Datenbanken / Informationssysteme
Werbung

Fachhochschule für Technik und Wirtschaft Berlin
FB 4 / Angewandte Informatik
Prof. Dr.-Ing. habil. R. Oßwald
Lehrhilfen:
Datenbanken /
Informationssysteme
Datenbankgrundlagen
relationales Datenmodell
Datenbankentwurf
Hinweis:
Diese Unterlagen haben nicht den Charakter eines Lehrbuchs. Sie sind nur
sinnvoll nutzbar innerhalb der Vorlesung "Einführung in Datenbanken" (DB I)
und sollen dort durch eigene Anmerkungen der Hörer ergänzt werden.
Bearbeitungsstand:
Datum
neu hinzugefügte Seiten
09.10.03
1 – 15
22.10.03 Inhaltsverzeichnis, 16 – 24
23.11.03
25 – 33
29.11.03
04.04.05
20.05.05
05.10.05
23.11.05
22.11.07
34 – 41
42 - 43
geänderte Seiten
Anmerkungen
--ohne Inhaltsverzeichnis
--Seitennummerierung eingefügt
14, 20, 21, 22, 25
beachten: Seitennummern sind
(nach neuer
wegen längerem InhaltsSeitennummerierung)
verzeichnis verschoben
--10, 18, 29, 34-39
21
11, 23
39
Inhalt
INFORMATION
4
Beziehung „Informationen –––– Daten“
4
Informationssystem (IS)
5
automatisiertes Informationssystem (AIS)
5
Daten und Metadaten in einer Datenbank
5
Die Datenbank im automatisierten Informationssystem
6
Voraussetzungen für den Datenbankeinsatz
6
Mängel der klassischen Datenverarbeitung
6
Vorteile von Datenbanksystemen
7
Datenunabhängigkeit
7
wesentliche DBBS-Funktionen
8
Transaktionen
8
Entscheidende Ereignisse für die Datenbank-Entwicklung
9
Phasen der Datenbankentwicklung
11
Generalisierung der Datenverwaltung
12
Datenbanksprachen
12
Zwei- und Dreiebenenarchitektur
13
Beispiele zur Mehrebenenarchitektur
14
allgemeine Grundbegriffe
14
Definition: Datenmodell
15
Hierarchie, Netzwerk, Relationen
16
Entity-Relationship-Modell
16
Vergleich: Netzwerk- und Relationenmodell
17
Grundbegriffe des Relationenmodells
17
Terminologie aus unterschiedlicher Sicht
18
Eigenschaften einer relationalen Datenbank
18
Eigenschaften von Relationen
18
Relationenalgebra
19
Beispiele mit tupelorientierten Operationen
20
allgemeine Regeln
22
Übersicht über die Verbundarten:
22
Vorzüge der relationalen Algebra
23
Indextabellen
23
Kriterien für ein voll relationales DBBS
24
2
Datenbankentwurf
25
graphische Grundelemente des ERM
26
Kardinalitäten
26
Umsetzung eines ERD in Relationenschemata
27
Umsetzungsbeispiel: ERD in Relationenschemata
28
Schlüsselreduktion
29
Reduzierung auf die unbedingt notwendige Tabellen
29
Auflösung einer ternären Beziehungsmenge
30
Entwurfsschritte
31
Datenbankentwurf mit "Power Designer"
32
referentielle Integrität
33
Normalformen (Übersicht)
34
Beispiel zur Normalisierung
34
erste Normalform (1NF)
34
Änderungsanomalien in der 1NF
36
zweite Normalform (2NF)
36
funktionale Abhängigkeit (FD)
36
volle funktionale Abhängigkeit (FFD)
37
Änderungsanomalien in der 2NF
38
dritte Normalform (3NF)
39
transitive Abhängigkeit
39
Änderungsanomalien in der 3NF
40
Boyce-Codd-Normalform (BCNF)
40
vierte Normalform (4NF)
40
mehrwertige Abhängigkeit (MVD)
40
Übung "Lieferungen"
41
Übung "Bibliothek"
41
3
INFORMATION
Antike:
Erklärung, Darlegung, Interpretation
Shannon
(1948):
Verringerung der Unbestimmheit
Ursul
(1973):
-Aufhebung der Identität / der Monotonie
- Widerspiegelung von Verschiedenartigkeit
Lehmann:
Schlüsselwort und zugehörige Aussage
Informationsgehalt =
Grad der beseitigten Unbestimmtheit
Wiedergabe mit Hilfe der Entropie (oder besser: der Negentropie)
Definition:
"Wissen über ein Ereignis / einen Tatbestand,
semantisch
das dem Empfänger in verständl. Form mitgeteilt wird,
sigmatisch, syntaktisch
um dort eine zielgerichtete Reaktion auszulösen."
pragmatisch
Beziehung „Informationen –––– Daten“
D
I
= Daten
= Informationen
(1) Datenverarbeitung
(2) Interpretation
(3) Informationsverarbeitung
4
Informationssystem (IS)
- geordnetes Netz von informationellen Beziehungen
zwischen: - informationserzeugenden,
- informationstragenden (-speichernden)
- informationsverarbeitenden Elementen
automatisiertes Informationssystem (AIS)
automatisiertes Informationsverarbeitungssystem (AIVS)
- geordnetes Netz von informellen Beziehungen zwischen:
- Menschen
- EDVA
- Programmen
Daten und Metadaten in einer Datenbank
Datenbasis
Daten
Datenbankschema
Metadaten
Daten:
über Materialbestände, Lieferungen, Gebäude, Forschungsmittel, Personen, usw.
Metadaten:
über Datentyp, Speicherort, Datenfeldname, Zugriffsberechtigungen, Versionen,
Änderungsdatum, Gültigkeitsgrenzen, usw.
5
Die Datenbank im automatisierten Informationssystem
Voraussetzungen für den Datenbankeinsatz
–
Automatisierbarkeit / Automatisierungswürdigkeit der Datenverwaltungsprozesse
–
Ermittlung und Festlegung des Datenflusses
–
Erfassen und Bereitstellen der Daten
–
Organisation der Datenbehandlung / Pflege der Daten
Mängel der klassischen Datenverarbeitung
(d.h. ohne DB-Anwendung)
–
satzweise Verarbeitung
–
logische und physische Datenorganisation getrennt, lediglich primitive Beziehungen
–
Zugriffe über Nebenordnungskriterien nicht unterstützt
–
Dateiaufbau und Datenstruktur im Programm verankert
–
Daten an spezielle Anwendungsfälle angepasst
–
Mehrfachspeicherung der Daten für verschiedene Projekte
–
aufwendige Programmierung wegen expliziter Berücksichtigung der Datenorganisation
–
auf dynamische Informtionsbedürfnisse kann kaum reagiert werden
6
Vorteile von Datenbanksystemen
–
mehrere Dateien in einem System zusammengefasst:
Verweise auf zugehörige Daten, Redundanzverringerung
–
große Datenmengen / gemeinsame Nutzung:
Teilhaber- bzw. Teilnehmerbetrieb
–
Programmsystem zur Verwaltung der Daten:
einheitliche Verwaltungsoperationen, zentrale Integritätskontrolle, erhöhte Aktualität
–
Trennung zwischen Nutzerprogramm und Dateien
= vertikale Datenunabhängigkeit: Zugriffspfad- und Datenstruktur-Unabhängigkeit
–
- beliebige Verknüpfung und Auswertung der Daten:
Indextabellen, Sekundärschlüssel,
Sekundärketten / rückwärts gerichtete Ketten,
strukturauflösende Funktionen,
Sortierfunktionen,
Tabellen- und Programmgeneratoren
–
- einfache Datenbehandlung für Endbenutzer:
nicht-prozedurale Sprachen,
Sprachniveau entsprechend Nutzerqualifikation
Datenunabhängigkeit
- vertikal (Anwenderprogramme - Daten):
Programme sind anwendungsstabil durch Unabhängigkeit gegenüber Änderungen der:
Hardware,
Basissoftware,
Datenstrukturen,
Zugriffspfade.
