Inhaltsverzeichnis - Universität Paderborn
Werbung

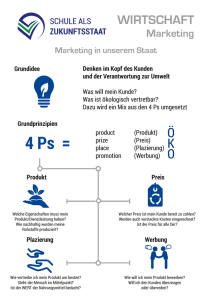
Inhaltsverzeichnis 1 Einleitung ............................................................................................................................ 2 2 Die Plazierungsinstanz als Dienstgeber................................................................................. 3 2.1 Dienste der Plazierungsinstanz ...................................................................................... 3 2.2 Einbettung in das System .............................................................................................. 4 2.3 Beauftragung des Dienstgebers ..................................................................................... 5 2.3.1 Auftragsentgegennahme ......................................................................................... 5 2.3.2 Auftragswarteschlange ........................................................................................... 6 3 Systeminformationen ........................................................................................................... 8 3.1 Lokale dynamische Systeminformationen ...................................................................... 8 3.2 Dynamische Systeminformationen vom Lastmonitor...................................................... 9 4 Plazierung.......................................................................................................................... 10 4.1 Plazierungsstrategien................................................................................................... 10 4.2 Plazierungsstrategien mit Partitionen........................................................................... 11 5 Implementierung................................................................................................................ 12 5.1 Dienstgeber................................................................................................................. 12 5.1.1 Auftragswarteschlange ......................................................................................... 14 5.1.2 Unterstützung mehrerer Plazierungsstrategien ...................................................... 16 5.2 Verwaltung der Systeminformationen.......................................................................... 17 5.2.1 Speicherung von Auslastungen ............................................................................. 17 5.3 Departitionierungsstrategie ......................................................................................... 17 5.3.1 Kommunikationsgraph ......................................................................................... 18 5.3.2 Struktur der Partitionen........................................................................................ 19 5.3.3 Partitionen-Baum ................................................................................................. 20 5.3.4 Behandlung von fest plazierten Knoten................................................................. 21 5.3.5 Departitionierung ................................................................................................. 23 5.4 Meßergebnisse ............................................................................................................ 24 6 Zusammenfassung.............................................................................................................. 25 6.1 Ausblick...................................................................................................................... 26 1 Einleitung Am Institut für Betriebs- und Dialogsysteme der Universität Karlsruhe wird ein Betriebssystem namens COSY (Concurrent Operating SYstem) entwickelt, das speziell auf die Bedürfnisse einer Multiprozessorarchitektur zugeschnitten ist. Es unterstützt unter anderem den Austausch von Nachrichten zwischen verteilten Anwendungen und die gemeinsame Nutzung von Betriebsmitteln durch parallel arbeitende Prozesse. Verteilte Anwendungen werden vom Programmierer in parallel arbeitende Prozesse zerlegt, die untereinander lediglich Nachrichten austauschen können. Diese werden beim Programmstart auf verschiedene Prozessoren geladen und ausgeführt. Die Plazierung der Module ist dabei vom Programmierer in einer Beschreibungsdatei festgelegt. Eine genauere Beschreibung von COSY befindet sich in [8] und [9]. Ein Entwurfsziel von COSY ist die Möglichkeit des Mehrbenutzer- bzw. Mehrprogrammbetriebs. Um eine möglichst optimale Leistung des Multiprozessorsystems zu erreichen, müssen die Module einer verteilten Anwendung, in Abhängigkeit von der momentanen Belegungssituation und der vom Programm erzeugten Last, plaziert werden. Eine statische, einmal festgelegte und dann für alle Ausführungen gleichbleibende Plazierung ist demnach nicht für den Einsatz in einem Parallelrechner, in dem Programme dynamisch eintreffen und sich den Prozessor räumlich und zeitlich teilen, geeignet, da bei jeder Ausführung eine andere Lastsituation vorliegt. Es sollte in der Verantwortung einer speziellen Instanz liegen, bei jeder Ausführung eine sinnvolle Plazierung für eine verteilte Anwendung zu finden. Aufgabe dieser Studienarbeit ist die Entwicklung einer Instanz zur Plazierung paralleler Programme. Die Instanz erhält die momentane Belegungssituation des Systems und einen Kommunikationsgraphen, der die Interaktionsbeziehungen innerhalb des auszuführenden Programms beschreibt. Daraus soll eine möglichst gute Plazierung berechnet werden. Die Aufgabe dieser Studienarbeit besteht nicht aus der Entwicklung einer optimalen Plazierungsstrategie, sondern aus dem Aufbau eines möglichst allgemeinen Grundgerüsts für eine Plazierungsinstanz. Die realisierte Plazierungsstrategie ist nur eine von vielen möglichen. Zukünftige Entwicklungen von Plazierungsstrategien sollen in die Instanz integriert werden können. Beim Entwurf der Plazierungsinstanz sind mehrere Ziele zu verfolgen: • Der Durchsatz des gesamten Systems soll aufgrund von guten Plazierungen möglichst hoch sein. • Die Bestimmung einer Plazierung soll keinen hohen Rechenaufwand benötigen und mit einer möglichst geringen Menge an Arbeitsspeicher auskommen. • Fest vorgegebene Plazierungen müssen berücksichtigt werden, da dies z. B. für die Nutzung an Prozessoren gebundener Dienste (z. B. Festplatte) wichtig ist. • Neue Plazierungsalgorithmen müssen auf einfache Weise in die Instanz integriert werden können. • Der Anwender soll die Möglichkeit besitzen, zur Laufzeit einen Plazierungsalgorithmus auszuwählen. 