studie na rbei tа ifp - Institut für Photogrammetrie
Werbung

VWX G LH Q D UE H LWD
LIS
Universität Stuttgart
Jan-Martin Bofinger
Realisierung von verteilten
GIS-Funktionalitäten unter
Verwendung der Java
Remote Method Invocation
ifp
Betreuer: Dipl.-Geogr. Steffen Volz
Prüfer: Prof. Dr.-Ing. habil Dieter Fritsch
Inhaltsverzeichnis
Einleitung
1
EINLEITUNG ....................................................................................................... 2
2
VERTEILTE GIS-FUNKTIONALITÄTEN ............................................................ 3
3
2.1
GIS im Internet...................................................................................................... 3
2.2
Interoperabilität .................................................................................................... 5
2.3
Das Projekt NEXUS .............................................................................................. 6
REMOTE METHOD INVOCATION (RMI) UNTER JAVA.................................... 7
3.1
Einführung ............................................................................................................ 8
3.2
Architektur ............................................................................................................ 9
3.2.1
Transportschicht ............................................................................................. 9
3.2.2
3.2.3
Remote Reference Layer.............................................................................. 10
Stubs und Skeletons..................................................................................... 10
3.3
Vorgehensweise bei der Implementierung einer RMI-Anwendung ................. 11
3.3.1
Definition der RMI-Schnittstelle..................................................................... 11
3.3.2
Erstellen des Remote-Objektes .................................................................... 12
3.3.3
Implementierung des Clients......................................................................... 13
3.3.4
Starten der Registry...................................................................................... 13
3.4
4
Dynamisches Herunterladen des Stubs ........................................................... 14
ALGORITHMEN ZUM „KÜRZESTE WEGE“-PROBLEM ................................ 15
4.1
Single Source Shortest Path.............................................................................. 16
4.1.1
Der Dijkstra-Algorithmus ............................................................................... 17
4.1.2
Implementierung des Dijkstra-Algorithmus in Java........................................ 18
4.2
All-Pairs Shortest Path....................................................................................... 19
4.2.1
Der Floyd-Algorithmus .................................................................................. 19
4.2.2
Implementierung des Floyd-Algorithmus in Java........................................... 20
5
LÖSUNGSANSATZ UND IMPLEMENTIERUNG DER RMI-ANWENDUNG .... 21
5.1
Schnittstellen...................................................................................................... 22
5.2
Server.................................................................................................................. 23
5.3
Client ................................................................................................................... 25
5.3.1
Bedienung der graphischen Oberfläche........................................................ 25
5.3.2
Implementierung des Clients......................................................................... 27
6
TEST DER CLIENT-SERVER-ANWENDUNG .................................................. 29
6.1
Initialisierung der Server.................................................................................... 29
6.2
Ausführung von GIS-Funktionalitäten .............................................................. 30
7
ZUSAMMENFASSUNG/AUSBLICK ................................................................. 33
8
LITERATURVERZEICHNIS .............................................................................. 34
ANHANG, ANLAGE
Seite 1
Einleitung
1 Einleitung
In den letzten Jahren konnten verschiedene Anbieter Dienste auf dem GIS-Markt etablieren,
die Geodaten, wie z.B. Karten, über das Internet zur Verfügung stellen. Für die Auswahl der
relevanten Geodaten kann der Nutzer umfangreiche GIS-Funktionalitäten einsetzen,
dennoch steht bei diesen Diensten, die auch als Geodaten-Dienste bezeichnet werden, die
Bereitstellung der Daten im Vordergrund.
In aktuellen Ansätzen der GIS-Forschung wird versucht, eine Trennung von Geodaten und
GIS-Funktionalitäten herbeizuführen und die jeweiligen GIS-Funktionalitäten unabhängig von
spezifischen Geodaten anzubieten [1]. Diese Dienste werden als Geoverarbeitungs-Dienste
bezeichnet.
Die Bereitstellung der GIS-Funktionalitäten kann über eine Client-Server-Architektur realisiert
werden. In diesem Fall werden die Funktionalitäten als Objekte implementiert, welche auf
verschiedenen Servern abgelegt sind. Damit der Client Zugriff auf diese Objekte hat, muss
eine Schnittstelle bereitgestellt werden. Abhängig von der Leistung des Client-Rechners und
dem jeweiligen Datenaufkommen ist der Client dann in der Lage, die GIS-Funktionalitäten
entweder direkt auf dem Rechner des Servers zu berechnen oder die benötigten Objekte
herunterzuladen und lokal auszuführen.
Im Rahmen dieser Studienarbeit soll nun untersucht werden, ob der Kommunikationsmechanismus der Programmiersprache Java, Remote Method Invocation (RMI) genannt, für
die Umsetzung der Client-Server-Architektur in eine Anwendung geeignet ist. RMI erlaubt es,
Objekte auf entfernten Rechnern in genau derselben Weise anzusprechen wie Objekte, die
auf demselben Rechner laufen. Diese Eigenschaft erleichtert das Erstellen von verteilten
Anwendungen erheblich, da der Entwickler keine Funktionen für den Austausch von
Objekten zwischen den verschiedenen Rechnern implementieren muss. Nach der Definition
geeigneter Schnittstellen können Client und Server implementiert werden.
In Kapitel 2 werden verschiedene Aspekte zum Einsatz von GIS im Internet angesprochen
und es wird die mögliche Einbindung von RMI in das NEXUS-Projekt [7] aufgezeigt. Das
darauf folgende Kapitel gibt eine Einführung in die Architektur und die Vorgehensweise bei
der Implementierung einer Client-Server-Anwendung.
Für die Demonstration der implementierten Client-Server-Applikation sollen Aufgaben aus
der Netzwerkanalyse herangezogen werden. Hier bietet sich z.B. die Lösung von Problemen
der Kürzesten Wege an. Deshalb wird Kapitel 4 auf diese Problematik eingehen und zwei
Lösungsalgorithmen, den Dijkstra- und den Floyd-Algorithmus, vorstellen.
Kapitel 5 zeigt einen Lösungsansatz für die Client-Server-Architektur und dessen Umsetzung
in Java. In den danach folgenden Kapiteln wird die Anwendung einem Test unterzogen und
es werden mögliche Erweiterungen für eine zukünftige Weiterentwicklung angedacht.
Seite 2
Verteilte GIS-Funktionalitäten
2 Verteilte GIS-Funktionalitäten
Die Bereitstellung von Geodaten über das Internet wird bereits seit längerer Zeit erfolgreich
betrieben. So gibt es einige Anbieter, die zentralisierte Geodaten-Dienste auf der Basis von
Client-Server-Architekturen zur Verfügung stellen. Der Benutzer dieser Dienste hat die
Möglichkeit, über eine graphische Schnittstelle raumbezogene Anfragen an den Server zu
schicken. Diese Anfragen werden auf dem Server mittels der erforderlichen GISFunktionalitäten bearbeitet und die Ergebnisse an den Client übertragen.
Es gibt jedoch Fälle, in denen die Geodaten auf der Client-Seite gespeichert und verwaltet
werden. Dann benötigen die Clients lediglich die GIS-Funktionalitäten, um ihre Daten zu
verarbeiten. Diese Funktionalitäten sind zum Beispiel Werkzeuge für die Konvertierung von
Daten, für die Kartenprojektion oder für die Bearbeitung von Daten. Diese Arbeit wird
versuchen, einen möglichen Lösungsansatz für die Bereitstellung von benötigten GISFunktionalitäten über das Internet aufzuzeigen.
In den folgenden Unterkapiteln wird näher auf GIS im Internet, den Begriff der
Interoperabilität und das Projekt NEXUS eingegangen.
2.1
GIS im Internet
Grundsätzlich gibt es zwei verschiedene Ansätze, GIS-Funktionalitäten über das Internet
verfügbar zu machen. Zum einen existiert der serverbasierte und zum anderen der
clientbasierte Ansatz.
Im serverbasierten Ansatz werden sämtliche Berechnungen, die für das Ausführen der GISFunktionalitäten benötigt werden, auf dem Server ausgeführt. Dies bedeutet, dass sich
neben den Geodaten auch die erforderliche Software auf dem Server befindet. Der Client,
der zumeist als Applet in einem Internet-Browser implementiert ist, wird lediglich dazu
benötigt, die Anfragen an den Server zu stellen und die übermittelten Resultate graphisch
oder in Textform darzustellen. Berechnungen, welche die Geodaten betreffen, werden auf
der Clientseite nicht durchgeführt.
Die Software, welche die GIS-Funktionalitäten auf dem Server zur Verfügung stellt, kann
eine extra für diesen Zweck programmierte Anwendung in C++ oder Visual Basic sein. Es
kann aber auch eine Anwendung sein, die von kommerziell erhältlichen GIS-Paketen wie
ArcInfo implementiert wurde.
Wie bereits weiter oben erwähnt, basieren die serverbasierten Anwendungen auf Applets,
die in einem Internet-Browser geladen werden können. Auf die Anfrage des Clients hin wird
eine Karte auf dem Server generiert, als Rasterbild an das Applet gesendet und im Browser
dargestellt. Der Nachteil dieses Verfahrens ist die eingeschränkte Interaktivität zwischen
Client und Server. Einfache Operationen wie das Zoomen in Bildern mittels Zeichnen eines
Rechteckes können nicht in das Applet integriert werden. Folglich müssen auch diese
Aufgaben durch den Server erledigt werden, was zu einer hohen Belastung des Servers
Seite 3
Verteilte GIS-Funktionalitäten
führen kann, der für jedes Zoomen oder Verschieben der Karte kontaktiert werden muss.
Gerade in Zeiten, in denen der Server mit rechenintensiven Aufgaben beschäftigt ist, kann
es dann auch bei diesen vermeintlich einfachen Funktionen zu größeren Wartezeiten
kommen.
Die serverbasierten Anwendungen haben jedoch auch einige Vorteile. Da die Berechnungen
auf dem Server ausgeführt werden, ist die Rechenzeit für die einzelnen Anfragen nicht von
der Rechenleistung des Client-Rechners abhängig und auch bei sehr großen und komplexen
Datensätzen sind die Rechenzeiten zumeist akzeptabel. Außerdem entfällt die Installation
und Wartung der Programme auf dem Client-Rechner, weil die Applets über den InternetBrowser geladen werden. Dies bewirkt, dass der Client auf allen Computersystemen, die
einen Internetanschluss haben, verfügbar ist.
Im clientbasierten Ansatz werden einige der Berechnungen vom Rechner des Clients
übernommen. Wenn die Datenmenge nicht zu groß ist, können bestimmte Geodaten an den
Client übertragen werden. Darum bietet es sich an, die Ergebniskarte nicht im Rasterformat,
sondern als Vektordaten an den Client zu übermitteln. Der für die Darstellung der Daten
verantwortliche Client ist dann in der Lage, so einfache Darstellungsfunktionen wie das
Zoomen oder Verschieben des Sichtfensters eigenständig durchzuführen. Dies hat zur
Folge, dass die Zahl der Anfragen an den Server zurückgeht. Der Server wird dadurch
entlastet und kann sich auf die Bearbeitung von komplexeren Anfragen konzentrieren. Der
Nachteil kann allerdings die Übertragung von nicht unerheblichen Datenmengen an den
Client sein, die je nach Größe der Datensätze zu längeren Wartezeiten führen kann. Ist der
Client auf einem leistungsschwachen Rechner installiert, so bereitet die Darstellung der
Geodaten ebenfalls Probleme.
