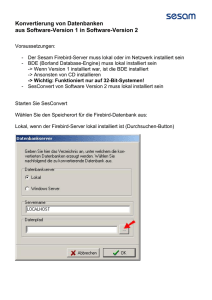
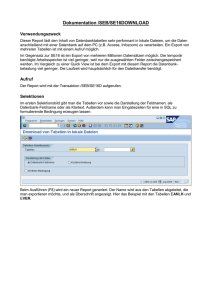
Bachelorarbeit - Universität Zürich
Werbung

Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Rahmen der Arbeit: - 50-60 Seiten Deutsch Zitieren nach APA Interface für output plugin Sprachen aus sesamutil.propertymanager editorpane getAditionalColumninformation ist für nur neu zugekommene Spalten (nicht vererbte) Hilfsmittel für Datenbankabfrage - JDBC TODO ExportPlugin o ColumnInformation benutzen, um SPSS Export mit Metadaten anzureichern o SPS-File mit SPSS testen und gegebenenfalls anpassen Stefan Schurgast I Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Zusammenfassung Deutscher abstract S. 2 / 39 Stefan Schurgast II Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Abstract English abstract S. 3 / 39 Stefan Schurgast III Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Anmerkung Diese Bachelorarbeit wurde durch die Database Technology Research Group des Instituts für Informatik der Universität Zürich unterstützt. Sämtliche in dieser Arbeit ausgedrückten Meinungen, Ergebnisse und Schlussfolgerungen sind diejenigen des Autors und entsprechen nicht notwendigerweise der Sichtweise der vorher genannten Parteien. An dieser Stelle möchte ich mich insbesondere bei Boris Glavic herzlich für die gute Unterstützung während der gesamten Ausarbeitung dieser Bachelorarbeit bedanken. S. 4 / 39 Stefan Schurgast IV Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Inhaltsverzeichnis I Zusammenfassung ........................................................................................................................... 2 II Abstract............................................................................................................................................ 3 III Anmerkung ...................................................................................................................................... 4 IV Inhaltsverzeichnis ............................................................................................................................ 5 V Abbildungsverzeichnis ..................................................................................................................... 7 VI Tabellenverzeichnis ......................................................................................................................... 7 VII Abkürzungsverzeichnis .................................................................................................................... 8 1 2 Einleitung ......................................................................................................................................... 9 1.1 Ausgangslage und Problemstellung ........................................................................................ 9 1.2 Zielsetzung und Vorgehensweise ............................................................................................ 9 1.3 Aufbau der Arbeit .................................................................................................................. 10 Das sesam Projekt.......................................................................................................................... 11 2.1 Einführung in das sesam Projekt ................................................................................................. 11 2.2 Teilprojekt N: sesamDB ......................................................................................................... 12 2.3 Datenmanagement in Langzeitstudien ................................................................................. 13 2.4 Datenbankmanagementsystem PostgreSQL ......................................................................... 15 2.4.1 Typhierarchien und Vererbung ..................................................................................... 15 2.2.1 Trigger und Regeln ........................................................................................................ 16 2.5 3 Verwandte Arbeiten ...................................................................................................................... 17 3.2 Gängige Statistiksoftware und assoziierte Datenformate .................................................... 17 3.2.1 SPSS ............................................................................................................................... 17 3.2.2 SAS ................................................................................................................................. 18 3.3 Datenexport in Statistikprogramme...................................................................................... 20 3.3.1 Exportanwendungen für allgemeine Datenbanken ...................................................... 20 3.3.2 Exportanwendungen in Statistikformate ...................................................................... 20 3.4 4 Sesam Datenbank .................................................................................................................. 16 Repräsentation von Abfragen für den Benutzer ................................................................... 20 3.4.1 Repräsentation in Skriptform ........................................................................................ 20 3.4.2 Grafische Repräsentation .............................................................................................. 22 3.5 Anonymität und Pseudonymität ........................................................................................... 22 3.6 Aufbau von modellbasierten Anwendungen ........................................................................ 24 Analyse der Anforderungen an Sesam Export Manager ............................................................... 25 S. 5 / 39 Stefan Schurgast 4.2 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Anforderungen an Funktionalität der Anwendung ............Fehler! Textmarke nicht definiert. Exportanwendungen für sesamDB // Titel gleicher Aufbau wie 2.3.1 ....... Fehler! Textmarke nicht definiert. Anforderung an statistikformatexportanwendung ....................Fehler! Textmarke nicht definiert. 4.3 5 Anforderungen an Bedienbarkeit der Anwendung ................................................................. 1 Entwurf und Umsetzung des Sesam Export Managers ................................................................. 29 5.2 5.2.1 konzeptioneller Aufbau ................................................................................................. 29 5.2.2 verwendete Hilfsmittel .................................................................................................. 34 5.2.3 Tests............................................................................................................................... 34 5.3 6 Aufbau der Anwendung ........................................................................................................ 29 Vorgehen bei Entwicklung ..................................................................................................... 34 5.3.1 Hilfsmittel ...................................................................................................................... 34 5.3.2 Aufgetretene Probleme und Lösungen ......................................................................... 34 Evaluation der entwickelten Lösung.............................................................................................. 35 6.2 Erfüllung der Anforderungen an Funktionalität .................................................................... 35 6.3 Validierung der Funktionalität............................................................................................... 35 6.4 Erfüllung der Anforderungen an Bedienbarkeit .................................................................... 35 7 Zusammenfassung und Ausblick ................................................................................................... 36 VIII Anhang ........................................................................................................................................... 37 i IX sesam Datenbankschema .......................................................................................................... 37 Literaturverzeichnis ....................................................................................................................... 38 S. 6 / 39 Stefan Schurgast V Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Abbildungsverzeichnis Abbildung 1: Screenshot von SPSS (Variable View und Syntax) ............................................................ 17 Abbildung 2: SPSS Syntax Datei mit Metadaten.................................................................................... 18 Abbildung 3: SPSS Syntax Datei mit Metadaten und Verweis auf externe Datei.................................. 18 Abbildung 4: Screenshot von SAS (Clusteranalyse) ............................................................................... 19 Abbildung 5: SAS Data File mit Metadaten ........................................................................................... 19 Abbildung 6: SAS Data File mit Metadaten und Verweis auf externe Datei ......................................... 20 Abbildung 7: Klauseln einer Abfrage in SQL .......................................................................................... 20 Abbildung 8: Beispiel einer Abfrage in T-SQL ........................................................................................ 21 Abbildung 9: Screenshot aus Microsoft Access (grafische Repräsentation einer Abfrage) .................. 22 Abbildung 10: Design Pattern Model View Controller (MVC) ............................................................... 