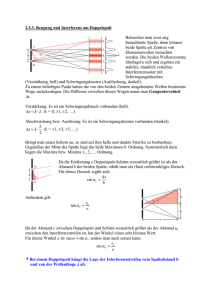
Eine Methode zur Gesangsdetektion basierend auf musikalischen
Werbung

Carl von Ossietzky Universität Oldenburg Masterstudiengang Hörtechnik + Audiologie Masterarbeit Eine Methode zur Gesangsdetektion basierend auf musikalischen Merkmalen und Merkmalen aus den Frequenzmodulationen tonaler Komponenten vorgelegt von: Gunnar Geißler Betreuender Gutachter: Prof. Dr. Steven van de Par Zweiter Gutachter: Dr. Jörn Anemüller Oldenburg, den 23. November 2011 Zusammenfassung Um Gesang in Musik zu detektieren reichen die Ansätze einer Speech Activity Detection nicht aus, da hier das Störgeräusch (die Instrumentalbegleitung) eine dem Gesang ähnliche harmonische und temporale Struktur aufweisen kann. Daher sind mit klassischen Merkmalen wie z.B. MFCC’s, dem spektralen Schwerpunkt oder der spektralen Veränderung keine zufriedenstellenden Resultate erreichbar. Um dennoch bessere Klassifikationsraten zu erzielen, sollen die Unterschiede der zeitlichen Entwicklung der Teilharmonischen von Instrumenten und Gesang in die Klassifikation einbezogen werden. Da die Teilharmonischen der meisten Sänger eine größere Frequenzmodulation aufweisen als die der meisten Instrumente, könnten Merkmale, die diese Modulationen beschreiben, eine Verbesserung der Klassifikation erzielen. Zu diesem Zweck werden aus den Teilharmonischen, über lokale spektrale Maxima, Tracks extrahiert. Um „spontane“ Tracks, die aus zufälligen Maxima resultieren, zu vermeiden, werden diejenigen Tracks zu einer Gruppe kombiniert, deren Frequenzänderungen stark miteinander korreliert sind. Anschließend werden die Modulationsmerkmale der gruppierten Tracks gemittelt. Anhand einer Database aus 47 Musikstücken verschiedener Genres und Interpreten ergibt sich, dass durch die entwickelten Merkmale die Klassifikationsrate um fast 5 % verbessert werden konnte. Abstract The task to detect singing voice within instrumental accompaniment is difficult to realize and a standard speech activity detection isn’t sufficient, because of the spectral and temporal similarities between the accompaniment and the singing voice. With this in mind, features considering the harmonic structure of the signal (e. g. MFCC’s, spectral centroid) will not adduce satisfying results. This might be corrected by taking features into account, describing the temporal evolution of the harmonics frequencies. Since the harmonics produced by a singer will possess larger frequency modulations than those of most instrument, features describing these modulations could improve the classification. For this purpose, so-called tracks will be extracted representing the harmonics by usage of maxima in the local spectra. To avoid coincidental tracks, only tracks will be considered that are highly correlated with other tracks. The modulation features of these correlated tracks are averaged. Using a database with 47 songs of different genres (all by different artists), it is shown that the modulation features are improving the classification rate by nearly 5 %. I Inhaltsverzeichnis Inhaltsverzeichnis Abbildungsverzeichnis III Tabellenverzeichnis V 1 Einleitung 1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2 Stand der Forschung . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1 2 4 2 Genre-Klassifikation 2.1 System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.1 Merkmalsextraktion . . . . . . . . . . . . . . . . . . . . . . . 2.1.2 Gaussian Mixture Models . . . . . . . . . . . . . . . . . . . . 2.2 Benutzte Merkmale . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.1 LowLevel-Merkmale . . . . . . . . . . . . . . . . . . . . . . . 2.2.2 Auf musikalischen Eigenschaften basierende Merkmale . . . . 2.3 Database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.1 Dimensionsreduktion . . . . . . . . . . . . . . . . . . . . . . . 2.4.2 Beste Kombination von Merkmalen und Anzahl Gaußverteilungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.3 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 6 6 8 10 10 13 21 22 22 24 26 3 Spezielle Merkmale für die Gesangserkennung 3.1 Eigenschaften von Gesang . . . . . . . . . . . . . . . . . 3.2 Tracking der Verläufe von Teiltönen . . . . . . . . . . . 3.2.1 Lokale Maxima-Suche . . . . . . . . . . . . . . . 3.2.2 Tracking . . . . . . . . . . . . . . . . . . . . . . . 3.2.3 Korrelationsmatrix und Gruppierung von Tracks 3.3 Merkmalsberechnung . . . . . . . . . . . . . . . . . . . . 3.3.1 Die Tracks beschreibende Merkmale . . . . . . . 3.3.2 Mitteln der Track-Merkmale einer Gruppe . . . . . . . . . . . . 27 27 29 30 31 33 35 36 37 4 Database 4.1 Beschreibung der Database . . . . . . . . . . . . . . . . . . . . . . . 4.2 Manuelle Annotation . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3 Betrachtung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 38 38 39 5 Evaluation 5.1 Extraktionssystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.1.1 Unterteilung in Entscheidungsblöcke . . . . . . . . . . . . . . 5.1.2 Berechnung der Merkmale . . . . . . . . . . . . . . . . . . . . 41 41 41 42 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . II Inhaltsverzeichnis 5.2 5.3 Training und Testen . . . . . . . . . 5.2.1 Trainieren der GMM . . . . . 5.2.2 Testen der Klassifikation . . . Evaluation der Merkmale . . . . . . 5.3.1 Anzahl der Gaußverteilungen 5.3.2 Einfluss der Track-Merkmale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44 44 44 48 48 49 6 Fazit und Ausblick 52 Literaturverzeichnis 54 A Anhang A.1 Tabellen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.2 Erklärung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . i i v Abbildungsverzeichnis III Abbildungsverzeichnis 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3.1 3.2 3.3 3.4 3.5 3.6 4.1 Die verschiedenen Blockgrößen zur Merkmalsberechnung. Die senkrechten Striche zeigen die Blockgrenzen an. Bei den Chromagramund den LowLevel-Blocks sind diese mit 50 % Überlapp angeordnet. Wahrscheinlichkeitsdichten einzelner Normalverteilungen (blau) und gemeinsame Wahrscheinlichkeitsdichte (rot) . . . . . . . . . . . . . . Links: Trainingspunkte im zweidimensionalen Merkmals-Raum, Rechts: Wahrscheinlichkeitsdichte des darauf angepassten GMM’s (mit drei Komponenten), wobei rot eine hohe und blau eine niedrige Wahrscheinlichkeit kodiert . . . . . . . . . . . . . . . . . . . . . . . . . . . Mel-Filterbank mit 15 Kanälen . . . . . . . . . . . . . . . . . . . . . a) Eingangssignal der Tempoerkennung, b) Signal nach den Schritten Halbwellengleichrichtung, TP-Filterung und Unterabtastung, c) Autokorrelationsfunktion von Signal in b) . . . . . . . . . . . . . . . Tempo-Histogramm des Liedes „Nirvana - Come as you are“. . . . . Beispiel zur quadratischen Interpolation: bei 237 Hz ist das ursprünglich detektierte Maximum, mit den benachbarten Werten wird die Interpolation durchgeführt (gestrichelte Linie) und das neue Maximum berechnet (rot). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Klassifikationsraten in Abhängigkeit der Anzahl der benutzten Merkmale und der Anzahl der Gaußverteilungen. . . . . . . . . . . . . . . Verwechslungsmatrix der Genre-Klassifikation für 5 Gaußverteilungen und 19 benutzte Merkmale. Für jedes Genre wird zeilenweise dargestellt, wieviel Prozent der Lieder welchem Genre zugeordnet werden. Schematische Darstellung des Anregungsspektrums und des gefilterten Spektrums (aus: [Sun77]). . . . . . . . . . . . . . . . . . . . . . . Links: Spektrogramm eines Ausschnittes aus dem Stück „Mondnacht“ von Robert Schumann, deutlich zu sehen die Frequenzmodulationen des Gesangs, Rechts: Spektrogramm eines Ausschnittes aus „As long as you love me“ von den Backstreet Boys mit einem Ansteigen der Frequenzen der Teilharmonischen. . . . . . . . . . . . . . . . . . . . Logarithmiertes Betragsspektrum |Y (k)| (blau), Schwelle Ysmooth (k) (rot) und detektierte Maxima (rote Kreuze). . . . . . . . . . . . . . . Beispiele zum Tracking . . . . . . . . . . . . . . . . . . . . . . . . . . Spektrogramm mit den lokalen Maxima und den daraus abgeleiteten Tracks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Spektrogramme, alle detektierten Tracks (dünne Linien) und die Tracks, die zur Merkmalsberechnung genutzt werden (dicke Linien) für zwei beispielhafte Entscheidungsblöcke . . . . . . . . . . . . . . . . . . . . Kennzeichnen der Gesang beinhaltenden Segmente mit Praat . . . . 7 8 9 12 14 15 20 25 26 28 29 31 33 34 35 39 Abbildungsverzeichnis 4.2 Histogramme der Segmentlängen für Segmente ohne (links), und mit Gesang (rechts) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.1 Oben: in blau der Spectral Flux eines Musikausschnittes, in rot die vorläufigen Maxima und der auf dem Median basierende Schwellwert. Unten: die am Ende zur Blockbildung genutzten Maxima. . . . . . . Spektrogramm eines Ausschnittes aus dem Lied „Losing my Religion“ von R.E.M. mit einer Analyseblocklänge von 0.046 s und einem Überlapp von 87.5%, in schwarz die Grenzen der zu klassifizierenden Blöcke. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Histogramm der Längen der Entscheidungsblöcke. . . . . . . . . . . Ablaufplan der Evaluation des Klassifikationssystems, in grün sind Eingangs- und in rot Ausgabewerte markiert. . . . . . . . . . . . . . Die Zeitpunkte, zu denen mittels Gl. 5.1 Gesang detektiert wird, sind blau, und die, zu denen nach Gl. 5.2 Gesang detektiert wird, schwarz markiert. In rot sind die Zeitpunkte nach der Annotation dargestellt. In Klammern ist jeweils die Klassifikationsrate (Richtig erkannte Blöcke durch Gesamtanzahl Blöcke) für das jeweilige Lied bei Verwendung der Entscheidung „Mit Glättung“ angegeben. . . . . . . . . . . Klassifikationsraten für verschiedene Kombinationen der Anzahl der Gaußverteilungen und der Anzahl der benutzten Merkmale (ausgewählt nach Fisher). . . . . . . . . . . . . . . . . . . . . . . . . . . . . Klassifikationsraten für die beiden Merkmalsgruppen über der Anzahl der benutzten Merkmale. . . . . . . . . . . . . . . . . . . . . . . . . Verwechslungsmatrix für die optimale Kondition (Merkmalsgruppe KLASS+TRACK, 40 Gaußverteilungen, 13 benutzte Merkmale). . 5.2 5.3 5.4 5.5 5.6 5.7 5.8 IV 40 42 43 43 45 47 48 50 50 Tabellenverzeichnis V Tabellenverzeichnis 2.1 2.2 2.3 2.4 2.5 Die verschiedenen Fensterbezeichnungen und deren Blocklänge. . . . Den Zahlen zugeordnete Töne und deren Frequenzen. . . . . . . . . . Die benutzten Merkmale für die Genre-Erkennung. . . . . . . . . . . Anzahl und Dauer der Lieder der verschiedenen Klassen. . . . . . . . Reihenfolge der Merkmale durch die Merkmalsselektion und die zugehörigen Klassifikationsraten. . . . . . . . . . . . . . . . . . . . . . 6 17 18 21 3.1 Die Merkmale der Gruppen . . . . . . . . . . . . . . . . . . . . . . . 37 A.1 Musikstücke, welche für die Evaluation der GD verwendet wurden mit Dauer, Geschlecht des Interpreten, dem Genre und der erzielten Klassifikationsrate mit 40 Gaußkomponenten und dem Merkmalssatz KLASS+TRACK . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A.2 Gesamtergebnisse der Merkmalsselektion . . . . . . . . . . . . . . . . i iii 25 1 Einleitung 1 1 Einleitung 1.1 Motivation Bei immer größer werdenden Musikbibliotheken im Internet wächst der Bedarf, diese nach bestimmten Parametern zu sortieren. So möchte ein Benutzer vielleicht mehr Lieder mit einem bestimmten Instrument hören oder ein Lied finden, welches dem aktuell gespielten Lied möglichst ähnlich ist. Ein anderer möchte weitere Lieder einer bestimmten Stilrichtung und noch ein anderer möchte ausschließlich Lieder seines Lieblingssängers. Um diese Funktionen zu ermöglichen gibt es verschiedene Möglichkeiten: • die manuelle Annotation bei der für jedes Lied gewisse Eigenschaften (Rhythmus, Instrumente, Charakter der Stimme, . . . ) bewertet werden. Diese Vorgehensweise ist mit einem immensen Aufwand verbunden, liefert aber bei entsprechender Schulung der Mitarbeiter zuverlässige Resultate. Für das InternetRadio www.pandora.com werden z. B. die Annotationen des Music Genome Project verwendet. Hierbei sind bisher für ca. 800000 Stücke für jeweils etwa 250 Merkmale Werte vergeben worden ([Wal09]). • die Nutzung der Vorlieben anderer Benutzer. Durch viele Benutzer entsteht mit der Zeit ein Bild davon, welche Interpreten oder Lieder bei anderen Nutzern beliebt sind, die den Interpreten mögen, den der Nutzer selbst gerade hört. Dadurch können weitere Vorschläge gemacht werden. Diese Technik wird u. a. von dem Internet-Radio www.lastfm.de benutzt. Es werden also keine Eigenschaften der Lieder beschrieben, sondern lediglich der soziale Kontext, in den sie eingebettet sind. • die automatisierte Beschreibung durch Algorithmen. Das Ergebnis sollte dabei möglichst dicht an der manuellen Annotation sein, was sich aber in vielen Punkten als schwierig erweist. Die eigene Musiksammlung anhand solcher Algorithmen nach verschiedenen Aspekten zu sortieren verspricht der mufin player pro (www.mufin.com). Wie gut dies funktioniert, ist nicht bekannt. Auf den letzten Punkt soll im Folgenden weiter eingegangen werden. Diese Forschungsrichtung hat sich in den letzten Jahren herausgebildet und wird auch als Music Information Retrieval (MIR), also das „Herausziehen“ von Informationen 1 Einleitung 2 aus Musik, bezeichnet. Hierbei können natürlich verschiedenste Dinge von Interesse sein. Es kann sich aber als zum Teil außerordentlich schwierig erweisen, Eigenschaften von Musik mittels Algorithmen zu extrahieren, deren Erfassung durch Menschen leicht und ohne größere Konzentration möglich ist. Neben den oben beschriebenen Szenarien kann z. B. außerdem versucht werden, die stimmlichen Eigenschaften eines Sängers bzw. einer Sängerin zu beschreiben. Um dies zu tun, muss jedoch zuerst festgestellt werden, zu welchen Zeitpunkten Gesang präsent ist, und zu welchen das Musikstück nur aus instrumentalen Passagen besteht. Zu diesem Zweck wird eine Gesangsdetektion (GD, oder engl. Singing Voice Detection: SVD) benötigt. Seit einigen Jahren wird diese Problemstellung bearbeitet. Dabei gibt es Analogien zu der Speech Activity Detection (SAD, dt.: Sprachaktivitätserkennung), die in Algorithmen zur Rauschunterdrückung zum Einsatz kommen. Durch die ähnliche Struktur von Gesang und Musik treten bei der GD allerdings weitere Problematiken auf. Mögliche Anwendungen für eine GD wären: • halbautomatische Karaoke-Systeme, die zusätzlich zu der Musik den Text erhalten, und die richtige Textzeile zum richtigen Zeitpunkt einblenden können • Grundlage für eine Stimmanalyse um z. B. alle Lieder eines Interpreten zu erhalten oder von Interpreten mit ähnlichen Stimmen • sehr schwierig, aber auch sehr attraktiv, wäre ein System, das aus Musik den Text transkribieren kann. Im nächsten Abschnitt soll kurz auf bisher durchgeführte Bemühungen und Ansätze verschiedener Autoren eingegangen werden. 