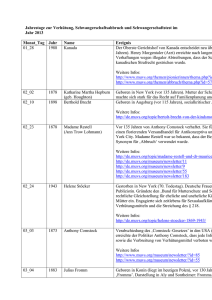
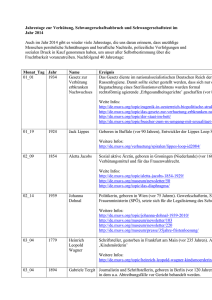
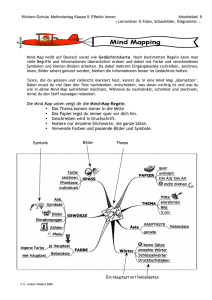
Diplomarbeit Entwicklung eines interaktiven
Werbung

Fachhochschule Köln University of Applied Sciences Cologne Campus Gummersbach Fakultät für Informatik und Ingenieurwissenschaften Diplomarbeit zur Erlangung des akademischen Grades Diplom-Informatiker (FH) Entwicklung eines interaktiven dynamischen semantischen Netzes mit multimedialen Informationsobjekten am Beispiel eines wissenschaftlichen digitalen Schriftarchivs vorgelegt am: von: E-Mail: Matr.-Nr.: 16. Dezember 2004 Alex Maier Jochen-Klepper-Weg 1 51545 Waldbröl [email protected] 11026063 Erstprüfer: Zweitprüfer: Prof. Dr. Heiner Klocke Dipl.-Inform. Uwe Poborski Alexander Peters In der Mühlhelle 40 51645 Gummersbach [email protected] 11024987 Vorwort Vorwort Diese Diplomarbeit besteht aus zwei Teilen. Im ersten Teil wird eine Idee zur Darstellung von Informationen und deren Beziehungen in einem semantischen Netzwerk beschrieben. Eine mögliche Realisierung der Idee wird an einem Beispiel gezeigt. Im zweiten Teil wird beschrieben, wie die Informationsobjekte, die in einem Bild enthalten sind, mit zusätzlichen multimedialen Informationen versehen werden können. Als Informationsbestand diente ein digitales Schriftarchiv, das im Rahmen des Forschungsprojektes „Hebräische Typographie im deutschsprachigen Raum“ entstanden wurde. Für das Gelingen dieser Arbeit möchten wir uns bei all denjenigen bedanken, die dazu beigetragen haben: An erster Stelle möchten wir ein Dank den Betreuern dieser Diplomarbeit Prof. Dr. Heiner Klocke und Dipl.-Inform. Uwe Poborski aussprechen, die uns immer bei Fragen zur Hilfe standen und wertvolle Ratschläge gaben. Besonderer Dank geht an den Buchwissenschaftler Dr. Ittai Tamari für die freundliche und hilfsbereite Unterstützung bei der Ermittlung der fachlichen Anforderungen. Für die wertvollen Tipps und die Diskussionsbereitschaft bedanken wir uns bei Dipl.-Inform. Juri Bauer, Alexander Fischer und Dipl.-Inform. Kirill Poletajew. Nicht zuletzt geht unser ganz besonders herzlicher Dank an unsere Ehefrauen Anna Peters und Viktoria Maier, ohne derer Liebe und Rücksichtnahme die Durchführung dieser Arbeit nicht in der Form möglich gewesen wäre. Alex Maier und Alexander Peters Gummersbach, im Dezember 2004 Inhaltsverzeichnis Inhaltsverzeichnis 1. Visualisierung der Informationen in einem semantischen Netz 1.1 Einführung 1 1 1.1.1 Problemstellung 3 1.1.2 Vorgehensweise 7 1.2 Topic Map und Topic Map-Tools 1.2.1 ISO/IEC 13250 9 9 Das Topic Element 10 Das Association Element 13 Zusätzliche Elemente 14 Das Topic Map Element 15 1.2.2 15 XML Topic Maps (XTM) Grundlagen von XML 15 Grundlagen von DTD 17 XLink 19 Beschreibung von XTM 19 Änderungen im Bezug auf ISO 13250 24 1.2.3 25 Topic Map Tools Ontopia 25 Empolis 26 Mondeca 26 Moresophy 27 Tmproc 27 SemanText 28 Nexist 28 TM4J 28 i Inhaltsverzeichnis 1.3 TM4J (Topic Map for Java) 1.3.1 Beschreibung von TM4J 30 1.3.2 Installation, Konfiguration und Einsatz von TM4J 31 Kommandozeile-Anwendungen 31 Möglichkeiten für Entwickler 36 1.4 Realisierung eines semantischen Netzes 1.4.1 41 44 Implementieren der XTMGenerator-Klasse 48 1.4.2 Visualisierung von XTM Dokumenten 62 1.4.3 Realisierung der graphischen Darstellung 70 Grundlagen der eingesetzten Technologien 71 Idee zur Darstellung der relevanten Informationsobjekte 73 Erweiterung der XTMGenerator Klasse 76 Klasse Graph 78 HebrewTypeNavigator 78 Zusätzliche Funktionen des HebrewType Navigators 81 Implementierung der Buchseite bzw. Buchstabe Detailsicht 83 1.4.4 Ausprobieren der Anwendung und erste Probleme 88 1.4.5 Client-Server Architektur des HebrewType Navigators 89 HebrewType Navigator Server 90 HebrewType Navigator Client 91 Sockets und Objektserialisierung 92 Ergebnisse und Erkenntnisse Erfassung multimedialer Zusatzinformationen 2.1 ii Automatische Generierung von XTM 40 Festlegen der relevanten Topic Typen, Topics und Assoziationen 1.5 2. 30 Einführung 93 95 95 2.1.1 Problemstellung 97 2.1.2 Vorgehensweise 99 Inhaltsverzeichnis 2.2 Realisierung 2.2.1 Modellierung eines Datenbankschema 99 Tabelle Markierung 100 Tabelle Audio 100 Tabelle Bild 100 Tabelle Video 101 2.2.2 Implementierung einer Schnittstelle zur Datenbank 102 2.2.3 Werkzeug zum Markieren und Visualisieren der Informationsobjekten 2.2.4 104 User Interface zur Erfassung und Darstellung von Zusatzinformationen 108 Audio-Aufnahme und -Wiedergabe 110 Weitere Zusatzfunktionen 111 2.2.5 Erweiterung der Server- und Client- Seiten des HebrewType Navigators 112 Erweiterung der Serverseite 112 Entwicklung einer zusätzlichen Serverapplikation 113 Erweiterung der Clientseite 114 2.2.6 115 2.3 3. 99 Sichere Kommunikation zwischen Client und Server Ergebnisse und Erkenntnisse Zusammenfassung der Diplomarbeit 118 119 Abbildungsverzeichnis 121 Tabellenverzeichnis 123 Glossar 124 Literaturverzeichnis 130 Anhang 133 CD-Inhalt 133 iii Visualisierung der Informationen in einem semantischen Netz Einführung 1. Visualisierung der Informationen in einem semantischen Netz 1.1 Einführung Heutzutage sind fast alle Informationen in digitalem Format erfasst und archiviert. Doch allein das Vorhandensein von Informationen reicht nicht aus. Selbst wenn die Informationen gut und übersichtlich strukturiert sind, ist es immer noch schwierig, die notwendige Information zu finden. Es gibt viele Tools, die es erlauben, nach Informationen zu suchen, wie zum Beispiel Suchmaschinen im Web, oder Dateisuche auf dem PC. Die Problematik besteht erstmals darin, dass diese Tools meist auf Volltextsuche basieren. So kriegt der Benutzer dieser Tools oft nicht das, wonach er suchte. Zum weiteren besteht die Fehlsuche darin, dass die Bedeutung und der Zusammenhang von Informationen fehlen. Und genau aus dem Grund ist es besonders schwer, die Informationen zu finden, bei denen die Volltextsuche überhaupt nicht funktioniert. Solche Informationen sind zum Beispiel Bilder oder Graphen. Um diese Probleme zu verdeutlichen, wird ein kleines Beispiel gezeigt: Immer häufiger werden Fotos in digitaler Form gespeichert. Damit die schneller gefunden werden, soll eine übersichtliche Verzeichnisstruktur überlegt werden. In der Abbildung 1 ist ein Beispiel abgebildet, wie solche Verzeichnisstruktur aussehen kann. Jeder Benutzer wählt für sich selbst eine Struktur aus und wird vielleicht mit dieser Struktur nicht klar kommen, weil diese für den Benutzer nicht ausreichend ist. Selbst die eigene Struktur wird für bestimmte Suchanforderungen nicht ausreichen. Zum Beispiel wird es in gezeigtem Fall schwierig sein, alle Urlaubsfotos zu finden, die im Sommer gemacht sind, oder alle Fotos aus einer bestimmten Stadt zu zeigen usw. 1 Visualisierung der Informationen in einem semantischen Netz Einführung Abbildung 1 Verzeichnisstruktur Aus dem Beispiel ist ersichtlich, dass es kaum möglich ist, die Informationen so zu strukturieren, dass jede denkbare Suchanforderung zum schnellen Erfolg führt. Und das nicht nur aus dem Grund der schlechten Strukturierung, sondern auch weil es sich um nicht Textbasierte Informationen handelt, auf die eine Volltextsuche nur begrenzt angewendet werden kann. Als Lösung dieses Problems, soll parallel zur bestehenden Struktur ein semantisches Netz aufgebaut werden, das ein gezielter Zugriff auf einen vorhandenen Informationsbestand ermöglicht. Ein semantisches Netz ist eine formale Begriffssammlung, die zur Beschreibung der Informationen dient. Ein semantisches Netz besteht aus Knoten und Verbindungen. Knoten repräsentieren Begriffe und Objekte innerhalb eines spezifischen Gebiets. Verbindungen (Relationen) vertreten Beziehungen zwischen den Knoten, wodurch der Zusammenhang zwischen den Knoten ersichtlich wird. „The semantic network is a representation formalism that has been used for many years in artificial intelligence (AI) research. Semantic networks consist of nodes and links. Nodes usually represent objects, concepts, or situations within a specific domain. Links represent relationships between the nodes that have a semantic meaning to them. “(vgl. [XMLTM], S.328) 2 Visualisierung der Informationen in einem semantischen Netz Einführung Abbildung 2 semantisches Netz Mit dem in der Abbildung 2 aufgebauten semantischen Netz wird erreicht, dass zu gewünschten Informationen durch mehrere Wege gelangt werden kann und der Zusammenhang der einzelnen Informationen besser erkannt wird. 1.1.1 Problemstellung Von der Problematik, die in der Einführung beschrieben wurde, sind auch zahlreiche Informationsbestände betroffen. Das wissenschaftliche digitale Schriftarchiv, das im Rahmen des Forschungsprojektes „Hebräische Typographie im deutschsprachigen Raum“ entstanden ist, gehört auch dazu. Nähere Informationen zum Projekt sind auf der Projektwebseite1 zu sehen. Die Menschen, die mit dem Schriftarchiv arbeiten, sind auf die erstellte Webapplikation „HebrewTypeShow“2 angewiesen. Diese Applikation hat eine fest definierte Struktur. Ein Benutzer, der nach Informationen im digitalen Schriftarchiv 1 2 http://www.gm.fh-koeln.de/hebrewtype http://fsygs21.inf.fh-koeln.de/HebrewShow/servlet/HebrewShow 3 Visualisierung der Informationen in einem semantischen Netz Einführung sucht, benötigt eine bestimmte Zeit, bis die gewünschten Informationen gefunden werden. Zum Beispiel, es wird nach allen Druckschriftdokumenten und Schriftsätzen gesucht, die im Jahre „1516“ gedruckt bzw. geschnitten wurden. In der Webapplikation „HebrewTypeShow“ soll ein Benutzer dann so vorgehen: • Um alle Schriftsätze aus dem Jahr zu finden, wird in der „Typografie – Übersicht“ Sicht ein Zeitraum von „1516“ bis „1516“ ausgewählt. Das Ergebnis wird wie in der Abbildung 3 aussehen. Abbildung 3 Typografie - Übersicht • Um alle Druckschriftdokumente, die in dem Jahr gedruckt wurden, zu finden, soll in der „Bibliografie - Übersicht“ Sicht, ähnlich wie bei Schriftsätzen, der Zeitraum auf das Jahr „1516“ eingegrenzt werden. In der Abbildung 4 ist das Resultat dieser Suche zu sehen. 4 Visualisierung der Informationen in einem semantischen Netz Einführung Abbildung 4 Bibliografie - Übersicht Um beide Ergebnisse gleichzeitig zu betrachten, sollten diese in verschiedenen Browser - Fenstern gesucht werden. Um die eventuellen Zusammenhänge zwischen mehreren Druckschriftdokumenten und Schriftsätzen nachzuvollziehen, soll der Benutzer sich einzelne Details bei jedem Druckschriftdokument bzw. Schriftsatz merken und mit anderen vergleichen. Die Idee bestand darin, eine Lösung zu finden, die dem Benutzer eine Möglichkeit bietet, frei im digitalen Bildatlas zu navigieren und dadurch die Suche nach bestimmten Informationen zu erleichtern. Dann könnte die Suche nach Druckschriftdokumenten und Schriftsätzen zu einem bestimmten Jahr wie in der Abbildung 5 aussehen. Somit bekommt der Benutzer auf einmal alle mit diesem Jahr assoziierten Druckschriftdokumente und Schriftsätze präsentiert. Abbildung 5 Idee der Suche nach einem Jahr 5 Visualisierung der Informationen in einem semantischen Netz Einführung Zusätzlich sollte es nachvollziehbar sein, wie einzelne Informationen zueinander im Zusammenhang stehen. So würde es, wie in der Abbildung 6 dargestellt ist, zu erkennen, dass die gefundenen Druckschriftdokument und Schriftsatz durch ein Ort miteinander verknüpft sind. Abbildung 6 Zusätzliche Verknüpfungen Wenn ein Benutzer zum Beispiel gesuchten Schriftsatz gefunden hat, soll er die Informationen, ähnlich wie in der Abbildung 7, zur Ansicht bekommen. Abbildung 7 Gesuchtes Schriftsatz Ein gefundenes Druckschriftdokument soll, ähnlich wie ein Schriftsatz, mit allen damit verknüpften Informationen präsentiert werden. Die Details der einzelnen Buchstaben eines Schriftsatzes, oder Buchseiten eines Druckschriftdokumentes 6 Visualisierung der Informationen in einem semantischen Netz Einführung sollten auch zur Auswahl bereitstehen. In der Abbildung 8 wird eine mögliche Darstellung der Buchstabe „Alef“ aus einem Schriftsatz gezeigt. Abbildung 8 Detail des Buchstabens Zusammenfassend bestand die Aufgabe darin, eine Anwendung zu entwickeln, die dem Benutzer eine Möglichkeit bietet, frei im digitalen Bildatlas zu navigieren und dadurch die Suche nach bestimmten Informationen zu erleichtern. Zusätzlich sollte es nachvollziehbar sein, wie einzelne Informationen zueinander im Zusammenhang stehen. 1.1.2 Vorgehensweise Alle Informationen, wie die Bilder der Schriftzeichen und Buchseiten, sowie die beschreibenden Texte, die im digitalen Schriftarchiv vorhanden sind, sind in einer relationalen Datenbank gespeichert. Wie in Abbildung 9 abgebildet ist, erfolgt der Zugriff auf die in der Datenbank gespeicherten Daten mit Hilfe der vorhandenen Fachklassen „HebrewTypeDataModel“, die es ermöglichen, Daten als Java-Objekte mit allen ihren Eigenschaften in einem objektorientierten Datenmodell abzubilden. 7 Visualisierung der Informationen in einem semantischen Netz Einführung Die Verbindung zwischen der Datenbank und dem Web-Server wird mit Hilfe der JDBC Schnittstelle realisiert. [HTidR] Abbildung 9 HebrewType Basierend auf der Schnittstelle „HebrewTypeDataModel“ wurden schon die WebAnwendungen „HebrewWork“ und „HebrewTypeShow“ implementiert. Zur Visualisierung der Informationen aus dem digitalen Schriftarchiv in Form eines semantischen Netzes soll die vorhandene Schnittstelle „HebrewTypeDataModel“ auch verwendet werden. Zum Aufbau und zur Präsentation eines semantischen Netzes wurde der Standard Topic Map ISO/IEC-13250 eingesetzt. Es wurde nach einem Tool gesucht, das Topic Map Standard realisiert. Dabei war wichtig, dass es Java-basiert ist, damit die vorhandene Schnittstelle benutzt werden kann. Java ist eine objektorientierte Programmiersprache, die später näher 8 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools beschrieben wird. Zweiter wichtiger Aspekt bei der Wahl des Tools ist, dass es kein kommerzielles Produkt ist. Ein Vorgehensmodell zum Erzeugen des Topic Maps wurde entwickelt und realisiert. Zur grafischen Darstellung der Topic Maps wurden vorhandene Topic Map Visualisierer analysiert. Die grafische Darstellung der Informationen sowie die Navigationselemente wurden festgelegt und mit Java API realisiert. Damit die Informationen übers Internet abrufbar sind, wurde die Anwendung auf Client-Server-Architektur umgestellt. 1.2 Topic Map und Topic Map-Tools In diesem Kapitel werden die grundlegenden Bestandteile des Standards ISO/IEC 13250 vorgestellt. Das daraus abgeleitete XML Topic Map (XTM) 1.0 wird beschrieben und ein kurzer Überblick der Softwaretools, die diese Spezifikation implementieren, wird gegeben. 1.2.1 ISO/IEC 13250 Topic Map ist ein ISO - Standard, der Ende 1999 unter dem Namen ISO/IEC -13250 von der Arbeitsgruppe ISO JTC1/SC34/WG3 verabschiedet wurde. Mit Topic Map wurde eine Möglichkeit gegeben, über ein semantisches Netz auf Informationen zuzugreifen. Topic Map basiert auf Teilen des SGML1 - Standards ISO 8879. Der HyTime2 – Standard ISO 10744 wurde auch zugrunde gelegt. [ToMap] Die Idee war, ähnlich wie bei Indexen, Glossaren oder Lexika, die Qualität und Geschwindigkeit der Suche nach bestimmter Information zu verbessern: Jede Informationseinheit, wie zum Beispiel ein Bild, ein Artikel, ein Dokument oder etc., wird durch Schlagwörter (Topics) beschrieben und beinhaltet Referenzen zu der Informationsquelle. Die Topics werden in Verbindung gebracht, wodurch eine 1 2 http://th-o.de/sgml/ http://www.y12.doe.gov/sgml/wg8/docs/n1920/html/n1920.html 9 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Wissensbasis entsteht. Im Folgenden werden die grundlegenden Elemente des ISO/IEC -13250 –Standards beschrieben. Das Topic Element Ein elementares Grundelement des Topic Map Standards ist Topic. Ein Topic kann alles Beschreibbare sein: es kann ein Gegenstand bzw. ein Thema abbilden. In einem digitalen Schriftarchiv, hier „Hebräische Typografie im deutschsprachigen Raum“ kann ein Topic zum Beispiel ein Autor, ein Drucker, ein Druckort, ein Titel oder ein Druckschriftdokument sein. Basel Sanctae linguae Hebraeae Erotemata 200002281056 Michael Neander Bartholomeus Franco Abbildung 10 Topics Ein Topic kann ein oder mehrere Typen haben. In der Abbildung 10 sind als Beispiel einige Topics abgebildet. „Michael Neander“ ist vom Typ „Autor“, „Sanctae linguae Hebraeae Erotemata“ ist vom Typ „Titel“, „Basel“ ist vom Typ „Druckort“, „Bartholomeus Franco“ ist vom Typ „Drucker“ und „200002281056“ ist vom Typ „Druckschriftdokument“. Die Typen eines Topics sind wiederum Topics. Bevor einem Topic ein Typ zugewiesen wird, soll dieser Typ als Topic erstellt werden. In der Abbildung 11 ist die Zugehörigkeit eines Topics zu seinem Topic Typ durch die Pfeile mit der Beschriftung „vom Typ“ dargestellt. Es kann vorkommen, dass ein Topic Typ selbst von einem Typ ist. Durch solche Verkettung kann eine Typhierarchie gebildet werden. 10 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Abbildung 11 Topics mit Topics Typen Ein Topic hat mehrere Eigenschaften. Eine davon ist der Name Topic Name. Es gibt drei Namensarten: • Base Name – wird zu Identifizierung eines Topics verwendet, deswegen muss mindestens ein Base Name definiert sein. Es können aber auch mehrere Base • • Namen vergeben werden, die zum Beispiel bei mehrsprachigen Anwendungen hilfreich sein können. • Display Name – wird zur Darstellung eines Topics in einer Anwendung verwendet. Die Eingabe ist nicht zwingend. Bei der Nichteingabe wird Base Name verwendet. • Sort Name – wird als Schlüsselwort bei der Sortierung der Topics in einer Anwendung verwendet. Die Eingabe ist wie bei Display Name nicht zwingend. Beim Weglassen wird auch Base Name verwendet. Wie in der Abbildung 12 zu sehen ist, hat Druckort „Basel“ mehrere Namen: „Basel“, „ “בסיליאהund “Basileae“, die in einem Rechteck aufgelistet sind. 11 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Abbildung 12 Topic Namen Zweite wichtige Eigenschaft eines Topics ist ein Identity-Attribut auch Public Subject Descriptor genannt. Jedes Topic ist durch dieses Attribut eindeutig identifizierbar. Wenn zwei Topics ein gleiches Identity –Attribut besitzen, werden diese Topics zu einem zusammengefügt. Der daraus entstandenes Topic erhält alle Eigenschaften der beiden Topics. Zum Beispiel es gibt zwei Topics: Ein Topic hat ein Base Name „Basel“, ein zweites hat Base Name „Basileae“. Wenn beide Topics ein gleiches Identity Attribut besitzen, werden diese zu einem neuen Topic zusammengefügt. Dieses Topic wird zwei Base Namen beinhalten: „Basel“ und „Basileae“. Dritte Eigenschaft eines Topics ist Occurrence (Vorkommen), die ein Verweis auf externe Ressource beinhaltet. Die externe Ressource kann zum Beispiel eine Web Seite, ein Textdokument, ein Bild, ein Video, ein Audio, usw. sein. Jede Occurrence kann eine Occurrence Role besitzen, die wiederum ein Topic ist. Occurrence Role beschreibt den Typ der Ressource. In der Abbildung 13 sind die „Occurrencen“ als gestrichelte Linien dargestellt. Die verweisen auf externe Ressourcen in World Wide Web. Zum Beispiel hat das Topic „Basel“ zwei Occurrencen. Eine davon verweist auf die Web-Seite von Basel http://www.basel.ch/, die andere verweist auf ein Bild http://ccat.sas.upenn.edu/rs/rak/gen/hrks/bickels/images/basel.jpg, das in dieser Stadt aufgenommen wurde. Es besteht eine Möglichkeit, für diese Occurrencen 12 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Occurrence Rollen zu definieren. Dann würde im Beispiel die erste Occurence die Occurrence Rolle „Web-Site“, die Zweite die Occurrence Rolle „Bild“ bekommen. Abbildung 13 Occurrences Das Association Element Association ist ein Element des Topic Map Standards, das eine Verknüpfung zwischen mindestens zwei Topics beschreibt. Jede Association kann, muss aber nicht, einen Association Type haben. Dieser Typ wird zur Beschreibung der Art der Verknüpfung verwendet und muss zuvor als Topic deklariert werden. Alle Topics spielen in dieser Association eine bestimmte Rolle, die als Association Role bezeichnet wird. Ähnlich wie Association Type, muss die Association Role als ein Topic deklariert werden. In der Abbildung 14 sind mögliche Associations zwischen Topics dargestellt. Zum Beispiel wird das Topic „200002281056“ durch die Association vom Typ „hat Titel“ mit dem Topic „Sanctae linguae Hebraeae Erotemata“ verbunden. Dabei nimmt das Topic „Sanctae linguae Hebraeae Erotemata“ die Association Role „Titel“ an und das Topic „200002281056“ hat die Association Role „Druckschriftdokument“. 13 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Abbildung 14 Associations Zusätzliche Elemente Scope ist ein weiteres Element des Topic Map Standards. Scope beschreibt den Gültigkeitsbereich, zu dem ein oder mehrere Topics und deren Namen und Assoziationen gehören können. Dadurch wird erreicht, dass in diesem Bereich keine Topics mit gleichen Namen aber unterschiedlicher Bedeutung vorkommen. Um Scopes einsetzen zu können, müssen diese zuerst als Topics deklariert werden. Besonders hilfreich ist es Scopes einzusetzen, wenn zum Beispiel zwei Topics mit gleichen Namen aus verschiedenen Themengebieten kommen. So könnte Basel als Druckort eines Druckschriftdokumentes, aber auch als Stadt in der Schweiz auftauchen. Es wäre denkbar, zwei Themengebiete (Scopes) zu definieren: Ein Themengebiet könnte „Typographie“ für „Basel“ als Druckort eines Druckschriftdokumentes sein, ein zweites Themengebiet - „Geografie“. Facets werden im Topic Map Standard dazu benötigt, die Eigenschaften des Topics oder anderen Elementen zu beschreiben. 14 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Zum Beispiel könnte dem Topic „Michael Neander“ die Eigenschaft „Geboren am“ mit dem Wert „xx.xx.1525“ hinzugefügt werden. Dem Facet selbst kann eine weitere Eigenschaft zugeordnet werden, zum Beispiel „Ort“ mit dem Wert „Żary“. Daraus wird die Zusatzinformation zum Autor „Michael Neander“ gewonnen und zwar, dass er 1525 in Żary geboren wurde. Das Topic Map Element Unter dem Element Topic Map werden alle zuvor beschriebenen Elemente gepackt. Das heißt, eine Menge von Topics, Associations, Occurrences, Scopes und Facets wird als Topic Map bezeichnet. Ein Topic Map kann selbst Scopes haben. Damit wird das Thema des im Topic Map enthaltenen Wissens von vornherein deutlich gemacht. 1.2.2 XML Topic Maps (XTM) Der zuvor beschriebene Standard ISO/IEC 13250 wurde als ein Meta-DTD modelliert. Daraus wurden verschiedene Spezifikationen abgeleitet. Eine der erfolgreichsten und meist eingesetzten ist XML Topic Map (XTM). XTM Version 1.0 wurde im Jahre 2001 von TopicMaps.org verabschiedet. Dabei wurden folgende Ziele verfolgt: • Realisierung nur nötiger Eigenschaften des Topic Map Standards • Dadurch Gewährleistung der Einfachheit bei der Erstellung, Pflege und Lesbarkeit • Unterstützung einer Vielzahl von Anwendungen • Kompatibilität zu bestehenden Standards • Einfache Verbreitung übers Internet Um den XTM Aufbau verständlich zu machen, werden zuerst die Grundlagen von XML, DTD und XLink kurz erläutert. Grundlagen von XML XML - eXtensible Markup Language wurde 1998 mit Version 1.0 von W3C verabschiedet. XML vereinigt die Eigenschaften von SGML und HTML. 15 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools XML ist eine Markup – Sprache und wurde zum Austausch und zur Speicherung von Informationen gedacht. Der Vorteil von XML ist, dass es leichter als SGML zu verstehen ist, weil XML nur wesentliche Elemente des SGML Standards beinhaltet und die Einfachheit des HTML’s hat. Im Vergleich zu HTML werden im XML nur reine Daten gehalten und nicht die Informationen, wie diese Daten zu präsentieren sind. Darüber entscheidet letztlich der Endbenutzer zum Beispiel mit Hilfe von XSLT oder CSS, wie die Daten dargestellt werden. Jedes XML - Dokument fängt mit Angabe der XML-Version, so wie mit der Angabe der in diesem Dokument benutzten Kodierung. <?xml version="1.0" encoding="UTF-8"?