Oracle 10G and Linux (CentOS) - Fachbereich Informatik und
Werbung
 - Fachbereich Informatik und")
UNIVERSITÄT KONSTANZ
Database Tuning &
Administration
Dokumentation: Oracle 10g Express &
CentOS 4.4
Michael Seiferle (596485)
Marco Matt (591693)
Sommersemester 2007
Fachbereich Informatik & Informationswissenschaft
Database & Information Systems Group
Prof. Marc H. Scholl
Christian Grün
I NHALTSVERZEICHNIS
1 Aufgabenstellung ............................................................................................................................................................................... 4
2 Installation & Konfiguration ............................................................................................................................................................... 4
2.1 CentOS 5.0 .................................................................................................................................................................................. 4
2.2 CentOS 4.4 .................................................................................................................................................................................. 4
2.3 Oracle 10g Express Edition.......................................................................................................................................................... 4
3 Benchmark ......................................................................................................................................................................................... 6
3.1 Erste Schritte: CDDB Daten ......................................................................................................................................................... 6
3.1.1 Vorbereitung DDL ................................................................................................................................................................ 6
3.1.2 Einlesen der Daten (sqlplus & sqlldr) ................................................................................................................................... 6
3.1.3 Queries ................................................................................................................................................................................. 7
3.2 TPC-H Benchmark ....................................................................................................................................................................... 7
3.2.1 Datenbasis generieren und einlesen ................................................................................................................................... 8
3.2.2 Queries generieren .............................................................................................................................................................. 8
3.2.3 Erste Tuningmaßnahmen ..................................................................................................................................................... 9
3.2.4 Wie wir gemessen haben ..................................................................................................................................................... 9
4 Tuning einzelner Queries ................................................................................................................................................................. 11
4.1 Query 14 ............................................................................................................................................................................... 11
4.2 Query 15 ............................................................................................................................................................................... 11
4.3 Query 9 ................................................................................................................................................................................. 11
4.4 Query 2 ................................................................................................................................................................................. 12
4.5 Query 3 ................................................................................................................................................................................. 12
4.6 Query 6 ................................................................................................................................................................................. 12
4.7 Query 18 ............................................................................................................................................................................... 12
4.8 Verändern der Buffer Größe ................................................................................................................................................. 13
5 Fazit .................................................................................................................................................................................................. 14
Anhang ................................................................................................................................................................................................ 15
2
convert.py ....................................................................................................................................................................................... 15
CDDB Queries ................................................................................................................................................................................. 16
Beispiel Control-File für SQL-Loader (Tabelle Customer TPCH) ...................................................................................................... 16
Primär- und Fremdschlüssel des TPC-H Schemas ........................................................................................................................... 16
TPC-H Querys .................................................................................................................................................................................. 17
Query 2 ....................................................................................................................................................................................... 17
Query 3 ....................................................................................................................................................................................... 18
Query 6 ....................................................................................................................................................................................... 18
Query 9 ....................................................................................................................................................................................... 18
Query 14 ..................................................................................................................................................................................... 19
Query 15 ..................................................................................................................................................................................... 19
Query 18 ..................................................................................................................................................................................... 20
Framwork in Java ............................................................................................................................................................................ 20
Class BenchmarkTest.java ........................................................................................................................................................... 20
Class Query.java .......................................................................................................................................................................... 22
Class QueryLoader.java ............................................................................................................................................................... 23
Bibliographie ....................................................................................................................................................................................... 24
3
1 A UFGABENSTELLUNG
Ziel der Lehrveranstaltung war es ein DBMS samt zu Grunde liegendem Betriebssystem aufzusetzen, zu
konfigurieren und zu tunen. Das Augenmerk wurde hier vor allem auf das Tuning der Queries des TPCH
Benchmarks gelegt. Der TPCH Benchmark beinhaltet in erster Linie Anfragen die in Decision Support Systemen
vorkommen und auf großen Datenmengen ohne Vorwissen operieren [1].
Gleich zu Beginn mussten wir uns zwischen den Betriebssystemen Microsoft Windows XP oder einer Linux
Distribution unserer Wahl entscheiden. Außerdem standen die Datenbankmanagementsysteme Microsoft SQL
Server 2005 Express, IBMs DB2 Express Edition oder Oracle 10g Express Edition (10.2) zur Auswahl. Unsere Wahl fiel
auf CentOS und Oracle Express. Da CentOS binärkompatibel zu Red Hat Enterprise Linux (im folgenden RHEL) ist
und Oracle seine DBMS für RHEL zertifiziert, erschien uns diese Auswahl sinnvoll.
2 I NSTALLATION & K ONFIGURATION
2.1 C ENT OS 5.0
Die Installation von CentOS 5.0 (CD) war auf Grund von inkompatiblen Gerätetreibern nicht möglich. Die
Installations-CD erkannte den verwendeten SATA-Controller nicht und weigerte sich nach der Installation des
Basissystems das CD-Laufwerk anzusprechen und die Installation fortzusetzen. Nach Studium der Hardware
Dokumentation versuchten wir unser Glück mit einer Installation über den FTP-Server des CentOS Projekts.
Die Installation verlief soweit erfolgreich allerdings hatten wir nach dem ersten Reboot Probleme mit dem
Device Manager udev, die sich auch mit mehreren Lösungsansätzen nicht beheben ließen.
