3.6 Tabelle mit Filestream und FileTable
Werbung

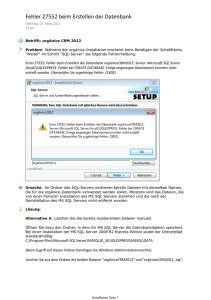
150 3 Eine neue Datenbank erstellen ■ 3.6 Tabelle mit Filestream und FileTable In einem früheren Abschnitt dieses Kapitels habe ich Ihnen gezeigt, wie man eine Datenbank mit einer Filestream-Dateigruppe anlegt, und Ihnen das grundlegende Konzept von Filestream und FileTable erläutert. FileTable ist eine Erweiterung, die mit dem SQL Server 2012 eingeführt worden ist, und auf Filestream basiert. Nun möchte ich Ihnen in zwei Abschnitte unterteilt zeigen, wie man Filestream in einer Tabelle nutzt und wie man FileTable einsetzt. 3.6.1 Tabelle mit Filestream erstellen Leider bietet der Tabellen-Designer im Management Studio keine Möglichkeit, eine Spalte für Filestream zu definieren. Daher müssen Sie Tabellen mit Filestream manuell mit einer SQL-Anweisung erstellen. Das ist auch der Grund, warum ich dieses Thema erst gegen Ende des Kapitels behandle. Ich möchte mit Ihnen in der Video-Datenbank eine Tabelle erstellen, in der Videodateien mit ein wenig Zusatzinformation versehen gespeichert werden sollen. Für diese Videodateien soll Filestream genutzt werden. Um Filestream zu nutzen, muss eine Tabelle folgende Voraussetzungen erfüllen: Eine Spalte vom Datentyp varbinary(max) muss mit dem Attribut FILESTREAM versehen werden. ACHTUNG! Filestream ist auch beim SQL Server 2014 nur für den Datentyp varbinary(max) und nicht für varchar(max) verfügbar. Wenn Sie Filestream für umfangreiche Texte nutzen möchten, müssen Sie für diese anstelle von varchar(max) daher varbinary(max) verwenden. Die Tabelle muss eine Spalte enthalten, die als UNIQUEIDENTIFIER und ROWGUID definiert ist. Ein UNIQUEIDENTIFIER ist ein Wert, der aus 32 hexadezimalen Stellen besteht. Nach der achten, zwöl en, sechzehnten und zwanzigsten Stelle kommt jeweils ein Bindestrich (xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx). Während eine als IDENTITY definierte Spalte immer innerhalb der Tabelle eindeutige Werte enthält, enthält eine als Unique Identifier festgelegte Spalte eindeutige Werte über alle Tabellen einer Datenbank hinweg. Damit ist ein absolut eindeutiger Wert innerhalb der Datenbank gegeben. Während Identity-Spalten beim Anlegen eines neuen Datensatzes automatisch mit einem neuen Wert versehen werden, geschieht dies bei Unique Identifier-Spalten nicht. Die ROWGUID-Eigenscha muss zusätzlich gesetzt werden, sonst bekommen Sie beim Erstellen der Tabelle mit Filestream eine Fehlermeldung. Ähnlich wie eine IDENTITY, kann diese Eigenscha auch nur für eine Spalte in einer Tabelle gesetzt werden. Anstelle über referenziert den Spaltennamen kann sie in einem SELECT-Statement auch mit werden, analog zu einer Identitätsspalte, die Sie auch mit $IDENTITY auswählen können. FROM tabellenname;) ( 3.6 Tabelle mit Filestream und FileTable 151 Dieser eindeutige Wert wird für die Assoziierung der im Filesystem gespeicherten Datei mit dem Datensatz verwendet. Damit ist ausgeschlossen, dass es auf dieser Ebene zu Namenskonflikten kommt, auch wenn in mehreren Tabellen Filestream genutzt wird. (Unique Identifier werden ja auch bei Replikation genutzt, um Datensätze eindeutig zu identifizieren.) Die Unique Identifier-Spalte darf nicht leer sein und muss daher als NOT NULL definiert werden. Außerdem muss sie mit einem UNIQUE KEY-Constraint versehen werden, um Eindeutigkeit zu erzwingen. Damit diese Werte automatisch vergeben werden, was sehr oder zweckmäßig ist, wird als Standardwert die Funktion verwendet. Die erste Funktion liefert einen global eindeutigen zufälligen Wert, die zweite einen sequenziell aufsteigenden, ähnlich zu IDENTITY. Der Vorteil von liegt darin, dass sie schneller einen Wert liefert. Dafür ist der nächste Wert vorhersehbar, was aber in unserem Szenario keine Rolle spielt. Erstellen wir in der Datenbank video nun eine neue Tabelle mit dem Namen medien. Dazu verwenden wir folgende Anweisung. In der ersten Variante nehmen wir die Spalte id als UNIQUEIDENTIFIER. Anstelle eines -Constraints mit NOT NULL versehen kann -Constraint verwendet werden. natürlich auch gleich ein CREATE TABLE dbo.medien ( id UNIQUEIDENTIFIER ROWGUIDCOL CONSTRAINT pk_medien PRIMARY KEY CONSTRAINT df_medien_id DEFAULT NEWSEQUENTIALID(), aufnahmedatum date NOT NULL, video varbinary(max) FILESTREAM Die Spalte titel soll die Kurzbezeichnung des Videos aufnehmen. Deren Eingabe soll verpflichtend sein. Die beschreibung kann einen längeren Beschreibungstext aufnehmen. Ebenso soll das aufnahmedatum nicht fehlen. Die Spalte Video muss mit dem Datentyp varbinary(max) definiert werden. Entscheidend ist der Zusatz FILESTREAM dahinter. Durch diesen wird diese Spalte für Filestream definiert, sonst würden die Videoclips später direkt in der Datenbank gespeichert werden und die maximale Größe pro Video wäre 2 GB. Da wir in der Datenbank nur eine