Simon, Alexander: Entwicklung eines Abfragesystemes für
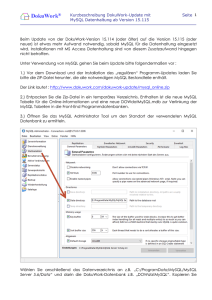
Werbung

Entwicklung eines Abfragesystemes für verfahrenstechnische Messdaten Magisterarbeit von Alexander Simon, Bakk.techn. 9630284, Telematik Institut für Informationssysteme und Computer Medien (IICM) in Kooperation mit Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik der Technischen Universität Graz Graz, September.2005 Begutachter: Ao.Univ.-Prof. Dipl.-Ing.Dr.techn. Nikolai Scerbakov Betreuer: Dipl.-Ing. Alexander Slanina INHALTSVERZEICHNIS 1 Inhaltsverzeichnis 1 Einleitung 3 2 Zielsetzung 4 3 Übersicht von existierenden Systemen und Lösungen 3.1 DDBST - Dortmund Data Bank Software and Separation Technology GmbH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2 DETHERM-Datenbank . . . . . . . . . . . . . . . . . . . . . . . . 5 4 Architektur und Technologie 4.1 Auswahl einer geeigneten Programmierumgebung . . . 4.2 Auswahl einer geeigneten Datenbank . . . . . . . . . . 4.3 Verwendete Software . . . . . . . . . . . . . . . . . . 4.3.1 Apache-HTTP-Server . . . . . . . . . . . . . . 4.3.2 PHP . . . . . . . . . . . . . . . . . . . . . . . . 4.3.3 MySQL . . . . . . . . . . . . . . . . . . . . . . 4.3.4 Eclipse . . . . . . . . . . . . . . . . . . . . . . 4.3.5 MySQL Querybrowser . . . . . . . . . . . . . . 4.3.6 Concurrent Versions System - CVS . . . . . . . 4.3.7 Versionen der verwendeten Programme und Tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 6 7 7 8 8 8 9 10 10 13 15 15 5 Struktur der Datenbank 16 6 Use Cases 6.1 Definition von Use Cases . . . . . . . . . . . . . 6.2 Use Cases im Abfragesystem . . . . . . . . . . . 6.2.1 UC1: Einfache Suche . . . . . . . . . . . . 6.2.2 UC2: Ausbessern fehlerhafter Datensätze . 6.2.3 UC3: Visualisierung gefundener Datensätze 6.2.4 UC4: Löschen von Messdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 18 18 18 18 20 21 7 User Roles 7.1 Definition von User Roles . . . . . . . . . . 7.2 User Roles im Abfragesystem . . . . . . . . 7.2.1 UR1: Normale Benutzer . . . . . . . 7.2.2 UR2: Autor mit beschränkten Rechten 7.2.3 UR3: Administrator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 . 22 . 22 . 22 . 22 . 22 . . . . . . . . . . . . . . . 8 Implementation 23 8.1 Online-Abfragesystem Implementation . . . . . . . . . . . . . . . . 23 8.1.1 Hauptmenü . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 INHALTSVERZEICHNIS 8.1.2 8.1.3 8.1.4 8.1.5 8.1.6 8.2 8.3 8.4 8.5 Suche nach Substanzen . . . . . . . . . . . . . . . . . . . . . Suche nach Journaleinträge . . . . . . . . . . . . . . . . . . . Suche nach Literatureinträge . . . . . . . . . . . . . . . . . . Einfache Messdaten Suche(„simple data property search“) . . Erweiterte Messdaten Suche, Expertensuche („advanced data property search“) . . . . . . . . . . . . . . . . . . . . . . . . Datenimport . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8.2.1 Format der CSV-Daten . . . . . . . . . . . . . . . . . . . . . 8.2.2 Ausschnitt aus HTML-Code für „upload“ Funktionalität . . . Löschen von Messdaten. . . . . . . . . . . . . . . . . . . . . . . . Modifikation von Tabellen . . . . . . . . . . . . . . . . . . . . . . Überblick über GET and POST Requests . . . . . . . . . . . . . . . 2 25 29 33 37 41 45 45 46 48 48 50 9 Ergebnisse und Ausblick 51 A Anhang A.1 Apache . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.2 CVS - Concurrent Versions System . . . . . . . . . . . . . . . . . . A.2.1 Konfiguration für Debian-Distribution . . . . . . . . . . . . . A.2.2 Häufigsten Befehle bei der Arbeit mit dem Concurrent Versions System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.3 Benutzte Sql Anweisungen . . . . . . . . . . . . . . . . . . . . . . A.3.1 Übersicht wichtiger Hyperlinks für die Benutzung von MySql A.3.2 Nutzung der „update“ Anweisung . . . . . . . . . . . . . . . A.3.3 Nutzung der „alter table“ Funktionalität . . . . . . . . . . . . A.3.4 „like“ Funktionalität . . . . . . . . . . . . . . . . . . . . . . A.3.5 „order by“ Funktionalität . . . . . . . . . . . . . . . . . . . . A.3.6 „join“ Funktionalität . . . . . . . . . . . . . . . . . . . . . . A.3.7 „delete“ Funktionalität . . . . . . . . . . . . . . . . . . . . . A.4 Nutzung des „mysqldump“ Backuptools . . . . . . . . . . . . . . . 52 52 52 52 53 54 54 54 55 55 56 56 56 56 B MySQL Code 58 B.1 MySQL „update“ Code Auszüge . . . . . . . . . . . . . . . . . . . 58 B.2 MySQL ‘"join“ Code Auszüge . . . . . . . . . . . . . . . . . . . . 60 B.3 MySQL „order by“ Code Auszüge . . . . . . . . . . . . . . . . . . 64 1 EINLEITUNG 3 1 Einleitung Am Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik der TU Graz wurde seit 1992 in Zusammenarbeit mit Prof. Matous von der Technischen Hochschule Prag und Prof. Gmehling von der Universität Oldenburg eine Datensammlung für Gasdichten und Virialkoeffizienten erstellt, um daraus für den Verfahrenstechniker interessante Stoffdaten zu gewinnen[1, 2, 3] Die Messergebnisse von Gasdichten sind für den Verfahrenstechniker besonders bei der Auslegung von chemischen Anlagen relevant, da sie einen großen Einfluss auf die Dimensionierung der Apparate haben. Die Integration der Messdaten in einer Datenbank ermöglicht einen strukturierten Zugriff auf Stoffdaten, welche in weiteren Arbeiten am Institut zur Berechnung von Zustandsgleichungen und deren Mischungsregeln herangezogen werden. Vorarbeit für ein gut funktionierendes System wurde geleistet von Dipl.Ing. B. Edegger in der Diplomarbeit „Automatische Umrechnung von Messdaten in ihre SI-Einheiten, Evaluierung und Speicherung in einer Online-Datenbank“[1]. Um den Zugriff auf die Daten zu erleichtern, wird nun das existierende System um ein Abfragesystem erweitert. Dieses ermöglicht dann die zielgerichtete Suche nach Daten, welche dann in weiteren Schritten verarbeitet werden sollen. 2 ZIELSETZUNG 4 2 Zielsetzung Ziel dieser Arbeit ist es, am Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik der TU-Graz, ein Online-Abfragesystem für die Messdatensammlung von Gasdichten und Virialkoeffizienten zu erstellen. Die Arbeit gliedert sich in folgende Teilbereiche: • Das Kapitel „Übersicht von existierenden Systemen und Lösungen“ beschäftigt sich mit dem am Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik benutzten System. Es wird begründet, warum es notwendig war, auf ein neues System zu wechseln und welche Vorteile es bringt. • Das Kapitel „Architekturen und Technologien“ beschreibt den eingesetzten Webserver, die benutzte Skriptsprache und das dahinterliegende Datenbank Management System. Zusätzlich werden technische Hilfsmittel beschrieben, die für das zu entwickelnde System eingesetzt wurden. • Das Kapitel „Use Case“ zeigt vorhandene Prozesse für ein Abfragesystem. Beschrieben werden alle Suchvarianten, die in einem Abfragesystem vorkommen können. • Das Kapitel „User Roles“ beschreibt existierende Rollen für ein Abfragesystem. • Das Kapitel „Implementation“ beschäftigt mit Modifikationen und Erweiterungen des bestehenden Systems. Der Hauptteil diese Kapitels macht die Suche aus, die Ziel dieser Arbeit war. Detaillierter betrachtet wird hier die Suche nach Messdaten, Substanzen, Literatur und Journalen, Aufbau der Suchmasken und Darstellung der gefundenen Ergebnisse. Erwähnt wird in diesem Kapitel auch das Löschen von Datensätzen, der Import von Messdaten und die Modifikationen an der Tabelle „Substance“. • Das Kapitel „Ergebnisse und Ausblick“ beschreibt das Resultat der Arbeit und liefert Informationen, wo noch Energie eingesetzt werden muss um ein zuverlässiges sicheres System zu erhalten. 3 ÜBERSICHT VON EXISTIERENDEN SYSTEMEN UND LÖSUNGEN 5 3 Übersicht von existierenden Systemen und Lösungen Am Markt befinden sich nur sehr vereinzelt Informationssysteme, welche sich mit der Speicherung und Weiterverarbeitung von Messdaten beschäftigen. Allen Systemen ist aber gemein, dass sie von professionellen Firmen programmiert wurden. Sie sind deshalb sehr ausgereift, aber leider auch sehr kostenintensiv. Zwei dieser Systeme sollen hier nun kurz vorgestellt werden. 