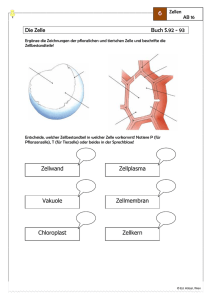
Tabellenkalkulationsprogramme in der Pädagogik
Werbung

. . Tabellenkalkulationsprogramme in der Pädagogik . . Hiermit erkläre ich an Eides statt, die vorliegende Forschungsarbeit selbstständig und ohne unzulässige Hilfe angefertigt zu haben. Die verwendeten Literaturquellen sind im Literaturverzeichnis vollständig aufgeführt. Frank Rollinger Frank Rollinger Candidat-professeur au Lycée Technique Mathias Adam Tabellenkalkulationsprogramme in der Pädagogik Lamadelaine 2015 Zusammenfassung Der theoretische Teil beinhaltet die Entstehungsgeschichte und die Entwicklung von den ersten einfachen Tabellenprogrammen hin zu der heute aktuellen Software. Die wichtigsten Entwicklungsschritte dieser Programme werden herauskristallisiert und in chronologischer Reihenfolge mit dem geschichtlichen Hintergrund beleuchtet. Anschließend wird die Wichtigkeit analysiert, die dem Einsatz solcher Programme an den Universitäten, sowie an den Klassen der Oberstufe des „Enseignement secondaire“ heutzutage zukommt. Dies erfolgt mittels Umfragebögen, durch die man ein möglichst objektives Bild über den Einsatz von Tabellenkalkulationsprogrammen in der Ausbildung und im Berufsleben sowie im privaten Einsatz liefert. Der praktische Teil kombiniert Konzepte aus der deskriptiven Statistik mit dem Einsatz von Tabellenkalkulationsprogrammen. Also Kenntnisse, die in der Ausbildung und in der beruflichen Karriere heutzutage immer öfter vorausgesetzt und eingesetzt werden. Durch die Benutzung von Tabellenkalkulationsprogrammen kann man die Zusammenhänge der Kennziffern besser veranschaulichen und interpretieren. Am Ende des Kurses sollen die Auszubildenden selbstständig in der Lage sein, ein Tabellenkalkulationsprogramm für ihre individuellen Zwecke effizient einzusetzen. Inhaltsverzeichnis I Theoretischer Teil 3 1 Geschichtlicher Hintergrund 5 2 Bedarf an Tabellenkalkulationssoftware 2.1 Vorbereitungen . . . . . . . . . . . . . . 2.2 Der Umfragebogen . . . . . . . . . . . . 2.3 Auswertung des Fragebogens . . . . . . 2.4 Excel und die Statistik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 . 9 10 11 16 II Praktischer Teil 19 3 Einführung in Microsoft Excel 3.1 Grundlagen . . . . . . . . . . . . . . . . . 3.2 Die ersten Schritte . . . . . . . . . . . . . 3.2.1 Die Arbeitsoberfläche . . . . . . . . 3.2.2 Zellinhalte formatieren . . . . . . . . 3.2.3 Formeln, Shortcuts und Funktionen . 23 23 23 23 26 30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 Häufigkeiten und Diagramme 37 4.1 Einführungsbeispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 4.2 Histogramme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 5 Zentralwerte 5.1 Der Modus . . . . . . . . 5.2 Der Median . . . . . . . . 5.3 Das arithmetische Mittel . 5.4 Wann nimmt man welchen . . . . . . . . . . . . . . . . . . . . . . . . Zentralwert? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 49 51 58 61 ii Inhaltsverzeichnis 6 Streuungsmaße 65 6.1 Die Spannweite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65 6.2 Die Standardabweichung . . . . . . . . . . . . . . . . . . . . . . . . . 66 7 Korrelation 71 7.1 Der Korrelationskoeffizient . . . . . . . . . . . . . . . . . . . . . . . . 71 7.2 Grafische Darstellung . . . . . . . . . . . . . . . . . . . . . . . . . . 77 7.3 Die Regressionsgerade . . . . . . . . . . . . . . . . . . . . . . . . . . 82 Literaturverzeichnis 101 A 103 104 106 106 108 110 114 Anhang A.1 Ein Histogramm mit Geogebra erstellen A.2 Weitere Mittelwerte . . . . . . . . . . . A.2.1Das harmonische Mittel . . . . . . A.2.2Das geometrische Mittel . . . . . . A.3 Wörterbuch . . . . . . . . . . . . . . . . A.4 Aufgabenstellungen . . . . . . . . . . . . . . . . . . . . . . . . Travail de candidature . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Eigentlich weiß man nur, wenn man wenig weiß. Mit dem Wissen wächst der Zweifel. Johann Wolfgang von Goethe Teil I. Theoretischer Teil 1. Geschichtlicher Hintergrund In früheren Zeiten ohne Computer mussten alle Berechnungen von Hand oder im Kopf ausgeführt werden. Bei kleinen Rechnungen und weniger Operationsfolgen sollte dies für die meisten Menschen kein Problem darstellen. Werden es aber mehr Operationen oder hängt das Endergebnis von vielen anderen Ergebnissen ab, impliziert das Abändern einer einzelnen Variable oder Zahl, dass alle nachfolgenden Rechnungen ebenfalls neu ausgeführt werden müssen. Die Buchhaltung ist ein klassisches Beispiel dafür. Die kleinsten Parameteränderungen, ja sogar einige wenige „Wenn-dann“ Szenarien benötigen gegebenenfalls mehrere Arbeitsstunden. Mit der Verbreitung der ersten Computer kam Dan Bricklin während einer Vorlesung, in der der Professor alle Berechnungen umständlich mit einem Schwamm und Kreide neu anpassen musste, auf die Idee, diese Berechnungen mit dem Computer zu automatisieren. Dies sollte so geschehen, dass man nicht alle Rechnungen einzeln neu berechnen musste, sondern alle Werte automatisch neu ausgeführt werden, wenn sich eine davon abhängige Zahl ändert. Mit der Umsetzung dieser Idee wurde 1979 von Dan Bricklin die erste Tabellenkalkulationssoftware entwickelt. Er schrieb die Anwendung für einen Apple-Computer und nannte sie VisiCalc.1 Der größte Vorteil von Bricklins VisiCalc bestand demzufolge darin, dass es in Sekundenbruchteilen eine Vielzahl von Berechnungen automatisch ausführen konnte. Für die Verbreitung war es jedoch viel wichtiger, dass VisiCalc ohne Programmierkenntnisse bedient werden konnte und die Benutzung damit nicht nur Computerexperten und „Nerds“ vorenthalten war. VisiCalc mauserte sich dadurch zu einer sogenannten „Killerapp2 “: eine Killerapp bezeichnet ein Computerprogramm, das den Kauf eines ganzen Computers rechtfertigt. In diesem Fall durch die extrem schnelle Berechnung verschiedener Szenarien, gepaart mit der einfachen Bedienung, die unzählige Arbeitsstunden von Angestellten und damit sehr hohe Arbeitszeiten und -kosten, einsparte. Der Kaufpreis eines damals sehr teuren Computers war allein mit VisiCalc also schnell amortisiert.3 VisiCalc war zudem die erste kommerziell benutzte Software in dem Bereich der Tabellenkalkulationssoftware. Bricklin selbst brachte dies allerdings keinerlei finanziel1 Siehe [16]. Der Begriff „Killerapp“ wurde von VisiCalc mitbegründet. Siehe [8]. 3 Siehe [8]. 2 6 1. Geschichtlicher Hintergrund le Bereicherung, denn er versäumte es wegen der damaligen Situation, aber auch wegen schlechter Beratung, sein Programm 1979 patentieren zu lassen. Hier ein Auszug aus Bricklins Stellungnahme, wieso er VisiCalc nicht schützen ließ: „[...] in 1979, when VisiCalc was shown to the public for the first time, patents for software inventions were infrequently granted. Programs were thought to be mere mathematical algorithms, and mathematical algorithms, as laws of nature, were not patentable. [...] The patent attorney explained to us the difficulty of obtaining a patent on software, and estimated a 10% chance of success, even using various techniques for hiding the fact that it was really software (such as proposing it as a machine). [...] If I invented the spreadsheet today, of course I would file for a patent. That’s the law of the land...today. The companies I have been involved with since Software Arts have filed for patents on many of their inventions. In 1979, almost nobody tried to patent software inventions.“4 Detailliertere geschichtliche Hintergründe sowie Texte und Bilder sind auf Bricklins persönlicher Homepage veröffentlicht und erlauben es anhand von Originaldokumenten, nachträglich veröffentlichten Stellungnahmen und älteren Videos aus jener Zeit, weiter in die Geschichte von VisiCalc und der damaligen Epoche einzutauchen.5 Ohne Patentierung erschienen sehr schnell Konkurrenzprogramme zu Bricklins VisiCalc, die dem Original mit der Zeit den Rang abliefen. Die Firma Lotus Software veröffentlichte 1983 das erste Tabellenkalkulationsprogramm namens Lotus 1-2-3 mit einer grafischen Oberfläche.6 Die Software war bis Ende der Achtziger einer der Marktführer und begründete nebenbei die Erfolgsgeschichte des IBM-PC, da die Software auf diesen PC zugeschnitten war. Nachdem Lotus 1-2-3 aus verschiedenen Gründen an Bedeutung verlor, kam es nie wieder an seine anfängliche Popularität heran und die Anwendung wurde schließlich von IBM selbst aufgekauft. Seit 2013 wird das Programm nicht mehr verkauft und ab dem 30. September 2014 wurde jegliche Unterstützung der Anwendung eingestellt.7 Neben Lotus 1-2-3 ist das Programm Boeing Calc des gleichnamigen Flugzeugherstellers zu erwähnen. Anfangs wurde Boeing Calc für firmeneigene Bedürfnisse entwickelt, später jedoch auch als Software für PCs verkauft. Bekannt wurde es unter anderem wegen den dreidimensionalen Tabellen8 , so wie man sie in den heuti4 Das komplette Zitat, sowie weiterführende Dokumente findet man in [2]. Siehe [3]. 6 Siehe [14]. 7 Siehe [13]. 8 Siehe [12]. 5 Travail de candidature 7 gen Kalkulationsprogrammen kennt: die ersten zwei Dimensionen wurden wie bisher üblich durch Zeilen und Spalten dargestellt, die dritte Dimension erhielt man durch das Hinzufügen von weiteren Tabellenblättern. 1993 wurde das Programm Lotus Improv veröffentlicht.9 Wie der Name vermuten lässt stammte es von demselben Entwickler wie Lotus 1-2-3. Das neue Produkt war aber keineswegs eine simple Weiterentwicklung von Lotus 1-2-3, sondern ein direktes Konkurrenzprodukt. Der Unterschied zum bereits existierenden Produkt bestand darin, dass die Daten nicht wie bisher direkt in die Zellen geschrieben wurden, sondern den Zellen wurden Namen zugeordnet, wie etwa „Verkaufte Einheiten“ und „Preis“. Anschließend wurde der Gewinn mit der Formel „Gewinn = Verkaufte Einheiten * Preis“ berechnet. Danach rechnete man mit dem „Gewinn“ weiter, ohne die genannte Formel nochmal eingeben zu müssen. Mit dieser Vorgehensweise lassen sich die Daten sehr einfach kategorisieren und gruppieren. Heutzutage wird eine ähnliche Vorgehensweise in modernen Datenbankprogrammen angewendet. Trotz des zu diesem Zeitpunkt großen technologischen Vorsprungs blieb Lotus Improv der Erfolg verwehrt. Ob es daran lag, dass die Technologie zu früh kam, lässt sich nicht eindeutig belegen. Es könnte auch daran gelegen haben, dass die bereits vorhandenen Produkte so weit verbreitet waren, dass sich die Benutzer schwertaten, sich in ein neues System einzuarbeiten. Microsoft integrierte Jahre später unter der Bezeichnung „Pivot-Tabelle“ eine ähnliche Vorgehensweise wie die, die Lotus Improv bereits 1993 besaß, in sein eigenes Produkt namens Excel. Die erfolgreiche Idee von VisiCalc und später Lotus 1-2-3 wurde ebenfalls von Microsoft übernommen. Zunächst wurde die Tabellenkalkulationssoftware namens Multiplan im Jahre 1982 veröffentlicht, die 1985 von Excel abgelöst wurde. Die beiden wichtigsten Neuerungen in Excel waren zum einen die grafische Oberfläche, die Lotus 1-2-3 bereits zwei Jahre früher einführte, und zum anderen die erstmalige Unterstützung der Maus als Eingabegerät. In seinen Anfangsjahren war Excel nur für Apple Macintosh verfügbar und im Jahr 1988 kam eine erste Version für Windows auf den Markt. Bis heute gibt es Excel immer noch für Apples Betriebssystem zu kaufen. Seit 1983 hatten sich die sogenannten „integrierten Office-Pakete“ von verschiedenen Software-Entwicklern durchgesetzt. Sie beinhalteten mehrere Büroprogramme gleichzeitig, wie zum Beispiel eine Anwendung für Tabellenkalkulationen und eine für Textverarbeitungen. Microsoft ließ seine Pendants Excel und Word allerdings noch getrennt, ehe es 1989 die erste Office-Version zusammen mit Powerpoint ausschließlich für den Macintosh von Apple veröffentlichte. Drei Jahre später, zu9 Siehe [17]. Travail de candidature 8 1. Geschichtlicher Hintergrund sammen mit Windows 3.1, erschien die erste Office-Ausgabe für Windows.10 Seitdem ist Excel fester Bestandteil der bis heute vertriebenen Office-Produktreihe von Microsoft. 10 Siehe [14]. Travail de candidature 2. Bedarf an Tabellenkalkulationssoftware 2.1. Vorbereitungen Seit der Einführung von Tabellenkalkulationssoftware im Jahre 1979 hat sich der Funktionsumfang dieser Anwendungen stetig erweitert. Nach etwa 30 Jahren Entwicklung beherrschen sie umfangreiche Berechnungsalgorithmen, mit denen selbst komplexe Probleme in Sekundenbruchteilen gelöst werden können. Ferner besitzt nahezu jeder moderne Haushalt einen Computer, auf dem ein Tabellenkalkulationsprogramm bereits vorhanden ist oder zumindest einfach nachinstalliert werden kann. Aufgrund dieser Voraussetzungen ist es durchaus verständlich, dass die Anforderungsprofile an Studenten und Arbeitnehmer grundlegende bis fortgeschrittene Kenntnisse im Umgang mit Tabellenkalkulationsprogrammen voraussetzen. Ebenso besteht die Möglichkeit, solche Programme im Privatbereich einzusetzen. Beispielsweise um ein effizientes Haushaltsbuch zu führen, das einen geordneten Überblick der eigenen Einnahmen und Ausgaben zu verschaffen hilft. Diese Veränderungen der Anforderungen im Studenten- und Berufsleben, sowie erweiterte Möglichkeiten im Privaten, bedürfen einer Anpassung in der Ausbildung. Wie stark jener Bedarf eines entsprechenden Kurses ist soll anhand eines Umfragebogens ergründet werden. Das primäre Ziel dieses Umfragebogens liegt also darin herauszufinden, wie hoch die Nachfrage nach einem interdisziplinären Kurs eines Tabellenkalkulationsprogrammes in Kombination mit der Statistik ist. Kernpunkt der Umfrage ist demnach die Nutzung und der Bedarf eines Tabellenkalkulationsprogrammes, sei es privat oder beruflich. Dieser Punkt gilt gleichermaßen für Schüler und Studenten wie für Erwerbstätige und Privatleute, denn es macht keinen wesentlichen Unterschied, ob man seine erworbenen Kenntnisse anwendet, um private Daten zu verarbeitet, oder ob diese Kenntnisse im Berufsleben notwendig sind: eine Ausbildung ist in jedem Fall von Nöten. 10 2. Bedarf an Tabellenkalkulationssoftware 2.2. Der Umfragebogen Aus [4] geht hervor, dass man bis zu acht verschiedene Aussagen oder Fragen formulieren sollte, um ein möglichst genaues Ergebnis anhand eines Fragebogens zu erhalten. Diese Formulierungen sollten auch umgeändert oder verneint werden, damit der Befragte möglichst nicht in eine Richtung manipuliert wird. Anschließend soll man das arithmetische Mittel aller Aussagen bilden, um das Ergebnis eines erforschten Bereichs zu erhalten. Die Sprache soll klar strukturiert und einfach zu verstehen sein. Die Fragen und Aussagen sollten also so kurz wie möglich sein, damit jeder Zugang hat und sofort weiß, was gemeint ist. Allgemeine Wörter wie „nie“, „nichts“, „alle“, „immer“, u.s.w., sollten aufgrund der Klarheit der Aussage vermieden werden. Darüber hinaus sollten ebenfalls Wörter mit emotioneller Bedeutung, wie „Freiheit“, „Frieden“, oder ähnliches, vermieden werden, da sie den Befragten beeinflussen könnten. Um die wichtigsten Punkte in Erfahrung zu bringen, werden die Befragten zunächst gebeten anzugeben, welche Kenntnisse sie bereits mit einem Tabellenkalkulationsprogramm besitzen und ob sie sich dieses Wissen selbst angeeignet haben. Sei es durch eine Einheit in der Schule oder einen nach der Schule freiwillig besuchten Kurs. Zeitgleich wird unterschieden, ob man Schüler/Student ist oder nicht, um einerseits die Lebenserfahrung einschätzen zu können und andererseits einen Indikator dafür zu erhalten, wie stark Tabellenkalkulationsprogramme im Berufsleben verbreitet sind beziehungsweise ob sie in der Ausbildung benutzt werden. Beachtet man diese Punkte beinhaltet der Fragebogen die folgenden zu beantwortenden Punkte. Dabei wird unterschieden, ob eine Person bereits Kenntnisse im Umgang mit Tabellenkalkulationsprogrammen besitzt oder nicht. Leute, die bereits Kenntnisse mit Excel1 oder ähnlicher Software besitzen, erhalten den Fragebogen mit folgenden Formulierungen: 1. Ich arbeite regelmäßig mit Excel. 2. Ohne Excel würde ich auch gut zurecht kommen. 3. Ich nutze Excel beruflich (bzw. in der Schule/an der Uni). 4. Ich benutze Excel außerhalb der Arbeit, z.B. privat, um ein Haushaltsbuch zu führen. 5. Es ist im Interesse der Schüler einen Excel-Kurs in der Schule anzubieten. 1 Excel wird stellvertretend für alle Tabellenkalkulationsprogramme benutzt, da sehr viele Leute die Anwendung wegen seiner Popularität namentlich kennen. Die meisten Nutzer anderer Software wissen auch was gemeint ist, da sie in diesem Bereich augenscheinlich besser informiert sind. Travail de candidature 2.3. Auswertung des Fragebogens Für diejenigen, die noch keine Erfahrung mit Excel haben, werden die Aussagen sinngemäß angepasst: 1. Ich habe noch nie daran gedacht Excel zu benutzen. 2. Ich hatte schon einmal eine andere Personen beauftragt oder um Hilfe gebeten, Daten für mich aufzubereiten. (Z.B. um aus einer Datenmenge ein Diagramm zu erstellen, einen Mittelwert zu berechnen, o.ä.) 3. Excel könnte mir beruflich weiterhelfen. 4. Ich könnte mir vorstellen, Excel außerhalb der Arbeit zu benutzen, z.B. privat, um ein Haushaltsbuch zu führen. 5. Es ist im Interesse der Schüler, einen Excel-Kurs in der Schule anzubieten. Zu jeder Aussage gibt es nach der Theorie aus [4] genau vier Antwortmöglichkeiten: • Trifft zu, • trifft eher zu, • trifft eher nicht zu und • trifft nicht zu. Dadurch werden die Befragten indirekt aufgefordert, sich für eine Richtung zu entscheiden, anstatt einen einfachen Mittelweg zu wählen, für den weder die eine, noch die andere Aussage zutrifft. 2.3. Auswertung des Fragebogens Da der Fragebogen möglichst kurz gehalten wurde und nur die wichtigsten Elemente enthält, sind alle Daten in der Tabelle in Abbildung 2.1 zusammengefasst. Die Mittelwerte der letzten fünf Fragen und deren Standardabweichungen wurden in Abbildung 2.2 veranschaulicht. Anhand dieser Daten lässt sich ablesen, dass es zunächst niemanden gibt, der nicht weiß, was Excel ist. Das lässt sich wahrscheinlich dadurch erklären, dass die Umfrage über das Internet verbreitet wurde. Es liegt nahe, dass diejenigen Leute, die ein Mindestmaß an Erfahrung mit Computern oder Ähnlichem besitzen, auch wissen, was Excel ist. Zieht man zusätzlich in Betracht, dass Tabellenkalkulationsprogramme mittlerweile zur Standardausrüstung eines jeden Rechners zählen, kann man davon ausgehen, dass man als Besitzer weiß, worum es sich bei Excel handelt. Travail de candidature 11 12 2. Bedarf an Tabellenkalkulationssoftware Abbildung 2.1.: Zusammenfassung der Ergebnisse der Umfrage. Travail de candidature Trifft nicht zu Trifft eher nicht zu Trifft eher zu Trifft zu 2.3. Auswertung des Fragebogens Ich arbeite regelmäßig mit Excel. Ohne Excel würde ich auch gut zurecht kommen. Ich nutze Excel beruflich. Ich benutze Excel außerhalb der Arbeit. Excel-Kurs in der Schule? Abbildung 2.2.: Bedarf an Tabellenkalkulationssoftware. Aufgrund dieser Gegebenheit könnte man anführen, dass durch eine reine Onlinebefragung der Kreis der Teilnehmer unnötigerweise eingeschränkt wurde. Allerdings muss man sich direkt im Anschluss fragen, ob die durch eine Onlineumfrage außen vor Gebliebenen eine Relevanz in Bezug auf die gezogenen Schlussfolgerungen der Ergebnisse spielen. Heutzutage ist das Internet sehr verbreitet und man holt seine Informationen immer öfters online. Zumindest die ersten Schritte werden meistens übers Internet in Erfahrung gebracht. Unterstützend wirkt dann natürlich, dass nahezu alle Schulen, Universitäten und sogar viele öffentliche wie gewerbliche Plätze einen kostenlosen Internetzugang anbieten. Deswegen kann man davon ausgehen, dass kaum ein Student oder Berufstätiger das Internet nicht in irgendeiner Weise nutzt, oder nutzen muss. An eben genau diese Zielgruppe der Erwerbstätigen und zukünftigen Berufstätigen richtet sich ein Kurs über Tabellenkalkulation. Erstaunlicherweise gibt es nicht nur niemanden, der nicht weiß, was Excel oder ein Tabellenkalkulationsprogramm ist, es gibt auch bis auf eine einzige Person niemanden, der nicht zumindest grundlegende Kenntnisse im Umgang mit diesen Programmen besitzt. Zum einen könnte dies daran liegen, dass solche Anwendungen mittlerweile so einfach zu bedienen sind, dass ein wenig Neugier, gepaart mit Experimentierfreudigkeit, ausreichen, um herauszufinden, wie die Programme funktionieren. Zum anderen, und dies ist die weitaus wahrscheinlichere Erklärung, liegt wohl eher darin, dass 85% der Befragten Excel beruflich nutzen oder in der Ausbildung benötigen, beziehungsweise benötigt haben. Travail de candidature 13 14 2. Bedarf an Tabellenkalkulationssoftware Neben dem exorbitant hohen Anteil von über 80% der Befragten, die Excel in ihrer beruflichen Karriere benötigen, gibt es einen ebenso hohen Anteil an Leuten, die sich die Kenntnisse selbst angeeignet haben. Bei der Benutzung kommt man also nicht daran vorbei, sich selbst ein wenig einzuarbeiten, oder zumindest ab und zu die eigenen Kenntnisse selbstständig nachzuschlagen. Im Internet sollte dies keine allzu große Hürde darstellen. Zumindest dann, wenn man ein wenig Erfahrung besitzt und weiß, wie man eine Suchmaschine zu bedienen hat. Diese Vorgehensweise der autonomen Recherche im Netz dürfte ausreichen, um zumindest grundlegende Lücken zu schließen. Gegenüber den 85%, die Excel