Wenn die clientbasierte Anwendung nur auf die Geodaten des Servers zugreifen soll, kann
der Client wie im serverbasierten Ansatz als Applet implementiert werden. Sollen jedoch die
Ergebnisse von Analysen auf dem Rechner des Clients abgespeichert oder Daten genutzt
werden, die auf dem Client-Rechner abgelegt sind, muss eine Anwendung programmiert
werden, die unabhängig vom Internet-Browser läuft. Dies liegt daran, dass Applets die
folgenden Einschränkungen haben:
•
Applets haben keinen Lese- oder Schreibzugriff auf das Dateisystem des
ausführenden Computers. Es sind lediglich Zugriffe auf eine URL-Adresse des
Servers möglich, der das Applet bereitstellt.
•
Ein Applet kann keine Netzwerkverbindung zu anderen Rechnern aufbauen, mit
Ausnahme des Rechners, von dem es geladen worden ist.
Bevor also ein GIS für das Internet aufgebaut wird, müssen die jeweiligen Anforderungen an
das System ermittelt werden. Daraufhin kann unter Berücksichtigung der verfügbaren
Hardwareressourcen der geeignete Ansatz gewählt werden.
Seite 4
Verteilte GIS-Funktionalitäten
2.2
Interoperabilität
In einem Artikel von P. Ladstätter [4] befindet sich eine dem heutigen Stand der Entwicklung
entsprechende Definition für den Begriff Interoperabilität:
Interoperabilität ist die Möglichkeit von Softwareprodukten oder -komponenten, innerhalb
einer verteilten Anwendung (Client-Server- oder Multi-Tier-Architektur) Informationen oder
Dienste über standardisierte und eindeutig spezifizierte Interfaces oder Protokolle zu nutzen.
Die Interoperabilität zielt – im Gegensatz zum Datenaustausch – darauf ab, dass Programme
direkt miteinander kommunizieren statt Informationen über Dateien auszutauschen. Ein
klassisches Beispiel sind Datenbank-Anwendungen in Client-Server-Architektur. In diesem
Fall kommunizieren zwei unabhängige Programme – der Client und der Server – miteinander
über eine gemeinsame Schnittstelle.
Typischerweise laufen beide Programme auf unterschiedlichen Rechnerplattformen. Für die
Kommunikation zwischen Client und Server wird dann eine sogenannte Middleware
verwendet, die in diesem speziellen Fall einer Datenbank-Anwendung entweder vom
Datenbankanbieter selbst stammt oder, wie z.B. ODBC, weitgehend datenbankunabhängig
ist.
Bekannt geworden ist der Begriff Interoperabilität im Zusammenhang mit der Common
Object Request Broker Architecture (CORBA). CORBA ist ebenfalls eine Middleware, die
von einem Industriekonsortium, der Object Management Group (OMG) [10], speziell für
verteilte Anwendungen entwickelt wurde.
Die wesentlichen Voraussetzungen für interoperable Software sind Software-Programme
oder Komponenten, die als Client oder Server fungieren, definierte Schnittstellen und eine
gemeinsame Middleware.
Die definierten Schnittstellen stellen die Verbindung zwischen Client und Server dar. Durch
sie ist der Client in der Lage, Funktionen aufzurufen, die dann auf dem Server ausgeführt
werden. Die Schnittstellen dürfen nach dem Starten der Client-Server-Applikation auf keinen
Fall verändert werden, da sie die Kommunikation zwischen Client und Server gewährleisten.
Änderungen im Server- oder im Clientprogramm können auch nach dem Starten noch
vorgenommen werden, natürlich unter der Voraussetzung, dass sie die Schnittstellen
weiterhin implementieren.
In dieser Studienarbeit soll die Interoperabilität zwischen einem Client und mehreren Servern
ermöglicht werden, d.h. der Client kann die jeweiligen Funktionen der verschiedenen Server
nutzen. Als Middleware zwischen Client und Server wird Remote Method Invocation (RMI)
eingesetzt. Im Gegensatz zu CORBA kann RMI nur unter Java eingesetzt werden, so dass
die Implementierung von Client und Server in Java erfolgen muss. Die Vorgehensweise bei
der Definition von Schnittstellen und bei der Implementierung von Client und Server wird in
Kapitel 3 ausführlich beschrieben.
Seite 5
Verteilte GIS-Funktionalitäten
2.3
Das Projekt NEXUS
Dieser Abschnitt soll einen kurzen Einblick in das Projekt NEXUS geben, an dem das Institut
für Photogrammetrie beteiligt ist [7]. Außerdem soll die mögliche Einbindung von RMI in
dieses Projekt aufgezeigt werden.
NEXUS beschäftigt sich mit dem Problem, dass es aufgrund der wachsenden Datenmengen
in der heutigen Zeit immer schwieriger erscheint, ohne größeren Aufwand genau die
Informationen ausfindig zu machen, die man gerade benötigt. Deshalb wird eine geeignete
Strukturierung der Daten immer bedeutsamer. Ein Ansatz besteht nun darin, den räumlichen
Bezug von Informationen bzw. deren Verknüpfung mit einem bestimmten Ort auszunützen.
Anwendungen, welche diesen Ansatz berücksichtigen, versuchen dem Benutzer den Zugriff
auf jene Informationen zu erleichtern, die an seinem Aufenthaltsort von Bedeutung sind.
Die Idee von NEXUS ist es nun, eine generische Plattform für diese Art von Anwendungen
bereitzustellen, wobei die Mobilität der Benutzer durch die Verwendbarkeit von Kleinrechnern
wie Subnotebooks, PDAs oder Wearable Computers unterstützt werden soll. Über diese als
NEXUS-Stations bezeichneten Kleinrechner, in denen Positionierungssensoren und
Kommunikationseinrichtungen integriert sind, können die Benutzer bzw. die ortsbewussten
Anwendungen auf die Plattform zugreifen.
Zur Unterstützung der Benutzer auf dem Weg durch die NEXUS-Welt, die sich aus einem
Modell der realen Welt und zusätzlichen virtuellen Objekten zusammensetzt, müssen GISFunktionalitäten in die Plattform integriert werden (siehe Abbildung 1). Als Beispiel hierfür
sind „Kürzeste Wege“-Algorithmen oder räumliche Selektionen zu nennen.
NEXUS Plattform
Clients
NEXUSNEXUS(NEXUSStations
Stations
Station)
BenutzerSchnittstelle
Lokations-Server
GIS-Datenserver
Server für
GIS-Funktionalitäten
Abbildung 1: Vereinfachtes Modell der NEXUS-Plattform
Mit RMI können Schnittstellen für die Benutzung der GIS-Funktionalitäten zur Verfügung
gestellt werden, die unabhängig von den verschiedenen Arten der NEXUS-Stations sind.
Abhängig von der Rechenleistung der NEXUS-Station können die Clients dann entscheiden,
ob die GIS-Funktionalitäten direkt auf den jeweiligen Servern ausgeführt und die Ergebnisse
an den Client gesendet werden, oder die GIS-Funktionalitäten an den Client übertragen und
auf der NEXUS-Station berechnet werden.
Seite 6
Remote Method Invocation (RMI) unter Java
3 Remote Method Invocation (RMI) unter Java
RMI erlaubt es Entwicklern, Programme zu schreiben, die Objekte auf entfernten Rechnern
in genau derselben Weise ansprechen wie Objekte, die auf demselben Rechner laufen.
Diese Eigenschaft erleichtert das Erstellen von verteilten Anwendungen wesentlich, da der
Entwickler keine Funktionen für den Austausch von Objekten zwischen den verschiedenen
Rechnern implementieren muss.
Entwicklungsgeschichtlich geht RMI aus dem Remote Procedure Calls (RPC) genannten
Konzept von SUN Microsystems hervor. Dies hatte anfangs der 80er Jahre den
Prozeduraufruf auf einem entfernten Computer methodisch einem Aufruf auf dem gleichen
Rechner angeglichen. Die Technik des RMI erweitert nun dieses Konzept hinsichtlich der
objektorientierten Programmierung in Java. So wird der Polymorphismus vollständig
unterstützt. Referenzen zu Objekten auf anderen Virtuellen Maschinen (JVM) werden
aufgebaut und konsistent verwaltet.
RMI beschränkt sich nicht nur auf ein einfaches Aufrufen von entfernten Methoden, sondern
lässt die Möglichkeit, direkte Implementierungen von Schnittstellen und Unterklassen zu
versenden, offen. Es werden konkrete Objekte als Argumente übergeben. Erhält eine
Methode ein zulässiges Objekt als Argument, dessen Klasse es nicht kennt, kann unter
bestimmten Voraussetzungen die Klasse dynamisch vom fernen Host geladen werden.
RMI ist ein sprachgebundenes Werkzeug, dass nur unter Java läuft. Es grenzt sich dadurch
von der offenen CORBA-Technologie ab. Allerdings besitzt RMI neben dem Nachteil der
Sprachgebundenheit auch einige Vorteile gegenüber CORBA. So kann zum Beispiel auf den
Einsatz einer von der Implementierung unabhängigen Meta-Sprache (IDL) für die
Schnittstellendefinition verzichtet werden. Die Benutzung von CORBA-spezifischen Typen ist
ebenfalls nicht notwendig, da die Speicherplatzbelegung der einzelnen Typen in den JVMs
unabhängig von der Architektur des Rechners ist. Bei anderen Programmiersprachen kann
es z.B. vorkommen, dass ein Integer-Wert, der auf dem einen System 32 Bit auf dem
anderen aber 16 Bit belegt, bei der Übertragung seinen Wert verändert.
RMI kapselt den Datentransfer weitgehend vom Systementwurf ab und stellt verschiedene
Mechanismen bereit, die nach den aktuellen Möglichkeiten vom System genutzt werden. Der
Programmierer kümmert sich nicht darum, ob die Verbindung zwischen den Computern über
eine Socket-Socket Leitung oder aus Sicherheitsgründen über das HTTP-Protokoll
(Firewalls) zustande kommt.
Die Zahl der potenziellen Fehlermöglichkeiten in Netzwerk-Programmen steigt gegenüber
einfachen Java-Anwendungen enorm an. Dies muss im Softwareentwurf sehr frühzeitig
beachtet werden. RMI bietet aber eine leicht zu handhabende Fehlerkontrolle mittels des
Exception-Mechanismus, die leider durch ein schlechteres Laufzeitverhalten erkauft werden
muss.
Seite 7
Remote Method Invocation (RMI) unter Java
3.1
Einführung
Eine einfache RMI-Anwendung besteht aus zwei Programmen, die auf unterschiedlichen
Rechnern laufen. Dabei hat das eine Programm die Funktion eines Servers, das andere
übernimmt die Aufgaben des Clients. Im folgenden soll die Funktionsweise dieser RMI
Anwendung kurz beschrieben werden.