> Die Elemente des XML - Dokuments bestehen aus so genannten Tags. Es gibt einen Anfang-Tag, der durch einen End-Tag geschlossen werden soll. Dazwischen können Daten oder weitere Elemente stehen. Hier ist ein kurzes Beispiel eines XML Dokumentes, das die Daten von mehreren Druckschriftdokumenten beinhaltet. <DruckschriftDokumente> <DruckschriftDokument> <Titel>Sanctae linguae Hebraeae Erotemata</Titel> <DruckOrt>Basel</DruckOrt> <Autor>Michael Neander</Autor> <Schluessel>200002281056</Schluessel> </DruckschriftDokument> <DruckschriftDokument> <Titel>Portae lucis</Titel> <DruckOrt>Augsburg</DruckOrt> <Autor><יוסף בן אברהם גיקטילה/Autor> <Schluessel>200207011149</Schluessel> </DruckschriftDokument> <DruckschriftDokument> ... </DruckschriftDokument> </DruckschriftDokumente> Im Beispiel gezeigtes XML - Dokument besteht aus einem Root-Tag (Wurzel) mit dem Namen „DruckschriftDokumente“. Innerhalb des Root-Tags sind „DruckschriftDokument“ - Elemente beschrieben, die wiederum weitere Elemente 16 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools beinhalten. Diese sind die Tags, die die Namen „Titel“, „DruckOrt“, „Autor“ und „Schluessel“ haben, und mit den entsprechenden Werten gefüllt sind. Innerhalb eines XML – Tags sind außer Namen die zusätzlichen Attribute zulässig. Zum Beispiel könnte dem Tag „Autor“ ein Attribut „geburtsOrt“ hinzugefügt werden. <Autor geburtsOrt="Zary">Michael Neander</Autor> Der Wert der Attribute muss immer in Anführungszeichen sein. XML hat eine starre hierarchische Baumstruktur. In der Abbildung 15 ist eine solche Struktur zum beschriebenen Beispiel abgebildet. Diese Abbildung wurde mit Hilfe von Altova xmlspy1 generiert. Abbildung 15 XML Baum Grundlagen von DTD Es besteht die Möglichkeit, die Namen von Tags und die Struktur eines XMLDokumentes fest zu definieren. Dies geschieht mit Hilfe vom Document Type Definition (DTD). DTD’s sind insbesondere dann sinnvoll zu definieren, wenn das XML - Format zum Austausch von Informationen zwischen mehreren Organisationen benutzt werden soll. Ein Beispiel DTD könnte wie folgt aussehen: <?xml version="1.0" encoding="UTF-8"?> <!--DTD generated by XMLSPY v2004 rel. 4 U (http://www.xmlspy.com)--> <!ELEMENT Autor (#PCDATA)> <!ATTLIST Autor geburtsOrt CDATA #REQUIRED> <!ELEMENT DruckOrt (#PCDATA)> <!ELEMENT DruckschriftDokument (Titel, DruckOrt, Autor, Schluessel)> 1 http://www.xmlspy.de/ 17 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools <!ELEMENT DruckschriftDokumente (DruckschriftDokument*)> <!ELEMENT Schluessel (#PCDATA)> <!ELEMENT Titel (#PCDATA)> Für das Erstellen von DTD’s werden nur wenige Schlüsselwörter benutzt, die in der Tabelle 1 erfasst sind. [DocTD] Schlüsselwort <!ELEMENT Name (#Wert)> Bedeutung Markup-Befehl: beschreibt, welche Tags in einem XML – Dokument verwendet werden dürfen <!ATTLIST Elementname Attributliste> Attributliste: beschreibt die zusätzlichen Attribute innerhalb eines bestimmten Tags. <!ENTITY Referenzname Ersetzung> Substitutionselement: beschreibt eine statische Variable, die mehrfach auftretenden Definitionen innerhalb des Dokuments aufzählt. <!NOTATION name Quelle software> Datentypdeklaration: beschreibt, mit welchem Programm die deklarierten Datentypen ausgeführt werden sollen. <!-- Kommentar --> Kommentar Tabelle 1 DTD – Schlüsselwörter Laut der XML Spezifikation, beginnen die Namen der XML Tags mit einem Buchstaben, Doppelpunkt oder Unterstrich und können anschließend weitere solchen Zeichen, sowie auch Ziffern, Punkte und Bindestriche enthalten. Die Werte der Attribute werden durch die Angabe des Attribute Typs bestimmt. Jedes Attribut Typ beschreibt, welche Zeichen als Werte genommen werden dürfen. So zum Beispiel muss ein Attribut vom Typ „ID“, das als eindeutiger Bezeichner für ein Element dient, wie die Namen der XML Tags, mit einem Buchstaben, Doppelpunkt oder Unterstrich beginnen. Anschließend darf dieses Attribut weitere 18 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools solchen Zeichen, sowie auch Ziffern, Punkte und Bindestriche enthalten. Eine weitere Einschränkung ist, dass dieses Attribut keine Leerzeichen beinhalten darf. [DmDTD] XLink XML Linking Language (XLink) Version 1.0 wurde am 27.06.2001 als ein Standard von W3C verabschiedet. XLink erlaubt, in einem XML - Dokument verschiedene Verknüpfungen (Link’s) zu erstellen und zu beschreiben. (vgl. [XLink]) Beschreibung von XTM XML Topic Map (XTM) ist XML basiert, verwendet Elemente des XLink Standards und wird durch eine DTD definiert, die auf www.topicmaps.org veröffentlicht wurde. XTM erhält durch DTD eine feste Struktur. Das heißt, dass die Elemente des XTM – Dokumentes bestimmte Namen haben, und es keine Möglichkeit besteht, eigene Namen zu definieren. Im Folgenden werden die Elemente des XTM – Dokumentes beschrieben und deren Bedeutung erläutert. • topic entspricht dem in Topic Map Standard definierten Topic – Element. Nach DTD muss jedem Topic eine id zugewiesen werden. <topic id="Basel"> <baseName> <baseNameString>Basel</baseNameString> </baseName> </topic> <topic id="Bartholomeus_Franco"> <baseName> <baseNameString>Bartholomeus Franco</baseNameString> </baseName> </topic> <topic id="Sanctae_linguae_Hebraeae_Erotemata"> <baseName> <baseNameString>Sanctae linguae Hebraeae Erotemata</baseNameString> </baseName> </topic> <topic id="Michael_Neander"> 19 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools <baseName> <baseNameString>Michael Neander</baseNameString> </baseName> </topic> <topic id="buch_200002281056"> <baseName> <baseNameString>200002281056</baseNameString> </baseName> </topic> Die id dient der eindeutigen Referenzierung innerhalb des Topic Maps. Ein baseName dient der Darstellung des Topics. Ähnlich wie beim Topic Map Standard besteht bei XTM die Möglichkeit, mehrere Namen für ein Topic zu definieren. Um den Zweck von alternativen Namen zu beschreiben, soll das variant – Element verwendet werden. Dabei ist es zwingend, ein parameters – Element zu definieren, das angibt, welche Rolle der alternative Name spielen soll (zum Beispiel zur Suche, Anzeige oder Sortierung). Dies wird durch ein Topic mit Hilfe von topicRef – Element oder durch eine externe Ressource mit Hilfe von subjectIndicatorRef - Element beschrieben. Das Element variantName beschreibt entweder durch resourceData – oder durch resourceRef - Elementen den eigentlichen alternativen Namen. Wobei resourceRef – Element auf Ressource zeigt, und resourceData – Element im Gegensatz als Datencontainer dient. Das heißt, dass mit resourceData nicht auf eine Ressource verwiesen wird, sondern die eigentliche Information abgebildet wird. Das variant - Element kann weitere variant – Elemente beinhalten. <topic id="Basel"> <baseName> <baseNameString>Basel</baseNameString> <variant> <parameters> <subjectIndicatorRef xlink:href="http://www.topicmaps.org/xtm/1.0/psi1.xtm#display"/> <topicRef xlink:href="#Topic"/> </parameters> <variantName> <resourceData>Basileae</resourceData> </variantName> 20 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools </variant> </baseName> </topic> Das, was im Topic Map Standard zur Beschreibung der Identität und des Subjekts eines Topics als Public Subject Descriptor definiert wurde, wird in XTM durch das subjectIdentity – Element realisiert. Dieses Element kann höchstens ein resourceRef – Element haben, das auf eine externe Ressource zeigt, dafür aber mehrere topicRef – oder subjectIndicatorRef – Elemente beinhalten. <topic id="Autor"> <subjectIdentity> <subjectIndicatorRef xlink:href="http://de.wikipedia.org/wiki/Autor"/> </subjectIdentity> <baseName> <baseNameString>Autor</baseNameString> </baseName> </topic> Wenn zwei Topics auf gleiche Ressourcen verweisen, also gleiche Identität haben, sollen diese Topics zu einem Topic zusammengefasst werden. • instanceOf - Element charakterisiert, zu welchem Typ ein Topic gehört. Dabei wird unterschieden, ob ein Topic oder eine externe Ressource diesen Typ beschreibt. <topic id="Basel"> <instanceOf> <topicRef xlink:href="#Druckort"/> </instanceOf> <instanceOf> <subjectIndicatorRef xlink:href="externe_Ressource"/> </instanceOf> </topic> Ein Topic kann zu mehreren Typen gehören, dabei wird für jeden Typ ein instanceOf – Element definiert. Außerdem kann instanceOf – Element auch zur Bestimmung des Typs von occurence -, association - und member - Elementen, die folgend näher beschrieben werden, verwendet werden. • occurence – Element beschreibt die Verweise auf Ressourcen, in denen das Topic vorkommt. Dies geschieht mit Hilfe von resourceRef - oder resourceData 21 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools - Elementen. Eine occurence kann durch ein instanceOf – Element zu einem Typ zugeordnet werden, der selbst ein Topic ist. <topic id="Basel"> <occurence> <baseName> <baseNameString>Webseite von Basel</baseNameString> </baseName> <instanceOf> <topicRef xlink:href="#webseite"/> </instanceOf> <resourceRef xlink:href="http://www.basel.ch/"/> </occurence> </topic> Laut DTD kann occurence optional ein baseName Element beinhalten und als Attribut eine id besitzen. • association – Element wird benötigt, um zwei oder mehrere Topics miteinander zu verbinden. Einem association - Element muss, wie dem topic – Element, eine id zugewiesen werden. Durch instanceOf – Element kann der association ein Typ zugeordnet werden. Die teilnehmenden Topics in einer association werden durch member – Elementen beschrieben. <association id="x1k3edjriq-468"> <instanceOf> <topicRef xlink:href="#verknuepfung"/> </instanceOf> <member> <roleSpec> <topicRef xlink:href="#druckortvon"/> </roleSpec> <topicRef xlink:href="#Basel"/> </member> <member> <roleSpec> <topicRef xlink:href="#gedrucktin"/> </roleSpec> <topicRef xlink:href="#buch_200002281056"/> </member> </association> Jedes member – Element kann folgende Elemente beinhalten: 22 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools o ein oder mehrere topicRef – Elemente o ein oder mehrere resourceRef – Elemente o ein oder mehrere ressourceData – Elemente o ein roleSpec – Element, das die Assoziationsrolle der referenzierten Ressource definiert. Dieses Element muss entweder auf ein Topic durch topicRef - Element oder auf eine Ressource durch subjectIndicatorRef – Element verweisen. • scope – Element wird innerhalb der baseName -, occurence - und association Elemente zur Bestimmung des Gültigkeitsbereichs eingesetzt. <topic id="Basel"> <baseName> <scope> <topicRef xlink:href="#de"/> </scope> <baseNameString>Basel</baseNameString> </baseName> <baseName> <scope> <topicRef xlink:href="#hebr"/> </scope> <baseNameString><בסיליאה/baseNameString> </baseName> <baseName> <baseNameString>Basel</baseNameString> </baseName> </topic> Die Zuordnung des Gültigkeitsbereichs wird durch Referenzierung auf ein Topic oder eine Ressource mit Hilfe von schon erwähnten topicRef - oder resourceRef und subjectIndicatorRef - Elementen erreicht. • mergeMap Element kann benutzt werden, um zwei oder mehrere Topic Maps zu einem zusammenzufügen. Das mergeMap - Element muss ein Topic Map durch das xlink:href - Attribut einbinden. <mergeMap xlink:href="ein_XTM.xtm"> <topicRef xlink:href="#ein_Topic"> </mergeMap> 23 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Es können topicRef-, resourceRef- oder subjectIndicatorRef - Elemente unter einem mergeMap – Element vorkommen. • topicMap Element ist das Root – Element eines Topic Maps. Das topicMap – Element kann die zuvor beschriebenen topic -, association - oder mergeMap Elemente haben. <topicMap xml:base="http://localhost/beispiel.xtm" xmlns="http://www.topicmaps.org/xtm/1.0/" xmlns:xlink="http://www.w3.org/1999/xlink"> <topic id="Basel"> ... </topic> <association id="x1k3edjriq-468"> ... </association> <mergeMap xlink:href="ein_XTM.xtm"> ... </mergeMap> </topicMap> Aus DTD wird ersichtlich, dass das topicMap – Element zwei festgelegte Attribute hat: XTM – Default Namespace xmlns mit dem Wert "http://www.topicmaps.org/xtm/1.0/" und den XLink Namespace xmlns:xlink mit dem Wert "http://www.w3.org/1999/xlink". Es besteht auch die Möglichkeit, für ein topicMap – Element eine id und ein Basis – URI xml:base zu definieren. Änderungen im Bezug auf ISO 13250 Die wichtigsten Elemente des ISO – Standards, „Topic“, „Occurence“ und „Association“, werden in XTM wieder gefunden. Viele Unterschiede liegen in der Syntax. Zum Beispiel eine Assoziation wird im ISO – Standard durch das assoc – Element beschrieben. Im XTM dagegen heißt dieses Element association. Weitere wesentliche Änderungen werden im Folgenden aufgelistet: • benutzt XML • wird durch eine feste DTD beschrieben • Facets werden durch Topics und Assoziation ersetzt 24 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools • Sort und Display Namen werden durch variant – Element mit parameters – Element beschrieben • werden längere und verständlichere Namen den Elementen vergeben • der Typ einer Ressource wird anhand des Elementes unterschieden • bei der Referenzierung wird XLink benutzt • werden nur benötigten Attribute in einem Element verwendet, der Rest wird als ein Element dargestellt XTM realisiert nur die nötigen Eigenschaften des ISO 13250 Topic Map Standards. Durch die Änderungen syntaktischer Art, vor allem durch die bessere Namensgebung, wird eine einfache Lesbarkeit erreicht und einfache Erstellung und Pflege gewährleistet. Die durch DTD fest definierte Struktur ermöglicht einen reibungslosen Austausch der XTM – Dokumenten zwischen verschiedenen Anwendungen und deren Umwandlung in andere Formate. Zur Erstellung, Verarbeitung von XTM – Dokumenten sowie Visualisierung der Informationen, die in diesen Dokumenten beschrieben sind, werden Softwarelösungen benötigt. Im folgenden Kapitel werden die bestehenden Softwarelösungen (Topic Map Tools) kurz vorgestellt. 1.2.3 Topic Map Tools In letzter Zeit gibt es viele Entwickler - Teams, die verschiedene Softwarelösungen zur Erstellung, Verarbeitung von XTM – Dokumenten sowie Visualisierung der Informationen, die in diesen Dokumenten beschrieben sind, anbieten. Es wird ein Überblick sowohl über die kommerziellen Produkte als auch über Freeware und OpenSource Lösungen gegeben. Ontopia Ontopia AS ist eine Firma mit dem Sitz in Oslo, die die Lösungen zur Informationsund Wissensmanagement anbietet. Folgende Produkte sind kostenpflichtig und sind deswegen für die Lösung des Problems nicht geeignet: 25 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools • Ontopia Topic Map Engine ist ein Java basiertes Framework, das ermöglicht, Topic Map – Dokumente zu laden, in einer relationalen Datenbank zu speichern, zu modifizieren und zu verwalten. Diese Engine kommt sowohl mit XTM 1.0 als auch mit ISO 13250 klar, ist plattformunabhängig und unterstützt alle Zeichensätze. • Ontopia Navigator Framework ist eine Servererweiterung, die durch Java Servlets und Java Server Page(JSP) realisiert wurde. Diese Erweiterung wird dazu benötigt, die Inhalte des Topic Maps in verschiedene Formate, wie HTML, XML oder WML umzuwandeln. Ontopia bietet auch eine kostenfreie Web-Applikation Ontopia Omnigator, die auf der Basis von Ontopia Navigator Framework entwickelt wurde. Damit ist es aber nur möglich, existierende Topic Map – Dokumente zu laden und diese als HTML Dokumente in einem Web - Browser darzustellen. [Ontop] Empolis Die empolis GmbH ist einer der führenden Anbieter von unternehmensweiten Content- und Knowledge Management Lösungen. Einer der Lösungen heißt e:kms (empolis knowledge management suite) und beinhaltet ein innovatives System für Dokumentenmanagement, XML Content Management sowie Web Content Management mit flexibler Verwaltung von Metadaten, leistungsfähigem Workflow-Management sowie eine Integration in die MS Office Umgebungen. Dieses System ist Java basiert und unterstützt Topic Map Format. [Empol] Der Nachteil dabei ist, dass es nicht frei zur Verfügung steht. Mondeca Mondeca SA ist eine Softwarefirma mit dem Sitz in Paris, die die Wissensmanagement Lösungen für verschiedene Branchen anbietet. ITM (Intelligent Topic Manager) ist eine Java basierte Anwendung, die es ermöglicht, Topic Maps zu erzeugen, zu verwalten und in einer Datenbank zu speichern. Außerdem enthält ITM verschiedene Module, die Import/Export und 26 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Darstellung von Topic Maps sowie Navigation und Suche innerhalb der Topic Maps erlauben.[Monde] ITM ist kommerziell und daher nicht als Lösungstool geeignet. Moresophy Moresophy GmbH mit dem Sitz in München, „berät Unternehmen bei der Erzielung von Wettbewerbs- und Kostenvorteilen durch die Erhöhung der Informationsqualität.“ Das Produkt L4 Semantic NetWorking ermöglicht verteilte elektronische Wissensquellen zu strukturieren und mit ihren Beziehungszusammenhängen verfügbar zu machen. L4 besteht aus drei Komponenten: • L4 Modeller ist ein grafisches Tool zur Modellierung der vernetzten Wissensstrukturen (Semantisches Netz). Dieses Tool verwendet XML und ist zu dem XTM Standard kompatibel. • L4 Indexer erfasst Wissensquellen und erkennt die begrifflichen Bezüge. Außerdem erlaubt dieses Tool, die Suche in verschiedenen Speichermedien gleichzeitig durchzuführen. • L4 Networker ist eine Entwicklungsplattform mit integrierten Diensten, wie semantische Navigation, Suche und Klassifikation von Informationen. Dieses Tool führt das mit Hilfe von L4 Modeller modellierte Wissen mit elektronischen Wissensressourcen über L4 Indexer zusammen. [Mores] Die Lösungen, die Moresophy anbietet, sind kommerziell und daher auch nicht für den Einsatz relevant. Tmproc Tmproc ist eine freiverfügbare Topic Map Engine, die Import, Export, Abfrage und Pflege von Topic Maps ermöglicht. Diese Engine implementiert ISO 13250 – Standard in Python, unterstützt aber nicht XTM 1.0 Standard. [Tmpro] Da Tmproc nicht in Java, sondern in Python entwickelt wurde, ist es auch nicht zum Lösungseinsatz geeignet. 27 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools SemanText SemanText ist eine Applikation, die als ein Prototyp entwickelt wurde, um zu demonstrieren, wie der ISO 13250 – Standard zur Repräsentierung der semantischen Netze benutzt werden kann. Dieser Prototyp ermöglicht, eine Wissensbasis anhand der vorhandenen Topic Maps in Form eines semantischen Netzes aufzubauen und zu erweitern. SemanText soll in Zukunft ein vollfunktionsfähiges Tool zur Erstellung, Verwaltung und Darstellung/Navigation von Topic Map Dokumenten werden.[SemTe] Der Prototyp benutzt Tmproc Engine und ist auch in Python realisiert, daher wird der nicht als Lösung betrachtet. Nexist Nexist ist eine Java Applikation, die als ein Testumfeld zum Verstehen und zum Veranschaulichen der Idee des Topic Maps realisiert wurde. Dieses Programm gibt dem Benutzer die Möglichkeit, Topic Maps in XTM Format zu erstellen, zu verwalten und darzustellen. Außerdem ist es möglich, die existierenden XTM Dokumente einzulesen und kreierte Dokumente zu exportieren. Zur Suche innerhalb des Topic Maps und zur persistenten Speicherung wurde eine relationale opensource Datenbank HSQL1 benutzt. Durch die Client – Server Architektur wird ein gleichzeitiger Zugriff von mehreren Benutzern auf die Informationen gewährleistet. Nexist ist OpenSource und ist frei verfügbar. [Nexis] Prinzipiell ist es denkbar, einzelne Teile dieser Applikation zur Lösung einzusetzen. Da es sich aber um ein komplettes Programm handelt, wo die für die Lösung wichtige Topic Map Engine integriert ist, ist es mit einem großen Aufwand verbunden, diese Engine zu benutzen. TM4J TM4J Topic Maps for Java ist ein Projekt, das sich die Aufgabe gestellt hat, eine Reihe von Werkzeugen zur Erstellung, Verwaltung und Visualisierung der Topic 1 HypersonicSQL http://sourceforge.net/projects/hsqldb 28 Visualisierung der Informationen in einem semantischen Netz Topic Map und Topic Map-Tools Maps in XTM 1.0 Standard zu entwickeln. Alle Werkzeuge sind in Java implementiert und frei verfügbar. Das Projekt besteht aus vier Unterprojekten: • TM4J Engine ist ein Framework, das Import und Export von XTM Dokumenten unterstützt und die Möglichkeit bietet, die Informationen aus Topic Maps persistent in verschiedene Datenbanken zu speichern oder als Java-Objekte im Speicher zu halten. Ebenso erlaubt diese Engine, nach Informationen in Topic Maps zu suchen. • TM4Web ist eine Sammlung von Werkzeugen, die es ermöglichen, basierend auf TM4J Web-Applikationen Engine, zu entwickeln. Die Web- Applikationen dienen zur Repräsentation der Informationen aus Topic Maps in Form von statischen oder dynamischen Webseiten. • Panckoucke ist eine Java-Bibliothek für die Erstellung eines abstrakten Graphmodells aus einem Topic Map. Damit wird dem Entwickler eine Möglichkeit gegeben, Daten aus dem Topic Map in eine anwendungsspezifische Datenstruktur umzuwandeln. Diese Datenstruktur kann dann in verschiedenen Formaten repräsentiert werden. • TMNav ist eine Java/Swing Applikation zur Navigation von Topic Maps. TMNav hat eine graphbasierte Benutzeroberfläche, die dem Benutzer eine intuitive Navigation bietet. Das Ziel dieses Unterprojekts bestand darin, ein Werkzeug zur Entwicklung eines Topic Map Navigators oder Editors zur Verfügung zu stellen und eine Beispiel Implementierung zu zeigen. TM4J ist ein OpenSource Projekt. [TM4Ja] Wie es schon erwähnt wurde, sind alle TM4J Komponenten in der Programmiersprache Java implementiert und dürfen frei benutzt werden. Zudem ist es nennenswert, dass die von TM4J entwickelte TM4J Engine eine standardisierte Schnittstelle TMAPI1 (Topic Map Application Programming Interface) implementiert. Dadurch wird erreicht, dass die Entwickler Anwendungen schaffen, die kompatibel zu anderen TMAPI-konformen Anwendungen sind. 1 http://tmapi.org/ 29 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) TM4J wurde als ein geeignetes Tool für die Lösung ausgewählt und wird im nächsten Kapitel näher beschrieben. 1.3 TM4J (Topic Map for Java) 1.3.1 Beschreibung von TM4J TM4J wurde im Jahre 2001 unter Führung von Kal Ahmed als ein OpenSource Projekt gestartet. Kal Ahmed spezialisiert sich auf Wissensmanagement – Lösungen und XML. Er beschäftigte sich viel mit Topic Maps, war sowohl ein gründendes Mitglied des TopicMaps.org1 – Konsortiums als auch ein Mitwirkender bei der Entwicklung des XTM 1.0 Standards. TM4J Engine (Framework) ist das Herzstück des Projektes TM4J. Dieses Framework wird zur Entwicklung der Topic Map basierten Anwendungen benutzt. Die wichtigsten Funktionen zur Verwaltung von Topic Maps sind bereits im Framework implementiert. Die Möglichkeiten, die dieses Framework einem Entwickler bietet, sind: • Import und Export der Topic Map Dokumenten im XTM 1.0 Format • Zusammenfügen von zwei oder mehreren XTM – Dokumenten, auch Mergen genannt • Erzeugen eines Fragments aus dem XTM - Dokument • Persistente Speicherung von Topic Map Dokumenten • Integration von Web-Anwendungen • Eine Schnittstelle zur Programmierung von benutzerspezifischen JavaAnwendungen Ein Teil der oben beschriebenen Features von TM4J, sowie weitere Funktionen können als Kommandozeile - Anwendungen Anwendungen werden später näher beschrieben. 1 http://topicmaps.org 30 ausgeführt werden. Diese Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) 1.3.2 Installation, Konfiguration und Einsatz von TM4J Zur Installation von TM4J wird vorausgesetzt, dass eine Java Virtual Maschine auf einem System vorhanden ist. Das heruntergeladene Archiv tm4j-bin-x.x.x.zip1 (x.x.x steht für eine Versionsnummer, zum Beispiel 0.8.2) soll in das gewünschte Verzeichnis entpackt werden. Um TM4J-Engine nutzen zu können, soll laut Dokumentation eine Umgebungsvariable gesetzt werden. Wenn zum Beispiel TM4J Engine unter Windows in das Verzeichnis C:\Development\ entpackt wurde, dann wird der Eintrag wie folgt lauten: set TM4J_HOME=C:\Development\tm4j set PATH=%TM4J_HOME%\bin;%PATH% unter Linux wird es mit Hilfe des „export“ - Befehls gesetzt: export TM4J_HOME ~/Development/tm4j export PATH=$TM4J_HOME/bin:$PATH Das Setzen der Umgebungsvariable ist insbesondere dann wichtig, wenn die Kommandozeile-Anwendungen genutzt werden sollen. Kommandozeile-Anwendungen Die Entwickler von TM4J Engine haben die wichtigsten Funktionen zur Verarbeitung der Topic Maps in Form von Kommandozeile –Anwendungen zur Verfügung gestellt. Diese werden folgend mit ihren Optionen beschrieben. Merge ist ein Tool zum Zusammenfügen von zwei oder mehreren Topic Map Dokumenten in XTM 1.0 Format und zur Ausgabe des Resultates auf dem Bildschirm oder, wenn eingegeben, in ein neues Topic Map Dokument. Mit folgendem Befehl wird Merge-Tool aufgerufen: merge [OPTION]... [FILE [-b|--baseuri uri]... Die Optionen sind nicht zwingend erforderlich. 1 Die aktuelle Version kann unter http://sourceforge.net/projects/tm4j/ heruntergeladen werden. 