Kein Folientitel - Hochschule Flensburg
Werbung

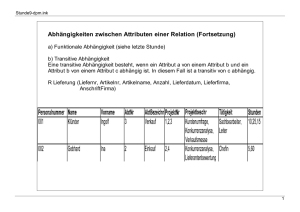
Datenbanken Diplomanden-Seminar [2 Tage] Prof. Dr. Wolfgang Riggert Lernziele Grundlegende Kenntnisse zu Datenbanken anschaulich darstellen können. [Wiederholung wichtiger Begriffe] Relationale Datenbanken ausgehend von einem betrieblichen Anwendungsprofil sicher konzipieren können. [Erstellung von ER-Modellen] Die Abfragesprache SQL im Hinblick auf Datendefinitionen anwenden und bezüglich Datenmanipulationen sicher beherrschen. [Interpretation und Entwicklung einfacher und komplexer Befehle] Klausur-Anforderungen Detailfragen [5 Fragen, zusammen maximal 30 P] Die Einordnung des Themas, die kausalen Zusammenhänge und die Gesamteinschätzung in vollständigen Sätzen darstellen. Faktenwissen kann in Form von Aufzählungen präsentiert werden. Wenn möglich: Ergänzung und Veranschaulichung der Texte durch Grafiken und Tabellen. Komplexaufgaben [2 von 3 Aufgaben, jeweils maximal30 P] Schwerpunktthema - es werden mehrere Fragen zu einem Thema gestellt. Ausführlich beschreiben analysieren und begründen, Wissen auf den Fall übertragen, Eigene Vorschläge entwickeln, Systematische Bearbeitung/ systematische Gliederung. Zusammenhängend formulieren; Faktenwissen in Form von Aufzählungen. Datenbanken: Einführung Einsatzbereiche von Datenbanken Leistungsmerkmale von Datenbanken Begriffsbestimmungen Anwendungsprogramm und DBMS Datenunabhängigkeit beim Drei-Ebenen-Modell Datenintegrität Einsatzbereiche von Datenbanken Als Basis eines betrieblichen Informationssystems [Ganzheitlicher Ansatz] Als Subsystem [Nur bestimmte Unternehmensteile oder Funktionsbereiche werden mit Datenbanken unterstützt] Externe Datenbanken [Zum Beispiel Adressen-Datenbanken, Bezugsquellennachweise, wissenschaftliche Dokumentendatenbanken] Leistungsmerkmale von Datenbanken Unabhängigkeit von Daten und Programm Verringerung beziehungsweise systematische Kontrolle der Redundanz Leistungsfähige Konsistenzprüfungen [zum Beispiel Überprüfung, ob alle Rechnungen bezahlt sind, bevor die Daten eines Kunden gelöscht werden.] Flexible Verknüpfungen und Auswertungen [Die Nutzer können eigene Auswertungen realisieren – es besteht keine Abhängigkeit von der hausinternen EDV-Abteilung] Mehrfachzugriff auf die Daten [durch viele Nutzer und unterschiedliche Programme] Umfassender Zugriffsschutz [Bis auf Feldebene und differenziert nach der Art der Operation] Hohe Ausfallsicherheit [durch integrierte Mechanismen zur Rekonstruktion der Daten] Datenbanken versus Dateisystem Probleme von Datenbanken Die hohen Anforderungen bezüglich Sicherheit und Zuverlässigkeit sind zeit- und kostenintensiv Zugriffe können über mehrere Tabellen erfolgen, was längere Laufzeiten verbunden mit vielen Ein- und Ausgaben und einer hohen Rechenleistung zur Folge hat. Datenbanken sind in den meisten Fällen nicht portabel, was Hardwareänderungen oder Softwareanpassungen - z.B. aufgrund unterschiedlicher SQL-Dialekte - erforderlich macht. Ziele der Datenorganisation Unter Datenorganisation versteht man Verfahren, um Daten hinsichtlich ihrer logischen Zusammenhänge zu analysieren, zu strukturieren und zu ordnen - logische Datenorganisation auf Medien abzulegen und für den Zugriff verfügbar zu halten physische Datenorganisation Ziele schneller Datenzugriff leichte Aktualisierbarkeit beliebige Auswertbarkeit flexible Verknüpfung wirtschaftliche Speicherausnutzung Vermeidung von Redundanzen Datei, Datensatz, Datenelement Datenbank Projekte Dateien Kunden Aufträge Projektorganisation Personal Datensatz Mitarbeiter n Mitarbeiter 1 Name Datensegment Datenelement Nr Nachname Anschrift Vorname Titel PLZ Ort Straße Gehalt Qualifikation Logische Datenorganisation Hierarchischer Aufbau/ Gliederung Datenelement Datensatz Datei Datenbank Datenelement kleinste nicht weiter zerlegbare logische Einheit entspricht einem Datenfeld einer Bildschirmmaske Datensatz Zusammenfassung von Datenelementen entspricht einer Gruppe logisch zusammengehöriger Datenfelder wie z.B. Name oder Adresse Datensatzarten Formatierte Sätze: sie besitzen eine feste Einteilung in Datenelemente mit festen Feldgrenzen entsprechend einer tabellarischen Strukturierung Variable Sätze: sie besitzen keine Strukturierung, sondern die Datenelemente werden fortlaufend erfasst und durch ein oder mehrere Trennsymbole unterschieden Wertung : Formatierte Datensätze gestatten einen schnellen Zugriff, führen aber zu einer unwirtschaftlichen Speicherausnutzung Variable Datensätze hingegen sind langsam im Zugriff, nutzen den Speicher aber effizient aus konkurrierende Ziele Datei- versus Datenbankorganisation Datei Zusammenfassung gleichartiger, logisch zusammengehörender Datensätze Dateien erlauben mehrere Operationen: Suchen, Ändern, Einfügen und Entfernen von Datensätzen Datenbank Zusammenfassung mehrerer Dateien zwischen denen logische Abhängigkeiten existieren und die von einem eigenen Datenbankverwaltungssystem verwaltet werden. Datei- und Datenbankanwendungen Anwendungsprogramm und DBMS Anwendungssysteme Datenbankverwaltungssysteme Datenbestände DBMS: Datenbankmanagementsystem • Bereitstellung der Daten für verschiedene Anwendungsprogramme • Koordination von parallelen Zugriffen auf die Datenbestände • Schaffung der Voraussetzungen für flexiblen Datenzugriff und unterschiedliche Sichtweisen. DBMS - Positionierung Datenunabhängigkeit beim Drei-Ebenen-Modell Externe Ebene Logische/ Konzeptionelle Ebene Interne Ebene Logische Datenunabhängigkeit. Es können neue externe Sichten angelegt werden, ohne dass die logische Ebene modifiziert werden muss. Physische Datenunabhängigkeit. Es erfolgt eine Trennung zwischen der logischen Ebene und den Daten beziehungsweise den ZugriffsMechanismen. Datenintegrität Datenintegrität: Alle Aspekte, die das korrekte und zuverlässige Arbeiten mit Datenbanken sicherstellen und unterstützen Datenkonsistenz Datensicherheit Datenschutz Inhaltliche Richtigkeit Sicherung der Daten gegen Verlust und zulässige Änderung Schutz der Daten gegen unberechtigten Zugriff Freiheit von Widersprüchen Betrifft das logische Datenschema Betrifft den technischorganisatorischen Betrieb Betrifft den technischrechtlichen Umgang mit Daten Datenmodelle Arbeitsschritte zur Entwicklung einer Datenbank Das semantische Datenmodell Logische Datenmodelle Bedeutung der Datenmodell am Markt Arbeitsschritte zur Entwicklung einer Datenbank Realität Semantisches/ Logisches Konzeptionelles Datenmodell Datenmodell DatenbankDefinition Anwendungsentwicklung Physische Datenorganisation Systemdenken. Betrachtung eines Ausschnitts der Realität mit einer spezifischen Fragestellung. Semantisches Datenmodell. Dargestellt als ER-Diagramm. DatenbankDefinition/ Beschreibung. Einsatz des DDL des eingesetzten Datenbankverwaltungssystems. Anwendungsprogramm. Definition der externen BenutzerSichten. Physische Datenorganisation. (Speicher- und Datenorganisation, Zugriffsmethoden, Reorganisation etc.) Logisches Datenmodell. Umsetzung des semantischen Modells in ein logisches Datenmodell. 