24 VI Tabellenverzeichnis Es konnten keine Einträge für ein Abbildungsverzeichnis gefunden werden. S. 7 / 39 Stefan Schurgast VII Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Abkürzungsverzeichnis ORDBMS objektrelationales Datenbanksystem sesam Swiss Etiological Study of Adjustment and Mental Health MVC Model-View-Controller NFS S. 8 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen 1 Einleitung 3-4 Seiten 1.1 Ausgangslage und Problemstellung es gibt problem, dass viele statistiker keine informatiker sind. Aber sie wollen daten aus datenbank holen um weiterverwenden. Keine vernünftige datenbankanbindung für spss (d.h. nicht für diesen zweck). Viele randbedingungen beachten, die jedoch sonst bei export nicht beachtet werden vor allem aber psychologen Sesam: Swiss ethiological study of adjustment and mental health, Kurz erwähnen, in einleitung kurze einführung in sesam. Interdisziplinäre Langzeitstudie zur Ätiologie von psychischen Krankheiten Sesamdb: Beschäftigt sich mit Entwicklung einer Datenbank (sesamDB) und implementierung von Client-Anwendungen für sesam-Projekt. Datenbank verwaltet wissenschaftliche und administrative Daten von Sesam Daten werden in Statistiksoftware zur Analyse benötigt Problem: Benutzer jedoch keine Informatiker, also auch keine Kenntnisse über SQL, DB-Layout, etc. 1.2 Zielsetzung und Vorgehensweise Aufgabe: export plus exportlogik mit oberfläche, mit der benutzer auf einfache art und weise gewünschte exporte zusammenstellen und in gewünschten formaten in versch. Statisitkprogramme exportieren. Wer verwendet: Genetika, psychologen, … (alle benutzen andere programme, machen andere berechnungen) Benötigen andere sichten auf die daten Benötigt: Software für Export der Daten in bestimten Datenformaten, die von Statistikprogrammen unterstützt sind Anwendung für technisch nicht versierte Benutzer ohne SQL-Kenntnisse Konstruktion der Anfragen auf leicht verständliche Weise über grafische Benutzeroberfläche S. 9 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Zum Datenschutz Pseudonymisierung Bisher alles in Java, deshalb auch hier sinnvoll, natürlich auch standardvorteile von java: plattformunabhängigkeit, Verbreitung, und noch ein paar gründe Ziel: Funktionstüchtige Exportanwendung Getestet an beispielhafter Ausprägung der Datenbank (hierfür evtl. Generierung von Testdaten) Dokumentation der Anwendung (gemäss JavaStyleguide V3.0 (Berner, et al., 2002)) Installations- und Konfigurationsanleitungen, um alle erstellten Softwarekomponenten zuverlässig und leicht in Betrieb nehmen zu können 1.3 Aufbau der Arbeit Fundament mit Prozess aufgesetzt (für Kapitel 2 als Fundament und 3,4,5 als Prozess) S. 10 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen 2 Das sesam Projekt Als Grundlage für die folgenden Kapitel wird an dieser Stelle das sesam Projekt vorgestellt. Dabei wird zuerst im Kapitel 2.1 auf die Kernstudie eingegangen. Anschliessend folgt in Kapitel 2.2 eine Einführung ins Teilprojekt N, das Projekt sesamDB, zu welchem auch vorliegende Arbeit und die erstellte Exportanwendung für Statistikdaten, sesam Export Manager, angehört. Kapitel 2.3 zeigt auf, aus welchen Gründen man sich für die Haltung der Studiendaten für eine Datenbanklösung entschieden hat. In Kapitel 2.4 wird dargestellt, mit welcher Technologie die Datenbank realisiert wurde und Kapitel 2.5 beschreibt, wie die Datenbank im sesam Projekt konkret aufgebaut wurde. 2.1 Einführung in das sesam Projekt Einer Studie der WHO zur Folge sind in den Industriestaaten psychische Erkrankungen, insbesondere Depressionen, zurzeit die viert häufigste Ursache von schwerwiegenden gesundheitlichen Beeinträchtigungen oder sogar vorzeitiger Sterblichkeit. Die Tendenz zu Depressionserkrankungen ist jedoch stark steigend, warum man bereits für das Jahr 2020 damit rechnet, dass Depressionen Verkehrsunfälle als zweit häufigste Ursache verlorener Lebensjahre durch schwerer gesundheitlicher Beeinträchtigung oder vorzeitiger Sterblichkeit ablösen werden (Murray & Lopez, 1997). Derzeit liegt die durchschnittliche Wahrscheinlichkeit einer psychischen Erkrankung bei rund 40%, die Wahrscheinlichkeit im Laufe des Lebens an einer Depression zu erkranken bei 15% (Gaebel, 2007). Diese Entwicklung ist beängstigend und gibt sesam Anlass, dem entgegenzuwirken. Sesam ist gemäss sesam Schweiz eine interdisziplinäre Langzeitstudie der Universität Basel in Zusammenarbeit mit mehreren Partnerinstitutionen1 und Spitälern in der ganzen Schweiz2. Die Abkürzung steht für „Swiss Etiological Study of Adjustment and Mental Health”, zu Deutsch “Schweizerische ätiologische Studie zur psychischen Gesundheit“. Sie begleitet 3000 Kinder ab der 20. Schwangerschaftswoche zusammen mit ihren Familien (Eltern und Grosseltern) über 20 Jahre bis ins junge Erwachsenenalter. Dabei werden in der Kernstudie psychologische, genetische, umweltbedingte und soziale Faktoren betrachtet (2007). Das Ziel des Projekts ist es, die komplexen Ursachen, die zu einer gesunden psychischen Entwicklung führen, aufzudecken, wie auch Ursachen und Auslöser für psychische Störungen frühzeitig erkennen zu können. Diese gewonnenen Erkenntnisse sollen dabei helfen, wirksame Prävention sowie Behandlung und Bewältigungsstrategien bei psychischen Krankheiten und Lebenskrisen zu entwickeln (2007). 1 Zu den Partnerinstitutionen zählen: Universität Zürich, Universität Düsseldorf (D), University of Warwick (GB), Nationaler Forschungsschwerpunkt 2 Partnerspitäler sind: Frauenklinik Universitätsspital Basel, Frauenklinik Universitätsspital Zürich, Frauenklinik Inselspital Bern, Maternité Hôpitaux Universitaires Genève, Maternité CHUV Lausanne S. 11 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Zusätzlich zur Kernstudie (A) besteht sesam aus einer Reihe von weiteren Teilstudien, insgesamt 13 an der Zahl (sesam Schweiz, 2007): Teilstudie B: Risiko Reduktion Teilstudie C: Befinden in der Schwangerschaft Teilstudie D: Bedeutung der Grosseltern Teilstudie E: Schwangerschaft und psychische Störungen Teilstudie F: Neurotizismus Teilstudie G: Genetik Teilstudie H: Modell elterlicher Vernachlässigung bei nicht-menschlichen Primaten Teilstudie I: Blinzelreaktion Teilstudie J: Autobiographie Teilstudie K: Soziale Determinanten Teilstudie L: Familienprozesse Teilstudie M: Autonomes Nervensystem Teilstudie N: Entwicklung einer Datenbank (siehe sesamDB) Unterstützt wird das sesam Projekt durch den Nationalen Forschungsschwerpunkt (NFS), einem Förderungsinstrument des Schweizerischen Nationalfonds (SFN) (Schweizerischer Nationalfonds, 2005). 2.2 Teilprojekt N: sesamDB Sesam als interdisziplinäre Langzeitstudie über einen Zeitraum von 20 Jahren erzeugt eine grosse Menge an Daten, darunter Fragebögen, biologische Analysen, genetische Daten, Multimediainhalte und Sequenzdaten, die über den Zeitraum der Studie hinaus in ihrer Form wie auch in ihrer Semantik erhalten bleiben soll (Glavic & Dittrich, 2006, S. 2). Persönliche Daten über die Studienteilnehmer unterliegen ausserdem dem Datenschutz und müssen deshalb vor Datenverlust und unberechtigtem Zugriff geschützt werden. Um einem Verlust der Datenqualität durch uneinheitliche Speicherung, aber auch Sicherheitsmängel vorzubeugen, ist ein einheitliches Datenmanagement erforderlich. Ausserdem sollen für alle Formen des Datenzugriffs Client-Anwendungen erstellt werden, die so den komplexen und damit zeitaufwendigen Zugriff auf die Daten vereinfacht. Das Ziel von sesamDB ist der Entwurf und die Implementierung einer Datenbank inklusive der dazugehörigen Anwendersoftware, um die durch die Studie gesammelten wie auch administrativen Daten optimal zu verwalten und später auswerten zu können. Ausserdem sollen die eigens für sesam entwickelten Anwendungen helfen, die Abläufe während der Studie zu vereinfachen oder gar zu ganz zu automatisieren. Der Schutz der Daten wird durch ein Sicherheitskonzept sichergestellt. Der Nutzen des Teilprojekts sesamDB ist also eine starke administrative Vereinfachung der Datenhaltung sowie eine bedeutende Verbesserung der Datenqualität und Sicherheit für das Gesamtprojekt. S. 12 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen 2.3 Datenmanagement in Langzeitstudien In Langzeitstudien wird dem Datenmanagement trotz der grossen Menge anfallender Daten häufig nur ungenügend Beachtung geschenkt (Quelle hierfür suchen). Oft werden nur Personendaten in Datenbanken abgelegt, die übrigen Daten werden direkt in den betreffenden Statistikprogrammen wie beispielsweisse SPSS zur Auswertung gespeichert (auch hier Quelle nötig). Das führt dazu, dass bei dieser Art von Datenmanagement auf allen Ebenen die erwünschten ACID-Eigenschaften nicht eingehalten werden können (nochmal eine Quelle): Atomarität Eine atomare Operation ist eine Operation, die entweder ganz oder gar nicht ausgeführt wird. Datenbankmanagementsysteme verhalten sich so, als ob eine elementare Operation ausgeführt würde, die nicht durch andere Operationen unterbrochen werden könnte. Dies ist wichtig, da zur korrekten Darstellung eines Sachverhalts müssen die Daten vollständig vorhanden sein. Eine manuelle Eingabe in einem Statistikprogramm ermöglicht im Normalfall keine atomare Operation, da die auszuführenden Operationen oft nicht elementar sind. Konsistenz Nach Durchführung der Transaktion müssen wieder die inhärenten und explizit definierten Integritätsbedingungen gelten, die auch schon vor der Durchführung der Transaktion galten. Dies gilt insbesondere für Schlüssel- und Fremdschlüsselbedingungen. Durch eine Sicherung von Daten in verschiedenen Systemen findet keine Konsistenzprüfung statt. Die Daten müssen für übergreifende Auswertungen mühsam zusammengeführt werden. Insbesondere die Pflege von