Oracle 10G and Windows XP
Werbung

Universität Konstanz
Information Engineering
Datenbanken und Informationssysteme
Seminar: Database Tuning & Administration
Windows XP mit Service Pack 2
&
Oracle 10g Expres Edition
Studenten:
Elena Povalyayeva
Eduard Schibrowski
Inhaltsverzeichnis:
1. Installation des Betriebsystems ............................... 3
2. Installation des Datenbankmanagementsystems Oracle 10g Expres.............................................................. 3
3. Anlegen einer neuen Datenbank und Einfügen der
„cddb“ Daten: ..................................................................... 5
4. Dupplikatenelimination und Abfragen an die
Datenbank............................................................................ 9
4.1 Datenbankstruktur: .................................................................................................... 9
4.2 Abfragen: .................................................................................................................... 11
5. Datenbank mit TCP-H Schema ................................ 13
5.1
Aufbauen der Umgebung unter Windows .................................................... 13
5.2
Erstellen der Tabellen und einspielen der TPC-H Daten .......................... 14
5.3
Generieren und ausführen der Anfragen...................................................... 16
5.4
Tuning..................................................................................................................... 17
5.4.1 Ausführzeiten der Abfragen ohne Indexes oder andere Verbesserungen. 17
5.4.2 Ausführzeiten der Abfragen mit Primary und Foregn Keys. ......................... 18
5.4.3
Ausführzeiten der Abfragen mit indexierten Tabellen.............................. 18
5.4.4 Ausführzeiten der Abfragen mit Cluster-Indexes............................................ 19
5.5
Fazit......................................................................................................................... 22
5.6
Anlagen .................................................................................................................. 23
Automatic Optimizer Statistics Collection........................................................................... 23
1. Installation des Betriebsystems
Für die Installation des Betriebsystems waren folgende Schritte notwendig:
-
Einfügen der „Windows XP“ CD mit Service Pack 1 und neu Start des
Rechners
Die System Installation wird gestartet
Die Festplatte des Rechners ist 24 GB groß, davon werden 2 Partitionen
erstellt:
o C:\ die 6 GB (5514 MB) groß ist, und die fürs System und für die
Datenbank notwendig sind
o D:\ die 18 GB groß ist und für Daten benutzt werden sollen
Während der Installation sind auch folgende Informationen angegeben worden:
-
Name des Besitzers:
DBTuner
Computen Name:
PHOBOS83
Benutzer Name
DBTuner
Administrator Passwort: dbmanager
Desweiteren werden die Netzwerktreibern installiert und die Netzwekeinstellungen
vorgenommen:
IP Adresse: 134.34.57.197 – phobos83.inf.uni-konstanz.de
Subnetzt: 255.255.0.0
Gateway: 134.34.57.1
DNS :
134.34.3.2 oder 134.34.3.3
Nach der Installation, wird das System aktualisiert mit Sevice Pack 2 und weitere
verfügbare Updates.
2. Installation des Datenbankmanagementsystems
- Oracle 10g Expres
Die Installation von Oracle wird gestartet (doppel Click auf der ausführbaren Datei).
Als Installationsverzeichniss schlägt Oracle „C:\oraclexe“ automatisch vor. Für die
Installation werden 1593016 K an Speicherplatz gebraucht.
Es wird auf dem Desktop eine Verknüpfung zu der „Erste Schritte“ Help Dateien
automatisch angelegt.
Es gibt 2 Möglichkeiten mit der Datenbank zu arbeiten:
-
über das Browser:
o Start Programs (oder All Programs) Oracle Database 10g
Express Edition Go To Database Home Page.
Man kann sich mit dem Username „system“ und dem bei der Installation
angegebenen Kennwort.
Mit der Installation ist für Trainingzwecke auch die Datenbank „User“ vorangelegt, die
mit username „hr“ ereichbar ist. Der Benutzer muss noch unlocked werden.
-
über die Kommandozeile: Start Run cmd sqlplus
Als nächstes wird es nach Benutzer Name und Passwort gefragt:
3. Anlegen einer neuen Datenbank und Einfügen
der „cddb“ Daten:
Mit dem Anlegen eines neuen Benutzer wird auch eine leere Datenbank angelegt.