4-Schema-Konzept Konzeptionelles Schema: Beschreibung des Datenbankinhaltes unabhängig von der technischen Umsetzung, d.h. fachliche Anforderungen der Anwender unabhängig von der Implementierung Logisches Schema: Inhaltsbeschreibung auf der Grundlage der DDL eines bestimmten DBMS Internes Schema: Inhaltsbeschreibung und die physische Datenablage Externes Schema: Darlegung der Benutzersicht = spezifische Ausschnitte des konzeptionellen Schemas Häufig werden die konzeptionelle und die logische Sicht als Einheit betrachtet, so dass ein 3-Schema-Modell entsteht Drei-Ebenen-Architektur Datenmodellierung Ausschnitt der realen Miniwelt Manuelle/intellektuelle Modellierung Konzeptuelles Schema (ER-Schema) Transformation Relationales Schema Netzwerk Schema Objektorientiertes Schema Konzeptionell Datensicht - Semantisches Datenmodell Ziel des konzeptionellen Modells ist es, ein normalisiertes, redundanzfreies Datenmodell zu erstellen 1. Erfassung und Beschreibung aller relevanten Objekte und zwischen ihnen bestehender Beziehungen sowie Darstellung dieser Objekte und Beziehungen (ER-Modell) 2. Umsetzung des konzeptionellen Modells in ein logisches Datenbankmodell – hierarchisch, Netzwerk oder relational 3. Beschreibung der Objekte und Beziehungen mit der Datenbeschreibungssprache Konzeptionelles – logisches Datenschema Ein konzeptionelles Datenschema ist eine systemunabhängige Datenbeschreibung Ein logisches Datenschema beschreibt die Daten in der Datenbeschreibungssprache DDL eines bestimmten DBMS Modellierungsphasen Datenbankentwurf Entwurf der Tabellen Spaltennamen Spaltendatentypen Integritätsregeln Beziehungen zwischen den Tabellen festlegen referentielle Integrität Verteilung der Datenbank im Netz auf Platten Tuningvorkehrungen Festlegung der Benutzersichten und Zugriffsrechte Datenbankarchitektur Externes Schema/ RaumbeBenutzersicht legung konzeptionelles Schema Prüfungsliste Prüfung Prüfungsaushang Aufsicht Prüfungsfach internes Schema Aufsichteneinteilung ERM Dozent Basistabellen Basistabellen DBMS ER-Diagramm Softwarehaus ER-Diagramm – relationales Modell Student (0,m) belegt (0,n) Mtnr Name SemGr Adresse Student ( Mtnr, Name, SemGr, Adresse) Vorlesung( Vorlnr, Fach, Semester, Raum, Zeit) Belegung (Mtnr, Vorlnr) Vorlesung Vorlnr Fach Semester Raum Zeit Traditionelle Datenbeschreibungen Dateien: Die Anfänge der Datenverarbeitung bilden große Datenstrukturen, die eine Ansammlung von Datensätzen waren und die sequentiell abgelegt wurden. Hierarchien: Diese Struktur wird in Baumform abgebildet, erlaubt damit eine Gliederung der Datenmenge in einer Ordnungsbeziehung Netzwerke: Sie entstehen dadurch, dass ein Strukturelement nicht nur Mitglied einer einzigen, sondern gleichzeitig mehrerer Gruppen ist. Die Baumstruktur in reiner Form wird durch ein Netz aufgelöst, da es kein eindeutiges „Root-Element“ mehr gibt Logische Datenmodelle: klassische Formen Baumstruktur Netzstruktur Baumstruktur beim hierarchischen Datenmodell Kunde Müller Auftrag 711 Auftragsposition 1 Auftrag 823 Auftrag 925 Auftragsposition 2 • Entwicklung erfolgte auf Basis klassischer Dateisysteme • Die Darstellung erfolgt in Form einer Baumstruktur. Das „Wurzelobjekt“ ist oben. Problembereiche des hierarchischen Modells Die reale Welt ist nicht immer hierarchisch strukturiert. Deshalb können mit diesem Modell nicht alle Strukturen abgebildet werden. Mit hierarchischen Modellen lassen sich nur 1:1 und 1:nBeziehungen abbilden. Jede m:n-Beziehung muss in 1:nBeziehungen aufgelöst werden. Dies führt zu redundanter Datenhaltung. Änderungen von Hierarchiebeziehungen sind aufwendig. Es entsteht ein großer Aufwand bei Auswertungen, die von hierarchischen Zugriffspfaden abweichen. Struktur des Netzwerkmodells Kunde 1 ordert mc Artikel mc liefert 1 Lieferant mc liegt auf 1 Lagerort • Jedes Objekt kann mehrere Vorgänger und mehrere Nachfolger aufweisen. • Damit können 1:1, 1:m, m:1 und n:m-Beziehungen abgebildet werden. Problembereiche des Netzwerkmodells Einsatzbereiche. Heute werden nur noch wenige Datenbankverwaltungssysteme eingesetzt, die auf Netzwerkmodellen basieren. Vorteile. Die Abbildung vielfältiger Beziehungen, auch von m:n-Beziehungen, ist möglich. Gegenüber dem hierarchischen Modell verringern sich hierbei die Redundanzen. Nachteile. Die Verarbeitung von Daten ist aufwendiger als bei hierarchisch strukturierten Modellen; Die Änderung der Datenstruktur ist aufgrund der zahlreichen Verknüpfungen sehr aufwendig. Logische Datenmodelle - Tabelle FNR FNR FNAME FNAME FSEM FSEM DAUER DAUER TAG TAG ZEIT_VON ZEIT_VON ZEIT_BIS ZEIT_BIS ZAHL ZAHL 1 21 32 43 54 65 76 87 98 10 9 10 11 11 12 12 12 12 Grundlagen der Betriebswirtschaftslehre Grundlagen der Betriebswirtschaftslehre Finanzund Investitionswirtschaft Finanzund Investitionswirtschaft Marketing Marketing Materialund Fertigungswirtschaft Material- und Fertigungswirtschaft Personalführung Personalführung Buchführung und Bilanzierung Buchführung und Bilanzierung Kostenund Leistungsrechnung Kostenund Leistungsrechnung Wirtschaftsmathematik Wirtschaftsmathematik Betriebsstatistik Betriebsstatistik Grundlagen der Volkswirtschaftslehre Grundlagen der Volkswirtschaftslehre Wirtschaftsprivatrecht Wirtschaftsprivatrecht Englisch 1 Englisch 1 1 Französisch Französisch 1 2B 42BB 4 4BB 4 4BB 44BB 2 4BB 42BB 24BB 2 2BB 2 2BB 42BB 2 4BB 2 2BB 2B 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 