- horizontal (Anwenderprogramm - Anwenderprogramm):
Programme sind änderungsstabil durch Unabhängigkeit gegenüber Änderungen anderer
Programme.
Daten werden mehrfach genutzt (einmalige Speicherung)
Vertikale und horizontale Datenunabhängigkeit ermöglichen die Zentralisierung von Maßnahmen
zur Gewährleistung von:
Datenintegrität,
Datensicherheit,
autorisiertem Zugriff.
7
wesentliche DBBS-Funktionen
1. Grundfunktionen
- Speichern und Wiederauffinden
- Datenmanipulation (Selektieren, Ändern, Zufügen, Löschen)
- Abbildung und Nutzung logischer Beziehungen zwischen Daten
- Verwaltung des physischen Speicherplatzes / Adressierung
- Übersetzen / Interpretieren der DB-Sprachen
2. Zusatzfunktionen:
- Entwurfsunterstützung
- definieren von Datenstrukturen und Behandlungsfunktionen
- prüfen und umwandeln der Daten
- Zugriffsschutz
- Datensicherung
- Datenfernverarbeitung
- Dialogbetrieb
- sammeln statistischer Daten zur Optimierung
- restrukturieren
3. Systemfunktionen:
- Einrichten einer DB
- Verwaltung der Datendefinition
- Mehrfachnutzung (Sperrmechanismen, Warteschlangenverwaltung)
Transaktionen
Eine Transaktion (TA) ist eine Folge von logisch zusammengehörenden Aktionen, welche in ihrer
Gesamtheit die Datenbank von einem konsistenten (zulässigen) Zustand in einen neuen
konsistenten Zustand überführen.
i.a.:
TA = Nutzerauftrag
Eigenschaften:
atomar
=
ACID
„Alles oder Nichts“ – Eigenschaft
konsistent =
DB ist in konsistentem Zustand
isolierend =
fiktiver 1-Nutzer-Betrieb
dauerhaft =
Ergebnisse bleiben erhalten
8
Entscheidende Ereignisse für die Datenbank-Entwicklung
Jahr
Plattenkapazität
1936
1942
1943
1944
1945
1946
1947
1948
1949
1950
1951
1952
1953
1954
1955
1956
1957
1958
Konrad Zuse:
128 KB
4 MB
1960
1961
42 MB
7 MB
1965
1966
1967
1968
1969
1970
1971
1972
Z1 (mechanisch)
Z3 (elektromechanisch)
MARK I
ENIAC (30t, 18000 Röhren, 300 Op./s)
erste Datenbankstudie (Bush: MEMEX)
Magnetbandtechnologie (analog)
Transistor (Bardeen, Brattain, Shockley)
(Nobelpreis 1956)
Informationstheorie (Shannon)
digitale magnetische Aufzeichnung
1959
1960
1962
1963
1964
Ereignisse
29 MB
H
H
H
H
T
G
H
T
G
Rechner für wissenschaftliche Zwecke
H
elektronische Datenverarbeitung
H
kleine Festkopfplattenspeicher
H
Plattenspeicher mit beweglichen Lese-/
Schreibköpfen, Hashverfahren
Multilistverfahren
Inventursystem,
indexsequentielle Zugriffsmethode
Flugreservierungssystem (SABRE)
Materialabrechnung (BOMP),
Studien zum Information Retrieval
Informationenalgebra
MEDLARS
Wechselplattenspeicher,
IMS (North American Rockwell)
Semaphore
H
G
G
A
S
A
A
T
T
A
Set-Modell ( =hierarchisches Datenmodell)
IMS (IBM)
CODASYL DBTG
SHARE DB COMMITTEE,
relationales Datenmodell,
B-Bäume
Transaktionen-Konzept,
CODASYL-Empfehlungen
Datenschutz (privacy)
T
S
T
T
T
G
G
T
T
9
A
G
Jahr
Plattenkapazität
1973
1974
58 MB
1975
1976
1977
100 MB
1978
1979
200 MB
1980
2,5 GB
1981
1,2 MB
1982
1983
100 MB
1984
540 MB
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
1... 2 GB
Ereignisse
SYSTEM 2000
SYSTEM R-Projekt,
ADABAS
neuer DBTG-Report,
erste VLDB-Untersuchungen,
ANSI-SPARC Report,
QBE
Datenbankmaschinen
Datenmodell-Diskussionen
(hierarchisch/Netzwerk/relational)
CODASYL (internes Schema)
konkurrierender Zugriff,
verschiedene relationale DBBS
Datenmodell der Universellen Relation
erster PC mit eingebauter Festplatte (Apple 3 mit 5 MB)
Floppy Disk,
SQL/DS (IBM)
relationale Standards
Hard Disk,
Mikrorechnerzugang zu großen Datenbanken
20 MB-Platte für PC
Datenbanken in lokalen Rechnernetzen
erster SQL-Standard
ANSI-SQL
internationale ANSI-SQL-Übernahme (ISO 9075)
G
T
T
S
G
H
H
S
T
H
A
H
S
T
T
T
SQL-2-Standard,
SQL+ referentielle Integrität
T
T
MB-Kassetten (DAT)
SQL2 (Domänen, Schlüsseldefinitionen)
H
T
1 GB-Platte für PC
Vorbereitung SQL3 (Sub-Tables, Rekursion, Prozeduren, oo)
kommerzielle DB-Anwendung im Internet, Java
8...12 GB multidimensionale Datenbanken,
"Groß"-DBMS auf "Klein"-Rechnern
(Oracle 2000, SQL-Anywhere)
Data Warehouses
XML
SQL3
objektrelationale Datenbanken
mobile Datenbanken
SQL mit objektrelationalen Erweiterungen
A = Anwendung
S = Software
G = Grundlagen
T = Theorie / Studie / Standard
10
H = Hardware
S
T
S
T
T
T
S
T
H
T
A
G
A
A
G
T
S
G+H
T
Phasen der Datenbankentwicklung
industrieller Bedarf,
industrielle Förderung
50er
erste Versuche
Schema-Konzept
(McGee)
nicht-sequentielle
Speicherung (hash)
60er
kommerzielle
DBMS
hierarchisches
Modell
B-Zugriffsbaum
indexsequentieller
Zugriff
Netzwerkmodell
wissenschaftliche Formalisierung
70er
80er
90er
2000 ff.
Standardisierung
Nutzernähe
Integration in
Anwendungssysteme
Datenbankdienste und
XML
Angleichung der
Leistungsspektren
gleiche DBMS auf unterschiedlicher Hardware
(incl. PC)
Datenbankfunktionen als
implizite
Anwendungsfunktionen
Relationenmodell
einfachere Nutzung
(Codd, 1970)
nicht-prozedurale
Schnittstellen
Such- u.
