Routinedaten aus haus ä rztlichen Arztinformationssystemen
Werbung

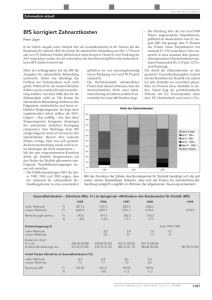
Originalarbeit 323 Routinedaten aus hausärztlichen Arztinformationssystemen – Export, Analyse und Aufbereitung für die Versorgungsforschung Routine Data from General Practitioner’s Software Systems – Export, Analysis and Preparation for Research Autoren M. Kersting, A. Gierschmann, J. Hauswaldt, E. H.-Pradier Institut Institut für Allgemeinmedizin, Medizinische Hochschule Hannover Schlüsselwörter ▶ Routinedaten ● ▶ BDT ● ▶ Schnittstellen ● ▶ Versorgungsforschung ● ▶ Allgemeinmedizin ● Zusammenfassung ▼ Abstract ▼ Eine einheitliche und ausgereifte Informationsund Kommunikationstechnologie ist unerlässlich für die optimale Unterstützung zukünftiger Prozesse im Gesundheitswesen einschließlich der Versorgungsforschung. Sekundäranalysen von Routinedaten aus der ambulanten Primär- und Sekundärversorgung sind häufig auf die Untersuchung von Abrechnungsdaten begrenzt. Ziel dieser Untersuchung ist das Aufzeigen der Möglichkeiten und Grenzen der Forschung mit Routinedaten, welche aus hausärztlichen Praxen über die Behandlungsdatentransfer (BDT)-Schnittstelle exportiert und für die Verarbeitung in SPSS aufbereitet wurden. Im Zeitraum von Mitte 2005 bis Ende 2007 wurden alle 168 Lehrpraxen der MHH einmalig schriftlich um die Teilnahme an einer BDT-Datenerhebung gebeten, welche bei 28 Praxen anschließend durchgeführt wurde. Der Bestand wurde ergänzt um die Daten von 139 anderen Praxen aus dem Projekt „Medizinische Versorgung in der Praxis“ (MedViP). Der gesamte Prozess der Datenaufbereitung umfasste einen kompletten Zyklus von der Erhebung per BDTExport über das Zusammenfügen der Daten in einer zentralen Datenbank, bis hin zur Aufbereitung dieser Daten für die Forscher, Publikationen und einem Feedback-Bericht für die teilnehmenden Praxen. Dabei sollten Möglichkeiten und Grenzen des Verfahrens systematisch herausgearbeitet werden. Von 168 Lehrpraxen der MHH haben 68 (40,5 %) Interesse signalisiert, wobei 28 (16,7 %) letztlich erfolgreich erhoben werden konnten. Bei 15 (8,9 %) war aus technischen und bei 26 (15,5 %) aus administrativen Gründen keine Erhebung möglich. Die BDT-Schnittstelle ist in den einzelnen Arztpraxisinformationssysteme (AIS) unterschiedlich implementiert, was sich auch auf die Erhebungsmöglichkeiten auswirkte. Mit den MedViP-Daten zusammen befinden sich aktuell 167 Praxen mit insgesamt 974 304 An advanced and integrative information technology (IT)-landscape is needed for optimal support of future processes in health-care, including health services research. Most researches in the primary care sector are based on data collected for reimbursement. The aim of this study is to show the limits and options of secondary analysis based on data that was exported via the “Behandlungsdatentransfer” (treatment data transport) BDT-interface in the software systems of German general practitioners and afterwards prepared for further research in SPSS. From the middle of 2005 to the end of 2007 all 168 teaching practices of the Hannover Medical School (MHH) were invited to join the study. Finally routine data from 28 practices could be collected successfully. The data from 139 other practices which had been collected for the project “Health Care in Practice” (“Medizinische Versorgung in der Praxis” – MedViP) was also added to the pool. The process of data preparation included a complete cycle from data collection, merging the data in a relational database system, via statistics and analysis to publishing and generating a feedback report for the participating practices. During the whole study the limits and options of this method were systematically identified. Of the 168 practices, 68 (40.5 %) were interested to participate. From 28 (16.7 %) physicians the data could be exported from their software systems. In 15 (8.9 %) cases no collection was possible due to technical and in 26 (15.5 %) to administrative reasons. The method of data extraction varied, as the BDT-interface was differently implemented by the software companies. Together with the MedViP data, the database at the MHH now consists of 167 practices with 974 304 patients and 12 555 943 treatments. For 44.1 % of the 11 497 899 prescription entries an anatomic therapeutic chemical (ATC) code could be applied, Key words ▶ routinely collected data ● ▶ BDT ● ▶ interfaces ● ▶ health services research ● ▶ primary care ● Bibliografie DOI http://dx.doi.org/ 10.1055/s-0030-1249689 Online-Publikation: 20.5.2010 Gesundheitswesen 2010; 72: 323–331 © Georg Thieme Verlag KG Stuttgart · New York ISSN 0941-3790 Korrespondenzadresse M. Kersting Medizinische Hochschule Hannover Carl-Neuberg-Straße 1 30625 Hannover kersting.markus@ mh-hannover.de Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 324 Originalarbeit Patienten und 12 555 943 Behandlungen in der Datenbank des Instituts für Allgemeinmedizin der Medizinischen Hochschule Hannover (MHH). Den 11 497 899 Verordungseinträgen konnte in 44,1 % der Fälle durch Abgleich mit den Arzneimittelstammdaten des Wissenschaftlichen Instituts der Ortskrankenkassen (WIdO) ein Wirkstoff nach Anatomisch-Therapeutisch-Chemischer (ATC)-Klassifikation zugeordnet werden. Aus dem gesamten Datenbestand konnten mehrfach erfolgreich ein konsistentes Set von SPSS-Dateien für die Forscher sowie FeedbackBerichte für die teilnehmenden Praxen im Portable Document Format (PDF) erstellt werden. Die BDT-Schnittstelle ist bereits vor langem (1994) definiert worden, erlaubt jedoch immer noch Zugang zu interessanten Informationen, insbesondere Behandlungsdaten. Diese liegen häufig in Freitextfeldern vor, was die Auswertung