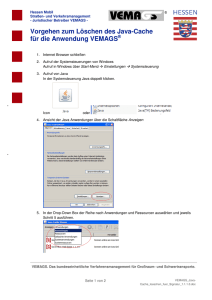
- Fachgebiet Datenbanken und Informationssysteme
Werbung

Fakultät für Elektrotechnik und Informatik Institut für Praktische Informatik Fachgebiet Datenbanken und Informationssysteme Duplikateliminierung in Bibliotheksdatenbanken Bachelorarbeit im Studiengang Informatik Lukas Schink 13.07.2015 Prüfer: Prof. Dr. Udo Lipeck Zweitprüfer: Dr. Hans Hermann Brüggemann Betreuer: Prof. Dr. Udo Lipeck Inhaltsverzeichnis 1 Einleitung 1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2 Aufgabe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3 Überblick über die Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . 2 Grundlagen 2.1 Matching . . . . . . . . . . . 2.1.1 Vergleichsfunktionen . 2.1.2 Matching-Funktion . . 2.2 Fusion . . . . . . . . . . . . . 2.3 Blocking/Indexing . . . . . . 2.3.1 Standard Blocking . . 2.3.2 Sorted Neighbourhood 2.3.3 q-Gram-Indexing . . . . . . . . . . . . . . . . . . . 3 Zustandsanalyse 3.1 Aufbau der Schriftendatenbank . 3.1.1 Tabelle SCHRIFT . . . . . . 3.1.2 Tabelle FLIT . . . . . . . . 3.1.3 Tabelle ABSCHLUSSARBEIT 3.1.4 Tabelle LITERATURINDEX . 3.1.5 Tabelle ANSCHAFFUNG . . . 3.1.6 Tabelle ABTEILUNG . . . . 3.1.7 Tabelle SCHRIFTTYP . . . . 3.2 Datenbestand . . . . . . . . . . . 3.2.1 Duplikatbeispiele . . . . . 3.2.2 Statistiken . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 Entwurf 4.1 Anforderungen . . . . . . . . . . . . . 4.2 Auswahl der Datenbanktabellen . . . . 4.3 Matching-Prozedur . . . . . . . . . . . 4.3.1 Matching-Ansatz . . . . . . . . 4.3.2 Edit-Distanz . . . . . . . . . . . 4.3.3 Betrachtung der Objekt-Ebene . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1 2 3 . . . . . . . . 5 5 5 7 11 11 12 12 14 . . . . . . . . . . . 17 17 18 18 19 19 20 20 21 22 22 24 . . . . . . 25 25 26 27 27 28 28 III Inhaltsverzeichnis 4.4 4.5 Datenbankschema . Webschnittstelle . . 4.5.1 Match-Tool 4.5.2 Fusions-Tool . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 Implementierung 5.1 Datenbankschema . . . . . . . . . . . . 5.2 PL/SQL: Matching-Prozedur . . . . . 5.2.1 Aufbau . . . . . . . . . . . . . . 5.2.2 Iteration über Spalten . . . . . 5.2.3 Spaltenvergleiche . . . . . . . . 5.2.4 Laufzeit und Optimierungen . . 5.3 PHP-Webschnittstelle . . . . . . . . . . 5.3.1 Anbindung der Datenbank . . . 5.3.2 Login . . . . . . . . . . . . . . . 5.3.3 Einstellen der Gewichte . . . . 5.3.4 Starten der Matching-Prozedur 5.3.5 Ergebnisübersicht . . . . . . . . 5.3.6 Fusionsansicht . . . . . . . . . . 5.3.7 Auflösen der Relationen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 Handbuch 6.1 Installation/Vorbereitung . . . . . . . . . . . . . 6.1.1 Anlegen des Views . . . . . . . . . . . . 6.1.2 Das Kontrollschema anlegen . . . . . . . 6.1.3 Matching-Prozedur . . . . . . . . . . . . 6.1.4 PHP-Skripte . . . . . . . . . . . . . . . . 6.2 Benutzung . . . . . . . . . . . . . . . . . . . . . 6.2.1 Einen neuen Matching-Durchlauf anlegen 6.2.2 Gewichte einstellen . . . . . . . . . . . . 6.2.3 Einen Matching-Durchlauf starten . . . . 6.2.4 Ergebnisse ansehen . . . . . . . . . . . . 6.2.5 Fusions-Übersicht . . . . . . . . . . . . . 6.2.6 Ein Paar fusionieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 31 32 32 . . . . . . . . . . . . . . 35 35 37 37 38 39 40 41 41 42 42 43 44 44 45 . . . . . . . . . . . . 47 47 47 47 47 47 48 48 49 49 50 51 51 7 Reflexion 53 7.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 7.2 Fazit und Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53 Abbildungsverzeichnis 55 Tabellenverzeichnis 57 Literaturverzeichnis 59 IV 1 Einleitung 1.1 Motivation Im Bibliothekswesen werden Duplikate als „Dubletten“ bezeichnet, wobei damit zwei unterschiedliche Bedeutungen verknüpft sind. Zum Einen werden real existierende physische Kopien von Werken als Dubletten bezeichnet. Diese sind in der Regel gewollt und wurden gezielt angeschafft, um bei großer Nachfrage nach bestimmten Werken mehrere Exemplare verleihen zu können. Die andere Bedeutung bezieht sich auf mehrfach vorhandene Datensätze innerhalb des Bibliothekskatalogs, die aber das selbe Werk beschreiben. Dies entspricht dem Duplikatbegriff, der in dieser Arbeit behandelt wird. Solche Duplikate entstehen typischerweise durch Fehleingaben beim Erfassen von Werken, wenn zuvor nicht geprüft wird, ob es bereits einen passenden Eintrag gibt, oder wenn mehrere Datenbestände zusammengeführt werden. Beide Fälle treten allgemein nicht nur bei Bibliotheksdatenbanken auf, sondern beispielsweise auch bei Kundendatenbanken in Unternehmen. Die daraus resultierenden Probleme sind ähnlich. Abgesehen von unnötig verbrauchtem Speicherplatz, ist die Pflege eines Duplikate enthaltenden Datenbestandes schwierig, da die Änderung eines Datensatzes möglicherweise Inkonsistenzen zu den bestehenden Duplikaten verursacht. Im Falle einer Bibliotheksdatenbank verhindern derartige Inkonsistenzen schlimmstenfalls eine effiziente Literaturrecherche: Bei der Suche nach einem Buch können beispielsweise mehrere Einträge vorhanden sein. Diese suggerieren, dass sich ein Buch in unterschiedlichen Abteilungen befindet, obwohl es real nur in einer Abteilung vorkommt. Weil die Änderung der Abteilung nur bei einem Eintrag erfasst wurde, das Duplikat aber noch auf dem alten Stand geblieben ist, sucht dann der Benutzer vergeblich in der falschen Abteilung. Wenn solche Duplikate entstanden sind, müssen diese folglich erkannt und aufgelöst werden, um die Benutzbarkeit zu gewährleisten. Aufgrund der Größe von Bibliotheksdatenbanken und der Inkonsistenzen zwischen den Duplikaten ist eine Bereinigung jedoch oftmals schwierig. Unter Bezeichnungen wie „data matching“, „Record-Linkage“, „data deduplication“, „duplicate detection“ oder „matching“ ist dieses Problem Gegenstand aktueller Forschung und auch dieser Arbeit. 1 1 Einleitung 1.2 Aufgabe Das Fachgebiet Datenbanken und Informationssysteme betreibt seit 25 Jahren eine Datenbank zur Erfassung des internen Literaturbestands, der hauptsächlich aus Forschungsliteratur, Abschlussarbeiten, und Lehrbüchern besteht. Eine Umstrukturierung und Integration verschiedener Datenbanken im Jahr 2005 hatte zur Folge, dass einige Schriftstücke mehrfach in der Datenbank erfasst wurden, manche mit teilweise abweichenden Angaben. Zudem sind im Laufe der Zeit zusätzliche Duplikate durch Eingabefehler entstanden. Deswegen ist das Ziel dieser Arbeit, eine Anwendung zu entwickeln, die das Auffinden und Zusammenführen dieser Mehrfachbeschreibungen innerhalb der Datenbank unterstützt. Im Laufe der Arbeit wurde deutlich, dass das Aufstellen geeigneter Kriterien zum Identifizieren tatsächlicher Duplikate fundiertes Domänenwissen erfordert. Daher wurde die Zielvorgabe um das Auffinden lediglich ähnlicher Einträge erweitert. So sollen nun auch Beziehungen, die keine echten Duplikate darstellen, wie z. B. Vorversionen von Dokumenten, erfasst werden, bevor diese durch einen Benutzer überprüft und endgültig entschieden werden. Durch Analyse der Datenbank sollen außerdem geeignete Kriterien ermittelt werden, um die Ähnlichkeit zweier Einträge zu bestimmen. Der Fokus liegt hierbei in der Implementierung eines Matching-Algorithmus zum Erkennen von ähnlichen Einträgen anhand der Kombination aller relevanten Attribute. Hierbei sollen Vergleichsoperationen innerhalb der Attribut-Ebene auf Wertegleichheit und einfache Ähnlichkeitsfunktionen beschränkt werden, da die Darstellung der Werte in den Einträgen bereits in einem separaten Projekt vereinheitlicht wird. Damit nach dem Matching eine Fusion der Datensätze durchgeführt werden kann, müssen die gefundenen Einträge vom Anwender entsprechend ihrer Beziehung zueinander, zum Beispiel als Duplikat, gekennzeichnet werden können. Dabei ist zu berücksichtigen, dass die Einträge nicht notwendigerweise in allen Attributen übereinstimmen. Daher ist zu empfehlen, spezielle Vorschriften zu erarbeiten, die festlegen, wie diese zusammenzuführen sind. Bei der Datenbank handelt es sich um eine Oracle-Datenbank der Version 12c. Operationen auf der Datenbank sind in SQL oder, wenn es sich um Prozeduren bzw. Funktionen handelt, in PL/SQL zu entwickeln. Der Anwendungsprototyp soll als Webapplikation mit PHP und JavaScript implementiert werden. Dies ermöglicht eine einfache Integration in das bereits bestehende Administrationssystem der Fachgebietsverwaltung. Aufbauend auf Ergebnissen dieser Arbeit kann anschließend systematisch Erfahrung über die Zusammenhänge der Daten gesammelt werden. 2 1.3 Überblick über die Arbeit 1.3 Überblick über die Arbeit Nach dem einleitenden ersten Kapitel werden in Kapitel 2 die zugrunde liegenden Verfahren und Algorithmen zu Matching und Fusion von Datenbanken beschrieben. Dazu zählen Funktionen zum Vergleich von Attributwerten, Methoden zum Klassifizieren der Datenbankeinträge in Ähnlichkeitsklassen und schließlich Blocking bzw. Indexing, um die Zahl der nötigen Vergleiche zu reduzieren. Kapitel 3 behandelt den Aufbau der Datenbank mit einer Beschreibung der ausschlaggebenden Tabellen. Im zweiten Abschnitt dieses Kapitels wird ein Überblick über typische Duplikate und statistische Daten bezüglich des Inhalts der Datenbank gegeben. Der Entwurf der in dieser Arbeit entwickelten Anwendung wird in Kapitel 4 erläutert. Hierzu werden zunächst die Anforderungen an die Anwendung beschrieben, bevor eine Auswahl der in Kapitel 3 beschriebenen Tabellen für das Matching erfolgt. Den Erläuterungen des gewählten Matching-Verfahrens folgend wird ein Datenbankschema entworfen, in dem die für den Betrieb der Anwendung benötigten Daten gespeichert werden können. Auch die Konzeption der Webschnittstelle, gegliedert in Match-Tool und Fusions-Tool wird hier dargestellt. Die konkrete Umsetzung wird in Kapitel 5 erläutert. Hierbei wird auf die Besonderheiten des verwendeten Datenbankschemas eingegangen sowie die Funktionsweise der Matching-Prozedur geschildert. Dabei wird auch auf die implementierten Optimierungen zur Verringerung der Laufzeit eingegangen. Nachfolgend wird aufgezeigt wie einzelne Aspekte der Webschnittstelle, darunter die asynchrone Ausführung der Matching-Prozedur im Hintergrund und das Eintragen der Spaltengewichtungen in die Datenbank, realisiert wurden. Eine Anleitung zur Benutzung der einzelnen Funktionen der Anwendung befindet sich in Kapitel 6. Zuletzt wird in Kapitel 7 ein Fazit gezogen, weiterhin werden Ansätze zur Erweiterung des Funktionsumfangs der entwickelten Anwendung gegeben. 3 2 Grundlagen Die Algorithmen und Verfahren, die zur Lösung der gegebenen Problemstellung verwendet werden können, umfassen Vergleichsfunktionen, Matching-Verfahren, die Fusion von Einträgen sowie Blocking- und Indexing-Algorithmen zur Reduktion der zu vergleichenden Paare. Ihre Eigenschaften und Funktionsweisen sind Gegenstand dieses Kapitels. 2.1 Matching Der Prozess des Auffindens von Duplikaten wird Matching genannt. Für jedes Feld der zu vergleichenden Einträge in der Datenbank, Records genannt, benötigt man zunächst eine für den Datentyp und den Inhalt passende Vergleichsfunktion, die die jeweiligen Werte aus den beiden Records vergleicht. So entsteht für jedes Record-Paar ein Vektor, der die Ähnlichkeitswerte für die einzelnen Attributwerte beinhaltet. Die Auswertung erfolgt mit Hilfe der eigentlichen Matching-Funktion, bei der dieser Ähnlichkeitsvektor im einfachsten Fall bei Übereinstimmung als „Match“ und bei Abweichungen als „Non-Match“ eingeteilt wird. Eine feinere Unterteilung, die auch ähnliche Ergebnisse als „Potential Match“ berücksichtigt, ermöglicht dem Benutzer, nicht eindeutige Fälle im Zuge einer Revision zu bewerten, so dass dieser entscheiden kann, ob es sich um ein Duplikat handelt oder nicht [Chr12b]. 