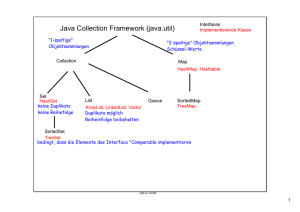
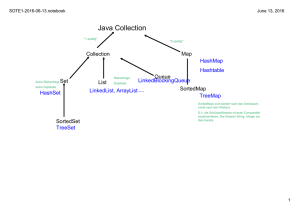
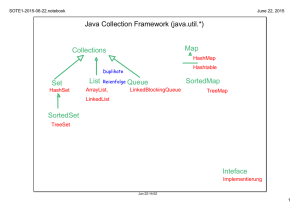
informatik • informatique 4/1997
Werbung

Inhalt • Sommaire Impressum Herausgeber • Editeur SVI/FSI Schweizerischer Verband der Informatikorganisationen / Fédération suisse des organisations d’informatique Postfach 71, 8037 Zürich vertreten durch • représenté par Prof. Dr. Helmut Schauer, Prof. Dr. Beat Schmid, Prof. Dr. Carl August Zehnder Redaktion • Rédaction François Louis Nicolet Schwandenholzstr. 286, 8046 Zürich Telefon 01 371 73 42, Telefax 01 371 23 00 e-mail <[email protected]> Beirat • Comité consultatif Dr. Martin Dürst (Universität Zürich), Martin Egli (Osys AG, Zürich), Dr. Stefan Klein (Universität Koblenz-Landau), Prof. Dr. Rudolf Marty (IFA Informatik, Zürich), Prof. Dr. Jean-Daniel Nicoud (EPF Lausanne), Prof. Dr. Moira C. Norrie (ETH Zürich), Prof. Dr. Hans-Jörg Schek (ETH Zürich), Helmut Thoma (Norvartis AG Basel), Dr. Reinhold Thurner, Rudolf Weber (RWC Consulting, Binz ZH) English proof-reading: Michael Hird, Alasdair MacLeod Druck, Versand • Impression, expédition Stulz AG, 8942 Oberrieden Inseratenverwaltung • Régie des annonces Jean Frey Fachmedien, Postf., 8021 Zürich Telefon 01 448 86 34, Telefax 01 448 89 38 E-Mail <[email protected]> Object Data Models 2 3 10 16 20 24 31 36 Editorial Introduction – Einführung The Object Database Standard: ODMG 2.0 – François Bancilhon and Guy Ferran Abbildung von Objektmodellen auf RDBMS – Klaus Grieger Applications – Anwendungen Supporting Distributed and Adaptive Workflow Systems – Ilham Alloui and Flavio Oquendo Applikationsentwicklung mit Object Server – Jakob Bräuchi und Beat Winistörfer Research – Forschung OM Framework for Object-Oriented Data Management – Moira Norrie and Alain Würgler Object-Based Data Models – Gottfried Vossen Commercial Future SQL3 and OQL – Drew Wade Jahrgang • Année de parution 4. Jahr • 4ème année Erscheinungsweise • Parution Jährlich 6 mal • 6 fois par an Mosaic Auflage • Tirage: 5’000 Exempl. 41 Die Zeitschrift sowie alle in ihr enthaltenen Beiträge und Abbildungen sind urheberrechtlich geschützt. La revue ainsi que toutes les contributions et figures qu’elle contient sont protégées par la loi sur les droits d’auteur. Bezugsmöglichkeiten, Abonnements Possibilités d’obtention, abonnements Die Zeitschrift INFORMATIK/INFORMATIQUE ist offizielles Organ der folgenden Informatikorganisationen • La revue INFORMATIK/INFORMATIQUE est l’organe officiel des organisations d’informatique suivantes SI Schweizer Informatiker Gesellschaft Société Suisse des Informaticiens Schwandenholzstr. 286, 8046 Zürich Tel. 01 371 73 42, Fax 01 371 23 00 E-mail <si@ifi.unizh.ch> WIF Wirtschaftsinformatik-Fachverband Hans Huber-Str. 4, Postfach, 8027 Zürich Tel. 01 283 45 30, Fax 01 283 45 50 E-Mail <[email protected]> INFORMATIK/INFORMATIQUE kann von den Mitgliedern folgender Informatikverbände über ihren Verband bezogen werden • Les membres des associations suivantes peuvent obtenir la revue INFORMATIK/INFORMATIQUE auprès de leur association GRI Groupement Romand pour l’Informatique Case postale 90, 1000 Lausanne 21 GST Gesellschaft zur Förderung der Software-Technologie, Fritz Käser-Str. 10, 4562 Biberist SIK Schweizer Informatik-Konferenz Postfach 645, 4003 Basel SVD Schweiz. Vereinigung für Datenverarbeitung Postfach 373, 8037 Zürich. INFORMATIK/INFORMATIQUE kann nur über die Mitgliedorganisationen des SVI/FSI bezogen werden (Ausnahme: öffentliche Bibliotheken über SVI/FSI). INFORMATIK/INFORMATIQUE ne peut être obtenue que par les organisations affiliées à la SVI/FSI (exception: les bibliothèques publiques auprès de la SVI/FSI). 44 15 46 47 La Productivité des Travailleurs de l’Information: Nouveaux outils de mesure – Christophe Legrenzi Bildungsinitiative Neue Medien – Helmut Thoma Adaptive Problem Solving – Call for contributions Buchbesprechungen • Notes de lecture Book Reviews Einladungen • Invitations Mitteilungen des SVI/FSI • Communications de la SVI/FSI 48 49 IMIA, the International Medical Informatics Association – Jean-Raoul Scherrer The Global Information Society on the way to the next millennium – XV. IFIP World Computer Congress Mitteilungen der Schweizer Informatiker Gesellschaft (SI) Communications de la Société Suisse des Informaticiens (SI) 51 51 52 53 55 56 57 57 Einladung zur Generalversammlung 1997 Invitation à l’Assemblée générale 1997 CHOOSE DBTA Security SGAICO SIPAR Software Ergonomics ISSN 1420-6579 INFORMATIK • INFORMATIQUE 4/1997 1 ODBMS: Object Data Models Editorial Objektdatenmodelle Modèles de données-objet Objektorientierte Persistenz eröffnet neue Möglichkeiten, beispielsweise im Bereich objektorientierter Anwendungsentwicklung oder genereller im Umgang mit beliebig strukturierten Daten. Die bereits eingesetzte Standardisierung, im Bereich objektrelationaler Systeme die objektorientierten Teilbereiche von SQL3 und für OODBMS der ODMG-93-Standard, unterstützt Systemunabhängigkeit und stellt somit die Basis für breiten Praxiseinsatz dar. Während OODBMS-Anbieter den “revolutionären” Ansatz verfolgen und ein vollständig neues Datenmodell definieren, sind ORDBMS-Hersteller bestrebt, Objektorientierung relational verträglich anzubieten. Jeder dieser Ansätze bringt unterschiedliche Vor- und Nachteile mit sich; beiden gemeinsam ist, dass sie die konzeptionelle Einfachheit des Relationenmodells sprengen und somit zahlreiche neue Problemstellungen aufwerfen. So scheinen weder die definierten Beziehungskonzepte den Anforderungen der Praxis zu genügen, noch existieren dringend notwendige Modellierungsmethoden oder Modellarchitekturen, die aufzeigen, wie die neuen Persistenzkonzepte im Rahmen der Gesamtarchitektur einer Anwendung eingesetzt werden sollen. Sicherlich lassen sich viele der noch offenen Punkte auf die kurze Anwendererfahrung zurückführen, so dass zahlreiche mittelfristig einer Lösung zugeführt werden. Weiterführende Forschungsmodelle führen zu grundsätzlich neuen Objektdatenmodellen, die einerseits zahlreiche Probleme kommerzieller Produkte lösen, andererseits aber noch über wenig Praxisrelevanz verfügen. Das vorliegende Themenheft diskutiert Objektdatenmodelle aus diesen unterschiedlichen Blickwinkeln von Forschung, Kommerz und Praxiseinsatz. Hierdurch soll die Diskussion darüber stimuliert werden, – was kommerzielle Modelle auszeichnet, indem kommerziell relevante Modelle erläutert werden – wie Objektdatenmodelle sein sollten, indem gewonnene Praxiserfahrungen beschreiben und bewertet werden – welche konzeptionellen Vorteile aktuelle Forschungsmodelle bieten. Ich hoffe, dass diese Mischung auf Anklang und Interesse bei der Leserschaft stossen wird und bedanke mich bei allen Beitragenden für die motivierte und intensive Mitarbeit, die dieses Themenheft Objektdatenmodelle ermöglicht hat. Vielleicht werden Sie über den einen oder anderen Artikel zu einer vertieften Auseinandersetzung mit Objektpersistenz angeregt. Thomas Wüst, Gastredaktor La persistance orientée-objet présente de nouvelles possibilités, par exemple dans le domaine du développement d’application orienté-objet ou, de façon plus générale, dans le traitement de données structurées arbitrairement. La standardisation qui s’amorce déjà assiste l’indépendance de système et constitue ainsi la base pour une utilisation plus vaste dans la pratique: SQL3 pour les systèmes objet-relationnels dans les domaines partiels orientés-objet, et le standard ODMG-93 pour les OODBMS. Les constructeurs de OODBMS poursuivent une disposition « révolutionnaire » en offrant un modèle de données complètement nouveau alors que les constructeurs ORDBMS s’efforcent à offrir une orientation-objet compatible avec le modèle relationnel. Chacune de ces dispositions procurent des avantages et des désavantages distincts. Ce qui est commun aux deux est qu’ils passent au-delà de la simplicité du concept relationnel et créent de nouveaux problèmes. Ainsi, les concepts simples de relation semblent ne plus satisfaire aux exigences de la pratique, et on n’a pas de méthodes de modélisation indispensables ni d’architectures de modélisation indiquant comment mettre en œuvre les nouveaux concepts de persistance dans le cadre de l’architecture globale de l’application. Plusieurs de ces lacunes sont certes à attribuer au manque d’expérience de la part des utilisateurs et l’on peut espérer quelques solutions dans un proche avenir. Les modèles de recherche plus évolués mènent par principe à de nouveaux modèles de données-objet qui résolvent de nombreux problèmes des progiciels actuels mais n’ont que peu d’importance pratique. Dans le présent cahier nous discutons des modèles de données-objet du point de vue de la recherche, du commerce et de l’utilisation pratique. Nous voulons ainsi stimuler le débat sur quelques points : – ce qui distingue les modèles commerciaux, en élucidant des modèles applicables à la pratique, – la constitution adéquate des modèles de données-objet, en décrivant et évaluant les expériences faites dans la pratique – les bénéfices qu’apportent les modèles de recherche actuels. J’espère que ce choix trouvera votre intérêt, et je remercie tous ceux qui par leur engagement et leur travail intensif, ont contribué à la réalisation de ce cahier. L’un ou l’autre article inciteront peut-être un débat approfondi sur la persistance des objets. Thomas Wüst, rédacteur invité 2 INFORMATIK • INFORMATIQUE 4/1997 Object Data Models The Object Database Standard: ODMG 2.0 François Bancilhon and Guy Ferran This tutorial gives an informal presentation of the ODMG standard for object databases by presenting the data model, the query language OQL and the language bindings. Research on object databases started at the beginning of the 1980’s and became very active in the mid 1980’s. At the end of the 1980’s, a number of start-up companies were created. As a result, a wide variety of products are now commercially available. The products have quickly matured after several years of market presence. Production applications are being deployed in various areas: CAD, software engineering, geographic information systems, financial applications, medical applications, telecommunications, multimedia and MIS. As more and more applications were being developed and deployed and as more vendors appeared on the market, the user community voiced a clear concern about the risk of divergence of the products and expressed their need for convergence and standards. The return from the vendor community was both implicit and explicit. Implicit, because as the vendors understood more and more the applications and the user needs, the systems architecture started to converge and the systems to look alike. Explicit, because the vendors got together to define and promote a standard. The Object Database Management Group (ODMG) was created in 1991 by five object database vendors (O2, Object Design, Objectivity, Ontos and Versant) under the chairmanship of Rick Cattell, it published an initial version of a standard interface, it was joined by two more vendors (Poet and Servio) at the end of 1993, and produced a first complete revision in early 1994, which has been recently upgraded [Cattell et al. 97]. Thus, all object database vendors are active members of the François Bancilhon was a team leader and chief architect at MCC, Austin, Texas, working on the design of “Bubba”, a deductive database system. He then managed the Altair R&D consortium, which designed and developed O2. Founder and CEO of O2 Technology, he is the author of numerous articles on relational, deductive and object databases. Guy Ferran is a founder and VP of engineering of O2 Technology. He took part in the design of ADA, and implemented a distributed database system at IN2 (now Siemens-Nixdorf). After acting as the architect of a PCTE project at Thomson, he joined the ALTAIR project which gave birth to the O2 object database. Address: O2 Technology, 3600 West Bayshore Road – Suite 106, Palo Alto, California 94043. An early version of this paper has been published in Object Magazine, Feb 95. group and are totally committed to comply to the standard in future releases of their products. For instance, the current release of O2 [O2] fully complies with the ODMG OQL query language, and the C++ and Smalltalk bindings. The ODMG Java binding will be delivered in Q4 of 1997. This standard is a major event and a clear signal for the object database market. It is clearly as important for object databases as SQL was for relational databases. The ODMG standard is a portability standard, i.e. it guarantees that a compliant application written on top of compliant system X can be ported on top of compliant system Y, as opposed to an interoperability standard, such as CORBA, that allows an application to run on top of compliant systems X and Y at the same time. Portability was chosen because it was the first users demand. Because object databases cover more ground than relational databases, the standard covers a larger area than SQL does. An object database schema defines the data structure and types of the objects of the database, but also the “methods” associated to the objects. Therefore a programming language must be used to write these methods. Instead of inventing “yet another programming language”, ODMG strongly believes that it is more realistic and attractive to use existing object oriented programming languages. Moreover, during the last few years a huge effort has been carried out by the programming language community and by the OMG organization to define and adopt a commonly accepted “object model”. The ODMG contribution started from this state and proposed an object model which is a simple extension of the OMG object model. This paper gives an informal presentation of the ODMG standard by presenting the data model, the query language and the language bindings. The rest of this paper is organized as follows: Section 1 describes the data model, Section 2 introduces the C++ binding, and Section 3 presents OQL. Defining an Object Database Schema In ODMG, a database schema can either be defined using the Object Definition Language (ODL), a direct extension of the OMG Interface Definition Language (IDL), or using Smalltalk, Java or C++. In this presentation, we use C++ as our object definition language. We first briefly recall the OMG object model, then describe the ODMG extensions. 1 INFORMATIK • INFORMATIQUE 4/1997 3 Object Data Models 1.1 The OMG object model The ODMG object model, following the OMG object model supports the notion of class, of objects with attributes and methods, of inheritance and specialization. It also offers the classical types to deal with date, time and character strings. To illustrate this, let us first define the elementary objects of our schema without establishing connection between them. class Person{ String name; Date birthdate; // Methods: Person(); int age(); }; // Constructor: a new Person is born // Returns an atomic value class Employee: Person{ float salary; }; // A subclass of Person class Student: Person{ String grade; }; // A subclass of Person class Address{ int number; String street; }; class Building{ Address address; // A complex value (Address) // embedded in this object }; class Apartment{ int number; }; Let us now turn to the extensions brought by ODMG to the OMG data model: relationships and collections. 1.2 One-to-one relationships An object refers to another object through a d_Ref. A d_Ref behaves as a C++ pointer, but with more semantics. Firstly, a d_Ref is a persistent pointer. Then, referential integrity can be expressed in the schema and maintained by the system. This is done by declaring the relationship as symmetric. For instance, we can say that a Person lives in an Apartment, and that this Apartment is used by this Person, in the following way: class Person{ d_Ref<Apartment> lives_in }; class Apartment{ d_Ref<Person> }; inverse is_used_by; ver, if an Apartment object is deleted, the corresponding “lives_in” attribute is automatically reset to NULL, thereby avoiding dangling references. 1.3 Collections The efficient management of very large collections of data is a fundamental database feature. Thus, ODMG introduces a set of predefined generic classes for this purpose: d_Set<T>, d_Bag<T> (a multi-set, i.e., a set allowing duplicates), d_Varray<T> (variable size array), d_List<T> (variable size and insertable array). A collection is a container of elements of the same class. As usual, polymorphism is obtained through the class hierarchy. For instance a d_Set<d_Ref<Person>> may contain Persons as well as Employees, if the class Employee is a subclass of the class Person. In ODMG the extent of a class can be optionally maintained by the database engine and furthermore, the application can define as many collections as needed to group objects which match some logical property. For instance, the following collections can be defined: d_Set< d_Ref<Person> > Persons; // The Person class extent. d_Set< d_Ref<Apartment> > Apartments; // The Apartment class extent. d_Set< d_Ref<Apartment> > Vacancy; // The set of vacant apartments. d_List< d_Ref<Apartment> > Directory; // The list of apartments. // ordered by their number of rooms. 1.4 Many-to-many Relationships Very often, an object is related with more than one object through a relationship. Therefore, the notion of 1-1 relationship defined previously has to be extended to 1-n and n-m relationships, with the same guarantee of referential integrity. For example, a Person has two Parents and possibly several Children; in a Building, there are many Apartments. class Person{ d_Set < d_Ref<Person> > parents inverse children; // 2 parents. d_List < d_Ref<Person> > children inverse parents; // Ordered by birthday }; class Building{ d_List< <d_Ref<Apartment> > apartments inverse building; // Ordered by apartment number }; is_used_by inverse lives_in; The keyword inverse is a “syntactical sugar” accepted by O2 which can be replaced by an equivalent template instantiation (d_Rel_Ref). It is, of course, optional. It ensures the referential integrity constraint: if a Person moves to another Apartment, the attribute “is_used_by” is automatically reset to NULL until a new Person takes this apartment again. Moreo- 4 INFORMATIK • INFORMATIQUE 4/1997 class Apartment{ int number; d_Ref<Building> building inverse apartments; }; 1.5 Naming ODMG enables explicit names to be given to any object or collection. From a name, an application can directly retrieve Object Data Models the named object and then operate on it or navigate to other objects following the relationship links. A name in the schema plays the role of a variable in a program. Names are entry points in the database. From these entry points, other objects (in most cases unnamed objects) can be reached through associative queries or navigation. In general, explicit extents of classes are named. 1.6 The sample schema Let us now define our example schema completely. class Person{ String name; Date birthdate; d_Set < d_Ref<Person> > parents inverse children; d_List < d_Ref<Person> > children inverse parents; d_Ref<Apartment> lives_in inverse is_used_by; // Methods: Person(); int age(); void marriage( d_Ref<Person> spouse); void birth( d_Ref<Person> child); d_Set< d_Ref<Person> > ancestors; virtual d_Set<String> activities(); }; class Employee: Person{ float salary; // Method virtual d_Set<String> activities(); }; class Student: Person{ String grade; // Method virtual d_Set<String> activities(); }; // // // // // // Constructor: a new Person is born Returns an atomic value This Person gets a spouse This Person gets a child Set of ancestors of this Person A redefinable method // A subclass of Person // The method is redefined // A subclass of Person // The method is redefined class Address{ int number; String street; }; class Building{ Address address; // A complex value (Address) embedded in this object d_List< <d_Ref<Apartment> > apartments inverse building; // Method d_Ref<Apartment> less_expensive(); }; class Apartment{ int number; d_Ref<Building> building; d_Ref<Person> is_used_by inverse lives_in; }; d_Set< d_Ref<Person> > Persons; d_Set< d_Ref<Apartment> > Apartments; d_Set< d_Ref<Apartment> > Vacancy; d_List< d_Ref<Apartment> > Directory; // // // // All The The The persons and employees Apartment class extent set of vacant apartments list of apartments ordered by their number of rooms C++ Binding To implement the schema defined above, we write the body of each method. These bodies can be easily written using C++. In fact, because d_Ref<T> is equivalent to a pointer (T*), manipulating persistent objects through d_Refs is done in exactly the same way as through normal pointers. 2 To run applications on a database instantiating such a schema, ODMG provides classes to deal with Databases (with open and close methods) and Transactions (with start, commit and abort methods). When an application creates an object, it can create a transient object which will disappear at the end of the program, or a persistent object which will survive when the program ends and can be shared by many other programs pos- INFORMATIK • INFORMATIQUE 4/1997 5 Object Data Models sibly running at the same time. Here is an example of a program to create a new persistent apartment and let “john” move into it. Transaction move; move.begin(); d_Ref< Apartment > home = new(database) Apartment; d_Ref< Person > john = database->lookup_object(“john”); Apartments.insert_element(home); john->lives_in = home; move.commit(); Object Query Language, OQL ODMG introduces a query language, OQL. OQL is a super set of the query part of SQL’92 (entry-level). It allows easy access to objects. We just presented an object definition language (based on the C++ type system) and a C++ binding. We strongly believe that these two languages are not sufficient for writing database applications and that many situations require a query language: • Interactive ad hoc queries A database user should not be forced to write, compile, link edit and debug a C++ program just to get the answer to simple queries. OQL can be used directly as a stand alone query interpreter. Its syntax is simple and flexible. For someone familiar with SQL, OQL can be learned in a few hours. • Simplify programming by embedded queries Embedded in a programming language like C++, OQL dramatically reduces the amount of C++ code to be written. OQL is powerful enough to express in one statement the equivalent to a long C++ program. Besides, OQL directly supports the ODMG model. Therefore, OQL has the same type system as C++ and is able to query objects and collections computed by C++ and passed to OQL as parameters. OQL then delivers a result which is put directly into a C++ variable with no conversion. This definitively solves the well known “impedance mismatch” which makes embedded SQL so difficult to use, since SQL deals with “tables” not supported by the programming language type system. • Let the system optimize your queries Well known optimization techniques inspired from relational technology and extended to the object case can be used to evaluate an OQL query by virtue of its declarative style. For instance, the OQL optimizer of O2 finds the most appropriate indexes to reduce the amount of data to be filtered. It factorizes the common subexpressions, finds out the expressions which can be computed once outside an iteration, pushes up the selections before starting an inner iteration. • Logical/Physical independence OQL differs from standard programming languages in that the execution of an OQL query can be dramatically improved without modifying the query itself, simply by declaring new physical data structures or new indexing or clustering strategies. The optimizer can benefit from these changes and then reduce the response time. Doing such a change in a purely imperative language like C++ requires an algorithm to be completely rewritten be- 3 6 INFORMATIK • INFORMATIQUE 4/1997 // Start a transaction // // // // Retrieve a named object Put this new apartment in the class extent Set reference to this apartment object Commit the transaction cause it cannot avoid making explicit use of physical structures. • Higher level constructs OQL, like SQL provides very high level operators which enables the user to sort, group or aggregate objects or to do statistics, all of which would require a lot of C++ tedious programming. • Dynamicity C++ is a compiled programming language which requires heavy compiling and link edition. This precludes having a function dynamically generated and executed by an application at runtime. OQL does not suffer from this constraint since a query can be dynamically computed immediately. • Object server architecture The new generation of Object Database Systems have a very efficient architecture. For instance, O2 has a page server which minimizes the bottleneck in multi-user environment and draws all the benefits of the CPU and Memory available on the client side which holds visited objects in its own memory. This architecture suits local area network applications very well. For wide area network and/or more loosely coupled database applications this architecture can be supplemented by an OQL server, where the client sends a query to the server which is completely executed on the server side. Without a query language, this architecture is impossible. • SQL’92 compliant Object Database Systems must propose the equivalent of relational systems, i.e., a query language like SQL. Whenever possible, OQL is SQL. This facilitates the learning of OQL and its broader acceptance. Obviously, OQL offers more than SQL in order to accommodate the ODMG data model: path expressions, complex objects, methods invocation, etc. • Support for advanced features (views, integrity constraints, triggers) Finally, without OQL it would be impossible to offer advanced services in object database systems. Features such as views, triggers and integrity constraints need a declarative language. Let us now turn to an example based presentation of OQL. We use the database described in the previous section, and instead of trying to be exhaustive, we give an overview of the most relevant features. Object Data Models 3.1 Path expressions As explained above, one can enter a database through a named object, but more generally as soon as one gets an object (which comes, for instance, from a C++ expression), one needs a way to “navigate” from it and reach the right data one needs. To do this in OQL, we use the “.” (or indifferently “->”) notation which enables us to go inside complex objects, as well as to follow simple relationships. For instance, if we have a Person “p” and we want to know the name of the street where this person lives, the OQL query is: p.lives_in.building.adddress.street This query starts from a Person, traverses an Apartment, arrives in a Building and goes inside the complex attribute of type Address to get the street name. This example treated 1-1 relationship, let us now look at n-p relationships. Assume we want the names of the children of the person p. We cannot write: p.children.name because “children” is a List of references, so the interpretation of the result of this query would be undefined. Intuitively, the result should be a collection of names, but we need an unambiguous notation to traverse such a many-to-many relationship and we use the select-from-where clause to handle collections just as in SQL. select c.name from c in p.children The result of this query is a value of type Bag<String>. If we want to get a Set, we simply drop duplicates, like in SQL by using the “distinct” keyword. select distinct c.name from c in p.children Now we have a means to navigate from an object towards any object following any relationship and entering any complex subvalues of an object. For instance, we want the set of addresses of the children of each Person of the database. We know the collection named “Persons” contains all the persons of the database. We have now to traverse two collections: Persons and Person::children. Like in SQL, the select-from operator allows us to query more than one collection. These collections then appear in the “from” part. In OQL, a collection in the “from” part can be derived from a previous one by following a path which starts from it, and the answer is: select c.lives_in.building.address from p in Persons, c in p.children Predicate Of course, the “where” clause can be used to define any predicate which then serves to select only the data matching the predicate. For instance, we want to restrict the previous query to the people living on Main Street, and having at least two children. Moreover we are only interested in the addresses of the children who do not live in the same apartment as their parents. And the query is: select c.lives_in.building.address from p in Persons, c in p.children where p.lives_in.building.address.street = “Main Street” and count(p.children) >= 2 and c.lives_in != p.lives_in Join In the “from” clause, collections which are not directly related can also be declared. As in SQL, this allows us to compute “joins” between these collections. For instance, to get the people living in a street and have the same name as this street, we do the following: the Building extent is not defined in the schema, so we have to compute it from the Apartments extent. To compute this intermediate result, we need a select-from operator again. This shows that in a query where a collection is expected, this can be computed recursively by a select-fromwhere operator, without any restriction. So the join is done as follows: select p from p in Persons, b in (select distinct a.building from a in Apartments) where p.name = b.address.street This query highlights the need for an optimizer. In this case, the inner select subquery must be computed once and not for each person! 3.2 Complex data manipulation A major difference between OQL and SQL is that object query languages must manipulate complex values. OQL can therefore create any complex value as a final result, or inside the query as intermediate calculation. To build a complex value, OQL uses the constructors struct, set, bag, list and array. For example, to obtain the addresses of the children of each person, along with the address of this person, we use the following query: This query inspects all children of all persons. Its result is a value whose type is Bag<Address>. select struct (me: p.name, my_address: p.lives_in.building.address, my_children: (select struct(name: c.name, address: c.lives_in.building.address) from c in p.children)) from p in Persons INFORMATIK • INFORMATIQUE 4/1997 7 Object Data Models This gives for each person the name, the address, and the name and address of each child and the type of the resulting value is: struct result_type{ String me; Address my_address; Bag<struct{String name; Address address}> my_children; } OQL can also create complex objects. For this purpose, it uses the name of a class as a constructor. Attributes of the object of this class can be initialized explicitly by any valid expression. For instance, to create a new building with 2 apartments, if there is a type name in the schema, called List_apart, defined by: tydedef d_List<<d_Ref<Apartment> > List_apart; the query is: Building(address: struct(number: 10, street: “Main street”), apartments: List_apart (Apartment(number: 1), Apartment(number: 2))) 3.3 Method invocation OQL allows us to call a method with or without parameters anywhere the result type of the method matches the expected type in the query. The notation for calling a method is exactly the same as for accessing an attribute or traversing a relationship, in the case where the method has no parameter. If it has parameters, these are given between parenthesis. This flexible syntax frees the user from knowing whether the property is stored (an attribute) or computed (a method). For instance, to get the age of the oldest child of the person “Paul”, we write the following query: select max(select c.age from p.children c) from p in Persons, where p.name = “Paul” Of course, a method can return a complex object or a collection and then its call can be embedded in a complex path expression. For instance, inside a building b, we want to know who inhabits those least expensive apartment. The following path expression gives the answer: b.less_expensive.is_used_by.name Although “less_expensive” is a method we “traverse” it as if it were a relationship. 3.4 Polymorphism A major contribution of object orientation is the possibility of manipulating polymorphic collections, and thanks to the “late binding” mechanism, to carry out generic actions on the elements of these collections. For instance, the set “Persons” contains objects of class Person, Employee and Student. So far, all the queries against the Persons extent dealt with the three possible “objects” of the collection. If one wants to restrict a query on a subclass of Per- 8 INFORMATIK • INFORMATIQUE 4/1997 son, either the schema provides an extent for this subclass which can then be queried directly, or else the super class extent can be filtered to select only the objects of the subclass, as shown in the example below with the “class indicator”. A query is an expression whose operators operate on typed operands. A query is correct if the type of operands matches those required by the operators. In this sense, OQL is a typed query language. This is a necessary condition for an efficient query optimizer. When a polymorphic collection is filtered (for instance Persons), its elements are statically known to be of that class (for instance Person). This means that a property of a subclass (attribute or method) cannot be applied to such an element, except in two important cases: late binding to a method, or explicit class indication. Late binding Give the activities of each person. select p.activities from p in Persons “activities” is a method which has 3 incarnations. Depending on the kind of person of the current “p”, the right incarnation is called. Class indicator To go down the class hierarchy, a user may explicitly declare the class of an object that cannot be inferred statically. The interpreter then has to check at runtime, that this object actually belongs to the indicated class (or one of its subclasses). For example, assuming we know that only “students” spend their time in following a course of study, we can select those persons and get their grade. We explicitly indicate in the query that these persons are students: select (Student)p. grade from p in Persons where “course of study” in p.activities 3.5 Operator composition OQL is a purely functional language: all operators can be composed freely as soon as the type system is respected. This is why the language is so simple and its manual so short. This philosophy is different from SQL, which is an ad-hoc language whose composition rules are not orthogonal. Adopting a complete orthogonality, allows us not to restrict the power of expression and makes the language easier to learn without losing the SQL style for the simplest queries. Among the operators offered by OQL but not yet introduced, we can mention the set operators (union, intersect, except), the universal (for all) and existential quantifiers (exists), the sort and group by operators and the aggregative operators (count, sum, min, max and avg). To illustrate this free composition of operators, let us write a rather complex query. We want to know the name of the street where employees live and have the smallest salary on average, compared to employees living in other streets. We proceed step Object Data Models by step and then do it all at once. We can use the “define” OQL instruction to evaluate temporary results. 1. Build the extent of class Employee (if not supported directly by the schema) define Employees as select (Employee) p from p in Persons where “has a job” in p.activities 2. Group the employees by street and compute the average salary in each street define salary_map as select street, average_salary: avg(select e.salary from partition) from e in Employees group by street: e.lives_in.building.address.street The group by operator splits the employees into partitions, according to the criterion (the name of the street where this person lives). The “select” clause computes, in each partition, the average of the salaries of the employees belonging to this partition. The result of the query is of type: Set<struct{String street; float average_salary;}> 3. Sort this set by salary define sorted_salary_map as select s from s in salary_map order by s.average_salary The result is now of type List<struct{String street; float average_salary;}> 4. Now get the smallest salary (the first in the list) and take the corresponding street name. This is the final result. sorted_salary_map[0].street 5. In a single query we could have written: (select street, average_salary: avg(select e.salary from partition) from e in (select (Employee) p from p in Persons where “has a job” in p.activities) group by street: e.lives_in.building.address.street order by average_salary )[0].street 3.6 C++ embedding An oql_execute function is provided as part of the ODMG C++ binding. This function allows to run any OQL query. Input parameters can be passed to the query. A parameter is any C++ expression. Inside the sentence, a parameter is referred to by the notation: $<position> where “position” gives the rank of the parameter. Let us now write as an example the code of the “ancestors” method of the class Person. This example shows how a recursive query can be easily written that gives OQL the power of a recursive query language. Recursive query d_Set < d_Ref<Person> > Person::ancestors(){ d_Set < d_Ref<Person> > result; if(parents.is_empty()) return EMPTY_SET; d_OQL_Query q("flatten(select distinct a->ancestors from a in $1) union $1"); d_oql_execute(q << parents, // Pass “parents” as parameter // to the query result); // execute it and get the result return result; }; “$1” refers to the first parameter, i.e, the Set “parents”. In the select clause, we compute the set of ancestors of each parent. We get therefore a set of sets. The “flatten” operator converts this set of sets into a simple set. Then, we take the union of this set with the parent set. The recursion stops when the parents set is empty. In this case, the select part is not executed and the result is the empty set. Conclusion The ODMG standard provides a complete framework within which one can design an object database, write portable applications in C++, Smalltalk or Java, and query the database with a simple and very powerful query language. Based on the OMG, SQL, C++, Smalltalk, Java standards, and available today in industrial products such as O2 it is supported by all the actors of the object database world. 