irgendwann im Laufe ihres Lebens gebraucht haben, stehen nur etwa 40%, die von einem Kurs in der Schule profitieren konnten. Demnach hatte knapp die Hälfte der regelmäßigen Benutzer die Möglichkeit, ihre Kenntnisse durch einen Kurs in der Schule anzueignen. Hier besteht also noch viel Nachholbedarf. Wenn man die Befragten auf die Gruppe der Schüler einschränkt (siehe Abbildung 2.3), ist der prozentuale Anteil der angebotenen Excel-Kurse in der Schule mit etwa 50% ein wenig höher, aber immer noch verbesserungswürdig. Betrachtet man die außerschulische Fortbildung, stellt man fest, dass der Anteil der Besucher eines Weiterbildungskurses mit unter 5% vernichtend gering ist. Die Ursache mag vielleicht darin liegen, dass es Überwindung kostet, sich für einen solchen Kurs anzumelden, weil er auf Kosten der Freizeit zusätzliche Zeit in Anspruch nimmt und darüber hinaus auch oft mit finanziellen Kosten einhergeht. Aufgrund eigener Erfahrungen und Beobachtungen bleibt ohnehin festzuhalten, dass man heute im Internet manchmal viel schneller und flexibler Hilfe bekommt, als wenn man sich räumlich zu einem Kurs fortbewegen muss. Dementsprechend hat sich die Gewohnheit der Fortbildung möglicherweise in Richtung Internet verlagert. Nichtsdestotrotz kann man in einem von Menschenhand geführten Kurs viele nützliche Tipps in Erfahrung bringen, die in einem rein autodidaktischen Kurs nicht zur Geltung kommen würden. Daher ist seine Daseinsberechtigung nicht zu unterschätzen. Eine weitere interessante Beobachtung liegt darin, dass von denjenigen, die regelmäßig mit Excel arbeiten, mehr als zwei Drittel die Anwendung ebenfalls für private Zwecke nutzen.2 Hat man die Vorteile erst einmal „gezwungenermaßen“ entdecken müssen, lernt man sie schätzen und es liegt nahe, dass man diese Kenntnisse auch noch in anderen Bereichen anwendet. Obschon dies eine logische Vorgehensweise ist, ist der prozentuale Anteil derer, die es in die Tat umsetzen, erstaunlich hoch. 2 Alle angegebenen Daten, sowie alle Primärdaten, befinden sich in folgender Datei und können dort nachgeschlagen werden: https://www.dropbox.com/s/psrak0mq70t7pkq/umfrage_ergebnisse.xlsx. Travail de candidature 2.3. Auswertung des Fragebogens Abbildung 2.3.: Einschränkung der Umfrage auf die Schüler/Studenten. Travail de candidature 15 16 2. Bedarf an Tabellenkalkulationssoftware Abschließend bleibt zu erwähnen, dass etwa 95% der Befragten einen Excel-Kurs in der Schule als sehr nützlich empfinden. Selbst bei aktuellen Schülern und Studenten ist der Anteil derer, die diese Meinung vertreten, außergewöhnlich hoch, so dass der Mehrwert von Tabellenkalkulationskursen in der Ausbildung kaum zu bestreiten ist. 2.4. Excel und die Statistik Schaut man sich die in Excel integrierten Funktionen an, befinden sich die Hauptanwendungsgebiete einerseits in der Finanzmathematik und andererseits in der Statistik. Ersterer Bereich setzt umfangreiche mathematische Grundlagen voraus, wie zum Beispiel im Rechnungswesen oder in der Zinsrechnung. Außerdem stellt die Finanzmathematik ein Fachgebiet für spezifischere Berufszweige dar, während sie für die Mehrzahl der Berufstätigen keine allzu große Bedeutung spielt. Demgegenüber liegen die am meisten und öftesten benutzten Funktionen von Excel größtenteils im Anwendungsgebiet der Statistik. Zudem ist die Statistik allgegenwärtig: in nahezu allen Zeitungs- und Fernsehberichten, sei es aus der Politik, in der Werbung oder im Sport, tauchen immer wieder Zahlen auf, um potenzielle Kunden zu überzeugen, um Wähler bewusst oder unbewusst zu beeinflussen oder einfach nur um Information zu veranschaulichen.3 Darüber hinaus trägt das berühmte Zitat „Ich glaube nur der Statistik, die ich selbst gefälscht habe.“, das Winston Churchill von den Nazis angehängt wurde4 , nicht unbedingt dazu bei, das Vertrauen in die Statistik zu stärken. Wenn keiner mehr an die veröffentlichten Statistiken glaubt, erreichen sie oft das Gegenteil von dem, was sie bezwecken. Dann könnte man nämlich dazu neigen, alle Auswertungen kategorisch als Fehlinformation, oder gar als Betrug zu verunglimpfen, anstatt die möglichen Vorteile darin zu erkennen. Dabei sind es nicht die Zahlen, die irrtümlicherweise falsch sind, sondern deren Darstellung und Interpretation. Man könnte somit behaupten, dass die Zahlen eigentlich beides tun: sie lügen und sie lügen nicht. Zum einen kann man nämlich die Ergebnisse der statistischen Daten grafisch falsch darstellen, wenn zum Beispiel die richtigen Daten vorliegen, man sie aber nicht richtig zu präsentieren weiß. Oder man versucht mit Absicht die Meinung des Lesers in die gewünschte Richtung zu lenken. Einige ausgewählte Beispiele dafür findet man in [6]. Zum anderen kann man die richtigen Kennzahlen benutzen, sie aber auf die falschen Daten anwenden, wodurch man an 3 Viele Beispiele und Belege, die beweisen, dass Verbraucher bewusst oder unbewusst getäuscht werden, beziehungsweise getäuscht werden können, findet man unter anderem in [6]. 4 Die Nazis hängten Churchill das Zitat an, um den Kriegsgegner im eigenen Land als Lügner und Zahlenverdreher darzustellen. Siehe [5]. Travail de candidature 2.4. Excel und die Statistik dem gestellten Problem vorbei arbeitet. Das heißt, die Kennzahl wurde zwar richtig berechnet, kann im Bezug auf das zu lösende Problem aber keine adäquate Hilfestellung anbieten, da die dadurch gewonnenen Erkenntnisse im Hinblick auf das zu lösende Problem irrelevant sind.5 Folglich ist es umso wichtiger einen Statistikkurs anzubieten, der bewusst auf das Verständnis zielt und den Lernenden zum Nachdenken anregt, anstatt eine reine „Zahlenhexerei“ zu betreiben. Der Schüler wird also mehr gefordert als nur ein paar Zahlenwerte blind in seinen Taschenrechner einzugeben und die Ergebnisse als Lösung zu präsentieren. In der Statistik geht es weniger um das richtige Ausrechnen von simplen Operationsfolgen, als vielmehr um das tiefere Verständnis der geforderten Aufgabenlösung und das korrekte Auswählen der entsprechenden statistischen Kennzahlen, die zur Lösung des Problems führen. Die Daten müssen also richtig aufbereitet und ausgewertet werden. Dies kann jedoch nur dann geschehen, wenn die verschiedenen Bewertungskennzahlen sowie deren Vor- und Nachteile bekannt sind und verstanden werden. Die Statistik ist für eine ganze Reihe von Studiengängen, wie zum Beispiel der Physik, Chemie, Biologie, Volks- und Betriebswirtschaftslehre sowie vielen Anderen ein Pflichtfach. Staatliche Ämter, die nur statistischen Erhebungen und deren Auswertungen nachgehen, unterstreichen die Bedeutung der Statistik im Alltag und im Berufsleben. Statistiken helfen nämlich, Trends besser zu erkennen. Dadurch fällt es vielfach leichter, die besseren Entscheidungen in verschiedenen Situationen zu fällen. Winston Churchill war, im Gegensatz zu dem, was das oben genannte Zitat vermuten lässt, ein Politiker, dessen Entscheidungen oft auf statistischen Gegebenheiten beruhten.6 Er war sich dessen bewusst, dass man mit den richtigen Daten einen Überblick über die möglichen Konsequenzen erhält und man anschließend die bessere Entscheidung zu treffen vermag. Churchills Entscheidungen beruhten deshalb oft auf Erfahrungswerten, die statistisch belegbar waren. Er behauptete nachweislich belegbar im Jahre 1925: „Du musst die Tatsachen anschauen, denn sie schauen dich an!“ Eine vergleichbare Situation ergibt sich in der Wirtschaft. Man nehme nur einen Zeitungsartikel, der über die aktuelle wirtschaftliche Lage berichtet. In diesen Berichten kommt man kaum mehr an Zahlen und statistischen Daten vorbei. Hier ist das Erkennen der wichtigsten Trends enorm wichtig, um die möglichst beste Wahl für die Zukunft treffen zu können. 5 Siehe Seite 65ff, wo der Mittelwert im Vergleich zu den einzelnen Testwerten wenig darüber aussagt, ob ein Kandidat wirklich besser ist, als alle Anderen. 6 Siehe [5]. Travail de candidature 17 18 2. Bedarf an Tabellenkalkulationssoftware Im Alltag kann man statistische Werte heranziehen, um verschiedene Situationen zum eigenen Vorteil zu beeinflussen oder um sich einer bewussten, fremden Manipulation zu entziehen. In einem Geschäft zum Beispiel sind die Waren aus einem einzigen Grund so angeordnet wie sie sind: sie liegen nämlich genau dort, wo sie statistischen Erkenntnissen zufolge am meisten verkauft werden. Kennt man diese Statistiken, kann man versuchen, sich dieser Manipulation zu entziehen. In anderen Situationen trifft man wahrscheinlich öfters die bessere Entscheidung, wenn man sich der entsprechenden Statistiken bewusst ist. Das Buch von Richard Wiseman beinhaltet eine Vielzahl solcher Beispiel und erklärt, wie man sie zum persönlichen Vorteil nutzen kann.7 Ein Kurs über Statistik ist also doppelt interessant, weil man neben der Einarbeitung in Excel die Schüler mit einem durchaus kontroversen Thema vertraut machen kann und ihnen aufzeigt, wie man Statistiken lesen muss und wo ihre Grenzen liegen. Darüber hinaus bieten interdisziplinäre Kurse ausreichend Abwechslung, um dem Schüler fortwährend neue, abwechslungsreiche Reize zu geben, damit sein Interesse und seine Lernbereitschaft auf einem hohen Niveau bleiben. 7 Siehe [15]. Travail de candidature Teil II. Praktischer Teil Vorwort Da es sich in diesem Teil um einen Kurs über Microsoft Excel handelt, der eine aktive Teilnahme voraussetzt, ist es unumgänglich, einige vorbereitete Dateien mitzuliefern. Diese Dateien befinden sich im angehängten pdf-Dokument und können durch Anklicken der Grafik in der Fußnote geöffnet werden. Diese Grafiken, die auf eine angehängte Datei verweisen, sind in der Druckversion dieses Dokuments gegebenenfalls nicht sichtbar. Um dennoch einen Zugang auf diese Dateien zu gewährleisten, beinhaltet der Text in der Fußnote einen Link, unter dem man den entsprechenden Anhang herunterladen kann. Die Sicherheitseinstellungen des pdf-Betrachters müssen lediglich so eingestellt sein, dass sie dem Benutzer erlauben die Datei direkt (durch anklicken der Grafik) zu öffnen oder den Link, der auf die herunterladbare Datei verweist, zu öffnen. Darüber hinaus befinden sich die Dateien in einem eigenen Ordner auf dem hier hinterlegten Datenträger. Die Bezeichnungen der Dateien auf der CD sind identisch mit dem jeweiligen Text in der Fußnote. 3. Einführung in Microsoft Excel 3.1. Grundlagen Voraussetzung für die Bedienung und die Umsetzung der folgenden Anwendungen ist eine vollständige Installation von Microsoft Excel. Grundlage aller abgebildeten Grafiken und Erläuterungen ist Excel 2010 (aus der MS Office 2010 Professional Plus Suite1 ). Der Nutzer sollte ebenso oberflächliche Allgemeinkenntnisse im Umgang mit PCs und insbesondere Windows besitzen. Dieser Kurs dient unter anderem zur Vorbereitung auf eine weitergehende naturwissenschaftliche Ausbildung, in denen statistische Auswertungen und Analysen von Primärdaten als Grundkenntnisse vorausgesetzt werden. Oft sind dies nicht nur die Studiengänge Mathematik und Physik, sondern auch Chemie und Biologie. Während der Ausbildung, aber auch danach, bieten Tabellenkalkulationsprogramme und deren Möglichkeiten zur grafischen Aufbereitung von Daten eine notwendige Hilfe, um die erworbenen Erkenntnisse adäquat zu präsentieren. Ob zur Kostenübersicht und Kategorisierung großer Datenmengen in Firmen oder als einfaches, privates Haushaltsbuch zur Überwachung der Einnahmen und Ausgaben dienen Tabellenkalkulationen in vielen Bereichen des Alltags. Die hier vorgeschlagenen Aufgaben basieren zumeist auf Daten aus [1], [7], [10] und [11]. Manche Daten wurden auch aus dem „Statistics Portal2 “ vom Statec entnommen. 3.2. Die ersten Schritte 3.2.1. Die Arbeitsoberfläche Startet man Excel, so gelangt man zur Arbeitsoberfläche, wie sie in Abbildung 3.1 erscheint. 1 Bis auf wenige oder keine Einschränkungen dürfte die günstigere Home-Version für diese Zwecke auch genügen. 2 http://www.statistiques.public.lu/en/actors/statec/index.html. 24 3. Einführung in Microsoft Excel Abbildung 3.1.: Arbeitsoberfläche von MS Excel. Travail de candidature 3.2. Die ersten Schritte Im Folgenden befinden sich die Bezeichnungen der in Abbildung 3.1 nummerierten Elemente aufgelistet sowie eine kurze Erklärung ihrer jeweiligen Funktion. 1. Die Titelleiste. Sie gibt den Dateinamen und die Anwendung an. In der linken, oberen Ecke daneben befindet sich die Schnellstartleiste, um zum Beispiel unter anderem das Dokument mit einem einzigen Klick abzuspeichern, oder um die Schriftfarbe zu ändern. 2. Das Menü. In Abhängigkeit des gewählten Menüeintrags (hier: „Start“) erscheinen andere Schaltflächen im Menüband darunter. Diese Schaltflächen sind unterteilt in Gruppen, deren Bezeichnung in grauer Farbe unterhalb dieser Gruppe steht. Auf dieser Abbildung zu erkennen sind unter anderem die Einteilungen Zwischenablage, Schriftart, Ausrichtung und Zahl. 3. Menüband minimieren. Dadurch verschwinden die Schaltflächen unterhalb des Menüs. Erst wenn man auf den entsprechenden Menüeintrag klickt, treten sie wieder hervor. 4. Die Scrollbalken, vertikal (4a) und horizontal (4b). Unterhalb der Scrollbalken befindet sich die Zoomeinstellung, um die Ansicht zu verkleinern oder zu vergrößern, indem man entweder den Balken nach links/rechts bewegt oder direkt /⊕ anklickt. 5. Die Tabellenblätter. Sie stellen, wie im geschichtlichen Hintergrund erwähnt, die dritte Dimension dar. Klickt man auf das weiße Blatt rechts, kann man ein neues, leeres Tabellenblatt erstellen. Durch einen Rechtsklick auf ein bereits bestehendes Blatt, kann man dieses beispielsweise umbenennen oder löschen. Standardmäßig enthält eine neue Arbeitsmappe drei leere Tabellenblätter. 6. Die aktivierte (oder ausgewählte, markierte) Zelle. Hier ist es die Zelle A1. Sie ist schwarz umrandet. Durch einen Mausklick auf eine andere Zelle wird diese andere Zelle aktiviert. 7. Die Bearbeitungszeile zeigt den Inhalt (oder Formel) der aktivierten Zelle an. Auf der Abbildung 3.1 gut zu erkennen ist die alphabetische Nummerierung der Spalten und die arabische Nummerierung der Zeilen. Dementsprechend setzt sich die Bezeichnung jeder Zelle aus einem Buchstaben und einer Zahl zusammen. Befindet man sich beispielsweise in der neunten Zeile der Spalte C, so handelt es sich in dem Fall um die Zelle C9. In Abbildung 3.1 ist beispielsweise die Zelle A1 aktiviert. Travail de candidature 25 26 3. Einführung in Microsoft Excel Abbildung 3.2.: Formatierung der Schrift. Um von einer Zelle zur Nächsten zu gelangen kann man entweder mit der Maus direkt in die gewünschte Zelle klicken oder die Pfeiltasten auf der Tastatur benutzen, um dorthin zu navigieren. 3.2.2. Zellinhalte formatieren . Aufgabe 1 Schreiben Sie den Text „Dies ist die Zelle C5“ in die entsprechende Zelle und formatieren Sie die Zelle wie im unten angefügten Bild. Geben Sie ebenfalls den Text aus der folgenden Abbildung in die Zelle D5 ein. Lösung der Aufgabe Aktivieren Sie die Zelle C5 und tippen Sie den Text „Dies ist die Zelle C5“ ein, gefolgt von der Eingabe-Taste. Diesen Text kann man nun beliebig formatieren. Dazu muss man die Zelle C5 wieder auswählen, indem man beispielsweise mit der Pfeiltaste ↑ zurück navigiert. Die Schaltflächen in der rot eingefärbten Gruppe in Abbildung 3.2 dienen dazu, den Text beispielsweise fett darzustellen oder zu unterstreichen. Es muss aber nicht zwangsweise dieselbe Formatierung auf die komplette Zelle angewendet Travail de candidature 3.2. Die ersten Schritte Abbildung 3.3.: Nur einen Teil der Zelle formatieren. Abbildung 3.4.: Die Höhe der Zelle anpassen. werden. Es ist ebenfalls möglich nur einen Teil des Textes zu formatieren. Dazu muss die Zelle aktiviert und anschließend in der Bearbeitungszeile den zu formatierenden Textteil markiert werden. Nun kann man diesen markierten Text beispielsweise rot einfärben. Diese Prozedur ist zusätzlich in Abbildung 3.3 veranschaulicht. Klickt man , erhält man mehr Farben zur Auswahl. auf den Pfeil rechts neben dem Symbol Bemerkung: Vergrößert man die Schrift, so wird die Zeilenhöhe automatisch angepasst. Man kann die Zellenhöhe aber auch manuell einstellen, indem man, wie in Abbildung 3.4, die untere Grenze der entsprechenden Zeilennummer links im Rand verschiebt. Genauso kann man die Spaltenbreite in der Spaltenleiste anpassen. Gibt man nun „1-2“ in die Zelle D5 ein, stellt man folgendes fest: 1. Der Text in Zelle C5, der in die angrenzende Zelle D5 hineinragte, wurde abgeschnitten. 2. In der Zelle D5 erscheint das Datum „01. Feb“ anstatt der Eingabe „1-2“. Travail de candidature 27 28 3. Einführung in Microsoft Excel Das Abschneiden des Textes in der Zelle C5 kann man verhindern indem man entweder die Spaltenbreite anpasst oder einen Zeilenumbruch innerhalb derselben Zelle erzwingt. Dazu aktiviert man die gewünschte Zelle und klickt die in Abbildung 3.5 markierte Schaltfläche. Abbildung 3.5.: Zeilenumbruch erzwingen. Wieso erscheint nun das Datum „01.Feb“ in der Zelle D5? Ein großer Vorteil von Excel besteht darin, dass das Programm viele Arbeitsschritte vorwegnimmt und diese automatisch im Hintergrund ausführt, um dem Benutzer einen Teil der Arbeit abzunehmen. In diesem Fall erkennt Excel die Eingabe „1-2“ als Datum. Die erste Zahl stellt den Tag und die zweite Zahl den Monat des aktuellen Jahres dar. Wenn die Eingabe jedoch so erscheinen soll wie man sie eingegeben hat, muss man das Format der jeweiligen Zelle auf „Text“ umstellen. Dazu markiert man die Zelle D5 und klickt in der Gruppe „Zahl“ auf den Pfeil rechts neben der Kom. Aus der Liste der möglichen Formate wählt man den untersten bobox: Eintrag „Text“. Die Zelle enthält nun eine fünfstellige Zahl und man muss erneut „1-2“ eingeben um das gewünschte Ergebnis zu erhalten. Wieso macht Excel aus „1-2“ eine fünfstellige Zahl? Excel hat die Eingabe „1-2“ als Datum (1. Februar) umgewandelt. Dabei erhält man eben diese fünfstellige Zahl, denn Excel interpretiert jedes Datum als fortlaufende Zahl, mit 1 beginnend am 1.1.1900. Die Zahl 1 steht also für den 1.1.1900, die Zahl 32 dementsprechend für den 1.2.1900 und 367 für den 1.1.1901. Die fünfstellige Zahl steht also für den ersten Februar des aktuellen Jahres. Darüber hinaus speichert Excel die Zeiten als Nachkommazahl. Da ein Tag genau Travail de candidature 3.2. Die ersten Schritte 1 ist und ein Tag 24 Stunden hat, entspricht eine Stunde 1 24 von 1, also 0, 0416. Zum Abschluss dieses Unterkapitels befindet sich in Abbildung 3.6 eine Übersicht einiger anderer, oft benutzter Formatierungen. Abbildung 3.6.: Verschiedene Textformatierungen. . Aufgabe 2 Erstellen Sie eine Arbeitsmappe, in der das erste Tabellenblatt wie in der folgenden Abbildung aussieht. Speichern Sie das Dokument für die folgenden Aufgaben ab. Lösung der Aufgabe Die Lösungsdatei ist angehängt3 und die Vorgehensweise ist analog wie die in Abbildung 3.6 erklärten Formatierungen. 