erschwert. Kodierte Informationen wie Wirkstoffe (ATC) lassen sich zum Teil extrahieren und sind leicht für die Forschung aufzubereiten. Inhalt und Qualität der Daten liegen vor allem in der Hand der Nutzer, also der Ärzte und Dokumentare. Für die Versorgungsforschung wären mehr klassifizierte Daten hilfreich, dies könnte eine weiter entwickelte Schnittstelle vermutlich besser transportieren als BDT. by matching the entries to the master data from the Scientific Institute of Local Health-Care Funds (“Wissenschaftliches Instituts der Ortskrankenkassen” – WIdO). Periodically consistent sets of SPSS files could successfully be created for further research and feedback reports for the participating practices were generated as portable document format (PDF) files. The BDT-interface seems quite out of date, but can still reveal interesting information, especially on data about medical treatments and findings. Much of the data is contained in fields based on free text, which makes analysis difficult. Coded information, like agents, as ATC, could partially be extracted from the data, which afterwards was easy to prepare for further research. Quality and content of the data depend mainly on the data enterer, the physicians and their practice staff. Future research could be improved by more classified and coded data, which would better be transported through an interface more advanced than BDT. Hintergrund ▼ Ziele ▼ Sekundäranalysen von Routinedaten aus der Primärversorgung beschränken sich häufig auf Abrechnungsdaten [1, 2] und verzichten damit möglicherweise auf ebenfalls elektronisch verfügbare Informationen aus dem Kontext der hausärztlichen Informations- und Kommunikationstechnologie (IKT). Dem dringenden Bedürfnis elektronischer Kommunikation zwischen den Akteuren im Gesundheitswesen, auch sektorenübergreifend, versuchen Entwicklungen, z. B. von elektronischer Gesundheitskarte und zugehöriger Telematik – Infrastruktur [3] oder elektronischer Arztbrief [4], zu entsprechen. Bei deren Entwicklung spielt die Nutzung im Rahmen der Versorgungsforschung selten eine führende Rolle, ebenso wie in den häufig noch durch Insellösungen geprägtem IKT-Umfeld im primären Sektor und den ca. 200 in Deutschland eingesetzten Systemen [5]. Eine rationale Analyse der zunehmend komplexen Strukturen und hoch interdependenten Prozesse im Gesundheitswesen sowie deren Ergebnisse für die medizinische Versorgung ist ohne IKT nicht mehr vorstellbar, ebenso wenig wie effektive Praxisorganisation, strukturierte Behandlungsprogramme, Leitlinienimplementation, internes Qualitätsmanagement und externe Qualitätssicherung. Die wissenschaftliche Nutzung und Analyse anfallender Routinedaten und IKT-Instrumente ist notwendig und sinnvoll [6–10]. Es liegt also nahe, unter den verschiedenen Teilnehmern des deutschen Gesundheitswesens nach bereits verfügbaren elektronischen Prozessen und Daten zu forschen und diese statistisch aufzubereiten. Die weit verbreitete Familie der xDTSchnittstellen [11] scheint neben der Möglichkeit erbrachte Leistungen zu übertragen auch dazu geeignet, weitere dokumentierte Behandlungsdaten zeitnah, strukturiert und elektronisch an einer ihrer Entstehungsquellen, den hausärztlichen Praxen, zu erheben. Hauptziel dieser Untersuchung ist das Aufzeigen der Möglichkeiten und Grenzen der Forschung mit Routinedaten, welche aus hausärztlichen Praxen über die Behandlungsdatentransfer (BDT)-Schnittstelle exportiert wurden. Als Fragen lassen sich ableiten: „Welche Aussagen lassen sich zu Zugänglichkeit, Inhalt und Qualität der Daten machen?“, „Wie können die Daten für die weitere Analyse in einem Statistikprogramm aufbereitet werden?“ und „Können aus den Daten neue, bisher nicht verfügbare Informationen gewonnen werden?“. Die inhaltliche Beantwortung medizinisch-wissenschaftlicher Fragestellungen ist nicht Teil dieses Artikels. Dazu finden sich motivierende Themen und Ziele in Arbeiten, die auf dem hier vorgestellten Verfahren aufbauen, etwa zu Hausbesuchen [12], Schwindel [13] oder dem Artikel über Grippeschutzimpfungen von Hauswaldt et al. in diesem Heft. Methoden ▼ Überblick Die Untersuchung basiert auf einer einmaligen Erhebung und Zusammenführung von Routinedaten aus den Arztpraxisinformationssystemen (AIS) hausärztlicher Praxen. Die mittels BDT-Schnittstelle exportierten Daten wurden am Institut für Allgemeinmedizin der Medizinischen Hochschule Hannover (MHH) aufbereitet und in Form von anonymisierten SPSS-Dateien den dortigen Forschern für ihre Projekte zur Verfügung gestellt. Über das Durchlaufen eines kompletten Zyklus von der Erhebung, über die Aufbereitung, bis hin zur Auswertung, Publikationen und Erzeugung eines Feedback-Berichts für die teilnehmenden Praxen wurden die technischen Möglichkeiten und Grenzen der Erhebung und Nutzung für die Versorgungsforschung von hausärztlichen Routinedaten, insbesondere über die BDT-Schnittstelle, systematisch herausgearbeitet. ▶ Abb. 1. Einen Überblick des gesamten Prozesses zeigt ● Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 Originalarbeit 325 Arzt / Praxis Anfragen und Praxenberichte BDT-Daten und Feedback zu den Berichten ArztpraxisInformationssystem (AIS) BDT-Export (Direkt/Externes Tool/Aus Datensicherung) BDT-Datei(en) Pseudonymisieren und Verschüsseln (Java) Übertragung (E-Mail, Web, Post oder persönlich) Praxenberichte (PDF) Datenbank (MySQL) Java/SQL BDT-Datei (verschlüsselt) ODBC/SQL (SPSS-Skript) Import (Java/SQL) BDT-Datei Entschlüsseln BDT-Datei (verschlüsselt) SPSS-Dateien Forscher/MHH Abb. 1 Überblick der Datenerhebung und Datenaufbereitung. Rekrutierung Im Zeitraum von Mitte 2005 bis Ende 2007 wurden alle 168 Lehrpraxen der MHH einmalig