Das ist wieder über Browser und über Kommandozeile möglich:
Um es über das Kommandozeile zu erstellen verwendet man folgendes Befehl:
(es werden die Pfade für die log files spezifiziert und deren Grösse, den Pfad und die
Grösse der Datenbank). Verwendung der Weiteren Parameter ist möglich.
CREATE DATABASE media
LOGFILE
'/home/oracle/log/log1media.dbf' size 20M,
'/home/oracle/log/log2.dbf' size 20M,
DATAFILE
'/home/oracle/dbs/sys1media.dbf' size 100M;
Über Browser funktioniert wie folgt:
Man loggt sich mit dem system/dbmanager ein, Administration Database Users Create Useres
Als nächstes werden die Daten Importiert. Da die *.sql Datei für Posgresql erstell
worden ist, sind auf die Daten verschiedene Bearbeitungen notwendig:
-
erstens werden die create Anfragen extrahirt und die Datentypen an Oracle
angepasst:
o varying --> varchar (Datentyp varying ist dementsprechen in
Varchar(länge) umgewandelt)
o bigint --> number (Datentyp bigint wird number)
Die Anfragen mit den geänderten Datentypen sehen wie folgt aus:
CREATE TABLE albums (
albumid number,
album varchar(80) NOT NULL
);
CREATE TABLE angebot (
angnr numeric(5,0) NOT NULL,
ort varchar(20)
);
CREATE TABLE artist2album (
artist2albumid number NOT NULL,
artistid number,
albumid number
);
CREATE TABLE artist2num_albums (
artistid number,
num_albums number
);
CREATE TABLE artists (
artistid number NOT NULL,
artist varchar(60) NOT NULL
);
CREATE TABLE cds (
cdid number NOT NULL,
artist2albumid number NOT NULL,
ayear integer,
genreid number,
discid varchar(8) NOT NULL
);
CREATE TABLE cdtracks (
songid number NOT NULL,
cdid number NOT NULL,
track integer NOT NULL
);
CREATE TABLE genres (
genreid number NOT NULL,
genre varchar(20) NOT NULL
);
CREATE TABLE song (
songid number,
song varchar(80)
);
CREATE TABLE terms_copy (
doc_id integer,
term varchar(100),
frequency integer
);
wichtig dabei ist dass man die Befehle zur Erstellung der Tabellen mit commit
abgeschlossen sein müssen.
-
zweites werden die Datensätze jeder Tabelle aus der sql Datei in separaten
Dateien kopiert und verarbeitet:
Beim Import der Daten traten im Grunde folgende Fehler ein:
- „ORA-01722: Ungültige Zahl
Import der Albums Tabelle.
Row 1: ¿1 the best of the modern years” beim
Zur Lösung dieses Problems haben wir die Spaltennamen am Anfang der Datei noch
hinzugefügt, mit Tab getrennt, so dass der erste Spaltenindex der Datei, in der
Zweiten Spalte steht. Dazu kann mann in Oracle explizit angeben dass die Datei
Spaltennamen beinhaltet.
- „ORA-20001: Load csv data error: ORA-01461: Ein LONG-Wert kann nur zur
Einfügung in eine LONG-Spalte gebunden werden“ beim Einfügen der Daten in der
Tabelle Artists.
Dafür haben wir die Datei eingelesen und in einer separaten Datei wieder
geschieben, diesmal aber ohne spezielle Zeichen (special characters).
Die Schritte zum Einfügen der Daten sind: (nach dem Anmelden mit media/media)
Schritt 1
-
Utilities Load
Schritt 2
Schritt 3
Schritt 4
Schritt 5
Schritt 6
4. Dupplikatenelimination und Abfragen an die
Datenbank.
