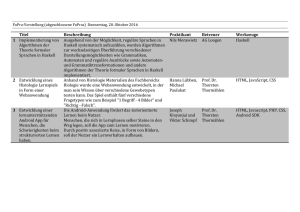
Praktikum Funktionale Programmierung - Goethe
Werbung

Begleitmaterial zum Praktikum Funktionale Programmierung Sommersemester 2011 Dr. David Sabel Institut für Informatik Fachbereich Informatik und Mathematik Goethe-Universität Frankfurt am Main Postfach 11 19 32 D-60054 Frankfurt am Main Email: [email protected] Stand: 4. April 2011 Inhaltsverzeichnis 1 Concurrent Versions System 1.1 Zugriff per ssh . . . . . . . . . . . . . . . . . 1.2 Arbeitskopie vom Server holen . . . . . . . . 1.3 Arbeitskopie lokal aktualisieren . . . . . . . 1.4 Dateien einchecken . . . . . . . . . . . . . . . 1.5 Hinzufügen von Dateien und Verzeichnissen 1.6 Keyword-Substitution und Binäre Dateien . 1.7 Graphische Oberflächen für CVS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2 3 3 3 4 4 4 2 Debugging 5 3 Haddock – A Haskell Documentation Tool 3.1 Dokumentation einer Funktionsdefinition . . . . . . . . . . . . 3.2 Haddock aufrufen . . . . . . . . . . . . . . . . . . . . . . . . . 7 7 8 4 Parser und Parsergeneratoren 4.1 Parser und Syntaxanalyse . . . . . . . . . 4.1.1 Was ist ein Parser? . . . . . . . . . 4.1.2 Beispiel: einfacher Taschenrechner 4.2 Parsergeneratoren . . . . . . . . . . . . . . 4.2.1 Was ist ein Parsergenerator? . . . 4.2.2 Lexikalische Analyse . . . . . . . . 4.3 Happy . . . . . . . . . . . . . . . . . . . . 4.3.1 Aufbau eines Happy-Skripts . . . . . . . . . . . 9 9 9 10 12 12 12 13 14 5 Datentypen und Typklassen in Haskell 5.1 Datentypdefinition . . . . . . . . . . . . . . . . . . . . . . . . . 5.2 Typklassen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3 Record-Syntax für Haskell data-Deklarationen . . . . . . . . . 19 19 21 23 6 Modularisierung in Haskell 26 D. Sabel, FP-PR, SoSe 2011 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Stand: 4. April 2011 Inhaltsverzeichnis 6.1 7 8 Module in Haskell . . . . . . . . . . 6.1.1 Modulexport . . . . . . . . . 6.1.2 Modulimport . . . . . . . . . 6.1.3 Hierarchische Modulstruktur . . . . . . . . . . . . . . . . . . . . 26 28 29 32 . . . . . 34 36 37 39 40 41 Concurrent Haskell 8.1 Erzeuger / Verbraucher-Implementierung mit 1-Platz Puffer 8.2 Das Problem der Speisenden Philosophen . . . . . . . . . . . 8.3 Futures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 50 50 53 I/O in Haskell 7.1 Primitive I/O-Operationen . . . . . . . . . 7.1.1 Komposition von I/O-Aktionen . . 7.1.2 Einige gebräuchliche IO-Funktionen 7.2 Monaden . . . . . . . . . . . . . . . . . . . . 7.3 Verzögern innerhalb der IO-Monade . . . . D. Sabel, FP-PR, SoSe 2011 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Stand: 4. April 2011 1 Concurrent Versions System CVS ist ein Software-System zur Versionsverwaltung von Dateien insbesondere für den Mehrbenutzerbetrieb. Hierbei werden die Dateien zentral auf einem Server in einem so genannten Repository gespeichert. Die Benutzer greifen auf die Dateien über einen CVS-Client zu und erhalten ihre lokale Arbeitskopie. Beim so genannten Einchecken lädt der Benutzer seine geänderten Dateien auf den Server. Wurde zwischenzeitlich die Datei auf dem Server geändert, so versucht CVS die Änderungen nachzuziehen, d.h. die beiden Dateien zu “mergen”. Kommt es hierbei zu Konflikten, so muss der Benutzer diese per Hand beheben. 1.1 Zugriff per ssh Um sichere Verbindungen zu verwenden, ist es möglich per ssh auf einen CVS-Server zuzugreifen. Bei Unix/Linux-System ist dafür notwendig, dass die Umgebungsvariable CVS_RSH auf den Wert ssh gesetzt ist. Verwendet man z.B. die Bash-Shell, so sollte in der Konfigurationsdatei .bashrc ein Eintrag der Art export CVS_RSH=ssh stehen. Genauere Informationen zum Zugang zum CVS-Server werden während der ersten Besprechung bekannt gegeben. D. Sabel, FP-PR, SoSe 2011 Stand: 4. April 2011 1.2 Arbeitskopie vom Server holen 1.2 Arbeitskopie vom Server holen Um eine Arbeitskopie vom Repository auf den lokalen Rechner zu laden, sollte man cvs get verwenden, wobei der Server, das Repository, den UserNamen und das auzucheckende Modul spezifiziert werden müssen, in der Form: cvs -d user@hostname:repositorypfad get modulname Beim Zugang über ssh muss man anschließend sein Passwort eingeben und erhält dann eine Arbeitskopie. 1.3 Arbeitskopie lokal aktualisieren Um eine Arbeitskopie lokal zu aktualisieren, also Änderungen vom Server in die lokale Kopie einzuspielen, kann man cvs update benutzen. Es empfiehlt sich die Option -d zu verwenden, die auch neu hinzugefügte Verzeichnis herunter lädt. D.h. wenn man sich innerhalb der Arbeitskopie befindet: cvs update -d 1.4 Dateien einchecken Um die eigenen Änderungen auf den CVS-Server hochzuladen, ist das Kommando cvs commit zu verwenden, welches zusätzlich mit der Option -m aufgerufen werden sollte, die es erlaubt noch einen Kommentar bezüglich der Änderungen anzugeben (was wurde geändert, warum). Ruft man cvs commit ohne Dateinamen aus, so werden alle geänderten Dateien hochgeladen. Noch zwei Beispiele: cvs commit -m "Programm verbessert, Bug XYZ entfernt" datei.hs lädt die Änderungen an der Datei datei.hs auf den Server. cd tmp cvs commit -m "" lädt alle Änderungen an Dateien ab dem Verzeichnis tmp auf den CVSServer. D. Sabel, FP-PR, SoSe 2011 3 Stand: 4. April 2011 1 Concurrent Versions System 1.5 Hinzufügen von Dateien und Verzeichnissen Um Dateien oder Verzeichnisse hinzu zu fügen, reicht es nicht ein cvs commit auf diese Datei zu machen. Man erhält dann die Fehlermeldung cvs commit: nothing known about ‘dateiname’ Zum Hinzufügen muss das Kommando cvs add verwendet werden. Hiermit werden Verzeichnisse sofort hinzugefügt (allerdings nicht deren Inhalt!). Dateien werden zwar hinzugefügt, aber nach dem Hinzufügen muss noch ein cvs commit auf die Datei erfolgen. Ein Beispiel: cvs add tmp/ cvs add datei.hs cvs commit -m "" datei.hs 1.6 Keyword-Substitution und Binäre Dateien Da CVS in Dateien Schlüsselwörter ersetzt (z.B. wird $Date$ durch das Datum des letzten Eincheckens ersetzt) muss man beim Einchecken von binären Dateien aufpassen, da dort ja kein Ersetzen erfolgen sollte. Hierfür sollte man die Option -kb beim cvs add verwenden, z.B. cvs add -kb anleitung.pdf Man kann diese Option auch noch später setzen mit cvs admin und anschließendem cvs update. 1.7 Graphische Oberflächen für CVS Neben den hier vorgestellten Kommandos für die Konsole gibt es zahlreiche graphische Oberflächen zum Benutzen von CVS. Z.B. verfügt die IDE Eclipse (http://www.eclipse.org/) bereits über eingebaute CVS-Unterstützung. Unter KDE gibt es das Programm cervisia (http://cervisia.kde.org/), für MS Windows empfiehlt sich das Programm TortoiseCVS (http://www.tortoisecvs.org/) Stand: 4. April 2011 4 D. Sabel, FP-PR, SoSe 2011 2 Debugging Haskell stellt nicht viele Tools zum Debuggen zur Verfügung. Der Hauptgrund dafür ist das mächtige statische Typsystem, welches bereits zur Compilezeit viele Programmierfehler erkennen lässt. Trotzdem geben wir hier einige Hinweise zum Debuggen. In der Standardbibliothek Debug.Trace findet sich die Funktion trace vom Typ > trace :: String -> a -> a Wenn diese aufgerufen wird, gibt sie den String des ersten Arguments aus und liefert dann als Ergebnis das zweite Argument. Mit dieser Funktion kann man Zwischenwerte beim Berechnen zum Debuggen ausgeben. In Verbindung mit Guards kann man dies relativ komfortabel bewerkstelligen, ohne den Code mit vielen trace-Aufrufe zu verseuchen. Wir betrachten ein Beispiel. Sei f definiert als > f x y z = e wobei e irgendeinen Code darstellt. Um nun zum Debugging, bei jedem Aufruf von f die Werte der Argumente auszugeben, kann man wie folgt vorgehen: > f x y z Stand: 4. April 2011 D. Sabel, FP-PR, SoSe 2011 2 Debugging > > | trace (show x ++ show y ++ show y) False = undefined | otherwise = e Der erste Guard wird immer ausgewertet und deshalb werden mittels trace die Argumente ausgedruckt. Da trace aber insgesamt stets False liefert trifft der Guard nicht zu und der otherwise-Guard wird immer aufgerufen. Will man den trace-Aufruf entfernen, so reicht es die zweite Zeile auszukommentieren: > f x y z > -- | trace (show x ++ show y ++ show y) False = undefined > | otherwise = e Stand: 4. April 2011 6 D. Sabel, FP-PR, SoSe 2011 3 Haddock – A Haskell Documentation Tool Haddock (http://haskell.org/haddock) dient zum Erstellen einer HTMLDokumentation anhand speziell kommentierter Haskell-Quellcode-Dateien. Hierbei wird im Allgemeinen nur für jene Funktionen und Datentypen eine Dokumentation erstellt, die in der Exportliste eines Moduls vorhanden sind, und – bei Funktionen – explizit mit einer Typsignatur versehen sind. Wir gehen in diesem Abschnitt auf einige Grundfunktionalitäten von Haddock ein, die vollständige Dokumentation ist auf oben genannter Webseite verfügbar. 3.1 Dokumentation einer Funktionsdefinition Wir betrachten das folgende Beispiel quadrat :: Integer -> Integer quadrat x = x * x Ein Dokumentationsstring für diese Definition kann wie folgt hinzugefügt werden: -- | Die ’quadrat’-Funktion quadriert Integer-Zahlen quadrat :: Integer -> Integer quadrat x = x * x Stand: 4. April 2011 D. Sabel, FP-PR, SoSe 2011 3 Haddock – A Haskell Documentation Tool D.h. Haddock-Kommentare beginnen mit -- | und müssen vor der Typdeklaration stehen. Man beachte, dass bei Verwendung von Literate Haskell, die Haddock-Kommentare im Code-Teil stehen müssen, d.h. die Definition hat dann die Form > -- | Die ’quadrat’-Funktion quadriert Integer-Zahlen > quadrat :: Integer -> Integer > quadrat x = x * x während | Die ’quadrat’-Funktion quadriert Integer-Zahlen > quadrat :: Integer -> Integer > quadrat x = x * x nicht funktioniert. 