schriftlich um ihre Teilnahme gebeten. Mit der Anfrage wurden die Praxen um eine kurze Auskunft zu ihrem eingesetzten AIS, sowie dem Umfang der Nutzung von elektronischer Dokumentation gebeten. Im Projekt „Medizinische Versorgung in der Praxis“ (MedViP) [14, 15] der Abteilung Allgemeinmedizin der Universitätsmedizin Göttingen wurden Export und Auswertung von BDT-Routinedaten erstmals verwendet, um krankheitsbezogen praxisepidemiologische Fragen zu beantworten und Patienten zu identifizieren, die dann nach Reidentifikation durch den eigenen Hausarzt von diesem zur Teilnahme an weiteren, klinisch orientierten Studien eingeladen wurden. Im Gegensatz zum MedViP-Projekt wurde bei unserer Erhebung nicht nur ein Zweijahreszeitraum, sondern der gesamte verfügbare Zeitraum der Praxistätigkeit erhoben, also die gesamte vom Arzt jemals in seinem AIS erfasste und über BDT auslesbare Dokumentation. Ferner wurden den teilnehmenden Ärzten keine Honorare oder Aufwandsentschädigungen in Aussicht gestellt oder gezahlt. 88 (52,4 %) Praxen haben schriftlich oder per Fax geantwortet. Von 28 (31,8 %) dieser Praxen konnten die Daten erfolgreich erhoben werden. Für die späteren Auswertungen wurden zusätzlich noch die BDT-Dateien von 139 Praxen aus dem MedViP-Projekt in die Datenbank der MHH importiert. Behandlungsdatentransfer (BDT) Die BDT-Schnittstelle gehört zur Gruppe der xDT-Schnittstellen [11], ebenso wie die Abrechnungsdatentransfer-(ADT)-Schnittstelle, welche zur Übertragung der abzurechnenden Leistungen der Ärzte, im Prinzip einer BDT-Untermenge, an die Kassen bzw. KVen genutzt wird. Ursprüngliche Intention von BDT war dem Arzt eine komplette Übernahme seiner Stamm- und Behandlungsdaten in ein neues AIS zu ermöglichen. Die Entwicklung der BDT-Satzbeschreibung wurde durch das Zentralinstitut für kassenärztliche Versorgung [16], früher Köln, jetzt Berlin, durchgeführt. Dort ist auf Anfrage auch die letzte offizielle Spezifikation zu BDT (Version 2/94) [17] erhältlich, auf der die Entwick- lungen des hier beschriebenen Projekts basieren. Struktur und Aufbau eines BDT-Datensatzes ist an ADT angelehnt. Es handelt sich um eine oder mehrere zusammenhängende Textdateien. Deren generelle Struktur ist durch die 14 BDT-Satzarten, wie „Datenträger-Header“, „Praxisdaten“, „Behandlungsdaten“ usw. bestimmt. Innerhalb der Satzarten sind alle Informationen in BDT-Feldern (einer Zeile) abgelegt. Die Art des Feldes ist durch eine vierstellige Zahl gekennzeichnet. Den Aufbau illustriert ▶ Abb. 2. ● Erhebung, Pseudonymisierung Die Implementierung der BDT-Schnittstelle wurde von den Systemherstellern unterschiedlich umgesetzt, woraus sich folgenden Varianten der Erhebungsart ergaben: ▶ Direkter Export durch den Benutzer (Arzt, Mitarbeiter) möglich. ▶ Kein direkter Export möglich – Das Erstellen des BDT-Datensatzes geschah durch den Systemhersteller, auf Basis einer Datensicherungskopie, die an diesen geschickt wurde. Die erstellten BDT-Dateien wurden zurück in die Praxis geschickt und dort weiterverarbeitet. ▶ Kein direkter Export möglich – Zum Exportieren war ein separates Programm des Herstellers erforderlich, welches der MHH für den Export in den teilnehmenden Praxen zur Verfügung gestellt wurde. ▶ Kein Export möglich. Bei Systemen mit der Möglichkeit zum direkten Export war es in der Regel erforderlich, sich die BDT-Schnittstelle einmalig vom Softwareanbieter freischalten zu lassen oder für den Export einen Tages-Freischaltcode vom Anbieter anzufordern. Den teilnehmenden Praxen wurde angeboten, alle erforderlichen Schritte mit persönlicher oder telefonischer Unterstützung durch die MHH oder komplett eigenständig, mithilfe schriftlicher Anleitungen durchzuführen. In jedem Fall kam ein eigens entwickeltes Java-Programm zum Einsatz, mit welchem noch in der Arztpraxis die BDT-Dateien pseudonymisiert und verschlüsselt wurden. Pseudonymisierung bedeutet hier, dass alle personenbezogenen Daten (BDT-Felder) aus einer zuvor ex- Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 326 Originalarbeit Abb. 2 Auszug aus einer BDT-Datei mit Erläuterung zum Aufbau. portierten Datei entfernt wurden, wie z. B. „3101 (Name des Versicherten)“. Lediglich die systeminterne Patientennummer (BDT-Feld „3000“) musste in der Datei verbleiben, um alle Informationen beim späteren Einlesen in die Datenbank wieder patientenbezogen zusammensetzen zu können. Die pseudonymisierte und mit dem öffentlichen Schlüssel des Instituts für Allgemeinmedizin chiffrierte Datei wurde anschließend per E-Mail, Web-Upload, persönlich oder per Post an das Institut geliefert und dort für den Datenbankimport wieder entschlüsselt. Datenbank und Entwicklung Die Datenbank- und Anwendungstechnologie wurde aus dem MedViP-Projekt [14, 15] und den Vorarbeiten von Weitling [18] übernommen und weiterentwickelt. Als Datenbanksystem kam MySQL [19] unter Ubuntu [20] zum Einsatz. Sämtliche Softwaremodule wurden in Java [21] mit Eclipse [22] entwickelt. Alle selbst entwickelten Komponenten des Projekts sind quelloffen, unterliegen der GNU General Public License (GPL) [23] und sind auf Anfrage von den Autoren frei erhältlich. Die aus der BDT-Spezifikation abgeleiteten Zusammenhänge und Strukturen bilden die Basis für das verwendete Datenbankschema. Es sollte alle relevanten Informationen aus allen BDT▶ Abb. 3 zeigt ein ScheDateien der Praxen aufnehmen können. ● ma der Datenbank, in dem neben Variablenname und -typ auch die Kennung des BDT-Feldes vermerkt ist, aus dem die ursprüngliche Information stammt. Als Primärschlüssel der Praxen dient die Arztnummer (BDT-Feld „0201“). Dies bedeutet, dass Ärzte in Praxisgemeinschaften (mit separater Abrechnung) später als eigene „Praxis“ gezählt