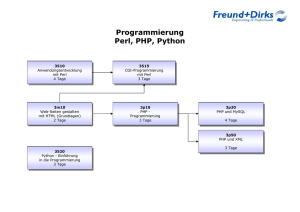
Programmieren in Perl
Werbung

Übersicht Programmieren in Perl WS 2012 Thorsten Küfer Zentrum für Informationsverarbeitung Stand: 24.09.2012 Übersicht • • • • • • • • • • • • • • • • • • • • Was ist Perl? Wo bekomme ich Perl? Welche Bücher gibt es? Welche zusätzliche Software gibt es? Erste Schritte: Hallo_Welt.pl Datentypen: Skalar, Array, Hash Kontext: Skalar- und Listen-Kontext, Boolean-Kontext Operatoren (numerisch, string, logisch) Variablen: Name, Scope Kontrollstrukturen: if, unless, while, for, foreach Funktionen Dateizugriff Ausführen von Shell-Befehlen Reguläre Ausdrücke Pakete, Module, Klassen (objektorientierte Programmierung) Datenbankinterface: DBI Webinterface: CGI Grafikinterface: GD GUI-Interfaces: Tk, Gtk2 Ausblick: Perl 6 Ziel Das Ziel dieses Kurses ist es, die (Skript-)Programmiersprache Perl kennen zu lernen, mit der wir die Aufgaben des täglichen (Programmierer-)Lebens schnell lösen können. Dazu gehören neben der einfachen Ein- und Ausgabe auch Dateisystem-Zugriffe und die Verwendung regulärer Ausdrücke. Im weiteren Verlauf werden sowohl die funktionale als auch die objektorientierte Programmierung mit Perl erläutert. Da sich Perl besonders für den Einsatz als CGI-Programm in Verbindung mit einem Webserver und einer Datenbank eignet, werden auch das DBI-Modul als Datenbankinterface und das CGI-Modul zur einfachen Generierung von Webinterfaces behandelt. Zum Abschluss werden das von Tcl bekannte TkModul sowie das aus dem Gnome Desktop stammende GTK-Modul zur Erzeugung von grafischen Oberflächen vorgeführt. Kontakt Thorsten Küfer, ZIV Einsteinstr. 60, R111 Email: [email protected] Web: http://zivkuefer.uni-muenster.de/Perl Skript: http://zivkuefer.uni-muenster.de/Perl/Perl.pdf Beispiele: http://zivkuefer.uni-muenster.de/Perl/Beispiele/ Übungsaufgaben: http://zivkuefer.uni-muenster.de/Perl/Aufgaben/ Virtuelle Maschine: \\zivpool1.uni-muenster.de\Perlkurs\ 1 Übersicht Termine Mo, 10.09.2012 Organisatorisches & Erste Schritte Datentypen: Skalar, (Array, Hash) (Skalar-) Operatoren Anweisungen, Datentypen, Operatoren Kontext: Boolean-Kontext Variablen: Name, Scope, undef Beispiele: hallo_welt.pl, echo.pl, farbe.pl, sin.pl Aufgaben: Aufg2.pl, Aufg3.pl, Aufg4.pl Di, 11.09.2012 Weitere Datentypen: Array, Hash Kontext: Skalar- und Listen-Kontext Kontrollstrukturen: for, foreach Beispiele: foreach.pl, ascii.pl, list.pl, join.pl, zeit.pl, eingabe.pl, woerter.pl, Aufgaben: Aufg5.pl, Aufg6.pl, Aufg7a.pl, Aufg7b.pl, Aufg7c.pl, Aufg8.pl Mi, 12.09.2012 Weitere Kontrollstrukturen: if, unless, while Weiteres zum Dateizugriff Ausführen von Shell-Befehlen Beispiele: argv.pl, open.pl, qx.pl, rechner.pl, for.pl Aufgaben: Aufg9a.pl, Aufg9b.pl, Aufg9c.pl, Aufg10.pl Do, 13.09.2012 Funktionen Reguläre Ausdrücke Beispiele: sub.pl, my.pl, fib.pl, user_info.pl, apache.pl (und eine Beispiel-Logdatei: apache.log), text-statistik.pl Aufgaben: Aufg11.pl, Aufg12.pl, Aufg13.pl, Aufg14.pl Fr, 14.09.2012 Pakete, Module und objektorientierte Programmierung Beispiele: package.pl, modul.pl, Modul.pm, class.pl, Class.pm, Haustier.pl, Haustier.pm, Katze.pm, Hund.pm Aufgaben: Aufg16.pm, Aufg16d.pl, Aufg17.pl, Aufg17a-b.pm, Aufg17c.pm Mo, 17.09.2012 Einführung in SQL (Vorbereitung zu DBI) Das Datenbankinterface DBI Beispiele: perl-dbi.pl, dbd-test.pl Aufgaben: Aufg19a.pl, Aufg19b.pl Di, 18.09.2012 Das Webinterface CGI Dynamisches Erstellen von Grafiken mit dem GD-Modul Beispiele: ripe-dbi.pl, env_sh.cgi, env_pl.cgi, env_info.cgi, date.cgi, param_list.cgi, dbabfrage.cgi Aufgaben: Aufg20.pl, Aufg21a.pl, Aufg21b.pl, Aufg22.cgi, Aufg23.cgi Mi, 19.09.2012 GUI-Interfaces: Perl/Tk, Perl/Gtk2 Erstellen von grafischen Oberflächen mit Tk und Gtk2 Ausblick: Perl 6 Beispiele: dbabfrage-v2.cgi, perl-tk.pl, perl-tk-button.pl, perl-tk-radiobutton.pl, perl-tk-menu.pl, perl-tk-pack.pl, perl-tkbind.pl, perl-tk-draw.pl Aufgaben: Aufg24a.pl, Aufg24b.pl, Aufg25.pl Do, 20.09.2012 (Prüfungstag) Fr, 21.09.2012 (Fällt aus!) 2 Übersicht Inhaltsverzeichnis Übersicht...................................................................................................................................................1 Ziel........................................................................................................................................................1 Kontakt.................................................................................................................................................1 Termine.................................................................................................................................................2 Organisatorisches & Erste Schritte...........................................................................................................6 Literatur................................................................................................................................................6 Online Dokumentation.........................................................................................................................6 Software................................................................................................................................................6 Erste Schritte........................................................................................................................................6 Übungsaufgabe.....................................................................................................................................8 Anweisungen, Datentypen, Operatoren..................................................................................................10 Struktur eines Perl-Programms...........................................................................................................10 Welche Datentypen gibt es?...............................................................................................................10 Datentyp Skalar.......................................................................................................................................10 Skalare................................................................................................................................................10 Skalar-Operatoren..........................................................................................................................13 Skalar-Variablen............................................................................................................................15 Spracheigene Funktionen...............................................................................................................17 Übungsaufgaben.................................................................................................................................19 Datentyp Array, Skalar- und Listen-Kontext..........................................................................................20 Listen und Arrays...............................................................................................................................20 Begriffe..........................................................................................................................................20 Listen.............................................................................................................................................20 Array-Variablen.............................................................................................................................20 Array-Operatoren...........................................................................................................................21 Array-Funktionen...........................................................................................................................23 Spezielle Arrays.............................................................................................................................25 Kontrollstrukturen: for, foreach (Schleifen)............................................................................................25 foreach-Schleife.............................................................................................................................25 for-Schleife....................................................................................................................................25 Übungsaufgaben.................................................................................................................................26 Weitere Kontrollstrukturen: if/unless, while/until, for............................................................................28 Steueranweisungen.............................................................................................................................28 if/unless..........................................................................................................................................28 while/until......................................................................................................................................29 do {} while/until............................................................................................................................29 for-Schleife....................................................................................................................................29 Schleifen-Steueranweisungen........................................................................................................30 Datentyp Hash.........................................................................................................................................32 Hash-Variablen..............................................................................................................................32 Hash-Funktionen............................................................................................................................33 Spezielle Hashes............................................................................................................................35 Referenzen.....................................................................................................................................35 Das Modul Data::Dumper..............................................................................................................36 Das Modul Storable.......................................................................................................................37 Übungsaufgaben.................................................................................................................................37 Dateizugriff, Ausführen von Shell-Befehlen..........................................................................................38 Kommandozeilenparameter................................................................................................................38 Dateizugriff.........................................................................................................................................38 Verzeichniszugriff..............................................................................................................................42 3 Übersicht Aufruf von externen Programmen......................................................................................................44 Aufruf von Perl-Code.........................................................................................................................44 Übungsaufgaben.................................................................................................................................45 Funktionen...............................................................................................................................................46 Verwendung von eigenen Funktionen................................................................................................46 Eine Funktion definieren...............................................................................................................46 Funktionen aufrufen.......................................................................................................................46 Werte zurückgeben........................................................................................................................46 Argumente übergeben....................................................................................................................47 Lokale Variablen............................................................................................................................48 Rekursion.......................................................................................................................................49 Prototypen......................................................................................................................................50 Signale...........................................................................................................................................50 Übungsaufgaben.................................................................................................................................51 Einführung in reguläre Ausdrücke..........................................................................................................52 Reguläre Ausdrücke...........................................................................................................................52 Weiterführende Literatur...............................................................................................................52 Einführungsbeispiel.......................................................................................................................52 Suchmuster.....................................................................................................................................53 Der Binding-Operator =~...................................................................................................................56 Was wurde gefunden?....................................................................................................................56 Die Suchmethode verändern..........................................................................................................57 Suchen mit variablen Argument....................................................................................................58 Beispiele.............................................................................................................................................58 Umrechnung Fahrenheit/Celsius....................................................................................................58 Auf Teile der Unix-Mailbox zugreifen..........................................................................................59 Doppelte Worte in einem Text finden...........................................................................................61 Übungsaufgaben.................................................................................................................................62 Weiteres zu den regulären Ausdrücken...................................................................................................63 Rückblick............................................................................................................................................63 Suchen und Ersetzen......................................................................................................................63 split() und join().............................................................................................................................64 Pakete, Module und objektorientierte Programmierung.........................................................................66 Pakete und Module.............................................................................................................................66 Verwenden von eigenen Paketen...................................................................................................66 Objektorientierte Programmierung................................................................................................68 Wiederverwendung von Code: Vererbung....................................................................................69 Das Perlmodul Moose....................................................................................................................72 Übungsaufgaben.................................................................................................................................73 Einführung in relationale Datenbanken...................................................................................................74 Relationale Datenbanken...............................................................................................................74 Weiterführende Literatur...............................................................................................................74 Erste Schritte..................................................................................................................................74 Structured Query Language (SQL )....................................................................................................76 Einführung in das Datenbankinterface Perl DBI................................................................................79 Weiterführende Literatur...............................................................................................................79 Erste Schritte..................................................................................................................................79 Die Struktur eines Perl DBI-Programms.......................................................................................80 Hilfsmethoden................................................................................................................................83 Übungsaufgaben.................................................................................................................................83 Programmierung einfacher Abfragen............................................................................................85 Vieles auf einmal...........................................................................................................................86 Meta-Informationen.......................................................................................................................87 Übungsaufgaben.................................................................................................................................88 4 Übersicht Einführung in das Webinterface Perl-CGI..............................................................................................90 Weiterführende Literatur...............................................................................................................90 Web-Programmierung...................................................................................................................90 Das Perlmodul CGI........................................................................................................................91 Übungsaufgaben.................................................................................................................................97 Dynamische Grafiken, Grafische Oberflächen.......................................................................................99 Dynamisch erzeugte Grafiken............................................................................................................99 GD::Graph...................................................................................................................................100 Übungsaufgaben...............................................................................................................................101 Grafische Oberflächen in Perl...............................................................................................................103 Perl/Tk..............................................................................................................................................103 Weiterführende Literatur.............................................................................................................103 Erste Schritte................................................................................................................................103 Klassen.........................................................................................................................................104 Eigenschaften...............................................................................................................................105 Methoden.....................................................................................................................................109 Perl/Gtk2...........................................................................................................................................115 Weiterführende Literatur.............................................................................................................115 Erste Schritte................................................................................................................................115 Das Boxen-Layout.......................................................................................................................117 Widgets........................................................................................................................................117 Eigenschaften...............................................................................................................................117 Methoden.....................................................................................................................................117 Kurzvorstellung Perl 6..........................................................................................................................118 5 Organisatorisches & Erste Schritte Organisatorisches & Erste Schritte • • • • • 10 Termine, Uhrzeit: 10:15-12:30 Uhr & 13:30-16:00 Uhr Um einen Schein zu erhalten ist die Anmeldung über ZIVlehre nötig. Es gibt einen unbenoteten Teilnahmeschein bei Anwesenheit an mindestens ¾ der Termine (je nach Prüfungsamt kann dieser Schein unterschiedlich angerechnet werden). Bei Teilnahme an der Prüfung wird zusätzlich die Note auf dem Schein vermerkt. Für die Anrechnung im Rahmen der Allgemeinen Studien ist die Prüfungs-Anmeldung über QISPOS und die Teilnahme an der Prüfung nötig. Literatur • • • • • Perl – Eine Einführung, Gerd Pokorra, 2. Auflage, März 2005, RRZN Hannover (6 €) Learning Perl, Randal L. Schwartz, Tom Phoenix & Brian D Foy, 4th Edition, August 2005, ISBN 0-596-10105-8 Programming Perl, Larry Wall, Tom Christiansen & Jon Orwant, 3rd Edition, August 2000, ISBN 0-596-00027-8 CGI Programming with Perl, Scott Guelich, Shishir Gundavaram & Gunther Birznieks, 2nd Edition, June 2000, ISBN 1-56592-419-3 Programming the Perl DBI, Alligator Descartes & Tim Bunce, 1st Edition, February 2000, ISBN 1-56592-699-4 Weitere (auch deutsche Titel): http://www.oreilly.de/perl/ oder http://www.amazon.de/ Online Dokumentation • • • • Perl Online Dokumentation: http://perldoc.perl.org/ Perl Forum: http://www.perlmonks.org/ Einführung in Perl bei SELFHTML: http://de.selfhtml.org/perl/ Wikipedia zu Perl: http://de.wikipedia.com/wiki/Perl Software • • • • • • • The Source for Perl: http://www.perl.org/ Comprehensive Perl Archive Network (CPAN): http://www.cpan.org/ Scintilla Text Editor (Windows & Linux): http://www.scintilla.org/SciTE.html Notepad++ (Windows): http://notepad-plus.sourceforge.net/ ActivePerl (Windows): http://www.activestate.com/Products/activeperl/ Komodo Entwicklungsumgebung (Windows & Linux): http://www.activestate.com/Products/komodo_ide/ XAMPP – Apache + MySQL + Perl (Windows & Linux): http://www.apachefriends.org/de/xampp.html Erste Schritte Was ist Perl? Perl (Practical Extraction and Report Language) ist eine praktische Sprache, die darauf zielt dem Nutzer viele Möglichkeiten zu geben, ohne dabei viel Wert auf Eleganz zu legen. Funktionen zur Manipulation von Zeichenketten und die einfache Verwendung von regulären Ausdrücken sind die ursprünglichen Stärken. Heute – nach über 20 Jahren PerlEntwicklung – gibt es viele Erweiterungen (Module) von Perl mit denen fast jedes Problem lösbar ist. Das CPAN (Comprehensive Perl Archive Network) ist die zentrale Stelle, an der alle Module gesammelt werden. Perl ist eine Skriptsprache, d.h. es gibt keinen Compiler, der Perl-Programme in Maschinencode übersetzt sondern einen Interpreter, der ein Perl-Programm direkt ausführt. Allerdings ist Perl ein Sonderfall, denn hier wird das Programm vom Interpreter vor der Ausführung compiliert und erst dann ausgeführt. Damit laufen Perl-Programme performanter ab und Syntaxfehler werden sofort (und nicht erst zur Laufzeit) erkannt. Außerdem gibt es ein (experimentelles) Projekt perlcc, das Perl-Code direkt in eine ausführbare Datei compiliert (eingestellt seit Perl 5.10, siehe dazu das neue Projekt PAR – Perl Archive Toolkit). Entwicklungsgeschichte Hier ist eine kleine Übersicht über die Entwicklungsgeschichte von Perl (Auszug von http://history.perl.org/). • Dezember 1987 Perl 1.000 6 Organisatorisches & Erste Schritte • • • • • • • • • • • Juni 1988 Oktober 1989 März 1991 Oktober 1994 März 2000 Juli 2002 Dezember 2007 April 2010 Juli 2010 Mai 2011 Mai 2012 Perl 2.000 Perl 3.000 Perl 4.000 Perl 5.000 Perl 5.6.0 Perl 5.8.0 Perl 5.10.0 Perl 5.12.0 Perl 6 (Rakudo Star) Perl 5.14.0 Perl 5.16.0 Hier sind einige Meilensteine (Hauptversionen) aufgelistet. Auch nach 23 Jahren ist Perl quicklebendig: Die Änderungen seit Version 5.12 umfassten über 550.000 Codezeilen und wurden von über 150 Autoren vorgenommen. Die Anzahl der über CPAN verfügbaren zusätzlichen Module soll nun an die 21.000 heranreichen. Perl 5.10 wird jetzt nicht mehr offiziell unterstützt. Einige der Korrekturen von Perl 5.14 wurden in 5.12 übernommen und in Updates dieser Version bereits publiziert1. Eine erste Version von Perl 6 wurde im Juli 2010 veröffentlicht. Perl 6 ist ein „neuer Dialekt“ von Perl, der sich noch stark in der Entwicklung befindet und viele Neuerungen bringt, unter anderem einen neuen Compiler (Rakudo) für die virtuelle Maschine Parrot. Für den produktiven Einsatz ist Perl 6 noch nicht geeignet, da noch die Unterstützung der bisherigen Menge an Perl-Modulen im CPAN fehlt und die Performance nicht optimal ist. Diese Mängel sollten sich in Zukunft aber ändern und Perl 6 auch vorhandene Perl 5 Programme ausführen können.Eine Kurzvorstellung von Perl 6 gibt es am Ende dieses Skriptes. Wie installiere ich Perl? Auf Unix/Linux Systemen ist Perl standardmäßig vorhanden. Unter Windows sollten Sie ActivePerl installieren. Dazu benötigen Sie nur noch einen Editor, wie Kwrite (KDE), SciTE (GTK) unter Linux oder Notepad++ unter Windows. Alternativ kann eine komplette Entwicklungsumgebung wie Komodo (mit grafischem Debugger) verwendet werden. Wenn Sie Perl durch den Aufruf perl starten, dann liest der Interpreter (Perl-)Befehle von der Standardeingabe (STDIN). Mit dem Aufruf perl Programm.pl werden die Perl-Befehle in der Datei Programm.pl der Reihe nach ausgeführt. Alternativen sind perl < Programm.pl (Pipe) oder perl -e"Einzeiler" (wobei auch mehrere -e Parameter übergeben werden können, die automatisch zu einem Programm zusammengefügt werden). Eine umfangreiche Dokumentation zu den eingebauten Perl-Befehlen gibt es mit perldoc. Die Hilfeübersicht erhalten Sie mit perldoc perl. Die Syntax der eingebauten Perl-Befehle kann gezielt abgerufen werden mit perldoc -f "Befehl", z.B. perldoc -f print liefert Hilfe zu der Perl-Funktion print(). Wie sieht nun ein Perl-Programm aus? Ein Perl-Programm (oder auch Skript) ist sehr einfach gehalten. Sie können sofort mit dem Programmieren loslegen und müssen sich nicht mit viel Programmstruktur, Variablendeklarationen u.ä. herumschlagen (vgl. z.B. in Java public static void main()). Es gibt dabei meistens mehrere Wege ein Problem zu lösen („There's more than one way to do it.“, Larry Wall). Damit Sie mit Ihren Programmen auch nach längerer Zeit noch etwas anfangen können, sollten Sie allerdings selbst für Struktur und Kommentare sorgen! Das Erlernen einer Programmiersprache ist zu Beginn eine eher theoretische und trockene Angelegenheit. Ich versuche das mit vielen Beispielen etwas spannender zu gestalten. Dabei werden allerdings auch vereinzelt Methoden verwendet, die erst später im Skript erklärt werden können. Hallo Welt! Kommen wir zum Standardbeispiel, der Ausgabe des Textes „Hallo Welt!“ auf dem Bildschirm. Der einzige dafür nötige Befehl kann direkt auf der Kommandozeile an den Perl-Interpreter übergeben werden: bash> perl -e 'print "Hallo Welt!\n"'; Dieser Perl-Befehl kann natürlich auch in eine Datei geschrieben werden, z.B.: Hallo_Welt.pl 1 Quelle: http://www.pro-linux.de/news/1/17050/perl-5140-freigegeben.html 7 Organisatorisches & Erste Schritte print "Hallo Welt\n"; Unter Linux/Unix gibt es eine einfache Möglichkeit, um Perl-Dateien (*.pl) direkt ausführbar zu machen. Dazu muss in der ersten Zeile der Datei mit #!<Pfad_zu_Interpreter> der Interpreter für die Datei angegeben werden. Diese spezielle Zeile (Shebang) sagt der Shell womit die Datei ausgeführt werden soll, z.B. /usr/bin/perl. Damit haben Sie folgenden Inhalt von Hallo_Welt_v2.pl: #!/usr/bin/perl print "Hallo Welt\n"; Diese Datei kann dann mit chmod u+x Hallo_Welt_2.pl ausführbar gemacht und mit ./Hallo_Welt_2.pl gestartet werden. Möchte Sie wissen wie oder unter welchem Namen das Perl-Programm aufgerufen wurde, können Sie in die spezielle Variable $0 schauen... Aber eins nach dem anderen. Wir wollen jetzt unser Beispiel-Programm durch eine Eingabe noch personalisieren. Hallo_Welt_v3.pl: #!/usr/bin/perl # # Hallo Welt # print "Wie heißt du? "; $name = <STDIN>; print "Hallo $name"; Tipps Mit dem Parameter -c führt Perl einen Syntax-Check durch, ohne das Programm auszuführen. Um die Ausgabe von Warnungen während der Laufzeit zu erzwingen, kann Perl mit dem Parameter -w aufgerufen werden. Dabei werden Warnungen in allen verwendeten Bibliotheken aktiviert! Um nur die Warnungen in einem bestimmten Bereich zu aktivieren, lesen Sie den nächsten Absatz. Pragmas Neben Kommandozeilenparamtern kann das Verhalten des Perl-Interpreters auch mit sogenannten Pragmas (siehe http://perldoc.perl.org/index-pragmas.html) verändert werden, die im Skript stehen und schon vor der Compilierungsphase ausgewertet werden. Pragmas werden wie Perl-Module (dazu später mehr) mit use eingebunden. Um die Perl-Warnungen zu aktivieren, kann z.B. das Pragma warnings mit use warnings verwendet werden. Das warnings Pragma bezieht sich dann nur auf einen Anweisungsblock und sollte an Stelle des -w Perl-Kommandozeilenparameters verwendet werden, der Warnungen auch in allen verwendeten Modulen aktiviert. Außerdem ist das Pragma strict (use strict) nützlich, um die Deklaration von Variablen zu erzwingen (siehe dazu 10.0.0.6). Dies vermindert die Fehlerhäufigkeit in großen Programmen und verbessert den Programmierstil. Empfehlungen für guten Perl-Stil gibt perldoc perlstyle. Ein weiteres nützliches Pragma ist lib (use lib), mit dem sich zur Laufzeit weitere Include-Verzeichnisse für Module zum Perl-Interpreter hinzufügen lassen. Zu einem guten Programmierstil gehören natürlich auch Kommentare, die Funktionen und kompliziertere Anweisungsblöcke erklären. Kommentare beginnen in Perl mit # (Gatter, Raute, Doppelkreuz, engl.: „hash“) und gehen bis zum Zeilenende. Es gibt keine Möglichkeit für mehrzeilige Kommentare. Übungsaufgabe Aufg.1) Perl installieren 8 Organisatorisches & Erste Schritte Installieren Sie auf Ihrem Computer zu Hause Perl und einen Editor Ihrer Wahl (Syntax-Highlighting erleichtert die Arbeit!) und probieren Sie die oben vorgestellten "Hallo Welt"-Programme aus. Wer keinen eigenen Computer zur Verfügung hat kann z.B. die LinuxPoolrechner im ZIV verwenden. Viel Spass! 