Kein Folientitel - Webarchiv ETHZ / Webarchive ETH
Werbung

Multidimensionale Datenbanken
Teil I:
Operationen in
mehrdimensionalen Daten
Patrick Sager & Thomas Stocker
1
Übersicht
Teil I: Operationen in mehrdimensionalen Daten
Motivation
Aggregate und GROUP BY in Standard-SQL
Cross-Tables
Operatoren:
CUBE
ROLLUP
Teil II: Modellierung und Erstellung eines Data Cubes mit
dem MS OLAP Manager für TPC-D Daten
Aufgabe
Begriffe
Architektur des Servers
Design unserer Cubes
Verbesserungsvorschläge
Patrick Sager & Thomas Stocker
Übersicht
2
Daten-Analyse
Summiere Werte und extrahiere statistische
Informationen
Meist nach mehreren Kriterien:
Tiefste Temperatur in New York an Weihnachten während
den letzten 100 Jahren
Durchschnittlicher Umsatz der Abteilung „Schuhe“ in
Frankreich im Monat Mai
Unterstützung der Entscheidungsfindung in der
Betriebsführung (MIS)
Ziel: Möglichst einfacher und effizienter Zugriff auf
solche Informationen
Patrick Sager & Thomas Stocker
Motivation
3
Mehrdimensionale Daten im Relationen-Modell
Länge
37:58:33N
43:45:22N
23:13:43N
Breite
122:45:28W
90:34:23W
34:16:18W
Wetter
Höhe
500
250
710
Temperatur
20
18
16
Luftdruck
1029
1002
1020
Höhe
(20, 1029)
Länge
Breite
Patrick Sager & Thomas Stocker
Motivation
4
Aggregate
Prinzip: Kombiniere alle Werte eines Attributes in
einen einzigen skalaren Wert.
Aggregatsfunktionen in Standard-SQL
COUNT(), SUM(), MIN(), MAX(), AVG()
Erweiterte Versionen von SQL bieten zusätzliche
Aggregatsfunktionen (Statistik, Physik, ...).
Einige Systeme erlauben es dem Benutzer eigene
Aggregatsfunktionen hinzuzufügen.
Patrick Sager & Thomas Stocker
Aggregate und GROUP BY in Standard-SQL
5
GROUP BY
Durch den Standard-SQL GROUP BY Operator wird
eine Tabelle in Gruppen unterteilt.
Auf jede Gruppe wird dann die Aggregatsfunktion
angewendet.
Das Resultat ist eine Menge von Werten.
Aggregate Values
Grouping Values
Partitioned Table
Sum()
Patrick Sager & Thomas Stocker
Aggregate und GROUP BY in Standard-SQL
6
Cross-Table
Darstellung einer 2-dimensionalen Aggregation
erfolgt am einfachsten in einer Cross-Table
(Pivottabelle):
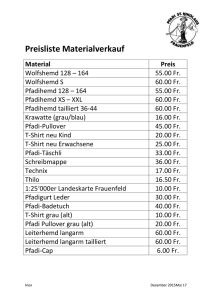
T-Shirt Verkäufe
T-Shirt
1996 1997
rot
500
450
blau
300
400
total (ALL) 800
850
Patrick Sager & Thomas Stocker
total (ALL)
950
700
1650
Cross-Tables
7
Relationale Darstellung der Cross-Table
'ALL' wird verwendet um Mehrfach-Aggregationen
auszudrücken.
Verkauf: Zusammenfassung
Modell Jahr
Farbe Stücke
T-Shirt 1996
rot
500
T-Shirt 1996
blau
300
T-Shirt 1997
rot
450
T-Shirt 1997
blau
400
T-Shirt ‘ALL’
rot
950
T-Shirt ‘ALL’
blau
700
‘ALL’
T-Shirt 1996
800
‘ALL’
T-Shirt 1997
850
‘ALL’
T-Shirt ‘ALL’
1650
Patrick Sager & Thomas Stocker
SELECT Modell, 'ALL', 'ALL', SUM(Stücke)
FROM
Verkauf
WHERE
Modell = 'T-Shirt'
GROUP BY Modell
UNION
SELECT Modell, Jahr, 'ALL', SUM(Stücke)
FROM
Verkauf
WHERE
Modell = 'T-Shirt'
GROUP BY Modell, Jahr
UNION
SELECT Modell, 'ALL', Farbe, SUM(Stücke)
FROM
Verkauf
WHERE
Modell = 'T-Shirt'
GROUP BY Modell, Farbe
UNION
SELECT Modell, Jahr, Farbe, SUM(Stücke)
FROM
Verkauf
WHERE
Modell = 'T-Shirt'
GROUP BY Modell, Jahr, Farbe;
Cross-Tables
8
CUBE - Operator
Data Cube als n-dimensionale Generalisierung von
GROUP BY und Aggregaten
0D: Punkt
1D: Linie mit Punkt
2D: Pivottabelle (Fläche mit 2 Linien und einem Punkt)
3D: Würfel mit 3 sich schneidenden 2D-Cubes
Vorschlag der Erweiterung des SQL GROUP BYs
GROUP BY ( { ( <column name> | <expression>)
[ AS <correlation name>]
[ <collate clause> ]
,...}
[ WITH ( CUBE | ROLLUP)] )
Patrick Sager & Thomas Stocker
CUBE
9
Data-CUBE
Group By
(mit Total)
Aggregat
Pivot Tabelle
T-Shirt Hosen nach Farbe
nach Farbe