werden. Während des Imports wurden lediglich Prüfungen des Datentyps vorgenommen. Bekannte BDT-Fehler bestimmter AIS wurden korrigiert. Inhaltliche Plausibilitätsprüfungen wurden an dieser Stelle nicht durchgeführt. Datenimport und Wirkstoffe Der Import der pseudonymisierten BDT-Dateien in die Datenbank erfolgte durch das entsprechende Java-Modul. Es liest die Datei zeilenweise ein, setzt die gefundenen Informationen in Relation zueinander, z. B. alle Behandlungen zu einem Patienten, und generiert die entsprechenden (Structured Query Language) SQL-Befehle. In diesem Schritt wurden auch die BDT-Felder mit möglichen Inhalten zu Medikamenten geprüft, insbesondere Feld „6210 (Medikament verordnet auf Rezept)“. Sofern in dem dortigen Texteintrag vorhanden, wurde die enthaltene Pharmazentralnummer (PZN) extrahiert. Diese wurde mit den Arzneimittelstammdaten des Wissenschaftlichen Instituts der AOK (WIdO) verglichen, um den Wirkstoff zu ermitteln und diesen als Anatomisch-Therapeutisch-Chemische (ATC) [24] Klassifikation mit in der Datenbank zu hinterlegen. Konnte keine PZN bestimmt werden, wurde ein Textvergleich der Verordnung mit den WIdO-Daten durchgeführt. Nur im Fall einer eindeutigen Zuordnung wurden der ATC-Code mit in die Datenbank übernommen. Anonymisierung, Datenansichten, SPSS Forscher und Doktoranden, welche für ihre Projekte Daten aus dem Pool benötigten, erhielten aus Gründen der Performance und Sicherheit keinen direkten Zugriff auf die Tabellen der Datenbank. Entweder erfolgte der Zugriff auf freigegebene, anonymisierte Datenansichten (Views) oder es wurde mit bereits aus der Datenbank exportierten SPSS-Dateien gearbeitet. Für jede ▶ Abb. 3 dargestellte Tabelle wurde je eine anonyme Sicht erin ● stellt. Das Erstellen der SPSS-Dateien erfolgte durch Exportieren der kompletten View – Inhalte über Open Database Connectivity (ODBC) aus SPSS-Syntax-Skripten heraus, welche auch die Variablen und Werte mit entsprechenden Labels aus dem BDT-Kontext versehen. Die ersten Spalten aller SPSS-Dateien sind identisch (Praxis-ID, Patient-ID, Geburtsdatum, Geschlecht, Datum), wodurch sich diese durch die Forscher leicht verknüpfen und aggregieren lassen. Die in den Views und SPSS-Dateien verwendeten Nummern (IDs) der Patienten und Praxen wurden bereits während des Importierens in die Datenbank neu vergeben und sind aus Sicht der Forscher vollständig anonym und über alle SPSS-Dateien und Views hinweg eindeutig. Zugriff auf die Dateien und Views haben die Mitarbeiter des Instituts der Autoren, eine Nutzung durch Dritte ist nicht vorgesehen. Zu bestimmten Zeitpunkten wurde ein konsistentes Set von SPSS-Dateien aus der Datenbank erstellt, mit dem die Forscher – unabhängig von der Datenbank – arbeiten konnten. Durch Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 Originalarbeit 327 Abb. 3 Datenbankschema der MySQL-Datenbank. dieses Verfahren konnte gewährleistet werden, dass laufende Analysen durch das Importieren neuer BDT-Dateien nicht beeinträchtigt wurden, wie es in dem begrenzten, aber langen Erhebungszeitraum mehrmals vorkam. Die ersten Auswertungen der Daten wurden ursprünglich mit SPSS Version 13 durchgeführt. Alle Ergebnisse in diesem Artikel sind mit SPSS Version 16 berechnet worden. Analysen, Berichte und Feedback Wichtige Kennzahlen zum Datenbestand wurden regelmäßig per SQL aus der Datenbank abgefragt, zum einen, um die Softwaremodule zu prüfen und weiterzuentwickeln, zum anderen, um Inhalt und Umfang der Datenbank zu skizzieren. In diesem Zusammenhang sollen vier Methoden kurz vorgestellt werden: BDT-Dateianalyse, zwei Beispielanalysen ins SPSS, sowie die Praxenberichte. Eine Analyse der BDT-Dateien bestand darin, während des Imports Metadaten, etwa die Häufigkeiten aller vorkommenden BDT-Felder, in einer Protokolldatei zu hinterlegen, um diese Informationen später in SPSS auszuwerten. Dort wurde geprüft, ob sich Auffälligkeiten bei der Häufigkeitsverteilung wichtiger BDT-Felder in Abhängigkeit vom eingesetzten AIS ergaben. Ferner wurde für diesen Artikel, um die Nutzbarkeit für weitere quantitative Analysen zu skizzieren, beispielhaft eine fiktive Quer- sowie eine Längschnittstudienfrage an die BDT-Datenbank gestellt und zwar: „In wie vielen Praxen sind 2001 Befunde im AIS elektronisch dokumentiert worden?“ und „Hat sich das Verhältnis der Anzahl der Kontakte pro Patient und Jahr seit 1996 verändert?“. In beiden Fällen wurden Häufigkeiten der Kontakte (Einträge in der Tabelle „Behandlung“) sowie die jeweils zugehörige Anzahl der Patienten und gefüllter Befund- felder (BDT-Felder „6220“–„6225“), aggregiert nach Jahr und Praxis per SQL ermittelt. Für die erste Frage wurden in SPSS nach dem Jahr 2001 gefiltert, ein Quotient Befunde/Behandlungen berechnet und die Praxen danach gruppiert. Im zweiten Fall wurde nach Jahr (ab 1996) in SPSS gefiltert, ein Quotient Behandlungen/Patienten berechnet und daraus per Aggregation ein Durchschnitt für die Jahre erstellt. Im letzten Schritt eines Zyklus der BDT-Datenauswertung sind Berichte für die teilnehmenden Praxen erstellt worden. Darin erhielten sie neben den wichtigsten Kennzahlen ihrer gelieferten Daten auch die Anzahlen zu den Vorkommen von kodierten Informationen, wie Verordnungen (ATC, PZN), Diagnosen (ICD) und dem Vergleich dieser Werte mit dem Durchschnitt aller Praxen. Die Berichte wurden mit einem eigens dafür entwickelten Java-Programm als Portable Document Format (PDF)-Datei erzeugt und den Praxen per E-Mail oder Post zugestellt. Anbei erhielten die Teilnehmer einen kurzen Fragebogen, in dem sie um eine Einschätzung zu Informationsgehalt, sowie Validität und Qualität der Daten gebeten wurden. Ergebnisse ▼ Rekrutierung Von 168 Lehrpraxen der MHH haben 88 (52,4 %) auf die Anfrage geantwortet. Von allen antwortenden MHH-Praxen haben 68 (77,3 %) Interesse an einer Teilnahme signalisiert. 