Sortierverfahren
(Knuth, 1973)
logging
MULTILIST
ERM (Chen, 1976)
IRS
DBS
(IDS, IMS,
BOMP)
breite Anwendung
Standardisierung
(CODASYL,
ANSY/SPARC)
Leistungsanpassung
Nicht-StandardAnwendungen
komfortable Sprachen
(4GL, SQL)
verteilte Systeme
data directory
DB-Maschinen
Client-ServerTechnologie
SQL-Standards
(1989, 1992, 2000)
objektrelationale
Schnittstellen
XML-Schnittstellen
Server-Server-Kopplung / XML-Datenbanken
Verteilung
(remote-procedure-call)
leistungsfähige
Volltextfunktionen
kommerzielle oo-DBMS
erste MM-Funktionen
(Verwaltung von Bildern,
blob)
Internet-Anwendungen
objektrelationale DBMS
11
breite Anwendung von
open-source-Systeme
Generalisierung der Datenverwaltung
Datenbanksprachen
QL
große Datenträger für Direktzugriff:
Z
E
I
T
DDL
•
bewusste Vorausplanung (Erzeugung neuer Metadaten)
•
Zusammenfassung aller Metadaten in einer Metadatenbasis
(Auswertung mittels QL)
•
gezielte Änderung einzelner Daten
DML
DCL
QL
12
Zwei- und Dreiebenenarchitektur
externe Ebene
Transformationen
interne Ebene
externe Ebene
Transformationen
konzeptuelle
Ebene
Transformationen
interne Ebene
13
Beispiele zur Mehrebenenarchitektur
CODASYL:
= Sprachenmodell:
Subschemata
Schema
ANSI/SPARC:
= Schnittstellenmodell
externe Schemata
(Anwendungsadministrator)
konzeptuelles Schema
(Betriebsadministrator)
interne Schemata
(Datenbankadministrator)
allgemeine Grundbegriffe
Integrität
=
Übereinstimmung mit dem Diskursbereich
Konsistenz
=
gegenseitige Widerspruchsfreiheit
Sicherheit
=
Vermeidung physischer Verluste
Zugriffsschutz
=
Verhinderung unautorisierter Lese-/Schreibzugriffe
Datenschutz
=
Schutz vor missbräuchlicher Verwendung der Daten
14
Definition: Datenmodell
Ein Datenmodell beschreibt das Organisationsprinzip, nach dem Daten
über Objekte sowie
über die Beziehungen zwischen den Objekten
in einer Datenbasis abgespeichert werden.
Durch dieses Organisationsprinzip wird eine bestimmte Menge von erlaubten Operationen
festgelegt, die damit zum Bestandteil des Datenmodells werden.
Die verschiedenen Datenmodelle unterscheiden sich hauptsächlich durch die Darstellungsform der
Beziehungen, die zwischen den durch die Daten repräsentierten Objekten bestehen.
Modell zur Beschreibung von Daten und Datenstrukturen
und der auf ihnen ausführbaren Operationen.
Schema
=
maschinenlesbares
Modell
Modell des
Diskursbereiches
Datenmodell
DBBS
Datenmodelle
ebene M.
ERM
graph. M.
formal-log. M
hierarch. M..
mengentheoret. M.
BinärAssoziationen-M.
Netzwerk-M.
relationale M.
binärrelationales M.
relational-hierarch. M
normalisierte
Relationen
15
NF2Tabellen
Hierarchie, Netzwerk, Relationen
Hierarchie:
1:n-Beziehungen
Netzwerk:
n:m-Beziehungen
Relationen:
inhaltsabhängige Beziehungen
Entity-Relationship-Modell
Teile
M
erhält
verwendet
N
Kunden
1
1
zahlt
bestellt
N
N
Rechnungen
1
gehoert_zu
16
1
Bestellungen
Vergleich: Netzwerk- und Relationenmodell
Beispiel "Baugruppen und Teile"
Netzwerkmodell:
Relationenmodell:
Baugruppe
P1
P1
P5
P3
P6
P5
P2
Anzahl
2
4
1
3
9
8
3
Teil
P2
P4
P3
P6
P1
P6
P4
Grundbegriffe des Relationenmodells
Datenbank: "Raubritter"
Relation:
"Ausruestung"
Attribut A
Ritter
Pferd
Franz der Verkniffene
Kuno der Heizbare
Rueckenwind
Rosinante
D
E
Kuno der Heizbare
Dagobert
E
Karl der Rostfreie
Regenwetter
B
Ruestung
Domäne (= Definitionsbereich):
Schlüssel:
Schema R
Tupel t
Relation
Wert v
Dom (Ruestung) = {A, B, C, D, E}
Menge von Attributen, durch deren Werte sich jedes Tupel eindeutig identifizieren
lässt
Schemadarstellung:
– formal:
R ( A1 , A2 , ... , An )
– Beispiel:
Ausruestung ( Ritter , Pferd , Ruestung )
17
Terminologie aus unterschiedlicher Sicht
Relationenmodell
Relation / relation
umgangssprachlich
Tabelle
traditionelle EDV-Sicht
Datei
Attribut / attribute
Spalte
Feld
Tupel / tupel
Zeile
Satz
Domäne / domain
Definitionsbereich
---
Attributwert / attribute value
( Wert / value )
Spaltenwert
( Wert )
Feldwert
( Wert )
Eigenschaften einer relationalen Datenbank
1.
Daten in Tabellenform
2.
Datenbank = Menge von Tabellen
3.
alle Informationen Attributwerte (nicht Position)
4.
dem Nutzer verborgene Zugriffsverfahren (vom System festgelegte Zugriffspfade)
5.
Operationen sind Mengenoperationen (ausgeführt auf Tupel-Mengen)
6.
Ergebnis einer Operation:
7.
relationale Datenbanksprachen basieren ausschließlich auf relationalen Operationen
neue Relation
Eigenschaften von Relationen
1.
Alle Tupel einer Relation haben denselben Aufbau.
2.
Jedes Tupel enthält eine feste Anzahl von benannten Attributwerten.
3.
Attributwerte sind stets atomar.
4.
Jedes Tupel ist einmalig; Duplikate sind nicht erlaubt. Es kann eine identifizierende
Attributmenge angegeben werden.
5.
Die Reihenfolge der Tupel in einer Relation ist ohne Bedeutung.
6.
Jedem Attribut ist eine Domäne zugeordnet. Dieselbe Domäne kann mehreren Attributen
zugeordnet sein (auch in verschiedenen Relationen).
7.
Mit der Zuordnung einer Domäne wird der Definitionsbereich für ein Attribut festgelegt.
8.
Neue Relationen können gebildet werden durch:
a) Auswahl von Attributen aus einer Relation
Projektion
b) Auswahl von Tupeln aus einer Relation
Selektion
c) Zusammenfassen von Relationen durch Vergleich von Attributwerten für alle Tupel in
diesen Relationen.
Verbund / Join
d) mengenorientierte Operationen
18
Relationenalgebra
Die Relationenalgebra bietet Möglichkeiten, um aus einer Menge von Datenelementen beliebige
Untermengen ("Ergebnis-Relationen") auszuwählen bzw. Relationen miteinander zu verknüpfen.
1. mengenorientierte Operationen
(Operationen der gewöhnlichen Mengenalgebra)
Die Relationen R, S müssen vereinigungsverträglich sein:
Die Relationen haben die gleiche Anzahl von Attributen
und diese besitzen paarweise denselben Grunddatentyp.
– Vereinigung
R ∪ S = { t | t ∈ R oder t ∈ S }
– Durchschnitt
R ∩ S = { t | t ∈ R und t ∈ S }
– Differenz
R – S = { t | t ∈ R und t ∉ S }
kommutativ
– symmetrische Differenz R ∆ S = { t | entweder t ∈ R oder t ∈ S }
2. tupelorientierte Operationen:
– Selektion
Auswählen derjenigen Tupel, die
die angegebene Bedingung erfüllen
σ [ bedingung ] relation
z.B.: σ [ Ruestung = 'E' ] Ritter
Mit der Liste von Ausdrücken
werden die Ergebnisspalten beschrieben.