2.2 C ENT OS 4.4
Die Installation von CentOS 4.4 verlief hingegen ohne nennenswerte Probleme. Die komplette Hardware
inklusive beider Prozessorkerne wurde erkannt. Allerdings installierte die Update Automatik nach der Installation
unbemerkt das Update auf CentOS 4.5 welches im Kernel erneut keine Unterstützung für den SATA-Controller
bereithielt.
Glücklicherweise blieb der alte Kernel weiterhin auf dem System installiert, so dass wir ihn nur im Bootmanager
als Standardkernel eintragen mussten. Danach installierten wir noch SSH um per Remote Login auf dem Rechner
arbeiten zu können.
2.3 O RACLE 10 G E X PRESS E DITION
Für die Installation des Oracle DBMS meldeten wir uns im Oracle Technology Network [2] an und konnten die
aktuelle Version als RPM-Paket herunterladen. Danach starteten wir die Installation auf der Konsole:
$ rpm -ivh downloads/oracle-xe-univ-10.2.0.1-1.0.i386.rpm
und konfigurierten die frisch installierte Datenbank mit folgendem Befehl:
4
$ /etc/init.d/oracle-xe configure
Wir beließen alle Einstellungen auf ihrem voreingestellten Wert und vergaben lediglich das Passwort für den
SYSTEM Account. Nach einem Reboot des kompletten Systems legten wir zunächst eingeschränkte
Benutzerkonten für die weitere Arbeit mit Hilfe des Webinterfaces der Datenbank an.
Um auch über den Konsolenclient sqlplus auf die Datenbank zugreifen zu können waren zusätzliche Maßnahmen
notwendig; sqlplus benötigt einige Umgebungsvariablen um zu starten:
# vi ~/.bash_profile
ORACLE_BASE=/usr/lib/oracle/xe/app/oracle/product/10.2.0export
ORACLE_BASEORACLE_HOME=$ORACLE_BASE/serverexport
ORACLE_HOMEORACLE_SID=XEexport
ORACLE_SIDPATH=.:$PATH:$ORACLE_HOME/bin:$ORACLE_HOME/libLD_LIBRARY_PATH=$LD_LI
BRARY_PATH:$ORACLE_HOME/libORA_NLS33=$ORACLE_HOME/ocommon/nls/admin/dataCLASSP
ATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlibexport
LIBPATH=$LIBPATH:$ORACLE_HOME/libexport ORACLE_BASE ORACLE_HOME PATH
LD_LIBRARY_PATH ORA_NLS33 CLASSPATH
5
3 B ENCHMARK
3.1 E RSTE S CHRITT E : CDDB D ATEN
Unsere nächste Aufgabe war es das Datenbanksystem samt der mitgelieferten Werkzeuge kennenzulernen.
Hierzu sollten wir zunächst einen Auszug der CDDB Daten[3] als PostgreSQL-Dump in die Datenbank einlesen,
dazu fünf Queries definieren und mit ersten Tuningmaßnahmen beginnen.
3.1.1 V O R BE R EI T UN G DDL
Da die Syntax der Schemadefinitionen von Oracle und PosgreSQL weitgehend kompatibel sind (vergleiche [4] &
[5]) konnten wir die entsprechenden CREATE Statements einfach aus dem Schema Dump kopieren und
mussten nur wenige Schlüsselwörter durch ihre Pendants in Oracle ersetzen. Namentlich waren das VARCHAR
durch VARCHAR2.
3.1.2 E I N L E S EN DE R D AT EN ( SQ LP L US & SQ L L DR )
Da der PostgreSQL Dump die Daten nicht als INSERT-Statements enthält, sondern als tabulatorgetrennte
Spalten, schrieben wir zunächst ein kleines Python-Skript [Anhang], welches den Reintext in INSERTStatements umwandelt und in einer Textdatei als SQL-Skript speichert. Danach galt es noch die Sonderzeichen
wie & und ' zu escapen: sqlplus erwartet die Ersetzung jedes & durch eine Benutzereingabe.
Mit Hilfe des Konsolenclients sqlplus lassen sich so generierte SQL-Anweisungen dann einfach einlesen:
$ sqlplus Benuter/Passwort
$ @<Pfad zu>dss.ddl
Da das Einlesen der Daten jedoch schon für das vergleichbar kleine Datenvolumen unerwartet langsam war,
bemühten wir uns um ein Bulk Loading Utility [6], welches wir im mitgelieferten sqlldr fanden. Das
Kommandozeilentool sqlldr benötigt, um die Daten zu importieren eine Steuerdatei. In dieser ist spezifiziert aus
welcher Datendatei und in welchem Format die Daten in eine Tabelle der Datenbank importiert werden müssen.
Das Control File für cddb.genres hat beispielsweise folgendes Format:
# sqlldr Control File for cddb.genres
load data
infile '/home/michael/csv/csv/genres.csv'
into table genres
fields terminated by "\t" optionally enclosed by '"'
(genreid,genre)
Der Import selbst wird durch den Befehl
6
$ sqlldr benutzer/passwort@datenbank control=cddb.genres.ctl
gestartet.
3.1.3 Q U ERI E S
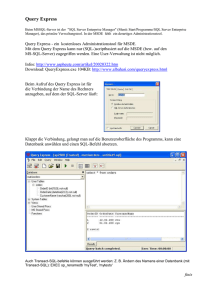
Die nächste Aufgabe bestand darin, Queries für die neu erstellte Datenbasis zu entwerfen und erste
Tuningmaßnahmen zu ergreifen um diese Anfragen zu beschleunigen.
