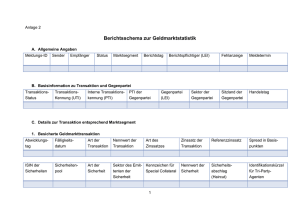
Übung 5 Prozeduren, Triggers und Transaktionen 1. Ablauf der
Werbung

Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
Übung 5
Prozeduren, Triggers und Transaktionen
1. Ablauf der Übung
•
Besprechung der SQL-Abfragen aus Übung 4
•
Views
•
SQL-Erweiterungen
•
Datenbank-Prozeduren (Stored Procedures)
•
Triggers
•
Transaktionen
•
Bearbeiten von Aufgaben zu den obigen Themen
2. Views
Bisher sind vor allem Basistabellen erörtert worden. Die Eigenschaft aller Basistabellen ist, dass
sie physikalisch existieren. Eine Basistabelle enthält also Objekte, die alle auf der Platte
gespeichert sind. Im Unterschied zu Basistabellen belegen Views keinen Speicherplatz. Views
werden immer aus existierenden Basistabellen abgeleitet.
Views erlauben es, bestimmte Sichten auf Tabellen zu erzeugen. So können z.B. nur bestimmte
Attribute einer Tabelle angezeigt werden. Dies erlaubt es, Nutzern Zugriff auf bestimmte
Informationen zu geben, und andere Informationen zu schützen.
(Bemerkung: Views werden in MS Access Queries genannt)
2.1. Erstellen von Views
CREATE VIEW view_name [(spalten_liste)]
AS select_anweisung
Select_anweisung kennzeichnet die Select-Anweisung, mit der die Auswahl der Reihen und
Spalten aus der/den Basistabelle(n) durchgeführt wird. Spalten_liste ist eine Liste der Namen der
Viewspalten. Falls diese optionale Angabe ausgelassen wird, werden die Namen der Spalten aus
der Projektion der Select-Anweisung übernommen.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 1 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
Beispiel:
CREATE VIEW v_red_wine
As SELECT id, name, vintage
FROM wine
WHERE category = `Red Wine`
Ist eine View einmal erzeugt, kann man mit ihr arbeiten als ob es sich um eine Basistabelle
handeln würde.
Beispiele:
SELECT * FROM v_red_wine;
INSERT INTO v_red_wine
VALUES (11,`Faustiono I`,1995);
etc.
3. Transakt-SQL-Erweiterungen
In den letzten Übungen wurden die von Transact-SQL unterstützten Datendefinitions- und
Datenmanipulationsanweisungen besprochen. Diese Anweisungen können in
Anweisungsgruppen, die beim SQL-Server batch heissen, zusammengefasst werden. D.h., dass
ein batch eine Folge von Transact-SQL-Anweisungen ist, der als Einheit an das System zur
Ausführung gesendet wird.
3.1. Der Begin-Block
Die Begin-Anweisung ermöglicht die Ausführung mehrerer Anweisungen blockweise:
BEGIN
Anweisung_1
Anweisung_2
...
END
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 2 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
Der Begin-Block wird meistens in IF-Anweisungen verwendet, um die Ausführung mehrerer
Anweisungen, abhängig von einer Bedingung zu ermöglichen.
3.2. Die IF-Anweisung
Mit der IF-Anweisung wird die spezifizierte Bedingung getestet und, abhängig vom Ergebnis,
entweder der IF-Zweig oder der ELSE-Zweig ausgeführt.
Beispiel:
If (select count (*)
From wine
Where category = ‘White Wine’
Group by category) > 3
Print ‘Number of white wines is bigger or equal 4’
Else Begin
Print ‘The following white wines are in the database’
Select name, vintage
From wine
Where category = ‘White Wine’
End
In diesem Beispiel wird die Anwendung der IF- und BEGIN-Anweisung in einer
Anweisungsgruppe gezeigt. Im ELSE-Zweig der IF-Anweisung ist der BEGIN-Block deswegen
notwendig, weil dieser Zweig zwei Anweisungen – PRINT und SELECT – enthält.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 3 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
3.3. Die WHILE-Anweisung
Mit der WHILE-Anweisung kann ein Anweisungsblock wiederholt ausgeführt werden, solange
der spezifizierte Boolesche Ausdruck wahr ist. Der Anweisungsblock kann u.a. auch zwei weitere
Anweisungen enthalten:
•
BREAK und
•
CONTINUE
Die Anweisung BREAK verursacht die Beendigung der Ausführung eines Anweisungsblocks.
Die Anweisung, die nach dem Blockende unmittelbar folgt, wird danach ausgeführt. Die
CONTINUE-Anweisung führt nach Beendigung der Ausführung in einem Block wieder zum
Blockanfang zurück.
Beispiel:
While (select sum(price)From sell) < 1000
Begin
Update sell set price = price*1.1
If (select max(price)
From sell)> 500
Break
Else
Continue
End
Print ‚Der maximale Preis eines Weines übersteigt 500.- CHF.’