3.1 DDBST - Dortmund Data Bank Software and Separation Technology GmbH Seit 1973 beschäftigt sich das Institut für Reaktionstechnik der Universität Oldenburg mit der Sammlung aller Art von Stoffdaten. Sie wurde immer mehr erweitert, sodass es sich als notwendig erwies, 1989 die Firma DDBST(Abb. 1) zu gründen, welche den damaligen Datenbestand kommerziell weiterbetreute, um eine immerwährende Aktualisierung zu gewährleisten. Abbildung 1: DDBST Datenbank System. Die Daten der Grazer Datenbank werden der DDBST zur Verfügung gestellt. Leider ist durch die Kommerzialisierung des Systemes der Preis eines solchen Pro- 3 ÜBERSICHT VON EXISTIERENDEN SYSTEMEN UND LÖSUNGEN 6 grammes auch sehr hoch, für den klassischen Verfahrenstechniker aber trotzdem unverzichtbar. 3.2 DETHERM-Datenbank Die DETHERM-Datenbank (Abb. 2) der DECHEMA (Gesellschaft für Chemische Technik und Biotechnologie e.V.) stelle ebenfalls ein ähnliches System dar. Es beinhaltet die meisten Daten der Datenbank der DDBST und noch einige mehr. In der neuesten Version bietet sie sogar einen online-Zugang über den Web-Browser. Leider sind auch hier die Kosten sehr hoch (12 Euro für eine Zeile einer Datentabelle). Die Grazer Stoffdaten-Datenbank versteht sich daher eher als System, welches oben genannten zuarbeitet. Es bietet nun eine Möglichkeit on-line Daten in die Datenbank einzutragen, diese zu überprüfen, zu speichern und auszuwerten. Bisher fehlte aber die Möglichkeit, in den bestehenden Beständen, gezielt Daten zu suchen. Abbildung 2: DETHERM Datenbank System. 4 ARCHITEKTUR UND TECHNOLOGIE 7 4 Architektur und Technologie Bevor man zu entwickeln beginnt, müssen wichtige Punkte geklärt werden, warum für die Realisierung dieses Systems die Skriptsprache Hypertext Preprocessor (PHP) in Verbindung mit der Datenbank MySQL und dem HTTP-Server Apache gewählt wurde und welche Vorteile sich daraus ergeben. Fragen, die es zu beantworten gibt: • Welche Programmierumgebung ist für die Implementation am besten geeignet? • Wie sollten die Daten abgespeichert werden? 4.1 Auswahl einer geeigneten Programmierumgebung Die Architektur „Webanwendung“, welche für die Implementierung des Abfragesystems gewählt wurde, setzt zwingend einen HTTP-Server voraus. Für die Programmierung von Anwendungen unterstützt dieser idealerweise eine Anzahl von Skriptsprachen, welche wiederum der Lage sind, mit den verschiedensten Systeme zu kommunizieren. Der Http-Server Apache[4] bietet die Möglichkeit, mittels serverseitiger Skriptsprachen Webseiten dynamisch zu erstellen. Häufig verwendete Skriptsprachen sind PHP oder Perl. Diese sind kein Bestandteil des Webservers, sondern müssen ebenfalls entweder als Module eingebunden werden oder über die CGI-Schnittstelle angesprochen werden. Bis vor kurzem lautete die Antwort auf diese Anforderungen noch ’Perl & Apache’. Perl (Practical Extraction and Report Language), eine universell einsetzbare Skriptsprache mit weitreichender Unterstützung der verschiedensten Systeme sowie der Apache-HTTP-Server waren lange Zeit das ideale Gespann zur Realisation von Webanwendungen. Doch PHP hat viele Vorteile (Überblick von PHP). Es ist relativ leicht zu erlernen und nach kurzer Einarbeitung effizient anwendbar, bietet aber auch einen riesigen Funktionsumfang für den professionellen Programmierer, vorallem in Hinblick auf Verwendung mit Datenbanken. 4 ARCHITEKTUR UND TECHNOLOGIE 8 4.2 Auswahl einer geeigneten Datenbank Für die Abspeicherung der Daten ist es notwendig, ein geeignetes Datenbank Management System (DBMS) zu finden. Für die Implementation ist der relationale Ansatz am besten geeignet. Darüber hinaus sind die performantesten Systeme zur Zeit noch immer relationale Datenbank Management Systeme, wobei sich MySQL[5] als besonders geeignet erweist. Es unterstützt Transaktionen, ist frei verfügbar, wird über die Datenbanksprache SQL (Structured Query Language) angesprochen und besitzt eine gute Einbindung in PHP. 4.3 Verwendete Software Es wird nun ein wenig auf die am meist benutzten Programme und Tools eingegangen. Für PHP wurde das Integrated Developement Environment (IDE) Eclipse benutzt, für MySQL empfehlenswert ist der Mysql-Query-Browser. Weiters wurde für die Konfiguration der Datenbank das mächtige PHP-Tool „phpmyadmin“ benutzt, welches nur einen WebBrowser benötigt. 4.3.1 Apache-HTTP-Server Einer der am meist verbreitesten Server ist der Apache HTTP Server. Gezählt wurden weltweit etwa 50 Millionen Server. Der frei verfügbare, sehr leistungsfähige Server ist in einer Linux und in einer Windows-Version verfügbar, welche beide immer weiter entwickelt werden. Aufgebaut ist in modularer Form, dies bietet großen Vorteil in der Neuentwicklung zusätzlicher Funktionalitäten. Weltweit vertreten ist er mit etwa 70% von den eingesetzten Http-Server. Aktuelle Informationen kann man auf Netcraft [6] finden. Die tragende Organisation ist die im Juni 1999 gegründete und aus der Apache Group hervorgegangene Apache Software Foundation (ASF), die die Entwicklung rund um den Web-Server und viele andere Vorhaben betreut. Das traditionelle, verteilte Entwicklungsmodell von Open Source findet sich nur entfernt wieder, denn ein Merkmal dieses Projekts ist die zentrale Kontrolle des Quellcodes, die erlaubt, schnell Änderungen vorzunehmen. Obwohl die ASF eine non-profit-Organisation ist, weist sie Charakteristika eines Unternehmens auf. Beispielsweise gibt es einen Aufsichtsrat, der von Mitgliedern der ASF gewählt wird, Verantwortung trägt und Entscheidungen fällt. 4 ARCHITEKTUR UND TECHNOLOGIE 9 Weitere Informationen zum Apache-HTTP-Server kann man auf der [4, Apache] Seite finden. 4.3.2 PHP PHP Hypertext Preprocessor[7] ist eine weit verbreitete, universell nutzbare Skriptsprache. Speziell optimiert wurde sie jedoch für den Einsatz als server-seitig interpretierte, in HTMLCode eingebettete Sprache zur dynamischen Erzeugung von Web-Inhalten. Das bedeutet, dass spezifische PHP-Anweisungen (PHP-Tags) in HTML eingebunden werden, die, wenn die entsprechende HTML-Seite angefordert wird, vom Web-Server beziehungsweise vom PHP-Modul im Web-Server gelesen und ausgeführt werden. Die Syntax entspricht weitestgehend der der Programmiersprache C. PHP hat aber auch aus vielen anderen Programmiersprachen (zum Beispiel Perl) Syntaxelemente entlehnt. PHP wurde 1995 von Rasmus Lerdorf entwickelt und war in erster Linie eine Sammlung von Perl-Skripten, welches dann von ihm in C umgesetzt wurde. Die ersten Versionen von PHP/FI (FI stand für Form Interpreter) waren zu schwach für Internetanwendungen, wodurch es neu geschrieben wurde. PHP entwickelte sich dann schnell zu einer vollwertigen Programmiersprache für das Web mit Datenbankschnittstelle und Unterstützung diverser Internet-Protokolle (NNTP, POP3, IMAP usw.). Von Beginn an als Open-Source-Projekt konzipiert ist PHP für viele Unix-Systeme, Microsoft Windows, Mac und RISC-OS erhältlich. PHP unterstützt auch die meisten der heute gebräuchlichen Webserver. Dies umfasst Hyperwave, Apache, Microsoft Internet Information Server, Netscape Server, Caudium, Xitami, OmniHTTPd und viele andere. Für den Großteil der Server bietet PHP ein eigenes Modul, für die anderen, welche den CGI Standard unterstützen, kann PHP als CGI Prozessor arbeiten. Vielleicht die größte und bemerkenswerteste Stärke von PHP ist seine Unterstützung für eine breite Masse von Datenbanken. Dazu zählen unter anderem dBase, IBM DB2, Microsoft SQL Server, MySQL, Oracle und PostgreSQL, um nur einige zu nennen. PHP verfügt auch über äußerst hilfreiche Textverarbeitungsfunktionen, von den regulären Ausdrücken (POSIX erweitert oder Perl) bis zum Parsen von Extensible Markup Language (XML) Dokumenten, wobei es sich an die Standards Simple API for XML (SAX) und Document Object Model (DOM) hält. 4 ARCHITEKTUR UND TECHNOLOGIE 10 4.3.3 MySQL MySQL[5] ist ein relationales Datenbank Management System (RDBMS). Als Open Source SQLDatenbank steht MySQL unter der GPL (GNU General Public License). MySQL wird von der Firma „MySQL AB“[36] zur Verfügung gestellt. MySQL AB ist ein kommerzielles Unternehmen, dessen Geschäft darin besteht, Serviceleistungen rund um die MySQL-Datenbank zur Verfügung zu stellen. Als relationale Datenbank speichert MySQL Daten in separaten Tabellen, anstatt sie alle in einem einzigen großen Speicherraum unterzubringen. Hierdurch werden hohe Geschwindigkeit und Flexibilität erreicht. Die Tabellen werden durch definierte Beziehungen verbunden (Relationen), wodurch es möglich ist, Daten aus verschiedenen Tabellen auf Nachfrage zu kombinieren. Der SQL-Teil von MySQL steht für „Structured Query Language“ (strukturierte Abfragesprache) - die verbreiteste standardisierte Sprache für Datenbankzugriffe. MySQL wurde ursprünglich entwickelt, um sehr große Datenbanken handhaben zu können, und zwar deutlich schneller als existierende Lösungen. Es wurde mehrere Jahre in höchst anspruchsvollen Produktionsumgebungen eingesetzt. Heutzutage bietet MySQL eine umfangreiche Reihe nützlicher Funktionen. Connectivity, Geschwindigkeit und Sicherheit machen MySQL äußerst geeignet, um auf Datenbanken über das Internet zuzugreifen. MySQL ist ein Client-Server-System, das aus einem multi-thread SQL-Server besteht, der unterschiedliche Backends, verschiedene Client-Programme und -Bibliotheken, Verwaltungswerkzeuge und eine Vielzahl an Programmschnittstellen (zum Beispiel für Java, Perl, C, C++, Eiffel und PHP) unterstützt. An Betriebssystemen werden Linux, Microsoft Windows, Mac OS XServer und FreeBSD unterstützt, um nur einige zu nennen. Auch Transaktionen sind mit MySQL einfach möglich. Diese stellen sicher, dass Datenbankänderungen vollständig oder gar nicht ausgeführt werden. 