Da es in erster Linie darum ging möglichst aufwändige Queries zu schreiben, haben wir keinen großen Wert auf
den Sinn oder die Alltagsrelevanz der Anfragen gelegt.
Mit den von uns formulierten Queries [Anhang] haben wir uns bemüht, möglichst alle Anfrageszenarien
abzudecken: Punktanfragen, Rangeanfragen, Aggregationen, Joins und Pattern Matching. Im Zuge der
Optimierungen erstellten wir Primär- und Fremdschlüssel und belegten geeignete Felder mit Constraints.
Zusätzlich erstellten wir Indizes für die Volltextsuche von der der LIKE Operator profitierte.
3.2 TPC-H B ENCHMARK
Der TPC Benchmark H ist ein Decision-Support-Benchmarksystem. Es besteht aus 22 businessorientierten
Abfragen bzw. parallelablaufenden Datenmanipulationen. In unserem Test benutzten wir Version 2.6.0.
Datenbasis des Benchmarks bildeten 8 Tabellen von zum Teil erheblich unterschiedlicher Größe. Die
Beziehungen der einzelnen Tabellen werden in Abbildung 1 dargestellt.
A BBILDUNG 1: TPC-H S CHEMA
7
Wie aus der Abbildung ersichtlich, bildet der TPC-H Benchmark die Geschäftsprozesse eines
Handelsunternehmens ab. Es bezieht Waren (Parts) von Lieferanten (Supplierer). Es wird festgehalten, welche
Waren, mit Preis und Anzahl, von welchem Lieferanten bezogen werden können (Partsupp). Kunden
(Customer) können Bestellungen (Orders) aufgeben, die aus mehreren Bestellposten (Lineitem) bestehen können.
Kunden und Lieferanten können unterschiedlicher Nationalität (Nation) und somit auch aus unterschiedlichen
Kontinenten (Region).
3.2.1 D AT EN B ASI S GE N E R I E R EN U N D EI N L E S EN
Die Tabellen und die Datenbasis werden mittels Skript automatisch generiert. Dazu musste im Makefile der
Compiler (in unserem Fall gcc), das Betriebssysten (LINUX) und der Benchmarktyp (TPCH) bestimmt werden.
Da Oracle als Datenbank nicht wählbar war, benutzten wir DB2. Nach dem Kompilieren musste das Skript dbgen
ausgefüht werden, das die DDL der Tabellen und die Datenbasis erstellt. Hierbei ist eine unterschiedliche
Skalierung der Größe der zufällig erstellten Datenbasis möglich. Wir wählten eine Größe von 1 GB.
$ run dbgen -v -s 1
Das Erstellen der Tabellen der Datenbank geschah mit Hilfe des Kommandozeilentools sqlplus und der erstellten
DDL.
$ sqlplus Benuter/Passwort
$ @<Pfad zu>dss.ddl
Die Daten wurden, wie schon bei der cddb-Datenbank mit Helfe des Tools sqlloader in die Tabellen eingefügt.
$ sqlldr benutzer/passwort@datenbank control=<Name>.ctl
Bis auf die Angabe des richtigen Datumformats (date yyyy-mm-dd) musste hier nichts weiter beachtet werden
[Anhang].
3.2.2 Q U ERI E S G EN E R I ER EN
Die vorgegebenen Anfragen sollten durch das Programm qgen, mit Zufallswerten gefüllt, erstellt werden.
$ run qgen
-N -d
1 > 1_g.sql
8
Da die Generierung der Anfragen bei uns mit Fehlermeldung abbrach und im Internet gefundene
Lösungsansätze keinen Erfolg brachten, ersetzten wir die Variablen durch selbst gewählte und an die
Datenbasis angepasste Werte.
3.2.3 E R ST E T UN I N G M Aß N A HM EN
Da alle Anfragen mit selbst ausgesuchten Werten ergänzt wurden, haben wir als erstes diese
Anfragen ohne Primär- und Fremdschlüsselbedingungen getestet. Dabei gab es schon Anfragen, die nach einigen
Minuten abgebrochen werden mussten. Durch das Anlegen der Primär- und Fremdschlüsselbedingungen
[Anhang] und den damit von Oracle erstellten Indexe auf die Primärschlüssel in Form von B-Trees konnten
keine generellen Verbesserungen der Abfragezeit gemessen werden. Einige Abfragezeiten verbesserten sich
erheblich, andere Abfragen wurden daduch sogar langsamer. Ein möglicher Grund für die Verlangsamung der
Anfrage bei Benutzung von Indizes könnte sein, da unser Rechner über zu wenig RAM verfügte, so dass Teile
der gecachten Tabellen aus dem Buffer entfernt werden mussten, um den Index zu cachen. Die Tabellen müssen
später wieder neu eingelesen werden.
Die vom Advisor der Web-Oberfläche vorgeschlagenen Indizes brachten ebenfalls keine merklichen
Verbesserungen der Abfragezeiten, weshalb wir generell keine benutzt haben und weitere Indizes nur zur
Optimierung der einzelnen Anfragen nutzten. Das Anlegen weiterer Index-Strukturen wie Hash clustered oder
B-clusterd Index ist in der Express-Ausgabe von Oracle nicht möglich.
