung 2 Indizes 3 4 5 6 25 8 200 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 10 10 5 10 5 10 100 50 50 SMP-Support Multithreading Parallel Query Processing Performance-Messung 15 10 10 0 8 0 0 0 120 0 0 0 100 22,5 580 Summe © it-novum GmbH 2010 66 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Datenintegrität und -sicherheit Transaktionen PostgreSQL unterstützt Transaktionen. Bis auf wenige Ausnahmen (z.B. das erwähnte nebenläufige Indizieren) werden alle Aktionen innerhalb einer Transaktion ausgeführt. Sofern ein Nutzer die Transaktion nicht explizit durch START TRANSACTION oder BEGIN startet, setzt PostgreSQL automatisch eine Transaktion um jede einzelne Anweisung (sog. Autocommit). Genau bedeutet das, dass PostgreSQL zuerst BEGIN aufgeruft, danach die Anweisung des Nutzers ausführt und schließlich ein COMMIT hinterherschickt. PostgreSQL kennt alle vier Transaktionslevels des SQL-Standards, verwendet intern aber nur READ COMMITTED und SERIALIZABLE. Die Voreinstellung des Isolationslevel ist READ COMMITTED. Wenn ein Nutzer READ UNCOMMITTED angibt, wird READ COMMITTED verwendet, wenn er REPEATABLE READ wählt, wird stattdessen SERIALIZABLE verwendet. Ebenso wie MySQL unterstützt PostgreSQL Savepoints. PostgreSQL erhält einen leichten Punktabzug bei den Isolationslevels und dadurch 9,71 Punkte in diesem Kriterium. Locking und Nebenläufigkeit Wie MySQL unterstützt PostgreSQL die Multiversion Concurrency Control (MVCC), damit Lesezugriffe schreibende Transaktionen nicht blockieren und umgekehrt. Modifizierte Zeilenversionen werden in PostgreSQL nicht überschrieben, sondern die modifizierte Version wird an einer anderen Stelle in der Tabelle, genannt Heap, abgespeichert. Die ältere Version wird als ungültig markiert und mit der aktuellen verkettet. Da dieses Vorgehen zu einer Fragmentierung des Heaps führt, sollte der Heap gelegentlich gewartet werden. Dazu verwendet man den Wartungsbefehl VACUUM. Sofern MVCC innerhalb einer Anwendung nicht angewendet werden kann (oder nicht soll), können Locks auf Tabellen-und Zeilenebene benutzt werden. Dabei ist zu beachten, dass in PostgreSQL einmal gesetzte Locks bis zum Ende der Transaktion bleiben und es keine Möglichkeit gibt, sie vorher aufzuheben. Derzeit gibt es acht Lock-Level, die den Grad der Sperre definieren. Sie reichen von einfachen Lesesperren (während eine Transaktion die Daten liest, dürfen sie nicht gelöscht werden) bis zur vollständigen Sperre gegen jeglichen Zugriff. Teilweise blockieren sich diese Locks gegenseitig, weshalb man auf allzu häufiges Locking verzichten sollte. Darüber hinaus sind in PostgreSQL sogenannte Advisory Locks implementiert. Sie helfen dabei, das Zusammenspiel verschiedener Anwendungen zu koordinieren © it-novum GmbH 2010 67 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 und werden über Transaktionen hinweg bis zum Verbindungsende gehalten. Für das Kriterium “Locking und Nebenläufigkeit” erhält PostgreSQL insgesamt 9,5 Punkte. Benutzerrollen / Berechtigungskonzepte PostgreSQL verfügt über ein Rollenkonzept, das Benutzer und Gruppen vereinheitlicht. Eine Rolle kann Zugriffsrechte besitzen, aber auch wiederum Mitglied in einer anderen Rolle sein. Dadurch lassen sich sehr komplexe Verschachtelungen innerhalb von Rollen realisieren. Es wird dabei zwischen Gruppenrollen und Loginrollen unterschieden: Eine Gruppenrolle hat keine Berechtigung, sich im DBS anzumelden, eine Loginrolle dagegen schon. Loginrollen werden durch das Attribut LOGIN bei der Erstellung der Rolle definiert. Neben diesem Attribut gibt es