Multi-Tenant-Datenbanken für SaaS
Werbung

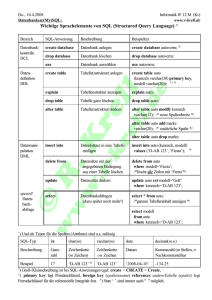
Universität Leipzig Fakultät für Mathematik und Informatik Institut für Informatik Professur Datenbanksysteme Seminararbeit Multi-Tenant-Datenbanken für SaaS (Schema Management) Betreuerin: Sabine Maßmann Bearbeiter: Hendrik Kerkhoff Nürnberger Str. 20 04103 Leipzig Matr.-Nr: 1501624 MSc. 1. Semester Eingereicht am: 24.01.2010 Inhaltsverzeichnis I Inhaltsverzeichnis Abkürzungsverzeichnis II 1 Einleitung 1 1.1 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 1.2 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2 Grundlagen 3 2.1 Software as a Service . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2.2 Anforderungen an Multi-Tenancy Datenbanken . . . . . . . . . . . . . 3 2.3 Einsatzszenarien 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 Multi-Tenancy mit aktuellen Datenbanken 6 3.1 Shared Machine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.2 Shared Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.3 Shared Table . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 3.3.1 Private Table Layout . . . . . . . . . . . . . . . . . . . . . . . . 9 3.3.2 Basic Table Layout . . . . . . . . . . . . . . . . . . . . . . . . . 9 3.3.3 Extension Table Layout . . . . . . . . . . . . . . . . . . . . . . 10 3.3.4 Universal Table Layout . . . . . . . . . . . . . . . . . . . . . . . 10 3.3.5 Pivot Table Layout . . . . . . . . . . . . . . . . . . . . . . . . . 11 3.3.6 Chunk Table Layout . . . . . . . . . . . . . . . . . . . . . . . . 11 3.3.7 Chunk Folding . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 Beispiel: force.com . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 3.4 4 Ausblick 15 Abbildungsverzeichnis III Verzeichnis der Listings IV Literaturverzeichnis V Inhaltsverzeichnis Abkürzungsverzeichnis CRM . . . . . . . . . . Customer Relationship Management DBS . . . . . . . . . . . Datenbanksystem ERP . . . . . . . . . . . Enterprise Resource Planning ID . . . . . . . . . . . . . Identifikationsnummer QTL . . . . . . . . . . . Query Transformation Layer SaaS . . . . . . . . . . . Software as a Service SLA . . . . . . . . . . . Service Level Agreements TCO . . . . . . . . . . . Total Cost of Ownerchip II 1 Einleitung 1 1 Einleitung In seinem Blog1 stellt Robert Warfield die These auf, dass Unternehmen durch den Einsatz von Software as a Service im Vergleich zu klassischer Software bis zu 16% ihrer Kosten einsparen können [War07]. Dies wird durch Mehrmandantenfähigkeit (engl. Multi-Tenancy) erreicht: Mehrere Kunden nutzen gemeinsam ein Softwaresystem, welches von einem Serviceanbieter bereitgestellt wird. Hierdurch sinken die Kosten, die für das Betreiben notwendig sind. 1.1 Ziel der Arbeit Diese Arbeit soll Möglichkeiten zeigen und erläutern, wie Multi-Tenancy Datenbanken implementiert werden können. Da für den performanten und somit kostensparenden Betrieb einer Mehrmandanten-Datenbank eine möglichst hohe Konsolidierung (“Vereinheitlichung”) benötigt wird, werden verschiedene Möglichkeiten gezeigt, diese zu erreichen, ohne dabei auf flexibele Datenbankschemas für die Mandanten verzichten zu müssen. 