Datenbanken Theorie
Werbung

Udo Matthias Munz
Relationale
Datenbanken
und
SQL
Informationstechnik
Einführung
Unformatierte Daten
EINFÜHRUNG ................................................................................................................................................4
Daten und Information...............................................................................................................................4
MODELLE VON DATENBANKEN .............................................................................................................4
UNFORMATIERTE DATEN ...............................................................................................................................4
HIERARCHISCHES MODELL ............................................................................................................................4
TABELLE.........................................................................................................................................................5
ARBEITEN MIT EINER DATENBANK......................................................................................................5
RELATIONALE DATENBANKEN ..............................................................................................................6
NORMALISIEREN EINER RELATION / TABELLE AM BEISPIEL .........................................................................6
Die erste Normalform (1NF)......................................................................................................................6
Die zweite Normalform (2NF) ...................................................................................................................7
Die dritte Normalform (3NF).....................................................................................................................7
Verknüpfung...............................................................................................................................................8
Nachteile einer extremen Normalisierung .................................................................................................8
EINIGE BEGRIFFE............................................................................................................................................8
Entität, Entitätstyp .....................................................................................................................................8
Entitätsbeziehungen ...................................................................................................................................8
Identifikationsschlüssel ..............................................................................................................................8
Redundanz, Mutation und Anomalie ..........................................................................................................9
REFERENTIELLE INTEGRITÄT .......................................................................................................................10
ENTITY-RELATIONSHIP-DIAGRAMM (ER-DIAGRAMM) ...............................................................10
Entitytyp (Objekt).....................................................................................................................................10
Attribute ...................................................................................................................................................11
Abhängige (weak) Entities .......................................................................................................................12
Relation ....................................................................................................................................................13
Kardinalität..............................................................................................................................................14
Die Darstellung in einem vereinfachten ER-Diagramm ..........................................................................14
FÜNF SCHRITTE ZUM ER-MODELL ..............................................................................................................15
ÜBERLEGUNGEN BEIM ENTWURF EINES DATENMODELLS.......................................................16
ER-DIAGRAMM ............................................................................................................................................16
TABELLEN ERSTELLEN .................................................................................................................................17
RELATIONEN MIT ATTRIBUTEN ....................................................................................................................17
DATENTYPEN ...............................................................................................................................................17
AUF DEM INDEX: DIE SCHLÜSSELFELDER ....................................................................................................17
DATENBANKANWENDUNG FERTIGSTELLEN .................................................................................................17
UMSETZUNG ER-DIAGRAMM IN TABELLEN ....................................................................................18
Die erste Regel:........................................................................................................................................18
Die zweite Regel: .....................................................................................................................................18
Die dritte Regel:.......................................................................................................................................19
Die vierte Regel: ......................................................................................................................................19
ZUSAMMENFASSUNG ...............................................................................................................................20
REKURSIVE BEZIEHUNGEN ...................................................................................................................23
Beispiel: ...................................................................................................................................................23
TERNÄRE BEZIEHUNGEN .......................................................................................................................23
Beispiel1: .................................................................................................................................................23
Beispiel2: .................................................................................................................................................23
UMSETZUNG IN RELATIONEN (TABELLEN) ..................................................................................................23
GENERALISIERUNG ..................................................................................................................................26
2
Einführung
Unformatierte Daten
DATENBANKZUGRIFFE MIT SQL..........................................................................................................27
Kleine SQL-Geschichte ............................................................................................................................27
Ein SQL-Beispiel: ....................................................................................................................................28
SQL - BEFEHLSÜBERSICHT ..........................................................................................................................28
ABFRAGEFORMULIERUNG MIT SQL ..................................................................................................29
BEISPIEL-DATENBANK .................................................................................................................................29
1 PROJEKTION UND FORMATIERUNG ...........................................................................................................30
2 SELEKTION ................................................................................................................................................31
3 VERBUND VON TABELLEN ........................................................................................................................32
4 AGGREGATFUNKTIONEN UND GRUPPEN ...................................................................................................33
5 UNTERABFRAGEN (SUBQUERIES)..............................................................................................................34
6 STRUKTUR VON TABELLEN ERZEUGEN, ÄNDERN UND LÖSCHEN ..............................................................35
WEITERE HINWEISE ZUM VERBUND VON TABELLEN ..................................................................................36
Inner Join: Verknüpfung von Tabellen ....................................................................................................36
Auto Join/Self Join: Verknüpfung einer Tabelle mit sich selbst...............................................................36
Outer Join: Verknüpfung von Tabellen....................................................................................................36
Unterabfragen: Einzeilige (= Single Row Subquery) ..............................................................................36
Unterabfragen: Mehrzeilige (= Multiple Row Subquery)........................................................................37
WEITERE BEISPIELE ZUM VERBUND VON TABELLEN ..................................................................................37
3
Einführung
Unformatierte Daten
Einführung
Daten und Information
Grundsätzlich ist eine Datenbank eine Sammlung von Daten. Diese können in beliebiger Form gespeichert
sein, auf fliegenden Blättern genauso wie in einem Karteikasten oder auf einem Computersystem. Datenbanken haben aber erst mit der Verbreitung des Computers an Brisanz gewonnen, weil nur mit ihrer Hilfe aus
den Daten Informationen gewonnen werden können, die so nicht gespeichert sind. Deshalb sind neben der
Entwicklung von Datenbanksystemen die Fragen des Datenschutzes bedeutsam geworden. Datenschutz bedeutet, dass nicht die Daten selbst geschützt werden sollen (das wäre die Frage der Datensicherheit, z.B.
regelmäßige Sicherungskopien anfertigen) sondern es sollen die Personen geschützt werden, deren Daten
gespeichert werden.
Datenbanken, Informationssysteme sowie Datenschutz und Datensicherheit als Expertengruppenarbeit
Siehe http://www.educeth.ch/informatik/puzzles/rundum/
Modelle von Datenbanken
Unformatierte Daten
Keine feste Struktur.
Hierarchisches Modell
In Computer-Datenbanken werden die Daten meist in einer bestimmten, klar beschriebenen Struktur verwaltet:
Auf dem Datenträger sind die Daten meist
linear angeordnet. Als Modell für die Datenbank kann man sich daher vorstellen,
dass die einzelnen Zeichen aneinander gereiht sind. Daraus bilden sich die Datenfelder, welche Datensätze ergeben. Insgesamt
ergibt sich eine Datei. Mehrere Dateien, die
zu einem gemeinsamen Projekt gehören
bilden die Datenbank.
4
Arbeiten mit einer Datenbank
Tabelle
BOF
Zeiger
Datenfeld1
Datenfeld2
EOF
Datenfeld3
Datenfeld4
Datensatz1
Datensatz2
Datei1
Der Zugriff auf die Datei geschieht über Zeiger, die auf das jeweils gelesene Zeichen zeigen. Ein Zeiger
bezeichnet den Anfang der Datei (begin of file, BOF) einer deren Ende (end of file, EOF).
1:
Datenbank1
Zeichnen Sie die Struktur einer hierarchischen Datenbank mit folgenden Feldern: Name(3),
PLZ(5) und Ort(4) für die Personen: Tom, 77815, Bühl; Ben, 77654, OG, Ali, 77815, Bühl
Nennen Sie einige Probleme bei dieser Datenbank.
Tabelle
Man kann sich die Organisation einer Datei auch wie eine Tabelle vorstellen. Dieses Modell ist weiter weg
von der technischen Wirklichkeit, ist aber für die Anwendung praktischer. Jeder Datensatz bildet eine Zeile
der Tabelle. Die einzelnen gleichen Datenfelder jeden Datensatzes kommen dadurch direkt untereinander zu
stehen, wodurch die Übersichtlichkeit erheblich gesteigert wird.
Datenfelder
Datensatz
Beachten Sie, dass dieser Aufbau nicht den realen, physischen Aufbau der Daten auf dem Datenträger widerspiegelt.
Arbeiten mit einer Datenbank
Auch bei einer Datenbank gilt das EVA-Prinzip:
Die Daten werden
•
in Formularen, Datenzugriffseiten eingelesen, die Speicherung der Datenfelder und Datensätze stellen wir uns in Form von Tabellen vor.
•
vom Database Managementsystem (DBMS) verarbeitet,
•
mit Abfragen und Berichten ausgegeben.
5
Relationale Datenbanken
Normalisieren einer Relation / Tabelle am Beispiel
Relationale Datenbanken
Eine komplette Datenbank besteht zur Zeit des Datenbankaufbaus nur aus der Software, mit der man die
Datenbank bearbeiten kann und der Hardware, auf der das Programm läuft. Beides hat seinen Preis, der gut
kalkulierbar ist. Die Kosten der Datenbasis selbst spielen zu diesem Zeitpunkt eine untergeordnete Rolle. Im
Laufe der Zeit werden aber die Daten einen Wert darstellen, der die Hard- und Softwarekosten um ein Vielfaches übersteigen kann. Die Stammdaten müssen über Jahre hinweg gepflegt und erweitert werden. Für
Versicherungsdaten beispielsweise ist eine Lebensdauer der Stammdaten von 50 und mehr Jahren angesagt.
Vor diesem Hintergrund wird klar, dass man dem Aufbau der Datenbasis erheblich mehr Aufmerksamkeit
widmen sollte als der Hardware, die vielleicht nach 3-5 Jahren bereits ersetzt werden muss.
Anfang der 70er Jahre entwickelten Codd, Chen und andere Mathematiker das relationale Datenbankmodell,
welches bereits Anfang der 80er Jahre als „dBase“ auf Personalcomputern implementiert wurde und sich bis
heute allgemein für PC-Datenbanken durchgesetzt hat.
Im relationalen Datenbankmodell werden die Daten in (meist mehreren) Tabellen unabhängig voneinander
gespeichert. Die Beziehungen zwischen den Daten werden erst durch die Anwendung realisiert.
Normalisieren einer Relation / Tabelle am Beispiel
Redundanzen sind in relationalen Datenbanken zu vermeiden. Im Verlaufe der Normalisierung sollen einerseits die Relationen aufgebaut und andererseits die Redundanzen verringert werden.
Ich verwende zur Erläuterung der Normalisierung als Beispiel eine Freunde- und CD-Datenbank. Meine
Ausleihtabelle FREUNDE.DB besteht zunächst nur aus einer einzigen Tabelle:
Name
Unsinn
Maus
Düsentrieb
Maus
Vorname
Reiner
Mickey
Daniel
Mickey
Telefon
564321
1234
9999
1234
Datum
01.01.97
12.01.97
14.11.97
14.11.97
Titel
Tina Dreams
Tina Dreams, Stones Best
Harry Lemon Tree, Tina Dreams, Beatles Rotes
Stones Best
Die gesamte Datenbank besteht aus einer einzigen Tabelle. Wir brauchen keine Schlüssel zu definieren, weil
wir keine Verknüpfungen mit anderen Tabellen bilden müssen und somit Eindeutigkeit nicht unbedingt erforderlich ist.
Diese Tabelle ist aber nicht sehr sinnvoll: die Anzahl der ausgeliehenen Titel ist begrenzt auf die Zahl, die in
das Feld „Titel“ hineinpasst. Außerdem ist eine Suche rückwärts („Wer hat meine Beatles-CD?“) sehr erschwert. Jede neue Ausleihe erzeugt eine (unkontrollierte) Redundanz!
Die erste Normalform (1NF)
Der erste Schritt der Normalisierung vermeidet mehrere Merkmale in einem Feld.
Name
Unsinn
Maus
Maus
Düsentrieb
Düsentrieb
Düsentrieb
Maus
Vorname
Reiner
Mickey
Mickey
Daniel
Daniel
Daniel
Mickey
Telefon
564321
1234
1234
9999
9999
9999
1234
Datum
01.01.97
12.01.97
12.01.97
14.11.97
14.11.97
14.11.97
14.11.97
Titel
Tina Dreams
Tina Dreams
Stones Best
Harry Lemon Tree
Tina Dreams
Beatles Rotes
Stones Best
Fertig sind wir mit dieser Form noch nicht, denn jetzt haben wir neben dem Problem der vielen redundanten
Daten noch weitere Problembereiche:
Die Änderungsabhängigkeit (Update-Dependency): eine Änderung der Telefonnummer von Mickey
muss in allen Zeilen durchgeführt werden um eine „Änderungsanomalie“ zu verhindern.