60 60 60 60 08.07.1993 08.07.1993 15.07.1993 15.07.1993 14.07.1993 14.07.1993 09.07.1993 09.07.1993 08.07.1993 08.07.1993 09.07.1993 09.07.1993 13.07.1993 13.07.1993 12.07.1993 12.07.1993 14.07.1993 14.07.1993 13.07.1993 13.07.1993 12.07.1993 12.07.1993 24.06.1993 24.06.1993 24.06.1993 24.06.1993 830 830 830 830 1130 1130 1100 1100 1400 1400 830 830 1330 1330 830 830 830 830 830 830 1130 1130 830 830 1330 1330 1000 1000 1000 1000 1300 1300 1230 1230 1530 1530 1000 1000 1500 1500 1000 1000 1000 1000 1000 1000 1300 1300 930 930 1430 1430 320 320 200 200 250 250 200 200 160 160 380 380 200 200 320 320 360 360 320 320 180 180 290 290 40 40 Sichten Anwender Anwender Tabelle Tabellenzeile Tabellenspalte Tabellenelement Tabellenüberschrift Spaltenbezeichnung Informatik Informatik Datenobjekt Entität Wertebereich Attributswert Entitätstyp Attribut (Eigenschaft) Datenverarbeitung Datenverarbeitung Datei Datensatz Datenfeld Datenelement Datenfeldbezeichnung Datenfeld Mathematik Mathematik Relation Tupel Domäne Wert Attribut Begriffe des relationalen Datenmodells [01] Bei neueren Datenbankverwaltungssystemen hat sich das relationale Datenmodell [auch Relationenmodell] durchgesetzt. Es wurde 1968 bis 1973 von E.F. CODD entwickelt und 1970 veröffentlicht. Entitätstypen werden in Form von zweidimensionalen Tabellen dargestellt. Die Tabellen können beliebig viele Entitäten beinhalten. Die Tabellen, die über einen Primärschlüssel verfügen, werden als Relationen bezeichnet. Begriffe des relationalen Datenmodells [02] Innerhalb der Tabelle ist die Reihenfolge der Attribute und der Tupel beliebig. Die Datenbasis eines Datenbanksystems wird gemeinsam durch alle Relationen gebildet. Beispiele für Datenbankverwaltungssysteme auf Basis des Relationenmodells: Oracle, Ingres, MS-Access, Interbase, DB2, Adabas, Informix, Progress, Sybase, MS-SQL, My-SQL. Begriffe des relationalen Modells [03] Tabelle: Relation; Entitätstypen Tabellenkopf: Name der Relation R. KUNDEN KundenNr Name Wohnort 1000 Detmer Hamburg 1001 Friedrich Lübeck 1002 Berg Rendsburg 1003 Müller Buchholz 1004 Schmidt Flensburg Domäne: Wertebereich - Zusammenfassende Darstellung aller möglichen Attributwerte eines Attributs Attribute: Spalte Attributwert: Datenfeld Entität: Zeile; Tupel; Datensatz Primärschlüssel und Fremdschlüssel R. KUNDEN KundenNr Beziehung Name Wohnort R. Rechnungen Nichtschlüsselattribut RechnNr Betrag KundenNr Primärschlüssel NichtFremdschlüssel Schlüsselattribut 1000 Detmer Hamburg 1001 Friedrich Lübeck 1002 Berg Rendsburg 7765 117,75 1000 1003 Müller Buchholz 7766 188,20 1003 7767 25,82 1000 7768 733,20 1000 Primärschlüssel Logischer Datenbankentwurf auf Basis des relationalen Modells Unterschiedliche Vorgehensweise Ziele der Normalisierung Funktionale und transitive Abhängigkeit Probleme unnormalisierter Relationen Arbeitsschritte der Normalisierung Ergebnisse der Normalisierung Aufgaben der Normalisierung Vermeidung von Redundanzen Vermeidung von Anomalien Vermeidung von Null-Werten Sicherung der Daten-Integrität Optimierte Speicherplatz-Ausnutzung Prozess der Normalisierung Daten in 3 NF-Form Prozess der Normalisierung AusgangsRelation R.Rechnung Unnormalisierte Form der Daten: Alle Daten befinden sich in einer Tabelle, unabhängig von ihren Beziehungen. Name Wohnort Strasse Art ... ..... .... ..... Von der Ausgangsrelation zur 3NF-Form 3 NF Dritte Normalform Daten in 3 NF-Form 2 NF Zweite Normalform 1 NF Erste Normalform AusgangsRelation R. Rechnung Die Daten der Ausgangsrelation werden im Rahmen der Normalisierung durch schrittweise Zerlegung in mehrere Relationen aufgeteilt. Informationsverluste dürfen dadurch nicht entstehen. Bedingungen der Normalformen Dritte Normalform (3 NF) Die Relation muss sich in der 2 NF befinden Alle Nicht-Schlüsselattribute müssen direkt vom Primärschlüssel abhängig sein. Zweite Normalform (2 NF) Die Relation muss sich in der 1 NF befinden Jedes Nicht-Primärschlüsselattribut muss von allen Teilen des Primärschlüssels abhängig sein. Erste Normalform (1 NF) Attribute müssen atomar sein. Es dürfen keine Wiederholungsgruppen auftreten Jede Relation hat einen Primärschlüssel. Dieser identifiziert jedes Tupel eindeutig. Funktionale Abhängigkeit Drei Formen von Abhängigkeiten werden unterschieden. Diese drei Varianten sind Basis des Normalisierungsprozesses und entsprechen den Normalisierungsformen. Funktionale Abhängigkeit: Funktional abhängig sind Attribute einer Relation, die sich nicht unabhängig voneinander ändern können. Das Attribut A heißt funktional abhängig vom Schlüssel S, wenn genau zu jedem Wert von S ein Wert von A gehört. Beispiel: S = Fahrgestell-Nr. und A = Halter => eine Fahrgestell-Nr. ein Halter aber ein Halter kann viele Fahrgestell-Nr. besitzen Volle funktionale Abhängigkeit Volle funktionale Abhängigkeit: Voll funktional abhängig sind Attribute immer dann, wenn mit einer bestimmten Wertekombination zweier oder mehrerer unabhängiger Attribute genau ein Wert des abhängigen Attributes einhergeht. Ein Attribut A heißt voll funktional abhängig wenn zu jeder zulässigen Wertekombination des zusammengesetzten Schlüssels genau ein Wert des Attributes A gehört Beispiel: Automodell (S1) Typ (S2) Preis (A) Mazda 626 Fließheck 15 000 € Mazda 626 Kombi 17 000 € Transitive Abhängigkeit Transitive Abhängigkeit: Diese Form beschreibt indirekte Abhängigkeiten zwischen Nichtschlüsselattributen. Attribut B heißt transitiv abhängig, wenn Attribut A von Schlüssel S, aber S nicht von A funktional abhängt, B jedoch von A funktional abhängig ist. Beispiel: Art und Ausstattung eines Zimmers bestimmen den Preis. Alle Attribute sind Nichtschlüsselattribute der Relation Zimmer, die Zimmer-Nr als Schlüssel hat. Beispiel: Daten normalisieren 1. Normalform Eine Relation ist in der 1. Normalform, wenn kein Attribut enthalten ist, zu dem es pro Datensatz mehrere Attributswerte geben kann, d.h. wenn in jeder Zeile und Spalte nur atomare, nicht weiter zerlegbare Werte gespeichert werden. Auftrag (Aufnr, Artikelnr, Artikelbezeichnung, Menge, Preis, Kundennr, Kundenname, Adresse, Datum) Auftrag Bestellartikel (Aufnr, Kundennr, Kundenname, Adresse, Datum) (Aufnr, Artikelnr, Artikelbezeichnung, Menge, Preis) Primärschlüssel