3.2 Haddock aufrufen Man beachte, dass Haddock mit sämtlichen Quelldateien aufgerufen werden muss, um eine korrekte Verlinkung der Dokumente zu erhalten. Für Dateien file1, . . . , fileN ist der Haddock-Aufruf haddock ... --html -o ausgabe file1 ... fileN Hierbei bedeutet --html, dass eine HTML-Dokumentation generiert wird, und -o ausgabe bedeutet, dass die HTML-Dateien im Verzeichnis ausgabe abgelegt werden (dieses muss vorher vorhanden sein!). Da sämtliche Quelltextdateien aufeinmal übergeben werden müssen, lohnt es sich den Haddock-Aufruf zu automatisieren und ein Shell-Skript (oder unter Windows eine entsprechende Batch-Datei) anzulegen. Stand: 4. April 2011 8 D. Sabel, FP-PR, SoSe 2011 4 Parser und Parsergeneratoren Zum automatischen Erstellen eines Parser in Haskell kann der Parsergenerator Happy1 verwendet werden. Dieses Kapitel beschreibt, was ein Parser ist und motiviert die Verwendung von Parsergeneratoren in der Softwareentwicklung. Am Schluß wird auf die Benutzung des Happy eingegangen. 4.1 Parser und Syntaxanalyse 4.1.1 Was ist ein Parser? Wer einen Compiler für eine Programmiersprache entwickeln möchte, steht u.a. vor der Aufgabe, eine Funktion zu schreiben, welche den Quellcode auf syntaktische Korrektheit überprüft. Der Quellcode ist zunächst nichts anderes als eine sehr lange Folge von ASCII-Zeichen ohne inhaltliche Bedeutung. Damit dieser String als ein korrektes Programm erkannt werden kann, muss die Anordnung der Zeichen gewissen Regeln genügen. Die Gesamtheit dieser Regeln wird als Syntax der Programmiersprache bezeichnet. Ein Programm, welches die Syntaxanalyse durchführt, nennt sich Parser. Man kann sich nun viele Beispiele ausdenken, wo auch in anderen Gebieten — also nicht nur im Bereich des Compilerbaus — Parser eingesetzt 1 Verfügbar unter http://haskell.org/happy Stand: 4. April 2011 D. Sabel, FP-PR, SoSe 2011 4 Parser und Parsergeneratoren werden können. Ein solches Beispiel ist eben gerade die Überprüfung eines aussagenlogischen Ausdrucks. Ein anderes Beispiel wird im nächsten Unterabschnitt vorgestellt. 4.1.2 Beispiel: einfacher Taschenrechner Wir wollen nun an einem einfachen Beispiel sehen, wie man zu einem gegebenen Problem eine exakte Syntaxbeschreibung angibt. Die Notation, welche wir hier verwenden, nennt sich Backus Naur Form oder kurz: BNF. Die Syntax wird in Form von Ableitungsregeln angegeben. Dabei stehen auf der linken Seite einer Regel Variablennamen (Nonterminals), auf der rechten Seite stehen Strings aus weiteren Variablen und Symbolen aus dem Eingabestrom des Parsers (Terminals). Der Parser versucht nun ausgehend von einer Startvariablen solange Ableitungen durchzuführen, bis ein String aus Terminals entstanden ist, der mit dem Eingabestring identisch ist. Nehmen wir an, unsere Syntax (in BNF) lautete: S ::= a | aX X ::= Xb | ε wobei S das Startsymbol bezeichne, wir davon ausgehen, dass Nonterminals fett und groß und Terminals klein geschrieben werden, das Zeichen «|» eine Art „Oder“ und ε das „leere Terminal“ darstellt. Dies ist die Syntax der formalen Sprache {a, ab, abb, ...}. Die Ableitung des Wortes abb sieht dann z.B. wie folgt aus: S → aX → a(bX) → a(b(bX)) → a(b(bε)) Als ein etwas komplexeres Beispiel betrachten wir einen Taschenrechner, welcher die vier Grundrechenarten beherrscht. Unser erster Ansatz wird wohl wie folgt lauten: Stand: 4. April 2011 10 D. Sabel, FP-PR, SoSe 2011 4.1 Parser und Syntaxanalyse Expr ::= Zahl | ( Expr ) | Expr + Expr | Expr − Expr | Expr ∗ Expr | Expr / Expr Zahl ::= Ziff | Zahl Ziff Ziff ::= 1 | 2 | ... | 9 | 0 d.h. Zahlen werden aus einzelnen Ziffern gebildet (wir verzichten auf negative Zahlen) und ein Rechenausdruck ist eine Zahl oder ist aus Unterausdrücken der gleichen Form zusammengesetzt. Dies sieht recht einleuchtend aus, aber es ist nicht wirklich das was wir wollen: 2+5∗3 Dieser Eingabestring läßt sich auf verschiedene Arten ableiten: Expr → Expr + Expr → ... → 2 + Expr → 2 + (Expr ∗ Expr) → ... Expr → Expr ∗ Expr → ... → Expr ∗ 3 → (Expr + Expr) ∗ 3 → ... Die zweite Ableitung entspricht nicht dem, was wir von der Mathematik her kennen („Punkt-vor-Strich Regel“). Wir werden also diese zusätzlichen Regeln in irgendeiner Weise in unsere BNF einbauen müssen. Die folgende Syntax erfüllt die bekannten Präzedenzregeln: Expr ::= Expr + Term | Expr − Term | Term Term ::= Term ∗ Fact | Term/Fact | Fact Fact ::= ( Expr ) | Zahl Zahl ::= Ziff | Zahl Ziff Ziff ::= 1 | 2 | ... | 9 | 0 Es braucht ein wenig Übung zu verstehen, wie und warum dies funktioniert. D. Sabel, FP-PR, SoSe 2011 11 Stand: 4. April 2011 4 Parser und Parsergeneratoren 4.2 Parsergeneratoren 4.2.1 Was ist ein Parsergenerator? Nachdem man für eine Sprache eine Syntax in Form einer BNF erstellt hat, geht es an die Umsetzung der Syntax in die Zielsprache. Je nach Komplexität der Syntax wird man diese Aufgabe irgendwo zwischen ‚lästig‘ und ‚unzumutbar‘ einordnen. Auch sieht man dem geschriebenen Quelltext oft kaum mehr die ursprüngliche Syntax an. An dieser Stelle kommen Parsergeneratoren ins Spiel. Ein Parsergenerator ist ein Programm, welches als Eingabe eine Syntax in BNF2 erhält und daraus einen Parser in der Zielsprache — in unserem Fall also Haskell — erzeugt. Dadurch konzentriert sich die Arbeit im wesentlichen auf das Finden einer Syntax, und die Fehler die auftreten sind i.a. logischer Natur (keine Programmierfehler). Der bekannteste Parsergenerator ist Yacc,3 welcher in den 70er Jahren für die Herstellung der Parser in UNIX C-Compilern entwickelt wurde und vielen anderen Parsergeneratoren (z.B. dem Happy), zumindest was die Notation betrifft, als Vorbild gedient hat. 4.2.2 Lexikalische Analyse Wir hatten gesagt, dass es sich bei der Eingabe eines Parsers um einen String von Zeichen handelt — üblicherweise sind dies ASCII-Zeichen. Dabei gibt es aber ein paar Dinge zu beachten. Betrachten wir dazu folgenden HaskellText: > func var = 5 * var Es ist offenbar unerheblich, ob beispielsweise zwischen den Zeichen 5 und * kein, ein oder beliebig viele Freizeichen stehen. Auf der anderen Seite ergibt sich ein völlig anderes Programm, wenn wir schreiben: > func v ar = 5 * v ar Wir müssen also unterscheiden zwischen den ASCII-Zeichen, wie sie uns im Eingabestring begegnen und den Zeichen, die aus der Sicht der Syntax Sinneinheiten bilden. Solche Sinneinheiten sind im obigen Beispiel die „Zeichen“ func, var, =, 5, * und var. Keine Sinneinheiten sind dagegen die Zwischenräume und der abschließende Wagenrücklauf (’\n’).4 Man nennt 2 bzw. einer der BNF ähnlichen Notation, wie im Beispiel des Happy steht für Yet another Compiler Compiler 4 Diese Zeichen werden auch als „Whitespace“ bezeichnet. 3 Stand: 4. April 2011 12 D. Sabel, FP-PR, SoSe 2011 4.3 Happy diese Sinneinheiten Token — es ist die Aufgabe eines Lexers, aus dem Strom von ASCII-Zeichen eine Folge von Token zu generieren, um den Parser von technischen Details zu entlasten. Eine solche Tokenfolge könnte für obiges Beispiel wie folgt aussehen:5 [BEZEICHNER func, BEZEICHNER var, ZUWEISUNG, INT 5, MULT, BEZEICHNER var] Eine lexikalische Analyse ist nun ein Pattern Matching ähnlich dem, wie wir es von Haskell her kennen. D.h. auf der linken Seite stehen Muster, denen gewisse Folgen von ASCII-Zeichen entsprechen können. Diese Muster sind reguläre Ausdrücke. Auf der rechten Seite stehen Token, die im Falle eines Matchings erzeugt werden sollen. Einige Beispiele sollen dies klarmachen: * (0-9)+ TokenTimes TokenInt $$ Die erste Zeile ordnet dem Zeichen ‚*‘ das entsprechende Token TokenTimes zu. In der zweiten Zeile werden Zahlen aus Ziffern erkannt. $$ steht hierbei für den Teilstring, der gematcht wurde, also z.B. 100. Das Programm Alex6 ist wie bereits erwähnt ein Lexer-Generator. Da man aber den ASCII-Strom häufig recht einfach „von Hand“ in den zugehörigen Tokenstrom überführen kann, wird ein solches Programm seltener benutzt als ein Parsergenerator. 4.3 Happy Happy7 ist ein Parsergenerator, dessen Zielsprache Haskell ist. Er hat viel von Yacc übernommen. Die offizielle Referenz ist (?). Einen Lexer-Generator gibt es zwar auch für Haskell (Alex), aber es zeigt sich, dass es gerade in Haskell durch dessen ausgefeiltes Patternmatching selten nötig ist, eine solche Software zu verwenden. Stattdessen schreibt man einen Lexer gewöhnlich von Hand als ein eigenständiges Modul und bindet dieses mit dem Befehl import in das Happy-Skript ein (s. nächsten Unterabschnitt). 5 wobei wir gleich eine Schreibweise wählen, wie wir sie auch in Haskell benutzen würden, vorausgesetzt ein Datentyp Token existierte. 6 http://haskell.org/alex/ 7 http://haskell.org/happy/ D. Sabel, FP-PR, SoSe 2011 13 Stand: 4. April 2011 4 Parser und Parsergeneratoren 4.3.1 Aufbau eines Happy-Skripts In diesem Abschnitt werden wir beschreiben, wie eine Parserspezifikation für Happy aussieht. Hierfür verwenden wir als Beispiel arithmetische Ausdrücke, mit der (mehrdeutigen!) Grammatik: Expr ::= | | | | | Expr + Expr Expr − Expr Expr ∗ Expr Expr / Expr ( Expr ) Zahl Die Produktionen für Zahl geben wir nicht an, da wir das eigentlich Parsen der Zahl dem Lexer überlassen werden. Jedes Happy-Skript besteht aus bis zu 4 Teilen. Der erste (optionale) Teil ist ein Block Haskell-Code, der von geschweiften Klammern umschlossen wird. Dieser Block wird unverändert an den Anfang der durch Happy generierten Datei gesetzt. Für gewöhnlich stehen hier der Modulkopf, Typdeklarationen, import-Befehle usw. { module Calc where import Char } Der nächste Teil enthält verschiedene Direktiven, die Happy für eine korrekte Funktionsweise unbedingt benötigt: • %name NAME bezeichnet den Namen der Parserfunktion. Unter diesem Namen kann der Parser also später aufgerufen werden. • %tokentype { TYPE } Dies ist der Ausgabetyp des Lexers und damit der Eingabetyp des Parsers. • %token MATCHLIST Hier werden den Token, die vom Lexer erzeugt wurden, die Terminals zugewiesen, die in der BNF verwendet werden. Ein Beispiel ist: %name calculator %tokentype { Token } Stand: 4. April 2011 14 D. Sabel, FP-PR, SoSe 2011 4.3 Happy %token int ’+’ ’-’ ’*’ ’/’ ’(’ ’)’ { { { { { { { TokenInt $$ } TokenPlus } TokenMinus } TokenTimes } TokenDiv } TokenOB } TokenCB } Der Parser wird somit den Namen calculator erhalten, die verwendeten Tokens sind vom Datentyp Token und für die Zuweisung der Terminals an die Tokens gilt: Links stehen die Terminals, rechts in geschweiften Klammern die Token. Das Symbol $$ ist ein Platzhalter, das den Wert des Tokens