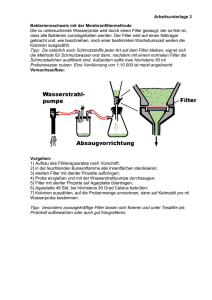
Hauptseminar: Medizinische Bildverarbeitung
Werbung

Hauptseminar: Medizinische Bildverarbeitung Seminararbeiten Prof. Dr.-Ing. Dietrich Paulus, Sahla Bouattour Sommersemester 2003 Sommersemester 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz paulus|[email protected] http://www.uni-koblenz.de/∼paulus|bouattour Inhaltsverzeichnis 1 Bildgebende Verfahren in der Medizin 1.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2 Röntgentechnik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3 Erzeugung von Röntgenstrahlen . . . . . . . . . . . . . . . . . . . . 1.3.1 Röntgenröhre . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3.2 Bohr’sches Atommodell . . . . . . . . . . . . . . . . . . . . 1.3.3 Bremsstrahlung . . . . . . . . . . . . . . . . . . . . . . . . . 1.3.4 Charakteristische Strahlung . . . . . . . . . . . . . . . . . . 1.4 Schwächung der Röntgenstrahlung . . . . . . . . . . . . . . . . . . . 1.4.1 Eigenschaften von Röntgenstrahlen . . . . . . . . . . . . . . 1.4.2 Photoeffekt . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4.3 Compton-Effekt . . . . . . . . . . . . . . . . . . . . . . . . 1.4.4 Von welchen Faktoren hängt die Schwächung der Strahlung ab? 1.5 Beeinflussung der Bildwirkung . . . . . . . . . . . . . . . . . . . . . 1.5.1 Kontrast . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5.2 Schärfe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.6 Weitere röntgenologische Verfahren . . . . . . . . . . . . . . . . . . 1.6.1 Durchleuchtung . . . . . . . . . . . . . . . . . . . . . . . . . 1.6.2 Mammographie . . . . . . . . . . . . . . . . . . . . . . . . . 1.6.3 Angiographie . . . . . . . . . . . . . . . . . . . . . . . . . . 1.6.4 Röntgencomputertomographie . . . . . . . . . . . . . . . . . 1.6.5 Fenstertechnik mit der Hounsfiledskala . . . . . . . . . . . . 1.7 Weitere tomographische Verfahren . . . . . . . . . . . . . . . . . . . 1.7.1 Kernspintomographie . . . . . . . . . . . . . . . . . . . . . . 1.7.2 Emissioncomputertomographie: SPECT/PET . . . . . . . . . 1.7.3 Weitere tomographische Verfahren . . . . . . . . . . . . . . . 1.8 Weitere bildgebende Verfahren . . . . . . . . . . . . . . . . . . . . . 1.8.1 Szintigraphie . . . . . . . . . . . . . . . . . . . . . . . . . . 1.8.2 Sonographie . . . . . . . . . . . . . . . . . . . . . . . . . . 1.9 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2 2 2 2 3 3 5 6 6 6 6 7 7 8 8 9 9 10 10 10 12 13 13 14 14 14 14 15 15 2 Röntgen CT: gefilterte Rückprojektion 2.1 Problemstellung . . . . . . . . . . . . . . . . . . . . 2.2 Röntgen Computertomographie . . . . . . . . . . . . 2.3 Definition einer Projektion . . . . . . . . . . . . . . 2.3.1 Projektionsarten . . . . . . . . . . . . . . . 2.3.2 Prjektion einer Bleikugel (einfaches Beispiel) 2.3.3 Projektion eines Körpers (allgemein) . . . . 19 20 20 21 21 22 23 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 INHALTSVERZEICHNIS 2.4 2.5 2.6 2.7 Radon Transformation . . . . . . . . . . . . . . . . . . . Anwendung der Radon Transformation . . . . . . . . . . Rekonstruktion . . . . . . . . . . . . . . . . . . . . . . . 2.6.1 Fourier-Scheiben-Theorem (fourier slice theorem) 2.6.2 Zusammenfassung . . . . . . . . . . . . . . . . . 2.6.3 Interpolation . . . . . . . . . . . . . . . . . . . . 2.6.4 Vor- und Nachteile . . . . . . . . . . . . . . . . . Gefilterte Rückprojektion (filtered backprojection) . . . . . 2.7.1 Rückprojektion (backprojection) . . . . . . . . . . 2.7.2 Filterung . . . . . . . . . . . . . . . . . . . . . . 2.7.3 Vor- und Nachteile . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 25 26 26 27 27 28 28 28 29 30 3 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter 3.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2 Bildaufnahmeprozess . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.1 Der Weg zum digitalisierten Bild . . . . . . . . . . . . . . . . 3.2.2 Die Weiterverarbeitung durch einen Filter . . . . . . . . . . . 3.3 Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.1 Lineare Filter: . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.2 Nichtlineare Filter . . . . . . . . . . . . . . . . . . . . . . . 3.3.3 Adaptive Filter . . . . . . . . . . . . . . . . . . . . . . . . . 3.4 Wiener Filter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.4.1 Mathematische Herleitung . . . . . . . . . . . . . . . . . . . 3.4.2 Adaptiver Wiener Filter . . . . . . . . . . . . . . . . . . . . 3.4.3 Schema des Wiener Filters . . . . . . . . . . . . . . . . . . . 3.4.4 Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.5 Anisotropischer adaptiver Filter . . . . . . . . . . . . . . . . . . . . 3.5.1 Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . 3.5.2 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.6 Schlusswort . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 34 34 34 35 35 35 36 36 36 36 39 40 40 41 41 42 43 4 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen 4.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2 Das klassische Snake-Modell . . . . . . . . . . . . . . . . . . . . . . 4.2.1 Mathematische Grundlagen . . . . . . . . . . . . . . . . . . 4.2.2 Energieminimierungsverfahren . . . . . . . . . . . . . . . . . 4.2.3 Dynamisch deformierbare Modelle . . . . . . . . . . . . . . 4.2.4 Nachteile klassischer Snakes . . . . . . . . . . . . . . . . . . 4.3 T-Snakes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3.1 Eigenschaften . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3.2 Komponenten der T-Snake . . . . . . . . . . . . . . . . . . . 4.3.3 Iterative Neubestimmung der geometrischen Parameter . . . . 4.3.4 T-Snake Algorithmus . . . . . . . . . . . . . . . . . . . . . . 4.3.5 Interaktive Kontrolle . . . . . . . . . . . . . . . . . . . . . . 4.3.6 Beurteilung der T-Snakes . . . . . . . . . . . . . . . . . . . . 4.4 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 48 48 48 49 51 51 52 52 52 53 54 55 56 57 INHALTSVERZEICHNIS 5 5 Registrierungsverfahren 5.1 Motivation und Nutzen in der Medizin . . . . . . . . . . . 5.2 Registrierungsverfahren . . . . . . . . . . . . . . . . . . . 5.2.1 Definition . . . . . . . . . . . . . . . . . . . . . . 5.3 Klassifikation der Verfahren . . . . . . . . . . . . . . . . 5.3.1 Modalität . . . . . . . . . . . . . . . . . . . . . . 5.3.2 Dimensionalität . . . . . . . . . . . . . . . . . . . 5.3.3 Subjekt . . . . . . . . . . . . . . . . . . . . . . . 5.3.4 Objekt . . . . . . . . . . . . . . . . . . . . . . . . 5.3.5 Interaktion . . . . . . . . . . . . . . . . . . . . . 5.3.6 Basis . . . . . . . . . . . . . . . . . . . . . . . . 5.3.7 Transformation (modellbasiert) . . . . . . . . . . 5.3.8 Transformationsbereich . . . . . . . . . . . . . . 5.3.9 Optimierungsverfahren . . . . . . . . . . . . . . . 5.4 Registierungsverfahren von Penney . . . . . . . . . . . . 5.4.1 Klassifikation des Registrierungsverfahren . . . . 5.4.2 Digitally Reconstructed Radiograph . . . . . . . . 5.4.3 Registrierungsverfahren als Optimierungsproblem 5.4.4 Ähnlichkeitsmaße . . . . . . . . . . . . . . . . . 5.4.5 Bewertung des Verfahrens von Penney . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 62 64 64 64 65 65 65 66 66 66 67 68 68 69 69 69 70 70 72 6 Bayes Netze 6.1 Motivation . . . . . . . . . . . . . . 