1.2 Stand der Forschung In den letzten Jahren wurden verschiedene Ansätze erprobt um eine gute Gesangsdetektion zu erreichen. Hier soll ein kurzer Überblick über einige dieser Ansätze gegeben werden. Dabei werden auch zum Teil die in den zitierten Quellen angegebenen erreichten Klassifikationsraten (korrekt klassifizierte Blöcke durch Gesamtanzahl der Blöcke) genannt. Es sollte allerdings beachtet werden, dass diese Ergebnisse nicht direkt miteinander vergleichbar sind, da alle Autoren eine unterschiedliche Database verwenden. Der Begriff Database umfasst hier alle Lieder, die zum Trainieren und Testen des Systems verwendet werden, sowie die Annotation, die die „wahren“ Gesangsabschnitte kennzeichnet. Somit kann die Schwierigkeit für einen Klassifikator zum einen stark von der Art der Musik (Gesangsstil, Verhältnis der Energien von Gesang und Musik), aber auch von der Vielfalt der Database abhängen. So ist es wahrscheinlich einfacher, eine Gesangsdetektion für ein einzelnes bekanntes Genre 1 Einleitung 3 durchzuführen, als wenn sehr viele verschiedene Genres berücksichtigt werden müssen. Ein naheliegender Ansatz wird in [BE01] beschrieben. Hier wird ein Spracherkenner, der unabhängig vom Kontext die Wahrscheinlichkeiten für verschiedene Phoneme berechnet, auf Musik angewandt. Als Merkmale wird ein Vektor mit eben diesen Wahrscheinlichkeiten, darauf aufbauende weitere Merkmale, sowie PLPC (Perceptual Linear Predictive Coefficients) verwendet, auf die hier nicht weiter eingegangen wird. Abhängig davon, über wieviele Blöcke die Wahrscheinlichkeiten kombiniert wurden, wurden Klassifikationsraten von bis zu 81 % erreicht. Hierbei wurden randomisiert aus dem Radio aufgenommene 15 s lange Abschnitte als Database verwendet. Das Genre dieser Abschnitte ist nicht angegeben. Sowohl in [LGD07] als auch in [LW07] wurden MFCC (Mel Frequency Cepstral Coefficients, siehe Seite 11) als Merkmal, und ein GMM (Gaussian Mixture Model, siehe Seite 8) als Klassifikator verwendet. Dabei werden in [LGD07] die lokalen Wahrscheinlichkeiten für eine der beiden Klassen mittels ARMA-Filterung (Autoregressive Moving Average) geglättet. Dadurch verbessert sich die Klassifikationsrate von 72.7 % (ohne ARMA-Filterung) deutlich auf 81.3 %. Die 84 Lieder in der Database sind dabei zwar aus verschiedenen Genres, allerdings nur von zehn verschiedenen Sängern. Es wird also auch auf die gleichen Stimmen getestet, mit denen auch trainiert wurde. In [LW07] werden die Merkmale von allen Blöcken gemittelt, die zu einem Entscheidungsblock gehören. Die Grenzen der Entscheidungsblöcke werden nach musikalischen Aspekten, und zwar an Zeitpunkten mit hoher spektraler Fluktuation, gesetzt. So werden je nach Kondition Klassifikationsraten von 80 % bis 90 % erreicht. Hierbei sind in der Database zehn Liedern aus den Genres Rock und Country enthalten. Die bisher beschriebenen Ansätze basieren überwiegend auf typischen, weit verbreiteten Merkmalen der Audio-Klassifikation. In der folgenden Literatur werden einige Ansätze beschrieben, die mehr auf die typischen Eigenschaften von Gesang abzielen. So wird in [KW02] im ersten Schritt das Signal mit einem Bandpassfilter von 200 Hz bis 2.5 kHz gefiltert, da der größte Energieanteil von Gesang in diesen Bereich fällt. Anschließend wird das Signal mit Kammfiltern, die auf verschiedene Grundfrequenzen abgestimmt sind, gefiltert. Es wird die Annahme gemacht, dass das Filter, dessen Ausgangssignal die geringste verbleibende Energie hat, am besten auf die dominante harmonische Quelle passt. Mit der Annahme, dass Gesang in Audiodateien in den meisten Fällen mehr Energie hat als Instrumente, kann über den Anteil der herausgefilterten Energie zwischen Gesang und Instrumenten unterschieden werden. Mit diesem Ansatz wurde allerdings nur eine Klassifikationsrate von 55.4 % erreicht. Hier wurden als Database etwas mehr als 200 Lieder von 20 verschiedenen Interpreten der populärsten Alben (also in erster Linie Pop- und Rockmusik) benutzt. 1 Einleitung 4 Dadurch sind aber auch hier in Trainings- und Testmaterial die gleichen Interpreten enthalten. In [NL07], [RR09] und [RP09] hingegen wird die zeitliche Entwicklung der Teiltöne (Harmonische eines Tones) betrachtet. Da die meisten Instrumente eine relativ konstante Frequenz über die Zeit aufweisen, Gesang aber meistens starke Frequenzmodulationen aufweist, sind aus dieser Betrachtung durchaus gute Ergebnisse zu erwarten. Alle drei Ansätze haben gemeinsam, dass versucht wird, den zeitlichen Verlauf der Teiltöne zu extrahieren. Aus diesen sogenannten „Tracks“ können nun Merkmale berechnet werden. So wird in [RR09] die Standardabweichung der Tracks als Merkmal genutzt. Damit wird eine Klassifikationsrate von 90 % erreicht, wobei dem Algorithmus zum Teil mit der wahren Grundfrequenz „nachgeholfen“ wurde. Getestet wurde mit einer Database, die Ausschnitte aus 7 klassischen Nord-Indischen Musikstücken von insgesamt 23 Minuten enthält. In [RP09] werden neben den Frequenzvariationen (Vibrato) auch die Amplitudenvariationen (Tremolo) untersucht. Ein Track wird der Klasse Gesang zugeordnet, wenn dessen Vibrato- und Tremoloamplituden zwischen 4 Hz und 8 Hz größer als entsprechende Schwellenwerte sind. Mit einer Nachbearbeitung, in der als Instrumental klassifizierte Abschnitte mit einer Dauer von weniger als einer Sekunde ignoriert werden, erreicht diese Methode eine Klassifikationsrate von 76.8 %. Hierbei wurden 93 Lieder, die verschiedenen Genres repräsentieren und alle von unterschiedlichen Interpreten stammen, als Database genutzt. In [NL07] werden ähnliche Merkmale benutzt. Allerdings wird die Klassifikation nicht über Schwellwerte sondern ein GMM realisiert. So ergibt sich eine Klassifikationsrate von bis zu 82.8 %. Hier wurden zum Testen insgesamt 84 Songs von 12 verschiedenen Interpreten aus der Pop-Musik benutzt. 1.3 Ziel der Arbeit Um Gesang zu detektieren, müssen musikalische Eigenschaften in Zahlen erfasst werden, mit denen Modelle angepasst bzw. trainiert werden können. Um zu testen, ob die in dieser Arbeit zu entwickelnden Merkmale eine Verbesserung der Klassifikation im Vergleich zu „Standard-Merkmalen“ bringen, soll zuerst in Kapitel 2 getestet werden, ob einige dieser „Standard-Merkmale“ überhaupt musikalische Informationen erfassen können. Dies soll an der Aufgabe der Genre-Klassifikation erfolgen. Es werden die Merkmale und das Klassifikationssystem erläutert. In Kapitel 3 werden die speziellen Merkmale zur Gesangsdetektion abgeleitet, die auf den Frequenzmodulationen der Grundfrequenz beruhen. Die Annahme hierbei ist, dass Instrumente nur geringe Frequenzmodulationen aufweist, Gesang jedoch sehr große. Um zu überprüfen, ob diese Merkmale die Klassifikation verbessern, werden sie in Kapitel 5 anhand einer Database (Kapitel 4) getestet. Diese Database soll dabei 1 Einleitung 5 möglichst allgemein gehalten werden und, anders als die der meisten in Abschnitt 1.2 vorgestellten Studien, nicht auf wenige Genres bzw. Interpreten beschränkt sein. Es soll also evaluiert werden, ob die Informationen dieser zu entwickelnden Merkmale die der „Standard-Merkmale“ bereichern und damit die Klassifikation verbessern können. 6 2 Genre-Klassifikation 2 Genre-Klassifikation Um das Klassifikationssystem und die Merkmale zu evaluieren, sollen diese an der Aufgabe Genre-Klassifikation getestet werden. Dabei soll einem Musikstück automatisch die richtige Klasse (also das richtige Genre) zugeordnet werden. Typische Genres wären z. B. Klassik, Rock oder Jazz. In diesem Kapitel soll zuerst das System zur Merkmalsextraktion und Klassifikation beschrieben werden. Anschließend werden einige typische Merkmale der AudioSignalverarbeitung, sowie einige Merkmale, die auf musikalische Inhalte abzielen, erläutert. Letztendlich wird die Datenbank der benutzten Musikstücke beschrieben und die Klassifikationsrate ermittelt. 2.1 System In diesem Abschnitt soll die grundsätzliche Funktionsweise des kompletten Systems beschrieben werden: also dem Berechnen von verschiedenen Merkmalen, der Bildung von Modellen, die die Genres möglichst gut voneinander unterscheiden, sowie der letztendlichen Klassifikation. 2.1.1 Merkmalsextraktion Um die verschiedenen zu extrahierenden Merkmale (siehe Abschnitt 2.2) zu berechnen, werden unterschiedliche Blocklängen benötigt. Um auch noch eher langsame Tempi detektieren zu können, muss die Länge des Tempo-Blocks recht groß sein. Um hingegen Aussagen über die Veränderung der spektralen Form machen zu können, werden eher kleine Blöcke benötigt. Daher werden drei unterschiedliche Blocklängen (siehe Tabelle 2.1) angewendet. In Abb. 2.1 sind die Längen der verschiedenen Blöcke veranschaulicht. Die Tempo-Blöcke müssen, wie oben schon erwähnt, recht lang Tabelle 2.1: Die verschiedenen Fensterbezeichnungen und deren Blocklänge. Bezeichnung LowLevel Chromagram Tempo Blocklänge 0.023 s 0.093 s 1.486 s 7 2 Genre-Klassifikation 1,486 s Tempo-Blocks 0,093 s Chromagram-Blocks 0,023 s LowLevel-Blocks Abbildung 2.1: Die verschiedenen Blockgrößen zur Merkmalsberechnung. Die senkrechten Striche zeigen die Blockgrenzen an. Bei den Chromagramund den LowLevel-Blocks sind diese mit 50 % Überlapp angeordnet. 2 Genre-Klassifikation 8 sein, da nur Tempi erkannt werden können, deren Periode T kleiner als die Blocklänge ist. Bei einer verwendeten Länge von 1.486 s sind Tempi ab etwa 60 BPM (beats per minute, dt.: Schläge pro Minute) detektierbar, was für die meisten Stücke ausreichend ist. Für die Chromagram-Blöcke, in denen Tonhöhen extrahiert werden sollen, muss zwischen Zeit- und Frequenzauflösung abgewogen werden. Bei 0.093 s kann zum einen davon ausgegangen werden, dass in dieser Zeit die Töne annähernd stationär sind, zum anderen ist die Frequenzauflösung bei einer verwendeten Abtastrate von fs = 44.1 kHz mit 10.8 Hz einigermaßen genau. Für die LowLevel-Blöcke, in denen einfache Merkmale wie spektrale Schwerpunktmaße berechnet werden, soll vor allem eine möglichst hohe zeitliche Auflösung gewährleistet werden. Da die Signale der Chromagram- und der LowLevel-Blöcke in den Frequenzbereich transformiert werden, werden diese jeweils mit Hann-Fenstern multipliziert und mit 50 % Überlapp angeordnet. 