Neuronale Netze, Fuzzy Control, Genetische Algorithmen Prof
Werbung

Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Neuronale Netze, Fuzzy Control, Genetische Algorithmen
Prof. Jürgen Sauer
Lehrbrief Nr. 1: Einführung in die Theorie künstlicher Neuronale Netze
Inhaltsverzeichnis
1. Die biologische Inspiration
2. Neuronen Modelle
3. Bestandteile eines Neuronalen Netzes
3.1 Verbindungen
3.2 Neuronen
3.3 Aktivierungsfunktion
3.4 Schichten
3.5 Einführendes Beispiel
4. Trainieren Neuronaler Netze
4.1 Trainings- und Ausbreitungsphase
4.2 Trainings- und Testmenge
4.3 Trainingsüberwachung
4.4 Verschiedene Trainingsarten
5. Lernregel
5.1 Hebb’sche-Regel und Delta-Regel
5.2 Beispiele für Lernregeln
5.3 Offline oder Online Lernen
6. Architekturen
6.1 Assoziative Netze
6.2 Mehrschichtige Netze
6.3 Rekurrente Netze
1
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
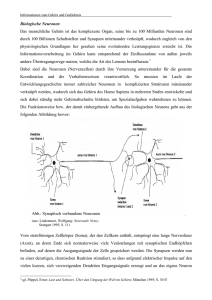
1. Die biologische Inspiration
In der Biologie bzw. Medizin existieren simple Modelle für die Funktionsweise des Gehirns 1.
Diese Modelle wurden zum Vorbild für Neuronale Netze.
Dendrite
Dendrite
Zellkörper
Axon
Synaptic Gap
Dendrite
Abb.1 Aufbau einer Nervenzelle
Bestandteile eines Neurons
-
-
Zellkörper
Ein- oder mehrere Eingänge
Genau einen Ausgang (Axon), der sich am Ende verzweigen kann
Das Ende eines Axons ist über Synapsen mit Dendriten verbunden. Über das Axon
kann ein Neuron elektronisches Aktionspotential zu den Dendriten anderer Neuronen
weiterleiten.
Die Verbindungsstelle von Axon und Dendrit heißt Synapse
Funktionsweise eines Neurons
-
1
Signale werden über Axone übertragen ( v ≈ 100m / s )
An den Synapsen werden Signale verstärkend oder hemmend weitergegeben (positive
oder negative Gewichte)
Im Neuron wird eine gewichtete Summe der Eingangsregeln berechnet
Falls die Summe einen Schwellwert übersteigt feuert das Neuron und liefert über das
abgehende Axon ein Ausgangssignal
Vgl. Skriptum, 1.1.1
2
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
2. Neuronen-Modelle
wi1
wi 2
x1
x2
∑
…..
xn
Dendriten
-
n
j =1
x j wij
win
Synapsen
Axon
-
Die an einem Neuron ankommende Signale werden nach der Effizienz der einzelnen
Synapsen gewichtet und aufsummiert
n
Neuron feuert, falls Potentialschwelle überschritten wird: ∑ j =1 x j wij
-
Lernen: Verändern der synaptischen Effizienz
3. Bestandteile eines Neuronalen Netzes
Ein neuronales Netz 2
-
besteht aus einer Menge von Neuronen und einer Netzstruktur
ist ein Schaltkreis, der aus künstlichen Neuronen besteht.
die Netzstruktur beschreibt, welche Neuronen mit welchem Gewicht verknüpft sind.
r
die Netzstruktur lässt sich als Gewichtsmatrix angeben: W = ( wij )
-- wij gibt das Gewicht der Verbindung von Neuron j nach Neuron i an
-- wij > 0 : Verbindung heißt exzitatorisch, d.h. anregend
-- wij < 0 : Verbindung heißt inhibitorisch, d.h. hemmend
-- wij = 0 : Ein Gewicht von Null besagt, dass ein Neuron auf ein anderes Neuron derzeit
keinen Einfluß ausübt
Das Wissen eines Neuronalen Netzes ist in seinen Gewichten gespeichert
Lernen kann man bei Neuronalen Netzen als Gewichtsveränderungen zwischen den Einheiten
Units) definieren 3
3.1 Verbindungen
Sie sind unidirektional und verbinden die Neuronen des Netzes untereinander. Außerdem gibt
es Verbindungen, die von außen an das Neuronale Netz herankommen und die Eingabe an das
Netz transportieren. Die Verbindungen enden meistens an speziellen Eingabeneuronen. Anlog
dazu gibt es Ausgabeneuronen, deren Ausgabeverbindungen das Neuronale Netz verlassen
und der Außenwelt die Ausgabe des Netzes liefern.
Je nach Art eines speziellen Netzes ist die Art der Vernetzung (welche Neuronen mit welchen
verbunden werden) unterschiedlich
2
3
http://www.neuronalesnetz.de/
vgl. Skriptum 1.2
3
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
3.2 Neuronen
Ein Neuron 4 hat eine beliebige Anzahl von Verbindungen (Eingabeverbindungen), die bei
ihm ankommen. Für jede Eingabe x j ( j = 1,..., n) besitzt das Neuron ein Gewicht wij . Alle
r
Gewichte eines Neurons werden zu dem Gewichtsvektor wi = ( w1 , w2 ,..., wn ) T
zusammengefasst. Der Gewichtsvektor wird üblicherweise im lokalen Speicher abgelegt.
wi1
wi 2
x1
x2
∑
…..
xn
n
j =1
x j wij
f
oi
win
Netzeingabe (Netto-Input der Unit i):
r v
n
net i = ∑ j =1 x j wij = wi 0 + x1 wi1 + x 2 wi 2 + ... + x n win = x T ⋅ wi
r
wi = ( wi 0, wi1 , wi 2 ,..., win )
x = (1, x1 , x 2 ,..., x n )
3.3 Aktivierungsfunktion
Jedes Neuron besitzt eine Transferfunktion (oft auch Aktivierungsfunktion 5) genannt. Als
Argumente dienen der Transferfunktion Werte aus den Eingabeverbindungen und dem
lokalen Speicher des Neurons.
