Organisationsformen der Speicherstrukturen
Werbung

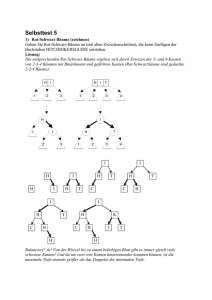
Organisationsformen der Speicherstrukturen Bäume und Hashing Wintersemester 16/17 DBIS 1 Motivation • Ablage von Daten soll einfachen, schnellen und inhaltsbezogenen Zugriff ermöglichen (z.B. Zeige alle Schüler des Lehrers X am heutigen Tag) • Probleme: • Große Datenmengen passen nicht vollständig in den Arbeitsspeicher des Rechners, sondern müssen auf langsameren Sekundärspeichern gelagert werden • Sequentielle Suche (also alle Elemente anfassen) dauert zu lange • DBMS-Intern wird daher oft mit Seiten (Pages) gearbeitet: • Größe durch Datenbankadministrator festgelegt (typischerweise 4 – 32 KB) • Seiten enthalten Header und eine Menge an Datensätzen • Seiten können „als Block“ im Arbeitsspeicher gepuffert werden Dadurch: feste Größen (gut für die Performance) Aber: Welcher Datensatz befindet sich in welcher Seite? Wintersemester 16/17 DBIS 2 Lösung: Mehrwegbäume und Hashing • Bäume = • Spezielle Struktur (Graphentheorie) zur Speicherung von Elementen • Besteht aus Kanten, inneren Knoten und Blättern • Zu jedem Knoten kann man sagen, ob (und welche) Kinder er hat • Damit kann man sich einfach über die Eltern zu einem Kind „durchhangeln“ und muss sich nicht alle Elemente ansehen, um ein spezielles Kind zu finden • Hashing = • Eine feste Funktion, über die sich der Speicherort ermitteln lässt • Für jeden Datensatz wird ein Hashwert berechnet, wodurch der Datensatz wesentlich schneller gefunden werden kann Wintersemester 16/17 DBIS 3 Ein Beispielbaum Quelle: https://de.wikipedia.org/wiki/Datei:Binary-tree.svg Wintersemester 16/17 DBIS 4 Arten von Bäumen • Wurzelbaum: • Spezieller gerichteter Graph mit Knoten und gerichteten Kanten • Ausgezeichnete Wurzel mit nur ausgehenden Kanten • Knoten ohne ausgehende Kanten heißen Blätter • Binärbaum: • Alle Knoten haben maximal zwei Kinder • Häufig gefordert: Kind ist entweder linkes oder rechtes Kind • Binärer Suchbaum: • Effizientes Suchen durch eine Totalordnung • Suchaufwand ist proportional zur Baumhöhe • Vollständige Balanciertheit: • Höhe aller Blätter unterscheidet sich maximal um 1 • Vermeidet die Entartung des Suchbaumes Wintersemester 16/17 DBIS 5 Arten von Bäumen II • Mehrwegbaum: • Ausgangspunkt: Vollständig balancierter binärer Suchbaum • Problem: großer Baum passt nicht vollständig in den Primärspeicher • Zielstellung: Zusammenfassung mehrerer Elemente zu einem Knoten Höherer Verzweigungsgrad = niedrigere Baumhöhe • Beispiele: B- und B+-Baum Wintersemester 16/17 DBIS 6 B-Baum • Vorschlag von R. Bayer und E. McCreight (1970) • Daten und Suchinformationen in Baumstruktur angeordnet • Baumknoten werden auf Seiten abgebildet, die vom DBMS verwaltet werden • Definition eines B-Baumes mit Ordnung n: • Jeder Weg von der Wurzel zum Blatt hat die gleiche Länge h • Jeder innere Knoten hat mindestens n+1 Kinder • Die Wurzel ist ein Blatt oder hat mindestens zwei Kinder • Jedes Blatt besitzt mindestens n Einträge • Jeder Knoten hat höchstens 2n+1 Kinder Wintersemester 16/17 DBIS 7 Beispiel B-Baum https://de.wikipedia.org/wiki/Datei:B-Baum.svg Wintersemester 16/17 DBIS 8 Suchen im B-Baum • Suche nach Schlüssel k liefert speichernden Knoten x und Position i innerhalb des Knotens bzw. ein „nicht enthalten“ • Abfolge: 1. Die Suche beginnt im Wurzelknoten 2. Ist der aktuelle Knoten ein innerer Knoten? 1. Ja: Bestimme die Position des kleinsten Schlüssels, der größer oder gleich k ist. Wurde eine solche Position gefunden? 