Zusammenfassung ST
Werbung

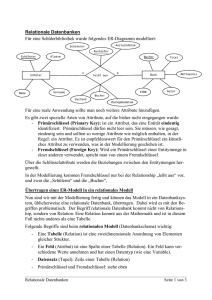
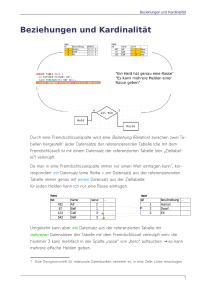
Zusammenfassung ST-Traub Inhalt 1. ERM/ERD ......................................................................................................................................... 2 1.1 Begriffe .......................................................................................................................................... 2 1.2 Aufbau ERD .................................................................................................................................... 2 Regeln und Vorgehensmuster ............................................................................................................. 4 2. Relationales Datenmodell (RDM) ........................................................................................................ 4 2.1 Unterschiede zu ERM .................................................................................................................... 4 2.2 Umsetzung ERD zu RDM ................................................................................................................ 5 2.3 Normalisierung .............................................................................................................................. 5 2.3.1 Erste Normalform ................................................................................................................... 5 2.3.2 Zweite Normalform ................................................................................................................ 6 2.3.3 Dritte Normalform .................................................................................................................. 6 3. SQL ....................................................................................................................................................... 6 3.1 SELECT ........................................................................................................................................... 6 3.2 JOIN ............................................................................................................................................... 7 3.3 CREATE .......................................................................................................................................... 7 3.4 UPDATE, INSERT, DELETE .............................................................................................................. 8 3.5 VIEW .............................................................................................................................................. 8 3.6 INDEX ............................................................................................................................................. 8 4. Embedded SQL ................................................................................................................................... 8 5. Oracle .................................................................................................................................................. 9 5.1 PL/SQL ........................................................................................................................................... 9 5.2 Rechteverwaltung unter Oracle .................................................................................................. 10 6. RDBMS ............................................................................................................................................... 10 1 1. ERM/ERD Dient der Modellierung eines Ausschnitts der realen Welt, dabei steht das Was (Sachlogik), und nicht das Wie (Technik) im Vordergrund. Das ERM ist Grundlage 1.1 Begriffe Datenmodell Legt Regeln für Datenstrukturen fest (z.B. ERD) Entität Repräsentiert ein Objekt/Ding/Vorgang/Sachverhalt aus der Wirklichkeit, der Informationen hat die in einer DB gespeichert werden können Entitätsmenge Zusammenfassung von Entitäten mit gleichen Merkmalen, aber evtl. unterschiedlichen Ausprägungen. Entitätstyp/Teilmenge Eine Menge von Entitäten mit gleichen Attributen/gleichen Ausprägungen von Merkmalen. Beziehung/Relationship Semantischer Zusammenhang zwischen zwei Dingen. Wird als Beziehungsname an Kante geschrieben. Rolle Bezeichnung für eine Teilmenge von Entitäten, die die entsprechende Beziehung eingehen (z.B. „Vorgesetzter“). Aggregation Eine „part-of“-Beziehung. 