15 (17,0 %) haben eine Teilnahme abgelehnt und 5 (5,7 %) haben einer Teilnahme mit Vorbehalt, etwa einer vorherigen Rücksprache mit ihrem Systembetreuer, zugestimmt. Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 328 Originalarbeit Dokumentation und elektronische Patientenakten Auf die Frage wie sie Behandlungen, Befunde usw. dokumentieren, gaben 36 (40,9 %) an, sämtliche medizinische und nichtmedizinische Angaben elektronisch in ihrem AIS zu dokumentieren. Teilweise elektronisch zu dokumentieren gaben 33 (37,5 %) Praxen an. 10 (11,4 %) würden demnach das AIS nur für die Abrechung nutzen und 9 (10,2 %) machten hierzu keine Angabe. Ob sie die elektronische Übertragung von Patientenakten mit anderen Praxen nutzen würden, beantworteten 72 (81,8 %) mit „Nein“ und 8 (9,1 %) mit „ Ja“. Ebenfalls 8 (9,1 %) machten dazu keine Angabe. Erhebung Bei 28 (31,8 %) Praxen konnte eine Datenerhebung erfolgreich durchgeführt werden. In 41 (46,6 %) Fällen war keine Erhebung möglich. Dies war bei 15 (17,0 %) aufgrund technischer Hürden und bei 26 (29,5 %) aus administrativen Gründen nicht möglich, weil sich mangels personeller oder zeitlicher Ressourcen seitens des Instituts oder der Praxis kein Termin vereinbaren ließ. Bei 24 (27,3 %) Praxen wurde die Erhebung durch einen Mitarbeiter des Instituts durchgeführt. 4 (4,5 %) Praxen waren in der Lage, den BDT-Export nach telefonischer oder schriftlicher Anleitung komplett selbst durchzuführen. Bei 22 (25,0 %) der Praxen war ein direkter Export aus dem AIS (mit oder ohne Freischaltung) möglich und bei 6 (6,8 %) musste für die Erstellung der BDT-Daten eine Sicherung an den Systemhersteller geschickt werden oder es war ein spezielles Exporttool verfügbar. BDT-Datenbank Zum aktuellen Zeitpunkt (Oktober 2009) befinden sich in der Datenbank am Institut für Allgemeinmedizin der MHH die Daten aus den 28 Lehrpraxen der MHH sowie Daten von 139 Praxen aus dem MedViP-Projekt. Die MedViP-Daten stammen vornehmlich aus den Jahren 2000–2002, weshalb hier eine hohe Datendichte erkennbar ist. Daten aus den MHH-Praxen liegen in Einzelfällen bis weit über 20 Jahre in die Vergangenheit (bis zum Erhebungszeitpunkt) vor. Die 167 Praxen umfassen 974 304 Patienten und 12 555 943 Behandlungen. Es liegen 19 242 258 Gebührenziffern, 4 828 330 Abrechnungsdiagnosen sowie 11 497 899 Medikationseinträge (aus den BDT-Feldern 6 211–6 215) vor. In letzteren konnte bei 4 213 550 (33,6 %) Einträgen eine PZN extrahiert werden und in 5 540 121 (44,1 %) Fällen ein Wirkstoff nach ATC bestimmt werden. Dies bedeutet, dass in 1 326 571 (10,6 %) Fällen eine eindeutige Zuordnung des Wirkstoffs per Textvergleich mit den WiDoDaten möglich war. Die Daten der importierten Praxen lagen in 174 BDT-Dateien vor. Die Größe der BDT-Dateien variierte zwischen einem und knapp 500 Megabyte. Die Häufigkeit einiger wichtiger BDT-Felder ▶ Tab. 1. Dort ist auch die Häufigkeit der eingesetzten AIS zeigt ● abzulesen. Beispiel Querschnitt – Elektronische Befunde Für das Jahr 2001 liegen Daten aus 159 Praxen vor. Bei 64 (40,3 %) sind keine elektronischen Befunde in den dafür vorgesehenen BDT-Feldern zu finden. In 82 (51,6 %) Fällen ist das Verhältnis Befunde/Behandlungen kleiner als 0,75. Bei 13 (8,2 %) Praxen ist dieses Verhältnis 0,75 oder größer. Beispiel Längsschnitt – Kontakte pro Patient ▶ Tab. 2. Die Analyse war durchführbar. Das Das Ergebnis zeigt ● Verhältnis von Kontakten pro Patient scheint über die Jahre er- staunlich stark zu schwanken. Die weitere inhaltliche Interpretation scheint hier nicht sinnvoll. Dazu wären mehr Daten und zusätzliche Analysen, etwa der Ausreißer, nötig, um Eingabeoder Systemfehler im AIS zu identifizieren und herauszurechnen. BDT-Dateien Transport aus der Datenbank in die Statistiksoftware Der ODBC-Transfer von MySQL nach SPSS verursachte größere Schwierigkeiten. Datentypen (Zahlen) werden nicht immer korrekt erkannt. Dies macht die gelieferten Ergebnisse unbrauchbar. Dieses Phänomen gilt für die ODBC-Versionen 3.51 und 5.1, sowie SPSS Version 13–16. Auch das Anpassen der ODBC-Treibereinstellungen änderte daran nichts. Umgehen lässt sich dies, indem die problematischen Spalten bereits in der Abfrage in Text und später in SPSS zurück in Zahlen konvertiert werden. Ebenfalls war es nicht möglich, Abfrageergebnisse mit mehr als einem Gigabyte zu übertragen. Deshalb wurden derartig große Abfragen, auf Basis von Variablen, wie dem Geschlecht aufgeteilt. Alternativ wären auch andere Übertragungswege als ODBC, etwa der Umweg über Textdateien, denkbar. Damit würde man jedoch SPSS-seitig auf die von uns genutzten Möglichkeiten eigener View-Abfragen aus SPSS heraus und der Automatisierung der Übertragung mit SPSS-Syntax-Skripten verzichten. Feedback Von den 28 teilnehmenden Praxen kamen 4 (14,3 %) Fragebögen zur Bewertung der Praxenberichte per Fax zurück. Darin kreuzten 3 (75,0 %) u. a. die Auswahl „Die Daten scheinen korrekt zu sein“ an und einer (25,0 %) machte zur Datenqualität keine Angaben. Diskussion ▼ Eine Erhebung von Routinedaten über die BDT-Schnittstelle der AIS in allgemeinmedizinischen Praxen und deren Auswertung ist prinzipiell möglich und sinnvoll, wie auch schon von Himmel et al. [15] gefolgert. Positiv am Erhebungsverfahren ist – im seltenen Fall eines direkten, freigeschalteten Exports aus dem AIS – der kaum spürbare Eingriff in den Praxisalltag. Ebenso wenig sind Beobachtungseinflüsse zu erwarten, da rückwirkend erhoben wird. Ein Vorteil gegenüber Kassendaten ist das verfügbare Spektrum aller Patienten einer Praxis, so