In diesem Beispiel werden die Preise der Weine zusammengezählt und in mehreren Schritten um
10% erhöht, bis die Summe aller Weine 1000.- CHF erreicht, aber eine einzelne Flasche nicht
mehr als 500.- CHF kostet.
3.4. Lokale Variablen
Eine zusätzliche Erweiterung der Transact-SQL-Sprache bilden die Variablen, die für eine
Anweisungsgruppe definiert werden können. Diese Variablen gelten nur innerhalb der
Anweisungsgruppe, in der sie definiert sind und werden deswegen lokale Variablen genannt.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 4 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
(Neben den lokalen Variablen existieren beim SQL-Server auch die globalen Variablen, die
systemweit gelten.)
Die lokalen Variablen werden mit der DECLARE-Anweisung definiert. Die Definition jeder
Variablen enthält ihren Namen und den Datentyp. Jede lokale Variable ist durch das Präfix @
gekennzeichnet. Die Zuweisung der Variablenwerte wir mit Hilfe folgender Anweisungen
durchgeführt:
•
SELECT
•
SET
Beispiel:
Declare @durchschnitt_preis money, @zusatz_preis money
Set @zusatz_preis = 5
Select @durchschnitt_preis = avg(price) from sell
If (select price From sell < @durchschnitt_preis
Begin
Update sell set price = price + @zusatz_price
Print „Preise sind um ‚+ @zusatz_preis +’ erhöht’
End Else
Print ‚Preise sind unverändert geblieben’
Hier wurde zuerst der Durchschnittspreis aller verkaufbaren Weine berechnet und anschliessend
getestet, ob die Preise kleiner als der Durchschnitt sind. Falls dies der Fall ist, werden die Preise
mit Hilfe einer lokalen Variablen erhöht.
Bemerkung: Um Variablen im PRINT-Befehl zu nutzen muss die folgende Syntax verwendet
werden: PRINT ‚TEXT’+ @Variablenname +’ Text’.
Für weitere Informationen konsultieren Sie die Online-Hilfe von SQL-Server
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 5 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
4. Datenbankprozeduren (Stored Procedures)
Datenbankprozeduren haben Ähnlichkeit mit den Funktionen, die in einer prozeduralen
Programmiersprache programmiert sind. Der SQL-Server unterscheidet zwischen den
benutzerdefinierten und den Systemprozeduren. Die benutzerdefinierten Prozeduren werden
ähnlich wie alle anderen Datenbankobjekte mit Hilfe einer Datendefinitionsanweisung erstellt,
während Systemprozeduren der integrale Teil des SQL-Servers sind.
Jede benutzerdefinierte Datenbankprozedur kann sowohl SQL- als auch prozedurale
Anweisungen enthalten. Die prozeduralen Anweisungen entsprechen den im letzten Abschnitt
beschriebenen SQL-Erweiterungen.
Jeder Datenbankprozedur können Daten als Parameter zugewiesen werden. Die Übergabe der
Parameter wird beim Prozeduraufruf durchgeführt. Datenbankprozeduren können auch einen
Rückgabewert übergeben.
Datenbankprozeduren werden übersetzt, bevor sie in der Datenbank gespeichert werden. Damit
wird für jede Datenbankprozedur ein Ausrührungsplan gespeichert, der bei der Ausführung der
Prozedur benutzt wird. Diese Vorgehensweise bringt für oft verwendete Prozeduren einen
entscheidenden Performance-Vorteil: Die wiederholte Übersetzung der Datenbankprozedur kann
eliminiert werden und damit ihre Ausführung wesentlich beschleunigt werden.
4.1. Die Erstellung und Ausführung von Datenbankprozeduren
Der CREATE PROCEDURE Befehl dient der Erstellung einer benutzerdefinierten
Prozedur.Beispiel:
CREATE PROCEDURE erhoehe_preis @prozent int=5
AS UPDATE sell
SET price = price + price * @prozent/100
Die Prozedur erhoehe_preis erhöht die Preise aller Weine um einen festgelegten Wert, der mit
Hilfe des Parameters prozent übergeben werden kann. Falls kein Parameter übergeben wird, wird
der Prozentsatz um den Standardwert 5 erhöht.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 6 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
(Jene Parameter, die einen Rückgabewert an das aufrufende Programm liefern, haben immer die
Angabe OUTPUT als Zusatz.)
Mit der Anweisung;
[EXECUTE] [@rueckgabe_wert=] proz_name
{[@param_name1=]wert | [@param_name1=] @variable} OUTPUT...
kann eine existierende Prozedur namens proz_name ausgeführt werden. rueckgabe_wert ist eine
optionale, ganzzahlige Variable, die den Rückgabewert der ausgeführten Datenbankprozedur
speichert. Der Parameterwert kann entweder als ein Datenwert (wert) oder mit Hilfe einer lokalen
Variable (@variable) zugewiesen werden.