noch eine Reihe weiterer, darunter CREATEDB: Recht, eine DB erstellen zu dürfen CREATEROLE: Recht, andere Rollen anzulegen SUPERUSER: umgeht sämtliche Zugriffsbeschränkungen im DBS, kann Befehle ausführen, die sonst niemand ausführen darf Eine wichtige Funktion hat die Konfigurationsdatei pg_hba.con. Sie legt fest, welcher Benutzer sich zu welcher DB verbinden darf. Außerdem wird hier die Authentifizierungsmethode eingestellt (z.B. per MD5, LDAP oder Zertifikat). Die Vergabe von Privilegien an Benutzer für DB-Objekte mittels GRANT hält sich an die bekannten Standards. Zudem kann man seit Version 8.4 nicht nur den Zugriff auf eine gesamte Tabelle gestatten, sondern auch auf einzelne Spalten mit speziellen Rechten. Dabei haben die Tabellenrechte immer Vorrang. Erst wenn kein Tabellenrecht existiert, wird geprüft, ob ein Spaltenrecht vorhanden ist. Aufgrund der kompletten und verständlichen Umsetzung des Rollenkonzepts erhält PostgreSQL die volle Punktzahl. © it-novum GmbH 2010 68 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Fazit: Datenintegrität und -sicherheit Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Skalierbarkeit 1.1 Replikation 1.2 Partitionierung 2 Indizes 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 3 SMP-Support Summe 35 9,71 340 25 10 10 9 250 90 40 9,5 380 10 10 20 10 10 9 100 100 180 25 10 250 100 29,21 970 graphisches Tool Administration / Wartung Client-und Hilfsprogramme PostgreSQL bietet mit pgAdmin ein zur Datenbankadministration, das unter der GPL-Lizenz steht und für eine Vielzahl an Betriebssystemen verfügbar ist. Es verfügt im Gegensatz zu MySQL über Popup-Meldungen, beispielsweise wenn empfohlen wird, den Wartungsbefehl VACUUM auszuführen. Abbildung: Der Hinweis-Wizard “pgAdmin Guru” mit einem Hinweis auf eine empfohlene Datenbankwartung © it-novum GmbH 2010 69 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Außerdem enthält PostgreSQL das Kommandozeilen-Tool psql, das SQL-Befehle entweder direkt oder per Datei ausführen kann und z.B. das Schreiben von Skripten vereinfacht. Des Weiteren unterstützt psql Features wie die TabulatorKomplettierung von SQL-Syntax und Objektnamen. Für die Administration im Browser eignet sich das Tool phpPgAdmin, das auf dem sehr beliebten phpMyAdmin für MySQL basiert. Die Client- und Hilfsprogramme bieten alle wichtigen Funktionalitäten und einen guten Bedienkomfort, daher erhält PostgeSQL auch für sie die volle Punktzahl. Backup-Möglichkeiten Zur regelmäßigen Sicherung der Datenbanken enthält PostgreSQL zwei Programme: pg_dump und pg_dumpall. Ersteres exportiert eine einzelne DB (oder Teile davon) im SQL-Format, letzteres den gesamten Datenbankcluster (d.h. alle darin enthaltenen DB). Ist eine Migration der DB auf eine neuere PostgreSQLVersion geplant, muss die Sicherung mit Hilfe des pg_dump oder pg_dumpall Programms der neueren Version erfolgen, denn nur sie kennt alle Änderungen der älteren Version und kann die Daten kompatibel zur neuen Version in einen Dump schreiben. PostgreSQL enthält auch eine Möglichkeit für das Online-Backup (teilweise auch Hot Copy genannt), bei der man die Datenbank für das Backup nicht herunterfahren muss. Allerdings muss bei der Wiederherstellung die gleiche Software (PG-Version und Betriebssystem) verwendet werden wie bei dem Backup. Die Konfiguration des Online-Backups wird in der Konfigurationsdatei postgresql.conf durchgeführt – allerdings sind noch mehr Schritte notwendig, um ein funktionierendes Online-Backup zu erstellen. Aufgrund dieser Einschränkungen erhält PostgreSQL in diesem