Eine Serveranwendung erzeugt ein sogenanntes Remote-Objekt, macht eine Referenz auf
dieses Objekt zugänglich und wartet darauf, dass ein Client Methoden dieses Objektes
aufruft. Die Clientanwendung bekommt auf Anfrage die entfernte Referenz zu einem oder
mehreren Remote-Objekten des Servers von der Registry zugewiesen und ruft dann
Methoden dieser Objekte auf. RMI stellt den Mechanismus zur Verfügung, mit dem Server
und Client miteinander kommunizieren und Informationen austauschen können.
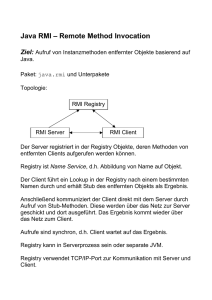
Die Abbildung 2 soll einen ersten Einblick in die Abläufe einer RMI Anwendung geben.
Client
ruft Methoden des
Remote-Objekts auf
holt sich Referenz
auf Remote-Objekt
Server
bindet Referenz auf
Remote-Objekt ein
Registry
Abbildung 2: Einfaches Ablaufschema einer RMI Anwendung
Der Server benutzt die sogenannte Registry von RMI, um die Referenzen der RemoteObjekte für den Client zugänglich zu machen. Jede Instanz eines Remote-Objekts wird vom
Server mittels eines spezifischen Namens in die Registry eingebunden. Dieser Name muss
dem Client bekannt sein und ist vom Typ String. Der Client kann nun mit Hilfe des Namens
das gewünschte Remote-Objekt in der Registry auffinden und die Methoden des Objektes
ausführen, die für einen fernen Aufruf zugänglich sind.
Die Methoden des Remote-Objektes, die vom Client aufgerufen werden können, sind in einer
Schnittstelle definiert, welche vom Server implementiert werden muss. Da der Client aus
Sicherheitsgründen nur auf diese Methoden zugreifen soll, werden sie in einer Stub-Klasse
zusammengefasst, deren Code vom Client dynamisch geladen werden kann, wenn dieser
auf der JVM des Clients nicht existiert. Die Klasse des Stubs beinhaltet neben den entfernt
aufrufbaren Methoden noch Funktionen für die Kommunikation zwischen Client und Server.
Die folgenden Kapitel werden die Architektur von RMI und die Vorgehensweise bei der
Implementierung einer RMI Anwendung beschreiben.
Seite 8
Remote Method Invocation (RMI) unter Java
3.2
Architektur
Der Aufruf einer Methode von der Clientseite aus wird auf der lokalen JVM zuerst durch
mehrere Schichten geleitet, bevor er zur JVM des Servers gelangt. Abbildung 3 zeigt den
Weg eines Methodenaufrufs durch die verschiedenen Schichten des RMI Systems. Der
Entwickler ist lediglich für das Erzeugen des Stubs und des Skeletons mit dem RMIWerkzeug rmic verantwortlich. Mit den beiden unteren Schichten wie dem Remote
Reference Layer (RRL) oder dem Transport muss er sich bei der Implementierung seiner
Client-Server-Anwendung überhaupt nicht befassen.
RMI Client
RMI Server
Stub
Skeleton
RRL
RMI System
RRL
Transport
Transport
JVM 1
JVM 2
Abbildung 3: Die Architektur von RMI
Die einzelnen Schichten des RMI Systems sollen mit der untersten Schicht beginnend in den
folgenden Unterkapiteln näher erläutert werden.
3.2.1
Transportschicht
Die Transportschicht ist sowohl für das Verbindungssetup und die Verbindungsverwaltung
als auch für die Verwaltung der Remote-Objekte verantwortlich. Dies alles geschieht im
Adressraum der Transportschicht. Es folgt eine Aufzählung der Aufgaben, welche die
Transportschicht übernehmen muss.
•
Empfang der Anfragen der clientseitigen RRL.
•
Lokalisierung des RMI-Servers für die entfernte Objektanfrage.
•
Etablierung einer Socketverbindung mit dem Server.
•
Weiterleiten der Verbindung zur clientseitigen RRL.
•
Hinzufügen des Remote-Objektes zu einer Tabelle von Remote-Objekten, mit denen
die Transportschicht kommunizieren kann.
•
Überwachung der Verbindung, ob sie noch steht.
Seite 9
Remote Method Invocation (RMI) unter Java
3.2.2
Remote Reference Layer
Diese Schicht verwaltet die Kommunikation zwischen Stubs und Skeletons und der
Transportschicht, indem sie das Protokoll bestimmt, nach dem die entfernten Referenzen
zugeordnet werden. Als Standard wird das Remote Reference Protocol (RRP) verwendet,
welches unabhängig von den Stubs und Skeletons ist.
Der RRL hat zwei Komponenten, eine clientseitige und eine serverseitige. Die clientseitige
Komponente enthält spezifische Informationen des entfernten Servers und kommuniziert
über die Transportschicht mit der serverseitigen Komponente. Die serverseitige Komponente
ihrerseits implementiert die spezifische Referenz-Semantik (Remote Reference Semantic),
bevor eine Anfrage an das Skeleton weitergeleitet wird.
In der Referenz-Semantik des Servers abstrahiert der RRL die verschiedenen Arten, mit
denen ein Objekt implementiert werden kann. So kann ein Objekt auf Servern implementiert
sein, die immer auf einer Maschine laufen, oder auf Servern, die nur dann aktiv werden,
wenn eine Anfrage auftritt. Dies wird dann als Aktivierung (Activation) bezeichnet.
3.2.3
Stubs und Skeletons
Wenn von einem Objekt im Client eine Methode eines Serverobjekts aufgerufen werden soll,
bzw. dem Serverobjekt eine Nachricht gesendet werden soll, wird ein lokales
Stellvertreterobjekt verwendet, welches als Stub bezeichnet wird. Dieses existiert im
Adressraum der JVM, welche das Clientobjekt ausführt und stellt somit für die restliche
Applikation ein reguläres Java-Objekt dar. Die Stub-Methode fasst die Parameter des
Methodenaufrufs zusammen, was auch als "parameter marshalling" bezeichnet wird, und
zusammen mit der eindeutigen Referenz des Remote-Objekts und der Nummer der
aufgerufenen Methode wird ein Datenblock gebildet, der über den Remote Reference Layer
zum Server gesendet wird.
Client
Server Aufruf des
Methodenaufruf
Applikation
Methodenaufruf, vom
Stub weitergeleitet
Stub
Methodenergebnis
eigentlichen Objektes
Skeleton
Methodenergebnis
Objekt
Methodenergebnis
Abbildung 4: Stub und Skeleton
Auf der Serverseite empfängt das entfernte Stellvertreterobjekt des eigentlichen RemoteObjektes, bezeichnet als Skeleton, über den dortigen Remote Reference Layer den
Datenblock und ruft die gewünschte Methode des Serverobjekts auf. Rückgabewerte, wozu
auch ausgelöste Ausnahme- bzw. Fehlerobjekte (Exceptions) gehören, werden auf dem
analogen Weg zum Clientobjekt zurückgesendet.
Seite 10
Remote Method Invocation (RMI) unter Java
3.3
Vorgehensweise bei der Implementierung einer RMI-Anwendung
Der Entwicklungsprozess einer verteilten Anwendung mit RMI gliedert sich in mehrere
Schritte, die in der folgenden Reihenfolge ausgeführt werden sollten.
•
Definieren einer Schnittstelle, in der alle öffentlichen Methoden des entfernt
aufrufbaren Objektes deklariert werden.
•
Erstellen des Remote-Objektes, welches die Schnittstelle implementiert und
zusätzlich intern benötigte Methoden definiert.
•
Kompilieren der Schnittstelle und des Remote-Objektes mit javac.
•
Stubs und Skeletons mit dem Tool rmic erzeugen.
•
Einen Client (Applet/Applikation) schreiben und kompilieren, der die entfernten
Methodenaufrufe durchführt.
•
Die RMI Registry als Hintergrundprozess auf dem Rechner des Servers starten.
•
Das Remote-Objekt, d.h. den Server, ebenfalls starten.
•
Den Client starten.
Die aufwendigeren Schritte werden in folgenden Unterkapiteln näher erläutert.
3.3.1
Definition der RMI-Schnittstelle
In der RMI-Schnittstelle, auch Remote-Interface genannt, werden die Methoden deklariert,
die von anderen Objekten (auf anderen JVMs) aufgerufen werden können. Hier werden die
benötigten Methodennamen und deren Parameter- und Rückgabetypen festgelegt.
Der folgende Quellcode zeigt ein einfaches Beispiel für ein Remote-Interface.
public interface MyService extends java.rmi.Remote {
void doSomething(Object param) throws java.rmi.RemoteException;
}
Indem ein Remote-Interface von der Schnittstelle java.rmi.Remote erbt, kennzeichnet es
sich als eine Schnittstelle, deren Methoden von anderen JVMs aufgerufen werden können.
Jedes Objekt, welches das Remote-Interface implementiert, wird zu einem Remote-Objekt.
Die Methoden, die in der RMI-Schnittstelle definiert sind, müssen alle eine throws - Klausel
für die java.rmi.RemoteException enthalten, da diese ausgelöst wird, wenn ein Fehler
in der Kommunikation oder im Protokoll auftritt.
Die Parameter- oder Rückgabewerte der Methoden können nahezu von jedem beliebigen
Typ sein, lokale Objekte, Remote-Objekte und einfache Typen eingeschlossen. Die einzige
Voraussetzung ist die Serialisierbarkeit der Objekte. In einfachen Datentypen und in RemoteObjekten ist diese Eigenschaft bereits implizit enthalten. Die anderen Objekte müssen die
Schnittstelle java.io.Serializable implementiert haben, damit sie als Parameter- oder
Rückgabewerte eingesetzt werden können.
Seite 11
Remote Method Invocation (RMI) unter Java
RMI nutzt den Mechanismus der Objektserialisierung, um die Objekte „by value“ zwischen
Virtuellen Maschinen zu transportieren, d.h. es wird eine Kopie des Objektes erstellt. Die
Implementierung von Serializable ermöglicht es einem Objekt, in eine Folge von Bytes
umgewandelt zu werden. Nach dem Transport der Bytefolge an eine andere JVM kann eine
exakte Kopie des serialisierten Objektes erstellt werden. Im Gegensatz zu allen anderen
Objekten werden Remote-Objekte per Referenz übergeben.
3.3.2
Erstellen des Remote-Objektes
Der Server erzeugt das Remote-Objekt und bindet es in die Registry ein. Diese Prozedur
kann entweder in der main-Funktion der Implementierung des Remote-Objektes oder
vollständig in einer anderen Klasse enthalten sein. Im folgenden Beispiel ist der Server in die
Implementierung des Remote-Objektes integriert.
public class MyServiceImpl extends java.rmi.server.UnicastRemoteObject
implements MyService
{
public MyServiceImpl() throws java.rmi.RemoteException {
super();
}
void doSomething(Object param) throws java.rmi.RemoteException {
...
}
...
public static void main(String[] args) {
System.setSecurityManager(new java.rmi.RMISecurityManager());
String name = "//host:2001/ServiceName";
try {
MyServiceImpl obj = new MyServiceImpl();
Java.rmi.Naming.rebind(name, obj);
catch (RemoteException e) {
...