Zusammengesetzter Schlüssel Beispiel: Daten normalisieren 1. Normalform Als Beispiel sollen die Tourendaten verwendet werden. Die Tabelle Tourendaten genügt nicht der 1. NF, da die dritte Spalte noch weiter aufgeteilt werden könnte. Die geteilten Tabellen und entsprechende Beziehung zueinander erfüllt die 1. NF Tourendaten TourenZiele TourenTermine (TourendatenNr, Bezeichnung, Länge, Termine) (TourenNummer, Tour, Kurzbeschreibung,Länge, Grad, Start, Ziel) (TourTerminNr, TourenNummer, Beginn, Ende , MaxTeilnehmer) Primärschlüssel Zusammengesetzter Schlüssel Beispiel: Daten normalisieren 2. Normalform Gilt nur bei zusammengesetztem Primärschlüssel! Eine Relation ist in der 2. Normalform, wenn sie in der 1. Normalform ist und keine Attribute enthält, die in einer 1:1 Beziehung zum Primärschlüssel oder Teilen des Primärschlüssels stehen, d.h. jede Spalte die nicht zum Primärschlüssel gehört, ist vom kompletten PS abhängig. Auftrag Bestellartikel (Aufnr, Kundennr, Kundenname, Adresse, Datum) (Aufnr, Artikelnr, Artikelbezeichnung, Menge, Preis) Auftrag Bestellartikel Artikel Preis (Aufnr, Kundennr, Kundenname, Adresse, Datum) (Aufnr, Artikelnr, Menge) (Artikelnr, Artikelbezeichnung) (Artikelnr, Preis) Beispiel: Daten normalisieren 3. Normalform Eine Relation ist in der 3. Normalform, wenn sie in der 2. Normalform ist und keine Attribute enthält, die untereinander abhängig sind. Auftrag Bestellartikel Artikel (Aufnr, Kundennr, Kundenname, Adresse, Datum) (Aufnr, Artikelnr, Menge) (Artikelnr, Artikelbezeichnung, Preis) Auftrag Kunde Bestellartikel Artikel (Aufnr, Kundennr, Datum) (Kundennr, Kundenname, Adresse) (Aufnr, Artikelnr, Menge) (Artikelnr, Artikelbezeichnung, Preis) Daten integrieren Auftrag Kunde Anschrift Bestellartikel Artikel Preis (Aufnr, Kundennr, Datum) (Kundennr, Kundenname) (Kundennr, Adresse) (Aufnr, Artikelnr, Menge) (Artikelnr, Artikelbezeichnung) (Artikelnr, Preis) Auftrag Kunde Bestellartikel Artikel Auftrag 1:n Kunde 1:1 1:n Bestellartikel Anschrift n:1 Artikel (Aufnr, Kundennr, Datum) (Kundennr, Kundenname, Adresse) (Aufnr, Artikelnr, Menge) (Artikelnr, Artikelbezeichnung, Preis) 1:1 Preis Wesentliche Merkmale von Transaktionen Atomarität [Atomicity] Eine Transaktion wird nur vollständig ausgeführt oder gar nicht. Konsistenz [Consistency] Eine Transaktion ist eine konsistenzerhaltende Operation. Isoliertheit [Isolation] Andere gleichzeitig ablaufende Transaktionen haben keinen Einfluss auf das Ergebnis einer aktiven Transaktion. [Erforderlich für reibungslosen Mehrbenutzerbetrieb] Mehrere gleichzeitig ablaufende Transaktionen haben das gleiche Resultat, als hätten sie nacheinander stattgefunden. Dauerhaftigtkeit [Durability] Änderungen, die durch Transaktionen bewirkt wurden, können nicht mehr verloren gehen. [Siehe auch: Matthiesen, G. u. M. Unterstein (2000): Relationale Datenbanken und SQL. Konzepte der Entwicklung und Anwendung. 2. Aktualisierte Auflage. München. S. 228] Datenbanken und Objektorientierung Grenzen des Relationalen Modells. Anfang der 80er Jahre wurde deutlich, dass für einige Anwendungsgebiete das relationale Datenmodell nicht optimal ist: Karthografische Anwendungen Multimedia-Anwendungen CAD-Datenbanken Dokumentenverwaltungssysteme Ablauf der Diskussion. Zunächst wurde Konzepte zur Erweiterung des relationalen Datenmodells entwickelt. Ab 1985 erschienen Arbeiten zu objektorientierten Datenbanksystemen. Standardisierung objektorientierter Datenbanken Früher Start. Seit 1993 versuchen Vertreter verschiedener Softwarehäuser einen Standard für OO-Datenbanken zu etablieren. Bildung der Gruppen ODMG (Object Database Management Group) und OMG (Object Management Group). Veröffentlichung in: [Catell, R.G. (1997): Object Database Standard ODMG 2.0. Zusammenarbeit mit Gruppen, die andere Standards erarbeiten. [ANSI X3H2: SQL3; ANSI X3H7: Object Information Management; ANSI X3J16: C++] Kein Industriestandard. Das veröffentlichte Konzept bildet noch keinen Industriestandard oder gar eine Norm. Begriffe zum Thema Datenbanken Entitätsintegrität Referentielle Integrität Datenbankentwurf Entitätsintegrität Jede Relation muss über ein Schlüsselattribut verfügen, das die Tupel eindeutig identifiziert. Dieser sogenannte Primärschlüssel kann aus einem einzelnen Attribut oder einer Kombination von Attributen bestehen. Referentielle Integrität Aus jeder im Rahmen der Normalisierung gebildeten Form der Daten müssen die in der unnormalisierten Ausgangsrelation vorhandenen Informationen wieder rekonstruiert werden können. Die Referentielle Integrität einer Datenbank wird durch das Einfügen von Fremdschlüssel sichergestellt. Die DBMS stellen sicher, dass für jedes Fremdschlüsselattribut ein entsprechendes Primärschlüsselattribut vorhanden ist. Operationen, die ausgeführt werden sollen, wenn diese Bedingungen nicht erfüllt sind, werden zurückgewiesen oder aber es ist eine Reihenfolge der Operationen einzuhalten. vom DBMS vorgegebene Wertebereich und referentielle Integrität Die referentielle Integrität ist eine Konsistenzbedingung, die verlangt, dass die Fremdschlüsselwerte in einer Relation nur Tupel referenzieren, die tatsächlich zur Zeit existieren. Beispiele: Einfügen oder Ändern einer Kunden-Nr in Vermietung nur für Gäste, die in Relation Gast aktuell eingetragen sind. Löschen eines Zimmers in der Relation Zimmer, das noch vermietet ist, d.h. einen Eintrag in Vermietung hat. Wertebereich und Fremdschlüssel – Strukturregel Jedes globale Attribut darf nur in einer einzigen Relation auf einem statischen Wertebereich basieren und muss in dieser Relation Primärschlüssel sein (Beispiel Attribut Zimmer-Nr in Relation Zimmer). In allen anderen Relationen muss es sich auf einen dynamischen Wertebereich stützen, d.h. als Fremdschlüssel in einer anderen Relation fungieren Lokale Attribute können im Rahmen ihres Wertebereichs beliebig verändert werden – globale Attribute können als Fremdschlüssel in einer anderen Relation auftreten und dort dynamisch verändert werden, z.B. Zimmer-Nr in Vermietung Strukturregel Rekursive Beziehungen zwischen Relationen sind verboten Ein globales Attribut in einer Relation darf nur mit einem solchen Fremdschlüssel gebildet werden, dessen