2.1.2 Gaussian Mixture Models Da die Gaussian Mixture Models (GMM, dt. Gauß’sche Mischverteilungen) im Folgenden für die Klassifikation benutzt werden, soll hier die Grundidee dieser erklärt werden. Diese besteht darin, dass versucht wird, anhand von Trainingsdaten für jede Klasse eine Wahrscheinlichkeitsdichtefunktion zu konstruieren, die aus der Summation mehrerer Normalverteilungen besteht. In Abb. 2.2 ist ein 1-dimensionales Beispiel mit drei Gaußkurven zu sehen. Abbildung 2.2: Wahrscheinlichkeitsdichten einzelner Normalverteilungen (blau) und gemeinsame Wahrscheinlichkeitsdichte (rot) 9 2 Genre-Klassifikation Diese Kombination von J Normalverteilungen mit den Gewichten (auch a prioriWahrscheinlichkeiten) Pj , j = 1, 2, . . . , J lässt sich schreiben als [TK99]: p(x) = J X p(x|j)Pj , (2.1) Pj = 1 , und (2.2) j=1 wobei gilt, dass: J X j=1 Z x p(x|j)dx = 1 . (2.3) x ist hierbei der Merkmalsvektor, dessen Länge der Anzahl der verwendeten Merkmale entspricht. Mit entsprechend großer Anzahl an Normalverteilungen lässt sich somit jede beliebige Wahrscheinlichkeitsverteilung annähern. In Abb. 2.3 (links) sind Punkte einer zweidimensionalen Verteilung aufgetragen. Rechts ist die auf diese Punkte angepasste Wahrscheinlichkeitsdichte abgebildet. Hierfür sind drei Normalverteilungen angepasst worden. Abbildung 2.3: Links: Trainingspunkte im zweidimensionalen Merkmals-Raum, Rechts: Wahrscheinlichkeitsdichte des darauf angepassten GMM’s (mit drei Komponenten), wobei rot eine hohe und blau eine niedrige Wahrscheinlichkeit kodiert Die Anpassung erfolgt über den Expectation Maximization-Algorithmus (EM, dt. Erwartungsmaximierung) auf den hier nicht näher eingegangen werden soll, der aber z. B. in [TK99] ausführlich beschrieben ist. 10 2 Genre-Klassifikation Soll nun ein neuer Datenpunkt klassifiziert werden, wird die Wahrscheinlichkeit für jede Klasse berechnet, dass der Punkt aus deren GMM stammt. Der Klasse mit der höchsten Wahrscheinlichkeit wird der Punkt zugeordnet. GMM’s haben den Vorteil, dass die Klassifikation eines Datenpunktes recht wenig Rechenzeit in Anspruch nimmt. Dafür kann das Trainieren des GMM’s sehr aufwändig sein. Außerdem werden für eine gute Anpassung des Modells im Trainingsprozess große Mengen an Trainingsmaterial benötigt. Sowohl für die Anpassung der GMM, als auch die Klassifikation wird in dieser Arbeit eine Skriptsammlung von Tobias May verwendet, die für viele Funktion auf die Toolbox Netlab von Ian Nebney zugreift. 2.2 Benutzte Merkmale Merkmale (oder Features) sollen die wichtigen Eigenschaften (die aufgabenabhängig sind) der komplexen Wellenform eines Audio-Signals widerspiegeln. Anhand der Werte eines (oder mehrerer) Merkmale soll möglichst gut entschieden werden können, zu welcher Klasse ein Datenpunkt gehört. Dieser Datenpunkt ist ein Merkmalsvektor, der ein Lied repräsentiert. Im Folgenden sollen einige der „klassischen“ Merkmale vorgestellt werden, die für verschiedene Klassifikations-Aufgaben benutzt werden. 2.2.1 LowLevel-Merkmale Spectral Centroid Der Spectral Centroid (SC) (dt. spektraler Schwerpunkt) charakterisiert ein Spektrum und ist ein Maß dafür, in welchem Frequenzbereich der Großteil der Energie liegt [TC02]. SC = PN −1 X(k)f (k) k=0 X(k) k=0 PN −1 (2.4) 11 2 Genre-Klassifikation Spectral Rolloff Der Spectral Rolloff (SRO) charakterisiert den Frequenzwert fSR eines Spektrums, unterhalb dessen ein gewisser Prozentsatz der Gesamtenergie des Spektrums liegt (hier 85 %). fX SRO k=0 X(k) = 0.85 · N −1 X X(k) (2.5) k=0 Spectral Flux Der Spectral Flux SF (kurzform für Spectral fluctuation, dt. spektrale Schwankung) beschreibt, wie stark sich das Betragsspektrum von Block m − 1 zu Block m verändert. Er berechnet sich aus der euklidischen Distanz zwischen diesen beiden Spektren. SF = N −1 X (|X(m, k)| − |X(m − 1, k)|)2 (2.6) k=0 Zero Crossings Der Wert Zero Crossings (ZC) (dt. Nulldurchgänge) gibt an, wie oft ein Signal die Nulldurchgangslinie in einer bestimmten Zeit „überquert“ (wie oft sich das Vorzeichen ändert). Dieser Wert kann ein Indiz dafür sein, wie rauschhaft ein Signal ist; periodische Signale (z. B. gesprochene Vokale) haben eher wenige ZC, rauschhafte Signale eher hohe. MFCC Mel Frequency Cepstral Coefficients MFCC (dt. Mel-Frequenz Cepstral-Koeffizienten) stellen ein kompaktes Kurzzeit-Amplitudenspektrum dar und werden für verschiedene Klassifikationsaufgaben (z. B. in der Sprechererkennung) verwendet. Sie werden berechnet, indem ein Spektrum mit einer Mel-Filterbank gefiltert wird. Die Mittenfrequenzen dieser Filter sind dabei logarithmisch angeordnet (siehe Abb. 2.4). Dies ist der menschlichen Wahrnehmung nachempfunden (siehe [FZ07]). Anschließend werden diese Filterausgänge logarithmiert und über eine Discrete Cosine Transform (DCT, dt. Diskrete Cosinus-Transformation) dekorreliert. Dabei beschreiben die niedrigeren MFCC’s eher die Grobstruktur und die höheren MFCC’s die Feinstruktur (schnelle Schwankungen) des Spektrums. Da bei der Genre-Klassifikation in erster Linie die grobe Verteilung des Spektrums von Interesse ist, werden die ersten fünf Koeffizienten verwendet. Die MFCC’s beschreiben also die spektrale Verteilung, 12 2 Genre-Klassifikation angelehnt an die menschliche Wahrnehmung. Abbildung 2.4: Mel-Filterbank mit 15 Kanälen Im Folgenden sollen die einzelnen Berechnungsschritte dargestellt werden. Von einem Signalabschnitt x[n] mit N Samples wird das Spektrum X(k) über eine Fouriertransformation berechnet X(k) = N −1 X x[n] · e− i2π·k·n N , 0 ≤ k ≤ N − 1. (2.7) n=0 Dieses wird energetisch mit den Übertragungsfunktionen der einzelnen Filter (zeilenweise in W ) multipliziert um den Ausgang Xfilt (k) zu erhalten. Xfilt (k) = W · |X(k)|2 (2.8) MFCC = DCT (10 · log10 (Xfilt (k) + eps)) (2.9) Low Energy Mit Low Energy (LE) ist der Anteil aller LowLevel-Blöcke gemeint, deren RMSWert unterhalb des Mittelwertes der RMS-Werte aller Blöcke liegt. Dieser Wert lässt Rückschlüsse darüber zu, ob die Energie über das gesamte Stück in etwa gleich bleibt, oder ob sie stark schwankt. 13 2 Genre-Klassifikation Ableitungen von Merkmalen Um zu beobachten, wie stark sich gewisse Eigenschaften zwischen den Blöcken verändern kann, es sinnvoll sein, zusätzlich die Ableitungen mancher Merkmale zu berechnen. Die Ableitung des Merkmals M soll hier als ∆M gekennzeichnet werden. Statistik von Merkmalen Um noch mehr Informationen darüber zu benutzen, wie sich ein Feature über die Zeit verhält, können die Werte mehrerer Blöcke zur Berechnung von statistischen Maßen (Mittelwert, Varianz, Schiefe, . . . ) herangezogen werden. Hier wird nur die Varianz berechnet, die als VAR(M ) geschrieben wird. 2.2.2 Auf musikalischen Eigenschaften basierende Merkmale Im Folgenden sollen Merkmale berechnet werden, die mehr auf musikalische Aspekte eingehen. Tempobasierte Merkmale Um Merkmale zu extrahieren, die Tempo und Rhythmik der Musik beschreiben, wurde ein Algorithmus nach [TC02] implementiert. Es wird eine Blocklänge gewählt, die nicht zu klein ist, da sonst langsame Tempi nicht erfasst werden könnten (hier ca. 1,5 s). Dieser Block x(n) (siehe Abb. 2.5 a) wird anschließend wie folgt verarbeitet. Lokale Temposchätzung Um eine Einhüllende extrahieren zu können, wird das Signal halbwellengleichgerichtet. xpos [n] = |x[n]| (2.10) Die Einhüllende wird anschließend per IIR-Tiefpassfilterung berechnet. Dabei ist hier α = 0.99. xTP [n] = (1 − α) · xpos [n] + α · xTP [n − 1] (2.11) Da die hohen Frequenzen herausgefiltert sind, kann das Signal über x↓U [n] = xTP [U · n] (2.12) 14 2 Genre-Klassifikation unterabgetastet werden. Der Faktor U für die Unterabtastung wurde als U = 16 gewählt. Anschließend wird das Signal über xAC [n] = x↓U [n] − x̄↓U [n] (2.13) vom Mittelwert befreit. Das Signal nach diesen Schritten ist in Abb. 2.5 b) zu sehen. Über Formel 2.14 wird die Autokorrelationsfunktion C[L] für einen bestimmten Bereich von Verzögerungen L berechnet (Abb. 2.5 b). C[L] = N 1 X x[n] · x[n − L] N n=1 (2.14) Sowohl die Amplitude, als auch der entsprechende Tempo-Wert in BPM der drei Abbildung 2.5: a) Eingangssignal der Tempoerkennung, b) Signal nach den Schritten Halbwellengleichrichtung, TP-Filterung und Unterabtastung, c) Autokorrelationsfunktion von Signal in b) größten Maxima von C[L] pro Block werden abgespeichert. Globale Tempo-Merkmale Anschließend wird ein Histogramm der lokalen Tempi über die gesamte Länge des Liedes berechnet. In dieses fließt jedoch nicht nur die Häufigkeit der Beobachtungen für ein bestimmtes Tempo ein, sondern auch deren Amplituden. Dabei wird nach Tempi von 40 bis 250 BPM gesucht, womit so ziemlich alle auftretenden Tempi abgedeckt sind. In Abb. 2.6 ist ein Beispiel eines solchen Histogramms zu sehen. Das Maximum liegt bei etwa 120 BPM. Dies ist auch das tatsächliche Tempo des Liedes. 15 2 Genre-Klassifikation Deutlich erkennbar sind auch Nebenmaxima bei dem doppelten bzw. halben Tempo (also bei 60 bzw. 240 BPM). Aus diesem Tempo-Histogramm T werden letztendlich Abbildung 2.6: Tempo-Histogramm des Liedes „Nirvana - Come as you are“. drei Merkmale abgeleitet: das Tempo Tmax (in BPM) sowie die Amplitude A(Tmax ) des höchsten Wertes, sowie ein Merkmal T S (Tempostetigkeit), das die Variation des Tempos beschreibt. Dieses wird nach Formel 2.15 berechnet, wobei |T | die Länge des Histogramms ist. TS = A(Tmax ) 1 |T | P|T | t=1 T (t) (2.15) Der Wert dieses Merkmals ist groß für Lieder, die eine durchgängige und ausgeprägte rhythmische Struktur haben (z. B. bei Techno). Für Lieder mit vielen Tempowechseln bzw. ohne starke Rhythmik, wie z. B. in der Klassik oft vorkommend, ist er hingegen eher klein. Chromagramm Die bisherigen spektralen Merkmale aus Abschnitt 2.2 beschreiben lediglich die grobe Verteilung der Energie im Spektrum. Zumindest die westliche Musik wird jedoch in Noten verfasst, die in Abständen von 1 12 einer Oktave angeordnet sind. Mehrere gleichzeitig gespielte Noten ergeben einen Akkord. Sowohl in den lokalen Akkorden, als auch insbesondere in der zeitlichen Abfolge dieser stecken Informationen, die die Musik charakterisieren könnten. Zu diesem Zweck soll ein Chromagramm 16 2 Genre-Klassifikation berechnet werden, in dem für jeden Zeitpunkt die Stärke aller zwölf Halbtöne repräsentiert wird. Die Berechnung dieses Chromagrams basiert in großen Teilen auf [vdPMR06]. Lokale Verarbeitung Es werden Blöcke von N = 4096 Samples (≈ 0.093 s) verarbeitet. Diese werden von 44.1 kHz auf 11.025 kHz unterabgetastet (Unterabtastungsfaktor U = 4) und mit einem Hann-Fenster multipliziert. Von diesem Signal x[n] wird über eine Fouriertransformation das Betragsspektrum |X(k)| berechnet. Es ergibt sich eine Frequenzauflösung von fs N = 11025 Hz 1024 = 10.8 Hz. Aus |X(k)| wird nach allen Maxima fmax und den zugehörigen Amplituden amax gesucht. Allerdings erst ab einem Frequenzbereich, in dem die gegebene Frequenzauflösung hoch genug ist, um zwischen zwei benachbarten Halbtönen unterscheiden zu können. Dies ist ab etwa 110 Hz der Fall. Wie die Schätzung der „wahren“ Frequenz eines Maximums verbessert werden kann, ist in Abschnitt 2.2.2 dargestellt. Um lokale Maxima mit sehr geringer Energie nicht zu berücksichtigen, werden nur diejenigen in die Auswertung übernommen, die folgende Bedingung erfüllen: ! amax > F · D+1 X Xmel (d), (2.16) d=D−1 wobei F ein Faktor ist (hier 0.1), Xmel (d) der d’te Ausgang des melgefilterten Spektrums und D die Nummer des Melfilters ist, in den am meisten Energie des Maximums fällt. Es werden also nur Maxima berücksichtigt, die deutlich aus den umliegenden Werten herausragen. Um eine einfachere Auswertung der einzelnen Maxima zu ermöglichen, werden diese alle auf den Bereich einer Oktave (von 260 Hz bis 520 Hz) gebracht. Im letzten Schritt wird jede Frequenz der nächstliegenden musikalischen Note zugeordnet, die in Tab. 2.2 dargestellt sind. Die Frequenz eines Maximums bei f = 730 Hz würde also durch zwei geteilt, womit sich 365 Hz ergeben würden. Der am nächsten liegende Ton wäre dann F] mit 369.99 Hz. Globale Betrachtung des Spektrogramms Es kann nun versucht werden, durch die vorliegenden Informationen über die lokal aufgetretenen Töne, Aussagen über die harmonische Struktur des Musikstückes zu machen. Dafür werden die lokalen Amplituden der einzelnen Töne über alle Blöcke logarithmisch aufaddiert. Dabei wird der Anfang und das Ende jeden Stückes stärker gewichtet als der Mittelteil, da diese oft in der eigentlichen Tonart des Stückes stehen. Es ergibt sich somit ein Vektor C mit zwölf Einträgen, von denen jeder die Häufigkeit und Stärke eines bestimmten Tones (siehe Tab. 2.2) über das gesamte Stück beschreibt. 17 2 Genre-Klassifikation Tabelle 2.2: Den Zahlen zugeordnete Töne und deren Frequenzen. Zahl 1 2 3 4 5 6 7 8 9 10 11 12 13 Note C C] D D] E F F] G G] A A] H C Frequenz [Hz] 261.63 277.18 293.66 311.13 329.63 349.23 369.99 392.99 415.30 440 466.16 493.88 523.25 Tonale Gleichheit Das Merkmal Tonale Gleichheit (T G) soll beschreiben, ob in einem Stück überwiegend wenige Töne dominieren oder viele verschiedene Töne mit hoher Amplitude vorhanden sind. Dafür wird die Amplitude A des Maximums Cmax des Chromagrams in das Verhältnis zu dessen Mittelwert gesetzt. TG = 1 12 A(Cmax ) P12 c=1 C(c) (2.17) Außerdem wird die absolute Amplitude des Maximums A(Cmax ) als Merkmal verwendet. Tonart Anhand des Vektors C kann außerdem versucht werden die Tonart eines Musikstückes zu schätzen. Bei Musik, die über das ganze Stücke in der gleichen Tonart steht, kommt im Allgemeinen die Tonika am häufigsten vor. Zwischen Dur und Moll lässt sich am leichtesten anhand der Terz unterscheiden. Um die Tonart feststellen zu können, wird C einmal mit ΨDur und einmal mit ΨMoll zirkulär gefaltet, wobei ΨDur = [1 0 0 0 1 0 0 1 0 0 0 0] und ΨMoll = [1 0 0 1 0 0 0 1 0 0 0 0] ist. Ist D-Dur die „wahre“ Tonart (und ist auch durch die auftretenden Töne als solche erkennbar) wird die Faltung von C mit ΨDur den größten Wert ergeben, und zwar bei einer Verschiebung von zwei. Als Feature wird dann die Zahl, die für den entsprechenden Grundton steht verwendet, sowie eine binäre Variable, die für Dur bzw. Moll steht. 