Dateigruppe für Filestream definiert haben, ist diese die Default-Dateigruppe dafür und muss in der SQL-Anweisung daher als Ziel nicht extra angegeben werden. PRAXISTIPP: Falls Sie als Primärschlüssel beziehungsweise als ID gerne einen anderen Wert als den kryptischen 32-stelligen Unique Identifier verwenden möchten, können Sie auch die Funktionen von Primärschlüssel und Unique Identifier voneinander trennen. Dies ist vor allem auch dann sinnvoll, wenn Sie später mit einem Fremdschlüssel auf diese Tabelle verweisen möchten. Dafür käme dann zum Beispiel folgende Tabellendefinition zum Einsatz: CREATE TABLE dbo.medien ( id int IDENTITY CONSTRAINT pk_medien PRIMARY KEY, aufnahmedatum date NOT NULL, 152 3 Eine neue Datenbank erstellen video varbinary(max) FILESTREAM, stream_id UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL CONSTRAINT uk_medien_stream UNIQUE CONSTRAINT df_medien_stream_id DEFAULT NEWSEQUENTIALID() Gegenüber der ersten Variante habe ich hier die id als Identität mit dem Datentyp int definiert. Für den benötigten Unique Identifier habe ich dafür die Spalte stream_id ergänzt. gesetzt. Das für den Wieder wird die RowGuid-Eigenscha über den Zusatz Anwendungsfall geforderte Unique Key-Constraint ersetzt hier den Primärschlüssel. Wichtig ist auch die Definition dieser Spalte als NOT NULL. Für die weiteren Schritte des Beispiels habe ich die zweite Variante verwendet. Um Ihnen eine mögliche Verwendung des Filestreams in einer Anwendung zu zeigen, möchte ich eine „quick and dirty“ erstellte Access-Anwendung verwenden. HINWEIS: Sie finden diese Datei mit dem Namen filestream.accdb unter den Buchdateien und können diese ab der Version Access 2007 einsetzen. Ebenso finden Sie dort das Skript Kapitel3.sql, das die Anweisungen zum Erstellen der Datenbank video und der Tabelle medien enthält. Diese Anweisungen können Sie verwenden, um jene in diesem Kapitel beschriebenen nicht abtippen zu müssen. Achten Sie aber bitte darauf, dass Sie bei Ihrer Konfiguration gegebenenfalls die Pfade der Dateigruppen an Ihre Gegebenheiten anpassen. Die Access-Datei nutzt die zweite vorgestellte Variante der Tabelle medien mit dem separaten Primärschlüssel. Wenn Sie diese Datei öffnen, muss diese mit Ihrer Datenbank auf Ihrem Server verbunden werden. Dazu muss die ODBC-Verbindungszeichenfolge angepasst werden. Um Ihnen die Verwendung der Datei so einfach wie möglich zu machen, bekommen Sie automatisch die Aufforderung zur Eingabe derselben, wenn Access beim Öffnen der Datei keine Verbindung zum aktuell hinterlegten SQL Server herstellen kann. Wegen des Verbindungstimeouts wird dies beim ersten Öffnen etwas dauern. Sie erhalten danach eine ODBC-Fehlermeldung und den Standarddialog zur Anpassung der ODBC-Anmeldung. Brechen Sie diese ab und Sie bekommen die Anzeige von Bild 3.69. Bild 3.69 ODBC-Verbindung eintragen 3.6 Tabelle mit Filestream und FileTable 153 Passen Sie hier die ODBC-Verbindungszeichenfolge an Ihre Gegebenheiten an: Wenn Sie Windows-Authentifizierung verwenden, müssen Sie lediglich Ihren Servernamen oder die IP-Adresse, analog zur Anmeldung mit dem Management Studio, eintragen: DATABASE=video;LANGUAGE=Deutsch IHR_SERVER;Trusted_Connection=Yes; Verwenden Sie SQL Server-Authentifizierung, ersetzen Sie zusätzlich Trusted_ Connection=Yes durch UID und : PWD=ihr_pwd;DATABASE=video;LANGUAGE=Deutsch UID=ihr_login; Ist bei Ihnen auf dem Client der hier verwendete ODBC Driver 11 für SQL Server noch nicht installiert, laden Sie sich diesen über das SQL Server 2014 Feature Pack wie in Kapitel 1 beschrieben herunter und installieren ihn nach. Speichern Sie Ihre Änderung, danach erfolgt neuerlich eine Prüfung, ob die Verbindung hergestellt werden kann. Ist diese erfolgreich, wird auch die ODBC-Verbindung der in Access verknüp en Tabelle medien angepasst und das Zielformular geöffnet. Da diese neue Verbindung nun gespeichert ist, ist diese Vorgangsweise nur einmalig notwendig und beim erneuten Öffnen von filestream.accdb gelangen Sie direkt ins Eingabeformular. Sie können nun einen ersten Datensatz erfassen. Ein paar Videoclips im Format WMV habe ich beigefügt, die Sie dazu verwenden können. Natürlich können Sie jede andere beliebige Mediadatei verwenden. Bevor wir einen ersten Datensatz anlegen, werfen wir einen Blick auf das Verzeichnis, das wir für die Filestream-Dateigruppe festgelegt haben. Bei mir ist dies der Ordner D:\DB_FS\ video_stream auf dem Server. Ich verbinde mich über den $-Share dorthin. Dieser Ordner ist – wie erwartet – im Moment noch fast leer: Nach dem Anlegen der Datenbank video befinden sich im Ordner ein Unterordner mit dem Namen $FSLOG und die Datei filestream.hdr. Nach dem Anlegen der Tabelle medien kommt ein Ordner, dessen Name das Format eines Unique Identifier aufweist, hinzu. Bild 3.70 Basisordner für Filestream, bevor Daten erfasst werden 154 3 Eine