auch der Privatversicherten. Zudem ließen sich Kassenwechsel der Patienten nachvollziehen. Arztwechsel hingegen sind problematisch. Dafür müsste ein bundesweit einheitliches Patientenpseudonym in das Verfahren integriert werden. Bereits auf der Basis der 167 erfassten Praxen lassen sich wichtige Rückschlüsse für weitere Einsatzmöglichkeiten und zukünftige Entwicklungen ableiten. Dass von den 68 interessierten MHH-Praxen nur 41,2 % Daten liefern konnten, lag nicht zuletzt an fehlenden personellen Ressourcen seitens des Instituts für Allgemeinmedizin. Andererseits sollte diesem Zustand von vornherein vorgebeugt werden, indem den Praxen bereits AISspezifische Anleitungen für den Datenexport zugesandt wurden. Dass die über ganz Niedersachsen verstreuten Praxen dennoch eine persönliche EDV-Unterstützung vor Ort benötigten, lässt die Benutzerfreundlichkeit der implementierten BDT-Schnittstellen in keinem guten Licht erscheinen. Diese Tatsache führte einerseits zu dem erhöhten Aufwand bei der Erhebung, andererseits auch zu einer „natürlichen Selektion“ der Praxen in Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 Adamed Plus Albis on Windows ARCOS ARZTPRAXIS WIEGAND CompuMED-M1-Sysmed Data-AL DAVID DOCconcept DOCexpert DOCexpert Comfort DORSYMED IV Duria INA 4,2/5,1 INA 4,4 LEISYS M1 MCS-ISYNET Medical Office MediStar PROFIMED WIN QUINCY PCnet S3 TurboMed (DOS) TurboMed@Windows Summe AIS 2 5 3 7 1 3 27 6 6 15 2 6 5 1 3 2 7 1 16 1 11 3 9 32 174 Quell-Dateien 79 618 86 393 91 917 97 865 14 016 116 493 577 208 228 889 66 888 216 809 0 88 013 45 277 19 666 98 314 25 659 336 914 19 343 897 688 23 486 148 928 73 336 107 338 929 993 4 390 051 3000 (Pat-Nr.) 4 13 611 0 0 0 2 0 81 13 955 0 222 0 0 0 0 59 284 0 0 4 1 686 0 0 0 75 862 3622 (Größe) 4 13 611 0 0 0 2 0 96 13 963 0 226 0 0 0 0 58 757 0 0 2 1 686 0 0 0 75 360 3623 (Gewicht) 507 408 275 975 167 129 379 764 51 662 744 484 1 734 601 1 200 421 399 283 1 330 806 706 770 384 261 204 217 95 809 562 963 76 683 308 932 173 586 6 489 935 113 036 588 522 0 310 272 2 867 745 19 674 264 5001 (GNR) 105 353 287 502 185 011 31 907 243 295 1 110 168 2 0 0 128 230 55 707 32 295 16 940 0 16 011 695 271 82 093 1 507 779 183 374 109 580 384 767 187 332 45 422 5 303 144 diagnose) diagnose) 377 300 137 218 546 181 617 899 0 1 570 765 218 212 69 858 211 149 356 336 64 884 101 457 53 283 93 009 744 64 765 129 228 1 375 668 67 890 281 938 0 75 591 550 169 6 063 445 6205 (Behandlungs- 6000 (Anrechnungs- Tab. 1 Häufigkeit der AIS und BDT-Felder. Aufsummierte Häufigkeiten ausgewählter BDT-Felder. Bestimmt aus den 174 verfügbaren BDT-Dateien. 273 947 109 011 841 668 150 083 121 814 423 286 1 015 942 23 447 258 190 998 576 214 755 132 729 46 148 33 169 331 861 28 270 712 185 20 892 2 553 513 34 642 221 093 702 608 460 080 1 606 959 11 314 868 auf Rezept) 6210 (Medikament 19 252 87 914 156 089 75 340 1 552 814 14 956 782 12 840 52 920 464 112 8 840 28 767 0 0 25 804 14 753 44 340 2 574 723 9 628 247 036 0 103 287 106 759 4 542 016 6220 (Befund) Originalarbeit 329 Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 330 Originalarbeit Tab. 2 Auswertung Längsschnittbeispiel. Ergebnis des Längsschnittbeispiels. Jahr Kontakte/Patienten Anzahl Praxen 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2014 2020 2094 2095 5,92 5,93 6,45 6,41 7,00 6,46 6,79 4,91 5,76 9,22 8,47 6,32 1,00 1,00 1,00 1,00 62 65 68 73 80 159 162 113 32 25 27 21 1 2 1 1 Abhängigkeit vom eingesetzten AIS. Dies geht auch teilweise ▶ Tab. 1 hervor. Zwar gehören die Systeme „Turbomed“, aus ● „David“, „Medistar“ und „DocExpert comfort“ ohnehin zu den am häufigsten eingesetzten AIS [5], diese ermöglichten aber auch einen direkten BDT-Export (nach Freischaltung), was die Erhebung vereinfachte. Aus Sicht der Autoren stellen andere Verfahren der Erhebung, etwa per Datensicherung über den Systemhersteller, keine ausreichende „Implementierung“ der BDTSchnittstelle dar. Sind die Hürden der Erhebung erst einmal genommen, lassen sich die BDT-Dateien mit den entwickelten Programmen recht ▶ Abb. 3) offenbart begut verarbeiten. Das Datenbankschema (● reits wichtige Aussagen: Es gibt eine Trennung zwischen Abrechungs- und Behandlungsdaten. Dies manifestiert sich unter anderem in zwei separaten Diagnosefeldern („6000“ und „6205“). Interessant, weil bisher kaum zugänglich, ist hier der Behandlungsteil der Daten. Dieser Bereich der elektronischen Dokumentation von Befunden wird auch zunehmend von den Ärzten genutzt, wie die Antworten auf die Dokumentationsart ▶ Tab. 1 anund die Häufigkeit der gefunden Befundfelder in ● deuten. Dort und im Datenbankschema lassen sich auch die Grenzen erkennen: Viele Informationen sind in Freitexten abgelegt. Hier neue Ansätze des Informationsextraktes zu entwickeln [25], könnte sich als fruchtbar erweisen, etwa um Diskrepanzen in der Dokumentation zwischen Behandlung und Abrechnung effizienter analysieren zu können, wie von Erler et al. [26] manuell durchgeführt. Anders sieht dies bei Feldern mit kodierten Informationen aus, insbesondere den ICD-Diagnosen und den abgerechneten Gebührennummern des Einheitlichen Bewertungsmaßstabes (EBM) [27]. Diese lassen sich erwartungsgemäß gut weiter verarbeiten. Sie sind den Patienten eindeutig zuzuordnen, lediglich die zeitliche Zuordnung scheint minimal auf Quartalsniveau zuverlässig und sinnvoll zu sein. Behandlungsdiagnosen und Verordnungen dagegen scheinen tagesgenau erfasst und auswertbar zu sein. Die Medikationsfelder beinhalten Freitext. Sofern darin eine PZN enthalten war, ließen sich zuverlässig Wirkstoffe bestimmen und auswerten. Der Datenbestand macht aber deutlich: Nur in 33,6 % der Fälle ist eine PZN verfügbar, vermutlich weil diese