Aktivierungsfunktion: oi = f i (net i )
Typische Aktivierungsfunktionen
⎧+ 1, falls net i > θ
- Binäre Schwellwertfunktion: oi = σ (net i ) = ⎨
⎩ 0, falls net i ≤ θ
⎧+ 1, falls net i > θ
- Bipolare Schwellwertfunktion: oi = sign(net i ) = ⎨
⎩− 1, falls net i ≤ θ
- Binäre sigmoide Funktion: oi = f (net i ) =
1
1 + exp(−λ ⋅ net i )
- Bipolare sigmoide Funktion: oi = f (net i ) =
2
−1
1 + exp(−λ ⋅ net i )
4
Typ: McCulloch&Pitts
Der Begriff “künstliches Neurons wurde erstmals vom Neurophysiologen W.S. McCulloch und dem 18jährigen
Mathematiker W. Pitts (1943) veröffentlicht. Die Jahrzente später erfundenen, zahlreichen Neuronenmodelle
stützen sich im wesentlichen auf dieses Grundmodell
5 vgl. Skriptum 1.2.2
4
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
- Identitätsfunktion: oi = net i
3.4 Schichten
Beliebige disjunkte Mengen von Neuronen können zu einer Schicht zusammengefasst
werden. Alle Neuronen einer Schicht sollen die gleiche Transferfunktion besitzen und werden
gleichzeitig aktiviert. Die Neuronen, die Eingabeverbindungen aus der Außenwelt
empfangen, werden oft in der Eingabeschicht zusammengefasst. Entsprechend bilden die
Neuronen, die Ausgaben an die Außenwelt schicken, die Ausgabeschicht. Die übrigen
Schichten heißen verborgen, da sie keine Verbindung nach außen besitzen.
Eingabeschicht mit Input Units
Verborgene Schicht mit Hidden Units
Ausgabeschicht mit Output-Units
Notation: 4 – 3 – 2 Netz (4 Neuronen in der Eingabeschicht, 3 Neuronen in der verborgenen Schicht, 2
Neuronen in der Ausgabeschicht
Abb.: Vorwärtsgerichtetes azyklisches Netz
Die einfachsten neuronalen Netze bestehen nur aus einer Eingabe- und einer Ausgabeschicht..
Derartige Neuronale Netze kann man durch eine Gewichtsmatrix darstellen, z.B.
1
2
3
r ⎛w
W = ⎜⎜ 11
⎝ w21
1
w12
w22
w13 ⎞
⎟
w23 ⎟⎠
2
Der jeweilige erste Index des Gewichts bezieht sich auf die Output-Unit, der zweite Index auf
die entsprechende Input-Unit
5
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
3.5 Ein einführendes Beispiel
Beschreibung der Aufgabe: Ein Student der Fachhochschule Regensburg steht vor der
folgenden Situation: Wieder einmal drohen die lästigen Semesterabschlußprüfungen. Das hebt
nicht gerade sein augenblickliches Stimmungstief, denn der Vorlesungsbesuch war mäßig,
und die Übungen und Ausarbeitungen zum Vorlesungsstoff hat er nicht richtig verstanden. Es
ist zu befürchten, daß er die Prüfung nicht schafft. Zum Stimmungstief kommt hinzu, daß der
Vater des Studenten für eine gute Prüfung die Finanzierung einer Urlaubsreise zu den
Malediven (Schwimmen, Tauchen) in Aussicht gestellt hat, die er angesichts seiner Lage
abschreiben kann.
Ein einfaches Modell eines neuronalen Netzes soll die möglichen Zusammenhänge zwischen
dem Prüfungsvorbereitungen und den Handlungen bzw. Stimmungslagen einer Person
beschreiben.
Modellbeschreibung: Das Modell besteht aus 2 Schichten, der Eingabe- und Ausgabeschicht.
Nur die Elemente der Eingabeschicht nehmen Informationen auf, nur die Elemente der
Ausgabeschicht geben Informationen vom Modell an die Außenwelt weiter. Jedes Element
der Eingabeschicht ist mit jedem Element der Ausgabeschicht verbunden. Ein einzelnes
Element der Eingabe- und Ausgabeschicht heißt Neuron bzw. Prozessorelement bzw.
Verarbeitungseinheit (Unit).
regelmäßiger
Vorlesungsbesuch
Erfolgreiche
Semester
Übungsteilnahme Abschlußprüfung
Eingabeschicht
Ausgabeschicht
Schwimmen
Tauchen
Stimmungshoch
negative Prüfung
Abb. Einfaches Modell eines NN
Die Informationsverarbeitung des Modells erfolgt schichtenweise von oben nach unten.