18 2 Genre-Klassifikation Tabelle 2.3: Die benutzten Merkmale für die Genre-Erkennung. Nummer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Kürzel MFCC1 MFCC2 MFCC3 MFCC4 MFCC5 ZC VAR(ZC) VAR(∆ZC) RMS VAR(RMS) VAR(∆RMS) SC VAR(SC) VAR(∆SC) SRO SFL LE A(Tmax ) Tmax TS A(Cmax ) TG D/M GT Erklärung Zero Crossings [ 1s ] Varianz von ZC Varianz von der Ableitung der ZC Leistung (Root Mean Square) Varianz von RMS Varianz von der Ableitung des RMS Spectral Centroid Varianz von SC Varianz von der Ableitung der SC Spectral Rolloff Spectral Flux Low Energy Amplitude des stärksten Tempos Stärkstes Tempo [BPM] Tempostetigkeit Amplitude des stärksten Tones Tonale Gleichheit Dur/Moll Grundton 19 2 Genre-Klassifikation Verbesserung der Frequenzschätzung Da bei der diskreten Fouriertransformation gilt, dass ähnlich wie bei der Heisenberg’schen Unschärferelation eine Verbesserung der Frequenzauflösung zu Lasten der Zeitauflösung geht und anders herum, sind der Frequenzauflösung Grenzen gesetzt. Um bei einer gegebenen erforderlichen Zeitauflösung dennoch eine verbesserte Schätzung der „wahren“ Frequenz eines Maximums zu erlangen, gibt es verschiedene Möglichkeiten, von denen hier zwei erläutert werden sollen. Die einfachste (und ungenaueste) Art der Frequenzschätzung eines Maximums ist f =k· fs , Nfft (2.18) wobei k der Frequenz-Bin des Maximums ist. Fällt beispielsweise die Frequenz eines Sinustones genau mit der Mittenfrequenz eines Frequenz-Bins zusammen, ist die Schätzung ausnahmsweise richtig. In den allermeisten Fällen wird dies jedoch nicht der Fall sein. Dann ist die „wahre“ Frequenz des Tones nicht gleich der Mittenfrequenz des Frequenz-Bins. Durch eine Interpolation der Werte des Betragsspektrums an den Stellen fu , fm und fo lässt sich die Schätzung deutlich verbessern, wobei fm die Frequenz des Frequenz-Bins mit dem Maximum ist, und fu und fo die Frequenzen der benachbarten Frequenz-Bins sind. Im folgenden soll die quadratische Interpolation genauer betrachtet werden. Dabei wird ein Polynom zweiter Ordnung (siehe Gleichung 2.19) so angepasst, dass es die Werte des Betragsspektrums |Y (fu )|, |Y (fm )| und |Y (fo )| (im Folgenden auch Yu , Ym und Yo ) durchläuft. Y (f ) = d2 = d2 (f − fm )2 + d1 (f − fm ) + d0 2 Yo −Ym Ym −Yu fo −fm − fm −fu fo − fu Yo − Ym d2 d1 = − (fo − fm ) fo − fm 2 d0 = Ym (2.19) (2.20) (2.21) (2.22) Die Koeffizienten d2 , d1 und d0 können anhand der Steigungen berechnet werden (Gleichungen 2.20 bis 2.22). Diese sind notwendig um die Extremstelle der Interpolationsfunktion zu berechnen. Der Frequenzwert des Maximums lässt sich durch Ableiten und Nullsetzen von der Gleichung 2.19 berechnen. 20 2 Genre-Klassifikation d1 d2 d1 = Ym + (fmax − fm ) 2 fmax = fm − (2.23) Ymax (2.24) In Abb. 2.7 ist ein Beispiel dargestellt. Bei 237 Hz liegt ein Maximum vor. Über die oben beschriebene Schätzung wird ein Polynom 2. Grades an das Maximum und die benachbarten Punkte angepasst (gestrichelte Linie). Anschließend wird das Maximum der Interpolation als neue Schätzung für Amplitude und Frequenz genutzt. Abbildung 2.7: Beispiel zur quadratischen Interpolation: bei 237 Hz ist das ursprünglich detektierte Maximum, mit den benachbarten Werten wird die Interpolation durchgeführt (gestrichelte Linie) und das neue Maximum berechnet (rot). Eine weitere Möglichkeit, die nach hier gemachten Erfahrungen sehr präzise ist, wird in [DCM00] beschrieben. Wenn x[n] das ungefensterte Signal, x0 [n] das Differenzsignal x0 [n] = fs · (x[n + 1] − x[n]), X(k) = DFT(x[n]) das Spektrum von x[n], X 0 (k) = DFT(x0 [n]) das Spektrum von x0 [n] und k die Nummer des Frequenz-Bins ist, das das Maximum beinhaltet, lässt sich über f= fs 1 |X 0 (k)| arcsin π 2fs |X(k)| (2.25) 21 2 Genre-Klassifikation Tabelle 2.4: Anzahl und Dauer der Lieder der verschiedenen Klassen. Klasse # Lieder Rock Klassik Jazz Pop 72 128 40 126 Durchschn. Dauer und Standardabweichung [min] 4.23 ± 1.32 5.16 ± 3.68 5.33 ± 3.04 4.01 ± 1.15 eine sehr gute Schätzung der „wahren“ Frequenz berechnen. Da weiterhin durch die Fensterfunktion nicht die gesamte Energie eines Tones in ein Frequenzband fällt, entspricht der Wert |X(k)| nicht exakt der wahren Amplitude. Diese kann über a= |X(k)| W (0) (2.26) berechnet werden, wobei W (0) der Gleichanteil des Spektrums der Fensterfunktion w[n] ist. Diese Art der Schätzung schneidet sowohl bei [DCM00] als auch bei [KM02] sehr gut ab. In den meisten Fällen sind die Abweichungen von „echter“ und geschätzter Frequenz vernachlässigbar klein. Von daher wird sie in dieser Arbeit überall dort verwendet, wo die Frequenz eines Maximums im Spektrum möglichst genau geschätzt werden muss. 2.3 Database Um eine grundsätzliche Aussage über den Nutzen und die Struktur des Klassifikationssystems zu machen sind wenige Klassen ausreichend. Hier sollen fünf der gängigsten Genres verwendet werden: Klassik, Rock, Pop, Jazz und Elektro. Im Folgenden sollen diese Genres kurz erläutert werden. Es wurde darauf geachtet, dass die ausgewählten Lieder möglichst eindeutig einem Genre zugeordnet werden können. Das heißt, dass subjektiv schwierig einzusortierende Lieder vermieden wurden. Um nicht von speziellen Eigenschaften bestimmter Komponisten/Interpreten abhängig zu sein, sind in jedem Genre viele verschiedene Künstler vertreten. Wie in Tabelle 2.4 zu sehen ist, sind pro Klasse 40 bis 128 Musikstücke vorhanden. Die Lieder der Klassen Klassik und Jazz sind im Mittel am längsten, wobei hier auch die Standardabweichung recht groß ist. Die Lieder der Klassen Rock und Pop hingegen sind im Mittel etwa eine Minute kürzer. Außerdem ist hier die Standardabweichung recht gering, was auch zu erwarten war, da die Musik in diesem Bereich häufig auf die Bedürfnisse der Radiosender zugeschnitten ist. In der Klassik hingegen 2 Genre-Klassifikation 22 ist die Variabilität der Längen sehr groß, da hier verschiedene Kompositionsformen auftreten: von recht kurzen Menuetten bis zu Sätzen von Sinfonien. 2.4 Ergebnisse 2.4.1 Dimensionsreduktion Trägt ein Merkmal nicht oder nur wenig zur Unterscheidung zwischen zwei Klassen bei, so könnte angenommen werden, dass das Einbeziehen dieses Merkmals zwar keinen Nutzen, aber auch keinen Schaden nach sich zieht. Durch den „Curse of dimensionality“ (dt.: Fluch der Dimensionalität) schaden aber solche Merkmale durchaus. Wird ein Histogramm der Merkmalsvektoren angefertigt, bei dem jede Dimension in m Abschnitte unterteilt wird, so ergeben sich daraus mD Unterräume. Liegen z. B. 10000 Merkmalsvektoren vor, und jede Dimension wird in m = 100 Abschnitte unterteilt, liegen im 1-dimensionalen Fall für jeden Abschnitt im Mittel 100 Werte vor. Schon für D = 3 würden sich allerdings 1003 = 1000000 Unterräume ergeben, die mit den vorhandenen Merkmalsvektoren nur noch sehr grob abgebildet werden können. Von daher ist es sinnvoll, nur Merkmale zu benutzen, die entscheidende Informationen für die Unterscheidung der Klassen enthalten. Es gibt zwei verschiedene Ansätze, die die Dimensionalität verringern. Zum einen gibt es die Merkmalsextraktion, bei der die wichtigen Informationen der Merkmale mittels PCA (Principal Component Analysis) auf weniger „neue“ Merkmale projiziert werden können. Dafür werden Redunanzen zwischen den Merkmalen genutzt. Nachteilig hierbei ist sowohl, dass die Merkmale durch die Transformation ihre physikalische Bedeutung verlieren als auch, dass trotzdem immer alle Merkmale berechnet werden müssen. Dafür lässt sich die Transformation schnell durchführen. Die zweite Möglichkeit ist die Merkmalsselektion. Hier wird eine Teilmenge der verfügbaren Merkmale nach bestimmten Kriterien ausgewählt. Im Folgenden sollen zwei Möglichkeiten zur Merkmalsselektion vorgestellt werden, die im weiteren Verlauf genutzt werden. Merkmalsselektion nach Fisher Bei der Merkmalsselektion nach Fisher wird für jedes Merkmal ein Gewicht W berechnet. In dieses fließen die Distanzen der Klassen ein, sowie die Varianzen der einzelnen Klassen. Wenn M ij der Mittelwert und Var(Mij ) die Varianz der Werte von Merkmal i und Klasse j ist, M i der Mittelwert aller Werte von Merkmal 23 2 Genre-Klassifikation i und p(j) die a priori-Wahrscheinlichkeit von Klasse j, dann berechnet sich nach Gleichung 2.27 das Gewicht W (i) für das Merkmal i. PC W (i) = j=1 p(j) · M ij − M i PC j=1 p(j) 2 · Var(Mij ) (2.27) Ein großer Unterschied der Werte eines Merkmals für verschiedene Klassen führt also zu einem hohen Wert von W und eine große Gesamtstreuung eines Merkmals (unabhängig von den Klassen) zu einem niedrigen. Anschließend kann eine beliebige Anzahl von Merkmalen selektiert werden, indem die Merkmale mit den höchsten Werten von W benutzt werden. Der Vorteil dieser Merkmalsselektion ist, dass sie nur einen sehr geringen Rechenaufwand erfordert. Dafür wird aber auch nur jedes Merkmal isoliert betrachtet. Effekte, die durch Kombinationen von Merkmalen entstehen, werden somit nicht berücksichtigt. „Greedy“ Merkmalsselektion Es gibt eine Kombination aller zur Verfügung stehenden Merkmale, die die mit diesen Merkmalen beste erreichbare Klassifikationsrate liefert. Wird diese gesucht, ergeben sich bei einer Gesamtanzahl von F verfügbaren Merkmalen und einer nicht festgelegten Zahl von zu benutzenden Merkmalen K mögliche Kombinationen. K= F X p=1 F p ! (2.28) Mit F = 20 ergäben sich schon 1048575 verschiedene Kombinationen der Merkmale. Diese können nicht alle getestet werden. Deswegen soll ein anderer Ansatz gewählt werden, bei dem nicht alle Kombinationen getestet werden, sondern bei dem Schritt für Schritt die besten Merkmale zu einem Merkmalssatz hinzugefügt werden. Dieses Verfahren, welches dem Optimum recht nahe kommen sollte, ist als Pseudocode in Algorithmus 1 dargestellt. Hierbei wird aus allen F Merkmalen zuerst dasjenige gesucht, durch welches die beste Klassifikationsrate erzielt werden kann. In der zweiten Iteration wird jedes der verbleibenden Merkmale M mit dem bereits gewählten Merkmal B kombiniert. Es wird wieder das gewählt, welches die beste Klassifikationsrate in Verbindung mit dem ersten Merkmal erzielt. Dieser Vorgang wird solange wiederholt, bis alle Merkmale „einsortiert“ sind. Auf diese Weise müssen nur F +(F −1)+(F −2)+. . .+2 verschiedene Kombinationen berechnet werden. Im Beispiel mit F = 20 würden die 1048575 damit auf 209 zu berechnende Kombinationen reduziert werden. Allerdings ist auch nicht gewährleistet, dass wirklich die beste Kombination gefunden wird. So würden zwei Merkmale, die alleine jeweils schwach aber im Zusammenspiel miteinander mächtig sind, wohl eher als unbedeu- 2 Genre-Klassifikation 24 tend für das Klassifikationsresultat eingestuft. So lassen sich alle Merkmale nach ihrem Beitrag zum Klassifikationsresultat sortieren. Algorithmus 1 Merkmalsselektion 1: M ← 1 : F . Nummern aller Merkmale 2: B ← [ ] . Benutzte Merkmale leer initialisieren 3: for i ← 1 : F do 4: R ← length(M ) 5: C ← [] 6: for j ← 1 : R do . Schleife über alle verbliebenen Merkmale 7: C(j) ← KlassRate(B, M (j)) . Teste bisherige Merkmale B mit einem 8: . neuen 9: end for 10: Idx ← Index(max(C)) 11: B(i) ← Idx . Wähle das Merkmal, das die Rate maximiert 12: M (Idx) ← [ ] . und lösche es aus den verfügbaren Merkmalen 13: end for 2.4.2 Beste Kombination von Merkmalen und Anzahl Gaußverteilungen Ein weiterer Parameter, der sich auf die Klassifikationsrate auswirkt, ist die Anzahl der Gaußverteilungen mit denen die GMM gebildet werden. Um die beste Kombination von Merkmalen und Anzahl der Gaußverteilungen herauszufinden, wird die „Greedy“ Merkmalsselektion für acht verschiedene Anzahlen von Gaußverteilungen getestet. Es werden jeweil 90 % der Merkmalsvektoren (bzw. der Lieder) für das Training und 10 % für das Evaluieren des GMM verwendet. Um die Einflüsse der zufälligen Auswahl der Trainings- und Evaluationsvektoren gering zu halten, werden jeweils 500 Iterationen durchgeführt. Die Ergebnisse sind in Abb. 2.8 dargestellt. Es ist gut zu erkennen, dass die Klassifikationsrate sowohl bei sehr wenigen, als auch bei sehr vielen benutzten Merkmalen schlechter wird. Außerdem fällt auf, dass die Klassifikationsrate bei 13 und 14 benutzten Merkmale ein deutliches Minimum aufweist. Die Anzahl der Gaußverteilungen scheint hingegen kaum einen Einfluss zu haben. Dies liegt vermutlich vor allem daran, dass die Database recht klein ist, und somit für das Training pro Klasse auch nur ca. 30-100 Merkmalsvektoren vorliegen. Bei vielen Gaußverteilungen wird das GMM dann sehr spezifisch auf die Trainingsdaten angepasst. Das Maximum der Klassifikationsrate wird hier bei der Kombination von fünf Gaußverteilungen und 19 benutzten Merkmalen erreicht. Die Reihenfolge der ausgewählten Merkmale für 5 Gaußverteilungen ist in Tab. 2.5 aufgelistet. In Abb. 2.9 ist die Verwechslungsmatrix für diese Kombination (5 Gaußverteilungen, 19 benutzte Merkmale) dargestellt. Es ist gut zu erkennen, dass die Stücke des Genres „Klassik“ sehr zuverlässig klassifiziert werden können. „Jazz“ und „Rock“ werden überwiegend richtig erkannt (70.5 % bzw. 81.9 %), während „Pop“ lediglich zu 44 % 25 2 Genre-Klassifikation Abbildung 2.8: Klassifikationsraten in Abhängigkeit der Anzahl der benutzten Merkmale und der Anzahl der Gaußverteilungen. Tabelle 2.5: Reihenfolge der Merkmale durch die Merkmalsselektion und die zugehörigen Klassifikationsraten. Nummer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Bezeichnung VAR(SC) MFCC1 MFCC3 GT MFCC5 VAR(∆RMS) RMS MFCC4 TG VAR(RMS) LE D/M ZC TS SFL VAR(ZC) MFCC2 A(Cmax ) A(Tmax ) SRO SC VAR(∆SC) Tmax Var(∆ZC) Klassifikationsrate 60.53 65.66 69.9 71.35 71.72 71.65 72.25 72.31 72.43 72.44 72.3 72.48 70.74 70.66 72.3 72.19 72.8 72.17 73.02 71.72 71.1 70.91 69.85 68.22 2 Genre-Klassifikation 26 korrekt klassifiziert wird. Dies ist nicht allzu überraschend, da manche Popmusik nicht gut von Jazz- oder Rockmusik abzugrenzen ist. Abbildung 2.9: Verwechslungsmatrix der Genre-Klassifikation für 5 Gaußverteilungen und 19 benutzte Merkmale. Für jedes Genre wird zeilenweise dargestellt, wieviel Prozent der Lieder welchem Genre zugeordnet werden. 