}
}
}
Wie aus der Klassendeklaration hervorgeht, implementiert die Klasse des Remote-Objektes
die Schnittstelle MyService aus dem vorherigen Kapitel und erbt zusätzlich von der Klasse
UniCastRemoteObject. Diese Klasse ist von der abstrakten Klasse RemoteServer
abgeleitet, welche eine Umgebung für das Funktionieren des RMI-Mechanismus bereitstellt.
Die Klasse des Remote-Objektes muss einen Konstruktor enthalten, der ebenfalls eine
java.rmi.RemoteException weiterleitet und den Konstruktor der Basisklasse mit dem
super()-Befehl aufruft. Neben den Methoden der RMI-Schnittstelle können in der Klasse
noch zusätzliche lokale Methoden für Berechnungen auf Server-Seite enthalten sein.
Die Initialisierung des Remote-Objektes wird in der main-Funktion durchgeführt. Zuerst
muss jedoch ein sogenannter Security-Manager installiert werden [11]. Dieser schützt die
Systemressourcen
vor
Manipulation
durch
heruntergeladenen
Code,
der
nicht
Seite 12
Remote Method Invocation (RMI) unter Java
vertrauenswürdig ist. Der Security-Manager legt z.B. fest, ob der heruntergeladene Code
Zugriff auf das lokale Dateisystem hat. Mit RMISecurityManager wird ein Manager zur
Verfügung gestellt, der einem Security-Manager für Applets gleicht. Um trotzdem den Zugriff
auf das lokale Dateisystem zu ermöglichen, kann eine Datei java.policy für die
Gewährung bestimmter Rechte eingesetzt werden [3].
Nach der Installation des Security-Managers wird eine Instanz des Remote-Objektes obj
erzeugt und mit der Methode rebind() in die Registry eingebunden. Der Parameter name
enthält den Namen des Hosts, auf dem die Registry läuft, und den Port, an den sie geknüpft
ist. Wird die Portnummer weggelassen, so wird der Default-Port 1099 verwendet. Am Ende
des Strings steht der Name, mit dem die Instanz in die Registry eingebunden werden soll.
Aus Sicherheitsgründen darf eine Server-Anwendung nur die Registry benutzen, die auf dem
gleichen Host läuft.
3.3.3
Implementierung des Clients
Der folgende Quellcode zeigt die Schritte, welche der Client für den Aufruf einer entfernten
Methode ausführen muss.
public class MyClient extends Applet
{
...
System.setSecurityManager(new java.rmi.RMISecurityManager());
String name = "//host:2001/ServiceName";
try {
MyService RMIServer = (MyService) java.rmi.Naming.lookup(name);
RMIServer.doSomething(param);
}
catch (RemoteException e) {
...
}
...
}
Bevor der Client die Verbindung zu einem Remote-Objekt herstellen darf, muss analog zum
Server ein Security-Manager installiert werden. Danach sucht die Methode lookup() in der
Registry des Server-Hosts nach dem Remote-Objekt mit dem Namen ServiceName. Ist die
Suche erfolgreich, so wird die Referenz auf den Stub des Remote-Objektes zurückgeliefert
und in der Variable RMIServer abgespeichert, die als eine RMI-Schnittstelle definiert ist. Mit
Hilfe der Referenz kann die entfernte Methode doSomething() auf der Seite des Servers
ausgeführt werden.
3.3.4
Starten der Registry
Um mehrere Remote-Objekte in der Registry binden zu können, muss das Tool
rmiregistry eingesetzt werden. Beim Starten von rmiregistry in der Kommandozeile
ist es wichtig, dass die Umgebungsvariable CLASSPATH nicht auf Klassen des RemoteObjektes zeigt, da die Registry sonst nicht in der Lage ist, den Stub aus der JVM des
Servers zu laden.
Seite 13
Remote Method Invocation (RMI) unter Java
3.4
Dynamisches Herunterladen des Stubs
Wie bereits in vorherigen Kapiteln erwähnt, benötigt der Client einen Stub des RemoteObjektes. Für das erfolgreiche Implementieren einer RMI-Anwendung kann es von Vorteil
sein, die einzelnen Schritte beim Herunterladen des Stubs zu kennen. Der Client muss sich
den Stub mit Hilfe eines Uniform Resource Locators (URL) besorgen. Dieser URL kann sich
auf das Dateisystem des Rechners, einen FTP- oder einen Web-Server beziehen. Die
einzelnen Schritte beim dynamischen Herunterladen des Stubs sollen anhand der Abbildung
5 erläutert werden.
Client
2
Registry
3
1
5
Server
4
URL-Quelle
myHost
(file, ftp oder http)
Abbildung 5: Dynamisches Herunterladen eines Stubs
1
Bevor der Server das Remote-Objekt in die Registry einbinden kann, muss er in die
JVM-Eigenschaft java.rmi.server.codebase den URL für die Stub-Klassendatei
eintragen. Daraufhin registriert der Server das Remote-Objekt in der Registry, indem
er es an einen Namen bindet. Zusätzlich wird die Codebase, welche in der JVM des
Servers eingetragen ist, an die Referenz des Remote-Objektes angehängt.
2
Mit Hilfe des Namens fordert der Client eine Referenz des Remote-Objektes an.
Diese Referenz kann der Client benutzen, um Methodenaufrufe auf dem entfernten
Objekt zu realisieren.
3
Die Registry liefert eine Referenz auf die angeforderte Klasse zurück. Wenn die
Klassendefinition für die Instanz des Stubs lokal im Klassenpfad des Clients gefunden
wird, lädt der Client die Klasse lokal und die Schritte 4 und 5 entfallen. Findet er sie
jedoch nicht in seinem Klassenpfad, so versucht er die Klassendefinition von der
Codebase des Remote-Objektes abzurufen.
4
Der Client fordert die Klassendefinition von der Codebase an, welche zu dem
Zeitpunkt, an dem die Stub-Klasse in die Registry geladen wurde, an die Instanz des
Stubs gehängt wurde.
5
Die Klassendefinition für den Stub wird an den Client übertragen.
Seite 14
Algorithmen zum „Kürzeste Wege“-Problem
4 Algorithmen zum „Kürzeste Wege“-Problem
Die GIS-Funktionalitäten, welche in dieser Arbeit für die Demonstration der Client-ServerAnwendung eingesetzt werden sollen, stammen aus dem Bereich der Netzwerkanalyse. Die
folgenden Ausführungen zu dieser Thematik halten sich an das Skript zur Vorlesung GeoInformationssysteme III [2].
Ein Teilgebiet der Netzwerkanalyse beschäftigt sich mit der Lösung des „Kürzeste Wege“Problems, welches unterschiedliche Ausprägungen und Anwendungsgebiete hat. So kann
man sich vorstellen, den kürzesten Weg zwischen einer Stadt A und einer Stadt B auffinden
zu wollen. Besteht eine direkte Verbindung zwischen den beiden Städten, dann ist das
Problem äußerst leicht zu lösen. Je mehr Zwischenpunkte oder Städte jedoch zwischen A
und B liegen, um so komplizierter wird es, die kürzeste Verbindung zu finden.
Die Definition des Begriffs kürzest spielt bei diesem Problem eine wichtige Rolle. Er kann
sich auf die Zeitdauer, aber auch auf die Weglänge beziehen. Außerdem können noch
zusätzliche Faktoren wie die Beschaffenheit der Straßen berücksichtigt werden. Dies zeigt,
dass der Begriff kürzest immer auch auf die Anforderungen des jeweiligen Benutzers
bezogen werden muss. Deshalb wird der Begriff Kosten eingeführt, der die einzelnen
Faktoren in einem Wert zusammenfasst, wobei diese unterschiedlich gewichtet werden
können.
Die Graphentheorie stellt nun wichtige Werkzeuge für die Lösung des Problems zur
Verfügung, d.h. das Problem kann auf einen Graphen abgebildet werden. Ein Graph besteht
aus Knoten und Kanten und kann ungerichtet oder gerichtet sein. Außerdem können die
Kanten mit einer Bewertung versehen werden. Dadurch können die unterschiedlichen
Anforderungen der Benutzer in das Problem miteinbezogen werden, d.h. jede Kante erhält
ein Maß für die Kosten des Weges.
Die folgenden Probleme werden im Zusammenhang mit den Kürzesten Wegen behandelt:
•
Single Source Shortest Path: Kürzeste Wege von einer Quelle zu allen anderen Knoten
•
All-Pairs Shortest Path: Kürzeste Wege zwischen allen Knoten
•
Zentrumsproblem: z.B. optimaler Standort für ein Kaufhaus
•
Minimales Gerüst: Suche nach minimaler Länge der Verbindungen zwischen
gegebenen Punkten
•
Rundreiseproblem: Besuch aller Städte in kürzester Zeit
Für diese Arbeit wurden die ersten beiden Probleme genauer untersucht und die Lösungen
in Java implementiert. Auf die Algorithmen zur Lösung des Single Source Shortest Path und
des All-Pairs Shortest Path Problems wird in den folgenden Unterkapiteln eingegangen
werden. Zuvor sollen allerdings die benötigten Werkzeuge der Graphentheorie erläutert
werden.
Seite 15
Algorithmen zum „Kürzeste Wege“-Problem
Beide genannte Aufgaben werten einen gerichteten Graphen aus. Es gibt verschiedene
Datenstrukturen für einen gerichteten Graphen. Die Wahl der Datenstruktur orientiert sich an
der jeweiligen Aufgabenstellung. Für die beiden zu untersuchenden Probleme bietet sich die
Speicherung des Graphen in einer Nachbarschaftsmatrix (Adjazenzmatrix) an. Abbildung 6
zeigt in (a) einen gerichteten Graphen und in (b) dessen Abbildung auf eine Adjazenzmatrix.
An den Stellen, an denen es eine Verbindung zwischen den Knoten gibt, wird eine 1
eingetragen. Die restlichen Elemente sind 0.
Ein Vorteil der Adjazenzmatrix ist der schnelle Zugriff auf die einzelnen Elemente der Matrix,
der unabhängig von der Anzahl der Kanten oder Knoten ist. Als nachteilig muss jedoch der
hohe Speicherbedarf vom Grad n2 angesehen werden (n ist die Anzahl der Knoten). Da bei
den meisten Graphen die Anzahl der Kanten viel kleiner als n2 ist, werden viele Nullen
mitabgespeichert.
0
1
2
3
−
0
0
0
1 1
− 0
0 −
1 0
(b)
(a)
Abbildung 6:
1
0
1
−
(a) Gerichteter Graph
(b) Adjazenzmatrix
∞ 30 50 20
∞ ∞ ∞ ∞
∞ ∞ ∞ 10
∞ 40 ∞ ∞
(c)
(c) Kostenmatrix
Für die Auswertung des gerichteten Graphen in den zu untersuchenden Problemen werden
neben den gerichteten Verbindungen zwischen den Knoten auch die Kosten der einzelnen
Kanten benötigt. Eine Adjazenzmatrix, welche diese Kosten berücksichtigt, bezeichnet man
als Kostenmatrix. Wie man in Abbildung 6 (c) erkennen kann, wird an den Stellen, an denen
es keine Verbindung gibt, das Symbol für unendlich eingetragen. Damit wird ausgedrückt,
dass der Weg auf keinen Fall über diese Verbindung führen kann, da die Kosten ansonsten
ins Unendliche steigen würden. In der Studienarbeit wird an diesen Stellen für die
Darstellung im Rechner eine -1 eingesetzt, die dann aber für die Berechnungen durch eine
sehr große Zahl ersetzt wird.