Zur Vereinfachung wird festgelegt:
- aktiv entspricht dem Wert +1
- inaktiv entspricht dem Wert -1
Ein Testfall mit Kodierung der Eingabe kann für das vorliegende Beispiel somit
folgendermaßen dargestellt werden:
6
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Erfolgreiche
Semester
Übungsteilnahme Abschlußprüfung
-1
+1
regelmäßiger
Vorlesungsbesuch
-1
-1
-1
+1
Eingabeschicht
-1
-1
+1
Ausgabeschicht
-1
+1
-1
Schwimmen
Tauchen
Stimmungshoch
negative Prüfung
Abb. Verarbeitungsmodell
Die Neuronen im vorliegenden Modell haben mindestens einen Eingang, der Informationen
aufnimmt und einen Ausgang, der das Ergebnis der vorliegenden Verarbeitung der
Eingangswerte beschreibt. Er kann den anderen Neuronen in darüberliegenden Schichten als
Eingangswert dienen.
Trainingsphase
1. Schritt: Einfaches Aufsummieren der Eingangswerte
kein
regelmäßiger
Vorlesungsbesuch
-1
keine
erfolgreiche
Semester
Übungsteilnahme Abschlußprüfung
Eingabeschicht
-1
-1
+1
Eingaben
(+)
(+)
(+)
Summe
-1
-1
+1
-1
+1
-1
-1
(+)
(+)
-1
-1
+1
-1
-1
(+)
-1
Ergebnis
+1 Eingaben
Summe
Ergebnis
Ausgabeschicht
kein
Schwimmen
Tauchen
kein
Stimmungshoch
keine
negative Prüfung
Abb.: Einfaches Aufsummieren der Eingaben
7
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Das einfache Aufsummieren führt nicht zum gewünschten Ergebnis.
2. Schritt
- Verschieden starke Gewichtung der Eingänge (unterschiedliche Bewertung der Verbindungen)
- Aufsummieren
- Schwellwertabgleich (zur Bestimmung definierten Ausgangszustände)
Ein Modellneuron umfaßt somit:
Eingang/Eingang/...
Gewicht/Gewicht/...
Verarbeitung
Ergebnis
Ergebnis > Schwellwert
Eine mögliche Lösung ist dann:
Testfall:
kein
regelmäßiger
Vorlesungsbesuch
keine
erfolgreiche
Übungsteilnahme
-1
Eingaben
Gewichte
Semester
Abschlußprüfung
-1
-1 -1
1 0
Summe
-1
Schwellenwert
>0?
1
0
-1
0
-1
-1
1
+1
1
0
-1
0
-1
0
-1
1
>0?
>0?
-1
1
1
1
Ergebnis
(nach Decodierung)
kein
Schwimmen, Tauchen
kein
Stimmungshoch
negative
Prüfung
Abb.: Verarbeitung mit gewichteten Verbindungen
Das Modell liefert aber nicht nur Empfehlungen für die vor der Tür stehenden Abschlußprüfungen, sondern auch Reaktionen auf "regelmäßigen Vorlesungsbesuch" (Schwimmen,
Tauchen) bzw. auf "erfolgreiche Bearbeitung der Übungen" ("Stimmungshoch"). Das Modell
arbeitet aber nicht vollständig korrekt. So müßte bei "regelmäßigem Vorlesungsbesuch" bzw.
8
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
"erfolgreicher Bearbeitung der Übungen" zwar "Schwimmen,
"Stimmungshoch" aktiv sein, aber "schlechte Prüfung" inaktiv werden.
Tauchen"
bzw.
3. Schritt: Modifikation der Verbindungsstärken (Gewichte) über eine Lernregel
Neuronale Netze können lernen. Das Lernen geschieht durch Modifikation der
Verbindungsstärken nach einer vorgegebenen Lernregel:
Die Modifikation der Verbindungen soll hier auf einer Hypothese beruhen, die besagt, daß die
Verbindungen zwischen zwei Neuronen immer verstärkt wird, wenn beide Neuronen
gleichzeitig aktiv sind (Hebbsche Hypothese) 6.
Δwij = ε ⋅ ai ⋅ a j
ai : Aktivität {-1,1} des Ausgabeneurons
a j : Aktivität {-1,1} des Eingabeneurons
ε : Lernrate
Ausgangslage: Das Trainingsbeispiel umfaßt die Eingabe "regelmäßigen Vorlesungsbesuch",
"keine erfolgreiche Übungsbearbeitung", "keine Semesterabschlußprüfung" (d.h. aktiv inaktiv - inaktiv) und die Ausgabe "Schwimmen, Tauchen", "Stimmungshoch", "keine
schlechte Prüfung" (d.h. aktiv - aktiv - inaktiv).
Testfall:
regelmäßiger
Vorlesungsbesuch
keine
erfolgreiche
Übungsteilnahme
1
Eingaben
Gewichte
-1
1 -1
1 0
Summe
-1
0
1
0
1
Schwellenwert
Semester
Abschlußprüfung
>0?
1
-1
1
-1
-1
0
1
0
-1
0
-1
-1
>0?
>0?
-1
-1
1
-1
Ergebnis
(nach Decodierung)
Schwimmen, Tauchen
kein
Stimmungshoch
Abb.: Verarbeitung mit gewichteten Verbindungen
6
Vgl. Skriptum 2.3.2.1
9
keine negative
Prüfung
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Anwendung der Hebbschen-Hypothese mit ε = 1
1
Eingaben
Gewichte
-1
1 -1 -1
2 -1 -1
Summe
4
Schwellenwert
>0?