4.1 Datenbankstruktur:
Die Datenbankstruktur sieht wie folgt aus:
Artists
ArtistID
Artist
Albums
AlbumID Album
Artists2Album
Artists2AlbumID ArtistID AlbumID
Songs
SongID
Song
cdtracks
songID cdID
Cds
cdID Artists2AlbumID ayear genreID discID
artist2num_albums
artistID
Num_albums
Genres
GenreID Genre
Angebot
AngebotID Ort
terms_copy
docID term
frequency
track
4.2 Abfragen:
//query 1
//Abgelaufen: 00:03:06.90
select "SONG"."SONG" as "SONG",
"CDS"."CDID" as "CDID",
"CDS"."AYEAR" as "AYEAR"
from "SONG" "SONG",
"CDTRACKS" "CDTRACKS",
"CDS" "CDS"
where "CDTRACKS"."SONGID"="SONG"."SONGID"
and "CDS"."CDID"="CDTRACKS"."CDID"
and "CDS"."AYEAR" >2005;
//query 2
//Abgelaufen: 00:00:00.03
select genres.genre, cds.ayear
from genres, cds
where cds.genreid=genres.genreid
and ayear >2005;
// query 3
// dauert ewig
select "ARTISTS"."ARTIST" as "ARTIST",
"ARTIST2NUM_ALBUMS"."NUM_ALBUMS" as "NUM_ALBUMS"
from "ARTIST2NUM_ALBUMS" "ARTIST2NUM_ALBUMS",
"ARTIST2ALBUM" "ARTIST2ALBUM",
"ARTISTS" "ARTISTS",
"ALBUMS" "ALBUMS"
where "ALBUMS"."ALBUMID"="ARTIST2ALBUM"."ALBUMID"
and "ARTISTS"."ARTISTID"="ARTIST2ALBUM"."ARTISTID"
and "ARTIST2NUM_ALBUMS"."ARTISTID"="ARTIST2ALBUM"."ARTISTID"
and "ARTIST2NUM_ALBUMS"."NUM_ALBUMS" > 5;
// query 4
// Abgelaufen: 00:00:01.20
select count(CDS.CDID) as "CDID",
"GENRES"."GENRE" as "GENRE"
from "GENRES" "GENRES",
"CDS" "CDS"
where "GENRES"."GENREID"="CDS"."GENREID"
group by GENRES.GENRE;
// query 5 (kleine abfrage um doppelte zeilen zu entfernen)
delete from song t1
where t1.songid in (select songid
from song t2
where t1.rowid > t2.rowid
and t1.songid = t2.songid
);
Die lätzte Abfrage entfernt die Zeilen deren ID doppelt vorkomt.
Über Kommandozeile erlaubt uns die Funktion „set timing on“ die Dauer einer Anfrage zu
messen.
Oracle erlaubt die Erstellung der Abfragen auch über GUI.
Wie in dem Screenshot ersichtlich ist kann man die Tabellen selektieren , die Felder die man
ausgeben möchte, Bedingungen hinzufügen, etc.....
Zu der in GUI erstellten Abfrage wird ein SQL Code generiert die später verbessert oder
ergänzt werden kann.
Wir haben die Abfragen ausgeführt und die Zeit gemessen. Die lätzte Abfrage haben wir gebraucht
um die Dupplikate zu entfernen. Dann haben wir für jede Tabelle jeweils ein Index angelegt und die
Abfragen erneut ausgeführt. Diesmal hat die Ausführung der Abfragen (im Schnitt) nur die Hälfte
der Zeit gebraucht.
5. Datenbank mit TCP-H Schema
5.1 Aufbauen der Umgebung unter Windows
Unter Windows ist eine Linux Umgebung notwenwendig damit „gcc“ und „make“ funktionieren.
Dafür haben wir Cygwin installiert, und zwar die „develeoper“ Version und den VIM Editor
dazu.
Nach dem Download der Dateien für den „Database Generator“ und den ” Query Generator“
müssen diese zuerst kompiliert werden. Hierzu wird eine Datei namens makefile.suite
mitgeliefert. Zuerst sollte eine Kopie der Datei mit dem Namen Makefile erstellt werden. In
dieser müssen vier Parameter zur Anpassung an die vorhandene Datenbank eingestellt
werden. Für unseren Oracle RAC passen die folgenden Werte am besten, da Oracle selbst
nicht zur Auswahl steht:
CC = gcc
DATABASE= SQLSERVER
MACHINE = LINUX
WORKLOAD = TPCH
Nach dem Speichern der Änderungen kompiliert man die Quelldateien mittels make. Dadurch
werden die beiden Tools dbgen und qgen erzeugt.