Die Einfügungsabhängigkeit (Insertion-Dependency): zum Identifizierungsschlüssel muss das Ausleihdatum und der Titel hinzugefügt werden (Eindeutigkeit der Tupel!, siehe „Identifikationsschlüssel“ Seite
6
Relationale Datenbanken
Normalisieren einer Relation / Tabelle am Beispiel
8). Will man einen neuen Freund in die Liste aufnehmen, funktioniert das nur, wenn er gleichzeitig eine
Ausleihe vornimmt, weil die Felder Datum und Titel ja zum Schlüssel gehören müssen und daher nicht
leer bleiben dürfen.
Die Löschabhängigkeit (Deletion-Dependency): ist das Gegenstück zur Einfügungsabhängigkeit. Wenn
Daniel seine beiden ausgeliehen CDs zurückgibt, dann werden mit dem Löschen auch alle seine Daten
gelöscht.
Die zweite Normalform (2NF)
Wir teilen die Datenbank in mehrere Tabellen auf, die jede nach den Entitäten: Freundedaten und Verleihdaten unterschieden sind. In beiden Tabellen wird das Feld FID zusätzlich eingefügt. Mit Hilfe dieser Identifizierungsnummer (Identifizierungsschlüssel) können die Beziehungen zwischen den beiden Tabellen wieder
hergestellt werden. Die Freundetabelle ist nun unabhängig von der Verleihtabelle erweiterbar, und diese
wieder unabhängig von der Freundetabelle.
Freundetabelle
FID Name
Maus
1
Düsentrieb
2
Unsinn
3
Vorname
Mickey
Daniel
Reiner
Telefon
1234
9999
564321
Verleihtabelle
FID
Datum
01.01.97
3
12.01.97
1
12.01.97
1
14.11.97
2
14.11.97
2
14.11.97
2
14.11.97
1
Titel
Tina Dreams
Tina Dreams
Stones Best
Harry Lemon Tree
Tina Dreams
Beatles Rotes
Stones Best
Das DBMS muss die Verbindung zwischen den Tabellen herstellen können. Daher ist in der Verleihtabelle
der Schlüssel FID mit aufzunehmen. Man nennt diesen Schlüssel in der Verleihtabelle einen „Fremdschlüssel“, das entsprechende Attribut in der Freundetabelle ist dort der Identifikations- oder Primärschlüssel.
Die dritte Normalform (3NF)
Wir haben in der Verleihtabelle aber immer noch Redundanzen, nämlich beim Datum und beim Titel. Daher
müssen wir die zweite Tabelle noch weiter aufteilen und gelangen zur 3. Normalform.
tbFreunde
FID Name
Maus
1
Düsentrieb
2
Unsinn
3
Vorname
Mickey
Daniel
Reiner
Telefon
1234
9999
564321
tbVerleih
FID Datum
01.01.97
3
12.01.97
1
12.01.97
1
14.11.97
2
14.11.97
2
14.11.97
2
14.11.97
1
TID
1
1
2
4
1
5
2
tbCDs
TID
1
2
3
4
5
Titel
Tina Dreams
Stones Best
Elvis Jailhouse
Harry Lemon Tree
Beatles Rotes
Betrachten Sie nun einmal die Beziehungen zwischen diesen Tabellen. Ein Tupel in der Freundetabelle
tbFreunde kann auf mehrere Tupel in der Verleihtabelle tbVerleih verweisen (1:n), d.h. ein Freund kann
mehrmals CDs ausleihen. Anders sind die Verhältnisse jedoch zwischen der Verleihtabelle tbVerleih und der
CDs-Tabelle tbCDs. Hier haben wir eine n:1-Beziehung, weil ja dieselbe CD auch mehrmals ausgeliehen
werden kann. (Zwischenzeitliche Rückgabe natürlich vorausgesetzt. Dies ist aber in diesem DatenbankModell nicht erkennbar.)
In der Tabelle tbVerleih erscheinen zwei Fremdschlüssel: FID und TID. Diese Tabelle hat eine zentrale Bedeutung für die Verknüpfungen (Relationen) der Datenbank.
Damit hätten wir für die meisten Fälle die optimale Datenbankrelation erreicht. Die Redundanz beim Datum
werde ich bestehen lassen und die Verleihtabelle nicht noch mal unterteilen. Das wäre dann die 4NF.
Für die fünfte Normalform betrachten wir kein Beispiel mehr. Nur ein Hinweis: wenn sich Datenmengen
überschneiden, kann wieder Redundanz auftreten. Dann nämlich, wenn wir beispielsweise noch eine Komponistentabelle anlegen und ein Freund auch Komponist ist; sein Name müsste dann mehrfach gespeichert
werden, nämlich sowohl in der Freunde als auch in der Komponisten-Tabelle.
7
Relationale Datenbanken
Einige Begriffe
Verknüpfung
Die einzelnen Tabellen enthalten jetzt neben den Schlüsselfeldern (Identifikations- bzw. Fremdschlüssel) nur
noch Daten. Die Beziehung der Daten zueinander ist aber verloren gegangen! Die Beziehungen werden aus
den Tabellen allein nicht unmittelbar ersichtlich. Eine Beschreibung einer Datenbank, die die Relationen
besser darstellt ist das ER-Diagramm.
Nachteile einer extremen Normalisierung
Bei extremer Normalisierung können viele kleine Tabellen entstehen, die die Leistung (z.B. Antwortverhalten) der Datenbank negativ beeinflussen. Durch die vielen künstlichen Schlüssel und die erforderlichen zusätzlichen Verknüpfungen wird das System komplexer, was zu größerer Fehleranfälligkeit führen kann. Die
Schlüssel erfordern Speicherplatz, stellen also auch wieder eine Art von Redundanz dar. Es ist daher ein
Kompromiss zwischen Redundanzfreiheit der Daten und Performance des System anzustreben. Es ist nicht
erforderlich jede Redundanz zu entfernen, sondern nur die „unkontrollierte“ Redundanz.
Einige Begriffe
Entität, Entitätstyp
Die einzelnen Objekte der Datenbasis können Personen sein, Vorgänge oder Handlungsmuster. Sie werden
als „Entitäten“ bezeichnet. Jede Entität weist „Merkmale“ auf. Eine Entitätsmenge (z.B. die Daten aller
Freunde) wird in einer Tabelle abgebildet. Die Tabelle baut sich aus Datensätzen („Tupeln“) auf, die die
Merkmale (Attribute, Felder) enthalten; jeder Datensatz ist eine Entität. Die (allgemeine) Struktur eines Datensatzes ist der Entitätstyp.
Entitätsbeziehungen
In unserem Beispiel der CD-Verleihdatenbank haben wir die Tabelle mit den Freunden. In der zweiten Tabelle sind den Freunden die ausgeliehenen CDs zugeordnet. Dabei kann ein Freund keine, eine oder mehrere
CDs ausgeliehen haben. Entsprechend sind einem Tupel in der Freunde-Tabelle kein, ein oder mehrere Tupel
in der Ausleihtabelle zugeordnet. Es handelt sich hier um eine 1:n-Beziehung. In einer dritten Tabelle sind
die Titel und Interpreten der CDs verzeichnet. In Bezug auf die Freundetabelle haben wir es mit einer m:nBeziehung zu tun: jeder Freund kann mehrere CDs ausleihen und jede CD kann mehrmals ausgeliehen werden (vorausgesetzt sie wurde in der Zwischenzeit wieder zurückgegeben).
Identifikationsschlüssel
Im Relationenmodell werden in den Tabellen nur die reinen Daten gespeichert. Wie diese miteinander in
Beziehung stehen, muss durch (aufwendige) Methoden in Form von Verknüpfungen realisiert werden. Damit
eine Verknüpfung von zwei Tabellen überhaupt funktionieren kann, muss jedes einzelne Tupel eindeutig
identifiziert werden. Dieses Merkmal nennt man den „Schlüssel“. Im Prinzip kann jedes (natürliche) Schlüsselattribut verwendet werden. Das gibt aber oft Probleme mit der Eindeutigkeit: gleiche Namen kommen oft
mehrfach für verschiedene Personen vor. Deshalb verwendet man meist eine Nummer. Dieser künstliche
Schlüssel kann stets so gewählt werden, dass er eindeutig ist.
Der (willkürlich gewählte) künstliche Schlüssel hat noch den weiteren Vorteil, ausschließlich der Identifikation des Datensatzes zu dienen und keinerlei weitere Informationen zu enthalten. Warum ist das nötig? Beispielsweise könnte die Postleitzahl Bestandteil des Schlüssels sein. Dieser „sprechende Schlüssel“ enthält
also eine zusätzliche Information. Wenn sich aber das Merkmal ändert, weil der Kunde umzieht, wird der
Schlüssel fortan mit „gespaltener Zunge“ sprechen, weil ja der Schlüssel nicht geändert werden darf. Würde
der Schlüssel nachträglich bei einem Kunden geändert, würden alle bisherigen Verknüpfungen verloren gehen oder man müßte alle Verknüpfungen mitanpassen!
8
Relationale Datenbanken
Einige Begriffe
Redundanz, Mutation und Anomalie
Redundanz bedeutet, dass Daten mehrfach gespeichert werden. Bei der Redundanz ist die Speicherplatzverschwendung das kleinere Problem; viel schlimmer ist die Gefahr, dass sich „Mutationsanomalien“ einschleichen. Ganz allgemein ist die Änderung auf einem Datensatz eine Mutation. Solche Änderungen sind nie zu
vermeiden: z.B. Namensänderung bei Heirat. Wird bei einer solchen Mutation vergessen sämtliche Redundanzen mit zu verändern, dann entstehen widersprüchliche, inkonsistente Datensätze, die man als Anomalien
bezeichnet.
2:
Normalisieren
Das Normalisieren einer Relation hat die Ziele:
•
•
•
Redundanzfreiheit
keine zusammengesetzten Attribute
keine transitiven Abhängigkeiten
Geben Sie an, an wo die Ziele in der folgenden Tabelle verletzt sind und führen Sie die
Normalisierung bis zur dritten Normalform durch.
Lösungsvorschlag:
Nach Beseitigung mehrfach besetzter Felder und zusammengesetzter Attribute:
Aufteilung in mehrere Tabellen:
Die Zuordnung des Attributs ‚Gruppe’ ist nicht klar. Hat jeder Artikel eine besondere Rabattgruppe, jeder Kunde oder jede Position eines Auftrags? Hier wird angenommen, dass die Rabattgruppe an den Artikel gebunden ist. In der Tabelle fehlen noch Angaben über die Artikel: Bezeichnung Preis usw. Die lassen sich aber ohne Weiteres in der Tabelle Artikel unterbringen.
9
Entity-Relationship-Diagramm (ER-Diagramm)
3:
Referentielle Integrität
Bücherei
ISBN-Nr
0-201-14192-2
Autoren
Date, Ch.
3-89319-117-8
Finkenzeller, H.
Kracke, U.
Unterstein, M.
Melton, J.
Simon, A.
1-55860-245-3
Titel
The Relational Model for Database
Management: Version 2
Systematischer Einsatz von SQL-Oracle
Jahr
1990
Seiten
538
1989
494
Understanding the new SQL
1993
536
a) Welche Normalformen sind verletzt?
b) Erzeugen Sie ein äquivalentes System in normalisierter Form.
4:
Kurs-Noten
Matrikel
30321
30321
30346
30346
30346
30378
Student
Meyer, J.
Meyer, J.
Ahrens, H.
Ahrens, H.
Ahrens, H.
Knudsen, K.