Stammdaten kann zum Problempunkt solcher verteilten, unorganisierten Datensysteme werden. Isolation Das Prinzip der Isolation bedeutet die Trennung von Transaktionen, sodass laufende Transaktionen sich nicht gegenseitig beeinflussen. Werden zur Sicherung der gewonnenen Daten unterschiedliche Systeme ohne oder mit nur eingeschränkter Mehrbenutzerfunktonalität verwendet, so kann auch die Isolation einer Transaktion nicht garantiert werden. SPSS beispielsweise unterstützt zwar wenige Mehrbenutzerfunktionalitäten, jedoch sind diese längst nicht so ausgeprägt, wie man sich dies von Datenbanksystemen gewohnt ist. Es fehlen: …. Kommentar [SS1]: Was fehlt SPSS an Mehrbenutzerfunktionalität? Dauerhaftigkeit Eine Transaktion ist dann dauerhaft, wenn nach einer erfolgreich abgeschlossenen Transaktion die S. 13 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Wirkung beständig bleibt. Auch nach Systemabstürzen müssen die Daten zur korrekten Wiedergabe eines Sachverhalts vollständig im System enthalten sein. Unorganisierten Datensystemen fehlen jedoch die dafür nötigen Unterstützungsprozesse. Gängige Datenbanksysteme bieten jedoch solche Funktionalität beispielsweise durch Verwendung eines Pufferpools an. Zusätzlich zu der ACID-Problematik kommen in sesamDB einige Punkte hinzu, die das Datenmanagement erschweren. Grosse Datenmengen: Eine Studie mit einer Laufzeit von 20 Jahren generiert riesige Datenmengen. Dies lässt die Frage aufkommen, wie diese gespeichert werden sollen. Würden alle Daten einfach in einzelne Dateien mit Formaten wie Excel-Arbeitsmappen abgelegt, hätte das zur Folge, dass irgendwann die maximale Grösse einer Datei erreicht wäre (in Excel z.B. die maximale Anzahl Zeilen) oder dass gewisse Formate auf neuen Systemen nicht mehr unterstützt werden. Die Daten müssten also auf mehrere Dateien aufgeteilt werden. Dies würde es stark erschweren, bei der Abfrage und Analyse einen einheitlichen Blick auf die Gesamtheit der Daten zu bekommen. Ausserdem könnten grosse Kommentar [SS2]: Hier anderes Wort dafür suchen, da es nicht eine eigentliche ACID-Problematik gibt, jedoch möchte ich noch zusätzliche Punkte aufführen. Kommentar [SS3]: Quelle für Probleme mit grossen Datenmengen Hier kommt hinzu, dass nicht nur Studiendaten, sondern auch Administrationsdaten, etc. gespeichert werden. Alles am gleichen Ort vereinfacht Datenhaltung, etc. enorm! Hierzu gehört auch Mehrsprachigkeit der Daten. Einzel aufgelistet macht das allerdings höchstens in Anforderungen Sinn. Datenmengen das System vor Performanceprobleme stellen. Durch die Verwendung einer Datenbank können die grossen Datenmengen ohne grosse Schwierigkeiten gemanaged werden. Die Menge der Daten in einer PostgreSQL-Datenbank beispielsweise ist nur begrenzt durch den Speicher, der ihr zur Verfügung steht. Ausserdem löst eine Datenbank wie PostgreSQL das Performanceproblem, indem sie Daten rasch laden kann. Zur Auswertung und Analyse wäre es sinnvoll, nur die benötigten Daten in der benötigten Granularität oder Aggregation auswählen zu können. Dies würde die Handhabung beispielsweise im Statistikprogramm erleichtern und Rechenzeiten kürzen. Langer Zeitraum Werden Daten über einen langen Zeitraum gesammelt und gesichert, müssen sie auch Jahre später noch zur Verfügung stehen. Ändern sich die IT-Systeme und werden die verwendeten Dateiformate dann nicht mehr unterstützt, so kann dies zu einem Problem werden. Werden die Daten durch ein verbreitetes Datenbankmanagementsystem verwaltet, so sollten auch Jahre danach noch Zugriffsmöglichkeiten auf die Daten bestehen. Ist der Systemquellcode offengelegt, so könnte auch hier das Risiko reduziert werden, dass das System irgendwann nicht mehr mit dem Datenbanksystem kompatibel ist. Im Notfall könnten dann Anpassungen am System durchgeführt werden. Auch für die Exportanwendungen könnte der lange Zeitraum zum Problem werden. Erstens wäre es möglich, dass die Exportanwendung irgendwann nicht mehr lauffähig wäre. Diese müsste dann auf ein neues System portiert werden. Oder aber das verwendete Format wäre nicht mehr aktuell. Da dies aufgrund der verschiedenen weiteren Verwendungszwecke eher wahrscheinlich ist, würde eine S. 14 / 39 Kommentar [SS4]: Dieser Satz schlecht geschrieben. Ausserdem fehlt die Quelle. Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Anpassung des Exportskripts ausreichen. Die Verwendung von leicht erneuerbaren Export-Plugins würde sich anbieten. Neben den technischen Herausforderungen zur Speicherung von Daten aus der Langzeitstudie, gibt es auch inhaltliche Schwierigkeiten, die sich während der Entwicklung stellen. So ändern mit Sicherheit auch viele Stammdaten (wie beispielweise der Name des Studienteilnehmers oder die Wohnadresse). Um dies repräsentieren zu können, ist es nötig, Gültigkeitszeiträume von Daten zu definieren. In sesamDB ist dies mittels des temporalen Datenbankansatzes umgesetzt worden (Quelle und Erklärung). Anonymität muss gewährleistet sein Benutzerrechtsbeschränkungen Die oben aufgezählten Anforderungen an das Datenmanagement in einer Langzeitstudie machen deutlich, dass nur ein übergreifendes Konzept unter Verwendung eines Datenbanksystems alle Bedürfnisse erfüllen kann. Andere notizen 2.4 Datenbankmanagementsystem PostgreSQL Bei PostgreSQL handelt es sich nach Angaben der PostgreSQL Global Development Group (2007) um eines der ältesten und am weitesten fortgeschrittenen objektrelationalen Datenbanksysteme (ORDBMS). Es unterstützt neben einer Reihe von eigenen Erweiterungen den SQL92 und den SQL 99 Kommentar [SS5]: Quelle und Erklärung dazu. Evtl. noch genauer darauf eingehen. Kommentar [SS6]: Passt eigentlich nicht in dieses Kapitel, mehr in Anforderungen für Exportanwendung Kommentar [SS7]: Später… Kommentar [SS8]: Jedoch keine statistische Datenbank, da dies etwas völig anderes ist. Relationale Datenbank gefragt. Kommentar [SS9]: Sub-Projekt von SESAM (sesamDB): Verantwortlich für das Design und Implementation der Datenbank sowie der Client-Anwendungen, welche für das Management der administrativen und wissenschaftlichen Daten notwendig ist. Subject data Scientific data such as questionairy, genetic data, biological analysis, aso Daten müssen zu jedem zeitpunkt nachvollziehbar sein: d.h. ein früherer Zeitpunkt der Daten in Datenbank muss auch analysiert werden können (d.h. es braucht gültigkeiten, etc.) Stammdaten ändern über verlauf der zeit (z.b. namen) Evtl. ändern auch eltern-verhältnisse zu hause, etc. Temporal database (database that Abbildung: Gesamtmodell mit Lupe Umgekehrte Pyramide als Abbildung Erst warum sinnvoll, Daten in db zu speichern Keine komplexen zugriffsregelungen: oder keine komplexeren. Man kann ja z.B. bei den von SPSS verwendeten Daten die Rechte festlegen 3) zielt eher auf Transaktionen. Als vorhersagbares Verhalten wenn mehrere Leute gleichzeitig was ändern wollen. Atomare Aktionen. Halt die ganze ACID-Schiene Welche form von datenbank Was wird in sesam verwendet Standard. PostgreSQL ist eine freie Datenbank unter der BSD-Lizenz, womit ihr Quellcode für Erweiterungen oder Verbesserungen offen steht. Sie gilt unter den lizenzkostenfreien Datenbanken als eine der stabilsten und zuverlässigsten überhaupt, ist in ihrer Grösse lediglich durch den zur Verfügung stehenden Speicher beschränkt und bietet eine hohe Transaktionssicherheit an. Im nächsten Unterkapitel 2.4.1 folgt eine Übersicht über die Möglichkeiten zu Typhierarchien und Vererbung, in Kapitel 2.4.2 dann eine Einführung in Triggern und Regeln, wie sie in sesamDB verwendet wurden. 2.4.1 - Typhierarchien und Vererbung Wie funktioniert vererbung in ordbms Typenhierarchien mit beispiel person und employee, kind, mutter, grossvater, mit abbildung Kommentar [SS10]: Die Vorteile von PostgreSQL PostgreSQL bietet gegenüber anderen Datenbanksystemen viele Vorteile für Ihre Firma oder Ihr Geschäft: Schutz vor Over-Deployment Over-deployment, das Benutzen von mehr Datenbank Instanzen als lizensiert wurden, wird von einigen Anbietern kommerzieller Datenbanksysteme als das Hauptproblem bei der Einhaltung der Lizenzbedingungen genannt. Mit PostgreSQL kann Sie niemand deswegen belangen, weil keine Lizenzgebühren für die Software erhoben werden. Dies hat mehrere zusätzliche Vorteile: •Profitablere Geschäftsmodelle in weitgefächerten Einsatzgebieten. •Es gibt keine Möglichkeiten, irgendwann wegen der Einhaltung ... der[1] Kommentar [SS11]: Genauer erklären und Quellen finden Kommentar [SS12]: ergänzen S. 15 / 39 Stefan Schurgast 2.2.1 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Trigger und Regeln Ausserdem kann in PostgreSQL Gebrauch von Triggern und eigens definierten Regeln gemacht werden. - Triggerbeispiel: bei neueinfügung eines datensatzes wird alter datensatz verschoben in _oldTabelle _all ist = _new UNION _old 2.5 Sesam Datenbank Die sesam-Datenbank (sesamDB) ist eine speziell für das sesam-Projekt zugeschnittene PostgreSQLDatenbank. - - Kommentar [SS13]: Nicht zugeschnitten, es läuft einfach auf PostgreSQL Layout (Schema) -> siehe Anhang PostgreSQL (vererbung, deshalb schwieriger, warum was wie gelöst.) nur so viel wie für verständnis notwenig Keine statistische Datenbank (probability database): Statistische datenbanken. Vom pronzip her andes, da daten eine gewisse wahrscheinlichkeit haben, wahr zu sein. Aber das passt nich zu unserem thema. Da wir von anfang an noch keine wahrscheinlichkeit haben für die daten. Das gibt’s schon, aber es ist was anderes…. Deshalb ausschliessen (probailtiy datenbanken). Keine wahrscheinlichkeit sondern nur menge von fällen und statisiche auswertungen drau Datenbankinhalte Was bedeutet das für meine arbeit Hier sollte ich doch stark auf das Schema und auf den Aufbau der Datenbank eingehen. Also was bedeutet