9 Anweisungen, Datentypen, Operatoren Anweisungen, Datentypen, Operatoren Struktur eines Perl-Programms In Perl wird im einfachsten Fall keine bestimmte Programm-Struktur benötigt. Ein Programm besteht aus einer Liste von Anweisungen. Jede Anweisung wird mit ; (Semikolon) abgeschlossen. Mit {} können mehrere Anweisungen zu einem Block zusammengefasst werden. Die Perl-Syntax im Detail finden Sie in perldoc perlsyn. # Ein Anweisungsblock mit zwei Anweisungen { Anweisung1; Anweisung2; } Mögliche Anweisungen sind z.B.: $i=0; $s="Hallo Welt\n"; print $s; $i++; print $i; exit 0; # # # # # # Zuweisung, Zahl Zuweisung, String Funktionsaufruf mit Parameter, Ausgabe Anweisung, Inkrementierung Funktionsaufruf mit Parameter, Ausgabe Funktionsaufruf mit Parameter, Programm beenden Sie sehen hier eine Reihe von Variablenzuweisungen und Ausgaben, die nacheinander ausgeführt werden. Was eine Variable ist und welche Werte sie enthalten kann, wird gleich besprochen. Im weiteren Verlauf der Vorlesung werden wir Möglichkeiten zur Strukturierung eines Programms kennenlernen. Selbstverständlich gibt es Schleifen (for, while, until), Bedingungsabfragen (if, unless) und Unterprogramme (sub). Welche Datentypen gibt es? 1. 2. 3. Skalar Ein Typ für Integer, Real, Char und Strings, also Zahlen, Buchstaben und mehrere Buchstaben Array Eine (geordnete) Liste von Skalaren. Der Zugriff erfolgt über einen (numerischen) Index. Hash Eine (ungeordnete) Gruppe von skalaren Paaren. Der Zugriff erfolgt über (skalare) Schlüssel. Weitere Details gibt es in perldoc perldata. Datentyp Skalar Skalare Ein Skalar-Literal (Skalar-Konstante), kurz Skalar, ist entweder eine Zahl, ein Buchstabe oder eine Zeichenkette. Was genau, hängt vom Kontext ab, in dem der Skalar verwendet wird. Damit ein Skalar in einem numerischen Kontext verwendet werden kann, muss er ein bestimmtes Format haben, das als Zahl interpretiert werden kann. Ganze Zahlen Ganze Zahlen sehen so aus, wie man es vermutet (Dezimalsystem). Negative ganze Zahlen haben ein vorangestelltes Minus-Zeichen. Oktale ganze Zahlen beginnen mit einer führenden Null, hexadezimale Zahlen mit einem führenden 0x und binäre Zahlen mit einem führenden 0b. 12 -2004 10 Datentyp Skalar 0377 # 377 oktal, entspricht 255 dezimal -0xff # negatives FF hexadezimal, entspricht -255 dezimal 0b11 # 11 binär, entspricht 3 dezimal Gleitkommazahlen Perl unterstützt vollständig den gleichen Satz von Gleitkomma-Literalen wie C: 1.25 7.25e45 -6.5e24 -12e-24 -1.2e-23 Brüche Mit der Erweiterung bigrat, die im Standardumfang von Perl enthalten ist, ist auch das Rechnen mit Brüchen möglich, dazu später mehr. Zeichenketten Eine Zeichenkette (engl.: „string“) ist eine Folge von beliebigen 8-Bit oder Unicode-Zeichen. Die kürzeste Zeichenkette hat die Länge 0 und enthält keine Zeichen. Die längste Zeichenkette ist diejenige, die gerade noch in den Speicher des Computers passt. Im wesentlichen gibt es zwei Arten von Zeichenketten-Literalen: Zeichenketten in einfachen Anführungszeichen Zeichenketten in einfachen Anführungszeichen (single-quoted strings) sind Zeichenfolgen, die von einfachen Anführungszeichen eingeschlossen sind. Die Anführungszeichen sind nicht Teil der Zeichenkette: 'hello' 'don\'t' '' 'silly\\me' 'hello\n' Im zweitem Beispiel maskiert der Backslash (\) die besondere Bedeutung des Anführungszeichens und im vierten Beispiel die besondere Bedeutung des Backslash. Das letzte Beispiel enthält 7 Zeichen und nicht 6. Zeichenketten in doppelten Anführungszeichen Zeichenketten in doppelten Anführungszeichen (double-quoted strings) unterscheiden sich in zwei Aspekten von denen in einfachen Anführungszeichen: 1. Folgen bestimmte Zeichen einem Backslash, so werden diese als ein Steuerzeichen interpretiert (backslash escape). Steuerzeichen Bedeutung \n Newline \r (Carriage) Return, ^M \t Tabulator-Zeichen \f Formfeed (Seitenvorschub), ^L \b Backspace 11 Datentyp Skalar \a Bell \e Escape (siehe Beispiel farbe.pl) \007 Jeder oktale ASCII-Wert (hier: 007 = bell) \x7f Jeder hexadezimake ASCII-Wert (hier: 7F = delete) \cC Jeder "Control Character" (hier ^C) \\ Backslash \" Doppelte Anführungszeichen \l Das nächste Zeichen wird zum Kleinbuchstaben \L Alle Zeichen bis zum nächsten \E werden zu Kleinbuchstaben \u Das nächste Zeichen wird zum Großbuchstaben \U Alle Zeichen bis zum nächsten \E werden zu Großbuchstaben \E Beendet: \U und \L 2. Sind in der Zeichenkette Perl-Variablen enthalten, so werden diese durch ihren Inhalt ersetzt (variable interpolation). Dazu später mehr. Beachten Sie, dass das einfache Anführungszeichen in diesem Zusammenhang keine besondere Bedeutung hat. Die Operatoren q() und qq() Sollten die Anführungszeichen (beide Arten) aus irgendeinem Grund umständlich in der Handhabung sein, so bietet Perl die Möglichkeit, eigene Anführungszeichen zu definieren: q/einfache Anführungszeichen/ qq+doppelte Anführungszeichen+ Die Semantik entspricht den jeweiligen Originalen. q steht für "quote" und qq für "double-quote". Die im Beispiel verwendeten Zeichen / und + sind willkürlich gewählt. Sie sind frei, sich ein bequemes Zeichen auszusuchen. Im Übrigen gibt es noch eine dritte Quotierungsart, die back quotes (``). Diese werden zu einem späteren Zeitpunkt behandelt. Boolesche Werte Viele Programmentscheidungen werden danach getroffen, ob eine Aussage wahr oder falsch ist. In Perl werden true (wahr) und false (falsch) nach folgenden Regeln ermittelt: 1. 2. 3. 4. Jeder String ist true außer "" und "0" Jede Zahl ist true außer 0 Jede Referenz ist true Jeder undefinierte Wert ist false Beispiele: 0 1-1 1 "" "1" "00" "0.0" undef # # # # # # # # => "0", also falsch => 0 => "0", also falsch => "1", also wahr falsch nicht "" oder "0", also wahr nicht "" oder "0", also wahr (!) nicht "" oder "0", also wahr (!) => "", also falsch 12 Datentyp Skalar Logische Operatoren Oft möchte man eine Entscheidung von mehreren Bedingung abhängig machen. Um die Booleschen Werte zu kombinieren, stehen die logischen Operatoren && (and) und || (or) zur Verfügung. 0 && 0 1 || 0 0 or "1" # => "0", also falsch # => "1", also wahr # => "1", also wahr Skalar-Operatoren Skalare Operatoren haben ein oder mehrere Operanden und liefern ein skalares Ergebnis. Auch hier unterscheidet man wieder Operatoren für Zahlen und für Zeichenketten. Operatoren für Zahlen Perl hat alle Operatoren, die auch C, Java, Fortran oder Pascal (zusammen) so bieten (die Gesamtübersicht finden Sie in perldoc perlop), u.a.: Operator(en) Assoziativ Wertig Bedeutung ++ -- nicht ein Autoincrement und Autodecrement (voran- oder nachgestellt) ** rechts zwei Exponentiation +- rechts ein Vorzeichen(wechsel) */% links zwei Multiplikation, Division und (ganzzahliger) Divisionsrest +- links zwei Addition und Subtraktion < <= > >= nicht zwei kleiner(gleich), größer(gleich). Ergebnis: wahr="1" oder falsch="" == != nicht zwei gleich, ungleich. Ergebnis: wahr="1" oder falsch="" Die Operatoren sind nach ihrer Präzedenz (Operatorrangfolge) von oben nach unten geordnet, also Autoincrement und -decrement binden am stärksten. Mit runden Klammern kann die Reihenfolge der Berechnung explizit festgelegt oder geändert werden. Links-assoziativ bedeutet es werden implizit um den linken Operanden Klammern gesetzt. Die Wertigkeit gibt an wie viele Operanden benötigt werden. Beispiele: 2+3*4**2; 2-3*-4**2; 2*3+4**$a++; 2*3+4**++$a; # # # # => => => => liefert liefert liefert liefert 50, implizit 2+(3*(4**(2))) 50, implizit 2-(3*(-(4**2))) 7, implizit (2*3)+(4**($a++)) 10, Inkrementierung vor Ausführung! Operatoren für Zeichenketten Perl kennt mächtige Werkzeuge zur Manipulation von Zeichenketten. Diese werden später in der Vorlesung ausführlich vorgestellt (siehe Reguläre Ausdrücke). Hier sollen zunächst nur die Grundoperationen vorgestellt werden. Die Operatoren sind wieder nach ihrer Präzedenz geordnet. Operator(en) Assoziativ Wertig Bedeutung x links zwei Zeichenkettenvervielfältigung. 'ha' x 2 --> 'haha' . links zwei Zeichenkettenverkettung. 'ha' . 'ha' --> 'haha' lt le gt ge nicht zwei kleiner(gleich), größer(gleich). Ergebnis: wahr="1" oder falsch="" eq ne nicht zwei gleich, ungleich. Ergebnis: wahr="1" oder falsch="" 13 Datentyp Skalar Wie Sie sehen gibt es in Perl zwei Vergleichsarten: Einmal den numerischen Vergleich und einmal den Vergleich von Zeichenketten. Beide haben natürlich eine unterschiedliche Semantik: '01' == '1' # wahr '01' eq '1' # falsch Hier unterscheidet sich Perl ein wenig von anderen Sprachen, in denen es verschiedene Datentypen und einen Satz von Vergleichsoperatoren gibt. In Perl gibt es einen Datentyp Skalar, der kontextabhängig mal als Zahl und mal als Zeichenkette interpretiert wird. Deshalb braucht man zwei Sätze von Vergleichsoperatoren. Und was passiert, wenn aus Versehen der falsche Operator verwendet wird? Automatische Umwandlung Wird eine Zeichenkette in einem numerischen Kontext benutzt, so wird Sie automatisch in eine Zahl umgewandelt (konvertiert). Dies gilt allerdings nicht für Oktal- und Hexdezimalzahlen. Perl ist bei der Umwandlung relativ tolerant: Führende Leerzeichen und nachstehende nicht-numerische Zeichen werden ignoriert. " 123.45fred" # => Zahlenwert: 123.45 Dies führt gerade bei Vergleichen zu teilweise merkwürdigem Verhalten: 'x' == 0 'x' == 1 '1EUR' == 1 # => true # => false # => true Wenn Sie Perl mit der Option -w laufen lassen, mahnt Perl diese Umwandlung an, was wahrscheinlich eine gute Idee ist. Umgekehrt wird eine Zahl automatisch in eine Zeichenkette umgewandelt, wenn das in dem speziellen Kontext notwendig ist. Allerdings ist diese Umwandlung unproblematisch, da keine Informationen verloren gehen. 'X' . (4*5) # => Ergebnis "X20" Wertebereich Aus alten Zeiten, in denen Speicher und Rechenkapazität noch teuer und sehr begrenzt war, ist Ihnen vielleicht noch die Problematik mit dem Wertebereich einer Variablen bekannt. Was ist die größte bzw. kleinste in einer Skalarvariablen speicherbare Zahl oder Zeichenkette? Für Zeichenketten gibt es keine Einschränkung durch Perl (nur durch den Systemspeicher). Das Speichern von Zahlen ist abhängig von der Art der Compilierung und dem Zielsystem (vgl. perl -V). Normalerweise werden Integer-Zahlen nativ mit 32-bit Genauigkeit gespeichert (Bereich -2**31 .. 2**32-1). Darüber hinausgehende Zahlen können nur noch näherungsweise gespeichert und berechnet werden (Gleitkommadarstellung). Die Perl-Module Math::BigInt (bzw. bigint) und Math::BigFloat erlauben das Rechnen mit beliebig großen Integer- bzw. FloatZahlen! Mit der Anweisung use bigint werden alle Zahlen und numerische Operatoren durch selbige aus dem Modul Math::BigInt ausgetauscht. Beispiel: # Integer print 2**64,"\n"; use bigint; print 2**64,"\n"; # => 1.84467440737096e+19 # => 18446744073709551616 # Ungenauigkeit bei reellen Zahlen if (10/3 == 1/3*10) { print "Gleich!"; } else { print "Nicht gleich!"; } 14 Datentyp Skalar Wie in jeder Programmiersprache können unendliche Dezimalbrüche nur mit endlicher Genauigkeit gespeichert werden. Alle Details findet man in perldoc perlnumber. Brüche Als Alternative zu unendlichen Dezimalbrüchen kann in Perl auch mit normalen Brüchen gerechnet werden. Dafür gibt es das Perl-Modul Math::BigRat. Mit der Anweisung use bigrat werden alle Zahlen und numerische Operatoren durch selbige aus dem Modul Math::BigRat ausgetauscht. use bigrat; print 1/2 + 3/4; print 1/3 + 2/3; print 10/3 - 1/3*10; # => 5/4 # => 1 # => 0 Skalar-Variablen Eine Variable ist ein Name für einen Speicher, der ein oder mehrere Wert enthalten kann. Der Variablenname bleibt im Rahmen des Programms unverändert, der oder die Speicherwerte können sich während der Programmausführung ändern. Skalare Variablen enthalten zu jedem Zeitpunkt genau einen Wert, der eine Zahl, eine Zeichenkette oder eine Referenz sein kann. Skalare Variablennamen beginnen mit einem $-Zeichen, gefolgt von maximal 255 weiteren alphanumerischen Zeichen oder dem Unterstrich. Groß- und Kleinschreibung werden unterschieden, d.h. $a und $A sind verschiedene Variablen. Zuweisung Die Zuweisung ist die grundlegende Variablen-Operation. Sie weist einer Variablen einen Wert zu: $a = 17; $b = $a + 3; $b = $b + 2; # => $b = 20 # => $b = 22 Eine Zuweisung kann wie in C auch eine Operation sein. Der Wert einer Zuweisungs-Operation ist der zugewiesene Wert: $b = 4 + ($a = 3); $d = ($c = 5); $d = $c = 5; # => $a = 3, $b = 7 # => $c = 5, $d = 5 # dasselbe wie oben Wie in C gibt es für fast alle binären (zweiwertigen) Operationen eine interessante Zuweisungsvariante (binary assignment): $a = $a + 4; $a += 4; $str .= ' '; $b = ($a **= 2); # dasselbe wie oben Perl kennt mehr Operatoren als hier vorgestellt wurden. Für den Anfang reicht das aber aus. Eine vollständige Übersicht finden Sie mittels perldoc perlop. Variablen in Zeichenketten Enthalten Zeichenkettenkonstanten in doppelten Anführungszeichen Variablennamen, so werden die Variablennamen durch ihren Wert ersetzt. Dieses Prinzip wird Variableninterpolation genannt. Dieses an sich sinnvolle Verhalten bietet leider einige unvermutete Fallstricke. $a = 'fred'; 15 Datentyp Skalar $b = "$a feuerstein"; $c = "$fred feuerstein"; Die letzte Zeile ist trickreich. Ist $fred nicht definiert (undef), so enthält $c nach der Zuweisung der Wert " feuerstein". Ein Grund mehr, Perl-Programme mit der Option -w laufen zu lassen. Enthält die ersetzte Zeichenkette selbst wieder einen Variablennamen, so bleibt der so, wie er ist und wird nicht ersetzt: $a = '$fred'; # keine Ersetzung $a = "\$fred"; # keine Ersetzung (alternativ) $a = "$a feuerstein"; # => "$fred feuerstein" Wenn Sie die Variableninterpolation ausschalten wollen, dann benützen Sie entweder Zeichenketten mit einfachen Anführungszeichen oder maskieren das $-Zeichen mit einem Backslash. Wie werden Variablennamen in Zeichenketten erkannt? Perl sucht nach dem längsten sinnvollen Namen, was nicht immer sinnvoll ist. $fr = 'fr'; $fred = 'fred'; $b = "$fred feuerstein"; # => fred feuerstein $b = "${fr}ed feuerstein"; # => fred feuerstein Variableninterpolation arbeitet auch mit der Umwandlung von Groß/Kleinbuchstaben zusammen: $fred = 'fred'; $a = "\u$fred"; # => Fred $a = "\U$fred\E \ufeuerstein"; # => FRED Feuerstein Der Wert undef Welchen Wert hat eine Variable, wenn Sie noch keinen Wert zugewiesen bekommen hat? Variablen haben anfänglich den Wert undef (für undefined), der in einem numerischen Kontext als 0 und sonst als leere Zeichenkette "" verstanden werden kann. Die Option -w mahnt den Gebrauch von undefinierten Variablen an. Der Wert undef wird häufig als Merkmal für ein Problem genommen. Verlassen z.B. die Operanden einer numerischen Operation den Definitionsbereich dieser Operation, so hat das Ergebnis den Wert undef. Oder erreichen Sie beim Lesen einer Datei das Dateiende (EOF), so ist das Ergebnis der Lese-Operation ebenfalls undef. Mittels der spracheigenen Funktion defined() kann im Programm der Zustand einer Variablen geprüft werden, bevor sie benützt wird. Der Speicher einer Variable wird von Perl automatisch freigegeben, wenn keine Referenzen mehr auf sie zeigen und sie damit nicht mehr benötigt wird. Möchten Sie dies selbst in die Hand nehmen, steht die Funktion undef() zur Verfügung. Referenzen Die Referenz einer Variable ist die Adresse im Hauptspeicher, an der der Wert der Variable steht. Die Referenz ist ein Skalar. Man erhält sie mit dem Operator \. Möchten Sie den Wert der Variablen ausgeben, so muss die Referenz mit $ dereferenziert werden. Beispiel: $a = 1234; $ref_a = \$a; print "\$ref_a: $ref_a\n"; # => $ref_a: REF(0x82890bc) print "$ref_a zeigt auf $$ref_a\n"; # => REF(0x82890bc) zeigt auf 1234 $$ref_a = 4321; print "\$a: $a\n"; # => $a: 4321 16 Datentyp Skalar Spezialvariablen Perl ist berühmt für seine Spezialvariablen, die aus einem Sonderzeichen bestehen. Diese Variablen werden vor oder während der Laufzeit mit Werten gefüllt. Dazu gehören z.B. Variable Inhalt $0 Programmname (z.B. ./hello.pl) $$ Prozess-ID $_ „Default“-Variable $! Fehlermeldung des letzten Systemaufrufs $@ Fehlermeldung des letzten eval-Aufrufs $| Ausgabepuffer aktivieren/deaktivieren (Default: 0, Pufferung an) $a, $b Werden innerhalb von sort verwendet @_ Parameter einer Funktion Gerade die Variable $_ wird oft verwendet, um sehr kurze Programme (insbes. Einzeiler) zu schreiben, in denen man keine zusätzlichen Variablen definieren möchte. Alle Spezialvariablen sind dokumentiert in perldoc perlvar. Spracheigene Funktionen Spracheigene (built-in) Funktionen sind Teil der Perl-Distribution und Sie können beim Programmieren annehmen, dass es diese Funktionen auch überall gibt (allerdings kann die Funktionsweise der systemnahen Funktionen zwischen Unix und Windows abweichen). Einige dieser Funktionen werden hier vorgestellt. Eine komplette Liste der eingebauten Funktionen gibt es unter http://perldoc.perl.org/index-functions.html. readline(STDIN) oder <STDIN> Daten werden in Perl mit der Funktion readline von dem angegebenen Filehandle (dazu später mehr) gelesen. Das Filehandle STDIN steht automatisch zur Verfügung und liefert standardmäßig Daten von der Tastatur. Statt readline(STDIN) kann auch kurz <STDIN> geschrieben werden. Bemerkung Wird beim Einlesen das Dateiende (EOF) erreicht, so wird der Wert undef zurückgegeben, der nach den erwähnten Regeln als logisch falsch interpretiert wird. Mit der Tastatur kann EOF über die Tastenkombination STRG-D signalisiert werden. chop() und chomp() Beide Funktionen haben ein Argument. Während chop ein beliebiges letztes Zeichen aus der Zeichenkette entfernt, entfernt chomp dieses Zeichen nur, wenn es das Newline-Zeichen \n ist. chop liefert das entfernte Zeichen als Rückgabewert. chomp dagegen gibt 0 oder 1 zurück, je nachdem, ob ein Newline-Zeichen entfernt wurde oder nicht. Diese Funktionen werden häufig beim Einlesen von Daten benötigt, um das manchmal störende \n aus der Zeichenkette zu entfernen: $a = readline(STDIN); # Text einlesen chomp($a) # \n entfernen Oder kürzer chomp($a = <STDIN>); 17 Datentyp Skalar Hier sehen Sie eine weitere Eigenschaft der Zuweisungs-Operation. chop und chomp arbeiten offensichtlich nicht mit Werten, sondern mit Adressen (Referenzen). Wird eine Zuweisung in diesem Kontext benützt, so ist der Adressenwert die Adresse der Zuweisungsvariablen. lc() und uc() Mit den Funktionen lc und uc lassen sich die Zeichen eines Strings in Klein- (lowercase) bzw. Großbuchstaben (uppercase) umwandeln. Beide Funktionen liefern den umgewandelten String zurück. substr() und index() Mit substr können Teile eines Strings extrahiert oder ersetzt werden. Eine Besonderheit ist, dass substr auch auf der linken Seite einer Zuweisung stehen kann! $fredstein = "Fred stein"; $fred = substr($fredstein,0,4); substr($fredstein,5) = "Feuer"; # => $fred = "Fred" # => $fredstein = "Fred Feuer" Im letzten Beispiel wird der String in $fredstein ab Position 5 mit den Zeichen „Feuer“ überschrieben. Die Variable enthält also hinterher „Fred Feuer“ und nicht „Fred Feuerstein“! Die index-Funktion ermöglicht es in einer Zeichenkette ein Zeichen oder eine andere Zeichenkette zu finden und liefert die Position des ersten Vorkommens zurück. print()und printf() Zeichenketten werden mit print auf die Standardausgabe (STDOUT) geschrieben: print("Hallo\n"); print "Hallo\n"; # Geht auch ohne Klammern print STDOUT "Hallo\n"; # Explizit mit Ausgabestream In Perl steht auch die Funktion printf() zur Verfügung, die genau wie in C Formatbezeichner der Form %s, %d, %5.2f usw. zur formatierten Ausgabe versteht. Die Funktion ist langsamer als print und sollte nur benützt werden, wenn die zusätzlichen Formatierungen benötigt werden. Wird die Ausgabe nicht mit \n abgeschlossen, so kann es sein, dass die Ausgabe verzögert erfolgt, da sie erst in einem Puffer zwischengespeichert wird. Um das zu unterbinden, können Sie die spezielle Variable $| (flush) auf 1 setzen, und die Pufferung damit abschalten. Bemerkung Die Perl eingebauten Funktionen können meistens mit oder ohne rundes Klammernpaar aufgerufen werden. Die meisten Funktionen können auch ganz ohne Parameter aufgerufen werden. In diesen Fällen wird von Perl automatisch die Variable $_ (die default Skalarvariable) eingesetzt. while(<>) # Liest in $_ { print; # Gibt $_ aus } Mathematische Funktionen Nicht alle Funktionen stehen direkt zur Verfügung. Oft müssen Sie ein Modul dafür einbinden, z.B. Math::Trig für die Verwendung der trigonometrischen Funktionen. Siehe Beispiel sin.pl. POSIX-Funktionen Das Modul POSIX bietet ein Perl-Interface für (fast) alle POSIX 1003.1 Funktionen. POSIX (Portable Operating System 18 Datentyp Skalar Interface) ist eine standardisierte, platformunabhängige Programmier-Schnittstelle. Viele der Funktionen werden durch die Perl eingebauten Funktionen abgedeckt, es gibt aber auch noch einige nützliche POSIX-Funktionen, die extra importiert werden müssen, wie z.B. ceil() und floor() zur Rundung oder strftime() zur formatbedingten Ausgabe der Zeit. Übungsaufgaben Erste Schritte mit Perl. Aufg. 2) Fehler finden Was ist an folgenden Anweisungen falsch? a) print 'Hallo\n'; b) print chop "Halloo"; c) $str=="Hallo"; # Ausgabe von Hallo und Newline-Zeichen # Entfernen des doppelten o und Ausgabe von Hallo # Überprüfen, ob in $str der String Hallo steht Aufg. 3) Operatoren a) Berechnen Sie das negative Produkt der Quadrate von 2 und 3. b) Addieren Sie 20 zu dem Ergebnis aus a), multiplizieren das mit -5 und berechnen dann den Rest bei Division durch 7. c) Speichern Sie Ihren Namen in einem String und vervielfältigen Sie diesen um das Ergebnis aus b). Aufg. 4) Ausgabe Was liefern die folgenden Ausgaben? Warum ist das so? a) b) c) d) print print print print $a=1; $str=="Hallo"; chomp($a=1); chop($str="Hallo"); Viel Spass! 19 Datentyp Array, Skalar- und Listen-Kontext Datentyp Array, Skalar- und Listen-Kontext Listen und Arrays Begriffe Eine Liste ist eine Menge von geordneten skalaren Daten. Ein Array ist eine Variable, die eine Liste beinhaltet. Jedes Element eines Arrays ist eine eigene skalare Variable, die einen eigenen Wert hat. Diese Werte sind geordnet in dem Sinne, dass es eine definierte Reihenfolge vom ersten bis zum letzten Element des Arrays gibt. Beachten Sie, dass eine definierte Reihenfolge nicht notwendig sortiert ist. Listen Ein Listen-Literal (Listen-Konstante), kurz Liste, besteht aus einer durch Kommata getrennten Folge von Werten, eingeschlossen in runden Klammern. Eine Liste ohne Werte heißt leere Liste. (1,2,3) ("fred",4.5) () # Liste mit drei Werten # Zwei Werte # Leere Liste, keine Werte Listenelemente sind nicht notwendig konstant; sie können auch Ausdrücke sein, die bei jeder Verwendung neu berechnet werden: ($a,17) ($b+$c,$a+$d) # 2 Werte: Wert von $a und 17 # 2 Werte Für Listen gibt es einen speziellen Operator, der eine aufsteigende Liste von Werten erzeugt (in Einserschritten): (1 .. 5) (2 .. 6,10,12) ($a .. $b) # (1, 2, 3, 4, 5) # (2, 3, 4, 5, 6, 10, 12) # Werte im Intervall [$a,$b] Listen-Literale mit vielen kurzen Zeichenkette sehen unübersichtlich aus. Deshalb gibt es eine spezielle spracheigene Funktion qw(), die aus ihrem Argumente eine Liste von Werten generiert. Die Begrenzungszeichen können wie bei q und qq wieder frei gewählt werden. ("fred","barney","betty","wilma") qw(fred barney betty wilma) qw/fred barney betty wilma/ # na ja # besser! # dasselbe Listen-Literale können auch Argumente für die bereits eingeführte print()-Funktion sein. print("Die Antwort ist ", $a ,"\n") # Liste mit 3 Elementen Die drei Listenelemente werden ohne Leerzeichen hintereinander ausgegeben. Diese syntaktische Interpretation ist etwas gewöhnungsbedürftig, man erwartet eher einen Funktionsaufruf mit drei Argumenten! Array-Variablen Eine Array-Variable beeinhaltet eine Liste, die auch leer sein darf. Array-Variablen-Namen können wie skalare Variablen-Namen gebildet werden, nur muss ihnen ein @ anstelle eines $ vorangestellt sein. Arrays bilden in Perl einen eigenen Namensraum. Sie können also ein Array und einen Skalar gleichen Namens haben, die sich nicht in die Quere kommen; ob das empfehlenswert ist, steht auf einem anderen Blatt. 20 Datentyp Array, Skalar- und Listen-Kontext @fred = (); $fred = 1; # Array Fred, Inhalt: leere Liste # Skalar Fred, Inhalt: 1 Es gibt Operationen, die sich auf das ganze Array beziehen, und solche, die einzelne Array-Elemente modifizieren. Array-Operatoren Zuweisung Wie im skalaren Fall ist der Zuweisungs-Operator das Gleichheitszeichen „=“. Abhängig davon, ob auf der linken Zuweisungsseite ein Array oder ein Skalar steht, erfolgt eine Listen- oder eine Skalar-Zuweisung. @fred = (1,2,3); @barney = @fred; @uups = 1; # aus 1 wird automatisch (1) Arrays können auch Teil von Listen-Literalen sein. Ihre Elemente werden ununterscheidbar einfach zu Elementen der neuen Listen. Mit anderen Worten: Arrays können selbst keine Listenelemente sein, d.h. wir können nicht ohne Weiteres mehrdimensionale Arrays erzeugen. Möglich sind allerdings Listen von Referenzen auf Arrays (dazu später). @fred = @barney @barney @barney qw(one two); = (1,2,@fred,3); = (0,@barney); = (@barney,4); # (1, 2, "one", "two", 3) # (0, 1, 2, "one", "two", 3) # (0, 1, 2, "one", "two", 3, 4) Enthält ein Listen-Literal nur Variablen, so kann diese „Konstante“ auch auf der linken Seite einer Zuweisung stehen. Stehen rechts mehr Werte als links aufgenommen werden können, so werden diese stillschweigend verworfen. Stehen umgekehrt links mehr Variablen als rechts Werte, so werden die überflüssigen Variablen zu undef. Eine Array-Variable sollte als letzte auf der linken Seite einer Variablenliste stehen, denn sie saugt gierig (engl.: „greedy“) alle übriggebliebenen Zuweisungswerte auf. ($a,$b,$c) = (1,2,3); ($a,$b) = ($b,$a); ($a,@fred) = (1,2,3); ($a,@fred) = @fred; # # # # wie: $a=1; $b=2; $c=3; vertauscht $a und $b wie: $a=1; @fred=(2,3); $a=2, @fred=(3); Wird eine Array-Variable einem Skalar zugewiesen, so enthält der Skalar die Array-Länge. Die Länge eines Arrays ist gleich der Anzahl der Elemente des Arrays. @fred = (1,2,3); $a = @fred; ($a) = @fred; # Skalar-Kontext: $a=3 # Listen-Kontext: $a=1 Der Wert einer Array-Zuweisung ist die zugewiesene Liste selbst, so dass die Array-Zuweisung wie im skalaren Fall auch als Operation verwendet werden kann: @fred = (@barney = (1,2,3)); @fred = @barney = (1,2,3); Array-Elemente Wie kann auf einzelne Array-Elemente zugegriffen werden? Wie in anderen Sprachen auch lautet die Antwort: über den Array-Index. Jedes Array-Element ist von Null beginnend aufsteigend durchnummeriert. Gewöhnungsbedürftig ist allerdings, dass Array-Elemente mit einem vorangestellten $ bezeichnet werden. Array-Elemente können genauso wie skalare Variablen benützt werden. @fred = (7,8,9); # mal ein anderer Wert 8-) $b = $fred[0]; # $b=7 $fred[1] = 5; # @fred=(7, 5, 9) $fred[2]++; # @fred=(7, 5, 10) $fred[1] -= 4; # @fred=(7, 1, 10) ($fred[2],$fred[0]) = ($fred[0],$fred[2]); # @fred=(10, 1, 7) 21 Datentyp Array, Skalar- und Listen-Kontext Der gleichzeitige Zugriff auf mehrere Array-Elemente wird Array-Slice („Scheibe“, „Stück“) genannt. Dieser Zugriff kommt häufig genug für eine eigene (Array-)Notation vor, die nicht nur für Arrays, sondern für alles funktioniert, was eine Liste zurückgibt. @fred[0,2] = @fred[2,0]; @fred[0,1,2] = @fred[0,0,0]; @fred[1,2] = (8,9); # @fred=(7, 1, 10) # @fred=(7, 7, 7) # @fred=(7, 8, 9) # right back where we started from! @wifes = qw(fred barney betty wilma)[2,3]; # @wifes=("betty", "wilma") Wie in anderen Programmiersprachen auch, können Array-Indizes und -Slices auch Ausdrücke sein, die zur Ausführungszeit berechnet werden: @fred = (7,8,9); $a = 2; $b = $fred[$a]; $c = $fred[$a-1]; ($c) = (7,8,9)[$a-1]; # @barney = (2,1,0); @backfred = @fred[@barney]; # wie gehabt. # $b=9 # $c=8 # Listen-Kontext! $c=8 # @fred=(9,8,7). OK? Wie in anderen Programmiersprachen nicht, sind die Konsequenzen vorhersehbar, wenn man den Index-Bereich des Arrays verlässt: @fred = (1,2,3); $barney = $fred[7]; $fred[3] = 4; $fred[6] = 7; $c = $#fred; # # # # $barney wird undef @fred=(1,2,3,4); @fred=(1,2,3,4,undef,undef,7); $c=6 (höchster Index) Negative Indizes zählen vom Array-Ende her. Das letzte Elemente hat den Index -1 , das vorletzte den Index -2 usw. @fred = qw(fred wilma peebles dino); print $fred[-1]; # druckt "dino" print $fred[$#fred]; # ebenso Arrays in Zeichenketten Einzelne Array-Elemente in Zeichenketten mit doppelten Anführungszeichen verhalten sich wie skalare Variablen. Ein Array als Ganzes oder als Slice wird in Zeichenketten interpoliert, mit jeweils einem Leerzeichen zwischen den ArrayElementen. Über die spezielle Variable $" (list separator) ist es möglich, ein anderes Zeichen bzw. eine Zeichenkette als Seperatorzeichen anzugeben. @fred print print print print = qw(wilma dino barney); "$fred[0] und $fred[1]" # "@fred"; # @fred; # "@fred[0,1]"; # "wilma und dino" "wilma dino barney" ohne Leerzeichen! "wilmadinobarney" "wilma dino" Referenzen auf Arrays Referenzen auf Arrays werden mit dem \-Operator genau so erzeugt wie bei Skalaren. Zur Dereferenzierung kann bei Array- (oder Hash-)Referenzen jedoch auch der Pfeiloperator -> verwendet werden. Dieser sorgt für eine bessere Lesbarkeit des Programms. @array = qw(1 2); $ref = \@array; print "@{$ref}\n"; # => 1 2 Array als Ganzes dereferenziert print "${$ref}[0] ${$ref}[1]\n"; # => 1 2 Einzelelemente als Skalar print "$ref->[0] $ref->[1]\n"; # => 1 2 Einzelelemente mit Pfeiloperator, übersichtlicher! 