4.1
Single Source Shortest Path
Bei diesem Problem ist ein attributierter Graph G = (V,E) gegeben, d.h. es sind die Kosten
der einzelnen Verbindungen an den Kanten (E) angebracht. Außerdem wird der Startknoten
als die Quelle bezeichnet. Die Aufgabe besteht nun darin, „ die Kosten des kürzesten Weges
von der Quelle zu jedem anderen Knoten der Knotenmenge V zu bestimmen. Die Länge des
Weges ist dabei die Summe der Kosten der besuchten Kanten des Pfades.“ [2].
Für die Lösung des Problems kann der Algorithmus von Dijkstra verwendet werden. Dieser
wird im folgenden Unterkapitel eingehend erläutert werden.
Seite 16
Algorithmen zum „Kürzeste Wege“-Problem
4.1.1
Der Dijkstra-Algorithmus
Der Dijkstra-Algorithmus kann mit der folgenden Definition kurz umschrieben werden:
In einer Menge S werden alle besuchten Knoten gesammelt. Zunächst ist nur die Quelle in S
enthalten. In jedem Schritt wird der Knoten aus der Menge V-S zu S hinzugefügt, der die
geringste Distanz zur Quelle hat. Diese minimalen Distanzen werden in einem Vektor
abgespeichert. Die Kosten für die Verbindung zweier Knoten werden einer Kostenmatrix
entnommen.
Beispiel
In Abbildung 7 ist ein attributierter Graph in Form einer Kostenmatrix gegeben.
0
80
0
10
1
4
40
40
20
10
2
3
0
1
2
3
4
1
2
3
4
∞ 80 ∞ 40 10
∞ ∞ 10 ∞ ∞
∞ ∞ ∞ ∞ ∞
∞ 40 30 ∞ ∞
∞ ∞ ∞ 20 ∞
30
Abbildung 7: Beispielgraph in Form einer Kostenmatrix
Die folgende Tabelle zeigt die Iterationsschritte des Dijkstra-Algorithmus für den Graphen in
Abbildung 7. In S werden die bereits besuchten Knoten abgespeichert. Der Vektor d nimmt
die minimalen Distanzen zur Quelle 0 auf, er wird zu Beginn des Algorithmus mit der ersten
Zeile der Kostenmatrix initialisiert. Im Vektor p wird der jeweilige Vorgängerknoten notiert.
i
1
2
3
4
S
[0]
[0,4]
[0,4,3]
[0,4,3,2]
d(0), p(0)
-
d(1), p(1)
80, 0
80, 0
70, 3
70, 3
d(2), p(2)
∞, 0
∞, 0
60, 3
-
d(3), p(3)
40, 0
30, 4
-
d(4), p(4)
10, 0
-
In der ersten Iteration wird der Knoten 4 ausgewählt, der die minimale Distanz von 10 zum
Quellknoten hat. Daraufhin ändert sich die Distanz zum Knoten 3, da der Weg über den
Knoten 4 mit 10 + 20 = 30 kürzer ist als der direkte Weg von der Quelle. Zusätzlich wird der
Knoten 4 als Vorgängerknoten in p(3) festgehalten. Die nächsten Iterationsschritte laufen
analog zum ersten Schritt ab.
Das Ergebnis des Algorithmus sind die Vektoren d und p. Der Vektor d enthält die minimalen
Distanzen der einzelnen Knoten zur Quelle. Im Vektor p sind die Pfade zu den
verschiedenen Knoten implizit abgespeichert, d.h. sie können mit Hilfe von p rekonstruiert
werden.
Seite 17
Algorithmen zum „Kürzeste Wege“-Problem
Die Rekonstruktion des Pfades soll am Beispiel des Knoten 2 erläutert werden. Dort ergibt
sich die Abfolge: p(2) = 3, p(3) = 4, p(4) = 0. Somit verläuft der kürzeste Weg von der Quelle
0 zum Knoten 2 über 4 und 3.
4.1.2
Implementierung des Dijkstra-Algorithmus in Java
In diesem Abschnitt sollen die wichtigsten Teile aus der Java-Implementierung erläutert
werden. Der gesamte Quellcode des Dijkstra-Algorithmus befindet sich im Anhang dieser
Studienarbeit.
Zu Beginn wird die übergebene Kostenmatrix kopiert, deren Größe size bestimmt und es
werden die Elemente, in denen -1 steht, auf eine sehr große Zahl INFINITE gesetzt.
Danach beginnt der eigentliche Schritt der Initialisierung, d.h. es werden Arrays definiert und
mit Startwerten belegt.
int[] p = new int[size];
int[] d = new int[size];
for(int i=0;i<size;i++) d[i] = costMatrix[0][i];
int[] S = new int[1];
S[0] = 0;
int[] T = new int[size-1];
for (int i=1;i<size;i++) T[i-1] = i;
Wie aus dem Java-Code ersichtlich ist, werden alle Elemente des Pfadarrays p[] mit dem
Knoten 0 vorbelegt, der die Quelle des Algorithmus ist (Java initialisiert die Werte in p[]
automatisch mit 0). In das Distanzarray d[] wird die erste Zeile der Kostenmatrix
geschrieben. Daraufhin werden die Listen S und T als Arrays angelegt. In S[] wird der
Knoten
0,
in
T[]
werden
die
restlichen
Knoten
abgespeichert.
Nach
diesem
Initialisierungsschritt beginnt die Hauptschleife des Algorithmus, die insgesamt (size-1)mal durchlaufen wird. In jedem Schleifendurchlauf wird zuerst das kleinste Element und
dessen Index in d bestimmt.
min_d = d[T[0]];
min_element = T[0];
// min_d = minimale Kosten zum Quellknoten
// min_element = Knoten mit den geringsten Kosten
for (int j=1;j<T.length;j++){
if (d[T[j]]<min_d){
min_d = d[T[j]];
min_element = T[j];
}
}
Der Knoten mit den geringsten Kosten wird aus T[] gelöscht und in S[] eingetragen. Da bei
der Implementierung des Algorithmus mit Absicht auf komplexere Speicherstrukturen
verzichtet wurde, um den Quellcode so einfach wie möglich zu halten, werden für diesen
Schritt zwei temporäre Arrays angelegt.
Seite 18
Algorithmen zum „Kürzeste Wege“-Problem
Danach erfolgt für jeden Knoten in T[] eine Überprüfung, ob der Weg über den soeben
gelöschten Knoten min_element kürzer als der direkte Weg vom Quellknoten ist. Wenn
diese Bedingung erfüllt ist, wird min_element in den Pfad und die Kosten des kürzeren
Weges in d[] eingetragen.
for(int j=0;j<T.length;j++){
if((d[min_element] + costMatrix[min_element][T[j]]) < d[T[j]])
p[T[j]] = min_element;
d[T[j]] = d[min_element] + costMatrix[min_element][T[j]];
}
Nachdem die Hauptschleife durchlaufen ist, stehen in d[] die minimalen Kosten für den
Weg vom Quellknoten zu den anderen Knoten. Der Pfad kann über das Array p[]
rekonstruiert werden, da für jeden Knoten der Vorgängerknoten abgespeichert wurde.
4.2
All-Pairs Shortest Path
Der Ausgangspunkt für diesen Algorithmus ist wiederum ein attributierter Graph G = (V,E).
Die Aufgabe besteht nun darin, „die Kosten des kürzesten Weges zwischen jedem
Knotenpaar der Knotenmenge V zu bestimmen. Die Länge des Weges ist dabei die Summe
der Kosten der besuchten Kanten des Pfades.“ [2].
Die Lösung des Problems kann theoretisch durch die Anwendung des Dijkstra-Algorithmus
auf alle n Knoten als Quelle erfolgen. Eine elegante Alternative ist der Algorithmus von
Floyd. Beide Möglichkeiten liegen vom Rechenaufwand her im gleichen Bereich, der FloydAlgorithmus ist allerdings einfacher zu implementieren.
4.2.1
Der Floyd-Algorithmus
Die Eingangsgröße beim Floyd-Algorithmus ist eine Kostenmatrix. Alle Berechnungen im
Algorithmus können auf den Elementen dieser Matrix durchgeführt werden. Der Algorithmus
wird in Abbildung 8 veranschaulicht.
k
(a)
Ak −1 (i , j )
Ak (i , j ) = min
Ak −1 (i , k ) + Ak −1 (k , j )
Abbildung 8:
(a) Formel für Floyd-Algorithmus
(b)
i
j
(b) Geometrischer Grundgedanke
Der Algorithmus hat n Iterationsschritte, wobei n die Größe der Kostenmatrix ist. Der
Parameter k, der vor dem ersten Schritt auf 0 gesetzt wird, läuft von 0 bis n-1. In jedem
Schritt wird die gesamte Matrix so aufdatiert, dass im Element Ak(i,j) jeweils der kürzeste
Weg von Knoten i zum Knoten j verzeichnet ist. Die zwei möglichen Wege sind in Abbildung
8 (b) dargestellt. Nach der Aufdatierung wird k um 1 erhöht.
Folglich werden in jedem Schritt nur die Knoten berücksichtigt, deren Verbindungen in den
vorhergehenden Schritten bereits minimiert wurden.
Seite 19
Algorithmen zum „Kürzeste Wege“-Problem
4.2.2
Implementierung des Floyd-Algorithmus in Java
Am Anfang der Implementierung wird die übergebene Kostenmatrix in eine Matrix d[][]
kopiert, auf welcher die Berechnungen durchgeführt werden. Dies gewährleistet, dass die
Kostenmatrix nicht überschrieben wird. Außerdem werden die Elemente, in denen eine -1
steht auf eine sehr große Zahl INFINITE gesetzt.
Nach diesem Initialisierungsschritt wird der Floyd-Algorithmus auf die Matrix d[][]
angewendet.
for(int k=0;k<size;k++){
for(int i=0;i<size;i++){
for(int j=0;j<size;j++){
d[i][j] = Math.min(d[i][j],(d[i][k] + d[k][j]));
}
}
}
Danach werden Elemente, die auf INFINITE stehen, wieder auf -1 zurückgesetzt. Das
Ergebnis des Algorithmus steht nun in der Matrix d[][].
Seite 20
Lösungsansatz und Implementierung der RMI-Anwendung
5 Lösungsansatz und Implementierung der RMI-Anwendung
Ziel der Studienarbeit ist es, GIS-Funktionalitäten mit Hilfe von RMI zur Verfügung zu stellen.
Diese Funktionalitäten sollen von verschiedenen Servern bereitgestellt und von einem Client
genutzt werden (siehe Abbildung 9).
Server 1
GIS-Funktionalität 1
GIS-Funktionalität n
Client
Schnittstelle
Server n
GIS-Funktionalität 1
GIS-Funktionalität n
Abbildung 9: Verteilte GIS-Funktionalitäten
Für den Zugriff auf die einzelnen Funktionalitäten benötigt der Client eine Schnittstelle,
welche die Kommunikation zwischen Client und Server ermöglicht. Die Server sollen in der
Lage sein, die GIS-Funktionalitäten direkt auf ihrer Seite auszuführen und das Ergebnis an
den Client zu senden. Da aber auch das Herunterladen der Funktionalitäten auf den ClientRechner möglich sein soll, müssen diese in einzelnen Objekten zusammengefasst werden.