1.2 Aufbau der Arbeit In Kapitel 2 werden die Grundlagen zu Software as a Service erklärt und die Anforderungen an Multi-Tenancy-Datenbanken erläutert sowie mögliche Einsatzszenarien skizziert. Kapitel 3 beleuchtet die drei Grundmöglichkeiten für den Aufbau einer Mehrmandantendatenbank. Hierbei liegt der Schwerpunkt auf den verschiedenen Ansätzen zum Schema-Mapping in der Shared Table-Methode. Zudem wird anhand der Plattform Force.com die Umsetzung und Optimierung in der Praxis gezeigt. 1 http://smoothspan.wordpress.com/ 1 Einleitung 2 Im Ausblick (Kapitel 4) werden Methoden und Techniken vorgestellt, mit denen Forscher der Technischen Universität München sowie der SAP AG die Umsetzung einer reinen Multi-Tenancy Datenbank planen. 2 Grundlagen 3 2 Grundlagen In diesem Kapitel wird zunächst das Konzept von Software as a Service erläutert. Im Anschluss werden Anforderungen an eine Multi-Tenancy Datenbank für Software as a Service beschrieben sowie mögliche Einsatzszenarien beschrieben. 2.1 Software as a Service Software as a Service (SaaS) ist ein Geschäftsmodell, in dem Software nicht als Produkt an Kunden verkauft wird, sondern als Dienstleistung für viele Kunden bereitgestellt wird [BHS08, S. 88]. Ziel hierbei ist es, die Total Cost of Ownerchip (TCO) im Vergleich zu den Kosten von “on-premises” Lösungen, also vom Kunden selbst betriebene Software, zu senken [AJKS09, S. 881]. Um dieses zu erreichen wird die Software vielen Kunden zur Verfügung gestellt, was dazu führt, dass Kosten wie Thirdparty-Softwarelizenzen, Hardwarekosten und Kosten für die Administration auf die Mandanten verteilt werden und somit im Durchschnitt sinken. Bei der Nutzung von SaaS sind häufig Service Level Agreements (SLA) Bestandteil der Verträge. In diesen werden nicht-funktionale Anforderungen wie die Kosten für die Nutung der Services sowie Anforderungen an Verfügbarkeit und Performanz festgelegt [Pap08]. 2.2 Anforderungen an Multi-Tenancy Datenbanken Bob Warfield, Mitgründer von SmoothSpan und Author von mehreren Artikeln zum Thema SaaS, leitet in einem seiner Blog-Artikel eine Definition für Multi-Tenancy her: “Multitenancy is the ability to run multiple customers on a single software instance installed on multiple servers to increase resource utilization 2 Grundlagen 4 by allowing load balancing among tenants, and to reduce operational complexity and cost in managing the software to deliver the service. Tenants on a multitenant system can operate as though they have an instance of the software entirely to themselves which is completely secure and insulated from any impact by other tenants.” [War07] Diese Definition beschreibt Multi-Tenancy Systeme aus Sicht von Serviceanbieter sowie der Mandanten. Die Mandaten werden in [AJPK09] weiter unterschieden zwischen Kunde und Anwendungsentwickler. Für den Kunden sind “hohe Verfügbarkeit bei hoher Datensicherheit” zentrale Aspekte eines Multi-Tenancy Systems. Die Anforderungen der Anwendungsentwickler sind “einfache, aber mächtige Funktionsmodelle”. Eine gemeinsame Instanz wächst aus der Anforderung heraus, dass die operationale Komplexität minimiert werden soll. Da der Ressourcenbedarf einzelner Instanzen auf Shared Machine Systemen zu hoch ist, wird gefordert, dass es eine gemeinsame Datenbankinstanz für mehrere Mandanten gibt. Isolation der Mandanten ist notwendig für die geforderte Sicherheit und dient der Herstellung von Transparenz für die Mandanten. Für die Kunden soll das MultiTenancy System aussehen, als hätten sie eine eigene Datenbankinstanz. Schemaflexibilität muss gewährleistet werden. Insbesondere ist es notwendig, Schemaänderungen während