DataItemClass, was ist ExperimentClass, etc. S. 16 / 39 Kommentar [SS14]: Sehr wichtig für weiteres Verständtnis Stefan Schurgast 3 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Verwandte Arbeiten 3.1 Gängige Statistiksoftware und assoziierte Datenformate Mit aktueller Statistiksoftware ist es möglich, mit rechenintensiven Methoden grosse Datenmengen zu analysieren und statistisch auszuwerten. Die Auswahl an Statistikprogrammen ist riesig. Einige Programme wie SPSS und SAS sind inzwischen sehr weit verbreitet eingesetzt und somit zum QuasiStandard geworden. Weitere häufig verwendete Statistikpakete sind STATA und R, auf diese wird jedoch an dieser Stelle nicht weiter eingegangen. Im Folgenden wird zur Übersicht kurz auf die Statistiksoftware SPSS und SAS eingegangen und dabei auch die mit ihr assoziierten Datenformate vorgestellt. Zwar können alle erwähnten Programme Standardformate wie Excel-Arbeitsmappen, Access-Datenbanken oder CSV (Comma Separated Values) lesen, jedoch unterstützen diese Formate keine oder zu wenig Metainformationen über die Daten. Alle erwähnten Statistikprogramme werden als „Stand-Alone“ Anwendungen auf einem einzelnen Arbeitsplatz (PC oder Notebook) installiert und verwendet. Somit arbeitet der Benutzer jeweils selbständig mit seinen Daten. … Kommentar [SS15]: Sagen, was das für sesam heisst 3.1.1 Besonderes Augenmerk wird SPSS geschenkt, da es sich dabei um die meist verwendete Statistiksoftware im sesam Projekt handelt. SPSS SPSS (siehe Abbildung 1) aus dem gleichnamigen Softwarehaus steht für Statistical Product and Service Solution und ist im Jahr 2007 in der Version 16 auf den Markt gekommen. Sie wurde in Java implementiert und ist deshalb auf Windows, Mac OS X wie auch Linux in der gleichen Version verfügbar. Bei SPSS handelt es sich um ein modular aufgebautes Programmpaket zur statistischen Datenanalyse und beinhaltet im Basismodul das grundlegende Datenmanagement sowie häufig verwendete statistische und grafische Datenanalysen. Über dies verfügt SPSS über eine Vielzahl weiterer Funktionen und Zusatzapplikationen wie OLAP, Data Mining und viele mehr. … Kommentar [SS16]: Haupteinsatzort erwähnen Abbildung 1: Screenshot von SPSS (Variable View und Syntax) S. 17 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Das in SPSS standardmässig verwendete Datenformat ist .SAV und steht für SPSS Datensatz. Allerdings sind SAV-Dateien im Binärformat erstellt und somit nur mit dem System lesbar, welches die Datei auch erstellt hat, wie z.B. Windows. Müssen die Daten aber auch auf einem anderen System wie UNIX lesbar sein, so muss die Datei in das portable Format .POR konvertiert werden. Das .POR Format ist zwar in ASCII geschrieben und kann somit problemlos von System zu System portiert werden. Ein Blick in die Datei mit Hilfe eines Editors macht allerdings rasch deutlich, dass dieses Format nicht einfach so intuitiv verstanden werden kann. Einfacher als .POR Dateien sind Syntax-Dateien (.SPS) zu verstehen (siehe auch kleines Fenster in Abbildung 1). Auch Variablen- und Wertebeschriftungen sowie weitere Variableneigenschaften können einfach hinzugefügt werden. Das Format unterstützt sowohl fixe Kolonnenbreiten wie auch Unterteilung durch Deliminiter. Zusätzlich können auch Gültigkeitsbereiche eingesetzt werden. Das folgende Beispiel zeigt auf, wie in der Syntax-Datei erst die Datei selbst, danach das Aufzählungsformat und die Variablen definiert werden. Anschliessend folgen die eigentlichen Daten (Levesque, 2006, S. 38). *testfile_20071211_094000.sps. DATA LIST LIST ("; ") /spss_export_row_id (F8) sid (a255) d1_data_item_id (F8). BEGIN DATA 1; 1; 10 2; 1; 8 3; 4; 6 END DATA. Abbildung 2: SPSS Syntax Datei mit Metadaten Eine weitere Möglichkeit ist das Aufsplitten von Daten und Metainformationen über die Daten in je unterschiedliche Dateien (Levesque, 2006, S. 40). *delimited_list.sps. DATA LIST LIST FILE='c:\examples\data\delimited_list.txt' /id(F3) sex (A1) age opinion1 TO opinion5 (6F1). EXECUTE. Abbildung 3: SPSS Syntax Datei mit Metadaten und Verweis auf externe Datei 3.1.2 SAS SAS vom amerikanischen Softwarehersteller SAS Institute ist ein Programmpaket, das ursprünglich für statistische Auswertungen entwickelt worden ist. SAS steht für Statistical Analysis Systems. Inzwischen wurde es jedoch stark ausgebaut und verfügt über viele andere Funktionen wie die Datenerfassung, die Datenhaltung, aber auch weitere Auswertungsmethoden wie Data Mining. Dank der langjährigen Kontinuität hat sich SAS vor allem im Pharma-Bereich zum Standardprodukt für die S. 18 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Auswertung klinischer Studiendaten entwickelt. SAS ist sowohl für Windows wie auch UNIX und IBM z/OS verfügbar (SAS Institut, 2007). Abbildung 4: Screenshot von SAS (Clusteranalyse) SAS verwendet als proprietäres Dateiformat SAS Tabellen (SAS data file). Ähnlich wie das SPSSFormat unterstützen SAS-Tabellen auch Metainformationen zu Daten. Auch SAS benutzt zum Einlesen von Daten eine Form von Syntax-Datei. Darin wird im Header erst die Datenmenge mit Namen und Variablenbezeichnungen beschrieben. Anschliessend folgen die eigentlichen Daten entweder in fixer Breite oder delimitiert durch ein beliebiges Zeichen (standardmässig mit einem Leerzeichen) (UCLA Academic Technology Services, 2007). DATA cars; INPUT make $ 1-5 model $ 6-12 mpg 13-14 weight 15-18 price 19-22; CARDS; AMC Concord2229304099 AMC Pacer 1733504749 AMC Spirit 2226403799 BuickCentury2032504816 BuickElectra1540807827 ; RUN; Abbildung 5: SAS Data File mit Metadaten Zusätzlich bietet sich die Möglichkeit an, Daten und Metainformationen in einzelne Dateien zu unterteilen. Im folgenden Beispiel werden nur die Metainformationen gespeichert. Die eigentlichen Daten befinden sich in der Datei cars.dat (UCLA Academic Technology Services, 2007). DATA cars; S. 19 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen INFILE ‘D:\data\cars.dat'; INPUT make $ 1-5 model $ 6-12 mpg 13-14 weight 15-18 price 19-22; RUN; Abbildung 6: SAS Data File mit Metadaten und Verweis auf externe Datei … Kommentar [SS17]: Was bedeutet das für meine arbeit Welche möglichkeiten für outputdesigns hat man, wieviel kann man im … definieren? 3.2 Datenexport in Statistikprogramme … 3.2.1 3.2.2 - Exportanwendungen für allgemeine Datenbanken Microsoft Query Probleme dabei, warum geht das nicht immer (viel zu allgemein, ) Geht nicht (überleitung) Exportanwendungen in Statistikformate Warum genau dieses Format (*.sps) in SPSS gewählt (weil nicht binär und weil einfach zu generieren, übersichtlich und Daten können gut beschrieben werden) nichts bestehendes (anforderung) 3.3 Repräsentation von Abfragen für den Benutzer 3.3.1 Repräsentation in Skriptform Die Standardabfragesprache im Bereich Datenbanken ist ohne Zweifel SQL3. Mit ihr können Kommentar [SS18]: Warum exportanwendung: -da gibst dann folgende Probleme. Bei einem komplexen Schema wie bei sesam machen nur bestimmte Datenkombinationen sinn, aus denen der User über ein intuitives Interface welche auswählen können soll. Selbst wenn man alla Acess Queries zusammenstellen kann wird der Nutzer nicht gewarnt wenn er mist auswählt. Außerdem bietet deine Anwendung die Möglichkeit Exporte zu dokumentieren und wiederzuverwenden. wobei man aufgrund der History mehr Möglichkeiten hat, die sonst der Nutzer selber über Queries lösen können müsste und du weißt ja aus eigener Erfahrung das da selbst für simple Anwendungen halbwegs komplizierte Queries rauskommen ;) -oki ja.. ich nimm auch an, dass die daten dann in spss lokal gespeichert werden und nicht einfach nur ein link bestehen würde. somit gibt es auch keinen mehrwert in dem sinn.. -[15:54:27] Boris Glavic says: genau, daran wird ja dann beliebig rumgeschraubt (nach der Maßregeln mit der selbstgefälschten Statistik ;-außerdem kann man so überall damit rechnen, bei sesam wichtig da die Datenbank nur lokal erreichbar ist) Datenbanken auf Inhalte durchsucht und diese dann ausgegeben werden. Die Syntax ist einfach, und semantisch ist SQL sehr nah an die englische Umgangssprache angelehnt. Eine Abfrage kann aus bis zu sechs Klauseln bestehen, wobei folgende Reihenfolge eingehalten werden muss und nur SELECT und FROM zwingend sind: SELECT <Attribut- und Funktionsliste> FROM <Tabellenliste> [WHERE <Bedingung>] [GROUP BY <Gruppierungsattribute>] [HAVING <Gruppenbedingungen>] [ORDER BY <Attributliste>] Abbildung 7: Klauseln einer Abfrage in SQL 3 SQL ist eine Datenbanksprache zur Definition, Abfrage und Manipulation von Daten. Für den hier verfolgten Zweck ist jedoch nur das SELECT-Statement von Bedeutung. S. 20 / 39 Kommentar [SS19]: Quelle suchen Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Im Folgenden werden nur auf die für diese Arbeit relevanten Anweisungen eingegangen. SQL selbst bietet jedoch weit umfangreichere Möglichkeiten. Abfragen werden in SQL durch die Anweisung „SELECT“ gestartet (siehe Abbildung 8). Ihr folgt eine Kommentar [SS20]: Schöner schreiben Liste mit Attributnamen, deren Werte mit der Ausführung der Abfrage aus der Datenbank gelesen werden. Um alle verfügbaren Attribute zu ermitteln, wird ein Stern (*) verwendet. Neben den vorhandenen Attributen können auch weitere abgeleitete oder eigendefinierte Attribute erzeugt werden (Elmasri & Navathe, 2005, S. 190). Hierzu werden Werte oder Operationen (z.B. Produkte oder Aggregationen wie SUM oder MAX) durch die Verwendung des Statements „AS“ in einem neu benannten Attribut dargestellt (Elmasri & Navathe, 2005, S. 192). SELECT [Erweitertes Personal].Mitarbeitername, [Erweiterte Kunden].Kontaktperson, Verkaufschancen.Mitarbeiter AS [Zugewiesen an], Verkaufschancen.