6.2 Statistischer Grundlagen . . . . . . 6.3 Aufbau Bayes-Netze . . . . . . . . 6.4 Diagnose mit Hilfe von Bayes-Netze 6.5 Klassifikation mit Bayes-Netzen . . 6.6 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75 76 76 78 80 83 85 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 Retina 89 8 Endoskopie 8.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8.2 Verschiedene Endoskope und Funktionsweisen . . . . . . . . . . . 8.2.1 Entwicklung des Endoskops . . . . . . . . . . . . . . . . . 8.2.2 Aufbau eines Endoskops . . . . . . . . . . . . . . . . . . . 8.2.3 Der Schritt zur digitalen Verarbeitung . . . . . . . . . . . . 8.3 Verfahren am Beispiel der laparoskopische Gallenblasenentfernung . 8.3.1 Typische Probleme einer Laparoskopie . . . . . . . . . . . 8.3.2 Das Problem der Glanzlichter . . . . . . . . . . . . . . . . 8.4 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8.4.1 Virtuelle Endoskopie . . . . . . . . . . . . . . . . . . . . . 8.4.2 Kamerakapseln . . . . . . . . . . . . . . . . . . . . . . . . 8.5 Zusammenfassung und Ergebnis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93 94 95 95 95 96 96 97 97 101 102 102 103 9 Dermatologie 9.1 Einleitung . . . 9.2 Motivation . . . 9.3 Dermatoskopie 9.4 Merkmale . . . . . . . 107 108 108 109 109 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 INHALTSVERZEICHNIS 9.5 9.6 9.4.1 dermatoskopische ABCD-Regel 9.4.2 Verwendete Merkmale . . . . . Verfahren zur Merkmalsanaylse . . . . 9.5.1 Haardetektion . . . . . . . . . . 9.5.2 Segmentierung . . . . . . . . . 9.5.3 Asymmetrie der Farbverteilung 9.5.4 Vielfalt der Farben . . . . . . . 9.5.5 Klassifikator . . . . . . . . . . Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110 110 110 111 111 112 115 116 117 0 INHALTSVERZEICHNIS Kapitel 1 Bildgebende Verfahren in der Medizin Verena Würbel 08.April 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼wrena 2 Bildgebende Verfahren in der Medizin Abbildung 1.1: Röntgenaufnahme der menschlichen Hand 1.1 Einleitung Diese Ausarbeitung gibt einen Überblick über die bildgebenden Verfahren in der Medizin. Zuerst wird ein detaillierter Einblick in die Röntgentechnik gegeben. Entstehung und Eigenschaften der Strahlung werden erklärt und später anhand von röntgenologischen Verfahren, speziell der Computertomographie erläutert. Desweitern werden weiter bildgebende Verfahren vorgestellt. 1.2 Röntgentechnik Die Röntgenstrahlung wurde 1895 von Wilhelm Conrad Röntgen entdeckt. 1901 wurde er mit dem ersten Nobelpreis für Physik ausgezeichnet. Bei röntgenologischen Verfahren durchdringen Röntgenstrahlen (auch γ-Strahlung genannt) den Körper und werden dabei unterschiedlich stark geschwächt. Hinter dem Objekt wird die Intensität der geschwächten Strahlung von Detektoren (Film, Leuchtschirm, CCD-Sensor) gemessen. Die entstehenden schattenartigen Bilder sind an Stellen starker Absorption weiß und an Stellen schwacher Absorption schwarz. (siehe Abbildung 1.1) 1.3 Erzeugung von Röntgenstrahlen In diesem Abschnitt wird die Erzeugung von Röntgenstrahlung in der Röntgenröhre erläutert. Desweiteren wird das Bohr‘sche Atommodell kurz erklärt, um die Entstehung von charakteristischer Strahlung und Bremsstrahlung zu verstehen. 