der Laufzeit durchzuführen, da aufgrund der Transparenzforderung für andere Mandanten das Gesamtsystem online bleiben muss. Jedoch dürfen Änderungen die Performanz des Systems nicht beeinflussen. Um dieses zu gewährleisten müssen gegebenenfalls temporäre Tabellen mit dem neuen Schema erstellt werden und zu einem Zeitpunkt mit niedriger Last permanent einbunden werden. Hohe Verfügbarkeit ist für das Anwendungsgebiet von SaaS notwendige Bedingung, da im Rahmen von Service Level Agreements meist Vereinbarungen über die Verfügbarkeit getroffen werden. 2.3 Einsatzszenarien Durch die steigende Komplexität von Anwendungen sinkt die mögliche Konsolidierung der Mandaten und somit die Anzahl der Mandanten, die durch ein Multi-Tenancy System gehandhabt werden können [AGJ+ 08]. Einfache Software, wie E-Mail Plattfor- 2 Grundlagen 5 men, bieten den Kunden keine oder nur sehr beschränkte Anpassungungen der Software. Somit werden erweiterbare Datenstrukturen kaum benötigt und es reichen einfache und einheitliche Schemas für die Nutzer der Software. Enterprise Resource Planning (ERP) Systeme hingegen haben eine hohe Komplexität. Es werden viele Erweiterungen und Anpassungen benötigt, um die Geschäftsprozesse der Mandanten umzusetzen. Die benötigten Ressourcen, auch hinsichtlich der Laufzeit von einzelnen Operationen, sind um ein Vielfaches höher, als das einer E-MailPlattform. Dieser Zusammenhang ist in Abbildung 2.1 schematisch dargestellt. Durch Rechner mit mehr Ressourcen ist es möglich, die Anzahl der Mandanten zu vervielfachen. Daher ist der Einsatz von Clustern, welche relativ niedrige Hardwarekosten haben, für den Einsatz für Multi-Tenancy Datenbanken sehr gut geeignet. Größe des Rechners Mainframe BladeServer 10.000 1.000 10.000 1.000 100 10.000 1.000 100 10 E-Mail Kollaborationsplattformen CRM ERP Komplexität der Anwendung Abbildung 2.1: Mandanten pro Datenbank (in Anlehnung an [AGJ+ 08, S. 1196]) Hauptanwendung finden Multi-Tenancy Datenbanken bei Systemen mit mittlerer Komplexität [AGJ+ 08, S. 1196]. Beispiele hierfür sind Kollaborationsplattformen wie Google Docs2 , Conject3 und Microsofts Office Live4 . Die SaaS-Plattform salesforce.com5 (siehe hierzu auch Abschnitt 3.4) bietet Customer Relationship Management (CRM) Software unter Verwendung von Multi-Tenancy Datenbanken an. 2 http://docs.google.com/ 3 http://www.conject.com/ 4 http://www.officelive.com/ 5 http://www.salesforce.com/ 3 Multi-Tenancy mit aktuellen Datenbanken 6 3 Multi-Tenancy mit aktuellen Datenbanken In diesem Kapitel werden drei Möglichkeiten vorgestellt, Mehrmandanten-Fähigkeit in aktuelle Datenbanksysteme zu integrieren. Bei dem Shared Machine Ansatz erhält jeder Mandant eine eigene Datenbankinstanz auf einem gemeinsamen Computer. Teilen sich alle Mandaten eine Datenbankinstanz, wobei jeder Mandant sein eigenes Schema erhält, spricht man von Shared Process. Der Schwerpunkt dieses Kapitels liegt auf dem Shared Table Ansatz. In Abschnitt 3.3 werden mehrere Techniken vorgestellt, um das Teilen einer gemeinsamen Tabellenstruktur für alle Mandanten zu ermöglichen. Mandant Mandant Mandant Mandant Mandant Mandant Schema Schema Schema Schema Schema Schema DB DB DB Mandant Mandant Mandant Schema DB DB Computer / Cluster / Grid Computer / Cluster / Grid Computer / Cluster / Grid a) Shared Machine b) Shared Process c) Shared Table Ressourcenteilung Isolation Abbildung 3.1: Shared