Beispiel:
EXECUTE erhoehe_preis 10
Die Anweisung führt die Prozedur erhoehe_preis mit dem Parameterwert 10 aus und erhöht
somit die Weinpreise um 10%.
5. Triggers
Ein Trigger ist eine besondere Art gespeicherter Prozedur, die von SQL Server automatisch
ausgeführt wird, wenn eine Tabelle mit einer der drei Anweisungen UPDATE, INSERT oder
DELETE bearbeitet wird. Trigger können ebenso wie andere gespeicherte Prozeduren einfache
oder komplexe T-SQL-Anweisungen enthalten. Im Unterschied zu anderen gespeicherten
Prozeduren werden Trigger bei bestimmten Datenänderungen automatisch ausgeführt; sie können
also nicht manuell über ihren Namen aufgerufen werden. Wenn ein Trigger ausgeführt wird,
heisst es, dass er ausgelöst wurde. Ein Trigger wird in einer Datenbanktabelle erstellt, er kann
jedoch auf andere Tabellen und Objekte in anderen Datenbanktabellen zugreifen. Trigger können
nicht in temporären Tabellen oder Systemtabellen, sondern nur in benutzerdefinierten Tabellen
oder Sichten erstellt werden. Die Tabelle, in der ein Trigger definiert ist, heisst Triggertabelle.
Ein Trigger besteht aus drei Teilen:
-
dem Namen
-
der Bedingung
-
dem Ausführungsteil
Die Bedingung eines Triggers enthält entweder eine INSERT-, eine UPDATE-, oder eine
DELETE-Anweisung oder eine Kombination dieser Anweisungen. Der Ausführungsteil umfasst
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 7 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
gewöhnlich mehrere Transact-SQL-Anweisungen. Die Trigger werden mit folgendem Befehl
erstellt:
CREATE TRIGGER tr_name
ON tab_name
FOR {INSERT,UPDATE,DELETE}
AS anw_gruppe¦{IF UPDATE(sp_name1)[{{AND¦OR}
UPDATE(sp_name2)}] anw_gruppe}
Tr_name spezifiziert den Namen des Triggers und muss den allgemeinen Regeln für Objektnamen
beim SQL-Server entsprechen.
Tab_name ist der Name der Tabelle, für die der Trigger definiert wird.
Die Angaben INSERT, UPDATE und DELETE stellen die Triggerbedingungen dar und
spezifizieren die Art der Datenmodifikation, nach der die Trigger enthaltene Anweisungsgruppe
ausgeführt wird. Diese drei Angaben können in jeder beliebigen Kombination geschrieben werden
(Die DELETE-Angabe darf mit der IF UPDATE-Klausel nicht verwendet werden).
Wie aus der Syntax der CREATE TRIGGER-Anweisung ersichtlich, kann nach der AS-Angabe
entweder eine Anweisungsgruppe folgen oder das IF UPDATE-Konstrukt kann, jeweils mit einer
eigenen Anweisungsgruppe, einmal oder mehrmals verwendet werden.
Das IF UPDATE-Konstrukt stellt die zweite, zusätzliche Form der Triggerbedingung dar, und
wird benutzt, um festzustellen, ob Datenwerte der spezifizierten Spalte (sp_namex) in irgendeiner
Form geändert worden sind. In einer CREATE TRIGGER-Anweisung können mehrere IF
UPDATE-Konstrukte (für mehrere Spalten) definiert werden. (Die Verwendung eines IF
UPDATE-Konstruktes entspricht damit der Definition einer spaltenbezogenen Integritätsregel.)
Es können für jede Tabelle und jede Aktion (UPDATE, INSERT und DELETE) mehrere Trigger
definiert werden.
Die CREATE TRIGGER-Anweisung verwendet zwei spezielle Namen: DELETED, INSERTED,
die zwei logische, bei der Ausführung einer CREATE TRIGGER-Anweisung vom SQL-ServerSystem erstellte Tabellen sind. Ihre Struktur (Tabellenschema) entspricht genau der Struktur der
Tabelle, für die der Trigger spezifiziert wird. Die Tabelle DELETED enthält die alten Werte der
Tabellenreihe(n), die durch die Triggeraktion geändert werden, während die Tabelle INSERTED
die entsprechenden neuen Werte enthält. Die DELETED- und die INSERTED-Tabelle werden
vom Trigger verwendet, um zu spezifizieren, wie die Ausführung der Anweisung innerhalb des
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 8 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
Triggers durchgeführt werden soll. (Diese Tabellen können aber selbst nicht durch die
Triggeraktion geändert werden.)
create table tr_price_protocol
(wine_id float null,
seller_id float null,
user char(16) null,
time datetime null,
price_old float null,
price_new float null)
go
create table sell
(wine_id float not null,
seller_id float not null,
price float null)
go
create trigger change_price
on sell
for update as
if update(price)
begin
declare @value_before float
declare @value_after float
declare @wine_id float
declare @seller_id float
select @value_before=(select price from deleted)
select @value_after=(select price from inserted)
select @wine_id=(select wine_id from deleted)
select @seller_id=(select seller_id from deleted)
insert into tr_price_protocol values
(@wine_id,@seller_id,user_name(),
getdate(),@value_before,@value_after)
end
go
Obiges Beispiel geht davon aus, dass nur eine Reihe zu einem gewissen Zeitpunkt geändert wird.