3 Lösung Aufgabe 2: Travail de candidature 29 J 30 3. Einführung in Microsoft Excel Das erstellte Dokument speichert man am schnellsten über die Tastenkombination „Strg+S“ ab. Beim ersten Speichern wird automatisch nach dem Dateinamen gefragt, bei späteren Speichervorgängen wird die angelegte Datei überschrieben. J 3.2.3. Formeln, Shortcuts und Funktionen Im vorigen Unterkapitel wurde erläutert, dass Excel die Eingabe „1-2“ nicht als Rechnung wertet, sondern als Datum interpretiert. Soll Excel das Ergebnis von einer oder mehreren Rechenoperationen berechnen, muss man der Rechnung ein Gleichheitszeichen „=“ vorschieben. Dann wird das Ergebnis „−1“ im Arbeitsblatt angezeigt. Die eigentliche Rechnung bleibt aber weiterhin erhalten und man kann sie, wenn man die entsprechende Zelle aktiviert hat, in der Bearbeitungszeile einsehen und anpassen. Wenn man sich beispielsweise vertippt hat, genügt ein Klick in die Bearbeitungszeile. Abbildung 3.7 veranschaulicht die Funktionsweise von Formeln. Abbildung 3.7.: Die Bearbeitungszeile. Worin besteht der Sinn, dass Excel einen Unterschied zwischen der Eingabe „1-2“ und der Eingabe „=1-2“ macht? Meistens benötigt man ein und dieselbe Angabe mehrmals und diese Angaben können variieren, während die Rechnung aber dieselbe bleibt. Anstatt die Angabe dann jedes Mal neu einzugeben, schreibt man sie einmal in eine eigene Zelle und verweist dann in allen Rechnung auf diese Zelle. Ändert man nun den Wert einer Angabe, berechnet Excel automatisch alle davon abhängigen Zellen neu. In Aufgabe 3 wird die Funktionsweise von Formeln in die Praxis umgesetzt. . Aufgabe 3 Berechnen Sie mit Excel die Umsätze für jede Filiale und jeden Artikel aus den aus Aufgabe 2 vorgegebenen Daten. Schreiben Sie diese Umsätze in die Zellen C5 bis E6. Travail de candidature 3.2. Die ersten Schritte Lösung der Aufgabe Wählen Sie zunächst die Zelle C5 aus, in der Sie das Ergebnis angezeigt haben möchten. Dann tippen Sie das Gleichheitszeichen „=“ ein, um Excel anzuweisen, dass eine Rechnung ausgeführt werden soll. Anschließend markieren Sie die Zelle C3, die den Preis des Artikels enthält. Dadurch erscheint „C3“ hinter dem Gleichheitszeichen. Die Multiplikation mit der Anzahl der verkauften Artikel erfolgt durch die Eingabe eines Sternchen „*“, gefolgt von der Zelle C4 in der die Anzahl der verkauften Artikel steht. Drücken Sie am Ende „Eingabe“, so zeigt Excel das gewünschte Ergebnis der Multiplikation an. Wählt man nun erneut die Zelle C5 mit der eben eingetragenen Formel aus, steht in der Bearbeitungszeile immer noch die Formel „=C2*C3“. Hat man sich nur leicht vertippt, klickt man in der Bearbeitungszeile an die entsprechende Stelle um gegebenenfalls einzelne Veränderungen vorzunehmen. Dadurch muss man nicht mehr die komplette Formel neu eingeben. Bemerkung: Man hätte die Formel „=C2*C3“ auch manuell nur mit Hilfe der Tastatur eingeben können (hier wird nicht zwischen Groß- oder Kleinbuchstaben unterschieden). Anstatt die Maus zu benutzen kann man die Zellen auch mit den Pfeiltasten ansteuern. Bemerkung: Passt man einen Wert in den Zellen C2 oder C3 an, wird das Ergebnis in der Zelle C5 automatisch neu berechnet. Deswegen sollte man, sofern möglich, alle Primärdaten einmal auflisten und dann die Berechnungen mit Hilfe der Zellbezüge auf die Primärdaten eingeben. Um den Umsatz für die beiden anderen Artikel zu berechnen, muss man die Formel nicht noch einmal eingeben, sondern man kann sie aus der Zelle C5 in die Zelle D5 kopieren. Hierzu aktiviert man die Zelle C5 und „zieht“ die Formel dann mit Hilfe des schwarzen Quadrats unten rechts, dem sogenannten Ausfüllkästchen, in die anliegende Zelle D5. Dies wird in Abbildung 3.8 illustriert. Excel kopiert dann die Formel aus der Zelle C5 in die Zelle D5. Dabei werden die Zellbezüge so angepasst, dass wenn die Formel um genau eine Zelle nach rechts kopiert wird, alle Spaltenindizes in der Formel ebenfalls um eine Einheit nach rechts verschoben werden. Aus der Spalte C wird so die Spalte D. Da wir uns aber immer noch in derselben Zeile befinden, bleiben die Zeilenindizes in der Formel unverändert. Das heißt, aus C2 wird D2 und aus C3 wird D3. Insgesamt wird aus der Formel „=C2*C3“ in der Zelle C5 nach dem Kopiervorgang in die Zelle D5 die Formel „=D2*D3“. Will man die Formel aus einer Zelle (hier C5), in eine nicht benachbarte Zelle (hier Travail de candidature 31 32 3. Einführung in Microsoft Excel Abbildung 3.8.: Kopieren einer Formel mit Hilfe des Ausfüllkästchens. E5) kopieren, muss man die Formel (in Zelle C5) erst kopieren und dann (in die Zelle E5) einfügen. Das Kopieren erfolgt mit dem Symbol im Menüband links oben. Dann wählt man die Zielzelle (E5), aus und klickt links neben dem Kopieren-Symbol auf „Einfügen“. Die Bezeichnung dieses Vorganges wurde aus dem englischen Sprachgebrauch übernommen und heißt „copy-paste“ (kopieren-einfügen). Bemerkung: Anstatt die „Kopieren-Einfügen“ Symbole im Menüband anzuklicken, genügt es, die Tastenkombination (Shortcut) „Strg+C“ auszuführen, um die Formel aus der aktivierten Zelle zu kopieren und anschließend „Strg+V“, um die Formel in die gewünschte Zelle einzufügen. Da die Buchstaben C und V auf der Tastatur nebeneinanderliegen, geht es mit diesen Shortcuts im Allgemeinen schneller von der Hand. Kopiert man nun die Formel für die Umsätze der ersten Filiale wie oben beschrieben in die Zeile darunter, sind die Zahlenwerte für die Umsätze offensichtlich viel zu hoch. Schaut man sich die Formel in der Bearbeitungszeile genauer an erkennt man, dass die beiden falschen Zellen miteinander multipliziert werden. Das liegt daran, dass Excel beim Kopieren der Formel in die Zeile darunter die Zeilennummern in der Formel entsprechend um eins anpasst. Der Preis für den jeweiligen Artikel steht aber immer noch in derselben Zeile und wurde nicht um eine Zelle nach unten verschoben. Dieser Zeilenindex darf beim Kopieren also nicht angepasst werden. Hierfür bietet Excel eine komfortable Lösung an: Soll der Zeilenindex beim Kopieren unverändert bleiben, muss man ein Dollarzeichen „$“ davor setzen. Damit erhält man in der Zelle C5 die Formel „=C$2*C4“. Diese Formel kann nun mit „Strg+C“ kopiert und gleichzeitig in alle Zellen C5 bis E6 eingefügt werden. Dazu wählt man die sechs Zellen aus und fügt die Formel mit „Strg+V“ ein. Alternativ kann die Formel aus Zelle C5 direkt in alle sechs Zellen C5 bis E6 geschrieben werden, indem man das Ausfüllkästchen bis zur Zelle E6 zieht. Schaut man sich nun die eingefügten Formeln an, sieht man, dass die Spaltenindizes angepasst wurden, während die „$2“ der Zeilenindizes unverändert Travail de candidature 3.2. Die ersten Schritte 33 Abbildung 3.9.: Lösung der Aufgabe 3. übernommen wurden. Die Ergebnisse aller Berechnungen aus dieser Aufgabe sind in Abbildung 3.9 abgebildet. Bemerkung: Soll der Spaltenindex beim Kopieren unverändert bleiben, schreibt man ein $ vor den entsprechenden Großbuchstaben des Spaltenindex. . Aufgabe 4 Berechnen Sie den Gesamtumsatz für jede der zwei Filialen aus Aufgabe 2, sowie die Summe aller Umsätze. Lösung der Aufgabe Berechnet man die Summe aller Umsätze einer Filiale in Zelle F5 (beziehungsweise F6) kann man die Formel „=C5+D5+E5“ benutzen. Excel bietet hierfür aber die Funktion „SUMME(Zellbezug)“ an. Um sie anzuwenden, schreibt man „=SUMME(C5:E5)“. Der Doppelpunkt zwischen C5 und E5 gibt an, dass die Werte in allen Zellen von C5 bis E5 summiert werden. Dies kann man über beliebig viele Zellen tun. In der Abbildung 3.10 sind beispielsweise die Zellen C5 bis E6 markiert. Das heißt, die Zelle C5 stellt die linke obere Ecke und die Zelle E6 stellt die rechte untere Ecke der gesamten Auswahl dar. Mit „=SUMME(C5:E6)“ wird so die Summe aus den entsprechenden sechs Zellen berechnet. Travail de candidature J 34 3. Einführung in Microsoft Excel Abbildung 3.10.: Ergebnisse der Aufgabe 4. Bemerkung: Wenn man die Summenfunktion inklusive der ersten Klammer hingeschrieben hat, kann man die Zellen C5 bis E5 mit der Maus auswählen. Excel schreibt sie dann automatisch in die Formel. Alternativ kann man die Zellen auch mit den Pfeiltasten auswählen, während man gleichzeitig die „Shift“-Taste gedrückt hält. J Excel bietet eine Vielzahl von Funktionen an, die weit mehr als den mathematischen und statistischen Bereich abdecken. Einige davon werden im Verlauf dieses Kurses vorgestellt. Die anderen findet man indem man eine leere Zelle auswählt und links klickt. Nach der Auswahl neben der Bearbeitungszeile auf das Funktionssymbol einer Funktion bietet Excel eine Erklärung und eine Hilfestellung bei der Eingabe der Formel an. . Aufgabe 5 Die angehängte Datei4 beinhaltet eine Auflistung der aktiven Bevölkerung Luxemburgs, der Anzahl der Erwerbstätigen und die Anzahl der Angestellten, geordnet nach den 12 Kantonen. Berechnen Sie anhand dieser Daten die Anzahl der Freiberufler, der Arbeitslosen und die Arbeitslosenquote für alle Kantone, sowie alle Daten für das ganze Land. Lösung der Aufgabe Die Lösungsdatei ist angehängt.5 Die benutzten Formeln kann man in Abbildung 3.11 ablesen. J 4 Aufgabe 5: 5 Lösung Aufgabe 5: Travail de candidature 3.2. Die ersten Schritte Abbildung 3.11.: Ergebnisse der Aufgabe 5. . Aufgabe 6 In der angehängten Datei6 befinden sich die Einnahmen, die Ausgaben und die Angestelltenlöhne des Luxemburger Staates in den Jahren 1995 bis 2012. Errechnen Sie daraus die Summe, sowie den Mittelwert über alle Jahre. Berechnen Sie anschließend für jedes Jahr den prozentualen Anteil der Ausgaben für Angestelltenlöhne und den Überschuss des jeweiligen Jahres. Hinweis: Den Mittelwert berechnet man mit der Funktion „MITTELWERT(Zellbezug)“. Lösung der Aufgabe Die Lösungsdatei ist angehängt7 und die Abbildung 3.12 zeigt die Ergebnisse der Aufgabe. J Die roten und grünen Zahlen der Überschüsse in Abbildung 3.12 wurden nicht etwa manuell eingefärbt, sondern wurden über eine sogenannte „bedingte Formatierung“ eingefügt. In diesem Fall wurde es so festgelegt, dass der Wert in der jeweiligen Zelle rot erscheinen soll, wenn er negativ ist und grün, wenn er positiv ist. Um eine solche bedingte Formatierung zu erstellen, markiert man zunächst die Zellen, auf die man diese Formatierung anwenden möchte. Dann geht man im Menü in der Gruppe „Formatierung“ auf „bedingte Formatierung“, dann auf „neue Regel“ und füllt das Formular wie in Abbildung 3.13 aus. Für jedes Format muss eine neue Regel definiert werden. 6 Aufgabe 6: 7 Lösung Aufgabe 6: Travail de candidature 35 36 3. Einführung in Microsoft Excel Abbildung 3.12.: Ergebnisse der Aufgabe 6. Abbildung 3.13.: Einfügen einer bedingten Formatierung. Travail de candidature 4. Häufigkeiten und Diagramme Große Datenmengen sind oft unübersichtlich und dadurch schwer zu bewerten. Um es anhand eines Beispiels zu veranschaulichen, befinden sich hier die Ergebnisse der Befragung von 130 Leuten nach deren bevorzugten Jahreszeit: Nur mit Hilfe dieser Tabelle ist es sehr aufwendig herauszufinden, welche Jahreszeit die Meistgenannte ist. Es ist klar, dass die Ergebnisse anders aufbereitet werden müssen. Dies wird durch grafische Darstellungen oder Diagramme ermöglicht. Sie erlauben es eine große Datenmenge sehr schnell bezüglich ausgewählten Kriterien zu interpretieren und zu bewerten. 4.1. Einführungsbeispiel In der angehängten Excel-Datei1 befinden sich die Antworten aus dem Einführungsbeispiel. Bevor man diese Daten in einem Diagramm darstellen kann, müssen sie in einer Tabelle gruppiert und abgezählt werden. Man muss aber nicht alles von Hand nachzählen, denn die Funktion „ZÄHLENWENN(Bereich; Suchkriterien)“ übernimmt diesen Teil der Arbeit. Das erste Argument „Bereich“ gibt die Zellen an, in denen sich die zu zählenden Daten befinden. Das zweite Argument „Suchkriterien“ definiert das zu zählende Kriterium. Die Abbildung 4.1 verdeutlicht, wie es geht. 1 Aufgabe 7: 38 4. Häufigkeiten und Diagramme Abbildung 4.1.: Benutzung der Formel „ZÄHLENWENN“. Zunächst werden die Namen der Jahreszeiten in die Zellen A16 bis A19 geschrieben. Rechts daneben wird dann mit der Funktion „ZÄHLENWENN“ aufgezählt, wie oft die entsprechende Jahreszeit genannt wurde. Im zweiten Argument dieser Funktion kann man entweder die Jahreszeit direkt, zum Beispiel „Frühling“, reinschreiben oder auf die entsprechende Zelle links daneben klicken, in der man die gewünschte Jahreszeit bereits aufgelistet hat. Bemerkung: Gibt man anstelle des Verweises auf die Zelle A16 (siehe Abbildung 4.1) direkt die Jahreszeit (z.B. „Frühling“) ein, müssen vor und hinter das Wort Gänsefüßchen gesetzt werden, damit Excel weiß, dass es sich nicht um eine Formel oder einen Verweis handelt, sondern um den genauen Text nach dem gesucht werden soll. Sind die Daten in einer Tabelle zusammengefasst, kann man ein erstes Diagramm erstellen. Klickt man im Menüband auf „Einfügen“, erscheinen die Schaltflächen der verfügbaren Diagrammarten: Markiert man nun die eben erstellte Tabelle in den Zellen A15 bis B19 und wählt unter dem Säulendiagramm das erste Symbol mit der Bezeichnung „Gruppierte Säulen“ aus, dann erstellt Excel eine bereits vorgefertigte Grafik wie sie in Abbildung 4.2 zu Travail de candidature 4.1. Einführungsbeispiel Abbildung 4.2.: Diagramm mit den Bezeichnungen der Elemente. Abbildung 4.3.: Beispiel farbiger Säulen. sehen ist. In der Abbildung 4.2 sind auch die wichtigsten Diagrammelemente beschriftet. Will man beispielsweise den Diagrammtitel ändern, muss man ihn nur anklicken und die gewünschten Änderungen vornehmen. Im Menüband „Start“, kann man darüber hinaus andere Schriftformate wählen. Alternativ erreicht man diese Einstellungsmöglichkeiten auch durch einen Rechtsklick in den zu ändernden Text. Die Legende kann man einfach löschen, indem man darauf klickt und „Entfernen“ („Delete“) auf der Tastatur drückt. Zudem können die Farben der Säulen individuell anpasst werden, indem man die sie doppelklickt. Will man nur eine einzige Säule einfärben, muss diese Säule zunächst einzeln ausgewählt werden. Anschließend kann sie durch einen Doppelklick geändert werden. Das Ergebnis könnte beispielsweise wie in Abbildung 4.3 aussehen. Die Achsenbeschriftung ist ein wichtiges Element, was Excel standardmäßig ein wenig vernachlässigt. Die Beschriftung der Achsen fügt man hinzu, indem man das Travail de candidature 39 40 4. Häufigkeiten und Diagramme Abbildung 4.4.: Korrekte Achsenbeschriftung. Diagramm auswählt und im dann erscheinenden Menüband unter „Layout“ die Schaltfläche „Achsenbeschriftung“ anklickt. Dort findet man in der dritten Gruppe „Beschriftungen“ die Schaltfläche „Achsentitel“ um die horizontalen und vertikalen Achsentitel einzufügen. Anschließend müssen die Elemente nur noch verschoben werden, so dass das Diagramm wie in Abbildung 4.4 aussieht. . Aufgabe 7 1. Erstellen Sie aus den Daten in der Datei auf Seite 37 folgendes Kreisdiagramm: 2. Erstellen Sie ebenfalls ein Kreis- und ein Säulendiagramm, in dem die Prozentualwerte der Antworten angezeigt werden. Lösung der Aufgabe Wie man ein Diagramm einfügt, die Schriftart und die Schriftgröße des Titels ändert oder die Legende löscht, wurde bereits erläutert. Die Datenbeschriftung außerhalb des Kreises stellt man im Menüband unter „Layout“, „Datenbeschriftung“, „Weitere Datenbeschriftungsoptionen“ ein. Dann muss man die in Abbildung 4.5 rot hinterlegten Einträge so wie in der Abbildung anpassen. Um das Säulendiagramm mit den prozentualen Werten zu erstellen, genügt es unter „Achsenbeschriftung formatieren“ das Kästchen vor „Prozentsatz“ auszuwählen. In Abbildung 4.5 ist dieser Punkt blau hinterlegt. Gegebenenfalls muss das Kästchen mit dem Eintrag „Wert“ deaktiviert werden. Die komplette Lösungsdatei ist angehängt.2 J 2 Lösung Aufgabe 7: Travail de candidature 4.1. Einführungsbeispiel Abbildung 4.5.: Beschriftung der Daten in einem Diagramm. Travail de candidature 41 42 4. Häufigkeiten und Diagramme Abbildung 4.6.: Ein Histogramm. 4.2. Histogramme Um ein Histogramm zu erstellen, benötigt man im Gegensatz zu den Jahreszeiten im Einführungsbeispiel auf Seite 37 konkrete Zahlenwerte. In der angehängten Datei3 beispielsweise ist es das Alter der Teilnehmer eines pädagogischen Kolloquiums. Die Zahlenwerte sind erforderlich, weil man die Daten in einem Histogramm in Intervalle einteilt. Die Veranschaulichung der Datenverteilung aus den angehängten Daten soll im Endergebnis so wie in Abbildung 4.6 aussehen. Um die Altersintervalle oder -klassen zu definieren, muss zunächst das Minimum und das Maximum bestimmt werden. Dafür bedient man sich der Funktionen „MIN(Bereich)“ und „MAX(Bereich)“. Da das Mindestalter hier 20 und das Höchstalter 68 ist, beginnt man bei der Klasseneinteilung mit 20 und erhöht in 10-er Schritten. Diese Werte schreibt man vertikal untereinander, damit die Zellen rechts daneben die Werte für die Anzahl der jeweiligen Klasse Platz beinhalten können. Abbildung 4.7 zeigt, wie es aussehen könnte. Die Teilnehmeranzahl einer Altersklasse bestimmt man mit der Funktion „HÄUFIGKEIT(Daten; Klassen)“. Um die Werte aller Intervalle in einem Zug einzugeben, geht man wie folgt vor: 1. Man markiert alle Zellen hinter den Intervallen, in denen die Teilnehmeranzahl stehen soll. In Abbildung 4.7 sind dies die Zellen D6:D11. 2. Man gibt die Formel „=HÄUFIGKEIT(A1:A84;C6:C11)“ ein und bestätigt mit „Strg+Shift+Eingabe“. Dabei hält man „Strg“ und „Shift“ gedrückt, während man mit „Eingabe“ bestätigt. 3 Aufgabe Histogramm: Travail de candidature 4.2. Histogramme Abbildung 4.7.: Erstellen der Daten für ein Histogramm. Mit dieser Vorgehensweise schreibt Excel die Formel automatisch in alle markierten Felder. Bemerkung: Bei der Eingabe von „Strg+Shift+Eingabe“ handelt es sich um eine Matrixformel, die man in der Bearbeitungszeile an den geschwungenen Klammern erkennen kann, sobald man die Formel bestätigt hat. Diese Matrixformeln können nicht einzeln geändert werden, sondern es muss immer die ganze Matrix (hier D6:D11) markiert werden, bevor man eine Änderungen vornehmen kann. Diese Änderung wird dann auf den gesamten Bereich angewendet. In diesem Beispiel zählt die erste Klasse 0 Teilnehmer, da der Wert 20 die obere Grenze der ersten Klasse darstellt. Das heißt, es gibt keinen Teilnehmer, der jünger als 20 Jahre ist. Zwischen 20 und 30 Jahren werden entsprechend 15 Teilnehmer gezählt. Um mit Hilfe der gruppierten Daten ein Histogramm zu erstellen, wählt man die zu repräsentierenden Daten aus. Hier sind es die Zellen D7 bis D11. Man beachte, dass die erste Zelle, die 0 Teilnehmer zählt, ignoriert wird! Anschließend fügt man ein 2DSäulendiagramm ein. Löscht man die Legende, bleibt das Diagramm aus Abbildung 4.8. Die wesentlichen Unterschiede vom Diagramm in Abbildung 4.8 zu einem richtigen Histogramm wie in Abbildung 4.6, sind die Folgenden: 1. Die Säulen oder Rechtecke müssen aneinander liegen. 2. Die Beschriftung der Klassengrenzen müssen zwischen diesen Rechtecken stehen und geben die obere, beziehungsweise untere Grenze der jeweiligen Klasse an. Travail de candidature 43 44 4. Häufigkeiten und Diagramme Abbildung 4.8.: Diagramm, was als Grundlage für ein Histogramm dient. Abbildung 4.9.: Rahmenfarbe anpassen. Mit den folgenden Schritten passt man diese Unzulänglichkeiten an: 1. Die Entfernung der Abstände zwischen den Säulen erfolgt durch einen Doppelklick auf eine der fünf Säulen. Im darauf folgenden Fenster setzt man die Abstandsbreite auf 0%. Damit die Rechtecke klar getrennt sind, wählt man in demselben Fenster noch eine Rahmenfarbe aus, so wie es in Abbildung 4.9 gezeigt wird. 2. Die beiden Achsenbeschriftungen und den Titel fügt man so ein, wie es bereits für andere Diagramme gezeigt wurde. Zum Schluss ordnet man die einzelnen Elemente durch Ziehen mit der Maus an. 3. Im letzten Schritt müssen die Klassengrenzen unter die Intervallgrenzen geschrieben werden. Hier bietet Excel keine vorgefertigte Funktion an, mit der man es problemlos machen könnte. Dadurch muss man ein wenig basteln, um ein echtes Histogramm zu erhalten: zunächst löscht man die vorhandenen horizontalen Achsenbeschriftungen, indem man einen Rechtsklick auf die Rechtecke ausführt und anschließend „Daten auswählen“ anklickt. Nun klickt man in der rechten Fensterhälfte unter „Horizontale Achsenbeschriftung“ auf „Bearbeiten“ und setzt ein Semikolon „;“ ein. Dadurch ersetzt Excel alle Beschriftungen durch leere Felder. Travail de candidature 4.2. Histogramme Abbildung 4.10.: Klassengrenzen in ein Histogramm einfügen. Um die neuen Beschriftungen einzufügen, ist das kostenlose Add-In-Programm „XY Chart Labeler“4 sehr nützlich. In der Fußnote5 befindet sich die Version 7.1.05 für MS Windows. Nachdem das Programm installiert wurde6 , erscheint ein zusätzlicher Eintrag namens „XY Chart Labels“ im Menüband. Nun kann man die Beschriftungen im Diagramm einfügen und an die richtige Stelle verschieben. Dazu klickt man „Add Chart Labels“ an und markiert im nächsten Fenster in der zweiten Bearbeitungszeile die unteren Grenzen der Intervalle. (Siehe Abbildung 4.10.) In der letzten Zeile muss „Inside Base“ ausgewählt werden. Die nun eingefügten Beschriftungen bringt man mit Hilfe des Add-Ins und „Move Chart Labels“ in die richtige Position. 4. Für die letzte obere Grenze ist kein Platz mehr frei, da man nur eine Klassengrenze pro Intervall definieren kann. Deswegen fügt man die letzte, obere Klassengrenze mit der Achsenbeschriftung ein. Dazu schreibt man den Wert links vor die Achsenbeschriftung und passt das Format dieser Zahl an, indem man sie markiert und mit der rechten Maustaste in diese Markierung klickt. Zum besseren Verständnis ist die Vorgehensweise nochmal in Abbildung 4.11 illustriert. Nach diesen Schritten erhält man ein richtiges Histogramm. Soll die horizontale Achse bei 0 beginnen, muss man lediglich eine weitere Klasse in der Tabelle hinzufügen bevor man das Diagramm erstellt. 4 Erhältlich unter www.appspro.com. 5 XY Chart Labeler: Datei speichern, Excel schließen, Installation durchführen, Excel wieder öffnen. 6 Travail de candidature 45 46 4. Häufigkeiten und Diagramme Abbildung 4.11.: Einfügen der letzten Klassengrenze in ein Histogramm. Bemerkung: Die Einteilung der horizontalen Achse eines Histogramms muss nicht zwingend gleichmäßig sein. Ist dies nicht der Fall, so muss die Breite der Rechtecke entsprechend angepasst werden. Excel unterstützt jedoch keine Histogramme mit ungleichmäßigen Intervallen. Für diese Zwecke kann man das kostenlose Programm GeoGebra benutzen. Die Umsetzung wird im Anhang A.1 beschrieben. . Aufgabe 8 In der angehängten Datei7 befinden sich im ersten Tabellenblatt die Einkommensdaten von 5 000 amerikanischen Haushalten aus dem Jahr 2006 und im zweiten Blatt das Einkommen von 50 Studenten während der Sommermonate. 1. Veranschaulichen Sie die beiden Verteilungen dieser Einkommen anhand jeweils eines Histogramms. Wählen Sie dafür eine geeignete Klasseneinteilung. 2. Vergleichen Sie die Histogramme in beiden Tabellenblättern. Was kann man über die Verteilungen sagen? 3. Erweitern Sie die Tabellen in den beiden Arbeitsblättern um die relativen Häufigkeiten. Man berechnet sie, indem man die Häufigkeit der jeweiligen Klasse durch die Gesamtsumme der Häufigkeiten teilt. 4. Erweitern Sie die beiden Tabellen um eine weitere Spalte, die die kumulierten relativen Häufigkeiten enthält. Das ist die Summe der relativen Häufigkeit der entsprechenden Klasse und allen vorangehenden Klassen. 