4.3.4 Eclipse Eclipse[9] ist eine auf Java basierte Open Source Entwicklungsumgebung, die sich besonders durch ihre starke Integrationsfähigkeit auszeichnet (Abb. 3)). Eclipse unterstützt Syntax Highlighting für viele Programmiersprachen, darunter Java, Perl, C/C++ und PHP. Weiters hat sie eingebaute Funktionen zum Suchen und Ersetzen und unterstützt reguläre Ausdrücke. Es können auch so genannte Projekte angelegt werden, die aus mehreren Dateien bestehen. Das Öffnen eines Projektes bewirkt das Öffnen aller zugehörigen Dateien, was eine große Arbeits- 4 ARCHITEKTUR UND TECHNOLOGIE 11 erleichterung darstellt. Die Eclipse Plattform selbst stellt lediglich ein einfaches und schlankes Framework für Basisfunktionalitäten und Anwendernavigation bereit. Die gesamte Funktionalität wird über Plugins in das Integrated Developement Environment (IDE) integriert. Einige Plugins für Standardfunktionalitäten werden gleich mitgeliefert: • JDT (Java Development Tools): Das JDT-PlugIn erweitert die Eclipse Plattform um Funktionalitäten die benötigt werden, um Java Programme zu erstellen, editieren, compilieren und debuggen. • PDE (Plugin Development Environment): Das PDE wird benötigt um Eclipse Plugins zu entwickeln. Eclipse basiert zwar auf der Programmiersprache Java und ist auch in Java programmiert, das heißt aber nicht, dass sie auf Java beschränkt ist. Beispielsweise existieren entsprechende Plugins, die es dem Benutzer ermöglichen, auch PHP, C++ oder Perl-Programme zu erstellen. • Concurrent Versions System (CVS) • Unified Modeling Language (UML) • Webentwicklung (HTML, XML) • Application Server Integration (Jboss) Neben den Plugins existiert eine weitere Möglichkeit den Funktionsumfang der Eclipse Plattform zu erweitern, nämlich die Einbindung von so genannten externen Tools. Eclipse bietet die Möglichkeit externe Programme aus der IDE heraus zu starten, deren Ausgabe mitzuverfolgen und zu steuern. Diese Möglichkeit unterstreicht die starke Integrationsfähigkeit dieser IDE und macht die Plattform zu einer wirklich integrierten Entwicklungsumgebung. 4 ARCHITEKTUR UND TECHNOLOGIE Abbildung 3: Eclipse mit Codeausschnitt. 12 4 ARCHITEKTUR UND TECHNOLOGIE 13 4.3.5 MySQL Querybrowser Der MySQL Query Browser[8] ist ein einfach zu bedienendes Visualisierungswerkzeug zur Erstellung, Ausführung und Optimierung von SQL-Abfragen für die MySQL-Datenbank (Abb. 4)). Er bietet eine vollständige Auswahl an Dragand-Drop-Werkzeugen, um die Abfragen visualisiert zu erstellen, zu analysieren und zu verwalten. Zusätzlich werde folgende Funktionalitäten und Werkzeuge angeboten: • Die Symbolleiste, um Abfragen einfach zu erstellen und auszuführen und in der Abfragenhistorie zu navigieren. • Den Skripteditor, der die Möglichkeit bietet, SQL-Befehle manuell zu erstellen und zu editieren. • Das Ergebnisfenster, so daß man auch ganz einfach mit Mehrfachabfragen arbeiten und diese vergleichen kann. • Den Objektbrowser, der die Möglichkeit anbietet, Datenbanken, Lesezeichen und Historie mit einer webbrowserähnlichen Oberfläche zu verwalten. • Den Datenbankexplorer, mit dem man Tabellen und Felder zur Abfrage auswählen sowie Tabellen erstellen und löschen kann. • Den Tabelleneditor, der das einfache Erstellen, Verändern und Löschen von Tabellen erlaubt • Die Direkthilfe, die sofortigen Zugriff auf ausgewählte Objekte, Parameter und Funktionen gibt. 4 ARCHITEKTUR UND TECHNOLOGIE Abbildung 4: MySQL Query Browser mit beispielhafter Abfrage. 14 4 ARCHITEKTUR UND TECHNOLOGIE 15 4.3.6 Concurrent Versions System - CVS Concurrent Versions System [11] ist wie der Name sagt ein Hilfsmittel für die Versionskontrolle. In diesem Falle wird der Sourcecode verwaltet. Dieses Tool ist hilfreich, wenn mehrere Programmierer am gleichen Projekt arbeiten. Man kann immer am neuesten Stand bleiben, durch Aufruf von „cvs update“. Arbeitet man auf unterschiedlichen Rechner, so gibt es Vorteile durch das Concurrent Versions System. Man kann von jeden Rechner aus mit den aktuellsten Stand arbeiten. Die Daten selbst liegen auf einem Rechner, der als Server fungiert. Auf diesen werden die Daten gespeichert, inklusive Versionsinformationen und Änderungen. 4.3.7 Versionen der verwendeten Programme und Tools • Apache/2.0.54 (Debian GNU/Linux) • PHP/4.3.10-15 Server at localhost Port 80 • MySQL Ver 12.22 Distrib 4.0.23, for pc-linux-gnu (i386) • Eclipse 3.0.1 • Phpeclipse-plugin 1.1.3 [10] • Concurrent Versions System (CVS) 1.12.9 (client/server) • MySQL QueryBrowser 1.1.5 Nachdem nun nun die Vorteile des benutzten Systemes gezeigt wurden, wird nun etwas auf die Struktur der vorhandenen Datenbank eingegangen. 5 STRUKTUR DER DATENBANK 16 5 Struktur der Datenbank Die Datenbank für das Speichern der Messdaten und zusätzlichen Informationen hat momentan 13 verschiedene Tabellen. Diese teilen sich in zwei Hauptgruppen auf, wobei die eine Hälfte der Beschreibung der Messdatenquelle dient, die andere Hälfte der Speicherung der Messwerte. Zur ersten Hälfte gehören die Tabellen „substance“, „literature“, „journal“ und „data_property“ (Abb. 5). Die Tabelle „substance“ speichert alle vorkommenden Substanzen, mit denen Messungen durchgeführt wurden. Die Substanz wird durch eine eindeutige Substanznummer gekennzeichnet. Die Literaturstelle, in der die Messdaten veröffentlicht werden, sind in der Tabelle „literature“ abgelegt. Auch hier werden die Literaturstellen durch eindeutige Literaturnummern identifiziert. Zusätzlich wird auch das jeweilige Journal festgelegt, diese kann man in der Tabelle „journal“ finden. In der Tabelle „data_property“ wird eine genaue Beschreibung der gemessenen Werte, sowie der Messanordnung gespeichert. Weiters enthält jeder Messdatensatz eine eindeutige Messdatensatznummer. Die Messwerte werden in neun Tabellen gespeichert, wobei je drei Tabellen einem Messdatentyp zugehörig sind. Diese drei Tabellen enthalten Informationen über die Originalmesswerte, SI-Messwerte und Einheiten der Messwerte. Die Messdatentypen sind „Gasdichtemessdaten“, „Virialkoeffizienten“, „Kreuzvirialkoeffizienten“. Diese Art der Strukturierung, welche eigentlich der dritten Normalform widerspricht war deshalb notwendig, um einen einfachen Datenaustausch mit am System beteiligten Institutionen zu ermöglichen. Dies beizubehalten war auch eine Vorgabe an diese Arbeit. 5 STRUKTUR DER DATENBANK Abbildung 5: Entity Relationship Diagramm der Datenbank 17 6 USE CASES 18 6 Use Cases 6.1 Definition von Use Cases Use Cases sind Anwendungsfälle, die man sich als eine Sammlung von Szenarenien über den Systemeinsatz vorstellen kann. Jedes Szenario beschreibt eine Sequenz von Schritten. Jede dieser Sequenzen wird von einem Menschen, einem anderen System, einem Teil der Hardware oder durch Zeitablauf in Gang gesetzt. Entitäten, die solche Sequenzen anstoßen, nennt man Akteure. Das Ergebnis dieser Sequenz muß etwas sein, was entweder dem Akteur, der sie initiierte oder einem anderen Akteur nutzt. Ein Use Case ist eine typische Handlung, die ein Benutzer mit dem System ausführt, z.B. Aktienkauf. Use Cases werden durch ein Unified Modeling Language (UML) Diagramm dargestellt, welche eine bestimmten Anwendungsfall abbildet. Im Diagramm werden Use Cases durch Ellipsen dargestellt. Verbindungen zu den entsprechenden Use-Cases werden durch Linien dargestellt. Damit wird angezeigt, welche Aktoren an dem entsprechenden Use Case beteiligt sind. 6.2 Use Cases im Abfragesystem Für die Umsetzung eines Abfragesystems existieren mehrere Fallbeispiele. 