22 Datentyp Array, Skalar- und Listen-Kontext Mehrdimensionale Arrays Array-Referenzen sind skalare Daten und stellen die einzige Möglichkeit dar mehrdimensionale Arrays zu realisieren. print $r[2]->[1]->[2]; # prints "bar" print $r[2][1][2]; # arrow optional between brackets Array-Funktionen push() und pop() Häufig finden Arrays als Datenstapel (engl.: „stack“) Verwendung. Neue Daten werden auf den Stapel gelegt (rechts an das Array gehängt) und wieder entfernt (rechts aus dem Array geholt). Hierfür gibt es in Perl eigene Funktionen: push und pop. push(@Stapel,$Neuwert); $Altwert = pop(@Stapel); @Stapel = (1,2,3); push(@Stapel,4,5,6); # # # # wie: @Stapel=(@Stapel,$Neuwert) entfernt das letzte Element man kann auch mehr als ein Element pushen @Stapel=(1, 2, 3, 4, 5, 6) Es wäre gegen den Stil von Perl, wenn pop() sich bei einem leeren Array beschweren würde. Der zugewiesene Wert in einem solchen Fall ist natürlich undef. shift() und unshift() pop und push arbeiten auf der rechten Seite des Arrays. shift und unshift dagegen arbeiten entsprechend auf der linken Seite: unshift(@fred,$a); unshift(@fred,$a,$b,$c); $x = shift(@fred); # wie: @fred=($a,@fred) # wie: @fred=($a,$b,$c,@fred) # wie: ($x,@fred)=@fred shift schiebt die Listenelemente nach links; das am weitesten links stehende Element fällt heraus. unshift schiebt die Listenelemente nach rechts und macht das neue Element zum am weitesten links stehenden. splice() Mit splice können beliebig viele Elemente eines Arrays hinzugefügt, ersetzt oder gelöscht werden. Diese universelle Einsatzmöglichkeit von splice kann die Einzelfunktionen shift, unshift, pop und push ersetzen. push(@a,$x,$y) pop(@a) shift(@a) unshift(@a,$x,$y) $a[$i] = $y splice(@a,@a,0,$x,$y) splice(@a,-1) splice(@a,0,1) splice(@a,0,0,$x,$y) splice(@a,$i,1,$y) readline() oder <STDIN> als Array Wird <STDIN> im Listen-Kontext aufgerufen, liest Perl die gesamte Eingabedatei auf einmal. Das ist bei den heutigen Speichergrößen weniger schlimm, als man vermuten würde. @Datei = <STDIN>; @Datei = readline(STDIN); chomp(@Datei); # Datei einlesen # Datei einlesen # Zeilentrennzeichen entfernen chomp() Die schon für Skalare vorgestellte spracheigene Funktion chomp arbeitet auch mit Listen. Dann werden von allen Listenelementen die Zeilentrennzeichen entfernt. Im Gegensatz zu den bisher vorgestellten Funktionen verändert chomp 23 Datentyp Array, Skalar- und Listen-Kontext sein Argument. (Vergleiche das folgende Beispiel im Zusammenhang mit der Eingabe.) join() Mit der Funktion join können die Elemente einer Liste unter Verwendung eines beliebigen Zeichens (bzw. einer Zeichenkette) zu einer Zeichenkette zusammengefügt werden. @fred = qw(wilma dino barney); print join ' und ', @fred; # "wilma und dino und barney" reverse() reverse dreht die Reihenfolge der Elemente seines Listenarguments um: @a @b @b @a = = = = (1,2,3); reverse(@a); reverse(1,2,3); reverse(@a); # @b=(3, 2, 1) # ebenso # @a=(3, 2, 1) reverse ändert das Argument nicht. Wollen Sie das, so müssen Sie das Resultat dem Argument zuweisen (vgl. letztes Beispiel). sort() sort nimmt seine Argumente, behandelt sie als einzelne Zeichenkette und sortiert sie aufsteigend. Die Argumente bleiben unverändert. @x = sort(qw(schmitt meier schulze)); # @x=("meier","schmitt","schulze") @y = sort(1,2,4,8,16,32,64); # @y=(1,16,2,32,4,64,8) Wie das letzte Beispiel zeigt, ist die Sortierreihenfolge nicht numerisch sondern basiert auf String-Vergleichen. Wir werden gleich sehen, wie man in Perl nach anderen Kriterien sortieren kann. sort sortiert in der Verwendung ohne Parameter alphabetisch (durch String-Vergleiche). Dieses Verhalten lässt sich beliebig abändern, indem als erster Parameter ein Anweisungsblock übergeben wird, der eine eigene Vergleichslogik enthält und für seine Elemente als Ergebnis einen Wert kleiner Null, gleich Null oder größer Null berechnet. In diesem Anweisungsblock erscheinen automatisch die beiden Variablen $a und $b, denen jeweils zwei Elemente der Liste zugeweisen werden. Um Elemente nach eigenen Regeln zu sortieren, übergeben wir z.B.: sort { $a cmp $b } ( @liste ) # cmp ist Vergleichsoperator für Strings sort { $a <=> $b } ( @liste ) # <=> ist numerische Vergleichsoperator grep() Soll auf alle Elemente einer Liste oder eines Arrays eine oder mehrere Operationen angewendet werden, so ist die Funktion grep behilflich. Diese nimmt wie die sort-Funktion als ersten Parameter einen Anweisungsblock entgegen. Damit lassen sich z.B. bestimmte Elemente selektieren, die dann im Listenkontext zurückgegeben werden. Im Skalarkontext wird die Anzahl der selektierten Elemente zurückgegeben. Über die Default-Variable $_ kann aber auch gleich das Ursprungsarray verändert werden. @list = (1..10); @list = grep { $_ > 5 } @list; # Nur die Elemente >5 der Liste zurückgeben print "@list\n"; # => @list = (6, 7, 8, 9, 10) $n = grep { $_ > 5 } @list; # Anzahl der Elemente>5 in der Liste zurückgeben print "$n\n"; # => $n = 5; @n = grep { $_++ if $_ % 2 == 0 } @list; # Gerade Zahlen in @list um eins erhöhen print "@list\n@n\n"; # => @list = (7, 7, 9, 9, 11), @n = (7, 9, 11) $s = 'wilma'; if (grep { $_ eq $s } qw(fred barney wilma)) # Suche nach Element in Liste { print "$s ist in Liste\n"; } 24 Datentyp Array, Skalar- und Listen-Kontext Weitere praktische Listenfunktionen, wie z.B. max() zur Bestimmung des Maximums in einer Liste, findet man im Modul List::Util. Spezielle Arrays Das Array @ARGV enthält Kommandozeilen-Parmeter, die an das Skript übergeben wurden. Kontrollstrukturen: for, foreach (Schleifen) Wenn man mit großen Datenstrukturen wie Arrays arbeitet, werden Anweisungen einer Programmiersprache benötigt, die es erlauben ohne viel programmier-technischen Aufwand dieselbe Operation auf mehreren Elementen auszuführen. Diese Anweisungen werden auch Schleifen genannt. foreach-Schleife foreach weist einer skalaren Schleifenvariablen nacheinander die Werte einer Liste oder eines Listen-Ausdrucks zu. foreach $i (@Liste) { Anweisung1; Anweisung2; } Die Schleifenvariable, zum Beispiel $i, ist quasi lokal im foreach-Anweisungsblock. Hat es also vor der foreachAnweisung kein $i gegeben, so gibt es hinterher auch keines. Gab es dagegen vorher ein $i schon, so hat es hinterher seinen vorherigen Wert. (Wir sehen weiter unten, dass die Schleifenvariable keine lokale Variable im eigentlichen Sinn ist.) @a = (1,2,3,4,5); foreach $b (reverse @a) { print $b; } Die Reihenfolge der Listenelemente wird mit reverse umgekehrt, anschließend in 5 Schleifendurchläufen nacheinander der Schleifenvariablen $b zugewiesen und im Anweisungsblock ausgegeben. Sie können die Schleifenvariable auch weglassen. Dann tut Perl so, also hätte man die Variable $_ angegeben. Diese ist das Defaultargument für viele Perl-Funktionen, so dass obiges Beispiel knapper wie folgt formuliert werden kann: @a = (1,2,3,4,5); foreach (reverse @a) { print; } Dieses Feature sieht nur zu Anfang etwas extravagant aus, man lernt es aber sehr schnell zu schätzen. Die Schleifenvariable ist keine lokale Variable des foreach-Anweisungsblocks. In Wirklichkeit ist sie ein Alias für das jeweilige Listenelement, d.h. verändere ich die Schleifenvariable, so verändere ich die Liste! 2 @a = (1,2,3,4,5); foreach $b (@a) { $b++; } # hinterher: @a = (2,3,4,5,6) for-Schleife Wie C und Java kennt Perl auch die for-Anweisung: 2 „It's not a bug, it's a feature!“ 25 Kontrollstrukturen: for, foreach (Schleifen) for ( init_exp; test_exp; re_init_exp ) { Anweisung1; Anweisung2; } Vor dem ersten Schleifendurchlauf wird init_exp ausgeführt. Dann wird test_exp ausgewertet. for wird solange ausgeführt, wie test_exp wahr ist. Am Ende jedes Schleifendurchlaufs wird re_init_exp ausgeführt. for ($i = 1; $i <= 10; $i++) { print "$i "; } In dieser Form genutzt, bezeichnet man $i auch als Schleifenvariable. init_exp setzt $i = 1. Da 1 kleiner als 10 ist, ist test_exp wahr. print gibt 1 aus. re_init_exp erhöht $i auf 2. Da 2 kleiner 10 ist, usw. Die Schleife endet, wenn re_init_exp den Wert von $i auf 11 erhöht und damit test_exp nicht mehr wahr ist. Formatierte Ausgabe auf STDOUT mit printf() Unter formatierter Ausgabe versteht man die Ausgabe mit einem Format, das der Programmierer festgelegt hat. Wie in C benützt man in Perl dazu die spracheigene Funktion printf(). Die Beschreibung der Formatcodes sind leider nicht Teil der Perl-Dokumentation, sondern Teil der Betriebssystem-Dokumentation für die C-Bibliothek. $s = "Zeichenkette"; $n = 143; $r = -123.45; print "---------1---------2---------3---------4\n"; printf "%15s %5d %10.2f\n", $s, $n, $r; # Ausgabe ---------1---------2---------3---------4 Zeichenkette 143 -123.45 Das erste printf()-Argument definiert das Format, welches drei Ausgabefelder enthält, die durch Leerzeichen voneinander getrennt sind. Für jedes Ausgabefeld ist eine Feldweite angegeben. Die Ausgabe erfolgt bei diesen Formatcodes rechtsbündig in die Ausgabefelder. %s ist der Formatcode für Zeichenketten, %d der für ganze Zahlen und %f der für Zahlen mit Nachkommastellen. Übungsaufgaben Zwei Aufgaben zur Verwendung von Listen & Arrays. Aufg. 5) Listen a) Erzeugen Sie eine Array-Variable und weisen Sie dieser die sieben Wochentage zu. b) Verwenden Sie ein Array-Slice, um die Arbeitstage und die Wochenendtage jeweils an eine neue Variable zuzuweisen. c) Erweitern Sie das Beispiel zeit.pl aus der Vorlesung um die Ausgabe des jeweiligen Wochentags. Aufg. 6) Zahlen sortieren Schreiben Sie ein Perl-Programm, das eine beliebige Anzahl von Zahlen in ein Array einliest bis CTRL-D gedrückt wird. Geben Sie die Zahlen dann numerisch sortiert aus. Zum Einlesen können Sie die bereits in der Vorlesung verwendete Schleife benützen: while($zahl = <STDIN>) 26 Kontrollstrukturen: for, foreach (Schleifen) { } # tue etwas mit $zahl Viel Spass! 27 Weitere Kontrollstrukturen: if/unless, while/until, for Weitere Kontrollstrukturen: if/unless, while/until, for Steueranweisungen Steueranweisungen, manchmal auch strukturierende Anweisungen genannt, verändern den sequentiellen Programmablauf und sind der Kern jeder Programmierung. Sie ermöglichen oder verhindern das Ausführen von Programmteilen in Abhängigkeit von bestimmten Eingaben. Es folgt eine Zusammenfassung, welche Steueranweisungen Perl kennt. Anweisungsblöcke Ein Anweisungsblock ist eine Folge von Anweisungen, die von geschweiften Klammern eingeschlossen wird. Die Anweisungen werden in ihrer Reihenfolge ausgeführt. { } Anweisung1; Anweisung2; # usw. Ein Anweisungsblock wird überall dort benützt, wo syntaktisch nur eine Anweisung stehen darf. Diese Eigenschaft haben Anweisungsblöcke in vielen anderen Programmiersprachen auch. Wo andere Sprachen syntaktisch eine Anweisung erlauben, fordert Perl Anweisungsblöcke. Das Semikolon der letzten Anweisung eines Blockes darf fehlen, je nach dem, ob man Perl mit C- oder Pascal-Akzent sprechen will. if/unless Die if-Anweisung entscheidet anhand des Wahrheitsgehaltes eines Ausdrucks, ob ein Anweisungsblock ausgeführt wird oder nicht. Optional kann ein zweiter Anweisungsblock ausgeführt werden, wenn der Ausdruck falsch ist: if (Ausdruck) { Anweisung1; Anweisung2; } else { Anweisung3; Anweisung4; } # ausgeführt, wenn der # Ausdruck wahr ist # ausgeführt, wenn der # Ausdruck falsch ist Die Frage ist nun, wann ist ein Ausdruck wahr oder falsch? Vgl. Sie dazu den Abschnitt „Boolesche Werte“ aus der zweiten Vorlesung. Der Ausdruck wird in skalarem Kontext als Zeichenkette ausgewertet. Ist diese Zeichenkette entweder leer oder enthält sie als einziges das Zeichen 0, dann ist der Ausdruck falsch. In allen anderen Fällen ist er wahr. Will man eine Bedingung „Tue das wenn dieses falsch ist" mit der if-Anweisung ausdrücken, so hat man einen unschönen leeren then-Teil. Hier hilft die unless-Anweisung: if ($age < 18) { } else { print "Du bist alt genug zum Wählen!\n"; } # äquivalent unless ($age < 18) { print "Du bist alt genug zum Wählen!\n"; } unless wird verwendet, wenn die Bedingung dann sprechender klingt. unless kann auch einen else-Zweig haben. Hat man mehr als zwei Alternativen, so kann man mittels elsif die if-Anweisung (fast) beliebig schachteln. if ($age >= 18) { print "Du kannst den Land- und Bundestag wählen!\n"; 28 Weitere Kontrollstrukturen: if/unless, while/until, for } elsif ($age >= 16) { print "Du kannst den Stadtrat wählen.\n"; } else { print "Du kannst noch nicht wählen.\n"; } while/until Keine Programmiersprache kommt ohne Iteration aus. Iteration meint die wiederholte Ausführung eines Anweisungsblockes. Perl kennt verschiedene Iterations-Arten, wovon wir for/foreach schon kennengelernt haben. while führt einen Anweisungsblock solange aus, wie ein Ausdruck wahr bleibt. Dies wird vor jedem Schleifendurchlauf geprüft. while (Ausdruck) { Anweisung1; # ausgeführt, solange der Anweisung2; # Ausdruck wahr ist } Perl wäre nicht Perl, wenn es hierzu nicht auch die Verneinung gäbe: until (Ausdruck) { Anweisung1; # ausgeführt, solange der Anweisung2; # Ausdruck nicht wahr ist } Werden die Schleifenbedingungen für while oder until bei der ersten Prüfung nicht erfüllt, so wird der Anweisungsblock überhaupt nicht ausgeführt. Damit das Programm beendet wird, sollte die Schleifenbedingung irgendwann einmal falsch werden. Hat man sich an dieser Stelle "vertan", so dreht sich das Programm endlos im Kreise, es "looped". Loopende Programme muss man durch externe Eingriffe (STRG-C, ^C unter Unix, Task-Manager unter Windows) abbrechen. Bevor Sie Iterationen programmieren, machen Sie sich bitte mit den notwendigen Handgriffen vertraut! do {} while/until Will man den Schleifentest am Ende der Schleife und damit die Garantie, dass der Anweisungsblock wenigstens einmal ausgeführt wird, so ist die do-Anweisung das Richtige: do { Anweisung1; Anweisung2; } while Ausdruck; Solange der Ausdruck wahr ist, wird die Schleife (mindestens einmal) ausgeführt. Eine until-Variante gibt es natürlich auch: do { print "Wie alt bist Du? "; chomp($age = <STDIN>); } until $age > 0 ; for-Schleife Wie C und Java kennt Perl auch die for-Anweisung: for ( init_exp; test_exp; re_init_exp ) { Anweisung1; Anweisung2; } Diese for-Anweisung ist semantisch mit folgender while-Anweisung äquivalent: 29 Weitere Kontrollstrukturen: if/unless, while/until, for init_exp; while (test_exp) { Anweisung1; Anweisung2; re_init_exp; } Vor dem ersten Schleifendurchlauf wird init_exp ausgeführt, dann wird test_exp ausgewertet. for wird solange ausgeführt, wie test_exp wahr ist. Am Ende jedes Schleifendurchlaufs wird re_init_exp ausgeführt. for ($i = 1; $i <= 10; $i++) { print "$i "; } In dieser Form genutzt, bezeichnet man $i auch als Schleifenvariable. init_exp setzt $i = 1. Da 1 kleiner als 10 ist, ist test_exp wahr. print gibt 1 aus. re_init_exp erhöht $i auf 2. Da 2 kleiner 10 ist, usw. Die Schleife endet, wenn re_init_exp den Wert von $i auf 11 erhöht und damit test_exp nicht mehr wahr ist. Schleifen-Steueranweisungen In Perl ist es möglich Schleifen vorzeitig zu verlassen wenn eine bestimmte Bedingung erfüllt ist. So lässt sich z.B. mit next zum nächsten Iterationsschritt springen und mit last entsprechend zum letzten Iterationsschritt. while (1) { chomp($in = <STDIN>); if ($in eq "q") { last }; } Perl kennt eine Reihe von Schleifenbefehlen. Was ist, wenn man innnerhalb einer Schleife zum Schleifen-Anfang oder -Ende oder ganz aus der Schleife herausspringen möchte? Hier helfen die Schleifen-Steuer-Anweisungen next, last und redo. Die Schleifen-Steueranweisungen sind in for-, foreach-, while- und until-Schleifen möglich und - als Sonderfall in einem nackten Anweisungsblock, dazu später. Zunächst brauchen wir einen Möglichkeit, Blöcke zu benennen. Label Label sind Namen, die man einem Block gibt. Auf diesem Namen kann man sich in Schleifen-Steuer-Anweisungen beziehen. Oder zu ihm mittels goto springen, was aber ganz aus der Mode gekommen ist. Label bilden zusammen mit den Perl-Schlüsselwörtern einen eigenen Namensraum. Deswegen sollte man Label nur aus Großbuchstaben und Ziffern bilden, da Perl-Schlüsselwörter diese Zeichen nie enthalten. ZEILE: while (<>) { } Der Block der while-Schleife bekommt den Namen ZEILE. BEGIN-/END-Blöcke Ein Perl-Programm kennt einige speziell benannte Blöcke, wozu z.B. BEGIN und END gehören. Anweisungen, die in so markierten Blöcken enthalten sind, werden ganz zu Beginn des Skriptes bzw. bei Beendigung des Skriptes ausgeführt. Es spielt dabei keine Rolle, an welcher Stelle im Skript die BEGIN-/END-Blöcke stehen. BEGIN { print "Starting up..."; } END { print "Shutting down..."; } 30 Weitere Kontrollstrukturen: if/unless, while/until, for next next ist wie continue in Java/C. Der Rest der Schleife wird nicht ausgeführt und sofort der nächste Schleifendurchlauf begonnen. ZEILE: while (<>) { next ZEILE if /^#/; } # Kommentarzeilen ueberlesen Ohne Angabe eines Labels iteriert next die innerste Schleife. Es zählen hierbei nur Schleifen-Blöcke, und nicht etwa ein ifBlock. Man benennt Schleifen in der Regel nur dann, wenn sie geschachtelt sind und man die Schleifen-SteuerAnweisungen benützt. while (<>) { next if /^#/; } # Kommentarzeilen ueberlesen last last ist wie break in Java/C. Die Ausführung der Schleife wird abgebrochen und mit der ersten Anweisung hinter der Schleife fortgefahren. ZEILE: while (<>) { last ZEILE if /^$/; } # Stop nach der erste Leerzeile Auch hier kann das Label fehlen, wenn die innerste Schleife beendet werden soll. redo redo beendet den aktuellen Schleifendurchlauf und startet ihn erneut, ohne das die Schleifenbedingung überprüft wird. Auch redo bezieht sich ohne Angabe eines Labels auf den innersten Block. Mit redo, last und einem nackten Block lässt sich eine eigene Schleifenstruktur bauen: { Anweisungen; if (Bedingung) { last } Anweisungen; redo; # moegliches Schleifenende } Expression Modifier Alle bislang vorgestellte Steueranweisungen erfordern Anweisungsblöcke. Auch wenn man nur die Ausführung einer einzelnen Anweisung von etwas anderem abhängig machen möchte, ist man gezwungen, die geschweiften Klammern zu benutzen, was die Lesbarkeit des Programmes nicht unbedingt erhöht. So gibt es folgende Expression Modifier, die als "syntaktischen Abkürzungen" zu erstaunlich gut lesbaren Programmen führen: Anweisung Anweisung Anweisung Anweisung if unless while until Ausdruck; Ausdruck; Ausdruck; Ausdruck; # Beispiele print "Du kannst wählen.\n" print (++$i, " ") # # # # if unless while until (Ausdruck) (Ausdruck) (Ausdruck) (Ausdruck) {Anweisung;} {Anweisung;} {Anweisung;} {Anweisung;} if $age >= 18; while $i < 10; Das zweite Beispiel ist etwas trickreich, da while die Bedingung vor der Ausführung der Anweisungsblocks testet. Angenommen: $i ist undef. Ausgegeben werden dann die Zahlen von 1 bis 10, was man bei der Schleifenbedingung nicht vermuten würde. Zuerst wird die while-Bedingung überprüft. Der Vergleich (<) ist numerisch. In diesem Kontext wird undef als 0 interpretiert; die Schleifenbedingung also wahr. Danach wird print ausgeführt, wobei vorher $i inkrementiert wird. Bei der letzten erfolgreiche Schleifenbedingung wird $i mit einem Wert von 9 getestet und mit dem Wert 10 ausgegeben. 31 Weitere Kontrollstrukturen: if/unless, while/until, for Das Beispiel chomp($age = <STDIN>) until $age >= 0; ist dagegen fehlerhaft. Denn obwohl das until nachgestellt ist, ist es eben kein do {} until, das heißt die Schleifenbedingung wird zuerst überprüft und die ist für $age mit dem Wert undef wahr. Die Anweisung wird also nicht ausgeführt, d.h. man hat gar keine Möglichkeit etwas einzugeben. Programmbeendigung Die Funktion exit() beendet das Perl-Programm und gibt optional einen Rückgabewert zurück. Mit der Funktion die() wird das Programm mit einer optionalen Fehlermeldung abgebrochen. In beiden Fällen wird noch ein existierender ENDBlock ausgeführt. Datentyp Hash Ein Hash ist ein verallgemeinertes Array. Die Verallgemeinerung bezieht sich dabei auf den Index: Bei einem Array besteht der Index aus postiven ganzen Zahlen einschließlich der Null. Bei einem Hash dagegen ist der Index eine beliebige Zeichenkette. Hier wird auch nicht von „Index“, sondern von „Schlüssel“ gesprochen. Die Elemente eines Hashes haben keine spezielle Reihenfolge. Wenn der Name Hash irgendetwas mit Hash-Funktionen zu tun hat, kann man den Grund erraten. Grob gesprochen bildet eine Hash-Funktion einen Schlüssel auf eine Zahl ab, die als Index eines Arrays interpretiert werden kann. Die Reihenfolge der Elemente in diesem Array ist zwar durch seinen Index definiert, aber diese Reihenfolge hat wegen der Eigenschaft der Hash-Funktion nichts mit Reihenfolge der Schlüssel zu tun. Ob ein Schlüssel auch Umlaute enthalten darf, hängt von der C-Bibliothek ab, mit der Perl übersetzt wurde. Moderne Systeme erlauben es in der Regel. Hash-Variablen Hash-Variablen bilden wieder einen eigenen Namensraum. Man erkennt sie an dem vorangestellten %. Jedes Element eines Hashes kann wie eine skalare Variable benützt werden. Auf ein bestimmtes Element wird über eine Zeichenkette, den Schlüssel, zugegriffen. Der Schlüssel wird ebenfalls im Hash abgelegt, so dass ein Hash-Element aus zwei Komponenten besteht: dem Schlüssel und dem zugehörigem Wert, auch Schlüssel-Wert-Paar genannt. $fred{"aaa"} = "bbb"; $fred{234.5} = "456.7"; print $fred{"aaa"}; $fred{234.5}++; # %barney = %fred; @barney = %fred; %fred = @barney; # # # # Schlüssel: "aaa", Wert: "bbb" Schlüssel: "234.5", Wert: 456.7 druckt "bbb" Wert 457.7 # %barney ist Kopie von %fred; # @barney=("aaa","bbb","234.5",457.7); # %fred unverändert Die letzten beiden Beispiele zeigen die Umwandlung von Hashes in Arrays und umgekehrt. Dies ist offensichtlich unproblematisch: die Schlüssel-Wert-Paare werden einfach zwei aufeinander folgende Array-Elemente und vice versa. Also überrascht es nicht, das Hash-Literale eigentlich Array-Literale mit Werte-Paaren sind. %Frucht_Farbe = ("Apfel","rot","Banane","gelb","Zitrone","gelb"); # äquivalent zu: $Frucht_Farbe{"Apfel"} = "rot"; $Frucht_Farbe{"Banane"} = "gelb"; $Frucht_Farbe{"Zitrone"} = "gelb"; Da die Paar-Relation bei dieser Notation leicht verloren geht, gibt es einen Operator =>, der die Relation dokumentiert. Der linke Operand wird automatisch quotiert. Das gleiche gilt für Schlüssel, die nur aus einem Wort bestehen. %Frucht_Farbe = (Apfel => "rot", Banane => "gelb", Zitrone => "gelb"); # äquivalent zu: $Frucht_Farbe{Apfel} = "rot"; $Frucht_Farbe{Banane} = "gelb"; $Frucht_Farbe{Zitrone} = "gelb"; 32 Datentyp Hash Hash-Funktionen Rezepte für typische Hash-Operationen Ein Hash ist eine bequeme und schnelle Datenstruktur und deshalb auch sehr populär. Es folgt nun eine Aufzählung der häufigsten Hash-Operationen und wie man sie in Perl formulieren kann. Wie fügt man einem Hash ein Element hinzu? Indem man es einfach hinschreibt. Für einen neuen Schlüssel wird ein Element erzeugt und der Wert gespeichert. Für einen alten Schlüssel wird der alte Wert überschrieben. $Frucht_Farbe{Gurke} = "grün"; $Frucht_Farbe{Apfel} = "rot-grün"; # neues Element # altes überschrieben Höchstens ein Hash-Schlüssel kann den Wert undef haben. Dagegen können beliebig viele Werte undef sein. Besitzt ein Hash einen Schlüssel bereits? Man möchte wissen, ob ein Hash einen bestimmten Schlüssel schon enthält, ohne sich für den damit verbundenen Wert zu interessieren. Die Antwort gibt die spracheigene Funktion exists(). Folgendes Beispiel entscheidet auf Grund einer Existenz-Aussage, ob ein Begriff eine Frucht ist oder ein Getränk. foreach $name ("Apfel","Bier") { if ( exists($Frucht_Farbe{$name}) ) { print "$name ist eine Frucht.\n"; } else { print "$name ist ein Getränk.\n"; } } exists() testet nur, ob es den Schlüssel gibt. Der zugehörige Wert kann undef sein! Wie löscht man etwas selektiv aus einem Hash? Mit der Zuweisung von undef auf den Wert jedenfalls nicht. Damit wird eben nur der Wert undef und der Schlüssel und damit das Element bleiben erhalten. Stattdessen nimmt man die spracheigene Funktion delete(), die sowohl den Schlüssel als auch den zugehörigen Wert aus dem Hash entfernt. delete $Frucht_Farbe{"Apfel"}; # ein Element delete @Frucht_Farbe{"Banane","Gurke"} # eine hash-slice Ein Hash-Slice ist analog zu einem Array-Slice der Zugriff auf ein Teil eines Hashes. Zu beachten ist, dass er syntaktisch zu einem Array wird (vorangestelltes @). Was, wie wir später sehen werden, sehr praktisch ist. Es folgen drei äquivalente Formulierungen der gleichen Aufgabe, 3 Hash-Elementen einen Wert zuzuweisen. # Elementweise $hash{"eins"} = 1; $hash{"zwei"} = 2; $hash{"drei"} = 3; # oder durch mehrere Elemente in einer Listenzuweisung ($hash{"eins"},$hash{"zwei"},$hash{"drei"}) = (1,2,3); # oder durch ein Hash-Slice @hash{"eins","zwei","drei"} = (1,2,3); Wie greift man auf alle Elemente eines Hashes zu? Einen einfachen, ganzzahligen Array-Index gibt es ja nicht. Man braucht die Schlüssel, um an die Werte zu kommen. Die erste Antwort lautet: Man benütze while und die spracheigene Funktion each() wie folgt: 33 Datentyp Hash while ( ($key,$value) = each(%hash) ) { # $key und $value können verarbeitet werden } each() liefert nacheinander die Schlüssel-Wert-Paare des Hashes. Bekommt der Hash als ganzes einen neuen Wert zugewiesen, so wird each() zurückgesetzt. Löscht man in der while-Schleife Elemente oder fügt neue hinzu, so ist man selbst Schuld. Die zweite Antwort lautet: Man benütze foreach und die spracheigene Funktion keys wie folgt: foreach $key (keys %hash) { $value = $hash{$key}; # $key und $value können verarbeitet werden } keys gibt als Liste alle Hash-Schlüssel zurück. Und da man Listen mit sort sortieren kann, hat man so eine einfache Möglichkeit, auf alle Hash-Elemente in aufsteigend sortierter Schlüssel-Reihenfolge zuzugreifen: %Frucht_Farbe = (Apfel => "rot", Banane => "gelb", Zitrone => "gelb", Gurke => "grün"); foreach $frucht (sort keys %Frucht_Farbe) { print "$frucht ist $Frucht_Farbe{$frucht}.\n" } # Ausgabe: Apfel ist rot. Banane ist gelb. Gurke ist grün. Zitrone ist gelb. Wie druckt man einen Hash? Das Problem ist, dass print "%hash" nicht funktioniert. Die einfachste Antwort lautet: Indem man elementweise druckt. Vergleiche die Antwort auf die letzte Frage. %Frucht_Farbe = (Apfel => "rot", Banane => "gelb", Zitrone => "gelb", Gurke => "grün"); foreach $frucht (keys %Frucht_Farbe) { print "$frucht ist $Frucht_Farbe{$frucht}.\n" } # Ausgabe: Apfel ist rot. Zitrone ist gelb. Banane ist gelb. Gurke ist grün. Will man nur einen Teil des Hashes ausdrucken, kann man einen Hash-Slice verwenden. Ein Hash-Slice ist syntaktisch ein Array und wird in Zeichenketten interpoliert: %Frucht_Farbe = (Apfel => "rot", Banane => "gelb", Zitrone => "gelb", Gurke => "grün"); print "@Frucht_Farbe{Apfel,Gurke,Banane}\n"; # Ausgabe: rot grün gelb Wie invertiert man einen Hash? Das Problem: Man hat einen Hash und einen Wert. Wie findet man den bzw. die zugehörigen Schlüssel? Antwort: Man benutze die spracheigene Funktion reverse, mit der man einen invertierten Hash erzeugt. In diesem Hash sind die Werte die Schlüssel und umgekehrt. %Frucht_Farbe = (Apfel => "rot", Banane => "gelb", Zitrone => "gelb", Gurke => "grün"); %Farbe_Frucht = reverse %Frucht_Farbe; foreach $farbe (keys %Farbe_Frucht) { print "$farbe -- $Farbe_Frucht{$farbe}\n"; 34 Datentyp Hash } # Ausgabe gelb -- Zitrone. grün -- Gurke. rot -- Apfel. reverse erwartet ein Listen-Argument. %Frucht_Farbe wird als Liste von Schlüssel-Wert-Paaren interpretiert. Die Element-Reihenfolge wird umgekehrt und %Farbe_Frucht zugewiesen. Datenverlustfrei ist dieses Verfahren natürlich nur, wenn alle Werte eindeutig sind, was in diesem Beispiel nicht der Fall war. Es gab zwei gelbe Früchte, von denen nur die Zitrone "überlebt" hat. Spezielle Hashes Der Hash %ENV enthält Informationen über die Laufzeitumgebung des Perl-Interpreters und Betriebssystems. Referenzen Zeiger enthalten die Speicheradressen der Objekte, auf die sie zeigen. Perl-Referenzen sind Zeiger auf Skalare, Arrays, Hashes oder Funktionen. Referenzen unterscheiden sich von Zeigern anderer Programmiersprachen dadurch, dass Perl intern mitzählt, wieviele Referenzen zu jeder Zeit für eine Variable existieren. So wird eine Variablen erst dann wirklich gelöscht, wenn es keine gültige Referenz auf sie mehr gibt. Referenzen zeigen damit niemals auf bereits wieder frei gegebene Speicherbereiche, was eine wirklich feine Sache ist. C-Programmierer wissen, wovon ich rede. Die Anweisung $SkalarRef = \$Skalar; speichert die Adresse von $Skalar in der (skalaren) Variablen $SkalarRef ab. Der Zugriff auf den Speicherinhalt von $Skalar kann entweder über $Skalar direkt oder über die Dereferenzierung der Referenz $$SkalarRef erfolgen. Die Dereferenzierung erfolgt mit dem »Buchstaben« ($, @, % und &) des referenzierten Objektes. # Skalare $SkalarRef = \$Skalar; $$SkalarRef; ${$SkalarRef}; # Arrays $ArrayRef = \@Array; @$ArrayRef; @{$ArrayRef}; ${$ArrayRef}[2]; $ArrayRef->[2]; # Hashes $HashRef = \%Hash; %$HashRef; %{$HashRef}; ${$HashRef}{key}; $HashRef->{key}; # Funktionen $FuncRef = \&Func; &$FuncRef; $FuncRef->(); # Referenz # Dereferenz # Dereferenz # Array-Dereferenz # Deferenz Array-Element # Hash-Dereferenz # Deferenz Hash-Element # Funktions-Dereferenz Es ist syntaktisch also immer klar, welcher Objekttyp dereferenziert wird. Natürlich wird man, wo möglich, die PfeilNotation verwenden. Nicht nur, weil es eine gute optische Hervorhebung ist, sondern auch, weil man die syntaktische Ähnlichkeit mit Array- und Hash-Slices vermeidet. Neben der Möglichkeit Referenzen von Variablen zu erzeugen, gibt es in Perl auch die Möglichkeit Referenzen auf ein anonymes, also nicht mit einer Variable benanntes, Array oder einen anonymen Hash zu erzeugen. Für ein anonymes Array verwendet man die eckigen Klammern, für einen anonymen Hash die geschweiften Klammern: @array = ( 2, 3, 4); $array_ref = [ 5, 6, 7 ]; # Initialisiert Array @array mit Liste # Erzeugt Referenz auf ein anonymes Array 35 Datentyp Hash @array = @$array_ref; @array # Kopiert die Daten aus dem anonymen Array in Array %hash = ( 2, 3, 4, 5 ); $hash_ref = { 6 => 7 , 8 => 9 }; %hash = %$hash_ref; Hash @hash # Initialisiert Hash %hash mit Liste # Erzeugt Referenz auf einen anonymen Hash # Kopiert die Daten aus dem anonymen Hash in Weitere Details dazu findet man in 'perldoc perlref'. Skalar oder Referenz? Ob eine Variable $var einen skalaren Wert oder eine Referenz enthält, kann man ihr von außen (also syntaktisch) nicht ansehen. Hierfür gibt es die spracheigene Funktion ref(), deren Verwendung in folgendem Beispiel erläutert wird. #!/usr/bin/perl $scalar = $hash{"KEY"} = @array = -w "SCALAR_VALUE"; "HASH_VALUE"; ("ARRAY_VALUE"); $scalar_ref $array_ref $hash_ref $code_ref $scalar_ref_ref = = = = = \$scalar; \@array; \%hash; sub { return "RETCODE" }; \$scalar_ref; # Skalar # Hash # Array # Referenz auf ... # Skalar # Array # Hash # Code # Referenz print "Datentypen: ", ref($scalar_ref), " ", ref($array_ref), " ", ref($hash_ref), " ", ref($code_ref), " ", ref($scalar_ref_ref), "\n"; # Typen ermitteln print "Werte: ", $$scalar_ref, @$array_ref, %$hash_ref, &$code_ref, $$$scalar_ref_ref, # Ausgabe: Datentypen: SCALAR ARRAY Werte: SCALAR_VALUE # Dereferenzierte ... # Skalarreferenz # Arrayreferenz # Hashreferenz # Codereferenz # Referenz auf Skalarreferenz " ", " ", " ", " ", "\n"; HASH CODE REF ARRAY_VALUE KEYHASH_VALUE RETCODE SCALAR_VALUE Das Modul Data::Dumper Mit dem Modul Data::Dumper ist die einfache Ausgabe von beliebigen Perl-Variablen als Zeichenkette möglich, egal ob es ein Array, Hash, Referenz oder ein komplizierteres Objekt ist. Dies ist sehr praktisch beim Auswerten von Strukturen, die mit Referenzen arbeiten. #!