Kurs-Nr
706S6
715S4
715S4
706S6
713S5
706S6
Kurs-Titel
Datenbanksysteme
Software-Engineering
Software-Engineering
Datenbanksysteme
relationale u. funktionale Programmierung
Datenbanksysteme
Note
1,0
1,7
3,0
2,0
1,7
2,0
a) Welche Normalformen sind verletzt?
b) Erzeugen Sie ein äquivalentes System in normalisierter Form.
Referentielle Integrität
Durch die Normalisierung und die anschließende Verknüpfung haben wir uns das Problem der Redundanz
und der damit verbundenen Mutationsanomalien vom Halse geschafft, aber dafür ein neues Problem erzeugt.
Wird beispielsweise ein Freund aus der Freundetabelle gelöscht und nicht alle Datensätze aus den Kindtabellen, die in irgendeiner Beziehung zu diesem Datensatz stehen, dann entstehen Waisen also „elternlose“ Datensätze. Die referentielle Integrität ist damit nicht mehr gegeben. Ganz schlimm kann so etwas werden,
wenn irgendwann später einmal der gelöschte Schlüssel für einen anderen Freund neu vergeben wurde. Das
Wiederaufleben des Schlüssels stellt auch die Referenzen wieder her. Die möglichen Folgen können Sie sich
leicht selbst ausmalen! Viele Datenbanksysteme haben Mechanismen eingebaut, die die referentielle Integrität gewährleisten können.
Entity-Relationship-Diagramm (ER-Diagramm)
Der Entwurf einer Datenbank kann wie eben gesehen von den Daten her ausgehen, wobei oft eine vorhandene, gewachsene Tabelle als Ausgangsbasis dient. Wenn man aber eine Datenbank komplett neu konzipiert,
empfiehlt es sich, davon auszugehen in welchen Beziehungen die Daten untereinander stehen. Aus diesem
Entwurf werden direkt die Tabellen abgeleitet, die dann häufig bereits normiert sind. Es ist aber unerlässlich,
die entstandenen Tabellen auf die Einhaltung der Normalitätsregeln zu überprüfen.
Entitytyp (Objekt)
Eine Entity ist vergleichbar mit einer Tabelle. Die Daten eines bestimmten Kunden sind eine Entity. Eine
Datenbank besteht demnach aus mehreren Entities, die innerhalb einer Tabelle jeweils die gleiche Struktur
aufweisen.
10
Entity-Relationship-Diagramm (ER-Diagramm)
Referentielle Integrität
Attribute
Attribute sind die „Daten“ der Entity. Im Datenmodell einer Tabelle sind dies die Datenfelder in einer Spalte.
Wenn die Entity ein eindeutig identifizierbares Attribut besitzt (z.B. Kundennummer), dann wird es unterstrichen.
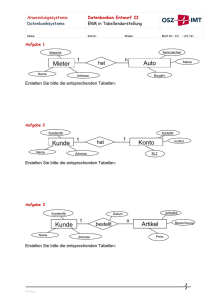
5:
Versandhandel 1
Zeichnen Sie das ER-Diagramm für folgende Entities:
ENTITY TYPE Artikel
DESCRIPTION Beschreibung für die verschiedenen Artikel. Artikel ist hier als
Kategorie einer Ware gemeint, die in einer größeren Menge auf Lager vorhanden sein kann.
ATTRIBUTES
Artikel-Nr
CHAR(4);
Bezeichnung
STRING;
Listenpreis
Geldbetrag;
Bestand
CARDINAL;
Mindestbestand
CARDINAL;
Verpackung
STRING;
Lagerplatz
Lager;
Kann-wegfallen
BOOLEAN;
keine Nachbestellung, wenn Lager geräumt
Bestellvorschlag
Zeitpunkt;
vom System automatisch erzeugt
Nachbestellung
Zeitpunkt;
tatsächliche Bestellung
Nachbestellmenge
CARDINAL;
KEY (Artikel Nr)
END
Artikel;
ENTITY TYPE MWSt-Satz
DESCRIPTION Mehrwertsteuersatz. Da der Mehrwertsteuersatz gesetzlichen Änderungen unterliegt und da es mehrere Möglichkeiten der Versteuerung gibt
(keine MWSt, reduzierte MWSt, volle MWSt), werden die verschiedenen Sätze in dieser Tabelle beschrieben.
ATTRIBUTES
MwSt
CARDINAL;
Prozent
NUMERIC(3,1);
Beschreibung
STRING;
KEY (MWSt)
END MWSt-Satz;
ENTITY TYPE Kunde
DESCRIPTION Beschreibung der relevanten Kundendaten.
ATTRIBUTES
Kunden-Nr
CARDINAL;
11
Entity-Relationship-Diagramm (ER-Diagramm)
Referentielle Integrität
Status
(Stammkunde, Werbung, Gelegenheitskunde)
Name
STRING;
Straße
Straßen;
PLZ
Postleitzahlen;
Ort
Orte;
letzte-Bestellung
DATE;
letzte-Werbeaktion DATE;
KEY (Kunden-Nr)
END Kunde;
ENTITY TYPE Bestellung
DESCRIPTION Dieser Entitätstyp beschreibt einen Bestellvorgang von der Bestell-Aufnahme bis zur Lieferung. Allerdings wird eine stornierte Bestellung aus der Datenbank gelöscht, ohne dass dieser Vorgang in der Datenbank vermerkt wird.
ATTRIBUTES
Bestell-Nr
CARDINAL;
Bestell-Datum
DATE;
Liefer-Datum
DATE;
Rechnungsbetrag
Geldbetrag;
KEY (Bestell-Nr)
END Bestellung;
Abhängige (weak) Entities
Um Speicherplatz zu sparen, kann man Entities als von einer anderen Entity abhängig deklarieren. Die weak
Entity „erbt“ dann gewissermaßen das Schlüsselattribut von der strong Entity. Man kann das so sehen, als ob
an eine Karteikarte (manchmal) ein weiteres Blatt angeheftet wird. In der graphischen Darstellung wird diese
Entity mit einem doppelten Rahmen gezeichnet. Wichtig ist, dass diese Entität mit verschwinden muss, wenn
die zugehörige „Hauptindentität“ gelöscht wird.
6:
Versandhandel 2
Zeichnen Sie die vom Kunden abhängige Entity „Girokonto“ in das Diagramm der vorigen Aufgabe ein.
ENTITY TYPE Girokonto
DEPENDENT ON Kunde
DESCRIPTION Bankverbindungen der Kunden, die eine Einzugsermächtigung erteilt
haben. Falls (ausnahmsweise) mehrere Kunden dieselbe Bankverbindung belasten, ist das Konto mehrfach aufzunehmen, da andernfalls die Konto-Änderung eines Kunden problematische Konsequenzen hätte.
ATTRIBUTES
Konto-Inhaber String;
BLZ
Bankleitzahlen;
Konto-Nr
String(10);
END Girokonto;
Lösung:
12
Entity-Relationship-Diagramm (ER-Diagramm)
Referentielle Integrität
Relation
Das ER-Modell kennzeichnet die Beziehungen der Entities (die Relationen) durch eine Raute. Die beteiligten
Entitäten haben eine „Rolle“.
7:
Schule
Erstellen Sie ein Entity-Relationship-Diagramm mit folgenden Begriffen:
Entities:
Schüler, Schule, Ort
Attribute:
PLZ, Einwohnerzahl, Ortsname, Schülername, Schulname, Schülernummer,
Schulart, Schüleranzahl, Vorname, Klasse, Schulnummer (unterstreichen des
eindeutigen Attributs nicht vergessen!)
Relationen:
wohnt, besucht
Lösung:
13
Entity-Relationship-Diagramm (ER-Diagramm)
Referentielle Integrität
Kardinalität
Schauen Sie sich wieder die Aufgabe „Versandhandel 1“ an. Beziehungen bestehen hier zwischen jeweils einer Bestellung und genau einem
Kunden und zwischen jeweils einer Bestellung
und mehreren Artikeln. Man kann bei den Beziehungen vier Fälle unterscheiden:
0..1
null-one
0..*
null-many
1..1
one-one
1..*
one-many
Der fünfte Fall: n..m many-many kann stets
aufgelöst werden indem man die eine Relation
in zwei Relationen auftrennt.
Die Darstellung in einem vereinfachten ER-Diagramm
In einem vereinfachten ERDiagramm werden die entities als
Kästen dargestellt und die Beziehungen als Striche mit Beschriftung und nicht als Raute. Die
weak (abhängigen) entities werden normalerweise unter oder
neben den strong (unabhängigen)
entities aufgelistet. Die Beziehungen werden ebenfalls näher beschrieben, wenn es dazu Daten
gibt. In diesem Fall wird hier der
Vorgang des Ausleihens näher
durch Ausleihdatum und Rückgabedatum beschrieben. Die Beziehungen werden an dieser Stelle
bereits in 1:N-, M:N- und 1:1Beziehungen festgelegt. Beim ER-Modell ist der Vorgang, das Diagramm zu erstellen, wohl der aufwendigste und manchmal auch komplizierteste Schritt. Ein Fehler an dieser Stelle bringt das ganze Modell zum
Scheitern. Daher ist dieser Schritt sehr gründlich durchzuführen.
Bitte beachten Sie, daß es sich nach wie vor um keine Tabellen und deren Beziehnungen handelt, sondern
um die Darstellung eines ER-Modells.
Die obige M:N-Beziehung zwischen Kunde und Kassette ergibt sich daraus, daß ein Kunde mehrere Kassetten leihen kann, eine Kassette aber an mehrere Kunden verliehen werden kann.
8:
Versandhandel 3
Fügen Sie die Relationen zur Aufgabe Versandhandel1 hinzu.
RELATIONSHIP TYPE Bestellung-Kunde
ROLES
Bestellung Bestellung OPTIONAL MULTIPLE;
kunde
Kunden
MANDATORY UNIQUE;
END Bestellung-Kunden;
RELATIONSHIP TYPE Position
ROLES
14
Entity-Relationship-Diagramm (ER-Diagramm)
Bestellung
artikel
ATTRIBUTES
menge
preis
END Position;
Bestellung
Artikel
Fünf Schritte zum ER-Modell
OPTIONAL MULTIPLE;
MANDATORY MULTIPLE;
CARDINAL;
Geldbetrag
RELATIONSHIP TYPE Kunde-Girokonto
ROLES
kunde
Kunde
MANDATORY UNIOUE;
konto
Girokonto
OPTIONAL UNIQUE;
END
Kunde-Girokonto,
RELATIONSHIP TYPE Artikel-Mwstsatz
ROLES
artikel
Artikel
OPTIONAL MULTIPLE;
mwstsatz
Mwstsatz
MANDATORY UNIQUE;
END Artikel-Mwstsatz;
Lösung
Der Beziehungstyp der zweiten Relation enthält noch ein Attribut über die Anzahl der georderten Artikel und
den Gesamtpreis für diese Artikel (dieser kann später nicht mehr aus den ArtikelDaten rekonstruiert werden,
da der Preis sich geändert haben kann; außerdem sind gegebenenfalls auch Sonderkonditionen möglich).
Fünf Schritte zum ER-Modell
Ein ER-Modell wird in folgenden Schritten erstellt:
1. Datenobjekte werden aus der Beschreibung des Systems identifiziert. Dazu müssen für jedes Datenobjekt die relevanten Attribute bestimmt werden. Die Attribute sollten einfache, nichtstrukturierte
Eigenschaften darstellen, die sich mit nichtstrukturierten Werten belegen lassen.
2. Entitäten werden teilweise direkt aus der Beschreibung des Systems identifiziert, teilweise durch
Verallgemeinerung der gruppierten Datenobjekte. Jede Entität modelliert genau ein Konzept. Es
handelt sich um alle im System vorhandenen physischen Elemente (z.B. Lehrer, Klasse).
3. Die Menge der Entitäten wird dadurch erweitert, daß auch abstrakte (nicht sichtbare) Entitäten (z.B.
Projekt, Budget) identifiziert werden.