2.1.1 Vergleichsfunktionen Eine Vergleichsfunktion arbeitet auf Attribut-Ebene. Durch sie wird ein Ähnlichkeitsvektor mit n Einträgen erstellt, wobei n die Anzahl der Attribute der zu vergleichenden Records ist. Hierbei beschreiben die einzelnen Felder des Vektors den Grad der Ähnlichkeit zwischen den verglichenen Attributwerten durch Werte im Intervall [0,1]. Sind die Attributwerte identisch, folgt daraus eine Ähnlichkeit von 1. Umgekehrt bedeutet ein Wert von 0, dass die Attributwerte gänzlich verschieden sind. Gleichheit Eine grundlegende Vergleichsfunktion ist die Überprüfung auf Gleichheit der Werte. Für die meisten Datentypen ist eine solche Funktion bereits im Datenbanksystem vordefiniert. Sie erlaubt keine graduellen Ähnlichkeiten, sondern liefert einen booleschen 5 2 Grundlagen Wert, der angibt ob die beiden Werte x1 und x2 exakt gleich sind, oder nicht. sim(x1 ,x2 ) = 1, falls x1 = x2 0, falls x1 = 6 x2 (2.1) Dadurch eignet sich die Funktion nur eingeschränkt für den Vergleich von StringWerten, da bereits ein kleiner Tippfehler zu einer Abweichung führt, so dass die Werte nicht als gleich bzw. ähnlich erkannt werden können. Edit-Distanz Die Edit-Distanz ist eine Vergleichsfunktion für String-Werte. Sollen beispielsweise die Strings s1 und s2 verglichen werden, wird eine Matrix aufgestellt, deren Zellen d[i, j] die Edit-Distanz der ersten i Buchstaben von s1 und der ersten j Buchstaben von s2 angeben. Der Eintrag in d[|s1 |, |s2 |] gibt dann die Edit-Distanz für die gesamte Länge beider Strings an, wobei | · | die Länge eines Strings angibt. Die Werte der Matrix sind, unter der Annahme gleicher Kosten für alle Operationen, rekursiv definiert als d[i − 1, j] + 1, Buchstabe löschen d[i, j] = min d[i, j − 1] + 1, Buchstabe einfügen d[i − 1, j − 1] + 1, Buchstabe ersetzen (2.2) falls s1 [i] 6= s2 [j] ist. Für s1 [i] = s2 [j] gilt d[i, j] = d[i − 1, j − 1]. Mit der Edit-Distanz dist(s1 , s2 ) = d[|s1 |, |s2 |) für s1 und s2 kann nach folgender Formel ein Ähnlichkeitswert berechnet werden [Chr12b]: sim(s1 ,s2 ) = 1 − dist(s1 , s2 ) max(|s1 |, |s2 |) (2.3) In Tabelle 2.1 ist die Edit-Distanzmatrix für die Strings s1 =„nicht“ und s2 =„nciht“ dargestellt. Dieses Beispiel ist ein typischer Schreibfehler, bei dem zwei Buchstaben innerhalb des Wortes vertauscht wurden. Daraus ergibt sich die Edit-Distanz dist(s1 , s2 ) = 2. Der Ähnlichkeitswert ergibt sich aus Gleichung 2.3: sim(s1 ,s2 ) = 1 − = 0,6 6 2 max(5, 5) (2.4) 2.1 Matching 0 n 1 c 2 i 3 h 4 t 5 n 1 0 1 2 3 4 i 2 1 1 1 2 3 c 3 2 1 2 2 3 h t 4 5 3 4 2 3 2 3 2 3 3 2 Tabelle 2.1: Edit-Distanz Matrix für die Zeichenketten „nicht“ und „nciht“ Unten rechts steht hervorgehoben die Edit-Distanz: 2 2.1.2 Matching-Funktion Die Matching-Funktion arbeitet im Gegensatz zur Vergleichsfunktion nicht mehr auf Attribut-Ebene, sondern nutzt die attributsbezogenen Ähnlichkeitswerte aus dem mit Vergleichsfunktionen (siehe 2.1.1) erstellten Ähnlichkeitsvektor, um zu ermitteln, wie ähnlich sich die beiden Records sind. Einfache Summierung Ein grundlegender Ansatz für solch eine Funktion ist, eine Summe aus den einzelnen Ähnlichkeitswerten des Ähnlichkeitsvektors zu bilden. Durch die anschließende Division durch n wird das Ergebnis auf einen Bereich zwischen 0 und 1 normiert. Die MatchingFunktion match() ist demnach wie folgt definiert: match :[0,1]n → R, n ∈ N n P v 7→ vi (2.5) i=1 n Mit Hilfe von Grenzwerten wird angegeben, ab welchem Wert das Paar als „Match“, „Non-Match“ oder „Potential Match“ klassifiziert wird. Dazu werden tl , als untere Grenze des „Potential Match“-Bereichs, und tu , als obere Grenze, benötigt. Für die Matching-Funktion und einen Ähnlichkeitsvektor vsim ergibt sich somit folgender Zusammenhang [Chr12b] match(vsim ) ≥ tu ⇒ Match tl < match(vsim ) < tu ⇒ Potential Match match(vsim ) ≤ tl ⇒ Non-Match (2.6) Durch die Normierung auf das Intervall [0,1] ergibt sich außerdem 0 ≤ tl ≤ tu ≤ 1. Diese Grenzwerte müssen sehr sorgfältig gewählt werden, weil sie einen großen Einfluss 7 2 Grundlagen auf die Qualität des gesamten Matchings haben. Wird beispielsweise tl zu niedrig gewählt, werden viele Paare fälschlicherweise als „Potential Match“ erkannt, was einen größeren nachträglichen Aufwand in der manuellen Revision zur Folge hat. Äquivalent verhält es sich mit einem zu hohen Wert für tu . Bei dieser Methode werden alle Attribute gleichberechtigt behandelt. Oftmals sind allerdings einzelne Attribute relevanter als andere, was so nicht berücksichtigt werden kann. Gewichtete Summierung Mit Hilfe von Gewichten kann festgelegt werden, dass bestimmte Attribute präzisere Auskunft darüber geben, ob es sich um ein Duplikat handelt. Im Falle einer Kundendatenbank könnte man beispielsweise dem Attribut „Kontonummer“ ein hohes Gewicht zuweisen, da anzunehmen ist, dass es sich bei gleicher Kontonummer auch um die gleiche Person handelt. Zusätzlich zum Ähnlichkeitsvektor wird also noch ein Gewichtungsvektor w = (w1 ,w2 , . . . ,wn ) ∈ Rn definiert. Die modifizierte Matching-Funktion lautet dann: match :[0,1]n × Rn → R, n ∈ N n P v,w 7→ wi · vi i=1 n P (2.7) wi i=1 Dadurch kann der Einfluss, den einzelne Attribute auf die Einordnung haben, sehr fein eingestellt werden. Abhängigkeiten zwischen den Attributen können aber nicht berücksichtigt werden. Ist also die Kombination mehrerer Attribute geeignet, um Duplikate zu erkennen (beispielweise Name, Vorname und Geburtsdatum von Kunden), gibt es mit diesem Ansatz keine Möglichkeit dies darzustellen. Eine hohe Gewichtung dieser Attribute würde hier den Einfluss der einzelnen Felder erhöhen, so dass Kunden, die zwar gleiche Vornamen und Geburtsdaten, aber gänzlich verschiedene Nachnamen haben, ebenfalls als ähnlich erkannt werden. Wahrscheinlichkeitsbasierte Einordnung Die Klassen „Match“ und „Non-Match“ werden als Mengen M und U bezeichnet. Das Record-Paar wird beschrieben durch den Ähnlichkeitsvektor v, welcher durch bedingte Wahrscheinlichkeiten diesen Mengen zugeordnet wird: v∈ 8 M, falls U, sonst p(M |v) ≥ p(U |v) (2.8) 2.1 Matching Gleichung 2.8 sagt aus, dass ein Ähnlichkeitsvektor v in M ist, falls die Wahrscheinlichkeit, dass dieser in M liegt, größer ist als die Wahrscheinlichkeit, dass er in U liegt, unter der Bedingung, dass der Vektor v vorliegt [EIV07]. So wird die Wahrscheinlichkeit des Auftretens der entsprechenden Ausprägung von v berücksichtigt. Durch Anwendung des Satzes von Bayes lassen sich diese Wahrscheinlichkeiten wie folgt umformen: p(M |v) ≥ p(U |v) ⇐⇒ p(v|M ) · p(M ) p(v|U ) · p(U ) ≥ p(v) p(v) ⇐⇒ p(v|U ) · p(U ) p(v|M ) ≥ p(v) p(v) · p(M ) ⇐⇒ p(v|M ) · p(v) p(U ) ≥ p(v|U ) · p(v) p(M ) ⇐⇒ p(v|M ) p(U ) ≥ p(v|U ) p(M ) Satz v. Bayes (2.9) Damit lässt sich die Gleichung 2.8 umformulieren: v∈ M, falls R= p(v|M ) p(v|U ) ≥ p(U ) p(M ) U, sonst (2.10) Das Verhältnis R= p(v|M ) p(v|U ) (2.11) kann gemäß Christen [Chr12b] nun für eine Einteilung, ähnlich der gewichteten Summierung, durch die Grenzwerte tu und tl folgendermaßen genutzt werden: R ≥ tu ⇒ v → Match tl < R < tu ⇒ v → Potential Match R ≤ tl ⇒ v → Non-Match (2.12) Die Berechnung der Wahrscheinlichkeiten in Gleichung 2.11 gestaltet sich in der Praxis jedoch oftmals schwierig. Zur Vereinfachung nehmen wir an, dass die einzelnen Ähnlichkeitswerte in v unabhängig von einander sind, also dass p(vi |M ) unabhängig 9 2 Grundlagen von p(vj |M ) ist, falls i 6= j ist. Für p(v|U ) gilt dies analog. Dadurch können die Wahrscheinlichkeiten nun wie folgt berechnet werden: p(v|M ) = p(v|U ) = n Y i=1 n Y p(vi |M ) (2.13) p(vi |U ) (2.14) i=1 Die Werte für p(vi |M ) und p(vi |U ) können mit Hilfe von Trainingsdaten, oder auf der Basis von Domänenwissen bestimmt werden. Regelbasierter Ansatz Das Aufstellen von Regeln in Form aussagenlogischer Formeln ermöglicht Bedingungen über mehrere Attribute zu definieren. Jede Regel besteht aus einem Prädikat P und einer Einordnung C, so dass P ⇒C (2.15) gilt. C ist hierbei entweder „Match“ oder „Non-Match“. Das Prädikat ist eine Formel in konjunktiver Normalform mit den Termen ti,j mit i,j ∈ [1,n] [Chr12b]. P = (t1,1 ∨ t1,2 ∨ . . . t1,n ) ∧ . . . ∧ (tn,1 ∨ tn,2 ∨ . . . ∨ tn,n ) (2.16) Jeder Term entspricht einer Bedingung, die für die Einordnung nach C erfüllt sein muss und die sich hierbei immer auf die Werte des Ähnlichkeitsvektors bezieht. Auf diese Weise können für jedes einzelne Attribut Grenzwerte festgelegt werden, ab welchem Maß an Ähnlichkeit diese als „Match“ bzw. als „Non-Match“ gelten. So können auch Abhängigkeiten zwischen den Attributen berücksichtigt werden. Eine kombinierte Betrachtung der Ähnlichkeiten in bestimmten Attributen erlaubt oftmals eine genauere Aussage darüber, ob es sich um Duplikate handelt oder nicht. Wird beispielsweise eine Datenbank mit Kundendaten betrachtet, ist bei Einträgen eine große Ähnlichkeit in Name, Vorname und Geburtsdatum ein starkes Indiz, dass es sich um ein Duplikat handelt. Umgekehrt ist ein Duplikat bei einer niedrigen Ähnlichkeit dieser Attribute nahezu ausgeschlossen. Dies könnte man mit folgenden Regeln ausdrücken: (v[name] ≥ 0.9) ∧ (v[vorname] ≥ 0.9) ∧ (v[geburtsdatum] ≥ 0.9) ⇒ „Match“ (v[name] ≤ 0.2) ∨ (v[vorname] ≤ 0.2) ∨ (v[geburtsdatum] ≤ 0.2) ⇒ „Non-Match“ (2.17) Im Idealfall trifft auf jedes Record-Paar eine Regel zu. Alle Paare, die nicht durch eine Regel klassifiziert werden, müssen als „Potential Match“ behandelt werden, da keine klare Einordnung möglich ist. 10 2.2 Fusion 2.2 Fusion Nachdem Duplikate identifiziert wurden, müssen sie vereinigt, also fusioniert, werden. Das bedeutet, dass die Attributwerte der Records r1 und r2 zu einem fusionierten Record r1,2 zusammengeführt werden. Stimmen die Attributwerte überein, ist eine Fusion einfach, denn die Attributwerte können übernommen werden. Unterscheiden sich r1 und r2 jedoch in einigen Attributwerten liegt ein Konflikt vor. Dies tritt insbesondere bei der Verwendung gradueller Vergleichsfunktionen auf, da diese auch ähnliche Werte zulassen. Eine allgemeine Vorgehensweise im Konfliktfall ist aufgrund der individuellen Semantik der jeweiligen Attributwerte schwer festzulegen. Daher muss hier auf Domänenwissen zurückgegriffen werden, um Regeln zu definieren, wie die Werte tatsächlich zusammenzufügen sind. Zur Veranschaulichung sei ein Record-Paar gegeben, das korrekt als Duplikat erkannt wurde, dessen Einträge sich allerdings in dem Feld „URL“, in dem eine Internetadresse gespeichert wird, unterscheiden: r1 URL http://www.dbs.uni-hannover.de r2 https://www.dbs.uni-hannover.de Bei diesem Konflikt muss der Algorithmus nun entscheiden, welche Variante der URL in das neue Record r1,2 übernommen werden soll. Man könnte festlegen, dass in einem solchen Fall immer der Wert des ersten Records, also r1 , Priorität hat. Dies würde aber die Gefahr erhöhen, falsche Werte zu übernehmen, da die Reihenfolge der Records nicht eindeutig ist. Wird nun in dem Beispiel festgelegt, dass das HTTPS-Protokoll zu bevorzugen ist, wird folglich der Wert aus r2 übernommen. Derartige Regeln müssen für jedes einzelne Attribut festgelegt werden, wobei insbesondere der Umgang mit NULL-Werten Berücksichtigung finden muss. Hat einer der beiden Records einen NULL-Wert in einem Attribut, in dem der andere einen Wert hat, ist es oftmals sinnvoll, den vorhandenen Wert zu übernehmen. Dies ist jedoch nur möglich, sofern dem Fehlen eines Wertes in der Datenbank keine Bedeutung zukommt. 