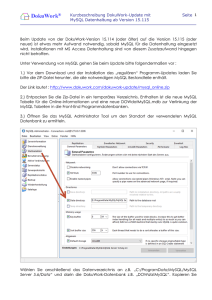
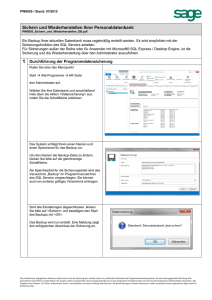
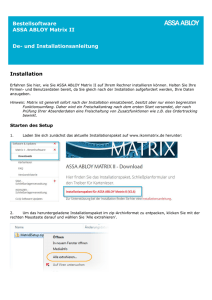
Relationale Datenbanken
Werbung

Marcus Börger Relationale Datenbanken Modellierung und SQL Relationale Datenbanken, Modellierung und SQL, richtet sich an alle, die sich in das Thema Relationale Datenbanken einarbeiten wollen. Es bietet dazu eine praktisch orientierte Einführung in die Konzepte Relationaler Datenbanken sowie einen Einstieg in die drei verbreiteten Datenbank Managementsysteme MySQL, PostgreSQL und Oracle. Titel Relationale Datenbanken Thema Modellierung und SQL Herausgeber Marcus Börger Autor Marcus Börger Email [email protected] Umschlagdesign Martine Windt, Marcus Börger Erstellt am 05.12.2001 Aktuelle Version http://www-users.rwth-aachen.de/Marcus.Boerger/db/Datenbanken.pdf Relationale Datenbanken Inhalt Inhalt 1 Einleitung............................................................................................................... 8 2 Datenbank Schemata.......................................................................................... 10 2.1 Das Physische Schema...........................................................................................................11 2.2 Das Konzeptuelle Schema .....................................................................................................12 2.2.1 Tabellen ..............................................................................................................................................................12 2.2.2 Attribute..............................................................................................................................................................12 2.2.3 Datentypen..........................................................................................................................................................13 2.2.4 Indizes ................................................................................................................................................................15 2.2.5 Relationen...........................................................................................................................................................16 2.2.6 Keys....................................................................................................................................................................22 2.2.7 Referenzielle Integrität .......................................................................................................................................24 2.3 Views .......................................................................................................................................28 2.4 Aufgaben.................................................................................................................................29 3 Modellierung ....................................................................................................... 30 3.1 Normalformen........................................................................................................................31 3.1.1 Erste Normalform...............................................................................................................................................31 3.1.2 Zweite Normalform ............................................................................................................................................32 3.1.3 Dritte Normalform..............................................................................................................................................33 3.1.4 Vierte Normalform .............................................................................................................................................35 3.1.5 Jenseits der Normalformen.................................................................................................................................36 3.1.6 Normalform oder Optimierung...........................................................................................................................36 3.2 Namensgebung .......................................................................................................................36 3.3 ER-Diagramme ......................................................................................................................37 3.4 Aufgaben.................................................................................................................................38 4 Anwendungsstrukturen ..................................................................................... 39 4.1 1-tier........................................................................................................................................39 4.2 2-tier........................................................................................................................................40 4.3 3-tier........................................................................................................................................40 5 Installation........................................................................................................... 41 5.1 MySQL ...................................................................................................................................41 5.1.1 Windows.............................................................................................................................................................41 5.2 PostgreSQL ............................................................................................................................42 5.2.1 Windows.............................................................................................................................................................42 5.2.2 Initialisierung von Postgres ................................................................................................................................44 5.2.3 Postgres als Windows Service............................................................................................................................45 5.3 Oracle......................................................................................................................................46 5.3.1 Windows.............................................................................................................................................................47 5.3.2 Linux ..................................................................................................................................................................47 5.3.3 Database Configuration Assistant.......................................................................................................................48 5.3.4 Net8 Assistant.....................................................................................................................................................49 5.3.5 DBA Studio ........................................................................................................................................................50 5.3.6 SQL*Plus............................................................................................................................................................53 6 Data Definition Language .................................................................................. 54 6.1 CREATE DATABASE..........................................................................................................54 6.2 Verbinden mit der Datenbank..............................................................................................54 6.3 Anlegen und Verbinden mit dem Beispiel...........................................................................54 6.4 CREATE TABLE ..................................................................................................................55 Marcus Börger 5 Inhalt Relationale Datenbanken 6.4.1 CREATE TABLE für MySQL ...........................................................................................................................55 6.4.2 Spaltendefinitionen.............................................................................................................................................56 6.4.3 Constraints..........................................................................................................................................................59 6.4.4 CREATE TABLE SELECT ...............................................................................................................................61 6.4.5 Anlegen der Tabellen der Datenbank Uni ..........................................................................................................62 6.5 CREATE INDEX...................................................................................................................63 6.6 CREATE VIEW ....................................................................................................................63 6.7 CREATE TRIGGER.............................................................................................................63 6.8 CREATE RULE ....................................................................................................................64 6.9 CREATE SEQUENCE..........................................................................................................64 6.10 ALTER TABLE...................................................................................................................64 6.10.1 ALTER TABLE und MySQL ..........................................................................................................................64 6.10.2 ALTER TABLE und Oracle.............................................................................................................................64 6.10.3 ALTER TABLE und PostgreSQL ....................................................................................................................64 6.11 DROP....................................................................................................................................65 6.12 TRUNCATE TABLE ..........................................................................................................65 7 Data Manipulation Language............................................................................ 66 7.1 INSERT INTO .......................................................................................................................66 7.1.1 INSERT INTO SELECT ....................................................................................................................................66 7.1.2 Eingabe der Beispieldaten ..................................................................................................................................67 7.2 SELECT .................................................................................................................................68 7.2.1 FROM.................................................................................................................................................................68 7.2.2 WHERE..............................................................................................................................................................69 7.2.3 Aliasnamen.........................................................................................................................................................69 7.2.4 Abfragen über mehrere Tabellen ........................................................................................................................69 7.2.5 Tabellen mehrmals in einer Abfrage ..................................................................................................................70 7.2.6 Abfragen mit indirekten Tabellen.......................................................................................................................70 7.2.7 Aggregation ........................................................................................................................................................71 7.2.8 GROUP BY........................................................................................................................................................71 7.2.9 HAVING ............................................................................................................................................................72 7.2.10 ORDER BY......................................................................................................................................................72 7.2.11 UNION .............................................................................................................................................................73 7.2.12 UNION ALL ....................................................................................................................................................74 7.2.13 EXCEPT...........................................................................................................................................................74 7.2.14 INTERSECT ....................................................................................................................................................74 7.2.15 Subselects .........................................................................................................................................................75 7.2.16 SELECT DISTINCT ........................................................................................................................................81 7.2.17 SELECT ohne FROM ......................................................................................................................................81 7.2.18 Top-Level Abfragen .........................................................................................................................................81 7.3 UPDATE.................................................................................................................................82 7.3.1 SELECT FOR UPDATE; UPDATE; .................................................................................................................82 7.4 REPLACE INTO...................................................................................................................83 7.5 DELETE .................................................................................................................................84 7.5.1 Top-Level Delete................................................................................................................................................84 7.5.2 Löschen doppelter Datensätze ............................................................................................................................84 7.6 Operatoren und Funktionen.................................................................................................85 7.6.1 Mathematische Operatoren.................................................................................................................................85 7.6.2 Bitweise Operatoren ...........................................................................................................................................85 7.6.3 Logische Operatoren ..........................................................................................................................................85 7.6.4 Vergleichsoperatoren..........................................................................................................................................86 7.6.5 Bedingungsoperatoren........................................................................................................................................86 7.6.6 Umgang mit NULL ............................................................................................................................................87 7.6.7 Funktionen für Zeichenketten.............................................................................................................................88 7.7 Online Analytical Processing................................................................................................88 8 Transactions ........................................................................................................ 89 6 Marcus Börger Relationale Datenbanken Inhalt 9 Rechteverwaltung ............................................................................................... 90 9.1 MySQL ...................................................................................................................................91 9.1.1 Die Datenbank mysql .........................................................................................................................................91 9.1.2 Rechte applizieren ..............................................................................................................................................94 9.1.3 Verlust des root Paßworts...................................................................................................................................94 9.1.4 phpMyAdmin .....................................................................................................................................................95 9.2 PostgreSQL ............................................................................................................................96 9.3 Oracle......................................................................................................................................96 10 Trigger ............................................................................................................... 97 10.1 PostgreSQL und PL/PGSQL..............................................................................................98 10.2 Oracle und PL/SQL.............................................................................................................99 10.3 Microsoft und VBA .............................................................................................................99 11 Zusammenfassung .......................................................................................... 100 A EBNF................................................................................................................. 101 B Lösungen ........................................................................................................... 102 C Verzeichnis der Abbildungen und Tabellen.................................................. 105 D Literaturverzeichnis ........................................................................................ 108 Marcus Börger 7 Einleitung Relationale Datenbanken 1 Einleitung Gegenstand dieses Booklets sind relationale Datenbanken. Relationale Datenbanken arbeiten mit strukturierte Daten, daß heißt sie arbeiten üblicherweise mit großen Mengen von ähnlich strukturierten Daten und können diese in Relation zu einander bringen. Neben diesem Konzept existieren noch andere Ansätze, die mit semistrukturierten Daten arbeiten, Verzeichnisdienste, Objektorientierte Datenbanken und XML1 [BeMi00], [Boe00], [NWB00]. Verzeichnisdienste2 wie DAP [HSG98], NDS oder ADS werden oft zur hierarchischen Speicherung von Zugriffsrechten verwendet. Es wäre zwar möglich diese auf relationalen Datenbanken ab zu bilden aber diese eignen sich dafür nur eingeschränkt. Ebensowenig eignen sich relationale Datenbanken zur Speicherung von XML Daten. Zwar erweitern alle großen Datenbankhersteller ihre Datenbanken immer mehr um Fähigkeiten zum Umgang mit XML Daten, jedoch ermöglichen erst native Datenbanken wie Tamino [SAG00] einen effektiven Umgang. Die Reihenfolge der Kapitel entspricht dem Bottom-Up Ansatz. Es werden also zuerst die Grundlagen erarbeitet und am Ende die Anwendungen vorgestellt. Wenn ein grundlegendes Verständnis der einzelnen Kapitel bereits vorhanden ist, so kann jedes Kapitel für sich getrennt unabhängig von der Reihenfolge betrachtet werden. Zunächst sollen im Kapitel 2 Datenbank Schemata die Struktur und die Funktionsweise von relationalen Datenbanken kurz angerissen werden. Dies ist wichtig um die weiteren Abschnitte verstehen zu können. Ein exaktes Verständnis bis ins Detail ist jedoch nicht notwendig. Dieses bleibt dem Selbststudium in der einschlägigen Literatur vorbehalten [HeSa00], [SKS97]. Nachdem grundlegende Strukturen und Begriffe eingeführt sind, erfolgt in Kapitel 3 Modellierung eine Einführung in die Modellierung relationaler Datenbanken. Hierbei handelt es sich um eine verkürzte Einführung, die anhand von Beispielen praktische Modellierungskonzepte vorstellt. Auch hierbei gilt, daß eine exakte wissenschaftliche Einführung der Fachliteratur vorbehalten bleibt. Das Kapitel 4 Anwendungsstrukturen beschäftigt sich mit den Strukturen, in denen Datenbanken eingesetzt werden. Bevor die erstellten Modelle umgesetzt werden können, muß zunächst ein geeignetes Datenbank Managementsystem installiert werden. In Kapitel 5 Installation wird die Installation für einige Systeme vorgestellt. Stark mit der Modellierung verbunden ist das Anlegen der Datenstrukturen. Bei relationalen Datenbanken erfolgt dies meist mit einem Teilsatz der Structured Query Language (SQL). Dieses wird in Kapitel 6 Data Definition Language behandelt. Den zweiten wichtigen Teil von SQL stellt das Kapitel 7 Data Manipulation Language vor. Er dient der Bearbeitung/Abfrage von Daten. Ein Teil des Kapitels ist dem Thema Funktionen und Online Analytical Processing (OLAP) gewidmet. 1 XML: eXtensible Markup Language Verzeichnisdienste stellen hierarchische Informationen bereit. Diese können erst mit den in SQL-99 definierten rekursiven Anfragen effektiv in relationalen Datenbanken realisiert werden. Beispiele: DAP: Directory Access Protocol und LDAP: Lightweight Directory Access Protocol; NDS: Novell Directory Service, Rechteverwaltung auf Novell Servern; ADS: Advanced Directory Service, von Microsoft mit Windows 2000 eingeführte Rechteverwaltung. 2 8 Marcus Börger Relationale Datenbanken Einleitung Die Data Maipulation Language bietet lediglich Atomare Befehle. Oft sind aber für Änderungen an einem Datenbestand mehrere Befehle notwendig. In Kapitel 8 Transactions wird die Lösung dazu vorgestellt. Wenn mehrere Personen mit einer Datenbank arbeiten, so ist es meist erforderlich Rechte zu vergeben mit denen man die Möglichkeiten der Datenmanipulation und des Datenzugangs für einzelne Nutzer einschränken zu können. Dieses Thema wird in Kapitel 9 Rechteverwaltung behandelt. Größere Datenbank Management Systeme bieten Methoden zur Automatisierung von Vorgängen in der Datenbank. Lesen Sie hierüber in Kapitel 10 Trigger. Am Ende einiger Kapitel befinden sich Übungen mit denen der jeweilige Stoff vertieft werden kann. Die anfänglichen Übungen bauen auf den Beispielen des Textes auf. Ihnen schließen sich komplexere Aufgaben an. Marcus Börger 9 Datenbank Schemata Relationale Datenbanken 2 Datenbank Schemata Wenn man die logische Architektur einer Datenbank betrachtet, dann besteht eine Datenbank aus drei Schemata (Ebenen) [FNA99], [HeSa00], [SKS97]. • Das Physische Schema abstrahiert von der Art und Weise, wie die Daten physikalisch abgelegt sind. Das bedeutet, daß es außerhalb des Physischen Schemas keine Rolle spielt, ob die Daten in einer Datei oder mehreren Dateien abgelegt sind, wie die Dateien organisiert sind, wie sie angesprochen werden oder ob überhaupt Dateien zum Einsatz kommen. Weiterhin abstrahiert das Physische Schema von der internen Struktur der abgelegten Daten. • Das Konzeptuelle Schema bildet die logische Struktur der Daten ab. Wird eine Datenbank geplant, so werden zunächst die Daten und ihre Zusammenhänge analysiert. Hieraus entsteht das eingesetzte Datenmodell, das frei von Redundanz ist. Im relationalen Datenmodell werden Datensätze gleichen Typs in Tabellen abgelegt. • Auf dem konzeptuellen Schema basieren schließlich Views (Sichten). Views sind unabhängig von logischen Änderungen in den unterliegenden Schemata. Views erlauben unterschiedliche Ausschnitte des Datenmodels und verschiedene Sichten darauf für unterschiedliche Anwendungen und Anwender. Sie bringen Sicherheit und Konsistenz in die Datenbank. Views für Studenten • • Kein Zugriff auf andere Studenten Nur Leseoperationen Views für Dozenten • Kein Zugriff auf persönliche Daten anderer Personen Views für Verwaltung • • Noten nur Lesen, außer Prüfungsamt Gehälter ändern Konzeptuelles Schema • • • Personen (PNr, PTyp [Student, Dozent], Name, Adresse, Login, Gehalt, Datum) Veranstaltungen (VNr, PNr, VName, VZeit, VOrt) besuchen (PNr, VNr, Note) Physisches Schema • • • Daten in physischer Form Indizes auf Datensätze Kontrollinformationen, Scripte Abbildung 2.1: Datenbank Schemata 10 Marcus Börger Relationale Datenbanken Datenbank Schemata 2.1 Das Physische Schema Wie bereits erläutert werden im physischen Schema die Daten gespeichert. Werden etwa Adreßdaten in einer Textdatei abgelegt und entspricht jeder Zeile eine Adresse, so sind dadurch bereits physisches und konzeptuelles Schema bestimmt. Die Suche nach einzelnen Adressen erfordert hier jedoch ein Durchsuchen der gesamten Liste für jede Einzelne. Noch schlimmer wird es, wenn Teile der Adreßdatei weitergegeben werden sollen, die Reihenfolge geändert oder Analysen durchgeführt werden sollen, wie etwa die Berechnung der Personen, die in einer bestimmten Stadt wohnen. Ein weiteres Problem ist auch die Übersichtlichkeit der Adressen innerhalb der Dateien, denn egal wie man seine Adressen innerhalb der Datei formatiert, es finden sich immer Adressen, die nicht in das Format passen. Eine Datenbank kann hier wesentlich mehr leisten, denn die Ausgabe kann immer neu angepaßt werden und es ist dabei nicht zwingend notwendig jedesmal die physikalische Struktur der Daten zu kennen. Ein genaues Verständnis, wie die Daten abgelegt werden, ist nicht notwendig. Jedoch speichern die meisten Datenbanken in Dateien auf Standard Dateisystemen. Bei großen Datenbanken ist es hilfreich die Organisation zu verstehen, da bereits hier eine Optimierung erfolgen kann bzw. die Eigenschaften des Dateisystems Einfluß auf Eigenschaften der Datenbank hat. Während kleinere Datenbanken üblicherweise eine einzige Datei benutzen, legen größere Datenbanken ihre Daten meist in mehreren Dateien ab. Eine erste Aufteilung ergibt sich, wenn die Datenbank für jede Tabelle eine eigene Datei anlegt und Indizes getrennt speichert. Meist benutzen die Datenbanken jedoch sogenannte Extends die unabhängig von den Strukturen im Konzeptuellen Schema sind (Informationstheoretisch wäre eine Vermischung der Schemata ein großer Nachteil). Die Einflußmöglichkeiten des Dateisystems sind weitreichend, werden jedoch meist unterschätzt und zu spät erkannt. Wichtigstes Augenmerk ist hier die Beachtung der maximalen Dateigröße des Dateisystems. Wenn die Datenbankkonfiguration größere Dateien erlaubt als das System sind Fehler vorprogrammiert. Das Wissen um die Einflußmöglichkeiten auf die Speicherorte der Daten kann Kosten und/oder Zugriffszeiten senken. Zum einen können Daten die selten benötigt werden auf langsameren und damit billigeren Medien oder Systemen gespeichert werden. Zum anderen kann man bei großen Datenbanken Informationen nach Teilinformationen getrennt ablegen. Üblicherweise können solche Datenbanken auch mit mehreren Prozessoren gleichzeitig arbeiten, wodurch sich für die Datenbank die Möglichkeit ergibt eine Aufgabe vollkommen parallel auszuführen. Besonders die Kenntnis der Art und Weise, wie eine Datenbank mit verschiedenen Datentypen umgeht, kann zu Optimierungszwecken genutzt werden. Werden im Konzeptuellen Schema beispielsweise viele mathematische Berechnungen mit einem Wert durchgeführt, so empfiehlt es sich ihn von der Datenbank im Physischen Schema als Zahl abspeichern zu lassen. Werden hingegen Textoperationen mit einem Wert ausgeführt sollte man den Wert im Textformat speichern. Ist hingegen die Datenbank ungeeignet ein bestimmtes Format zu speichern, so kann eine andere Lösung sinnvoll sein. Hat eine Datenbank zum Beispiel Probleme mit großen Datenmengen, so werden in der Datenbank einfach Referenzen auf Dateien gespeichert und in diesen Dateien werden dann die Daten abgelegt. Als Referenz kann der Dateiname benutzt werden, so daß das Dateisystem hierbei zur Datenbank wird. So bleiben bei Webanwendungen Bild- und Musikdaten meist auf dem Webserver und in der Datenbank werden nur ihre Dateinamen gespeichert. Marcus Börger 11 Datenbank Schemata Relationale Datenbanken 2.2 Das Konzeptuelle Schema Im Konzeptuellen Schema definiert der Datenbank Entwickler das Datenmodell, die wie bereits erwähnt unabhängig von den Strukturen des physischen Schemas sind. Denn alle Datenabfragen und Dateneingaben erfolgen hier im Konzeptuellen Schema. Schon während der Modellierung muß die Anwendung bekannt sein, damit man nicht an der Anwendung vorbei modelliert. Man hat im dann Extremfall zwar ein Datenmodell, daß die Daten speichert, nicht aber die Anfragen der Anwendung effektiv bearbeiten kann. Man muß also während der gesamten Modellierungsphase die Eignung des Datenmodells zur Realisierung der Aufgaben innerhalb der Anwendung prüfen. Bevor eine Datenbank modelliert werden kann, ist also ein genaues Verständnis der Strukturen einer Datenbank sowie ihren Werkzeugen und Funktionsweisen unabdingbar. 2.2.1 Tabellen Relationale Datenbanken verwenden Tabellen zum Speichern von Daten. Bei der Modellierung der Datenbank ermittelt man in welcher Form Daten vorliegen. Für die unterschiedlichen Formen legt man dann jeweils Tabellen an. Diese bilden eine Ablageschablone für die gefundenen Datenformen. Der allgemeine Datenbanktheoretische Begriff für Tabellen lautet Entity oder zu Deutsch Entität. 2.2.2 Attribute Die einzelnen Spalten einer Tabelle bezeichnet man als Attribute. Die einzelnen Zellen der Tabelle werden als Felder und die Zeilen der Tabelle als Datensätze bezeichnet. Die Felder nehmen also die einzelnen Werte auf, aus denen ein Datensatz besteht. Dabei wird der Datentyp bereits durch die Spalte bestimmt. Alle Felder einer Spalte haben also den gleichen Datentyp. In Kapitel 3.3 ER-Diagramme wird ein sehr oft benutzter Diagrammtyp vorgestellt. Zur besseren Veranschaulichung wird aber zunächst die folgende Darstellung für Tabellen benutzt: Datensatz 1 2 3 4 Tabellenname Attribut 1 Attribut 2 Attribut 3 Attribut 4 Attribut 5 Datensatz Feld Spalte Abbildung 2.2: Tabellendarstellung Die Spalte Datensatz dient der Numerierung der Datensätze und damit lediglich der Veranschaulichung. Zwar benutzen Datenbanksysteme tatsächlich zusätzliche Verwaltungsinformationen, allerdings sind diese nicht zugänglich vom verwendeten System abhängig und werden damit in der Modellierung und Veranschaulichung auch nicht benötigt. 12 Marcus Börger Relationale Datenbanken Datenbank Schemata Als Beispiel für Datenbanktabellen mit ihren Attributen dienen hier die Tabellen für Personen, Veranstaltungen und die Relationstabelle besuchen. Datensatz PNr PTyp 1 2 3 4 5 100000 100001 100002 100003 100004 Dozent Dozent Student Student Student Personen Name Adresse Ebert, K. Zucker, G. Meier, A. Kühn, H. Muster, M. Login Gehalt Datum ebert zucker 100002 100003 100004 10.000 11.000 NULL NULL NULL 13.9.1980 5.3.1982 1.10.1998 1.10.1999 1.10.1999 Abbildung 2.3: Tabelle Personen Datensatz VNr 1 2 3 4 1 2 3 4 Veranstaltungen PNr VName 100000 100000 100001 100001 Einführung Modellierung SQL-DDL SQL-DML VZeit VOrt Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 H1 H2 H3 H1 Abbildung 2.4: Tabelle Veranstaltungen besuchen Datensatz VNr 1 2 3 4 5 6 2 3 2 1 1 4 PNr 100002 100002 100004 100003 100004 100002 Abbildung 2.5: Tabelle besuchen 2.2.3 Datentypen Die einzelnen Attribute einer Tabelle können einwertig, mehrwertig oder zusammengesetzt sein. Einwertige Attribute enthalten Texte oder Zahlen oder Werte aus einer Liste. Eine genaue Auflistung dieser Datentypen findet sich weiter unten. Man kann eine weitere Tabelle mit der Liste aller möglichen Werte für ein Attribut füllen und auf diese Weise den Wertebereich für ein Attribut dynamisch verwalten. Mehrwertige Attribute stellen eine Liste einwertiger Datentypen dar. Dieses wird oft benutzt, um Flags oder benannte Eigenschaften zu speichern. Das Speichern der besuchten oder gelesenen Veranstaltungen ist ein Beispiel hierfür. Mehrwertige Attribute sind in einem Relationalen Datenmodell nicht zulässig. Kommt bei einem mehrwertigem Attribut eine Liste mit bekannter maximaler Länge zum Einsatz, so kann man das mehrwertige Attribut durch den Einsatz entsprechend vieler einwertiger Attribute gleichen Datentyps ersetzen. Ansonsten muß eine weitere Tabelle angelegt werden. Das wird in Kapitel 3.1 Normalformen deutlich. Zusammengesetzte Attribute sind im Prinzip einzelne Attribute die als ganzes betrachtet werden können. Man kann zusammengesetzte Attribute in einer weiteren Tabelle auslagern, wenn immer gleiche Paare auftreten. Anders verhält sich das Beispielsweise bei Namen. Diese können natürlich in einem einzelnen Attribut gespeichert werden, dabei geht jedoch verloren welcher Teil Anrede, Vorname oder Nachname ist. Die einzelnen Attribute von zusammengesetzten Attributen müssen im Gegensatz zu mehrwertigen Attributen nicht vom gleichen Datentyp sein. Auch können Teilinformationen als Referenz auf eine andere Tabelle realisiert werden. Nachteilig ist, daß das Zusammensetzten der Teilinformationen einen zusätzlichem Aufwand darstellt. Marcus Börger 13 Datenbank Schemata Relationale Datenbanken Relationale Datenbanken unterscheiden die folgenden einwertigen Datentypen: • Integerzahlen; ganzzahlige Werte eignen sich besonders gut als Indizes und für einfache mathematische Berechnungen. • Fließkommazahlen; Mathematische Berechnungen jeder Art. • Festkommazahlen; Fließkommazahlen mit fester Anzahl der Nachkommastellen für mathematische Berechnungen, besonders für Währungsrechnungen geeignet. Einsatz ist nicht empfehlenswert, wenn Genauigkeit und Darstellung nicht identisch sind, damit keine Eignung für Wirtschaftssysteme. • Währung; Festkommazahlen die mit einer Währungskennzeichnung versehen sind. • Zeichen ;Einzelne beliebige Zeichen, oft als Flags oder Status genutzt. • Zeichenketten; Zeichenfolgen mit fester oder variabler Länge. • Boolesche Werte; Speicherung der Zustände JA/NEIN. • Zeiten; Zeitangaben mit festgelegter Genauigkeit eignen sich in einfachen Systemen gut für Zeitberechnungen. • Datumsangaben; Datumsangeben sind wie Zeitangaben meist Systemabhängig. Kommen mehrere Systeme zum Einsatz, sind andere Lösungen zu prüfen. • Binary Large Objects (BLOB); Speicherung beliebiger Informationen. Dabei bieten die meisten RDBMS rein binäre und textorientierte Typen, die Textfunktionen erlauben. Neben diesen Standardtypen existieren in vielen Datenbanken noch spezielle andere Datentypen und oft haben die Datenbanken unterschiedliche Bezeichnungen für obige Datentypen. Bei der Modellierung sollte darauf Acht gegeben werden, daß nicht zu oft zwischen den Datentypen konvertiert werden muß, da jede Konvertierung zusätzliche Zeit beansprucht. Bei den meisten Datentypen können zusätzliche Angaben zur Genauigkeit oder Länge angegeben werden. Die SQL Datentypen werden in 6.4.2.1 SQL Datentypen beschrieben. 