1
1
-1
-1
2
-1
-1
1
1 -1
-1 1
-4
-4
>0?
>0?
-1
-1
2
-1
Ergebnis
(nach Decodierung)
Schwimmen, Tauchen
kein
Stimmungshoch
keine negative
Prüfun
Abb.: Trainingsbeispiel nach Anwendung der Hebbschen Regel
Nach diesem Lernschritt mit Lernrate 1 haben Neuronen der Ausgabeschicht noch immer
nicht die gewünschte Aktivität (anstattt „kein Stimmungshoch“ ist „Stimmungshoch“
gewünscht). Die Anwendung der Hebbschen Regel im Sinne unüberwachten Lernens führt
nicht zu dem gewünschten Ergebnis.
Es gibt bei der Hebb’schen Lernregel generell ein Problem: Bei anhaltenden Aktivitäten
beider Zellen i und j wachsen die Gewichte ins Unendliche; die Zellen kennen kein
„Vergessen“. Somit ist die Hebb’sche Lernregel nicht realistisch. Durch entsprechende
Modifikationen läßt sich dieser Nachteil jedoch beseitigen.
4. Schritt: Modifikation der Gewichte mit Hilfe der sog. Delta-Regel 7
Δwij = ε ⋅ δ i ⋅ a j
δ i = t i − ai (Fehler: gewünschter Zustand – tatsächlicher Zustand)
wijneu = wijalt + Δwij
Da hier ein neues Lernverfahren zur Anwendung kommt, muß das Training von Anfang an
wiederholt werden.
7
Vgl. Skriptum 2.3.2.3
10
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
1. Testfall:
kein
regelmäßiger
Vorlesungsbesuch
keine
Semester
erfolgreiche
Abschlußprüfung
Übungsteilnahme
-1
Eingaben
Gewichte
-1
-1 -1
0 0
Summe
1
0
-1
0
0
Schwellenwert
-1
0
1
1
0
-1
0
0
>0?
1
0
0
>0?
-1
-1
0
>0?
-1
-1
Ergebnis
Abb.: Verarbeitung mit gewichteten Verbindungen
Der Fehler führt zu einer Modifikation der Gewichte:
ti
-1
ai
-1
δi
0
-1
1
-1
-1
0
2
Mit ε = 0.25 ergibt sich
aj
-1 -1
1
-1
-1
wij
0
0
0
0
0
1
0
-1
-1
-0.5 -0.5 0.5
Test:
Summe
Schwellenwert
0
>0
-1
0
>0
-1
11
1
1.5
>0
1
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
2. Testfall:
regelmäßiger
Vorlesungsbesuch
keine
keine Semester
erfolgreiche
Abschlußprüfung
Übungsteilnahme
1
Eingaben
Gewichte
-1
1 -1
0 0
Summe
-1
0
1
0
0
Schwellenwert
-1
0
-1
-1
0
1 -1 -1
-0.5 -0.5 0.5
0
>0?
-0.5
>0?
-1
>0?
-1
-1
Ergebnis
Abb.: Verarbeitung mit gewichteten Verbindungen
Der Fehler führt zu einer Modifikation der Gewichte:
ti
1
1
-1
ai
-1
-1
-1
δi
2
2
0
Mit ε = 0.25 ergibt sich
aj
wij
1
-1
-1
0.5 -0.5 -0.5
1
-1
-1
0.5 -0.5 -0.5
1
-1
-1
-0.5 -0.5 0.5
Test:
Summe
Schwellenwert
1.5
>0
1
1.5
>0
1
-0.5
>0
-1
Der Fehler wird nicht sofort weiter verfolgt. Es werden alle vorhandenen Muster erst einmal
bearbeitet (Trainingszyklus, Trainingsepochen).
12
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
⎛−1 −1 1 ⎞
⎟⎟ mit dem Ziel (gewünschtes
Bisher wurden folgende Muster bearbeitet: P = ⎜⎜
⎝ 1 − 1 − 1⎠
⎛−1 −1 1 ⎞
⎟⎟ . Der Fehler nach einer Epoche wird bestimmt durch
Ergebnis) T = ⎜⎜
⎝ 1 1 − 1⎠
∑∑ (t
p
ip
− ai p ) 2 und führt hier auf den Wert 12. Dieser Fehler muß auf eine vorgegebene
i
Schranke reduziert werden können, d.h.: Das Training muß solange wiederholt werden, bis
die vorgegebene Fehlergröße unterschritten ist.
Im vorliegenden Fall wird das aber nur dann gelingen, wenn die Eingabevektoren linear
unabhängig 8 sind.
4. Trainieren Neuraler Netzwerke
Ein NN macht sich über das Training mit den Problemen vertraut. Nach ausreichendem
Training können auch bis dahin unbekannte Probleme gelöst werden (Generalisierung).
4.1 Trainingsphase und Ausbreitungsphase
Bei Neuronalen Netzen unterscheidet man zwischen
-
-
Trainingsphase: In dieser Phase lernt das Neuronale Netz das vorgegebene
Lernmaterial. Dementsprechend werden in der Regel die Gewichte zwischen den
einzelnen Neuronen modifiziert. Lernregeln geben dabei die Art und Weise an, wie
das Neuronale Netz diese Veränderungen vornimmt. Man unterscheidet grundsätzlich
zwischen
supervised learning: Die korrekte Ausgabe wird vorgegeben und daran werden die
Gewichte optimiert
unsupervised learning: Es wird kein Ziel (Ausgabe) vorgegeben. Das Netz versucht
ohne Beeinflussung von außen die präsentierten Daten selbstständig in
Ähnlichkeitsklassen aufzuteilen.
reinforcement learning: Dem Netz wird lediglich mitgeteilt, ob seine Ausgabe
korrekt ider inkorrekt war. Das Netz erfährt nicht den exakten Wert des Unterschieds.