3.2.4 W I E W I R G E M ES S EN HA B E N
Um verlässliche Meßergebnisse zu erhalten, wurde jede Query mindestens sechs Mal ausgeführt. Dabei wurde die
erste Zeit ignoriert und danach der Durchschnitt der verbleibenden fünf Zeiten gebildet. Da wir nicht sicher
sagen konnten, ob die Veränderung des Schemas (beispielsweise Indizes deaktivieren) nicht vielleicht doch
Auswirkungen auf nachfolgende Queries hatte, erstellten wir zwei identische Datenbanken des TPC-H
Benchmarks und ließen davon eine gänzliche unoptimiert, um verlässliche Vergleichswerte zu erhalten.
Um die Messergebnisse von äußeren Einflüssen weitgehend unabhängig zu machen, hatten wir uns überlegt in
Java ein Benchmark Framework zu erstellen, das über den Oracle Net Listener von einem Remoterechner die
Anfragen sendet. Außerdem sollten die Möglichkeiten von Oracle ein Tracefile zu erstellen, in dem detaillierte
Angaben zu CPU-Cycles, der Speicherauslastung und den Query Plänen gespeichert sind genutzt werden.
Dieses Tracefile lässt sich mit dem Tool tkprof parsen und generiert daraus einen ausführlichen Report.
Der Java Rumpf unseres Frameworks ist als [Anhang] der Arbeit beigefügt.
Leider scheiterten wir mit unserem Framework aber an zwei Problemen:
9
Die von Oracle generierten Tracefiles enthielten zwar alle relevanten Informationen, jedoch ließ sich der
Name unter dem die Tracefiles abgelegt wurden nicht verändern oder abfragen.
Außerdem wurde mit dem Parsen des Tracefiles der Query Plan neu von der Datenbank angefragt, so
dass wir nach jeder Tracefile Generierung sofort den Report manuell generieren mussten.
Wir gingen deshalb dazu über für unsere Benchmarks nur noch die Ausführungszeiten und die jeweiligen Query
Pläne in Betracht zu ziehen, die wir mit dem Tool Oracle SQL Developer [7] ausführten und erstellten.
10
4 T UNING EINZELNER Q UERIES
4.1 Q U ER Y 14
Query 14 war für uns vor allem interessant, weil es gleiche mehrere teure Operationen verknüpft: Intervallsuche,
Bedingte Selektion mit String Matching und einen Join.
Schon durch das hinzufügen eines Primärschlüssels auf eines der beiden Join-Attribute
partsupplier.ps_partkey konnte die Ausführungszeit von 15,7 auf ~0,51 Sekunden gesenkt werden. Den
zusätzlich definierten Fremdschlüssel auf l_partkey wird dabei vom Scheduler nicht berücksichtigt und ließ
sich auch durch einen HINT nicht erzwingen.
4.2 Q U ER Y 15
Bei diesem Query, welches neben einer View Creation auch 2 Aggregationen enthält, galt es vor allem die Anzahl
der Physical Reads, also das Lesen der Blöcke von der Festplatte, zu reduzieren. Ohne Optimierungen wurden
zur Durchführung der Anfrage über 100 000 Blöcke gelesen, was die Ausführung des Queries, mit knapp über 17
Sekunden, stark verlangsamte. Die Analyse der Query Plans zeigte, dass vor allem der FULL TABLE ACCESS
auf lineitems, in unserem Fall eine Relation mit über 5 Millionen Datensätzen, für die große Anzahl an
Physical Reads verantwortlich war. Da auf lineitems eine RANGE selektiert wird und auf dem Attribut
l_shipdate kein Index definiert ist, werden hier erst alle Zeilen gelesen und danach diejenigen aussortiert die
dem Selektionskriterium nicht entsprechen. Das spiegelt sich auch im Query Plan wieder, der als Zugriffspfad
"Filter Predicates" für l_shipdate angibt.
Den Auswirkungen dieses Zugriffspfades war durch einen Index auf l_shipdate gut beizukommen: Der
Scheduler wählt "Access Predicates" als Zugriffspfad auf die Daten:
Wir vermeiden somit den Full Table Scan und greifen stattdessen über den Index auf die Tabelle zu. Das senkt
die Laufzeit in unserem Fall von über 17 auf ~1,02 Sekunden.
4.3 Q U ER Y 9
Mit Query 9 förderten wir ein interessantes Phänomen zu Tage: Oracle scheint sich den günstigsten
Ausführungsplan zu merken - und lässt sich auch durch Compiler Hints nicht mehr davon abbringen.
Query 9 berechnet den Gewinn pro Jahr und Land für alle Produkte, deren Name dem Muster '%snow'
entspricht. Hierzu wird eine Subquery benutzt die praktisch alle Tabellen der Datenbank (PART, SUPPLIER,
LINEITEM, PARTSUPP, ORDERS, NATION) via NATURAL JOIN verknüpft und daraus alle PARTS
entfernt die dem Pattern '%snow' nicht entsprechen.
Ohne Optimierungen benötigte die Query ~28 Minuten, waren Indizes, Schlüssel und Constraints angelegt
benötigte die Anfrage immerhin noch etwas über 3 Minuten.
Um die Geschwindigkeit weiter zu verbessern versuchten wir dem Compiler mit HINTS zu helfen; sinnvoll
erschien uns hier vor allem die Angabe des /* ORDERED */ Flags, es teilt dem Compiler mit alle Joins in der
angegeben Reihenfolge durchzuführen. Das brachte schon ohne Umstellung der Reihenfolge (am wichtigsten
war es hier so früh wie möglich nur die Parts zu selektieren, die der WHERE Bedingung auch entsprechen) einen
11
enormen Zuwachs in der Ausführungsgeschwindigkeit: Die Anfrage benötigte nur mehr 95 Sekunden.