Mittels RMI können die Objekte an den Client-Rechner übermittelt und deren Methoden
ausgeführt werden.
Damit der Client die benötigten Funktionalitäten auf den Servern finden kann, muss jeder
Server eine Liste der verfügbaren GIS-Funktionalitäten bereitstellen. Nach der erfolgreichen
Verbindung zum Server lädt der Client die Liste herunter, um sie einer Suchfunktion für GISFunktionalitäten zur Verfügung zu stellen.
Die Implementierung der RMI-Anwendung erfolgt nach der Vorgehensweise in Kapitel 3.3.
Bevor die einzelnen Server und der Client erstellt werden können, müssen sinnvolle
Schnittstellen definiert werden, welche die Umsetzung des vorgestellten Ansatz in eine
Client-Server-Anwendung ermöglichen.
Die folgenden Unterkapitel werden die wichtigsten Teile der Implementierung ausführlich
beschreiben.
Seite 21
Lösungsansatz und Implementierung der RMI-Anwendung
5.1
Schnittstellen
Bevor die entfernt aufrufbaren Methoden des Servers definiert werden können, muss eine
Schnittstelle für das Ausführen einer GIS-Funktionalität festgelegt werden. Die Schnittstelle
GISTask erweitert Serializable, damit sie in den entfernt aufrufbaren Methoden des
Servers als Parameter eingesetzt werden kann. Jede GIS-Funktion, die in der Anwendung
eingesetzt werden soll, muss in eine Klasse umgeschrieben werden, welche die Schnittstelle
GISTask implementiert.
public interface GISTask extends Serializable
{
String getName();
void init(Object param);
Object execute();
}
Um die Identität der GIS-Funktion kontrollieren zu können, liefert die Methode getName()
den Namen der Funktionalität. In der Methode init(Object param) werden dann die
Eingabeparameter an die GIS-Funktion übergeben. Da param vom Typ Object ist, können
alle Typen, die von Object abgeleitet sind, verwendet werden. Dies bedeutet, dass mit Hilfe
von Container-Klassen, wie z.B. Vector, beliebig viele Parameter unterschiedlichen Typs
an die GIS-Funktion übermittelt werden können.
Nachdem die Funktion nun initialisiert ist, wird sie mittels execute() ausgeführt. Das
Ergebnis der Funktion wird in den Rückgabewert der execute()-Methode geschrieben und
ist ebenfalls vom Typ Object.
Nach der Definition von GISTask kann die Definition des Remote-Interfaces für die ClientServer-Anwendung erfolgen. Die Schnittstelle FunctionServer muss von jedem RemoteObjekt implementiert werden. In unserem Fall wird das Remote-Objekt die Funktion eines
Servers für GIS-Funktionalitäten übernehmen.
public interface FunctionServer extends java.rmi.Remote
{
GISTask getFunction(String name) throws java.rmi.RemoteException;
Object executeFunction(String name, Object param) throws java.rmi...
String[] getFunctionList() throws java.rmi.RemoteException;
}
Bevor ein Client auf die GIS-Funktionen zugreift, holt er sich mit getFunctionList() die
Liste der verfügbaren GIS-Funktionalitäten. Der Client ist nun in der Lage, mit Hilfe von
getFunction(String name) die Funktion herunterzuladen, welche die Bezeichnung
name hat. Diese Bezeichnung muss eindeutig und sowohl Server als auch Client bekannt
sein. Die Methode executeFunction(String name, Object param) ermöglicht das
Ausführen der Funktion auf dem Rechner des Servers. Die benötigten Eingabeparameter
werden in param übergeben.
Nachdem die erforderlichen Schnittstellen definiert sind, kann mit der Implementierung von
Server und Client begonnen werden.
Seite 22
Lösungsansatz und Implementierung der RMI-Anwendung
5.2
Server
Die eingesetzte Client-Server-Architektur ermöglicht den Einsatz mehrerer Server. Diese
Server müssen in Abhängigkeit der vorhandenen GIS-Funktionalitäten implementiert werden,
d.h. die GIS-Funktionalitäten werden in den Quellcode der Server aufgenommen. Server und
Remote-Objekt sind identisch, da die main-Funktion des Remote-Objektes die Funktion des
Servers übernimmt.
Analog zu Kapitel 3.3.3 erfolgt die Deklaration der Klasse.
public class FunctionServerOne
extends UnicastRemoteObject
implements FunctionServer
Die Bezeichnung der Klasse ist beliebig, sollte jedoch die Funktion der Klasse wiedergeben.
FunctionServerOne übernimmt die Schnittstelle FunctionServer aus 5.1. Um die
Serverfunktion der Klasse zuzulassen, müssen die entfernt aufrufbaren Methoden in
FunctionServerOne implementiert werden. Für die Einbindung der RMI-Umgebung wird
die Klasse UnicastRemoteObject geerbt.
Die Implementierungen der entfernt aufrufbaren Methoden werden in den folgenden
Absätzen beschrieben.
Die Methode getFunctionList() liefert die Liste der vorhandenen GIS-Funktionalitäten.
public String[] getFunctionList(){
String[] list = {"SingleSourceShortestPath"};
return list;
}
Das String-Array list wird mit der Liste initialisiert, die bereits vor der Implementierung des
Servers bekannt sein muss, und an den aufrufenden Client übergeben.
Mit Hilfe der Methode getFunction(String name) kann der Client das Objekt einer GISFunktion herunterladen.
public GISTask getFunction(String name){
if (name.equals(new String("SingleSourceShortestPath"))==true){
System.out.println("SingleSourceShortestPath-Objekt exportieren");
return new SingleSourceShortestPath();
}
return new EmptyFunction();
}
Zu Beginn der Methode wird für jede vorhandene GIS-Funktionalität eine if-Abfrage
durchgeführt, die überprüft, ob der Bezeichner der angeforderten Funktionalität mit dem der
jeweiligen GIS-Funktionalität übereinstimmt. Ist dies der Fall, so wird das relevante Objekt
erzeugt und an den Client übermittelt.
Wenn die angeforderte GIS-Funktionalität nicht auf dem Server vorhanden ist, wird die
Instanz eines GISTask-Objektes erzeugt, welche in der Funktion getName() den String
"EmptyFunction" zurückgibt. Dies ermöglicht dem Client, eine Kontrolle durchzuführen.
Seite 23
Lösungsansatz und Implementierung der RMI-Anwendung
Mit der Methode executeFunction(String name, Object param) kann der Client
eine GIS-Funktionalität direkt auf dem Server ausführen. Allerdings müssen dazu die
Eingabeparameter in der Variablen param übergeben werden.
public Object executeFunction(String name,Object param){
if (name.equals(newString("SingleSourceShortestPath"))==true){
System.out.println("SingleSourceShortestPath-Objekt wird direkt
ausgefuehrt...");
SingleSourceShortestPath ssp = new SingleSourceShortestPath();
ssp.init(param);
return ssp.execute();
}
Vector result = new Vector();
result.add(new Boolean(false));
return result;
}
Auch in dieser Methode wird zuerst ein Vergleich der angeforderten Funktionalität mit den
vorhandenen GIS-Funktionalitäten gemacht. Wenn es zu einer Übereinstimmung kommt,
wird das relevante Objekt erzeugt, mit den Eingabeparametern initialisiert und ausgeführt.
Lediglich das Ergebnis der Funktion wird an den Client übergeben. Das Ergebnis sollte
immer ein Vektor sein, in dem das erste Element ein Boolean-Objekt ist, welches Auskunft
über den Erfolg der Ausführung gibt. Dadurch kann am Ende der Methode auch eine nicht
vorhandene Funktionalität abgefangen werden.
In der Methode main(String args[]) sind die Serverfunktionalitäten implementiert. Im
Quellcode stehen lediglich die relevanten Schritte für das Starten des Servers.
public static void main(String args[])
{
...
try {
FunctionServerOne obj = new FunctionServerOne();
Naming.rebind("//"+args[0]+"/"+args[1], obj);
} catch (Exception e) {
...
}
}
}
Zunächst wird das Remote-Objekt obj erzeugt. Danach wird versucht, dass Objekt in die
Registry einzubinden, die zuvor gestartet worden ist. Mit Hilfe der Argumente args[] der
Befehlszeile kann der erste Parameter von rebind() den jeweiligen Eigenschaften der
Registry und des Servers angepasst werden.
In args[0] wird der Host und die Portnummer der Registry angegeben. Das Argument hat
das Format host:port, wobei die Portnummer auch weggelassen werden kann. Dann wird
die Portnummer auf den Default-Wert 1099 eingestellt.
Das Argument args[1] gibt den Bezeichner des Servers an, mit dem der Client den Server
auf dem entfernten Rechner finden kann.
Seite 24
Lösungsansatz und Implementierung der RMI-Anwendung
5.3
Client
Das Client wurde als Java-Applikation unter Verwendung der Swing-Klassen implementiert,
damit der Benutzer auf das Dateisystem des Client-Rechners zugreifen kann. Während das
nächste Unterkapitel eine Art Bedienungsanleitung des Programms ist, erläutert das darauf
folgende Unterkapitel die Umsetzung der wichtigsten Bestandteile in Java.
5.3.1
Bedienung der graphischen Oberfläche
Nach dem Starten des Clients erscheint die graphische Oberfläche, die in Abbildung 10
dargestellt ist.
Abbildung 10: Swing-Oberfläche des Clients
Bevor der Benutzer jedoch mit dem Programm interagieren kann, lädt der Client eine
Initialisierungsdatei, welche als Argument in der Befehlszeile angegeben wurde. Dabei ist
wichtig, dass der vollständige Pfad der Datei angegeben wird. Die Initialisierungsdatei hat
das folgende Format.
Server-Einstellungen d:\studienarbeit-gis\RMIApp\Client\server.txt
Arbeitsverzeichnis
d:\studienarbeit-gis\RMIApp\Client
In der ersten Zeile steht eine Textdatei für die Server-Einstellungen, in der zweiten das
Arbeitsverzeichnis des Clients. Die Textdatei server.txt ist folgendermaßen gegliedert.
ifppcz 1099 ServerOne true
ifppcx 1099 ServerTwo true
In jeder neuen Zeile stehen die Einstellungen für einen Server. Die erste Spalte enthält den
Namen des Hosts, auf dem der Server läuft. In der zweiten Spalte steht die Portnummer der
Registry und in der dritten der Bezeichner des Servers. Die vierte Spalte gibt an, ob eine
Verbindung zu diesem Server hergestellt werden soll und kann die Werte true oder false
enthalten. Über den Menüpunkt Einstellungen/Server-Einstellungen können die Werte vor
dem Verbindungsaufbau noch geändert werden (siehe Abbildung 11). Auch das Laden einer
neuen Datei mit Server-Einstellungen ist möglich.
Nachdem die Server-Einstellungen korrekt eingestellt sind, kann über Datei/Verbinden
versucht werden, die Verbindungen zu den Servern herzustellen.