Kriterium sieben Punkte. Fazit: Administration und Wartung Kriterium Gewichtung Erfüllungsgrad Nutzwert 1 Client- und Hilfsprogramme 2 Backup-Möglichkeiten Summe © it-novum GmbH 2010 70 50 50 10 7 500 350 100 17 850 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Zukünftige Entwicklungen Das letzte große Release von PostgreSQL, Version 9.0, wurde am 20. September 2010 veröffentlicht. Es enthält eine Reihe neuer Funktionen, unter anderem: • Binärer Replikationsmechanismus mit Streaming Replication und Hot Standby (das könnte den Einsatz von Zusatzprogrammen wie Slony-I unnötig machen) • Spaltenbasierte und aufrufbedingte Trigger • Erweiterte Unterstützung für Stored Procedures • Das Wartungskommando VACUUM wurde grundlegend geändert, um eine bessere Performance bei der Bereinigung von Tabellen zu erreichen • © it-novum GmbH 2010 64-Bit Windows-Unterstützung 71 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 6. MySQL und PostgreSQL im direkten Vergleich Anhand der bereits anfangs vorgestellten Kriterien möchten wir am Ende einen abschließenden Vergleich von MySQL und PostgreSQL vornehmen. Ziel ist es, sowohl die Gemeinsamkeiten als auch die Vor-und Nachteile der beiden Datenbanken aufzuzeigen. Beginnen wir beim Grundlegenden, der Lizenz: Die von MySQL verwendete GPL schränkt wegen des Copylefts kommerzielle Entwicklungen ein – hier bietet die von PostgreSQL verwendete BSD einen klaren Vorteil. Was die Community betrifft, so ist die von MySQL sehr groß und bietet hilfreiche Unterstützung. Bei PostgreSQL ist ebenfalls eine große Community vorhanden, sodass man auch hier mit Hilfestellungen bei Problemfällen rechnen kann. Die Dokumentation von MySQL lässt ebenso wie die von PostgreSQL kaum Wünsche offen, die Referenzhandbücher behandeln ausführlich alle relevanten Themen. Allerdings gibt es das Handbuch nur bei MySQL auch in einer aktuellen deutschen Fassung. A) Allgemeine Kriterien MySQL PostgreSQL Erfüllungs- Nutzwert Erfüllungs- Nutzwert grad Gewichtung grad Kriterium 1 Lizenz 15 7 105 10 150 2 Referenzkunden 15 10 150 8 120 3 Support 25 9 225 8,5 212,5 0 25 12,5 12,5 0 9 9 9 0 225 112,5 112,5 0 8,5 9 8 0 212,5 112,5 100 4 Dokumentation 20 10 200 9 180 5 Produkt-Updates 25 7 175 9 225 3.1 Hersteller-Support 3.2 Community-Support 3.2.1 Support-Kanäle 3.2.2 Qualität Summe 100 855 887,5 Die Systemanforderungen von MySQL und PostgreSQL sind ähnlich gering. In der Standardkonfiguration sind sie darauf ausgelegt, auch auf Rechnern mit wenig Leistung annehmbare Ergebnisse zu liefern. Für eine gute Performance, gerade im analytischen Bereich mit mehreren Benutzern, ist selbstverständlich eine gute Hardware-Ausstattung Pflicht. Was die Geschwindigkeit der Weiterentwicklung anbelangt, hat PostgreSQL durch die Einführung der beschriebenen Commit Fests © it-novum GmbH 2010 72 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 im Moment die Nase vorn. Bei den Betriebssystemen ist es MySQL, obwohl PostgreSQL durch die Unterstützung von Windows 64-Bit in der neuen Version 9.0 aufholen konnte. Hinsichtlich der Datentypen nehmen sich beide Systeme nicht viel. PostgreSQL bietet jedoch mehr Flexibilität durch die Möglichkeit, eigene Datentypen zu erstellen. Auch bei der XML-Unterstützung liegt PostgreSQL im Moment vorn, allerdings sind hier die Implementierungen für beide Systeme noch nicht abgeschlossen, sodass sich das mit den nächsten Versionen bereits ändern kann. Für die Anwendungsanbindung liefern beide Programme alle notwendigen Programmierschnittstellen. B) Systemanforderungen und Softwareanbindung