31 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) In der Tabelle 2 sind alle Optionen des Merge Tools und deren Beschreibungen aufgelistet. Option -o Bezeichnung output-file Beschreibung schreibt in ein vorgegebenen File (bei nicht verwenden wird die Ausgabe auf dem Bildschirm ausgegeben) -d include -doctype fügt ein XTM1.0 DTD in den erzeugten Topic Map Dokument hinzu (bei nicht verwenden wird kein DTD hinzugefügt) -S system-id bestimmt den Systembezeichner (bei nicht verwenden wird „http://www.topicmaps.org/xtm/1.0/xtm1.dtd“ genommen) -P public-id bestimmt den öffentlichen Bezeichner (bei nicht verwenden wird „-//TopicMaps.Org//DTD XML Topic Map (XTM) 1.0//EN“ genommen) -B output-base-uri benutzt den eingegebenen base URI, wenn xml:base Element fehlt (bei nicht verwenden wird „file:/Aktuelles Verzeichnis“ genommen) -e encoding benutzt die eingegebene Zeichenkodierung für die Ausgabe (bei nicht verwenden wird UTF-8 Kodierung verwendet) -I indentation bestimmt wie viele Leerzeichen bei der Ausgabe zum Einrücken benutzt werden sollen (bei nicht verwenden sind es zwei Leerzeichen) -F factory benutzt die eingegebene topic map provider factory Klasse (bei nicht verwenden wird „org.tm4j.topicmap.memory.TopicMapProviderFac toryImpl“ – Klasse benutzt) 32 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) -n nomerge ignoriert <mergeMap> und <topicRef> Elemente beim zusammenfügen der Topic Map Dokumenten -c consistent eliminiert doppelte Namen, Associationen und Occurencen aus dem Topic Map Dokument entsprechend der XTM 1.0 Vorschriften -? help gibt eine Liste der Optionen und deren Beschreibungen aus Tabelle 2 Merge Optionen Stats ist ein Tool, das nützliche statistische Informationen zu einem Topic Map Dokument liefert und wird mit folgendem Befehl ausgeführt: stats [options] [input_xtm|tm_base_loc] [input_xtm|tm_base_loc] ... Wie bei Marge Tool sind bei Stats Tool die Optionen auch nicht zwingend erforderlich. In der Tabelle 3 sind alle Optionen des Stats Tools und deren Beschreibungen aufgelistet. Option Bezeichnung Beschreibung -v verbose erzeugt eine ausführliche Statistik -m minimal erzeugt eine minimale Statistik und gibt diese in XML Format aus -o output-file schreibt die Ausgabe in ein vorgegebenen File (bei nicht verwenden wird die Ausgabe auf dem Bildschirm ausgegeben) -p processor-class bestimmt die Klasse der Prozessor Engine, die verwendet werden soll(wenn nicht verwendet wird „org.tm4j.topicmap.cmd.DefaultStatsProcesor“ verwendet) 33 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) -n nomerge ignoriert <mergeMap> und <topicRef> Elemente beim erzeugen der Statistik Tabelle 3 Stats Optionen Fragment ist ein Tool, das zum Erzeugen eines kleinen Topic Map Dokumentes aus dem großen Topic Map Dokument dient. Mit folgendem Befehl wird Fragment-Tool ausgeführt: fragment [options] ... [FILE [-b|--baseuri uri]... Bei dem Fragment Tool sind die Optionen nicht zwingend erforderlich, außer der Eingabe –O, oder –I, oder –S Optionen. In der Tabelle 4 sind alle Optionen des Fragment Tools und deren Beschreibungen aufgelistet. Option -O Bezeichnung object-id Beschreibung bestimmt die ID eines Topics, zu dem ein Fragment erstellt werden soll -I subject-indicator bestimmt das subject-indicator URI, das auf ein Topic zeigt, zu dem ein Fragment erstellt werden soll -S subject bestimmt das subject URI, das auf ein Topic zeigt, zu dem ein Fragment erstellt werden soll -r radius bestimmt den „Radius“ des zu erzeugenden Fragmentes. Beim Radius 0 wird nur das Topic, zu dem das Fragment erzeugt werden soll, eventuell mit seinem Typ kopiert. Beim Radius 1 werden zusätzlich die Assoziationen und assoziierte Topics in das Ausgabefragment mitkopiert. Je größer der Radius, desto mehr Topics und Assoziationen mitkopiert werden. 34 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) -o output-file schreibt die Ausgabe in ein vorgegebenen File (bei nicht verwenden wird die Ausgabe auf dem Bildschirm ausgegeben) -b baseuri benutzt das eingegebene base URI für das xml:base Element (wenn nicht verwendet, wird „http://www.tm4j.org/tm4j/fragment.xtm“ gesetzt) -c consistent eliminiert doppelte Namen, Associationen und Occurencen aus dem Topic Map Fragment entsprechend der XTM 1.0 Vorschriften Tabelle 4 Fragment Optionen Compress ist ein Tool, das ähnlich dem Merge Tool mit Verwendung der Option –c ist. Mit folgendem Befehl wird Compress Tool ausgeführt: compress [OPTION]... [FILE [-b|--baseuri uri]... Bei dem Compress Tool gibt es nur eine Option, die nicht zwingend erforderlich ist. In der Tabelle 5 sind die Option des Compress Tools und die Beschreibung erläutert. Option -o Bezeichnung output-file Beschreibung schreibt die Ausgabe in ein vorgegebenen File (bei nicht verwenden wird die Ausgabe auf dem Bildschirm ausgegeben) Tabelle 5 Compress Option In vielen Fällen werden die Kommandozeile Anwendungen nicht ausreichen, insbesondere wenn es darum geht, neue Topic Maps zu erstellen. Dafür gibt es die Möglichkeiten, TM4J Engine bei der Entwicklung benutzerspezifischen Applikationen zu nutzen. Diese Möglichkeiten werden folgend erläutert. 35 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) Möglichkeiten für Entwickler Die meisten Informationsbestände liegen strukturiert in irgendeiner Form vor. Es kann sich dabei um ein Filesystem, eine relationale Datenbank, HTML Dokumente und so weiter handeln. Die entsprechenden Topic Map Dokumente zu den vorhandenen Informationen müssen erst erstellt werden. Trotzt dieser Tatsache haben die meisten Entwickler-Teams, die das Topic Map Standard realisieren, den Schwerpunkt auf die Entwicklung von Tools zur Bearbeitung und Verwaltung der schon vorhandenen Topic Map Dokumenten gelegt. Mit TM4J Framework wird, neben der Nutzung der schon zuvor beschriebenen Tools zur Verwaltung, Bearbeitung und Speicherung von XTM Dokumente, dem Entwickler die Möglichkeit gegeben, eigene Applikationen zur Erstellung von Topic Maps zu realisieren. Die Organisation der TM4J Engine wird in der Tabelle 6 dargestellt. Dabei wird der Package – Name genannt und beschrieben. Zusätzlich wird das JAR – Archiv, wo dieses Package zu finden ist, angegeben. Package - Name org.tm4j.topicmap Beschreibung Ein Kern - Packet von TM4J, das die JAR - Archiv tm4j.jar Schnittstellen – Definitionen beinhaltet. Diese Schnittstellen werden in verschiedenen Speicherungsmodellen implementiert org.tm4j.topicmap.memory Dieses Packet wurde zur Speicherung tm4j.jar der Topic Map Informationen in JVM – Speicher implementiert. org.tm4j.hibernate Dieses Packet wurde zur Speicherung tm4jdbc.jar der Topic Map Informationen in relationalen Datenbanken mit Hilfe der JDBC Verbindung implementiert. org.tm4j.topicmap.ozone Dieses Packet wurde zur Speicherung tm4ozone.jar der Topic Map Informationen in einer 36 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) lokalen oder entfernten Ozone Datenbank implementiert. org.tm4j.topicmap.dom org.tm4j.topicmap.unified Dieses Packet wird noch entwickelt noch nicht ein und in Zukunft dazu dienen, XTM Bestandteil Dokumente im Speicher als eine der DOM Struktur zu halten. Distribution Dieses Packet ermöglicht ein tm4j.jar transparenter Zugriff auf mehrere Topic Maps, als wären die zu einem Topic Map vereinigt. org.tm4j.net Ist ein Packet, das eine Reihe von tm4j.jar Schnittstellen für das Erzeugen, die Manipulierung und die Auflösung von Netzwerk-Adressen beinhaltet. Diese Schnittstellen werden auch in verschiedenen Speicherungsmodellen implementiert org.tm4j.net.memory Dieses Packet beinhaltet die für das tm4j.jar Speicherungsmodell, das das Speichern im JVM Speicher ermöglicht, spezifische Implementierung der org.tm4j.net – Schnittstellen. org.tm4j.topicmap.hibernate Dieses Packet beinhaltet die für das tm4jdbc.jar Speicherungsmodell, das das Speichern in einer relationalen Datenbank ermöglicht, spezifische Implementierung der org.tm4j.net – Schnittstellen. 37 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) org.tm4j.net.ozone Dieses Packet beinhaltet die für das tm4ozone.jar Speicherungsmodell, das das Speichern in der Ozone Datenbank ermöglicht, spezifische Implementierung der org.tm4j.net – Schnittstellen. org.tm4j.topicmap.utils Die in diesem Packet tm4j.jar implementierten Tools sind von den verschiedenen Speicherungsmodellen unabhängig. Diese Tools dienen zum Serialisieren und zur Syntaxanalyse von XTM Dokumenten; zur Traversierung der Topic Maps sowie zur Filterung und Sortierung von mehreren Objekten. org.tm4j.tolog Dieses Packet implementiert eine tm4j-tolog.jar Abfrage Engine, die es ermöglicht, mit Hilfe der Tolog Querylanguage von Ontopia, innerhalb von Topic Maps nach Informationen zu suchen. Diese Engine unterstützt die Suche in allen Speicherungsmodellen. org.tm4j.topicmap.cmd Dieses Packet beinhaltet alle tm4j.jar Kommandozeile – Anwendungen, die zuvor schon beschrieben wurden. Tabelle 6 Organisation der TM4J Engine Die TM4J Bibliotheken, die in JAR – Archivs gepackt sind, sind von einer Reihe der Drittanbieter - Bibliotheken abhängig. Diese werden mit jeder TM4J-Distribution mitgeliefert. In der Tabelle 7 sind die wichtigsten JAR - Archivs mit der Beschreibung und Angabe, wo diese verwendet wurden, zusammengefasst. 38 Visualisierung der Informationen in einem semantischen Netz TM4J (Topic Map for Java) JAR-Archiv mango.jar jargs.jar log4j.jar Beschreibung Einsatz Ist eine Java Bibliothek, die verschiedenen Die Schnittstellen der Iteratoren, Algorithmen und Funktionen mango Bibliothek wer- beinhaltet. Diese Bibliothek ist unter den im TM4J Packet http://www.jezuk.co.uk/cgi- org.tm4j.topicmap.utils bin/view/mango erhältlich. implementiert. Ist eine Java – Bibliothek, die zur Diese Bibliothek wird Erstellung von Optionen und zum Parsen im TM4J Packet von Eingaben in den Kommandozeile- org.tm4j.topicmap.cmd Anwendungen eingesetzt wird. benutzt. Ist ein von Apache entwickeltes Wenn diese Bibliothek Protokollierungsmechanismus. Diese vorhanden ist, wird die Bibliothek ist unter in tm4j.jar verwendet. http://logging.apache.org/ erhältlich. jakarta-oro.jar Ist eine von Apache entwickelte Java Diese Bibliothek wird Bibliothek, die zur Verarbeitung von im org.tm4j.net Packet Zeichenketten dient und unter eingesetzt. http://jakarta.apache.org/oro/ zu finden ist. ozone.jar Ist eine Java-basierte objektorientierte Diese Datenbank wird Datenbank, die unter http://www.ozone- in tm4ozone.jar db.org/frames/download/distributions.html benutzt. zum Download zur Verfügung steht. hibernate.jar Ist eine Java Bibliothek, die zur Diese Bibliothek wird Entwicklung von persistenten in tm4jdbc.jar benutzt. Schnittstellen zu objektorientierten und relationalen Datenbanken eingesetzt wird. Die ist unter http://www.hibernate.org/ zu beziehen. 39 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes xerces.jar xalan.jar Ist eine von Apache angebotene Java Diese Bibliothek wird Bibliothek, die zur Syntaxanalyse der in TM4J zur XML Dokumente dient. Diese Bibliothek Syntaxanalyse von ist unter http://xml.apache.org/xalan-j/ XTM Dokumenten verfügbar. eingesetzt. Ist eine von Apache angebotene Java Diese Bibliothek wird Bibliothek, die zur Transformation der in TM4J zum Erstellen XML Dokumenten mit Hilfe von von XTM XSL/XSLT Dokumenten in verschiedene Dokumenten Formate dient. Diese Bibliothek ist unter eingesetzt. Ab Java http://xml.apache.org/xalan-j/ erhältlich. Version 1.4 ist diese Bibliothek in Java integriert. Tabelle 7 Drittanbieter Bibliotheken Die Benutzung der TM4J Bibliotheken, sowie der von diesen abhängigen Bibliotheken, hängt vom jeweiligen Einsatzfall ab. TM4J Engine bietet zum Beispiel mehrere Möglichkeiten, Topic Maps zu speichern: JVM Speicher, relationale Datenbank, objektorientierte Datenbank usw. Wenn bei der Entwicklung einer Anwendung eine relationale Datenbank eingesetzt wird, soll tm4jdbc.jar und hibernate.jar verwendet werden. Beim Einsatz der objektorientierten Datenbank (hier Ozone - Datenbank) soll tm4ozone.jar und ozone.jar benutzt werden. Der Einsatz der TM4J Engine an einem konkreten Beispiel wird im weiteren Kapitel beschrieben. 1.4 Realisierung eines semantischen Netzes Bevor es mit der Realisierung begonnen werden kann, sollte ein Vorgehensmodell überlegt werden. Die Informationen werden aus verschiedenen Quellen bezogen. Es kann sich dabei um eine Datenbank, ein Filesystem, eine Web – Seite usw. handeln. 40 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Um zu den Informationen ein Topic Map erzeugen zu können, sollen diese Informationen analysiert werden. Dabei soll ein Fachmann die Topic Typen Namen festlegen, die als Typen für bestimmte Informationseinheiten (Topics) gelten. Außerdem sollen alle möglichen Beziehungen (Assoziationen) zwischen den Topics und die Rollen, die diese Topics dabei spielen, definiert werden. Nach der Analyse soll ein Topic Map Modell erstellt werden. Als nächstes soll eine Anwendung entwickelt werden, die zu den Informationen automatisch ein Topic Map generiert. Zum Schluss soll ein Front – End - Tool gefunden bzw. entwickelt werden, um die Topic Maps darzustellen. Dieses Tool soll den letztendlichen Benutzern eine einfache und intuitive Navigation im Topic Map bieten und einen schnellen Zugriff auf die gewünschten Informationen gewährleisten. In der Abbildung 16 wird das Vorgehensmodell noch Mal grafisch dargestellt. Abbildung 16 Vorgehensmodell Im Folgenden wird das vorgestellte Vorgehensmodell an einem praxisbezogenen Beispiel schrittweise näher beschrieben. 1.4.1 Automatische Generierung von XTM Die Informationen des wissenschaftlichen digitalen Schriftarchivs, das im Rahmen des Forschungsprojektes „Hebräische Typographie im deutschsprachigen Raum“ entstanden ist, sind in einer relationalen Datenbank gespeichert. Die Verwaltung 41 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes geschieht mit Hilfe der „HebrewWork“1 Web-Applikation. Zur Präsentation dient die „HebrewTypeShow“2 Web-Applikation. Bei der Analyse der Informationen aus dem Schriftarchiv wurde festgestellt, dass es mehrere Möglichkeiten zur Modellierung des Topic Maps gibt: • Bei der Betrachtung des Datenbankschemas können Topic Typen wie Tabellen Namen oder Attribute benannt werden. Die Relationen zwischen den Tabellen können die Assoziationen in einem Topic Map sein. In der Abbildung 17 ist ein Ausschnitt der Datenbankschema „TYPOGRAF“ abgebildet. Ein Teil der möglichen Topic Typen ist zur Veranschaulichung rot markiert, die Assoziationen sind grün markiert. Abbildung 17 Analyse der Datenbankschema • In der „HebrewWork“ Applikation benutzte Feldnamen können als Topic Typen übernommen werden, die Werte der Felder stellen die Topics dar, die 1 2 https://fsygs21.inf.fh-koeln.de/hebtypo/servlet/HebrewWork http://fsygs21.inf.fh-koeln.de/HebrewShow/servlet/HebrewShow 42 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Hyperlinks können Assoziationen sein. Die Abbildung 18 beinhaltet eine Eingabemaske der „HebrewWork“ Web Applikation. Hier wurden auch nur zur Deutlichkeit einige Topic Typen rot, Topics violett und Assoziationen grün markiert. Abbildung 18 Analyse der HebrewWork Applikation • In der Abbildung 19 sind zwei Ausschnitte aus der „HebrewTypeShow“ Web- Applikation dargestellt. In dem Ausschnitt aus der „Typografie Detailsicht“ sind die Buchstabenbilder eines Schriftsatzes abgebildet und die Eigenschaften dieses Schriftsatzes mit Angabe der Eigenschaftsnamen und – werten beschrieben. Die Eigenschaftsnamen (rot markiert) können in einem Topic Map die Topic Typen darstellen, die Eigenschaftswerte (violett markiert) sind die Topics. Zweiter Ausschnitt stammt aus der „Bibliografie Detailsicht“. Dieser Ausschnitt enthält Bilder aus einem Druckschriftdokument und die Beschreibung der Eigenschaften dieses Druckschriftdokumentes. Wie im ersten Ausschnitt, bestehen die Beschreibungen der Eigenschaften aus Eigenschaftsnamen und –werten, wo 43 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes die Namen (rot markiert) die Rolle eines Topic Typs spielen und Werte (violett markiert) die eigentlichen Topics sind. Jede Sicht verweist auf eine andere Sicht mit Hilfe eines Hyperlinks. Diese Beziehung (mit grünen Pfeilen gezeichnet) zwischen den Sichten kann als eine Assoziation betrachtet werden. Wie in vorherigen Beispielen, sind nicht alle möglichen Topic Map Elemente farblich markiert. Die Markierungen dienen nur der Veranschaulichung. Abbildung 19 Analyse der HebrewTypeShow Applikation Die vorgestellten Möglichkeiten der Ermittlung von Topic Map Elementen sind nicht als Vorgabe anzusehen, sondern als eine mögliche Analyse der Informationen, die bei der Modellierung eines Topic Maps zur Hilfe gezogen werden kann. Wie schon in der Beschreibung des Vorgehensmodells (Abbildung 16) angedeutet wurde, soll letztendlich ein Fachmann, in diesem Fall ein Buchwissenschaftler, zur Hilfe stehen, insbesondere wenn es darum geht zu entscheiden, welche Informationseinheiten als Topics in einem Topic Map vorkommen können oder welche Namen den Topic Typen vergeben werden sollen. Festlegen der relevanten Topic Typen, Topics und Assoziationen Bei der Festlegung der Topic Typen wurden die Möglichkeiten zur Modellierung des Topic Maps, die zuvor beschrieben sind, angewandt. In der Zusammenarbeit mit 44 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes einem Buchwissenschaftler wurde entschieden, welche Topic Typen und Topics relevant sind. In der Tabelle 8 werden die relevanten Topic Typen genannt. Dazu wird beschrieben, welches Topic bzw. welche Topics vom jeweiligen Topic Typ sind. Topic Typ Autor Beschreibung der Topics Autor eines oder mehreren Druckschriftdokumenten. Dem Element <baseName> wird der Name des Autors zugewiesen. Besitz Besitzer(zum Beispiel eine Bibliothek) eines oder mehreren Druckschriftdokumenten. Dem Element <baseName> wird der Name des Besitzers zugewiesen. Buch Druckschriftdokument selbst. Dem Element <baseName> wird der Schlüssel des Druckschriftdokumentes aus der Datenbank zugewiesen. Drucker Person, die ein oder mehrere Druckschriftdokumente gedruckt hat. Dem Element <baseName> wird der Name des Druckers zugewiesen. Druckort Ort, wo ein oder mehrere Druckschriftdokumente gedruckt wurden, oder ein oder mehrere Schriftsätze geschnitten wurden. Dem Element <baseName> wird der Name des Druckortes zugewiesen. Jahr Jahresangabe, wann ein oder mehrere Druckschriftdokumente gedruckt wurden bzw. ein oder mehrere Schriftsätze geschnitten wurden. Dem Element <baseName> wird die Jahreszahl zugewiesen. Kategorie Kategorie, zu der ein oder mehrere Druckschriftdokumente zugeordnet sind. Dem Element <baseName> wird die Bezeichnung der Kategorie zugewiesen. 45 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Schriftart Druckschriftart, von der ein oder mehrere Schriftsätze sind. Im digitalen Schriftarchiv existieren die Schriftsätze, die nur zu einem von drei bestimmten Druckschriftarten zugeordnet werden können. Diese Schriftarten sind „quadrat“, „halbkursiv“ und „kursiv“. Das bedeutet, dass es nur drei Topics vom Typ Schriftart existieren können. Das <baseName> Element dieser drei Topics erhält entsprechend die Werte: „quadrat“, „halbkursiv“ und „kursiv“. Schriftsatz Schriftsatz selbst. Dem Element <baseName> wird der Schlüssel des Schriftsatzes aus der Datenbank zugewiesen. Schriftsatzname Name eines oder mehreren Schriftsätze. Dem Element <baseName> wird der Name des Schriftsatzes zugewiesen. Schriftstil Schriftstil, von dem ein oder mehrere Schriftsätze sind. In digitales Schriftarchiv wurden nur die Schriftsätze aufgenommen, die von einem der drei bestimmten Schriftstilen sein können. Diese Schriftstile sind „aschkenasisch“, „italienisch“ und „sefardisch“. Das bedeutet, dass es nur drei Topics vom Typ Schriftstil existieren können. Das <baseName> Element dieser drei Topics erhält entsprechend die Werte: „aschkenasisch“, „italienisch“ und „sefardisch“. Titel Titel eines oder mehreren Druckschriftdokumente. Dem Element <baseName> wird der Titel des Druckschriftdokumentes zugewiesen. Verlag Verlag, der ein oder mehrere Druckschriftdokumente veröffentlicht hat. Dem Element <baseName> wird der Name des Verlages zugewiesen. Tabelle 8 Relevante Topic Typen und dazugehörige Topics Nachdem die Topic Typen und Topics festgelegt wurden, sollen alle Assoziationen zwischen den einzelnen Topics beschrieben werden. Die Rollen, die diese Topics dabei spielen, sollen definiert werden. 46 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Bei der Analyse der Beziehungen wurde festgestellt, dass Topics vom Typ „Buch“ und vom Typ „Schriftsatz“ die meisten Verbindungen zu anderen Topics besitzen. So wurden zuerst die Assoziationen der Topics vom Typ „Schriftsatz“ zu anderen Topics näher betrachtet. Diese werden in der Tabelle 9 beschrieben. Dabei werden die Rolle des Topics vom Typ „Schriftsatz“ und die Rolle und der Typ des assoziierten Topics angegeben. Assoziationsrolle des Topics Assoziationsrolle des Typ des vom Typ „Schriftsatz“ assoziierten Topics assoziierten Topics gehört zu enthält Buch heißt Name von Schriftsatzname ist von Schriftart Schriftart des Schriftsatzes Schriftart ist vom Schriftstil Schriftstil des Schriftsatzes Schriftstil im Jahr Jahr von Jahr Tabelle 9 Assoziationen der Topics vom Typ „Schriftsatz“ Als zweites wurden die Assoziationen der Topics vom Typ „Buch“ zu anderen Topics analysiert. Diese werden in der Tabelle 10 beschrieben. Dabei werden die Rolle des Topics vom Typ „Buch“ und die Rolle und der Typ des assoziierten Topics angegeben. Assoziationsrolle des Topics Assoziationsrolle des Typ des vom Typ „Buch“ assoziierten Topics assoziierten Topics enthält gehört zu Schriftsatz ist geschrieben von Autor des Buches Autor ist gedruckt von Drucker des Buches Drucker hat Titel Titel des Buches Titel 47 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes gedruckt in Druckort von Druckort bei Verlag Verlag von Verlag im Jahr Jahr von Jahr im Besitz Besitzer von Besitz gehört zur Kategorie Kategorie von Kategorie Tabelle 10 Assoziationen der Topics vom Typ „Buch“ Eine Assoziation kann von einem Typ sein. Für alle Assoziationen wurde ein Typ „Verbindung“ festgelegt. Alle Topics, Topic Typen und Assoziationen, die festgelegt wurden, beschreiben das Topic Map Modell. Nach dem Vorgehensmodell (Abbildung 16) steht jetzt nichts mehr im Wege, eine Anwendung zu implementieren, die ein XTM – Dokument automatisch generiert. Implementieren der XTMGenerator1-Klasse Diese Klasse liest mit Hilfe der Schnittstelle „HebrewTypeDataModel“ die Informationen aus der Datenbank und generiert daraus mit Hilfe des Topic Map Modells ein Topic Map. Das generierte Topic Map wird im JVM Speicher gehalten. Diese Klasse bietet zusätzlich eine Möglichkeit, ein komplettes Topic Map oder ein Teil davon im XTM 1.0 Format in einer Datei zu speichern. Nötige Initialisierungen zum Erzeugen des TopicMap Objektes TM4J unterstützt mehrere Speicherungsmöglichkeiten der erstellten Topic Maps. Jedes Speicherungsmodell implementiert das TopicMapProvider Interface. Mit dieser Schnittstelle wird ermöglicht, auf die gespeicherten Topic Maps zuzugreifen oder die neuen Topic Maps in das Speicherungsmodell hinzuzufügen. Um eine Instanz des TopicMapProviders erzeugen zu können, soll die Implementierung 1 des Interfaces TopicMapProviderFactory Quellcode der Klasse „XTMGenerator.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\server\“ zu finden. 