Online Dokument auf der CSC website
Werbung

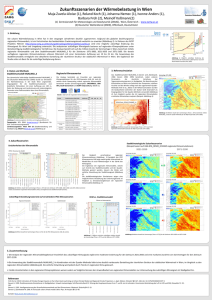
Online Dokument auf der CSC website http://www.climate-service-center.de/031081/index_0031081.html.de Klimamodelldaten für Deutschland und Europa Hintergrund und Anleitung für Datennutzer Viele Anfragen an das CSC befassen sich mit Klimamodellen und Klimamodelldaten. Was sind Klimamodelle? Welche Klimamodelle gibt es? Welches Modell ist für meine spezifische Fragestellung am besten geeignet? Welche Klimamodelldaten kann ich für meine Frage nutzen und wie komme ich an die relevanten Daten? Auf den folgenden Seiten haben wir die wesentlichen Informationen für Nutzer von Klimamodelldaten zusammengestellt. Klimamodelldaten für Deutschland und Europa Klimamodelldaten für Deutschland und Europa Hintergrund und Anleitung für Datennutzer Viele Anfragen an das CSC befassen sich mit Klimamodellen und Klimamodelldaten. Was sind Klimamodelle? Welche Klimamodelle gibt es? Welches Modell ist für meine spezifische Fragestellung am besten geeignet? Welche Klimamodelldaten kann ich für meine Frage nutzen und wie komme ich an die relevanten Daten? In dieser Rubrik haben wir die wesentlichen Informationen für Nutzer von Klimamodelldaten zusammengestellt. Klima und Klimawandel Unter dem Begriff "Klima" versteht man das „mittlere Wetter“, d.h. den Zustand der Atmosphäre an einem Ort oder in einer Region, der über einen längeren Zeitraum durch den Mittelwert und die Schwankungsbreite, also die Variabilität, der meteorologischen Größen beschrieben werden kann. Der betrachtete Zeitraum muss lang genug sein, so dass einzelne extreme Jahre nicht überproportional ins Gewicht fallen. Was versteht man unter Klima? Wann spricht man von Klimawandel? Mehr Klimamodellierung Das Klima und dessen Veränderungen können mit Klimamodellen beschrieben werden. Dies sind Computermodelle, die auf physikalischen und biogeochemischen Grundgleichungen der Massen-, Impuls- und Energieerhaltung basieren. Das Modell umfasst die für das Klima wichtigen Prozesse in der Atmosphäre, im Ozean, an der Erdoberfläche, im Boden, in der Biosphäre, in den Eisschilden und Gletschern mit ihren vielfältigen Wechselwirkungen. Unterschiedliche regionale Klimamodelle wurden entwickelt, um die simulierten globalen Klimaänderungen auf die regionale Ebene zu übertragen. Was ist ein Klimamodell? Regionale Klimamodelle allgemein Dynamische Regionalmodelle Statistische Regionalmodelle Klimaprojektionen Wie kann ein Klimamodell das gegenwärtige Klima beschreiben und worauf beruhen die Projektionen? Mehr Bandbreiten der Klimamodelle Die Zukunftsszenarien enthalten Annahmen, kein Modell ist fehlerlos und das Klima ist variabel - wie geht man damit um? Mehr Regionale Klimamodelldaten Welche Klimamodelldaten kann ich für meine Fragen nutzen? Regionalmodelle für Deutschland Regionalmodelle für Europa (ENSEMBLES-Daten) Wie kann ich Datensätze in der CERA Datenbank auswählen? Klima und Klimawandel Der Begriff „Wetter“ beschreibt den augenblicklichen Zustand der Atmosphäre. Unter dem Begriff „Klima“ versteht man dagegen das „mittlere Wetter“. Dies ist der Zustand der Atmosphäre an einem Ort oder in einer Region, der über einen längeren Zeitraum durch den Mittelwert und die Schwankungsbreite, also die Variabilität der meteorologischen Größen, beschrieben werden kann. Der betrachtete Zeitraum muss lang genug sein, so dass einzelne extreme Jahre nicht überproportional ins Gewicht fallen. Das Wetter können wir mit unseren Sinnen erfassen. „Klima“ dagegen ist die Statistik über alle Wetterereignisse. Als Referenzzeiträume für die Bestimmung des Klimas der Gegenwart wurden von der WMO (World Meteorological Organization) 30-jährige Klimaperioden zugrunde gelegt, z.B. bislang die Jahre 1901–1930, 1931–1960 und 1961–1990. Betrachtete Klimavariable sind z.B. die Temperatur, der Niederschlag, der Wind und die Einstrahlung (meistens in Bodennähe). Werden nun Mittelwerte für andere Zeiträume als die Klimaperioden berechnet und entsprechen ihre langjährigen Mittelwerte (gegenwärtig oder auch zukünftig, ermittelt durch Klimasimulationen) den Mittelwerten der Referenzperiode, bleibt das Klima stabil. Wenn sich der Mittelwert und die Variabilität erkennbar verändern, liegt eine Klimaänderung vor. Die kurzwellige Einstrahlung der Sonne ist der „Motor“ unseres Wetters. Ihre Strahlung trifft wegen der Kugelgestalt unseres Planeten nicht überall gleichmäßig, sondern unter unterschiedlich großen Einfallswinkeln auf die Erde. Am Äquator ist die Sonneneinstahlung bedeutend größer als an den Polen. Die atmosphärische Zirkulation (heiße Luft steigt auf, kalte Luft sinkt ab) sorgt - sehr Das Klimasystem und seine Komponenten vereinfacht dargestellt - für einen (Cubasch und Kasang, 2000); zum Vergrößern Bild anklicken Temperaturausgleich zwischen