MySQL PostgreSQL Erfüllungs- Nutzwert Gewichtung grad Kriterium 1 Unterstützte Betriebssysteme/ Architekturen Erfüllungs- Nutzwert grad 15 10 150 8,67 130 5 10 10 10 50 100 10 10 50 100 2 Beschränkungen 20 9,75 195 9,5 190 2.1 pro Datenbank 2.2 pro Tabelle 2.3 pro Spalte 2.4 pro Index 5 5 5 5 10 10 10 9 50 50 50 45 10 8 10 10 50 40 50 50 3 Unicode-Support 15 10 150 10 150 4 Datentypen 25 9 225 10 250 5 XML-Support 15 6 90 8 120 6 Schnittstellen 10 10 100 10 100 1.1 32-Bit 1.2 64-Bit Summe 100 910 940 Im Bereich der Datenbankobjekte zeigt sich ein gemischtes Bild. MySQL unterstützt zwar keine Schemata, inwieweit das aber für die Praxis von Relevanz ist, sei dahingestellt. Views unterstützen beide Systeme, die Erstellung von Updateable Views ist in PostgreSQL aber schwieriger als in MySQL. Über recht aufwendige Wege können in PostgreSQL auch Materialized Views erstellt werden, MySQL erlaubt hingegen nur eine rudimentäre Simulation durch Update-Skripte. Nicht nur in diesem Punkt zeigt sich, dass die große Flexibilität von PostgreSQL © it-novum GmbH 2010 73 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 oft durch zusätzlichen Aufwand erkauft werden muss. Bei Stored Procedures und Triggern sind keine großen Unterschiede zwischen MySQL und PostgreSQL auszumachen. C) Datenbankobjekte MySQL Kriterium PostgreSQL Erfüllungs- Nutzwert Erfüllungs- Nutzwert grad Gewichtung grad 1 Schemata 10 0 0 10 100 2 Views 40 5 200 6,5 260 2.1 nichtveränderbar 2.2 updateable 2.3 materialized 10 10 20 10 10 0 100 100 0 10 8 4 100 80 80 3 Stored Procedures / Functions 25 8 200 10 250 4 Trigger 25 10 250 9 225 Summe 100 650 835 Der erste Platz im Bereich “OLAP im SQL-Standard” gebührt eindeutig PostgreSQL. In MySQL wurde bisher lediglich die Erweiterung der GROUP BY-Klausel durch ROLLUP implementiert – alle anderen Features fehlen. Seit Version 8.4 hat PostgreSQL hier einen bedeutenden Schritt nach vorne gemacht, denn sowohl die Fensterfunktionen als auch die CTE bieten weitreichende Möglichkeiten. Lediglich auf die Erweiterungen von GROUP BY muss hier bisher noch verzichtet werden. © it-novum GmbH 2010 74 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 D) Unterstützung des SQL-OLAP-Standards / OLAP-Funktionalitäten Kriterium 1 Erweiterung des Group-By Operators 1.1 Group By Rollup 1.2 Group By Cube 1.3 Group By Grouping Sets 2 Fensterfunktionen 2.1 Partitioning 2.2 Ordering 2.3 Framing 3 OLAP-Funktionen 3.1 Rangfunktionen 3.2 Statistische Funktionen 4 Common Table Expressions Summe MySQL PostgreSQL Erfüllungs- Nutzwert Erfüllungs- Nutzwert Gewichtung grad grad 25 3,332 83,3 0 0 8,33 8,33 8,33 10 0 0 83,3 0 0 0 0 0 0 0 0 30 0 0 8,33 250 10 10 10 0 0 0 0 0 0 10 10 5 100 100 50 20 1,5 30 10 200 10 10 0 3 0 30 10 10 100 100 25 100 0 0 113,3 10 250 700 Im Bereich Performance sind die Indizes ein wichtiger Faktor. Sie lassen sich auf beiden Systemen erstellen, allerdings verfügt nur PostgreSQL über eine fortgeschrittene Technik, um logische Operationen zwischen Indizes zu beschleunigen (Bitmap Index Scan). Wir verzichten an dieser Stelle darauf, ein abschließendes Urteil über die Performance beider Systeme zu fällen, weil zu viele Faktoren berücksichtigt werden müssen und Anpassungen an den Systemen zu einer schlechteren Vergleichbarkeit führen (weil u.U. das eine System mehr optimiert wird als das andere). Stattdessen empfehlen wir, vor einer endgültigen Entscheidung beide Datenbanken auf den Systemen mit den beabsichtigten Anwendungen zu testen, anstatt sich auf ein pauschales Urteil zu verlassen. © it-novum GmbH 2010 