Künstliche Intelligenz - Neuronale Netze Proseminarbeitrag BIT
Werbung

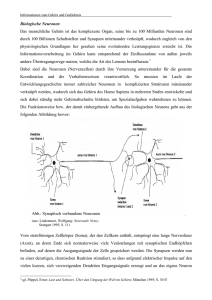
Künstliche Intelligenz Neuronale Netze Proseminarbeitrag BIT September 2003 Thomas Thiel (MatrNr: 1277982, Uni Bonn) Inhaltsverzeichnis 1. Einleitung . . . . . . . 2. Der biologische Kontext von neuronalen Netzen . 1. Ein Neuron im Detail . . . . . 2. Zusammenarbeit mehrerer Neuronen . . 3. Der Schritt zur Abstraktion . . . . 1. Das Neuron als Modell . . . . 2. neuronale Netzmodelle . . . . 4. Lernfähigkeit neuronaler Netze . . . 5. Praktisches Beispiel von Neuronalen Netzen in der KI 6. Literatur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 4 4 5 6 6 7 8 9 11 Einleitung Die Begrifflichkeit der “künstlichen Intelligenz” ist heutzutage in aller Munde, und das nicht nur in der Spieleindustrie um Computergegener für interessantere und herausfordernde Spiele zu schaffen. Künstliche Intelligenzen spielen heutzutage eine viel größere Rolle, als man es sich vielleicht denken könnte. Doch der Terminus allein impliziert schon, das es sich um etwas künstliches handelt, was der natürlichen Intelligenz nachempfunden sein soll. Daher stößt man schon unweigerlich auf die Frage, wie natürliche Intelligenz eigentlich funktioniert. Wer sich mit dieser Fragestellung eingehender beschäftigt, dem wird schnell klar, das hinter zum Beispiel dem menschlichen Verhalten viel mehr steckt als eine Menge festgelegter Verhaltensregeln, die man mehr oder weniger klar in agorithmische Strukturen abbilden kann. Um biologische Intelligenzen zu begreifen, muß man das Zentrum dieser Intelligenzen finden. Das Zentrum, in dem alle Vorgänge, die den Begriff der Intelligenz umfassen, zusammengefasst sind, ist das Gehirn, ein Netz aus Milliarden von kleinen, hochspezialisierten Zellen, den Neuronen. Dieser Seminarbeitrag soll sich speziell mit der Thematik neuronaler Netze beschäftigen, der Abstraktion biologischer Vorgänge auf eine theoretische Basis, durch die komplexe Aufgaben, die ohne diese Technologie menschliche Fähigkeiten erfodern würden, technologisch automatisierbar werden. Im folgenden werde ich eine Einführung über die biologischen Zusammenhänge von natürlichen Neuronen geben. In ihr werde ich über deren Aufbau, Funktion und Zusammenarbeit schreiben. Danach werde ich die Abstraktion auf das theoretische Modell hinter virtuellen Neuronen erläutern. Wenn somit die Grundlagen über Aufbau und Zusammenspiel von Neuronalen Netzen gelegt sind, werde ich mich mit dem zentralen Vorteil dieser Netze beschäftigen, der Lernfähigkeit. Teil 1 – Der biologische Kontext neuronaler Netze Ein Neuron im Detail Das Gehirn ist aus Milliarden hochspezialisierten Zellen zusammengesetzt, den Neuronen. Ein Neuron hat die Eigenschaft, auf externe Reizung mit einer Spannungspotentialsteigerung auf der äußeren Zellmembran zu reagieren. Technisch ist grundsätzlich jede Zelle zu einer vergleichbaren Reaktion fähig, aber bei Neuronen entsteht unter besonderen Bedingungen eine Kettenreaktion, die die Funktion des Gehirns erst möglich macht, da sich Neuronen besonders durch Leitfähigkeit und Erregbarkeit hervorheben. Doch bevor ich auf diese Tatsache eingehe, hier erstmal ein Neuron im schematischen Aufbau: • • • Axon: ein langer Fortsatz, der in einer oder mehreren Synapsen endet, den Verbundsstellen an andere Neuronen. Zellkörper: der für Zellen typische Kern einer Zelle. Dendriten: Weite, baumartige Verzweigungen (dendron, griechisch für Baum). Sowohl am Zellkörper als auch an den Dendriten könen Synapsen anderer Neuronen anlaufen. Wie eben schon erwähnt, heben sich Neuronen besonders hervor, daß