4. Die Beziehungen werden identifiziert. Es wird ermittelt, in welche Wechselwirkungen die Datenobjekte einzelner Entitäten treten. Die gefundenen Wechselwirkungen werden durch Tupel der Beziehungen modelliert.
5. Die Kardinalität der Beziehungen wird untersucht und bestimmt.
15
Überlegungen beim Entwurf eines Datenmodells*)
9:
ER-Diagramm
CD-Verleih
Gehen Sie zurück zum Beispiel der normalisierten Tabellen des CD-Verleihs auf der Seite 7.
Zeichnen Sie das ER-Diagramm für diese Tabellen. Beachten Sie, dass die Tabellenfelder mit
den Fremdschlüsseln nicht als Attribute im ER-Diagramm erscheinen! Setzen Sie die Tabelle
tbVerleih als Relation und nicht als Entity um.
Überlegungen beim Entwurf eines Datenmodells*)
Ergebnis der folgenden Überlegungen soll
eine Verwaltung für eine private Büchersammlung sein. Bei Büchern ist es sicher
sinnvoll, Daten wie Autor, Titel, Untertitel,
Verlag und Sprache zu erfassen und vielleicht noch Felder für Kaufdatum, Erscheinungsjahr und Bemerkungen vorzusehen.
Enthält die Sammlung vorwiegend Sachbücher. hilft eine Klassifizierung nach Sachgebieten, Belletristik könnte man nach Genre
sortieren. Wer es bunt mag, spendiert noch
ein Feld, das einen Scan des Einbands aufnimmt. Bei verliehenen Büchern sind der
Entleiher, Verleih- und versprochenes Rück,gabedatum zu erfassen.
Bei der Festlegung, wie die Tabellen der zu
erstellenden Datenbank aufgebaut sein sollen, ist es oft hilfreich, einfach erst einmal
die Hauptwörter aus einer solchen groben
Beschreibung herauszuschreiben, zu gruppieren und sich zu überlegen. in welcher
Beziehung sie stehen. Zwei Tabellen kristallisieren sich sofort heraus: 'Buch' und 'Entleiher'. Bei der Entscheidung, welche Attribute als Felder beispielsweise der Tabelle
'Buch' zu realisieren sind und für welche
eine verknüpfte Tabelle zu spendieren ist,
helfen Fragen wie: 'Hat dieses Attribut jedes Buch, die meisten oder nur wenige?', 'Kann es mehrfach bei
einem Buch vorhanden sein?' und 'Ist es atomar, also durch eine Zahl, einen kurzen Text oder Ähnliches
darstellbar, oder besteht es aus weiteren Unterattributen?' Jedes Buch hat einen Titel und eine Sprache, ist in
einem bestimmten Jahr in einem Verlag erschienen und zu einem Zeitpunkt gekauft worden. Einige Bücher
haben einen Untertitel, für einige liegt ein Umschlag-Scan vor, und zu einigen fällt mir sofort eine Bemerkung ein. Bücher haben einen oder mehrere Autoren und gehören zu einer oder mehreren Kategorien. Ein
Verlag ist gekennzeichnet durch Name, Land und Ort, ein Autor durch Vor- und Nachname. Letzteres gilt
auch für einen Entleiher, der außerdem eine Telefonnummer und eine E-Mail-Adresse hat. Eine Person kann
sich zu unterschiedlichen Zeitpunkten mehrere Bücher leihen und für jedes ein anderes Rückgabedatum vereinbaren; ein Buch kann nur an eine Person verliehen sein.
ER-Diagramm
Die geschilderten Zusammenhänge kann man grafisch wie in der Abbildung auf dieser Seite darstellen. Die
Rechtecke kennzeichnen dabei Objekte aus der realen Welt, die abgerundeten Kästen ihre Attribute. Rauten
stehen für Beziehungen zwischen Objekten; an den Enden ihrer Verbindungslinien steht ihre sogenannte
Kardinalität. die 1:n-, m:n- und 1:1-Beziehungen auseinander hält.
*)
(nach c’t Heft 18/2001)
16
Überlegungen beim Entwurf eines Datenmodells*)
Tabellen erstellen
Tabellen erstellen
Aus einer solchen Grafik lässt sich unmittelbar die Tabellenstruktur der Datenbank ableiten: Rechtecke werden zu Tabellen, die dazugehörigen Attribute zu deren Feldern. Die Tabelle am Ende jeder 1:n-Beziehung
bekommt ein weiteres Feld mit einem entsprechenden Fremdschlüssel. Zusätzliche Tabellen sind für
m:n-Beziehungen vorzusehen, neben eventuellen Attributen besitzen sie ein Feld für jede an der Relation
beteiligte Tabelle.
Relationen mit Attributen
Einen Sonderfall stellt in diesem Beispiel die 1:n-Relation 'hat geliehen’ dar, die man eigentlich ohne zusätzliche Tabelle realisieren könnte. Aber wo bringt man Entleih- und geplantes Rückgabedatum unter? Speichert man sie in der Buch-Tabelle, verschwendet man Speicherplatz. denn die müsste diese Felder für jedes
Buch bereithalten, obwohl in der Regel nur wenige Bücher verliehen sind. Schlägt man sie andererseits der
Entleiher-Tabelle zu, müsste man Name, Telefonnummer und E-Mail-Adresse des Empfängers jedes Mal
neu ausfüllen, auch wenn sich ein und dieselbe Person mehrere Bücher leiht; außerdem gehen diese Informationen verloren, wenn man den entsprechenden Eintrag löscht, weil jemand ein Buch zurückgibt. Die beste
Lösung ist hier wohl, eine Extra-Tabelle 'Leihe' zu spendieren, die die Felder 'Buch' und 'Entleiher’ als
Fremdschlüssel sowie die beiden Datumsfelder enthält.
Datentypen
Die Datentypen der einzelnen Tabellenfelder ergeben sich meist intuitiv. Zu beachten ist, dass Frerndschlüsselfelder denselben Typ besitzen müssen wie das Primärschlüsselfeld, auf das sie verweisen. Ansonsten sollte man Zahlentypen nur dann verwenden, wenn man die Werte für Berechnungen verwenden oder Datensätze numerisch sortieren will - für deutsche Postleitzahlen ist beispielsweise ein fünf Zeichen fassendes Textfeld angebrachter, denn sonst erscheint Leipzig (04105) nur vierstellig. Bei der Dimensionierung von Textfeldem sollte man nicht zu sparsam sein, denn bei den meisten modernen Datenbankprogrammen belegen
Datensätze auf der Festplatte nur die Anzahl von Zeichen, die tatsächlich benutzt sind. Lediglich ältere Datenbankformate wie dBase arbeiten mit festen Feldlängen und verbraten für ein Textfeld, das 100 Zeichen
fassen darf, in jedem Datensatz 100 Bytes, auch wenn dort nur 'Der Herr der Ringe' steht.
Auf dem Index: die Schlüsselfelder
Für die Primärschlüssel der Tabellen kommen in diesem Beispiel eigentlich nur automatisch hochgezählte
laufende Nummern in Frage, es gibt bei keinem der Objekte Attribute, die es eindeutig kennzeichnen. Man
könnte auf die Idee kommen, zu jedem Buch seine ISBN zu speichern und als Primärschlüssel zu verwenden, das kann aber zu Problemen führen, wenn man mehrere Bände eines Werkes getrennt verwalten will
oder wenn etwa ein Versandhauskatalog seinen Platz in der Bibliothek finden soll.
Für Sekundärindizes sind selbstverständlich erst einmal alle Fremdschlüsselfelder vorzusehen, damit man
beispielsweise schnell von einem Verlag zu den Büchern gelangt, die er herausgegeben hat. Welche weiteren
Felder man indiziert, ist weitgehend Geschmackssache und hängt davon ab, wonach man häufig suchen und
sortieren will. Folgendes ist dabei allerdings zu beachten: Man wird die Datenbank wohl selten benutzen, um
beispielsweise herauszufinden, wie ein Autor namens Brecht mit Vornamen heißt, also für eine Suche nur in
der Autoren-Tabelle. Allerdings ist eine Anfrage wie 'alle Bücher eines Autors, der mit Nachnamen Brecht
heißt' durchaus sinnvoll. Daher sollte die Datenbank einen Sekundärindex über die Nachnamen der Autoren
enthalten. Dasselbe gilt für die Namen von Verlagen und Entleihern.
Datenbankanwendung fertigstellen
Mit dem Entwurf des Datenmodells und dem Anlegen der Tabellen ist ein Großteil der Handarbeit auf dem
Weg zu einer Datenbankanwendung erledigt. Was fehlt, sind Eingabeund Suchmasken, mit denen man den
Datenbestand bequem pflegen und durchforschen kann, sowie Formulardefinitionen zum Drucken von Berichten. Die meisten modernen Datenbankprogramme bieten dafür aber recht brauchbare Vorlagen oder Assistenten an, die zumindest ein funktionierendes Grundgerüst erstellen.
17
Umsetzung ER-Diagramm in Tabellen
Datenbankanwendung fertigstellen
Der Rest ist Kosmetik. So kann man sich die Dateneingabe dadurch erleichtern, dass die Datenbank beim
Anlegen eines neues Datensatzes bestimmte Felder mit sinnvollen Vorgaben belegt, etwa 'Heute' als Kaufdatum und 'Deutsch' als Sprache beim Eintragen eines neuen Buches. Wer zusätzlich Lust verspürt, sich in die
Skript- oder Programmiersprache eines Datenbanksystems einzuarbeiten, eröffnet sich die Möglichkeit, weitere Funktionen um die eigentliche Datenbank herum zu programmieren, etwa das automatische Versenden
von ErinnerungsMails an säumige Entleiher.
Umsetzung ER-Diagramm in Tabellen
Die nachfolgenden Regeln sind für eine schrittweise Erstellung eines normalisierten Datenmodells gedacht.
Die Verfahrensweise soll an folgendem Beispiel erläutert werden. Ein Kunde leiht Video-Kassetten. Jede
Kassette hat einen Titel und ist in einer Kategorie eingeteilt. Die Kategorien haben unterschiedliche Leihpreise.
Die erste Regel:
Wertetypen werden 1:1 auf Datentypen abgebildet. Hier wird also festgelegt, dass z. B. das Feld »Name« ein
Textfeld ist und das Geburtsdatum in einem Datumsfeld gespeichert wird. Es werden die Datentypen festgelegt.
Durch diesen Schritt entstehen die Entitäten und deren Attribute
Die zweite Regel:
Ein Gegenstand (Entity) wird mit all seinen Attributen zu jeweils einer Tabelle zusammengefasst.
Durch die zweite Regel erfolgt also die Umsetzung in Tabellen. Die strong entities werden mit den dazugehörigen weak entites in einer Tabelle abgelegt. Ab diesem Punkt existieren die ersten Tabellen in unserem
Modell und wir haben eine gute Basis für die weitere Regel geschaffen. Die Kassettentabelle hat im Moment
noch gar kein Feld, aber wir sind noch nicht fertig.
18
Umsetzung ER-Diagramm in Tabellen
Datenbankanwendung fertigstellen
Die dritte Regel:
Jeder Gegenstand erhält ein 1:1-Attribut als Identifikator (Primärschlüssel), soweit noch nicht vorhanden.
Der notwendige Primärschlüssel in einem relationalen Datenbankmodell wurde bereits besprochen. Als Primärschlüssel kann hier ein vorhandenes Datenfeld benutzt werden, oder es wird ein Feld hinzugefügt (z.B.
eine »Kundennummer«). Nach diesem Schritt haben wir also alle Objekte untergebracht, und es sind nur
noch die Beziehungen zu definieren.
Die vierte Regel:
Jede M:N-Beziehung wird in einer eigenen Tabelle abgebildet. Diese Tabelle enthält die Primärschlüssel der
beteiligten Entitäten und die Datenfelder, die die Beziehung selbst beschreiben.
1:N-Beziehungen werden durch Einfügen des Primärschlüssels der 1-Tabelle in der N-Tabelle als Fremdschlüssel realisiert.
Dieser Schritt löst unsere verbleibenden Beziehungen auf, so dass diese in Tabellen realisiert werden können.