rot
blau
weiss
rot
blau
weiss
Sum
nach Modell
Sum
Sum
Data Cube und
Sub-Space Aggregates
Hosen
T-Shirts
Nach Jahr
1994
1995
1996
1997
nach Modell
Nach Modell & Jahr
rot
blau
weiss
Nach Farbe & Jahr
Sum
Patrick Sager & Thomas Stocker
Nach Modell & Farbe
nach Farbe
CUBE
10
Beispiel eines 3D-Data-Cubes
Verkauf
Modell
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
Hosen
Hosen
Hosen
Hosen
Hosen
Hosen
Hosen
Hosen
Hosen
Jahr
1995
1995
1995
1996
1996
1996
1997
1997
1997
1995
1995
1995
1996
1996
1996
1997
1997
1997
Farbe
rot
weiss
blau
rot
weiss
blau
rot
weiss
blau
rot
weiss
blau
rot
weiss
blau
rot
weiss
blau
Stücke
300
75
250
500
100
300
450
500
400
100
220
300
50
100
420
70
60
300
CUBE
SELECT Modell, Jahr, Farbe, SUM(Stücke) AS Total
FROM Verkauf
WHERE Modell IN {‘T-Shirt‘, ‘Hosen‘}
AND Jahr BETWEEN 1995 AND 1997
GROUP BY Modell, Jahr, Farbe WITH CUBE;
Patrick Sager & Thomas Stocker
DATA CUBE
Modell Jahr Farbe Total
ALL
ALL ALL 4495
T-Shirt ALL ALL 2875
Hosen ALL ALL 1620
ALL
1995 ALL 1245
ALL
1996 ALL 1470
ALL
1997 ALL 1780
ALL
ALL rot
1470
ALL
ALL weiss 1055
ALL
ALL blau 1970
T-Shirt 1995 ALL 625
T-Shirt 1996 ALL 900
T-Shirt 1997 ALL 1350
Hosen 1995 ALL 620
Hosen 1996 ALL 570
Hosen 1997 ALL 430
T-Shirt ALL rot
1250
T-Shirt ALL weiss 675
T-Shirt ALL blau 950
Hosen ALL rot
220
Hosen ALL weiss 380
Hosen ALL blau 1020
ALL
1995 rot
400
ALL
1995 weiss 295
ALL
1995 blau 550
ALL
1996 rot
550
ALL
1996 weiss 200
ALL
1996 blau 720
ALL
1997 rot
520
ALL
1997 weiss 560
ALL
1997 blau 700
CUBE
11
Zugriff auf Elemente des CUBEs
Zusätzliche Angabe des Anteils der verkauften Stücke an
den total verkauften Stücken:
SELECT v.Modell, v.Jahr, v.Farbe,
SUM(Stücke) AS Total,
SUM(Stücke) / Total(ALL, ALL, ALL) AS Verhältnis
FROM Verkauf v
WHERE Modell = 'T-Shirt'
AND Jahr BETWEEN 1996 AND 1997
GROUB BY Modell, Jahr, Farbe WITH CUBE
v.Modell
T-Shirt
T-Shirt
T-Shirt
T-Shirt
Patrick Sager & Thomas Stocker
v.Jahr
1996
1996
1997
1997
v.Farbe
rot
blau
rot
blau
Total
500
300
450
400
Verhältnis
0.303
0.182
0.273
0.242
CUBE
12
Berechnung des Data CUBEs
Grösse des CUBEs:
Falls Basisrelation N Attribute mit Kardinalitäten C1, C2,..., CN hat,
so besitzt der CUBE (Ci + 1) Tupel.
Berechnung des CUBEs:
Da der CUBE Operator eine Erweiterung der Aggregate und des
GROUP BY's ist, verwende die dort bekannten Techniken:
Berechne Aggregate auf tiefst möglichem Systemlevel
Verwende bei grossen Strings Indizes
Hashing
Einfacher Algorithmus:
Alloziere Handle für jede CUBE-Zelle
Rufe für jedes Tupel alle betroffenen Handles auf (2N)
Übernehme die Resultate
Laufzeit: T*2N (T: Anzahl Tupel; N: Anzahl Dimensionen)
Patrick Sager & Thomas Stocker
CUBE
13
Data-CUBE
Hosen
T-Shirts
Nach Jahr
1994
1995
1996
1997
nach Modell
Nach Modell & Jahr
rot
blau
weiss
Nach Farbe & Jahr
Sum
Patrick Sager & Thomas Stocker
Nach Modell & Farbe
nach Farbe
CUBE
14
Berechnung eines Data-CUBEs am Beispiel
Wenn die Aggregatsfunktion distributiv ist, so kann man
den CUBE einfacher berechnen:
Baue den 2D Kern eines 2*3 CUBE auf
1995
300
250
1996
500
300
1997
450
400
total
rot
blau
total
1995
300
250
550
1996
500
300
800
1997
450
400
850
total
1250
950
rot
blau
total
1995
300
250
550
1996
500
300
800
1997
450
400
850
total
1250
950
2200
rot
blau
total
Berechne die 1D Kanten
Berechne den 0D Punkt
Patrick Sager & Thomas Stocker
CUBE
15
MS-SQL-Server
Abweichung zur bisherigen Definition des CUBE-Operators:
NULL Wert anstelle des ALL Wertes
Neue Funktion GROUPING():
TRUE, falls Element ein ALL Wert
FALSE sonst
Überall wo vorher im Resultat der ALL-Wert erschien, kommt
jetzt NULL, und das dazugehörige grouping Feld enthält
TRUE.