Diese Art des Lernens hat ihr Vorbild in der Erziehung eines Tiers, das ebenfalls nur
durch Lob und Tadel erzogen werden kann.
Ausbreitungsphase: In der Ausbreitungsphase werden hingegen keine Gewichte
verändert. Statt dessen wird hier auf Grundlage der bereits modifizierten Gewichte
untersucht, ob das Netz etwas gelernt hat.
4.2 Trainings- und Testmenge
Die Trainingsmenge bilden repräsentative Ein-/Ausgabe-Daten. Gewöhnlich operiert ein
Neuronales Netz nach dem Training besser auf Eingaben, die auch schon während des
Trainings gemacht wurden. Daher muß die Leistung des Neuronalen Netzes nach dem
Training mit ebenso repräsentativen Testbeispielen überprüft werden. Trainings- und
Testmenge müssen unbedingt verschieden sein.
8
Vgl. Skriptum 1.2.4
13
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Die Elemente der Trainingsmenge müssen dem Neuronalen Netz im allg. mehrere Male
repräsentiert werden, da die Anpassung des Netzes nur langsam erfolgt. Eine einmalige,
vollständige Repräsentation der Trainingsmenge heißt Lernzyklus.
4.3 Trainingsüberwachung
Bei allen Trainingsmethoden muß bestimmt werden, wann das Training weit genug
fortgeschritten ist, um es abzubrechen. Im wesentlichen gibt es drei Mechnismen:
-
-
-
Mit Hilfe einer Fehlerfunktion wird die Abweichung der Trainingsausgaben von den
konkreten Ausgaben gemessen. Je nach Problemstellung kann dafür ein anderen
Fehlermaß (z.B. kleinster quadratischer Fehler, absoluter Fehler, Durchschnittsfehler)
verwendet werden. Ist der Fehler befriedigend klein, kann das Training abgebrochen
werden.
Das Neuronale Netz kann eine Energiefunktion besitzen, die mißt, wie oft, wie stark
etc. das neuronale Netz sich verändert hat. Die Funktion ist so gewählt, daß sie mit
zunehmender Veränderung des Netzes immer kleinere Werte liefert. Ist der Wert der
Energiefunktion unter eine gegebene Schwelle gefallen, wird das Training beendet.
In der Lernregel des Neuronalen Netzes gibt es variable Faktoren, die steuern, wie
stark sich das Netz verändert. Abhängig von Daten wie Fehlermessungen, Dauer der
Lernphase etc. werden diese Faktoren immer näher bei 0 gewählt, bis sich das
Neuronale Netz schließlich kaum noch verändern kann. Dann ist das Ende der
Lernphase erreicht.
4.4 Verschiedene Trainingsarten
r r r r
r r
Lernaufgabe: Menge von Eingabemustern L = {( p1 , t1 ), ( p 2 , t 2 ),...( p n , t n )}
r
p k ist ein Eingabevektor (Eingabemuster, input pattern)und dient als Eingabe
im
r Netz
t k ist ein Ausgabevektor (target) und legt die gewünschte Ausgabe fest
r r
Lernziel: jedes ( p, t ) aus L soll vom Netz mit möglichst kleinem Fehler berechnet werden.
Häufig verwendetes Fehlermaß: Fehler bzgl. eines Ein-/Ausgabepaares aus L
2
E p ,t = ∑ ( y k − t k )
k
r
y : Ausgabe des Netzes bei Eingabe p
Gesamtfehler (Sum Squared Error, sse): E = ∑ E p ,t
p ,t∈L
Vorgehen:
r
v r
- Wähle ein Ein-/Ausgabepaar ( p, t ) aus L und gebe p im Netz ein
r
- Berechne Ausgabe y des Netzes
r
r
- Vergleiche y mit gewünscheter Ausgabe t
r
- Ändere Gewichtsmatrix W möglichst so, daß E p ,t minimiert wird.
- Falls eine Epoche (vollständiger Durchlauf durch die Ein-, Ausgabepaare)
abgelaufen, prüfe, ob Gesamtfehler E gewünschten Grenzwert erreicht hat.
Falls nicht, starte eine neue Epoche (Musterlernen, lerning by pattern, onlinelearning)
r
Variante: Ändere Gewichtsmatrix W epochenweise. (Epochenlernen, learning by
epoch, offline-learning)
14
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Unüberwachtes Lernen
r r
r
Lernaufgabe: Menge von Eingabemustern L = ( p1 , p 2 ,..., p n )
r
p k ist ein Eingabevektor und dient als Eingabe im Netz
Lernziel: Finde Klassifizierung, ähnliche Eingaben sollen gleich klassifiziert werden.
Vorgehen:
r
r
- Wähle ein Eingabemuster p k aus L und gebe p k ins Netz.
r
- Berechne Ausgabe y des Netzes
r
- Ändere Gewichtsmatrix W gemäß einer Lernregel
- Falls am Ende einer Epoche ein Endekriterium erfüllt ist, breche ab.