Lösung:
19
Zusammenfassung
Datenbankanwendung fertigstellen
Zusammenfassung
10:
1.
Das Datenmodell wird mit keinerlei Blickpunkt auf die Programmierung erstellt. Es ist einzig
und allein die Umsetzung der realen Welt auf die Ebene der Datenverarbeitung. Programmiertechnische Überlegungen haben an dieser Stelle nichts zu suchen. Diese Regel gilt jedoch nur,
wenn Aspekte der Geschwindigkeit unberücksichtigt bleiben können. Bei DataWarehouseAnwendungen ist es oft erforderlich, daß redundante Daten angelegt werden, um die Zugriffszeiten auf Tabellen und Datenbanken zu reduzieren. In diesem Fall wird nach der dritten Normalform oder beim ER-Modell nach der vierten Regel das Modell mit dem Gesichtspunkt der optimalen Geschwindigkeit modifiziert.
2.
Das Normalisieren nach Codd und das ER-Modell sind zwei getrennte, unabhängig voneinander
existierende Methoden. Natürlich kann ein Datenmodell, das nach Codd erstellt wurde, immer
mit einem ER-Diagramm dargestellt werden, da beide Verfahren das relationale Datenbanksystem zum Ziel haben.
3.
Bevorzugen Sie das Datenbank-Design mit dem ER-Modell, prüfen Sie wenigstens die Werte
auf Abhängigkeit, wie es bei der Methode von Codd erfolgt. Dies erspart Ihnen oft nachträgliches Ändern im Datenmodell.
4.
Das Modellieren der Daten in Tabellen ist ein nicht zu unterschätzender Punkt. Fehler beim Modellieren kosten zu einem späteren Zeitpunkt enorm viel Zeit. Sollen Änderungen an dem Modell
durchgeführt werden, müssen diese Änderungen durch alle Stufen der benutzten Methode durchgezogen werden. Es führt zu Fehlern, wenn versucht wird, die dritte Normalform, die ja das Ergebnis beider besprochener Verfahren ist, abzuändern und anzupassen.
5.
Änderungen an einem fertigen Datenmodell sind immer ein Hinweis darauf, daß die Tabellen
nicht korrekt normalisiert worden sind. Die Ursache ist meist, daß in der Anwendungsanalyse
nicht gründlich genug gearbeitet wurde. Diese Phase kann bis zu 30% des Aufwandes für die Erstellung der gesamten Anwendung einnehmen, und man sollte sich diese Zeit unbedingt nehmen.
6.
Tabellen müssen in einer bestimmten Reihenfolge gefüllt werden. Die Tabellen ohne Fremdschlüssel müssen zuerst mit Daten gefüllt werden. In unserem Beispiel kann keine Kassette erfaßt werden, wenn keine Titel und keine Kategorien mit ihren Preisen eingegeben wurden. Es ist
die Aufgabe der Programmierung, dies abzufangen und den Benutzer hier richtig zu leiten.
ER-Diagramm1
Erstellen Sie für das Beispiel in der dritten Normalform (Seite 7) das ER-Diagramm.
11:
Kardinalitäten
Untersuchen Sie, welche Kardinalitäten in folgenden Beziehungen möglich sind - geben Sie dafür gegebenenfalls Randbedingungen vor:
12:
a)
Postleitzahlen Orte (in Deutschland)
b)
Steuernummer Steuerpflichtiger
c)
Kind
↔
Vater
d)
Kind
↔
Mutter
e)
Kind
↔
Elternteil
ER-Diagramm2
Erstellen Sie für die Beziehungen der vorigen Aufgabe ER-Diagramme. Beachten Sie dabei,
dass wir in c), d), und e) in der Aufgabenstellung nicht die Entitätenmengen angegeben haben
(die auf beiden Seiten jeweils »Person« ist), sondern Rollen.
20
Zusammenfassung
13:
Datenbankanwendung fertigstellen
Schlüsselattribute
Erstellen Sie für die folgenden Angaben jeweils ein Entity-Relationship-Diagramm und bestimmen Sie die Schlüsselattribute.
14:
a)
Es gibt Personen, Bücher und Verlage. Jedes Buch hat einen oder mehrere Autoren.
Jedes Buch kann zu gegebener Zeit von höchstens einem Ausleiher ausgeliehen werden. Ein Ausleiher kann mehrere Bücher leihen, Ein Buch ist von einem Verlag.
b)
Ein Auto ist von einem Hersteller. Es hat zum Zeitpunkt der Herstellung keinen Halter,
sonst höchstens einen Halter. Auf einen Halter können mehrere Autos eingetragen
sein.
c)
In einer Bibliothek gibt es »Buchtitel« und »Buchexemplare«. Für einen Buchtitel können mehrere Exemplare vorhanden sein, jedoch immer mindestens eins. Ausleiher leihen Buchexemplare. Ausleiher können Buchtitel vormerken lassen. Ausleiher und Autoren sind Personen.
d)
Personen sind Studenten oder Professoren. Jede Vorlesung wird von einem Professor
gehalten. Ein Professor hält mehrere Vorlesungen. Ein Student besucht mehrere Vorlesungen. Eine Vorlesung wird von mehreren Studenten besucht, aber erst nach Semesterbeginn steht fest, von wem. Ein Professor empfiehlt für eine bestimmte Vorlesung ein
Buch.
Segeltörn
Eine Yachtagentur will die Törns (Touren) ihrer Segelyachten mit einer Datenbank verwalten.
Dabei geht es darum, die Mitfahrer ebenso zu erfassen wie die im Lauf der Tour angelaufenen
Häfen. Es gelten folgende Regeln:
1.
Eine Crew setzt sich aus mehreren Mitfahrern zusammen. Mitfahrer müssen an keiner
Crew teilnehmen, können aber auch an mehreren Crews beteiligt sein.
2.
Eine Crew bezieht sich immer auf eine Tour. Während einer Tour kann aber die Crew
wechseln.
3.
Für jede Tour gibt es einen Kapitän. Ein Kapitän kann natürlich an mehreren Touren
teilnehmen,
4.
Kapitäne und Mitfahrer sind Personen.
5.
Eine Tour wird immer von einer Yacht gefahren. Meistens überlebt eine Yacht die erste
Fahrt. Dann kann sie an weiteren Touren teilnehmen.
6.
Während einer Tour läuft eine Yacht mehrere Häfen an.
Modellieren Sie grafisch die Entitätenmengen- und Beziehungsmengen. Legen Sie Schlüsselattribute und die wichtigsten anderen Attribute fest.
15:
Arztpraxis1
Nichts ist ernüchternder als die Wirklichkeit! Nach mehrmaligem Umdrehen Ihrer leeren Taschen
beschließen Sie, den am Uni-Aushang angekündigten Hilfsjob bei den Medizinern (Seufz!) als
Systemdesigner im Projekt "Diabetes" bei Chefarzt Prof. Dr. Dr. hc. mult. Gerngroß anzunehmen. Die erste Begegnung verläuft wie folgt: Sie betreten nach langem Warten das Vorzimmer
des Chefs. Sie betreten nach langem Warten das Arbeitszimmer des Chefs. Nach langem Warten kommt der Chef herein, im grünen Kittel (Vorsicht: Klischee!), und reicht Ihnen die plastikbehandschuhte Hand. Nun geht alles ziemlich rasch:
"Schön, dass Sie den Job bei uns angenommen haben. Unsere Sekretärin wird nachher mit Ihnen den Papierkram erledigen. Projektgelder sind genug da. Also, nächste Woche brauche ich
einen Datenbankentwurf für unsere Diabetesambulanz. Nun ... Die Diabetikerbetreuung läuft bei
1
Universität Ulm -Sektion Angewandte Informationsverarbeitung 3.Übungsblatt (09.11.98 bis
16.11.98) zur Vorlesung Software Engineering Praxis (WS 98/99)
21
Zusammenfassung
Datenbankanwendung fertigstellen
uns in etwa wie folgt ab: Also, ähh, die Patienten kommen halt regelmäßig zur Untersuchung. Ja
- stationär zur Stoffwechseleinstellung, so alle zwei Jahre. Dann aber regelmäßig alle Vierteljahr
zur ambulanten Untersuchung. Die stationäre lassen wir mal weg! Ambulant - ja, das ist wegen
des neuen EBM-Katalogs und des GSG III primär dringend. Bis nächste Woche, das sagte ich ja
schon. Die Patienten werden also ambulant untersucht ... Auf der Akte sehe ich immer, wen ich
vor mir habe. Alter, Geschlecht und so. Wohnort... Na ja, alle unveränderlichen Merkmale eines
Menschen halt, Stammdaten sagt man glaub'. Auch den betreuenden Hausarzt vor Ort. Da
kommen viele vom gleichen Hausarzt. Da könnte ich Geschichten erzählen... Jedenfalls werden
die Patienten dann untersucht. Pro Untersuchung: Gewicht, Größe, Blutdruck etc. eben die ganzen antropometrischen Daten, Sie wissen! Dann halt das Labor. Ja mei, HbA1c-Wert, Kalium,
Natrium. Betreut werden die bei uns von 6 Klinikärzten. Jeder hat seine festen Patienten. Wir
sind ein eingespieltes Team. Nicht so wie an der Uni XYZ! Ach ja ... Natürlich wird die Insulintherapie des Patienten eingestellt. Bei uns ist die Intensivierte Therapie als Ergebnis der DCCTStudie eingeführt worden! Die Patienten spritzen bis zu 7 mal pro Tag. Keine festen Dosen ... Sie
wissen das sicher! Wir sagen ihnen nur wie viel Insulin pro gegessener Broteinheit sie spritzen
sollen. Und geben Ihnen mit, wie viel Broteinheiten wir empfehlen. Noch Fragen? Nein? Gut! Ich
fasse zusammen: Also bis nächste Woche der Entwurf. Patientenstammdaten, ambulante Untersuchungen. Sie machen das schon! Hals- und Beinbruch! Auf Wiedersehen! Der nächste bitte!"
Sie machen das schon: Bis nächste Woche ein ER-Diagramm, bei dem Sie versuchen, das
Durcheinander des Chefarztes in sinnvolle Relationen und auf Papier zu bannen. Zu einem guten Entwurf gehört natürlich auch eine Umsetzung in Tabellen. Der Chefarzt würde zwar nichts
merken, da Sie aber auch Ihrem Gewissen verpflichtet sind, beschließen Sie, dass die Tabellen
alle der 3.Normalform genügen sollen. Und einem Chefarzt (hier: Tutor) legt man seinen Entwurf
natürlich nicht handschriftlich vor! Sondern eben mit einem netten Malprogramm gezeichnet
Der nächste bitte!
16:
Uni1
Erstellen Sie die Tabellen für die Universitätsverwaltung
22
Rekursive Beziehungen
Umsetzung in Relationen (Tabellen)
Rekursive Beziehungen
Beispiel:
"Ein Angestellter kann einem oder mehreren anderen Angestellten vorgesetzt
sein. Wir halten das Datum der Übernahme dieser Führungsfunktion fest."
N am e
A d re s s e
D a tu m
(0 ,n )
A n g e s te llte r
le ite n
(0 ,1 )
Dies ist eine binäre Beziehung und damit problemlos in eine Tabelle abbildbar:
Projektleiter
Mitarbeiter
Datum
Ternäre Beziehungen
Beispiel1:2
"Wir beziehen die Bestandteile über Artikelnummer - von einem Lieferanten für ein bestimmtes Projekt. Den Lieferanten identifizieren wir mit einer
Lieferantennummer, jedes Projekt verfügt über einen einmaligen Codenamen. Die bestellte
Menge und den Preis halten wir
natürlich fest."
Lief.-N r.
M en g e
Lie fe ra n t
(0,m )
C o d en am e
P reis
beziehe n
(0 ,m )
P ro je kt
(0,m )
A rtike l-N r.
