4. Praktikumsblatt - Chair 11: ALGORITHM ENGINEERING
Werbung

Fakultät für Informatik
Lehrstuhl 11 / Algorithm Engineering
Prof. Dr. Petra Mutzel, Carsten Gutwenger
Sommersemester 2009
DAP2 Praktikum – Blatt 4
Ausgabe: 12. Mai — Abgabe: 27.–29. Mai
Bei diesem Übungsblatt werden wir Priority-Queues dazu benutzen, um Huffman-Codes zur
Komprimierung von Texten zu berechnen.
Unsere Eingabe ist ein Text aus m 8-Bit Ascii-Zeichen, d.h. wir benötigen eigentlich m Bytes um
diesen Text zu speichern. Kommen in dem Text lediglich n unterschiedliche Zeichen vor, dann
benötigen wir natürlich nur k = dlog ne Bits zur Kodierung eines Zeichens und entsprechend
dm ∗ k/8e Bytes zur Speicherung des Text (plus eine kleine “Übersetzungstabelle” für die
Zeichen). In jedem dieser Fällen kodieren wir aber alle Zeichen mit einer festen Bitlänge, also
mit 8 oder k Bits.
Wir können die Komprimierung jedoch deutlich verbessern, wenn wir die Zeichen mit variabler
Länge kodieren: Häufig vorkommende Zeichen im Text bekommen eine kurze Kodierung und
selten vorkommende Zeichen dafür eine längere Kodierung. Damit wir den Text später wieder
dekodieren können, stellen wir sicher, dass es keine Zeichenkodierung gibt, die ein Präfix einer
anderen Zeichenkodierung ist.
Mit Hilfe des Huffman-Algorithmus können wir optimale Zeichenkodierungen berechnen, d.h.
der entsprechend kodierte Text besitzt minimale Länge. Der Algorithmus berechnet zunächst
für jedes Zeichen, wie oft es im Eingabetext vorkommt. Danach konstruiert er einen geordneten
binären Baum, dessen Blätter die im Text vorkommenden Zeichen sind und dessen innere
Knoten zwei Kinder besitzen. Die Kodierung eines Zeichens ist dann gegeben durch den Pfad
von der Wurzel zu diesem Zeichen: Immer wenn wir zu einem linken Kind gehen, hängen wir
eine ’0’ an die Kodierung an, und wenn wir zu einem rechten Kind gehen eine ’1’.
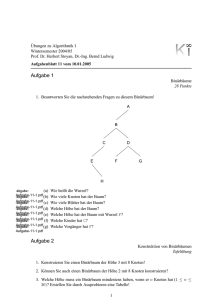
Das folgende Beispiel zeigt einen optimalen Baum für einen Text mit 45 ’a’, 13 ’b’, 12 ’c’,
16 ’d’, 9 ’e’ und 5 ’f’. Die Kodierung für das häufigste Zeichen ’a’ wäre dann 0 und die für
das seltenste Zeichen ’f’ wäre 1100. Jeder innere Knoten ist mit der Summe der Vorkommen
der Zeichen in seinem Unterbaum beschriftet, z.B. 30 = 5 + 9 + 16.
100
0
1
a:45
55
0
1
25
0
c:12
30
0
1
b:13
1
d:16
14
0
f:5
1
e:9
Sei C die Menge der Zeichen und count[c] die Anzahl der Vorkommen des Zeichens c im Text.
Dann kann der Algorithmus mit Hilfe einer Priority-Queue wie folgt implementiert werden.
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
n := |C|
PriorityQueue pq
for all c ∈ C do
x := new Node
x.character := c; x.priority := count[c]
pq.Insert(x)
end for
for i := 1 to n − 1 do
x := pq.ExtractMin(); y := pq.ExtractMin()
z := new Node
z.left := x; z.right := y
z.priority := x.priority + y.priority
pq.Insert(z)
end for
return pq.ExtractMin()
Wir speichern hier die Prioritäten einfach in den Knoten. Die erste for-Schleife erzeugt alle
Blätter und die zweite for-Schleife die inneren Knoten. Es werden einfach (greedy) jeweils die
beiden Knoten mit geringster Priorität genommen und darüber ein neuer innerer Knoten als
Elter gesetzt, dessen Priorität die Summe der Prioritäten seiner beiden Kinder ist. In unserem
Beispiel würden die inneren Knoten also in der Reihenfolge 14, 25, 30, 55, 100 erzeugt.