neue Datenbank erstellen Erfassen Sie nun über die Access-Anwendung Titel, Bezeichnung und Aufnahmedatum für den ersten Clip. Fügen Sie den Clip entweder per Drag & Drop ein oder verwenden Sie dazu im Kontextmenü den Befehl Objekt Einfügen. Bild 3.71 Datensatz über Access-Formular erfasst Für die Anwendung (in diesem Fall MS Access) ist Filestream vollkommen transparent. Es macht für Sie keinen Unterschied, ob die Videodatei direkt in der Datenbank oder auf dem Server im Filesystem gespeichert wird. Wo finden wir diese Datei nun auf dem Server? In einem der Unterordner. Der Filename ist für uns nicht sprechend, muss er aber auch nicht sein. Bild 3.72 Filestream-Objekt im Filesystem des Servers Wenn Sie diesen Datensatz löschen, verschwindet diese Datei wieder. Aktivieren Sie die Datei über ihre Anwendung, zum Beispiel indem Sie sie im Access-Formular doppelt anklicken, wird Sie vom SQL Server aus dem Filesystem gestreamt und an den Client übertragen. Wie gesagt, dies ist für die Clientanwendung alles transparent. Wenn wir den Datensatz im Abfrageeditor des Management Studios anzeigen, sehen wir die ID des Streamings in Form des Unique Identifiers. 3.6 Tabelle mit Filestream und FileTable 155 Bild 3.73 Datensatz mit Filestream Um den Film in der Beispielanwendung anzusehen, müssen Sie das Symbol im Formular nur doppelt anklicken. Der SQL Server streamt die Datei dann vom Filesystem an die Anwendung, in diesem Fall an Access. Hier wird das Objekt dann mit der mit dem Filetyp assoziierten Anwendung – in diesem Fall dem Media Player – abgespielt. Entscheidend ist, dass hier aus der Anwendung heraus kein Unterschied gegenüber einer in der Datenbank gespeicherten Datei zu erkennen ist. Bild 3.74 Wiedergabe der vom Filesystem des Servers gestreamten Datei Legen Sie noch weitere Datensätze an und löschen Sie auch wieder welche, um den Vorgang zu testen! ACHTUNG! Folgendes müssen Sie beim Einsatz von Filestream unbedingt beachten: Die vom SQL Server angelegten Ordner und Dateien sind nicht für den direkten Zugriff gedacht. Greifen Sie ausschließlich in Testumgebungen und auch nur lesend darauf zu. In Produktivsystemen sollten keine Benutzer Zugriffsrechte auf diese Ordnerstruktur haben. Der Tabellen-Designer des Management Studios kann mit Filestream nicht umgehen. Wenn Sie über diesen eine Änderung an der Tabelle vornehmen, die wie beschrieben eine Neuerstellung der Tabelle erfordert, dann fehlt der Filestream danach bei der neu angelegten Tabelle. Zumindest erfolgt das so sauber, dass bei meinem Test die Datei dabei in die Datenbank kopiert 156 3 Eine neue Datenbank erstellen worden ist. Wenn auch kein Filestream mehr vorhanden ist, so sind wenigstens keine Daten abhanden gekommen. d. h., nach außen hat die Änderung keine Probleme verursacht. Dennoch ist das natürlich nicht erwünscht. Daher bearbeiten Sie in der Praxis Tabellen mit Filestream mit DDL-Anweisungen wie ALTER TABLE direkt und nicht über den grafischen Tabellen-Designer. Wie Sie Datenbanken mit Filestream sichern und wiederherstellen und damit auch auf einen anderen Server transferieren können, lesen Sie in Kapitel 9, das sich unter anderem mit dem Thema Sicherung beschä igt. 3.6.2 Objekte in einer FileTable speichern Mit FileTable liefert der SQL Server eine spannende Erweiterung von Filestream. FileTable basiert auf der Technologie von Filestream und bietet die Möglichkeit, Dateien über das Netzwerk in einem Share auf dem Datenbankserver zu speichern. Diese Dateien tauchen dann wie von Zauberhand in einer Tabelle in einer Datenbank auf. Damit hat man dann in weiterer Folge die spannende Möglichkeit, über SQL in den Dateien zu suchen und diese auszuwerten. Da FileTable auf der Technologie von Filestream basiert, werden dieselben Anforderungen an den Server und die verwendete Datenbank gestellt. Diese habe ich Ihnen in diesem Kapitel unter Punkt 3.1.4 erläutert. Für unser Beispiel erstellen wir eine neue Datenbank mit Filestream. Sie können dies wahlweise über den grafischen Dialog im Objekt-Explorer oder über folgende DDL-Anweisung realisieren. Passen Sie dabei die Pfade an Ihre Gegebenheiten an. CREATE DATABASE dateien CONTAINMENT = NONE ON PRIMARY ( NAME = 'dateien_data', FILEGROUP DATENFILES CONTAINS FILESTREAM ( NAME = 'dateien_fs', FILENAME = 'D:\DB_FS\dateien_fs') LOG ON ( NAME = 'dateien_log', Zur Erinnerung: Wir haben in diesem Kapitel Filestream für unseren Server aktiviert und als Freigabename dabei dateiablage vergeben und Vollzugriff aktiviert. Diese Einstellungen können über die Servereigenscha en vom Objekt-Explorer aus eingestellt werden. Damit besteht schon einmal der Zugriff auf den Share auf meinem Server mit \\srvsql2014\ dateiablage. In diesen Ordner kann ich natürlich direkt keine Datei kopieren, ich erhalte dabei eine Fehlermeldung über eine Zugriffsverletzung. Damit wir Dateien hier