75 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 E) Performance MySQL PostgreSQL Erfüllungs- Nutzwert Erfüllungs- Nutzwert Gewichtung grad grad 40 6,5 260 6,5 260 Kriterium 1 Skalierbarkeit 1.1 Replikation 1.1.1 a) synchrone 1.2.1 b) asynchrone 1.2 Partitionierung 20 10 10 20 4 0 8 9 80 0 80 180 2 Indizes 25 5,2 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 10 10 5 10 0 6 15 10 10 0 100 8 10 0 0 3 4 5 6 SMP-Support Multithreading Parallel Query Processing Performance-Messung Summe 6 4 8 7 120 40 80 140 130 8 200 100 0 30 10 5 10 100 50 50 120 100 0 0 610 8 0 0 0 120 0 0 0 580 Leichter bewerten lassen sich die Funktionalitäten, die zu einer Verbesserung der Performance beitragen. So unterstützen sowohl MySQL als auch PostgreSQL Multi-CPU (SMP), im Gegensatz zu PostgreSQL verfügt MySQL allerdings über Multithreading. Das kann bei vielen Clientverbindungen auf verschiedene Tabellen zu einer merklich besseren Performance führen. Parallel Query Processing unterstützen beide Systeme nur im Cluster-Betrieb (Replikation). Während MySQL bei der Replikation direkt auf sein spezielles Produkt “MySQL Cluster” verweist, verfügt PostgreSQL nach dem letzten Release über binäre Replikation, die sich aus Streaming Replication und Hot-Standby zusammensetzt. Die Partitionierung von Tabellen ist bei beiden Produkten möglich, allerdings auf sehr unterschiedliche Art und Weise. MySQL unterteilt die Tabelle über verschiedene Funktionen in einzelne Partitionen und speichert sie physisch voneinander getrennt als einzelne Tabellen ab. PostgreSQL greift auf seine Objektrelationalität zurück und realisiert partitionierte Tabellen über Vererbung. Mit MySQL lassen sich partitionierte Tabellen schneller und einfacher erstellen. Bei der Transaktionsunterstützung und den Locking-Strategien liegen beide Produkte fast gleichauf. Sie liefern die notwendigen Techniken, um konkurrierende Zugriffe effektiv zu verwalten. Bei der Benutzerverwaltung findet man zwei unterschiedliche Ansätze: Während PostgreSQL ein Rollenkonzept © it-novum GmbH 2010 76 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 besitzt, bietet MySQL nur ein Benutzerkonzept, das aber dafür sehr ausgereift und bedienungsfreundlich ist. F) Datensicherheit und Datenintegrität MySQL PostgreSQL Erfüllungs- Nutzwert Erfüllungs- Nutzwert Gewichtung grad grad 35 10 350 9,71 340 Kriterium 1 Skalierbarkeit 1.1 Replikation 1.2- Partitionierung 2 Indizes 2.1 gewöhnliche Indizes 2.2 Bitmapindizes 2.3 Volltextindizes 3 SMP-Support Summe 25 10 10 10 250 100 10 9 250 90 40 8,5 340 9,5 380 10 10 20 10 10 7 100 100 140 10 10 9 100 100 180 25 100 8 200 890 10 250 970 Die mitgelieferten Clientprogramme sind für beide Systeme als gut einzustufen. Die Kommandozeilen-Tools werden auch ausführlich in den Dokumentationen behandelt. Was Backup-Verfahren betrifft, so liefern beide ebenfalls die notwendigen Tools mit. Geht es aber um erweiterte Techniken wie OnlineBackups, muss auf Produkte von Drittherstellern zurückgegriffen werden. Um eine höhere Ausfallsicherheit, Lastverteilung und Performance zu erreichen, ist bei beiden Produkten das Anlegen eines Clusters (Replikation) empfehlenswert. G) Administration und Wartung MySQL PostgreSQL Erfüllungs- Nutzwert Erfüllungs- Nutzwert Kriterium Gewichtung grad grad 1 Client- und Hilfsprogramme 50 10 500 10 500 2 Backup-Möglichkeiten 50 8 400 7 350 Summe 100 900 850 © it-novum GmbH 2010 77 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Das Die Abbildung zeigt das Abschneiden von PostgreSQL und MySQL in den sieben untersuchten