2.2.3.1 NULL Der Wert NULL ist eigentlich gar kein Wert, denn er repräsentiert die Aussage ‚kein Wert’ oder ‚Wert nicht bekannt’. Alle Spaltenwerte, die nicht explizit oder implizit durch Standardwerte belegt werden haben den Wert NULL. Der Wert NULL ist gänzlich von der Zahl 0, der leeren Zeichenfolge '' sowie der leeren Menge () zu unterscheiden. Alle Vergleiche mit dem NULL ergeben falsch. Für eine Überprüfung auf den Wert NULL benötigen Datenbanken also spezielle Funktionen bzw. Operatoren. SQL benutzt hierzu den Operator IS NULL (siehe 7.6.6.1 IS NULL). Folgende Aussagen veranschaulichen NULL: • NULL != 0 NULL ist ungleich der Zahl 0 • NULL != '' NULL ist ungleich einer leeren Zeichenfolge • NULL != () NULL ist ungleich der leeren Menge • (NULL != NULL) = NULL NULL ist weder gleich noch ungleich NULL • (NULL IS NULL) = true NULL wird über den Operator IS NULL erkannt Für nahezu alle Funktionen und Operatoren außer IS NULL gilt, wenn ein Parameter den Wert NULL hat, so ist das Ergebnis NULL. 14 Marcus Börger Relationale Datenbanken Datenbank Schemata 2.2.3.2 Berechnete Spalten Eine Besonderheit bilden berechnete Spalten, die von einigen wenigen Datenbanken unterstützt werden. Solche Spalten repräsentieren das Ergebnis einer Berechnung anderer Spalten des Datensatzes. Damit lassen sich einige Aufgaben vereinfachen. Angenommen in einer Tabelle werden Anzahl und Preis einer Ware gespeichert, dann könnte man den Gesamtpreis als berechnete Spalte „Anzahl*Preis“ definieren. Dieses Konzept hat den Nachteil, daß nun nicht mehr alle Spalten der Tabelle geändert werden können. Denn solche Spalten dürfen logischerweise nur gelesen werden. Eine elegantere Methode stellen Views bereit. Diese bieten zudem die Möglichkeit andere Datensätze auch aus fremden Tabellen mit in die Berechnung einzubeziehen (2.3 Views). Beispiele für berechnete Spalten: • (Anzahl * Preis + Porto) * MWSt • Vorname || ' ' || Nachname 2.2.4 Indizes Wenn Daten ohne irgendeine Sortierung geliefert werden sollen, so nimmt das DBMS immer einen sogenannten full-table-scan vor. Daß heißt es wir ein Datenzeiger auf den ersten Datensatz in der physikalischen Tabelle positioniert und der Datensatz geliefert. Danach wird der Datensatzzeiger zum nächsten Datensatz verschoben und der dortige Datensatz geliefert. Das wird solange wiederholt, bis alle Datensätze zurückgegeben worden sind. Datensatzzeiger Datensatz hört VNr PNr 1 2 3 4 5 6 2 3 2 1 1 4 100002 100002 100004 100003 100004 100002 Datensatz Abbildung 2.6: full-table-scan Indizes bilden eine Möglichkeit schnell und geordnet auf einzelne Datensätze innerhalb einer Tabelle zu zugreifen. Hierzu speichert ein Index eine bestimmte Sortierfolge der Datensätze einer Tabelle ab und ordnet dieser den Positionen innerhalb der Tabelle zu. Wenn ein Zugriff auf eine Tabelle unter einer Sortierung erfolgt, für die es keinen Index gibt, so wird dieser temporär angelegt und nach dem Zugriff verworfen3. Da die Berechnung der Reihenfolge der Datensätze für einen Index zeitaufwendig ist, sollten für solche Zugriffe alle notwendigen Indizes vorhanden sein. Das Fehlen eines Index wirkt sich besonders dann dramatisch aus, wenn er häufig benutzt wird. Dies kann der Fall sein, wenn sich der Index in einer Unterabfrage oder einer Funktion fehlt, das Fehlen sich also über eine Nebenaktion auswirkt und nicht offensichtlich ist. Wenn ein Index eindeutig ist, so wird er als unique bezeichnet. Eine besondere Form eindeutiger Indizes wird in 2.2.6 Keys vorgestellt. Dort finden sich auch Grafiken, die den Tabellenzugriff über Indizes veranschaulichen (Abbildung 2.18: Primary Key, Abbildung 2.19: Primary Key bei ungeordneter Tabelle und Abbildung 2.20: Primary Key und Index (VZeit, VOrt)). 3 Manche Datenbanken ersetzen sortierte Abfragen auch durch full-table-scans. Das Anlegen eines temporären Index hat aber den enormen Vorteil, daß der Datenbank Programmcode mit einer Funktion auskommt. Auch macht es zeitlich oft keinen Unterschied ob ein Index erstellt wird oder ein Sortierkriterium für jeden einzelnen Datensatz geprüft werden muß. Marcus Börger 15 Datenbank Schemata Relationale Datenbanken 2.2.5 Relationen Relationen stellen die Verbindung mehrerer Tabellen zueinander her. Durch sie können Daten, die sich über mehreren Tabellen verteilen, zusammengefügt werden. Relationen können durch den Einsatz von Constraints und Triggern (6.4.3 Constraints) gesichert werden. Insbesondere ist es damit möglich ein getrenntes Löschen bzw. Anlegen von Teildatensätzen zu verhindern (siehe 2.2.7 Referenzielle Integrität). 2.2.5.1 Relationstyp 1 zu 1 Eine Relation der Form 1 zu 1 entsteht, wenn es zu jedem Spaltenwert einer Tabelle genau einen Spaltenwert in einer zweiten Tabelle gibt. Relationen der Form 1 zu 1 sollten in einer relationalen Datenbank niemals vorkommen, da sie in einer Tabelle zusammengefaßt werden können. Sollte sich eine 1 zu 1 Relation durch nachträgliche Modifikation ergeben, so sollte die Relation zumindest gesichert werden, es empfiehlt sich jedoch die Ursprungstabellen zu vereinigen und durch Views abzubilden. Wenn eine neue Tabelle unter einem neuen Namen angelegt wird, so können die alten Tabellen durch Views simuliert werden. Dadurch ist es insbesondere möglich, die Restlich Anwendung ohne weitere Änderung weiter zu nutzen. Besonderen Nutzen der Zusammenfassung erhält man allerdings erst, wenn die Anwendung auf die neue Tabelle umgestellt wird. Mit diesem Hintergrund ergibt sich jedoch umgekehrt, daß eine 1 zu 1 Relation sinnvoll sein kann, wenn sie sich aus anfänglichen Anwendungsanforderungen ergibt, sich in späteren Erweiterungen aber 1 zu n Relationen ergeben. Als Beispiel sei hier die Speicherung von Personen und Adressen angegeben. Anwendungen kommen oft mit nur einer Adresse pro Person aus. Sollen die Personen/Adreßdaten jedoch etwa zu einem Contact Relation Management (CRM) Modul erweitert werden, so ist es erforderlich mehrere Adressen pro Person zu speichern (Privatadresse, Firmenadresse, Lieferadresse). Ein weiterer Grund für die Verwendung von 1 zu 1 Relationen liegt in der Optimierung. Wenn es gelingt den oft benutzen Teil der Datensätze in einer Tabelle aus Spalten fester Länge zu bilden, so erfolgt der Zugriff meist wesentlich schneller. Dies liegt daran, daß sich die Position der Datensätze innerhalb des Speicherortes aus Datensatznummer und Datensatzgröße direkt ergibt. Bei Datensätzen mit variabler Länge muß die Datenbank hingegen ständig Indizes korrigieren oder beim Zugriff die Position jedesmal neu berechnen. Die folgende Abbildung zeigt eine 1 zu 1 Beziehung zwischen einer modifizierten Version von Personen genannt Personen 2, bei der das Feld Adresse fehlt und der neuen Tabelle Adresse, die Adreßangaben auf mehrere Spalten aufteilt. Wäre die Relation über das Feld Adresse definiert hätte man nicht einmal die Tabelle Personen modifizieren müssen. PNr Personen 2 Name Login PTyp PNr 1 = Straße Gehalt Datum Adressen Straße2 PLZ Stadt Land 1 Abbildung 2.7: Relationstyp 1 zu 1 16 Marcus Börger Relationale Datenbanken Datenbank Schemata 2.2.5.1.1 Relationstyp 1 zu 0/1 Optionale Elemente werden oft in getrennten Tabellen gespeichert. Dies hat vor allem bei Optionen, die aus mehreren Feldern bestehen, den Vorteil, daß man Speicherplatz einsparen kann. Im Übrigen sind 1 zu 0/1 Relationen ein Sonderfall von 1 zu 1 Relationen, bei denen es Datensätze gibt, deren einer Teil komplett mit dem Wert NULL belegt ist. Ein Beispiel hiefür sind Studenten und Professoren. Man kann sie in einer Tabelle speichern, wie im Beispiel der Tabelle Personen, da Studenten im Gegensatz zu Professoren jedoch kein Gehalt beziehen, braucht man für sie aber weder Bankverbindungen noch Gehälter speichern. Werden Studenten und Dozenten hingegen in verschiedenen Tabellen gespeichert, so ist es sinnvoll für die gemeinsamen Informationen gleiche Strukturen zu nutzen. Durch den Einsatz entsprechender Techniken (siehe 2.3 Views) kann dann eine Tabelle simuliert werden. Dabei gehen allerdings Key Eigenschaften und gegebenenfalls auch Sortiereigenschaften verloren. PTyp Name Dozenten Adresse PNr PTyp Studenten Name Adresse Login PNr Studenten & Dozenten" PTyp Name Adresse Login PNr Login Gehalt Datum Abbildung 2.8: Relationstyp 1 zu 0/1 vs. Strukturgleichheit Ein weiteres Beispiel ergibt sich aus Abbildung 2.7: Relationstyp 1 zu 1, wenn für Personen, deren Adresse unbekannt ist, keine leeren Datensätze in der Tabelle Adressen erzeugt werden. Zunächst ändert sich an den sichtbaren Strukturen nichts, allerdings ergeben sich aus der Änderung des Relationstyps Konsequenzen bei der Datenorganisation. Werden 1 zu 1 Relationen über Constraints gesichert, so kann ein Löschen eines Datensatzes zur Löschung des entsprechenden Datensatzes genutzt werden. Bei 1 zu 0/1 Relationen geht das nur in einer Richtung. Das Löschen des nicht optionalen Datensatzes führt zum Löschen des optionalen. PNr PTyp PNr 1 = Personen 2 Name Straße Login Datum Adressen und Gehalt Straße2 PLZ Stadt Land Gehalt 0/1 Abbildung 2.9: Relationstyp 1 zu 0/1 Die Abbildung 2.9: Relationstyp 1 zu 0/1 zeigt auch, daß Datenmodellierung nicht immer offensichtlich ist. Ausgehend davon, daß Adressen nur für Dozenten gespeichert werden, wurde auch direkt das Gehalt in die Tabelle Adressen und Gehalt verschoben, da auch nur Dozenten ein Gehalt beziehen. Marcus Börger 17 Datenbank Schemata Relationale Datenbanken 2.2.5.2 Relationstyp 1 zu n Wenn es zu jedem Datensatz einer Tabelle mehrere zugehörige andere Datensätze einer anderen Tabelle geben kann, spricht man von einer 1 zu n Relation. Die 1 Seite bezeichnet man dann als Master- oder Referenztabelle und die andere als Detailtabelle. Dementsprechend werden die Werte in der Mastertabelle als Referenz- oder Key Werte bezeichnet. Die Werte der Detailtabelle werden Foreign Key Werte genannt. Beispiele hierfür sind Vorlesungen, denn jeder Professor soll mehrere Vorlesungen geben. Werden 1 zu n Relationen aus der anderen Richtung betrachtet, so werden sie zu n zu 1 Relationen. Außer der Bezeichnung und dem Betrachtungswinkel ändert sich jedoch nichts. Auch hierzu kann aus Abbildung 2.7: Relationstyp 1 zu 1 ein Beispiel erzeugt werden, indem man für Professoren sowohl Privatadresse, als auch Lehrstuhladresse angibt. In solchen Fällen empfiehlt es sich dann, die einzelnen Datensätze der n Seite der 1 zu n Relation unterscheiden zu können, am einfachsten durch einfügen einer Typ Spalte. In Abbildung 2.10: Relationstyp 1 zu n gibt es zu jedem Datensatz in Personen 2 beliebig viele Datensätze in Adresse 2. In diesem Beispiel sollte jeder Adreßtyp pro Person maximal einmal existieren, damit aus den Spalten PNr und AdrTyp ein eindeutiger Index für die Tabelle Adresse 2 gebildet werden kann. PNr Personen 2 Name Login PTyp PNr 1 = AdrTyp Gehalt Datum Adressen 2 Straße PLZ Ort Land n Abbildung 2.10: Relationstyp 1 zu n 2.2.5.2.1 Relationstyp 1 zu c, c klein Manchmal begrenzt man die maximale Anzahl möglicher Relationen zu einem Datensatz, um die Relationen innerhalb der gleichen Tabelle speichern zu können, was die Abfragen wesentlich schneller macht. Häufiges Beispiel hierzu sind Adreßdaten. Oft reicht es vollkommen aus, Privatadresse und Firmenadresse zu speichern (1 zu 2). Dies veranschaulicht Abbildung 2.11: Mehrfache Felder vs. Relation mit der Tabelle Personen 3, die zwei Adreßfelder enthält (Adresse1, Adresse2). Die oben genannten Vorteile werden allerdings durch den Nachteil erkauft, daß man sehr unflexibel wird, was spätere Erweiterungen angeht. Außerdem wird Speicherplatz verschwendet, wenn selten alle Felder benötigt werden. PNr PTyp Name Personen 3 Adresse1 Adresse2 Login Gehalt Datum Abbildung 2.11: Mehrfache Felder vs. Relation 2.2.5.2.2 Relationsauszeichnung Jede einzelne Beziehung, die aus einem Key Wert und einem Foreign Key Wert gebildet wird, kann ein Label bekommen das genau diese Beziehung beschreibt. Ein Label kann dabei entweder implizit bekannt sein oder es wird explizit abgespeichert. Damit für das Label keine neue Tabelle angelegt werden muß, kann es entweder aus der Zieltabelle hervorgehen, sofern unterschiedliche Referenztabellen möglich sind, oder es wird in der Detailtabelle abgelegt. Ein Beispiel für das getrennte Speichern eines Relationenlabels in der Detailtabelle ist das Feld AdrTyp in Abbildung 2.10: Relationstyp 1 zu n. 18 Marcus Börger Relationale Datenbanken Datenbank Schemata Abbildung 2.12: Relation umgekehrt greift noch mal die Tabelle Personen 3 aus Abbildung 2.11: Mehrfache Felder vs. Relation auf. Hier werden die beiden Adressen allerdings in einer getrennten Tabelle gespeichert. Damit ist möglich, daß eine Adresse mehreren Personen zugeordnet wird. Die Lehrstuhladresse muß daher nicht für jeden Mitarbeiter getrennt abgespeichert werden. Andererseits ist ein implizites Label vorhanden, wenn Adresse1 immer die Privatadresse und Adresse2 immer die Firmenanschrift referenziert. PNr PTyp Personen 3 Privat Firma Name 1 Gehalt Datum n = 1 ANr Login = n Adressen 3 Straße 2 PLZ Straße Stadt Land Abbildung 2.12: Relation umgekehrt 2.2.5.2.3 Relationen zu verschiedenen Tabellen Eine Tabelle kann von mehreren Tabellen referenziert werden und sie kann Relationen zu verschiedenen anderen Tabellen enthalten. Während der erste Fall unproblematisch ist, muß im zweiten Fall beachtet werden, daß eine Spalte keine Relation zu verschiedenen Tabellen realisieren kann, insbesondere kann dazu auch kein Label benutzt werden4 (siehe 2.2.6.2 Foreign Keys). Wenn für Privat/Firmenadressen getrennte Tabellen existieren, müssen auch getrennte Spalten für die verschiedenen Relationen benutzt werden. Haben die Zieltabellen die gleiche Struktur, können diese zu einer virtuellen zusammengefaßt werden (siehe 2.3 Views), dabei gehen ggf. Informationen verloren, hier die Unterscheidung zwischen Privat- und Firmenadresse. Sind diese Informationen abhängig vom Modell, wie die hier vorhandene Zuordnung von Adresse1 für Firmenadressen und Adresse2 für Privatadressen, so können sie in der virtuellen Tabelle eingeblendet werden. PNr PTyp Name 1 „Privat“ „Firma“ AdrTyp Personen 3 Adresse1 Adresse2 Gehalt Datum ANr Privatadressen Straße Straße2 PLZ Stadt Land ANr Firmenadressen Straße Straße2 PLZ Stadt Land ANr Alle Adressen Straße Straße2 Stadt Land = n 1 = Login n PLZ Abbildung 2.13: Relationen zu verschiedenen Tabellen 4 Das könnte zwar mit Triggern realisiert werden, das Ergebnis wäre jedoch kein relationales Datenmodell mehr. Marcus Börger 19 Datenbank Schemata Relationale Datenbanken 2.2.5.2.4 Rekursion Es kommt vor, daß sich Tabellen selbst referenzieren. Solchen Relationen bilden also eine Rekursion. Dabei ist das Einfügen des ersten Wertes problematisch, wenn die Relation gesichert wird. Denn eine leere Tabelle enthält noch keinen zulässigen Wert für das Referenz Feld, da keine Werte für das referenzierte Feld vorhanden sind. Der Wert NULL muß für das Referenzfeld explizit erlaubt sein. Wenn ein Datenbank Managementsystem benutzt wird, daß die Relationen am Ende der Transaktion überprüft, kann auf NULL verzichtet werden. Ein Beispiel hierzu zeigt die Abbildung 2.14: Relationstyp 1 zu n mit Rekursion, in der die modifizierte Tabelle Personen 4 das neue Feld Chef enthält. Damit kann man Mitarbeitern einen Abteilungsleiter, Professoren einen Dekan und Studenten einen Mentor zuordnen. Wird ein Datensatz eingefügt, so muß der Wert für das Referenzfeld Chef bereits als Wert für das referenzierte Feld PNR in einem bestehenden Datensatz vorhanden sein. PNr PTyp Name Personen 4 Login 1 = Gehalt Datum Chef n Abbildung 2.14: Relationstyp 1 zu n mit Rekursion 2.2.5.3 Relationstyp n zu m Eine weitere Klasse von Relationen sind die n zu m Relationen. Hierbei stehen jeweils beliebig viele Datensätze einer Tabelle mit beliebig vielen Datensätzen einer anderen Tabelle in Relation. Es wird nicht von n zu n Relationen gesprochen, da die Anzahl der in Relation zu einander stehenden Datensätzen in beiden Tabellen nicht identisch sein müssen. Bei den verschiedenen Modellen für Adressen trat das Problem auf, daß eine Person mehrere Adressen haben kann, aber eine Adresse auch für mehrere Personen gleich ist. Die bisherigen Lösungen konnten diesem Umstand nur Ansatzweise gerecht werden. Den günstigsten Kompromiß stellt Abbildung 2.12: Relation umgekehrt dar. Hier wird möglichst wenig Speicher genutzt, es gibt jedoch maximal zwei Adressen je Person. Ein weiteres Beispiel für n zu m Relationen stellt die Relation „Studenten besuchen Vorlesungen“ dar. Diese Relation ist dadurch gekennzeichnet, daß sowohl eine Vorlesung von mehreren Studenten besucht wird, als auch ein Student mehrere Vorlesungen besucht. Diese Relationen sind nicht direkt in einer relationalen Datenbank darstellbar. Es sind hierzu zwei 1 zu n Relationen und eine weitere Tabelle notwendig. Die zwischengeschaltete Tabelle muß nicht Zwingenderweise auf die beiden Foreign Keys beschränkt sein. Da jeder Datensatz einer solchen Tabelle exakt einer Relation entspricht, kann man diese Relation in weiteren Spalten auszeichnen. Da n zu m Relation über drei Tabellen realisiert werden, ist der Zugriff darauf langsamer als der Zugriff auf zwei Tabellen, wie er bei Relationen der Form 1 zu n gegeben ist. Personen Name PNr 1 = besuchen PNr VNr n m Veranstaltungen VNr VName = 1 "Studenten besuchen Veranstaltungen" Name PNr VNr VName Abbildung 2.15: Relationstyp n zu m 20 Marcus Börger Relationale Datenbanken Datenbank Schemata Das bisher verwendete Beispiel geht davon aus, daß eine Veranstaltung nur von einem Dozenten gelesen wird, es sieht also nicht den Fall vor, daß sich zwei Dozenten im Wechsel eine Veranstaltung teilen. Um das in der Datenbank zu speichern, wird in der Tabelle Veranstaltungen das Feld PNr entfernt. Denn die Lese Beziehung soll ja ersetzt werden. Es gibt hier nun zwei Möglichkeiten. Entweder wird aus der Tabelle besuchen in Abbildung 2.15: Relationstyp n zu m eine Tabelle "lesen und besuchen", indem man die einzelnen Beziehungen mit dem Wert liest oder besucht auszeichnet. Oder man zerlegt die Tabelle in eine Tabelle besuchen und eine Tabelle lesen wie es Abbildung 2.16: Doppelte n zu m Relation zeigt. In diesem Fall kommt man gänzlich ohne direktes Speichern der Information liest/besucht aus, denn diese Information ergibt sich implizit aus der Tabelle. Da man aber zwei Tabellen benutzt, sind natürlich auch alle Hilfsstrukturen wie Indizes und Keys doppelt vorhanden. Daher führt dieses Vorgehen selten zu Speicherersparnissen. Aber es kann einen anderen Gewinn bringen. Zum einen muß kein weiteres Feld ausgewertet werden, um die Art der Beziehung zu kennen. Zum anderen kann man die Zweiteilung nutzen, um den Zugriff auf eine der beiden Tabellen zu Beschleunigen, wenn eine der beiden Tabellen wenige Einträge enthält aber häufig benötigt wird. Größere RDBMS bieten oft Möglichkeiten Einfluß auf die Zugriffsgeschwindigkeit zu nehmen, meist auf Kosten von Speicherplatz. Personenen Name PNr 1 besuchen PNr VNr = lesen PNr VNr n n 1 n n = = Veranstaltungen VNr VName = 1 1 "Studenten besuchen Veranstaltungen" Name PNr VNr VName "Dozenten lesen Veranstaltungen" Name PNr VNr VName Abbildung 2.16: Doppelte n zu m Relation Eine weitere Alternative ist es, die Tabelle Personen in Studenten und Dozenten aufzuteilen. Hierbei geht im Beispiel dann allerdings die Möglichkeit verloren, daß ein Dozent auch eine Veranstaltung besuchen kann, es sei denn man legt für ihn zwei Datensätze an. Es entstehen auch bei dieser Lösung wieder zwei n zu m Relationen, da es nicht erlaubt ist eine Relation zu zwei verschiedenen Tabellen herzustellen. Insbesondere kann hierzu auch kein Label benutzt werden. Studenten Name PNr 1 besuchen PNr VNr = n n Veranstaltungen VNr VName = 1 "Studenten besuchen Veranstaltungen" Name PNr VNr VName 1 lesen VNr PNr = n n Dozenten PNr Name = 1 "Dozenten lesen Veranstaltungen" VName VNr PNr Name Abbildung 2.17: Parallele n zu m Relationen Marcus Börger 21 Datenbank Schemata Relationale Datenbanken 2.2.6 Keys Wie bereits in 2.2.4 Indizes erwähnt, sind eindeutige Indizes in der Lage Datensätze zu identifizieren, daher nennt man sie auch Datensatzschlüssel oder kurz Schlüssel, im Englischen also Keys. Keys spielen in Relationalen Datenbanken eine wichtige Rolle, da über sie die Relationen definiert werden. 2.2.6.1 Primary Keys In relationalen Datenbanken ist jeder Datensatz eindeutig gekennzeichnet. Diese eindeutige Kennzeichnung wird durch den Primary Key realisiert. Man kann ihn entweder als Teil einer Tabelle definieren oder von der Datenbank generieren lassen. Letzteres passiert genaugenommen immer dann, wenn kein Primary Key explizit definiert wird. In fast allen Datenbanken legt der Primary Key zusätzlich fest, daß seine Werte nicht NULL sein dürfen. Ohne diese Festlegung darf NULL als Wert des Primary Keys dann exakt einmal in der Tabelle vorhanden sein. Wird der Primary Key bei der Modellierung hingegen explizit definiert, so kann er über einem oder mehreren Attributen definiert sein. Ein weiterer Index ist für diese Attributkombination nicht mehr notwendig, da der Primary Key immer auch ein Index ist. Es empfiehlt sich den Primary Key möglichst kurz zu definieren, um den Zugriff auf ihn zu beschleunigen. Da alle Tabellenzugriffe über den Primary Key abgewickelt werden, beschleunigt man so alle Zugriffe auf die zugehörige Tabelle. Es gibt verschiedene Möglichkeiten Primary Keys zu erzeugen: 22 • Attribute einer Tabelle sind häufig bereits eindeutig (siehe auch 2.2.6.4 Anerkannte Standards). Wenn die einzelnen Werte jetzt noch wenig Platz zur Speicherung benötigen so eignen sie sich besonders. • Jedem Datensatz wird eine eindeutige Zahl zugewiesen. Hierzu gibt es von vielen Datenbanken Unterstützung. Einige Datenbanken bieten sogenannte Autoinkrement Werte an, die bei jedem neuen Datensatz um den Wert 1 erhöht werden. Nachteilig ist dabei, daß es einen weiteren eindeutigen Schlüssel geben muß, um den Datensatz nach dem ersten einfügen in der Tabelle finden zu können. Andere Datenbanken bieten sogenannte Sequences, die bei jedem Zugriff eindeutige Werte liefern können. Wird in der gesamten Anwendung nur eine Sequence genutzt, so hat das den Nachteil, daß es das System verlangsamen kann, bei Systemen, die seltener neue Datensätze anlegen, lassen sich so Systemweit eindeutige Primary Keys generieren. Eine besondere Stellung nimmt hier PostgreSQL ein, da hier Autoinkrement Werte durch Sequences realisiert werden, die automatisch angelegt werden. • Bei den Verknüpfungstabellen von n zu m Relationen werden beide Foreign Keys zu einem Primary Key zusammengefaßt (siehe auch 2.2.5.3 Relationstyp n zu m und 2.2.6.2 Foreign Keys). • Oft finden bei der Erzeugung von Datensätzen Algorithmen Verwendung, die bereits eindeutige Werte generieren, die als Primary Key genutzt werden können. • Manche Betriebssysteme/APIs bieten Funktionen, die eindeutige Werte generieren. Diese sind oft weltweit eindeutig, meist jedoch relativ lang. • Die Verbindung von Foreign Keys und einem weiteren Typfeld wird ebenfalls häufig als Primary Key genutzt. In Abbildung 2.10: Relationstyp 1 zu n könnten die Spalten PNr und AdrTyp den Primary Key bilden. Marcus Börger Relationale Datenbanken Datenbank Schemata Intern dient der Primary Key wie bereits erwähnt dem Auffinden der Datensätze. Dabei werden im Primary Key die Positionen der einzelnen Datensätze innerhalb der Tabelle gespeichert. Wenn die Länge der Datensätze variabel ist, so wird auch die Länge der einzelnen Datensätze gespeichert. Dadurch ist es möglich eine Tabelle linear in einer Datei abzulegen und außerdem können Lücken innerhalb der Datendatei aufgefunden und ggf. mit neuen Datensätzen aufgefüllt werden. Bei Datensätzen mit konstanter Länge ist das Speichern der Länge der einzelnen Datensätze natürlich nicht erforderlich. Im folgenden werden Systeme betrachtet, die den Primary Key in einer eigenen Datenstruktur Speichern. Die folgende Abbildung 2.18: Primary Key zeigt den Primary Key, dessen Spalte Position auf die jeweiligen Datensätze in der Tabelle Veranstaltungen zeigt. Die Spalte Datensatz dient hier nur der Übersicht und repräsentiert die Reihenfolge in der die Datensätze eingefügt wurden, sie ist in einem realen DBMS nicht erforderlich. Allerdings verwenden Reale DBMS oft zusätzliche Felder in den Datensätzen und den Primary Key Listen, die für interne Tabellenreorganisationen benutzt werden. Im Beispiel sind die Längen der Datensätze nicht angegeben, da sie hier nicht von Interesse sind: Primary Key Datensatz Position Länge 1 2 3 4 1 2 3 4 VNr ? ? ? ? 1 2 3 4 Veranstaltungen PNr VName VZeit 100000 100000 100001 100001 Einführung Modellierung SQL-DDL SQL-DML Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 VOrt H1 H2 H3 H1 Abbildung 2.18: Primary Key Die Abbildung 2.18: Primary Key läßt noch nicht ganz den Sinn der Datensatzidentifikation über den Primary Key erkennen, da die Datensätze innerhalb der Tabelle Veranstaltungen nach den Werten VNR, also den Primary Key Werten sortiert sind. In der nächsten Abbildung wurden die Datensätze in einer anderen Reihenfolge eingegeben. Daher stimmt die Reihenfolge in der Tabelle nicht mehr mit der Reihenfolge überein, die sich aus den Primary Key Werten ergibt: Primary Key Datensatz Position Länge 1 2 3 4 1 3 4 2 VNr ? ? ? ? 1 4 2 3 Veranstaltungen PNr VName VZeit 100000 100001 100000 100001 Einführung SQL-DML Modellierung SQL-DDL Mo, 10:00 Di, 10:00 Di, 12:00 Mo, 10:00 VOrt H1 H1 H2 H3 Abbildung 2.19: Primary Key bei ungeordneter Tabelle Als nächstes folgt die Einbeziehung eines Index. Dieser enthält nun nur noch Verweise auf die Position im Primary Key. Wird etwa der Datensatz Nummer drei im Index VZeit, VOrt benötigt, so wird zunächst die Position im Primary Key gelesen. Nach Lesen der Position aus dem Primary Key kann dann der Datensatz innerhalb der Tabelle gelesen werden. Index D.S. Pos. 1 2 3 4 1 3 4 2 Primary Key Pos. L. 1 3 4 2 ? ? ? ? VNr 1 4 2 3 Veranstaltungen PNr VName VZeit 100000 100001 100000 100001 Einführung SQL-DML Modellierung SQL-DDL Mo, 10:00 Di, 10:00 Di, 12:00 Mo, 10:00 VOrt H1 H1 H2 H3 Abbildung 2.20: Primary Key und Index (VZeit, VOrt) Indizes und Keys können in einer Tabelle gespeichert werden, denn sie benutzen Datenstrukturen fester Länge. Die Position einzelner Index/Keywerte läßt sich also mittels der Multiplikation Datensatznummer * Datensatzlänge berechnen. Daher benötigen DBMS keine weitere Organisationsform. Der Zugriff auf einen Datensatz über einen Index bewirkt intern also den Zugriff auf drei Tabellen. Marcus Börger 23 Datenbank Schemata Relationale Datenbanken 2.2.6.2 Foreign Keys Eine sehr wichtige Rolle im Zusammenhang mit Relationen spielen Foreign Keys. Sie legen fest, auf welchen Key in welcher Tabelle sich die Werte einer Spalte beziehen. Man sagt hierzu auch, daß ein Foreign Key einen Key einer anderen Tabelle referenziert (siehe 2.2.7 Referenzielle Integrität). Berücksichtigt die Datenbank das Konzept Foreign Key vollständig, so können als Werte für Spalten, die als Foreign Key definiert sind, nur solche benutzt werden, die in der referenzierten Tabelle vorhanden sind oder aber der Wert NULL. In einigen Datenbanken beziehen sich Foreign Keys immer auf den Primary Key der referenzierten Tabelle. Immer jedoch bezieht sich ein Foreign Key aber auf exakt eine Tabelle. Daher werden in Abbildung 2.17: Parallele n zu m Relationen auch die beiden Tabellen lesen bzw. besuchen benötigt. Unterstützt die Datenbank auch Constraints, so ist es möglich dafür zu sorgen, daß Relationen zwischen Datensätzen, die über Foreign Key Beziehungen bestehen gesichert werden. Sicherung bedeutet hierbei, daß die Datenbank die Konsistenz der Daten bezüglich dieser Relation gewährleistet. Hierzu kann beim Erzeugen der zugehörigen Tabellen bereits festlegt werden, wie sich die Datenbank verhalten soll, wenn durch eine Aktion die Konsistenz verletzt wird. Es gibt dabei unter anderen die beiden Möglichkeiten kaskadierendes Löschen und Abbrechen. Wird für einen Foreign Key kaskadierendes Löschen eingestellt, so werden vor dem Löschen eines Key Wertes alle Datensätze gelöscht, die diesen Wert als Foreign Key benutzen. 2.2.6.3 Alternate Keys Jeder weitere eindeutige Index wird auch als Alternate Key bezeichnet. Einige Datenbank Management Systeme erlauben es Relationen über Alternate Keys zu definieren. Das macht einige Aufgaben zwar einfacher oder besser verständlich, notwendig ist das jedoch nicht. Denn bei jedem Zugriff über den Primary Key stehen alle Felder beider beteiligten Tabellen zur Verfügung, insbesondere auch die Alternate Key Felder. 2.2.6.4 Anerkannte Standards Der Modellierung einer Datenbank sollte immer eine gründliche Analyse der zu speichernden Daten vorausgehen. Wenn hierbei Standards auftauchen, so ist es immer empfehlenswert diese möglichst ohne Änderung zu verwenden. Innerhalb einer Adreßdatenbank wird so zum Beispiel auch das Land zu jeder Adresse gespeichert. Hierzu gibt es die Norm ISO 3166 [ISO3166], die Ländercodes und Ländernamen international eindeutig festlegt. Die vorgenannte Norm ist im Internet als Textdatei verfügbar und läßt sich mittels einfacher Konvertierungen in eine Datenbank einlesen. Danach reicht es zu jeder Adresse den Ländercode zu speichern. Als Ergebnis erhält man weltweit eindeutige und gültige Ländernamen. 2.2.7 Referenzielle Integrität Bei der referenziellen Integrität geht es um die implizite Kontrolle und Steuerung von Referenzen durch das Datenbank Management System. Sind alle Foreign Key Werte einer Tabelle dereferenzierbar, daß bedeutet es existieren die referenzierten Werte in der referenzierten Tabelle, so gilt die Relation, die durch den Foreign Key bestimmt ist, als integer. Gilt das für alle Relationen einer Datenbank, so ist die referenzielle Integrität der Datenbank gewährleistet, andernfalls ist sie verletzt. Es sei hier nochmals auf Constraints hingewiesen, die eine Methode zur automatischen Überwachung und Gewährleistung der referenziellen Integrität bereitstellen. Sie übernehmen die im folgenden beschriebenen naheliegenden Konzepte. 24 Marcus Börger Relationale Datenbanken Datenbank Schemata Um die einzelnen Vorgehensweisen zu verdeutlichen, wird das in der Abbildung 2.21: Einfaches Datenmodell der Universität dargestellte Datenmodell zusammen mit den Ausgangsdaten, wie sie in der Abbildung 2.22: Ausgangssituation dargestellt werden, benutzt: Personen Name PNr besuchen PNr VNr 1 = n n 1 n = VNr = PNr Veranstaltungen VName VZeit VOrt 1 Abbildung 2.21: Einfaches Datenmodell der Universität Personen Name PNr Ebert K. Zucker G. Meier A. Kühn H. Muster M. 100000 100001 100002 100003 100004 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 VNr 1 2 3 4 PNr 100000 100000 100001 100001 Veranstaltungen VName VZeit Einführung Modellierung SQL-DDL SQL-DML Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 VOrt H1 H2 H3 H1 Abbildung 2.22: Ausgangssituation 2.2.7.1 Restrict Das Löschen oder Ändern von referenzierten Datensätzen wird mit dem Verhalten RESTRICT verhindert. Existiert ein Datensatz dessen Foreign Key den zu löschenden oder zu ändernde Datensatz referenziert, wird die Aktion abgebrochen. In Abbildung 2.22: Ausgangssituation können nur Datensätze in der Tabelle besuchen gelöscht oder geändert werden, da alle anderen Datensätze referenziert werden. Somit ist es nicht möglich den Datensatz des Dozenten Ebert K. zu löschen, da die beiden Veranstaltungen mit den VNr Werten 1 und 2 den gleichen Wert für PNr besitzen. 