ablegen können, müssen wir noch einen Ordnernamen für unsere Datenbank festlegen. Hier ist folgende hierarchische Struktur vorgesehen: 3.6 Tabelle mit Filestream und FileTable 157 Der Freigabename repräsentiert die gesamte Serverinstanz von SQL Server 2014. Für jede Datenbank auf dieser Serverinstanz wird ein eigener Ordner darin festgelegt. Sie können auf einem Server mehrere Datenbanken mit FileTable verwenden, daher ist diese Ebene notwendig. Den Ordnernamen auf Datenbankebene sowie die Zugriffsart können Sie entweder über den grafischen Dialog oder über entsprechende ALTER TABLE-Anweisungen festlegen. Öffnen Sie die Datenbankeigenscha en über den Objekt-Explorer. Auf der Seite OPTIONEN finden Sie die notwendigen Einstellungen in der Kategorie FILESTREAM. Legen Sie den Namen des Ordners in der Eigenscha FILESTREAM-Verzeichnisname fest. Damit Sie später Dateien dort ablegen können, müssen Sie die Eigenscha Nicht transaktionsgebundener FILESTREAM-Zugriff auf Full einstellen. Sollen die Dateien später einmal nur gelesen werden können, können Sie diese Eigenscha auf ReadOnly setzen. Um den Zugriff überhaupt zu sperren, stellen Sie die Voreinstellung Off wieder her. Bild 3.75 Verzeichnisname und Zugriff Alternativ können Sie diese Einstellungen auch über folgende SQL-Anweisungen vornehmen: ALTER DATABASE dateien ALTER DATABASE dateien Über die Zusatzoption legen Sie fest, dass diese Änderung nicht auf das Beenden von Transaktionen in der Datenbank wartet und in diesem Fall fehlschlägt. Typi- 158 3 Eine neue Datenbank erstellen scherweise verwenden Sie diese Anweisungen jedoch nicht, wenn in der Datenbank gerade Transaktionen ablaufen. Die weiteren Optionen, die in SQL neben FULL für die Zugriffsoption vergeben werden können, lauten OFF und READ_ONLY. Nach dieser Änderung können wir nun eine Ebene weiter über den Explorer zugreifen, aber noch immer keine Dateien ablegen: \\srvsql2014\dateiablage\dateidatenbank Erstellen einer FileTable Der letzte Schritt ist das Erstellen einer FileTable. Diese Tabelle hat eine fixe systemseitig vorgegebene Struktur. Da diese Tabellen auch keine gewöhnlichen Tabellen im herkömmlichen Sinne sind, finden wir sie im Objekt-Explorer auch in einer eigenen Rubrik unter den Tabellen wieder. Es macht durchaus Sinn, sich das Statement zum Erstellen einer solchen Tabelle automatisch zu generieren. Dazu wählen Sie im Kontextmenü entweder auf dem Ordner Tabellen oder FileTables den Befehl Dateitabelle . . . aus. Bild 3.76 Neue FileTable erstellen Falls Sie nun einen grafischen Dialog erwartet haben, werden Sie hier enttäuscht. Was Sie erhalten, ist eine Vorlage für eine entsprechende SQL-Anweisung in einem neuen Abfrageeditor-Fenster. Dies ist aber durchaus in Ordnung, haben Sie hier ohnehin nur geringen Spielraum in der Anpassung der Anweisung. Lediglich die Namen für interne Constraints können Sie in dieser Anweisung ergänzen. In der vorgegebenen Basisanweisung ist die Angabe des Basisordners und der Sortierreihenfolge vorgesehen: FILETABLE_DIRECTORY: Der hier definierte Ordnername stellt den Basisordner der FileTable dar. In diesem können nun über die Freigabe auf Ebene des Betriebssystems Ordner erstellt und Dateien abgelegt werden. FILETABLE_COLLATE_FILENAME: Der Name für die Sortierreihenfolge, die für die Dateiund Ordnernamen innerhalb von SQL bei Zugriffen auf die FileTable verwendet werden soll. Geben Sie hier eine Sortierreihenfolge wie zum Beispiel Latin1_General_CI_AS an oder verweisen Sie mit database_default auf die diesbezügliche Standardeinstellung der Datenbank. Diese entspricht dem bei der Installation gewählten Serverstandard, wenn Sie bei der Erstellung der Datenbank nichts anderes angegeben haben. 3.6 Tabelle mit Filestream und FileTable 159 Bild 3.77 Anweisungsvorlage für eine FileTable Entfernen Sie aus der Anweisung in der Vorlage alle nicht benötigten Elemente. Auch die erste Anweisung, die prüfen soll, ob diese Tabelle schon besteht, und sie dann gegebenenfalls vor der Erstellung löscht, können Sie getrost löschen. Diese Anweisung beginnt mit . Optional können Sie die Namen für drei interne Constraints mit in der Anweisung angeben. Tun Sie dies nicht, werden diese automatisch vom System vergeben. : Legen Sie mit dieser Option den Namen für das Primärschlüssel-Constraint der Tabelle fest. Dieses wird auf die Spalte path_locator gesetzt. FILETABLE_STREAMID_UNIQUE_CONSTRAINT_NAME: Die Eindeutigkeit der Spalte stream_id wird über ein Unique Key-Constraint erzwungen. Der Name dieses Constraints wird über diese Option bestimmt. FILETABLE_FULLPATH_UNIQUE_CONSTRAINT_NAME: Ein weiteres Unique Key-Constraint erzwingt die Eindeutigkeit von Datei- und Ordnernamen. Dieser besteht zum einen aus dem parent_path_locator, der den Ordner, in dem die Datei gespeichert ist, angibt; des Weiteren aus dem Datei- oder Ordnernamen, der in der