Machine, Shared Process und Shared Table (in Anlehnung an [JA07a, S. 1198]) 3 Multi-Tenancy mit aktuellen Datenbanken 7 3.1 Shared Machine Jeder Mandant erhält bei Shared Machine seine eigene Datenbankinstanz auf einer gemeinsamen Maschine. Dieser Ansatz ist leicht umzusetzen, da hier keine Modifikationen an dem Datenbanksystem vorgenommen werden müssen. Alle Mandanten sind bis auf den gleichen Computer voneinander isoliert (vgl. Abbildung 3.1). Jedoch wirkt sich diese Isolation negativ auf die Ressourcennutzung aus: Jede Datenbankinstanz benötigt Speicher für die Grundfunktionen. Aufgrund dieses hohen Speicherbedarfs skaliert der Shared Machine Ansatz nur bis circa zehn Instanzen pro Rechner [JA07b]. Zudem kann der Administrationsaufwand nicht gesenkt werden. Daher eignet sich dieser Ansatz nur bedingt für die Verwendung als Multi-Tenancy Datenbank für SaaS. 3.2 Shared Process Abbildung 3.1 b) zeigt schematisch den Shared Process Ansatz: Jeder Mandant erhält hier ein eigenes Schema, welches auf einer gemeinsamen Datenbankinstanz läuft. Durch die Möglichkeit der physisch getrennten Speicherung der Daten der einzelnen Mandanten ist die Migration von Mandanten auf andere Server sowie die Implementierung von Load-Balancing einfach zu realisieren [JA07b]. Die physische und logische Trennung der Daten muss hierbei auf Anwendungsebene vorgenommen werden. Durch die gemeinsame Nutzung einer Instanz wird lediglich für die verschiedenen Schemas und Daten der Mandanten, jedoch nicht für mehrere Instanzen des Datenbanksystems Speicher benötigt. Wenn die Anzahl der Tabellen pro Mandant auf wenige beschränkt ist, skaliert dieser Ansatz für bis zu 1000 aktiver Mandanten pro Server [JA07b]. Daher ist er gut für kleine und mittlere SaaS-Anwendungen geeignet. 3.3 Shared Table Durch die Verwendung des Shared Table Ansatzes können die meisten Einsparungen hinsichtlich Hardwarekosten gemacht werden. Jedoch müssen zusätzliche Erweiterungen am Datenbanksystem implementiert werden: Da alle Mandanten die gleichen Tabellen nutzen muss eine Zwischenschicht, die Query-Transformation-Schicht (QTL) (siehe Abbildung 3.2) entwickelt werden [AGJ+ 08]. Diese sorgt dafür, dass für die Mandanten das physische Schema transparent ist. Jeder Mandant hat ein eigenes, lo- 3 Multi-Tenancy mit aktuellen Datenbanken 8 gisches Schema. Die QTL wandelt die Anfragen um und mappt diese auf das physische Datenbankschema. Hierbei muss zudem sichergestellt werden, dass nur die Daten des Mandanten angefragt werden. Die Ergebnisse werden dann wieder passend zu dem logischen Schema des Mandanten umgewandelt. Mandant 1 Mandant 2 Mandant 3 Software Software Software logisches Schema logisches Schema logisches Schema Query Transformation Schicht physisches Schema Datenbank Betriebsystem Hardware Abbildung 3.2: Query Transformation Layer (selbsterstellte Grafik) Die Datenmigration für einzelne Mandanten ist nicht problemlos möglich, kann jedoch auf Kosten zusätzlicher Abfragen durchgeführt werden. Es gibt verschiedene Tabellen-Layouts, die den Shared Table Ansatz ermöglichen. Alle diese Ansätze sind hierbei Kompromisse zwischen Performanz, Funktionaliät und Flexibilität. In den folgenden Abschnitten werden diese Layouts dargestellt und erläutert. Die Beispiele hierfür entstammen dem Paper [AGJ+ 08]. Es wurde ein Szenario mit drei Mandanten gewählt. Der Mandant mit der ID 17 stammt aus dem Gesundheitsbereich, Mandant 42 hat eine Erweiterung im Bereich der Automobilindustrie. Mandant 35 hat keine Erweiterungen. 