Überrascht hingegen waren wir, als wir der HINT /* PUSH_SUBQ */ ausprobierten, der das innere Query so
früh wie möglich zur Ausführung bringen sollte. Die Ausführungszeit sank um weitere 60% auf nur noch 29s.
Erklären konnten wir uns dieses Verhalten zunächst nicht, zumal die Anfrage auch so aufgebaut ist, dass das
SUBQUERY die einzige Quelle für Tupel im Äußeren Query darstellt; also ohnehin so früh wie möglich zur
Ausführung gebracht werden muss. Auch der Queryplan wies zwischen den beiden HINTs keine Unterschiede
auf, was zu der Vermutung führte, dass unser HINT auf Grund der Erstellung der im Ausführungsplan
aufgeführten temporären View irrelevant wurde[7].
4.4 Q U E RY 2
Query 2 ist eine Anfrage mit einer Aggregation in der Subquery und Joins in Haupt- und Subquery. Weiterhin
enthält sie im Haupteil ein Matching auf einen Substring. Das Resultat soll nach drei Attributen
(Supplier.acctbal, Nation.name, Supplier.name, Part.partkey) geordnet zurückgegeben
werden. Ohne Indizes brauchte diese Anfrage durschnittlich 2,84 Sekunden. Durch Indizes konnte diese Zeit
auf durchschnittlich 0,431 Sekunden verbessert werden, da hier Sortierung im Buffer und Bildung des
Kartesischen Produkts vermieden werden konnte. Weitere Indizes oder die Angabe von Hints verbesserten die
Geschwindigkeit der Anfrage nicht bzw. führten zu keiner Änderung des Ausführungplans.
4.5 Q U E RY 3
Query 3 berechnet den Erlös durch Bestellungen die vor einem bestimmten Datum aufgegeben, aber noch nicht
vollständig ausgeliefert worden sind in absteigender Reihenfolge. Sie beinhaltet somit eine Aggregation,
Gruppierung und Sortierung. Ohne Optimierung brauchte sie über zwei Minuten zur Ausführung. Mit Indizes
konnte die Ausführungszeit auf unter 20 Sekunden reduziert werden. Weitere Indizes auf orderdate und
shipdate oder die Angabe von Hints verbesserten die Geschwindigkeit der Anfrage nicht bzw. führten zu
keiner Änderung des Ausführungplans.
4.6 Q U E RY 6
Query 6 berechnet die Erhöhung der Erlöse in einem bestimmten Zeitraum, wenn ein gewährter Nachlass bei
weniger als 24 Teilen nicht gegeben worden wäre. Mit und ohne Indizes brauchte diese Anfrage 15 Sekunden.
Ein Index auf discount brachte auch keine weitere Verbesserung.
4.7 Q U ER Y 18
Query 18 beinhaltet eine Subquery auf der großen Tabelle lineitems. In der Hauptquery werden die Tabellen
customer, orders und lineitems gejoint. Es findet ein Gruppierung und eine Sortierung des Resultats
statt. Mit und ohne Indizes brauchte diese Anfrage jeweils über 80 Sekunden. Erklärung hierfür ist, dass für die
12
Gruppierungen, welche die teuersten Operationen in dieser Anfrage sind, keine Indizes verwendet werden und
somit kein Unterschied messbar ist.
Durch das Ablegen der Subquery in einer Materialized View wurde die Abfrage in durchschnittlich 43 Sekunden
ausgeführt. Weitere Optimierungsversuche wie die Änderung der Joinreihenfolge und die Änderung der
Joindurchführung durch Hints brachten keinen messbaren Erfolg.
4.8 V ER ÄN D ER N D ER B UF F E R G R Ö ß E
Oracle unterscheidet im Wesentlichen drei Kategorien von Buffer. Im Keep-Pool werden Informationen, die lange
gehalten werden sollen, gelagert, im Recycle-Pool Informationen, die schnell wieder gelöscht werden können um im
Default-Pool Informationen, die den anderen beiden nicht zuzuordnen sind. Tabellen können mittels
ALTER TABLE table_name STORAGE (buffer_pool KEEP);
einem speziellen Pool zugeordnet werden.
Eine Vergrößerung des Buffers bzw. die Zuordnung einzelner Tabellen zu einem bestimmten Pool brachten
keine signifikanten Geschwindigkeitszuwächse der Anfragen. Eine Verkleinerung des Buffer-Pools hingegen
brachte den erwarteten Geschwindigkeitsverlust der Anfragen.
13
5 F AZIT
Im Laufe der Veranstaltung wurde uns schnell klar, dass ein großes DBMS wie Oracle im Bezug auf
Performance, Leistungsumfang und Einarbeitungszeit nicht ohne weiteres zu vergleichen ist mit freien
Datenbankmanagementsystemen wie MySQL oder PostgreSQL. Eine zusätzliche Hilfe waren Werkzeuge wie der
Oracle SQLDeveloper, der das erstellen und parsen der Tracefiles zu jedem Query übernimmt.
Wir bemerkten aber auch sehr schnell, dass uns die abgespeckte Version von Oracle 10.2 viele Funktionien
vorenthielt die wir durchaus gerne ausprobiert hätten: Seien es die verschiedenen Indextypen, geclusterte
Tabellen, oder auch die Möglichkeit vor allem die großen Tabellen komplett im Arbeitsspeicher des Rechner
vorzuhalten.