Bereichen. © it-novum GmbH 2010 78 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 7. Sonderbetrachtung: Infobright Infobright ist, wie bereits erwähnt, ein spaltenbasiertes, relationales DBS auf Basis von MySQL. Es besitzt neben der eigenen Speicher-Engine auch einen eigenen Abfrageoptimierer. Ausgelegt für sehr große Datenmengen im TerabyteBereich, soll es für analytische Data Warehouses optimal geeignet sein. Durch die spaltenbasierte Speicherung kann eine bessere Kompression der Daten erreicht werden. Infobright teilt die Daten während des Ladeprozesses in die Tabellen in mehrere Gruppen aus jeweils 65.536 Elementen auf. Diese Ebene wird von Infobright “Data Packs” genannt, in sie werden die Inhalte der Spalten gespeichert. Darüber sind die sog. “Data Pack Nodes”, welche StatistikInformationen (Meta-Daten) über die in den Datenpaketen komprimierten Daten besitzen. Das Verhältnis von diesen Data Pack Nodes zu den Data Packs ist 1:1, wodurch Infobright jederzeit alle Informationen über die gespeicherten Daten hat. Außerdem gibt es noch “Knowledge Nodes”, die weitergehende Informationen zu den Datenpaketen enthalten, bspw. wie diese in Relation zueinander stehen und wie die Spannbreite der Werte in einer Spalte ist. Diese Knowledge Nodes werden nicht nur bei dem Ladevorgang in die Datenbank erstellt, sondern auch als Reaktion auf eingehende Queries zum Zwecke der Performance-Optimierung. Abbildung: Infobright -Architektur Quelle: http://www.infobright.com/Products/Technology/ © it-novum GmbH 2010 79 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Laden der Daten in Infobright Infobright liefert ein eigenes Loader-Programm, das gegenüber dem von MySQL mit¬gelieferten deutliche Geschwindigkeitsvorteile bieten soll. Im Rahmen der Performance-Messung wurden die Dimensions-und Faktentabellen als Flatfiles exportiert und mit diesem Loader in Infobright geladen. Teilweise war dieser etwas schneller als der originale Loader von MySQL, bemerkenswerte Unterschiede ließen sich allerdings nicht feststellen. Eventuell lag dies am Testsystem oder an den Beschränkungen der Community-Version. Der mitgelieferte Loader von Infobright unterstützt auch nicht die komplette Syntax von dem MySQL Loader -lediglich LOAD DATA INFILE, gefolgt von der Angabe der verwendeten Zeichen in dem Flatfile, wird unterstützt. Eigenschaften der Community-Version Die Community-Version (Infobright CE) steht unter der GPL-Lizenz und ist sowohl für Linux als auch Windows in 32-und 64-Bit Versionen verfügbar. Auf der Community-Seite ist sowohl ein Forum, als auch ein FAQ und ein Wiki verfügbar49. Der Loader der Enterprise-Version soll laut einer Gegenüberstellung auf dieser Seite und einem Whitepaper von Infobright bis zu sechs Mal schneller als der der Community-Version sein. Diese unterstützt auch kein Multi-Threading im Gegensatz zur Enterprise-Version50. Ein entscheidender Einschnitt bei der Community-Edition ist die fehlende Unterstützung von DML-Befehlen, d.h., dass keine Einfüge-, Änderungs-und Löschoperationen möglich sind. © it-novum GmbH 2010 80 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 8. Fazit Ein wesentlicher Betrachtungspunkt sollte sein, wie gut die zu evaluierenden Systeme als Data Warehouse mit einer Business Intelligence-Anwendung zusammenarbeiten. Hierfür wurden die ausgewählten Systeme an das BI-System Pentaho angebunden. In diesem Punkt hat sich gezeigt, dass die beiden evaluierten Systeme sich als Data Warehouse eignen, allerdings Optimierungen bei der Konfiguration dieser Systeme notwendig sind, um