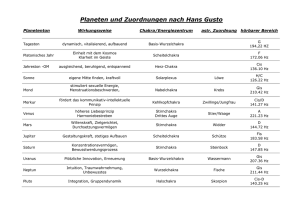
Geoinformationssysteme
Werbung

Eidgenössische Technische Hochschule Zürich Institut für Geodäsie und Photogrammetrie Bericht 309 Geoinformationssysteme Band 1 Alessandro Carosio Oktober 2006 Geoinformationssysteme Band 1 Alessandro Carosio Auflage Oktober 2006 Eidgenössische Technische Hochschule Zürich Institut für Geodäsie und Photogrammetrie Geoinformationssysteme Band 1 Auflage Oktober 2006 © 2006 Institut für Geodäsie und Photogrammetrie Eidgenössische Technische Hochschule Zürich Alle Rechte vorbehalten ISBN 3-906467-02-3 Alessandro Carosio Inhaltsverzeichnis 1. Einführung 1.1. 1.2. 1.3. 1.4. 1.5. 1.6. 1.7. 1.8. 1.9. Allgemeines Informationssysteme Zum Begriff "Geo-Informationssystem" Geo-Informationssysteme und Computergraphik Bedürfnisse und ihre Entwicklungstendenzen Die Entwicklung der GIS-Technologie Die Aufgaben des Vermessungsingenieurs Komponente, Investition, Lebensdauer Umgang mit den Daten 1.9.1. Die zentrale Bedeutung der Daten 1.9.2. Datenakquisition 1.9.3. Datenverwaltung 1.9.4. Datenausgabe 1.9.5. Produkte und Verwendung der Geo-Information 1 1 2 4 5 6 8 8 9 9 10 10 11 12 2. Architektur von Geo-Informationssystemen 13 2.1. 2.2. 2.3. 2.4. Einleitung Komponenten eines Geo-Informationssystems Zentrale Komponenten: Personal, Aufgabenteilung und Organisation Technische Infrastruktur 2.4.1. Übersicht 2.4.2. Geodätische Messtechnik 2.4.3. Bürotechnik und Kommunikation 2.4.4. Informatikmittel 2.5. Hardware-Komponenten eines GIS 2.5.1. Arbeitsstationen und Prozessoren 2.5.2. Massenspeicher 2.5.3. Dateneingabe 2.5.4. Datenausgabegeräte 2.6. Funktionale Komponenten eines GIS (Software-Module) 2.6.1. Gliederung 2.6.2. Zur Benutzeroberfläche 2.6.3. Änderungen und Ergänzungen 2.6.4. Abfrage und Darstellung 2.6.5. Datenverwaltungssystem 2.6.6. Digitalisieren von Plänen und Karten 2.6.7. Transformations- und Interpolationsverfahren 2.6.8. Treiber für die Hardware-Komponenten, Datensicherungseinheit 1 13 14 15 16 16 17 17 18 20 20 21 21 22 22 22 23 23 24 24 26 27 27 3. Datenstrukturen und Datenbanken 29 3.1. Einleitung 3.2. Das Datenbankkonzept 3.2.1. Definition 3.3. Architektur eines Datenbanksystems 3.4. Standard-Datenbanksysteme 3.5. Nicht-Standard-Datenbanksysteme 3.5.1. Zusatzschichtarchitektur 3.5.2. Datenbankkernarchitektur 3.5.3. Das NF2-Modell 3.5.4. Objektorientierung 3.6. Datenbankentwurf 3.6.1. Die Modellierung der Realität - die Modellbildung 3.6.2. Entwurfsphasen 3.6.3. Konzeptionelle Modellierung 3.6.4. Logische Modellierung 3.7. Das Entity-Relationship Modell 3.7.1. Beschreibungsformalismus 3.7.2. Die Entitätsmenge 3.7.3. Die Entität 3.7.4. Das Attribut 3.7.5. Die Beziehung 3.7.6. Das Entitätenblockdiagramm 3.7.7. Beispiel: Vereine eines Dorfes 3.8. Relationales Modell 3.8.1. Operationen der Relationenalgebra 3.9. SQL - Eine relationale Datenbanksprache 3.9.1. Datendefinition mit SQL 3.9.2. Datenabfrage und -manipulation mit SQL 3.9.3. Abfragen von Daten aus mehreren Tabellen (JOIN-Abfrage) 3.10. Objektrelationale Datenbanksysteme 3.10.1. Objektrelationale Erweiterungen gegenüber den relationalen Modellen 3.10.2. Abbildung in das logische Modell 3.10.3. Datenhaltung im ORDBMS ORACLE 29 30 30 31 32 34 35 36 37 37 38 38 38 40 40 41 41 41 42 42 43 45 46 48 48 54 54 56 61 62 63 64 68 4. 73 Datenmodelle für raumbezogene Informationen 4.1. Das Vierschalen-Modell 4.1.1. Modelle im Allgemeinen 4.1.2. Die vier Stufen eines Modells für raumbezogene Daten 4.2. Aufgaben und Verantwortung 4.2.1. Räumliches Modell 4.2.2. Konzeptionelles Modell 4.2.3. Logisches Modell 4.2.4. Physikalisches Modell 73 73 73 75 75 75 75 75 4.3. 4.4. 4.5. 4.6. 5. 4.2.5. Eine interdisziplinäre Aufgabe Modellierungsansätze 4.3.1. Bedeutung und Auswirkungen 4.3.2. Rasterstrukturen 4.3.3. Ungeordnete Polygone (Spaghetti-Daten) 4.3.4. Geordnete Polygone 4.3.5. Liniendefinitionen mit Punktverzeichnissen 4.3.6. Ebenenprinzip 4.3.7. Thematische und geometrische Information Geometrische Modelle 4.4.1. Grundkomponenten der Geometrie 4.4.2. Metrische Informationen 4.4.3. Topologische Informationen 4.4.4. Die Verwaltung der topologischen Informationen 4.4.5. Eindeutigkeit der geometrischen Grundelemente 4.4.6. Datenstrukturen für die geometrische Information Thematische Informationen 4.5.1. Funktion der Thematik 4.5.2. Beziehungen zwischen Thematik und Geometrie 4.5.3. Einfache thematische Objekte 4.5.4. Komplexe Objekte 4.5.5. Thematische Ebenen 4.5.6. Thematische und topologische Konsistenzbedingungen Inhalt und Datentransfer 4.6.1. Beschreibung des Inhaltes 4.6.2. Referenzdatenstrukturen 76 76 76 76 77 78 79 79 80 81 81 82 82 85 86 87 89 89 90 91 92 94 94 97 97 97 Räumliche Datenanalyse 99 5.1. Einleitung/Definition 5.2. Gliederung 5.3. Direkte Abfrage 5.3.1. Abfragestruktur 5.3.2. Thematische Abfrage 5.3.3. Geometrische Abfrage 5.3.4. Topologische Abfrage 5.3.5. Darstellung von Abfrageergebnisse 5.3.6. Komplexe räumliche Abfragen 5.4. Datenmanipulation 5.5. Spezialauswertungen 5.6. Algorithmen der räumlichen Datenanalyse 5.6.1. Geometrische Algorithmen 5.6.2. Geometrische und thematische Algorithmen 99 100 100 100 102 103 105 106 107 109 109 111 111 113 6. Rastermodelle in Geo-Informationssystemen 115 6.1. Grundlagen 6.1.1. Eigenschaften und Begriffe (Rasterbilder) 6.1.2. Anwendungen 6.1.3. Vorteile und Nachteile 6.2. Datenstrukturen 6.2.1. Ungeordnete Pixellisten 6.2.2. Vollständige Tabellen (Matrizen) 6.2.3. Blockweise Kodierung 6.2.4. Quadtrees 6.2.5. Lauflängenkodierung mit variabler Bit-Anzahl 6.3. Arbeiten mit Rasterdaten 6.4. Grundoperationen mit Rasterdaten 6.4.1. Einzelpixel Operationen (punktautonome Operationen) 6.4.2. Lokale Operationen 6.5. Hybride Systeme 115 115 116 117 118 119 119 120 121 123 126 127 127 128 132 7. 133 Interoperabilität und GIS 7.1. Interoperabilität und Datentransfer: Eine zentrale Funktion jedes GIS 7.2. Bedürfnisse, Lösungsansätze 7.2.1. Die Vielfalt der Anforderungen 7.2.2. Die Vielfalt der Lösungen 7.3. Der eigentliche Datentransfer 7.3.1. Proprietäre Transferformate: ein Grundbedürfnis 7.3.2. Standard-Formate 7.3.3. Modellbasierte Transferverfahren 7.4. Interoperabilität 7.5. Metadaten 7.6. Die Wünsche und das Erreichbare 7.6.1. Wünschbares 7.6.2. Technische Grenzen 7.7. Entwicklungsstrategien 7.8. Schlussfolgerung 133 134 135 135 136 136 136 138 139 141 142 142 142 144 146 1. Einführung 1.1. Allgemeines Die heutige Zeit ist charakterisiert von der immer grösser werdender Bedeutung der Information. Wir sprechen sogar von Informationszeitalter und Informationsgesellschaft. Leistungsfähige und schnell arbeitende Anlagen können immer komplexere Operationen nach Bedarf automatisch und kostengünstig ausführen. Um solche Prozesse auszulösen und zu steuern, benötigt man Informationen, die oft der eigentliche Engpass sowohl im Hinblick auf die Kosten als auch bezüglich der Ausführungszeit werden. Die Informationen sind der Schlüssel vieler moderner Technologien geworden. Die Computertechnik bietet Lösungsansätze, um wirksam Informationsbedürfnisse zu befriedigen. So findet man neben den numerischen Applikationen viele Informatikanwendungen im Bereich der Datenverwaltung, wo das Speichern, das Ordnen und das Wiederauffinden von Informationen die zentrale Aufgabe ist. In diesem Umfeld sind die heutigen Informationssysteme entstanden, ohne die weder grosse noch keine kleine Organisationen mehr denkbar sind. 1.2. Informationssysteme Eine eindeutige Definition für ein Informationssystem lässt sich nicht angeben. Je nach Anwendungsbereich findet man leicht andere Formulierungen. Die einfachste Form eines Informationssystems kann wie folgt definiert werden: Definition 1 Ein Informationssystem ist ein auf einem Datenbestand aufgebautes Frage-AntwortSystem. Beispiele • Der Telefonauskunftsdienst Nr. 111 • Das (elektronische oder gedruckte) Kursbuch der SBB Heute spielt die Informatikkomponente eine immer grössere Rolle und die Definitionen berücksichtigen diese Entwicklung. 1 Definition 2 Informationssysteme sind Allzweckwerkzeuge zum rechnergestützten Behandeln und Analysieren von Informationen /Brassel 1990/. Sie bestehen aus der Gesamtheit der Daten und der Verarbeitungsfunktionen /Conzett 1980/. Datenbank Daten Anwendung 1 Datenbank Verwaltungssystem Anwendung 2 Anwendung 3 Anwendung 4 Abb. 1.1: Informationssystem als Frage-Antwort-System Verfahrensorientierte Definitionen, wie man sie in der modernen Literatur findet, erwähnen die einzelnen Funktionen explizit: Definition 3 Ein Informationssystem schliesst eine Kette von Schritten ein, beginnend mit der Beobachtung und Erfassung der Daten über deren Analyse und Nutzung für Entscheidungsprozesse, die aus der Sicht eines Vierkomponenten-Modells zu sehen sind: Erfassung, Verwaltung, Analyse und Präsentation - E V A P. Im englischen Sprachraum lauten diese Komponenten: Input, Management, Analysis and Präsentation - I M A P. Die Verwaltung von Daten schliesst die Datenmodellierung, Datenstrukturierung und Datenspeicherung mit ein. /Bill, Fritsch 1991/ 1.3. Zum Begriff "Geo-Informationssystem" In vielen Informationssystemen findet man Ortsangaben als Teil der Daten. Wenn die Lageinformation nicht nur nebenbei behandelt wird, spricht man von einem GeoInformationssystem. Im Bereich der Geo-Information findet man nicht nur unterschiedliche Definitionen, sondern auch verschiedene Begriffe, die hier kurz erwähnt werden. 2 Definition 1 Raumbezogene Informationssysteme (RIS) sind geordnete Sammlungen von Informationen, in welchen Lageangaben in einem einheitlichen Bezugssystem eine Verknüpfung zwischen den enthaltenen Daten und der Umwelt ermöglichen. Definition 2 Ein geographisches Informationssystem (Abkürzung: GIS) enthält raumbezogene Daten über Atmosphäre, Erdoberfläche und Lithosphäre und gestattet eine systematische Erfassung, Aktualisierung, Verarbeitung und Umsetzung dieser Daten auf der Grundlage eines einheitlichen räumlichen Bezugssystems. Siehe z.B. /Göpfert 1987/. Definition 3 Ein Landinformationssystem (LIS) ist ein Instrument zur Entscheidungsfindung in Recht, Verwaltung und Wirtschaft sowie ein Hilfsmittel für Planung und Entwicklung. Es besteht einerseits aus einer Datensammlung, welche auf Grund und Boden bezogene Daten einer bestimmten Region enthält, andererseits aus Verfahren und Methoden für die systematische Erfassung, Aktualisierung, Verarbeitung und Umsetzung dieser Daten. Die Grundlage eines LIS bildet ein einheitliches, räumliches Bezugssystem für die gespeicherten Daten, welches auch eine Verknüpfung der im System gespeicherten Daten mit anderen bodenbezogenen Daten erleichtert. /FIG 1978/ In modernen Publikationen hat man diese zwei letzten unterschiedlichen Begriffe, die sich nicht genau abgrenzen lassen, unter der Bezeichnung Geo-Informationssysteme zusammengefasst. Dieser Begriff wird im Vermessungsbereich bevorzugt. Die folgende Definition Informationssystems: beschreibt Inhalte und Funktionen eines Geo- Definition 4 Ein Geo-Informationssystem (Abkürzung ebenfalls GIS) ist ein rechnergestütztes System, das aus Hardware, Software, Daten und den Anwendungen besteht. Mit ihm können raumbezogene Daten digital erfasst und redigiert, gespeichert und reorganisiert, modelliert und analysiert sowie alphanumerisch und graphisch präsentiert werden. /Bill, Fritsch 1991/ 3 Die folgende Darstellung zeigt die gegenseitigen Beziehungen und Abgrenzungen der häufig verwendeten Begriffe: Raumbezogene Informationssysteme GeoInformationssysteme Geographische Informationssysteme Landinformationssysteme Abb. 1.2: Gegenseitige Beziehungen und Abgrenzungen der häufig verwendeten Begriffe. 1.4. Geo-Informationssysteme und Computergraphik Man darf Geo-Informationssysteme nicht mit Computergraphik verwechseln. Die Informatik bietet heute leistungsfähige Instrumente für die Arbeit mit raumbezogenen Informationen. Man kann Computer einsetzen, um sowohl graphische Darstellungen (Karten und Pläne) schnell und günstig zu erzeugen (Graphische Software, CAD) als auch Computer-Systeme verwenden, um logisch strukturierte Daten zu verwalten, um weitere Informationen wunschgemäss herleiten zu können. (Geo-Informationssysteme). Im geographischen Bereich finden wir beide Formen von Computer-Anwendungen. In der kartographischen Produktion ist die reine Darstellung die eigentliche Aufgabe. Heute erlauben geeignete Software-Produkte die Herstellung von kartographischen Bildern (topographische Karten, Stadtpläne usw.). Die Qualität der Darstellung kann das Niveau der klassischen Kartographie erreichen. So können topographische Karten sowohl mit der bisherigen Technik (Gravur, photographische Reproduktion) als auch mit Bildverarbeitungsverfahren (Rasteroperationen) produziert werden, ohne dass ein Unterschied erkennbar wird. 4 Im Geo-Informationsbereich hingegen ist die graphische Darstellung nur eine von vielen Aufgaben. Geographische Daten werden gebraucht, um neue Informationen herzuleiten. • So will der Geometer Flächen berechnen, besondere Gebäudetypen suchen, Mutati- onen abwickeln usw. • Der Umweltingenieur will die Auswirkungen von neuen Vorhaben mit Simulations- berechnungen beschreiben, Umweltdaten verwalten und abfragen usw. • Der Planer möchte die Eigenschaften des Bodens sichtbar machen, eine geordnete Nützung bewirken, Zonenpläne und Vorschriften verwalten usw. Dafür benötigen diese Fachspezialisten Informationssysteme, die die Logik der geographischen Information speichern und verwalten können. Es genügt nicht, zu wissen, welche Linie mit welcher Farbe zu zeichnen ist. Notwendig ist zu wissen, wie die Beziehungen zwischen einfachen Elementen und Objekten (Linien zu Häusern, Punkte zu Grenzlinien usw.) sind. Einfache Elemente und Objekte sind begleitet von ganzen Listen von Attributen (qualitative und quantitative Merkmale), Beziehungen zwischen Objekten (Nachbarschaft, Überlappung usw.) sowie Hierarchien, die komplexe Elemente beschreiben (mehrere Gebäude zu Ortschaften usw.). 1.5. Bedürfnisse und ihre Entwicklungstendenzen Informationssysteme sind keineswegs eine Errungenschaft der heutigen Zeit. Alle konsultierbaren Datensammlungen (wie das Telefonbuch, das Kursbuch usw.) sind seit langem sehr nützliche Informationssysteme. Im Geo-Informationsbereich sind die topographischen Karten und das Grundbuch Beispiele bisheriger GeoInformationssysteme. Die Bedeutung der Informationssysteme hat sich mit der Zeit grundlegend verändert. Einerseits erlauben heute die Informatikwerkzeuge sehr leistungsfähige Systeme zu entwickeln, die grosse Mengen von Daten verwalten können. Andererseits haben sich die Bedürfnisse der Anwender stark entwickelt. Man möchte immer grössere Mengen Informationen verarbeiten und dafür benötigt man in vielen Fällen digitale Daten. In den meisten Bereichen der Technik werden mathematische Modelle eingesetzt und wenn das zu lösende Problem eine geographische Komponente hat, benötigt man raumbezogene Daten in numerischer Form. 5 Karten und Pläne genügen nicht mehr. Die geographische Information muss von Anfang an numerisch erfasst und verwaltet werden. Die Bedürfnisse nach digitalen Daten zeigen steigende Tendenz und zwingen zur Umstellung von den bisherigen geographischen Verfahren zu den neuen numerischen beschleunigten Systemen. Diese Umstellung ist zu einer zentralen Herausforderung in unserem Beruf geworden. Simulationen im Militärbereich, das Projekt DfA der SBB, Modelle für die Umweltüberwachung, Führungs- und Einsatzsysteme (Polizei, Alarmzentralen) usw. sind Beispiele dieser Entwicklung. 1.6. Die Entwicklung der GIS-Technologie Die Verfahren, mit denen die geographischen Informationen verwaltet werden, haben sich nicht nur in der Form der Speicherung (graphisch, digital) verändert, sondern auch in den organisatorischen Grundsätzen gewandelt. Während in der Vergangenheit ein grosser Teil der thematischen Daten unabhängig von den geometrischen Informationen bearbeitet wurden, tendieren die modernen Systeme zur ganzheitlichen Betrachtung der Informationen mit einheitlichen Werkzeugen. 6 Die folgende Graphik beschreibt schematisch die Phasen dieser Evolution: Was (Thematik) Wo (Geometrie) Phase 1 nach Bedarf Phase 2 systematisch mit Plänen und Verzeichnissen Phase 3 Dateien und Computergraphik (digital) Phase 4 Geographisches Informationssystem 7 1.7. Die Aufgaben des Vermessungsingenieurs Die Projektierung, Realisierung und der Betrieb von Geo-Informationssystemen ist die neue anspruchsvolle Hauptaufgabe für den Ingenieur geworden, der sich im GeoInformationswesen spezialisiert hat. Die Projektierung und Realisierung eines GIS ist nicht zu verwechseln mit der Entwicklung der Informatik-Werkzeuge (Software, Hardware-Konfigurationen, methodische Komponenten usw.), die im Tätigkeitsbereich der Informatiker anzusiedeln sind. Zur Projektierung und Realisierung gehören: • Analyse der Informationsbedürfnisse • Modellieren der Realität, Implementation • Datenstrukturen und Datenbanken für geometrische und thematische Daten • Suche von Datenquellen • Wahl von Datenerfassungsverfahren • Organisation der Datenverwaltung (informativer Daten, rechtsrelevanter Daten) • Analyse der Raumbezogenen Information • Repräsentation und Darstellung • Dienstleitungen und Produkte 1.8. Komponente, Investition, Lebensdauer Ein Geo-Informationssystem setzt sich aus mehreren Komponenten zusammen. Im Kapitel 2 werden die einzelnen Komponenten ausführlich beschrieben. Bereits im allgemeinen Teil ist aber wichtig zu erkennen, dass die Grundbausteine sehr unterschiedliche Merkmale aufweisen, dies insbesondere im Hinblick auf die Investition und Lebensdauer. Während Hardware und Software den kleinsten Teil der erforderlichen Investitionen darstellen, verursachen die Daten (Akquisition, Nachführung und Verwaltung) den grössten Teil der Kosten. Die Lebensdauer der Hardware ist die kürzeste. Sie kann 5 bis 7 Jahre betragen. Die Software kann das Dreifache erreichen. Die Daten haben eine viel grössere Lebensdauer und im geographischen Bereich kann man von einem praktisch unbeschränkten Zeitraum sprechen (50 bis .... Jahre). 8 Die folgende Abb. 1.3 /Studemann 1988/ verdeutlicht mit den Flächenangaben die Investition für die einzelnen Komponenten: ......... ............. ............... Hardware 5 - 7 Jahre Software 10 - 20 Jahre Daten 50 - .... Jahre Abb. 1.3: Investition und Lebensdauer der Komponenten eines GIS /Studemann 1988/ 1.9. Umgang mit den Daten 1.9.1. Die zentrale Bedeutung der Daten Die Daten sind die aufwendigste und dauerhaftere Komponente eines GeoInformationssystems. Der Umgang mit den Daten steht daher immer im Vordergrund. Bei der Projektierung eines GIS sind Datenakquisition, Datenverwaltung und Datenabgabe die wichtigsten Probleme und bestimmen die Effizienz des Informationssystems. Zu bemerken sind folgende Tatsachen: • Eingabe, Verwaltung und Ausgabe von Informationen sind stark voneinander ab- hängig. Eine gegenseitige Abstimmung (Optimierung) ist erforderlich. • Selten entsteht ein GIS als vollständig neues Projekt. Oft ist ein GIS die Weiterent- wicklung bestehender Systeme. Zur Datenakquisition gehört daher auch der Datentransfer vom alten zum neuen System. • Die Realisierung eines GIS beansprucht einen langen Zeitraum. Man muss daher an Übergangslösungen denken, da die Inbetriebnahme nach Vollendung des ganzen Systems wirtschaftlich nicht tragbar wäre. 9 1.9.2. Datenakquisition Die folgenden Datenquellen und Akquisitionsverfahren geben eine Übersicht über mögliche Lösungswege. • Örtliche Feldarbeiten Vermessungen (Tachymetrie, Satellitengeodäsie usw.) Datenerhebungen jeder Art • Photographische, elektronische Bilder Luftbilder Satellitenaufnahmen Terrestrische Aufnahmen (z.B. Dokumentationsbilder) Analoge oder digitale Bilder • Vorhandene Karten und Pläne Grundbuchpläne Topographische Karten Thematische Karten • Bestehende GIS Datenübernahme Datentransferstandard Transformationen und Interpolationen • Statistische Erhebungen und andere Datensammlungen Jahrbücher Karteien usw. In der Regel stammen die erfassten Daten aus verschiedenen Quellen und haben kein einheitliches Bezugssystem, so dass die eigentliche Datenakquisition mit der Transformation in das gewählte Bezugssystem vervollständigt werden muss. 1.9.3. Datenverwaltung In diesem Bereich finden wir alle Massnahmen und Techniken zur Erhaltung der Verfügbarkeit und der Qualität der Daten über längere Zeit (viele Jahrzehnte), damit sie bei Bedarf genützt werden können. 10 Die folgenden Elemente charakterisieren die Datenverwaltung • Inhalt Bedürfnisse, Kompromiss Grenzen (Kosten, Aufwand) • Operationen Abfragen, Mutationen, Darstellungen • Datenorganisation Datenbankverwaltungssystem Datenform (Rasterdaten, Vektordaten) Datenstruktur (Ordnung, Datenorganisation) Integration von heterogenen Datenformen • Datenintegrität Richtigkeit, Konsistenz Schutz, Sicherheit (SNV-Norm) • Arbeitsorganisation Dezentrale Einheiten Einheitliche Vorschriften Technische Normen • Schwierigkeiten Komplexität, Führbarkeit Informationsflut Kosten, Recht 1.9.4. Datenausgabe Ziel eines Informationssystems ist es, Daten verfügbar zu halten, um sie nach Bedarf auszugeben. Während in der Vergangenheit die Speicherung der Information weitgehend mit der Ausgabeform identisch war (Pläne, topographische Karten), ist heute die Ausgabe immer mit einer Verarbeitung verbunden (Datensuche, Auswahl, Repräsentation, Transformationen usw.). Zwei Hauptformen der Ausgabe können unterschieden werden: • Graphische Ausgabe Sie ist die traditionelle Form für die Darstellung von raumbezogenen Informationen und hat grosse Tradition (kartographische Technik). Karten und Pläne werden im11 mer grosse Bedeutung haben. Neue technische Hilfsmittel erlauben vermehrt eine Datendarstellung nach Bedarf (Bildschirm, Papierausdruck) und ermöglichen eine Anpassung der Qualität und der Inhalte an die Anwenderbedürfnisse. 1) Numerische Ausgabe Wenn der Benützer die geographische Information mit eigenen Programmen und Werkzeugen weiter verarbeiten will, benötigt er Geo-Information in digitaler Form. Diese Art der Ausgabe hat heute immer grössere Bedeutung (steigende Tendenz), da ständig neuere Methoden und Applikationen im Informatikbereich entstehen. Dafür benötigt man geeignete Ausgabemedien (Magnetbänder, optische Disks usw.) oder Kommunikationseinrichtungen (z.B. lokale Netze in den Gebäuden, landesweit digitale Telefonverbindungen usw.) sowie technische Normen für Schnittstellen und Kommunikationsprozeduren. Das Innovationspotential ist in diesem Bereich sehr gross. 1.9.5. Produkte und Verwendung der Geo-Information Während langer Zeit hat sich eine klare Trennung zwischen der Produktion von Informationsbeständen im geographischen Bereich und der Anwendung abgezeichnet. Die Produktion war eindeutige Aufgabe von geographischen Instituten, Landesvermessungsämtern, Ingenieurbüros usw. Das Produkt war eine geeignete graphische Darstellung (topographische oder thematische Karte, Katasterpläne) oder Listen und Verzeichnisse. Die Anwender waren Interessierte, die Kopien der Originalprodukte erworben haben und daraus für ihre Zwecke Informationen integriert, analysiert und hergeleitet haben. Analyse und Interpretation fanden weitgehend auf visueller Basis statt, ohne oder mit einfachen Werkzeugen (Massstab, Kartenwinkelmesser usw.). Heute erlauben die Daten eines Geo-Informationssystems weitaus komplexere Analysen und Verwendungsarten, die ihrerseits leistungsfähige Installationen (ComputerSysteme) erfordern. Die Rollen des Produzenten und des Anwenders sind nicht mehr klar abgegrenzt. Der Ingenieur-Geometer sammelt und ordnet die Informationen der amtlichen Vermessung. Er verfügt über die Instrumente, um diese Informationen zu verarbeiten. Daraus entsteht die Möglichkeit, neue Applikationen als Dienstleistungen anzubieten. Die Aufgabe des Vermessungsingenieurs könnte in wesentlichen Teilen erweitert werden. 12 2. 2.1. Architektur von Geo-Informationssystemen Einleitung Ein Geo-Informationssystem setzt sich aus mehreren Komponenten zusammen, deren Bedeutung je nach Betrachter sehr unterschiedlich gewichtet werden kann. Der Hersteller von Informatikmitteln sieht vor allem die Hardware- und Softwarekomponente eines GIS, mit welchen raumbezogene Daten verwaltet werden können. Er verkauft solche Systeme, die er oft als GIS bezeichnet. Für den GIS-Anwender als Benutzer von raumbezogenen Daten steht die Datenanalyse und -darstellung im Vordergrund. Von Interesse sind für ihn die Selektionsmöglichkeiten (Abfragesprache), die Visualisierung räumlicher Informationen und deren Zusammenhänge sowie die für den vorgesehenen Anwendungsbereich notwendigen Datenverarbeitungsfunktionen. Politische Entscheidungsträger benötigen aktuelle Informationen über die Umwelt und deren Nutzung. Der Einsatz von Geo-Informationssystemen ist zwingend und es müssen Mittel und Wege gefunden werden, um ein adäquates GIS rasch und günstig zu realisieren. Ein GIS ist für sie eine komplexe Organisation, die viel Geld kostet. Die Geoinformatik-Spezialisten konzentrieren ihre Aufmerksamkeit auf die Abstraktionsschritte in der Konzeption eines GIS. Das konzeptionelle Modell ist für sie die wesentliche Komponente. Die Ordnung der Daten, die Formalismen für die Beschreibung der Datenstruktur (Datenbeschreibungssprache) und die logischen Grundelemente der raumbezogenen Information mit den dazugehörigen Zusammenhängen sind für sie von grösster Bedeutung. Vermessungsingenieure und Geometer denken vor allem an die zuverlässige Akquisition der Raumdaten. Die Datenflüsse, die Wahrung und Sicherung (Nachführung der Daten) der Datenqualität über lange Zeiträume, die Verwaltung und die Abgabe der raumbezogenen Informationen stellen die Hauptaufgaben dar. In den folgenden Kapiteln wird die Architektur eines GIS aus einer möglichst neutralen Perspektive dargestellt. Trotz bester Absicht, kann aber eine persönliche Wertung nicht vermieden werden. 