– Projektion π [ausdr_liste ] relation
z.B.: π [ Name, Ruestung ] Ritter
– Verbund
ν relation_1 [ausdr_1 θ ausdr_2] relation_2 Jedes Tupel der einen Relation
z.B.: ν Ritter [ Ruestung = Service ] Plattner
- gewöhnlicher / natürlicher Verbund,
- Gleich- / Ungleich-Verbund,
wird im Prinzip mit jedem Tupel
der anderen Relation verglichen.
Immer wenn die Vergleichsbedingung (Verbundbedingung)
erfüllt ist, wird jeweils ein
Ergebnistupel gebildet.
- verlustfreier / verlustbehafteter Verbund
– Kartesisches Produkt
jedes Tupel der einen Relation wird mit jedem Tupel der anderen
Relation verknüpft
– Division
im Prinzip ähnlich einer Unterabfrage mit IN
Namen aller Spieler, die in einer (beliebigen) Mannschaft spielen,
in der auch der Spieler 007 einmal gespielt hat
z.B.
– Verkettung
Ergebnisrelation enthält alle Spalten der Ursprungsrelationen
z.B.
R ( X, Y, Z ) || S ( A, B, C, D ) T ( X, Y, Z, A, B, C, D )
(praktisch identisch mit kartesischem Produkt)
19
Beispiele mit tupelorientierten Operationen
Selektion:
σ [ bedingung ] relation
vorgegeben
σ [B = C] R
σ [B > C] R
σ [C >2] R
R (A, B, C, D)
s 5 1 9
t 5 4 9
u 3 3 9
(A, B, C, D)
u 3 3 9
(A, B, C, D)
s 5 1 9
t 5 4 9
(A, B, C, D)
t 5 4 9
u 3 3 9
Projektion:
vorgegeben
π [ausdr_liste] relation
π [B, C] R π [D, B] R
R (A, B, C, D)
s 5 1 9
t 5 4 9
u 3 3 9
(B, C)
5 1
5 4
3 3
π [D] R
(D, B)
9 5
9 3
(D)
9
– doppelte Ergebnistupel werden eliminiert (bei SQL nur, wenn DISTINCT angegeben)
z.B.:
SELECT DISTINCT Name, Ort
Projektion
FROM Spieler
Selektion
WHERE Ort = 'Karlshorst'
Verbund / Join:
ν relation_1 [ausdr_1 θ ausdr_2] relation_2
– siehe auch Relation "Ausruestung“ (S.15) unter "Grundbegriffe des Relationenmodells"!
Plattner
Name
Ort
Typ
Till
Nauen
E
Ingo
Ingo
Utz
Gosen
Gosen
Ulm
B
E
A
ν Ausruestung [Ruestung = Typ] Plattner
Ausruestung.Name
Pferd
Kuno der Heizbare
Kuno der Heizbare
Kuno der Heizbare
Kuno der Heizbare
Karl der Rostfreie
Rosinante
Rosinante
Dagobert
Dagobert
Regenwetter
Gleichverbund
Ruestung
E
E
E
E
B
20
Plattner.Name Ort
Till
Ingo
Till
Ingo
Ingo
Nauen
Gosen
Nauen
Gosen
Gosen
Typ
E
E
E
E
B
ν Ausruestung [Ruestung = Typ] Plattner (Ausruestung.Name, Pferd, Ruestung, Plattner. Name, Ort)
natürlicher Gleichverbund
Ausruestung.Name
Pferd
Ruestung
Plattner.Name Ort
Kuno der Heizbare
Kuno der Heizbare
Rosinante
Rosinante
E
E
Till
Ingo
Nauen
Gosen
Kuno der Heizbare
Kuno der Heizbare
Karl der Rostfreie
Dagobert
Dagobert
Regenwetter
E
E
B
Till
Ingo
Ingo
Nauen
Gosen
Gosen
ν Ausruestung [Ruestung <> Typ] Plattner
Ungleichverbund
Ausruestung.Name
Pferd
Ruestung
Franz der Verkniffene
Franz der Verkniffene
Franz der Verkniffene
Franz der Verkniffene
Kuno der Heizbare
Rueckenwind
Rueckenwind
Rueckenwind
Rueckenwind
Rosinante
D
D
D
D
E
Till
Ingo
Ingo
Utz
Ingo
Nauen
Gosen
Gosen
Ulm
Gosen
E
B
E
A
B
Kuno der Heizbare
Kuno der Heizbare
Kuno der Heizbare
Karl der Rostfreie
Rosinante
Dagobert
Dagobert
Regenwetter
E
E
E
B
Utz
Ingo
Utz
Till
Ulm
Gosen
Ulm
Nauen
A
B
A
E
Karl der Rostfreie
Karl der Rostfreie
Regenwetter
Regenwetter
B
B
Ingo
Utz
Gosen
Ulm
E
A
ν Ausruestung [Ruestung *=* Typ] Plattner
Plattner.Name Ort
Typ
voller verlustfreier Gleichverbund
Ausruestung.Name
Pferd
Ruestung
Franz der Verkniffene
Rueckenwind
D
NULL
NULL
NULL
Kuno der Heizbare
Kuno der Heizbare
Kuno der Heizbare
Rosinante
Rosinante
Dagobert
E
E
E
Till
Ingo
Till
Nauen
Gosen
Nauen
E
E
E
Kuno der Heizbare
Karl der Rostfreie
Dagobert
Regenwetter
E
B
NULL
NULL
Ingo
Ingo
Utz
Gosen
Gosen
Ulm
E
B
A
NULL
21
Plattner.Name Ort
Typ
allgemeine Regeln
1.) Anstelle eines Attributnamens darf stets ein beliebig komplexer Ausdruck, ein sog.
"synthetisches Attribut" stehen, z.B.:
vorgegeben
σ [B*C/2 <= D–3] R
R (A, B, C, D)
s 5 1 9
t 5 4 9
u 3 3 9
(A, B, C, D)
s 5 1 9
u 3 3 9
π [(B+C)*2, B–C] R
((B+C)*2, B–C)
12
18
12
4
1
0
2.) Anstelle des Namens einer Basisrelation oder einer Sicht darf stets eine tupelorientierte
Operation stehen, z.B.:
vorgegeben
π [A, B] (σ [C>2] R)
R (A, B, C, D)
s 5 1 9
t 5 4 9
u 3 3 9
(A, B)
t 5
u 3
Übersicht über die Verbundarten:
verlustbehaftet
(inner)
verlustfrei
(lossless)
(outer)
Legende: V
N
O
X
linker
(left)
voller
(full)
rechter
(right)
Gleichverbund
(equi join)
gewöhnlich
natürlich
(common)
(natural)
Ungleichverbund
(unequi join)
V
V
V
V
V
V, (X)
N
N
N, X
O
O
O, X
Verwendung lt. Definition
nicht implementiert
oft nicht implementiert
wenig sinnvoll
22
Vorzüge der relationalen Algebra
1.
Basis für deskriptive Anfragesprache
2. Abgeschlossenheit
3. Adäquatheit
4. Optimierbarkeit
5. effiziente Implementierbarkeit
6. Sicherheit
7. Eingeschränktheit
Indextabellen
Basisrelation "Personal"
Pers_Nr
13
9
5
12
7
4
14
Fam
Vorname
Bause
Biller
Angerer
Bause
Bause
Kunz
Kunz
S
K
A
R
T
L
F
Gehalt
Kinder
...
...
0
2
1
3
0
1
0
...
...
...
...
...
...
...
...
...
...
...
...
...
...
1800
600
950
1200
1100
1500
900
1.
2.