Deswegen stellt es eine Vereinfachung des allgemeinen Falles dar, wo ein Trigger gleichzeitig
Änderungen mehrerer Reihen behandelt.
Das Beispiel zeigt, wie Trigger in der Praxis sinnvoll als Kontrollmechanismen angewendet
werden können. In diesem Beispiel wird zuerst eine Tabelle sell und eine Tabelle price_protocol
in der alle Änderungen bei den Weinpreisen protokolliert werden, erstellt. Die Protokollierung
wird durch den anschliessend definierten Trigger tr_change_price durchgeführt.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 9 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
Jede Änderung der Spalte price der Tabelle sell aktiviert mit Hilfe der UPDATE-Anweisung den
Trigger. Bei der Aktivierung des Triggers werden den Variablen value_before, value_after,
wine_id und seller_id aus den erstellten Tabellen DELETED und INSERTED die entsprechenden
Datenwerte zugewiesen. Anschliessen werden diese Werte, gemeinsam mit dem Namen des
Benutzers, der die UPDATE-Anweisung ausgeführt hat, und der aktuellen Zeit in der Tabelle
price_protocol eingefügt. Falls z.B. folgende Anweisung ausgeführt wird:
Insert into sell values(4,2,100)
Update sell set price=110 where wine_id=4 and seller_id=2;
wird die Tabelle price_protocoll folgende Reihe enthalten:
wine_id
seller_id
4
benutzer
zeit
price_old
price_new
DBS
2004-01-11 15:22:24.147
100
110
2
Damit kann der Trigger tr_change_price als Kontrollmechanismus für die Änderungen der
Datenwerte der Projektmittel eingesetzt werden.
Ein weiteres Anwendungsgebiet für Trigger stellt die referentielle Integrität dar. Diese wichtige
Integritätsregel kann entweder deklarativ oder mit Hilfe von Triggern spezifiziert werden.
Hinweise:
-
Trigger werden nur nach dem Abschluss der Anweisung ausgeführt, durch die sie
ausgelöst werden.
-
Wenn mit einer Anweisung versucht wird, eine Operation auszuführen, die eine
Einschränkung für eine Tabelle verletzt oder einen anderen Fehler verursacht, wird der
entsprechende Trigger nicht ausgelöst.
-
Ein Trigger bildet zusammen mit der Anweisung, durch die er aufgerufen wird, eine
Transaktion. Im Trigger kann daher eine Rollback-Anweisung (siehe 5. Transaktionen)
aufgerufen werden, die sowohl den Trigger als auch das Datenänderungsereignis
rückgängig macht. Auch im Falle eines schwerwiegenden Fehlers, beispielsweise wenn
die Verbindung eines Benutzers getrennt wird, macht SQL Server die gesamte Transaktion
automatisch rückgängig.
-
Ein Trigger wird für eine Anweisung nur einmal ausgelöst, auch wenn die Anweisung
viele Datenzeilen betrifft.
Mit der Anweisung DROP TRIGGER trigger_name wird ein existierender Trigger gelöscht.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 10 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
6. Transaktionen
6.1. Einführung
Eine Transaktion besteht aus einer Reihe von Operationen, die als eine logische Funktionseinheit
ausgeführt werden. Über Transaktionen kann SQL Server eine bestimmte Stufe der
Datenintegrität und der Wiederherstellbarkeit der Daten sicherstellen. Im Transaktionsprotokoll,
das in jeder Datenbank vorhanden sein muss, werden alle Transaktionen aufgezeichnet, die
Änderungen an der Datenbank vornehmen (Einfügungen, Aktualisierungen oder Löschungen).
Beim Auftreten von Fehlern oder Systemausfällen stellt SQL Server die Daten anhand dieses
Transaktionsprotokolls wieder her.
Die Integrität einer Transaktion hängt auch vom SQL-Programmierer ab. Der Programmierer
muss wissen, wann die Transaktion beginnen und enden soll und in welcher Reihenfolge die
Datenänderungen vorgenommen werden sollen, damit die Daten logisch konsistent und sinnvoll
sind.
Eine Transaktion muss vier Anforderungen erfüllen, damit sie gültig ist. Diese Anforderungen
werden als ACID-Eigenschaften bezeichnet. ACID ist ein Akronym für Atomicity (Unteilbarkeit),
Consistency (Konsistenz), Isolation (Isolation) und Durability (Dauerhaftigkeit). SQL Server
verfügt über Verfahren, die dafür sorgen, dass eine Transaktion jede dieser Anforderungen erfüllt.