7 Aufgabe 8: Travail de candidature 4.2. Histogramme 47 5. Erstellen Sie eine Liniengrafik der kumulierten relativen Häufigkeiten für beide Arbeitsblätter. Das Ergebnis soll wie in der folgenden Grafik aussehen. Lösung der Aufgabe Die Erläuterungen zu den einzelnen Punkten: 1. Die benutzten Formeln kann man in Abbildung 4.12 nachsehen. Die beiden Histogramme befinden sich in der Abbildung 4.13. Man beachte, dass die Häufigkeiten mit einer Matrixformel eingegeben wurden, so wie es auf Seite 43 erklärt wird. 2. Während die Einkommen der Studenten symmetrisch um eine Klasse, die in der Mitte liegt, verteilt sind, ist die Verteilung der Haushaltseinkommen asymmetrisch: es gibt sehr viel mehr Haushalte mit einem niedrigen Einkommen. 3. Diese Antwort wurde bereits im ersten Punkt erläutert. 4. Die Formeln befinden sich in der Abbildung 4.12 und können dort abgelesen werden. 5. Man wählt die Daten der Klassengrenzen und die der kumulierten relativen Häufigkeiten aus, um das Diagramm zu erstellen. Die Klassengrenzen der Beschriftung auf der horizontalen Achse werden auf die Teilstriche positioniert indem man einen Doppelklick auf die Achsenbeschriftung ausführt und die Option „Auf Teilstrichen“ im unteren Bereich des Fensters aktiviert. Die Lösungsdatei mit allen Diagrammen ist in der Fußnote angehängt.8 8 Lösung Aufgabe 8: Travail de candidature J 48 4. Häufigkeiten und Diagramme Abbildung 4.12.: Formeln im ersten und zweiten Tabellenblatt aus Aufgabe 8. Abbildung 4.13.: Verteilung der Haushaltseinkommen und der Studenteneinkommen aus Aufgabe 8. Travail de candidature 5. Zentralwerte Wie der Begriff „Zentralwert“ schon verrät, geht es in diesem Kapitel um Werte, die im Zentrum, also in der „Mitte“ liegen. Die Meisten denken hier wohl an den klassischen Mittelwert, mit dem das arithmetische Mittel gemeint ist.1 Allerdings benötigt man mehr als einen einzigen Mittelwert, um vernünftig Statistik zu betreiben. Bei politischen Wahlen zum Beispiel macht das arithmetische Mittel keinen Sinn. Hier zählt allein die Anzahl der Sitze einer Partei, die ihrerseits anhand der Anzahl der Stimmen bestimmt wird. In der Politik kommt es also darauf an, die meisten Wähler zu gewinnen. Womit man beim Modus wäre, der im nächsten Unterkapitel näher beleuchtet wird. 5.1. Der Modus . Aufgabe 9 In der angehängten Datei2 sind die Benotungen von etwa 120 Schülern. Erstellen Sie eine Tabelle, die die Häufigkeiten jeder Benotung auflistet. Welche Benotung kommt am häufigsten vor? Lösung der Aufgabe Die folgende Tabelle enthält die Ergebnisse. Die Lösungsdatei ist angehängt.3 Benotung Schüleranzahl sehr gut 15 gut 32 ausreichend 68 ungenügend 18 1 Neben dem arithmetischen Mittel existieren weiterhin das harmonische und das geometrische Mittel. In diesem Kurs wird lediglich auf das arithmetische Mittel im Detail eingegangen. Einen Überblick über andere Mittelwerte ist im Anhang ab Seite 106 zu finden. 2 Aufgabe 9: 3 Lösung Aufgabe 9: 50 5. Zentralwerte Die Häufigkeiten erhält man mit der Funktion „ZÄHLENWENN(Bereich; Suchkriterien)“. Ins erste Argument schreibt man „A:A“ damit die gesamte erste Spalte betrachtet wird. Ins zweite Argument schreibt man die jeweilige Benotung. Der Modus ist in diesem Beispiel „ausreichend“, da er im Vergleich zu allen anderen Benotung viel häufiger vorkommt. J Liegen Zahlenwerte vor, kann Excel den Modus mit der Funktion „Modus.einf“ ermitteln. Allerdings hat diese Vorgehensweise den Nachteil, dass man nicht erkennt, ob nur ein oder mehrere Modalwerte existieren. Darüber hinaus erkennt man nicht, wie groß der Unterschied zwischen der Häufigkeit des Modus und des nächsten Wertes ist. Treten nämlich mehrere Werte annähernd gleich oft auf, sagt man, dass kein Modus existiert. Benutzt man in dem Fall die Funktion „MODUS.EINF“ definiert man womöglich einen Modus, den es mathematisch gesehen zwar gibt, den man im Allgemeinen aber nicht annimmt. Daher sollte man immer eine vollständige Tabelle mit den Häufigkeiten erstellen um den Modus selbst zu bestimmen. . Aufgabe 10 Bestimmen Sie den Modus der Punktzahl der Schüler in der angehängten Datei.4 Lösung der Aufgabe In den folgenden Tabellen stehen die Ergebnisse. Die entsprechende Datei ist angehängt.5 Benotung 0 1 2 3 4 5 6 7 8 9 10 Häufigkeit - 6 - 3 7 8 11 23 22 27 23 Benotung 11 12 13 14 15 16 17 18 19 20 Häufigkeit 26 26 28 25 19 13 6 4 2 - Wendet man hier die Funktion „Modus.einf“ an, liefert Excel den Wert 13. In Anbetracht dessen, dass es mehrere Werte gibt, die sehr nahe beieinander liegen, definiert man in diesem Fall jedoch keinen Modus. J . Aufgabe 11 Folgendes Histogramm repräsentiert die Verteilung der Anzahl der Arbeiter einer Firma in Funktion ihres Dienstalters. 4 Aufgabe 10: 5 Lösung Aufgabe 10: Travail de candidature 5.2. Der Median Arbeiter [#] 60 50 40 30 20 10 0 5 10 15 20 25 30 35 40 Dienstalter [Jahre] Bestimmen Sie den Modus anhand dieser Daten. Lösung der Aufgabe Am Histogramm liest man ab, dass sich zwei Klassen in Bezug auf die Häufigkeitsverteilung von allen anderen Klassen absetzen. In diesem Fall existieren zwei Modi: einerseits die Klasse der Altersgruppe zwischen 5 und 10 Dienstjahren und andererseits die Altersgruppe von 20 bis 25 Dienstjahren. Eine solche Verteilung nennt man bimodal. J Bemerkung: Einen Modus gibt es nur dann, wenn sich ein Wert in der Häufigkeit von allen anderen Werten absetzt. Existieren zwei oder mehr Werte, die im Vergleich zu allen Anderen viel öfter auftreten, definiert man entsprechend zwei oder mehr Modi. 5.2. Der Median Der Modus gehört zwar zur Gruppe der Zentralwerte, er liegt aber offensichtlich nicht notwendigerweise im „Zentrum“ einer Datenreihe. Dieses Zentrum würde man eher in der Mitte zwischen allen anderen Werten vermuten. Genau so ist der Median definiert. Betrachtet man die Zahlen 1; 2; 5, dann ist 2 der Median, weil er, nachdem man alle Daten sortiert hat, zwischen den beiden Anderen liegt. Für die Zahlen 7; 0; 5; 7; 6 ist 6 der Median, da er nach dem Sortieren (0; 5; 6; 7; 7) in der Mitte von allen Zahlen liegt. Um einen Median zu bestimmen, muss man die Daten also sortieren können. Travail de candidature 51 52 5. Zentralwerte . Aufgabe 12 Versuchen Sie zunächst ohne Excel den Median der jeweiligen Datenreihe zu bestimmen. Überprüfen Sie anschließend Ihre Ergebnisse mit der Funktion „Median“. Datenreihe Median 0; 1; 0 2; 2; 57; 3; 3 0; 3; 4; 5 Lösung der Aufgabe Excel liefert die folgenden Ergebnisse. Datenreihe Median 0; 1; 0 2; 2; 57; 3; 3 0; 3; 4; 5 0 3 3,5 Der Median stellt immer den mittleren oder den zentralen Wert einer Zahlenfolge dar. Nachdem man die Daten also sortiert hat, liegt dieselbe Anzahl an Werten links und rechts vom Median. Anders ausgedrückt befindet sich rund die Hälfte der Werte links vom Median. Das heißt, ungefähr die Hälfte der Daten ist kleiner oder gleich dem Median. Ist die Anzahl der Daten ungerade, beispielsweise 121, dann ist der Median der 61. Wert, da genau 60 Werte davor und 60 Werte dahinter liegen. Berechnen tut man die Position des Median, indem man zu 121 eins hinzu addiert und durch 2 teilt. Bei einer geraden Anzahl von Werten gibt es zwei zentrale Werte. Der Median ist dann die Summe dieser beiden Werte, geteilt durch 2. Dadurch wird sichergestellt, dass ungefähr die gleiche Anzahl an Werten links und rechts vom Median liegen. Das letzte Beispiel aus der Tabelle beinhaltet vier Datenwerte. Das heißt, der Median ist die Hälfte der Summe des zweiten und dritten Wertes: 3+4 = 3, 5. 2 J Travail de candidature 5.2. Der Median Abbildung 5.1.: Neue Sortierreihenfolge definieren. . Aufgabe 13 In der Fußnote6 befindet sich eine Datei mit der Benotung von etwa 200 Studenten. 1. Bestimmen Sie den Median dieser Daten. 2. Erstellen Sie eine Tabelle mit der Häufigkeitsverteilung der Benotungen. 3. Erweitern Sie diese Tabelle um die relativen Häufigkeiten sowie um die kumulierten relativen Häufigkeiten. 4. Wie kann man den Median aus der Tabelle der kumulierten Häufigkeiten lesen? Lösung der Aufgabe 1. Zunächst muss man die Daten sortieren. Dazu markiert man die Spalte A und wählt dann im Menüband „Start“ die Schaltfläche „Sortieren und Filtern“, „Benutzerdefiniertes Sortieren“. Da die gewünschte Reihenfolge noch nicht aufgelistet ist, fügt man sie unter „Benutzerdefinierte Liste“ hinzu. Abbildung 5.1 illustriert, wie man vorgehen muss. Da insgesamt 120 Werte vorliegen, gibt es 2 zentrale Werte: den 60. und den 61. Wert. Die Benotungen, die nach dem Sortieren in den Zeilen 60 und 61 stehen, heißen „ausreichend“. Der Median ist dementsprechend ebenfalls „ausreichend“. 2. Die Zahlenwerte befinden sich in Tabelle 5.1 und die benutzten Formeln in Abbildung 5.2. 3. Siehe Tabelle 5.1 und Abbildung 5.2. 6 Aufgabe 13 Travail de candidature 53 54 5. Zentralwerte Benotung Häufigkeit rel. Hfgk. ungenügend 30 25% ausreichend 56 47% 24 20% gut sehr gut 10 8% Total: 120 100% rel. Kum. Hfgk. 25% 72% 92% 100% Tabelle 5.1.: Ergebnisse der Aufgabe 13. Abbildung 5.2.: Benutzte Formeln in Aufgabe 13. 4. Da der Median so definiert ist, dass die Hälfte der Werte, also 50%, links und 50% rechts von ihm liegen, muss er sich in der Klasse befinden, die die 50%Marke zuerst überschreitet. In diesem Fall ist es die Klasse mit der Bewertung „ausreichend“. Die Ergebnisse befinden sich ebenfalls in der angehängten Datei.7 Bemerkung: Ähnlich wie bei der Funktion „MODUS.EINF“ ist es nicht möglich, den Median zu bestimmen, wenn die vorliegenden Werte keine Zahlenwerte sind. In dem Fall muss man wie in Aufgabe 13 vorgehen und die Werte sortieren. Aus Aufgabe 13 geht ebenfalls hervor, dass der Median in der Gruppe oder Klasse liegt, die als Erste die 50%-Marke der kumulierten relativen Häufigkeiten überschreitet. Daher nennt man ihn auch noch das 50. Quantil (Quantil bedeutet Hunderstel). Dementsprechend definiert man das 25. Quantil und das 75. Quantil, die auch noch das erste und das dritte Quartil (Viertel) genannt werden. Insgesamt sind der Median, das 50. Quantil und das 2. Quartil also identisch. Manchmal wurden die Daten in Klassen gruppiert und die Primärdaten liegen nicht mehr vor. Beispielsweise in einer Zeitschrift, in der die Daten aufgrund eines besseren Überblicks in einer Tabelle gruppiert wurden. Zur Tabelle 5.2 liegen die Primärdaten auch nicht vor. Der Median dieser Daten befindet sich in der Klasse [100; 150[, da die kumulierten relativen Häufigkeiten dieser Klasse die 50%-Marke zuerst überschreitet. 7 Lösung Aufgabe 13: Travail de candidature J 5.2. Der Median Ausgaben [e] rel. Hfgk. [%] [0; 50[ 20% [50; 100[ 26% 34% [100; 150[ [150; 200[ 15% 5% [200; 250[ kum. rel. Hfgk. [%] 20% 46% 80% 95% 100% Tabelle 5.2.: Tabelle ohne Primärdaten. Abbildung 5.3.: Den Median grafisch bestimmen. Man könnte also einfach den Mittelwert beider Klassengrenzen wählen und behaupten, der Median sei 125. Betrachtet man aber das Diagramm der kumulierten relativen Häufigkeiten in Abbildung 5.3, stellt man fest, dass das 50. Quantil, also der Median, wesentlich näher an 100 e liegt. Anhand der Abbildung 5.3 kann man den Median eingrenzen und behaupten, dass er in etwa zwischen 102 e und 110 e liegt. Eine viel genauere Abschätzung kann man alleine mit Hilfe der Grafik aber nicht erreichen. Wenn man jedoch die Zahlenwerte aus der Tabelle hinzuzieht, kann man einen exakten Wert berechnen. Man erkennt, dass der Weg vom Punkt A unterhalb der Pfeiles bis zum nächstgelegenen Punkt B oberhalb, gleichmäßig verläuft. Hat man also zum Beispiel die Hälfte des Weges von A nach B zurückgelegt, so hat man auch die Hälfte des Weges in der Horizontalen und auch die Hälfte des Weges in der Vertikalen von A nach B zurückgelegt. Entsprechend nutzt man diese „Gleichmäßigkeit“ oder Proportionalität innerhalb der Klassen aus, um die Distanz in der Horizontalen von 100 e bis zum Median zu berechnen. Da der Median bei genau 50% der kumulierten relativen Häufigkeiten liegt, Travail de candidature 55 56 5. Zentralwerte weiß man, dass in diesem Beispiel genau 4 Prozentpunkte zwischen dem unteren Ende A und dem Median liegen. Die ganze Breite dieser Klasse beträgt 34 Prozentpunkte. 4 Man hat also 34 des Weges von A nach B zurückgelegt, um zum Median zu gelangen. 4 von der Breite In der Horizontalen muss man also, beginnend bei 100 e, ebenfalls 34 4 der Klasse, also 50, zurücklegen, um zum Median zu gelangen. 34 von 50 sind ungefähr 5,9. Der Median liegt also bei etwa 105,9 e. Die ganze Rechnung sieht wie folgt aus: M = 100 + 4 · 50 ≈ 105, 9 e. 34 Bezeichnet man die Höhe der Punkte A und B auf der horizontalen Achse mit xA , xB und die Höhe auf der vertikalen Achse entsprechend mit yA und yB , erhält man die Formel 0, 5 − yA · (xB − xA ). M = xA + yB − yA Setzt man die Werte aus dem Beispiel oben ein, erhält man M = 100 + = 100 + 0, 50 − 0, 46 · (150 − 100) 0, 80 − 0, 46 0, 04 · 50 0, 34 ≈ 105, 9. Multipliziert man den Zähler und den Nenner des Bruchs mit 100, erhält man genau die gleiche Formel wie oben. . Aufgabe 14 Die folgende Tabelle enthält die Amtszeiten englischer Monarchen zwischen 827 und 1952. Bestimmen Sie den Median. Was sagt er aus und was kann man daraus schließen? Amtszeit [Jahre] Monarchen [#] [0; 10[ [10; 20[ [20; 30[ [30; 40[ [40; 50[ [50; 60[ [60; 70[ 22 16 11 7 1 2 2 Travail de candidature 5.2. Der Median 57 Lösung der Aufgabe Der Median ist etwa 15 Jahre und wird wie oben anhand der kumulierten Häufigkeiten berechnet. Erweitert man die Tabelle um die entsprechenden Spalten, erhält man folgende Werte: Amtszeit [Jahre] Monarchen [#] rel. Hfgk. [0; 10[ [10; 20[ [20; 30[ [30; 40[ [40; 50[ [50; 60[ [60; 70[ 22 16 11 7 1 2 2 36% 26% 18% 11% 2% 3% 3% kum. rel. Hfgk. 36% 62% 80% 91% 93% 97% 100% Mit Hilfe der allgemeinen Formel weiter oben erhält man: M = xA + ≈ 10 + = 10 + 0,50−yA · (xB − xA ). yB −yA 0,50−0,36 · (20 − 10) 0,62−0,36 0,14 · 10 0,28 = 15 Ungefähr 50% der Monarchen hat demnach nicht länger als 15 Jahre regiert. . Aufgabe 15 In der angehängten Datei8 sind die Antworten einer Umfrage, in der etwa 100 Haushalte nach der Anzahl der vorhandenen Fernsehgeräte befragt wurden. Bereiten Sie die Daten in einer Häufigkeitstabelle auf, die auch die kumulierten relativen Häufigkeiten enthält und bestimmen Sie den Median. Überprüfen Sie das Ergebnis anhand der Funktion „Median“. Lösung der Aufgabe Hier liegen keine Klassen vor! Den Median bestimmt man also anhand der kumulierten relativen Häufigkeiten. Der erste Wert, für den die kumulierten relativen Häufigkeiten 8 Aufgabe 15: Travail de candidature J 58 5. Zentralwerte die 50%-Marke überschreiten ist 2. Der Median ist also 2. Anzahl Fernseher Anzahl Familien rel. Hfgk. rel. kum. Hfgk. 0 1 2 3 4 5 1 26 46 20 10 1 1% 25% 44% 19% 10% 1% 1% 26% 70% 89% 99% 100% Die Datei mit den Ergebnissen ist in der Fußnote angehängt.9 5.3. Das arithmetische Mittel Beim arithmetischen Mittel handelt es sich um den bekanntesten aller Mittelwerte. Hier wird auf das arithmetische Mittel im Detail eingegangen, während weitere Mittelwerte im Anhang A.2 erläutert werden. Das arithmetische Mittel bildet die Summe aller Werte, geteilt durch die Anzahl dieser Werte. Schreibt man xi für die einzelnen Werte, nimmt i die Zahlen 1 bis n an, wobei n die Anzahl der Werte repräsentiert. Die Formel für das arithmetische Mittel ergibt dann x1 + x2 + .. + xn = n n P xi i=1 n = n 1X xi . n i=1 An dieser Berechnungsweise erkennt man, dass das arithmetische Mittel den durchschnittlichen Wert angibt, den man erhält, wenn man eine Gesamtsumme gleichmäßig aufteilen würde. Um die Bedeutung des Mittelwerts zu veranschaulichen kann man beispielsweise die Löhne einer Firma mit 10 Mitarbeitern analysieren: 852 e, 1 250 e, 1 751 e, 1 751 e, 1 820 e, 1 857 e, 1 867 e, 2 200 e, 2 200 e, 4 721 e. Die Summe aller Löhne beträgt 20 269 e. Würde man sie gleichmäßig aufteilen, würde jeder Mitarbeiter 20 269 : 10 = 2 026, 90 e erhalten. Dieser Wert entspricht genau dem arithmetischen Mittelwert aller Löhne. In Excel kann man den arithmetischen Mittelwert mit der Funktion „MITTELWERT“ berechnen. 9 Lösung Aufgabe 15: Travail de candidature J 5.3. Das arithmetische Mittel . Aufgabe 16 Berechnen Sie den Mittelwert der Einkommen der Haushalte aus Aufgabe 8. Wofür steht dieser Mittelwert? Lösung der Aufgabe Das arithmetische Mittel der Einkommen beträgt ungefähr 78 195 e. Würde das gesamte Einkommen gleichmäßig auf alle Lohnempfänger aufgeteilt werden, erhielt jeder diese Summe von etwa 78 195 e. J Liegen nicht alle Primärdaten vor, muss man unterscheiden, wie die Daten aufbereitet sind: • Sind die Daten in einer Tabelle wie auf Seite 58 zusammengefasst, muss jeder Wert mit der entsprechenden Anzahl multipliziert werden: 0 · 1 + 1 · 26 + 2 · 46 + 3 · 20 + 4 · 10 + 5 · 1 26 + 92 + 60 + 40 + 5 = ≈ 2, 14 1 + 26 + 46 + 20 + 10 + 1 104 Im Durchschnitt besitzt also jede Familie 2,14 Fernseher. Dies entspricht dem Mittelwert, den man mit den allen Primärdaten erhalten würde. Durch das Zusammenfassen gehen nämlich keine Daten verloren. In diesem Beispiel kann man über die Sinnhaftigkeit vom arithmetischen Mittel diskutieren. Vor allem dann, wenn man im Allgemeinen davon ausgeht, dass nur ganze Fernseher existieren. • Liegen wie in Aufgabe 14 Klassen vor, multipliziert man die Häufigkeiten der Klassen mit dem Mittelwert der beiden Intervallgrenzen der entsprechenden Klasse. Man erhält 5 · 22 + 15 · 16 + 25 · 11 + 35 · 7 + 45 · 1 + 55 · 2 + 65 · 1 ≈ 19. 22 + 16 + 11 + 7 + 1 + 2 + 2 Im Durchschnitt hat also jeder Monarch etwa 19 Jahre regiert. Ein Mittelwert mit Nachkommastellen macht hier keinen Sinn, denn die gegebenen Daten ermöglichen keine präziseren Schätzungen. . Aufgabe 17 Untenstehend die Stundenlöhne (in e) von 10 Angestellten in zwei verschiedenen Unternehmen. Unternehmen 1 10 10 10 10 10 10 15 15 50 50 Unternehmen 2 16 16 17 17 17 17 17 17 18 19 Berechnen Sie das arithmetische Mittel der Stundenlöhne beider Unternehmen. Welche Schlussfolgerungen kann man ziehen, wenn man beide Werte vergleicht? Travail de candidature 59 60 5. Zentralwerte Lösung der Aufgabe Der Mittelwert des Stundenlohns im ersten Unternehmen beträgt 19 e, der im zweiten Unternehmen 17,1 e. Der Mittelwert ist im ersten Unternehmen höher ist als im Zweiten. Trotzdem verdienen die meisten Lohnempfänger aus dem ersten Unternehmen bedeutend weniger als den Durchschnittsstundenlohn, während die Löhne im zweiten Unternehmen viel homogener aufgeteilt sind. Der Mittelwert sagt also nichts über die Verteilung der Löhne aus. J . Aufgabe 18 Die folgende Tabelle stellt das Einkommen der Haushalte von 10 kanadischen Provinzen im Jahr 1997 dar: Einkommen, ø [$] Einkommen, Median [$] Provinz Alberta British Columbia Manitoba Neufundland und Labrador New Brunswick Nova Scotia Ontario Prince Edward Island Québec Saskatchewan 47 539 47 041 43 556 37 438 39 549 38 524 52 072 37 914 41 499 40 921 40 403 37 957 36 872 31 125 33 977 32 585 42 753 32 466 33 858 32 974 1. Wieso ist das durchschnittliche Einkommen in allen Provinzen höher als der Median des Einkommens? 2. Berechnen Sie den Mittelwert der Einkommen. Wieso entspricht er nicht den vom kanadischen Statistikamt veröffentlichten Wert von $ 46 556? Lösung der Aufgabe 1. Es liegt eine asymmetrische Verteilung der Einkommen vor. In dieser Verteilung gibt es weniger höhere Werte, die dafür aber umso höher ausfallen. In etwa so wie beim ersten Unternehmen in der Aufgabe 17. 2. Berechnet man den Mittelwert aller Einkommen, wird jede der zehn Provinzen gleich gewichtet. Dies entspricht aber nicht der Realität, da nicht die gleiche Anzahl an Einwohnern in jeder Provinz leben. Man müsste also die Einkommen mit der Anzahl der Einwohner der entsprechenden Provinz multiplizieren und die Travail de candidature 5.4. Wann nimmt man welchen Zentralwert? 