Die Arbeit mit Oracle war sehr interessant und brachte uns viele der theoretischen Konzepte, die wir aus
vorangegangen Veranstaltungen kannten, auch praktisch näher. Auch wenn wir mit unseren Maßnahmen zur
Verbesserung der Performance einige gute Erfolge erzielen (siehe Abbildung 2) konnten bleibt natürlich immer
noch Raum für Verbesserungen. Für den Produktiveinsätz wäre zu überlegen, nicht die Express Edition von Oracle
einzusetzen um in den Genuss der zusätzlichen Features zu kommen und die Performance weiter zu verbessern.
A BBILDUNG 2: T UNING Ü BERSICHT
14
A NHANG
CONVERT . PY
#!/usr/bin/python
# convert.py
# convert postgres dump to std. sql
import re
infile = open("cddb.sql","r")
outfile = open("outfile.sql","w+")
copy_matcher = re.compile('COPY (\w*) \((.*)\)')
stdin_match = re.compile('[0-9]+\w')
komma_splitter = re.compile(',')
current_table = ""
cols = ""
for line in infile:
# check for COPY FROM STDIN STRING
match = copy_matcher.match(line)
match_data = stdin_match.match(line)
insertstring = """"
if match: # set new column & table names
current_table = match.group(1)
columns = re.split(komma_splitter,match.group(2))
cols = match.group(2)
print "We found a matching line: ",current_table, columns
# start reading columns for current_table
if match_data: # yeehaw a line of data....
line = line.strip()
line = line.replace('\'',"\'")
words = line.split("\t")
values = []
for word in words:
word = "'",word.strip(),"'"
values.append("".join(word))
insertstring = "INSERT INTO ",current_table," (",cols, ") VALUES (", ",
".join(values),");","\n"
outfile.write(insertstring )
infile.close()
outfile.close()
15
CDDB Q UERIES
SELECT DISTINCT a.artist,al.album,s.song, genre from genres
g,artists a,cds c, cdtracks ct, songs s, artist2album a2a, albums al
WHERE
(a.artist LIKE 'a%')
AND a.artistid = a2a.artistid
AND a2a.albumid = al.albumid
AND a2a.artist2albumid = c.artist2albumid
AND ct.cdid = c.cdid
AND g.genreid = c.genreid
AND ct.songid = s.songid
B EISPIEL C ONTROL -F ILE
FÜR
SQL-L OADER (T ABELLE C USTOMER TPCH)
------------------------------------------------------------------------------- file: tpch-customer.ctl
-----------------------------------------------------------------------------LOAD DATA
INFILE ’tpch-customer.data’
INTO TABLE tpch.customer
FIELDS TERMINATED BY ’,’ OPTIONALLY ENCLOSED BY ’"’
( c_custkey,
c_name,
c_address,
c_nationkey,
c_phone,
c_acctbal,
c_mktsegment,
c_comment)
P RIMÄR -
UND
F REMDSCHLÜSSEL
DES
TPC-H S CHEMAS
-- Primary key constraints
ALTER
ALTER
ALTER
ALTER
ALTER
TABLE
TABLE
TABLE
TABLE
TABLE
tpchmm.part ADD CONSTRAINT c_pk01 PRIMARY KEY (p_partkey);
tpchmm.supplier ADD CONSTRAINT c_pk02 PRIMARY KEY (s_suppkey);
tpchmm.partsupp ADD CONSTRAINT c_pk03 PRIMARY KEY (ps_partkey, ps_suppkey);
tpchmm.customer ADD CONSTRAINT c_pk04 PRIMARY KEY (c_custkey);
tpchmm.orders ADD CONSTRAINT c_pk05 PRIMARY KEY (o_orderkey);
16
ALTER TABLE tpchmm.lineitem ADD CONSTRAINT c_pk06 PRIMARY KEY (l_orderkey,
l_linenumber);
ALTER TABLE tpchmm.nation ADD CONSTRAINT c_pk07 PRIMARY KEY (n_nationkey);
ALTER TABLE tpchmm.region ADD CONSTRAINT c_pk08 PRIMARY KEY (r_regionkey);
-- Foreign key constraints.