4 References [Cattell 97] Rick Cattell and al. The Object Database Standard: ODMG, release 2.0 Morgan Kaufmann, May 1997. [O2] O2 Technology. The O2 Documentation. http://www.o2tech.com INFORMATIK • INFORMATIQUE 4/1997 9 Object Data Models Abbildung von Objektmodellen auf RDBMS Klaus Grieger Seit Beginn der 80er Jahre sind relationale DBMS erfolgreich zur Datenhaltung in Client/Server Umgebungen eingesetzt worden und haben hier einen grossen Marktanteil erreicht. Der breite Einsatz von objektorientierten Programmiersprachen sowie zunehmend komplexere Objektmodelle haben in den letzten Jahren jedoch neue Anforderungen hervorgebracht, die relationale Systeme manchmal nicht oder nur unvollständig abdecken. Man ist dann meistens vor die Wahl gestellt das Objektmodell auf ein relationales Modell abzubilden oder gleich ein objektorientiertes DBMS einzusetzen. Dieser Artikel formuliert Anforderungen an Objektmodelle und untersucht Abbildungsmöglichkeiten auf relationale und objektorientierte DBMS. Dabei werden Aspekte betrachtet, die für Realisierung und Betrieb grosser Systeme von Bedeutung sind. Anforderungen an Datenbankmanagementsysteme Relationale und objektorientierte DBMS unterscheiden sich durch das zugrundeliegende Datenmodell und die Zugriffsmöglichkeiten. Allen Datenbanksystemen gemeinsam ist die Tatsache, dass Zugriffe im Kontext von Transaktionen erfolgen. Die Transaktionen müssen dabei die „ACID“-Eigenschaften erfüllen: Atomicity, Consistency, Isolation und Durability (Siehe INFORMATIK/INFORMATIQUE 2/1997, April 1997, Seite 9). Da das DBMS meist die Basis für die Datenverarbeitung im Unternehmen darstellt, ergeben sich eine Reihe weiterer Anforderungen. So ist häufig eine hohe Datenverfügbarkeit durch Online-Administrationsmöglichkeiten (Datensicherung und -reorganisation und Schemamanagement), die Skalierbarkeit bezüglich Datenbankgrösse und Zahl der Clients und ein verteilter Datenzugriff notwendig. Da Datenbestände oft eine lange Lebensdauer haben, muss eine Unabhängigkeit der Datenrepräsentation von der aktuellen Anwendung bestehen sowie die Zugreifbarkeit der Daten über verschiedene Programmiersprachen und offene Schnittstellen möglich sein. 1 Anforderungen an persistente Objektmodelle Dieser Abschnitt definiert die Anforderungen an ein objektorientiertes Datenmodell sowie die Implikationen auf persistente Objektmodelle. 2 2.1 Definition Objektmodell Das Objekt (d.h. die Objektinstanz) stellt die zentrale Komponente eines objektorientierten Datenmodells dar. Ein Objekt kapselt Attribute (Zustand) und Methoden (Verhalten) in eine Einheit. Gleichartige Objekte werden zu Klassen zusammenKlaus Grieger arbeitet als Senior Systems Engineer bei Versant Object Technology in Weiterstadt. Zu seinen Aufgabenbereichen zählt die Kundenberatung beim Entwurf von Systemarchitekturen im C++-, Smalltalk- und Java-Umfeld. <[email protected]> 10 INFORMATIK • INFORMATIQUE 4/1997 gefasst und erlauben so eine gemeinsame Beschreibung von Attributen und Methoden in der Klassendefinition. Klassen müssen nicht immer vollständig neu definiert werden. Sie können auch auf einer bestehenden Klasse durch Vererbung aufbauen. Die neue Klasse stellt dann eine Spezialisierung der Basisklasse dar und erweitert deren Zustand und Verhalten. Es können auch Methoden der Basisklasse redefiniert werden. Das Laufzeitsystem ist dann in der Lage, die für ein bestimmtes Objekt definierte Methode dynamisch zu bestimmen und Fallunterscheidungen in der Anwendung zu vermeiden (Polymorphismus). Eng verknüpft mit dem Begriff des Objektes ist die Objektidentität, die jedes Objekt eindeutig identifizierbar macht. So können zwei Objekte mit gleichen Attributwerten trotzdem unterschiedlich sein. Der Vergleich auf Objektidentität gibt hier Aufschluss. Die Objektidentität basiert auf einer eindeutigen Kennzeichnung jedes Objektes (OID). OIDs sind systemdefiniert, werden bei einer Objekterzeugung automatisch vergeben und sind durch die Anwendung nicht beeinflussbar. Durch die Angabe der OID kann ein Objekt lokalisiert werden. Die bereits erwähnten Objektattribute haben keine eigene Identität. Sie dienen der Speicherung des Objektzustandes und werden über das Objekt, in dem sie enthalten sind, und einen Attributnamen angesprochen. Neben einfachen Attributen können auch Vektoren und mehrdimensionale Attributwerte definiert werden. Auch Klassen stehen als Attributtypen zur Verfügung. Mit Ihnen können aus einfachen Objekten komplexere aufgebaut werden. Beziehungen zwischen Objekten werden durch Referenzen ausgedrückt. Da Objekte unter Verwendung der OID angesprochen werden, wird durch die Speicherung der OID eines Objektes implizit eine Beziehung zu diesem Objekt ausgedrückt. Eine Referenz ist deshalb nur eine besondere Art von Attribut, welches als Wert eine OID enthält (Abb. 1). Mehrwertige Beziehungen können durch Referenzvektoren mit unterschiedlichen Eigenschaften aufgebaut werden (Listen, Mengen, Multimengen, Vektoren, …). Object Data Models Kunde – OID 74 Ort – OID 21 Name: Müller Wohnort: <OID 21> Stadt: Frankfurt Land: Hessen Abb. 1: OIDs modellieren Beziehungen Die objektorientierte Vorgehensweise kann durchgängig von der Analyse über das Design bis in die Programmierung angewendet werden. Der Vorteil ist, dass komplexe Objekte der realen Welt von der Analyse bis zur Implementierung durch gleiche Konzepte modelliert werden und durch die Phasen des Entwicklungsprozesses verfolgt werden können. Primäre Kandidaten für die Realisierung neuer Softwaresysteme sind die Programmiersprachen C++, Smalltalk und Java. Diese Sprachen unterstützen die genannten Konzepte, wenngleich bestimmte Unterschiede bestehen. So stehen in den einzelnen Sprachen unterschiedliche Attributtypen zur Verfügung, und die Verwendung beliebiger Klassen als Attributtyp ist nur in C++ möglich. Java und Smalltalk decken dies durch Objektreferenzen zu eigenständigen Objekten ab. C++ unterstützt als einzige Sprache Mehrfachvererbung, wobei Java und Smalltalk die beabsichtigte Semantik mit Delegation abbilden. C++ verlangt im Gegensatz zu Smalltalk eine starke Typisierung. Auch die für Mehrfachbeziehungen verwendeten Collection-Bibliotheken unterscheiden sich bei den Programmiersprachen sowohl vom Charakter (Collections versus Container) als auch in der konkreten Implementierung und im definierten Verhalten. Trotz dieser Unterschiede lassen sich die Objektmodelle in allen drei Sprachen meist hinreichend gut abbilden, da die grundlegenden Mechanismen vorhanden sind. 2.2 Unterstützung von Objektmodellen durch DBMS Um das Objektmodell einer Anwendung oder gar ein Unternehmensobjektmodell auf ein Datenbanksystem abzubilden, müssen die obigen Anforderungen an das Objektmodell auf die Konzepte des DBMS umgesetzt werden. Eine vollständige Unterstützung der objektorientierten Konzepte und der damit verbunden Programmiersprachen ist wünschenswert. Eine möglichst transparente Sprachintegration soll den Anwendungsentwickler von Datenkonvertierungen zwischen Datenbank und Hauptspeicher befreien und ein einheitliches Programmiermodell bieten. Andererseits müssen die Objekte so abgebildet werden, dass sie ihre Semantik behalten und vom Datenbanksystem “verstanden” werden. Eine Speicherung als unstrukturierter Datenstrom (binary large objects, BLOBS) kommt deshalb ebenso wenig in Frage wie Verfahren, die die Skalierbarkeit oder allgemeine Verwendbarkeit einschränken. Abbildung von Objektmodellen auf RDBMS Das Datenmodell eines RDBMS basiert auf dem Relationenmodell. Alle Informationen sind als Datenwerte in Tupeln repräsentiert. Tupel gleichen Typs werden in einer Tabelle gespeichert. Jede Tabelle besitzt ein Primärschlüsselattribut (bzw. eine Menge von solchen Attributen). Der Primärschlüssel 3 identifiziert ein Tupel eindeutig innerhalb einer Tabelle. 1:nBeziehungen werden durch die Speicherung des Primärschlüsselattributes in einer anderen Tabelle ausgedrückt und durch einen Wertevergleich zwischen Primär- und Fremdschlüssel (Join) zur Laufzeit dynamisch wiederhergestellt. Da mehrwertige Attribute nicht erlaubt sind, werden diese in eigene Tabellen ausgelagert. n:m-Beziehungen werden ebenfalls durch eine zusätzliche Tabelle in zwei 1:n Beziehungen aufgespaltet. Für eine vollständige Diskussion der relationalen Grundlagen siehe [Sauer 92]. 3.1 Abbildung von Objekten auf das relationale Datenmodell Auf den ersten Blick scheinen Objektmodell und Relationenmodell sehr ähnlich: OIDs und Referenzen scheinen Primärund Fremdschlüssel zu entsprechen und Klassen, Objekte und Attribute sehen Tabellen, Datensätzen und Tabellenspalten ähnlich. Bei genauerer Betrachtung stellt sich jedoch heraus, dass die Konzepte unterschiedlich sind. Die automatische Generierung künstlicher Primärschlüssel lässt sich durch Funktionen des RDBMS realisieren. Jedoch sind Primärschlüssel immer nur innerhalb einer Tabelle definiert und der Zugriff auf einen Datensatz über den Primärschlüssel ist nur mit Angabe der entsprechenden Tabelle möglich (Abb. 2). Kunde Auftrag 1 String name Set<Auftrag>: auftraege n String auftragsnummer Float getAuftragsvolumen() Standardauftrag String artikelnummer Float menge Float getAuftragsvolumen() Sonderauftrag String leistungsbeschreibung Float gesamtpreis Float getAuftragsvolumen() Abb. 2: Objektmodell zur Abbildung auf relationales Modell Betrachten wir hierzu das Objektmodell (Abb. 2) bestehend aus der Kundenklasse und drei Auftragsklassen. Ein Kunde kann mehrere Aufträge haben. Ein Auftrag ist entweder ein Standardauftrag oder ein Sonderauftrag. D.h. bei der Klasse Auftrag handelt es sich um eine abstrakte Basisklasse, von der keine Instanzen erzeugt werden. Die Methode getAuftragsvolumen() berechnet die Höhe eines Auftrags. Beim Standardauftrag berechnet sich diese aus Menge und Einheitspreis des Artikels, während der Sonderauftrag einfach den Gesamtpreis für den Auftrag zurückgibt. In einer konkreten Auftrags-Collection eines Kunden können sich sowohl Standardauftragswie auch Sonderauftragsobjekte befinden. Um diese Vererbungsstruktur auf Tabellen abbilden zu können, gibt es drei alternative Vorgehensweisen, die im folgenden untersucht werden. INFORMATIK • INFORMATIQUE 4/1997 11 Object Data Models a) Eine “flache” Tabelle pro Klasse Eine Möglichkeit, Vererbungshierarchien abzubilden, besteht darin, für jede Klasse eine Tabelle mit den für diese Klasse definierten Attributen anzulegen. Ein Objekt wird in der Datenbank durch je ein Tupel in den zu der Klasse und allen Basisklassen gehörenden Tabellen repräsentiert. Über gemeinsame Primärschlüssel können die einzelnen Klassenanteile eines Objektes aus den verschiedenen Tabellen wieder zusammengebaut werden (Abb. 3). Kunde (KID, Name) Auftrag (AID, KID, Auftragsnummer) Standardauftrag (AID, Artikelnummer, Menge) Sonderauftrag (AID, Leistungsbeschreibung, Gesamtpreis) KundenTabelle INTEGER KID VARCHAR Name StandardauftragsTabelle INTEGER AID INTEGER Artikelnummer FLOAT Menge AuftragsTabelle INTEGER AID INTEGER KID VARCHAR AuftragsNummer SonderauftragsTabelle INTEGER AID INTEGER Leistungsbeschreibung FLOAT Gesamtpreis SonderauftragsTabelle) zusammengebaut werden. Die Zahl der Joins nimmt mit jedem neuen Auftragstyp zu. b) Eine “komplexe” Tabelle pro Klasse Das Tabellenmodell (Abb. 3) kann durch Kopieren der Attribute aus den Basisklassen in die abgeleiteten Klassen optimiert werden. Ein Objekt entspricht genau einem Tupel in einer der Tabellen. (Abb. 4) Kunde (KID, Name) Auftrag (AID, KID, Auftragsnummer) Standardauftrag (AID, KID, Auftragsnummer, Artikelnummer, Menge) Sonderauftrag (AID, KID, Auftragsnummer, Leistungsbeschreibung, Gesamtpreis) KundenTabelle INTEGER KID VARCHAR Name StandardauftragsTabelle INTEGER AID INTEGER KID VARCHAR Auftragsnummer VARCHAR Artikelnummer FLOAT Menge AuftragsTabelle INTEGER AID INTEGER KID VARCHAR AuftragsNummer SonderauftragsTabelle INTEGER AID INTEGER KID VARCHAR Auftragsnummer VARCHAR Leistungsbeschreibung FLOAT Gesamtpreis Abb. 3: Modellierung von Vererbung mit mehreren Tabellen Diese Lösung ist gut geeignet für Zugriffe, die eine polymorphe Menge von Aufträge zurückliefern sollen (d.h. der eigentliche Typ des Auftrags interessiert zunächst einmal nicht; wir arbeiten nur mit der abstrakten Basisklasse), da nur ein Zugriff auf die Auftragstabelle notwendig ist. Beim Speichern von Aufträgen muss die Anwendung eindeutige AIDs in der Auftragstabelle erzeugen und dafür sorgen, dass eine 1:1 Beziehung mit genau einer Unterklasse sichergestellt wird. In dem Beispiel werden für jeden Auftrag zwei Datensätze in der Datenbank angelegt: Einer in der Tabelle Auftrag und ein weiterer in der Tabelle Sonder- bzw. Standardauftrag. Sollen nun die Aufträge eines Kunden aus der Datenbank gelesen werden, so müssen hierfür sowohl die Tabellen Auftrag und Standardauftrag als auch die Tabellen Auftrag und Sonderauftrag über einen Join verknüpft werden (ggf. wäre ein äusserer Verbund über alle 3 Tabellen möglich (UNION Join). Man sieht, dass der Zugriff auf die polymorphe Menge aller Aufträge gut modelliert wird. Ein konkreter Auftrag muss allerdings zur Laufzeit immer wieder mittels eines Joins aus zwei Tabellen (Auftragstabelle und Standardauftrags- oder 12 INFORMATIK • INFORMATIQUE 4/1997 Abb. 4: Modellierung von Vererbung mit mehreren komplexen Tabelle Im konkreten Beispiel kann die Tabelle Auftrag auch ganz eingespart werden, da von dieser abstrakten Klasse keine Instanzen erzeugt werden sollen. Zum Lesen der Aufträge eines Kunden müssen die Tabellen Standardauftrag und Sonderauftrag abgefragt werden. Ebenso müssen beim Speichern die Objekte nach Typ in der richtigen Tabelle abgelegt werden. Die Überwachung der Integrität zwischen Basisklasse und abgeleiteten Klassen entfällt, da sie durch die Modellierung erzwungen wird. Jedoch führt das Kopieren der Attribute der Basisklassen in die abgeleiteten Klassen zu einer redundanten Schemadefinition. Der Zugriff auf konkrete Objektinstanzen wird von diesem Ansatz gut unterstützt. Allerdings muss nun zum Erstellen einer Liste aller Aufträge auf zwei Tabellen zugegriffen werden. c) Abbildung der Vererbungshierarchie auf eine Tabelle Eine deutliche Verbesserung der Zugriffsgeschwindigkeit lässt sich häufig durch die Zusammenfassung aller Attribute Object Data Models des Vererbungsbaums in eine einzige Tabelle erreichen (Denormalisierung, siehe auch [Sauer 92]). Kunde (KID, Name) Auftrag (AID, KID, Auftragstyp, Auftragsnummer, // Auftrag Artikelnummer, Menge, // Standardauftrag Leistungsbeschreibung, Gesamtpreis)// Sonderauftrag KundenTabelle INTEGER KID VARCHAR Name AuftragsTabelle INTEGER AID INTEGER KID VARCHAR Auftragsnummer INTEGER Auftragstyp VARCHAR Artikelnummer FLOAT Menge VARCHAR Leistungsbeschreibung FLOAT Gesamtpreis Abb. 5: Modellierung von Vererbung mit einer komplexen Tabelle Über das zusätzliche Attribut Auftragstyp wird die tatsächliche Klassenzugehörigkeit des Objektes angezeigt und die entsprechenden Attribute im Datensatz ausgelesen. Attribute, die das aktuelle Objekt nicht enthält werden ignoriert und der unnötige Speicherplatzverbrauch zugunsten der höheren Geschwindigkeit in Kauf genommen. Ein Zugriff auf alle Aufträge eines Kunden kann nun ohne einen zusätzlichen Join durchgeführt werden. Die Zuordnung der zurückgegebenen Objekte zu den verschiedenen Klassen kann im Anwendungsprogramm durchgeführt werden und beeinträchtigt die Datenbankgeschwindigkeit nicht mehr. Dies setzt jedoch voraus, dass sich der Speicherplatzverbrauch durch nicht benötigte Attribute in Grenzen hält. Wenn die Zahl der Attribute und abgeleiteten Klassen zunehmen, steigt die Anzahl der nicht benötigten Attribute in der Auftragstabelle im Verhältnis zur Menge der tatsächlich gespeicherten Information stark an. Zudem wird der schnellere Zugriff auf die Aufträge über den Kunden gegen eine schlechtere Performanz bei der Selektion über die Aufträge eingetauscht. Möchte man beispielsweise eine Selektion auf den Standardaufträgen durchführen, so müssen die Standardaufträge aus der Menge der Aufträge über eine zusätzliche Bedingung auf dem Attribut “Auftragstyp” herausgefiltert werden. d) Zusammenfassung Die Diskussion zeigt, dass sich einfache Objektmodelle auf relationale Konzepte abbilden lassen und dies ist meist dann eine gute Lösung, wenn z.B. bereits ein relationales DBMS im Hause ist, Erfahrung mit dem System vorhanden sind und man die Investition in eine neue Technologie bzw. ein neues Produkt scheut. Für komplexere Objektmodelle lassen die Ansätze erkennen, dass eine Abbildung von OIDs und Objektreferenzen auf relationale Datenbanken mit einem Speicheroverhead und langsa- men Zugriffen verbunden sein kann. Es muss daher ein der konkreten Situation am besten angepasstes Verfahren gewählt werden. Desweiteren sollte man beachten, dass selbst wenn man eine tragbare Lösung für ein Objektmodell mit einer grossen Anzahl von Klassen gefunden hat, diese durch das Hinzufügen weiterer Klassen unbrauchbar werden kann. Durch die Vermeidung polymorpher Beziehungen im Objektmodell können die Abbildungsprobleme reduziert werden. Damit wird jedoch ein wesentlicher Vorteil der objektorientierten Programmierung aufgegeben. In dem gezeigten Objektmodell haben die Auftrags-Referenzen des Kunden keine Information über die Aufträge, die sie referenzieren können. Die notwendigen Methoden zum Zugriff auf den Auftrag (hier: getAuftragsvolumen()) befinden sich in der Basisklasse und verrichten ihre Arbeit entsprechend des gerade vorliegenden Auftragstyps. Bei der strukturierten Programmierung benötigt man für die Behandlung der verschiedenen Auftragstypen Fallunterscheidungen, die die jeweils passende Berechnung aufrufen. Ein neuer Auftragstyp erfordert, dass die betreffenden Programmstellen um eine weitere Fallunterscheidung erweitert werden. Im objektorientierten Programm entfallen diese Sonderbehandlungen. Der Entwickler muss nur die spezifischen Methoden für den neuen Auftrag definieren. Das Laufzeitsystem sorgt automatisch über die späte Bindung der Methoden dafür, dass auch der neue Auftrag richtig behandelt wird, ohne dass hierfür die Anwendung angepasst werden muss. Da jede Klasse des Objektmodells spezialisiert werden kann, gelten diese Überlegungen entsprechend für jede Klasse und jede Beziehung im Objektmodell. Selbst wenn im aktuellen Entwurf bestimmte Klassen noch nicht durch abgeleitete Klassen spezialisiert wurden, so kann dies durch eine neue Anforderung an das Datenmodell geschehen und eine entsprechende Modellierung erforderlich machen. 3.2 Objektorientierte Zugriffsschichten für relationale Datenbanken Sowohl für C++ als auch für Smalltalk gibt es eine Reihe von Produkten, die die Transformation des Objektmodells auf das relationale Schema automatisieren und eine transparente objektorientierte Schnittstelle zur Datenbank bieten. Die konzeptionellen Probleme bei der Abbildung von Objekten auf Tabellen können jedoch meistens nicht vollständig gelöst werden, da sie in den unterschiedlichen Datenmodellen begründet liegen. Generische Zugriffsschichten verschlechtern oft die Zugriffsgeschwindigkeit, da der Anwendungsdesigner freizügiger die Möglichkeiten der Objektorientierung einsetzt und in der Zugriffsschicht anwendungsspezifische Optimierungen kaum noch ausgenutzt werden können. Im wesentlichen wird man mit der Entscheidung konfrontiert entweder eine sehr allgemeine Zugriffsschicht zu entwerfen, die dann allgemein einsetzbar und nicht so empfindlich gegen Änderungen im Objektmodell ist, dafür aber keine anwendungsspezifischen Optimierungen enthält oder aber man entscheidet sich für eine Zugriffsschicht, die sich am Objektmodell orientiert und den Zugriff auf dieses spezielle Modell INFORMATIK • INFORMATIQUE 4/1997 13 Object Data Models optimiert, was dann aber zu einem Mehraufwand führen kann, wenn sich das zugrunde liegende Modell doch nochmal ändert. Ein wesentlicher Gesichtspunkt für mögliche Optimierungen in der Zugriffsschicht kann unter anderem der Optimierer des DBMS sein. Der objektorientierte Zugriff unterscheidet sich wesentlich von der mengenorientierten Verarbeitung. Anstatt die benötigten Informationen mit einer Abfrage zu selektieren, greift die objektorientierte Anwendung navigierend auf die benötigten Objekte zu. Die Objektkapsel generiert aus dem navigierenden Zugriff jeweils ein oder mehrere DatenbankQueries. Statt effiziente Ausführungspläne für mengenorientierte Anfragen zu berechnen, wird das RDBMS mit einer sehr hohen Zahl einfacher Select-Anweisungen konfrontiert, wobei der hochentwickelte Query-Optimierer nicht immer ausgenutzt werden kann. Auch hier gilt wieder, dass wie auch schon bei der Datenmodellierung, dass der dem Projekt angepasste Ansatz gewählt werden muss. Eine gute Diskussion des Themas kann man in [Hahn et al. 95] finden. Objektmodelle von ODBMS Objektdatenbanksysteme basieren auf einem objektorientierten Datenmodell und versuchen die zuvor geschilderten Abbildungsprobleme zu vermeiden. Objektidentität, Referenzen, Vererbung, späte Bindung und komplexe Attributtypen werden von Objektdatenbanken unterstützt. Der navigierende Zugriff kann sehr effizient und ohne spezielle Programmierung durchgeführt werden. Durch eine transparente Sprachschnittstelle, eine automatische Schemaerzeugung und die Verwaltung des Client-Caches wird eine produktive Entwicklungsumgebung bereitgestellt, die von Routineaufgaben entlastet. Die Sprachanbindungen für C++, Smalltalk und Java sind im Standard der ODMG (Object Database Management Group) spezifiziert. Des weiteren definiert die ODMG das Objektmodell und die Abfragesprache OQL (Object Query Language). Objektdatenbanken stellen Transaktionen mit ACID-Eigenschaft zur Verfügung und erfüllen damit die grundlegende Definition eines Datenbanksystems. Wie bei relationalen Datenbanken müssen jedoch auch bei Objektdatenbanken Anforderungen an die Entkopplung von Datenhaltung und Anwendung und universelle Zugreifbarkeit über verschiedene Programmiersprachen und Schnittstellen erfüllt werden. Objekte müssen über eine deskriptive Query-Sprache selektiert werden können. Das ODBMS muss Abfragen interpretieren und unter der automatischen Verwendung existierender Indizes auswerten können. Während diese Anforderungen bei relationalen Systemen seit über 15 Jahren berücksichtigt werden, legen Objektdatenbankhersteller unterschiedliche Gewichte auf ihre Umsetzung. 4 4.1 Der Sprachansatz Häufig sind Objektdatenbanksysteme aus der Idee entstanden, einen transparenten und effizienten Persistenzmechanismus für eine objektorientierte Programmiersprache bereitzustellen. Konzeptionell wird die Datenbank dabei als Erweiterung des transienten Objektspeichers betrachtet, der Transaktionen, Verteilung und Persistenz realisiert. Attribut- 14 INFORMATIK • INFORMATIQUE 4/1997 typen und Collections der Programmierumgebung werden dabei auch in der Datenbank abgelegt, wodurch eine homogene Umgebung für die Anwendungsentwicklung erreicht wird. Daraus ergeben sich allerdings unter anderem folgende Implikationen: • Da sich die Attributtypen, Klassendefinitionen und Collection-Bibliotheken eng an eine Programmiersprache anlehnen, wird der Zugriff mit verschiedenen Sprachen (C++, Smalltalk, Java) auf dieselben Objekte erschwert. • Das DBMS muss ohne Unterstützung der Applikation in der Lage sein, Objekte und Indizes zu verwalten und die Objekte zu interpretieren. Diese Mechanismen legen die Grundlage für eine deskriptive Query-Sprache und sprachunabhängige Funktionalitäten. 4.2 Der Datenbankansatz Ein weiterer Ansatz zur Konzeption eines Objektdatenbanksystems liegt in der Realisierung des DBMS unabhängig von der Sprachanbindung. Sprachschnittstelle A Sprachschnittstelle B Sprachschnittstelle C Objektdatenbankkern Abb. 6: Grundlegende Architektur eines ODBMS Der in der Abbildung gezeigte Objektdatenbankkern realisiert die eigentliche Datenbankfunktionalität. Die Objekte werden sprachunabhängig abgelegt und vom Datenbanksystem verwaltet. Indexpflege und Queryverarbeitung sind für die Externspeicherverwaltung optimiert und sind unabhängig von der eingesetzten Applikation verfügbar. Hierdurch wird das Prinzip der “Unabhängigkeit von den physischen Zugriffspfadstrukturen”, wie sie für Datenbanksysteme gefordert ist, erreicht. Durch die konzeptionelle Trennung von Datenbankmanagementsystem und Sprachanbindung wird dieser Ansatz sehr vielseitig einsetzbar. Objekte werden für mehrere Anwendungen und Programmiersprachen nutzbar und gehen nicht mit der Ablösung der Anwendung verloren. Das Objektmodell des Datenbankkerns ist bei diesem Ansatz nicht durch eine Programmiersprache definiert. Deshalb stellt sich erneut die Frage nach der Abbildung des Objektmodells auf die Datenbank. Da es sich jedoch sowohl bei dem Datenmodell der Anwendung als auch bei dem des Datenbankkerns um Objektmodelle handelt, ist die Anbindung weitaus einfacher und performanter, als dies bei der Abbildung von Objekten auf Relationen der Fall ist. Objektidentität, Referenzen, Vererbung, Attributtypen sowie Collection-Klassen können ohne Transformation unterstützt werden. Falls die Anwendung von Konzepten Gebrauch macht, die spezifisch für eine Sprachanbindung sind, so bestehen hier grundsätzlich zwei Möglichkeiten. Der aus Sicht der Systemarchitektur sauberste Weg besteht darin, diese Spezialkonstrukte auf die elementaren Typen des Kerns abzubilden. So können z.B. Enumerationen in C++ auf Object Data Models Integers und Symbole in Smalltalk auf Strings im Datenbankkern abgebildet werden. Alternativ kann der Kern um diese speziellen Attributtypen oder Collection-Typen erweitert werden, wodurch jedoch die heterogene Verwendbarkeit der Objekte mit zusätzlichen Aufwänden belegt wird. Für eine umfassende Beschreibung der möglichen Konzepte zur Realisierung eines ODBMS verweise ich auf [Heuer 93] und [Bancilhon et al. 92]. Zusammenfassung Generell können Objekte in relationalen Datenbanken gespeichert werden. Wesentliche Merkmale eines Objektmodells sind jedoch im Relationenmodell nicht vorhanden. Der Zugriff auf Objekte über OIDs sowie die Modellierung von Vererbung und heterogenen Objektmengen ist auf relationalen Datenbanken manchmal nur schwer möglich. Objektorientierte Aufsätze für relationale Datenbanken bieten zwar einen transparenten Zugriff auf Objekte, können aber gegebenfalls zur Laufzeit zu einem erhöhten Resourcenverbrauch führen. Objektdatenbanksysteme können komplexe Objektmodelle ohne Umwandlungen persistent ablegen. Die direkte Unterstützung von Objekten in der Datenbank erlaubt eine hohe Zugriffsgeschwindigkeit. Objektdatenbanken bieten eine transparente Sprachintegration und verwalten Client- und ServerCaches transparent für die Anwendung. Objektdatenbanksysteme unterstützen Transaktionen mit ACID-Eigenschaft. Um jedoch Objektdatenbanken auch zur anwendungsübergreifenden Objektspeicherung verwenden zu können, ist es notwendig, 5 dass das ODBMS eine eigene Repräsentation für das Objektmodell aufbaut. Deskriptive Abfragesprachen und automatische Pflege und Auswertung von Indizes erlauben eine Abstraktion von den physischen Zugriffspfaden. Die steigende Bedeutung von CORBA Architekturen tragen Objekte in viele Bereiche des Unternehmens. Ein ORB erlaubt es, bestehende Systeme zu kapseln und über Objektmodelle zugreifbar zu machen. Durch die direkte Unterstützung der in IDL spezifizierten Objektmodelle ergeben sich hier weitere Einsatzmöglichkeiten für Objektdatenbanken. Gegen den Einsatz von Objektdatenbanksystemen sprechen vor allem nicht technische Gründe. Die Produkte sind, verglichen zu den relationalen Anbietern, relativ jung und man muss das notwendige Know-How meist neu aufbauen. Referenzen: [Heuer 92] Andreas Heuer. Objektorientierte Datenbanken. Addison Wesley, 1992. [Sauer 92] Hermann Sauer. Relationale Datenbanken. Addison Wesley, 1992 [Bancilhon et al. 92] François Bancilhon Claude Delobel, Paris Kanellakis. Building an Object-Oriented Database System: The story of O2. Morgan Kaufmann, 1992 [Hahn et al. 95] Wolfgang Hahn, Fridtjof Toenniessen, Andreas Wittkowski. Eine Objektorientierte Zugriffsschicht zu relationalen Datenbanken. Informatik Spektrum, Nr. 18, 1995; http://www.sdm.de/e/www/fachartikel/themen/ Call for contributions Adaptive Problem Solving INFORMATIK/INFORMATIQUE 1/1998 will cover the important topic of Adaptive Problem Solving. For several applications, a complete model of the problem domain is not available, or it is too complex to be implemented on present-day computers. Some of these problems include hand-written character recognition, financial forecasting, risk assessment, non-linear plant control, time-series prediction, autonomous robots, etc. In the last decade a set of new techniques, such as Artificial Neural Networks, Neuro-Fuzzy Logic, and Genetic Algorithms, have been successfully employed to learn a model and/ or predict the evolution of important parameters. These methods automatically build and adapt an estimate of the model or of the missing parameters on the basis of available data. The issue will present practical examples of Adaptive Problem Solving, recent improvements of adaptive algorithms, realisation of adaptive hardware, comparison with traditional techniques, and prospects for future applications. Topics of interest include (but are not limited to): • Industrial applications • New algorithms • • • • • • • • Evaluation of advantages and risks of adaptive techniques Comparisons with traditional methods Adaptive hardware Review of commercial software Cost-benefits of adaptive techniques Control systems of autonomous robots Future prospects of new adaptive techniques Software and hardware issues in adaptive Problem Solving Deadlines: Oct. 1, 1997 Nov. 20, 1997 Nov. 6, 1997 Feb. 1, 1998 Submission deadline Notification to authors Final version of the paper Publication Submission Coordinators Guest Editors: Dario Floreano <fl[email protected]fl.ch>, J.D. Nicoud <[email protected]fl.ch>, LAMI-EPFL, CH-1015 Lausanne Editor: François Louis Nicolet <[email protected]> INFORMATIK • INFORMATIQUE 4/1997 15 Object Data Models Supporting Distributed and Adaptive Workflow Systems Ilham Alloui and Flavio Oquendo This paper presents an advanced application of object database technology. It defines object database requirements for distributed and adaptive workflow systems and identifies suitable state-of-the-art concepts and mechanisms of the commercially available ITASCA OODBMS that meet these challenging requirements. It describes the ITASCAFlow approach, based on the European ESPRIT ALF and SCALE Projects, its metamodel, and its implementation in terms of the ITASCA object data model and system. 1. Introduction Workflow provides an integration framework for enterprisewide and inter-enterprise business processes. It has the advantage of bringing advances in software technology together in a mutually complementary way. Furthermore, it fits such trends as business process re-engineering, process improvement, software-intensive process systems, object distributed, network, and web-based computing, downsizing, multi-agent and cooperative information systems, and above all object-oriented database systems. Workflow systems can be characterised as “Administrative”, “Production”, or “Ad-hoc”. Administrative workflows involve repetitive, predictable processes with simple task coordination rules, such as routing an expense report or travel request through an authorisation process. Production (mission-critical) workflows involve repetitive and predictable business processes, such as loan applications or insurance claims; they encompass an information process involving access to one or more distributed, heterogeneous, and autonomous information systems. Ad-hoc workflows involve human coordination and Ilham Alloui is a post-doctorate researcher of computer science at ESIA Engineering School of University of Savoie, with support from IBEX Systems Computing SA. Her primary research focus is process modelling and software environments, particularly the normalisation and support of cooperative work in software and workflow process-oriented systems. Alloui received a PhD in computer science (Doctorat en informatique) from University of Grenoble II. <[email protected]> Flavio Oquendo is full professor of computer science and research director at ESIA Engineering School of University of Savoie. His research interests include object-oriented, agentoriented and process-oriented information systems, formal description techniques as applied to software and workflow process modelling, and software engineering environments. His past projects include PCTE, PACT, ALF, and SCALE ESPRIT Projects. He has been technical director of the SCALE ESPRIT Project and head of the PEACE Research Project. Oquendo received a PhD in computer science (Doctorat en informatique) from University of Grenoble II and a Research Direction Degree in computer science (Habilitation à Diriger des Recherches) from University of Grenoble I. <[email protected]> 16 INFORMATIK • INFORMATIQUE 4/1997 collaboration; they often appear in office processes such as product documentation or sales proposals. Administrative and production workflows relate mainly to stable process definitions and clerical workers, while ad-hoc ones relate to changing process definitions and knowledge workers. A new generation of workflows, characterised as Adaptive, has arisen, involving adaptations, changes and extensions of workflow process definitions and/or instances on the fly (i.e. evolvable processes); they require features for dynamic reconfiguration of workflows. Users are both clerical and knowledge workers. But in terms of technology, workflow systems increasingly pose challenges for databases, stressing object database technology beyond its current capabilities. Section 2 of this paper presents database requirements for distributed and adaptive workflow systems and outlines the ITASCAFlow approach. Section 3 describes the underlying concepts and architecture. Section 4 presents the implementation. Finally, the conclusion recalls the main results achieved and summarises on-going work. 2. Object database requirements for workflow systems A distributed and adaptive workflow system must provide features to: • model workflow process classes, instances and related complex data, including workflow decomposition in terms of work activities and routing rules; • route and manage work activities throughout the enterprise, including their dynamic assignment and reconfiguration; • support workflow process partial automation (including integration with legacy systems and new systems), monitoring, communication, coordination, cooperation, negotiation, etc.; • exchange workflow related information between distinct workflow engines; • evolve and maintain workflow processes. To meet the above requirements, the object database system must support [Oquendo 95]: • composite objects, able to model the structure and behaviour of complex workflow processes; • distribution across networked computers, enabling client applications to access data at different servers; Object Data Models • active change notification, enabling automatic reaction to workflow changes by performing necessary actions on definitions and instances; • long-duration transactions, enabling users to coordinate and cooperate, sharing and manipulating different versions of the same objects in private and shared workspaces; • dynamic database schema modification, enabling schema changes at run time and the updating of existing instances at access time to conform to new class definitions (without recompiling or relinking existing applications). Among the commercially available object database systems, at least one product provides the required support for distributed and adaptive workflow systems, the ITASCA™ OODBMS. Our approach was to develop a reflective multi-agent system for workflows based on the selected OODBMS. The metamodel and supporting software environment is based on results and lessons learned from the two European ESPRIT projects ALF [Oquendo et al. 92] and SCALE [Oquendo 94], and the PEACE research project [Alloui et al. 96]. 