3.
4.
5.
6.
7.
Tupelnummern
(nicht
gespeichert!!)
CREATE TABLE Personal (Pers_Nr integer primary key,
Fam
.... ,
...
... );
eindeutige Indextabelle zum Primärschlüssel
mehrdeutige Indextabelle zum Attribut Fam
Tupelnummer Pers_Nr
6
3
5
2
4
1
7
Tupelnummer Fam
4
5
7
9
12
13
14
3
4
1
5
2
7
6
Angerer
Bause
Bause
Bause
Biller
Kunz
Kunz
CREATE INDEX i_Gehalt
ON personal (Gehalt)
23
Kriterien für ein voll relationales DBBS
E.F.Codd:
An Evaluation Scheme for Database Management Systems that are claimed to be Relational
1.) CW Communications, 1985, 720-729 oder 2.) Computerworld, Oct 14 and 21, 1985
0. Grundregel:
Die Datenbank wird vollständig mit relationalen Mitteln bearbeitet.
1. Informationsregel:
Alle Informationen werden auf der logischen Ebene explizit beschrieben, und ihre
Datenwerte werden ausschließlich als Tabellenwerte gespeichert.
2. Zugriffsregel:
Jeder Wert in der Datenbank ist erreichbar über die Kombination
( Relationenname, Primärschlüsselwert, Attributname )
3. NULL-Werte:
Fehlende, unbekannte, nicht verfügbare Werte werden (unabhängig vom Datentyp)
systematisch behandelt.
4. Katalogregel:
Alle Datenbank-Definitionen werden wie gewöhnliche Daten behandelt ("dynamischer online-Katalog").
5. DML-Regel:
Es existiert mindestens eine vollständige Datenmanipulationssprache:
– beschrieben durch wohldefinierte Syntax,
– Anweisungen in Zeichenkettenform,
– Ergebnisse sind stets wieder Elemente des relationalen Datenmodells,
– erforderliche Bestandteile: 1. Datendefinition,
2. Sichtendefinition,
3. Datenmanipulation
4. Definition von Integritätsregeln
5. Autorisierung
6. Transaktionsgrenzen
6. Sichtenregel:
Alle theoretisch änderungsfähigen Sichten erlauben eine eindeutige, unmittelbare Änderung
der enthaltenen Basisrelationen.
7. Operationenregel:
Alle Operationen (auch Einfügen, Löschen und Ändern) werden als relationale Operationen
ausgeführt.
8. Datenunabhängigkeitsregel (physisch):
Anwendungsprogramme bzw. Bildschirmaktivitäten bleiben in ihrer Struktur und Ausführung
unbeeinflusst von Änderungen der physischen Speicherung bzw. der Zugriffsmethoden.
24
9.
Datenunabhängigkeitsregel (logisch):
Anwendungsprogramme bzw. Bildschirmaktivitäten bleiben in ihrer Ausführung
unbeeinflusst von informationserhaltendem Aufspalten bzw. Zusammenfassen von
Relationen.
10. Integritätsregel:
Integritätsbedingungen können mit Hilfe der DML definiert werden;
ihre Speicherung erfolgt im (zentralen) Katalog.
11. Verteilungsregel:
Die Arbeit des DBBS (einschl. aller Nutzerprogramme) ist unhängig von der konkreten
physischen Verteilung der Daten auf einzelne Knoten:
a) Übergang lokal ==> verteilt,
b) Umverteilung zwischen Knoten.
12. Umgehungssperrregel:
In einer höheren Sprache beschriebene Integritätsbedingungen dürfen nicht auf tieferem
Niveau umgehbar sein; z.B.: Mehrtupelschnittstelle (multi-records-at-a-time) vs.
Eintupelschnittstelle (single-record-at-a-time)
Datenbankentwurf
1. Normalisierung relationaler Tabellen
2. Entity-Relationship-Modell (ERM)
- neutrale Darstellung hinsichtlich aller möglichen Anwendungen
- elementare Beschreibung des Diskursbereichs
=
nicht weiter auflösbare Elemente
Primitive
entities
=
Primitive der Miniwelt (Merkmalsträger)
(Dinge:
Orte, Gebäude, Geräte, Personen, ...
Ereignisse: Geburt, Unfall, Lottogewinn, ...
Abstrakte: Befugnisse, Betriebszugehoerigkeit, Ehe, ...)
- entity set
=
entities derselben Eigenschaftsart
(eindeutige Identifizierbarkeit der Entities einer Entity-Menge durch
entsprechende Eigenschaften)
25
graphische Grundelemente des ERM
Name
Entity-Menge
(entity-set)
Name
Beziehungsmenge
(relationship set)
Wertemenge
(value set)
Attribut
(attriute)
zusammengesetzte
Wertemenge
(composed
value set)
mehrwertige
Wertemenge
(multivalued
value set)
schwache oder
abhängige Entity-Menge
(weak or
dependent entity set)
schwache oder EigentumsBeziehungsmenge
(weak or ownership
relationship set)
Name
bzw.
Name
Name
Name
Name
Kardinalitäten
einfach
n:m
1:n
n:1
1:1
n:m
1:n
n:1
1:1
bedingt
nc : m
n : mc
1c : n
1 : nc
nc : 1
n : 1c
1c : 1
1 : 1c
Minimum-Maximum
nc : mc
1c : nc
nc : 1c
1c : 1c
26
( min , max ) : ( min , max )
Umsetzung eines ERD in Relationenschemata
1.
Jeder Entity-Menge E (mit mindestens 1 Nicht-Schlüssel-Attribut) entspricht ein
Relationenschema, das als Attribute alle einwertigen Attribute von E enthält. Der Identifikator
der Entity-Menge wird zum Primärschlüssel.
2.
Jeder Relationship-Menge R über den Entity-Mengen E1, E2, ..., Ek, entspricht ein
Relationenschema, das als Attribute die Identifikatoren der Ei, (1<=i<=k) enthält sowie (falls
vorhanden) die eigenen einwertigen Attribute von R. Alle Identifikatoren zusammen bilden
den zusammengesetzten (maximalen) Primärschlüssel.
PM (PERSNR, PRONR; ZEIT)
3.
Jedem mehrwertigen Attribut A entspricht ein Relationenschema, das keine Attribute außer
einem zusammengesetzten Primärschlüssel besitzt. Der Primärschlüssel besteht aus dem
mehrwertigen Attribut und dem Identifikator der Entity-Menge, zu der das mehrwertige
Attribut gehört.
BERUFE (PERSNR; BERUF)
MITARB
PERSNR
BERUF
Ausnahmen:
a) Bei schwachen (= abhängigen) Entity-Mengen müssen (ergänzend zu Regel 1) zusätzlich alle
Schlüsselattribute der übergeordneten Entity-Menge in das Relationenschema übernommen
werden. Sie werden dort zum Bestandteil des Schlüssels, so dass aus der zugehörigen
Relationship-Menge kein Relationenschema entsteht.
b) Bei 1:1- und n:1- Beziehungen kann der Schlüssel der einen Entity-Menge als Fremdschlüssel in die aus der anderen Entity-Menge (n-Seite!) entstandene Relation aufgenommen
werden. Aus der Relationship-Menge entsteht dann ebenfalls kein Relationenschema (siehe
"Reduzierung auf die unbedingt notwendigen Tabellen").