- Sonst starte eine neue Epoche
Bewertetes Lernen
r
r
Das Netz erhält zu den Trainingseingaben x k nicht die korrekten Ausgaben y k . Stattdessen
wird die Leistung des Neuronalen Netzes von Zeit zu Zeit bewertet (jeweils für den Zeitraum
seit der letzten Wertung). Daraufhin kann es versuchen, sich zur Zufriedenheit des
Bewertenden zu ändern.
Selbstordnung (self organization)
Hier werden dem Neuronalen Netz nur repräsentative Eingaben geliefert, in dem es
bestimmte Gemeinsamkeiten „erkennen“ soll. Dabei soll es bestimmte Musterkategorien
bilden,in die sich Eingaben einordnen lassen. Der Vorgang der Kategoriebildung wird auch
Clustering genannt.
5. Lernregeln
Während des Trainings sorgt die Anwendung der Lernregel eines Neuronalen Netzes dafür,
daß es sich den Trainingsdaten anpaßt bzw. Kategorien formt.
Die Lernregel ist ein Algorithmus, der das NN verändert und ihm so beibringt, für eine
vorgegebene Eingabe eine gewünschte Ausgabe zu produzieren.
5.1 Hebb’sche Regel und Delta-Regel
1. Hebb’sche Regel
Im menschl. Gehirn erfolgt Lernen durch Ändern der Synapsenstärken. Der Psychologe
Donald Hebb (1949) stellte die Hypothese auf, daß sich die Gewichtung der Synapse
verstärkt, wenn Neuronen vor oder nach der Synapse gleichzeitig aktiv sind.
Die Hebb’sche Regel besagt: Wenn Neuron „i“ und Neuron „j“ zur gleichen Zeit stark
aktiviert sind, dann erhöhe das Gewicht wij , das diese beiden Neuronen verbindet.
Δwij = ε ⋅ ai ⋅ a j
15
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Die Lernrate " ε ≥ 0 " bemißt die Größe des Lernschritts. Wird von Gewichten mit dem Wert 0
ausgegangen und baut sich das Netzwerk schrittweise auf, dann ist das Gewicht am Ende
einer Reihe von Lernschritten (indiziert durch l):
wij = ε ⋅ ∑ ail ⋅ a jl
j
Motivation: Beobachtungen zur Ableitung der Hebb’schen Regeln erfolgten an „echten
neuronalen Netzen“
Nachteil: Gewichte können nur größer werden 9, nur geringe Flexibilität
2. Delta-Regel 10
Δwij = ε ⋅ δ i ⋅ a j
δ i = ti − ai
Aus der Differenz von gewünschtem und erzieltem Ausgabeverhalten berechnet man einen
Fehlerkorrekturwert, das sog. Delta und ändert die Gewichte in Abhängigkeit von diesem
Fehlerkorrekturwert.
- Gewichtsänderung ist proportional zum Fehler an den Ausgabe-Neuronen
- In dieser Form nur für Feedforward-Netzwerke mit Ein- und Ausgabeschicht sinnvoll
- Eingeschränkte Mächtigkeit: Nur eine Teilmenge der möglichen Eingabe, Ausgabe –
Funktionen kann gelernt werden.
Es gibt eine Verallgemeinerung der Delta-Regel für Netzwerke mit mehr als 2 Schichten
(Eingabe, Ausgabe).
5.2 Beispiele für Anwendungen der Lernregeln
1. Bsp.: Trainieren mit der Hebbschen Regel 11
1. Ein positiver Fall
1
0
2
Dieses NN soll aus Eingabemustern nach folgender Zusammenstellung Ausgabemuster
erzeugen.
Eingabe
0
1
Eingabe
1
1
Ausgabe
2
1
9
vgl. Skriptum, 2.3.2.2
Widrow&Hoff-Regel
11 Skiptum, 2.3.2.1
10
16
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
1
-1
-1
-1
1
-1
1
-1
-1
Nach der Hebbschen Regel erhält w20 den Wert von ε (Annahme: ε = 1. 0 ) zugeordnet, w21
dagegen wird reduziert auf den Wert 0. Eingabemuster 0 korreliert zum Ausgabemuster. Auf
diese Weise können über die Hebbsche Hypothese Assoziationen erlernt werden.
2. Ein negativer Fall
0
1
2
3
4
Das NN soll aus Eingabemustern nach folgender Zusammenstellung ein Ausgabemuster
erzeugen:
Eingabe
0
1
1
1
1
1
-1
1
1
-1
2
1
1
1
-1
3
-1
1
-1
1
Ausgabe
4
1
1
-1
-1
3 der möglichen Verbindungen zwischen Eingabe- und Ausgabeschicht führen auf den Wert 0
(keine Korrelation zwischen den Aktivitäten). Nur Einheit 2 hat zur Ausgabeeinheit eine
positive Korrelation.
Eine Lösung der vorliegenden Aufgabe kann durch die folgende Zuordnung von Werten zu
den Verbindungen erreicht werden:
0
1
-1
2
2
-1
3
1
4
17
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
2.Bsp.: Lernen nach der Delta-Regel 12
0
1
2
3
4
Das NN soll aus Eingabemustern nach folgender Zusammenstellung ein Eingabemuster
erzeugen.
Muster
0
1
2
3
Eingabe
0 1 2 3
1 -1 1 -1
1 1 1 1
1 1 1 -1
1 -1 -1 1
Ausgabe
4
1
1
-1
-1
Nach der Delta-Regel sind die Gewichte der Verbindungen zwischen den Einheiten der Einund Ausgabeschicht zuzuordnen. Die Gewichte sind mit 0 initialisiert, die Lernrate ε hat den
Wert 0.25.