-
Editieren der Makefile:
DBTuner@phobos83 /cygdrive/e/tpch_20070105
$ cp makefile.suite ./Makefile
DBTuner@phobos83 /cygdrive/e/tpch_20070105
$ vim Makefile
- Kompilieren mit make
DBTuner@phobos83 /cygdrive/e/tpch_20070105
$ make
update_release.sh 2 6 0
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER
s.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER
tub.c
-DTPCH
-DTPCH
-DTPCH
-c -o build.o build.c
-c -o driver.o driver.c
-c -o bm_utils.o bm_util
-DTPCH
-DTPCH
-DTPCH
-c -o rnd.o rnd.c
-c -o print.o print.c
-c -o load_stub.o load_s
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o bcd2.o bcd2.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o speed_seed.o speed
_seed.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o text.o text.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o permute.o permute.
c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o rng64.o rng64.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -g -o dbgen build.o driver
.o bm_utils.o rnd.o print.o load_stub.o bcd2.o speed_seed.o text.o permute.o rng
64.o -lm
Info: resolving _optarg by linking to __imp__optarg (auto-import)
Info: resolving _optind by linking to __imp__optind (auto-import)
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o qgen.o qgen.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -c -o varsub.o varsub.c
gcc -O -DDBNAME=\"dss\" -DLINUX -DSQLSERVER -DTPCH -g -o qgen build.o bm_util
s.o qgen.o rnd.o varsub.o text.o bcd2.o permute.o speed_seed.o rng64.o -lm
Info: resolving _optarg by linking to __imp__optarg (auto-import)
Info: resolving _optind by linking to __imp__optind (auto-import)
-
Aufrufen von dbgen für daten generieren
$ ./dbgen
TPC-H Population Generator (Version 2.6.0 build 1)
Copyright Transaction Processing Performance Council 1994 – 2005
-
Verzeichnis für die Daten erstellen und die Daten darin verschieben
mkdir ./data
mv *.tbl ./data
mv dss.ddl ./data
5.2 Erstellen der Tabellen und einspielen der TPC-H Daten
Als erstes, erstellt man eine neue Datenbank (indem man einen neuen Benutzer anlegt), in
unserem Fall „Xantia“.
Zweitens
müssen die Tabellen der Benchmark-Datenbank angelegt werden. Die
Tabellendefinitionen sind in der Datei dss.ddl im TPCH-Verzeichnis enthalten. Dieses Skript
wird an sqlplus üubergeben, z.B. mithilfe von:
sqlplus benutzer/passwort@datenbank < dss.ddl
Dadurch werden die Tabellendefinitionen erstellt.
Bevor man die Daten in die Datenbank einspielt sind ein paar Bearbeitungen notwendig, wie
Umwandlung der Daten vom amerikanischen in der deutschen Schreibweise:
•
•
http://www.dbasupport.com/forums/archive/index.php/t-31555.html
http://www.stanford.edu/dept/itss/docs/oracle/10g/server.101/b10749/ch3globenv.htm#i1007705
-
Dezimalpunkte durch Kommata ersetzten (bsp)
Starten von VIM Editor: vim customer.tbl. Dann Befehl eingeben (ohne "): ":%s/\./,/" - (ersetzt
in der ganzen datei [%], in jeder Zeile das erste Auftreten von „.“ durch „,“)
!!!! Bei der Datei lineitem.tbl tratt folgendes Problem auf: „vim out of memory“.
Daher haben wir sed benutzt (streaming editor):
sed -e 's/\./,/' -e 's/\./,/' -e 's/\./,/' lineitem.tbl > lineitem.new
ersetzt die ersten 3 Auftreten von „.“ in jeder Zeile durch „,“.