Spalte name gespeichert wird. Den Namen für dieses Constraint bestimmen Sie mit dieser Option. Die fertige Anweisung könnte nun folgendermaßen aussehen: CREATE TABLE dbo.meine_dokumente AS FileTable FILETABLE_DIRECTORY = 'db_docs', FILETABLE_COLLATE_FILENAME = database_default, FILETABLE_STREAMID_UNIQUE_CONSTRAINT_NAME = uk_meine_dokumente_streamid, FILETABLE_FULLPATH_UNIQUE_CONSTRAINT_NAME = uk_meine_dokumente_fullpath Auffallend ist, dass diese CREATE TABLE-Anweisung keine Spaltendefinitionen enthält. Dies liegt daran, dass die Struktur einer FileTable fix vorgegeben ist. Dass diese verwendet wird, legt der Zusatz AS FileTable hinter dem Tabellennamen in der Anweisung fest. Erstellen wir nun diese Tabelle, indem wir die Anweisung im Editor markieren und ausführen, taucht nun der im Statement angegebene Ordnername db_docs unter der bereits vorhandenen Freigabe auf: \\srvsql2014\dateiablage\dateidatenbank\db_docs 160 3 Eine neue Datenbank erstellen In diesem Ordner können nun erstmals zum Beispiel über den Explorer weitere Ordner erstellt und Dateien abgelegt werden. Ich habe dies getan, das Ergebnis oder einen Teil davon können Sie in Bild 3.78 sehen. Bild 3.78 In der Freigabe angelegte Ordnerstruktur Für den Zugriff auf den Ordner benötigen Sie also ausgehend vom Datenbankserver den Freigabenamen, der für eine Instanz definiert wird, gefolgt vom Share, der für jede Datenbank auf dieser Instanz, von der FILESTREAM genutzt wird, erstellt wird. Für jede FileTable innerhalb einer Datenbank wird ein eigenes Verzeichnis sichtbar. Unter dieser vierten Ebene kann nun die weitere Struktur frei definiert und genutzt werden. SQL Server 2014 FILESTREAMShare der Instanz Verzeichnis der Datenbank Verzeichnis der FileTable Benutzerverzeichnisse DB Server Beispiel: \\srvsql2014\dateiablage\dateidatenbank\db_docs\......... Bild 3.79 Basisstruktur für FileTable mit FILESTREAM Im Beispiel habe ich vorerst die drei Ordner dokumente, musik und videos erstellt. Im Ordner musik habe ich vier weitere Unterordner angelegt und in diese jeweils ein paar Musikdateien kopiert. Diese Ordner und Dateien erscheinen nun automatisch als Datensätze in 3.6 Tabelle mit Filestream und FileTable 161 der FileTable. Dies ist das Wesen dieser Tabellenart. Betrachten wir uns nun danach das Ergebnis, indem wir den kompletten Inhalt der Tabelle mit der Anweisung SELECT * FROM dbo.meine_dokumente; im Management Studio ausgeben. Bild 3.80 Befüllte FileTable In der Spalte name erkennen Sie im Ergebnis die Namen der Dateien und Verzeichnisse. Die genauen Inhalte der Tabelle finden Sie in Tabelle 3.5 aufgeschlüsselt. Tabelle 3.5 Struktur einer FileTable Spalte Beschreibung stream_id Diese stellt, wie schon vom „normalen“ FILESTREAM her bekannt, eine eindeutige ID für jede Datei oder jeden Ordner bereit. Sie ist auch hier als UNIQUEIDENTIFIER ausgeformt. file_stream Diese Spalte repräsentiert die Inhalte von Dateien. Diese sind binär hier in einer varbinary(max)-Spalte verfügbar. Für Ordner enthält diese Spalte daher keinen Wert. Auch hier ist der Zusammenhang zu klassischem FILESTREAM zu erkennen. name Der Name der Datei oder des Ordners. path_locator Diese Spalte vom Datentyp hierarchyid repräsentiert den Primärschlüssel in einer FileTable. Er setzt sich aus den Werten der übergeordneten Pfade und jenem der Datei zusammen und ist somit eindeutig. parent_path_locator Diese Spalte, ebenfalls vom Datentyp hierarchyid, stellt einen Verweis auf den übergeordneten Ordner dar. Er enthält den Eintrag aus der Spalte path_locator des Ordners, in dem sich die Datei oder das Verzeichnis befindet. Über einen Fremdschlüssel wird hier die Konsistenz gesichert file_type Enthält die Dateierweiterung bei Dateien, wie zum Beispiel mp3 oder m4a. cached_file_size Diese Spalte ist als bigint ausgeformt und zeigt bei Dateien die Größe in Bytes an. 162 3 Eine neue Datenbank erstellen Tabelle 3.5 Struktur einer FileTable (Fortsetzung) Spalte Beschreibung creation_time Diese Spalte zeigt an, wann die Datei erstellt beziehungsweise in den Ordner kopiert worden ist. Dies ist nicht jener Zeitpunkt, den Sie im Explorer als Änderungsdatum angezeigt bekommen. Diese Logik entspricht dem bekannten Verhalten, wenn Sie eine Datei in einen gewöhnlichen Ordner kopieren. Sie sehen denselben Zeitpunkt als Erstellt, wenn Sie sich im Explorer die Eigenscha en der Datei anzeigen lassen. Für diese Spalte wird der Datentyp datetimeoffset verwendet, der auch die Zeitzone mit speichert und anzeigt. last_write_time Dieser Wert entspricht jenem, der im Explorer als Änderungsdatum angezeigt wird. Sie ist ebenfalls mit dem Datentyp datetimeoffset definiert. last_access_time In den Eigenscha en einer Datei finden Sie den Eintrag Letzter Zugriff. In der FileTable finden Sie diesen Wert in dieser Spalte. Wie die beiden zuvor hat diese den Datentyp