3 Multi-Tenancy mit aktuellen Datenbanken 9 3.3.1 Private Table Layout Beim Private Table Layout erhält jeder Mandant eigene Tabellen. Diese werden lediglich umbenannt, um zu gewährleisten das ein bestimmter Tabellenname nicht nur von einem Mandanten genutzt werden kann. Hierzu werden in den Meta-Daten des Datenbanksystems bzw. des Query-Transformation-Layers Mapping Daten gehalten. Eine Konsolidierung der Mandanten findet hier nicht statt. Abbildung 3.3 zeigt ein Schema mit privaten Tabellen. Die Tabellen sind hier nach “Account” sowie der Mandanten-ID benannt. Wenn diese Tabellen für alle Mandanten “Account” heißen, so muss bei der Abfrage ein Mapping von AccountXX <-> Account durchgeführt werden, wobei XX die Mandanten-ID repräsentiert. Abbildung 3.3: Private Table Layout (aus [AGJ+ 08, S. 1198]) 3.3.2 Basic Table Layout Da sich die Mandanten alle Tabellen beim Basic Table Layout teilen, ist es nicht möglich, mandantenspezifische Erweiterungen zu handhaben. Die Datensätze der jeweiligen Mandanten werden durch eine hinzugefügte Tenant-Spalte unterschieden (siehe Abbildung 3.4). Das Basic Table Layout eignet sich lediglich für angebotene Software, in der keine Erweiterungen benötigt werden, wie z.B. Webmail oder Blogs. Account Tenant 17 17 35 42 Aid Name 1 2 1 1 Acme Gump Ball Big Abbildung 3.4: Basic Table Layout (selbsterstellte Grafik) 3 Multi-Tenancy mit aktuellen Datenbanken 10 3.3.3 Extension Table Layout Beim Extension Table Layout werden mandantenspezifische Erweiterungen in zusätzlichen Tabellen gespeichert. Alle Tabellen erhalten eine Spalte mit der ID des Mandanten sowie eine Spalte durch welche der Datensatz identifiziert wird. Durch die MandantenID ist es möglich, dass mehrere Mandanten eine Erweiterung nutzen. Die Datensatz-IDs sind notwendig, um die Tabellen durch einen JOIN zum logischen Datenbankschema zurückzuführen. Abbildung 3.5 zeigt das Schema einer Extension Table. Durch die Fragmentierung in mehrere Tabellen entstehen zusätzliche Schreib-/Lesezugriffe, da nicht sichergestellt werden kann, dass zusammengehörige Reihen zusammenhängend in den Speicher geschrieben werden. 1 2 3 4 5 SELECT Aid, Name, Hospital, Beds FROM (SELECT Aid, Name, Hospital, Beds FROM AccountExt a, HealthcareAccount h WHERE a.Row = h.Row AND a.Tenant = 17 AND h.Tenant = 17) AS Account17 Listing 3.1: Transformierte SQL Anfrage für Extension Table Layout Listing 3.1 zeigt eine Anfrage an die Daten. Hierbei wird eine JOIN-Verknüpfung zwischen den Tabellen AccountExt und Healthcare Account durchgeführt. Das Ergebnis wird in einer Tabelle mit dem Namen “Account17” ausgegeben. Abbildung 3.5: Extension Table Layout (aus [AGJ+ 08, S. 1198])) 3.3.4 Universal Table Layout Das Univeral Table Layout hat nur eine Tabelle, in der sämtliche Daten gespeichert werden. Um dies zu ermöglichen wird eine Table-Spalte eingeführt, mit der die einzelnen Tabellen des logischen Schemas unterschieden werden. Die Daten werden beim Universal Table Layout in Spalten mit einem universellem Datentyp, wie z.B. VARCHAR, gespeichert. 