[Gesch Abschlussdatum], [Gesch Einnahmen]*[Wahrscheinlichkeit] AS Prognosewert FROM (Verkaufschancen LEFT JOIN [Erweiterte Kunden] ON Verkaufschancen.[Kunde/Kundin] = [Erweiterte Kunden].ID) LEFT JOIN [Erweitertes Personal] ON Verkaufschancen.[Mitarbeiter] = [Erweitertes Personal].ID WHERE ((Verkaufschancen.Geschlossen)<>True); Abbildung 8: Beispiel einer Abfrage in T-SQL Das „FROM“-Statement dient dazu, die Quelle der Daten zu definieren. Ihm folgt eine Liste mit Relationsnamen, auf die für die Ausführung der Abfrage zugegriffen wird. Dies können Tabellen- oder Abfragenamen sein, aber auch selbst wiederum vollständige Abfragen (Elmasri & Navathe, 2005, S. 198). Mittels Komma abgetrennte Quellen werden als kartesisches Produkt4 aufgerufen, die Anweisung „JOIN“ bildet einen Verbund. Kommentar [SS21]: Fussnote ergänzen! Im „WHERE“-Statement werden die Tupel eingeschränkt. Dabei handelt es sich um Bedingungen in Form eines boolschen Ausdrucks, unter der.denen die Daten ausgegeben werden sollen (Elmasri & Navathe, 2005, S. 193). Weitere Möglichkeiten bieten Mengenoperatoren, mit denen die Abfragen um eine Anzahl Tubel erweitert oder gekürzt werden kann. Hierzu gehören unter anderem UNION (vereint zwei Abfragen miteinander) und INTERSECT (bildet Schnittmenge). Für den nicht erfahrenen Computerbenutzer ist jedoch diese Art von Datenbankabfrage viel zu schwierig, braucht es doch Erfahrung, um komplexe Abfragen über mehrere Tabellen durchführen zu können. Ausserdem fehlen dem Benutzer die Informationen über den Datenbankaufbau. Geeigneter wäre also eine grafische Repräsentation der vorhandenen Elemente, die er sich wie gewünscht aneinanderreihen könnte. 4 Kommentar [SS22]: Quelle hierzu ????????????????????????? S. 21 / 39 Stefan Schurgast 3.3.2 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Grafische Repräsentation Gewisse Datenbankmanagementsysteme bieten wie beispielsweise Microsoft Access ein grafisches Front-End an (siehe Abbildung 9). Sie ermöglichen dem Benutzer, sich ohne Kenntnisse über den Aufbau der Datenbank oder über eine Datenbanksprache, Abfragen zu erstellen. Abbildung 9: Screenshot aus Microsoft Access (grafische Repräsentation einer Abfrage) Dies gilt natürlich nur solange, wie nicht zu viele Auswahlmöglichkeiten zur Verfügung stehen und diese eindeutig und übersichtlich benannte sind. In grossen Datenbanken mit hunderten von Tabellen jedoch wird auch dies rasch unübersichtlich. Der Benutzer kann sich nicht mehr zurecht finden. Häufig benötigt der Benutzer auch nicht die gesamte Datenmenge einer Datenbank, wie einzelne Attribute, z.B. die letzte Änderung einer Tabelle. Die Daten müssen also für den ungeübten Benutzer ohne das Dazulernen von Konzepten oder Sprachen abrufbar sein. Da aber keines dieser beiden eben vorgestellten Konzepte die Anforderungen eines Benutzers der sesamDB genügen würde, ist hier eine eigene, individuelle Umsetzung nötig. 3.4 Anonymität und Pseudonymität Für die Auswertung medizinischer Daten für Forschungszwecke ist ein direkter Personenbezug nicht nötig. Damit verschiedene Daten verschiedene Daten eines Falls zusammengeführt oder neu erhoben werden können, werden Personenangaben jedoch trotzdem oft mitgeführt (Pommerening, 2000, S. 1). Gemäss Art. 19a des Datenschutzgesetzes müssen Personendaten jedoch Personendaten für statistische Auswertungen jedoch anonymisiert werden, sobald dies der Verwendungszweck erlaubt (Bundesstatistikgesetz, 2007). Unter Anonymität versteht man gemäss dem Deutsche Wörterbuch Wahrig definiert Anonymität als „Verschweigung, Nichtangabe des Namens“ (Wahrig, 1997). Somit ist Anonymität im Falle von statistischen Auswertungen die Geheimhaltung der Identität einer Person. Dies umzusetzen ist jedoch im Alltag beinahe unmöglich, können doch einzelne Angaben über eine Person ihre Identität aufdecken (wie z.B. der Schweizerischer Bundesrat, abgewählt am 12. Dezember 2007). Somit ist S. 22 / 39 Kommentar [SS23]: Quelle hierzu Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen gemäss Rost der Grad der Anonymität zentral, also inwiefern es möglich ist, aufgrund von Einzelattributen auf eine Identität zu schliessen. Je nach Grad der Anonymität entscheidet man in der Statistik folgende drei Stufen (2003): Formale Anonymität: Alle Namen sind zwar entfernt, die anderen Daten bleiben jedoch unverändert bestehen. Die Daten können relativ leicht einer Identität zugeordnet werden. Faktische Anonymität: Die Daten sind nur mit unverhältnismässig grossem Aufwand zuordenbar. Komplett Anonym: Die Zuordnung zu einer Identität ist nicht möglich. Zu veröffentlichende Statistikdaten sind wie oben bereits festgehalten so weit wie möglich zu anonymisieren, d.h. die personenbezogenen Daten müssen soweit verändert werden, dass sie nicht mehr einer Person zugeordnet werden können. Eine einfache Möglichkeit dazu ist die Pseudonymisierung. Bei der Pseudonymisierung wird gemäss Pfitzmann das Identifikationsmerkmal (in der Regel ein Name) durch ein Pseudonym5 ersetzt (2004, S. 9). Auf diese Wiese soll der Nachweis der Personenbezug so verschleiert werden, dass faktische Anonymität entsteht. Die Pseudonymisierung hat jedoch den Vorteil, dass Bezüge verschiedener Datensätze, die auf die gleiche Weise pseudonymisiert wurden, erhalten bleiben. Je nach Art der Erzeugung der Pseudonyme können hier nach Pommerening unterschiedliche Typen definiert werden (2000, S. 1): Deterministische Pseudonyme: Die Erzeugung des Pseudonyms erfolgt über eine schlüsselabhängige Hashfunktion aus Identitätsdaten durch eine vertrauenswürdige Instanz. Willkürliche Pseudonyme: Der Benutzer erzeugt ein Pseudonym in einem Einmal-Algorithmus aus einem Geheimnis, wie beispielsweise einer Passphrase. Zufällige Pseudonyme Das Pseudonym wird zufällig mittels eines Zufallsverfahrens erzeugt oder wird frei gewählt. Auf diese Weise erzeugte Pseudonyme eignen sich für den einmaligen Gebrauch, wie zur Zusammenführung verschiedener Datenquellen zu Statistikzwecken. Sonst macht sie nur Sinn, wenn sie in einer Referenzliste gespeichert wird. Je nach Anwendungsgebiet ist die geeignete Form von Pseudonymen zu wählen. Die Einführung von Pseudonymen ist ein Kompromiss zwischen der Weiterverwendbarkeit von Daten und datenschutzrechtlichen Überlegungen. Kryptische Pseudonyme stellen somit „eine Grundtechnik 5 Ein Pseudonym ist gemäss dem Deutschen Wörterbuch Wahrig ein Deckname für eine Entität (Wahrig, 1997). S. 23 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen des praktischen Datenschutzes dar“, so Pommerening (2000) und sollten deshalb „wo immer möglich eingesetzt werden“. 3.5 Aufbau von modellbasierten Anwendungen Das Architekturmuster Model-View-Controller (MVC) dient dazu, Softwaresysteme in drei Einheiten, nämlich das Model (Datenmodell), die View (Präsentation) sowie den Controller Kommentar [SS24]: Wer hats erfunden? Quelle (Programmsteuerung) aufzuteilen (siehe Abbildung 10). Abbildung 10: Design Pattern Model View Controller (MVC) Das Modell repräsentiert laut Middendorfer et al. die darzustellenden Daten sowie die Geschäftslogik. Die Daten werden unabhängig vom Erscheinungsbild bereitgestellt. Die Präsentation dient zur Programmsteuerung durch den Benutzer und nimmt stellt Inhalte für ihn dar. Durch die Unabhängigkeit der Präsentation ist es meist relativ einfach möglich, weitere Benutzeroberflächen wie beispielsweise eine GUI sowie eine Konsolenbedienung zu erstellen. Die Einheit Controller ist die eigentliche Programmsteuerung. Sie nimmt Benutzeranweisungen entgegen und agiert entsprechend. Der Vorteil einer Aufteilung in diese drei Einheiten liegt vor allem in der Wiederverwendbarkeit einzelner Programmkomponenten und vereinfacht Programmerweiterungen und Änderungen (Middendorf, Singer, & Heid, 2002). .. Kommentar [SS25]: Evtl. an dieser Stelle auf Importmanager oder so eingehen. S. 24 / 39 Stefan Schurgast 4 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Analyse der Anforderungen an Sesam Export Manager … In diesem Kapitel werden die Anforderungen an die zu entwickelnde Exportanwendung, Sesam Export Manager, detailliert dokumentiert werden. Die Aufgabenstellung der Bachelorarbeit gibt zwar hier einen groben Rahmen vor, konkretisiert wurden die Spezifikationen jedoch in mehreren ausführlichen Gesprächen mit meinem Betreuer Boris Galvic6. Das Hauptziel der Anwendung ist es, Daten der sesam Datenbank so zu extrahieren, dass diese in ein gängiges Statistikprogramm eingelesen werden können. Kommentar [SS26]: Kurzer Einblick ins Kapitel und Übersicht Was gibt’s für Möglichkeiten, das zu machen? Anforderungen (Benutzer bedienen, flexibel, versch. Statistikprogramme, Beispiele) Entscheidungen mit bezug auf related work und Anforderungen (alternativen und daraus einen auswählen aus diesen Gründen, da deshalb besser (evtl. besser oder einfacher, etc.) 6 Seiten Der gesamte Prozess kann dabei in drei Teile unterteilt werden. Präsentation der Auswahlmöglichkeiten für den Benutzer (Kapitel 4.1) Import der Daten aus der Datenbank nach Sesam Export Manager (Kapitel 4.2) Schreiben der Daten im Statistikformat (Kapitel 4.3) Kommentar [SS27]: Anstatt Aufzählung, Verwendung der Grafik. Allerdings noch anpassen! Abbildung 11: Datenfluss in Sesam Export Manager 4.1 Präsentation der Auswahlmöglichkeiten Um dem Benutzer die Möglichkeit zu geben, Daten aus einer Datenbank auszulesen, muss dieser erst wissen, welche Daten verfügbar sind. Dem Anwender, meist Psychologen und Soziologen, jedoch auch Mediziner, Biologen, etc., kann allerdings nicht zugetraut werden, sich mit SQL auszukennen, geschweige denn das Datenbankschema zu verstehen. Der komplizierte Aufbau der Datenbank mit Vererbung erschwert ausserdem das Zurechtfinden in den Datenbankinhalten weiter. Des Weiteren sollen auch aus Gründen des Datenschutzes gewisse Aspekte gegen aussen verborgen bleiben. Damit der Benutzer trotzdem für seine Bedürfnisse sinnvolle Abfragen erstellen kann, muss er dabei vom Programm geführt werden. Ein Standard-Datenbankabfrageprogramm kommt aus diesen Gründen nicht in Frage, es bedarf einer für diesen Zweck spezialisierten Anwendung. Ein Beispiel soll dies verdeutlichen: Der Benutzer möchte die Ergebnisse des CIDI7-Interviews mit Müttern, die zum Zeitpunkt des Interviews in der 20. Schwangerschaftswoche waren, erhalten. 