3. Concepts and architecture In ITASCAFlow, a workflow system follows the life-cycle depicted in Fig. 1. This life-cycle is specified in terms of interactive phases for defining, instantiating, activating and improving workflow processes. In the business process modelling phase, business processes are modelled in terms of what they are intended to achieve (business goals). In the workflow process modelling phase, the sub-set of the business process that will be automated through a workflow system is defined. In the workflow process instantiation phase, work activities are allocated to workflow participants (e.g. employees of an enterprise or software resources such as intelligent agents) or are bound to applications (in order to automate those activities). In the workflow process enactment phase, instantiated workflow processes are activated by a workflow engine which is able to interpret the process definitions of the instantiated processes, interacting with workflow participants and invoking tools and applications. These workflow process definitions and instances may evolve in an incremental way to improve the business processes. In order to define, instantiate, activate and improve workflow processes, ITASCAFlow provides a number of framework components represented by the meta-model depicted in Fig. 2. business process modelling definition workflow process modelling instantiation workflow process instantiation improvement Fig. 1: Workflow process life-cycle activation workflow process enactment ITASCAFlow System (Abstract) Modelling Instantiation manages manages evolves Execution Import/Export Evolution manages Model (Abstract) Enactable Enacting WF Model WF Model has_instance has_exec WF Model Fig. 2: ITASCAFlow meta-model The modelling, instantiation, execution and evolution components represent sub-systems that manage workflow processes during the different phases of their life-cycle (Fig. 1). The import/export sub-system allows interoperability of workflow systems, importing workflow definitions provided by other workflow systems and exporting ITASCAFlow workflow definitions to other external workflow systems [WFMC 96]. ITASCAFlow-based workflow systems are reflective and their semantics are defined according to reification and denotation principles. Components of the ITASCAFlow meta-model are expressed in terms of ITASCA classes using its class management mechanisms. ITASCA considers two kinds of objects: instance and class objects. Objects may be versioned and are simple or composite which allows modelling and management of complex workflow processes and related documents. Class definitions form the basis for the database schema that describes the structure (by means of instance and class attributes) and behaviour (by means of instance and class methods) of workflow and document related objects. The ITASCAFlow reflection approach is enabled by the ITASCA feature of handling class objects as first class objects. At the enactment level, adaptability of workflow systems benefits from ITASCA powerful dynamic change mechanisms. When a class definition is modified at run time, ITASCA marks as changed existing instances and at the next access time, it performs the appropriate updates on behalf of the users. Longduration transactions, private/shared databases and active notification are the ITASCA mechanisms used to support distributed coordination and cooperation among workflow participants. This section focuses on the meta-model component of the WF Model. Conceptually, workflow models defined in ITASCAFlow are expressed by a set of performer roles, a set of activities, and a set of agents that assist performers (i.e. workflow participants) connected to roles in performing the assigned activities. Performer roles express the organisational view point INFORMATIK • INFORMATIQUE 4/1997 17 Object Data Models has_sub_activity 1+ Role has_acquaintance executes_activity Activity Agent 1+ has_goal has_role User requires_tool has_intermediate has_output has_input Goal 1+ Product 1+ interacts_via Protocol Tool has_sub_product Fig. 3: ITASCAFlow workflow model ITASCA Object Base of a workflow process. Activities express the functional view and agents the dynamic. A performer role defines the role of an enterprise member in the workflow process. It is described in terms of his/her view of the workflow process and by the set of activities that he/she can enact. An activity is defined by input/output typed parameters (i.e. respectively objects that are provided to the activity and those produced by it), a precondition (i.e. a necessary condition for starting its enactment), the goal that should be satisfied by the agents executing the activity, and finally the kind of interaction (interactive or not) required with its performer (i.e. assigned user to the activity). An agent is defined by its goal, its private object base, its capabilities, and its acquaintances and protocols. The agent private object base specifies its partial view of the workflow process, i.e. its database view and the set of objects it has. Agent capabilities designate the set of tools it is able to execute. Agent interaction capabilities are defined by a set of acquaintances and a set of protocols that express interaction models. Agent acquaintances designate other agents known by the agent and the way it can interact with them to achieve a goal. Acquaintances are represented to an agent by their name, services it can request of them (out-messages) and those services it is able to provide in turn (in-messages), and the set of possible protocols between them. Protocols are represented by state-transition diagrams where transitions are fired by sending or receiving messages. In addition, different enactment policies are provided by ITASCAFlow, ranging from user initiative to proactive automation through system initiative. Some policies provided are [Alloui/Oquendo 96]: • user’s initiative: the user selects the next process state for the interaction and the workflow system checks its consistency with the defined protocols; • user’s assistance: the workflow system computes possible next process states and the user chooses one of them; • partial automation: the system computes possible next process states and, according to automation specifications, selects one or proposes all of them to the user; • total automation: the workflow system always selects the next process state according to the protocol and the current state. The ITASCAFlow software architecture is depicted in Fig. 4. It consists of different kinds of agents: User agents, Tool agents, Workflow agents and five agents called Infrastructure agents namely Object Manager, Broker, Launcher, Workflow Manager and Chronometer. Object manager is in charge of notifying agents of events raised in the object base and managing changes when needed. Broker is responsible for routing events among agents following a subscribe/publish policy. Launcher has the role of starting agents and finding the required resources to support their execution. Workflow manager manages the state of the workflow system and is in charge of agents’ storage and recovery. 4. Implementation ITASCAFlow is built as a framework of ITASCA meta-classes and classes. All ITASCAFlow software components, called agents, are reified in the ITASCA object database. The Object manager agent is the ITASCA OODBMS itself. Agents are distributed on a wide area network of Sun workstations. Each agent is a Unix process that can migrate in a transparent manner from a workstation to another. All agents communicate through the Broker, a multicast service implemented using the ITASCA active notification mechanism. User interfaces (worklists, workspaces, etc.) are implemented as Web clients. User Agent User Agent User Agent Object Manager Agent Tool Agent Tool Agent Tool Agent WF Model Launcher Agent Fig. 4: ITASCAFlow architecture 18 INFORMATIK • INFORMATIQUE 4/1997 Workflow Workflow Agent Workflow Agent Agent Workflow Manager Agent Chronometer Agent Object Data Models 5. Conclusion This paper briefly presents ITASCAFlow, an object database technology for supporting distributed and adaptive workflow systems. The approach and the underlying concepts are depicted. Reification allows querying of workflow process states, automatically starting and monitoring activities. Reflection provides flexible and uniform means for dynamic modification and evolution of workflow process models, instances and even the workflow engine itself. At run time, ITASCA as a distributed active database with powerful advanced features enables execution of distributed adaptive workflow processes that require user interactions and partial automation. On the one hand, ITASCAFlow benefits from ITASCA for supporting build time and run time features for workflow systems; on the other, it enhances ITASCA with an open framework for widearea multi-agent cooperative applications. Acknowledgements We thank Dr. Cheryll Gerelle and Dr. Eric Gerelle for their significant scientific, technical and business insights. ITASCAFlow has been designed and implemented in a joint research and development project between the LLP/CESALP Lab of the University of Savoie and IBEX Object Systems SA. The ITASCA technology, acquired in 1995 by IBEX, is founded on the Microelectronics and Computer Technology Corporation’s (MCC) Orion technology. References [Alloui et al. 96] I. Alloui, S. Latrous and F. Oquendo, “A MultiAgent Approach for Modelling, Enacting And Evolving Distributed Cooperative Software Processes”, Proceedings of the 11th European Workshop on Software Process Technology (EWSPT’96), Nancy, October 1996. Lecture Notes in Computer Science. [Alloui/Oquendo 96] I. Alloui and F. Oquendo, “Peace+: A MultiAgent System for Computer-Supported Cooperative Work in Software Process Centred Environments”, Proceedings of the 8th International Conference on Software Engineering and Knowledge Engineering (SEKE’96), Nevada, June 1996. [Oquendo 94] F. Oquendo, “SCALE: A Next Generation ComputerAssisted Process Support Environment for Systems Integration”, Proceedings of the 3rd IEEE International Conference on Systems Integration, Sao Paulo, August 1994. IEEE Computer Society Press. [Oquendo 95] F. Oquendo, “SCALE: Process Modelling Formalism and Environment Framework for Goal-Directed Cooperative Processes”, Proceedings of the 7th International Conference on Software Engineering Environments, Noordwijkerhout, April 1995. IEEE Computer Society Press. [Oquendo et al. 92] F. Oquendo, J. D. Zucker and Ph. Griffiths, “A Meta-Case Environment for Software Process Centred CASE Environments”, Proceedings of the 4th International Conference on Advanced Information Systems Engineering (CAiSE’92), Manchester, May 1992. Lecture Notes in Computer Science. [WFMC 1996] Workflow Management Coalition, WfMC Interface 1: Process Definition Interchange, Document Number WfMC-TC1016, Draft 6.0, August 1996. INFORMATIK • INFORMATIQUE 4/1997 19 Object Data Models Erfahrungsbericht Applikationsentwicklung mit Object Server Jakob Bräuchi und Beat Winistörfer Die Objekttechnologie ist ein geeignetes Mittel, um die Komplexität und Anforderungsvielfalt der heutigen Informationssysteme zu bewältigen. Wir beschreiben die Erfahrungen, die während der Realisierung einer objektorientierten Anwendung zur Verteilung medizinischer Stammdaten im Gesundheitswesen gemacht wurden und zeigen, welche Erweiterung am Objektdatenmodell der Datenbank benötigt werden und wie diese Lücke durch den Einsatz eines Frameworks geschlossen werden kann. Seit 1989 realisiert FIDES Informatik Softwareprojekte mit Hilfe der Objekttechnologie auf der Basis von Smalltalk. In dieser Zeit wurde eine einheitliche, technische und organisatorische Infrastruktur als Plattform für die objektorientierte Analyse, den Entwurf und die Realisierung geschaffen. Das firmeneigene Smalltalk-Applikationsframework RAP (Reusable Application Parts) und das im FIDES-Projekthandbuch definierte OO-Vorgehen sind Ausgangspunkt aller Projektrealisierungen in der Objekttechnologie. Das Projekt MediFrame wurde auf dieser Basis durchgeführt. Alle OO-Projekte der FIDES Informatik basieren auf einer Client/Server-Architektur, wobei bisher nur die Clientseite mit Smalltalk realisiert wurde. Auf der Serverseite befanden sich relationale Datenbanksysteme. Im Projekt MediFrame kam erstmals die objektorientierte Datenbank GemStone mit Smalltalk auf dem Server zur Anwendung. Unsere Erfahrungen mit GemStone sind Gegenstand dieses Artikels. Das Projekt MediFrame MediFrame der Firma MediData bildet eine elektronische Drehscheibe für medizinische Stammdaten im Gesundheitswesen. Diese Stammdaten umfassen Produkte wie zum Beispiel die schweizerische Operationsklassifikation, verschiedene Tarife, die Laboranalyseliste sowie die Leistungserbringer und Kostenträger. Diese zum Teil mehrsprachigen Daten werden von verschiedenen Lieferanten im Gesundheitswesen zur Verfügung gestellt und in die objektorientierte Datenbank importiert. Die Import-Funktion prüft die einzelnen Datensätze auf formale Gültigkeit: zum Beispiel bezüglich der Anzahl AttribuJakob Bräuchi ist technischer Projektleiter von MediFrame. Er realisiert und leitet seit drei Jahren Smalltalk-Projekte. jakob.<braeuchi@fides.ch> Beat Winistörfer, lic.oec.publ., dipl. Wirtschaftsinformatiker, ist Projektleiter des Smalltalk-Applikations-Frameworks RAP der FIDES Informatik. Er realisiert und leitet seit über drei Jahren Smalltalk-Projekte. Neben der Projektrealisierung ist er auch als Berater für objektorientierte Software- und Framework-Entwicklung tätig. <beat.winistoerfer@fides.ch> 20 INFORMATIK • INFORMATIQUE 4/1997 te oder dem Aufbau des Schlüssels und auf die Integrität des ganzen Produktes. Ausserdem wird geprüft, ob bereits vorhandene Produkteteile mutiert worden sind. Die Mutationen der einzelnen Produkteteile werden historisiert. Anschliessend werden die Produkteteile zu einer hierarchischen Struktur von Objekten verknüpft. MediData-Kunden können die Produktedaten in verschiedenen Formaten mit unterschiedlichem Umfang und über diverse Medien beziehen. Dieser Vorgang wird als Export bezeichnet. Die exportierten Daten werden dem Kunden entweder via EDIFACT übermittelt oder in einem FTP-Verzeichnis zur Verfügung gestellt. Alternativ können auch Datenträger erstellt werden. Die Export-Funktion kann alle Produkteteile einer bestimmten Version liefern, ebenso Mutationen seit einem Referenzdatum oder alle Produkteteile, die in einem angegebenen Zeitbereich gültig waren. Mit Hilfe von Filtern ist es möglich, nur bestimmte Produkteteile auszuwählen, zum Beispiel Medikamente einer bestimmten Gruppe in französischer Sprache. Eine zweite Datenart, die Administrativdaten, wie Teilnehmer, Verträge oder Accountdaten, regelt die Beziehung von MediData zu ihren Kunden. Die Kunden können Aufträge über Internet erteilen. In einer späteren Version sollen die exportierten Daten auch über Internet visualisiert werden. Motivation für objektorientierte Datenbank Die Produktedaten und die Administrativdaten von MediFrame haben viele Beziehungen untereinander. Daraus resultieren komplexe, hierarchische Datenstrukturen, die zudem noch historisiert werden müssen. Zur Abbildung solcher Datenstrukturen eignet sich ein objektorientiertes Datenmodell besser als ein relationales, da die Beziehungen zwischen den Objekten direkt als Links implementiert werden können. Die Sprache Smalltalk, die auf dem Server eingesetzt wird, ist zur Realisierung der komplexen Historisierungs- und Beziehungsfunktionen wesentlich besser geeignet als SQL. Durch eine einmal aufgebaute Objektstruktur lässt sich danach effizient navigieren. Der Aufbau der Beziehungen erfolgt während des Imports der Daten. Bei der Erstellung der Exports kommt der Vorteil der objektorientierten Datenstruktur voll zum Tragen: die Object Data Models GEMSTONE Exportfunktion navigiert über die BeFTP Datenträger ziehungen durch die Struktur der Produkteteile. Mit einer relationalen DatenAuslösung durch: Flatfile Format – Benutzer Medidata struktur könnte der Export nur mit Hilfe Checking umfangreicher Joins gelöst werden. Historisierung Import und Export der Produktedaten Import können auf dem Server realisiert werAuslösung durch: den, da GemStone sowohl eine Daten– Benutzer MediData bank, als auch ein objektorientierter ApDatenvisualisierung plikationsserver ist. Client und Server Clients (vorgesehen) können beide in Smalltalk verwirklicht werden, womit eine vereinfachte PartiWWW Admin. Daten MediFrame tionierung der Applikation zwischen – Verträge Auftragserteilung Client und Server möglich wird. Die – Teilnehmer Mechanismen für Import, Export und – Accounting Produktedaten Historisierung der ProduktekomponenMail ten können bei einer durchgängig Avisierung bei Export Produkte-Update Export admin. Daten objektorientierten Realisierung echt Auslösung durch: wiederverwendet werden. Mit einer – Benutzer MediData – periodisch SQL-Datenbank wäre dies nicht mög– Produkte-Update lich. So können zum Beispiel Tabellen Volle Version – WWW-Auftrag Inkrementelle Version und Kolonnen nicht als dynamische Gültige pro Zeitbereich Parameter für eine SQL-Funktion verwendet werden. Flatfile Format EDIFACT Format Eine Hauptanforderung an das System ist, dass neue Produkte oder andere Exportformate mit möglichst geringem FTP Datenträger EDIFACT Aufwand integriert werden können und die damit verbundene Systemerweiterung keine neue Applikationsversion Abb. 1: Funktionsübersicht der Applikation MediFrame erfordert. Bei einem relationalen Datenbanksystem würde ein neues Produkt eine eigene Datenbank den. Nach Abschluss der Transaktion durch commit oder abort oder zumindest einen Tabellenbereich bilden, für welchen die synchronisiert GemStone den Client mit dem neuesten Stand in ganze Funktionalität mehr oder weniger neu geschrieben wer- der Datenbank, d.h. persistente Objekte im Client, die von einer anderen Transaktion verändert wurden, werden aktualisiert, den müsste. entweder sofort oder beim nächsten Zugriff. Pro Session kann nur eine offene Transaktion existieren (Single Transaction). Der Object Server Mit dem GemStone Object-Server können Smalltalk-Objek- Mit einem Locking auf Objektstufe kann die konkurrente Bearte einfach persistent gemacht werden. Neben der Objektstruk- beitung von Objekte verhindert werden. Bezüglich Konkurtur wird auch die Funktionalität durch Smalltalk-Methoden in renz-Detektion können zwei Stufen gewählt werden: “Nur der Datenbank abgebildet. Das Objektdatenmodell entspricht Schreiben” oder “Lesen und Schreiben”. Die Verbindung des Smalltalk-Clients mit dem Object Server weitgehend demjenigen in Smalltalk: Objekte werden durch untypisierte Instanzvariablen und Methoden mit einfacher Ver- wird durch die vollständig in Smalltalk integrierte Schnittstelle erbung modelliert. GemStone erweitert das Smalltalk-Objekt- GemBuilder sichergestellt. Damit können globale Smalltalkdatenmodell um die Möglichkeit, Instanzvariablen zu typisie- Variable mit den Einstiegspunkten in GemStone verknüpft werden und die Klassen zwischen Client und Server flexibel ren, d.h. deren Klasse zu deklarieren. Die Objekte in der Datenbank werden durch die gängigen abgebildet werden. Bei der Verbindung des Clients mit dem Smalltalk-Collection-Objekte organisiert, die an deklarierten Server wird zwischen Stubs und Forwarders unterschieden. Einstiegspunkten abgelegt werden. Zusätzlich existieren spezi- Stubs sind Proxys, die bei einem Zugriff das entsprechende Obelle Listen-Subklassen, die einen konkurrenten Zugriff erlau- jekt aus der Datenbank in den Client holen, Forwarders leiten ben. Die Abfrage von Objekten in den Listen erfolgt durch die die Message an das Objekt auf dem Server weiter. bekannten Smalltalk-Blöcke oder mit speziellen GemStoneBlöcken, bei denen auf die für die Liste definierten Indizes zu- Anforderungen an ein Business Object Model Das einfache Objektdatenmodell von Smalltalk eignet sich gegriffen wird. Objekte werden über Objekttransaktionen erstellt, bearbeitet nur beschränkt zur Modellierung von Business-Objekten. Für und gelöscht. Innerhalb einer Transaktion können Objekte auf die konsequente Umsetzung eines Objektmodells ergeben sich dem Client und auf dem Server gleichermassen verändert wer- folgende weitere Anforderungen: INFORMATIK • INFORMATIQUE 4/1997 21 Object Data Models der erweiterten Objektmodell-Definitionen nach GemStone wird ebenfalls durch das Werkzeug ObjectHistory unterstützt. Aufgrund der speziellen Historisierungsanforreferenced derungen des Projekts MediFrame wurde das Referenced Object objects childobjects Business Object Model um eine Historisierungs-Komponente erweitert. Das Historisiechildobjects Other Object with History Aggregated Object with own history rungs-Framework erlaubt die Versionierung von beliebigen Business Objekten. Für die HistoriNicht Bestandteil der Historisierungseinheit sierung werden die Beziehungen der Objekte Historisierungseinheit berücksichtigt, so dass aggregierte Objekte Abb. 2: Objektdiagramm von historisierten Objekten ebenfalls mithistorisiert werden können. Die Versionen eines Objekts werden in einem Histo• Eine Attributdeklaration, mit der Typ, Standard-Konvertie- ry-Objekt verwaltet. Die historisierten Objekte verfügen zurung, Formatierung und Validierung festgelegt werden kön- sätzlich zur Versionsnummer über einen Gültigkeitsbereich. nen. Die Versionierung kann pro Business Objekt Klasse flexibel • Die Modellierung von uni- und bidirektionalen Beziehungen definiert werden. Die Historisierung steht auch auf dem Object zwischen Klassen. Solche Beziehungsdefinitionen sichern Server zur Verfügung. die referentielle Integrität und Konsistenz im Objektmodell. So sollten zum Beispiel die Rückverknüpfungen bei bidirek- Erfahrungen tionalen Beziehungen automatisch durchgeführt werden. Die Beziehungen erlauben weiter die Navigation durch die MediFrame Objektstruktur, in dem sie bei Bedarf die referenzierten MediFrame läuft seit Anfang 1997 produktiv und befindet Objekte transparent nachladen. sich noch in der Aufbauphase. Die Applikation bedient zur Zeit • Object-Queries, die den Zugriff auf die Instanzen definieren 10–15 Teilnehmer und beinhaltet mehrere, zum Teil komplexe und zentral pro Klasse verwaltet werden. So können diese Produkte. Täglich werden Updates importiert sowie mehrere Queries aus den verschiedenen Teilen der Applikation aufge- Exports durchgeführt. Bei MediData arbeiten zur Zeit vier Berufen werden. Die Resultate sollten wahlweise in den Client nutzer mit MediFrame. Sie erfassen und pflegen die adminigeholt oder in GemStone weiterverarbeitet werden können. strativen Daten und importieren die Produkte. Der Produkte• Eine Zustandsmaschine, die die Deklaration der Zustände Export läuft automatisch. eines Objekts und die Kontrolle der Zustandsübergänge Die Performance des Systems ist zur Zeit noch nicht vollgestattet. ständig zufriedenstellend: so dauert zum Beispiel der InitialWird dieses Modellierungsdefizit des Smalltalk-Objekt- Import des grössten Produktes (ca. 200’000 Datensätze, Datendatenmodells nicht durch ein entsprechendes Framework auf- menge 20 MB) ungefähr 9 Stunden, d.h. ca. sechs Datensätze gefangen, liegt die volle Verantwortung für die Konsistenz des pro Sekunde. Der Grund dafür liegt vor allem in den ProdukteObjektmodells bei der Applikation. Das FIDES RAP-Frame- teilen mit mehreren Beziehungen, die überprüft und aufgebaut work stellt eine entsprechende Business Object Model-Kom- werden müssen; bei Produkteteilen ohne Beziehungen ist die ponente zur Verfügung. Das Business Object Model ist unab- Import-Performance drei bis vier mal höher. An der Erhöhung hängig von der Persistenzschicht und kann sowohl für der Import-Performance muss zu einem späteren Zeitpunkt objektorientierte Datenbanken als auch mit relationalen Daten- noch gearbeitet werden. Die bisherigen Erfahrungen haben gebanken eingesetzt werden. Die Business Objekte werden durch zeigt, dass vor allem der Aufbau der Beziehungen und die Reiein vollständig in die Smalltalk-Umgebung integriertes Werk- henfolge des Aufbaus die Performance massiv beeinflussen zeug modelliert. Die Definition umfasst Attribut- und Bezie- können. Der Export ist ca. fünf mal schneller als der Import. hungs-Deklarationen sowie Object-Queries und eine optionale Hier kann von den beim Import aufgebauten Beziehungen proZustandsverwaltung: fitiert werden. Die Performance-Daten wurden mit GemStone Die RAP Business Object Model-Komponente wurde auch 5.0 unter NT 4.0 auf einem ein Intel-Pentium System mit 150 nach GemStone Smalltalk portiert und steht damit sowohl auf Mhz Taktfrequenz und 128 MB RAM ermittelt. dem Client wie auf dem Server zur Verfügung. Zur SicherstelDurch die durchgehende Verwendung der Objekttechnologie lung der Konsistenz des Objektmodells wurden die Objekt- lassen sich neue Produkte einfacher integrieren. Änderungen transaktionen durch eine Validierung der veränderten Business und Erweiterungen lassen sich flexibel und mit geringerem Objekte vor dem commit erweitert. Aufwand realisieren als mit herkömmlicher Technologie. Mit der RAP GemStone Persistenz-Komponente können die Durch die objektorientierte Benutzeroberfläche kann jeder AnBusiness Objekte persistent gemacht werden. Die Verbindun- wender die für ihn effizienteste Sicht auf die Daten selber eingen zu den Objektlisten in der Datenbank werden automatisch richten und ist nicht an starre Abläufe gebunden; das bedingt hergestellt. Neue Objekte werden falls nötig eingefügt und die aber, dass er die Zusammenhänge der Applikation im Detail gelöschten wieder entfernt. Zur Implementation der Abfragen kennt. wurde ein spezielles Werkzeug entwickelt. Die Übertragung Object with History version, validFrom, validTo attributes 22 INFORMATIK • INFORMATIQUE 4/1997 Object Data Models GemStone Die Einheit des Objektdatenmodells auf dem Client und dem Server ermöglicht eine effiziente Entwicklung. Die ganze Realisierung erfolgt in ein und derselben Sprache. Das SmalltalkObjektdatenmodell reicht für die Modellierung von Business Objekten nicht aus. Der GemStone Object Server ist offen bezüglich einer flexiblen Erweiterung und Anpassung des verwendeten Objektdatenmodells an die jeweiligen Bedürfnisse. Die Verantwortung für ein konsistentes Objektmodell obliegt damit der Applikation. Die flexible Verteilung der Funktionalität ermöglicht eine optimale Aufteilung der Aufgaben zwischen Client und Server, auch zu einem späten Zeitpunkt. Die Verlagerung von Funktionalität auf den Server verringert den Kommunikationsaufwand. Die unscharfe Trennung zwischen Server- und Client-Funktionalität führt zu Redundanz: Klassen und Methoden werden oft sowohl auf dem Client wie auf dem Server implementiert. Diese Redundanz erfordert zusätzlichen Aufwand durch die Portierung, die Koordination und die doppelten Tests. Dies um so mehr, als GemStone weder über ein Werkzeug zur Sourcecodeverwaltung noch zur Koordination solcher Redundanzen verfügt. Die beiden Smalltalk-Dialekte, VisualAge und GemStone, sind nicht 100% kompatibel. Sie unterscheiden sich beispielsweise bezüglich Exception Handling und Umfang der Methoden von Systemklassen, wie String oder Collection. Dies muss bei der Portierung beachtet werden. Die Objekttransaktionen ermöglichen eine sichere Durchführung der Modell-Bearbeitungen. Nach dem Transaktionsabschluss durch commit oder abort ist der Client ohne zusätzlichen Aufwand wieder mit der Datenbank synchronisiert und konsistent. Da GemStone keine verschachtelten Transaktionen kennt, können die Longtime-Transaktionen nicht strukturiert werden. Das Rückgängigmachen von Teiloperationen, zum Beispiel bei einem Undo in einem Benutzerfenster, muss durch die Applikation gelöst werden und schafft zusätzlichen Aufwand. Die Limitierung auf nur eine Transaktion pro Session erschwert die gleichzeitige Bearbeitung verschiedener paralleler Aufgaben, was von den heutigen interaktiven Anwendungen eigentlich zur Verfügung gestellt werden sollte. Der Einsatz mehrerer Sessions ist komplex und ressourcen-intensiv. Die Lösung in MediFrame, das Ende einer Transaktion weitgehend dem Benutzer zu überlassen, delegiert die Verantwortung: der Benutzer ist selber verantwortlich, durchgeführte Operationen mit einem commit der Bearbeitung abzuschliessen. Der Zugriff auf den GemStone Object Server aus anderen Applikationen ist nur mit grösserem Aufwand möglich. Es existiert auch keine Möglichkeit zur Formulierung von AdhocAbfragen durch den Endbenutzer. Das Fehlen solcher Schnittstellen zum Zeitpunkt der Realisierung von MediFrame kostete zusätzlichen Aufwand in Form von speziellen DatenexportFunktionen. Für Administration der Datenbank sind gründliche Smalltalk-Kenntnisse notwendig. Highend-Administrationswerkzeuge sind kaum verfügbar. Insbesondere fehlte eine Sourcecode-Verwaltung, so dass ein Werkzeug für das Erstellen und Verwalten der Fileouts entwickelt werden musste. Es fehlt auch ein Profiler-Werkzeug, mit dem verteilte Operationen auf dem Client und dem Server untersucht werden können. Es existieren nur Profiler, die entweder den Client-Teil oder den Server-Teil analysieren. RAP Business Object Model Das Modellierungs-Framework ermöglicht eine effiziente, einheitliche Realisierung des Objektmodells. Die Beziehungen und die Validierungen stellen die Konsistenz des Modells sicher. Damit wird die Applikation von dieser Aufgabe entlastet, was zu einer höheren Entwicklungseffizienz und Qualität führt. Dies wirkt sich auch positiv auf die Teamarbeit und die Wartbarkeit aus. Nur mit einer solchen Objektdatenmodell-Erweiterung lässt sich ein kommerzielles Objektmodell auf einer hohen Abstraktionsstufe effizient umsetzen. Die Business Object Model-Komponente versteckt die Komplexität von GemStone vor dem Applikationsentwickler und minimiert damit den Ausbildungsaufwand; allerdings erkennt der Entwickler die Konsequenzen einzelner Handlungen nicht mehr. Die Object-Queries erlauben eine zentrale Verwaltung der Datenbankzugriffe, was die Wartbarkeit erhöht. Aufgrund der ausführlichen Metainformation über das Objektmodell stellt das RAP Framework einen generischen Applikationsdesktop mit einer objektorientierten Oberfläche zur Verfügung, die dem Benutzer einheitliche Navigation durch das Objektmodell und seine Bearbeitung erlaubt. Folgerungen Die Bereitstellung eines Objektdatenmodells für die detaillierte Modellierung der Attribute, Beziehungen und allenfalls der Zustände ist für ein kommerzielles Objektmodell absolute notwendig. Wird ein solches Objektdatenmodell nicht durch die Datenbank angeboten, muss diese Lücke durch ein entsprechendes Framework geschlossen werden. Die Delegation der Verantwortung an die Applikation ist kein geeigneter Weg und rächt sich bei der Wartung und der Software-Qualität. Die Unterteilung der Objektransaktionen durch Subtransaktionen würde die Entwicklung der Benutzeroberfläche erleichtern und die Applikationsentwicklung vereinfachen. Für die Administration von GemStone stehen keine geeigneten Highend-Werkzeuge zur Verfügung. Die angekündigte Sourcecodeverwaltung ENVY wird dringend benötigt und sollte auch Möglichkeiten bieten, die Koordination zwischen Server- und Client-Funktionalität zu unterstützen. Der GemStone Object Server bietet flexible Gateways auf relationale Datenbanken. Der Zugriff von relationalen Datenbanken oder anderen Applikationen auf GemStone ist aber nicht realisierbar. Die angekündigte ODBC-Schnittstelle und ein CORBA Object Request Brokers dürfte die nötige Öffnung bringen. Es fehlt auch ein Werkzeug, das dem Endbenutzer Adhoc-Abfragen bieten würde. Hier stellt sich die Frage, ob auf Grund des einfachen Objektdatenmodells von GemStone ein solches Werkzeug überhaupt sinnvoll realisiert werden kann. Referenzen FIDES Informatik http://www.fides.ch GemStone Systems http://www.gemstone.com MediData http://www.medidata.ch INFORMATIK • INFORMATIQUE 4/1997 23 Object Data Models OM Framework for Object-Oriented Data Management Moira Norrie and Alain Würgler We present an overview of the generic object-oriented data model OM together with a methodology for developing database application systems based on the OM model and its associated system OMS. Fundamental to our approach is a refinement process which retains the same structural model from the conceptual modelling phase through to implementation on one of a variety of implementation platforms. Introduction Ideally, both the development and use of a database application system should be based on a single abstract model of the application domain. This means that the same basic structural model should support all of the development stages from conceptual modelling through to implementation. It follows that the underlying data model should be: • semantically expressive for conceptual modelling • independent of the implementation platform, since this is often determined after the initial design phase • supported on a number of implementation platforms including at least one for rapid prototyping • amenable to a refinement process from design to implementation. Unfortunately, most of today’s object-oriented data models fall short in one or more of these requirements. Commercial object-oriented database management systems (OODBMS), such as Objectivity/DB and O2, tend to have a data model closely tied to the implementation and programming environment and have next to no support for the conceptual design phase. For example, while object data models for conceptual modelling are rich in terms of semantic expressiveness, most OODBMS offer little in the way of constraints and also provide rather limited ways of modelling object roles, classification structures and associations. Even the data model proposed by 1 Moira Norrie is a Professor in the Institute for Information Systems at ETH Zurich. She formed a research group in the area of Global Information Systems in February 1996. The main interests of the group are in object-oriented data models and systems, internet databases and advanced database applications such as document management systems, product information systems and scientific data systems. Alain Würgler is a Research Assistant in the Institute for Information Systems at ETH Zurich. He designed and implemented the OMS object-oriented database system which is now used as the basis for a number of research projects and also for teaching both basic and advanced concepts of information systems. Currently, he is developing novel modular architectures for database application development. {norrie,wuergler}@inf.ethz.ch http://www.inf.ethz.ch/department/IS/globis 24 INFORMATIK • INFORMATIQUE 4/1997 the Object Data Management Group, ODMG [Cattell 96], falls somewhere in-between in that it is too type model specific to be suitable for conceptual modelling, but on the other hand too general in that it does not correspond exactly to the data models of the OODBMS. For example, the relationship constraints expressed in the ODMG data model are not supported in many commercial OODBMS. Conceptual modelling systems such as ConceptBase [Jarke et al. 95] and MOSAICO [Missikoff/Toiati 94] place a strong emphasis on prototyping as an integral part of the design and specification process. Their conceptual schemas can be considered as executable specifications and further can be developed incrementally. The underlying models are semantically rich, thereby allowing systems to be modelled easily and quickly. In the case of MOSAICO, there is also a strong theoretical basis upon which a schema validation process is based. However, there is still a large semantic gap between these models and those of the eventual implementation platform. We advocate an approach of refinement rather than mapping. At all levels of design and implementation, the information is viewed in terms of the same basic model and schema with detail being added at each stage. This contrasts with mapping approaches where constructs of one model are mapped into another and the final implementation model may bear little resemblance to the original design. One of the best known general object-oriented modelling techniques is OMT [Rumbaugh et al. 91], which is also intended to support all stages of application development from initial design to implementation. However, OMT is not intended primarily for database system development, but rather for the development of application systems of which a database may form a part. Thus the emphasis is more on the development of code and application classes and it is often assumed that database functionality will ultimately be provided by a relational storage system. This means that often there is a mapping from the object model to a relational model as described, for example, in the book of [Rumbaugh et al. 91]. Further, a prototyping tool for information system development is not explicitly part of the OMT approach. Rather, prototyping is supported implicitly through the general principle of incremental system development supported by object-oriented technologies through techniques such as subtyping and inheritance. We strongly Object Data Models Model Level Conceptual Modelling OM OM[t] Specification & Prototyping Implementation OMS OM/Objectivity OM/Oberon …… OMS Fig. 1: OM Framework believe that a database prototyping system is invaluable for validating the basic model before proceeding with method and application program implementation. We propose a refinement approach to the development of object-oriented databases based on the generic object data model OM and its associated interactive object-oriented database management system OMS which supports rapid prototyping. The OM model is independent of a particular implementation platform in that, unlike most object-oriented data models, it is independent of a particular type model and hence of a particular programming language environment. The generic model has been instantiated in number of environments including ones based on C++, Oberon [Reiser/Wirth 92] and Prolog. We begin in section 