2.4.3 Fazit Es wurde gezeigt, dass mit den benutzten Merkmale 73.02 % der Lieder in das richtige Genre eingeordnet werden können. Dies macht deutlich, dass die GenreKlassifikation grundsätzlich funktioniert und die benutzten Merkmale musikalische Aspekte widerspiegeln. Besonders die MFCC’s scheinen einen großen Einfluss auf die Klassifikation zu haben. Es ließen sich unter Verwendung weiterer Merkmale und/oder anderer Methoden aber auch sicherlich noch bessere Ergebnisse erzielen. 3 Spezielle Merkmale für die Gesangserkennung 27 3 Spezielle Merkmale für die Gesangserkennung Die für die Genre-Klassifikation genutzten Merkmale sind eher allgemeiner Natur und sollen in verschiedener Art die lokalen Spektren bzw. deren zeitliche Entwicklung, oder musikalische Parameter wie z. B. das Tempo oder die Tonart beschreiben. Es sollen nun Merkmale entwickelt werden, die bei den konkreten Unterschieden zwischen Gesang und Instrumenten ansetzen. Hierfür werden zuerst die Charakteristika von Gesang untersucht, durch die Gesang von Instrumenten unterschieden werden könnte, mögliche Merkmale genannt und abschließend beschrieben, wie diese extrahiert werden können. 3.1 Eigenschaften von Gesang Zunächst soll die grundlegende Funktionsweise der menschlichen Spracherzeugung beschrieben werden. Auf dieser aufbauend kann anschließend analysiert werden, welche Eigenschaften Gesang ausmachen. Die Erzeugung von Sprache lässt sich im Wesentlichen in drei „Schritte“ unterteilen: • die Erzeugung des Luftstromes, • das Generieren der Anregungsimpulse und • das Filtern durch den Vokaltrakt. Die Lungen stellen einen konstanten Luftstrom bereit, der zu den (geschlossenen) Stimmlippen geführt wird. Für die Erzeugung von stimmhaften Lauten (z. B. æ, u) wird vor den geschlossenen Stimmlippen ein Druck aufgebaut, bis dieser groß genug ist um die Stimmlippen auseinanderzudrücken. Sind sie geöffnet, werden sie durch die erhöhte Strömungsgeschwindigkeit und den dadurch entstehenden BernoulliEffekt wieder dazu veranlasst, sich zu schließen [Sun77]. So werden immer nur kurze Druckimpulse erzeugt, die sich mit einer Frequenz von etwa 60 Hz - 400 Hz wiederholen. Das dadurch entstehende Spektrum enthält Frequenzkomponenten bei eben dieser Frequenz (auch Grundfrequenz), und allen Vielfachen. Die Amplitude fällt dabei zu höheren Frequenzen mit etwa 12 dB pro Oktave ab, wie auch in Abb. 3.1(a) dargestellt ist. Anschließend werden diese Impulse im Vokaltrakt gefiltert. Dieser 28 3 Spezielle Merkmale für die Gesangserkennung kann vereinfacht als eine Röhre mit sich änderndem Querschnitt angesehen werden. Die Stellung von Kehlkopf, Zunge, Kiefer und Lippen beeinflusst dabei die Länge und Form dieses Rohres und damit auch die akustische Wirkung. Je nach Stellung werden verschiedene Frequenzen betont (siehe Abb. 3.1(b)). Diese Frequenzen sind die Resonanzen, oder auch Formanten, des Systems und machen das Unterscheiden verschiedener Laute möglich. Bei der Erzeugung von stimmlosen Lauten sind die Stimmlippen durchgängig geöffnet. Je nach Laut geschieht die Artikulation dann durch turbulente Strömungen (Frikative, z. B. S, Z) oder durch ein plötzliches Entweichen angestauten Druckes (Plosive, z. B. p, k). Nun soll nach der Betrachtung der Sprachproduktion genauer (a) Anregungsspektrum (b) Gefiltertes Spektrum Abbildung 3.1: Schematische Darstellung des Anregungsspektrums und des gefilterten Spektrums (aus: [Sun77]). auf den Gesang eingegangen werden. Ein wesentlicher Unterschied zu Sprache besteht im Verhältnis von stimmhaften zu stimmlosen Lauten: während bei Sprache nach [Kim03] etwa 60% der Zeit mit stimmhaften Lauten gefüllt wird, liegt dieser Anteil bei Gesang bei etwa 90%. Somit würde es für eine Gesangsdetektion ausreichen, sich auf diese Laute zu konzentrieren. Konsonanten wären wohl auch nur sehr schwer von perkussiven Instrumenten zu unterscheiden. Nach [Sun77] ist ein wesentlicher Grund dafür, warum Sänger der klassischen Stilrichtung über ein ganzes Orchester hin zu hören sind, der „Gesangs-Formant“. Durch eine spezielle Stellung des Vokaltraktes wird bei etwa 2500 Hz bis 3000 Hz ein zusätzlicher Formant erzeugt, der bei normalem Sprechen nicht vorhanden ist. In diesem Bereich ist die Energie der begleitenden Instrumente bereits ziemlich niedrig, sodass der Formant gut hörbar ist, während tiefere Frequenzen des Sängers verdeckt werden. Dies könnte zur Gesangsdetektion in klassischer Musik beitragen. In anderen Stilrichtungen hingegen weisen die Sänger diesen Gesangs-Formanten meist nicht auf, da sie über elektrische Verstärkung verfügen und somit nicht auf ihn angewiesen sind. Außerdem sind oftmals Instrumente vorhanden, die ebenfalls hochfrequente Anteile besitzen, wie z.B. Becken, Snare und Hi-hat. Durch die in moderner Musik sehr „dichte“ spektrale Verteilung würde es somit sehr schwierig, einen eventuell vorhanden Gesangs-Formant 29 3 Spezielle Merkmale für die Gesangserkennung zu detektieren. Außerdem werden bereits Merkmale benutzt, die die spektrale Form beschrieben. In Abb. 3.2(a) ist ein Ausschnitt des romantischen Stückes Mondnacht von Robert (a) Vibrato (b) Frequenzanstieg Abbildung 3.2: Links: Spektrogramm eines Ausschnittes aus dem Stück „Mondnacht“ von Robert Schumann, deutlich zu sehen die Frequenzmodulationen des Gesangs, Rechts: Spektrogramm eines Ausschnittes aus „As long as you love me“ von den Backstreet Boys mit einem Ansteigen der Frequenzen der Teilharmonischen. Schumann als Spektrogramm dargestellt. In diesem Stück besteht die Instrumentalbegleitung aus einem ruhigen Piano. Der Gesang ist in diesem Stück in der Lautstärke sehr dominant, wodurch er in dem Spektrogramm auch gut zu erkennen ist. Hier fällt auf, dass die Teiltöne stark frequenzmoduliert sind. Dabei schwankt die Frequenz eines gehaltenen Tones mit etwa 4 Hz bis 8 Hz. Zwar können auch etliche Musikinstrumente Vibrato produzieren, jedoch tritt dies meist nicht in so starkem Umfang auf. Außerdem kommt es bei Gesang oft zu einem stufenlosen Übergang zwischen den Frequenzen zweier aufeinanderfolgender Töne, wie er in Abb. 3.2(b) zu sehen ist. Bei den meisten Instrumenten hingegen werden die Töne einzeln gespielt. Diese beiden zeitlichen Entwicklungen der Frequenz von Teiltönen könnten also eventuell dazu genutzt werden, um zu entscheiden ob dieser Teilton durch ein Instrument oder durch Gesang erzeugt wurde. Allerdings müsste dafür zum einen der Verlauf der Teiltöne erfasst werden, und zum anderen anschließend durch geeignete Maße beschrieben werden. Diese beiden Schritte sollen in den folgenden Abschnitten erklärt werden. 3.2 Tracking der Verläufe von Teiltönen Um die Tonhöhen von Teiltönen zu „tracken“, also über die Zeit zu verfolgen, wird ein System angewandt, das in der ersten Stufe lokal in kleinen Fenstern Maxima 3 Spezielle Merkmale für die Gesangserkennung 30 im Spektrum detektiert, und in der zweiten Stufe versucht diese über die Zeit zu verfolgen. 3.2.1 Lokale Maxima-Suche Für die lokale Maxima-Suche wird das einseitige, logarithmierte Betragsspektrum des aktuellen Blocks berechnet. Damit sowohl die zeitliche Auflösung ausreicht um schnelle Frequenzänderungen zu verfolgen, als auch die Frequenzauflösung um kleine Änderungen der Frequenz zu detektieren, wird mit einer Blockgröße von 46.4 ms und einer Schrittweite von 5.8 ms gearbeitet. Dadurch ergibt sich bei einer Abtastfrequenz von fs = 44.1 kHz eine Frequenzauflösung von 21.5 Hz. Um zu verhindern, dass Werte als Maximum detektiert werden, die zwar sehr klein, aber größer als die beiden Nachbarwerte sind, wird ein geglättetes Spektrum berechnet, welches als adaptiver Schwellwert benutzt wird. Hier werden die einzelnen durchgeführten Schritte beschrieben. Glättung des Spektrums Um eine geglättete Version des Spektrums |Y (k)| zu erhalten, wird die Grobstruktur Ysmooth (k) nach Formel 3.1 berechnet. Ysmooth (k) = O X 1 |Y (j)| · H(j), mit O − U + 1 j=U k U = round b 2 und O = round k · 2b . (3.1) (3.2) (3.3) Diese bedeutet lediglich, dass der Mittelwert über einen bestimmten mit einer Fensterfunktion H multiplizierten Bereich berechnet wird. U und O sind dabei die untere bzw. obere Grenze dieses Bereiches, die durch den Parameter b, der die Größe des Bereiches angibt, bestimmt werden. Dieser Parameter gibt an, wieviel einer Oktave das Fenster nach unten, sowie nach oben reicht (siehe auch Gl. 3.2 und 3.3). Ist z. B. b = 21 , wird der Mittelwert über einen Bereich von einer halben Oktave unterhalb des aktuellen Wertes bis einer halben Oktave oberhalb des aktuellen Wertes gebildet. Dies bedeutet, dass das Fenster für höhere Frequenzen immer breiter wird. Für die Fensterfunktion wurde hier ein Hann-Fenster gewählt. Die Breite wurde auf b= 1 3 gesetzt. 3 Spezielle Merkmale für die Gesangserkennung 31 Maximumsselektion Anschließend werden alle Maxima aus |Y (k)| gesucht, die über dem jeweiligen Wert aus Ysmooth (k) liegen. Dabei wird nur der Frequenzbereich 90 Hz bis 6 kHz berücksichtigt, da unterhalb von 90 Hz die Frequenzauflösung sehr schlecht wird, und über 6 kHz nur wenige relevante Anteile von Gesang liegen. Die Frequenzschätzung der Maxima wird auch hier wieder über die Verwendung des differenzierten Signals verbessert (siehe Abschnitt 2.2.2). Abbildung 3.3: Logarithmiertes Betragsspektrum |Y (k)| (blau), Schwelle Ysmooth (k) (rot) und detektierte Maxima (rote Kreuze). 3.2.2 Tracking Liegen die Frequenzen und die Amplituden der lokalen Maxima für alle Analyseblöcke innerhalb des Entscheidungsblockes vor, wird im nächsten Schritt versucht diese möglichst sinnvoll über die Zeit miteinander zu verbinden. Wie die Entscheidungsblöcke gebildet werden, wird in Abschnitt 5.1.1 erläutert. Das Tracking wurde zu großen Teilen nach [LMR05] implementiert. Der zugrunde liegende Ansatz ist dabei recht simpel: liegt im Block m und bei der Frequenz f (in Hertz) ein Maximum fm vor, so wird im Block m + 1 nach einem Maximum pred fm+1 gesucht, wobei die Vorraussetzung aus Gleichung 3.4 erfüllt sein muss. fm+1 ist dabei eine Schätzung, welche Frequenz für das nächste Maximum wahrscheinlich wäre. Diese Schätzung berechnet sich aus der extrapolierten Steigung zwischen den 32 3 Spezielle Merkmale für die Gesangserkennung Maxima fm−1 und fm . Damit soll die bisherige Entwicklung des Tracks berücksichtigt werden. Da es zu vielen Fehlern kommt, wenn die volle Steigung extrapoliert wird, wird die Schätzung nach Gleichung 3.5 nur mit der halbierten Steigung berech(i) net. Liegen mehrere Maxima fm+1 im Block m + 1 vor, die maximal ∆f von dieser Schätzung entfernt liegen, so wird jenes mit dem größten Wert der Kostenfunktion (i) (i) W fm+1 gewählt (siehe Formel 3.6). In diese fließen die Amplituden A fm+1 der pred Maxima, sowie die Distanz zu dem vorhergesagten Frequenzwert fm+1 ein. ! pred |fm+1 − fm+1 | ≤ ∆f pred fm+1 = (i) W fm+1 = 3 · fm − fm−1 2 (i) A fm+1 (i) pred |fm+1 − fm+1 | (3.4) (3.5) (3.6) Um zu vermeiden, dass wenige, fehlende Maxima die Bildung eines Tracks verhindern bzw. unterbrechen, werden Geistermaxima eingeführt. Wird im Block m + 1 kein Maxima gefunden, das die Bedingung in Gleichung 3.4 erfüllt, so wird ein Geispred eingefügt. Wird in einem der termaximum mit der Frequenz der Schätzung fm+1 folgenden Blöcke wieder ein „echtes“ Maximum gefunden, so werden die Geistermaxima durch Interpolation der an die Lücke angrenzenden „echten“ Maxima ersetzt. Bei der maximalen Anzahl der hintereinander zugelassenen Geistermaxima wird zwischen „jungen“ und „alten“ Tracks entschieden. Wird ein Maximum gefunden, welches keinem bestehenden Track zugeordnet werden kann, wird ein neuer Track geöffnet, der als „jung“ markiert wird. Überschreitet die Anzahl der zu diesem Track zugeordneten Maxima die Schwelle Nj2a , wird der Track als „alt“ markiert. Für junge Tracks werden maximal NjG hintereinander liegende Geistermaxima zugelassen, und für alte Tracks maximal NaG . Ist der letzte der Analyseblöcke erreicht und alle Maxima wurden einem Track zugeordnet, werden am Ende alle Tracks mit weniger als Nmin Maxima gelöscht. In Abb. 3.4 (Beispiel 1) ist dargestellt, wie das Abschätzen des Frequenzwertes im nächsten Block funktioniert. Liegt lediglich ein bisheriges Maximum in dem Track vor, so wird dessen Frequenz für die Schätzung f pred verwendet. Ansonsten wird die Hälfte der Steigung verwendet, die zwischen den beiden letzten Maxima zu beobachten ist. Es ist zu erkennen, dass (bei angenommenen gleichen Amplituden) das Maximum gewählt wird, dessen Distanz zu f pred am geringsten ist. In Beispiel 2 ist skizziert, wie bei fehlenden Maxima Geistermaxima mit der Frequenz der Schätzung f pred eingesetzt werden. Werden anschließend wieder Maxima gefunden (der Track wird also fortgesetzt), so werden anstelle der Geistermaxima normale Maxima eingesetzt, deren Frequenz und Amplitude anhand der angrenzenden Maxima interpoliert wird. 33 3 Spezielle Merkmale für die Gesangserkennung Benutzte Maxima Nicht benutzte Maxima Schätzung fpred Geistermaxima >Δf Finaler Track Frequenz Bsp. 3 Bsp. 2 Bsp. 1 ... m-3 m-2 m-1 m m+1 m+2 ... Blocknummer Abbildung 3.4: Beispiele zum Tracking In Beispiel 3 ist zu erkennen, wie sich der Parameter ∆f auswirkt. Da der Frequenzabstand zwischen den jeweiligen Maxima größer als dieser Wert ist, entstehen zwei getrennte Tracks, deren Lücken mit Geistermaxima und anschließend mit echten Maxima aufgefüllt werden. Die Parameter wurden durch Erprobung wie folgt gewählt: Nj2a = 3, NjG = 2, NaG = 5, Nmin = 10 und ∆f = 60 Hz. In Abb. 3.5 ist ein Beispiel zu sehen. Als „x“ sind die lokalen Maxima eingezeichnet, als durchgehende Linien die aus den Maxima abgeleiteten Tracks. Es ist zu erkennen, dass die deutlich heraustretenden Teiltöne gut erkannt und verfolgt werden. Es kommt allerdings auch zu weniger sinnvollen, zufälligen Tracks. Wie versucht werden kann diese zu vermeiden, soll im nächsten Abschnitt erklärt werden. 