2.3 Blocking/Indexing Der Vergleich einzelner Paare ist in der Regel der zeitaufwändigste Schritt beim Matching. In typischen Anwendungsszenarien ist die Anzahl der tatsächlich ähnlichen Einträge gering im Vergleich zu ihrer Gesamtzahl. Das führt dazu, dass der überwiegende Teil der Vergleiche nicht in Matches resultiert. Es wird versucht diese unnötigen Vergleiche einzusparen, indem man vor dem eigentlichen Matching ein Indexing oder Blocking der Records durchführt. Es handelt sich hierbei um eine Vorabfilterung der Datenbank, um das Matching nur mit potentiell ähnlichen Paaren durchzuführen, statt alle Paare zu vergleichen, was auch diejenigen einschließen würde, die gänzlich 11 2 Grundlagen verschieden sind. 2.3.1 Standard Blocking Grundlage für dieses bewährte Verfahren ist ein Blocking Key, also eine Formel nach der für jeden Eintrag ein Block-Wert berechnet wird. Alle Einträge mit dem gleichen Wert gehören zu dem selben Block, wobei jeder Eintrag nur zu genau einem Block gehört. Innerhalb dieser Blöcke befinden sich jetzt Einträge, die gemäß der Definition des Blocking Keys potentiell ähnlich sind. Im anschließenden Matching werden dann nur jeweils die Paare innerhalb eines Blocks miteinander verglichen. Blöcke mit nur einem Eintrag werden ignoriert. Der kritische Punkt bei diesem Verfahren ist das Aufstellen eines geeigneten Blocking Keys. Hierbei können unterschiedliche Codierungen (z. B. phonetische Codierungen von Namen [Chr12b]) angewendet und mehrere Attribute kombiniert werden. Dabei muss zwischen einem Blocking Key, der viele kleinere Blöcke erzeugt und einem Blocking Key, der wenige große Blöcke, erzeugt abgewogen werden. Sind die Blöcke zu groß, ist der Gewinn durch das Blocking gering, da wiederum viele Paare miteinander verglichen werden. Sind die Blöcke hingegen zu klein, steigt die Wahrscheinlichkeit, dass echte Duplikate beim Matching nicht berücksichtigt werden. 2.3.2 Sorted Neighbourhood Ein anderer Ansatz benutzt keine disjunkte Einteilung in Blöcke, sondern eine Sortierung der Grundmenge gemäß eines Sorting Keys. In dieser sortierten Liste befinden sich im Idealfall ähnliche Einträge nah bei einander. Mit einem Sliding Window, dessen Größe vorher definiert wurde, wird diese Liste schrittweise durchlaufen und alle Einträge innerhalb des Windows paarweise miteinander verglichen. Bereits verglichene Paare werden dabei nicht nochmals verglichen. Die Anzahl der so erzeugten Paare ergibt sich aus der Anzahl der Records n und der Größe des Sliding Windows w, wobei es insgesamt p=n−w+1 (2.18) mögliche Positionen für das Sliding Window gibt. Für die erste Position werden w·(w−1) 2 Paare generiert und für alle weiteren Positionen ergeben sich w − 1 neue Paare. Alle anderen Kombinationen sind bereits in vorherigen Window-Positionen erzeugt worden. 12 2.3 Blocking/Indexing Die Anzahl c der erzeugten Kandidatenpaare ist dann nach Christen ([Chr12a]): w · (w − 1) + (w − 1) · (n − w) 2 w · (w − 1) + 2 · (w − 1) · (n − w) = 2 2wn − w2 − 2n = 2 w2 = wn − n − 2 w = (w − 1)(n − ) 2 c= (2.19) In Tabelle 2.2 sind beispielhafte Daten dargestellt. Der gewählte Sorting Key ist hier die Spalte „Name“, wobei die Namen in Kleinbuchstaben konvertiert werden. ID 1 2 3 4 5 6 Name schmidt schmied schmitt schmidt schmitts schmidt Vorname Fritz Paul Gertrud Ursula Johann Elfriede Neue Position 1 2 3 4 5 6 ID 6 1 4 2 3 5 Name schmidt schmidt schmidt schmied schmitt schmitts Vorname Elfriede Fritz Ursula Paul Gertrud Johann Tabelle 2.2: Beispieldaten für den Sorted Neighbourhood Algorithmus Links sortiert nach dem Schlüssel (ID), Rechts sortiert nach Namen Die sortierte Tabelle rechts wird mit dem Sliding Window der Größe w = 3 durchlaufen, woraus sich dann die Paare in Tabelle 2.3 ergeben. Daraus ergeben sich gemäß Gleichung 2.18 vier verschiedene Positionen für das Sliding Window. In der ersten Position werden drei Paare erzeugt, in allen darauf folgenden nur noch zwei Paare, weil jeweils eines bereits in der vorherigen Position vorkommt. Insgesamt werden neun Paare generiert. Window Position 1-3 2-4 3-5 4-6 Paare (6, 1), (1, 4), (4, 2), (2, 3), (6, (1, (4, (2, 4), 2), 3), 5), (1, (4, (2, (3, 4) 2) 3) 5) Tabelle 2.3: Alle erzeugten Paare bei einem Sliding-Window-Durchlauf mit w = 3 Die Paare, die bereits bei der vorherigen Window-Position erzeugt wurden, sind durchgestrichen. 13 2 Grundlagen Bei der Erstellung des Sorting Keys ist zu beachten, dass bei einer Sortierung nach den dabei berechneten Werten den ersten Stellen eine höhere Bedeutung zukommt, da zuerst nach diesen sortiert wird. Benutzt man beispielsweise Nachnamen als Sorting Key, würden zwei Einträge zur gleichen Person, die einmal als „Pohl“ und einmal fälschlicherweise als „Wohl“ erfasst wurde, aller Vorasussicht nach nicht bei einander liegen und daher auch nicht als Duplikat erkannt. Die Größe des Sliding Windows hat ebenfalls Einfluss auf die Qualität und die Anzahl der erzeugten Paare. Abhängig vom Sorting Key kann es eine lange Reihe ähnlicher Einträge geben, die miteinander verglichen werden müssten. Ist das Window allerdings zu klein, wird jeweils nur ein Teil dieser ähnlichen Einträge verglichen, so dass einige Duplikate möglicherweise nicht identifiziert werden. Ist das Window zu groß, werden mehr Paare verglichen und das Matching nimmt mehr Zeit in Anspruch. 2.3.3 q-Gram-Indexing Beim q-Gram-Indexing werden die Blocking-Werte in Listen, bestehend aus den TeilStrings der Länge q, umgewandelt. Diese Teil-Strings werden q-Grams genannt. Beispielsweise wird der Nachname „wohl“ aus für q = 2 in [wo, oh, hl] zerlegt. Aus dieser Liste wird ein Indexschlüssel erzeugt, indem die einzelnen q-Grams zu einem String konkateniert werden. Für das obige Beispiel ergibt sich so der String „woohhl“. Weitere Index-Strings werden aus den Teillisten der q-Gram Liste erzeugt, bis eine minimale Länge l mit l = max(1,bk · tc) (2.20) erreicht wurde. Dabei ist k die Anzahl der ursprünglichen q-Grams und t ein festzulegender Grenzwert mit t ≤ 1. Für jede dieser Kombinationen wird auf gleiche Weise ein String erzeugt, so dass jedem Record eine Menge von Index-Strings zugeordnet wird. Die Anzahl s der Listen und damit die Anzahl der Index-Strings, die für ein Record gebildet werden, hängt von der Länge des Blocking-Wertes und der minimalen Länge der Sublisten ab: s= k X i=l k i ! (2.21) Der Binomialkoeffizient gibt hier die Anzahl der möglichen q-Gram Kombinationen an, für den Fall dass für k q-Grams Listen der Länge i gebildet werden sollen. Ein Beispiel für die Namen „wohl“ und „pohl“ ist in Tabelle 2.4 zu sehen. Aus t = 0,7 ergibt sich in dem Beispiel eine minimale Länge der Teillisten von l = b3 · 0,7c = 2. Da beide Wörter die gleiche Länge haben, ergibt sich daraus für beide die Anzahl der Listen s = 3 + 1 = 4. 14 2.3 Blocking/Indexing Name wohl pohl 2-Gram Listen [wo, oh, hl] [oh, hl] [wo, hl] [wo, oh] [po, oh, hl] [oh, hl] [po, hl] [po, oh] Index-String woohhl ohhl wohl wooh poohhl ohhl pohl pooh Tabelle 2.4: 2-Gram Listen für die Namen „Wohl“ und „Pohl“ mit t = 0,7 Beide haben den hervorgehobenen Index-String „ohhl“ gemeinsam. Beim Matching werden dann alle Records mit einander verglichen, die einen übereinstimmenden Index-String haben. In dem Beispiel haben beide Records den Index-String „ohhl“, so dass sie miteinander verglichen werden würden. 15 3 Zustandsanalyse Dieses Kapitel befasst sich hauptsächlich mit der Datenbank, die Gegenstand dieser Arbeit ist. Es wird zunächst der Aufbau des Datenbankschemas und der zugehörigen Tabellen erläutert, bevor auf den Inhalt der Datenbank mit konkreten Beispielen und Statistiken eingegangen wird. 3.1 Aufbau der Schriftendatenbank abteilung SCHLAGWORT person ABTEILUNG schlagwort MITARBEITER PERSON gehört zu aus autor Betreuer SCHRIFTTYP hat SCHRIFT Erstpruefer schrift Zweitpruefer schrifttyp FLIT LITERATURINDEX ABSCHLUSSARBEIT astatus ASTATUS hat ANSCHAFFUNG Abbildung 3.1: ER-Diagramm des Datenbankaufbaus Die Attribute wurden, bis auf die Primärschlüssel, zur besseren Übersichtlichkeit nicht dargestellt. Die Struktur des Datenbankschemas wurde im Wesentlichen von Mewe [Mew05] entworfen. Der Entwurf sieht neben der Erfassung von Schriften noch weitere Bestandteile 17 3 Zustandsanalyse der Fachgebietsverwaltung vor. Allerdings wurde die Schriftenverwaltung in ein eigenes Schema ausgegliedert und so von dem Rest der Datenbank (z. B. vom Lehrveranstaltungskatalog) entkoppelt. Die für das Matching relevanten Tabellen des aktuellen Schemas sind nachfolgend erläutert und der Zusammenhang zwischen diesen Tabellen wird durch das Entity-Relationship-Diagramm in Abbildung 3.1 veranschaulicht, welches durch ReEngineering der Tabellenschemata entstanden ist. 3.1.1 Tabelle SCHRIFT SCHRIFT (schrift, autor , titel NOT NULL , schrifttyp NOT NULL →SCHRIFTTYP , schrifttyp_erg , abteilung→ABTEILUNG , anm1 , anm2 , url1 , url2 , url3 , doknr , erfdatum ) In dieser Tabelle werden die gemeinsamen Daten aller in der Datenbank erfassten Dokumente gespeichert (siehe Abbildung 3.1). Dies beinhaltet zunächst eine eindeutige ID im Attribut schrift, das auch Primärschlüssel ist. Es werden titel und autor gespeichert sowie das Datum, an dem das Dokument erfasst wurde (erfdatum). abteilung ist eine Fremdschlüsselbeziehung zur Tabelle ABTEILUNG, mit der angegeben wird, zu welcher Abteilung das Dokument gehört. Eine weitere Fremdschlüsselbeziehung ist das Feld schrifttyp, welches auf die Tabelle SCHRIFTTYP verweist und so jedem Dokument genau einen Schrifttyp zuordnet. Zu diesem Schrifttyp kann noch eine Ergänzung (schrifttyp_erg) angegeben werden. Weiterhin gibt es zwei Felder für Anmerkungen (anm1, anm2) und drei für Weblinks (url1, url2, url3). 3.1.2 Tabelle FLIT FLIT (schrift→SCHRIFT , erscheinungsjahr , referenz , vorversion , seite , band , ausgabennr , zeitschrreihe , signatur , anzahl NOT NULL , standort , cr , deskriptoren , vzweck , hrsg , sprache , auflage , ort , instorg , verlag , isbn , literaturkuerzel ) In dieser Tabelle wird Forschungsliteratur erfasst. Das Attribut schrift ist sowohl Fremd- als auch Primärschlüssel, so dass die Tabelle eine Teilmenge der Tabelle SCHRIFT bildet. Bis auf die Anzahl der Exemplare (anzahl) sind alle anderen Attribute optional, da es sich bei den Einträgen um unterschiedliche Medien handelt und daher nicht immer alle Felder benötigt werden. Ist für die Schrift eine ISBN bekannt, kann diese im Feld isbn eingetragen werden. In der Spalte ort wird, falls vorhanden, der Sitz des Verlags (verlag) gespeichert und, falls das Dokument von einer anderen Organisation (instorg), wie z. B. einer Universität, veröffentlicht wurde, der Sitz dieser Organisation. Ist der Autor auch der Herausgeber, wird dies in der Spalte hrsg mit Wert „1“ vermerkt. Die Sprache, in der 18 3.1 Aufbau der Schriftendatenbank die Schrift verfasst wurde, kann als Länderkürzel (z. B. „deu“ für Deutschland) in der Spalte sprache registriert werden. In welchem Jahr das Schriftstück erschienen ist, wird in erscheinungsjahr dokumentiert. Für Bücher kann auch die Auflage (auflage) und gegebenenfalls die Nummer des Bandes (band) bei mehrbändigen Werken vermerkt werden. In zeitschrreihe kann der Name einer Zeitschrift oder Reihe angegeben werden und in ausgabennr die Heft- oder Ausgabennummer innerhalb der Zeitschriftenreihe. Für Schriften, die Auszüge aus einem ebenfalls erfassten Dokument sind, kann die dazugehörige Schrift-ID in referenz angegeben werden. Auch die Seitenzahl (seite), auf der das verzeichnete Dokument beginnt, kann gespeichert werden. Ist eine Vorversion der Schrift erfasst, kann diese in vorversion referenziert werden. Über eine Klassifikation gemäß „ACM Computing Classification System“ kann in der Spalte cr eine fachliche Zuordnung angegeben werden sowie zusätzliche Deskriptoren in der Spalte deskriptoren. literaturkuerzel stellt eine interne Bezeichnung dar, die innerhalb des Fachgebiets zur Referenzierung der Schriften benutzt wird. An welchem Ort sich das Dokument innerhalb des Fachgebiets befindet, wird in standort angegeben. Informationen zum Verwendungszweck werden in vzweck vermerkt. 