diesen Extremen. Anderenfalls würde es am Äquator immer heißer und an den Polen immer kälter werden. Weitere Einflüsse auf die groß- und kleinräumige Zirkulation der Atmosphäre entstehen durch die Tages- und Jahreszeiten (durch die Erddrehung und die Drehung der Erde um die Sonne), durch die Oberflächengestalt der Erde (Land-Meer-Verteilung, Relief, Vegetation) und durch die Wechselwirkung aller Komponenten des Klimasystems. Das Klimasystem beinhaltet die Atmosphäre, den Boden, die Meere und Seen, Eisschilde und Gletscher sowie die Pflanzen. In den Teilen des Klimasystems werden Wärme, Wasser und Impuls transportiert, und zwischen allen Teilen besteht ein Austausch. Dabei gibt es Wechselwirkungen, die schnell ablaufen und das Wetter bestimmen – wie z.B. Transport von kalter arktischer Luft durch ein Tiefdruckgebiet – und langsam ablaufende Prozesse, die einen Einfluss auf das zukünftige Klima haben – wie z.B. das Freisetzen von CO2 aus Permafrostböden. Auch der Mensch hinterlässt Spuren im Klimasystem und beeinflusst so das Klima. Dies geschieht am stärksten durch Änderungen in der Landnutzung (etwa durch Abholzen von Wäldern, Verstädterung) und durch die Emission von Treibhausgasen (Verbrennung fossiler Brennstoffe, industrielle Prozesse) sowie durch Partikel, sogenannte Aerosole (z.B. Ruß oder Schwefel u.a.). Der Klimawandel findet bereits statt Natürliche Klimänderungen, sowohl auf langen (100.000 Jahre), als auch kürzeren Zeitskalen (500 Jahre) hat es immer gegeben. Sie beruhen auf externen Einflüssen (z.B. astronomische Veränderungen, Vulkanausbrüche) oder internen Prozessen aufgrund von Wechselwirkungen innerhalb des Klimasystems (interne Variabilität). Speziell in Regionen der gemäßigten Breiten gibt es immer wieder mehrere Jahre mit kühlen und verregneten Sommern oder mit ungewöhnlich kalten Wintern hintereinander. Das ist nicht eine Änderung des Klimas, sondern es ist ein Merkmal des Klimas, das eine interannuale und dekadische Variabilität aufweist. Von einer Änderung des Klimas kann man erst sprechen, wenn sich über Zeiträume von mehr als etwa 30 Jahren Änderungen im Mittelwert, beispielsweise der Temperatur oder in deren Extremen, zeigen. Es gibt Indikatoren, die auf längerfristige Änderungen hinweisen wie z.B. der Rückzug der Gletscher oder die sich nach vorne verschiebende Blüte der Obstbäume. Tatsächlich wird in Deutschland seit einigen Jahrzehnten eine Erwärmung beobachtet - ebenso wie weltweit, beispielsweise durch die Abnahme arktischen Eises. Klimamodellierung Ein Klimamodell ist ein Computermodell, in dem die für das Klima und dessen Veränderung wichtigen Komponenten und Prozesse im Erdsystem beschrieben sind. Es basiert auf den physikalischen und biogeochemischen Grundgleichungen der Massen-, Impuls- und Energieerhaltung. Das Modell umfasst die für das Klima wichtigen Prozesse in der Atmosphäre, im Ozean, an der Erdoberfläche, im Boden, in der Biosphäre, in den Eisschilden und Gletschern mit ihren vielfältigen Wechselwirkungen. Für die Modellierung des Klimas müssen bspw. die Sonneneinstrahlung, die chemische Zusammensetzung der Atmosphäre und die Beschaffenheit der Erdoberfläche bekannt sein. Globalmodelle Ein Klimamodell ist ein in sich geschlossenes System, es umfasst den gesamten Globus, lediglich die Energiezufuhr durch Sonneneinstrahlung von außen wird vorgeschrieben. Klimamodelle bestehen aus verschiedenen Modulen für die Komponenten des Klimasystems, Atmosphäre, Ozean, Land, Chemie, Kryosphäre, Vegetation. Die Parameter der Klimamodelle werden auf einem dreidimensionalen numerischen Gitter dargestellt. Zwischen den benachbarten Gitterpunkten werden von Zeitschritt zu Zeitschritt der Austausch an Masse, Impuls. Stoffen und Energie durch mathematische Gleichungen mit Hochleistungsrechnern realisiert. © IPCC Das Modellgitter der globalen Klimamodelle hat etwa eine horizontale Maschenweite von 100 - 200 km. Die Ozeane sind für Binnenmeere wie etwa das Mittelmeer häufig feiner aufgelöst. Im Modul Atmosphäre wird auf 20 – 30 vertikalen Schichten bis in die Stratosphäre gerechnet, wobei die untere Troposphäre höher aufgelöst ist. Entsprechend der horizontalen Auflösung wird mit einem Zeitschritt von etwa 5 - 12 min gerechnet. Die berechneten Parameter werden alle 6 h ausgeschrieben, z.T. als Momentanwerte, z.T. als Mittelwerte oder Summen über das Ausgabeintervall. So erhält man für jede Gitterbox Zeitreihen der Variablen. Die Anforderungen durch die wachsende Vielfalt der zu beschreibenden Prozesse und durch den Wunsch nach einer immer höheren räumlichen und zeitlichen Auflösung können auch mit den größten derzeitigen Rechnern nicht erbracht werden, denn die räumliche Skala vom molekularen Bereich (Wolkenbildung, Dissipation der Turbulenz, …) bis hin zur großräumigen Skala im Bereich des Erdumfangs