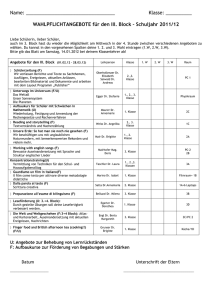
WIE wird innerhalb der ´normalen´ Baumverarbeitung erkannt, daß
Werbung

WIE wird innerhalb der ´normalen´ Baumverarbeitung erkannt, daß Operationsabbruch aufgetreten und Baum inkonsistent ist? • Bsp.: Suche nach Einträgen N,O,P führt fälschlicherweise in Block4 → Meldung „Einträge existieren nicht“ Beim Abstieg von Block i (hier:7) über Verweis Pj (hier:2) zu Block k (hier:4) wird geprüft, ob NEXT(k)=Pj+1 (hier:9≠5) Inkonsistenzen? erkannt (falls Pj+1 ex.) c) Einfügung von „O“ abgeschlossen, Einfügung von „E“ nach Schritt 5 8 ∞ I 6 B P1 B A 1 7 LNQ ∞ I P2 C 2 D EG 10 L K 3 N M 4 OP 9 Q SUV ∞ 5 • Bsp.: Suche nach Einträgen D, E, G: Verweis Pj+1 existiert in Block i nicht. Prüfung deshalb, ob NEXT(k) = NEPHEW(i) (hier: 10 ≠ 3) Inkonsistenz erkannt Fehlertoleranz 01.06.2006 44 Fehlerbehandlung in B`-Bäumen • Ausgangspunkt: Beim Abstieg von Block i auf Baumebene e zu Block k auf Ebene e-1 wird Inkonsistenz festgestellt: laufende Operation wird zunächst angehalten; es folgt die Fehlerbehandlung Einfügealgorithmus wird gestartet in Schritt 2: Einfügen von MEDIAN(k) in Block i und zu Ende geführt Suspendierte Operation wird dann (auf nun konsistenten Baum!) fortgesetzt Abschließende Bemerkungen zum B`-Baum • Kein besonderes Reparaturverfahren, sondern Nutzung des normalen Einfügealgorithmus: Vorteil insbesondere, wenn Operationsabbruch bei Reparaturdurchführung • Hier nicht betrachtet: - Wartung der Redundanzen - Löschalgorithmus 1 Originalliteratur Fehlertoleranz 01.06.2006 45 2. Erkennung/Behandlung „beliebiger“ Verfälschungen Begriffe: • Elementare Änderung ("Elementary Modifikation"): Änderung eines einzelnen, atomaren Elements einer Speicherungsstruktur (etwa ein Schlüsselwert, ein Verweis, ein Zähler …) • Eine Speicherungsstruktur heißt "n-detectable", wenn es stets möglich ist, bei bis zu n beliebigen inkorrekten atomaren Elementen die Inkonsistenz zu erkennen • . . . "n-correctable", … die Konsistenz (automatisch) wiederherzustellen Detectability und Correctability sind somit wichtige Maße zur Bewertung der Fehlertoleranzeigenschaften einer Speicherungsstruktur. Fehlertoleranz 01.06.2006 46 Einige fehlertolerante Listenimplementierungen und deren "detectability" und "correctability" "detectability" Kopf Listenelemente 1 2 "correctability" 3 0 ● 0 Zähler Identifikator 1 Fehlertoleranz ID ID ID 0 ID ID ID 1 ID ID ID 1 3 2 3 3 ID ID I II 3 ID ID 01.06.2006 47 in Praxis nicht 100%ig realisierbar Betrachtungen der Listenimplementierungen im Einzelnen 0: Setze beliebigen NEXT-Verweis fälschlicherweise auf NIL: nicht zu erkennen, nicht zu korrigieren 1: ID für alle Listenelemente gleich Annahme: Tritt in keinem anderen über Verweise erreichbaren Element (z.B. in einer anderen Liste) auf; d.h. z.B. jede Liste besitzt eigene, eindeutige ID • Nachweis der "1-detectability" durch Fallunterscheidung (Hausaufgabe!) • Nicht "2-detectable": Z.B. Zähler im Listenkopf um 1 dekrementieren und NEXT-Verweis vom vorletzten Listenelement zum Listenkopf „zurückbiegen“ → nicht zu erkennen • Nicht "1-correctable„: Z.B. kann ein inkorrekter NEXT-Verweis zum irreparablen Abtrennen von Kettenteilen führen • „Geschlossenheit“ der Kette für „detectability“ und „correctability“ ohne Bedeutung: NIL-Verweis am Ende wäre ebenfalls als Vereinbarung möglich Fehlertoleranz 01.06.2006 48 2: Doppelt verkettete