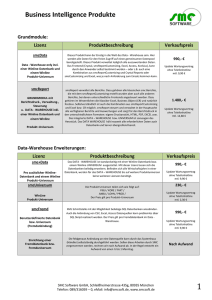
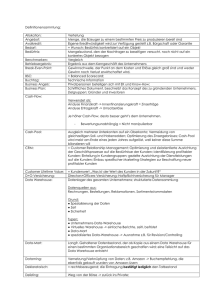
00_Oracle_DWH_Architektur_und Konzepte_Reader_Mai_2011
Werbung

Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Oracle Data Warehouse - Data Warehouse Technik im Fokus Teil 1: Architektur und Konzepte Die Themen Aufgaben und Entwicklung des Data Warehouse Das Schichten-Modell: Information-Factory Die Data Mart Schicht Quellsysteme Die Stage Schicht Die Kern-Data Warehouse Schicht ETL Check-Liste zur Planung Hardware Anforderungen Vorschau Datenbankmittel 1 Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte 2 Vier wichtige Aspekte machen das Data Warehouse so erfolgreich Data Warehouse Systeme gehören heute zu den erfolgreichsten Anwendungen in modernen Unternehmen. Grund dafür ist zum einen der zentrale Charakter. Ein Data Warehouse ist meist das einzige System, in dem man unternehmensweit an einer einzigen Stelle eine umfassende zusammenhängende Information erhält. Viele OLTP-Systeme beschäftigen sich dagegen nur mit einzelnen Sachgebieten und Fragenstellungen. Der zweite wichtige Vorzug des Data Warehouse Systems ist die verständliche Darstellung von Informationen. Während sachbezogene Anwendungen ihre Informationen nur in ihrem speziellen Kontext verwalten, überführt ein Data Warehouse diese spezifische Terminologie in eine allgemein verständliche Form und Sprache und macht sie so auch für sachgebietsfremde Mitarbeiter (z. B. aus anderen Abteilungen) verstehbar. Darüber hinaus harmonisiert ein Data Warehouse Begriffe, Formate, Betrachtungsebenen und Definitionen. Informationen aus unterschiedlichen Sachgebieten können somit zusammenhängend benutzt werden, ein einheitliches unternehmensweites Bild entsteht. Der dritte wichtige Aspekt von Data Warehouse Systemen ist das Vorhalten von historischen Daten. Operative Anwendungen verändern ihre Daten permanent. Die Planung und weitere Ausrichtung der Aktivitäten eines Unternehmens erfordern jedoch eine vergleichende Betrachtung aktueller und historischer Daten. Das vierte wichtige Merkmal von Data Warehouse Systemen ist die Separierung von Daten aus ihrem operativen Kontext heraus. Durch das „Weg-Kopieren“ kann man diese Daten unabhängig von den operativen Anwendungen beliebig verändern. um sie einer weiteren Verwendung zuzuführen. Operative Systeme bleiben dadurch unberührt. Der Aspekt des „Unternehmensweiten“ Business Intelligence Lösungen werden meist mit Blick auf einzelne Sachgebiete oder Abteilungen betrachtet. Data Warehouse Systeme verfügen dagegen über einen unternehmensweiten Wirkungsbereich. Wie zuvor bereits ausgeführt, liegen hier wesentliche Aufgaben. Diese unternehmensweite Ausrichtung macht Data Warehouse Systeme zu einem idealen MonitoringInstrument für abteilungsübergreifende aber auch Zeitenübergreifende Vergleiche. Unternehmen müssen heute in immer kürzerer Zeit geänderte oder komplett neue Geschäftspraktiken anwenden, um erfolgreich zu sein. Diese permanenten Änderungen erfordern ein stabilisierendes Kontrollinstrument, um Fragen zu beantworten wie: Welche Bereiche/Produktlinien sind die profitabelsten? Haben sich neue Produktionsverfahren gegenüber früheren bewährt? Gibt es territoriale Veränderungen bei der Geschäftsentwicklung? Solche Fragen können begrenzt auch direkt betroffenen Fachmitarbeiter beantworten. Das Abstrahieren aus dem unmittelbaren Aktionsumfeld heraus, sowohl räumlich als auch zeitlich, ist jedoch meist nur schwer machbar. Hier bietet das Data Warehouse eine unternehmensweite, sachgebietsübergreifende und auch historische Datensammlung an, um diese nötige Abstraktion von der direkten „Jetzt- und HierErfahrung“ zu ermöglichen So lassen sich schneller Fehlentwicklungen erkennen. Ein frühzeitiges Gegensteuern ist möglich. Dies verdeutlicht, wie wichtig es ist, möglichst alle Geschäfts(erfolgs-) relevanten Prozesse an ein Data Warehouse anzuschließen, d. h. Daten aus diesen Prozessen in das zentrale System zu überführen. Um so besser kann das Systeme seine übergreifende Monitoring-Funktion erfüllen. Weitere positive Aspekte können dem unternehmensweiten Charakter des Data Warehouse abgewonnen werden: Unternehmensweit Informationen o o o o gemeinsame, standardisierte Glossare / Definitionen als Nachschlagewerk Standardisierte Begriffe Gleiches Verständnis über den Inhalt Kennzahlen und Sachverhalten Gemeinsam genutzte Berichte von Gleicher aktueller Kenntnisstand o Verhindern von “Information Hiding” o Demokratisierung durch gleiche Informationen o Beschleunigte Informationsweitergabe Reduzierung des Aufwands für die Informationsbeschaffung o Wiederverwendung von bereits an anderer Stelle erstellten Informationen Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Rolle und Eigenschaften haben sich permanten verändert Man spricht seit Anfang der 90er Jahre von Data Warehouse Systemen. Aufgrund der vorgenannten positven Eigenschaften finden die Systeme eine immer weitreichendere Verwendung. Dienten sie ursprünglich nur dem Reporting auf einer strategischen Ebene und füllten Monats-/Quartalsberichte so sind Warehouse Systeme heute oft direkt mit operativen Anwendungen verzahnt. Viele Fachmitarbeiter auch ausserhalb der Controlling-Abteilung oder Planungsstäbe haben das verlockende Informationsangebot des Data Warehouse erkannt und wollen mit ihren Geschäftsprozessen „angedockt“ werden. Das führte zu neuen Datenbereichen und auch oft zu einer feineren Granularität der Daten, denn auf der operativen Ebene stehen meist konkrete Transaktionen bzw. Geschäftsvorfälle im Vordergrund. Die Folgen sind kürzere Betrachtungszeiträume (der Zeitpunkt des Geschäftsvorfalls wird wichtig) und ein massives Anwachsen der Datenmengen. Data Warehouse-Systeme sind heute die am schnellsten wachsenden Anwendungen mit sichtbaren finanziellen Folgen in den IT-Budges. Dies erklärt die z. T. angestrengte Suche von IT-Verantwortlichen nach Alternativen für hochvolumigen Speicher. Neben der Betrachtung von fachlichen Aspekten bei der Gestaltung und Modellierung von Warehouse-Systemen spielt heute daher auch die Betrachtung von Hardware-Aspekten eine bedeutende Rolle. Operationalsierung der Data Warehouse-Rolle Diese geänderte Verwendung kann man auch als Operationalisierung bezeichnen. Also die Nutzung des ursprünglich für dispositive Zwecke entworfenen Systems für operative Aufgaben. 3 aggregierten Informationen über görßere Zeitabstände hinweg. Heute bewegt sich das Data Warehouse schon nahe an den Anforderungen an operative Systeme mit vielen Benutzern, sehr großen Datenmengen und permanenten Änderungsvorgängen. War es früher geboten eine separate, für aggregierte Auswertungszwecke passende Datenhaltung zu wählen, ist es heute wichtig nicht mehr zwischen einer Datenhaltung für operative und dispositive Zwecke zu unterscheiden. Heute ist es wichtig für OLTP und Data Warehouse-Zweck durchgängig einheitliche Datenhaltungs-Komponenten nutzen zu können, weil beide Anforderungen durchmischt, eng verzahnt und kaum noch trennbar sind. Hinzu kommt die immer geringere Zeit, die bleibt, um Daten aus einem operativen Verwendungkontext in einen dispositiven zu überführen (ETL). Die Oracle Datenbank erfüllt genau diese Anforderung. Ursprünglich für operative Zwecke entwickelt, hat sie sich seit dem Release 7 (1995) kontinuierlich auch als ideale Data Warehouse etabliert und ist heute die am meisten verwendete Datenhaltung für ein Data Warehouse. Angleichung der Anfordergungen an OLTP und DWH - Systeme im Zuge der Operationalisierung des DWHs Warehouse-Organisation in drei Daten-Schichten Das Data Warehouse erreicht die vorgenannten Ziele durch eine methodisch begründete Einteilung in mehrere Schichten, in denen die enthaltenen Daten durch entsprechende Bearbeitungsschritte aus ihrer ursprünglichen Form in den operativen Systemen in eine benutzergerechtere Form für die Endbenutzer überführt werden. Vor allem in unternehmensweit aufgestellten Data Warehouse Systemen hat sich die Aufbereitung der Daten in drei Schritten bewährt: 1) 2) 3) Man sammelt, integriert und prüft auszuwertende Daten der operativen Vorsysteme. (Stage) Man granularisiert diese Daten in einem alle Sachgebiete umfassenden (meist 3 NF) - Schema. (DWH-Schicht) Je nach Zielgruppe und Sachgebiet fügt man im letzten Schritt die granularen Informationsbausteine meist zu multidimensionalen Endbenutzer-Modellen (meist Star Schemen) zusammen. (Data Marts) Dieses ist eine Ressourcen-schonende Vorgehensweise mit der Betonung auf Wiederverwendung von Daten und Entwicklungsarbeiten bei gleichzeitiger Flexibilität durch beliebige Auswerte-Szenarien. Beispiele für operative Verwendung von Data Warehouse-Systemen Das Hervorheben dieses Aspekts zielt vorallem auf die in einem Data Warehouse verwendetet Datenhaltungsplattform. In der Vergangenheit belieferten die Systeme wenige Personen mit Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte 4 kann durch das Ausnutzen von Synergien Aufwand und Zeit sparen. Um Synergie-Effekte möglichst komplett zu nutzen, empfiehlt Oracle alle 3 Verarbeitungsschritte bzw. Schichten in einer einzigen Datenbank-Instanz und damit auch Hardware-Umgebung anzusiedeln. 3-Schichten-Modell historisch Seit den 1980er Jahren hatte man unterschiedliche Varianten der Organisation der Daten für dispositive Zwecke erprobt. Die aktuelle Organisation in 3 Schichten hat sich seit Mitte der 1990er bewährt. Die Mehrwert-Leistungen des Data Warehouse Auf dem Weg zu den Benutzern durchlaufen operative Daten mehrere Wandlungsschritte in den einzelnen Warehouse-Schichten. 1. Operative Systeme nutzen Daten für ihre Zwecke ideal zusammengesetzt und auch nur diejenigen Informationen, die sie wirklich benötigen. Für Analysten oder Mitarbeiter, die eine unternehmensweite prozessübergreifende Aufgabe verfolgen, reicht dies nicht aus, bzw. die Daten sind wenig verständlich. Der Wandlungsprozess im Data Warehouse löst die Datenstrukturen der operativen Systeme auf und überführt die Kerninformation in eine Form, die leicht und flexible für unterschiedliche Zielgruppen und deren Bedürfnisse neu kombiniert werden kann. Man bedient sich der Hilfsmittel aus der Datenmodellierung, mit denen man die operativen Informationen in einem ersten Schritte in die kleinst möglichen Informationsbausteine zerlegt (Normalisierung in Richtung 3. NF) und sie dann je nach Endbenutzeranforderung wieder neu kombiniert. Die Vorgänge finden bei dem Übergang von Stage zur DWH-Schicht (Normalisierung) und von der DWHSchicht in die Data Mart-Schicht (Denormalisierung) statt. Heute ist die Verwendung dieser Organisation nicht unumstritten. Die Kritik an diesem Modell lautet: Zu viele redundante Daten Gefahr für höherer Latenzzeiten Hoher Entwicklungsaufwand Diese Punkte sollten ernst genommen werden, da sie in manchen Diskussionen die unbestreitbaren Vorteile des 3-Schichten-Modells überlagern können. Im Ergebnis können dann heutige Lösungen wie Lösungen aus den 1980ern aussehen, bei denen Daten direkt aus den operativen Systemen in die proprietäre Speicherung bestimmter BI-Tools gelangen. Das Ziel der 3-Schichten-Architektur ist der Entwurf einer möglichst umfassenden, mehrere Unternehmensund Themenbereiche abdeckenden stabilen Informationsablage, die in kurzer Zeit konsolidierte Berichte und Analysen für alle (!) Zielgruppen des Unternehmens bereitstellt. Das 3-Schichten-Modell gibt dem Data Warehouse die Möglichkeit, Informationen zunächst zu harmonisieren und zu vereinheitlichen, bevor sie in Business Intelligence Systemen ausgewertet werden, sorgt für eine „zeit-und Phasen-überdauernde“ Konstante, während sich Geschäftsprozesse wesentlich häufiger verändern, 2. Das Normalisierungs-/Denormalisierungsverfahren verhindert noch nicht ein potentielles Informationschaos im Data Warehouse. Denn aufgrund der sog. Homonymen-/Synonymen-Problematik können bei einem unklaren Begriffsverständnis unerkannt Informationen mehrfach in einem Data Warehouse abgelegt sein. Diese Gefahr ist umso größer, je mehr Prozesse und Abteilungen an dem DWH-System angeschlossen sind. Hier helfen: Glossars mit abgestimmten Begriffsdefinitionen Deskriptoren-Verfahren zur Standardisierung und für das Wiederauffinden von Begriffen Metadaten-Management Datenqualitätsstandards Dies wird in der aktuellen Data Warehouse Diskussion unter dem Begriff Data Governance zusammengefasst. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte 3. Die Erwartungen der Endbenutzer an die Informationen des Data Warehouse gehören zu den Schlüsselaufgaben. Diese Erwartungen richtig zu treffen ist ein immer wiederkehrender Entwicklungsschritt. Die erwarteten Informationen muss man aus den Fragestellungen der Fachanwender herleiten. Diese sind i. d. Regel an den Geschäftsprozessen orientiert, die bis zu einer gewissen Tiefe verstanden werden müssen. Ein Data Warehouse ist jedoch nach den Konstruktionsprinzipien von Datenstrukturen konzipiert und bildet die Informationen zu den Objekten der Geschäftsprozesse ab. Ein wichtiger Modellierungsschritt ist daher das Identifizieren der richtigen Geschäftsobjekte und die IT-technische Beschreibung der Geschäftsobjekte mittels leicht verstehbaren und leicht auswertbaren Datenmodellen bzw. Tabellenstrukturen. Das Ergebnis sind meist multidimensionale Modelle. 5 Data Marts sind redundant und „flüchtig“ Die Data Mart Schicht Der Hauptzweck der Data Mart-Schicht ist die Endbenutzergerechte Aufbereitung der Warehouse-Daten. Gegenüber der Data Warehouse-Schicht entstehen keine zusätzlichen Informationen. Aber die Datenmodellart und die Granularität der Daten kann sich ändern. Aufgrund des 3-Schichten-Konzeptes sind Data Marts prinzipiell redundant zur Data Warehouse-Schicht. Daher ist die Frage berechtigt, ob zu jedem Zeitpunkt alle Data Marts auch physisch vorhanden sein müssen, oder nur dann, wenn Endbenutzer die Marts benötigen. Um Kosten zu senken, können Data Marts auch nach Anforderung erzeugt werden. Das erleichtern auf der anderen Seite die Verwaltung und das Laden eines Data Marts: Als Datenmodellform werden multidimensionale Modelle (StarSchema, Snowflake) bevorzugt, weil diese für Endbenutzer intuitiver sind. Ziel ist es so viele Abfrage-Ergebnisse wie möglich präpariert zu haben. Deswegen ergänzt durch vorbereitete Data Warehouse Kennzahlenbäume Views. man multidimensionale Abfragemodelle auch Kennzahlen-Tabellen, die man in dem Oracle meist als Materialized Views erstellt. sind aufeinander aufbauende Materialized Zusammenfassend: Alle Varianten, meist multidimensional (Star) o Star, Snowflake, Ansammlung einzelner Tabellen, Cubes o Außer 3 NF-Modelle Abfrage-/End User-orientiert Teils temporär, warden eventuell nur bei bedarf aufgebaut Kann historisiert sein Daten redundant zur DWH-Schicht Je nach Anforderung regelmäßiger Neuaufbau Keine Updates sondern nur Inserts (Append) in der Datenbank. Das sind schnelle Vorgänge in einer OracleDatenbank. Das schnelle Neuaufbauen erfolgt als sogenannter Massenladevorgang. Damit ist das Komprimieren der Daten durch die Datenbank leichter möglich. Durch regelmäßiges Neuaufbauen wird das Ansammeln von alternden Daten verhindert und es befinden sich nur wirklich benötigten Daten in dem Data Mart. Teurer Plattenplatz wird gespart. Historisierung Historisierung findet auf zwei unterschiedliche Weisen statt. Zum einen beziehen sich die auszuwertenden Daten auf einen historischen Zeitraum (i. d. R. vom „Jetzt“ bis zu einem Zeitpunkt in der Vergangenheit). Zum anderen können sich die Rahmenbedingungen unter denen Daten entstehen verändert haben. In diesem Fall redet man von Slowly Changing Dimensions. Haben sich z. B. die Verkaufsgebiete verändert, so hat dies auch Auswirkungen auf Verkaufszahlen. Zur Darstellung der veränderten Rahmenbedingungen wird man bei den beschreibenden Informationen (Dimensionen) Versionen einführen. Zur Darstellung der unterschiedlichen Zeiten in denen Daten anfallen nutzt man Zeitattribute in den Datentabellen. Solche Zeitattribute sind eine gute Voraussetzung für das physische Partitionieren großer Tabellen (Oracle Partitions), was dann wieder Abfragen beschleunigen kann. Slowly Changing Dimensions können aufwendig sein. Sie erschweren das Abfragen. Deshalb sollte man diese nur einsetzten, wenn es nötig ist. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Weil Data Marts flüchtig sein können, sollte die Historisierung bereits in der Kern-DWH-Schicht angelegt sein. Bei dynamisch aufgebauten Data Marts hat man dann die Möglichkeit, nur einen Teil der Historisierung in den Data Marts zu realisieren. 6 Stamm-Objekte Eigenschaften der Stamm-Objekte Die Ergebnisse lassen sich in einem Analysemodell (Prozess-Sicht) darstellen. Empfehlung Star Schema verwenden Oracle empfielt die Verwendung des Star Schema-Modells. Anstelle von Snowflake oder 3 NF Intuitives Modell Auch für Fachanwender verständlich Performance-Optimierungen durch Datenbank möglich Flexibler, da Änderungen leichter umsetzbar ETL-Aufwand ist geringer, da weniger Tabellen Analyse - bzw. Proze ssmodell Umgang mit großen Faktentabellen Große Fakten - Tabellen stellen aufgrund des enormen Platzbedarfes und der doppelten Ladenaktivität eine besondere Herausforderung dar. Es ist daher sinnvoll, solche großen Objekte nur einmal in dem gesamten Data Warehouse aktiv zu halten. Diese Objekte kann man in der Data Warehouse-Schicht einmalig persistent vorhalten und aus den Data Marts darauf verweisen. Zum Schritt 2 (Geschäftsobjekt-Modell) Durch eine Umgruppierung bzw. Zusammenfassung und Anwendung von Datenmodellierungsmethoden (Spezialisierung und Generalisierung) kann man das Objektmodell herleiten. Das ist dann schon ein direkter Vorläufer des dimensionalen Modells, weil bereits Hierarchien, Dimensionen und Fakten erkennbar sind. Das ist ein weiterer Grund, weshalb Data Marts und Kern-Data Warehouse gemeinsam in einer Umgebung anzusiedeln sind. Strukturierung und Beziehungen der Objekte Herleitung der multidimensionalen Modell eines Data Marts Die Entwicklung multidimensionaler Modelle gliedert sich in 3 Schritten: 1. 2. 3. Analyse der Fachanwenderfragen (mit Analysemodell bzw. Prozessmodell Herleitung (Geschäfts-)Objektmodell Herleitung multidimensionale Struktur Objektmodell Zur Schritt 3 (Multidimensionale Struktur) Durch eine Schlüsselbildung zwischen den Bewegungsdatentabellen und den Geschäftsobjekte-Tabellen entsteht die multidimensionale Sicht. Zum Schritt 1 (Fachanwenderfragen) Ausgangspunkt für die Herleitung sind Fragen, die gemeinsam mit Fachwendern entwickelt werden: Z B: Die Informationen in diesen Fragen lassen sich klassifizieren in: Bewegungsdaten Alle Eigenschaften eines Geschäftsobjektes werden zu Spalten in den Dimensionstabellen. In diesen Dimensionstabellen werden alle (!) Eigenschaften aufgenommen. Dimensions-Objekte sind eindeutig, sie werden „durchgezählt“. Aggregationen und Spezialisierungen werden zu HierarchieStufen. Bewegungsdaten werden zu Faktentabellen-Feldern, die eine gewisse Größe ausdrücken (Kennzahlen) Die Beziehung zwischen den Geschäftsobjekten und dem was passiert (Bewegungsdaten) werden durch Schlüssel dargestellt, wobei die Dimensionstabelle das Master-Objekt darstellt und seinen Primary - Key an die Detail-Tabelle vererbt. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Das Star-Schema 7 Welche Verkäufer verkauften welche Produkte an welchen Tagen in welcher Stadt wie oft Soll bei einem Star Schema noch eine zusätzliche Sicht hinzugenommen werden, so wird lediglich eine Dimension mit einem zusätzlichen Schlüssel in der Fakten-Tabelle hinzugefügt. Varianten des Star Schemas Multidimens ionale Str uktur Die vorherrschende Modellform in der Data Mart-Schicht ist das Star Schema . Es ist einerseits ein multidimensionales Modell, auf der anderen Seite ist es mit Mitteln einer relationalen Datenbank wie Oracle physisch realisierbar. Diese Modell-Form stellt eine ideale Brücke zwischen Fachanwender-Fragen (Informationsbedürfnis der Anwender) und den technischen Möglichkeiten einer Datenbank dar. Star Schema-Modelle können direkt von Fachanwendern verstanden werden, da die Dimensionen den Informationsgehalt der Geschäftsobjekte wiedergeben. Wie flexibel das Star Schema mit komplexen Informationen umgehen kann, zeigt folgendes Beispiel Abbildungsversuch mit klassischen Spreadsheets Komplexität der Abfrage Dimensionen können mehrere Fakten-Tabellen referenzieren. Zwischen Fakt-Tabellen können selbst PK/FK-Beziehungen bestehen. Zwischen Fakten-Tabellen und Dimensionen können N zu N - Beziehungen bestehen. Degenerated Dimension Dimensionen können auch völlig in eine Fakten-Tabelle übernommen werden. Das wird immer dann gemacht, wenn die Dimensions-Tabelle nur wenige Spalten umfasst und man damit für die spätere Abfrage einen Join sparen kann. Welche Produkte werden an welchen Tagen wie oft verkauft? Welche Produkte werden an welchen Tagen in welcher Stadt wie oft verkauft? Typische Beispiele sind Dimensionen wie Geschlecht mit den Werten [Männlich / weiblich / XX]. Anstelle des Schlüssels kann man hier den Wert direkt in die Fakten-Tabelle aufnehmen. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Factless Fact Table 8 Höhere Granularität bei Fakten-Tabellen wählen Die Datenbank-Technologie und die Hardware-Mittel sind in den letzten Jahren sehr stark verbessert worden. Daher kann man heute die Granularität der Fakten-Tabellenwerte so klein wie möglich wählen. Früher Heute Wenn eine Fakten-Tabelle nur Schlüsselwerte und keine zusätzlichen Wertfelder enthält, dann wird sie nur zum Zählen der jeweiligen Dimensionen-Verknüpfungen genutzt. Empfehlungen für den Aufbau von Faktentabellen So granular wie möglich aufbauen o Performance-Thematik separat lösen o Keine eigene Faktentabelle bilden, nur um eine höhere Aggregations-Ebene zu erhalten o Keine separate Faktentabelle aus PerformanceGründen “Verwandte” Faktentabellen schaffen o Über gemeinsam genutzte Dimensionen Die Faktentabelle besitzt keinen eigenen PK o Zugriff nur über die Foreign Key-Felder o Sätze müssen nicht eindeutig sein, d. h. die Fakten-Tabelle enthält keinen Primary Key (Ausnahme: Eine Fakten-Tabelle ist Master in einer Master/Detail-Beziehung zwischen Fakten-Tabellen) Partitioning-Kandidat Star vs. Snowflake Schema In einem sog. Snowflake Schema sind die Aggregationsstufen einer Dimensionstabelle als separate Tabellen modelliert. Eine Dimension entspricht damit eher dem Modell der 3. Normalform. Informationsmenge und Abfrageoptionen Endbenutzer wünschen meist ein Höchstmaß an Abfragemöglichkeiten und Flexibilität. Wählt man die Granularität der einzelnen Dimensionen kleiner, so steigt damit automatisch die Menge der Abfrageoptionen. Es steigt aber auch die Menge der Sätze in der Fakten-Tabelle. Abfragen auf ein Snowflake-Modell erfordern komplexere Join-Formulierungen. Ein Snowflake-Modell ist schwerer lesbar In der Vergangenheit konnten einige Business Intelligence - Tools besser mit Snowflake umgehen, da dimensionale Beschreibungswerte in normalisierten Tabellen leichter abgegriffen werden konnten. Die Werkzeuge konnten damit leichter LookupTabellen bilden. Heute gibt es in diesem Bereich keinen Grund mehr ein Snowflake-Modell aufzubauen. Die Oracle Datenbank arbeitet effizienter mit einem Star Schema. Auslagern von weniger häufig genutzt Attributen Werden Spalten von Dimensions-Tabellen weniger häufig genutzt, so kann man diese in eine separate Dimension auslagern. An der Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Faktentabelle ändert sich dadurch nichts, denn es wird derselbe FKSchlüssel von allen Dimensionen genutzt. 9 Die Schlüssel / Indizierung im Star Schema Schlüssel in Dimensionen Dimensionen sind als eindeutige Tabellen aufzubauen. Sie besitzen also einen Primary Key, der so auch in der Datenbank angelegt ist. Dieses Schlüsselfeld ist i. d. R. sehr einfach gehalten und wird im Verlauf des ETL-Prozesses gebildet. Weitere eindeutige Schlüssel (Alternate Key, Unique Key) können enthalten sein, sie spielen aber für die Konstruktion des Star Schemas keine Rolle. Durch den Denormalisierungs-Schritt gibt es im Gegensatz zu dem 3NF-Modell der Kern-Data Warehouse - Schicht auf den höheren Aggregat-Stufen keine eindeutigen Schlüssel mehr, auch wenn die Namensgebung dieses suggeriert. Wahl der Schlüsselfelder Wenn kein künstliches Zählfeld als Primary Key gewählt wird, sondern echte Felder, dann sollten folgende Regeln angewendet werden: Ein analoges Verfahren erhält man, wenn man zwischen zwei Dimensionen eine 1:1 Beziehung erstellt. Einfach benutzbare und kurze Felder o Speicherplatz sparen o Fehler vermeiden Nach Möglichkeit nicht zusammengesetzt o Erfordert beim Zugriff unnötig viel Vorwissen zu den einzelnen Schlüsselbestandteilen o Schlüsselbestandteile können leicht NULL-Wert annehmen, Eindeutigkeit ist gefährdet Keine Felder wählen, die NULL werden können Spaltenwerte sollten stabil sein und sich nicht mehr ändern Generell sollte man solche Lösungen gut überdenken, denn sind machen das gesamte Datenmodell komplex. Datenbanken sind heute wesentliche performanter als früher. Daher sind solche Lösungen aus Performancegründen heute kaum noch nötig. Manchen Systeme werden jedoch heute auch operativ genutzt. Durch dieses Verfahren, kann man operativ genutzte Spalten von den übrigen trennen. Allgemeine Regeln für das Star Schema Star Schema einfach halten o Für Endbenutzer überschaubarer o Nicht mit zu vielen Dimensions-Attributen überfrachten Code-Attribute vermeiden o Attribute mit beschreibenden Inhalten verwenden o Sprechende Column-Namen verwenden o Level-bezogene Präfixe verwenden Operativ genutzte Daten in separate Tabellen auslagern o 1:1-Beziehung zu Dimensionen Überfrachtete Dimensionen aufspalten o Bei zu vielen Attributen o Bei sehr oft genutzten Selektionskriterien Dimensionen mit nur einem Attribut in die Faktentabelle verlagern Umschlüsselung Das Umschlüsseln erfolgt zwar bereits in der Stage-Schicht. Es hat aber Auswirkungen auch auf die Data Mart - Schicht. Denn Geschäftsobjekte erscheinen hier entgegen der Situation in den operativen Systemen mit neuen künstlichen Schlüsseln, die auch bei Abfragen genutzt werden müssen. Eine Umschlüsselung auf künstliche Schlüssel ist aus mehreren Gründen notwendig: Integration o In mehreren Vorsystemen kann es unterschiedliche Schlüssel geben. Um nicht ein System zu bevorzugen, wählt man einen neuen. Stabilität o Natürliche Schlüssel können sich leichter ändern. o Geschäftsbereiche können sich ändern. o Ein DWH ist meist langlebiger als operative Anwendungen. Künstliche Schlüssel bedeuten Performance für das Star Schema, da die Datenbank mit solchen Schlüsseln besser umgehen kann. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Business Key Die Originalschlüssel aus den Vorsystemen übernimmt man zur Orientierung der Endbenutzer als sogenannte Business Keys bis in die Dimensionen hinein. Dort findet man sie auf der gleichen Stufe wie die neuen künstlichen Schlüssel. Es kann vorkommen, dass in einer Dimension gleich mehrere Originalschlüssel enthalten sind, weil die Geschäftsobjekte in mehreren Vorsystemen unterschiedlich verwendet wurden. In diesem Be is pie l finde t m an die be ide n „ Business Key “ „Kunden_NR“ und „Par tne rnummer“ ne ben dem küns tlic hen Schlüsse l „Dim _Kd_NR“ Zus ammenfassende Dar ste llung. Der Untesc hie d zwisc he n Btree und Bitm ap - Indexe n wird s päter v orge ste llt. 10 Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Quellsysteme 11 In Data Warehouse Systemen treffen diese Daten jedoch auf Daten anderer Vorsysteme oder sie werden anders verwendet. Aus der übergreifenden Sicht des Data Warehouses sind die Quelldaten dann fehlerhaft. Zur Lösung gibt es folgende Verfahren: Quellsysteme können sehr herausfordernd sein. Z. B. Verschiedene OLTP-Systeme wie CRM und ERP Legacy Systeme Externe Daten von Partnern Unterschiedliche Zugriffsmethoden o Middleware Sources -> Message - basiert o Push / Pull - Anforderungen o Standard - Driver wie ODBC, JDBC o Text-basiert: CSV, fixed length, Copy books, EBCDIC, ASCII o Call-Schnittstellen o Satzarten-strukturiert Problemfall: oft fehlende beschreibende Informationen o Zugriff auf Dictionary-Systeme o Dokumentation o Müssen hergeleitet oder generiert werden Ausnahmefälle manchmal nicht dokumentiert Zeitliche Verfügbarkeit Unsaubere oder komplexe Schlüssel Andere Hardware / Betriebssystem-Plattformen Schwer nachvollziehbare Ablagelogik o „Wenn in Feld A der Wert XYZ dann in Feld B ein gütiger Wert“ Datenqualitätshürden Umgang mit dem Aspekt des Operativen der Vorsysteme Operative Vorsysteme sind eingebunden in z. T. erfolgskritische Unternehmensprozesse. Daher unterliegt der Umgang mit ihnen aus Sicht des Data Warehouse besonderen Regeln: Sie dürfen durch das Abziehen der Daten nicht behindert werden o Kein Einfluss auf die Performance o Kein Anhalten, um Daten herauszulesen Sie sollten nicht modifiziert werden o Keine zusätzlichen Tabellen einfügen o Keine Trigger einfügen Es sollten keine Daten-manipulierenden Aktivitäten erfolgen (Inserts, Updates), also auch keine “Marken”, die bereits gelesene Informationen kennzeichnen. Auf den Maschinen des Quellsystems sollten nach Möglichkeit keine zusätzlichen Programme installiert werden, die sich negativ auf das Performanceverhalten auswirken. Umgang mit Datenqualitätsproblemen Operative Vorsysteme gehen in einer besonderen Art und Weise mit Datenqualitätsproblemen um. Meist benutzen die Systeme die Daten aufgrund ihrer eigenen Verwendungsansprüche und die Daten sind aus dieser Sicht sauber. Festlegen von Qualitätsstandards gemeinsam mit den Vorsystem-Verantwortlichen (z. B. Fachanwendern). Prüfung der Einhaltung dieser Standards in der Stage-Schicht des Data Warehouses. Nach Möglichkeit fehlerhafte Informationen zurückweisen, bzw. aussondern und sie den Vorsystemverantwortlichen zur Korrektur anbieten. Fehlerhafte Sätze sollten nicht „auf eigene Faust“ korrigiert werden. Stage - Schicht Die Stage - Schicht oder „Integration Layer“ ist eine eher technisch ausgerichtete Arbeitsebene. Hier findet statt: Überprüfung von o Syntaktischer Korrektheit (Typ, Länge, NULL) o Vollständigkeit der Daten und Mengenverhältnisse o Gültigen Wertebereichen o Vorhandensein von Referenzdaten o Eindeutigkeit (optional) o Eliminierung von NULL-Werten Zusammenführung operativ getrennter Daten Bilden neuer Informationsobjekte mit dem Ziel der einfacheren Weiterverarbeitung (optional) Waisen-Management (optional) Bildung von Daten-Deltas (optional) Folgende Empfehlungen gelten für den Umgang mit der Stage Schicht: Keine 1:1-Kopien Keine besonderen Datenmodell-Strukturen Wenn möglich, bereits beim Extrahieren Prüfungen und Wandlungen von Daten vornehmen Keine Indizes verwenden Stage ist leer, wenn nicht geladen wird Archivierung gelesener Sätze Eine sehr praktische Funktion kann es sein, die geladenen Informationen nach der Bearbeitung zu archivieren. Diese Daten können bis zum Abschluss einer folgenden Ladephase aufbewahrt werden, um z. B. Delta-Abgleiche vorzunehmen. Generische Stage-Strukturen Eine der häufigsten neu wiederkehrenden Anforderungen an Data Warehouse-Systeme ist das Einbinden von neuen Eingangsdatenströmen. Um nicht permanent neue Entwicklungsarbeiten an dem System vornehmen zu müssen, kann es sinnvoll sein, für einfach strukturierte neue Quellen (z. B. TextDateien), generische Eingangsschnittstellen zu entwerfen. Hierbei wird über eine einfache Metadaten-Information (z. B. Feldliste) ein Generator gesteuert, der dann ein neues Einlese-Programm erzeugt. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Operational Data Store (ODS) Operational Data Store Strukturen dienen: dem schnellen Bereitstellen aktueller Informationen der Unterstützung von Real-Time-Fähigkeit der Unterstützung von operativem Reporting Die Schicht ist eine Hilfsschicht, um temporär die relativ aufwendigen Prüf- und Integrationsvorgänge in der Stage - Schicht zu umgehen. Operational Data Store - Informationen gelangen erst zu einem späteren Zeitpunkt oder sogar gar nicht in die Data Warehouse - Schicht. Diese Informationen sind nur für ausgesuchte Zwecke bestimmt und erheben nicht den Qualitätsanspruch der übrigen Data Warehouse - Daten. Folgende Eigenschaften gelten: Es findet eine auf Subjekte / Objekte bezogene Integration statt o Wie z.B. Kunde, Bestellung Die Gültigkeit ist auf die aktuelle Ladeperiode beschränkt. Es sind daher flüchtige Daten Die Daten befinden sich auf Transaktionslevel Direkter Zugriff durch Benutzer ist möglich Daten befinden sich in einem syntaktisch und semantisch geprüften Zustand (wenn möglich) Letztlich analog zur DWH-Schicht, nur ohne Historisierung Die (Kern-) Data Warehouse Schicht 12 allgemeine Sammlungen wie Feiertage, Steuertabellen, Geographiedaten, Währungskurse Bewegungsdaten o Angesammelte Daten aus allen Berichtsperioden o Zumindest die letzten Ladeperioden in sehr granularer Form, danach eventuell aggregiert oder mit Referenzen auf Archivierungen o Management von Daten und Informationen in der Data Warehouse Schicht - gegen Datenchaos An die Data Warehouse-Schicht werden ganz besondere Ansprüche gestellt. Die in ihr gesammelten Daten sind nicht nur von einer besonderen Datenqualität geprägt, ihre Ablage erfolgt auch in einer besonders systematisierten Art und Weise. Diese Systematik ist unbedingt notwendig, um den Wert und die volle Funktionsfähigkeit des Systems zu erhalten. In heutigen Data Warehouse Systemen tritt eine Herausforderung besonders