1. Ja, es handelt sich sogar um den gesuchten Schlüssel Fertig. Gefunden! 2. Ja, aber es handelt sich nicht um den gesuchten Schlüssel Weitersuchen im angehängten Unterknoten 3. Nein. Weitersuchen im letzten Kindknoten 2. Nein, es ist ein Blattknoten. k in den Schlüsseln von x suchen. Entweder „Gefunden!“ oder „nicht enthalten“. Wintersemester 16/17 DBIS 9 Einfügen im B-Baum • Einfügen von Datensatz d mit Schlüssel s • Abfolge: 1. Suche s im Baum 1. Gefunden Fehlermeldung, fertig! 2. Nicht gefunden Merke Blatt b, in dem die Suche endete 2. Füge (s,d) in Blatt b ein 1. Wenn genug Platz ist, alles i.O. 2. Wenn nicht genug Platz ist: 1. Teile b in der Mitte in zwei Unterbäume 2. Der neue Vaterknoten ist das Mittelelement Wintersemester 16/17 DBIS 10 Löschen im B-Baum • Löschen von Datensatz mit Schlüssel s • Abfolge: • Suche s im Baum • Nicht gefunden Fertig! • Gefunden merke Knoten k, in dem s gefunden wurde • Lösche den Datensatz • Wenn aus einem Blatt gelöscht wurde, überprüfen ob das Blatt noch gebraucht wird • Wenn aus einem inneren Knoten gelöscht wurde, muss ein neuer Wurzelknoten bestimmt werden! Wintersemester 16/17 DBIS 11 Bewertung B-Baum • Robust gegen Entartung durch Reorganisation • Je flacher der Baum ist, desto höher ist die Performance • Möglichst große Seiten helfen also • Man könnte den Baum noch deutlich effizienter machen, wenn man die eigentlichen Daten nicht für die Suche brauchen würde… Wintersemester 16/17 DBIS 12 B+-Baum • Vorschlag von Donald Knuth (1973) • Häufigste Art der Index-Implementierung in DBMS • Indexbaum: • Keine Datensätze, sondern Schlüssel und Zeiger auf Kinder • Datensätze befinden sich ausschließlich in der Blattebene des B+-Baumes Mehr Platz pro Schlüssel pro Seite! • Lösch-Vorgang einfacher als im B-Baum • Daten werden nur in Blättern entfernt • Schlüssel im inneren Knoten bleiben als Wegweiser erhalten Weniger Seiten müssen geändert werden • Sequentieller sortierter Zugriff und wahlfreier Schlüsselzugriff sind effizient Bereichsanfragen, Extremwertanfragen gehen besonders performant Wintersemester 16/17 DBIS 13 B+-Bäume in der Praxis Typische Werte: • Ordnung: 100 • Höhe: 3-4 • Füllfaktor: 70% • Durchschnittliche Anzahl von Kindern: 133 • Kapazität bei Höhe 3: 2 Mio. Datensätze • Kapazität bei Höhe 4: 300 Mio. Datensätze • Pufferung Indexbaum bis Ebene 1: 1MB • Pufferung Indexbaum bis Ebene 2: 133 MB Wintersemester 16/17 DBIS 14 Statisches Hashing • Grundidee: Warum den Speicherort nicht aus dem Schlüssel ableiten? • Hashtabelle als Indexstruktur • Berechnung der Speicheradresse eines Datensatzes über den Schlüssel • Dazu: Spezielle Hashfunktion, die zu einem beliebigen Schlüssel die richtige Seite liefert • Beispiel einer Hashfunktion: Divisionsrestverfahren • Eine gute Hashfunktion verteilt die Schlüssel möglichst gleichmäßig auf die verfügbaren Seiten Wintersemester 16/17 DBIS 15 Typische Operationen bei statischem Hashing • Einfügen: • Generierung der zukünftigen Speicheradresse • Datensatz an entsprechender Adresse speichern • Direkte Suche: • Ermittlung der zugehörigen Speicheradresse • Auslesen des Datensatzes an der Speicheradresse • Sequentielle Suche: • Da die Daten durch das Hashing in den Seiten verstreut sind, schwierig! • Löschen: • Ermittlung der zugehörigen Speicheradresse • Löschen des Datensatzes an der Speicheradresse Wintersemester 16/17 DBIS 16 Kollisionsbehandlung bei statischem Hashing • Kollisionen treten immer auf, wenn die Hashfunktion für unterschiedliche