1.3.1 Röntgenröhre In einer Vakuumröhre treten durch den thermoelektrischen Effekt Elektronen aus der Kathode aus. Die Kathode ist ein Glühdraht, in dem die Elektronen sich so schnell bewegen, dass sie im Vakuum die Kathode verlassen können. Eine Erhöhung der Stromstärke führt also zu einer höheren Temperatur und Elektronen werden emittiert. Die freien Elektronen (Elektronen sind negativ geladen) werden durch eine Hochspannung im elektrischen Feld zur Anode hin beschleunigt (siehe Abbildung 1.2). Je größer die 1.3 Erzeugung von Röntgenstrahlen 3 Röntgenstrahlen Kathode Anode PSfrag replacements Hochspannung Abbildung 1.2: schematische Darstellung der Röntgenröhre Spannung, desto größer ist die Geschwindigkeit der Elektronen. Geladene Teilchen, die abgebremst werden oder ihre Richtung verändern verlieren Energie und senden somit Strahlung aus. Und genau das passiert an der Anode. Das heißt, je größer die Geschwindigkeit und somit die kinetische Energie der Elektronen ist, desto intensiver ist auch die resultierende Strahlung. Dabei ist noch zu sagen, dass nur ca. 1% der Energie in Strahlungsenergie umgesetzt wird. Die restlichen 99% werden in Form von Wärmeenergie abgegeben, was eine gute Wärmeleitfähigkeit der Anode fordert. Um zu verstehen was in der Anode passiert ist eine kleine Einführung in die Idee des Bohr’schen Atommodells von Nöten. 1.3.2 Bohr’sches Atommodell Nach Bohr besteht ein Atom aus einem Atomkern, der aus einer Zahl von Protonen und Neutronen besteht und somit positiv geladen ist. Die Elektronen befinden sich auf Bahnen um den Atomkern herum. Diese Schalen haben verschiedene Energieniveaus. Das heißt, es muss je nach Schale eine bestimmte Energie aufgebracht werden um ein Elektron aus der Schale zu lösen. Die Schalen werden von innen bei K beginnend alphabetisch benannt (siehe Abbildung 1.3). Die Anzahl der auf der Schale befindlichen Elektronen liegt bei 2n 2 . Wobei n die Nummer der Schale ist. Kommen wir nun zurück zu der Erzeugung der Röntgenstrahlen in der Anode. Dort entstehen zwei Strahlungen die sich zum Röntgenspektrum addieren: die Bremsstrahlung und die charakteristische Strahlung. 1.3.3 Bremsstrahlung Bei der Bremsstrahlung dringen die schnellen Elektronen in das Anodenmaterial ein und werden auf einer hyperbelförmigen Bahn durch den Atomkern abgelenkt (siehe 4 Bildgebende Verfahren in der Medizin K-Schale L-Schale M-Schale PSfrag replacements Abbildung 1.3: Bohr‘sches Atommodell resultierende Strahlung PSfrag replacements Atom Elektron Abbildung 1.4: Bremsstrahlung 1.3 Erzeugung von Röntgenstrahlen 5 resultierende Strahlung PSfrag replacements Elektron Abbildung 1.5: charakteristische Strahlung Abbildung 1.6: Das Röntgenspektrum Abbildung 1.4). Das passiert, weil Atomkerne positiv und die Elektronen negativ geladen sind. Die dabei abgegebene Strahlungsenergie ist die Differenz der Energie des Elektrons vor und nach der Ablenkung. Elektronen können auch mehrfach abgelenkt werden und es entstehen verschiedene Frequenzen der Strahlung. Dabei ist die Strahlungsenergie (Frequenz) am höchsten, wenn das Elektron nur einmal abgelenkt wird und möglichst nah am Atomkern vorbeifliegt. Außerdem hängt die Energie von der Geschwindigkeit der Elektronen und somit von der Spannung ab, womit bei höherer Spannung intensivere Strahlung erzeugt wird (harte Strahlung entsteht ab 100 kV). 1.3.4 Charakteristische Strahlung Die charakteristische Strahlung ist abhängig vom Anodenmaterial. Hat ein Elektron genügend Energie, kann es ein Elektron aus der Schale des Atoms herrausstoßen (siehe Abbildung 1.5). Man sagt: das Atom wird ionisiert. Der freie Platz auf einer inneren Schale wird von einem Elektron einer äußeren aufgefüllt. Die entstehende Strahlungsenergie ist gerade die Differenz der beiden Energieniveaus auf den Schalen. Da diese Energieniveaus bei den Elementen verschieden sind erkennt man charakteristische Peaks im Spektrum. Das Röntgenspektrum ergibt sich aus der Addition von der Bremsstrahlung und der charakteristischen Strahlung (siehe Abbildung 1.6). 