repräsentiert. Normalerweise ist der Wert eines Tokens der Token selbst, mit $$ wird ein Teil des Tokens als Wert spezifiziert. Im Beispiel ist der Wert des Tokens TokenInt zahl die Zahl. Es schließt sich der Grammatikteil an (vom zweiten Teil durch ein %% getrennt), in dem also in einer BNF ähnlichen Notation die Syntax, wie man sie sich zuvor überlegt hat, aufgeschrieben wird. Auf die kleinen Unterschiede zur BNF möchte ich hier nicht eingehen, wichtiger ist, dass man hinter jede Regel eine so genannte Aktion schreiben kann. %% Expr :: { Expr } Expr : Expr ’+’ Expr | Expr ’-’ Expr | Expr ’*’ Expr | Expr ’/’ Expr | ’(’ Expr ’)’ | int { { { { { { Plus $1 $3} Minus $1 $3} Times $1 $3} Div $1 $3 } $2 } Number $1} Hinter den Regeln steht in geschweiften Klammern jeweils ein Stück Haskell-Code. Dies sind „Aktionen“, die immer dann ausgeführt werden, wenn diese Regel abgeleitet wird. Mittels $i wird auf den Wert von i-ten Terminals bzw. Nonterminals zugegriffen. Der Wert eines Terminals ist dabei normalerweise das Terminal selbst. Durch die Aktionen hat der Parser also eine Ausgabe (und ist nicht nur ein reiner Syntax-Überprüfer). In unserem Beispiel ist die Ausgabe eine Objekt vom Typ Expr. Wie wir nun schon D. Sabel, FP-PR, SoSe 2011 15 Stand: 4. April 2011 4 Parser und Parsergeneratoren sehen, werden die Zahlen nicht mittels der Grammatik geparst, sondern direkt vom Token TokenInt bzw. Terminal int übernommen. Dies ist eine Vereinfachung, d.h. wir überlassen das korrekte Parsen der Zahlen dem Lexer (er erstellt ja das Token TokenInt). Der vierte Teil eines Happy-Skripts ist wieder ein in geschweifte Klammern gesetzter Block mit Haskell-Code, welcher unverändert ans Ende der erzeugten Datei gesetzt wird. Hier muss zumindest die Funktion happyError stehen, welche im Fall eines Syntax-Fehlers von der Parser-Funktion automatisch angesprungen wird (damit dies funktioniert, darf für diese Funktion kein anderer Name verwendet werden.) Oft ist hier auch der Lexer implementiert, wenn der Programmierer zu faul war, ihn in ein eigenes Modul zu stecken. Für unser Beispiel müssen auch die Datentypen Expr und Token sowie der Lexer irgendwo definiert werden, d.h. entweder in einem der Haskell-Code-Abschnitte der Parserspezifikationsdatei oder in externen Haskell-Dateien, die dann importiert werden. Der Vollständigkeit halber, der Rest der der Parserspezifikation für unser Beispiel: { happyError :: [Token] -> a happyError _ = error "parse error!" data Token = | | | | | | data Expr TokenInt Int TokenPlus TokenMinus TokenTimes TokenDiv TokenOB TokenCB = Plus | Minus | Times | Div | Number deriving(Show) Expr Expr Expr Expr Int Expr Expr Expr Expr lexer :: String -> [Token] Stand: 4. April 2011 16 D. Sabel, FP-PR, SoSe 2011 4.3 Happy lexer [] = [] lexer (’+’:cs) lexer (’-’:cs) lexer (’*’:cs) lexer (’/’:cs) lexer (’(’:cs) lexer (’)’:cs) lexer (c:cs) | isSpace c = | isDigit c = | otherwise = = = = = = = TokenPlus : lexer cs TokenMinus : lexer cs TokenTimes : lexer cs TokenDiv : lexer cs TokenOB : lexer cs TokenCB : lexer cs lexer cs lexNum (c:cs) error ("parse error, can’t lex symbol " ++ show "c") lexNum cs = TokenInt (read num) : lexer rest where (num,rest) = span isDigit cs } Mit der so erstellten Parserspezifikation (die Dateien haben die Endung .y bzw .ly falls es sich um ein literate skript handelt), kann nun mittels happy der Parser generiert werden: happy example.y shift/reduce conflicts: 16 Die Meldung der Konflikte sagt uns, dass etwas nicht stimmt. Der erstellte Parser weiß in manchen Situationen nicht was er tun soll. Der Grund hierfür liegt in der Mehrdeutigkeit unserer Grammatik. Wir könnten nun eine eindeutige (aber auch komplizierte Grammatik) benutzen, aber happy bietet uns die Möglichkeit Präzedenz und Assoziativität von Operatoren am Ende der Direktiven festzulegen. Hierbei gilt • %left Terminal(e) legt fest, dass diese Terminale links-assoziativ sind (d.h. ein Ausdruck a ⊗ b ⊗ c wird als (a ⊗ b) ⊗ c aufgefasst). • %right Terminal(e) legt fest, dass diese Terminale rechts-assoziativ sind (d.h. ein Ausdruck a ⊗ b ⊗ c wird als a ⊗ (b ⊗ c) aufgefasst). • %nonassoc Terminal(e) legt fest, dass diese Terminale nicht assoziativ sind (d.h. ein Ausdruck a ⊗ b ⊗ c kann nicht geparst werden und es tritt ein Fehler auf) D. Sabel, FP-PR, SoSe 2011 17 Stand: 4. April 2011 4 Parser und Parsergeneratoren Die Präzedenz der Terminale gegenüber den anderen Terminalen wird durch die Reihenfolge %left, %right und %nonassoc Direktiven festgelegt, wobei „früher“ „weniger Präzedenz“ bedeutet. Nach dem Einfügen der Zeilen %left ’+’ ’-’ %left ’*’ ’/’ direkt vor %%, hat der Parser keine Konflikte mehr und parst arithmetische Ausdrücke entsprechend der üblichen geltenden Konventionen (Punkt vor Strich usw.). Stand: 4. April 2011 18 D. Sabel, FP-PR, SoSe 2011 5 Datentypen und Typklassen in Haskell In diesem Kapitel werden in Kurzform selbst definierte Datentypen, Typklassen und die Record-Syntax für Datentypen erläutert. 5.1 Datentypdefinition Neben primitiven Datentypen, die Haskell bereits bereitstellt, (z.B. für ganze Zahlen (Int für beschränkte Zahlen, Integer für unbeschränkte Zahlen) für Fließkommazahlen (Double und Float), für Bruchzahlen Rational) und komplexeren Typen wie Tupel, Listen, Arrays, etc., kann man in Haskell Datentypen selbst definieren. Hierfür gibt es im Wesentlichen drei verschiedene Möglichkeiten: • Mit type kann ein Typsynonym definiert werden, d.h. man vergibt einen neuen Namen für schon definierte Typen. Ein einfaches Beispiel ist: type Wahrheitswert = Bool Ein komplexeres Beispiel ist ein Typsynonym für Wörterbücher, welches polymorph über dem Typ der Einträge ist: type Woerterbuch a = [(Integer,a)] Stand: 4. April 2011 D. Sabel, FP-PR, SoSe 2011 5 Datentypen und Typklassen in Haskell • Mit data wird ein neuer Datentyp definiert. Ein einfacher Aufzählungstyp für die RGB-Farben kann z.B. definiert werden mit data RGB = Rot | Gruen | Blau Hierbei ist RGB ein neuer Typ und Rot, Gruen, Blau sind neue Datenkonstruktoren. Für diese Datenkonstruktoren kann Pattern-Matching verwendet werden. Z.B. kann man eine Funktion definieren, die jede RGB-Farbe in einen String konvertiert: rgbToString Rot = "rot" rgbToString Gruen = "gruen" rgbToString Blau = "blau" Datentypen können polymorph sein, z.B. entwederOder a b = Links a | Rechts b und Datentypen können rekursiv sein. Die in Haskell eingebauten Listen sind rekursive Datentypen. Man könnte diese selbst definieren als data Liste a = Nil | Cons a (Liste a) Binäre Bäume mit Blattmarkierungen können rekursiv definiert werden als data Baum a = Blatt a | Knoten (Baum a) (Baum a) • Mit newtype wird ein Typsynonym definiert, dass durch einen zusätzlichen Datenkonstruktor verpackt wird. Rein syntaktisch ist newtype überflüssig, da dies auch stets durch eine data-Deklaration möglich ist. Das Verwenden der newtype-Syntax hat den Vorteil, dass der Compiler weiß, dass es sich eigentlich nur um ein verpacktes Typsynonym handelt. Ein weiterer Grund ist, dass für mit type-deklarierte Typsynonyme keine Typklasseninstanzen definiert werden können, während dies für mit newtype definierte Typen möglich ist. Stand: 4. April 2011 20 D. Sabel, FP-PR, SoSe 2011 5.2 Typklassen 5.2 Typklassen Typklassen dienen dazu Funktionsnamen und Operatoren zu überladen, d.h. den gleichen Funktionsnamen oder Operator für unterschiedliche Typen zu verwenden. Z.B. kann deshalb in Haskell den Gleichheitstest == sowohl auf Integerzahlen aber auch auf Listen von Zeichen verwenden. Hierfür ist in Haskell bereits die Typklasse Eq wie folgt vordefiniert: class Eq a where (==), (/=) :: a -> a -> Bool -- Minimal complete definition: -(==) or (/=) x /= y = not (x == y) x == y = not (x /= y) Dieser Code definiert die Klasse Eq. Für Typen die Instanz dieser Klasse sind, kann der Gleichheitstest == und der Ungleichheitstest /= verwendet werden. Innerhalb der Definition sind noch Default-Implementierungen für == und /= angegeben. Beim Instantiieren eines Typs können diese defaultImplementierungen überschrieben werden. Für die Klasse Eq muss entweder der Gleichheitstest oder der Ungleichheitstest beim instantiieren überschrieben werden, den jeweils anderen Test erhält quasi „geschenkt“. Die Abhängigkeit von einer Klasseninstanz sieht man auch, wenn man sich den Typ von == im Interpreter anzeigen lässt: > :t (==) (==) :: (Eq a) => a -> a -> Bool Die Angaben links vom => sind Typklassenbeschränkungen. Das ganze ist zu lesen als, Für alle Typen a, die Instanzen der Klasse Eq sind, hat == den Typ a -> a -> Bool. Eine Instanz der Klasse Eq für den eben definierten Datentypen RGB könnte man definieren als: instance Eq (RGB) (==) Rot Rot (==) Gruen Gruen (==) Blau Blau (==) _ _ D. Sabel, FP-PR, SoSe 2011 where = True = True = True = False 21 Stand: 4. April 2011 5 Datentypen und Typklassen in Haskell Manche Typklasseninstanzen können jedoch auch automatisch aufgrund der Struktur der Datentypdefinition automatisch vom Compiler generiert werden. Hierfür dient das Schlüsselwort deriving. Wir hätten schreiben können: data RGB = Rot | Gruen | Blau deriving(Eq) und uns damit die Angabe der Typklasseninstanz ersparen können, da sie automatisch generiert wird. Typklasseninstanzen können nicht für Typsynonyme definiert werden, es sei denn sie wurden mittels newtype definiert. Z.B. können wir für den Typ Wahrheitswert mit der Definition newtype Wahrheitswert = WW Bool eine Typklasseninstanz für Eq definieren: instance Eq Wahrheitswert where (==) (WW a) (WW b) = a == b Hierbei haben wir den Gleichheitstest einfach auf den Gleichheitstest für Boolesche Werte zurück geführt. Weitere oft verwendete Typklassen sind die Klassen Show und Read. Daten der Typen Instanz der Klasse Show sind können in Strings konvertiert (mit der Funktion show) und damit angezeigt werden. Umgekehrt können Strings mit der read-Funktion in Daten eines Types konvertiert werden, wenn der Typ Instanz der Klasse Read ist. Da der GHCi die show-Funktion zum Anzeigen von Werten verwendet, erhält man im