3 Multi-Tenancy mit aktuellen Datenbanken 11 Um Flexibilität zu gewährleisten, muss die Anzahl der Spalten sehr breit gewählt werden. Hierduch entstehen viele Zellen mit NULL-Werten, welche zwar von den meisten Datenbanksystemen effizient verwaltet werden, aber dennoch einen Speicher-Overhead erzeugen. Zusätzlich muss das DBS Meta-Daten halten, in denen die Datentypen sowie die logischen Namen der Spalten in Abhängigkeit der jeweiligen logischen Tabelle gespeichert werden. Ein großer Nachteil vom Universal Table Layout ist, dass die Indizierung nicht praktikabel ist. Abbildung 3.6: Universal Table Layout (aus [AGJ+ 08, S. 1198]) 3.3.5 Pivot Table Layout Beim Pivot Table Layout werden neben der Mandanten- und Tabellen-Spalte Reihensowie Spalten-Werte eingefügt. Jeder Wert eines Datensatzes in der logischen Tabelle wird hier in einem eigenen Datensatz gespeichert. Hierduch sind für die Rückführung einer n-Spaltigen Tabelle n − 1 Join-Verknüpfungen notwendig. Jedoch entfällt im Vergleich zu Universal Tables die Speicherung von NULL-Werten. Die Daten selbst können hierbei entweder als variabler Datentyp VARCHAR gespeichert werden oder man führt für jeden Datentyp eine eigene Pivot-Tabelle ein (siehe Abbildung 3.7), wodurch das Casten der Datentypen entfällt. Um Indizies zu unterstützen können zusätzliche Index-Tabellen für jeden Datentyp eingeführt werden. 3.3.6 Chunk Table Layout Die Datensätze werden in Chunks, also “Datenblöcke” untergliedert. Mehrere dieser Chunks bilden gemeinsam einen logischen Datensatz. Dazu wird beim Chunk-TableLayout neben Spalten für Tenant, Tabelle und Reihe eine Chunk-Nummer vergeben. Physische Zeilen mit gleicher Tenant-ID, gleicher Tabellennummer und gleicher Rei- 3 Multi-Tenancy mit aktuellen Datenbanken 1 2 3 4 5 6 7 8 9 10 11 12 SELECT Beds FROM (SELECT s.Str as Hospital, i.Int as Beds FROM PivotStr s, PivotInt i WHERE s.Tenant = 17 AND i.Tenant = 17 AND s.Table = 0 AND s.Col = 2 AND i.Table = 0 AND i.Col = 3 AND s.Row = i.Row) WHERE Hospital=’State’ Listing 3.2: Transformierte SQL Anfrage für Pivot Table Layout Abbildung 3.7: Pivot Table Layout (aus [AGJ+ 08, S. 1198]) he gehören zu einem logischen Datensatz, sortiert nach den inkrementierten ChunkNummern. In Abbildung 3.8 sind dieses beispielsweise die ersten beiden Zeilen. In einem Chunk werden verschiedene Attribute mit verschiedenen Datentypen, wahlweise mit Indizierung, gespeichert. Hierdurch ist es möglich, häufig zusammen auftretende Werte zu gruppieren, wodurch die Schreib-/Lesezugriffe optimiert werden können. Abbildung 3.8: Chunk Table Layout (aus [AGJ+ 08, S. 1198]) 3 Multi-Tenancy mit aktuellen Datenbanken 13 Im Vergleich zu Pivot Tabellen wird hier nur eine Tabelle benötigt, wodurch der Aufwand für die Rekonstruktion der logischen Tabellen geringer ausfällt. Die AnfrageTransformation ist jedoch komplexer. Dieses wird leicht aus einem Beispiel ersichtlich: Für das Auflösen der Spaltennamen wird beim Pivot Table Layout ein Mapping Tenant, Table, Col -> Spaltenname benötigt. Hingegen beim Chunk Table Layout Tenant, Table, Chunk -> Int1 = Spaltenname1 | Str1 = Spaltenname2. Die Spalten in der physischen Schicht müssen hier nochmal zugeordnet werden. 