mit so großen Datenbeständen arbeiten zu können. Auch die Beispiel-Datenbank selbst musste noch durch das Setzen von Indizes optimiert werden. Die vielen einzelnen Prozessschritte von der Benutzerinteraktion im BI-Tool bis zur Ausgabe eines Ergebnisses sind sehr beeindruckend. Solange die Daten von Mondrian im Cache gehalten werden können, liefern die evaluierten Datenbanken beide eine sehr schnelle Performance ab. Sobald allerdings eine Spalte der Faktentabelle komplett von der Festplatte gelesen werden muss, brechen beide Systeme merklich ein, da hier Indizes auch nicht mehr weiterhelfen. Hier zeigt sich, dass die Festplatte der begrenzende Faktor ist und noch Optimierungen an den Abfragen selbst und am Datenmodell (Verwendung der optimalen Datentypen usw.) für eine bessere Performance erfolgen müssen. In diesem Zusammenhang wäre es interessant zu messen, wieviel schneller SSDs (Solid State Drives) solche Abfragen bewältigen können. Zu Testzwecken wurden die Dimensionstabellen für einen weiteren Durchlauf in die hierfür von MySQL empfohlene “memory”-Speicherengine geladen. Die gewählten Abfragen zeigten eine bessere Performance von Faktor 2,5 bis 5 -daher sollten zumindest die Dimensionstabellen (nach Möglichkeit) in dieser Speicherengine liegen, auch wenn ein Shutdown des MySQL-Servers die Datensätze aus ihnen logischerweise löscht. Infobright als Vertreter einer neuen Generation von DBS konnte in den ausgewählten Abfragen mit einer sehr guten Leistung überzeugen, einzig die stark eingeschränkte Funktionalität der Community Version würde hier gegen einen Einsatz in größerem Umfang sprechen. Außerdem lässt sich feststellen, dass der modulare Aufbau von MySQL sowohl Vorteile als auch Nachteile mit sich bringt. Sehr viele Funktionalitäten hängen von der verwendeten Speicherengine ab. Daher muss vor Aufbau der Datenbank genau überlegt werden, für welche Tabelle welche Speicherengine am Sinnvollsten ist -eine Umwandlung von einem Typ auf den anderen ist später selten problemlos möglich. PostgreSQL überzeugt dagegen mit der Vielseitigkeit der Möglichkeiten der prozeduralen Abfragesprachen und seines objektrelationalen Prinzips, welches einige Eigenheiten mit sich bringt und in manchen Situationen versiertere Nutzer erfordert als MySQL. Das in der © it-novum GmbH 2010 81 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Einleitung formulierte Ziel des teilweisen Vergleichs Februar 2011 mit Produkten kommerzieller Hersteller konnte leider aus Zeitgründen nicht zufriedenstellend erreicht werden. Im Rahmen der Recherchen ist jedoch klar geworden, dass Microsoft, Oracle & Co. den Open Source-Produkten zumindest im Bereich der SQL-OLAP-Unterstützung weit überlegen waren, der Vorsprung aber kleiner wird (zumindest zu PostgreSQL, MySQL hat hier noch sehr viel aufzuholen). Hinsichtlich der Zukunftsaussichten von MySQL und PostgreSQL ist es schwer, Prognosen zu treffen. Gerade MySQL könnte durch die Übernahme durch Oracle sowohl eine positive, als auch eine negative Entwicklung erfahren. Sofern Oracle nur an die eigenen Interessen denkt, werden sie in MySQL gerade nur so viel investieren, um es gegen die Open Source-Konkurrenz bestehen lassen zu können. Ob es aber in Oracle’s Interesse liegt, MySQL neue Meilensteine setzen zu lassen, ist sehr fraglich. Da PostgreSQL seit den letzten 18 Monaten eine schnellere Entwicklung nimmt, wird es spannend sein, die Zukunft der beiden größten Open Source DBS zu verfolgen. Sie liefern beide in vielen Bereichen dasselbe Ergebnis und doch sind sie unterschiedlich genug, um