3.2.3 Korrelationsmatrix und Gruppierung von Tracks Bei der vorgestellten Form des Trackings, können Tracks entstehen, deren Ursache keine Teilharmonischen sind, sondern zufällige, sporadisch auftretende Maxima, die miteinander verbunden werden. Um im Folgenden zu verhindern, dass diese Tracks in die Auswertung mit einfließen, werden nur Tracks berücksichtigt, die eine relativ 34 3 Spezielle Merkmale für die Gesangserkennung Abbildung 3.5: Spektrogramm mit den lokalen Maxima und den daraus abgeleiteten Tracks hohe Korrelation mit mindestens einem anderen Track aufweisen. Die Idee dahinter ist, dass sich die einzelnen Teiltöne eines Tones identisch über die Zeit verändern und damit eine hohe Korrelation untereinander besitzen. Dahingegen werden die zufälligen Tracks in den meisten Fällen zu keinem anderen Track stark korreliert sein. Außerdem werden durch diese Korrelationsberechnung auch Tracks „aussortiert“, die Teilharmonische repräsentieren, deren Grundfrequenz sehr konstant ist. Dies ist durchaus erwünscht, da diese Tracks mit konstanter Frequenz meistens durch Instrumente erzeugt werden, und nur sehr selten durch Gesang. Für jeden Track wird der normierte Kreuzkorrelationskoeffizient r nach Gleichung 3.7 zu allen anderen Tracks im Entscheidungsblock berechnet, wobei xi und yi mit i = 1, 2, . . . , N die Teile der beiden Tracks Tx und Ty sind, die sich überlappen. N ist damit die Länge des überlappenden Bereiches. r(x, y) = 1 PN i=1 (xi − x)(yi − y) N qP PN N 2 i=1 (xi − x) · i=1 (yi − y)2 (3.7) Dabei werden nur die Anteile der Tracks berücksichtigt, die sich zeitlich überlappen. Außerdem wird der Korrelationskoeffizient nur für Paare von Tracks berechnet, die sich um mindestens 15 Analyseblöcke überlappen. Für Tracks, die sich nicht ausreichend (oder auch gar nicht) überlappen, wird der Korrelationskoeffizient r = 0 gesetzt. Dies soll verhindern, dass eine zufällige ähnliche Entwicklung über nur wenige Analyseblöcke zu einem hohen Korrelationskoeffizienten führt. Da gilt, dass r(Tx , Ty ) = r(Ty , Tx ) und r(Tx , Tx ) = 1 ist, wird der Koeffizient nur für Track-Kom- 35 3 Spezielle Merkmale für die Gesangserkennung binationen (Tx , Ty ) mit y > x berechnet. Im Folgenden werden alle Tracks gruppiert, die untereinander eine Korrelation aufweisen, die größer ist als rthresh = 0.9. Dabei muss jeder Track nur mit mindestens einem anderen Track hoch korreliert sein. Es können mehrere Gruppen in einem Entscheidungsblock entstehen. Ist dies der Fall, wird die Gruppe gewählt, die die meisten Tracks beinhaltet. Für die Tracks dieser Gruppe werden dann die TrackMerkmale berechnet, die im nächsten Abschnitt beschrieben werden. In Abb. 3.6(a) sind die detektierten Tracks eines Entscheidungsblockes ohne Gesang eingezeichnet. Da die Teiltöne und damit auch die Tracks kaum Frequenzvariationen beinhalten, fällt die Korrelation zwischen den Tracks gering aus. Somit wird keine Gruppe gebildet. In Abb. 3.6(b) ist dagegen ein Entscheidungsblock mit Gesang dargestellt. Hier ist gut zu erkennen, dass die Teiltöne und damit auch die Tracks deutliche Frequenzvariationen aufweisen und sehr ähnlich verlaufen. Dadurch ist auch die Korrelation zwischen den Tracks relativ hoch, und es werden viele von ihnen zu einer Gruppe zusammengefasst. (a) Abschnitt ohne Gesang (b) Abschnitt mit Gesang Abbildung 3.6: Spektrogramme, alle detektierten Tracks (dünne Linien) und die Tracks, die zur Merkmalsberechnung genutzt werden (dicke Linien) für zwei beispielhafte Entscheidungsblöcke Durch diese Gruppierung werden im optimalen Fall die Teiltöne der dominanten Quelle bzw. der Quelle, die starke Frequenzvariationen aufweist, von den übrigen Bestandteilen der Musik getrennt. Dadurch soll versucht werden, die Quelle getrennt zu betrachten. Die meisten „klassischen“ Merkmale hingegen beschreiben immer das komplette Spektrum oder Signal. 3.3 Merkmalsberechnung Liegen die Tracks vor, die zu der größten Gruppe gehören, sollen von diesen Merkmale berechnet werden, die die zeitlichen Frequenzvariationen beschreiben. Dafür 3 Spezielle Merkmale für die Gesangserkennung 36 sollen zum einen Merkmale entwickelt werden, die die relative Spanne der vorkommenden Frequenzen beschreiben, aber auch welche, die die Geschwindigkeit der Frequenzänderungen beschreiben. Diese Merkmale werden in den nächsten Abschnitten erläutert. 3.3.1 Die Tracks beschreibende Merkmale Standardabweichung Als Maß dafür, wie stark ein Track Tx in seiner Frequenz variiert, wird die Standardabweichung σ(Tx ) der Frequenzwerte der Maxima berechnet. Da höherfrequente Harmonische eines Tones absolut gesehen stärker in ihrer Frequenz schwanken als niederfrequente Harmonische des gleichen Tones, wird die berechnete Standardabweichung noch über den Mittelwert des Tracks normalisiert. ST D(Tx ) = σ(Tx ) Tx (3.8) Frequenzbereich Ein ähnliches Maß ist der Frequenzbereich, der die absolute Spanne der vorkommenden Frequenzen beschreibt. Auch hier wird wieder über den Mittelwert des Tracks normalisiert. F B(Tx ) = max Tx − min Tx Tx (3.9) Mittlere Steigung Um zu erfassen, wie schnell und stark sich die Frequenz eines Tracks ändert, wird zusätzlich die mittlere Ableitung über die gesamte Länge des Tracks berechnet, wobei N die Länge des Tracks ist. Auch dieser Wert wird wieder über den Mittelwert des Tracks normalisiert. N 1 1 X DEV (Tx ) = |Tx (n) − Tx (n − 1)| Tx N − 1 n=2 (3.10) Modulationsfrequenz Um die Art der zeitlichen Frequenzschwankungen zu beschreiben, wird die diskrete Fouriertransformation (DFT) des Tracks berechnet. Als Merkmale werden die 3 Spezielle Merkmale für die Gesangserkennung 37 Tabelle 3.1: Die Merkmale der Gruppen ST D(G) F B(G) DEV (G) M F (G) AM F (G) N RT (G) Standardabweichung Frequenzbereich Mittlere Steigung Modulationsfrequenz mit größter Amplitude Amplitude von M F (G) Anzahl Tracks Modulationsfrequenz M F (Tx ) mit der höchsten spektralen Leistung, sowie die Amplitude AM F (Tx ) von dieser genutzt. Das Spektrum wird dabei auf die Länge des Tracks normalisiert. 3.3.2 Mitteln der Track-Merkmale einer Gruppe Diese Merkmale werden für alle Tracks berechnet, die zu der größten Gruppe gehören. Um trotzdem für jede Gruppe nur einen Merkmalsvektor zu erhalten, werden die Merkmale der Tracks gemittelt. Wenn A (Tx (m)) die Amplitude des Tracks x im Block m, NTx die Länge des Tracks und NG die Anzahl der Tracks in der Gruppe ist, werden die Merkmale nach Gleichung 3.11 gemittelt. M (G) soll dabei ein beliebiges Merkmal der gesamten Gruppe sein, und M (Tx ) das gleiche Merkmal eines einzelnen Tracks Tx . M (G) = A(Tx ) = K x=1 M (Tx ) · A(Tx ) PNG K x=1 A(Tx ) NTx PNG 1 X A (Tx (m)) NTx m=1 (3.11) (3.12) Die Merkmale von Tracks mit hoher mittlerer Amplitude werden also stärker berücksichtigt, als die von Tracks mit eher geringer mittlerer Amplitude. Durch den Exponenten K ≤ 1 wird dabei eine Komprimierung erreicht. Dadurch werden höhere Amplituden nicht so stark gewichtet, wie es bei einer linearen Gewichtung (K = 1) der Fall wäre. Somit werden die oben aufgeführten Merkmale der Tracks auf Merkmale der Gruppe abgebildet, welche in Tabelle 3.1 zusammengefasst sind. Es wurde K = 0.2 gesetzt. Als zusätzliches Merkmal wird noch die Anzahl N RT (G) der in der Gruppe vertetenen Tracks benutzt. Ist in einem Entscheidungsblock kein Track mit einem anderen stark korreliert und ist damit auch keine Gruppe vorhanden, werden diese sechs Merkmale gleich Null gesetzt. Inwiefern die einzelnen Merkmale zu der Erkennung von Gesang beitragen, wird in Kapitel 5 evaluiert. 4 Database 38 4 Database Um eine Aussage machen zu können, wie gut eine Gesangsdetektion funktioniert, müssen Musikstücke vorhanden sein, die als Trainings- und Testmaterial benutzt werden können. In diesem Kapitel soll erläutert werden, nach welchen Kriterien diese Musikstücke ausgewählt wurden und wie die manuelle Annotation erzeugt wurde, die als „wahre“ Referenz bei den späteren Klassifikationsexperimenten dienen soll. 4.1 Beschreibung der Database Da die Gesangsdetektion für die am meisten verbreiteten Musikrichtung der westlichen Welt funktionieren soll, sollten im Trainingsmaterial auch diese Stile vertreten sein. Im Anhang auf Seite ii sind alle annotierten und in den späteren Evaluationen verwendeten Musikstücke aufgeführt. Diese sind alle von unterschiedlichen Künstlern. Dies soll verhindern, dass das System eventuell auf spezielle Eigenschaften einer bestimmten Stimme trainiert wird. Allerdings sei gesagt, dass in allen Stücken nur „normaler“ Gesang enthalten ist, also keine geschrienen, gegrunzten oder experimentellen Passagen. In 31 der Lieder sind ausschließlich männliche, in 14 Liedern ausschließlich weibliche und in zwei Liedern sowohl männliche als auch weibliche Stimmen enthalten. Weiterhin sind die Stücke aus verschiedenen Genres, wie z. B. Klassik, Pop, Rock, HipHop, Jazz oder Metal. Die Einordnung der Lieder in diese Genres erfolgte auf subjektiver Basis. Demnach sind 16 Lieder aus dem Genre Pop, 13 aus Rock, fünf aus Metal, jeweils drei aus Jazz, Blues und Klassik, zwei aus Folk und jeweils eins aus den Genres HipHop und Musical. Auch wenn hier ein deutlicher Schwerpunkt auf den Genres Rock und Pop liegt, kann sichergestellt werden, dass die Modelle nicht auf ein bestimmtes Genre abgestimmt werden, sondern die gängigen Musik- und Gesangsstile der westlichen Welt repräsentieren. 4.2 Manuelle Annotation Um später eine Aussage machen zu können, ob ein Entscheidungsblock (siehe Abschnitt 5.1.1) der richtigen Klasse zugeordnet wurde, muss eine „wahre“ Referenz vorliegen. Diese wurde mit Hilfe der freien Software Praat: doing phonetics by computer (Version: 5.2.21) erstellt, die von Paul Boersma und David Weenink entwickelt 4 Database 39 wurde. In Abb. 4.1 ist die Software zu sehen. Es ist mit ihr möglich, verhältnismäßig schnell die Abschnitte zu annotieren. Abgespeichert wird eine Datei, in der für jedes Segment die Anfangs- und Endzeit, sowie die Annotation (hier „voc“) enthalten ist. Sehr kurze Pausen (< 0.3 s) zwischen zwei Abschnitten mit Gesang wurden nicht Abbildung 4.1: Kennzeichnen der Gesang beinhaltenden Segmente mit Praat . berücksichtigt. Hier würde auch der Mensch eine durchgehende Gesangslinie erkennen. Es soll noch angemerkt werden, dass es keine „absolut richtige“ Annotation gibt, da die Grenzen eines vokalen Abschnittes zum Teil durch langsam ein- oder ausgeblendeten Gesang nicht eindeutig festzulegen sind. 4.3 Betrachtung Wird die Gesamtlänge aller instrumentalen Abschnitte betrachtet, ergibt sich eine Gesamtlänge von 74.09 Minuten. Die Gesamtlänge der Abschnitte, die Gesang beinhalten, beträgt 116.33 Minuten. Damit sollte für beide Klassen eine genügend große Menge an Trainingsmaterial vorliegen. In Abb. 4.2 sind die Längen der instrumentalen Abschnitte, und der Abschnitte mit Gesang in zwei Histogrammen visualisiert. Die grundsätzliche Form ist ähnlich, allerdings gibt es deutlich mehr Abschnitte mit Gesang, die über zehn Sekunden lang sind. Entscheidend sind aber vielmehr die kurzen Segmente. Hier fällt auf, dass in beiden Histogrammen nur ein sehr kleiner Anteil der Segmente kürzer als etwa eine halbe Sekunde ist. Da die meisten Entscheidungsblöcke (siehe Abschnitt 5.1.1) auf deren Basis die Klassifikation getroffen 40 4 Database werden soll, eine ähnliche Länge aufweisen, bzw. sogar kürzer sind, ist somit eine genügend hohe Auflösung gegeben. (a) ohne Gesang (b) mit Gesang Abbildung 4.2: Histogramme der Segmentlängen für Segmente ohne (links), und mit Gesang (rechts) 5 Evaluation 41 5 Evaluation In diesem Kapitel soll die Leistung der Gesangsdetektion genauer untersucht werden. Dafür soll zu Beginn das Merkmalsextraktions- und Klassifikationssystem im Detail beschrieben werden. Im Anschluss folgen einige Experimente um zu überprüfen ob, und wenn ja, in welchem Umfang die entwickelten Track-Merkmale zu einer Verbesserung der Gesangsdetektion beitragen. Sowohl die Extraktion der Merkmale als auch die Klassifikation wurden mit der Software Matlab (Version: 7.9.0) durchgeführt. 