48 aus dem Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes jeweiligen Speicherungsmodell verwendet werden. Hier wird ein Speicherungsmodell verwendet, das die Topic Maps im JVM Speicher hält. TopicMapProviderFactory providerFactory = new org.tm4j.topicmap.memory.TopicMapProviderFactoryImpl(); TopicMapProvider m_provider = providerFactory.createTopicMapProvider(props); Der Parameter props ist ein Java Objekt vom Typ Properties. Mit Hilfe der Properties kann angegeben werden, welche Topic Maps bei der Erzeugung des TopcMapProvider’s geladen werden sollen. Wenn es keine Topic Maps zum Laden gibt, wird der TopicMapProvider mit einem leeren Properties Objekt erzeugt. Methode createTopicMap Diese Methode erzeugt ein TopicMap Objekt und liefert es zurück. Dieser Methode wird ein String Parameter übergeben, der zur Lokalisierung des Topic Map Dokumentes dient und im XTM dem Wert des xml:base Attributs des topicMap – Elementes entspricht. TopicMap createTopicMap(String baseAdress){ ... Zuerst wird ein Locator Objekt tmLoc erzeugt. Für die Erzeugung sind zwei String - Parameter nötig: erster Parameter bestimmt den Typ der Referenz, zweiter Parameter ist baseAdress. ... Locator tmLoc = m_provider.getLocatorFactory().createLocator("URI",baseAdress); ... Ein neues TopicMap Objekt wird mit der TopcMapProvider - Methode createTopicMap erzeugt. Dabei wird das Locator Objekt tmLoc als Parameter übergeben. ... return m_provider.createTopicMap(tmLoc); } 49 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Um zum Beispiel ein TopicMap Objekt tm zu erzeugen, wird die Methode wie folgt aufgerufen: TopicMap tm = createTopicMap("http://fsygs21.inf.fhkoeln.de/HebrewType.xtm"); Das erstellte TopicMap Objekt ist noch leer, das heißt, dass das noch keine Elemente enthält. Um das Topic Map mit den Elementen zu füllen, müssen die Elemente zuvor erstellt werden. Methode createTopic Diese Methode erzeugt ein Topic Objekt, fügt dieses dem TopicMap Objekt hinzu und liefert es zurück. Diese Methode wird benutzt, um Topic Objekte zu erstellen, die Topics, Topic Typen (Tabelle 8) oder Assoziationsrollen (Tabelle 9 und Tabelle 10) beschreiben. Dieser Methode werden folgende Parametern übergeben: TopicMap Objekt tm, zu dem ein Topic erzeugt werden soll; ein String id, das zur eindeutigen Referenzierung innerhalb des Topic Maps dient; ein String nameString, das ein Name für das Topic wird; ein Topic Objekt type, das den Typ des zu erzeugenden Topics beschreibt; ein String subjectIndicator, das eine Referenz auf eine Ressource, die dieses Topic eindeutig identifizieren soll, enthält. Topic createTopic(TopicMap tm, String id, String nameString, Topic type, String subjectIndicator){ ... In dieser Methode wird die Methode des TopicMap Objektes tm mit dem Parameter id aufgerufen. Damit wird ein Topic Objekt ret mit dem Attribut id erzeugt und in das TopicMap Objekt tm hinzugefügt. ... Topic topic = tm.createTopic(id); ... Nachdem das Topic Objekt erzeugt wurde, wird dem ein BaseName Objekt mit dem Wert nameString zugewiesen. Dabei wird dem BaseName Objekt ein id – Attribut automatisch vergeben. ... 50 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes topic.createName(null).setData(nameString); ... Zusätzlich wird dem erzeugten Topic Objekt topic der Typ type hinzugefügt, wenn dieses nicht null ist. ... if (type != null) topic.addType(type); ... Als Nächstes wird, falls subjectIndicator einen Wert hat, ein Locator Objekt siLoc erzeugt und dem Topic Objekt zugewiesen. Dieses Objekt enthält eine Referenz auf eine Ressource (subjectIndicator), die zur eindeutigen Identifizierung dieses Topics benutzt wird. ... if (subjectIndicator != null) { Locator siLoc = tm.getLocatorFactory().createLocator("URI", subjectIndicator); topic.addSubjectIndicator(siLoc); } ... Zum Schluss wird das erzeugte Topic – Objekt topic zurückgeliefert. ... return topic; } Um, zum Beispiel, ein Topic Objekt, das den Topic Typ „Schriftart“ beschreiben soll, zu erzeugen, wird die Methode wie folgt aufgerufen: Topic schriftart = createTopic(tm, "Schriftart", "Schriftart", null, null); Der erste Übergabeparameter ist TopicMap tm, der zweite ist eine id „Schriftart“, der dritte Parameter ist der Name „Schriftart“. Der vierte und der fünfte Parametern sind gleich null, weil dieses Topic von keinem Typ ist und keine Referenz auf eine Ressource, die diesen identifizieren soll, besitzt. Um, zum Beispiel, ein Topic Objekt quadrat, das vom Topic Typ „Schriftart“ ist, zu erzeugen, wird die Methode wie folgt aufgerufen: Topic quadrat = createTopic(tm, "quadrat", "quadrat", 51 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes schriftart, null); Der erste Übergabeparameter ist TopicMap tm, der zweite ist eine id „quadrat“, der dritte Parameter ist der Name „quadrat“. Der vierte Parameter ist der Typ dieses Topics, der selbst auch ein Topic ist, in diesem Fall schriftart. Der fünfte Parameter ist gleich null, weil dieses Topic keine Referenz auf eine Ressource, die diesen identifizieren soll, besitzt. Methode createAssociation Diese Methode erzeugt ein Association Objekt, fügt dieses dem TopiMap Objekt hinzu und liefert es zurück. Ein Association Objekt beschreibt die Verknüpfung zwischen zwei Topics. Der Methode createAssociation werden folgende Parametern übergeben: TopicMap Objekt tm, in das die zu erzeugende Assoziation gespeichert werden soll; Topic Objekt assocType, das den Typ der zu erzeugenden Assoziation beschreibt; Topic Objekt role1Type, das die Rolle des ersten Topics in dieser Assoziation beschreibt; Topic Objekt role1Player, das den ersten Topic in dieser Assoziation beschreibt; Topic Objekt role2Type, das die Rolle des zweiten Topics in dieser Assoziation beschreibt; Topic Objekt role2Player, das den zweiten Topic in dieser Assoziation beschreibt. Association createAssociation(TopicMap tm, Topic assocType, Topic role1Type, Topic role1Player, Topic role2Type, Topic role2Player){ ... In dieser Methode wird zuerst ein Association Objekt assoc erzeugt, dabei wird ein id – Attribut automatisch vergeben. Zusätzlich wird dem erzeugten Association Objekt assoc der Typ assocType gesetzt. ... Association assoc = tm.createAssociation(null); assoc.setType(assocType); ... Nachdem das Association Objekt erzeugt wurde, werden die Teilnehmer der Assoziation erstellt und dieser hinzugefügt. Die Teilnehmer werden durch die Member Objekte member1 und member2 beschrieben. 52 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes ... Member member1 = assoc.createMember(null); Member member2 = assoc.createMember(null); ... Dem ersten Member Objekt wird das Topic role1Player, das assoziiert wird, hinzugefügt und das Topic role1Type, das die Rolle bestimmt, gesetzt. ... member1.setRoleSpec(role1Type); member1.addPlayer(role1Player); ... Dem zweiten Member Objekt wird das Topic role2Player, das assoziiert wird, hinzugefügt und das Topic role2Type, das die Rolle bestimmt, gesetzt. ... member2.setRoleSpec(role2Type); member2.addPlayer(role2Player); ... Zum Schluss wird das erzeugte Association – Objekt assoc zurückgeliefert. ... return assoc; } Methode writeTopicMap Diese Methode ermöglicht, ein Topic Map Dokument im XTM Format in ein Ausgabe-Strom zu schreiben. Die Methode wird mit zwei Parametern aufgerufen: TopicMap Objekt tm, das als ein XTM – Dokument gespeichert werden soll, und OutputStream os, das ein Ausgabestrom referenziert, in das ein XTM – Dokument geschrieben wird. void writeTopicMap(TopicMap tm, OutputStream os){ ... Der Zugriff auf die Topic Map Elemente geschieht mit Hilfe des TopicMapWalker Objektes aus dem Packet org.tm4j.topicmap.utils. Mit Hilfe des XTMWriter Objektes aus dem gleichen Packet werden die Elemente des Topic Maps laut XTM 1.0 Syntax in XTM transformiert. Das XMLSerializer 53 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Objekt aus der Bibliothek xalan.jar dient dazu, mit dem vorgegebenen AusgabeFormat das XTM Dokument in einen Ausgabestrom zu schreiben. ... TopicMapWalker walker = new TopicMapWalker(); XTMWriter writer = new XTMWriter(); walker.setHandler(writer); OutputFormat of = new OutputFormat(); of.setEncoding("UTF-8"); of.setIndenting(true); of.setIndent(2); XMLSerializer serializer = new XMLSerializer(os, of); writer.setContentHandler(serializer); try { walker.walk(tm); } catch(TopicMapProcessingException ex) { System.out.println("XTM konnte nicht erzeugt werden: " + ex.toString()); } } Methode generiereXTM Diese Methode generiert aus einem TopicMap Objekt ein XTM Dokument und speichert es in eine Datei. Die Methode wird mit zwei Parametern aufgerufen: TopicMap Objekt tm, das als XTM Dokument gespeichert werden soll und String fileName, das den Pfad und den Namen der Datei enthält. void generiereXTM(TopicMap tm, String fileName){ ... In der Methode werden ein File Objekt out mit dem Parameter fileName und ein FileOutputStream Objekt stm mit dem Parameter out erzeugt. ... File out = new File(fileName); FileOutputStream stm = new FileOutputStream(out); ... Danach wird die Methode writeTopicMap mit den Parametern tm und stm aufgerufen. ... 54 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes writeTopicMap(tm, stm); } Die Methode kann zum Beispiel wie folgt aufgerufen werden: generiereXTM(tm, "C:\\projekt\\komplettXTM.xtm"); Methode generiereTeilXTM Diese Methode generiert aus einem TopicMap Objekt ein Fragment zu einem Topic mit bestimmter ID. Dieses Fragment ist wiederum ein TopicMap Objekt, aus dem ein XTM Dokument generiert und in eine Datei gespeichert wird. Die Methode wird mit drei Parametern aufgerufen: ein TopicMap Objekt tm, aus dem ein Fragment erstellt und als ein XTM Dokument gespeichert werden soll; ein String id, das ein ID des Topics ist, zu dem ein Fragment erstellt werden soll; ein String fileName, das den Pfad und den Namen der Datei enthält. void generiereTeilXTM(TopicMap tm, String id, String fileName){ ... In der Methode werden ein File Objekt out mit dem Parameter fileName und ein FileOutputStream Objekt stm mit dem Parameter out erzeugt. ... File out = new File(fileName); FileOutputStream stm = new FileOutputStream(out); ... Ein neues TopicMap Objekt teilTopicMap wird erzeugt. ... TopicMap teilTopicMap = createTopicMap("http://fsygs21.inf.fhkoeln.de/HebrewTypeTeil.xtm"); ... In das neu erzeugte TopicMap Objekt wird das Topic mit ID id aus dem kompletten TopicMap Objekt tm kopiert. ... Topic copyMe = (Topic)tm.getObjectByID(id); teilTopicMap.addTopic(copyMe); ... 55 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Zusätzlich werden alle Assoziationen des Topics und alle assoziierten Topics in das TopicMap Objekt teilTopicMap hinzugefügt. ... Association[]topAss = new Association[tm.getUtils().getAssociations(copyMe).size()]; tm.getUtils().getAssociations(copyMe).toArray(topAss); for(int i=0; i<topAss.length; i++){ teilTopicMap.addAssociation(topAss[i]); Member[] topMems=new Member[topAss[i].getMembers().size()]; topAss[i].getMembers().toArray(topMems); for(int j=0; j<topMems.length; j++){ teilTopicMap.addTopic(tm.getTopicByID(topMems[j]. getRoleSpec().getID())); Topic[] play = new Topic[topMems[j].getPlayers().size()]; topMems[j].getPlayers().toArray(play); for(int k=0; k<play.length; k++){ teilTopicMap.addTopic(play[k]); } } } ... Schließlich wird die Methode writeTopicMap mit den Parametern teilTopicMap und stm aufgerufen. ... writeTopicMap(teilTopicMap, stm); } Die Methode kann zum Beispiel wie folgt aufgerufen werden: generiereTeilXTM(tm, "quadrat", "C:\\projekt\\TeilXTM.xtm"); Zusätzliche Initialisierung zum automatischen Erzeugen des Topic Maps Wie es am Anfang erwähnt wurde, wird der Zugriff auf die Informationen des digitalen Schriftarchivs mit Hilfe der Schnittstelle „HebrewTypeDataModel“ erfolgen. Es wird eine Verbindung zur Datenbank aufgebaut. Connection verbindung = DBVerbindung.loginPlus2("hebrewtype", "hebrewtype"); 56 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Mit Hilfe der Mengen-Klassen, die die Schnittstelle „HebrewTypeDataModel“ zur Verfügung stellt, werden alle Informationen aus der Datenbank „HebrewTypeDatabase“ geladen und im Speicher als Java-Objekte gehalten. Alle Schriftsätze werden mit Hilfe der Mengen-Klasse SchriftsatzMenge in ein Array schriftsaetze vom Typ Schriftsatz geladen. Schriftsatz[] schriftsaetze = SchriftsatzMenge.createMenge().getSchriftsaetze(); Alle Jahreszahlen, wann die Schriftsätze geschnitten wurden, werden mit Hilfe der Mengen-Klasse SchriftsatzJahrMenge in ein String - Array schriftsatzJahrMenge geladen. String[] schriftsatzJahrMenge = SchriftsatzJahrMenge.createMenge().getJahr(); Alle Druckorte, wo die Schriftsätze geschnitten wurden, werden mit Hilfe der Methode createMengeRefSchriftsatz aus der Mengen-Klasse DruckortMenge in ein String - Array schriftsatzDruckortMenge geladen. String[]schriftsatzDruckortMenge = DruckortMenge.createMengeRefSchriftsatz().getNamen(); Alle Druckschriftdokumente werden mit Hilfe der Mengen-Klasse DruckschriftDokumentenMenge in ein Array druckschriftDokumente vom Typ DruckschriftDokument geladen. DruckschriftDokument[] druckschriftDokumente = DruckschriftDokumentenMenge.createMenge().getDruckschriftdokume nte(); Alle Jahreszahlen, wann die Druckschriftdokumente gedruckt wurden, werden mit Hilfe der Mengen-Klasse DruckschriftDokumentenJahrMenge in ein String - Array druckschriftDokumentenJahrMenge geladen. String[] druckschriftDokumentenJahrMenge = DruckschriftDokumentenJahrMenge.createMenge().getJahr(); 57 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Alle Druckorte, wo die Druckschriftdokumente gedruckt wurden, werden mit Hilfe der Methode createMengeRefBuch aus der Mengen-Klasse DruckortMenge in ein String - Array druckschriftDokumentenDruckortMenge geladen. String[] druckschriftDokumentenDruckortMenge = DruckortMenge.createMengeRefBuch().getNamen(); Alle Namen der Drucker, die die Druckschriftdokumente gedruckt haben, werden mit Hilfe der Mengen-Klasse DruckerMenge in ein String - Array druckerMenge geladen. String[] druckerMenge = DruckerMenge.createMengeNamen().getDruckerNamen(); Alle Bezeichnungen der Kategorien, zu denen die Druckschriftdokumente zugeordnet sind, werden InhaltskategorieMenge mit in Hilfe ein der Mengen-Klasse String - Array inhaltskategorieMenge geladen. String[] inhaltskategorieMenge = InhaltskategorieMenge.createMenge().getNamen(); Nachdem alle notwendigen Initialisierungen vorgenommen wurden, kann die automatische Generierung des Topic Maps erfolgen. Diese Aufgabe wird die Methode generiereTopicMap übernehmen. Methode generiereTopicMap Die Methode dient dazu, ein Topic Map aus den geladenen Informationen mit Hilfe des erstellten Topic Map Modells zu generieren. Als erstes wird ein TopicMap Objekt tm mit Hilfe der Methode createTopicMap erzeugt. TopicMap tm = createTopicMap("http://fsygs21.inf.fhkoeln.de/HebrewType.xtm"); Die vordefinierten Topic Typen, der vordefinierte Assoziationstyp, die vordefinierten Assoziationsrollen und die Topics vom Typ „Schriftart“ und „Schriftstil“ werden mit Hilfe der Methode createTopic erzeugt und in das TopicMap Objekt hinzugefügt. Folgend wird ein Beispiel gezeigt, wie diese Objekte erzeugt werden: 58 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes • Topic – Objekt schriftart, das ein Topic Typ „Schriftart“ beschreibt Topic schriftart = createTopic(tm, "Schriftart", "Schriftart", null, null); • Topic – Objekt verknuepfung, das ein Assoziation Typ „Verbindung“ beschreibt Topic verknuepfung = createTopic(tm, "verknuepfung", "Verknuepfung", null, null); • Topic – Objekte istvomschriftart und schriftartdesSS, die die Rollen des Topics vom Typ „Schriftsatz“ und des Topics vom Typ „Schriftart“ in einer Assoziation beschreiben. Topic istvomschriftart = createTopic(tm, "istvomschriftart", "ist vom Schriftart", null, null); Topic schriftartdesSS= createTopic(tm, "schriftartdesSS", "Schriftart des Schriftsatzes", null, null); • Topic – Objekt quadrat, das ein Topic vom Typ „Schriftart“ ist Topic quadrat = createTopic(tm, "quadrat", "Quadrat", schriftart, null); Nachdem die vordefinierten Objekte erzeugt wurden, werden die Informationen behandelt, die aus dem digitalen Schriftarchiv geladen wurden. Alle String – Arrays, welche Kategorien, Namen der Druckern, Jahreszahlen und Druckortnamen beinhalten, werden in einer for-Schleife durchgegangen, und zu jedem Element der Arrays wird mit Hilfe der Methode createTopic ein Topic Objekt erzeugt. Zum Beispiel alle Topics vom Typ „Drucker“ werden beim Durchlaufen des String-Arrays druckerMenge wie folgt erzeugt. for(int i=0; i<druckerMenge.length; i++){ Topic ddDrucker = createTopic(tm, toID(TOPIC_PREFIX, laufendeNummer), druckerMenge[i], drucker, null); } Dabei wird die ID des Topics mit Hilfe der Funktion toID erzeugt. Die erzeugte ID wird aus einem String TOPIC_PREFIX „t“, einem Unterstrich „_“ und der laufenden Nummer laufendeNummer zusammengesetzt. 59 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Beim Durchlaufen der Elemente des Schriftsatz – Arrays wird zuerst zu jedem Schriftsatz ein Topic Objekt vom Typ „Schriftsatz“ erzeugt. Dabei wird der Schlüssel dieses Schriftsatzes BaseName des Topics repräsentieren. Die ID wird aus einem String SCHRIFT_TOPIC_PREFIX „schrift“, einem Unterstrich „_“ und dem Schlüssel des Schriftsatzes zusammengesetzt. for(int i=0; i< schriftsaetze.length; i++){ Topic schriftsatz = createTopic(tm, toID(SCHRIFT_TOPIC_PREFIX , schriftsaetze[i].schriftsatzPersistent().getSchluessel().toStri ng()), schriftsaetze[i].schriftsatzPersistent().getSchluessel().toStri ng(), schriftsatz, null); ... Da es keine Mengen-Klasse gibt, die alle möglichen Schriftnamen der Schriftsätze liefert, soll zu jedem Schriftsatz ein Topic Objekt vom Typ „Schriftsatzname“ erzeugt werden. Dabei wird zuerst überprüft, ob ein Topic Objekt, das diesen Namen beschreibt, im Topic Map tm existiert. ... if(getTopicByName(tm, schriftsaetze[i].name())==null) Topic sName = createTopic(tm, toID(TOPIC_PREFIX, laufendeNummer), schriftsaetze[i].name(), schriftsatzName, null); ... Zum Schluss wird zu jedem Schriftsatz erzeugtes Topic Objekt mit den Topics assoziiert, die die Eigenschaften dieses Schriftsatzes beschreiben. Dies wird mit Hilfe der Methode createAssociation gemacht. Zum Beispiel eine Assoziation vom Typ „Verknuepfung“ zwischen dem Topic vom Typ „Schriftsatz“ und dem Topic vom Typ „Schriftart“ wird wie folgt erzeugt. Dabei stellen die Topics schriftartdesSS und istvomschriftart die Rollen dar. ... createAssociation(tm, verknuepfung, schriftartdesSS, getTopicByName(tm, schriftsaetze[i].schriftart()), istvomschriftart, s); ... } Beim Durchlaufen der Elemente des druckschriftDokumente – Arrays wird zuerst zu jedem Druckschriftdokument ein Topic Objekt vom Typ „Buch“ erzeugt. 60 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Dabei wird der Schlüssel dieses Druckschriftdokumentes BaseName des Topics repräsentieren. Die ID wird aus einem String BUCH_TOPIC_PREFIX „buch“, einem Unterstrich „_“ und dem Schlüssel des Druckschriftdokumentes zusammengesetzt. for(int i=0; i< druckschriftDokumente.length; i++){ Topic ddd = createTopic(tm, toID(BUCH_TOPIC_PREFIX, druckschriftDokumente[i].druckschriftDokumentPersistent().getSc hluessel().toString()), druckschriftDokumente[i].druckschriftDokumentPersistent().getSc hluessel().toString(), buch, null); ... Da es keine Mengen-Klassen gibt, die alle möglichen Titeln, Autoren, Besitzern und Verlage der Druckschriftdokumenten liefern, sollen zu jedem Druckschriftdokument Topic Objekte vom Typ „Titel“, „Autor“, „Besitz“ und „Verlag“ erzeugt werden. Dabei wird zuerst überprüft, ob jedes Topic Objekt, das erzeugt werden soll, im Topic Map tm existiert. ... if(getTopicByName(tm,druckschriftDokumente[i].autor())==null) Topic ddAutor = createTopic(tm, toID(TOPIC_PREFIX, laufendeNummer), druckschriftDokumente[i].autor(), autor, null); ... Zum Schluss wird zu jedem Druckschriftdokument erzeugtes Topic Objekt mit den Topics assoziiert, die die Eigenschaften dieses Druckschriftdokumentes beschreiben. Dies wird mit Hilfe der Methode createAssociation gemacht. Zum Beispiel eine Assoziation vom Typ „Verknuepfung“ zwischen dem Topic vom Typ „Buch“ und dem Topic vom Typ „Autor“ wird wie folgt erzeugt. Dabei stellen die Topics autordesB und istgeschriebenvon die Rollen dar. ... createAssociation(tm, verknuepfung, autordesB, getTopicByName(tm, druckschriftDokumente[i].autor()), istgeschriebenvon, ddd); ... } Nachdem das TopicMap Objekt tm generiert wurde, wird dieses mit Hilfe der Methode generiereXTM in eine XTM-Datei geschrieben. generiereXTM(tm, "C:\\projekt\\komplettXTM.xtm"); 61 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Die Informationen, die das erzeugte XTM Dokument beinhaltet, können in verschiedenen Formen dargestellt werden. Diese Darstellungsmöglichkeiten sowie die Tools, die es ermöglichen, werden im nächsten Kapitel beschrieben. 1.4.2 Visualisierung von XTM Dokumenten Um dem Benutzer die XTM Dokumente in einer verständlicheren Form präsentieren zu können, muss ein Tool gefunden werden, das die erzeugten Topic Map Dokumente visualisieren kann. Wie es schon mal erwähnt wurde, ist XML Topic Map auf dem XML Standard basiert. Dadurch liegt ein XTM Dokument in einem austauschbaren Format vor und kann mit Hilfe eines Transformers und eines Style Sheets in ein anderes Format, wie HTML, PDF usw. umgewandelt werden. Zwei Web-Applikationen, die aus einem XTM Dokument dynamische HTML Seiten generieren, sind Ontopia Omnigator von Ontopia und TM4Web aus dem TM4J Projekt. Mit Ontopia Omnigator können mehrere XTM Dokumente geladen werden, und die Informationen aus diesen in einem Web-Browser angesehen werden. Die Abbildung 20 zeigt eine HTML-Sicht, die mit dem Ontopia Omnigator generiert wurde. In dieser Abbildung ist ein mit Hilfe der XTMGenerator Klasse generiertes XTM Dokument geladen. Ein Topic mit dem Namen „200207011149“ vom Typ „Buch“ ist ausgewählt. Die mit diesem Topic assoziierten Topics sind als Hyperlinks aufgelistet. Die Rollen, die diese Topics dabei spielen, werden beim Bewegen des Mauszeigers auf das jeweilige Topic angezeigt. Beim Klicken auf ein Topic wird von der Web-Applikation eine neue Sicht erzeugt, wo dieses Topic mit seinen Eigenschaften wie Name, Typ usw., so wie alle mit diesem Topic assoziierten Topics gezeigt werden. 62 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 20 Ontopia Omnigator Ontopia Omnigator wurde auf Basis von Ontopia Navigator Framework entwickelt und von Ontopia frei zur Verfügung gestellt. Mit TM4Web können ebenfalls mehrere XTM Dokumente geladen und deren Inhalte in einem Web-Browser dargestellt werden. In der Abbildung 21 ist eine mit TM4Web generierte HTML Sicht dargestellt. Diese Sicht zeigt, ähnlich wie beim Ontopia Omnigator, ein ausgewähltes Topic mit dem Namen „200207011149“ vom Typ „Buch“. Alle assoziierten Topics sind auch als Hyperlinks dargestellt. Im Unterschied zum Ontopia Omnigator werden die Rollen, die diese Topics in der Assoziation spielen, direkt neben diesen Topics platziert und als Hyperlinks dargestellt. 63 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 21 TM4Web TM4Web ist ein Unterprojekt von TM4J und ist als OpenSource frei verfügbar und frei erweiterbar. Außer der Möglichkeit, die XTM Dokumente als HTML Seiten darzustellen, gibt es eine graphbasierte Darstellung, die dem Benutzer eine bessere Anschaulichkeit bietet. Damit ist gemeint, dass alle Topics als Knoten und alle Assoziationen als Kanten (Linien zwischen den Knoten) in einem Graph dargestellt werden. Solch ein Darstellungsmechanismus bietet dem Benutzer eine interaktive Navigation durch die Informationen und ist immer öfter im Internet angeboten. 64 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Wissen.de1 bietet ein Java - Applet „Matrix – vernetzte Begriffswelten“ an, wo die Benutzer ein Wissenslexikon durchsuchen können. Die Suchergebnisse sowie verwandte Themen werden in einem Graph dargestellt. Ein Ausschnitt aus der „Matrix – vernetzte Begriffswelten“ ist in der Abbildung 22 zu sehen. Abbildung 22 Matrix - vernetzte Begriffswelten In der Abbildung 23 ist ein weiteres Beispiel gezeigt. Dieses Darstellungsmechanismus wird bei einer Suchmaschine webbrain.com2 eingesetzt und ermöglicht nach bestimmten Begriffen zu suchen. Die Suchergebnisse sowie weitere in Beziehung zu dem Suchergebnis stehende Begriffe werden in einem Graph dargestellt. 1 2 http://www.wissen.de http://www.webbrain.com 65 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 23 Webbrain Das TM4J Projekt bietet ein Werkzeug TMNav zur Navigation von Topic Maps in Form einer Java/Swing Applikation an. TMNav verwendet auch den graphbasierten Darstellungsmechanismus. Mit dieser Applikation ist es möglich, XTM Dokumente zu laden und durch die Informationen zu navigieren. In der Abbildung 24 ist die graphische Oberfläche der TMNav - Applikation abgebildet. Die wichtigsten Bereiche sind durch Zahlen markiert. Im ersten Bereich werden die Pfade zu und die Namen von den geladenen XTM – Dokumenten angezeigt. Im zweiten Bereich können die Elemente des im ersten Bereich markierten XTM – Dokumentes mit Hilfe des Pulldown – Menüs ausgewählt und aufgelistet werden. Im dritten Bereich wird ein Graph gezeichnet. In diesem Graph wird ein Element, das im zweiten Bereich markiert wurde, als ein Knoten in der Mitte platziert. Die mit diesem Element assoziierten Elemente werden ebenfalls als Knoten dargestellt. Die Assoziationen zwischen einzelnen Knoten, die im Graph als Kanten bezeichnet werden, werden durch Linien dargestellt. 