3.1.3 Tabelle ABSCHLUSSARBEIT ABSCHLUSSARBEIT (schrift→SCHRIFT , erstpruefer→MITARBEITER , zweitpruefer→MITARBEITER , betreuer→MITARBEITER , key NOT abgabedatum ) NULL , Hier werden die spezifischen Attribute zu Abschlussarbeiten erfasst, die im gegebenen Fachgebiet geschrieben wurden. Jede Abschlussarbeit ist auch eine Schrift, weshalb der Primärschlüssel eine Fremdschlüsselbeziehung auf das Attribut schrift der Tabelle SCHRIFT ist. Es können ein erstpruefer und ein zweitpruefer, sowie ein betreuer angegeben werden. Dies sind jeweils Fremdschlüssel auf die Tabelle MITARBEITER, in der Mitarbeiter des Fachgebiets gespeichert werden. key gibt an, ob die Abschlussarbeit auf der Internetseite des Fachgebiets zugriffsbeschränkt werden soll. 3.1.4 Tabelle LITERATURINDEX LITERATURINDEX (schrift→SCHRIFT , abstract , bemerkung , url1_pubflag , url2_pubflag , url3_pubflag ) Publikationen des Fachgebiets werden in dieser Tabelle, die ebenfalls eine Teilmenge von SCHRIFT ist, gekennzeichnet. Es können außerdem der Abstract (abstract) der Publikation und eine zusätzliche Bemerkung (bemerkung) gespeichert werden. Über die drei Flags url1_pubflag, url2_pubflag, url3_pubflag kann festgelegt werden, welche der drei URLs aktiviert sind. 19 3 Zustandsanalyse astatus 0 1 2 3 4 5 9 10 status kein Status inventarisiert bestellen vormerken verzeichnen nicht bestellen vorhanden, nicht inventarisieren Leihgabe Tabelle 3.1: Codierung des Anschaffungsstatus 3.1.5 Tabelle ANSCHAFFUNG ANSCHAFFUNG (schrift →FLIT , astatus NOT NULL →ASTATUS , lieferant , ansicht , inventarnr , preis , waehrung , interessent , warenkorb ) Hier sind ausschließlich Schriften aus FLIT gespeichert. Im Feld astatus wird der Anschaffungsstatus codiert (siehe Tabelle 3.1). Interessant ist hier die Integritätsbedingung, die als Check-Klausel in der Datenbank umgesetzt ist: ( astatus = ’1 ’ and inventarnr is not null ) or ( astatus <> ’1 ’ and astatus <> ’10 ’ and inventarnr is null ) or ( astatus = ’10 ’) Dadurch wird sichergestellt, dass jede Schrift, die als inventarisiert gilt, auch eine Inventarnummer hat. Es ist davon auszugehen, dass Schriften, die eine Inventarnummer haben, garantiert im Fachgebiet zu finden sind. Deshalb ist bei der Fusion zweier Einträge ein Eintrag mit Inventarnummer dominierend. 3.1.6 Tabelle ABTEILUNG ABTEILUNG (abteilung, name , institut , uni , gueltig_von , gueltig_bis ) Der Inhalt dieser Tabelle wird für das Matching nicht benötigt. Allerdings muss im Rahmen dieser Arbeit auf die Abteilungen 3 und 5 eingeschränkt werden, da die Schriften der anderen Abteilungen nur noch aus historischen Gründen verzeichnet sind und heute nicht mehr genutzt werden. 20 3.1 Aufbau der Schriftendatenbank 3.1.7 Tabelle SCHRIFTTYP SCHRIFTTYP (schrifttyp, typ ) In dieser Tabelle werden die Schrifttypen codiert. Jede Schrift hat einen schrifttyp, der als Fremdschlüssel auf eine ID der Einträge (schrifttyp) der Tabelle SCHRIFTTYP verweist. In typ ist jeweils eine Textbezeichnung angegeben. Die Zuordnung der Typen zu den IDs, also dem Inhalt dieser Tabelle, ist in Tabelle 3.2 dargestellt. schrifttyp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Typ Studienarbeit Diplomarbeit Bachelorarbeit Masterarbeit Dissertation Habilitation article book booklet cd inbook incoll indok inproc manual master misc phd proc report unpubl Tabelle 3.2: Inhalt der Tabelle SCHRIFTTYP 21 3 Zustandsanalyse 3.2 Datenbestand 3.2.1 Duplikatbeispiele Schrift-ID Titel Tabellen 95 Implementierung einer SQLErweiterung für temporale Datenbanken ABSCHLUSSARBEIT/nicht in FLIT Wenige zusätzliche Daten 5934 Implementierung einer SQLErweiterung für temporale Datenbanken FLIT und ANSCHAFFUNG/ nicht in ABSCHLUSSARBEIT Viele zusätzliche Daten Tabelle 3.3: Beispiel eines Duplikats einer Abschlussarbeit Es gibt Schriften, die einmal als Abschlussarbeit und ein weiteres Mal als Forschungsliteratur erfasst sind. Ein Beispiel für diesen Fall ist in Tabelle 3.3 dargestellt. Diese getrennte Erfassung ist nicht nötig und auch nicht gewollt, da diese Arbeit mit einer einzigen Schrift-ID sowohl als Forschungsliteratur, als auch als Abschlussarbeit eingetragen werden könnte. Da es nur 191 Abschlussarbeiten gibt (siehe Tabelle 3.6), ist die erwartete Anzahl der Duplikate dieser Art, im Vergleich zur gesamten Anzahl der Schriften, gering. Die Existenz dieser Art von Duplikaten war bereits im Vorfeld bekannt; sie sind vermutlich durch einen fehlerhaften Datenimport entstanden. Im Laufe der Bearbeitung sind weitere größere Gruppen von Duplikaten aufgefallen, wobei hauptsächlich in FLIT erfasste Bücher betroffen sind. Wenn bei diesen der Anschaffungsstatus bekannt ist, wird er in der Tabelle ANSCHAFFUNG vermerkt. Allerdings existiert nicht zu jedem Eintrag in Forschungsliteratur ein solcher Eintrag, was aber so gewollt ist. Nun gibt es jedoch Bücher, die einmal nur als Forschungsliteratur und noch einmal als Forschungsliteratur mit Anschaffung erfasst sind, wobei typischerweise die Anschaffung inventarisiert worden ist. Hierzu gibt es zwei Beispiele (Tabelle 3.4 und Tabelle 3.5). Bei dem ersten Beispiel fällt auf, dass das Erfassungsdatum identisch ist. Dies legt nahe, dass der Fehler bei einem Datenimport entstanden ist, im Zuge dessen die Daten kopiert wurden. Beim zweiten Fall wurde der inventarisierte Eintrag etwa zwei Jahre später angelegt, daher ist hier von einem Erfassungsfehler auszugehen. Vermutlich wurde beim Inventarisieren des Buches nicht nachgesehen, ob dieses Buch bereits in der Datenbank erfasst ist. 22 3.2 Datenbestand Schrift-ID Titel Autor Tabellen Status Erfassungsdatum ISBN Verlag 9497 The Art of Computer Programming - Vol.III: Sorting and Searching (Second Edition) Knuth, Donald E. FLIT/nicht in ANSCHAFFUNG N/A 04-JAN-99 0-201-89685-0 Addison-Wesley 12105 The Art of Computer Programming - Vol.III: Sorting and Searching (Second Edition) Knuth, Donald E. FLIT und ANSCHAFFUNG Inventarisiert 04-JAN-99 0-201-89685-0 Addison-Wesley Tabelle 3.4: Beispiel eines Duplikats eines Lehrbuchs Beide Einträge haben das gleiche Erfassungsdatum. Schrift-ID Titel Autor Typ Status Erfassungsdatum Verlag 3648 Object-Oriented Databases Hughes, John G. FLIT/nicht in ANSCHAFFUNG N/A 14-SEP-92 Prentice-Hall 12115 Object-Oriented Databases Hughes, John G. FLIT und ANSCHAFFUNG Inventarisiert 29-JUL-94 Prentice-Hall Tabelle 3.5: Beispiel eines Duplikats eines Lehrbuchs Das inventarisierte Exemplar wurde etwa 2 Jahre später erfasst. 23 3 Zustandsanalyse 3.2.2 Statistiken In Tabelle 3.6 sind einige Kardinalitäten dargestellt, die die Beziehungen zwischen den Datenbanktabellen verdeutlichen. Es sind, nach der Einschränkung auf die relevanten Abteilungen, insgesamt 15.302 Schriften zu betrachten. Im folgenden wird immer von dieser Einschränkung ausgegangen. Von diesen Schriften haben 15.236 einen zugehörigen Eintrag in FLIT, das heißt umgekehrt es gibt nur 66 Schriften, die keinen solchen Eintrag haben. Die Anzahl der Abschlussarbeiten, die auch in der Tabelle ABSCHLUSSARBEIT erfasst sind, beträgt 191. Unter der Annahme, dass jede dieser Arbeiten als Duplikat in der Form von Tabelle 3.3 vorkommt, gäbe es also 191 Duplikate dieser Art. Von den Duplikatarten, wie sie in Tabelle 3.4 und Tabelle 3.5 dargestellt sind, bei denen eine Schrift in FLIT einmal mit einem Eintrag in ANSCHAFFUNG und einmal ohne erfasst wurde, kann es maximal 9.595 geben. Größe Anzahl Einträge in SCHRIFT mit abteilung in (3,5) 15302 Verschiedene titel in SCHRIFT 13957 SCHRIFT join FLIT 15236 SCHRIFT join ABSCHLUSSARBEIT 191 SCHRIFT join ANSCHAFFUNG 5641 Einträge in FLIT ohne Eintrag in ANSCHAFFUNG 9595 Tabelle 3.6: Tabellengrößen 24 4 Entwurf Die an die Anwendung gestellten Anforderungen sowie die Konzepte mit denen diese umgesetzt werden sollen, sind nachfolgend dargestellt. Dies beinhaltet die Auswahl der relevanten Daten für das Matching, die dabei angewendeten Verfahren sowie den Aufbau der Webschnittstelle und der für den Betrieb der Anwendung angelegten Datenbanktabellen. 4.1 Anforderungen Im Zuge der Bearbeitung haben sich in Gesprächen mit dem Betreuer folgende Anforderungen an die Anwendung ergeben: • Die Webschnittstelle soll mit PHP implementiert werden, da dies eine einfache Einbindung in bestehende, ebenfalls mit PHP entwickelte, Verwaltungsschnittstellen des Fachgebiets ermöglicht. • Für Attribute mit String-Datentyp wird die Edit-Distanz zum Vergleich benutzt, um Schreibfehler bei der Erfassung zu tolerieren. Hierfür steht bereits eine Funktion in der Oracle-Datenbank zur Verfügung (siehe Unterabschnitt 4.3.2). • Um eine flexible Kontrolle über das Matching-Ergebnis zu ermöglichen, müssen die Auswahl der beim Matching zu berücksichtigenden Spalten und die Gewichte dieser Spalten in der Webschnittstelle anpassbar sein. • Die Einstellungen und das dazugehörige Resultat sollen gespeichert werden, um eine spätere Analyse und Referenzierung der Ergebnisse zu ermöglichen. Daher muss es eine Möglichkeit zum Einrichten mehrerer Matching-Durchläufe geben. • Damit die Anwendung sinnvoll nutzbar ist, muss das Matching auf dem Datenbankserver in akzeptabler Zeit (maximal einige Stunden) laufen. • Eine eindeutige Erkennung der Ähnlichkeitsbeziehung zweier ähnlicher Records ist, auf automatische Weise, innerhalb der Anwendung nicht umsetzbar (vgl. Abschnitt 1.2). Stattdessen soll die Einordnung dieser Beziehungen durch den Benutzer geschehen, wofür in der Weboberfläche Funktionen zur Verfügung gestellt werden müssen. 25 4 Entwurf • Zur endgültigen Auflösung der Duplikate soll ermöglicht werden die beteiligten Einträge zu einem einzigen Eintrag zu fusionieren und in die Originaldatenbank einzufügen. • Zur Vereinfachung der Benutzerinteraktion wird, auf Basis der festgestellten Ähnlichkeitsbeziehung, ein Vorschlag für die Fusion der Einträge gemacht. 4.2 Auswahl der Datenbanktabellen Von den in Abschnitt 3.1 beschriebenen Tabellen wird nur ein Teil in der Anwendung verwendet. Die Verwendung bzw. nicht Verwendung ist nachfolgend erläutert: SCHRIFT muss verwendet werden, da dies die grundlegende Tabelle ist, in der alle Schriften erfasst sind. Hier sind vor allem titel und autor zu berücksichtigen, weil diese zu den bibliographischen Kerndaten der Dokumente gehören und somit bei deren Übereinstimmung eine hohe Ähnlichkeit der Dokumente zu erwarten ist. Für autor ist allerdings die nicht normierte Darstellung der Werte zu beachten (siehe Abschnitt 5.2.3). Die abteilung wird auf die Nummern 3 und 5 beschränkt. FLIT wird in das Matching einbezogen, weil die hier gespeicherten bibliographischen Daten zum Auffinden von Ähnlichkeiten benötigt werden. Für fast jede Schrift sind hier entsprechende Daten hinterlegt. Zur Identifikation von Ähnlichkeiten können aus dieser Tabelle insbesondere die Spalten erscheinungsjahr, isbn, instorg, verlag sowie zeitschrreihe beitragen. ABSCHLUSSARBEIT ist notwendig, um Abschlussarbeiten identifizieren zu können. Hierbei werden die Einträge dieser Tabelle vor allem benötigt, damit der Benutzer solche Duplikate wie in Tabelle 3.3 dargestellt erkennen kann. ANSCHAFFUNG wird genutzt um die Information über den Anschaffungsstatus in das Matching und die Fusion einfließen zu lassen. Insbesondere das Erkennen von bereits inventarisierten Schriften (astatus = 1 oder inventarnummer vorhanden) wird so ermöglicht. AUTOR ist nicht geeignet, da hier nur vermerkt ist, welche Mitarbeiter des Fachgebiets Autor einer Schrift sind. Diese Tabelle wird aber derzeit ohnehin nicht mehr gepflegt. SCHLAGWORT ist wegen des inkonsistenten Inhalts ebenfalls nicht für das Matching geeignet. Nach einer Bereinigung könnte diese Tabelle aber später für das Matching hilfreich sein. SCHRIFTTYP wird nicht zur Unterscheidung der Schriften nach ihrem Typ verwendet. So können Einträge unterschieden werden, die ansonsten eine hohe Ähnlichkeit 26 4.3 Matching-Prozedur aufweisen, wie z. B. die zu einer Abschlussarbeit gehörende CD (schrifttyp = 10). LITERATURINDEX ist für das Auffinden ähnlicher Schriften nur wenig geeignet, da die Spalten abstract und bemerkung lange Texte enthalten, die bei einer Mehrfacherfassung anfällig für Eingabefehler sind, wodurch sie nicht mehr übereinstimmen. Das Anwenden der Edit-Distanz auf derart lange Zeichenketten würde den gesamten Prozess verlangsamen. 