Liste (NEXT- und PRIOR-Verweise) • „Detectability“- und „correctability“-Nachweis wie zuvor; offensichtlich: Listenelemente auf zwei unterschiedlichen Wegen erreichbar → ein inkorrekter Verweis kann nicht mehr zum Abtrennen von Kettenteilen führen ! • NICHT „3-detectable“: 2 Verweisänderungen plus Zähler um 1 dekrementieren → nicht erkennbar Element nicht erkennbar ausgekoppelt • NICHT „2-correctable“: 2 Verweisänderungen koppeln Kettenteile irreparabel aus 3: Ebenfalls doppelte Verkettung, aber PRIOR-Verweis zeigt auf Vorvorgänger • Zweigeteilter Listenkopf erforderlich (sonst könnte etwa Liste der Länge 1 durch 2 Änderungen unbemerkt in Liste der Länge 0 verwandelt werden) → Hausaufgabe Fehlertoleranz 01.06.2006 49 • Implementierung und Fehlererkennungsalgorithmen etwas trickreich • Angelegenheit etwas exotisch Zu den Verarbeitungskosten atom. Element • Betrachte Einfügung eines neuen Listenelements • Jede Änderung/Wertzuweisung für einen Verweis / Zähler / Identifikator trage mit 1 zu den Gesamtkosten bei (elementare Änderung nach obiger Definition) → für Datenbanksysteme ungeeignetes Kostenmaß Verarbeitungskosten 7 6 5 2 Verweise + Zähler + ID 4 3 2 Verweise 2 1 0 Fehlertoleranz 0 1 2 01.06.2006 3 Implementierung 50 Der "Chained and Threaded B-tree" (CTB-Baum) Kopf ID 8 "chain pointer" DOWN-Verweis ID ID ID ID ID ID ID ID "thread pointer" Legende: ID "chain pointer" Identifkator Fehlertoleranz 01.06.2006 51 Eigenschaften des CTB-Baums • Separater Knoten („Kopf“) mit ID und Zähler: Anzahl der Knoten im Baum • NEXT-Verweise auf Blattebene unter Einbeziehung des Kopfs → geschlossene Kette • THREAD-Verweise auf Blattebene: „The thread pointer in a leaf is non-null if and only if that leaf is the rightmost leaf in the leftmost subtree of a node X, in which case the thread points to X.“ inneren Knoten ! Konsequenz: Auf jeden Nicht-Blattknoten im CTB-Baum zeigt genau ein TREAD-Verweis • Für CTB-Baum kann „2-detectability“ und „1-correctability“ nachgewiesen werden • „2-detectability“ nur, wenn Fehlererkennungsalgorithmus den Baum vollständig durchläuft → als „online“-Prüfung durch das DBVS somit nicht geeignet Fehlertoleranz 01.06.2006 52 Der "Robust Contiguous List Storage" (RCLS) a) Modell zum Listenformat Zähler K1 K2 K3 K4 K5 5 7 2 15 0 6 9 7 8 l-1 l … Kopf Freiplatz b) Beispiel für einen RCLS Zähler K0 D0 K1 D1 K2 D2 K3 D3 K4 D4 K5 D5 F1 F2 F3 F4 F5 F6 F7 F8 5 2 5 7 11 2 13 15 1 0 9 9 9 7 Kopf 7 7 7 7 7 7 7 Freiplatz (markiert) c) Beispiel zur falschen Festlegung der Füllwerts 6 0 Zähler K0 D0 K1 D1 K2 D2 K3 D3 K4 D4 K5 D5 F1 F2 F3 F4 F5 F6 F7 F8 5 2 5 7 11 2 13 15 1 0 9 Kopf Fehlertoleranz 9 9 2 2 2 2 2 2 2 2 Freiplatz (markiert) 01.06.2006 53 Eigenschaften den RCLS M = größter darstellbarer Schlüsselwert Einträgen • Für fortlaufende, lückenlose Speicherung von Listenelementen • Speicherbereich fester Länge, Einträge (Schlüssel) ebenfalls fester Länge • Fehlerhafte Werte können auftreten im Zähler oder in den Schlüsseln Ki (etwa eine Schlüsselvertauschung Ki Kj gilt auch als Fehler) • Ziel: „2-detectability“ und „1-correctability“ • Hinter jedem Schlüssel Ki (1 ≤ i ≤ Zähler) wird eine Distanz Di eingefügt, zusätzlich Listenkopf mit K0/D0 (K0 beliebig) i<Zähler Ki+1≥Ki Di:=Ki+1-Ki Fehlertoleranz i=Zähler Ki+1<Ki Di:=Ki+1-Ki +M+1 01.06.2006 K0≥Ki Di:=K0-Ki K0<Ki Di:=K0-Ki +M+1 54 • Freiplatz zwischen aktuellem