2 • Programme mit hohen Anforderungen an die Betriebsmittel dürfen nicht auf ewig zurückgestellt werden. • Die Instanz soll für den Anwender transparent arbeiten. Im nachfolgenden soll zuerst eine theoretische Beschreibung der Bestandteile der Plazierungsinstanz gegeben werden. Daraufhin wird die Implementierung der Instanz betrachtet. Den Schluß bildet eine kurze Zusammenfassung der Arbeit. 2 Die Plazierungsinstanz als Dienstgeber Die Plazierungsinstanz muß als systemweit angebotener Dienst von allen Prozessen in Anspruch genommen werden können. Entstehende Aufträge müssen vom Dienstgeber empfangen, bearbeitet und die Ergebnisse an die beauftragenden Prozesse zurückgesendet werden. Prozeß 1 senden Auftrag 1 Prozeß 2 Dienstgeber empfangen Auftrag 1 bearbeiten Auftrag 1 empfangen Ergebnis 1 senden Ergebnis 1 empfangen Auftrag 2 senden Auftrag 2 bearbeiten Auftrag 2 senden Ergebnis 2 empfangen Ergebnis 2 Abbildung 1: Dienstgeber und Dienstnehmer im Mehrprozeßbetrieb Eine Instanz zur Plazierung von parallelen Programmen muß ihre Dienste jedem Prozeß im System zur Verfügung stellen können. Deshalb wird die Plazierungsinstanz als Dienstgeber realisiert. Diese Entscheidung erfordert nicht die Existenz einer zentralen Plazierungsinstanz, sondern läßt prinzipiell eine verteilte Realisierung zu. Im Rahmen dieser Arbeit wurde allerdings ausschließlich der Fall einer zentralen Plazierungsinstanz betrachtet. 2.1 Dienste der Plazierungsinstanz In einem Mehrprozessorsystem mit mehreren parallel arbeitenden Prozessen ist eine spezielle Instanz zur Plazierung von Prozessen hilfreich. Sie ist für eine sinnvolle Zuteilung der Prozessoren zuständig. Die Plazierungsinstanz sollte verteilte Anwendungen in Abhängigkeit der 3 momentanen Auslastungen und der Topologie des Systems plazieren. Unter Auslastung eines Systems werden in diesem Fall folgende Faktoren verstanden: • Rechenlast auf jedem Prozessor • Speicherbelegung auf jedem Prozessor • Kommunikationslast auf jeder Verbindung im System Die Plazierungsinstanz stellt dem System einen Dienst zur Plazierung verteilter, paralleler Programme zur Verfügung. Genauer betrachtet ermittelt die Instanz aus der Beschreibung des Programms und der Auslastungsinformation des Systems die Plazierung für die parallelen Prozesse der Anwendung. Die Plazierungsinstanz wird immer benötigt, wenn ein paralleles verteiltes Programm gestartet wird. Weitere Einzelheiten zum Zusammenspiel der Plazierungsinstanz mit anderen Bestandteilen des Systems werden im Kapitel 2.2 beschrieben. 2.2 Einbettung in das System Die Plazierungsinstanz kooperiert mit dem Abwickler und dem Lastmonitor. Der Abwickler ist für die Einrichtung der Prozesse auf den Prozessoren verantwortlich. In diesem Zusammenhang beauftragt er die Plazierungsinstanz mit der Ermittlung einer sinnvollen Plazierung und richtet danach die Prozesse auf den ermittelten Prozessoren ein. Zur Berechnung der Plazierungsinformation erfragt die Plazierungsinstanz die momentanen Auslastungen im System. Belegungsänderung bzw. plaziere Kommunikationsgaph Kommunikationsgraph Abwickler Plazierungsinstanz Auftragskanal KommunikationsgraphDatenkanal Auftragskanal Datenkanal AuslastungenDatenkanal empfange Plazierungsinformation Plazierunginformation Abbildung 2: Interaktion mit anderen Instanzen 4 sende Auslastungen Auslastungen Lastmonitor Auftragskanal Der Dienstgeber besitzt eine Auftragswarteschlange, in der momentan nicht erfüllbare Aufträge gespeichert werden, bis sich die Belegungssituation des Parallelrechners ändert. Tritt eine Belegungsänderung ein, so erzeugt der Abwickler eine entsprechende Nachricht für die Plazierungsinstanz. Diese versucht nun Aufträge aus der Warteschlange, die aufgrund der Belegungsänderung erfüllbar geworden sein können, zu plazieren. Es ist zu beachten, daß der Abwickler, die Plazierungsinstanz und der Lastmonitor auf verschiedenen Prozessoren laufen können. Jeder Datenaustausch erzeugt Kommunikationslasten, die für eine effiziente Realisierung des Plazierungsdienstes, ebenso wie die Rechenzeit der Plazierungsinstanz selbst, möglichst gering gehalten werden sollten. 2.3 Beauftragung des Dienstgebers In diesem Kapitel werden Aspekte beschrieben, die für die Beauftragung des Dienstgebers relevant sind. Hierzu gehören der Algorithmus zur Auftragsentgegennahme, die Auftragswarteschlange und die Strategie, mit der Aufträge aus der Warteschlange ausgewählt werden. 2.3.1 Auftragsentgegennahme Die vom Dienstnehmer erzeugten Aufträge treten aus der Sicht des Dienstgebers zu unbestimmten Zeitpunkten auf. Aufträge mit einem für das System zu großen Ressourcenbedarf kann die Plazierungsinstanz niemals bearbeiten und müssen deshalb sofort abgelehnt werden. Aufträge, die unter der momentanen Auslastung des Systems nicht bearbeitet werden können, stellt die Plazierungsinstanz zunächst zurück. Zu diesem Zweck besitzt die Plazierungsinstanz eine Auftragswarteschlange, welche die momentan nicht erfüllbaren Aufträge enthält. Abbildung 3 verdeutlicht die beschriebene Arbeitsweise. empfangen Auftrag Auftrag jemals erfüllbar? Nein Ja Auftrag momentan erfüllbar? Nein Ja Auftrag bearbeiten Auftrag in Warteschlange einreihen senden Ablehnung Abbildung 3: Programmablauf bei der Auftragsentgegennahme 5 2.3.2 Auftragswarteschlange Die Auftragswarteschlange enthält alle Aufträge, die momentan nicht erfüllt werden können. Ein Belegungsversuch der in der Warteschlange stehenden Aufträge findet bei Änderung der Belegungssituation statt. Die dabei verwendete Strategie bei der Auswahl aus den Aufträgen der Warteschlange ist maßgeblich für eine faire Abwicklung und einen möglichst hohen Durchsatz des Systems. In dieser Arbeit wird eine Abwicklung als fair bezeichnet, wenn Aufträge bei einer Änderung der Belegungssituation im Parallelrechner in der Reihenfolge ihres Auftretens auf Erfüllbarkeit getestet werden. Neu ankommende Aufträge