6.2.1 UC1: Einfache Suche Die Suche selbst ist ein Use Case. Unterscheiden kann man hierbei mehrere Szenarien. Je nach Szenario existiert eine geeignete Suchmaske. Vorhanden sind Suchmasken für unterschiedliche Tabellen, in denen man suchen kann: • Suche nach Substanzen(Abb. 6, Maske 14). • Suche nach Literatur(Abb. 7, Maske 20). • Suche nach Journalen(Abb. 8, Maske 17). • Suche nach Messdaten(Abb. 9, Masken 23, 25). 6.2.2 UC2: Ausbessern fehlerhafter Datensätze Aufgrund möglicher fehlerhafter Eingabe von Datensätzen will man die Möglichkeit wahren, eingegebene Daten ausbessern zu können. Nach dem Korrigieren 6 USE CASES 19 Abbildung 6: Use Case Diagramm Substanzsuche Abbildung 7: Use Case Diagramm Literatursuche Abbildung 8: Use Case Diagramm Journalsuche Abbildung 9: Use Case Diagramm Messdatensuche 6 USE CASES 20 müssen die Daten wieder in der Datenbank abgelegt werden. Dazu benötigt man Abfragesystem, welchen in bestimmten Tabellen sucht. Die gefundenen Ergebnisse sollen anzeigt und von Benutzern mit Rechten zum Modifizieren der Daten bearbeitet werden können(Diagramm 10). Abbildung 10: Use Case Diagramm Datenkorrektur 6.2.3 UC3: Visualisierung gefundener Datensätze Für Präsentationen besteht der Bedarf, bestimmte Datenbereiche mit speziellen Eigenschaften darzustellen. Um Eigenschaften oder Verlauf von Werten leichter zu verstehen , greift man auf die Technik der Visualisierung zurück. Um spezielle Messbereiche grafisch darzustellen, benötigt man ein Abfragesystem, mit welcher man eine detaillierte Suche starten kann(Diagramm 11). Abbildung 11: Use Case Diagramm Visualisierung 6 USE CASES 21 6.2.4 UC4: Löschen von Messdaten Dieser Use Case beschreibt die Suche nach Messdaten, welche aus der Datenbank entfernt werden sollen(Diagramm 12). Abbildung 12: Use Case Diagramm Messdatenlöschung 7 USER ROLES 22 7 User Roles 7.1 Definition von User Roles Die Rolle eines Benutzers bestimmt einen Arbeitsbereich für eine bestimmte Benutzergruppe, definiert Rechte und Anwendungen. Diese Rollenverteilung ist notwendig, um die Datenbank gegen unerwünschte Änderungen oder Einträge zu schützen. 7.2 User Roles im Abfragesystem Für die Umsetzung eines Abfragesystems existieren mehrere Rollen. 7.2.1 UR1: Normale Benutzer Dieser hat Zugriff auf das System, kann im System suchen und lesen, hat aber keine Rechte zum Ändern der Daten. 7.2.2 UR2: Autor mit beschränkten Rechten Dieser Benutzertyp hat nur die Aufgabe, Daten ins System einzuspielen. Autoren besitzen alle Rechte, die auch normale Benutzer haben. 7.2.3 UR3: Administrator Dieser hat die gleichen Rechte wie der Autor, nur kann er zusätzlich Daten editieren und löschen. 8 IMPLEMENTATION 23 8 Implementation Beschrieben werden hier die Modifikationen, Änderungen und Erweiterungen am bestehenden System. Ein Überblick über Veränderungen an der vorhandenen Tabellenstruktur wird geliefert, sowie Information über Einbau neuer Funktionalität für Import von Messdaten und Löschung dieser. Den größten Bereich in diesem Kapitel deckt das Unterkapitel „Abfragesystem“ ab. 8.1 Online-Abfragesystem Implementation Das Abfragesystem teilt sich in mehrere Bereiche auf. Die wichtigsten zu erwähnenden Bereiche sind die „simple data property search“ und die „advanced data property search“. Der Einstiegspunkt zum Abfragesystem beginnt beim Hauptmenü(Abb. 13). Von diesem aus kommt man über das einfache Suchformular zur erweiterten Suche. 8.1.1 Hauptmenü Das Hauptmenü bietet den Einstiegspunkt für die Suche. Sie bietet Suchmöglichkeiten in unterschiedlichen Tabellen: • Substanzsuche • Journalsuche • Literatursuche • Die „Messdaten“ Suche unterteilt sich in zwei Suchvarianten: Die einfache Suche oder „simple data property search“ Die erweiterte Suche, Expertensuche oder „advanced data property search“ 8 IMPLEMENTATION Abbildung 13: Hauptmenüseite 24 8 IMPLEMENTATION 25 8.1.2 Suche nach Substanzen Bei der Suche nach Substanzen können folgende Felder (Abb. 14) als Suchbegriff benutzt werden: • Substanz Nummer • CAS(Chemical Abstracts Service)[15] • Name der Substanz in Englisch • Name der Substanz in Deutsch • Synonyme der Substanz. • chemische Formel der Substanz Die einzelnen Suchfelder können „AND“ oder „OR“ verknüpft werden. Die Ergebnisse werden in einer Tabelle angezeigt(Abb. 15). Aus dieser Liste kann man die gewünschte Substanz auswählen und den Inhalt in einer für die Substanz angepasste Maske anzeigen lassen(Abb. 16). Ist man als Benutzer mit Editierrechten eingeloggt, kann man bei dieser Ergebnisanzeige, Daten ändern. Diese Änderungen können dann in der Datenbank abgespeichert werden. 8 IMPLEMENTATION Abbildung 14: Suche nach Substanzeinträgen. 26 8 IMPLEMENTATION Abbildung 15: Liste der gefundenen Substanzeinträge. 27 8 IMPLEMENTATION Abbildung 16: Anzeige eines gefundenen Substanzeintrages. 28 8 IMPLEMENTATION 29 8.1.3 Suche nach Journaleinträge Bei der Suche nach Journalen können folgende Felder (Abb. 17) als Suchbegriff benutzt werden: • Journal Nummer • CASSI (Chemical Abstracts Service Source Index)[12] • Titel des Journals • Herausgeber des Journals • ISSN (International Standard Serial Number) [13] Die einzelnen Suchfelder können „AND“ oder „OR“ verknüpft werden. Die Ergebnisse werden in einer Tabelle angezeigt(Abb. 18). Aus dieser Liste kann man das gewünschte Journal auswählen und den Inhalt in einer für das Journal angepasste Maske anzeigen lassen(Abb. 19). Ist man als Benutzer mit Editierrechten eingeloggt, kann man bei dieser Ergebnisanzeige, Daten ändern. Diese Änderungen können dann in der Datenbank abgespeichert werden. 8 IMPLEMENTATION Abbildung 17: Suche nach Journalen. 30 8 IMPLEMENTATION Abbildung 18: Liste der gefundenen Journaleinträge. 31 8 IMPLEMENTATION Abbildung 19: Anzeige eines gefundenen Journaleintrages. 32 8 IMPLEMENTATION 33 8.1.4 Suche nach Literatureinträge Die Literatursuche wurde etwas anders konzipiert, als die Suche nach Substanzen oder Journalen. Sie enthält neben der Abfrage in der Tabelle Literatur eine zusätzliche Abfrage in der Tabelle Journal, welche durch ein „Join“ verbunden sind. Die einzelnen Suchfelder können „AND“ oder „OR“ verknüpft werden. Bei der Suche nach Literatur können folgende Felder (Abb. 20) als Suchbegriff benutzt werden: • Literatur Nummer • Titel des Artikels • Autor oder Autoren • Erscheinungsjahr des Artikels • Flags Zusätzlich kann man die Sucheergebnisse einschränken, indem man auch nach Journal (Abb. 20) sucht. Hier sind folgende Suchfelder vorhanden: • Journal Nummer • Titel des Journals • ISBN/ISSN Die Ergebnisse werden in einer Tabelle angezeigt(Abb. 21). Aus dieser Liste kann man die gewünschte Literatur auswählen und den Inhalt in einer für die Literatur angepasste Maske anzeigen lassen(Abb. 22). Ist man als Benutzer mit Editierrechten eingeloggt, kann man bei dieser Ergebnisanzeige, Daten ändern. Diese Änderungen können dann in der Datenbank abgespeichert werden. 8 IMPLEMENTATION Abbildung 20: Suche nach Literatur. 34 8 IMPLEMENTATION Abbildung 21: Liste der gefundenen Literatureinträge. 35 8 IMPLEMENTATION Abbildung 22: Anzeige eines gefundenen Literatureintrages. 36 8 IMPLEMENTATION 37 8.1.5 Einfache Messdaten Suche(„simple data property search“) Bei der einfachen Suche nach Messdaten kann man nach folgenden Feldern suchen (Abb. 23): • Nummer der erste Substanz. • Nummer der zweiten Substanz. • Literatur Nummer. • Journal Nummer • Art der Daten. Bei der Literatur wird selektiert, ob überhaupt nutzbare Daten vorkommen. Folgende Möglichkeit stehen zur Auswahl: blank; Literatur hat keine verwertbaren Messdaten. pure data; Literatur hat Messdaten für Reinstoffe. binary data; Literatur hat Messdaten für Binärgemische. ternary data; Literatur hat Messdaten für Gemische aus drei oder mehr Substanzen. • Typ der Messdaten. Folgende stehen momentan zur Auswahl: PVT Data Virial coefficients - Leidenform Virial coefficients - Berlinform Cross Virial coefficients - Leidenform Cross Virial coefficients - Berlinform • Bereich den die Messung abdeckt. Hier stehen sechs Möglichkeiten zur Auswahl: sub super dew crit extended unknown 8 IMPLEMENTATION 38 • Für Messdatensätze können Flags gesetzt werden. Diese sind ebenfalls ein Kriterium für die Suche. • Literatureinträge können bestimmte Flags gesetzt haben. Diese sind ebenfalls ein Kriterium für die Suche. Die vorhandenen Buttons mit der Beschriftung „search...