Lösung: Zuerst wird Muster 0 betrachtet. Das führt auf den Ausgabewert 0. Zum
vorgegebenem Ziel ergibt sich die Differenz 1, d.h. Änderungen der Gewichte sind
proportional zu den Aktivierungen der Eingabeeinheiten. Das führt zur folgenden
Tabellenzeile für Muster 0.
Muster
0
Eingabe
Ziel
1 -1 1 -1
1
Ausgabe
0.0
Fehler
Δwij
wij
1.0
0.25 -0.25 0.25 -0.25
0.25 -0.25 0.25 -0.25
Fortsetzung der Lösungsangaben: Skript, 2.3.2.3
12
vgl. Skriptum, 2.3.2.4
18
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
5.3 Offline oder Online-Lernen
Lernen kann offline oder online erfolgen.
offline: eine Menge von Trainingsmustern wird präsentiert, danach werden Gewichte
verändert, der Gesamtfehler wird mit Hilfe einer Norm errechnet bzw. einfach aufkumuliert.
Offline-Trainingsverfahren werden auch Batch-Trainingsverfahren genannt, da ein Stapel
Ereignisse auf einmal korrigiert wird. Einen sochen Trainingsabschnitt von einem ganzen
Stapel Trainingsbeispiele samt zugehöriger Veränderung der Gewichtswerte nennt man
Epoche.
online: Nach jedem präsentierten Beispiel werden Gewichte verändert.
6. Architekturen
Mit Architektur ist der Aufbau Neuronaler Netze gemeint. Dieser Begriff beinhaltet
Informationen über Zahl und Art der Schichten, über Vernetzung und über die verwendete
Lernregel.
Generell ist der Aufbau Neuronaler Netze bestimmt durch
-
eine Menge von Neuronen und eine Netzwerkstruktur
die Netzwerkstruktur beschreibt, welche Neuronen mit welchem Gewicht miteinander
verknüpft sind
r
die Netzwerkstruktur läßt sich als Gewichtsmatrix W = (wij ) angeben.
-
wij gibt die Verbindung von einem Neuron der Schicht „j“ zu einem Neuron der
-
Schicht „i“ an
6.1 Assoziative Netze
Als assoziative Netze werden im allg. Neuronale Netze bezeichnet, die aus einer
Eingabeschicht mit Verteilerneuronen und einer Ausgabeschicht bestehen. Nur die Neuronen
der Ausgabeschicht besitzen Gewichtsvektoren und das Neuronale Netz hat demzufolge nur
eine „Arbeitsschicht“.
r r
Typische Aufgabe: Lernen von „l“ Assoziationen der Form ( x k , y k ) . Die „l“ Paare werden
dem Neuronalen Netz während des Trainings präsentiert. Nach dem Training soll das Netz
r
r
dann zur Eingabe x k die Ausgabe y k liefern (für k = 1, … ,l), für andere Eingaben wird die
r r
r
Ausgabe durch Interpolation ermittelt. Die Punkte ( x k , y k ) mit gleichen y k bilden zusammen
r r
eine Klasse. Soll ein assoziatives Netz alle l Assoziationen ( x k , y k ) perfekt lernen, müssen
die Klassen linear separabel sein.
Wichtigstes Anwendungsgebiet: Pattern Assoziator. Er kann Muster erkennen, die er zuvor
gelernt hat. Die Trainingsphase kann entweder mit der Hebb-Regel oder mit der DeltaRegel 13 vorgenommen werden. Der Pattern Assoziator verfügt über eine Reihe
wünschenswerter Eigenschaften:
-
13
Generalisierung: Ähnliche Muster werden zu selben Mustergruppe kategorisiert.
Toleranz gegenüber internen Schäden: Hier ist gemeint, dass trotz innerer Schäden
des Neuronalen Netzes (z.B. durch das Absterben einzelner Neuronen) dieses oftmals
dennoch die richtige Ausgabe produziert.
vgl. Skriptum 2.3.2
19
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
-
Ausgabe der zentralen Tendenz bzw. des Prototypen der Kategorie: Bei mehreren
gelernten Inputmustern bildet der Pattern Assoziator einen Prototypen der gelernten
Muster aus.
6.2 Mehrschichtige Netze
Mit „mehrschichtig“ ist hier gemeint, daß das Neuronale Netz mindestens eine verborgene
Schicht hat.
Durch die Mehrschichtigkeit werden die beiden großen Probleme der assoziativen Netze
überwunden:
1. Mehrschichtige Netze besitzen die Fähigkeit zur Abstraktion, so dass auch nicht linear
separable Klassen gelernt werden können.
2. Die Dimension der Eingaben beschränkt nicht die Zahl der exakt lernbaren Ein/Ausgabepaare
Der wichtigste Vertreter der mehrstufigen Netze ist das Backpropagation-Netz 14 mit
zahlreichen Varianten (z.B. Quickprop).
Mehrschichtige Netze besitzen keine Zyklen (azyklisch) und sind vorwärtsgerichtet
(feedforward).