Falle, dass keine Klasseninstanz definiert wurde die Fehlermeldung: <interactive>:1:0: No instance for (Show (Baum t)) arising from a use of ‘print’ at <interactive>:1:0-25 Possible fix: add an instance declaration for (Show (Baum t)) In a stmt of a ’do’ expression: print it Typklassen bieten auch eine Möglichkeit der Vererbung, d.h. man kann fordern, dass eine Instanz einer Typklasse ABC nur dann erlaubt ist, wenn der Typ bereits Instanz einer anderen Typklasse XYZ ist. Eine solche Klasse ist die Klasse Num, die bereits fordert, dass der Typ Instanzen für Eq und Show ist. Stand: 4. April 2011 22 D. Sabel, FP-PR, SoSe 2011 5.3 Record-Syntax für Haskell data-Deklarationen class (Eq a, Show a) => Num a where (+), (-), (*) :: a -> a -> a negate :: a -> a abs, signum :: a -> a fromInteger :: Integer -> a Dies entspricht quasi einer Mehrfachvererbung: Man kann Num als Subklasse der beiden Klassen Eq und Show auffassen. Umgekehrt kann man bei der Instanzbildung auch Bedingungen stellen: Wir betrachten als Beispiel eine Instanz der Klasse Show für den Typ Baum von oben. Wir können polymorphe Bäume nur dann sinnvoll anzeigen, wenn wir bereits wissen wie die Markierungen des Baum angezeigt werden. In der Instanzdefinition können wir dies wie folgt ausdrücken: instance Show a => Show (Baum a) where show (Blatt a) = show a show (Knoten l r) = "<" ++ show l ++ "|" ++ show r ++ ">" Diese Bedingung ist zwingend erforderlich, da wir ansonsten den Aufruf show a für die Blattmarkierung nicht durchführen dürfen. Lassen wir Show a => in obiger Definition weg, dann meldet uns der Compiler wie erwartet einen Fehler: Could not deduce (Show a) from the context (Show (Baum a)) arising from a use of ‘show’ at test.hs:5:18-23 Possible fix: add (Show a) to the context of the instance declaration In the expression: show a In the definition of ‘show’: show (Blatt a) = show a In the instance declaration for ‘Show (Baum a)’ 5.3 Record-Syntax für Haskell data-Deklarationen Haskell bietet neben der normalen Definition von Datentypen auch die Möglichkeit eine spezielle Syntax zu verwenden, die insbesondere dann sinnvoll ist, wenn ein Datenkonstruktor viele Argumente hat. Wir betrachten zunächst den normal definierten Datentypen Student als Beispiel: > data Student = Student D. Sabel, FP-PR, SoSe 2011 23 Stand: 4. April 2011 5 Datentypen und Typklassen in Haskell > > > > > Int String String String Int ------ Matrikelnummer Vorname Name Studiengang Fachsemester Ohne die Kommentare ist nicht ersichtlich, was die einzelnen Komponenten darstellen. Außerdem muss man zum Zugriff auf die Komponenten neue Funktionen definieren. Beispielweise > vorname :: Student -> String > vorname (mno vorname name stdgang fsem) = vorname Wenn nun Änderungen am Datentyp vorgenommen werden – zum Beispiel eine weitere Komponente für das Hochschulsemester wird hinzugefügt – dann müssen alle Funktionen angepasst werden, die den Datentypen verwenden: > data Student = Student > Int -- Matrikelnummer > String -- Vorname > String -- Name > String -- Studiengang > Int -- Fachsemester > Int -- Hochschulsemester > > vorname :: Student -> String > vorname (mno vorname name stdgang fsem hsem) = vorname Um diese Nachteile zu vermeiden, bietet es sich an, die Record-Syntax zu verwenden. Diese erlaubt zum einen die einzelnen Komponenten mit Namen zu versehen: > data Student = Student { > matrikelnummer > vorname > name > studiengang > fachsemester > } Stand: 4. April 2011 24 :: :: :: :: :: Int, String, String, String, Int D. Sabel, FP-PR, SoSe 2011 5.3 Record-Syntax für Haskell data-Deklarationen Eine konkrete Instanz würde mit der normalen Syntax initialisiert mittels Student 1234567 "Hans" "Mueller" "Informatik" 5 Für den Record-Typen ist dies genauso möglich, aber es gibt auch die Möglichkeit die Namen zu verwenden: Student{matrikelnummer=1234567, vorname="Hans", name="Mueller", studiengang="Informatik", fachsemester=5} Hierbei spielt die Reihenfolge der Einträge keine Rolle, z.B. ist Student{fachsemester=5, vorname="Hans", matrikelnummer=1234567, name="Mueller", studiengang="Informatik" } genau dieselbe Instanz. Zugriffsfunktionen für die Komponenten brauchen nicht zu definiert werden, diese sind sofort vorhanden und tragen den Namen der entsprechenden Komponente. Z.B. liefert die Funktion matrikelnummer angewendet auf eine Student-Instanz dessen Matrikelnummer. Wird der Datentyp jetzt wie oben erweitert, so braucht man im Normalfall wesentlich weniger Änderungen am bestehenden Code. Die Schreibweise mit Feldnamen darf auch für das Pattern-Matching verwendet werden. Hierbei müssen nicht alle Felder spezifiziert werden. So ist z.B. eine Funktion die testet, ob der Student einen Nachnamen beginnend mit ’A’ hat implementierbar als > nachnameMitA Student{nachname = ’A’:xs} = True > nachnameMitA _ = False Diese Definition ist äquivalent zur Definition > nachnameMitA Student _ _ (’A’:xs) _ _ = True > nachnameMitA _ = False D. Sabel, FP-PR, SoSe 2011 25 Stand: 4. April 2011 6 Modularisierung in Haskell Module dienen zur Strukturierung / Hierarchisierung: Einzelne Programmteile können innerhalb verschiedener Module definiert werden; eine (z. B. inhaltliche) Unterteilung des gesamten Programms ist somit möglich. Hierarchisierung ist möglich, indem kleinere Programmteile mittels Modulimport zu größeren Programmen zusammen gesetzt werden. Kapselung: Nur über Schnittstellen kann auf bestimmte Funktionalitäten zugegriffen werden, die Implementierung bleibt verdeckt. Sie kann somit unabhängig von anderen Programmteilen geändert werden, solange die Funktionalität (bzgl. einer vorher festgelegten Spezifikation) erhalten bleibt. Wiederverwendbarkeit: Ein Modul kann für verschiedene Programme benutzt (d.h. importiert) werden. 6.1 Module in Haskell In einem Modul werden Funktionen, Datentypen, Typsynonyme, usw. definiert. Durch die Moduldefinition können diese exportiert Konstrukte werden, die dann von anderen Modulen importiert werden können. D. Sabel, FP-PR, SoSe 2011 Stand: 4. April 2011 6.1 Module in Haskell Ein Modul wird mittels module Modulname(Exportliste) where Modulimporte, M odulrumpf Datentypdefinitionen, Funktionsdefinitionen, . . . definiert. Hierbei ist module das Schlüsselwort zur Moduldefinition, Modulname der Name des Moduls, der mit einem Großbuchstaben anfangen muss. In der Exportliste werden diejenigen Funktionen, Datentypen usw. definiert, die durch das Modul exportiert werden, d.h. von außen sichtbar sind. Für jedes Modul muss eine separate Datei angelegt werden, wobei der Modulname dem Dateinamen ohne Dateiendung entsprechen muss. Ein Haskell-Programm besteht aus einer Menge von Modulen, wobei eines der Module ausgezeichnet ist, es muss laut Konvention den Namen Main haben und eine Funktion namens main definieren und exportieren. Der Typ von main ist auch per Konvention festgelegt, er muss IO () sein, d.h. eine Ein-/Ausgabe-Aktion, die nichts (dieses „Nichts“ wird durch das Nulltupel () dargestellt) zurück liefert. Der Wert des Programms ist dann der Wert, der durch main definiert wird. Das Grundgerüst eines Haskell-Programms ist somit von der Form: module Main(main) where ... main = ... ... Im folgenden werden wir den Modulexport und -import anhand folgendes Beispiels verdeutlichen: Beispiel 6.1.1. module Spiel where data Ergebnis = Sieg | Niederlage | Unentschieden berechneErgebnis a b = if a > b then Sieg else if a < b then Niederlage else Unentschieden istSieg Sieg = True istSieg _ = False D. Sabel, FP-PR, SoSe 2011 27 Stand: 4. April 2011 6 Modularisierung in Haskell istNiederlage Niederlage = True istNiederlage _ = False 6.1.1 Modulexport Durch die Exportliste bei der Moduldefinition kann festgelegt werden, was exportiert wird. Wird die Exportliste einschließlich der Klammern weggelassen, so werden alle definierten, bis auf von anderen Modulen importierte, Namen exportiert. Für Beispiel 6.1.1 bedeutet dies, dass sowohl die Funktionen berechneErgebnis, istSieg, istNiederlage als auch der Datentyp Ergebnis samt aller seiner Konstruktoren Sieg, Niederlage und Unentschieden exportiert werden. Die Exportliste kann folgende Einträge enthalten: • Ein Funktionsname, der im Modulrumpf definiert oder von einem anderem Modul importiert wird. Operatoren, wie z.B. + müssen in der Präfixnotation, d.h. geklammert (+) in die Exportliste eingetragen werden. Würde in Beispiel 6.1.1 der Modulkopf module Spiel(berechneErgebnis) where lauten, so würde nur die Funktion berechneErgebnis durch das Modul Spiel exportiert. • Datentypen die mittels data oder newtype definiert wurden. Hierbei gibt es drei unterschiedliche Möglichkeiten, die wir anhand des Beispiels 6.1.1 zeigen: – Wird nur Ergebnis in die Exportliste eingetragen, d.h. der Modulkopf würde lauten module Spiel(Ergebnis) where so wird der Typ Ergebnis exportiert, nicht jedoch die Datenkonstruktoren, d.h. Sieg, Niederlage, Unentschieden sind von außen nicht sichtbar bzw. verwendbar. – Lautet der Modulkopf module Spiel(Ergebnis(Sieg, Niederlage)) so werden der Typ Ergebnis und die Konstruktoren Sieg und Niederlage exportiert, nicht jedoch der Konstruktor Unentschieden. Stand: 4. April 2011 28 D. Sabel, FP-PR, SoSe 2011 6.1 Module in Haskell – Durch den Eintrag Ergebnis(..), wird der Typ mit sämtlichen Konstruktoren exportiert. • Typsynonyme, die mit type definiert wurden, können exportiert werden, indem sie in die Exportliste eingetragen werden, z.B. würde bei folgender Moduldeklaration module Spiel(Result) where ... wie vorher ... type Result = Ergebnis der mittels type erzeugte Typ Result exportiert. • Schließlich können auch alle exportierten Namen eines importierten Moduls wiederum durch das Modul exportiert werden, indem man module Modulname in die Exportliste aufnimmt, z.B. seien das Modul Spiel wie in Beispiel 6.1.1 definiert und das Modul Game als: module Game(module Spiel, Result) where import Spiel type Result = Ergebnis Das Modul Game exportiert alle Funktionen, Datentypen und Konstruktoren, die auch Spiel exportiert sowie zusätzlich noch den Typ Result. 