werden am Ende der Warteschlange angehängt. Bei einem Belegungsversuch werden die Elemente der Warteschlange ausgehend vom ersten Element der Reihe nach überprüft. So ist sichergestellt, daß die am längsten in der Warteschlange stehenden Aufträge zuerst geprüft werden. Zu einer fairen Abwicklung gehört allerdings auch, daß kein Auftrag in der Warteschlange „verhungert“, das heißt niemals zur Ausführung ausgewählt wird. Dieser Fall tritt zum Beispiel ein, wenn kleinere Aufträge die freigegebenen Ressourcen immer neu belegen und so niemals genügend freie Ressourcen vorhanden sind, um einen größeren Auftrag zu bearbeiten. Die Strategie zur Auswahl aus der Warteschlange muß solche Situationen berücksichtigen. Bei Einsatz der Strategie FCFS (first-come-first-serve) ist kein hoher Durchsatz des Systems zu erwarten, obwohl in diesem Fall das zuvor geschilderte Problem des „Verhungerns“ nicht auftritt. Größere Aufträge verhindern stets die Bearbeitung erfüllbarer kleinerer Aufträge, bis sie selbst erfüllt worden sind. Im Rahmen dieser Studienarbeit sollte, aufgrund eines möglichst geringen Rechen- und Speicherplatzbedarfs, auf eine einfache Warteschlangenstrategie zurückgegriffen werden. Deshalb wurden in dieser Arbeit lediglich zwei einfache Strategien berücksichtigt, die im folgenden vorgestellt werden. 2.3.2.1 Fenster-Strategie Bildlich gesprochen wird bei dieser Strategie ein Fenster über den Anfang der Warteschlange gelegt. Nur Aufträge innerhalb des Fensters werden bei einem Belegungsversuch auf ihre Erfüllbarkeit geprüft. Dabei gibt die Fenstergröße an, wie viele Aufträge vom Anfang der Warteschlange bei einem Belegungsversuch geprüft werden. Konnte der erste Auftrag innerhalb des Fensters nicht zugeordnet werden, wird das Fenster verkleinert, bis es im Extremfall die Größe eins besitzt wodurch bei jedem Belegungsversuch lediglich der erste Auftrag getestet wird. Es ist also sichergestellt, daß jeder erfüllbare Auftrag zugeordnet wird. Konnte der erste Auftrag erfüllt werden, wird das Fenster vergrößert, sofern es nicht bereits seine maximale Größe besitzt. Diese Vergrößerung des Fensters ist notwendig, um einen Zustand, in dem die Warteschlange nur wenige Aufträge bei einem Belegungsversuch testet, wieder zu verlassen. Folgende Faktoren könnten bei einer Realisierung frei gewählt werden: • Maximalgröße des Fensters • Dekrement der Fenstergröße • Inkrement der Fenstergröße 6 Wählt man eine maximale Fenstergröße von eins, dann entspricht die Fenster-Strategie dem Verfahren FCFS. momentanes Fenster Größe 3 Auftrag 1 maximales Fenster Größe 6 Auftrag 2 Auftrag 3 Auftrag 4 Auftrag 5 Auftrag 6 Auftrag 7 Auftrag 8 Abbildung 4: Auftragswarteschlange mit Fenster-Strategie 2.3.2.2 Zähler-Strategie Dieses Verfahren ist der zuvor beschriebenen Strategie ähnlich. Allerdings wird das Fenster durch einen Zähler pro wartenden Auftrag ersetzt. Der Zähler eines neu ankommenden Auftrags wird mit Null initialisiert. Analog zur Fenster-Strategie werden die Aufträge in der Reihenfolge ihres Auftretens berücksichtigt. Der Zähler eines Auftrages wird nach jedem erfolglosen Belegungsversuch erhöht. Erreicht der Zähler des ersten Auftrags eine zuvor festgelegte Grenze, so wird nur noch dieser Auftrag geprüft. Die Grenze kann als Toleranzgrenze angesehen werden. Das „Verhungern“ eines Auftrags ist demnach nicht möglich. Als variabler Faktor bei einer Realisierung kann lediglich der Toleranzgrenze frei gewählt werden. Als Vorteil gegenüber der Fenster-Strategie erscheint mir die Berücksichtigung aller in der Warteschlange stehenden Aufträge, falls die Toleranzgrenze des ersten Auftrags noch nicht erreicht wurde. Die Fenster-Strategie muß ankommende erfüllbare Aufträge in die Warteschlange einreihen, falls das Fenster bereits voll ist, obwohl kein Auftrag zu „verhungern“ droht. Es ist also im Normalfall mit einem höheren Durchsatz des Systems zu rechnen, als bei der Fenster-Strategie. Wird die Toleranzgrenze auf Null gesetzt, so entspricht dieses Verfahren dem Verfahren FCFS. 7 3 Systeminformationen Informationen über die Konfiguration und die Auslastung des Parallelrechners werden als Systeminformationen bezeichnet. Im Rahmen dieser Studienarbeit existieren zwei verschiedene Arten von Systeminformationen, statische und dynamische Informationen. Statische Systeminformationen betreffen im wesentlichen die Konfiguration des Parallelrechners. Als statische Informationen müssen in dieser Arbeit folgende Informationen berücksichtigt werden: • Anzahl der Prozessoren im Parallelrechner • Maximale Rechenlast pro Prozessor • Arbeitsspeicher pro Prozessor • Physikalische Verbindungen zwischen den Prozessoren • Maximale Kommunikationslast pro physikalischer Verbindung Dynamische Systeminformationen beschreiben die momentane, sich mit der Zeit ändernde Auslastung des Systems. Als dynamische Systeminformationen treten in dieser Arbeit folgende Informationen auf: • Rechenlast pro Prozessor • verfügbarer Arbeitsspeicher pro Prozessor • Kommunikationslast pro physikalischer Verbindung Um die von der Plazierungsinstanz erzeugte Rechenlast gering zu halten, muß die Beschaffung der Systeminformationen möglichst effizient erfolgen. Statische Informationen werden bereits bei Initialisierung der Plazierungsinstanz aufgebaut. Dynamische Systeminformationen werden bei jeder Änderung der Belegungssituation aufgefrischt. Das Auffrischen der dynamischen Systeminformationen sollte daher eine geringe Rechenlast und Kommunikationslast erzeugen. Maßgeblich für die Leistungsfähigkeit der gesamten Plazierungsinstanz ist die gute Zusammenarbeit zwischen der Verwaltung der Systeminformationen und der eigentlichen Plazierung. Das heißt, der Entwickler des Verwaltungsmoduls sollte bereits Kenntnisse über die später verwendeten Einplanungsstrategien besitzen, um die Zusammenarbeit mit der Plazierungsstrategie zu vereinfachen. In den nachfolgenden Kapiteln wird auf diese Zusammenarbeit noch ausführlicher eingegangen. 