Ausgangsrelation unabhängig von dieser Relation definiert werden kann Überlappungen Überlappungen von Entitätsmengen können drei Formen annehmen: Zugelassene Überlappungen – EM 2 und EM 3 überdecken sich teilweise und liegen vollständig in EM 1 (Strukturregel 2) Disjunkte aber vollständige Überdeckung von EM 1 durch EM 2 und EM 3 Disjunkte Überdeckung – EM 2 und EM 3 haben keine Gemeinsamkeiten, liegen aber vollständig in EM 1 Beispiel für 1: Personen einer Hochschule EM 1, Doktoranden EM 2 und Sudierende EM 3, EM 2 und EM 3 haben eine Schnittmenge aber füllen alle Personen einer Hochschule nicht aus, weil es noch Angestellte gibt Überlappungen - graphisch EM 2 EM 3 EM 1 EM 2 EM 2 EM 1 EM 3 EM 1 EM 3 Arten von Konsistenzbedingungen Strukturgestützte Konsistenzbedingungen sind Regeln, die mit den Sprachelementen des Entwicklungs- und Datenbanksystems dargestellt werden Strukturexterne Konsistenzregeln gehen über die Strukturgestützten hinaus und werden in Programmiersprachen ausgedrückt, z.B. Plausibilitätsprüfungen bei der Dateneingabe Die Unterscheidung ist abhängig von den verfügbaren Sprachelementen und Entwurfsmethoden Konsistenzbedingungen des Relationenemodells Für das Relationenmodell sind folgende strukturgestützten Bedingungen wichtig: Einhaltung der Wertebereiche Eindeutigkeit der Primärschlüssel Referentielle Integrität Kaskadierung Kaskadierungen sind eine Folge der referentiellen Integrität. Sie beschreiben die konsistenzbedingten Auswirkungen von Änderungen auf Entitäten anderen Entitätsmengen Beispiel: Löschen eines Bibliotheksnutzers Löschen aller Ausleihen, aller Sperren, aller Vormerkungen Entwurfsphasen 1 1. Abstecken des Problems und seines Umfeldes – Beschreiben des Arbeits- und Organisationsgebietes: Benötigt wird ein datenbankgestütztes System zur Verwaltung von Gästen und Zimmern eines Hotels. Die Zimmer werden durch eine Zimmernummer bezeichnet, die Gäste können ein Kürzel zugewiesen bekommen. 2. Bildung von Entitätsmengen: Zimmer und Gäste sind unterschiedliche Bestandsdaten 3. Festlegung von Beziehungen: Verknüpfung der einzelnen Entitätsmengen Entwurfsphasen 2 4. Definition von Primärschlüsseln: Festelegung der Merkmale, die die Entitätsmenge eindeutig identifizieren 5. Globale Normalisierung: Ersetzen nicht-hierarchischer und rekursiver Beziehungen durch hierarchische Beziehungen (1:1, 1:n, 1:c) 6. Definition der Lokalattribute: Festlegung der Attribute pro Relation. Dazu gehören lokale Attribute mit statischem Wertebereich als auch Globalattribute in Form von Fremdschlüsseln Entwurfsphasen 3 7. Bereinigung von Konsistenzbedingungen: Überprüfung der eingefügten Konsistenzbedingungen und Einführung zusätzlicher Konsistenzprüfungen 8. Transaktionskonzept: Überlegungen, welche Abläufe notwendig sind und welche Benutzergruppe welche Aktionen ausführen darf. Der Ablauf ist iterativ. So sind Erweiterungen und Verfeinerungen möglich, die einen erneuten Durchlauf einzelner Phasen erzwingen Aspekt der Langlebigkeit Kernaufgabe der DB: Datenbestände effizient, sicher und dauerhaft aufzubewahren. Problem: Die Nutzdaten werden permanent und effizient aktualisiert, ergänzt oder gelöscht. Das Datenschema bleibt dabei unverändert. Die langlebigste Komponente ist daher das Datenschema. Daraus ergibt sich die Notwendigkeit, dass die logischen Daten auch über Generationen von Datenbanksystemen erhalten bleiben müssen Deduktiv vs. induktiv Deduktiver Ansatz: Entwicklung als klassischer Top-DownAnsatz durch schrittweise Verfeinerung. Voraussetzung: der Designer hat detaillierte Kenntnisse des Problems – häufig bei großen Anwendungen nicht gegeben Induktiver Ansatz: entgegen gesetzte Entwicklungsrichtung Bottom-Up, d.h. vom Speziellen zum Allgemeinen Beispiel: Bibliotheksverwaltungssystem SQL: Datenbeschreibung/ Datenmanipulation Grundlegende Merkmale, Begriffe und Transaktionen Datenabfragen mit SQL Datenmanipulation - Views Beispiele Datenbeschreibung Mit einer Datenbeschreibungssprache wird das logische Datenmodell in eine Datenbank-Definition umgesetzt. Anlage von Datenstrukturen Keine Dateneingabe Eintrag der Datenbeschreibung in ein Data Dictionary Grundbegriffe Abfrage: Auffinden eines Ausschnitts einer Datenbank sowie dessen Darstellung Mutation: Auffinden eines Ausschnitts einer Datenbank, sowie dessen konsistenzerhaltende Modifikation Transaktion: Ausführung einer konsistenzerhaltenden Operation auf einer Datenbank Trennung Datenbank - Anwendung Elemente dieser Trennung: Transaktion: erfolgt durch ein Anwendungsprogramm, wird durch eine DML formuliert und steuert damit das DBMS Anwendungsprogramm: erfüllt Anwenderforderungen und benötigt dazu Daten der Datenbank Benutzerschnittstelle: umfasst Bedienungs- und Anzeigeelemente für den Nutzer Transaktionstypen Direkte und indirekte Anfrage: direkte = eindeutige Beschreibung, z.B. durch Eingabe des Primärschlüsselwertes: Matrikel-Nr., indirekt = schrittweises Weitersuchen, z.B. Navigieren durch die Personalliste Datensätze und Datenmengen: das Ergebnis einer Abfrage kann ein einzelner Datensatz oder eine Menge von Datensätzen sein, z.B. ein Student oder aller Studenten mit Schwerpunkt Marketing Deskriptiv und prozedural: zielorientiert = Was ist gesucht? oder durch navigierendes Vorgehen – schrittweises Durchgehen eines Datenbestandes Parallele Transaktionen: unkritische Operationen Die Transaktionen lassen sich sequentialisieren Die Transaktionen betreffen völlig unterschiedliche Datenbereiche Die Transaktionen sind ausschließlich lesende Operationen Kritischer Fall: mehrere Benutzer arbeiten simultan an der Datenbank und mindestens ein Nutzer nimmt schreibende Operationen vor Mehrbenutzersynchronisation (a)Sequentielle Transaktionen Zeitachse T1 T2 T3 (b) Parallele Transaktionen (gestrichelte Linien repräsentieren Wartezeiten) T1 T2 T3 Synchronisation Aufteilung der Datenbank in Teilbereiche und Sperrung der Bereiche für konkurrierende Transaktionen, wenn eine Transaktionen einen Teilbereich betreten hat. Sperrprotokolle Formulierung von Bedingungen, deren Einhaltung eine konsistente Ausführung paralleler Transaktionen sicherstellt Arten von Sperren Sperre = lock: ein Datenbereich ist für eine Transaktion für einen bestimmten