6.1.2 Modulimport Die exportierten Definitionen eines Moduls können mittels der import Anweisung in ein anderes Modul importiert werden. Diese steht am Anfang des Modulrumpfs. In einfacher Form geschieht dies durch import Modulname Durch diese Anweisung werden sämtliche Einträge der Exportliste vom Modul mit dem Namen Modulname importiert, d.h. sichtbar und verwendbar. Will man nicht alle exportierten Namen in ein anderes Modul importieren, so ist dies auf folgende Weisen möglich: D. Sabel, FP-PR, SoSe 2011 29 Stand: 4. April 2011 6 Modularisierung in Haskell Explizites Auflisten der zu importierenden Einträge: Die importierten Namen werden in Klammern geschrieben aufgelistet. Die Einträge werden hier genauso geschrieben wie in der Exportliste. Z.B. importiert das Modul module Game where import Spiel(berechneErgebnis, Ergebnis(..)) ... nur die Funktion berechneErgebnis und den Datentyp Ergebnis mit seinen Konstruktoren, nicht jedoch die Funktionen istSieg und istNiederlage. Explizites Ausschließen einzelner Einträge: Einträge können vom Import ausgeschlossen werden, indem man das Schlüsselwort hiding gefolgt von einer Liste der ausgeschlossen Einträge benutzt. Den gleichen Effekt wie beim expliziten Auflisten können wir auch im Beispiel durch Ausschließen der Funktionen istSieg und istNiederlage erzielen: module Game where import Spiel hiding(istSieg,istNiederlage) ... Die importierten Funktionen sind sowohl mit ihrem (unqualifizierten) Namen ansprechbar, als auch mit ihrem qualifizierten Namen: Modulname.unqualifizierter Name, manchmal ist es notwendig den qualifizierten Namen zu verwenden, z.B. module A(f) where f a b = a + b module B(f) where f a b = a * b module C where import A import B g = f 1 2 + f 3 4 -- funktioniert nicht Stand: 4. April 2011 30 D. Sabel, FP-PR, SoSe 2011 6.1 Module in Haskell führt zu einem Namenskonflikt, da f mehrfach (in Modul A und B) definiert wird. Prelude> :l C.hs ERROR C.hs:4 - Ambiguous variable occurrence "f" *** Could refer to: B.f A.f Werden qualifizierte Namen benutzt, wird die Definition von g eindeutig: module C where import A import B g = A.f 1 2 + B.f 3 4 Durch das Schlüsselwort qualified sind nur die qualifizierten Namen sichtbar: module C where import qualified A g = f 1 2 -- f ist nicht sichtbar Prelude> :l C.hs ERROR C.hs:3 - Undefined variable "f" Man kann auch lokale Aliase für die zu importierenden Modulnamen angeben, hierfür gibt es das Schlüsselwort as, z.B. import LangerModulName as C Eine durch LangerModulName exportierte Funktion f kann dann mit C.f aufgerufen werden. Abschließend eine Übersicht: Angenommen das Modul M exportiert f und g, dann zeigt die folgende Tabelle, welche Namen durch die angegebene import-Anweisung sichtbar sind: D. Sabel, FP-PR, SoSe 2011 31 Stand: 4. April 2011 6 Modularisierung in Haskell Import-Deklaration import M import M() import M(f) import qualified M import qualified M() import qualified M(f) import M hiding () import M hiding (f) import qualified M hiding () import qualified M hiding (f) import M as N import M as N(f) import qualified M as N definierte Namen f, g, M.f, M.g keine f, M.f M.f, M.g keine M.f f, g, M.f, M.g g, M.g M.f, M.g M.g f, g, N.f, N.g f, N.f N.f, N.g 6.1.3 Hierarchische Modulstruktur Diese Erweiterung ist nicht durch den Haskell-Report festgelegt, wird jedoch von GHC und Hugs unterstützt1 . Sie erlaubt es Modulnamen mit Punkten zu versehen. So kann z.B. ein Modul A.B.C definiert werden. Allerdings ist dies eine rein syntaktische Erweiterung des Namens und es besteht nicht notwendigerweise eine Verbindung zwischen einem Modul mit dem Namen A.B und A.B.C. Die Verwendung dieser Syntax hat lediglich Auswirkungen wie der Interpreter nach der zu importierenden Datei im Dateisystem sucht: Wird import A.B.C ausgeführt, so wird das Modul A/B/C.hs geladen, wobei A und B Verzeichnisse sind. Die „Haskell Hierarchical Libraries2 “ sind mithilfe der hierarchischen Modulstruktur aufgebaut, z.B. sind Funktionen, die auf Listen operieren, im Modul Data.List definiert. Damit der ghci die Module auch findet, muss das oberste Verzeichnis der Modulstruktur für ihn auffindbar sein. Dafür gibt es beim ghci den Parameter -i<dir> Search for imported modules in the directory <dir>. 1 An der Standardisierung der hierarchischen Modulstruktur wird gearbeitet, siehe http://www.haskell.org/hierarchical-modules 2 siehe http://www.haskell.org/ghc/docs/latest/html/libraries Stand: 4. April 2011 32 D. Sabel, FP-PR, SoSe 2011 6.1 Module in Haskell Wenn wir z.B. gerade im Verzeichnis Verzeichnis1/Verzeichnis2/ sind und wollen das Modul Verzeichnis1.Verzeichnis2.Datei mit Dateinamen Datei.lhs laden, so sollten wir ghci wie folgt aufrufen: ghci -i:../../ Datei.lhs D. Sabel, FP-PR, SoSe 2011 33 Stand: 4. April 2011 7 I/O in Haskell In einer rein funktionalen Programmiersprache mit verzögerter Auswertung wie Haskell sind Seiteneffekte zunächst verboten. Fügt man Seiteneffekte einfach hinzu (z.B. durch eine „Funktion“ getZahl), die beim Aufruf eine Zahl vom Benutzer abfragt und anschließend mit dieser Zahl weiter auswertet, so erhält man einige unerwünschte Effekte der Sprache, die man im Allgemeinen nicht haben möchte. • Rein funktionale Programmiersprachen sind referentiell transparent, d.h. eine Funktion angewendet auf gleiche Werte, ergibt stets denselben Wert im Ergebnis. Die referentielle Transparenz wird durch eine Funktion wie getZahl verletzt, da getZahl je nach Ablauf unterschiedliche Werte liefert. • Ein weiteres Gegenargument gegen das Einführen von primitiven Ein/ Ausgabefunktionen besteht darin, dass übliche (schöne) mathematische Gleichheiten wie e + e = 2 ∗ e für alle Ausdrücke der Programmiersprache nicht mehr gelten. Setze getZahl für e ein, dann fragt e∗e zwei verschiedene Werte vom Benutzer ab, während 2 ∗ e den Benutzer nur einmal fragt. Würde man also solche Operationen zulassen, so könnte man beim Transformieren innerhalb eines Compilers übliche mathematische Gesetze nur mit Vorsicht anwenden. D. Sabel, FP-PR, SoSe 2011 Stand: 4. April 2011 • Durch die Einführung von direkten I/O-Aufrufen besteht die Gefahr, dass der Programmierer ein anderes Verhalten vermutet, als sein Programm wirklich hat. Der Programmierer muss die verzögerte Auswertung von Haskell beachten. Betrachte den Ausdruck length [getZahl, getZahl], wobei length die Länge einer Liste berechnet als length [] = 0 length (_:xs) = 1 + length xs Da die Auswertung von length die Listenelemente gar nicht anfasst, würde obiger Aufruf, keine getZahl-Aufrufe ausführen. • In reinen funktionalen Programmiersprachen wird oft auf die Festlegung einer genauen Auswertungsreihenfolge verzichtet, um Optimierungen und auch Parallelisierung von Programmen durchzuführen. Z.B. könnte ein Compiler bei der Auswertung von e1 + e2 zunächst e2 und danach e1 auswerten. Werden in den beiden Ausdrücken direkte I/O-Aufrufe benutzt, spielt die Reihenfolge der Auswertung jedoch eine Rolle, da sie die Reihenfolge der I/O-Aufrufe wider spiegelt. Aus all den genannten Gründen, wurde in Haskell ein anderer Weg gewählt. I/O-Operationen werden mithilfe des so genannten monadischen I/O programmiert. Hierbei werden I/O-Aufrufe vom funktionalen Teil gekapselt. Zu Programmierung steht der Datentyp IO a zu Verfügung. Ein Wert vom Typ IO a stellt jedoch kein Ausführen von Ein- und Ausgabe dar, sondern eine I/O-Aktion, die erst beim Ausführen (außerhalb der funktionalen Sprache) Ein-/Ausgaben durchführt und anschließend einen Wert vom Typ a liefert. D.h. man setzt innerhalb des Haskell-Programms I/O-Aktionen zusammen. Die große (durch main) definierte I/O-Aktion wird im Grunde dann außerhalb von Haskell ausgeführt. Eine anschauliche Vorstellung dabei ist die folgende. Eine I/O-Aktion ist eine Funktion, die als Eingabe einen Zustand der Welt (des Rechners) erhält und als Ausgabe den veränderten Zustand der Welt sowie ein Ergebnis liefert. Als Haskell-Typ geschrieben: type IO a = Welt -> (a,Welt) Man kann dies auch durch folgende Grafik illustrieren: D. Sabel, FP-PR, SoSe 2011 35 Stand: 4. April 2011 7 I/O in Haskell Aus Sicht von Haskell sind Objekte vom Typ IO a bereits Werte, d.h. sie können nicht weiter ausgewertet werden. Dies passt dazu, dass auch andere Funktionen Werte in Haskell sind. Allerdings im Gegensatz zu „normalen“ Funktionen kann Haskell kein Argument vom Typ „Welt“ bereit stellen. Die Ausführung der Funktion geschieht erst durch das Laufzeitsystem, welche die Welt auf die durch main definierte I/O-Aktion anwendet. Um nun I/O-Aktionen in Haskell zu Programmieren werden zwei Zutaten benötigt: Zum Einen benötigt man (primitive) Basisoperationen, zum Anderen benötigt man Operatoren, um aus kleinen I/O-Aktionen größere zu konstruieren. 