Eingabeschicht (input layer)
Verdeckte Schichten
(hidden layers)
Ausgabeschicht (output layer)
Abb.: Vorwärtsgerichtetes 3-2-3-2-Netz
Schichtenarchitektur:
- Nur Verbindungen zwischen aufeinander folgenden Schichten
- Schichten müssen nicht vollständig miteinander verknüpft sein
14
vgl. Skriptum 2.4
20
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Arbeitsweise mehrschichtiger Netze, z.B. 2-2-2-Netz
1
3
5
⎛x ⎞
r
x T = ⎜⎜ 1 ⎟⎟
⎝ x2 ⎠
⎛y ⎞
v
y T = ⎜⎜ 1 ⎟⎟
⎝ y2 ⎠
2
Gewichte:
Aktivierungsfunktion:
4
v ⎛w
W1 = ⎜⎜ 31
⎝ w41
6
w32 ⎞ v ⎛ w53
⎟ W2 = ⎜⎜
w42 ⎟⎠
⎝ w63
w54 ⎞
⎟
w64 ⎟⎠
f3 = f4 = f5 = f6 = f
Berechnung der
Netzausgabe:
⎛ o3 ⎞
⎜⎜ ⎟⎟ =
⎝ o4 ⎠
⎛⎛ w
f ⎜⎜ ⎜⎜ 31
⎝ ⎝ w41
r r
w32 ⎞⎛ x1 ⎞ ⎞
⎟⎟⎜⎜ ⎟⎟ ⎟⎟ = f W1 ⋅ x T
w42 ⎠⎝ x 2 ⎠ ⎠
⎛⎛ w
⎛o ⎞
r
y T = ⎜⎜ 5 ⎟⎟ = f ⎜⎜ ⎜⎜ 53
⎝o 6 ⎠
⎝ ⎝ w 63
(
w 54
w 64
⎞⎛ o 3
⎟⎟⎜⎜
⎠⎝ o 4
)
r
r r
⎞⎞
⎟⎟ ⎟⎟ = f W 2 f W 1 x T
⎠⎠
(
(
))
6.3 Rekurrente Netze
Sie sind dadurch gekennzeichnet 15, dass Rückkopplungen von Neuronen einer Schicht zu
anderen Neuronen derselben oder einer vorangegangenen Schicht existieren. Damit sollen
zeitlich kodierte Informationen in den Daten entdeckt werden.
Rekurrente Netze lassen sich unterteilen in Neuronale Netze mit
-
15
direkten Rückkopplungen (direct feedback): Hier existieren vom Output zum Input
derselben Unit. Der Aktivitätslevel der Einheit wird zum Input der gleichen Einheit.
Indirekte Rückkopplungen (indirect feedback): In diesem Fall wird die Aktivität an
vorangegangene Schichten zurückgesandt.
Seitliche Rückkopplungen (lateral feedback): Hier erfolgt die Rückmeldung der
Information einer Unit an Neuronen, die sich in derselben Schicht befinden
Vollständige Verbindungen: Die Netze besitzen Verbindungen zwischen sämtlichen
Neuronen
vgl. Skriptum 2.5 bzw. 2.1.2.2
21
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Eingabeschicht
Verborgene Schicht
Ausgabeschicht
Abb.: Schematische Darstellung eines Simple Recurrent Network mit 3 Kontext-Units (in
blau)
Simple Recurrent Networks zeichnen sich durch ihre Kontexteinheiten aus.
Kontexteinheiten sind Neuronen, die sich quasi auf gleicher Ebene wie die der InputSchichten befinden und von Units der Hidden-Schicht Informationen erhalten. Diese
Informationen werden dann dort verarbeitet und sodann einen Schritt verzögert an die Hidden
Units der betreffenden Schicht zurückgesendet.
Kompetitive Netze (Self Organizing Maps)sind NN mit einer Input- und einer
Outputschicht 16 und greifen auf die Competitive Lernregel (Wettbewerbslernen) zu. Das
Lernen nach dieser Lernregel ist unsupervised, das NN nimmt anhand der Ähnlichkeit der
repräsentativen Input-Reize eine Kategorisierung vor. Es können 3 verschiedene Phasen
unterschieden werden:
1. Erregung: Zunächst wird wie gewohnt für alle Ausgabe-Units der Netto-Input durch
folgende Formel berechnet: ∑ x j ⋅ wij
2. Anschließend werden die Netto-Eingaben sämtlicher Ausgabe-Einheiten miteinander
verglichen. Diejenige Unit mit dem höchsten Netto-Input ist der Gewinner.
3. Adjustierung der Gewichte: Im letzten Schritt werden die Gewichte verändert und
zwar bei allen Verbindungen, die zur Gewinner-Unit führen. Alle anderen Gewichte
werden nicht verändert („The winner takes it all“)
Kohonen-Netze 17 sind eine Erweiterung kompetitiver Netze. Auch sie agieren ohne externen
Lehrer.
16
und damit auch wie der Musterassoziator ohne verborgene Schichten
Der Begriff stammt von Teuvo Kohonen, der ein sehr bekanntes Netzwerk konzipierte, das seinen Namen
trägt.
17
22
Neuronale Netze, Fuzzy Control und Genetische Algorithmen
Zweidimensionale Ausgabeschicht
Abb.: Schematische Darstellung eines 2-dimensionalen Kohonen-Netzes. In blau und rot 2 Input-Units mit ihren
Verbindungen zu sämtlichen Ausgabe-Units (in grün), die 2-dimensional angeordnet sind.
Kohonen-Netze können in selbstorganisierender Weise lernen, Karten (maps) von einem
Eingaberaum) zu erstellen. Man kann auch sagen: Kohonen-Netze clustern den Eingaberaum.
23