61 Werte anschließend addieren und durch die gesamte Einwohnerzahl dividieren. Erst dann würde man auf den vom kanadischen Statistikamt veröffentlichten Wert kommen. Da diese Daten hier aber nicht vorliegen, kann man den Wert nicht nachrechnen. . J . Aufgabe 19 Nach einer Studie der Uni Kassel im Jahr 2010 verdienen vollzeitbeschäftigte Fachhochschulabsolventen zehn Jahre nach ihrem Abschluss im Schnitt etwa 59 400 e. Nun behauptet ein Freund, dass sein Vater, Hochschulabsolvent, aber 95 000 e im Jahr verdient. Stehen beide Aussagen im Widerspruch? Erläutern Sie Ihre Antwort. Lösung der Aufgabe Nein, beide Aussagen stehen nicht im Widerspruch. Es gibt immer Ausreißer nach oben und die Jahresgehälter können teilweise erheblich vom Durchschnittseinkommen abweichen. Dadurch sind viel höhere Gehälter als das Durchschnittsgehalt möglich. Andererseits gibt es dann unter Umständen mehr niedrige Gehälter, die diese wenigen hohen Gehälter „ausgleichen“. J 5.4. Wann nimmt man welchen Zentralwert? Von den drei hier vorgestellten Zentralwerten, dem Modus, dem Median und dem arithmetischen Mittel, hat jeder seine Daseinsberechtigung. Im Allgemeinen gibt es keine goldene Regel, die jederzeit besagen kann, welchen Zentralwert man nehmen muss. Man kann aber anhand einiger charakteristischer Merkmale festmachen, zu welchem Zentralwert man tendieren sollte. Den Modus wählt man, wenn sich ein oder mehrere Werte in der Häufigkeit von allen Anderen abheben. Zum Beispiel wenn eine bimodale Verteilung vorliegt, wie in der Abbildung 5.4. Bei einer solchen Verteilung liegen sehr wenige Werte in der Nähe des Medians oder des arithmetischen Mittelwertes. In diesem Fall einer bimodalen Verteilung liegen sogar zwei Modi vor. Es ist also durchaus möglich, dass zwei oder mehr Modi existieren. Die Modi müssen sich lediglich in der Häufigkeit von allen anderen Werten abheben. Wenn es einen Modus gibt, der nur ein wenig öfter als alle Anderen auftritt, sagt man, dass es keinen Modus gibt. Konkret wird der Modus zum Beispiel von einem Textilhersteller benutzt, der für den breitesten Markt produzieren möchte und daher wissen will, welche Kleidergröße Travail de candidature 62 5. Zentralwerte Abbildung 5.4.: Beispiel einer bimodalen Verteilung. am meisten verkauft wird. Ihn wird das arithmetische Mittel der Größe aller produzierten Kleider wahrlich nicht interessieren, denn was nützt es ihm, wenn er seine Kleider in „Mittelwert“-Größe produziert, sie aber niemandem passen? Der Median ist der Wert, der in der „Mitte“ liegt. Er wird benutzt, wenn einige wenige Ausreißer nach unten oder oben existieren, die den arithmetischen Mittelwert zu sehr in ihre Richtung beeinflussen würden. Dies ist unter anderem bei asymmetrischen Verteilungen der Fall. Ein Anwendungsbeispiel wären die Gehälter einer Firma oder eines Landes, wo wenige Besserverdiener einen wesentlich höheren Lohn erhalten als die restliche Belegschaft. Aufgabe 17 stellt hierfür ein theoretisches Beispiel dar. Den bekanntesten aller Zentralwerte, den arithmetischen Mittelwert, nimmt man meistens dann, wenn die oben genannten Fälle nicht vorliegen. Das heißt, wenn eine symmetrische und unimodale Verteilung der Werte vorliegt. Anders ausgedrückt sollen die Werte mehr oder weniger gleichmäßig verteilt sein, um einen aussagekräftigen Mittelwert zu erhalten. Als Beispiel könnte man hier den Absatz oder Umsatz des Textilverkäufers nennen, der wissen möchte, wie viele Kleider er im Durchschnitt verkauft hat. Travail de candidature 5.4. Wann nimmt man welchen Zentralwert? . Aufgabe 20 Welchen Zentralwert sollte man in jedem der folgenden Beispielen nehmen? 1. Aufteilung der Angestellten nach ihrer Muttersprache. Muttersprache Anzahl Angestellter Luxemburgisch Französisch Deutsch Sonstige 25 81 57 9 2. Aufteilung der Angestellten nach ihrer Zufriedenheit. Zufriedenheit Anzahl Angestellter sehr unzufrieden eher unzufrieden eher zufrieden sehr zufrieden 18 27 60 45 3. Aufteilung der Angestellten nach ihren Krankentagen. Krankentage Angestellte [%] 0 1 2 3 85 12 2 1 4. Die Ergebnisse einer Schulklasse in einer Klausur. 1; 5; 24; 26; 28; 31; 32; 34; 34; 35; 35; 35; 37; 38; 40; 42. Lösung der Aufgabe Die Ergebnisse im Überblick: Teilaufgabe Modus Median Arithmetisches Mittel 1. 2. 3. 4. Französisch eher zufrieden 0 35 eher zufrieden 0 34 0,19 ≈ 30, 33 Travail de candidature 63 64 5. Zentralwerte Während in den ersten beiden Beispielen keine Wahl bleibt, sollte man im dritten Beispiel den Modus oder den Median wählen, da die Verteilungen asymmetrisch sind. In der vierten Teilaufgabe gibt es zwei Ausreißer, die den Mittelwert nach unten ziehen. Einen Modus möchte man hier nicht definieren, da sich kein Wert zahlenmäßig von allen Anderen absetzt. Der Median wäre hier also der geeignetere Zentralwert. J Travail de candidature 6. Streuungsmaße Ein Zentralwert gibt an um welchen Wert die Daten verteilt sind. Will man beispielsweise die Ausgangsqualität eines Produktes bewerten, reicht ein Zentralwert allein nicht aus. Der Produzent möchte nämlich eine möglichst gleichbleibende Qualität seiner Produkte erreichen. Die Schwankungen sollten also möglichst klein sein. Umgekehrt sollten die Schwankungen in einem Eignungstest möglichst groß sein um die Spreu vom Weizen trennen. Man benötigt also eine Kennzahl für die Verteilung der vorliegenden Daten. Hierüber liefert ein Zentralwert aber keine Erkenntnis, denn er gibt lediglich ein „Zentrum“ an, je nachdem wie er definiert ist. Ein ähnliches Bild zeichnet sich bei den Kennwerten, die die Verteilung von Daten messen, denn auch hier existieren Mehrere. Die Geläufigsten sind jedoch die Spannweite und die Standardabweichung, die in der Folge vorgestellt werden. 6.1. Die Spannweite Im ersten Einführungsbeispiel will man eine möglichst stabile Produktqualität erreichen, denn die Firma möchte eine ausreichend gute und stabile Qualität ihrer Produkte sicherstellen. Es ist also erwünscht, dass die Ergebnisse der Qualitätstests eng zusammen liegen. Hier liegt es nahe, die Differenz zwischen dem höchsten und dem niedrigsten Wert zu berechnen. Diese Kennzahl definiert die Spannweite. Um die Spannweite zu veranschaulichen, kann man die beiden Einführungsbeispiele mit Zahlen unterlegen. . Aufgabe 21 In der angehängten Datei1 befinden sich in zwei Tabellenblättern die Testergebnisse der Belastungstests von Beton, sowie die Punktzahl der Bewerber einer Arbeitsstelle. Berechnen Sie mit den Funktionen „MIN(Bereich)“ und „MAX(Bereich)“ die Spannweite beider Datenreihen. 1 Aufgabe 21: 66 6. Streuungsmaße Lösung der Aufgabe Die Spannweite im ersten Beispiel beträgt etwa 0,9 und die Spannweite im zweiten Beispiel beträgt 11 Punkte. Die Datei mit den Ergebnissen ist in der Fußnote angehängt.2 J Die beiden Spannweiten 0,9 und 11 liegen weit auseinander und sind als einzelne Zahlen wenig aussagekräftig. Um sie besser einordnen und vergleichen zu können, setzt man sie deswegen in Bezug zum arithmetischen Mittelwert. Man erhält eine Spannweite von etwa 10% im ersten Beispiel und eine Spannweite von etwa 83% im zweiten Beispiel. Auf den ersten Blick erscheint der zweite Test durch die große Spannweite der Ergebnisse als geeignet, den kompetentesten Kandidaten zu ermitteln. Allerdings erkennt man bei genauerem Hinsehen, dass die erhöhte Spannweite durch einen einzigen Ausreißer bedingt ist und die restlichen Werte annähernd gleich sind. Somit ist es nicht eindeutig möglich, den besten Kandidaten zu finden. Die Spannweite gibt die Breite der Testergebnisse sehr gut wieder. Sie ist aber keine zuverlässige Kennzahl, wenn es um die Verteilung der Gesamtheit aller Daten geht. Es braucht also eine weitere Kennzahl, die im nächsten Abschnitt analysiert wird. 6.2. Die Standardabweichung Im Gegensatz zur Spannweite zieht die Standardabweichung alle Werte zur Berechnung heran. Sie wird mit Hilfe der Varianz berechnet. Das ist die Summe der Quadrate der Abweichungen aller Werte vom arithmetischen Mittel, geteilt durch die Anzahl der Werte. Sind x1 ; x2 ; ..; xn die vorhandenen Werte und x deren Mittelwert, so wird die Varianz wie folgt berechnet: 2 2 2 (x1 − x) + (x2 − x) + .. + (xn − x) = n n P (xi − x)2 i=1 n = n 1X (xi − x)2 n i=1 Wieso es gerade die Quadrate der Abweichungen sind, die summiert werden, und nicht die Abweichungen selbst, wird im nächsten Kapitel veranschaulicht. Durch das Quadrieren der Terme sind die Einheiten der Varianz und der Daten xi verschieden. Deswegen berechnet man die Quadratwurzel der Varianz, um die Standardabweichung 2 Lösung Aufgabe 21: Travail de candidature 6.2. Die Standardabweichung 67 zu erhalten. Sie wird mit σ bezeichnet: σ= v u n u1 X t (x n i=1 i − x)2 . In Excel berechnet man die Standardabweichung mit Hilfe der Funktion „STABW.N(Bereich)“. . Aufgabe 22 Acht Bewerber des vorher erwähnten Einführungstests unterzogen sich einem zweiten Test, dessen Ergebnisse in der Tabelle unten hinzugefügt wurden: Punkte (von 20) Test 1: Test 2: 14 17 13 14 15 13 5 16 15 7 16 17 10 7 17 14 Berechnen Sie den arithmetischen Mittelwert, die Spannweite und die Standardabweichung der beiden Tests. Vergleichen Sie die Ergebnisse der drei Kennzahlen. Lösung der Aufgabe Die Ergebnisse beider Datenreihe ergeben folgende Werte. Test 1 Test 2 MW Spannweite Stdabw. 13,125 13,125 11 10 ≈ 3,22 ≈ 4,17 Während die Mittelwerte in beiden Fällen identisch sind, weichen die Spannweite und die Standardabweichung voneinander ab. Im ersten Test liegt die Spannweite um 10% höher, die Standardabweichung aber um 25% kleiner als im zweiten Test. Da die Standardabweichung die Abweichung jedes einzelnen Wertes vom (arithmetischen) Mittelwert summiert, wird die Zahl um so höher, je weiter die Daten vom Mittelwert entfernt liegen. Umgekehrt gilt natürlich auch, dass, je näher die Daten am arithmetischen Mittel liegen, desto kleiner wird die Standardabweichung. Sie ist also ein Indikator dafür, ob die Mehrzahl der Daten nahe um den Mittelwert liegen oder weiter vom Mittelwert entfernt liegen. J . Aufgabe 23 Berechnen Sie die Standardabweichung der 5 000 Einkommen aus Aufgabe 8. Lösung der Aufgabe Die Standardabweichung beträgt ungefähr 123 611 e. Travail de candidature J 68 6. Streuungsmaße . Aufgabe 24 Folgende Tabelle enthält die Kundenumsätze (in Tsd. e) von vier verschiedenen Firmen. Firma Firma Firma Firma A: B: C: D: 121 132 132 122 134 135 135 125 137 138 138 138 142 141 142 158 162 148 165 160 Schätzen Sie zunächst von welcher Firma die Kundenumsätze die höchste Standardabweichung aufweisen. Überprüfen Sie Ihre Vermutung anschließend mit Hilfe von Excel. Lösung der Aufgabe Die Mittelwerte der Umsätze der vier Firmen liegen alle zwischen ungefähr 136 und 138, denn die äußeren Werte liegen jeweils paarweise in etwa gleich weit davon entfernt. Der kleinste und der größte Wert von Firma A liegen sehr viel weiter vom geschätzten Mittelwert weg, als die entsprechenden Werte von Firma B. Die Standardabweichung von Firma A muss demnach höher sein. Die Argumentation zwischen A und C ist fast identisch. Hier ist es nun der kleinste Wert, der bei Firma A weiter vom Mittelwert entfernt liegt. Man erhält also vorerst die Reihenfolge B < C < A. Vergleicht man A mit D, sind die beiden äußeren und der mittlere Wert ungefähr gleich, während die restlichen zwei aber bei Firma D weiter voneinander entfernt sind. Folglich muss die Standardabweichung von Firma D den höchsten Wert aufweisen. Die berechneten Werte stehen in der folgenden Tabelle und bestätigen die vorangegangenen Überlegungen. σ Firma Firma Firma Firma A B C D ≈ 13, 35 ≈ 5, 49 ≈ 11, 77 ≈ 15, 97 J Travail de candidature 6.2. Die Standardabweichung . Aufgabe 25 Das folgende Histogramm enthält die Verteilung der Umsätze von zwei Firmen. 20 15 10 5 0 100 200 300 400 500 600 Welche der beiden Verteilungen weist die kleinere Standardabweichung auf? Lösung der Aufgabe Die Standardabweichung der grünen Verteilung ist kleiner, denn die Abweichung der Höhe der Säulen und damit der Daten vom Mittelwert sind kleiner als die der blauen Säulen. J Travail de candidature 69 7. Korrelation Das Wort Korrelation stammt aus dem mittellateinischen ’correlatio’, dessen Übersetzung ins Deutsche „Wechselbeziehung“ bedeutet. Die Korrelation beschreibt also die Beziehung oder den Zusammenhang zwischen zwei oder mehr Variablen, Merkmalen oder Ähnlichem. Dieser Kurs behandelt die Korrelation zwischen genau zwei Variablen, die durch x und y dargestellt werden. Faltet man beispielsweise ein Blatt Papier immer in der Mitte, so hängt die Anzahl der Lagen direkt von der Anzahl der Faltungen ab. Hat man 4 Lagen, weiß man, dass das Papier zweimal gefaltet wurde. Kennt man die Anzahl der Papierlagen, kann man Rückschlüsse auf die Anzahl der Faltungen ziehen. Die Anzahl der Lagen ist also mit der Anzahl der Faltungen korreliert. Ein anderes Beispiel ist die Weltbevölkerung. Sie wächst (exponentiell) mit der Zeit. Das heißt, die Größe der Population ist abhängig von der Zeit. Hier spielen aber noch andere Faktoren eine Rolle, so dass man nicht wie beim Papierfalten eindeutig sagen kann, wie die groß die Population y nach x Jahren ist. 7.1. Der Korrelationskoeffizient Als Einstieg kann man drei typische Situationen betrachten, wie sie in der folgenden Aufgabe vorkommen. . Aufgabe 26 Erläutern Sie für die folgenden drei Situationen, ob eine Korrelation, also ein Zusammenhang oder eine Abhängigkeit, besteht. 1. Die Anzahl der Touristen, die eine Stadt besuchen und die Höhe der Einnahmen dieser Stadt. 2. Das Gewicht eines Menschen und dessen Intelligenzquotient (IQ). 3. Die Dauer der Ausbildung eines Arztes und die Zeit, die er benötigt um eine richtige Diagnose zu erstellen. 72 7. Korrelation Lösung der Aufgabe In den einzelnen Fällen kann man teilweise anders argumentieren, was aber in der Natur der Sache liegt, da sich je nach Situation ein anderes Bild ergeben kann und die betrachteten Merkmale oder Eigenschaften nicht immer nur von einer einzigen Variable abhängig sind. Im Allgemeinen sind aber die folgenden Lösungen vertretbar: 1. In der Regel steigen die Einnahmen mit der Anzahl der Touristen. Es besteht also eine Korrelation oder Abhängigkeit zwischen beiden Merkmalen. 2. Da das Gewicht im Allgemeinen unabhängig von der Intelligenz eines Individuums ist, kann man hier von keiner Korrelation ausgehen. 3. Die Dauer der Ausbildung erhöht die Urteilskraft eines Arztes, so dass dieser - dank besserer Ausbildung - schneller auf die richtige Diagnose kommt. Beide Merkmale korrelieren also. Insbesondere im letzten Fall ist die Korrelation auch von anderen Faktoren, hier zum Beispiel von der Qualität des Ausbilders, abhängig. Es gibt also nicht immer eine Abhängigkeit von nur einer einzigen Variable. J Tritt eine Korrelation zwischen zwei Variablen auf, definiert man eine abhängige Variable, die mit y bezeichnet wird, und eine unabhängige Variable, die mit x bezeichnet wird: die abhängige Variable y variiert in Abhängigkeit von der unabhängigen Variable x. . Aufgabe 27 Definieren Sie in den drei Situationen aus Aufgabe 26 jeweils die unabhängige Variable x und die von x abhängige Variable y. Lösung der Aufgabe Sofern man von einer Korrelation ausgeht, kann man x und y wie folgt definieren: Situation x y 1 2 3 Anzahl der Touristen nicht definiert Dauer der Ausbildung Höhe der Einnahmen nicht definiert Zeit bis zur Diagnose Da im zweiten Fall keine Korrelation vorliegt, definiert man keine abhängige und auch keine unabhängige Variable. J Im Falle einer Korrelation unterscheidet man nicht nur zwischen zwei verschiedenen Variablen, sondern auch zwischen positiver und negativer Korrelation. Dazu kann man das erste und das letzte Beispiel aus Aufgabe 26 heranziehen: Travail de candidature 7.1. Der Korrelationskoeffizient • Im Allgemeinen steigen die Einnahmen mit der Anzahl der Touristen. Es liegt eine positive Korrelation vor. Steigt nämlich die erste, unabhängige Variable, also die Anzahl der Touristen, so steigt auch die davon abhängige Variable, die Einnahmen. • Im Falle einer negativen Korrelation fällt eine Variable, während die Andere im Gegenzug steigt. Im dritten Beispiel aus Aufgabe 26 fällt die benötigte Zeit des Arztes bis er eine richtige Diagnose stellt, wenn man seine Ausbildungsdauer erhöht. Die abhängige Variable (=„Dauer der Diagnosestellung“) fällt also, während die unabhängige Variable (=„Ausbildungsdauer“) steigt. Der umgekehrte Fall gilt natürlich auch. (Kürzere Ausbildungsdauer impliziert längere Diagnosestellung.) An den vorangegangen Beispielen erkennt man, dass es nicht nur die Zustände „korreliert“ und „nicht korreliert“ gibt, so wie es bei einer Glühbirne „an“ und „aus“ gibt, sondern dass es ein kontinuierlicher Übergang von einem Zustand zum Anderen ist. Man muss also zunächst herausfinden, ob überhaupt ein Zusammenhang, eine Korrelation, zwischen zwei Variablen besteht und wenn, dann möchte man auch wissen, wie stark diese Korrelation ist. Aus diesem Grund definiert man einen Korrelationskoeffizienten zwischen −1 und 1: liegt er nahe 1, sagt man, dass die zwei Variablen stark positiv korreliert sind. Je schwächer die positive Korrelation wird, desto kleiner wird der Korrelationskoeffizient, bis er schließlich 0 ist. Entsprechendes gilt für Korrelationskoeffizienten zwischen −1 und 0. Nahe −1 sind die beiden Variablen stark negativ korreliert und die negative Korrelation wird immer schwächer, je näher der Korrelationskoeffizient an 0 herankommt. Betrachtet man den Korrelationskoeffizienten ohne Vorzeichen, spricht man von • keiner Korrelation, wenn er kleiner als 0,2 ist, • schwacher Korrelation, wenn er zwischen 0,2 und 0,4 liegt, • mittlerer Korrelation, wenn er zwischen 0,4 und 0,7 liegt, • starker Korrelation, wenn er zwischen 0,7 und 0,9 liegt, • sehr starker Korrelation, wenn er zwischen 0,9 und 1 liegt, • perfekter Korrelation, wenn er genau 1 ist. Den Korrelationskoeffizienten berechnet Excel mit der Funktion Travail de candidature 73 74 7. Korrelation „KORREL(X-Werte;Y-Werte) “. Dabei können die beiden Argumente auch vertauscht werden, ohne das Ergebnis zu beeinflussen. Die Einführungsbeispiele werden in der folgenden Aufgabe mit Zahlen unterlegt, um den Korrelationskoeffizienten konkret zu berechnen. . Aufgabe 28 Schreiben Sie die folgenden Daten in ein Tabellenblatt und berechnen Sie den Korrelationskoeffizienten für jedes der drei vorliegenden Beispiele mit der Funktion „KORREL“. 1. Die Anzahl der Touristen und die Höhe der Einnahmen: Land Anzahl Touristen [·106 ] Einnahmen [·109 e] A 4,9 3,5 B 4,1 2 C 5,5 4 D 6,6 5 E 4,4 2,5 2. Das Gewicht eines Menschen und dessen IQ. Gewicht [kg] 70 65 85 90 75 70 80 75 58 48 IQ [Punkte] 120 95 110 100 112 100 105 95 120 98 3. Die Dauer der Ausbildung eines Arztes und die Zeit, die er braucht um eine richtige Diagnose zu erstellen. Ausbildungsdauer [Tage] 2 2 3 3 4 4 5 5 5 6 Zeit bis zur Diagnose [Min] 25 23 17 21 18 20 15 12 13 10 Lösung der Aufgabe Die Berechnung ergibt folgende Werte: 1. Da der Korrelationskoeffizient mit etwa 0,98 nahe 1 liegt, hat man hier eine starke positive Korrelation. 2. Hier liegt keine Korrelation vor, da der Koeffizient etwa 0 (−0, 02) beträgt. 3. Mit einem Korrelationskoeffizienten von etwa −0, 93 liegt eine starke negative Korrelation vor. J Möchte man den Korrelationskoeffizienten selbst nachrechnen, benötigt man zunächst die Mittelwerte der beiden vorliegenden Datenreihen, die mit x1 ; x2 ; ..; xn für Travail de candidature 7.1. Der Korrelationskoeffizient i 1 2 3 4 5 xi x1 = 4, 9 x2 = 4, 1 x3 = 5, 5 x4 = 6, 6 x5 = 4, 4 x = 5, 1 yi xi − x yi − y (xi − x) · (yi − y) y1 = 3, 5 −0, 2 0, 1 −0, 02 y2 = 2, 0 −1, 0 −1, 4 1, 40 y3 = 4, 0 0, 4 0, 6 0, 24 y4 = 5, 0 1, 5 1, 6 2, 40 y5 = 2, 5 −0, 7 −0, 9 0, 63 y = 3, 4 Summe: 4, 65 Tabelle 7.1.: Daten zur Berechnung des Zählers des Korrelationskoeffizienten. die Daten der ersten Variable und mit y1 ; y2 ; ..; yn für die Daten der zweiten Variable dargestellt werden. Zur Veranschaulichung dienen die Daten im ersten Beispiel aus Aufgabe 28. Für den Mittelwert der ersten Datenreihe, also der Anzahl der Touristen, errechnet man x = 5, 1. Der Mittelwert der zweiten Datenreihe, den Einnahmen, ergibt y = 3, 4. Anschließend berechnet man die Differenzen xi − x und yi − y jedes einzelnen Datenwertes zum jeweiligen Mittelwert. Multipliziert man die Differenzen, die von je zwei voneinander abhängigen Daten xi und yi stammen, so stellt deren Summe den Zähler des Korrelationskoeffizienten dar. Alle Zwischenwerte findet man in der Tabelle 7.1 wieder. In diesem Beispiel ist die Summe der Produkte und damit der Zähler des Korrelationskoeffizienten 4,65. Die entsprechende allgemeine Formel des Zählers des Korrelationskoeffizienten ist also (x1 − x) · (y1 − y) + (x2 − x) · (y2 − y) + ... + (xn − x) · (yn − y) = n P (xi − x) · (yi − y). i=1 Um den Nenner des Korrelationskoeffizienten zu erhalten, quadriert man die bereits berechneten Differenzen aus Tabelle 7.1. Die Ergebnisse befinden sich in der Tabelle 7.2. In der letzten Zeile dieser Tabelle stehen die Summen der Quadrate. Zieht man nun die Wurzel des Produktes beider Summen, erhält man den Nenner des Korrelationskoeffizienten: √ 3, 94 · 5, 70 ≈ 4, 74 Travail de candidature 75 76 7. Korrelation i 1 2 3 4 5 x1 x2 x3 x4 x5 yi (xi − x)2 (yi − y)2 y1 = 3, 5 0, 04 0, 01 y2 = 2, 0 1, 00 1, 96 y3 = 4, 0 0, 16 0, 36 y4 = 5, 0 2, 25 2, 56 y5 = 2, 5 0, 49 0, 81 Summe: √ 3, 94 5, 70 Nenner: 3, 94 · 5, 70 ≈ 4, 74 xi = 4, 9 = 4, 1 = 5, 5 = 6, 6 = 4, 4 Tabelle 7.2.: Daten zur Berechnung des Nenners des Korrelationskoeffizienten. Die entsprechende allgemeine Formel des Nenners des Korrelationskoeffizienten lautet somit q (x1 − x)2 + (x2 − y)2 + .. + (xn − y)2 · s = n P q (xi − x)2 · i=1 (y1 − x)2 + (y2 − y)2 + .. + (yn − y)2 n P (yi − y)2 . i=1 Insgesamt ergibt sich der von Excel berechnete Korrelationskoeffizient von etwa 4, 65 ≈ 0, 98. 4, 74 Aus den bisherigen Herleitungen erhält man die allgemeine Formel des Korrelationskoeffizienten: n P (xi − x) · (yi − y) s i=1 n P n P i=1 i=1 (xi − x)2 · (yi − y)2 Diese Zahlen und Formeln sind teilweise etwas abstrakt und die Zusammenhänge lassen sich anschaulicher anhand einer grafischen Darstellung der Daten erklären. Das nächste Unterkapitel verrät, wie man diese Daten grafisch auftragen kann und wie man mit Hilfe dieser Veranschaulichung eine (positive oder negative) Korrelation erkennt. Travail de candidature 7.2. Grafische Darstellung 7.2. Grafische Darstellung Die Datenpaare (xi ; yi ), die je einen Eintrag für die Variable x und y darstellen, stehen zusammen für einen Punkt in einer Ebene: die unabhängige Variable x und die abhängige Variable y stellen jeweils die horizontale, beziehungsweise vertikale Achsen dar, in der man je ein Datenpaar als Punkt mit den Koordinaten (xi ; yi ) eintragen kann. Dadurch erhält man die Streudiagramme, wie sie in der folgenden Aufgabe abgebildet sind. . Aufgabe 29 Erklären Sie mit Hilfe der Erkenntnisse aus den vorherigen Aufgaben, wie man an den folgenden grafischen Darstellungen erkennen kann, ob und welche Korrelation vorliegt. 