B e stan d te il
Beispiel2:3
"Unser Schulungsinformationssystem soll folgende Tatbestände abbilden: Ein Kurs kann wegen des großen
Andranges in mehreren Kursräumen gleichzeitig gehalten werden. Um die einzelnen Schulungen identifizieren zu können, verwenden wir daher neben den Kursnamen eindeutige KursIDs. An einem Kurs können
natürlich mehrere Personen teilnehmen, von denen wir Name und Addresse erfassen. Die Räumlichkeiten
identifizieren wir anhand von Raumnummern; wir wollen vor allem die Rechnerausstattung festhalten."
Umsetzung in Relationen (Tabellen)
Beziehungstypen, die mehr als zwei Entitätstypen miteinander in Beziehung setzen, werden in einer eigenen
Relation abgebildet. Die Relation erhält als Fremdschlüsselattribut die Primärschlüssel der Entitätstypen, die
dadurch verbunden werden.
2
Beispiel von WU Wien
3
Beispiel von WU Wien
23
Ternäre Beziehungen
Umsetzung in Relationen (Tabellen)
Existiert eine strukturelle Bedingung, deren Maximalwert 1 ist, reicht es, dieses Fremdschlüsselattribut in der
abgeleiteten Relation als Primärschlüssel zu definieren. Ansonsten bilden alle Fremdschlüsselattribute den
Primärschlüssel.
Wunsch
W-Nr.
Wunsch
(0,1)
beauftragen
(0,m)
(0,m)
stationiert
Hilfsosterhase
Name
SV-Nr.
Osterhase
Name
SV-Nr.
Wunsch
W-Nr.
...
Wunsch
K-SVNr
O-SVNr
Auftrag
W-Nr.
...
H-SVNr.
O-SVNr.
Osterhase
SV.-Nr.
Name
Hilfsosterhase
SV.-Nr.
...
17:
Name
stationiert
...
Transportkompanie
Eine Transportkompanie der Schweizer Armee benötigt zur Abwicklung der Transportzentrale eine Datenbank. Früher wurde die Abwicklung in MS Excel gemacht.
Ein Unteroffizier verwaltet die Standalone Datenbank. Die Fahraufträge kommen per Fax oder
telefonisch. Angegeben wird bei der Bestellung die Route das Transportgut und die am Auftragsort zuständige Person.
Der Unteroffizier wählt anhand des Transportguts und der Strecke das passende Fahrzeug aus.
Er wählt einen Motorfahrer, der dieses Fahrzeug führen kann. Der Unteroffizier nimmt die Datenbank zu Hilfe.
In der Datenbank sind alle Fahrer erfasst. Unterschieden werden sie anhand der eindeutigen
Matrikel – Nummer. Des weiteren hat ein Fahrer noch einen Dienstgrad, Namen und Vornamen. Er hat die Fahrerlaubnis einer bestimmten Kategorie.
In einer Tabelle Kategorie sind der Kategoriename und die Bezeichnung der dazugehörigen
erlaubten Fahrzeuge gespeichert. Von einer Kategorie können mehrere Fahrer die Erlaubnis
haben.
Die Fahrzeuge müssen auch erfasst werden. Jedes Fahrzeug hat eine eindeutige Nummer
(Verkehrsschild) und eine Bezeichnung.
24
Ternäre Beziehungen
Umsetzung in Relationen (Tabellen)
Ein bestimmtes Fahrzeug gehört zu einem Typ. Ein Typ kann mehrere Fahrzeuge beinhalten.
Der Typ beinhaltet die Bezeichnung, Höhe, Breite, das Leergewicht in Kilo, das Höchstgewicht in
Zusatzaufgaben:
Erweitern Sie den Entwurf so, dass je Fahrauftrag mehrere Artikel transportiert werden können.
Kann das System so erweitert werden, dass jeder Artikel einen anderen Zielort erhält? Mit anderen Worten: Je Fahrauftrag müssen mehrere Ziele gespeichert werden.
Wenn die Fahrer alle KfZ fahren dürften, kann die Relation „darffahren“ entfallen. Dann kann der
Entitätentyp „Klasse“ ebenfalls entfallen und das Attribut dieses Typs direkt im Entitätentyp
„Fahrzeug“ erscheinen. Führen Sie die entsprechenden Änderungen durch.
25
Generalisierung
Umsetzung in Relationen (Tabellen)
Generalisierung
Zur weiteren Strukturierung der
Entity-Typen wird die Generalisierung eingesetzt. Hierbei werden
Eigenschaften von ähnlichen Entity-Typen einem gemeinsamen
Obertyp zugeordnet. Bei dem jeweiligen Untertyp verbleiben nur
die nicht faktorisierbaren Attribute. Somit stellt der Untertyp eine
Spezialisierung des Obertyps dar.
Diese Tatsache wird durch eine
Beziehung mit dem Namen is-a
(ist ein) ausgedrückt, welche durch
ein Sechseck, verbunden mit gerichteten Pfeilen symbolisiert
wird. In Abbildung 2.5 sind Assistenten und Professoren jeweils
Spezialisierungen von Angestellte
und stehen daher zu diesem EntityTyp in einer is-a Beziehung.
Beispiel:
"Bei unseren Angestellten unterscheiden wir zwischen den Sekretären und
den Managern. Namen und Adressen
halten wir von allen fest; von den Sekretären interessieren uns die Anschläge
pro Minute und von den Managern
wollen wir wissen, welche Projekte sie
leiten."
26
Datenbankzugriffe mit SQL
18:
Umsetzung in Relationen (Tabellen)
Uni2
Erstellen Sie die Tabellen für die Universitätsverwaltung
Datenbankzugriffe mit SQL
SQL (Structured Query Language) ist eine »Programmiersprache«, die nur noch ausdrückt, welches Ergebnis
gewünscht wird, und nicht wie der Rechner zu diesem Ergebnis kommt. Der Programmierer braucht sich
daher nicht um den Algorithmus der Datengewinnung zu kümmern. Diese „nicht-prozeduralen“ Sprachen
werden zu den Programmiersprachen der vierten Generation (4GL) gezählt (im Gegensatz zu prozeduralen
3GL-Sprachen wie Modula-2, Pascal, ADA, COBOL, BASIC, Fortran usw).
Die derzeit verbreitetste Sprache für relationale Datenbanken ist unbestritten SQL. Auch in Zukunft wird
diese Sprache keine Konkurrenz bekommen, was sich aus der Tatsache ableiten läßt, daß mittlerweile alle
Hersteller relationaler Datenbanken ihr System auf diese Sprache umgestellt haben.
Kleine SQL-Geschichte
Anfang der siebziger Jahre wurde in den IBM Forschungslaboratorien in San Jose, Kalifornien, ein Forschungsprojekt begonnen, das sich »System R« nannte. Es sollte die Praktizierbarkeit der relationalen Theorien untersuchen. Von den IBM-Mitarbeitern R.F. Boyce und D.D. Chamberlain wurde die Sprache
SEQUEL (sprich: siequel) entwickelt, die später in SQL umbenannt wurde. Man lehnte hierbei die Syntax an
Begriffe der englischen Umgangssprache wie z.B. SELECT, FROM, WHERE an.
Seit dieser Zeit wurden von fast allen DB-Herstellern SQL-Schnittstellen zu ihren relationalen und nichtrelationalen Datenbanksystemen entwickelt. Da nun auch eine ANSI- und eine IS0-Definition der Sprache SQL
27
Datenbankzugriffe mit SQL
SQL - Befehlsübersicht
vorliegt, ist zu erwarten, daß SQL die Sprache für alle zukünftigen relationalen Datenbanksysteme werden
wird.
Ein SQL-Beispiel:
Mit der Anweisung
CREATE TABLE ARTIKEL (ART_NR SMALLINT, ART_BEZ CHAR(13),
ART_ART CHAR(11), LIEF_NR SMALLINT)
wird eine leere Tabelle mit dem Namen ARTIKEL und dem folgendem Aufbau erzeugt:
Mit dem INSERT-Befehl ist es möglich, Daten in eine Tabelle einzufügen:
INSERT INTO ARTIKEL VALUES (1, 'Multisync II', 'Monitor', 1)
INSERT INTO ARTIKEL VALUES (2, 'Multisync I', 'Monitor', 2)
Mit dem SELECT-Befehl werden Daten aus der Tabelle selektiert:
SELECT ART_BEZ, ART_ART FROM ARTIKEL WHERE LIEF_NR = 2
Diese Abfrage liefert das Ergebnis:
SQL - Befehlsübersicht
Man unterscheidet fünf SQL-Kommandoklassen:
DATA Definition Language (DDL) (Daten-Definitions-Sprache)
Dazu zählen alle Datenbankanweisungen, mit denen die logische Struktur der Datenbank bzw. der Tabellen
der Datenbank beschrieben bzw. verändert wird, um Tabellen zu erzeugen, zu ändern und zu löschen und um
Indizes zu erzeugen und zu löschen.
DML Data Manipulation Language (Daten-Manipulations-Sprache)
Dazu zählen alle Anweisungen an das Datenbanksystem, die dazu dienen, die Daten zu verarbeiten, um Tabelleneinträge auszuwählen, einzufügen, zu aktualisieren und zu löschen. Hierzu gehören folgende Befehle:
Die SET-Klausel ist eine durch Kommas getrennte Liste von Aktualisierungsausdrücken. Jeder Ausdruck
setzt sich aus dem Namen einer Spalte, dem Zuweisungsoperator (=) und dem Aktualisierungswert (Aktualisierungsatom) für diese Spalte zusammen.
Die optionale WHERE-Klausel beschränkt Aktualisierungen auf einen Teil der Zeilen in der Tabelle. Ist
keine WHERE-Klausel angegeben, so werden alle Zeilen in der Tabelle unter Verwendung der Aktualisierungsausdrücke der SET-Klausel aktualisiert.
Transaction Control Language (TCL) (Daten-Steuerungs-Sprache
Die Transactionskommandos stellen die Datenintegrität sicher, indem logisch zusammenhängende Anweisungen entweder komplett oder gar nicht ausgeführt werden.
28
Abfrageformulierung mit SQL
Beispiel-Datenbank
Database Administration Language (DAL) (Datenbank-Verwaltungs-Sprache
Die Befehle aus dieser Kategorie dienen dem Anwendungsentwickler bzw. dem Datenbankadministrator.
Über SQL werden auch Datenbanken angelegt und geartet. Außerdem müssen Benutzer für die Datenbank
eingerichtet werden, wobei jedem Benutzer bestimmte Rechte für die Tabellen in der Datenbank einzuräumen sind.
DATA Query Language (DQL) (Daten-Abfrage-Sprache)
Dies wird wohl die meistgebrauchte Gruppe sein, da hier die SELECT-Anweisung auftaucht.
Abfrageformulierung mit SQL
Beispiel-Datenbank
Die Beispiele in der folgenden Tabelle beziehen sich auf diese Datenbank mit den Tabellen Teilnehmern,
Kurs und Ort.