13 2.2. Komponenten eines Geo-Informationssystems Eine umfassende Betrachtung des gesamten Umfeldes, in dem GeoInformationssysteme eingesetzt werden, gibt einen Überblick, der erforderlich ist, um die materiellen und nicht materiellen Komponenten dieser Systeme zu erkennen. RIS Organisation Instrumente, Werkzeuge (Vermessung, Bürotechnik) Personal D a t e n Informatikmittel Fachwissen Verfahren Die Anschaffung von Hard- und Software stellt nur einen ersten Schritt der GISRealisierung dar. Ein Geo-Informationssystem ist ein logisches Gesamtkonzept, nach welchem ein Unternehmer im Bereich der Geo-Informatik sein administratives und Fachpersonal, sein Instrumentarium, seine Einrichtungen und Informatikmittel sowie die zugehörigen Arbeitsmethoden und Fachkenntnisse einsetzt, um raumbezogene Informationen zu beschaffen, zu verarbeiten, zu verwalten, zu analysieren und abzugeben. 14 Die organisatorischen und rechtlichen Voraussetzungen spielen dabei eine ebenso wichtige Rolle wie die Erfahrung und die Qualifikation des Personals oder die Leistungsfähigkeit der GIS-Software und -Hardware. Landesweite Geo-Informationssysteme, wie die Amtliche Vermessung der Schweiz, entstehen oft als Netzwerk von unabhängigen Teileinheiten, die unterschiedliche Computersysteme (Hardware und Software) betreiben. Um sicherzustellen, dass einerseits die einzelnen Teilsysteme die jeweiligen lokalen Verhältnisse optimal berücksichtigen können aber andererseits alle diese Teilsysteme in ein landesweites Geo-Informationssystem integriert werden können, werden auf der Stufe der Gesetzgebung direkt oder indirekt nur die Minimalinhalte, die Referenzdatenstrukturen und die gemeinsame Schnittstellen verbindlich vorgeschrieben. 2.3. Zentrale Komponenten: Personal, Aufgabenteilung und Organisation Die technischen Komponenten eines GIS können nur dann erfolgreich eingesetzt werden, wenn die Verantwortung für die anfallenden Aufgaben gut qualifiziertem Personal über einen längeren Zeitraum übertragen werden kann. Im Vergleich zur materiell einfach zu beschaffenden technischen Infrastruktur, ist der Erwerb von Erfahrung und Fachkompetenz weitaus schwieriger. Fachspezialisten mit entsprechender Erfahrung in der Erfassung und Verwaltung von raumbezogenen Informationen (Vermessungsingenieure, Geometer), sind im Vorteil, da sie über ein breites Grundwissen verfügen. Es erstaunt deshalb nicht, dass in der Schweiz bedeutende GIS-Projekte (z. B. die Reform der amtlichen Vermessung, die Datenbank der festen Anlagen der Schweizerischen Bundesbahnen, verschiedene kantonale GIS) Vermessungsfachleuten anvertraut werden. Die Strukturen des Vermessungswesens in der Schweiz mit ca. 3000 Mitarbeitern in mehr als 300 Ingenieurbüros und behördlichen Dienststellen werden auch in Zukunft den organisatorischen Rahmen für die Mehrzahl der grossen GIS-Projekte darstellen. Voraussetzung ist allerdings, dass die grosse Bedeutung der geographischen Information auf allen Stufen unseres Berufs erkannt wird und die entsprechenden Rahmenbedingungen geschaffen werden. 15 2.4. Technische Infrastruktur 2.4.1. Übersicht Geo-Informationssysteme verdanken ihre heutige grosse Bedeutung zum grossen Teil dem technischen Fortschritt im Bereich der Informationsverarbeitung. Die technischen Komponenten spielen daher eine sehr wichtige Rolle. Die Informatik gilt eindeutig als die integrierende und treibende Kraft in der GIS-Entwicklung. Die Datenbanktechnologie, die moderne Computer-Graphik, die immer leistungsfähigeren Prozessoren, die Vielfalt der Peripheriegeräte und nicht zuletzt die umfangreichen GIS-Softwarepakete haben die aktuelle, nach wie vor sprunghafte Entwicklung im Bereich der GeoInformationsverarbeitung ausgelöst. GIS-Computer GIS-Grundmodul (Datenverwaltung Interaktion) amtliche Vermessung Geodäsie DBMS FELDRECHNER TACHI ABST. Kartographie PC (MS-Dos) DTM DATEN GPS FAX Eisenbahn Wasserwerk •••••••••••••• Die Bedeutung anderer technischer Bereiche ist jedoch nicht zu unterschätzen: Die geodätische Messtechnik oder die Büro- und Kommunikationstechnik, die oft direkt Komponenten für hybride GIS liefern. Um den Umfang der Publikation im Rahmen zu halten, werden im folgenden nur einige allgemeine Bemerkungen angefügt. Dem Leser wird die einschlägige Fachliteratur empfohlen. 16 2.4.2. Geodätische Messtechnik Die geodätische Messtechnik konnte in den letzten Jahrzehnten enorme Fortschritte verzeichnet. Insbesondere die Möglichkeiten der Optoelektronik und der modernen Mechanik haben die heutigen Vermessungsinstrumente stark verändert. Einige Aspekte: • Mit modernen Theodoliten werden höchste Messgenauigkeiten erzielt, sie sind mit elektronischen Ableseeinrichtungen ausgerüstet und eine Reihe systematischer Fehler des Messvorgangs können automatisch kompensiert werden. Ein genauer Distanzmesser kann in vielen Fällen voll integriert werden. • Dank dem globalen Postitionierungssystem (NAVSTAR-GPS) der Vereinigten Staaten ist es möglich, Relativpositionen mit Genauigkeiten im Zentimeterbereich zu bestimmen. Die Satellitengeodäsie bringt eine grosse technische Revolution der Vermessung. • Robotertheodolite werden durch verschiedenste Sensoren (z.B. CCD-Kameras) ge- steuert. Eine hochpräzise Servomotorsteuerung erlaubt die automatische Zielverfolgung und die elektronische Ablesung ist für eine Fernübertragung der Ergebnisse bestens geeignet. • Bildverarbeitungsnivelliere können die Zielhöhe auf der Messlatte selbständig er- kennen und automatisch registrieren. • In der Photogrammetrie und in der Fernerkundung lösen digitale Techniken mehr und mehr die konventionellen Verfahren ab. Diese neuen Techniken in der Vermessung werden in der Gewinnung der Primärdaten (z.B. Punktkoordinaten im Gelände) voll eingesetzt. Die Instrumente sind mit integrierten Informatikbestandteilen ausgerüstet und benötigen entsprechende Datenerfassungsund Auswertesoftware. Die Arbeitsproduktivität und die Anforderungen an die Mitarbeiter sind stark gestiegen. Ausbildungs- und Einführungszeiten sind dementsprechend lange und teuer. Das Personal stellt somit immer mehr das eigentliche Betriebskapital einer Unternehmung dar. 2.4.3. Bürotechnik und Kommunikation Auch heute, trotz Informatikzeitalter, gibt es Informationen, die nicht notwendigerweise voll in einem Computersystem verwaltet werden müssen. Man kann Karteien und Pläne weiter verwenden. Die moderne Bürotechnik kann dabei die Wirtschaftlichkeit der Arbeit wesentlich verbessern. Digitalkameras können aufwendige Skizzen ersetzen. Textverarbeitungssysteme und Tabellenkalkulationsprogramme können helfen, einfa- 17 che Datensammlungen zu erstellen und zu verwalten. Traditionelle Arbeitsmethoden können ebenfalls Bestandteil eines GIS sein. Die Telekommunikation, die heute zunehmend mit der Informatik verknüpft wird, (man spricht von "Telematik") ist eine unentbehrliche Ergänzung jedes GIS. GeoInformationssysteme werden in den meisten Fällen in öffentlichem Interesse aufgebaut. Mehr oder weniger öffentlich zugängliche Kommunikationsnetze stellen daher eine sehr wichtige Komponente dar, um die Verfügbarkeit und die Zugänglichkeit zu Daten für den Benutzer zu gewährleisten. Die Nachfrage nach schneller digitaler Kommunikation hat stark zugenommen. Dank den ADSL-Diensten der Swisscom oder anderen Anbietern und den schnellen Datenübertragungsdiensten von Cablecom verursacht der Austausch von grossen Datenmengen auch in kleineren und mittelgrossen Betrieben kein Problem mehr. Deshalb werden vermehrt Geoinformationssysteme als Webdienst angeboten. 2.4.4. Informatikmittel Die Informatikkomponente ist das koordinierende und integrierende Element in einem heutigen Geo-Informationssystem. Für die Verwaltung von raumbezogenen Daten wird allgemein eine Vielfalt von Systemen auf dem Markt angeboten, die von den Herstellern als Geo-Informationssysteme bezeichnet werden. Häufig handelt es sich dabei um Software-Pakete, die auf verschiedenen Rechnern installiert werden können. Nicht selten werden aber auch schlüsselfertige Systeme (kombinierte Hard- und Softwarelösungen) angeboten. GIS-Softwarepakete werden seit den Siebzigerjahren entwickelt. Die einzelnen Hersteller haben bei der Entwicklung sehr verschiedene Lösungswege gewählt. Im folgenden Kapitel werden Eigenschaften, Komponenten und Beziehungen zwischen den einzelnen Elementen dargestellt. Es handelt sich dabei um typische, bereits realisierte Systeme, die auch in der Schweiz Verbreitung gefunden haben. Andere GIS-Produkte sind ähnlich aufgebaut. Kleine Unterschiede sind in erster Linie auf andere Voraussetzungen (spezielle Ziele, Erweiterung von älterer, bereits bestehender Software usw.) zurückzuführen. Dies gilt nicht für Prototypen, die vorrangig für die Erprobung neuer Informatikkonzepte (objektorientierte Datenbanken usw.) entwickelt werden. Diese werden in der Folge nur am Rande erwähnt, da deren praktische Bedeutung zur Zeit nicht relevant ist. 18 Damit allgemein von einem Geo-Informationssystem gesprochen werden kann, müssen folgende Eigenschaften vorliegen: • Alle Einzelkomponenten passen in ein logisches Gesamtkonzept. • Ein logisch strukturierbares Datenverwaltungssystem ist Bestandteil des GIS und si- chert die langfristige Verwaltung aller Daten. • Die Datenstruktur (Inhalte und Ordnung der Daten) ist frei definierbar in Abhängig- keit der Bedürfnisse und offen gegenüber künftigen Veränderungen und Erweiterungen. • Auch das System ist in der Konfiguration offen. Zusätzliche Hardware- und Soft- ware-Komponenten können nach Bedarf mit der Zeit beschafft und integriert werden. • Eine verlustfreie Datenübertragung zu anderen Systemen (zumindest zu Systemen des gleichen Herstellers) und zu Systemen der nächsten Generation ist vorgesehen und problemlos durchführbar. • Die Ausgabe von Daten - auch auszugsweise - muss nach verbreiteten Standards er- folgen. • Ein kontinuierlicher Datenfluss von der Datenerfassung (oder der vorhandenen Da- tenquellen) bis zum Datenverwaltungssystem und zur Datenausgabe muss gewährleistet sein. • Eine leicht erlernbare Benutzeroberfläche erlaubt eine einheitliche Anwendung von Grundoperationen und Arbeitsabläufen. Nicht alle Funktionen und Eigenschaften müssen zwangsläufig auch mit Informatikmitteln realisiert werden. Im GIS Konzept sind auch manuelle Operationen, klassische Archive und organisatorische Massnahmen enthalten. Unbedingt notwendig ist aber eine reibungslose Integration aller Einzelkomponenten in das Gesamtkonzept, ohne von den ursprünglich definierten Zielvorgaben abzuweichen. 19 2.5. Hardware-Komponenten eines GIS 2.5.1. Arbeitsstationen und Prozessoren Ein Geo-Informationssystem ist im Normalfall mit mehreren Arbeitsplätzen ausgestattet, an denen die Operateure die Funktionen des Systems auslösen und steuern und die relevanten Informationen visualisieren. Die erforderliche Rechenleistung, die in der Vergangenheit von einem Zentralcomputer im Hintergrund zur Verfügung gestellt wurde, kommt heute aus leistungsfähigen Arbeitsstationen, die so vernetzt werden, dass sie sich für den Anwender wie ein einziges grosses Computersystem verhalten. Grundlage bildet ein gemeinsames Fileverwal- 20 tungssystem, das zwar auf allen Arbeitsstationen physikalisch verteilt werden kann, aber dennoch eine logische Einheit bildet. In nächster Zukunft ist eine Rückkehr zum Zentralrechner zu erwarten, da die angebotenen Rechenleistungen weiter steigen werden. Bereits heute übersteigen sie die Bedürfnisse. Die modernen graphischen Terminals (X-Terminals) ermöglichen gleiche Benützeroberflächen wie vollständige Arbeitsstationen. Die Prozessoren, die auf RISC-Architektur basieren, werden den Markt der Arbeitsstationen beherrschen. Ihre Leistung wird stark steigen. In grösseren Systemen wird man mehrere Prozessoren parallel einsetzen. Alle anderen Prozessortypen, die sich mehrheitlich auf Entwicklungen der 70er Jahre stützen, werden sukzessiv verschwinden. 2.5.2. Massenspeicher Die Verwaltung von raumbezogenen Daten bedingt die Speicherung von grossen Datenmengen und einen möglichst schnellen Zugriff. Magnetplattenspeicher sind heute die leistungsfähigste Lösung für Grössenordnungen einiger Giga-Bytes. Daneben findet man magneto-optische Platten, die bezüglich des Datenzugriffs zwar etwas langsamer sind, sich aber in riesigen Datenarchiven (mehrere Terabytes) organisieren und einsetzen lassen. Neben einem manuellen Handling kann auch eine automatische Einrichtung zum Auswechseln der Platten (Juke Box) vorgesehen werden. Die Bedeutung der einmal beschreibbaren und n-mal lesbaren optischen Platten (WORM = "write once, read many times") wird weiter abnehmen. Gewöhnliche CDPlatten werden dagegen überall dort im Gebrauch bleiben, wo die gleichen statischen Informationen an mehreren Orten Verwendung finden. Für die Datenarchivierung setzt man zur Zeit Magnetbandkassetten ein, die aus der Unterhaltungselektronik stammen (Video 8 und DAT-Kassetten). Sie erlauben die Speicherung von einigen Giga-Bytes auf einem einzigen Datenträger. 2.5.3. Dateneingabe Zur Datengewinnung und -speicherung werden bereits im Feld Informatikmittel eingesetzt. Diese unterstützen die vermessungstechnischen Operationen, wie z.B. Satellitenempfänger mit der entsprechenden Auswertesoftware, Feldrechner für elektronische Tachimeter usw. Die zur Datenübertragung notwendige Verbindung mit dem GeoInformationssystem im Büro findet periodisch statt. In der Photogrammetrie werden analytische oder digitale Auswertegeräte eingesetzt, die direkt an ein Geo-Informationssystem gekoppelt sind; die gewonnenen Daten können somit direkt dem Datenverwaltungssystem übergeben werden. 21 Digitalisiertische sind klassische Werkzeuge für die Umwandlung von graphischen Informationen (Pläne, Karten usw.) in numerische Daten. Eine Automatisierung des eigentlichen Datenerfassungsprozesses erfolgt durch den Einsatz von Scannern. Karten oder Pläne können fast beliebig genau abgetastet werden. Die resultierenden Rasterdaten entsprechen dem Originalbild. Eine automatische Interpretation der Bildinhalte für die zwingend notwendige strukturierte Speicherung in einem Informationssystem ist zur Zeit nur beschränkt möglich. Die erforderlichen Techniken sind Gegenstand intensiver Forschung; Fortschritte sind zu erwarten. 2.5.4. Datenausgabegeräte Die graphische Datenausgabe ist die wichtigste Kommunikationsform bei GeoInformationssystemen. Die Auswahl der Peripheriegeräte ist sehr gross und deckt nahezu alle Bedürfnisse ab: Stiftplotter (Trommel) günstig, in allen Formaten, farbig, langsam Zeichentische genau, Grossformat, farbig, langsam Thermotransferdrucker farbig, günstig, Kleinformat Laserplotter schwarzweiss in Grossformat, sehr schnell farbig in sehr guter Qualität, nur in Kleinformat (<A3) Farbplotter (Laser-Belichter) direkte Filmbelichtung für die Reproindustrie, höchste Präzision, Raster- und Vektordaten, sehr teuer Elektrostatischer Farbplotter bis A3, mehrfarbig, schnell, teuer gute Auflösung bei der Verwendung der 8 Grundfarben Mischfarben werden durch Pixelmuster erzeugt, die Auflösung ist dann 3 bis 4 Mal kleiner. Tintenstrahl-Plotter Zukunftstechnologie für Farbzeichnungen auch grossformatig 2.6. Funktionale Komponenten eines GIS (Software-Module) 2.6.1. Gliederung Ein Geo-Informationssystem setzt sich grundsätzlich aus einer Vielfalt einzelner Software-Modulen zusammen. Zum Teil stellen diese Komponenten Grundfunktionen dar, während andere eher Spezialmodule sind, die jeweils für besondere Applikationen benötigt werden. 22 Zu den Grundfunktionen sind insbesondere zu zählen: • Benutzeroberfläche • Funktionen zur Änderung und Ergänzung der Daten • Funktionen zur Abfrage und Darstellung • Datenverwaltungssystem (mit Datendefinitionssprache und Manipulations- funktionen) • Digitalisieren von Plänen und Karten • Transformationen, Interpolationen • Treiber für die Hardware-Komponenten • Datensicherungsfunktionen Zu den Spezialmodulen gehören Funktionen oder komplexe Programme, die für eine besondere Applikation benötigt werden, wie z.B. hydraulische Berechnung für das Wasserversorgungsnetz, die Ausgleichungsrechnung für die Fixpunktbestimmung, die Ausbreitung von Schallwellen für Lärmbelastungsstudien u.v.a.. 2.6.2. Zur Benutzeroberfläche Unter diesem Begriff versteht man das Medium, das dem Operateur zur Verfügung steht, um mit dem Geo-Informationssystem zu kommunizieren, d.h. um es zu steuern, Operationen auszulösen, Informationen abzufragen usw. In der Regel ist eine graphische Benutzeroberfläche vorgesehen (direkt am Bildschirm und/oder auf einem Graphiktablett), in dem ein Zeiger für die Objektwahl bewegt wird (Tastatur, Maus), und über Funktionstasten bestimmte Operationen ausgelöst werden. Sofern die Einzelfunktionen auch über Tastatureingabe gesteuert werden können, ist es möglich ganze Ketten von Einzelfunktionen zu einer neuen, komplexen Funktion in einem File zusammenzufassen (sogenannte Makros, Command file), die in der Folge durch die Eingabe eines einzigen Befehls ausgelöst wird. Die heutigen GIS unterscheiden sich in der Benützeroberfläche stark, da sich jetzt kein Standard durchgesetzt hat. 2.6.3. Änderungen und Ergänzungen Die geometrischen und thematischen Datenbestände sind während der ganzen Lebensdauer des Systems nachzuführen. Diese Arbeit ist eine sehr häufig auftretende Tätigkeit. Um rasch und flexibel arbeiten zu können, sind eine Reihe von Nachführungsfunktionen direkt in der Benutzeroberfläche integriert. Sie enthalten notwendigerweise 23 auch Funktionen zur Konsistenzprüfung und zur Kontrolle der Ausführungsberechtigung (sofern dies nicht bereits vom Datenverwaltungssystem übernommen wird). 2.6.4. Abfrage und Darstellung Vorrangiges Bedürfnis im Umgang mit einem GIS ist das Abfragen und Analysieren von Daten. Abfrageergebnisse sind häufig Listen geschriebener Informationen (z.B. Tabellen von Objekten und Attributen). Relationale Datenbankverwaltungssysteme stellen leistungsfähige Werkzeuge zur Verfügung, um Ausgabetabellen frei zu definieren. Es liegt nahe, diese Techniken auch in einem GIS zu verwenden. Die Tabellendefinition wird gespeichert und nach Bedarf aufgerufen und/oder abgeändert. In den meisten Fällen sind die Ergebnisse einer Abfrage allerdings eine Kombination von geometrischen und thematischen Inhalten, die zweckmässigerweise graphisch dargestellt werden. Auf die gleiche Art und Weise wie die Definition numerischer Ausgabetabellen erfolgt, muss in einem GIS die graphische Darstellung bedarfsorientiert gesteuert werden können. Eine erste Definition der graphischen Eigenschaften eines Elementes muss bereits unmittelbar nach der Definition des Objektes im Datenbankverwaltungssystem stattfinden, da die graphischen Elemente fortlaufend am Bildschirm dargestellt werden müssen. Bereits auf dieser Stufe können mehrere Darstellungsarten notwendig sein: z.B. je nach Massstab de Betrachtung, je nach Applikation usw.. Neben diesen graphischen Grundformen muss die Darstellung bei den Abfragen in Abhängigkeit der Dateninhalte (z.B. Attribute), des Ausgabemediums (Papier, Bildschirm, Folie usw.), des Planmassstabes, der thematischen Zielsetzungen usw. beeinflusst werden können. Auch in diesem Bereich ist eine Standardisierung ein fernes Ziel, die heutigen GIS unterscheiden sich diesbezüglich sehr stark. 2.6.5. Datenverwaltungssystem Die Idee, ein Datenverwaltungssystem zum Management von Informationen einzusetzen, die in Abhängigkeit des Projekts flexibel strukturiert werden müssen, entspricht dem grundlegenden, seit langem bekannten Datenbankkonzept. Die Entwickler von Geo-Informationssysteme stützen sich auf ähnlichen Gedanken ab. Bei der Realisierung von GIS-Projekten ist der Umgang und die Verwaltung sehr heterogener Informationen vorzusehen, die in einer ersten Phase festgelegt werden. Dann wird eine geeignete Datenstruktur gewählt, die man ins Datenbankverwaltungssystem überträgt. So können die gespeicherten Informationen langfristig verwaltet und nach Bedarf abgefragt und analysiert werden. 24 Raumbezogene Daten besitzen allerdings gewisse Eigenschaften, welche die geschilderte Lösung erheblich erschweren. Insbesondere sind folgende Probleme zu überwinden: • Abfragen erfordern die Suche nach sehr vielen geometrischen Elementen • die Suchkriterien sind hauptsächlich räumlich (2- oder 3-dimensional) • die Konsistenzbedingungen sind komplex Diese Schwierigkeiten werden heute in der Praxis mit einer Kombination von einem lokalen Datenspeicher und einer relationalen Datenbank bewältigt. Der lokale Datenspeicher dient vor allem, um die geometrischen Informationen schnell genug abzufragen und zu speichern (Dialog am Bildschirm). Die relationale Datenbank dient vor allem für die langfristige Verwaltung der Daten und für die Abfragen und Analysen der thematischen Informationen (Eigentümer, Rohrdurchmesser, Parzellennummer, Bodenbedeckungsart usw.). Die heute eingesetzten Geo-Informationssysteme (Software) sind so aufgebaut. Einige Systeme verwenden den lokalen Datenspeicher auch für die langfristige Verwaltung der geometrischen Daten, die nie in der relationalen Datenbank gespeichert werden. Andere Systeme kopieren vor Arbeitsbeginn ein Teil der Daten (Arbeitsgebiet) in den lokalen Datenspeicher, um den neuen Zustand nach Arbeitsschluss in die relationale Datenbank zurück zu kopieren. Die geometrischen Daten können in normale Datenbankstrukturen (Tabellen mit Entitäten und Attributen) abgelegt werden oder blockweise in verschlüsselter Form. Nur wenige Systeme versuchen direkt alle Daten in der relationalen Datenbank zu verwalten. Dies benötigt eine besondere Datenbankverwaltung, die schnelle räumliche Zugriffe erlaubt, in welcher ein modifizierter Datenbankkern verwendet wird. Eine Vereinheitlichung des Datenbankverwaltungssystems in den GIS wird angestrebt. Die Forschung befasst sich mit verschiedenen Lösungsansätzen, die vielleicht zur GISDatenverwaltung der Zukunft führen werden. 25 DATE N GIS DB Verwaltung SQL LOKALER DATENSPEICHER Geometrie und ev. Thematik So werden zur Zeit in folgenden Richtungen geforscht /H.J. Schek, A. Wolf 1992/: • Modifizierte relationale Datenbankkerne • Modelle mit geschachtelten Relationen (NF2-Relationenmodell) • Objektorientierte Datenbanksysteme • Erweiterbare Datenbanksysteme Diese neuen Konzepte spielen bisher für die Praxis noch eine bescheidene Rolle. 2.6.6. Digitalisieren von Plänen und Karten Das klassische Speicher- und Archivierungsmedium für eine Vielzahl raumbezogener Informationen sind analog vorliegende Karten, Pläne, Zeichnungen etc. Die Umsetzung dieser graphischen Informationen auf digitale Medien ist ein Arbeitsschritt, der bei vielen GIS-Realisierungen mehr oder weniger häufig vorzunehmen ist. Entsprechende Software-Module gehören deshalb zur Grundausstattung eines GIS. 26 2.6.7. Transformations- und Interpolationsverfahren Die Übernahme von vorhandenen Daten (aus numerischen oder graphischen Datenquellen) erfordert oft eine Änderung des Bezugssystems (z.B. digitalisierte Plankoordinaten in Landeskoordinaten). Dafür benötigt man entsprechende mathematische Verfahren, um aufgrund der vorliegenden Angaben (funktionale Beziehungen, Stützwerte) optimale Transformationsfunktionen zu bestimmen. Die Auswahl ist in den angebotenen Systemen leider sehr oft beschränkt (Ähnlichkeitstransformation, Affinität). Unregelmässige Verzerrungen können deshalb in der Regel nicht direkt behandelt werden. 2.6.8. Treiber für die Hardware-Komponenten, Datensicherungseinheit Die Hardware-Konfiguration eines Geo-Informationssystems ist nicht als konstant zu betrachten. Jedes System enthält Komponenten, die im Laufe der Zeit ergänzt, ersetzt oder ausgetauscht werden. Das Angebot von Hardware-Komponenten ist sehr gross. Es ist daher vorteilhaft, wenn bereits in der Grundsoftware der Anschluss für die verschiedensten Peripheriegeräte (Plotter, Digitalisiertische, Photogrammetrische Auswertegeräte, Drucker, Bildschirme usw.) vorgesehen ist. Bei der Evaluation eines Systems ist diese Frage abzuklären, da für die nachträgliche Anschaffung auch einfachster Treiber nicht selten übersetzte Preise verlangt wird. Von grosser Bedeutung ist ferner ein Software-Modul für die komplette Datensicherung. Um die Datensicherung kontinuierlich und vollautomatisch (z.B. nachts) ablaufen zu lassen, muss die Kopie des gesamten Datenbestandes eines Projekts auf einen einzigen Datenträger problemlos möglich sein. 27 Literaturverzeichnis Bartelme 1988: gis Technologie, Geoinformationssysteme, Landinformationssysteme und ihre Grundlagen, SpringerVerlag Bill/Fritsch 1992: Grundlagen der Geo-Informationssysteme, Hardware, Software und Daten, Wichmann-Verlag Burrough 1986: Principles Geographical Information Systems for Land Resources Assessment, Oxford Science Publications Golay 1990: Cours SIT III, EPFL Göpfert 1987: Raumbezogene Informationssysteme, Datenerfassung, Verarbeitung, Integration. Ausgabe auf der Grundlage digitaler Bild- und Kartenverarbeitung, WichmannVerlag Miserez 1991: Système d'information du territoire 1+2, Cours EPFL Pornon 1992: Les SIG, mise en oeuvre et appplications, Hermes Rouet 1991: Les données dans les systèmes d'information géographique, Hermes 28 3. 3.1. Datenstrukturen und Datenbanken Einleitung In technischen wie in kommerziellen und administrativen Bereichen werden immer grössere Mengen von Daten und Informationen erfasst und verarbeitet. Wegen der hohen Kosten der Datenerfassung will man sie über eine längere Zeit sicher aufbewahren, fehlerfrei verwalten, verschiedenen Benutzern zugänglich machen und in mehreren Applikationen verwenden. Das Ziel ist zu vermeiden, dass gleiche Daten mehrfach erfasst und verwaltet werden. Die Konsistenz, d.h. die Widerspruchsfreiheit der Daten ist eine grundlegende Voraussetzung der Datenqualität. Konsistenzbedingungen sind Regeln, die von allen Daten eingehalten werden müssen. Diese Regeln über Zusammenhänge von Sachverhalten müssen streng formuliert werden. Je komplexer die Daten sind, desto komplexer ist es, die Datenkonsistenz zu erreichen. Der Ingenieur wird mit diesen Problemen in besonderem Masse konfrontiert. Gerade in der amtlichen Vermessung ist die Erfassung besonders zeit- und kostenaufwendig, die Konsistenzregeln sind sehr komplex, und die Rechtsgültigkeit der Daten ist zeitlich unbeschränkt. Erfasste Daten müssen zugänglich bleiben und in anpassungsfähiger Form herausgegeben werden können. Um die Daten verwalten zu können, braucht es einen physikalischen Träger (die Hardware) und ein Verwaltungssystem, das die Daten geordnet speichert, vor unerlaubten Zugriffen schützt und ihre Konsistenz prüft (die Software). Bei den meisten Betriebssystemen ist vorgesehen, dass die Daten in Files (eindimensionale Datenlisten), in einer Hierarchie von Directories (deutsch: Ordner) gruppiert werden. Einige Betriebssysteme oder Programmiersprachen (z.B. COBOL) stellen in ihren Filesystemen auch indexsequentielle Files zur Verfügung, die neben der sequentiellen Grunddatei auch sortierte Inhaltsverzeichnisse mit Zeigern (Pointers) führen, um einen schnellen Zugriff nach mehreren Schlüsselfeldern zu ermöglichen. Weitergehende Datenverwaltungsbedürfnisse können mit zweckentsprechenden Software-Modulen (z.B. Datenbankverwaltungssysteme) befriedigt werden. 