Im Verzeichnis /home/gutwen00/DAP2/Zusatzmaterial/PB_04/Code befindet sich das Grundgerüst für das zu implementierende Testprogramm inklusive Makefile. Der Aufruf des Programms sieht wie folgt aus:
hcode filename [ -mode m ] [ -log logfile ]
Dabei gibt filename die einzulesende Textdatei an, der Modus m ist entweder sort (für Sortieren) oder code (für die Berechnung des Huffman-Code) und mit logfile kann ein Filename für das
Logfile angegeben werden (standardmäßig wird Dateiname ohne Pfad plus .log genommen).
• Im Modus sort sollen die Zeichen c mit Hilfe einer Priority-Queue nach ihrer Häufigkeit
count[c] sortiert werden. Es wird kein Logfile erzeugt.
• Im Modus code soll mit Hilfe des Huffman-Algorithmus der Code für jedes Zeichen berechnet werden. Das Programm gibt außerdem die Größe des resultierenden Huffman-Codes
aus und schreibt die Zeichencodes und die Bitlänge des kodierten Textes in das Logfile.
In /home/gutwen00/DAP2/Zusatzmaterial/PB_04 findet man Eingabetexte mit den zugehörigen
Logfiles. Das Programm lässt sich bereits mit make erzeugen, allerdings werden Aufrufe im Modus sort oder code zu Fehlern führen, da noch Teile der Implementierung fehlen.
Langaufgabe 4.1
Implementiere die Priority-Queue für das Testprogramm (Quelldateien PriorityQueue.h und
PriorityQueue.cpp) mit Hilfe eines Min-Heaps. Die Elemente in der Priority-Queue sind Zeiger
auf Instanzen vom Typ Node, welche später die Knoten unseres Binärbaums repräsentieren
werden und auch die Prioritäten speichern. Wir benötigen folgende Methoden in der Klasse
PriorityQueue:
• PriorityQueue(Node **nodes, int n)
Konstruktor: Bekommt als Eingabe ein Array von n Zeigern auf Node und erzeugt eine
Priority-Queue, die diese Elemente enthält. Die Priority-Queue wird auch nie mehr als n
Elemente enthalten. Die Laufzeit soll linear in n sein. Welche Operation auf Min-Heaps
muss man dazu verwenden?
• Node *extractMin()
Entfernt ein Element mit minimaler Priorität aus der Priority-Queue und gibt es zurück.
• void insert(Node *v)
Fügt das Element v in die Priority-Queue ein.
Teste, ob das Programm im Modus sort jetzt die Elemente korrekt sortiert ausgibt.
Hinweis: Da unsere Priority-Queue nur die oben genannten Operationen unterstützen muss,
benötigen wir nicht die zusätzliche Verwaltung des Index im HeapElement, wie sie in Kapitel 3.1.6 des Skripts beschrieben ist.
Langaufgabe 4.2
Vervollständige die Implementierungen des Huffman-Algorithmus und der Berechnung der Zeichencodes. Dazu müssen zwei Funktionen in huffman.cpp implementiert werden:
• Node *huffman(Node **inputNodes, int n)
Diese Funktion bekommt als Eingabe bereits ein Array mit Zeigern auf die Blätter des
Baumes. Konstruiere nun eine Priority-Queue mit diesen Elementen und führe den zweiten Teil des Huffman-Algorithmus (ab Zeile 8) durch, so dass der Binärbaum zur Repräsentation der Zeichencodes erzeugt wird. Die Funktion gibt die Wurzel dieses Baumes
zurück.