1. Die Anzahl der Touristen und die Höhe der Einnahmen. Einnahmen [·109 e] 5 4 3 2 1 0 1 2 3 4 5 6 7 Touristen [·106 ] 2. Das Gewicht eines Menschen und dessen IQ. IQ [Pkt] 120 100 80 60 40 20 0 20 40 60 80 Gewicht [kg] 3. Die Dauer der Ausbildung eines Arztes und die Zeit, die er braucht um eine richtige Diagnose zu erstellen. Zeit bis zur Diagnose [Min] 25 20 15 10 5 0 1 2 3 4 5 6 Ausbildungsdauer [Tage] Travail de candidature 77 78 7. Korrelation Lösung der Aufgabe Sind zwei Variablen positiv korreliert, wie im ersten Beispiel, steigt die abhängige Variable y, wenn x ansteigt. Das heißt, wenn man sich auf der Grafik nach rechts bewegt, also x erhöht, müssen die Datenpunkte höher liegen, da y auch ansteigt. Im dritten Beispiel ist es genau umgekehrt. Die Punkte liegen nahe einer (gedachten) Geraden, die von links nach rechts abfällt. Dementsprechend sind die beiden Variablen negativ korreliert. Im zweiten Beispiel gleicht die Ansammlung der Datenpunkte eher einer Wolke, als dass sie an einer Geraden liegen würden. Umkreist man also die Daten in der Grafik, kann man Rückschlüsse auf den Korrelationskoeffizienten ziehen: je deutlicher eine Gerade zu erkennen ist, desto stärker ist die Korrelation und desto näher liegt der Korrelationskoeffizient an 1 oder −1. J . Aufgabe 30 Ordnen Sie den folgenden Grafiken ihrem jeweiligen Korrelationskoeffizienten zu: −0, 90; Grafik A 0, 50; 0, 85; Grafik B −0, 20. Grafik C Grafik D Lösung der Aufgabe Anhand der Erläuterungen in der Lösung der Aufgabe 29 kommt man auf folgende Ergebnisse: Grafik Korrelationskoeffizient A B C D −0, 20 0, 85 0, 50 −0, 90 J Travail de candidature 7.2. Grafische Darstellung Abbildung 7.1.: Erstellung eines Streudiagramms. . Aufgabe 31 In der angehängten Datei1 ist die Länge und die Breite von mehreren Yachten aufgelistet. 1. Tragen Sie die Werte in ein Streudiagramm auf und fügen Sie den „Mittelpunkt“ ein. Die Koordinaten des Mittelpunktes sind die Mittelwerte der jeweiligen Variablen. 2. Schätzen Sie den Korrelationskoeffizienten und überprüfen Sie den Wert mit Hilfe von Excel. Lösung der Aufgabe Um das Streudiagramm zu erstellen, wählt man die Daten in der Tabelle aus und fügt ein Punktediagramm ein, wie es in Abbildung 7.1 gezeigt wird. Nachdem die zwei Mittelwerte x und y der beiden Variablen in einer neuen Zeile berechnet wurden, fügt man diesen Punkt mit den Koordinaten (x; y) hinzu: dazu wählt man nach einem Rechtsklick auf das Diagramm „Daten auswählen“ und fügt die Daten mit „Hinzufügen“ hinzu. Gegebenenfalls kann man den Mittelpunkt hervorheben, indem man ihn einzeln auswählt und farblich markiert. Im Anschluss müssen der Diagrammtitel und die beiden Achsentitel manuell angepasst werden um das Diagramm wie in Abbildung 7.2 zu erhalten. Für den Korrelationskoeffizienten berechnet Excel etwa 0,96. 1 Aufgabe 31: Travail de candidature 79 80 7. Korrelation Abbildung 7.2.: Streudiagramm. Die Diagramme befinden sich in der angehängten Lösungsdatei.2 J . Aufgabe 32 Nennen Sie ein paar Beispiele, in denen der Korrelationskoeffizient genau 1 ist. Geben Sie zusätzlich etwa 5 Zahlenwerte zu jedem Beispiel an und prüfen Sie mit Excel, ob Sie richtig liegen. Lösung der Aufgabe Ist der Korrelationskoeffizient 1, also eine perfekte Korrelation, liegen alle Datenpunkte exakt auf einer Geraden. Steigt die erste Variable beispielsweise um 1, während die zweite Variable um k steigt, so muss mit jeder Erhöhung der ersten Variable um 1 die zweite Variable zwingend um k steigen, da der entsprechende Datenpunkt sonst nicht auf derselben Gerade liegt. Das heißt, es muss eine direkte (lineare) Abhängigkeit zwischen den zwei Variablen existieren. Hier sind einige mögliche Beispiele: 1. Die getankte Spritmenge und der zu zahlende Preis an der Tankstelle. Spritmenge [l] 10 20 30 40 50 Preis [e] 12 24 36 48 60 2. Die Anzahl der Zementsäcke und ihr Gesamtgewicht. Zementsäcke [#] 1 2 3 4 Gewicht [kg] 25 50 75 100 5 125 3. Die Anzahl der Zementsäcke und ihr Gesamtgewicht inklusive der tragenden Palette. Zementsäcke [#] Gewicht [kg] 2 5 10 155 280 15 20 25 405 530 655 Lösung Aufgabe 31: Travail de candidature 7.2. Grafische Darstellung 81 4. Das Gewicht eines Getränkekastens in Abhängigkeit der Anzahl der darin enthaltenen Flaschen. (Die Flaschen müssen alle gleich leer oder voll sein!) 5. Die Höhe des Wasserstandes in einem Schwimmbecken und die Zeit, während der die Pumpe eingeschaltet ist, um das Wasser abzupumpen. 5 20 25 Wasserstand [cm] 150 125 100 075 050 Zeit [min] 10 15 J In der Einführung des Kapitels wurde die Abhängigkeit der Papierlagen von der Anzahl der (mittigen) Faltungen erwähnt. Die folgende Tabelle enthält die entsprechenden Daten: Faltungen (x) [#]: Lagen (y) [#] 0 1 2 3 4 1 2 4 8 16 Hier steigt die Anzahl der Lagen nicht um genau denselben Wert, wenn man die Faltungen um jeweils 1 erhöht. Deswegen liegt keine lineare Korrelation vor. In diesem Fall spricht man von einer exponentiellen Korrelation, denn der Exponent der Variable y erhöht sich mit der Variable x. Man erkennt den Zusammenhang gut, wenn man die Tabelle um eine Spalte mit den Exponenten erweitert: Faltungen Lagen Exponent (Basis 2) 0 1 2 3 4 1 = 20 2 = 21 4 = 22 8 = 23 16 = 24 0 1 2 3 4 Travail de candidature 82 7. Korrelation Abbildung 7.3.: Beispiel exponentieller Korrelation. . Aufgabe 33 Erweitern Sie die Tabelle um ein paar Werte und tragen Sie die Anzahl der Faltungen und die der Lagen in einem Streudiagramm graphisch auf. 1. Wie erkennt man eine exponentielle Korrelation anhand des Streudiagramms? 2. Geben Sie andere Beispiele exponentieller Korrelation. Lösung der Aufgabe Das Streudiagramm der Papierlagen in Abhängigkeit der Anzahl der Faltungen ist in Abbildung 7.3 abgebildet. Anhand der Grafik kann man folgende Schlussfolgerungen ziehen: 1. Eine exponentielle Kurve erkennt man daran, dass Sie immer schneller ansteigt. Mit jedem Schritt auf der Horizontalen nach rechts wird y verdoppelt. 2. Andere Beispiele mit exponentieller Korrelation sind beispielsweise das Wachstums einer Population (trifft in manchen Industriestaaten heute nicht mehr zu) oder der Kontostand, der verzinst wird. J 7.3. Die Regressionsgerade Im vorigen Unterkapitel wurde analysiert, wie man erkennt, ob ein Zusammenhang zwischen zwei Variablen existiert. Besteht eine solche Abhängigkeit einer Variablen zu einer Anderen, kann man die Zweite abschätzen, wenn man die Erste kennt. Wie man eine möglichst genaue Abschätzung erhält, wird in diesem Unterkapitel erläutert. Travail de candidature 7.3. Die Regressionsgerade Im Falle einer (linearen) Korrelation liegen die Datenpaare nahe einer virtuellen Geraden. Deswegen kann man annehmen, dass zukünftige oder nicht bekannte Werte ebenfalls nahe dieser Gerade liegen. Kennt man diese virtuelle Gerade, kann man Prognosen über Werte erstellen, die man noch nicht kennt. Bevor jedoch solche Prognosen aufgestellt werden, werden zunächst die Kernelemente einer Geraden veranschaulicht. . Aufgabe 34 Angenommen y stellt das Gesamtgewicht eines Bierkastens dar, in dem sich x Flaschen befinden. Drücken Sie y mit Hilfe von x aus, wenn der leere Kasten 5 kg und jede Flasche 0,4 kg wiegt. Erstellen Sie ein Diagramm, in das Sie einige Werte graphisch auftragen. (Die horizontale Achse stellt die Anzahl der Flaschen und die vertikale Achse das Gesamtgewicht dar.) Lösung der Aufgabe Man hat folgende Zusammenstellung des Gesamtgewichts: Gewicht der Flaschen: Leergewicht Kasten: Gesamtgewicht: 0, 4 · x 5 y = 0, 4 · x + 5 Anhand der Formel erkennt man, dass sich y um 0,4 erhöht, wenn x um genau eine Einheit (Flasche) erhöht wird. Deswegen wird der Faktor 0,4 als „Steigung“ bezeichnet. Betrachtet man die grafische Darstellung der Werte, liegen die Punkte auf einer Geraden, die die vertikale Achse bei y = 5 schneidet. Deswegen wird dieser Wert als „Achsenabschnitt“ bezeichnet. Rechnerisch lässt sich leicht nachvollziehen, dass der yWert für x = 0 genau 5 ist. Man beachte, dass die Punkte genau über den Zahlenwerten auf der horizontalen Achse liegen. Hierfür muss die Option „Achse positionieren“ der horizontalen Achse, erreichbar durch einen Doppelklick auf die Achse selbst, auf den Wert „Auf Teilstrichen“ gesetzt werden. J Verallgemeinert man die Daten aus der letzten Aufgabe und steht a für das Gewicht einer Flasche und b für das Leergewicht des Kastens, führt es zur allgemeinen Formel einer Geraden: y = a · x + b, wobei • a die Steigung und • b den Achsenabschnitt bezeichnet. Liegen nun Datenpaare (xi ; yi ) vor und geht man von einer (linearen) Korrelation aus, kann man eine Gerade bestimmen, die die Abhängigkeit der beiden Variablen x Travail de candidature 83 84 7. Korrelation Abbildung 7.4.: Grafische Darstellung zur Aufgabe 34. und y beschreibt. Es genügt also, die Steigung und den Achsenabschnitt so festzulegen, dass die Gerade möglichst nah an den gegebenen Datenpunkten liegt. Bestimmt man dann noch einen Punkt, der diese Gerade schneidet, reicht es, entweder die Steigung oder den Achsenabschnitt festzulegen, um die Gerade vollständig zu bestimmen. In den folgenden Aufgaben wird genau so vorgegangen, um zur Regressionsgeraden zu gelangen. . Aufgabe 35 Berechnen Sie den Achsenabschnitt b einer Geraden, die den Mittelpunkt M (x; y) einer Datenmenge schneidet und deren Steigung a frei bestimmbar, also variabel, ist. Lösung der Aufgabe Die Gerade soll den Mittelpunkt schneiden. Deswegen gilt folgende Gleichung für alle Steigungen a: y =a·x+b Stellt man die Gleichung nach b um, erhält man bereits die Formel, mit der man den Achsenabschnitt berechnen kann: b=y−a·x J Travail de candidature 7.3. Die Regressionsgerade . Aufgabe 36 In der angehängten Datei3 befinden sich vorgegebene Datenpaare und eine Gerade, die bereits in ein Diagramm eingetragen wurden. Mit dem Schieberegler können Sie die Steigung der Gerade frei bestimmen. Der Achsenabschnitt wird automatisch so angepasst, dass die Gerade den Mittelpunkt der Datenpunkte schneidet. Finden Sie ein Kriterium, nach dem Sie die Gerade so bestimmen, dass sie möglichst gleichmäßig an allen Datenpunkten liegt. Tipp: Betrachten Sie der Einfachheit halber die vertikalen Distanzen der Punkte zur gesuchten Regressionsgeraden. Lösung der Aufgabe Um den Achsenabschnitt nach Aufgabe 35 zu bestimmen, muss man vorher die Mittelwerte x und y der einzelnen Variablen berechnen. In der Datei aus der Aufgabenstellung ist dies bereits vorbereitet. Die Gerade, dessen Steigung man frei bestimmen kann, ist ebenfalls bereits im Diagramm eingetragen. Die Regressionsgerade soll die möglichst „beste“ Gerade darstellen, auf die sich (zukünftige) Prognosen stützen. Sie soll also so nahe wie möglich an den gegebenen Datenpunkten liegen, um genauere Prognosen sicherzustellen. Deswegen fügt man zunächst eine neue Spalte mit den Differenzen der einzelnen Punkte zur Geraden hinzu. Der Einfachheit halber nimmt man die vertikalen Differenzen. Bei xi befindet sich die Gerade auf der Höhe axi + b. Hier stellt a die frei einstellbare Steigung dar und b wird nach den Berechnungen aus Aufgabe 35 (automatisch) so bestimmt, dass die Gerade den Mittelpunkt schneidet. Die vertikale Differenz der Gerade zum Datenpunkt (xi ; yi ) beträgt demnach ∆i = yi − (axi + b). Der Begriff Differenz wird bewusst verwendet, da ∆i auch negativ sein kann. Da die Gerade möglichst nahe an allen Datenpunkten liegen soll, bietet es sich an, die Summe der vertikalen Differenzen ∆i zu betrachten. Diese Summe ergibt aber in 3 Aufgabe Regressionsgerade: Travail de candidature 85 86 7. Korrelation jedem Fall 0, denn die Gerade schneidet den Mittelpunkt M (x; y): n P = = ∆i i=1 n P (yi − axi − b) i=1 n P yi − i=1 n P axi − i=1 = n·y−a· n P n P b i=1 n P xi − i=1 (y − a · x) i=1 = n·y−a·n·x−n·y+a·n·x = 0 Somit kann man die Summe der Differenzen ∆i nicht direkt als Qualitätskriterium für die Regressionsgerade heranziehen. Ersetzt man die Differenzen ∆i durch deren Absolutbeträge |∆i |, also die (positiven) Abstände der Datenpunkte zur Geraden, kann man versuchen die Summe dieser Abstände n X |∆i | i=1 zu minimieren. Durch das Verändern der frei bestimmbaren Steigung der Gerade in der ExcelDatei bemerkt man, dass diese Summe innerhalb bestimmter Intervalle konstant bleibt! In diesen Intervallen hätte man also unendlich viele Möglichkeiten eine Regressionsgerade auszuwählen. Verfolgt man jedoch das Ziel, die beste Regressionsgerade zu bestimmen, sucht man nach genau einer eindeutig bestimmten Gerade. Die Summe der (positiven) Abstände ist dafür also auch nicht geeignet. Im Eingang des Kapitels wurde erwähnt, dass die Regressionsgerade eine stabile Prognose liefern soll. Die Streuung der Datenpunkte um den prognostizierten Wert auf der Geraden, also um die Regressionsgerade selbst, sollte dementsprechend möglichst gleichmäßig sein. Um diese Gleichmäßigkeit zu erreichen, muss man die Varianz minimieren, denn nach Kapitel 6.2 ist die Varianz ein Maß für die Streuung der Daten. Sie ist also das Kriterium, nach dem man die Regressionsgerade bestimmt. Betrachtet man die Minimierung der Varianz der Differenzen ∆i , erhält man laut Definition der Varianz auf Seite 66: min a,b n 2 1X ∆i − ∆ . n i=1 Nach obigen Anführungen könnte man natürlich auch die Varianz der Abstände |∆i | Travail de candidature 7.3. Die Regressionsgerade minimieren, womit man den Ausdruck n 2 1X min |∆i | − |∆| , a,b n i=1 erhalten würde. Aufgabe 37 greift die Unterschiede zwischen dem Minimieren dieser beiden Ausdrücke auf und erläutert, wieso der Zweite ungeeignet ist. Zur Minimierung der Varianz der Differenzen ∆i und damit der Bestimmung der Regressionsgeraden wird also der Ausdruck n 2 1X ∆i − ∆ n i=1 minimiert. Der Faktor n1 hängt nur von der Anzahl n der Datenpunkte ab und spielt beim Minimieren keine Rolle. Er kann also weggelassen werden. Des Weiteren wurde n P bereits bewiesen, dass ∆i = 0 und damit der (arithmetische) Mittelwert ∆ ebenfalls i=1 0 ergibt: n 1 1X ∆i = · 0 = 0 ∆= n i=1 n Der zu minimierende Ausdruck vereinfacht sich somit zu n X (∆i − 0)2 = n X (∆i )2 . i=1 i=1 Hier erkennt man, dass gleichzeitig auch die Summe der Abstände |∆i | zum Quadrat minimiert wird, da n X i=1 2 (|∆i |) = n X (∆i )2 . i=1 Die Differenzen der Datenpunkte zur Geraden (zum Quadrat) werden also einerseits möglichst klein gewählt, andererseits aber aufgrund der Definition der Varianz auch so gleichmäßig wie möglich verteilt. Eine Veranschaulichung, wieso das Quadrieren zu einer gleichmäßigeren Verteilung um die Regressionsgerade führt, wird in Aufgabe 38 gegeben. Bestimmt man die Gerade nach diesen Herleitungen, so dass die Summe der Differenzen (oder der Abstände) zum Quadrat minimiert wird, sollte man also dieselbe Gerade erhalten, wie diejenige, die Excel als Regressionsgerade einzeichnet. Man fügt sie in das Punktediagramm ein, indem man einen Rechtsklick auf einen der Datenpunkte ausführt, gefolgt von einem Klick auf „Trendlinie hinzufügen“. Es erscheint das Fenster in Abbildung 7.5. Im Grunde ist bereits alles richtig voreingestellt. Einzig Travail de candidature 87 88 7. Korrelation Abbildung 7.5.: Regressionsgerade einfügen. die beiden Einträge unter der Gruppe „Prognose“ kann man gegebenenfalls nach links oder rechts erweitern, wenn man die Regressionsgerade etwas weiter über den ersten, beziehungsweise letzten Datenpunkt hinaus zeichnen möchte. Auf den Sinn und Zweck dieser Maßnahme wird in den weiteren Aufgaben eingegangen. Die Lösungsdatei mit allen berechneten Werten ist in der Fußnote angehängt.4 J Neben dem Einfügen der Regressionsgerade in ein Diagramm kann Excel auch die genauen Werte für die Steigung und den Achsenabschnitt dieser Regressionsgeraden mit folgenden Funktionen direkt berechnen: • „STEIGUNG(Y-Werte; X-Werte)“ und • „ACHSENABSCHNITT(Y-Werte; X-Werte)“ Es ist darauf zu achten, dass die „Y-Werte“ der abhängigen Variable im ersten Argument und die „X-Werte“ der unabhängigen Variable im jeweils zweiten Argument stehen. 4 Lösung Aufgabe Regressionsgerade: Travail de candidature 7.3. Die Regressionsgerade Die entsprechenden Formeln für die Steigung a und den Achsenabschnitt b der Regressionsgeraden lauten5 : n P • a= (xi − x)(yi − y) i=1 n P (xi − x)2 i=1 • b = y − ax Aus der zweiten Gleichung kann man ableiten, dass die Regressionsgerade den Mittelpunkt schneidet, ohne dass man es zusätzlich voraussetzen müsste! In Aufgabe 36 wurden zwei Ausdrücke hergeleitet, die in Frage kamen um die Regressionsgerade zu bestimmen. Einer davon wurde jedoch verworfen, weil er als ungeeignet erklärt wurde. Die nächste Aufgabe zeigt die Unterschiede der Regressionsgeraden zu der Geraden, die man mit dem zweiten, verworfenen Ausdruck erhalten hätte. . Aufgabe 37 Finden Sie mit Hilfe der Datei aus Aufgabe 36 eine Anordnung der Datenpunkte, so dass die Steigung der Geraden, die man durch das Minimieren des Ausdrucks n 2 1X |∆i | − |∆| n i=1 erhält, eine möglichst hohe Differenz zur Steigung der Regressionsgeraden aufweist. Die Regressionsgerade erhält man durch das Minimierung von n n 2 1X 1X (∆i )2 . ∆i − ∆ = n i=1 n i=1 Lösung der Aufgabe Minimiert man die Varianz der Abstände |∆i |, erhält man folgenden Ausdruck: (das Minimum ist unabhängig vom Faktor n1 .) min a,b 5 n X 2 |∆i | − |∆| . i=1 Man erhält die beiden Formeln, indem man die Varianz n X i=1 2 (∆i ) = n X (yi − (axi + b)) 2 i=1 einmal als Funktion f : a 7→ f (a) und einmal als Funktion f : b 7→ f (b) betrachtet und sie dann nach a, beziehungsweise nach b ableitet. Die Nullstellen beider Ableitungen ergeben dann nach einigen Umformungen die oben angegebenen Formeln für a und für b. Travail de candidature 89 90 7. Korrelation Abbildung 7.6.: Minimierung der Varianz der (positiven) Abstände (gelb). Zum Vergleich die Regressionsgerade (schwarz). |∆| stellt hier den Mittelwert der Abstände |∆i | dar. Anhand der Formel erkennt man, dass nicht die Abstände |∆i | selbst minimiert werden, sondern deren Verteilung um den Mittelwert |∆|. Je nachdem wie die Datenpunkte verteilt sind, wird die Gerade deswegen stark in die Richtung eines Ausreißers gezogen, oder die Abstände zu verschiedenen Punkten werden vergrößert, damit sie eben näher an jenem Mittelwert liegen. Abbildung 7.6 zeigt zwei solche Beispiele. Sie enthalten jeweils die Regressionsgerade in schwarz und die gelbe Gerade, die man erhält, wenn man die Varianz der Abstände |∆i | minimiert. Die (gelbe) Gerade ragt relativ weit über die äußeren Punkte hinaus, weil die Ausreißer, also einige Datenpunkte, einen großen (vertikalen) Abstand zum Mittelpunkt und damit auch zur Gerade aufweisen. Durch das Minimieren des obigen Ausdrucks werden die Abstände der (gelben) Gerade zu den anderen Datenpunkten ebenfalls so vergrößert, dass sie näher am Mittelwert |∆| liegen. Die gelbe Gerade ist also genau so bestimmt, dass die (positiven) Abstände der Datenpunkte zur Geraden zwar näher zusammen liegen (also gleichmäßiger verteilt sind) aber eben höhere Werte aufweisen. Im Gegenzug sind Abstände der Datenpunkte zur (schwarzen) Regressionsgerade kleiner und die Regressionsgerade ragt in der Vertikalen auch nicht über den Höchst- beziehungsweise Minimalwert der Datenpunkte hinaus. J In den letzten Aufgaben wurde angeschnitten, dass durch das Minimieren der Quadratsummen die Werte ∆i selbst auch gleichmäßig verteilt werden. Um diesen sehr theoretischen Teil anschaulicher zu gestalten, wird die Idee in der folgenden Aufgabe anhand eines Minimalbeispiels gezeigt. Travail de candidature 7.3. Die Regressionsgerade . Aufgabe 38 Gegeben seien folgende Datenpaare: xi yi 1 2 3 3 0 3 Erstellen Sie das Streudiagramm und berechnen Sie die Differenzen ∆i der Datenpunkte zu einer möglichen Regressionsgeraden. Für welche Gerade wird 3 X (∆i )2 i=1 minimal? (Die Regressionsgerade schneidet den Mittelpunkt.) Lösung der Aufgabe Fügt man die Mittelwerte beider Variablen in die Tabelle ein, erhält man gleichzeitig die Koordinaten des Mittelpunktes. Das Abschätzen des Verlaufs der Regressionsgeraden wird somit um ein Vielfaches vereinfacht. xi y i 1 3 2 0 3 3 Mittelwert: 2 2 Trägt man die Daten in ein Diagramm wie in der Abbildung 7.7 auf, erkennt man, dass der Wert ∆2 = −2 konstant bleibt, da die Gerade den Mittelpunkt direkt über dem zweiten Datenpunkt schneidet. Die Summe 3 X (∆i )2 i=1 kann man also nur über die beiden äußeren Werte ∆1 und ∆3 minimieren. Liegt die Regressionsgerade unterhalb dieser beiden Datenpunkte, bleibt die Summe der Abstände zu den einzelnen Datenpunkten gleich. Verringert man nämlich den Abstand ∆1 oder ∆3 zu einem Punkt um den Wert k, so wird der andere Abstand zum entsprechenden Punkt um genau den gleichen Betrag k vergrößert. In der Summe bleiben die Abstände also erhalten. Anhand der Abbildung 7.7 ist dieses Verhalten gut zu erkennen. Travail de candidature 91 92 7. Korrelation Abbildung 7.7.: Das Ändern des Abstands der Geraden zu einem Datenpunkt verändert automatisch den Abstand der Geraden zu einem anderen Datenpunkt. Betrachtet man nun die Quadrate der Differenzen ∆i und verändert die Steigung der Geraden, so vergrößert man wie eben erwähnt ein ∆i um beispielsweise k, während das Andere um genau k verkleinert wird. Vergleicht man anschließend die so von den Quadraten (∆i )2 erhaltenen Flächen in Abbildung 7.8, erkennt man, dass durch das Vergrößern einer Seitenlänge mehr Fläche gewonnen wird, als durch das Verkleinern verloren geht! In der Abbildung 7.8 ist die Differenz dieser Flächen blau dargestellt. Im Umkehrschluss werden durch das Minimieren die Flächen dieser Quadrate und damit die Seitenlängen der Quadrate einander angeglichen. Die Seitenlängen repräsentieren aber gerade die Abstände der einzelnen Datenpunkte zur Regressionsgeraden. Die Abstände ∆i der Datenpunkte zur Gerade werden also über das Minimieren Ihrer Quadrate angeglichen. Im Allgemeinen kann man innerhalb eines bestimmten Bereiches die Abstände zur Geraden nicht mehr nur verkleinern. Stattdessen muss man einige Distanzen automatisch vergrößern, wenn man Andere verkleinern will. Gleichen sich in einem Bereich also die Änderungen der Differenzen zur Geraden mehr oder weniger aus, dann wird die Steigung der Geraden so bestimmt, dass durch das Minimieren der Quadrate die ∆i sich gleichmäßig um die zu bestimmende Regressionsgerade verteilen. Das Minimieren der Quadratsummen stellt also eine Kombination zwischen Minimierung und Streuung der Datenpunkte um die Regressionsgerade dar. In der unten angehängten Datei6 befindet sich das Minimalbeispiel aus der Aufgabenstellung inklusive aller Berechnungen aus dieser Aufgabe. In dieser Datei kann man beliebig viele Punkte hinzufügen7 und ausprobieren, wie die Summe der Quadrate in 6 7 Lösung Aufgabe 38: Die Formeln müssen gegebenenfalls kopiert werden. Travail de candidature 7.3. Die Regressionsgerade 93 +k ∆i −k Abbildung 7.8.: Auswirkung der Änderung einer Seite auf die Fläche eines Quadrates. verschiedenen Situationen und mit noch mehr Datenpunkten variiert. Beispielsweise kann man den dritten Datenpunkt aus obigem Beispiel um 1 nach rechts verschieben und dann die Steigung der Geraden variieren, um zu analysieren, wie es die Quadratsummen beeinflusst. J Die vorigen Aufgaben erklären die Vorgehensweise, wie man die Regressionsgerade bestimmt. In den folgenden Aufgaben wird darauf eingegangen, wie man anhand dieser Regressionsgerade die prognostizierten Werte grafisch und rechnerisch erhält. Darüber hinaus wird auf die Grenzen dieser Prognosen hingewiesen und Beispiele angeführt, in denen es keinen Sinn macht, die Regressionsgerade zu benutzen. . Aufgabe 39 Im Anhang befindet sich eine Datei8 , die das Gehalt und die davon abhängigen Alltagsausgaben von 50 Arbeitnehmern beinhalten. 