2.2.7.2 Cascade CASCADE wirkt sich für Lösch- bzw. Änderungsoperationen sehr unterschiedlich aus. 2.2.7.2.1 Cascade bei Änderungen Das Ändern eines Key Wertes hat hingegen das Ändern aller Foreign Key Werte zur Folge, die diesen Wert referenzieren. Notwendige Änderungen zum Erhalt der Relationen werden in anderen Tabellen automatisch vorgenommen. Damit haben Änderungen innerhalb der Datenbank also keinerlei Auswirkung auf die in den Relationen gespeicherten Zusammenhänge der Datensätze. Wenn die Relation zwischen PNr in Veranstaltungen und PNr in Personen auch für Änderungen auf CASCADE gestellt wird, dann bewirkt das Ändern der PNR 100000 zu 1 in der Tabelle Personen automatisch das Ändern der diese referenzierenden PNr Werte in der Tabelle Veranstaltungen. Das Ergebnis ist in Abbildung 2.23: Relationen und Ändern mit CASCADE zu sehen. In der Tabelle Veranstaltungen darf die PNr hingegen nicht auf einen Wert gesetzt werden, der in der Tabelle Personen nicht existiert, ausgenommen NULL. Personen Name PNr Ebert K. Zucker G. Meier A. Kühn H. Muster M. 1 100001 100002 100003 100004 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 VNr PNr 1 2 3 4 1 1 100001 100001 Veranstaltungen VName VZeit Einführung Modellierung SQL-DDL SQL-DML Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 VOrt H1 H2 H3 H1 Abbildung 2.23: Relationen und Ändern mit CASCADE Marcus Börger 25 Datenbank Schemata Relationale Datenbanken 2.2.7.2.2 Cascade bei Löschen Mittels Cascade werden Datensätze, deren Foreign Key Werte nicht mehr dereferenzierbar sind, gelöscht. Das ist mit der Garbage Collection moderner Programmiersprachen wie Java und C# vergleichbar. Datenbank Management Systeme führen dabei die notwendige Löschoperationen automatisch aus, wenn Datensätze gelöscht werden. Das bedeutet, daß durch eine Löschoperation im Extremfall die gesamte Datenbank geleert werden kann. Die Abbildung 2.24: Löschen mit CASCADE veranschaulicht das Ergebnis der Löschoperation für die Person mit der PNr 100000, also das Löschen des Datensatzes für den Dozenten Ebert K. Wenn kein Dozent die Veranstaltung übernimmt und keine weiteren Daten gespeichert werden macht es Sinn, die dann nicht mehr benötigten Daten auch gleich zu löschen. Sind in den betroffenen Datensätzen hingegen Daten gespeichert, die noch benötigt werden, hier wären etwa Noten denkbar, dann ist dieser Ansatz nicht benutzbar. Wenn andererseits die Personalhierarchie gespeichert wird, also Student/Dozent Beziehungen und Dozent/Dozent Beziehungen mit einem Institutsleiter. So hätte das Löschen des Institutsleiters das leeren der Datenbank zur Folge. Personen Name PNr besuchen PNr VNr Veranstaltungen VName VZeit VNr PNr Zucker G. Meier A. Kühn H. Muster M. 100001 100002 100003 100004 100002 100002 3 4 3 4 100001 100001 SQL-DDL SQL-DML Mo, 10:00 Di, 10:00 VOrt H3 H1 Ebert K. 100000 100002 100004 100003 100004 2 2 1 1 1 2 100000 100000 Einführung Modellierung Mo, 10:00 Di, 12:00 H1 H2 Abbildung 2.24: Löschen mit CASCADE 2.2.7.3 Set NULL Ändern oder Löschen eines Key Wertes bewirkt, daß zugehörige Foreign Key Werte auf den Wert NULL gesetzt werden. Damit gehen zwar alle Informationen über die in den Relationen gespeicherten Informationen verloren aber die Datensätze bleiben unverändert erhalten. Dieses Verhalten kann mit Triggern nachgebildet werden, falls der Default Wert NULL ist, kann auch das Verhalten SET DEFAULT benutzt werden. Werden die Relationen über SET NULL gesichert und der Datensatz des Dozenten Ebert K. gelöscht, so ist lediglich für seine Veranstaltungen kein Dozent mehr bekannt. Die Information darüber, welche Studenten diese Veranstaltungen besuchen, bleiben erhalten. Wenn alle übrigen Foreign Key Werte, wie in diesem Beispiel gültige Referenzen darstellen, oder anders ausgedrückt nur die gerade betroffenen den Wert NULL erhalten, so kann dies benutzt werden, um sehr schnell alle betroffenen Datensätze einem andern Dozenten zu zuordnen. Allerdings müßte man dann auch gleichzeitige Zugriffe auf die Datenbank verbieten, um zu verhindern, daß gleichzeitig weitere NULL Werte eingetragen werden. Eleganter ist es also die Neuen Beziehungen vor dem Löschen einzutragen. Personen Name PNr Zucker G. Meier A. Kühn H. Muster M. 100001 100002 100003 100004 Ebert K. 100000 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 VNr PNr 1 2 3 4 NULL NULL 100001 100001 Veranstaltungen VName VZeit Einführung Modellierung SQL-DDL SQL-DML Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 VOrt H1 H2 H3 H1 Abbildung 2.25: Relationen und Set NULL 26 Marcus Börger Relationale Datenbanken Datenbank Schemata 2.2.7.4 Set Default Durch Ändern oder Löschen eines Key Wertes werden zugehörige Foreign Key Werte auf den Default Wert gesetzt. Bei hierarchischen Daten kann man hierdurch Datensätze sehr einfach nach Änderungen dem höchsten Element der Hierarchie zuordnen. Eine Gefahr besteht hier im Verlust des Default Wertes. Wenn in der Ursprungstabelle der Default Wert nicht mehr vorhanden ist, so kann keine Operation mehr ausgeführt werden, da das Anwenden der Set Default Regel zu einer Verletzung der referenziellen Integrität führen würde. Das Ergebnis ist ein Verhalten das RESTRICT nachempfindet. Auch dieses Verhalten kann mit Triggern simuliert werden. Wenn der Default Wert NULL ist, kann auch SET NULL eingesetzt werden. Wird im Beispiel der Datensatz des Dozenten Ebert K. gelöscht und die Referenz zwischen Veranstaltungen und Personen über Set Default 100001 in Veranstaltungen gesi- chert, so übernimmt der Dozent Zucker G. automatisch alle Veranstaltungen, bei denen der Dozent gelöscht oder sein PNr geändert wird. Wenn der Wert 100000 Default für PNr in der Tabelle Veranstaltungen ist, so kann der Datensatz des Dozenten Ebert K. nicht mehr gelöscht werden. Denn diese Operation hätte zur Folge, daß den Datensätzen der ersten beiden Veranstaltungen die PNr 100000 zugewiesen würde und somit eine ungültige Referenz entstünde. Personen Name PNr Zucker G. Meier A. Kühn H. Muster M. 100001 100002 100003 100004 Ebert K. 100000 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 VNr PNr 1 2 3 4 100001 100001 100001 100001 Veranstaltungen VName VZeit Einführung Modellierung SQL-DDL SQL-DML Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 VOrt H1 H2 H3 H1 Abbildung 2.26: Relationen und Set DEFAULT 2.2.7.5 Löschen bei Änderung Denkbar ist auch das automatische Löschen von Datensätzen deren Relationsursprung sich geändert hat. Diese verhalten wird aber zur Zeit von keinem Datenbank Management System unterstützt und kann nur durch den Einsatz von Triggern realisiert werden. Das folgende Beispiel zeigt, daß hierbei das Ändern eines Veranstaltungsnamen noch nicht das Löschen der zugehörigen Datensätze zur Folge hätte, auch wenn sich das genauso mit Triggern realisieren ließe. Die Aktion würde ebenfalls nicht ausgeführt, wenn der gesamte Datensatz neu geschrieben wird, sich der Primary Key, also der Ursprung der Relation, nicht ändert. Vielmehr würde ausschließlich das Verändern des Ursprungs zur Aktion führen. Hier würde zum Beispiel das Ändern der Veranstaltungsnummer 4 in 5, zum Löschen des entsprechenden Datensatzes in der Tabelle besuchen führen. Im beschriebenen Szenario ist es sinnvoll die Besucherdatensätze zu löschen, wenn sich eine Vorlesung grundlegend ändert. Allerdings ist bei derartigen Änderungen immer die Frage ob sich der Datensatz ändert oder ein Datensatz gelöscht und ein neuer Datensatz erstellt wird, der einen anderen Wert für den Primary Key erhält. Personen Name PNr Ebert K. Zucker G. Meier A. Kühn H. Muster M. 100000 100001 100002 100003 100004 besuchen PNr VNr 100002 100002 100004 100003 100004 2 3 2 1 1 100002 4 VNr PNr 1 2 3 5 100000 100000 100001 100001 Veranstaltungen VName VZeit Einführung Modellierung SQL SQL-DML Mo, 10:00 Di, 12:00 Mo, 10:00 Di, 10:00 VOrt H1 H2 H3 H1 Abbildung 2.27: Relationen und Löschen bei Änderung Marcus Börger 27 Datenbank Schemata Relationale Datenbanken 2.3 Views Eine View kann die folgenden Aufgaben leisten: • Filtern von Information: Eine View kann Teile eines Datensatzes ausblenden. Im Beispiel sollen Studenten keine Angaben zu anderen Studenten erhalten. Weiterhin sollen Studenten und Dozenten nur ihre eigenen Daten sehen können. Hierzu kann eine View erstellt werden, die für Studenten und Dozenten die Felder Adresse, Login, Gehalt und Datum (Einschreibung bzw. Einstellung) ausblendet: PNr PTyp Name Personen Adresse Login Gehalt Datum Nur eigener Datensatz "Personen aus Sicht von Studenten & Dozenten" PNr PTyp Name Adresse Login Abbildung 2.28: View als Filter • Verknüpfen von Informationen: Die vorhandenen Informationen können über Relationen verknüpft werden. Dabei können neue Informationsansichten entstehen. Beispielsweise werden Personen und Vorlesungen über PNr verknüpft, um anzuzeigen, welcher Dozent welche Vorlesung liest: Veranstaltungen PNr VName VZeit VNr Personen PNr Name VOrt = VNr PNr "Was, Wann, Wo, Wer?" VName VZeit VOrt Name Abbildung 2.29: View über Join • Erzeugen von zusätzlichen Informationen: Wenn die Liste aller Vorlesungen durchsucht bzw. angezeigt wird, kann die Datenbank dabei die Datensätze zählen und das Ergebnis als View liefern. Eine View könnte etwa zählen, wie viele Vorlesungen ein Dozent hält. • Sicherheit (Access Control): Anwendergruppen können eingeschränkten Zugriff auf die Datenbank haben. Hier ist nicht nur Ausblenden von Informationen gemeint, sondern Zugriffssteuerung. So dürfen im Beispiel Studenten nur lesen und Gehälter dürfen nur von der Verwaltung geändert werden. • Zurückschreiben: Generierte Daten, die nicht in der Datenbank gespeichert werden, können nicht zurückgeschrieben werden, wie etwa die Anzahl der Vorlesungen aus obigem Beispiel. Problematisch ist das Zurückschreiben über Views auch, wenn diese Informationen ausblenden. Es muß dann ein Verfahren zur Berechnung der gefilterten Daten existieren. Views die über Relationen definiert werden, die nicht im Konzeptuellen Schema definierbar sind, werden virtual Views genannt. Werden Views gespeichert, so nennt man sie materialized Views. Diese Views müssen bei Änderungen in einer der verwendeten Tabellen aktualisiert werden. 28 Marcus Börger Relationale Datenbanken Datenbank Schemata 2.4 Aufgaben Soweit nicht anders angegeben beziehen sich die folgenden Aufgaben auf das Datenmodell aus Abbildung 2.21: Einfaches Datenmodell der Universität. 2.1 Teilen Sie den Namen für Personen in seine Bestandteile auf und modifizieren Sie die Tabelle aus Abbildung 2.3: Tabelle Personen entsprechend. Ist es dabei möglich bestimmte Namensteile durch Listen zu Beschränken? Diskutieren Sie Ihr Ergebnis. 2.2 In Aufgabe 2.1 wurde der Name in seine Bestandteile aufgeteilt, wobei der Titel bzw. die Anrede einen Teil ausmachen sollte. Leider verwenden die verschiedenen Benutzer in solchen Situationen unterschiedliche Anreden. Lösen Sie dieses Problem durch die Verwendung einer Tabelle in der alle erlaubten Anreden gespeichert sind. 2.3 Veranstaltungen haben im allgemeinen eine Anfangszeit und eine Zeitliche Dauer. Das läßt sich durch Anfangszeit und Dauer oder Anfangs/Endzeit darstellen. Ergänzen Sie die Tabelle und erklären Sie die Unterschiede (Welche Berechnungen lassen sich mit welcher Darstellung besser durchführen). 2.4 Zu jeder Veranstaltung gehören neben den Zeiten auch ein Anfangsdatum und ein Enddatum. Ergänzen Sie diese Angaben. 2.5 Häufig ist es so, daß Veranstaltungen zu verschiedenen Zeiten an unterschiedlichen Orten stattfinden. So könnte eine Veranstaltung an drei Wochentagen zu verschiedenen Zeiten in jeweils anderen Räumen gehalten werden. Ergänzen Sie das Modell erstens indem Sie eine maximale Anzahl von 3 Terminen zulassen und zweitens indem Sie beliebig viele Termine zulassen. Erklären Sie Vor- und Nachteile beider Lösungen. 2.6 Ergänzen Sie das Modell um die folgenden Beziehungen. Ein Student hat einen Dozenten als Tutor. Alle Dozenten sind entweder einem Lehrstuhl zugeordnet oder Sie sind Lehrstuhlinhaber. Jeder Lehrstuhl gehört einem Fachbereich an und über allen Fachbereichen steht der Dekan. Das Speichern der Lehrstühle ist hier noch nicht notwendig, die Struktur zu erkennen reicht aus (siehe Abbildung 2.14: Relationstyp 1 zu n mit Rekursion). 2.7 Ausgehend von Aufgabe 2.6 sei angenommen, daß Ebert K. Dekan und Zucker G. Fachbereichsleiter 1 seien und alle Studenten den Dozenten Zucker G. als Tutor haben. Zeichnen Sie die Abhängigkeiten, indem Sie die Relationen in den gefüllten Tabellen eintragen. Zeigen Sie weiterhin, daß bei entsprechender Definition der Relationen (siehe 2.2.7 Referenzielle Integrität) durch Löschen des Datensatzes des Dekans die Tabellen Personen, Veranstaltungen und besuchen geleert werden. 2.8 Legen Sie Bedingungen fest, mit denen es möglich ist, die Anzahl der Datensätze in einer Tabelle zu beschränken. Versuchen Sie mittels der von Ihnen gefundenen Techniken eine Warteschlange mit festgelegter Länge zu realisieren. Übertragen Sie dabei möglichst viele Teilaufgaben der Warteschlangensteuerung auf das Datenbank Management System. Marcus Börger 29 Modellierung Relationale Datenbanken 3 Modellierung Warum sollte man seine Daten überhaupt modellieren, wenn man seine Daten auch einfach auf Karteikarten oder in einer Textdatei speichern kann? Sicher kann man Daten auf Karteikarten oder in Textdateien speichern aber man kann sie dann immer nur genau aus dem Blickwinkel betrachten unter dem sie angelegt wurden, und eine Sortierung ist immer nur nach der Ablagesortierung sinnvoll. Zudem ist eine solche Speicherung bei größeren Datenmengen nicht mehr sinnvoll handhabbar. Das Kapitel 2.1 Das Physische Schema zeigte, daß Adreßlisten durchaus in reinen Textdateien abgelegt werden können. Hier nun die Textdatei zu Abbildung 2.3: Tabelle Personen, Abbildung 2.4: Tabelle Veranstaltungen und Abbildung 2.5: Tabelle besuchen: Ebert, K. 10.000 DM 13.9.1980 liest Einführung, Modellierung Zucker, G. 11.000 DM 5.3.1982 liest SQL-DDL, SQL-DML Meier, A. 1.10.1998 bescuht Modellierung, SQL-DDL, SQL-DML Kühn, H. 1.10.1999 besucht Einführung Muster, M. 1.10.1999 besucht Einführung, Modellierung Abbildung 3.1: Die UNI in einer Textdatei Das Beispiel macht sehr deutlich, daß Änderungen kompliziert sind. Auch das Filtern oder Umsortieren ist offensichtlich aufwendig. So ist es an Universitäten beispielsweise nicht erlaubt Noten und Namen öffentlich aus zu hängen. Daher würde ein Lehrstuhl nach einer Prüfung einfach eine Kopie der womöglich nach Namen sortierten Datei erstellen, in der nur die Namen und Nummern der Studenten enthalten sind. In dieser Liste müßten nun die Noten für jeden Studenten an das Ende seiner Zeile angehängt werden. Das Prüfungsamt würde die vollständige Liste erhalten und für den Aushang würde man einfach die Spalte mit den Namen entfernen. Das Ergebnis wäre, das nun jeder Student die komplette Liste durchsucht, bis er seine Nummer gefunden hat5. Einfacher wäre die Noten direkt nach der Korrektur in die Datenbank einzugeben und anschließend eine nach Nummern sortierte Liste aus zu hängen. Andererseits haben solche Textdateien durchaus ihren Wert, denn ja nach Bedarf kann eine entsprechend aufbereitete Datenpräsentation, auch in Form solcher Textdateien, sehr sinnvoll sein. Aufgabe der Datenbankmodellierung ist es daher ein Modell zu finden, daß alle geforderten Ansichten erzeugen kann. Das Wichtigste bei der Modellierung einer Datenbank ist also die Analyse der zu speichernden Daten und der zu ermittelnden Daten, sowie der daraus resultierenden Strukturen. Grundsätzlich sollte eine Datenbank keine redundanten Daten enthalten, insbesondere keine die sie berechnen kann. Aber keine Regel ohne Ausnahme; wenn das Berechnen von Daten sehr aufwendig ist, kann es sehr wohl angebracht sein, redundante Daten zu speichern. Da Daten oft mit verschiedenen Strukturen gespeichert werden können, ist es wichtig sich schon vor der Modellierung Gedanken über die spätere Anwendung zu machen. Hierbei sollte man spätere Erweiterungen nicht außen vor lassen, da ein nachträgliches Ändern der Datenstrukturen meist nicht möglich ist oder mit großen Änderungen in den bestehenden Anwendungen verbunden ist. Oft entspricht der Aufwand solcher Änderungen dem Aufwand einer kompletten Neuerstellung der Anwendung. Es ist also insbesondere zeitgünstiger und damit kostensparender sich bei der Modellierung der Datenbank Zeit zu lassen und das Modell theoretisch zu testen. 5 Hier soll keiner sagen, daß es das nicht geben würde. Der Lehrstuhl II für Informatik der RWTH-Aachen hat genau das bei einer Klausur gemacht, an der etwa 200 Studenten teilgenommen haben. Man stelle sich das Chaos vor. 30 Marcus Börger Relationale Datenbanken Modellierung 3.1 Normalformen Theoretiker haben nicht nur die Konzepte der relationalen Datenbanken erstellt, sie haben auch gleich Regeln zu deren Modellierung geliefert. Diese Regeln berücksichtigen die relationalen Konzepte und so hilft ihre Anwendung Datenbanken zu modellieren, die effizient in einem relationalen Datenbank Management System eingesetzt werden können. Und gerade bei den ersten Modellen sind sie sehr hilfreich und man erreicht mit ihnen saubere Konzepte. Diese Regeln werden hier zunächst als Anwendung auf die bisherigen Daten erklärt. 3.1.1 Erste Normalform Die erste Normalform verlangt, daß für alle gleichartigen Daten eine eigene Tabelle angelegt wird und daß jede Tabelle einen Primary Key erhält: • Durchsehen und ordnen der Daten. Wenn sich hierbei eine Struktur erkennen läßt, wird eine Tabellenstruktur gesucht, die das gefundene Modell nachbilden kann. • Eine geeignete Spalte wird als Primary Key gewählt oder es wird eine neue Spalte angelegt, die dann Primary Key wird (siehe 2.2.6.1 Primary Keys). • Spalten mit gleichartigem Inhalt werden eliminiert. Diese Regel unterbindet also 1 zu n Beziehungen innerhalb einer Spalte. Für die Relation „Studenten besuchen Veranstaltungen“ bedeutet diese Regel, daß es für jeden Studenten genau so viele Zeilen geben wird, wie er Vorlesungen besucht. PNr Name Gehalt Datum liest/besucht Vname ========-------------------------------------------------============ 100000 Ebert, K. 10.000 DM 13.9.1980 liest Einführung 100000 Ebert, K. 10.000 DM 13.9.1980 liest Modellierung 100001 Zucker, G. 11.000 DM 5.3.1982 liest SQL-DDL 100001 Zucker, G. 11.000 DM 5.3.1982 liest SQL-DML 100002 Meier, A. 1.10.1998 besucht Modellierung 100002 Meier, A. 1.10.1998 besucht SQL-DDL 100002 Meier, A. 1.10.1998 besucht SQL-DML 100003 Kühn, H. 1.10.1999 besucht Einführung 100004 Muster, M. 1.10.1999 besucht Einführung 100004 Muster, M. 1.10.1999 besucht Modellierung Abbildung 3.2: Erste Normalform Wie Abbildung 3.2: Erste Normalform zeigt, schaffen diese Regeln offensichtlich Redundanzen innerhalb der Tabellen. Auch sind die hierbei entstehenden Tabellen noch unabhängig von einander, daß heißt es existieren noch keine Relationen. Die Spalte PNr übernimmt hier die Funktion des Primary Key. Sie wurde den gegebenen Informationen zugefügt, da sich aus den Ausgangsdaten keine Spalte mit den Primary Key Eigenschaften ergibt. Einzig die Spalte Name wäre in Frage gekommen, doch kann es durchaus vorkommen, daß zwei Personen den gleichen Namen besitzen. Das Format der Spalte PNr wurde hierbei gewählt, damit alle Personen eine 6 stellige Nummer als PNr erhalten. Wird als Datentyp für PNr Integerzahl gewählt, ist der Platzbedarf recht gering und der Wertebereich sollte zumindest für die nächste Zeit ausreichen. Nach einer Millionen Dozenten und Studenten müßte man sich jedoch Gedanken für ein Neudesign der Studien/Personalausweise machen (welchen Grund sollte es sonst für diese Selbstbeschränkung geben). Die dritte Regel zerstört die Primary Key Eignung der Spalte PNr jedoch direkt. Die Tabelle bleibt aber zunächst so bestehen, denn das Problem wird durch die folgenden Normalformen gelöst. Als Primary Key kann zunächst (PNr, Vname) benutzt werden. Marcus Börger 31 Modellierung Relationale Datenbanken 3.1.2 Zweite Normalform Redundanzen wie sie durch die Anwendung der Regeln der ersten Normalform entstehen, werden durch Anwendung der Regeln der zweiten Normalform beseitigt. • Sich wiederholende Spaltenwerte werden in eigenen Tabellen gespeichert. Die entstehenden Tabellen werden durch Primary Keys und Foreign Keys miteinander verknüpft, denn es entstehen Relationen vom Typ 1 zu n (siehe 2.2.5 Relationen und 2.2.6 Keys). Anders formuliert darf es keine Spalten geben, die bereits von Teilen des Primary Keys abhängig sind. In Abbildung 3.2: Erste Normalform bilden die Spalten (Name, Gehalt, Datum, liest/besucht) eine Gruppe von Spalten die nur von PNr abhängig sind. Aus dieser Gruppe und PNr wird eine neue Tabelle erstellt. Übrig bleiben die Spalten PNr und Vname und man erkennt leicht, daß der Primary Key dieser Tabelle ausschließlich aus PNr gebildet wird. PNr Name Gehalt Datum lies/besucht ========-----------------------------------------------------100000 Ebert, K. 10.000 DM 13.9.1980 liest 100001 Zucker, G. 11.000 DM 5.3.1982 liest 100002 Meier, A. 1.10.1998 besucht 100003 Kühn, H. 1.10.1999 besucht 100004 Muster, M. 1.10.1999 besucht Abbildung 3.3: Zweite Normalform, Personen PNr Vname ========================= 100000 Einführung 100000 Modellierung 100001 SQL-DDL 100001 SQL-DML 100002 Modellierung 100002 SQL-DDL 100002 SQL-DML 100003 Einführung 100004 Einführung 100004 Modellierung Abbildung 3.4: Zweite Normalform, Veranstaltungen In der dargestellten Tabelle werden Vor- und Nachname in einer Spalte gespeichert, besser wäre den Namen in Anrede, Titel, Vorname, Zusatz und Nachname zu trennen. Damit könnte man dann richtig sortierte Listen erstellen (Entfällt hier der Einfach halber). Das Feld Gehalt enthält hier immer die gleiche Währungskennzeichnung, daher eignet sich das Format Währung besser. Dabei ist jedoch zu prüfen, ob sich die Genauigkeit eignet. Kommen unterschiedliche Währungen vor, so werden diese in eine neue Tabelle verlagert, die weitere Angaben, wie Umrechnungskurse enthält und die Werte in der Spalte Gehalt werden alle in der gleichen Währung abgelegt, denn andernfalls wären sie nicht direkt vergleichbar. Das Datum findet immer am Ort der Universität statt, damit braucht man sich sicherlich keine weiteren Gedanken über den Datentyp zu machen und benutzt Datum. Die Spalte liest/besucht enthält entweder den Wert liest oder den Wert besucht. Daher könnte man auch einfach 0 als liest und 1 als besucht vereinbaren, wodurch man auf Integerzahlen, Zeichen oder Boolesche Werte ausweichen könnte, die alle wesentlich weniger Platz beanspruchen. Im Falle des Datentyps Zeichen könnte man auch gleich L und B vereinbaren, was sich Kollegen sicherlich besser merken können. 32 Marcus Börger Relationale Datenbanken Modellierung 3.1.3 Dritte Normalform Bevor die Dritte Regel angewandt werden kann, muß das Datenmodell in zweiter Normalform vorliegen. Mit der einzigen Regel der dritten Normalform werden dann weitere Redundanzen eliminiert: • Spalten, die nicht Teil des Primary Key sind und voneinander abhängig sind, werden in einer eigenen Tabelle gespeichert. Um dies zu veranschaulichen soll die Tabelle Personen um den Lehrstuhl erweitert werden, wobei jeder Lehrstuhl eine Nummer und einen Namen hat. Zudem soll jede Person einem Lehrstuhl zugeordnet werden. Die folgende Abbildung zeigt ein Beispiel: PNr Name Gehalt Datum liest/besucht LNr LName ========-------------------------------------------------------------100000 Ebert, K. 10.000 13.9.1980 liest 1 DB Theorie 100001 Zucker, G. 11.000 5.3.1982 liest 2 DB Praxis/SQL 100002 Meier, A. 1.10.1998 besucht 1 DB Theorie 100003 Kühn, H. 1.10.1999 besucht 1 DB Theorie 100004 Muster, M. 1.10.1999 besucht 2 DB Praxis/SQL Abbildung 3.5: Personen und Lehrstühle Man sieht hierbei sehr leicht, daß zwischen der Lehrstuhlnummer LNr und dem Lehrstuhlnamen Lname eine 1 zu 1 Beziehung besteht. Die beiden Spalten sind also direkt voneinander abhängig und nicht ausschließlich vom Primary Key. Damit die abhängigen Spalten in einer eigene Tabelle gespeichert werden können, muß entweder eine geeignete Spalte ausgewählt werden, die in der ursprünglichen Tabelle als Foreign Key und in der neuen Tabelle als Primary Key fungiert, oder es muß eine neue Spalte kreiert werden. Eine solche neue Spalte würde in der Ursprungstabelle alle auszulagernden Spalten ersetzen. In obigem Beispiel eignet sich LNr sehr gut als Primary Key für die neue Tabelle mit den abhängigen Spalten LNr und LName: PNr Name Gehalt Datum liest/besucht LNr ========-----------------------------------------------100000 Ebert, K. 10.000 13.9.1980 liest 1 100001 Zucker, G. 11.000 5.3.1982 liest 2 100002 Meier, A. 1.10.1998 besucht 1 100003 Kühn, H. 1.10.1999 besucht 1 100004 Muster, M. 1.10.1999 besucht 2 Abbildung 3.6: Dritte Normalform, Personen und LNr LNr LName ======---------------------1 DB Theorie 2 DB Praxis/SQL Abbildung 3.7: Dritte Normalform, Lehrstühle Ein nicht offensichtlicher Vorteil Namen über Indizes in einer anderen Tabelle anzusprechen ist, daß Änderungen an den Namen nur einmal ausgeführt werden müssen. Da die Änderungen nur in der zweiten Tabelle ausgeführt werden, sind die Datensätze von den Änderungen nicht betroffen. Nachteilig ist jedoch der erhöhte Zeitbedarf bei Abfragen, die den Namen enthalten, da diese den Zugriff auf zwei Tabellen erfordern. Marcus Börger 33 Modellierung Relationale Datenbanken Die dritte Normalform kann man auch für sich wiederholende lange Namen anwenden, indem man sie über Nummern oder ähnliches identifiziert. Es wird also genau der oben beschriebene Fall erzeugt und dann die Regel der dritten Normalform angewandt. Um Platz zu sparen wird diese Methode auch dann angewandt, wenn die Texte vermutlich nur einmal in der Tabelle vorkommen. Damit betrifft die dritte Normalform hier vor allem den Vorlesungsnamen, denn er wiederholt sich ständig und ist relativ lang. Wird statt des Vorlesungsnamen in der zweiten Tabelle eine Referenz auf eine dritte Tabelle gespeichert, die alle Vorlesungsnamen auflistet, so gelangt man zum folgenden Modell: PNr Name Gehalt Datum liest/besucht ========--------------------------------------------------100000 Ebert, K. 10.000 13.9.1980 liest 100001 Zucker, G. 11.000 5.3.1982 liest 100002 Meier, A. 1.10.1998 besucht 100003 Kühn, H. 1.10.1999 besucht 100004 Muster, M. 1.10.1999 besucht Abbildung 3.8: Dritte Normalform, Personen PNr VNr ============= 100000 1 100000 2 100001 3 100001 4 100002 2 100002 3 100002 4 100003 1 100004 1 100004 2 Abbildung 3.9: Dritte Normalform, lesen/besuchen VNr Vname =====-----------------------1 Einführung 2 Modellierung 3 SQL-DDL 4 SQL-DML Abbildung 3.10: Dritte Normalform, Veranstaltungen Die Spalte VNr dient hier als Primary Key für die Tabelle Vorlesungen. Die Tabelle Lesen/Besuchen enthält VNr als Foreign Key. Ihr Primary Key wird aus PNr und VNr gebildet (siehe 2.2.6.1 Primary Keys). Für die Spalte VNr wird erneut Integerzahl als Datentyp festgelegt. Da schon der Name einer Veranstaltung eindeutig ist, hätte der Name bereits als Key dienen können, in diesem Fall hätte man die Tabellen nicht trennen müssen, jedoch kann der Name einer Veranstaltung relativ lang werden und damit ist die Spalte nicht mehr als Key geeignet. Die hier beschriebene Überlegung ist auch gleich Beispiel einer ständig gemachten Fehleinschätzung, warum sollten denn nicht zwei Dozenten, etwa von verschiedenen Studienrichtungen, eine Vorlesung mit gleichem Namen geben? 34 Marcus Börger Relationale Datenbanken Modellierung 3.1.4 Vierte Normalform Genau wie die dritte Normalform beseitigt auch die einzige Regel der vierten Normalform weitere Redundanzen. Vor der Anwendung muß das Datenmodell in dritter Normalform vorliegen: • Mehrwertige Abhängigkeiten werden durch Aufteilen der abhängigen Spalten in mehrere Tabellen beseitigt. Bei zusammengesetzten Primary Keys können mehrwertige Abhängigkeiten entstehen. Wenn mindestens drei Spalten von einander abhängig sind, kann man die Abhängigkeiten dadurch auflösen, daß zwei Spalten eine neue Tabelle bilden und zwischen den so entstandenen zwei Tabellen eine neue 1 zu n Beziehung geschaltet wird. Dieses Vorgehen entspricht dem Vorgehen bei der Dritten Normalform mit dem Unterschied, daß hier auf jeden fall in der Auslagerungstabelle ein neuer Primary Key erzeugt wird, da die beiden ausgelagerten Spalten nicht direkt voneinander abhängig sind. Denn wären die beiden ausgelagerten Spalten direkt voneinander abhängig, dann wäre das Datenmodell nicht in erster Normalform, da der Primary Key aus abhängigen Spalten gebildet wäre. Als Beispiel soll hier eine andere Darstellung der Informationen benutzt werden. Dabei soll eine Tabelle die Informationen Besucher, Dozent und Vorlesung (BNr, DNr, Vname) enthalten. Ausgehend von den bisherigen Daten entsteht somit eine Tabelle deren Primary Key aus den drei Spalten gebildet wird. Die Abbildung unten veranschaulicht das: BNr DNr Vname ================================ 100002 100000 Modellierung 100002 100001 SQL-DDL 100002 100001 SQL-DML 100003 100000 Einführung 100004 100000 Einführung 100004 100000 Modellierung Abbildung 3.11: Besucher, Dozent und Vorlesung Im Beispiel werden jetzt die Spalten DNr und Vname in einer neuen Tabelle ausgelagert. Diese Auswahl wird getroffen, da so die kleinste ausgelagerte Tabelle entsteht: BNr VNr ============= 100002 2 100002 3 100002 4 100003 1 100004 1 100004 2 Abbildung 3.12: Vierte Normalform, Besucher und Vorlesung VNr DNr Vname =====-----------------------1 100000 Einführung 2 100000 Modellierung 3 100001 SQL-DDL 4 100001 SQL-DML Abbildung 3.13: Vierte Normalform, Dozent und Vorlesung Marcus Börger 35 Modellierung Relationale Datenbanken 3.1.5 Jenseits der Normalformen Es existieren neben den vorgenannten Normalformen noch andere Modelle, die jedoch komplex und relativ unwichtig sind. Aus der Praxis gibt es aber noch eine weitere häufig genutzte Methode. Enthält eine Spalte viele NULL Werte und wenigen Werte, die viel Platz belegen oder sind alle übrigen Spalten Datentypen fester Länge, so kann es sinnvoll sein diese Spalten in eine neue Tabelle zu verlangen (siehe 2.2.5.1 Relationstyp 1 zu 1 und 2.2.5.1.1 Relationstyp 1 zu 0/1). 3.1.6 Normalform oder Optimierung Die zuvor beschriebenen Normalformen bilden ein Schema F System das mit Sicherheit nicht immer Ergebnisse liefert, die der Weisheit letzter Schluß sind. Daher sollte man immer Das Ergebnis der Normalisierung erneut analysieren. Bei dieser erneuten Analyse sollte vor allem der spätere Einsatz mit einbezogen werden. Dabei wird das Datenmodell für alle bekannten Datenabfragen auf seine Tauglichkeit hin überprüft. Auffällig ist im Beispiel das Feld liest/besucht. Sollen Dozenten auch Vorlesungen besuchen können, da sie neben ihrer Arbeit ein weiteres Studium angefangen haben (auch solche eher merkwürdigen Fälle müssen in einem Datenmodell immer berücksichtigt werden), muß das Feld liest/besucht in die Tabelle lesen/besuchen verlagert werden. Eine weitere Möglichkeit ist, den Vortragenden in der Tabelle Veranstaltungen zu notieren und aus der Tabelle Lesen/Besuchen eine Tabelle besuchen ohne liest Relationen zu machen. Damit ergibt sich das Modell aus 2.2.2 Attribute. Dieses Modell hat den Vorteil, daß es zumindest für die liest Relationen ohne zusätzliche Tabelle auskommt und damit schneller ist als das Normalformmodell. Nachteilig ist jedoch, daß immer nur ein Dozent einer Veranstaltung zugeordnet werden kann. 3.2 Namensgebung Für Namensgebung in Computersystemen gibt es verschiedene Ansätze. Bei Datenbanken hat sich als günstig erwiesen Tabellen nach den dort gespeicherten Daten zu benennen. Man benutzt bei Tabellen meist den Plural, da dort ja auch mehrere Datensätze des benannten Typs gespeichert werden. Das ist kein Zwang hat aber den Vorteil bei Beschreibungen der Datenbank keine unsinnigen Texte entstehen, wie etwa „wähle aus Person diejenigen aus, die...“. Entsprechend werden für die Spalten Namen im Singular benutzt. Für Foreign Keys gibt es zwei Ansichten zur Namensvergabe. Erstens können alle Spalten, die sich auf einen Key beziehen, den gleichen Namen erhalten, wie der Key selbst. Das hat den Vorteil, daß sofort ersichtlich ist, worauf sich ein Foreign Key bezieht. Nachteilig ist, daß in Abfragen immer vollständige Namen verwendet werden müssen. Zweitens kann man den Namen der Foreign Keys um den Namen der referenzierten Tabelle ergänzen. Da die Namenslänge begrenzt ist, werden häufig Kürzel verwendet, vor allem bei Zusammengesetzten Namen. In der Tabelle Personen hätte man die Spalte PTyp auch PersonenTyp oder PersonTyp nennen können. Es ist nicht wichtig, Namen möglichst kurz zu wählen, sie sollten aber nicht unnötig lang werden, da sich ansonsten sehr lange Abfragen ergeben könnten. Wesentlich wichtiger ist, die Regeln der Datenbank zu berücksichtigen. Diese beschränken häufig den benutzbaren Zeichensatz. Auch legen sie die maximale Länge für Namen fest. Im übrigen sollte man wissen ob die Datenbank Klein/Großschreibung unterscheidet. Da Klein/Großschreibung oft nicht unterschieden wird sollte man also darauf achten, immer gleich zu schreiben, um eine Datenbank Unabhängigkeit zu erreichen. Auch wenn die meisten Datenbank Management Systeme mit Sonderzeichen umgehen können, sollten die Namen ausschließlich aus den 26 Buchstaben des Standardalphabetes den 10 Ziffern und dem Underscore gebildet werden. 