datetimeoffset. is_directory Diese bit-Spalte enthält für Ordner den Eintrag Wahr (1) und für Dateien den Wert Falsch (0). is_offline Wird dazu verwendet, um das Dateiattribut Offline innerhalb der FileTable anzuzeigen. is_hidden Dieser Wert entspricht dem Dateiattribut Versteckt. is_readonly Das Dateiattribut Schreibgeschützt wird in dieser Spalte abgebildet. is_archive Das Dateiattribut Archiv wird von dieser Spalte dargestellt. is_system Enthält den Wert 1 für Wahr, wenn eine Datei oder ein Ordner als Systemdatei beziehungsweise als Systemordner markiert ist. is_temporary Übernimmt das Dateiattribut Temporär. ACHTUNG! Sie sind besser mit der Anweisung SELECT * FROM ... bei einer FileTable vorsichtig, da in Form von Binärdaten die gesamte Datenmenge, die sich gerade im Verzeichnis befindet, abgerufen werden kann. Das können riesige Datenmengen sein, die Sie in diesem Moment bewegen und den Server sowie Datenleitungen belegen. Verzichten Sie vor allem auf die Spalte file_stream in Ihrem SELECT, denn diese Spalte enthält die Daten in binärer Form. Zugriff über SQL Mich fasziniert an FileTables, dass man die Ordner und Dateien nun bequem über SQLAnweisungen auswerten kann. In eingeschränkter Form können Sie sogar über SQL Veränderungen vornehmen. Auf die Dateien können Sie programmatisch wie generell auf Binärdaten in einer Datenbank zugreifen. Leider unterstützen dies die aktuellen ODBCTreiber noch nicht. Wir bekommen kein Ergebnis angezeigt, wenn wir die Tabelle wie im FILESTREAM-Beispiel in eine Access-Datei verknüpfen. Beschä igen wir uns nun mit ein paar Beispielen, wie Sie mit SQL auf diese Daten zugreifen können. HINWEIS: Wenn Sie mit SQL noch nicht vertraut sind, lesen Sie zuvor das nachfolgende Kapitel. Dort erkläre ich Ihnen die Grundlagen dazu. 3.6 Tabelle mit Filestream und FileTable 163 Verzeichnisse sind in einer FileTable daran zu erkennen, dass einerseits in der Spalte file_ stream der Wert NULL zu finden ist, andererseits daran, dass die Spalte is_directory den Wert 1 als Bit-Wert für Wahr enthält. Mit nachfolgender Anweisung können Sie alle Ordner anzeigen. SELECT name FROM dbo.meine_dokumente liefert: name -------------------------------------------------dokumente musik videos James Blunt Shakira Tim Bendzko Um Ordner gemeinsam mit ihren Unterordnern darzustellen, wählen Sie einen Self Join und verknüpfen die Tabelle über die Spalten path_locator und parent_path_locator. d.name AS unterordner FROM dbo.meine_dokumente d LEFT OUTER JOIN dbo.meine_dokumente p ON d.parent_path_locator = p.path_locator liefert: ordner --------------------------root root root unterordner -------------------------------dokumente musik videos musik musik musik James Blunt Shakira Tim Bendzko Über spezielle Funktionen lässt sich der Pfad zu einer Datei in lesbarer Form ausgeben. Die vorhandene Form als hierarchyid ist für uns ja nicht gut lesbar. FileTableRootpath : Diese Funktion liefert den Basispfad, der sich aus der Freigabe und den Verzeichnissen von Datenbank und FileTable ergibt. GetFileNamespacePath : Mit dieser Funktion kann der relative Pfad einer Datei unterhalb der von der FileTable festgelegten Ordnerstruktur ausgelesen werden. Kombinieren Sie beide, können Sie den gesamten Pfad von Dateien eruieren. FROM dbo.meine_dokumente liefert: 164 3 Eine neue Datenbank erstellen Datei ------------------------------------------------------------------------- Lieder.mp3 PRAXISTIPP: Da Funktionen für jede Zeile separat ausgeführt werden, muss der Basispfad für jeden Eintrag mit der Funktion FileTableRootpath() mehrfach eruiert werden, obwohl er für jede Zeile denselben Wert ergeben wird. Um diesen Vorgang effizienter zu gestalten, können Sie diesen konstanten Wert zuvor in einer Transact-SQL-Variablen speichern und verwenden. Eine ausführliche Einführung in Transact-SQL bietet Ihnen Kapitel 5. Folgende drei Anweisungen liefern dasselbe Ergebnis wie die Anweisung zuvor, reduzieren allerdings den Aufwand für das System, da der Basispfad nur ein einziges Mal eruiert werden muss. FROM dbo.meine_dokumente In einem eingeschränkten Umfang können über SQL auch Schreibzugriffe auf eine FileTable erfolgen. Das nachfolgende Beispiel zeigt, wie Sie einen Ordner umbenennen. Mit einer UPDATE-Anweisung ändern wir den Namen des Ordners videos zu fotos. Ich gehe dabei davon aus, dass es in der gesamten Verzeichnisstruktur nur einen Ordner mit diesem Namen gibt und daher die Einschränkung name = 'video' ausreichend ist. UPDATE dbo.meine_dokumente SET name = 'fotos' AND is_directory = 1; An dieser Stelle ist für mich eine deutliche Verbesserung gegenüber dem SQL Server 2012 zu erkennen. Hier hat es immer wieder etwas gedauert, bis diese Änderung in der FileTable auch im Filesystem direkt erkennbar gewesen ist. Insbesondere, wenn der betroffene Ordner im Moment im Zugriff gewesen ist, hat sich die Änderung erst etwas später gezeigt. Beim SQL Server 2014 fällt diese Verzögerung in meinen Tests weg. Im Gegenteil, habe ich den Ordner beim Umbenennen gerade geöffnet, „verschwinden“ die Dateien unmittelbar und der Ordner ist leer. Ich muss dann zum neuen Ordner navigieren, um die Dateien wieder zu sehen. 