-
Unteilbarkeit: Es wird sichergestellt, dass alle Datenänderungen einer Transaktion aus
Gruppe ausgeführt werden, wenn die Transaktion erfolgreich war, resp. keine der
Transaktionen ausgeführt wird, falls die Transaktion nicht erfolgreich war, d.h. die
Unteilbarkeit einer Transaktion wird sichergestellt.
-
Konsistenz: Sie bedeutet, dass nach dem Abschluss einer Transaktion alle Daten konsistent
bleiben – dass die Datenintegrität gewahrt bleibt – unabhängig davon, ob die Transaktion
fehlgeschlagen ist oder erfolgreich abgeschlossen wurde.
-
Isolation: Sie bedeutet, dass die Wirkungen jeder Transaktion immer gleich sind, ganz so,
als würde im System nur eine einzige Transaktion ausgeführt. Das bedeutet, dass von einer
Transaktion vorgenommene Änderungen von allen Änderungen isoliert sind, die von einer
anderen gleichzeitigen Transaktion vorgenommen werden. So wird eine Transaktion erst
dann durch einen Wert beeinflusst, der mit einer anderen Transaktion geändert wurde,
wenn ein Commit für die Änderung ausgeführt wurde. Schlägt eine Transaktion fehl,
haben deren Änderungen keine Wirkung, weil sie rückgängig gemacht werden.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 11 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
SQL Server unterstützt vier Isolationsstufen. Eine Isolationsstufe ist eine Einstellung, die
bestimmt, auf welcher Stufe eine Transaktion inkonsistente Daten annehmen darf, also den
Grad, zu dem eine Transaktion von einer anderen isoliert ist. Eine höhere Isolationsstufe
erhöht die Genauigkeit der Daten, reduziert jedoch möglicherweise die Anzahl gleichzeitiger
Transaktionen. Eine niedrigere Isolationsstufe dagegen ermöglicht eine höhere Parallelität,
führt jedoch zu geringerer Datengenauigkeit. Die Isolationsstufen im Einzelnen:
-
Read uncommitted: Niedrigste Isolationsstufe.
-
Read committed (Standardstufe für SQL Server). Auf dieser Stufe sind Lesevorgänge nur
für Daten zulässig, für die ein Commit ausgeführt wurde.
-
Repeatable read: Stufe, auf der ein wiederholtes Lesen derselben Zeile oder Zeilen in
einer Transaktion dieselben Ergebnisse zur Folge hat. (Erst nach Abschluss einer
Transaktion können die Daten von anderen Transaktionen geändert werden.)
-
Serializable: Höchste Isolationsstufe; die Transaktionen sind vollständig voneinander
isoliert. Auf dieser Stufe sind die Ergebnisse von Transaktionen, die an einer Datenbank
gleichzeitig ausgeführt werden, identisch mit den Ergebnissen von nacheinander
ausgeführten Transaktionen.
Festlegen der Isolationsstufe:
Set transaction isolation level [read uncommitted¦read
committed¦repeatable read¦serializable]
go
-
Dauerhaftigkeit: Sie bedeutet, dass die Wirkungen einer Transaktion auch bei einem
Systemfehler permanent in die Datenbank übernommen werden, nachdem für die
Transaktion ein Commit ausgeführt wurde. Das SQL Server-Transaktionsprotokoll und
ihre Datenbanksicherungen gewährleisten Dauerhaftigkeit. Bei einem Ausfall von SQL
Server, des Betriebssystems oder einer Serverkomponente wird die Datenbank nach einem
Neustart von SQL Server automatisch wiederhergestellt. SQL Server führt die
übernommenen Transaktionen, die von dem Systemabsturz betroffen waren, anhand des
Transaktionsprotokolls erneut aus und macht alle nicht übernommenen Transaktionen
wieder rückgängig.
6.2. Transaktionsmodi
Eine Transaktion kann in einem von drei Modi gestartet werden: Autocommit, explizit oder
implizit. Der Standardmodus für SQL Server ist Autocommit.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 12 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
-
Autocommit-Modus: Hier wird für jede T-SQL-Anweisung ein Commit ausgeführt, wenn
die Anweisung beendet ist. In diesem Modus sind keine weiteren Anweisungen zur
Steuerung von Transaktionen notwendig.
-
Impliziter Modus: Im impliziten Modus beginnt eine Transaktion automatisch, sobald
bestimmte T-SQL-Anweisungen (alter table, create, delete, drop, grant, insert, open,
revoke, select, update) verwendet werden, und sie wird so lange fortgesetzt, bis sie mit
einer COMMIT- oder ROLLBACK-Anweisung explizit beendet wird. Wird keine
Anweisung zum Beenden angegeben, wird die Transaktion rückgängig gemacht, wenn der
Benutzer die Verbindung trennt. Der Befehl, um den impliziten Transaktionsmodus zu
aktivieren, lautet: SET IMPLICIT_TRANSACTIONS [ON¦OFF]
-
Expliziter Modus: Der explizite Modus wird häufig für Programmieranwendungen und für
gespeicherte Prozeduren, Trigger und Skripte verwendet. Wenn für eine bestimmte
Aufgabe eine Gruppe von Anweisungen ausgeführt wird, muss unter Umständen
festgelegt werden, an welchem Punkt die Transaktion beginnen und enden soll, damit die
gesamte Gruppe von Anweisungen erfolgreich ist oder die Änderungen der gesamten
Gruppe rückgängig gemacht werden.