36 Marcus Börger Relationale Datenbanken Modellierung 3.3 ER-Diagramme Die bisher verwendeten Abbildungen verwenden Tabellen, so wie man sie kennt. Das hat den enormen Vorteil, daß man sich Begriffe besser vorstellen kann. Zur Modellierung ist diese Vorgehensweise aber unbrauchbar. Das sicherlich bekannteste und verbreitete Konzept zur Datenbankmodellierung ist das Konzept der ER Diagramme. Dabei steht ER für EntityRelationship. Es geht also um Tabellen-Beziehungen Diagramme. Die wichtigsten Elemente solcher Diagramme sind Ellipsen, die Attribute darstellen, Rechtecke für Tabellen und Routen für Relationen. Die Zugehörigkeiten werden durch einfache Linien ausgedrückt. Bei 1 zu x Relationen werden die 1 Seiten durch eine Pfeilspitze auf die Tabelle markiert, 1 zu 1 Relationen haben also zwei Pfeilspitzen und n zu m Relationen keine. Auch in diesen Diagrammen werden die Namen der Primary Key Attribute unterstrichen. Die Abbildung unten ist das ER Diagramm zu Abbildung 2.21: Einfaches Datenmodell der Universität. Man erkennt im Diagramm sehr leicht, daß die Tabelle besuchen, die zur Realisierung der n zu m Relation besuchen benutzt wurde, hier nicht als Tabelle sondern lediglich als Relation auftaucht: VOrt VZeit VNr VOrt Vname Personen VZeit VNr besuchen Vname Veranstaltungen lesen Abbildung 3.14: Einfaches ER Diagramm der Universität Marcus Börger 37 Modellierung Relationale Datenbanken 3.4 Aufgaben 3.1 Erstellen ausgehend vom bisherigen Datenmodell (Abbildung 2.21: Einfaches Datenmodell der Universität) ein erweitertes, das Lehrstühle verwalten kann. In der Datenbank soll also gespeichert werden, welcher Dozent der Lehrstuhlinhaber ist und wo sich der Lehrstuhl befindet. Dabei soll es möglich sein, daß ein Lehrstuhl auf mehrere Gebäude aufgeteilt ist. Sehen Sie in dem neuen Datenmodell auch die Möglichkeit vor zu den Veranstaltungen beliebig viele Termin/Ortkombinationen speichern zu können (siehe Aufgabe 2.5). Weiterhin soll die Hierarchie der Dozenten und Studenten wie in Aufgabe 2.6 gespeichert werden und allen Personen, Lehrstühlen und Veranstaltungsräumen Adressen zugewiesen werden könne. Benutzen Sie dabei zunächst verschiedene Tabellen für die einzelnen Adressangaben (Personen, Lehrstühle, Veranstaltungen). 3.2 Modifizieren Sie ihr in Aufgabe 3.1 erstelltes Datenmodell dahingehend, daß alle Adressen in einer Tabelle gespeichert werden. Erklären Sie die Vor/Nachteile beider Lösungen. 3.3 Views eignen sich dazu die gemeinsamen Teile von ähnlichen Tabellen zu einer virtuellen zusammen zu fassen. Sie eignen sich jedoch nicht als Ziel von Referenzen. Es ließen sich damit zwar die verschiedenen einzelnen Tabellen aus Aufgabe 3.1 zu einer zusammen fassen aber weitere Tabellen könnten diese View nicht als Referenzziel nutzen. Eine andere Lösung besteht darin, mit Tabellen und Vererbung zu arbeiten. Dabei kann die Vatertabelle bereits alle Gemeinsamkeiten enthalten und als Referenzziel benutzt werden. Ändern Sie das Modell aus Aufgabe 3.2 dahingehend, sofern noch Änderungen erforderlich sind. Erklären Sie auch hier wieder Vor- und Nachteile der beiden Lösungswege. 3.4 Ordnen Sie jeder Vorlesung eine Fach- und Studienrichtung zu. Ferner sollen für jede Fachrichtung Lehrpläne aufgestellt werden. Dabei soll es jedem Studenten möglich sein sich in verschiedene Studienrichtungen zu spezialisieren. Daher muß aus der Datenbank ersichtlich werden, welche Fachkombinationen möglich sind und welche Vorlesungen in welchen Fachrichtungen zwingend sind. Neben den reinen Pflicht und Wahlvorlesungen muß es also noch Mindestanzahlen für Semesterwochenstunden6 geben. 3.5 Nehmen Sie in ihr Datenmodell nun noch die Noten, die ein Student in Prüfungen abgelegt hat auf. Dabei sollen die Informationen aus Aufgabe 3.4 derart erweitert werden, daß aus der Datenbank ersichtlich ist, welche Prüfungen ein Student ablegen muß. Gehen Sie davon aus, daß prinzipiell jede Vorlesung sowohl schriftlich, als auch mündlich geprüft werden kann. 3.6 Erstellen Sie ein Datenmodell, mit der Sie Ihre CD-Sammlung verwalten können. Das Modell muß also Interpreten, Titel und CDs speichern können. Zu jeder CD sollen Kaufdatum und Kaufpreis gespeichert werden. 3.7 Entwickeln Sie ein Datenmodell für eine Bücherei. Es werden also Informationen über Autoren, Titel und Bücher inklusive ISBN, Verlag und Erscheinungsdatum sowie deren Standort benötigt. Weiterhin sollen alle Ausleiher inklusive ihrer Adressen und Telefonnummern gespeichert werden. Damit soll es möglich sein zu jedem Buch entweder den Standort zu ermitteln oder den Ausleiher zu benachrichtigen. Bedenken Sie daß es maximale Ausleihzeiten gibt und das Ausleihen von Büchern nicht kostenfrei ist. 6 Semesterwochenstunden bezeichnet die Anzahl von Stunden die eine Vorlesung je Woche über die Dauer von einem Semester gehalten wird. Es wird hierbei vom Normalfall ausgegangen, daß jedes Semester ½ Jahr dauert. 38 Marcus Börger Relationale Datenbanken Anwendungsstrukturen 4 Anwendungsstrukturen Der Begriff Datenbank ist ein übergeordneter Begriff, dessen Landläufige Bedeutung lediglich das Bereithalten von Daten meint. Eine Datenbank im Sinne von Datenlieferant und Speicherort ist hingegen ein sogenanntes Database Management System (DBMS). Im Falle relationaler Datenbanken spricht man von Relational Database Management System (RDBMS). Drei sehr bekannte Systeme hierfür sind MySQL [FNA99], PostgreSQL [Mom00] und Oracle [CHRS00]. Sie vertreten jedes für sich eine Kategorie von Datenbanken. MySQL ist ein Beispiel für ein einfaches RDBMS. Es kennt weder Constraints noch externe Funktionen oder Trigger. Es wird aber gerade darum oft eingesetzt, da viele Datenbank Anwendungen ohne diese Mechanismen auskommen und MySQL dadurch wesentlich schneller sein kann. Da MySQL standardmäßig zudem auf Transaktionen verzichtet ist es nochmals schneller7. Besonders im Internet Umfeld ist die Verbindung von Linux, Apache, MySQL und PHP (LAMP) sehr weit verbreitet, da alle vier Komponenten weit verbreitet, frei verfügbar und sehr ausgereift sind. PostgreSQL sei hier als ein Vertreter von RDBMS genannt, die eben erwähnte Schwächen nicht aufweisen. Das Fehlen von Triggern und Constraints ist eine Schwäche, da diese ein sehr mächtiges Werkzeug für Sicherheit und Konsistenz bereitstellen. Mit Constraints ist es möglich Gültigkeitsregeln auf zu stellen und die Integrität der Datenbank zu gewährleisten. Mit Triggern schließlich können einige Automatismen im Datenumgang an die Datenbank übertragen werden. Damit lassen sich sowohl komplexe Integritätsregeln aufstellen, als auch zusätzliche Daten berechnen. Als letzter Vertreter sei hier Oracle erwähnt. Anbieter dieser Größenordnung liefern neben dem reinen RDBMS weitere speziell darauf zugeschnittene Zusatzprodukte aus, welche sämtliche Stärken ausnutzen können. Vor allem ist es aus Gründen wie Anschaffungspreis, Support, Weiterentwicklung usw. häufig interessant viele Komponenten von einem Anbieter zu beziehen. RDMBS stellen in heutigen Anwendungen nur noch einen Teil der Systemstruktur dar. Auf den RDBMS sitzen meist noch Anwendungsserver und die Clients. Generell unterteilt man die Systeme in 1-tier8, 2-tier und 3-tier Systeme (siehe auch [dtec97]). 4.1 1-tier Wenn das System lediglich aus einem RDBMS besteht, so spricht man von einem 1-tier System. Solche Systeme unterstützen maximal externe Terminals in der Ausführung sogenannter Datensichtgeräte. Alle Aufgaben des Systems erfolgen auf einer einzigen Maschine, dem sogenannten Mainframe. Mainframe Daten Terminals Abbildung 4.1: Mainframe 7 8 MySQL kennt seit Version 3.23.34 Transaktionen mit den Tabellentypen BDB und InnoDB. Mit n-tier ist hier n-Schichtenmodell gemeint (tier [engl.]: Schicht, Lage). Marcus Börger 39 Anwendungsstrukturen Relationale Datenbanken 4.2 2-tier Als Computer immer billiger wurden und die Anwendungen immer größer, wurde irgendwann der Punkt erreicht, an dem es billiger wurde, einen Teil der Aufgaben in die Terminals zu verlagern. In solchen als Client-Server bezeichneten Systemen, werden üblicherweise Teile der Applikationslogik auf den intelligenten Terminals oder Clients ausgeführt. Oft sind das vorverarbeitende Aufgaben oder Kontrollen der Eingaben. 4.3 3-tier Das Hauptaugenmerk bei 3-tier Systemen liegt darin die Anwendungslogik getrennt von der Datenhaltung auf einem Server oder einer Serverfarm zu realisieren, während die Präsentation vom Client ausgeführt wird. Die meisten Internet Informationsdienste sind als 3-tier Systeme realisiert. Hierbei wird ein RDBMS als Datenlieferant eingesetzt, der jedoch keine oder nur sehr einfache Berechnungen ausführt. Diese Berechnungen werden dann auf dem Applikationsserver ausgeführt. Dies hat zwei große Vorteile. Erstens minimiert man den Verwaltungsaufwand und zweitens braucht man keinen Zugriff auf die unverarbeiteten Daten zu gewähren. Damit erreicht man zum einen höhere Sicherheitsanforderungen und zum anderen ist es nicht erforderlich Algorithmen bekannt zu geben. Aber das Ganze hat noch weitere positive Effekte. Man kann sehr einfach Systemtunabhängigkeit erreichen, indem man nur einfache Dienste beim Client einsetzt. So werden immer häufiger Webbrowser als Anwendung beim Client genutzt. In Internet Szenarien kommen häufig noch weitere Computer oder Spezialisierte Geräte zum Einsatz, die zusätzliche Aufgaben wahrnehmen. Da diese Aufgaben aber meist mit Nebeneffekten oder der Kontrolle des Systems und nicht direkt damit zu tun haben bleibt es beim 3-tier Modell (Auch wenn mehr aktive Schichten/Komponenten zum Einsatz kommen spricht man noch vom 3-tier Modell). Die folgende Grafik veranschaulicht das zur Zeit am weitesten verbreitete Modell derartiger Intranet Anwendungen. Das eigentliche 3-tier Modell wird dabei aus Dantenbankserver, Applikationsserver und den Browsern im Internet gebildet. Die Daten werden für den Internet Transport vom Webserver aufbereitet, das hat keinen direkten Einfluß auf die eigentliche Anwendung. Die bereits genannten drei Server stehen meist als Serverfarm bei einem Internet Service Provider (ISP), der die Zugriffe mittels einer Firewall kontrolliert und im Falle mehrerer Webserver mittels eines Proxy auf diese verteilt. Der Betreiber der Anwendung kann über ein virtual private network (VPN) direkt auf die Server zugreifen. Zusätzlich zum Internet Zugang wird meist als Notlösung ein ISDN Zugang installiert. DB-Server AppServer WebServer Firewall Proxy Internet Daten Templates dHTML VPN ISDN Abbildung 4.2: Internet 3-tier Modell 40 Marcus Börger Relationale Datenbanken Installation 5 Installation Spätestens nachdem ein erstes Datenmodell kreiert wurde, sollten einige Überlegungen über das zu verwendende DBMS angestellt werden. Erst mit der Implementierung der Datenbank können reale Tests und weitere Analysen durchgeführt werden. Besonders das Zeitverhalten ist zu komplex, um es im Vorfeld theoretisch exakt bestimmen zu können. 5.1 MySQL MySQL wird unter der GNU General Public License vertrieben. Das bedeutet, daß der Einsatz kostenlos ist. Der weitere Vertrieb von MySQL wird in der GPL Lizenz geregelt, die jeder Distribution beiliegen muß. MySQL kann von der Internetseite www.mysql.com geladen werden. Ab Version 3.23.34 existieren 2 Versionen von MySQL. Die Standardausführung unterstützt ausschließlich solche Tabellentypen, die keine Transactions unterstützen, im einzelnen sind das MyISAM, ISAM, Heap und Merge. Die zweite Version, MySQL-max, unterstützt hingegen Transactions mit den neuen Tabellentypen BDB, innoDB und Gemini. Leider existiert zur Zeit noch keine Gemini Unterstützung für Windows Systeme. 5.1.1 Windows Bei der Installation unter Windows wird nach dem Zielverzeichnis gefragt, wenn dies nicht das Standard Verzeichnis c:\mysql ist, so muß das Zielverzeichnis im weiteren Verlauf der Installation manuell angepaßt werden. Im weiteren wird von einer Installation in das Verzeichnis c:\Programme\mysql ausgegangen. Ansonsten sollten bei der Installation alle Abfragen mit der Standardeinstellung quittiert werden. Sofern ein anderes Installationsverzeichnis gewählt wurde muß zunächst die Datei my-example.cnf als my.ini in das Windows Verzeichnis oder nach c:\my.cnf kopiert werden. Dort muß der Eintrag #basedir = d:/mysql/ auskommentiert werden indem das # Zeichen gelöscht wird. Dann muß noch das korrekte Zielverzeichnis angegeben werden. Wurde MySQL etwa in das Verzeichnis = C:\Programme\MySQL installiert, so wir die Zeile geändert zu basedir c:/programme/mysql/. Nun kann MySQL gestartet werden. Am besten installiert man MySQL als Service und startet ihn auch gleich. Hierbei ist zu überlegen, ob MySQL oder MySQL-max benutzt werden soll. Letzteres unterstützt auch die Tabellen Formate, die Transactions unterstützen. Danach sollte man ein Paßwort für den User root vergeben. Dazu wechselt man in das Verzeichnis bin unter mysql und startet dort mysql.exe. Dann wechselt man in die mysql Datenbank und ändert das Paßwort. Die Änderungen werden allerdings erst nach einem Neuladen der Tabellen wirksam. Hierzu dient der Aufruf von mysqladmin.exe mit Parameter reload. Zu beachten ist auch, daß die Paßwörter nicht im Klartext geschrieben werden und statt dessen die Funktion password genutzt werden sollte. Alle weitern Aufrufe von mysql müssen jetzt mit dem Parameter –p erfolgen. C:\Programme\mysql\bin\> mysql-max-nt.exe –-install C:\Programme\mysql\bin\> net start mysql C:\Programme\mysql\bin\> mysql.exe mysql> use mysql; mysql> update user set password=password('mysql'); mysql> exit C:\Programme\mysql\bin\> mysqladmin.exe reload C:\Programme\mysql\bin\> ? Abbildung 5.1: MySQL Installation unter Windows Marcus Börger 41 Installation Relationale Datenbanken 5.2 PostgreSQL PostgreSQL oder kurz Postgres ist eine Open Source Entwicklung mit Ursprung an der University of California at Berkeley. Open Source bedeutet, daß keinerlei Beschränkungen in Bezug auf die Nutzung von Postgres existieren. Neben der freien Version von Postgres, die unter der Internet Adresse http://www.postgresql.org verfügbar ist, existiert noch eine kommerzielle Version der Firma Great Bridge (http://www.greatbridge.com). 5.2.1 Windows Um PostgreSQL auf einem Windows Rechner zu installieren, muß zunächst cygwin mit Cygwin32 IPC installiert werden. Cygwin kann von der Webseite http://www.cygwin.com bzw. http://sources.redhat.com/cygwin/ geladen werden, es enthält in der aktuellen Version bereits PostgreSQL. Es wird zunächst der Cygwin Installer (setup.exe) benötigt, dazu einfach das Installer Icon rechts anklicken. Es empfiehlt sich Cygwin zunächst komplett als Paket zu laden und dann zu installieren. Das hat den enormen Vorteil, daß man Cygwin jederzeit neu installieren kann, ohne noch mal die ca. 60MB von der Website zu laden. Es muß zunächst ein Ziel (Local Package Directory) zum Speichern der einzelnen Installations Pakete angegeben werden. Danach wird die Verbindungsart festgelegt und eine Download Site ausgewählt. Sollten Probleme mit dem Zugriff über das Internet erfolgen, kann man die Internet Explorer Einstellungen übernehmen (Use IE5 Settings). Abbildung 5.2: Cygwin Download Sobald die Verbindung zur Download Site erfolgreich war, können die benötigten Pakete ausgewählt werden. Die Option Prev lädt die jeweils letzte Version, die Option Curr hingegen die Aktuelle und mit Exp bzw. Full/Part können die Pakete einzeln ausgewählt werden, wobei durch einen Klick auf das Symbol die gewünschte Aktion eingestellt wird. Wenn bereits Pakete geladen wurden, so findet sich deren Versionsnummer in der Spalte Current. Ein Häkchen in der Spalte Src? kann benutzt werden, um auch die Sourcen zu laden. Für ein brauchbares Minimalsystem empfehlen sich: ash, bash, binutils, cygwin, cygrunsrv, gawk, fileutils, findutils, less, man, sh-utils, login, postgres, sed, termcap, textutils und w32api. 42 Abbildung 5.3: Cygwin Download, Paketauswahl Marcus Börger Relationale Datenbanken Installation Nachdem die Paketauswahl erfolgt ist, kann der Download durch Klicken auf den Next Button gestartet werden. Nach einem erfolgreichem Download erscheint der Hinweis Download Complete und der Installer wird zunächst beendet. Durch einen erneuten Start des Installers kann Cygwin nun installiert werden. Im Gegensatz zum oben beschriebenen Download wird dazu die Installationsmethode Install from local Directory benutzt. Dabei muß zunächst das Local Package Directory angegeben werden. Wird der Installer aus dem Verzeichnis gestartet, indem der Download erfolgte, so ist das Verzeichnis bereits vorgewählt. Im nächsten Schritt wird das Zielverzeichnis der Installation (Select install root directory) festgelegt. Zusätzlich kann der Zeilenumbruch für Textdateien festgelegt werden, wobei Windows/DOS Carrige Return (ASCII 13) und Linefeed (ASCII 10) benutzt, während Unix nur Linefeed verwendet. Weiterhin kann festgelegt werden, ob die Installation für alle Benutzer oder nur für den Benutzer, der die Installation ausführt, zugänglich sein soll. Es folgt erneut die Paketauswahl, wobei hier nur die Pakete zur Auswahl stehen, die zuvor mit der Download from Internet Funktion geladen wurden. Nach erfolgter Auswahl sieht man den Fortschritt der Installation. Als letztes kann für eine Windowsinstallation typisch noch entschieden werden, ob man ein Icon auf der Oberfläche bzw. ein Eintrag im Startmenü erstellen möchte. Abbildung 5.4: Cygwin Installation Leider fehlt der Cygwin Distribution derzeit noch das erwähnte Cygwin32 IPC Paket. Dieses ist auf der Webseite http://www.neuro.gatech.edu/users/cwilson/cygutils/V1.1/cygipc/ verfügbar. Es muß die aktuelle Version geladen werden und in das Root Verzeichnis der Cygwin Installation kopiert werden. Die folgende Abbildung zeigt die Installation mit dem tar zxvf Aufruf für die Paketdatei cygipc-1.09-2.tar.gz und den Start des ipc-daemon. administrator@BAUMBART ~ $ cd / administrator@BAUMBART / $ tar zxvf cygipc-1.09-2.tar.gz administrator@BAUMBART / $ ipc-daemon & [1] 308 Abbildung 5.5: Cygwin32 IPC Installation Marcus Börger 43 Installation Relationale Datenbanken 5.2.2 Initialisierung von Postgres Bevor Postgres benutzt werden kann muß nun noch das Datenbankmanagementsystem initialisiert werden. Dazu wird die notwendige Verzeichnisstruktur sowie eine Datenbankvorlage erzeugt. Die Datenbankvorlage enthält alle Informationen, die für den Betrieb einer Datenbank notwendig sind. Das folgende Beispiel benutzt /usr/local/pgsql als Datenverzeichnis, da der Aufruf unter Cygwin erfolgte, wurde zunächst der ipc-daemon gestartet, bevor der initdb Aufruf ausgeführt werden konnte. Das dritte Kommando pg_ctl schließlich startet Postgres. Wenn der Start erfolgreich ist erhält man eine Bestätigung vom postmaster. Die beiden folgenden Befehle schließlich beenden Postgres bzw. den IPC-daemon (bitte auf die korrekte Prozeß-ID, hier 308, achten). administrator@BAUMBART / $ ipc-daemon & [1] 308 administrator@BAUMBART / $ initdb -D /usr/local/pgsql This database system will be initialized with username “administrator". This user will own all data files and must also own the server process. Creating directory /usr/local/pgsql Creating directory /usr/local/pgsql/base Creating directory /usr/local/pgsql/global Creating directory /usr/local/pgsql/pg_xlog Creating template1 database in /usr/local/pgsql/base/1 Done first run Creating global relations in /usr/local/pgsql/global Initializing pg_shadow. Enabling unlimited row width for system tables. Creating system views. Loading pg_description. Setting lastsysoid. Vacuuming database. Copying template1 to template0. Success. You can now start the database server using: /usr/bin/postmaster -D /usr/local/pgsql or /usr/bin/pg_ctl -D /usr/local/pgsql -l logfile start administrator@BAUMBART ~ $ pg_ctl -D /usr/local/pgsql start postmaster successfully started administrator@BAUMBART ~ $ pg_ctl stop waiting for postmaster to shut down.....done postmaster successfully shut down administrator@BAUMBART ~ $ kill 308 administrator@BAUMBART ~ $ [1]+ Terminated ipc-daemon Abbildung 5.6: Postgres Initialisierung 44 Marcus Börger Relationale Datenbanken Installation 5.2.3 Postgres als Windows Service Mit Cygwin kann Postgres unter Windows auch als Service eingerichtet werden. Dazu wird das Cygwin Paket cygrunsrv benutzt. Zunächst wird der ipc-daemon aus dem Cygwin32 IPC Paket als Service eingerichtet. Danach wird postgres als Service angelegt, wobei festgelegt wird, daß postgres von ipc-daemon abhängig ist. Wichtig ist, daß nicht die Datei postgres.exe als Service eingerichtet wird, sondern der Link postmaster benutzt wird. Nur über diesen Link kann Postgres als Server gestartet werden. Die Funktionsfähigkeit des Service kann mit dem SQL Interpreter psql nachgewiesen werden. Dazu wird eine Verbindung zur Datenbank template1 erstellt und die Versionsnummer von Postgres mit der Abfrage ‚select version();’ gelesen. Der Interpreter kann danach mit dem Kommando \q beendet werden. administrator@BAUMBART ~ $ cygrunsrv --install ipc-daemon –o -p /usr/local/bin/ipc-daemon.exe administrator@BAUMBART ~ $ cygrunsrv --install postgres –o -y ipc-daemon -p /bin/postmaster -a "-D /usr/local/pgsql" administrator@BAUMBART ~ $ cygrunsrv --start postgres administrator@BAUMBART ~ $ psql template1 Welcome to psql, the PostgreSQL interactive terminal. Type: \copyright for distribution terms \h for help with SQL commands \? for help on internal slash commands \g or terminate with semicolon to execute query \q to quit template1=# select version(); version -------------------------------------------------------------PostgreSQL 7.1.2 on i686-pc-cygwin, compiled by GCC 2.95.3-5 (1 row) template1=# \q administrator@BAUMBART ~ $ Abbildung 5.7: Postgres als Windows Service einrichten Da die beiden Installationsaufrufe von cygrunsrv mit dem Parameter –o ausgeführt wurden, werden beide Services beim Beenden von Windows automatisch beendet. Sollen die Services deinstalliert werden, so müssen sie zunächst mit cygrunsrv –stop ipc-daemon bzw. cygrunsrv –stop postgres beendet und dann mit cygrunsrv –remove ipc-daemon bzw. cygrunsrv –remove postgres entfernt werden, wobei jeweils der Aufruf für PostgreSQL zuerst erfolgen muß. Marcus Börger 45 Installation Relationale Datenbanken 5.3 Oracle Das Oracle Datenbank Management System ist auf der Internetseite www.oracle.com verfügbar. Es kann für den privaten Gebrauch und für Geschäftsinterne Entwicklungsaufgaben kostenlos genutzt werden. Einzelheiten hierzu bitte den jeweiligen Lizenzbestimmungen von Oracle entnehmen. Die folgenden Abschnitte beschreiben die Installation der Version 8.1.7 [HLU98], [CHRS00]. Eine Oracle Datenbank besteht immer aus dem Datenbank Managementsystem, der Kommunikationsschicht (Net8) und den Datenbankdiensten. Leider trennt Oracle die Begriffe Datenbank, Managementsystem und Dienst nicht eindeutig. Wenn man die korrekten Begriffe nutzt, so unterstützt ein Oracle Datenbank Management System mehrere Datenbankdienste. Neben den lokalen Datenbankdiensten kann ein Oracle System entfernte Datenbankdienste ansprechen. Innerhalb eines Datenbankdienstes existieren mehrere Tablespaces. Diese können mit den Datenbanken einer MySQL Installation verglichen werden. Die folgende Graphik veranschaulicht die Struktur eines Oracle Systems. Die darin unterstrichenen Elemente werden in den folgenden Abschnitten angelegt: Datenbankdienst (baumbart.boerger.de) Tabellen Schemaobjekte Tablespaces Objekte Personen Views System Benutzer Veranstaltungen Tabellen Uni Tablespaces besuchen Indizes Temporär Rolle Net8 Kommunikationsschicht SQL*Plus> _ Clients Weitere Computer Abbildung 5.8: Oracle System Struktur 46 Marcus Börger Relationale Datenbanken Installation 5.3.1 Windows Zur Oracle Installation unter Windows starten wir der Oracle Universal Installer benutzt (setup.exe). Es erscheint ein Splashscreen mit dem Logo und kurz darauf die Willkommenmeldung. Durch drücken des Button ‚Weiter’ gelangt man zur eigentlichen Installation. Zunächst werden Quell und Zielverzeichnis benötigt, wobei das Quellverzeichnis bereits korrekt ausgewählt sein sollte. Bei der Wahl des Zielverzeichnisses ist darauf zu achten, daß man durchaus mehrere Gigabyte an Platz benötigt, als Minimum kann man zunächst von einem Gigabyte ausgehen. Nachdem beide Angaben erfolgt sind und erneut ‚Weiter’ geklickt wurde, wird die Produktliste geladen. Hier wird durch Wahl der Option ‚Oracle8i Enterprise Edition’ die Installation des Datenbank Management Systems eingeleitet. Um die Installation den Erfordernissen anzupassen muß dann die Option ‚Benutzerdefiniert’ gewählt werden. Aus der Liste der verfügbaren Produktkomponenten können jetzt die Einzelkomponenten gewählt werden9. Nach der Auswahl, erfolgt die Möglichkeit für alle Komponenten getrennt den Speicherort zu wählen. Nach Klicken auf ‚Weiter’ gelangt man zu einer weiteren Auswahl. Es kann nach der Installation des Datenbank Management Systems die automatische Installation eines Datenbankdienstes gestartet werden. Wenn dies später erfolgen soll, so kann die Installation der Datenbank auch später durch den Aufruf des Oracle Database Configuration Assistent erfolgen. Das getrennt Vorgehen erscheint ratsamer, da zunächst die erfolgreiche Installation des Management Systems abgewartet werden kann. Nach Auswahl der Option ‚Nein’ für Datenbank nicht (später) installieren erfolgt eine Übersicht der ausgewählten Komponenten. Wenn hier ‚Installieren’ gewählt wird startet die Installation. Diese kann auch auf schnellen Systemen länger als eine halbe Stunde dauern. Nach der Installation des Management Systems wird automatisch der Net8 Konfigurationsassistent gestartet. Mit diesem kann nun ein zwingend erforderlicher Listener erstellt und konfiguriert werden. Im Normalfall reicht es aus hier die Checkbox ‚Typische Konfiguration’ zu nutzen. Auch hierbei können notwendige Änderungen später vorgenommen werden. Sollte sich der Universal Installer danach nicht mehr bedienen lassen, kann man ihn einfach beenden. Je nach Windows Version ist hierzu der Task Manager notwendig (Task jre). Bis hierher wurde das reine Datenbank Management System erstellt. Es gibt jetzt bereits die Möglichkeit mit einer anderen Oracle Datenbank zu kommunizieren, es wurde jedoch noch keine Datenbankinstanz erstellt. Es gibt auch noch keinerlei Datenbanktemplates oder Datenbankräume wie bei anderen Systemen. Das weitere Vorgehen ist unter 5.3.3 Database Configuration Assistant beschrieben. 5.3.2 Linux 9 Hier können Beispielsweise neben den zwingend erforderlichen Java 1.1 Komponenten auch die Java Komponenten in der Version 1.2 selektiert werden. Marcus Börger 47 Installation Relationale Datenbanken 5.3.3 Database Configuration Assistant Mit dem Database Configuration Assistant kann ein Datenbankdienst erstellt, konfiguriert oder geändert werden (Oracle benutzt in diesem Werkzeug den Begriff Datenbank). Wenn ein neuer Dienst angelegt werden soll, so empfiehlt es sich bei reinen Testinstallationen die Option Benutzerdefiniert, da man dadurch den Notwendigen Platz auf ein erträgliches Niveau drücken kann. Wenn Speicherplatz auch oberhalb von weiteren Gigabytes keine Rolle spielt, kann man sich die Mühe sparen und nutzt die Standard Option. Bei der Standardinstallation wird zunächst unterschieden, ob die Datenbank von einer bestehenden Vorlage oder komplett neu erstellt werden soll. Da hier normalerweise keine Vorlagen vorhanden ist, wird ‚Neue Datenbank erstellen’ aktiviert. Anschließend kann der Typ der Datenbank ausgewählt werden. Im allgemeinen empfiehlt sich hier der Typ ‚Mehrzweck’. Danach erfolgt die Abfrage der Anzahl der gleichzeitig angemeldeten Benutzer. Hierbei ist zu bedenken, daß jedes Dienstprogramm eine eigene Anmeldung benötigt. Die Standardeinstellung 15 ist also nicht übertrieben. Der nächste Schritt erlaubt die Festlegung der benötigten Komponenten. Eine genaue Beschreibung der einzelnen Komponenten kann der Online verfügbaren Hilfe entnommen werden. Für die hier dargestellten Beispiele reicht es vollkommen die Komponente SQL*Plus-Hilfe zu wählen. Abschließend wird nach einem Globalen Datenbanknamen und einem Oracle Systembezeichner, kurz SID, gefragt. Der globale Datenbankname besteht aus dem lokal eindeutigen Datenbanknamen und einem Domänennamen, die durch einen Punkt getrennt werden. Dabei darf der Datenbankname aus maximal 8 alphanumerischen Zeichen bestehen und muß mit einem Buchstaben beginnen. Der SID darf ebenfalls aus maximalen 8 alphanumerischen Zeichen bestehen und muß auch mit einem Buchstaben beginnen. Es empfiehlt sich den gleichen Namen für Datenbanknamen und SID zu benutzen. Falls auf einem Rechner mehrere Datenbankdienste installiert werden sollen, muß dieser auf dem jeweiligen System eindeutig sein. Der Domänenname sollte der Netzwerkdomäne entsprechen. Wenn keine Netzwerkdomäne festgelegt ist, so kann man einfach den Namen des Rechners benutzen. Die benutzerdefinierte Installation entspricht bis einschließlich der Auswahl der Anzahl der gleichzeitig angemeldeten Benutzer identisch der oben beschriebenen Standardinstallation. Es folgt die Festlegung des Datenbank Modus. Für kleiner Tests empfiehlt sich hierbei die Auswahl ‚Dedizierter Server-Modus’. Nachfolgend wird auch hier ein globaler Datenbankname und ein SID erfragt. Zusätzlich können noch ein Dateiname für die Initialisierung, der zu verwendende Zeichensatz und der Kompatibilitätstyp festgelegt werden. In der Initialisierungsdatei werden Steuerinformationen des zu erstellenden Datenbankdienstes gespeichert. Die zusätzlichen Parameter können im allgemeinen den Defaultwert behalten. Auf der nachfolgenden Seite können einige Parameter der Initialisierungsdatei geändert werden. Es ist dabei günstig alle Dateien, die zu einer Datenbank gehören in einem Verzeichnis zu speichern. Bei größeren Datenbanken sollte hingegen die eigentlichen Datendateien der Datenbank auf mehrere Festplatten verteilt werden. Diese Verteilung und die Größe bzw. das Verhalten bei notwendigen Größenänderungen kann auf der nächsten Seite für System, Werkzeuge, Benutzer, Rollback, Index und den Temporären Tablespace getrennt eingestellt werden. Dabei stellt ein Tablespace einen Bereich zur Speicherung von Tabellen etc. dar. Dies kann man mit dem Anlegen einer Datenbank bei anderen Systemen vergleichen. MySQL hat im Vergleich nur einen Dienst und jede Datenbank ist mit einem Tablespace vergleichbar. Der Tablespace System hat etwa die gleichen Aufgaben der Datenbank mysql unter MySQL. Die Tabelle 5.1: Oracle, Tablespace Parameter zeigt ein Beispiel für einen Datenbankdienst, dessen Größe zum Austesten der Beispiele und zum Anlegen einfacher eigener Datenbanken vollkommen ausreichend ist. Neben den in der Tabelle angegebenen Parametern kann hier für jeden einzelnen Tablespace ein Dateiname festgelegt werden. 48 Marcus Börger Relationale Datenbanken Tablespace Größe System Werkzeuge Benutzer Rollback Index Temporär 32 12 16 128 32 32 Installation Autom. Min. Nächste Wachstum Ausgangs- Nächste Min Erweitern Extent Wert Ja 64 512 50 64 64 1 Ja 32 320 0 32 32 1 Ja 128 1024 0 128 128 1 Ja 512 4096 -/512 512 4 Ja 128 1024 0 128 128 1 Ja 64 1024 -/64 64 -/- Max Unbegrenzt -/4096 -/4096 4096 -/- Ja Nein Ja Nein Nein (Ja) Tabelle 5.1: Oracle, Tablespace Parameter Auf den nächsten Seiten werden die Dateien und Größen der Redo-Log-Dateien, Angaben zu Checkpoints und SGA-Parameterinformationen bestimmt. Bei Testsystemen reicht für die Größe des gemeinsamen Pools die Angabe von 33554432 Byte (32 MByte) und als Blockgröße empfehlen sich 4096 Byte, da dieser Wert im allgemeinen der Clustergröße auf den Festplatten entspricht. Wenn Java benötigt wird muß der Pool mindestens 52428800 Byte (50 MByte) groß sein. Anschließend können noch Verzeichnisse für Traceinformationen festgelegt werden. Danach kann die eigentliche Installation gestartet werden. Wenn die oben genannten Größen übernommen werden, muß man für die Installation etwa eine halbe Stunde veranschlagen. Wenn eine Oracle Datenbank nicht mehr für Testzwecke sondern für eine Tatsächliche Anwendung installiert werden soll, so empfiehlt es sich dringend mit den einzelnen Komponenten und den mit ihnen verbundenen Parametern eingehend zu beschäftigen. Erst ein Verständnis der Parameter führt zu einer Datenbank die einerseits schnell genug reagiert und andererseits adäquates Speichervolumen belegt. Nach der Installation der Datenbank existieren zwei Benutzer. Der Benutzer scott hat das Paßwort tiger und der Benutzer system das Paßwort manager. Diese beiden Benutzer werden benötigt um die Datenbank weiter an die eigenen Ansprüche anzupassen bzw. mit ihr zu arbeiten. SQL Statements können nun mit SQL*Plus ausgeführt werden. Dabei ist darauf zu achten, daß jedem Benutzer ein Tablespace zugewiesen ist. Diese und andere Anpassung erfolgen mit dem DBA Studio. 5.3.4 Net8 Assistant Einen ersten Test der Installation kann man auch mit dem Net8 Assistant vornehmen. Dazu wird der eben erstellte Datenbankdienst ausgewählt und die Funktion ‚Dienst testen...’ gewählt. Wie in Abbildung 5.9: Oracle, Net8 Assistant zu sehen ist, wurde der Datenbankdienst mit dem globalen Datenbanknamen baumbart.boerger.de installiert. Abbildung 5.9: Oracle, Net8 Assistant Marcus Börger 49 Installation Relationale Datenbanken Der Net8 Assistant kann auch benutzt werden, um einen Datenbankdienst, der auf einem anderen Computer ausgeführt wird, als lokalen Datenbankdienst ansprechen zu können. Dazu wird zunächst Dienstbenennung selektiert und dann der ‚Erstellen...’ Button geklickt. In den folgenden Dialogen wird nach den Verbindungsparametern gefragt. Dabei ist der Net Service Name, der Name, den der Datenbankdienst lokal bekommen soll. Dieser Name hat lediglich auf dem Computer Bedeutung, auf dem die Verbindung konfiguriert wird. Daher auch die Bezeichnung Dienstbenennung. Am einfachsten benutzt man hier den globalen Datenbanknamen. Die Kommunikation erfolgt im allgemeinen über TCP/IP. Abschließend werden noch der Hostname und der globale Datenbankname benötigt. Der Hostname ist dabei der DNS Name oder die IP Adresse des Computers auf dem die Datenbank installiert ist. 5.3.5 DBA Studio Mit dem DBA Studio können alle Objekte von Oracle Datenbanken (auch auf entfernten Rechnern) eingesehen und meist auch modifiziert werden. Die Datenbanken müssen entweder mit dem Net8 Assistant als Dienst eingetragen werden oder es muß eine Verbindung zur lokalen Installation erfolgen. Wenn noch keine Verbindung besteht, zum Beispiel beim ersten Aufruf, kann eine Verbindung ausgewählt bzw. eingerichtet werden. Im Normalfall steht kein Management Server zur Verfügung, so daß die Option Launch DBA Studio alone benutzt werden muß. Abbildung 5.10: Oracle, Anmelden bei Oracle Enterprise Manager Wenn keine bevorzugten ID-Daten eingestellt wurden aber bereits Dienste in der Liste eingetragen sind, kann jetzt ein Datenbankdienst ausgewählt werden. Dazu muß lediglich der Name in der Liste der konfigurierten Dienste angeklickt werden. Es erscheint der Anmelde Dialog. Bereits beim Anmelden wird die Rolle festgelegt mit der die Verbindung arbeiten soll. Diese kann NORMAL, SYSOPER oder SYSDBA sein. Wenn die Datenbank konfiguriert werden soll, muß die Anmeldung als SYSDBA erfolgen. Abbildung 5.11: Oracle, Datenbank-Anmeldung als SYSDBA Bei der Installation werden wie bereits erwähnt die beiden folgenden Benutzer angelegt: Benutzer scott system Paßwort tiger manager Tabelle 5.2: Oracle, Standardbenutzer 50 Marcus Börger Relationale Datenbanken Installation Wenn noch keine Datenbank in der Liste bekannt ist, folgt die Auswahl der Verbindung. Am einfachsten kann hier ein Dienst aus der Liste der bereits konfigurierten Datenbankdienste ausgewählt werden. Abbildung 5.12: Oracle, Datenbank hinzufügen zeigt das am Beispiel baumbart.boerger.de. Abbildung 5.12: Oracle, Datenbank hinzufügen Jetzt kann ein eigener Tablespace angelegt werden. Im folgenden wird hier der Tablespace UNI angelegt. Nach Klicken des ‚Erstellen’ Button kann der Typ des zu erstellenden Objektes augesucht werden. Hier also Tablespace. Neben dem Namen des Tablespace können weitere Eigenschaften festgelegt werden. Insbesondere kann das Größenverhalten bestimmt werden. Entweder kann die Größe lokal oder vom Dictionary verwaltet erfolgen. Bei Auswahl der zweiten Möglichkeit können zusätzlich noch die einzelnen Parameter der Extent Verwaltung geändert werden. Die lokale Verwaltung hat den Vorteil, daß der Tablespace sich alleine Verwaltet. Das ist meist schneller als globale Organisationstabellen der Dictonary Verwaltung zu benutzen. Damit aber überhaupt eine automatische Größenanpassung erfolgen kann, muß dieses noch für die Datendatei eingeschaltet werden. Hierzu wird die Datendatei markiert und mit dem ‚Datendatei bearbeiten’ Button konfiguriert. Abbildung 5.13: Oracle, Tablespace erstellen Marcus Börger 51 Installation Relationale Datenbanken Im erscheinenden Dialog kann die Anfangsgröße der Datendatei festgelegt werden und es kann die Funktion ‚Datendatei automatisch erweitern...’ eingeschaltet werden. Damit das ganze funktioniert muß natürlich auch eine Inkrement Größe angegeben werden. Bei jeder Anforderung die zu einer größeren Datendatei führt wird diese dann mindestens um diesen Wert vergrößert. Weiterhin kann die Größe der Datendatei noch beschränkt werden. Abbildung 5.14: Oracle, Datendatei bearbeiten Nachdem der Tablespace erstellt wurde kann nun ein Benutzer angelegt werden, und diesem die beiden Tablespaces Standard und Temporär zugewiesen werden. In Abbildung 5.15: Oracle, Benutzer bearbeiten wurde dem neu erstellten Benutzer der Name UNI gegeben und ihm der Standard Tablespace UNI zugewiesen. Bei jeder weiteren Verbindung des Benutzers UNI erfolgen dessen Tätigkeiten im Tablespace UNI. Damit können mittels des Benutzers UNI im Tablespace UNI alle Beispiele der folgenden Kapitel ausgetestet werden. Abbildung 5.15: Oracle, Benutzer bearbeiten In Abbildung 5.15: Oracle, Benutzer bearbeiten wurde dem Benutzer Uni auch die DBA (Database Administrator) Rolle übertragen. Damit kann dieser Benutzer alle Objekte des Datenbankdienstes bearbeiten; sowohl die Objekte im Tablespace UNI als auch alle anderen Objekte. Da jetzt ein DBA erstellt und bekannt ist, können die beiden Standardbenutzer scott und system gelöscht oder ihre Kennwörter deaktiviert werden. Zum Deaktivieren wird einfach die Checkbox ‚Kennwort läuft jetzt ab’ auf der Seite ‚Allgemein’ eingeschaltet. 52 Marcus Börger Relationale Datenbanken Installation 5.3.6 SQL*Plus Zur Ausführung von SQL Befehlen wie sie in den folgenden Kapiteln beschrieben werden gibt es bei Oracle das SQL*Plus Worksheet und SQL*Plus Zeilenmodus. Während SQL*Plus Zeilenmodus einzelne Befehle entgegen nimmt und diese direkt ausführt, kann mit dem SQL*Plus Worksheet ein ganzes Skript ausgeführt werden. Das kann benutzt werden, um umfangreiche Datenbankaufgaben zu erledigen oder formatierte Berichte zu erstellen. Näheres zu den Formatierungsfunktionen findet sich in [Genn99]. Wie bei allen Werkzeugen erfolgt zunächst die Anmeldung die einem Datenbankdienst. Die Abbildung 5.16: Oracle, Anmeldung als Normal zeigt dies für den Datenbankdienst baumbart.boerger.de als Benutzer UNI: Abbildung 5.16: Oracle, Anmeldung als Normal Da dem Benutzer UNI der Tablespace UNI zugewiesen wurde, finden also alle folgenden Befehle solange im Tablespace UNI statt, wie nicht explizit ein anderer angegeben wird. Das eigentliche SQL*Plus Worksheet besteht aus zwei Bereichen, dem Eingabebereich, weiß hinterlegt, und dem Ausgabebereich, grau hinterlegt. Im Eingabebereich können beliebig viele SQL Befehle hintereinander eingegeben werden. Diese werde bei Klicken auf den ‚Ausführen’ Button abgeschickt. Das Ergebnis ist dann im Ausgabebereich zu sehen. Beide Bereiche können getrennt von einander gelöscht und abgespeichert werden. Abbildung 5.17: Oracle, SQL*Plus Worksheet Die aktuelle Datenbankverbindung kann durch Klicken auf den ‚Datenbankverbindung ändern...’ Button geändert werden. Einfache Texte können mit dem PROMPT Befehl ausgegeben werden: PROMPT Text; Abbildung 5.18: Oracle, SQL PROMPT Marcus Börger 53 Data Definition Language Relationale Datenbanken 6 Data Definition Language Die folgenden Kapitel geben eine Einführung in die Structured Query Language (SQL). SQL ist zwar ein oft zitierter Standard, doch weichen manche Datenbanken in Teilen davon ab und die meisten haben eigene Erweiterungen, insbesondere gibt es jedoch Unterschiede in der Syntax und den unterstützten Datenformaten. Daraus ergibt sich die folgende Empfehlung bei der Arbeit mit einem bestimmten Datenbank Management System. Entweder man benutzt ein Modellierungswerkzeug, daß die benutzte Datenbank unterstützt oder man besorgt sich vor der Arbeit ein Buch oder eine Online Hilfe, in der man die verwendete Syntax und den verwendeten Umfang nachschlagen kann. Die Data Definition Language (DDL) dient dem Erzeugen der Datenstrukturen, die während der Modellierungsphase erstellt wurden. Weiterhin existieren Befehle zur Manipulation der Strukturen und zur Vergabe von Rechten auf diesen Datenstrukturen. Auf den folgenden Seiten wird SQL mit Hilfe der EBNF beschrieben (siehe A EBNF). Ein Verständnis des hier verwendeten EBNF Teilumfangs ist zwingend erforderlich. 6.1 CREATE DATABASE Als erstes wird mit dem Befehl CREATE DATABASE eine neue Datenbank angelegt: CREATE DATABASE Datenbankname; Abbildung 6.1: Aufbau des Befehles CREATE DATABASE Dieser Befehl wird unter MySQL und PostgreSQL zum Erfolg führen. Die meisten anderen Datenbank Managementsysteme benötigen weitere Angaben, die das Erstellen der Datenbankdateien regeln. Bei diesen Systemen sollten spezialisierte mitgelieferte Werkzeuge benutzt werden. Im Falle von Oracle siehe hierzu 5.3.3 Database Configuration Assistant. 6.2 Verbinden mit der Datenbank Nachdem eine Datenbank angelegt worden ist, kann dorthin verbunden werden. Danach beziehen sich dann alle Befehle auf diese Datenbank. Die Art und Weise, wie mit einer Datenbank verbunden wird, ist sehr stark abhängig vom verwendeten Datenbank Managementsystem. Viele bieten jedoch den Befehl CONNECT, der genau diese Aufgabe erfüllt: CONNECT Datenbankname; Abbildung 6.2: Verbinden mit der Datenbank 6.3 Anlegen und Verbinden mit dem Beispiel Die Beispieldatenbank Uni wird mit dem folgenden Aufruf angelegt und mit dem zweiten Befehl wird dorthin verbunden: Not connected> CREATE DATABASE Uni; Database Uni created. Not connected> CONNECT Uni; Connected to Database Uni Uni> ? Abbildung 6.3:Anlegen der Datenbank Uni 54 Marcus Börger Relationale Datenbanken Data Definition Language 6.4 CREATE TABLE Sobald eine Datenbank angelegt worden ist und die Verbindung besteht, können Tabellen erzeugt werden. Jede Tabelle erhält mindestens eine Spaltendefinition, sind mehrere notwendig, so werden die einzelnen Spaltendefinitionen durch Kommata getrennt. Wird der Primary Key einer Tabelle aus einer einzigen Spalte gebildet, so kann die Definition des Primary Key bereits in der entsprechenden Spaltendefinition erfolgen. Wenn der Primary Key nicht aus einer einzelnen Spalte gebildet wird, muß er in einem Constraint festgelegt werden. Nach den Spaltendefinitionen können weitere Constraints folgen, die jeweils durch ein Komma getrennt werden. Indizes verwenden anstelle von PRIMARY KEY das Schlüsselwort INDEX, oder im Falle eindeutiger Indizes das Schlüsselwort UNIQUE. Die Erzeugung von nicht eindeutigen Indizes kann in den meisten Datenbank Management Systemen jedoch nur außerhalb der Tabellen Deklaration mit Hilfe des Befehles CREATE INDEX erfolgen. CREATE [ TEMPORARY ] TABLE Name ( Spaltendefinitionen[, Constraints] ) [ Optionen ]; Abbildung 6.4: Aufbau des CREATE TABLE Befehles Eine Tabelle kann durch Angabe der Option TEMPORARY als temporäre Tabelle angelegt werden. In diesem Fall ist die Tabelle nur für die aktuelle Session sichtbar. Sie wird also einerseits am Ende der Session gelöscht und andererseits ist sie für andere Benutzer nicht sichtbar. Daraus ergibt sich auch, daß zwei Benutzer eine temporäre Tabelle mit gleichem Namen anlegen können. Einige DBMS erlauben in Optionen zusätzliche Parameter am Ende der Definition. 6.4.1 CREATE TABLE für MySQL MySQL verfügt über einige Erweiterungen im CREATE TABLE Befehl. Neben der Möglichkeit den Tabellentyp festzulegen ist besonders die Erweiterung IF NOT EXISTS interessant, die es ermöglicht eine Tabelle nur dann anzulegen, wenn sie noch nicht existiert. Mittels der Angabe eines SELECT Befehls kann die Tabelle als Kopie einer Anderen erstellt werden (6.4.4 CREATE TABLE SELECT). CREATE [ TEMPORARY ] TABLE [ IF NOT EXISTS ] Name ( Spaltendefinitionen [, Constraints ] ) [TYPE={ISAM|MYISAM|HEAP|MERGE|BDB|INNODB}][UNION=( Tabellen )] [SELECT ... ]; Abbildung 6.5: CREATE TABLE für MySQL Die folgende Tabelle zeigt eine Übersicht der möglichen Tabellentypen. Option Bemerkung Alter Standard Tabellentyp. Standard Tabellentyp (Typ ISAM erweitert). Temporäre Tabellen, die nicht auf Festplatte gelangen. Unterstützt nicht: BLOB, TEXT, AUTO_INCREMENT, etc. TYPE=MERGE Nein Zusammenfassung mehrerer Tabellen. Liste der Tabellen wird in der Option UNION gesetzt. TYPE=BDB Page Locking Berkeley Database ( ab 3.23.34). TYPE=INNOBASE Row Locking Tabellentyp unter GPL Lizenz ( ab 3.23.34). TYPE=ISAM TYPE=MYISAM TYPE=HEAP Transactions Nein Nein Nein Tabelle 6.1: MySQL Tabellentypen Marcus Börger 55 Data Definition Language Relationale Datenbanken 6.4.2 Spaltendefinitionen Jede Spaltendefinition beginnt mit dem Namen der zu definierenden Spalte gefolgt vom Datentyp. Alle anderen Angaben sind optional. Zunächst kann ein Standardwert mit DEFAULT Wert festgelegt werden. Danach kann eine Angabe erfolgen ob der Wert NULL erlaubt ist oder nicht. Hierbei ist darauf zu achten, ob das Datenbank Management System den Wert NULL in Primary Key oder Index Spalten erlaubt. Soll der Wert NULL erlaubt werden, so ist keine Angabe erforderlich, die Angabe NULL darf aber enthalten sein. Im anderen Fall wird NOT NULL benutzt. Mit AUTO_INCREMENT wird eine Spalte definiert, die automatisch einen eindeutigen Wert erhält, falls kein Wert angegeben wird. AUTO_INCREMENT ist eine SQL Erweiterung die von unter anderen von MySQL und MS Access benutzt wird. Oracle unterstützt keine AUTO_INCREMENT Felder, das Verhalten kann aber mit einer Sequence manuell nachgebildet werden. In PostgreSQL existiert der Datentyp SERIAL als Ersatz für AUTO_INCREMENT10. Spaltenname Datentyp [ DEFAULT Wert ] 10 [ AUTO_INCREMENT ] [ NOT NULL | NULL ] Abbildung 6.6: Einfache Spaltendefinitionen Die Spaltendefinition kann auch Constraints enthalten, wobei optional Namen vergeben werden können. Die Angabe PRIMARY KEY legt die Spalte als Primary Key fest und darf nur für eine einzige Spaltendefinition benutzt werden. Ein zusammengesetzter Primary Key kann also nicht angelegt werden, indem jede beteiligte Spaltendefinition das Schlüsselwort PRIMARY KEY erhält. Alternativ zu PRIMARY KEY kann mit UNIQUE eine Spalte als Alternate Key definiert werden. Erhalten mehrere Spalten UNIQUE, so bildet jede dieser Spalten einen eigenen Alternate Key. Wie bereits erläutert, kann eine Spalte, die Teil des Primary Key ist, nicht den Wert NULL erhalten, die Angabe NULL ist also zusammen mit PRIMARY KEY nicht zulässig. Im Gegensatz dazu sind NULL Werte bei UNIQUE zulässig und das sogar mehrfach. Die Angabe von NOT NULL bei UNIQUE ist also erforderlich, um NULL Werte zu verhindern. Ein Foreign Key kann natürlich nur zu einer Spalte einer Tabelle erfolgen, wobei auch der Datentyp übereinstimmen muß. Wenn die Primary Key Spalte der angegebenen Tabelle referenziert werden soll, kann die Angabe der Spalte inklusive Klammern entfallen. Spaltenname Datentyp [ DEFAULT Wert ] [ [ NOT ] NULL ] 10 [ AUTO_INCREMENT ] [[ CONSTRAINT Name ] { UNIQUE | PRIMARY KEY } ] [[ CONSTRAINT Name ] CHECK (Bedingung) ] [[ CONSTRAINT Name ] REFERENCES Tabelle [(Spaltenname)] [ Deferrment ] [ ON UPDATE Aktion ] [ ON DELETE Aktion ] ] Abbildung 6.7: Spaltendefinitionen MySQL erlaubt weder die Angabe von Bedingungen über CHECK(...) noch die Definition einer Relation mittels REFERENCES. Da MySQL diese Angaben aber ignoriert, können SQL DDL Dateien, die für andere Datenbank Management Systeme geschrieben worden sind, meist ohne Änderung übernommen werden. Oracle setzt bei Relationen immer das Verhalten ON UPDATE RESTRICT ein. Angaben zur Steuerung der Relationssicherung sind nur für ON DELETE erlaubt. 10 Anlegen einer impliziten Sequence in MySQL. In PostgreSQL wird durch SERIAL implizit eine Sequence angelegt. Alternativ kann der Default Wert einer Spalte das Ergebnis einer explizit deklarierten Sequence sein DEFAULT nextval(′Sequencename′). Siehe auch 6.9 CREATE SEQUENCE. 56 Marcus Börger Relationale Datenbanken Data Definition Language 6.4.2.1 SQL Datentypen In 2.2.3 Datentypen wurden Datentypen grundsätzlich behandelt. Dieser Abschnitt beschreibt jetzt die mit SQL verwendbaren Datentypen. 6.4.2.1.1 Alphanumerische Datentypen Datentyp MySQL PostgreSQL Oracle CHAR CHAR CHAR Exakt 1 Zeichen Exakt 1 Zeichen Exakt 1 Zeichen CHAR(n) Exakt n Zeichen, wobei 1<=n<=255. CHAR(n) Exakt n Zeichen, wobei 1<=n<=255. VARCHAR(n) Maximal n Zeichen. [N]VARCHAR[2](n) Zeichenketten CHAR(n) exakter Länge Exakt n Zeichen, wobei aufgefüllt mit 0<=n<=255. Leerzeichen CHAR(0) NULL Datentyp der exakt zwei Werte hat: NULL und ''. VARCHAR(n) Zeichenketten variabler Länge Maximal n Zeichen, wobei 1<=n<=255. In späteren Versionen sollen bis zu 65535 Zeichen unterstützt werden. Vor Version 7.1 je nach Binaries zwischen 8192 und 32768 Bytes. Ab Version 7.1 abhängig vom System bis zu 1GB bzw. 4GB11. NAME Maximal 32 Zeichen. TINYTEXT Max. 255=28-1 Zeichen Maximal n Bytes, wobei 1<=n<=4000. VARCHAR2 unterstützt lediglich ASCII Zeichen. NVARCHAR2 unterstützt ebenfalls maximal 4000 Bytes jedoch mit konfigurierbaren Zeichensätzen, so daß die Anzahl der Zeichen in Abhängigkeit vom Zeichensatz kleiner der Anzahl der Bytes sein kann. TEXT [N]CLOB Verhält sich wie ein unbeschränktes VARCHAR. Maximal 4 GB Daten, wobei CLOBs ASCII Zeichen speichert und NCLOBs in Abhängigkeit vom verwendeten Zeichensatz arbeitet. TEXT Max. 65535=216-1 Zeichen. Text 12 MEDIUMTEXT Max. 16777215=224-1 Zeichen. LONGTEXT Max. 4294967295=232-1 Zeichen. Tabelle 6.2: Alphanumerische Datentypen 11 Bei 64bit Binaries vermutlich mehr. 12 Mit Version 8 wurden die neuen Datentypen [N]VARCHAR2 eingeführt. Die alte Datentypen [N]VARCHAR existieren weiterhin, die Unterschiede sind jedoch unbekannt. Marcus Börger 57 Data Definition Language Relationale Datenbanken 6.4.2.1.2 Numerische Datentypen Datentyp MySQL Oracle SMALLINT, INTEGER 2 Bytes mit Vorzeichen: Eine Beschränkung [ -32768 ; +32767 ] 1 Byte [ -128 ; 127 ], ähnlich der von vzl.13: [ 0 ; 255 ] MySQL und INTEGER, INT, INT4 PostgreSQL konnte 4 Bytes mit Vorzeichen: SMALLINT[(m)] nicht festgestellt wer[UNSIGNED][ZEROFILL] [-2147483648;+2147483647] den. 2 Byte [ -32768 ; 32767 ] BIGINT, INT8 vzl.13: [ 0 ; 65535 ] 8 Bytes mit Vorzeichen: Folgendes kann mit Oracle 8i2 unter Win[ -263 ; +263-1 ] MEDIUMINT[(m)] dows 2000 i86 [UNSIGNED][ZEROFILL] SERIAL ermittelt werden: 3 Byte [-8388608;8388607] 13 4 Bytes ohne Vorzeichen: vzl. : [ 0; 16777215 ] 133 133 2133 == 2133-50 [ 0 ; 2147483647 ] 2132 != 2132-51 Werte werden aus einer INT[EGER][(m)] 2 != 2 +1 [UNSIGNED][ZEROFILL] impliziten Sequence generiert. 4 Byte: [ -232 ; 232-1 ] Das entspräche 16,5 13 vzl. : [ 0 ; 4294967295 ] Byte. Oracle selbst ermittelt einen PlatzBIGINT[(m)][UNSIGNED] bedarf von 40 Bytes. TINYINT[(m)] [UNSIGNED][ZEROFILL] Fixkomma PostgreSQL SMALLINT, INT2 [ZEROFILL] 8 Byte: [ -263 ; 263-1 ] vzl.13: [ 0 ; 264-1 ]14 Jeder Integer Typ kann mit Formatierungen versehen werden (sieh FLOAT). FLOAT[(p|m,d)] Fließkomma FLOAT4 Einfache Genauigkeit, falls 4 Byte, Einfache Genaup,m,d<=24 sonst doppelte igkeit: [ -1.175494351E-38 , Genauigkeit. -3.402823466E+38 ; 15 {DOUBLE PRECISION | +1.175494351E-38 , DOUBLE|REAL}[(p|m,d)] +3.402823466E+38] Doppelte Genauigkeit Es kann optional entweder die Genauigkeit (p<53) oder die Anzeigelänge (m<256) und die Anzahl der Nachkommastellen (d<30, d<m-2) angegeben werden. ZEROFILL füllt links mit 0en auf. FLOAT REAL 15 DOUBLE PRECISION FLOAT, FLOAT8, 15 DOUBLE PRECISION 8 Byte, doppelte Genauigkeit: [-1.7976931348623157E-308, -2.2250738585072014E+308; +1.7976931348623157E-308, +2.2250738585072014E+308] Tabelle 6.3: Numerische Datentypen 13 vzl: Vorzeichenlose Werte können ein Bit mehr benutzen, indem ansonsten das Vorzeichen gespeichert wird. Wegen der verwendeten Rechenwerke heutiger Prozessoren (auch 64-bittige) sollten die Werte kleiner +263 sein. 15 Der Datentyp DOUBLE PRECISION benutzt tatsächlich zwei Wörter und wird von allen drei unterstützt. 14 58 Marcus Börger Relationale Datenbanken Data Definition Language 6.4.3 Constraints Den Abschluß einer Spaltendefinition bildet die Angabe über Bedingungen (Constraints). Es gibt verschiedene Arten von Constraints, sie schränken jedoch alle den Wertebereich von Spalten oder Spaltengruppen ein. Mit MySQL können keine Constraints benutzt werden. Wie bereits erwähnt ignoriert MySQL allerdings die meisten Angaben zu Constraints, so daß korrekte Definitionen wenigstens eingelesen werden können. 6.4.3.1 Check Constraint Mit Check Constraints können die Wertebereiche von Spalten eingeschränkt werden. [ CONSTRAINT Name ] CHECK (Bedingung) Abbildung 6.8: Check Constraint Dazu können sowohl Operatoren wie <, <=, >, >=, =, <>, and, or, not, in sowie IS NULL als auch Funktionen wie length zum Einsatz kommen. Bereits durch den Einsatz der Operatoren können Intervalle und Aufzählungen16 realisiert werden. Hierzu einige Beispiele: CREATE TABLE test t1 INT t2 INT t3 INT t4 INT t5 INT t6 CHAR t7 CHAR t8 VARCHAR(3) t9 VARCHAR(4) ); ( CHECK ( t1 > 0 ), CHECK ( t2 != 0 ), CHECK ( t3 <> 0 ), CHECK ( t4 < 0 AND t4 > 0 ), CHECK ( NOT t5 IS NULL AND NOT t5=0 ), NOT NULL CHECK ( t6=’A’ OR t6=’B’ OR t6=’C’), NOT NULL CHECK ( t7 IN (’A’,’B’,’C’) ), NOT NULL CHECK ( length(t8) > 1 ), NOT NULL CHECK ( length(t9) > length(t8) ) Abbildung 6.9: Check Constraints Die Spalte t1 darf nur NULL oder solche Werte annehmen die größer 0 sind. Die Werte der Spalten t2 und t3 müssen ungleich 0 sein, wobei auch hier NULL zulässig ist. In t4 ist nur der Wert NULL zulässig, denn es existiert keine Zahl, die sowohl kleiner als auch größer 0 ist. Auch die Werte für t5 müssen ungleich 0 sein, nur daß hier zusätzlich keine NULL Werte erlaubt sind. Alle anderen Spalten müssen ebenfalls einen Wert ungleich NULL annehmen. In den Spalten t6 und t7 sind nur die Zeichen A, B und C zulässig. Die Bedingung der Spalte t8 legt fest, daß die Werte mehr als 1 Zeichen lang sein müssen. Eine Besonderheit ist die Definition für t9, die verlangt, daß die Werte in t9 länger als die Werte in t8 des gleichen Datensatzes sein müssen. Die oben verwendete Funktion length zeigt das gleiche Verhalten wie alle herkömmlichen Operatoren und Funktionen in Bezug auf den Wert NULL. Sie liefern für NULL Werte als Ergebnis ebenfalls NULL. Damit gelten: • (1 < NULL) = NULL • (1 > NULL) = NULL 17 • (NULL = NULL) = NULL • length(’’) = 0 • length(NULL) = NULL • (length(NULL) < length(’’)) = NULL 16 MySQL stellt den Datentyp ENUMERATION zur Verfügung. Dieser stellt eine sehr einfache Möglichkeit zur Erstellung von Aufzählungen dar, da man so auf eine Realisierung durch komplexe CONSTRAINTS verzichten kann. 17 Bei binären Vergleichen ist das Ergebnis NULL gleichbedeutend mit false (falsch). Postgres implementiert den Vergleichsoperator = mit einem Wert NULL als Abkürzung für IS NULL. Marcus Börger 59 Data Definition Language Relationale Datenbanken 6.4.3.2 Primary Key Contraint Mit Primary Key Constraints können Primary Keys, über Spaltenlisten, definiert werden. Werte von Primary Key Feldern müssen eindeutig und ungleich NULL sein (2.2.6.1 Primary Keys). Primary Key Namen beginnen häufig mit dem Präfix „PK_“ gefolgt vom Tabellennamen. [ CONSTRAINT Name ] PRIMARY KEY (Spaltenliste) Abbildung 6.10: Primary Key Constraint 6.4.3.3 Alternate Key Constraint Alternate Keys sind eindeutige Indizes und können im Gegensatz zu einfachen Indizes innerhalb einer Tabellendefinition angelegt werden. Im Gegensatz zu diesen stellt die Eindeutigkeit ja eine Bedingung dar, denn es können nur Datensätze eingefügt werden, die noch nicht in der Tabelle vorhanden sind. Ausgenommen sind NULL Werte, die mehrfach vorkommen dürfen. Alternate Keys werden meist aus Präfix „AK_“ gefolgt vom Tabellennamen und einer Nummer oder dem Zweck gebildet. [ CONSTRAINT Name ] UNIQUE (Spaltenliste) Abbildung 6.11: Alternate Key Constraint 6.4.3.4 Foreign Key Constraint Foreign Key Constraints, die über mehr als ein Feld definiert sind, müssen extra definiert werden, wobei die Typen der Spalten beider Spaltenlisten übereinstimmen müssen. Während die Spaltenliste1 angegeben werden muß, ist die Angabe der Spaltenliste2 zur Auswahl der Spalten in der Zieltabelle optional, wenn der Primary Key referenziert wird. Die zusätzlichen Angaben ON DELETE und ON UPDATE legen das Verhalten der Constraint fest und sind optional. Die Aktionsangaben zu ON DELETE bzw. ON UPDATE können RESTRICT, CASCADE, SET NULL oder SET DEFAULT sein (siehe 2.2.7 Referenzielle Integrität). Oracle kennt weder ON UPDATE noch RESTRICT. Der Name von Foreign Keys wird meist aus dem Präfix „FK_“ und den Namen der beteiligten Tabellen oder der Bedeutung der Relation gebildet. [ CONSTRAINT Name ] FOREIGN KEY (Spaltenliste1) REFERENCES Tabelle[(Spaltenliste2)] [ Deferrment ] [ ON UPDATE Aktion ] [ ON DELETE Aktion ] Abbildung 6.12: Foreign Key Constraint 6.4.3.5 Constraint Deferrment Mache Datenbank Managementsysteme erlauben weiteren Einfluß auf das Verhalten der Constraints zu nehmen, indem zu jeder einzelnen Constraint eine Deferrment Angabe erfolgen kann. Dabei bedeutet INITIALLY IMMEDIATE, daß die Constraint sofort geprüft wird und INITIALLY DEFERRED, daß die Constraint am Ende der Transaktion geprüft wird. Zusätzlich legt die Option DEFERRABLE fest, daß einer Constraint manuell in den Zustand DEFERRED versetzen kann, und somit deaktiviert wird. Die Option NOT DEFERRABLE verhindert das. [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ] [[NOT] DEFERRABLE] Abbildung 6.13: Constraint Deferrment 60 Marcus Börger Relationale Datenbanken Data Definition Language 6.4.4 CREATE TABLE SELECT Tabellen können auch über SELECT Abfragen, wie sie in 7.2 SELECT beschrieben werden, erstellt und mit Daten aufgefüllt werden. Dieses Vorgehen ermöglicht zum Beispiel eine Teilmenge der Daten in einer temporären Tabelle weiter zu verarbeiten. MySQL benutzt dazu die Form CREATE TABLE SELECT und kann die neue Tabelle durch die Angabe von Spaltendefinitionen um zusätzliche Spalten erweitern. Wird das ausgenutzt, müssen Vorkehrungen zur Behandlung der zusätzlichen Spalten getroffen werden, denn diese Spalten können nicht über den nachfolgenden SELECT Befehl mit Daten gefüllt werden. Als Lösung bieten sich daher die Verwendung von AUTO_INCREMENT oder Defaultwerten sowie das Zulassen von NULL an. Alternativ können weitere Spalten auch durch die Angabe von Konstanten im SELECT Abschnitt angefügt werden, wobei sich die Benutzung von Aliasnamen für diese Spalten empfiehlt, da andernfalls der Spaltenname aus dem Wert der Konstante gebildet wird. Durch die Angabe eines immer ungültigen WHERE Abschnittes (wie WHERE 0=1) läßt sich eine Tabellenstruktur auch ohne Daten kopieren. CREATE [ TEMPORARY ] TABLE Tabelle [ (Spaltendefinitionen) ] [ AS ] SELECT Spaltenliste [ FROM ... ]; Abbildung 6.14: CREATE TABLE SELECT, MySQL PostgreSQL erlaubt zwei syntaktisch verschiedene Varianten. Die erste Variante erinnert sehr stark an die MySQL Form, mit dem Unterschied, daß keine Erweiterung durch die Angabe von Spaltendefinitionen möglich ist und das Schlüsselwort AS zwingend ist. Da PostgreSQL ferner typgenau arbeitet, legt der SELECT Abschnitt die Spaltentypen exakt fest. Allerdings werden keine CONSTRAINTS oder Indizes kopiert und in allen Spalten ist NULL erlaubt. Diese syntaktische Variante ist eng mit INSERT INTO SELECT verwandt (siehe 7.1.1 INSERT INTO SELECT). CREATE [ TEMPORARY ] TABLE Tabelle AS SELECT Spaltenliste [ FROM ... ]; Abbildung 6.15: CREATE TABLE SELECT, PostgreSQL & Oracle Die zweite Variante benutzt eine andere Syntax, verhält sich ansonsten aber exakt wie die oben beschriebene erste Variante. SELECT Spaltenliste INTO [ TEMPORARY ] Tabelle FROM ... ; Abbildung 6.16: SELECT INTO FROM, PostgreSQL Oracle erlaubt die Benutzung der ersten Variante und verlangt wie PostgreSQL die Verwendung des Schlüsselwortes AS. Marcus Börger 61 Data Definition Language Relationale Datenbanken 6.4.5 Anlegen der Tabellen der Datenbank Uni Die folgenden drei Abbildungen legen die drei Tabellen Personen, Veranstaltungen und besuchen an. Die Constraint Angaben in den Tabellen Veranstaltungen und besuchen bewirken, daß ein Löschen eines Dozenten zur Folge hat, daß alle seine Veranstaltungen aus der Tabelle Veranstaltungen gelöscht werden. Dies wiederum bewirkt ein Löschen aller zugehörigen Datensätze in der Tabelle besuchen. Wird eine PNr geändert, so werden die Änderungen in den Tabellen Veranstaltungen und besuchen nachvollzogen. Als letztes bewirkt das Löschen eines Datensatzes aus Persononen, das Löschen aller zugeordneten Datensätze in der Tabelle besuchen, also aller Datensätze mit gleicher PNr. Uni> CREATE TABLE Personen ( PNr INT NOT NULL, Name VARCHAR(255) NOT NULL, Gehalt FLOAT, Datum VARCHAR(30), CONSTRAINT PK_Personen PRIMARY KEY (PNr) ); Abbildung 6.17: Erzeugen der Tabelle Personen Uni> CREATE TABLE Veranstaltungen ( VNr INT NOT NULL, PNr INT NOT NULL, VName VARCHAR (255) NOT NULL, VZeit VARCHAR (32) NOT NULL, VOrt VARCHAR (32) NOT NULL, CONSTRAINT PK_Veranstaltungen PRIMARY KEY (VNr), CONSTRAINT AK_Veranst_VName UNIQUE (VName), CONSTRAINT AK_Veranst_VZeit UNIQUE (VZeit, VOrt), CONSTRAINT FK_Veranst_Personen FOREIGN KEY (PNr) REFERENCES Personen(PNr) ON DELETE CASCADE ON UPDATE CASCADE ); Abbildung 6.18: Erzeugen der Tabelle Veranstaltungen Uni> CREATE TABLE besuchen ( VNr INT NOT NULL, PNr INT NOT NULL, CONSTRAINT PK_besuchen PRIMARY KEY (VNr, PNr), CONSTARINT FK_besuchen_Veranst FOREIGN KEY (VNr) REFERENCES Veranstaltungen(VNr) ON DELETE CASCADE ON UPDATE CASCADE, CONSTARINT FK_besuchen_Personen FOREIGN KEY (PNr) REFERENCES Personen(PNr) ON DELETE CASCADE ON UPDATE CASCADE ); Abbildung 6.19: Erzeugen der Tabelle besuchen Die Kommandos lassen sich sowohl mit MySQL als auch mit Postgres direkt ausführen, wobei MySQL sämtliche Angaben über Relationen ignoriert. Für die Ausführung unter Oracle müssen alle ON UPDATE CASCADE Regeln entfernt werden. Denn bei Oracle ist immer ON UPDATE RESTRICT eingestellt und es kann nur für Löschoperationen das Verhalten festgelegt werden. 62 Marcus Börger Relationale Datenbanken Data Definition Language 6.5 CREATE INDEX Das Anlegen der Indizes muß nicht unbedingt innerhalb der Tabellendefinition erfolgen. In vielen Datenbank Management Systemen könne Indizes sogar nur außerhalb der Tabellendefinitionen erzeugt werden. Insbesondere kann man dadurch auch nachträglich Indizes anlegen. Neben der Angabe der Spalten kann auch die Sortierrichtung angegeben werden, dabei steht ASC für aufsteigend und DESC für Absteigend. Durch den Zusatz UNIQUE können eindeutige Indizes also Alternate Keys erzeugt werden. Bei der Benennung von Indizes wird oft „IX_“ gefolgt vom Tabellennamen als Präfix benutzt. CREATE [ UNIQUE ] INDEX Name ON Tabelle (Spaltenliste); Abbildung 6.20: Aufbau des CREATE INDEX Befehles Das folgende Beispiel legt die Indizes für die Datenbank Uni an: Uni> CREATE ON Uni> CREATE ON INDEX IX_Personen_Name Personen (Name ASC, Gehalt ASC, Datum ASC); INDEX IX_Veranst_PNr Veranstaltungen (PNr); Abbildung 6.21: Anlegen der Indizes für die Datenbank Uni 6.6 CREATE VIEW Virtuelle Tabellen können mit dem Befehl CREATE VIEW erzeugt werden. Dazu kann jede beliebige SQL Abfrage benutzt werden, mit der Einschränkung, daß manche Datenbank Management Systeme keine Sortierung (ORDER BY) zulassen. CREATE VIEW Name AS SELECT Abfrage; Abbildung 6.22: Aufbau des CREATE VIEW Befehles Ein komplexes Beispiel wird in Abbildung 7.21: VIEW Anzahl gezeigt. 6.7 CREATE TRIGGER Trigger ermöglichen es auf Aktionen in der Datenbank mit komplexen Funktionen zu reagieren. Genaugenommen können Trigger auf verändernde DML Aktionen innerhalb einer Datenbank reagieren, also Einfügen, Löschen oder Verändern von Daten. Sie können nicht auf Abfragen oder Befehle aus dem DDL Bereich reagieren wie etwa Erzeugen oder Löschen von Tabellen. Trigger können sowohl vor (BEFORE) als auch nach (AFTER) der Aktion ausgeführt werden und sie können auf einzelne Befehle (FOR EACH STATEMENT) oder für jeden einzelnen Datensatz (FOR EACH ROW) der von dem Befehl beeinflußt wird ausgeführt werden. Manche DBMS haben auch die sogenannten INSTEAD OF Trigger implementiert, bei denen der auslösende Befehl durch die Triggerfunktion ersetzt wird18. Das Kapitel 10 Trigger befaßt sich ausführlich mit dem Thema. 18 Der Microsoft SQL Server erlaubt nur INSTEAD OF Trigger, also weder BEFORE noch AFTER. Während Oracle und Postgres keine INSTEAD OF Trigger erlauben. Marcus Börger 63 Data Definition Language Relationale Datenbanken 6.8 CREATE RULE Mit Regeln kann man viele einfache Anwendungen von Triggern elegant lösen. Im Gegensatz zu Triggern kann man mit Regeln allerdings DML Befehle lediglich durch andere DML Befehle ersetzen und nicht durch komplexe Funktionen. Im Gegensatz zu Triggern können Rules aber auch für Abfragen also SELECT Befehle erstellt werden. 6.9 CREATE SEQUENCE MySQL unterstützt ausschließlich implizite Sequences über den Zusatz AUTO_INCREMENT zu einer numerischen Spalte. 6.10 ALTER TABLE Der ALTER TABLE Befehl ermöglicht es Tabellen Definitionen zu ändern, allerdings ist der Umfang des Befehles sehr stark vom verwendeten DBMS abhängig. 6.10.1 ALTER TABLE und MySQL 6.10.2 ALTER TABLE und Oracle 6.10.3 ALTER TABLE und PostgreSQL 64 Marcus Börger Relationale Datenbanken Data Definition Language 6.11 DROP Mit DROP können Objekte innerhalb der Datenbank gelöscht werden. Dazu wird neben dem Namen des zu löschenden Objektes noch der Objekttyp benötigt. DROP Objekttyp Objektname; Abbildung 6.23: Aufbau des DROP Befehles Der folgende Befehl löscht Beispielsweise die Tabelle besuchen: DROP TABLE besuchen; Abbildung 6.24: Löschen der Tabelle besuchen Neben TABLE kommen als Objekttyp noch DATABASE, CONSTRAINT, INDEX, TRIGGER, RULE in Frage. Wenn ein Objekt gelöscht wird, so werden auch alle direkt abhängigen Objekte gelöscht. Beim Löschen eines DATABASE Objektes werden also insbesondere alle darin gespeicherten TABLE Objekte ohne Einschränkung inklusive aller Datensätze gelöscht. Wird ein TABLE Objekt gelöscht, so werden alle darin enthaltenen Daten gelöscht. Weiterhin werden alle direkt zusammenhängende Objekte wie CONSTRAINT19, INDEX und TRIGGER gelöscht. Eine Tabelle kann daher nicht gelöscht werden, wen andere Objekte der Datenbank auf sie verweisen. Wenn die Tabelle A von der Tabelle B referenziert wird, es also in der Tabelle B einen FOREIGN KEY auf die Tabelle A gibt, so kann die Tabelle A nicht gelöscht werden, ohne zuvor die Tabelle B oder die FOREIGN KEY Definition zu löschen. 6.12 TRUNCATE TABLE Mit dem TRUNCATE Befehl besteht die Möglichkeit eine Tabelle sehr schnell zu leeren. Während der in 7.5 DELETE beschriebene Befehl Datensätze einzeln löscht, erfolgt dies bei TRUNCATE als Mengenoperation. Das bedeutet, daß abhängig vom Datenbank Management System Datensätze Blockweise oder sogar alle Datensätze auf einmal gelöscht werden. Der TRUNCATE Befehl löst in den meisten DBMS keine TRIGGER aus. Allerdings verhindern Trigger und Foreign Key Constraints bei manchen Systemen die Ausführung des Befehles. TRUNCATE TABLE Objektname; Abbildung 6.25: Aufbau des TRUNCATE TABLE Befehles Natürlich könnte man die Tabelle auch mit dem Befehl DROP TABLE löschen, dann müsste man aber alle Strukturen, die zur Datenbank gehören neu anlegen. Weiterhin ist es auch nicht immer möglich eine Tabelle zu löschen und neu zu erstellen, da dadurch Tabellenabhängigkeiten zerstöt werden. 19 Bei Oracle muß hierzu der Befehl DROP TABLE Name CASCADE CONSTRAINTS benutzt werden. Marcus Börger 65 Data Manipulation Language Relationale Datenbanken 7 Data Manipulation Language Mit den Befehlen der Data Manipulation Language (DML) können Daten erzeugt, ermittelt, verändert und gelöscht werden. 