von den Systemen gar nicht gespeichert werden oder der Arzt dies bewusst abgestellt hatte. Hier wäre aus Sicht der Forschung eine Speicherung des Wirkstoffes als ATC zu jeder Verordnung wün- schenswert. Aus derartig kodierten Informationen lässt sich leicht ein Feedback-Bericht für die Praxen generieren, welcher hilft, das ganze Verfahren zu überprüfen und weiterzuentwickeln. Dies wurde bereits durch die wenigen Rückmeldungen der Ärzte deutlich, nach denen das gesamte Verfahren offensichtlich keine auffälligen Systemfehler mehr zu enthalten scheint. Ein Problem der Auswertung von Verordnungen ist, dass hier keine Kontrolle darüber vorliegt, ob der Patient das Rezept eingelöst hat, wie es immerhin mit den Daten der Kassen möglich ist. Ein Vergleich beider Bestände könnte interessant sein. Einen weiteren interessanten Aspekt zu den Inhalten wird ▶ Tab. 1 deutlich: Es gibt BDT-Felder für Größe und Gewicht aus ● des Patienten („3622“, „3623“). Diese werden in einigen Fällen sogar genutzt und könnten damit wichtige Informationen für Auswertungen liefern – wenn sie an der korrekten Stelle abgelegt wären und nicht irgendwo im Befundtext untergehen. Man kann folglich nicht alle Unzulänglichkeiten des Verfahrens dem betagten BDT-Standard anrechnen. Zwar definiert dieser etwa für Größe und Gewicht keine Maßeinheiten, was für zuverlässige Auswertungen unzureichend ist. Andererseits ist es, wenn der Arzt diese Daten überhaupt erhebt, Aufgabe der Systemhäuser, dafür zu sorgen, dass diese Daten im korrekten BDT-Feld landen. Einen anderen interessanten Weg, geht hier das Content-Projekt [28], welches die zu dokumentierenden Items vorgibt und seine eigene Exportschnittstelle mitbringt. Seitens der Datenbanktechnologie scheint MySQL nicht die optimale Lösung zu sein. Das Zusammenspiel mit SPSS über ODBC bereitete Probleme. Für konsistente Imports wurde auf „InnoDB“ als Speichertechnologie gesetzt, um auf Transaktionen und referentielle Integrität zurückgreifen zu können. Dadurch blieb aber der Weg für Volltextindizes und damit eine schnelle Ad-hoc-Recherche in den Freitextfeldern verbaut, wie dies von „MyISAM“Tabellen unterstützt wird. Als Datenbank wären vielleicht PostgreSQL [29] oder kommerzielle Systeme mit besserer Anbindung an gängige Statistikprogramme besser geeignet. Java hat sich dagegen als Anwendungsplattform bewährt, vor allem vor dem Hintergrund der heterogenen IT-Landschaft unter den niedergelassenen Ärzten. Verschlüsselung, Import und Zuordnung der Wirkstoffe stellten technisch gesehen keine großen Hürden dar. Die Auswertung der Daten auf der Basis von SPSS-Datei-Sets hatte große Vorteile gegenüber SQL-intensiven Ansätzen. Den Forschern wird ein anonymer, konsistenter und temporär abgeschlossener Datensatz bereitgestellt, mit dem sie autark arbeiten können. Bei einer Größenordnung von weniger als 200 Praxen kommen nur wenige Gigabyte an SPSS-Nutzdaten zusammen, die modernen Arbeitsplatzrechnern keine Schwierigkeiten bereiten. Diese Möglichkeit der dezentralen Auswertung entlastete EDV-Personal und Serverressourcen. Das Verfahren ist sicherlich auch mit anderen Statistikprogrammen durchführbar, ebenso wie ein direkter SQL/ODBC-Zugriff auf die freigegebenen Views eines – ebenfalls austauschbaren – Datenbanksystems. Die beiden kurzen Beispielanalysen liefern inhaltlich keinen Mehrwert, zeigen aber bereits deutlich Schwierigkeiten mit dem Umgang der Daten auf, welche die Forscher im Blick haben müssen. Zum einen lässt sich festhalten, dass beide Verfahren ohne weiteres möglich sind, zum anderen ist die Interpretation der Ergebnisse mitunter schwierig, weshalb die Forscher ent▶ Abb. 3 an sprechendes Hintergrundwissen und das Schema in ● die Hand bekamen. Abschließend wird die Erhebung als wichtiger Schritt für weitere zukünftige Entwicklungen bewertet. Die verfügbaren Daten sind für die Versorgungsforschung interessant, insbesondere die Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331 Originalarbeit 331 nicht in ADT und damit nicht den Daten der Gesetzlichen Krankenversicherung (GKV) enthaltenen Datenfelder. Deren Vollständig und Validität zu bewerten bedarf allerdings noch weiterer Analysen, um eine solide wissenschaftliche Basis zu erhalten, die das Krankengeschehen dann direkter und umfangreicher als ADT abbilden könnte. Ohne dies muss man sich bei der Auswertung von BDT-Daten auf jene Praxen und AIS beschränken, bei denen die Vollständig und Validität der untersuchten Felder nach eingehender Prüfung als gegeben angesehen werden kann. Der Reduktion auf die für eine bestimmte Fragestellung gültigen Daten erfolgte in unseren Auswertungen innerhalb von SPSS durch die jeweiligen Forscher. Für eine Erhebung von Routinedaten ist die BDT-Schnittstelle grundsätzlich geeignet, könnte aber weitaus besser sein, wenn sie zugänglicher, besser implementiert wäre und weiterentwickelt würde. Noch besser wäre eine Ablösung durch eine (Extensible Markup Language)XML-basierte [30] Schnittstelle, basierend z. B. auf „Health Level 7/Clinical Document Architecture (HL7/CDA)“ [31], mit der es möglich sein sollte, anhand allgemein verfügbarer XML-Schemas die Daten auf Datentypen, Konsistenz und Plausibilität zu prüfen. Allerdings bräuchte auch eine neue Schnittstelle entsprechende politische Unterstützung, etwas, das BDT zu fehlen scheint. Die Initiative zum einheitlichen Arztbrief der Systemhersteller gibt Anlass zur Hoffnung [32] und bietet Ansatzpunkte für die Zukunft. Abgesehen vom Transportformat für Behandlungsdaten fehlt ein bundesweit einsetzbares Pseudonymisierungsverfahren für Patienten und Ärzte. Unser Ansatz erfüllt seinen Zweck innerhalb unseres Instituts, für das bundesweite Auffinden und Auswerten von Patienten und Behandlungsdaten müsste eine zentrales System integriert werden, wie z. B. vom TMF e.V. angeboten [33]. Inhalt und Qualität der Daten liegen vor allem in der Hand der Nutzer, also der Ärzte und Dokumentare. Für die Versorgungsforschung wären mehr klassifizierte Daten hilfreich, dies könnte eine neue Schnittstelle vermutlich besser transportieren als BDT. Literatur 1 Koch H, Kerek-Bodden H. Die 50 häufigsten ICD-10-Schlüsselnummern nach Fachgruppen. 