7.1 Primitive I/O-Operationen Wir gehen zunächst von zwei Basisoperationen aus, die Haskell primitiv zur Verfügung stellt. Zum Lesen eines Zeichens vom Benutzer gibt es die Funktion getChar: getChar :: IO Char In der Welt-Sichtweise ist getChar eine Funktion, die eine Welt erhält und als Ergebnis eine veränderte Welt sowieso ein Zeichen liefert. Man kann dies durch folgendes Bild illustrieren: Analog dazu gibt es die primitive Funktion putChar, die als Eingabe ein Zeichen (und eine Welt) erhält und nur die Welt im Ergebnis verändert. Da alle I/O-Aktionen jedoch noch ein zusätzliches Ergebnis liefern müssen, wird hier der 0-Tupel () verwendet. putChar :: Char -> IO () Auch putChar lässt sich mit einem Bild illustrieren: Stand: 4. April 2011 36 D. Sabel, FP-PR, SoSe 2011 7.1 Primitive I/O-Operationen 7.1.1 Komposition von I/O-Aktionen Um aus den primitiven I/O-Aktionen größere Aktionen zu erstellen, werden Kombinatoren benötigt, um I/O-Aktionen miteinander zu verknüpfen. Z.B. könnte man zunächst mit getChar ein Zeichen lesen, welches anschließend mit putChar ausgegeben werden soll. Im Bild dargestellt möchte man die beiden Aktionen getChar und putChar wiefolgt sequentiell ausführen und dabei die Ausgabe von getChar als Eingabe für putChar benutzen (dies gilt sowohl für das Zeichen, aber auch für den Weltzustand): Genau diese Verknüpfung leistet der Kombinator >>=, der „bind“ ausgesprochen wird. Der Typ des Kombinators ist: (>>=) :: IO a -> (a -> IO b) -> IO b D.h. er erhält eine IO-Aktion, die einen Wert vom Typ a liefert, und eine Funktion die einen Wert vom Typ a verarbeiten kann, indem sie als Ergebnis eine IO-Aktion vom Typ IO b erstellt. Wir können nun die gewünschte IO-Aktion zum Lesen und Asgegeben eines Zeichens mithilfe von >>= definieren: echo :: IO () echo = getChar >>= putChar Ein andere Variante stellt der >>-Operator (gesprochen: „then“) dar. Er wird benutzt, um aus zwei I/O-Aktionen die Sequenz beider Aktionen zur erstellen, wobei das Ergebnis der ersten Aktion nicht von der zweiten Aktion benutzt wird (die Welt wird allerdings weitergereicht). Der Typ von >> ist: (>>) :: IO a -> IO b -> IO b Allerdings muss der Kombinator >> nicht primitiv zur Verfügung gestellt werden, da er leicht mithilfe von >>= definiert werden kann: (>>) :: IO a -> IO b -> IO b (>>) akt1 akt2 = akt1 >>= \_ -> akt2 Mithilfe der beiden Operatoren kann man z.B. eine IO-Aktion definieren, die ein gelesenes Zeichen zweimal ausgibt: D. Sabel, FP-PR, SoSe 2011 37 Stand: 4. April 2011 7 I/O in Haskell echoDup :: IO () echoDup = getChar >>= (\x -> putChar x >> putChar x) Angenommen wir möchten eine IO-Aktion erstellen, die zwei Zeichen liest und diese anschließend als Paar zurück gibt. Dann benötigen wir eine weitere Operation, um einen beliebigen Wert (in diesem Fall das Paar von Zeichen) in eine IO-Aktion zu verpacken, die nichts anderes tut, als das Paar zu liefern (die Welt wird einfach von der Eingabe zur Ausgabe weitergereicht). Dies leistet die primitive Funktion return mit dem Typ return :: a -> IO a Als Bild kann man sich die return-Funktion wie folgt veranschaulichen: Die gewünschte Operation, die zwei Zeichen liest und diese als Paar zurück liefert kann nun definiert werden: getTwoChars :: IO (Char,Char) getTwoChars = getChar >>= \x -> getChar >>= \y -> return (x,y) Das Verwenden von >>= und dem nachgestellten „\x -> ...“-Ausdruck kann man auch lesen als: Führe getChar durch, und binde das Ergebnis an x usw. Deswegen gibt es als syntaktischen Zucker die do-Notation. Unter Verwendung der do-Notation erhält die getTwoChars-Funktion folgende Definition: getTwoChars :: IO (Char,Char) getTwoChars = do { x <- getChar; y <- getChar; return (x,y)} Diese Schreibweise ähnelt nun sehr der imperativen Programmierung. Die do-Notation ist jedoch nur syntaktischer Zucker, sie kann mit >>= wegkodiert werden unter Verwendung der folgenden Regeln: Stand: 4. April 2011 38 D. Sabel, FP-PR, SoSe 2011 7.1 Primitive I/O-Operationen do { x<-e; s } do { e; s } do { e } = e >>= \x -> do { s } = e >> do { s } = e Als Anmerkung sei noch erwähnt, dass wir im Folgenden die geschweifte Klammerung und die Semikolons nicht verwenden, da diese durch Einrückung der entsprechenden Kodezeilen vom Parser automatisch eingefügt werden. Als Fazit zur Implementierung von IO in Haskell kann man sich merken, dass neben den primitiven Operationen wie getChar und putChar, die Kombinatoren >>= und return ausreichen, um genügend viele andere Operationen zu definieren. Wir zeigen noch, wie man eine ganze Zeile Text einlesen kann, indem man getChar wiederholt rekursiv aufruft: getLine :: IO [Char] getLine = do c <- getChar; if c == ’\n’ then return [] else do cs <- getLine return (c:cs) 7.1.2 Einige gebräuchliche IO-Funktionen Haskell bietet in der Prelude (und hauptsächlich in der Bibliothek System.IO) jede Menge monadische Funktionen. Für die Ein- und Ausgabe auf dem Bildschirm empfehlen sich die Funktionen • getChar :: IO Char: Lesen eines Zeichens von der Standardeingabe • getLine :: IO Char: Lesen einer Zeile von der Standardeingabe • putChar :: Char -> IO (): Drucken eines Zeichens auf die Standardausgabe • putStr :: String -> IO (): Drucken eines Strings auf die Standardausgabe • putStrLn :: String -> IO (): Drucken eines Strings und anschließendem Zeilenende auf die Standardausgabe D. Sabel, FP-PR, SoSe 2011 39 Stand: 4. April 2011 7 I/O in Haskell • print :: (Show a) => a -> IO () und anschließendes Ausdrucken, print a = putStrLn (show a)) Anzeigen eines Types (print ist definiert als Für die Dateibehandlung bietet sich im Wesentlichen an: • readFile :: FilePath -> IO String: (Verzögertes) Lesen einer Datei (FilePath ist ein Synonym für String und bezeichnet den Dateinamen (einschließlich eines Pfades)) • writeFile :: FilePath -> String -> IO (): Schreiben eines Strings in eine Datei • appendFile :: FilePath -> String -> IO () Strings an eine bereits bestehende Datei Anhängen eines Beachte, dass es mittels readFile und writeFile im Allgemeinen nicht ohne Weiteres möglich ist, zunächst eine Datei zu lesen und anschließend in die gleiche Datei zu schreiben, da das Lesen den Zugriff auf die Datei solange blockiert, bis die gesamte Datei gelesen wurde. Man kann dies jedoch durch explizites Öffnen und Schließen der Dateihandles umgehen (siehe Dokumentation der Bibliothek System.IO). 7.2 Monaden Bisher haben wir zwar erwähnt, dass Haskell monadisches IO verwendet. Wir sind jedoch noch nicht darauf eingegangen, warum dieser Begriff verwendet wird. Der Begriff Monade stammt aus dem Gebiet der Kategorientheorie (aus der Mathematik). Eine Monade besteht aus einem Typkonstruktor M und zwei Operationen: (>>=) :: M a -> (a -> M b) -> M b return :: a -> M a wobei zusätzlich die folgenden drei Gesetze gelten müssen. (1) return x >>= f =f x (2) m >>= return (3) m1 >>= (\x -> m2 >>= (\y -> m3)) = (m1 >>= (\x -> m2)) >>= (\y -> m3) Stand: 4. April 2011 =m 40 D. Sabel, FP-PR, SoSe 2011 7.3 Verzögern innerhalb der IO-Monade Da Monaden die Sequentialisierung erzwingen, ergibt sich, dass die Implementierung des IO in Haskell sequentialisierend ist, was i.A. gewünscht ist. Eine der wichtigsten Eigenschaften des monadischen IOs in Haskell ist, dass es keinen Weg aus einer Monade heraus gibt. D.h. es gibt keine Funktion f:: IO a -> a, die aus einem in einer I/O-Aktion verpackten Wert nur diesen Wert extrahiert. Dies erzwingt, dass man IO nur innerhalb der Monade programmieren kann und i.A. rein funktionale Teile von der I/OProgrammierung trennen sollte. Dies ist zumindest in der Theorie so. In der Praxis stimmt obige Behauptung nicht mehr, da alle Haskell-Compiler eine Möglichkeit bieten, die IOMonade zu „knacken“. 7.3 Verzögern innerhalb der IO-Monade Wir betrachten ein Poblem beim monadischen Programmieren. Wir schauen uns die Implementierung des readFile an, welches den Inhalt einer Datei ausliest. Hierfür werden intern Handles benutzt. Diese sind im Grunde „intelligente“ Zeiger auf Dateien. Für readFile wird zunächst ein solcher Handle erzeugt (mit openFile), anschließend der Inhalt gelesen (mit leseHandleAus). -- openFile :: FilePath -> IOMode -> IO Handle -- hGetChar :: Handle -> IO Char readFile readFile do handle inhalt return :: FilePath -> IO String path = <- openFile path ReadMode <- leseHandleAus handle inhalt Es fehlt noch die Implementierung von leseHandleAus. Diese Funktion soll alle Zeichen vom Handle lesen und anschließend diese als Liste zurückgegeben und den Handel noch schließen (mit hClose). Wir benutzen außerdem die vordefinierten Funktion hIsEOF :: Handle -> IO Bool, die testet ob das Dateiende erreicht ist und hGetChar, die ein Zeichen vom Handle liest. Ein erster Versuch führt zur Implementierung: D. Sabel, FP-PR, SoSe 2011 41 Stand: 4. April 2011 7 I/O in Haskell leseHandleAus handle = do ende <- hIsEOF handle if ende then do hClose handle return [] else do c <- hGetChar handle cs <- leseHandleAus handle return (c:cs) Diese Implementierung funktioniert, ist allerdings sehr speicherlastig, da das letzte return erst ausgeführt wird, nachdem auch der rekursive Aufruf durchgeführt wurde. D.h. wir lesen die gesamte Datei aus, bevor wir irgendetwas zurückgegeben. Dies ist unabhängig davon, ob wir eigentlich nur das erste Zeichen der Datei oder alle Zeichen benutzen wollen. Für eine verzögert auswertende Programmiersprache und zum eleganten Programmieren ist dieses Verhalten nicht gewünscht. Deswegen benutzen wir die Funktion unsafeInterleaveIO :: IO a -> IO a, die die strenge Sequentialisierung der IO-Monade aufbricht, d.h. anstatt die IO-Aktion sofort durchzuführen wird beim Aufruf innerhalb eines do-Blocks: do ... ergebnis <- unsafeInterleaveIO aktion weitere_Aktionen nicht die Aktion aktion durchgeführt (berechnet), sondern direkt mit den weiteren Aktion weitergemacht. Die Aktion aktion wird erst dann ausgeführt, wenn der Wert der Variablen ergebnis benötigt wird. Die Implementierung von unsafeInterleaveIO verwendet unsafePerformIO: unsafeInterleaveIO a = return (unsafePerformIO a) Die monadische Aktion a vom Typ IO a wird mittels unsafePerformIO in einen nicht-monadischen Wert vom Typ a konvertiert; mittels return wird dieser Wert dann wieder in die IO-Monade verpackt. Stand: 4. April 2011 42 D. Sabel, FP-PR, SoSe 2011 7.3 Verzögern innerhalb der IO-Monade Die Funktion unsafePerformIO “knackt” also die IO-Monade. Im WeltModell kann man sich dies so vorstellen: Es wird irgendeine Welt benutzt um die IO-Aktion durchzuführen, anschließend wird die neue Welt nicht weiter gereicht, sondern sofort weg geworfen. Die Implementierung von leseHandleAus ändern wir nun ab in: leseHandleAus handle = do ende <- hIsEOF handle if ende then do hClose handle return [] else do c <- hGetChar handle cs <- unsafeInterleaveIO (leseHandleAus handle) return (c:cs) Nun liefert readFile schon Zeichen, bevor der komplette Inhalt der Datei gelesen wurde. Beim Testen im Interpreter sieht man den Unterschied. Mit der Version ohne unsafeInterleaveIO: *Main> writeFile "LargeFile" (concat [show i | i <- [1..100000]]) *Main> readFile "LargeFile" >>= print . head ’1’ (7.09 secs, 263542820 bytes) Mit Benutzung von unsafeInterleaveIO: *Main> writeFile "LargeFile" (concat [show i | i <- [1..100000]]) *Main> readFile "LargeFile" >>= print . head ’1’ (0.00 secs, 0 bytes) D. Sabel, FP-PR, SoSe 2011 43 