6 Boris Glavic ist Assistent in der Database Technology Research Group am IFI (Institut für Informatik der Universität Zürich) und ist bei sesamDB Project Leader. 7 Noch rasch erklären, was das für ein Test ist…………………………..??????????????????????????? S. 25 / 39 Kommentar [SS28]: Datenquelle wählen Kommentar [SS29]: Anforderungen an Bedienbarkeit der Anwendung Die beteiligten Forscher und Forscherinnen kommen aus der Psychologie, Soziologie, Epidemiologie, Familienforschung, Gynäkologie, Geburtshilfe, Kinder- und Jugendpsychiatrie, Psychiatrie, Genetik, Psychobiologie, Pharmakologie, Biologie, Anthropologie und anderen Disziplinen. Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Dem Benutzer muss also präsentiert werden, welche Tests zur Verfügung stehen (CIDI-Fragebogen), um welches Experiment es sich dabei handelt (CIDI Fragebogen ausfüllen), welcher ProzessOutput dabei genau benötigt wird (Resultate des ausgefüllten Tests) und schlussendlich wer den Fragebogen ausgefüllt hat (die Mutter). Über dies wird eine Bedingung benötigt, die alle Ergebnisse der Abfrage auf Mütter der 20. Schwangerschaftswoche einschränkt. Ein etwas komplizierteres Beispiel ist die Frage nach den Resultaten eines Bluttests der Mutter in einem Stress-Experiment mit mehreren Bluttests, wie beispielsweise einem Bluttest vor und einem nach dem Stresstest (siehe Abbildung 12). In diesem Beispiel wird der Wert vor dem Stresstest gesucht. Abbildung 12: Bluttest vor und nach Stresstest In diesem Fall muss die Art der Probe (also Bluttest der Mutter vor einem Stresstest), das Experiment (Stress-Test), der Prozess-Output (Blutwert) sowie der Proband (Mutter) angegeben werden. Zusätzlich muss der Workflow Node (Bluttest vor dem Stresstest) definiert werden, d.h. an welcher Stelle des Experiments der Test erfolgt. Abfragen können beliebig kompliziert werden, indem beispielsweise mehrere verschiedene Probanden (Mütter und Väter) ausgewählt, weitere Bedingungen (z.B. nur Probanden aus Basel) hinzugefügt oder gar mehrere Datenobjekte (Blutwert von Adrenalin und Körpertemperatur) verknüpft (z.B. als JOIN) ausgewertet werden müssen. Um den Benutzer der Exportapplikation nicht zu überfordern, muss deshalb abgeschätzt werden, nach welchen Datenobjekten er am ehesten suchen wird. Die meist benutzte Funktion wird gemäss Gespräch mit Boris Glavic die Suche nach Ergebnissen aus Experimenten sein. Aus diesem Grund wird ihr die höchste Priorität zugemessen. Weitere mögliche Suchstrategien sind die Suche nach Probanden (z.B. zum Vergleich einzelner Testwerte) oder nach Instrument (z.B. zum Vergleich der Testgenauigkeit). Die Auswahl der für die Suche benötigten Angaben sollte, um den Benutzer nicht mit Abfragesprachen oder Datenbankaufbau zu belasten, mittels einer für seine Zwecke zugeschnittenen, gut strukturierten grafischen Benutzeroberfläche erfolgen. Aus den obigen Beispielen folgt, dass unten stehende Auswahlkriterien in der grafischen Benutzeroberfläche vorhanden sein müssen: DataItemClass ExperimentClass ProcessOutput ExperimentWorkflowNode Kommentar [SS30]: Klassen kurz erklären (Seitens sesamDB) S. 26 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen SubjectPriorityPath Zusätzlich müssen weitere Datenobjekte ausgewählt werden können. zu oben gehört noch… Kommentar [SS31]: Ein weiteres Anwendungsbeispiel ist das Abrufen von Daten zu einem früheren Zeitpunkt. Dies findet häufige dann Verwendung, wenn beispielsweise Papers veröffentlicht und erst danach Daten korrigiert werden. Wird nun von Reviewern eine Ausweitung der Studie auf weitere Attribute erwartet, so ist dies nicht mehr möglich, da die Datengrundlage geändert hat. Bei sesamDB handelt es sich jedoch um eine bitemporale (wie in Kapitel………….) Datenbank, d.h. die Daten sind für jeden Zeitpunkt verfügbar. Somit kann dies relativ einfach umgesetzt werden. Hat der Anwender schon einige Abfragen erstellt, so ist er vielleicht daran interessiert, diese zu Irgendwo sollte noch das Datenbankschema kurz erklärt werden, damit ich dann zeigen kann, warum man so viel auf GUI auswählen muss, um Daten zu bekommen. Experiment: Bei einem Experiment handelt es sich um eine Messung eines Sachverhalts für einen bestimmten Zweck zu einer bestimmten Zeit an einem bestimmten Ort. Umfang der Abfrage beinhaltet. Prozess: Ein Prozess ist ein Ablauf von Aktivitäten zur Veränderung oder Erzeugung von Datenobjekten. Darin können Personen involviert sein und Instrumente sowie Hilfsmaterial verwendet werden. Ein Prozess besitzt immer einen Input und einen Output. 4.2 Import der Daten aus der Datenbank nach Sesam Export Manager Datenobjekt: Dateobjekte (DataItems) sind Outputdaten aus Prozessen. Sie repräsentieren Ergebnisse aus beispielsweise Fragebögen, Messungen oder Beobachtungen. speichern und bestehende Abfragen wiederzuverwenden oder zu modifizieren. Fertige Abfragen sollten deshalb gespeichert und als Datei abgelegt, wie auch wieder ins Programm geladen werden können. Die Anwendung sollte demnach eine Historisierung anbieten, welche den Zeitpunkt und den Die durch den Benutzer über das GUI festgelegten Abfrageparameter bilden im nächsten Schritt die Grundlage für die Generierung des entsprechenden Abfragestatements. Dieses soll genau die Daten zurückgeben, die der Benutzer aufgrund seiner Auswahl erwartet. Kommentar [SS32]: Noch was dazu schreiben in verwandte arbeiten 4.3 Schreiben der Daten im Statistikformat Nachdem die Daten in Sesam Export Manager vorhanden sind, müssen diese in eine Datei im benötigten Format geschrieben werden. Als geeignetes Format für Statistikdaten hat sich in einem ersten Schritt das SPSS Syntax File herauskristallisiert. In Kapitel 3.1.1 wurde dieses Format bereits genauer diskutiert. Sesam Export Manager sollte jedoch in der Lage sein, relativ einfach um weitere Exportformate erweitert zu werden. Diese sollte der Benutzer auf der grafischen Oberfläche auswählen können. Der Umfang der zu exportierenden Daten soll sich allerdings nicht nur auf die effektiven Messdaten beschränken, sondern sollte auch auf die dazugehörigen Metadaten beinhalten. Diese beinhalten: Irgendwann, wenn ich wieder schreiben mag Variablennamen (Name der zu exportierenden Spalte) Datentyp (z.B. Integer, Text, Datum, etc.) Variablenbeschriftung (Beschreibung der Variablen) Weitere sinnvolle Parameter sind: S. 27 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Skalentypen Wertebeschriftungen Um ein ausreichendes Mass an Datenschutz gewährleisten zu können, müssen alle personenspezifischen Daten vor dem Export in die Datei pseudonymisiert werden. Kommentar [SS33]: Evtl. darauf noch rasch eingehen. Testen ist auch eine anforderung Kommentar [SS34]: Weitere anforderung gefunden Allgemein gibt es auch anforderungen nicht für jetzt, sondern für die zukunft: also einfache erweiterbarkeit für neue exportformate oder wenn db-struktur ändert Installationsanweisung Dokumentation der anwendung (im code und für benutzer) Ausgehend von sesamDB (siehe evtl. auch ERM mit 6 Kategorien, entwickelt unter unizh mit beteiligung uni basel, evtl. kurz jede kategorie erklären (2 sätze)) - Vorgesehen: Benutzerlogin, Datenbank auswählen (mit diesen Zwischenspeichern), Pluginauswahl Hier fehlt noch Zusammenfassung als Prioritätsliste Kommentar [SS35]: Fehlt noch was Falls Zeit, noch use cases wie in skript von glinz Kommentar [SS36]: Glinz: use cases oder uml buch fowler S. 28 / 39 Stefan Schurgast 5 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Entwurf und Umsetzung des Sesam Export Managers 15 Seiten Habe ich besonderes Vorgehensmodell (z.b. wachstumsmodell) gewählt? 5.1 Aufbau der Anwendung Dieses Kapitel beschreibt in den folgenden vier Teilkapiteln den Aufbau von Sesam Export Manager. Im Kapitel 5.1.1 wird aufgezeigt, aus welchen Komponenten die Applikation besteht, für was die einzelnen Komponenten zuständig sind, wie sie zusammenspielen und warum sie so umgesetzt werden. Das Kapitel 5.1.2 enthält einen Detailentwurf zu einzelnen Kernkomponenten. Diese werden im Detail analysiert. Damit wird der bewusst abstrakt gehaltene Teil über den konzeptionellen Aufbau verfeinert. In Kapitel 5.1.3 werden die zur Umsetzung benötigten Hilfsmittel wie beispielsweise die Datenbankschnittstellenkomponente diskutiert sowie deren Vor- und Nachteile abgewogen. Im letzten Teilkapitel 5.1.4 folgen einige Testdefinitionen, welche die Funktionsfähigkeit von Sesam Export prüfen sollen. 