• void constructCodewords(Node *v, const string &str, string *codeword)
Diese Funktion berechnet rekursiv den Zeichencode codeword[c] für jedes Zeichen c.
Dabei ist str der Binärstring, der sich durch den Pfad von der Wurzel bis zum Knoten v
ergibt. Falls v ein Blatt ist, dann weist die Funktion v seinen Zeichencode zu, sonst ruft
sie sich rekursiv für die beiden Kinder von v auf.
Teste dein Programm im Modus code auf den Texten im Zusatzmaterial. Dort liegt auch für
jede Instanz das entsprechende Logfile, so dass du schnell mit einem diff die Korrektheit deiner
Implementierungen überprüfen kannst.
Hinweise und Tipps
4.1 Klassen in C++
Im Unterschied zu Java trennt man bei C++ die Deklaration einer Klasse von der Implementierung: Die Deklaration der Klasse wird in eine Header-Datei (.h) und die Implementierung
in eine .cpp-Datei geschrieben. Anderer Quellcode, der diese Klasse verwenden will, inkludiert lediglich die Header-Datei. Die .cpp-Datei wird für sich compiliert und die resultierende
Objektdatei (.o) wird später dazugelinkt.
Betrachten wir als Beispiel eine Klasse Feld, die ein Array kapselt. Die Deklaration könnte wie
folgt aussehen:
class Feld {
int m_size;
float *m_array;
public:
Feld(int n);
~Feld();
int groesse() const { return m_size; }
};
Hier haben wir eine private Variable m size, einen Konstruktor, einen Destruktor und eine
Methode groesse() deklariert. Für groesse() ist bereits die Implementierung bei der Deklaration angegeben. Das macht man üblicherweise, wenn die Implementierung sehr kurz ist. Der
Destruktor wird durch die führende Tilde (~) gekennzeichnet und wird normalerweise benutzt,
um allozierten Speicher wieder freizugeben oder sonstige Aufräumarbeiten durchzuführen. Die
Implementierung in Feld.cpp könnte so aussehen:
#include "Feld.h"
Feld::Feld(int n) : m_size(n) {
m_array = new float[n];
}
Feld::~Feld() {
delete [] m_array;
}
Zu beachten ist, dass die Methoden mit vorangestelltem Feld:: geschrieben werden müssen, damit der Compiler weiß, zu welcher Klasse die Methode gehört. Die Initialisierung von MemberVariablen im Konstruktor kann direkt nach einem : aufgelistet werden (bei mehreren Variablen
durch Komma getrennt); in unserem Beispiel wird m size mit n initialisiert.
4.2 Der C++-Präprozessor
Der C++-Präprozessor wird immer automatisch vor dem Compiler aufgerufen und führt textuelle Ersetzungen auf dem Quellcode durch. Alle Präprozessor-Kommandos beginnen mit #.
Das Kommando #include haben wir schon häufig benutzt: Es fügt den Inhalte der zu inkludierenden Datei an dieser Stelle in den Quellcode ein.
Weitere häufig benutzte Kommandos dienen zur Definition von Symbolen und zur bedingten
Compilierung. Das Kommando
#define symbol wert
definiert, dass das Symbol symbol den Wert wert bekommt und ersetzt jedes Vorkommen des
Textes symbol im Quelltext durch wert. Dabei muss der Wert nicht unbedingt angegeben
werden, in dem Fall ist das Symbol quasi mit einem leeren Wert definiert.
Eine wichtige Anwendung dieser Defines ist die bedingte Compilierung, denn wir können mit
#ifdef symbol testen, ob ein Symbol definiert ist, und mit #ifndef symbol, ob es nicht definiert ist. Das benutzt man immer in Header-Dateien, um Mehrfach-Includes zu verhindern,
z.B. in Feld.h könnten wir schreiben:
#ifndef _FELD_H
#define _FELD_H
... hier kommt die Deklaration von Feld
#endif
Beim ersten Include von Feld.h ist FELD H noch nicht definiert und die Deklaration wird an
den Compiler weitergegeben, bei einem weiteren Include ist dann aber FELD H definiert und
die Deklaration wird einfach ausgelassen.