3.6 Tabelle mit Filestream und FileTable 165 Löschen Sie einen Datensatz aus der FileTable, verschwindet die betroffene Datei oder der betroffene Ordner ebenso aus dem Filesystem. Die nachfolgende Anweisung löscht eine Datei: DELETE FROM dbo.meine_dokumente Ein Ordner kann auf diese Art und Weise nur dann gelöscht werden, wenn er bereits leer ist. Ist dies nicht der Fall, bekommen Sie eine Fehlermeldung, die auf eine FremdschlüsselVerletzung hinweist. Wir erinnern uns, die Spalte path_locator verweist mit einem Fremdschlüssel auf die Spalte parent_path_locator. Folgende Anweisung wird in unserem Beispiel daher nicht erfolgreich ausgeführt. DELETE FROM dbo.meine_dokumente AND is_directory = 1; Die Fehlermeldung lautet: SAME TABLE REFERENCE-Einschränkung Tabelle 'dbo.meine_dokumente', column 'parent_path_locator' auf. HINWEIS: Wie wir gesehen haben, können wir beim Erstellen der FileTable für bestimmte Constraints selber einen Namen vergeben. Leider ist dies nicht durchgängig für alle Constraints möglich. Daher sehen wir für diesen Fremdschlüssel einen systemseitig vergebenen Namen. Dies stört nicht weiter, außer dass er nicht so „schön“ ist wie selbst vergebene. Auch das Umbenennen über das Kontextmenü im Objekt-Explorer ist in diesem Fall nicht möglich. Bild 3.81 Schlüssel der FileTable Nach dem Ändern und Löschen betrachten wir uns abschließend noch das Einfügen von neuen Datensätzen. Mit der nachfolgenden Anweisung erstellen wir ein weiteres Verzeichnis im Basisordner. 166 3 Eine neue Datenbank erstellen Nun kopieren wir eine bestehende Datei ebenfalls in den Basisordner. Dazu müssen wir den Inhalt der Spalte file_stream kopieren. Natürlich können wir dabei auch einen anderen Dateinamen vergeben. FROM dbo.meine_dokumente Als Ergebnis sehen Sie sowohl den neuen Ordner als auch die neue Datei im Basisordner. HINWEIS: Um Objekte in einem Unterordner zu erstellen, muss man sich ein wenig mit der Verwendung und Erstellung von Werten für den Datentyp hierarchyid befassen. Informationen dazu finden Sie auch in Kapitel 5. Im , um einen neuen Besonderen benötigen wir die Methode untergeordneten Wert in einer Hierarchie zu bekommen. Für die nachfolgenden Beispiele verwende ich Variablen, über die Sie auch in Kapitel 5 detailliert informiert werden. Bild 3.82 Objekte über INSERT mit SQL erstellt Ich erstelle nun einen Unterordner für den Ordner musik. Dazu muss ein passender Hierarchiewert als Nachfolger für den Hierarchiewert dieses Ordners generiert werden. Dazu lese ich zuerst den Wert der Spalte path_locator für den Ordner musik aus und speichere ihn in ab. Danach benutze ich die Methode , um für der Variablen diesen Hierarchiewert einen Nachfolger zu generieren, und weise diesem der Variablen unterordner zu. Beide Variablen müssen den passenden Datentyp hierarchyid verwenden. Den neu generierten Hierarchiewert kann ich nun beim Einfügen in die Tabelle für die Spalte path_locator verwenden. Zur Erinnerung: Im vorhergehenden Beispiel haben wir diese Spalte nicht befüllt und das neue Verzeichnis daher im Basisordner angelegt. 3.6 Tabelle mit Filestream und FileTable 167 DECLARE @unterordner hierarchyid = @ordner.GetDescendant(NULL, NULL) INSERT INTO dbo.meine_dokumente (name, is_directory, path_locator @unterordner Mit dem weiteren folgenden Beispiel kopiere ich nun eine Datei in diesen Unterordner. Wieder muss ich einen Nachfolgewert für die Hierarchie des Zielordners erstellen und diesen dann als path_locator eintragen. DECLARE @datei hierarchyid = @ordner.GetDescendant(NULL, NULL) FROM dbo.meine_dokumente path_locator @datei Sie sehen an diesen Beispielen, dass Sie beim Erstellen eines Hierarchie-Nachfolgewertes keinen Unterschied machen müssen, ob Sie diesen für einen Ordner oder eine Datei benötigen. Allerdings müssen wir noch eine Kleinigkeit zusätzlich beachten. Die Methode besitzt die beiden Parameter child1 und child2, um die Position in der Hierarchie genauer zu bestimmen. Bisher haben wir für beide Parameter den Wert NULL übergeben. Dies bedeutet, dass quasi der erste Nachfolger in der Hierarchie gebildet wird. Dies wird zum Problem, wenn Sie auf dieselbe Art und Weise nun einen weiteren Ordner in demselben anlegen oder eine weitere Datei einfügen möchten. Denn dann können Sie nicht ist mehr denselben Nachfolgewert erneut verwenden. Denn die Methode deterministisch, was bedeutet, dass sie mit denselben Parametern aufgerufen immer dasselbe Ergebnis liefert. Würde ich also nun, nachdem ich die Datei zu „Am seidenen Faden“ bereits in den Ordner deutsch kopiert