zu Tage, die auch nicht durch die Mittel der Datenmodellierung zu erfüllen ist. Es ist die Verwaltung von Dateninhalten nach semantischen Gesichtspunkten. Die Datenmodellierung löst die Datenobjekte nur nach ihrer Struktur auf. Sie hat aber keinen Einfluss auf die Inhalten der Daten. Verhindert wird nicht, dass eine bestimmte Information mehrfach unter geänderten Namen vorkommen kann. Man spricht von Homonymen und Synonymen. Diese Problematik kann den Nutzen eines Data Warehouse Systems erheblich schmälern. In einigen Fällen sind durch diese unkoordinierte Verwendung von Inhalten mehrjährige Investitionen im Millionen-Umfang gefährdet. Die Kern Data Warehouse - Schicht ist die eigentliche, „wichtige“ Daten-Instanz des gesamten Data Warehouse - Systems. Hier befinden sich die Warehouse-Informationen, nachdem sie in der Stage Schicht geprüft und integriert wurden und bevor sie wieder in der Data Mart-Schicht für die Verteilung aufbereitet werden. Folgende Anforderungen gelten für die Data Warehouse - Schicht: Eindeutigkeit aller Objekte und Namen Redundanzfreiheit aller Informationen Bereichs- und Themen-übergreifend Anwendungs- und Geschäftsprozess-neutral o Objekte werden in mehreren Geschäftsprozesse benötigt o Daten müssen tauglich genug sein, um sie in allen Anwendungen zu verwenden Langlebigkeit der Daten (Historisierung) o Historisierung wird hier angelegt. In der Data Mart - Schicht kann es seine alternative oder ergänzende Historisierung geben Die Informationen liegen auf einem sehr granularen Level vor, damit die Daten leicht in neue Informationszusammenhänge überführt werden können. o 3 NF Modellform Folgende Informationsarten sind hier zu finden: Stammdaten o Historisiert (Slowly Changing Informationen) o Synchronisiert mit MDM-System Referenzdaten o externe (Partnerinformationen, Partnerproduktkataloge, Kontaktdaten etc. o interne (Mitarbeiter-, Abteilungsverzeichnisse, Abkürzungen, Regeln etc. Homonyme n / Sy nonymen - Problematik als Hauptur sac he für „Datenc haos“ Gelöst wird die Problematik durch eine Reihe von zusätzlichen Maßnahmen in der Data Warehouse - Schicht bzw. bei dem Übergang von der Stage - in die Kern-Warehouse-Schicht. Diese Maßnahmen können im weitesten Sinn auch als Data Governance-Maßnahmen bezeichnet werden. Die Aufgabenstellung und die damit verbundenen Lösungen sind alt, der Begriff Data Governance wird heute aber breit diskutiert. Hilfsmittel sind: Repository-System Informationskatalog oder Inventar o Metadaten-gestütztes Verzeichnis aller Datenobjekte in einem Data Warehouse o Mehrere Zugriffs- / Suchstrategien auf bestehende Objekte o Deskriptoren-Verfahren zum Qualifizieren von Objektnamen und Erleichtern der Suchstrategien Beschreibungen über den Zustand, Alter und Zuständigkeiten zu den Informationen Datenqualitätsstandards und Prüfregeln Namenskonventionen Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Metadaten Repository zur Dokumentation der Inhalte und Zusammenhänge Eines der wichtigsten Hilfsmittel für die zu lösende Dokumentationsaufgabe ist ein Metadaten Repository. Ein solches Hilfsmittel ist bei den heute genutzten Data Warehouse Systemen wichtiger denn je, auch wenn es in der Praxis bislang kaum in der gewünschten Art eingesetzt wird. Hier ist kein Tool-bezogenes Repository gemeint, also ein Repository, das ein ETL-, Daten- oder Prozessmodellierungstool mitbringt. Es ist ein Werkzeug gemeint, das übergreifend Strukturen und inhaltliche Zusammenhänge in dem gesamten Data Warehouse beschreibt. Ein solches Werkzeug verhindert die mehrfache Modellierung von gleichen ETL-Strecken, Tabellen- und View- Definitionen, sowie redundante Dimensionen und Kennzahlen. 13 Suche über o Scope, Typen und beliebige Attribute Strukturauflösung in beliebiger Tiefe Automatischer Metadaten-Import Externe Referenzen Beliebig erweiterbar Frei programmierbar Data Warehouse Information Model In einem solchen Repository System wird ein Data Warehouse Informations-Modell implementiert. Das ist die Summe aller Metadaten-Typen, deren beschreibende Attribute-Typen und die Beziehungen zwischen den Metadaten-Typen. Ein solches MetadatenInformationsmodell ist von Data Warehouse zu Data Warehouse unterschiedlich, weil jedes Data Warehouse andere Inhalte aus dem jeweiligen Unternehmen widerspiegelt. Hierzu benötigt man ein generisches Repository, in dem die Definitionshilfsmittel in Form von Metadaten-Typen, MetadatenAttributen und Metadaten-Beziehungen selbst individuell definiert werden können. Beis piel für e in Metadaten -Informations-Mode ll Prinzip de s gener isc hen 4 -Schichte n-Repos itorie s Ein Beispiel für ein solches Repository ist der folgende Oracle-APEXbasierte Prototyp. Mit diesem Repository ist die Grundlage für alle anderen Data Governance-Maßnahmen gelegt. Begriffsdefinitionen und Glossars Die unternehmensweite Standardisierung von Begriffen und Bezeichnern ist eine wichtige Voraussetzung für ein gemeinsames Verständnis der Informationen in einem Data Warehouse. Über die Attributierung in dem Repository wird zu jedem Begriff eine Definition, der Verwendungszweck und die Herkunft beschrieben. Über Beziehungen lässt sich eine synonymes oder auch homonymes Verhältnis zu anderen Begriffen dokumentieren. Bei solchen Begriffsdefinitionen ist regelmäßige Pflege wichtig. Daher wird auch die für die Pflege verantwortliche Stelle dokumentiert. Dieser Prototyp verfügt über: Frei definierbare Meta-Typen o Objekte, Attribute, Beziehungen Die Begriffe präsentiert man über eine Web-Oberfläche, so dass alle Mitarbeiter die Definitionen einsehen können. Sollen neue Begriffe erfasst werden, sucht man zunächst mit den Hilfsmitteln des Repositories ob entsprechende Begriffe bereits vorhanden sind. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Deskriptoren-Verfahren Die zuvor dargestellten Begriffslisten bzw. Glossare eignen sich gut als Anwendungsfall für das Deskriptoren-Verfahren. Die Definition der Begriffe alleine ist es noch nicht ausreichend. Bei mehreren Tausend Definitionen wird die Menge den Erfolg zunichte machen und es schleichen sich doch wieder Synonyme bzw. Homonyme ein. Das Deskriptoren-Verfahren beschreibt die einzelnen Begriffe zusätzlich über feststehende Schlagwörter die in unterschiedlichen Kategorien, oder auch Klassen genannt, definiert wurden. Die Klassen entsprechen den Blickwinkeln aus denen heraus man den Begriff beschreiben will. Beis piel für die K lassifizierung eines Be gr iffs Beis piel für De skr iptore n -Klass en: Sammlunge n von festste hende n Beschre ibungsw erten Das Deskriptoren-Verfahren kann man auf alle relevanten Metadaten-Typen anwenden, z. B. auf Kennzahlenbeschreibungen, Berichte aber auch auf mehr technisch ausgerichtete MetadatenTypen wie Tabellen oder Materialized Views. Alte Daten - neue Daten Eine weitere Herausforderung kann es sein, das Data Warehouse von obsoleten Daten zu entrümpeln. Hierzu müssen alte und nicht mehr genutzte Daten identifiziert werden können. Hilfsmittel sind: Markieren aller Sätze beim Laden mit o Load-Datum o Letztes Änderungsdatum o Status-Feld für Aktuell Für Jahresvergleiche relevant Obsolet o Geladen aus Verfahren X,Y,Z o Geladen für Abt. A, B, C Herausfiltern der aktuellen Sätze über Beziehungsabfragen mit Zeiteinschränkung Einsatz von Partitioning o Erlaubt das Arbeiten nur auf den aktuellen Daten 14 Tabellen, i . d. R. aus dem Bereich der Bewegungsdaten im Data Warehouse können mit zusätzlichen Spalten versehen werden wie etwa: Owner Org_Unit Benutzer Angelegt _am Zuletzt_geändert_am Geschäftsprozess Status Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte ETL - Extraktion, Transformation, Load Data Warehouse Systeme erhalten in definierten Zeitabständen neue Daten aus den operativen Vorsystemen. Waren früher die Zeitabstände eher länger (Wochen, Monat, Quartal), so ist heute das tägliche Laden der Standard-Fall, oft findet man bereits untertägiges, stündliches Laden oder sogar das permanente Laden. Entscheidend bleibt der Punkt: Folgende Aktivitäten finden während des ETL-Prozesses statt: Erfüllt das Data Warehouse noch seine originären Funktionen des Integrierens, des semantischen Abgleichs und der Umwandlung im Sinne von Normalisieren und Denormalisieren. In manchen Diskussion wird der Realtime-Aspekt als Merkmal des Modernen dargestellt. In solchen Diskussionen sollte man immer den Zweck des Systems mit bewerten bevor die reine Technologie zum Selbstzweck wird. ETL vs. ELT In jüngster Zeit ist in Diskussionen der Begriff ETL durch den Begriff ELT ersetzt worden. Auch solche Begrifflichkeiten sollten auf ihren Zweck hin hinterfragt werden. Mit dem Begriff ELT (Extract Load Transform) wollen Tool-Hersteller zum Ausdruck bringen, dass Daten aus den Vorsystemen zunächst in das Zielmedium (Datenbank) geladen werden, um sie dort zu transformieren. Die Datenbank ist die eigentliche Transformations-Engine. Die Argumentation kommt ehemals von der Firma Sunopsis, die damit das Native-Generieren von SQL-Kommandos unterstreichen wollte. Dies ist eine Abgrenzung gegenüber Engine-basierten Werkzeugen wie Informatica, Data Stage oder Ab Initio, bei denen Daten in einem separaten Programm (Engine) transformiert werden und das Ergebnis dann in die Zieldatenbank gelangt. Sunopsis wurde von Oracle gekauft und das Produkt in ODI umgetauft. Oracle verfügte jedoch bereits über ein Native-SQLgenerierendes Werkzeug (Oracle Warehouse Builder). Die Argumentation ELT vs ETL wurde beibehalten. Sie trifft aber auch für Warehouse Builder zu. Hier werden beide Begriffe synonym genutzt, da es hier primär nicht um Marketingaussagen geht. Die Aufgabenstellung des ETL Folgende Anforderungen sind an den ETL-Prozess zu stellen: Backbone des DWH Transfer-Medium über alle Schichten hinweg o Vermittlungsfunktion o Übernimmt oft Dokumentationsaufgabe Bewegen großer Datenvolumina bei gleichzeitiger komplexer Transformation Standard-Lösung wird benötigt o Nicht zu komplex (Entwickler-Spielzeug) o Verständlich auch für Business User o Leichte Erklärbarkeit für Dritte Bereitstellen von Daten in adäquater Weise o Zeitlich passend o Richtige Form o Passende Inhalte Daten so ablegen, dass man sie wiederfindet o Dokumentation Daten Ressourcen-ökonomisch speichern o Berücksichtigung von Plattenplatz Es sollte nur das geladen werden, was wirklich gebraucht wird 15 Gibt es einen Auftrag für das Laden bestimmter Daten? o Wer braucht die Daten? o Welche Daten werden gebraucht? Sind die zu ladenden Daten in einem brauchbaren Zustand? o Welche Anforderungen sind an Quelldaten zu stellen? o Wer definiert die Anforderungen? Standardfunktionen Insert, Update, Delete, Merge (Insert / Update) 1:1-Transformationen (reines Kopieren, auch mit minimalen Änderungen) Selektionen (z.B. Where-Klauseln, Bedingungen) Gruppierende Transformationen (Aggregationen, Sortieren, Segmentieren) Pivotierende Transformationen (Verändern der Kardinalität von Zeilen und Spalten) Berechnungen (einfache oder komplexe, Funktionen oder Programme) Formatieren von Daten Zusammenführende und spaltende Transformationen (Join / Split) Anreichernde Transformationen (Referenzen auslesen, Lookups, Konstanten, Fallunterscheidungen) Aussortieren / Trennen von Datenbereichen Prüflogik (logisch / fachliche und physisch / technische) Protokollierende Maßnahmen (Log Files, Statistiken) Steuerungen (Rules-Systeme) Kommunizieren mit anderen Systemen (Messages senden / empfangen / quittieren) Die ETL-Aktivitäten lassen sich in 4 Bereiche gliedern: 1. Integrieren: Identifizieren von identischen oder zusammenhängenden Informationen o Synonymen-/Homonymen-Thematik Aggregationslevel angleichen o Identifizieren und Angleichen Formate, Zustände, Sichtweisen etc.... 2. Informations-Mehrwerte Qualitativ gute Informationen schaffen o Datenqualitäts-Checks Vollständigkeit Datentypen Referentielle Integrität Eindeutigkeit Korrekte Werte o Fachliche Regeln überprüfen Berechnungen / Aggregationen / Zusammenfassungen Anreichern und Vermengen mit Referenzdaten o Lookups o Marktdaten o Vergleichszahlen 3. Kopieren 1:1-Datenbewegung o Einfachste Aufgabe Mengen-Operationen o Ohne zusätzliche Logik Überwindung von Systemgrenzen Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte o Vorschriften zum Mapping o Schnittstellen-Konventionen Aspekt der Performance 4. Sammeln Einlagern von Daten o Zeitliche Rahmenvorgaben o Historisierung Versionieren von Daten Kategorisieren / Inventarisieren von Daten o Dokumentieren der eingelagerten Informationen Referenzen aufbauen Alterungs-Eigenschaften berücksichtigen Dokumentieren Mehr als nur eine Momentaufnahme 16 Zus ammenzie he n von Tr ans for mationen in den Bere ich der Stage Schic ht Zusammenfassen kann der ETL-Prozess wie folgt auf das SchichtenModell übertragen werden: Datennahe Transformationen für Daten-orientiertes Data Warehouse Im Gegensatz zu OLTP- oder SOA-basierten Systemen sind Data Warehouse - Systeme Daten-orientiert. Die Datenablage an sich stellt den eigentlichen Wert dar. Ein Datenbank-System wie Oracle stellt damit die ideale Plattform für ein Data Warehouse dar. Daher ist es nur folgerichtig, wenn auch das Laden und Transformieren der Informationen möglichst nahe an den Daten stattfindet. Auch wenn moderne Anwendungen heute über eine Middleware Komponente verfügen ist das Laden und Transformieren über die Datenhaltungs-Instanz am sinnvollsten, da hier die größten Synergie-Effekte erzielt werden können. Verteilung der ETL -Aktiv itäte n auf die 3 Sc hic hte n des Data Warehouse Sys tems Generieren statt modellieren Programmieren- Mit Graphik Auch wenn mit Bordmitteln der Datenbank (SQL, PL/SQL) gearbeitet wird, sollten die nötigen Datenbank-Objekte nicht manuell programmiert werden. Hierzu stehen heute graphische Editoren, wie z. B. durch Oracle Warehouse Builder (In Database ETL) zur Verfügung. ETL-Operationen im Data Ware house s ollten Daten - zentr iert in der Datenbank s tattfinden Das bedeutet, auch wenn operative Systeme z. B. über eine Service-orientierte Kommunikationsstruktur verfügen und darüber Daten auch in ein Data Warehouse gelangen können, so sollten das Gros der Transformationsroutinen und Logik Daten-nah, also mit den Bordmitteln der Datenbank stattfinden. Das 3-Schichten-Modell und der ETL-Prozess Die oben vorgestellte Schichten-Architektur kann und sollte auch zur besseren Organisation des ETL-Prozesses beitragen. Ein gut organisierter ETL-Prozess versucht so viele Transformationen so früh wie möglich durchzuführen, damit diese nur ein einziges Mal zu erledigen sind. Übertragen auf das Schichten-Modell bedeutet dies, dass die meisten Transformationen innerhalb der Stage-Schicht stattfinden sollten. Auf dem Weg der Daten in Data Mart-Schicht sollten dagegen nur einfache, aggregierende Join-Operationen erfolgen. Diese Vorgehensweise hat folgende Vorteile: Vermindern von Fehlern durch Handprogrammierung Tabellen- und Spaltennamen müssen nicht mehr mühsam geschrieben werden Steuerung vieler Entwicklungsschritte durch Wizards Automatische Steuerung von Ziel- und Quellschemata Automatische Validierung (z.B. Typverträglichkeiten) Debugging der Laderoutinen Laufzeitumgebung steht bereit Dokumentation Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte 17 Wiederholbarkeit des Ladelaufs Ladeläufe sollten generell so gestaltet sein, dass sie jederzeit mit der gleichen Quelldatenmenge wiederholt werden können. Hilfsmittel hierfür sind: Flashback (Oracle Datenbank - Flashback, damit wird ein Zustand vor der Ladeaktivität wieder eingestellt) Steuerung über eindeutige Schlüssel. Hierbei merkt man sich die durch die letzte Ladeaktivität neu entstandenen Schlüssel. Mengen-basiertes oder Einzel-Delete löscht die fehlerhaften Sätze. Separates Datenschema und späteres Überführen in Zielschema bzw. Laden in getrennten Partitionen. Steuerung über Inkrement-Load-Nummer oder Tagesdatum. Mengen-basiertes oder Einzel-Delete löscht die fehlerhaften Sätze. Load-Inkremente als Strukturierungshilfe für den Ladeprozess Die Einteilung in sogenannte Load-Inkremente hilft beim Steuern des Lade-Vorgangs. Portionierung von Ladestrecken-Etappen Einteilung nach o Schichten o Quellsystemen o Zielsystemen o Datum / Zeit o Versionen o Häufigkeitsnummern (Load-Inkrement) Die Verteilung von Load-Inkrementen auf die Schichten des Data Warehouses erfolgt nach folgendem Schema: Tabelle n des L oad-Managers Deltadatenerkennung Das Erkennen von geänderten Daten der operativen Vorsysteme stellt eine besondere Herausforderung da. Es gibt folgende technische Möglichkeiten zur Steuerung: Das Vorsystem liefert nur die geänderten Daten. Dies stellt die einfachste Lösung dar, sie ist jedoch selten, da dies zusätzlichen Aufwand für die Vorsysteme bedeutet. Allerdings kommt dies im Umfeld von SAP R/3 relativ häufig vor, weil R/3 sehr stark gekapselt ist. Abgreifen über Zeitstempel in den Quell-Tabellen. Dies ist eine einfache Methode. Sie funktioniert jedoch nur, wenn es solche Zeitstempel gibt. Erstellen von Triggern und temporären Tabellen im Quellsystem. Diese Variante ist nicht zu empfehlen, da sie das Quellsystem beeinflusst. Auslesen der Log-Dateien. Diese im Prinzip sehr gute Variante funktioniert jedoch nur bei Datenbanken mit LogDateien. Oracle Golden Gate nutzt diese Variante. Komplett-Kopie und SQL-Minus-Operation. Diese auf den ersten Blick sehr aufwendige Operation funktioniert in der Praxis trotz der großen Datenmenge, die bewegt werden muss, erstaunlich gut. Verteilung von Load-Inkreme nten auf die W arehous e Schic hten Die einzelnen Load-Inkremente können Namenskonventionen zusätzlich verwaltet werden: auch über Delta-Date n-Erkennung mit SQL -Minus-Oper ation Datenbank-interne Lade-Läufe schnell machen Beis piel für die Be nennung von Load -Inkreme nte n Load Inkremente können schließlich mit einem Load-Manager verwaltet werden. Der Load Manager stellt nur ein einfaches Tabellenwerk dar, in dem alle Load Inkremente erfasst sind. Über eine zentrale Load-Nummer (RUN_NUMBER) werden alle Inkremente eines zusammenhängenden Ladelaufs identifiziert. Das Laden von Daten mit SQL - Mitteln innerhalb der Datenbank erfordert einige Grundprinzipien in dem Umgang mit Constraints und Indexen. Ein typicher Ablauf sieht wie folgt aus: Constraints abschalten Indizes löschen Laden über “Direct Path” o Constraint-Prüfung mit SQL-Mitteln Eventuell Löschen alter Daten o Oder Archivieren Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Aktivieren der Constraints o (Sofern überhaupt gebraucht) Neu-Aufbau von Indizes Statistiken aktualisieren o DBMS_STAT Der Umgang m it Tabellen im V erlauf de s L ade ns in der Date nbank Die Vorteile des SQL der Datenbank bei den Ladeaktivitäten SQL kann in dem gesamten Data Warehouse als Haupt-Lade- und Transformationssprache eingesetzt werden. Hierdurch vereinfacht sich der Umgang mit der eingesetzten Technologie erheblich, da nur eine Sprache beherrscht werden muss: SQL als Transformations-Sprache hat folgende Vorteile: SQL basiert, d.h. die Oracle Datenbank wird ausgenutzt o Möglichkeit primär mengenbasierte Operationen durchzuführen o Wesentlich höhere Performance o Automatisiertes Datenbankgeregelte Parallelisieren o Datenbankgestütztes Ressourcen Management Unterstützung aller aktuellen Datenbank-ETL-Funktionen wie o Multiple Inserts o Merge (Insert/Update) o Direct Path Load o Table Functions o Partition Exchange and Load Vollständige Hints-Bibliothek Verwendung aller Datenbank-Funktionen, z.B. auch analytische Funktionen o Im Gegensatz zu den von Drittherstellern nachgebildeten z.T. unvollständigen Funktionen (Beispiel SQL CASE, Decode) Datennahes Entwickeln 18 Leichtes, performantes und mengenbasiertes Update von Sätzen o Ausnutzen temporärere Strukturen Temp-Tables Cache-Tables o Ausnutzen besonders schneller Tabellen-Objekte Index-Based Tables o Direkter Zugriff auf Tabelleninhalte Nähe zu Katalogstrukturen o Alle Informationen stehen sofort zur Verfügung Komplett-Definition aller physikalischen Objekte im Data Warehouse o (Tables, Index, Materialized Views, Partitioning ...) o Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Checkliste zur Planung und dem Neuaufbau von Data WarehouseSystemen Anforderungsdefinition zu dem System Ziel des Systems abstimmen Nutzergruppen und Nutzererwartung feststellen / Nutzen Lifecycle der Warehouse-Daten Aktualität der Daten festlegen Delivery Management Wiederholbarkeit von Ladeläufen prüfen Update-Plan (Update / Read-Only) Beschaffungs-/aufbereitungslatenz prüfen / definieren Architektur So kompakt wie möglich wählen - minimieren auf ein System Schichten-Schnitte nach fachlogischen Gesichtspunkten wählen (3-Schichten-Modell) Organisatorische Einbindung Mitarbeit Endbenutzer Managementsponsor Security Zugriffsplan für Kennzahlen festlegen Zugriff auf alle Schichten durch Endbenutzer Mandantenfähigkeit Logische Modellierungung Homonymen / Synonymen - Check Einführen von DWH-spezifischen Schlüsseln für KernStammobjekte Logische Datenmodellstrukturen in den Schichten Physikalisches Design Tabellenplan / Tablespaces Indexstruktur (Einsatz von Varianten) Sizing-Plan Datenmengen kontrollieren (Nutzerdaten) Wachstumserwartung feststellen Hardware „Private“ Hardware für das DWH o Storage nur für DWH o Netzwerk zwischen Storage und DWH Server nur für DWH o Konzentration aller Schichten auf einer zusammenhängenden Hardware o Ausbaufähigkeit für Wachstumserwartung berücksichtigen DWH-System verändern ihre Größe schneller als OLTP Skalierung über Hardware-Cluster prüfen 19 Effizienz im DWH Reduzieren von Datenmengen o Nur genutzte Daten speichern (Usage: Records und Columns) Reduzieren von Ladeläufen o Keine unnötigen Kopien o Kompakte Ladeläufe o Keine 1:1 Bewegungen Synergien schaffen o So früh wie möglich transformieren Keine Maintenance-Aktivitäten während ETL o Aktualisierungsplan von Indexen Kontinuierliche Verbrauchsdaten sammeln o Belegter Plattenplatz o Laufzeiten o Antwortzeiten Übersicht im DWH Ownerschaften feststellen Inventar/Metadaten-System implementieren Glossar zur Begriffsstandardisierung einführen Datenmodelle visualisieren Lineage/Impact visualisieren Quell- / Zielsysteme bekannt? Struktur Zugriffsmethode Verfügbarkeit Grad der Verfügbarkeit festlegen Gesamtsystem Teilsysteme Backup- / Recovery für das DWH Incremental Diversifizierung der Datenbestände