3.3.7 Chunk Folding In [AGJ+ 08] stellen die Autoren eine weitere Schema-Mapping Technik vor: Chunk Folding. Es werden die Techniken des Extension Tables mit denen der Chunk Tables kombiniert. Abbildung 3.9 zeigt ein Schema für Chunk Folding. Hierbei gibt es eine (oder auch mehrere) gemeinsame Tabelle, die von allen (oder vielen) Mandanten genutzt werden sowie eine Erweiterungstabelle deren Struktur dem Chunk Table Layout entspricht. Abbildung 3.9: Chunk Folding (aus [AGJ+ 08, S. 1198]) Durch diese Kombination wird erreicht, dass häufig genutzte Attribute in herkömmlichen Tabellen gespeichert werden, wodurch erhöhter I/O- sowie Transformationsaufwand beim Zugriff auf Attribute dieser Tabelle entfällt. Durch Variation der Breite der Chunk-Tabelle wird diese zu einer Mischform von Universal Table Layout und Chunk Table Layout: Die Breite kann so optimiert werden, dass z.B. 80% der logischen Datensätze in einen Chunk passen. Tabellen mit vielen Attributen werden hingegen in zwei oder mehr Chunks verteilt. Dadurch wird der Aufwand, mandantenspezifische Erweiterungen zu Laden und Verarbeiten, gering gehalten. 3 Multi-Tenancy mit aktuellen Datenbanken 14 3.4 Beispiel: force.com Die Plattform Salesforce.com, Anbieter von Customer Relationship Management (CRM), sowie deren Tochter-Plattform Force.com, eine Entwicklungsumgebung für die Entwicklung von Cloud-basierter Software, nutzen Multi-Tenancy für die Datenhaltung. Das Datenbankschema zeigt Abbildung 3.10. Es handelt sich hierbei um ein Universal Table Layout mit mehreren Erweiterungen zur Optimierung sowie Flexibilisierung. # Metadaten Datentabellen Spezielle Pivot Tabellen Objects Data Indexes GUID OrgID ObjID ObjName Fields # GUID OrgID ObjID FieldName Datatype isIndexed FieldNum ...weitere... # GUID OrgID ObjID Name Value0 Value1 ... Value500 # # # OrgID ObjID FieldNum GUID StringValue NumValue DateValue Relationships Clobs Character Large Objects bis zu 32.000 Zeichen OrgID ObjID GUID RelationID TargetObjID ...weitere... Abbildung 3.10: Force.com Datenbankschema (in Anlehnung an [For08]) Mithilfe von Pivot-Tabellen werden beispielsweise Indizierungen ermöglicht. Die Indexes Tabelle enthält hierfür neben Schlüsseln, die das zu indizierende Objekt referenzieren, Spalten mit verschiedenen Datentypen. Über diese wird die Indizierung durchgeführt. Zudem gibt es Tabellen für Relationen zwischen den Objekten, eine Tabelle für Unique-Werte, History-Tracking Tabellen und viele weitere [For08]. In Metadaten-Tabellen werden Informationen über die gespeicherten Objekte (ObjectsTabelle) sowie Meta-Informationen über die einzelnen Werte in der Datentabelle gespeichert. Mit diesen Informationen kann das logische Schema der Mandanten aus diesem physischem Schema rekonstruiert werden. 4 Ausblick 15 4 Ausblick In ihrer Arbeit [AJPK09] stellen Aulbach et al. ein Modell für die Implementierung einer “echten” Multi-Tenant-fähigen Datenbank vor. Dieses soll mithilfe von GridTechnologien sowie Virtualisierung ermöglicht werden. Abbildung 4.1: Multi-Tenancy DBMS (aus [AJPK09]) Die Authoren wollen hierfür ein Grid-Cluster verwenden, wobei auf die einzelnen Knoten die Datenbanken der Mandaten aus einem Archiv-Speicher geladen werden (vgl. Abbildung 4.1). Je nach Auslastung soll dieser Vorgang dynamisch erfolgen. Bei hoher Last werden die Datenbanken auf andere Knoten repliziert. Hierbei werden zunächst die veralteten Abbilder aus dem Archivspeicher kopiert und anschließend durch einen Roll-Forward mithilfe von Log-Dateien aktualisiert [AJPK09]. Durch Tenant Swizzling, einer von den Autoren entwickelten Technik, die sich an “das Pointer Swizzling in objekt-orientierten DBMS” [AJPK09] anlehnt, wird ein schneller Datenzugriff gewährleistet: Die Daten im Hauptspeicher werden von den Daten des Archivspeichers vollkommen getrennt, wodurch Lese- und Schreibzugriffe auf langsamen