Für das Laden der Daten in die Tabellen erstellt man für jede Tabelle eine *.ctl Datei mit
folgendem Inhalt:
load data
INFILE '<filename>'
INTO TABLE <tablename>
FIELDS TERMINATED BY '<delimiter>'
<table_format>
•
Siehe: http://bhairav.serc.iisc.ernet.in/doc/Installation/Oracle.htm#load
Zum Beispiel für die Datei “lineitem” sieht der Inhalt wie folgt aus:
load data
INFILE 'LINEITEM.tbl'
INTO TABLE LINEITEM
FIELDS TERMINATED BY '|'
(L_ORDERKEY ,
L_PARTKEY ,
L_SUPPKEY ,
L_LINENUMBER ,
L_QUANTITY ,
L_EXTENDEDPRICE ,
L_DISCOUNT ,
L_TAX
,
L_RETURNFLAG ,
L_LINESTATUS ,
L_SHIPDATE "to_date(:L_SHIPDATE, 'YYYY/MM/DD')",
L_COMMITDATE "to_date(:L_COMMITDATE, 'YYYY/MM/DD')",
L_RECEIPTDATE "to_date(:L_RECEIPTDATE,
'YYYY/MM/DD')", L_SHIPINSTRUCT ,
L_SHIPMODE, L_COMMENT)
Nachdem für jede Tabelle die .ctl Datei erstellt wurde und die Daten bearbeitet, werden die
Daten eingelesen:
sqlldr xantia/xantia control=region.ctl
Der Screenshot stellt den Prozess des Einlesen der Daten dar.
Alle Daten in allen Tabellen sind erfolgreich geladen worden.
5.3 Generieren und ausführen der Anfragen
Aus dem mit 1 bis 22 benannten Abfragen werden mit dem „run qgen“ Befehl die 1_new.sql bis
22_new.sql Abfragen generiert:
In dem Ausschnitt sieht man am Beispiel die Generierung der Abfragen 1:
Für die Abfrage 1:
DBTuner@phobos83 /cygdrive/e/tpch_20070105
$ run qgen -N -d 1 > 1_new.sql
Nach der Generierung werden die Abfragen ausgeführt und die Zeit gemessen die für die
jeweiligen Abfragen notwendig ist. Bei manchen Abfragen sind Änderungen vorzunehmen
damit sie von Oracle interpretiert werden können:
-
Meistens weden die „as“ Aliases entfernt: „as shipping“, „as all_nations“, “as profit”, usw.
Die Funktion “substring” wird mit “substr” ersetzt und die Syntax angepasst indem man
„for“ und „from“ mit Kommatas ersetzt.
5.4 Tuning
Oracle Database Software ist für fast alle heute verwendeten Betriebssysteme erhältlich und als ExpressEdition (XE) kostenlos nutzbar. Allerdings ist die Express-Edition stärker als die kostenlose DB2Version eingeschränkt, weil sie Java nicht unterstützt.
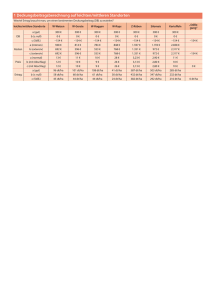
5.4.1 Ausführzeiten der Abfragen ohne Indexes oder andere Verbesserungen.
In der folgenden Tabele sind die Ausführzeiten für die Abfragen eingetragen, mit und ohne
dass auf die Tabellen speziele Verbesserungsverfahren angewendet wurden. Ziel der
Untersuchung ist ein Performance-Vergleich zwischen verschiedenen Tuning-Verfahren.
Alle Abfragen haben wir von der Kommandozeile ausgeführt. Für die Messung der Zeit haben
wir die Oracle Funktion „set timing on“ aktiviert.
Query
Number
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
Without
any keys
00:29 (00005 r)
00:32 (00460 r)
00:34 (11620 r)
00:18 (00005 r)
00:20 (00005 r)
00:14 (00001 r)
00:17 (00004 r)
00:19 (00002 r)
00:29 (00175 r)
05:24 (37967 r)
00:34 (01048 r)
00:17 (00004 r)
00:11 (00042 r)
00:20 (00001 r)
00:31 (00001 r)
03:14 (18314 r)
00:44 (00001 r)
00:37 (00057 r)
00:15 (00001 r)
00:31 (00204 r)
00:48 (00411 r)
00:05 (00007 r)
Primary and Bitmap
foreign keys indexes
00:29
00:49
00:28
00:17
00:18
00:14
00:19
00:19
00:32
05:20
00:08
00:17
00:08
00:15
00:28
07:33
00:15
00:34
00:15
00:32
01:03
00:05
B
Baum
Indexes
00:55
00:42
00:56
00:64
00:56
00:45
00:62
00:59
00:77
00:56
00:21
00:62
00:13
00:54
01:51
00:04
00:53
02:19
00:42
01:05
01:45
00:02
Cluster
indexes
00:33
01:16
00:21
00:21
00:22
00:18
00:22
02:06
03:37
02:04
00:17
04:00
04:05
04:19
03:38
02:44
10:15
04:41
00:18
5.4.2 Ausführzeiten der Abfragen mit Primary und Foregn Keys.
Primary Key (Primärschlüssel) ist ein einmaliger Eintrag eines Datensatzes, damit man ihn
zweifelsfrei erkennen (und ansprechen) kann. Zum Beispiel eine automatisch hochzählende ID.