von 40.000 km, sowie die zeitliche Skala von Bruchteilen von Sekunden bis hin zu Jahrhunderten und ggf. mehr, umfasst ein zu großes Spektrum an Größenordnungen. Daher werden alle Prozesse, die in Bereichen kleiner als die zweifache horizontale Auflösung des Modells ablaufen, durch Annäherungen dargestellt. Ihre Auswirkungen auf das Gesamtsystem werden so berücksichtigt. Würde man zu einem Zeitpunkt alle Parameter des Erdsystems in hoher Auflösung genau kennen (Wind, Temperatur, Eis- und Wasserwolken, Wasser im Boden, Waldanteil der Landflächen, Meerestemperatur, …), so könnte man das Modell starten und würde für die ersten Tage eine passable Wettervorhersage erhalten. Liefe das Modell aber länger als etwa 10 Tage, so könnte die wirklich eintretende Wetterentwicklung nicht mehr realistisch simuliert werden. Die Prozesse in der Atmosphäre sind nicht-linear und somit "chaotischer" Natur, so dass mehr und mehr ein zufälliges Modellwetter ausgebildet würde. Das bedeutet, dass kleine Einflüsse mit der Zeit einen großen Effekt hervorrufen können. Hätte man die Modellvorhersage zum gleichen Zeitpunkt, aber mit geringfügig geänderten Startbedingungen gestartet, hätte sich nach und nach ein ganz anderes Wetter entwickelt (das ist der berühmte Flügelschlag eines Schmetterlings oder der Schmetterlingseffekt, wie er in der Chaostheorie genannt wird: Der Meteorologe Edward Lorenz fand schon 1963 mit einfachen Computersimulationen heraus, dass durch eine bloße Abrundung der Anfangsdaten hinter der Kommastelle am Ende völlig unterschiedliche Ergebnisse herauskommen). Bezogen auf das Klima wären aber alle Simulationen mit geringfügig anderen Anfangsbedingungen gleichwertig, denn sie liefern im statistischen Mittel in etwa das gleiche Ergebnis. Eine Beschreibung des globalen Atmosphären- und Ozeanmodells des Max-Planck-Institus für Meteorologie findet man unter MPI ECHAM-Modell MPI MPIOM-Modell Regionale Klimamodelle allgemein Regionale Klimamodelle wurden entwickelt, um die simulierten globalen Klimaänderungen auf die regionale Ebene zu übertragen. Regionale Klimamodelle decken also mit ihrem Modellgebiet nur einen Teil der Erde ab. Sie werden in globale Klimamodelle eingebettet und am Rand mit der global simulierten, großskaligen Zirkulation "angetrieben". So ist es möglich, ausgewählte Region detaillierter zu untersuchen und eine Brücke zwischen globalen Klimaprojektionen und lokalen Auswirkungen zu schlagen. Regionale Klimamodelle stellen somit eine wichtige Ergänzung der globalen Klimamodelle dar. Bild zum Vergrößern anklicken Verfeinerung Modelle Erdkugel Global Regional Dynamische Regionalmodelle Dynamische regionale Klimamodelle sind 3-dimensionale atmosphärische Zirkulationsmodelle in einem begrenzten Ausschnitt des Globus. In ihnen werden alle relevanten physikalischen Prozesse dynamisch berechnet. Hierdurch können auch nichtlineare Prozesse berücksichtigt werden. Die räumliche Auflösung der regionalen Klimamodelle liegt derzeit zwischen 7 km und 50 km. Die Ergebnisse sind Flächenmittelwerte der Gitterboxen. Durch die hohe horizontale Gitterauflösung liefert ein regionales Modell wesentlich kleinräumigere Klimainformationen durch eine bessere Repräsentierung des Untergrundes (z.B. Orographie, Landnutzung) und eine Auflösung wichtiger kleinerskaliger Prozesse, die in Globalmodellen parameterisiert werden müssen. Allerdings müssen auch in regionalen Klimamodellen Prozesse mit räumlichen und zeitlichen Skalen unterhalb der Auflösung des Modells näherungsweise durch physikalische Parametrisierungen berechnet werden. Regionalmodelle benötigen an den seitlichen Modellgebietsrändern Informationen über die großräumige Zirkulation. Dieser „Antrieb“ wird den regionalen Klimamodellen auf einer Randzone des Modellgebiets vorgegeben. Die „antreibenden“ Daten können dabei von einem globalen Klimamodell, von einer regionalen Klimasimulation auf einem größeren Modellgebiet oder aus Analyse- bzw. Reanalysedaten stammen, wie sie beispielsweise in Europa vom Europäischen Zentrum für Mittelfristige Wettervorhersage (ECMWF) und in den USA vom National Center for Atmospheric Research (NCAR) zur Verfügung gestellt werden. Struktur dynamischer Regionalmodelle Dynamische Regionalmodelle verwenden als grundlegende Gleichungen die hydro- und thermodynamischen Grundgleichungen, die Modelle für die Region Deutschland verwenden in der Regel ein rotiertes sphärisches Koordinatensystem. Die Rotation der Pole wird im Allgemeinen so gewählt, dass der reale Äquator zentral durch das Modellgebiet verläuft. Damit wird sichergestellt, dass die Modellgitterboxen annähernd gleiche Flächen und rechtwinklige Gitterkanten haben. Die prognostischen Variablen sind die horizontalen Komponenten des kartesischen Windvektors, Luftdruck, Temperatur, spezifische