1. Erstellen Sie ein Streudiagramm mit den Datenpaaren. Folgern Sie aus diesem Diagramm, ob eine Korrelation zwischen dem Gehalt und den Ausgaben besteht. 8 Aufgabe 39: Travail de candidature 94 7. Korrelation 2. Überprüfen Sie Ihre Vermutung, indem Sie den Korrelationskoeffizienten berechnen. 3. Fügen Sie die Regressionsgerade ein und schätzen Sie anhand des Diagramms ab, wie hoch die Ausgaben wahrscheinlich wären, wenn man 45 000 e im Jahr verdienen würde. 4. Geben Sie die Formel der Regressionsgeraden an und rechnen Sie den abgelesenen Wert nach. 5. Erweitern Sie die Regressionsgerade um die jeweiligen Ausgaben für ein Gehalt von 60 000 e abschätzen zu können. Interpretieren und erläutern Sie das Ergebnis. Rechnen Sie auch hier nach. 6. Wie hoch sind die prognostizierten Ausgaben ohne Gehalt? Interpretieren und erklären Sie das Ergebnis. Lösung der Aufgabe Die Lösungsdatei befindet sich in der Fußnote.9 1. Man erkennt, dass die Punktewolke nahe einer Geraden liegen. Es liegt also eine positive Korrelation zwischen dem Gehalt und der Höhe der Ausgaben vor. 2. Die Berechnung ergibt einen Korrelationskoeffizienten von ungefähr 0, 97. Die Vermutung erweist sich damit als richtig, weil der Korrelationskoeffizient größer als 0, 9 ist. 3. In der Abbildung 7.9 erkennt man, dass bei einem Gehalt von 45 000 e die prognostizierten Ausgaben ungefähr 40 000 e betragen. Der vorhandene Wert in der Tabelle gibt aber einen Wert von ungefähr 37 000 e an. Die Differenz zwischen der Schätzung und dem tatsächlichen Wert ist aber völlig normal, denn es kann sich bei den vorliegenden Daten um eine überdurchschnittlich sparsame Familie handeln. 4. Die Funktionen „STEIGUNG“ und „ACHSENABSCHNITT“ liefern für die Steigung a ≈ 0, 846 und für den Achsenabschnitt b ≈ 1 459. Demnach lautet die Formel der Regressionsgeraden: y ≈ 0, 846 · x + 1 459, 9 Lösung Aufgabe 39: Travail de candidature 7.3. Die Regressionsgerade 95 Abbildung 7.9.: Streudiagramm der Daten aus Aufgabe 39. wobei x das Einkommen und y die davon abhängigen Alltagsausgaben darstellt. Für x = 45 000 e errechnet man somit Alltagsausgaben in Höhe von etwa y ≈ 0, 846 · 45 000 + 1 459 = 39 529 e. Die Rechnung liefert also prognostizierte 39 529 e Ausgaben bei einem Einkommen von 45 000 e. 5. Bei einem Gehalt von 60 000 e erhält man prognostizierte Ausgaben in Höhe von etwa 52 000 e. Der berechnete Wert ergibt ungefähr 52 219 e. Diese Werte sind genauer als die von der Grafik abgelesenen Werte, aber sie sind mit Vorsicht zu genießen, denn sie stellen lediglich eine ungefähre Prognose dar und keinesfalls eine präzisere Vorhersage! Im Allgemeinen lässt sich der letzte Wert nicht so genau abschätzen, denn die Prognose kann man gegebenenfalls nicht beliebig nach links oder rechts fortsetzen. Man sollte die geschätzten Prognosen also mit Vorsicht genießen. 6. Liegt kein Gehalt vor, liest man für die prognostizierten Ausgaben einen Wert von etwa 1 000 e ab. Rechnet man nach, beträgt der Achsenabschnitt ungefähr 1 459 e. Anhand dieser Werte sollte klar sein, dass man die Regressionsgerade je nach Situation nicht beliebig fortsetzen kann und trotz „genauer“ Berechnung auch nur eine (ungenaue) Schätzung liefert. J Durch die folgende Aufgabe sollte es noch klarer werden, dass die Regressionsgerade kein Allheilmittel darstellt, wenn es darum geht, (zukünftige) unbekannte Daten abzuschätzen. Travail de candidature 96 7. Korrelation . Aufgabe 40 Die folgende Tabelle enthält die Sprunghöhe einiger Schüler in Abhängigkeit ihres Alters: Alter [Jahre] Sprunghöhe [m] 6 6 7 8 8 9 9 0,6 0,8 0,9 0,7 1,0 1,1 1,0 11 12 12 1,2 1,4 1,1 1. Berechnen Sie den Korrelationskoeffizienten zwischen dem Alter und der Sprunghöhe und entscheiden Sie, ob es Sinn macht, eine Ausgleichsgerade ins Diagramm einzufügen. 2. Geben Sie die Formel der Ausgleichsgeraden an. 3. Berechnen Sie die Prognose der Sprunghöhe für ein Alter von 10 Jahren, 3 Jahren und für ein Alter von 30 Jahren. Kommentieren Sie die Ergebnisse. Lösung der Aufgabe Nach dem Eintragen aller Daten in eine Excel-Tabelle errechnet man die Werte mit den entsprechenden Funktionen KORREL; STEIGUNG; ACHSENABSCHNITT: 1. Der Korrelationskoeffizient beträgt etwa 0,86. Da der Korrelationskoeffizient über 0,7 liegt, macht es Sinn, von einer positiven Korrelation auszugehen und eine Ausgleichsgerade zu berechnen. 2. Die Formel der Ausgleichsgeraden lautet y ≈ 0, 09 · x + 0, 18. 3. Laut Prognose springt ein Zehnjähriger ungefähr 0, 9 · 10 + 0, 18 = 1, 08 m, ein Dreijähriger etwa 0, 09 · 3 + 0, 18 = 0, 45 m und ein Dreißigjähriger etwa 0, 09 · 30 + 0, 18 = 2, 88 m. Spätestens mit der Berechnung der prognostizierten Sprunghöhe eines Achtzigjährigen sollte klar sein, dass die Prognose zumindest für ein solches Alter keinen Sinn ergibt. Die Prognosen sind in diesem Fall nur auf einen eingeschränkten Bereich anwendbar, der sich von etwa 5 bis 15 Jahren erstreckt, also über den Zeitraum, über den sich die gegebene Datenmenge erstreckt. Über diesen Bereich hinaus macht es keinen Sinn, Prognosen zu erstellen. J Travail de candidature 7.3. Die Regressionsgerade . Aufgabe 41 In der angehängten Datei10 befindet sich eine Tabellen mit den Siegern des „Tour de France“ und ihrer jeweiligen Durchschnittsgeschwindigkeit. 1. Erstellen Sie ein Streudiagramm der Durchschnittsgeschwindigkeiten in Abhängigkeit der Jahrgänge und entscheiden Sie ob eine Korrelation vorliegt. 2. Berechnen Sie den Korrelationskoeffizienten und die Formel der Regressionsgeraden. 3. Welche durchschnittliche Geschwindigkeit könnte man im Jahr 2030 erwarten? 4. Überprüfen Sie den berechneten Wert grafisch, indem Sie die Regressionsgerade bis 2030 erweitern. Lösung der Aufgabe Für die Berechnung des prognostizierten Wertes anhand des Achsenabschnitts und der Steigung werden die genauen Werte aus den Zellen übernommen. Die gerundeten Werte sollten nicht abgeschrieben werden, da der Fehler sonst zu groß wird. Die Datei mit den errechneten Werten befindet sich in der Fußnote11 . J In der Statistik ist die Unterscheidung zwischen Korrelation und Kausalität ein wichtiger Kernpunkt. Oft geht man bei einer Korrelation davon aus, dass tatsächlich eine Kausalität besteht. Deswegen ist es umso wichtiger, den Unterschied zu kennen. Die folgenden Aufgaben erläutern diesen Unterschied anhand konkreter Beispiele. 10 Aufgabe 41: 11 Lösung Aufgabe 41: Travail de candidature 97 98 7. Korrelation . Aufgabe 42 Die folgende Tabelle enthält die Anzahl der Storchenpaare sowie die Anzahl der Geburten in einem gegebenen Land.12 Land Albanien Bulgarien Griechenland Österreich Polen Portugal Rumänien Schweiz Spanien Türkei Ungarn Storchenpaare Geburten 100 5 000 2 500 300 30 000 1 500 5 000 150 8 000 25 000 5 000 83 000 117 000 106 000 87 000 610 000 120 000 23 000 82 000 439 000 1 576 000 124 000 Berechnen Sie die Formel der Regressionsgeraden und schätzen Sie die ungefähre Anzahl an Störchen, die notwendig ist, um 50 000 Geburten zu sichern. Hängt die Anzahl der Geburten tatsächlich von der Anzahl der Storchenpaare ab? Lösung der Aufgabe Es besteht eine Korrelation, denn der Korrelationskoeffizient ist etwa 0,8. Allerdings bedeutet das nicht, dass eine Kausalität zwischen beiden Merkmalen besteht. Eine Korrelation kann dadurch entstehen, dass zu wenig Daten vorliegen und deswegen eine rein durch Zufall entstandene Scheinkorrelation auftritt. Trägt man die Daten grafisch auf, erhält man das Diagramm in Abbildung 7.10. Hier erkennt man, dass es nur zwei Werte gibt, die etwas weiter von allen anderen Werten entfernt liegen. Dadurch erscheint es so, als würden die anderen Datenpunkte nahe einer Geraden liegen. (Siehe Abbildung 7.10.) Allein durch das Hinzufügen der folgenden drei Datenwerte, die in der Aufgabenstellung bewusst weggelassen wurden, sinkt der Korrelationskoeffizient signifikant auf etwa 0,58. Land Deutschland Italien Frankreich 12 Storchenpaare Geburten 3 300 5 140 901 000 551 000 774 000 Siehe [9]. Travail de candidature 7.3. Die Regressionsgerade Abbildung 7.10.: Geburten in Abhängigkeit der Storchenpaare. Man sollte also sehr vorsichtig damit sein, eine Prognose nur aufgrund des Korrelationskoeffizienten aufzustellen. Vor allem dann, wenn nur wenig Daten vorliegen. Einige andere Beispiele für Scheinkorrelationen sind in [6] zu finden. J . Aufgabe 43 Die angehängte Datei13 enthält die Anzahl der Bienenvölker, die Honig produzieren und die Anzahl der Festnahmen von Jugendlichen wegen des Besitzes von Marihuana. 1. Tragen Sie die Daten in ein Streudiagramm auf und entscheiden Sie, ob eine Korrelation zwischen der Anzahl der Bienenvölker und der Anzahl der Festnahmen vorliegt. 2. Überprüfen Sie, ob der Korrelationskoeffizient zwischen beiden Variablen ungefähr −0, 93 beträgt und ob damit eine negative Korrelation vorliegt. 3. Besteht tatsächlich eine Abhängigkeit zwischen beiden Variablen? Lösung der Aufgabe Die Lösungsdatei ist in der Fußnote.14 Hier liegt zwar eine Korrelation vor, aber diese Korrelation impliziert keine Kausalität, denn der gesunde Menschenverstand sagt einem, dass die Anzahl der Bienenvölker die Anzahl der Festnahmen keineswegs derart beeinflusst, dass der Korrelationskoeffizient −0, 93 sein könnte. Es wäre möglich, dass eine Abhängigkeit beider Variablen zu einer unbekannten dritten Variable besteht, was in diesem Fall aber sehr unwahrscheinlich ist. Die starke negative Korrelation liegt wohl eher an der kleinen Datenmenge, die eine zufällige Korrelation erscheinen lässt. 13 Aufgabe 43: 14 Lösung Aufgabe 43: Travail de candidature 99 100 7. Korrelation Andere Korrelationen, die aufgrund einer sehr kleinen Datenmenge auftreten, sind im Internet unter http://www.tylervigen.com veröffentlicht. J Travail de candidature Literaturverzeichnis [1] Amyotte, Luc: Méthodes quantitatives. Editions du Renouveau Pédagogique Inc., Québec, 2002. [2] Bricklin, Dan: Patenting VisiCalc, 2014. http://bricklin.com/patenting.htm. [3] Bricklin, Dan: VisiCalc, 2014. www.bricklin.com/visicalc.htm. [4] Dörnyei, Zoltán: Teaching and researching: motivation. Pearson Longman, Harlow, 2001. [5] Drösser, Christoph: Stimmt’s - Zahlenschwindel. Die Zeit, 18, 2002. http://www.zeit.de/2002/18/200218_stimmts_churchill.xml. [6] Dubben, Hans-Hermann und Hans-Peter Beck-Bornhold: Der Hund, der Eier legt - Erkennen von Fehlinformationen durch Querdenken. Rowohlt Taschenbuch Verlag, Hamburg, 2007. [7] Fourastié, Jacqueline und Sophie Saguery: Exercices résolus de statistiques appliquées à l’économie. Masson, Paris, 1993. [8] Leitenberger, Bernd: Computergeschichte(n): Die ersten Jahre des PC. Books on demand GmbH, Norderstaedt, 2012. [9] Matthews, Robert: Storks Deliver Babies (p = 0, 008). Teaching Statistics, 22(2):36–38, 6 2000. [10] Matthäus, Wolf-Gert und Jörg Schulze: Statistik mit Excel. B.G. Teubner Verlag, Wiesbaden, 2008. [11] Radke, Horst-Dieter: Statisitik mit Excel. Mark+Technik Verlag, München, 2006. [12] Toole, Jim: Program Tackles Large Corporate Spreadsheets. Info World, 9:50ff, 8 1987. Info World. 102 Literaturverzeichnis [13] Vaughan-Nichols, Steven J.: Goodbye, Lotus http://www.zdnet.com/goodbye-lotus-1-2-3-7000015385/. 2013. 1-2-3, [14] Wieland, H. R.: Computergeschichte(n) - Nicht nur für Geeks. Galileo Press, Bonn, 2011. [15] Wiseman, Richard: :59 seconds. Think a little, change a lot. Macmillan, London, 2009. [16] Ziegler, Peter-Michael: Vor 30 Jahren: Mit Visicalc bricht eine neue Ära an. Heise, 10 2009. heise online. [17] Zisman, Alan: Lotus Improv. Our Computer http://www.zisman.ca/Articles/1993/Improv.html. Travail de candidature Player, 6 1993. A. Anhang Der Hund der Eier legt. (Aus dem gleichnamigen Buch von Dubben und Beck-Bornholdt.1 ) 1 Siehe [6]. 104 A. Anhang Abbildung A.1.: Eine Liste erstellen. A.1. Ein Histogramm mit Geogebra erstellen Geogebra ist eine kostenlose Anwendung, die man im Internet herunterladen kann. 2 Nach der Installation aktiviert man die Tabellenansicht, in die man die Daten aus Excel schreibt. Die Tabelle auf Seite 43 kann man aus Excel kopieren und direkt in eine Geogebra-Tabelle einfügen. Um ein Histogramm mit Geogebra zu erstellen, gibt man die Intervallgrenzen als erstes Argument und die Spaltenhöhe als zweites Argument an. Man markiert alle Einträge der ersten Spalte und erstellt eine Liste mit Hilfe eines Rechtsklicks in die Markierung. In der zweiten Spalte markiert man alle Einträge bis auf den Ersten und erstellt eine zweite Liste. Der Vorgang wird in Abbildung A.1 dargestellt. Standardmäßig heißen die neu erstellten Listen „Liste1“ und „Liste2“. Nachdem man in der Eingabeleiste unten den Befehl Histogramm(Liste1,Liste2) eingibt erhält man das Histogramm, wie es in Abbildung A.2 erscheint. Die Farbwahl kann man je nach Belieben anpassen. 2 www.geogebra.org Travail de candidature A.1. Ein Histogramm mit Geogebra erstellen Abbildung A.2.: Histogramm. Möglicherweise muss man mit dem Mausrad rauszoomen, um es vollständig zu erkennen. Travail de candidature 105 106 A. Anhang A.2. Weitere Mittelwerte Im Kapitel 5.3 wurde das arithmetische Mittel im Detail erklärt. Neben diesem Mittelwert gibt es noch: • das harmonische Mittel, • das geometrische Mittel, • das quadratische Mittel und • das kubische Mittel. Beide letzteren benötigt man eher in speziellen Fachgebieten, wie zum Beispiel in der Physik. In der Statistik treten hauptsächlich die beiden Erstgenannten auf, weswegen der Sinn und Zweck von diesen Beiden anhand von einigen Beispielen näher erläutert wird. A.2.1. Das harmonische Mittel Nimmt man der Einfachheit halber an, man würde eine Strecke über einen Kilometer zweimal mit dem Fahrrad zurücklegen und man würde auf dem Hinweg 10 km/h und auf dem Rückweg 15 km/h fahren. Wie hoch schätzen Sie die Durchschnittsgeschwindigkeit ein? a) 12 km/h ? b) 12,5 km/h ? c) 13 km/h ? Natürlich könnte man annehmen, es seien 12,5 km/h, da es schließlich der Mittelwert von 10 und 15 km/h ist. Hier liegt aber ein Denkfehler vor, denn der Durchschnitt der Geschwindigkeiten entspricht nicht notwendigerweise der Durchschnittsgeschwindigkeit! Die Durchschnittsgeschwindigkeit ist die Geschwindigkeit, mit der man dieselbe Distanz in derselben Zeit, aber mit konstanter Geschwindigkeit zurückgelegt hätte. Um zu widerlegen, dass die Durchschnittsgeschwindigkeit nicht 12,5 km/h beträgt, muss man also lediglich die benötigte Zeit für beide Varianten berechnen und die Ergebnisse anschließend vergleichen. Fährt man auf dem Hinweg 10 km/h und auf dem Rückweg 15 km/h, so benötigt man insgesamt für Hin- und Rückweg zusammen, also für 2 km: 1 km 1 km + = 0, 1 h + 0, 06 h = 0, 16 h = 10 min. 10 km/h 15 km/h Travail de candidature A.2. Weitere Mittelwerte Im zweiten Fall, mit einer konstanten Geschwindigkeit von 12,5 km/h, benötigt man lediglich 2 km = 0, 16 h = 9, 6 min. 12, 5 km/h Die Durchschnittsgeschwindigkeit kann also nicht 12,5 km/h betragen. Man berechnet die Durchschnittsgeschwindigkeit also nicht anhand des Mittelwertes beider Geschwindigkeiten, sondern indem man die gesamte Distanz durch die benötigte Gesamtzeit teilt: 2 km = 12 km/h 0, 16 h Demnach wäre also Antwort a) richtig gewesen. Wie kann man sich den Unterschied zwischen der Durchschnittsgeschwindigkeit und dem Durchschnitt der Geschwindigkeiten besser vorstellen? Fährt man beispielsweise während 1 km mit 10 km/h und weitere 99 km mit 50 km/h liegt es auf der Hand, dass die Durchschnittsgeschwindigkeit nicht 30 km/h sein kann, sondern viel näher an 50 km/h liegen muss, da man bedeutend länger mit 50 km/h fährt. Hier ist die Durchschnittsgeschwindigkeit etwa 48 km/h, wohingegen der Durchschnitt der Geschwindigkeiten 30 km/h ist. Mathematisch ausgedrückt entspricht der Durchschnitt der Geschwindigkeiten dem arithmetischen Mittelwert und die Durchschnittsgeschwindigkeit dem harmonischen Mittelwert. Um die Formel des harmonischen Mittelwertes herzuleiten, kann man die obigen Zahlenwerte nehmen: 2 km 2 km = 1 km km 0, 16 h + 151 km/h 10 km/h Fährt man also zweimal dieselbe Strecke oder Distanz einmal mit der Geschwindigkeit a = 10 km/h und einmal mit der Geschwindigkeit b = 15 km/h, berechnet man die Durchschnittsgeschwindigkeit (=harmonisches Mittel) mit der Formel 1 a 2 . + 1b Hat man nun n verschiedene Werte, beziehungsweise Geschwindigkeiten, die man mit x1 , x2 , .., xn bezeichnet (hier wäre x1 = a; x2 = b und n = 2), erhält man die allgemeine Formel für das harmonische Mittel mit n verschiedenen Werten: 1 x1 + 1 x2 n + .. + 1 xn n = P . n 1 i=1 xi Travail de candidature 107 108 A. Anhang Angewendet auf das zweite Beispiel mit 10 km/h und 50 km/h wäre • n = 100, weil man 100 km fährt, • x1 = 10 km/h und • x2 = x3 = .. = x100 = 50 km/h. Da alle Werte gleich gewichtet werden, muss man die Geschwindigkeiten in gleich große Teilstücke einteilen. Deswegen erhält man 99 mal denselben Wert für x2 bis x100 . Für die Durchschnittsgeschwindigkeit erhält man somit n n P i=1 100 = 1 xi 1 10 100 = ≈ 48, 08 km/h. 1 0, 1 + 1, 98 + 99 · 50 Damit liegt die Durchschnittsgeschwindigkeit wie erwartet bedeutend näher an 50 km/h. A.2.2. Das geometrische Mittel Das geometrische Mittel findet meist dort Anwendung, wo ein exponentielles Wachstum vorliegt. Ab Seite 71 werden in der Einführung zum Kapitel die Papierlagen nach einer bestimmten Anzahl an Faltungen erwähnt. Nach 5 Faltungen wurde die Anzahl der Papierlagen verzweiunddreißigfacht. Um auf die Verdopplung mit jeder Faltung zu kommen, muss man die fünfte Wurzel von 32 ziehen: √ 5 32 = 2, da 25 = 32. Genauso verhält es sich mit der Zinsrechnung. In einer Reportage waren folgende Daten über den Preis eines Warenkorbs bekannt: Jahr Warenkorb 1960 2007 13,50 e 31,37 e Nun behauptete der Reporter3 , dass die durchschnittliche Steigerungsrate 2,82% betragen würde. Er hat zunächst die gesamte Steigerungsrate wie folgt berechnet: 31, 37 e ≈ 2, 32. 13, 50 e 3 RTL Radio Montag 17. September 2007 um 8:15. Bericht über einen Beitrag aus dem Stern vom Nr. 37/2007. Travail de candidature A.2. Weitere Mittelwerte Das heißt, der Preis hat sich etwa ver-2,32-facht, womit die Wertsteigerung ungefähr +132% beträgt. Anschließend wurde dieser Prozentsatz durch 47 Jahre geteilt, um auf eine durchschnittliche Rate von etwa 2,82% zu kommen. Der Wert des Warenkorbs hätte sich demnach also jedes Jahr im Schnitt um den Faktor 1,0282 gesteigert. Nach 47 Jahren erhielt man somit eine Multiplikation mit dem Faktor 1, 028247 ≈ 3, 7. Der Warenwert hätte 2007 also etwa 3, 7 · 13, 50 = 49, 9 e betragen müssen. Der Fehler in obiger Rechnung liegt darin, dass man in diesem Fall das geometrische Mittel nehmen muss, da es sich um eine exponentielle Steigerung handelt. Um die durchschnittliche jährliche Steigerung zu erhalten, muss man demnach die 47. Wurzel von 2,32 ziehen, da der Preis sich in 47 Jahren ver-2,32-facht hat. √ 2, 32 ≈ 1, 018. 