Tabelle: Teilnehmer
Teiln
Nr
Name
Vorname
Strasse
Wohnort
100
101
102
103
104
105
106
107
108
Hirsch
Nicks
Unterländer
Peters
Wallung
Pfeiffer
Hauer
Hofmann
Sorglos
Harry
Steffi
Elke
Paul
Walther
Claudia
Hans
Helma
Susi
Baumgartenstr. 2
Holzweg 8
Max-Weber-Str. 12
Am Markt 1
Panoramapfad 33
Mozartweg 6
Im Winkel 16a
Am Bächle 3
Hauptstr. 143
75175 Pforzheim
73124 Oberndorf
81023 München
53522 Köln
09663 Grünstadt
74121 Ludwigshafen
12329 Talhausen
66822 Heidelberg
40210 Sonnstetten
Tabelle: Kurs
Kurs
Nr
Kurs
Dauer
Voraussetzungen
Ort_Nr
2.0
3.1
3.2
Projektmanagement
Kostenrechnung
IT-Marketing
5
2
1
010
011
011
1.0
3
4.1
5.1c
5.1b
5.1d
5.6
5.3
Geschäftsprozess,
betriebl. Organisation,
Grundlagen PC-Technik
C++ Anfängerkurs
Java Fortgeschrittenen-kurs
C++ Fortgeschrittenen-kurs
Grundlagen Datenbanken
Vertiefung Java
keine
keine
Teilnahme am Modul Kostenrechnung
keine
2
14
10
10
5
1
013
014
014
014
013
015
5.4
Dynamische Web-Seiten
2
4.3
Vertiefung PC-Technik
2
keine
keine
Programmiererfahrung
Programmiererfahrung
keine
Teilnahme am Fortgeschrittenenkurs oder vergleichbare
Kenntnisse
Kenntnisse einer höheren
Programmiersprache
Modul 4.1
012
010
013
29
Abfrageformulierung mit SQL
1 Projektion und Formatierung
Tabelle: Ort
Ort Nr
Ort
Schule
010
011
012
013
014
015
Ulm
Binzen
Ehingen
Pforzheim
Freiburg
Lörrach
Robert-Bosch-Schule
Fritz-Erler-Schule
Kfm. Schule
Heinrich-Wieland-Schule
Walther-Rathenau-Schule
Gewerbeschule
1 Projektion und Formatierung
Auswahl aller Spalten einer Tabelle
SELECT
*
FROM
<Tabelle>
Gesucht wird die Tabelle "Kurs".
Beispiel :
SELECT
*
FROM
Kurs
Auswahl einer Spalte einer Tabelle
Syntax :
SELECT
<Spalte>
FROM
<Tabelle>
Gesucht werden die Nachnamen aller Teilnehmer der Kurse.
Beispiel :
SELECT
Name
FROM
Teilnehmer
Auswahl mehrerer Spalten einer Tabelle
Syntax :
SELECT
<Spalte1> , <Spalte2> , ...
FROM
<Tabelle>
Gesucht werden die Vor- und Nachnamen aller Teilnehmer der Kurse.
Beispiel :
SELECT
Vorname, Name
FROM
Teilnehmer
Hinweis :
In SQL kann ein Anfrageergebnis mehrere identische Tupel enthalten.
Auswahl ohne mehrfaches Auftreten desselben Tupels
Syntax :
SELECT
DISTINCT
<Spalte>
FROM
<Tabelle>
Gesucht werden die verschiedenen Nachnamen der Teilnehmer der Kurse. Tragen zwei
Beispiel :
Teilnehmer den gleichen Nachnamen, so wird dieser nur einmal aufgeführt.
SELECT
DISTINCT
Name
FROM
Teilnehmer
Formatierte Ausgabe und Berechnungen in einer Selektion
Syntax :
Beispiel :
Es soll für jeden Kurs berechnet werden, wieviel Stunden dieser dauert.
SELECT
"Die Fortbildung ", Kurs, "dauert ", Dauer*8, " Stunden"
FROM
Kurs
Umbenennen von Spalten
Syntax :
Beispiel :
SELECT
<Spalte> AS <neuer Spaltenname>
FROM
<Tabelle>
Unter der Bezeichnung “Schulorte“ sind alle Schulen gesucht, die in der Tabelle "Ort"
gespeichert sind.
SELECT
DISTINCT
Ort AS Schulorte
FROM
Ort
30
Abfrageformulierung mit SQL
2 Selektion
Sortierung
Syntax :
Beispiel :
SELECT
<Spalte>
FROM
<Tabelle>
ORDER BY
<Spalte> {DESC | ASC}
Gesucht wird für jeden Teilnehmer der Name und sein Wohnort. Dabei ist die Ergebnistabelle absteigend nach dem Namen sortiert auszugeben.
SELECT
Name, Wohnort
FROM
Teilnehmer
ORDER BY
Name DESC
2 Selektion
SELECT
<Spalte>
FROM
<Tabelle>
WHERE
<Bedingung>
Selektion mit einfachem Vergleich
Syntax :
Beispiel :
Gesucht werden die Kurse, bei denen keine Voraussetzungen notwendig sind.
SELECT
Kurs
FROM
Kurs
WHERE
Voraussetzungen = 'keine'
Gesucht werden die Kurse, bei denen Voraussetzungen gefordert werden.
Beispiel :
SELECT
Kurs, Voraussetzungen
FROM
Kurs
WHERE
NOT (Voraussetzungen = 'keine')
Gesucht werden die Kurse, die mindestens 3 Tage dauern.
Beispiel :
SELECT
Kurs, Dauer
FROM
Kurs
WHERE
Dauer >= 3
Selektion mit mehreren Bedingungen
Beispiel :
Gesucht werden alle Kurse, die Programmiererfahrung erfordern und weniger als 10
Tage dauern.
SELECT
Kurs
FROM
Kurs
WHERE
Voraussetzungen = 'Programmiererfahrung'
AND
Dauer < 10
Gesucht werden die Namen und Wohnorte aller Teilnehmer, deren Vorname Harry oder
Beispiel :
Susi ist.
SELECT
Name, Wohnort
FROM
Teilnehmer
WHERE
Vorname = 'Harry'
OR
Vorname = 'Susi'
Selektion mit dem Operator IN
Beispiel :
Gesucht werden die Namen aller Schulen, die in Binzen oder Freiburg sind.
SELECT
Schule
FROM
Ort
WHERE
Ort IN (''Binzen, 'Freiburg')
Gesucht werden die Namen aller Schulen, die nicht inLörrach, Binzen und Freiburg
Beispiel :
sind.
SELECT
Schule
FROM
Ort
WHERE
Ort NOT IN ('Lörrach', 'Binzen, 'Freiburg')
Selektion mit dem Operator LIKE
Der LIKE-Operator ermöglicht den Vergleich eines Strings mit einem Muster. Muster werden aus beliebigen
Zeichen eines Strings und den beiden Sonderzeichen '?' und '*' gebildet. '?' steht für genau ein beliebiges
31
Abfrageformulierung mit SQL
3 Verbund von Tabellen
Zeichen, während '*' für eine beliebig große (evtl. leere) Kette von beliebigen Zeichen steht. Achtung: In
ANSI-SQL: '?' = '_' und '*' = '%'.
Beispiel :
Gesucht werden die Vornamen aller Teilnehmer, deren Postleitzahl mit "3" endet.
SELECT
Vorname
FROM
Teilnehmer
WHERE
Wohnort LIKE '????3*'
Gesucht werden die Vornamen aller Teilnehmer, deren Name mit "H"- und deren
Beispiel :
Wohnort nicht mit "H" beginnt.
SELECT
Vorname
FROM
Teilnehmer
WHERE
Name LIKE 'H*' AND Wohnort NOT LIKE '??????H*'
Selektion und NULL-Werte
NULL wird i.a. interpretiert als ein Platzhalter für die Aussage "Information/Attribut ist nicht vorhanden
oder nicht bekannt oder nicht anwendbar". SQL betrachtet daher im Vergleich zwei NULL-Werte immer als
unterschiedlich. Möglich ist es allerdings abzufragen, ob die Aussage "Spalten-Wert ist NULL" für ein Tupel
gilt.
Beispiel :
Gesucht werden die Kurse, die keine Dauer angegeben haben (oder deren Dauer nicht
bekannt ist)
SELECT
Kurs
FROM
Kurs
WHERE
Dauer IS NULL
3 Verbund von Tabellen
Einfacher Equijoin mit zwei Tabellen
SELECT
<Spalte1> , <Spalte2>, ...
FROM
<Tabelle1> , <Tabelle2>
WHERE
<Join-Bedingung>
Hinweis :
Wenn die Tabellen, die miteinander zu verbinden sind, Spalten mit gleichem
Spaltennamen aufweisen, dann muß jeweils spezifiziert werden, welche Spalte
welcher Tabelle gemeint ist.
Zur Verkürzung des Anfragetextes können für die Tabellen in der FROM-Komponente
Beispiel :
auch Alias-Namen vergeben werden.
SELECT
Schule, Kurs
FROM
Ort O, Kurs K
WHERE
O.Ort_Nr = K.Ort_Nr ORDER BY Schule ASC, Kurs ASC
Hinweis :
Die Alias-Namen können bereits in der SELECT-Komponente verwendet werden, auch wenn sie erst in der FROM-Komponente definiert werden.
Einfacher Equijoin über n>2 Tabellen
Syntax :
Beispiel :
Welche Kurse belegt Frau Hofmann in Binzen?
SELECT
Kurs
FROM
Teilnehmer T, TeilnehmerKursZuordnung TK, Kurs K, Ort O
WHERE
(T.Vorname = ‘Hofmann‘) AND (O.Ort_Nr = ‘Binzen‘) AND
(T.Teiln_Nr = TK.Teiln_Nr) AND (K.Kurs_N r = TK.Kurs_Nr)
AND (O.Ort_Nr = K.Ort_Nr) ORDER BY Kurs ASC
Equijoin mit Umbenennen der Spalte
Hinweis :
Beispiel :
Es ist oft sinnvoll, Spalten umzubenennen, um Mißverständnisse auszuschließen.
Für jeden Teilnehmer wird die Schulungsdauer in Stunden gesucht.
SELECT
Name, Vorname, Kurs, Dauer*8 AS Stunden
FROM
Teilnehmer T, TeilnehmerKursZuordnung TK, Kurs K
WHERE
(T.Teiln_Nr = TK.Teiln_Nr) AND
(K.Kurs_Nr = TK.Kurs_Nr ORDER BY Name
32
Abfrageformulierung mit SQL
4 Aggregatfunktionen und Gruppen
Vereinigung und Durchschnitt mit UNION
Die Datensätze von Tabellen, die identische Spalten enthalten, können durch UNION zusammengefaßt werden.
Beispiel :
Gewünscht wird eine Tabelle mit den Ortsnummern Ort_Nr, der Orte, an denen das Modul 4.1 Voraussetzung ist oder deren OrtLörrach oder Binzen ist.
SELECT
Ort_Nr
FROM
Kurs K
WHERE
K.Voraussetzungen = 'Modul 4.1'
UNION
SELECT
FROM
WHERE
Ort_NR
Ort O
(O.Ort = 'Lörrach') OR (O.Ort = 'Binzen')
4 Aggregatfunktionen und Gruppen
Hinweis: NULL-Werte werden vor der Auswertung einer Aggregatfunktion eliminiert.
Zählfunktion
SELECT
COUNT ([DISTINCT] <Spaltenliste|*>)
FROM
<Tabelle>
Gesucht wird die Anzahl aller Fortbildungsteilnehmer.
Beispiel :
SELECT
COUNT (*)
FROM
Teilnehmer
Wieviel verschiedene Schulorte existieren?
Beispiel :
SELECT
COUNT (DISTINCT Ort) AS Schulorte
FROM
Ort
Arithmetische Funktionen
Syntax :
Syntax :
SELECT
SUM ({numerische Spalte |
Arithmetischer Ausdruck mit numerischen Spalten})
FROM
<Tabelle>
Gesucht wird die Gesamtdauer aller Fortbildungen, die in Binzen stattfinden.
Beispiel :
SELECT
SUM (Dauer) AS Gesamtdauer_in_Binzen
FROM
Kurs K, Ort O
WHERE
(K.Ort_Nr = O.Ort_Nr) AND (O.Ort = ‘Binzen‘)
SELECT
AVG ({numerische Spalte |
Syntax :
Arithmetischer Ausdruck mit numerischen Spalten }
FROM
<Tabelle>
Gesucht wird die Durchschnittsdauer aller Fortbildungsveranstaltungen.
Beispiel :
SELECT
AVG (Dauer) AS Durchschnittsdauer
FROM
Kurs
Min-/Max-Funktionen
Syntax :
SELECT
Syntax :
Beispiel :
MAX ({numerische Spalte |
Arithmetischer Ausdruck mit numerischen Spalten})
FROM
<Tabelle>
SELECT
MIN ({numerische Spalte |
Arithmetischer Ausdruck mit numerischen Spalten})
FROM
<Tabelle>
Gesucht wird die kürzeste Kursdauer.