29 3.2. Das Datenbankkonzept Da die Datenverwaltung in verschiedensten Anwendungen in ähnlicher Form auftritt, wurden verschiedene allgemeingültige Software-Werkzeuge entwickelt, die so genannten Datenbankverwaltungssysteme oder DBMS (Databasemanagementsystem). Diese bestehen aus Funktionen und Algorithmen für die zentrale oder verteilte permanente Speicherung, Organisation und Suche von Daten in einer Datenbasis. Solche Systeme können in unterschiedlichen Fachgebieten angewendet werden. Die Daten werden ausschliesslich über eine festgelegte Schnittstelle (DML, Data Manipulation Language) abgefragt und bearbeitet. Diese Schnittstelle (DML) ist Bestandteil des Datenbankverwaltungssystems (DBMS). Es handelt sich um eine Sammlung von Befehlen und Funktionen (Such-, Lösch-, Sortier-, Nachführfunktionen), die man direkt im Datenbankverwaltungssystem aufrufen oder in Anwenderprogrammen als Prozeduren einbauen kann. Die meisten DBMS erlauben den Mehrbenützerbetrieb und stellen die gespeicherten Daten mehreren Anwendern "gleichzeitig" zur Verfügung. 3.2.1. Definition Wenn ein so genanntes Datenverwaltungssystem einen auf Dauer angelegten Datenbestand organisiert, schützt und verschiedenen Benutzern zugänglich macht, bilden diese (Datenverwaltung und Daten) eine Datenbank /Zehnder 87/. DML DATEN DBMS DATENBANK AnwenderProgramm 1 AnwenderProgramm 2 AnwenderProgramm 3 Abb. 3.1: Architektur einer Datenbank 30 Folgende Punkte können als Vorteile der Datenbank-Architektur angeführt werden: a) Die Zweiteilung der Architektur: (Siehe Abb. 3.1) Ein anwendungsunabhängiges Datenbankverwaltungssystem (DBMS) als Kern. Eine anwendungsbezogene Schicht: die Anwenderprogramme. Die Daten und ihre Organisation sind von den Anwendungen getrennt. Mit dieser Architektur will man verhindern, dass jeder Benutzer die interne Organisation der Daten zu kennen braucht und dass er Funktionen für die Manipulation der Daten implementieren muss. Datenunabhängigkeit: Die Anwenderprogramme können abgeändert, neue Programme angehängt werden, ohne dass die gespeicherten Daten davon betroffen werden. Das Datenbankschema kann erweitert werden, ohne dass bisherige Anwenderprogramme davon betroffen werden. b) Das Datenbankverwaltungssystem gewährleistet Datenintegrität auf lange Zeit: Durch Eingabekontrollen, Plausibilitätstest oder vom Benutzer vorprogrammierte Funktionen wird die Widerspruchsfreiheit (Datenkonsistenz) der Daten überprüft. Höhere und komplexere anwendungsorientierte Konsistenzprüfungen müssen in die Anwendersoftware integriert werden. Die Konsistenz ist immer in dem Rahmen gewährleistet, der durch die Datenbanksoftware einerseits und die Anwendersoftware andererseits definiert ist. Durch die Regelung der Zugriffs-Berechtigungen (Passwörter) und Sperren von verschiedenen Datenfeldern und Datenmanipulationsfunktionen (Zugriffsberechtigungs-Tabellen) wird der Schutz der Daten gegen unerlaubte Einsicht oder absichtliche Veränderung gewährleistet (Datenschutz). Mit geeigneten Dienstprogrammen können die Daten gegen Verlust und irrtümliche Verfälschung geschützt werden: Backup und Recovery Funktionen des DBMS erlauben bei Systemzusammenbrüchen beschädigte Datenbestände zu rekonstruieren (Datensicherheit). 3.3. Architektur eines Datenbanksystems Um eine Datenbank effizient zu betreiben, benötigt man zusätzlich zu den Datenverwaltungsfunktionen im engeren Sinn noch weitere Software-Komponenten, die ebenfalls zum Datenbanksystem gehören. 31 Die Komponenten eines Datenbanksystems: • Ein Datenbankverwaltungssystem (DBMS). • Eine Datenmanipulationssprache (DML) für Abfragen und Eingaben. • Eine Datenbeschreibungssprache (Data Description Language DDL) mit dem ent- sprechenden Compiler für die Eingabe und Übersetzung der logischen Datenstruktur (konzeptionelles Schema) in eine für das DBMS verständliche Form. • Abfragesprachen zur Vereinfachung der Datenmanipulation mit Hilfe von Masken. • Report Writer für die Ausgabe von DB-Abfragen. • Dienstprogramme zur Verfügung des Datenbankadministrators (Betreuer des DBS innerhalb des Betriebs) für die Steuerung und Überwachung der Speicherplatzverwaltung, der Zugriffsberechtigungen und der Datenbankanwendungen. • Prozeduren als Schnittstelle für die eigenen Anwendungsprogramme. 3.4. Standard-Datenbanksysteme Standard-Datenbanksysteme (handelsübliche DBMS) werden erfolgreich in Wirtschaft und Verwaltung eingesetzt. Sie erfüllen alle gewünschten Anforderungen (Konsistenzprüfung, Schutz der Daten, Mehrbenützerbetrieb). Die meisten auf dem Markt angebotenen DB-Systeme haben das so genannte relationale Datenmodell implementiert: Oracle, Informix, Sybase, DB2, Ingres.... Diese verwalten die Daten in Form von Tabellen. Standard-Datenbanksysteme, wie z.B. Oracle verwenden SQL als prozedurale und eingebettete Datenmanipulationssprache (DML); sie bieten auch Befehle, die als Prozeduren in Anwenderprogrammen eingesetzt werden können (oft <Host Language Interface> genannt). Die Abfragesprache SQL (Structured Query Language) erlaubt komplexere Abfragen über Kombinationen von mehreren Objekten zu formulieren. SELECT punktnummer, hoehe wähle punktnummer und höhe FROM punkt derjenigen Entitäten vom Typ "punkt', WHERE punktnummer >200 wo punktnummer grösser 200 und AND y.koord <600000.01 y-Koordinate < 600 000 ist Abb. 3.2: Beispiel von SQL 32 Die folgende, geschachtelte Abfrage demonstriert die Verwendung einer Querbeziehung zwischen den Entitäten <punkt> und <operat> mit der zum <operat> gehörenden <operatnummer> als Identifikationsschlüssel: SELECT * FROM punkt WHERE operatnummer = SELECT operatnummer FROM operat WHERE operatname = 'west' / Wähle alle Attribute derjenigen Entitäten vom Typ <punkt>, wo operatnummer gleich ist wie die operatnummer derjenigen Entitäten vom Typ <operat>, wo der operatname gleich «west» ist Abb. 3.3: Beispiel von SQL Eine Datenbeschreibungssprache (DDL) für die interaktive Schemadefinition ist ebenfalls Bestandteil von SQL, so dass DML und DDL in kombinierter Form zur Verfügung stehen. Eine Abfragesprache des Typs <Query by Form> oder <Query By Example>, die die Manipulation der Daten mittels Masken erlaubt und ein Maskengenerator für die automatische Erzeugung der Eingabe- und Abfragemasken sind ebenfalls in einer StandardDatenbanksoftware enthalten. Auch die Abfragesprachen <Query by Forms> und <SQL> mit dem Datenbankverwaltungssystem über die Datenmanipulationssprache DML kommunizieren. Für die Ausgabe auf Papier oder auf dem Bildschirm von Resultaten von Abfragen wird ein <Report-Writer> zur Verfügung gestellt, der die Ergebnisse von SQLSelektionen nach den Wünschen der Bearbeiter formatiert. Für den Datenbankadministrator werden viele Hilfsprogramme für die Steuerung und Überwachung der Datenbank angeboten: • Schemaerweiterung und Rekonfiguration der DB, ohne den Datenbestand neu laden zu müssen • Ein- und Ausgabemasken- und Menugenerator • Backup durchführen • Bei Systemabbrüchen: Recovery Funktion, mit der der Datenbestand seit dem letz- ten Backup mit einem Journal rekonstruiert werden kann • Zugriffsberechtigung für den Datenschutz: Individuell, Gruppenweise mit Sperren von einzelnen Funktionen und einzelnen Attributen. 33 Die Anwendungen von Datenbanksystemen ist nicht auf Grosscomputer beschränkt. DBS wie Oracle oder Informix, die auf Rechnern der mittleren Klasse laufen, stehen auch für PC's zur Verfügung. Allerdings, wenn die Daten von mehreren Benutzern gebraucht werden und wenn grosse Datenmengen und komplexe Datenstrukturen erwartet werden, erfordert die Datenbanksoftware für den Betrieb einen leistungsfähigen Rechner. Aus diesem Grund hat sich in der Datenbankwelt das Client-Server-Konzept weitgehend durchgesetzt. Dabei laufen das Datenbankverwaltungssystem (DBMS) auf einem oder mehreren leistungsstarken Rechnern (Server) und die Datenbankanwendungen mit ihren Benutzeroberflächen auf den jeweiligen Arbeitsplatzrechnern (Clients). 3.5. Nicht-Standard-Datenbanksysteme Neben der Datenverarbeitung im Verwaltungsbereich hat die Anzahl der NichtStandard-Anwendungen in den letzten Jahren stark zugenommen, z.B. GIS (Geolnformationssysteme), Büroautomation, CAD-CAM, Expertensysteme, Bildverarbeitung. Nicht Standard-Anwendungen stellen andere Anforderungen, die das Datenbankverwaltungssystem erfüllen sollte: • grosse Menge vielseitiger Daten • Raumbezogenheit • komplexe Konsistenzbedingungen gewährleistet • Nachbarschaftsbeziehungen • effiziente Zugriffe nach Lage auch in 2 oder 3 D • verschiedene Versionen der gleichen Objekte • lang dauernde Transaktionen • Unterstützung für das Modellieren komplexer Objekte • Konsistenzprüfung an komplexen Objekten • vielseitiges Typen-Konzept • Datenaustausch mit anderen Systemen leicht möglich Unter komplexen Objekten versteht man Objekte, die aus einer Hierarchie von Gegenständen bestehen. Eine Liegenschaft kann als komplexes Objekt betrachtet werden: eigene Attribute beschreiben ihre rechtlichen und administrativen Eigenschaften, ihre metrische und topologische Beschreibung definiert eine Fläche, die ihrerseits durch 34 Kanten und Knoten definiert ist. Dazu kommen die weiteren Bestandteile (Gebäude, Wege usw.), die als selbständige Objekte definiert werden können. Die Konsistenzprüfung von komplexen Objekten ist weitgehender und differenzierter als in klassischen Anwendungsbereichen. Es genügt nicht mehr, Standardtypen zu prüfen. Man muss Beziehungen zwischen den Komponenten überprüfen (z.B. Liegenschaften dürfen sich nicht überlappen, Wege nicht durch Häuser gehen usw.). Herkömmliche Datenbanksysteme lassen sich nicht leicht für Nicht-StandardAnwendungen einsetzen. Sie bieten: • keine Unterstützung für das Modellieren von komplexen Objekten • ungenügendes Typen-Konzept • Mangel an Konsistenzprüfungen für komplexe Objekte • Ungenügende Leistung bei Abfragen mit einer grossen Anzahl Elemente • Langsamer Zugriff nach räumlichen Attributen (Koordinaten) Als Lösung sieht man heute die Entwicklung von Spezialdatenbanksystemen oder die Ergänzung von Standarddatenbanken mit spezifischen Funktionen. Die Möglichkeit besteht auch, eine neu entwickelte Datenverwaltung für die Geometrie neben einer handelsüblichen Datenbank zu betreiben. Diese beiden Datenbanken sind zu verknüpfen. 3.5.1. Zusatzschichtarchitektur Eine erste Idee Ende der siebziger Jahre, die auch vielfach heute in der Praxis angewendet wird, weil derzeit keine Alternativen angeboten werden, war es, auf bestehenden Datenbankschnittstellen eine weitere Softwareschicht aufzusetzen, also die sogenannte Zusatzebenenarchitektur zu verfolgen. Performanz-Messungen, die an vielen Stellen praktisch durchgeführt wurden, bestätigen die Befürchtungen, dass so die gewünschte Leistungsfähigkeit nicht erreicht werden kann. Glücklicherweise ist durch die enorme Steigerung der Prozessorleistungen dieser Engpass durch Einsatz leistungsfähiger Hardware praktisch nicht überall offensichtlich geworden. Eine zweite Idee, die ebenfalls realisiert wurde, besteht darin, neben ein relationales Datenbanksystem ein Spezialsystem "Geometrie" zu setzen. Bei dieser Lösung müssen viele Komponenten nochmals implementiert werden und die Subsysteme müssen, ähnlich wie bei verteilten Datenbanken nicht sichtbar für den Benutzer, ebenfalls durch eine Zusatzschicht integriert werden /Schek, Wolf 1988/. 35 a) Applikation b) GEOSchich Aplikatio GEO-Schich RDBMS RDBMS GEOManager Abb. 3.4: Erweiterungen klassischer Datenbanksysteme 3.5.2. Datenbankkernarchitektur Da die herkömmlichen DBMS nicht die erforderlichen Eigenschaften aufweisen, wurden Versuche unternommen, um den Datenbanksystemkern zu erweitern. Mehrere Prototypen existieren (EXODUS, DAMOKLES, PRIMA usw.). Es handelt sich allerdings um Forschungsversionen, die noch nicht in der Praxis eingesetzt werden können /Schek, Wolf 1988/. Raumbezogene Datenbanksysteme müssen Algorithmen für den Zugriff auf ein mehrdimensionales Gebiet kombiniert mit verschiedenen Kategorien von Objekten anbieten. Sie sollen auch die Beschreibung von Beziehungen zwischen allen Objekttypen unterstützen. Zu diesem Zweck werden für die Behandlungen von raumbezogenen Daten Verwaltungssysteme entwickelt, die die Nachbarschaft von raumbezogenen Objekten auch in der Speicherorganisation berücksichtigen können. Durch die physikalische Bündelung von Nachbarinformationen werden die Daten - unabhängig von <Datenebenen> - benachbart auf der Disk gespeichert, was die Anzahl Diskzugriffe (Abb. 3.5) und die Wartezeiten bei einer inter-aktiven Arbeit wie Planzeichnen auf dem Bildschirm stark reduziert. 36 Feldereinteilung Betroffene Felder bei raumbezogenem Zugriff Abb. 3.5: Feldereinteilung der raumbezogenen Daten 3.5.3. Das NF2-Modell Eine weitere Lösung, die vorgeschlagen wurde, ist das NF2-Modell (Non-First Normal-Form oder Modell der geschachtelten Relationen), das die Behandlung komplexer Objekte unterstützt und welches neue Datentypen wie "Video" oder "Ton" mit den dazu passenden Funktionen zur Verfügung stellt. 3.5.4. Objektorientierung Unter der Richtung der objektorientierten Datenbanksysteme finden sich viele Datenbankforschungsprojekte, die interessante, aber durchaus nicht einheitliche Ziele verfolgen. Daher gibt es leider noch keine allgemein anerkannte Definition, was Objektorientierung in Datenbanken ist. Jedoch gibt es einige gemeinsame Merkmale. Gemeinsames Ziel ist die stärkere Berücksichtigung von Operationen und Funktionen auf Datenbankobjekten und weniger deren Struktur. Objektorientierte Datenbanksysteme werden daher durch ihre Konzeption zu jedem Objekt eine Datenstruktur und eine (objektspezifische) Menge von Operationen besitzen. 37 3.6. Datenbankentwurf Wie bereits erwähnt stellen Standard-Datenbanksysteme zumeist nur die Basiswerkzeuge zur Verfügung (DBMS, DDL, DML) (vgl. Kap. 3.3). Die Entwicklung einer Datenbankanwendung für eine spezifische Problemstellung (z.B. BodenbelastungsInformationssystem) erfordert zusätzlich einen Datenbankentwurfsprozess, in welchen normalerweise Fachleute aus verschiedenen Fachdisziplinen involviert sind. Ziel dieser Arbeit ist die Projektierung und Beschreibung der Datenstruktur. Nur für sehr verbreitete Applikationen kann der Datenbank-Hersteller eine Datenstruktur entwickeln und vorkonfigurieren. Ein Beispiel dafür sind Landinformationssysteme, in welchen das Datenmodell der Amtlichen Vermessung 93 bereits implementiert ist. Allerdings sollten auch diese Systeme eine Anpassung oder Erweiterung der Datenstruktur ermöglichen. 3.6.1. Die Modellierung der Realität - die Modellbildung Bei jeder Problemstellung wird der Ingenieur mit einem Teil der Realität und ihrer Komplexität konfrontiert. Durch sein Fachwissen und die Fähigkeit abstrakt zu denken, wird die Aufgabe analysiert und auf das Wesentliche vereinfacht. Die Teile der Realität, die man berücksichtigen möchte, werden auf die Datenbank-Informationselemente abgebildet. Diese Aufgabe nennt sich Modellierung. Dafür nützt man Ähnlichkeiten zwischen der Realität und bekannten Elementen unseres Grundwissens (Mathematik, Geometrie usw.) Zusätzlich erfordert der Entwurf einer Datenbankanwendung den Einsatz von geeigneten Entwurfsmethoden und Formalismen. Das Zusammenspiel dieser Faktoren erlaubt eine systematische und exakte Beschreibung des zu modellierenden Sachverhaltes. Eine sorgfältige und systematische Modellierung ist unerlässlich für den Einsatz einer Datenbank und ist häufig das entscheidende Kriterium für den Erfolg oder Misserfolg eines Datenbankprojekts. 3.6.2. Entwurfsphasen Der Datenbankentwurf kann in mehrere Phasen mit spezifischen Arbeitsschritten, Abstraktionsstufen und (Zwischen-) Resultaten unterteilt werden. Diese sind in Abb. 3.6 zusammengestellt. 38 Modell Formalismus Abstraktionsstufen Entwurfsphase Modellierungsschritt Vereinfachte Realität Konzeptionelle Modellierung unabhängig vom Datenmodell eines DBMS z.B. Entity-RelationshipModel (ERM) Konzeptionelle (oder Semantisches) Schema z.B. Datendefinitionssprache SQL im Falle des relationalen Datenmodells Logische Modellierung Datenmodell-abhängig (z.B. für relationales Modell) Logisches Schema Physische Modellierung systemabhängig (z.B. Oracle auf Windows NT) Physisches Schema Abb. 3.6: Schematischer Ablauf des Datenbankentwurfs 39 Für den Datenbankentwurfsprozess werden heute von verschiedenen Datenbankherstellern Softwarepakete angeboten, sogenannte CASE-Tools (Computer Aided Software Engineering). Diese Programme unterstützen zusätzlich zum Datenmodellierungsprozess häufig auch den Entwurf des funktionalen Verhaltens (z.B. Abläufe, Bearbeitungsschritte) und der Benutzeroberfläche einer Datenbankanwendung. In der Folge sollen nur diejenigen Modellierungsphasen und -konzepte detaillierter beschrieben werden, an welchen Fachspezialisten, Geomatik-, Umwelt- oder Forstingenieurinnen und -ingenieure aktiv beteiligt sind. 3.6.3. Konzeptionelle Modellierung In dieser Phase wird die zumeist in Prosa gefasste Beschreibung der Problemstellung oft auch "Miniwelt" oder "räumliches Modell" (für GIS) genannt - in eine formale Beschreibung, das konzeptionelle Schema, überführt. Die konzeptionelle Modellierung ist unabhängig vom "Datenmodell" bzw. der Art der Datenbank (relational, hierarchisch, netwerkförmig, objektorientiert, etc.). Für die konzeptionelle Modellierung hat sich das Entity-Relationship-Model (ERM) als einfache Modelliermethodik etabliert (vgl. Kap. 3.7). Das Resultat dieser Modellierungsschritts ist - wie bereits erwähnt - ein konzeptionelles Schema. Dieses besteht bei der Verwendung des ERM-Modells aus einem oder mehreren Entitätenblockdiagramm(en). 3.6.4. Logische Modellierung Bei der logischen Modellierung wird das konzeptionelle Schema auf ein datenmodellabhängiges Schema abgebildet. Im Falle des relationalen Datenmodells (vgl. Kap. 3.7), d.h. beim geplanten Einsatz eines relationalen Datenbankverwaltungssystems, kann für die logische Modellierung die Datendefinitionsfunktionalität (DDL) der Datenbanksprache SQL eingesetzt werden. Das Resultat der logischen Modellierung ist das logische Schema einer Datenbankanwendung. Dieses enthält eine formale Beschreibung der Datenstruktur. Bei einem relationalen DBMS besteht diese Beschreibung aus der Definition von Tabellen, Attributen, Primär- und Fremdschlüsseln (primary and foreign keys) und aus der Beschreibung von Integritätsbedingungen (constraints). 40 3.7. Das Entity-Relationship Modell 3.7.1. Beschreibungsformalismus Gestützt auf die Methoden der Abstraktion entwickelten die Informatiker Modellierungs-Werkzeuge, um die Struktur der Daten formal beschreiben zu können. Diese Werkzeuge nennen sich Datenmodelle oder Datenbeschreibungssprache. Es ist zu beachten, dass die Informatiker unter Datenmodell die Formalismen (Beschreibungssprache) verstehen, mit welchen die Datenstruktur beschrieben wird. Manchmal wird der Begriff "Datenmodell" falsch verwendet. Man will damit von der Struktur der Daten sprechen. Das bekannteste konzeptionelle Datenmodell ist das ER-Modell ("Entity-Relationship Modell", "Entitätsbeziehungsmodell"). Dieses Modell ermöglicht, Datenstrukturen unabhängig vom relationalen oder Netzwerk-Modell in verschiedenen Varianten zu entwickeln und beschreiben. Dieses Datenmodell besteht aus vier Grundbegriffen mit den entsprechenden Konstruktionsregeln. Wie der Name des Modells andeutet, wird im ERM zwischen Entitäten und Relationen unterschieden. Das ERM ist unabhängig von einem Datenbanktyp und dient dazu, unsere Vorstellung von der zu modellierenden 'Miniwelt' festzuhalten. Im Folgenden werden die im Zusammenhang mit dem ERM verwendeten Begriffe kurz erläutert. 3.7.2. Die Entitätsmenge Die Menge aller Objekte eines für die Anwendung benötigten Ausschnittes der Wirklichkeit werden in Klassen gleichartiger Elemente eingeteilt. Eine solche Klasse wird Entitätsmenge genannt. Die im Modell zu beschreibende Realität wird mit einer beschränkten Anzahl von Entitäts-mengen modelliert. Beispiel: Betrachten wir die am Betrieb der ETH beteiligten Personen, so können verschiedene Klassen (Entitätsmengen) von Personengruppen gebildet werden: Professoren, Assistenten, Studenten, usw. Professor Assistent Abb. 3.7: Entitätsmengen 41 Student 3.7.3. Die Entität Einzelne Elemente aus den Entiätsmengen werden Entitäten genannt, welche alle dieselben Merkmale besitzen. Eine Entität ist eine selbständige Einheit, entweder der Realität oder der Gedankenwelt /Zehnder 1998/. Die Realität wird in Entitäten diskretisiert. Wenn wir vom oben genannten Beispiel mit den Entitätsmengen Professor, Assistent und Student ausgehen, so sind Entitäten einzelne Personen der jeweiligen Entitätsmenge, z.B. der Student Markus Müller, die Assistentin Hanna Hell etc. Beispielsweise können einzelne Personen (z.B. Meier Hans-Peter), Punkte (z.B. Punkt 504, Titlis), Beobachtungen (z.B. Distanz 103-106), Fahrzeuge (der Wagen ZH 500 396) als Entitäten betrachtet werden. 3.7.4. Das Attribut Durch Attribute werden Einzelmerkmale von Entitäten festgelegt. Beispiele: Personenname, Punktnummer, Baujahr eines Wagens, X-Koordinate eines Punktes. Zu einem Attribut gehört ein (statischer) Wertebereich. Wenn ein Attribut oder eine Attributskombination eine Entität eindeutig identifiziert, ist es Identifikationsschlüssel. Entitäten werden durch ihre Attribute (Merkmale) beschrieben. Entitäten aus derselben Entitätsmenge besitzen gleiche Attribute, aber mit unterschiedlichen Werten dieser Attribute. So haben etwa alle Studenten das Attribut 'Name', einige davon mit dem Attributswert 'Meier'. Identifikationsschlüssel ist ein Attribut oder eine Kombination von Attributen, die jede Entität einer Entitätsmenge eindeutig identifiziert. Da es oft schwierig ist, eindeutige natürliche Identifikationsschlüssel zu finden, führt man in vielen Fällen ein künstliches Identifikationsattribut ein (z.B: Studentennummer). Professor Assistent Name Vorname Institut Forschungsgebiet Lehrgebiet Publikationen ... Name Vorname Institut Professor Forschungsgebiet Publikationen ... Student Name Vorname Abteilung Semester ... Abb. 3.8: Die Entitätsmengen Professor, Assistent und Student mit ihren Attributen 42 3.7.5. Die Beziehung Die Klassierung (Entitätsmengen) und die Merkmale (Attribute) von Objekten allein erlauben nicht, wichtige Sachverhalte der Realität zu beschreiben. Es müssen auch Beziehungen zwischen den Informationselementen bekannt sein, wie z.B. ein Kind, das genau einen Vater und eine Mutter hat. In der realen Welt existieren Beziehungen zwischen Entitätsmengen (z.B. gehören Studenten der ETH zu einer bestimmten Abteilung). Zur Beschreibung der Beziehung zwischen zwei Entitätsmengen EM1 und EM2 untersucht man die Zuordnung (EM1,EM2) sowie die inverse Zuordnung (EM2, EM1). Man unterscheidet dabei vier Zuordnungstypen: • einfache Zuordnung (Typ '1'): jeder Entität aus EM1 ist genau eine Entität aus EM2 zugeordnet • konditionelle Zuordnung (Typ 'c'): jeder Entität aus EM1 ist entweder eine oder keine Entität aus EM2 zugeordnet • multiple Zuordnung (Typ 'm'): jeder Entität aus EM1 sind mehrere Entitäten (mindestens eine) aus EM2 zugeordnet • multipel - konditionelle Zuordnung (Typ 'mc'): jeder Entität aus EM1 sind keine, eine oder mehrere Entitäten aus EM2 zugeordnet Damit gibt es die folgenden Beziehungstypen: 1 c m mc Beziehungstypen 1 1-1 1-c 1-m 1-mc hierarchische c c-1 c-c c-m c-mc konditionelle m m-1 m-c m-m m-mc mc mc-1 mc-c mc-m mc-mc Netzwerkförmige Abb. 3.9: Beziehungstypen zwischen Relationen Graphisch werden Entitätsmengen als Rechtecke und Beziehungen als Verbindungslinien dargestellt, ergänzt durch die beiden Zuordnungstypen und allenfalls ergänzt durch den Namen der Beziehung. 43 Es können verschiedene Typen von Beziehungen unterschieden werden. Beispiele: • Zu jedem Kanton gehören eine oder mehrere Gemeinden. Andererseits gehört zu jeder Gemeinde genau ein Kanton. Die Beziehung Kanton-Gemeinde ist vom Typ 1:m. Gemeinde Kanton Name Hauptstadt 1 m Name Anzahl Einwohner Fläche Abb. 3.10: Beziehung Kanton-Gemeinde • Eine Gemeinde hat genau einen Gemeindepräsidenten. Dieser steht genau einer Gemeinde vor. Es handelt sich um eine 1:1 Beziehung. Gemeinde Name Anzahl Einwohner Fläche Gemeindepräsident 1 1 Abb. 3.11: Beziehung Gemeinde-Gemeindepräsident 44 Name Vorname 3.7.6. Das Entitätenblockdiagramm Die logische Datenstruktur kann mit einem Entitätenblockdiagramm (Konzeptionelles Schema) dargestellt werden. Diese formale Darstellung der Datenstruktur erlaubt, allfällig übersehene redundante Informationen zu erkennen und zu eliminieren. Koordinatenversion Punktgruppe Versionsname Versionsbeschreibung Eröffnungsdatum 1 Punktname Ortsbezeichnung Operat Punktordnung Allg. Angaben 1 1 1 mc Punkt THEO-EDM Stat. Stationierungsnr. Z/Exz. Aufstellung m Aufstellungsdatum Koordinaten mc Stellzeitpt. Y Abbruchdatum mc X Abbruchzeitpt. H Instrumentenhöhe Punktsuffix Datum Versicherungsart 1 Distanz m 1 Bemerkungen Zeit mc Azimut mc kyy Wetterangabe Lotabweichung XI kxx Bemerkung Lotabweichung ETA khh Geoidhöhe 1 1 1 Bemerkungen Bem. zur Lotabw. 1 1 mc mc Richtungssatz Satznummer 1. Ri Lage I 1. Ri Lage II 2. Ri Lage I 2. Ri Lage II 3. Ri Lage I 3. Ri Lage II 4. Ri Lage I 4. Ri Lage II ... mc mc Signalisierung EDM Theodolith mc Höhenw. Satz Satznummer Signalisierungsnr. 1. Ri Lage I Aufstellungsdatum 1. Ri Lage II Aufstellzeitpt. 2. Ri Lage I Abbruchdatum mc 1 Abbruchzeitpt. 