3.1 Lokale dynamische Systeminformationen Informationen über die Auslastung der Systemressourcen können von der Plazierungsinstanz lokal berechnet werden. In diesem Fall muß die Instanz die gesamte Plazierungsinformation aller laufenden Anwendungen protokollieren und daraus die momentanen Auslastungen berechnen. Die Tatsache, daß ein Programm beendet ist, wird der Plazierungsinstanz über den 8 Abwickler mitgeteilt. Daraufhin kann diese, mit Hilfe der protokollierten Plazierungen, die neuen Auslastungen ermitteln. Der Vorteil dieses Verfahrens ist die geringe Kommunikationslast zwischen dem Lastmonitor und der Plazierungsinstanz. Der größte Nachteil der Strategie ist die Ungenauigkeit der vorhandenen Lastdaten, die nur Schätzwerte darstellen oder eventuell überhaupt nicht vorhanden sind. Ebenfalls nachteilig erscheint die Tatsache, daß jede aktuelle Plazierung protokolliert werden muß, was zu einem beträchtlichen Speicherplatzbedarf führt. Hinzu kommt der erhöhte Aufwand bei der Suche innerhalb der Protokollstrukturen. Ein weiterer Nachteil liegt darin, daß jede Anwendung über die Plazierungsinstanz eingerichtet werden muß, um korrekte Auslastungsinformationen zu erhalten. 3.2 Dynamische Systeminformationen vom Lastmonitor Ein einfaches Verfahren empfängt bei jedem Belegungsversuch die Lastinformationen vom Lastmonitor. Vorteilhaft ist der geringere Speicherbedarf der Plazierungsinstanz, aufgrund der fehlenden Speicherung von Lastinformationen. Der hohe Kommunikationsaufwand mit dem Lastmonitor ist allerdings nicht akzeptabel, weshalb von einer genaueren Betrachtung dieses Verfahrens abgesehen wird. Eine weitere Strategie soll die Vorteile beider zuvor beschriebenen Verfahren vereinigen. Die ermittelten dynamischen Systeminformationen werden von der Plazierungsinstanz gespeichert und nur zu bestimmten Zeitpunkten beim Lastmonitor erfragt. Zu folgenden Ereignissen könnten solche Abfragen stattfinden: • eine bestimmte Zeitspanne ist seit der letzten Abfrage abgelaufen • eine Nachricht vom Abwickler über die Beendigung einer Anwendung wird empfangen • eine bestimmte Anzahl von Programmbeendigungen ist aufgetreten • eine bestimmte Anzahl von Plazierungen wurde durchgeführt • die Inaktivität des Systems wurde festgestellt Bei jeder Form der Abfrage der dynamischen Systeminformationen beim Lastmonitor wird eine gewisse Ungenauigkeit der Auslastungsinformationen toleriert. In diesem Punkt liegt meiner Meinung nach der größte Vorteil dieses Verfahrens. Die Systeminformationen werden nur erfragt, falls sie mit hoher Wahrscheinlichkeit entscheidende Ungenauigkeiten aufweisen. Dadurch werden die von der Instanz erzeugten Kommunikationslasten möglichst gering gehalten. 9 4 Plazierung In der Einleitung wurde bereits darauf eingegangen, daß auf die Entwicklung komplexer bzw. optimaler Plazierungsstrategien zugunsten einer flexiblen Dienstgeberinstanz verzichtet wurde. Die folgenden Abschnitte betrachten deshalb lediglich eine einfache Plazierungsstrategie. Tiefergehende Einblicke finden sich in [1]. 4.1 Plazierungsstrategien Bei der Plazierung paralleler Programme handelt es sich um ein NP-hartes Problem, das heißt nur mit Hilfe einer vollständigen Suche kann definitiv eine optimale Lösung gefunden werden. Eine vollständige Suche ist im allgemeinen mit einem sehr hohen Aufwand verbunden. Deshalb werden sogenannte heuristische Verfahren eingesetzt. Dabei wird die Ermittlung der Lösung durch eine gezielte Suche ersetzt, die jedoch auch in einem lokalen statt einem globalen Extremum hängen bleiben kann. Lösung := Anfangslösung Ja Ist die Suche beendet? Nein neue Lösung := modifizieren(Lösung) Ist die neue Lösung besser? Nein Ja Lösung := neue Lösung Abbildung 5: Programmablauf der heuristischen Suche Am dargestellten schematischen Algorithmus sind bereits die Probleme bei der Realisierung einer heuristischen Suche zu erkennen. Nachfolgend werden die offenen Fragen mit möglichen Antworten aufgelistet: − Welches Kriterium soll zur Terminierung der Hauptschleife gewählt werden? • Anzahl der Iterationen • Laufzeit des Algorithmus • Verschlechterungen der Lösung 10 − Wie sieht die Modifikation der Lösung aus? • Verschiebung von Prozessen auf andere Prozessoren − Nach welchen Kriterien werden die neue und die alte Lösung verglichen? • Gesamtlaufzeit des verteilten Programms • ausgeglichene Last auf allen Prozessoren • geringer Kommunikationsaufwand auf den Verbindungen 4.2 Plazierungsstrategien mit Partitionen Eine Familie von Plazierungsstrategien benutzt Partitionen zur Strukturierung der Prozeßmenge einer verteilten Anwendung. Initial bildet jeder Prozeß eine eigene Partition. Mehrere Partitionen können im Prozeß der Partitionierung zu einer größeren Partition zusammengefaßt werden. Jede Partition besitzt als Kommunikations- bzw. Rechenlast die Summe der Lasten seiner Elemente. Dabei werden Kommunikationen innerhalb einer Partition entweder gelöscht oder durch eine Erhöhung der Rechenlast der Partition berücksichtigt. Die Partitionierung ist beendet, wenn nur noch eine Partition vorhanden ist, die alle Prozesse enthält. Diese Partition wird auf einen Prozessor plaziert. Die Abbildung 6 stellt die nach der Partitionierung entstandene Struktur dar. Abbildung 7 veranschaulicht die Hierarchie von Partitionen, wobei an der vertikalen Anordnung der Partitionen die Reihenfolge ihrer Entstehung zu erkennen ist. Durch die Hierarchie ist eine strukturierte Bearbeitung der Plazierung möglich. Die Partitionen werden in umgekehrter Reihenfolge ihres Entstehens wieder aufgespalten. Dabei überprüft der Algorithmus, ob eine Verschiebung der Teilpartitionen der gerade gespaltenen Partition auf einen anderen Prozessor einen Gewinn bringt. Auf diese Weise werden die Prozesse auf die Prozessoren des Parallelrechners verteilt. Der Prozeß der Departitionierung ist beendet, falls alle zuvor erstellten Partitionen aufgespalten sind. Partition 3 Prozeß 5 Partition 2 Partition 1 Prozeß 2 Prozeß 4 Prozeß 6 Prozeß 3 Prozeß 1 Abbildung 6: Struktur von Partitionen 11 Partition 3 Prozeß 5 Partition 2 Prozeß 1 Prozeß 2 Partition 1 Prozeß 3 Prozeß 4 Prozeß 6 Abbildung 7: Hierarchie von Partitionen 5 Implementierung Die Plazierungsinstanz wurde unter dem Betriebssystem COSY in der Programmiersprache C implementiert. Am Institut für Betriebs- und Dialogsysteme der Universität Karlsruhe existiert für den Betrieb von COSY ein Transputersystem mit 32 Prozessoren. Der Arbeitsspeicher pro Prozessor beträgt 4 Megabyte. Jeder