4.3 Matching-Prozedur Die Berechnung der Ähnlichkeiten aller Paare wird mit einer Stored Procedure in PL/SQL innerhalb der Datenbank durchgeführt. 4.3.1 Matching-Ansatz Als grundlegender Ansatz soll ein Matching anhand von gewichteten Summen (siehe Abschnitt 2.1.2) angewendet werden. Dadurch ist eine feine Steuerung des Einflusses der einzelnen Attribute möglich. Zudem ist die Bedeutung der Gewichte einem späteren Benutzer leicht verständlich zu machen. Ein auf Wahrscheinlichkeiten basierender Ansatz (siehe Abschnitt 2.1.2) würde nämlich zur Festlegung der Auftrittswahrscheinlichkeiten bestimmter Werte ausgeprägtes Domänenwissen oder geeignete Trainingsdaten erfordern. Solche Trainingsdaten liegen allerdings nicht vor und zur Erlangung der nötigen Erfahrung mit den Daten wäre eine deutlich tiefere Analyse der vorliegenden Datenbank erforderlich. Grundsätzlich handelt es sich beim Matching um ein Problem quadratischer Komplexität. Für die Anzahl n der Einträge in SCHRIFT (n = 15301) müssten so folglich 153012 = 234.120.601 Paare miteinander verglichen werden. Die Reihenfolge der einzelnen Elemente der Paare ist aber irrelevant, sodass symmetrisch vertauschte Paare nur einmal miteinander verglichen werden müssen. Außerdem können auch Vergleiche der Records mit sich selbst ausgeschlossen werden. Daraus ergibt sich, dass der jeweils i-te Eintrag mit n−i anderen Einträgen verglichen werden muss. Für die Gesamtzahl x der Vergleiche erhält man: x= n X (n − i) i=1 2 =n − n X i (4.1) i=1 1 = n(n − 1) 2 Somit werden noch 117.052.650 Paarvergleiche benötigt. 27 4 Entwurf Die Anzahl der betrachteten Paare lässt sich stark einschränken, indem ein Indexing angewendet wird. Hierfür wird für den Titel die Annahme getroffen, dass sich die ersten sechs Zeichen der Titel bei ähnlichen Einträgen nicht unterscheiden. So muss jeder Eintrag nur noch mit denen verglichen werden, deren Titelanfang übereinstimmt. Auf diese Weise werden Vergleiche, die mit großer Wahrscheinlichkeit ein nicht sehr ähnliches Paar betrachten, ausgeschlossen. Mit dieser Einschränkung werden noch 336.509 Paarvergleiche durchgeführt. Dies ist jedoch eine sehr grobe Annahme, durch die Records mit Eingabefehlern (wie z. B. Leerzeichen am Anfang des Titels oder zwei vertauschten Zeichen) nicht mehr in den Vergleich mit einbezogen werden. 4.3.2 Edit-Distanz Für String-Werte soll als Vergleichsfunktion die Edit-Distanz benutzt werden. Dafür wird auf die bereits im Datenbanksystem vorhandene Funktion EDIT_DISTANCE_SIMILARITY aus dem Paket UTL_MATCH zurückgegriffen. So kann Implementierungs- und Testaufwand eingespart werden. Der Aufruf dieser Funktion bei allen Spalten mit einem String-Datentyp steigert allerdings die Laufzeit des Matchings, im Vergleich zum Prüfen auf exakte Gleichheit, erheblich. Dies ließe sich über die Auswahl der Spalten für das Matching steuern, was zur Folge hätte, dass die Laufzeit abhängig von den gewählten Spalten stark schwankt. Zusätzlich könnte sich ein Einschränken auf wenige Spalten negativ auf die Qualität des Matchings auswirken. Daher wird als Kompromiss die Edit-Distanz nur auf den Titel der Schriften angewendet, bei allen anderen Spalten wird lediglich auf Gleichheit geprüft. So können viele String-Werte berücksichtigt werden ohne den ganzen Prozess zu verlangsamen. 4.3.3 Betrachtung der Objekt-Ebene Wie in Abschnitt 3.1 beschrieben, besteht die Bibliotheksdatenbank aus mehreren Tabellen, die miteinander in Beziehung stehen. Insbesondere sind die Teilmengenbeziehungen zwischen SCHRIFT, ABSCHLUSSARBEIT, ANSCHAFFUNG, und FLIT zu beachten. Die für das Matching benötigten Informationen sind über diese Tabellen verteilt. Um den Zugang zu diesen Informationen zu erleichtern, wird eine Sicht definiert, in der diese Tabellen, ausgehend von SCHRIFT, per Outer Join zusammengefügt werden. Diese Sicht wird im folgenden als Ursprungssicht bezeichnet, da sie die ursprünglichen Werte enthält. 28 4.4 Datenbankschema 4.4 Datenbankschema Zur Speicherung und Verwaltung mehrerer Matching-Durchläufe wird ein Datenbankschema benötigt. Hier sollen die Matching-Durchläufe zusammen mit einer Bezeichnung gespeichert werden sowie für jeden Durchlauf die ausgewählten Spalten und ihre Gewichte. Außerdem sollen die Ähnlichkeitsvektoren, der Gesamtähnlichkeitswert der Paare und ihre Klassifizierung als „Match“ oder „Non-Match“ in der Datenbank abgelegt werden. Aus diesen Anforderungen ist das ER-Diagramm für den DB-Entwurf in Abbildung 4.1 entstanden. runnr name match column_name schrift1 COMPVEC von CTRLMATCH gehört zu MATCH_WEIGHTS schrift2 weight sim ... Abbildung 4.1: ER-Entwurf für das Datenbankschema der Anwendung Die Attribute für die einzelnen Ähnlichkeitswerte der Spalten wurden im Entity COMPVEC ausgelassen. Dies entspricht folgendem Relationenschema: CTRLMATCH (runnr, name NULL ) MATCH_WEIGHTS (runnr →CTRLMATCH , column_name, weight ) COMPVEC (runnr →CTRLMATCH , schrift1, schrift2, sim , match , ...) CTRLMATCH wird genutzt, um mehrere Matching-Durchläufe zu speichern. Das Attribut runnr stellt hierbei eine laufende ID dar. Zusätzlich kann noch ein name zur besseren Unterscheidbarkeit gespeichert werden. Die Relation COMPVEC enthält einen Ähnlichkeitsvektor pro Schrift-Paar. In schrift1 und schrift2 werden die beiden Schrift-IDs des Record-Paares gespeichert. Zusammen mit der runnr wird auf diese Weise der Ähnlichkeitsvektor eines Paares in einem Matching-Durchlauf identifiziert. Neben den jeweiligen Schrift-IDs sind zusätzlich noch der errechnete Gesamtähnlichkeistwert (sim) und die Klassifizierung des Paares (match) erfasst, die durch den Benutzer im Match-Tool (Unterabschnitt 4.5.1) festgelegt wird. Zusätzlich gibt es hier alle Spalten, die auch in der Ursprungssicht (Unterabschnitt 4.3.3) vorkommen. Diese stammen aus den Originaldaten. Gegenüber einem Entwurf mit wenigen Spalten, in dem für jeden Ähnlichkeitswert eine neue Zeile eingefügt wird, hat dieser Entwurf den Vorteil, dass die Anzahl der benötigten Insert-Operationen geringer ist. Auf diese Weise wird nur eine Insert-Operation pro Paar benötigt und nicht ein Insert pro Spalte bei jedem Paar. Bei Anfragen in der Anwendung werden 29 4 Entwurf in der Regel sämtliche Ähnlichkeitswerte benötigt, so dass zudem das Auslesen und Bearbeiten einer langen Zeile hier effizienter ist, als die Verwendung mehrerer Zeilen. Aufgrund der großen Anzahl der Spalten werden diese in dem ER-Diagramm und dem Relationenschema zur besseren Übersichtlichkeit nicht explizit dargestellt. Die zu vergleichenden Spalten werden mit dem ihnen zugeordneten Gewicht (weight) in MATCH_WEIGHTS verzeichnet. 30 4.5 Webschnittstelle 4.5 Webschnittstelle php index.php login.php logout.php common dbconn.php utils.php fusions-tool matches.php merge.php match-tool insert_match.php manage.php pair_details.php result.php start.php view_result.php weights.php Abbildung 4.2: Dateistruktur der Webschnittstelle Die PHP-Webschnittstelle besteht aus dem Match-Tool und dem Fusions-Tool sowie einer allgemein genutzten Startseite mit Login-Funktion und gemeinsam benutzten Funktionen (im Ordner common). Eine Übersicht über die Dateien und Ordner gibt die Abbildung 4.2. Die einzelnen Handlungsschritte im Ablauf des gesamten Prozesses sind in Abbildung 4.3 dargestellt. Nach dem Login sind auf der Startseite (index.php) Links zu den Startseiten des Match-Tools und des Fusions-Tools. Das Match-Tool stellt die Einstellungs- und Verwaltungsmöglichkeiten für den Matching-Prozess bereit. Des Weiteren können in der Webschnittstelle die Ergebnisse des Matchings angesehen und die Klassifikation der Paare festgelegt werden. Das Fusions-Tools ermöglicht das Betrachten der bereits klassifizierten Paare sowie deren Zusammenführung. 31 4 Entwurf Matching−Durchlauf anlegen Spalten und Gewichte auswählen Matching starten Ergebnis ansehen Paare klassifizieren Paare fusionieren Abbildung 4.3: Genereller Ablauf des Prozesses Im Ordner common befinden sich gemeinsam genutzte Funktionen der PHP-Skripte, wie z. B. das Herstellen der Datenbankverbindung. 4.5.1 Match-Tool Einen Überblick über die Matching-Durchläufe gibt die Seite manage.php. Zu jedem Durchlauf gibt es die Möglichkeit, zur Einstellung der Gewichte oder zur Ergebnisansicht zu gelangen. Auch das Ausführen der Matching-Prozedur kann hier angestoßen werden, wobei sichergestellt wird, dass zu einem Zeitpunkt immer nur eine Instanz dieser Prozedur läuft. Das Einstellen der Gewichte wird auf der Seite weights.php vorgenommen. Hier werden alle möglichen Spalten für das Matching angezeigt, die dann vom Benutzer ausgewählt und mit Gewichten versehen werden können. Das Starten des Matchings erfolgt anschließend wieder aus der Übersichtsseite (manage.php) heraus. Liegt ein Matching-Ergebnis für den entsprechenden Durchlauf vor, kann dieses über einen Link von der Übersichtsseite betrachtet werden. Auf der Seite view_results.php können dafür zunächst die anzuzeigenden Spalten und die Anzahl der zu betrachtenden Paare ausgewählt werden. Anschließend werden in results.php die gefundenen Paare entsprechend der Einstellungen angezeigt. In der Ergebnisübersicht ist es nun möglich, die Paare als „Duplikat“ oder „NonMatch“ zu klassifizieren. Diese Einteilung wird dann in der Datenbank vermerkt. Falls der Benutzer zur Einschätzung mehr als die in der Übersicht angezeigten Daten benötigt, kann für jedes Paar auch eine Detailansicht (pair_details.php) aufgerufen werden, in der alle vorhandenen Daten und gegebenenfalls ihre Ähnlichkeitswerte zu dem Paar angezeigt werden. 4.5.2 Fusions-Tool Auf der Startseite (matches.php) des Fusions-Tools werden die zuvor im Match-Tool klassifizierten Paare angezeigt. In einer Detailansicht (merge.php) der Paare können die Werte der einzelnen Spalten zusammengeführt werden, so dass ein neuer Eintrag 32 4.5 Webschnittstelle für die Datenbank entsteht. Abhängig von der Ähnlichkeitsklasse des Paares wird hier ein Vorschlag zur Fusionierung gemacht. Im Falle von Duplikaten werden alle übereinstimmenden Werte übernommen. Spalten, in denen ein Record einen Wert hat und der andere nicht, werden mit dem existierenden Wert belegt. Liegt ein Datenkonflikt vor, also verschiedene Werte für die gleiche Spalte bei beiden Records, werden im Vorschlag die Werte des Records eingetragen, der Priorität hat. Dies ist der Fall, wenn einer der beteiligten Einträge inventarisiert ist (astatus = 1 oder vorhandenen Inventarnummer), weil davon auszugehen ist, dass die Daten in inventarisierten Einträgen überwiegend korrekt sind. Sind keiner oder beide inventarisiert, bekommt derjenige Priorität, der die meisten Daten, also am wenigsten NULL-Werte, hat. Dieser Vorschlag sollte dann vom Benutzer noch einmal auf Richtigkeit geprüft werden. Anschließend werden die Daten in die Datenbank geschrieben, indem die Tupel, die zu dem priorisierten Eintrag gehören in den jeweiligen Datenbanktabellen aktualisiert werden; die Tupel des nicht priorisierten werden gelöscht. Dabei werden Abhängigkeiten und Referenzen der anderen, für das Matching selbst nicht relevanten, Tabellen berücksichtigt. So dürfen z. B. Schriften, auf die aus der Autor-Tabelle heraus verwiesen wird, nicht gelöscht werden, ohne dass der Verweis entsprechend angepasst wird. Für die Fälle, in denen beide Einträge behalten werden sollen (z. B. Vorversionen), werden die ursprünglichen Records angepasst, indem beispielsweise der Verweis auf die Vorversion gesetzt wird. 33 5 Implementierung Nachdem im vorigen Kapitel der Entwurf beschrieben wurde, werden hier Aspekte der konkreten Umsetzung dargestellt. Nach einer Beschreibung der Besonderheiten des gewählten Datenbankmodells wird die Funktionsweise des implementierten MatchingAlgorithmus erläutert. Hierbei wird insbesondere auf die Laufzeit und Maßnahmen zu ihrer Reduzierung eingegangen. Anschließend werden Details zur Implementierung der Webschnittstelle geschildert. 