Ein Foreign Key (Fremdschlüssel) ist ein Feld in der Tabelle, der auf einen anderen Primary Key
verweist.
Die Summe aus Primary Keys und Referenzen wird unter anderem dazu genutzt vom
Datenbank System die Logische Konsistenz der Daten zu erzwingen.
5.4.3 Ausführzeiten der Abfragen mit indexierten Tabellen.
Indizes sind Zugriffspfade, bilden logische Identifizierer auf physischen ab und müssen schnell
berechenbar sein. Der interne Zugriff auf Sätze erfolgt per TID, der externe Zugriff über
benutzerdefinierte Attribute. Die Abbildung von Attributen auf TID wird über Hilfsstrukturen
realisiert. Die geläufigste Variante schneller Berechnung sind B-Bäume (Tiefensuche: Knoten
und Blätter sind Seiten). Indizes sollten auf Primärschlüssel, referentielle Integrität
(Fremdschlüssel) und eventuell häufige Suchstellen gesetzt werden.
Ein Index beschleugnigt lesende Zugriffe, verlangsamt aber Änderungsoperationen auf
indizierte Attribute, da der Index dann aktualisiert werden muss. Indexe sind logisch und
phisisch unabhängig von den Tabellendaten, somit können die Indexe jederzeit eingefügt und
auch wieder gelöscht werden.
Bitmap Indices unterscheiden sich von "normalen" Indices hauptsächlich in der internen Darstellung:
Während ein "normaler" (also ein B-Tree Index) für jeden Wert eine Liste von Rows mit dem
betreffenden Schlüssel (Schnelldenker merken: bei unique Indices ist das immer nur ein Eintrag pro
Liste) speichert, werden bei einem Bitmap Index Bitmaps (Überraschung!) für die Referenzeirung der
Daten verwendet. Dabei wird für jeden Schlüsselwert eine Folge von Bits gespeichert, wobei jedes Bit
einer Row in der Tabelle entspricht, 0 steht dann für "Row enthält diesen Schlüssel nicht" und 1 für
"Row enthält diesen Schlüssel".
Anders formuliert: B-Tree Indices speichern für jeden Schlüssel alle Rows, die diesen auch enthalten,
Bitmap Indices speichern für jeden Schlüssel alle Rows mit Kennzeichen, ob der Schlüssel enthalten ist
oder nicht. Bitmap Indices sind vor allem für Spalten mit wenigen unterschiedlichen Werten geeignet,
da speziell dann noch bei der Kombination von mehreren Kriterien, da ein AND bzw. ein OR binär ja
recht einfach zu realisieren sind.
Oracle 10g Express Edition ünterstützt keine bitmap Indexe.
Also haben wir folgende Indexe angelegt:
-
customer_idx1, der aus c_custkey und c_name besteht
lineitem_idx1, bestehend aus l_linenumber, l_orderkey, l_partkey, l_suppkey
nation_idx11 aus n_nationkey und n_name
orders_idx1 aus o_orderkey, o_custkey, o_orderdate
part_idx1, der aus P_partkey und p_partname besteht
partsupp_idx1, aus ps_partkey und ps_suppkey
region_idx1, aus r_regionkey und r_name
supplier_idx1, aus s_suppkey und s_name
5.4.4 Ausführzeiten der Abfragen mit Cluster-Indexes.
Ein Cluster ist ein Objekt, welches die Daten von einer oder mehreren Tabellen in einem Segment
speichert.