/usr/bin/perl use Data::Dumper; @array = qw(eins 1 zwei 2 drei 3); %hash = @array; print Dumper(\@array, \%hash); # liefert $VAR1 = [ 36 Datentyp Hash 'eins', '1', 'zwei', '2', 'drei', '3' ]; $VAR2 = { 'eins' => '1', 'drei' => '3', 'zwei' => '2' }; Das Modul Storable Das Modul Storable erlaubt uns den Inhalt von Perl-Variablen abzuspeichern. Das ist insbesondere für große Arrays oder Hashes interessant, die so von einem Programmaufruf zum anderen gesichert werden können. use Storable; store(\$i, 'save.dat'); # Inhalt von $i sichern $i = ${retrieve('save.dat')}; # Inhalt wieder herstellen Übungsaufgaben Ein paar Aufgaben aus der Mathematik zur Übung der Perl-Grundlagen (Eingabe, Ausgabe, Schleifen, usw.). Die Lösungen gibt es Anfang nächster Stunde. Aufg. 7) Primzahlen a) Schreiben Sie ein Perl-Programm, das das Sieb des Eratosthenes für n=1000 berechnet, also die Primzahlen <= 1000 in einem Array abspeichert und diese dann der Reihe nach ausgibt. Tipp: <http://de.wikipedia.org/wiki/Sieb_des_Eratosthenes> b) Erweitern Sie die Ausgabe in a) um eine Statistik, wieviele Primzahlen jeweils unter 100 Zahlen vorkommen, also im Intervall 1-100, 101-200, usw. c) Verwenden Sie das Array mit den Primzahlen aus a), um die Primfaktorzerlegung einer einzugebenden Zahl (< 1000^2) zu berechnen. Tipp: <http://de.wikipedia.org/wiki/Probedivision> Aufg. 8) Euklidischer Algorithmus Schreiben Sie ein Perl-Programm, das wiederholt zwei Zahlen einliest und den größten gemeinsamen Teiler (ggT) ausgibt. Verwenden Sie zur Berechnung den Euklidischen Algorithmus. Tipp: Auf <http://de.wikipedia.org/wiki/Euklidischer_Algorithmus> wird der Algorithmus erklärt und ein Pseudocode angegeben. Viel Spaß! 37 Dateizugriff, Ausführen von Shell-Befehlen Dateizugriff, Ausführen von Shell-Befehlen Bei der Verwendung der Ein-/Ausgabe-Funktionen von Perl ist die Nähe zu Unix unverkennbar. Da aber auch das Dateisystem von Windows seinen Unix-Ursprung nicht verbergen kann, kann viel von dem hier gesagten auch auf Windows-Systeme angewendet werden. Kommandozeilenparameter Die Variable @ARGV wird vom Perl-Interpreter beim Programm-Aufruf gesetzt. Damit hat man Zugriff auf alle Parameter, die an das Programm übergeben wurden. #!/usr/bin/perl # Haben wir Parameter? if (@ARGV>0) { # Dann alle durchgehen for ($i=0; $i<=$#ARGV; $i++) { print "$0: Parameter $i: $ARGV[$i]\n"; } } Das geht noch kürzer: while (@ARGV) { print shift @ARGV, "\n"; } Dateizugriff Filehandle Ein Filehandle (engl.: „handle“ = Griff, Stiel) ist ein Objekt, über das man Daten ein- und ausgeben kann. Nach dem Öffnen (open) ist ein Filehandle mit einer Datei verbunden. Die Datei kann gelesen oder geschrieben werden. Was genau eine Datei ist, definiert das zugrundeliegende Betriebssystem. Nach dem Schließen (close) ist die Verbindung zwischen Filehandle und Datei getrennt. Ein Filehandle kann anschließend erneut, entweder mit der gleichen oder einer anderen Datei, geöffnet werden. Öffnet man ein Filehandle, ohne es vorher zu schließen, so wird die alte Verbindung automatisch geschlossen bevor die neue Verbindung geöffnet wird. Filehandle-Namen bilden zusammen mit Labeln einen Namensraum. Die Empfehlung lautet, sie durchgängig groß zu schreiben. Vordefinierte Filehandle Unix- und Windows-Systeme kennen vordefinierte Filehandle, die bereits offen und ohne spezielle Anweisungen sofort nutzbar sind, dazu gehören STDIN (Standardeingabe), STDOUT (Standardausgabe) und STDERR (Fehlermeldungen). Welche Dateien mit ihnen verbunden sind, ist systemabhängig. Normalerweise sind sie an das Fenster gebunden, in dem das Perl-Skript ausführt wird. Eingabe von STDIN Wir haben schon gesehen, wie man im Skalar- sowie im Array-Kontext Datenzeilen einliest. Will man von STDIN zeilenweise in einer while-Schleife einlesen, so empfiehlt sich folgendes Muster unter Verwendung des <STDIN> Operators und der Defaultvariablen $_. while(<STDIN>) { 38 Dateizugriff, Ausführen von Shell-Befehlen chomp; # irgendwelche Operationen mit $_ } # steht für while(defined($_ = <STDIN>)) { chomp($_); # irgendwelche Operationen mit $_ } Liefert <STDIN> bei Dateiende keine Daten mehr, so wird der Wert von $_ undefined. Damit ist die Schleifenbedingung nicht mehr wahr und die while-Schleife bricht ab. Mehrere Dateien verarbeiten Ein weitere Möglichkeit, Daten einzulesen, ist die Verwendung des diamond-Operators <>. Er verhält sich im Skalarenund Array-Kontext wie der <STDIN>-Operator. Der Unterschied ist folgender: Wird das Perl-Skript mit Argumenten aufgerufen, so werden diese Argumente als Dateinamen interpretiert, die nacheinander gelesen werden. Fehlen diese Dateinamen, so wird von Standard-Eingabe gelesen. Ein Perl-Skript namens kitty werde mit drei Argumenten aufgerufen: #!/usr/bin/perl -w while(<>) { print $_; } # Aufruf: kitty Datei1 Datei2 Datei3 Dann öffnet der diamond-Operator nacheinander alle drei Dateien zum Lesen. Dazu liest er nicht direkt die Informationen von der Befehlszeile, sondern alle Argumente werden in einem spracheigenem Array @ARGV abgelegt. Dieses Array kann vom Programmierer beliebig benützt werden. Obiges Beispiel könnte auch geschrieben werden als: #!/usr/bin/perl -w @ARGV = qw(Datei1 Datei2 Datei3); while(<>) { print $_; } # Aufruf: kitty Natürlich macht es in der Regel keinen Sinn Dateinamen in dieser Form fest im Programm zu "verdrahten". Ausgabe auf STDOUT Wir haben bereits die Funktionen print und printf zur Ausgabe auf dem Bildschirm (=STDOUT) kennen gelernt. Wird bei diesen Funktionen kein Filehandle als erster Parameter angegeben, schreiben sie automatisch auf die Standardausgabe. print "Hallo Welt!\n"; # bedeutet also implizit print STDOUT "Hallo Welt!\n"; Eine weitere Möglichkeit ist das Ausgeben von mehrzeiligem Text als „Here“-Dokument. Dabei wird dem print-Befehl als Parameter ein Label angegeben, bis zu diesem der folgende Text ausgegeben werden soll. In diesem Fall müssen keine Anführungszeichen „escaped“ werden und die Variableninterpolation funktioniert wie normal. #!/usr/bin/perl $wert = "4321"; print <<EOT; <<< Hier wird mehrzeiliger Text ausgegeben >>> Wert = $wert # Mit "Variableninterpolation" 39 Dateizugriff, Ausführen von Shell-Befehlen EOT Die Variableninterpolation kann abgeschaltet werden, indem das Label in einfache Anführungszeichen gesetzt wird. print <<'EOT'; To: ZIVline <[email protected]> EOT Filehandle öffnen und schließen Will man mehr als die Standardkanäle zur Ein-/Ausgabe benützen, muss man explizit Filehandle beim Öffnen mit Dateien verbinden. Dabei muss angegeben werden, ob man aus der Datei lesen oder in sie schreiben will. Dateien werden mit der spracheigenen Funktion open() geöffnet. open(IN,"</etc/passwd"); open(OUT,">ausgabe.datei"); open(OUT,">>ausgabe.datei"); open(IN,"ls -l |"); open(OUT,"| more"); # # # # # lesen (ueber)schreiben anhaengen Ausgabe von "ls -l" lesen eigene Ausgabe an "more" pipen Die letzten beiden Beispiele haben weniger mit Dateien als mit Standardeingabe-Kanälen zu tun. "ls -l" schreibt seine Ausgabe auf STDOUT. Diese wird mit einer pipe zum Filehandle IN umgeleitet. open öffnet in diesem Fall also nicht nur das Filehandle, sondern führt vorher das "ls -l"-Kommando asynchron aus. Das letzte Beispiel ist analog: Die SkriptAusgabe wird über eine pipe zur Standardeingabe des "more"-Programms, das von open aufgerufen wird. Filehandle werden beim Skript-Ende oder beim erneuten Öffnen automatisch geschlossen. Bei schreibend geöffneten Filehandlen kann man erst nach dem Schließen sicher sein, dass auch alle Daten in die Datei gespeichert wurden. Dateien werden mit der spracheigenen Funktion close() geschlossen. close(IN); # IN schliessen Fehlerbehandlung Beim Öffnen und Schließen von Filehandlen ist es dringend nötig, auf mögliche Fehler zu achten und entsprechend zu reagieren. Reagieren kann man, indem man den Rückgabewert prüft: Wird eine Datei erfolgreich geöffnet (bzw. geschlossen), so ist der Rückgabewert von open (bzw. close) wahr (ein gültiges handle), ansonsten ist er falsch (undef). Eigentlich sollte im folgenden Beispiel die Datei /etc/passwd gelesen werden. Tatsächlich aber wird sie zum Schreiben geöffnet, was für fast alle Nutzer nicht erlaubt ist: open (IN,">/etc/passwd") or die "Fehler beim Oeffnen von /etc/passwd: $!\n"; while (<IN>) { print } # Ausgabe: # Fehler beim Oeffnen von /etc/passwd: Permission denied In der zweiten Zeile verbindet or zwei Anweisungen. Die erste Anweisung wird ausgeführt. or testet den Erfolg. Nur bei einem Fehlschlag wird die zweite Anweisung ausgeführt. or kann man auch als || (logisches oder) schreiben. Allerdings muss man beachten, dass sich or und || in ihrer Priorität unterscheiden! $a = $b or $c; # Falsch: Zuweisung bindet stärker als or ($a = $b) or $c; # => ist äquivalent hierzu $a = $b || $c; # Richtig: entweder $b oder $c an $a zuweisen (|| bindet stärker als Zuweisung) Die zweite Anweisung, die(), schreibt die angegebene Zeichenkette auf STDERR und beendet das Skript. Die 40 Dateizugriff, Ausführen von Shell-Befehlen spracheigene Variable $! enthält die Fehlermeldung des Betriebssystems („Permission denied“) und sollte unbedingt zur weiteren Fehleranalyse ausgegeben werden. Man kann die Ausführung zweier Anweisungen auch mit einem logischen und aneinander knüpfen. Dann wird die zweite Anweisung nur dann ausgeführt, wenn die erste erfolgreich wahr: open (IN,"</etc/passwd") and print "/etc/passwd erfolgreich geoeffnet.\n"; while (<IN>) { print } # Ausgabe: # /etc/passwd erfolgreich geoeffnet. # root:x:0:0:root:/root:/bin/bash # bin:x:1:1:bin:/bin:/bin/bash and kann man (unter Beachtung der Priorität) auch als && schreiben. Will man nur eine Warnung auf STDERR ausgeben und ansonsten weitermachen, so kann man warn() nutzen: open (IN,">/etc/passwd") or warn "Fehler beim Oeffnen von /etc/passwd: $!\n"; while (<IN>) { print } # Ausgabe: # Fehler beim Oeffnen von /etc/passwd: Permission denied # Read on closed Filehandle <IN> at ./x line 6. Offensichtlich ist warn an dieser Stelle nicht Warnung genug. Filehandle benützen Wie man Filehandle benützt, soll folgendes Programm zeigen, dass eine Datei, deren Name sich in der Variablen $a befindet, in eine andere Datei (Name in $b) kopiert. $a = "x.html"; $b = "y.html"; open(IN,"<$a") or die "Kann $a nicht lesen: $!\n"; open(OUT,">$b") or die "Kann $b nicht beschreiben: $!\n"; while (<IN>) { print OUT $_; } close(IN) or die "Kann $a nicht schliessen: $!\n"; close(OUT) or die "Kann $b nicht schliessen: $!\n"; print "$a nach $b kopiert.\n"; Ist das erste print-Argument ein Filehandle, so erfolgt die Ausgabe zu diesem Handle. Ist das erste Argument kein Filehandle, so schreibt print auf STDOUT. Dateizustand testen Häufig möchte man vor einem open testen, ob das Öffnen wahrscheinlich erfolgreich sein wird. Aus diesem Grund gibt es eine Reihe von Fragen, die man einer Datei stellen kann. Erweitern wir unser obiges Kopierprogramm wie folgt: Es soll vor dem Öffnen geprüft werden, ob es die Datei schon gibt und man sie lesen kann. Die Ausgabedatei dagegen darf noch nicht existieren: $a="x.html"; $b="y.html"; unless ( -r $a ) { die "$a nicht lesbar.\n" } if ( -e $b ) { die "$b existiert schon.\n" } # open(IN,"<$a") or die "Kann $a nicht oeffnen: $!\n"; open(OUT,">$b") or die "Kann $b nicht oeffnen: $!\n"; while (<IN>) { print OUT $_; } 41 Dateizugriff, Ausführen von Shell-Befehlen close(IN) or die "Kann $a nicht schliessen: $!\n"; close(OUT) or die "Kann $b nicht schliessen: $!\n"; print "$a nach $b kopiert.\n"; Der Test -r prüft, ob eine Datei lesbar ist. Um lesbar zu sein, muss die Datei existieren. Zusätzlich muss der Benutzerkennung, die das Skript ausführt, Zugriff auf das Verzeichnis, in dem die Datei steht, möglich sein. Und, last not least, die Datei selbst muss für die Benutzerkennung lesbar sein. -e testet einfach, ob die Datei schon existiert. Nachstehende Tabelle listet einige der Datei-Test-Möglichkeiten auf (aus perldoc -f -X): Test Beschreibung -r Ist die Datei oder das Verzeichnis lesbar? -w Ist die Datei oder das Verzeichnis schreibbar? -x Ist die Datei oder das Verzeichnis ausführbar? -o Gehört die Datei oder das Verzeichnis demjenigen, der das Skript ausführt? -e Existiert die Datei oder das Verzeichnis? -z Existiert die Datei und ist leer? (Verzeichnisse sind niemals leer) -s Existieren die Datei oder das Verzeichnis bereits. Wenn ja, ist der Rückgabewert die Dateigröße. -f Ist die Datei normal? (Also kein Verzeichnis, kein Link, etc.) -d Ist die Datei ein Verzeichnis? -l Ist die Datei ein symbolischer Link? -T Enthält die Datei Text-(=nicht-binäre)-Daten? -B Enthält die Datei binäre Daten? Diese Teste sind nicht nur für Dateinamen, sondern auch für Filehandle möglich. Perl bietet noch weitere Funktionen an, mit denen man im Dateisystem nach Dateien eines bestimmten Typs suchen kann; diese Funktionen behandeln wir gleich (Stichwort: Globbing). Verzeichniszugriff Verzeichnisse sind spezielle „Dateien“, die Informationen über die Dateien und Verzeichnisse enthalten, die in ihnen eingetragen sind. Verzeichnisse sind niemals leer, sie enthalten wenigstens einen Bezug auf sich selbst (.) und auf das übergeordnete Verzeichnis (..). Das Schreiben von Verzeichnissen ist eine privilegierte Operation, das Lesen nicht. Verzeichnisse öffnen und lesen Mit opendir() lässt sich ein ganzes Verzeichnis zur Verarbeitung (mittels eines directory handles) öffnen. Z.B. um alle Dateien darin der Reihe nach zu bearbeiten. !/usr/bin/perl -w # Skalarkontext opendir(DIR, ".") or die "Error opening .\n"; while ($_ = readdir DIR) { print "$_\n"; } closedir DIR; # Listkontext opendir(DIR, ".") or die "Error opening .\n"; my @files = readdir DIR; foreach $file (sort @files) 42 Dateizugriff, Ausführen von Shell-Befehlen { print "$file\n"; } closedir DIR; Die Funktion readdir() liefert im skalaren Kontext die nächste Datei im Verzeichnis und im Listenkontext alle Dateien. Mit der while-Schleife lässt sich so über alle Dateien iterieren. closedir() schließt das Verzeichnishandle wieder. Das Arbeitsverzeichnis wechseln Der vollständige Namen einer Unix-/Windows-Datei besteht aus zwei Teilen, dem Verzeichnis- und dem Datei-Namen. Der Verzeichnisname wird auch Pfadname genannt. Fehlt die Angabe des Verzeichnisses, so ist die Datei im gerade eingestellten Arbeitsverzeichnis (working directory) gemeint. Das Arbeitsverzeichnis kann auf Kommandozeilenebene mit dem cd-Befehl verändert werden und in einem Perl-Skript mit der spracheigenen Funktion chdir(). chdir("/etc") or die "Kann nicht nach /etc wechseln ($!)\n"; Wird chdir ohne Argument aufgerufen, so wird in das HOME-Verzeichnis gewechselt. Beachten Sie bitte, dass chdir nur das Arbeitsverzeichnis des Prozesses ändert, der das Perl-Skript gerade ausführt. Globbing Möchte man in einem Verzeichnis eine Gruppe von Dateinamen für eine bestimmte Aktion selektieren, so benützt man dazu auf Kommandozeilenebene so genannte Wildcards wie *, ? oder [], die man als Metazeichen für reguläre Ausdrücke verstehen kann, mit denen Dateinamen gesucht werden. In Perl gibt es hierfür die spracheigene Funktion glob(). # Skalarer Kontext: while (glob "*.pre.html") { print "$_\n"; } # Array-Kontext: @Dateien = <*.pre.html>; # entspricht glob "*.pre.html" print "@Dateien\n"; Die bei glob verwendbaren Metazeichen hängen von der verwendeten Kommandozeilenebene ab und haben nichts mit den regulären Ausdrücken Perls zu tun. Gibt es keine Dateien, die auf das glob-Muster passen, so ist je nach Kontext der Rückgabewert undef oder eine leere Liste. Manchmal enthalten geglobbte Dateinamen noch den Pfadnamen. Folgendes Programm zerlegt solche Namen in ihren Pfad- und Datei-Anteil. while (glob "/etc/*") { ($Pfad,$Datei) = m#(.*)/(.*)#; print "$Pfad - $Datei\n"; } Dateinamen haben manchmal die Form basename.extension. Will man diese trennen, so kann man nach folgendem Muster vorgehen: while (glob "/etc/*") { s#.*/##; # entferne Pfadanteil, if any if (m#\.#) { ($base,$ext) = m#(.*)\.(.*)#; print "$base - $ext\n"; } else { print "$_\n"; } } Bei diesen beiden Beispielen haben wir schon wieder vorausgegriffen und reguläre Ausdrücke (in magenta) verwendet. Diese werden in der nächsten Stunde erklärt. Für die Aufteilung von Dateinamen in Pfad, Basisname und Erweiterung ist das Perl-Modul File::Basename hilfreich. 43 Dateizugriff, Ausführen von Shell-Befehlen Aufruf von externen Programmen qx() (quoted execution) Mit qx(Befehl) wird ein Befehl ausgeführt und dessen Ausgabe zurückgeliefert. Dies ist die ausführliche Variante des Backtick-Operators `Befehl`. # TMP Verzeichnis-Inhalt auflisten print qx(/bin/ls -l /tmp); # dasselbe print `/bin/ls -l /tmp`; system() Mit system werden Befehle ausgeführt, ohne die Ausgabe für das Perl-Skript einzufangen. Die Ausgabe erscheint auf STDOUT und kann mit einer Umleitung nach >/dev/null unterdrückt werden. Das Ergebnis von system ist der return-Wert des jeweiligen Programms. So können evtl. aufgetretene Fehler behandelt werden. if (system ("/bin/ls -l /tmp") == 0) { print "Kein Fehler.\n"; } else { print "Fehler: $!\n"; } Sicherheit: qx() und system() in den beiden voranstehenden Beispielen übergeben den Programmstring jeweils an die System-Shell (/bin/sh) zur Ausführung. Enthält der Programmstring Variablen, deren Inhalt nicht überprüft wurde, so ist es möglich Schadcode auszuführen (einfachstes Beispiel ist das Anhängen von ';rm -rf /' bei obigem system-Befehl). Um dies zu verhindern kann system() mit einer Liste als Parameter aufgerufen werden. Dann wird die Shell umgangen und das erste Element der Liste als Befehl mit den restlichen Elementen als Parameter ausgeführt. $cmd = "/bin/ls"; @args = ("-l", "/tmp"); if (system ($cmd, @args) == 0) { print "Kein Fehler.\n"; } else { print "Fehler: $!\n"; } Aufruf von Perl-Code eval() Mit der Funktion eval ist es möglich in einem Perl-Programm dynamischen Perl-Code auszuführen, quasi ein Interpreter im Interpreter. Damit lässt sich einfach ein kleiner Taschenrechner programmieren: #!/usr/bin/perl # # Einfacher Taschenrechner basierend auf eval() # do { print "Einfacher Rechner> "; chomp($in = <STDIN>); $res = eval $in; if ($@) { print "Illegale Eingabe!\n"; } else { $res+=0; # Konvertiere in Zahl print "Ergebnis: ", $res , "\n"; 44 Dateizugriff, Ausführen von Shell-Befehlen } } while ($in); exit 0; Exception-Handling Eine weitere Anwendung der Funktion eval ist, in Perl ein Exception-Handling zu realisieren. Wenn innerhalb von eval ein fataler Fehler auftritt (oder ein die-Aufruf), wird nur eval beendet und nicht das ganze Programm. Die Fehlermeldung steht danach in der speziellen Variable $@ zur Verfügung. Es ist also möglich mit die eine Exception zu werfen, die von eval abgefangen und hinterher über $@ behandelt wird. eval { if ($x == 0) { die "\$x is not set.\n"; } }; # <- Ende von eval, ';' nicht vergessen! if ($@) { warn "An exception has been raised.\n -> $@"; } # An exception has been raised. # -> $x is not set. Übungsaufgaben Zwei Aufgaben zum Üben von Dateioperationen, Ausführen von Shell-Befehlen und Verwendung von Hashes. Aufg. 9) Dateien auflisten a) Schreiben Sie ein Perl-Programm, das eine nach Namen sortierte Liste der Dateien mit den Spalten Name, Änderungsalter und Dateigröße im aktuellen Verzeichnis ausgibt. Alternativ soll ein gewünschtes Verzeichnis als Kommandozeilenparameter übergeben werden können. Der Parameter -h soll eine Hilfeseite ausgeben. b) Erweitern Sie das Programm aus a) um eine zusätzliche Spalte, die den Typ der Datei ausgibt. Rufen Sie dazu das Programm /usr/bin/file auf. (siehe dazu 'man file'). Tipp: Mit dem Befehl /bin/cut lassen sich bestimmte Spalten eines Textes extrahieren (siehe 'man cut'). c) Ändern Sie das Programm aus b) so ab, dass nur Dateien vom Typ "ASCII text" ausgegeben werden und für diese zusätzlich eine Spalte mit der Anzahl der Zeilen. Tipp: Mit dem Befehl /usr/bin/wc lässt sich die Anzahl der Zeilen einer Textdatei ausgeben (siehe 'man wc'). Aufg. 10) Hash Verwenden Sie einen Hash, um alle Informationen aus Aufgabe 9a zwischenzuspeichern. Über die Kommandozeilenparameter -n, -t, -s soll die Dateiliste dann jeweils sortiert nach Name, Alter oder Größe ausgegeben werden. Viel Spass! 45 Funktionen Funktionen Wir haben bis jetzt schon eine Reihe von spracheigenen Funktionen in Perl kennen gelernt. Im Folgenden geht es darum, eigene Funktionen zu schreiben. Mit Funktionen können häufig wiederkehrende Anweisungsblöcke „benannt“ werden oder ganz Allgemein die Struktur eines Programms verbessert werden. Außerdem ermöglichen Funktionen die Programmierung von „Rekursionen“, mit denen viele mathematische Probleme elegant gelöst werden können. Verwendung von eigenen Funktionen Eine Funktion definieren Eine nutzereigene Funktion, auch subroutine oder kurz sub genannt, wird in Perl wie folgt definiert: sub subname { Anweisung1; Anweisung2; } # "subname": Funktionsname Hinter dem Schlüsselwort sub steht der Funktionsname. Funktionen bilden wie Skalare, Arrays und Hashes einen eigenen Namensraum. Die Anweisungsfolge in den geschweiften Klammern ist die Funktionsdefinition. Funktionen können irgendwo in der Quelldatei stehen, häufig findet man sie am Ende der Programmdatei. Alle Variablen- und FunktionsNamen einer Quelldatei sind global, also können alle Funktionen alle Variablen benützen und jede Funktion aufrufen. Diese Eigenschaft der "maximalen Gemeinsamkeit" kann eingeschränkt werden, indem eine Funktion lokale Variablen verwendet, die nur in dieser Funktion sichtbar sind und Variablen gleichen Namens außerhalb der Funktion ausblenden. Wird eine Funktion in einem Programm mehr als einmal definiert, so gilt - stillschweigend - die letzte Definition. Funktionen aufrufen Nutzereigene Funktionen werden wie spracheigene Funktionen aufgerufen. say_hello(); # oder alternativ &say_hello; # sub say_hello { print "Hello.\n"; } Das runde Klammernpaar hinter say_hello macht aus der Zeichenfolge einen Funktionsaufruf. Die Klammer ist leer; es werden keine Argumente an die Funktion übergeben. Das runde Klammernpaar kann entfallen, wenn dem Funktionsnamen ein &-Zeichen vorangestellt wird. Werte zurückgeben Funktionen geben immer einen Funktionswert (return code) zurück. Entweder wird dieser explizit mit der return()Anweisung gesetzt und hat damit den Sinn eines berechneten Funktionswertes. Oder es ist implizit der Rückgabewert der letzten in der Funktion ausgeführten Anweisung. Beide Rückgabewerte können in Ausdrücken weiterverwendet werden. $a = 3; $b = 4; $c = summe_von_a_und_b(); $d = 3 * &summe_von_a_und_b; print "$a $b $c $d\n"; # sub summe_von_a_und_b { return $a + $b; } 46 Funktionen # Ausgabe 3 4 7 21 Werden Funktionen im Listenkontext aufgerufen, so kann der Rückgabewert eine Liste sein. $a = 5; $b = 13; @c = liste_von_a_und_b(); print "@c\n"; # sub liste_von_a_und_b { return ($a,$b); } # Ausgabe 5 13 Wenn Sie, wie bei den Perl eingebauten Funktionen, abhängig vom Kontext einen Skalar oder eine Liste zurückgeben wollen, so steht die Funktion wantarray() zur Verfügung, die true zurück liefert, wenn die Funktion im Listenkontext aufgerufen wurde. $a = 5; $b = 13; $c = summe_oder_liste_von_a_und_b(); print "$c\n"; @c = summe_oder_liste_von_a_und_b(); print "@c\n"; # sub summe_oder_liste_von_a_und_b { if (wantarray()) { return ($a,$b); } else { return $a+$b; } } # Ausgabe 18 5 13 Argumente übergeben Wirklich nützlich werden Funktionen erst dann, wenn man sie durch die Übergabe von Argumenten parametrisieren kann. Beim Aufruf werden die Argumente nach dem Funktionsnamen als Liste angegeben. In der Funktion steht diese Liste im spracheigenen Array @_ zur Verfügung. $a = 5; $b = 13; $c = addiere($a,$b); print "$a + $b = $c\n"; # sub addiere { return $_[0]+$_[1]; } # Ausgabe: 5 + 13 = 18 Zurückgegeben wird die Summe der beiden Argumente, die man in den ersten beiden Elementen des Arrays @_ findet. Man kann addiere erweitern, so das die Funktion eine beliebige Anzahl von Argumenten aufsummiert. $c = addiere(1..10); print "Summe der ersten 10 Zahlen: $c\n"; # sub addiere { $s = 0; foreach (@_) { $s += $_ } return $s; } 47 Funktionen # Ausgabe: Summe der ersten 10 Zahlen: 55 Der Gebrauch des Listenkonstruktions-Operators .. zeigt sehr schön, dass das, was beim Funktionsausfruf hinter dem Funktionsnamen steht, syntaktisch eine Liste ist. In der foreach-Schleife werden alle Elemente von @_ in der Variablen $s aufsummiert. Die Defaultvariable $_ zeigt iterativ auf jedes Element von @_. Bitte beachten Sie den Unterschied zwischen den Variablen $_ und beispielsweise $_[0]. Lokale Variablen Das letzte Beispiel hat einen Schönheitsfehler: Was ist, wenn es die Variable $s irgendwo anders im Programm schon gibt? Bislang waren die Variablen global gültig, so dass, sollte es irgendwo sonst eine Variablen mit gleichem Namen gegeben haben, der Wert dieser Variablen überschrieben wird. Es sollte eine Möglichkeit geben, $s in addiere so zu vereinbaren, dass $s in addiere lokal wird. sub addiere { my($s) = 0; foreach (@_) { $s += $_ } return $s; } Die spracheigene Funktion my() hat als Argument eine Liste von Variablen, die lokal für die Funktion sein sollen. Für sie wird Speicherplatz angelegt, der beim Verlassen der Funktion wieder freigegeben wird. Eine evtl. existierende globale Variable wird ausgeblendet. Verlässt man die Funktion, etwa durch einen Funktionsaufruf oder das normalen Funktionsende, wird die globale Variable eingeblendet und damit die lokale Variable unzugreifbar. Zurückgegeben wird eine Liste von Zeigern auf die lokalen Instanzen dieser Variablen, die man zum Initialisieren verwenden kann: sub addiere { my(@Summanden) = @_; my($s) = 0; # foreach (@Summanden) { $s += $_ } return $s; } Die erste my-Anweisung erzeugt eine lokale Liste @Summanden, die die Werte der Argumentenliste zugewiesen bekommt. Was eine nette Möglichkeit ist, den Argumenten sprechende Namen zu geben. Aber diese Version hat immer noch einen Fehler. addiere benützt die Defaultvariable $_. Was ist, wenn addiere von einer Programmstelle aus aufgerufen wird, die selbst gerade $_ benützt? $_ müsste ebenfalls lokal sein. Das Problem ist, dass my nicht auf die spracheigenen Variablen wie $_ angewandt werden kann. Für diesen und andere Zwecke gibt es eine weitere spracheigene Funktion zur Lokalisierung von Variablen: local(). local funktioniert fast wie my, aber eben nur fast: $wert = "global"; # &up1; &up1_via_up2; &up1; # sub up1 { print "$wert\n" } # sub up1_via_up2 { local ($wert) = "lokal"; &up1; } # Ausgabe: global lokal global Der Wert von $wert ist nicht so privat, wie man denkt. Wird up1 von up1_via_up2 aus aufgerufen, so sieht up1 für diesen Aufruf den lokalen Wert von $wert. Hätte man my statt local in up1_via_up2 verwendet, so wäre in allen drei Fällen der Wert der globalen Variablen ausgegeben worden. local macht eine Variable lokal für die aktuelle Funktion und alle von dort aufgerufenen Unterfunktionen (dynamic scope). my wirkt sich dagegen nur auf den aktuellen Anweisungsblock aus (lexical scope). 48 Funktionen Beide Strategien haben ihren Sinn. Man muss sich nur überlegen, was die aufgerufene Funktion sehen soll. Die Lokalisierung mit my ist häufig effizienter als die Lokalisierung mit local. Dafür kann man mit local spracheigene Variablen lokalisieren, was für solch häufig gebrauchte Variablen wie $_ mehr als sinnvoll ist: sub addiere { my(@Summanden) = @_; my($s) = 0; local $_; # foreach (@Summanden) { $s += $_ } return $s; } So haben wir dann mit etwas Mühe das Perl-Prinzip der "maximalen Gemeinsamkeit" außer Kraft gesetzt. Man kann Perl deswegen kritisieren. Perl bietet Anhängern der objekt-orientierten Programmiermethode die Möglichkeit, mittels packages globale Variablen pro Perl-Modul einzuführen. Die globalen Variablen eines packages sind von einem anderem package aus unsichtbar. Variablendeklaration Variablendeklaration bedeutet das Bekanntmachen einer Variable durch Festlegen von Name und Datentyp, wonach dann Speicherplatz reserviert wird. In Perl findet eine implizite Deklaration statt, d.h. Variablen werden bei erstmaligem Auftreten automatisch deklariert. Mit dem Schlüsselwort my können außerhalb von Funktionsdefinitionen die globalen Programm-Variablen explizit deklariert werden. Dies hat zwei Vorteile: 1. Das Programm läuft etwas schneller. 2. Schreibfehler bei Variablennamen fallen schneller auf. Mit der Anweisung use strict; bittet man Perl, die Deklaration aller Variablen zu erzwingen. Gibt man zusätzlich die Option -w beim Programm-Aufruf an, so hat man eine gute Hilfe bei der Programmentwicklung. Die Variablendefinition ist ein Sonderfall der Deklaration, bei dem der Variable zusätzlich ein Wert zugewiesen wird (Initialisierung). use strict; # my $a; # deklariert, Wert: undef my @b = qw(fred wilma); # deklariert, initialisiert @c = sort @b; # Fehler: @c nicht deklariert. Call by Reference Arrays oder Hashes können nicht direkt als Parameter an Funktionen übergeben werden. Deren Elemente werden mit möglichen anderen Parametern in das Array @_ übernommen. Will man an eine Funktion nicht die Werte eines Objektes (Call by Value), sondern seine Referenz übergeben, so kann man folgendes Muster verwenden: func(\@Array, \%Hash, \&Funktion); # sub func { my ($ArrayRef, $HashRef, $SubRef) = @_; my @Array = @$ArrayRef; # Kopieren auf lokale Objekte my %Hash = %$HashRef; # als Beispiel der Nutzung # ... $SubRef->(); } Rekursion Ruft sich eine Funktion selbst auf, so wird dies rekursiver Aufruf oder Rekursion genannt. Mit dieser Möglichkeit ergeben sich elegante Lösungen für viele Probleme. Insbesondere in der Mathematik sind viele Funktionen rekursiv definiert. Ein bekanntes Beispiel dafür ist die Fibonacci-Folge: # Fibonacci-Folge (aus "Liber Abaci", 1202 AD) 49 Funktionen sub Fib() { my $n = shift; if ($n == 0) { return 0; } elsif ($n == 1) { return 1; } elsif ($n >= 2) { return Fib($n-1)+Fib($n-2); } } Bei Rekursionen muss man genau wie bei Schleifen, die auch Iterationen genannt werden, auf eine Abbruchbedingung achten! Andernfalls befindet sich das Programm in einer Endlosschleife. Außerdem ist es wichtig, dass die Variablen der sich aufrufenden Funktion mit my lokal definiert werden, da ansonsten der Inhalt des vorherigen Rekursionsschrittes überschrieben wird. Prototypen Funktions-Prototypen sind in Perl dazu da, um selbst definierte Funktionen genau so aufrufen zu können wie die bereits eingebauten Funktionen. Einerseits wird damit der Typ und die Anzahl der Parameter festgelegt und zum anderen ist es damit möglich, die Klammern um die Parameter beim Aufruf der Funktion weg zu lassen. #!/usr/bin/perl # addiere1 erwartet genau zwei Skalare, alles andere produziert eine Fehlermeldung sub addiere1 ($$) { # ... } # normaler Aufruf addiere1(1,2); # durch Prototyp wird dieser Aufruf möglich addiere1 1,2; # addiere2 erwartet eine Liste sub addiere2 (@) { # ... } addiere2(1..9); addiere2 1..9; Signale Ein Programm kann Signale vom Betriebssystem bekommen, die entsprechend abgefangen und beantwortet werden können. Ein wichtiges Signal ist SIGINT (Signal Interrupt), mit dem ein Programm abgebrochen werden kann. Dieses Signal wird z.B. mit CTRL-C ausgelöst. $SIG{'INT'} = sub { die("Abbruch mit CTRL-C\n"); }; # CTRL-C abfangen und Meldung ausgeben 50 Funktionen Übungsaufgaben Zur Übung der Dateioperationen, sowie der funktionalen Programmierung drei weitere Aufgaben: Aufg. 11) Fakultät Schreiben Sie ein Perl-Programm, das die Fakultät berechnet, wobei die Berechnung a) iterativ, d.h. mit einer Schleife (z.B. for, while), erfolgt b) rekursiv, d.h. mit einer sich selbst aufrufenden Funktion, erfolg. Informationen zur Definition der Fakultät: http://de.wikipedia.org/wiki/Fakultät Aufg. 12) Verzeichnisbaum auflisten Schreiben Sie ein Perl-Programm, das rekursiv den Verzeichnisbaum ab einer bestimmten Stelle ausgibt. Alternativ soll das Verzeichnis als Kommandozeilenparameter übergeben werden können. Der Parameter -h gibt eine Hilfeseite aus. Versuchen Sie das Programm mit Hilfe von Funktionen zu strukturieren! Die Lösungen gibt es Anfang nächster Stunde. Danach geht es weiter mit regulären Ausdrücken. Viel Spass! 