Feuchte, Flüssigwassergehalt und ggf. turbulente kinetische Energie und der spezifische Wassergehalt von Regen und Schnee. Zu den parameterisierten Prozessen gehören Turbulenz, Strahlung, Wolken- und Niederschlagsprozesse, Bodenprozesse sowie der Austausch an der Grenzfläche Boden/Atmosphäre. Der Erdboden bzw. die Meeresoberfläche stellen die untere Randbedingung der Atmosphäre dar. Die Meeresoberflächentemperatur wird als zeitlich variable Größe aus dem globalen Klimamodell vorgegeben. Die Land-Meer-Verteilung wird fest vorgegeben und ist an die horizontale Auflösung des Modells angepasst. Die Land-See Verteilung wird fraktionell für jede Gitterbox vorgegeben, eine Gitterbox kann also Land und Wasseranteile enthalten. Für die Landflächen werden die Bodenfeuchte und die Bodentemperatur in mehreren Schichten vom Modell berechnet. Dynamische Regionalmodelle geben feste Randbedingungen über eine „Bodenbibliothek“ vor. Diese liefert Parameter wie die Höhe der Erdoberfläche über dem Meeresniveau, die Rauhigkeitslänge, den Blattflächenindex, die Vegetationsbedeckung, die Wurzeltiefe, den Bodentyp, die fraktionelle Waldbedeckung, die maximale Wasserhaltekapazität des Bodens und die Temperatur der untersten Bodenschicht. Die Vegetationsbedeckung, der Blattflächenindex sowie die Hintergrundalbedo des Bodens werden monatlich variabel als mittlerer Jahresgang vorgeschrieben. Statistische Regionalmodelle Die statistischen regionalen Klimamodelle basieren auf der Analyse statistischer Zusammenhänge zwischen beobachteten großräumigen atmosphärischen Strukturen und dem lokalen Wettergeschehen. Die Ergebnisse liegen auf Stationsbasis vor. Unter der Annahme, dass diese Zusammenhänge auch in Zukunft gültig bleiben, wird die Ursache für eine lokale Klimaänderung in einer sich ändernden Häufigkeit und Intensität großräumiger meteorologischer Strukturen gesehen. Auch statistische Modelle benötigen die Vorgaben von globalen dynamischen Modellen zur Regionalisierung. Klimaprojektionen Zur Simulation der Vergangenheit - etwa der letzten 150 Jahre - wird in der Klimamodellierung folgendermaßen vorgegangen: .© IPCC 2007- Vergleich der beobachteten Änderungen der Erdoberflächentemperatur auf kontinentaler und globaler Skala mit den von Klimamodellen auf Grund entweder natürlicher oder sowohl natürlicher als auch anthropogener Antriebe berechneten Resultaten. Die 10-Jahrzehnt-Mittel der Beobachtungen sind für den Zeitraum 1906–2005 (schwarze Linie) im Zentrum des Jahrzehnts und relativ zum entsprechenden Mittel von 1901–1950 eingezeichnet. Die Linien sind gestrichelt, wenn die räumliche Abdeckung weniger als 50% beträgt. Blau schattierte Bänder zeigen die 5-95%-Bandbreite für 19 Simulationen von 5 Klimamodellen, welche nur die natürlichen An- triebe durch Sonnenaktivität und Vulkane berücksichtigen. Rot schattierte Bänder zeigen die 5–95%-Bandbreite für 58 Simulationen von 14 Klimamodellen unter Verwendung sowohl der natürlichen als auch der anthropogenen Antriebe. Zum Vergrößern Bild anklicken Ein Klimamodell wird zunächst unter festgehaltenen Bedingungen der extraterrestrischen Einstrahlung, der Landnutzung und der vorindustriellen Treibhausgaskonzentration (Jahr 1850) gestartet und über ca. 300 Jahre gerechnet. Nach vielen Jahren stellt sich nach einer Einschwingzeit ein Gleichgewicht zwischen Ozean – Biosphäre – Kryosphäre und Atmosphäre ein und der Klimalauf spiegelt die für das Klimasystem typische Variabilität über Witterungsperioden, interannuelle und dekadische Perioden wider. Dann beginnt man einen weiteren Klimalauf auf der Basis dieses sogenannten „Kontrolllaufs“ zu einem beliebigen Zeitpunkt nach der Einschwingphase und fügt die bekannten veränderten, global ermittelten Treibhausgaskonzentrationen ein. Das Resultat ist EINE Realisierung des Klimas bis zum Jahr 2000. Setzt man eine weitere Simulation zu einem anderen beliebigen Zeitpunkt auf – also unter etwas unterschiedlichen Anfangsbedingungen – so erhält man eine andere Realisierung. Ein Ensemble vieler solcher Klimaläufe beschreibt das tatsächlich beobachtete Klima relativ gut. Es konnte gezeigt werden, dass der in den letzten Jahrzehnten beobachtete globale Temperaturanstieg mit Klimamodellen nur nachvollzogen werden kann, wenn neben den natürlichen Antriebsfaktoren auch der Antrieb durch die anthropogenen Treibhausgasemissionen berücksichtigt wird. Wenn nur die natürlichen Antriebe (Sonnenaktivität, Vulkanausbrüche) berücksichtigt werden, bleibt dieser Temperaturanstieg aus. Auf diese Weise gewinnt man Vertrauen in Klimasimulationen. Für die Zukunft müssen Annahmen über die globale Entwicklung der Treibhausgase bis zum Jahr 2100, teilweise auch darüber hinaus, gemacht werden. Für den 4. Sachstandsbericht (Fourth Assessment Report:AR4) wurden verschiedene Annahmen über mögliche zukünftige