1 mc 2. Ri Lage II 3. Ri Lage I Signalhöhe 3. Ri Lage II Signaltyp 4. Ri Lage I Bemerkung 4. Ri Lage II ... Abb. 3.12: Beispiel eines ERM-Diagramms 45 Theodolithnr. c c Instr. Typ Hersteller Bemerkungen 1 1 Person Name Vorname 1 1 1 EDMnr. Instr. Typ Hersteller Bemerkungen Brechungsindex Trägerwellenlänge Eichdatum c Bereich 1 von bis Add.kst. 1 Mult.kst. 1 Bereich 2 von bis ... mc mc mc Reflektoraufst. Distanz Stationierungsnr. Distanz Z/Exz. Aufstellung Trockentemp. St. Aufstellungsdatum 1 m Feuchttemp. St. Aufstellzeitpunkt Luftdruck St. Abbruchdatum Trockentemp. Zi. Abbruchzeitpunkt Feuchttemp. Zi. Reflektorhöhe Luftdruck Zi. Reflektortyp Anzahl Reflektoren Distanz Richtung Pt. Richtung EDM Azimut Bemerkung 3.7.7. Beispiel: Vereine eines Dorfes Anhand des folgenden Beispieles sollen die in einem früheren Kapitel erwähnten Begriffe erläutert, auftretende Probleme gezeigt und anschliessend ein ERM aufgebaut werden. Dieses Beispiel wird in allen drei Phasen der Datenbankentwicklung weiterverwendet. Unsere (vereinfachte) Vereinsstruktur besteht aus drei Entitäten: • Vereine • Sektionen • Mitglieder und drei Beziehungsklassen • Mitgliedschaft • Sektionszugehörigkeit • Vereinsorganisation Daraus ergibt sich das folgende ERM-Diagramm: Aus dieser Graphik wird bereits eine Problematik ersichtlich, die man bei der Datenmodellierung berücksichtigen muss. Die Beziehung 'Mitgliedschaft' ist bereits durch die andern beiden Beziehungen abgedeckt, wodurch eine unerwünschte Redundanz entsteht. Eine Redundanz wird jedoch sehr einfach durch Weglassen einer Beziehung aufgelöst. Welche der Beziehungen weggelassen wird, hängt von den Informationen ab, die man verwalten möchte und von der zukünftigen Nutzung der Datenbank. So ist es zum Beispiel für den Gemeindepräsidenten wahrscheinlich unwesentlich, welcher Sektion eines Vereines ein Mitglied angehört, für einen Vereinspräsidenten ist gerade diese Frage von grosser Bedeutung. Daraus erkennen wir, dass bereits bei der Datenmodellierung die zukünftige Nutzung der Datenbank beachtet werden muss. 46 Wir entscheiden uns für den 2. Fall. (Es ist zu beachten, dass eine Struktur wie im 1. Fall keine Aussage über die Sektionszugehörigkeit eines Mitgliedes zulässt, da diese Information nicht vorhanden ist. Der 2. Fall lässt jedoch eine Aussage über die Vereinsmitgliedschaft zu, da die ganze Struktur hierarchisch aufgebaut ist.) Die Entität 'Vereine' habe die folgenden Attribute: • Vereinsname (I) • Gründungsjahr Die Entität 'Sektionen' habe die folgenden Attribute: • Sektionsname (I) • Vereinsnamename Die Entität 'Mitglieder' habe die folgenden Attribute: • Persnr (I) • Name • Vorname • Jahrgang Die mit einem (I) gekennzeichneten Attribute sind die Identifikationsschlüssel. Die zukünftige Nutzung einer Datenbank beeinflusst ebenfalls die Zuweisung der Attribute zu den verschiedenen Entitäten. Die Beziehungsklasse 'Sektionszugehörigkeit' lässt sich wie folgt definieren: Mitglieder-Sektionen: m-m Das heisst, dass jede Sektion ein oder mehrere Mitglieder umfasst und dass jedes Mitglied mehreren (mindestens einer) Sektion angehört. 47 Falls wir annehmen, dass jedes Mitglied nur in einer Sektion dabei sein kann, ist die Beziehung Mitglieder - Sektionen eine m-1 Beziehung. Mitglieder-Sektionen: m-1 Das heisst, dass jede Sektion ein oder mehrere Mitglieder umfasst und dass jedes Mitglied nur einer Sektion angehören kann. Die Beziehungsklasse 'Vereinsorganisation' sei wie folgt definiert: Verein-Sektionen: 1-mc Dies heisst, dass jeder Verein in keine, eine oder mehrere Sektionen aufgegliedert ist, dass aber jede Sektion sicher zu einem Verein gehört. Für die weiteren Betrachtungen werden wir das im Folgenden dargestellte ERMDiagramm verwenden: 3.8. Relationales Modell 3.8.1. Operationen der Relationenalgebra Das relationale Modell ist Grundlage für einen Typ von Datenbank, nämlich die relationalen Datenbanken. Eine relationale Datenbank besteht aus Sicht des Benutzers nur aus einem einzigen Datentyp, der Relation oder der Tabelle. Erinnern wir uns: Im ERM gab es zwei Typen: Entitäten und Beziehungsklassen. Eine Tabelle hat einen Namen und besteht aus den zwei Teilen Schema und Tupelmenge. Das Schema ist die Kopfzeile der Tabelle, wo jeder Kolonne ein Feldname und -typ gegeben wird. Ein Tupel der Tupelmenge liefert für jedes Feld einen Wert. 48 Studenten Tabellenname Feldname Feldtyp (Datentyp) Name CHAR Studenten-Nr. NUMBER Tupel Feldwert } } Schema Tabelle Tupelmenge Abb. 3.13: Beispiel einer Tabelle im relationalen Modell Die folgende Aufstellung versucht, die Begriffe des Relationenmodells mit jenen des ERM in Verbindung zu bringen. Relationenmodell ERM Tabelle Tupelmenge Tupel Feldname und Feldtyp Feldwert Entitätsmenge, Klasse Entitätsmenge, Klasse Entität, Objekt Attributsbeschreibung Attributswert Für die 'Berechnungen' mit Tabellen gibt es fünf Grundoperationen (vergleichbar mit den vier Grundoperationen der reellen Zahlen): • Vereinigung • Differenz • Projektion • Selektion • Join 49 Dies sind die Basisoperationen der Relationenalgebra, auf der die Theorie der Abfragesprachen (z.B.) relationaler Datenbanken beruht. Die verschiedenen Operationen werden mit Hilfe der folgenden Tabellen erläutert: Tabelle A Tabelle B Bankkonto Bank B Bankkonto Bank A Tabelle C Zinstabelle Inhaber Kontotyp Inhaber Kontotyp Kontotyp Zins Meier Müller Müller Sutter Huber Salärkonto Sparkonto Salärkonto Sparkonto Jugendkto Müller Brunner Sparkonto Jugendkto Salärkonto 3 % Sparkonto 5 % Jugendkto 6 % Vereinigung: Durch die Vereinigung werden zwei Tabellen zusammengefügt, die doppelt vorkommenden Werttupel werden dabei nur einmal in die neu entstehende Tabelle aufgenommen. Differenz: In der Differenztabelle sind alle Werttupel der ersten Tabelle minus jene der zweiten Tabelle enthalten. Resultat aus der Differenz A x B AxB Inhaber Kontotyp Meier Müller Sutter Huber Salärkonto Salärkonto Sparkonto Jugendkto Selektion: Es werden eine oder mehrere Bedingungen formuliert, die die zu selektierenden Tupel erfüllen müssen. Das Schema der Tabelle bleibt dabei unverändert, die Wertmenge ändert. Resultat der Selektion (Sparkto.) AxS (Kontotyp = Sparkonto) Inhaber Kontotyp M üller Sutter Sparkonto Sparkonto Projektion: Die Projektionstabelle entsteht, indem man in einer Tabelle eine oder mehrere Kolonnen streicht und allfällige Duplikate von Tupeln eliminiert. Die Wert50 menge der Tabelle bleibt damit im Wesentlichen unverändert, das Schema wird verändert. Resultat der Projektion (Inhaber) AxP (Inhaber) Inhaber Meier Müller Sutter Huber Join: Die bisherigen vier Operationen verknüpften nur Tabellen mit gleichem Aufbau oder haben gar nur eine Tabelle als Input. Die Join-Operation ermöglicht es, verschiedenartige Tabellen miteinander zu verbinden. Ein Join kombiniert jeden Tupel der einen Tabelle mit jedem Tupel der anderen Tabelle. Join der Tabellen A und C Meier Meier Meier Müller Müller Müller Müller Müller Müller KontoA.Kontotyp Salärkonto Salärkonto Salärkonto Salärkonto Salärkonto Salärkonto Sparkonto Sparkonto Sparkonto Sutter Sutter Sutter Huber Huber Huber Sparkonto Sparkonto Sparkonto Jugendkonto Jugendkonto Jugendkonto KontoA.Inhaber AxC Zinstabelle.Kontotyp Zinstabelle.Zins Salärkonto Sparkonto Jugendkonto Salärkonto Sparkonto Jugendkonto Salärkonto Sparkonto Jugendkonto 3% 5% 6% 3% 5% 6% 3% 5% 6% Salärkonto Sparkonto Jugendkonto Salärkonto Sparkonto Jugendkonto 3% 5% 6% 3% 5% 6% Normalerweise wird der Join zusammen mit einer Selektion verwendet, bei der die Werte korrespondierende Felder der beiden Ursprungstabellen miteinander verglichen werden. In diesem Fall werden die Attribute 'Kontotyp' der Tabelle 'Bankkonto A' und 'Kontotyp' der Tabelle 'Zinstabelle' miteinander verglichen. Mit dieser Bedingung (KontoA.Kontotyp = Zinstabelle.Kontotyp) erhalten wir die um die Spalte 'Zins' ergänzte Tabelle A. 51 Verknüpfung der Tabellen A und C AxCxS Inhaber Kontotyp Zins Meier Müller Müller Sutter Huber Salärkonto Sparkonto Salärkonto Sparkonto Jugendkto 3% 5% 3% 5% 6% Die oben beschriebenen Operationen der Relationenalgebra werden uns später (leicht modifiziert) in Form von SQL-Abfragen wieder begegnen. Übersetzung ERM -> Relationenmodell am Beispiel 'Vereine eines Dorfes' Die Übersetzung eines ERM-Entwurfes in eine tabellenartige Form lässt sich im Wesentlichen mit drei Regeln beschreiben: Æ Für jede Entität wird eine Tabelle geschaffen, wobei jedem Attribut ein Feld (Kolonne) zugeordnet wird Bei Beziehungsklassen unterscheidet man zwei Fälle: 2) Æ Es handelt sich um eine hierarchische oder um eine konditionelle Beziehung: Im Schema der Entitätsmenge, deren Entitäten in Beziehung mit einer (oder keiner) Entität der zweiten Entitätsmenge stehen, wird ein zusätzliches Feld (Kolonne) eröffnet. Dieses Feld enthält einen Identifikationsschlüssel der Partnerentität. Man spricht von einem Fremdschlüssel (F). 3) Æ Es handelt sich um eine netzwerkförmige Beziehung: Für die Beziehungsklasse wird eine eigene Tabelle geschaffen. Diese enthält Felder für die Beziehungsattribute und für Identifikationsschlüssel der Entitäten, die miteinander in Beziehung stehen. 52 In unserem Beispiel 'Vereine eines Dorfes' übersetzen wir in einem ersten Schritt die drei Entitäten Vereine, Sektionen und Mitglieder in drei Tabellen: Vereine Vereinsname Sektionen Mitglieder Gründungsjahr Sektionsname Vereinsname 1925 1931 1967 Männerriege Damenriege Jugendriege Tambouren Bläser Schützen Turnverein Turnverein Turnverein Musikgesellschaft Musikgesellschaft Schützenverein Schützenverein Turnverein Musikgesellschaft Pers. Nr. Name 1007 1008 1010 1034 1056 1077 2001 2006 2023 2045 2087 Sutter Weber Kunz Kunz Lüthi Weber Weber Kunz Meier Muster Beck Vorname Jhg Hans Jürg Karl Hans Fritz Reto Anna Heidi Helen Karin Anja 1923 1934 1944 1946 1958 1972 1942 1948 1954 1956 1974 Die Beziehung 'Vereinsorganisation' ist durch die Kolonne Vereinsname in der Tabelle 'Sektionen' bereits realisiert. Für die Beziehung 'Sektionszugehörigkeit' (m-m - Beziehung) müssen wir eine eigene Tabelle einführen. Nennen wir diese zum Beispiel 'Sektionsmitgliederliste'. Diese Tabelle lässt sich durchaus mit weiteren Attributen versehen, z.B. mit den Eintrittsdaten in diese Sektion. Sektionsmitgliederliste Pers. Nr. Sektionsname Eintrittsdatum 1007 1008 1008 1010 1034 1056 1056 1056 1077 2001 2006 2006 2023 2045 2087 Schützen Schützen Männerriege Männerriege Bläser Tambouren Männerriege Schützen Jugendriege Damenriege Damenriege Bläser Damenriege Damenriege Jugendriege 12-JAN-42 23-SEP-56 14-JUL-67 31-AUG-64 21-NOV-67 13-APR-81 18-JAN-80 23-FEB-88 12-JAN-90 30-JUL-62 23-AUG-74 12-MAI-71 16-OKT-87 13-OKT-83 09-FEB-85 Die Entität 'Sektionsmitgliederliste' enthält somit die folgenden Attribute: • Persnr (F) • Sektionsname (F) • Eintrittsdatum 53 Als Identifikationsschlüssel kann die Kombination der Attribute 'Persnr' und 'Sektionsname' verwendet werden. Das im Kapitel 3.7.7 dargestellte ERM-Diagramm muss somit wie folgt erweitert werden: Vereine m 1 Sektionen 1 m Mitglieder 1 Sektionsmitgliederliste m Dies bedeutet, dass für alle Sektionen nur eine solche Liste besteht, dass aber jede Sektion mehrmals in der Liste vorkommen kann. Dasselbe gilt für die Mitglieder: In der Sektionsmitgliederliste kann jedes Mitglied mehrfach vorkommen, jedoch gibt es für jedes Mitglied nur eine solche Liste. 3.9. SQL - Eine relationale Datenbanksprache 3.9.1. Datendefinition mit SQL Die Übersetzung von einem ERM in eine tabellenartige Form geschieht mit der so genannten Data-Definition-Language (DDL). Im Falle des relationalen Datenmodells, d.h. beim Einsatz eines relationalen DBMS, wird dazu die relationale Datenbanksprache SQL verwendet. Anwender Data Definition Language DDL Daten Data Base Management System DBMS Data Manipulation Language DML Fortran ++ C Datenbank Pascal eigene Programme Abb. 3.14: Das Datenbankkonzept 54 Die Datenbanksprache SQL (Structured Query Language) enthält neben den Befehlen für die Abfrage und die Datenmanipulation (DML) auch solche für die Datendefinition (DDL) und für die Datensteuerung. Abfrage: Abrufen von Daten aus einer Datenbank interaktiv durch den Anwender oder durch Anwenderprogramme Datenbearbeitung: Einsetzen, Fortschreiben und Löschen von Daten Datendefinition: Eingabe neuer Tabellen in die Datenbank Datensteuerung: Ausschliessen des Zugriffs zu privaten Daten in der Datenbank (Datenschutz) (Die Befehle der Datensteuerung werden in dieser Übersicht nicht behandelt) SQL ist heute weitgehend standardisiert, d.h. es kann auf relationalen Datenbanken verschiedener Hersteller (ORACLE, UNIFY,...) verwendet werden. Es basiert auf dem Tabellenmodell und den im Kapitel 3.8.1 erwähnten Operationen der Relationenalgebra. Erstellen einer Tabelle Befehl CREATE TABLE: CREATE TABLE Sektionsmitgliederliste (Persnr NUMBER (4) NOT NULL, Sektionsname CHAR (12) NOT NULL, Eintrittsdatum DATE); Bildschirmanzeige: Table created Tabelle: Sektionsmitgliederliste Persnr Sektionsname Eintrittsdatum Mit diesem Befehl wird auf der Datenbank eine Tabelle mit dem Namen 'Sektionsmitgliederliste' mit den drei Kolonnen 'Persnr', 'Sektionsname' und 'Eintrittsdatum' erstellt. Zudem wird für jede Kolonne der Typ der zukünftigen Daten definiert. 55 bedeutet, dass die Spalten 'Persnr' und 'Sektionsname' der Tabelle 'Sektionsmitglieder' nicht leer sein darf. Anders ausgedrückt: Jede Zeile der Tabelle 'Sektionsmitglieder' muss in den Feldern 'Persnr' und 'Sektionsname' einen Wert enthalten. NOT NULL DATENTYPEN: Zahl (4-stellig) Zahl (7-stellig, davon 2 Nachkommastellen) Datum (Standardformat DD-MON-YY (z.B. 03-SEP-90) Zeitangabe Zeichenkette (mit max. 12 Zeichen) NUMBER (4) NUMBER (7,2) DATE TIME CHAR (12) Die Eingaben werden automatisch geprüft, ob sie mit dem angegebenen Datentyp übereinstimmen. Bemerkung: Jeder SQL-Befehl muss mit einem ';' abgeschlossen werden! Löschen einer Tabelle Befehl DROP TABLE: DROP TABLE Sektionsmitgliederliste Dieser Befehl löscht die Tabelle 'Sektionsmitgliederliste' 3.9.2. Datenabfrage und -manipulation mit SQL SQL bietet eine Reihe von anschaulichen Operationen, um Tabelleninformationen einzufügen, zu löschen, abzufragen und zu verknüpfen. Die nächsten Kapitel zeigen eine Auswahl dieser Befehle. Einfügen von Zeilen in eine Tabelle Befehl INSERT: INSERT INTO Mitglieder VALUES (2097, 'Schmid', 'Susanne', 1975); Bildschirmanzeige: 1 record created 56 Tabelle: Mitglieder Pers.Nr. 1007 1008 1010 1034 1056 1077 2001 2006 2023 2045 2087 2097 Name Vorname Jhg Sutter Hans 1923 Weber Jürg 1934 Kunz Karl 1944 Kunz Hans 1946 Lüthi Fritz 1958 Weber Reto 1972 Weber Anna 1942 Kunz Heidi 1948 Meier Helen 1954 Muster Karin 1956 Beck Anja 1974 Schmid Susanne 1975 Mit diesem Befehl wird in die Tabelle 'Mitglieder' ein neuer Datensatz eingefügt. Die Kolonnen 'Persnr', 'Name', 'Vorname' und 'Jahrgang' erhalten die Werte (2097, 'Schmid', 'Susanne', 1975). Ändern gespeicherter Daten Befehl UPDATE: UPDATE Mitglieder SET Persnr = Persnr + 2000 WHERE Jahrgang > 1970 Bildschirmanzeige: 2 records updated Tabelle: Mitglieder Pers. Nr. Name 1007 1008 1010 1034 1056 3077 2001 2006 2023 2045 4087 Sutter Weber Kunz Kunz Lüthi Weber Weber Kunz Meier Muster Beck Vorname Jhg Hans Jürg Karl Hans Fritz Reto Anna Heidi Helen Karin Anja 1923 1934 1944 1946 1958 1972 1942 1948 1954 1956 1974 Der Befehl UPDATE dient zum Ändern von Zeilen in mehrzeiliger Verarbeitung. Mit der UPDATE-Klausel wird die Tabelle bezeichnet, mit der Klausel SET wird das angegebene Feld auf einen bestimmten Wert gesetzt und in der WHERE-Klausel wird die 57 Menge von Zeilen bezeichnet, die geändert werden soll. (In unserem Fall werden in der Tabelle 'Mitglieder' alle 'Persnr' von Mitgliedern, die nach 1970 geboren wurden, um 2000 erhöht.) Löschen von gespeicherten Daten Befehl DELETE: DELETE FROM Mitglieder WHERE Name = 'Schmid’ Bildschirmausgabe: 1 record deleted Dieser Befehl löscht aus der Tabelle, die mit der Klausel DELETE FROM bezeichnet wurde, eine oder mehrere Zeilen (Anzahl Zeilen gemäss der WHERE-Klausel). Ein DELETE FROM ohne WHERE-Klausel bewirkt, dass alle Zeilen einer Tabelle gelöscht werden. Abfragen von Daten aus einer Tabelle Der häufigste Vorgang in SQL ist das Auffinden von Daten in einer Datenbank. Diesen Vorgang bezeichnet man als Abfrage. Befehl SELECT: (Grundform) SELECT Vereinsname, Gründungsjahr FROM Vereine WHERE Gründungsjahr > 1950 Bildschirmausgabe: Vereine Vereinsname Musikgesellschaft Gründungsjahr 1967 Beim Befehl SELECT wird zuerst angegeben, welche Kolonnen ausgegeben werden sollen, mit der FROM-Klausel wird die dazugehörige Tabelle angezeigt. Mit der WHEREKlausel, welche fakultativ ist, können bestimmte Zeilen ausgewählt werden. 58 mögliche Vergleichsoperatoren: gleich nicht gleich grösser, grösser gleich kleiner, kleiner gleich = != ^= > >= < <= <> Kombinationen logischer Ausdrücke: beide müssen erfüllt sein einer der beiden muss erfüllt sein erfüllt, falls zwischen zwei Werten AND OR BETWEEN Angabe der Reihenfolge der Zeilen bei der Ausgabe: geordnet nach (aufsteigend) geordnet nach (absteigend) ORDER BY ORDER BY ... DESC Verhindern von Doppelzeilen: alle Zeilen, die genau die gleiche Information wie eine andere enthalten, werden nicht ausgegeben DISTINCT Beispiele: Gesucht: Die ganze Tabelle 'Vereine' Befehl: SELECT * FROM Vereine; Lösung: Vereine Vereinsname Gründungsjahr Schützenverein Turnverein Musikgesellschaft 1925 1931 1967 Gesucht: Alle Mitglieder, die vor 1950 geboren wurden und die 'Weber' heissen. Befehl: SELECT Name, Vorname, Jahrgang FROM Mitglieder WHERE Jahrgang < 1950 AND Name = 'Kunz'; 59 Lösung: Mitglieder Name Vorname Jhg Kunz Kunz Kunz Karl Hans Heidi 1944 1946 1948 Gesucht: Alle Mitglieder, die zwischen 1930 und 1960 geboren wurden, geordnet nach Jahrgang Befehl: SELECT Name, Vorname, Jahrgang FROM Mitglieder WHERE Jahrgang BETWEEN 1940 AND 1950 ORDER BY Jahrgang DESC Lösung: Mitglieder Name Vorname Jhg Lüthi Muster Meier Kunz Kunz Kunz Weber Weber Fritz Karin Helen Heidi Hans Karl Anna Jürg 1958 1956 1954 1948 1946 1944 1942 1934 Gesucht: Alle Familiennamen der Mitglieder, alphabetisch geordnet. Befehl: Lösung: SELECT DISTINCT Name FROM Mitglieder ORDER BY Name; Mitglieder Name Beck Kunz Lüthi Meier Muster Sutter Weber 60 3.9.3. Abfragen von Daten aus mehreren Tabellen (JOIN-Abfrage) Bisher haben wir bei allen Beispielen nur eine Tabelle abgefragt. Es ist nun aber durchaus denkbar, dass die gewünschten Informationen in zwei oder mehreren Tabellen enthalten sind. Zu diesem Zweck brauchen wir die JOIN-Bedingung, die zwei Tabellen miteinander verknüpft. Beispiele: Gesucht: In welcher Sektion ist Frau Beck Mitglied und wann ist sie dort eingetreten? Befehl: SELECT Name, Vorname, Sektionsname, Eintrittsdatum FROM Mitglieder, Sektionsmitgliederliste WHERE Name = 'Beck' AND Mitglieder.Persnr = Sektionsmitgliederliste.Persnr; JOIN- Bedingung Mitglieder Pers. Nr. Name 2087 Beck Sektionsmitgliederliste Vorname Jhg Pers. Nr. Sektionsname 2087 1974 Anja Jugendriege Eintrittsdatum 09-FEB-85 Lösung: Name Vorname Sektionsname Eintrittsdatum Beck Anja Jugendriege 09-FEB-85 Gesucht: In welchem Verein (oder in welchen Vereinen) ist Herr Lüthi Mitglied? Befehl: SELECT Name, Vorname, Vereinsname FROM Sektionen, Mitglieder, Sektionsmitgliederliste WHERE Name = 'Lüthi' AND Mitglieder.Persnr = Sektionsmitgliederliste.Persnr AND Sektionsmitgliederliste.Sektionsname = Sektion.Sektionsname; 61 Sektionen Sektionsmitgliederliste Sektionsname Vereinsname Männerriege Tambouren Schützen Pers. Nr. Turnverein Musikgesellschaft Schützenverein 1056 1056 1056 Mitglieder Sektionsname Eintrittsdatum Pers. Nr. Name Vorname Jhg Tambouren Männerriege Schützen 2 13-APR-81 18-JAN-80 23-FEB-88 1056 Lüthi Fritz 1 Lösung: Name Vorname Verein Lüthi Fritz Lüthi Fritz Lüthi Fritz Turnverein Musikgesellschaft Schützenverein Natürlich können auch bei Abfragen mit JOIN-Bedingungen aufgezeigten Möglichkeiten angewendet werden. Bemerkung: Bei den in diesem Papier aufgezeigten SQL-Befehlen und Möglichkeiten handelt es sich nur um eine kleine Auswahl, die jedoch helfen soll, die Grundideen einer Datenabfragesprache zu erkennen. Mit der Anwendung dieser Befehle befasst sich die Übung 2. 3.10. Objektrelationale Datenbanksysteme (Text aus der Promotionsarbeit von Karin Hosse "Objektorientierte Modellierung und Implementierung eines temporalen Geoinformationssystems für kulturelles Erbe", TU München, Juli 2005) Seit einigen Jahren werden relationale Datenbanksysteme mit zusätzlichen objektorientierten Erweiterungen (ORDBMS) angeboten. Für die Verwaltung räumlicher Daten verfügen sie über Zusatzmodule (z. B. Oracle Spatial) für den Zugriff auf raumbezogene Daten. Diese Datenbanksysteme ermöglichen eine integrierte Datenhaltung von räumlichen und nicht-räumlichen Daten und bieten hierzu entsprechend erweiterte, meist noch herstellerspezifische Datenbankschnittstellen an. Die bereitgestellten Möglichkeiten offerieren damit nicht nur eine gewisse Basisfunktionalität für die Datenhaltung komplexer Geoinformationssysteme, sondern werden mittlerweile sogar um eigene Simple Viewing Tools zur einfachen Visualisierung der Geometriedaten ergänzt. Damit könnte dann theoretisch je nach Anforderung an die Leistungsfähigkeit und Umfang der GIS-Funktionalität auf externe GIS-Softwarekomponenten verzichtet werden. 62 1958 GIS-Hersteller haben in diesem Zusammenhang externe Datenbank-Aufsätze entwickelt und versprechen umfangreiche zusätzliche Möglichkeiten bezüglich raumbezogener Funktionen und Analysen auf Basis bestehender Datenbanksysteme. Zu den wichtigsten Vorteilen beim Einsatz solcher Datenbank-Aufsätze gehören spezielle Konzepte für lange Datenbanktransaktionen, offene Schnittstellen für den Zugriff auf räumliche Daten (beispielsweise in Form von SQL-Erweiterungen) und ein breites Spektrum von raumbezogenen Anweisungen. Diese externen Datenbank-Erweiterungen nutzen teilweise Funktionen und Datentypen von Software-Produkten wie Oracle Spatial als Basisfunktionalität [ESRI 2000]. Aus theoretischer Sicht ist die Speicherung räumlicher Daten in objektrelationalen Strukturen erstrebenswert, denn auf diese Weise wird nur eine einzige Datenquelle (mit einem einheitlichen Datenbankmodell) benötigt. Nach ESRI [1998] ergeben sich zufolge zwei wesentliche Vorteile: Die räumlichen Daten können gemeinsam mit anderen numerischen und beispielsweise auch zeitlichen Datentypen über SQL-basierte Funktionen angesprochen werden, und es sind verringerte Serveraufgaben bei der Bereitstellung von räumlicher Funktionalität zu leisten. 3.10.1. Objektrelationale Erweiterungen gegenüber den relationalen Modellen Objektrelationale Datenbanksysteme bieten nach [KEMPER, EICKLER 2004] im Wesentlichen folgende funktionale Erweiterungen gegenüber dem relationalen Datenmodell an: • Große Objekte (Large Objects, LOBs) Diese werden trotz eines „reinen“ Wertes den objektrelationalen Konzepten zugeordnet: Sie erlauben es, in den neu verfügbaren Basisdatentypen (z. B. BLOB und CLOB) sehr große Attributwerte wie beispielsweise Multimediadaten zu speichern. • Kollektionswertige Attribute Hier wird die flache Struktur des relationalen Modells aufgegeben, um einem Tupel (Objekt) in einem Attribut eine Menge von Werten zuordnen zu können. • Geschachtelte Relationen Hier wird erlaubt, dass Attribute selbst wiederum Relationen sind. • Typdeklarationen Durch die Unterstützung der Definition von anwendungsspezifischen Datentypen, oft auch userdefined types (UDT) genannt, können komplexe Datenstrukturen aufgebaut werden. 63 • Referenzen Attribute können direkte Referenzen auf Tupel (Objekte) derselben oder einer anderen Relation als Wert haben. Insbesondere kann ein Attribut auch eine Menge von Referenzen als Wert haben, so dass auch N : M - Beziehungen ohne separate Beziehungsrelation repräsentiert werden können. • Objektidentität Referenzen setzen voraus, dass Objekte anhand eines Objektidentifikators eindeutig identifizierbar sind und im Unterschied zu relationalen Schlüsseln nicht veränderbar sind. • Vererbung Realisierung des Konzepts der Generalisiuerng/Spezialisierung. • Operationen / Methoden Gegenüber der im relationalen Modell fehlenden Möglichkeit, können nun den Daten auch Methoden zugeordnet werden. Bei einfachen Operationen können diese direkt in SQL implementiert werden. Die Standardisierung dieser Erweiterungen liegt derzeit in SQL 1999 vor. Die kommerziellen Datenbanksysteme bieten häufig noch von SQL 1999 abweichende Syntax zur Umsetzung der OR-Konzepte an. 3.10.2. Abbildung in das logische Modell In der logischen Modellierung erfolgt die Transformation des konzeptionellen OOModells in das für die Implementierung vorgesehene OR-Datenmodell von Oracle. In Oracle 9i sind Typklassen (in gewissen Grenzen) auch dann änderbar, wenn bereits Instanzen der Klassen existieren, womit z.B. die Tabelle KULTURERBE als Objekttabelle einer entsprechenden Klasse definiert werden könnte. Diese Klasse KulturERBE_TYP bildet dann die Spitze der Vererbungshierarchie und erlaubt somit eine echte objektorientierte, logische Modellierung. Damit verbunden ist eine deutliche Steigerung der Flexibilität bei der Methodenprogrammierung. In diesem Zusammenhang ist zu sehen, dass die Bildung eines Index über das Ergebnis von Methoden selbst definierter Klassen möglich ist. Gerade bei sehr zeitintensiven Abfragen von einzelnen Funktionsergebnissen lässt sich durch diesen Mechanismus ein deutlicher Performancegewinn erzielen. Anhand der Beschreibung des Basismodells sowie der thematischen, geometrischen und zeitlichen Bestandteile des Modells werden an mehreren Beispielen die benötigten Konstrukte für die Umsetzung des Modells für kulturelles Erbe vorgestellt. 