51 Einführung in reguläre Ausdrücke Einführung in reguläre Ausdrücke Reguläre Ausdrücke Mit regulären Ausdrücken (engl.: „regular expressions“) formuliert man Muster, die den prinzipiellen Aufbau einer Zeichenkette beschreiben. Dazu stehen normale Zeichen, nach denen literal (d.h. Buchstabe für Buchstabe) gesucht wird, und Metazeichen, um nach bestimmten Zeichenkonstruktionen, Kombinationen oder Anordnungen zu suchen, zur Verfügung. Reguläre Ausdrücke bieten somit ein mächtiges und leistungsfähiges Werkzeug zum Suchen und Ersetzen von Zeichenketten. Reguläre Ausdrücke können nicht nur in Perl verwendet werden sondern in vielen Unix-Programmen wie grep, awk, sed und auch anderen Programmiersprachen wie PHP und Java. Das Thema ist so umfangreich, dass es dazu eigene Bücher gibt. Weiterführende Literatur • • Mastering Regular Expressions, Jeffrey Friedl, 2nd Edition, July 2002, ISBN 0-596-00289-0 Reguläre Ausdrücke, Jeffrey Friedl, 2. Auflage, April 2003, ISBN 3-897-21349-4 Nehmen wir an, wir wollen eine gegebene Datei daraufhin untersuchen, ob eine bestimmte Klasse von Zeilen darin vorkommen. Man formuliert diese Klasse mit einem regulären Ausdruck und benützt diese Formulierung als Suchmuster, mit dem alle Dateizeilen verglichen werden. Man kann im Programm testen, ob ein Suchmuster passt oder nicht, und entsprechend reagieren. Einführungsbeispiel Ein Beispiel: Eine Mailbox im Unix-System ist eine einfache Textdatei. Man möchte alle Absender-Zeilen extrahieren, also alle Zeilen, die die Buchstabenfolge From enthalten, #!/usr/bin/perl -w # while (<>) { print $_ if /From/; } Das Suchmuster steht zwischen den Schrägstrichen // und besteht einfach aus den Zeichen F r o m, die in dieser Reihenfolge gesucht werden. // ist der Operator zur Mustersuche, auch Pattern-Matching-Operator genannt. Angewandt auf eine meiner Mailboxen, die 19 Mails enthält, ergibt das Skript eine Ausgabe von 45 Zeilen (Auszug): From ost Fri Jul 16 13:44:22 1999 >From [email protected] Fri Jul 16 13:44:20 1999 From: [email protected] From ost Tue Jul 20 01:30:38 1999 >From [email protected] Tue Jul 20 01:30:37 1999 From: Willi Book <[email protected]> From ost Thu Jul 22 22:07:48 1999 >From [email protected] Thu Jul 22 22:07:47 1999 From: [email protected] (Sebastian Bader) From ost Thu Sep 16 01:51:08 1999 >From [email protected] Thu Sep 16 01:51:07 1999 From: "Babylon" <[email protected]> From ost Wed Oct 6 15:25:57 1999 >From [email protected] Wed Oct 6 15:25:55 1999 From: [email protected] Verändern wir das Muster von From in From:, erhalten wir als Ausgabe 20 Zeilen (Auszug): From: From: From: From: From: Mail System Internal Data <[email protected]> [email protected] Ram Greenshpon <[email protected]> Margret Greenshpon <[email protected]> "Bette S. Feinstein" <[email protected]> 52 Einführung in reguläre Ausdrücke ReSent-From: Stefan Ost <[email protected]> From: "Bette S. Feinstein" <[email protected]> Es stört nur noch die Zeile, die mit ReSent-From: beginnt. Man müsste also sagen können, dass einen nur die Zeilen interessieren, in denen From: am Zeilenanfang steht. #!/usr/bin/perl -w # while (<>) { print $_ if /^From:/; } Das Dach ^ ist ein Metazeichen, das nicht für sich selbst steht, sondern das Suchmuster am Zeilenanfang verankert; ReSent-From: passt also nicht mehr auf das Suchmuster. Regulären Ausdrücke sind in der Unix-Kultur sehr populär. Das Problem ist nur, dass es so viele unterschiedliche Varianten und Interpretationen der Meta-Zeichen gibt, die die Funktionalität der regulären Ausdrücke definieren. Wer sich für diese, manchmal sehr feinen, Unterschiede interessiert, dem sei das Buch von Jeffrey Friedl „ Mastering Regular Expressions“ empfohlen, das es inzwischen auch in einer deutschen Ausgabe gibt. Suchmuster Suchmuster für ein einzelnes Zeichen Die einfachsten Komponenten eines Suchmuster sind die Zeichen, die einfach für sich selbst stehen. Ein F beispielsweise fordert nichts mehr, als das ein großes F gefunden werden muss. Ein Punkt . dagegen steht nicht für sich selbst, sondern passt auf jedes beliebige Zeichen außer dem \n-Zeichen. Als Beispiel passt /F./ auf jede Zeichenkette, die die Zwei-Buchstaben-Sequenz enthält, die mit F beginnt, gefolgt von einem beliebigen Zeichen außer dem \n. Man kann in Mustern eine Zeichenmenge (engl. „character class“) angeben. Das Muster passt dann, wenn genau ein Zeichen aus dieser Menge passt. Die Zeichenmenge wird in eckigen Klammern [] eingeschlossen. Sollen Zeichen, die innerhalb der Zeichenmenge eine besondere Bedeutung haben, selbst Teil der Zeichenmenge sein, so müssen sie mit einem Backslash \ maskiert werden. /[abcdef]/ /[aA]/ /[0123456789]/ /[0-9]/ /[0-9\-]/ /[0-9a-z]/ /[0-9][a-z]/ /[^0-9]/ /[^\^]/ # # # # # # # # # a, b, c, d, e oder f kleines oder grosses a irgendeine Ziffer irgendeine Ziffer irgendeine Ziffer oder das Minus-Zeichen Kleinbuchstaben oder Ziffern eine Ziffer gefolgt von einem Kleinbuchstaben alles, was keine Ziffer ist alles, was kein ^ ist Aus Bequemlichkeit sind einige Zeichenmengen mit Abkürzungen vordefiniert. Die Tabelle enthält Abkürzungen für (Nicht-)Zahlen, für (Nicht-)Worte und für die Zeichen, die Worte (nicht) trennen. Abkürzung Zeichenmenge Negation Negierte Zeichenmenge \d [0-9] \D [^0-9] \w [a-zA-Z0-9_] \W [^a-zA-Z0-9_] \s [ \r\t\n\f] \S [^ \r\t\n\f] Diese Zeichenmengenabkürzungen können selbst Teil einer Zeichenmenge sein, zum Beispiel passt das Muster /\da-fA-F/ auf eine hexadezimale Ziffer. 53 Einführung in reguläre Ausdrücke Muster, die auf Zeichengruppen passen Sequenz Eine Sequenz ist eine Reihe von Zeichen, die in der angegebenen Reihenfolge vorkommen müssen. Multiplier Mit „Vervielfachern“ (engl. „multiplier“) lassen sich Muster bauen wie: Diese Sequenz soll sich mindestens 3-mal und höchstens 7-mal wiederholen. Greedy Non-Greedy Bedeutung {n,m} {n,m}? Muß wenigstens n-mal und darf höchstens m-mal vorkommen. {n,} {n,}? Muß wenigstens n-mal vorkommen. {n} {n}? Muß genau n-mal vorkommen. * *? Entspricht {0,}: Braucht nicht, kann aber mehrfach vorkommen. + +? Entspricht {1,}: Muß mindestens einmal, kann aber mehrfach vorkommen. ? ?? Entspricht {0,1}: Braucht nicht, kann aber einmal vorkommen. Greedy heißt soviel wie gefräßig. Normalerweise sind Verfielfacher gefräßig, d.h. sie versuchen soviel Zeichen zu matchen wie möglich. Non-greedy heißt, dass sie sich mit dem minimal Nötigem zufrieden geben. Betrachten wir drei Beispiele: $_ = "a xxx c xxxxxxx c xxx d"; /a.*c.*d/; # greedy Die Frage ist, wie gefräßig der erste Multiplier .* ist. Bis zum ersten oder zum zweitem c? Nun, da das Fragezeichen fehlt, wird er das maximal mögliche verbrauchen, also alle Zeichen bis zum zweitem c. Möglich in diesem Kontext heißt: Solange das gesamte Muster passt. $_ = "a xxx c xxxxxxx c xxx d"; /a.*?c.*d/; # non-greedy Hier ist der erste Multiplier non-greedy, das heißt er verbraucht die Zeichen nur bis zum ersten c; der zweite Multiplier verbraucht vom ersten c aus alle Zeichen bis zum d. $_ = "a xxx ce xxxxxxx ci xxx d"; /a.*ce.*d/; # greedy Der erste Multiplier ist greedy, d.h. er verbraucht die Zeichen bis zum zweitem c. Danach passt das e aber nicht mehr zur Zeichenkette. Nun folgt automatisches Backtracking: Die verbrauchten Zeichen werden wieder „ausgespuckt“ und der erste Multiplier verbraucht im zweitem Versuch nur noch die Zeichen bis zum ersten c. Danach passt das e und der zweite Multiplier verbraucht die weiteren Zeichen bis zum d. Eigentlich hat es in diesen Beispielen keine Rolle gespielt, ob die Multiplier greedy sind oder nicht: Alle Suchmuster passten so oder so. Aber wir werden gleich sehen, wie man auf das zugreifen kann, was ein Multiplier gefressen hat; und dann macht es sehr wohl einen Unterschied. Die Muster-Suche kennt noch ein zweites Prinzip: Sie ist eifrig (engl. „eager“), will sagen: Das am weitesten links stehende Muster gewinnt. Damit kann man sehr schön hereinfallen, z.B. #!/usr/bin/perl -w $_ = "Fred"; if (/x*/) { print "$_ hat ein x.\n" } else { print "$_ hat kein x.\n" } # Ausgabe: Fred hat ein x. Überraschend, nicht? x* meint ein auch leere Folge von x. Eine leere Zeichenfolge passt aber schon vor Fred, und die Mustersuche meldet eifrig: Das Muster passt. Mit dem Suchmuster x+ wäre das nicht passiert, aber man macht den Fehler mit dem Stern-Multiplier häufiger als man denkt. 54 Einführung in reguläre Ausdrücke Klammern als Zwischenspeicher Wird ein Teil eines Suchmuster in runde Klammern () gesetzt, so ändert das nichts an der Tatsache, ob das Muster passt oder nicht. Auf das, was zum Klammerausdruck passt, kann man sich aber dann später beziehen. Folgendes Programm sucht in einer Datei nach Zeilen, in denen Worte doppelt hintereinander stehen, was ein Hinweis auf einen möglichen Tippfehler sein kann: #!/usr/bin/perl -w # while (<>) { print $_ if /[ ]*(\w+)[ ]*\1[ ]*/; } Der reguläre Ausdruck enthält insgesamt 3-mal das Muster [ ]*, das auf eine beliebig lange, aber auch leere, Folge von Leerzeichen passt. Das Muster \w+ passt auf eine Zeichenkette, die wenigstens ein Wort-Zeichen enthält. Es wird bis zum nächsten Leerzeichen alle Wortzeichen verbrauchen. Das Muster ist geklammert, das \1 erinnert sich an die in der ersten Klammer verbrauchten Zeichen und versucht sie erneut zu matchen. Gelingt dies, so muss dann nochmals eine leere Folge von Leerzeichen folgen. Das Beispiel stellt einen ersten Versuch zur Lösung des Problems dar. Die Lösung ist nicht vollständig, denn Worte werden nicht nur durch Leerzeichen voneinander getrennt. Weiter unten werden wir bessere Lösungen für dieses Problems kennen lernen. Alternativen Kann an einer Stelle der Zeichenkette etwas oder etwas anderes stehen, so formuliert man diese Alternative mit einem senkrechten Strich |: /Fred|Barney|Wilma|Betty/ Dies definiert vier alternative Suchmuster: Entweder Fred oder Barney oder Wilma oder Betty. Die Alternativen werden von links nach rechts geprüft. Text-Anker Anker passen auf keine Textzeichen, sie passen auf Positionen im Text. Wenn etwas am Zeilenanfang oder am Wortende stehen soll, so formuliert man dieses mit Anker-Metazeichen: Anker Bedeutung ^ Passt auf den Anfang einer Zeichenkette. $ Passt an das Ende einer Zeichenkette. \b Markiert eine Wortgrenze (zwischen \w und \W). \B Passt überall hin, nur nicht an den Wortanfang. Es gibt weitere Text-Anker im Zusammenhang mit den Erweiterten Regulären Ausdrücken, die in dieser Vorlesung nicht besprochen werden. Siehe dazu auch 'perldoc perlre'. Mit Hilfe von Text-Ankern kann man das Doppelt-Wort-Problem vollständiger formulieren: #!/usr/bin/perl -w # while (<>) { print $_ if /\b(\w+)\s+\1\b/; } Ein Wort beginnt also an einer Wortgrenze (\b). Dann kommt eine Folge von Wortzeichen ((\w+)), auf die man sich später bezieht (\1). Danach folgt eine Reihe von Worttrennzeichen (\s+), danach die gleiche Wortzeichenfolge und das Wortende (\b). Diese Lösung ist zweifellos besser. Allerdings werden Doppel-Worte, die sich über zwei Zeilen verteilen, nicht gefunden. Und natürlich ist die Definition der Wortzeichen amerikanisch. Und Klein- und Großbuchstaben werden unterschieden. 55 Einführung in reguläre Ausdrücke Rangfolge Wie bei den anderen Operatoren auch muss in regulären Ausdrücken bei zusammengesetzten Suchmustern festgelegt sein, welches Teilmuster den höheren Rang hat. Teilmuster mit höherem Rang stehen in folgender Tabelle über den Teilmustern mit niedrigerem Rang: Muster-Klasse Zugehörige Muster Klammern ( ) Multiplier ? + * {m,n} ?? *? +? {m,n}? Sequenz und Anker abc ^ $ \b \B Alternative | Beispiele: /abc*/ /(abc)*/ /^x|y/ /^(x|y)/ /a|bc|d/ /(a|b)(c|d)/ /(U|S)-Bahn/ # # # # # # # ab abc abcc abccc ... "" abc abcabc abcabcabc ... ein x am Anfang oder ein y irgendwo ein x oder y am Anfang a bc d ac ad bc bd U-Bahn S-Bahn Man sieht, dass die Klammern zwei Funktionen haben. Einmal die Veränderung der Rangfolge und einmal das Speichern von verbrauchten Zeichen. Will man die Erinnerung nicht, so kann man sie mit der Zeichenfolge ?: ausstellen: /(?:Fred|Wilma) Flintstone/ # keine Speicherung in \1 Der Binding-Operator =~ Will man Suchmuster auf andere Variablen als $_ anwenden, so benützt man dazu den Binding-Operator =~ (im Sinne von: passt) oder seine Verneinung !~ (im Sinne von: passt nicht). Obwohl er eine gewisse äußere Ähnlichkeit mit den binary assignment Operatoren (z. B. +=) hat, verändert er den linken Operanden nicht. Das Ergebnis der Operation ist im Skalarkontext wahr oder falsch, je nach dem, ob das Suchmuster passt oder nicht. Die Operation hat (gewünschte) Seiteneffekte, wie wir weiter unten sehen werden: $a $a $a if } = "hello world"; =~ m/^he/; # wahr =~ /^he/; # wahr ($a =~ m/(.)\1/) { print "$a hat zwei aufeinanderfolgende gleiche Zeichen.\"; Der Bezeichner m kann entfallen, wenn die Begrenzer des Suchmusters Schrägstriche sind. Enthält das Suchmuster selbst Schrägstriche, so sind andere Begrenzer wegen der leichteren Lesbarkeit sinnvoll: $path = <STDIN>; # Unix-Pfadname einlesen if ($path =~ /\/home\/ost\//) { print "Pfad in mein HOME-DIR\n"; } # oder alternativ if ($path =~ m#/home/ost/#) { print "Pfad in mein HOME-DIR\n"; } Bei geänderten Begrenzern (hier #) müssen die Schrägstriche in der Alternative nicht mehr maskiert werden, was eindeutig besser lesbar ist. Man kann sich auch angewöhnen, dass m grundsätzlich zu schreiben. Was wurde gefunden? Formuliert man Suchmuster mit Multipliern, so möchte man vielleicht wissen, auf was genau sie gepasst haben. Perl stellt 56 Einführung in reguläre Ausdrücke zu diesem Zweck spezielle Variablen $1, $2 usw. zur Verfügung, die nach der Suche die gleichen Werte haben wie \1, \2 usw. in der Suche. #!/usr/bin/perl -w # $_ = "12 34 56 78 90"; # /(\w+)\W+(\w+)\W+(\w+)/; print "$1 - $3\n"; # oder im Listenkontext ($eins, $zwei, $drei) = /(\w+)\W+(\w+)\W+(\w+)/; print "$zwei\n"; # Ausgabe 12 - 56 34 Gesucht wird nach den ersten drei Worten der Zeichenkette. Das Wort, das in den ersten runden Klammernpaar gematched wird, steht hinterher in der Variablen $1 und das dritte Wort in der Variablen $3. Im Listenkontext werden alle Matches den jeweiligen Listenvariablen zugewiesen. Diese Schreibweise wird bevorzugt, weil die Auswertung des regulären Ausdrucks und Zuweisung klar an einer Stelle erfolgt. Dies funktioniert auch bei expliziter Angabe des Binding-Operators, da dieser vor der Zuweisung ausgeführt wird. Die Suchmethode verändern Mit einem nachgestellten Modifier kann die Suchmethode verändert werden. Es folgt ein eine nicht vollständige Liste: Modifier Bedeutung i Ignoriere Klein/Großschreibung x Das Suchmuster darf über mehrere Zeilen geschrieben werden und Kommentare enthalten. g Finde (global) alle Zeichen. s Der Punkt passt auch auf das \n. m ^ und $ passen auch auf eingebettete \n. Nachstehend eine nochmals verbesserte Version des Doppel-Wort-Problems, die jetzt auch doppelte Worte erkennt, wenn ihre Groß/Kleinschreibung nicht übereinstimmt. #!/usr/bin/perl -w # while (<>) { print $_ if m/\b(\w+)\s+\1\b/i; } Der g-Modifier macht auch bei reinen Suchmuster Sinn: #!/usr/bin/perl -w # $_ = "12 34 56 78 90"; # while ( m/(\d+)/g ) { print "$1 gefunden.\n"; } # Ausgabe 12 gefunden. 34 gefunden. 56 gefunden. 78 gefunden. 90 gefunden. Auf magische Art und Weise wurde in der Schleifenbedingung der Zustand der Suche aufbewahrt, so dass bei der zweiten Prüfung nicht wieder von vorne gesucht wird. Ohne g-Modifier auch keine Magie. Und ohne Magie ist das Programm in 57 Einführung in reguläre Ausdrücke einer Endlos-Schleife. Suchen mit variablen Argument In regulären Ausdrücken werden Variablen vor der Suche ersetzt. Deshalb können Suchmuster mit variablen Inhalt formuliert werden. #!/usr/bin/perl -w # $z = "12 34 56 78 90"; # print "Zeichenkette: $z\nSuchmuster? "; chomp($muster = <STDIN>); if ($z =~ m/($muster)/) { print "$muster passt: $1\n" } else { print "$muster passt nicht.\n" } # Ausgabe Zeichenkette: 12 34 56 78 90 Suchmuster? \d+ \d+ passt: 12 Enthält die Variable Meta-Zeichen der Suchmaschine, so sind diese wirksam. Will man sie unwirksam machen, so schließe man die Variable in ein \Q-\E-Paar ein: #!/usr/bin/perl -w # $z = "12 34 56 78 90"; # print "Zeichenkette: $z\nSuchmuster? "; chomp($muster = <STDIN>); if ($z =~ m/(\Q$muster\E)/) { print "$muster passt: $1\n" } else { print "$muster passt nicht.\n" } # Ausgabe: Zeichenkette: 12 34 56 78 90 Suchmuster? \d+ \d+ passt nicht. Beispiele Es folgen drei Programme, die die typische Verwendungen von regulären Ausdrücken zeigen: Umrechnung Fahrenheit/Celsius Ein Programm soll von der Kommadozeile eine Temperatur in Fahrenheit oder Celsius einlesen und die jeweils andere Temperatur-Einheit umrechnen. Die Umrechnungsformeln lauten: F = C * 9/5 +32; C = (F - 32) * 5 / 9; Der Eingabewert besteht aus einer Zahl mit optionalen Nachkommastellen, gefolgt von einem groß- oder kleingeschrieben F oder C. Die Umrechnung erfolgt dann in die jeweils andere Einheit. Negative Gradzahlen sind erlaubt. Positive Gradzahlen können ein Plus-Zeichen vorangestellt haben. Zwischen Zahl und Gradzeichen können Leerzeichen stehen. Natürlich besteht der Witz dieser Aufgabe darin, den regulären Ausdruck zu finden, der einen gültigen Eingabewert beschreibt. #!/usr/bin/perl -w 58 Einführung in reguläre Ausdrücke # # Fahrenheit in Celsius umrechnen und umgekehrt. # print "Temperatureingabe (z. B. 32F, -25.4C):\n"; chomp($Eingabe = <stdin>); # # regex: m/^([+-]?[0-9]+(\.[0-9]*)?)\s*([CF])$/ix # # liest sich etwas schwer, deshalb unten über mehrere Zeilen # verteilt und kommentiert. Möglich durch den "x"-Modifier. # if ($Eingabe =~ m/^ # Zeilenanfang ( # $1 - Anfang [+-]? # optionales Vorzeichen [0-9]+ # mindestens eine Ziffer ( # $2 - Anfang \.[0-9]* # Dezimalpunkt, Nachkommastellen ) # $2-Ende ? # Nachkommastellen optional ) # $1-Ende \s* # beliebig viele whitespace character ( # $3-Anfang [CF] # C oder F ) # $3-Ende $ # Zeilenende /ix # (i)gnore case ) { $Zahl = $1; $Grad = $3; if ($Grad =~ m/[cC]/) { # Eingabe in Celsius $Celsius = $Zahl; $Fahrenheit = ($Celsius * 9 / 5) + 32; } else { # Eingabe in Fahrenheit $Fahrenheit = $Zahl; $Celsius = ($Fahrenheit - 32) * 5 / 9; } printf "%.2f C = %.2f F\n", $Celsius, $Fahrenheit; } else { print "Ungültige Eingabe: $Eingabe\n"; } Typisch an diesem Beispiel ist, dass man die Syntax von Eingabewerten mit regulären Ausdrücken beschreibt und überprüft. Auf Teile der Unix-Mailbox zugreifen Eine Unix-Mailbox ist einfach aufgebaut. Eine Mailbox enthält eine oder mehrere Mails, die voneinander durch eine Leerzeile, der eine Zeile folgt, die mit From " beginnt, getrennt werden. Eine Mail selbst besteht aus zwei Teilen, dem Header und dem body, die voneinander durch eine Leerzeile getrennt sind. Der Mail-Header enthält Status und Adressinformationen. Der Mail-Body ist irgend etwas. Er darf insbesondere Leerzeilen enthalten. Dieser Datenstruktur wollen wir uns vorsichtig nähern. Zunächst einmal soll gezählt werden, wie viele Mails eine Mailbox enthält. #!/usr/bin/perl -w # # count_mail <mailbox> zählt, wie viele Mails eine Mailbox enthält # $line = <>; if ( $line !~ /^From / ) { print "Fehler: Ungültiges Mailbox-Format!\n"; exit 1; } 59 Einführung in reguläre Ausdrücke $count = 1; $pre_line = $line; while ($line = <>) { if ( $pre_line =~ /^\s*$/ and $line =~ /^From / ) { $count++ } $pre_line = $line; } print "$count Mails in $ARGV\n"; # Eine Leerzeile # gefolgt von einer # From-Zeile. Das ist ein ganz traditioneller Algorithmus, der ein wenig schwerfällig wirkt. Es geht auch ein wenig eleganter: #!/usr/bin/perl -w # # count_mail <mailbox> zählt, wie viele Mails eine Mailbox enthält # $/ = "\n\nFrom "; # Neudefinition des Zeilentrennzeichens $count = 0; while (<>) { $count++; } print "$count Mails in $ARGV\n"; Die spracheigene Variable $/, der input record separator, enthält die Zeichenfolge, die Perl das Zeilenende signalisiert. Die Voreinstellung ist $/="\n". Die Redefinition in diesem Beispiel bewirkt, das eine Mail vollständig in eine Eingabezeile gelesen wird, die dann eingestreute \n-Zeichen enthält. Und die Zahl dieser Eingabezeilen ist die Anzahl der Mails in der Mailbox. Nun wollen wir auf die Struktur einer Mail eingehen. Sie besteht aus dem Header, einer Leerzeile und dem Body. Nachstehendes Programm druckt die Mail-Header aller Mails in einer Mailbox: #!/usr/bin/perl -w # # header_mail <mailbox> gibt den Mail-Header jeder Mail aus. # $/ = "\n\nFrom "; while (<>) { ($from,$header) = m/(.+?)\n(.+?)\n\n/s; $from =~ s/^/From / if $from !~ m/^From /; print "--- $from ---\n"; print "$header\n"; } # Ausgabe (teilweise) --- From MAILER-DAEMON Tue Nov 23 11:33:54 1999 --Date: 23 Nov 1999 11:33:54 +0100 From: Mail System Internal Data <[email protected]> Subject: DON'T DELETE THIS MESSAGE -- FOLDER INTERNAL DATA Message-ID: <[email protected]> X-IMAP: 0943353176 0000000069 Status: OR --- From [email protected] Mon Oct 19 01:32:30 1998 +0200 --Received: from pop2.uni-muenster.de (POP2.UNI-MUENSTER.DE [128.176.188.88]) by pylartes.uni-muenster.de (AIX4.3/UCB 8.8.8/8.8.7) with ESMTP id BAA19936 for <[email protected]>; Mon, 19 Oct 1998 01:32:29 +0200 Received: from mail.teletel.co.il ([192.115.207.125]) by pop2.uni-muenster.de (8.8.8/8.8.7) with ESMTP id BAA137780; Mon, 19 Oct 1998 01:32:03 +0200 Received: (from majordomo@localhost) by mail.teletel.co.il (8.9.1/8.9.1) id UAA01460 for babylon-mail-list; Sat, 3 Oct 1998 20:15:50 +0300 Message-Id: <[email protected]> Precedence: bulk Reply-To: [email protected] 60 Einführung in reguläre Ausdrücke From: [email protected] Sender: [email protected] To: [email protected] Subject: Babylon - News & Updates Date: Sat, 3 Oct 1998 20:15:48 +0300 Man muss natürlich einen Preis für die Redefinition des input record separators bezahlen. Er besteht darin, dass, mit Ausnahme der ersten Mail, der From-Zeile die anfängliche Zeichenfolge From fehlt. Diese Zeichenfolge wird deshalb an den Anfang $from eingefügt, wenn sie nicht schon da ist. $_ enthält eingestreute \n-Zeichen, die normalerwiese nicht auf den Punkt passen. Der s-Modifier ändert dies. Die Multiplier müssen non-greedy sein. Will man noch tiefer in die Mail-Header-Struktur einsteigen, so werden die Dinge allmählich kompliziert, denn dann muss man verstehen, was die einzelnen Zeilen des Mail-Headers bedeuten. Und das ist nicht Gegenstand dieser Vorlesung. Doppelte Worte in einem Text finden Diese Problem war schon mehrfach ein Beispiel in dieser Vorlesung. In dieser letzten Form werden Worte voneinander nicht nur durch whitespace character getrennt, sondern auch durch HTML-Tags, die ja bekanntlich die Form <...> haben. Zusätzlich sollen die Fundstellen im reverse video mode markiert werden, was ein wenig Unix-Magie erfordert. Es sollen nur die Absätze ausgegeben werden, die auch doppelte Worte enthalten. Und, da man ja vielleicht mehr als eine Datei mit einem Befehl überprüfen will, soll zu der Zeile der Dateiname gedruckt werden. #!/usr/bin/perl -w # # Aus: Mastering Regular Expressions # use locale; # Auch Umlaute gehoeren zu \w $/ = ".\n"; # Input Record Separator # in etwa: ein Absatz while (<>) { next unless s # Start des substitute-Operator s{...}"..." { # Beginn des Suchteils \b # Wortgrenze ( [\w]+ ) # Wort, gespeichert in $1 und \1 ### Nun koennen Leerzeichen oder HTML tags folgen ( # gespeichert in $2 werden entweder ( \s # whitespace character | # oder <[^>]+> # beliebige HTML tags )+ # und zwar wenigstens eins von beiden. # $3 wird nicht gebraucht ) # Ende von $2 ### gefolgt vom ersten Wort und einer Wortgrenze (\1\b) # gespeichert in $4 # Ende des Suchteils } # Ersetzungsteil folgt "\e[7m$1\e[m$2\e[7m$4\e[m"igx; s/^([^\e]*\n)+//mg; # Alle unmarkierten Zeilen entfernen s/^/$ARGV: /mg; # Dateiname der Ausgabe voranstellen print; } use locale berücksichtigt bei der Definition von \w nationale (in meinem Linux-System: deutsche) Besonderheiten. So gehören Umlaute zur Zeichenmenge \w. Der input record separator wird auf einen Punkt am Zeilenende gesetzt, was eine zwar nicht vollständige, aber für diesen Zweck ausreichende Absatz-Definition ist. Man kann die Begrenzer von Such- und Ersetzungsteil unabhängig voneinander redefinieren. Der Modfier x ermöglicht es, den Suchteil über Zeilen hin zu verteilen. Was allerdings nicht für den Ersetzungsteil gilt. Im Ersetzungsteil werden Escape-Sequenzen eingebaut, die den reverse video mode ein und wieder ausschalten. Gleichzeitig dienen diese EscapeSequenzen als Markierung, in welchen Absätzen doppelte Worte gefunden wurden. Es werden diejenigen Absätze entfernt, in denen keine Markierungen gefunden wurden. 61 Einführung in reguläre Ausdrücke Auf Grund der Redefinition von $/ enthält $_ eingestreute \n-Zeichen. Der m-Modifier bewirkt, das die Metazeichen ^ und $ auch auf diese eingestreuten Newlines passen. Übungsaufgaben Hier nun ein paar Übungen zur Erstellung von regulären Ausdrücken. Aufg. 5) Reguläre Ausdrücke Geben Sie einen regulären Ausdruck an, der a) Telefonnummern in der internationalen Form, d.h. "+49 251 8331639" oder "+49-251-8331639" oder "0049(0251)8331639", erkennt. b) Reelle Zahlen, d.h. Gleitkommazahlen der Form "4.53" oder "-2.30E10" oder "3.07e-3", erkennt. (Für Nicht-Mathematiker: nach dem 'e' steht der ganzzahlige Exponent zur Basis 10. Also 3.07e-3 = 3.07*10^(-3) = 0.00307) c) Zeit & Datum in der Form "Wed, 14 Dec 2005 16:29:50 +0100" wie es z.B. von 'date -R' ausgegeben wird (vgl. RFC2822 http://www.ietf.org/rfc/rfc2822.txt, §3.3), erkennt Aufg. 6) CSV-Dateien Schreiben Sie ein Perl-Programm, das die Daten einer CSV-Datei ("Character Separated Values", vgl. RFC4180 http://www.ietf.org/rfc/rfc4180.txt) in einen Hash einliest und eine Statistik ausgibt. Verwenden Sie die Datei ftp://ftp.ripe.net/pub/stats/ripencc/delegated-ripencclatest, die eine Liste aller von der RIPE in Europa zugewiesenen IP-Addressbereiche enthält. Die Einträge sind hierbei durch das '|' Zeichen getrennt. An zweiter Stelle steht die Länderkennung. Generieren Sie eine Tabelle, die zu jedem Land die Anzahl zugewiesenener IP-Addressbereiche sowie den Prozentsatz von allen in Europa ausgibt. Viel Spass! 62 Weiteres zu den regulären Ausdrücken Weiteres zu den regulären Ausdrücken Rückblick Ein regulärer Ausdruck ist einfach ausgedrückt ein Muster („pattern“), das auf einen String passt („match“). Ein regulärer Ausdruck beschreibt Textmuster mit Hilfe von (normalen) Zeichen und Metazeichen. /muster/ # Einfacher String /\w+/ # Mehrere Wortzeichen /h...o/ # Erst ein h, dann drei beliebige Zeichen, dann ein o /[a-z]/ # Genau ein Zeichen aus a-z /[a-zA-Z]+/ # Ein oder mehrere Buchstaben /(0|1|2|3|4|5|6|7|8|9)/ # Genau eine Zahl zwischen 0 und 9 matchen /[0-9]/ # Dasselbe mit [] und Bereichsoperator /\d/ # Dasselbe mit der Zeichenklasse \d Der schwierigste Teil bei der Verwendung ist das erstmalige Erstellen des regulären Ausdrucks. Man geht dabei am besten von einem Beispielstring aus. Stringvergleich vs. Stringmatch: $str = "2005-12-13:dies:ist:1:testmuster"; if ($str eq "2005-12-13:dies:ist:1:testmuster") # Erkennt nur diesen einen String { print "match\n"; } if ($str =~ m/\d+-\d+-\d+:\w+:\w+:\d+:\w+/) # Erkennt viele Strings mit diesem Muster { print "match\n"; } Dies ist nur die einfachste Verwendung von regulären Ausdrücken. Sie erlauben viel komplexere Vergleiche. Es können nun z.B. einzelne 'gematchte' Teile aus einem String extrahiert werden, bestimmte Teile können ersetzt werden, usw. $str = "Bilbo"; $str =~ m/Bilbo/; $str =~ s/Bilbo/Frodo/; # Match (liefert true) # Substitute (evtl. mit Modifier ig) $path = "/tmp"; $path =~ s#/tmp#/var/tmp#; $path =~ s#/tmp#$user_tmp#; # Quotes sind frei wählbar # Variablen werden interpoliert Der Match-Operator (m//) ist nur einer von mehreren Operatoren, die mit regulären Ausdrücken arbeiten. Als weitere Beispiele werden wir im folgenden noch den s///-Operator und die split()-Funktion kennen lernen. Suchen und Ersetzen Wenn man etwas in einer Zeichenkette gefunden hat, so will man es vielleicht auch verändern. Hierfür gibt es den sOperator (substitution): $z = qw(fred barney); $z =~ s/fred/wilma/; $z =~ s/fred/betty/; # wilma ersetzt fred in $z # $z bleibt unveraendert. Der Ersetzungsteil kann natürlich variabel sein. Insbesondere stehen einem hier die speziellen Variablen $1, $2 usw. zur Verfügung: 63 Weiteres zu den regulären Ausdrücken #!/usr/bin/perl -w # $z = "12 34 56 78 90"; # $z =~ s/\b(\w+)(\s+)(\w+)/$3$2$1/; print "$z\n"; # Ausgabe 34 12 56 78 90 Das Suchmuster hat drei Gruppen: Ein Wort, Worttrennzeichen und wieder ein Wort. Da es verschieden viele Worttrennzeichen geben kann, erinnert man sich auch an diese. Modifizierer sind auch möglich, z.B. globales Suchen und Ersetzen (g). #!/usr/bin/perl -w # $z = "12 34 56 78 90"; # $z =~ s/\b(\w+)(\s+)(\w+)/$3$2$1/g; print "$z\n"; # Ausgabe 34 12 78 56 90 Nachdem das erste Paar gefunden und vertauscht wurde, wird das zweite Paar gefunden und vertauscht. Für das letzte Wort 90 gibt es keinen Partner. Will man Datenzeilen "auseinanderfieseln" oder zusammensetzen, so erweisen sich die spracheigenen Funktionen split() und join() in Zusammenarbeit mit den regulären Ausdrücken als mächtige Werkzeuge. split() und join() split zerteilt eine Zeichenkette an all den Stellen, an denen ein regulärer Ausdruck passt, in Abschnitte. Diese Abschnitte werden als Listenelemente zurückgegeben. Möchte man in einer Zeichenkette mehrere Felder mit unterschiedlicher und variabler Länge speichern, so kann man ein Trennzeichen einführen, das Felder voneinander trennt und nicht selbst Teil des Feldes ist. Dies ist in der Unix-Kultur relativ populär und viele Unix-Kommandos können mit dieser Datenstruktur umgehen. Häufig verwendete Trennzeichen sind der Doppelpunkt oder das Tabulatorzeichen. Ein Beispiel: Der Mail-Reader pine verwaltet ein Adressbuch von E-Mail-Adressen. Diese Adressen werden in der Datei .addressbook im HOME-Verzeichnis des Benutzers gespeichert. Im einfachsten Fall besteht ein Adressbucheintrag aus einer Datenzeile. Die Zeile besteht aus 5 Feldern: Spitzname, Name, E-Mail-Adresse, Ablage und Kommentar. Getrennt werden diese Felder durch das Tabulatorzeichen. Nachstehendes Programm listet alle Spitznamen und die zugehörigen EMail-Adressen auf: #!/usr/bin/perl -w # while (<>) { @pine_ab = split(/\t/); print "$pine_ab[0] - $pine_ab[2]\n"; } In der Eingabezeile ($_) werden alle Tabulatoren gesucht. Die hierdurch definierten Teilketten werden Listenelemente des Arrays @pine_ab. Das erste Listenelement ist der Spitzname und das dritte Element die E-Mail-Adresse. Hinweis: Wenn Sie dieses Programm auf ihr "richiges" Pine-Adressbuch anwenden, so werden Sie nur für einige Einträge die richtige Ausgabe erhalten. Das Pine-Adressbuchformat ist komplizierter als hier vorgestellt. In weiteren Verlauf der Vorlesung werden wir ein besseres Programm für diesen Zweck kennen lernen. Worte einer Zeichenkette sind durch ein oder mehrere whitespace character voneinander getrennt. Wird split ohne Argumente aufgerufen, so wird die Zeichenkette $_ in ihre Worte zerlegt: @Worte = split(/\s+/,$_); # identisch mit # @Worte enthaelt alle Worte aus S_ 64 Weiteres zu den regulären Ausdrücken @Worte = split; # Voreinstellung join verbindet Listenelemente mit "Leim" zu einer Zeichenkette. Der "Leim" ist eine Zeichenkette und kein regulärer Ausdruck! Folgendes Programm liest eine positive ganze Zahl ein und druckt die Folge der Zahlen von 1 bis zu dieser Zahl, jeweils verbunden mit einem Minuszeichen, aus. #!/usr/bin/perl -w # print "Positive ganze Zahl: "; chomp($n=<STDIN>); print join('-',(1..$n)) . "\n"; # Ausgabe Positive ganze Zahl: 10 1-2-3-4-5-6-7-8-9-10 (1..