Eingabewerte gleiche Ausgabewerte bestimmt. • Wie wahrscheinlich sind Kollisionen? • Kollisionsbehandlung: • Finden einer alternativen freien Speicheradresse • Sicherstellen, dass der Datensatz auch wiedergefunden werden kann • Offenes Hashing: Synonyme im Primärbereich • Suche nach noch nicht belegter Adresse z.B. durch doppeltes Hashen • Problem beim Löschen: Einträge einfach löschen ändert die Voraussetzungen • Geschlossenes Hashing: separater Überlaufbereich • Überlauf für alle Kollisionen oder pro Adresse • Gefahr der Entartung zu Listensystem Je mehr Kollisionen, desto komplizierter wird die Verwaltung Wintersemester 16/17 DBIS 17 Fazit statisches Hashing • Bei Kollisionsfreiheit extrem schnelle Grundoperationen • Kein sequentieller Zugriff auf Daten möglich • Hashfunktion entscheidet über die Qualität des Verfahrens (dummerweise gibt es nicht DIE Hashfunktion) • Ineffizient bei stark wachsenden Datenmengen: • Viel leerer Speicher am Anfang • Wachsende Überlaufketten • Nachträgliche Anpassung der Größe kompliziert (Re-Hashing) Wintersemester 16/17 DBIS 18 Erweiterterbares Hashing I • Zielstellung: • Dynamisches Wachsen und Schrumpfen des benötigten Speicherplatzes • Vermeidung der totalen Reorganisation der Hashtabelle • Konstantes Laufzeitverhalten • Grundidee: Hashfunktion kann gröber oder feiner auflösen • Dazu: • Hashtabelle gliedert sich in Directory und mehrere Hashbuckets fester Kapazität • Zugriff auf die Hashbuckets nur über Directory • Wenn ein Bucket voll wird, wird ein neuer Bucket hinzugefügt und die Hashwerte werden auf beide Buckets aufgeteilt, indem ein zusätzliches Bit des Hashwertes mit beachtet wird Es entstehen lokal unterschiedliche Tiefen Wintersemester 16/17 DBIS 19 Beispiel erweiterbares Hashing I • Schrittweiser Aufbau einer Hashtabelle durch sukzessives Einfügen der Werte in vorgegebener Reihenfolge • Unten: Situation nach Einfügen der Werte 134, 8, 113 und 89 Wintersemester 16/17 DBIS 20 Beispiel erweiterbares Hashing II • Einfügen von Wert 20: Bucket-Überlauf in B1 • Splitting von B1 in zwei Buckets • Erhöhung der lokalen Tiefe an der Splittstelle um 1 (andere Tiefen werden nicht verändert) • Bucket-Zugehörigkeit bestimmt das erste Bit des Pseudoschlüssels • Wiederholung des Vorgangs bei jedem Bucket-Überlauf Wintersemester 16/17 DBIS 21 Beispiel erweiterbares Hashing III • Einfügen von Wert 118: Problemlos • Einfügen von Wert 30: Überlauf in B2 • Splitting in B2 und B3 • Neue lokale Tiefe 2 Jetzt bestimmen hier die ersten zwei Bits im Hashwert den Bucket Wintersemester 16/17 DBIS 22 Erweiterbares Hashing II • Suche: • Hashfunktion liefert den zugehörigen Pseudoschlüssel • Directory liefert das zugehörige Bucket • Bucket laden und Wert entnehmen • Löschen: leere Buckets wieder entfernen? • Hashfunktion auch hier entscheidend für die Performance (möglichst gleichverteiltes Ergebnis und Bitmuster) • Eine Einfügung kann mehrere Directory-Verdopplungen erzeugen Wintersemester 16/17 DBIS 23 Fazit Organisationsformen der Speicherstrukturen • Die Informatik beschäftigt sich seit langem mit effektiven Speicherstrukturen • Gerade für ein DBMS ist das ein wichtiges Thema • Performancekritisch, da Einfügen, Suchen und Löschen Grundoperationen • Bäume und Hashing sind deutlich effizienter als einfache Listen • Jedes Verfahren hat jedoch Vor- und Nachteile Zu wählendes Verfahren ist abhängig von der Aufgabenstellung • Wenn die Performance wichtig ist, DBMS hinterfragen / korrekt einstellen! Wintersemester 16/17 DBIS 24