Prozessor besitzt 4 bidirektionale Verbindungen, mit deren Hilfe er mit seinen Nachbarn kommunizieren kann. Das Prozessornetzwerk ist momentan ausschließlich als Gitterstruktur aufgebaut, weshalb die Plazierungsinstanz unter anderen Topologien nicht getestet werden konnte. Ein Lastmonitor ist bereits implementiert, aber noch nicht für die Zusammenarbeit mit der Plazierungsinstanz modifiziert. Obwohl die Plazierungsinstanz schon für die Kooperation vorbereitet ist, mußten die Test ohne eine Anbindung an den Lastmonitor ausgeführt werden. Dies bedeutet, daß die Auslastungsinformation lediglich auf der Basis eigener Berechnungen verwaltet werden kann. Die Abwicklerinstanz wurde für die Zusammenarbeit mit der Plazierungsinstanz geändert. Vor dem Start eines parallelen Programms wird nun die Plazierungsinstanz mit der Plazierung der Prozesse beauftragt. Der Abwickler nimmt nach erfolgreicher Bearbeitung die Plazierungsinformation entgegen und erzeugt die Prozesse auf den ermittelten Prozessoren. Eine weitere Aufgabe des Abwicklers ist die Benachrichtigung der Plazierungsinstanz nach einer Änderung der Belegungssituation. 5.1 Dienstgeber Die Plazierungsinstanz empfängt Nachrichten von der Abwicklerinstanz und dem Lastmonitor. Zu jedem Auftrag für die Plazierungsinstanz gehört ein Kommunikationsgraph, der das zu plazierende Programm beschreibt. Der Kommunikationsgraph wird, ebenso wie die Lastinforma12 tionen, mit Hilfe von Nachrichten empfangen. Dabei könnte es aufgrund der begrenzten Paketgröße zu der Situation kommen, daß die Daten in mehrere Einzelnachrichten aufgeteilt werden müssen. Um die verschiedenen Arten von Nachrichten differenzieren zu können, sind ein Auftrags- und zwei Datenkanäle vorgesehen. Abbildung 8 zeigt die verschiedenen Nachrichten an die Plazierungsinstanz. Plazierungsinstanz Aufträge Auftragskanal AuslastungenDatenkanal Kommunikationsgraph Auslastungen KommunikationsgraphDatenkanal Abbildung 8: Nachrichten an den Dienstgeber Die Plazierungsinstanz bietet folgende Dienste an: • INSPECT_QUEUE: veranlaßt einen erneuten Belegungsversuch • PLACE_COMM_GRAPH: fordert die Plazierung eines Kommunikationsgraphen an • SET_STRATEGY: bestimmt den Plazierungsalgorithmus • SHUTDOWN: beendet die Plazierungsinstanz Es ist zu beachten, daß ein neuer Auftrag erst nach dem Bearbeiten des vorhergehenden Auftrags empfangen werden kann. Den Empfang des Kommunikationsgraphen bzw. der Auslastungsinformation an dem entsprechenden Datenkanal wird innerhalb der Bearbeitung des entsprechenden Auftrags abgewickelt. Im System können mehrere Abwickler vorhanden sein, die gleichzeitig einen Kommunikationsgraphen an die Plazierungsinstanz senden wollen. In diesem Fall ist die Plazierungsinstanz nicht mehr in der Lage die Datenpakete dem korrekten Kommunikationsgraphen zuzuordnen. Deshalb muß sichergestellt sein, daß ein Kommunikationsgraph an die Plazierungsinstanz erst gesendet wird, wenn keine anderen Abwickler Daten an den Datenkanal senden. Aus diesem Grund muß jeder Abwickler einen Auftrag zum Plazieren eines Programmes synchron an die Plazierungsinstanz senden. Durch den Empfang des Auftrags bestätigt die Plazierungsinstanz implizit die Verfügbarkeit des Datenkanals. Die Benachrichtigung zur Änderung der Bele13 gungssituation kann asynchron erfolgen, da keine weitere Kommunikation stattfinden muß. In den folgenden Abbildungen sind die Kommunikationsabläufe zwischen Plazierungsinstanz und Abwickler bzw. Plazierungsinstanz und Lastmonitor dargestellt. Abwickler Plazierungsinstanz send_syn(PLACE_COMM_GRAPH) receive_syn(PLACE_COMM_GRAPH) send_asyn(CommGraph) receive_syn(CommGraph) send_syn(NOTIFY_CONTROLLER) receive_syn(NOTIFY_CONTROLLER) send_asyn(PlaceInfo) receive_syn(PlaceInfo) Abbildung 9: Kommunikation zwischen Plazierungsinstanz und Abwickler Plazierungsinstanz Lastmonitor send_asyn(GET_SYS_LOADS) receive_syn(GET_SYS_LOADS) send_asyn(SystemLoads) receive_syn(SystemLoads) Abbildung 10: Kommunikation zwischen Plazierungsinstanz und Lastmonitor 5.1.1 Auftragswarteschlange Die Vor- bzw. Nachteile der Warteschlangenstrategien wurden bereits in Kapitel 2.3.2 diskutiert. Aufgrund des zu erwartenden höheren Durchsatzes wurde die Zähler-Strategie implementiert. Diese Wahl war nicht durch Tests begründet, sondern beruht lediglich auf der persönlichen Meinung des Autors. Die Warteschlange wurde als doppelt verkettete Liste implementiert. Dadurch ist das Entfernen eines Elements aus der Warteschlange effizienter zu realisieren. Ein Element der Warteschlange enthält außer den Zeigern zum Aufbau der Liste auch einen Zähler für die Anzahl der erfolglosen Plazierungsversuche und einen Zeiger auf den zugehörigen Kommunikationsgraphen. 14 Auftrag 1 Auftrag 2 Auftrag 3 . Zähler Kommunikationsgraph 1 Zähler Kommunikationsgraph 2 Zähler Kommunikationsgraph 3 Abbildung 11: Struktur der Warteschlange Die Toleranzgrenze ist als Konstante definiert. Es wäre möglich, im Sinne einer flexiblen Anpassung an die Systemverhältnisse, die Einstellung dieses Wertes während der Laufzeit vorzunehmen. In Abbildung 12 ist der Programmablauf beim Empfang eines neuen Auftrags dargestellt. Nachdem die Plazierungsinstanz den Kommunikationsgraphen empfangen hat, wird zuerst geprüft, ob der Zähler des ersten Elements die Toleranzgrenze überschritten hat. Ist dies nicht der Fall, dann folgt eine Prüfung auf Erfüllbarkeit der Anforderung. Kann der Auftrag plaziert werden, dann erhöht die Instanz die Zähler aller Aufträge in der Warteschlange. Andernfalls wird der Auftrag an die Warteschlange angefügt. receive_syn(PLACE_COMM_GRAPH) receive_syn(CommGraph) Toleranz des Ersten überschritten? Ja Nein paßt der CommGraph in das System? add_to_queue(CommGraph) Nein Ja place(CommGraph) add_to_queue(CommGraph) send_syn(NOTIFY_CONTROLLER) send_asyn(PlaceInfo) erhöhe Zähler aller Elemente in der Warteschlange Abbildung 12: Empfang eines neuen Auftrags 15 Abbildung 13 beschreibt den Programmablauf bei Änderung der Belegungssituation. Die Warteschlange muß nach Erhalten dieser Nachricht auf erfüllbare Aufträge durchsucht werden. Ist die Toleranzgrenze des ersten Auftrags überschritten, so wird nur dieser auf Erfüllbarkeit geprüft. Andernfalls prüft die Plazierungsinstanz