47 Damit ver-1,018-facht sich der Preis im Schnitt jedes Jahr, was einer jährlichen Steigerung von etwa +1,8% anstatt +2,82% entspricht. Travail de candidature 109 110 A. Anhang A.3. Wörterbuch Folgende Tabelle enthält eine Übersicht der Excel-Funktionen in drei verschiedenen Sprachen. Deutsch Englisch Französisch ABRUNDEN ROUNDDOWN ARRONDI.INF ABS ABS ABS ACHSENABSCHNITT INTERCEPT ORDONNEE.ORIGINE ANZAHL COUNT NB ANZAHL2 COUNTA NBVAL ANZAHLLEEREZELLEN COUNTBLANK NB.VIDE ARBEITSTAG WORKDAY SERIE.JOUR.OUVRE AUFRUNDEN ROUNDUP ARRONDI.SUP DATUM DATE DATE DATWERT DATEVALUE DATEVAL DBANZAHL DCOUNT BDNB DBANZAHL2 DCOUNTA BDNBVAL DBMAX DMAX BDMAX DBMIN DMIN BDMIN EDATUM EDATE MOIS.DECALER ERSETZEN, ERSETZENB REPLACE, REPLACEB REMPLACER, REMPLACERB EUROCONVERT EUROCONVERT EUROCONVERT FAKULTÄT FACT FACT FEHLER.TYP ERROR.TYPE TYPE.ERREUR FINDEN, FINDENB FIND, FINDB TROUVE, TROUVERB GANZZAHL INT ENT GEOMITTEL GEOMEAN MOYENNE.GEOMETRIQUE GERADE EVEN PAIR GLÄTTEN TRIM SUPPRESPACE GROSS UPPER MAJUSCULE GROSS2 PROPER NOMPROPRE HÄUFIGKEIT FREQUENCY FREQUENCE HEUTE TODAY AUJOURDHUI IDENTISCH EXACT EXACT ISOKALENDERWOCHE ISOWEEKNUM ISOWEEKNUM ISTFEHL ISERR ESTERR ISTFEHLER ISERROR ESTERREUR ISTFORMEL ISFORMULA ISFORMULA ISTGERADE ISEVEN EST.PAIR Travail de candidature A.3. Wörterbuch ISTLEER ISBLANK ESTVIDE ISTLOG ISLOGICAL ESTLOGIQUE ISTUNGERADE ISODD EST.IMPAIR ISTZAHL ISNUMBER ESTNUM JAHR YEAR ANNEE JETZT NOW MAINTENANT KALENDERWOCHE WEEKNUM NO.SEMAINE KGRÖSSTE LARGE GRANDE.VALEUR KKLEINSTE SMALL PETITE.VALEUR KLEIN LOWER MINUSCULE KORREL CORREL COEFFICIENT.CORRELATION KOVAR COVAR COVARIANCE KOVARIANZ.P COVARIANCE.P COVARIANCE.PEARSON KOVARIANZ.S COVARIANCE.S COVARIANCE.STANDARD KÜRZEN TRUNC TRONQUE LÄNGE, LÄNGEB LEN, LENB NBCAR, LENB LINKS, LINKSB LEFT, LEFTB GAUCHE, GAUCHEB MAX MAX MAX MAXA MAXA MAXA MEDIAN MEDIAN MEDIANE MIN MIN MIN MINA MINA MINA MINUTE MINUTE MINUTE MITTELABW AVEDEV ECART.MOYEN MITTELWERT AVERAGE MOYENNE MITTELWERTA AVERAGEA AVERAGEA MITTELWERTWENN AVERAGEIF MOYENNE.SI MITTELWERTWENNS AVERAGEIFS MOYENNE.SI.ENS MODALWERT MODE MODE MODUS.EINF MODE.SNGL MODE.SIMPLE MODUS.VIELF MODE.MULT MODE.MULTIPLE MONAT MONTH MOIS MONATSENDE EOMONTH FIN.MOIS NICHT NOT NON NOMINAL NOMINAL TAUX.NOMINAL ODER OR OU PI PI PI POTENZ POWER PUISSANCE PRODUKT PRODUCT PRODUIT Travail de candidature 111 112 A. Anhang PROGNOSE FORECAST PREVISION QUADRATESUMME SUMSQ SOMME.CARRES QUANTIL PERCENTILE CENTILE QUANTIL.EXKL PERCENTILE.EXC CENTILE.EXCLURE QUANTIL.INKL PERCENTILE.INC CENTILE.INCLURE QUANTILSRANG PERCENTRANK RANG.POURCENTAGE QUANTILSRANG.EXKL PERCENTRANK.EXC RANG.POURCENTAGE.EXCLURE QUANTILSRANG.INKL PERCENTRANK.INC RANG.POURCENTAGE.INCLURE QUARTILE QUARTILE QUARTILE QUARTILE.EXKL QUARTILE.EXC QUARTILE.EXCLURE QUARTILE.INKL QUARTILE.INC QUARTILE.INCLURE RANG RANK RANG RANG.GLEICH RANK.EQ EQUATION.RANG RANG.MITTELW RANK.AVG MOYENNE.RANG RECHTS, RECHTSB RIGHT, RIGHTB DROITE, DROITEB RUNDEN ROUND ARRONDI SÄUBERN CLEAN EPURAGE SEKUNDE SECOND SECONDE SPALTE COLUMN COLONNE SPALTEN COLUMNS COLONNES STABW STDEV ECARTYPE STABW.N STDEV.P ECARTYPE.PEARSON STABW.S STDEV.S ECARTYPE.STANDARD STABWA STDEVA STDEVA STABWN STDEVP ECARTYPEP STABWNA STDEVPA STDEVPA STEIGUNG SLOPE PENTE STFEHLERYX STEYX ERREUR.TYPE.XY STUNDE HOUR HEURE SUCHEN, SUCHENB SEARCH, SEARCHB CHERCHE, CHERCHERB SUMME SUM SOMME SUMMENPRODUKT SUMPRODUCT SOMMEPROD SUMMEWENN SUMIF SOMME.SI SUMMEWENNS SUMIFS SOMME.SI.ENS SVERWEIS VLOOKUP RECHERCHEV TAG DAY JOUR TAGE DAYS JOURS TAGE360 DAYS360 JOURS360 TEILERGEBNIS SUBTOTAL SOUS.TOTAL Travail de candidature A.3. Wörterbuch TEXT TEXT TEXTE TREND TREND TENDANCE UND AND ET UNGERADE ODD IMPAIR VAR.P VAR.P VAR.P VAR.S VAR.S VAR.S VARIANZ VAR VAR VARIANZA VARA VARA VARIANZEN VARP VARP VARIANZENA VARPA VARPA VARIATIONEN PERMUT PERMUTATION VERGLEICH MATCH EQUIV VERKETTEN CONCATENATE CONCATENER VERWEIS LOOKUP RECHERCHE VORZEICHEN SIGN SIGNE WENN IF SI WENNFEHLER IFERROR SIERREUR WERT VALUE CNUM WIEDERHOLEN REPT REPT WOCHENTAG WEEKDAY JOURSEM WURZEL SQRT RACINE WVERWEIS HLOOKUP RECHERCHEH ZÄHLENWENN COUNTIF NB.SI ZÄHLENWENNS COUNTIFS NB.SI.ENS ZAHLENWERT NUMBERVALUE NUMBERVALUE ZEILE ROW LIGNE ZEILEN ROWS LIGNES ZEIT TIME TEMPS ZELLE CELL CELLULE ZUFALLSBEREICH RANDBETWEEN ALEA.ENTRE.BORNES ZUFALLSZAHL RAND ALEA FALSCH FALSE FAUX WAHR TRUE VRAI Travail de candidature 113 114 A. Anhang A.4. Aufgabenstellungen Aufgabe 1: Schreiben Sie den Text „Dies ist die Zelle C5“ in die entsprechende Zelle und formatieren Sie die Zelle wie im unten angefügten Bild. Geben Sie ebenfalls den Text aus der folgenden Abbildung in die Zelle D5 ein. Aufgabe 2: Erstellen Sie eine Arbeitsmappe, in der das erste Tabellenblatt wie in der folgenden Abbildung aussieht. Speichern Sie das Dokument für die folgenden Aufgaben ab. Aufgabe 3: Berechnen Sie mit Excel die Umsätze für jede Filiale und jeden Artikel aus den aus Aufgabe 2 vorgegebenen Daten. Schreiben Sie diese Umsätze in die Zellen C5 bis E6. Aufgabe 4: Berechnen Sie den Gesamtumsatz für jede der zwei Filialen aus Aufgabe 2, sowie die Summe aller Umsätze. Travail de candidature A.4. Aufgabenstellungen Aufgabe 5: Die angehängte Datei4 beinhaltet eine Auflistung der aktiven Bevölkerung Luxemburgs, der Anzahl der Erwerbstätigen und die Anzahl der Angestellten, geordnet nach den 12 Kantonen. Berechnen Sie anhand dieser Daten die Anzahl der Freiberufler, der Arbeitslosen und die Arbeitslosenquote für alle Kantone, sowie alle Daten für das ganze Land. Aufgabe 6: In der angehängten Datei5 befinden sich die Einnahmen, die Ausgaben und die Angestelltenlöhne des Luxemburger Staates in den Jahren 1995 bis 2012. Errechnen Sie daraus die Summe, sowie den Mittelwert über alle Jahre. Berechnen Sie anschließend für jedes Jahr den prozentualen Anteil der Ausgaben für Angestelltenlöhne und den Überschuss des jeweiligen Jahres. Hinweis: Den Mittelwert berechnet man mit der Funktion „MITTELWERT(Zellbezug)“. Aufgabe 7: 1. Erstellen Sie aus den Daten in der Datei auf Seite 37 folgendes Kreisdiagramm: 2. Erstellen Sie ebenfalls ein Kreis- und ein Säulendiagramm, in dem die Prozentualwerte der Antworten angezeigt werden. 4 Aufgabe 5: 5 Aufgabe 6: Travail de candidature 115 116 A. Anhang Aufgabe 8: In der angehängten Datei6 befinden sich im ersten Tabellenblatt die Einkommensdaten von 5 000 amerikanischen Haushalten aus dem Jahr 2006 und im zweiten Blatt das Einkommen von 50 Studenten während der Sommermonate. 1. Veranschaulichen Sie die beiden Verteilungen dieser Einkommen anhand jeweils eines Histogramms. Wählen Sie dafür eine geeignete Klasseneinteilung. 2. Vergleichen Sie die Histogramme in beiden Tabellenblättern. Was kann man über die Verteilungen sagen? 3. Erweitern Sie die Tabellen in den beiden Arbeitsblättern um die relativen Häufigkeiten. Man berechnet sie, indem man die Häufigkeit der jeweiligen Klasse durch die Gesamtsumme der Häufigkeiten teilt. 4. Erweitern Sie die beiden Tabellen um eine weitere Spalte, die die kumulierten relativen Häufigkeiten enthält. Das ist die Summe der relativen Häufigkeit der entsprechenden Klasse und allen vorangehenden Klassen. 5. Erstellen Sie eine Liniengrafik der kumulierten relativen Häufigkeiten für beide Arbeitsblätter. Das Ergebnis soll wie in der folgenden Grafik aussehen. Aufgabe 9: In der angehängten Datei7 sind die Benotungen von etwa 120 Schülern. Erstellen Sie eine Tabelle, die die Häufigkeiten jeder Benotung auflistet. Welche Benotung kommt am häufigsten vor? 6 Aufgabe 8: 7 Aufgabe 9: Travail de candidature A.4. Aufgabenstellungen Aufgabe 10: Bestimmen Sie den Modus der Punktzahl der Schüler in der angehängten Datei.8 Aufgabe 11: Folgendes Histogramm repräsentiert die Verteilung der Anzahl der Arbeiter einer Firma in Funktion ihres Dienstalters. Arbeiter [#] 60 50 40 30 20 10 0 5 10 15 20 25 30 35 40 Dienstalter [Jahre] Bestimmen Sie den Modus anhand dieser Daten. Aufgabe 12: Versuchen Sie zunächst ohne Excel den Median der jeweiligen Datenreihe zu bestimmen. Überprüfen Sie anschließend Ihre Ergebnisse mit der Funktion „Median“. Datenreihe Median 0; 1; 0 2; 2; 57; 3; 3 0; 3; 4; 5 Aufgabe 13: In der Fußnote9 befindet sich eine Datei mit der Benotung von etwa 200 Studenten. 1. Bestimmen Sie den Median dieser Daten. 2. Erstellen Sie eine Tabelle mit der Häufigkeitsverteilung der Benotungen. 3. Erweitern Sie diese Tabelle um die relativen Häufigkeiten sowie um die kumulierten relativen Häufigkeiten. 4. Wie kann man den Median aus der Tabelle der kumulierten Häufigkeiten lesen? 8 Aufgabe 10: 9 Aufgabe 13 Travail de candidature 117 118 A. Anhang Aufgabe 14: Die folgende Tabelle enthält die Amtszeiten englischer Monarchen zwischen 827 und 1952. Bestimmen Sie den Median. Was sagt er aus und was kann man daraus schließen? Amtszeit [Jahre] Monarchen [#] [0; 10[ [10; 20[ [20; 30[ [30; 40[ [40; 50[ [50; 60[ [60; 70[ 22 16 11 7 1 2 2 Aufgabe 15: In der angehängten Datei10 sind die Antworten einer Umfrage, in der etwa 100 Haushalte nach der Anzahl der vorhandenen Fernsehgeräte befragt wurden. Bereiten Sie die Daten in einer Häufigkeitstabelle auf, die auch die kumulierten relativen Häufigkeiten enthält und bestimmen Sie den Median. Überprüfen Sie das Ergebnis anhand der Funktion „Median“. Aufgabe 16: Berechnen Sie den Mittelwert der Einkommen der Haushalte aus Aufgabe 8. Wofür steht dieser Mittelwert? Aufgabe 17: Untenstehend die Stundenlöhne (in e) von 10 Angestellten in zwei verschiedenen Unternehmen. Unternehmen 1 10 10 10 10 10 10 15 15 50 50 Unternehmen 2 16 16 17 17 17 17 17 17 18 19 Berechnen Sie das arithmetische Mittel der Stundenlöhne beider Unternehmen. Welche Schlussfolgerungen kann man ziehen, wenn man beide Werte vergleicht? 10 Aufgabe 15: Travail de candidature A.4. Aufgabenstellungen Aufgabe 18: Die folgende Tabelle stellt das Einkommen der Haushalte von 10 kanadischen Provinzen im Jahr 1997 dar: Provinz Einkommen, ø [$] Einkommen, Median [$] Alberta British Columbia Manitoba Neufundland und Labrador New Brunswick Nova Scotia Ontario Prince Edward Island Québec Saskatchewan 47 539 47 041 43 556 37 438 39 549 38 524 52 072 37 914 41 499 40 921 40 403 37 957 36 872 31 125 33 977 32 585 42 753 32 466 33 858 32 974 1. Wieso ist das durchschnittliche Einkommen in allen Provinzen höher als der Median des Einkommens? 2. Berechnen Sie den Mittelwert der Einkommen. Wieso entspricht er nicht den vom kanadischen Statistikamt veröffentlichten Wert von $ 46 556? Aufgabe 19: Nach einer Studie der Uni Kassel im Jahr 2010 verdienen vollzeitbeschäftigte Fachhochschulabsolventen zehn Jahre nach ihrem Abschluss im Schnitt etwa 59 400 e. Nun behauptet ein Freund, dass sein Vater, Hochschulabsolvent, aber 95 000 e im Jahr verdient. Stehen beide Aussagen im Widerspruch? Erläutern Sie Ihre Antwort. Travail de candidature 119 120 A. Anhang Aufgabe 20: Welchen Zentralwert sollte man in jedem der folgenden Beispielen nehmen? 1. Aufteilung der Angestellten nach ihrer Muttersprache. Muttersprache Anzahl Angestellter Luxemburgisch Französisch Deutsch Sonstige 25 81 57 9 2. Aufteilung der Angestellten nach ihrer Zufriedenheit. Zufriedenheit Anzahl Angestellter sehr unzufrieden eher unzufrieden eher zufrieden sehr zufrieden 18 27 60 45 3. Aufteilung der Angestellten nach ihren Krankentagen. Krankentage Angestellte [%] 0 1 2 3 85 12 2 1 4. Die Ergebnisse einer Schulklasse in einer Klausur. 1; 5; 24; 26; 28; 31; 32; 34; 34; 35; 35; 35; 37; 38; 40; 42. Travail de candidature A.4. Aufgabenstellungen Aufgabe 21: In der angehängten Datei11 befinden sich in zwei Tabellenblättern die Testergebnisse der Belastungstests von Beton, sowie die Punktzahl der Bewerber einer Arbeitsstelle. Berechnen Sie mit den Funktionen „MIN(Bereich)“ und „MAX(Bereich)“ die Spannweite beider Datenreihen. Aufgabe 22: Acht Bewerber des vorher erwähnten Einführungstests unterzogen sich einem zweiten Test, dessen Ergebnisse in der Tabelle unten hinzugefügt wurden: Punkte (von 20) 14 17 Test 1: Test 2: 13 14 15 13 5 16 15 7 16 17 10 7 17 14 Berechnen Sie den arithmetischen Mittelwert, die Spannweite und die Standardabweichung der beiden Tests. Vergleichen Sie die Ergebnisse der drei Kennzahlen. Aufgabe 23: Berechnen Sie die Standardabweichung der 5 000 Einkommen aus Aufgabe 8. Aufgabe 24: Folgende Tabelle enthält die Kundenumsätze (in Tsd. e) von vier verschiedenen Firmen. Firma Firma Firma Firma A: B: C: D: 121 132 132 122 134 135 135 125 137 138 138 138 142 141 142 158 162 148 165 160 Schätzen Sie zunächst von welcher Firma die Kundenumsätze die höchste Standardabweichung aufweisen. Überprüfen Sie Ihre Vermutung anschließend mit Hilfe von Excel. Aufgabe 25: Das folgende Histogramm enthält die Verteilung der Umsätze von zwei Firmen. 20 15 10 5 0 100 200 300 400 500 600 Welche der beiden Verteilungen weist die kleinere Standardabweichung auf? 11 Aufgabe 21: Travail de candidature 121 122 A. Anhang Aufgabe 26: Erläutern Sie für die folgenden drei Situationen, ob eine Korrelation, also ein Zusammenhang oder eine Abhängigkeit, besteht. 1. Die Anzahl der Touristen, die eine Stadt besuchen und die Höhe der Einnahmen dieser Stadt. 2. Das Gewicht eines Menschen und dessen Intelligenzquotient (IQ). 3. Die Dauer der Ausbildung eines Arztes und die Zeit, die er benötigt um eine richtige Diagnose zu erstellen. Aufgabe 27: Definieren Sie in den drei Situationen aus Aufgabe 26 jeweils die unabhängige Variable x und die von x abhängige Variable y. Aufgabe 28: Schreiben Sie die folgenden Daten in ein Tabellenblatt und berechnen Sie den Korrelationskoeffizienten für jedes der drei vorliegenden Beispiele mit der Funktion „KORREL“. 1. Die Anzahl der Touristen und die Höhe der Einnahmen: Land Anzahl Touristen [·106 ] Einnahmen [·109 e] A 4,9 3,5 B 4,1 2 C 5,5 4 D 6,6 5 E 4,4 2,5 2. Das Gewicht eines Menschen und dessen IQ. Gewicht [kg] 70 65 85 90 75 70 80 75 58 48 IQ [Punkte] 120 95 110 100 112 100 105 95 120 98 3. Die Dauer der Ausbildung eines Arztes und die Zeit, die er braucht um eine richtige Diagnose zu erstellen. Ausbildungsdauer [Tage] 2 2 3 3 4 4 5 5 5 6 Zeit bis zur Diagnose [Min] 25 23 17 21 18 20 15 12 13 10 Travail de candidature A.4. Aufgabenstellungen Aufgabe 29: Erklären Sie mit Hilfe der Erkenntnisse aus den vorherigen Aufgaben, wie man an den folgenden grafischen Darstellungen erkennen kann, ob und welche Korrelation vorliegt. 1. Die Anzahl der Touristen und die Höhe der Einnahmen. Einnahmen [·109 e] 5 4 3 2 1 0 1 2 3 4 5 6 7 Touristen [·106 ] 2. Das Gewicht eines Menschen und dessen IQ. IQ [Pkt] 120 100 80 60 40 20 0 20 40 60 80 Gewicht [kg] 3. Die Dauer der Ausbildung eines Arztes und die Zeit, die er braucht um eine richtige Diagnose zu erstellen. Zeit bis zur Diagnose [Min] 25 20 15 10 5 0 1 2 3 4 5 6 Ausbildungsdauer [Tage] Travail de candidature 123 124 A. Anhang Aufgabe 30: Ordnen Sie den folgenden Grafiken ihrem jeweiligen Korrelationskoeffizienten zu: −0, 90; 0, 50; 0, 85; −0, 20. Grafik A Grafik B Grafik C Grafik D Aufgabe 31: In der angehängten Datei12 ist die Länge und die Breite von mehreren Yachten aufgelistet. 1. Tragen Sie die Werte in ein Streudiagramm auf und fügen Sie den „Mittelpunkt“ ein. Die Koordinaten des Mittelpunktes sind die Mittelwerte der jeweiligen Variablen. 2. Schätzen Sie den Korrelationskoeffizienten und überprüfen Sie den Wert mit Hilfe von Excel. Aufgabe 32: Nennen Sie ein paar Beispiele, in denen der Korrelationskoeffizient genau 1 ist. Geben Sie zusätzlich etwa 5 Zahlenwerte zu jedem Beispiel an und prüfen Sie mit Excel, ob Sie richtig liegen. Aufgabe 33: Erweitern Sie die Tabelle um ein paar Werte und tragen Sie die Anzahl der Faltungen und die der Lagen in einem Streudiagramm graphisch auf. 1. Wie erkennt man eine exponentielle Korrelation anhand des Streudiagramms? 2. Geben Sie andere Beispiele exponentieller Korrelation. 12 Aufgabe 31: Travail de candidature A.4. Aufgabenstellungen Aufgabe 34: Angenommen y stellt das Gesamtgewicht eines Bierkastens dar, in dem sich x Flaschen befinden. Drücken Sie y mit Hilfe von x aus, wenn der leere Kasten 5 kg und jede Flasche 0,4 kg wiegt. Erstellen Sie ein Diagramm, in das Sie einige Werte graphisch auftragen. (Die horizontale Achse stellt die Anzahl der Flaschen und die vertikale Achse das Gesamtgewicht dar.) Aufgabe 35: Berechnen Sie den Achsenabschnitt b einer Geraden, die den Mittelpunkt M (x; y) einer Datenmenge schneidet und deren Steigung a frei bestimmbar, also variabel, ist. Aufgabe 36: In der angehängten Datei13 befinden sich vorgegebene Datenpaare und eine Gerade, die bereits in ein Diagramm eingetragen wurden. Mit dem Schieberegler können Sie die Steigung der Gerade frei bestimmen. Der Achsenabschnitt wird automatisch so angepasst, dass die Gerade den Mittelpunkt der Datenpunkte schneidet. Finden Sie ein Kriterium, nach dem Sie die Gerade so bestimmen, dass sie möglichst gleichmäßig an allen Datenpunkten liegt. Tipp: Betrachten Sie der Einfachheit halber die vertikalen Distanzen der Punkte zur gesuchten Regressionsgeraden. Aufgabe 37: Finden Sie mit Hilfe der Datei aus Aufgabe 36 eine Anordnung der Datenpunkte, so dass die Steigung der Geraden, die man durch das Minimieren des Ausdrucks n 2 1X |∆i | − |∆| n i=1 erhält, eine möglichst hohe Differenz zur Steigung der Regressionsgeraden aufweist. Die Regressionsgerade erhält man durch das Minimierung von n n 2 1X 1X ∆i − ∆ = (∆i )2 . n i=1 n i=1 13 Aufgabe Regressionsgerade: Travail de candidature 125 126 A. Anhang Aufgabe 38: Gegeben seien folgende Datenpaare: xi y i 1 2 3 3 0 3 Erstellen Sie das Streudiagramm und berechnen Sie die Differenzen ∆i der Datenpunkte zu einer möglichen Regressionsgeraden. Für welche Gerade wird 3 X (∆i )2 i=1 minimal? (Die Regressionsgerade schneidet den Mittelpunkt.) Aufgabe 39: Im Anhang befindet sich eine Datei14 , die das Gehalt und die davon abhängigen Alltagsausgaben von 50 Arbeitnehmern beinhalten. 1. Erstellen Sie ein Streudiagramm mit den Datenpaaren. Folgern Sie aus diesem Diagramm, ob eine Korrelation zwischen dem Gehalt und den Ausgaben besteht. 2. Überprüfen Sie Ihre Vermutung, indem Sie den Korrelationskoeffizienten berechnen. 3. Fügen Sie die Regressionsgerade ein und schätzen Sie anhand des Diagramms ab, wie hoch die Ausgaben wahrscheinlich wären, wenn man 45 000 e im Jahr verdienen würde. 4. Geben Sie die Formel der Regressionsgeraden an und rechnen Sie den abgelesenen Wert nach. 5. Erweitern Sie die Regressionsgerade um die jeweiligen Ausgaben für ein Gehalt von 60 000 e abschätzen zu können. Interpretieren und erläutern Sie das Ergebnis. Rechnen Sie auch hier nach. 6. Wie hoch sind die prognostizierten Ausgaben ohne Gehalt? Interpretieren und erklären Sie das Ergebnis. 14 Aufgabe 39: Travail de candidature A.4. Aufgabenstellungen Aufgabe 40: Die folgende Tabelle enthält die Sprunghöhe einiger Schüler in Abhängigkeit ihres Alters: Alter [Jahre] 6 6 7 8 8 9 9 11 12 12 Sprunghöhe [m] 0,6 0,8 0,9 0,7 1,0 1,1 1,0 1,2 1,4 1,1 1. Berechnen Sie den Korrelationskoeffizienten zwischen dem Alter und der Sprunghöhe und entscheiden Sie, ob es Sinn macht, eine Ausgleichsgerade ins Diagramm einzufügen. 2. Geben Sie die Formel der Ausgleichsgeraden an. 3. Berechnen Sie die Prognose der Sprunghöhe für ein Alter von 10 Jahren, 3 Jahren und für ein Alter von 30 Jahren. Kommentieren Sie die Ergebnisse. Aufgabe 41: In der angehängten Datei15 befindet sich eine Tabellen mit den Siegern des „Tour de France“ und ihrer jeweiligen Durchschnittsgeschwindigkeit. 1. Erstellen Sie ein Streudiagramm der Durchschnittsgeschwindigkeiten in Abhängigkeit der Jahrgänge und entscheiden Sie ob eine Korrelation vorliegt. 2. Berechnen Sie den Korrelationskoeffizienten und die Formel der Regressionsgeraden. 3. Welche durchschnittliche Geschwindigkeit könnte man im Jahr 2030 erwarten? 4. Überprüfen Sie den berechneten Wert grafisch, indem Sie die Regressionsgerade bis 2030 erweitern. 15 Aufgabe 41: Travail de candidature 127 128 A. Anhang Aufgabe 42: Die folgende Tabelle enthält die Anzahl der Storchenpaare sowie die Anzahl der Geburten in einem gegebenen Land.16 Land Albanien Bulgarien Griechenland Österreich Polen Portugal Rumänien Schweiz Spanien Türkei Ungarn Storchenpaare Geburten 100 5 000 2 500 300 30 000 1 500 5 000 150 8 000 25 000 5 000 83 000 117 000 106 000 87 000 610 000 120 000 23 000 82 000 439 000 1 576 000 124 000 Berechnen Sie die Formel der Regressionsgeraden und schätzen Sie die ungefähre Anzahl an Störchen, die notwendig ist, um 50 000 Geburten zu sichern. Hängt die Anzahl der Geburten tatsächlich von der Anzahl der Storchenpaare ab? Aufgabe 43: Die angehängte Datei17 enthält die Anzahl der Bienenvölker, die Honig produzieren und die Anzahl der Festnahmen von Jugendlichen wegen des Besitzes von Marihuana. 1. Tragen Sie die Daten in ein Streudiagramm auf und entscheiden Sie, ob eine Korrelation zwischen der Anzahl der Bienenvölker und der Anzahl der Festnahmen vorliegt. 2. Überprüfen Sie, ob der Korrelationskoeffizient zwischen beiden Variablen ungefähr −0, 93 beträgt und ob damit eine negative Korrelation vorliegt. 3. Besteht tatsächlich eine Abhängigkeit zwischen beiden Variablen? 16 Siehe [9]. 17 Aufgabe 43: Travail de candidature