Beispiel:
begin transaction
update wine
set id=1 where id=2
if (@@error <> 0) rollback transaction
commit transaction
Der SQL Server kennt mehrere Transact-SQL-Anweisungen:
-
BEGIN TRANSACTION [transaktions_name]: Mit dieser Anweisung wird eine
Transaktion gestartet
-
COMMIT TRANSACTION [transaktions_name]: Mit dieser Anweisung wird eine
Transaktion beendet, und alle ursprünglichen Datenwerte, die innerhalb der Transaktion
geändert wurden, werden in das Transaktionsprotokoll geschrieben.
-
ROLLBACK TRANSACTION [transaktions_name]: Mit dieser Anweisung werden alle
schon ausgeführten Anweisungen innerhalb einer Transaktion rückgängig gemacht. Diese
Anweisung wird entweder vom System implizit durchgeführt oder muss explizit vom
Programmierer im Programm angegeben werden. Der Programmierer verwendet die
Anweisung ROLLBACK TRANSACTION, wenn er nicht sicher ist, ob alle Änderungen
an der Datenbank korrekt ausgeführt wurden.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 13 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
-
SAVE TRANSACTION transaktions_name: Diese Anweisung erstellt eine Marke für
eine TRANSACT SQL-Anweisung innerhalb einer Transaktion. Eine anschliessende
ROLLBACK TRANSACTION-Anweisung mit demselben Transaktionsnamen setzt alle
Anweisungen zwischen der SAVE- und ROLLBACK TRANSACTION-Anweisung
zurück. (Hinweis: Die SAVE TRANSACTION-Anweisung veranlasst nicht, dass die
Datenänderungen in das Transaktionsprotokoll geschrieben werden. Diese Anweisung
zeigt lediglich eine Marke auf, die mit einer anschliessenden ROLLBACK-Anweisung mit
der gleichnamigen Marke als Bereich definiert wird, wo alle Anweisungen zurückgesetzt
werden.
Beispiel: Welche INSERT-Anweisungen werden effektiv ausgeführt?
begin transaction
insert into degustator (id, name, age,
(15,’Francois Jimenez’,25,’m’)
save transaction a
insert into degustator (id, name, age,
(16,’Michael Jackson’,37,’unknown’)
save transaction b
insert into degustator (id, name, age,
(17,’Samuel Schmid’,48,’m’)
rollback transaction b
insert into degustator (id, name, age,
(18,’Britney Spears’,12,’f’)
rollback transaction a
commit transaction
gender) values
gender) values
gender) values
gender) values
Hinweise:
-
Die SAVE TRANSACTION-Anweisung stellt ein nützliches Konstrukt dar, um die
Ausführung verschiedener Teile einer Transaktion, mit Hilfe der if- bzw. whileAnweisung zu ermöglichen. Andererseits widerspricht ihre Verwendung dem Prinzip, dass
eine Transaktion so kurz wie möglich sein soll.
-
Jede Transact-SQL-Anweisung befindet sich immer innerhalb einer Transaktion, entweder
implizit oder explizit. Die explizite Transaktion kennzeichnet alle Anweisungen zwischen
der BEGIN TRANSACTION und der COMMIT (bzw. ROLLBACK) TRANSACTION.
Andererseits wird jede Anweisung implizit als eine einzelne Transaktion behandelt, falls
keine expliziten Transaktionen angegeben sind.
-
Der SQL-Server erlaubt die Verwendung von geschachtelten Transaktionen. Jedes
Anweisungspaar BEGIN/COMMIT bzw. BEGIN/ROLLBACK kann innerhalb eines oder
mehrerer solcher Paare geschrieben werden. Die praktische Anwendung der
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 14 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
geschachtelten Transaktionen liegt darin, dass die Datenbankprozeduren, die Anweisungen
bezüglich einer Transaktion enthalten, selbst innerhalb einer Transaktion aufgerufen
werden können. Die Systemvariable @@trancount enthält die augenblickliche
Schachtelungstiefe innerhalb der geschachtelten Transaktion.
6.3. Sperren
Ein Datenbankmanagementsystem (DBMS) muss beim Mehrbenutzerbetrieb Mechanismen
enthalten, die allen Benutzern zur selben Zeit den Zugriff auf Daten einer Datenbank
ermöglichen. Beim SQL-Server, wie bei den meisten anderen DBMS wird dies mit Hilfe von
Sperren erreicht.
Das Sperrverfahren dient dem Zweck, einem Benutzer die Möglichkeit zu geben, eine oder
mehrere Reihen exklusiv zu bearbeiten, ohne dass die anderen Benutzer diese Reihe in der
Zwischenzeit in unvorhergesehener Weise benutzen bzw. ändern können.