Zeitraum unzugänglich Exklusive Sperre: die Transaktion, die die Sperre anfordert, benötigt den Datenbereich für Schreiboperationen Teilsperre: die Transaktion, die diese Sperrart anfordert, will die Daten nur lesen, aber verhindern, dass andere Transaktionen den Datenbereich verändern Sperrprotokoll für parallele Transaktionen Schritt 1: Die Transaktion sperrt alle Datenbereiche, die sie verändert, exklusiv Schritt 2: Die Transaktion belegt alle Datenbereiche, die sie liest, mit Teilsperren Schritt 3: Die Transaktion gibt erst Sperren frei, wenn in Schritt 1 und 2 alle notwendigen Sperren gesetzt wurden Aufgaben der Datenbeschreibung Benennen von Relationen und Attributen Definition der Beziehungen zwischen Relationen Definition von Datentypen, Wertebereichen und Schlüsseleigenschaften Definition von Zugriffsrechten Definition von Integritätsbedingungen Definition von modellexternen Konsistenzbedingungen Globale und lokale Attribute Ein Attribut heißt global, wenn es in mindestens einer Relation im Primärschlüssel vorkommt, z.B. Zimmer-Nr Ein Attribut heißt lokal, wenn es nur in einer einzigen Relation und dort nur als Nichtschlüsselattribut vorkommt, z.B. Preis Problem: Attribute, die weder global noch lokal sind. Tritt dann auf, wenn die gleiche Eigenschaft in zwei verschiedenen Relationen beschrieben wird. Beispiel: Doktoranden können gleichzeitig Studierende und Angestellte sein. Schlüsselbegriffe Ein Schlüssel ist ein Attribut oder eine Kombination von Attributen, die Datensätze in einem Entitytypen auszeichnen Ein Primärschlüssel besitzt die identifizierende Eigenschaft Ein Fremdschlüssel ist ein Primärschlüssel in einer Relation und ein Attribut in einer anderen Ein Sortierschlüssel bestimmt die physische Reihenfolge der Datensätze in einer Datei Ein Suchschlüssel stimmt mit einem Attributwert einer Entität überein. Konsistenz - Transaktion Konsistenz ist die Freiheit von Widersprüchen bezüglich der Daten in einer Datenbank Eine Transaktion ist eine kosistenzerhaltende Operation auf einer Datenbank. Dieses Konstrukt spielt eine Rolle beim Abbruch einer Mutation. Eine Mutation erlaubt das Auffinden eines bestimmten Ausschnittes einer Datenbank und deren konsistenzerhaltende Veränderung Eine Abfrage zeigt einen bestimmten Ausschnitt einer Datenbank, ohne diesen zu verändern Begriffshierarchie Datenmanipulation Transaktion Mutation Nicht konsistenzerhaltende Operation Abfrage Entitäten - Entitätsmengen Eine Entitätsmenge = Entitytyp ist eine Menge von Datensätzen mit gleichen Attributen aber unterschiedlichen Attributwerten Eine Entität = Entity entspricht einem Datensatz Überlappende Entitätsmengen ergeben sich, wenn Entitäten mehreren Entitätsmengen angehören können, z.B. Studierende als auch Angestellte können Doktoranden sein. Beispiel: Entitytyp Assoziationen Eine Assoziation zwischen zwei Entitäten legt fest, wie viele Entitäten aus Entitätsmenge 2 einer Entität aus Entitätsmenge 1 zugeordnet sind Die Kombination einer Assoziation mit ihrer Gegenassoziation ergibt eine Beziehung Vorgehensweise 1. Schritt : Sammeln der Datenelemente Datenliste PS Datenfeld Typ Länge PS : Datenfeld : Typ : Länge : NULL : Entität : Alias : Beschreib. NULL Entität Alias Beschreibung Primärschlüssel [Ja / Nein] Bezeichnung des Datenfeldes, wie es gespeichert werden soll Datentyp (z.B. Integer, Währung, Text, ext.) maximale Zahl der Zeichen pro Wert leeres Datenfeld zulässig? [Ja / Nein] Welcher Entitätsmenge wird das Datenfeld zugeordnet Alternative Bezeichnungen für das Datenfeld : Weiter Angaben zum Datenfeld (z.B. zulässige Werte etc.) Vorgehensweise 2. Schritt : Datenobjekte (Entitäten) finden Datenliste PS J Datenfeld Typ Länge NULL Entität Alias AUFNR INT 10 N Auftragsnummer DATUM DAT 8 N Auftragsdatum ARTNR INT 10 N Artikelnummer ARTIKEL TXT 80 J Artikelbezeichnung KNR INT 10 N Kundennummer KNAME TXT 50 J Auftrag Auftrag Artikel Artikel Kunde Kunde Kundenname Beschreibung Entity-Relationship-Modell (ERM) Beziehungsarten 1 : 1 1 : n n : m identifizierende Beziehung z.B. Student hat Matrikelnummer charakterisierende und klassifizierende Beziehung z.B. Semestergruppe hat Student nicht eindeutige Beziehung, sie muß im Rahmen der Datennormalisierung aufgelöst werden. Beispiel: Student besucht Vorlesung Hierarchische Beziehung Definition. Zu jeder Entität eines untergeordneten Entitätstyps (Kindrelation) existiert genau eine Entität eines übergeordneten Entitätstyps (Elternrelation) mc KUNDEN RECHNUNGEN Erläuterung. Jede Rechnung ist einem Kunden zugeordnet, ein Kunde kann keine, eine oder mehrere Rechnungen erhalten. Arbeitsschritte bei hierarchischen Beziehungen: Hierarchische Beziehungen werden direkt in Relationen umgesetzt. Primärschlüssel der Elternrelation werden als Fremdschlüssel in die Kindrelation übernommen. Hierbei kann der Fremdschlüssel sowohl Schlüssel- als auch Nichtschlüsselattribut sein. Er kann jedoch in der Kindrelation nicht alleiniger Primärschlüssel sein. Ein Beispiel: R. KUNDE KundenNr R. RECHNUNG ... RechnNr KundenNr ... erweitertes Entity-Relationship-Modell (eERM) 1. Optionale Beziehungen Eine Beziehung ist optional, wenn sie auch den Wert "NULL" haben kann : 1 : c Student Note c : c Student Parkplatz Student belegt Parkplatz c : n Fachbereich Parkplatz Fachbereich hat Parkplätze in der Tiefgarage 1 : cn Fachbereich Student c : cn Student Buch n : cm Student Vorlesung cn : cm Bauteil Bauteil Student hat Note Fachbereich hat Studenten (Ausnahme FB13) Student hat Buch ausgeliehen Student besucht Vorlesung Bauteil enthält Bauteil (Stückliste) Konditionelle Beziehung Definition. Bei einer konditionellen Beziehung ist jeder Entität eines Entitätstyps eine oder keine Entität eines anderen Entitätstyps zugeordnet. c LIEFERANT mc ARTIKEL Erläuterung. Ein Lieferant kann keinen, einen oder mehrere Artikel liefern. Ein Artikel kann von einem oder keinem Lieferanten geliefert werden. (Falls er selbst hergestellt wird.) Vorgehensweise: Es wird eine zusätzliche Relation eingefügt. LIEFERANT 1 mc LIEFERBEZIEH UNG c 1 ARTIKEL R. LIEFERANT R. LIEFERBEZIEHUNG R. ARTIKEL LieferantN r. LieferantN r. ArtikelNr. .. ArtikelNr. .. Vorgehensweise 3. Schritt : Beziehungen zwischen den Entitätsmengen