Read-Only Aus Fremdbeständen wieder herstellbare Daten Backup reduzieren auf geänderte Daten Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Hardware wichtiger Bestandteil im Data Warehouse Für die Konzeption von Data Warehouse-Systemen ist in den letzten Jahren die Hardware noch stärker in den Fokus gerückt. Gründe sind die enormen Leistungsanforderungen eines DWHSystems gegenüber den meisten OLTP-Anwendungen wobei z. T. sehr große Datenmengen in angemessener Zeit zu bearbeiten sind. Bei der Lösung dieser Herausforderung helfen gleich mehrere Technologien. Die Hardware stellt eine wichtige Voraussetzung dar. Hardwar e-Kompone nte n in einem Data Warehouse als Einheit betr achte n „Private“ Hardware ungeschriebene Regel DWH Systeme nutzen Speicherplatten und Netzwerk in einer anderen Weise als OLTP-Anwendungen. Daten werden in größeren Mengen und eher in zusammenhängenden Einheiten verarbeitet. Wichtig ist die Datenmenge pro Sekunde, die ein System bereitstellen kann (MB/sec). OLTP-Systeme lesen und schreiben dagegen mit höherer Frequenz kleinere Datenmengen. Die Anzahl der IO-Operationen pro Sekunde ist die Kenngröße (IOPS). Die Hardware kann nicht für beide gegenläufige Anforderungen gleichzeitig konfiguriert werden. Eine einfache Lösung ist das Trennen der Hardware für DWH und OLTPSysteme. DWH-Systeme sollten über eigene Rechner, eigenen Speicher und ein separates Netzwerk verfügen, über das auf die Speicherplatten zugegriffen werden kann. 20 Oracle’s Database Machine verfolgt diesen Ansatz konsequent, indem sie Speicher, das extrem schnelle Infiniband-Netzwerk und die Server-Maschinen in einer Einheit zusammenfasst und ein Data Warehouse als Datenbank-Anwendung bedient. Speicherhierarchien Anwender nutzen die Daten in einem Data Warehouse meist unterschiedlich häufig. Die wenigsten Daten nutzen sie regelmäßig und die Nutzungshäufigkeit nimmt mit zunehmendem Alter der Daten ab. Heute stehen unterschiedlich performante Speichermedien bereit, wobei eine höhere Zugriffsgeschwindigkeit auch höhere Kosten mit sich bringen. Die Oracle Datenbank erlaubt es mit ihren technischen Möglichkeiten unterschiedliche Speichervarianten auszunutzen. Häufig genutzte Daten können permanent im Hauptspeicher (RAM) vorgehalten werden. Damit sind komplette Data Mart extrem performant InMemory abfragbar, auch wenn sie mehrere Terabytes umfassen. Die nächste etwas kostengünstigere Technologie, Flash Speicher, kann man als 2nd Level Cache konfigurieren, der Daten persistent vorhalten kann und immer noch bis zu 200 mal kürzere Antwortzeiten liefert als Festplatten. SAS und SATA Platten unterscheiden sich durch ihr Speichervolumen und durch Performancewerte. Die schnelleren aber kleineren SAS-Platten eignen sich als klassische Speicherablage im Data Warehouse, während SATA-Platten durch ihr höheres Speichervolumen für seltener genutzte Daten sinnvoll sind. Das kommt der typischen Data Situation in Warehouse-Systemen entgegen, bei der meist ein überproportional großer Anteil der Daten sehr selten gelesen wird. Zur Entlastung des DWH-Systems ist es sinnvoll, kaum genutzte Daten zu archivieren. Sollen dieses Daten dennoch im Zugriff sein, sollten sich diese „prinzipiell“ archivierten Daten dennoch im Online Zugriff befinden. Das Oracle Datenbank-System kann solche Daten auf kostengünstigem Massenspeicher vorhalten und sie Benutzern ständig online verfügbar anbieten. Über die DWH Logistic Utilities stehen Funktionen für ein intelligentes Verschieben alternder oder weniger häufig genutzter Daten bereit. Spe icher-Hier arc hie für unters chie dliche Nutzungs ar ten In Memory Parallel Execution Die Oracle Datenbank kann über die Real Application Clusters (RAC) - Technologie mehrere Rechner als Cluster zusammenschalten. Das garantiert zum einen eine sehr hohe Ausfallsicherheit, zum anderen können Rechnerknoten dediziert einzelnen Aufgabenstellungen (ETL-Load-Jobs, Reporting-Jobs, Online-Betrieb usw. ) effizient zugeordnet werden. Damit können unterschiedliche Nutzungsprofile die gleiche Hardware ausnutzen. Das neue Verfahren des InMemory Parallel Execution kann die Hauptspeicher (RAM) aller RAC-Knoten-Rechner so nutzen, als wenn es sich um einen durchgängigen Speicher handeln würde. So kann das System auch große Datenmengen (ganze Data Marts) permanent im Hauptspeicher des GesamtClusters für Abfragen anbieten. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte 21 Architektonische Vorteile RAC und ETL Alle E bene ne n eines Sys tems als Cluster aufge baut Hardware-Aspekte Storage und Plattensysteme Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Allgemeine Aus ETL-Sicht Aufbauempfehlungen RAC Kompression: Verwaltung und Kosten reduzieren Wieviele Platten-Controller? Database Machine (Exadata) Alle vorgenannten Hardware-Aspekte lassen sich mit konventioneller Hardware-Technik von den meisten HardwareAnbietern umsetzen. Den geringsten Aufwand und die größten Nutzen-Effekte erzielt man jedoch mit dem Einsatz von Oracle’s Database Machine (DBM) und der dort implementierten ExadataStorage-Software. Als fertig vorkonfiguriertes System senkt die DBM Einführungsaufwand und Verwaltungskosten. Sie liefert 8 RAC-Knoten-Rechner mit 96 CPU Cores und 14 Storage-Server mit weiteren 112 CPU-Cores und 30 TB (100 TB Kapazität) SAS Storage bzw. 98 TB (300 TB Kapazität) SATA Storage. Verbunden sind beide Rechnergruppe mit einem eigenen 40 Gb InfinibandNetzwerk. 22 Die Exadata-Storage Software beschleunigt das System über sog. Smart-Scan-Verfahren, einem neu entwickelten Zero-CopyDatenprotokoll und einer speziellen Storage-Index-Technik auf bis zu 25 GB/Sec Datendurchsatz, die Abfragen in der Datenbank zur Verfügung stehen. Aufsc hnitt e ine r Database Mac hine Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Kleine Vorschau auf einzelne Oracle Datenbank-Technologien Immer die passende Datenmodell-Form Grundsätzlich gibt es keine Einschränkung bei der Wahl einer passenden Daten- und Schichten-Architektur. Die Oracle Datenbank ist für die unterschiedlichsten Verwendungen, ob OLTP oder Data Warehouse, ob klassisches DWH, Realtime- oder Active-DWH einsetzbar. Sie unterstützt alle Datenmodell-Varianten wie 3NF, Star- und Snowflake-Schema. Sie bietet mit der OLAP-Option auch eine multidimensionale Speichervariante mit vorberechneten Kennzahlen an. 23 Mit Partitioning große verwalten Datenmengen leicht Das Partitionieren großer Tabellen gehört mit zu den wichtigsten Hilfsmitteln des Oracle Data Warehouse. Partitioning teilt die Daten großer Tabelle in physikalisch separierte Mengen und spricht diese Teilmengen separat an. Dadurch müssen bei entsprechenden Abfragen nur die Partitionionsdaten aber nicht die gesamte Tabelle gelesen werden, so dass eine gute Abfrageperformance entsteht. Zum anderen schafft es durch die kleineren Datenpakete Verarbeitungseinheiten für die Verwaltung. Das hilft in dem ETLProzess, bei der Indizierung, bei der Komprimierung oder dem Sichern der Daten. Würfel, Star-Sc hema und 3NF Mode lle in e iner D ate nbank In dem jüngsten Release kommt auch eine spalten-orientierte Speicherung zum Zuge, die für das Lesen von lediglich wenigen Spalten in einer Tabellen Vorteile zeigt. Entscheidend ist die Wahlfreiheit bei der Verwendung dieser Modelle. Für das Anbieten Geschäftsobjekt-naher Daten bei EndbenutzerAbfragen eignen sich Starschema-Modelle. Zum Vorhalten unternehmensweit-geltender einmaliger Informationen in zentralen Warehouse-Schichten eignen sich 3NF-Datenmodelle mit sehr granularen Informationseinheiten, weil aus diesen Daten meist andere Daten abgeleitet oder neu kombiniert werden. Empfohlene Architekturen in unternehmensweiten Systemen Partitionen habe n v iele Funktione n Die am häufigsten genutzte Variante ist das Rang-Partitioning bei dem die Einteilung der Partitionen entlang definierter Wertebereiche erfolgt. Das im DWH am häufigsten genutzte Kriterium ist die Zeit (z. B. Tage, Monate). Auch zusammengesetzte Felder oder über Funktionen ermittelte Werte können ein Partitionierungskriterium sein. Die Variante List-Partitionierung ordnet Daten aufgrund der Zugehörigkeit zu definierten Werten oder Begriffen. Die Einteilung nach Verkaufsgebieten „Nord“, „Sued“, „West“, „Ost“, „Mitte“ ist ein Beispiel. Klass isc hes 3 -Sc hic hten-Sc hem a In unternehmensweit aufgestellten Data Warehouse Systemen hat sich Aufbereitung der Daten in drei Schritten bewährt: 4) 5) 6) Man sammelt, integriert und prüft auszuwertende Daten der operativen Vorsysteme. (Stage) Man granularisiert diese Daten in einem alle Sachgebiete umfassenden (meist 3 NF) - Schema. (DWH-Schicht) Je nach Zielgruppe und Sachgebiet fügt man im letzten Schritt die granularen Informationsbausteine meist zu zu multidimensionalen Endbenutzer-Modellen (meist Starschemen) zusammen. (Data Marts) Nicht immer liegen Partitionierungskriterien vor. Die HashPartitionierung überlässt das Partitionieren der Daten der Datenbank. Dies ist dann hilfreich, wenn einerseits Datengruppen gebildet werden sollen und andererseits Daten gleichmäßig über die Datengruppen hinweg zu verteilen sind. Die Varianten lassen sich über Sub-Partitioning mischen, um das Partitionieren noch flexibler zu gestalten. Das grundlegende Partitionierungskriterium kann z. B. eine Monatseinteilung sein (Range) und die Monatspartitionen können noch weiter nach Verkaufsgebieten unterteilt sein. Dieses ist eine Ressourcen-schonende Vorgehensweise mit der Betonung auf Wiederverwendung von Daten und Entwicklungsarbeiten bei gleichzeitiger Flexibilität durch beliebige Auswerte-Szenarien. Um Synergie-Effekte möglichst komplett zu nutzen empfiehlt Oracle alle 3 Verarbeitungsschritte bzw. Schichten in einer einzigen Datenbank-Instanz und damit auch HardwareUmgebung anzusiedeln. Partitioning mit Subpartitioning Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Aufbau eines Daten Life Cycle Mangements Man kann das Partitioning-Instrument nutzen, um alternde Daten innerhalb der Speichermedienhierarchie auf weniger performante aber dafür kostengünstigeren Speicher zu kopieren. Diese Kopierprozesse sind über die Warehouse-ManagementFunktionen automatisierbar. 