“ ermöglichen die Suche in der dem Feld entsprechenden Tabelle. Benötigt man eine Journal Nummer, so wird man nach drücken des Buttons „search journal“ die dazugehörige Suchmaske (Abb. 17) geöffnet. Die Ergebnisse werden in einer Tabelle angezeigt(Abb. 24). Aus dieser Liste kann man das gewünschte Ergebnis auswählen und anzeigen lassen. Ist man als Benutzer mit Löschrechten eingeloggt, hat man die Möglichkeit, die Messdaten zu löschen. 8 IMPLEMENTATION Abbildung 23: Einfaches Suchformular. 39 8 IMPLEMENTATION Abbildung 24: Ergebnis der einfachen Suche. 40 8 IMPLEMENTATION 41 8.1.6 Erweiterte Messdaten Suche, Expertensuche („advanced data property search“) Die Expertensuche ist eine Erweiterung zur einfachen Suche. Die erweiterte Suche enthält zusätzliche Felder, welche als Suchkriterium gesetzt werden können(Abb. 25). So werden hier nicht nur vollständige Datensätze ausgegeben, sondern die gesamten Messdaten auch zusammengefasst, um eine weitere Verarbeitung - grafisch oder analytisch - zu ermöglichen. Beispielsweise kann der gesuchte Temperatur- oder Druckbereich eingeschränkt werden. Dies kann die Anzahl der gefundenen Elemente wesentlich reduzieren. Weiters existiert die Möglichkeit, die Ergebnisse in bestimmter Reihenfolge anzeigen zu lassen(Abb. 26). Durch den Button „set sortorder“ kann man die Reihenfolge festlegen. Zur Auswahl stehen bestimmte Felder, die sortiert werden können. Man kann festlegen, ob ein Feld aufsteigend oder absteigend sortiert werden soll. Das Resultat kann man in Abb. 27 betrachten. Auf dieser Seite werden mehrere Anforderungen realisiert. 8 IMPLEMENTATION Abbildung 25: Erweitertes Suchformular. 42 8 IMPLEMENTATION Abbildung 26: Sortierung der Ergebnisse festlegen. 43 8 IMPLEMENTATION Abbildung 27: Ergebnis der erweiterten Suche. 44 8 IMPLEMENTATION 45 8.2 Datenimport Dieser Punkt erweitert die Eingabe von Daten in der Weise, dass Datenproperties über eine existierende Exceldatei importiert werden. Der Datensatz in Excelformat basierend, wird in ein „comma seperated format“ (csv) umgewandelt. Dieses Format hat den Vorteil, leicht lesbar zu sein. Diese Daten werden in die Datenbank portiert. Dazu muss das existierende Inputhandling erweitert werden. In input_unit3 [1] wird das tabellarische Eingabesystem um eine Datenupload Funktionalität erweitert(Abb. 28). Diese Funktionalität liefert mehrere Vorteile. • Der Arbeitsvorgang wird beschleunigt. Messdaten brauchen nicht mehr via Formular eingegeben werden. Dieser zeitintensive Vorgang entfällt. • Die Daten, welche eingegeben werden, enthalten weniger Fehler, da Eingabe via Formulare fehleranfälliger ist. • Zusätzlich findet eine Überprüfung der importierten Daten auf Korrektheit statt. Fehlerhafte Einträge in der „csv“-Datei werden gemeldet. • Die Arbeit, Messdaten von Datenblättern direkt in die Datenbank einzugeben fällt weg, diese Arbeit kann ausgelagert werden. Das Einlesen von „csv“-Daten findet mit der „php“-Hifsmethode „fgetcsv“ statt [38]. Diese kann „csv“ Dateien mit unterschiedlichen Seperatoren lesen. In diesem Fall wurde vorgeschlagen, Messdateneinträge durch Tabulatoren zu trennen. Diesen Trenner kann man als Argument bei der Methode „readcsv“ mitangeben. 8.2.1 Format der CSV-Daten Die Daten haben folgendes Format zu erfüllen. • Dateneinträge werden durch einen Tabulator getrennt. • Numerische Datensätze können gelesen werden, wenn sie folgende Bedingungen erfüllen: Eine Zahl [0-9]. Eine Zahl [0-9], umgeben von Anführungszeichen. • Nicht gesetzte Werte werden gekennzeichnet durch: „“ leeres Feld. 8 IMPLEMENTATION 46 Eingefügt wird das ganze im bestehenden Code bei der switch Abfrage: "check input unit3". Es kommt ein Fileabfrage hinzu, die mit $next verknüpft auf switch das lesen triggert. 8.2.2 Ausschnitt aus HTML-Code für „upload“ Funktionalität Eingebunden im Html Code (Abb. 28) sieht die „upload“-Funktionalität folgendermassen aus. <form enctype=“multipart/form-data“ method=“post“> <input type=“hidden“ name=“MAX_FILE_SIZE“ value=“99000“ /> Upload CSV file: <input name=“userfile“ type=“file“ /> <input name=“next“ type=“submit“ value=SSend File"/> </form> Das Attribut „name“ setzt den angegeben Wert für den bestimmten Typ. Somit kann dieser Wert global in der php-session gelesen werden. Will man in diesem Codeausschnitt den Namen von der Datei auslesen, erfolgt der Zugriff durch: „$_FILES[’userfile’][’name’];“ Die Grösse der zu lesenden Dateien ist konfigurierbar, wurde in diesem Codeausschnitt aber auf 99000 Bytes festgelegt. 8 IMPLEMENTATION Abbildung 28: Importieren von Messdaten als csv-Datei. 47 8 IMPLEMENTATION 48 8.3 Löschen von Messdaten. Messdaten können nur von einem Benutzer mit dementsprechenden Rechten gelöscht werden. Einen normallen Benutzer steht diese Möglichkeit nicht zur Verfügung. Der Löschbutton wird in diesem Falle nicht angezeigt. Siehe Abb. 29). Als Administrator bekommt man eine andere Darstellung mit der zusätzlichen Option zur Löschung des Datensatzes(Abb. 30). Hauptmenü Für den Löschvorgang lese Kapitel Daten löschen. Abbildung 29: Anzeige für gesuchten Eintrag in Tabelle „Data_Property“ aus Sicht eines normalen Benutzers. Abbildung 30: Anzeige für gesuchten Eintrag in Tabelle „Data_Property“ aus Sicht eines Administrators. 8.4 Modifikation von Tabellen An der Tabelle „substance“ wurden Erweiterungen getätigt, es wurden zusätzlich sechs neue Felder angelegt: • group mit dem Typ varchar(4). • dipole mit dem Typ decimal(18,5). • omega mit dem Typ decimal(18,5). 8 IMPLEMENTATION 49 • polarity mit dem Typ tinyint(8). • vdw_a mit dem Typ decimal(18,5). • vdw_b mit dem Typ decimal(18,5). Bei dem Feld „group„ muss geachtet werden, dass dieser Name bei der Suche unter Anführungszeichen gestellt wird, da sonst MySQL die Query falsch interpretiert. Umgesetzt wurde die Modifikation der Tabellen mit dem MySQL Befehl „alter table“, Beschreibung siehe Anhang A. 8 IMPLEMENTATION 50 8.5 Überblick über GET and POST Requests Dieses Kapitel wurde hinzugefügt, da es wichtig für die Suche war, Daten zum Server zu schicken und wieder zu empfangen. Das HTTP Protokoll[40] unterscheidet zwei verschiedene Möglichkeiten Daten zu senden. Einerseits gibt es den „GET“ Request und andererseits den „POST“ Request. Der GET Request bedeuted, dass die Formulardaten in die URL kodiert sind, während bei „POST“ die Forumlardaten im Body des HTTP Requests enthalten sind. Zusätzlich sagt die HTML Spezifikation aus, dass die „GET“ Methode benutzt werden soll, wenn der „GET“ Request idempotent[41] ist(das heißt, keine Nebeneffekte hat). Viele Datenbankanfragen haben keinen sichtbaren Nebeneffekt und bieten ideale Anwendungen für den „GET“ Request. Modifiziert eine Datenbankanfrage die enthaltenen Daten, so sollte als Requesttyp „POST“ verwendet werden. 