5.1.1 konzeptioneller Aufbau Sesam Export Manager ……………. Abbildung verbessern. Man sieht da gar nicht, was passiert und was das alles bedeutet. Irgendwie Ablauf aufzeigen. Dieser Abschnitt beschreibt den konzeptionellen Aufbau der Anwendung dar. Dazu wird in einem ersten Teil ein Gesamtüberblick über die verwendete Architektur gegeben, danach werden die einzelnen Schichten genauer erläutert sowie die darin enthaltenen Komponenten diskutiert. Sesam Export Manager ist als Einzelplatzanwendung aufgebaut, das heisst, sie kann auf einem Einzelplatzrechner installiert und ausgeführt werden. Dies ist sinnvoll, weil sich die Datenbank geschützt und gegen aussen abgeschlossen in der Sesam Zentralstelle befindet. Ein Zugriff über Internet ist also nicht möglich, sondern die Daten können nur vor Ort an einer an die sesamDB angeschlossene Arbeitsstation abgerufen werden. Wäre die Datenbank durch das Internet erreichbar, so würde sich eine Webanwendung eignen. Allerdings würde dies zu einem erhöhten Wartungsaufwand führen, da zusätzlich ein Webserver nötig wäre und bedeutend höhere Sicherheitsvorkehrungen getroffen werden müssten. Nachteilig wirkt sich dagegen die Versionsverwaltung für die Einzelplatzanwendung aus, da jede installierte Version einzeln bei einem neuen Release auf den neusten Stand gebracht werden muss. Eine weitere Möglichkeit wäre die Umsetzung als Erweiterung für eine bereits vorhandene Statistikanwendung. Dies würde es zwar für den Benutzer der einzelnen Statistikanwendung komfortabel gestalten, Daten zu importieren, hätte jedoch auch einige Nachteile. Zum einen müsste für jede Statistikanwendung eine eigene Erweiterung geschrieben werden, was einen enormen Aufwand bedeuten würde. Aufgrund mangelnder Schnittstellen wäre dies jedoch sicherlich nicht überall möglich und die Exporte würden sich auf wenige Statistikformate beschränken, was wiederum den Anforderungen an die zu wählende Lösung wiederspricht. S. 29 / 39 Kommentar [SS37]: bei der Anzahl von Clients die in dem lokalen Netzwerk möglich sind ist Überwiegen die nachteile der Clientanwendungen [13:53:55] Boris Glavic says: zusätzlich bräuchte man aus Performancegründen eventuell einen weiteren Server [13:54:55] Boris Glavic says: außerdem gibt es für die sesam-Anwendungen einen JavaUpdater, der als GUI zum Updaten von Programmen benutzt werden kann oder in eine Anwendung integriert wird und dann beim Start Änderungen installiert Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Gemäss dem Model-View-Controller Ansatz ist sesam Export Manager in drei Teile aufgeteilt und enthält zum einen die grafische Benutzeroberfläche, die Main Application (Steuerung) sowie darunterliegende Datenmodell. Die nachfolgende Abbildung 13 stellt die Architektur der Applikation schematisch gegliedert dar. Abbildung 13: Aufbau von Sesam Export Manager Bei Sesam Export Manager sind diese drei Schichten jedoch strikt übereinander, sodass die Main Application alleine für die Steuerung der GUI und des Modells zuständig ist. Dieser Aufbau bietet den Vorteil, dass Änderungen leicht vollzogen oder Programmteile erweitert werden können, da die einzelnen Klassen Teile so unabhängig wie möglich von einander sind. Ausserdem ist das Testen in einer solchen Architektur bedeutend einfacher, da die einzelnen Teile so für sich abgeschlossen auf ihre richtige Funktionstätigkeit geprüft werden können. Natürlich könnte die Applikation auch ohne Steuerungsklasse aufgebaut werden. Dies gäbe jedoch keinen nennenswerten Vorteil, da die Methoden nur in andere Klassen verlagert würden und somit Sesam Export Manager nicht schlanker würde. Die Testbarkeit, wie auch die leichte Erweiterbarkeit wäre dann aber eingeschränkt oder erschwert. S. 30 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen In erste Schicht, die Benutzeroberfläche, dient zur Entgegennahme von Benutzerinteraktionen mit Sesam Export Manager. Dies sind beispielsweise die Auswahl der zu exportierenden Daten oder der Anstoss zum Ausführen der Abfrage. Die Benutzeroberfläche selber ist wiederum in einzelne Elemente aufgeteilt. Dies erhöht die Übersichtlichkeit, erleichtert das Testen und macht es möglich, dass einzelne Teile wiederverwendet werden können. Benutzerbefehle werden durch eigene Aktionsklassen repräsentiert. So kann die Benutzeroberfläche vollständig von der Steuerung getrennt werden. Die Modelschicht repräsentiert die Daten in der Datenbank. In ihr sind alle für die Applikation relevanten Datenbankinhalte wie beispielsweise die ExperimentClass oder ProcessOutputClass auf ein eigenes Objekt gemappt und bereits benötigte Daten aus der Datenbank geladen. Jedoch ist es nicht sinnvoll, gleich die gesamte Datenbank mit allen Inhalten zu laden, da dies erstens bei der grossen Datenmenge sehr lange dauert und viel Speicher benötigt, aber auch weil ein Grossteil der Daten gar nie verwendet würde. Es werden also nur die zur Zeit benötigten Daten geladen. Zwischengespeichert werden die Datenbankhilfe mit einer Klasse ‚MetaModelReader‘ aus der Steuerungsschicht, die bei Bedarf die noch nicht im Puffer vorhandenen Daten aus der Datenbank abfragt und diese dann als Objekt in den Speicher lädt. Ebenfalls denkbar wäre es, die azuzeigenden Daten jeweils bei Bedarf aus der Datenbank direkt zu holen. Dies würde aber zu einer hohen Anzahl Zugriffe auf die Datenbank führen und somit erstens die Datenbank belastet und zweitens aufgrund der Verzögerung durch den entfernten Zugriff zu wenig Benutzerkomfort während der Bedienung der Applikation führen. Die Steuerungsschicht verwaltet alle Abläufe in Sesam Export Manager und wird beim Start der Applikation als erstes aufgerufen. Sie lädt zu Beginn alle Programmeinstellungen, wozu in einer ersten Umsetzungsphase auch die Datenbankeinstellungen wie URL, Port, Datenbankname, Benutzername und Passwort gehören. Später sollen diese Angaben jedoch durch eine Eingabe beim Start des Programms zur Verfügung stehen. Mit diesen Informationen stösst die Applikation dann das Mapping der relevanten Datenbankinhalte auf die Klassen im Modell an. Abschliessend wird die Benutzeroberfläche gestartet und die Klassendaten darin dargestellt. Nach einer Benutzerinteraktion nimmt die Steuerungsklasse den Befehl entgegen und agiert entsprechend. Wurden vollständige Abfragewerte eingegeben, so wird durch das Auslösen einer Aktion eine Query gestartet. Dies Query erhält alle Abfragewerte, den Dateinamen sowie das gewünschte Exportformat, lädt die Daten aus der Datenbank und speichert die abgefragten Datenbankinhalte mithilfe des Export-Plugins im entsprechenden Dateiformat und in den gewählten Pfad. Der Aufbau des Exportprozesses wurde deshalb mithilfe von Plugins konzeptioniert, da auf diese Weise einfach neue Exportformate und Exportmethoden zur Applikation ergänzt werden können. Ohne diesen Ansatz wären die Abfrage und der Export der Datenbankinhalte nicht sauber von einander getrennt, was zu Problemen bei der Definition weiterer Exportformate führen würde. 5.1.2 Detailentwurf … hier folgend Infos zum Abschnitt S. 31 / 39 Kommentar [SS38]: Hier könnte man ein aktivitätsdiagramm reinknallen und dann alles noch ein wenig genauer ausformulieren Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Der Singleton-Ansatz Der Singleton ist ein Design Pattern und bewirkt, dass von der Singletonklasse nur ein einziges Objekt erzeugt werden kann. Er dient zur Erzeugung und Verwaltung von einzelnen Objekten einer Klasse und ermöglicht einen globalen Zugriff auf über eine statisch gebundene Methode, die in Sesam Kommentar [SS39]: Designfrage: wäre es hier sinnvoll, evtl. Singleton-Teil in Abstract Class zu schmeisse und dies nur einmal zu implementieren? Also.. klass erbt singleton? Export Manager getInstance() genannt wird. Diese Methode gibt das private und statische Attribut ‚Instance‘ zurück. Die Verwendung von Klassen als Singletons ist ähnlich wie wenn die Klassen statisch wären. Allerdings bietet der Singleton-Ansatz den Vorteil, dass Kommentar [SS40]: FactoryPattern kann auch checken, dass es nur eine Instanz davon gibt. Spart allerdings keinen Implementierungsaufwand Allgemein: - - - Stand-Alone-Anwendung o D.h. kein Plugin für bspw. SPSS o Keine Webanwendung Singleton-Ansatz o Einfacher zu ändern im Nachhinein als static (das wäre alternative, erwähnen!) o Prinzip dahinter und dann warum angewendet (mit konkretem Beispiel) Trennung von Model, View und Controller o Übersichtlicher o Elemente können einfach wiederverwendet werden o Erweiterungen einfacher (z.B. weiteres GUI oder Konsole zur Befehlseingabe) o Controller steuert programm. Alternativ könnte direkt zugriff aus gui, oder model stattfinden. Allerdings gleiche komplexität (zugriffe müssten gleich gemacht werden), dafür alles verteilt und zu sehr ineinander verschlungen. Ausserdem kann dann nicht mehr alles einzeln aufgerufen werden. o Testen ist so viel einfacher o Starke aufteilung in klassen: ist einfacher zu testen, kann eher wiederverwendet werden - Eigenschaften separat als Klasse geführt o Zur besseren Übersicht, damit andere Klasse nicht so voll wird - Konfiguration unter configuration.xml abgelegt und wird daraus geladen - Ablauf: Daten laden, Auswählen, Query, Export Datenimport - Datenbankanbindung (ist abgeschlossene DB, nicht mit netzwerk verbunden) - Zwischenspeicherung der wichtigsten Daten mittels MetaModelReader o Erst laden aller daten, die ganz sicher verwendet werden. o Neue objekte werden dann bei bedarf nachgeladen. Mmr schaut, ob sie in map vorhanden sind, wenn nicht, lädt er sie aus DB und speichert sie in map o Objekte und Relationen werden auf Java-Objekte gemappt o (später benutzt in Gui) S. 32 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Gui - Mit SWT gemäss Vorgabe plus JFace - Benutzerbefehle werden als Actions implementiert, um diese vom GUI zu trennen, GUI ruft nur Action auf - Beim Start werden Daten aus Datenbank geladen - Benutzer wählt seine Daten aus - Vorgesehen: Benutzerlogin, Datenbank auswählen (mit diesen Zwischenspeichern), Pluginauswahl - Bei Eingabe eines Wertes wird Relation benutzt, für Einschränkung - Reset-Button löst dies wieder auf Query - Ich erstelle Query in Main application und übergib der QueryConfig und Exportplugin - Resultset muss vollständig übergeben werden, da man nicht vor und zurück kann - Erfolgt mittels JDBC, Resultset wird auch gebraucht, um Metadaten herauszubekommen (warum nicht anders?) Export - Es gibt ein QueryConfiguration-Objekt (Auswahl), welches an die Query übergeben wird o Man kann von überall drauf zugreiffen o Objekt könnte so als Ganzes