1.2 Aufbau ERD Entitätstyp Kardinalität Haus 1 wird bewohnt von n Person wohnt in Beziehungsname Beziehung/Kante 2 Rekursive Beziehung ist Vater von 1 Person n Part-of-Beziehung (Aggregation) Roboter 1 part of n Armelement Block c1 part of n Blatt Attribute RNr ANr Datum Preis Rechnung n n hat Artikel Anzahl Schlechtere Alternative RNr RNr ANr ANr Datum Preis Rechnung 1 hat n Position n hat 1 Artikel Anzahl Vererbung Person Angestellter Kind-Entitäten erben Primarykey und alle Attribute der Eltern-Entität. Die Kind-Entitäten können nur neue, eigene Attribute definieren. Kunde 3 Mehrfachbeziehungen a) = N Firmen liefern n Produkte in n Länder. Land Vorgehensweise: Die Beziehung von Entitätstyp A zu B wird an Entitätstyp C geschrieben. n a n Firma n Produkt Regeln und Vorgehensmuster Vererbung Attribute und Primärschlüssel stehen beim Eltern-Entitätstyp. Die Sub-Entitätstypen müssen mindestens ein eigenes Attribut haben. Primärschlüssel Jeder Entitätstyp benötigt einen Primärschlüssel. Fremdschlüssel Ein ERD hat keine Fremdschlüssel Historie Wird über Beziehungsattribute abgebildet (z.B. für Beziehung “hat” Attribute “von” und “bis”) Listen Werden als part-of-Beziehung realisiert (Listenteil ist Teil von Liste) Rollen Werden über mehrere Beziehungen zwischen den Entitäten abgebildet (z.B. zischen „Hotel“ und „Person“ die Beziehungen „Gast“, „Mitarbeiter“ und „Besitzer“ 4 2. Relationales Datenmodell (RDM) 2.1 Unterschiede zu ERM ERM Entität Entitätsmenge n:m-Beziehung Beziehungsattribute Mehrfachbeziehungen ERD Tupel Relation Domäne max. 1:n-Beziehung, daher n:m Join-Tabelle Fremdschlüssel neue Relation neue Relation 2.2 Umsetzung ERD zu RDM MatNr Student Student (MatNr, …) 123, … 111, … 987, … VorlNr n hört Hört (MatNr, 123, 123, 987, m VorlNr) 1 2 1 Ein ERM enthält keine Beispieldaten wie hier in der Zeichnung! 5 Vorlesung Vorlesung (VorlNr, …) 1, … 2, … 3, … 2.3 Normalisierung Ziel: Verhindern von Redundanzen und Anomalien (Widersprüche) , so dass ein RDM zur Speicherung von Daten in einer relationalen DB verwendet werden kann. Manchmal ist es sinnvoll nicht vollständig zu normalisieren, um eine höhere Performance zu erreichen oder leichtere Abfragen zu ermöglichen. 2.3.1 Erste Normalform Keine multiplen Attribute, d.h. ein Attribut kann nicht weiter (sinnvoll) zerlegt werden. Beispiel: Adresse (Johannes Degler, Weiherstr. 18. 72585 Riederich) Name (Johannes), Nachname (Degler), Straße (Weiherstr.), Nr (18), PLZ (72585), Ort (Riederich) 2.3.2 Zweite Normalform Jedes Nicht-Schlüsselattribut ist vom gesamten Primärschlüssel abhängig. Beispiel: CD_Lied (Track, CD_ID, Albumtitel, Interpret, Titel) 1 1000, Remasters, Led Zeppelin Communication Breakdown 4 1000, Remasters, Led Zeppelin Dazed and Confused Album und Interpret sind von CD_ID abhängig, aber nicht von Track Verletzung der 2NF Lösung: Auslagern von CD_ID, Interpret und Albumtitel in extra Tabelle. CD_ID bleibt weiter Teil des Primarschlüssels von CD_Lied, ist aber gleichzeit ein Fremdschlüssel. 2.3.3 Dritte Normalform Nicht-Schlüsselattribute sind nicht von anderen Nicht-Schlüsselattributen abhängig. Beispiel: CD ( CD_ID, Albumtitel, Interpret, Gründungsjahr) Das Gründungsjahr ist vom Interpreten und nicht von CD_ID abhängig, hängt also nur indirekt mit CD_ID zusammen. Lösung: Auslagern von Interpret und Gründungsjahr in extra Tabelle 6 3. SQL Datenbanksprache für relationale Datenbanken zur Manipulation von Datenbeständen. Ermöglicht Sicherung der Datenintegrität durch Primary Keys, Unique-Spalten, Check-Bedingungen, Default-Werte, Foreign Keys, On-Delete-Aktionen. 3.1 SELECT SELECT [DISTINCT] Auswahlliste FROM Quelle WHERE Where-Klausel [GROUP BY (Group-by-Attribut)+ [HAVING Having-Klausel]] [ORDER BY (Sortierungsattribut)+ [ASC|DESC]] DISTINCT Entfernen gleicher Ergebnistupel GROUP BY &HAVING Zusammenfassen von Tupeln (Aggregationsfunktion) mit GROUP BY. Mit HAVING werden Bedingungen angegeben (wie in WHERE). 