5.1 Extraktionssystem In diesem Abschnitt soll beschrieben werden, wie die Grenzen der Blöcke, für die eine Entscheidung getroffen werden soll, berechnet, und wie die verschiedenen Merkmale extrahiert werden. 5.1.1 Unterteilung in Entscheidungsblöcke Da die Gesangsdetektion eine Entscheidung ist, die vom Zeitpunkt im jeweiligen Musikstück abhängig ist, müssen zeitliche Abschnitte definiert werden für die dann die Entscheidung getroffen werden kann. Dies kann über feste Blöcke geschehen. Diese weisen allerdings den Nachteil auf, dass deren Grenzen nicht von dem musikalischen Inhalt abhängig sind. Dadurch könnte die erste Hälfte eines Blockes ausschließlich instrumental sein, und in der zweiten Hälfte setzt Gesang ein. Dies würde die Klassifikation erschweren. Um dies so weit wie möglich zu verhindern, soll ein Ansatz nach [LW07] implementiert werden. In diesem werden Blöcke variabler Länge verwendet. Die Grenzen dieser werden so gewählt, dass sie mit Zeitpunkten hoher spektraler Veränderung zusammenfallen. Dies geschieht aus der Annahme heraus, dass sich am Beginn oder Ende eines Gesangsabschnittes die spektrale Verteilung relativ stark ändert. Im ersten Schritt wird für ein komplettes Musikstück der Spectral Flux SF(m) (siehe Seite 11) mit einer hohen zeitlichen Auflösung (Blocklänge von 0,0116 s und nicht überlappende Fenster) berechnet, wobei m der Blockindex ist. Anschließend werden alle Maxima SF(m) markiert, die größer als C · Median(SF(t)) sind, wobei 5 Evaluation 42 m − H ≤ t ≤ m + H und C ein konstanter Faktor ist. Dies ist in Abb. 5.1 (oben) dargestellt. H gibt folglich nur an, über welchen Bereich (oder über wieviele Blöcke) der Median gebildet wird. Um zu kurze Entscheidungsblöcke zu vermeiden, werden im nächsten Schritt nur Maxima beibehalten, in deren Umgebung ±Tmin es kein höheres Maximum gibt (siehe Abb. 5.1 unten). Somit werden immer die Zeitpunkte mit der größten spektralen Änderung als Beginn eines neuen Entscheidungsblockes gewählt. Für die Parameter wurden Werte von C = 1.5, H = 40 Blöcke Abbildung 5.1: Oben: in blau der Spectral Flux eines Musikausschnittes, in rot die vorläufigen Maxima und der auf dem Median basierende Schwellwert. Unten: die am Ende zur Blockbildung genutzten Maxima. und Tmin = 0.2 s verwendet. In Abb. 5.2 ist an einem Spektrogramm eines Musikausschnittes zu erkennen, dass die Blockgrenzen (schwarze vertikale Linien) recht gut mit der musikalischen Struktur übereinstimmen. In Abb. 5.3 ist ein Histogramm der Längen der Entscheidungsblöcke aller 47 Musikstücke zu sehen. Wie zu erwarten, sind alle Entscheidungsblöcke länger als Tmin = 0.2 s. Außerdem ist ein Großteil der Blöcke kürzer als 0.5 s, was eine genügend hohe zeitliche Auflösung bedeutet, da die meisten instrumentalen bzw. vokalen Segmente, wie in Abschnitt 4.3 gezeigt wurde, länger als 0.5 s sind. 5.1.2 Berechnung der Merkmale Anschließend müssen die verschiedenen Merkmale für jeden dieser unterschiedlich langen Entscheidungsblöcke berechnet werden. Für diese Berechnung werden Analyseblöcke der Länge 0.0464 s verwendet, die sich zu 87.5 % überlappen. Für jeden 5 Evaluation 43 Abbildung 5.2: Spektrogramm eines Ausschnittes aus dem Lied „Losing my Religion“ von R.E.M. mit einer Analyseblocklänge von 0.046 s und einem Überlapp von 87.5%, in schwarz die Grenzen der zu klassifizierenden Blöcke. Abbildung 5.3: Histogramm der Längen der Entscheidungsblöcke. 5 Evaluation 44 dieser Analyseblöcke werden die MFCC, die LMSC (Logarithm Mel Spectrogram Coefficients) und die weiteren spektralen Merkmalen (Spectral Centroid, Spectral Rolloff, Spectral Flux) berechnet. Von diesen Werten wird für jeden Entscheidungsblock der Mittelwert als Merkmal abgespeichert. Zusammengenommen sind dies 33 Merkmale (15 MFCC, 15 LMSC, 3 spektrale Merkmale). Die Berechnung der LMSC ist dabei identisch mit der der MFCC, nur wird die abschließende diskrete CosinusTransformation ausgelassen. Außerdem werden die Track-Merkmale berechnet. Dazu werden wie in Abschnitt 3.2 beschrieben, die Tracks extrahiert. Von derjenigen Gruppe mit den meisten Tracks werden anschließend die Track-Merkmale gemittelt. Diese repräsentieren dann die sechs Track-Merkmale des Entscheidungsblockes. Sind in einem Entscheidungsblock keine Tracks miteinander korreliert, es also auch keine Gruppe gibt, werden diese Track-Merkmale gleich Null gesetzt. 5.2 Training und Testen In diesem Abschnitt soll erläutert werden, wie das Klassifikationssystem evaluiert werden kann. In Abb. 5.4 ist der grundlegende Ablauf dargestellt, nach dem der Klassifikator trainiert und anschließend getestet wird. 5.2.1 Trainieren der GMM Um das System entscheiden zu lassen, ob in einem Entscheidungsblock Gesang vorhanden ist oder nicht, müssen zuvor die Modelle für diese beiden Klassen trainiert werden. Hierfür werden die Merkmalsvektoren von 46 der 47 Musikstücken verwendet. Nach der Unterteilung ergeben sich gut 26000 Entscheidungsblöcke. Da über alle Lieder gemittelt die instrumentalen Passagen 39 % der Gesamtzeit, und damit die vokalen 61 %, ausmachen, liegen etwa 10000 bzw. etwa 16000 Merkmalsvektoren vor. An diese werden die Mischverteilungen für die beiden Klassen bestmöglich angepasst. 5.2.2 Testen der Klassifikation Die Merkmalsvektoren der Entscheidungsblöcke des nicht für das Training verwendeten Musikstückes werden schließlich benutzt, um das trainierte Modell zu testen. Für jeden Entscheidungsblock z werden die Wahrscheinlichkeiten P (M (z) = CI ) (für die Klasse Instrumental) und P (M (z) = CG ) (für die Klasse Gesang) berechnet, dass 45 5 Evaluation Datenbank mit Musikstücken Partitionierung Partitionierung Merkmale und Gruppierung der Tracks Merkmale und Gruppierung der Tracks Nein TrackMerkmale = 0 Gruppe enthalten? Ja Ja Mitteln der TrackMerkmale Gruppe enthalten? Mitteln der TrackMerkmale Trainiere GMM Nein TrackMerkmale = 0 Klassische Merkmale Teststücke Klassische Merkmale Trainingsstücke Lokale Wahrscheinlichkeiten GMM Manuelle Annotation Geglättete Entscheidung Klassifikationsrate Abbildung 5.4: Ablaufplan der Evaluation des Klassifikationssystems, in grün sind Eingangs- und in rot Ausgabewerte markiert. 46 5 Evaluation der Merkmalsvektor M (z) aus der jeweiligen Mischverteilung erzeugt wurde. Die einfachste Art um ausgehend von diesen Wahrscheinlichkeiten zu einer Entscheidung E(z) für jeden Block zu kommen wäre die nach Gleichung 5.1, wobei I und G für die Entscheidungen Instrumental bzw. Gesang stehen. E(z) = I wenn P (M (z) = CI ) > P (M (z) = CG ), G wenn P (M (z) = CG ) > P (M (z) = CI ). (5.1) Es würde also für jeden Entscheidungsblock nur die Informationen des aktuellen Blockes genutzt. Dadurch kann es jedoch zu schnellen Schwankungen der Entscheidung kommen. Zuverlässiger wird die Entscheidung, wenn zusätzlich die Wahrscheinlichkeiten der benachbarten Entscheidungsblöcke genutzt werden. Dies wird erreicht, indem soviele umliegenden Blöcke mit einbezogen werden, dass eine Gesamtlänge von zwei Sekunden erreicht wird. Die Wahrscheinlichkeiten dieser Blöcke könnten nun miteinander multipliziert werden. Bei den sehr kleinen Werten könnte es dabei aber zu numerischen Ungenauigkeiten kommen. Deswegen werden sie erst logarithmiert und anschließend aufaddiert. Die Entscheidung wird dann nach Gleichung 5.2 über den direkten Vergleich dieser aufaddierten Wahrscheinlichkeit getroffen, wobei Z für die Entscheidungsblöcke steht, die innerhalb dieser zwei Sekunden liegen. E(z) = I wenn P G wenn P i∈Z log (P (M (i) = CI )) > P i∈Z log (P (M (i) = CG )) > P i∈Z i∈Z log (P (M (i) = CG )), log (P (M (i) = CI )) . (5.2) In Abb. 5.5 sind für fünf beispielhaft ausgewählte Lieder die Zeitpunkte dargestellt, zu denen Gesang detektiert worden ist. Es ist gut zu erkennen, dass es durch die einfache Entscheidungsvorschrift („Ohne Glättung“) zu vielen Wechseln der Entscheidung zwischen den beiden Klassen kommt. Durch die Entscheidungsvorschrift, die die Wahrscheinlichkeiten von mehreren Blöcken berücksichtigt („Mit Glättung“) wird diese Entscheidung verlässlicher. Es ist auch zu erkennen, dass die Klassifikationsrate des Systems stark von dem Lied abhängig ist, auf welches getestet wird. So wird der Gesang in den Liedern in den Abbildungen 5.5(a) bis 5.5(d) recht gut erkannt, wohingegen in Abb. 5.5(e) deutlich wird, dass hier die Klassifikationsrate kaum oberhalb der Ratewahrscheinlichkeit von 50 % liegt. Für diese Abbildungen wurden die optimalen Parameter benutzt, die in Abschnitt 5.3 optimiert werden. Die Raten für alle Lieder sind der Tabelle A.1 zu entnehmen. 47 5 Evaluation (a) Jewel - Standing Still (89.59 %) (b) Hoodys - Judgement Day (86.6 %) (c) Stratovarius - Falling Star (85.02 %) (d) Kings of Leon - Beach Side (70.1 %) (e) Haydn - Il pensier sta negli ogetti (51.41 %) Abbildung 5.5: Die Zeitpunkte, zu denen mittels Gl. 5.1 Gesang detektiert wird, sind blau, und die, zu denen nach Gl. 5.2 Gesang detektiert wird, schwarz markiert. In rot sind die Zeitpunkte nach der Annotation dargestellt. In Klammern ist jeweils die Klassifikationsrate (Richtig erkannte Blöcke durch Gesamtanzahl Blöcke) für das jeweilige Lied bei Verwendung der Entscheidung „Mit Glättung“ angegeben. 5 Evaluation 48 5.3 Evaluation der Merkmale 5.3.1 Anzahl der Gaußverteilungen Die Anzahl der für die Klassifikation benutzten Gaußverteilungen kann einen großen Einfluss auf die Klassifikationsrate haben. Bei zu wenigen Verteilungen kann evtl. die „wahre“ Form der Verteilung nicht detailliert genug wiedergegeben werden, und es gehen wichtige Informationen verloren. Andererseits kann es bei zu vielen benutzten Gaußverteilungen zu einer zu genauen Anpassung der Verteilung an die Trainingsdaten kommen, zu einer sogenannten Überanpassung. Da noch nicht geklärt ist, wie viele Merkmale letztendlich benutzt werden, wird im Folgenden die Klassifikationsrate für verschiedene Kombinationen aus Anzahl der Gaußverteilungen und Anzahl der benutzten Merkmale berechnet, um die optimale Anzahl der Gaußverteilungen festzustellen. Dafür wurden 1 bis 50 Gaußverteilungen und die 7 bis 39 nach Fisher (siehe Abschnitt 2.4.1) wichtigsten Merkmale kombiniert. Es wurde hier die Merkmalsselektion nach Fisher gewählt, um den Rechenaufwand nicht zu groß werden zu lassen. Die erhaltenen Ergebnisse sind in Abb. 5.6 dargestellt. Es ist zu erkennen, Abbildung 5.6: Klassifikationsraten für verschiedene Kombinationen der Anzahl der Gaußverteilungen und der Anzahl der benutzten Merkmale (ausgewählt nach Fisher). dass die Rate mit zunehmender Anzahl von Gaußverteilungen etwas ansteigt, um ab einer Anzahl von 40 wieder recht stark abzufallen. Bei der Anzahl der benutzten Merkmale ist ebenfalls zu beobachten, dass die Rate zu sehr kleinen und sehr großen Werten abfällt. Die besten Ergebnisse werden mit 40 Gaußverteilungen und 5 Evaluation 49 10 benutzten Merkmalen erzielt. Im nächsten Abschnitt wird für 40 Gaußverteilungen erneut eine Merkmalsselektion durchgeführt, nämlich die „Greedy Merkmalsselektion“, von der sich eine Verbesserung erhofft werden kann, die allerdings auch rechenaufwändiger ist. 5.3.2 Einfluss der Track-Merkmale Um die in der Einleitung gestellte Frage zu untersuchen, inwiefern Merkmale, die die zeitlichen Frequenzänderungen von Teilharmonischen beschreiben, die Gesangsdetektion verbessern können, sollen nun die Merkmalsgruppen KLASS (nur die 33 „klassischen“ Merkmale: 15 MFCC’s, 15 LMSC (Mel-Koeffizienten ohne DCT), Spectral Centroid, Spectral Rolloff und Spectral Flux) und KLASS+TRACK (zusätzlich die 6 Track-Merkmale) verglichen werden. Um für beide Merkmalsgruppen möglichst gewährleisten zu können, dass die beste Merkmalskombination benutzt wird, wird für beide Gruppen getrennt die „Greedy“ Merkmalsselektion aus Abschnitt 2.4.1 angewendet. Um dabei zufällige Schwankungen anhand der Auswahl von Trainings- und Testmaterial auszuschließen, werden für jeden Durchgang 47 Iterationen durchgeführt. Es wird also auf jedes Musikstück einmal getestet. Somit wird für jede Merkmalskombination auf die exakt gleichen Trainings- und Testdaten getestet. Die erhaltenen Klassifikationsraten spiegeln also eindeutig die für diese Database besten Kombinationen wider. In Abb. 5.7 sind die Klassifikationsraten über der Anzahl der benutzten Merkmale für beide Gruppen aufgetragen. Es ist gut zu erkennen, dass die Klassifikationsraten für beide Gruppen sowohl zu sehr wenig benutzten, als auch zu sehr vielen benutzten Merkmalen stark abfällt. Durch die Track-Merkmale fällt die Klassifikationsrate insgesamt um einige Prozent besser aus. Werden die maximal erzielten Raten der beiden Merkmalsgruppen verglichen, kommt es zu einer Verbesserung von 4.78 %. Im Anhang sind in Tab. A.2 die Zahlenwerte aus Abb. 5.7 dargestellt. Außerdem ist die Reihenfolge, in der die Merkmale selektiert wurden, ersichtlich. Vier der sechs Track-Merkmale sind dabei unter den besten fünf Merkmalen. Im Merkmalssatz, der zu der besten Klassifikationsrate von 77.45 % führt, ist nur eines der Track-Merkmale nicht vorhanden. Die wichtigsten Track-Merkmale sind dabei N RT (Anzahl der gruppierten Tracks) und M F und AM F (die Modulationsfrequenz und Amplitude des Maximums im Modulationsspektrum der Tracks). Diese Merkmale tragen also entscheidende Informationen in sich. Die Ergebnisse der besten Kondition sollen nun genauer betrachtet werden. In Abb. 5.8 ist die Verwechslungsmatrix zu sehen. Es werden also nur gut zwei Drittel (68.93 %) aller instrumentalen Blöcke richtig der instrumentalen Klasse (InstrumentalRichtig, IR), und 31.07 % der vokalen (Vokal-Falsch, VF ) zugeordnet. Allerdings 5 Evaluation 50 Abbildung 5.7: Klassifikationsraten für die beiden Merkmalsgruppen über der Anzahl der benutzten Merkmale. Abbildung 5.8: Verwechslungsmatrix für die optimale Kondition (Merkmalsgruppe KLASS+TRACK, 40 Gaußverteilungen, 13 benutzte Merkmale). 