66 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 24 TMNav Maske In der Abbildung 25 ist die TMNav Maske abgebildet, wo das mit Hilfe der XTMGenerator - Klasse automatisch generiertes XTM – Dokument dargestellt ist. Im dritten Bereich ist ein Topic vom Typ „Buch“ mit dem BaseNamen „200207011149“ in der Mitte platziert. Die mit diesem Topic assoziierten Topics umkreisen diesen. Alle Topics sind mit einem Icon in Form eines Kreises gekennzeichnet. Die Assoziationen zwischen den einzelnen Topics werden mit Linien erkennbar gemacht. In der Mitte der Linie wird jeweils ein Topic platziert, das die Rolle des im Zentrum stehenden Topics beschreibt. Die Rolle des zweiten Topics in einer Assoziation wird hinter dem BaseNamen dieses Topics in Klammern angegeben. 67 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 25 Darstellung von XTM im TMNav Außer der vorgestellten Möglichkeiten zur Darstellung der Informationen aus einem XTM Dokument, sind noch weitere Darstellungsmechanismen denkbar. Es ist auch denkbar, die vorgestellten Mechanismen so zu erweitern, dass die in einem speziellen Fall einem Benutzer die Suche erleichtern. Dieser spezielle Fall kann zum Beispiel beim Suchen nach Informationen auftreten, die ein Benutzer mit einem Objekt assoziiert, das selbst schwer mit einem Begriff zu ersetzen ist. In diesem Fall wäre es besser, dieses Objekt direkt darzustellen und nicht eine Referenz darauf. Angenommen, ein Benutzer hat ein Bild aus einem Buch gesehen. Ihm ist es bekannt, dass das Buch, zu dem er weitere Informationen haben möchte, in Fürth gedruckt wurde. So würde er zum Beispiel im TMNav das Topic mit dem Namen „Fürth“ vom Typ Druckort auswählen und in der Abbildung 26 abgebildete Sicht bekommen. 68 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 26 TMNav Druckortauswahl Wie in der Abbildung zu sehen ist, werden als Ergebnisse der Suche zwei Topics mit den Namen „199905121017“ und „199902011032“ dargestellt, weil es im Digitalen Schriftarchiv zwei Druckschriftdokumente gespeichert sind, die in Fürth gedruckt wurden. Da der Benutzer nicht weiß, welche Schlüssel zu dem gesuchten Buch gehört, ist es für ihn an der Stelle nur möglich auf das Buch zu kommen, indem er die referenzierten Bilder zu jedem Buch ansieht und das gesehene Bild wieder erkennt. Um dem Benutzer an dieser Stelle die Suche zu erleichtern, wäre es sinnvoll, die Topics nicht als Schlüsseln darzustellen, sondern direkt als Bilder. Eine mögliche Darstellung ist in der Abbildung 27 gezeigt. Abbildung 27 Topic als Bilder Diese Darstellung hat für den Benutzer nicht nur den Vorteil, dass er die Bilder direkt sieht, sondern auch, dass er in der gewohnten Umgebung bleibt und nicht zu externen Quellen springen muss. 69 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Vor allem für die Fachleute, die mit dem digitalen Schriftarchiv intensiv arbeiten, ist es besonders wichtig, dass ihre Arbeit nicht durch die lange und aufwendige Suche beeinträchtigt wird. So sollte eine Anwendung überlegt und realisiert werden, wo alle oben beschriebenen Aspekte berücksichtigt werden. Im nächsten Kapitel werden die Schritte der Realisierung einer solchen Anwendung beschrieben. 1.4.3 Realisierung der graphischen Darstellung Bei der Realisierung der graphischen Darstellung der Informationen aus dem generierten XTM Dokument wurde in der Zusammenarbeit mit einem Buchwissenschaftler sowie mit den Betreuern der Diplomarbeit ein User Interface festgelegt. Das User Interface soll aus drei Bereichen bestehen. In der Abbildung 28 sind diese Bereiche durch Zahlen markiert. Im ersten Bereich werden alle Namen der Topic Typen in einem Aufklappmenü aufgelistet. Im zweiten Bereich werden alle Namen der Topics, die von dem in erstem Bereich ausgewählten Typ sind, aufgelistet. Im dritten Bereich wird ein Ausschnitt aus dem Graph gezeichnet. In diesem Graph wird ein Topic, das im zweiten Bereich markiert bzw. im ersten Bereich ausgewählt wurde, als ein Knoten in der Mitte platziert. Die mit diesem Topic assoziierten Topics werden ebenfalls als Knoten dargestellt. Die Assoziationen zwischen einzelnen Knoten, werden durch Linien dargestellt. Abbildung 28 Hebrew Type Navigator Struktur 70 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Bevor die Details der Realisierung beschrieben werden, wird zuerst auf die Grundlagen der eingesetzten Technologien eingegangen. Grundlagen der eingesetzten Technologien Wie in der Vorgehensweise eingedeutet wurde, soll die Realisierung der Anwendung mit Java Technologien erfolgen. Java ist eine objektorientierte, plattformunabhängige Programmiersprache. Bei der Entwicklung der Java Sprache waren vier Grundkonzepte wichtig. • Objektorientierung - die Grundidee dabei ist die softwaretechnische Abbildung in einer Art und Weise, wie wir Menschen auch Dinge der realen Welt erfahren. • Plattformunabhängigkeit - ist die Eigenschaft eines Programms, auf verschiedenen Computersystemen mit Unterschieden in Architektur, Prozessor, Betriebssystem, etc. lauffähig zu sein. • Vernetzbarkeit – ist eine Möglichkeit, Anwendungen zu entwickeln, die auf Client-Server Architektur basieren. • Sichere Ausführung der Anwendungen – erlaubt die Entwicklung von sicheren Anwendungen, die keinen Schaden einrichten können. [WikiA] Im Folgenden werden die Technologien, die Java basiert sind und bei der Realisierung verwendet wurden, kurz beschrieben. Java AWT/Swing Um unter Java graphische Benutzeroberflächen zu gestalten, wurde eine Bibliothek namens Abstract Windowing Toolkit AWT entwickelt. AWT ist Bestandteil der Java Foundation Classes (JFC) und stellt eine Standard-API dar. AWT ist das so genannte Heavyweight-Framework zur Darstellung von Steuerelementen. Das heißt, das AWT die nativen GUI-Komponenten des jeweiligen Betriebssystems zur Darstellung verwendet. Dadurch ist ein Programm, das mit AWT Klassen entwickelt wurde, zu einem bestimmten Betriebssystem angepasst und kann unter anderen Betriebssystemen anders aussehen. Um das zu vermeiden, wurde von Sun Microsystems eine Bibliothek namens „Swing“ entwickelt. 71 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Mit der Swing Bibliothek werden dem Java-Entwickler Leightweight-Komponenten zur Verfügung gestellt, die auf jedem Betriebssystem ein einheitliches Erscheinungsbild (Look And Feel) liefern. Bis Java-Version 1.4 wurde Swing komplett in Java implementiert. Seit Version 1.4 gibt es so genannte "native Bindungen", bei denen Swing Benutzerschnittstellen-Elemente mit den Elementen des Betriebssystems in Beziehung stehen. [WikiA] GraphLayout Wie es schon mal erwähnt wurde, ist ein Graph durch eine Menge von Knoten und Kanten beschrieben. Die Kanten verbinden die Knoten miteinander. Es existieren verschiedene Algorithmen, die für die Platzierung von Knoten in einem Graph eingesetzt werden. Ab der Java Version 1.0 werden von Sun Microsystems einige Beispiele zur Entwicklung von verschiedenen Java Applikationen angeboten. Dabei ist auch ein Beispiel zur Realisierung eines Graphen zu finden. Dieses wurde von einem Mitentwickler von Java geschrieben. Die Anwendung1 steht als ein Java Applet zur Verfügung und kann mit einem Browser gestartet werden. Die Knoten werden als Rechtecke mit einer Beschriftung gezeichnet. Die Kanten werden als Linien, die die Knoten verbinden, dargestellt (Abbildung 29). Abbildung 29 Graph Layout 1 http://java.sun.com/applets/jdk/1.4/demo/applets/GraphLayout/example1.html 72 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Zur Platzierung der Knoten wird ein Spring Algorithmus, auch „Spring Embedder“ genannt, eingesetzt. Die Idee bei diesem Algorithmus ist, dass jede Kante als eine Feder mit einer bestimmten Länge betrachtet wird. Die Knoten werden als kleine Metallteilchen angesehen, die durch die Federn miteinander verbunden sind und sich deswegen anziehen bzw. abstoßen. Der Algorithmus arbeitet in Iterationen (Schleifen). In jeder Iteration werden für jeden Knoten die auf ihn wirkenden Kräfte berechnet. Nachdem alle Kräfte berechnet wurden, werden die Teilchen mit einer bestimmten Beschleunigung bewegt. Danach wird dieser Prozess wiederholt. Nach ausreichenden Durchläufen wird ein Gleichgewichtszustand erreicht, bei dem die auf jedes Teilchen wirkenden Kräfte gleich null sind. [AzZvG] Idee zur Darstellung der relevanten Informationsobjekte Um die Informationen aus einem XTM Dokument in Form eines Graphs zu visualisieren, sollen alle Topics als Knoten und alle Assoziationen als Kanten dargestellt werden. Es wurde drei mögliche Darstellungsvarianten von Knoten festgelegt. • „KnotenDruckschriftdokument“ wird verwendet, um alle Topics vom Typ „Buch“ grafisch darzustellen. Dabei sollen die Bilder der Buchseiten jenes Druckschriftdokumentes in dem Knoten angezeigt werden. • „KnotenSchriftsatz“ wird verwendet, um alle Topics vom Typ „Schriftsatz“ grafisch darzustellen. Dabei sollen die Bilder der Buchstaben jenes Schriftsatzes in dem Knoten angezeigt werden. • „KnotenText“ wird für die Darstellung allen übrigen Topics verwendet. Dabei wird der Name des jeweiligen Topics in dem Knoten angezeigt. Zu jeder Darstellungsvariante KnotenDruckschriftdokument, wurden Klassen implementiert: KnotenSchriftsatz und KnotenText. Alle diesen Klassen wurden von der Klasse Knoten abgeleitet. Mit der Klasse Knoten wird ein Objekt erzeugt, das von der Java Swing Komponente javax.swing.JPanel abgeleitet wurde. Die wichtigen Eigenschaften des Knoten Objektes sind in der Tabelle 11 aufgelistet. 73 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Eigenschaft Beschreibung String ID ID Attribut des Topics String name BaseName des Topics String[] topicTypen ein String Array, in dem die ID’s der Topics gehalten werden, die als Topic Typen für das darzustellende Topic dienen. Set verbindungen beinhaltet alle ID’s der Topics, die mit dem darzustellenden Topic assoziiert sind. double x x-Koordinate für die Platzierung des Knotens im Graph double y y-Koordinate für die Platzierung des Knotens im Graph double dx eine Länge um die die x-Koordinate des Knotens geändert werden muss. double dy eine Länge um die die y-Koordinate des Knotens geändert werden muss. boolean fixed true wenn Der Knoten optimal platziert ist, false wenn der Knoten noch platziert werden muss. int hoehe Höhe des Knotens int breite Breite des Knotens Tabelle 11 Eigenschaften des Knoten Objektes Mit der Auswahl der JPanel Komponente als Grundgerüst für ein Knoten wird erreicht, dass der Knoten zusätzlich alle Eigenschaften des JPanel’s übernimmt. Damit wird es möglich, unterschiedliche Swing-Komponenten im Knoten zu platzieren, wodurch ein individuelles Aussehen eines Knotens erreicht werden kann. Beim Erzeugen eines KnotenText Objekts wird eine Swing Komponente JLabel erzeugt und auf dem JPanel platziert. Der Name des Topics, zu dem dieser Knoten 74 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes erzeugt werden soll, wird mit der Methode der JLabel Komponente setText in dieses JLabel gesetzt. In der Abbildung 30 ist ein Knoten zu dem Topic „Miller“ dargestellt. JLabel Miller JPanel Abbildung 30 KnotenText Für die Darstellung der Topics vom Typ „Buch“ werden nicht die Namen der Topics, sondern die Bilder der Buchseiten des jeweiligen Druckschriftdokumentes benutzt. Zu jedem Topic vom Typ „Buch“ wird ein KnotenDruckschriftdokument Objekt erzeugt. Zu jeder Buchseite des Druckschriftdokumentes wird eine JLabel Komponente erzeugt, wo das Bild dieser Buchseite als ein ImageIcon dargestellt wird. Alle erzeugten JLabel Komponenten werden nacheinander auf der JPanel platziert. In der Abbildung 31 ist ein Knoten dargestellt, der ein Topic vom Typ „Buch“ repräsentiert. JLabel JPanel Abbildung 31 KnotenDruckschriftdokument Um die Topics vom Typ „Schriftsatz“ als Knoten darstellen zu können, wird die Klasse KnotenSchriftsatz verwendet. Zu jedem Buchstaben des Schriftsatzes wird 75 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes eine JLabel Komponente erzeugt, wo das Bild dieses Buchstabens als ein ImageIcon dargestellt wird. Alle erzeugten JLabel Komponenten werden nacheinander auf der JPanel platziert. In der Abbildung 32 ist ein Knoten dargestellt, der ein Topic vom Typ „Schriftsatz“ repräsentiert. Abbildung 32 KnotenSchriftsatz Kompletter Quellcode der Klassen „Knoten.java“, „KnotenText.java“, „KnotenSchriftsatz.java“ und „KnotenDruckschriftdokument.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. Um zu jedem Topic ein Knoten Objekt erzeugen zu können, soll die XTMGenerator Klasse erweitert werden. Erweiterung der XTMGenerator Klasse Alle zu erzeugenden Knoten werden in einem HashMap knotenMap gehalten. Die Knoten vom Typ KnotenText werden mit der Methode addKnotenTopicText erzeugt und in knotenMap eingefügt. Diese Methode wird mit zwei Parametern aufgerufen: String ID, das ein id des Topics ist; String name, das ein BaseName des Topics ist. void addKnotenTopicText(String ID, String name){ Knoten knoten=new KnotenText(ID, isoToUtf(name)); knotenMap.put(ID, knoten); } Die Knoten vom Typ KnotenDruckschriftdokument werden mit der Methode addKnotenTopicDruckschriftdokument erzeugt und in das knotenMap eingefügt. Diese Methode wird mit drei Parametern aufgerufen: String ID, das ein id des Topics ist; String name, das ein BaseName des 76 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Topics ist; DruckschriftDokument d, das ein DruckschriftDokument Objekt ist. void addKnotenTopicDruckschriftdokument(String ID, String name, DruckschriftDokument d){ Knoten knoten=new KnotenDruckschriftdokument(ID, name, d); knotenMap.put(ID, knoten); } Die Knoten vom Typ KnotenSchriftsatz werden mit der Methode addKnotenTopicSchriftsatz erzeugt und in das knotenMap eingefügt. Diese Methode wird mit drei Parametern aufgerufen: String ID, das ein id des Topics ist; String name, das ein BaseName des Topics ist; Schriftsatz s, das ein Schriftsatz Objekt ist. void addKnotenTopicSchriftsatz(String ID, String name, Schriftsatz s){ Knoten knoten=new KnotenSchriftsatz(ID, name, s); knotenMap.put(ID, knoten); } Beim Generieren von Topics werden gleichzeitig mit den beschriebenen Methoden die Knoten zu jedem Topic erzeugt. Nachdem alle Knoten erzeugt wurden, wird bei jedem Knoten die ID des darzustellenden Topics genommen. Mit Hilfe der Methode getTopics werden alle ID’s der Topics, die mit diesem assoziiert sind, ermittelt und als ein String - Array zurückgeliefert. Die ermittelten ID’s werden dem Knoten Objekt mit dessen Methode addVerbindungen zugewiesen. Damit die erzeugten Knoten Objekte bei Bedarf geliefert werden, wird die Klasse XTMGenerator um weitere drei Methoden erweitert: • getTopicTypenKnoten liefert ein Knoten - Array zurück, wo alle Knoten Objekte enthalten sind, die die TopicTypen darstellen. • getKnoten liefert zu einem Topic mit einer bestimmten ID den entsprechenden Knoten Objekt aus dem knotenMap zurück. 77 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes • getKnotens sucht zu einem Topic mit einer bestimmten ID alle mit diesem Topic assoziierten Topics und liefert die entsprechenden Knoten Objekte aus dem knotenMap als ein Knoten - Array zurück. Klasse Graph1 Diese Klasse wurde zur Darstellung der Knoten und Verbindungen zwischen den Knoten implementiert. Der Algorithmus für die Positionierung der Knoten wurde aus dem zuvor beschriebenen GraphLayout Beispiel übernommen. Die Klasse ist von der Swing Komponente javax.swing.JScrollPane abgeleitet. Der Graph wird auf einer JPanel Komponente gezeichnet, die wiederum in der JScrollPane platziert wird. Um die Arbeit des Positionierungsalgorithmus zu erleichtern, werden die Knoten zuerst mit Hilfe der Layout Klassen entweder im Kreis oder in zwei Reihen platziert. Danach wird die Aufgabe zur optimalen Positionierung der Knoten vom Algorithmus übernommen. Die Platzierung läuft in einem eigenständigen Prozess, auch Thread genannt, und kann bei Bedarf gestoppt bzw. gestartet werden. Dies kann durch Ausführen der Methoden start und stop der Graph Klasse erfolgen. Wenn die Knoten optimal platziert sind, wird dieser Thread ebenfalls gestoppt. HebrewTypeNavigator2 Nachdem alle Vorkehrungen getroffen wurden, kann mit der Implementierung der grafischen Benutzeroberfläche begonnen werden. Das festgelegte User Interfase, siehe Abbildung 28, wird mit Hilfe der Swing Komponenten realisiert. Das HebrewTypeNavigator Fenster ist von der Swing Komponente javax.swing.JFrame abgeleitet. Zur Darstellung des Aufklappmenüs, wo alle Knoten, die Topic Typen repräsentieren, enthalten sind, wird die javax.swing.JComboBox Komponente verwendet. Zur Auflistung der Knoten, die die Topics repräsentieren, wird die javax.swing.JList Komponente eingesetzt. Zur Darstellung der Knoten in einem Graph wird ein 1 Quellcode der Klasse „Graph.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 2 Quellcode der Klasse „HebrewTypeNavigator.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 78 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Graph Objekt erzeugt und im rechten Bereich des HebrewTypeNavigator Fensters gezeigt. Um die Knoten, die im XTMGenerator erzeugt wurden und im JVM Speicher gehalten werden, im HebrewType Navigator darzustellen, wird die Dispatcher Klasse implementiert, die die Aufgabe hat, die Applikation mit benötigten Knoten zu versorgen. Außerdem wird diese Klasse auch zur Synchronisation zwischen den einzelnen Bereichen der HebrewType Navigator Applikation benutzt. So enthält die Dispatcher1 Klasse die Referenzen auf die XTMGenerator-, Graph- und HebrewTypeNavigator- Objekte. In der Abbildung 33 ist eine Sicht des HebrewType Navigators dargestellt. In dem Auswahlmenü ist ein Topic Typ „Buch“ ausgewählt. Alle Topics, die von diesem Typ sind, sind in der Topics-Liste als Knoten aufgelistet. Im rechten Bereich ist ein Graph dargestellt, wo der Knoten, der den ausgewählten Topic Typ „Buch“ darstellt, in der Mitte platziert ist. Alle Knoten, die die Topics von diesem Typ darstellen, stehen im Kreis und sind durch Linien mit dem zentralen Knoten verknüpft. Der ausgewählte Knoten ist durch eine rote Umrandung erkennbar. Die verknüpften Knoten haben eine blaue Umrandung. 1 Quellcode der Klasse „Dispatcher.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 79 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 33 HebrewType Navigator mit allen Druckschriftdokumenten Durch Klicken auf ein Knoten, entweder in der Topics-Liste oder direkt im Graph, wird eine neue Sicht erzeugt. Dabei wird in der Topic-Liste der ausgewählte Knoten farblich markiert. Im Graph wird dieser Knoten, der ein bestimmtes Topic vom Typ „Buch“ darstellt, in die Mitte platziert. Die mit diesem Topic assoziierten Topics werden ebenfalls als Knoten in einem Kreis dargestellt. Alle Assoziationen, die die dargestellten Topics zueinander haben, werden als Linien gezeichnet. Die Topic Typen, von denen diese Topics sind, werden beim Bewegen des Mauszeigers auf den jeweiligen Knoten angezeigt. In der Abbildung 34 ist eine solche Sicht dargestellt. In dieser Sicht ist ein Topic mit dem BaseName „200207011149“ ausgewählt. 80 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 34 Topic "200207011149" im HebrewType Navigator In oben gezeigten Beispielen werden die Knoten in einem Kreis platziert. Dieses Layout heißt „Kreislayout“ und wird standardmäßig ausgewählt. Es gibt eine alternative Möglichkeit, die Knoten im Graph in zwei Reihen zu platzieren. Diese kann im Menüpunkt „Layout“ bestimmt werden und heißt „Zweiteilige Layout“. Zusätzliche Funktionen des HebrewType Navigators Alle Knoten im Graph können nach Belieben manuell verschoben werden. Dies ist nur dann sinnvoll, wenn der Positionierungsalgorithmus gestoppt ist, weil sonst die Knoten, die verschoben wurden, wieder auf eine andere optimale Stelle platziert werden. Das Starten und Stoppen von Positionierungsalgorithmus wird mit dem Button „Platzierung starten“, wenn der Algorithmus gestoppt ist, bzw. „Platzierung stoppen“, wenn der Algorithmus aktiviert ist, gesteuert. Um dem Benutzer die Möglichkeit zu geben, den Ablauf seiner Navigation im HebrewType Navigator zu verfolgen, und bei Bedarf einen Schritt nach Vorne bzw. Zurück zu ermöglichen, wird eine Historie Funktion eingebaut. Diese Funktion wird 81 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes durch das Betätigen von Buttons siehe Abbildung 35, die mit den Pfeilen nach Links, für Zurück, und nach Rechts, für Vorwärts, dargestellt sind, aufgerufen. Abbildung 35 Historie Buttons des HebrewType Navigators Beim Auswählen eines Knotens im HebrewType Navigator werden im Graph nur die Knoten dargestellt, die mit ausgewähltem Knoten in einer Beziehung stehen. Mit anderen Worten, es werden nur die Topics gezeigt, die mit dem ausgewählten Topic assoziiert sind. Um die Gemeinsamkeiten der Topics zueinander erkennbar zu machen, wird eine Funktion angeboten, die es ermöglicht, die Topics darzustellen, die mindestens mit zwei von dargestellten Topics assoziiert sind. Dabei wird das ausgewählte Topic nicht berücksichtigt. Das Zeigen und Verbergen von assoziierten Topics wird mit dem Button „Verknüpfungen zeigen“, wenn die verknüpften Topics angezeigt werden sollen, bzw. „Verknüpfungen verbergen“, wenn die verknüpften Topics verborgen werden sollen, gesteuert. In der Abbildung 36 ist das gleiche Topic mit dem BaseName „200207011149“ ausgewählt, wie in der Abbildung 34. Zusätzlich sind die Knoten dargestellt, die hinzugekommen sind, weil der Button „Verknüpfungen zeigen“ betätigt wurde. Die neu dargestellten Knoten sind durch gelbe Umrandung erkennbar. 82 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 36 "200207011149" und Verknüpfungen im HebrewType Navigator Eine weitere Funktion im HebrewType Navigator sollte erlauben, einzelne Bilder der Buchseiten eines Druckschriftdokuments und einzelne Bilder der Buchstaben eines Schriftsatzes auszuwählen. Das Auswählen der einzelnen Bilder soll nur dann möglich sein, wenn der Knoten im Zentrum steht. Die ausgewählten Bilder sollten in einem separaten Fenster in einem größeren Format dargestellt werden. Dazu sollte ein User Interface festgelegt werden. Implementierung der Buchseite bzw. Buchstabe Detailsicht Das User Interface zur Darstellung einzelnen Bilder der Buchseiten eines Druckschriftdokuments bzw. einzelnen Bilder der Buchstaben eines Schriftsatzes wurde in der Zusammenarbeit mit einem Buchwissenschaftler sowie mit den Betreuern der Diplomarbeit festgelegt In der Abbildung 37 ist das User Interface für die Darstellung der Bilder gezeigt. Das Fenster ist in drei Bereiche geteilt. Im ersten Bereich wird das Bild dargestellt, das mit Hilfe des unten stehenden Schiebereglers oder des Pull Down Menüs verkleinert bzw. vergrößert werden kann. Im zweiten Bereich werden die Informationen zu dem 83 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes ausgewählten Bild dargestellt. Im dritten Bereich wird der Knoten dargestellt, der die Bilder des Schriftsatzes bzw. des Druckschriftdokumentes enthält. Das Bild, das im großen Format dargestellt wird, wird im Knoten durch eine Umrandung markiert. Durch das Auswählen eines anderen Bildes wird dieses, im großen Format, im ersten Bereich angezeigt. Im zweiten Bereich werden die Informationen entsprechend aktualisiert. Um den Knoten im HebrewType Navigator auszuwählen, wird neben dem Knoten ein Button mit dem Namen des Schriftsatzes bzw. mit dem Titel des Druckschriftdokumentes platziert. Beim Betätigen dieses Buttons wird das Fenster des HebrewType Navigators angezeigt. Abbildung 37 HebrewType Navigator - Buchseite bzw. Buchstabe Detailsicht Um die Bilder und dazugehörige Informationen darstellen zu können, sollen Objekte erzeugt werden, die die Bilddaten und Informationen beinhalten. Zur Erzeugung der Objekte wurden zwei Klassen implementiert: • ObjektSeite1 beinhaltet die Bilddaten und Informationen einer Buchseite aus einem Druckschriftdokument. Die Eigenschaften des Objekts sind mit der Angabe von Name und Bedeutung in der Tabelle 12 beschrieben. 1 Quellcode der Klasse „ObjektSeite.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. 