5.1 Datenbankschema Zur Speicherung und Verwaltung mehrerer Matching-Durchläufe und ihrer Einstellungen wurde ein Tabellenschema angelegt. Von dem ursprünglichen Entwurf in Abschnitt 4.4 wurde, zugunsten einer erhöhten Ausführungsgeschwindigkeit der MatchingProzedur sowie einer einfacheren Verwaltung der Tabellen, abgewichen. Statt einer einzigen Ergebnistabelle COMPVEC wird eine eigene Ergebnistabelle für jeden Durchlauf verwendet. Daraus ergibt sich das folgende Schema: CTRLMATCH (runnr, name NULL , runflag ) MATCH_WEIGHTS (runnr →CTRLMATCH ,column_name, weight ) COMPVECS_ < runnr >( schrift1 , schrift2 , sim ,...) MATCHSTATE (schrift1,schrift2, match ) Quelltext 5.1: DB-Schema des Matching-Tools In CTRLMATCH wird für jeden Durchlauf ein neuer Eintrag mit einer ID (runnr) und einem optionalen Namen (name) angelegt. Die Spalte runflag wird genutzt, um zu kennzeichnen, dass die Matching-Prozedur für den entsprechenden Durchlauf momentan ausgeführt wird (siehe auch Unterabschnitt 5.3.4). Die Tabelle MATCH_WEIGHTS enthält zu jedem Lauf nur das Gewicht der ausgewählten Spalten im Matching. Dazu besteht jeder Eintrag der Tabelle aus der runnr und dem jeweiligen Spaltennamen (column_name), die zusammen den Primärschlüssel bilden, sowie dem gesetzten Gewicht(weight). Alle Spalten, die bei dem jeweiligen Lauf nicht berücksichtigt werden sollen, haben hier entsprechend keinen Eintrag. Wie im Entwurf festgelegt, werden zusätzlich die beiden IDs der Schriften (schrift1 und schrift2), sowie der Gesamtähnlichkeitswert, der sich aus der gewichteten Summe ergibt, gespeichert. 35 5 Implementierung SCHRIFT1 SCHRIFT2 SIM AUTOR TITEL SCHRIFTTYP URL1 URL2 ERFDATUM URL3 ISBN VERLAG INSTORG ORT SPRACHE HRSG DESKRIPTOREN STANDORT ZEITSCHRREIHE AUSGABENNR BAND SEITE ERSCHEINUNGSJAHR ERSTPRUEFER ZWEITPRUEFER BETREUER ABGABEDATUM INVENTARNR NUMBER (8) NUMBER (8) NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER NUMBER Quelltext 5.2: Beispielausprägung einer COMPVECS Tabelle Die Ergebnisse der Matching-Prozedur werden nicht, wie zuvor geplant, in einer einzigen Tabelle gespeichert, sondern in je einer separaten COMPVECS_<runnr>-Tabelle festgehalten. Diese werden dynamisch zur Laufzeit erstellt, wobei <runnr> ein Platzhalter für die ID des jeweiligen Durchlaufs ist. So wird für jeden Lauf eine eigene Ergebnistabelle angelegt (COMPVECS_1, COMPVECS_2 usw.), die für die Ähnlichkeitswerte nur die zuvor für das Matching ausgewählten Spalten enthält (Beispielausprägung in Quelltext 5.2). Neben der dynamischen Spaltenwahl ist ein weiterer Grund für diese Abweichung, dass ein Primärschlüssel auf der Tabelle den gesamten Matching-Prozess verlangsamen würde. Bei einer derartigen Umsetzung hätten bei jeder Insert-Operation die Indexe aktualisiert und die Schlüssel auf Verletzung des Unique-Constraints überprüft werden müssen. 36 5.2 PL/SQL: Matching-Prozedur Das Speichern der Klassifizierung durch den Benutzer wurde daher in eine separate Tabelle MATCHSTATE verschoben, weil diese global für alle Durchläufe gelten muss. Ansonsten könnten für das selbe Paar widersprüchliche Bewertungen eingetragen werden. Der Inhalt dieser Tabelle ist maßgeblich für die Fusion, da nur die hier verzeichneten Paare, die nicht als „Non-Match“ klassifiziert wurden, für eine Fusion in Frage kommen. 5.2 PL/SQL: Matching-Prozedur 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: procedure match(threshold, runID) simSum ← 0 for each rec1 in SCHRIFT loop for each rec2 in SCHRIFT where schrift > rec1.schrift loop for each column in MATCH_WEIGHTS where runnr = runID loop simValue ← calcSimilarity(rec1[column],rec2[column]) simSum ← column.weight · simValue end simSum ← simSum / sum(column.weights) if simSum ≥ threshold then insert values into COMPVECS_<runID> end if end end end procedure Algorithmus 5.1: Struktur der Matching-Prozedur 5.2.1 Aufbau Der Ablauf der Prozedur ist als Pseudocode in Algorithmus 5.1 dargestellt. Der Kern der Prozedur besteht aus zwei ineinander geschachtelten Cursor-Loops. Der äußere Cursor (Zeile 3) iteriert über alle Zeilen in der Ursprungssicht, aufsteigend nach der Datenbank-ID sortiert. Der innere Cursor (Zeile 4) iteriert nur über diejenigen Einträge, deren ID größer ist, als die ID des äußeren Eintrags. Dadurch wird ausgenutzt, dass die Reihenfolge der Paare nicht relevant ist, also die symmetrisch vertauschten Paare nicht verglichen werden müssen. Innerhalb der inneren Schleife wird nun über die zu vergleichenden Spalten iteriert (Zeile 5). Für jede Spalte wird der Wert des ersten (äußeren) Eintrags mit dem Wert des inneren verglichen und das Ergebnis als Ähnlichkeitswert gespeichert (Zeile 6). Aus diesen Ähnlichkeitswerten wird eine gewichtete Summe berechnet, die mithilfe der 37 5 Implementierung Summe aller Gewichte normiert wird. Diese gewichtete Summe wird zusammen mit den einzelnen Ähnlichkeitswerten der Spalten in einen Insert-String geschrieben, der die entsprechenden Werte mit dynamischem SQL in die entsprechende Ergebnistabelle einfügt. Über einen als Parameter an die Prozedur übergebenen Schwellenwert kann eingestellt werden, wie hoch die Gesamtähnlichkeit des Paares sein muss, damit die Werte in die Ergebnistabelle geschrieben werden (Zeile 10). 5.2.2 Iteration über Spalten Das Iterieren über die Spalten einer Zeile ist in PL/SQL nicht ohne Weiteres möglich. Daher werden zu Beginn die zu vergleichenden Spaltennamen mit den dazugehörigen Gewichten in eine Nested-Table Collection gespeichert. Über diese Collection kann nun iteriert werden. /* Typ - und V a r i a b l e n d e k l a r a t i o n */ TYPE weights_t IS TABLE OF match_weights % ROWTYPE ; columnNames weights_t ; /* Abfragen und Speichern der zum Durchlauf ( runID ) geh ö renden Zeilen aus match_weights */ SELECT * BULK COLLECT INTO columnNames FROM match_weights WHERE runnr = runID ; Quelltext 5.3: Speicherung der Spaltennamen und Gewichte in einem Nested-Table Allerdings ist ein dynamischer Zugriff auf die einzelnen Spalten der Record-Variablen der Cursor nicht möglich. Mit Hilfe eines selbstdefinierten SQL-Typs, der wiederum eine aus VARCHAR2 bestehende Nested-Table ist, lässt sich dieses Problem umgehen. Mit einer Anfrage, die ein Objekt dieses neuen Typs liefert, werden die benötigten Spaltenwerte des Eintrags in der Ursprungssicht implizit zu VARCHAR2 konvertiert und in diesem Nested-Table gespeichert. Nun kann auf die einzelnen Spaltenwerte über Angabe eines numerischen Indexes zugegriffen werden. CREATE TYPE bib_row IS TABLE OF VARCHAR2 (4000) ; Quelltext 5.4: Definition des globalen SQL-Typs 38 5.2 PL/SQL: Matching-Prozedur 5.2.3 Spaltenvergleiche Generell wird für jede Spalte auf einfache Gleichheit geprüft. Das heißt, die Werte haben bei exakter Übereinstimmung eine Ähnlichkeit von 100%, ansonsten haben sie 0% Ähnlichkeit. Ausnahmen hiervon bilden die Spalten titel, autor, und jede Spalte, in der beide Einträge des Paares keinen Wert, also NULL, haben. titel Um leichte Abweichungen im Titel der Schriften zu tolerieren, wird hier zum Vergleich die Edit-Distanz benutzt. Diese wird mittels der von Oracle im Paket UTL_MATCH zur Verfügung gestellten Funktion EDIT_DISTANCE_SIMILARITY berechnet. Sie gibt einen Wert zwischen 0 und 100 zurück, der die Ähnlichkeit zweier Zeichenketten in Prozent beschreibt. Da die Nutzung dieser Funktion einen höheren Rechenaufwand darstellt als ein exakter Vergleich, wird diese nur beim Titel benutzt. autor Wie in Unterabschnitt 3.1.1 beschrieben, enthält die Spalte autor eine Liste mit den Autoren der jeweiligen Schrift. Für diese Auflistung wird allerdings in der Datenbank kein einheitliches Format verwendet, so dass bei manchen Einträgen die Autoren mit einem Schrägstrich getrennt sind, bei anderen aber mit einem Komma. Auch die Schreibweise der Vornamen ist nicht normiert; einige liegen in abgekürzter Form vor. Daher sind die in dieser Spalte enthaltenen Daten nur schwer vergleichbar. Die Autorenangabe ist aber ein wichtiger Hinweis auf Duplikate. Bei fehlender Übereinstimmung kann es sich schließlich nicht um ein Duplikat handeln. Aus diesem Grunde wird zumindest der Nachname des ersten Autors in den Vergleich mit einbezogen. Als Vergleichsfunktion wird hier eine einfache Gleichheit geprüft. Dies ist möglich, da festgelegt wurde, dass der Nachname des ersten Autors am Anfang des Strings steht, gefolgt von einem Komma. Alles was nach diesem Komma steht, ist nicht sinnvoll vergleichbar. NULL-Werte Wenn beide Werte einer Spalte NULL sind, wird diese Spalte ignoriert. Die Spalte trägt mit einem Wert von 0 zur Ähnlichkeitssumme bei und das definierte Gewicht dieser Spalte wird von der Summe aller Gewichte subtrahiert. Auf diese Weise wird die Spalte weder als gleich noch als ungleich bewertet, sie wird komplett in der Berechnung ignoriert. Dies ist nötig, da eine Bewertung als Übereinstimmung dazu führt, dass Paare, die wenige gleiche Werte, aber viele NULL-Werte haben, als ähnlich gelten. Andersherum führt eine Bewertung von NULL als verschieden dazu, dass ursprünglich ähnliche 39 5 Implementierung Schriften einen niedrigen Ähnlichkeitswert bekommen, weil sie viele NULL-Werte enthalten. Beide Fälle führen zu einer geringeren Matching-Qualität und so zu einem größeren Aufwand bei der anschließenden Bearbeitung durch den Benutzer. 5.2.4 Laufzeit und Optimierungen Die ursprüngliche Implementierung benötigte bereits für den Vergleich von 10.000 Paaren 14:40 Minuten. Das entspricht 88ms pro Paar. Für die insgesamt erforderlichen 117.052.650 Vergleiche ergäbe das hochgerechnet eine Laufzeit von etwa 17 Wochen. Die tatsächliche Laufzeit wäre noch höher: Aufgrund einer Anfrage an die Ergebnistabelle ist die Bearbeitungszeit eines Paares abhängig von der Anzahl der bisher verglichenen Paare. Der Algorithmus wurde folglich langsamer, je mehr Paare verglichen wurden. Durch die nachfolgend erläuterten Optimierungen konnte die Laufzeit auf etwa 150µs pro Paar reduziert werden. Damit kann ein vollständiger Durchlauf über alle Einträge der Datenbank in etwa fünf Stunden durchgeführt werden. Werden nur die Einträge mit gleichen Titelanfängen verglichen, reduziert sich die Laufzeit auf wenige Minuten (siehe auch „Titel-Indexing“ auf Seite 41). Ausschluss symmetrisch vertauschter Paare In der ersten Implementierung wurde das Ausschließen der symmetrisch gleichen Kombinationen über eine Unteranfrage an die Ergebnistabelle realisiert. Dadurch wurde die Laufzeit linear in Abhängigkeit zur Größe der Ergebnistabelle erhöht. Das Ausschließen kann auch durch die Bedingung realisiert werden, dass die ID (schrift) des zweiten Eintrags größer sein muss, als die des ersten. Auf diese Weise konnte die Unteranfrage eingespart und die Laufzeit auf konstante Größen beschränkt werden. Materialized View und Index Die Umwandlung des Views in ein Materialized View, also eine physische Repräsentation des Anfrageergebnisses in Form einer Tabelle, brachte einen großen Performance-Gewinn mit sich. Auf diese Weise muss die Anfrage für die Ursprungssicht nicht mehrmals innerhalb der Prozedur ausgeführt werden, sondern nur einmal beim Anlegen der Sicht. Die Laufzeit konnte noch einmal stark reduziert werden, indem auf diesem Materialized View ein Index für die Spalte schrift angelegt wurde. Dadurch wird zum Einen das Überprüfen der oben genannten Bedingung für schrift beschleunigt und zum Anderen das Auslesen der jeweiligen Tupel aus dem View erleichtert. Bearbeitung der Spalten Das Zwischenspeichern der Records in Collections ermöglicht den Vergleich der einzelnen Spalten ohne für jede Spalte zwei weitere Anfragen pro Paar stellen zu müssen. 