64 UDT Zentraler Basistyp ist das Kulturerbe, der sich aus komplexen nutzerdefinierten Objektstrukturen aufbaut und wie folgt in SQL beschrieben werden kann. Create or replace type KULTURERBE_TYP as ( ID NUMBER (38, 0), Bezeichnung VARCHAR2 (500), Beschreibung CLOB (50K), Raum REF (GEOMETRIE_TYP), Zeit ZEIT_TYP, Ort ORTSANGABE_TYP, Multimedia MULTIMEDIA_TAB, Stichworte TEXT_TAB ) not final, nested table Multimedia store as MM_TAB, nested table Stichworte store as STWORT_TAB; Zunächst wurden die attributiven Eigenschaften mit ihren Datentypen definiert, der Raumbezug erfolgt über eine Referenz, Zeit und Ort werden über weitere UDTs definiert. Die Multimediadaten und Stichworte werden als kollektionswertige Attribute hinzugefügt. Die Vererbung ist am Superobjekt Kulturerbe noch nicht sichtbar. Referenzen Referenz-Typen werden mit dem Referenztyp-Konstruktor erzeugt. Über deren Instanzen wird auf die Objekte des referenzierten (strukturierten) Typs GEOMETRIE_TYP verwiesen. Voraussetzung für die spätere Dereferenzierung einer Referenz ist die scope-Klausel. Beim Aufbau der Referenz wird einer Referenzspalte eine Instanz des entsprechenden Referenztyps (OID) zugewiesen. Durch die systemweit eindeutige Object Identity (OID) und die REF lassen sich somit Beziehungen zwischen Objekten explizit modellieren. Referenzen sind im Vergleich zu Fremdschlüsseln streng typisiert. Kollektionswertige Attribute Die Stichworte werden in einer Nested Table gespeichert. Diese stellen die Möglichkeit zur Verfügung, in einem Attribut komplette Tabellen aufzunehmen, und so die Modellierung von “zu-n-Beziehungen” stark zu vereinfachen. Die interne Speicherung dieser Nested Tables erfolgt in einer Zwischentabelle, ähnlich der Modellierung einer n-zu-m-Beziehung in einem relationalen DBMS, wobei diese eine zusätzliche Spalte mit der Bezeichnung “NESTED_TABLE_ID” erhalten. Diese zusätzliche Spalte ermöglicht dem Datenbanksystem, auf den entsprechenden Eintrag in der Elterntabelle 65 zurück zu schließen, und kann zur Beschleunigung des Zugriffs mit einem Index versehen werden. Vererbung Ein Beispiel für eine Vererbung wird anhand der thematischen Angaben eines Kulturerbeobjekts dargestellt. In dem Subtyp OBJEKTART_TYP sind wiederum weitere ORKonstrukte wie Referenzen und kollektionswertigen Attributen möglich. Create or replace type OBJEKTART_TYP under KULTURERBE_TYP as ( Metadaten METADATEN_TYP ) not final; Die Vererbung kann mehrstufig sein: Create or replace type DENKMAL_TYP under OBJEKTART_TYP as ( Landkreis VARCHAR2(100), Gemeinde VARCHAR2(100), Gemeindekz NUMBER(10,0), Kartennummer VARCHAR2(20), Beschreibung CLOB (50K), Status VARCHAR2(255), Art VARCHAR2(100), … Änderungsdatum DATE ) not final; Methoden Neben der Möglichkeit, komplexe Strukturen in Form von Objekten abzubilden, liegt in der Formulierung von Methoden zu Objekten eine weitere wesentliche Stärke des objektrelationalen Modells. Durch Methoden können spezifische Operationen für einzelne Objekttypen definiert werden. Beispielsweise wird in der benutzerdefinierten Methode „MEETS“ abgefragt, ob das jeweils angesprochene Objekt (mit einer bestimmten Gültigkeitszeit) in Zusammenhang mit dem als Übergabeparameter definierten Zeitraum (Zeitpunkt oder Zeitspanne) steht. Create or replace type ZEIT_TYP ( Zeitangabe_unsicher NUMBER (1,0) ) not final method MEETS(ZEITPUNKT_TYP punkt) returns NUMBER(1,0); method MEETS(ZEITPUNKT_TYP beginn, ZEITPUNKT_TYP ende) returns NUMBER(1,0) ; 66 create or replace type ZEITDAUER_TYP ( Jahr NUMBER (4,0), Monat NUMBER (2,0), Tag NUMBER (2,0) ) not final; create or replace type ZEITPUNKT_TYP under ZEIT_TYP ( Jahr NUMBER (4,0), Monat NUMBER (2,0), Tag NUMBER (2,0), Zeitbereich_offen NUMBER (1,0), Zeitbereich_unsicher ZEITDAUER_TYP ) not final overriding method MEETS(ZEITPUNKT_TYP punkt) returns NUMBER(1,0); overriding method MEETS(ZEITPUNKT_TYP beginn, ZEITPUNKT_TYP ende) returns NUMBER(1,0) ; create or replace type ZEITSPANNE_TYP under ZEIT_TYP ( Beginn ZEITPUNKT_TYP, Ende ZEITPUNKT_TYP, ) not final overriding method MEETS(ZEITPUNKT_TYP punkt) returns NUMBER(1,0); overriding method MEETS(ZEITPUNKT_TYP beginn, ZEITPUNKT_TYP ende) returns NUMBER(1,0) ; Wie beispielsweise in C++ üblich erfolgt Definition und Deklaration streng getrennt. Da es sich bei ZEIT_TYP um einen abstrakten Datentyp handelt, werden die Methoden nicht definiert. Die Definition der Methoden erfolgt erst für die Subtypen ZEITPUNKT_TYP und ZEITSPANNE_TYP. Dadurch ergeben sich folgende 4 Funktionsdefinitionen: create method MEETS (ZEITPUNKT_TYP punkt) returns NUMBER(1,0) for ZEITPUNKT_TYP begin ... RETURN value; end; 67 create method MEETS (ZEITPUNKT_TYP beginn, ZEITPUNKT_TYP ende) returns NUMBER(1,0) for ZEITPUNKT_TYP begin ... RETURN value; end; create method MEETS (ZEITPUNKT_TYP punkt) returns NUMBER(1,0) for ZEITSPANNE_TYP begin ... RETURN value; end; create method MEETS (ZEITPUNKT_TYP beginn, ZEITPUNKT_TYP ende) returns NUMBER(1,0) for ZEITSPANNE_TYP begin ... RETURN value; end; In Oracle gilt die Einschränkung, dass kein entsprechender Datentyp vom Wert BOOLEAN zur Verfügung steht. Daher sind im Modell die Werte 0 für falsch und 1 für wahr vorgesehen, um so den fehlenden Datentyp zu emulieren. In einer Applikation kann anschließend dieser Wert direkt einer Variable vom Typ BOOLEAN zugewiesen werden. 3.10.3. Datenhaltung im ORDBMS ORACLE Das Datenbanksystem Oracle ist heute das führende Datenbanksystem auf dem Geoinformationsmarkt zur Verwaltung von großen Datenbeständen. Es erlaubt die logische Modellierung nach der relationalen Theorie und erweitert diese um Möglichkeiten aus dem Bereich der Objektorientierung. Es definiert sich selbst als objektrelationales Datenbanksystem. 68 Oracle 10g Oracle 10g enthält mehrere Erweiterungen seiner Datenbank-Engine, die gerade im Bereich der objektrelationalen Funktionalität Erleichterungen bei der Modellierung der Datenbank bringen. Die wichtigste Neuerung stellt die Unterstützung der Vererbung dar, und damit die Möglichkeit des Aufbaus einer echten Klassenhierarchie durch entsprechende Mechnismen. Oracle 10g ist in der Lage, mehrdimensionale Datenstrukturen aufzubauen. Beispielsweise wurde der Operator THE jetzt völlig durch TABLE ersetzt (nur für Nested Tables), und damit der Zugriff mittels Query- und DMLSprachelemente durch den gleichen Mechanismus und die gleiche Befehlssyntax ermöglicht. Dies erleichtert den Umgang mit Nested Tables gegenüber der Struktur, die noch in früheren Versionen vorgegeben war. Die Datenbank bietet auch die Möglichkeit Aggregierungsfunktionen zu den selbst definierten Klassen zu implementieren, wie das bereits mit den Sortierfunktionen möglich war. Dies erlaubt nun auch die Implementierung einer Funktion wie SUM für komplexe Daten. Das System benötigt deutlich mehr Speicherplatz als frühere relationale Datenbankapplikationen und stellt höhere Anforderungen an die Hardware des Systems, auf dem das Datenbanksystem installiert wird. Es sind damit deutlich leistungsfähigere Serversysteme nötig. Dies ist bei der Kostenanalyse zur Implementierung einer Datenbank beim Anwender mit zu beachten. Zugriff auf objektrelationale Datenstrukturen Der Zugriff auf objektrelationale Datenstrukturen kann in Oracle-Datenbanken über verschiedene Schnittstellen erfolgen. Das standardisierte SQL-99 (SQL3) berücksichtigt objektorientierte Ansätze nicht konsequent, denn Konzepte wie z. B. Mehrfachvererbung oder Kapselung von Objekten wurden in den Standardisierungsvorschlägen nicht miteinbezogen. In Verbindung mit den Programmiersprachen Java und Visual Basic werden für die Implementierung die Oracle JDBC-Erweiterung (Java) sowie Oracle Objects for OLE (Visual Basic) eingesetzt. Weitere Alternativen sind beispielsweise das Oracle Call Interface für Java und auch C++. Die JDBC-Erweiterungen stehen als kompilierte Java-Klassen zur Verfügung und werden in das jeweilige Java-Programm importiert. Bei Visual-Basic wird Oracle Objects for Object Linking and Embedding (bzw. Oracle Objects for OLE, kurz OO4O) als Projektverweis verknüpft. Nach der Einbindung der Bibliotheken stehen sowohl in Java als auch in Visual-Basic verschiedene Software-Konzepte für den objektrelationalen Datenbankzugriff bereit, diese lassen sich nach HOCHHÄUSLER [2003] in drei Kategorien unterteilen: 69 • Spezielle „SQL-Statements“, die einen Zugriff auf objektrelationale Strukturen in- nerhalb einer SQL-Anweisung ermöglichen. Dabei kann auch eine Vielzahl von (Oracle-spezifischen) Schlüsselwörtern verwendet werden. • „Recordset-Objekte“ als Container-Objekte für (objekt-)relationale Daten (bei Ja- va spricht man dabei von „Resultsets“ und bei Visual Basic von „Dynasets“). Diese können als „Behälter“ für die Ergebnisse von SQL-Select-Statements verstanden werden. Änderungen der Daten im Recordset wirken sich dann normalerweise automatisch auf den Datenbankinhalt aus. • „Oracle Objects“, die in externen Programmiersprachen wie Visual Basic bei- spielsweise als „OraRef“, „OraObject“, „OraAttribute“ oder „OraCollection“ bezeichnet werden und eins zu eins mit Referenz-Typen, Objekt-Typen, Tabellenattributen oder verschachtelten Tabellen in der Datenbank verglichen werden können. Ein objektrelationales „Recordset-Objekt“ setzt sich in der Regel aus mehreren „Oracle Objects“ zusammen. Diese können in der jeweiligen Programmiersprache iterativ ausgelesen werden. Ein Editieren oder Befüllen der Objekte bedingt automatisch eine Änderung der Datenbankinhalte. Durch diese Konzepte können über externe Programmiersprachen auf flexible Art und Weise kompliziert strukturierte Datenbankinhalte verwalten werden. ContainerObjekte in Form von Recordsets haben einen „read-only“-Status bzw. lassen keine Updates zu, wenn der zugrunde liegende SQL-Befehl sehr komplex ist. In einem Dateneingabemodul (realisiert in Visual Basic) kam dieser Fall genau dann vor, wenn auf BLOB-Daten, die in einer verschachtelten Tabelle gespeichert waren, zugegriffen wurde. Probleme dieser Art lassen sich lösen, indem SQL-Statements in Form von UpdateBefehlen in Kombination mit den „Oracle Objects“ (in diesem Fall ein so genanntes „OraBLOB“-Objekt) formuliert werden, anstatt „Recordset-Objekte“ zu benutzen. Die unterschiedlichen Konzepte beim Zugriff auf objektrelational strukturierte Datenbanken erfordern sowohl auf Datenbankebene als auch innerhalb der verwendeten Programmiersprache spezifische Ansätze bei der Implementierung. Dies soll an einem einfachen Beispiel verdeutlicht werden: Beispiel: Die Spalte „MULTIMEDIA“ in der Tabelle „KULTURERBE“ enthält den Datentyp „METADATEN_TYP“. In diesem „METADATEN_TYP“ sind weitere SubDatentypen enthalten, einer davon ist die „BEMERKUNG“, die eine einfache Zeichenkette (primitiver Datentyp) darstellt. Um auf die Bemerkung zugreifen zu können, gibt es auf Datenbankebene zwei Möglichkeiten: 70 1.Variante: SELECT K.MULTIMEDIA.BEMERKUNG FROM KULTURERBE K Die erste Abfrage selektiert die Bemerkung, die in Form eines primitiven Datentyps zurückgegeben wird. Somit kann das „SQL-Statement“ unkompliziert in ein (nichtobjektrelationales) „Recordset-Objekt“ der jeweiligen Programmiersprache übertragen werden. Die Verwendung von Alias-Namen (in diesem Fall "K") ist bei objektrelationalen Abfragen in Oracle obligatorisch 2. Variante: SELECT K.MULTIMEDIA FROM KULTURERBE K; Bei der 2. Abfrage wird ein komplexes Objekt vom Typ „MULTIMEDIA_TYP“ zurückgegeben. Dieses Objekt muss zuerst in ein (objektrelationales) „Recordset-Objekt“ der verwendeten Programmiersprache weitergereicht werden, anschliessend sollte es in ein Konstrukt auf Basis der „Oracle Objects“ übertragen werden, bevor es ausgelesen oder editiert wird. Die zuerst genannte SQL-Variante hat den Vorteil dass diejenigen Datenbankanweisungen, die im Dateneingabemodul (Visual Basic) und im GI-System (Java) in ähnlicher Form verwendet werden, insgesamt leichter übertragbar sind. Somit wird der Umfang einzelner SQL-Anweisungen etwas größer, aber die Menge des sprachspezifischen Visual Basic- bzw. Java-Codes zum Auswerten der objektrelationalen Daten sinkt. Literaturverzeichnis Bauknecht, K., Zehnder C.A. [1997]: Grundlagen für den Informatikeinsatz. Teubner Verlag, Stuttgart, 1997. Conzett R. [1983]: EDV in der Vermessung. Skript zur Vorlesung, 1987. Conzett R., Kuhn W., Studemann B., Wigger U. [1987]: Über Datenbanken. IGP-Bericht Nr. 136. Kuhn W. [1986]: Anmerkungen zu Informationssystemen und Datenbanken. IGP-Bericht Nr. 120. Pfund M. [2000]: Datenmodellierung, Relationenmodell, SQL. Vorlesungsunterlagen 2000, Manuskript, Institut für Geodäsie und Photogrammetrie, ETHZ, Zürich 2000. 71 Schek H.J., Türker, C., Informationssysteme, Nachdiplomkurs Breunig, M. [1999/2000]: Räumliche Daten ETHZ 1999/2000, Zürich 1999. Studemann B. [1988]: Datenstrukturen und Datenbanken. VPK 5/1988. Wicki F., Schaub, E. [1993]: Datenmodellierung, Relationenmodell, SQL. Vorlesungsunterlagen WS 93/94, Institut für Geodäsie und Photogrammetrie, ETHZ. Zehnder C.A. [1998]: Informationssysteme und Datenbanken. Verlag der Fachvereine Zürich, und B.G. Teubner Verlag, Stuttgart, 6. Auflage 1998. Hosse, Karin [2005] Objektorientierte Modellierung und Implementierung eines temporalen Geoinformationssystems für kulturelles Erbe. Diss TU München, Juli 2005-10-17 ESRI [2000] Environmental Systems Research Institut: ESRI and Oracle. Solutions for GIS and Spatial Data Management. Online im Internet. URL: http://www.esri.com/library/whitepapers/pdfs/e sri_and_oracle.pdf (Stand: 1.2.05) ESRI [1998] Environmental Systems Research Institut: ESRI and Oracle. ESRI Shapefile Technical Description. Online im Internet. URL: http://www.esri.com/library/whitepapers/pdfs/s hapefile.pdf (Stand: 1.2.05) Hochhäuser, T. [2003] Implementierung eines Geoinformationssystemes in Visual Basic and Java auf Basis einer objektrelationalen Oracle-Datenbank. TU München, Institut für Informatik, Institut für Geodäsie, GIS und Landmanagement, Abschlussarbeit 2003 Kemper, A., Eickler, A. [2004] Datenbanksysteme. München, Wien (Oldenburg) 2004 72 4. Datenmodelle für raumbezogene Informationen 4.1. Das Vierschalen-Modell 4.1.1. Modelle im Allgemeinen Ein Modell ist eine vereinfachte Darstellung der Realität. Ein Abstraktionsprozess trennt die wesentlichen Elemente von den unwesentlichen. Die ersten werden hervorgehoben, die zweiten entfernt. /Golay 1990/ Das Modell entsteht durch die Beziehung zwischen den Elementen der Realität und den Elementen des Modellierraumes. Wenn Elemente der Geometrie (geometrische Objekte und Operationen) Verwendung finden, spricht man von einem geometrischen Modell. Wenn man hingegen logische Symbole, ihre Bedeutung und die dazugehörigen Verwendungsregeln einsetzt, hat man mit einer Sprache zu tun. Die gleiche Realität kann mit ganz verschiedenen Modellen abgebildet werden. Die Wahl ist vom Modellierungszweck und von den verfügbaren Werkzeugen abhängig. 4.1.2. Die vier Stufen eines Modells für raumbezogene Daten Die Verwaltung von raumbezogenen Daten in einem Geo-Informationssystem bietet ähnliche Probleme wie die Speicherung von alphanumerischen Informationen in einer Datenbank. Das Modell zur Speicherung raumbezogener Daten wird ebenfalls in vier Schritten entwickelt. Man spricht von einem Schalenmodell. • • • • Räumliches Modell • • Konzeptionelles Model • Logisches Modell • Physikalisches Modell 73 Räumliches Modell Im ersten Schritt werden die Inhalte des Informationssytems festgelegt. Die benötigten raumbezogenen und ergänzenden Informationen werden als räumliches Modell verbal beschrieben. Diese Beschreibung ist eine idealisierte Diskretisierung der realen Welt. Beispiel: Wir möchten die Schweiz mit den Kantonen und den Kantonshauptorten speichern. Konzeptionelles Modell Danach wird das räumliche Modell in eine formal eindeutige Sprache übersetzt, um alle Elemente der raumbezogenen Information mit ihren Attributen und Beziehungen festzulegen. Daraus entsteht das konzeptionelle Modell. Dieses Modell kann mit geschriebenen Worten (z.B. Sprache INTERLIS) oder mit graphischen Symbolen (Entitätenblockdiagramm) beschrieben werden. Kantone 1 Kantonsname 1 1 m Hauptort Gemeinden Gemeindename 1 c Ortname Anz. Einwohner 1 m Flächenelement Je nach Leistung und Vielseitigkeit der zu verwendenden GIS-Software kann die Beschreibung sehr umfangreich und komplex werden. Das konzeptionelle Modell ist das eigentliche Projekt der Datenstruktur. Seine Eigenschaften werden durch die im System verfügbaren Elementbausteine massgebend bestimmt. Logisches Datenmodell Das konzeptionelle Modell wird dann in das vorhandene GIS-System eingeführt. Die systemeigene Datendefinitionssprache wird verwendet, um das logische Datenmodell zu beschreiben. Die eingesetzte GIS-Software begrenzt die Möglichkeiten und beeinflusst stark die Modellierungsarbeit. In vielen Systemen ist die Sprache für die Definition der Datenstrukturen umständlich zu gebrauchen. In anderen Systemen ist sie benützerfreundlich und gut erlernbar, so dass der Systemverantwortliche selber problem- 74 los Datenstrukturen definieren kann. In der Regel liefert der Systemhersteller eine passende Datenstruktur, die für Standardaufgaben (wie die amtliche Vermessung) bereits entwickelt wurde. Physikalisches Datenmodell Das physikalische Modell legt die Art der Datenspeicherung sowie die zugehörigen Zugriffsmechanismen fest. Das logische und das physikalische Datenmodell sind eng miteinander verknüpft. 4.2. Aufgaben und Verantwortung 4.2.1. Räumliches Modell Die Gestaltung des räumlichen Modells ist Aufgabe der Experten in der Thematik, z.B. Geologe, Umweltfachmann, Eisenbahnexperte, Verkehrsingenieur usw. Sie beschreiben die interessierenden Objekte mit ihren Eigenschaften und die gewünschten Operationen. 4.2.2. Konzeptionelles Modell Der Experte in raumbezogenen Daten (Vermessungsfachmann, neu Geo-Informatiker) ist verantwortlich für den Entwurf des konventionellen Modells. Er die Objekte in Grundelemente und beschreibt Verknüpfungen und Gemeinsamkeiten, damit die gewünschten Informationen vollständig und ohne Widersprüche die Inhalte des räumlichen Modells wiedergeben. 4.2.3. Logisches Modell Der Systemspezialist beschreibt mit den logischen Werkzeugen des raumbezogenen Informationssystems (Datendefinitionssprache) das konzeptionelle Modell und realisiert im Computersystem die entsprechenden Datenstrukturen. Die modernen GIS-Systeme bieten z.T. schon heute benützerfreundliche Datendefinitionssprachen, so dass diese Aufgabe von einem ausgebildeten Vermessungsfachmann übernommen werden kann. 4.2.4. Physikalisches Modell Bei der Realisierung des Verwaltungssystems für raumbezogene Daten haben Informatikspezialisten und Programmierer die Verbindung zwischen physikalischen Datenstrukturen (sequentielle Dateien, Direktzugriffsfiles, invertierte Dateien) und Inhalte des raumbezogenen Informationssystems hergestellt. Das System interpretiert das logische Modell und erzeugt die erforderlichen Dateien automatisch. Die GIS-Software 75 kann das logische Datenmodell interpretieren, die gewünschten Datenstrukturen in der Datenbank definieren und das physikalische Datenmodell auf dem Speichermedium entstehen lassen. 4.2.5. Eine interdisziplinäre Aufgabe Das 4-Schalen-Modell spiegelt die für Geo-Informationssysteme typische Interdisziplinarität wieder. Der im konzeptionellen Modell tätige Geo-Informatiker fungiert als Bindeglied zwischen dem Anwender und der reinen Informatik. 4.3. Modellierungsansätze 4.3.1. Bedeutung und Auswirkungen Zur Diskretisierung der komplexen Realität der Umwelt werden Elementbausteine benötigt, die eine schematische Darstellung der Information ermöglichen. Die Art dieser Bausteine beeinflusst die Verwendbarkeit des Systems und die Erfüllung der Aufgaben und hat direkte Auswirkungen auf der Stufe des konzeptionellen und logischen Modells. Die Vielfalt der Lösungsansätze und der marktreifen Systeme verunmöglicht eine vollständige Beschreibung der verwendbaren Datenstrukturen und noch mehr der Datenbeschreibungssprachen. Es ist daher zweckmässiger, mit Beispielen einige charakteristische Lösungen zu schildern, um den Leser die Bedeutung der Modellierung erkennen zu lassen. 4.3.2. Rasterstrukturen Die einfachste Form der Modellierung von Raumdaten sind Rasterstrukturen. Der abzubildende Raum wird in eine grosse Anzahl identischer geometrischer Elemente (Quadrate, Würfel, Sechsecke usw.) unterteilt. Zu jedem Element werden die Position im Raum und die Werte dazugehöriger Attribute gespeichert. • Zeile 2 Kolonne 4 Boden Farbe Wald grün Boden Farbe See blau • Zeile 4 76 Kolonne 3 Die Rasterstrukturen spielen dank ihrer Einfachheit eine wichtige Rolle und werden daher in einem speziellen Kapitel behandelt. 4.3.3. Ungeordnete Polygone (Spaghetti-Daten) Wir sind gewohnt, Raumdaten mit gezeichneten Linien, Punktsymbolen und Texten auf Papier darzustellen. In ähnlicher Art kann man als Modell für räumliche Informationen Linien, Punkte und Texte verwenden, welche bei Bedarf gezeichnet und interpretiert werden können. Linien werden als Listen von Koordinaten, Punkte werden als Koordinatenpaare und Texte als Schriftzeichen mit Positionsangaben gespeichert. Thematische Informationen können ebenfalls mitberücksichtigt werden. Linie A Punktsymbol Typ Y X Flp ••• ••• ••• ••• ••• TEXTE Linie B NR Y X NR Y X 1 ••• ••• 1 ••• 2 ••• ••• 2 ••• ••• Y X TEXT ••• ••• Zürich ••• ••• ••• Regensd 3 ••• ••• 3 ••• ••• ••• ••• ••• ••• ••• ••• ••• ••• In einer solch primitiven Struktur kann ein kartographisches Bild dargestellt werden. Die Bedeutung der Elemente ist nicht automatisch herleitbar. 77 Fragen wie • Welche Linien sind die Grenzen von Zürich? • An welche Ortschaften grenzt Zürich? können nicht direkt vom Computer beantwortet werden. 4.3.4. Geordnete Polygone Man kann Spagetti-Daten ordnen und mit gewissen thematischen Informationen verbinden, so z.B.: Rümlang Zürich NR 1 Y X ••• ••• NR 1 2 ••• ••• 3 ••• ••• Y X ••• 2 ••• ••• ••• 3 ••• ••• So wird ein Teil der logischen Zusammenhänge herleitbar. Die Daten werden allerdings schnell redundant, die Konsistenz wird fraglich, Mutationen und Korrekturen aufwendig. 78 4.3.5. Liniendefinitionen mit Punktverzeichnissen Dies ist eine Lösung, die im Vermessungswesen oft verwendet wurde, da die Punktkoordinaten und die Liniendefinitionen aus verschiedenen Quellen stammen (aus Messungen und Feldskizzen) und können daher getrennt verwaltet werden. Rümlang Zürich Punkte NR Y X 1, 2, 3, 1 ••• ••• ••• ••• 2 ••• ••• 3 4 ••• ••• ••• ••• 51 ••• ••• ••• ••• ••• 52 ••• ••• ••• 1, 2, 51, 52, ••• ••• In dieser Lösung, in welcher die Datenstruktur in der Regel fest programmiert ist, sieht man bereits die ersten Ansätze der modernen Systeme mit einer Gliederung der geometrischen Information in Topologie und Metrik. 4.3.6. Ebenenprinzip Die Sammlung vieler heterogener Informationen, vor allem mit einfachen Datenstrukturen, die nur graphische Merkmale enthalten, ist wenig benützerfreundlich. Um die raumbezogene Information mindestens teilweise thematisch zu gliedern, wurden die Daten in Ebenen (Layers) geteilt. 79 Oft bedeutet die Gliederung in Ebenen, dass die geometrische Information jeder Ebene getrennt gespeichert wird. Damit entsteht die Möglichkeit, beliebige Kombinationen von Ebenen darzustellen. Die Gesamtdarstellung wird erreicht durch Überlagerung aller Ebenen, die durch den Raumbezug miteinander verknüpfbar sind. Das Ebenenprinzip ist in der analogen Kartographie seit langem gebräuchlich, wo verschiedene thematische Inhalte in einzelne Folien getrennt werden. 4.3.7. Thematische und geometrische Information Der grosse Nachteil der bisher dargestellten Modelle liegt in der beschränkten Fähigkeit, thematische Informationen mit den geometrischen zu verknüpfen. Komplexe thematische Sachverhalte können nicht im Modell abgebildet werden. Moderne GIS müssen vielseitig einsetzbar sein und sich den Bedürfnissen der Anwender anpassen können. Solche Modelle erfordern daher Modellierbausteine, die so allgemein sind, dass möglichst viele Applikationen realisiert werden können. Die verschiedenen denkbaren Geo-Informationssysteme unterscheiden sich vor allem in der Thematik. Für die Planung ist die Bodennutzung wichtig, in der amtlichen Vermessung ist das Grundeigentum das zentrale Anliegen usw. Ein Umweltinformationssystem benötigt Angaben über Belastungswerte, Gefahrenquellen, Klassen von umweltrelevanten Objekten usw. Die Thematik (oft auch als Semantik bezeichnet) muss praktisch für jedes GIS besonders modelliert werden. 80 Die zugrunde liegende geometrische Information, die letztlich erst den Raumbezug bewirkt, ist hingegen viel weniger von der Anwendung abhängig. Die Grundelemente Punkte, Linien, Flächen usw. sind für die Modellierung der Geometrie bei der Mehrheit der Applikationen geeignet. Es überrascht daher nicht, dass die modernen GIS-Systeme die Modellierung der Thematik und der Geometrie trennen. Raumbezogene Information Geometrie Themati k Grundelemente variiert stark • Punkte • Linien • Flächen von Anwendung zu Anwendung Für die Thematik stellt ein GIS-System nur die Modellierwerkzeuge zur Verfügung, um z.B. ausgehend aus einem Entitätenblockdiagramm die erforderliche Datenstruktur in einem relationalen Modell zu definieren. Für die Geometrie hingegen wird in der Regel vom Hersteller eine mehr oder weniger grosse Vielfalt an Grundelementen und -operationen zur Verfügung gestellt. Die dazugehörigen Datenstrukturen sind bereits vorhanden, um alle Elemente mit ihren Standardattributen effizient verwalten zu können. 4.4. Geometrische Modelle 4.4.1. Grundkomponenten der Geometrie Die geometrische Information lässt sich ebenfalls in Komponenten unterteilen. Eine wirksame Gliederung entsteht, wenn die topologischen und metrischen Eigenschaften getrennt werden. Geometrie Topologie Metrik 81 4.4.2. Metrische Informationen Die metrische Komponente wird in der Regel durch die Position der Punkte im Modell festgehalten, die in zweidimensionalen oder dreidimensionalen Modellen, z.B. durch Landeskoordinaten gespeichert wird (Punktmetrik). Die Metrik der linearen Elemente ist durch die Lage der Anfangs- und Endpunkte gegeben, sofern nur Geraden vorgesehen sind. In vielen Systemen werden auch andere Linientypen vorgesehen: • Kreise (obligatorisch für die amtliche Vermessung) • Splinefunktionen • Klothoide • usw. In solchen Fällen müssen für die Linien entsprechende metrische Daten gespeichert werden. Z.B. Kreisdefinition (2 Punkte und Radius, 3 Punkte etc.) 4.4.3. Topologische Informationen Die Topologie beschäftigt sich mit den räumlichen und strukturellen Eigenschaften der geometrischen Objekte unabhängig von ihrer Ausdehnung und ihrer Form. Zu den topologischen Eigenschaften gehört die Anzahl Dimensionen eines Objektes: • Punkt (0-dimensional) • Linie (eindimensional) • Fläche (zweidimensional) • Körper (dreidimensional) und viele Beziehungen zwischen geometrischen Objekten wie z.B.: • Schnitt • Berührung • Umrandungen • Nachbarschaft • Verbindung • Geschlossenheit 82 Alle topologischen Eigenschaften sind invariant bei jeder stetigen Umformung (d.h. mathematische Abbildung in sich selbst) des Raumes. Man spricht daher manchmal auch von der Geometrie der Gummiobjekte oder der Gummiräume. Diese Informationen werden in einem modernen GIS explizit gespeichert. Die folgenden Beispiele veranschaulichen, was unter Speichern der Topologie zu verstehen ist. Es ist aber zu bemerken, dass eine solche Form der Datenverwaltung zu speicherplatzintensiv wäre und hier nur der Erläuterung dient. a) Verbindungen (Inzidenz) Verbindungen Punkte A B C D E A B C D E A * 1 0 0 1 B 1 * 1 0 1 C 0 1 * 1 0 D 0 0 1 * 1 E 1 1 0 1 * Beide Netze besitzen topologisch identische Verbindungen. 