84 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Eigenschaft String schluessel Beschreibung Schlüssel der Buchseite – wird aus der Datenbank übernommen byte[] bildGross Byte – Array, das die Bilddaten beinhaltet String name Name der Buchseite int letterZahl Anzahl der Letter pro Zeile int letterZahlMax Maximale Anzahl der Letter pro Zeile int letterZahlMin Minimale Anzahl der Letter pro Zeile double satzSpiegelBreite Breite des Satzspiegels double satzSpiegelHoehe Höhe des Satzspiegels int spaltenZahl Anzahl der Spalten String anmerkungen Anmerkungen zu der Buchseite String besonderheiten Besonderheiten der Buchseite String weitereHinweise Hinweise zu der Buchseite Date aufnahmeDatum Datum der Aufnahme des Bildes der Buchseite Tabelle 12 Eigenschaften des ObjektSeite Objekts • ObjektBuchstabe1 beinhaltet die Bilddaten und Informationen eines Buchstabens aus einem Schriftsatz. Die Eigenschaften des Objekts sind mit der Angabe von Name und Bedeutung in der Tabelle 13 beschrieben. 1 Quellcode der Klasse „ObjektBuchstabe.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. 85 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Eigenschaft String schluessel Beschreibung Schlüssel des Buchstabens – wird aus der Datenbank übernommen byte[] bildGross Byte – Array, das die Bilddaten beinhaltet double hoehe Höhe des Buchstabens double breite Breite des Buchstabens double obereDickte Obere Dickte des Buchstabens double untereDickte Untere Dickte des Buchstabens String name Name des Buchstabens String besonderheiten Besonderheiten des Buchstabens String wetereHinweise Weitere Hinweise zum Buchstaben String anmerkungen Anmerkungen zum Buchstaben Date aufnahmeDatum Datum der Aufnahme des Bildes des Buchstabens Tabelle 13 Eigenschaften des ObjektBuchstabe Objekts In der Abbildung 38 ist das Fenster mit dem Bild einer Titelseite aus dem Druckschriftdokument mit dem Titel „Portae lucis“ dargestellt. Dieses Fenster ist ein Objekt der Klasse BuchPanel1, das von der Java Swing Komponente javax.swing.JFrame abgeleitet ist. Die Bilddaten und Informationen der darzustellenden Buchseite werden aus dem Objekt ObjektSeite entnommen. Die Informationen einer Buchseite werden nur dann dargestellt, wenn diese auch existieren. Die Aufgabe, das BuchPanel mit benötigtem Objekt ObjektSeite zu versorgen, wird von der Dispatcher Klasse übernommen. 1 Quellcode der Klasse „BuchPanel.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 86 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 38 Buchseite Detailsicht In der Abbildung 39 ist das Fenster mit dem Bild des Buchstabens „Alef“ aus dem Schriftsatz mit dem Namen „001“ dargestellt. Dieses Fenster ist ein Objekt der Klasse SchriftPanel1, das von der Java Swing Komponente javax.swing.JFrame abgeleitet ist. Die Bilddaten und Informationen des darzustellenden Buchstabens werden aus dem Objekt ObjektBuchstabe entnommen. Die Informationen eines Buchstabens werden nur dann dargestellt, wenn diese auch existieren. Die Aufgabe, das SchriftPanel mit benötigtem Objekt ObjektBuchstabe zu versorgen, wird von der Dispatcher Klasse übernommen. Zu jedem Buchstaben wird ein entsprechendes Bild geladen, das zeigt, wie die Höhe, Breite, obere und untere Dickten dieses Buchstabens gemessen wurden. Dieses Bild wird unter den Informationen zu dem Buchstaben platziert. 1 Quellcode der Klasse „SchriftPanel.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 87 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Abbildung 39 Buchstabe Detailsicht Die Vergrößerung bzw. Verkleinerung der Bilder geschieht mit Hilfe der Methode getScaledInstance des Image Objekts aus der Java AWT Bibliothek. Um eine akzeptable Bildqualität mit geringerer Rechenzeit zu erreichen, wird das Bild mit Hilfe des SCALE_REPLICATE Algorithmus skaliert. 1.4.4 Ausprobieren der Anwendung und erste Probleme Die Anwendung „HebrewType Navigator“ könnte, wie diese bis jetzt implementiert wurde, von einem Benutzer auf einem Rechner eingesetzt werden. Vorausgesetzt ist, dass auf dem Rechner eine JRE (Java Runtime Environment) installiert ist, und eine Verbindung zum Internet besteht. Die Internetverbindung wird benötigt, um die Informationen aus der HebrewType Datenbank zu laden. Beim Ausführen der Anwendung werden aus den geladenen Informationen mit Hilfe der XTMGenerator Klasse ein Topic Map generiert und zu jedem Topic ein Knoten erzeugt. Das generierte Topic Map und alle Knoten werden in JVM Speicher gehalten. 88 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Das Ausführen der Anwendung wurde auf einem PC mit einem AMD Athlon(tm) Prozessor 1,2GHz und mit einem 512 MB Arbeitsspeicher durchgeführt. Dieser Rechner war mit dem Betriebssystem Windows XP Professional ausgestattet. Die Ladezeit der Informationen aus der HebrewType Datenbank betrug bei einer 100MBit/s Verbindungsgeschwindigkeit ca.10 Minuten. Zur Erzeugung des Topic Maps und der Knoten wurden zusätzlich ca. 4 Minuten benötigt. Das bedeutet, dass bei jedem Starten der Anwendung wird ca. 14 Minuten vergehen, bis ein Benutzer mit dieser Anwendung arbeiten kann. Zusätzlich wurde festgestellt, dass der Rechner mit dieser Ausstattung voll ausgelastet war. Zusammengefasst wurden bei diesem Test zwei große Probleme beobachtet: • Schlechte Performance • Starke Systemauslastung Um die Performance zu verbessern und die Systemauslastung zu minimieren, wurde entschieden, die Anwendung auf eine Client-Server Architektur umzustellen. Die Vorteile einer solchen Architektur und die Schritte der Umstellung des HebrewType Navigators auf die Client-Server Architektur werden im nächsten Kapitel beschrieben. 1.4.5 Client-Server Architektur des HebrewType Navigators Eine Client-Server Architektur ist dadurch gekennzeichnet, dass eine Anwendung auf zwei oder mehrere Rechnern verteilt ist. Dabei läuft auf einem Server Rechner ein Programm oder ein Dienst, das die Anfragen des Programms eines oder mehrerer Clients entgegennimmt, bearbeitet und die Antwort zurückschickt. In der Abbildung 40 ist der Ablauf der Kommunikation zwischen einem Client und einem Server dargestellt. Abbildung 40 Client-Server Architektur 89 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Der wesentliche Vorteil, sowie die Grundidee einer solchen Architektur ist die optimale Ausnutzung der Ressourcen der beteiligten Rechner. Dazu ist es sinnvoller, alle Informationen oder Datenbestände auf dem Server bereitzuhalten und nur die angefragten Informationen bzw. Daten dem Client zuschicken, als alle Informationen auf einem Client direkt zu halten, ohne diese zu benötigen. Ein weiterer Vorteil der Verteilung von der Anwendung auf Client und Server ist, dass für einen Client kein direkter Zugriff auf die Datenbestände erlaubt ist. Der Zugriff eines Client Programms auf die Datenbestände wird nur durch ein Server Programm ermöglicht. Dadurch ist eine zusätzliche Sicherheit gewährleistet. Die HebrewType Navigator Anwendung wird so verteilt, dass die Generierung von Topic Map und Knoten auf der Serverseite geschieht, auf der Clientseite bleibt nur der Teil der Anwendung, der für die grafische Darstellung der Informationen zuständig ist. Die darzustellenden Informationen werden als Objekte vom Server angefragt und geliefert. Um die Objekte vom Server zum Client übertragen zu können, werden Java Sockets verwendet. HebrewType Navigator Server Die Web Anwendung „HebrewTypeShow“ des Projekts „Hebräische Typografie im deutschsprachigen Raum“ wurde mit einem Servlet realisiert. Dabei werden bei der Initialisierung des Servlet Objektes alle Daten aus der Datenbank geladen und im JVM Speicher gehalten. Die Servlet Schnittstelle bietet eine Möglichkeit, die geladenen Objekte mittels ServletContext’s in einem anderen Servlet nutzen zu können. Vorausgesetzt ist, dass die beiden Servlet’s unter gleichen Servlet – Runner laufen. Da in der HebrewType Navigator Anwendung die gleichen Daten wie bei HebrewTypeShow Anwendung benötigt werden, wurde entschieden, für die Bereitstellung der HebrewType Navigator Server Anwendung ein Servlet namens HebrewTypeMMServlet zu implementieren. Standardmäßig werden Servlets zu Bearbeitung der HTTP Anfragen (Requests) eines Clients, sowie Antworten (Response) auf die Anfragen verwendet. Damit ein Servlet auch die Sockets Anfragen entgegennehmen und darauf antworten kann, wurde das 90 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes HebrewTypeMMServlet1 Objekt von dem DaemonHTTPServlet2 Objekt abgeleitet. Die Beschreibung der Klasse DaemonHTTPServlet ist unter [JaSeP] Seite 327ff zu finden. Bei der Initialisierung des HebrewTypeMMServlet’s wird zuerst überprüft, ob die Objekte, die zur Generierung des Topic Maps benötigt werden, schon im ServletContext existieren. Wenn die Objekte noch nicht vorhanden sind, werden diese erzeugt. Danach werden die Objekte dem erzeugten XTMGenerator Objekt für die Generierung des Topic Maps und Erzeugung der Knoten Objekte übergeben. Zur Bearbeitung der Socket Anfragen des Clients wird ein ServerSocket Objekt erzeugt, das in einem eigenen Thread läuft und auf einem bestimmten Port auf die Anfragen wartet. Dabei ist es möglich, Anfragen von mehreren Clients zu bearbeiten. Wenn eine Anfrage vom Client kommt, wird diese Anfrage zuerst analysiert. Danach werden die nötigen Informationen durch Aufrufen der entsprechenden Methoden des XTMGenerator Objekts geholt und dem Client zugeschickt. Der HebrewType Navigator Server lädt nur einmal die Daten aus der Datenbank, hält diese im Speicher und beantwortet die Anfragen von Clients solange, bis der gestoppt wird. HebrewType Navigator Client Die Dispatcher Klasse der HebrewType Navigator Anwendung wurde so geändert, dass sie die für die Darstellung benötigten Objekte nicht aus dem XTMGenerator Objekt nimmt, sondern beim HebrewType Navigator Server anfragt. Zu jeder Anfrage wird eine Socket Verbindung zum Server aufgebaut. Nachdem die angefragten Objekte erhalten wurden, wird die Socket Verbindung getrennt. Beim Starten des HebrewType Navigators werden zuerst alle Knoten Objekte, die die Topic Typen darstellen, vom Server angefragt. Dabei wird dem Server ein 1 Quellcode der Klasse „HebrewTypeMMServlet.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\server\“ zu finden. 2 Quellcode der Klasse „DaemonHTTPServlet.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\server\“ zu finden. 91 Visualisierung der Informationen in einem semantischen Netz Realisierung eines semantischen Netzes Schlüsselwort „TopicTypenKnoten“ gesendet. Die erhaltenen Knoten Objekte werden im Knoten Array gespeichert und in dem Aufklappmenü des HebrewType Navigator Fensters aufgelistet. Zu dem im Aufklappmenü ausgewählten Topic Typ werden vom Server alle Knoten, die die Topics von diesem Typ darstellen, mit dem Schlüsselwort „TopicsKnoten“ und dem ID dieses Topic Typs angefordert. Die erhaltenen Knoten werden in der Topic Liste aufgelistet und im Graph mit den Verbindungen grafisch dargestellt. Sockets und Objektserialisierung Bei der Übertragung der Java Objekte mit Hilfe von Sockets sollen die übertragenden Objekte serialisiert werden. Die einfachen Datentypen, wie int, String, double usw. können ohne Serialisierung übertragen werden. Alle Objekte, die serialisiert werden müssen, sollen das Interface Serializable implementieren. Dabei werden alle Attribute jenes Objektes rekursiv mitserialisiert. Diese Attribute müssen ebenfalls das Interface Serializable implementieren. Attribute, die static oder transient sind, werden nicht mitserialisiert. Bei der Serialisierung eines Objekts wird nicht nur der Inhalt dieses Objektes in den Ausgabestrom geschrieben. Zusätzlich wird ein von JVM automatisch generierte Schlüssel serialVersionUID, der die eindeutige Kennung der Klasse angibt, als ein Attribut mitgeliefert. Im Falle, dass die JVM Versionen auf dem Klient und dem Server sich unterscheiden, kann es dazu kommen, dass das serialVersionUID, das bei der Serialisierung generiert wurde, sich von dem serialVersionUID unterscheidet, das bei der Deserialisierung generiert wurde. Um dieses Problem zu vermeiden, soll ein eigenes serialVersionUID erstellt werden und in die Klasse als eine statische finale long Variable eingetragen werden. Das serialVersionUID kann mit einem kleinen Dienstprogramm serialver, das mit jeder Java Version mitgeliefert ist, berechnet werden. Die Klassen der HebrewType Navigator Anwendung, deren Objekte übertragen werden, werden serialsiert. Zusätzlich wird zu jeder serialisierten Klasse ein serialVersionUID berechnet und eingetragen. 92 Visualisierung der Informationen in einem semantischen Netz Ergebnisse und Erkenntnisse 1.5 Ergebnisse und Erkenntnisse Mit der Implementierung der HebrewType Navigator Anwendung wurde erreicht, dass die Informationen aus dem digitalen Schriftarchiv in Form eines semantischen Netzes dem Benutzer präsentiert werden. Dabei kann der Benutzer frei und unabhängig von einer festen Struktur im digitalen Archiv navigieren. Dadurch können die gesuchten Informationen schneller gefunden werden, und die Zusammenhänge der einzelnen Informationen werden besser erkennbar. Mit der Möglichkeit, die Bilder der einzelnen Buchseiten oder Buchstaben zu vergrößern, die bei der „HebrewTypeShow“ Anwendung nicht zur Verfügung stand, wurde erreicht, dass auch die kleinen Details der Bilder besser erkannt werden können. Beim Testen der Anwendung wurden schnell die Stellen in der Datenbank gefunden, wo die Informationen fehlten, nicht komplett oder falsch eingetragen waren. Damit konnten die Fehler des Datenbankbestandes gezielt korrigiert werden. Durch das Verwenden des Feder Algorithmus zur Platzierung von Knoten in einem Graph, wird eine optimale Platzierung von Knoten erreicht, wenn die Anzahl der Knoten gering ist. Beim Platzieren einer großen Anzahl von Knoten, taucht ein Problem auf, dass die Knoten nicht optimal platziert werden können, weil es nicht genug Platz im sichtbaren Fenster gibt, oder die Dimensionen der Knoten sehr groß sind. Dadurch hört der Feder Algorithmus nie auf, die Knoten zu platzieren. Ein Verbesserungsvorschlag wäre die Verwendung eines anderen Algorithmus zum Platzieren der Knoten. Mit der Umstellung der HebrewType Navigator Anwendung auf die Client-Server Architektur wurde die Startzeit wesentlich verkürzt. Das Performance Problem ist in zwei extremen Fällen trotzdem geblieben: beim Laden aller Schriftsätze und aller Druckschriftdokumente. Vor allem tritt dieses Problem auf, wenn zusätzlich die Verknüpfungen gezeigt werden sollen. Um das Performance Problem zu lösen, wäre es sinnvoller, die Knoten, die angefordert wurden, auf dem Client zu speichern. Eine Vorraussetzung dafür ist aber, dass auf dem Client genug Speicherplatz vorhanden ist. Damit werden die Knoten, die wiederholt angefordert werden, aus dem Cache 93 Visualisierung der Informationen in einem semantischen Netz Ergebnisse und Erkenntnisse geladen und nicht vom Server angefragt. Die Ladezeit würde sich dabei wesentlich verkürzen. Beim zweiten Start der Anwendung könnten die Knoten dann auch aus dem Cache geholt werden. Dabei ist zu sagen, dass zusätzlich eine Überprüfung der Daten auf Konsistenz durchgeführt werden muss, da die Daten im Cache veraltet sein können. Mit der Veröffentlichung von Java Version 5.0 wurde ein weiteres Problem beobachtet. Wenn auf dem Server eine Java Version 1.4.x installiert ist, und auf dem Client die Java Version 5.0 läuft, werden für ein Objekt bei der Serialisierung und der Deserialisierung unterschiedliche serialVersionUID Werte berechnet. Dieses Problem tritt aus dem Grunde auf, weil die Swing Komponenten in Java Version 5.0 geändert wurden. Um das Problem zu lösen, wären zwei Lösungen möglich. Damit die Anwendung ohne Veränderungen auf allen Clients funktioniert, wird die Java Version mitgeliefert, die auf dem Server installiert ist. Zweite Möglichkeit ist, die zu übertragenen Objekte nicht von Swing Komponenten abzuleiten. Der grafische Aufbau der Inhalte von Objekten soll mit Hilfe von Swing Komponenten auf dem Client geschehen. 94 Erfassung multimedialer Zusatzinformationen Einführung 2. Erfassung multimedialer Zusatzinformationen 2.1 Einführung Im ersten Teil dieser Diplomarbeit wurde gezeigt, wie die Suche nach digitalisierten Informationen, wie Bilder, Zeichnungen, oder Grafen, durch semantische Netze mit Unterstützung des Topic Map Standards erleichtert werden kann. Ein Bild, ein Foto oder eine Zeichnung enthalten meist sehr viele Informationsobjekte. Diese Informationsobjekte sollen auch erkennbar und verständlich sein. Dies könnte zum Beispiel bei einer Karte durch eine Legende erkennbar gemacht werden. Grafen, Zeichnungen oder Bilder werden meistens mit Texten beschrieben, wenn diese im Internet als HTML Dokumente präsentiert sind oder in einer druckbaren Form, etwa einem Buch, vorliegen. Bevor ein Informationsobjekt beschreiben werden kann, soll zuerst beschrieben werden, wo sich dieses auf dem Bild, in der Zeichnung oder im Graf befindet. Bei zwei bis vier Informationsobjekten ergibt sich auch kein Problem dabei. Doch wenn es sich um viel mehr Informationsobjekte handelt, wird es schon schwieriger, die Positionen dieser zu beschreiben. Um dieses Problem etwas deutlicher zu machen, wird ein kleines Beispiel gezeigt. In der Abbildung 41 ist ein Foto abgebildet, das in Jerusalem aufgenommen wurde. Auf diesem Foto sind Klagemauer, Felsendom und Al-Aqsa-Moschee zu sehen. Außerdem gibt es auf dem Foto viele andere Informationsobjekte, die interessant sein können. Ein Autor dieses Fotos möchte dies zum Beispiel auf seiner Homepage als eine HTML Seite präsentieren. Dabei ist es wichtig, auch die Informationsobjekte, die auf dem Foto zu sehen sind, zu beschreiben. Eine mögliche Vorgehensweise ist zuerst die Positionen dieser Objekte anzugeben. Eine Beschreibung der Position einiger Objekte kann zum Beispiel so aussehen: Der Felsendom ist auf dem Foto im linken oberen Bereich zu sehen und hat eine goldene Kuppel; die Al-Aqsa-Moschee hat eine graue Kuppel und ist im rechten oberen Bereich zu sehen; die Klagemauer ist links und der Eingang zum Tempelberg ist in der Mitte des Fotos zu sehen; usw.. 95 Erfassung multimedialer Zusatzinformationen Einführung Zusätzlich zu der Beschreibung der Position werden an gleicher Stelle die Objekte selbst beschrieben. Die Beschreibung der Objekte kann aus einem Text, weiteren Bildern, Audio- oder Videoaufnahmen bestehen. Abbildung 41 Jerusalem Aus dem beschriebenen Beispiel ergeben sich folgende Probleme: • Ein Interessent, der die Klagemauer schon mal gesehen hat und nur die Informationen dazu sucht, braucht keine Angabe der Position sondern nur die Beschreibung der Mauer. Dafür muss er zuerst die Stelle, wo die Klagemauer beschrieben wird, im Text suchen. • Ein anderer Betrachter dagegen könnte schon viel über den Felsendom gelesen haben und will nur wissen, wo der Felsendom auf dem Foto zu sehen ist. Dafür muss er im Text die Stelle finden, wo die Position angegeben ist. • Zusätzliches Problem ist, dass die Beschreibung der Position für den Autor sehr schwer sein kann und einem Benutzer nicht ausreicht, um das Objekt mit dieser Position auf dem Foto zu finden. Zum Beispiel ist es schwierig, die Position des Eingangs zum Tempelberg zu beschreiben und den Eingang anhand dieser Beschreibung wieder zu finden. 96 Erfassung multimedialer Zusatzinformationen Einführung Um einem Benutzer die Suche nach interessanten Informationsobjekten im Text zu ersparen, können diese Objekte direkt auf dem Foto markiert werden. Damit wird erreicht, dass der Benutzer auf einmal alle beschriebenen Informationsobjekte sieht, und der Autor sich die Beschreibung der Platzierung von Objekten ersparen kann. In der Abbildung 42 sind der Felsendom, die Klagemauer, die Al-Aqsa-Moschee und der Eingang zum Tempelberg durch Rechtecke mit verschiedenen Farben markiert. Damit der Benutzer erkennt, um welches Informationsobjekt es sich bei einer Markierung handelt, kann die Kurzbeschreibung dieses Objektes angezeigt werden. Abbildung 42 Jerusalem mit Markierungen Durch die Markierungen wird ermöglicht, schneller die gewünschte Information zu einem Informationsobjekt zu finden. Zusätzlich wird es für den Autor erspart, die Positionen der Informationsobjekte zu beschreiben. 2.1.1 Problemstellung Das wissenschaftliche digitale Schriftarchiv, das im Rahmen des Forschungsprojektes „Hebräische Typographie im deutschsprachigen Raum“ entstand, enthält viele Bilder der Buchseiten und der Buchstaben. Neben der Erfassung der formalen Informationen, wurde die Möglichkeit vorgesehen, für jedes Bild die Zusatzinformationen in Form eines Textes hinzuzufügen. Dabei ging es 97 Erfassung multimedialer Zusatzinformationen Einführung hauptsächlich darum, die Informationen für ein ganzes Bild zu erfassen. Grundsätzlich könnte ein Buchwissenschaftler auch die Informationsobjekte, die in diesen Bildern dargestellt sind, beschreiben. Dabei soll er die Positionen dieser Objekte angeben, damit ein späterer Benutzer die Beschreibung zu den Objekten zuordnen kann. Dabei treten ähnliche Probleme auf, die in der Einführung beschrieben wurden. Ein zusätzliches Problem ist, dass es nur möglich ist, die Informationsobjekte durch Text zu beschreiben und nicht durch andere multimedialen Formate, wie Bilder, Audio- oder Videoaufnahmen. Die Wichtigkeit der Beschreibung von Informationsobjekten durch verschiedene multimediale Formate wird folgend im Einzelnen erläutert. Im digitalen Schriftarchiv gespeicherte Bilder der Buchseiten oder Buchstaben stammen aus sehr wertvollen alten Büchern. Die Qualität der Bilder hängt vom Zustand dieser Bücher ab. Es kann vorkommen, dass eine Seite aus dem Buch nur zur Hälfte vorhanden ist oder ein interessantes Informationsobjekt schlecht zu erkennen ist. Aus diesem Grund wäre es sinnvoll, alternative Bilder, die das gleiche Informationsobjekt darstellen, zu diesem Objekt zu hinterlegen. Auf einigen Bildern sind die Texte schlecht lesbar, oder diese Texte für derjenigen, der die moderne hebräische Sprache beherrscht, alt hebräisch aber nicht lesen kann, nicht verständlich sind. In diesen Fällen wäre es sehr hilfreich, ein gesprochener Text in Form einer Audioaufnahme zu jedem solchen Text zu speichern. Öfters sind die komplexeren Informationsobjekte nur mit Sprachaufnahmen, Bildern oder Texten schwierig zu beschreiben. In diesen Fällen wäre es besser, eine Videoaufnahme, die verschiedene multimediale Formate kombiniert, zur Beschreibung solcher Informationsobjekte zu benutzen. Mit der Ermöglichung, die multimedialen Zusatzinformationen zu einem Informationsobjekt zu erfassen, könnte ein Buchwissenschaftler sein Wissen in einer digitalen Form festhalten und nach Bedarf weiter vermitteln. Um einem Buchwissenschaftler diese Möglichkeit zu bieten, sollte eine Anwendung entwickelt werden, die die Informationsobjekte markieren und verschiedene Zusatzinformationen zu diesen Objekten speichern lässt. Ein Endbenutzer sollte dann die Möglichkeit bekommen, die zu den markierten Informationsobjekten erfassten Zusatzinformationen anzusehen. 98 Erfassung multimedialer Zusatzinformationen Realisierung 2.1.2 Vorgehensweise Bevor es mit der Entwicklung einer Anwendung zum Markieren der Informationsobjekte eines Bildes und zum Speichern der Zusatzinformationen zu diesen Informationsobjekten begonnen werden kann, wurde überlegt, wie die Zusatzinformationen sowie die Markierungsdaten gespeichert werden. Um die Markierungsdaten und die Zusatzinformationen in einer relationalen Datenbank persistent zu speichern, wurde ein Datenbankschema modelliert. Zusätzlich wurde eine Schnittstelle entwickelt, die es ermöglicht, die Zusatzinformationen und die Markierungsdaten in einer Datenbank zu speichern, zu ändern und aus der Datenbank zu laden. Das User Interface zur Darstellung einzelnen Bilder der Buchseiten eines Druckschriftdokuments bzw. einzelnen Bilder der Buchstaben eines Schriftsatzes, das im ersten Teil dieser Diplomarbeit beschrieben wurde, wurde durch zusätzliche Methoden erweitert, die es einem Buchwissenschaftler ermöglichen, verschiedene Informationsobjekte zu markieren und schon markierte Objekte visuell sichtbar zu machen. Zum Erfassen, Bearbeiten und Darstellen von Zusatzinformationen wurde ein grafisches User Interface festgelegt und realisiert. Zur Übertragung der Daten vom Server zum Client wurden HebrewType Navigator Server und HebrewType Navigator Client, die im ersten Teil dieser Diplomarbeit beschrieben wurden, entsprechend erweitert. Für die Speicherung oder Änderung der Zusatzinformationen wurde eine zusätzliche Serverapplikation entwickelt. 2.2 Realisierung In diesem Kapitel werden einzelne Schritte, die in der Vorgehensweise kurz genannt wurden, genauer beschrieben. 