2 with a general description of our approach and then give further details of the OM model and OMS system in sections 3 and 4, respectively. Section 5 discusses issues regarding the development of various implementation platforms for the OM model. Concluding remarks are given in section 6. OM Framework OM is a generic object data model with influences from extended entity relationship models and semantic data models, as well as from object-oriented paradigms. There were two main driving forces in the development of the model. First, we wanted to combine ideas from conceptual modelling with object-oriented concepts. Second, we wanted to provide a model that is both a good framework on which to build a data management system and yet independent of a particular implementation platform. The key to achieving our desired aims was drawing a clear distinction between the notions of typing and classification. We model the application domain at the conceptual level by classifying entities into roles. How these entities are represented in the database is specified by the types of the associated objects. Thus, a database schema is considered as serving a dual purpose in that it is both a description of the application domain and also of its representation in the database. A more detailed discussion of the reasons for and benefits from this distinction can be found in [Norrie 95]. The strict separation of classification and typing supports the process of database development in various ways: It forms a vertical partition of the problem to be solved in terms of defin- 2 ing an interface between the conceptual application domain and the implementation. The conceptual model using classifications focuses on the entity roles & associations roles which the entities may take and on the dependencies among roles. It types results in conceptual portability by method specifications suppressing structural and behavioural details. Only after having application programs modelled the application domain in method implementations terms of a role model, is it important to think about the properties of those entities that are to be stored in the database and decide on the types of the objects representing those entities. The OM approach to database development is based on three basic levels as shown in figure 1. The general modelling strategy advocated is to first focus on the entity roles and associations in an application domain and produce an initial graphical OM schema. As will be seen later, OM graphical models are not unlike those of extended EntityRelationship models and OMT object models where only entity/object classes and relationships/associations are represented. We see this as an advantage of our model in that we are able to combine the benefits of Entity-Relationship-style modelling at the conceptual level with those of object-oriented systems at the operational level. Note however, that the OM model is not only a structural model, but also an operational model with operations over both roles and associations. The next stage is to refine the OM role model into a database description that can be used for prototyping. This means that the generic model has to be instantiated with a particular type model t which can be used to specify the representations of entities as database objects. In our case, we use the type model of OMS to specify the properties of objects in terms of attributes and methods. At this stage of the development process, the problem can be partitioned into the definition of structure and behaviour, without considering the actual implementation of behaviour. Note that as the schema is refined towards the implementation platform, additional methods and or attributes may have to be added to compensate for the rich set of types and operations system-supported in OMS. For example, OMS supports URLs as a base type such that clicking on such a value automatically calls Netscape to display the WWW document. In other systems, such an attribute would have to be replaced by a string attribute for the URL and a method to call Netscape with the appropriate address. We complete the description of the database by giving the method implementations. OMS provides a graphical interface for browsing and querying that allows objects to be manipulated directly without the need for any application programming other than a schema definition. Method implementations can be added incrementally and are specified in terms of Prolog rules using special OMS system-defined predicates for access to data, metadata, system calls and dialogue boxes for user interFocus INFORMATIK • INFORMATIQUE 4/1997 25 Object Data Models action. Thus, the method bodies can be considered as highlevel executable specifications. The second major refinement step involves taking the schema resulting from the prototyping stage and implementing it on the chosen OODBMS. It would be possible to map the schema to a schema expressed in terms of the data model of the OODBMS. However, as stated earlier, there are disadvantages to such a mapping approach. An alternative is to extend the platform to support constructs of the OM model. In our experiences, comparing the two approaches, the latter produces much more easily understood and flexible systems amenable to future extensions. Clearly, the amount of work involved in realising the OM model on a particular implementation platform depends on the semantic and functionality gap. In figure 1, we show a range of implementation platforms. Not only do these cover different programming language environments, but also different levels of support and different styles of system. For example, in terms of an actual OODBMS, such as Objectivity/DB, much of the database functionality such as persistence, transaction management and access methods are already there. In contrast, a system supporting database programming in Oberon has been developed and, in this case, it was necessary to implement all functionality including persistent storage [Supcik/Norrie 97]. We include OMS at the implementation level since it can be used not only as a prototyping system, but also as an implementation platform. OMS differs from the other implementation platforms in that it is a stand-alone database management system with support for direct database and schema manipulation. In the remaining sections, we describe the OM model and OMS system in further detail to show how, together, they support the database design activity. OM Model We now introduce the OM model by looking at an example of a database for maintaining information on contacts 3 contact which may be either persons or organisations. An organisation may be any organisational unit, such as a department of a company, and therefore be part of another organisation. Associated with persons and organisations are locations which have a physical address in terms of a building, street, map etc. An example of an OM graphical schema for such a contact database is shown in figure 2. A contact may be either a person or an organisation and so we have the role Contacts partitioned into the more specialised roles Persons and Organisations. Object roles actually correspond to collections of objects of a given type and we represent them graphically as a shaded rectangle with the name of the collection in the unshaded part and the type of the members given in the shaded part. Persons and Organisations are subcollections of Contacts. At this stage, the types are only named and the definitions are left unspecified. Note that an object may be a member of any number of collections. It has however only one representation and, in this context, a type specifies that part of an object’s representation, i.e. set of properties, which is currently of interest. OM has an association construct to represent relationships between objects at the same level of abstraction. For example, Works_for is an association between Persons and Organisations. The associated cardinality constraints indicate that the number of persons associated with an organisation, and vice versa, is unrestricted. An association also corresponds to a collection of values – but in this case it is a collection of pairs of related objects. We therefore distinguish unary collections, which contain atomic values and correspond to object roles, from binary collections, which correspond to associations. By having a general concept of collection that covers both, we are able to apply our notions of subcollection, constraints over subcollections such as partition and also operations over collections to both roles and associations. For example, the contacts database schema shows an association Lives_at which is a subcollection of (0:*) (1:*) Situated_at Contacts location Locations (1:*) partition Lives_at organisation person Organisations Persons (0:*) (0:*) (0:*) (0:*) Works_for Part_of Fig. 2: OM Schema 26 INFORMATIK • INFORMATIQUE 4/1997 (0:*) Object Data Models Situated_at, i.e. it represents a more specialised form of the association. While OM does not specify a particular type model, we note here that there are some features of a type model that allow the expressiveness and flexibility of the OM model to be exploited to the full. We consider that an object may be an instance of many types – which implies that it has the properties associated with all of those types. Each type has a set of explicit structural and behavioural properties, and further may inherit properties through subtype relationships. These subtype relationships between types defines a type graph which determines property inheritance. A particular type model may restrict the type graph and inheritance mechanisms – but, at the OM level, we do not assume any such restrictions. The above description of the OM model says little about the process of actually developing an OM schema. We are currently developing an OM design methodology together with design tools. The methodology is based on identifying key application entities, modelling their life cycles by means of entity state transition diagrams, refining these diagrams and then generating classification and association structures. The operational part of OM introduces a set of operations over collections. The OM model also allows for collections of different behaviours as arise in many OODBMS. The collection algebra is therefore generalised to operations over not only set, but also bag and sequence collections. The model also has support for object evolution. Information on the OM algebra and further details of the OM model are given in [Norrie et al. 96, Norrie 95, Norrie 93, Norrie 92]. In the next section, we consider how the OM schema for the contacts database system could be refined into an OMS schema and a prototype database generated. 4 OMS System In this section, we present the main features of OMS by considering the steps involved in refining the graphical OM schema of the contacts database and generating an OMS schema and database. An OMS schema definition consists of three main parts – a type definition part, a collection definition part and a constraint definition part. We describe each of these parts in turn. First, the required properties of the types named in the OM schema have to be determined and this is the main refinement step in going from an OM schema to an OMS schema. Object types consist of a number of attribute properties and a number of method properties. For example, the type definition for contact objects is defined as: type contact ( name phone fax email www send_email ); : : : : : ( string; string; string; string; url; ) -> ( ) Type contact has four attribute properties name, phone, fax, email which are of type string and one www of type url. These are all single valued attributes, but OMS also supports multi-valued attributes through set, bag and list constructors. The type definition for contact also includes the method property send_email which takes the value of attribute email and calls the Unix mail program. Method definitions may be included at this stage as part of the schema definition, but, in practice, the code associated with methods is often specified later once a database has been initialised and the basic structure validated. We therefore leave the method definition until later in this section. The type definitions also specify the type graph as given by subtype relationships. For example, type person subtype of contact ( title : string; birthdate : date; …… : …… age : ( ) -> (years:integer) ); is the type definition for person which is a subtype of contact. The method age has a single return parameter years of type integer. Generally, a method may have any number of input and output parameters. Note that the OMS type model supports multiple inheritance and also method overriding. The second part of the OMS schema specifies the collections of the database. These include both the unary and binary collections as shown below. collection collection collection collection collection Contacts : set of contact; Persons : set of person; Organisations : set of organisation; Locations : set of location; Part_of : set of (organisation,organisation); collection Works_for : set of (person,organisation); collection Situated_at : set of (contact,location); collection Lives_at : set of (person,location); OMS supports set, bag and sequence collections according to whether or not duplicates and an explicit ordering are required and, at this stage, it is necessary to decide whether any of the OM collections have other than set behaviour. In the example of the contacts database, all collections have set behaviour. The third step in producing an OMS schema is to specify the constraints and these come directly from the OM schema as seen below. constraint : Works_for association from Persons (0:*) to Organisations (0:*); constraint : Part_of association from Organisations (0:*) to Organisations (0:*); INFORMATIK • INFORMATIQUE 4/1997 27 Object Data Models constraint : Situated_at association from Contacts (0:*) to Locations (1:*); constraint : Lives_at association from Persons (0:*) to Locations (1:*); constraint : Persons subcollection of Contacts; constraint : Organisations subcollection of Contacts; constraint : Lives_at subcollection of Situated_at; constraint: (Persons and Organisations) partition Contacts; As can be seen, the major work involved in refining an OM schema to an OMS schema is determining the type definitions. This corresponds to the fact that OM basically deals with the levels of collections and constraints and the type model is provided by the OMS system. In total, the refinement step from OM to OMS is small, as would be expected from a system that supports prototyping as part of the design process. Clearly, the prototyping effort may lead to changes to the initial OM schema and therefore the whole process iterates over these two stages. With the OMS schema complete, the first major step of the refinement process from OM to OMS is complete and the schema can be loaded and a database initialised. Note that the schema can be examined, extended and updated at any time during system operation. Once the database has been created, the second major step in the refinement process can begin - specifying method operations. The methods in OMS are implemented in Prolog and this has the advantage of retaining a very high specification level. Access to database objects is provided through OMS defined predicates and OMS also provides an interface to the scripting Fig. 3: Object Browsing 28 INFORMATIK • INFORMATIQUE 4/1997 language Tcl [Ous94] to enable dialogue boxes to be easily generated. As an example, we give below the implementation of method send_email as a Prolog rule. method(_,_) :my_anval(self,email,''), !; ( my_anval(self,email,Email), tcl_VarEval(['exec xterm -e Mail ',Email],_) ). The OMS-defined predicate my_anval is used to access the email attribute values of the object self. If a non-empty email value is specified, a system call to the Unix Mail program with the appropriate address is made through the Tcl interface. Implementing an OMS object-oriented database design in another programming language environment would involve refining the Prolog rule into code of that language. By using OMS, the developer does not have to provide an application program. Effectively, the application is integrated into the system via its browsing and querying facilities. Several starting points for browsing have been provided. One of them is a general object matching facility which locates objects and displays them as shown in figure 3. Methods of an object are invoked by clicking on the appropriate method buttons, and any associated return values are displayed alongside. This is seen for example with the age method in figure 3. OMS assists navigation through the database by means of system-defined links based on associations of the database with compatible member types. For example, the person object shown in figure 3 has links to location and organisation objects according to the Situated_at, Lives_at and Works_for associations. It is also possible to query the database using the full query language interface and then browse the resulting objects. Note that the OMS query language is fully orthogonal and can process and return both values of base types and object types as well as collections. Further details of the OMS system and its query language are given in [Norrie/Würgler 97]. All information – including metadata – is represented within the OMS system as objects. This allows data and metadata to be handled uniformly. For example, it is possible to update and query not only the database, but also schema data. In OMS, all values entered at any stage are automatically made persistent as part of a current working space. An OMS transaction therefore represents a particular logical work activity on the database which may span several OMS user sessions or may be part of a single session. A commit operation checks that a particular work activity is valid in that it produces a consistent database state and, if this is so, it saves all the operations involved in that work activity by writing the values of the working space to the database. If a work activity does not produce a consistent database state, the system informs the user of the constraints violated and the user may then carry out the necessary operations to restore consistency before again trying to commit the work activity. At any stage, a user may abort a work activity. Object Data Models The system is implemented in SICStus Prolog [SICStus 95] using its database library facilities for the basic persistent store. Currently, the system is single user although a multi-user, client-server architecture is being developed. While the system is intended primarily as a prototyping system, the present functionality and performance provide good support for personal databases. Further, the system is used extensively in teaching both the concepts of object-oriented database systems and the design of object-oriented databases. OM Implementation Platforms While it is possible to use OM and OMS for object-oriented database design and then map to the model of another system, this approach may lose the basic structure of the conceptual schema and does not take advantage of many of the features inherent to the OM model. For example, most OODBMS do not clearly distinguish the notions of typing and classification and, as a result, have much more restrictive classification structures. Further, many do not support a separate association construct or any form of constraints such as the basic subcollection constraint. For example, in the O2 system all forms of referential integrity must be explicitly handled by the application programmer since it does not have any constraint management. Our experiences, and those of our students, show that there are many advantages to first implementing constructs for the OM model and then implementing the application objectoriented system in terms of these constructs. For example, we have done this in developing applications with both O2 and Objectivity/DB systems, and previously with the Ontos OODBMS system. To gain the full benefits of the OM model, it is even better to provide a full implementation of the model on top of the implementation platform in question. This means not only providing constructs for collections, but doing so efficiently with support for access methods and data independence. Additionally, it means providing constraint management and query evaluation, including optimisation facilities. Early versions of the OM model were implemented on top of the EXODUS [Carey et al. 89] and Comandos C** [Cahill et al. 93] storage systems in this way and we now have a corresponding implementation on top of Objectivity/DB. Such systems are able to exploit the basic persistence, transaction and distribution facilities of the underlying system. In the Oberon environment [Reiser/Wirth 92], a system has been developed to support database application programming based on the OM model. As stated in section 2, in this system, it was also necessary to implement a persistent storage system. A key factor in the development of the Oberon-based system was that we wanted to support object evolution and this demonstrates some interesting points that arise in supporting a model as general as OM in different language environments. As said earlier, the OM model assumes a very general and flexible type system. Unfortunately, this is not the case in many programming language environments where the desire for efficiency in terms of static / strict type checking has led to rather restrictive type models. For example, in many languages dy- 5 namic binding is not supported and hence method overriding is limited. Further, many do not support multiple inheritance. A severe problem with many of these systems is that they provide no, or very limited, support for object evolution. For example, it may be possible for an object to gain types, but not to lose types. In the case of Oberon, our desire to support object evolution in a way that was easy and flexible for the programmer conflicted with the Oberon type system. We have therefore adapted the OM model to explicitly model database object properties as being associated with collections rather than with Oberon object types. Thus, database objects have attributes and methods only in the context of a collection and an object viewed through different roles will therefore have different properties. Interestingly, attribute properties can be arbitrarily complex since these are indeed represented as Oberon types. Details of the system are given in [Supcik/Norrie 97]. In many cases, the OM model will appear in a more restricted form on implementation platforms other than OMS. For example, if the underlying type system does not support multiple inheritance, this may limit the forms of classification structures as it limits the usefulness of intersection collections which are supported in OM. However, in practice, we have found that while such restrictions highlight the flexibility of the OM model, they do not detract from the applicability of the model. If anything, designing the database from the OM point of view often frees the developer from many of the restrictions of the underlying model. Conclusion The OM model together with the OMS system provide general support for the development of object-oriented database systems. The model is a general model for conceptual modelling based on object role and association modelling. It also provides a general algebra over collections which can form the basis for query language development. The OMS system is an OODBMS based on the OM model and supports full browsing, querying and updating facilities. While the OMS system provides full interactive database support, it can also be regarded as a system on which to prototype object-oriented database designs before implementing a full application system on another platform. To exploit the features of the OM model across different platforms, we advocate support for the OM model in terms of providing the constructs, constraints and operations of the model through some form of class libraries. The user is then able to realise the application system through a refinement process which retains the structure of the initial conceptual schema and much of the flexibility and expressibility of the OM model. 6 References [Cattell 96] R. Cattell, The Object Database Standard: ODMG-93, pub. Morgan Kaufmann, release 1.2, 1996. [Cahill et al. 93] V.J. Cahill, R. Balter, N. Harris and X. Rousset de Pina, editors., The Comandos Distributed Application Platform, pub. Springer-Verlag, 1993. [Carey et al. 89] M.J. Carey, D.J. DeWitt, G. Graefe, D.M. Haight, J.E. Richardson, D.T. Schuh, E.J. Shekita and S. Vandenburg, The INFORMATIK • INFORMATIQUE 4/1997 29 Object Data Models EXODUS Extensible DBMS Project: An Overview, In S. Zdonik and D. Maier, editors, Readings in Object-Oriented Database Systems, pub. Morgan-Kaufmann, 1989. [Harper/Norrie 91] D.J. Harper and M.C. Norrie, Data Management for Object-Oriented Systems, In M.S. Jackson and A.E. Robinson, editors, Aspects of Database Systems, pub. ButterworthHeinemann, 1991. [Jarke et al. 95] M. Jarke, R. Gallersdörfer, M.A. Jeusfeld, M. Staudt and S. Eherer, ConceptBase – A Deductive Object Base for Meta Data Management, Journal of Intelligent Information Systems, 4(2):167–192, 1995. [Missikoff/Toiati 94] M. Missikoff and M. Toiati, MOSAICO – A System for Conceptual Modelling and Rapid Prototyping of Object-Oriented Database Applications, In Proc. of the 1994 ACM SIGMOD Intl. Conf. on Management of Data, ACM, 1994. [Norrie 92] M.C. Norrie, A Specification of an Object-Oriented Data Model with Relations, In D.J. Harper and M.C. Norrie, editors, Specifications of Database Systems, Workshops in Computing, pub. Springer-Verlag, 1992. [Norrie 93] M.C. Norrie, An Extended Entity-Relationship Approach to Data Management in Object-Oriented Systems, In 12th Intl. Conf. on Entity-Relationship Approach, Dallas, Texas, December 1993. Springer-Verlag, LNCS 823. 30 INFORMATIK • INFORMATIQUE 4/1997 [Norrie 95] M.C.Norrie, Distinguishing Typing and Classification in Object Data Models, In Information Modelling and Knowledge Bases, volumeVI, chapter 25. IOS, 1995. [Norrie et al. 96] M.C. Norrie, A. Steiner, A. Würgler and M. Wunderli, A Model for Classification Structures with Evolution Control, In Proc. of the 15th Int. Conf. on Conceptual Modelling (ER’96), Cottbus, Germany, October 1996. [Norrie/Würgler 97] M.C.Norrie and A.Würgler, OMS ObjectOriented Data Management System, Technical Report, Institute for Information Systems, ETH Zurich, 8092 Zurich, 1997. [Ousterhout 94] J.K. Ousterhout, Tcl and the Tk Toolkit, pub. Addison-Wesley, 1994. [Rumbaugh et al. 91] J.Rumbaugh, M.Blaha, W.Premerlani, F.Eddy and W.Lorensen, Object-Oriented Modeling and Design, pub. Prentice Hall, 1991. [Reiser/Wirth 92] M. Reiser and N. Wirth, Programming in Oberon: Steps beyond Pascal and Modula, pub. Addison Wesley, 1992. [SICStus 95] SICStus Prolog User’s Manual, Swedish Institute of Computer Science, S-164 28 Kista, Sweden, 1995 [Supcik/Norrie 97] J. Supcik and M.C. Norrie, An Object-Oriented Database Programming Environment for Oberon, In Proc. of the Joint Modular Languages Conference (JMLC’97), March 1997. Object Data Models Object-Based Data Models Gottfried Vossen Object-orientation has been an important topic in databases for more than ten years now. In the beginning, there was a lot of experimentation with (and confusion about) data models that are relevant to objects, or that are able to capture their essentials. Today the situation seems to be converging around two major approaches, object-oriented and object-relational, which are surveyed in this paper. Introduction Object-orientation has been an important topic in the area of databases and database management systems for more than ten years now. In this particular field, it emerged from the need and desire to capture the complex structure as well as the behavioural aspects of data, to model both appropriately in the context of a data model, and to extend database query languages beyond the scope of traditional relational languages. Since object-orientation had already proved useful in programming languages, it was already available for application to database systems as well. However, in the beginning there was much experimentation with (and confusion about) data models that are able to capture the essentials of objects. The situation now seems to have stabilised. This paper surveys the current field of object data models. There is an ever-increasing number of applications that employ database management systems [Kim 95]. While the relational model of data has been appropriate for a number of years, in the eighties a requirement emerged to capture structures in terms of a data model that does not fit well into flat tables [Vossen 94]. The answer to this has been a host of semantic data models, complex-object models, and nested relational models [Abiteboul et al. 95], which accommodated the needs of applications in which highly structured information comes together in various ways. A major step forward at that time was the recognition that identity should be distinguished from values, one of the essential features of an object model; 1 Gottfried Vossen received the M.Sc. degree (Dipl.-Inform.), the Ph.D. degree (Dr. rer.nat.), and the German Habilitation, all in Computer Science, from the Technical University of Aachen, Germany. He is professor of computer science and a director of the Institut für Wirtschaftsinformatik at the University of Münster, after having held visiting positions at the universities of California, San Diego, USA, Düsseldorf and Koblenz and the position of an associate professor at the University of Giessen. His research interests include theoretical and practical issues as well as applications of object-based database systems, in particular models for data and objects, database reverse engineering, database languages, transaction processing in database systems, integration of databases into scientific applications, and scientific workflow management. He is an author and co-author of many papers and books on databases and computer architecture. finally, there was the need to capture behaviour as well as structure. Object-orientation came at the right time to bring all of this into a single context. Object-orientation as a paradigm is based on five principles: 1. Each entity of a given application is modelled as an object which has an identity distinct from its value; 2. each object encapsulates structure and behaviour; structure is described by attributes whose values can be atomic, complex, or even references to other objects, and behaviour consists of methods that can be executed on the object; 3. the state of an object is exclusively accessible through messages, and objects only communicate through message passing; if an object receives a message it understands, it launches the execution of the corresponding method; 4. objects with common structure and behaviour are grouped into classes, and each object is usually in one and only one class; 5. classes can be defined as specializations of one or more other classes and then inherit structure and behaviour of their superclasses. In the context of databases, these general characteristics need to be combined with those of database systems, in particular this refers to the ability to model complex objects, to support object identity, to distinguish types and classes, and to support class hierarchies. Other interesting relevant features include query languages, overloading, overriding, and late binding, extensibility and persistence; for a complete catalogue which is still valid see [Atkinson et al. 89]. For databases it is crucial to distinguish schema from instances: A schema is developed during a design process, and essentially tells which kinds of real-world entities and their relationships should appear in the database, what reasonable abstractions exist for them, and how they are consequently structured using the features of the data model at hand. Thus, it is important for a database system to support the notion of object, to provide an object data model. The core aspects of any “pure” object data model are summarised in Figure 1: The (only) structuring mechanism is the class which describes both structure and behaviour for its instances, the objects. Structure is captured as a type for a class, where a type is nothing but a description of a domain, i.e., a set of values, and may or may not be named (in the former case, type names distinct from INFORMATIK • INFORMATIQUE 4/1997 31 Object Data Models First, since object-orientation is not confined to the database area, but also crops up in programhas understands ming languages, operating systems, or even comfrom outside puter hardware, a typical scenario nowadays is that type messages OO components from different vendors and with distinct tasks need to run on the same system and, implemented more importantly, need to understand each other describes by and even cooperate. In this situation, the development of standards is appropriate, and for the OO values methods world this was discovered early on by the Object Management Group (OMG), now one of the biggest consortia in the computer industry. Their major spin-off, the Object Database Management has has Group (ODMG), has presented a standardisation object 1 object 1 proposal for OO databases which covers an object model, a query language, and programming …… language bindings [Cattell 96, Bancilhon/Ferran state id behaviour state id behaviour 95]. The bottom-line situation nowadays is that every major OO model development essentially sticks to the ODMG proposal. Fig. 1: Informal view of an object data model Second, as already anticipated in [Schek/Scholl 90a], the presentation of data that is kept in a database in the two-dimensional form of a table is conclass names and attribute names must be provided). Values venient and appropriate even in cases where the data itself concomprise the state of an object and can be as complex as the sists not just of atomic values. Thus, even data that represents type system allows (i.e., depending on the availability of base the state of an object can be displayed in a relational format. types and constructors like tuple, set, bag, list, etc.). Behaviour Conversely, vendors of relational database systems are not is manifested in a set of messages associated with each class abandoning their investments, but tend to build OO features (its external interface), which are internally implemented by into subsequent versions of their products. The result is a commethods that are executable on objects. Formally, messages are bination of OO and relational, already termed object-relational specified by providing a signature, and by associating several or “OR” for short [Chamberlin 96, Silberschatz et al. 97, Stonesignatures with the same message name, the latter getting over- braker 96]. loaded. Not shown in Figure 1 is the possibility of organising At present, the results of these developments represent the classes in an inheritance hierarchy; also not shown is the fact state-of-the-art: The ODMG model is on the pure OO side, that class attributes are allowed to reference other classes, while OR models, which still come in various flavours, emphathereby forming an aggregation lattice. sise the merger of traditional and new technology worlds. At present, object data models no longer come just in the Standardisation is on its way for both, since an OR model is bapure form described above; indeed, they now come in two fla- sically what is envisaged for SQL3, the upcoming version of vours: (i) object-oriented (OO) data models and (ii) object- the SQL standard for relational databases. relational (OR) data models (and the two are commonly subToday it is widely understood what are reasonable ways to sumed under the term object-based data models). OO data define object data models, and what kinds of frameworks are models were developed first in the mid-80s. They marked a rad- needed for investigations that stay within precise technical ical departure from the relational model of data, by making the terms; the interested reader is referred to sources like [Abiteparadigm of object-orientation amenable to database systems boul et al. 95, Bancilhon et al. 92, Beeri 90, Kemper et al. 91, [Schek/Scholl 90b]. Distinct groups of researchers interpreted Lausen/Vossen 98, Lecluse/Richard 91, Vossen 94, Vossen 95]. the combination of OO with databases, or the introduction of We do not deal with this aspect any further in this paper, but OO features into the database area, in different ways. As a survey two languages for bringing object data models to end result a host of models appeared, most of which were used as a users and their applications. basis for the development of commercial or at least prototypical object-oriented database systems [Bancilhon et al. 92, Beeri 2 OO Models and the ODMG 90, Bertino et al. 90, Kemper et al. 91, Lecluse et al. 88, LecIn this section we sketch the ODMG-93 model, which has luse/Richard 91, Straube 90]. been proposed by the ODMG as a basis for standardisation Although initially it seemed that a situation was arising that [Bancilhon/Ferran 95, Carrell 96, Schader 97, Vossen 94]. The was entirely different from that of the relational model, namely ODMG model captures the essence of what has been discussed, that there was not just one OO model but a whole variety, there investigated and achieved over the years, and it can, in a sense, was soon a convergence on the horizon, mainly due to two be considered as a “summary” of how to bring object-orientaobservations: tion to databases. instantiated by class 32 INFORMATIK • INFORMATIQUE 4/1997 Object Data Models In essence, the ODMG proposal comprises an object model broadly following the basic principles and features described in the Introduction, an Object Definition Language (ODL), an Object Query Language (OQL) which is strongly based on O2SQL, the object-based SQL-derivative of the O2 programming language bindings to C++, Java, and Smalltalk. The object model can be characterised as follows: • The central modelling construct is the object; each object has a unique identity and can have one or more user-defined names. • Objects can have types associated with them, where all objects of the same type share structure and behaviour. • The behaviour of an object is determined by a set of operations which are applicable to an object of the corresponding type. Operations are specified through signatures which determine the name of an operation, the names and types of its arguments, and the type of the return value. • The state of an object is defined through values for a set of properties; these can be attributes or relationships to other objects. Attributes can only have literals as values, whereas relationships have object identities as values and hence create references between objects. The following example illustrates an object or interface definition in the ODMG language: interface Person // type properties: ( extent Persons key Name ) // instance properties: { attribute String Name; attribute Integer Age; attribute String Address; relationship Set<Vehicle> Cars inverse Vehicle::Driven_By; // instance operations: …… }; Each person object has a name, an age, an address, and a set of vehicles to drive, where each vehicle references an object in class Vehicle; in that class, a vehicle is equipped with a reference back to class Person indicating the person driving that vehicle. Class Vehicle is defined as follows: interface Vehicle // type properties: ( extent Vehicles key (Model, Manufacturer) ) { attribute String Model; attribute String Manufacturer; attribute String Color; relationship Person Driven_By inverse Person::Cars; // instance operations: …… }; Strictly speaking, an ODMG type has an interface and one or more implementations corresponding to the signature specified in that interface; only the combination of a signature with a particular implementation is called a class. Types are also considered to be objects, and can thus have properties themselves; these include supertype, i.e., types can be isa related such that attributes, relationships, and operations get inherited, extents referring to the set of all instances of a type, and key determining those attributes that form a key for that type. The ODMG-93 model recognises a number of predefined types [Cattell 96, Lausen/Vossen 98], where the basic distinction is between objects which can be modified and literals which can not (are immutable). Both categories are further divided into “atomic” versus “structured”, where the latter can be a tuple, set, bag, list, or array structure. The literals cover the ordinary base types like Integer or Float. Further details can be found in the cited references. It is clear that other OO models can be mapped to the ODMG model. Consequently, we may expect that vendors of OO databases will soon make their systems “ODMG-compliant”, just as middleware vendors make their software OMG- or CORBAcompliant. OR Models and SQL3 We next consider the second major current development in the area of object-based models, which is the combination of object-oriented concepts with the relational approach to organising data. The combination is generally termed OR in the literature, and has recently become popular due to the fact that big vendors of relational database management systems like Oracle and IBM, and also start-up companies like Illustra or UniSQL, are emphasising OR as their next generation of systems [Chamberlin 96, Silberschatz et al. 97, Stonebraker 96]. Since OR is newer than OO, the convergence of proposals into a single one is not yet as advanced as with ODMG, but due to the fact that SQL3 has been under discussion for so long now that it can even cover OR concepts, this state of confusion will hopefully disappear soon. To begin with, we consider a few examples referring to the Illustra database system, which follows the standardisation efforts for SQL3 [Stonebraker 96]. The main features are • support for base type extension in an SQL context, • support for complex objects in an SQL context, • support for inheritance in an SQL environment, and • support for a production rule system. 