sie sich durch elektrische Stimulation besonders gut erregen lassen. Sollte nun diese elektrische Stimulation einen bestimmten Schwellwert überschreiten, entwickelt sich an der Zellwand des Neurons eine elektrische Kettenreaktion, die über die gesamte Länge des Neurons und über das Axon, das bis mehrere Meter lang sein kann, Abb. 1: schematischer Aufbau eines Neurons fortläuft und schließlich in den dem Axon angeschlossenen Synapsen ankommt. Diese Reaktion bezeichnet man als “feuerndes Neuron”. Die an den Synapsen anliegenden Neuronen werden dann durch diese elektrische Stimulation gereizt und können, wird der entsprechende für das Neuron spezifische Schwellwert überschritten, ihrerseits auch feuern. Hierbei würde eine Erklärung der Wechselwirkungen auf chemischer Basis, die die Wanderung von elektrischer Spannung über die Zellmembran bewirken, den Rahmen dieses Seminars sprengen. Daher sei nur gesagt, daß das zu Grunde liegende Prinzip der Austausch von Natriumionen und Kaliumionen sind, die durch die Zellmembran hindurch ausgetauscht werden und so eine lokale Potentialdifferenz erzeugen. Dieser Austausch breitet sich dann im Feuerungsfall über die gesamte Zellmembran aus. Aber wie ermöglicht diese Reaktion die Funktion des Gehirns ? Bisher hab ich nur gezeigt, wie ein Neuron aufgebaut ist, das es auf elektrische Stimulation entsprechend reagiert und so einen elektrischen Impuls über weite Strecken durch den Körper übertragen kann. Daruaf werde ich im nächsten Teil eingehen. Zusammenarbeit mehrerer Neuronen Im letzen Teil habe ich gezeigt, das Neuronen auf elektrische Stimuli besonders reagieren. Die Frage, was sie eigentlich stimuliert, habe ich noch nicht angesprochen. Die Antwort darauf ist aber genau das, was die Funktionalität eines neuronalen Netzes ausmacht, nämlich die Verschaltung mehrerer Neuronen zu einem Verband. Das Schlüsselelement hierbei ist die Synapse. Eine Synapse ist das Bindeglied zwischen einem Axon und dem Zellkörper oder Dendrons eines Nachbarneurons. Läuft ein elektrischer Impuls über das Axon in die Synapse, wird in ihrem Inneren ein komplexer chemischer Vorgang initiiert. Dieser Vorgang reizt dann die anliegende Zelle. Das besondere allerdings ist, das dieser chemische Vorgang seinerseits noch die Möglichkeit hat, den ankommenden Impuls stärker oder schwächer als Reiz an das Neuron abzugeben. Die Größenordnung, unter dem die Hemmung oder Verstärkung der “Impulsweitergabe” steht, nennt sich Synapsengewichtung. In dieser Fähigkeit zur Hemmung und Verstärkung liegt erst die Fähigkeit eines neuronalen Netzes zur Lernfähigkeit begründet. Doch bevor ich mich mit konkreten Beispielen über das Lernen in neuronalen Netzen beschäftige, muß ich der Einfachheit halber erst den Abb. 2: schematische Darstellung einer Synapse Schritt in die Abstraktion vollführen. Denn erst, als neuronale Netze mathematisch abstrakt erfaßt werden konnten, also mathematische Modelle von neuronalen Netzen entstanden, konnte man sich mit konkreten Ideen des Lernens beschäftigen. Teil 2 – Der Schritt zur Abstraktion Das Neuron als Modell Wir haben kennengelernt, wie Neuronen in biologischem Kontext funktionieren. Doch der Schritt zur Abstraktion fehlt noch. Die frühesten Modelle neuronaler Netze stammen noch aus den 40er Jahren. Zwei Mathematiker, McCulloch und Pitts, schlugen 1943 vor, ein Neuron als logisches Schwellwertelement zu beschreiben, was zwei mögliche Ausgangszustände besitzt. Ein solches Element besitzt L Eingangleitungen und eine Ausgangsleitung, die entweder aktiv oder inaktiv sein können. Ein Eingabesignal wird daher durch einen Vektor von L binären