83 b) Adjazenz (Nachbarschaft) Adjazenz Flächen a b c d a * 1 0 1 c b 1 * 1 1 d c 0 1 * 1 d 1 1 1 * a b A B a b c d Beide Figuren haben identische Adjazenz-Eigenschaften Die topologischen Beziehungen zwischen Punkten und Linien sowie zwischen Linien und Flächen lassen sich mit Graphen darstellen. Die Graphentheorie mit ihren Begriffen wird bei der topologischen Modellierung verwendet. So werden Punkte mit rein geometrischer Bedeutung oft "Knoten" bzw. Linienverbindungen oft "Kanten" genannt. Man spricht von einer "Knoten-Kanten-Struktur". Die Erweiterung dieser Struktur um das Element Fläche lässt die geometrischen und topologischen Eigenschaften beschreiben, die in (2-dimensionalen) vorkommen. Da diese Bezeichnungen nicht allgemein verbreitet sind, werden wir sie im Folgenden nur teilweise gebrauchen. 84 4.4.4. Die Verwaltung der topologischen Informationen Damit alle Eigenschaften der geometrischen Elemente eines GIS direkt abfragbar sind, müssen die topologischen Eigenschaften bei der Datenakquisition erfasst und vollständig und explizit verwaltet werden. Die daraus entstehende Menge von Informationen ist sehr gross. Bereits ein einfaches Beispiel mit 3 Flächen, 3 Knoten und 4 Kanten zeigt wie viele Daten zu erfassen und zu speichern sind. Flächen ID Abgrenzung Nachbarfläche (Kanten) F1 a, b F2, F4 F2 c, b, d F1, F3, F4 F3 d F2 F4 a, c F1, F2 Linien (Kanten) Knoten ID Punkte (Knoten) ID Kanten A a, b, c B a, b, c C d 85 Nachbarfläche Anf. Ende rechts links a A B F1 F4 b A B F2 F1 c A B F4 F2 d C C F3 F2 Die topologische Modellierung im dreidimensionalen Raum ist analog vorzunehmen. Das Beispiel eines einfachen Würfels zeigt aber, wie komplex die Strukturen werden. Aus diesem Grunde werden bis jetzt keine dreidimensionalen Lösungen angeboten. S1, S2 - Grund-, Deckfläche S3...S6 - Seitenflächen E1...E12 - Kanten V1...V8 - Knoten Abb. 4.1: Topologische Zerlegung eines Würfels /Bill, Fritsch 1991/ 4.4.5. Eindeutigkeit der geometrischen Grundelemente Damit die gespeicherte topologische Information vollständig und konsistent ist, müssen einige primäre Konsistenzbedingungen erfüllt sein. Die wichtigste davon ist die Eindeutigkeit der geometrischen Grundelemente: 86 • An einem Ort im Raum darf nur ein Knoten sein (zwei Knoten dürfen nicht die glei- chen Koordinaten haben). • Zwei Kanten dürfen nicht einen gemeinsamen Verlauf haben, auch eine teilweise Überdeckung oder das Kreuzen sind nicht erlaubt. In solchen Fällen sind die Kanten in Teile zu trennen, und die erforderlichen Knoten sind einzuführen. • Zwei Flächen dürfen sich nicht (auch nicht teilweise) überdecken. Die Elementar- flächen müssen ebenfalls eindeutig im Raum sein. Diese Bedingungen werden in den landesüblichen Systemen weitgehend eingehalten. Die Flächeneindeutigkeit kann aber vor allem Probleme verursachen, da eine sehr grosse Anzahl Elementarflächen entsteht, die nur schwer zu verwalten ist. Systeme, die raumbezogene Informationen in vollständig getrennten Ebenen speichern, können die Eindeutigkeitsbedingungen nur innerhalb einer Ebene beachten. Wenn diese Bedingungen nicht eingehalten werden, kann man mit einem Knoten-, Kanten- und Flächenmodell nicht die volle topologische Information direkt abfragen. Die fehlenden Informationen können nur mit aufwendigen Schnitt-Algorithmen teilweise aus der Metrik hergeleitet werden. 4.4.6. Datenstrukturen für die geometrische Information In einem Geo-Informationssystem muss der Software-Hersteller den Anwendern eine grosse Freiheit bei der Wahl der zu speichernden thematischen Information lassen. Hingegen wird in der Regel festgelegt, welche geometrischen Elemente zur Verfügung stehen und wie diese unter sich verknüpft sind. Während der Anwender die Datenstruktur für die Thematik entwirft, wird die Datenstruktur für die Geometrie vom Hersteller des Systems festgelegt und mit der GIS-Software erworben. 87 Die geometrischen Elemente könnten zum Beispiel wie folgt verknüpft werden: Geometrische Punkte Punktidentifikation Y-Koordinate X-Koordinate Geometrische Linien 1 2 Linienidentifikation Anfangspunkt Endpunkt Fläche rechts Fläche links Geometrische Flächen m 2 Flächenidentifikation Enthalten in Fläche 1 Geometrische Zwischenpunkte Punktidentifikation Y-Koordinate X-Koordinate Linienidentifikation Punktzählung m Um die rekursive Definition der Fläche zu vermeiden, kann man die Inselränder mit Hilfe fiktiver Kanten der Aussenumrandung verbinden. Damit hat jede Fläche einen geschlossenen Rand. Der Anwender sieht die Datenstruktur der Geometrie nur indirekt durch die ihm zugänglichen Funktionen und Beziehungen zur Thematik. Die eigentliche Form der Datenspeicherung muss er nicht im Detail kennen. 88 4.5. Thematische Informationen 4.5.1. Funktion der Thematik Die geometrische Information gibt Auskunft über die Lage von Objekten und über die räumlichen Beziehungen unter den Objekten. Dies ist jedoch nur recht wenig. Ein Plan, in welchem alle Linien und alle Punktsymbole mit gleicher Strichstärke und Farbe gezeichnet sind, gibt die reine geometrische Information wieder. Wir sind es aber gewohnt, den geometrischen Elementen thematische Objekte zuzuordnen, die mit der Geometrie verknüpft sind. Man spricht von thematischen oder semantischen Informationen, aus denen Angaben über ein Thema oder über die Bedeutung der Elemente entnommen werden können. Die Teilung von Geometrie und Thematik ist in der Kartographie recht unüblich, da immer beide Arten von Informationen zusammen graphisch dargestellt werden. 89 Beim genauen Betrachten bemerkt man, dass Metrik, Topologie und Thematik auch in der klassischen Kartographie als trennbare Teilkomponenten betrachtet werden. Sie können mehr oder weniger gewichtet werden und manchmal sogar ganz verschwinden. Die folgende Tabelle lässt die drei Komponenten mit ihrem jeweiligen Gewicht erkennen: Topographische Karten Topologische Pläne Thematische Karten Grundbuchpläne 4.5.2. Komponente Gewicht Metrik Gross Topologie Mittel Thematik Gross Metrik Klein Topologie Gross Thematik Gross Metrik Klein Topologie Klein Thematik Gross Metrik Gross Topologie Gross Thematik Mittel Beziehungen zwischen Thematik und Geometrie Die Teilung der Geo-Information in Geometrie und Thematik bedeutet nicht, dass diese Komponenten unabhängig seien. Insbesondere die Beziehungen zwischen den thematischen und geometrischen Elementen sind wesentliche Bestandteile der GeoInformation. 90 Kommerzielle Geo-Informationssysteme unterscheiden sich in der Art der zugelassenen Beziehungen zwischen den thematischen Objekten und den dazugehörigen geometrischen Elementen. Der Fachmann in Geo-Information (Vermessungsingenieur, Geometer usw.) kann die Modellierung der Geometrie in einem GIS nur dadurch beeinflussen, indem er ein geeignetes System (GIS-Software) wählt und beschafft. Die Modellierung der Thematik hingegen gehört zum GIS-Projekt. Sie muss vor Beginn der Datenerfassung vorliegen, kann aber im Laufe der Zeit den neuen Bedürfnissen angepasst werden. 4.5.3. Einfache thematische Objekte Ein erster Schritt in der thematischen Modellierung ist die Wahl einfacher Objekte, die im GIS zu verwalten sind und ihre Zuordnung zu den verfügbaren Grundelementen der Geometrie. In einem GIS können zum Beispiel folgende Objekte verwaltet werden: Objektname Geometrie Seen Flächenförmig Bäche Linienförmig Eisenbahnlinien Linienförmig Kantonsgrenzen Linienförmig Kantone Flächenförmig Schlösser Punktförmig Kirchtürme Punktförmig Um punktförmige thematische Objekte von geometrischen Punkten zu unterscheiden, werden oft verschiedene Bezeichnungen verwendet. In den handelsüblichen GIS spricht man von: Geometrie Thematik Knoten Symbole Kanten Linien Flächen Regionen Diese Terminologie ist produkt- und firmenabhängig. Wir werden sie deshalb nicht weiterverwenden. 91 Neben der Wahl der geometrischen Art eines Objektes werden seine Attribute definiert, zum Beispiel: Eisenbahnlinien Linie Gemeinden Betreiber Name Anz. Spuren Anz. Einwohner Spurweite Sprache Fläche Kanton Die Attribute können qualitative Informationen enthalten (z.B. Strassentyp, Bodenbedeckung usw.) sowie quantitative (d.h. metrische) Informationen beinhalten (z.B. Durchschnittstemperatur, Schwermetallkonzentration, Jahresregenmenge usw.) Die geometrischen Elemente müssen eine 1:m Beziehung zu den verschiedenen thematischen Objekten zulassen, da der gleiche Punkt gleichzeitig Grenzpunkt, Hausecke usw. sein kann. Grenzpunkte Hausecke Thematik m m 1 1 (Geometrischer) Punkt (Geometrische) Linie Geometrie Für Linien- und Flächenelemente muss die Beziehung sogar eine m:m-Beziehung sein, da mehrere Linien oder mehrere Elementarflächen notwendig sind, um ein Objekt zu beschreiben. 4.5.4. Komplexe Objekte Oft können Gruppen von verschiedenartigen einfachen Objekten ebenfalls als Objekte angesehen werden. Man spricht dann von komplexen Objekten (manchmal von "Superobjekten"). Die meisten Systeme erlauben die Definition solcher komplexen Objekte in ihrer Datenstruktur. So kann ein Bezirk als Summe von Einzelgemeinden und ein Kanton als Summe von Bezirken modelliert werden. 92 Kantone Komplexe Objekte (2. Stufe) 1 m Bezirke Komplexe Objekte (1. Stufe) 1 m Gemeinden Einfache Objekte 1 m Geometrie Flächen Die gleiche Realität könnte aber ebenfalls ohne komplexe Objekte modelliert werden. Die Beziehungen zwischen Kanton, Bezirk und Gemeinde wären dann nur durch die gemeinsame Geometrie gegeben. Kantone Bezirk Gemeinden 1 1 1 m m m Flächen Einfache Objekte Geometrie Die hier dargestellte Datenstruktur der Thematik ist streng hierarchisch (nur 1:mBeziehungen), d.h. kein Bezirk ist Bestandteil von zwei Kantonen. 93 In anderen Fällen ist eine solche Hierarchie nicht vorhanden. Seen Kantone 1 1 m Bezirke 1 m m Seeteile Oft besteht der Wunsch nach Bildung netzwerkartiger komplexer Objekte. Heute eingesetzte Systeme unterstützen komplexe Objekte, beschränken aber oft die möglichen Beziehungen auf rein hierarchische Strukturen. Wichtig ist zu bemerken, dass sowohl zu den einfachen Objekten als auch zu den komplexen Objekten Attribute definiert werden können. 4.5.5. Thematische Ebenen Aus organisatorischen Gründen kann es wünschenswert sein, Gruppen von Objekten einer thematischen Ebene (Layer) zuzuordnen. So können z.B. alle Objekte, die mit der Raumplanung zu tun haben, als Elemente der Ebene "Raumplanung" definiert werden. Alle Objekte, die der Wasser-, Elektrizität- und Telefonversorgung dienen, können zur Ebene "Leitungen" gehören usw. Sofern alle Informationen auf eine gemeinsame Geometrie bezogen sind, ist eine solche Ebene nichts anderes als ein alles umfassendes komplexes Objekt. In anderen Fällen möchte man eine vollständige Trennung der unabhängigen Ebenen, damit die Informationen im Bedarfsfall an verschiedenen Orten dezentral und nicht auf demselben Computer erfasst und verwaltet werden können. In diesem Fall besitzt jede Ebene eine eigene Geometrie und man nimmt gewisse Doppelspurigkeiten und Konsistenzrisiken in Kauf. 4.5.6. Thematische und topologische Konsistenzbedingungen Die Qualität der Daten ist die wichtigste Eigenschaft eines Informationssystems. Über einen langen Zeitraum kommen kontinuierlich neue Daten hinzu, und vorhandene Daten werden modifiziert. Es werden rigorose Strategien benötigt, um eine Vielzahl möglicher Fehlerquellen auszuschalten. Ansonsten wird das Gesamtsystem für den Anwender rasch wertlos und der Betreiber muss zunehmende Kosten für die Wartung und Da- 94 tenverwaltung in Kauf nehmen. Eine wesentliche Komponente dieser Strategien ist die Definition und die Einhaltung von Konsistenzbedingungen. Wenn jede Mutation einen vorhandenen konsistenten Zustand in einen neuen konsistenten Zustand überführt, spricht man von einer Transaktion. Mit der Definition der Struktur der Thematik können Typen und Bereiche für die Attribute definiert werden. So kann man z.B. Wertbereiche für Koordinaten vorsehen, ein Eigentümername darf keine Ziffer enthalten, der Gebäudetyp darf nur einer der vorgesehenen Typen (aus einer Liste) sein usw. Die Graphentheorie bietet Hilfsmittel zur Formalisierung topologischer Konsistenzbedingungen. Für linienförmige Objekte kann gefordert werden, dass sie einem bestimmten Graphentyp entsprechen (zusammenhängend, mit oder ohne Zyklen, baumförmig usw.) Sätze der Graphentheorie eignen sich für die Formulierung von Konsistenzbedingungen. Als Beispiel kann der folgende Euler'sche Satz /Bill, Fritsch 1992/ erwähnt werden. Für jede zusammenhängende Abbildung (planarer Graph) gilt: p-l+f=2 wobei p = Anzahl Knoten l = Anzahl Kanten f = Anzahl Flächen (inkl. Aussenraum, der als eine Fläche zählt) 95 Abb. 4.2: Planare Graphen mit zugehöriger Euler'schen Charakteristik Andere Konsistenzbedingungen können mit Operatoren definiert werden. Wenn z.B. die Operationen "Schnitt" und "Vereinigung" definiert sind, können Konsistenzbedingungen wie folgt formuliert werden. Die folgenden Bedingungen: • "Parzellen dürfen sich nicht überschneiden" • "Zwischen den Parzellen darf keine Lücke entstehen" • "Häuser müssen innerhalb einer Parzelle sein" können wie folgt formuliert werden: Schnitt (Parzelle 1, Parzelle 2) = Vereinigung (aller Parzellen) = Schnitte (Haus, Parzelle) 96 = Parzelle 1 Null Gesamtgebiet Haus Null 4.6. Inhalt und Datentransfer 4.6.1. Beschreibung des Inhaltes Die vorgesehene Datenstruktur beschreibt die Dateninhalte eines GIS eindeutig. Für die Darstellung können ein Entitätenblockdiagramm oder ähnliche graphische Darstellungen verwendet werden. Eisenbahn Ort Adresse 1 1 Triangulationspunkte m Eisenbahnlinien m Bahnhöfe Y X H Länge Spuren Baujahr Name Punkte Linien Flächen Auch die Datendefinitionssprache der GIS-Datenbank kann für die Beschreibung gebraucht werden, sofern sie lesbar und leicht verständlich ist. In neuerer Zeit sind formale Sprachen für die Beschreibung von Strukturen für raumbezogene Daten entstanden. Die Schweiz hat mit der Entwicklung von INTERLIS Pionierarbeit geleistet. In Frankreich wurde ebenfalls eine solche Sprache entwickelt, die für den Datenaustausch (in EDIGéO) Anwendung findet. In Europa beginnt man jetzt damit, eine solche Datenbeschreibungssprache zu standardisieren. Die Beschreibung der Datenstruktur eines GIS ist das konzeptionelle Modell. 4.6.2. Referenzdatenstrukturen Eine Datenstruktur beschreibt die in einem GIS zu verwaltenden Informationen eindeutig. Eine Umkehrung dieser Aussage ist nicht gültig. Verschiedene Datenstrukturen können die gleichen Informationen enthalten. So kann z.B. ein Informationselement ein eigenständiges Objekt oder ein Attribut eines anderen Objekts sein, ohne dass daraus Informationsverluste entstehen. 97 Parzelle Liegenschaften 1 m Freie Flächen 1 mc Häuser 1 m Gebäude Bei der Realisierung eines landesweiten GIS müssen verschiedene GIS-Systeme eingesetzt werden, die die gleichen Informationen mit Hilfe verschiedener Datenstrukturen verwalten. Die vorgesehenen Inhalte müssen aber in einer formalen Sprache eindeutig beschreibbar sein, damit keine Informationslücken entstehen und der vollständige Datenaustausch gesichert wird. Ein konzeptionelles Modell als Referenz ermöglicht die Beschreibung von Minimalinhalten der Teilsysteme. Die Beschreibung des Grunddatensatzes der amtlichen Vermessung in INTERLIS ist ein Beispiel einer solchen Referenzdatenstruktur. Literaturverzeichnis Bartelme 1988: gis Technologie, Geoinformationssysteme, Landinformationssysteme und ihre Grundlagen, SpringerVerlag Bill/Fritsch 1992: Grundlagen der Geo-Informationssysteme, Hardware, Software und Daten, Wichmann-Verlag Burrough 1986: Principles Geographical Information Systems for Land Resources Assessment, Oxford Science Publications Golay 1990: Cours SIT III, EPFL Göpfert 1987: Raumbezogene Informationssysteme, Datenerfassung, Verarbeitung, Integration. Ausgabe auf der Grundlage digitaler Bild- und Kartenverarbeitung, WichmannVerlag Miserez 1991: Système d'information du territoire 1+2, Cours EPFL Pornon 1992: Les SIG, mise en oeuvre et appplications, Hermes Rouet 1991: Les données dans les systèmes d'information géographique, Hermes 98 5. 5.1. Räumliche Datenanalyse Einleitung/Definition Unter dem Begriff Datenanalyse versteht man in der Disziplin der Geoinformation jede Untersuchung, Abfrage, Auswertung usw., die mit Hilfe von gespeicherten Geodaten durchgeführt wird. Funktionen zur Datenanalyse dienen folglich der Problemlösung mit Geoinformationssystemen. Eine raumbezogene Fragestellung muss in einem GIS so umgesetzt werden, dass diese mit Operationen auf Basis von Thematik- und Geometriedaten beantwortet werden kann. Dazu gehören z.B. Abfragen nach Gemeinden mit der höchsten Arbeitslosigkeit oder auch eine Geländeperspektive berechnen und visualisieren. Die Analyseergebnisse können somit bei konkreten Fragestellungen zur Entscheidungsfindung beitragen. Bei der Definition des Begriffs der räumlichen Analyse gibt es keine allgemeingültige Antwort. Ein gängiges Definitionsbeispiel aus der Literatur: Die räumliche Analyse schliesst die Analyse und Synthese von raumbezogenen Daten zu einer Einheit. Dabei wird unterschieden zwischen der qualitativen und quantitativen räumlichen Analyse, d.h. einerseits einer Untersuchung der Art und Beschaffenheit des Problems und andererseits der Untersuchung der Menge und Grösse der vorkommenden Probleme. Jede räumliche Analyse beinhaltet die fachgerechte Interpretation der Ergebnisse. [BILL, 1999] Das Ziel der räumlichen Abfragen (spatial analysis) ist es, räumliche Beziehungen zwischen Elementen eines oder mehrerer Themen zu ermitteln, um auf dieser Basis eine Lokalisierung von Objekten zu erreichen. Meistens wird die Abfrage nicht von GISExperten selbst durchgeführt, sondern von Spezialisten anderer Fachgebiete. Die GISExperten verfügen aber in der Regel über Systeme, welche Geodaten bereitstellen und analysieren können und sie haben das erforderliche Wissen, um mit Geodaten umgehen zu können. 99 5.2. Gliederung Die Datenanalyse kann in die folgenden Teile gegliedert werden: • Direkte Abfragen (keine Änderungen der gespeicherten Daten) • Datenmanipulationen (Operationen, die eine Veränderung der Daten bewirken) • Spezialauswertungen (fachspezifische Auswertungen, Simulationen) 5.3. Direkte Abfrage Die Abfrage ermittelt räumliche Beziehungen zwischen Elementen eines oder mehrerer Themen, um auf dieser Basis eine Lokalisierung von Objekten zu erreichen. Die Analyseergebnisse können dann bei konkreten Fragestellungen zur Entscheidungsfindung beitragen. 5.3.1. Abfragestruktur Es werden nur bei einem Teil der Operationen der räumlichen Analyse wirklich neue Daten generiert. Es gibt auch reine Abfragen, bei denen das Resultat in der Datenbasis schon besteht. Dabei handelt es sich um die direkten Abfragen. Geoinformationssysteme können als Spezialfälle von Datenbankapplikationen betrachtet werden. Man kann sie ähnlich wie (relationale) Datenbanken mit Hilfe der Attribute abfragen. GIS bieten oft mehrere Möglichkeiten, um Daten auszuwählen und abzugeben. Dabei werden Daten aus einer Datenbank interaktiv durch Anwender/-innen oder durch Anwendungsprogramme abgerufen. Somit wird aus der Datenbank eine Teilmenge der Gesamtmenge der Daten extrahiert. Dabei bleiben die Ausgangsdaten unverändert. Abb. 5.1: Schema der Datenbankabfrage 100 Die Auswahlbefehle können in Textform oder durch Ausfüllen von Abfragemasken eingegeben werden. Komplexere Abfragen, die mehrere Einzelbefehle erfordern (z.B. Parzelle mit Eigentümer = „Müller“ und Bodennutzung = „Wiese“) können als Folgen von Kommandozeilen (command lines) vorbereitet werden. Um die Abfragen zu formulieren, steht in der Regel eine formale Abfragesprache zur Verfügung. Viele GIS unterstützen SQL (Structured Query Language) als Abfragesprache für die thematischen Inhalte. Abb. 5.2: Beispiele einer command line (links) und einer Abfragemaske (rechts) Die Unterteilung der Geoinformation in Thematik und Geometrie (Topologie und Metrik) charakterisiert die Abfrageformen, wie in Abb. 5.3 dargestellt. Abb. 5.3: Unterteilung der Geoinformation in Geometrie, Topologie und Thematik 101 5.3.2. Thematische Abfrage Bei der thematischen Abfrage werden Objekte selektiert, deren Attribute die gestellten Bedingungen erfüllen. Es handelt sich um eine Sachdatenauswertung. Bei der Formulierung der Fragen werden verschiedene algebraische Operatoren verwendet. Die Abfrage kann erfolgen nach • Einfache Bedingungen (eine Eigenschaft muss erfüllt sein) • Kombination von Bedingungen (min. 2 Eigenschaften werden verknüpft) Vergleichsoperatoren: Für die Formulierung von Fragen können neben dem Gleichheitszeichen auch Vergleichsoperatoren verwendet werden. Die Vergleichsoperatoren werden nicht nur für numerische Attribute, sondern auch für Text-Attribute oder andere Datentypen verwendet. Vergleichsoperatoren: = > >= < <= <> Arithmetische Operatoren: Die arithmetischen Operatoren werden für numerische Attribute verwendet. Arithmetische Operatoren: + * / exp. % Logische Operatoren: Eine Bedingung kann beliebig formuliert werden. Dabei müssen die Verknüpfungsmöglichkeiten der einzelnen Bedingungen erweitert werden. Komplexere Abfragen werden mittels Kombination von verschiedenen Attributen formuliert. Für solche Abfragen werden logische Operatoren verwendet, welche Ausdrücke - mit zwei möglichen Werten „wahr“ oder „falsch“ - verbinden. 102 Logische Operatoren Venn-Diagramme Ergebnis AND Wahr, wenn beide wahr sind. OR Wahr, wenn mind. einer wahr ist. XOR Wahr, wenn genau einer wahr ist. NOT Wahr, wenn einer falsch ist. Beispiel: Welche Parzelle enthält Lärchen und hat einen Vorrat der > 110m3 ist? Abb. 5.4: Eine Verknüpfung mit logischen Operatoren 5.3.3. Geometrische Abfrage Bei der geometrischen Abfrage werden Objekte selektiert, deren Attribute die gestellten geometrischen Bedingungen erfüllen. Die drei geometrischen Grundformen sind Punkte, Linien und Flächen. Um geometrische und auch topologische (siehe Kapitel 5.3.4) Analysen durchzuführen sind die üblichen Datenbankanfragen (Selektion von Objekten, etc.) und geometrischen Algorithmen (Berechnung von Abständen, etc.) erforderlich. 103 Die Abfrage kann erfolgen nach • Geokoordinaten (Wer ist Eigentümer von Punkt P(X/Y)?) • optischer Entscheidung (Wem gehört das Gebäude?) Beispiel 1: Selektiere die Bergspitzen, die weniger als 500 m von den Hütten entfernt sind. Abb. 5.5: Bergspitzen mit einer zirkularen Distanz von 100m (links) und die selektierten Hütten (rechts) Die räumlichen Analysen werden erweitert durch zusätzliche Funktionen wie Buffering. Ein Distanzpuffer ist eine räumliche Ausdehnung um einen Punkt, eine Linie oder eine Fläche, bestimmt durch eine Distanz. Abb. 5.6: Pufferzonen in einem Vektormodell um Punkt, Linie und Polygon Beispiel 2: Die Delaunay-Triangulation und das Voronoi-Diagramm Die Delaunay Triangulation ist eng verbunden mit dem Voronoi Diagramm. Sie ist nach B. Delaunay benannt, der diesen dualen Zusammenhang als erster nutzte In einer Delaunay-Triangulation wird jeder Punkt durch Dreieckseiten mit den Nachbarpunkten verbunden. Es entstehen Dreiecke • mit den kleinsten Umkreisradien • mit Umkreisen, in denen kein Eckpunkt eines anderen Dreiecks liegt • mit den grössten minimalen Winkeln (Min-Max-Kriterium) • mit Dreieckseiten, deren Längen am wenigsten differieren • die Umhüllende der DT ist konvex 104 • die DT-Dreiecke überlappen sich nicht • bei n Punkten, wobei n die Anzahl der Aussenpunkte sein soll, gibt es 3 (n-1) - n Dreieckseiten und 2 (n-1) - n Dreiecke (Eulersche Formel) • der zu einem Punkt nächstliegende Punkt ist durch eine Seite miteinander verbunden Abb. 5.7: Delaunay-Triangulation einer Menge von Punkten in der Ebene Die Ecken der Voronoizellen sind die Umkreismittelpunkte der Dreiecke der Delaunay-Triangulation. • Eine Voronoi-Region ist immer konvex. Ein solches Polygon wird auch Thiessen- Polygon genannt. • Am Gebietsrand verlaufen die Kanten des VD ins Unendliche. • Die Schnittpunkte der Mittelsenkrechten in den DT-Dreiecken sind die Knoten im VD. Diese Knoten sind die Mittelpunkte der Umkreise der Triangulation der Delaunay-Dreiecke. • In den Knoten des VD stossen in der Regel 3 Kanten zusammen. • Liegen vier Punkte der Delaunay-Triangulation auf einem Umkreis, stossen im VD- Knoten vier Kanten zusammen. Abb. 5.8: Voronoi-Diagramm (links); Voronoi-Diagramm und Delaunay-Triangulation (rechts) 5.3.4. Topologische Abfrage Während räumliche Selektionskriterien Objekte anhand ihrer Lage auswählen und thematische Abfragen Elemente bezüglich ihrer Eigenschaften identifizieren, basieren die topologischen Suchkriterien auf der Anordnung der Objekte im Raum; d.h. z.B. über Zugriffsmerkmale wie “nächster”, “Teil von” oder “innerhalb”. Bei der topologischen Abfrage werden Objekte selektiert, deren Attribute die gestellten Bedingungen bzgl. 105 den räumlichen Beziehungen zueinander erfüllen. Die topologischen Beziehungen werden ebenfalls aus den drei geometrischen Grundformen aufgebaut. Anhand dieser geordneten Struktur ist das System in der Lage, die topologischen Beziehungen zu erkennen und Analysen durchzuführen. Die Abfrage kann erfolgen nach • Nachbarschaft (Welches Grundstück grenzt an diesen Flussabschnitt?) • Festlegung durch Beziehungen der Geoobjekte zueinander (folgende Abbildung) Topologische Beziehungen 5.3.5. Graphische Darstellung Erklärung Disjoint Objekt A und Objekt B weisen keine Schnittfläche auf Meet Objekt A und Objekt B berühren sich an den Grenzlinien Overlap Objekt A und Objekt B überschneiden sich Contains Objekt A enthaltet Objekt B Inside Objekt B liegt innerhalb Objekt A Covers Objekt A deckt Objekt B Coverd by Objekt B ist vom Objekt A bedeckt Equal Objekt B und Objekt A stimmen überein Darstellung von Abfrageergebnisse Die räumliche Datenanalyse stellt besondere Anforderungen an die Darstellung der Abfrageergebnisse. Objekte, welche eine bestimmte Bedingung erfüllen, möchte man mit einer sichtbaren Farbe kennzeichnen, andere Objekte möchte man unauffällig abbilden. Das GIS ermöglicht die Darstellung nach den eigenen Wünschen zu beeinflussen. 