ALTER TABLE tpchmm.supplier ADD CONSTRAINT c_fk01 FOREIGN KEY (s_nationkey)
REFERENCES tpchmm.nation (n_nationkey);
ALTER TABLE tpchmm.partsupp ADD CONSTRAINT c_fk02 FOREIGN KEY (ps_partkey)
REFERENCES tpchmm.part (p_partkey);
ALTER TABLE tpchmm.partsupp ADD CONSTRAINT c_fk03 FOREIGN KEY (ps_suppkey)
REFERENCES tpchmm.supplier (s_suppkey);
ALTER TABLE tpchmm.customer ADD CONSTRAINT c_fk04 FOREIGN KEY (c_nationkey)
REFERENCES tpchmm.nation (n_nationkey);
ALTER TABLE tpchmm.orders ADD CONSTRAINT c_fk05 FOREIGN KEY (o_custkey)
REFERENCES tpchmm.customer (c_custkey);
ALTER TABLE tpchmm.lineitem ADD CONSTRAINT c_fk06 FOREIGN KEY (l_orderkey)
REFERENCES tpchmm.orders (o_orderkey);
ALTER TABLE tpchmm.lineitem ADD CONSTRAINT c_fk07 FOREIGN KEY (l_partkey)
REFERENCES tpchmm.part (p_partkey);
ALTER TABLE tpchmm.lineitem ADD CONSTRAINT c_fk08 FOREIGN KEY (l_suppkey)
REFERENCES tpchmm.supplier (s_suppkey);
ALTER TABLE tpchmm.lineitem ADD CONSTRAINT c_fk09 FOREIGN KEY (l_partkey, l_suppkey)
REFERENCES tpchmm.partsupp (ps_partkey, ps_suppkey);
ALTER TABLE tpchmm.nation ADD CONSTRAINT c_fk10 FOREIGN KEY (n_regionkey)
REFERENCES tpchmm.region (r_regionkey);
TPC-H Q UERYS
Q U E RY 2
SELECT s_acctbal, s_name, n_name, p_partkey, p_mfgr,
s_address, s_phone, s_comment
FROM part, supplier, partsupp, nation, region
WHERE p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND p_size = 15
AND p_type like '%BRASS'
AND s_nationkey = n_nationkey
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE'
AND ps_supplycost =
(SELECT MIN(ps_supplycost)
FROM partsupp, supplier, nation, region
WHERE p_partkey = ps_partkey
AND s_suppkey = ps_suppkey
AND s_nationkey = n_nationkey
17
AND n_regionkey = r_regionkey
AND r_name = 'EUROPE')
ORDER BY
s_acctbal desc, n_name, s_name, p_partkey;
Q U ER Y 3
SELECT l_orderkey,
SUM(l_extendedprice*(1-l_discount)) as revenue,
o_orderdate, o_shippriority
FROM customer, orders, lineitem
WHERE c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < '15-MAR-1995'
AND l_shipdate > '15-MAR-1995'
GROUP BY
l_orderkey, o_orderdate, o_shippriority
ORDER BY
revenue desc, o_orderdate;
Q U E RY 6
SELECT
SUM(L_EXTENDEDPRICE * L_DISCOUNT) AS REVENUE
FROM LINEITEM
WHERE L_SHIPDATE >= TO_DATE(’1997-01-01’,’YYYY-MM-DD’)
AND L_SHIPDATE < ADD_MONTHS(TO_DATE(’1997-01-01’,’YYYYMMDD’),12)
AND L_DISCOUNT BETWEEN 0.05 - 0.01 AND 0.05 + 0.01
AND L_QUANTITY < 24
Q U E RY 9
SELECT
NATION,
YEAR,
SUM(AMOUNT) AS SUM_PROFIT
FROM
(SELECT
N_NAME AS NATION,
TO_CHAR(O_ORDERDATE,’YYYY’) AS YEAR,
L_EXTENDEDPRICE * (1-L_DISCOUNT) - PS_SUPPLYCOST *
L_QUANTITY AS AMOUNT
FROM PARTS, SUPPLIER, LINEITEM, PARTSUPP, ORDERS, NATION
WHERE S_SUPPKEY = L_SUPPKEY
AND PS_SUPPKEY = L_SUPPKEY
AND PS_PARTKEY = L_PARTKEY
AND P_PARTKEY = L_PARTKEY
AND O_ORDERKEY = L_ORDERKEY
AND S_NATIONKEY = N_NATIONKEY
18
AND P_NAME LIKE ’%snow%’
) PROFIT
GROUP BY NATION, YEAR
ORDER BY NATION, YEAR DESC
Q U ER Y 14
select
100.00 * sum(case
when p_type like 'PROMO%'
then l_extendedprice * (1 - l_discount)
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
from
lineitem,
part
where
l_partkey = p_partkey
and l_shipdate >= date '1998-12-01'
and l_shipdate < date '1998-12-01' + interval '1' month;
Q U ER Y 15
create view revenues (supplier_no, total_revenue) as
select
l_suppkey,
sum(l_extendedprice * (1 - l_discount))
from
lineitem
where
l_shipdate >= date '1999-12-01'
and l_shipdate < date '1999-12-01' + interval '3' month
group by
l_suppkey;
select
s_suppkey,
s_name,
s_address,
s_phone,
total_revenue
from
supplier ,
revenues
where
s_suppkey = supplier_no
and total_revenue = (
select
max(total_revenue)
from
revenues
19
)
order by
s_suppkey;
drop view revenues;
Q U ER Y 18
select
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
sum(l_quantity)
from
customer,
orders,
lineitem
where
o_orderkey in (
select
l_orderkey
from
lineitem
group by
l_orderkey having
sum(l_quantity) > 15
)
and c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
c_name, c_custkey, o_orderkey,
o_orderdate, o_totalprice
order by
o_totalprice desc, o_orderdate;
F RAMWORK
IN J AV A
C L A SS B E N CH M AR K T E S T . JAV A
import java.util.*;
public class BenchmarkTest {
@SuppressWarnings("unused")
private List<Query> turnOns;
@SuppressWarnings("unused")
private List<Query> turnOffs;
@SuppressWarnings("unused")
private Query query;
private String name;
20
public BenchmarkTest(String name, String query, String[] ons, String[] offs) {
this.name = name;
this.query = new Query(query);
this.turnOffs = new ArrayList<Query>();
this.turnOns = new ArrayList<Query>();
/* add the tuning parameters to a query list */