27
Umsetzungsbeispiel: ERD in Relationenschemata
über
unter
aus den Entity-Mengen entstehen:
Abteilung
(Name, Kurzbez)
Person
(PersNr, Name, Kapazitaet, PLZ, Ort, Str, Nr, Einstellung)
Auftrag
(AuftragsNr, Bez, Beginn, Termin)
Kind
(PersNr, Vorname, geb_am)
aus den Beziehungsmengen können entstehen: (mit maximalem Primärschlüssel)
Leiter
(PersNr, Kurzbez)
hat_Mitarb (PersNr, Kurzbez, seit)
leitet
(PersNr, AuftragsNr)
bearbeitet
(PersNr, AuftragsNr, Beginn, h_pro_Mon)
Gliederung (AuftragsNrUeber, AuftragsNrUnter)
aus mehrwertigen Attributen entstehen:
Taetigkeit
(PersNr, Beruf)
28
Schlüsselreduktion
Ein maximaler Primärschlüssel kann wie folgt reduziert werden auf den Mindestumfang,
wenn das Relationenschema entstanden ist aus einer
1:n- bzw. n:1-Beziehungsmenge
1:1-Beziehungsmenge
Der von der n-Seite her kommende Identifikator ist ausreichend, den Primärschlüssel zu bilden.
Der von der 1-Seite her kommende Identifikator kann als gewöhnliches Attribut behandelt
werden.
Beispiel:
Leiter
hat_Mitarb
leitet
Gliederung
Einer der beiden Identifikatoren ist ausreichend, den Primärschlüssel zu bilden.
Der von der anderen Seite her kommende
Identifikator kann als gewöhnliches Attribut
behandelt werden.
(PersNr, Kurzbez)
oder
(PersNr, Kurzbez, seit)
(PersNr, AuftragsNr)
(AuftragsNrUeber, AuftragsNrUnter)
Leiter (PersNr, Kurzbez)
Reduzierung auf die unbedingt notwendige Tabellen
Nach der Schlüsselreduktion (s.o.) haben mehrere Tabellen gleiche Primärschlüssel. Diese
Tabellen können zu je einer Tabelle zusammengefasst werden. Die Umsetzung des o.a. ERD führt
zur folgenden minimalen Menge von unbedingt notwendigen Tabellen:
Abteilung
Person
Auftrag
Kind
bearbeitet
Taetigkeit
(Name, Kurzbez, PersNr_Leiter)
(PersNr, Name, Kapazitaet, Plz, Ort, Str, Nr, Einstellung, Kurzbez, seit)
(AuftragsNr, Bez, Beginn, Termin, PersNr_leitet, AuftragsNrUeber)
(PersNr, Vorname, geb_am)
(PersNr, AuftragsNr, Beginn, h_pro_Mon)
(PersNr, Beruf)
29
Auflösung einer ternären Beziehungsmenge
Die korrekte Umsetzung einer ternären (oder noch höherwertigen) Beziehungsmenge in ein
Relationenschema kann entweder
direkt erfolgen (siehe Umsetzung eines ERD in Relationenschemata, Regel 2),
oder
die Beziehungsmenge wird ersetzt durch eine Entity-Menge, die mit den übrigen Entitymengen
durch gewöhnliche (binäre) Beziehungsmengen in Verbindung steht.
liefert (LiefNr, ArtikelNr, AuftragsNr)
X
Lieferant
Berg
Artikel
Leim
Werk
Köln
Berg
Holt
Falk
Falk
Falk
Lack
Lack
Lack
Lack
Leim
Essen
Köln
Essen
Köln
Essen
30
Entwurfsschritte
1.
Anwendungsfall in natürlicher Sprache beschreiben,
2.
Objektmengen (Entity-Mengen) festlegen,
3.
Beziehungsmengen (Relationship-Mengen) zwischen den Objektmengen festlegen,
4.
Entity-Mengen und Relationship-Mengen in einem Diagramm graphisch darstellen,
5.
Wertemengen und der Attribute festlegen,
6.
zu jeder Entity-Menge einen Identifikator festlegen,
7.
Diagramm auf Übereinstimmung mit dem Anwendungsfall überprüfen,
8.
ERD überführen in Relationenschemata,
(Netzwerkschema,
hierarchisches Schema)
Anmerkung: Vor Schritt 8 kann ein ERD stets so umgeformt werden, dass ausschließlich
Relationen in mindestens vierter Normalform entstehen.
Bedingungen:
– das ERD ist logisch widerspruchsfrei,
– das ERD ist azyklisch,
– alle funktionalen Abhängigkeiten ergeben sich ausschließlich aus den
funktionalen Abhängigkeiten innerhalb der einzelnen Entity- und RelationshipMengen
31
Datenbankentwurf mit "Power Designer"
konzeptuelles Modell
(dateiname.CDM)
Entities,
Attribute, Domains,
Beziehungen, Generalisierungen
("Vererbungen")
physisches Modell
(dateiname.PDM)
Tabellen mit Spalten,
Primär- und Fremdschlüssel,
Indextabellen,
Beziehungen,
referentielle Integritätsbedingungen
Skript
für spezifisches Ziel-DBMS,
ausführbar: DB wird generiert
Anmerkung zu Beziehungen:
– logische n:1- bzw. l:l-Beziehung
Fremdschlüssel
– logische n:m-Beziehung
Tabelle
Beziehungsmengen:
Angestellte
Abteilungen
Attribute
Attribute
.
.
.
.
.
.
Kardinalität:
n : 1
Optionalität
- jeder Angestellte gehört zu genau l Abteilung,
- jede Abteilung kann l oder mehrere Angestellte haben
abhängige Beziehung:
= referenzierende Beziehung
= weak relationship
- der Identifikator des Angestellten wird vervollständigt durch den
Identifikator der Abteilung
reflexive Beziehungen ("fish hooks"): sind möglich
Vererbung:
= Umkehrung der Generalisierung
32
referentielle Integrität
delete cascade
update cascade
Angestellte
Kinder
Attribute
Attribute
.
.
.
.
.
.
– Das Löschen eines Angestellten bewirkt das Löschen "seiner"
Kinder.
– Das Ändern des Primärschlüsselwerts eines Angestellten
bewirkt das Ändern des entsprechenden Fremdschlüsselwerts
bei "seinen" Kindern.
delete restrict
update restrict
Leser
ausgeleihene
_Bücher
Attribute
.
.
.
Attribute
.
.
.
– Das Löschen eines Lesers oder das Ändern seines
Primärschlüsselwerts ist nur erlaubt, wenn er kein Buch
ausgeliehen hat.
set null
Lieferanten
Artikel
Attribute
Attribute
.
.
.
.
.
.
– Das Löschen eines Lieferanten bewirkt die Änderung des
Fremdschlüsselwerts der zugehörigen Artikel auf den Wert
NULL.
33
Normalformen (Übersicht)
(vorläufige, verkürzte Definitionen!)
unnormalisiert
– nicht-einfache Attributwerte,
– Wiederholungsgruppen,
– Attributhierarchien
1NF
– atomare Werte,
– keine Wiederholungsgruppen,
– einfache, ebene Struktur
2NF
– Attribute sind voll funktional vom Schlüssel abhängig
3NF
– es gibt keine echt transitiven Abhängigkeiten
( BCNF
– alle Attribute hängen nur vom Schlüssel ab )
4NF
– es gibt keine mehrwertigen Abhängigkeiten
Beispiel zur Normalisierung
unnormalisierte Tabelle:
LIEFERANT
LIEFERUNG
LNR
NAME
ADR
DATUM
1
Gross
Gera
18.01.03
GELIEFERTE_TEILE
TEILE_NR
MENGE
100
5
050
6
200
3
100
4
600
7
300
6
400
5
20.01.03
2
Naumann
Nauen
18.01.03
02.02.03
LIEFERANT (LNR, NAME, ADR)
LIEFERUNG (DATUM)
GELIEFERTE_TEILE (TEILE_NR, MENGE)
erste Normalform (1NF)
Eine Relation befindet sich in der ersten Normalform, wenn
- alle Werte atomar sind,
- keine Wiederholungsgruppen bestehen
und
- keine zusammengesetzten Attribute existieren.