106 Folgende Darstellungsarten werden oft verwendet: • tabellarisch (selektierte Objekte mit gewünschten Attributen) • Diagramme • graphisch (Plan, visuelle Darstellung) • textlich (v.a. für Attributswerte) • sonstige bildliche Darstellung… 5.3.6. Komplexe räumliche Abfragen Die Anzahl der möglichen Analyseverfahren ist nicht begrenzt, vor allem wenn auch mehr oder weniger komplexe Berechnungen verwendet werden. Die Berechnungen können als Bestandteil der Abfragen vorkommen oder als Funktionen der Abfrageergebnisse, um ihre Interpretation zu erleichtern. Die folgenden nicht vollständigen Beispiele zeigen Operationen, die oft für direkte Abfragen verwendet werden. Zählen und messen • Zählen von Objekten, die zu einer Klasse oder einem Gebiet gehören • Distanzen entlang von Linien berechnen • Azimute zwischen zwei Punkten bestimmen • Länge des Perimeters einer Fläche bestimmen • Flächeninhalt eines flächenförmigen Objektes berechnen • Volumenberechnungen zwischen 2 digitalen Geländemodellen (Aushubvolumen) • Höhenunterschiede zwischen Punkten ein einem digitalen Geländemodell berechnen Funktion der Raumanalyse • Überlagern von Flächen mit Punkten und bestimmen, welche Punkte in welchen Flächen liegen • Überlagern von Flächen und Linien. Die Linien bestimmen, welche über die einzel- nen Flächen verlaufen • Überlagern von mindestens zwei flächenartigen Objekten. Objekte suchen, die eine Überlappung mit den einzelnen Objekten der anderen Klasse aufweisen • Bestimmen der nächsten Nachbarpunkte, -linien, -flächen • Bestimmen der kürzesten Verbindung oder der Linie minimaler Kosten 107 Statistische Analyse • Erstellen von Listen und Verzeichnissen über Objekte und Attribute • Durchführen arithmetischer, algebraischer und logischer Operationen an Geometrie- und Attributdaten, einzeln und kombiniert • Schätzung von Erwartungswerten (Mittelwert) und Varianzen • Durchführung von deskriptiven oder analytischen statistischen Operationen (z.B. statistische Tests) • Vergleich von Zeitreihen; Bestimmen von Unterschieden; Berechnung von Verän- derungsfunktionen; usw. • Statistische Analysen von Funktionen von Attributen aus verschiedenen Objekten • Netzwerkanalysen, z.B. Simulation von Verkehrsflüssen • Mehrdimensionale Analysen; Analysen; Ordnungsstatistiken Regressionen; Diskriminanzanalysen; Cluster- Geländeinterpolation • Interpolation der Höhe in einem DGM an jedem beliebigen Punkt • Höhenberechnung entlang von Wasserlinien aus einem DGM • Berechnung von Höhenkurven oder Isolinien aus einem unregelmässigen Punktnetz • Berechnung von Höhenkurven mit gegebenen Intervallen aus einem DGM (Raster oder TIN) • Berechnung von Wasserscheiden und Einzugsgebieten aus einem DGM und dem zugehörigen Gewässernetz • Bestimmen der gegenseitigen Sichtbarkeit von Punkten, Teilen von Linien oder Flä- chen • Berechnung von sichtbaren Flächen eines DGM von einem gegebenen Betrach- tungspunkt aus (viewshed maps) • Berechnen der Steigung/Neigung entlang von Linien • Berechnen der mittleren Steigung/Neigung von Flächen • Berechnen der mittleren Orientierung von Flächen 108 Interpolation von Punkteigenschaften aus einem unregelmässigen Feld von Stützwerten • Interpolation von beliebigen Punktwerten • Berechnen von Isolinien • Maxima und Minima 5.4. Datenmanipulation Bei der Datenmanipulation können neue geographische Informationselemente erzeugt werden, die in späteren Schritten wiederum in Analyseoperationen verwendet werden können. In der Regel müssen die neuen Objekte vorgängig konzeptionell modelliert werden und ihre Datenstruktur muss im GIS mit der Datenbeschreibungssprache implementiert werden. Einzelne GIS können für die Objekte automatisch eine minimale Datenstruktur (ohne thematische Attribute) generieren. Die Kombination von unterschiedlichen Objekten führt zu neuen Informationen, mit verändertem Informationsgehalt, welche als neue geographische Objekte betrachtet und verwaltet werden können. Sie können im System für weitere Analysen verwendet werden. Gefahrenzone am Fluss Häuser am Fluss Häuser in der Flussgefahrenzone Abb. 5.9: Beispiel einer Datenmanipulation 5.5. Spezialauswertungen Eine der wichtigsten Applikation von Geoinformationssystemen ist die Bereitstellung der Geodaten für die Lösung von technischen, administrativen und politischen Problemen in speziellen Fachbereichen. Das GIS wird verwendet, um die erforderlichen räumlichen Informationen zu selektieren, die in der Regel exportiert und in Problem bezogenen Verfahren eingesetzt werden. Diese effektive Form der Datenanalyse wird vor allem von Fachpersonen ausgeführt. Zur effizienten Nutzung dieser Möglichkeiten sind oftmals fachspezifische GIS-Lösungen erforderlich. 109 Die Spannweite der Anwendungen reicht von der digitalen Biotopkartierung und dem elektronischen Stadtplan zur digitalen Planung von grossen Sportanlässen bis zur Berechung der Lande- und Anflugwege von Flugzeugen. Die Liste der Beispiele könnte beliebig fortgesetzt werden. Die folgenden Beispiele zeigen die Vielfalt der Anwendungen auf. Beispiel 1: Verkehrsmodelle, (http://www.swissinfo-geo.org) Fahrzeitberechnungen, Abb. 5.10: Routenberechnung und Fahrzeugnavigation mit GIS Beispiel 2: Meteorologie Abb. 5.11: Wettervorhersage von MeteoSchweiz mittels GIS 110 Fahrzeugnavigation 5.6. Algorithmen der räumlichen Datenanalyse 5.6.1. Geometrische Algorithmen Die Algorithmische Geometrie beschäftigt sich mit dem Entwurf und der Analyse von Algorithmen für geometrische Probleme für Objekte wie Punkte, Linien, Polygone, usw. in der Ebene und in höher dimensionalen Räumen. Geometrische Algorithmen müssen in allen Fällen funktionieren und leistungsfähig bleiben auch wenn die Datenmenge sehr gross ist. Zudem müssen sie eine hinreichende Genauigkeit besitzen. Sie werden angewandt bei Schnittproblemen, Einschlussproblemen und Distanzproblemen. Die folgenden Beispiele dienen dazu, die Vielfalt der Algorithmen zu illustrieren. Beispiel 1:Schnitt von zwei Geraden P1 P2: Ax + By = C P3 P4: Dx + Ey = F A = Y2 – Y1 B = X1 – X2 C = X1 * Y2 – Y1 * X2 D = Y4 – Y3 E = X3 – X4 F = X3 * Y4 – Y3 * X4 DELTA = A * E – D * B Wenn DELTA = 0 ist, sind die Geraden parallel Sonst (Schnittpunkt): X = (C * E – B * F) / DELTA Y = (A * F – C * D) / DELTA Wenn |X1 – X2| ≥ |Y1 – Y2| Wenn |X1 – X2| < |Y1 – Y2| L = (X – X1) / (X2 – X1) L = (Y – Y1) / (Y2 – Y1) Wenn 0 ≤ L ≤ 1 ist, befindet sich der Schnittpunkt innerhalb von P1P2 Analog bestimmt man die Lage von P innerhalb von P3P4 111 Abb. 5.12: Schnitt von zwei Geraden Beispiel 2:Schnitt von Polygonlinien Wenn die umschliessenden Rechtecke sich nicht überlappen, gibt es keinen Schnittpunkt (L1 mit L3). Wenn die umschliessenden Rechtecke sich überlappen, könnte ein Schnittpunkt existieren (Schnitt L1, L2). Dann berechnet man die Schnitte zwischen allen Strecken der ersten und der zweiten Polygonlinie, die sich mindestens teilweise im Überlappungsrechteck befinden. Abb. 5.13: Schnitt von Polygonlinien Beispiel 3: Bestimmung ob ein Punkt in einer Fläche enthalten ist Eine ungerade Anzahl Schnittpunkte zwischen der Halbgerade aus P und der Kurve L bedeutet, dass P sich innerhalb der Fläche befindet. Abb. 5.14: Die Lage des Punktes P bezüglich der Fläche 112 5.6.2. Geometrische und thematische Algorithmen Gemischte Algorithmen arbeiten nicht nur mit geometrischen oder thematischen Eigenschaften, sondern sie berücksichtigen alle Komponenten. Die geographischen Objekte werden auf Grund der kleinsten geometrischen Elemente unterteilt und allen dort bestehenden Attributen zugeordnet. Polygon A B Zonen Wohnzone Industrie Polygon C D Nr. Kulturen 2 1 Polygon Kombination A-C A-D B-D B-C E F G H Zonen Nr. Kulturen Wohnzone Wohnzone Industrie Industrie 2 1 1 2 Abb. 5.15: Schnittberechnung 113 Literaturverzeichnis Bailey, Trevor C., 1994: A Review of Statistical Spatial Analysis in Geographical Information Systems. Spatial Analysis and GIS (Editor: Fotheringham, Stewart and Rogerson, Peter. Publisher: Taylor and Francis, London.), 13-44. Berry, Brian J. L., Marble, Duane F., 1998: Spatial Analysis: A Reader in Statistical Geography. Englewood Cliffs, New Jersey: Prentice Hall. Bartelme, N., 2000: Geoinformatik - Modelle, Strukturen, Funktionen. 3rd. Berlin: Springer. Bill, Ralf, 1999: Grundlagen der Geo-Informationssysteme - Band 1. Heidelberg: Wichmann Verlag. Bill, Ralf, 1999: Grundlagen der Geo-Informationssysteme - Band 2. Heidelberg: Wichmann Verlag. Burrough, P. A., McDonnell, R. A., 1998: Principles of Geographical Information Systems. New York: Oxford University Press. Carosio, A., 2000: Geoinformationssysteme - Band 1. Institut für Geodäsie und Photogrammetrie, ETH Zürich. Chou, Yue-Hong, 1997: Exploring Spatial Analysis in GIS. Santa Fe: OnWord Press ESRI: ArcInfo Help Goodchild, Michael F., 1990: Spatial Analysis Using GIS. Publisher. In: Fourth International Symposium on Spatial Data Handling. Zurich, Switzerland: University of Zurich. Longley, Paul A., Goodchild Michael, F., Maguire David, J., Rhind David, W., 1999: Geographical Information Systems. Principles, techniques, applications and management. John Wiley & Sons, Inc. publishers. Saaty, Thomas L., 1980: The Analytic Hierarchy Process: Planning Setting Priorities, Resource Allocation. New York: McGraw-Hill International. 114 6. 6.1. Rastermodelle in Geo-Informationssystemen Grundlagen In den bisher betrachteten Beispielen wird die geometrische Komponente der GeoInformation mittels metrischen und topologischen Eigenschaften festgelegt. Koordinatenpaare bilden die Grundlage und stellen den Raumbezug her. Man spricht von vektororientierten Datenstrukturen. Eine Alternative zu dieser Form der Datenspeicherung bieten Rastermodelle, die nach folgendem Prinzip aufgebaut sind: Der betrachtete Raum wird in eine grosse Zahl gleichartiger Flächenelemente unterteilt und zu jedem Element wird die dazugehörige raumbezogene Information gespeichert. 6.1.1. Eigenschaften und Begriffe (Rasterbilder) Pixel Kurzform für "Picture element" (Bildelement); ist das kleinste Informationselement in einem zweidimensionalen Rastermodell Geometrische Auflösung ist die Anzahl Pixel, die eine Längeneinheit enthält, z.B. 20 Pixel/mm oder 400 Dots per Inch (= dpi) Radiometrische Auflösung Werte, die zu jedem Pixel gespeichert werden können, z.B. die Anzahl Bit oder der Wertebereich (z.B. 0255), der für die Kodierung der Pixel zur Verfügung steht Binärbilder zu jedem Pixel wird lediglich der Wert 0 oder 1 gespeichert Halbtonbilder zu jedem Pixel wird ein Wert (z.B. 0-255, d.h. 8 bit Auflösung) einer Grenzwertskala gespeichert Farbbilder entweder wird eine begrenzte Anzahl Farben aus einer Farbskala angegeben oder für Echtfarbendarstellungen die Intensität der 3 Grundfarben (3 mal 8 Bit, "True Color", ca. 16.7 Mio verschiedene Farbtöne) 115 6.1.2. Anwendungen Rastermodelle werden in unserem Umfeld täglich eingesetzt. Die folgende Liste zeigt einige Anwendungsbeispiele: • Fernsehbilder • Telefax • Satellitenfernerkundung (z.B. Meteobild) • Kartographische Reproduktionstechnik • Digitale Höhenmodelle • Areale Modelle (Statistik) Anwendungskategorien Die aufgeführten Applikationsbeispiele lassen zwei Anwendungskategorien erkennen: Thematische Rastermodelle, in welchen zu jedem Rasterelement thematische, raumbezogene Informationen gespeichert werden (z.B. digitales Geländemodell der Schweiz, Hektarraster) und Rasterbilder, in welchem zu jedem Rasterelement (entsprechende) Daten für die graphische Darstellung gespeichert sind. Abb. 6.1: Beispiel "Thematischer Rastermodelle" 116 Abb. 6.2: Beispiel „Graphischer Rastermodelle“ 6.1.3. Vorteile und Nachteile Die Entscheidung, ob Geo-Informationen mit koordinatenorientierten Strukturen (Vektorstrukturen) oder mit Rasterstrukturen zu speichern sind, hängt von vielen Faktoren ab. Die folgende Tabelle zeigt einige Merkmale beider Formen der Datenverwaltung: Vektorstrukturen Vorteile: Nachteile: • Speicherbedarf klein • Raumbezogener Zugriff aufwendig • Geometrische Transformationen leicht • Kombination von Datenebenen auf- durchführbar wendig • Objektorientierung • Datenerfassungsarbeiten intensiv • Komplexe thematische Verknüpfung möglich • Thematische Abfragen und Analysen in allen Formen • geometrisches Auflösungsvermögen (fast) beliebig gross 117 Rasterstrukturen Vorteile: Nachteile: • Einfache Konzeption • Speicherbedarf gross • Flächendarstellung unproblematisch • Geometrische Transformationen auf- wendig • Flächenoperationen leicht durchführ- • Algorithmen-Abfragen und -Analysen bar z.Z. unmöglich • Datenerfassung schnell und günstig • geometrisches Auflösungsvermögen durch die Datenmenge begrenzt • Raumbezogener Datenzugriff leicht 6.2. Datenstrukturen Die Speicherung von Informationen in Rastermodellen ist einfach, erfordert aber oft ausgeklügelte Kompressionsverfahren, um das Datenvolumen in annehmbaren Grössen zu halten. Auf der Stufe des konzeptionellen Modells kann die Datenstruktur folgendermassen dargestellt werden: Thema A PIXEL Zeile Kolonne 1 c 1 c Attribut Attribut ......... Thema B Attribut Attribut ......... Die Realisierung auf der logischen und physikalischen Ebene kann in verschiedenen Formen stattfinden. Die folgenden Beispiele zeigen einige charakteristische Lösungsansätze. 118 6.2.1. Ungeordnete Pixellisten Zu jedem Pixel wird die thematische Information (z.B. die Farbe) und die Position gespeichert. Zeile 6.2.2. Kolonne Farbe 2 3 Grün 3 4 Blau .... .... .... Vollständige Tabellen (Matrizen) Die thematischen Informationen werden tabellarisch gespeichert. Der Raumbezug wird durch die Reihenfolge der Speicherung hergestellt. Dadurch entstehen grosse Datenmengen, die entsprechend aufwendig zu verwalten sind. Beispiel: Das digitale Höhenmodell der Schweiz Row 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Column 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 3 3 3 3 3 2 2 0 0 0 0 0 0 0 0 0 0 0 3 3 3 3 3 3 2 2 2 2 2 0 0 0 0 0 0 0 0 0 3 3 3 3 3 1 2 2 2 2 2 2 0 0 0 0 0 0 0 3 3 3 3 3 1 1 2 2 2 2 2 2 0 0 0 0 0 0 0 1 1 1 1 1 1 1 2 2 2 2 2 2 2 0 0 0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 0 0 0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 0 0 0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 0 0 0 119 0 0 2 2 2 1 1 1 1 1 1 1 2 2 2 2 2 2 0 0 0 0 2 2 2 2 1 1 1 1 1 1 2 2 2 2 2 0 0 0 0 0 2 2 2 2 1 1 1 1 1 1 2 2 2 2 2 0 0 0 0 0 2 2 2 2 1 1 1 1 1 3 2 2 2 2 2 0 0 0 0 0 2 2 2 2 1 1 1 1 3 3 3 3 3 3 3 0 0 0 0 0 0 2 2 1 1 1 1 3 3 3 3 3 3 3 0 0 0 0 0 0 0 2 1 1 1 1 3 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 3 3 3 3 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Um das Problem der grossen Datenmengen zu entschärfen, wurden eine Vielzahl verschiedenster Datenkompressionsverfahren entwickelt. Unter Kompression ist eine Datenreduktion ohne Informationsverlust zu verstehen. Die Lauflängenkodierung (engl.: Run-length encoding) ist ein einfaches Verfahren, das wirksam eingesetzt wird, wenn Nachbarpixel gleiche Werte annehmen. Dies ist vor allem dann der Fall, wenn der Datensatz eine kleine Anzahl unterschiedlicher Grauwerte, Farben oder thematischer Informationen enthält (z.B. wird eine topographische Karte nur mit 5-10 Farben dargestellt). Das Rastermodell wird in Zeilen unterteilt und zu jeder Zeile werden Wertepaare aus Pixelwert (z.B. Farbe) und Anzahl Wiederholungen gebildet. 0 0 0 Zeile 0 0 0 0 0 0 0 0 0 0 0 0 0 3 3 3 3 3 0 Origninalzei- 0 0 0 0 3 3 3 3 3 3 2 0 0 0 3 3 3 3 3 3 2 2 0 0 0 3 3 3 3 3 1 2 2 0 0 3 3 3 3 3 1 1 2 2 0 0 1 1 1 1 1 1 1 2 2 0 1 1 1 1 1 1 1 1 1 2 0 1 1 1 1 1 1 1 1 1 2 0 1 1 1 1 1 1 1 1 1 2 0 2 2 2 1 1 1 1 1 1 1 0 2 2 2 2 1 1 1 1 1 1 0 2 2 2 2 1 1 1 1 1 1 0 2 2 2 2 1 1 1 1 1 3 0 2 2 2 2 1 1 1 1 3 3 0 0 2 2 1 1 1 1 3 3 3 0 0 2 1 1 1 1 3 3 3 3 0 0 0 3 3 3 3 3 3 3 3 0 0 0 0 0 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 3 3 1 1 1 1 2 2 2 2 2 2 1 3 0 0 Lauflängenkodierte Zeile 3, 0 3, 3 4, 1 6, 2 1, 1 1, 3 2, 0 Kartographische Bilder lassen sich mit der Lauflängenkodierung sehr gut komprimieren. Die Daten erreichen auch bei feinstrukturierten und komplexen Bildern ca. 1015% des ursprünglichen Datenvolumens. 6.2.3. Blockweise Kodierung Mit diesem Kompressionsverfahren wird das Rastermodell in unterschiedlich grosse Quadrate unterteilt. Zu jedem Quadrat wird die Lage (X, Y), die Grösse (Seitenlänge) und die thematische Information (z.B. Farbe) gespeichert. 120 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 6.2.4. Zeile Kolonne Grösse Farbe 9 2 1 1 9 3 1 1 9 6 1 1 9 8 1 1 9 9 2 1 10 1 1 1 10 2 1 1 10 3 4 1 10 7 2 1 .... .... .... .... Quadtrees Das Rastermodell wird zunächst in relativ grosse Quadrate unterteilt. Liegen innerhalb eines Quadrats unterschiedliche Informationen vor, wird dieses in 4 gleich grosse 121 Quadrate unterteilt. Dieser Vorgang wird solange wiederholt, bis das gesamte Gebiet innerhalb eines Quadrats identische Informationen aufweist, oder bis die - durch den Anwender vorgegebene - kleinste Einheit eines Quadrats erreicht ist. Diese hierarchische Quadtree-Unterteilung ist ein Prinzip, mit dem der Zugriff auf raumbezogene Rasterdaten effizient möglich ist. Nr Quadrat Farbe 6 06. 0 7 07. 0 8 08. 0 9 09.1.1 0 10 09.1.2 1 ... ... ... 28 09.3 1 ... ... ... 37 13.1 0 38 13.2.1 1 39 13.2.2 1 ... ... ... 48 13.2.3 0 ... ... ... 122 6.2.5. Lauflängenkodierung mit variabler Bit-Anzahl Um einen besonders hohen Komprimierungsgrad zu erzielen, wird die statistische Verteilung der Daten analysiert. Die Redundanz kann durch geeignete Verfahren erheblich reduziert werden. Die Speicherung durch Lauflängenkodierung zeigt, dass unterschiedliche Längen auch unterschiedlich häufig auftreten. Die Verteilung der auftretenden Lauflängen ist durch ein Histogramm übersichtlich darzustellen. Absolute Häufigkeit Lauflänge Histogramm p(L) 4.864 1 **** 7.829 2 ******* 23.671 3 *********************** 17.537 4 ***************** 9.253 5 ********* 4.905 6 **** 3.266 7 *** 2.063 8 ** 1.496 9 * 1.395 10 * 1.897 11 * 1.068 12 * 0.524 13 0.488 14 0.491 15 0.466 16 0.529 17 0.654 18 0.571 19 0.556 20 0.457 21 Bei der Lauflängenkodierung mit variabler Bitanzahl werden häufig auftretende Wertepaare durch wenige Bit kodiert und für selten auftretende Wertepaare wir eine entsprechend grössere Anzahl Bit reserviert. 123 Fortlaufende Nummer Lauflänge Rel.Häufigkeit Abs.Häufigkeit Kodierung 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 3 4 5 2 6 1 7 8 11 9 10 12 18 19 20 17 40 13 15 14 16 21 22 39 1727 23 24 25 26 300 64 27 128 35 118 63 28 0.236 0.175 0.092 0.078 0.048 0.048 0.032 0.020 0.018 0.014 0.017 0.010 0.006 0.005 0.005 0.005 0.005 0.005 0.004 0.004 0.004 0.004 0.004 0.003 0.003 0.003 0.002 0.002 0.002 0.002 0.002 0.002 0.002 0.001 0.001 0.001 0.001 40620 451 23799 26848 16820 16680 14000 10614 9768 7644 6612 6412 3927 3430 3339 3632 3608 3600 3368 3352 3200 3136 2832 2584 2392 2168 2052 1998 1962 1890 1881 1818 1782 1458 1449 1363 1350 10 000 111 0011 0111 1100 01010 001010 010001 010111 011011 0010000 0110100 1101101 11011110 00100011 00100101 00100110 00101110 00101111 01000011 01001000 01001101 01011010 01100011 11010001 001000101 001001111 001011000 001011011 010000000 010000011 010010010 010110110 010110111 011000100 011001000 1727 … … … 0110… Als Beispiel eines solchen Verfahrens ist das Morse-Alphabet zu erwähnen, in welchem die statistische Verteilung der einzelnen Buchstaben des Alphabets in englischen Texten berücksichtigt wurde. 124 Diese Komprimierungstechniken finden vor allem dort Verwendung, wo hohe Komprimierungsfaktoren gewünscht sind (Telekommunikation, Fax) und wo die RLCWertepaare sehr unterschiedliche relative Häufigkeiten aufweisen (z.B. Schriftdokumente). i Buchstabe xi p(xi) Morse Alphabet 1 A 0.082 •– 2 B 0.014 –••• 3 C 0.028 –•–• 4 D 0.038 –•• 5 E 0.131 • 6 F 0.029 ••–• 7 G 0.020 ––• 8 H 0.053 •••• 9 I 0.063 •• 10 J 0.001 •––– 11 K 0.004 –•– 12 L 0.034 •–•• 13 M 0.025 –– 14 N 0.071 –• 15 O 0.080 ––– 16 P 0.020 •––• 17 Q 0.001 ––•– 18 R 0.068 •–• 19 S 0.061 ••• 20 T 0.104 – 21 U 0.025 ••– 22 V 0.009 •••– 23 W 0.015 •–– 24 X 0.002 –••– 25 Y 0.020 –•–– 26 Z 0.001 ––•• N = 26 1.000 125 Um den Informationsgehalt eines lauflängenkodierten Rasterbildes zu prüfen bzw. um die tatsächliche Ausnützung der vorgesehenen Bitanzahl zu ermitteln, verwendet man die Entropie I als quantitatives Informationsmass Ν Ι = −∑ p(L i ) log 2 p(L i ) i =1 N Gesamtanzahl aller Längen. p(Li) relative Häufigkeit der Länge Li Treten alle Längen gleich häufig auf, d.h. p(Li) = 1/N, dann erreicht die Entropie den Maximalwert I0 Ν Ι 0 = −∑ i =1 1 1 ⋅ log 2 = log 2 Ν Ν Ν I0 entspricht in diesem Fall genau der Anzahl Binärziffern (Bit), die für die unterschiedliche Kodierung der N Längen notwendig sind. Für homogene Bilder (nur ein Grauwert, kein Informationsgehalt!) nimmt die Entropie den Wert Null an: I = 0. Für ein bestimmtes Bild kann nun die relative Redundanz r berechnet werden: r =1- Ι Ι0 Aus Versuchsreihen wurde für in englischer Sprache abgefasste Dokumente eine Entropie I = 4.129 bestimmt, während I0 = 4.7 ist. Die relative Redundanz ergibt sich in diesem Fall r = 0.121. 6.3. Arbeiten mit Rasterdaten Die üblichen Operationen, die in Rastermodellen ausgeführt werden, unterscheiden sich stark von denjenigen, die man in vektororientierten Systemen ausführt. Während mit Vektordaten Operationen typisch sind, wie z.B.: • Selektion von Objekten • Veränderung von Datenelementen (Topologie oder/und Metrik) • Geometrische Konstruktionen und Berechnungen • usw. 126 treten in Rastermodellen häufig andere Funktionen auf, wie z.B.: • Freihandzeichnen • Füllen von Flächen • Teilbilder einfügen oder überlagern • Farbwechsel • Flächen bestimmen (in Anzahl Pixel) • Ermitteln von Kanten, Skelette, Schwerpunkte ... • Filteroperationen • usw. Durch geeignete Abfolgen solcher Operationen können aus Bildern völlig neue Bilder hergeleitet werden, die für vorgesehene Anwendungen gewünschte Eigenschaften aufweisen und z.B. die visuelle Betrachtung oder Raumbezogene Analysen erleichtern. 6.4. Grundoperationen mit Rasterdaten Die Arbeit mit Rasterdaten stützt sich auf einige Grundoperationen, die entsprechend kombiniert, zu den gewünschten Funktionen führen. Man unterscheidet Einzelpixel Operationen und Lokale Operationen. 6.4.1. Einzelpixel Operationen (punktautonome Operationen) Es handelt sich um Farbänderungen (bzw. Grauwertänderungen) für einzelne Pixel aufgrund dessen Wert im Ausgangsbild, ohne Berücksichtigung der Lage oder der Nachbarschaft. Punktautonome Operationen werden auch als "Transfercharakteristik" bezeichnet. Im allgemeinen Fall ist diese durch eine Tabelle definiert, die zu jeder Farbe bzw. Grauwert des Ausgangsbildes B0 den entsprechende Wert des abgeleiteten Bildes B1 angibt (tabellarische Zuweisung, evtl. auch formale Beschreibung). Β 0 ( x, y ) → Β 1 ( x , y ) Typische Anwendungen punktautonomer Operationen sind Kontraständerungen, Verdunklung oder Aufhellung von Binärbildern, Zusammenfassen von Farb/Grauwertintervallen ("Äquidensitenbildung") oder die Erzeugung von Binärbildern aus Halbtonbildern ("Schwellwertbildung"). 127 6.4.2. Lokale Operationen Eine lokale Grauwertoperation ist definiert als die Berechnung eines Ausgangsbildelementes aus mehreren Eingangsbildelementen. Theoretisch hat man bei der Definition einer solchen lokalen Operation unendlich viele Freiheitsgrade und Auswahlmöglichkeiten. Von praktischer Bedeutung sind jedoch ausschliesslich Operationen, die eine thematische Interpretationsmöglichkeit aufweisen. Hierzu zählen allgemein die Faltungen, die Berechnung von Abstandstransformationen, die Skelettierung von Bildern, sowie Flächenfüllungen in Bildern. Zur Faltung: Hierbei definieren die Koeffizienten f (i, k) den Typ der linearen Ortsfilterung und werden daher auch als Filterkoeffizienten bezeichnet. Die Dimensionen n und m der Filtermatrix sind meist ungerade und ermöglichen somit eine Zentrierung der Filtermatrix über der Position x, y. Abb. 6.3: Prinzip der Faltung Die einzelnen Elemente der Filtermatrix entsprechen dem Gewicht, mit dem Grauwerte in die Summation über den Filter eingehen. Der Wert des zentralen Pixels der Filtermatrix wird durch die gewichtete Summe der Umgebung ersetzt. Filter werden üblicherweise verwendet, um spezielle Bildinhalte hervorzuheben oder zu unterdrücken (Rauschen beseitigen, Kantenermittlung u.v.a.). Zur Abstandstransformation: Die Abstandsformierte eines Eingangsbildes ist ein Ausgangsbild, in dem jedes Bildelement einen Grauwert gleich seinem Abstand vom nächstgelegenen "Situationsbildelement" des Eingangsbildes hat. Der Abstand kann hierbei auf verschiedene Weise definiert werden. 