Listenende und Ende des Speicherbereichs wird mit Füllwerten F versehen: 7 • • • • 2 F:= a+b∗K0 mit - b≠0 & - (2∗b-1) kein Teiler von a & - b kein Teiler von a & - (b-1) kein Teiler von a Konsistenzprüfung bei der (sequentiellen) Suche nach einem vorgegebenen Schlüsselwert K: if i<Zähler then (Ki+Di) mod (M+1) = Ki+1 else (Ki+Di) mod (M+1) = K0 Im Beispiel oben: - K0=2 - a=1, b=3 ⇒ F=7 Wahl des Füllwerts F ist wesentlich für „detectability“ (siehe Beispiel c oben) Problem beim RCLS: Speicherplatzmehrbedarf durch Mitführen der Distanzen Di 1 kann fast 100% betragen! Fehlertoleranz 01.06.2006 55 II. Fehlerklassifikation für Verletzungen der physischen Integrität einer Datenbank Fehlerklassen Lesen und Schreiben unmöglich Schreiben möglich Lesen unmöglich Plattendefekt Slotdefekt Blockdefekt Lesen möglich falscher Block richtiger Block Blockzuordungsfehler Blockinhaltsfehler Seiteninhaltsfehler E/A-bezogene Fehler Fehlertoleranz 01.06.2006 56 Einige Erläuterungen zur Fehlerklassifikation • Plattendefekt: Eine Magnetplatte ist insgesamt nicht mehr zugreifbar; die auf ihr gespeicherten Daten sind verloren: "head crash", manuelle Beschädigung o.ä. • Slotdefekt: (Slots nehmen Blöcke auf der Magnetplatte auf.) Ein Slotdefekt macht nur einen Teil einer Magnetplatte unbrauchbar: Staubablagerungen, Kratzer … • Blockdefekt: Die Magnetplatte ist physisch intakt. Aufgrund etwa von "umgekippten" Bits kann ein Block / können Blöcke nicht mehr von der Platte gelesen werden (autom. Korrektur scheitert). Überschreiben des Blocks / der Blöcke ist jedoch möglich. • Blockzuordnungsfehler: Block i auf der Platte wurde versehentlich von einem anderen Block j überschrieben: Adressierungsfehler im Kanal o.ä. Fehlertoleranz 01.06.2006 57 • Blockinhaltsfehler: Inhalt eines Datenblocks hat sich zwischen einer Schreib- und der nachfolgenden Leseoperation verändert („umgekippte“ Bits): dem DBVS wird ein inkorrekter Blockinhalt beim Lesen übergeben (sofern der Fehler nicht „unterhalb“ des DBVS – Geräte-/Kanalebene(, Betriebssystem) – erkannt wird und dies wird er höchstwahrscheinlich). • Seiteninhaltsfehler: stehen in keinem unmittelbaren Zusammenhang mit E/A-Operationen (im Gegensatz zu den o.g. Fehlerklassen): Seiteninhalt wird im Systempuffer des DBVS durch unzulässige (etwa „wild store“) oder fehlerhafte (algorith. Defekt im DBVS etc.) Modifikationen verfälscht. Fehlertoleranz 01.06.2006 58 III. Verfahren zur Fehlererkennung: Betrachtung entlang des Schichtenmodells • Ziel: Fehlererkennung möglichst weit unten im Schichtenmodell ansiedeln mit dem Ziel einer möglichst frühen Fehlererkennung, aber: - Klare Struktur mit Trennung der Aufgabenbereiche im DBVS beachten (Schichten) und nicht durch Fehlererkennungsmaßnahmen mit falscher Platzierung aufweichen, - Laufzeiteffizienz (Performance) beachten: keine mehrfache Interpretation/Analyse gleicher Daten auf verschiedenen Ebenen (z.B. im Pufferverwalter und dann nochmals im Record Manager) → viel zu teuer! Fehlertoleranz 01.06.2006 59 1. Fehlererkennung durch die Hardware und das Betriebssystem • Plattendefekte: - physische Zerstörung der Platte: Erkennung durch Plattensteuerung - Logische Zerstörung von Platteninhalten (Platteninhaltsverzeichnis (Volume Table of Contents, VTOC), Dateiverwaltungstabellen (Extent-Tabellen)): Erkennung durch Datenverwaltungssystem im Betriebssystem • Slotdefekte: Wie bei Plattendefekten (phys. Zerstörung) • Blockdefekte: Fehlererkennung in Plattensteuerung/Kanal möglich sowie – beschränkt – Fehlerbehandlung: durch Verwendung von Blockprüfinformation (etwa gleiches Prinzip wie Prüfziffer", nur ausgefeiltere Technik und umfangreichere redundante Information; z.B. 56 Bytes pro Block) Fehlertoleranz 01.06.2006 60 Ebenso: Bestimmte Arten (Ursachen) von Blockzuordnungsfehlern, da Blockmummer redundant auf der Platte abgelegt wird ≈ 2-4 KB und mehr ≈ 60 Byte Blocknummer i Blockprüfinformation eigentlichen Daten Block i auf Platte (inkl. Redundanzen) 2. Fehlererkennung durch den Pufferverwalter im DBVS • Stellt seitenorientierten linearen Adressraum bereit • Was kann/soll erkannt werden? Versehentliches Überschreiben der Seitengrenze bei Manipulation in Seite, etwa Einfügen eines neuen Satzes Idee: Schutzzonen im Systempuffer des DBVS . . . der Seite Seite h i j k Seite i Seite j Seite k ... festes Bitmuster Fehlertoleranz 4 Byte Systempuffer 4 Byte 01.06.2006 Seite l ... 61 Systempuffer Satz1 Seite i Satz2 Satz1 1 Freiplatz Seite j Satz4 Seite i Satz3 Satz4 ohne Schutzzonen Seite k INSERT Satz2 Seite j Satz3 Seite k • Teile des Inhalts von Seite k wurden unbemerkt überschrieben/zerstört durch Satz 3 in Seite j • Schutzzonen hätten (mit sehr hoher Wahrscheinlichkeit) zur Fehlererkennung geführt Allgemein: • Etwa 4 Bytes lange Schutzzonen (fast) beliebigen (zufällig bestimmten) Inhalts; Ws., dass Überschreiben der Seitengrenze nicht erkannt wird: 2-32 • Wann wird Unversehrtheit der Schutzzonen einer Seite überprüft? - BEREITSTELLEN Seite - FREIGEBEN Seite - RÜCKSCHREIBEN Seite Fehlertoleranz 01.06.2006 62 Record-Manager, Zugriffspfadverwaltung Fix-Phase Fix-Phase lesender Zugriff ändernder Zugriff BEREITSTELLEN Seite i, lesen FREIGEBEN Seite i BEREITSTELLEN Seite i, ändern FREIGEBEN Seite i Prüfung der Schutzzonen Prüfung der Schutzzonen Unifix-Phase Unifix-Phase Prüfung der Schutzzonen Pufferverwalter LIES Block k Systempufferschnittstelle SCHREIBE Block k DVS Dateischnittstelle Zeit t t1 Fehlertoleranz t2 t3 01.06.2006 t4 t5 63 Schutz von Seiten im Systempuffer gegen unbeabsichtiges Modifizieren („Schüsse von oben“) • Schutzzonen nur gegen „Schüsse von der Seite“ tauglich • Welche Seiten könnte man gegen unbeabsichtigtes Modifizieren schützen? - Seiten, die sich in der Unfix-Phase befinden - Seiten, die sich in der Fix-Phase für lesenden Zugriff befinden • Wie? BS-Aufruf - Supervisor Call (SVC), um Seite im (virtuellen) Speicher für „read only“ zu erklären - Seitenprüfinformation à la Blockprüfinformation (erfordert keinen BS-Aufruf) alles teuer (CPU-Zeit)! Fehlertoleranz 01.06.2006 64 Weitere Prüfmöglichkeiten auf der Ebene des Pufferverwalters • Seitenidentifikatoren Seitennummer wird redundant im Seitenkopf mitgeführt (wird nicht zur Seitenadressierung benötigt, nur zur Fehlererkennung) • Seitentypindikatoren Seitentyp wird (redundant) im Seitenkopf mitgeführt ? hängt ab von DBVS-Implementierung Mögliche Seitentypen: - FPA: Free Place Administration; Freiplatzverwaltung → am Beginn des DB-Segm. - DBTT: Data Base Key Translation Table; Satzadressierungstabelle (vor allem bei Netzwerk-Datenbanksystemen) - HASH: Buckets einer Hashtabelle - TREE: Knoten eines B- oder B*-Baums - DATA: Seiten (Behälter) für sonstige Datensätze - EMPTY: leere Seite - etc. Fehlertoleranz 01.06.2006 65