NULL Values – Bedeutung und Bereinigung
Werbung

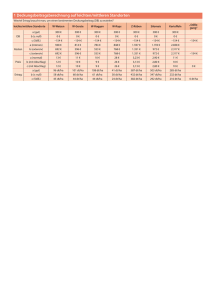
Seminar Wirtschaftsinformatik SS11 Modelle betrieblicher Informationssysteme NULL Values – Bedeutung und Bereinigung Benjamin Ulrich 24.06.2011 Abstract Die Bedeutung von Datenqualität wächst mit der wachsenden Menge an Daten und der Abhängigkeit gegenüber diesen Datenmengen, denen wir gegenüberstehen. Fehler in Daten, fehlerhafte Daten, unbekannte Daten und damit verbundene mit Fehlern behaftete Datenauswertungen und Abfragen können die Datenqualität beeinflussen und führen zu Statistiken, die keine Korrektheit garantieren können. Unbekannte und fehlende Informationen werden in Datenbanken als NULL Values dargestellt. Der fest in SQL verankerte Begriff NULL steht für einen unbekannten oder nicht existierenden „Wert“ in einem Feld der DB. Mit dem NULL Value kann nicht gerechnet werden und es können keine Vergleichsoperationen drüber ausgeführt werden. Viele Datenbankbefehle übersehen NULL Values und händeln ihn nicht, wie der Nutzer sich das wünscht. Diese Problematik und damit zusammenhängende Lösungsvorschläge beleuchte ich in meinem Vortrag und versuche darauf aufmerksam zu machen, was für Folgen die falsche Handhabung der NULL Values haben kann, aber auch welche Konsequenzen eine nicht wohldurchdachte Bereinigung dieser hat. Es wird deutlich, dass die Handhabung von NULLs in Datenbanken sehr schwierig ist und sich jeder, der eine Datenbank bedient, sich dieser Problematik bewusst sein muss. Quellen für meinen Vortrag: How to Handle Missing Information Without Using NULL“ (The Third Manifesto) // Hugh Darwen // Warwick University 2006 „Foundation for future database systems – The Third Manifesto“ // C.J. Date, Hugh Darwen // AddisonWesley Verlag 2000 „NULL values in a database: A programmer's nightmare“ // Alf A. Pedersen // databasedesign-resource.com „SQL NULL Values“ // w3schools.com Inf-IS „Informationssysteme“ - Technologie der Informationssysteme // Hans-Joachim Klein // Hans-ChristianAlbrecht Universität zu Kiel 2011