128 Zur Flächenfüllung: Beim Flächenfüllen geht es darum, einzelne Bildelementsgrauwerte innerhalb vorgegebener Flächen sich durch Verdicken derart vermehren zu lassen, dass die gesamte Fläche gefüllt wird. Es wird dabei so vorgegangen, dass Flächenkeime gesetzt werden, die über einen vorgegebenen Hintergrundgrauwert ausgebreitet werden. Diese Flächenkeime können interaktiv am Bildschirm, oder durch Bildkoordinaten definiert werden. Eine andere Gruppe lokaler Operationen ermöglichen die bitbezogenen logischen Operatoren • Und (AND) • Inklusiv Oder (IOR) • Exklusiv Oder (EXOR) • Nicht (NOT) Die Definitionen sind aus den folgenden Beispielen ersichtlich: 0 0 1 0 0 0 0 1 0 0 1 1 1 1 1 1 0 1 1 0 1 0 1 0 0 1 0 0 0 1 0 1 1 1 1 0 0 0 0 1 0 1 1 0 1 1 0 0 1 0 0 0 0 0 0 1 0 1 1 1 0 1 1 0 1 1 1 0 1 0 1 0 0 1 0 0 0 0 1 0 1 1 0 1 0 0 0 1 0 1 NOT AND IOR EXOR 1 0 1 0 0 0 1 0 0 = = = = 129 Die logischen Operationen lassen sich bitweise an den Grau- oder Farbwerten der einzelnen Pixel anwenden. Mit dem Operator AND lassen sich geometrische Durchschneidungen, mit IOR geometrische Vereinigungen und mit NOT geometrische Differenzen bilden. Diese Operatoren finden u.a. bei lokalen Operationen zwischen mehreren Eingangsbildern Anwendung. Durch geeignete Kombination der logischen Operatoren lassen sich 3 weitere typische lokale Operationen zusammenstellen: • Verdicken • Verdünnen • Bereinigen (Löschen von isolierten Pixel) Für ein Ausgangsbild A und ein hergeleitetes Bild B können folgende Formeln verwendet werden: Das Verdicken ("Blow"): B(x, y) = A(x,y) IOR A(x+1,y) IOR A(x-1,y) IOR A (x,y+1) IOR A(x,x-1) Das Verdünnen ("Shrink"): B(x,y) = A(x,y) AND A(x+1,y) AND A(x-1,y) AND A(x,y+1) AND A(x,y-1) Das Löschen isolierter Punkte (Bereinigen): B(x,y) = d(x,y) AND A(x+1,y) IOR A(x-1,y) IOR A(x,y+1) IOR A(x,y-1) IOR A(x+1,y+1) IOR A(x+1,y-1) IOR A(x-1,y+1) IOR A(x-1,y-1) Die folgenden Verarbeitungsfolge zeigt eine Anwendung dieser Operationen in der Kartographie: Änderung einer Liniendarstellung durch mehrfaches Verdicken und anschliessender NOT- und IOR-Operation. 130 Anfangsbild A A verdicken Æ B B verdicken Æ C C verdicken Æ D D AND (NOT C) Æ E E IOR A Æ F 131 Weitere Anwendungen in der digitalen Kartographie und der Fernerkundung: Durch die Verarbeitungsfolge von Verdickung und anschliessender Verdünnung können kleinere Flächenlücken (Rauscheffekte) geschlossen werden. Die umgekehrte Reihenfolge, erste Verdünnung und dann Verdickung führt zur Elimination kleinerer Flächen, in der Kartographie als "Generalisierung" bezeichnet. 6.5. Hybride Systeme Die heutige Tendenz führt zur Realisierung von hybriden Systemen, in welchen die Daten sowohl in vektororientierten Strukturen als auch mit Rasterstrukturen gespeichert werden können. Der Vorteil liegt in der Tatsache, dass nur die Informationen, die man für die Analysen und Selektionen benötigt, voll strukturiert erfasst werden müssen. Die Hintergrundinformation, die man lediglich zur Orientierung benötigt, kann preiswert und schnell aus vorhandenen Plänen mit dem Scanner vollautomatisch digitalisiert werden und wird als einfaches Rastermodell gespeichert und verwaltet. Dadurch erreicht man eine bessere Anpassung an die vorhandenen Datenquellen mit eindeutigen wirtschaftlichen Vorteilen. Erst eine vollständige Integration der Datentypen Punkt-, Vektor- und Rasterdaten macht aus einem Geo-Informationssystem ein hybrides System. Der sinnvolle GIS-Einsatz setzt grundlegende Kenntnisse über Eigenschaften, Möglichkeiten und Eignungsgrenzen verschiedener Datenformen und -strukturen beim Benutzer voraus. Das thematische Potential von Rasterdatenstrukturen wird z.Zt. noch eher unterschätzt. Es reicht über seine kartographischen Anwendungen hinaus, insbesondere in Bereichen Umweltplanung, Verkehrs- und Standortanalysen, Quantitative Geographie, Klimatologie etc. Literaturverzeichnis W. Göpfert Raumbezogene Informationssysteme Grundlagen der integrierten Verarbeitung von Punkt-, Vektor- und Rasterdaten, Anwendungen in Kartographie, Fernerkundung und Umweltplanung 2. Auflage 1991, Wichmann Verlag Karlsruhe 132 7. 7.1. Interoperabilität und GIS Interoperabilität und Datentransfer: Eine zentrale Funktion jedes GIS Das Entstehen und der erfolgreiche Einsatz von Geoinformationssystemen sind mit einer wirksamen Lösung des Problems der Interoperabilität und des Transfers der Geodaten untrennbar gekoppelt. Nur kleine Applikationen, die die Verarbeitung von kleinen Datenmengen während kurzer Zeit erfordern (z.B. GIS-Übungen in der Ausbildung), können ohne eine Lösung des Datentransferproblems auskommen. Wir verfügen heute über eine immer grösser werdende Menge geographischer Daten in digitaler Form und einer grossen Anzahl Organisationen, die mit Daten dieser Art arbeiten. Das Risiko, dass Doppelspurigkeiten und Widersprüche entstehen, ist gross. Oft existieren die benötigten Daten bereits. Sie werden aber wieder erfasst, weil: • eine geeignete Dokumentation fehlt oder • sie eine inkompatible Struktur aufweisen. Ein GIS ist nur erfolgreich, wenn es die Anforderungen möglichst vieler User erfüllt. Abb. 7.1: Die Kommunikation zwischen Geoinformationssystemen Die Anforderungen und die Bedürfnisse sind allerdings sehr unterschiedlich. Dies ist der Grund, warum es bis jetzt relativ schwierig war, eine alles umfassende Standardlösung zu finden. Die wirtschaftlich entwickelten Länder realisieren zur Zeit geeignete nationale Geodateninfrastrukturen (NGDI), in welchen Private, Ämter, Lieferanten und Anwender integriert werden, damit sie gemeinsam Technologien und existierende Daten nutzen können. 133 Voraussetzung für die Realisierung von Koordinationszentren (Clearinghouses), für den Informationsaustausch und für die interoperable Nutzung der Geodaten ist die Lösung der in Abb. 7.2 beschriebenen organisatorischen und technischen Problemen. Alle aufgezeigten Punkte sind sehr wichtig. Der vorliegende Beitrag befasst sich jedoch nur mit der technischen Thematik der Interoperabilität und der Datenübertragung zwischen Systemen unterschiedlicher Hersteller. Die erforderlichen Lösungsansätze für diese beiden Aufgaben sind besonders aktuell, da man zurzeit sowohl auf nationaler Ebene als auch in internationalen Institutionen (Europa, Welt) an der Entwicklung von technischen Normen arbeitet, die die Realisierung von interoperablen Systemen ermöglichen sollen. Abb. 7.2: Organisatorische und technische Voraussetzungen für eine NGDI 7.2. Bedürfnisse, Lösungsansätze Abb. 7.3: Datenaustausch und Interoperabilität 134 7.2.1. Die Vielfalt der Anforderungen Die Komplexität der Frage der Datenübertragung ist die direkte Folge der Vielfalt der Anwendungen. Ausgetauscht oder angefragt werden zum Beispiel: • Graphische Darstellungen (digitale Karten und Pläne) • Beschreibungen der GIS-Inhalte (Metadaten) • Resultate von Abfragen (Tabellen, Karten usw.) • Strukturierte Datenbankinhalte (z.B. Tabellen, Attribute) ohne Änderung der Datenstrukturen • Daten von einer Datenbank in eine andere Datenbank mit unterschiedlichen Datenstrukturen • Vollständige Objekte in einer objektorientierten Umgebung (inkl. Operationen) Bereits diese kleine Auswahl von häufig auftretenden Datentransferwünschen gibt einen Eindruck über die Vielfalt der Bedürfnisse mit ihren sehr unterschiedlichen Komplexitäten. 7.2.2. Die Vielfalt der Lösungen Interoperable GIS können auf unterschiedliche Arten realisiert werden: • Datentransfer • Datenaustausch zwischen gleichen Systemen • Datenaustausch mit Standardformaten • Modellbasierte Datentransfermethoden • Interoperabilität • Interoperabilität (nach OGC = Open Geospatial Consortium; früher Open GIS Consortium) 135 7.3. Der eigentliche Datentransfer 7.3.1. Proprietäre Transferformate: ein Grundbedürfnis Das Inbetriebsetzen einer GIS-Applikation, die Verkaufsvorführungen, die erste Schulung von neuen Anwendern und die Tests des Herstellers während der Softwareentwicklung erfordern die Übernahme von Demonstrationsdaten des gleichen GISHerstellers von einer Applikation zu einer anderen. So verfügen alle GIS über die Möglichkeit, die gespeicherten Daten in Standarddateien (in der Regel sequentielle Dateien) auszugeben und aus den gleichen Dateien wieder zu übernehmen. Die verwendeten Formate sind ausschliesslich geeignet für eine bestimmte GIS-Software (proprietäres Format) und erfordern beim Sender und beim Empfänger die identische Datenstruktur für die transferierten Daten. Abb. 7.4: Datentransfer mit proprietären Formaten Andere proprietäre Formate, welche oft de facto Standard geworden sind, werden für die Ausgabe von graphischen Darstellungen (z.B. Plottfiles), die aus der raumbezogenen Information hergeleitet werden (Karten und Pläne), verwendet. Die GIS-Software beinhaltet normalerweise die Treiber für die erforderliche Steuerung und Generierung der Datenformate. 7.3.2. Standard-Formate Das Bedürfnis, Geoinformationen zwischen Systemen unterschiedlicher Hersteller auszutauschen war bereits in der Vergangenheit, besonders in grossen Organisationen (Telecom, Eisenbahngesellschaften, militärische Organisationen, usw.), stark spürbar. Bei solchen Anwendungen hat man mit Geoinformationssystemen zu tun, in welchen die zu verwaltenden Informationen für alle Systeme einheitlich festgelegt sind. Dies ist vor allem in stark hierarchischen Organisationen der Fall (NATO, Staatsbetriebe usw.). Wenn sowohl die geometrischen als auch die thematischen Inhalte feststehen, kann man ein passendes Format definieren, das die Information aufnehmen kann und es ist möglich in jedem System die entsprechende Schnittstelle für das Lesen und Schreiben der Transferdateien in das definierte Format einzubauen. So wurden zum Beispiel für 136 die NATO das Austauschformat DIGEST (Digitial Geographic Information Exchange Standard) und für den Ordnance Suvey (OS) in Grossbritannien das Format NTF (National Transfer Format) definiert. Abb. 7.5: Datentransfer mit Standard-Formaten Ein weiteres Bedürfnis, das sehr verbreitet ist, ist die Abgabe von Geoinformationen an Partner, die sie nur graphisch auf ihren Computersystemen weiter verarbeiten werden. Auf diese Art verwenden oft Architekten und Bauingenieure die erhaltenen Geodaten. Sie werden in CAD-Systemen für die Projektierung eingesetzt. Der de facto Standard im CAD-Bereich ist zurzeit DXF, ein Format, in welchem die Information in thematische Ebenen (Layer) unterteilt wird. Die meisten GIS-Hersteller sehen vor, Daten in DXF auszugeben und auch zu lesen. Dabei ist zu beachten, dass nur eine Teilmenge der Information (hauptsächlich die Graphik) in DXF abgebildet werden kann (→Informationsverlust). Sehr vorteilhaft sind bei dieser Form der Datenabgabe Vereinbarungen oder Normen, um die LayerZuordnung und Nummerierung einheitlich zu gestalten. Als das Projekt der Reform der Amtlichen Vermessung in der Schweiz realisiert wurde, stellte man mit Besorgnis fest, dass die Festlegung von einheitlichen Datenstrukturen für die Systeme der 26 Kantone unrealistisch war. Folglich war auch die Definition eines gemeinsamen Datentransferformats ein unmögliches Bestreben. Nicht anders geschah es ein paar Jahre später auf europäischer Ebene. Auf Anregung von Frankreich wurde das TC 287 der europäischen Normungsorganisation CEN gegründet, um unter anderem auch Normen für den Transfer geographischer Daten in Kraft zu setzen. Grossbritannien und Frankreich hatten sich vorgestellt, ihre Formate NTF und EDIGéO (Echange de Données Informatisées GéOgraphiques) für Europa zu erweitern (z.B. ETF). Die ersten Sitzungen zeigten aber, dass die Bedürfnisse und die Systeminhalte sehr unterschiedlich und vor allem die Anwendungen extrem vielfältig sind und daher die Festlegung von Standardformaten ein unmögliches Unterfangen ist. Man brauchte andere Lösungsansätze. Wenn unterschiedliche Datenstrukturen erwartet werden, sind modellbasierte Verfahren anstatt feste Formate der richtige Weg. 137 7.3.3. Modellbasierte Transferverfahren Geoinformationen der heutigen Zeit bieten den Anwendern neben einer festgelegten Datenstruktur für die geometrischen Daten die Möglichkeit, die thematischen Inhalte frei zu definieren. Das System bildet dann aufgrund der Datenstrukturbeschreibung (Eingabe des DB-Schemas) die erforderlichen Entitätsklassen (in der Regel relationale DB-Tabellen). Somit passt sich die Datenverwaltung den Bedürfnissen an. Abb. 7.6: Modellbasierte Transferverfahren Man kann diese Idee auch brauchen, um den Datentransfer flexibel zu gestalten: Die Struktur der Daten, die man übertragen möchte, wird beschrieben und daraus kann ein Format für diese Daten hergeleitet werden. Dafür benötigt man zwei Komponenten: erstens eine standardisierte Datenbeschreibungssprache, um die Struktur der Daten, die man transferieren möchte, eindeutig und konsistent zu beschreiben, und zweitens ein genormtes Verfahren, um aus der Datenstruktur ein Format herzuleiten. Abb. 7.7: Komponente des modellbasierten Transferverfahrens In der europäischen Normung wurde EXPRESS als Sprache festgelegt, da sie bereits eine gewisse Verbreitung hat (CAD, Automobilindustrie usw.). Applikationen im GeoBereich existieren allerdings noch nicht und ihre Komplexität ist für eine Implementierung nicht förderlich. In der Schweiz wurde für die Amtliche Vermessung vor mehr als 10 Jahren die Sprache INTERLIS definiert, welche die Beschreibung der Thematik in einem GIS nach einem relationalen Modell und der Geometrie aufgrund von festgelegten Geometrieelementen (Punkte, Geraden, Kreisbögen, Einzelflächen, Gebietseinteilungen) ermöglicht. 138 Die Sprache passt sehr gut zu den heutigen GIS. Sie verfügte von Anfang an über einen Compiler für die automatische Herleitung der Transferformate und wird zunehmend eingesetzt. Zurzeit kann weltweit keine andere Lösung als operationell betrachtet werden. Im Technischen Komitee der ISO (TC 211) konnte nur INTERLIS als in GIS implementierter modellbasierter Transfermechanismus für Geodaten vorgeführt werden. ISO hat bisher folgendes beschlossen: • Die modellbasierten Transferverfahren sind als Standard erklärt. • UML wurde als graphischer Formalismus für die Beschreibung der Datenstrukturen festgelegt. • Eine textuelle Sprache, die automatisch gelesen und interpretiert werden kann, ist vorgesehen, ihre Eigenschaften wurden beschrieben und festgelegt. Kein Entscheid wurde getroffen. Mögliche Lösung INTERLIS 2. Die Schweiz hat die neue INTERLIS Version (INTERLIS 2) entwickelt, um die volle Kompatibilität mit den ISO-Normen (Objektorientierung, Inkrementelle Nachführung, usw.) zu erfüllen. In diesem Rahmen wurde auch die Schnittstelle zwischen UML und INTERLIS realisiert, damit ein UML-Schema in INTERLIS automatisch übersetzt werden kann (und umgekehrt). Ebenfalls wurde das Transferformat im InformatikStandard XML definiert. Demnächst wird man auch ein Transferformat auf der Basis von GML erzeugen können. Die modellbasierten Technologien bieten auch für andere Bereiche Lösungsansätze. Moderne GIS ermöglichen heute die Implementierung des Modells direkt aus dem konzeptionellen Schema (in UML oder in INTERLIS): • ArcGIS (ESRI) kann die Datenstruktur aus Schemata in UML (erzeugt mit Microsoft Visio) implementieren • GeosPro/GeoMedia (a/m/t, Intergraph) aus INTERLIS • Topobase (C-Plan) aus INTERLIS oder aus UML 7.4. Interoperabilität Während die bisherigen Lösungen alle als Ziel haben, die Daten von einem System zu einem anderen zu transferieren, sind Kommunikationsmöglichkeiten denkbar, die ohne Verschiebung der Originalgeodaten auskommen. Diese Lösung ist besonders interessant, wenn nur einfache Auswertungen der Information benötigt werden (z.B. eine graphische Darstellung von einem Ausschnitt oder die Auflistung von bestimmten Objek- 139 ten). In diesen Fällen ist es einfacher, die Auswertungsbefehle und -ergebnisse zu standardisieren und zu transferieren als die Grunddaten selbst. Die Interoperabilität bedeutet die Parallelnutzung von verschiedenen GIS, indem die Befehle (Anfragen) und die daraus entstehenden Ergebnisse (Antworten) ausgetauscht werden (siehe Abb.7.8). Die GIS-Industrie (Softwarehersteller) hat diesen Weg als für den Markt interessant angesehen und das Open Geospatial Consortium (OGC) gegründet, um diese Technik möglichst weit zu entwickeln. Dank der Beteiligung der führenden weltweit tätigen Firmen (ESRI, Intergraph, Siemens, Oracle, Microsoft usw.) und der Einbindung von Universitäten und Forschungsinstitutionen hat OGC grosse Resonanz erhalten und entsprechend grosse Erwartungen geweckt. Abb. 7.8: Interoperabilität Aus dem Konzept der Interoperabilität sieht man sofort die Vorteile: • das Datenverwaltungskonzept kann in den kommunizierenden Systemen sehr unterschiedlich sein. • Das abfragende System muss nichts über die Datenorganisation des angefragten Systems wissen. • Die Systeme geben nur Teile der Information weiter. Der volle Inhalt bleibt unter der eigenen Kontrolle (Urheberrecht). 140 Ein Vorteil für die GIS-Hersteller: • die Kunden können nicht so leicht das System wechseln Ebenfalls sichtbar sind die Grenzen: die Vielfalt der standardisierten Abfragen und der Antwortformen darf nicht zu gross sein. Falls die gewünschten Interoperationen zu komplex, zu vielfältig und anzahlmässig zu gross werden, ist der Austausch der Daten einfacher und günstiger als die Standardisierung der Operationen. Selbstverständlich müssen die Systeme vergleichbare Informationen enthalten. Zurzeit hat OGC nur Lösungen vorgesehen für Abfragen, die in den Bezeichnungen angeglichen wurde (syntaktische Interoperabilität). Zusammenfassend kann man sagen, dass die Interoperabilität interessant ist, wenn: • einfache Auswertungen der Geoinformationen benötigt werden (z.B. graphische Darstellungen, Listen von Objekten oder Attributen) • die Systeme, die angefragt werden, gleichzeitig in Betrieb sind 7.5. Metadaten Die immer grössere Verbreitung der Geoinformationssysteme stellt uns vor neue Probleme: es fehlen oft Informationen über die verfügbaren Geoinformationssysteme und ihre Daten. Um diese wichtigen Informationen zugänglich zu machen, entstehen Metainformationssysteme, welche Metadaten (Daten über die Daten) verwalten. Diese Systeme sind ihrerseits Geoinformationssysteme, in welchen ein Teil der Metainformationen raumbezogen ist (wo und über welches Gebiet findet man Daten). Zu den Metadaten gehören Informationen über die Qualität, die Verfügbarkeit, die Nutzungsbeschränkungen, die Kosten usw. Die Beschreibung der Datenstruktur in einer genormten Sprache (EXPRESS, INTERLIS, UML usw.) kann ebenfalls dazu gehören. Ansätze für die Normung von Metadaten befinden sich im ISO-Normenwerk. In der Nationalen Geodaten-Infrastruktur (NGDI) wird man aus den internationalen Normen nationale Profile (Teilmengen) definieren, um eindeutige Interpretationen zu ermöglichen. Zurzeit werden Metadaten zur visuellen Konsultation zur Verfügung gestellt. In Zukunft werden sie automatisch von interoperierenden Systemen bei der Datensuche genutzt werden. 141 7.6. Die Wünsche und das Erreichbare 7.6.1. Wünschbares Die optimistischen Beschreibungen der unterschiedlichen Datentransfer-Konzepte könnten den Eindruck entstehen lassen, dass - mit etwas Geduld und finanziellen Mitteln - das Problem des automatischen Austausches von Geoinformationen zwischen beliebigen Systemen ohne weiteres lösbar sei. Abb. 7.9: Interoperabilität zwischen beliebigen Systemen mit beliebigen Datenstrukturen sind gewünscht. Dies entspricht selbstverständlich dem, was man sich wünscht. Man möchte die wertvollen Informationen, die an verschiedenen Orten erfasst und verwaltet werden, gemeinsam nutzen. 7.6.2. Technische Grenzen Eine voll automatische Datenübertragung oder die gemeinsame Nutzung der Daten in beliebig konfigurierten Geoinformationssystemen ist nicht möglich. Die unüberwindbare Grenze liegt in der nicht standardisierten Semantik der Datenstrukturbeschreibungen. Die folgenden Beispiele illustrieren häufig vorkommende Fälle. Im Sendersystem wird eine thematische Klasse von Elementen mit dem Begriff „HÄUSER“ identifiziert, während der Empfänger dasselbe mit „GEBÄUDEN“ bezeichnet. Selbstverständlich können Fremdsprachen und Abkürzungen weitere Hindernisse zu einer automatischen Interpretation bieten. Es kommt auch die umgekehrte Situation vor. Gleiche Begriffe bedeuten in den zwei kommunizierenden Systemen andere Objekte. In einem System bedeutet der Begriff „WEGE“ die Menge aller Verkehrsverbindungen (Strassen, Eisenbahnen, schiffbare Kanäle usw.), im anderen sind „WEGE“ kleine Strassen in einer Ortschaft (Schlossweg, Alpenweg usw.). Noch häufiger sind die Fälle dazwischen, in welchen die thematischen Elemente andere Bezeichnungen und auch eine andere Unterteilung haben (Abb.7.10). 142 Abb. 7.10: Im allgemeinen Fall kann die Zuordnung der einzelnen Attribute nicht automatisch stattfinden. Die Semantik der Datenbeschreibung kann in einem freien Umfeld nicht standardisiert werden. Für die Zuordnung der Entitäten und der Attribute braucht man Zusatzinformationen. Es ist zu beachten, dass die Zuordnung von der Bedeutung der Objekte und der Attribute abhängig ist. Sie ist daher auch von den Betriebsanweisungen und von den Regeln der Datenakquisition beeinflusst. Weder Mensch noch Computer werden in der Lage sein, ohne Zusatzauskünfte die Zuordnung der Entitäten und der Attribute vorzunehmen. Man wird sich zuerst erkundigen müssen oder ausführliche Beschreibungen lesen, um aufgrund der eigenen Interpretationen und Zielsetzungen die Datenfelder in Beziehung zu bringen. Diese Zuordnung muss das erste Mal aufgrund von: • Einer Analyse eines Experten • Anfragen bei den Verantwortlichen • Konsultationen von Metadaten erfolgen Erst danach kann eine semantische Transformation automatisch ausgeführt werden. Für die modellbasierten Transferverfahren haben Software-Hersteller Module entwickelt, die zwei Datenstrukturen (z.B. aus ihrer Beschreibung in INTERLIS) darstellen und die Zuordnung der Entitätsklassen und Attribute auf Formatebene interaktiv am Bildschirm erlauben. Weitere Entwicklungen in dieser Richtung aber auf konzeptueller Ebene sind zu erwarten (semantische Transformationen, semantische Interoperabilität). 143 Abb. 7.11: Semantische Transformationen mit Hilfe von Ontologien Zwischen föderierten Systemen (unter gemeinsamen Regeln organisiert) wird es in spezifischen Bereichen möglich sein, Ontologien zu entwickeln, welche die Semantik von mehreren Systemen beschreiben und die Herstellung von automatischen Transformationsmodulen (Agenten) ermöglichen werden. Die Ontologien sind Gegenstand der heutigen Forschung. Man wird allerdings nur die Semantik in klar definierten und abgegrenzten Sektoren eindeutig beschreiben können. Eine Ontologie entspricht einer Standardisierung der Begriffe, die man für die Modellbildung und für die Bezeichnung der Elemente der Datenstruktur im GIS verwendet hat. 7.7. Entwicklungsstrategien Jeder der bisher geschilderten Lösungsansätze ist, trotz der erwähnten technischen Grenzen, eine optimale Antwort für einzelne Fälle mit ihren unterschiedlichen Anforderungen. Es ist daher nicht zu erwarten, dass sich ein einziger besonderer Lösungsansatz als Weltstandard für den Transfer von Geoinformationen durchsetzen wird: • Proprietäre Formate werden zu jeder GIS-Software gehören. Sie sind die optimale Lösung für die Systemadministration. Sie übertragen die Daten eines bestimmten Systems vollständig (inkl. Konfigurationsparameter). Sie können auch für den internen Datenaustausch in grossen Organisationen dienen, die mehrere identische Systeme betreiben. 144 • Standardformate sind einzusetzen, wenn die Inhalte der GIS zentral festgelegt werden. Zur beschlossenen Datenstruktur kann ein Format definiert werden, mit welchem die Daten sequentiell übertragen werden können. Standardformate sind ebenfalls die geeignete Lösung für die Abgabe von GIS-Daten an CAD-Systeme. DXF ist im CAD-Bereich am meisten verbreitet. Wünschenswert ist dabei die Normung der Layer. • Modellbasierte Transferverfahren sind die Lösung für den Datenaustausch zwischen Systemen, die eine eigene Datenstruktur besitzen. Die ankommenden Daten beinhalten die Datenstrukturbeschreibung in einem genormten Formalismus (Datenbeschreibungssprache). Zur Sprache gehört auch das Verfahren, um daraus die Formate herzuleiten. Wenn die Strukturen der erhaltenen Daten und der Daten des Empfänger-Systems nicht identisch sind, kann eine voll automatische Übernahme nicht stattfinden. Die Zuordnung der Entitätsklassen und der Attribute muss das erste Mal aufgrund menschlicher Interpretation geschehen. Um diese interaktive Arbeit zu erleichtern, haben Software-Hersteller Module entwickelt, die zwei Datenstrukturen vergleichen und am Bildschirm die Zuordnung der Tabellenfelder erlauben (z.B. INTERLIS-Studio von Leica). Abb. 7.12: Bei der ersten Datenübertragung muss die Beziehung zwischen den Attributen definiert sein. • Interoperabilität ist die Alternative, mit welcher die Kommunikation zwischen den GIS ohne Austausch der Geodaten stattfinden kann. Genormt werden die Anfragen und die Formate für die Übermittlung der Antworten (Services Interfaces). Der tatsächliche Umfang der Möglichkeiten, die im Rahmen der OGC-Arbeiten entstehen werden, ist schwer vorherzusagen. Zurzeit sind einfache Anfragen (Visualisierungen, Selektionen) und der Zugriff auf einfache geographische Objekte spezifiziert. Sicher werden einfache Anfragen (Visualisierungen, Selektionen) zur Verfügung stehen. Ebenfalls spezifiziert ist bereits der Zugriff zu einer einfachen Koordinatengeometrie. Da in den Absichten des Open Geospatial Consortium (OGC) nicht nur 145 die Kommunikation zwischen den Systemen im Vordergrund steht, sondern auch das Zusammensetzen von ganzen GIS aus selbstständigen Komponenten, werden die Schnittstellen zwischen den frei gewählten Software-Modulen ebenfalls benötigt. Die erforderliche Zeit und die Erreichbarkeit der Ziele sind nicht leicht vorsehbar. 7.8. Schlussfolgerung Die Kommunikation zwischen Geoinformationssystemen ist eine vielseitige Aufgabe, für welche eine Vielfalt von Lösungsansätzen zur Verfügung steht. Die Probleme, die Anforderungen und die technischen Grenzen sind erst in neuster Zeit in ihrer ganzen Breite wahrgenommen worden. Die heute eingesetzten Datentransferverfahren und die Interoperabilität werden sich in den nächsten Jahren stark entwickeln. Mehrere Methoden werden sich als Standard durchsetzen. Die nächsten Schritte der Forschung sind im Bereich der semantischen Interoperabilität und der semantischen Transformationen zu erwarten. Diese Arbeiten sind die Voraussetzung, damit Geoinformationssysteme ihre wertvollen Daten ohne Verzögerung und Hindernisse der ganzen Gesellschaft zur Verfügung stellen können. Literaturverzeichnis A. Carosio, 2005 Interoperabilität für die breite Nutzung von Geoinformation, Weiterbildungstagung 17. und 18. März 2005 Zürich, ETH Hönggerberg 146