SELECT
MIN (Dauer) AS Minimale_Kursdauer
FROM
Kurs
33
Abfrageformulierung mit SQL
5 Unterabfragen (Subqueries)
Gruppenbildung in SQL-Anfragen
In den vorangegangenen Beispielen wurden die Aggregatfunktionen immer auf eine ganze Tabelle angewandt. Daher bestand das Abfrageergebnis immer nur aus einem Tupel. In SQL ist es aber auch möglich,
eine Tabelle in Gruppen "aufzuteilen", d.h. die Tupel einer Tabelle in Gruppen einzuteilen, und dann die
Aggregatfunktionen jeweils auf die Gruppen anzuwenden.
SELECT
<Spalte> , <Aggregatfunktion ...>
FROM
<Tabelle>
GROUP BY
<Spalte>
Hinweis :
Die in der group by-Komponente spezifizierten Spalten müssen auch in der
SELECT-Komponente spezifiziert sein, da Basis für die Gruppierung die "Zwischen-Ergebnis"-Tabelle ist, die durch Select ... From ... Where ... spezifiziert
wurde. Andererseits müssen alle Spalten der Selektionsliste, die nicht durch
eine Aggregatfunktion gebunden sind, in der group by-Komponente aufgeführt
werden. Die Reihenfolge der Spaltenspezifikation in der GROUP BYKomponente hat keinen Einfluß auf das Resultat der Abfrage.
Es sind 2 Gruppen auszugeben: Alle verschiedenen Voraussetzungen und deren GesamtBeispiel :
Kursdauer nach Gesamt-Kursdauer absteigend sortiert.
SELECT
Voraussetzungen, SUM (Dauer) AS Gesamtdauer
FROM
Kurs
GROUP BY
Voraussetzungen ORDER BY Sum (Dauer) DESC
Für jeden Kursort soll die Anzahl der Veranstaltungen ermittelt werden.
Beispiel :
SELECT
Ort, COUNT (Ort) AS Veranstaltungen
FROM
Ort
GROUP BY
Ort ORDER BY COUNT(Ort) DESC, Ort ASC
Auswahl von Gruppen
Syntax :
Syntax :
Beispiel :
SELECT
<Spalte> , <Aggregatfunktion ...>
FROM
<Tabelle>
GROUP BY
<Spalte>
HAVING
<Bedingung>
Es sind alle Orte zusammen mit der Gesamtdauer auszugeben, wenn die Gesamtdauer
mindestens 10 Tage lang ist.
SELECT
Ort, SUM (Dauer) AS Gesamtdauer
FROM
Kurs, Ort
WHERE
Kurs.Kurs_Nr = Ort.Ort_Nr
GROUP BY
Ort
HAVING
SUM (Dauer) >= 10
5 Unterabfragen (Subqueries)
Eine Unterabfrage ist eine Abfrage, die in einer Abfrage eingebettet ist.
Unteranfragen mit dem IN-Operator
Syntax :
Hinweis :
Beispiel :
Hinweis :
SELECT
FROM
WHERE
<Spalte1>
<Tabelle>
<Spalte2>
IN (SELECT <Spalte3>)
FROM <Tabelle>
[WHERE <Bedingung>])
Spalte 1, Spalte 2 und Spalte 3 müssen nicht unterschiedlich sein.
Gesucht wird jede Schule an der ein Kurs stattfindet, der Programmiererfahrung verlangt.
SELECT
Ort, Schule
FROM
Ort
WHERE
Ort_Nr IN (SELECT Ort_Nr
FROM Kurs
WHERE Voraussetzungen = ‘Programmiererfahrung‘)
Jede Anfrage, die eine Unteranfrage mit dem IN-Operator enthält, ist als Equi-
34
Abfrageformulierung mit SQL
Hinweis :
Beispiel :
6 Struktur von Tabellen erzeugen, ändern und löschen
join formulierbar (gilt nicht für NOT IN). So ist die folgende Abfrage äquivalent
zur vorhergehenden.
SELECT
Ort, Schule
DISTINCT
FROM
Kurs K, Ort O
WHERE
(K.Ort_Nr = O.Ort_Nr) AND
(Voraussetzungen = ‘Programmiererfahrung‘)
Um das Ergebnis einer Unterabfrage zu negieren, kann der NOT-Operator benutzt werden.
Gesucht werden alle Kurse, die nicht in Binzen stattfinden.
Kurs
SELECT
FROM
Kurs
WHERE
Ort_Nr NOT IN (SELECT Ort_Nr
FROM
Ort
WHERE Ort = ‘Binzen‘)
Identisch wäre: SELECT
FROM
WHERE
Kurs
Kurs
Ort_Nr IN (SELECT Ort_Nr
FROM
Ort
WHERE Ort <> ‘Binzen‘)
6 Struktur von Tabellen erzeugen, ändern und löschen
Neue Tabelle zu einer bestehenden Datenbank hinzufügen
<Tabellenname>
(<Spalte1> Datentyp, <Spalte2> Datentyp, ...)
Es soll eine Tabelle “Referent“ erstellt werden.
Beispiel :
CREATE TABLE
Referent
(Ref_Nr Text(4), Name Text(20), Vorname Text(18))
Eine bestehende Tabelle aus einer Datenbank löschen
Syntax :
CREATE TABLE
DROP TABLE
<Tabellenname>
Es soll eine Tabelle “Referent“ endgültig entfernt werden.
CREATE TABLE
Referent
Eine neue Spalte zu einer bestehenden Tabelle hinzufügen
Syntax :
Beispiel :
<Tabellenname>
ADD COLUMN <Spalte> Datentyp
Zur Tabelle “Ort“ soll die Spalte “OSA“ hinzugefügt werden.
Beispiel :
ALTER TABLE
Ort
ADD COLUMN OSA Text(20)
Eine Spalte einer Tabelle löschen
Syntax :
ALTER TABLE
Syntax :
ALTER TABLE
<Tabellenname>
DROP COLUMN
Aus der Tabelle “Ort“ soll die Spalte “OSA“ dauerhaft entfernt werden.
Beispiel :
ALTER TABLE
Ort
DROP COLUMN OSA
An eine Tabelle ein Datensatz anfügen
Syntax :
INSERT INTO
Beispiel :
<Tabellenname>
(<Spalte1> Datentyp, <Spalte2> Datentyp, ...)
VALUES
(<Wert1>, <Wert2>, ...)
Zur Tabelle “Ort“ soll der Datensatz “016“,“Lörrach“, “Gewerbeschule“ hinzugefügt werden.
INSERT INTO Ort (Ort_Nr, Ort, Schule)
VALUES
(016, ‘Lörrach‘, ‘Gewerbeschule‘)
35
Abfrageformulierung mit SQL
Weitere Hinweise zum Verbund von Tabellen
Datensatz aus einer Tabelle löschen
Syntax :
DELETE FROM
<Tabellenname>
WHERE
<BEDINGUNG>
Von der Tabelle “Ort“ sollen die Datensätze gelöscht werden, deren Schulbezeichnung
“Heinrich-Hertz-Schule“ lautet.
DELETE FROM
Ort
WHERE
Schule = ‘Gewerbeschule-Loerrach‘
Beispiel :
Weitere Hinweise zum Verbund von Tabellen
Inner Join: Verknüpfung von Tabellen
Beispiel: SELECT
b.buch_nr, autor, titel, leser_nr
FROM buecher b, verleih v WHERE b.buch_nr = v.buch_nr; Beschreibung:
Hier werden die beiden Spalten buecher.buch_nr und verleih.buch_nr verglichen, und bei gleichem Inhalt in
der Tabelle ausgegeben. Somit erhält man eine Tabelle mit dem Inhalt von mehreren Tabellen. Alias-Namen
sind nicht zwingend, aber ratsam.
Auto Join/Self Join: Verknüpfung einer Tabelle mit sich selbst
Beispiel: SELECT
emp1.name, emp1.sal, emp2.name, emp2.sal
FROM emp emp1, emp emp2 WHERE (
(emp2.sal > emp1.sal) AND (emp1.ename = 'BLAKE') );
Beschreibung:
Hier können Angaben einer Tabelle miteinander verknüpft und verglichen werden. Alias-Namen sind wegen
der garantiert doppelt vorkommenden Namen Pflicht.
Outer Join: Verknüpfung von Tabellen
Beispiel: SELECT * FROM u, v WHERE u.s1(+) = v.s1(+);
SELECT * FROM u, v WHERE u.s1(+) = v.s1;
--> vollständig
--> einseitig
Beschreibung:
Bei dieser Tabellenverknüpfung werden auch Zeilen dargestellt, die nur in einer Tabelle vorhanden sind. Die
Spalten der anderen Tabelle bleiben an dieser Stelle leer. Beim vollständigen Outer Join geschieht dies bidirektional, beim einseitigen Outer Join nur in eine Richtung.
Unterabfragen: Einzeilige (= Single Row Subquery)
- Beispiel: SELECT
ename FROM emp WHERE hiredate >
( SELECT hiredate FROM emp
WHERE
ename = 'FORD' );
36
Abfrageformulierung mit SQL
Weitere Beispiele zum Verbund von Tabellen
Beschreibung:
Eine SELECT-Unterabfrage ist dann einzeilig (=Single Row Subquery), wenn sie genau eine Zeile als Ergebnis liefert. Das Ergebnis der einzeiligen SELECT-Abfrage kann mit <, =, >, <= und >= verglichen werden.
Unterabfragen: Mehrzeilige (= Multiple Row Subquery)
Beispiel: SELECT
* FROM buecher WHERE buch_nr IN ( SELECT buch_nr FROM verleih );
Beschreibung:
Eine SELECT-Unterabfrage ist dann mehrzeilig (=Multiple Row Subquery), wenn sie als Ergebnis eine
mehrzeilige Tabelle liefert, die nur mit Mengenoperatoren verglichen werden kann.
Mengenoperatoren sind:
ANY, ALL, [NOT] IN, EXISTS, UNION, INTERSECT, MINUS. Auf den Seiten DQL 40 und DQL 42
werden diese beschrieben.
Weitere Beispiele zum Verbund von Tabellen
SELECT * FROM testCompanies JOIN testEmployees";
SELECT * FROM testCompanies AS a
LEFT JOIN testEmployees AS b ON (a.ID = b.ID)";
SELECT * FROM testCompanies AS a
RIGHT JOIN testEmployees AS b ON (a.ID = b.ID)";
SELECT * FROM testCompanies
LEFT JOIN testEmployees USING (ID)";
SELECT * FROM testCompanies as A , testEmployees AS B
WHERE A.ID = B.ID
SELECT *
FROM testCompanies
JOIN testEmployees
ID name ID nachname position companyID 1 Firma 1 3 Schmidt
Hausmeister
1
2 Firma 2 3 Schmidt
Hausmeister
1
3 Firma 3 3 Schmidt
Hausmeister
1
1 Firma 1 1 Musterfrau
Geschäftsführerin 1
2 Firma 2 1 Musterfrau
Geschäftsführerin 1
3 Firma 3 1 Musterfrau
Geschäftsführerin 1
1 Firma 1 2 Mustermann Geschäftsführer
2
2 Firma 2 2 Mustermann Geschäftsführer
2
3 Firma 3 2 Mustermann Geschäftsführer
2
37
Abfrageformulierung mit SQL
SELECT *
Weitere Beispiele zum Verbund von Tabellen
FROM testCompanies AS a
LEFT JOIN testEmployees AS b
ON (a.ID = b.companyID)
ID name ID nachname position companyID 1 Firma 1 3 Schmidt
Hausmeister
1
1 Firma 1 1 Musterfrau
Geschäftsführerin 1
2 Firma 2 2 Mustermann Geschäftsführer
3
2
Firma 3
SELECT *
FROM testCompanies as A ,
testEmployees AS B
WHERE A.ID = B.companyID
ID name ID nachname position companyID 1 Firma 1 3 Schmidt
Hausmeister
1
1 Firma 1 1 Musterfrau
Geschäftsführerin 1
2 Firma 2 2 Mustermann Geschäftsführer
2
38