weiterhin ihre Daseinsberechtigung zu haben und für Diskussionspotential zu sorgen. © it-novum GmbH 2010 82 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Anhang: TestQueries © it-novum GmbH 2010 83 Version 1.0 it-novum White Paper © it-novum GmbH 2010 Open Source-Datenbanken im Vergleich 84 Februar 2011 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 Weiterführende Informationen /Links: Weiterführende Whitepapers zu Business Intelligence oder themen- bzw. produktspezifischen Analysen sind bei it-novum als Download oder auf Anfrage erhältlich: Zum Thema Business Intelligence: Vertriebscontrolling mit Open Source: Aufbau einer Vertriebssteuerung mit Palo und Pentaho http://www.it-novum.com/download/downloads/whitepapervertriebscontrolling-mit-palo-und-pentaho.html Open Source BI: Vergleich der führenden Open Source BI-Werkzeuge Pentaho, Jaspersoft und Palo http://www.it-novum.com/download/downloads/whitepaper-opensource-business-intelligence.html Open Source Business Intelligence: A Comparison of JasperSoft, Palo and Pentaho http://www.it-novum.com/download/downloads/whitepaper-opensource-business-intelligence.html Zum Thema Open Source: Die Top-10 Mythen und Irrtümer über Open Source: Einführung von Open Source aus der Sicht eines Anwenders http://www.it-novum.com/download/downloads/whitepaper-die-top-10mythen-und-irrtuemer-ueber-open-source.html Der Open Source-Diamant: Beurteilung von Open Source Lösungen nach fünf praxis-relevanten Kriterien http://www.it-novum.com/download.html 100% Open Source – ist das möglich? http://www.it-novum.com/download.html Weitere Themen: SAP-Monitoring mit Open Source: Umfassendes SAP-Monitoring mit einer Open Source-Plattform, die über CCMS hinaus geht http://www.it-novum.com/download/downloads/whitepaper-sapmonitoring-mit-open-source.html © it-novum GmbH 2010 85 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 openITCOCKPIT: Nagios-basiertes System- und Servicemanagement mit Enterprise-Fokus http://www.it-novum.com/download/downloads/whitepaperopenitcockpit.html IC-Abstimmung im Konzern. Intercompany-Abstimmungen toolunterstützt im SAP-Standard nutzen http://www.it-novum.com/download/downloads/whitepaperintercompany-abstimmung-im-sap-standard.html Konsolidierung im Konzern. Verbesserung des Konsolidierungspro-zesses im Konzern durch den Einsatz des Konsolidierungstools SAP SEM-BCS http://www.it-novum.com/download/downloads/whitepaperkonzernkonsolidierung-mit-sap-sem-bcs.html Modernes Open Source Dokumentenmanagement mit Alfresco: Wegweiser vom einfachen Enterprise Content Management bis hin zu komplexen Workflows mit jBPM und SAP-Integration Open Source CRM mit sugarCRM als nachhaltiger Beitrag zum Vertriebserfolg: Lassen sich moderne Anforderungen wie Abbildung von Vertriebsprozesse, Closed-Loop Marketing und analytisches CRM einfach mit Open Source umsetzen? SAP und Open Source – ein Widerspruch? Flexible Integration zum Aufbau individueller und effizienter Lösungen Aus unseren Projekten heraus ergeben sich immer neue themen- /produktspezifische Whitepapers. Sehen Sie regelmäßig auf unserer Homepage vorbei oder fragen Sie gezielt nach Themen, die sie interessieren unter den oben genannten Kontaktdaten. Kontaktadressen it-novum GmbH Deutschland: Edelzeller Straße 44 • 36043 Fulda • Tel: +49 (661) 103-333 Österreich: Mooslackengasse 17 • 1190 Wien • Tel: +43 (1) 230 60-41 50 © it-novum GmbH 2010 86 Version 1.0 it-novum White Paper Open Source-Datenbanken im Vergleich Februar 2011 [email protected] www.it-novum.com © it-novum GmbH 2010 87 Version 1.0