Alle Tabellen eines Clusters müssen eine oder mehrere gemeinsame Spalten enthalten, diese
gemeinsamen Spalten heißen Cluster-Schlüssel. Auf dem Cluster-Schlüssel muss zwingend ein Index
angelegt werden. Dieser Index heißt Cluster-Index und ist vom Objekttyp Index. Der Cluster sorgt dafür,
dass Daten aller Tabellen mit gleichem Cluster-Schlüssel in denselben physikalischen Blöcken liegen.
Ein Cluster ist besonders dann interessant, wenn die Tabellen im Cluster häufig verknüpft (JOIN) und
über den Cluster-Schlüssel angesprochen werden. Technisch gesehen findet also eine Optimierung des
Join auf physikalischer Ebene statt, ohne das logische Datenmodell zu ändern.
Besonders vorteilhaft ist es, wenn die Größe aller Zeilen zu einem Cluster-Schlüssel bekannt ist, dann
kann beim Erstellen des Clusters der entsprechende Speicherplatz reserviert werden. Dies geschieht mit
dem Schlüsselwort SIZE. Aus Sicht der Anwendung ist der Cluster also dann interessant, wenn bei der
1:n-Beziehung die Zahl n eine Konstante ist.
Eine sehr spezielle Form des Clusters ist der Sorted Hash Cluster, dessen Zugriff noch schneller ist, da
dessen interne Struktur sortiert ist. Hashing ist ein optionaler Weg, die Datenspeicherung zu
beeinflussen. Während bei B* - Baümen der gesamte Baum bis zu den Blätterdurchlaufen werden muss,
um an die RowID der Tupel zu gelanden, ist bei Hash-Index mitunter ein einzelnen Zugriff ausreichend.
Grundlage des Hasings ist eine Hash Funktion, die zu einem gegebenen Index einen Hash Wert
berechnet, unter dem ein Tupel zu finden ist. Da im Normallfall die Hash-Funktion nicht injektiv ist
kann es zu kolisionen komme, wenn zu zwei Tupeln derselbe Hash-Wert berechnet wird.
Die Daten werden erst nach dem Anlegen der Cluster indexe importiert. Die SQL Statements für die
Erstellung der Cluster sehen wie folgt aus:
create cluster part_partsupp_lineitem_clu (p_partkey integer) SIZE 512;
CREATE TABLE PART ( P_PARTKEY INTEGER NOT NULL,
P_NAME
VARCHAR(55) NOT NULL,
P_MFGR
CHAR(25) NOT NULL,
P_BRAND
CHAR(10) NOT NULL,
P_TYPE
VARCHAR(25) NOT NULL,
P_SIZE
INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE DECIMAL(15,2) NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL )
cluster part_partsupp_lineitem_clu (p_partkey);
CREATE TABLE PARTSUPP ( P_PARTKEY INTEGER NOT NULL,
PS_SUPPKEY INTEGER NOT NULL,
PS_AVAILQTY INTEGER NOT NULL,
PS_SUPPLYCOST DECIMAL(15,2) NOT NULL,
PS_COMMENT VARCHAR(199) NOT NULL )
cluster part_partsupp_lineitem_clu (p_partkey);
CREATE TABLE LINEITEM ( L_ORDERKEY INTEGER NOT NULL,
P_PARTKEY INTEGER NOT NULL,
L_SUPPKEY INTEGER NOT NULL,
L_LINENUMBER INTEGER NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX
DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR(1) NOT NULL,
L_LINESTATUS CHAR(1) NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL)
cluster part_partsupp_lineitem_clu (p_partkey);
create index part_partsupp_lineitem_index on cluster part_partsupp_lineitem_clu;
create cluster supplier_custom_nation_clu (s_nationkey integer)
SIZE 512;
CREATE TABLE NATION ( s_NATIONKEY INTEGER NOT NULL,
N_NAME
CHAR(25) NOT NULL,
N_REGIONKEY INTEGER NOT NULL,
N_COMMENT VARCHAR(152))
cluster supplier_custom_nation_clu (s_nationkey);
CREATE TABLE SUPPLIER ( S_SUPPKEY INTEGER NOT NULL,
S_NAME
CHAR(25) NOT NULL,
S_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY INTEGER NOT NULL,
S_PHONE
CHAR(15) NOT NULL,
S_ACCTBAL DECIMAL(15,2) NOT NULL,
S_COMMENT VARCHAR(101) NOT NULL)
cluster supplier_custom_nation_clu (s_nationkey);
CREATE TABLE CUSTOMER ( C_CUSTKEY INTEGER NOT NULL,
C_NAME
VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY INTEGER NOT NULL,
C_PHONE
CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL)
cluster supplier_custom_nation_clu (s_nationkey);
create index supplier_custom_nation_index on cluster supplier_custom_nation_clu;
5.5 Fazit
B-Bäume und Linear Hashing sind im allgemeinen sehr gut für dynamische Daten geeignet, die
hauptsächlich über einen Primärschlüssel angesprochen werden. Die Vorteile der schnellen Suche
werden mit höheren Aktualisierungskosten (Einfügen, Löschen) erkauft. So eignet sich Linear Hashing
zum Beispiel für das Management von Virtuellem Speicher.