alle Aufträge in der Warteschlange. Kann ein Auftrag plaziert werden, dann wird er aus der Warteschlange entfernt und die Plazierungsinformation an den Abwickler gesendet. receive_syn(INSPECT_QUEUE) send_asyn(GET_LOAD) receive_syn(SystemLoad) hole nächsten CommGraph aus der Warteschlange paßt der CommGraph in das System? Nein Ja remove_from_queue (CommGraph) erhöhe Zähler des Auftrags place(CommGraph) send_syn( NOTIFY_CONTROLLER) send_asyn(PlaceInfo) weiterer CommGraph in der Warteschlange und Toleranzwert nicht überschritten? Ja Nein Abbildung 13: Programmablauf bei Änderung der Belegungssituation 5.1.2 Unterstützung mehrerer Plazierungsstrategien Ein Entwurfsziel der Plazierungsinstanz ist die Unterstützung mehrerer Plazierungsstrategien. Aus diesen Strategien soll der Anwender zur Laufzeit auswählen können. Die zur Verfügung stehenden Strategien müssen zur Plazierungsinstanz gebunden werden. Ein Zeiger verweist auf die aktuell eingestellte Plazierungsfunktion. Dadurch wird ein Wechsel der Plazierungsfunktion 16 zur Laufzeit ermöglicht. Die Auswahl der Plazierungsstrategie zur Laufzeit geschieht mit Hilfe der Nachricht SET_STRATEGY. Diese Nachricht enthält einen zusätzlichen Parameter, mit dem die gewünschte Plazierungsfunktion angegeben wird. 5.2 Verwaltung der Systeminformationen Die Plazierungsinstanz erhält statische Systeminformationen entweder durch Konstanten innerhalb von Header-Dateien oder mit Hilfe von Systemaufrufen. Mit Hilfe von Systemaufrufen werden beim Initialisieren des Systems folgende Informationen ermittelt: • Anzahl der Prozessoren • Arbeitsspeicher pro Prozessor • Verbindungsstruktur des Prozessornetzwerks Die Lastinformationen werden als abstrakte Größen betrachtet. Der Abwickler und der Lastmonitor müssen lediglich für eine einheitliche Interpretation der Lastinformationen sorgen. Insbesondere müssen die Rechenlast und die Kommunikationslast vergleichbar sein. Maximal sind 65536 verschiedene Abstufungen möglich, da die Informationen in 16-Bit Variablen abgelegt sind. Die Anzahl der Prozessoren ist ebenfalls auf 65536 beschränkt. 5.2.1 Speicherung von Auslastungen Um die Kommunikation mit dem Lastmonitor so gering wie möglich zu halten, ist eine Speicherung der Lastinformationen innerhalb der Plazierungsinstanz vorgesehen, da diese Informationen zu noch unbestimmten Zeitpunkten beim Lastmonitor abgefragt werden. Die Datenstrukturen wurden als eindimensionale Felder implementiert. In Abbildung 14 sind diese Datenstrukturen dargestellt. Informationen, die den Arbeitsspeicher betreffen sind als 32-Bit Zahl ausgelegt und begrenzen damit den Arbeitsspeicher auf etwa 4 Gigabytes. Rechenlast Prozessor 1 Rechenlast Prozessor n freier Speicher Prozessor 1 freier Speicher Prozessor n Abbildung 14: Datenstrukturen zur Speicherung von Auslastungen 5.3 Departitionierungsstrategie Wie bereits einleitend erwähnt, sollte in dieser Arbeit lediglich eine einfache Plazierungsstrategie entworfen werden, die allerdings als Basis für zukünftige Entwicklungen dienen kann. Die 17 Wahl fiel auf eine Partitionierungsstrategie. Die Datenstrukturen zur Darstellung der Partitionshierarchie können als Basis komplexerer Partitionierungsstrategien verwendet werden. In den nächsten Abschnitten sollen die Implementierungen der benötigten Datenstrukturen und der Departitionierungsstrategie beschrieben werden. 5.3.1 Kommunikationsgraph Ein paralleles Programm ist in mehrere parallel arbeitende Prozesse aufgeteilt. Diese Prozesse bilden die Knoten des Kommunikationsgraphen. Das Gewicht der Knoten beinhaltet die Rechenlast und den Speicherbedarf des Prozesses. Es ist möglich, daß der Ausführungsort eines Prozesses bereits vor der Plazierung festliegt, z.B. weil er explizit durch den Programmierer festgelegt wurde. Eine solche fest vorgegebene Plazierung ist ebenfalls zusammen mit dem Knoten im Kommunikationsgraph gespeichert. Kommunikationen zwischen Prozessen werden als Kanten zwischen den Knoten dargestellt. Diese Kanten berücksichtigen die Kommunikationsrichtung und sind somit gerichtet. Das Gewicht der Kanten repräsentiert die erzeugte Kommunikationslast. Abbildung 15 zeigt schematisch die Darstellung eines Kommunikationsgraphen. Eine detaillierte Beschreibung ist in [7] zu finden. Knoten 1 Rechenlast: 212 Speicherbedarf: 10 KB Plazierung: Prozessor 7 Kommunikationslast: 170 Kommunikationslast: 1 Kommunikationslast: 25 Knoten 2 Rechenlast: 18 Speicherbedarf: 9 KB Plazierung: Prozessor 15 Kommunikationslast: 34 Knoten 3 Rechenlast: 124 Speicherbedarf: 145 KB Plazierung: Prozessor 3 Abbildung 15: Schematische Struktur des Kommunikationsgraphen Die Datenstrukturen zum Aufbau eines Kommunikationsgraphen in der Plazierungsinstanz wurden mit Blick auf einen geringen Speicherbedarf entworfen. Ein Kommunikationsgraph besteht aus einer Datenstruktur mit allgemeinen Informationen, einer Liste der Plazierungen, einer Liste zur Speicherung der Knoteninformationen und einer Liste zur Darstellung der Kanten. Die Plazierungs- und Knoteninformationen könnten zu einer Liste vereinigt werden. Die Aufteilung in zwei Listen bietet jedoch folgende Vorteile: • Das Versenden der Plazierungsinformation an den Abwickler ist einfacher. • Das Löschen der nicht weiter gebrauchten Informationen vor dem Versenden an den Abwickler ist einfacher. Es werden lediglich die allgemeinen und die Plazierungsinformationen benötigt. 