Objekte einer Datenbank können beim SQL Server sowohl implizit als auch explizit gesperrt
werden. Der SQL-Server kann verschiedene Objekte sperren:
-
Reihe: Eine Reihe ist das kleinste DB-Objekt, das gesperrt werden kann.
-
physikalische Seite: Dies ist das meistbenutzte Sperrobjekt von SQL-Server. Die
Seitensperre sperrt die physikalische Seite in der sich die Reihe befindet, die gesperrt
werden soll.
-
Tabelle
-
Datenbank
Die Entscheidung, welches Objekt beim SQL Server gesperrt werden soll, hängt von mehreren
Faktoren ab. Bei einer Seitensperre wird einerseits die Verfügbarkeit anderer Reihen der Tabelle,
die sich auf derselben Seite befinden, eingeschränkt, andererseits wird die Anzahl der Sperren
gering gehalten. Bei einer Reihensperre wird die Verfügbarkeit der Reihen für die anderen
Benutzer erhöht, gleichzeitig aber auch die Anzahl der notwendigen Sperren.
Das SQL-Server-System benutzt unterschiedliche Typen von Sperren, abhängig davon, ob es sich
um Reihen-, Seiten- oder Tabellensperren handelt.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 15 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
6.4. Blockierungen und Deadlocks
Blockierungen und Deadlocks sind zwei Probleme, die bei gleichzeitigen Transaktionen auftreten
können. Sie können in einem System zu schwer wiegenden Problemen führen und die Leistung
beeinträchtigen oder das System gar zu einem Stillstand bringen. Diese Probleme können in der
Anwendung behandelt werden, oder sie werden so gut wie möglich von SQL Server bearbeitet.
Blockierungen treten auf, wenn eine Transaktion eine Sperre für eine Ressource besitzt und eine
zweite Transaktion einen konfliktverursachenden Sperrtyp für die Ressource verlangt. Die zweite
Transaktion muss warten, bis die erste Transaktion die Sperre aufhebt, d.h. die zweite Transaktion
wird durch die erste Transaktion blockiert. Eine Blockierung entsteht in der Regel, wenn eine
Transaktion über einen längeren Zeitraum eine Sperre hält. Dadurch bildet sich eine Kette
blockierter Transaktionen, die darauf warten, dass andere Transaktionen abgeschlossen werden,
sodass sie die erforderlichen Sperren erhalten können. Diese Situation wird als Kettenblockierung
bezeichnet.
Tabelle_1
Tabelle_2
Benötigt die gleiche Sperre
Für Tabelle_2 – blockiert durch
Transaktion 2
Besitzt eine Sperre
für Tabelle_1
Blockierung
Blockierung
Transaktion 1
Transaktion 2
Besitzt eine Sperre für Tabelle_2
Transaktion 3
Benötigt die gleiche Sperre
Für Tabelle_1 – blockiert durch
Transaktion 1
Abbildung 1: Beispiel einer Kettenblockierung
Ein Deadlock unterscheidet sich von einer blockierten Transaktion dadurch, dass an einem
Deadlock zwei blockierte Transaktionen beteiligt sind, die aufeinander warten. Angenommen,
eine Transaktion besitzt eine Exclusive-Sperre für Tabelle_1, und eine zweite Transaktion besitzt
eine Exclusive-Sperre für Tabelle_2. Bevor eine der beiden Exclusive-Sperren aufgehoben
werden kann, benötigt die erste Transaktion eine Sperre für Tabelle_2 und die zweite Transaktion
eine Sperre für Tabelle_1. Jetzt wartet jede Transaktion darauf, dass die andere ihre ExklusiveSperre aufhebt. Beide Transaktionen heben ihre Exclusive-Sperre jedoch erst auf, wenn ein
Commit oder Rollback ausgeführt wird, um die Transaktion abzuschliessen. Keine der beiden
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 16 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
Transaktionen kann abgeschlossen werden, weil beide zur Fortsetzung eine Sperre benötigen, die
von der jeweils anderen Transaktion gehalten wird. Diese Situation bezeichnet man als Deadlock.
Bei einem Deadlock beendet SQL-Server eine der Transaktionen, die danach erneut ausgeführt
werden muss.
Tabelle_1
Tabelle_2
Besitzt eine Sperre
für Tabelle_1
Besitzt eine Sperre
für Tabelle_2
Blockierung
Transaktion 1
Benötigt eine Sperre
für Tabelle_2
Transaktion 2
Benötigt eine Sperre
für Tabelle_1
Abbildung 2: Beispiel eines Deadlocks
Beispiel: Zeigt eine Situation in der die gegenseitige Blockierung zweier Prozesse auftreten.