Wege vom Weltklimarat (International Panel on Climate Change: IPCC) vorgeschlagen. Die meistverwendeten Szenarien sind: © IPCC 2000 / Klimawiki / Kasang - Schematic illustration of SRES scenarios. The four scenario "families" are shown, very simplistically, as branches of a two-dimensional tree. In reality, the four scenario families share a space of a much higher dimensionality given the numerous assumptions needed to define any given scenario in a particular modeling approach. The schematic diagram illustrates that the scenarios build on the main driving forces of GHG emissions. Each scenario family is based on a common specification of some of the main driving forces. The A1 storyline branches out into four groups of scenarios to illustrate that alternative development paths are possible within one scenario family. Two of these groups were merged in the SPM. Zum Vergrößern Bild anklicken Szenario A1B: schnelle wirtschaftliche Entwicklung, Bevölkerungswachstum bis zur Mitte des Jahrhunderts, Einsatz von effizienten Technologien, Nutzung fossiler und nicht fossiler Energieträger, Globalisierung in kultureller und sozialer Hinsicht. Szenario A2: kontinuierlicher Anstieg der Weltbevölkerung, ökonomische Entwicklung ist primär regional bestimmt, langsame und regional unterschiedliche technologische Entwicklung. Szenario B1: schneller Wandel der globalen, wirtschaftlichen Struktur hin zur Dienstleistungs- und Informationsgesellschaft, Einführung sauberer und Ressourcen schonender Technologie, Bevölkerungswachstum bis zur Mitte des Jahrhunderts analog zum Szenario A1B. Szenario B2: Bevölkerung wächst kontinuierlich, aber weniger stark als bei A2, mäßiges Wirtschaftswachstum, Wandel zu neuen Technologien, Weg hin zu Umweltschutz und sozialer Angleichung eher auf lokaler und regionaler Ebene. © Jacob et. al. - Zeitliche Entwicklung der CO2 Konzentrationen gemäß Beobachtungen (1850-2000) sowie in den IPCC Szenarien A2, A1B und B1. Zum Vergrößern Bild anklicken Entsprechend den Annahmen über die ökonomische, demographische, technologische Entwicklung und über Schutzmaßnahmen können Emissionen und daraus abgeleitet ein zusätzlicher Treibhausgasausstoß ermittelt werden. In die Klimamodelle geht dieser als ein erhöhter Strahlungsantrieb ein. Weitere Informationen Klimanavigator.de: Dossier Treibhauseffekt und Emissionszenarien Bandbreiten der Klimamodelle Die Klimaentwicklung der Vergangenheit und der Zukunft kann nicht exakt simuliert werden, auch nicht auf der Basis von 30 Jahres-Mittelwerten und Standardbweichungen. Diese Unsicherheit ist System-immanent. Die Gründe sind Folgende: © K. Keuler, Forum "Klimawandel im 21. Jahrhundert", Dez. 2008, BTU Cottbus • Kein Klimamodell kann alle Vorgänge, die im Erdsystem ablaufen und sich wechselseitig beeinflussen, genau wiedergeben (vgl. Klimamodell). Dadurch treten Ungenauigkeiten auf, die sich bei den langen Simulationszeiträumen unter Umständen auch als systematische Fehler zeigen können. Jedes Klimamodell hat spezielle Eigenarten, daher ist die Nutzung eines Ensembles von Modellen empfehlenswert. • Die Klimavariabilität hat großen Einfluss auf die Größe des Mittelwertes. Wenn beispielsweise in den 30 Jahren eine Periode besonders kalter Winter auftritt, wird dadurch auch der Mittelwert beeinflusst. Auch eine Reihe unterschiedlicher 30-Jahres Mittelwerte aus einer Klimasimulation mit konstantem Antrieb weist daher eine Variabilität auf. Das gleiche gilt für die Standardabweichungen. Bei © IPCC 2007 - Left panel: Solid lines are multi-model global averages of surface warming (relative to 19801999) for the SRES scenarios A2, A1B and B1, shown as continuations of the 20th century simulations. The orange line is for the experiment where concentrations were held constant at year 2000 values. The bars in the middle of the figure indicate the best estimate (solid line within each bar) and the likely range assessed for the six SRES marker scenarios at 2090-2099 relative to 1980-1999. The assessment of the best estimate and likely ranges in the bars includes the Atmosphere-Ocean General Circulation Models (AOGCMs) in the left part of the figure, as well as results from a hierarchy of independent models and observational constraints. Beide Effekte zusammen bedingen eine Bandbreite der Ergebnisse, die keinesfalls als Fehler zu verstehen ist, sondern als eine Eigenschaft des Klimasystems. Bei den Zukunftsprojektionen kommt ein weiterer Einfluss durch die Wahl des Emissionsszenarios hinzu. Durch die unterschiedlichen Annahmen möglicher Treibhausgas- und Aerosolkonzentrationen (s. Klimaprojektionen) ergeben sich unterschiedliche Klimaverläufe, die sich im globalen Temperaturanstieg unterscheiden. Die Folgerung aus diesen Ungewissheiten ist, dass es keine 'Prognose' für die zukünftige Klimaentwicklung