18 Die Kanten zwischen Prozessen werden innerhalb der Kantenlisten gespeichert. Mit jedem Knoten ist eine Liste der Kanten, über die er selbst Nachrichten verschickt, verbunden. Das bedeutet im Falle einer bidirektionalen Kommunikation, daß beide beteiligte Prozesse eine Kante zu dem jeweilig anderen Prozeß besitzen. Die gerichtete Verbindungsstruktur zwischen den Knoten erfordert einen größeren Speicherplatz als eine ungerichtete Kommunikationsstruktur, könnte allerdings zu einer eventuell besseren Plazierung benötigt werden. Für die hier implementierte Plazierungsstrategie ist diese Information aber nicht notwendig. Abbildung 16 zeigt die Anordnung eines Kommunikationsgraphen im Arbeitsspeicher. Kennung des Ergebniskanals Plazierung Prozess 1 Anzahl der Knoten Plazierung Prozess 2 Summe der Rechenlasten gesamter Speicherbedarf Knoteninformation Knoten 1 Kennung des Auftragskanals des Abwicklers Rechenlast Plazierungsinformation Speicherbedarf Knoteninformation Anzahl Kanten Knoteninformation Knoten 2 Kantenliste Knoten 1 Kantenliste Knoten 2 Kantenlisten Knotennummer Kommunikationslast Knotennummer Kommunikationslast Knotennummer Kommunikationslast Knotennummer Kommunikationslast Abbildung 16: Datenstruktur des Kommunkationsgraphen 5.3.2 Struktur der Partitionen Zu Beginn bildet jeder Knoten im Kommunikationsgraph eine eigene einelementige Partition. Die hierarchische Partitionierung vereinigt jeweils zwei Partitionen zu einer neuen Partition. Zur Speicherung der Partitionen wird die Datenstruktur des Kommunikationsgraphen erweitert, um eine Partition genau wie ein Knoten behandeln zu können. Die Darstellung einer Partition erfordert allerdings zusätzliche Informationen, die innerhalb einer separaten Datenstruktur abgelegt sind. Neben den Partitionsnummern der beiden Vorfahren, wird ebenfalls die ungerichtete Kommunikationslast zwischen den zwei Vorfahren gespeichert. Abbildung 17 zeigt die 19 entsprechende Datenstruktur. Aus Speicherplatzgründen werden alle Datenstrukturen zur Speicherung der Partitionen nach jedem Plazierungsversuch gelöscht. ungerichtete Kommunikationslast zwischen den beiden Vorfahren hierarchische Partition 1 Partitionsnummer von Vorfahre 1 Partitionsnummer von Vorfahre 2 ungerichtete Kommunikationslast zwischen den beiden Vorfahren hierarchische Partition 2 Partitionsnummer von Vorfahre 1 Partitionsnummer von Vorfahre 2 Abbildung 17: Datenstruktur zur Speicherung der hierarchischen Partitionen 5.3.3 Partitionen-Baum Teil des Departitionierungsalgorithmus ist die Strukturierung der Knoten mit Hilfe von Partitionen. Danach wird eine Partitionenmenge erstellt, die alle noch nicht vorplazierten elementaren Partitionen enthält. Daraufhin werden jeweils zwei geeignete Partitionen zu einer neuen hierarchischen Partition vereinigt, bis nur noch eine Partition existiert. Diese enthält alle ursprünglichen Knoten des Kommunikationsgraphen. Beim Zusammenfassen zweier Partitionen ergeben sich folgende Merkmale für die Aktualisierung der Verbindungsstruktur: • Kanten zwischen den beiden zusammengefaßten Partitionen werden gelöscht • Kanten von anderen Partitionen zu den beiden Vorfahren werden auf die neue Partition gerichtet Den kompletten Algorithmus zur Erstellung des Partitionen-Baums zeigt Abbildung 18. In Abbildung 19 wird sein Verhalten an einem einfachen Beispielgraph aus vier Prozessen verdeutlicht. Die Partition mit der kleinsten Rechenlast und die von ihr ausgehende Kante mit der größten Kommunikationslast, die die Partition bestimmt, mit der eine Verschmelzung stattfindet, sind hervorgehoben dargestellt. 20 fülle Partitionenmenge mit allen nicht vorplazierten Partitionen P1 := Partition mit kleinster Rechenlast in der Partitionenmenge P2 := Partition in der Partitionenmenge mit größter Kommunikationslast mit P1 vereinige P1 und P2 zu P3 lösche P1 und P2 aus der Partitionenmenge und füge P3 ein aktualisiere Kantenlisten aller Partitionen in der Partitionenmenge mehr als eine Partition in der Partitionenmenge? Ja Nein Abbildung 18: Algorithmus zur Erstellung eines Partitionen-Baums 5.3.4 Behandlung von fest plazierten Knoten Ein Kommunikationsgraph kann fest plazierte Knoten enthalten, die von der Plazierungsinstanz nicht plaziert werden dürfen. Aus diesem Grund werden fest plazierte Knoten nicht in die Partitionenmenge aufgenommen. Vorplazierte Knoten werden nur bei der Suche nach dem geeigneten Startprozessor berücksichtigt. Der in Abschnitt 5.3.5 beschriebene Departitionierungsalgorithmus bestimmt den Startprozessor unter den Prozessoren, auf denen Prozesse gestartet werden müssen, als den Prozessor mit der geringsten Rechenlast. 21 Schritt 1: Partitionsnummer: 1 Rechenlast: 150 Speicherbedarf: 20 KB 400 200 300 Partitionsnummer: 2 Rechenlast: 200 Speicherbedarf: 9 KB Schritt 2: 400 Partitionsnummer: 5 Rechenlast: 1050 Speicherbedarf: 70 KB Vorfahre 1: 4 Vorfahre 2: 1 K- Last: 400 200 Schritt 4: 200 Partitionsnummer: 3 Rechenlast: 250 Speicherbedarf: 7 KB Partitionsnummer: 3 Rechenlast: 250 Speicherbedarf: 7 KB 400 500 Schritt 3: Partitionsnummer: 4 Rechenlast: 900 Speicherbedarf: 50 KB Partitionsnummer: 6 Rechenlast: 1250 Speicherbedarf: 79 KB Vorfahre 1: 5 Vorfahre 2: 2 K- Last: 500 600 Partitionsnummer: 2 Rechenlast: 200 Speicherbedarf: 9 KB Partitionsnummer: 3 Rechenlast: 250 Speicherbedarf: 7 KB Partitionsnummer: 7 Rechenlast: 1500 Speicherbedarf: 86 KB Vorfahre 1: 6 Vorfahre 2: 3 K- Last: 600 Abbildung 19: Ablauf für einen Beispielgraph aus vier Prozessen 22 5.3.5 Departitionierung Die Departitionierung spaltet die zuvor erstellten Partitionen auf und versucht, die Teilpartitionen auf geeignete Nachbarprozessoren zu verschieben. Durch diesen Vorgang werden die Partitionen auf den Prozessoren des Systems verteilt. Im ersten Schritt versucht der Algorithmus einen geeigneten Startprozessor für die Plazierung der Wurzelpartition zu finden. Der Startprozessor ist entweder der Prozessor im System mit der geringsten Rechenlast oder der Prozessor einer Vorplazierung mit der geringsten Rechenlast. Ist der Startprozessor gefunden, so wird die erste, alle Prozesse umfassende Partition darauf plaziert. Im nächsten Schritt spaltet der Algorithmus die Partition entsprechend der Partitionierungshierarchie und prüft zunächst die Verschiebung der größeren, danach die der kleineren Teilpartition auf einen geeigneten Nachbarprozessor. Der Nachbarprozessor mit der geringsten Rechenlast ist der geeignete Prozessor für die Verschiebung. Der Effekt der Verschiebung wird anhand einer Gütefunktion beurteilt. Diese Form einer Gütefunktion ist nur möglich, wenn eine Vergleichbarkeit der Werte für die Kommunikationslast und die Rechenlast sichergestellt ist. 1 P = zu verschiebende Partition 2 Proz1 = Prozessor, auf dem die Partition momentan plaziert ist 3 Proz2 = Nachbarprozessor 4 RL(x) = Rechenlast auf Prozessor x 5 P_KL(x) = Kommunikationslast zwischen den Vorfahren der Partition x 6 7 G(P, Proz1, Proz2) := ( RL(Proz1) - RL(Proz2) ) - P_KL(P) Liefert die Gütefunktion einen Wert größer als Null, so entscheidet sich der Algorithmus für eine Verschiebung. Ansonsten bleibt die Partition auf dem momentanen Prozessor. Der Algorithmus ist beendet, sobald nur noch einelementige Partitionen existieren. Danach folgt eine Überprüfung der ermittelten Plazierung. Diese ist notwendig, da der Algorithmus an keiner Stelle prüft, ob genügend Ressourcen auf den gewählten Prozessoren zur Verfügung stehen. Liefert diese Prüfung ein negatives Ergebnis, dann wird die gesamte Plazierung verworfen und der Auftrag in die Warteschlange des Dienstgebers zurückgestellt. Der folgende schematische Programmablauf soll die Arbeitsweise des Algorithmus verdeutlichen. 