for (String turnOn : ons) {
Query bla = new Query(turnOn);
this.turnOns.add(bla);
}
for (String turnOff : offs) {
this.turnOffs.add(new Query(turnOff));
}
}
public void bench() {
this.benchNoOpt();
this.benchOpt();
}
private void benchNoOpt() {
// run unoptimized query:
for (Query turnOff : this.turnOffs) { // turn all optimizations off
turnOff.run();
}
this.startTrace(this.name+"_no_opt");
// run the actual query
this.query.run();
this.stopTrace();
System.out.println("-- Query " + this.name
+ " without optimization ran...");
}
private void benchOpt() {
// run unoptimized query:
for (Query turnOn : this.turnOns) { // turn all optimizations off
turnOn.run();
}
// set the new name for the tracefile
// run the actual query
this.startTrace(this.name+"_opt");
// run the actual query
this.query.run();
this.stopTrace();
System.out.println("-- Query " + this.name
+ " with optimization ran...");
}
private void stopTrace() {
Query b = new Query("ALTER SYSTEM SET TIMED_STATISTICS=false");
b.run();
Query c = new Query("ALTER SESSION SET SQL_TRACE=false");
c.run();
return;
}
21
private void startTrace(String id) {
String[] timerOffString = {
"ALTER SESSION SET TRACEFILE_IDENTIFIER='" + id + "'",
"ALTER SYSTEM SET TIMED_STATISTICS=TRUE",
"ALTER SESSION SET SQL_TRACE=TRUE" };
List<Query> timer = new ArrayList<Query>();
for (String off : timerOffString) {
timer.add(new Query(off));
}
for (Query time : timer) {
time.run();
}
return;
}
}
C L A SS Q U E RY . JAV A
import
import
import
import
java.sql.DriverManager;
java.sql.SQLException;
java.sql.Connection;
java.sql.Statement;
public class Query {
@SuppressWarnings("unused")
private String query;
String url = "jdbc:oracle:thin:[email protected]:1521/XE";
static Connection con;
Statement stmt;
public Query(String query) {
this.query = query;
}
@SuppressWarnings("unused")
public String getQuery() {
return this.query;
}
public void run() {
System.out.println("Query: " + this.query);
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
} catch (java.lang.ClassNotFoundException e) {
System.err.print("ClassNotFoundException: ");
System.err.println(e.getMessage());
}
try {
if (con == null)
con = DriverManager.getConnection(url, "tpch", "tpch");
stmt = con.createStatement();
stmt.executeQuery(this.query);
} catch (SQLException e) {
System.err.println(e.getMessage());
22
}
}
public static void close() {
try {
if (!con.isClosed())
con.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
System.err.println(e.getMessage());
}
}
}
C L A SS Q U E RY L O A D ER . J AV A
public class QueryLoader {
public static void main(String args[]) {
final String query1 = "SELECT DISTINCT a.artist,al.album,s.song, genre from
genres g,artists a,cds c, "
+ "cdtracks ct, songs s, artist2album a2a, albums al WHERE
(a.artist LIKE 'ar%') AND "
+ "a.artistid = a2a.artistid AND a2a.albumid = al.albumid
AND
"
+ "a2a.artist2albumid = c.artist2albumid
AND
ct.cdid
= c.cdid
"
+ "AND g.genreid = c.genreid
AND
ct.songid =
s.songid";
final String[] on = { "CREATE INDEX artistsid on cddb.artists (artistid)",
"CREATE INDEX artistname on cddb.artists (artist)",
"CREATE UNIQUE INDEX genreid on cddb.genres (genreid)",
"CREATE INDEX cgenreid on cddb.cds (genreid)",
"CREATE INDEX ctcdid on cddb.cdtracks (cdid)",
"CREATE INDEX cda2a on cddb.cds (artist2albumid)",
"CREATE UNIQUE INDEX a2albumid on cddb.artist2album
(artist2albumid)",
"CREATE INDEX ctsid on cddb.cdtracks (songid)",
"CREATE INDEX songid on cddb.songs (songid)",
"ALTER TABLE albums add CONSTRAINT albumid PRIMARY KEY
(albumid)"
};
final String[] off = { "DROP INDEX artistsid ",
"DROP INDEX artistname ",
"DROP INDEX cgenreid ",
"DROP INDEX genreid",
"DROP INDEX cda2a",
"DROP INDEX ctcdid",
"DROP INDEX a2albumid",
"DROP INDEX ctsid",
"DROP INDEX songid",
"ALTER TABLE albums drop CONSTRAINT albumid" };
BenchmarkTest test = new BenchmarkTest("q1", query1, on, off);
test.bench();
Query.close();
}
}
23
B IBLIOGRAPHIE
[1] TPC Website, Stand 24.09.07, http://www.tpc.org/tpch/
[2] OTN Download Site, Stand 24.09.07,
http://www.oracle.com/technology/software/products/database/xe/htdocs/102xelinsoft.html
[3] CDDB Gracenote, Stand 25.09.07, http://www.gracenote.com/music/
[4] Oracle Datatypes Tech on the Net, Stand 25.09.07, http://www.techonthenet.com/oracle/datatypes.php
[5] PostgreSQL Datatypes PostgreSQL Manual, Stand 25.09.07, http://www.postgresql.org/docs/7.3/interactive/datatype.html
[6] Oracle FAQ, Stand 25.09.07, http://www.orafaq.com/faqloadr.htm
[7] Oracle Scratchpad Blog, 1.10.07, http://jonathanlewis.wordpress.com/2007/02/21/ignoring-hints/
24