geben kann. Es ist notwendig und sinnvoll, mit einer Bandbreite der möglichen Klimaveränderung zu planen. Regionalmodelle für Deutschland CLM Regionalmodell Detailinformationen REMO Modell Detailinformationen WETTREG Modell Detailinformationen STAR II Modell Detailinformationen COSMO CLM (Kurzinfo) CLM D3 Modellgebiet Mit Cosmo CLM_3.1 wurden die Simulationen des Globalmodells ECHAM5/MPIOM für Europa regionalisiert. • Enwickler: Consortium for Small-scale Modeling (COSMO) • Modellgebiet Europa • Räumliche Auflösung: 0.165° ≈ 18 km • Zeitliche Auflösung: viele Parameter sind stündlich verfügbar, einige täglich oder monatlich (Mittelwerte, Summen oder Instantanwerte). Nach Transformation auf ein geographisches Gitter wurden weitere Tages-, Monats- und Jahreswerte berechnet. • Simulierte Szenarien: Gegenwart C20, A1B, B1 • Es liegen drei Realisierungen für die nahe Vergangenheit und zwei für die Zukunft vor. COSMO-CLM (Modellinfo) Modelldokumentation Infos zu bestimmten Parametern Hier finden Sie Darstellungen Infos zu Gittern und Formaten Die Daten liegen auf dem Originalgitter (‚Datenstrom 2’) und auf einem geographischen Gitter (‚Datenstrom 3’) vor. Das Format ist NetCDF. Datenmengen Da das CLM-Gebiet Europa umfasst, sind die Datenmengen sehr groß, das Gebiet Deutschland beträgt davon ca. 7.8 %. Die Datenmengen für die Datenströme 2 und 3 sind für verschiedene Mittelungszeiten und Zeiträume hier aufgelistet. Nutzungsbedingungen und Datenzugriff Die Daten sind ohne Einschränkungen und ohne Antrag nutzbar. Wie komme ich an die Daten? REMO Regionales Modell (Kurzinfo) Mit REMO XX.x wurden die Simulationen des Globalmodells ECHAM5/MPIOM für Europa und Deutschland regionalisiert. • Entwickler: Max-PlanckInstitut für Meteorologie / Climate Service Center • Modellgebiet Deutschland und Einbettung in das europäische Modell • Räumliche Auflösung: 1/6° ≈ 10 km • Zeitliche Auflösung: viele Parameter sind stündlich verfügbar, einige täglich (Mittelwerte, Summen oder Instantanwerte). Nach Transformation auf ein geographisches Gitter wurden auch Monats- und Jahreswerte berechnet. • Simulierte Szenarien: Gegenwart C20, A1B, A2, B1 • Es liegen drei Realisierungen vor. © CSC - Modellgebiet Remo 50km REMO Regionales Modell (Modellinfo) Modelldokumentation Hinweise für Datennutzer (Teil 1) pdf Hinweise für Datennutzer (Teil 2) pdf Hier finden Sie Darstellungen Infos zu Gittern und Formaten Die Daten liegen auf dem Originalgitter (‚Datenstrom2’) im ieg-Format und auf einem geographischem Gitter (‚Datenstrom 3’) im NetCDF-Format vor. Datenmengen Die Datenmengen für die Datenströme 2 und 3 sind für verschiedene Mittelungszeiten und Zeiträume hier aufgelistet. Nutzungsbedingungen und Datenzugriff Nur für die REMO-UBA-Simulation muss beim Umweltbundesamt (UBA) ein Antrag gestellt werden. Antrag für REMO-Datennutzung Wie komme ich an die Daten? WETTREG (Kurzinfo) Mit WETTREG_UBA und WettReg2010 (Wetterlagenbasierte Regionalisierungsmethode) wurden die Simulationen des Globalmodells ECHAM5/MPIOM für Deutschland regionalisiert. • Entwickler: Climate & Environment Consulting Potsdam GmbH • Modellgebiet Deutschland • Räumliche Auflösung: 398 Klimastationen und 3012 Niederschlagsstationen • Zeitraum: 1951 - 2100 • Zeitliche Auflösung: Tageswerte (Mittelwerte bzw. Summen) © CEC - Wettreg Modellgebiet • Simulierte Szenarien WETTREG_UBA: Gegenwart C20, A1B, A2, B1, WETTREG2010: A1B • Es liegen je drei Realisierungen für alle Simulationen von WETTREG_UBA vor, je 10 Realisierungen des A1B von WETTREG2010 • Die Parameterliste umfasst: Maximum, Mittelwert , Minimum der Temperatur, Niederschlages, relativenFeuchte, Luftdruck, Dampfdrucks, Sonnenscheindauer, Bedeckungsgrad, Windstärke WETTREG (Modellinfo) Modelldokumentation WETTREG UBA Dokumentation WETTREG 2010 Hier finden Sie Darstellungen Infos zu Gittern und Formaten Das Ausgabeformat für alle Daten ist ASCII (durch Semikolon getrennte Werte). Alle Daten sind in 1/10 der gegebenen Einheit gespeichert. Fehlwerte sind auf -9990 gesetzt. Datenmengen rund 65 Gigabyte (pro Szenario für alle Dekaden) Nutzungsbedingungen und Datenzugriff Nutzungsbedingungen WETTREG.pdf Wie komme ich an die Daten? Das WETTREG Modell - Ausführliche Beschreibung Das statistische, regionale Klimamodell WETTREG (WETTerlagenbasierte REGionalisierungsmethode) wurde von der Firma Climate & Environment Consulting Potsdam GmbH (CEC) entwickelt. WETTREG arbeitet nach einer Konditionierungsmethode, in der die zeitliche Entwicklung der Wetterlagenhäufigkeit und der Eigenschaften einzelner Wetterlagen vorgegeben werden. Die Vorgaben können regionalspezifisch variieren. WETTREG benötigt direkt modellierte dynamische Größen eines Klimamodells. Extrahiert wird in WETTREG nicht die Information an einzelnen Gitterpunkten, sondern die simulierte