$n) generiert eine Liste von Werten von 1 bis $n. Die Listenelemente werden jeweils mit einem Minuszeichen verbunden und ausgegeben. 65 Pakete, Module und objektorientierte Programmierung Pakete, Module und objektorientierte Programmierung Pakete und Module Wir werden im weiteren Verlauf der Vorlesung mit den Perl-Modulen DBI und CGI arbeiten. Dazu wollen wir nun genauer untersuchen was Pakete und Module sind. Die große Verbreitung und Vielfältigkeit von Perl liegt auch darin begründet, dass Perl ein Konzept anbietet, SoftwarePakete für die verschiedensten Anwendungsbereiche zu schreiben und anderen zur Verfügung zu stellen. Mit dem Kommando package wird ein abgeschlossener Namensraum für Variablen und Funktionen definiert, ein sogenanntes Paket. Durch diesen Mechanismus ist es möglich, verschiedene Programmcodes zu entwickeln und miteinander zu kombinieren, ohne in Namenskonflikte mit bereits bestehenden Variablen oder Funktionen zu geraten. Jeder vergebende Name wird einem Paket zugeordnet mit Ausnahme der Systemvariablen, die für alle Pakete einheitlich sind. Wird kein Package angegeben, wie in den bisher verwendeten kleinen Skripten, so sind alle Variablen dem Paket main zugeordnet. $ perl -w -e 'print $a' Name "main::a" used only once: possible typo at -e line 1. Use of uninitialized value in print at -e line 1. Hier kommt der Operator :: zum Vorschein, der die Variable a dem Paket main zuordnet. Folgendes Beispiel zeigt, wie die Variable a über ihren voll-qualifizierten Namen initialisiert wird. $ perl -w -e '$main::a=2; print $a' Verwenden von eigenen Paketen Ein Paket wird durch das Schlüsselwort package eingeleitet. Pakete sind nicht auf eine bestimmte Datei beschränkt. Ein Paket kann sich über mehrere Dateien erstrecken, ebenso ist es möglich, dass eine Datei mehrere Pakete enthält. Gängig ist jedoch, dass eine Datei genau ein Paket enthält. #!/usr/bin/perl package pak1; sub funk() { print "Ausgabe von Paket1\n"; } package pak2; sub funk() { print "Ausgabe von Paket2\n"; } &funk(); &pak1::funk(); pak2::funk(); # # # # # Dies liefert die Ausgabe: Ausgabe von Paket2 Ausgabe von Paket1 Ausgabe von Paket2 Der Geltungsbereich einer package-Definition erstreckt sich bis zur nächsten package-Definition der gleichen Ebene oder bis zum Ende des umschließenden Bereichs (Block, Datei, eval). 66 Pakete, Module und objektorientierte Programmierung Ein Perl-Modul ist eine Datei, die nur ein Paket enthält und den Namen des Pakets mit Endung .pm trägt. Mit dem use Kommando wird das Modul ins Hauptprogramm integriert, so dass die Funktionen des Moduls verwendet werden können. Wir haben mit use strict oder use Term::ANSIColor schon Beispiele dafür gesehen. Der Aufbau eines Moduls sieht also wie folgt aus: # Beispiel.pm package Beispiel; sub funk1 { print "Funktion1: @_\n"; } sub funk2 { print "Funktion2; @_\n"; } 1; Mit der 1; in der letzten Zeile wird Perl das erfolgreiche Laden des Moduls signalisiert. Die Verwendung geht folgendermaßen: #!/usr/bin/perl # Beispiel.pl use Beispiel; Beispiel::funk1("Hallo Welt!"); Hier muss immer noch explizit der Paketname Beispiel:: angegeben werden, was wir von den bisher verwendeten Modulen nicht kennen und natürlich in Zukunft auch nicht wollen. Um die Funktion funk1() ohne Angabe des Paketes aufzurufen, müssen wir Beispiel.pm wie folgt ergänzen. # Beispiel.pm package Beispiel; use Exporter; our @ISA = qw(Exporter); our @EXPORT = qw(funk1 funk2); sub funk1 { print "Funktion1: @_\n"; } sub funk2 { print "Funktion2; @_\n"; } 1; Jetzt haben wir schon auf den nächsten Paragrafen vorgegriffen. Wir sehen zum einen das Einbinden des Moduls Exporter und zum anderen die Verwendung von zwei speziellen Arrays. Über das Array @EXPORT werden die Funktionen angegeben, die von dem Modul exportiert werden und in einem aufrufenden Programm zur Verfügung stehen. Das Array @ISA wird im folgenden besprochen. 67 Pakete, Module und objektorientierte Programmierung Objektorientierte Programmierung Durch die objektorientierte Programmierung soll die Wiederverwendbarkeit von Software erhöht werden. Programme sind hierarchisch aus kleineren Einheiten aufgebaut, die von verschiedenen Entwicklern betreut werden können. Nach aussen hin werden lediglich die verwendeten Schnittstellen definiert. In diesem Zusammenhang spricht man von Klasse (statt Paket/Modul) und Methode (statt Funktion). Variablen einer Klasse heißen Attribute und ein zur Laufzeit erzeugtes Objekt einer Klasse heißt Instanz (einer Klasse). Das Erzeugen einer Instanz erfolgt über den Konstruktor (die Methode mit Namen new()) Seit Version 5 kann in Perl objektorientiert programmiert werden. Die Mechanismen beruhen dabei auf den bisher besprochenen zur Definition und Verwendung von Paketen. Der schematischer Aufbau einer Klasse kann wie folgt dargestellt werden: # Beispiel2.pm # Klasse Beispiel2 package Beispiel2; # Eigenschaften (der Klasse) my $eigenschaft1; my @eigenschaft2; # Konstruktor (erzeugt Objekt) sub new { bless {}; } # Methoden sub methode1 { print "Funktion1: @_\n"; } sub methode2 { print "Funktion2; @_\n"; } 1; In der Funktion new(), die den Konstruktor implementiert, wird die Perl-Funktion bless() verwendet, die die Zuordnung zwischen Klasse und Objekt herstellt. Die Syntax ist: bless $ref; bless $ref, $cname; Als Parameter wird eine Referenz angegeben, die in ein Objekt umgewandelt wird. Ohne Angabe eines zweiten Parameters gehört das Objekt zur aktuellen Klasse. Es kann aber auch einer beliebigen Klasse $cname zugeordnet werden. Verdeutlichen wir dies am besten durch ein Beispiel: # Haustier.pm # Klasse Haustier package Haustier; # Konstruktor sub new { my $self = {name => undef}; bless $self; zurückgeben # Referenz auf Hash mit Objekt-Eigenschaft # Referenz zu Objekt konvertieren und 68 Pakete, Module und objektorientierte Programmierung } # Methoden sub setName { my $self = shift; # Erster Parameter ist Objekt my $name = shift; # Zweiter Parameter ist Name $self->{name} = $name; } sub getName { $self = shift; return $self->{name}; } 1; Die Klasse Haustier hat eine Eigenschaft name. Über den Konstruktor new() wird eine neues Haustier-Objekt erzeugt. Mit den beiden Methoden setName() und getName() kann die Eigenschaft name geschrieben und gelesen werden. Im folgenden Beispiel erzeugen wir zwei Instanzen der Haustier-Klasse und weisen ihnen unterschiedliche Eigenschaften zu: #!/usr/bin/perl # Haustier.pl use Haustier; my $katze = new Haustier; $katze->setName("Mimmi"); print $katze->getName(), "\n"; # => Mimmi my $hund = new Haustier; $hund->setName("Waldi"); print $hund->getName(), "\n"; # => Waldi Wiederverwendung von Code: Vererbung Erst durch den Mechanismus der Vererbung wird die Wiederverwundung von bereits geschriebenem Code möglich. Durch die Vererbung werden alle Methoden und Eigenschaften einer Klasse an eine andere Klasse weitergegeben. Diese abgeleitete Klasse kann dann gezielt bestimmte Methoden mit angepasstem Code überschreiben. Im folgenden Beispiel erben die beiden Klassen Katze und Hund von der Klasse Haustier die Eigenschaft name und die beiden Methoden setName() und getName(). Die abgeleiteten Klassen haben zusätzlich eine neue Methode sprich(), die jeweils unterschiedlich ist. # Katze.pm # Klasse Katze package Katze; # Erbt von Haustier our @ISA = "Haustier"; use Haustier; # alternativ: use base ("Haustier"); # Universeller Konstruktor sub new { my $class = shift; my $self = {}; # Referenz auf Hash bless $self, $class; # Referenz zu Objekt der Klasse $class konvertieren und zurückgeben 69 Pakete, Module und objektorientierte Programmierung } # Methoden sub sprich { return "Miau."; } 1; # Hund.pm # Klasse Hund package Hund; # Erbt von Haustier our @ISA = "Haustier"; use Haustier; # Konstruktor sub new { my $class = shift; my $self = {}; bless $self, $class; zurückgeben } # Referenz auf Hash # Referenz zu Objekt der Klasse $class konvertieren und # Methoden sub sprich { return "Wau!"; } 1; Über das Array @ISA werden eine oder mehrere Basisklassen angegeben, von denen die aktuelle Klasse erbt. Der Name kommt nicht von ungefähr, sondern der Perl-Code liest sich als: „Package Katze is a Haustier“. Über die folgende useKlausel werden die darin enthaltenen Methoden und Eigenschaften der aktuellen Klasse zur Verfügung gestellt. Wird nun eine Instanz der Klasse Hund mit der Methode setName() aufgerufen, sucht Perl diese Methode zuerst in der Klasse Hund, und wenn sie da nicht gefunden wird der Reihe nach (von links nach rechts) in allen über @ISA eingebundenen Klassen. Hier ist ein Programm, das Objekte der beiden neuen Klassen erzeugt und Methoden der Basisklasse verwendet: #!/usr/bin/perl # Haustier2.pl use Katze; use Hund; my $katze = new Katze; $katze->setName("Mimmi"); print $katze->getName(), " sagt ", $katze->sprich(), "\n"; my $hund = new Hund; $hund->setName("Waldi"); print $hund->getName(), " sagt ", $hund->sprich(), "\n"; Oft werden die Attribute eines Objekts direkt bei der Erzeugung mit angegeben: 70 Pakete, Module und objektorientierte Programmierung # Katze.pm # Konstruktor sub new { my $class = shift; # Aufrufende Klasse my $self = { name => "Kein Name", @_ }; # Referenz auf Hash mit Attributen bless $self, $class; # Referenz zu Objekt konvertieren und zurückgeben } Der Konstruktor kann dann mit beliebigen Parametern aufgerufen werden. Ein übergebenes „Name => Wert“-Paar überschreibt den vorherigen Standardwert. my $katze = new Katze(name => "Mimmi"); my $katze = Katze->new(name => "Mimmi"); # Klassenmethode my $katze = Katze->new(name => "Mimmi")->sprich(); # Instanzmethode Eine Klassenmethode bezieht sich auf eine Klasse und nicht auf ein Objekt bzw. eine Instanz davon. Vor dem -> Operator steht also ein Klassenname und keine Objektvariable. Die Instanzmethode bezieht sich jeweils auf eine bestimmte Instanz der Klasse. Da der Instanzoperator links-assoziativ ist, kann er hintereinander verwendet werden. Überschreiben (von Methoden) Eine Besonderheit des objektorientierten Programmierens ist die Möglichkeit ererbte Methoden zu überschreiben, d.h. es wird eine Methode mit dem selben Namen (wie in der Basisklasse) definiert, die aber für die Klasse speziellen Code enthält. Dieses Konzept wird auch Polymorphie genannt. So ist es z.B. möglich für jede Klasse eine eigene toString() Methode zu schreiben, die die Eigenschaften eines Objekts lesbar ausgibt. Die Klasse Haustier könnte die folgende Methode enthalten: # toString Methode sub toString { $self = shift; return "Name: $self->{name}\n"; } Die abgeleitete Klasse Hund könnte folgende Methode enthalten: # toString Methode sub toString { $self = shift; return "Mein Hund heisst: $self->{name}\n"; } Perl verwendet die als erstes zu einem Objekt passende Methode. Manchmal möchte man allerdings noch Methoden der Basisklasse verwenden, um daraus eine speziellere Version zu machen. Dafür gibt es die virtuelle Klasse SUPER. So ist es z.B. möglich, in der toString() Methode der Klasse Hund die toString() Methode der (Basis-)Klasse Haustier aufzurufen: # toString Methode sub toString { $self = shift; return "Hund: ".$self->SUPER::toString(); } Anstelle von SUPER hätte man hier auch Haustier schreiben können, allerdings will man im allgemeinen Fall nicht einen bestimmten Klassennamen angeben, sondern die Methode (irgend)einer Basisklasse aufrufen. Die SUPER Klasse kommt auch oft bei Konstruktoren zum Einsatz, um die Eigenschaften der Basisklasse zu setzen. Damit erhält man folgenden Konstruktor für abgeleitete Klassen (am Beispiel des Konstruktors für Hund): # Konstruktor 71 Pakete, Module und objektorientierte Programmierung sub new { my $class = shift; # Von welcher Klasse werde ich aufgerufen? my $self = $class->SUPER::new(@_); # Konstruktor der Basisklasse mit Parametern aufrufen -> $self ist Haustier-Objekt bless $self, $class; # $self zu Objekt von $class konvertieren -> $self ist Hund-Objekt return $self; # Hund-Objekt zurückgeben } Alternativ kann auch gleich in der Basisklasse (Haustier) die bless()-Funktion mit zwei Argumenten verwendet werden. Dann entfällt die vorletzte Zeile in diesem Beispiel (siehe auch 'perldoc perltoot' für weitere Beispiele). Überladen (von Operatoren) Überladen (engl.: „overload“) bedeutet das Überschreiben von Perl-Operatoren. Damit ist es z.B. möglich die „Stringification“, d.h. die Konvertierung in einen String, eines beliebigen Objektes zu definieren. Es wird dann beim Aufruf von print $katze automatisch die toString()-Methode aufgerufen. Um die „Stringification“ für die Klasse Katze zu realisieren, müssen wir die folgenden Zeilen hinzufügen (vgl. Beispiel Katze_v2.pm). use overload '""' => \&toString; # Meine toString-Methode sub toString { my $class = shift; use Data::Dumper; print Dumper($class); } Mit der Anweisung use overload können Operatoren überladen werden. Als Parameter gibt man an welche Operatoren das sein sollen. Im obigen Beispiel ist es nur ““ für die Stringkonvertierung, hier könnten jedoch noch beliebige andere Operatoren wie +, -, *, ++, *=, usw. stehen bzw. folgen (vgl. 'perldoc overload'). Zu jedem Operator wird eine (Referenz auf eine) Funktion angegeben, die an Stelle des Operators ausgeführt werden soll. Das Perlmodul Moose Moose ist eine Erweiterung des Objektsystems von Perl 5. Das Hauptanliegen von Moose ist es, objektorientierte Programmierung in Perl 5 einfacher, konsistenter und kurzweiliger zu machen. Mit Moose können wir mehr darüber nachdenken, was wir erreichen wollen und weniger über die Eigenheiten der OOP. Für zeitkritische KommandozeilenProgramme gibt es das schlankere Mouse-Paket, das die gleiche Syntax wie Moose bietet, aber um einige Erweiterungen verschlankt wurde und daher den Programmstart beschleunigt. package Point; use Moose; # automatically turns on strict and warnings has 'x' => (is => 'rw', isa => 'Int'); has 'y' => (is => 'rw', isa => 'Int'); sub clear { my $self = shift; $self->x(0); $self->y(0); } package Point3D; use Moose; extends 'Point'; 72 Pakete, Module und objektorientierte Programmierung has 'z' => (is => 'rw', isa => 'Int'); after 'clear' => sub { my $self = shift; $self->z(0); }; Übungsaufgaben Drei Aufgaben zur Vertiefung von Paketen, Modulen und objektorientierter Programmierung: Aufg. 15) CPAN Machen Sie sich mit CPAN (http://search.cpan.org) vertraut. Suchen Sie nach dem Module Term::ANSIColor und versuchen Sie die aktuellste Version zu installieren (vgl. 'perldoc cpan'). Aufg. 16) Pakete Schreiben Sie ein Paket CRT, das die folgenden Funktionen exportiert: a) println - Ausgabe des übergebenen Texts und Zeilenumbruch b) printinfo - wie a), aber mit "INFO: " vor dem Text und in grüner Farbe c) printerror - wie a), aber mit "ERROR: " vor dem Text und in roter Farbe d) Schreiben Sie ein Programm CRTtest.pl, das die oben definierten Funktionen einbindet und beispielhaft verwendet. Aufg. 17) Objektorientierte Programmierung a) Erweitern Sie die Klasse Haustier um zwei weitere Eigenschaften 'typ' und 'alter'. Alle Eigenschaften sollen im Konstruktor mit undef initialisiert werden, wenn keine anderen Werte als Parameter übergeben wurden. b) Erweitern Sie die Klasse Haustier um eine Methode toString(), die die Eigenschaften des Objekts lesbar ausgibt. c) Schreiben Sie eine Klasse Vogel, die von Haustier erbt, und über die Methode sprich() ein "Piep!" zurückliefert. Der Konstruktor von Vogel soll auch die Eigenschaften von Haustier setzen. Nächste Woche geht es weiter mit SQL und Perl DBI. Viel Spass! 73 Einführung in relationale Datenbanken Einführung in relationale Datenbanken Relationale Datenbanken Eine Datenbank ist eine geordnete Sammlung von Daten, die normalerweise in einer oder mehreren zusammengehörenden Dateien gespeichert ist. Die Daten sind als Tabellen strukturiert, wobei Verweise von einer Tabelle auf eine andere möglich sind. Aufgrund der Relationen (Verknüpfungen) zwischen den Tabellen wird die Datenbank relational bezeichnet. Oracle, MySQL, IBM DB2 oder der MS SQL-Server sind Beispiele für relationale Datenbanksysteme (engl.: „Relational database management system“, RDBMS). Ein Datenbanksystem ist geteilt in Datenbankserver und -client, die normalerweise auf verschiedenen Systemen laufen. Damit ist der gleichzeitige Zugriff von vielen Clients auf einen Server möglich. MySQL erfreut sich in den letzten Jahren immer größerer Beliebtheit und stellt bei freien Datenbanksystemen beinahe den De-Facto-Standard dar. Besonders beliebt ist die Kombination aus Linux + Apache + MySQL + Perl (oder PHP). Diese Kombinationen werden wir hier betrachten. Weiterführende Literatur Wer mehr über relationale Datenbanken und speziell MySQL erfahren möchte, dem stehen folgende Quellen zur Verfügung: • • • MySQL Online Dokumentation; http://dev.mysql.com/doc/ MySQL; Paul Du Bois; 2000; ISBN 0-7357-0921-1 MySQL – Einführung, Programmierung, Referenz; Michael Kofler; 2001; ISBN 3-8273-1762-2 Ein MySQL-Server zur Verwendung in der Vorlesung ist auf zivkuefer.uni-muenster.de installiert. Es ist möglich von jedem Rechner innerhalb der Universität (z.B. zivunix) über den MySQL-Kommandozeilen-Client dahinzuverbinden (Nutzer: 'perldbi', Passwort: 'pWS0607'): mysql -h zivkuefer -u perldbi -p Zum Experimentieren habe ich die Datenbank 'gnufsd' des GNU Free Software Directory importiert. Erste Schritte $ mysql -h zivkuefer.uni-muenster.de -u perldbi -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 53 to server version: 4.0.24_Debian-10ubuntu2-log Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql> show databases; +----------+ | Database | +----------+ | gnufsd | +----------+ 1 row in set (0.00 sec) mysql> use gnufsd Database changed mysql> show tables; +----------------------------+ | Tables_in_gnufsd | +----------------------------+ | category | | category_mapping | | computer_language | | contributor | 74 Einführung in relationale Datenbanken | developer | | entity | | interface | | interface_mapping | | irc_channel | | keyword | | license | | license_mapping | | maintainer | | platform | | platform_mapping | | program | | related_mapping | | source_language_mapping | | sponsor | | status | | subprogram | | supported_language_mapping | | version | | version_mapping | +----------------------------+ 24 rows in set (0.01 sec) mysql> describe program; +------------------------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------------------+---------------+------+-----+---------+----------------+ | id | int(11) | | PRI | NULL | auto_increment | | name | varchar(80) | YES | MUL | NULL | | | filename | varchar(80) | YES | | NULL | | | short_description | varchar(180) | YES | | NULL | | | full_description | text | YES | | NULL | | | license_verified_by_id | int(11) | YES | MUL | NULL | | | license_verified_on | date | YES | | NULL | | | updated | date | YES | | NULL | | | gnu | enum('y','n') | YES | | NULL | | | web_page | varchar(255) | YES | | NULL | | | support | text | YES | | NULL | | | doc | text | YES | | NULL | | | source_tarball | text | YES | | NULL | | | source_info | text | YES | | NULL | | | source_template | text | YES | | NULL | | | debian | text | YES | | NULL | | | rpm | text | YES | | NULL | | | repository | text | YES | | NULL | | | use_requirements | text | YES | | NULL | | | build_prerequisites | text | YES | | NULL | | | weak_prerequisites | text | YES | | NULL | | | source_prerequisites | text | YES | | NULL | | | announce_list | text | YES | | NULL | | | announce_news | text | YES | | NULL | | | help_list | text | YES | | NULL | | | help_news | text | YES | | NULL | | | help_irc_channel_id | int(11) | YES | MUL | NULL | | | dev_list | text | YES | | NULL | | | dev_news | text | YES | | NULL | | | changelog | text | YES | | NULL | | | dev_irc_channel_id | int(11) | YES | MUL | NULL | | | bug_list | text | YES | | NULL | | | bug_news | text | YES | | NULL | | | bug_database | text | YES | | NULL | | | entry_compiled_by_id | int(11) | YES | MUL | NULL | | | comments | text | YES | | NULL | | +------------------------+---------------+------+-----+---------+----------------+ 36 rows in set (0.00 sec) mysql> select id,name,filename,short_description,web_page from program order by id limit 5; +----+---------------------------+-------------+--------------------------------------------------------------------+----------------------------------------------+ 75 Einführung in relationale Datenbanken | id | name | filename | short_description | web_page | +----+---------------------------+-------------+--------------------------------------------------------------------+----------------------------------------------+ | 1 | Arguments | arguments | Assists with command line argument processing | http://www.aiksaurus.com/~jared/arguments/ | | 2 | StarDict | StarDict | International dictionary for Gnome | http://stardict.sourceforge.net/ | | 3 | Cvsauth | cvsauth | Authentication daemon for the CVS pserver method | http://cvsauth.sourceforge.net/ | | 4 | Height Map Generator | heightmapgen | Terrain map generator | http://hme.sourceforge.net/ | | 5 | Ada/Motif binding library | ambinding | Binding to X Windows and OSF/Motif for the Ada programming language | http://home.arcor.de/hfvogt/programming.html | +----+---------------------------+-------------+--------------------------------------------------------------------+----------------------------------------------+ 5 rows in set (0.00 sec) Structured Query Language (SQL ) Im voranstehenden Beispiel haben wir SQL-Befehle auf der MySQL-Kommandozeile eingegeben. Die „Structured Query Language“ (SQL) ist eine Sprache, um Anweisungen an das Datenbanksystem zu formulieren, z.B. Abfragen, Änderungsoder Löschkommandos. Die wichtigsten dazu geeigneten Kommandos sind SELECT, INSERT, UPDATE und DELETE. Die Syntax dieser Befehle mit allen Optionen kann unter http://dev.mysql.com/doc/refman/4.1/en/data-manipulation.html nachgesehen werden. Die einfachste Syntax, um Daten abzurufen ist select * from Tabelle1; was bedeutet „Zeige alle Spalten von Tabelle1 an“. In obigem Beispiel haben wir verwendet: mysql> select id,name,filename,short_description,web_page from program order by id limit 5; Das bedeutet „Zeige die Spalten id,name,filename,short_description,web_page der Tabelle program an, sortiere nach der id Nummer und liefere maximal 5 Ergebnisse“. Übersicht der wichtigsten SQL-Anweisungen: SELECT, INSERT, DELETE Die SELECT Anweisung von SQL stellt die für uns wichtigste Anweisung dar. Mit ihr lassen sich fast beliebig komplexe Abfragen ausführen die Daten aus einer oder mehrerer Tabellen holen und kombinieren. -- Ausgabe von Name, Beschreibung eines bestimmten Datensatzes SELECT name,short_description,web_page from program where name='Gimp'; -- Vergleiche dazu SELECT name,short_description,web_page from program where name like 'Gimp%'; -- % passt auf beliebig viele Zeichen (auch 0), _ passt auf genau ein Zeichen -- Ausgabe von Name, Beschreibung und Kategorie(n) SELECT p.name,p.short_description,c.description from program as p, category as c, category_mapping as cm where p.id=cm.program_id and cm.category_id=c.id order by p.name limit 30; -- Ausgabe von Name, Beschreibung und Kategorie sortiert nach Kategorien SELECT p.name,p.short_description,c.description from program as p, category as c, category_mapping as cm where p.id=cm.program_id and cm.category_id=c.id group by p.name order by c.description limit 30; -- Ausgabe von Name, Beschreibung und Kategorie mit eigenen Tebellenköpfen SELECT p.name as 'Name',p.short_description as 'Beschreibung',c.description 76 Einführung in relationale Datenbanken as 'Kategorie' from program as p, category as c, category_mapping as cm where p.id=cm.program_id and cm.category_id=c.id group by p.name order by p.name limit 30; Darüber hinaus ist es mit SELECT möglich einfache Funktionen direkt auf dem Datenbankserver auszuführen. -- Numerische Funktionen -- http://dev.mysql.com/doc/refman/4.1/en/numeric-functions.html SELECT 1+2*3; --> 7 SELECT (1+2)*3; --> 9 -- Sinus SELECT Sin(2*PI()); --> 0 -- Maximum SELECT Max(3,2,5,4,1,2); --> 5 (vor MySQL 3.22.5) SELECT Greatest(3,2,5,4,1,2); --> 5 (nach MySQL 3.22.5) -- String-Funktionen -- http://dev.mysql.com/doc/refman/4.1/en/string-functions.html SELECT Length('Hallo Welt!'); --> 11 -- Längster Programmname in Tabelle 'program' SELECT Max(Length(name)) from program; --> 52 -- Unterstrings SELECT Substring('Hallo Welt!', 7, 4); -- Sonstige Funktionen -- Aktuelle Zeit SELECT Curtime(); --> Welt --> 10:06:51 Wie man eine neue Datenbank und Tabellen anlegt soll hier nicht im einzelnen erklärt werden. Dazu gibt es eine eigene Vorlesung „Einführung in MySQL“, die regelmäßig im ZIV angeboten wird. Ich möchte nur noch die zwei SQL-Befehle zum Einfügen von Daten in eine vorhandene Tabelle und zum Löschen von Daten erwähnen. Das ist zum einen das INSERT Statement: -- Einen Wert einfügen -- http://dev.mysql.com/doc/refman/4.1/en/insert.html INSERT into category_mapping (program_id, category_id) values (1, 219); --> Query OK, 1 row affected (0.01 sec) Dabei werden die Spaltenwerte entweder explizit angegeben oder sind das Ergebnis einer SELECT-Anweisung. Zeilen können nur eingefügt werden, wenn sie nicht das Duplikat einer bereits vorhandenen Zeilen sind. Duplikate sind Zeilen mit gleichen Wert für Spalten, die einen Unique Index haben. Treten Duplikate bei einem INSERT mit mehreren Zeilen auf, so wird die Operation mit dem ersten Duplikat abgebrochen. Die bis dahin eingefügten Zeilen bleiben eingefügt. Ist in einem solchen Fall die Ignore-Klausel angegeben, so wird das Duplikat ignoriert und die INSERT-Operation wird fortgesetzt. MySQL gibt in den Fällen eine Warnung aus, wo die einzufügenden Werte nicht problemlos zu den Spaltentypen passen. Und nun noch das DELETE Statement: -- Einen Wert löschen -- http://dev.mysql.com/doc/refman/4.1/en/delete.html DELETE from category_mapping where program_id=1 and category_id=219; --> Query OK, 1 row affected (0.00 sec) Er werden nur die Zeilen gelöscht, auf die die Where-Klausel zutrifft. Ist keine Where-Klausel angegeben, so werden alle (!) Zeilen gelöscht. Der Befehl sollte also mit der nötigen Sorgfalt behandelt werden. Da die Syntax von SELECT und DELETE gleich ist, bietet es sich an, erst mit einer SELECT-Anweisung abzufragen, was man löschen möchte und dann das 77 Einführung in relationale Datenbanken SELECT durch DELETE zu ersetzen. 78 Einführung in relationale Datenbanken Einführung in das Datenbankinterface Perl DBI CPAN Wir werden in den folgenden Vorlesungen einige bekannte und sehr praktische Perl-Module besprechen. Im Comprehensive Perl Archive Network (CPAN) gibt es unzählige Module, die alle Bereiche und Probleme des Programmierens lösen können. Die Sammlung ist so umfangreich, dass nur wenige Module in die Perl-Distribution aufgenommen werden können. Unter Unix steht der Befehl cpan auf der Kommandozeile zur Verfügung, um Perl-Module aus dem CPAN zu installieren, die nicht standardmäßig vorhanden sind. cpan bietet eine kleine Shell, die über help eine Hilfe zu allen Funktionen ausgibt. Auch 'perldoc cpan' hilft weiter. Weiterführende Literatur Als Einsteiger- und Referenzhandbuch für Perl DBI eignet sich • Programming the Perl DBI, Alligator Descartes & Tim Bunce, 1st Edition, February 2000, ISBN 1-56592-699-4 Im Prinzip handelt es sich dabei aber um die gedruckte Form der DBI Manpage 'perldoc DBI'. Das DBI-Modul wurde ursprünglich von Tim Bunce entwickelt. Die jeweils aktuelle Version und ihre Dokumentation finden Sie unter http://search.cpan.org/~timb/DBI/. Erste Schritte Die Abfragen mit dem MySQL-Client aus dem vorangegangenen Kapitel wollen wir im folgenden mit Perl durchführen. Dazu steht das Perl Database Interface (DBI) zur Verfügung, das eine allgemeingültige Schnittstelle zur Datenbank bietet, die unabhängig von dem speziellen Datenbanksystem ist. Die Verwendung von DBI wird jetzt an einem Beispiel gezeigt: use DBI; #main() { # Connect to the database. print "Verbinde zur Datenbank... "; my $dbh = DBI->connect("DBI:mysql:database=gnufsd;host=zivkuefer.unimuenster.de", "perldbi", "pWS0607", {'RaiseError' => 1}); print "ok\n"; print "Preparing SELECT... "; $sth = $dbh->prepare("SELECT * FROM program limit 1;"); $sth->execute(); print "ok\n"; DBI::dump_results($sth); # Disconnect from the database. $dbh->disconnect(); } Das Modul DBI wird mit use DBI; in das Programm eingebunden. Damit stehen alle von DBI bereitgestellten Funktionen zum direkten Aufruf zur Verfügung. In 'perldoc DBI' werden alle Funktionen und ihre Parameter beschrieben. 79 Einführung in relationale Datenbanken Die Struktur eines Perl DBI-Programms DBI-Architektur Das DBI ist ein Datenbank-Interface für Perl-Programme. Es definiert einen Satz von Methoden, Variablen und Konventionen, die eine konsistente Datenbank-Schnittstelle unabhängig von der aktuell verwendeten Datenbank zur Verfügung stellen. ● ● ● DBI Data Base Interface. Oder auch: Data Base Independent. DBD Data Base Driver. Oder auch: Data Base Dependent. RDBMS Relational Data Base Management System Es gibt DBDs für alle relevanten Datanbanken: Oracle, DB2, SQL-Server, MySQL, PostgreSQL. Aber es müssen gar nicht einmal wirkliche Datenbanken sein. Ein Datei mit einer Komma-separierten Liste von Werten (CSV) tut es unter Umständen auch. DBI-Handles Das DBI definiert 3 Objekttypen, hier auch Handles genannt, zur Interaktion mit Datenbanken. ● ● ● Driver Handle Es gibt genau einen Treiber Handle pro Treibertyp. Man kann mehrere Treibertypen gleichzeitig nutzen. Dieser Handle wird in der Regel von der Anwendung nicht explizit manipuliert. Database Handle (meist $dbh) Dieser Handle steht für eine Verbindung zu einer Datenbank. Mehrere gleichzeitige Verbindungen zu Datenbanken sowohl des gleichen als auch unterschiedlichen Typs sind möglich. Statement Handle (meist $sth) Statement Handles stammen von Database Handles ab. Sie führen die einzelnen SQL-Anweisungen aus und steuern den Datenfluss zwischen Anwendung und Datenbank. Theoretisch kann man eine beliebige Anzahl von Statement Handles in seiner Anwendung benützen. In der Praxis wird die Anzahl durch die Datenbank beschränkt. Welche DBDs sind installiert? Das DBI stellt eine Methode available_drivers() zur Verfügung, die als Array die installierten DBDs zurückgibt. Hierbei wird nur geprüft, welche DBDs als Datei installiert sind. Ob sie funktional sind, kann man mit einer zweiten Methode data_sources() testen. Diese Methode prüft, welche Datenquellen tatsächlich zur Verfügung stehen. #!