24 ersten Schritt eine Reihe von Materialized Views, die nur allgemein einschränkende Bedingungen haben und noch viel Raum für weitere Spezialisierungen lassen. Hier würden etwa aufwendige Join-Operationen Platz finden. Eine Reihe weiterer Materialized Views basiert auf den Ergebnissen der vorgenannten Views, und sie nutzen die bereits erstellten Leseergebnisse. Mandantenfähigkeit Das Partitioning kann auch Grundlage für ein MandantenVerfahren sein, bei dem Tabellen nur einmal zu pflegen sind, einzelne Partitionen aber nur für die dafür autorisierten Personengruppen offen stehen. Über Label-Security ist ein Zeilen-orientiertes (bzw. Partition-bezogenes) Schützen von Tabellendaten möglich. Optimierte Starschema-Zugriffe Star-Schemen stellen typische Auswerte-Datenmodelle in Warehouse-Systemen dar. Um Abfragen auf ein Star-Schema noch schneller durchzuführen, kann man die Option der StarTransformation nutzen. Hier spaltet der Datenbank-Optimizer eine Abfrage optimal in Teilabfragen auf, die das System unter Verwendung von Bitmap-Indizes separat abarbeitet. Das Verfahren arbeitet eng mit der Bitmap-Indizierung zusammen. Bitmaps besonders Strukturen gut für denormalisierte Bei sehr stark denomalisierten Daten, wie diese das Data Warehouse z. B. in Star-Schemen nutzt, Ausschnitt aus einem Starsche ma mit I ndizier ung werden in bestimmten Tabellenspalten Informationen häufig redundant abgelegt. Um hierauf schnelle Zugriffe bei großen Datenmengen zu gewährleisten, hat Oracle eine spezielle Indizierungsart den Bitmap-Index entwickelt. Eine Bit-Codierung dokumentiert das Vorkommen bestimmter Werte in den Spalten. Die Bitmap-Indizierung gehört zu den effizientesten Verfahren bei der Zugriffsbeschleunigung im Starschema Sich selbst aktualisierende Kennzahlensysteme Ein sehr hoher Anteil von Benutzerabfragen in einem Data Warehouse ist vorhersehbar. Die Oracle Datenbank kann immer wiederkehrende Abfragen feststellen und sie für den Administrator dokumentieren. Dieser kann solche Abfragen über sog. Materialized Views vorbereiten und Abfrageergebnisse speichern. Wenn Benutzer zum wiederholten Mal solche Abfragen starten, bedient sich das System der gespeicherten Ergebnisse, ohne dass der Benutzer hierfür an seiner Abfrage etwas verändern muss. Die Benutzer erhalten Ergebnisse in einer wesentlich kürzeren Zeit. Über dieses Datenbank-Feature lassen sich intelligent strukturierte Kennzahlensysteme aufbauen. Man erstellt in einem Aufe inander aufbauende Mate rialized Views Materialized Views aktualisieren sich selbst ohne dass administrativ eingegriffen werden muss. Das Aktualisieren erfolgt auch (wenn sinnvoll) über das gezielte Nachladen von Änderungen in den zugrundeliegenden Basistabellen. Das beschleunigt die Verarbeitung. Materialized Views sparen ETL-Aufwand Mit dem Einsatz von Materialized Views spart man ETL-Aufwand. Die Aggregations-/Leseleistung müsste alternativ über ein ETLTool bzw. mit Programmiermitteln erbracht werden. Definiert man Materialized Views in Oracle Warehouse Builder, so erhält man auch eine graphische Dokumentation, z. B. welche Basistabellen werden von einer Materialized View gelesen. Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Modell-basiertes ETL Eine der größten Herausforderungen bei dem Aufbau von Data Warehouse Systemen ist die Wahrung der Übersicht über die Menge der Objekte und verworrenen Datenflüsse. Dem begegnet das graphisch gestützte Modellieren der Datenstrukturen und der Datentransformationen. Die Oracle Datenbank verfügt mit Oracle Warehouse Builder (OWB- InDatabase-ETL) über ein graphisch arbeitendes ETL-Tool (Extraktion, Transition and Load) in dem alle Data Warehouse-Strukturen beschrieben sind. Die Datenflüsse von Quell- zu Ziel-Objekten sind dokumentiert und graphisch visualisiert. Über Metadaten-Auswertungen lassen sich auch extrem komplexe Datenflüsse bis auf die Feldebene aufzeigen. 25 Die Daten müssen, um transformiert zu werden, nicht die Datenbank verlassen. Die Ladelogik wird über mengenbasiertes SQL abgebildet. OWB-Transformationen bzw. - ETL stellen die schnellste Art dar, mit der ein Data Warehouse gefüllt und aktualisiert werden kann. Neutrales und Management übergreifendes Metadaten- Oracle Warehouse Builder deckt neben der ETL-Funktionalität auch die Rolle des Metadaten-Managements ab. Mit dem frei konfigurierbaren Repository lassen sich auch fachliche Metadaten beschreiben. Alle Metadaten liegen in offen zugänglichen Datenbank-Tabellen, so dass sie beliebig für andere Tools zur Verfügung stehen. Über eine Webanwendung kann man das Repository auswerten. Die entscheidenden AuswerteInformationen sind dabei die Beziehungen zwischen den Objekten. Diese können entweder als eingerückte Listen oder als graphische Flussdiagramme angezeigt werden. Graphische s Mapping zur Tr ansform ation v on Date n (ETL ) Extrem hohe Performance mit InDatabase ETL Einer der großen Vorteile von Oracle Warehouse Builder (InDatabase ETL) ist das Erzeugen von 100% Oracle-Datenbank Code (SQL bzw. PL/SQL). Oracle 10, 11.1, 11.2 und künftig auch 12 Datenbank-Syntax wird ohne manuelles Zutun direkt in die Datenbank gestellt. Metadate n-Auflistung v on O bj ekte n Wichtige Auswertungen auf der Metadaten sind Herkunfts- und Auswirkungs-Analyse (Lineage und Impact). Diese Analysen sind interaktiv und graphisch machbar. Graphische und int er aktive Auswirkungs- und Her kunfts analy se über Metadate n in einem Data Ware house -Sys tem Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Würfel oder Star Flexibel formulierte Adhoc-Abfragen bieten einen hohen Komfort für Benutzer gerade dann, wenn es noch keine genaue Formulierung für eine Abfrage gibt. Die Oracle OLAP-Option berechnet Daten für alle potentiellen Abfrageergebnisse eines dimensionalen Datenraums vor. Diese vorberechneten Ergebnisse kann der Benutzer ohne Zeitverzug „abholen“. Es ermöglicht das leichte Navigieren auch in großen Datenmengen mit ständig wechselnden Abfragen. Die Abfragesprache bleibt SQL und die Wahl zwischen Abfragen auf klassische relationale Tabellen (wie in einem Starschema) oder auf einen OLAP-Würfel ist automatisiert und transparent. Bei zeitbezogenen Abfragen, Periodenvergleichen, „Year-toDate“-Abfragen usw. zeigen OLAP-Würfel Vorteile, da sie die typische Struktur eines Kalenders mit z. B. einer wechselnden Anzahl von Tagen pro Zeiteinheit, gesondert vermerkt haben. Relationales und m ultidimens ionales OLAP in e iner Date nbank Schlanke Architekturen mit OLAP-Würfeln 26 sich mit einfachen Mitteln passgenaue Testdaten bereitstellen. Z. B. kann man verschiedene Wertebereiche innerhalb einer Tabellenspalte gewichten, man kann Teildatensegmente aus operativen Tabellen extrahieren und sie als Grundbestand für Testdaten verwenden. Bereichsübergreifendes Metadaten Management Das Oracle Information Catalogue Framework ist ein erweiterbares Metadaten-Repository mit einer Web-basierten Oberfläche. Dokumentiert werden können alle relevanten Fragestellungen, die auch Fachanwender interessieren. Mit vorbereiten Strukturen des Oracle Data Warehouse -FrameWorks schnell implementiert Die besten Data Warehouse Systeme sind nach wie vor Eigenentwicklungen, weil nur spezifische Anpassungen die individuellen Anforderungen im Unternehmen berücksichtigen. Das bedeutet jedoch nicht, dass jedes technische Verfahren neu zu entwickeln ist. Die Data Warehouse Logistic Utilities sind ein Framework, in dem die wichtigsten technischen Verfahren und Konzepte eines modernen Data Warehouse Systems bereits vorgedacht und vorimplementiert sind. Die Utilities bestehen aus: Einer sehr einfachen aber flexiblen MetadatenVerwaltung für beliebige Datenund Informationsobjekte. Ein bereits in dem Repository implementiertes Data Warehouse Information Model Einer ETL-Tool-unabhängigen Laufzeitumgebung zur automatischen Dokumentation von Ladeläufen. Einer Job-Managementumgebung zum Verwalten von eingehenden Datenbeständen und Ladejobs. Einer Data Quality-Prüfumgebung zum regelgestützten Monitoring von Datenqualitätsanforderungen. Ausführliche Dokumentation zur Anwendung der Utilities OLAP-Würfel flexibilisieren die Data Mart Schicht einer unternehmensweiten Data Warehouse Architektur. Mit der OLAP Option ersetzt man eine separate, losgelöste OLAP-Infrastruktur in Fachabteilungen und verhindert unkontrollierten Wildwuchs. Permanentes Kopieren zwischen redundanten SatellitenDatenbeständen entfällt, die Gesamtarchitektur wird schlanker. Praxistaugliche Testdaten Die Neu- oder auch Weiterentwicklung von Warehouse-Systemen erfolgt meist unter Laborbedingungen. Das bedeutet, dass Routinen für Transformationen und Datenprüfungen ohne das Vorhandensein von Echtdaten entwickelt werden müssen. Reichen zunächst wenige manuell erstelle Testsätze um eine Grundfunktionalität zu entwickeln, muss man in einem anspruchsvolleren Testszenario Grenzsituationen und Ausnahmekonstellationen mit einem hohen Datenvolumen ermitteln. Über ein Oracle Data Warehouse Framework lassen Data War ehouse Me tam ode l Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Inhalt Die Themen ............................................................................................................................................................................................... 1 Vier wichtige Aspekte machen das Data Warehouse so erfolgreich ......................................................................................................... 2 Der Aspekt des „Unternehmensweiten“ ................................................................................................................................................... 2 Rolle und Eigenschaften haben sich permanten verändert ....................................................................................................................... 3 Operationalsierung der Data Warehouse-Rolle......................................................................................................................................... 3 Warehouse-Organisation in drei Daten-Schichten .................................................................................................................................... 3 3-Schichten-Modell historisch ................................................................................................................................................................... 4 Die Mehrwert-Leistungen des Data Warehouse ........................................................................................................................................ 4 Die Data Mart Schicht ................................................................................................................................................................................ 5 Data Marts sind redundant und „flüchtig“ ............................................................................................................................................ 5 Historisierung ........................................................................................................................................................................................ 5 Empfehlung Star Schema verwenden .................................................................................................................................................... 6 Umgang mit großen Faktentabellen ...................................................................................................................................................... 6 Herleitung der multidimensionalen Modell eines Data Marts .............................................................................................................. 6 Strukturierung und Beziehungen der Objekte ....................................................................................................................................... 6 Das Star-Schema .................................................................................................................................................................................... 7 Varianten des Star Schemas .................................................................................................................................................................. 