Signalkomponenten spezifiziert. Die synaptische Hemmung wird mitberücksichtigt und wird als Faktor von +/-1 zum zugeordneten Eingabesignal mutlipliziert. Die gewichteten Eingabesignale werden dann aufsummiert und mit einem neuronspezifischen Schwellwert verglichen. Ist er erreicht oder überschritten, feuert das Neuron, wird er unterschritten, bleibt es still.Der Ausgabewert y eines Neurons ist daher definiert als: wobei (x) = 1 für x >= 0 und (x) = 0 für x<0. Dieses Modell zeigte erstmals, das mit Hilfe von Neuronalen Netzen beliebige logische Operationen durchfühbar waren, beweisbar dadurch, das Spezialfälle der oben aufgeführten Formel als AND- und Invertergatter funktionieren und somit jede logische Operation durch sie repräsentierbar wird. Auch der moderne Ansatz eines mathemathischen Modells eines Neurons hat diese Fähigkeit noch. Nur ist in modernen Modellen die Verarbeitung innerhalb des Neurons nicht mehr an boolsche Werte gebunden, sondern ist nun vollständig analog, ganz nach dem Vorbild natürlicher Neuronen. Abb. 3: modernes Neuronenmodell. Links ist der Eingabevektor W, die Summe der Synapsengewichtungen wird in der Eingabefunktion in gebildet und dann über die Aktivierungsfunktion mit dem Schwellwert verglichen. Abb. 4: Abbildung boolscher Grundfunktionen über Neuronen Doch eine wichtige Eigenschaft neuronaler Netze fehlte: die Lernfähigkeit und nicht zuletzt die hohe Schadens- und Fehlertoleranz biologischer Netze. Das änderte sich erst, als der kanadische Neurophysiologe Donald Hebb eine wichtige Entdeckung machte. Er fand heraus, das die synaptische Hemmung oder Verstärkung des auf ein Neuron einwirkendes Signals keinesfalls statisch ist, sondern an sich variabel und abhängig von der Dauer und Häufigkeit des einlaufenden Signals. Sein Originaltext hierzu lautete: “Sofern ein Axon der Zelle A einer Zelle B nahe genug ist, um sie immer wieder zu erregen bzw. Dafür zu sorgen, das sie feuert, findet ein Wachstumsprozeß oder eine metabolische Veränderung in einer der beiden Zellen oder in beiden statt, so daß die Effektivität der zelle A, die Zelle B zu erregen, gesteigert wird.” (Hebb, 1949/1988, S.50) Diese “Hebbsche Lernregel” ist die Grundlage für Lernprozesse in Modellen neuronaler Netze. Sie besagt, daß ein Neuron eine Art Gewöhnungsprozess durchmacht. Wird eine Zelle über eine bestimmte Synapse sehr häufig stimuliert, steigt ihr Verstärkungs- oder Hemmungsfaktor, und die Zelle wird leichter über diese spezifische Synapse erregt. Die Hebbsche Lernregel hat als mathematische Eigenschaft in vielen Netzmodellen bis heute überlebt, obwohl sie experimentell bis heute nicht hundertprozentig nachgewiesen werden konnte. Eine ihrer einfachsten mathematischen Fassungen ist wi = * y(x) * xi für die Änderungsdifferenz der Synapsengewichtung wi eines Neurons unter einem Input x=(x1,x2,...xn). Dabei ist y(x) die Erregung eines Neurons und >0 ein Parameter, der die Größeordnung einer Änderung der Synapsengewichtung beschreibt. Neuronale Netzmodelle Als durch die Einführung mathematischer Modelle die computergestütze Simulation neuronaler Netze möglich wurde, entwickelten sich verschiedene weiterführende Verbundstrategien von Neuronen, die jeweils verschiedene Ansätze verfolgten, Lern- und Verarbeitungsprozesse zu implementieren. Ein sehr frühes Modell war das des Perzeptrons. Ein Perzeptron ist eine endliche Menge von N Neuronen, die jeweils eine für alle Neuronen fixe Menge von L Eingabeleitungen besitzen, die, wie üblich in der Arbeit mit Neuronalen Netzen, durch einen Eingabevektor mit L Elementen, genannt Eingabemuster, repräsentiert werden. Jedes