34
Normalisierungsregel:
unnormalisiert 1NF
Beginnend an der Baumwurzel:
1.
Primärschlüssel in die direkt untergeordnete Relation übernehmen und dort zum
Bestandteil des Primärschlüssels machen,
2.
alle nicht-einfachen Attribute in der übergeordneten Relation streichen.
LIEFERANT (LNR, NAME, ADR)
LIEFERUNG (LNR, DATUM)
GELIEFERTE_TEILE (TEILE_NR, MENGE)
LIEFERANT (LNR, NAME, ADR)
LIEFERUNG (LNR, DATUM)
GELIEFERTE_TEILE (LNR, DATUM, TNR, MENGE)
LIEFERANT (LNR, NAME,
ADR)
1 Gross
Gera
2 Naumann Nauen
GELIEFERTE_TEILE (LNR,
1
1
1
1
2
2
2
LIEFERUNG (LNR,
1
1
2
2
DATUM, TNR, MENGE)
18.01.03 100
5
18.01.03 050
6
20.01.03 200
3
20.01.03 100
4
18.01.03 600
7
02.02.03 300
6
02.02.03 400
5
35
DATUM)
18.01.03
20.01.03
18.01.03
02.02.03
Änderungsanomalien in der 1NF
PRUEFUNGEN (PRNR, FACH, PRUEFER)
Wiederholungsgruppe:
Jede Prüfung wird von
mehreren Studenten abgelegt.
STUDENTEN (MATNR, NAME, GEB, ADR, FB, NOTE)
PRUEFUNGEN (PRNR, FACH,
3
SE
4
BS
5
DB
PRÜFER)
Naumann
Hansen
Oßwald
STUDENTEN (PRNR, MATNR, NAME,
3
570
Huber
3
058
Maier
4
570
Huber
4
058
Maier
5
570
Huber
5
457
Bauer
Problem:
Anomalien:
a) Ändern:
GEB,
01.10.78
21.08.78
01.10.78
21.08.78
01.10.78
13.05.78
ADR,
XX
G
XX
G
XX
XX
FB, NOTE)
20
3
20
2
20
2
20
1
20
2
19
5
Relation STUDENTEN enthält Informationen zu den Prüfungen!
Huber zieht um:
3 Änderungen!
b) Einfügen:
neuer Student, der noch keine Prüfung abgelegt hat:
fiktive Prüfungsnummer erforderlich!
c) Löschen:
Prüfungsergebnis von Bauer soll annulliert werden:
Information über Bauer geht verloren!
zweite Normalform (2NF)
Eine Relation befindet sich in der zweiten Normalform,
- wenn sie in der ersten Normalform ist
und
- wenn jedes Attribut im Komplement eines Schlüsselkandidaten
voll funktional abhängig ist von diesem Schlüsselkandidaten.
funktionale Abhängigkeit (FD)
A und B seien Attribute (bzw. Attributmengen) einer Relation R:
R (A, B, ... )
B ist funktional abhängig von A,
wenn zu jedem Zeitpunkt jedem Wert von A nicht mehr als ein Wert von B entspricht.
Darstellung: R.A
R.B
36
Attributbeziehungen:
n:1
entspricht
1:1
entspricht
bzw.
R.A
R.B
R.A
R.A
R.B
R.B
und
R.B
R.A
volle funktionale Abhängigkeit (FFD)
A und B seien zwei verschiedene (nicht notwendig disjunkte) Teilmengen von
Attributen einer Relation R:
A = {A1, A2, ... , An}
und B = {B1, B2, ... , Bm}
Außerdem sei C = {C1, C2, ... , Cp}eine (beliebige) echte Teilmenge von A: C ⊂ A
B ist voll funktional abhängig von A
gdw.
R.A
R.B
aber
Darstellung: R.A
Beispiel:
/
R.C
R.B
R.B
STUDENTEN (PRNR, MATNR)
STUDENTEN (NOTE)
Trivialfall: Jede Relation in der 1NF ist auch in der 2NF, wenn alle Schlüsselkandidaten nur aus
je einem Attribut bestehen
Beispiel:
Funktionale Abhängigkeiten in STUDENT:
* = Annahme: Es gibt keine zwei Studenten (mit verschiedenen Matrikelnummern!), die
denselben Namen,
dasselbe Geburtsdatum und
dieselbe Anschrift haben.
STUDENTEN ist nicht in der 2NF,
da zwar
STUDENTEN (PRNR, MATNR)
aber auch
und
STUDENTEN (MATNR)
{MATNR} ⊂ {PRNR, MATNR}
37
STUDENTEN (NAME, GEB, ADR)
STUDENTEN (NAME, GEB, ADR)
Damit gilt:
STUDENTEN (PRNR, MATNR)
/
STUDENTEN (NAME, GEB, ADR)
Deshalb wird STUDENTEN aufgespaltet in
STUDENTEN2 und ABGELEGTE_PRUEFUNGEN
STUDENTEN2 (MATNR,
570
058
457
NAME,
GEB,
Huber
01.10.78
Maier
21.08.78
Bauer
13.05.78
ABGELEGTE_PRUEFUNGEN (PRNR,
3
3
4
4
5
5
ADR,
XX
G
XX
FB)
20
20
19
MATNR, NOTE)
570
3
058
2
570
2
058
1
570
2
457
5
optimale 2NF: aus einer 1NF-Relation wurde nur eine minimale Anzahl von
2NF-Relationen gebildet.
Änderungsanomalien in der 2NF
STUDENTEN_2B (MARNR,
570
058
457
869
223
916
a) Ändern:
NAME,
Huber
Maier
Bauer
Kern
Scheu
Volk
GEB,
01.10.78
21.08.78
13.05.78
04.12.77
11.01.78
01.03.79
ein neuer Dekan wird gewählt:
b) Einfügen: neuer Student:
c) Löschen:
Bauer wird exmatrikuliert:
ADR,
XX
G
XX
TT
TT
U
FB,
20
20
19
20
20
19
DEKAN,
Kunze
Kunze
Berger
Kunze
Kunze
Berger
FBNAME)
Technik
Technik
Wirtschaft
Technik
Technik
Wirtschaft
mehrere Änderungen!
bei jedem Studenten sind alle Angaben zum
Fachbereich erforderlich!
Informationen über den FB 19 gehen verloren!
38
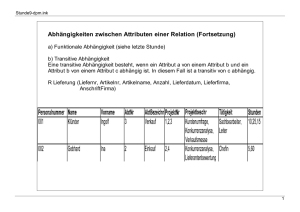
dritte Normalform (3NF)
Eine Relation befindet sich in der dritten Normalform,
- wenn sie in der zweiten Normalform ist
und
- wenn jedes Attribut im Komplement eines Schlüsselkandidaten
nicht transitiv abhängig ist von diesem Schlüsselkandidaten.
transitive Abhängigkeit
A, B und C seien Attribute (bzw. paarweise disjunkte Attributmengen) einer Relation R:
R (A, B, C, ... )
C ist transitiv abhängig von A, gdw.