Linear Hashing eignet sich wenig für die Suche nach mehreren Schlüsseln und die Bereichssuche. Da
die Daten nicht auf- oder absteigend sortiert vorliegen.
B+-Bäume erweitern die Funktion der B-Bäume um den Vorteil der guten sequentiellen Suche
(Bereichssuche). Daher sind sie sehr verbreitet und werden auch in großen Datenbankensystemen
(Oracle u.ä.) benutzt.
Bitmap-Indexe eignen sich vor allem für die mehrdimensionale Suche in großen Datenbanken, z.B. in
Data Warehouses. Dort spielen die Aktualisierungskosten kaum eine Rolle. Viel wichtiger ist die
schnelle Ausführung der Suche bei Einschränkung mehrerer Dimensionen.
Ein Blick auf die Ergebnisse wird in dem folgenden Schaubild präsentiert:
Ausführzeiten
16:48
14:24
12:00
Zeit
09:36
07:12
04:48
02:24
00:00
1
2
3
4
5
6
7
8
9
10 11 12 13 14 15 16 17 18 19 20 21 22
Abfrage Nummer
ohne tuning
primary&foreign keys
B Indexes
cluster Indexes
Die Durschnittliche Ausführzeiten der Abfragen sind auch sehr Interessant da man leicht erkennen kann
welches Verfahren zu einer Verbesserung geführt hat:
Average Time
04:48
04:19
03:50
03:21
Tim e
02:52
ohne tuning
primary and foreign keys
02:24
B Indexes
01:55
Cluster Indexes
01:26
00:57
00:28
00:00
Case
5.6 Anlagen
Automatic Optimizer Statistics Collection
By default Oracle 10g automatically gathers optimizer statistics using a scheduled job called
GATHER_STATS_JOB. By default this job runs within maintenance windows between 10 P.M. to 6 A.M. week
nights and all day on weekends. The job calls the DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC internal
procedure which gathers statistics for tables with either empty or stale statistics, similar to the
DBMS_STATS.GATHER_DATABASE_STATS procedure using the GATHER AUTO option. The main difference is
that the internal job prioritizes the work such that tables most urgently requiring statistics updates are processed
first.
In some cases automatically gathering statistics can cause problems. Highly volatile tables and load tables may
have their statistics gathered when there is an unrepresentative number of rows present. These situations can be
avoided by using one of two methods:
•
The current statistics can be deleted and locked to prevent DBMS_STATS from gathering new statistics. If
the OPTIMIZER_DYNAMIC_SAMPLING parameter is set to 2 (the default) or higher the necessary
statistics will be gathered as part of the query optimization stage (See Dynamic Sampling):
BEGIN
DBMS_STATS.delete_table_stats('MY_SCHEMA','LOAD_TABLE');
DBMS_STATS.lock_table_stats('MY_SCHEMA','LOAD_TABLE');
END;
•
•
•
•
/
•
The statistics can be gathered then locked at a time when the table contains the appropriate data:
BEGIN
DBMS_STATS.gather_table_stats('MY_SCHEMA','LOAD_TABLE');
DBMS_STATS.lock_table_stats('MY_SCHEMA','LOAD_TABLE');
END;
•
•
•
•
/
http://www.oraclebase.com/articles/10g/PerformanceTuningEnhancements10g.php#automatic_optimizer_statisti
cs_collection