Neuron r berechnet seinen Zustand über: Die Koeffizienten wri, für i = 1,2,...,L bestimmen das Verhalten von Neuron r, wie im letzten Kapitel angesprochen. Während der Trainingsphase passt dann jedes Neuron r seine Koeffizienten so an, das es auf “seine” Eingabeklasse Cr hin feuert und auf keine sonst. Dieses Vorgehen ist sehr einleuchtend und leicht zu analysieren. Doch hat es einige schwerwiegende Nachteile. So genügt für komplexere Aufgaben die Menge geeigneter Gewichte wri nicht, was den Einsatzbereich des Perzeptrons zum Beispiel in Aufgaben der Mustererkennung verhindert. Dieser Nachteil wurde dann aber durch die Einführung mehrschichtiger Netzmodelle überkommen. Diese Modelle zeichnen sich dadurch aus, das es eine Schicht von Eingabeneuronen gibt, eine Schicht von Ausgabeneuronen und eine endliche Menge von Zwischenschichten, deren Neuronen mit allen Neuronen der Vorgänger- und Nachfolgeschichten verbunden sind. Dieser Aufbau ermöglicht eine sehr viel höhere Erkennungsgenauigkeit und Abstraktionsfähigkeit des Netzes. Abb. 5: Dreilagiges Neuronennetz Grundsätzlich unterscheidet man zwei mehrschichtige Netztopologien: Feed-forward Netze: Die Eingabe wird von einer Schicht zur nächsten weitergereicht, bis sie die letzte erreicht. Ein Beispiel dieser Topologie wäre das Perzeptron. Rekurrente Netze: Neuronen können untereinander Zyklen bilden, das Durchschreiten des Netzes ist nicht mehr linear und somit nicht mehr leicht überschaubar. Rekurrente Netze sind kaum erforscht. Ein Beispiel dieser Topologie wäre das menschliche Gehirn. Lernen in neuronalen Netzmodellen Die Existenz der Hebbschen Regel ermöglicht es uns nun, mathematisch zu erfassen, wie Neuronale Netze lernen. Aber wie sieht es nun konkret in der Implementierung aus ? In der Einführung des Perzeptrons oder mehrschichtiger Netze ist lediglich erwähnt worden, das die Synapsengewichtungen extern zu variieren sind. Wie sie variiert werden, wurde nicht erwähnt. Grundsätzlich gibt es drei verschiedene Ansätze, was das Lernen in neuronalen Netzen angeht: • • • Überwachtes Lernen (supervised learning) Bestärkendes Lernen (reinforcement learning) Unüberwachtes Lernen (unsupervised learning) Überwachtes Lernen braucht einen externen Lehrer, der von sich aus die Synapsengewichtungen korrigiert. Hierzu speist der Lehrer verschiedene Referenzmuster in das Netz ein, beobachtet die Ausgabe und korrigiert dann die Gewichtungen so, das nach Wiederholung der Einspeisung die Ausgabe von sich aus korrekt ist, dies insbesondere auch bei ähnlichen Eingaben zwecks Generalisierung. Diese Methode ist die schnellste Lernmethode, da die Änderungen der Gewichtung zielgerichtet gegen den Fehler angewendet werden kann. Allerdings ist diese Lernmethode biologisch nicht plausibel, da im Idealfall das neuronale Netz sich selbst organisieren sollte. Als Beispiel für solche Netze sei das oben angesprochene Perzeptron zu nennen, das in der gezeigten Form keine Möglichkeit hat, sich selbst zu organisieren. Bestärkendes Lernen hingegen nutzen selbstorganisierende Netzmodelle, die minimale Einwirkung von außen benötigen. Der Vergleich zwischen Eingabemuster und Ausgabemuster erfolgt hierbei ebenfalls extern, die Gewichtungskorrektur jedoch wird durch das Netz selbst vorgenommen. Der Lehrer gibt hierbei nur ja/nein Antworten. Diese Lernmethode kostet natürlich viel mehr Zeit, da die Änderung der Gewichtungen nicht mehr so distingiert erfolgen kann, wie durch den externen Lehrer im vorigen Lernmodell. Dieses Modell ist biologisch schon plausibler, doch an die Realität kommt es trotzdem nicht sehr nah heran. Unüberwachtes Lernen ist