9 ERGEBNISSE UND AUSBLICK 51 9 Ergebnisse und Ausblick Ziel dieser Arbeit war es, ein Abfragesystem zu entwickeln, welches die Suche nach unterschiedlichen Messdaten ermöglicht. Im speziellen wurde nun am Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik der TU Graz ein Abfragesystem entwickelt, welches eine effiziente Suche nach Gasdichtemessdaten und Virialkoeffizienten bietet. Weiters deckt das Abfragesystem die Suche in anderen Tabellen ab, welche zusätzliche Informationen zu den Messdaten speichert. Gemeint sind die Tabellen „journal“, „literature“ und „substance“. Hier existieren nun zusätzliche Suchmasken. Jede Suchmaske ist einer Tabelle angepasst, um effizient nach gewünschten Daten suchen zu können. Die Ergebnisse können dann einzeln in einer weiteren Maske betrachtet werden. Benutzer mit Editierrechten können die Datensätze bearbeiten und vorhandene Fehler korrigieren. Nach Beendigung des Arbeitsvorganges können modifizierte Datenfelder wieder in der Datenbank abgespeichert werden. Ein weiterer Vorteil dieses Systems liegt darin, das nach der Expertensuche die Messdaten einfach weiterverarbeitet werden können. Die Daten können grafisch dargestellt, oder auch im Filesystem abgelegt werden. Damit aus dem vorhandenen Produkt ein zuverlässiges, sicheres System wird, muss noch viel Energie investiert werden. Obwohl schon viel an Vorarbeit geleistet wurde, fehlt in Bereichen „Sicherheit“, „Hochverfügbarkeit des Computersystemes“, "Datensicherungsstrategie„, „Benutzerverwaltung“ eine Strategie, dies umzusetzen. A ANHANG 52 A Anhang A.1 Apache Benutzt wird Apache mit der Version 2.0.54 (Debian GNU/Linux). Die Konfigurationsdatei php4.ini muss um den Eintrag „extension=mysql.so“ erweitert werden. Weiters wird die Datei „/etc/apache/conf.d/config_file“ modifiziert. <IfModule mod_php4.c> php_flag display_errors on php_flag log_errors on php_flag register_globals on php_value max_execution_time 90 php_value memory_limit 20M php_value session.save_path "/tmp" php_value upload_max_filesize 1M php_value session.gc_maxlifetime 3600 </IfModule> A.2 CVS - Concurrent Versions System A.2.1 Konfiguration für Debian-Distribution „/etc/inetd.conf“ um folgende Zeile erweitern: „cvspserver stream tcp nowait root /usr/sbin/tcpd /usr/sbin/cvs-pserver“ Als Benutzer „root“ initialisiert man das Verzeichnis, in dem man das Repository ablegt via Kommando: cvs -d /usr/local/cvsroot init Um Zugriff für andere Benutzer auf das Repository zu ermöglichen, müssen zwei Dateien erzeugt und im „CVSROOT“-Verzeichnis abgelegt werden. Diese sind READERS und WRITERS. In diesen werden Benutzer oder Gruppen eingetragen, die Lese- und Schreibrechte für das Repository haben. Benutzt man „cvs“ in der Konsole benötigt man zusätzlich die Umgebungsvariable „CVSROOT“. Gesetzt wird sie: A ANHANG 53 „export CVSROOT=:pserver:asimon@localhost:/usr/local/cvsroot“ Lokaler Zugriff auf Repository: „export CVSROOT=:local:/usr/local/cvsroot“ Remote Zugriff auf Repository: „CVSROOT=:ext:username@host:/usr/local/cvsroot“ A.2.2 Häufigsten Befehle bei der Arbeit mit dem Concurrent Versions System • cvs import -m „Abfragesystem“; erzeugt ein Modul im Repository mit dem Name „Abfragesystem“. • cvs login; greift man das erste Mal auf das Repository zu, muss man sich identifizieren mit Name und Passwort. Bei Erfolg wird im „HOME“ Verzeichnis eine .cvslogin Datei gespeichert. Diese notiert den erfolgreichen Zugriff, das identifizieren erspart man sich in Zukunft. • cvs co pvt; holt den Inhalt von Modul „pvt“ aus dem Repository und legt diesem in dem momentan befindlichen Verzeichnis ab. • cvs edit index.php ändert die Attribute von „index.php“. Die Datei hat danach das zuätzliche Attribut beschreibbar gesetzt. Vor dieser Aktion hat man die Datei nur lesen können. • cvs diff index.php vergleicht die lokale Datei mit der Datei im Repository und zeigt die Zeilen an, die unterschiedlichen Inhalt haben. • cvs commit Unterschiede werden im Repository abgespeichert, Versionsnummer dieser Datei wird erhöht. Zusätzlich kann man eine Loginformation mitangeben. In dieser gibt man meist den Grund an, warum die Datei editiert, wurde. Wurde Funktionalität verändert. Dies kann mit einem Editor der Wahl eintragen. A ANHANG 54 • cvs update holt vom lokalen Filesystem unterschiedliche Daten mit neueren Ursprungs aus dem Repository und überschreibt die lokalen Dateien. Sind lokale Dateien mit dem Befehl „cvs edit“ bearbeitet, werden diese nicht überschrieben. Geänderte Zeilen werden ersetzt, bei Konflikten wird man über Position des Konfliktes informiert. • cvs -n update simuliert ein update. Es zeigt die Unterschiede an, ohne wirklich die Daten lokal zu überschreiben. A.3 Benutzte Sql Anweisungen A.3.1 Übersicht wichtiger Hyperlinks für die Benutzung von MySql Benutzte Links für die Umsetzung der gestellten Anforderungen. Diese decken nur den MySQL Bereich ab. http://dev.mysql.com/doc/mysql/en/delete.html http://dev.mysql.com/doc/mysql/en/truncate.html http://dev.mysql.com/doc/mysql/en/load-data.html http://dev.mysql.com/doc/mysql/en/mysqlimport.html http://dev.mysql.com/doc/mysql/en/adding-users.html http://dev.mysql.com/doc/mysql/en/grant.html http://dev.mysql.com/doc/mysql/en/select.html http://dev.mysql.com/doc/mysql/en/update.html http://dev.mysql.com/doc/mysql/en/mysqldump.html http://dev.mysql.com/doc/mysql/en/alter-table.html http://dev.mysql.com/doc/mysql/en/replace.html http://dev.mysql.com/doc/mysql/en/join.html A.3.2 Nutzung der „update“ Anweisung Schnelle Hilfe kann man auf http://dev.mysql.com/doc/mysql/en/update.html finden. Benutzt wurde „update“ einerseits, um alte Datensätze zu auszubessern, andererseits um den Benutzer mit Editierrechten Datensätze ändern zu lassen. • Modifizieren alter Tabelleneinträge mit update. A ANHANG 55 • Benutzer mit Editierrechten können via Formular Dateneinträge editieren und abspeichern. A.3.3 Nutzung der „alter table“ Funktionalität Informationen kann auf der Seite http://dev.mysql.com/doc/mysql/en/alter-table. html finden. Verwendet wurde „alter table“ Syntax um die Tabelle „Substance“ um Felder hinzuzufügen. Auszug eines verwendeten Codestückes: ALTER TABLE „substance“ ADD „polarity“ TINYINT, ADD „group“ VARCHAR ( 4 ) , ADD „vdw_a“ DECIMAL ( 18, 5 ) , ADD „vdw_b“ DECIMAL ( 18, 5 ) , ADD „omega“ DECIMAL ( 18, 5 ) , ADD „dipole“ DECIMAL ( 18, 5 ) ; Anzumerken ist ein Feld mit dem Namen „group“, welches unter MySQL ein Schlüsselwort ist. Dieses muß bei einem MySQL-Statement immer unter Anführungzeichen gestellt werden, andernfalls wäre MySQL irritiert und meldet einen Fehler im MySQL-Statement. A.3.4 „like“ Funktionalität Informationen zu „like“ kann man unter den String Funktionen http://dev.mysql. com/doc/mysql/en/string-comparison-functions.html finden. Ein Codestück, welches im Feld „d_range“ nach dem Vorkommen von „sub“ sucht und zurückgibt, unabhängig von der Position im Feld. SELECT count (*), d_range FROM data_property where d_range like "%sub%" group by d_range; A ANHANG 56 A.3.5 „order by“ Funktionalität Bei der erweiterten Suche wurde verlangt, Ergebnisse nach bestimmten Feldern zu sortieren. Ermöglicht wird das durch die „order by“ Funktionalität, wobei man zusätzlich noch die Richtung der Sortierung angeben kann (aufsteigend oder absteigend). Codestücke kann man im order by Abschnitt von Anhang B finden. A.3.6 „join“ Funktionalität „JOIN“ verbindet Tabellen miteinander wobei die Verbindung im „ON“ Teil beschrieben wird. „JOIN - ON“ und „, - WHERE“ sind bei der Verarbeitung ähnlich. Unterschiede gibt es aber in der Geschwindigkeit der Bearbeitung der Abfrage, da im zweiten Fall ein kartesisches Produkt der Tabellen gebildet wird, welche in einer temporären Zwischentabelle abgespeichert werden. Erst dann werden die Zeilen gelöscht, die nicht die WHERE-Bedingung erfüllen. Dies kann zu deutlichen Verschlechterung der Performance führen. Oft gemachter Fehler bei „JOIN“ Statements ist die Angabe von Bedingungen im „ON“ Teil, welche sich nur auf eine Tabelle beziehen. Diese Bedingungen gehören in die „WHERE“ Abfrage. Codestücke kann man im join Abschnitt von Anhang B finden. A.3.7 „delete“ Funktionalität Information zu MySQL „delete“ Funktionalität kann man auf http://dev.mysql. com/doc/mysql/en/delete.html finden. A.4 Nutzung des „mysqldump“ Backuptools Hilfe zu dem MySQL - Backuptool kann man unter http://dev.mysql.com/doc/ mysql/en/mysqldump.html. Das Tool „mysqldump“ hat die Aufgabe, Daten von Datenbanken auszulesen und im „xml“-Format abzuspeichern. Es ist sehr flexibel in Bezug auf Datensicherung. Neben Sicherung ganzer Datenbanken kann es auch einzelne Tabellen exportieren. Angewendet wurde das Backuptool zum Sichern der „pvt“-Datenbank. Hierzu wurde die Optionen „–opt“ genommen. Diese liefert eine schnelle Datensicherung und die „dump“ Datei kann wieder sehr schnell in den MySQL Server geladen werden. A ANHANG 57 Für die „pvt“-Datenbank wurde folgende Befehl angewandt: mysqldump –opt pvt > backup-pvt.sql -p Um Daten in die Datenbank einspielen zu können, wurde folgende Anweisung ausgeführt: mysql -u root pvt < backup-pvt.sql B MYSQL CODE 58 B MySQL Code B.1 MySQL „update“ Code Auszüge Im folgenden werden ein paar Zeilen Code zur „update“ Funktionalität