2.2.1 Modellierung eines Datenbankschema Um die Markierungsdaten und die Zusatzinformationen zu den Bildern aus dem digitalen Schriftarchiv persistent zu speichern, wurde entschieden, eine relationale 99 Erfassung multimedialer Zusatzinformationen Realisierung Datenbank zu verwenden. Dafür wurde in enger Zusammenarbeit mit einem Buchwissenschaftler festgelegt, welche Eigenschaften von Zusatzinformationen gespeichert werden müssen. Tabelle Markierung In dieser Tabelle werden alle Daten, die eine Markierung beschreiben, gespeichert. Diese Tabelle beinhaltet neun Datenfelder. In dem Feld „SCHLUESSEL“ wird der Schlüssel jener Markierung gespeichert, der diese Markierung eindeutig identifiziert. Die Felder „X“, „Y“, „BREITE“ und „HOEHE“ beinhalten Daten, die die Position und die Größe der Markierung beschreiben. Das Feld „FARBE“ beinhaltet die Farbe des Rahmens der Markierung. Die Farbe wird als eine Ganzzahl des RGB Wertes angegeben. Die Felder „TITEL“ und „BESCHREIBUNG“ sprechen für sich und dienen der Speicherung von Informationen über die Markierung in einer Textform. Das Feld „OBJEKT“ beinhaltet den Schlüssel eines Bildes aus dem digitalen Schriftarchiv, zu dem diese Markierung zugeordnet ist. Tabelle Audio In dieser Tabelle werden alle Audioaufnahmen und deren Eigenschaften gespeichert. Diese Tabelle beinhaltet acht Datenfelder. In dem Feld „SCHLUESSEL“ wird der Schlüssel jenes Audios gespeichert, der dieses Audio eindeutig identifiziert. Das Feld „ORDNUNGSZAHL“ beinhaltet eine Zahl, die bei der Einordnung in einer Folge zur Bestimmung der Position benötigt wird. In dem Feld „NAME“ wird die Kurzbezeichnung für das Audio festgehalten. Das Feld „GROESSE“ enthält die Angabe der Größe des Audios in Byte. Das Feld „FORMAT“ beinhaltet das Format des Audios, zum Beispiel „mp3“ oder „wave“. In dem Feld „AUDIODATEN“ wird das Audio in binärer Form abgelegt. Das Feld „AUFNAHMEDATUM“ enthält das Datum der Aufnahme des Audios. Das Feld „MARKIERUNG“ beinhaltet ein Schlüssel der Markierung, zu der dieses Audio zugeordnet ist. Tabelle Bild In dieser Tabelle werden alle Bilder und deren Eigenschaften gespeichert. Die Tabelle beinhaltet neun Datenfelder. In dem Feld „SCHLUESSEL“ wird der Schlüssel jenes Bildes gespeichert, der dieses Bild eindeutig identifiziert. Das Feld 100 Erfassung multimedialer Zusatzinformationen Realisierung „ORDNUNGSZAHL“ beinhaltet eine Zahl, die bei der Einordnung in einer Folge zur Bestimmung der Position benötigt wird. In dem Feld „NAME“ wird die Kurzbezeichnung für das Bild festgehalten. Das Feld „GROESSE“ enthält die Angabe der Größe des Bildes in Byte. Das Feld „FORMAT“ beinhaltet das Format des Bildes, zum Beispiel „jpg“, „gif“ usw. In dem Feld „BILDDATEN“ wird das Bild in binärer Form in originaler Größe abgelegt. In dem Feld „BILDKLEINDATEN“ wird ein Thumbnail für dieses Bild in binärer Form abgelegt. Das Feld „AUFNAHMEDATUM“ enthält das Datum der Aufnahme des Bildes. Das Feld „MARKIERUNG“ beinhaltet ein Schlüssel der Markierung, zu der dieses Bild zugeordnet ist. Tabelle Video In dieser Tabelle werden alle Videoaufnahmen und deren Eigenschaften gespeichert. Die Tabelle beinhaltet acht Datenfelder. In dem Feld „SCHLUESSEL“ wird der Schlüssel jenes Videos gespeichert, der dieses Video eindeutig identifiziert. Das Feld „ORDNUNGSZAHL“ beinhaltet eine Zahl, die bei der Einordnung in einer Folge zur Bestimmung der Position benötigt wird. In dem Feld „NAME“ wird die Kurzbezeichnung für das Video festgehalten. Das Feld „GROESSE“ enthält die Angabe der Größe des Videos in Byte. Das Feld „FORMAT“ beinhaltet das Format des Videos, zum Beispiel „mpeg“ oder „avi“. In dem Feld „VIDEODATEN“ wird dieses Video in binärer Form abgelegt. Das Feld „AUFNAHMEDATUM“ enthält das Datum der Aufnahme des Videos. Das Feld „MARKIERUNG“ beinhaltet ein Schlüssel der Markierung, zu der dieses Video zugeordnet ist. In der Abbildung 43 sind die Tabellen Markierung, Audio, Bild und Video mit deren Feldern dargestellt. Fett markierte Felder zeigen, dass die Angaben in diese Felder pflichtig sind. Das heißt, dass diese Felder einen Wert beinhalten müssen. Die Felder, die unterstrichen sind, stellen die privaten Schlüsseln dar. Die restlichen Felder sind optional, das heißt, dass diese Felder leer bleiben können. Die Relationen(Beziehungen) zwischen den Tabellen sind als gestrichelte Linien dargestellt. Demnach wird ersichtlich, dass eine Markierung eine „1 zu n“ Beziehung zu Audio, Bild oder Video hat. Das heißt, dass zu einer Markierung mehrere Audios, Bilder oder Videos zugeordnet werden dürfen. Um Missverständnisse zu vermeiden, 101 Erfassung multimedialer Zusatzinformationen Realisierung wird hier noch erwähnt, dass diese Relationen nur der Veranschaulichung dienen und auf der Datenbankebene nicht existieren. Die Datenbank wird nur zur persistenten Speicherung benutzt. Alle Beziehungen werden auf der Softwareebene realisiert. Abbildung 43 Datenbankschema Um die Markierungsdaten und die Zusatzinformationen zu den Bildern aus dem digitalen Schriftarchiv in der beschriebenen Datenbank persistent zu speichern, zu bearbeiten und aus dieser Datenbank zu laden, wurde eine Schnittstelle implementiert, die im folgenden Kapitel näher beschrieben wird. 2.2.2 Implementierung einer Schnittstelle zur Datenbank In diesem Kapitel wird die Schnittstelle zu der Datenbank beschrieben, in der die Markierungsdaten und die Zusatzinformationen zu den Bildern aus dem digitalen Schriftarchiv gespeichert werden. Zuerst wurden die Klassen implementiert, die die Markierung1-, Audio2-, Bild3- und Video4-Objekte erzeugen und den Zugriff auf deren Eigenschaften ermöglichen. Der Zugriff geschieht mit Hilfe der Methode getXx, die den Wert 1 Quellcode der Klasse „Markierung.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. 2 Quellcode der Klasse „Audio.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. 3 Quellcode der Klasse „Bild.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. 4 Quellcode der Klasse „Video.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\“ zu finden. 102 Erfassung multimedialer Zusatzinformationen Realisierung einer Eigenschaft liefert, und der Methode setXx, die den Wert einer Eigenschaft setzt. „Xx“ steht dabei für die jeweilige Bezeichnung der Eigenschaft. Das Objekt Markierung hat zum Beispiel, unter Anderen, die Eigenschaft „Breite“. Der Zugriff auf den Wert dieser Eigenschaft geschieht mit Hilfe der Methoden getBreite und setBreite. Die Objekte Audio, Bild, Video und Markierung besitzen alle Eigenschaften, die bei der Modellierung des Datenbankschemas als Datenfelder vorgesehen wurden. Das Objekt Markierung hat zusätzlich die Methoden, die alle Audio, Bild und Video Objekte zurückliefern oder setzen. Zu jedem Markierung-, Audio-, Bild- und Video-Objekt werden die Klassen implementiert, die es ermöglichen, die Eigenschaftswerte dieser Objekte in der Datenbank zu speichern, die Eigenschaften mit den Werten aus der Datenbank zu füllen, die geänderten Werte in der Datenbank zu aktualisieren oder die Eigenschaftswerte der gelöschten Objekte aus der Datenbank zu entfernen. Diese Klassen sind MarkierungDB1, AudioDB2, BildDB3 und VideoDB4. Jede Klasse hat die Methoden speichern zum Speichern der Daten in einer Datenbank, laden zum Laden der Daten aus der Datenbank, loeschen zum Löschen der Daten aus der Datenbank und aendern zum Ändern der Daten in der Datenbank. Die Methode holen, die zusätzlich in den Klassen implementiert ist, lädt, ähnlich wie die Methode laden, die Daten aus der Datenbank, allerdings ohne den binären Daten der Audio, Bild und Video Objekten. Das Laden nur der binären Daten kann mit Hilfe der Methode ladeDaten geschehen. Außerdem besitzen die Klassen MarkierungDB, AudioDB, BildDB und VideoDB eine Methode getNextSchluessel, die jeweils für jedes neues Markierung-, Audio-, Bild- oder Video-Objekt einen Schlüssel erzeugt. Der Schlüssel eines Markierung Objektes setzt sich aus dem Schlüssel des Bildes, der aus dem 1 Quellcode der Klasse „MarkierungDB.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\database\“ zu finden. 2 Quellcode der Klasse „AudioDB.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\database\“ zu finden. 3 Quellcode der Klasse „BildDB.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\database\“ zu finden. 4 Quellcode der Klasse „VideoDB.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\database\“ zu finden. 103 Erfassung multimedialer Zusatzinformationen Realisierung digitalen Schriftarchiv übernommen wurde, einem „/“ und einer fortlaufenden Nummer zusammen. Die Schlüssel für Audio, Bild und Video Objekte werden aus dem Schlüssel des zugehörigen Markierung Objektes, einem „/“ und der fortlaufenden Nummer zusammengesetzt. Die Kommunikation mit der Datenbank wird mittels JDBC Schnittstelle realisiert. Zum Aufbau einer Verbindung zur Datenbank wird die Klasse DBVerbindung1 aus dem HebrewType Framework benutzt. Um zu einem Bild aus dem digitalen Schriftarchiv alle Markierungen zu laden, wird die Klasse MarkierungenMenge2 implementiert. Diese Klasse wird mit der Methode createMenge initialisiert, der als Parameter der Schlüssel des Bildes übergeben wird. Durch Aufruf der Methode getMarkierungen wird ein Array der Markierung Objekte zurückgeliefert. Nachdem die Klassen für die Erzeugung der Markierung-, Audio-, Bild- und Video-Objekten und die Schnittstelle zu der Datenbank implementiert wurden, kann mit der Realisierung der grafischen Benutzerschnittstelle begonnen werden. Die Schritte der Realisierung werden folgend beschrieben. 2.2.3 Werkzeug zum Markieren und Visualisieren der Informationsobjekten Um die Informationsobjekte eines Bildes aus dem digitalen Schriftarchiv markieren zu können und auch zu visualisieren, wird das im ersten Teil dieser Diplomarbeit beschriebe User Interface für Buchseite bzw. Buchstabe Detailsichten durch zusätzliche Funktionen erweitert. Bevor die Methoden beschrieben werden, wird kurz erklärt, wie die Ausgabe von grafischen Objekten auf einem Bildschirm funktioniert. In der Abbildung 44 ist ein zweidimensionales Koordinatensystem dargestellt auf dem die Ausgabe basiert ist. Der Ursprungspunkt liegt in der linken oberen Ecke. 1 Quellcode der Klasse „DBVerbindung.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\database\“ zu finden. 2 Quellcode der Klasse „MarkierungenMenge.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\mengen\“ zu finden. 104 Erfassung multimedialer Zusatzinformationen Realisierung Positive x-Werte erstrecken sich nach rechts, positive y-Werte nach unten. Alle großen Bilder, die in Buchseite bzw. Buchstabe Detailsichten angezeigt werden, haben die Anfangskoordinaten (0, 0). Eine Markierung, die innerhalb des Bildes liegt, erhält die Anfangskoordinaten (X0, Y0). Die Endkoordinaten der Markierung sind (X1, Y1). Die Breite der Markierung ergibt sich aus der Differenz von X1 und X0. Die Höhe ergibt sich aus der Differenz von Y1 und Y0. Abbildung 44 Koordinaten der Markierung Die Anfangskoordinaten sowie die Breite und die Höhe einer Markierung werden sowohl zur Speicherung als auch zur Darstellung benötigt. Jede grafische Java Komponente hat ein Graphics Objekt, das aus der Java AWT Bibliothek stammt und die Methoden zum Zeichnen von verschiedenen grafischen Objekten enthält. Die Markierungen werden als Rechtecke mit der Methode drawRect des Graphics Objektes gezeichnet. Dieser Methode werden als Parametern die Anfangskoordinaten, die Breite und die Höhe der zu zeichnenden Markierung übergeben. Die Farbe der Umrandung von Rechtecken wird mit der Methode setColor des Graphics Objektes gesetzt. Bis jetzt wurde beschrieben, wie die schon vorhandenen Markierungen dargestellt werden. Das Markieren eines Informationsobjekts wird durch Drücken der linken Maustaste aktiviert, dabei werden die Koordinaten des Mauszeigers festgehalten. Beim Ziehen der Maus werden die Anfangskoordinaten, die Breite und die Höhe des 105 Erfassung multimedialer Zusatzinformationen Realisierung Rechtecks mit jeder Bewegung des Mauszeigers ermittelt und festgehalten, und dieses Rechteck wird mit der Methode drawRect des Graphics Objektes gezeichnet. Beim Loslassen der Maustaste wird der Markierungsvorgang beendet und die zuletzt festgehaltenen Anfangskoordinaten, die Breite und die Höhe werden dem Markierung Objekt übergeben. Neben der Möglichkeit eine neue Markierung zu erstellen, kann eine existierende Markierung verschoben, vergrößert oder verkleinert werden. Das Verschieben wird durch Drücken der rechten Maustaste im Bereich der zu verschiebenden Markierung aktiviert, dabei wird die Darstellung des Mauszeigers auf „move“ geändert. Nach dem Loslassen der Taste werden neue Anfangskoordinaten ermittelt und dem Markierung Objekt übergeben. Der Typ des Mauszeigers wird zurückgesetzt. Das Verkleinern bzw. Vergrößern einer Markierung kann durch Drücken der rechten Maustaste auf eine der vier Ecken des Rechtecks, der diese Markierung visualisiert, aktiviert werden. Dabei wird die Darstellung des Mauszeigers auf „resize“ geändert. Nach dem Loslassen der Taste werden neue Anfangskoordinaten, Breite und Höhe ermittelt und dem Markierung Objekt übergeben. Der Typ des Mauszeigers wird zurückgesetzt. Um die Markierungen in Buchseite bzw. Buchstabe Detailsichten ansehen zu können und die beschriebenen Funktionen zu benutzen, wurde ein Button mit der Beschriftung „Infos zeigen“ in diese Sichten hinzugefügt. Nach dem Betätigen des Buttons ändert sich die Beschriftung auf „Infos verbergen“ und die existierenden Markierungen zu ausgewähltem Bild werden als Rechtecke gezeichnet. In der Abbildung 45 ist ein Fenster mit dem Bild einer Titelseite aus dem Druckschriftdokument mit dem Titel „Portae lucis“ dargestellt. Sechs Informationsobjekte sind auf dem Bild durch Rechtecke markiert. Um die Markierungen auf dem Bild erkennbar zu machen oder voneinander zu unterscheiden, wurden die Umrandungen der Rechtecke durch verschiedene Farben dargestellt. Wenn beim Bewegen der Maus, der Mauszeiger in den Bereich einer Markierung kommt, wird die Farbe der Umrandung auf invertierte Farbe geändert. Zusätzlich wird der markierte Ausschnitt des Bildes aufgehellt, die Darstellung des 106 Erfassung multimedialer Zusatzinformationen Realisierung Mauszeigers wird auf „hand“ gesetzt und die Kurzbeschreibung zum markierten Ausschnitt wird als ToolTipText angezeigt. Beim Vergrößern bzw. Verkleinern des Bildes werden die Markierungen mitskaliert. Das heißt, dass die Anfangskoordinaten, die Breite und die Höhe jedes Rechtecks um den Skalierungsfaktor geändert werden. Abbildung 45 Buchseite Detailsicht mit Markierungen Um die zusätzlichen Informationen zu einem markierten Informationsobjekt zu erfassen, wurde eine Eingabemaske implementiert, die durch Klicken mit einer Maustaste oder beim Erstellen einer neuen Markierung aktiviert wird. Die Implementierung des User Interfaces zu dieser Eingabemöglichkeit wird im nächsten Kapitel beschrieben. 107 Erfassung multimedialer Zusatzinformationen Realisierung 2.2.4 User Interface zur Erfassung und Darstellung von Zusatzinformationen Die Maske zur Erfassung und zur Darstellung von Zusatzinformationen wird mit einem Objekt der Klasse MarkierungInternalFrame1 erzeugt. Dieses Objekt wurde von der Java Swing Komponente javax.swing.JInternalFrame abgeleitet. Die existierenden Zusatzinformationen werden aus dem Objekt Markierung entnommen und die neu erfassten bzw. geänderten Zusatzinformationen werden in dem Objekt Markierung gespeichert. In der Abbildung 46 ist eine Maske mit den Zusatzinformationen zu einem Informationsobjekt abgebildet. Der Titel des markierten Informationsobjektes, in diesem Fall „Graphische Darstellung der zehn Sefirot“, ist in einem editierbaren Textfeld dargestellt. Die Farbe der Umrandung einer Markierung, in diesem Fall „Blau“ ist als ein Button gezeigt. Durch Betätigen des Buttons wird eine Farbpalette angezeigt, in der die Farbe geändert werden kann. Das Informationsobjekt wird als ein Ausschnitt aus dem gesamten Bild extrahiert, damit der Bezug besser zu erkennen ist. Neben dem Informationsobjekt ist eine Textarea platziert, in der die Beschreibung dieses Informationsobjektes steht. Zusätzlich ist im Bereich „Audioaufnahmen“ eine Audioaufnahme im MP3 Format zu sehen. Das Format dieser Audiaufnahme ist anhand eines Icons zu erkennen. Im weiteren Bereich mit der Bezeichnung „Bilder“ sind vier Bilder zu sehen, die als Thumbnails dargestellt sind. Bei den Audioaufnahmen und Bildern sind jeweils zwei Felder vorgesehen: ein für den Namen, zweites für das Datum der Aufnahme bzw. Erstellung. 1 Quellcode der Klasse „MarkierungInternalFrame.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 108 Erfassung multimedialer Zusatzinformationen Realisierung Abbildung 46 Maske zur Erfassung von Zusatzinformationen Die Audioaufnahmen können mit dem Button „Hinzufügen“ als Dateien hinzugefügt werden, mit dem Button „Aufnehmen“ können neue Audioaufnahmen über Mikrofon aufgenommen werden, mit dem Button „Abspielen“ können die ausgewählten Aufnahmen angehört und mit dem Button „Löschen“ entfernt werden. Die Bilder können ebenfalls mit dem Button „Hinzufügen“ hinzugefügt werden, mit dem Button „Anschauen“ können die Bilder in einem separaten Fenster angesehen werden, mit dem Button „Löschen“ werden die ausgewählten Bilder entfernt. Nachdem alle Zusatzinformationen zu einem Informationsobjekt erfasst bzw. geändert sind, werden diese durch betätigen des Buttons „Speichern“, der im Fenster ganz unten platziert und mit einem grünen Häkchen versehen ist, gespeichert werden. 109 Erfassung multimedialer Zusatzinformationen Realisierung Beim Betätigen des Buttons „Schliessen“, der mit einem roten Kreuz versehen ist, wird das Fenster geschlossen. Falls die Zusatzinformationen geändert bzw. neu sind und nicht gespeichert sind, wird vor dem Schließen ein Dialogfenster angezeigt, wo gefragt wird, ob das Fenster ohne Speicherung geschlossen werden soll. Um die Markierung mit allen dazugehörigen Informationen zu löschen, wird der Button „Löschen“, der mit einem Papierkorb versehen ist, benutzt. Beim Betätigen dieses Buttons wird ein Dialogfenster angezeigt, wo gefragt wird, ob die Markierung wirklich gelöscht werden soll. Audio-Aufnahme und -Wiedergabe Um einem Benutzer die Möglichkeit zu geben die Sprachaufnahmen zu hinterlassen, wurde nach Java Lösungen gesucht, die es ermöglichen, über ein Mikrofon gesprochene Texte aufzunehmen. Dabei war es in erster Linie wichtig, eine plattformunabhängige Lösung zu finden. Zweiter wichtiger Aspekt war, die Audioaufnahmen im MP3 Format aufzunehmen, weil die Größe der Aufnahmen im Vergleich zu anderen Formaten wesentlich kleiner ist. Zuerst wurde die Lösung, die von Sun entwickelt wurde, analysiert. JMF (Java Media Framework) ist eine Java Bibliothek zur Handhabung von Audio- und Videosignalen. Das API unterstützt die Aufnahme von Mikrofon und Kamera und erlaubt das einlesen und speichern von Audio/Video Formaten. [WikiA] Bei der Analyse der Lösung wurde festgestellt, dass diese Bibliothek native Methoden enthält und diese noch nicht für alle gängigen Betriebssysteme implementiert sind. Genauer gesagt gab es nur eine Version für Windows, die eine Aufnahme im MP3 Format ermöglichte. Das Abspielen der MP3 Dateien war ebenfalls nur unter Windows möglich. Aus diesem Grund wurde diese Bibliothek für die Lösung nicht eingesetzt. Stattdessen wurde eine Java Schnittstelle zur Ausgabe und Verarbeitung von Audio-Daten benutzt, die mit einer Java Version standardmäßig mitgeliefert wird und im Paket javax.sound.sampled zu finden ist. Damit wird allerdings nur möglich, die Audioaufnahmen im Wave Format aufzunehmen und abzuspielen. 110 Erfassung multimedialer Zusatzinformationen Realisierung Zum Abspielen der Audioaufnahmen im MP3 Format wurde eine Open Source Bibliothek JLayer eingesetzt, die bei Javazoom1 angeboten wird. Zum Aufnehmen und zum Abspielen von Audioaufnahmen wurde die Klasse Mikrofon2 implementiert. Mit dieser Klasse wird ein Objekt Mikrofon erzeugt, dass die Methode aufnehmen zur Aufnahme eines Audios im Wave Format über ein Mikrofon, die Methode abspielenWav zum Abspielen der Audioaufnahmen im Wave Format und die Methode abspielenMp3 zum Abspielen der Audioaufnahmen im MP3 Format beinhaltet. Die Daten einer Audioaufnahme werden mit Hilfe der Methode setData dem Mikrofon Objekt gesetzt und mit Hilfe der Methode getData zurückgeliefert. Weitere Zusatzfunktionen Um die Reihenfolge der Darstellung von Bildern oder von Audioaufnahmen in dem Bereich „Bilder“ bzw. „Audioaufnahmen“ zu ändern bzw. zu bestimmen, wurde eine Klasse DragAndDropPanel implementiert. Mit der Methode addPanel des DragAndDropPanel Objektes werden die grafischen Objekte, die eine Audioaufnahme oder ein Bild repräsentieren, zu dem Bereich „Audioaufnahmen“ bzw. „Bilder“ hinzugefügt. Das DragAndDropPanel Objekt implementiert zusätzlich die Methoden, die bestimmte Maus-Events innerhalb der Bereiche, wo die grafischen Objekte platziert sind, abfangen und die Reihenfolge dieser Objekte ändern bzw. die Objekte neu positionieren. Eine weitere Zusatzfunktion ermöglicht das Auf- und Zuklappen der Bereiche „Bilder“ und „Audioaufnahmen“. Beim Aufruf der Maske (Abbildung 47) zum Erfassen von Zusatzinformationen sind diese beiden Bereiche zugeklappt. Das heißt, dass in diesen Bereichen weder Bilder bzw. Audioaufnahmen noch die dazugehörigen Buttons zu sehen sind. Abbildung 47 Audioaufnahmen und Bilder zugeklappt 1 http://www.javazoom.net/ Quellcode der Klasse „Mikrofon.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\tools\“ zu finden. 2 111 Erfassung multimedialer Zusatzinformationen Realisierung Dadurch wird erreicht, dass die Erfassungsmaske kompakter und übersichtlicher wird. Beim Bedarf kann durch das Klicken auf das Symbol „►“ der jeweilige Bereich aufgeklappt werden. Dadurch werden die Audioaufnahmen bzw. Bilder und dazugehörige Buttons sichtbar. In der Abbildung 48 ist der Bereich „Bilder“ aufgeklappt. Abbildung 48 Bilder aufgeklappt Durch das Klicken auf das Symbol „▼“ kann der aufgeklappte Bereich jederzeit zugeklappt werden. Die Größe der Erfassungsmaske wird dabei automatisch verkleinert. 2.2.5 Erweiterung der Server- und Client- Seiten des HebrewType Navigators In diesem Kapitel werden die Erweiterungen der bestehenden HebrewType Navigator Anwendung beschrieben, die zur Erfassung und Speicherung der Zusatzinformationen notwendig sind. Erweiterung der Serverseite Damit die Markierung Objekte beim Laden einer Buchseite bzw. eines Buchstabens mitgeholt werden, wurden die Objekte ObjektSeite und ObjektBuchstabe um eine Eigenschaft Markierung[] markierungen erweitert. Diese Eigenschaft ist ein Array vom Typ Markierung, das alle Markierung Objekte enthält, die zu jeweiliger Buchseite bzw. jeweiligem Buchstabe gehören. 112 Erfassung multimedialer Zusatzinformationen Realisierung Die Objekte Audio, Bild, Video und Markierung werden beim Bedarf vom Server zum Client geschickt. Aus diesem Grunde sollen diese Objekte serialisiert werden. So implementieren die das Interface Serializable. Zusätzlich wird zu jedem serialisierten Objekt ein serialVersionUID berechnet und eingetragen. Entwicklung einer zusätzlichen Serverapplikation Die Serveranwendung, die im ersten Teil dieser Diplomarbeit beschrieben wurde, dient nur zum Bereitstellen und zum Liefern der angefragten Objekte zum Client. Um die neue bzw. geänderte Zusatzinformationen in die Datenbank zu speichern oder nicht mehr benötigten Informationen aus der Datenbank zu entfernen, wurde entschieden, eine zusätzliche Server Applikation zu implementieren und nicht die bestehende zu erweitern. Bei der Entscheidung wurden zwei andere Lösungsmöglichkeiten untersucht: • Die Überlegung, den direkten Zugriff des Clients auf die Datenbank zu erlauben, wurde sofort abgelehnt, weil dies eine Erleichterung für die Hackerangriffe darstellt. Die Erleichterung wird dadurch gemacht, dass erstens die vorkompilierten Java Klassen, die für die Kommunikation mit der Datenbank zuständig sind und jedem Benutzer zur Verfügung stehen, dekompiliert werden können. Zweiter Schwachpunkt ist, dass die JDBC Verbindungen standardmäßig nicht verschlüsselt sind. Das heißt, dass die Anfragen an die Datenbank im Klartext übertragen werden und mit einer Leichtigkeit abgefangen werden können. In beiden Fällen kann ein Angreifer im schlimmsten Fall den Datenbankbestand komplett löschen. • Zweite Möglichkeit war, die bestehende Server Applikation zu erweitern. Das würde bedeuten, dass die Applikation noch mehr Arbeitsspeicher für die JVM benötigen würde, weil sie neben den Objekten, die vom Client angefragt werden, noch zusätzlich die Objekte verwalten muss, die gespeichert werden sollen. Dies könnte dazu führen, dass die Anwendung mehr Arbeitsspeicher benötigt, als für die JVM von einem Betriebssystem zugewiesen werden kann. Aus diesem Grund wurde diese Lösungsmöglichkeit auch abgelehnt. 