die biologisch plausibelste Lernmethode. Netzmodelle, die eine solche Organisationsstruktur implementieren, sind vollständig selbstorganisierend. Es wird kein Lehrer mehr benötigt, das Lernen beruht auf einer fixen Trainingsmenge von Ein/Ausgabemustern, die nach einer unüberwachten Trainingszeit das Netz selbst zur Gewichtungskontrolle nutzt. Praktisches Beispiel von Neuronalen Netzen in der KI Zur bisherigen eher grundsätzlichen Betrachtung der Funktionsweise neuronaler Netze möchte ich nun noch ein konkretes Beispiel anführen, was mit diesem äußerst mächtigen Werkzeug der Informatik möglich ist. Als Grundlage dient hier ein mehrschichtiges Netzmodell, eine Eingabeschicht, eine Ausgabeschicht, mehrere Verarbeitungsschichten. Abb. 6: Eingabe/Ausgabemodell NN Als Problem nehmen wir uns ein biologisches heraus, die Mustererkennung. Die Eingabeschicht repräsentiert hier ein optisches Eingabegerät, möglicherweise ein Auge, die Ausgabeschicht zeigt das erkannte Muster. Abb. 7: Beispielmuster In den obigen Abbildungen erkennt unser biologisches neuronales Netz problemlos Krokodil, JFK, Bananen und Spinne. Die Netzhaut des menschlichen Auges, welches die Bildinformationen dieser Grafiken aufnimmt, besteht aus Sinneszellen, die einfachen Neuronen sehr ähneln. Sie reagieren auf photonische Stimulation bestimmter Frequenzbereiche und setzen diese in Nervenimpulse um, die über bekannte Abläufe in das Gehirn weitergeleitet werden. Dort werden sie verarbeitet und in Assoziationen umgesetzt. Die Netzhautzellen repräsentieren nun also unsere Eingabeschicht. Und im Gehirn sitz irgendwo ein Bereich von Neuronen, der das erkannte, das assoziierte Objekt repräsentiert, unsere Ausgabeschicht. Abstrahieren wir nun diesen Ablauf, so sehen wir, das eine bestimmte Konstellation erregter Neuronen in der Eingangsschicht, ein Neuron in der Ausgabeschicht erregen soll: Abb. 8: Eingabe/Ausgabemustererkennung Nach entsprechendem Training mit einer dem Problem entsprechenden Trainingsmenge (in einem entsprechend umfangreicheren Netz als in der obigen Grafik) sind wir nun in der Lage, komplexe Muster zu erkennen, ein Prozeß, der in der Informatik eines der anspruchsvollsten Themenbereiche ist. Aber dieses Netz wäre nicht nur in der Lage, Muster zu erkennen, es wäre auch in der Lage, innerhalb einer bestimmten Toleranzgrenze Fehler zu berücksichtigen und zu filtern: Abb. 9: Fehlertoleranz Neuronale Netze haben aber auch schwere Nachteile. Das Training zum Beispiel ist teilweise sehr aufwendig und komplex, dabei entstehende Fehler können sehr schwer zu finden sein, weil neuronale Netze wie eine Blackbox arbeiten. Sind sie trainiert, weiß man nicht genau, wie es arbeitet. War die Trainingsmenge zu klein, kommt es zu Abweichungen in der Ausgabe, weil die Abstraktionsfähigkeit des Netzes nicht ausreicht, benutzt man ein zu großes Netz, kann das Netz alle gelernten Entscheidungen treffen, aber durch die Größe des Netzes sind alle Eingabedaten fest kodiert, so das keine Abstraktionsfähigkeit existiert. Neuronale Netze sind enorm mächtige Werkzeuge in Prozessen, die sonst komplexe Algorithmen erforden würden, die zum größten Teil so noch nicht einmal existieren. Ihre Abstraktionsfähigkeit und Fehlertoleranz sind die Gründe, warum sie heute einen sehr wichtigen Teil in der Forschung nach künstlicher Intelligenz spielen und deshalb kaum noch wegzudenken sind. Literatur Ritter, Helge: Neuronale Netze : eine Einführung in die Neuroinformatik selbstorganisierender Netzwerke, Addison-Wesley, 1990 Spitzer, Manfred: Geist im Netz: Modelle für Lernen, Denken und Handeln. Berlin: Spektrum, Akad. Verl., 1996