3 // instance properties: INFORMATIK • INFORMATIQUE 4/1997 33 Object Data Models The system provides for complex data and object-oriented concepts in an SQL setting through unique record identifiers, user-defined types and corresponding operators as well as functions and access methods, complex objects, inheritance of data and functions, polymorphism, overloading, dynamic extensibility, ad-hoc queries and active rules to ensure data integrity. The following are valid type and table declarations in the Illustra language: create type Address_t (Street varchar(40), Location varchar(30)); create type Auto_t (Model varchar(20), Manufacturer varchar(25), Colour char(5)); create type Person_t (Name varchar(30), Age int, Domicile Address_t, Fleet setof(Auto_t)); create table Person of type Person_t; These definitions first create three types describing the relevant features of an address, an automobile, and a person, respectively Notice that type Person_t makes use of the two other types. Finally, a table named Person is created whose tuples are of type Person_t. The base data types used in these definitions are the standard ones from SQL; however, as can be seen in type Person_t, the set constructor (setof) can also be used. The following type declarations introduce subtypes of type Person_t: create type Employee_t (Qualifications setof(varchar(20), Salary int, FamilyMembers setof(ref(Person_t)) under Person_t; create type Student_t (Major varchar(20), GPA float) under Person_t; create type StudentEmployee_t (Percent float) under Employee_t, Student_t; Each subtype inherits all attributes from every supertype. Ambiguities are avoided since the system will disallow a type declaration inheriting incompatible attributes from distinct supertypes. Since types describe domains at an abstract level (and hence cannot store data), corresponding tables are needed as well. To this end, the following table definitions introduce the relevant data structures for storing tuples over the types introduced earlier: 34 INFORMATIK • INFORMATIQUE 4/1997 create table Employee of type Employee_t under Person; create table Student of type Student_t under Person; create table StudentEmployee of type StudentEmployee_t under Employee, Student; Finally it is worth mentioning that, in Illustra, inheritance applies not only to attributes, but also to functions; see [Stonebraker 96] for details. Other OR systems are similar to Illustra in their data modelling capabilities. For example, UniSQL [Kim 95] comes with a model based on classes and methods, where a class involves a row type plus extent table to make it look relational. IBM’s DB2 for Common Servers (Version 2), has the Distinct Type for creating user-defined column types in a table, besides several types for describing large streams of bytes; it also allows for user-defined functions on such types. Oracle 8 is expected to comprise OR features in the Oracle Type System (OTS) object types. In addition to what these systems have built-in, it is common now to offer packages of pre-defined types (similar to dedicated class libraries) for certain areas of application such as text, images, Web documents, spatial data, audio and video. In this respect, Illustra offers DataBlades, IBM offers Database Extenders, Oracle will offer Data Cartridges, and UniSQL has the Multimedia Framework. We now turn to SQL3, whose major OO characteristics are similar to those of Illustra and can be summarised as follows: • The traditional type system of SQL is extended by abstract data types (ADTs), where a distinction is made between value types, which essentially generalise domains, and object types which support objects with value-independent identity. ADT structures can use a list, set or multiset constructor. • Types, both value and object types, can be arranged in a specialisation hierarchy which acknowledges inheritance; in such a hierarchy, each type must have a maximal supertype. • A similar feature applies to relations: A table can be defined as a subtable of one or more other tables and then inherits their attributes. • ADTs can also comprise user-defined functions, which can be SQL expressions or written in a foreign language. • SQL expressions may contains method or function calls; their execution will then launch a corresponding nested execution. Each tuple in each table can be equipped with a unique row identifier, which can be used either implicitly for identification purposes, or explicitly, for example, as a foreign-key value. Technically, a row id is a specific data type; its values can even be made visible (and then accessed as any other attribute). SQL3 can be seen as an effort to enhance and broaden the scope of the SQL language and its underlying relational data model. So it is, in a sense, a bottom-up approach, since new features are added to a model and a language that originally were Object Data Models not very powerful. ODMG goes in the opposite direction, since here the wider context is the OMG activities, which generally concentrate on object-oriented programming languages and their interfaces. Here the goal consequently is to cut down until a reasonable balance between expressive power and complexity has been reached; in this sense, ODMG is “top-down.” However, it is not unreasonable to expect a merger (or at least a convergence) of the two approaches, since the differences in terms of modelling capabilities between OO and OR are vanishing. Conclusions and Outlook I have tried to give a personal account of the work on object data models done during the past decade and in particular of the visible results of this work; for another such account, see [Carey/DeWitt 96]. This work has been relevant to both objectoriented and object-relational databases, or in essence to the idea of combining databases and objects. The current position are two basic standards proposals, ODMG-93 and SQL3, which have already started to converge (for up-to-date information, keep monitoring [OMG, SQL3]). The fact that ODMG is essentially a part of the bigger OMG effort is no coincidence, but reflects the current situation very well: Objects are everywhere, even on the Web, and the emphasis is on interoperability as well as on integration. The general goal now is to build Distributed Object Management Systems (DOMS) in which a variety of software (and maybe hardware) components can interoperate, and into which even legacy systems can be integrated. A variety of techniques in this direction is currently emerging, including middleware platforms such as CORBA [Vossen 97], component object models, mediators, wrappers, to name just a few. What has been learned about object data models over the past ten years now comes in useful, since this provides the fundamentals onto which it is possible to build heterogeneous system, federations of databases, or even DOMS. In terms of applications, it seems to me that the shift to OO is still slow. Indeed, major relational vendors make more money with their single product than the entire community of OO database vendors taken together. This is not surprising, given the fact that big applications, which have been growing for many years, often represent a considerable financial investment which nobody can afford to abandon overnight. As a consequence, predictions like the one found in [Stonebraker 96] that in a few years most of the picture will be OR, not pure OO, are probably right, since there is a clear migration path from relational to OR. Moreover, there are novel applications (such as NASA’s EOSDIS project) which rely on OR and hence nonstandard database technology right from the start. Nevertheless, the study of the OO paradigm in the context of data models has been productive, and OR – as a current conclusion – would not have been possible without it. Acknowledgement. The author is grateful to an anonymous referee for fruitful remarks on an earlier version of this paper. 4 References [Abiteboul et al. 95] S. Abiteboul, R. Hull, V. Vianu: Foundations of Databases; Addison-Wesley 1995 [Atkinson et al. 89] M. Atkinson, F. Bancilhon, D. DeWitt, K. Dittrich, D. Maier, S. Zdonik: The object-oriented database system manifesto; Proc. 1st International Conference on Deductive and Object-Oriented Databases 1989, 40–57 [Bancilhon et al. 92] F. Bancilhon, C. Delobel, P. Kanellakis (eds.): Building an Object-Oriented Database System –The Story of O2. Morgan-Kaufmann 1992 [Bancilhon/Ferran 95] F. Bancilhon, G. Ferran: The ODMG Standard for Object Databases; Proc. 4th International Conference on Database Systems for Advanced Applications (DASFAA) 1995, 273–283 [Beeri 90] C. Beeri: A Formal Approach to Object-Oriented Databases; Data & Knowledge Engineering 5, 1990, 353–382 [Bertino et al. 90] E. Bertino et al.: An Object-Oriented Data Model for Distributed Office Applications; Proc. ACM Conference on Office Information Systems 1990, 216–226 [Carey/DeWitt 96] M. Carey, D. DeWitt: Of Objects and Databases: A Decade of Turmoil; Proc. 22nd Internaional Conference on Very Large Data Bases 1996, 3–14 [Cattell 96] R.G.G. Cattell (ed.): The Object Database Standard: ODMG-93, Release 1.2; Morgan Kaufmann 1996 (latest version: Release 2.0, 1997) [Chamberlin 96] D. Chamberlin: Using the New DB2 – IBM’s ObjectRelational Database System; Morgan Kaufmann 1996 [Kemper et al. 91] A. Kemper et al.: GOM: A Strongly Typed Persistent Object Model with Polymorphism; Proc. German GI Conference on “Datenbanken für Büro, Technik und Wissenschaft” (BTW) 1991, Springer Informatik-Fachbericht 270, 198–217 [Kim 95] W. Kim (ed.): Modern Database Systems – The Object Model, Interoperability, and Beyond; Addison-Wesley 1995 [Lausen/Vossen 98] G. Lausen, G. Vossen: Object-Oriented Databases: Models and Languages; Addison-Wesley 1998, to appear [Lecluse et al. 88] C. Lecluse et al.: O2, an Object-Oriented Data Model; Proc. ACM SIGMOD International Conference on Management of Data 1988, 424–433 [Lecluse/Richard 91] C. Lecluse, P. Richard: Foundations of the O2 Database System; IEEE Data Engineering Bulletin 14 (2) 1991, 28–32 [OMG] Object Management Group Home Page, see http://www.omg.org [Schader 97] M. Schader: Objektorientierte Datenbanken – Die C++-Anbindung des ODMG-Standards; Springer 1997 [Schek/Scholl 90a] M.H. Scholl, H.J. Schek: A Relational Object Model; Proc. 3rd International Conference on Database Theory 1990, Springer LNCS 470, 89–105 [Schek/Scholl 90b] H.J. Schek, M.H. Scholl: Evolution of Data Models; Proc. Database Systems of the 90s, November 1990, Springer LNCS 466, 135–153 [Silberschatz et al. 97] A. Silberschatz, H.F. Korth, S. Sudarshan: Database System Concepts; 3rd edition, McGraw-Hill 1997 [SQL3] SQL Standards Home Page, see http://www.jcc.com/sql_stnd.html#Current Status [Stonebraker 96] M. Stonebraker: Object-Relational DBMSs – The Next Great Wave; Morgan Kaufmann 1996 [Straube 90] D.D. Straube, M.T. Özsu: Queries and Query Processing in Object-Oriented Database Systems; ACM Transactions on Information Systems 8, 1990, 387–430 [Vossen 94] G. Vossen: Datenmodelle, Datenbanksprachen und Datenbankmanagement-Systeme; 2. Auflage, Addison-Wesley 1994 [Vossen 95] G. Vossen: On Formal Models for Object-Oriented Databases; OOPS Messenger 6 (3) 1995, 1–19 [Vossen 97] G. Vossen: The CORBA Specification for Cooperation in Heterogeneous Information Systems; Proc. 1st International Workshop on Cooperative Information Agents (CIA) 1997, Springer LNAI 1202, 101–115 INFORMATIK • INFORMATIQUE 4/1997 35 Object Data Models SQL3 and OQL Drew Wade SQL has served for decades now as the standard database query language. With the emergence of object technology, SQL is being expanded to support objects. Meanwhile, the Object Database Management Group (ODMG) has published its standard, OQL. We discuss how these each support declarative access to objects, how they differ, and efforts to merge them. Query and Objects Does it make sense to query objects? Some have suggested it doesn’t. After all, objects are defined in terms of their interfaces, which are operations that the user may invoke. Shouldn’t this be the way to use them? Actually, queries can also be used effectively with objects. Why not allow a user of an object system to ask for, say, all employee objects representing employees with salaries > $100K who have had raises in the last year? Moreover, in actual production usage, users are in fact doing this. There are still open research issues in object queries; e.g., how best to optimize. In the relational world, in which data types are limited to tables and operations to select, project, and join, and insert, update, and delete, it is possible to completely define the algebra and calculus of queries and to prove many theorems about the optimization of these queries. However, objects can have any structure, any relationships, and any operations, so it is much more difficult to define a complete, closed model, and to prove theorems on the behaviour of optimization algorithms. Nonetheless, it is very important, because the objects represent the desired application structures and behaviours. It is these that the application wishes to query, and it is for these queries that it is important to establish optimization mechanisms. Forcing the user to first decompose his objects into flat tables and his operations into relational ones simply moves the problem of optimization to that decomposition process, to the application developer, effectively leaving it unsolved. Clearly, it is better for the DBMS to take the problem itself. Despite these open problems on querying ODBMSs, in practice it is quite useable. 1 Dr. Andrew E. Wade, Ph.D., is the Founder and Vice President of Objectivity, Inc. He previously built DBMSs to support complex, interconnected information at Hewlett-Packard (CAD), Daisy System (CAE), and Digital F/X (Video). He helped found the Object Management Group(OMG), where he co-sponsored the Persistence Service and led the Query Service, and also helped found the Object Database Management Group (ODMG) and co-authored the book ODMG-93, as well many articles. More information on Objectivity is available on the world-wide web at http://www.objectivity.com. Drew may be contacted at [email protected]. 36 INFORMATIK • INFORMATIQUE 4/1997 The fundamental capability of query is to provide declarative access, as opposed to procedural access. In the latter, the user specifies how to obtain the desired result (e.g., in a programming language like C, C++, or Java). In the declarative approach, the user specifies what he desires, leaving the query engine to determine how to obtain that information. This is often much simpler for the user. Also, the state of query technology is such that query engines can do as well as typical programmers and can also take advantage of knowledge of the database structure and indices. operations Object In the object world, all interaction is in the form of invocation of operations on the objects. The internals of the objects are necessarily hidden; this is called encapsulation. The common object models (ODMG, OMG) include the ability to define attributes, which are much like fields in traditional data structures, and represent state information. Access to such attributes is usually by methods (e.g., get(), set()), though it is often abbreviated for the simplicity of the user. This allows users to have a simple view for accessing the state information, and still allows implementors to hide the implementation of those attributes. In addition, objects have operations, and it is useful to be able to invoke those operations within queries; e.g., a person object might have an attribute for the birthdate, and an operation for calculating the current age. Such operations are procedurally programmed, usually in object languages such as C++ or Java, by the developer of the class library for each type of object. So, using such operations might be viewed as crossing the boundary between the declarative world of queries into the procedural world. On the other hand, to the user of the object, such operations are opaque and indistinguishable from any system Object Data Models built-in operations (such as select, project, join in the relational world). To the user, then, it makes sense to invoke these operations in a query. More to the point, access to such operations are necessary to get the functionality of objects, so a query system lacking such access would be extremely restricted in capability and useability. In fact, the relational world, including the SQL standard and many products, have already taken a half-way step towards operations in the form of stored procedures. These, too, are procedural, programmed by users (typically not end users), and so have the primary characteristics of object operations. What they lack is the ability to define arbitrary operations for arbitrary types. Instead, they are typically limited to only a few operations (e.g., delete, update) on the one relational type, table. Although the object notion of operation is more general and powerful, the concept of stored procedure already raises the issues we have discussed above; i.e., it allows the use of user-written procedural code within declarative queries, and moves the query process out of the realm of the mathematical theorems on optimization. Finally, objects also have relationships. The relational world lacks a direct concept of relationships. Instead, a secondary data structure, a foreign key, is created, and the same value of that key is stored in the two pieces of information (tuples) to be related. Then, at run time, the join operation searches down the tables, comparing foreign key values, to discover who is related to whom. Instead, objects allow direct declaration of relationships. Users need not define or manage secondary data structures. The operations for the relationships (traversal, adding or removing elements to many-sided relationships, etc.) are automatically provided by the DBMS, so the user need not write any stored procedures to maintain referential integrity, etc. As with operations, these are a fundamental part of the concept of objects, are heavily used, and should be supported in the query language if it is to be useful. Next we turn to how the two major standards efforts address querying for objects, starting with SQL, which grew out of the relational world, and then OQL, from ODMG and OMG, the object world. SQL3 Approach SQL is clearly the most widely used standard in the database world. It grew out of the relational model, though additions have been made for practical usage, and is widely supported by RDBMSs and also by front-end graphical tools. At this point, it makes little sense to start a query language from a widely different point of view. Why say, e.g., “CHOOSE … OVER …” when the world is already used to “SELECT … FROM …” and it works fine? Of course, as we get into the object functionality, we’ll see there are places where it doesn’t work just fine, and how those are addressed. Although it originally came from industry (IBM), and was widely used by leading database vendors (including DEC and Oracle) before codification as a formal standard, SQL did emerge from ISO in 1986 as SQL86, colloquially SQL1. This very simple specification was followed four years later by SQL92, which had grown to about 600 pages. Colloquially 2 called SQL2, it was release with 3 levels, entry, intermediate, and advanced. The SQL committee knows of no implementations of all of it, though the entry level, and parts of the intermediate, are widely supported. The draft of the next revision, colloquially called SQL3, is now over 1100 pages, and is still undergoing major modifications. The basic SQL capabilities include: Query (SELECT) DML (Insert/Update/Delete) DDL (CREATE TABLE) Security (GRANT, REVOKE) Other capabilities including more advanced features such as triggers and stored procedures. SQL3 is adding many features, but includes two major thrusts: – PSM, a computationally complete (procedural) language – Object support PSM is a new language, with object capabilities, intended to be used for stored procedures. From our point of view, it is just another language. Users can choose which languages they want to use. Since many users are already familiar with the popular languages, like C++ and Java, they are more likely to choose those, so the large effort on PSM might be better directed on other priorities. In any case, for this article, and for the expanded capabilities of SQL3, the far more important issue is object support. The SQL3 committee is not trying to add full object support, in the sense of an object database. Rather, in the words of the paper that established the current direction, they are trying to add “oo-ness to tables.” This makes sense for vendors who have table-based engines and products, yet want to begin to support some object capabilities. Similarly, it can be useful for users who are happy with the table model, but want a few more capabilities. In order to achieve this, SQL3 has elevated the rows of tables to a type, and added a couple more types. – Unnamed row types – Abstract data types (ADTs) – Functions – Named row types The first is the same as in SQL2, but since it is possible to call it out explicitly, one can create a TABLE as a MULTISET(ROW) (multi-set is often called bag, a set that allows duplicates). Lacking names, these row types lack the ability to be used repeatedly, and so really serve just as a short-hand notation, used in place in a table definition. ADTs are a step towards objects. They allow users to define more complex structures. The also support inheritance (new types can be defined as sub-types of other types by specifying the difference) and polymorphism (operations invoked on ADTs may result in different code being executed depending on the type of the ADT). Functions are much like operations in the object world, except they are not encapsulated, not combined with ADTs, but rather are free-standing. Object Models (including ODMGs) often include such free standing functions, or at least functions which are global in the sense that they are operations attached to the database (or session or DBMS) type. However, object INFORMATIK • INFORMATIQUE 4/1997 37 Object Data Models models always include operations that are attached to, indeed form a key part of the definition of, the object itself. In this sense, encapsulation is weaker for ADTs. Named row types add to row types the ability to instantiate the type (in the transient language PSM as well as in slots in tables) and also to reference it. Like ADTs, they support polymorphism, but not directly inheritance, although there is a table inheritance mechanism. Additionally, they add identity, an important feature of object models (incl. ODMGs), along with the related ability to create reference (REF) objects that act much like persistent pointers. To object users, the existence of the two different type systems, named row types and ADTs, seems redundant. One single concept, that of an object, can subsume both. If restructured this way, SQL3 could be significantly simplified, improved, and made more powerful. More importantly, though, are the lacking features. Missing, in addition to the encapsulation of operations with ADTs, are collections (multiset, set, list, etc.). In the object world, some notion of aggregation of objects is clearly necessary, not only for basic functionality of applications, but as the target (domain) and result (range) of queries. In SQL2, the target of queries is always tables, and the result always tuples or tables. In adding objects, it would be desirable to add the ability to query objects and collections of objects, and have those queries return results that are objects or collections of objects. In fact, the United States national standards body, ANSI, did exactly that. Partly in an effort to add better object capability, and partly in an effort to converge with the common object system usage including OQL (see below), they defined ADTs to include encapsulation (operations), added a complete set of collections and operations, and extended the query syntax to allow querying and returning arbitrary objects and collections. In addition to the familiar SELECT … FROM … WHERE syntax, this addition adds a newer query syntax illustrated by this example. SELECT DISTINCT ITEM i /* DISTINCT returns set rather than bag*/ FROM i IN lucky_numbers /* lucky_numbers is a set of integers */ WHERE i>13. The new FROM … IN syntax allows queries over collections, and can also be used for TABLEs. It has an additional benefit of allowing significant simplification of many kinds of queries. Further, it was specifically chosen to provide compatibility with OQL (see below). These enhancements to support objects, to comply with the OMG and ODMG object models, and to make a major step towards convergence with OQL were all adopted, also, by ISO. Unfortunately, though, at the time of this writing, ISO has just made a major switch, and voted to remove these objects capabilities (encapsulation for ADTs and collections), delaying them until SQL4. We emphatically hope this step backwards is a temporary one. Another significant issue is worth mentioning. In the approach of SQL3 TABLEs are the only persistent entities. 38 INFORMATIK • INFORMATIQUE 4/1997 Specifically, although there are ADTs, instances of those ADTs can be persistent (hence, saved in the database) only if they are inserted into a TABLE somewhere. This is quite different from the object view, in which any object can itself become persistent. Instead, the object users would tend to view a TABLE as just one of many data types (a collection type) that could itself become persistent. These two views, one upside down compared to the other, are a fundamental difference, but they don’t necessarily present an insurmountable barrier to a common query language. It is still possible, as we’ll see below, to have a single, common query language that would query TABLES and ADTs in an SQL3 implementation just as it could query objects. OQL Approach The Object Database Management Group (ODMG) was formed in 1991 by the vendors of Object Database Management Systems (ODBMSs), in order to jointly draft and support common proposals for ODBMS standards, jointly submit them to relevant consortia (like OMG) and accredited standards organizations (like ISO), and help them to become working, de facto standards by implementing them in products. The first version was published in 1993 under the title ODMG-93, The Object Database Standard (ed. Rick Cattell, chair of ODMG and Distinguished Engineer at SunSoft, and now JavaSoft). The latest edition, V1.2, includes an object model, appendices on relationship to OMG work, and four specified interfaces: – ODL, Object Definition Language – OQL, Object Query Language – C++ Binding – Smalltalk Binding Version 2.0 of the ODMG book is due from the publisher July, 1997, and adds: – Meta-Object access – OIF, Object Interchange Format – Java Binding The ODL is a strict superset of the Object Management Group’s (OMG’s) IDL, or Interface Definition Language. It provides a mechanism to define all the types (or schema) independent of the particular implementation languages (C++, etc.). The extensions to IDL are for database capabilities, 3 Database language Host language programmer must translate SQL Model Host language transparent database functionality ODBMS Model Object Data Models including declaration of bi-directional relationships and keys. These extensions are defined to generate an equivalent set of operations, which allows automatic translation of the ODL into IDL for OMG compatibility. The language bindings provide, as close as technically possible, a seamless integration between the standard host language (C++, etc.) and the ODBMS. This allows the programmer to use the familiar language and transparently or automatically achieve database capability, including persistence, recovery, integrity, concurrency, etc. This is a different approach from traditional database systems (including SQL), in which the host and database language each have their own paradigm, their own language, and their own data structures, requiring the user to write code to translate back and forth. Instead, the goal of the ODBMS approach is to allow the user to use the same object in his design, programming, and database. The OIF adds the ability to dump one or more objects to a text format, then load it into a different database (and possibly different DBMS). Meta-object access allows programmatic access to the schema, or type-defining objects, at run time. All of these are different from what the SQL standard does. True, there is some overlap with ODL and the DDL portion of SQL, but SQL2 lacks a type system (other than tables), so it is not really comparable. SQL3 does have such a type system (see above), but expands upon it largely in PSM. To ODMG, PSM looks just like any other programming language (C++, etc.) to which it might do a binding, if there is sufficient user demand. However, in one area, OQL, there is direct overlap. OQL was designed to be a simple, functionally complete query language that would give natural support to objects. The result is a straightforward language that provides read-only ad hoc query, much like the SELECT statement in SQL, but also allows querying objects, collections of objects, with their operations and inheritance. Since ODMG realized that users were demanding SQL as a standard, they tried to make OQL compliant with SQL2’s read-only query subset. By the time V1.2 was published, changes to OQL were accomplished to come close to achieving this, but did not succeed entirely. Some have described the resulting OQL as approximately 90% compatible with SQL2. The remaining 10% mainly involved typing issues. The very same syntax might, in SQL, return a TABLE with one column, while in OQL return a SET of OBJECTs. Because SQL2 lacks a type system, and because of the long history of details incorporated into it, the effort required to push OQL the last 10% proved prohibitive, and would also make OQL quite a bit more complicated, defeating the initially desired goal. So, instead, it was decided to attempt the last 10% of the convergence at the SQL3 level. Convergence Efforts Towards this end, an ad hoc working group was formed, consisting of key technical members of both ODMG and the ANSI SQL committee. The group quickly agreed on the goal to make OQL the read-only query subset of SQL3 by changing both as necessary. This would allow users to use exactly the same query syntax against products conforming to SQL3 and products conforming to ODMG, thereby unifying the languag- 4 es, even if the remainder of the products and approaches continued to differ. The group made change proposals to both OQL and SQL3. The OQL ones were much easier to accommodate because ODMG is a smaller organization. The SQL3 changes were more difficult, both because the organizations involved (ANSI and ISO) were larger with more complicated processes and because the SQL3 specification itself is significantly more complex. The work began as a white paper, specifying the differences, and outlining three different approaches to convergence. The ANSI SQL committee, in December 1995, heard this paper and enthusiastically supported it, encouraging one specific approach, involving incremental changes to SQL3. During 1996, and continuing to the present time, the convergence group authored several change proposals to move SQL3 step by step closer to OQL, thereby not only moving closer to convergence, but also incrementally adding improved object query functionality. The major issue, described above, the ability to query objects and collections, was addressed first, and that as well as several other less significant change proposals were adopted by both ANSI and ISO. Just recently, unfortunately, a major portion of that, querying collections and encapsulation of operations in ADTs, was reversed and postponed until SQL4. As progress continues, it remains to be seen exactly how this will end. Assuming the resolution, eventually, of this issue of querying collections of objects, the next largest outstanding work item for the convergence group is the syntax of name resolution. Syntax sounds like it should be a minor problem. However, in this case, history and backwards compatibility conspire to make it quite difficult. Object systems typically use dot (.) for specifying the connection between a object and one of its attributes, operations, or relationship to another object. Arrow is also used, especially for the latter, or relationship dereference. For example, C++ uses dot for attributes, and arrow for