113 Erfassung multimedialer Zusatzinformationen Realisierung Die zusätzliche Server Applikation wurde durch die Klasse HebrewTypeMMAdmin1 implementiert. Beim Starten der Applikation wird eine Verbindung zu der Datenbank aufgebaut, in der die Zusatzinformationen gespeichert sind bzw. werden. Zusätzlich wird für die Bearbeitung der Socket Anfragen des Clients ein ServerSocket Objekt erzeugt, das in einem eigenen Thread läuft und auf einem bestimmten Port auf die Anfragen wartet. Dabei ist es möglich, Anfragen von mehreren Clients zu bearbeiten. Die Anfragen der Clients werden entgegengenommen und der Methode handleSocket weitergeleitet. In dieser Methode werden die Anfragen analysiert und entsprechende Prozesse durchgeführt. Nach dem erfolgreichen Durchführen jedes Prozesses wird dem Client entsprechende Antwort geschickt. Erweiterung der Clientseite So wie die Serverseite, sollte die Clientseite auch erweitert werden, damit neue oder geänderte Markierungen mit den Zusatzinformationen gespeichert und gelöschte Markierungen mit entsprechenden Zusatzinformationen gelöscht werden können. Dazu wurde eine zusätzliche Klasse DispatcherAdmin2 implementiert. Diese Klasse erzeugt ein Objekt, das drei Methoden enthält: • markierungSpeichern speichert neue Markierung mit allen Zusatzinformationen. • markierungAendern ändert die Markierungsdaten und/oder die Zusatzinformationen zu existierender Markierung. • markierungLoeschen löscht eine Markierung mit dazugehörigen Zusatzinformationen. Beim Aufrufen jeder Methode wird eine Socket Verbindung zum Server aufgebaut. Danach wird zum Server ein Schlüsselwort geschickt, das die Aufgabe definiert. Das Schlüsselwort für das Speichern ist „Speichern“, für das Ändern „Aendern“ und für das Löschen „Loeschen“. Als nächstes wird beim Speichern und beim Ändern das 1 Quellcode der Klasse „HebrewTypeMMAdmin.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\server\“ zu finden. 2 Quellcode der Klasse „DispatcherAdmin.java“ ist auf der beiliegenden CD im Verzeichnis „Source\de\fhkoeln\gm\hebtypo\hebrewtypemm\client\“ zu finden. 114 Erfassung multimedialer Zusatzinformationen Realisierung Markierung Objekt zum Server geschickt, das gespeichert bzw. geändert werden soll. Beim Löschen wird der Schlüssel des Markierung Objektes übertragen, das gelöscht werden soll. Anschließend wird die Socket Verbindung geschlossen. 2.2.6 Sichere Kommunikation zwischen Client und Server Bei der HebrewType Navigator Anwendung erfolgte die Kommunikation zwischen Client und Server bis jetzt unverschlüsselt. Das heißt, dass jeder, der die Datenpakete abfangen kann, kann auch die übertragene Informationen im Klartext lesen. In der Abbildung 49 ist ein Ausschnitt aus dem Programm Ethereal1 zu sehen. Dieses Programm ermöglicht die Pakete, die in einem Netzwerk ausgetauscht werden, abzufangen, zu analysieren und den Inhalt der Pakete anzuzeigen. Abbildung 49 Unverschlüsseltes Paket Um die Manipulation der Datenpakete von Dritten verhindern oder erschweren zu können, sollen diese Pakete verschlüsselt werden. 1 http://www.ethereal.com/ 115 Erfassung multimedialer Zusatzinformationen Realisierung Für die Verschlüsselung der Daten, die im Internet übertragen werden, wird ein Protokoll verwendet, das von der Firma Netscape1 entwickelt wurde und die Bezeichnung SSL (Secure Sockets Layer) trägt. Für Java Anwendungen gibt es eine Java-Erweiterung zur sicheren Kommunikation im Internet, die JSSE (Java Secure Socket Extension) genannt wird. JSSE implementiert das verbreitete Protokoll SSL und wird seit Java Version 1.4 mitgeliefert. Damit wird die Verschlüsselung der Nachrichten ermöglicht. [JiaeI] Die Umstellung der HebrewType Navigator Anwendung auf eine sichere Kommunikation wurde mit Hilfe der JSSE Bibliothek realisiert. Dabei war eine Änderung sowohl auf der Serverseite als auch auf der Clientseite nötig. Auf der Serverseite wird anstatt eines ServerSocket Objektes ein SSLServerSocket Objekt aus dem Paket javax.net.ssl der JSSE Bibliothek erzeugt. SSLServerSocketFactory factory = (SSLServerSocketFactory)SSLServerSocketFactory.getDefault(); SSLServerSocket s = (SSLServerSocket)factory.createServerSocket(PORT); Auf der Clientseite wird entsprechend ein Socket Objekt durch ein SSLSocket Objekt aus dem Paket javax.net.ssl der JSSE Bibliothek ersetzt. SSLSocketFactory factory = (SSLSocketFactory)SSLSocketFactory.getDefault(); SSLSocket s = (SSLServerSocket)factory.createSocket(host,PORT); Um die Anwendung nach den vorgenommenen Änderungen benutzen zu können, sollte ein Zertifikat erstellt werden und auf der Serverseite abgelegt werden. Ein gültiges Zertifikat kann bei einer Zertifizierungsstelle beantragt werden, was mit Kosten verbunden ist. Eine günstigere Möglichkeit ist, ein eigenes Zertifikat zu erzeugen. Diese Möglichkeit soll bei den Anwendungen, die über das Internet kommunizieren, aus Glaubwürdigkeitsgründen nicht benutzt werden. 1 http://home.netscape.com/ 116 Erfassung multimedialer Zusatzinformationen Realisierung Eine dritte Möglichkeit ist ohne einen Zertifikat zu kommunizieren. Dabei ist zu beachten, dass die Authentifizierung des Servers beim Klient nicht erfolgt. Das heißt, dass es nicht sichergestellt werden kann, ob der Server auch tatsächlich der Server ist, für den er sich ausgibt. Die letzte Möglichkeit wurde benutzt, um zu testen, dass die Daten auch tatsächlich verschlüsselt werden. In der Abbildung 50 ist noch mal ein Ausschnitt aus dem Programm Ethereal dargestellt, wo der Inhalt des gleichen Pakets zu sehen ist, diesmal aber nicht im Klartext, sondern verschlüsselt. Abbildung 50 Verschlüsseltes Paket Um die Anwendung bei dem späteren Einsatz sicher zu machen, sollte ein Zertifikat gekauft werden. Dies kann zum Beispiel bei Verisign1 erfolgen. 1 http://www.verisign.de/ 117 Erfassung multimedialer Zusatzinformationen Ergebnisse und Erkenntnisse 2.3 Ergebnisse und Erkenntnisse Mit der Erweiterung der HebrewType Navigator Anwendung wurde erreicht, dass die interessanten Informationsobjekte innerhalb eines Bildes markiert und die Zusatzinformationen zu diesen Objekten gespeichert werden können. Ebenso wurde erreicht, dass die markierten Informationsobjekte dem Benutzer visuell erkennbar gemacht werden. Die Beschreibung dieser Objekte kann durch Aufrufen der gespeicherten Zusatzinformationen angesehen oder verändert werden. Mit der Möglichkeit, einen gesprochenen Text über ein Mikrofon im Wave Format aufzunehmen, wurde zwar eine plattformunabhängige Lösung gefunden, die kann aber zu einem Performance Problem führen. Dieses Problem tritt dann auf, wenn die Aufnahmezeit sehr lang ist und dadurch die Datenmenge sehr groß ist. Um dieses Problem zu vermeiden, soll ein Benutzer ein externes Programm benutzen, das die Audioaufnahme in einem anderen Format wie zum Beispiel MP3 ermöglicht. Danach kann diese Aufnahme als eine Datei hinzugefügt werden. Für die Speicherung der Videoaufnahmen in einer Datenbank wurde eine Schnittstelle vorbereitet. Damit die Videos aufgenommen bzw. abgespielt werden können, soll eine plattformunabhängige Java Applikation gefunden und eingesetzt werden. Bis jetzt wurde eine solche Applikation nicht implementiert. Um das Speichern bzw. Ändern von Markierungsdaten und Zusatzinformationen nur von autorisierten Benutzern zu erlauben, soll auf der Serverseite ein Anmeldevorgang sowie die Benutzerverwaltung implementiert werden. Die Benutzerverwaltung ist wichtig, weil es mehrere Benutzern geben kann, die mit der Anwendung arbeiten und die Zusatzinformationen bearbeiten werden. Eine mögliche Lösung dazu wäre, die Datenbank um eine zusätzliche Tabelle zu erweitern, in der die Benutzerkennungen und Passwörter gespeichert werden. Die Passwörter sollen aus Sicherheitsgründen verschlüsselt werden. Der Verschlüsselungsalgorithmus soll so ausgewählt werden, dass die verschlüsselten Passwörter nicht mehr oder sehr schwer zu entschlüsseln sind. Die Clientseite soll entsprechend um eine Anmeldemaske erweitert werden. 118 Zusammenfassung der Diplomarbeit 3. Zusammenfassung der Diplomarbeit Das Ziel dieser Diplomarbeit war die Entwicklung eines interaktiven semantischen Netzes und die Realisierung der Erfassung von multimedialen Zusatzinformationen. Als Informationsbestand sollte ein digitales Schriftarchiv dienen, das im Rahmen des Forschungsprojektes „Hebräische Typographie im deutschsprachigen Raum“ entstanden wurde. Mit dieser Arbeit wurde an einem Beispiel gezeigt, wie die Suche nach bestimmten Informationen erleichtert werden kann und wie die Informationsobjekte, die in einem Bild vorhanden sind, visuell sichtbar gemacht werden und die Zusatzinformationen zu diesen Objekten erfasst werden. Im ersten Teil dieser Diplomarbeit wurde gezeigt, wie die Suche nach digitalisierten Informationen, wie Bilder, Zeichnungen, oder Grafen, durch semantische Netze erleichtert werden kann. Zuerst wurde ein ISO/IEC -13250 Standard, auch Topic Map genannt, beschrieben, mit dem eine Möglichkeit gegeben wurde, über ein semantisches Netz auf ein Informationsbestand zuzugreifen. Für den praktischen Einsatz wurde die von dem Standard abgeleitete Spezifikation XML Topic Map (XTM) gewählt. Um den XTM Standard einsetzen zu können, wurden verschiedene Lösungen analysiert, die diesen Standard realisieren. Aus diesen Lösungen wurde eine Javabasierte Engine TM4J genommen, die gestellten Anforderungen entsprach. Mit Hilfe dieser Engine wurde eine Anwendung implementiert, die ein XTM Dokument generiert. Für die Visualisierung der Inhalte des generierten XTM Dokumentes wurde eine grafische Oberfläche implementiert. Um die Performance zu verbessern und die Systemauslastung zu minimieren, wurde die Anwendung auf eine Client-Server Architektur umgestellt. Im zweiten Teil dieser Diplomarbeit wurde beschrieben, wie die Informationsobjekte, die in einem Bild existieren, beschrieben werden können. 119 Zusammenfassung der Diplomarbeit Ergebnisse und Erkenntnisse Es wurde ein Datenbankschema erstellt, das zur Speicherung der Markierungsdaten und Zusatzinformationen zu einem Informationsobjekt dient. Um ein Zugriff auf die Datenbank zu ermöglichen, wurde eine Schnittstelle implementiert. Das User Interface für Buchseite bzw. Buchstabe Detailsichten wurde durch zusätzliche Funktionen erweitert, die es ermöglichen, die Informationsobjekte zu markieren und visuell sichtbar zu machen. Für die Erfassung bzw. Darstellung von Zusatzinformationen zu einem markierten Informationsobjekt wurde ein zusätzliches grafisches User Interface realisiert. Die Serverseite und die Clientseite der im ersten Teil realisierten Anwendung wurden entsprechend erweitert. Während der Entwicklung wurde die HebrewType Navigator Anwendung bei der Bayerischen Staatsbibliothek in München präsentiert. Dabei wurde großes Interesse von der Seite der Beteiligten gezeigt. Bei den regelmäßigen Besprechungen hat ein Buchwissenschaftler die Anwendung selbst getestet und überprüft, ob die Funktionen dieser Anwendung den fachlichen Anforderungen entsprechen. Dabei wurde sehr oft ein positives Feedback gegeben. Mit der Berücksichtigung der in der Diplomarbeit beschriebenen Vorschläge kann die Anwendung in das bestehende Projekt „Hebräische Typografie im deutschsprachigen Raum“ integriert werden und dadurch allen Interessenten zugänglich sein. 120 Abbildungsverzeichnis Abbildungsverzeichnis Abbildung 1 Verzeichnisstruktur 2 Abbildung 2 semantisches Netz 3 Abbildung 3 Typografie - Übersicht 4 Abbildung 4 Bibliografie - Übersicht 5 Abbildung 5 Idee der Suche nach einem Jahr 5 Abbildung 6 Zusätzliche Verknüpfungen 6 Abbildung 7 Gesuchtes Schriftsatz 6 Abbildung 8 Detail des Buchstabens 7 Abbildung 9 HebrewType 8 Abbildung 10 Topics 10 Abbildung 11 Topics mit Topics Typen 11 Abbildung 12 Topic Namen 12 Abbildung 13 Occurrences 13 Abbildung 14 Associations 14 Abbildung 15 XML Baum 17 Abbildung 16 Vorgehensmodell 41 Abbildung 17 Analyse der Datenbankschema 42 Abbildung 18 Analyse der HebrewWork Applikation 43 Abbildung 19 Analyse der HebrewTypeShow Applikation 44 Abbildung 20 Ontopia Omnigator 63 Abbildung 21 TM4Web 64 Abbildung 22 Matrix - vernetzte Begriffswelten 65 Abbildung 23 Webbrain 66 Abbildung 24 TMNav Maske 67 Abbildung 25 Darstellung von XTM im TMNav 68 Abbildung 26 TMNav Druckortauswahl 69 Abbildung 27 Topic als Bilder 69 Abbildung 28 Hebrew Type Navigator Struktur 70 Abbildung 29 Graph Layout 72 Abbildung 30 KnotenText 75 Abbildung 31 KnotenDruckschriftdokument 75 121 Abbildungsverzeichnis Abbildung 32 KnotenSchriftsatz 76 Abbildung 33 HebrewType Navigator mit allen Druckschriftdokumenten 80 Abbildung 34 Topic "200207011149" im HebrewType Navigator 81 Abbildung 35 Historie Buttons des HebrewType Navigators 82 Abbildung 36 "200207011149" und Verknüpfungen im HebrewType Navigator 83 Abbildung 37 HebrewType Navigator - Buchseite bzw. Buchstabe Detailsicht 84 Abbildung 38 Buchseite Detailsicht 87 Abbildung 39 Buchstabe Detailsicht 88 Abbildung 40 Client-Server Architektur 89 Abbildung 41 Jerusalem 96 Abbildung 42 Jerusalem mit Markierungen 97 Abbildung 43 Datenbankschema 102 Abbildung 44 Koordinaten der Markierung 105 Abbildung 45 Buchseite Detailsicht mit Markierungen 107 Abbildung 46 Maske zur Erfassung von Zusatzinformationen 109 Abbildung 47 Audioaufnahmen und Bilder zugeklappt 111 Abbildung 48 Bilder aufgeklappt 112 Abbildung 49 Unverschlüsseltes Paket 115 Abbildung 50 Verschlüsseltes Paket 117 122 Tabellenverzeichnis Tabellenverzeichnis Tabelle 1 DTD – Schlüsselwörter 18 Tabelle 2 Merge Optionen 33 Tabelle 3 Stats Optionen 34 Tabelle 4 Fragment Optionen 35 Tabelle 5 Compress Option 35 Tabelle 6 Organisation der TM4J Engine 38 Tabelle 7 Drittanbieter Bibliotheken 40 Tabelle 8 Relevante Topic Typen und dazugehörige Topics 46 Tabelle 9 Assoziationen der Topics vom Typ „Schriftsatz“ 47 Tabelle 10 Assoziationen der Topics vom Typ „Buch“ 48 Tabelle 11 Eigenschaften des Knoten Objektes 74 Tabelle 12 Eigenschaften des ObjektSeite Objekts 85 Tabelle 13 Eigenschaften des ObjektBuchstabe Objekts 86 123 Glossar Glossar API Application program interface - eine Schnittstelle, die es den Anwendungsprogrammen ermöglicht, auf die Systemkomponenten oder auf Middleware zuzugreifen. Applikation Ist ein Synonym für Anwendungssoftware, die eine Lösung zu einem Bestimmten Problem bietet. AWT Abstract Windowing Toolkit – eine Bibliothek von JavaKlassen zur Gestaltung graphischer Benutzeroberflächen. CSS Cascading Style Sheets – W3C-Standard zur Formatierung der Darstellung von Murkup-Dokumenten. Datenbanktreiber Eine Implementierung der JDBC-API, die einen spezifischen Zugriff auf die Datenbank erlaubt. DOM Document Object Model ist ein W3C Standard, der die Beund Verarbeitung von XML - Dokumenten regelt. DTD Document Type Definition – Regelwerk für den Dokumentenaufbau. Die Dokumente sind dabei XML oder SGML basiert. Engine Ist eine Programmbibliothek, die wichtigen und oft benutzten Funktionen zur Verfügung stellt. GIF Graphic interchange format – ein kommerzieller Format für die Komprimierung und Austausch von Bildern. GIF ist 8-BitFarbtiefe beschränkt. HTML Hyper Text Murkup Language – eine Sprache zur Beschreibung von Hypermediadokumenten, die durch ein Browser präsentiert werden. HyTime 124 Ist eine verkürzte Bezeichnung des ISO/IEC 10744 Standards, Glossar Hypermedia/Time-based Structuring Language. Es ist eine auf SGML basierende Sprachspezifikation, die ermöglicht es die Beziehungen zwischen verschiedenen Arten von Daten zu beschreiben. ISO/IEC International Standardization Organisation / International Electrotechnical Commission beschäftigen sich mit dem Entwerfen und Verabschieden von Hardware- und Softwarenormen. Java Objektorientierte Programmiersprache, die im Jahre 1995 von der Firma Sun Microsystems entwickelt wurde. Das ursprüngliche Ziel war, eine möglichst plattformunabhängige Sprache. JDBC Java Database Connectivity – ist ein Java-API zur Kommunikation und zum Austausch von Daten zwischen einem Programm und einer Datenbank. Zur Kommunikation wird ein datenbankspezifischer Datenbanktreiber benötigt. JPEG Joint Photographic Experts Group – ein Dateiformat, das zur Komprimierung und Übertragung der Bilder genutzt wird. JSSE Java Secure Socket Extension - eine Java-Erweiterung zur sicheren Kommunikation im Internet. JSSE implementiert das verbreitete Protokoll SSL (Secure Sockets Layer) und TLS (Transport Layer Security) und erlaubt damit Verschlüsselung, Server-Authentifizierung und Integrität von Nachrichten. JTC1 Joint Technical Committee 1-ist ein Komitee innerhalb der ISO, das generell für Fragen der Informationstechnologie zuständig ist. JVM Java virtual machine ist eine abstrakte Maschine für Java, die Java-Bytecode ausführen kann. 125 Glossar Middleware Bezeichnet eine Softwareschicht zwischen dem Übertragungsnetzwerk und den Anwendungen und stellt vor allem Dienste für Identifikation, Authentifizierung, Zugriff und Informationsaustausch oder Sicherheit zur Verfügung. MP3 MPEG 1 Audio Layer 3 – ein Format zur Audiokompression. Ein patentiertes Format, das am Fraunhofer-Institut entwickelt wurde. MPEG 1 Ein ISO-Normierter Video-Codec, der durch die Motion Picture Express Group entwickelt wurde. Wird benutzt, um die Video-Daten zu komprimieren. OpenSource Siehe Open-Source-Software. Open-Source- Programme, deren Quelltext für jeden Benutzer frei zum Software Lesen ist. Es gibt verschiedene Lizenzen zur Nutzung der Programme. Diese Softwareprogramme können sowohl kostenlos benutzt werden als auch kostenpflichtig beim Kommerziellen Einsatz sein. PC Personal Computer - Computer unterschiedlicher Art und Leistungsfähigkeit, die meist von einer einzigen Person für ihre Aufgaben am Arbeitsplatz oder im privaten Bereich eingesetzt werden. PDF Portable Document File – ein Format für den Austausch von unveränderlichen elektronischen Dokumenten. Wurde von Adobe entwickelt. PNG Portable Network Graphics Format - unterstützt 16 Mio. Farben, Transparenz, verlustfreie Kompression, inkrementelle Anzeige der Grafik und das Erkennen beschädigter Dateien. Port Adresskomponente, die in Netzwerkprotokollen eingesetzt wird, um Datenpakete den richtigen Anwendungen 126 Glossar zuzuordnen. Python Python ist eine interpretierte, interaktive und objektorientierte Skriptsprache. Relationale Datenbank, in der Daten gemäß einem relationalen Schema in Datenbank Tabellen gespeichert werden. SC34 Subcommittee 34 ist ein Unterkomitee von JTC1, deren Aufgabengebiete als „Document description and processing languages“ bezeichnet werden. Semantisches Netz Ein semantisches Netz ist eine formale Begriffssammlung, die zur Beschreibung der Informationen dient. Semantisches Netz besteht aus Knoten und Verbindungen. Knoten repräsentieren Begriffe und Objekte innerhalb eines spezifischen Gebiets. Verbindungen (Relationen) vertreten Beziehungen zwischen den Knoten, wodurch der Zusammenhang zwischen den Knoten ersichtlich wird. Servlet Ist ein Java-API, das zur Erweiterung der Funktionalität des Servers eingesetzt wird. Servlets nehmen die Anfragen von Klienten entgegen, bearbeiten diese und schicken dem jeweiligen Klient die gewünschten Informationen zu. SGML Standard Generalized Markup Language, ISO 8879 Standard. Das Ziel und die Idee dieses Standards ist es, die Struktur des Inhalts eines Dokuments von seiner layoutorientierten Erscheinungsform zu trennen. Sockets Wörtlich übersetzt "Sockel" oder "Steckverbindungen" bilden eine Schnittstelle (API) zwischen der TCP/IP Implementierung und der eigentlichen Applikationssoftware. SSL Secure Sockets Layer bezeichnet ein von der Firma Netscape entwickeltes Übertragungsprotokoll, mit dem verschlüsselte 127 Glossar Kommunikation möglich ist. Style Sheet Wird verwendet, um die Form der Darstellung von Inhalten eines strukturierten Dokuments (z.B. XML) zu beschreiben. Swing Java-API zur Erstellung von graphischen Benutzeroberflächen. Wurde als eine Alternative zur JavaAWT entwickelt, wobei Swing nicht die AWT ersetzt, sondern diese erweitert. Thumbnail Kleine Voransicht (Preview) eines Bildes. Topic Map Ist ein ISO-Standard, das ende 1999 unter dem Namen ISO/IEC -13250 von der Arbeitsgruppe ISO JTC1/SC34/WG3 verabschiedet wurde. W3C World Wide Web Consortium ist eine gemeinnützige Organisation für die Weiterentwicklung von Internet Techniken Wave Audiodateiformat für Windows. Wurde von Microsoft und IBM entwickelt. Web-Browser Ein Programm, das dem Benutzer ermöglicht, Webressourcen im WWW abzurufen und darzustellen. Web-Server Ist ein Server-Programm, das Webressourcen über das HTTP Protokoll zur Verfügung stellt. WG3 Working group 3 ist eine der 3 Arbeitsgruppen von SC34, die sich mit Assoziationen der Informationen beschäftigt. XLink XML Linking Language ist ein W3C – Standard, der erlaubt, in einem XML - Dokument verschiedene Verknüpfungen (Link’s) zu erstellen und zu beschreiben. XML 128 eXtensible Markup Language – eine Sprache zur Glossar Beschreibung von Inhalten und Strukturen. XML wurde Anfang 1998 vom W3C als Standard verabschiedet. XSLT eXtentible Stylesheet Language Transformations – W3C Empfehlung für die Darstellung einer Markup-Sprache. XTM XML Topic Map ist ein besonderes XML-Dokument mit einer eigenen Notation als Vorgabe zur Beschreibung (Meta-Daten) von Inhalten und Vorkommen. 129 Literaturverzeichnis Literaturverzeichnis [AWinf] Hans Robert Hansen, Gustaf Neumann Arbeitsbuch Wirtschaftsinformatik – IT-Lexikon, Aufgaben, Lösungen Stuttgart; Lucius & Lucius Verlagsgesellschaft; 2002 [JaSeP] Jason Hunter, William Crawford (Deutsche Übersetzung: Matthias Kalle Dalheimer, Jörg Staudemeyer) Java Servlet Programmierung Köln; O’Reilly; 2002 [HTidR] Heiner Klocke, Ittai Joseph Tamari Hebräische Typographie im deutschsprachigen Raum. Gummersbach; Fachhochschule Köln, Campus Gummersbach; 2001 [XMLTM] Jack Park, Sam Hunting XML Topic Maps - Creating and Using Topic Maps fort the Web Boston; Addison-Wesley; 2003 [ToMap] Richard Widhalm, Thomas Mück Topic Maps Berlin Heidelberg; Springer; 2002 [DocTD] Prof. Prof. Dr. Eduard Heindl ([email protected]) XML Kurs, DTD Document Type Definition http://www.heindl.de/xml/dtd.html (22.09.2004) [XLink] Steve DeRose, Eve Maler, David Orchard (Übersetzer: Daniel Hinz, Stefan Mintert, Axel Wienberg) XML Linking Language (XLink) Version 1.0 Deutsche Übersetzung http://www.edition-w3c.de/TR/2001/REC-xlink-20010627/ (23.09.2004) [Ontop] Ontopia AS Solutions for managing knowledge and information 130 Literaturverzeichnis http://www.ontopia.net/ (30.09.2004) [Empol] empolis GmbH The Information Logistics Company http://www.empolis.de/ (30.09.2004) [Monde] Mondeca Intelligent Topic Manager http://www.mondeca.com/ (30.09.2004) [Mores] Moresophy L4 Semantic NetWorking http://www.moresophy.de/ (04.10.2004) [SemTe] SemanText SemanText http://www.semantext.com/ (04.10.2004) [Tmpro] Ontopia tmproc: A Topic Map engine http://www.ontopia.net/software/tmproc/ (06.10.2004) [Nexis] Nexist Technology with purpose http://www.thinkalong.com/Nexist/ (06.10.2004) [TM4Ja] TM4J TM4J - Topic Maps For Java http://www.tm4j.org (04.10.2004) [DmDTD] Oliver Becker Dokumentenmodellierung: DTDs Teil 2 http://www.informatik.huberlin.de/~obecker/Lehre/SS2002/XML/04b-dtd.html (04.10.2004) 131 Literaturverzeichnis [AzZvG] Joachim Ziegler Das LEDA-Tutorium: Algorithmen zum Zeichnen von Graphen http://www.mpi-sb.mpg.de/~ziegler/LEDATutorium/in.work/ (10.11.2004) [JiaeI] Christian Ullenboom Java ist auch eine Insel http://www.galileocomputing.de/openbook/javainsel4/ (10.11.2004) [WikiA] WikipediA Die freie Enzyklopädie http://www.wikipedia.de/ (10.11.2004) 132 Anhang Anhang CD-Inhalt Auf der CD sind folgende Informationen gespeichert: • Der komplette Quellcode liegt im Verzeichnis „Source“ • Die Java Dokumentation zu den Klassen der HebrewType Navigator Anwendung liegt im Verzeichnis „Javadoc“ • Die HebrewType Navigator Serverapplikationen liegen im Verzeichnis „Server/HebrewTypeMMServlet“ und „Server/HebrewTypeMMAdmin“ • Die HebrewType Navigator Clientapplikation liegt im Verzeichnis „Client“ • Die digitale Version dieser Diplomarbeit liegt im PDF - Format im Verzeichnis „Ausarbeitung“ 133