5 Evaluation 51 werden dafür 82.28 % aller Blöcke, die Gesang beinhalten, der richtigen Klasse zugeordnet (Vokal-Richtig, VR). Damit ergibt sich auch, dass 17.72 % dieser Blöcke fälschlicherweise als Instrumental klassifiziert werden (Instrumental-Falsch, IF ). Je nach Anwendung kann entweder die IR- oder die VR-Rate besonders wichtig sein. So wäre es für eine Sängeridentifikation wichtig, möglichst keine VF -Entscheidungen zu haben, da sonst das Modell auch auf Blöcke trainiert wird, in denen keine Stimme präsent ist. Wird für eine andere Anwendung eine hohe VR-Rate benötigt, kann dies über ein Verändern der a priori-Wahrscheinlichkeiten der GMM erreicht werden. Es sollen nun noch die fünf Musikstücke in Tabelle A.1 betrachtet werden, bei denen weniger als 60 % Klassifikationsrate erreicht wurde. Zwei der Stücke sind aus dem Genre Klassik. Hier könnte der Grund in dem von den anderen Genres sehr unterschiedlichen Gesangsstil liegen. Da aus diesem Genre auch nur 3 Stücke in der Database vorhanden sind, liegt somit nur wenig Trainingsmaterial vor. Bei den ebenfalls schlecht abschneidenden Stücken „Black Sabbath - Hole in the Sky“ und „Charles Brown - Is You is or is You Ain’t“ könnte der Grund ebenfalls in Gesangsstimmen mit besonderen Eigenheiten liegen: die Stimme von Black Sabbath’s Sänger Osbourne ist sehr „kratzig“. Eventuell wird sie deswegen nur schlecht vom System erkannt. Für Charles Browns sehr tiefe Bassstimme gibt es in der Database kein ähnliche Stimme, die in das Training des GMM einfließen könnte. Außerdem ist in diesem Stück ein Saxophon enthalten, welches mit fließenden Frequenzübergängen gespielt wird. Dies könnte ebenfalls zu Verwechslungen führen. Bei dem Stück „Queen - Another Bytes the Dust“ ist eine Erklärung hingegen schwieriger, da die Gesangsstimme relativ normal ist, und auch die instrumentale Begleitung keine Besonderheiten aufweist. 6 Fazit und Ausblick 52 6 Fazit und Ausblick Es sollte untersucht werden, ob die Hinzunahme von Merkmalen, die die zeitliche Entwicklung der Frequenz von Teiltönen betrachten, eine Verbesserung einer Gesangsdetektion bewirken können. Um die Methode und einige allgemeine Merkmale zu verifizieren, wurde eine Genre-Klassifikation durchgeführt. Einige dieser Merkmale wurden anschließend benutzt, um eine Gesangsdetektion zu entwickeln. So wurden maximal 72.67 % korrekt klassifizierte Blöcke erreicht. Durch Hinzunahme der eingeführten Track-Merkmale konnte diese Rate um fast 5 % auf 77.45 % verbessert werden. Es kann also gefolgert werden, dass diese Track-Merkmale Informationen enthalten, die einen Beitrag zur Gesangsdetektion liefern und nicht in den „klassischen“ Merkmalen enthalten sind. Dies ist prinzipiell auch so erwartet worden, da die meisten dieser „klassischen“ Merkmale nur Informationen eines kurzen Zeitpunktes erfassen, bzw. höchstens statistische Maße von mehreren, aufeinanderfolgende Werte berechnen. Durch die Track-Merkmale wird hingegen gezielt auf die Art guckt, wie sich die Frequenz über die Zeit ändert. In dieser Arbeit wurde viel Wert auf das Tracking gelegt, welches in vielen Fällen auch ausreichend gut funktioniert. Bei spektral sehr dichter Musik, bzw. wenn das Verhältnis der Leistungen von Gesang zu den begleitenden Instrumenten sehr schlecht ist, kommt es allerdings zu erheblichen Problemen. Hier könnten andere Verfahren sicherlich noch Verbesserungen bewirken. So könnten beispielweise Algorithmen aus der Bildbearbeitung zur Objekt- bzw. Kantenerkennung getestet werden um die zeitliche Entwicklung der Teiltöne im Spektrogram zu erfassen. Da die beiden Modulationsfrequenz-Merkmale zu den besten Merkmalen gehören, könnten weitere Merkmale basierend auf dem Modulationsspektrum getestet werden. Außerdem könnte neben der Entwicklung der Frequenz auch die Entwicklung der Amplitude der Tracks in Merkmalen erfasst und für die Klassifikation benutzt werden. Wird die letztendliche Klassifikation betrachtet, so ließen sich auch dort alternative Verfahren testen. Zum einen könnten andere Arten erprobt werden, um die Entscheidung zu glätten (Filter, Hidden Markov Models, . . . ), zum anderen könnte auch statt der GMM ein anderer Klassifikator bessere Ergebnisse liefern. Um das in Abschnitt 5.3.2 besprochene Problem der unterschiedlichen Gesangsstile zu verringern, würden wahrscheinlich zwei Ansätze weiterhelfen: zum einen werden 6 Fazit und Ausblick 53 für die Berechnung des GMM mehr Trainingsdaten benötigt damit möglichst alle Gesangsstile verteten sind. Zum anderen könnte vor der Gesangsdetektion eine Genre-Klassifikation durchgeführt werden. Somit gäbe es für jedes Genre ein eigenes Modell, mit dem dann die Gesangsdetektion betrieben werden könnte. Mit den hier besprochenen Erweiterungen/Veränderungen könnte es möglich sein, die Gesangsdetektion noch weiter zu verbessern. Die in dieser Arbeit zu untersuchende Fragestellung wurde jedoch in der Art beantwortet, dass Merkmale, die auf den Frequenzmodulationen tonaler Komponenten basieren, die Gesangsdetektion erheblich verbessern können. Literaturverzeichnis 54 Literaturverzeichnis [BE01] Adam L. Berenzweig and Daniel P.W. Ellis. Locating singing voice segments within music signals. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2001. [DCM00] Myriam Desainte-Catherine and Sylvain Marchand. High precision fourier analysis of sounds using signal derivatives. Journal of the Audio Engineering Society, 2000. [FZ07] Hugo Fastl and Eberhard Zwicker. Psychoacoustics - Facts and Models, chapter 6: Critical Bands and Excitation. Vieweg+Teubner, 2007. [Kim03] Youngmoo Edmund Kim. Singing voice analysis/synthesis. PhD thesis, MIT, 2003. [KM02] Florian Keiler and Sylvain Marchand. Survey on extraction of sinusoids in stationary sounds. Digital Audio Effects Conference, 2002. [KW02] Youngmoo Edmund Kim and Brian Whitman. Singer identification in popular music recordings using voice coding features. unpublished, 2002. [LGD07] Hanna Lukashevich, Matthias Gruhne, and Christian Dittmar. Effective singing voice detection in popular music using arma filtering. Proc. of the 10th Int. Conference on Digital Audio Effects, 2007. [LMR05] Mathieu Lagrange, Sylvain Marchand, and Jean-Bernard Rault. Enhancing the tracking of partials for the sinusoidal modeling of polyphonic sounds. IEEE Transactions on Audio, Speech and Language Processing, 2005. [LW07] Ypeng Li and DeLiang Wang. Separation of singing voice from music accompaniment for monaural recordings. IEEE Transactions on Audio, Speech and Language Processing, 2007. [NL07] Tin Lay Nwe and Haizhou Li. Singing voice detection using perceptually-motivated features. unpublished, 2007. [RP09] L. Regnier and G. Peeters. Singing voice detection in music tracks using direct voice vibrato detection. unpublished, 2009. [RR09] Vishweshwara Rao and S. Ramakrishnan. Singing voice detection in polyphonic music using predominant pitch. Proc. of Interspeech, 2009. [Sun77] Johan Sundberg. The acoustics of the singing voice. Scientific American, 1977. [TC02] George Tzanetakis and Perry Cook. Musical genre classification of audio signals. IEEE Transactions on Speech and Audio Processing, 2002. Literaturverzeichnis [TK99] 55 Sergios Theodoridis and Konstantinos Koutroumbas. Pattern Recognition. Academic Press, 1999. [vdPMR06] Steven van de Par, Martin McKinney, and André Redert. Musical key extraction from audio using profile training. unpublished, 2006. [Wal09] Rob Walker. The song decoders. http://www.nytimes.com/2009/10/ 18/magazine/18Pandora-t.html, 2009. Stand vom 10.11.2011. i A Anhang A Anhang A.1 Tabellen Tabelle A.1: Musikstücke, welche für die Evaluation der GD verwendet wurden mit Dauer, Geschlecht des Interpreten, dem Genre und der erzielten Klassifikationsrate mit 40 Gaußkomponenten und dem Merkmalssatz KLASS+TRACK Künstler Caught in the Act Hoodys Phantom Planet Rapalje Rosie Gaines Van Halen Michael Jackson Véronique Sanson Stratovarius Dream Theater Deep Purple Staind The Dandy Warhols Mando Diao Titel Do It For Love Judgement Day California Yo Skippely Closer Than Close Jump She’s Out Of My life Sans Regrets Falling Star I Walk Beside You Walk On Fade Bohemian Like You Down In The Past You Know What I Mean Charles Brown Is You Is or Is You Ain’t Charlie Haden Quar- Everything Happens tet West To Me Mississippi John Make Me A Pallet Hurt On The Floor Kings Of Leon Beach Side Foo Fighters These Days Afterlife Sunrise Beagle Music Ltd. Like Ice In The Sunshine The Beatles Penny Lane Blondie Call Me Coldplay A Rush Of Blood To The Head Fortsetzung auf der nächsten Seite m:ss 3:39 3:51 3:16 1:02 3:45 4:03 3:40 5:21 4:33 4:27 7:03 4:01 3:33 3:56 2:38 |~ | |+~ | | ~ | | ~ | | | | | | ~ Genre Pop HipHop Rock Folk Pop Metal Pop Pop Metal Metal Rock Rock Rock Rock Musical % 83.5 86.6 85.8 88.66 71.6 61.24 89.22 81.67 85.02 80.95 71.75 85.2 79.59 86.95 88.03 5:34 | Blues 53.03 6:27 | Jazz 75.91 3:50 | Blues 75.84 2:51 4:58 6:26 3:01 | | ~ |+~ Rock Rock Jazz Pop 70.1 80.62 69.51 83.76 3:03 3:32 5:06 | ~ | Pop Rock Pop 76.29 70.69 74.01 ii A Anhang Fortsetzung der vorherigen Seite Künstler Titel Elvis Presley Devil In Disguise Mike Oldfield To France Nelly Furtado Powerless Backstreet Boys As Long As You Love Me Counting Crows Round Here Jewel Standing Still Kt Tunstall Suddenly I See Melanie C First Day Of My Life Natalia Imbruglia Torn Patrice Murderer The Pogues & The The Irish Rover Dubliners Queen Another Bytes The Dust REM Losing My Religion Tennessee Ernie Sixteen Tons Ford Texas Lightning No No Never Robert Schumann Mondnacht Joseph Haydn Il pensier sta negli ogetti Francesco Araia Cadro ma qual si mira Iron Maiden Different World Black Sabbath Hole in the Sky The Doors You’re Lost Little Girl Harry Connick Only ’cause I Don’t Have You Dauer 2:20 4:36 3:58 3:40 |~ | ~ ~ | Genre Rock Pop Pop Pop % 80.34 67.14 82.54 84.05 5:16 4:30 3:19 4:04 4:07 3:11 4:06 | ~ ~ ~ ~ | | Rock Pop Pop Pop Pop Pop Folk 89.16 89.59 93.14 75.78 82.09 97.44 77 3:33 | Rock 55.73 4:28 2:39 | | Rock Blues 81.07 74.93 3:01 4:28 3:08 ~ ~ | Pop Klassik Klassik 92.24 74.05 51.41 4:28 ~ Klassik 46.42 4:18 4:00 3:04 | | | Metal Metal Rock 81.05 43.74 67.22 3:04 | Jazz 77.82 iii A Anhang Tabelle A.2: Gesamtergebnisse der Merkmalsselektion 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 Ohne Track-Merkmale Merkmal Rate [%] LMSC6 62.5056 MFCC5 65.0838 SC 67.3616 MFCC8 69.8212 LMSC9 70.6967 LMSC13 70.8302 MFCC4 71.2049 MFCC10 71.6278 MFCC7 72.2214 LMSC10 72.6666 LMSC8 71.6649 MFCC14 72.4551 MFCC2 72.559 MFCC11 71.6353 MFCC12 70.9267 MFCC15 72.1064 MFCC9 71.5536 MFCC6 71.9209 LMSC1 71.7985 LMSC5 71.0491 LMSC7 71.6798 LMSC12 71.754 LMSC14 71.4609 LMSC11 70.2144 LMSC15 70.0475 MFCC1 69.5801 LMSC3 68.571 LMSC2 68.6267 MFCC3 69.1238 LMSC4 67.2429 MFCC13 65.325 SFL 64.5422 SRO 62.7949 Mit Track-Merkmale Merkmal Rate [%] NRT 68.5042 LMSC15 72.3327 AMF 72.789 MF 73.0895 DEV 73.39 MFCC8 73.4271 MFCC5 75.0519 LMSC2 76.5989 MFCC2 76.5024 MFCC12 76.2539 STD 76.2131 MFCC10 76.7584 LMSC7 76.8734 MFCC11 77.4484 LMSC11 76.5952 LMSC14 76.6991 LMSC6 76.38 LMSC10 76.5507 FB 75.9126 LMSC1 75.9608 LMSC13 74.9666 LMSC8 76.5321 LMSC9 76.0091 LMSC12 75.7197 MFCC14 75.1706 MFCC3 74.5734 MFCC9 74.8145 MFCC13 74.8108 SC 74.0651 LMSC4 73.8871 MFFC7 73.2675 LMSC5 72.3587 MFCC6 72.0767 LMSC3 72.3661 MFCC1 71.4461 MFCC4 71.8764 MFCC15 70.3665 SFL 65.3101 SRO 64.6275 A Anhang v A.2 Erklärung Hiermit versichere ich, dass ich diese Arbeit selbstständig verfasst und keine anderen als die angegebenen Quellen und Hilfsmittel benutzt habe. Außerdem versichere ich, dass ich die allgemeinen Prinzipien wissenschaftlicher Arbeit und Veröffentlichung, wie sie in den Leitlinien guter wissenschaftlicher Praxis der Carl von Ossietzky Universität Oldenburg festgelegt sind, befolgt habe. Oldenburg, den 23. November 2011 Gunnar Geißler