Stand: 4. April 2011 7 I/O in Haskell Beachte, dass beide Funktionen unsafeInterleaveIO und unsafePerformIO nicht vereinbar sind mit monadischen IO, da sie die strenge Sequentialisierung aufbrechen. Ein Rechtfertigung die Funktionen trotzdem einzusetzen besteht darin, dass man gut damit Bibliotheksfunktionen oder ähnliches definieren kann. Wichtig dabei ist, dass der Benutzer der Funktion sich bewusst ist, dass deren Verwendung eigentlich verboten ist und dass das Ein- / Ausgabeverhalten nicht mehr sequentiell ist. D.h. sie sollte nur verwendet werden, wenn das verzögerte I/O das Ergebnis nicht beeinträchtig Stand: 4. April 2011 44 D. Sabel, FP-PR, SoSe 2011 8 Concurrent Haskell Concurrent Haskell ist eine Erweiterung von Haskell um Konstrukte zur nebenläufigen Programmierung. Diese Erweiterung wurde als notwendig empfunden, um IO-lastige Real-World-Anwendungen, wie. z.B. Graphische Benutzeroberflächen oder diverse Serverdienste (z.b. http-Server) in Haskell zu implementieren. Die neuen Konstrukte sind • Nebenläufige Threads und Konstrukte zum Erzeugen solcher Threads • Konstrukte zur Kommunikation zwischen Threads und zur Synchronisation von Threads. Insgesamt wurden dafür folgende neue primitive Operationen zu Haskell hinzugefügt, die innerhalb der IO-Monade verwendet werden dürfen. Zur Erzeugung von nebenläufigen Threads existiert die Funktion forkIO :: IO () -> IO ThreadId Diese Funktion erwartet einen Ausdruck vom Typ IO () und führt diesen in einem nebenläufigen Thread aus. Das Ergebnis ist eine eindeutige Identifikationsnummer für den erzeugten Thread. D.h. aus Sicht des Hauptthreads liefert forkIO s sofort ein Ergebnis zurück. Im GHC ist zusätzlich eine Funktion killThread :: ThreadId -> IO () implementiert, die es erlaubt einen nebenläufigen Thread anhand seiner ThreadId zu beenden. Ansonsten führt Stand: 4. April 2011 D. Sabel, FP-PR, SoSe 2011 8 Concurrent Haskell das Beenden des Hauptthreads auch immer zum Beenden aller nebenläufigen Threads. Im GHC steht zusätzlich noch die sehr ähnliche Funktion forkOS :: IO () -> IO ThreadId zur Verfügung. Der Unterschied zwischen forkIO und forkOS besteht darin, wer den erzeugten nebenläufigen Thread verwaltet. Während mit forkIO erzeugte Threads vom Haskell Runtime-System erzeugt und verwaltet werden, werden mit forkOS erzeugte Threads vom Betriebssystem verwaltet. Zur Synchronisation und Kommunikation zwischen mehreren Threads wurde ein neuer Datentyp MVar (mutable variable) eingeführt. Hierbei handelt es sich um Speicherplätze die im Gegensatz zum Datentyp IORef auch zur Synchronisation verwendet werden können. Für den Datentyp stehen drei Basisfunktionen zur Verfügung: • newEmptyMVar :: IO (MVar a) erzeugt eine leere MVar, die Werte vom Typ a speichern kann. • takeMVar :: MVar a -> IO a liefert den Wert aus einer MVar und hinterlässt die Variable leer. Falls die entsprechende MVar leer ist, wird der Thread, der die MVar lesen möchte, solange blockiert, bis die MVar gefüllt ist. Wenn mehrere Threads ein takeMVar auf die gleiche (zunächst leere) Variable durchführen, so wird nachdem die Variable einen Wert hat nur ein Thread bedient. Die anderen Threads warten weiter. Die Reihenfolge hierbei ist first-in-first-out (FIFO), d.h. jener Thread der zuerst das takeMVar durchführt, wird zuerst bedient. • putMVar :: MVar a -> a -> IO () speichert den Wert des zweiten Arguments in der übergebenen Variablen, wenn diese leer ist. Falls die Variable bereits durch einen Wert belegt ist, wartet der Thread solange, bis die Variable leer ist. Genau wie bei takeMVar wird bei gleichzeitigem Zugriff von mehreren Threads auf die gleiche Variable mittels putMVar der Zugriff in FIFO-Reihenfolge abgearbeitet. MVars können leicht wie binäre (und sogar starke) Semaphoren benutzt werden. das Anlegen einer Semaphore (mit 0 initialisiert) geschieht durch das Anlegen einer leeren MVar. Die signal-Operation füllt die MVar mit irgendeinem Wert und die wait-Operation versucht die MVar zu leeren. Da der Wert in der MVar nicht von Belang ist, verwenden wir das 0-Tupel (). Insgesamt ergibt sich die Implementierung von Semaphoren als: Stand: 4. April 2011 46 D. Sabel, FP-PR, SoSe 2011 type Semaphore = MVar () newSem newSem :: IO Semaphore = newEmptyMVar wait wait sem :: Semaphore -> IO () = takeMVar sem signal :: Semaphore -> IO () signal sem = putMVar sem () Beachte, dass die wait-Operation blockiert, wenn die MVar leer ist. Sobald eine signal-Operation die MVar füllt, wird die erste wartende waitOperation durchgeführt und der zugehörige Prozess entblockiert. Wird eine verbotene signal-Operation auf einer vollen MVar durchgeführt, so ist das Verhalten nicht undefiniert, sondern der signal ausführende Prozess wird blockiert. Dieses Verhalten ist nicht durch Semaphoren festgelegt, deswegen ist es eher uninteressant. Wir betrachten nun, wie man mit MVars kritische Abschnitte direkt schützen kann. Die im folgenden gezeigte echoS-Funktion liest eine Zeile von der Standardeingabe und druckt anschließend den gelesenen String auf der Standardausgabe aus. Die Funktion zweiEchosS erzeugt zwei nebenläufige Threads, welche beide die echoS-Funktion ausführen. Würde man das Einlesen und Ausgeben ungeschützt durchführen, so entsteht durch das Interleaving Chaos. Unsere Implementierung schützt jedoch den Zugriff auf die Standardeingabe und Standardausgabe durch Verwendung einer Semaphore (die ja durch eine MVar implementiert ist). Nur derjenige Thread der ein erfolgreiches wait durchgeführt hat, darf passieren und auf die Standardeingabe bzw. -ausgabe zugreifen. Nachdem er dies erledigt hat, gibt er den kritischen Abschnitt wieder frei, indem er eine signal-Operation durchführt. echoS sem i = do wait sem putStr $ "Eingabe fuer Thread" ++ show i ++ ":" line <- getLine signal sem D. Sabel, FP-PR, SoSe 2011 47 Stand: 4. April 2011 8 Concurrent Haskell wait sem putStrLn $ "Letzte Eingabe fuer Thread" ++ show i ++ signal sem echoS sem i zweiEchosS = do sem <signal forkIO forkIO block ":" ++ line newSem sem (echoS sem 1) (echoS sem 2) Beachte, dass sich MVars in ihrem Blockierverhalten symmetrisch verhalten. Deshalb hätten wir die Implementierung von Semaphoren auch andersherum gestalten können: Ein Semaphore, die mit 0 belegt ist, wird durch eine gefüllte MVar dargestellt, die wait-Operation führt eine putMVar-Operation durch und mit takeMVar wird signalisiert. Die Haskell Bibliothek Control.Concurrent.MVar stellt noch weitere Operationen auf MVars zur Verfügung. Einige dieser Operationen werden im folgenden erläutert. • newMVar:: a -> MVar a Erzeugt eine neue MVar, die mit dem als erstes Argument übergebenen Ausdrück gefüllte wird. • readMVar :: MVar a -> IO a Liest den Wert einer MVar, entnimmt ihn aber nicht. Ist die MVar leer, so blockiert der aufrufende Thread, bis die MVar gefüllt ist. Die Implementierung von readMVar ist eine Kombination von takeMVar und putMVar • swapMVar :: MVar a -> a -> IO a Tauscht den Wert einer MVar aus, indem zunächst mit takeMVar der alte Wert gelesen wird, und anschließend der neue Wert mit putMVar in die MVar geschrieben wird. Die Rückgabe besteht im alten Wert der MVar. Beachte, dass der Austausch nicht atomar geschieht, d.h. falls nach dem herausnehmen des alten Werts ein zweiter Thread die MVar beschreibt, kann ein “falscher” Wert in der MVar stehen. Stand: 4. April 2011 48 D. Sabel, FP-PR, SoSe 2011 • tryTakeMVar :: MVar a -> IO (Maybe a) tryTakeMVar versucht eine takeMVar-Operation durchzuführen. Ist die MVar vorher gefüllt, so wird sie entleert und der Wert der MVar als Ergebnis (mit Just verpackt) zurück geliefert. Ist die MVar leer, so wird nicht blockiert, sondern Nothing als Wert der I/O-Aktion zurück geliefert. • tryPutMVar :: MVar a -> a -> IO Bool Analog zu tryTakeMVar ist tryPutMVar eine nicht-blockierende Version von putMVar. Das Ergebnis der Aktion ist ein Boolescher Wert: War das Füllen der MVar erfolgreich, so ist der Wert True, anderfalls False • isEmptyMVar :: MVar a -> IO Bool Testet, ob eine MVar leer ist. • modifyMVar_ :: MVar a -> (a -> IO a) -> IO () modifyMVar_ wendet eine Funktion auf den Wert eine MVar an. Die Implementierung ist sicher gegenüber Exceptions: Falls ein Fehler bei der Ausführung auftritt, so stellt modifyMVar_ sicher, dass der alte Wert der MVar erhalten bleibt. Auch für Concurrent Haskell selbst gibt es weitere Operationen (definiert in Control.Concurrent). Wir zählen diese mit einigen bereits erwähnten Operationen auf: • forkIO :: IO () -> IO ThreadId forkIO erzeugt einen nebenläufigen Thread. Dieser ist leichtgewichtig, er wird durch das Haskell-Laufzeitsystem verwaltet. • forkOS :: IO () -> IO ThreadId forkOS erzeugt einen “bound thread”, der durch das Betriebssystem verwaltet wird. • killThread :: ThreadId -> IO () killTread beendet den Thread mit der entsprechenden Identifikationsnummer. Wenn der Thread bereits vorher beendet ist, dann ist killThread wirkungslos. • yield :: IO () yield forciert einen Context-Switch: Der aktuelle Thread wird von aktiv auf bereit gesetzt. Ein anderer Thread wird aktiv. D. Sabel, FP-PR, SoSe 2011 49 Stand: 4. April 2011 8 Concurrent Haskell • threadDelay :: Int -> IO () threadDelay verzögert den aufrufenden Thread um die gegebene Zahl an Mikrosekunden. 8.1 Erzeuger / Verbraucher-Implementierung mit 1-Platz Puffer Mithilfe von MVars kann ein Puffer mit einem Speicherplatz problemlos implementiert werden. Der Puffer selbst wird durch eine MVar dargestell type Buffer a = MVar a Das Erzeugen eines Puffers entspricht dem Erzeugen einer MVar. newBuffer = newEmptyMVar Der Erzeuger schreibt Wert in den Puffer, und blockiert, solange der Puffer voll ist. Dies entspricht genau der putMVar-Operation: writeToPuffer = putMVar Der Verbraucher entnimmt einen Wert aus dem Puffer und blockiert, falls der Puffer leer ist. Dieses Verhalten wird genau durch takeMVar implementiert. readFromBuffer = takeMVar 8.2 Das Problem der Speisenden Philosophen In diesem Abschnitt betrachten wir das Problem der speisenden Philosophen und Implementierung für fas Problem in Haskell. Es sitzen n Philosophen um einen runden Tisch und zwischen den Philosophen liegt genau je eine Gabel. Zum Essen benötigt ein Philosoph beide Gabeln (seine linke und seine rechte). Ein Philosoph denkt und isst abwechselnd. Wir stellen jede Gabel durch eine MVar () dar, die Philopsophen werden durch Threads implementiert. Die naive Lösung kann wie folgt implementiert werden philosoph i gabeln = do let n = length gabeln -- Anzahl Gabeln takeMVar $ gabeln!!i -- nehme linke Gabel putStrLn $ "Philosoph " ++ show i ++ " hat linke Gabel ..." takeMVar $ gabeln!!