3.2 JOIN Spezialfall von SELECT bei dem Daten aus mehreren Tabellen abgefragt werden. Equi-Join / Inner-Join Nennung mehrerer Tabellen bei FROM, Verknüpfung in WHERE-Bedingung. SELECT a.NAME, b.GEHALT FROM Mitarbeiter a, Gehalt b WHERE a.NR = b.NR Auto-Join / Self-Join Nur eine Tabelle mit zwei Synonymen, Verknüpfung über WHERE Natural-Join Verknüpfung automatisch über gleichnamige Spalten SELECT Name, Gehalt FROM Mitarbeiter NATURAL JOIN Teile [USING Nr] Outer-Join Wie Innter-Join (nur eben ON statt WHERE), gibt auch Zeilen aus, die auf einer Seite keine Daten haben (z.B. Lieferanten die nichts liefern). SELECT * FROM Mitarbeiter a LEFT|RIGHT|FULL OUTER JOIN Gehalt b ON a.NR = b.NR Z.B. bei LEFT: Alle linken Zeilen (Mitarbeiter) und nur die rechten Zeilen die der Bedingung entsprechen (alle Mitarbeiter, auch solche ohne Gehalt) 7 3.3 CREATE CREATE TABLE Kurs ( Nummer INT NOT NULL, ReferentNr INT NOT NULL, Beginn DATE NOT NULL, Ende DATE CHECK (Beginn < Ende), PRIMARY KEY(Nummer), FOREIGN KEY (ReferentNr) REFERENCES Referent ON DELETE RESTRICT ) NOT NULL CHECK (…) PRIMARY KEY FOREIGN KEY Einträge dürfen nicht leer sein Einträge müssen der Bedingung entsprechen Primärschlüssel (bei Angabe mehrere Spalten zusammengesetzter PK) Fremdschlüssel, muss gleichen Namen wie PK in referenzierter Tabelle haben ON DELETE: Gibt an, was passieren soll, wenn der als Fremdschlüssel in seiner Herkunfts-Tabelle gelöscht werden soll. RESTRICT Darf nicht gelöscht werden SET [NULL|DEFAULT] Auf NULL oder DEFAULT-Wert setzen CASCADE Tupel löschen. Vorsicht: Kann weitere Löschaktionen auslösen! 3.4 UPDATE, INSERT, DELETE UPDATE tabelle SET spalte = wert WHERE bedingung INSERT INTO tabelle VALUES wert1, wert2 DELETE FROM tabelle WHERE bedingung 3.5 VIEW Dritte Ebene im ANSI-SPARC-Architekturmodell (VIEW, Table, Tablespace). Bildet eine virtuelle, temporäre Ergebnistabelle. Updates sind möglich, aber nur wenn die DB die zu ändernden Daten einer Tabelle zuordnen kann. Vorteile: Logische Datenunabhängigkeit und Sicherheit CREATE VIEW name AS SELECT … 3.6 INDEX Beschleunigt Zugriff aus Schlüsselfelder (einzelne oder mehrere Spalten) durch Indexierung .# CREATE INDEX name ON tabelle (spalte1 [, spalte 2]) 8 4. Embedded SQL Einbetten von SQL-Befehlen in eine höhere Programmiersprache (Hostsprache). • • • SQL-Anweisungen und –Deklarationen werden in Schlüsselwörter eingeschlossen. Für den Datenaustausch zwischen Programm und DB werden HOST-Variablen benötigt, diese werden in der DECLARE-SECTION deklariert NULL-Werte werden über eine Indikator-Variable (int) erkannt if(indikator < 0) Ablauf Quellcode zu Programm Precompiler •erzeugt Quellcode in Sprache der Hostprogramms HostsprachenCompiler •erzeugt Objektprogramm Loader/Binder •Linkt DB-Bibliothek (herstellerspezifisch) Ausführbares Programm 9 5. Oracle 5.1 PL/SQL Proprietäre Sprache von Oracle Programmaufbau CREATE OR REPLACE PROCEDURE machwas (zahl IN INT) IS DECLARE CURSOR cur1 IS SELECT * FROM Tabelle WHERE Anzahl = zahl; rec1 Tabelle%ROWTYPE; BEGIN Deklarationsteil OPEN cur1; FETCH cur1 INTO rec1; LOOP … EXIT WHEN cur1%NOTFOUND; END LOOP; CLOSE cur1; Cursor-Handling END; Trigger Spezielle Stored Procedure die nur automatisch aufgerufen wird (bei best. Aktion gegen eine Tabelle) Kann aufgerufen werden: BEFORE|AFTER INSERT|DELETE|UPDATE [OF spaltenname] ON tabelle Zusätzlich kann FOR EACH ROW angegeben werden, dann ist ein Zugriff auf alte und neue Daten über „:OLD“ bzw. „:NEW“ möglich (natürlich nur wenn sinnvoll, z.B. kein :OLD bei INSERT). 5.2 Rechteverwaltung unter Oracle Rechtevergabe erfolgt an Benutzer, Rolle oder Alle (Public). Ein Benutzer bzw. eine Rolle wird mit CREATE USER, ALTER USER und DROP USER bzw. CREATE ROLE,… Mit GRANT erfolgt die Zuordnung von Rollen zu Benutzern, aber auch von Rechten zu einer Rolle oder zu einem Benutzer: - GRANT administratorrolle TO testbenutzer - GRANT INSERT ON tabelle TO administratorrolle Mit REVOKE wird eine Zuordnung wieder aufgehoben. 10 6. RDBMS Eine DB ist in drei Schichten zu betrachten: Interne Ebene: TABLESPACE Ort an dem Tabellen und andere DB-Objekte gespeichert werden. Die Speicherverwaltung (Memory Harddisk) wird vom Betriebssystem oder von der DB übernommen. Konzeptionelle Ebene: TABLE Abbildung der internen auf die externe Ebene und umgekehrt. Z.B. die physisch gespeicherten Daten als Tabelle. Externe Ebene: VIEW Physisch nicht vorhandene, zur Laufzeit erstellte Sichten auf Daten (nicht nur View, sondern z.B. auch die Sicht auf die Daten durch eine Anwendung). 11