großräumige atmosphärische Situation jedes Tages, so z. B. die Felder des Geopotentials, der Luftfeuchte und der Temperatur. Als Globalmodell wird wie bei den dynamischen Modellen ECHAM5/MPIOM genutzt. Es werden Wetterlagenklassifikationen (Enke et al., 2005) genutzt, die sowohl den Temperaturbezug als auch den Feuchtebezug enthalten. Die Zeitreihen der Messdaten werden anhand der Leitgröße Temperatur in übernormal warme bzw. unternormal kalte Abschnitte unterteilt. Per Zufallsgenerator wird eine Neukombination der Witterungsabschnitte zu einer simulierten Zeitreihe unter der Prämisse einer bestmöglichen Annäherung an die vorgegebene Häu-figkeitsverteilung der Wetterlagen durchgeführt. Aufeinanderfolgende Wetterlagen müssen eine Übergangswahrscheinlichkeit von mehr als 10% aufweisen. Jeder Tag dieser simulierten Zeitreihe enthält eine Zuordnung zu Wetterlagen des Temperatur- und Feuchte-Regimes und den originalen Datumsbezug. Der Jahresgang der meteorologischen Größen, der als Abweichung vom stationsspezifischen Jahresgang vorliegt, wird anschließend auf die simulierte Zeitreihe aufgeprägt. Die simulierten Werte liegen auf dieser Verarbeitungsstufe im Wertebereich der Messwerte, können jedoch eine andere Häufigkeitsverteilung annehmen. Quelle für den vorangegangenen Text-Abschnitt Die Regionalisierung wird für die nahe Vergangenheit (1960-2000) und für die Szenarien A1B, A2 und B1 (2001-2100) durchgeführt. Die Ausgabedaten sind Tageswerte, die repräsentativ für eine Dekade sind. Es stehen 282 Klima- und 1695 Niederschlagsstationen zur Verfügung. Ausgewertet werden 10 Parameter: Temperatur (Minimum, Mittel, Maximum), Niederschlag, relative Feuchte, Bedeckungsgrad, Luftdruck, Dampfdruck, Sonnenscheindauer und Windgeschwindigkeit. Das statistische Klimamodell WETTREG beinhaltet keine Rückkopplungen wie z. B. das Abtauen der Gletscher oder Landnutzungsänderungen. Es geht davon aus, dass sich diese Rückkopplungen in den atmosphärischen Eigenschaften des globalen Klimamodells widerspiegelt. Die regionalen Klimaprojektionen für Deutschland mit WETTREG wurden im Auftrag des Umweltbundesamtes mit einer Finanzierung durch die Bundesländer durchgeführt. Die Daten sind im World Data Center for Climate (WDCC) archiviert. Ein Beispiel für die mittleren 2 m Temperaturen in Zeitintervall 1961 – 1990 ist in Abbildung 9 gezeigt. Es ist möglich, dass die Eigenschaften der Wetterlagen sich ändern und auch neue Extreme auftreten. Die bisherige Prämisse des WETTREG war, dass die Eigenschaften der zukünftigen Wetterlagen sich nicht fundamental ändern. In der modellierten 2. Hälfte des 21. Jahrhunderts können Abweichungen insbesondere im Sommer auftreten. Eine neue Modellversion (WETTREG2010) berücksichtigt auch Wetterlagen, die gegenwärtig nicht oder nur selten auftraten. Das WETTREG2010 ist dadurch stark an die Vorgabe des verwendeten globalen Klimamodells angepasst. STAR II Modell (Kurzinfo) Mit STAR II (STAtistisches Regionalisierungsmodell) wurden die Simulationen des Globalmodells ECHAM5/MPIOM ausgehend von Klimatrends für Deutschland regionalisiert. © CEC - Star Niederschlag Deutschland 2031-2060 • Entwickler: Potsdam Institut für Klimafolgenforschung • Modellgebiet Deutschland • Räumliche Auflösung: 265 Klimastationen und 2072 Niederschlagsstationen • Zeitraum Projektionen: 2007 2060 • Zeitliche Auflösung: Tageswerte (Mittelwerte bzw. Summen) • Simulierte Szenarien A1B (zusätzlich möglich 0.5K Schritte von 0K bis 3K) • Realisierungen: es liegen eine feuchte, eine normale und eine trockene Realisierung vor, die jeweils eine Auswahl aus 1000 realisierungen darstellen. • Die Parameterliste umfasst: Temperatur (tmax, tmea, tmin), Niederschlag (prec), relative Feuchte (rehu), Luftdruck (aipr), Dampfdruck (vapr), Sonnenscheindauer (sudu), Bedeckungsgrad (clou), Globalstrahlung (glra) and Windgeschwindigkeit (wive). STAR II (Modellinfo) Modelldokumentation Ergebnisse eines regionalen Szenarienlaufs Hier finden Sie Darstellungen Infos zu Gittern und Formaten Das Ausgabeformat für alle Daten ist ASCII (durch Semikolon getrennte Werte). Alle Daten sind in 1/10 der gegebenen Einheit gespeichert. Fehlwerte sind auf -9990 gesetzt. Datenmengen rund 65 Gigabyte (pro Szenario für alle Dekaden) Nutzungsbedingungen und Datenzugriff Wie komme ich an die Daten? Das STAR II Modell - Ausführliche Beschreibung Das STAR II (STAtistisches Regionalisierungsmodell) ist ein Stations-basiertes, statistisches Klimamodell. Es wurde am Potsdam-Institut für Klimafolgenforschung entwickelt und von der Firma Climate & Environment Consulting Potsdam GmbH (CEC )umgesetzt. Für die statistische Regionalisierung wird der Temperaturtrend aus globalen Klimaprojektionen sowie die Beobachtungsdaten von Klimastationen benutzt. Die Vorgehensweise ist in Orlowsky et al. (2008) beschrieben