(mod (i+1) n) -- nehme rechte Gabel Stand: 4. April 2011 50 D. Sabel, FP-PR, SoSe 2011 8.2 Das Problem der Speisenden Philosophen putStrLn $ "Philosoph " ++ show i ++ " isst ..." putMVar (gabeln!!i) () -- lege linke Gabel ab putMVar (gabeln!!(mod (i+1) n)) () -- lege rechte Gabel ab putStrLn $ "Philosoph " ++ show i ++ " denkt ..." philosoph i gabeln Das Hauptprogramm dazu erzeugt die Gabeln und die Philosophen: philosophen n = do -- erzeuge Gabeln (n MVars): gabeln <- sequence $ replicate n (newMVar ()) -- erzeuge Philosophen: sequence_ [forkIO (philosoph i gabeln) | i <- [0..n-1]] block Beachte, dass sequence_ :: [IO a] -> IO () eine Liste von IO-Aktionen sequentiell hintereinander ausführt, d.h. sequence_ [a1 ,. . .,an ] ist äquivalent zu a1 >> a2 >> . . . >> an . Diese Lösung für das Philosophen-Problem kann in einem globalen Deadlock enden, wenn alle Philosophen die linke Gabel belegen, und damit alle unendlich lange auf die rechte Gabel warten. Eine Deadlock- und Starvationfreie Lösung besteht darin, den letzten Philosophen die Gabeln in verkehrter Reihenfolge aufnehmen zu lassen, da dann das Total-Order Theorem gilt. Die Haskell-Implementierung muss hierfür wie folgt modifiziert werden: philosophAsym i gabeln = do let n = length gabeln -- Anzahl Gabeln if length gabeln == i+1 then -- letzter Philosoph do takeMVar $ gabeln!!(mod (i+1) n) -- nehme rechte Gabel putStrLn $ "Philosoph " ++ show i ++ " hat rechte Gabel ..." takeMVar $ gabeln!!i -- nehme linke Gabel putStrLn $ "Philosoph " ++ show i ++ " hat linke Gabel und isst" else do takeMVar $ gabeln!!i -- nehme linke Gabel putStrLn $ "Philosoph " ++ show i ++ " hat linke Gabel ..." D. Sabel, FP-PR, SoSe 2011 51 Stand: 4. April 2011 8 Concurrent Haskell takeMVar $ gabeln!!(mod (i+1) n) -- nehme rechte Gabel putStrLn $ "Philosoph " ++ show i ++ " hat rechte Gabel und isst" putMVar (gabeln!!i) () -- lege linke Gabel ab putMVar (gabeln!!(mod (i+1) n)) () -- lege rechte Gabel ab philosophAsym i gabeln Das Hauptprogramm zum Erzeugen der Philosophenprozesse und der Gabeln bleibt dabei unverändert. Wir hatten bereits gesehen, dass eine weitere Starvation- und Deadlockfreie Lösung des Philosophenproblems darin besteht, zu verhindern, alle Philosophen gleichzeitig an die Gabeln zu lassen. Hierfür hatten wir eine generelle Semaphore raum benutzt, die mit dem Wert n − 1 initialisiert wurde. Bisher haben wir keine Implementierung von generellen Semaphoren in Haskell gesehen. Es gibt zwar Kodierungen von generellen Semaphoren mithilfe von binären Semaphoren. Diese sind jedoch im Allgemeinen kompliziert. Da wir jedoch MVars zur Verfügung haben, ist die Implementierung von generellen Semaphoren relativ einfach. In der Bibliothek Control.Concurrent.QSem findet man die Implementierung von generellen Semaphoren. Zunächst benutzen wir diese Semaphoren, um eine weitere Lösung für das Philosophen-Problem zu erstellen. Im Anschluss werden wir die Implementierung der generellen Semaphoren erörtern. Wir benutzen eine QSem, die mit n − 1 initialisiert wird und dadurch verhindert, dass mehr als n − 1 Philosophen Zugriff auf die Gabeln erhalten. Die Implementierung in Haskell für eine Philosophenprozess ist philosophRaum i raum gabeln = do let n = length gabeln -- Anzahl Gabeln waitQSem raum -- generelle Semaphore putStrLn $ "Philosoph " ++ show i ++ " im Raum" takeMVar $ gabeln!!i -- nehme linke Gabel putStrLn $ "Philosoph " ++ show i ++ " hat linke Gabel ..." takeMVar $ gabeln!!(mod (i+1) n) -- nehme rechte Gabel putStrLn $ "Philosoph " ++ show i ++ " hat rechte Gabel und isst" putMVar (gabeln!!i) () -- lege linke Gabel ab putMVar (gabeln!!(mod (i+1) n)) () -- lege rechte Gabel ab signalQSem raum putStrLn $ "Philosoph " ++ show i ++ " aus Raum raus" putStrLn $ "Philosoph " ++ show i ++ " denkt ..." Stand: 4. April 2011 52 D. Sabel, FP-PR, SoSe 2011 8.3 Futures philosophRaum i raum gabeln Das Hauptprogramm muss leicht abgeändert werden, da die generelle Semaphore erzeugt werden muss: philosophenRaum n = do gabeln <- sequence $ replicate n (newMVar ()) raum <- newQSem (n-1) sequence [forkIO (philosophRaum i raum gabeln) | i <- [0..n-1]] block 8.3 Futures Futures sind Variablen deren Wert am Anfang unbekannt ist, aber in der Zukunft (daher der Name) verfügbar wird, sobald die zur Future zugehörige Berechnung beendet ist. In Haskell ist eigentlich jede Variable eine Future, da verzögert ausgewertet wird. Wir betrachten in diesem Abschnitt jedoch nebenläufige Futures, d.h. der Wert der Future wird durch eine nebenläufige Berechnung ermittelt. Man kann zwischen expliziten und impliziten Futures unterscheiden: Bei expliziten Futures muss der Wert einer Future explizit angefordert werden. D.h. wenn ein Thread den Wert einer Future benötigt muss er eine Operation auf der Future-Variablen ausführen, die solange wartet, bis der Wert der Future berechnet wurde. Bei impliziten Futures ist diese Operation unnötig, da die Auswertung automatisch den Wert der Future bestimmt, wenn dieser benötigt wird. Der Vorteil von (impliziten) Futures liegt darin, dass man manche Anwendungen relativ einfach programmieren kann, da die Synchronisation automatisch geschieht. Mithilfe von forkIO und MVars kann main explizite Futures wie folgt implementieren: type EFuture a = MVar a efuture :: IO a -> IO (EFuture a) efuture act = do ack <- newEmptyMVar forkIO (act >>= putMVar ack) return ack D. Sabel, FP-PR, SoSe 2011 53 Stand: 4. April 2011 8 Concurrent Haskell force :: EFuture a -> IO a force = readMVar Eine explizite Future wird dabei durch eine MVar dargestellt. Das Erstellen einer expliziten Future wird durch die Funktion efuture durchgeführt. Diese erwartet eine IO-Aktion (die den Wert der Future berechnet) und liefert (eine Referenz auf) die Future. Zunächst wird eine leere MVar erstellt, anschließend wird eine nebenläufige Auswertung angestoßen: Diese führt die übergebene IO-Aktion aus und schreibt das Ergebnis in die MVar Da beim Aufruf von forkIO sofort weitergerechnet werden kann, wird sofort die letzte Zeile ausgeführt: Die MVar wird zurück gegeben (diese stellt die explizite Future dar). Wenn der Wert der Future benötigt wird, muss der entsprechende Thread die Funktion force ausführen. Diese versucht mittels readMVar den Wert der Future zu lesen. Ist dieser noch nicht fertig berechnet, so wartet der aufrufende Thread bis der Wert der Future verfügbar ist. Ein Beispiel zur Verwendung von Futures ist die parallele Berechnung der Summe der Knoten eines Baumes data BTree a = Leaf a | Node a (BTree a) (BTree a) treeSum (Leaf a) = return a treeSum (Node a l r) = do futl <- efuture (treeSum l) futr <- efuture (treeSum r) resl <- force futl resr <- force futr let result = (a + resl + resr) in seq result (return result) Für jeden inneren Knoten des Baumes werden für den linken und rechten Teilbaum zwei Futures angelegt, die rekursiv deren Baumsummen berechnen. Anschließend wird auf den Wert beider Futures gewartet, zum Schluss wird addiert. Hierbei wird seq verwendet, welches die verzögerte Auswertung in Haskell aushebelt, damit das Resultat wirklich ausgewertet wird, Stand: 4. April 2011 54 D. Sabel, FP-PR, SoSe 2011 8.3 Futures bevor es zurück gegeben wird. Ohne seq hätten wir parallel die unausgewertete Summe erzeugt. Die Programmierung mit expliziten Futures ist nicht wirklich komfortabel, da der Wert der Futures explizit angefordert werden muss. Im Beispiel wird dies auch noch sequentiell durchgeführt: Zuerst wird gewartet, dass der Wert der linken Teilsumme danach der Wert der rechten Teilsumme verfügbar ist. Es wäre eventuell effizienter zunächst resl + a als Zwischenergebnis zu berechnen und danach erst den Wert von futr anzufordern. Es wäre besser, wenn wir auf das force-Kommando verzichten könnten und direkt schreiben könnten: result = (a + futl + futr). Dies leisten die expliziten Futures allerdings nicht. Mithilfe von unsafeInterleaveIO ist es jedoch möglich implizite Futures zu implementieren: future :: IO a -> IO a future code = do ack <-newEmptyMVar thread <- forkIO (code >>= putMVar ack) unsafeInterleaveIO (do result <- takeMVar ack killThread thread return result) Mit future wird eine implizite Future erzeugt: Zunächst wird eine leere MVar erzeugt, anschließend wird (wie vorher) nebenläufig die übergebene IO-Aktion ausgeführt und das Resultat in die MVar geschrieben. Der letzte Schritt besteht darin, das Resultat aus der MVar zu lesen, den nebenläufigen Thread zu beenden und das Ergebnis zurück zu liefern. Würden wir dies ohne den umgebenen unsafeInterleaveIO-Aufruf durchführen, würde ein future e Aufruf solange blockieren, bis der Wert der Future ermittelt ist. Durch unsafeInterleave wird jedoch sofort ein Ergebnis geliefert (da die Sequentialisierung der IO-Monade aufgebrochen wird). Beachte auch, dass es wenig sinnvoll wäre unsafeInterleaveIO um den gesamten Code zu schreiben, da dann der nebenläufige Thread nicht sofort gestartet würde. Die parallele Baumsumme kann nun wie folgt berechnet werden treeSum (Leaf a) = return a treeSum (Node a l r) = do futl <- future (treeSum l) futr <- future (treeSum r) D. Sabel, FP-PR, SoSe 2011 55 Stand: 4. April 2011 8 Concurrent Haskell let result = (a + futl + futr) in seq result (return result) Wir sehen, dass die Implementierung nun einfach wurde, die Werte der Futures werden implizit durch die Auswertung angefordert (da (+) beide Argumentwerte benötigt). Stand: 4. April 2011 56 D. Sabel, FP-PR, SoSe 2011