beschreiben Kunde (1,1) • • • • erteilt Kunde erteilt einen oder mehrere Aufträge Ein Auftrag ist eindeutig einem Kunden zugeordnet Ein Auftrag enthält einen oder mehrere Artikel Ein Artikel ist in keinem, einem oder mehreren Aufträgen enthalten (1,n) Auftrag Artikel (1,1) (1,1) (1,n) enthält Auftragsposition (1,n) enthält Beispiel: 1:n Beziehung graphisch Eine Abteilung kann mehrere Mitarbeiter haben, ein Mitarbeiter gehört genau einer Abteilung an Beispiel: n:m Beziehung graphisch Ein Mitarbeiter kann an mehreren Projekten mitarbeiten – in einem Projekt sind mehrere Mitarbeiter beschäftigt Datentypen Datentyp Erläuterung Beispiel char (Länge) Zeichenkette mit vorgegebener definierter Länge Artikel_name char (30), decimal (Länge, Dezimalstellen) numeric (Länge, Dezimalstellen) Dezimalstellen Artikel_menge mit vorgegebener numeric (4,2) maximaler Länge und Anzahl der Dezimalstellen date Syntax in SQLServer: datetime Datumswert Kunden_geburtsd atum datetime Datenmanipulation Operationen der Datenmanipulation: Abfragen von Daten Einfügen, Ändern oder Löschen von Daten Aufbereitung auszugebener Daten Definition von Views Merkmale der Abfragesprache SQL Entwicklung SQL: Structured Querry Language. Ursprünglich von IBM als Abfragesprache konzipiert. Inzwischen verfügt SQL über einen mächtigen Funktionsumfang. SQL hat sich als Standard für relationale Datenbanken durchgesetzt. Einsatz in der Regel durch Systementwickler Erste Normung durch American National Standards Institut (ANSI) 1981 und 1986 (SQL-86) Entstehung zahlreicher SQL-Dialekte 1992: SQL2 (ISO 9075) 1999: SQL:1999 wird veröffentlicht. (vormals als SQL3 bezeichnet.) Charakterisierung von SQL “SQL ist eine relationale, anweisungsorientierte, deskriptive und mengenorientierte Datenbanksprache, die sowohl selbstständig als auch eingebettet eingesetzt werden kann.” [Wirtschaftsinformatik, Lektion 3: 71] Abfragetypen Qualifizierte Abfrage: liefert genau einen oder keinen Datensatz – erfolgt meistens über Primärschlüssel. Über die Ablagestrukturen z.B. in Form eines Indes, kann das DBMS diese Form optimal bedienen. Teilqualifizierte Abfrage: wählt aus einer Datenmenge eine Teilmenge nach bestimmten Kriterien aus Nicht qualifizierte Abfrage: gibt den gesamten Tabelleninhalt zurück Vorbereitete Abfragen Vorbereitete Abfragen verlangen vom Nutzer keine Datenbankkenntnisse und haben drei Vorteile: Eingabeeffizienz: Präzise Definition der gewünschten Datenmenge Ausgabeeffizienz: Optimierung der Datendarstellung Maschineneffizienz: Optimierung der physischen Datenzugriffe Klassifikation von DMLs 1 Selbständig oder eingebettet: Befehlssatz zur Darstellung auf der Benutzeroberfläche ohne gesondertes Anwendungsprogramm oder Kombination von Befehlen mit einer Programmiersprache zum Einsatz in Anwendungsprogrammen Deskriptiv oder prozedural: direkte Bezeichnung der Datensätze ohne Suchprozesse oder Datenzugriff über Suchprozesse durch Festlegung einer Operationenfolge Mengen- oder tupelorientiert: Verwendung logischer Mengenoperationen wie Vereinigung oder Durchschnitt oder Verarbeitung von Datensätzen mit den Operationen Einfügen, Löschen, Ändern Klassifikation von DMLs 2 Textuell oder graphisch: Formulierung der Abfragen in Text oder Verwendung graphischer Elemente zur Abfragespezifikation 3. Generation oder 4. Generation: höhere Programmiersprachen erlauben die Verwendung eingebetteter DML-Befehle oder unabhängig in der Systemumgebung existierende DML-Befehle (Power Builder) SQL-Komponenten SQL DDL DML DCL (Data Definition Language) (Data Manipulation Language) (Data Control Language) Anlegen von Datenstrukturen Kernbereich von SQL Sprache für die Kontrolle der Privilegien; Festlegung der Zugriffsrechte Operationen zum Formulieren von Abfragen und zur Änderung des Datenbestandes CREATE, DROP, ALTER SELECT, INSERT, DELETE GRANT, REVOKE SQL-Struktur DDL Data Definition Language CREATE (Anlegen von Tabellen, Sichten, Indexen, ...) ALTER (Ändern) DROP (Löschen) DML Data Manipulation Language SELECT (Abfragen) INSERT (Einfügen von Zeilen) UPDATE (Ändern) DELETE (Löschen) DCL Data Control Language GRANT (Vergabe von Zugriffsrechten) REVOKE (Zurücknahme von Zugriffsrechten) COMMIT (Abschluß einer Transaktion) ROLLBACK (Abbruch einer Transaktion) SQL-Anweisungen SCHLÜSSELWORT Name (Werte und Parameter); Es folgen Namen, Werte und sonstige Parameter Schlüsselwort, kennzeichnet die auszuführende Funktionen Abschluss der Anweisung durch ein Semikolon Erzeugung von Tabellen CREATE TABLE tabellenname (spaltenbeschreibung, spaltenbeschreibung, ...); Spaltennamen, Datentypangabe, Angabe ob Nullwerte zulässig sind. Beispiel CREATE TABLE ARTIKEL (ARTNR NUMBER(8), Primary Key, NOT NULL, BEZEICHNUNG CHAR(30), EPREIS NUMBER(10,2)); Erläuterung: Eine Relation „Artikel“ mit drei Attributen wird definiert. Löschen von Tabellen DROP TABLE tabellenname Mit dem gleichen Befehl können auch Views gelöscht werden. Beispiel DROP TABLE ARTIKEL; Erläuterung: Die Tabelle „Artikel“ wird vollständig gelöscht. Primärschlüssel PRIMARY KEY (primärschlüssel, primärschlüssel), Beispiel 1 PRIMARY KEY (KUNR), Beispiel 2 CREATE TABLE KUGRUPPE (KUGRUNR NUMBER(4) NOT NULL, RABATTSATZ NUMBER(5,2), PRIMARY KEY (KUGRUNR)); Erläuterung: Im ersten Beispiel wird KUNR zum Primärschlüssel; das zweite Beispiel zeigt, wie die Tabelle KUGRUPPE erstellt und KUGRUNR als Primärschlüssel definiert wird. Fremdschlüsselbeziehungen FOREIGN KEY (primärschlüssel, primärschlüssel) REFERENCES tabellenname Es wird kontrolliert, ob die Fremdschlüsseleinträge immer auf gültige Primärschlüssel in einer anderen Relation verweisen (Referentielle Integrität) Beispiel 1 FOREIGN KEY (KUGRUNR) REFERENCES KUGRUPPE Beispiel 2 Primary KEY (RENR, REDAT, ARTNR), FOREIGN KEY (RENR, REDAT) REFERENCES RECHNUNGEN, FOEIGN KEY (ARTNR) REFERENCES ARTIKEL CHECK-Klausel CHECK ((primärschlüssel, primärschlüssel), IN (SELECT primärschlüssel FROM tabellenname)) Beispiel 1 CHECK ((KUGRUNR) IN (SELECT KUGRUNR FROM KUNDEN)) Beispiel 2 CHECK ((RENR, REDAT) IN (SELECT RENR, REDAT FROM RECHPOS)) Erläuterung: Im ersten Beispiel wird geprüft, ob einer Kundengruppe mindestens ein Kunde zugeordnet ist. Im zweiten Beispiel wird geprüft, ob mindestens