40 5.3 PHP-Webschnittstelle Außerdem wurde ursprünglich, nach dem Vergleich der Werte einer Spalte, ein Update auf der Ergebnistabelle ausgeführt, um den soeben errechneten Wert einzutragen. Dadurch entsteht viel Overhead beim Wechsel zwischen der SQL- und der PL/SQLEngine [Ros+11]. Dieser wurde minimiert, indem mittels dynamischem SQL ein Insert pro Paar erzeugt wird. Auch wenn das Ausführen der Insert-Operationen noch immer langsam ist, hat die Einführung eines Schwellenwertes für die Gesamtähnlichkeit eines Paares, ab der das Insert ausgeführt wird, die Laufzeit von 1ms pro Paar auf 100–180µs reduziert. Die Anzahl der Inserts und damit die Laufzeit der Prozedur sind abhängig von diesem Schwellenwert und den gewählten Gewichten. Je mehr Paare von ihrem Ähnlichkeitswert her über der Schwelle liegen, desto mehr Inserts werden ausgeführt und desto größer ist die Gesamtlaufzeit. Die Beschränkung der Anwendung der Edit-Distanz auf die Titel hat ebenfalls einen positiven Effekt auf die Laufzeit, da diese Berechnung mit Blick auf die Häufigkeit, mit der sie ausgeführt werden müsste, viel Zeit in Anspruch nimmt. Titel-Indexing Wie in Unterabschnitt 4.3.1 beschrieben, wird die Annahme getroffen, dass ähnliche Einträge einen gleichen Titelanfang haben. Hierfür werden zu dem Eintrag aus der äußeren Schleife nur die Einträge in der inneren Schleife ausgewählt, deren Titel mit den gleichen sechs Buchstaben beginnt. Der Titel des äußeren Eintrags ist in einer Record-Variable rec gespeichert. Für den inneren Cursor ergibt sich so für den Titel folgende Bedingung in SQL: WHERE substr ( titel ,1 ,6) = rec . titel Um eine effiziente Überprüfung zu ermöglichen, wurde auf dem Materialized View ein funktionsbasierter Index für die Spalte titel angelegt. CREATE INDEX titel_indx ON bib_all ( substr ( titel ,1 ,6) ) Quelltext 5.5: Befehl zum Anlegen des Index auf den Titelanfang So erhöht sich zwar die durchschnittliche Laufzeit pro Paar, aber durch die stark reduzierte Menge der Paare endet die Prozedur nach 1–2 Minuten. 5.3 PHP-Webschnittstelle 5.3.1 Anbindung der Datenbank In dem PHP-Skript dbconn.php befindet sich eine Klasse DBConn, in der die Verbindung zum Datenbankserver, mittels der PHP-Erweiterung „PHP Data Objects“ (PDO), hergestellt wird. Sie erbt von der Standard-PDO-Klasse und hat zusätzlich die Funktion: 41 5 Implementierung executeQuery ( $query , $param = NULL , $method = PDO :: FETCH_ASSOC ) Diese Funktion führt die Anfrage, die im ersten Parameter $query übergeben wird, als Prepared Statement aus. Die Belegung der in $query benutzten Bind-Variablen muss als assoziatives Array in $param angegeben werden. Da auch Anfragen ohne Bind-Variablen ausgeführt werden können, ist $param optional und hat NULL als Default-Wert. Die Art, wie die von der Anfrage zurückgegebenen Zeilen in PHP-Objekten dargestellt werden sollen, kann mit dem Parameter $method eingestellt werden. Dieser ist standardmäßig auf PDO::FETCH_ASSOC eingestellt, was zu einer Rückgabe der Zeilen als assoziatives Array führt. Mit der Verwendung dieser Funktion wird die Ausführung der Datenbankanfragen als Prepared Statement innerhalb der Anwendung vereinheitlicht und somit vereinfacht. Dadurch sinkt die Gefahr einer SQL-Injection, beispielsweise über Parameter aus den HTTP-Requests. Zusätzlich enthält dbconn.php die Funktion getConnection(), die, unter Verwendung der beim Login in der Session gespeicherten DB-Zugangsdaten, eine Verbindung zur Datenbank aufbaut und ein Objekt vom Typ DBConn zurückgibt. Die Adresse der Datenbank ist in der Variablen $dbname ebenfalls vordefiniert. 5.3.2 Login Mit der in utils.php enthaltenen Funktion check_login() wird zu Beginn jedes PHPSkripts geprüft, ob der Benutzername in der Session hinterlegt ist. Ist er dies nicht, wird der Benutzer auf die Login-Seite (login.php) weitergeleitet. Hier befinden sich Eingabefelder für Benutzername und Passwort zur Datenbank. Die Eingaben werden zwecks Authentifizierung mit des Nutzers mit der Datenbank abgeglichen. War die Prüfung erfolgreich, werden Benutzername und Passwort in der PHP-Session abgelegt, so dass sie im weiteren Verlauf zum Herstellen der DB-Verbindung zur Verfügung stehen. Schlägt der Login fehl, wird die Session beendet und die Login-Seite erscheint erneut. 5.3.3 Einstellen der Gewichte Die Liste der für das Matching auswählbaren Spalten des Views wird in weights.php mit einer Anfrage an das Data Dictionary generiert. Sofern vorhanden, werden die bereits gespeicherten Gewichte direkt in die Input-Felder eingetragen. Zum Speichern der Gewichte wird ein MERGE INTO Statement verwendet (siehe Quelltext 5.6). Bei :runnnr, :col und :weight handelt es sich um Bind-Variablen, die erst bei der Ausführung des Prepared Statements gesetzt werden. Somit ist es nicht erforderlich zu unterscheiden, ob bereits existierende Gewichte geändert oder neue Gewichte eingetragen werden müssen, da dies im MERGE Statement 42 5.3 PHP-Webschnittstelle behandelt wird. MERGE INTO match_weights w USING ( select : runnr runnr , : col column_name , : weight weight from dual ) v ON ( w . runnr = v . runnr and w . column_name = v . column_name ) WHEN MATCHED THEN UPDATE SET weight = v . weight WHEN NOT MATCHED THEN INSERT VALUES ( v . runnr , v . column_name , v . weight ) Quelltext 5.6: MERGE INTO Statement zum Speichern der Gewichte 5.3.4 Starten der Matching-Prozedur Das Starten der Datenbank-Matching-Prozedur aus PHP heraus gestaltet sich schwierig, da innerhalb der Session auf das Ergebnis der Prozedur gewartet werden würde. Das bedeutet, dass die Session erhalten bleiben muss, bis die Prozedur beendet ist. Dies kann im Rahmen einer Webanwendung nicht gewährleistet werden, da es bei zu langen Wartezeiten zu einem Timeout der Session kommt. Ein weiteres Problem ergibt sich, wenn durch das Schließen des Browserfensters auf Client-Seite ein Abbruch der Session bewirkt wird, was die Anfrage an die Datenbank ebenfalls beenden würde. Daher wird ein separates Skript mittels des PHP Command Line Interface (PHP Cli) in einem neuen Prozess ausgeführt. Ein auf herkömmliche Weise gestarteter Prozess wäre wieder ein Subprozess, den der Webserver — im Falle von zu vielen laufenden Prozessen — jederzeit beenden kann. Deshalb wird eine neue Instanz des PHP-Interpreters gestartet, die das Aufrufskript der Prozedur ausführt. Der Aufruf hierfür lautet: exec ( ’ nohup / usr / bin / php -f start . php [ param ] > / dev / null & ’) Als Parameter benötigt das Skript sowohl die Login-Daten des Benutzers, als auch die runnr des Matching-Durchlaufs. Der Benutzername, das Passwort, und die ID des Matching-Durchlaufs werden in ein Array gespeichert, das mittels der serialize()Funktion als String an start.php übergeben wird. Innerhalb des Skripts kann das Array dann mit unserialize() wieder rekonstruiert werden. Eine direkte Übergabe dieses Strings innerhalb des Aufrufs würde ein Sicherheitsrisiko darstellen, weil so über den Inhalt der Parameter beliebiger Shell-Code auf dem Server ausgeführt werden könnte. Daher wird der Parameter-String zuvor mit Base64 codiert, so dass die Ausführung von eingefügtem Shell-Code verhindert wird. So müssen auch die in der serialisierten Darstellung des Arrays enthaltenen Sonderzeichen nicht maskiert werden. 43 5 Implementierung Vor dem Starten der Matching-Prozedur wird noch ein Flag für das jeweilige Matching gesetzt, das kennzeichnet, dass dieser Prozess noch läuft. 5.3.5 Ergebnisübersicht Die Anzahl der angezeigten Paare in der Ergebnisübersicht (result.php) kann auf der vorherigen Seite (view_result.php) festgelegt werden. Dadurch kann der Benutzer selbst bestimmen, wie viele Einträge er angezeigt bekommen möchte und ist in der Lage Ladezeit der Seite anzupassen. Insbesondere wenn viele zusätzliche Spalten direkt in der Übersicht angezeigt werden sollen, kann es zu Verzögerungen kommen. Neben der Übertragungszeit der Seite sind diese auch von der Leistung und der Speicherauslastung des Client-Rechners abhängig. Das Klassifizieren der Paare in „Matches“ und „Non-Matches“ kann über die entsprechenden Schaltflächen vorgenommen werden. Hierbei wird ein AJAX-Request an insert_match.php gesendet und das jeweilige Paar aus der Ergebnisliste entfernt. 5.3.6 Fusionsansicht In der Fusionsansicht (merge.php) wird ein als Duplikat gekennzeichnetes Record-Paar dargestellt. Es werden alle Spalten aus der Ursprungssicht mit den dazugehörigen Werten angezeigt. Die Unterschiede zwischen den beiden Records werden über eine farbliche Kodierung verdeutlicht. Hierbei werden die von der Ampel bekannten Farben Rot, Gelb und Grün benutzt, um die Aufmerksamkeit des Benutzers gezielt auf die Werte zu lenken, die einen Konflikt darstellen. Die rot eingefärbten Zeilen sind die wahrscheinlichste Quelle für die Übernahme falscher Daten. Dies sind die Fälle, bei denen beide Werte vorhanden sind und sich unterscheiden. Hier wird für den Vorschlag der Wert des Records genommen, der inventarisiert ist oder am wenigsten NULL-Werte hat, was nicht immer die beste Lösung hervorbringt. Weniger problematisch sind einzelne NULL-Werte. Wenn für eine bestimmte Spalte einer der beiden Records einen Wert hat, der andere jedoch keinen, wird der existierende Wert in den Vorschlag übernommen. Dies führt auf keinen Fall zu einem Informationsverlust, dennoch könnten dadurch Inkonsistenzen erzeugt werden, wenn beispielsweise der eine Eintrag eine Angabe für instorg hat und der andere eine für verlag. Daher werden diese Zeilen gelb hinterlegt. Übereinstimmende Werte sind unproblematisch, daher bekommen sie die Farbe Grün, um darzustellen, dass hier kein Datenkonflikt vorliegt. Zwei NULL-Werte werden in diesem Sinne auch als Übereinstimmung interpretiert. Der aus diesen Daten zusammengefügte Vorschlag wird auf der rechten Seite dargestellt. Die einzelnen Felder können bearbeitet werden, um gegebenenfalls aufgetretene Fehler zu korrigieren. 44 5.3 PHP-Webschnittstelle 5.3.7 Auflösen der Relationen Nachdem in der Fusionsansicht der Vorschlag zur Fusion akzeptiert wurde, muss festgestellt werden, welche Änderungen an den Tabellen vorgenommen werden müssen. Zunächst wird für das nicht priorisierte Record geprüft, welche Tabellen darauf Verweisen. Die zu prüfenden Tabellen sind SCHLAGWORT und AUTOR, da dies die einzigen Tabellen mit Fremdschlüsseln auf schrift sind, die nicht eine Teilmenge von SCHRIFT darstellen. Diese Fremdschlüssel werden geändert, so dass sie auf die priorisierte Schrift zeigen. Nun können die Einträge der nicht priorisierten Schrift in ANSCHAFFUNG, FLIT, ABSCHLUSSARBEIT, LITERATURINDEX und schließlich in SCHRIFT entfernt werden. Für das priorisierte Record werden jetzt die neuen Daten in die Tabellen geschrieben. Hierfür werden MERGE INTO Statements verwendet, um den bestehenden Eintrag in den Tabellen zu aktualisieren, oder falls dieser nicht vorhanden ist, einen neuen einzufügen. Bevor die Änderungen jedoch final in die Datenbank geschrieben werden, bekommt der Benutzer diese in der Weboberfläche angezeigt. So können sie vorher noch überprüft werden und der Vorgang kann notfalls abgebrochen werden. 45 6 Handbuch 6.1 Installation/Vorbereitung 6.1.1 Anlegen des Views Als Basis für das Matching wird ein Materialized View benötigt, das die Daten enthält über die das Matching durchgeführt werden soll. Hier wurden die Tabellen SCHRIFT, ABSCHLUSSARBEIT, FLIT, und ANSCHAFFUNG per OUTER JOIN über die ID zusammengefügt. Hier wurde das View bib_all genannt, was so auch in der Matching-Prozedur verwendet wird. Sollte ein anderer Name für das View benutzt werden, muss die Prozedur entsprechend angepasst werden. Außerdem muss ein Index auf der Spalte schrift angelegt werden. Ein weiterer Index wird für die Spalte titel benötigt. Dieser darf aber nur die ersten sechs Zeichen betrachten. Ein Statement zum Anlegen dieses Index ist in Quelltext 5.5 auf Seite 41 zu finden. 6.1.2 Das Kontrollschema anlegen Die benötigten Kontrolltabellen (siehe Abschnitt 5.1) können durch Ausführen des SQL-Scripts install_schema.sql angelegt werden. 