methods and dereference. With the experience of hindsight, though, many feel that it would be better to use just one, so that implementation changes, such as the change from a stored attribute to an operation, would not affect existing users and programs. So, OQL adopted the use of either dot or arrow interchangeably. SQL2 uses dot for a very different purpose; viz., to resolve the name space hierarchy catalogue.schema.table.component. Backwards compatibility requires continued support for this, so the SQL committee added different symbols for the other kinds of resolution, including arrow for dereference, doubledot (..) for ADT attributes, and triple-dot for accessing a field of a row. Recent efforts were able to replace the triple-dot with double-dot, a step in the right direction, but it was widely believed that complete simplification down to a single dot was likely to be too difficult. The ad hoc merger group, with contributions led by David Beech, has in fact discovered a solution to this name resolution problem. Most of the technical details have been ironed out, though a few remain. The basic idea is to resolve a string of identifier.identifier …, all with single dots, by first examining up to the first (left-most) four components, and attempting to INFORMATIK • INFORMATIQUE 4/1997 39 Object Data Models use the SQL2 resolution approach for catalogue.schema. table.component. Once done, any remaining dot-separated identifiers are then resolved sequentially, for objects, nested objects, attributes, relationships, and operations, in the familiar way of many programming languages. The first of these two steps ensures compatibility with SQL2, while the remainder allows the full power of the object model. We expect to see this issue addressed during the next few months in ANSI and ISO, and hope to see it move towards the simplicity and convergence of the single dot1. The Future The database world has, for many years now, benefited from a strong and widely-supported standard, SQL. This has allowed the industry to grow, has allowed vendors to compete on value added, while users can freely choose the products that best meet their needs. The common language also allowed the birth of a large secondary industry of tools, including graphical forms generators, report writers, query tools, etc., such as PowerBuilder, Crystal Reports, Microsoft Access, and Visual Basic. This is one of the best examples of standards in the computer industry and illustrates their benefits. However, at the moment, we are perched in a precarious position, that might lead to bifurcation into two, or perhaps even more, query “standards”. The near universal adoption of the object paradigm has made it imperative for database standards to incorporate support for objects. In fact, one of the major benefits of object technology is the ability for different subsystems, built separately, to be combined together, as objects, communicate together, and interoperate. If the major database standard, SQL, does not in fact support interoperability with the object models and interfaces used in the rest of the industry, then users will have a difficult time integrating databases into their object systems and getting their jobs done. Of course, lack of object functionality in the SQL standard also will make it difficult for 5 1. Late breaking news: ANSI just (21 May) adopted this change. Next it goes to ISO. 40 INFORMATIK • INFORMATIQUE 4/1997 users, who are more and more using objects, to use SQL and SQL-based databases. Finally, the existence of competing standards can fragment the market, making it difficult for users to choose the desired products because they support different interfaces. For all these reasons, convergence of the object query standards is highly desirable. It is not a black-and-white or all-ornothing proposition. The closer the convergence of the standards, the better the object query functionality in SQL, the more users will be able to use different DBMSs with their objects, and the better the situation will be for vendors, users, and the industry as a whole. The risk, lacking convergence, is that users who want to use their traditional relational databases with their newer object systems will be burdened with much extra work, less flexibility, less choice in vendors, fragmenting the growth of the database industry, the tools industry, and having severe impact on all industries that rely on software systems and databases. The potential, with a successful, or even close to successful convergence, is much greater ease in using databases than ever before, because of the direct object support, rapid growth of the database industry, and the emergence of software information systems as the basis for the growth of commerce in our world-wide economies. To probe further ansi sql documents: ftp://jerry.ece.umassd.edu/isowg3/x3h2/1997docs/ iso sql documents: ftp://jerry.ece.umassd.edu/isowg3/dbl/ sql web site: http://www.jcc.com/sql_stnd.html sql/odmg convergence page on sql web site: http://www.jcc.com/sql_odmg_convergence odmg web site: http://www.odmg.org web site to see and give input on conformance levels for sql3: http://www.wiscorp.com/ a good set of introductory slides on sql and sql3 (may be out of date): <ftp://jerry.ece.umassd.edu/isowg3/TEMPdocs/SQL3_foils.ps> more on objectivity/db and references to other related odbms sites: http://www.objectivity.com Mosaic fonctions de l’entreprise, et en- sont devenus aujourd’hui plus imgendrer les futurs avantages com- portants que ceux de la fonction de production. pétitifs. La difficulté principale est Pour cela, il est crucial de posChristophe Legrenzi séder des outils et des méthodes d’imaginer et de concevoir ces qui permettront de gérer les diffé- nouveaux outils. A quel objectif Du fait des effets d’échelle, les rents paramètres de cette collabo- doivent-ils répondre? Quelle forLe besoin 1 de nouveaux outils montants en jeu sont considéra- ration homme / micro-ordinateur. me auront-ils? Comment fonctionneront-ils? Les théories économiques bles. Au-delà de la simple dimension Dans un tel contexte, toute tenTypologie classiques reposent toutes sur la 2 des nouveaux outils tative de réponse ne peut être que trilogie Capital, Travail et Outil de financière, c’est le résultat du traLa plupart des outils qui difficile et maladroite. production. La notion de travail vail homme / machine ou plutôt Cependant, une piste nous semremonte aux origines de l’huma- homme / micro-ordinateur qui est s’avéreraient nécessaires n’exisnité, alors que le capital n’est ap- devenu essentiel pour l’entreprise. tent pas encore ou sont peu répan- ble intéressante. Il s’agit de l’étuAlors que la grande majorité dus. Il n’existe que rarement au de de l’ensemble des interactions paru que plus tard avec la notion de monnaie d’échange. L’outil de des ressources sont investies dans sein des entreprises de réflexion de l’utilisateur avec le monde production quant à lui est contin- ce domaine, combien de diri- globale à ce sujet. Par contre, dans informatique (Figure 1). C’est au gent de l’époque. Ainsi à l’ère geants sont aujourd’hui capables les autres fonctions, elles sont ha- niveau de ces interactions qu’il est agraire, l’outil principal de pro- de dire, même approximative- bituelles. La fonction production possible d’obtenir de l’informaduction était la terre. Après la ment, ce que font leurs employés est par exemple fréquemment tion. Information qui pourra alors révolution industrielle, il est sym- avec leur PC? Quel est le produit l’objet d’études d’améliorations être traitée et analysée. Ces interactions sont au nombre bolisé par la machine à vapeur et de leur travail? Combien cela coû- et d’optimisations. Et de nomte-il? Est-ce que leur rendement breuses méthodes existent dans ce de trois et se déclinent suivant la la dynamo électrique. Aujourd’hui, à l’ère de l’infor- est satisfaisant par rapport à la secteur; des méthodes de gestion typologie suivante: mation, c’est incontestablement concurrence? Ont-ils reçu la for- de production (MRP I, MRP II, • formation l’informatique avec sa forme la mation nécessaire aux outils Kanban, etc.), de gestion de stock • assistance • utilisation plus répandue qu’est le micro- qu’ils utilisent? Autant de ques- ou des en-cours, etc. En effet: Dans le monde de l’informatiordinateur, qui constitue l’outil tions restant sans réponses... Or, lorsqu’un utilisateur perd que ou plus généralement de la • L’utilisateur doit passer obligadominant. toirement par une phase d’apEn effet, il a envahi la plupart du temps parce qu’il rencontre un gestion de l’information, il n’exisprentissage des outils qu’il est des bureaux et s’est imposé com- problème et que le groupe infor- te rien de comparable. Nous n’en censé utiliser dans sa fonction. me l’outil incontournable de cette matique de support est indisponi- sommes qu’à la genèse d’une véLors de cette phase qui se répète fin de siècle. Rappelons simple- ble, ou qu’il utilise inefficacement ritable gestion de l’information. avec l’installation de tout noument quelques chiffres. Au- l’outil informatique, cela repré- Pourtant, les enjeux de ce secteur jourd’hui, un travailleur de l’in- sente un coût bien réel. Un coût ou formation utilise en moyenne son plutôt une perte de productivité ordinateur durant près de la moitié qui se retrouvera irrémédiade son temps. Le département blement dans le prix des services américain du travail prévoit qu’en et des produits commercialisés ou l’an 2000 son emploi concernera qui affectera la marge brute de l’entreprise. 75% de la population active. Il est grand temps que les analyLe micro-ordinateur représente un coût total de l’ordre de 5000 ses de productivité intègrent aussi francs par mois en moyenne. Ce ces éléments car à l’échelle d’une coût est variable suivant l’intensi- entreprise ils peuvent s’avérer crité informationnelle du secteur tiques et déterminants. Ainsi, il devient fondamental de dans lequel se trouve l’entreprise. Assistance De plus, une partie importante de mesurer et de comprendre l’usage ce montant (un peu plus de la moi- de la micro-informatique afin de tié) est constituée de coûts cachés. pouvoir augmenter la productivité Figure 1: Les interactions de l’utilisateur avec le monde informatique des employés et des différentes Utilisation Formation La Productivité des Travailleurs de l’Information: Nouveaux outils de mesure INFORMATIK • INFORMATIQUE 4/1997 41 Mosaic veau logiciel or lors d’un changement de plate-forme, l’utilisateur va suivre des cours et sera alors en contact avec une instance informatique interne ou externe à l’entreprise. • S’il est confronté à un problème ou désire un renseignement, une cellule d’assistance se tient à sa disposition. C’est la deuxième confrontation avec la fonction informatique. • La troisième et la plus fréquente se produit lors de l’utilisation des différents outils que comporte son poste de travail. Les outils qui permettent d’observer et d’étudier les activités de l’utilisateur se trouvent aux interfaces de ces trois domaines. Ces événements se produisent selon une fréquence différente. Les premiers sont de l’ordre de quelques fois par année au plus. Alors que les seconds peuvent se répéter plusieurs fois par mois. Les derniers sont constants et sont présents à chaque fois qu’un utilisateur travaille avec son ordinateur. 3 Description Utilisation Formation 3.1. La Formation La formation aux outils qui composent l’environnement de travail de l’utilisateur est incontournable (Figure 2). Elle se déroule de manière formelle lors du suivi de cours ou de séminaires, ou de manière informelle au tra- vers d’un apprentissage autodidacte. En général, le temps que les utilisateurs investissent dans des programmes officiels est bien inférieur au temps passé à se former eux-mêmes. Cette phase est particulièrement critique puisqu’elle conditionne le comportement futur de l’utilisateur face aux outils qui sont mis à sa disposition. Les outils sont aussi bien matériels que logiciels. Au niveau matériel, ils correspondent au micro-ordinateur avec toutes ses composantes: écran, clavier, souris, lecteur de disquette, lecteur de CD-ROM, ainsi que les périphériques: imprimantes, table traçante, etc. Du côté logiciel l’on retrouve les outils bureautiques classiques: traitement de texte, tableur, outil graphique/de dessin, la messagerie électronique, les progiciels et les applications adaptées au contexte: comptabilité, production, recherche, marketing, etc. Autant d’éléments qu’il est nécessaire de maîtriser si l’on veut être performant. Qui n’a jamais perdu du temps avec une imprimante rebelle ou un logiciel mal configuré? Malheureusement, l’on estime qu’uniquement 40% des utilisateurs devant suivre une formation y participent effectivement. De plus, la rétention d’informations suite à une formation s’avère être faible. Après 30 jours les utilisateurs ne se souviendraient plus Assistance Figure 2: Les interactions de l’utilisateur avec le monde informatique : la Formation La formation est l’apprentissage par l’utilisateur des outils bureautiques, des progiciels et des applications 42 INFORMATIK • INFORMATIQUE 4/1997 que d’à peine 10% de ce qui leur a été enseigné. Malgré cela, le coût associé à la non-formation peut être près de six fois plus important que le coût d’une formation classique. Il se traduit par le temps que l’utilisateur passe à acquérir les connaissances nécessaires. C’est-à-dire consulter une documentation, tester directement les fonctionnalités d’un logiciel à l’écran, ou questionner des collègues plus compétents. Ce problème s’accroît au fur et à mesure que l'environnement devient plus complexe, plus diversifié et moins bien défini. Aujourd’hui, les utilisateurs ont besoin de deux à trois fois plus de temps pour apprendre à utiliser leurs applications que six ans auparavant. Afin de gérer efficacement cet élément critique qu’est la formation, deux outils principaux sont nécessaires: • une base de données des formations suivies par les utilisateurs • des tests de connaissance adaptés au contexte du travail Les ressources informatiques de l’entreprise étant précieuses et coûteuses, nous avons déjà observé des entreprises interdisant à leurs employés l’accès aux outils informatiques s’ils ne suivaient pas un programme de formation et s’ils ne passaient pas avec succès le test de connaissance qui leur était proposé. Ce principe certes extrême et critiquable peut se comprendre. En effet, ce sont souvent les gens mal formés qui sont à l’origine des problèmes et génèrent une demande importante en terme de support. Ce sont eux aussi pour lesquels l’utilisation des outils informatisés sera la plus approximative, et qui dérangeront le plus leurs collègues. Pourquoi ne pas imaginer sur le modèle du permis de conduire, un permis d’utilisation de tel ou tel outil. Ou mieux, en reprenant l’exemple des tests bien connus du TOEFL ou du GMAT, obligatoires pour l’accès aux formations de type MBA, d’imaginer une épreuve permettant d’estimer le niveau de connaissance par rap- port à un outil donné. Les résultats obtenus permettraient aux entreprises de positionner précisément le niveau de connaissance de leurs employés ou celui de candidats potentiels. Selon les postes, elles pourraient définir des minima obligatoires pour certains outils. Une secrétaire par exemple devrait posséder de bons résultats aux tests du traitement de texte et des outils de présentation, alors qu’un comptable devrait montrer un score élevé à l’épreuve concernant l’application comptable que possède l’entreprise. De plus, en fonction des lacunes, elle pourrait établir du même coup un programme de formation adapté afin que ses collaborateurs ou futurs employés soient en mesure d’être rapidement productifs ou d’améliorer encore leur connaissance. La base de données des formations suivies par les utilisateurs peut s’avérer très utile. Elle doit être traitée avec la même importance qu’un curriculum vitae classique. Elle va permettre d’identifier rapidement et globalement les lacunes du personnel. Des programmes de formation pourront alors être élaborés. Tout comme les tests, ils doivent être régulièrement examinés, comparés et adaptés à l’évolution des parcs matériels et logiciels de l’entreprise. Parallèlement aux formations classiques organisées en cours ou séminaires, de nombreuses autres méthodes peuvent être employées. L’on peut citer le cas des formations en “juste à temps” qui contrairement à la définition américaine (JITT: Just In Time Training) sont organisées juste au moment où l’utilisateur en a besoin, lorsqu’il rencontre un problème par exemple. Il existe à présent de très bons logiciels de formation interactifs sur CD-ROM. L’on peut aussi imaginer des programmes de formation sur le lieu de travail qui seront non seulement adaptés au contexte et à l’environnement de l’entreprise, mais seront basés sur la configuration réelle du poste de l’utilisateur. N’oublions pas qu’un travailleur de l’information passe la moitié de son temps à travailler Utilisation Formation Mosaic Assistance Figure 3: Les interactions de l’utilisateur avec le monde informatique : l’Assistance L’assistance est l’aide fournie aux utilisateurs par l’intermédiaire du Helpdesk et de la cellule informatique de support. avec son micro-ordinateur et que son niveau de maîtrise des outils qu’il est amené à utiliser dans sa fonction revêt une importance toute particulière. 3.2. L’Assistance La fonction d’assistance aux utilisateurs est injustement le parent pauvre de la fonction informatique (Figure 3). Elle ne bénéficie pas du prestige des fonctions de développement ou d’exploitation. Sans doute parce qu’elle est plongée dans le domaine opérationnel et que sa fonction est par nature polymorphe. Pourtant, c’est la fonction qui est le plus intensivement en contact avec les utilisateurs et les différentes fonctions de l’entreprise. De plus, elle requiert des compétences élargies couvrant l’ensemble du spectre de la fonction informatique au niveau du poste de travail. Ses membres sont des informaticiens « à tout faire ». Suivant le cas, ils résolvent des problèmes, administrent des serveurs, commandent et installent matériels et logiciels, ou développent des applications pour les utilisateurs. Les personnes du support doivent en outre être de bons communicateurs, savoir travailler sous la pression et être diplomates. Etant appelés en cas de problèmes, elles essuient fréquemment l’humeur et la colère des utilisateurs désabusés. C’est sans doute la raison pour laquelle cette fonction a du mal à recruter des candidats compétents, sérieux et motivés. C’est pourtant, à notre avis, la meilleure école pour apprendre le métier informatique. En période de restriction budgétaire ces groupes de support sont dans de nombreuses entreprises les premiers à être remis en question. On a du mal à les catégoriser. Ils ne sont ni développeurs, ni ingénieurs systèmes. Leurs activités sont multiples et hybrides. S’il s’agit de les fédérer et de mieux organiser leur fonctionnement cela est parfaitement justifié. Malheureusement, ils sont souvent l’objet de coupes sombres de leur ressources sous le couvert d’une pseudo-optimisation. Certains organismes dont le Gartner Group n’ont pas hésité à une certaine époque à évoquer les rapports de support (nombre d’utilisateurs supportés par informaticien) qui leur semblaient optimaux. Evidemment, plus il était élevé et mieux cela était. Cela est juste si l’on se restreint aux coûts directs, mais faux si l’on considère les coûts complets. Il peut être dangereux de réduire ou supprimer une telle fonction sans évaluer l’impact sur les utilisateurs qui peut s’avérer particulièrement négatif. En effet, les problèmes et autres requêtes subsisteront et seront alors traités par les utilisateurs eux-mêmes. N’étant pas formés pour et possédant des connaissances souvent sommaires, ils résoudront les problèmes bien moins rapidement (s’ils y arrivent), avec un niveau de qualité inférieur, et ceci au dé- triment de leurs propres attributions. A titre d’illustration, un département de recherche de 400 utilisateurs possédant une cellule d’assistance composée de 5 personnes, va devoir prochainement réduire son personnel de moitié. Elle traite quelque 20000 problèmes, requêtes et installations par an à la plus grande satisfaction des utilisateurs. Après cette coupe sombre, combien de personnes/an faudra-t-il aux utilisateurs pour résoudre les 10000 problèmes restant? Sans aucun doute bien plus, sans compter que le département est constitué essentiellement de chercheurs de haut niveau aux salaires horaires bien supérieurs aux personnes du support. Les chercheurs ayant alors moins de temps disponible pour leur activité de recherche seront moins productifs ou seront obligés, pour garder un niveau de productivité équivalent, d’embaucher de nouvelles personnes. En terme de productivité, c’est une ineptie. L’outil principal de la fonction de support est la banque de données regroupant l’ensemble des informations ayant trait aux requêtes des utilisateurs ainsi que leur suivi. Des logiciels élaborés existent depuis déjà quelques années. L’analyse des données qu’elle contient est riche. Elle permet d’identifier notamment: • les causes majeures de problèmes (applications, matériel, périphériques, etc.) • la fréquence des problèmes • le pourcentage de problèmes résolus en fonction du temps de traitement nécessité • le temps moyen de résolution • le pourcentage de problèmes ayant été transmis à une autre instance • le nombre de problèmes en attente • l’évolution du nombre de problèmes dans le temps • le nombre d’installations matérielles et logicielles réalisées • le nombre de déménagements • le type de demande d’informations Autant de chiffres qui vont permettre de prendre des décisions afin d’améliorer la situation. Il peut s’agir de la mise en place d’un programme de formation sur un outil en particulier si l’on s’aperçoit que les questions à son sujet sont nombreuses. L’on peut décider aussi de changer d’imprimante si elle est la cause de pannes à répétition ou si elle exige une maintenance trop importante. L’impact des mesures prises pourra aussi être suivi dans le temps. 3.3. L’Utilisation Même si l’utilisation est de très loin l’activité où l’utilisateur est le plus souvent en contact avec le monde informatique, c’est le domaine où les outils sont les plus rares (Figure 4). Malgré l’importance des montants consacrés au travail homme / micro-ordinateur, l’on ignore presque tout de cette interaction. Pourtant, chaque jour, des commerciaux ou des ingénieurs vont passer une grande partie de leur temps à effectuer des tâches de secrétariat. Des contrôleurs de gestion vont se créer des mini-banques d’informations contenant des informations-clés ayant nécessité des heures de collectes. Une secrétaire va passer du temps à recréer une présentation ou un document déjà édité. Sans une attention particulière, les risques d’activités redondantes, de développements anarchiques, de fragilisation de l’infrastructure informationnelle de l’entreprise et de détournement technologique, générant une perte globale d’efficience et d’efficacité de l’ensemble de l’entreprise sont bien réels. C’est pourquoi de nouveaux outils sont nécessaires pour appréhender cette problématique. Sans que cette liste soit exhaustive, l’on peut citer en l’occurrence: • les études d’analyse de la productivité des utilisateurs • la mesure de l’usage des outils informatiques • les enquêtes de satisfaction globale ou ponctuelle Les études d’analyse de la productivité des utilisateurs se décomposent en deux grandes familles. Celles dont l’objectif est INFORMATIK • INFORMATIQUE 4/1997 43 Utilisation Formation Mosaic Assistance Figure 4: Les interactions de l’utilisateur avec le monde informatique : l’Utilisation L’utilisation est l’interaction de l’utilisateur avec son poste de travail informatisé et les outils qu’il comporte. d’identifier les pertes de productivité liées à l’utilisation de l’outil informatique (cf. Les Travailleurs de l’Information: Etude Empirique, INFORMATIK/INFORMATIQUE 3/1997). Les autres, au contraire, se concentrent sur les gains de productivité. Les deux démarches sont en fait complémentaires. La deuxième est liée à la manière dont l’utilisateur emploie les outils informatiques par rapport aux tâches qu’il a à réaliser. En fonction d’un certain nombre de paramètres l’on va pouvoir estimer le gain potentiel de productivité par différentiation entre une solution informatisée et une solution manuelle. Mais aussi entre deux solutions automatisées comparables. Il sera alors possible d’optimiser la productivité des travailleurs en réorganisant astucieusement leurs tâches ou en leur fournissant les outils adéquats à leur fonction. Une personne effectuant quotidiennement des travaux répétitifs de type saisie de factures par exemple, sera nettement plus productive avec un terminal alphanumérique plutôt qu’avec un terminal graphique. La mesure de l’usage des outils est elle aussi fondamentale. Qui est capable à l’échelle d’une grande entreprise de dire combien de personnes utilisent régulièrement tel ou tel logiciel et ce pendant combien de temps? Or, les réponses à ces questions renseignent sur le degré d’intensi- té d’utilisation des applications. Elles permettent par exemple d’identifier les logiciels ou progiciels les moins utilisés de l’entreprise, et ainsi de les remettre en question. Elles permettent aussi d’adapter les programmes de formation en fonction du taux d’utilisation des différents outils. En effet, le bénéfice d’un cours sera plus important si le logiciel est utilisé en moyenne 200 heures par an et par utilisateur plutôt qu’une dizaine d’heures seulement. Des systèmes encore rares et sommaires apparaissent sur le marché. Les enquêtes de satisfaction sont considérées par beaucoup d’experts comme indispensables. Ils estiment qu’elles devraient être effectuées de une à deux fois par an afin de donner la possibilité aux utilisateurs de s’exprimer sur la qualité du service reçu. Ceux-ci peuvent aussi en profiter pour indiquer les niveaux de services attendus comme les horaires du helpdesk ou la rapidité d’intervention en cas de problème. Les enquêtes de satisfaction sont aussi très importantes et motivantes pour le groupe de support qui sachant qu’il sera jugé aura tendance à améliorer la qualité de ses prestations. Réitérées dans le temps, elles permettent d’observer l’évolution de la satisfaction des utilisateurs. Certaines enquêtes peuvent être effectuées ponctuellement suite à un événement particulier comme 44 INFORMATIK • INFORMATIQUE 4/1997 la migration d’une plate forme matérielle à une autre ou lors d’un changement de système d’exploitation par exemple. La liste d’outils cités n’est en rien exhaustive et mérite d’être complétée. Son seul objectif est de démontrer qu’il existe une utilité bien réelle à s’intéresser de plus près au travail de l’information en relation avec son potentiel support qu’est l’informatique. Conclusions A l’ère de l’information, c’est bel et bien le microordinateur, qui est devenu l’outil productif dominant. En moyenne, plus de la moitié de la masse salariale des cols blancs des entreprises est consommée lors d’un travail homme / machine ou plutôt homme / micro-ordinateur. Malheureusement, la grande majorité des dirigeants n’ont pas la moindre idée des activités effectuées durant ce temps et encore moins des résultats générés. Afin de pouvoir gérer cette activité au même titre que les autres ressources de l’entreprise, de nouveaux outils sont nécessaires. La plupart n’existent pas et sont encore à inventer. Afin de les déterminer, une approche consiste à observer 4 l’ensemble des interactions de l’utilisateur avec le monde informatique. Elles sont principalement au nombre de trois: • la formation • l’assistance • l’utilisation L’étude de ces interactions amène une meilleure compréhension de ce travail homme / micro-ordinateur afin de l’améliorer et de l’optimiser. Les informations obtenues sont particulièrement intéressantes. Elles permettent d’identifier les dysfonctionnements présents afin de développer les solutions adéquates. Dans certains cas, la façon même de travailler avec ces outils informatiques pourra être remise en question et réorganisée. Ces nouveaux outils illustrent un changement majeur quant au positionnement de la fonction informatique au sein de l’entreprise. Ils symbolisent le passage d’une vision techniciste à une logique de coopération et d’usage. Ainsi, ils constituent une opportunité certaine pour la fonction informatique de se rapprocher des mécanismes intimes de l’entreprise en signifiant l’importance des enjeux liés au travail de l’information. Bildungsinitiative Neue Medien Helmut Thoma Die neuen Informations- und Kommunikationstechnologien konfrontieren das Bildungswesen mit grossen Herausforderungen. Der Mensch ist gezwungen, ständig weiterzulernen – oder er verliert den Anschluss. So legte die EU bereits 1994 einen Bericht vor, in dem auf die Gefahr einer möglichen Spaltung der Gesellschaft in zwei Klassen hingewiesen wird: In eine Klasse, die einen reichen Informationsschatz besitzt und damit umgehen kann und in eine Klasse, die über geringe Informationsressourcen verfügt bzw. sie nicht zu nutzen weiss. Will also die Gesellschaft den Herausforderungen begegnen, die sich aus der Durchdringung aller Lebensbereiche mit neuen Medien ergeben, und sie positiv annehmen, ist eine grossangelegte Bildungsinitiative nötig. Auf diese Problematik hat auch der “Gesprächskreis Informatik” in seiner Schrift “Informationskultur für die Informationsgesellschaft” 1995 hingewiesen [GkI 95]. Als erste Vertiefungsstufe dieser Schrift hat nun der Gesprächskreis Informatik eine weitere Schrift “Informationskultur für die Informationsgesellschaft durch Bildungsinitiative Neue Medien” erarbeitet [GkI 97]. Er übergibt diese den Verantwortlichen in Parlament und Regierung, Mosaic Gesprächskreis Informatik(GkI) Der Gesprächskreis Informatik ist ein Zusammenschluss von deutschsprachigen Fachgesellschaften aus dem Bereich der Informatik und ihrer Anwendungen, der sich zusammengefunden hat, um alle Gesellschaften an einen Tisch zu bekommen, die sich in ihrem Fachgebiet mit Informationsverarbeitung beschäftigen. Fachgesellschaften die sich derzeit im Gesprächskreis Informatik engagieren: Anwenderverband Deutscher Informationsverarbeiter e.V. (Adi), Deutsche Gesellschaft für Dokumentation e.V. (DGD), Deutsche Gesellschaft für Recht und Informatik e.V. (DGRI), Gesellschaft für Informatik e.V. (GI), Gesellschaft für Informatik in der Land-, Forst- und Ernährungswirtschaft e. V. (GIL), VDI/VDE-Gesellschaft für Messund Automatisierungstechnik (GMA), Deutsche Gesellschaft für Medizinische Informatik, Biometrie und Epidemiologie (GMDS) e.V., VDE/VDI-Gesellschaft für Mikroelektronik, Mikro- und Feinwerktechnik (GMM), Informationstechnische Gesellschaft im VDE (ITG), Österreichische Computer Gesellschaft (OCG, 1997 Vorsitz des GkI), Schweizer Informatiker Gesellschaft (SI). Der Gesprächskreis Informatik repräsentiert insgesamt mehr als 60’000 Mitglieder. Wirtschaft und Wissenschaft, Verbänden, Gewerkschaften und Religionsgemeinschaften sowie insbesondere Lehrern und Lehrmittelherstellern. In der Industriegesellschaft des 18. und 19. Jahrhunderts mit ihren gesellschaftlichen Umwälzungen und Veränderungen der Anforderungen an die Einzelnen und die Gesellschaft wurde die schulische Ausbildung für möglichst alle Gesellschaftsmitglieder notwendig. In der heute entstehenden Informationsgesellschaft mit ihrer Informationsflut ist es für die einzelnen Menschen ohne einschlägige Kenntnisse und Fähigkeiten nicht möglich, das für sie wichtige Wissen zielgerichtet zu finden. Dies wird im bestehenden Bildungssystem noch nicht hinreichend berücksichtigt, wodurch das System immer stärker an seine Grenzen stösst. Um die Informationskultur zu schaffen, braucht die Informationsgesellschaft eine neue Bildungsinitiative. Das einfache Aneinanderreihen von Informationen in Form von Bildern und Schrift reicht oft nicht aus, Sachverhalte zu verstehen. Es müssen bereits bewährte Regeln auf allen Stufen des Bildungswesens eingeführt werden, wie Informationen sinnvoll geordnet und strukturiert werden. Erfahrungen aus der Informatik zeigen, wie man komplexe Informationen in einfacher verstehbare Einheiten zerlegen kann, wie man gleiche oder ähnliche Informationen zu übergeordneten Begriffen zusammenfasst und letztlich, wie man Informationen für unterschiedliche Anwendungen umformen muss. Diese Regeln bilden die Grundlage für das richtige Umgehen mit Informationen, auch wenn heute noch viele Autoren ihre Informationen chaotisch ins Internet einbringen. Neben der Strukturierung der Information ist eine, den menschlichen Wahrnehmungsmöglichkeiten unter Einsatz der Methoden der Informatik besser angepasste Präsentation der Information eine zentrale Aufgabe. Dies ist eine Aufgabe, die auch ohne elektronische Datenverarbeitung angesichts des rasanten Wachstums der weltweit erzeugten Informationen gelöst werden muss. Daher muss die technikorientierte Information in eine nutzungsorientierte Information für den Menschen umgeformt werden. Die Handhabung technischer Lösungen hat sich am Menschen und nicht an der Technik zu orientieren. Hierzu sind bei der Entwicklung der Mensch-RechnerSchnittstelle, auch Benutzungsoberfläche genannt, die Prinzipien der Selbsterklärbarkeit und fehlertolerierendes Verhalten zu beachten. Zeichnungen, Bilder – bewegt und unbewegt –, Schrift und Sprache, Geräusche und Musik… sind in geeigneter Form zu verwenden. Nicht das Werkzeug (Software oder Hardware) ist entscheidend, sondern die zu lösende Aufgabe. Ein schwerwiegender Missstand liegt häufig darin, dass der Programmierer und sein Programm im Vordergrund stehen und nicht zuerst die sorgfältige Aufgabenanalyse. “Wer als Werkzeug nur den Hammer kennt, für den besteht die ganze Welt aus Nägeln.” Da die Bildungsinhalte immer elementarer Bestandteil jeder Kultur sind, kann nicht eine Vereinheitlichung der Inhalte Ziel der Bildungsinitiative sein. Vielmehr muss der Zugang zu regionalen, nationalen und auch ethischen Kulturinhalten auf der Grundhaltung einer einfühlenden Toleranz gelehrt und gelernt werden. Allerdings ist es mehr denn je notwendig, dass jede Kultur Offenheit im Umgang mit der anderen sucht und sich nicht in ihrer Tradition allein abkapselt. Der weltweit gleichzeitige Zugang für jedermann zu Informationen, auch über Ethik und Religion, wird diese Offenheit ermöglichen, ohne eigene Wertvorstellungen aufgeben zu müssen. Neben der geistigen Auseinandersetzung mit nahezu unbeschränkten Informationen als einem Schwerpunkt der Bildungsinitiative steht der eigene Lernprozess, das Üben neuer Techniken bis zur Beherrschung der neuen Werkzeuge gleichbedeutend als Aufgabe vor uns. Hier muss Didaktik und Pädagogik Motivation zum Selbstlernen durch Einsicht und Anreiz schaffen: die zentrale Aufgabe für die Lehrenden. Die bildungsgemässe Vorbereitung der Bevölkerung auf die zu erwartenden Veränderungen der Informationsbereitstellung, -verteilung und –nutzung muss schon im vorschulischen Bereich begin- nen, im vorberuflichen Schulbereich – dem klassischen – intensiv betrieben, in der beruflichen Ausund Weiterbildung fortgesetzt werden und darüber hinaus Eingang in den allgemeinen Bildungsbereich finden. Lebenslanges Lernen wird wichtiger denn je. Die wissenschaftliche Aufbereitung dieser Zielvorstellungen durch entsprechende Didaktik ist zwingend notwendig. Dabei geht es nicht nur um die Einführung oder den Ausbau eines Schulfaches Informatik, sondern vor allem darum, dass Ansätze und Methoden der Informatik in möglichst viele Fächer eingearbeitet werden. Eine detaillierte Diskussion über Beiträge der Informatik zu den Lehrinhalten auf den unterschiedlichen schulischen Stufen findet sich in [GkI 97]. Literatur [GkI 95] Abeln, O.; Geidel, H.; Glatthaar, W.; De Kemp, A.; Piccolo, U.; Polke, M.; Rampacher, H.; Rienhoff, O.; Risak, V.; Ruppenthal, N.; Schanz, V.; Schüßler, H.: Informationskultur für die Informationsgesellschaft. Gesprächskreis Informatik, Selbstverlag, 1995. [GkI 97] Köpcke, W.; Leonhard, J.-F.; Loeper, A.; Nerlich, H.; Piccolo, U.; Polke, M.; Rampacher, H.; Risak, V.; Ruppenthal, N.; Schanz, V.; Schüßler, H.; Stucky, W.; Thoma, H.: Informationskultur für die Informationsgesellschaft durch Bildungsinitiative Neue Medien. Gesprächskreis Informatik, Selbstverlag, 1997. Die Schriften des Gesprächskreises Informatik können beim Sekretariat der SI bestellt werden. Weiterbildung NDIT/FPIT 1997/1998 Formation postgrade NDIT/FPIT 1997/98 Das neue Weiterbildungsprogramm für ETH- und HTL-Ingenieure in Informatik und Telekommunikation ist erhältlich. Es bietet eine Auswahl von ca. 100 Modulen zu 6 Tagen in verschiedenen Gebieten in der ganzen Schweiz an. Unter den Neuigkeiten gibt es mehrere Module über Java sowie eine virtuelle Klasse über ATM, wobei die Studenten per Videokonferenz im Kontakt bleiben. Le nouveau programme de formation postgrade pour ingénieurs ETS et EPF en informatique et télécommunications NDIT/FPIT offre un choix d’une centaine de modules de six jours dans différents domaines dans toute la Suisse, dont plusieurs modules sur Java ainsi que la possibilité de suivre une classe virtuelle sur les réseaux numériques à large bande (ATM), les étudiants pouvant communiquer par vidéoconférence. Auskunft / Renseignements: URL: http://www.ndit.ch, Tel. 021 626 15 01, e-mail fpit-offi[email protected]. INFORMATIK • INFORMATIQUE 4/1997 45 Mosaic Buchbesprechungen • Notes de lecture Book Reviews Spaniol, Otto; Linnhoff-Popien, Claudia; Meyer, Bernd (Eds.) Trends in Distributed Systems: CORBA and Beyond International Workshop TreDS ‘96 Aachen, Germany, Oct. 1–2, 1996; Proceedings. 