7.1 INSERT INTO Nachdem eine Datenbank modelliert und angelegt wurde, kann sie mit Daten gefüllt werden. Diese Aufgabe wird vor allem durch Verwendung von INSERT INTO Befehlen erledigt. Liegen die Daten bereits als Textdatei oder in anderen elektronischen Formaten vor, so gibt es eine Reihe wesentlich effizienterer Möglichkeiten, die jedoch sehr stark von dem verwendeten Datenbank Managementsystem sind. Eine dieser Möglichkeiten ist der Befehl LOAD FROM FILE, in vielen DNMS angeboten wird. Es gibt auch vielfältige Möglichkeiten eine Textdatei o.ä. zu einer Reihe von INSERT INTO Befehlen zu konvertieren und damit zurück zum Befehl: INSERT INTO Tabelle [ (Spaltenliste) ] VALUES (Wertliste); Abbildung 7.1: Aufbau des INSERT INTO Befehles Zunächst werden die Tabelle und die angegebenen Spalten festgelegt, wobei die Spaltenliste optional ist. Entfällt sie, müssen alle Spalten in der Wertliste belegt werden. Es dürfen beim INSERT INTO Befehl logischerweise keine Spalten ausgelassen werden, die als NOT NULL definiert sind und keinen Standardwert besitzen. Die Werte innerhalb der Wertliste werden durch Kommas voneinander getrennt und alle Werte außer Zahlen werden von einfachen Anführungsstrichen umschlossen. Wird der einfache Anführungsstrich als Wert oder Teil einer Zeichenkette benötigt kann man ihn escapen, indem man vor das Anführungszeichen ein Gegenschrägstrich (Backslash \) schreibt. Es ist durchaus sinnvoll auch bei vollständigen INSERT INTO Befehlen, wenn also alle Spalten belegt werden, die Spaltenliste anzugeben. Erstens kann man dann die Spaltenreihenfolge unabhängig von der Reihenfolge in der Datenbank wählen. Und Zweitens kann man die Befehle auch dann weiterverwenden, wenn sich die Struktur der Tabelle geändert hat. Dabei muß allerdings vorausgesetzt sein, daß die Spalten des alten Befehles in gleicher Form noch in der geänderten Tabelle benutzbar sind und es keine neuen Spalten gibt, die angegeben werden müssen. 7.1.1 INSERT INTO SELECT Der INSERT Befehl kann zusammen mit dem in 7.2 SELECT vorgestelltem SELECT Befehl verwendet werden. Im Gegensatz zu CREATE TABLE SELECT und SELECT INTO muß hier die Tabelle bereits vorhanden sein (siehe 6.4.4 CREATE TABLE SELECT). INSERT INTO Tabelle SELECT Spaltenliste FROM ...; Abbildung 7.2: Aufbau des INSERT INTO SELECT Befehles In der nachstehenden Abbildung wird zunächst eine leere Tabelle mit dem Namen Dozenten und der Struktur der Tabelle Personen erstellt. Danach werden alle Dozenten aus Personen in diese Tabelle kopiert. CREATE TABLE Dozenten AS SELECT * FROM Personen WHERE 0=1; INSERT INTO p SELECT * FROM Personen WHERE PTyp='Dozent'; Abbildung 7.3: INSERT INTO SELECT Beispiel 66 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.1.2 Eingabe der Beispieldaten Das folgende Beispiel fügt alle Personen in die Tabelle Personen ein, wobei die Spalte Adresse nicht angegeben wird: INSERT INTO Personen (PNr, Name, Gehalt, Datum) VALUES (100000, 'Ebert, K.', 10000, '13.9.1980'); INSERT INTO Personen (PNr, Name, Gehalt, Datum) VALUES (100001, 'Zucker, G.', 11000, '5.3.1982'); INSERT INTO Personen (PNr, Name, Gehalt, Datum) VALUES (100002, 'Meier, A.', NULL, '1.10.1998'); INSERT INTO Personen (PNr, Name, Gehalt, Datum) VALUES (100003, 'Kühn, H.', NULL, '1.10.1999'); INSERT INTO Personen (PNr, Name, Gehalt, Datum) VALUES (100004, 'Muster, M.', NULL, '1.10.1999'); Abbildung 7.4: Belegen der Tabelle Personen Das Zweite Beispiel belegt die Tabelle Veranstaltungen: INSERT INTO Veranstaltungen (VNr, PNr, VName, VZeit, VOrt) VALUES (1, 100000, 'Einführung', 'Mo, 10:00', 'H1'); INSERT INTO Veranstaltungen (VNr, PNr, VName, VZeit, VOrt) VALUES (2, 100000, 'Modellierung', 'Di, 12:00', 'H2'); INSERT INTO Veranstaltungen (VNr, PNr, VName, VZeit, VOrt) VALUES (3, 100001, 'SQL-DDL', 'Mo, 10:00', 'H3'); INSERT INTO Veranstaltungen (VNr, PNr, VName, VZeit, VOrt) VALUES (4, 100001, 'SQL-DML', 'Di, 10:00', 'H1'); Abbildung 7.5: Belegen der Tabelle Veranstaltungen Als letztes wird die Tabelle besuchen mit Werten gefüllt: INSERT INSERT INSERT INSERT INSERT INSERT INTO INTO INTO INTO INTO INTO besuchen besuchen besuchen besuchen besuchen besuchen (PNr, (PNr, (PNr, (PNr, (PNr, (PNr, VNr) VNr) VNr) VNr) VNr) VNr) VALUES VALUES VALUES VALUES VALUES VALUES (100002, (100002, (100002, (100003, (100004, (100004, 2); 3); 4); 1); 1); 2); Abbildung 7.6: Belegen der Tabelle besuchen Die Reihenfolge der INSERT INTO Befehle ist für die Beispiel Datenbank nicht unerheblich, wenn die Relationen gesichert werden. Wird PNr der Tabelle Veranstaltungen als Foreign Key definiert, so muß es einen Datensatz mit dem entsprechenden Wert für PNr in der Tabelle Personen geben, bevor ein Datensatz mit diesem Wert in die Tabelle Veranstaltungen eingefügt werden kann. Am einfachsten erreicht man das für die Beispieldatenbank, indem man zuerst alle Personen, dann alle Veranstaltungen und schließlich alle Werte der Tabelle besuchen in die Datenbank schreibt. In den drei vorangegangenen Abbildungen fällt auf, daß Zahlen nicht von einfachen Anführungsstrichen eingeschlossen sind. Das ist zwar erlaubt aber unnötig. Nachdem die Datenbank mit Werten gefüllt ist, kann nun die eigentliche Arbeiten mit der Datenbank beginnen. Es können nun Daten ermittelt und berechnet werden. Das nächste Kapitel zeigt, wie das gemacht werden kann. Marcus Börger 67 Data Manipulation Language Relationale Datenbanken 7.2 SELECT Der SELECT Befehl wird benutzt, um Daten aus der Datenbank zu ermitteln. Dies kann im einfachsten Fall bedeuten, daß ein Datensatz der Datenbank abgerufen wird. Im Extremfall kann man so aber auch Berechnungen über der gesamten Datenbank ausführen. Der SELECT Befehl hat den folgenden Aufbau: SELECT Spaltenliste [ FROM Tabellenliste ] [ WHERE Kriterium ] [ GROUP BY Gruppierung ] [ HAVING wobei ] [ ORDER BY Sortierung ] [ FOR UPDATE ]; Abbildung 7.7: Aufbau des SELECT Befehls 7.2.1 FROM Im einfachsten Fall selektiert man die Werte einer Spalte einer Tabelle, durch die Abschnitte SELECT und FROM, die zwingend sind (alle anderen sind optional). Im nachfolgenden Beispiel erhält man zweimal Dozent und dreimal Student als Ergebnis, da das SELECT Kommando nicht weiter eingeschränkt worden ist: Uni> SELECT PTyp FROM Personen; PTyp ---------Dozent Dozent Student Student Student (5 rows) Abbildung 7.8: Einfaches SELECT Mehrere Spalten können durch Kommata getrennt angegeben werden: Uni> SELECT Name, PTyp FROM Personen; Name PTyp ---------------------Ebert, K. Dozent Zucker, G. Dozent Meier, A. Student Kühn, H. Student Muster, M. Student (5 rows) Abbildung 7.9: SELECT mit mehreren Spalten Wird statt dessen der * Operator angegeben, so erhält man alle Spalten im Ergebnis: Uni> SELECT * FROM Personen; Abbildung 7.10: SELECT * 68 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.2 WHERE Der WHERE Abschnitt einer SELECT Abfrage dient dazu das Ergebnis zu beschränken, indem nur Datensätze zurückgeliefert werden, die ein bestimmtes Kriterium erfüllen. Über die Operatoren AND, OR sowie NOT lassen sich mehrere Kriterien zu einem zusammenfassen. Es existiert eine Vielzahl von Operatoren und Vergleichsoperationen (siehe 7.6 Operatoren und Funktionen). SELECT Name FROM Personen WHERE PTyp='Dozent'; SELECT Name FROM Personen WHERE PTyp='Dozent' AND Gehalt>10000; Abbildung 7.11: WHERE in SELECT 7.2.3 Aliasnamen Treten Namen in einer Abfrage mehrfach für verschiedene Verwendungszwecke auf, so kann man sie durch die Vergabe von Aliasnamen differenzieren. Man kann aber auch einfach die Spaltennamen der Rückgabewerte umbenennen. SELECT Name AS Professor FROM Personen WHERE PTyp='Dozent'; SELECT p.Name Professor FROM Personen p WHERE p.PTyp='Dozent'; Abbildung 7.12: Aliasnamen In Abbildung 7.12: Aliasnamen erkennt man, daß SQL das Schlüsselwort AS vorsieht, um Aliasnamen zu deklarieren. Das zweite Beispiel zeigt den Verzicht auf AS, daß bei den meisten Datenbanken entfallen kann. Es zeigt auch die Verwendung von Aliasnamen für Tabellen. Eine häufige Ursache für das mehrfache Auftreten von Namen für verschiedene Zwecke ist die Verwendung gleicher Spaltennamen in mehreren Tabellen. Sollen mehrere Wörter einen Spaltennamen bilden, so kann dies durch doppelte Anführungsstriche erreicht werden. 7.2.4 Abfragen über mehrere Tabellen SELECT Abfragen können sich natürlich über mehrere Tabellen erstrecken. Das wird vor allem im Zusammenhang mit definierten Relationen verwendet. Dabei ist es wichtig Spaltennamen, die in mehreren Tabellen vorkommen, durch den vorangestellten Tabellennamen eindeutig zu identifizieren. Die Abbildung unten zeigt die Relation aus Abbildung 2.15: Relationstyp n zu m: Uni> SELECT p.Name, v.VName FROM Personen p, Veranstaltungen v, besuchen b WHERE p.PNr=b.PNr AND b.VNr=v.VNr AND p.PTyp='Student'; Name VName ----------------------------Meier, A. Modellierung Kühn, H. Einführung Kühn, H. Modellierung Muster, M. Modellierung Muster, M. SQL-DML Muster, M. SQL-DDL (6 rows) Abbildung 7.13: SELECT über einer n zu m Relation Wird der * Operator bei SELECT Abfragen verwendet, die in ihrem FROM Teil mehrere Tabellen auflisten, so erhält man als Ergebnis alle Spalten aller gelisteten Tabellen. Um lediglich alle Spalten einer Tabelle zu ermitteln stellt man dem * Operator den Namen der Tabelle voran (SELECT tabelle1.* FROM tabelle1, tabelle2). Marcus Börger 69 Data Manipulation Language Relationale Datenbanken 7.2.5 Tabellen mehrmals in einer Abfrage Es kann durchaus sinnvoll sein eine Tabelle mehrfach in einer Abfrage zu benutzen, dann müssen verschiedene Aliasnamen für die Tabelle vergeben werden (eine Verwendung benötigt keinen Aliasnamen). Auch hierbei wird von der Abfrage das Kreuzprodukt aller Datensätze aller beteiligten Tabellen gebildet, wenn das Ergebnis durch den Einsatz von WHERE nicht weiter einschränkt. Das nachfolgende Beispiel ermittelt alle Dozenten und deren Gehalt, die ein höheres oder gleiches Gehalt haben, als der Dozenten mit der PNr 100000, ohne dessen Gehalt zu kennen: Uni> SELECT p2.Name, p2.Gehalt FROM Personen p1, Personen p2 WHERE p1.PNr=100000 AND p1.PNr<>p2.PNr AND p2.Gehalt>p1.Gehalt; Name Gehalt ---------------------Zucker, G. 11000 (1 rows) Abbildung 7.14: Mehrfachverwendung einer Tabelle in einer Abfrage Bei der Verwendung von p2.Gehalt>=p1.Gehalt und ohne p1.PNr<>p2.PNr würde die Abfrage in Abbildung 7.14: Mehrfachverwendung einer Tabelle in einer Abfrage neben dem Dozenten Zucker, G. ermitteln auch den Dozenten Ebert, K. ermitteln. 7.2.6 Abfragen mit indirekten Tabellen Es ist auch möglich Abfragen zu erstellen, bei denen Tabellen nur indirekt benötigt werden. Indirekte Tabellen finden dabei im WHERE Abschnitt Verwendung, aber keine ihrer Spalten werden zurück geliefert. Das passiert zum Beispiel, wenn alle Studenten-Dozenten Beziehungen gelistet werden sollen: Uni> SELECT p1.Name "Student hört", p2.Name Dozent FROM Personen p1, Personen p2, besuchen b, Veranstaltungen v WHERE p1.PNr=b.PNr AND b.VNr=v.VNr AND v.PNr=p2.PNr GROUP BY p1.PNr, p2.PNr; Student hört Dozent ------------------------Meier, A. Ebert, K. Meier, A. Zucker, G. Kühn, H. Ebert, K. Muster, M. Ebert, K. Muster, M. Zucker, G. (5 rows) Abbildung 7.15: SELECT mit indirekten Tabellen Die Abbildung 7.15: SELECT mit indirekten Tabellen zeigt zunächst die Verwendung von Aliasnamen in doppelten Anführungsstrichen. Das bewirkt, daß der gesamte enthaltene Text als Spaltenname genutzt wird und somit im Beispiel der Satz "Student hört Dozent" als Tabellenüberschrift entsteht. Außerdem werden die Tabellen besuchen und Veranstaltungen nur indirekt im WHERE Abschnitt benutzt, weshalb sie im FROM Teil gelistet werden. Als letztes bewirkt die Verwendung von GROUP BY, daß keine doppelten Datensätze im Ergebnis enthalten sind. 70 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.7 Aggregation Mittels Aggregation können schon während der Abfrage Daten berechnet werden. Das ist sehr nützlich, da oft nicht einzelne Datensätze, sondern vielmehr Informationen über diese benötigt werden. Dazu gibt es die folgen Aggregatfunktionen. 7.2.7.1 SUM, MAX, MIN, AVG Die vier Standard Aggregatfunktionen sind SUM, MAX, MIN und AVG. Zur Berechnung werden alle selektierten Werte einer Spalte herangezogen, welche nicht den Wert NULL haben. Sind hingegen alle betrachteten Werte mit NULL belegt, so ist auch das Ergebnis NULL. • SUM berechnet die Summe der Spaltenwerte. Hier verhalten sich NULL Werte also wie der Wert 0. • MAX ermittelt den größten Wert einer Spalte. Der kleinste Wert ist NULL. • MIN liefert den kleinsten Wert einer Spalte. Der größte Wert ist NULL. • AVG berechnet den Durchschnitt der Spaltenwerte. 7.2.7.2 COUNT Mit COUNT können Datensätze einer Tabelle oder nicht NULL Werte von Spalten gezählt werden. • COUNT(*) zählt alle Datensätze. Im Gegensatz zu den vorgenannten Aggregatfunktionen ignoriert COUNT in diesem Fall keine NULL Werte. • COUNT(sp) zählt alle Datensätze, die nicht NULL als Wert der Spalte sp besitzen. Da AVG nur nicht NULL Werte benutzt, muß COUNT(sp) benutzt werden um die Anzahl der von AVG(sp) berücksichtigten Werte zu ermitteln. 7.2.8 GROUP BY Das Gruppieren von Datensätzen erlaubt GROUP BY. Durch die Angabe einer Spalte im GROUP BY Abschnitt wird die Tabelle in disjunkte Gruppen zerlegt, denen jeweils exakt ein Wert der angegebenen Spalte entspricht. Diese Art der Gruppierung läßt sich auch über mehrere Spalten definieren. In der Tabelle Personen wurden bisher Studenten und Dozenten gespeichert. Wird GROUP BY auf PTyp angewandt, so entstehen genau die zwei Gruppen Studenten und Professoren. uni> SELECT PTyp, COUNT(*) AS count FROM Personen GROUP BY PTyp; PTyp count ----------------Dozent 2 Student 3 (2 rows) Abbildung 7.16: GROUP BY Abfrage Man erkennt in Abbildung 7.16: GROUP BY Abfrage, daß die Spaltenüberschrift im Ergebnis der Abfrage aus der Aggregatfunktion und nicht aus der Tabelle gebildet wird. Wird die gleiche Aggregatfunktion auf mehrere Spalten angewandt, müssen also Aliasnamen vergeben werden. Manche Datenbank Management Systeme liefern aber auch COUNT(*) als Überschrift. Marcus Börger 71 Data Manipulation Language Relationale Datenbanken 7.2.9 HAVING Aggregat Werte können nicht im WHERE Abschnitt einer SQL Abfrage genutzt werden. Hierzu dient der HAVING Teil. Meist wird HAVING im Zusammenhang mit GROUP BY genutzt, denn auf diese Weise kann man aus den Ergebnisgruppen diejenigen auswählen, die bezüglich der Aggregatwerte von Interesse sind. uni> SELECT PTy, COUNT(*) AS count FROM Personen GROUP BY PTyp HAVING COUNT(*) > 2; PTyp count ----------------Student 3 (1 row) Abbildung 7.17: HAVING Abfrage 7.2.10 ORDER BY In den vorangegangenen Kapiteln war schon mehrfach die Rede davon, Ausgaben sortieren zu können. Dazu wird im SELECT Befehl der Abschnitt ORDER BY verwendet. Sortierungen erfolgen immer Spaltenweise, wobei ein entsprechender Index vorhanden sein sollte, der die gewünschte Sortierfolge bereithält, da sie ansonsten bei jeder Abfrage temporär erstellt werden müßte. Uni> SELECT Name FROM Personen ORDER BY Name; Name ------------------------Ebert, K. Kühn, H. Meier, A. Muster, M. Zucker, G. (5 rows) Abbildung 7.18: Sortierte Abfrage Man kann die Sortierrichtung mit der Angabe ASC explizit als aufsteigend oder mit DESC als absteigend festlegen. Wird nur ein Sortierkriterium angegeben, so kann fast immer die Angabe der Richtung entfallen, wobei der Vorgabe Wert aufsteigend ist. Viele Datenbank Management Systeme verlangen jedoch die Angabe, wenn nach mehr als einer Spalte sortiert werden soll: Uni> SELECT PTyp, Name FROM Personen ORDER BY PTyp ASC, Name ASC; PTyp Name ---------------------Dozent Ebert, K. Dozent Zucker, G. Student Kühn, H. Student Meier, A. Student Muster, M. (5 rows) Abbildung 7.19: Mehrfachsortierung 72 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.11 UNION Mit UNION können die Ergebnisse von SELECT Abfragen zu einem Ergebnis zusammengefaßt werden, sofern sie die gleiche Datenstruktur zurück liefern. Haben die Ergebnisspalten dabei unterschiedliche Namen, so werden die Namen der ersten Abfrage genutzt. Die Abbildung 7.20: UNION zeigt eine einfache Union, die alle Namen für Personen und Veranstaltungen in einer Abfrage zurück liefert: Uni> SELECT Name FROM Personen UNION SELECT VName FROM Veranstaltungen; Name ------------Ebert, K. Zucker, G. Meier, A. Kühn, H. Muster, M. Einführung Modellierung SQL-DDL SQL-DML (9 rows) Abbildung 7.20: UNION Die folgende Abbildung zeigt, wie eine View erzeugt und benutzt wird. Dies wird oft bei sehr komplexen Abfragen wie der hier gezeigten dreifachen Union benutzt, um die Abfrage nach dem einmaligen Erzeugen als View einfacher handhaben zu können: Uni> CREATE SELECT UNION SELECT UNION SELECT VIEW Anzahl AS 'Personen' AS Tabelle, COUNT(*) FROM Personen 'Veranstaltungen', COUNT(*) FROM Veranstaltungen 'besuchen', COUNT(*) FROM besuchen; View created Uni> SELECT * FROM Anzahl; Tabelle Anzahl ------------------------Personen 5 Veranstaltungen 4 besuchen 6 (3 rows) Abbildung 7.21: VIEW Anzahl In diesem Beispiel wird auch demonstriert wie vorgegebene Texte (hier die Tabellennamen) als Ergebnis geliefert werden können. Bei kleinen Modellen, wie dem hier benutzten 3 Tabellen Modell, funktioniert die Abfrage sehr gut. Bei großen Modellen sollte man derartige Abfragen aus Datenbank spezifischen Befehlen erstellen, die eine derartige Aufgabe ohne View und Union ermöglichen. Marcus Börger 73 Data Manipulation Language Relationale Datenbanken 7.2.12 UNION ALL Eine UNION liefert keine doppelten Werte. Diese werden erst durch die Verwendung von UNION ALL anstelle von UNION ermittelbar. 7.2.13 EXCEPT EXCEPT verhält sich syntaktisch wie UNION, es faßt also zwei Abfragen zu einer zusammen. Al- lerdings enthält das Ergebnis alle Datensätze aus der ersten Abfrage, die nicht in der Zweiten enthalten sind. Das folgende Beispiel ließe sich natürlich auch wesentlich einfacher lösen (SELECT Name FROM Personen WHERE Gehalt IS NULL OR Gehalt=0;): Uni> SELECT Name FROM Personen EXCEPT SELECT Name FROM Personen WHERE Gehalt>0; Name ------------Meier, A. Kühn, H. Muster, M. (3 rows) Abbildung 7.22: Abfrage mit EXCEPT Bei Oracle wurde EXCEPT durch das Schlüsselwort MINUS ersetzt. 7.2.14 INTERSECT Der letzte Verwandte zu UNION ist INTERSECT. Mit INTERSECT können solche Datensätze ermittelt werden, die in verschiedenen SELECT Abfragen vorhanden sind. Es werden also die gemeinsamen Datensätze ermittelt. In Abbildung 7.23: UNION, EXCEPT, INTERSECT wird das Verhalten der drei Verwandten veranschaulicht: b = (2, 3) a = (1, 2) SELECT * FROM a UNION SELECT * FROM b 1, 2, 3 SELECT * FROM a UNION ALL SELECT * FROM b 1, 2, 2, 3 SELECT * FROM a EXCEPT SELECT * FROM b 1 SELECT * FROM a INTERSECT SELECT * FROM b 2 Abbildung 7.23: UNION, EXCEPT, INTERSECT 74 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.15 Subselects Während UNION, EXCEPT und INTERSECT Abfragen auf einer Ebene zusammenfassen konnten, ist es durch den Einsatz von Subselects (Unterabfragen) möglich Abfragen ineinander zu verschachteln. Leider sind Subselects zur Zeit in MySQL nicht möglich (MySQL 3.23), einige der hier vorgestellten Operatoren können aber dennoch mit Konstanten Verwendung finden. Subselects können sowohl in SELECT als auch in anderen SQL Befehlen (INSERT, UPDATE, DELETE) Verwendung finden. Sie fungieren dort als unabhängige Spalten oder Tabellen. 7.2.15.1 Subselect ersetzt Konstante Subselects können Konstanten ersetzen, so daß sich die Konstanten aus einer Abfrage ergeben und damit die Abfrage nicht ständig neu gestellt werden muß. Bei dieser Art der Verwendung muß darauf geachtet werden, daß die Unterabfrage immer exakt einen Wert liefert. Falls die Unterabfrage keinen oder mehrere Werte ermittelt, wird die gesamte Abfrage unmittelbar abgebrochen. Uni> SELECT AVG(Gehalt) FROM Personen; avg -------10500 (1 row) Uni> SELECT Name, Gehalt FROM Personen WHERE Gehalt > 1050; Name Gehalt ----------------------Ebert, K. 10000 Zucker, G. 11000 (2 rows) Uni> SELECT Name, Gehalt FROM Personen WHERE Gehalt > ( SELECT AVG(Gehalt) FROM Personen); Name Gehalt ----------------------Ebert, K. 10000 Zucker, G. 11000 (2 rows) Abbildung 7.24: Subselect ersetzt Konstante Für die Behandlung von Unterabfragen, die nicht zwingend genau ein Ergebnisdatensatz liefern existieren spezielle Operatoren die im Abschnitt 7.2.15.4 Subselect Operatoren behandelt werden. Das obige Beispiel zeigt auch ein Hauptproblem mit aufeinanderaufbauenden SQL Befehlen. Werden diese manuell eingegeben, so kommt es sehr leicht zu Übertragungsfehlern. Auf diese Art wurde der ermittelte Wert 10500 als Durchschnittsgehalt fälschlicherweise als 1050 in die zweite Abfrage übertragen und somit das falsche Gesamtergebnis erstellt. Marcus Börger 75 Data Manipulation Language Relationale Datenbanken 7.2.15.2 Subselects und Korrelation Beim Einsatz einer Subselect anstelle einer Konstante können die Werte der Subselect auch mit den Werten des äußeren Befehles korrelieren. Das bedeutet, daß die Datensätze des äußeren Befehles und der Unterabfrage Bezug zueinander nehmen dürfen. Wenn die Werte der äußeren Abfrage in der Unterabfrage benutzt werden, so muß die Unterabfrage für jeden möglichen Datensatz der äußeren Abfrage selbstverständlich erneut ausgeführt werden. Es empfiehlt sich also, die Daten der äußeren Abfrage derart zu sortieren, daß möglichst häufig Gruppen von gleichen Werten der äußeren Abfrage hintereinander in der Unterabfrage benutzt werden. Dieses sollte ein guter Optimizer erkennen und dementsprechend seltener die Unterabfrage ausführen. Wenn das gegeben ist, jedoch eine diesbezüglich ungünstigere Reihenfolge benötigt wird, kann es schneller sein, wenn die benötigte Sortierung erst in einer weiteren äußeren Abfrage realisiert wird. Das folgende Beispiel ermittelt zu jeder Person, die ein Gehalt bezieht, die Anzahl der Personen, die mehr Gehalt erhalten. Das Ergebnis wird zuerst nach der Anzahl, mehr verdienender Personen, und dann nach den Namen der schlechter verdienenden sortiert. Die innerste Unterabfrage benutzt jedoch das Gehalt, daß im Ergebnis unsortiert ist. Daher wird eine mittlere Abfrage benutzt, die das Zwischenergebnis zunächst nach dem Gehalt sortiert. Ausgehend davon, daß es wesentlich weniger Gehaltsbeträge als bezahlte Personen gibt, kommen in der innersten Unterabfrage also häufig gleiche Werte für Gehalt an. Uni> SELECT * FROM ( SELECT Name, Gehalt, ( SELECT COUNT(*) FROM Personen WHERE Gehalt > p.Gehalt ) AS Anzahl FROM Personen p WHERE Gehalt > 0 ORDER BY Gehalt) ORDER BY Anzahl ASC, Name ASC; Name Gehalt Anzahl ------------------------------Zucker, G. 11000 0 Ebert, K. 10000 1 (2 rows) Abbildung 7.25: Subselect mit Korrelation Zwei Unterabfragen auf einer Ebene können nicht miteinender Korrelieren, es sei denn die Korrelation basiert auf einem Wert der umschließenden Abfrage. Somit ist eine Abfrage der folgenden Form ungültig: SELECT * FROM ( SELECT a FROM ... ) AS A, ( SELECT b FROM ... WHERE A.b=b) AS B Abbildung 7.26: Korrelation auf gleicher Ebene ist unzulässig Folgende Formen sind zulässig: SELECT ..., ( SELECT b FROM ... WHERE A.a=b) FROM ( SELECT a ... FROM ... ) AS A, WHERE ... ( SELECT c FROM ... WHERE A.a=c) ... Abbildung 7.27: Zulässige Korrelationsformen 76 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.15.3 Subselects als unabhängige Spalten Es ist auch möglich Subselects als unabhängige Spalten zurück zu liefern. Dazu muß die Unterabfrage dann im FROM Abschnitt erfolgen und es muß zwingend ein Alias vergeben werden. Wenn die Unterabfrage nicht in Verbindung mit den anderen Tabellen der Abfrage gebracht wird, entsteht auch hier ein Kreuzprodukt. Um die Verwendung zu veranschaulichen, wird die folgende Abfrage umgestellt: Uni> SELECT p.Name,p.Gehalt,n.Name AS Name2, n.Gehalt AS Gehalt2 FROM Personen p, Personen n WHERE p.Gehalt > 0 AND n.Gehalt > 0 AND p.Name != n.Name ORDER BY p.Gehalt, n.Gehalt; Name Gehalt Name2 Gehalt2 ---------------------------------------------Ebert, K. 10000 Zucker, G. 11000 Zucker, G. 11000 Ebert, K. 10000 (2 rows) Abbildung 7.28: Abfrage mit zwei Tabellen Zunächst wird der zweite Zugriff auf die Tabelle Personen in eine Unterabfrage umgewandelt: Uni> SELECT Name, Gehalt, n.* FROM Personen p, (SELECT Name AS Name2, Gehalt AS Gehalt2 FROM Personen WHERE Gehalt > 0) n WHERE Gehalt > 0 AND Name != Name2 ORDER BY Gehalt, Gehalt2; Name Gehalt Name2 Gehalt2 ---------------------------------------------Ebert, K. 10000 Zucker, G. 11000 Zucker, G. 11000 Ebert, K. 10000 (2 rows) Abbildung 7.29: Subselect als unabhängige Spalten Das Beispiel in Abbildung 7.29: Subselect als unabhängige Spalten stellt eine Korrelation zwischen der Tabelle Personen und der Unterabfrage her, da im WHERE Abschnitt der äußeren Abfrage die Spalten Name aus Personen und Name2 aus der Unterabfrage verglichen werden. Es ist jedoch nicht möglich den Vergleich in die Unterabfrage zu verschieben, da die Unterabfrage hier als unabhängige Tabelle eingesetzt wird und somit in der Abfrage keine Spalte der äußeren Abfrage benutzt werden darf. Die folgende Abfrage zeigt, daß auch mehrere Unterabfragen parallel als unabhängige Tabellen eingesetzt werden können: Uni> SELECT p.*, n.Name AS Name2, n.Gehalt AS Gehalt2 FROM (SELECT Name, Gehalt FROM Personen WHERE Gehalt>0) p, (SELECT Name, Gehalt FROM Personen WHERE Gehalt>0) n WHERE p.Name != n.Name ORDER BY p.Gehalt, n.Gehalt; Name Gehalt Name2 Gehalt2 ---------------------------------------------Ebert, K. 10000 Zucker, G. 11000 Zucker, G. 11000 Ebert, K. 10000 (2 rows) Abbildung 7.30: Abfrage mit unabhängigen Subselects Marcus Börger 77 Data Manipulation Language Relationale Datenbanken 7.2.15.4 Subselect Operatoren und Quantoren Es ist offensichtlich, daß Subselects Wertlisten ermitteln können. Um solche Listen in Vergleichen nutzbar zu machen existieren die Operatoren IN, EXISTS ANY, und ALL eingesetzt. 7.2.15.4.1 Der Operator IN Der Operator IN ist ein binärer Operator, der ermittelt ob ein Wert in einer Liste von Werten enthalten ist. Das Ergebnis von Tests mit dem Wert NULL ist immer NULL bzw. false. • Wert IN ( Wertliste ) Wert IN ( SELECT Spalte1 FROM ... ) Überprüft ob Wert in Wertliste enthalten ist, wobei Wertliste auch aus einer Unterabfrage ermittelt werden kann. Diese Unterabfrage muß exakt eine Spalte, hier Spalte1, ermitteln. • Spalte IN ( Wertliste ) Spalte IN ( SELECT Spalte1 FROM ... ) Ist wahr, wenn der Wert von Spalte in Wertliste enthalten ist. Wobei Wertliste das Ergebnis eines SELECT Befehls sein kann, der eine Spalte, hier Spalte1, liefert. Beim Einsatz einer Unterabfrage sind die Spalten der Abfrage und der Unterabfrage unabhängig, auch wenn sowohl Abfrage als auch Unterabfrage sich auf die gleiche Tabelle beziehen. • Spalte IN ( Spaltenliste ) Bei dieser Form des Einsatzes von IN entstammen die Werte für Spalte und die aus Spaltenliste immer aus dem gleichen Datensatz. • Spalte IN ( SELECT Spaltenliste FROM ...) Eine solche Abfrage ist hingegen nicht zulässig. Es gibt zwei naheliegende Interpretationen für eine solche Anfrage. Erstens der Wert für Spalte ist in allen Spalten der Spaltenliste enthalten und zweitens er ist in mindestens einer der Spalten aus Spaltenliste enthalten: 1. Spalte IN ( SELECT Spalte1 FROM ...) AND Spalte IN ( SELECT Spalte2 FROM ...) AND … 2. Spalte IN ( SELECT Spalte1 FROM ...) OR Spalte IN ( SELECT Spalte2 FROM ...) OR … Eigentlich sollten alle beteiligten Werte bzw. Spalten vom gleichen Datentyp sein. Wenn dies nicht der Fall ist, wird eine Konvertierung ausgeführt, wobei die meisten Datenbanken die Werte in der Liste konvertieren. Dabei können Konvertierungsfehler entstehen, die zum Abbruch des SQL Befehls führen. So kann man Zahlen zwar in Zeichenketten konvertieren, meist jedoch nicht Zeichenketten in Zahlen (ab ist keine Zahl). Auch die Art und Weise wie Fließkommazahlen in Ganzzahlen konvertiert werden variiert. MySQL schneidet Nachkommazahlen einfach ab, während das bei PostgreSQL und Oracle nicht geschieht (0 ist ungleich 0,1 aber 0 ist gleich 0,0). Auch inverse Abfragen sind möglich, wozu der Operator NOT IN benutzt wird. Solle ein DBMS diesen Operator nicht unterstützen kann er nachgebildet werden: • 78 NOT ( ... IN ( ... )). Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.15.4.2 Der Quantor EXISTS Wie der Name vermuten läßt ist EXISTS ein Existenzoperator, der überprüft ob eine Unterabfrage mindestens ein Ergebnis Datensatz liefern kann. Das Ergebnis des Quantors EXISTS ist entweder true oder false und er kann im Gegensatz zum Operator IN ausschließlich mit einem SELECT Befehl als Eingabe verwendet werden. Auch wenn die benutzte Subselect den Wert NULL als einziges Ergebnis ergibt, muß der Quantor EXISTS als Ergebnis true ergeben. Denn es macht einen Unterschied ob eine Abfrage kein Ergebnis hat, also 0 Datensätze, oder ob sie NULL als einziges Ergebnis hat. Die inverse Form des Quantors ist NOT EXISTS, sie ermöglicht es auf Nicht-Existenz zu prüfen. Uni> SELECT Name, Gehalt FROM Personen p WHERE Gehalt > 0 AND EXISTS ( SELECT * FROM Personen WHERE Gehalt>p.Gehalt) ORDER BY Gehalt; Name Gehalt ----------------------Ebert, K. 10000 (1 row) Abbildung 7.31: Subselect und EXISTS Da MySQL keine Subselects unterstützt und Quantors ausschließlich mit Subselects arbeiten unterstützt MySQL diese nicht. Das gilt für die Quantoren EXISTS und NOT EXISTS genauso wie für die Quantoren ANY und ALL. 7.2.15.4.3 Die Quantoren ALL und ANY Die Quantoren ALL und ANY können auf alle binären Vergleichsoperatoren angewandt werden (<, >, = etc.). Sie müssen den Platz des zweiten Parameters gefolgt von einem Subselect einnehmen. Das Ergebnis eines solchen Vergleichs mit dem Operator ANY ist true, wenn der Vergleich für mindestens einen Wert aus der Liste true ist. Hingegen ist es bei ALL nur dann true, wenn der Vergleich für alle Werte true ist. Uni> SELECT Name, Gehalt FROM Personen p WHERE Gehalt < ANY (SELECT Gehalt FROM Personen) ORDER BY Gehalt; Name Gehalt ----------------------Ebert, K. 10000 (1 row) Uni> SELECT Name, Gehalt FROM Personen p WHERE Gehalt <= ALL (SELECT Gehalt FROM Personen) ORDER BY Gehalt; Name Gehalt ----------------------(0 rows) Abbildung 7.32: Subselect und ANY Die zweite Abfrage liefert kein Ergebnis, da es Personen mit Gehalt gleich NULL gibt. Marcus Börger 79 Data Manipulation Language Relationale Datenbanken 7.2.15.5 Simulation von Subselects Subselects können eingeschränkt mit temporären Tabellen simuliert werden. • Der Operator IN SELECT Spaltenliste FROM ... SW IN (SELECT Spalte FROM Tabelle…)… SELECT Spalte INTO TEMP t FROM Tabelle … SELECT Spaltenliste FROM t ... SW=t.Spalte …GROUP BY Spaltenliste Der Parameter SW kann sowohl eine Konstante als auch eine Spalte der äußeren Abfrage sein. Der Group By Abschnitt verhindert, daß für jedes Element der, durch die temporäre Tabelle t ersetzten, Unterabfrage ein Ergebnisdatensatz erstellt wird. • Der Quantor EXISTS SELECT ... EXITS(SELECT Spaltenliste FROM Tabelle... ) … SELECT COUNT(Spaltenliste) AS count INTO TEMP t FROM Tabelle … SELECT ... FROM t ... t.count > 0 ... Wenn der Quantor EXISTS durch die Aggregation COUNT ersetzt wird, ist unbedingt darauf zu achten, daß beide mit der gleichen Spaltenliste bzw. * arbeiten. Die vorgestellte Methode basiert darauf, daß die erste Abfrage eine Tabelle mit genau einem Ergebnis erstellt. Daher liefert das Kreuzprodukt aus der alten Abfrage und der neuen Tabelle die gleiche Anzahl Ergebnisse wie die alte Abfrage. • Der Quantor ANY SELECT ... Wert OP ANY ( SELECT Spalte FROM Tabelle ) ... SELECT 1 INTO TEMP t FROM Tabelle WHERE Wert OP Spalte SELECT ... FROM t ... COU 80 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.2.16 SELECT DISTINCT Der Zusatz DISTINCT zum SELECT Befehl bewirkt in den meisten Datenbanken, daß keine gleichen aufeinander folgenden Datensätze geliefert werden. In anderen bewirkt er, daß überhaupt keine doppelten Datensätze geliefert werden. Durch geeignete Verwendung von ORDER BY und GROUP BY ist es natürlich möglich beide Verhaltensweisen anzugleichen. Generell kann hier aber nur von der Verwendung abgeraten werden. Zumindest muß vor dem Einsatz das Verhalten in der eingesetzten Datenbank geprüft werden. 7.2.17 SELECT ohne FROM Der SELECT Befehl kann benutzt werden, um Funktionen des Datenbank Management Systems auszuführen oder einfache Berechnungen zu erledigen. In diesen Fällen wird also kein FROM benötigt. Eine Sonderstellung nimmt dabei Oracle ein, da dort die Pseudo-Tabelle DUAL benutzt werden muß. uni> SELECT 2*3 [ FROM DUAL ]; 2*3 -------6 (1 row) Abbildung 7.33: SELECT ohne FROM 7.2.18 Top-Level Abfragen Der Sprachstandard SQL selbst kennt keine sogenannten Top-Level Abfragen, die benutzt werden, wenn nur eine gewisse Anzahl von Datensätzen benötigt wird. Nahezu alle Datenbanksysteme haben aber eigene Ergänzungen, mit denen Abfragen wie „die ersten 10“ oder „die Datensätze 10 bis 20“ möglich sind. MySQL verwendet die Spracherweiterung LIMIT, die sowohl den Startindex als auch die Anzahl angeben kann: • SELECT * FROM tabelle LIMIT [ start, ] anzahl PostgreSQL benutzt zwei verschiedene Spracherweiterungen. Erstens wird LIMIT zur Angabe der Anzahl benutzt und zweitens OFFSET zur Angabe des Startindexes. Das hat den Vorteil, daß man auch ohne Angabe der Anzahl den Startwert festlegen kann: • SELECT * FROM tabelle [ LIMIT anzahl ] [ OFFSET start ] Bei Oracle wird die Pseudospalte ROWNUM genutzt. Damit ist es leider nicht möglich Anzahl und Offset in einer Abfrage ohne Subselect zu benutzen. Der einfachere Fall, in dem nur die ersten Datensätze benötigt werden, kann mit einem WHERE Abschnitt erfolgen. Soll ROWNUM zurückgeliefert werden, ist zu beachten ist, daß * nur noch mit Angabe der Tabelle benutzt werden darf: • SELECT [ ROWNUM, tabelle.]* FROM tabelle WHERE ROWNUM<=anzahl; Wird hingegen ein Ausschnitt aus der Ergebnismenge benötigt, so muß zunächst die Abfrage um ROWNUM ergänzt werden und darum eine umschließende Abfrage ergänzt werden, welche die innere ROWNUM auswertet, wodurch ein Alias in der inneren Abfrage notwendig wird. • SELECT * FROM ( SELECT ROWNUM r, tabelle.