habe, nun auch „Lieder“ in denselben Ordner verschieben, eine Primärschlüsselverletzung auslösen, da die eruierte Hierarchiestufe einsetzen, um bereits vergeben ist. Daher müssen wir die Parameter von dies zu vermeiden. Der Parameter child1 bedeutet, dass ein Wert „nach“ diesem, child2 bedeutet ein Wert „vor“ diesem generiert werden soll. Wir lesen also immer den größten Wert der betroffenen Hierarchiestufe aus und übergeben ihn als Parameter child1, damit kann dann nichts mehr schiefgehen. Im nächsten Beispiel verschieben wir eine Datei, anstelle sie zu kopieren. Dazu verwenden wir ein gewöhnliches UPDATE, um die neu eruierte Hierarchiestufe der Spalte path_locator zuzuweisen. Nebenbei können wir auch gleich den Dateinamen anpassen. In der nun lesen wir den größten Hierarchiewert aus, zusätzlich verwendeten Variablen der dem Zielordner zugewiesen ist. Diesen geben wir nun als Parameter child1 der Methode den Wert NULL mit. Gibt es noch gar keine Inhalte im Ordner, erhält die Variable und wir würden damit auch das gewünschte Ergebnis erzielen. DECLARE @vorhanden hierarchyid = (SELECT MAX(path_locator) FROM dbo.meine_dokumente WHERE parent_path_locator = @ordner) 168 3 Eine neue Datenbank erstellen (@vorhanden UPDATE dbo.meine_dokumente name = 'lieder.mp3' Mit dieser Variante können wir nun weitere Dateien in den Ordner deutsch verschieben, ohne auf einen Fehler aufzulaufen. HINWEIS: Wenn Sie sich mit dem Nachvollziehen der letzten Beispiele noch etwas schwergetan haben, dann empfehle ich Ihnen, die Kapitel 4 und 5 zu lesen, hier bekommen Sie die Grundlagen zu SQL und Transact-SQL. PRAXISTIPP: Wenn Sie mittels UPDATE zum Beispiel einen Ordner verschieben möchten, der andere Dateien enthält, bekommen Sie eine Fremdschlüsselverletzung. Sie können so etwas bewerkstelligen, indem Sie die Dateien einzeln verschieben, um so sauber jeweils den passenden Hierarchiewert zu ermitteln. Um das zu automatisieren, benötigen Sie zum Beispiel eine gespeicherte Prozedur mit einem Cursor, um die Dateien in einer Schleife zu bearbeiten. Dazu lesen Sie die Kapitel 5 und 6, um die dazu notwendigen Vorgangsweisen zu erlernen. Im letzten Beispiel kopiere ich ein Video aus der früher in diesem Kapitel erstellten Datenbank video in die FileTable. Da es sich um eine andere Datenbank handelt, geben wir vor dem Schemanamen der Tabelle medien noch den Namen der anderen Datenbank an. Da in der Ursprungstabelle zwar das Video, aber kein Filename gespeichert ist, vergebe ich diesen beim Anfügen. FROM video.dbo.medien Auch dieses Video erscheint letztendlich als Datei im Ordner und der Zugriff darauf über das Filesystem ist möglich. Um diese Datei in einen bestimmten Ordner einzufügen, gehen Sie wie in den vorangegangenen Beispielen vor. Was zum Thema FileTables noch wichtig ist . . . Prinzipiell unterstützen FileTables alle Funktionen eines normalen Dateisystems. Allerdings ist die Verzeichnistiefe eingeschränkt. Sie können Unterverzeichnisse nur in einer maximalen Tiefe von 15 Ebenen erstellen. Wenn Sie diese maximale Anzahl ausnützen, können Sie aber keine Dateien mehr auf der untersten Ebene speichern, da diese eine weitere Ebene in der für die Darstellung in der Spalte path_locator verwendeten hierarchyid bedeuten würden. Informationen über FileTables finden Sie in einer eigenen Systemtabelle filetables im Schema sys. 3.7 Beispieldatenbank generieren 169 Hier finden Sie Informationen darüber, ob der Zugriff aktiviert ist, wie der Verzeichnisname der Tabelle lautet sowie welche Sortierreihenfolge für die Namen verwendet wird. Bild 3.83 Informationen aus sys.filetables Wenn wir mit dem Explorer über das Dateisystem mit dem Share auf FileTables zugreifen, sehen wir eine vom SQL Server übersetzte Darstellung. Intern gleicht die Speicherung jener von Filestream. Auf der Datenplatte D haben wir für die verwendete Datenbank den Ordner DB_FS\dateien_fs gewählt. Darin hat der SQL Server beim Erstellen der FileTable einen weiteren Ordner für diese in der Syntax eines Unique Identifiers angelegt. Für jede FileTable innerhalb derselben Datenbank wird ein eigener Ordner auf dieser Ebene erstellt. Darunter verwaltet der SQL Server die Daten in der Art von FILESTREAM. Die einzelnen Dateien liegen in einer für uns nicht lesbaren Form vor, wie in Bild 3.84 zu sehen. Bild 3.84 Realsicht auf Inhalt einer FileTable ■ 3.7 Beispieldatenbank generieren Nachdem wir in diesem Kapitel jede Menge über das Erstellen von Datenbanken und Tabellen gehört haben, wird es Zeit, nun die Beispieldatenbank, die wir in den folgenden Kapiteln des Buches benötigen werden, zu generieren. Im ersten Kapitel habe ich Ihnen gezeigt, wie Sie die Beispieldatenbank wawi durch Anfügen der Datenbankdateien, die Sie heruntergeladen haben, verfügbar machen können. Nun möchte ich Ihnen zeigen, wie Sie dies anhand eines SQL-Skripts erledigen können.