6.1.3 Matching-Prozedur Die Matching-Prozedur ist in der Datei match.sql zu finden. Um die Prozedur zu kompilieren ist vorher allerdings noch das Anlegen des SQL-Typs, wie in Quelltext 5.4 auf Seite 38 gezeigt, notwendig. 6.1.4 PHP-Skripte Die PHP-Skripte befinden sich in dem Ordner php. Dieser Ordner muss auf den Webserver kopiert werden, wobei er auch umbenannt werden kann. Die darin enthaltene Ordnerstruktur sollte allerdings so beibehalten werden. Falls die Ordner an abweichende Orte kopiert oder umbenannt werden, müssten die Pfade innerhalb der Dateien entsprechend angepasst werden. 47 6 Handbuch Abbildung 6.1: Übersicht über das Matching-Ergebnis 6.2 Benutzung Nach dem Aufruf der Startseite muss zuerst ein Login mit den jeweiligen Daten des Datenbank-Benutzeraccounts durchgeführt werden. 6.2.1 Einen neuen Matching-Durchlauf anlegen Bevor Einstellungen für das Matching vorgenommen werden können, muss zunächst ein neuer Matching-Durchlauf angelegt werden. Dies ist in der Übersichtsseite (manage.php) des Match-Tools möglich, indem in der letzten Zeile der Tabelle auf „Neues Matching anlegen“ gedrückt wird. Optional kann vorher noch in das Textfeld links daneben ein Name für das Matching eingetragen werden. Abbildung 6.2: Die Übersichtsseite des Matching-Tools 48 6.2 Benutzung 6.2.2 Gewichte einstellen Über die Schaltfläche „Gewichte einstellen“ können die Spalten, die beim Matching berücksichtigt werden sollen, ausgewählt werden. Zudem kann deren Gewichtung durch Eingabe beliebiger ganzer Zahlen eingestellt werden. Die Gewichte werden beim Matching dann durch Division mit ihrer Summe in Verhältnisse umgerechnet. Beträgt also die Summe aller Gewichte 120, bestimmt eine Spalte mit Gewicht 60 zu 50% den Gesamtähnlichkeitswert jedes Paares. 6.2.3 Einen Matching-Durchlauf starten Die Schaltfläche „Matching Starten“ bewirkt, dass die Matching-Prozedur für den jeweiligen Durchlauf aufgerufen wird. Entsprechend der gewählten Einstellungen kann einige Zeit vergehen, bis ein Ergebnis vorliegt. Solange die Prozedur läuft, ist es nicht möglich, sie ein weiteres Mal zu starten; auch nicht für einen anderen Durchlauf. Abbildung 6.3: Einstellen der Gewichte 49 6 Handbuch Abbildung 6.4: Auswahl der Spalten für die Ergebnisübersicht 6.2.4 Ergebnisse ansehen Der Button „Ergebnis ansehen“ führt zunächst zu einer Auswahl, welche Spalten in der Ergebnisübersicht angezeigt werden sollen. So können die Spalten ausgewählt werden, die für einen ersten Eindruck interessant sind. Über das Eingabefeld „Anzahl“ wird eingestellt, wie viele Paare in der Übersicht auf der nächsten Seite dargestellt werden sollen. Ein hoher Wert kann hier zu langen Ladezeiten führen. In der Übersicht über das Ergebnis auf der nächsten Seite wird die zuvor festgelegte Anzahl an verglichenen Paaren angezeigt. Die Liste ist absteigend nach dem Ähnlichkeitswert (Spalte „sim“) sortiert. Abhängig von den zuvor ausgewählten Spalten werden die Werte der einzelnen Einträge für die Spalten ebenfalls angezeigt. Die Detailansicht eines einzelnen Paares ist mit der Schaltfläche „Details“ erreichbar. Hier werden alle vorhandenen Werte jeweils paarweise dargestellt. In der letzten 50 6.2 Benutzung Abbildung 6.5: Detailvergleich eines Paares Spalte steht, sofern das entsprechende Attribut in das Matching einbezogen wurde, der errechnete Ähnlichkeitswert für dieses Attribut. Attribute, die exakt übereinstimmen, werden grün hinterlegt. 6.2.5 Fusions-Übersicht Über die Startseite erreicht man die Übersichtsseite des Fusions-Tools über den Link „Fusions-Tool“. Hier werden die zuvor klassifizierten Paare angezeigt, die nicht als „Non-Match“ identifiziert wurden. Die jeweilige Ähnlichkeitsklasse steht oben links und ist grün hinterlegt. Für jedes Paar werden Autor und Titel beider Datensätze angezeigt. Der Button „fusionieren“ führt zur Fusionsansicht des Paares. 6.2.6 Ein Paar fusionieren In der Fusionsansicht werden auf der linken Seite die Werte der beiden Einträge angezeigt. Auf der rechten Seite ist der Vorschlag für einen fusionierten Record dargestellt. Dabei werden die Zeilen nach folgenden Kriterien farbig hinterlegt: • In rot hinterlegten Zeilen unterscheiden sich die Werte. Hier sollte der vorgeschlagene Wert noch einmal genau überprüft werden. • Bei gelb hinterlegten Zeilen hat einer der beiden Einträge keinen Wert, der andere hat jedoch einen. In diesem Fall wird der vorhandene Wert im Vorschlag übernommen. 51 6 Handbuch • Grün sind Zeilen mit übereinstimmenden Werten hinterlegt. Dies gilt auch, wenn beide Einträge NULL sind. Die Werte im Vorschlag können gegebenenfalls angepasst bzw. korrigiert werden. Ein Klick auf „Übernehmen“ führt zu einer Bestätigungsseite, auf der noch einmal die durchzuführenden Änderungen, z. B. welche Verweise angepasst werden, aufgelistet sind. Erst nach einer weiteren Bestätigung werden diese final in die Datenbank geschrieben. 52 7 Reflexion 7.1 Zusammenfassung Um Ähnlichkeiten zwischen Einträgen in der gegebenen Bibliotheksdatenbank zu finden, wurden zunächst gängige Matching-Verfahren zusammengetragen und ihre Funktionsweise erläutert. Nach einer Analyse der Datenbank wurden zunächst die Tabellen und Spalten der Datenbank ausgewählt, die für die Identifizierung geeignet sind. Ausgehend von der Auswahl konnte ein passender Matching-Algorithmus konzipiert werden, der basierend auf gewichteten Summen (Abschnitt 2.1.2) errechnet, wie ähnlich sich zwei Einträge in der Datenbank sind. Durch die quadratische Komplexität des Matching-Problems mussten Optimierungen vorgenommen werden, um die Laufzeit des Algorithmus auf praktikable Größen zu beschränkten. Hierbei hat sich gezeigt, dass der häufige Wechsel zwischen der PL/SQLEngine und der SQL-Engine die Ausführung des Algorithmus stark verlangsamt. Deshalb wurde die Anzahl der nötigen Wechsel, beispielsweise durch Zusammenfassen mehrerer Update-Operationen zu einem Insert, minimiert. Zusätzlich konnte durch ein Indexing nach den Titelanfängen der Schriften die Laufzeit erneut stark reduziert werden, da nun nicht mehr alle Schriften mit einander verglichen werden. Dies hat allerdings zur Folge, dass einige Ähnlichkeiten möglicherweise nicht mehr erkannt werden. Aufbauend auf dem Matching-Algorithmus wurde eine Weboberfläche zur Verwaltung und Konfiguration mehrerer Matching-Durchläufe entwickelt, die es ermöglicht, die zunächst nur als ähnlich erkannten Paare durch einen Benutzer näher zu klassifizieren. Für die so identifizierten Duplikate wurde eine Schnittstelle geschaffen, um diese Mehrfachbeschreibung unter Berücksichtigung der Fremdschlüsselbeziehungen anderer Tabellen zu einem einzigen Eintrag in der Datenbank zu fusionieren. 7.2 Fazit und Ausblick Mit der entwickelten Anwendung ist es möglich, die Datenbank näher zu untersuchen und die Beziehungen zwischen Einträgen aufzuzeigen, so dass tatsächliche Duplikate eliminiert werden können. Der Algorithmus zum Auffinden ähnlicher Einträge läuft mit der zuvor beschriebenen Einschränkung auf übereinstimmende Titelanfänge in akzeptabler Zeit. Sollen alle möglichen Paarkombinationen betrachtet werden, muss mit einer Laufzeit von etwa fünf Stunden gerechnet werden. Daher wird empfohlen, zunächst 53 7 Reflexion mit der Einschränkung zu arbeiten und die so gefundenen Duplikate zu beseitigen. Anschließend kann der Algorithmus ohne die Einschränkung auf alle verbleibenden Paare angewendet werden, um die zuvor nicht erkannten Ähnlichkeiten zu finden. Durch die im ersten Durchlauf reduzierte Zahl der Einträge wird der Algorithmus dann auch weniger Zeit benötigen. Insgesamt wird bei der entwickelten Anwendung noch stark auf die Interaktion mit einem Benutzer gesetzt, um die ähnlichen Paare zu klassifizieren und zu fusionieren. Hierbei kann aber Erfahrung bezüglich des Datenbestands aufgebaut werden, um die Anwendung später zu erweitern, so dass eine automatische Duplikateliminierung durchgeführt werden kann. So könnten beispielsweise Trainingsdaten für einen selbstlernenden Algorithmus gewonnen werden. Die Weboberfläche der entwickelten Anwendung hat einen eher prototypischen Charakter, weshalb für eine produktive Benutzung Maßnahmen zur Verbesserung der Usability ergriffen werden sollten. Um das Ziel eines konsistenten Datenbestandes in dieser Datenbank zu erreichen und für die Zukunft zu gewährleisten, ist eine Eliminierung der vorhandenen Duplikate allein nicht ausreichend. So stellt beispielsweise die Erfassung der Autoren auch in Zukunft eine Quelle für Inkonsistenzen dar, weil innerhalb eines Attributs mehrere Autoren angegeben werden — wodurch die Bedingung atomarer Attributwerte und somit die erste Normalform verletzt werden. Außerdem ist die Darstellung der Namen selbst ebenfalls nicht einheitlich, so dass eine gesonderte „Autor“-Tabelle sinnvoll wäre. Eine solche Tabelle existiert zwar, allerdings ist hier nur die Erfassung von Autoren vorgesehen, die in Beziehung mit dem Institut stehen. Des Weiteren wird diese Tabelle nicht mehr durchgängig gepflegt: Der neueste Eintrag stammt aus dem Jahr 2007. Ferner sollten auch die Eingabemasken zur Erfassung der Dokumente hinsichtlich ihrer Benutzerfreundlichkeit überprüft werden, da die Vermutung besteht, dass einige der Duplikate auf Eingabefehler zurückzuführen sind, die durch eine für den Benutzer unklare Funktionsweise der Masken entstanden sind. Somit stellt das Ergebnis dieser Arbeit die Grundlage zur Verfügung, um die Qualität des Datenbestandes der Bibliotheksdatenbank in zukünftigen Projekten weiter zu verbessern. 54 Abbildungsverzeichnis 3.1 ER-Diagramm des Datenbankaufbaus . . . . . . . . . . . . . . . . . . . 17 4.1 4.2 4.3 ER-Entwurf für das Datenbankschema der Anwendung . . . . . . . . . 29 Dateistruktur der Webschnittstelle . . . . . . . . . . . . . . . . . . . . 31 Genereller Ablauf des Prozesses . . . . . . . . . . . . . . . . . . . . . . 32 6.1 6.2 6.3 6.4 6.5 Übersicht über das Matching-Ergebnis . . . . Die Übersichtsseite des Matching-Tools . . . . Einstellen der Gewichte . . . . . . . . . . . . . Auswahl der Spalten für die Ergebnisübersicht Detailvergleich eines Paares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 48 49 50 51 55 Tabellenverzeichnis 2.1 2.2 2.3 2.4 Edit-Distanz Matrix für die Zeichenketten „nicht“ und „nciht“ . Beispieldaten für den Sorted Neighbourhood Algorithmus . . . . Alle erzeugten Paare bei einem Sliding-Window-Durchlauf mit w 2-Gram Listen für die Namen „Wohl“ und „Pohl“ mit t = 0,7 . . . . . . . . =3 . . . . 7 . 13 . 13 . 15 3.1 3.2 3.3 3.4 3.5 3.6 Codierung des Anschaffungsstatus . . . . . . . Inhalt der Tabelle SCHRIFTTYP . . . . . . . Beispiel eines Duplikats einer Abschlussarbeit Beispiel eines Duplikats eines Lehrbuchs . . . Beispiel eines Duplikats eines Lehrbuchs . . . Tabellengrößen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20 21 22 23 23 24 57 Literaturverzeichnis [Chr12a] Peter Christen. „A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication“. In: IEEE Transactions on Knowledge and Data Engineering 24.9 (Sep. 2012), S. 1537–1555. issn: 1041-4347. doi: 10.1109/TKDE.2011.127. [Chr12b] Peter Christen. Data Matching - Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Data-centric systems and applications. Springer, 2012. isbn: 978-3-642-31163-5. [EIV07] A.K. Elmagarmid, P.G. Ipeirotis und V.S. Verykios. „Duplicate Record Detection: A Survey“. In: IEEE Transactions on Knowledge and Data Engineering 19.1 (Jan. 2007). issn: 1041-4347. doi: 10.1109/TKDE.2007. 250581. [Mew05] Ulf Mewe. „Re-Design des Datenbankanwendungssystems für ein Hochschulinstitut“. Bachelorarbeit. Leibniz Universität Hannover, 2005. [Ros+11] M. Rosenblum u. a. Expert PL/SQL Practices: for Oracle Developers and DBAs. Apress, 2011. isbn: 978-1-4302-3485-2. 59 Erklärung Hiermit versichere ich, dass ich die vorliegende Arbeit und die zugehörige Implementierung selbstständig verfasst und dabei nur die angegebeben Quellen und Hilfsmittel verwendet habe. Hannover, 13.07.2015 Lukas Schink 61