eine Position pro Rechnung vorhanden ist. Abfragen von Daten Abfragen von Daten erfolgen mit der SELCET-Anweisung Selektion: Zeilen nach bestimmten Bedingungen auswählen Projektion: Auswahl gewünschter Spalten Verbund: Verknüpfung verschiedener Tabellen über gemeinsame Schlüssel Kombinationen der Operationen sind möglich. Ausgangsrelation Abfrage Ergebnisrelation SELECT-Klausel SELECT Spaltennamen INTO Zielvariable (nur bei SELECT in Anwenderprogramm) FROM Tabellenquelle(-n) WHERE Auswahlkriterien GROUP BY Gruppenbildung HAVING Gruppenbedingung UNION Vereinigungsmenge ORDER BY Sortierung SELECT - speziell SELECT * FROM KUNDE WHERE ORT = ‘Bremen’ AND KINFO = ‘Versicherung’ ORDER BY ORT; Logische Operatoren: NOT Verneinung der Bedingung AND Logisches UND OR Logisches ODER XOR Logische Antivalenz EQV Logische Äquivalenz IMP Logische Implikation Vergleichsoperatoren: = , < , > , <> , != , <= , >= Verknüpfungsoperator: & Verbindet Zeichenfolgen Mathematische Ausdrücke: +,-,*,/, \ (Div) , MOD , ^ (Potenz) Anfragetypen Grundlegende Anfragetypen Projektion: Zeige ausgewählte Attributwerte für alle Entities Selektion: Zeige alle Attributwerte für ausgewählte Entities E1 E2 E3 E4 E5 E6 E7 A1 AW 1,1 AW 2,1 AW 3,1 AW 4,1 AW 5,1 AW 6,1 AW 7,1 A2 A W 1,2 A W 2,2 A W 3,2 A W 4,2 A W 5,2 A W 6,2 A W 7,2 A3 AW 1,3 AW 2,3 AW 3,3 AW 4,3 AW 5,3 AW 6,3 AW 7,3 A4 A W 1,4 A W 2,4 A W 3,4 A W 4,4 A W 5,4 A W 6,4 A W 7,4 E1 E2 E3 E4 E5 E6 E7 A1 A W 1,1 AW 2,1 A W 3,1 AW 4,1 AW 5,1 A W 6,1 A W 7,1 A2 A W 1,2 AW 2,2 A W 3,2 AW 4,2 AW 5,2 A W 6,2 A W 7,2 A3 A W 1,3 AW 2,3 A W 3,3 AW 4,3 AW 5,3 A W 6,3 A W 7,3 A4 A W 1,4 AW 2,4 A W 3,4 AW 4,4 AW 5,4 A W 6,4 A W 7,4 Projektion/Selektion liefern neue Relation Anfragetypen Projektion und Selektion sind kombinierbar Zeige ausgewählte Attributwerte für ausgewählte Entities Weiterer Anfragetyp: Join Verbund Daten entstammen dabei aus mehr als einer Relation Beispiele: Liste aller Zimmer mit Art und Ausstattung (Projektion) Liste aller Gäste mit KdNr, Name, Wohnort und Strasse aus Schleswig (Selektion) Liste aller Einzelzimmer mit Ausstattung (Projektion und Selektion) Liste aller Zimmer mit ZiNr und Preis (Join aus Zimmer und Preis) Anfrage von Daten SELECT-Befehl von SQL SELECT-Befehl erwartet Einhaltung syntaktischer Regeln Reihenfolge der Schlüsselwörter Klammerung von Unteranfragen, etc. SELECT-Befehl stellt mächtige Funktionen zur Verfügung SELECT-Syntax Komponente SELECT Funktion Spaltenliste Projektion: Auswahl der gewünschten Spalten SELECT [DISTINCT | ALL] Spaltennamen | * FROM Tabellennamen | Viewnamen Verbund: Verbindung der verschiedenen gewünschten Tabellen über gemeinsamen Schlüssel [WHERE Bedingungen, die Tupel spezifizieren] Selektion: Auswahl bestimmter Zeilen DISTINCT: Ignoriert doppelte Datensätze ALL: Auch doppelte Datensätze werden gefunden Boolsche Operatoren (AND, OR, NOT) Relationenopertaoren (>, <, = ..) Spezielle Operatoren (BETEEN, IN, IS NULL, LIKE, EXISTS) Unterabfragen [GROUP BY Spaltenname, nach gruppiert wird] denen Tupel, die in einer ausgewählten Spalte gleiche Attributwerte enthalten, werden zu einer Gruppe zusammengefasst. [Having Auswahlbedingung] Auswahl bestimmter Gruppen. Die HavingKomponente kann nur zusammen mit der GROUP BY-Komponente verwendet werden. [ORDER BY Spaltenname |Spaltennummer ] Spaltenname ASC Spaltenname DESC] Erzwingt eine bestimmte Sortierreihenfolge der Zeilen in der Ergebnisrelation. Einfügen von Daten Ziel: Einfügen neuer Tupel in eine Relation INSERT INTO tabellenname (spaltenliste) VALUES (werteliste); Beispiel INSERT INTO KUNDEN (KNR, NAME, ORT) VALUES (123, ´Schulze´, ´Stuttgart´); Ändern von Daten Ziel: Ändern von Tupeln UPDATE tabellenname SET spalte = Ausdruck, ... WHERE auswahlbedingung; (WHERE-Bedingung ist optional) Beispiel 1 Beispiel 2 UPDATE KUNDEN SET ORT = ´Stuttgart´ WHERE ORT = ´Stuttgard´ UPDATE RECHNUNG SET BETRAG = BETRAG * 1.15 WHERE KNR NOT IN (SELECT KNR FROM KUNDEN WHERE ORT = ´München´); Erläuterung: Im ersten Beispiel wird die Schreibweise eines Ortsnamens korrigiert. Im zweiten Beispiel erhöht die Anweisung die Rechnungsbeträge der Kunden, die nicht aus München kommen, um 15 Prozent. Löschen von Daten Ziel: Löschen von Tupeln DELETE FROM tabellenname WHERE auswahlbedingung; (WHERE-Bedingung ist optional) Beispiel 1 Beispiel 2 DELETE FROM KUNDEN; DELETE FROM KUNDEN WHERE ORT = ´HAMBURG´; Erläuterung: Im ersten Beispiel werden alle Tupel aus der Relation Kunden gelöscht. Im zweiten Beispiel werden alle Tupel von Kunden aus Hamburg gelöscht. Definition von Views [01] View-Tabellen sind virtuelle Tabellen. CREATE VIEW viewname (spaltenliste) AS Select-Anweisung Tabellen und Spalten, die die Basis für den View bilden. Definition der Spalten, aus denen der View bestehen soll.Wenn keine Angaben gemacht werden, werden die Spalten aus den Tabellen übernommen, die den View bilden. Viewname = Name unter dem der View aufgerufen und im SQL-Systemkatalog verwaltet wird. Definition von Views [02] CREATE VIEW RECHKUNDE (RENR, BETRAG, KNR, NAME, ORT) AS SELECT RENR, BETRAG, R.KNR, NAME, ORT FROM RECHNUNG R, KUNDE K WHERE R.KNR = K.KNR ORDER BY RENR; Erläuterung:Das Beispiel liefert aus den Tabellen KUNDEN und RECHNUNG für jede Rechnung den zugehörigen Kundennamen und Wohnort. Funktion von Views Wiederkehrende Speicherung von Anfragen – Reproduktion auf Knopfdruck Views nutzen alle DML-Operationen Möglichkeit zur bewussten virtuellen Redundanz, z.B. Umsatz als Produkt aus Preis und Menge Bereitstellung von vorgefertigten Reports als Folge von SQLAnweisungen durch die SW-Hersteller Vorteile von Views Vereinfachung und Fehlerreduktion: komplizierte Abfragen werden einmalig definiert und sind dann wieder abrufbar Datenschutz: der Benutzer erhält nur Zugriff auf solche Daten, für die er eine Zugriffberechtigung besitzt. Vermeidung virtueller Redundanz: Attribute, die aus bestehenden Attributen erzeugt werden können, müssen nicht gesondert gespeichert werden, z.B. Umsatz als Produkt aus Preis*Menge. Erläuterungen zur SQL-Syntax Funktion MAX, AVG, SUM, COUNT, STDDEV ... Literal nummerische, „alphabetische“ Konstante Ausdruck Nummerisch: +, -, /, Bedingung Relational: =, <, >, <>, >=, <= Boolean: IN, Exists