Man kann Defines übrigens auch direkt beim Aufruf des Compilers angeben, indem man das
Flag -Dsymbol oder -Dsymbol =wert benutzt. Darüber hinaus kann man sogar Makros mit Parametern definieren, z.B.
#define maximum(a,b) (((a) > (b)) ? (a) : (b))
Die vielen Klammern um die Parameter schließen übrigens eine häufige Fehlerquelle aus, denn
wir bekommen die Parameter ja nur rein textuell geliefert, und dieser Text ersetzt lediglich jedes
Vorkommen des Parameters. Zur Definition solcher kleiner Funktionen verwendet man in C++
allerdings stattdessen parametrisierte Inline-Funktionen, die dem Compiler die Typprüfung zur
Compile-Zeit erlauben:
template<typename T>
inline bool maximum(const T &a, const T&b) { return (a > b) ? a : b; }
4.3 Zeiger und Referenzen
Ein Zeiger auf eine Variable x speichert die Adresse des für x angelegten Speichers und erlaubt
es, über den Zeiger auf die Variable zuzugreifen. Im Zusammenhang mit Zeigern sind zwei
Operatoren sehr wichtig: der Adressoperator (&) und der Dereferenzierungsoperator (*). Wir
betrachten folgendes Beispiel:
int x = 17;
int *p = &x;
*p = 20;
cout << x;
//
//
//
//
eine Variable vom Typ int
ein Zeiger auf einen int
weist der Variablen x den Wert 20 zu
gibt 20 aus
Der Typ “Zeiger” wird durch Anhängen von * an den jeweiligen Datentyp gekennzeichnet. Mit
dem Dereferenzierungsoperator erhalten wir die Variable, auf die der Zeiger zeigt.
Falls unsere Variable eine Klasse ist, so gibt es die abkürzende Schreibweise ->, um auf die
Member der Klasse zuzugreifen:
class A { public: int x, y; };
A a;
A *p = &a;
p->x = 15; // weist a.x 15 zu
// äquivalent: (*p).x = 15
Eine Referenz ist ein Stellvertreter für eine Variable. Ähnlich wie bei Zeigern muss intern lediglich die Adresse der Variablen gespeichert werden, jedoch kann bei der Referenz die gleiche
Syntax verwendet werden wie bei der Variablen selbst, d.h. es ist kein Dereferenzieren notwendig. Außerdem muss eine Referenz immer initialisiert werden. Eine Referenz wird durch
Anhängen von & an den jeweiligen Datentyp gekennzeichnet.
int x = 17;
int &y = x;
y = 20;
// weist der Variablen x den Wert 20 zu
Insbesondere bei Parametern von Funktionen benutzt man gerne const-Referenzen. Bei einer
const-Referenz ist es nicht erlaubt, der referenzierten Variablen über die Referenz einen Wert
zuzuweisen:
int x = 17;
const int &y = x;
cout << y; // gibt 17 aus
y = 20;
// Compile-Fehler: Zuweisung an const-Referenz nicht erlaubt
4.4 C++-Strings konkatenieren
C++-Strings lassen sich sehr elegant unter Verwendung des +-Operators konkatenieren:
string x = "C++ ist";
string y = "super!";
string z = x + " " + y;
// z = "C++ ist super!"
4.5 Links- und rechtsbündige Ausgabe
Um Ausgabe schön zu formatieren, kann man mit setw(b) die Breite eines Ausgabefeldes angeben und mit setiosflags(ios::left) bzw. setiosflags(ios::right) links- bzw. rechtsbündige Ausgabe erzeugen. Die Funktionen werden einfach in den Ausgabe-Stream eingefügt
(<iomanip> muss inkludiert werden):
for(int i = 0; i < 20; ++i)
cout << setiosflags(ios::right) << setw(4) << i << endl;
Lykke til!
– das DAP2-Team