Patrick Sager & Thomas Stocker
CUBE
16
MS-SQL-Server (Beispiel)
Select Modell, Jahr, Farbe, SUM(Stücke),
GROUPING(Modell),GROUPING(Jahr),GROUPING(Farbe)
FROM Verkauf
WHERE Modell = 'T-Shirt'
AND Jahr BETWEEN 1996 AND 1997
GROUP BY Modell, Jahr, Farbe WITH CUBE;
Version des MS-SQL-Servers
"original"
Modell
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
Jahr
1996
1996
1997
1997
‘ALL’
‘ALL’
1996
1997
‘ALL’
Farbe
rot
blau
rot
blau
rot
blau
‘ALL’
‘ALL’
‘ALL’
Stücke
500
300
450
400
950
700
800
850
1650
Patrick Sager & Thomas Stocker
Modell
Jahr
Farbe
Stücke
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
T-Shirt
1996
1996
1997
1997
NULL
NULL
1996
1997
NULL
rot
blau
rot
blau
rot
blau
NULL
NULL
NULL
500
300
450
400
950
700
800
850
1650
Grouping
(Modell)
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
Grouping
(Jahr)
FALSE
FALSE
FALSE
FALSE
TRUE
TRUE
FALSE
FALSE
TRUE
Grouping
(Farbe)
FALSE
FALSE
FALSE
FALSE
FALSE
FALSE
TRUE
TRUE
TRUE
CUBE
17
Drill-down
Modell
ALL
Jahr
ALL
Farbe
ALL
Stücke
2490
Modell
T-Shirt
Hosen
Jahr
ALL
ALL
Farbe
ALL
ALL
Stücke
1650
840
Modell
T-Shirt
Jahr
1996
1997
1996
1997
Farbe
ALL
ALL
ALL
ALL
Stücke
800
850
470
370
Jahr
1996
Farbe
rot
blau
rot
blau
rot
blau
rot
blau
Stücke
500
300
450
400
50
420
70
300
Hosen
Modell
T-Shirt
1997
Hosen
1996
1997
Patrick Sager & Thomas Stocker
Roll-up
Drill-down / Roll-up
ROLLUP
18
Symmetrische vs. Asymmetrische Aggregation
(Modell, Jahr, Farbe)
(Modell, Jahr, ALL)
(ALL, Jahr, Farbe)
(Modell, ALL, Farbe)
(Modell, ALL, ALL)
(ALL, Jahr, ALL)
(ALL, ALL, Farbe)
(ALL, ALL, ALL)
symmetrischen Aggregation: Berechne Resultate aller Knoten
(CUBE)
asymmetrische (lineare) Aggregation: Berechne nur die
Resultate der Knoten entlang eines Pfades (ROLLUP)
Patrick Sager & Thomas Stocker
ROLLUP
19
ROLLUP (Beispiel)
SELECT Modell, Jahr, Farbe,
SUM(Stücke) AS Total,
FROM Verkauf
WHERE Jahr BETWEEN 1996 AND 1997
GROUB BY Modell, Jahr, Farbe WITH ROLLUP
Patrick Sager & Thomas Stocker
Modell
T-Shirt
T-Shirt
T-Shirt
T-Shirt
Hosen
Hosen
Hosen
Hosen
T-Shirt
T-Shirt
Hosen
Hosen
T-Shirt
Hosen
‘ALL’
Jahr
1996
1996
1997
1997
1996
1996
1997
1997
1996
1997
1996
1997
‘ALL’
‘ALL’
‘ALL’
Farbe
rot
blau
rot
blau
rot
blau
rot
blau
‘ALL’
‘ALL’
‘ALL’
‘ALL’
‘ALL’
‘ALL’
‘ALL’
ROLLUP
Total
500
300
450
400
50
420
70
300
800
850
470
370
1650
840
2490
20
Ausblick
Materialisierung des CUBEs
Vorschlag mit neuer Arithmetik in [Agrawal 97]
Hierarchische Dimensionen
Zeit: Jahr, Monat, Woche, Tag
Ort: Kontinent, Land, Landesteil
Einfaches Browsen für Online Decision Support
Patrick Sager & Thomas Stocker
Ausblick
21