Seite 25
Lösungsansatz und Implementierung der RMI-Anwendung
Scheitert der Verbindungsaufbau zu einem Server, dann gibt der Client eine Fehlermeldung
mit den Einstellungen des Servers aus. Die Anzahl der verbundenen Server wird in der
Titelleiste des Clients angezeigt (siehe Abbildung 12). Damit das Menü Funktionen, in dem
die GIS-Funktionalitäten aufgerufen werden, aktiviert werden kann, muss mindestens ein
Server angeschlossen sein.
Abbildung 11: Server-Einstellungen
Für die Demonstration des RMI werden zwei Algorithmen zur Lösung von „Kürzeste Wege“Problemen eingesetzt. Diese benötigen als Eingabeparameter eine Kostenmatrix. Die Matrix
ist in der Textdatei gespeichert und wird über den Menüpunkt Datei/Graph einlesen geladen.
Damit das Einlesen fehlerfrei abläuft, muss die Datei folgendes Format haben:
5
-1
-1
-1
-1
-1
10
-1
-1
-1
-1
-1
50
-1
20
-1
30 100
-1 -1
-1 10
-1 60
-1 -1
In der ersten Zeile steht die Dimension n der Matrix. Die darauffolgenden Zeilen enthalten
die jeweiligen Elemente der Kostenmatrix. Alle fehlenden Verbindungen werden mit -1
eingegeben.
Nach dem erfolgreichen Laden der Kostenmatrix wird das Menü Funktionen aktiviert, da nun
die Algorithmen auf die Matrix angewendet werden können.
Abbildung 12: Verfügbare GIS-Funktionalitäten
Seite 26
Lösungsansatz und Implementierung der RMI-Anwendung
In Abbildung 12 sind die beiden Untermenüs von Funktionen dargestellt. Wählt der Benutzer
das Untermenü client-basiert aus, so werden die GIS-Funktionalitäten auf den Rechner des
Clients heruntergeladen und dort ausgeführt. Im Untermenü server-basiert können die
gleichen Funktionalitäten aufgerufen werden, jedoch werden diese auf dem Rechner des
Servers ausgeführt. Lediglich das Ergebnis wird an den Client übermittelt.
Für den Fall, dass sich die Liste der verfügbaren Server während der Ausführung des
Programms ändert, kann die Verbindung zu den Servern über Datei/Trennen gelöst werden.
Dadurch wird es möglich, die Server-Einstellungen der neuen Situation anzupassen.
5.3.2
Implementierung des Clients
Die Gestaltung der graphischen Oberfläche des Clients wurde mit der integrierten
Entwicklungsumgebung Forte for Java, Community Edition 1.0 von SUN Microsystems
durchgeführt. Einige Teile des Quellcodes, welche die graphische Oberfläche betreffen, sind
von der Entwicklungsumgebung automatisch eingefügt worden und sollten daher nicht
verändert werden.
In diesem Abschnitt werden die Bestandteile der Java-Implementierung näher erläutert,
welche die Interaktion des Clients mit dem Server ermöglichen.
Die Methode VerbindenActionPerformed() stellt die Verbindung vom Client zu den
ausgewählten Servern her. Die Server-Einstellungen sind in dem zweidimensionalen Array
serverdata abgelegt, das vom Typ Object ist. Der folgende Quellcode zeigt den
wichtigsten Teil der Methode.
int serverindex = 0; // Zähler für ausgewählte Server
for(int i=0;i<serverdata.length;i++){
if (((Boolean)serverdata[i][3]).booleanValue()==true){
try {
host = (String)serverdata[i][0];
port = ((Integer)serverdata[i][1]).toString();
servername = (String)serverdata[i][2];
functionObjectList[serverindex] =
(FunctionServer)Naming.lookup("//"+host+":"+port+"/"+servername);
functionList[serverindex] =
functionObjectList[serverindex].getFunctionList();
...
} catch (Exception e) {
...
}
serverindex++;
}
}
In jedem Durchlauf der for-Schleife wird überprüft, ob der Server ausgewählt ist. Wenn dies
der Fall ist, wird die RMI-Methode lookup() ausgeführt, um eine Referenz auf den Stub
des Remote-Objektes zu erhalten. Ist die Methode erfolgreich, so wird die Referenz in die
Liste functionObjectList aufgenommen, die vom Typ FunctionServer ist. Außerdem
wird die Liste der verfügbaren GIS-Funktionalitäten mit getFunctionList() vom Server
heruntergeladen.
Seite 27
Lösungsansatz und Implementierung der RMI-Anwendung
Die Methode searchFunction(String func) durchsucht die Funktionalitäten-Listen der
verbundenen Server nach dem Bezeichner func und liefert den Index des ermittelten
Servers in der functionObjectList zurück.
Mit der Methode ssp_cbActionPerformed() wird das Single Source Shortest Path
Problem auf der Clientseite gelöst. Der folgende Quellcode zeigt, welche Schritte dafür
notwendig sind.
int index = searchFunction("SingleSourceShortestPath");
...
try {
GISTask t =
functionObjectList[index].getFunction("SingleSourceShortestPath");
t.init(costMatrix);
result = (Vector)t.execute();
} catch (Exception e) {
...
}
Zu Beginn wird die GIS-Funktionalität SingleSourceShortestPath in den Listen der
Server gesucht. Wenn die Funktionalität auf keinem der Server vorhanden ist, gibt die
Methode searchFunction() eine -1 zurück und der Client gibt eine Fehlermeldung aus.
Ansonsten holt sich der Client die Funktionalität mittels getFunction() und führt sie auf
seiner Seite aus.
In der Methode sspActionPerformed() wird die GIS-Funktionalität auf der Seite des
Servers ausgeführt.
int index = searchFunction("SingleSourceShortestPath");
try {
result = (Vector)functionObjectList[index].executeFunction(
"SingleSourceShortestPath",costMatrix);
} catch (Exception e) {
...
}
Nachdem der richtige Server gefunden worden ist, wird das „Kürzeste Wege“-Problem
mittels executeFunction() direkt auf dem Server gelöst und das Ergebnis in den
Lösungsvektor result geschrieben. Als zweiter Parameter wird die Kostenmatrix in Form
eines zweidimensionalen Arrays vom Typ Integer übergeben.
Das Trennen des Clients von den Servern ist denkbar einfach realisiert. In der Methode
TrennenActionPerformed() werden sämtliche Listen, welche die Server betreffen, auf
null gesetzt.
functionObjectList = null;
connectedToFunctionObject = null;
functionList = null;
Dies hängt damit zusammen, dass RMI einen speziellen Mechanismus zur Beseitigung von
nicht referenzierten Remote-Objekten hat (Garbage Collection).
Seite 28
Test der Client-Server-Anwendung
6 Test der Client-Server-Anwendung
Dieser Test soll Aufschluss über die Funktionsfähigkeit der Client-Server-Anwendung in
einem Netzwerk geben. Deshalb wird die Anwendung auf drei Rechner verteilt, die im
Studentenraum des ifp stehen. Wie aus Abbildung 13 hervorgeht, werden zwei Server für die
Bereitstellung von GIS-Funktionalitäten verwendet.
ifppcx
Client
ifppcz
Class-Server
ifppcv
Registry
Registry
Class-Server
Single Source Shortest Path
All-Pairs Shortest Path
FunctionServerOne
FunctionServerTwo
Abbildung 13: Test-Konfiguration
Der FunctionServerOne stellt den Dijkstra-Algorithmus zum Lösen des Single Source
Shortest Path Problems zur Verfügung, der FunctionserverTwo den Floyd-Algorithmus für
das All-Pairs Shortest Path Problem. Neben der Registry wird ein Class-Server benötigt, der
dem Client die erforderlichen class-Dateien liefert. Diese Aufgabe kann auch durch einen
Web-Server erfüllt werden.
6.1
Initialisierung der Server
Zu Beginn des Tests müssen die Server ordnungsgemäß eingerichtet werden. Die nötigen
Schritte sollen anhand des FunctionServerOne gezeigt werden, der auf dem Rechner mit der
Bezeichnung ifppz laufen wird.
1) Starten der Registry mit dem Kommando rmiregistry, d.h. der Default-Port 1099
wird verwendet.
2) Starten des Class-Servers mit dem Kommando
java classServer.ClassFileServer 2001 ../Server1/classes.
Die Datei ClassFileServer.class liegt in dem Unterverzeichnis classServer.
Das erste Argument ist die Portnummer, auf welcher der Class-Server arbeiten soll und
das zweite Argument gibt das Basisverzeichnis für die class-Dateien an.
Seite 29
Test der Client-Server-Anwendung
3) Starten des Servers mit dem Kommando
java -Djava.security.policy=java.policy
-Djava.rmi.server.codebase=http://ifppcz:2001/
-Djava.rmi.server.hostname=ifppcz
server.FunctionServerOne ifppcz ServerOne
Die Datei java.policy legt die Einstellungen im Security-Manager [11] fest und
muss im aktuellen Verzeichnis liegen. Der Einfachheit halber wurden in java.policy
alle Rechte gewährt (permission java.security.AllPermission;).
Die Codebase wird auf die URL-Adresse des Class-Servers gesetzt und als Hostname
der Rechnername angegeben. Am Ende des Kommandos werden die Parameter für
das Binden des Servers an die Registry übergeben (siehe Kapitel 5.2).
Wie aus dem Protokoll des Class-Servers hervorgeht, lädt die Registry in diesem
Schritt die Dateien FunctionServerOne_Stub.class, FunctionServer.class
und GISTask.class herunter.
6.2
Ausführung von GIS-Funktionalitäten
Nach der erfolgreichen Initialisierung der Server werden die Server-Einstellungen des Clients
an die Situation angepasst. Danach wird der Client gestartet und mit Datei/Verbinden werden
die Verbindungen zu den Servern hergestellt. Dabei fällt auf, dass die Stubs der Server von
den jeweiligen Class-Servern geladen werden.
Für den Test der GIS-Funktionalitäten wird der Graph aus Kapitel 4.1.1, Abbildung 7
verwendet. Die Kostenmatrix des Graphen wurde mittels Datei/Graph einlesen in das ClientProgramm geladen (siehe Abbildung 14).
Abbildung 14: Server-basiertes Ausführen des Single Source Shortest Path
Seite 30
Test der Client-Server-Anwendung
In dem Test sollen beide GIS-Funktionen sowohl server- als auch clientbasiert ausgeführt
werden. Die dabei auftretenden Aktionen auf Client- und Serverseite werden in den nächsten
Absätzen mittels Tabellen aufgezeigt, welche die Ausgaben in den Konsolen der Server,
Class-Server und dem Client darstellen. Bei jedem Ausführen einer Funktionalität wird auch
die Bearbeitungszeit aufgezeichnet.
•
Single Source Shortest Path (server-basiert)
Die Lösung des Single Source Shortest Path Problems ist in Abbildung 14 dargestellt.
Wie aus der Abbildung zu erkennen ist, beträgt die Bearbeitungszeit beim ersten
Ausführen der GIS-Funktionalität 661 ms. Bei einem erneuten Ausführen sinkt diese
allerdings auf 80 ms.
Server
SingleSourceShortestPath-Objekt wird direkt ausgefuehrt...
Berechnung von SingleSourceShortestPath laeuft...
Class-Server
Client
Die Tabelle zeigt die gewünschten Effekte, d.h. die Funktion wird direkt auf dem Server
gestartet und dort berechnet.