7 Empfehlungen für den Aufbau von Faktentabellen ............................................................................................................................... 8 Star vs. Snowflake Schema .................................................................................................................................................................... 8 Höhere Granularität bei Fakten-Tabellen wählen ................................................................................................................................. 8 Informationsmenge und Abfrageoptionen ............................................................................................................................................ 8 Auslagern von weniger häufig genutzt Attributen ................................................................................................................................. 8 Allgemeine Regeln für das Star Schema ................................................................................................................................................ 9 Die Schlüssel / Indizierung im Star Schema ........................................................................................................................................... 9 Quellsysteme ........................................................................................................................................................................................... 11 Umgang mit dem Aspekt des Operativen der Vorsysteme .................................................................................................................. 11 Umgang mit Datenqualitätsproblemen ............................................................................................................................................... 11 Stage - Schicht ......................................................................................................................................................................................... 11 Archivierung gelesener Sätze .............................................................................................................................................................. 11 Generische Stage-Strukturen ............................................................................................................................................................... 11 Operational Data Store (ODS) .................................................................................................................................................................. 12 Die (Kern-) Data Warehouse - Schicht ..................................................................................................................................................... 12 Management von Daten und Informationen in der Data Warehouse Schicht - gegen Datenchaos .................................................... 12 Metadaten Repository zur Dokumentation der Inhalte und Zusammenhänge ................................................................................... 13 Data Warehouse Information Model................................................................................................................................................... 13 Begriffsdefinitionen und Glossars ........................................................................................................................................................ 13 Deskriptoren-Verfahren....................................................................................................................................................................... 14 Alte Daten neue Daten ........................................................................................................................................................................ 14 ETL - Extraktion, Transformation, Load ................................................................................................................................................... 15 ETL vs. ELT ........................................................................................................................................................................................... 15 Die Aufgabenstellung des ETL .............................................................................................................................................................. 15 Datennahe Transformationen für Daten-orientiertes Data Warehouse ............................................................................................. 16 Das 3-Schichten-Modell und der ETL-Prozess...................................................................................................................................... 16 Generieren statt Programmieren- Mit Graphik modellieren ............................................................................................................... 16 27 Data Warehouse Technik im Fokus - Teil 1 - Architektur und Konzepte Wiederholbarkeit des Ladelaufs .......................................................................................................................................................... 17 Deltadatenerkennung .......................................................................................................................................................................... 17 Datenbank-interne Lade-Läufe schnell machen .................................................................................................................................. 17 Die Vorteile des SQL der Datenbank bei den Ladeaktivitäten ............................................................................................................. 18 Checkliste zur Planung und dem Neuaufbau von Data Warehouse-Systemen ....................................................................................... 19 Hardware wichtiger Bestandteil im Data Warehouse ............................................................................................................................. 20 „Private“ Hardware - ungeschriebene Regel ........................................................................................................................................... 20 Speicherhierarchien ................................................................................................................................................................................. 20 In Memory Parallel Execution .................................................................................................................................................................. 20 Hardware-Aspekte ................................................................................................................................................................................... 21 Storage und Plattensysteme ................................................................................................................................................................ 21 Architektonische Vorteile RAC und ETL ............................................................................................................................................... 21 Allgemeine Aufbauempfehlungen RAC Aus ETL-Sicht ......................................................................................................................... 22 Kompression: Verwaltung und Kosten reduzieren .............................................................................................................................. 22 Wieviele Platten-Controller? ............................................................................................................................................................... 22 Database Machine (Exadata) ................................................................................................................................................................... 22 Kleine Vorschau auf einzelne Oracle Datenbank-Technologien .............................................................................................................. 23 Immer die passende Datenmodell-Form ............................................................................................................................................. 23 Mit Partitioning große Datenmengen leicht verwalten ...................................................................................................................... 23 Aufbau eines Daten Life Cycle Mangements ....................................................................................................................................... 24 Mandantenfähigkeit ............................................................................................................................................................................ 24 Optimierte Starschema-Zugriffe .......................................................................................................................................................... 24 Bitmaps besonders gut für denormalisierte Strukturen ...................................................................................................................... 24 Sich selbst aktualisierende Kennzahlensysteme .................................................................................................................................. 24 Materialized Views sparen ETL-Aufwand ............................................................................................................................................ 24 Modell-basiertes ETL ........................................................................................................................................................................... 25 Extrem hohe Performance mit InDatabase ETL ................................................................................................................................... 25 Neutrales und übergreifendes Metadaten-Management ................................................................................................................... 25 Würfel oder Star .................................................................................................................................................................................. 26 Schlanke Architekturen mit OLAP-Würfeln ......................................................................................................................................... 26 Praxistaugliche Testdaten .................................................................................................................................................................... 26 Bereichsübergreifendes Metadaten Management.............................................................................................................................. 26 Mit vorbereiten Strukturen des Oracle Data Warehouse -FrameWorks schnell implementiert ......................................................... 26 28