und wird im Folgenden erläutert. Langjährige Messreihen werden mit einem statistischen Verfahren so aufbereitet, dass sie in Form von Szenarienzeitreihen aus globalen Klimamodellen entnommene regionale klimatische Änderungen wiedergeben. Als Grundannahme wird die großräumige Änderung meteorologischer Größen (speziell der langjährigen Mittelwerte der Temperatur) regional als richtig angesehen. Der entsprechende Trend wird auf eine per Zufallszahlengenerator unter Berücksichtigung der interannuellen Variabilität und des Ranges erzeugte Rekombination der Jahresmittelwerte aufgeprägt. Für die gemessenen Tageswerte (Tagesmitteltemperatur) eines jeden Jahres werden die Abweichungen vom Jahresmittelwert ermittelt und unter Beachtung der Rangfolge zufällig ausgewählter Jahre der simulierten Zeitreihe der Jahresmittel zugeordnet. Die Zeitreihe der Meßdaten wird anhand von temperaturbezogenen Parameterkombinationen (Tagesmittel, Tagesamplitude, astronomisch mögliche Sonnenscheindauer, Temperaturverhalten der Vortage) einer Clusteranalyse unterzogen und die Tageswerte in Cluster ähnlicher Tage aufgeteilt. Für die simulierte Zeitreihe werden ebenfalls die Parameterkombinationen für jeden Tag berechnet und jede dieser Kombinationen über ein Distanzmaß einem der Beobachtungscluster und in diesem wiederum einem konkreten Tag zugeordnet. Damit können die kompletten meteorologischen Informationen dieses Tages in die Simulation übernommen werden. Diese Methode wird zunächst auf ausgewählte, für die Region repräsentative Stationen angewendet und danach aufgrund der Tageszuordnung auf alle Stationen übertragen. Somit wird die räumliche Konsistenz gewahrt. Quelle für den vorangegangenen Text-Abschnitt Im STAR II Modell werden 11 Klimaparameter: Temperatur (Minimum,mum), Niederschlag, relative Feuchte, Luftdruck, Dampfdruck, Sonnenscheindauer, Bewölkung, Globalstrahlung und Windgeschwindigkeit berücksichtigt. Mit den Tem-peraturtrends aus dem ECHAM5/MPIOM wurden 3 unterschiedliche Realisierungen des A1B Szenarios berechnet, eine trockene, eine mittlere und eine feuchte Reali-sierung. Diese sind für den Zeitraum von 2007 bis 2060 durchgeführt und im World Data Center for Climate (WDCC) archiviert. Das Modell benötigt nur geringe Rechnerkapazitäten. Nachteilig ist die Beschränkung auf die Änderung der Jahresmitteltemperatur, dadurch können keine jahreszeitlich spezifischen Trends erfasst werden. Durch erneute Rekombinationen der Jahresmittelwerte der Temperatur und Durchführung der nachfolgenden Arbeitsschritte können beliebig viele Szenarienrealisationen erstellt werden. Dadurch ist es möglich, ein statistisch bewertbares Stichprobenkollektiv zu erstellen, um so die Spannbreite möglicher Klimaänderungen abzusichern. Regionalmodelle für Europa (ENSEMBLES-Daten) In Kürze werden an dieser Stelle Informationen über Regionalmodelle für Europa zu finden sein. Zugang zur CERA Datenbank Um eine Zugangsberechtigung zur CERA-Datenbank zu erhalten, schickt man eine mail an: Mail an dkrz.de Wenn man einen Zugangsnamen und ein Passwort erhalten hat, kann man Daten aus der CERA-Datenbank laden: Zugang zur CERA-Datenbank Download • interaktiv über das CERA-Interface oder • mit dem jblob-Kommando Interaktiver download • aktivieren Sie "CERA user interface" (unten) durch „Click here to access to CERA database“ • Einloggen in CERA Datenbank mit username und password • Auswahl von "browse experiments" • Im oberen rechten Fenster Auswahl des Projektes durch „selct project“ (Informationen in "project information") • Auswahl eines Experiments aus der Liste im unteren Fenster (beachte u.U. die Datenströme und Realisierungen, Informationen in „Experiment information“) • Anzeige der Datensätze durch „show related entries“ • Metadaten (sind auch ohne login lesbar) können durch Anklicken eines Parameters gelesen werden, incl. Datails (Lupensymbol) • Auswahl der Parameter durch Anklicken der Box links neben dem Acronym/Namen und unten „Add selected dataset(s) to process list“, im neuen Fenster „Process list of …“ sind alle Datensätze für den download angezeigt. • Auswahl eines Datensatzes zum download durch Klicken auf das Diskettensymbol und ggf. Auswahl eines (zeitlichen) Teildatensatzes, dann Beginn des downloads durch „Next“ Download-Befehl jblob Einfacher und zeitsparender geht der download von Datensätzen mit dem Befehl „jblob“. In einem Scrip kann man auch mehrere Datensätze herunterladen. Auf der Startseite des „CERA user interface“ findet sich unter „Utilities“ der Link auf die jblob-Seite mit Hinweisen zum download, zur Installation und zur Anwendung. Jblob kann unter WINDOWS und Linux angewendet werden. Ein Beispiel für den download eines Teildatensatzes ist: jblob --dataset RE_UBA_A1B_D3_DS_PRECIP_TOT --tmin 2001-01-01 --tmax 2010-12-31 --dir verz_remo