•
Single Source Shortest Path (client-basiert)
Die Bearbeitungszeit bei der ersten Berechnung beträgt 260 ms, danach durchschnittlich
30 ms.
Server
Class-Server
Client
SingleSourceShortestPath-Objekt exportieren...
reading: server.SingleSourceShortestPath
Berechnung von SingleSourceShortestPath laeuft...
Wie man aus der Tabelle erkennen kann, exportiert der Server das Objekt für den Single
Source Shortest Path Algorithmus. Der Client lädt sich die Class-Datei des Objektes vom
Class-Server und führt die Berechnung lokal aus.
•
All-Pairs Shortest Path (server-basiert)
Auch hier beträgt die Bearbeitungszeit zuerst 161 ms, sinkt dann aber auf 20 ms ab.
Server
AllPairsShortestPath-Objekt wird direkt ausgefuehrt...
Berechnung von AllPairsShortestPath laeuft...
Class-Server
Client
Die Bearbeitung läuft analog zum Single Source Shortest Path Problem ab.
Seite 31
Test der Client-Server-Anwendung
•
All-Pairs Shortest Path (client-basiert)
Das Ergebnis der client-basierten Berechnung des All-Pairs Shortest Path Algorithmus ist
in Abbildung 15 dargestellt. Die Bearbeitungszeit beträgt zuerst 180 ms, dann nur noch
10 ms.
AllPairsShortestPath-Objekt exportieren...
Server
Class-Server
Client
reading: server.AllPairsShortestPath
Berechnung von AllPairsShortestPath laeuft...
Auch in diesem Fall entsprechen die Ausgaben auf den Konsolen den Erwartungen.
Abbildung 15: Client-basiertes Ausführen des All-Pairs Shortest Path
Der Test hat gezeigt, dass die GIS-Funktionalitäten korrekt ausgeführt werden. Allerdings
fällt die Interpretation der Bearbeitungszeiten etwas schwer, da die internen Vorgänge des
RMI dem Entwickler verborgen bleiben. Eine Möglichkeit ist jedoch, dass die Objekte beim
ersten Ausführen über das Netz geladen und im Speicher der JVM des Clients abgelegt
werden. Bei den darauf folgenden Aufrufen können die GIS-Funktionalitäten ohne lange
Ladezeiten ausgeführt werden.
Seite 32
Zusammenfassung/Ausblick
7 Zusammenfassung/Ausblick
Ziel der vorliegenden Arbeit war es, die Bereitstellung von GIS-Funktionalitäten über eine
Client-Server-Architektur zu ermöglichen. Einem aktuellen Ansatz in der GIS-Forschung
folgend, sollten die GIS-Funktionalitäten getrennt von spezifischen Geodaten zur Verfügung
gestellt werden. Außerdem sollte der Client in der Lage sein, die Funktionalitäten entweder
direkt auf den Servern auszuführen oder zu sich auf den Rechner herunterzuladen und dort
zu berechnen.
Für die Umsetzung der Client-Server-Architektur in eine Anwendung sollte die JavaTechnologie RMI eingesetzt werden. Bevor jedoch mit der Implementierung der Anwendung
begonnen werden konnte, mussten zunächst die Möglichkeiten dieser Technologie
untersucht werden. Dabei erwies sich RMI als sehr geeignet für die Programmierung einer
Client-Server-Architektur, da der Entwickler keine Funktionen für den Austausch von
Objekten implementieren muss.
Für den Test der Anwendung wurden zwei GIS-Funktionalitäten aus dem Bereich der
Kürzesten Wege in Objekte umgesetzt, welche sowohl auf dem Server ausgeführt als auch
auf den Client heruntergeladen werden können. Der Test verlief erfolgreich und bestätigte
die Erwartungen an die Applikation.
Die vorliegende Arbeit lässt für zukünftige Entwicklungen jedoch noch einigen Spielraum. Im
folgenden sollen daher einige Vorschläge für die Weiterentwicklung gemacht werden.
Bisher hat der Client zwei Möglichkeiten, eine GIS-Funktionalität auszuführen. Bei beiden
Möglichkeiten stammen die Funktionalitäten vom Server. Nicht vorgesehen ist jedoch das
Ausführen von GIS-Funktionalitäten, die nur der Client kennt. RMI könnte es nun Clients mit
leistungsschwachen Rechnern ermöglichen, Objekte mit eigenen, rechenintensiven GISFunktionalitäten an einen Server zu übertragen und dort Funktionen dieses Objektes
auszuführen. D.h. der Server stellt seine Rechenleistung dem Client zur Verfügung. Dieser
Ansatz wird besonders bei verteilten Anwendungen verfolgt.
Für die Anwendung des vorgestellten Verfahrens in einem größeren Rahmen, müsste ein
Katalog erstellt werden, der für jede GIS-Funktionalität einen individuellen Schlüssel im
String-Format bereithält. Außerdem sollten die Server in der Lage sein, neue GISFunktionalitäten ohne eine Änderung im Quellcode aufzunehmen.
Bei steigender Zahl der verfügbaren Server ist es wenig sinnvoll, dass der Client zu allen
Servern eine Verbindung herstellt, die Listen mit den verfügbaren GIS-Funktionalitäten
herunterlädt und die gewünschte Funktionalität in diesen Listen sucht. Diese Suchfunktion
könnte auch von einer Art Name-Server übernommen werden. Die einzelnen Server
schicken eine Liste mit ihren Funktionalitäten an diesen Name-Server, der die Liste mit der
Adresse des zugehörigen Servers abspeichert. Benötigt der Client eine GIS-Funktionalität,
so stellt er eine Anfrage an den Name-Server. Dieser liefert die Adresse des Servers zurück,
der die Funktionalität anbietet und am wenigsten ausgelastet ist.
Seite 33
Literaturverzeichnis
8 Literaturverzeichnis
[1]
Tao, V., Yuan, S.: Development of network-based GIServices in Support of
Online Geocomputing, IAPRS, Vol..XXXIII, Part B4, Amsterdam, 2000.
[2]
Sester, M.: Skript zur Vorlesung Geo-Informationssysteme III, Universität
Stuttgart, August 2000.
[3]
SUN Microsystems: Java-Tutorial, http://java.sun.com/docs/books/tutorial.
[4]
Ladstätter, P.: Interoperabilität und OpenGIS, GIS, Ausgabe 1/00.
[5]
Prastacos, P.: Putting GIS on the Web, GIS, Ausgabe 1/00.
[6]
Averdung, C.: Integration raumbezogener Daten über Schnittstellen, GIS,
Ausgabe 1/00.
[7]
Volz, S., Sester, M., Fritsch, D., Leonhardi, A.: Multi-Scale Data Sets in Distributed
Environments, APRS, Vol..XXXIII, Technical IV/I, Amsterdam, 2000.
[8]
Graf, T.: RMI (Seminar Java-Technologien), FH München, FB 07 Informatik,
http://www.informatik.fh-muenchen.de/~schieder/seminar-java-ss98/rmi, 1998.
[9]
Schulz, K.: Java professionell programmieren: eine Einführung in die erweiterten APIs
der Java 2 Plattform, Heidelberg, 2000.
[10]
Object Managment Group (OMG): http://www.omg.org/.
[11]
Gong, L.: Java™Security Architecture (JDK1.2), SUN Microsystems, Oktober 1998.
Seite 34
Anhang
Literaturverzeichnis
Anhang
•
Java-Quellcode zum Dijkstra-Algorithmus
•
Java-Quellcode zum Floyd-Algorithmus
Seite 35
Anhang
Literaturverzeichnis
Java-Quellcode zum Dijkstra-Algorithmus
In der Matrix inputMatrix sind die Kosten gespeichert. Unendlich wird mit -1 dargestellt.
// Größe der Kosten-Matrix
int size = inputMatrix.length;
// Kopieren und Umwandeln von Werten mit -1 in Unendlich
int[][] costMatrix = new int[size][size];
for(int i=0;i<size;i++){
for(int j=0;j<size;j++){
if(inputMatrix[i][j] == -1){
costMatrix[i][j] = INFINITE;
}
else{
costMatrix[i][j] = inputMatrix[i][j];
}
}
}
// Array für Rekonstruktion des Pfades (alle Elemente auf 0 setzen)
int[] p = new int[size];
// Initialisieren des Distanzenarrays mit erster Zeile von Kosten-Matrix
int[] d = new int[size];
for(int i=0;i<size;i++) d[i] = costMatrix[0][i];
// Liste für besuchte Knoten
int[] S = new int[1];
S[0] = 0;
// Liste für noch zu besuchende Knoten
int[] T = new int[size-1];
for (int i=1;i<size;i++) T[i-1] = i;
// Hilfsvariablen für die Berechnung
int min_d;
int min_element;
int index;
int[] tmp1;
int[] tmp2;
// Hauptschleife (Iterationen)
for(int i=1;i<size;i++){
// kleinstes Element und dessen Index in d bestimmen
min_d = d[T[0]];
// min_d = minimale Kosten zum Quellknoten
min_element = T[0]; // min_element = Knoten mit den geringsten Kosten
for (int j=1;j<T.length;j++){
if (d[T[j]]<min_d){
min_d = d[T[j]];
min_element = T[j];
}
}
// Knoten mit geringsten Kosten aus T löschen und in S hinzufügen
tmp1 = new int[T.length-1];
index = 0;
for (int j=0;j<T.length;j++){
if (T[j]!=min_element){
tmp1[index] = T[j];
index++;
Seite 36
Anhang
Literaturverzeichnis
}
}
tmp2 = new int[S.length+1];
for (int j=0;j<S.length;j++) tmp2[j] = S[j];
tmp2[S.length] = min_element;
T = tmp1;
S = tmp2;
// Überprüfen, ob der Weg von der Quelle zu einem Knoten über den
// ausgewählten Knoten kürzer ist als der direkte Weg
// -> aktuellen Knoten in Pfad aufnehmen und Strecke in
// Distanzenarray durch kleineren Wert ersetzen
for(int j=0;j<T.length;j++){
if((d[min_element] + costMatrix[min_element][T[j]]) < d[T[j]]){
p[T[j]] = min_element;
d[T[j]] = d[min_element] + costMatrix[min_element][T[j]];
}
}
}
Java-Quellcode zum Floyd-Algorithmus
In der Matrix inputMatrix sind die Kosten gespeichert. Unendlich wird mit -1 dargestellt.
// Größe der Kosten-Matrix
int size = inputMatrix.length;
// Kopieren der Eingabematrix in neue Matrix und Umwandeln in Unendlich
int [][] d = new int[size][size];
for(int i=0;i<size;i++){
for(int j=0;j<size;j++){
if(inputMatrix[i][j] == -1){
d[i][j] = INFINITE;
}
else{
d[i][j] = inputMatrix[i][j];
}
}
}
// Floyd-Algorithmus
for(int k=0;k<size;k++){
for(int i=0;i<size;i++){
for(int j=0;j<size;j++){
d[i][j] = Math.min(d[i][j],(d[i][k]+d[k][j]));
}
}
}
// Zurückwandeln von Unendlich auf -1
for(int i=0;i<size;i++){
for(int j=0;j<size;j++){
if(d[i][j] == INFINITE) d[i][j] = -1;
}
}
Seite 37
Anlage
Literaturverzeichnis
Anlage
•
CD-ROM mit Quellcode
Seite 38