R.A
R.B
R.B
R.C
Beispiel:
R.B
/
R.A
(siehe die o.a. Relation STUDENTEN_2B )
störende Transitivitäten:
1a
MATNR FB
1b
MATNR FBNAME
2a
MATNR FB
2b
MATNR DEKAN
3a
MATNR FBNAME
3b
MATNR DEKAN
FBNAME
FB
DEKAN
FB
DEKAN
FBNAME
Zerlegung in die drei Relationen
STUDENTEN3 (MATNR,
570
058
457
NAME,
Huber
Maier
Bauer
GEB,
01.10.78
21.08.78
13.05.78
ADR,
XX
G
XX
PRUEFG (MATNR, PRNR, NOTE)
570
3
3
058
3
2
570
4
2
858
4
1
570
5
2
457
5
5
FB)
20
20
19
FACHBER (FB, DEKAN, FBNAME)
20 Kunze Technik
19 Berger Wirtschaft
39
Änderungsanomalien in der 3NF
FACHBER2 (FB,
20
20
20
20
20
20
19
19
a) Ändern:
DEKAN, TEL_NR, KONTO)
Kunze
2877
053
Kunze
2222
053
Kunze
3300
053
Kunze
2877
099
Kunze
2222
099
Kunze
3300
099
Berger
5555
100
Berger
5555
304
eine Telefon- bzw. eine
Kontonummer ändert sich:
FB-Nummer ändert sich:
b) Einfügen: neuer Telefonanschluss bzw.
neue Kontonummer:
c) Löschen:
Telefonanschluss bzw.
Kontonummer wird entfernt::
Annahmen:
– Der Dekan ist über mehrere
Telefonnummern erreichbar.
– Der Dekan ist für mehrere
Haushaltskonten verantwortlich.
ggf. mehrere Änderungen (in Abhängigkeit von
der Anzahl der Konto- bzw. Telefonnummern)!
ggf. mehrere Änderungen (in Abhängigkeit vom
Produkt aus der Anzahl der Konto- und der
Anzahl der Telefonnummern)!
ggf. mehrere Tupel zufügen (in Abhängigkeit von
der Anzahl der Konto- bzw. Telefonnummern)!
ggf. mehrere Tupel zufügen (in Abhängigkeit von
der Anzahl der Konto- bzw. Telefonnummern)!
Boyce-Codd-Normalform (BCNF)
Eine Relation befindet sich in der Boyce-Codd-Normalform,
wenn alle Attribute nur vom Primärschlüssel abhängen.
vierte Normalform (4NF)
Eine Relation befindet sich in der vierten Normalform,
- wenn sie in der dritten Normalform ist
und
- wenn keine mehrwertigen Abhängigkeiten existieren.
mehrwertige Abhängigkeit (MVD)
A und B seien Attribute (bzw. Attributmengen) einer Relation R:
ti seien die Tupel dieser Relation:
R (A, B, ... ),
ti ∈ r
Für eine mehrwertige Abhängigkeit gilt:
wenn es zwei Tupel t1 und t2 gibt mit t1[A] = t2[A] ,
dann muss es ein weiteres Tupel t3 geben mit
t3 [A] = t1[A] = t2 [A]
t3 [B] = t1 [B]
t3 [Z] = t2 [Z]
wobei Z = R – AB
Darstellung:
R.A
R.B
40
MVD - Beispiel:
A
Name
B
Kind
C
Konto
Oßwald
Oßwald
Claudia
Marion
2385460
1111222
= t1 bzw. t2
= t2 bzw. t1
Oßwald
Oßwald
Claudia
Marion
1111222
2385460
= t3 A
= t3 B
aufspalten in:
R1 (Name, Kind)
und
R2 (Name, Konto)
Aufgaben:
1) Teilen Sie das o.a. Relationenschema FACHBER2 so auf, dass alle entstehenden Schemata
in der 4NF sind.
2) Tragen Sie zur Kontrolle alle Werte in diese Relationen ein.
3) Überprüfen Sie, ob die Anomalien alle beseitigt sind.
Übung "Lieferungen"
L (MatNr, Einheit, Menge, Mindestvorrat, Preis, LiefNr, LiefDat, VerfDat, Firma, Plz, Ort, Str, Nr, Tel)
(Anmerkung: Diese Übung ist schon einige Jahre alt. Inzwischen gibt es zwischen PLZ und Ort
keine funktionale Abhängigkeit mehr. Zu Übungszwecken wollen wir jedoch so verfahren als gäbe
es sie noch.)
Übung "Bibliothek"
B (Sig, Titel, Jahr, Verlag, SGNr, SG, Exemplar, Leser, Autor, Schlagwort)
41
Normierungsbeispiel "Werkzeuglieferanten"
nichtnormalisierte Relation:
Nr
Bez
Firma
Stadt
Land
Menge
231
Säge
Schwung
Schief
Stumpf
Zwick
Berlin
Burg
Celle
Aue
Berlin
Anhalt
N-Sachs
Sachsen
20
10
15
30
427
Zange
Schief
Schnapp
Burg
Köln
Anhalt
NRW
5
24
368
Beil
Ruck
Zuck
Rumms
Erfurt
Thür
Suhl
Thür
Langen Bayern
117
78
12
587
Bohrer Schwung Berlin
Zuck
Suhl
Berlin
Thür
37
78
erste Normalform (1NF):
Nr
Bez
Firma
Stadt
Land
231
231
231
231
427
427
368
368
368
587
587
Säge
Säge
Säge
Säge
Zange
Zange
Beil
Beil
Beil
Bohrer
Bohrer
Schwung
Schief
Stumpf
Zwick
Schief
Schnapp
Ruck
Zuck
Rumms
Schwung
Zuck
Berlin
Burg
Celle
Aue
Burg
Köln
Erfurt
Suhl
Langen
Berlin
Suhl
Berlin
Anhalt
N-Sachs
Sachsen
Anhalt
NRW
Thür
Thür
Bayern
Berlin
Thür
Menge
20
10
15
30
5
24
117
78
12
37
78
zweite Normalform (2NF):
Nr
Firma
231
231
231
231
427
427
368
368
368
587
587
Schwung
Schief
Stumpf
Zwick
Schief
Schnapp
Ruck
Zuck
Rumms
Schwung
Zuck
Menge
20
10
15
30
5
24
117
78
12
37
78
Firma
Stadt
Land
Nr
Bez
Schwung
Schief
Stumpf
Zwick
Schnapp
Ruck
Zuck
Rumms
Berlin
Burg
Celle
Aue
Köln
Erfurt
Suhl
Langen
Berlin
Anhalt
N-Sachs
Sachsen
NRW
Thür
Thür
Bayern
231
427
368
587
Säge
Zange
Beil
Bohrer
42
dritte Normalform (3NF):
Nr
Firma
231
231
231
231
427
427
368
368
368
587
587
Schwung
Schief
Stumpf
Zwick
Schief
Schnapp
Ruck
Zuck
Rumms
Schwung
Zuck
Menge
20
10
15
30
5
24
117
78
12
37
78
Nr
Bez
231
427
368
587
Säge
Zange
Beil
Bohrer
Firma
Stadt
Stadt
Land
Schwung
Schief
Stumpf
Zwick
Schnapp
Ruck
Zuck
Rumms
Berlin
Burg
Celle
Aue
Köln
Erfurt
Suhl
Langen
Berlin
Burg
Celle
Aue
Köln
Erfurt
Suhl
Langen
Berlin
Anhalt
N-Sachs
Sachsen
NRW
Thür
Thür
Bayern
vierte Normalform (4NF):
identisch mit 3NF
Begründung: Es existieren keine mehrwertigen funktionalen Abhängigkeiten (MVD).
43









![Aufgabe 1 [Relationale Abfragen: 30 Punkte] Aufgabe 2 [Query](http://s1.studylibde.com/store/data/006123063_1-f9bdc3ee9301ec6a3ba6f11be270bb03-300x300.png)