/usr/bin/perl use DBI; use strict; my @drivers = DBI->available_drivers(); foreach my $driver (@drivers) { print "Treiber: $driver\n"; my @dataSources = DBI->data_sources( $driver ); foreach my $dataSource ( @dataSources ) { print " Datenquelle ist $dataSource\n", } } # Ausgabe Treiber: DB2 Datenquelle ist dbi:DB2:UNIXDB Datenquelle ist dbi:DB2:SAMPLE Treiber: ExampleP 80 Einführung in relationale Datenbanken Datenquelle ist Treiber: Oracle Datenquelle ist Datenquelle ist Treiber: Proxy Treiber: mysql Datenquelle ist Datenquelle ist dbi:ExampleP:dir=. dbi:Oracle:INST1_HTTP dbi:Oracle:ZIVADM DBI:mysql:mysql DBI:mysql:test DBI->connect: Verbindungsaufbau zur Datenbank Die DBI-Methode connect() baut die Verbindung zur einer Datenbank auf. Der Funktionsaufruf hat 4 Argumente: $dbh = DBI->connect($Datenquelle,$Nutzer,$Kennwort,\%Attribute); Über den optionalen Hash %Attribute kann man Verbindungsattribute setzen, etwa zur Fehlerbehandung und zum AutoCommit. Die Kombination $Nutzer und $Kennwort wird von der angesprochenen Datenbank überprüft. Kennt eine Datenbank keine Nutzer, so können beide Variablenwerte undef sein. Die syntaktische Form der Datenquelle ist datenbankspezifisch. Vergleichen Sie folgende Beispiele: DBI:mysql:<datenbank>:<host> Angesprochen wird die MySQL-Datenbank <datenbank> auf der Server <host> DBI:DB2:<datenbank> Angesprochen wird die DB2-Datenbank <datenbank>. Wo sich diese befindet, wird an anderer Stelle nachgehalten. Das Perl-Skript muss sicherstellen, dass die zum DB2-Anwendungsaufruf notwendige Umgebung bereitgestellt wird. Ähnliches gilt für Oracle-Datenbanken. Nachstehendes Programm kopiert eine Tabelle einer MySQL-Datenbank in eine Tabelle einer DB2-Datenbank. Es gibt zwei Database Handels: $mysql und $unixdb. Beide Datenbanken kennen einen Nutzer »nutzer«, der das Kennwort »pass« besitzt. Die MySQL-Datenbank befindet sich auf dem Rechner »mysql«. Schlägt ein Verbindungsaufbau fehl, so wird die zugehörige Fehlermeldung $dbh->errstr ausgegeben. #!/usr/bin/perl # Umgebung für DB2 BEGIN { $ENV{DB2INSTANCE} = q(db2ziv1); } use DBI; # Zwei Datenbankverbindungen $mysql = DBI->connect("DBI:mysql:viralert:mysql","nutzer","pass") or die "Can't connect to database viralert: $!\n"; $unixdb = DBI->connect("DBI:DB2:unixdb","nutzer","pass") or die "Can't connect to database unixdb: $!\n"; # Zwei Handles, eins für SELECT und eins für INSERT $select = $mysql-> prepare( qq{ select wann,absender,adressat,meldung from viren } ) or die $mysql->errstr; $insert = $unixdb->prepare( q{ insert into viren(wann,absender,adressat,report) values(?,?,?,?) }) or die $unixdb->errstr; 81 Einführung in relationale Datenbanken # Kopieren $n = 0; $select->execute(); while ($ref = $select->fetch()) { $n++; ($wann, $absender, $adressat, $meldung) = @$ref; $insert->bind_param( $insert->bind_param( $insert->bind_param( $insert->bind_param( 1, 2, 3, 4, $wann ); $absender ); $adressat ); $meldung ); $insert->execute(); } if ( $n%1000 == 0 ) { print "$n\n"; } $insert->finish(); $unixdb->disconnect; $mysql->disconnect; Zum Database Handel $mysql gehört das Statement Handle $select. Das Statement Handle $insert gehört zum Database Handle $unixdb. Die datenbankabhängige Methode prepare() bereitet die Ausführung der als Argument übergebenen SQLAnweisung vor. Zur Vorbereitung gehört unter anderen die syntaktische Prüfung der Anweisung. Einige Datenbanken, z.B. DB2, entwerfen zu diesem Zeitpunkt einen optimierten Zugriffsplan auf die Daten. Die Daten werden zeilenweise ausgelesen und in die Zieltabelle eingetragen. Die »insert«-Anweisung demonstriert die Nutzung von Platzhaltern, die mit der Methode bind_param() an Perl-Variablen gebunden werden. Näheres dazu später. Das Programm endet mit dem expliziten Verbindungsabbau. Unbedingt nötigt ist das nicht: Mit dem Abbau der PerlLaufzeitumgebung würden die Datenbankverbindungen implizit ebenfalls geschlossen werden. Bitte gewöhnen Sie es sich trotzdem an, die DB-Verbindungen explizit zu schließen. Es könnte ja schließlich sein, dass ihr Skript aus einer Umgebung aufgerufen wird, dass die Perl-Umgebung nicht abbaut, wie z.B. Perl-Module, die als CGI-Skripte in Apache-Webservern ausgeführt werden. Fehlerbehandlung Die Behandlung von Fehlern kann entweder durch das DBI oder durch das Perl-Skript oder gemeinsam von beiden durchgeführt werden. Gesteuert wird dies durch die Verbindungsattribute PrintError (Fehlermeldung ausgeben und weitermachen) und RaiseError (Fehlermeldung ausgeben und Programmabbruch). Im folgende Beispiel werden mögliche Fehler allein vom Perl-Skript behandelt: %Attr = { PrintError => 0, RaiseError => 0 }; $dbh = DBI->connect( "DBI:mysql:gnufsd:zivkuefer.unimuenster.de","perldbi","perl2005",\%Attr ) or die "Kann Verbindung zu Datenbank nicht aufbauen: $DBI::errstr\n"; $select = $dbh->prepare( q{ select * from tabelle } ) or die $dbh->errstr(); # Nachträglich die Fehlermeldungen wieder anschalten $dbh->{PrintError} = 1; Schlagen DBI-Methoden fehl, so haben Sie in der Regel den Rückgabewert »falsch«. Es ist üblich, diese Fehler mit der Konstruktion or die zu behandeln. Wenn Sie die Fehler selbst behandeln wollen, so müssen sie den Erfolg jeder DBIMethode prüfen. Schalten Sie PrintError ein, so müssen Sie die Fehler nach wie vor selbst behandeln, die 82 Einführung in relationale Datenbanken Fehlermeldungen werden allerdings automatisch ausgegeben. RaiseError schließlich überlässt auch die Fehlerbehandlung dem DBI. Sind Sie mit dieser Behandlung in einigen Fällen nicht einverstanden, so können Sie dem vom DBI veranlassten Programmabbruch mit einem eval-Block abfangen und modifizieren. Ein pragmatischer Vorschlag: Überlassen Sie zunächst dem DBI die Fehlerbehandlung. Und wenn sich dieses als nicht geeignet herausstellt, übernehmen Sie an diesen Punkten die Fehlerbehandlung selbst. Es ist einfach bequemer, nicht jede DBI-Methode mit einem or die abschließen zu müssen. Die Variable $DBI::errstr enthält die Fehlermeldung der zuletzt ausgeführten DBI-Methode. Diese Variable wird von allen Driver, Database und Statement Handlen benutzt. Jeder gültige Handle stellt zusätzlich eine Methode $h->errstr() zur Verfügung, die die letzte Fehlermeldung zum Handle $h zurück gibt. Hilfsmethoden Das DBI stellt einige Methoden zur Verfügung, die die Programmierung von DBI-Anwendungen erleichtern sollen. Datenbankspezifische Quotierung Will man von Perl aus eine Zeichenkette in eine Tabelle einfügen, so konkurrieren zwei Quotierungsmechanismen mit einander: die von Perl und die der Datenbank. Abhängig vom Database Handle gibt es eine Quotierungsmethode quote(), die die besonderen Quotierungsanforderungen berücksichtigt. #!/usr/bin/perl -w use strict; BEGIN { $ENV{DB2INSTANCE} = q(db2ziv1); } use DBI; my $unixdb = DBI->connect("DBI:DB2:unixdb","nutzer","pass", { RaiseError => 1} ); my $Text1 = "Do it"; my $Text2 = "Don't do it"; print $unixdb->quote($Text1) . "\n"; print $unixdb->quote($Text2) . "\n"; $unixdb->disconnect(); # Ausgabe 'Do it' 'Don''t do it' Es gibt weitere Methoden, etwa zum Tracen von DBI-Methoden DBI->trace() oder zur lesbaren Formatierung von Zeichenketten DBI->neat(), die ich an dieser Stelle aber nicht besprechen werde. Übungsaufgaben Hier nun ein paar Übungen zu SQL und Perl-DBI. Weitere Informationen und Beispiele zu SQL gibt es auch unter <http://de.wikipedia.org/wiki/SQL>. Aufg. 18) MySQL-Abfrage Mit dem bisherigen Kenntnisstand hat eine SELECT-Abfrage die Form SELECT [* | Spalten] FROM Tabelle [WHERE Spalte LIKE '%Suchwort%'] [ORDER BY Spalte [ASC | DESC]] [LIMIT Anzahl]; 83 Einführung in relationale Datenbanken Schreiben Sie eine SQL-Abfrage, die a) alle Spalten der Tabelle 'category' ausgibt. b) die Spalten 'name' und 'description' der Tabelle 'category' sortiert nach 'name' ausgibt. c) die Spalten 'name', 'short_description' und 'web_page' der Tabelle 'program' ausgibt und zwar nur für die Programme, deren Spalte 'name' mit dem Buchstaben 'g' _beginnt_. d) die Spalten 'name' und 'updated' der 10 zuletzt aktualisierten Programme der Tabelle 'program' ausgibt. Sie können für diese Aufgaben den MySQL-Client auf zivunix.uni-muenster.de verwenden. Nutzername 'perldbi', Passwort 'pWS0607'. Aufg. 19) Perl-DBI a) Verwenden Sie das Perl-DBI Beispiel-Programm aus der Vorlesung, um die in Aufgabe 18 formulierten SELECT-Anweisungen auszuführen und geeignet formatiert auszugeben. b) Erweitern Sie das Programm aus Teil a) zur Abfrage 18 c) um eine Nutzerabfrage, zu welchem Buchstaben die Programme ausgegeben werden sollen. Viel Spass! 84 Einführung in relationale Datenbanken Programmierung einfacher Abfragen Aus Tabellen werden Daten mit der SQL-Anweisung »SELECT« gelesen. Die Ergebnisse werden in Tabellen-Form präsentiert. Aus Sicht des DBI in das Lesen von Tabellenzeilen ein 4-stufiger Zyklus: Schritt 1: prepare() In diesem Schritt wird die Select-Anweisung syntaktisch validiert. Resultat ist ein Statement Handle, die die Anweisung gegenüber der Datenbank vertritt. Möglicherweise entwirft die Datenbank zu diesem Zeitpunkt auch einen speziell für dieses Select optimierten Zugriffsplan. Aus Sicht von Perl ist die Select-Anweisung eine Zeichenkette, die vollständig variabel sein kann. Beachten Sie in diesem Zusammenhang die Variablen-Expansion in Zeichenketten, die in doppelten Hochkommata eingeschlossen sind. SQL-Anweisungen können an einigen Stellen auch Platzhalter enthalten. Diese Platzhalter werden vor der Ausführung durch aktuelle Werte ersetzt. Platzhalter können nur anstelle eines Wertes stehen und dürfen nicht an Stellen stehen, die eine Validierung der SQL-Anweisung verhindert: # Beispiele gültiger Platzhalter $sth = $dbh->prepare( "SELECT name, alter FROM TABLE WHERE name='?'" ); $sth = $dbh->prepare( "INSERT INTO TABLE(name,alter) values(?,?)" ); # Beispiele ungültiger Platzhalter $sth = $dbh->prepare( "SELECT name, alter FROM ?" ); $sth = $dbh->prepare( "SELECT name, ? FROM TABLE" ); $sth = $dbh->prepare( "INSERT INTO TABLE(name,alter) values(?)" ); Die Verwendung von Platzhaltern ist häufig weniger aufwändig als das erneute präparieren einer dynamischen SQLAnweisung. Schritt 2: execute() Im nächsten Schritt wird das präparierte Statement Handle ausgeführt. Die Datenbank beginnt, die SQL-Anweisung auszuführen und die Ergebnistabelle wird gefüllt. Es werden noch keine Daten zum Programm übertragen. Ist die Ergebnistabelle groß (evtl. Millionen von Zeilen), so erlauben manche Datenbanken der Anwendung schon, den ersten Teil der Daten zu lesen, während die Datenbank asynchron dazu die Ergebnistabelle weiter füllt. Muss die ErgebnisTabelle sortiert sein (»order by«), so ist diese Überlappung natürlich nicht möglich. execute() kann optionale Parameter haben. Die Parameterwerte werden vor der Ausführung für die etwaigen Platzhalter der preparierten SQL-Anweisungen substituiert. Alternativ können vor dem execute()-Aufruf mit der Methode $sth>bind_param Werte an Platzhalter gebunden werden. bind_param kann zusätzlich eine Anpassung der Datentypen von Datenbank und Perl vornehmen, wo dieses nötig ist. Schritt 3: fetch() Im dritten Schritt werden die Ergebniszeilen von der Datenbank, eventuell über ein Rechnernetz, zeilenweise in das Programm übertragen. Prinzipiell sieht der Algorithmus so aus: while ( noch_Zeilen_einzulesen_sind ) { @zeile = $aktuelle_zeile; tue_irgendwas(); } Die Ergebnistabelle kann entweder zeilenweise oder als Ganzes übertragen werden. Dabei steht eine Ergebniszeile entweder als Array oder als Hash zur Verfügung. Die Arrayelemente sind die Ergebnisspalten in der Reihenfolge, wie sie in der »SELECT«-Anweisung stehen. Bei einem Hash sind die Spaltennamen die Hash-Schlüssel und die Spaltenwerte die zugehörigen Hash-Werte. Vorsicht bei »SELECT«-Anweisungen, die mehrfach den gleichen Spaltennamen enthalten! # zeilenweise $arrayref = $sth->fetchrow_arrayref(); @array = $sth->fetchrow_array(); 85 Einführung in relationale Datenbanken $hashref = $sth->fetchrow_hashref(); Die Ergebnistabelle kann aber auch als Ganzes übertragen werden. Und zwar entweder in ein Array von Array-Referenzen (Tabelle) oder eine Hashreferenz auf Hash-Referenzen: # Array-Referenzen (Tabelle) $tbl_arrayref = $sth->fetchall_arrayref(); # Ganze Tabelle $tbl_arrayref = $sth->fetchall_arrayref($slice); # Ausgewählte Spalten $tbl_arrayref = $sth->fetchall_arrayref(undef, $max_row); # $max_row Zeilen bei jedem Aufruf $slice ist die Referenz auf einen Array- oder Hash-Slice, die die zu übertragenden Spalten einschränken können: $tbl_arrayref = $sth->fetchall_arrayref([0]); # 1.Spalte $tbl_arrayref = $sth->fetchall_arrayref([-2,-1]); # vorletzte und letzte Spalte $tbl_arrayref = $sth->fetchall_arrayref( {BAR=>1, FOO=>1} ); # Spalten FOO und BAR fetchall_hashref($key) gibt eine Hashreferenz auf Hash-Referenzen zurück: $dbh->{FetchHashKeyName} = 'NAME_lc'; # Schlüsselnamen kleingeschrieben $sth = $dbh->prepare("SELECT FOO,BAR,ID,NAME FROM TABLE"); $sth->execute(); $hashref = $sth->fetchall_hashref('id'); print "Name for ID 42 is $hashref->{42}->{name}\n"; Soll die gleiche Abfrage, eventuell anders parametrisiert, zu einem späteren Zeitpunkt erneut ausgeführt werden, so wird Schritt 2 (execute()) wiederholt. Schritt 4: finish() Im letzten Schritt wird aufgeräumt. Das macht Perl von sich aus. Alles, was intern zur Datenbank-Kommunikation benötigt wird, hängt logisch von den jeweiligen Database oder Statement Handle ab. Werden diese Variablen vernichtet, so verschwindet auch alles, was von ihnen abhängt. Der Aufruf von finish() wird nicht unbedingt benötigt. Er kann nützlich sein, wenn bei einer SELECT-Anweisung auf einer großen Tabelle nur ein Ergebnis interessiert. Die Datenbank hält alle Ergebnisse im Cache bis sie entweder abgefragt wurden (fetch()) oder finish() aufgerufen wird. Andere SQL-Anweisungen (»UPDATE«, »INSERT«, usw.) werden in einem 3-stufigen Zyklus bearbeitet. Die »fetch«Stufe fehlt. Vieles auf einmal do() Die Methode $dbh->do() führt den prepare- und execute-Schritt mit einem Funktionsaufruf aus. Zurückgegeben wird die Anzahl der betroffenen Zeilen. Für eine SELECT-Anweisung taugt diese Methode nicht, da kein Statement Handle zurückgegeben wird und man somit nicht auf die selektierten Daten zugreifen kann. Nicht-SELECT-Anweisungen werden häufig mit do ausgeführt. $rows_deleted = $dbh->do( q{ DELETE FROM rechner WHERE pool = 'Ausser Dienst'} ) or die $dbh->errstr; Die DELETE-Anweisung wird präpariert und ausgeführt. Die Anzahl der gelöschten Zeilen wird zurückgegeben. 86 Einführung in relationale Datenbanken selectrow_array() und selectrow_arrayref() Erwartet man nur eine Ausgabezeile, so kann man die prepare-, execute- und fetch-Schritte mit einem Funktionsaufruf erledigen: ($anzahl) = $gnufsd->selectrow_array( "select count(*) from program" ); print "Die Tabelle 'Program' enthält $anzahl Einträge.\n"; selectrow_array() ruft nacheinander prepare(), execute() und fetchrow_array() auf. Die Funktion muss selbst im ListenKontext aufgerufen werden. selectrow_arrayref() entsprechend mit fetchrow_arrayref() als letztem Funktionsaufruf. Zurückgegeben wird eine Referenz auf die Rückgabezeile. selectall_arrayref() selectall_arrayref() ruft nacheinander prepare(), execute() und fetchall_arrayref() auf. $pools = $unixdb->selectall_arrayref( q{ select distinct pool from rechner where pool is not null order by pool desc } ); Meta-Informationen Will man vollkommen allgemeine und flexible Anwendungen schreiben, so muss man die Datenbank nach Eigenschaften der von ihr verwalteten Objekte fragen können. Beispielhaft wollen wir erfragen, welche Tabellen in der Datenbank gespeichert sind. Die Methode $dbh-tables() gibt einen Array mit Tabellennamen zurück. Im Beispielprogramm werden die Tabellen des Nutzers »perldbi« ausgegeben. #!/usr/bin/perl -w use DBI; my $gnufsd = DBI->connect("DBI:mysql:gnufsd:zivkuefer.unimuenster.de","perldbi","perl2005") or die $DBI::errstr; my @tables = $gnufsd->tables(); print join( "\n",@tables ) . "\n"; $gnufsd->disconnect(); #Ausgabe (teilweise) `category` `category_mapping` `computer_language` `contributor` `developer` `entity` `interface` `interface_mapping` `irc_channel` `keyword` `license` `license_mapping` `maintainer` `platform` `platform_mapping` `program` $dbh->table_info() gibt mehr Informationen zu den Tabellen aus. 87 Einführung in relationale Datenbanken #!/usr/bin/perl -w use strict; use DBI; my $gnufsd = DBI->connect( "DBI:mysql:gnufsd:zivkuefer.unimuenster.de","perldbi","perl2005" ) or die $DBI::errstr; my $tinfo = $gnusfd->table_info(); print "Qualifier Owner Table Name Remarks\n"; print "========= ========= =============================== =======\n\n"; Type ============ while ( my ( $qual, $owner, $name, $type, $remarks ) = $tinfo->fetchrow_array() ) { foreach ( $qual, $owner, $name, $type, $remarks ) { $_ = "N/A" unless defined $_; } printf "%-9s %-9s %-32s %-12s %s\n", $qual, $owner, $name, $type, $remarks; } $unixdb->disconnect(); Ausgehend von einem Statement Handle liefert die Methode column_info() Informationen über die selektierten Spalten. Andere Methoden liefern Information über Primär- und Fremdschlüssel. Wer hier ein spezielles Interesse hat, der findet in der DBI-Dokumentation die nötigen Einzelheiten. Transaktionen Unterstützt eine Datenbank Transaktionen, so kann man über das DBI die Transaktionen steuern. Steuern meint hier, dass das Programm entscheidet, wann eine Folge von Daten-Änderungen erfolgreich und konsistent abgeschlossen ist. Erst wenn die Anwendung die Änderung explizit bestätigt, wird sie festgeschrieben ($dbh->commit()). Im Fehlerfalle kann sich die Anwendung entschließen, alle Änderungen rückgängig zu machen ($dbh->rollback()). Greifen andere Anwendungen in der Zeit der Änderungen auf die Daten zu, so sehen sie den konsistenten, unveränderten Zustand vor den Änderungen. Erst nach dem Commit werden die Änderungen nach außen sichtbar. Will man Transaktionen in diesem Sinne mit dem DBI steuern, so muss man das Verbindungsattribut AutoCommit ausschalten. Die Voreinstellung ist, dass jede Änderung sofort festgeschrieben wird. Beachten Sie, dass MySQL Transakionen nur mit bestimmten Tabellenformaten unterstützt. Übungsaufgaben Weitere Übungen zu Perl-DBI. Aufg. 20) Postleitzahlen Mit dem bisherigen Kenntnisstand hat eine INSERT-Anweisung die Form INSERT [IGNORE] INTO Tabelle (Spalte1, Spalte2, ...) VALUES(Wert1, Wert2, ...); Unter der URL <http://www.access-paradies.de/download/pool/plz_deutschland.txt> finden Sie eine CSV-Datei mit den Postleitzahlen von Deutschland. Schreiben Sie ein Perl-Programm, dass die Datensätze dieser Datei in die Tabelle 'plz' der Datenbank 'plz' importiert. Die Tabelle hat folgende Struktur: 88 Einführung in relationale Datenbanken +------------+------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+------------------+------+-----+---------+-------+ | Ort | varchar(100) | NO | | NULL | | | Zusatz | varchar(100) | YES | | NULL | | | Plz | int(10) unsigned | NO | PRI | 0 | | | Vorwahl | varchar(10) | YES | MUL | 0 | | | Bundesland | varchar(100) | NO | | NULL | | +------------+------------------+------+-----+---------+-------+ Aufg. 21) Tabellen-Kopie Anstelle von VALUES() kann in der INSERT-Anweisung auch ein SELECT vorkommen. Es werden dann die Ergebniswerte der SELECT-Anweisung in die Tabelle eingefügt. Die Anzahl der Ergebnisspalten aus der SELECT-Anweisung muss dabei mit der Anzahl der Spalten in der Zieltabelle übereinstimmen. Bsp.: INSERT INTO delegated_asn SELECT * FROM delegated WHERE type="asn"; a) Schreiben Sie ein Perl-Programm, das den Inhalt der Tabelle 'delegated' für die drei Typen ('asn','ipv4','ipv6') jeweils mittels obiger SQL-Anweisung in eine neue Tabelle ('delegated_<type>') kopiert. Löschen Sie vor dem Kopieren die Ziel-Tabelle und geben Sie dabei während der Ausführung an, wieviele Einträge kopiert wurden oder ob ein Fehler aufgetreten ist. b) Ändern Sie Teil a) so ab, dass das Programm nur eine INSERT- *oder* SELECTAnweisung ausführt und kopieren Sie die Daten selbst zwischen einem SELECTund einem INSERT-Statement-Handle. Viel Spass! 89 Einführung in das Webinterface Perl-CGI Einführung in das Webinterface Perl-CGI Weiterführende Literatur Als Einsteiger- und Referenzhandbuch für CGI allgemein und Perl-CGI bzw. mod_perl im Detail eignen sich • • • CGI Programming with Perl, Scott Guelich, Shishir Gundavaram & Gunther Birznieks, 2nd Edition, June 2000, ISBN 1-56592419-3 Practical mod_perl, Stas Bekman, Eric Cholet, 1st Edition, May 2003, ISBN 0-59600227-0 Perl Template Toolkit, Darren Chamberlain, David Cross, Andy Wardley, 1st Edition, Januar 2004, ISBN 059600476-1 Wenn Sie mit den folgenden CGI-Beispielen selbst experimentieren wollen, bietet das XAMPP-Projekt ein Komplettpaket aus Apache, MySQL und Perl (u.a.) für Windows und Linux an, dass Sie sich frei installieren können. Web-Programmierung Die Programmierung von Web-Anwendungen mit Perl ist ein eigenständiges Thema, dessen Behandlung eine eigene Vorlesung füllen könnte. Neben der CGI-Programmierung ist mit dem mod_perl-Modul für den Apache-Webserver eine sehr viel mächtigere und performantere Anwendungsentwicklung möglich. mod_perl-Programme werden vorkompiliert und laufen direkt als Handler im Apache-Webserver. Dadurch laufen sie schneller und haben Zugriff auf Funktionen (z.B. zur Authentifizierung und Konfiguration), die per CGI nicht möglich sind. Das Perl Template Toolkit erlaubt die Trennung von Programmierung und Webseitendesign und ermöglicht damit das Schreiben von übersichtlicherem Code und die Aufteilung eines Projekts an spezialisierte Mitarbeiter. Im folgenden werden die Grundlagen der CGI-Programmierung mit Perl anhand von einigen Beispielen vermittelt. Für eine umfassende Einführung und Referenz vgl. Sie die Literatur-Hinweise. Was bedeutet überhaupt CGI? Das Common Gateway Interface (CGI) ist eine Methode, um dynamische Inhalte im Internet anzubieten. Es stellt eine Schnittstelle zur Verfügung, über die Daten vom Nutzer an ein serverseitig ausgeführtes Programm übergeben werden. Dieses liefert dann abhängig von der Eingabe dynamische Webinhalte zurück. CGI ist dabei nicht auf eine bestimmte Programmiersprache festgelegt, ein CGI-Programm kann durch ein Shellskript, Skriptsprachen wie Perl, PHP oder Python oder eine binäre ausführbare Datei (z.B. Windows Executable) realisiert werden. Zur Erleichterung der CGI-Programmierung unter Perl gibt es das Modul CGI. Es stellt u. a. eine Reihe von Methoden zur Verfügung, die im Ausgabedatenstrom HTML-Tags mit entsprechendem Namen erzeugen. Die Methode h1("Überschrift") erzeugt z.B. den HTML-Tag <h1>Überschrift</h1>. Umgebung Ein CGI-Programm läuft in einer eingeschränkten Umgebung ab, die vom Web-Server vorgegeben wird. Dabei werden mehrere Umgebungsvariablen gesetzt, aus denen das CGI-Skript seine Informationen bezieht. CGI-Skripte schreiben ihre Ausgabe (meist HTML-Code) nach STDOUT. Diese Daten werden dann vom Web-Server an den Web-Browser weiter gegeben. #!/bin/sh # Ausgabe der Umgebungsvariablen von der Shell echo -e "Content-type: text/html\n\n"; echo "<h1>Umgebungsvariablen</h1>"; for i in `/usr/bin/env | sed -e 's/\s/_/g'`; do echo "$i <br>"; done Dieses beispielhafte Shell-Skript (=> Beispielaufruf) können wir durch folgendes Perl-Skript (=> Beispielaufruf) ersetzen: 90 Einführung in das Webinterface Perl-CGI #!/usr/bin/perl -wT # Ausgabe der Umgebungsvariablen von Perl # # Noch kein CGI-Modul use strict; print "Content-type: text/html\n\n"; print "<h1>Umgebungsvariablen</h1>"; my $var_name; foreach $var_name (sort keys %ENV) { print "<P><B>$var_name</B><BR>"; print $ENV{$var_name}; } Das Perlmodul CGI Das Perl CGI-Modul wird für die bisher gezeigten kleinen Programme nicht unbedingt benötigt. Es erleichtert allerdings die Arbeit mit großen CGI-Programmen bei der Auswertung von Formularen und bei der Bereitstellung von dynamischen Inhalten (z.B. aus einer Datenbank). Dazu betrachten wir im folgenden die wichtigsten CGI-Befehle. Das CGI-Modul von Lincoln D. Stein (http://search.cpan.org/~lds/CGI.pm/) bietet uns zwei Interfaces an, funktional und objektorientiert. Verwendet man die funktionale Version, so muss man die zu importierenden Funktionen mit angeben. Für die StandardFunktionen wird use CGI qw(:standard); als Import im Perl-Programm verwendet. Damit werden die im folgenden beschriebenen wichtigsten Befehle bereit gestellt. header() Damit startet jedes CGI-Programm, um dem Browser des Nutzers mitzuteilen, welche Daten nun dynamisch bereit gestellt werden. Mögliche Parameter sind hier "text/html", "text/plain" oder auch "image/png", falls das Programm dynamische Grafiken erzeugt. Z.B. print header("text/html"); Die objektorientierte Version sähe so aus: use CGI; my $cgi = new CGI; print $cgi->header("text/html"); # Keine weiteren Parameter benötigt # CGI Objekt erzeugen # Objekt-Methode header() aufrufen start_html(), end_html() Falls das Programm HTML-Code erzeugt ist der nächste Befehl start_html(). Damit werden die Anfangs-HTML-Tags <HTML> <HEAD> und <TITLE> geschrieben. Als Parameter kann optional der Titel des Dokuments übergeben werden. Analog dazu werden mit end_html() die End-Tags </BODY></HTML> geschrieben. Z.B. print start_html("Datenbankabfrage"); print end_html(); Das liefert folgenden HTML-Source-Code: 91 Einführung in das Webinterface Perl-CGI <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" lang="en-US" xml:lang="en-US"> <head> <title>Datenbankabfrage</title> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> </head> <body> </body> </html> Für die HTML-Ausgabe stellt CGI passend zu jedem HTML-Tag einen Befehl zur Verfügung. CGI Befehl HTML Tag h1 Überschrift <H1></H1> h2 Überschrift <H2></H2> p Paragraph <P></P> b fett gedruckter Text <B></B> i kursiver Text <I></I> em hervorgehobener Text <EM></EM> a Link <A></A> Eigenschaften von HTML-Tags werden als Parameter des CGI-Befehls übergeben. Die Syntax ist dabei folgende: print h1({-align => "center"}, "Ueberschrift1"); print a({-href => "http://www.google.com", -target => "blank"}, "Google.com"); Als Parameter wird also ein (anonymer) Hash übergeben. Die Schlüssel sind die gewünschten HTML-Eigenschaften mit vorangestelltem '-' Zeichen, die Werte sind die gewünschten Werte für die Eigenschaft. Groß- und Kleinschreibung der Eigenschaften spielt keine Rolle. Der letzte (oder einzige) Parameter der CGI-Funktionen ist ein String mit dem Wert, der im Tag stehen soll. Dadurch können die CGI-Befehle auch geschachtelt werden: print p("Paragraph:", i("Ein", b("dickes"), "Ding")); Hiermit wird folgender HTML-Code generiert: <p>Paragraph:<i>Ein <b>dickes</b> Ding</i></p> start_form(), end_form() Mit start_form() wird ein Formular <FORM> erzeugt. Es sollte dabei das Ziel angegeben werden und optional die Übermittlungsmethode (GET oder POST). Z.B. print start_form({-method => "get", -action => "/cgi-bin/dbabfrage.cgi"}); Ohne Parameter werden POST und aktuelles Skript als Ziel verwendet. Sollte man GET oder POST verwenden? Die GET-Methode hat für den Programmierer den Vorteil, dass Formulare leichter zu debuggen sind. Der Anwender kann sich ein fertig ausgefülltes Formular mit Parametern in die Bookmarks oder einen Link legen - das ist ebenfalls bequem und ergonomisch. GET ist allerdings seit HTML 4.0 „deprecated“ und sollte nicht mehr verwendet werden! Enthält das Formular Werte, die nicht in der URL, im Referer oder in Proxy-Logs auftauchen sollen, dann ist die 92 Einführung in das Webinterface Perl-CGI Verwendung von POST angezeigt. Dies ist zum Beispiel immer dann der Fall, wenn ein Eingabeelement 'Password' verwendet wird. Auch reagieren einige Browser bei POST-Formularen anders, wenn man die Vor- und Zurück-Knöpfe verwendet. Mozilla gibt z.B. eine Warnung aus, dass Formulardaten nochmals abgeschickt werden, was bei einer Bestellung z.B. meistens nicht erwünscht und sinnvoll ist! Bei der Arbeit mit Formularen benötigt man verschiedene Eingabemasken, die mit den folgenden CGI-Befehlen korrespondieren: CGI Befehl Formulartyp textfield <INPUT TYPE="TEXT"> password_field <INPUT TYPE="PASSWORD"> radio_group <INPUT TYPE="RADIO"> checkbox, checkbox_group <INPUT TYPE="CHECKBOX"> hidden <INPUT TYPE="HIDDEN"> button <INPUT TYPE="BUTTON"> reset <INPUT TYPE="RESET"> submit <INPUT TYPE="SUBMIT"> Beispiele: print p("SQL: ", textfield({-name => "sql", -size => 100, -default => "SELECT * FROM delegated LIMIT 50;"})); print p(radio_group({-name => "db", -values => ["gnufsd", "ripencc"], -labels => {gnufsd => "GNU Free Software Directory", ripencc => "Ripe NCC IP Adress Delegation"}})); print submit; Die Eigenschaft -name ist ein Muss und wird benötigt, um hinterher auf die gesetzten Werte zugreifen zu können. Parameterübergabe Die Ausgabe eines CGI-Programmes ist die HTML-Seite, die der Browser anzeigt. Was ist aber mit der Eingabe? Man hat zwei Möglichkeiten. Entweder programmiert man mit HTML-Mitteln eine Eingabemaske. Das mit dieser Maske verbundene (Perl-)Skript bekommt die eingegebenen Daten in Variablen zur Verfügung gestellt. Oder, und das taugt nur für die einfachsten Fälle, man übergibt bei Seitenaufruf Parameter nach folgender Syntax (vgl. GET): http://name.domain.de/skriptname?Param1=Wert1&Param2=Wert2 Der Teil hinter dem Fragezeichen ? wird »query string« genannt. Er besteht aus Parameter-Wert-Zuweisungen, die durch Ampersands & voneinander getrennt sind. Der »query string« darf aus folgenden Zeichen gebildet werden: • • Buchstaben a-z und A-Z Ziffern 0-9 • Den Zeichen - _ . ! ~ * ' ( ) Umlaute, Leerzeichen und andere Sonderzeichnen können also nicht direkt, sondern müssen url-enkodiert übergeben werden, also etwa das Leerezeichen als %20. param() Eine der wichtigsten CGI-Funktionen bei der Arbeit mit Formularen ist sicherlich param(). Diese Funktion ermöglicht den Zugriff auf die Parameter, die an das CGI-Skript übergeben wurden. Also z.B. die Werte, die von einem Formular aus abgeschickt wurden oder in der URL übergeben wurden. Ohne Angabe eines Parameters liefert die Funktion den Namen des nächsten an das Skript übergebenen Wertes. Wird die Funktion mit dem Namen eines Wertes aufgerufen, so liefert sie 93 Einführung in das Webinterface Perl-CGI den Wert des Parameters. In einer Schleife lassen sich somit leicht alle Parameter und ihre zugehörigen Werte abfragen: foreach $name ($cgi->param()) { foreach $value ($cgi->param($name)) { print "$name: $value\n"; } } Als Beispiel hier ein komplettes Programm: #!/usr/bin/perl -wT use strict; use CGI; my $cgi = new CGI; print $cgi->header( "text/plain" ); print "These are the parameters I received:\n\n"; my( $name, $value ); foreach $name ( $cgi->param() ) { print "$name:\n"; foreach $value ( $cgi->param( $name ) ) { print " $value\n"; } } ( => Beispielaufruf ) url(), self_url() Zwei weitere nützliche Funktionen sind url() und self_url(). Die erste Funktion liefert die komplette URL des aktuellen Skripts inklusive „http://“, Hostname, Port, usw. Die dabei zurückgelieferten URL-Teile lassen sich über Parameter bestimmen (siehe dazu 'perldoc DBI)'. self_url() ist eine spezielle Version, die die URL inkl. aller Parameter liefert. Das kann nützlich sein, wenn man in einem (mit Parametern aufgerufenen) Skript über Anker hin- und herspringen möchte. start_table(), end_table() Eine Tabellen-Umgebung (<TABLE>) kann über den start_table() Befehl begonnen werden. Um diese UmgebungsBefehle zu verwenden, muss im funktionalen Modus bei use CGI der Parameter *table angegeben werden. An start_table() können optionale Parameter z.B. für den Rand (-border) oder die Breite (-width) übergeben werden. Es stehen die folgenden drei Befehle zur Verfügung: CGI Befehl HTML Tag Tr (absichtlich mit großem T, da tr bereits Perl-Funktion ist) Tabellen-Spalte <TR> th Tabellen-Kopf <TH> td Tabellen-Daten <TD> Sehr nützlich ist dabei, dass diese Funktionen auf Listen angewendet werden können und die Tags dann um jedes Element geschrieben werden. ol(), ul() Geordnete- und ungeordnete Listen können mit ol() bzw. ul() begonnen werden. Einzelne Listeneinträge werden mit li() 94 Einführung in das Webinterface Perl-CGI generiert. Beispiel: print ol(li(["First", "Second", "Third"])); generiert folgenden Code: <ol> <li>First</li> <li>Second</li> <li>Third</li> </ol> Natürlich kann man an jeder Stelle auch selbst HTML-Code über print() ausgeben, wenn das für Einzelfälle einfacher erscheint. Um mehrere Zeilen HTML-Code auszugeben bietet sich das "Here"-Dokument an. Es ist möglich mit print <<MARKE; allen Text bis zu der angegebenen Marke auszugeben. Diese Methode bietet sich zum Beispiel an, um ein Standard HTML-Formular auszugeben, wenn das Skript ohne Parameter aufgerufen wurde. print <<END_OF_HTML; <HTML> <HEAD> <TITLE>Beispieltitel</TITEL> </HEAD> <BODY> <H1>Beispielueberschrift</H1> <P>Wert: $wert</P> </BODY> </HTML> END_OF_HTML Die Variablen-Interpolation von Perl funktioniert auch in diesem Zusammenhang. Mit Hilfe der jetzt erklärten CGI-Befehle ist es uns möglich, ein Web-Programm zu schreiben, mit dem wir vom Nutzer ausgewählte Informationen aus einer Datenbank abfragen und ausgeben können. #!