Festplattenspeicher entfallen. Dieses wird durch Pointer ermöglicht, die jeweils auf referenzierende Objekte zeigen. Sollen diese Objekte persistiert werden, so müssen die Pointer aufgeflöst und durch entsprechende Referenzierungen per ID ersetzt werden. Durch den Einsatz dieser Techniken sollen Probleme der “klassischen” Multi-TenancyLösungen hinsichtlich Isolation und Ressourcenverwaltung gelöst werden. Eine Umsetzung dieses Entwurfs ist geplant [AJPK09]. Abbildungsverzeichnis III Abbildungsverzeichnis Mandanten pro Datenbank (in Anlehnung an [AGJ+ 08, S. 1196]) . . . . 5 Shared Machine, Shared Process und Shared Table (in Anlehnung an [JA07a, S. 1198]) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2 Query Transformation Layer (selbsterstellte Grafik) . . . . . . . . . . . 3.3 Private Table Layout (aus [AGJ+ 08, S. 1198]) . . . . . . . . . . . . . . 3.4 Basic Table Layout (selbsterstellte Grafik) . . . . . . . . . . . . . . . . 3.5 Extension Table Layout (aus [AGJ+ 08, S. 1198])) . . . . . . . . . . . . 3.6 Universal Table Layout (aus [AGJ+ 08, S. 1198]) . . . . . . . . . . . . . 3.7 Pivot Table Layout (aus [AGJ+ 08, S. 1198]) . . . . . . . . . . . . . . . 3.8 Chunk Table Layout (aus [AGJ+ 08, S. 1198]) . . . . . . . . . . . . . . 3.9 Chunk Folding (aus [AGJ+ 08, S. 1198]) . . . . . . . . . . . . . . . . . . 3.10 Force.com Datenbankschema (in Anlehnung an [For08]) . . . . . . . . . 6 8 9 9 10 11 12 12 13 14 4.1 15 2.1 3.1 Multi-Tenancy DBMS (aus [AJPK09]) . . . . . . . . . . . . . . . . . . Verzeichnis der Listings IV Verzeichnis der Listings 3.1 3.2 Transformierte SQL Anfrage für Extension Table Layout . . . . . . . . Transformierte SQL Anfrage für Pivot Table Layout . . . . . . . . . . . 10 12 Literaturverzeichnis V Literaturverzeichnis [AGJ+ 08] S. Aulbach, T. Grust, D. Jacobs, A. Kemper, and J. Rittinger. Multi-tenant databases for software as a service: schema-mapping techniques. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 1195–1206. ACM New York, NY, USA, 2008. [AJKS09] S. Aulbach, D. Jacobs, A. Kemper, and M. Seibold. A comparison of flexible schemas for software as a service. In Proceedings of the 35th SIGMOD international conference on Management of data, pages 881–888. ACM, 2009. [AJPK09] S. Aulbach, D. Jacobs, J. Primsch, and A. Kemper. Anforderungen an Datenbanksysteme für Multi-Tenancy-und Software-as-a-ServiceApplikationen. BTW 2009 - Proceedings, 2009. http://131.159.16. 103/research/publications/conferences/btw2009-mtd.pdf. [BHS08] W. Beinhauer, M. Herr, and A. Schmidt. SOA für agile Unternehmen: Serviceorientierte Architekturen verstehen, einführen und nutzen. Symposion Publishing GmbH, 2008. [For08] Force.com. The force.com multitenant achitecture. Whitepaper, 2008. http://www.apexdevnet.com/media/ ForcedotcomBookLibrary/Force.com_Multitenancy_WP_ 101508.pdf. [JA07a] D. Jacobs and S. Aulbach. Ruminations on multi-tenant databases. BTW, 2007. Vortragsfolien, http://www.btw2007.de/vortraege/ JacobsAulbach.pdf. [JA07b] D. Jacobs and S. Aulbach. Ruminations on multi-tenant databases. In BTW Proceedings. Citeseer, 2007. [Pap08] M.P. Papazoglou. Web services: principles and technology. Pearson Prentice Hall, 2008. [War07] Robert Warfield. Multitenancy can have a 16:1 cost advantage over singletenant, 2007. http://smoothspan.wordpress.com/2007/10/28/ multitenancy-can-have-a-161-cost-advantage-over-single -tenant/.