1 bestimme Startprozessor 2 plaziere erste Partition auf den Startprozessor 3 While (Partitionshierarchie nicht komplett abgearbeitet) do 4 P = nächste Partition entsprechend der Partitionshierarchie 5 spalte Partition P 6 P1 := Teilpartition von P mit größerer Rechenlast 7 P2 := Teilpartition von P mit kleinerer Rechenlast 8 Proz1 := momentane Plazierung von P 9 Proz2 := Nachbarprozessor von Proz1 mit kleinster Rechenlast 10 If G(P1, Proz2, Proz1) > 0 11 plaziere P1 auf Proz2 23 then 12 Proz2 := Nachbarprozessor von Proz1 mit kleinster Rechenlast 13 endIf 14 If G(P2, Proz2, Proz1) > 0 then 15 plaziere P2 auf Proz2 16 endIf 17 endDo 18 überprüfe ermittelte Plazierung 5.4 Meßergebnisse Die Plazierung eines Programms erfordert einen hohen Rechenaufwand. Um den Aufwand der einzelnen Schritte des Algorithmus zu erkennen, wurden Messungen durchgeführt. Die Laufzeiten des Algorithmus wurden ermittelt, indem das Modul mit geeignet plazierten Zeitabfragen versehen wurde. Die Systemaufrufe zur Abfrage der aktuellen Zeit benötigen ebenfalls Rechenzeit, die in Relation zur Laufzeit des Algorithmus aber vernachlässigt werden kann. Die Messungen wurden nur in Abhängigkeit der Knotenanzahl im Kommunikationsgraph durchgeführt. Der dabei verwendete Kommunikationsgraph mit n Knoten besteht aus einem Senderprozeß, einem Gruppenrufkanal und n-1 Empfängerprozessen. Der Verlauf der gemessenen Zeiten ist in Abbildung 20 graphisch dargestellt. 90 Departitionierung Berechnung des PartitionenBaums 80 70 Sekunden 60 50 40 30 20 10 0 0 100 200 300 400 500 600 700 Knoten im Kommunikationsgraph 24 800 900 1000 90 80 erstelle Kantenliste 70 auffrischen der Kantenlisten ermittle Kommunikationspartner finde kleinste Partition Sekunden 60 50 40 30 20 10 0 0 100 200 300 400 500 600 700 800 900 1000 Knoten im Kommunikationsgraph Abbildung 20: Algorithmuslaufzeiten Aus den Grafiken läßt sich erkennen, daß der Plazierungsalgorithmus einen Aufwand besitzt, der mit steigender Knotenanzahl quadratisch wächst. Der Aufwand des Plazierungsalgorithmus ist hauptsächlich von der Funktion ermittle Kommunikationspartner abhängig. Diese Funktion wird für jede Partition ausgeführt und durchsucht bei jedem Aufruf die Kantenlisten aller Knoten im Kommunikationsgraph. Der Aufwand der Funktion ermittle Kommunikationspartner beträgt: O[ (Anzahl Knoten) * (Anzahl Kanten) ] Eine Laufzeit im Bereich weniger Sekunden läßt sich tolerieren. Allerdings tritt beim Start eines Programmes mit 500 Knoten bereits eine Verzögerung von etwa 17 Sekunden auf. Es besteht also die begründete Notwendigkeit, nach schnelleren und besseren Plazierungsstrategien zu suchen. 6 Zusammenfassung Diese Studienarbeit befaßt sich mit der Plazierung paralleler Programme unter COSY. Im Verlauf dieser Arbeit wurde ein Rahmenwerk für Plazierungsstrategien entwickelt. Die Plazierungsinstanz ist als Dienstgeber realisiert. Der Auftrag zur Plazierung einer verteilten parallelen Anwendung enthält eine Beschreibung des Programms in Form eines Kommunikationsgraphen. Die Plazierungsinstanz ermittelt mit Hilfe des Kommunikationsgraphen die Plazierungsinformation. Der Abwickler erhält die Plazierungsinformation und richtet die Programme auf den entsprechenden Prozessoren ein. Der Dienstgeber kann mehrere Plazierungsstrategien verwalten und stellt dem Anwender die Möglichkeit zur Verfügung, eine Strategie zur Laufzeit auszuwählen. Die Einbindung in das 25 System konnte im Rahmen dieser Studienarbeit nicht vollends realisiert werden, da sich die kooperierenden Instanzen entweder im Entwicklungsstadium befinden oder noch nicht entsprechend modifiziert wurden. Die realisierte Plazierungsstrategie gehört zu den sogenannten Partitionierungsverfahren. Die Plazierungsstrategie berücksichtigt auf einfache Weise vorplazierte Knoten im Kommunikationsgraph. Sie ist keinesfalls optimal, sondern lediglich als Grundlage zukünftiger Algorithmen gedacht. 6.1 Ausblick Aufbauend auf der vorliegenden Arbeit sollten neue Plazierungsstrategien entworfen werden, die eine möglichst optimale Plazierung berechnen. Diese werden zusammen mit den bisherigen Strategien in den Dienstgeber integriert. Die Möglichkeit zur Umschaltung der Plazierungsstrategie kann zum Vergleich der Plazierungsgüte verwendet werden. In Zukunft bleibt zu überprüfen, ob eine zentrale Plazierungsinstanz den Anforderungen in einem Parallelrechner gewachsen ist oder ob die Plazierung verteilt realisiert werden sollte. 26 Literatur [1] H.-U. Heiss, Prozessorzuteilung in Parallelrechnern, Band 98, BI Wissenschaftsverlag, 1994. [2] T. Ottmann, P. Widmayer, Algorithmen und Datenstrukturen, Band 70, BI Wissenschaftsverlag, 1993. [3] G. Sagar, A. K. Sarje, Task allocation model for distributed systems, Int. J. Systems Science., Vol. 22, No. 9, 1991. [4] V. A. Dixit-Radiya, D. K. Panda, Clustering and Intra-Processor Scheduling for Explicitly-Parallel Programs on Distributed-Memory Systems, Int. Prallel Processing Symposium, 1994. [5] G. C. Sih, E. A. Lee, Declustering: A New Multiprocessor Scheduling Technique, Transactions on Parallel and Distributed Systems, Vol. 4, No. 6, June 1993. [6] H. Wettstein, Systemarchitektur, Hanser Verlag, 1993. [7] M. Wagner, Interpretation paralleler Programme in Cosy, Studienarbeit am Institut für Betriebs- und Dialogsysteme, 1995. [8] R. Buthenuth, The COSY-Kernel as an Example for Efficient Kernel Call Mechanisms on Transputers, Transputer/Occam Japan 6, IOS Press, S. 89-101, Juli 1994. [9] R. Buthenuth, S. Gilles, COSY - ein Betriebssystem für hochparallele Computer, TAT ‘94, Aachen, S. 119-128, 1994. 27