1996, 289 pp. Softcover CHF 55.–. Springer-Verlag. ISBN 3-540-61842-2 Cet ouvrage réunit les articles présentés à Aachen en octobre 1996 à l’occasion du Congrès organisé par l’Université de technologie (TU) d’Aachen en collaboration avec la Commission Européenne, de la DGIII/F et la Gesellschaft für Informatik (GI). CORBA, Common Object Request Broker Architecture, l’architecture résultant du travail de l’Object Management Group (OMG), s’est appliqué depuis des années dans le développement d’un interface standard orientéobject. Le groupe de travail a privilégié les aspects de la réutilisation des composants logiciels, de la portabilité et de l’intégration du software propriétaire. Aujourd’hui, l’architecture CORBA est complétée par plusieurs produits provenant de fournisseurs différents. La rencontre d’Aachen a réuni des entreprises et des représentants du monde universitaire et même des utilisateurs en train de développer des nouvelles techniques, idées et outils; pour cette raison le titre est CORBA and beyond. À coté des travaux qui abordent le problème de quelques aspects particuliers (comme la réutilisation, l’hérédité et surtout l’interaction) de l’architecture CORBA, ce sont les descriptions d’applications réalisées dans un environnement CORBA qui retiendront particulièrement l’intérêt du lecteur. Parmi les articles de grand intérêt, il y a celui qui traite de la construction d’une base de données fédérée dans un système sa- nitaire et celui qui traite du déplacement de données dans un système distribué fondé sur l’architecture CORBA et réalisé par la Dresdner Bank dans le domaine du risque financier. Cette réalisation a montré dans la pratique une amélioration significative des performances. Parmi les auteurs, la présence du corps universitaire allemand est très marqué avec 9 articles, les Anglais sont représentés par 4 articles et les Italiens et les Français avec 2 chacun. Cela correspond au succès dans le domaine de l’architecture CORBA très apprécie par les Allemands. Le livre compte 290 pages imprimées en photo offset, la qualité de l’impression est nette et les figures sont très lisibles. Marco De Marco [email protected] Dietrich, Ute; Kehrer, Bernd; Vatterott, Gerhard (Hrsg.) CA-Integration in theorie und Praxis. Aktuelle Konzepte für Integrations- und Kommunikationstechnologien im CAD-Umfeld 1955. 153 Abb. 347 Seiten, brosch. CHF 85.50. Springer-Verlag, ISBN 3-540-59444-2 Die Sammlung der in diesem Buch enthaltenen Vorträge richtet sich an Spezialisten der Informationsverarbeitung im CAx-Feld mit Schwerpunkt CAD. Die Vorträge wurden anlässlich eines im Frühjahr 1995 in Rostock gehaltenen Workshops präsentiert und erweisen sich als ideale Mischung von theoretischen und praktischen Beiträgen. Aus diesem Grund sprechen die teils englisch teils deutsch zusammengefassten Arbeiten und Erkenntnisse den Leser in unterschiedlichem Masse an. Ebenfalls, wie in Konferenzbänden oft der Fall, sind die Artikel von unterschiedlicher Qualität. Nichts- 46 INFORMATIK • INFORMATIQUE 4/1997 destotrotz sind die Texte für den Fachmann interessant und zeigen die Entwicklungsrichtung zukünftiger Systeme klar auf. So ist die Komplexitätszunahme der Systeme von heute und morgen ein wiederkehrendes Thema. Dass dabei internationale Standards und Normen an Bedeutung gewinnen ist wohl folgerichtig. Daher sind die häufigen Verweise auf den Modellierkern ACIS wenig erstaunlich. Schon eher überraschend ist die grosse Zahl an Projekten, die in der einen oder anderen Form den erst Ende 1994 erschienenen Standard STEP (ISO 10303, Standard for the Exchange of Product Model Data) verwenden. Zusammenfassend lässt sich sagen, dass das Buch dem erfahrenen Informatikbeauftragten im CAD Umfeld gute Einstiegspunkte in aktuelle Projekte und Hinweise auf zukünftige Entwicklungen, aber auch Erkenntnisse aus dem Einsatz erwähnter Standards zu vermitteln vermag. Thomas Bühlmann Peter A. Gloor Elements of Hypermedia Design. Techniques for Navigation and Visualization in Cyberspace.1996. 400 pages, Hardcover CHF 74.00. Birkhäuser, ISBN 3-7643-3911-X Dass hinter einem guten Hypertext-Dokument mehr steht als hinter einem Papierdokument, das einfach mit der Textverarbeitung im HTML-Format abgespeichert wurde, ist heute allgemein anerkannt. Doch Prinzipien und Hilfsmittel zum Erzeugen von einfach zugänglichen Hypertexten sind noch wenig verbreitet. Hier setzt das Buch von Peter Gloor an. Nach einer kurzen Vorstellung von WWW folgt im ersten Teil des Buches gleich sein Hauptbeitrag: sieben Design-Konzepte zum Navigieren im Cyberspace. Dies sind verschiedene Methoden und Prinzipien, mit denen die Nodes eines Hyperdokuments zum Nutzen des Lesers strukturiert, verbunden und organisiert werden können. Neben den schon per Definition vorhandenen Links zählen dazu Vorrichtungen zum Suchen, Mechanismen zum Sequentialisieren wie in geführten Präsentationen, die Darstellung der Hierarchie analog dem Inhaltsverzeichnis und das Ausnutzen von Ähnlichkeit, wie z.B. im Index eines Buches. Als orthogonal dazu werden die letzten zwei Methoden präsentiert: graphische Maps zur Visualisierung und dynamische Agenten zur Benutzerführung mit komplexeren Strukturen. Jede Methode wird mit verschiedenen Beispielsystemen illustriert, so z.B. die MappingTechnik mit Cone Trees und Perspective Walls, die am XEROX PARC entwickelt wurden. Die meisten vorgestellten Systeme stammen aus der HCI-Forschung (Human Computer Interaction). Im Rest des Buches werden ausführlicher einige konkrete Projekte zur Implementation solcher Hilfsmittel beschrieben, an denen der Autor mitgearbeitet hat. So z.B. Cybermap, ein Programm zum automatisierten Erzeugen einer graphischen Übersicht eines Hypertext-Dokuments aufgrund einer inhaltlichen Analyse und unter Berücksichtigung der Vorlieben und Gewohnheiten des Benutzers. In mehreren Kapiteln werden ferner Visualisierungstechniken vorgestellt, die im Projekt Animated Algorithms entwikkelt wurden, einer interaktiven animierten Hypertextversion des klassischen Textbuchs Introduction to Algorithms von Cormen, Leiserson und Rivest. Das Buch von Peter Gloor kann und will seine akademischen Wurzeln nicht verstecken und präsentiert deshalb keine Hilfsmittel für den durchschnittlichen Webdesigner. Doch jeder Praktiker findet darin einen guten Einblick in die aktuelle Forschung und die modernsten Werkzeuge, deren Prinzipien er morgen schon wird anwenden können. Christian Cachin Mosaic Die Fachgruppe Informatik an der RWTH Aachen und die euregionale Industrie freuen sich als Ausrichter der Informatik ‘97 – der 27. Jahrestagung der GesellInformatik und Veränderungen schaft für Informatik – auf Ihre Symposium anlässlich des 60. Geburtstags von Prof. C.A. Zehnder am 30. Oktober 1997 im Auditorium Maximum, Rämistrasse 101, ETH Zürich Teilnahme! Einladungen • Invitations Dr. M. Reimer: Auswirkungen Programm von EDIFACT und Electronic 14.15 Prof. Dr. W. Gander: Commerce auf die internationaBegrüssung le Versicherungswirtschaft Prof. Dr. J. Nievergelt: Dr. B. Thurnherr: Impulse von Konstanten und steter Wandel in und für Informatiker beim der Informatik Umgang mit Veränderungen Dr. R. Marti: Theorie und Praxis Prof. Dr. N. Wirth: Informatik – konträr oder komplementär? zwischen Wissenschaft und Dr. G. Furrer: Interaktivität Kommerz im Wandel: Asymmetrie der 17.15 Prof. Dr. K. Bauknecht: Dialogpartner als Leitgedanke Würdigung des Wirkens von Dr. A. Meier: Zum Umgang mit Prof. Dr. C.A. Zehnder Informatik-Altlasten Die Teilnahme ist kostenlos. 15.30 Pause 16.00 Dr. J. Rebsamen: Wechsel- Eine Anmeldung ist nicht erforwirkungen zwischen Geschäfts- derlich. und Informatikstrategie Informatik ‘97 24.–26. September 1997, Aachen Die Informatik ‘97 ist Deutschlands zentrales Forum der Begegnung für Informatik-Fachkräfte, Studierende, Anwender und Entscheidungsträger in Wissenschaft, Wirtschaft und Politik. Kompakte Information und intensive Diskussion in vier Themenfeldern sollen die Rolle der Informatik als Innovationsmotor im deutschsprachigen Raum stärken: • Transparenz in der Spitzenforschung: 12 Sonderforschungsbereiche und 6 Schwerpunktprogramme der Deutschen Forschungsgemeinschaft stellen erstmals in einer gemeinsamen Vortragsreihe ihre Visionen, Ergebnisse und Transferleistungen vor. • Innovationsgrundlage Bildung und Forschung: strikt begutachtete Forschungsbeiträge mit hohem Innovationspotential und Konzepte zur Informatikausbildung, vom Schulunterricht bis zur lebenslangen Weiterbildung, unter Nutzung neuer Medien. • Industrielle Innovation und Technologietransfer: Erfahrungen mit Innovationsoffensiven, Unternehmensgründungen, verbesserten Produkteinführungsstrategien in Grossunternehmen • Das Beispiel Euregio Aachen: Forum Informatik und Regionaler Industrieklub Informatik als Beispiele interdisziplinärer und europäisch ausgerichteter Innovationsstrategien, dargestellt in Vorträgen, Instituts- und Firmenbesichtigungen. Die Innovationsthematik wird eingeführt durch Hauptvorträge aus Wirtschaft, Wissenschaft und Politik, die mit Rücksicht auf die Zeitknappheit von Führungskräften an einem Tag konzentriert werden. Hochrangig besetzte Podiumsdiskussionen zu den Themen Bildung und Arbeitsmarkt dienen der Einordnung der Einzelbeiträge. Tutorien und Workshops bieten Möglichkeiten zur Vertiefung der angesprochenen Themen. Studierende können zu einem besonders günstigen Beitrag an der Tagung teilnehmen. Ihnen werden ebenso wie Doktoranden der Graduiertenkollegs und der Wirtschaftsinformatik spezielle Workshops angeboten. Prof. Dr. M. Jarke, RWTH Aachen, Dr. K. Pasedach, Philips GmbH, Tagungsleitung Informatik 97 Prof. Dr. W. Stucky, Präsident der GI. Information and Communication Systems: State of the Art, Synergy and Future Directions Latsis Symposium 1997 ETH Zurich, September 22–23, 1997 Competence Center Information and Communication Systems The premise for the 1997 Latsis Symposium is that future technological advances will be driven by the synergy between communication and information systems. Concepts such as Internet, Intranet, World Wide Web, electronic commerce, clusters of workstations, or network computers represent both challenging frameworks and new opportunities for future information and communication systems. To face the challenges and take advantage of the opportunities, the Symposium will establish a dialogue between the two areas, a dialogue that will help to create the appropriate scenario for technological and social innovation. The Symposium will bring together practitioners, researchers, and policy makers to survey the current state of the art, discuss recent developments in information and communication systems, and provide a detailed analysis of future research directions in order to establish the research and development agenda for the coming years. The Symposium, sponsored by the Latsis Foundation, is organized by the Competence Centre Information and Communication Systems (CCIC), a centre established by the Institutes of Information Systems and Communication Networks of ETH Zurich. For more information visit <http://www.ccic.ethz.ch> Participation fee Fr. 100.– Uwe Röhm <[email protected]> International conference on Neural Networks ICANN’97 Lausanne, 8–10 October 1997, Tutorials 7 October 1997 Chairmen: W. Gerstner, A Germond, M. Hasler, J.D. Nicoud. Annual high-level conference of the European Neural network Society, sponsored by the Latsis Foundation and the FNRS/SNF. • 4 Tutorials on Oct. 7, • 11 keynote speakers within plenary sessions, • 104 papers with a 20min presentation in 4 parallel sessions, • 82 posters with a 3min spotlight presentation Ask for the program booklet and/or refer to the Web pages icann97@epfl.ch, fax 021 693 5656, http://www.epfl.ch/icann97. HIM’97 Hypertext – Information Retrieval – Multimedia 30 September – 2 October 1997 Dortmund Organised by Universität Dortmund together with Gesellschaft für Informatik (GI), Österreichische Computer Gesellschaft (OCG), Schweizer Informatiker Gesellschaft (SI) Visit <http://ls1-www.informatik.uni-dortmund.de/HIM97> for timely information. INFORMATIK • INFORMATIQUE 4/1997 47 Schweizerischer Verband der Informatikorganisationen • Fédération suisse des organisations d'informatique SVI/FSI Präsident/Président: Prof. Carl August Zehnder Schweizerischer Verband der Informatikorganisationen Fédération suisse des organisations d’informatique Federazione svizzera delle organisationi d’informatica Uniun svizra dallas organisaziuns d’informatica Swiss Federation of Information Processing Societies IMIA, the International Medical Informatics Association Jean-Raoul Scherrer Introduction Already in 1959, in its earliest stage, a proposal was sent to the United Nations, under the auspices of UNESCO, promoting the first IFIP conference. The use of computers in medicine was mentioned as a necessary part of its most progressive research [1]. After this the recognised value of information processing to the medical profession led to the formation of a Technical Committee of its own: TC-4 Medicine, in 1967. This committee was concerned with three main areas of effort: • Identification and detailed investigation of the problems that arise in medical data processing, e.g. computer-assisted diagnostic methods, resource allocation in hospitals, formulation and testing of mathematical models in medicine. • Means of obtaining information concerning medical data processing within member countries. • Extension of medical, paramedical and administrative staff’s education in the field of data processing. This field was assigned to the first working group (WG 4.1) devoted to Education of Medical and Paramedical Personnel. This WG was chaired by T. Husek (1968– 70) and worked closely with IFIP TC-3. The whole TC-4 held numerous working conferences and already at this stage produced many valu- able publications. The Chairman and founder was François Grémy (France) in charge from 1967 up to 1973. Then in 1979, TC-4 evolved into an IFIP Special Interest Group called the “International Medical Informatics Association (IMIA)” which included national societies not affiliated with IFIP, reflecting the fact that the interaction between computers and medicine is organised differently in different countries [2]. In 1989 the status of IMIA was transformed into a politically independent international organization with affiliation to IFIP. IMIA serves specific needs in the application of information science and information technology in the fields of health care and biomedical research. This field is also referred to as Medical or Health Informatics. IMIA has an official relationship with the World Health Organization (WHO-NGO). The basic aims of IMIA are: the promotion of informatics in medicine, health care and biomedical research, the advancement of international cooperation, the stimulation of research, development, and routine applications, the dissemination and exchange of information, the representation of the Health and Medical Informatics field in the World Health Organization and any other relevant professional or governmental organization. 48 INFORMATIK • INFORMATIQUE 4/1997 IMIA Profile and Mission IMIA has 40 National Members, as well as Institutional Members, Affiliate Members and Honorary Fellows. Any one society, or group of societies of an appropriate body which is representative of the Medical Informatics activities within that country, may become the National Member representing the country. National IMIA member societies can organize into Regional Groups. Universities, medical centres, professional organisations as well as vendors may become Institutional Members. Professional international organizations can become Affiliate Members. Societies or representatives from countries which are not Members of IMIA may be accepted as Observers for a limited period. Apart from this there are 18 Corresponding Members. The Association is governed by a General Assembly (GA) that meets annually and consists of one representative from each IMIA Member country, Honorary Fellows and a representative of IFIP and WHO. Only National Members have full voting rights. The General Assembly elects the IMIA Board. The IMIA Executive Board Since 1993, The IMIA Executive Board’s scope of actions has been extended by five new services, each one headed by an Executive Vice-President (VP): • A VP for MEDINFO Congresses • A VP for Services: particularly the IMIA Publication’s Office • A VP for Membership nominations SVI/FSI Postfach 71, 8037 Zürich <[email protected]> <http://www.svifsi.ch/> • A VP for Special Interest Groups (SIG) Working Groups (WG) • A VP for Special Activities. The VPs give added vigour and vitality to the Board to pursue IMIA’s missions. IMIA organises the tri-annual MEDINFO, the World Congress on Medical Informatics. Former MEDINFO conferences were held on Stockholm (1974), Toronto (1977), Tokyo (1980), Amsterdam (1983), Washington (1986), Beijing/Singapore (1989), Geneva (1992) and Vancouver (1995). The 1998 MEDINFO will be held in Seoul / Korea (1998). IMIA has established a number of Working Groups and is supporting and encouraging Working Conferences in the state-of-the art and on timely medical or health informatics issues. Meetings on medical workstations, biosignal interpretation, computer applications in developing countries and organizational and management issues are planned for the next three years. Working Groups and Special Interest Groups The Working Groups and Special Interest Groups, with their corresponding chairpersons, are the following: WG1: Information Science and Medical Education (Reinhold Haux, Germany) WG 4: Data protection in Health Information Systems (Albert R. Bakker, Netherlands) WG 5: Primary Health Care Informatics (Glyn M. Hayes, UK) WG 6: Classification, Language and Concept Representation (Christopher G. Chute, USA) Schweizerischer Verband der Informatikorganisationen • Fédération suisse des organisations d'informatique WG 7: Biosignal and Pattern Interpretation (Jan H. Van Bemmel, Netherlands) WG 9: Health Informatics and Development (Nora Oliveri, Argentina) •WG 10: Hospital Information Systems (Paul Clayton, USA) WG 11: Dental Informatics (Eva Piehslinger / John Eisner, Austria / USA) WG 13: Organizational Impact of Medical Informatics (Nancy Lorenzi, USA) WG 15: Technology Assessment and Quality Development in Health Informatics (Elisabeth van Gennip, Netherlands) WG 16: Standards in Health Care Informatics (Georges de Moor, Belgium) WG 17: Computerised Patient Records (Johan van der Lei, Netherlands) WG 18: Telematics in Health (Patrice Degoulet, France) Regional Groups Besides the MEDINFO conferences and the WG activities, particularly their Working Conferences, IMIA also has Regional Group Activities which are also very active. They are: 1.European Federation for Medical Informatics (EFMI, IMIA Europe), President: Prof. JeanRaoul Scherrer 2.Federation of Health Societies in Latin America (IMIA - LAC) President: Armando Rosales Fernandez 3.Asia-Pacific Association for Medical Informatics (APAMI, IMIA Asia Pacific), President: K.C. Lun. 4.African Regional Group / Helina, President: I. Isaacs. IMIA Publications The IMIA Publications Office is located in Rotterdam. The office stimulates the publication of results of Working Conferences in the form of books and increasingly Special Issues of international journals with editorial policy. Since 1992, IMIA also publishes the Annual Yearbook of Medical Informatics [3]. An IMIA Newsletter is published twice a year. Forthcoming Events and further information on IMIA As usual the IMIA main event is always MEDINFO that has its full paper Proceedings being indexed by the National Library of Medicine (NLM) in Washington, DC. The next MEDINFO to come is MEDINFO 98, 9th World Congress on Medical Informatics: August 18–22, 1998, Seoul, Korea. For further information on IMIA contact the IMIA Secretary: Bjarte G. Solheim, Red Cross & National Hospital, Holbergstr. 1, 0166 OSLO 1, Norway. Tel: +47 2 294 3014, Fax: +47 2 294 3025 References [1] Zemanek H. (ed.) : A quarter Century of IFIP. North Holland Publ. Amsterdam (1986), pp 64-5. [2] Zemanek H. op.cit. p.86 [3] Van Bemmel J, McCray A (Eds.). IMIA Yearbook of Medical Informatics 1992 - 1996. Schattauer Publ. (Stuttgart, Germany). XV. IFIP World Computer Congress The Global Information Society on the way to the next millennium 31 August – 4 September 1998, Vienna and Budapest The 15th IFIP World Computer enna and Budapest, well known Congress marks the first time that for their style and for being culturan IFIP World Computer Con- al centres of the Central European gress will be jointly organised by region. They are also centres for the computer societies of two research and development in inCentral European countries: the formation technology. Keeping in mind that informaAustrian Computer Society together with the Hungarian John tion technology is not a technolovon Neumann Computer Society. gy of the past but one of the fuThe event will take place in the ture, the Congress is entitled “The capitals of the host countries – Vi- Global Information Society on the way to the next millennium”, and the major part will cover technical, legal, and social areas important for the Information Society of the future. Congress outline The Congress will consist of seven carefully selected conferences with paper presentations and poster sessions. Programme Committees will be established for each conference, which will be organised in close co-operation with the Technical Committees and Working Groups of IFIP involved in these topics. The conferences will give an excellent outlook of what we can expect in the future: SEC’98 – Security in Information Systems As the annual conference of the Technical Committee 11 SEC’98 covers a wide range of security related topics. It comprises both emphasis in technical as well as commercial security. One of the special targets of the 1998 annual conference will be the security aspects of electronic commerce in the Global Information Infrastructure. ICCHP’98 – 6th International Conference on Computers Helping People with Special Needs This conference is concerned with all aspects of the use of computers by people with disabilities. That includes both the adaptation of the humancomputer interface to enable the person to access the computer for everyday use and the development of computer-based aids to reduce the handicapping effect of the disability. KnowRight’98 – Second International Conference on Intellectual Property Rights This conference has an interdisciplinary and integrative approach. It covers all aspects of the protection of intellectual property rights for specialised information and knowledge and is a forum for discussion between computer experts, jurists and scientists. Fundamentals – Foundations of Computer Science The talks will demonstrate the intellectual beauty as well as the practical relevance of various aspects of theoretical computer science, e.g. algorithms, logic, and cryptography. IT & KNOWS – Information Technology and Knowledge Systems This conference will provide a forum for discussion of the role of explicit domain models in the development of software of all kinds. There will be special emphasis on the application of methodologies for domain modelling and the use of knowledge acquisition and knowledge representation techniques in general software engineering. Teleteaching’98 – Distance Learning, Training, and Education The conference will investigate the pedagogical use of communication technologies in the classroom and in open, flexible and distance learning. Special focus will be on the use of internet services of all kinds, videoconferencing and multimedia. Telecooperation – The Global Office, Teleworking and Communication Tools Telecooperation will drastically change work in many aspect. The conference will cover topics with relevance to the field as, for example: technological infrastructure, systems for cooperation, innovative services, organisational forms, group decision making, collaborative interaction, legal framework. Congress venues The 15th IFIP World Computer Congress will start in Vienna and end in Budapest. The 256 km separating the capital cities of Austria and Hungary are no distance in the age of fast transport services. Transfer for all participants will be provided. As the river Danube connects the two cities geographically, the voyage from Vienna to Budapest will be provided by ships. In addition, transfer by train or bus is available. Further Information All information, news and links to tourist information are available via World-Wide Web: http:// www.ocg.or.at/ifip98 T get more information please use www or contact Österreichische Computer Gesellschaft, Wollzeile 1-3, A-1010 Wien. Phone +43 1 512 02 35, Fax +43 1 512 02 35 9, E-Mail ifi[email protected]. INFORMATIK • INFORMATIQUE 4/1997 49 Schweizerischer Verband der Informatikorganisationen • Fédération suisse des organisations d'informatique Fonds national suisse de la recherche scientifique Davantage de mémoire en moins d’espace Réaliser des mémoires offrant un maximum de capacité dans un minimum d’espace est un objectif que les ingénieurs-informaticiens poursuivent depuis longtemps. Or la miniaturisation des mémoires est susceptible de faire un bond en avant grâce à une technique que des physiciens zurichois développent dans le cadre du programme national de recherche « Nanosciences » (PNR 36) du Fonds national suisse. Les mémoires actuelles à semi-conducteurs ont une capacité de dix mille bits par millimètre carré. Des mémoires de la nouvelle génération pourraient contenir dix mille fois plus de données, donc cent millions de bits, sur la même surface. Grâce à une nouvelle technique, des chercheurs de l’Institut d’électronique quantique de l’EPF de Zurich sont parvenus à stocker de l’information à une échelle infinitésimale, en l’inscri- être inscrites et effacées autant de fois qu’on veut. La dimension infime des points d’image permettrait une énorme densité de mémoire : un millimètre carré pourrait contenir cent millions de bits. De telles mémoires de nouvelle génération n’appartiennent pas à la science-fiction. Les chercheurs de l’Institut d’électronique quantique estiment avoir poussé leurs travaux assez loin pour que des mémoires ferroélectriques puissent atteindre la maturité commerciale d’ici cinq à dix ans. Ceci pour autant qu’une entreprise s’engage activement à développer leur technologie en vue de son utilisation pratique. vant sur de matériaux ferroélectriques. Des champs électriques minuscules constituent autant de points d’image à la surface de ces matériaux et peuvent être inversés sous l’action d’un champ électrique extérieur. L’outil d’écriture est un microscope à effet de force atomique ; il permet de faire basculer de façon ciblée les point d’image dans une direction ou dans l’autre. Le résultat est une image en clair-obscur sur l’écran d’un ordinateur, par exemple des caractères dont les traits ont en réalité une épaisseur de seulement un demi-millième de millimètre. Le microscope à effet de force atomique, outil d’écriture rapide Maturité commerciale atteinte A l’origine, des physiciens se dans cinq à dix ans Les expériences des physiciens servaient du microscope à effet de de l’EPFZ ouvrent des possibilités force atomique pour observer l’inau développement d’une nouvelle finiment petit. Mais les chergénération de mémoires informa- cheurs zurichois du PNR «Nanostiques : des mémoires ferroélec- ciences » utilisent cet instrument triques. Les données pourraient y 50 INFORMATIK • INFORMATIQUE 4/1997 de haute technologie non seulement pour lire, mais aussi pour écrire. Une pointe électroconductrice extrêmement fine se déplace au-dessus de la surface ferroélectrique, munie à son verso d’une contre-électrode. Une tension continue, positive ou négative, est appliquée entre la pointe et la contre-électrode. Il est ainsi possible de faire basculer les points d’image, dans une direction ou dans l’autre, de façon ciblée. Si l’on explore ensuite l’échantillon ainsi modifié au moyen du même microscope à effet de force atomique, une des orientations des points d’image apparaît en clair sur l’écran, l’autre en sombre. Les points d’image individuels ont un diamètre inférieur à un demimillième de millimètre. La nouvelle technique permet d’inverser leur orientation en moins d’une milliseconde, donc de commuter du clair à l’obscur ou de l’obscur au clair, d’où la possibilité d’une technique d’écriture infinitésimale et ultra-rapide. Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens Schweizer Informatiker Gesellschaft Société Suisse des Informaticiens Società Svizzera degli Informatici Swiss Informaticians Society Präsident • Président: Helmut Schauer Sekretariat • Secrétariat: Schwandenholzstr. 286 8046 Zürich Tel. 01 371 73 42 Fax 01 371 23 00 E-mail: si@ifi.unizh.ch <http://www.svifsi/si/> Einladung zur Generalversammlung 1997 der Schweizer Informatiker Gesellschaft Invitation à l’Assemblée générale 1997 de la Société Suisse des Informaticiens Mittwoch 24. September 1997, 18.00 h Hörsaal 45, Universität Zürich-Irchel, Winterthurerstr. 190 Mercredi 24 septembre 1997, 18 h 00 Salle 45, Université de Zurich-Irchel, Winterthurerstr. 190 Die Generalversammlung findet im Rahmen der ESEC/FSE’97 (http://www.ifi.unizh.ch/congress/esec97.html) statt. L’assemblée générale aura lieu dans le cadre de l’ESEC/FSE (http://www.ifi.unizh.ch/congress/esec97.html). Zwischen 16.00 und 17.30 findet im gleichen Hörsaal eine Podiumsdiskussion zum Thema “Software Engineering – Old Problems, New Problems, and Unsolved Problems” statt, an der unter anderem Barry Boehm, Tom Gilb und David Parnas teilnehmen. SI-Mitglieder haben zu der Diskussion freien Zutritt. Un débat autour du sujet « Software Engineering – Old Problems, New Problems, and Unsolved Problems », à laquelle participeront entre autres Barry Boehm, Tom Gilb et David Parnas aura lieu entre 16.00 et 17.30 heures dans la même salle que l’assemblée générale. Entrée libre pour les membres de la SI. Tagesordnung Ordre du jour 1. Abnahme des Protokolls der Generalversammlung 1996 (siehe INFORMATIK/INFORMATIQUE 6/96) 1. Approbation du procès-verbal de l’Assemblée générale 1996 (c.f. INFORMATIK/INFORMATIQUE 6/96) 2. Jahresbericht des Präsidenten 2. Rapport du Président 3. Abnahme der Rechnung 1996 3. Approbation des comptes 1996 4. Budget 1998 4. Budget 1998 5. Decharge des Vorstandes 5. Décharge du comité exécutif 6. Wahlen 6. Elections 7. Aufnahme der Fachgruppe Java Users Group Switzerland 7. Admission du groupe spécialisé Java Users Group Switzerland 8. Verschiedenes 8. Divers Wahlen / Élections Zwei Mitglieder des Vorstands stehen zur Wiederwahl. Deux membres du comité exécutif sont à réélire. Dr. Isabelle Petoud (seit/depuis 1993) Prof. André-René Probst (depuis 1993) Die folgenden Mitglieder des Vorstands wurden von der Generalversammlung 1996 gewählt und müssen dieses Jahr nicht wiedergewählt werden. Les membres suivants du comité exécutif ont été élus par l’Assemblée générale de 1996 et ne doivent pas être réélus cette année. Prof. Helmut Schauer, Präsident (seit 1992 im Vorstand, Präsident seit 1996 depuis 1992 au comité exécutif, président depuis 1996) Prof. Andrea Back (seit/depuis 1994) Ronald Zürcher Prof. Klaus Dittrich (seit/depuis 1992) (seit/depuis 1996) Prof. Pierre-André Bobillier Vera Haas (seit/depuis 1996) muss als Vertreter der SISR im Dr. Ernst Rothauser SI-Vorstand nicht gewählt (seit/depuis 1986) werden. Prof. Hans-Jörg Scheck ne doit pas être réélu en tant que (seit/depuis 1992) délégué de la SISR au comité Helmut Thoma SI. (seit 1987 im Vorstand, 1992– 96 Präsident depuis 1987 au comité exécutif, président 1992–96) Die SI zählt gegenwärtig Roland Wettstein 1822 Einzelmitglieder und (seit/depuis 1992) 145 Kollektivmitglieder La SI compte actuellement 1822 membres individuels et 145 membres collectifs INFORMATIK • INFORMATIQUE 4/1997 51 Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens Jahresabschluss 1996 / Clôture des comptes 1996 vor Revision / avant révision Bilanz / Bilan Aktiven / Actifs Passiven / Passifs Post SI-Konto SBG Choose-Konto SBG SGAICO Anlagekonto Wertschriften Festgeld SI Darlehen Zeitschrift Verrechnungssteuer Verr.Steuer SGAICO Debitor Mastercard Debitor Ada Debitor Oberon Aufwandübersch. SGAICO Transitorische Aktiven Aufwandüberschuss Bilanzsumme 4’826.38 45’545.80 2’848.90 62’554.80 15’033.50 460’517.40 100’742.10 10’001.00 14’233.60 2’799.45 3’750.00 713.51 1’733.89 20’335.85 13’514.80 6’673.83 Kreditoren Choose Kreditoren DBTA Kreditoren HypEdu Kreditoren I&G Kreditoren SAUG Kreditoren Security Kreditoren SIPar Kreditoren SISE Kreditoren SISR Kreditoren SW Ergonomics Kreditoren SIWork Transitorische Passiven Kapital SI Kapital Ada Kapital Choose Kapital DBTA Kapital HypEdu Kapital I&G Kapital Oberon Kapital SAUG Kapital Security Kapital SGAICO Kapital SIPar Kapital SISE Kapital SW Ergonomics Förderungsfonds 765’824.81 8’747.46 11’111.03 175.11 1’775.06 1’160.01 3’508.53 1’081.96 1’617.45 7’765.00 4’287.69 5’856.95 32’503.60 147’218.58 9’354.27 106’799.51 157’584.64 8’029.88 6’001.06 16’641.96 22’506.97 9’342.24 116’072.34 21’654.23 10’563.36 10’920.62 43’545.30 765’824.81 Erfolgsrechnung / Résultat Aufwand / Dépenses Allg. Vereinsaufwand INFORMATIK CEPIS Steuern, SVI/FSI Ertrag / Recettes 49’370.91 77’773.00 7’246.60 6’255.70 Total allg. Aufwand 140’646.21 Gesamtaufwand 140’646.21 Mitgliederbeiträge Kapital-Wertschriftenertrag 128’062.00 3’210.38 Total allg. Ertrag ao Ertrag (Adressen) Gesamtertrag Aufwandüberschuss 131’272.38 2’700.00 133’972.38 6’673.83 Conference Announcement Sixth European Software Engineering Conference ESEC7FSE 97 Zurich, September 22–25, 1997 We are pleased to invite you to participate in the 1997 joint ESEC/FSE conference on software engineering. ESEC/FSE is the first joint meeting of the European Software Engineering Conference, which has now a ten-year tradition in Europe, and ACM SIGSOFT’s Symposium on the Foundations of Software Engi- neering, which has been running in the United States since 1993. Come to Zurich to share your ideas and results with your academic and industrial colleagues and hear about their experiences. Select from a rich choice of tutorials to hear about the state of the art. Listen to what leading people in the field have to say in the invited talks. Present your own ideas in 52 INFORMATIK • INFORMATIQUE 4/1997 the New Ideas session. Catch the latest research results from the paper presentations. Gaze into the industrial future by watching demonstrations of prototype tools. Participate in intensive one-day workshops on current research topics. And - come together. Make new friends, meet old friends and foster the human relations in our profession. Whatever your interests are, this conference has something to offer you. Register for ESEC/FSE 97 now and plan a rewarding trip. Organized by the ESEC steering committee, Sponsored by: ACM SIGSOFT, CEPIS (Council of European Professional Informatics Societies) and the Swiss Informaticians Society. CHOOSE Special Interest Group on Object-Oriented Systems and Environments Chairman: Dr. Rachid Guerraoui Correspondent: Dr. Laurent Dami http://iamwww.unibe.ch/CHOOSE/ Report on ECOOP’97 Tamar Richner (University of Berne) and Rui Carlos Oliveira (EPFL) This year’s ECOOP conference took place from June 9 to June 13 in Jyvaskyla, in central Finland, and attracted a record number of participants (450 people). The first two days were scheduled with tutorials and workshops, with the last three days devoted to a technical programme of 20 papers, three invited speakers and one panel discussion. Parallel to the technical program were several demo presentations as well as poster sessions. Invited Papers Kristen Nygaard, who pioneered object-oriented languages with his work on Simula, presented his current work on General Object-Oriented Distributed Systems, a project in Norway, introducing the metaphor of the theatre for the organization of a distributed system and drawing a parallel between a performance and a program execution. Gregor Kiczales gave a stimulating presentation of his work on Aspect-Oriented Programming. It addresses the separation of concerns in software design and proposes to carry this separation of concerns on to the program level, so that the program better reflects the design. It makes a distinction between software components, modular units of functionality which address the functional properties (what the software should do), and “emergent entities”, which address non-functional requirements (how the system should do) arising during execution. In aspect-oriented programming functional properties are described by components using a usual programming language, whereas emergent entities (e.g. performance, fault-tolerance) are described by an aspect language. An aspect weaver is then responsible for weaving together the component code with the aspect code to produce a running program. The talk illustrated the approach with a few examples, leaving open some of the technical problems related to the implementation of such aspect languages and aspect weavers. Erich Gamma’s “Going beyond Objects with Design Patterns” served to calm down some of the hype around design patterns, pointing out where design patterns were useful, and where their use was misplaced and raised expectations which were too high. Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens At the conference banquet, Dave Thomas, of Object Technology International, entertained and provoked with his view of the future of object technology, starting with his prediction for the ECOOP 2007 program. Three main themes arose: message-oriented programming will gain in prominence (“the message is the medium”), virtual communities (MUDs) will be used to model business communities, and technological advances, making possible a processor in every object, will spur the development of massively parallel applications. gramming to achieve some of these goals, where aspect-oriented programming seen as a control use of meta-programming- a harnessing of meta-programming to solve specific problems. There is interest in UML and at the same time scepticism about its usefulness: it is just a notation - the tools are still missing. Design patterns also elicit a lot of interest, on different levels. Finding new domain specific patterns, using patterns in the software development process, patterns for documentation, patterns for generating code from design elements. Panel Discussion The majority of the panel participants were from industry. The panellists were asked to address the advantages and disadvantages of object-technology in industry and to compare these to the view shared by the ECOOP community. The basic message was that the advantages which object-technology brings to industry are no longer contested. What is an issue for industry is how object-technology is deployed: the management of the software process and the commitment of senior management is crucial for the success of the projects. The introduction of object-technology in a company presents an opportunity for changing the software management process, but object -technology sells too well, resulting in unrealistic expectation on the part of clients. Products and tools are often immature, and incompatible with legacy systems. Workshops Object-oriented software evolution and re-engineering. The papers presented a range of ideas for representing the code at a useful level of abstraction, strategies for detecting and analysing problems in the code, and also more general issues such as the technical management of development and reengineering efforts. Two discussion groups followed: one concentrating on requirements for reengineering tools and methodology, and the second discussing how dynamic and static information can be extracted from code and combined to raise the level of abstraction, with the goal of representing system architecture. A general consensus was that current tools for re-engineering do not fulfil the needs, and that an organization doing re-engineering must create its own tool, either by investing in internal development or by integrating a variety of commercial tools. There is a lot of work to be done on the use of dynamic information to understand and analyse the code. Architectures are also poorly understood: how to recover an application’s architecture, how do to describe it and reason about its properties. Proceedings of the workshop are available at http://www.fzi.de/ ecoop97ws8/. CORBA: Implementation, use and evaluation. Several papers addressed fault tolerance issues through the proposal of new CORBA services and the integration with existing frameworks. Technical Sessions Let us try to forward a general message from the wealth of papers on a wide variety of topics. Java elicits a lot of interest. There is a lot of work on distributed systems and the problems in modelling them and in accommodating existing software into a distributed system. In general there is the acceptance that supporting evolution is required to accommodate changing requirements and that supporting heterogeneous platforms is essential. There was discussion on the use of metapro- Some presentations discussed the applicability of CORBA on the integration with other standards such as ISO-MMS and TINA. Implementation issues were discussed on different levels of the CORBA specification, and experiences were reported on new ways of using CORBA. The workshop proceedings are available at http:/ /sirac.inrialpes.fr/~bellissa/ wecoop97. Mobile Object Systems. We distinguish three main issues: (new) domains where the mobile object philosophy conceptually allow or improve the solutions, domains where mobile code take advantage of the trade-off between mobile code versus remote invocation calls, and domains or problems where mobile object techniques raise particular problems. Within this structuring, a couple of papers introduced novel applications which take clear advantage of mobile objects. A paper of the TACOMA group gave precise figures of the performance of their system. Other papers reported on interesting experiments, and addressed the difficulties and eventual solutions for some particular problems found when code is moved around. The workshop proceedings are available at http:/ /cuiwww.unige.ch/~ecoopws. DBTA Datenbanken, Theorie und Anwendung Bases de données, théorie et application Chairman: Prof. Stefano Spaccapietra Correspondent: Prof. Moira Norrie http://www.ifi.unizh.ch/groups/dbtg/DBTA/ Bericht über den Workshop Migration und Koexistenz von Paradigmen in der Welt der Datenbanken Michel Glaubauf Abstract: The subject of the 1996 DBTA-Workshop was migration and coexistence in the Database World. Different approaches were shown: Prof. Zehnder advocated federated databases to replace step by step the aging integrated systems and support new applications in a flexible way. Dirk Jonscher pointed out the problem of bringing together data from different applications: His solution is an integration without data migration in an object-oriented integration framework. Walter Schnider reported of a migration of an IMS-Application to DB2 in a Swiss Bank. An approach of a step-by-step integration with data propagation between the two systems was chosen and works now after some initial problems, thanks to highly motivated staff and loose time restrictions. Stefan Scherrer talked about his migration experience in a large insurance company: An OODBMS has been used to add functionality and flexibility to a DB2-System. The success of this project (in contrast to another project that was aborted) also relied on highly motivated staff and on the clear and immediate benefit from the project. Andreas Geppert finally presented the steps to a tool supporting the migration process from an RDBMS to an OODBMS: This tool is highly needed by the industry, and though some parts are quite readily definable, other parts of this transformation process will re- INFORMATIK • INFORMATIQUE 4/1997 53 Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens main complex conceptional work mente), die jetzt für neue Applikationen Daten austauschen müssen. not automatically performable. Statt der Migration (Konversion Am 21. Oktober 1996 fand in der Daten, Nachteil: ReimpleZürich besagter DBTA-Workshop mentierung aller Anwendungen), statt, der eine Diskussion angeris- der Definition von Austauschsen hat, die sowohl die Welt der formaten (Nachteile: RessourcenKonsistenz-/ Forschung als auch die Praxis be- verschwendung, wegt und auch in Zukunft für Aktualitätsprobleme u.a.) und DBTA ein Thema sein wird. Trotz Datenkatalogen (Nachteile: keine des zeitlichen Abstands hier eine Verteilungstransparenz, Schnittkleine Zusammenfassung dieses stellenproblem u.a.) schlägt er die logische Integration in föderierten interessanten Workshops. Prof. Dr. C. A. Zehnder (ETH Datenbanksystemen vor: Man tut Zürich) eröffnete mit dem Thema so, als ob man eine physische Mi“Migration von integrierten zu gration machte, aber die Daten föderierten Systemen”. Eine bleiben real in den lokalen DatenArbeitsgruppe an seinem Institut haltungssystemen, wodurch die beschäftigt sich mit dem Thema lokalen Applikationen nicht beRe-engineering, das den Studen- troffen sind. Auch hier stehen ten Probleme bereitet. Moderne, mehrere Methoden zur Veranwendernahe, flexible Sonderan- fügung: Schemaintegration, opewendungen brauchen eine stabile rationale Integration oder – am Basis für die flexible Datennut- flexibelsten – Integrations-Framezung. Aufgabe des Rechenzen- works. Das Projekt FRIEND1, im trums ist es, diese langlebige Da- Kern eine Zusammenarbeit von tenbasis zur Verfügung zu stellen INFO-B, IFI und GIUZ wird Pro– und zwar sowohl den aufwendi- totypen dieses Integrationsansatgen Routineanwendungen wie zes erarbeiten mit dem Ziel der auch den Sonderanwendungen. Vermarktung. Dies ist in den heute noch laufenDer Nachmittag begann mit den integrierten Systemen mit zwei Referaten aus der unmitteleinheitlicher Datenbasis nicht baren wirtschaftlichen Praxis. Zumöglich. Ziel muss es daher sein, nächst berichtete Walter Schniein koordiniertes föderatives Sy- der (Systor AG) von einem seit stem zu erstellen, d.h. ein System, 1993 laufenden Migrationsprojekt in dem ein unternehmensweites beim Bankverein. Eine IMS-ApDatenschema entworfen und im- plikation (die Titelbuchhaltung – plementiert wird, das auf zusam- 17 IMS-Segmenttypen aus dem menpassende Teilschemata, die Jahr 1982, 100 Mio Datensätze...) von Applikationen unabhängig wird auf DB2 migriert. Anstoss genutzt werden können, aufgeteilt für die Migration war u.a. ein “triwerden kann. Eine Ablösung der viales” Problem: die IMS-Felder bestehenden Systeme ist bekann- wurden zu klein für Yen-Beträge. termassen problematisch. Es emp- Die ersten Probleme tauchten fiehlt sich, jeweils Teilbereiche beim Ermitteln des Datenmodells aus dem integrierten System neu auf: Welche Felder werden noch zu implementieren und mit dem benötigt? Was ist ihre Bedeutung? bestehenden, reduzierten, alten Ihr Inhalt? Welche Anforderungen integrierten System zu koppeln. müssen noch (zusätzlich) abgeDirk Jonscher (Uni Zürich) deckt werden (eine unendliche Lisprach zum Thema “Aufbau hete- ste)? Das Mapping der IMS-Darogener Datenbank-Föderationen ten auf die DB2-Datenstruktur mittels operationaler Integration”. war wegen der unterschiedlichen Das Problem, das er behandelte, Datenmodelle problematisch: verwar gewissermassen das entge- schiedene Strukturen in einem gengesetzte, verglichen mit Prof. Segmenttyp, Homonyme/SynZehnder: Historisch sind in den onyme, Wiederholungsgruppen, letzten Jahren verschiedene Datenhaltungssysteme gewachsen 1. Siehe INFORMATIK/INFORMA(z.B. Dateisysteme, DatenbanksyTIQUE 5/1997 (erscheint Oktosteme, CAD-Systeme, Textdokuber 1997) 54 INFORMATIK • INFORMATIQUE 4/1997 Datenfelder mit verschiedenen Bedeutungen, unterschiedliche Datentypen. Die Datenkommunikation zwischen IMS und DB2 für die Übergangsphase wird mit dem Produkt DPROR-NR ermöglicht: in einem ersten Schritt werden die Daten von IMS zu DB2 propagiert, in einer zweiten Phase werden Daten in beide Richtungen propagiert (mit gewissen Konsistenzschwierigkeiten), in der letzten Phase ist das DB2-System steuernd und propagiert die Daten zum IMS-System. Eine schwierige Aufgabe war auch der Data Cleanup: ungültige Daten, Bereinigung numerischer Felder, Fremdschlüssel, Dateninkonsistenzen – die Datenqualität war mangelhaft, dadurch entstand ein hoher RZ-Aufwand. Bei der Einführung gab es noch das Problem des Zeitfensters für die Einführung: Nach erfolgreichem Piloten wurde zu Pfingsten 1996 der erste Load durchgeführt. Wegen Performanceproblemen und der hohen Komplexität des Gesamtsystems sowie dem unterschätzten Speicherbedarf musste nach einer Woche die Propagierung abgestellt werden. Seit September, mit der Lieferung einer neuen DB2Version, läuft das System aber. Voraussetzung für das Gelingen des Projekts waren klare Projektziele, qualifizierte und motivierte Mitarbeiter, hervorragende Kenntnisse des Ist-Systems, Management-Unterstützung und: kein Termindruck! Stefan Scherrer (CSS Luzern) berichtete in seinem Referat “Erfolg = Migration * Coexistenz2” von einer Migration von einer DB2-Umgebung in Richtung einer OO-Umgebung. Anstoss war hier ein gescheitertes Reengineering-Projekt im Jahr 1992, die zur Befassung mit neuen Technologien geführt hat. Die alternden Applikationen sind nicht mehr wartbar und müssen durch Neuentwicklungen abgelöst werden, die auch im härteren Wettbewerb die Krankenkasse besser rüsten. Eine eigentliche Strategie zur Ablösung aller Systeme besteht nicht: Es ist durchaus vorgesehen, stabile ältere Systeme mit den neuentwickelten laufen zu lassen. Bereits auf die Orbit 94 hin wurde ein Pilotprojekt mit OODBMS erfolgreich durchgeführt. Eine Evaluation führte zur Entscheidung für das Produkt O2 und zur Indentifikation von 2 Projekten: ProductWorkbench (PWB) und SHARK. Bei PWB geht es um die schnelle Entwicklung und Simulation von neuen Versicherungsprodukten. Dieses Projekt stellte sich aber als zu ambitiös heraus: Es fehlte eine Strategie für das bestehende System, das operationale System wäre sehr stark betroffen gewesen, fachliche Ansprechpartner waren schwer zu finden. Das Projekt wurde sistiert. Bei SHARK war das Ziel, Rechnungen automatisiert zu verarbeiten, bessere Statistiken zu liefern, die Qualität der Verarbeitung zu verbessern und fachlich interessantere Arbeitsplätze zu schaffen. Es sollten ausgereifte Host-Module weiterverwendet werden, kein redundanter Code geschrieben werden und die produktiven ISModule nicht angepasst werden. Technisch wurde dieses Projekt durch eine schmale, funktionale, service-orientierte Schnittstelle zu bestehenden IS begünstigt. Fachlich wurde es von einer visionären Fachabteilung mit sehr hoher Motivation getragen. Die Funktionalität war komplementär zum bestehenden System. Sozial war festzustellen, dass ein grosser Drang zur neuen Technologie bestand und arbeiten am alten System “unbeliebt” waren – was zu Spannungen führte, die durch “Team Design” gemildert wurden. Eine umfassende Ausbildung, aber auch aufwendiges Coaching waren notwendig. Die Akzeptanz des Systems wurde durch den sofortigen wirtschaftlichen Nutzen erreicht. Zentraler Erfolgsfaktor war auch die soziale Migration. Im letzten Referat der Tagung “Werkzeugunterstützte Migration relationaler Datenbestände in objektorientierte” betonte Andreas Geppert (Uni Zürich) die Notwendigkeit, Tools zur Unterstützung der Datenbankmigration zu entwickeln. Einige Gründe sprechen bereits heute – und vermehrt in Zukunft – für OODBMS: die Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens Funktionalität, das Leistungsverhalten (besonders bei komplexen Strukturen), die Produktivität und Wiederverwendbarkeit sowie die Einheitlichkeit von Paradigmen. Gegen eine völlige Neuentwicklung von Applikationen sprechen die prohibitiven Kosten, gegen eine paralleles Betreiben von OODBMS und RDBMS der höhere Aufwand. Das macht die Migration, also die Transformation des relationalen Schemas, die Migration der Datenbestände und die Re-Implementierung der Anwendungsprogramme und Schnittstellen zu einer interessanten Alternative. Eine manuelle Migration ist aber aufwendig und fehleranfällig, daher die Suche nach einer systematischen Vorgehensweise, die mit einem Werkzeug unterstützt werden kann. Der erste Schritt muss eine semantische Anreicherung des relationalen Schemas um seine Beziehungen. Dann werden die angereicherten relationalen Schemata nach fixen Regeln transformiert. Der nächste Schritt ist die Erweiterung des OO-Schemas bzgl. Extensionen, Persistenz und Verhalten und das Umsetzen von Triggern und Kon- sistenzbedingungen sowie Sichten – es handelt sich hier um einen komplexen Entwurfsprozess! Es schliesst sich die Datenmigration an, die aus den Tupeln Objekte generieren. Neben der möglichst weitgehenden Unterstützung bei diesen Schritten der Migration sollte ein Migrationswerkzeug auch die Migrationsgeschichte aufzeichnen, Überlegungen zu alternativen Transformationen gestatten, das partielle Rücksetzen von Transformationen ermöglichen und die Wiederverwendbarkeit unterstützen durch ein Repository zur Verwaltung und Manipulation von Entwurfsdaten und -metadaten. Das laufende Projekt SYNDAMMA von O2 und IFI Zürich hat bisher anhand von Fallstudien Transformationsregeln erarbeitet, ein Migrationswerkzeug spezifiziert und Repositories in einer Fallstudie verwendet. Die abschliessende Podiumsdiskussion konfrontierte die unterschiedlichen, sich ergänzenden Ansätze der Migration. Es wurden auch nochmals der soziale Aspekt der Migration betont. ne et pour appréhender les mutations en cours et à venir. Nous vous recommandons vivement d'y participer. Au programme de cette année: multimedia (conférence invitée), temps et versions, bases de données spatiales, systèmes répartis (dont une conférence invitée), parallélisme, conception et plusieurs sessions autour du systè- me O2. Une visite de l’INRIA et une excursion en Chartreuse complètent agréablement le programme. Pour tous renseignements, consulter le serveur WWW: http:// www-lsr.imag.fr/BDA97 ou demander le programme à l’adresse électronique <Christine.Collet @imag.fr>. Searching for Semantics: Data Mining, Reverse Engineering, etc. 7th IFIP 2.6 Working Conference on Database Semantics October 7–10, 1997 Leysin The IFIP 2.6 Database Semantics (DS) series has established a tradition of highly appreciated working conferences where quality of presentations is preferred to quantity. The DS-7 conference will be a four-day live-in working conference with limited attendance and extensive time for presentations and discussions. This year’s conference will focus on two of the major problems that enterprises are currently facing: the reverse engineering of old legacy systems and applications, and the discovery of unplanned knowledge hidden in existing data stores. Many more topics will also be part of the program, available on the web at URL http:// diwww.epfl.ch/w3lbd/conferences/ cfpds7/cfpds7.html or from the Database Lab at EPFL (1015 Lausanne). A highlight of the event will be an invited talk by one of the leading figures in data mining, Prof. Jiawei Han, from the Simon Fraser University, British Columbia, Canada. Innovative Applications for Database Systems February, 3–4 1998, Zurich This workshop aims to bring together researchers on DBMS and practitioners who have experience applying innovative DBMS technology. The latest research results as well as the issues and problems of practitioners will be discussed, what solutions they have developed and what lessons they have learned. The topics of the workshop include but are not restricted to: Data Visualization, Data Warehousing, Data Mining, Workflow Management and Groupware, Integration of existing DBMS, Tools and Applications, Delimitation between Application and DBMS, Event-Driven DBMS, Experienc- es with New Kinds of Standards, Models and Systems, Experiences with New Kinds of Application Using Database Systems, Databases and Internet The workshop will include a number of talks, a panel discussion as well as a poster exhibition. We ask people from industry and academia to submit proposals for talks and posters in form of abstract in German, French or English. The contributions must be received by September 30, 1997 by Dr. Barbara Laasch, GfAI Gruppe für Angewandte Informatik AG, Eichwatt 5, 8105 Regensdorf. Security Präsident: Adolf Dörig Korrespondentin: Dr. Stefanie Teufel http://www.ifi.unizh.ch/groups/bauknecht/si/FGSec/index.html/ Arbeitsgruppen Viele der Sicherheitsaspekte von Informationssystemen werden erst bei näherer Betrachtung sichtbar. In Ihrer täglichen Arbeit sind viele Mitglieder der Fachgruppe Security mit Einzelproblemen konfrontiert. Um Zusammenhänge zu diskutieren, bieten sich Arbeitsgruppen an; momentan wird in den Bereichen Sicherheit von OO-Systemen und Key Escrow gearbeitet. Ideen für neue Arbeitsgruppen bitten wir an Herr Dr. B. Hämmerli (bmhaemmerli@ztl. ch) zu richten, der die bestehenden und neuen Gruppen koordiniert. Mailingliste Zur Verteilung aktueller Informationen zum Sicherheitsbereich haben wir eine Mailingliste eingerichtet, in welche sich alle Interessierten über unsere WWW-Seite (http://www.ifi.unizh.ch/ikm/ FGSec) einschreiben können. Bases de Données Avancées Sicherheit in Informationssystemen SIS’98 9–12 septembre 1997, Grenoble Stuttgart, 26. und 27. März 1998 Ces XIIIèmes journées sont le nes en bases de données. C'est la rendez-vous annuel des profes- meilleure opportunité pour renInformation ist nicht nur ein sich zum eigenständigen Produkt sionnels et chercheurs francopho- contrer les spécialistes du domai- “Produktionsfaktor” sondern hat mit hohem Marktpotential ent- INFORMATIK • INFORMATIQUE 4/1997 55 Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens wickelt. Damit wächst natürlich auch das Bedürfnis nach “sicherer” Informationsverarbeitung, die Verbindlichkeit und Schutz gegen den Verlust von Verfügbarkeit, Integrität, Vertraulichkeit und Authentizität bietet. Im Bereich des elektronischen Geschäftsverkehrs wird der Ruf nach Rechtssicherheit immer lauter. Ausserdem werden nicht nur kommerzielle Unternehmen sondern auch die öffentliche Hand von Informationen und informationsverarbeitenden Systemen abhängig. Wir fordern zur Einreichung von Beiträgen zu den folgenden Themen auf: • Sichere Informationsverarbeitung im Gesundheitsbereich, im Bank-/Versicherungsbereich, im Handel und im öffentlichen Bereich • Sichere Verkehrstelematik und (Mobil-)Kommunikation • Sicherheit von Chipkartenanwendungen • Sicherheit von Outsourcingprozessen • Sicherheitsmanagement, Sicherheitsinfrastrukturen: Organisatorische Etablierung, rechtliche Begleitung, Haftungsfragen, Prüfung, Kontrolle, Revision, Audit • Telekommunikationsrecht und Internet-Recht, Sicherheit im elektronischen Geschäftsverkehr • Sicherheitsgrundausbildung und Weiterbildung • Praxis- und Erfahrungsberichte • Zukunft der Informationssicherheit Die vollständigen in Deutsch abgefassten Beiträge sind bis spätestens 15. November 1997 einzureichen an: Prof. Dr. A. Büllesbach, debis Systemhaus GmbH, Bereich Datenschutz und IV-Sicherheit, Fasanenweg 9, D70771 Leinfelden-Echterdingen. Das Tagungsprogramm wird durch Produktpräsentationen und zwei halbtägige Tutorien ergänzt. Der Tagungsband erscheint beim vdf-Verlag, Zürich. Best Paper Award Die beste Diplom- oder Lizentiatsarbeit im Bereich Informationssicherheit wird gesondert prämiert. Um Ihre Arbeit für den Best Paper Award einreichen zu können, muss sich Ihre Lizentiatsoder Diplomarbeit mit dem Thema Informaionssicherheit befassen und hierzu einen wesentlichen Beitrag leisten. Ausserdem sollte Ihre Arbeit mit der Note sehr gut oder einer entsprechenden Beurteilung bewertet sein. Wenn Sie diese Kriterien erfüllen, bitten Sie die Betreuerin bzw. den Betreuer Ihrer Arbeit diese bis spätestens 15. November 1997 bei Prof. Dr. Alfred Büllesbach, debis Systemhaus, Bereich Datenschutz und IV-Sicherheit, Fasanenweg 9, D70771 Leinfelden-Echterdingen einzureichen. Programmkomitee-Vorsitz: Prof. Dr. K. Bauknecht, Universität Zürich, Prof. Dr. A. Büllesbach, Daimler-Benz AG, Prof. Dr. H. Pohl, Fachhochschule Rhein-Sieg, Dr. S. Teufel, Universität Zürich Veranstalter: Fachgruppe Security der Schweizer Informatiker Gesellschaft, Arbeitskreis IT-Sicherheit der Österreichischen Computer Gesellschaft, Fachhochschule Rhein-Sieg, DaimlerBenz AG / debis Systemhaus GmbH Tagungsorganisation: Prof. Dr. A. Büllesbach / Dipl.-Inf. Susanne Röhrig, Daimler-Benz AG / debis Systemhaus GmbH, Bereich Datenschutz und IV-Sicherheit, Fasanenweg 9, D - 70771 Leinfelden-Echterdingen, Tel.: +49 711 972 2606, Fax.: +49 711 972 1918, Email: [email protected] Weitere Informationen unter http://www.ifi.unzh.ch/events/ SIS98/ 56 INFORMATIK • INFORMATIQUE 4/1997 SGAICO Swiss Group for Artificial Intelligence and Cognitive Science Chairman: Dr. Michael Wolf Correspondent: Holger Rietmann http://expasy.hcuge.ch/sgaico/ The First International Conference on Audio- and Video-based Person Authentication Crans-Montana, March 12–14, 1997 Conference Report The First International Conference on Audio- and Video-based Biometric Person Authentication (AVBPA’97) brought the speech and face recognition researchers together in an attempt to contribute to robust solutions for the problem of automatic person authentication. The conference was co-chaired by Josef Bigun and Gerard Chollet. Four invited talks were given during the conference. Rama Chellappa made a comparison between the film “2001, Space Odyssey” and the recent advances in artificial intelligence. John Mason, the second speaker, explained to us the precautions he took at the slopes in order to avoid to turn brown (the question was: are sunglasses prints across your face compatible with the attending of a serious conference?). After this introduction, he then presented his recent advances in combining speech and lip movement analysis for the purpose of speaker verification. During the third invited paper, Tomaso Poggio proved that human vision works mostly with illusions and is not as good as we think: by simply changing Mr. Clinton’s hairstyle, nobody was able to recognize the President any longer! The proceedings volume includes 54 contributions. Springer Lecture Notes No 1206 (e-mail: [email protected]). 6th International Workshop PASE ‘97 Computers in Finance and Economics Marienbad, Czech Republic, November 9–12, 1997 The purpose of this workshop is to bring together researchers interested in innovative information processing systems and their applications in the areas of statistics, finance and economics. The focus will be on in-depth presentations of state-of-the-art methods and applications as well as on communicating current research topics. This workshop is intended for industrial and academic persons seeking new ways to work with computers in finance and economics. Statistical Methods for Data Analysis and Forecasting Neural Networks in Finance and Econometrics Data Quality and Data Integrity Data Integration and Data Warehousing Risk Management Applications Real Time Decision Support Systems Banking and Financial Information on the Internet The Workshop will be organized by the Swiss Centre for Scientific Computing at ETH Zurich, Olsen & Associates (Research Institute for Applied Economics, Zurich) and the Institute of Computer Science of the Czech Academy of Sciences, Prague. For further Information visit http:// www.scsc.ethz.ch/PASE Schweizer Informatiker Gesellschaft • Société Suisse des Informaticiens Knowledge-Based Systems for Knowledge Management in Enterprises In conjunction with the 21st Annual German Conference on AI ‘97 (KI-Jahrestagung ‘97) September 9–12 Freiburg, Baden-Württemberg, Germany Tuesday, 9 Sept. Session: General Aspects Processes of Knowledge Preservation: Away from a Technology Dominated Approach (K. Romhardt) – Toward a Method for Providing Database Structures Derived from an Ontological Specification Process: the Example of Knowledge Management (G. Templeton and Ch. Snyder) Session: Applications Case-Based Reasoning for Customer Support (Stefan Wess Smart Product Catalogues at IBM (Markus Stolze) – Knowledge Management in Global Health Research Planning (C. Greiner and T. Rose) Wednesday, 10 Sept. Session: AI Approaches A Framework for Knowledge Management Systems: A Proposal (Wai Keung (Daniel) Pun, Craig McDonald, and John Weckert) – Knowledge Integration for Building Organisational Memories (U. Reimer) – ERBUS: Developing a Knowledge Management System for Industrial Designer (Manfred Daniel, Stefan Decker, Andreas Domanetzki, Christian Guenther, Elke Heimbrodt-Habermann, Falk Höhn, Alexander Hoffmann, Holger Röstel, Regina Smit, Rudi Studer, Reinhard Wegner) Session: KM Software Making the Tacit Explicit: The Intangible Assets Monitor in Software (Ch. Snyder and L. Wilson) – Multimediale Wissensrunde: Werkzeuge für Aufbau, Wartung und Nutzung eines gemeinschaftlichen Unternehmens-Gedächtnisses (H.-J. Frank) – The Acquisition of Novel Knowledge by Creative Re-Organizations (F. Schmalhofer and J. S. Aitken) Thursday, 11 Sept. Session: Enabling Technologies The Data Warehouse as a Means to Support Knowledge Management (M. Erdmann) – From Paper to a Corporate Memory: A First Step (St. Baumann, M. Malburg, H. Meyer auf’m Hofe, and C. Wenzel) – Knowledge-Based Interpretation of Business Letters (K.-H. Bldsius, B. Grawemeyer, I. John, and N Kuhn) – An Organizational-Memory Based Approach to Learning Workflow Management (Christoph Wargitsch) – Knowledge Management with CoMo-Kit (Barbara Dellen, Harald Holz, Gerd Pews) For more information see http:/ /www.dfki.uni-kl.de/km/ws-ki97. Beitrittsformular • Formulaire d’adhésion Ich möchte Mitglied der SI werden • Je désire adhérer à la SI als Einzelmitglied • en tant que membre individuel als Student(in) • en tant qu’étudiant(e) als Kollektivmitglie • en tant que membre collectif Ich möchte der (den) folgenden Fachgruppe(n) beitreten • Je désire adhérer au(x) groupe(s) spécialisé(s) suivant(s) Ada in Switzerland, CHOOSE, DBTA, HypEdu, Informatik & Gesellschaft, Oberon, SAUG, Security, SGAICO, SIPAR, Software Engineering, Software Ergonomics, SI-Work, Section romande SISR Name • Nom................................................................................... Vorname • Prénom ......................................................................... Adresse.......................................................................................... ....................................................................................................... .................................... E-mail...................................................... Meine Adresse soll ausschliesslich für Zusendungen der SI und ihrer Fachgruppen verwendet werden • Mon adresse ne doit servir qu’aux envois de la SI et de ses groupes, exclusivement. SI, Schwandenholzstr. 286, 8046 Zürich. Fax 01 371 23 00. SIPAR SI Group for Parallel Systems Chairman: Dr. Pierre Kuonen http://wwwiiuf.unifr.ch/SIPAR/sipar.html TelePar’97 Parallelism & Telecommunication SPEEDUP-SIPAR Workshop EPFL, Lausanne, the 18th and 19th of September 1997 The field of telecommunications is expanding rapidly, particularly because of the increasing success of mobile systems, satellite telecommunications, urban networks, etc. The field of telecommunications needs High Performance Computing in order to solve the numerous problems encountered when deploying, maintaining or running a telecommunication network. The TelePar workshop is an opportunity for computer scientists working in the area of parallelism and for experts in telecommunication to meet each other. TelePar’97 is the first workshop on High Performance Computing and Telecommunication. Interested persons and especially young swiss researchers are strongly invited to participate to this workshop. Further information can be found at: http://lithwww.epfl.ch/ w3lith/research/TelePar.html or by sending a e-mail to: [email protected]fl.ch Pierre Kuonen Software Ergonomics Serving the needs of professional interaction designers Vorsitzender: Daniel Felix Korrespondent: Markus Stolze http://www.zurich.ibm.com/pub/Other/SWE Software Ergonomics Events will take place every last non-holiday Thursday of each month. Tutorials cover hands on advice on well elaborated themes. The attendance fee for tutorials covers documentation and an apéro. Informal Events are less structured and free. Thursday 4 September (moved from 28. August): Tutorial: Metaphor Engineering – D. Gerkens, UBS, Chr. Hauri, ErgoConsult. 17:30 ETH Zentrum, Clausiusstrasse 25, Zürich Thursday 25 September: Informal Event: Hands-On Workshop: Redesign of the SW-Erg Web Site. Coordinator: Patrick Steiger. 17:30 ETH Zentrum, Clausiusstrasse 25, Zürich Thursday 30 October: Informal Event: 3 D GUI Design – Philipp Ackermann, Echtzeit- Perspectix AG. 17:30, EchtzeitPerspectix AG, Zürichbergstrasse 17, 3032 Zürich. Thursday 27 November: Informal Event: Visualizing Complex Information – Matthew Chalmers, UBILAB (UBS Research Lab). 17:30 ETH Zentrum, Clausiusstrasse 25, Zürich For up to date information about Software Ergonomics events visit our WWW page at http://www.zurich.ibm.com/pub/ Other/SWE/. This page also informs about other Software Ergonomics services like our Software Ergonomics Video and Proceedings Library. Recent additions include the video program of the CHI’97 Conference on Human Factors in Computing and a video on the history of computing (in German). INFORMATIK • INFORMATIQUE 4/1997 57 Mosaic Hinweise für Autoren Leserschaft und Erwartungen Gemäss redaktionellem Leitbild “dienen Übersichtsartikel (Surveys) und ein- und weiterführende Beiträge (Primers, Tutorials) über aktuelle Themen der Weiterbildung der Informatiker. Sie verbinden hohes fachliches Niveau mit guter Verständlichkeit und praktischer Verwertbarkeit der Information”. Die Leser unserer Zeitschrift sind qualifizierte InformatikFachleute. Entsprechende Fachkenntnisse dürfen vorausgesetzt werden. Bedenken Sie aber, dass das behandelte Spezialgebiet nicht unbedingt dem des Lesers entspricht. Annahme der Fachbeiträge Wir übernehmen nur Artikel, die nicht schon anderswo veröffentlicht und auch nicht anderswo zur Publikation eingereicht wurden. Die eingereichten Beiträge werden dem redaktionellen Beirat zur Begutachtung vorgelegt. Die Redaktion entscheidet aufgrund dieser Gutachten über deren Veröffentlichung. Die Begutachter und die Redaktion können Änderungen, Überarbeitungen oder Kürzungen vorschlagen. Grund für eine Ablehnung kann sein, dass ein Artikel mit ähnlichem Inhalt in unserer Zeitschrift schon veröffentlicht wurde oder geplant ist. Redaktionell aufbereitete Werbung für Produkte und Dienstleistungen werden abgelehnt. Bestandteile des Manuskripts – Kurzer, prägnanter Titel – Vorspann (50–60 Wörter), soll zum Lesen des Artikels anregen. – Vorstellung des Autors: Titel oder Funktion, gegenwärtige Tätigkeit oder Verantwortung, fachliche Interessengebiete, evtl. weitere Informationen, die im Zusammenhang mit dem Thema relevant sind (max. 75 Wörter). – Artikel: Ideal sind drei bis fünf Druckseiten. Gut fokussierte Darstellungen sind besser als lange Abhandlungen. Eine Druckseite ohne Bilder entspricht ca. 5’000 Zeichen. – Gute Bilder (schwarz/weiss) sind erwünscht. – Referenzen (max. 12). Recommendations à l’intention des auteurs Lecteurs et expectatives Le modèle rédactionnel précise que la revue publie « des articles synoptiques (surveys) et des contributions d’introduction (primers) et avancées (tutorials) sur des sujets d’actualité qui servent au perfectionnement des informaticiennes et informaticiens. Ils réunissent un haut niveau professionnel, une bonne intelligibilité et utilité de l’information ». Les lecteurs de notre revue sont des professionnels qualifiés de l’informatique : on peut donc présumer des connaissances techniques appropriées. Il ne faut cependant pas oublier que le domaine Copyright, Honorare spécial traité ne correspond pas Mit der Veröffentlichung in nécessairement à la spécialité du INFORMATIK/INFORMATIQUE ge- lecteur. hen alle Rechte an den HerausgeAcceptation des contributions ber über. Die Zeitschrift INFORMATIK/ techniques Seuls des articles qui n’ont pas INFORMATIQUE zahlt keine Autoété déjà publiés ou proposés pour renhonorare. publication ailleurs, sont acceptés dans notre revue. Datenträger Les contributions proposées Einreichung auf 3.5”-Diskette mit einem Ausdruck auf Papier. sont soumises pour expertise au Möglichst einfacher Umbruch, conseil consultatif de rédaction. mit deutlicher Kennzeichnung der La rédaction décide ensuite de la Titel, Untertitel, Absätze und publication. Les experts et la Bildlegenden. Disketten: Mac- rédaction peuvent proposer des intosh oder MS-DOS/Windows. amendements, une révision ou des Textformate MS-Word v2 Frame- coupures. Un article peut être Maker, RTF oder ASCII. Grafik- refusé, en particulier si un article formate: PICT, GIF und EPS so- de contenu analogue a déjà été wie als gute Originale auf Papier. publié ou prévu dans notre revue. Senden Sie Ihr Manuskript an La publicité pour des produits et die Redaktion INFORMATIK/IN- des services n’est pas admise. FORMATIQUE, Schwandenholzstr. 286, CH-8046 Zürich. Verges- Eléments du manuscrit sen Sie bitte nicht, Ihre Adresse, – Titre concis et suggestif Telefon- und Faxnummer sowie – Chapeau: texte qui surmonte et présente l’article (50–60 mots). E-mail-Adresse beizulegen. – Présentation de l’auteur : titre ou fonction, occupation ou res- 58 INFORMATIK • INFORMATIQUE 4/1997 ponsabilité actuelle, domaines d’intérêt professionnel, informations supplémentaires importantes en rapport avec le sujet (50–75 mots). – Article : de préférence de trois à six pages. Une page imprimée sans illustration correspond environ à 5000 caractères. Les présentations bien centrées sur le sujet sont préférables aux longues dissertations. – Illustrations : De bonnes illustrations et des graphiques (en noir et blanc) sont bienvenues. – Références : Passages auxquels le texte se réfère et ouvrages recommandés au lecteur pour approfondir le sujet (max. 12). Copyright, Honoraires Par la publication dans INFORMATIK/INFORMATIQUE tous les droits passent à l’éditeur. La revue INFORMATIK/INFORMATIQUE ne verse pas d’honoraires aux auteurs. Support de données Le manuscrit sera remis sur disquette 3.5” avec une copie papier. La mise en page sera la plus simple possible, mais mettra bien en évidence les titres, soustitres, alinéas, légendes de figures. Disquettes: Macintosh ou MSDOS/Windows. Texte: MS-Word v2, FrameMaker, RTF ou ASCII. Figures: séparément en format PICT, GIF ou EPS ainsi que bonnes copies papier. Le manuscrit sera envoyé à la rédaction INFORMATIK/INFORMATIQUE, Schwandenholzstr. 286, CH-8046 Zurich. N’oubliez pas de joindre l’adresse, le no de téléphone et de fax, ainsi que l’adresse Internet.