* FROM tabelle WHERE r < start + anzahl ) WHERE r >= start; Marcus Börger 81 Data Manipulation Language Relationale Datenbanken 7.3 UPDATE Mit Hilfe des UPDATE Befehles können Datensätze gezielt verändert werden. Zunächst wird hierzu die Tabelle ausgewählt, die geändert werden soll. Dann werden Spalten in der Form Spalte=Wert zugewiesen, wobei mehrere Spalten in einem Datensatz gleichzeitig geändert werden können, indem mehrerer solcher Zuweisungen durch Kommata getrennt angegeben werden. Der UPDATE Befehl wirkt sich ohne weitere Angaben auf alle Datensätze einer Tabelle aus. Falls das nicht gewünscht ist, können mit optionalen FROM und WHERE Abschnitten gezielt Datensätze geändert werden. Wobei der FROM Abschnitt nicht von allen Datenbank Management Systemen unterstützt wird. Die meisten Datenbank Management Systeme geben die Anzahl der veränderten Datensätze nach Ausführung zurück. UPDATE Tabelle SET Zuweisungsliste [ FROM Tabellenliste ] [ WHERE Kriterium ]; Abbildung 7.34: Aufbau des UPDATE Befehles Nachfolgend ist das UPDATE Kommando gezeigt, daß die in 2.2.7.2.1 Cascade bei Änderungen beschriebene Aktion auslösen soll. UPDATE Personen SET PNr=1 WHERE PNr=100000; Abbildung 7.35: UPDATE Beispiel 7.3.1 SELECT FOR UPDATE; UPDATE; Mit dem Befehl SELECT und dem Zusatz FOR UPDATE kann eine Transaktion eingeleitet werden (siehe auch 8 Transactions). Diese wird mit der Ausführung des UPDATE Befehles beendet (genaugenommen mit jedem anderen SQL Befehl). Man erreicht so, daß ein gefundener Datensatz nicht gleichzeitig von einer anderen Verbindungsinstanz geändert werden kann. Wenn mehrere Tabellen zur Ermittlung der zu sperrenden Datensätze benötigt werden, so kann man die zu sperrenden Tabellen angeben (SELECT ... FOR UPDATE OF tabelle). 82 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.4 REPLACE INTO Im Gegensatz zum INSERT INTO Befehl können über REPLACE INTO Datensätze sowohl eingefügt, als auch geändert werden. Wenn im REPLACE INTO Datensatz keine Primary Keys oder Alternate Keys vorhanden sind, so werden die übergebenden Daten immer eingefügt. Wird ein Teil des übergebenden Datensatzes vollständig in Alternate Keys bzw. Primary Keys abgelegt, so wird zunächst getestet, ob der durch diesen Index/Key identifizierte Datensatz bereits existiert. Falls vorhanden wird er durch den neuen ersetzt, ansonsten wird er neu angelegt. Sind mehrere Keys betroffen, so darf nur ein oder kein Datensatz betroffen sein. REPLACE INTO Tabelle [ (Spaltenliste) ] VALUES (Wertliste); Abbildung 7.36: Aufbau des REPLACE INTO Befehles Leider existiert REPLACE INTO nur in sehr wenigen Datenbanken. Dies liegt daran, daß es nicht im SQL Standard aufgelistet ist. Theoretisch ist es exakt definiert, so daß einer Implementierung eigentlich nichts im Wege steht. Wenn das REPLACE INTO Kommando nicht vorhanden ist, muß REPLACE INTO durch eine Folge von Befehlen ersetzt werden: Start SELECT FOR UPDATE >1 =1 Anzahl Datensätze =0 ERROR INSERT INTO UPDATE Ende Ende Ende Abbildung 7.37: REPLACE INTO ersetzen Im ersten Schritt wird dabei geprüft, ob der Datensatz bereits vorhanden ist. Falls vorhanden wird er im nächsten Schritt modifiziert, andernfalls wird er neu angelegt. Zum Auffinden des Datensatzes werden die angegebenen Key Felder (Primary Key und Alternate Key) genutzt. Werden mehrere Key Felder angegeben und eine OR Suche20 benutzt, so kann es passieren, daß mehr als ein Datensatz gefunden wird. Bei einer AND Suche kann es hingegen passieren, daß kein Datensatz gefunden wird, da sich zwei Key Werte widersprechen. In einem solchen wird REPLACE ebenfalls einen Fehler erzeugen, die Key Werte bereits in der Tabelle vorhanden sind. Datensätze: (1,2,'alt') (3,4,'alt') REPLACE INTO tabelle VALUES(1,1,'neu') ERROR UPDATE (1,2,'alt') REPLACE INTO tabelle VALUES(1,2,'neu') REPLACE INTO tabelle VALUES(1,4,'neu') REPLACE INTO tabelle VALUES(2,3,'neu') UPDATE (1,2,'alt') ERROR INSERT (2,3,'neu') UPDATE (1,2,'alt') ERROR INSERT (2,3,'neu') AND OR Tabelle 7.1: REPLACE INTO Verhalten 20 SELECT * FROM tabelle WHERE primaryKey='value1' OR alternateKey='value2'; Marcus Börger 83 Data Manipulation Language Relationale Datenbanken 7.5 DELETE Mit dem DELETE Befehl könne einzelne Datensätze aus Tabellen gezielt gelöscht werden. Im Gegensatz zu den anderen Befehlen hat der DELETE Befehl nur Zugriff auf eine Tabelle. Wenn das Löschen abhängig von den Werten anderer Tabellen ist, so kann dies nur durch Subselects gelöst werden. Solche Abhängigkeiten müssen bei MySQL also durch temporäre Tabellen oder Subselects gelöst werden. DELETE FROM Tabelle [ WHERE Kriterium ]; Abbildung 7.38: Aufbau des DELETE FROM Befehles Ohne eine Auswahl der zu löschenden Datensätze, also WHERE Abschnitt, kann eine Tabelle auch komplett geleert werden. Das läßt sich aber mit dem Befehl TRUNCATE schneller erledigen (siehe 6.12 TRUNCATE). Beide Befehle haben gemeinsam, daß sie die Struktur der Datenbank nicht verändern und insbesondere die Tabelle erhalten bleibt. Wird die Tabelle hingegen nicht mehr benötigt, so kann dies mit dem Befehl DROP TABLE erledigt werden (siehe 6.11 DROP). Der TRUNCATE Befehl kann in manchen DBMS jedoch nicht benutzt werden, wenn Foreign Key Constraints, also Referenzen, definiert sind und es in anderen Tabellen Referenzen auf zu löschende Datensätze gibt. Auch werden beim Löschen mittels TRUNCATE keine Trigger ausgeführt. In all diesen Fällen ist die Benutzung von DELETE also erforderlich. Zudem ist es mit DELETE möglich auch die Datensätze zu löschen, die ansonsten aufgrund von Referenzen nicht gelöscht werden könnten, indem man solche Datensätze über die Einstellung ON DELETE CASCADE aller Referenzen gleichfalls automatisch löscht. Im Extremfall kann das Löschen eines Datensatzes auf diese Art und Weise eine gesamte Datenbank leeren. 7.5.1 Top-Level Delete Sofern kein Primary Key bekannt ist, können in einer Tabelle identische Datensätze existieren. Um nur einen Teil dieser Datensätze zu löschen, kann man bei MySQL die Erweiterung LIMIT für Top-Level Abfragen direkt benutzen (siehe 7.2.18 Top-Level Abfragen). Bei PostgreSQL müssen die Datensätze über die DBMS interne Datensatzidentifizierung OID gelöscht werden, Oracle verwendet hierzu den Bezeichner ROWID. Zunächst werden also die entsprechenden Datensatzidentifizierer aufgelistet und dann die zugehörigen Datensätze darüber gelöscht. Da bei diesem Umweg eine Abfrage eingesetzt wird, kann man diese Abfrage zu einer Top-Level Abfrage erweitern und als Subselect des DELETE Aufrufes einsetzen. DELETE FROM Tabelle WHERE OID IN (SELECT OID FROM Tabelle LIMIT 1); Abbildung 7.39: Top-Level DELETE mit PostgreSQL 7.5.2 Löschen doppelter Datensätze Über die Identifizierer OID bzw. ROWID und Subselects kann man bei PostgreSQL und Oracle auf einfache Weise doppelte Datensätze löschen, ohne Top-Level Elemente zu nutzen. Der IN Operator wird benutz, um Fehler bei Nichtexistenz zu löschender Datensätze zu vermeiden. DELETE FROM Tabelle WHERE OID NOT IN (SELECT MIN(OID) FROM Tabelle); Abbildung 7.40: Löschen doppelter Datensätze mit PostgreSQL 84 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.6 Operatoren und Funktionen Das folgende Kapitel stellt die wichtigsten Operatoren und Funktionen vor. Einige der vorgestellten Operatoren und Funktionen sind boolesch, sie liefern also entweder wahr oder falsch als Ergebnis, der Ergebnistyp ist also BOOL. Während Postgres diese beiden Werte als t für wahr bzw. true und f für falsch bzw. false darstellt, benutzt MySQL die Darstellung 1 für wahr und 0 für falsch. Oracle wiederum kennt den Datentyp BOOL nicht, sodaß man zwar intern damit arbeiten kann, eine direkte Darstellung aber nicht möglich ist. Wenn einer der Parameter den Wert NULL hat, ist das Ergebnis häufig auch NULL. Die betreffenden Operatoren und Funktionen haben damit also drei Zustände. 7.6.1 Mathematische Operatoren Die folgende Übersicht zeigt die von MySQL, Postgres und Oracle unterstützten mathematischen Operatoren und ihre Bedeutung: • Addition 2 + 3 = 5 • Subtraktion 2 – 3 = -1 • Multiplikation 2 * 3 = 6 • Division21 2 / 3 = 0.67 • Divisionsrest22 2 % 3 = 2 7.6.2 Bitweise Operatoren Bitweise Operatoren arbeiten auf den jeweils größten verfügbaren ganzzahligen Datentyp. Das Ergebnis einer bitweisen Operation hat also maximal so viele Bits wie dieser Datentyp. • Bitweise Oder 2 | 5 = 7 • Bitweise Und 2 & 5 = 1 • Bitweise Negation • Bitweise links schieben 6 << 2 = 24 • Bitweise rechts schieben 6 >> 2 = 1 ~ 0 = -1 7.6.3 Logische Operatoren MySQL interpretiert alle Werte Boolesche Werte wenn man sie auf logische Operatoren anwendet. Dabei wird für alle sich ergebenden Zahlen deren Betrag größer oder gleich 1 ist der Boolesche Wert true angenommen. PostgreSQL und Oracle können logische Operatoren nur auf Boolesche Werte anwenden. 21 22 • Logische Und 0 and 1 = 0 • Logisches Oder 0 or 1 = 1 • Logische Negation NOT 0 = 1 Bei Division mit Divisor gleich 0 ergibt MySQL NULL und PostgreSQL sowie Oracle brechen mit Fehler ab. MySQL akzeptiert auch die a MOD b, während Oracle ausschließlich MOD(a,b) unterstützt. Marcus Börger 85 Data Manipulation Language Relationale Datenbanken 7.6.4 Vergleichsoperatoren Es stehen die üblichen Vergleichsoperatoren zur Verfügung: <, <=, <>, !=, >=, >. Bei MySQL können auch Zeichenketten verglichen werden. Dabei erfolgen alle Vergleiche ohne Berücksichtigung von Klein/Großschreibung und Leerzeichen am Ende werden ignoriert. Es gilt also 'A' = 'a ' und 'A A' = 'A a' nicht jedoch 'A' = 'A a'. Die beiden DBMS PostgreSQL und Oracle verlangen den Einsatz entsprechender Funktionen, siehe hierzu 7.6.7 Funktionen für Zeichenketten. 7.6.5 Bedingungsoperatoren Der Auswahloperator IF erwartet drei Parameter, das Ergebnis ist der Wert des zweiten Parameters, wenn der erste Parameter den Wert true hat, ansonsten der Wert des dritten Parameters. Das folgende Beispiel für MySQL veranschaulicht, wie MySQL die Operatoren = und < mit Zeichenketten verwendet. mysql> CREATE TABLE x ( v VARCHAR(2)); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO x VALUES('a'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO x VALUES('b'); Query OK, 1 row affected (0.00 sec) mysql> CREATE TABLE y ( w VARCHAR(2)) SELECT * FROM x; Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> SELECT x.v, IF(x.v=y.v,'=',IF(x.v<y.v,'<','>')) "?", y.v FROM x, y; +------+---+------+ | v | ? | v | +------+---+------+ | a | = | a | | b | > | a | | a | < | b | | b | = | b | +------+---+------+ 4 rows in set (0.02 sec) Abbildung 7.41: MySQL mit IF und <, = bei Zeichenketten 86 Marcus Börger Relationale Datenbanken Data Manipulation Language 7.6.6 Umgang mit NULL Wie bereits mehrfacherwähnt ist das Ergebnis nahezu aller Operatoren und Funktionen NULL, wenn einer der Parameter NULL ist. Da dieses vielfach zu Problemen führt existieren die verschiedensten Operatoren zum Umgang mit NULL Werten. 7.6.6.1 IS NULL Die Postfixoperatoren IS NULL und IS NOT NULL überprüfen einen Wert auf NULL oder nicht NULL. Das Ergebnis ist entweder true oder false. Uni> SELECT 1 IS NULL AS "NULL", 1 IS NOT NULL AS "Wert"; NULL Wert ---------------false true (1 row) Abbildung 7.42: Operator IS NULL 7.6.6.2 NULLIF Die Funktion NULLIF vergleicht zwei Parameter und hat bei Gleichheit den Wert NULL, ansonsten den Wert des ersten Parameters. Wenn der erste Parameter den Wert NULL hat, ist das Ergebnis immer NULL. Oracle unterstützt diesen Operator nicht und bei MySQL führen Konvertierungsprobleme zum Zwischenergebnis Ungleichheit und somit zum Wert des ersten Parameters als Ergebnis (NULLIF('a',1)='a'). Uni> SELECT NULLIF( 1, 1) AS "Gleich", NULLIF( 'a', 'b') AS "Ungleich"; Gleich Ungleich ----------------------------NULL a (1 row) Abbildung 7.43: Funktion NULLIF 7.6.6.3 IFNULL Durch die Funktion IFNULL ist es möglich NULL Werte durch Default Werte zu ersetzen ohne dabei einen Default Wert für Spalten vergeben zu müssen. Zudem kann jede Abfrage einen anderen Ersatzwert für NULL Werte benutzen. Uni> SELECT IFNULL( NULL, 1) AS "NULL", IFNULL( 2, 3) AS "Wert"; NULL Wert ----------------------------1 2 (1 row) Abbildung 7.44: Funktion IFNULL Marcus Börger 87 Data Manipulation Language Relationale Datenbanken 7.6.6.4 COALESCE Mit der Funktion COALESCE kann aus einer Liste von Werten oder Spalten der erste Wert ermittelt werden, der ungleich NULL ist. Haben alle Parameter den Wert NULL, so ist auch das Ergebnis von COALESCE gleich NULL. Der Funktion muß mindestens ein Parameter übergeben werden, damit ist COALESCE() nicht zulässig. Leider kann dieser Operator nicht auf Subselects angewandt werden. Uni> SELECT COALESCE(NULL,1,NULL,2,NULL) AS "1", COALESCE(NULL) AS "2"; 1 2 ----------------------------1 NULL (1 row) Abbildung 7.45: Funktion COALESCE 7.6.7 Funktionen für Zeichenketten 7.6.7.1 LIKE 7.6.7.2 Reguläre Ausdrücke 7.7 Online Analytical Processing 88 Marcus Börger Relationale Datenbanken Transactions 8 Transactions Transaktionen fassen Blöcke von SQL Befehlen zu einem Befehl zusammen. Die Befehle werden in einer temporären Kopie der Datenbank oder virtuell ausgeführt. Erst wenn Die Transaktion ohne Fehler als Beendet markiert wird, wirken sich die Befehle auf der Datenbank aus. Dazu wird dann entweder die Datenbank mit der veränderten temporären Kopie überschrieben oder es werden alle virtuellen Änderungen tatsächlich ausgeführt. Marcus Börger 89 Rechteverwaltung Relationale Datenbanken 9 Rechteverwaltung Spätestens dann, wenn mehrere Benutzer mit einer Datenbank arbeiten, stellt sich die Frage, wer auf welche Datenbank zugreifen darf und wer welche Aktionen ausführen darf. Wird ein Datenbank Managementsystem etwa von zwei Anwendungen genutzt, ist es sehr empfehlenswert, den Zugriff auf die Daten der jeweils anderen Anwendung zu verhindern. Aber auch innerhalb einer Anwendung gibt es Szenarios, in denen verschiedene Benutzer oder Benutzergruppen unterschiedliche Rechte haben sollten. In der nachfolgenden Abbildung sind einige oft anzutreffende Rechte und ihr Zusammenspiel dargestellt. Üblicherweise erfolgt die Vergabe von Rechten auf Basis der Informationen der benutzen Verbindung von Anwendung zum DBMS. Zu jeder Verbindung gehört die Angabe eines Benutzernamens und auch die Information von welchem Rechner die Verbindung aufgebaut wurde steht zur Verfügung. Zusätzlich kann meist schon beim Aufbau der Verbindung eine Datenbank ausgewählt werden. Diese drei Informationen werden benutzt, um die Rechte, die in den einzelnen Schemata des DBMS vergeben werden könne gezielt zu Filtern. Verbindungen der Anwendung zur Datenbank • • • Rechte in Abhängigkeit der Verbindung Rechte in Abhängigkeit des Benutzers Rechte in Abhängigkeit der Datenbank Konzeptuelles Schema und Views • • • Tabellen/Views Anlegen, Löschen, Ändern Daten Einfügen, Löschen, Ändern, Abfragen Datenbanken Erzeugen, Löschen, Sichern, Wiederherstellen, Kopieren Physisches Schema • • • Rechte Verwalten Benutzer Verwalten Datenorganisation Verwalten Abbildung 9.1: Rechte eines DBMS Die Rechteverwaltung einer Datenbank ist sehr stark vom eingesetzten Datenbank Managementsystem abhängig, denn jedes DBMS hat seine eigenen Strukturen auf denen die Verwaltung aufsetzt. Nahezu allen gemein ist jedoch, daß die Benutzer des DBMS nichts mit den Benutzern des zugrunde liegenden Betriebssystems haben. 90 Marcus Börger Relationale Datenbanken Rechteverwaltung 9.1 MySQL Das Datenbank Managementsystem MySQL speichert die Daten der Rechteverwaltung in der immer vorhandenen Datenbank mysql. Der Zugriff auf diese Datenbank sollte also nur dem Systembetreuer gewährt werden. Doch dazu muß zunächst einmal geklärt werden, wie das funktioniert. Bevor eine Verbindung mit MySQL zustande kommen kann, werden zunächst Benutzername, Paßwort sowie Hostname und optional die gewünschte Datenbank in der Datenbank mysql gesucht. Erst wenn dort der Zugriff mit mindestens einem Recht gewährt wird, kommt die Verbindung zustande. MySQL bietet selbst zwei Möglichkeiten der Rechteverwaltung. Zum einen können die Tabellen der Datenbank mysql mit den üblichen SQL-DML Befehlen wie INSERT, UPDATE und DELETE bearbeitet werden. Zum anderen können die SQL Befehle GRANT und REVOKE benutzt werden. Neben diesen eingebauten Methoden empfiehlt sich zudem noch der Einsatz von speziellen Werkzeugen wie etwa phpMyAdmin (siehe 9.1.4 phpMyAdmin). 9.1.1 Die Datenbank mysql MySQL kennt 14 verschiedene Rechte, auch Privilegien genannt. Vier Privilegien sind jeweils einem Befehl aus dem SQL-DML Umfang zugeordnet und steuern somit die Möglichkeiten Daten bearbeiten zu können. Fünf Privilegien regeln die Rechte Strukturen, also Datenbanken, Tabellen, Indizes und Referenzen, zu ändern. Ein Privileg legt fest, ob Dateien auf dem Server gelesen oder geschrieben werden. Dieses Recht kann selbstverständlich nur die Rechte des Benutzers freigeben, der den MySQL Server ausführt. Zu letzt gibt es vier Privilegien, die Rechte zur Administration des Servers festlegen. Das umfaßt auch ein Recht die Privilegien anderer zu verändern. MySQL Privilegien Daten Select_priv Insert_priv Update_priv Delete_priv Bedeutung SQL Kommando Daten abfragen Daten eingeben Daten modifizieren Daten löschen SELECT INSERT INTO UPDATE DELETE FROM Tabellen ändern Datenbank und Tabellen erzeugen Datenbanken bzw. Tabellen löschen Indizes erzeugen und löschen Zur Zeit noch nicht in Benutzung ALTER CREATE [ | ] DROP [DATABASE|TABLE] [CREATE|DROP] INDEX Dateien auf Serverlesen und schreiben SELECT ... INTO OUTFILE Struktur Alter_priv Create_priv Drop_priv Index_priv References_priv Dateizugriff File_priv Administration Grant_priv Process_priv Reload_priv Shutdown_priv Rechte verwalten GRANT, REVOKE MySQL Prozesse anzeigen und beenden Administrationskommandos (reload, refresh, flush-xxx) MySQL beenden (Daemon) Tabelle 9.1: MySQL Privilegien Marcus Börger 91 Rechteverwaltung Relationale Datenbanken Diese Privilegien werden in den Tabellen der Datenbank mysql gespeichert: Tabelle user Funktion Speichert zu jedem Benutzer (User) von welchem Rechner (Host) er mit welchem Paßwort (Password) zugreifen kann. Dabei wird der Benutzername mit Berücksichtigung von Klein/Großschreibung gespeichert. db Legt die Rechte eines Benutzers (User) innerhalb einer Datenbank (Db) für den Zugriff von einem Rechner (Host) fest. Hier kann auch festgelegt werden, daß ein Benutzer Rechte vergeben kann. Dabei ist zu beachten, daß ein Benutzer sowohl sich als auch anderen mehr Rechte geben kann, als er selbst zuvor hatte. host Wenn die host Einträge der Tabelle db leer bleiben, kann mit der Tabelle host geregelt werden, welche Rechte zu welcher Datenbank (Db) von welchem Rechner (Host) gewährt werden. tables_priv Gezielt Rechte für einzelne Tabellen festlegen. columns_priv Gezielt Rechte für einzelne Spalten festlegen. Abbildung 9.2: MySQL Datenbank mysql 9.1.1.1 MySQL Tabelle user.user Die Tabelle user verwaltet alle Kombinationen von Benutzer und Rechnername und legt somit alle erlaubten Verbindungen global, also für alle Datenbanken, fest. Es können alle 14 Rechte global vergeben werden. Lediglich, wenn hier für eine Verbindung keine Rechte vergeben werden, muß ein zum Benutzer und Rechner passender Eintrag in einer der anderen Tabellen existieren. Auf diese weise kann in der Tabelle user ein Benutzer festgelegt werden, der keine globalen Rechte hat aber zu einer bestimmten Datenbank Verbindungen aufbauen kann. Feld Host User Password Select_priv Insert_priv Update_priv Delete_priv Create_priv Drop_priv Reload_priv Shutdown_priv Process_priv File_priv Grant_priv References_priv Index_priv Alter_priv Datentyp char(60) char(16) char(16) enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') NULL NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL Default N N N N N N N N N N N N N N Abbildung 9.3: MySQL Tabelle user.user Die Spalte Host wird entweder der DNS Name oder die TCP/IP Adresse des Rechners gespeichert. Die internen Vergleiche benutzen den LIKE Operator, so daß man das % Zeichen als Platzhalter benutzen kann. Damit kann man zum Beispiel mit den Einträgen '192.168.%' und 92 Marcus Börger Relationale Datenbanken Rechteverwaltung '10.%' die Rechte für alle Computer im Class A bzw. Class C Intranet vergeben. Der Eintrag '%' bezieht sich demnach also auf alle Verbindungen des angegebenen Benutzers mit der Einschränkung, daß der lokale Rechner, also der Rechner, auf dem MySQL installiert ist, mit dem Eintrag 'localhost' und zwar nur diesem identifiziert wird. In der Spalte User wird der Benutzername mit Berücksichtigung von Klein/Großschreibung gespeichert. Das Paßwort wird verschlüsselt in der Spalte password gespeichert. Wenn ein Paßwort geändert werden soll, so muß dazu die Funktion password verwendet werden. 9.1.1.2 MySQL Tabelle user.db Die Tabelle db legt die Rechte eines Benutzers in einer Datenbank fest. Diese Rechte werden auf die Rechte, die sich aus der Tabelle user ergeben, aufaddiert. Damit ist es wie bereits oben angesprochen möglich einem Benutzer nur den Zugriff auf bestimmte Datenbanken zu geben. Auch in dieser Tabelle kann der Platzhalter '%' in der Spalte Host benutzt werden. Feld Host Db User Select_priv Insert_priv Update_priv Delete_priv Create_priv Drop_priv Grant_priv References_priv Index_priv Alter_priv NULL Datentyp char(60) char(64) char(16) enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL Default N N N N N N N N N N Abbildung 9.4: MySQL Tabelle user.db 9.1.1.3 MySQL Tabelle user.host Rechte zu Datenbanken können unabhängig vom Benutzer gefiltert werden, wenn für den Benutzer der Eintrag in der Tabelle db einen leeren Wert ('') für Host enthält. Auch hier kann man zwischen verschiedenen Rechner mittels des Host Feldes unterscheiden. Feld Host Db Select_priv Insert_priv Update_priv Delete_priv Create_priv Drop_priv Grant_priv References_priv Index_priv Alter_priv Datentyp char(60) char(64) enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') enum('Y','N') NULL NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NOT NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL Default N N N N N N N N N N Abbildung 9.5: MySQL Tabelle user.db Marcus Börger 93 Rechteverwaltung Relationale Datenbanken 9.1.1.4 MySQL Tabelle user.tables_priv 9.1.1.5 MySQL Tabelle user.columns_priv 9.1.2 Rechte applizieren Bevor MySQL veränderte Rechte berücksichtigt müssen die Tabellen der Datenbank mysql neu geladen werden. Dies kann durch den Befehl FLUSH PRIVILEGES im SQL Interpreter oder durch den Aufruf des Programms mysqladmin mit dem Parameter reload erreicht werden. Beides kann nur ein Benutzer, der über das Reload_priv Recht verfügt, durchgeführt werden. mysqladmin [ -u Benutzername –p ] reload Abbildung 9.6: mysqladmin reload 9.1.3 Verlust des root Paßworts Wenn das root Paßwort nicht mehr bekannt ist und kein Benutzer mit ausreichenden Berechtigungen vorhanden ist, kann man den MySQL Server so starten, daß der die Datenbank mysql nicht einließt und somit alle Rechte zur Verfügung stehen. Zunächst muß der Server beendet werden. Unter Unix ist das der MySQL Daemon, mysqld. Wenn kein Benutzer zur Verfügung steht, der den Daemon beenden kann, muß er auf andere Weise beendet werde (kill o.ä.). Danach wird er mit dem Parameter –-skip-grant-tables neu gestartet. Jetzt kann das Paßwort in der Tabelle user in der Datenbank mysql für den Benutzer root gesetzt werden. Jetzt muß der Daemon unbedingt beendet und ohne Parameter neu gestartet werden. Wenn MySQL unter Windows betrieben wird, kann man den Server mit dem Dienstmanager Beenden bzw. Starten. 94 Marcus Börger Relationale Datenbanken Rechteverwaltung 9.1.4 phpMyAdmin Das Frontend phpMyAdmin ist eine Webbasierte Anwendung zur Verwaltung von MySQL Datenbanken über ein Webinterface. Damit es installiert werden kann, benötigt man einen Rechner, der PHP Dateien in einem Webserver ausführen kann, das kann auch der Rechner sein, auf dem MySQL installiert ist. Der Zugriff auf phpMyAdmin erfolgt dann über einen Webbrowser wie den Microsoft Internet Explorer, Netscape Navigator oder ähnlichen. Bevor man phpMyAdmin jedoch benutzen kann muß es installiert und konfiguriert werden. 1. Es muß ein Rechner mit Webserver und Verbindung zur MySQL Installation existieren, der PHP Dateien im Webserver ausführen kann. 2. Das phpMyAdmin Paket kann von seiner Internetseite unter der Adresse http://phpmyadmin.sourceforge.net/ geladen werden. Es Steht dort als Anwendung mit Dateien der Endung .php sowie .php3, jeweils in verschiedenen Archivtypen, zum Download bereit 3. Das phpMyAdmin Archiv muß im Datenbereich des Webservers entpackt werden. Gegebenenfalls kann man für phpMyAdmin auch einen virtuellen Webserver einrichten. 4. Zum Paket gehört eine Datei mit Namen config.inc.php bzw. config.inc.php3. In dieser Datei wird die Verbindung zu MySQL konfiguriert, ohne die natürlich kein Arbeiten möglich ist. Zur Wahl stehen dabei grundsätzlich zwei Möglichkeiten: • Es wird fest ein Benutzer für eingestellt. Damit verfügt automatisch jeder im Internet/Intranet über die Rechte des dabei eingestellten Benutzers. Hierzu müssen die folgenden Variablen in der Datei geändert werden: $cfgServers[1]['host'] $cfgServers[1]['adv_auth'] $cfgServers[1]['user'] $cfgServers[1]['password'] = = = = '{localhost|host}'; FALSE; 'Benutzername'; 'Paßwort'; Wenn der Webserver und MySQL auf dem gleichen Rechner installiert sind, so kann man für host die Einstellung 'localhost' benutzen, andernfalls muß die TYP/IP Adresse oder der DNS Name des Rechners auf dem MySQL läuft eingetragen werden. Der Wert für adv_auth muß auf FALSE gesetzt werden. In den Variablen user und password müssen schließlich der Benutzername und das Paßwort angegeben werden, über den die Verbindung zwischen MySQL und phpMyAdmin erfolgen. • Die Identifizierung des Benutzers erfolgt über einen Paßwortdialog, jeder der phpMyAdmin benutzen möchte, muß also zunächst einen Benutzernamen und Paß- wort für MySQL eingeben. Dazu müssen folgende Variablen konfiguriert werden: $cfgServers[1]['host'] $cfgServers[1]['adv_auth'] = '{localhost|host}'; = TRUE; Auch bei dieser Betriebsart muß der host angegeben werden. Der Wert für adv_auth wird jedoch auf TRUE gesetzt. Da hierdurch für jede Verbindung Benutzername und Paßwort abgefragt werden, brauchen die beiden Variablen user und password nicht gesetzt werden. 5. phpMyAdmin kann nun benutzt werden. Eine weitergehende Dokumentation ist über die Einstiegsseite der Anwendung oder auf der Homepage verfügbar. Marcus Börger 95 Rechteverwaltung Relationale Datenbanken 9.2 PostgreSQL 9.3 Oracle 96 Marcus Börger Relationale Datenbanken Trigger 10 Trigger Durch den Einsatz von Triggern können Aufgaben, die Ansonsten in einer Applikation ausgeführt werden, vom Datenbank Management System automatisiert werden. Das hat den Vorteil, daß Daten unabhängig von der Applikation konsistent gehalten werden können. Dabei beginnt das Anwendungsspektrum bei Constraints und kann bis zur Implementierung von komplexen Applikationsabläufen selbst reichen, so daß im Extremfall auf den Einsatz eines Applikationsservers verzichtet werden kann. Aus heutiger Sicht ist allerdings der ausgewogene Einsatz beider Techniken der richtige Weg. Trigger ermöglichen es auf Aktionen in der Datenbank mit komplexen Funktionen zu reagieren. Genaugenommen können Trigger auf verändernde DML Aktionen innerhalb einer Datenbank reagieren, also Einfügen, Löschen oder Verändern von Daten. Sie können nicht auf Abfragen oder Befehle aus dem DDL Bereich reagieren wie etwa Erzeugen oder Löschen von Tabellen. Trigger können sowohl vor (BEFORE) als auch nach (AFTER) der Aktion ausgeführt werden. Sie können auf einzelne Befehle (FOR EACH STATEMENT) oder für jeden einzelnen Datensatz (FOR EACH ROW), der von dem Befehl beeinflußt wird, ausgeführt werden. Manche DBMS haben auch INSTEAD OF Trigger implementiert, bei denen der auslösende Befehl durch die Triggerfunktion ersetzt wird.23 Befehl Ausführen INSTEAD OF nein ja BEFORE EACH STATEMENT ja nein Triggerfunktion ausgeführt? nein ja Erster Datensatz nein Datensatz vorhanden? ja BEFORE EACH ROW ja nein AFTER EACH ROW Nächster Datensatz Triggerfunktion ausgeführt? ja nein ja Triggerfunktion ausgeführt? nein ja ja Triggerfunktion ausgeführt? nein ja nein AFTER EACH STATEMENT Triggerfunktion ausgeführt? ja ja Befehl Rückgängig nein Befehl Abgebrochen Befehl Ausgeführt Befehl Abgebrochen Abbildung 10.1: Trigger Ablaufdiagramm 23 PostgreSQL und Oracle haben BEFORE und AFTER Trigger, Microsoft SQL Server nur INSTEAD OF. Marcus Börger 97 Trigger Relationale Datenbanken 10.1 PostgreSQL und PL/PGSQL Zur Implementierung von Triggerfunktionen bietet PostgreSQL insbesondere die Programmiersprache Procedural Language/PostgreSQL an. Damit diese genutzt werden kann muß zunächst mit dem SQL Befehl CREATE LANGUAGE oder dem Konsolenbefehl createlang die Unterstützung in die Datenbank geladen werden. Wenn alle Datenbanken die Sprachunterstützung erhalten sollen, empfiehlt es sich nach der Installation die Spracheunterstützung in der Vorlage template1 zu laden. Jede danach angelegt Datenbank erhält die Sprachunterstützung dann automatisch. Mit dem SQL Befehl DROP LANGUAGE bzw. dem Konsolenbefehl droplang kann die Unterstützung einer Sprache wieder entfernt werden. Da die Konsolenbefehle wesentlich einfacher zu handhaben sind, werden nur sie beschrieben: createlang [ options ] { -l | language } dbname droplang [ options ] language dbname options: -h host -p port -U username -W -l language dbname Datenbankserver festlegen Port des Datenbankserver festlegen Benutzername festlegen (Postgres Superuser Privileg nötig) Paßwortabfrage Installierte Sprachen auflisten Die Unterstützung für die Sprache language laden Die Datenbank in der der Befehl ausgeführt wird Abbildung 10.2: createlang und droplang Neben PL/PGSQL unterstützt PostgreSQL auch andere Sprachen. Neben dem mitgelieferten Interfaces zum Beispiel für C und TCL (PLTCL) können auch eigene Sprachen eingebunden werden. Im folgenden wird jedoch nur auf PL/PGSQL eingegangen. Die Abbildung 10.3: Trigger mit PL/PGSQL zeigt den prinzipiellen Aufbau einer Triggerdeklaration. Zunächst wird eine parameterlose Funktion deklariert, die als Rückgabewert OPAQUE erhält. Auf diese können sich dann mehrere Trigger beziehen. Wenn dabei sowohl BEFORE als auch AFTER Trigger zum Einsatz kommen sollen sind allerdings mehrere CREATE TRIGGER Aufrufe erforderlich. CREATE FUNCTION func() RETURNS OPAQUE AS 'Triggerfunktion' LANGUAGE 'PLPGSQL'; CREATE TRIGGER name { BEFORE | AFTER } { INSERT | DELETE | UPDATE } [ OR { INSERT | DELETE | UPDATE }.] ON table FOR EACH { ROW | STATEMENT } EXECUTE PROCEDURE func(); Abbildung 10.3: Trigger mit PL/PGSQL Der Bezeichner OPAQUE, zu Deutsch undurchlässig, ist hier etwas verwirrend, denn eine Triggerfunktion erhält als Parameter die alten bzw. neuen Datensätze und kann den Neuen ggf. verändern, dazu später mehr. Eine weitere Besonderheit ergibt sich aus den Anführungsstrichen, durch die die Funktionsdeklaration eingeschlossen wird, denn daher müssen alle Anführungsstriche innerhalb der eigentlichen Triggerfunktion verdoppelt werden. 98 Marcus Börger Relationale Datenbanken Trigger 10.2 Oracle und PL/SQL Neben der reinen Programmiersprache Procedural Language/SQL, stellt Oracle noch eine sehr große Bibliothek zur Verfügung und bietet überdies noch ein Interface zu Java an [FePr99a] [FePr99b]. 10.3 Microsoft und VBA Wenn der Microsoft SQL Server zum Einsatz kommt ist man zwar einerseits auf die Verwendung von INSTEAD OF Triggern beschränkt hat aber andererseits die flexibelste Sprache zur Implementierung von Triggerfunktionen, namentlich VBA24, zur Verfügung. Wenn VBA als Implementierungssprache noch als Nachteil angesehen werden kann oder muß, so kann davon ausgegangen werden, daß neuere Versionen des MS SQL Servers voll in die .NET Strategie integriert sind und somit alle von Microsoft unterstützen Sprachen inklusive C# unterstützt werden. 