/usr/bin/perl -wT # # Datenbankabfrage mit DBI & CGI # $|=1; # Ausgabe sofort flushen open STDERR, ">&STDOUT"; # Fehler in Browser umleiten use strict; use DBI; # Datenbank-Modul use CGI qw(:standard *table); # CGI-Modul im funktionalen Modus # Header print header("text/html"); # HTML starten <head> print start_html({-title=>"Datenbankabfrage", -onload=>"document.sql_form.sql.focus();"}); #print "<html><body onload=\"document.sql_form.sql.focus();\">"; # Inhalt <body> print h1("Datenbankabfrage"); if (my $db = param("db")) { 95 Einführung in das Webinterface Perl-CGI #$db = $cgi->param("db"); print h2("Ausgewaehlte Datenbank: ", i($db)); if (my $sql = param("sql")) { print "Verbinde zur Datenbank..."; my $hostname = "zivkuefer.uni-muenster.de"; my $user = "perldbi"; my $pass = "pWS0607"; my $dbh = DBI->connect("DBI:mysql:database=$db;host=$hostname", $user, $pass, {'RaiseError' => 1}); print "ok<BR>\n"; print "Preparing SELECT... "; my $sth = $dbh->prepare($sql); $sth->execute(); print "ok<BR>\n"; print start_form({-name=>"sql_form", -method=>"get", -action=>"/cgibin/dbabfrage.cgi"}); print p("SQL: ", textfield({-name=>"sql", -size=>100, -default=>"$sql"})); print hidden({-name=>"db", -default=>"$db"}); print submit; print end_form(); # print p("Abfrage:", b($sql)); print p(); print start_table({-border=>1, -cellpadding=>2, -cellspacing=>0, -caption=>"Ergebnisse"}); my $rows=0; if ($db eq "gnufsd") { # Zeile für Zeile mit fetchrow_array() print Tr(th({-align=>"left"}, ["Name", "Beschreibung", "URL"])); while (my @row = $sth->fetchrow_array()) { print Tr(td([@row[0..1], a({-target=>"blank", -href=>"$row[2]"}, "$row[2]")])); $rows++; } } elsif ($db eq "ripencc") { print Tr(th({-align=>"left"}, ["Land", "Typ", "Datum", "Inetnum"])); while (my @row = $sth->fetchrow_array()) { print Tr(td([@row[0..2], a({-target=>"blank", -href=>"http://www.ripe.net/fcgi-bin/whois?searchtext=$row[3]"}, "$row[3]")])); $rows++; } } print end_table(); print p(b("$rows Ergebnisse")); # Disconnect from the database. $dbh->disconnect(); } else { 96 Einführung in das Webinterface Perl-CGI print h3("Geben Sie eine Abfrage ein:"); print start_form({-name=>"sql_form", -method=>"get", -action=>"/cgibin/dbabfrage.cgi"}); if ($db eq "gnufsd") { print p("SQL: ", textfield({-name=>"sql", -size=>100, -default=>"SELECT name,short_description,web_page FROM program where name LIKE \"A%\" LIMIT 50;"})); } elsif ($db eq "ripencc") { print p("SQL: ", textfield({-name=>"sql", -size=>100, -default=>"SELECT country,type,date,ip FROM delegated WHERE country=\"DE\" ORDER BY date DESC LIMIT 50;"})); } print hidden({-name=>"db", -default=>"$db"}); print submit; print end_form(); } } else { print h2("Waehlen Sie eine Datenbank:"); print start_form({-name=>"db_form", -method=>"get", -action=>"/cgibin/dbabfrage.cgi"}); print p(radio_group({-name=>"db", -values=>["gnufsd", "ripencc"], -labels=>{gnufsd=>"GNU Free Software Directory", ripencc=>"Ripe NCC IP Adress Delegation"}})); print submit; print end_form(); } # HTML beenden print end_html(); # EOF ( => Beispielaufruf ) Übungsaufgaben Vertiefende Übungen zu Perl/DBI und /CGI. Aufg. 22) Übungen zu Perl/CGI Erweitern Sie das Programm zur Abfrage der 'gnufsd'-Datenbank aus der Vorlesung um folgende Funktionen: a) eine Möglichkeit nach bestimmten Stichwörtern in der Beschreibung 'full_description' der Programme in der Tabelle 'program' zu suchen und die darauf passenden Ergebnisse anzuzeigen. b) eine Möglichkeit, die Programme mittels einer Drop-Down-Box (<INPUT TYPE="SELECT">) nach Kategorien aufzulisten. c) eine Möglichkeit, in der Ergebnisansicht auf einen Programmnamen zu klicken und dann alle dazu verfügbaren Informationen anzusehen. Aufg. 23) Postleitzahlen-Suche 97 Einführung in das Webinterface Perl-CGI Sie finden in der Datenbank 'plz' eine Tabelle 'plz', die die Postleitzahlen von Deutschland enthält und folgende Felder hat: +------------+------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+------------------+------+-----+---------+-------+ | Ort | varchar(100) | NO | | NULL | | | Zusatz | varchar(100) | YES | | NULL | | | Plz | int(10) unsigned | NO | PRI | 0 | | | Vorwahl | varchar(10) | YES | MUL | 0 | | | Bundesland | varchar(100) | NO | | NULL | | +------------+------------------+------+-----+---------+-------+ Schreiben Sie ein Perl/CGI-Programm, das ein Formular zur Abfrage der Tabelle anbietet. Der Nutzer soll dabei nach 'Ort' oder 'Plz' suchen können und als Ergebnis eine Liste der Treffer mit allen Informationen aus der Datenbank erhalten. Viel Spass! 98 Dynamische Grafiken, Grafische Oberflächen Dynamische Grafiken, Grafische Oberflächen Dynamisch erzeugte Grafiken Oft möchte man Daten im Web nicht nur in Textform (z.B. als Tabelle) darstellen, sondern auch als Grafik. Beispiele dafür sind Aktien-Charts oder Balken- und Kreisdiagramme. Das Perlmodul GD (http://search.cpan.org/~lds/GD/) stellt ein objektorientiertes Interface zur C-Bibliothek gd von Thomas Boutell (http://www.boutell.com/gd/) zur Verfügung, die das dynamische Erzeugen und Arbeiten mit PNG, JPG (und GIF veraltet) Bildern ermöglicht. Beginnen wir mit einem einfachen Beispiel zur GD::Image Klasse. #!/usr/bin/perl # use GD module use GD; # create a new image $im = new GD::Image(100,100); # allocate some colors $white = $im->colorAllocate(255,255,255); $black = $im->colorAllocate(0,0,0); $red = $im->colorAllocate(255,0,0); $blue = $im->colorAllocate(0,0,255); # make the background transparent and interlaced $im->transparent($white); $im->interlaced('true'); # Put a black frame around the picture $im->rectangle(0,0,99,99,$black); # Draw a blue oval $im->arc(50,50,95,75,0,360,$blue); # And fill it with red $im->fill(50,50,$red); # make sure we are writing to a binary stream binmode STDOUT; # Convert the image to PNG and print it on standard output print $im->png; Zuerst wird das GD-Modul eingebunden. Dann erzeugen wir ein neues Objekt (welches in diesem Fall ein Bild repräsentiert) mit den Dimensionen 100x100 Pixel. Als nächstes werden ein paar Standardfarben als Variablen definiert. Danach werden die Bildparameter Transparent und Interlaced gesetzt. Es folgt das Zeichnen eines Rechtecks und eines Kreises, der mit der Farbe rot gefüllt wird. Schließlich wird das Bild auf STDOUT ausgegeben. Dabei muss beachtet werden, dass der Binärmodus eingeschaltet ist. Konstruktor Mit der new()-Methode wird ein neues GD::Image Objekt erzeugt. Als Parameter kann entweder die gewünschte Größe des Bildes angegeben werden oder der Dateiname bzw. das Handle eines bereits vorhandenen Bildes, das dann geladen wird. $myImage = new GD::Image(100,100) || die; $myImage = new GD::Image("background.png") || die; 99 Dynamische Grafiken, Grafische Oberflächen Methoden Es stehen nun verschiedene Methoden zur Verfügung, die auf das GD::Image Objekt angewendet werden können. Dazu gehören u.a. ● ● ● Zeichen-Methoden, um einfache 2D-Objekte zu zeichnen line(), rectangle(), ellipse(), arc() Ausgabe-Methoden, um das Objekt als PNG-, JPG- oder GIF-Daten auszugeben png(), jpg(), gif() Sonstige Methoden, um mit Farben zu arbeiten, Bilder zu clonen oder Text auszugeben colorAllocate(), copy(), clone(), string() Die genaue Syntax dieser Methoden kann über 'perldoc GD' nachgelesen werden. Neben der GD::Image Klasse gibt es noch weitere Klassen zum Arbeiten mit Schriften (GD::Font), Polygonen (GD::Polygon) und Diagrammen (GD::Graph). Letztere Klasse ist für uns interessant, um unsere Datenbank-Abfragen grafisch zu erweitern. GD::Graph GD::Graph (http://search.cpan.org/~bwarfield/GDGraph/) von Benjamin Warfield ist ein Paket, das auf GD aufbaut und mehrere Klassen zur Verfügung stellt, um Daten zu plotten. Es gibt Möglichkeiten zum Erstellen von Linien-, Balken-, Kuchen- und noch weiteren Diagrammen. Konstruktor Nach dem Importieren der benötigten Klasse wird ein Objekt vom jeweiligen Typ erzeugt: my $graph = new GD::Graph::lines(400, 300) my $graph = new GD::Graph::bars(400, 300) my $graph = new GD::Graph::pie(400, 300) # Liniendiagramm # Balkendiagramm # Kuchendiagramm Optional kann dabei ein Parameter für die gewünschte Größe des Diagramms angegeben werden. Methoden Die Größe und alle weiteren Parameter können aber auch über die set()-Methode gesetzt werden. my $graph = new GD::Graph::bars(400, 400); $graph->set( x_label => 'Laender', y_label => 'Registrierungen', title => 'IPv4 Adressverteilung in Europa', y_max_value => 5000, y_tick_number => 100, y_label_skip => 2 ) or die $graph->error(); Die Methode error() liefert die Fehlermeldung der letzten Operation. Hat man alle Parameter des Diagramms gesetzt, so müssen die zu plottenden Daten übergeben werden. Dies geht mit der Methode plot(), die als Parameter die Referenz auf ein Array mit den Daten erhält. my @data = ( ["1st","2nd","3rd","4th","5th","6th","7th", "8th", "9th"], [ 1, 2, 5, 6, 3, 1.5, 1, 3, 4], [ sort { $a <=> $b } (1, 2, 5, 6, 3, 1.5, 1, 3, 4) ] ); print $graph->plot(\@data)->png() or die $graph->error(); Die erste Zeile des Arrays enthält die Einträge der X-Achse, alle weiteren Zeilen enthalten die jeweiligen Datenpunkte, die im Diagramm eingezeichnet werden. plot() liefert ein GD-Objekt zurück, das z.B. mit der png()-Methode ausgegeben werden kann. 100 Dynamische Grafiken, Grafische Oberflächen Wir beschränken uns im folgenden auf die Erweiterung des Skripts dbabfrage.cgi um die Anzeige einer Statistik zur jeweils gewählten Datenbank. Beispielauszug: my $dbh = DBI->connect("DBI:mysql:database=ripencc;host=$hostname", $user, $pass, {'RaiseError' => 1}); my $sth = $dbh->prepare("SELECT country,count(country) FROM delegated WHERE type=\"ipv4\" GROUP BY country ORDER BY count(country) DESC LIMIT 25;"); my (@data, @country, @count); $sth->execute(); while (my @row = $sth->fetchrow_array()) { push @country, $row[0]; push @count, $row[1]; } push @data, \@country, \@count; binmode STDOUT; print $graph->plot(\@data)->png() or die $graph->error(); ( => Beispielaufruf ) Leider können die Daten von DBIs fetch-Methoden nicht direkt an plot() übergeben werden, da Zeilen und Spalten vertauscht sind. Deshalb müssen die Daten nochmals über die Arrays @country und @count umsortiert werden. Es gibt noch eine Erweiterung von GD::Graph, die 3d-Diagramme erzeugt: GD::Graph3d von Jeremy Wadsack (http://search.cpan.org/~wadg/GD-Graph3d/). Die Verwendung erfolgt analog zu GD::Graph und wird hier nicht mehr vorgeführt. Übungsaufgaben Übungen zu Perl-GD und GD::Graph. Aufg. 24) GD Mit der Anweisung GD::Image->trueColor(1); können Sie den True Color Modus von GD einschalten. a) Schreiben Sie ein Perl-Programm, das ein Bild erzeugt mit jeweils einem Farbverlauf von einer Grundfarbe in eine andere, also z.B. von rot (255,0,0) nach grün (0,255,0) und grün (0,255,0) nach blau (0,0,255). Speichern Sie dieses Bild als PNG in einer Datei ab. b) Laden Sie das Bild aus a) und fügen Sie an der linken unteren Ecke einen Text in weißer Schrift ein, z.B. "(c) Copyright 2007, ...". Verwenden Sie dazu die GD-Methode $image->string(gdSmallFont,$x,$y,$string,$white). Aufg. 25) GD::Graph In der Tabelle 'source_language_mapping' der Datenbank 'gnufsd' ist (an Hand von IDs) gespeichert, welches Programm in welcher Programmiersprache geschrieben ist. Die Tabelle hat folgendes Format: +----------------------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------------------+---------+------+-----+---------+-------+ | program_id | int(11) | YES | MUL | NULL | | | computer_language_id | int(11) | YES | MUL | NULL | | +----------------------+---------+------+-----+---------+-------+ Den Namen der jeweiligen Programmiersprache bekommen Sie über die ID aus der Tabelle 'computer_language'; 101 Dynamische Grafiken, Grafische Oberflächen +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(80) | YES | MUL | NULL | | +-------+-------------+------+-----+---------+----------------+ Schreiben Sie ein Perl-Programm, das ein Kuchen- und ein Balkendiagramm der Top 20 Programmiersprachen generiert und jeweils in einer Datei im PNGFormat abspeichert. Viel Spass! 102 Grafische Oberflächen in Perl Grafische Oberflächen in Perl Bisher haben wir Perl als Skript-Sprache angesehen, die von Natur aus auf der Kommando-Zeile arbeitet und dabei so wenig Interaktion vom Nutzer verlangt wie möglich. Das muss aber nicht sein! Perl ist durchaus in der Lage grafische Nutzeroberflächen (engl.: „Graphical User Interface“, GUI) zu erzeugen, die anwenderfreundliche Programme ermöglichen. Das geht z.B. mit dem Perl/Tk-Modul, welches wir uns im Folgenden anschauen wollen. Perl/Tk Weiterführende Literatur O'Reilly bietet auch eine Einsteiger- und ein Referenzbuch zum Thema Perl/Tk an: ● Learning Perl/TK. Graphical User Interfaces with Perl; Nancy Walsh; 1st Ed., Jan 1999, O'Reilly; ISBN: 156592-314-6 ● Mastering Perl/TK. Graphical User Interfaces with Perl; Stephen O. Lidie, Nancy Walsh; 1st Ed., Jan 1999, O'Reilly; ISBN: 1-56592-716-8 Tk ist ein grafisches Toolkit, das ursprünglich für die Skriptsprache Tcl (http://www.tcl.tk) entwickelt wurde (deshalb das häufige Auftreten in Form von Tcl/Tk) und das einfache Erstellen von grafischen Oberflächen ermöglicht. Mit der immer größeren Beliebtheit von Perl und Python kam auch die Integration von Tk in diese Skript-Sprachen. Das Tk-Modul (http://search.cpan.org/dist/Tk/) wurde ursprünglich von Nick Ing-Simmons entwickelt und jetzt von Slaven Rezic betreut (letzte Änderung Okt 2011) und ermöglicht, in Perl sehr einfach grafische Oberflächen für Windows und Unix zu erstellen. Es wird ein objektorientiertes Interface zur Verfügung gestellt, mit dem Fenster und Grafikobjekte (engl.: „widgets“) erzeugt werden können. Es gibt noch zwei alternative Möglichkeiten, die eine Schnittstelle zu Tcl/Tk bieten, zum einen das Tkx-Modul (letzte Änderung Nov 2010), welches von ActiveState unterstützt wird, und zum anderen das Tcl::Tk-Modul (letzte Änderung Feb 2011). Daneben gibt es noch ganz andere Fenster Toolkits, wie Qt, Gtk oder wxWidgets, die moderner als Tk sind und eine ansprechendere Optik haben. Die Perl-Schnittstelle ist dabei nicht immer gelungen. Zu empfehlen sind das Gtk2-Modul, welches im nächsten Kapitel behandelt wird, und das Wx-Modul. Erste Schritte Für den schnellen Einstieg schauen wir uns das „Hallo Welt!“-Programm mit Perl/Tk an: #!/usr/bin/perl -w use Tk; use strict; my $mw = new MainWindow(-title => "Hello World!"); $mw->geometry('640x480'); $mw->Label(-text => "Hello World!")->pack(-fill => 'both', -expand => 1); $mw->Button(-text => "Quit", -command => sub {exit 0;})->pack(-side => 'bottom'); MainLoop; Was sehen wir hier? Das Modul Tk wird eingebunden, dann wird ein Objekt der Klasse MainWindow erzeugt. Dies ist das Hauptfenster, auf das sich alle folgenden Aufrufe beziehen. Die Größe des Hauptfensters wird auf 640x480 Pixel 103 Grafische Oberflächen in Perl gesetzt. Danach setzen wir in das Hauptfenster ein Label mit dem Text „Hello World!“ und einen Knopf mit dem Text „Quit“. Wird dieser Knopf gedrückt, so wird die implizite Funktion mit Inhalt exit 0 ausgeführt und das Programm somit beendet. Abbildung 1: Ausgabe von perl-tk.pl Und was bedeutet MainLoop? Die bisherigen Befehle haben nur die Oberfläche und deren Aktionen definiert. Erst mit dem Aufruf von MainLoop startet unser Programm. Es zeichnet die Grafikobjekte und leitet die vom Nutzer ausgeführten Aktionen an die dafür definierten Funktionen weiter. Ohne MainLoop passiert gar nichts und das Programm ist sofort (fehlerfrei) beendet. GUI-Programme laufen nicht linear ab, sondern werden über events gesteuert. Es steht dem Nutzer also frei, welche Bedienelemente er in welcher Reihenfolge aktiviert und benutzt. Klassen Perl/Tk ist komplett objektorientiert. Zu jedem Widget gibt es eine Klasse, aus der sich beliebig viele Objekte erzeugen lassen. Die Konstruktoren sind nach ihrem Klassennamen benannt, sie heißen also in diesem Fall nicht new() (nur MainWindow ist eine Ausnahme)! Die wichtigsten Klassen sind: Klasse Beschreibung MainWindow Das Hauptfenster, das alle Widgets enthält Toplevel Ein weiteres Fenster außerhalb von MainWindow Frame Ein Raum, der andere Widgets enthalten kann Menu (früher: Menubutton) Ein Menü mit Unterpunkten Label Ein Feld zum Anzeigen von Text Button Ein Knopf, der gedrückt werden kann Checkbutton Ein oder mehrere Knöpfe, die aktiviert und deaktiviert werden können Radiobutton Ein oder mehrere Knöpfe, von denen nur einer angeklickt werden kann 104 Grafische Oberflächen in Perl Klasse Beschreibung Entry Ein einzeiliges Texteingabefeld Text Ein mehrzeiliges Texteingabefeld Scrollbar (siehe auch Scrolled) Eine Bildlaufleiste Listbox Eine Listenbox Canvas Ein Zeichenraum für primitive 2d-Objekte Um nun ein neues Hauptfenster zu erzeugen, genügt der Aufruf: my $mw = new MainWindow(); Um ein Textlabel zu erzeugen: my $label = $mw->Label(-text => "Hello World!"); Eigenschaften Die Eigenschaften des jeweiligen Widgets werden beim Erzeugen als Parameter (wie bei CGI in Hashform) mit angegeben. Die Namen der wichtigen Eigenschaften sind für alle Objekte gleich. Eigenschaft Beschreibung -title Titel des Widgets -text Der vom Widget anzuzeigende Text -textvariable Referenz auf eine Variable, deren Inhalt angezeigt werden soll (oder umgekehrt für Eingabefelder) -anchor => 'n' | 'ne' | 'e' | 'se' | 's' | 'sw' | 'w' | 'nw' | 'center' Verankerung des Texts im Widget -justify => 'left' | 'center' | 'right' Ausrichtung von mehrzeiligem Text -command Referenz auf eine Funktion, die bei Anklicken ausgeführt werden soll -width Breite des Widgets -height Höhe des Widgets -disabled => 0 | 1 Damit kann das Widget deaktiviert werden, also ein Button ist nicht anklickbar, oder ein Textfeld ist nur lesbar. -state => 'normal' | 'disabled' | 'active' Erweiterte Version von -disabled, 'active' bedeutet, das Feld hat den Fokus -value Der Wert, auf den der Inhalt von -variable gesetzt wird -variable Referenz auf eine Variable, die den aktuellen Zustand des Widgets enthält Dazu gehören noch weitere Eigenschaften, die die Schriftart, Text- und Hintergrundfarben ändern können. Beispiel: $mw->Button(-text => "Quit", -command => sub {exit 0;}); Im folgenden Beispiel erzeugen wir einen Knopf, der mitzählt wie oft er gedrückt wurde: 105 Grafische Oberflächen in Perl #!/usr/bin/perl -w use Tk; use strict; my $mw = new MainWindow(-title => "Tk::Button"); $mw->geometry('640x480'); my $count; my $buttonText = "Press me!"; $mw->Button(-textvariable => \$buttonText, -command => sub {$count++; $buttonText = "You have pressed me $count times"; })->pack(-fill => 'x', -expand => 1, -side => 'left'); MainLoop; Abbildung 2: Ausgabe von perl-tk-button.pl Ein Beispiel zu Radiobuttons: #!/usr/bin/perl -w use Tk; use strict; my $mw = new MainWindow(-title => "Tk::Radiobutton"); $mw->geometry('640x480'); my $rb_value = "none"; my $rb_text = "No color selected."; my $frm1 = $mw->Frame->pack(-side => "top", -expand => "1", -fill => "both"); 106 Grafische Oberflächen in Perl my $frm2 = $mw->Frame->pack(-side => "bottom", -expand => "1", -fill => "both"); $frm1->Label(-text => "Please choose a color:")->pack(); $frm1->Radiobutton(-text => "red", -value => "red", -variable => \$rb_value, -command => \&set_color)->pack(-side => "left", -expand => "1"); $frm1->Radiobutton(-text => "blue", -value => "blue", -variable => \$rb_value, -command => \&set_color)->pack(-side => "left", -expand => "1"); $frm1->Radiobutton(-text => "green", -value => "green", -variable => \ $rb_value, -command => \&set_color)->pack(-side => "left", -expand => "1"); $frm2->Label(-textvariable => \$rb_text)->pack(-side => "top"); $frm2->Button(-text => "OK", -command => sub {print "You selected $rb_value.\n"; exit 0;})->pack(-side => "bottom", -expand => "1"); sub set_color { $rb_text = "Color is now $rb_value.\n"; } MainLoop; Abbildung 3: Ausgabe zu perl-tk-radiobuttons.pl Ein Fenster mit Haupt- und Untermenüs: #!/usr/bin/perl -w # # menubar2 - create a menubar in the modern Tk 8 style. # 107 Grafische Oberflächen in Perl use Tk 8.0; use strict; my $mw = MainWindow->new(-title => "Tk::Menu"); $mw->geometry('640x480'); my $menubar = $mw->Menu; $mw->configure(-menu => $menubar); my $file = $menubar->cascade(-label => '~File'); my $cas1 = $menubar->cascade(-label => 'Cas~cades'); my $help = $menubar->cascade(-label => '~Help'); # First, the File menu item. $file->command(-label => "Quit!", -command => \&exit); my $cas2 = $cas1->cascade(-label => 'Cascade Level 2');; my $cas3 = $cas2->cascade(-label => 'Cascade Level 3'); my $cas4 = $cas3->cascade(-label => 'Cascade Level 4'); $cas1->command(-label => -command => sub $cas2->command(-label => -command => sub $cas3->command(-label => -command => sub $cas4->command(-label => -command => sub 'Level {print 'Level {print 'Level {print 'Level {print 1', "Level 2', "Level 3', "Level 4', "Level 1\n"}); 2\n"}); 3\n"}); 4\n"}); # Finally, the Help menu items. $help->command(-label => -command => sub $help->separator; $help->command(-label => -command => sub 'Version', {print "Version\n"}); 'About', {print "About\n"}); MainLoop; 108 Grafische Oberflächen in Perl Abbildung 4: Ausgabe zu perl-tk-menu.pl Methoden Die wichtigsten allgemeinen Methoden sind pack() und bind(). pack() Wir haben bereits im ersten Beispiel die Methode pack() auf ein Label- und Button-Objekt angewendet, ohne das genauer zu erklären. pack() ist ein Fenstermanager, der das jeweilige Widget-Objekt auf dem Bildschirm zeichnet. Er geht dabei der Erstellungsreihenfolge nach vor und achtet darauf, dass kein Objekt verdeckt wird. Der verfügbare Fensterraum wird in vier Rechtecke aufgeteilt, wobei die Platzierung durch Angabe der Richtungen oben, links, unten und rechts beeinflusst werden kann. pack() ist die schnellste und einfachste Möglichkeit, um eine grafische Oberfläche zu generieren, die auch bei Größenveränderungen des Fensters erhalten bleibt. 109 Grafische Oberflächen in Perl Abbildung 5: Aufteilungs-Rechtecke In der folgenden Tabelle sind die wichtigsten Parameter von pack(), die die Position im Fenster genauer angeben, aufgelistet. Parameter Beschreibung -side => 'left' | 'right' | 'top' | 'bottom' Zu welcher Seite das Widget ausgerichtet wird -fill => 'none' | 'x' | 'y' | 'both' Den restlichen Platz im Aufteilungs-Rechteck auffüllen -expand => 1 | 0 Das Aufteilungs-Rechteck füllt den Platz im Fenster aus -anchor => 'n' | 'ne' | 'e' | 'se' | 's' | 'sw' | 'w' | 'nw' | 'center' Verankerung des Widgets im Fenster (bzw. Frame) Es folgt das Beispiel, das die Aufteilungs-Rechtecke in Abbildung 5 erzeugt: #!/usr/bin/perl -w use Tk; use strict; my $mw = new MainWindow(-title => "Allocation Rectangles"); $mw->geometry("640x480"); $mw->Button(-text => "Top", -command => sub {exit 0;})->pack(-side => "top", -fill => "both"); $mw->Button(-text => "Bottom", -command => sub {exit 0;})->pack(-side => "bottom", -fill => "both"); $mw->Button(-text => "Right", -command => sub {exit 0;})->pack(-side => "right", -fill => "both"); $mw->Button(-text => "Left", -command => sub {exit 0;})->pack(-side => "left", -fill => "both"); 110 Grafische Oberflächen in Perl MainLoop; Weitere Fenstermanager sind grid(), um Widgets in Zeilen und Spalten auszugeben und place(), um Widgets an festen Bildschirm-Koordinaten (Pixeln) auszugeben. bind() Eine grafische Oberfläche wird über bestimmte Aktionen, so genannte Ereignisse (engl.: „events“), gesteuert. Dazu gehört das Klicken mit der Maus oder auch das Drücken von Tasten auf der Tastatur. Um bestimmten Kombinationen einer Funktion zuzuordnen, wird die Methode bind() benutzt. Als erster Parameter wird die Art des Events angegeben, also z.B. ein gedrückter Mausknopf oder eine Taste, der zweite Parameter ist die Referenz auf die aufzurufende Eventmethode. Zu den wichtigsten Events gehören: Name Beschreibung Create Erzeugen eines Fensters Destroy Schließen eines Fensters Enter Betreten eines Fensters Leave Verlassen eines Fensters ResizeRequest Größenänderung eines Fensters Activate Aktivieren eines Widgets Deactivate Verlassen eines Widgets KeyPress (kurz: Key) Drücken einer Taste KeyRelease Loslassen einer Taste Escape Drücken der Escape-Taste ButtonPress (kurz: Button) Drücken einer Maustaste ButtonRelease Loslassen einer Maustaste Motion Bewegen der Maus MouseWheel Mausrad Im folgenden Beispiel werden einige Ereignisse abgefangen und teils durch anonyme, teils durch benannte Funktionen bedient. #!/usr/bin/perl -w use Tk; use strict; my $mw = new MainWindow(-title => "Tk::Bind"); $mw->geometry('640x480'); my $text = $mw->Text->pack(-fill => 'both', -expand => 1); tie *STDOUT, ref $text, $text; $text->bind("<Create>", sub {print "Window created.\n";}); $text->bind("<Destroy>", sub {print "Window destroyed.\n";}); $text->bind("<Enter>", sub {print "You entered the widget.\n";}); $text->bind("<Leave>", sub {print "You left the widget.\n";}); $mw->bind("<Button-1>", \&mb1); $mw->bind("<Button-2>", sub {print "You pressed the middle mouse button.\n";}); $mw->bind("<Button-3>", \&mb3); $mw->bind("<MouseWheel>", sub {print "You used the mouse wheel.\n";}); $mw->bind("<Escape>", \&quit); 111 Grafische Oberflächen in Perl # Mouse button 1 event sub mb1 { print "You pressed the left mouse button.\n"; } # Mouse button 3 event sub mb3 { print "You pressed the right mouse button.\n"; } # ESC event sub quit { print "Request for exit.\n"; exit 0; } MainLoop; Abbildung 6: Ausgabe zu perl-tk-bin.pl Zum Abschluss noch das Beispiel eines kleinen Malprogramms mit Hilfe des Tk::Canvas Objekts. #!/usr/bin/perl -w use Tk; use GD; use strict; # MainWindow 112 Grafische Oberflächen in Perl my $mw = new MainWindow(-title => "Tk::Canvas"); $mw->geometry('640x480'); my $menu = $mw->Menu(-type => 'menubar'); $mw->configure(-menu => $menu); # Erstes Menü my $file_menu = $menu->cascade(-label => '~Datei'); my $edit_menu = $menu->cascade(-label => '~Bearbeiten'); my $help_menu = $menu->cascade(-label => '~Help'); # Nur Help wird automatisch rechts ausgerichtet! # Die Menüpunkte $file_menu->command(-label $file_menu->command(-label $file_menu->command(-label $file_menu->separator; $file_menu->command(-label => "Oeffnen", -command => \&openFile); => "Speichern", -command => \&saveFile); => "Schliessen", -command => \&closeFile); => "Beenden", -command => \&exit); # Die weiteren Menüs $help_menu->command(-label => "Hilfe", -command => \&progHelp); $help_menu->separator; $help_menu->command(-label => "Ueber", -command => \&progAbout); # Und ein Canvas um den Raum zu füllen #my $canvas = $mw->Canvas(-height => 480, -width => 640)->pack; my $canvas = $mw->Canvas()->pack(-fill => 'both', -expand => 1); $canvas->Tk::bind("<ButtonPress-1>", [\&startLine, Ev('x'), Ev('y')]); $canvas->Tk::bind("<ButtonRelease-1>", [\&endLine, Ev('x'), Ev('y')]); # Die Methoden für Menüaktionen sub startLine { my ($canvas, $x, $y) = @_; $canvas->createOval($x, $y, $x, $y, -width => 4, -tags => 'drawmenow'); } $canvas->Tk::bind("<Motion>", [\&startLine, Ev('x'), Ev('y')]); sub endLine { my ($canvas, $x, $y) = @_; $canvas->createOval($x, $y, $x, $y, -width => 4, -tags => 'drawmenow'); $canvas->Tk::bind("<Motion>", ""); } sub openFile { } sub saveFile { } sub closeFile { } sub progExit { 113 Grafische Oberflächen in Perl exit 0; } sub progHelp { } sub progAbout { } MainLoop; Abbildung 7: Ausgabe von perl-tk-draw.pl 114 Grafische Oberflächen in Perl Perl/Gtk2 Das GIMP Toolkit (GTK+) ist eine freie Komponentenbibliothek, die ursprünglich für das Grafikprogramm GIMP entwickelt wurde (1996-1998). Mit GTK+ 1.2 (Feb 1999) hat sich die Bibliothek von GIMP losgelöst und bot eine Sammlung gängiger Widgets, die universell einsetzbar waren. Mittlerweile wird GTK+ von vielen Anwendungen und den Desktopumgebungen GNOME und Xfce verwendet und ist neben Qt eines der erfolgreichsten Grafik-Toolkits. • • • • • • • • • 1.0 (Apr 1998, ca 93.000 lines of code) 1.2 (Feb 1999, ca 160.000 lines of code) 2.0 (Mar 2002, ca 460.000 lines of code) 2.2 (Dec 2002, ca 488.000 lines of code) 2.4 (Mar 2004, ca 558.000 lines of code) ... 2.24 (Jan 2011) 3.0 (Feb 2011) 3.2 (Sep 2011) Das Gtk2-Modul von Torsten Schönfeld ermöglicht es die die Gtk+ 2.x API aus Perl heraus anzusprechen. Die Namensräume der GTK+-Bibliotheken werden wie folgt durch Perl-Packages repräsentiert: g_ => Glib (the Glib module - distributed separately) gtk_ => Gtk2 gdk_ => Gtk2::Gdk gdk_pixbuf_ => Gtk2::Gdk::Pixbuf pango_ => Gtk2::Pango GTK+-Objekte bekommen ihren eigenen Namensraum und werden ebenfalls durch Perl-Packages ersetzt. Z.B.: GtkButton => Gtk2::Button GdkPixbuf => Gtk2::Gdk::Pixbuf GtkScrolledWindow => Gtk2::ScrolledWindow PangoFontDescription => Gtk2::Pango::FontDescription Weiterführende Literatur • • • • • Projektseite: http://gtk2-perl.sourceforge.net/ Tutorial: http://gtk2-perl.sourceforge.net/doc/gtk2-perl-study-guide/ Mailingliste: https://mail.gnome.org/archives/gtk-perl-list/ Original GTK+ API: http://developer.gnome.org/gtk/stable/ Original GTK+ Tutorial: http://developer.gnome.org/gtk-tutorial/stable/ Erste Schritte Starten wir als erstes wieder mit unserem Hallo Welt-Programm. Ein GTK+-Fenster mit Label 'Hallo Welt' wird in Perl wie folgt erzeugt. #!/usr/bin/perl -w use strict; use Gtk2 qw(-init); my $window = new Gtk2::Window; $window->set_title('Hallo Welt!'); $window->set_default_size(640, 480); $window->signal_connect(delete_event => sub { Gtk2->main_quit(); }); my $label = new Gtk2::Label('Hallo Welt!'); $window->add($label); $window->show_all(); Gtk2->main(); 115 Grafische Oberflächen in Perl Die Grundstruktur des Programms ist dabei analog zu der eines Perl/Tk-Programms: Es werden Widgets erzeugt, angeordnet und dann die Ereignisbehandlung gestartet. Das Gtk2-Modul wird mit der Zeile use Gtk2 qw(-init) eingebunden. Auf diese Art und Weise wird automatisch alles Nötige initialisiert und die gängigen GTK-Kommandozeilenparameter werden geparst. Das Hauptfenster wird mit new Gtk2::Window erzeugt. In den folgenden zwei Zeilen werden Fenstertitel und Fenstergröße angegeben. Das Label wird mit new Gtk2::Label('Hallo Welt!') erzeugt und mit der add()-Methode zum Fenster hinzugefügt. Mit der show_all()-Methode wird das Hauptfenster mit allen Widgets angezeigt. Danach folgt der Aufruf von Gtk2->main(), womit die Ereignisbehandlung startet. Schon wenn wir versuchen dieses Programm um einen Beenden-Knopf (new Gtk2::Button('Beenden')) zu erweitern, stoßen wir an unsere Grenzen. Die add()-Methode erlaubt es nur ein einziges Widget zu platzieren. Damit wir in Zukunft mehrere Widgets verwenden können, benötigen wir z.B. ein Box-Layout (Gtk2::HBox, Gtk2::HBox). 116 Grafische Oberflächen in Perl Das Boxen-Layout Widgets Eigenschaften Methoden 117 Kurzvorstellung Perl 6 Kurzvorstellung Perl 6 118