/* beide Prozesse müssen gleichzeitig gestartet werden */
begin transaction
update wine
set name=’Faustino V’
where id=11
waitfor delay “00:00:05“
update degustator
set name=’Elvis Presley’
where id=4
commit transaction
Departement für Informatik
Universität Fribourg
begin transaction
update degustator
set age=64
where id=4
waitfor delay “00:00:05“
delete from wine
where id=11
commit transaction
2004-12-20
Seite 17 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
7. Aufgaben zu den obigen Themen
Wir werden das Tool „Query Analyzer“ von MS-SQL-Server für die praktischen Arbeiten
verwenden. Dieses befindet sich im Enterprise Manager unter Tools. Zuerst müssen wir eine
Verbindung zur Datenbank herstellen, die uns interessiert:
Server/Datenbank:
IIUFpc06/WeinDB_xx
Username:
dbs_user
Passwort:
dbs2000
wobei xx die entsprechende Gruppe darstellt [00..24].
Die folgenden Aufgaben sind zu lösen:
(Für die Aufgaben 1 bis 4 arbeiten Sie mit den Tabellen aus der Übung 3 (Wein-Datenbank).
Kopieren Sie diese falls nötig die Weindb in Ihre Datenbank oder führen sie die SQL-Skripte,
welche auf der Übungsseite verfügbar sind, aus.)
1. Erstellen Sie eine View, die die Weine mit ihren Produzenten auflistet.
2. Erstellen Sie eine View, die die Degustatoren mit deren bewerteten Weinen und den
dazugehörigen Bewertungen (ratings) darstellt.
3. Erstellen Sie eine DB-Prozedur change_name:
Parameter: @degustator_name_old varchchar (30), @degustator_name_new varchar (30)
Die Prozedur soll kontrollieren, ob der Degustator @degustator_name_old existiert
(Befehl IF EXISTS).
Falls ja, soll der Name geändert werden in @degustator_name_new und die Mitteilung
"Der Degustator "+@degustator_name_old+" wurde in "+@degustator_name_new+"
umbenannt." erscheinen.
Falls der Name nicht existiert, soll die folgende Mitteilung erscheinen: "Der Degustator
"+degustator_name_old+" existiert nicht.
4. Erstellen Sie die DB-Prozedur wine_rating:
Parameter: @wine_name varchar (30)
Falls der Wein Bewertungen hat, soll ein Titel erscheinen, der den Namen des Weines und
dessen Kategorie enthält.
Danach soll die Durchschnittsbewertung der verschiedenen Bewertungen berechnet und
ausgegeben werden.
Falls der Wein keine Bewertungen hat, soll dies in einem Text mitgeteilt werden.
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 18 von 19
Vorlesung Datenbanksysteme 2004/2005
Prof. Dr. Andreas Meier
Assistent: Christian Mezger
5. Definieren Sie mit Hilfe von Triggern die referentielle Integrität für den Primärschlüssel
der Tabelle abteilung (abt_nr) und des gleichnamigen Fremdschlüssels der Tabelle
mitarbeiter. Übernehmen Sie die explizite Transaktionskontrolle im Trigger.
create table abteilung
(abt_nr char(4) not null,
abt_name char(20) not null,
stadt char(15) null)
go
create table mitarbeiter
(m_nr int not null,
m_name char(20) not null,
m_vorname char(20) not null,
abt_nr char(4) null)
go
6. Erstellen Sie eine Journalisierung für sämtliche INSERT, UPDATE UND DELETEAnweisungen für die Mitarbeiter Tabelle. Dabei soll jeweils der Benutzer, die Zeit und der
geänderte Wert geführt werden. Zudem sollen sie mittels Triggers sicherstellen, dass das
Eintrittsdatum nach dem erstmaligen Einfügen nicht mehr geändert werden kann, dass das
Eintrittsgehalt nicht grösser als CHF 100'000.- ist, und die Lohnerhöhung jeweils nicht
mehr als 6% betragen kann.
CREATE TABLE [Mitarbeiter] (
[Mitarbeiter_ID] [int] NOT NULL ,
[Mitarbeiter_Name] [char] (20) NULL ,
[Mitarbeiter_Vorname] [char] (20) NULL ,
[Mitarbeiter_Geburtstag] [datetime] NULL ,
[Mitarbeiter_Einstellungsdatum] [datetime] NULL ,
[MA_Adresse] [varchar] (50) NULL ,
[MA_PLZ] [varchar] (10) NULL ,
[MA_Ort] [varchar] (50) NULL ,
[MA_Gehalt] [int] NULL ,
[Bemerkung] [varchar] (100) NULL
)
7. Erstellen Sie mit Transakt-SQL ein Beispiel für eine Kettenblockierung und ein Deadlock.
Zeigen Sie daraufhin, wie die Fehler für das vorgeschlagene Beispiel mit geeigneter
Applikationslogik verhindert werden können.
Die Lösungen sollen bis zum 12. Januar 2005 erstellt, und mir in einer Textdatei zugesandt
werden ([email protected]).
Departement für Informatik
Universität Fribourg
2004-12-20
Seite 19 von 19