2008, Available at: http://www.zi-berlin.de/morbilitaetsanalyse/downloads/Die_50_haeufigsten_ICD_07_11072008. pdf Accessed 7/3/2009 2 PMV forschungsgruppe – Gesundheitsberichterstattung Available at: http://www.pmvforschungsgruppe.de/content/02_forschung/02_d_ sekundaerd_1.htm Accessed 10/30/2009, 2009 3 gematik – Gesellschaft für Telematikanwendungen der Gesundheitskarte mbH. Available at: http://www.gematik.de/(S(fwp5dzizgia mxe455w0ous45))/Homepage.Gematik Accessed 7/3/2009, 2009 4 VHitG, Verband der Hersteller von IT-Lösungen für das Gesundheitswesen e.V. Available at: http://www.vhitg.de/vhitg/int/02_News_Presse/ News.php Accessed 6/24/2009, 2009 5 KBV – IT in der Arztpraxis – EDV-Statistik – Installationsstatistik Available at: http://www.kbv.de/ita/4299.html Accessed 10/30/2009, 2009 6 de Lusignan S, van Weel C. The use of routinely collected computer data for research in primary care: opportunities and challenges. Fam. Pract 2006 April 1; 23 (2): 253–263 7 de Lusignan S, Hague N, van Vlymen J et al. Routinely-collected general practice data are complex, but with systematic processing can be used for quality improvement and research. Inform.Prim.Care 2006; 14 (1): 59–66 8 Groot MM, Vernooij-Dassen MJFJ, Verhagen SCA et al. Obstacles to the delivery of primary palliative care as perceived by GPs. Palliat Med 2007; 21 (8): 697–703 9 Meulepas MA, Braspenning JCC, de Grauw WJ et al. Logistic support service improves processes and outcomes of diabetes care in general practice. Fam Pract 2007; 24 (1): 20–25 10 Grol R, Dautzenberg M, Brinkmann H. Quality Management in Primary Care. European Practice Assessment: Bertelsmann Stiftung; 2004 11 KBV – IT in der Arztpraxis – Schnittstellen – Weitere Informationen zu xDT. Available at: http://www.kbv.de/ita/4274.html Accessed 6/23/2009, 2009 12 Snijder E, Kersting M, Theile G et al. Hausbesuche: Versorgungsforschung mit hausärztlichen Routinedaten von 158 000 Patienten. Gesundheitswesen 2007; 69 (12): 679–685 13 Kruschinski C, Kersting M, Breull A et al. Diagnosehäufigkeiten und Verordnungen bei Schwindel im Patientenkollektiv einer hausärztlichen Routinedatenbank. Zeitschrift für Evidenz, Fortbildung und Qualität im Gesundheitswesen 2008 7/31; 102 (5): 313–319 14 Hummers-Pradier E, Simmenroth-Nayda A, Scheidt-Nave C et al. Versorgungsforschung mit hausärztlichen Routinedaten. Gesundheitswesen 2003; 65 (02): 109–114 15 Himmel W, Hummers-Pradier E, Kochen MM. Medizinische Versorgung in der hausärztlichen Praxis. Bundesgesundheitsblatt 2006 02; 49 (2): 151–159 16 Zentralinstitut für die kassenärztliche Versorgung in der Bundesrepublik Deutschland. Accessed 10/30/2009, 2009 17 Friedrich Lichtner, Jürgen Sembritzki. BDT-Satzbeschreibung – Schnittstellenbeschreibung zum systemunabhängigen Datentransfer von Behandlungsdaten 1995 18 Weitling F. Untersuchung hausärztlicher Routinedokumentation unter Qualitätsaspekten und Ausarbeitung von Methoden zur Qualitätssteigerung. 2006 19 MySQL: MySQL 5.0 Reference Manual. Available at: http://dev.mysql. com/doc/refman/5.0/en/index.html Accessed 6/24/2009, 2009 20 Ubuntu Home Page | Ubuntu Available at: http://www.ubuntu.com/ Accessed 10/30/2009, 2009 21 java.com: Java für Sie Available at: http://www.java.com/de/ Accessed 10/30/2009, 2009 22 Eclipse.org home Available at: http://www.eclipse.org/ Accessed 10/30/2009, 2009 23 The GNU General Public License – GNU Project – Free Software Foundation (FSF). Available at: http://www.gnu.org/copyleft/gpl.html Accessed 06/23/2009, 2009 24 DIMDI – ATC/DDD Anatomisch-therapeutisch-chemische Klassifikation mit definierten Tagesdosen. Available at: http://www.dimdi.de/static/ de/klassi/atcddd/index.htm Accessed 6/23/2009, 2009 25 Voorham J, Denig P. Groningen Initiative to Analyse Type 2 Diabetes Treatment. Computerized Extraction of Information on the Quality of Diabetes Care from Free Text in Electronic Patient Records of General Practitioners. J Am Med Inform Assoc 2007; 14 (3): 349–354 26 Erler A, Beyer M, Muth C et al. Garbage in – Garbage out? Validity of Coded Diagnoses from GP Claims Records. Gesundheitswesen 2009 Apr 22 27 KBV – EBM – Einheitlicher Bewertungsmaßstab. Available at: http:// www.kbv.de/8156.html Accessed 10/30/2009, 2009 28 Kühlein T, Laux G, Gutscher A et al. Kontinuierliche Morbiditätsregistrierung in der Hausarztpraxis – Vom Beratungsanlass zum Beratungsergebnis. Urban & Vogel, München; 2008 29 PostgreSQL, das fortschrittlichste Open Source Datenbanksystem – Startseite Available at: http://www.postgresql.de/ Accessed 10/28/2009, 2009 30 XML Essentials – W3C Available at: http://www.w3.org/standards/ xml/core Accessed 10/30/2009, 2009 31 HL7 Benutzergruppe in Deutschland e.V. Available at: http://www.hl7. de/standard/standards.php Accessed 10/30/2009, 2009 32 Heitmann KU, Kassner A, Gehlen E et al. Arztbrief auf Basis der HL7 Clinical Document Architecture Release 2 für das deutsche Gesundheitswesen – Implementierungsleitfaden. 2006 33 TMF e. V. – Pseudonymisierungsdienst – Available at: http://www.tmfev.de/Themen/Projekte/V00001PSD.ASPX – Accessed 10/30/2009, 2009 Kersting M et al. Routinedaten aus hausärztlichen Arztinformationssystemen … Gesundheitswesen 2010; 72: 323–331