24 Visual Basic for Applications stellt nicht nur in sich ein umfangreiches Programmiersystem zur Verfügung, sondern man hat auch Zugriff auf Bibliotheken anderer Sprachen über DLLs (Dynamic Link Library). Marcus Börger 99 Zusammenfassung Relationale Datenbanken 11 Zusammenfassung Relationale Datenbanken stellen eines der am weitesten verbreiteten Werkzeuge zur Verwaltung von Daten dar, auch wenn Sie sich nicht für jede Art von Daten und für jede Anwendung eigenen. Es gibt relationale Datenbanken für verschiedene Einsatzbereiche. Vor der Entwicklung einer Datenbankanwendung sollte also der spätere Einsatz gut überlegt sein, da dies einen großen Einfluß auf die Wahl des Datenbank Managementsystems hat. Es empfiehlt sich jedoch immer, Datenbankanwendungen möglichst allgemeingültig zu halten, so daß einerseits die Anwendung später erweitert werden kann, ohne die Datenbank völlig neu entwickeln zu müssen und andererseits das Datenbank Managementsystem gewechselt werden kann. Für die Entwicklung der einzusetzenden Modelle ist es ratsam geeignete Modellierungswerkzeuge zu verwenden. Das hier vermittelte Wissen zum Vorgehen bei der Modellierung und die Kenntnis der Möglichkeiten des Relationalen Modells sind aber auch beim Einsatz eines solchen Programms unabdingbar. Die Erstellung von Anwendungen verlangt heutzutage fast immer die Fähigkeit mit SQL Daten manipulieren zu können und selbst wenn eine Anwendung mit all ihren SQL Abfragen komplett entwickelt worden ist, wird es trotzdem immer notwendig sein, mit dem Einsatz von SQL Befehlen die Datenbank Pflegen und untersuchen zu können. Letzteres bedeutet also, daß eine fundierte Kenntnis der SQL Befehle und deren Einsatz im eingesetzten Datenbank Managementsystem für den Betrieb einer Datenbank gestützten Anwendung Vorraussetzung ist. 100 Marcus Börger Relationale Datenbanken EBNF A EBNF Die Extended Backus Naur Form EBNF dient der Definition der Syntax einer Sprache. Dieser Text nutzt die EBNF um die Sprache SQL zu erklären. Hier wird nur ein kleiner Teil der EBNF benutz. Dabei werden Elemente die kursiv dargestellt werden an einer andern Stelle exakt definiert. Elemente die nicht kursiv dargestellt werden, sind hingegen 1 zu 1 zu übernehmen: • ABC Steht für den Text ABC • ABC Wenn ABC als Text Hallo definiert wird, steht ABC für Hallo. Das wird an vielen Stellen benutzt, um Elemente einer Deklaration in einer getrennten EBNF Deklaration zu erklären. Abbildung 11.1: EBNF Definitionen Optionale Elemente können durch die eckigen Klammern „[“ und „]“ dargestellt werden: • A [ B ] C Steht für AC oder ABC. Mehrfaches Auftreten von B (etwa ABBC) ist nicht möglich. • A [ B ] [ C ] D Läßt die Zeichenketten AD, ABD, ACD sowie ABCD zu. Eine Vertauschung wie in ACBD ist nicht möglich. Abbildung 11.2: EBNF Option Eine Auswahl kann durch geschweifte Klammern „{“, „}“ und Trennstriche „|“ definiert sein: • A { B | C | D } E Erlaubt ABE, ACE und ADE. Die Folgen AE, ABCDE, ACDE, ABDE und ABCE sind nicht zugelassen. Abbildung 11.3: EBNF Auswahl Eine Auswahl kann innerhalb einer Option definiert werden: • A [ B | C ] D Ermöglicht AD, ABD oder ACD. Die Folge ABCD ist nicht zugelassen. • A [ { B | C } D | E ] F Ermöglicht AF, ABDF, ACDF und AEF. Nicht erlaubt sind ABF, ABCF, ACF, ABCDF, ABCDEF, ADF sowie ADEF. Abbildung 11.4: EBNF Auswahloption Marcus Börger 101 Lösungen Relationale Datenbanken B Lösungen 2 Datenbank Schemata 2.1 Der Name besteht im allgemeinen aus Vor- und Nachname. Zusätzlich gibt es noch die Anrede (Herr, Frau) und ggf. Titel (Prof., Dr., Ing.) sowie Namenserweiterungen. Namenserweiterungen sind etwa das Deutsche "von" oder das Holländische "van". In einigen Ländern sind zudem Zusätze wie "jr." für Junior üblich. In Manchen Anwendungen ist es zudem durchaus sinnvoll alle Vornamen zu speichern, wobei man zur Vereinfachung eine Spalte für den Hauptvornamen und eine Zweite für die weiteren Vornamen. Es gibt sich also Anrede, Titel, Vorname, Weitere Vornamen, Adelprädikat, Nachname, Namenszusatz. 2.2 Da die Anrede vom Kontext der Verwendung abhängt und in jeder Sprache anders lautet empfiehlt es sich nicht die Anrede selbst sondern lediglich das Geschlecht zu speichern. Aus den gespeicherten Informationen kann die Anwendung dann Anrede und Name im Kontext der Anwendung korrekt zusammenstellen. Dieses Vorgehen ist zudem hilfreich, da man aus dem Vornamen nicht immer auf das Geschlecht schließen kann, so ist Rene in Deutschland ein männlicher und in Frankreich ein weiblicher. PNr PTyp 1 Personen Vorname Adelrädikat Nachname TNr Zusatz … n = Titel Anrede Titel TNr … Geschlecht Abbildung 11.5: Lösungsvorschlag 2.2 Soll die Anrede dennoch gespeichert werden, so empfiehlt es sich eine Liste oder Tabelle für die Möglichkeiten vor zu sehen. Ansonsten besteht Gefahr, daß verschiedene Anwender unterschiedliche Formen und Schreibweisen der Anreden benutzen (Herr, Hr., herr). 2.3 Wenn mit der Dauer gearbeitet wird, braucht man sich keine Gedanken um Sommer/Winterzeit oder womöglich Schaltsekunden machen. Wird hingegen mit der Endzeit gearbeitet, so entfallen aufwendige Berechnungen der Endzeit, allerdings muß die Dauer berechnet werden. Oder war die Begründung umgekehrt? 2.4 Im Normalfall reicht es in solchen Anwendungen Anfangs- und Endtermin als Datum zu speichern. Wenn es jedoch vorkommt, daß Veranstaltungen zu verschiedenen Zeiten an einem Tag stattfinden, so ist neben dem Datum auch die Zeit wichtig. 2.5 Bei Beschränkung der maximalen Anzahl, können einfach alle notwendigen Felder durchnumeriert werden (Ort1, Zeit1, … Ortn, Zeitn). Andernfalls wird eine weitere Tabelle benötigt. Beachten Sie im Beispiel unten, daß nur TNr Primary Key der Tabelle Termine ist. Die erste Lösung ist schneller aber unflexibel und führt zu Platzverschwendung, wenn nur selten mehrere Felder benötigt werden (2.2.5.2.1 Relationstyp 1 zu c, c klein). Personen Name PNr 1 besuchen PNr VNr = n n 1 n = Veranstaltungen VNr PNr VName = 1 1 Termine TNr VNr Ort = Zeit n Abbildung 11.6: Lösungsvorschlag 2.5 102 Marcus Börger Relationale Datenbanken 2.6 Lösungen Da es nicht gefordert ist die Information über die Lehrstühle zu speichern, reicht es aus jeder Person eine übergeordnete Person zu zuordnen (Tutor, Lehrstuhlinhaber, Dekan). Diese übergeordnete Person wird im Feld CNr gespeichert und stellt somit eine rekursive 1 zu n Relation dar. In der Abbildung unten sind nur dir wichtigsten Spalten dargestellt: Personen CNr Name PNr n = besuchen PNr VNr 1 1 = n Veranstaltungen VNr PNr VName n 1 n = = 1 Abbildung 11.7: Lösungsvorschlag 2.6 2.7 Wenn alle Relationen mit CASCADE definiert sind, so wird die Datenbank durch Löschen des Datensatzes Ebert K. vollständig geleert. Die Abbildung unten greift Aufgabe 2.6 auf und zeigt zunächst die gefüllten Tabellen. In vier Schritten wird dann das Leeren der Datenbank gezeigt. Dazu werden jeweils die betroffenen Datensätze und die zugehörigen Relationen, beginnend beim Datensatz des Dozenten Ebert K., markiert: 1 Personen CNr Name PNr NULL Ebert K. 100000 100000 Zucker G. 100001 100001 Meier A. 100002 100001 Kühn H. 100003 100001 Muster M. 100004 2 Personen CNr Name PNr NULL Ebert K. 100000 Zucker G. 100001 Meier A. 100001 Kühn H. 100001 Muster M. 3 Personen CNr Name PNr NULL 100000 100001 100001 100001 4 100000 100001 100002 100003 100004 Ebert K. Zucker G. Meier A. Kühn H. Muster M. 100000 100001 100002 100003 100004 Personen CNr Name PNr NULL 100000 100001 100001 100001 Ebert K. Zucker G. Meier A. Kühn H. Muster M. 100000 100001 100002 100003 100004 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 besuchen PNr VNr 100002 100002 100004 100003 100004 100002 2 3 2 1 1 4 Veranstaltungen VNr PNr VName 1 2 3 4 100000 100000 100001 100001 Einführung Modellierung SQL-DDL SQL-DML Veranstaltungen VNr PNr VName 1 2 3 4 100000 100000 100001 100001 Einführung Modellierung SQL-DDL SQL-DML Veranstaltungen VNr PNr VName 1 2 3 4 100000 100000 100001 100001 Einführung Modellierung SQL-DDL SQL-DML Veranstaltungen VNr PNr VName 1 2 3 4 100000 100000 100001 100001 Einführung Modellierung SQL-DDL SQL-DML Abbildung 11.8: Lösungsvorschlag 2.7 Marcus Börger 103 Lösungen Relationale Datenbanken 2.8 3 Modellierung 3.1 3.2 3.3 3.4 3.5 3.6 3.7 104 Marcus Börger Relationale Datenbanken Verzeichnis der Abbildungen und Tabellen C Verzeichnis der Abbildungen und Tabellen Abbildung 2.1: Datenbank Schemata ..........................................................................................................................10 Abbildung 2.2: Tabellendarstellung ............................................................................................................................12 Abbildung 2.3: Tabelle Personen ................................................................................................................................13 Abbildung 2.4: Tabelle Veranstaltungen.....................................................................................................................13 Abbildung 2.5: Tabelle besuchen ................................................................................................................................13 Abbildung 2.6: full-table-scan.....................................................................................................................................15 Abbildung 2.7: Relationstyp 1 zu 1 .............................................................................................................................16 Abbildung 2.8: Relationstyp 1 zu 0/1 vs. Strukturgleichheit.......................................................................................17 Abbildung 2.9: Relationstyp 1 zu 0/1..........................................................................................................................17 Abbildung 2.10: Relationstyp 1 zu n ...........................................................................................................................18 Abbildung 2.11: Mehrfache Felder vs. Relation..........................................................................................................18 Abbildung 2.12: Relation umgekehrt ..........................................................................................................................19 Abbildung 2.13: Relationen zu verschiedenen Tabellen .............................................................................................19 Abbildung 2.14: Relationstyp 1 zu n mit Rekursion ...................................................................................................20 Abbildung 2.15: Relationstyp n zu m..........................................................................................................................20 Abbildung 2.16: Doppelte n zu m Relation .................................................................................................................21 Abbildung 2.17: Parallele n zu m Relationen..............................................................................................................21 Abbildung 2.18: Primary Key .....................................................................................................................................23 Abbildung 2.19: Primary Key bei ungeordneter Tabelle.............................................................................................23 Abbildung 2.20: Primary Key und Index (VZeit, VOrt) .............................................................................................23 Abbildung 2.21: Einfaches Datenmodell der Universität ............................................................................................25 Abbildung 2.22: Ausgangssituation ............................................................................................................................25 Abbildung 2.23: Relationen und Ändern mit CASCADE ...........................................................................................25 Abbildung 2.24: Löschen mit CASCADE...................................................................................................................26 Abbildung 2.25: Relationen und Set NULL ................................................................................................................26 Abbildung 2.26: Relationen und Set DEFAULT ........................................................................................................27 Abbildung 2.27: Relationen und Löschen bei Änderung.............................................................................................27 Abbildung 2.28: View als Filter ..................................................................................................................................28 Abbildung 2.29: View über Join..................................................................................................................................28 Abbildung 3.1: Die UNI in einer Textdatei .................................................................................................................30 Abbildung 3.2: Erste Normalform...............................................................................................................................31 Abbildung 3.3: Zweite Normalform, Personen ...........................................................................................................32 Abbildung 3.4: Zweite Normalform, Veranstaltungen................................................................................................32 Abbildung 3.5: Personen und Lehrstühle ....................................................................................................................33 Abbildung 3.6: Dritte Normalform, Personen und LNr ..............................................................................................33 Abbildung 3.7: Dritte Normalform, Lehrstühle...........................................................................................................33 Abbildung 3.8: Dritte Normalform, Personen .............................................................................................................34 Abbildung 3.9: Dritte Normalform, lesen/besuchen....................................................................................................34 Abbildung 3.10: Dritte Normalform, Veranstaltungen................................................................................................34 Abbildung 3.11: Besucher, Dozent und Vorlesung .....................................................................................................35 Abbildung 3.12: Vierte Normalform, Besucher und Vorlesung..................................................................................35 Abbildung 3.13: Vierte Normalform, Dozent und Vorlesung .....................................................................................35 Abbildung 3.14: Einfaches ER Diagramm der Universität .........................................................................................37 Abbildung 4.1: Mainframe ..........................................................................................................................................39 Abbildung 4.2: Internet 3-tier Modell .........................................................................................................................40 Abbildung 5.1: MySQL Installation unter Windows...................................................................................................41 Abbildung 5.2: Cygwin Download..............................................................................................................................42 Abbildung 5.3: Cygwin Download, Paketauswahl......................................................................................................42 Abbildung 5.4: Cygwin Installation ............................................................................................................................43 Abbildung 5.5: Cygwin32 IPC Installation .................................................................................................................43 Abbildung 5.6: Postgres Initialisierung .......................................................................................................................44 Abbildung 5.7: Postgres als Windows Service einrichten ...........................................................................................45 Abbildung 5.8: Oracle System Struktur.......................................................................................................................46 Tabelle 5.1: Oracle, Tablespace Parameter .................................................................................................................49 Abbildung 5.9: Oracle, Net8 Assistant........................................................................................................................49 Abbildung 5.10: Oracle, Anmelden bei Oracle Enterprise Manager...........................................................................50 Abbildung 5.11: Oracle, Datenbank-Anmeldung als SYSDBA..................................................................................50 Tabelle 5.2: Oracle, Standardbenutzer.........................................................................................................................50 Abbildung 5.12: Oracle, Datenbank hinzufügen .........................................................................................................51 Abbildung 5.13: Oracle, Tablespace erstellen .............................................................................................................51 Marcus Börger 105 Verzeichnis der Abbildungen und Tabellen Relationale Datenbanken Abbildung 5.14: Oracle, Datendatei bearbeiten...........................................................................................................52 Abbildung 5.15: Oracle, Benutzer bearbeiten .............................................................................................................52 Abbildung 5.16: Oracle, Anmeldung als Normal ........................................................................................................53 Abbildung 5.17: Oracle, SQL*Plus Worksheet...........................................................................................................53 Abbildung 5.18: Oracle, SQL PROMPT ......................................................................................................................53 Abbildung 6.1: Aufbau des Befehles CREATE DATABASE ......................................................................................54 Abbildung 6.2: Verbinden mit der Datenbank ............................................................................................................54 Abbildung 6.3:Anlegen der Datenbank Uni ................................................................................................................54 Abbildung 6.4: Aufbau des CREATE TABLE Befehles ............................................................................................55 Abbildung 6.5: CREATE TABLE für MySQL............................................................................................................55 Tabelle 6.1: MySQL Tabellentypen ............................................................................................................................55 Abbildung 6.6: Einfache Spaltendefinitionen..............................................................................................................56 Abbildung 6.7: Spaltendefinitionen.............................................................................................................................56 Tabelle 6.2: Alphanumerische Datentypen..................................................................................................................57 Tabelle 6.3: Numerische Datentypen ..........................................................................................................................58 Abbildung 6.8: Check Constraint ................................................................................................................................59 Abbildung 6.9: Check Constraints...............................................................................................................................59 Abbildung 6.10: Primary Key Constraint....................................................................................................................60 Abbildung 6.11: Alternate Key Constraint..................................................................................................................60 Abbildung 6.12: Foreign Key Constraint ....................................................................................................................60 Abbildung 6.13: Constraint Deferrment ......................................................................................................................60 Abbildung 6.14: CREATE TABLE SELECT, MySQL..............................................................................................61 Abbildung 6.15: CREATE TABLE SELECT, PostgreSQL & Oracle........................................................................61 Abbildung 6.16: SELECT INTO FROM, PostgreSQL ..............................................................................................61 Abbildung 6.17: Erzeugen der Tabelle Personen ........................................................................................................62 Abbildung 6.18: Erzeugen der Tabelle Veranstaltungen.............................................................................................62 Abbildung 6.19: Erzeugen der Tabelle besuchen ........................................................................................................62 Abbildung 6.20: Aufbau des CREATE INDEX Befehles ...........................................................................................63 Abbildung 6.21: Anlegen der Indizes für die Datenbank Uni .....................................................................................63 Abbildung 6.22: Aufbau des CREATE VIEW Befehles..............................................................................................63 Abbildung 6.23: Aufbau des DROP Befehles ..............................................................................................................65 Abbildung 6.24: Löschen der Tabelle besuchen..........................................................................................................65 Abbildung 6.25: Aufbau des TRUNCATE TABLE Befehles ......................................................................................65 Abbildung 7.1: Aufbau des INSERT INTO Befehles................................................................................................66 Abbildung 7.2: Aufbau des INSERT INTO SELECT Befehles .............................................................................66 Abbildung 7.3: INSERT INTO SELECT Beispiel...................................................................................................66 Abbildung 7.4: Belegen der Tabelle Personen ............................................................................................................67 Abbildung 7.5: Belegen der Tabelle Veranstaltungen.................................................................................................67 Abbildung 7.6: Belegen der Tabelle besuchen ............................................................................................................67 Abbildung 7.7: Aufbau des SELECT Befehls .............................................................................................................68 Abbildung 7.8: Einfaches SELECT.............................................................................................................................68 Abbildung 7.9: SELECT mit mehreren Spalten ..........................................................................................................68 Abbildung 7.10: SELECT *.......................................................................................................................................68 Abbildung 7.11: WHERE in SELECT...........................................................................................................................69 Abbildung 7.12: Aliasnamen.......................................................................................................................................69 Abbildung 7.13: SELECT über einer n zu m Relation ................................................................................................69 Abbildung 7.14: Mehrfachverwendung einer Tabelle in einer Abfrage ......................................................................70 Abbildung 7.15: SELECT mit indirekten Tabellen .....................................................................................................70 Abbildung 7.16: GROUP BY Abfrage.........................................................................................................................71 Abbildung 7.17: HAVING Abfrage .............................................................................................................................72 Abbildung 7.18: Sortierte Abfrage ..............................................................................................................................72 Abbildung 7.19: Mehrfachsortierung ..........................................................................................................................72 Abbildung 7.20: UNION..............................................................................................................................................73 Abbildung 7.21: VIEW Anzahl....................................................................................................................................73 Abbildung 7.22: Abfrage mit EXCEPT .......................................................................................................................74 Abbildung 7.23: UNION, EXCEPT, INTERSECT.................................................................................................74 Abbildung 7.24: Subselect ersetzt Konstante ..............................................................................................................75 Abbildung 7.25: Subselect mit Korrelation .................................................................................................................76 Abbildung 7.26: Korrelation auf gleicher Ebene ist unzulässig ..................................................................................76 Abbildung 7.27: Zulässige Korrelationsformen ..........................................................................................................76 Abbildung 7.28: Abfrage mit zwei Tabellen ...............................................................................................................77 Abbildung 7.29: Subselect als unabhängige Spalten ...................................................................................................77 Abbildung 7.30: Abfrage mit unabhängigen Subselects .............................................................................................77 106 Marcus Börger Relationale Datenbanken Verzeichnis der Abbildungen und Tabellen Abbildung 7.31: Subselect und EXISTS ....................................................................................................................79 Abbildung 7.32: Subselect und ANY ...........................................................................................................................79 Abbildung 7.33: SELECT ohne FROM ........................................................................................................................81 Abbildung 7.34: Aufbau des UPDATE Befehles .........................................................................................................82 Abbildung 7.35: UPDATE Beispiel .............................................................................................................................82 Abbildung 7.36: Aufbau des REPLACE INTO Befehles ...........................................................................................83 Abbildung 7.37: REPLACE INTO ersetzen ...............................................................................................................83 Tabelle 7.1: REPLACE INTO Verhalten....................................................................................................................83 Abbildung 7.38: Aufbau des DELETE FROM Befehles..............................................................................................84 Abbildung 7.39: Top-Level DELETE mit PostgreSQL ...............................................................................................84 Abbildung 7.40: Löschen doppelter Datensätze mit PostgreSQL ...............................................................................84 Abbildung 7.41: MySQL mit IF und <, = bei Zeichenketten.....................................................................................86 Abbildung 7.42: Operator IS NULL ..........................................................................................................................87 Abbildung 7.43: Funktion NULLIF ............................................................................................................................87 Abbildung 7.44: Funktion IFNULL ............................................................................................................................87 Abbildung 7.45: Funktion COALESCE .......................................................................................................................88 Abbildung 9.1: Rechte eines DBMS ...........................................................................................................................90 Tabelle 9.1: MySQL Privilegien .................................................................................................................................91 Abbildung 9.2: MySQL Datenbank mysql................................................................................................................92 Abbildung 9.3: MySQL Tabelle user.user...................................................................................................................92 Abbildung 9.4: MySQL Tabelle user.db .....................................................................................................................93 Abbildung 9.5: MySQL Tabelle user.db .....................................................................................................................93 Abbildung 9.6: mysqladmin reload ...................................................................................................................94 Abbildung 10.1: Trigger Ablaufdiagramm..................................................................................................................97 Abbildung 10.2: createlang und droplang ....................................................................................................98 Abbildung 10.3: Trigger mit PL/PGSQL ....................................................................................................................98 Abbildung 11.1: EBNF Definitionen......................................................................................................................... 101 Abbildung 11.2: EBNF Option.................................................................................................................................. 101 Abbildung 11.3: EBNF Auswahl............................................................................................................................... 101 Abbildung 11.4: EBNF Auswahloption .................................................................................................................... 101 Abbildung 11.5: Lösungsvorschlag 2.2 ..................................................................................................................... 102 Abbildung 11.6: Lösungsvorschlag 2.5 ..................................................................................................................... 102 Abbildung 11.7: Lösungsvorschlag 2.6 ..................................................................................................................... 103 Abbildung 11.8: Lösungsvorschlag 2.7 ..................................................................................................................... 103 Marcus Börger 107 Literaturverzeichnis Relationale Datenbanken D Literaturverzeichnis [BeMi00] XML in der Praxis Professionelles Web-Publishing mit der Extensible Markup Language Henning Behme, Stefan Mintert Addison Wesley, 2000, ISBN: 3-8273-1636-7 [Boe00] Marcus Börger Internet-Informationssysteme mit XML, XML-Views RWTH-Aachen, 2000 http://www-users.rwth-aachen.de/Marcus.Boerger/SemXML/SemXML.pdf [CHRS00] Andreas Christiansen, Michael Höding, Claus Rautenstrauch, Gunter Saake Oracle 8 effizient einsetzen Addison-Wesley, 2000, ISBN 3-8273-1347-3 [dtec97] 3- und n-schichtige Architekturen Copyright d-tec Distributed Technologies GmbH, 1997 http://www.corba.ch/3tier.html [FePr99a] Oracle PL/SQLP Grundlagen O'Reilly, 1999, ISBN: 3-89721-180-7 [FePr99b] Oracle PL/SQL Erweiterungen O'Reilly, 1999, ISBN: 3-89721-181-5 [FNA99] Peter Fankhauser, Erich J. Neuhold, Karl Aberer Grundlagen des Datenmanagements im World Wide Web GMD – IPSI, TU Darmstadt, 1998 http://www.darmstadt.gmd.de/~fankhaus/wwwdb.html Zugang auf Anfrage: mailto://[email protected] [Genn99] Oracle SQL*Plus The Definite Guide O'Reilly, 1999, ISBN: 1-56592-578-5 [HeSa00] Andres Heuer, Gunter Saake Datenbanken: Konzepte und Sprachen MITP, 2000, ISBN: 3-8266-0619-1 [HLU98] Uwe Herrmann, Dierk Lenz, Günter Unbescheid Oracle 8 für den DBA Addison-Wesley, 1998, ISBN: 3-8273-1310-4 [HSG98] Understanding and deploying LDAP Directory Services Timothy A. Howes, Ph.D., Mark C. Smith, Gordon S. Good New Riders, 1998, ISBN: 1-57870-070-1 [ISO3166] ISO 3166 Maintenance Agency (ISO 3166/MA) ISO 3166-1: The Code List International Organization for Standards, 2001 http://www.din.de/gremien/nas/nabd/iso3166ma/ [Kof01] Michael Kofler MySQL, Einführung, Programmierung, Referenz Addison-Wesley, 2001, ISBN: 3-8273-1762-2 [Mom00] Bruce Momjian PostgreSQL: Introduction and Concepts Addison-Wesley, 2000, ISBN: 0-201-70331-9 [NWB00] Ann Navarro, Chuck White, Linda Burman Mastering XML Sybex, 2000, ISBN: 0-7821-266-3 108 Marcus Börger Relationale Datenbanken Literaturverzeichnis [Pet01] Dušan Petković MS SQL Server 2000 Addison-Wesley, 2001, ISBN: 3-8273-1723-1 Auf CD: Bestellmöglichkeit für 120-Tage-Trialversion von MS SQL Server 2000 [SAG00] Software AG Tamino XML Database http://www.softwareag.com/tamino/ [SKS97] Abraham Silberschatz, Henry F. Korth, S. Sudashan Database system concepts; 3rd Edition McGraw-Hill, 1997, ISBN: 0-07-114810-8 [Wie01] Thomas Wiedmann DB2 – SQL, Programmierung und Tuning C&L Computer- und Literaturverlag, 2001, ISBN: 3-932311-80-9 Auf CD: DB2 Universal Database Personal Edition 7.1 (Windows) für 90 Tage Marcus Börger 109 Notizen Relationale Datenbanken Notizen: 110 Marcus Börger Relationale Datenbanken Marcus Börger Notizen 111 Relationale Datenbanken Relationale Datenbanken, Modellierung und SQL, richtet sich an alle, die sich in das Thema Relationale Datenbanken einarbeiten wollen. Es bietet dazu eine praktisch orientierte Einführung in die Konzepte Relationaler Datenbanken sowie einen Einstieg in die drei verbreiteten Datenbank Managementsysteme MySQL, PostgreSQL und Oracle. Notizen