abgespeichert werden, um Historisierung zu erreichen o Man könnte an mehreren Abfragen gleichzeitig arbeiten o Beim Ausführen der Query wird im Dialog Filename abgefragt, dann dieser mit den ausgefüllten Combos an QueryConfig übergeben - Export Plugin o Einfacher erweiterbar mit weiteren Exportformaten o Als abstract class (allerdings wäre darüber Interface schöner!) (da schnell umsetzbar, richtige Pluginschnittstelle könnte man noch erstellen, ist allerdings mehr Aufwand) - SPSS Plugin o Ausgabe in einem Stück o Daten werden ersetzt o In einer Datei, nicht aufgesplittet (da übersichtlicher und nur eine datei gehandelt werden muss, auch für benutzer nachher) variante: csv und andere datei (vorteil dort: könnte man auch in excel öffnen, jedoch ohne metadaten) o Debugging - Apache log4j S. 33 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Hilfsmittel: Noch sagen, warum welches hilfsmittel, z.b. hibernate 5.1.3 - verwendete Hilfsmittel Java (1.5 Vorgabe) Apache log4j SWT & JFace JDBC (Vorgabe) Hibernate 5.1.4 - Architektur, nicht jedoch, was jede Klasse macht Probleme, technisch, wie haben wir die gelöst Stand-alone-anwendung Alternative lösungsansätze mit anforderungen begründet. Warum nicht? Tests junit tests 5.2 Vorgehen und Implementierte Lösung 5.2.1 - Hilfsmittel Verwendung von SVN Eclipse … eher unwichtig 5.2.2 Aufgetretene Probleme und Lösungsansätze S. 34 / 39 Stefan Schurgast 6 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Evaluation der entwickelten Lösung 6.1 Erfüllung der Anforderungen an Funktionalität - Aufzählen aller erfüllten funktionalitäten 6.2 Validierung der Funktionalität - Junit tests 6.3 Erfüllung der Anforderungen an Bedienbarkeit S. 35 / 39 Stefan Schurgast 7 Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Zusammenfassung und Ausblick 2 Seiten -was haben wir gemacht? - wo hatten wir schlechte lösungen? Was war gut? Was müssen wir noch machen? Mehr plugins, flexibler für query-baseln, anzeigen von metainfos (nicht nur nach namen auswählen, sondern alles mögliche drüber arbrufen), browsen in gemachten exporten, wiederverwenden von exporten, bestehende exporte abändern Ausblick: - Möglicherweise verschlüsselte Verbindung von JDBC nutzen (bietet ja schon an) S. 36 / 39 Stefan Schurgast VIII i Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Anhang sesam Datenbankschema S. 37 / 39 Stefan Schurgast IX Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen Literaturverzeichnis Berner, S., Glinz, M., Joos, S., Meier, S., Merlo-Schett, N., Ryser, J., et al. (2002). Entwicklungsrichtlinien für Java-Software, 3.0. (U. Zürich, Herausgeber) Abgerufen am 02. 12 2007 von htp://www.ifi.unizh.ch/groupos/req/ftp/papers/JavaStyleguideV3.pdf Bundesstatistikgesetz. (1. 4 2007). Abgerufen am 12. 12 2007 von http://www.admin.ch/ch/d/sr/4/431.01.de.pdf Elmasri, R., & Navathe, S. B. (2005). Grundlagen von Datenbanksystemen (Grundstudium Ausg.). München: Pearson Studium. Gaebel, W. (10. 10 2007). Psychische Erkrankungen weiter auf dem Vormarsch. Abgerufen am 2. 12 2007 von media.dgppn.de/mediadb/media/dgppn/pdf/presseinfo/2007/dgppn-pm07-17-welttagseel-ges.pdf Glavic, B., & Dittrich, K. (2006). sesam: Ensuring Privacy for a Interdisciplinary Longitudinal Study. Abgerufen am 02. 12 2007 von http://www.ifi.uzh.ch/dbtg/fileadmin/storage/Glavic/publications/06_GI_2006_workshop.pdf Levesque, R. (2006). SPSS Programming and Data Management (3 Ausg.). Chicago, U.S.A.: SPSS Inc. Middendorf, S., Singer, R., & Heid, J. (2002). Programmierhandbuch und Referenz für die JavaTM-2Plattform, Standard Edition. Abgerufen am 11. 12 2007 von http://www.dpunkt.de/java/Programmieren_mit_Java/Oberflaechenprogrammierung/40.html Murray, C., & Lopez, A. (1997). Alternative projections of mortality and disability by cause 1990-2020: Global Burden of Disease Study. The Lancet , S. 1498-1504 (349). Pfitzmann, A. (2004). Anonymity, Unobservability, Pseudonymity, and Identity Management – A Proposal for Terminology. Abgerufen am 12. 12 2007 von http://dud.inf.tudresden.de/literatur/Anon_Terminology_v0.21.pdf Pommerening, K. (17. 05 2000). Pseudonyme – ein Kompromiß zwischen Anonymisierung und Personenbezug. Abgerufen am 12. 12 2007 von http://www.staff.unimainz.de/pommeren/Artikel/pseudony.pdf PostgreSQL Global Development Group. (2007). Abgerufen am 02. 12 2007 von PostgreSQL: http://www.postgresql.org/about/ Rost, M. (2003). Zur gesellschaftlichen Funktion von Anonymität. Datenschutz und Sicherheit (DuD) (27), S. 156-158. SAS Institut. (2007). SAS OnlineDoc 9.13. Abgerufen am 8. Dezember 2007 von http://support.sas.com/onlinedoc/913/docMainpage.jsp Schweizerischer Nationalfonds. (2005). NFS SESAM - Schweizerische ätiologische Studie zur psychischen Gesundheit (SESAM). Abgerufen am 02. 12 2007 von http://www.snf.ch/D/forschung/Forschungsschwerpunkte/LaufendeNFS/Seiten/_xc_nfssesam.aspx S. 38 / 39 Stefan Schurgast Bachelorarbeit Export von Datenbankinhalten in Datenformate von Statistikprogrammen sesam Schweiz. (2007). sesam Kernstudie: Besser verstehen – besser vorbeugen. Abgerufen am 02. 12 2007 von http://www.sesamswiss.ch/sesam/ueber-sesam/kernstudie/nutzen/ sesam Schweiz. (2007). sesam Teilstudien. Abgerufen am 2. 12 2007 von sesam swiss: http://www.sesamswiss.ch/sesam/ueber-sesam/teilstudien/ UCLA Academic Technology Services. (2007). SAS Learning Module: Inputting data into SAS. Abgerufen am 8. Dezember 2007 von http://www.ats.ucla.edu/stat/SAS/modules/input.htm Wahrig, G. (1997). Deutsches Wörterbuch Wahrig. Gütersloh: Bertelsmann Lexikon Verlag. S. 39 / 39 Seite 15: [1] Kommentar [SS10] Stefan Schurgast 16.12.2007 01:30:00 Die Vorteile von PostgreSQL PostgreSQL bietet gegenüber anderen Datenbanksystemen viele Vorteile für Ihre Firma oder Ihr Geschäft: Schutz vor Over-Deployment Over-deployment, das Benutzen von mehr Datenbank Instanzen als lizensiert wurden, wird von einigen Anbietern kommerzieller Datenbanksysteme als das Hauptproblem bei der Einhaltung der Lizenzbedingungen genannt. Mit PostgreSQL kann Sie niemand deswegen belangen, weil keine Lizenzgebühren für die Software erhoben werden. Dies hat mehrere zusätzliche Vorteile: • • • Profitablere Geschäftsmodelle in weitgefächerten Einsatzgebieten. Es gibt keine Möglichkeiten, irgendwann wegen der Einhaltung der Lizenzbedingungen überprüft zu werden. Flexibilität bei der konzeptionellen Forschung oder bei Testinstallationen, da keine zusätzlichen Lizenzkosten anfallen. Bessere Unterstützung als von kommerziellen Anbietern Zusätzlich zu unserem überzeugenden Support-Angebot gibt es bei PostgreSql eine lebendige Community aus Profis und Enthusiasten, von der Ihre Mitarbeiter profitieren und zu der sie beitragen können. Bedeutende Einsparungen bei den Personalkosten Die Software wurde so konzipiert und entwickelt, dass die Anforderungen zur Wartung und Leistungsverbesserung weitaus niedriger sind, als bei den führenden kommerziellen Datenbanksystemen. Dennoch bietet PostgreSql alle Leistungsmerkmale, Stabilität und Geschwindigkeit. Legendäre Zuverlässigkeit und Stabilität Im Gegensatz zu Benutzern vieler kommerzieller Datenbanksysteme ist es bei Unternehmen, die PostgreSQL einsetzen der Normalfall, dass das Datenbanksystem noch kein einziges Mal abgestürzt ist. Auch nicht bei jahrelangem Einsatz und großem Datenaufkommen. Es läuft einfach. Erweiterbar Der Quelltext ist kostenlos für jeden zugänglich. Sollte für Sie oder Ihre Mitarbeiter eine Notwendigkeit bestehen, PostgreSQL in irgendeiner Weise zu erweitern oder anzupassen, können Sie das mit minimalem Aufwand und ohne zusätzliche Kosten tun. Unterstützt werden Sie dabei von den Profis und Enthusiasten der PostgreSQL Community auf der ganzen Welt, die PostgreSQL täglich weiterentwickeln. Plattformunabhängig PostgreSQL ist nahezu für jede Unix-Variante verfügbar, (die letzte stabile Version läuft auf 34 Betriebssystemen), und eine native Windows Version ist seit der Version PostgreSQL 7.4 eingeführt. Für Umgebungen mit hohem Datenvolumen konzipiert PostgreSql benutzt MVCC, eine Speicherstrategie, durch die sich PostgreSQL speziell für Umgebungen mit hohem Datenaufkommen ausserordentlich gut eignet. Der führende kommerzielle Datenbankanbieter benutzt diese Technologie ebenfalls und aus demselben Grund. Grafische Benutzeroberflächen für Datenbankdesign und Administration Einige hochwertige grafische Benutzeroberflächen zur Administration (pgAdmin, pgAccess) sowie zum Datenbankdesign (Tora) stehen zur Verfügung. Die wichtigsten technischen Fähigkeiten, die PostgreSQL bietet: • • • • • • • • • • • • • • • • • • • • • • • • • • Volle Unterstützung von ACID Erfüllung der ANSI SQL Standards Referentielle Integrität Replikation (kommerzielle und nicht-kommerzielle Lösungen) ermöglicht das Duplizieren einer Master-Datenbank auf mehrere untergeordnete Rechner. Native Schnittstellen für ODBC, JDBC, C, C++, PHP, Perl, TCL, ECPG, Python und Ruby Rules (Regelsysteme) Views Trigger Unicode Unterstützung Sequences Vererbung Outer Joins Sub-Selects Offene API (Application Programming Interface) Stored Procedures Native Unterstützung von SSL Prozedurale Sprachen Hot stand-by (komerzielle Lösungen) Besser als Row-Level Locking Partielle Indizes und Indizes über Funktionsergebnisse Native Unterstützung von Kerberos Authentifizierung Unterstützung von UNION, UNION ALL und EXCEPT Abfragen Nachladbare Erweiterungen für SHA1, MD5, XML und andere Funktionalitäten Werkzeuge um portablen SQL Code zu erzeugen, der mit allen SQL-unterstützenden Systemen verwendbar ist Erweiterbares Datentyp System, das eigene, vom Benutzer definierte Datentypen und schnelle Entwicklung von neuen Datentypen ermöglicht Datenbank übergreifende Kompatibilitätsfunktionen um den Umstieg von anderen, weniger