gezeigt, welche zum Einsatz gekommen sind. Folgender Code beschreibt das Ersetzen eines Beistrichs durch einen Punkt in einem „Character“ Feld. Zu erwähnen ist hier die „replace“[39] Anweisung, welche in einem Feld passende Werte ersetzt. update orig_virial_dp set ov_t = (replace (ov_t, ’,’ , ’.’)); Folgender Code ist ein Beispiel für das Ersetzen eines Beistrichs durch einen Punkt in mehreren Feldern. update orig_virial_dp set ov_t = (replace (ov_t, ’,’ , ’.’)), ov_t_var = (replace (ov_t_var, ’,’ , ’.’)); Setzen eines leeren Feldes mit dem Wert 1. update orig_pvt_dp set op_x = „1“ where op_x = „“; update si_pvt_dp set sp_x = „1“ where sp_x = „“; update orig_virial_dp set ov_x = „1“ where ov_x = „“; update si_virial_dp set sv_x = „1“ where sv_x = „“; Bei Tabelle „orig_virial_dp“ werden alle Felder mit dem Typ „varchar(50)“, die vorhandenen Beistriche durch einen Punkt ersetzt. update orig_virial_dp set ov_t = (replace (ov_t, ’,’ , ’.’)), ov_t_var = (replace (ov_t_var, ’,’ , ’.’)), ov_x = (replace (ov_x, ’,’ , ’.’)), ov_x_var = (replace (ov_x_var, ’,’ , ’.’)), ov_2 = (replace (ov_2, ’,’ , ’.’)), ov_2_var = (replace (ov_2_var, ’,’ , ’.’)), ov_3 = (replace (ov_3, ’,’ , ’.’)), ov_3_var = (replace (ov_3_var, ’,’ , ’.’)), ov_4 = (replace (ov_4, ’,’ , ’.’)), ov_4_var = (replace (ov_4_var, ’,’ , ’.’)); B MYSQL CODE 59 Bei Tabelle „si_virial_dp“ werden alle Felder mit dem Typ „varchar(50)“, die vorhandenen Beistriche durch einen Punkt ersetzt. update si_virial_dp set sv_t = (replace (sv_t, ’,’ , ’.’)), sv_t_var = (replace (sv_t_var, ’,’ , ’.’)), sv_x = (replace (sv_x, ’,’ , ’.’)), sv_x_var = (replace (sv_x_var, ’,’ , ’.’)), sv_2 = (replace (sv_2, ’,’ , ’.’)), sv_2_var = (replace (sv_2_var, ’,’ , ’.’)), sv_3 = (replace (sv_3, ’,’ , ’.’)), sv_3_var = (replace (sv_3_var, ’,’ , ’.’)), sv_4 = (replace (sv_4, ’,’ , ’.’)), sv_4_var = (replace (sv_4_var, ’,’ , ’.’)); Weitere Änderungen betreffen dem Feld „l_flags“. update literature set l_flags = „0000000000“ where l_flags = „0“; update literature set l_flags = „1000000000“ where l_flags = „1“; Das Feld „d_range“ von der Tabelle „data_property“ wurde standardisiert. Die unterschiedlichen Benamsungen mit gleicher Bedeutung wurden angepasst. update data_property set d_range = „sub and super critical data“ WHERE d_range like „%sub%“ and d_range like „%super%“; update data_property set d_range = „dew line data“ WHERE d_range = „near dew line data“; update data_property set d_range = „extended critical data“ WHERE d_range = „near critical point data“; update data_property set d_range = „sub critical data“ WHERE d_range = „High temperature / pressure“ OR d_range = „sub and near the critical point data“; B MYSQL CODE 60 B.2 MySQL ‘"join“ Code Auszüge Im folgenden werden ein paar Zeilen Code zur „join“ Funktionalität gezeigt, welche zum Einsatz gekommen sind. Informationen zur Funktionalität von „join“ kann man hier http://dev.mysql.com/doc/mysql/en/join.html finden. Es gibt unterschiedliche „join“s. Relevant sind für die Abfrage nur die „inner join“s. Diese nehmen nur identische Werte, nicht existierende(NULL) werden ignoriert. Der einfachste JOIN ist der sogenannte „EQUI-JOIN“. Ein Beispiel : SELECT A.EineSpalte, B.EineAndereSpalte FROM Tabelle1 AS A, Tabelle2 AS B WHERE A.EinWert = B.EinAndererWert; Man kann ihn aber auch ganz anders schreiben, und die Ergebnismenge wird die gleiche sein, nämlich so : SELECT A.EineSpalte, B.EineAndereSpalte FROM Tabelle1 AS A JOIN Tabelle2 AS B ON A.EinWert = B.EinAndererWert; Wenn die Ergebnismenge die gleiche ist, wo liegt dann der Unterschied zwischen diesen beiden Formen? Gibt es überhaupt einen Unterschied? Der Unterschied liegt in der Laufzeit. Im ersten Beispiel wird zuerst das kartesische Produkt aus beiden Tabellen gebildet (jede Zeile aus Tabelle1 wird mit jeder Zeile aus Tabelle2 verknüpft), und wenn beide Tabellen nur jeweils 100 Zeilen enthalten, sind das schon 10.000 Zeilen in der temporären Zwischentabelle. Erst dann werden die Zeilen gelöscht, die nicht die WHERE-Bedingung erfüllen. Im zweiten Fall wird zuerst die Bedingung im ON-Teil geprüft und nur solche Zeilen in die Zwischentabelle übernommen, bei denen die Bedingung erfüllt ist. In dem Beispiel mit den je 100 Zeilen pro Tabelle sind das wahrscheinlich nicht mehr als 100 Zeilen. Das ist ein Faktor von 10! Bei „JOIN“ darf man nicht auf die „join_condition“ (ON) vergessen, den ohne diese wird das „JOIN“ als „,“ interpretiert und ein kartesisches Produkt wird gebildet. Mögliche Varianten für das Abfragesystems einmal mit „JOIN“ und einmal ohne. Implementiert wurde die Variante mit „JOIN“. B MYSQL CODE Variante ohne „JOIN“: SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_fk_journal, l.l_kind, l.l_flags, j.j_nr FROM data_property d, literature l, journal j WHERE d.d_fk_substance=41 and d.d_fk_literature = l.l_nr and l.l_fk_journal = j.j_nr and j.j_nr = 3 and l.l_nr = 1366 and (d.d_type=„PVT data“ or d.d_type=„Virial coefficients - Leidenform“) and (d.d_range=„unknown“ or d.d_range=„sub“ or d.d_range=ßuper“ or d.d_range=„dew“) and conv(l.l_kind,2,10) & conv(1100,2,10) ORDER BY d_nr ASC; Variante mit „JOIN“: SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_fk_journal, l.l_kind, l.l_flags, j.j_nr FROM data_property d JOIN literature l ON d.d_fk_literature = l.l_nr JOIN journal j ON l.l_fk_journal = j.j_nr WHERE d.d_fk_substance=41 AND j.j_nr = 3 AND l.l_nr = 1366 AND (d.d_type=„PVT data“ OR d.d_type=„Virial coefficients - Leidenform“) AND (d.d_range=„unknown“ OR d.d_range=„sub“ OR d.d_range=ßuper“ OR d.d_range=„dew“) AND conv(l.l_kind,2,10) & conv(1100,2,10) ORDER BY d_nr ASC; Mögliche Varianten eines „JOIN“s: • Variante mit „lit_nr“ als Suchkriterium und einem „JOIN“. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_kind, l.l_flags FROM data_property d JOIN literature l 61 B MYSQL CODE 62 ON d.d_fk_literature = l.l_nr WHERE l.l_nr = 1366 • Variante mit „lit_nr“ als Suchkriterium. • Variante mit „journal_nr“ als Suchkriterium und zwei „JOIN“s. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_fk_journal, l.l_kind, l.l_flags, j.j_nr FROM data_property d JOIN literature l ON d.d_fk_literature = l.l_nr JOIN journal j ON l.l_fk_journal = j.j_nr WHERE j.j_nr = 3 • Variante mit mehreren Werten von unterschiedlichen Tabellen als Suchkriterium. SELECT count(*),d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_fk_journal, l.l_kind, l.l_flags, j.j_nr FROM data_property d JOIN literature l ON d.d_fk_literature = l.l_nr JOIN journal j ON l.l_fk_journal = j.j_nr JOIN si_pvt_dp pvtTable ON d.d_nr = pvtTable.sp_fk_den WHERE d.d_fk_substance=41 and j.j_nr = 3 and l.l_nr = 1366 and (d.d_type=„PVT data“ OR d.d_type=„Virial coefficients - Leidenform“) and (d.d_range=„unknown“ OR d.d_range=„sub“ OR d.d_range=ßuper“ OR d.d_range=„dew“) and conv(l.l_kind,2,10) & conv(1100,2,10) and l.l_flags="1000000000" Group BY d_nr ASC; • Variante mit mehreren Werten von unterschiedlichen Tabellen als Suchkriterium. B MYSQL CODE SELECT count(*),d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_fk_journal, l.l_kind, l.l_flags, j.j_nr FROM data_property d JOIN literature l ON d.d_fk_literature = l.l_nr JOIN journal j ON l.l_fk_journal = j.j_nr JOIN si_pvt_dp pvtTable ON d.d_nr = pvtTable.sp_fk_den WHERE d.d_fk_substance=41 and j.j_nr = 3 and l.l_nr = 1366 and (d.d_type=„PVT data“ OR d.d_type=„Virial coefficients - Leidenform“) and (d.d_range=„unknown“ OR d.d_range=„sub“ OR d.d_range=ßuper“ OR d.d_range=„dew“) and conv(l.l_kind,2,10) & conv(1100,2,10) and l.l_flags="1000000000" and pvtTable.sp_weight >= 0 and pvtTable.sp_weight <= 6 Group BY d_nr ASC; Weitere Varianten: Variante mit „kind“ als Suchkriterium für Tabelle Literatur. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_kind, l.l_flags FROM data_property d JOIN literature l ON d.d_fk_literature = l.l_nr WHERE conv(l.l_kind, 2,10) & conv(0010,2,10) ORDER BY d_nr ASC; Variante mit „flags“ als Suchkriterium für Tabelle Literatur. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags, l.l_nr, l.l_kind, l.l_flags FROM data_property d JOIN literature l ON d.d_fk_literature = l.l_nr WHERE l.l_flags="1000000000" ORDER BY d_nr ASC; 63 B MYSQL CODE 64 Variante mit „d_fk_substance“ als Suchkriterium für Tabelle „Data_Property“. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags FROM data_property d WHERE d.d_fk_substance = 41 Variante mit „d_type“ als Suchkriterium für Tabelle „Data_Property“. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags FROM data_property d WHERE d.d_type="Virial coefficients - Leidenform" Variante mit „d_range“ als Suchkriterium für Tabelle „Data_Property“. SELECT d.d_nr,d.d_type, d.d_range, d.d_fk_substance, d.d_fk_substance2, d.d_fk_literature, d.d_flags FROM data_property d WHERE d.d_range="dew line data" B.3 MySQL „order by“ Code Auszüge Ein umfangreiches Statement mit „ORDER BY“, welches zuerst eine absteigende Sortierung und dann eine aufsteigend Sortierung verlangt. Zusätzlich enthält es „JOIN“ Ausdrücke zum Verbinden mehrerer Tabellen, mehrere „like“ Abfragen und eine binären „Und“-Vergleich. SELECT d_nr, d_type, d_data_points, d_fk_literature, d_fk_substance, d_fk_substance2 , sp_sort, sp_t, sp_t_var, sp_x, sp_x_var, sp_p, sp_p_var, sp_z, sp_z_var, sp_rho, sp_rho_var, sp_type, sp_weight FROM data_property density JOIN literature litTable ON density.d_fk_literature = litTable.l_nr JOIN journal journalTable ON litTable.l_fk_journal = journalTable.j_nr JOIN si_pvt_dp siTable ON density.d_nr = siTable.sp_fk_den WHERE journalTable.j_nr = 3 AND litTable.l_nr = 1366 AND conv(litTable.l_kind, 2, 10) & 15 AND B MYSQL CODE 65 density.d_fk_substance = 41 AND ( density.d_range like ’sub%’ OR density.d_range like ’%super%’ OR density.d_range like ’unknown%’ OR density.d_range like ’dew%’ OR density.d_range like ’crit%’ OR density.d_range like ’extended%’) AND ( density.d_type = ’PVT data’) AND siTable.sp_t <= 300 ORDER BY sp_t DESC , sp_p ASC Ein weiteres Statement, aber in Kombination von „GROUP BY“ und „ORDER BY“. SELECT count(siTable.sp_sort) "matched points", d_nr, d_type, d_data_points, d_fk_literature, d_fk_substance, d_fk_substance2 FROM data_property density JOIN literature litTable ON density.d_fk_literature = litTable.l_nr JOIN journal journalTable ON litTable.l_fk_journal = journalTable.j_nr JOIN si_pvt_dp siTable ON density.d_nr = siTable.sp_fk_den WHERE journalTable.j_nr = 3 AND litTable.l_nr = 1366 AND conv(litTable.l_kind, 2, 10) & 15 AND conv(litTable.l_flags, 2, 10) & 512 AND density.d_fk_substance = 41 AND ( density.d_range like ’sub%’ OR density.d_range like ’%super%’ OR density.d_range like ’unknown%’ OR density.d_range like ’dew%’ OR density.d_range like ’crit%’ OR density.d_range like ’extended%’) AND ( density.d_type = ’PVT data’) AND siTable.sp_weight >= 1 AND siTable.sp_weight <= 6 AND siTable.sp_t >= 13 AND siTable.sp_p >= 13 GROUP BY density.d_nr ASC ORDER BY "matched points"DESC LITERATUR 66 Literatur [1] B.Edegger: Automatische Umrechnung von Messdaten in ihre SI-Einheiten, Evaluierung und Speicherung in einer Online-Datenbank Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik, TU Graz, 2005 [2] A.M.Slanina: Berechnung der Abweichung von PvT-Messdaten zu Referenzmessdaten; Diplomarbeit, Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik, TU Graz, 2002 [3] R.Grinninger: Qualitätsüberprüfung und Datenbereichserfassung von PvTMessdaten sowie Importüberprüfung dieser Daten in einer Gasdichtendatenbank; Diplomarbeit, Institut für Grundlagen der Verfahrenstechnik und Anlagentechnik, TU Graz, 2001 [4] http://httpd.apache.org Homepage von Apache. [5] http://www.mysql.com Homepage von MySQL. [6] http://news.netcraft.com Statistik über weltweit eingesetzten Server. [7] http://www.php.net Homepage von PHP(Hypertext Preprocessor). [8] http://www.mysql.de/products/tools/query-browser MySQL Query Browser. [9] http://www.eclipse.org Eclipse Consortium Home Page. [10] sourceforge.net/projects/phpeclipse PHP - Support for the Eclipse IDE Framework. [11] http://www.nongnu.org/cvs CVS Homepage [12] http://www.infochembio.ethz.ch/cassi.html Homepage of Chemical Abstracts Service Source Index. LITERATUR [13] http://www.issn.org Homepage of International Standard Serial Number. [14] http://isbn-international.org Homepage of Internationale Standard-Buch-Nummer. [15] http://www.cas.org Homepage of Chemical Abstracts Service. [16] http://www.bravehack.de/html/node27.html Information zu Apache. [17] http://www.perl.org Homepage von Perl. [18] http://java.sun.com Homepage von Sun Microsystems. [19] http://www.freebsd.org Homepage von Open-Source-Betriebssystem FreeBSD. [20] http://www.apple.com/server/macosx Homepage zu Mac Os X. [21] http://www.microsoft.com/ Homepage von Microsoft Windows. [22] http://www.microsoft.com/iis Homepage von Internet Information Server. [23] http://www.jboss.com Homepage von Jboss. [24] http://www.hyperwave.com/e Homepage von Hyperwave. [25] http://wp.netscape.com/enterprise Homepage von Netscape. [26] OmniHTTPd Homepage von OmniHTTPd. [27] http://www.caudium.net Homepage von Caudium. 67 LITERATUR 68 [28] http://at.php.net/manual/de/install.general.php Liste von unterstützten Webserver. [29] http://www.xitami.com Homepage von Xitami. [30] http://www.php-center.de/de-html-manual/intro-whatcando.html Das Handbuch zu PHP. [31] http://www.dbase.com Homepage zu dBase. [32] http://www.ibm.com/software/data/db2 Startseite zu IBM DB2. [33] http://www.postgresql.org Startseite zu PostgreSQL. [34] http://www.oracle.com Homepage von Oracle. [35] http://www.w3.org/XML Information zu Extensible Markup Language (XML). [36] http://www.mysql.com/company MySQL Company. [37] http://www.phpmyadmin.net Das phpMyAdmin Projekt. [38] http://at.php.net/manual/de/function.fgetcsv.php Beschreibung der Methode „fgetcsv“. [39] http://dev.mysql.com/doc/mysql/en/replace.html Beschreibung der MySQl Anweisung „replace“ [40] http://www.w3.org/Protocols/rfc2616/rfc2616.html Beschreibung des HTTP Protokolls. [41] http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html#sec9.1.2 Information zu dem Begriff idempotent in Bezug auf das HTTP Protokolls. ABBILDUNGSVERZEICHNIS 69 Abbildungsverzeichnis 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 DDBST Datenbank System. . . . . . . . . . . . . . . . . . . . . . DETHERM Datenbank System. . . . . . . . . . . . . . . . . . . . Eclipse mit Codeausschnitt. . . . . . . . . . . . . . . . . . . . . . . MySQL Query Browser mit beispielhafter Abfrage. . . . . . . . . . Entity Relationship Diagramm der Datenbank . . . . . . . . . . . . Use Case Diagramm Substanzsuche . . . . . . . . . . . . . . . . . Use Case Diagramm Literatursuche . . . . . . . . . . . . . . . . . Use Case Diagramm Journalsuche . . . . . . . . . . . . . . . . . . Use Case Diagramm Messdatensuche . . . . . . . . . . . . . . . . Use Case Diagramm Datenkorrektur . . . . . . . . . . . . . . . . . Use Case Diagramm Visualisierung . . . . . . . . . . . . . . . . . Use Case Diagramm Messdatenlöschung . . . . . . . . . . . . . . . Hauptmenüseite . . . . . . . . . . . . . . . . . . . . . . . . . . . . Suche nach Substanzeinträgen. . . . . . . . . . . . . . . . . . . . . Liste der gefundenen Substanzeinträge. . . . . . . . . . . . . . . . . Anzeige eines gefundenen Substanzeintrages. . . . . . . . . . . . . Suche nach Journalen. . . . . . . . . . . . . . . . . . . . . . . . . . Liste der gefundenen Journaleinträge. . . . . . . . . . . . . . . . . Anzeige eines gefundenen Journaleintrages. . . . . . . . . . . . . . Suche nach Literatur. . . . . . . . . . . . . . . . . . . . . . . . . . Liste der gefundenen Literatureinträge. . . . . . . . . . . . . . . . . Anzeige eines gefundenen Literatureintrages. . . . . . . . . . . . . Einfaches Suchformular. . . . . . . . . . . . . . . . . . . . . . . . Ergebnis der einfachen Suche. . . . . . . . . . . . . . . . . . . . . Erweitertes Suchformular. . . . . . . . . . . . . . . . . . . . . . . . Sortierung der Ergebnisse festlegen. . . . . . . . . . . . . . . . . . Ergebnis der erweiterten Suche. . . . . . . . . . . . . . . . . . . . . Importieren von Messdaten als csv-Datei. . . . . . . . . . . . . . . Anzeige für gesuchten Eintrag in Tabelle „Data_Property“ aus Sicht eines normalen Benutzers. . . . . . . . . . . . . . . . . . . . . . . 30 Anzeige für gesuchten Eintrag in Tabelle „Data_Property“ aus Sicht eines Administrators. . . . . . . . . . . . . . . . . . . . . . . . . . 5 6 12 14 17 19 19 19 19 20 20 21 24 26 27 28 30 31 32 34 35 36 39 40 42 43 44 47 48 48