6 Bildgebende Verfahren in der Medizin Kern PSfrag replacements Photon Elektron Abbildung 1.7: Photoeffekt Elektron PSfrag replacements Photon Abbildung 1.8: Compton-Effekt 1.4 Schwächung der Röntgenstrahlung Röntgenstrahlen werden im Körper durch Wechselwirkung von Strahlung und Materie geschwächt. Dabei sind zwei wichtige Effekte zu nennen: der Photoeffekt und der Compton-Effekt. Der Grad der schwächung hängt von unterschiedlichen Faktoren ab, die in diesem Abschnitt erläutert werden. 1.4.1 Eigenschaften von Röntgenstrahlen Röntgenstrahlen sind elektromagnetische Wellen, die sich nahezu mit Lichtgeschwindigkeit (300000 km/s) ausbreiten. Elektromagnetische Wellen verhalten sich einerseits wie eine Welle, andererseits wie Teilchen. Das ist der so genannte Welle/TeilchenDualismus. Wir stellen uns den Röntgenstrahl also bestehend aus Photonen vor. Je intensiver die Strahlung, desto mehr Photonen sind in ihm enthalten. Außerdem hat die Röntgenstrahlung Welleneigenschaften wie Wellenlänge und Frequenz. 1.4.2 Photoeffekt Beim Photoeffekt stößt das Photon ein Elektron aus der Schale eines Atoms und wird dabei vernichtet. Das Atom wird ionisiert. Das freigewordene Elektron kann im Körper bis zu einen Meter zurücklegen und andere Atome ionisieren (siehe Abbildung 1.7). 1.4.3 Compton-Effekt Beim Compton-Effekt stößt ein Röntgenphoton gegen ein Elektron und bewegt sich mit weniger Energie in eine andere Richtung fort (siehe Abbildung 1.8). Hierbei entsteht 1.5 Beeinflussung der Bildwirkung Wellenlänge Ordnungszahl 7 Dichte Dicke PSfrag replacements Abbildung 1.9: Faktoren der Schwächung: der graue und der weisse Pfeil verdeutlichen lediglich die Änderung des Faktors der Schwächung, nicht die Art der Strahlung! Streustrahlung, die zu schlechten Bildergebnissen führt (siehe Abschnitt 4.1: Verringerung der Streustrahlung). Der Compton-Effekt tritt ab einer Beschleunigungsspannung von 50 keV (Kiloelektronenvolt) auf. 1.4.4 Von welchen Faktoren hängt die Schwächung der Strahlung ab? Wie man aus Abbildung 1.9 erkennen kann, hängt die Schwächung der Strahlung von mehreren Faktoren ab: 1. Wellenlänge: Je größer die Wellenlänge, desto stärker wird die Strahlung geschwächt. 2. Ordnungszahl: Je weniger Schalen die Atome haben, desto stärker wird die Strahlung geschwächt. 3. Dichte: Je dichter die Materie, desto stärker wird die Strahlung geschwächt. 4. Dicke: Je dicker die Materie, desto stärker wird die Strahlung geschwächt. 1.5 Beeinflussung der Bildwirkung Ziel der Röntgentechnik ist es, zu diagnostischen Zwecken ein möglichst aussagekräftiges Bild des Körpers zu erhalten. Dieses Bild entsteht, in dem nach der Bestrahlung die Restintensität des Röntgenstrahls gemessen wird. Das Bild zeigt die Stellen, wo der Strahl stark absorbiert wurde weiß, die anderen bis schwarz. Die Schwächung der Strahlung erfolgt durch Absorptions- und Streuprozesse im Körper durch die Wechselwirkung von Röntgenstrahl und Materie. Qualitätsmerkmale von Bildern sind Kontrast und Schärfe. 8 Bildgebende Verfahren in der Medizin Abbildung 1.10: Streustrahlung 1.5.1 Kontrast Als Kontrast bezeichnet man die unterschiedlichen Schwärzungen im Bild. Er hängt ab von: 1. Härte der Strahlung: Weiche Strahlung führt zu kontrastreicheren Bildern. Also je höher die Röhrenspannung, desto kontrastärmer werden die Bilder. Allerdings führt weiche Strahlung zu einer höheren Strahlenbelastung des Körpers. Deswegen ist es sinnvoll die Bilder so zu verbessern, dass trotz harter Strahlung eine Diagnose möglich ist. 2. Verringerung von Streustrahlung: Die Verringerung der Streustrahlung erhöht den Kontrast im Bild. Streustrahlung entsteht durch den Comptoneffekt bei der Wechselwirkung von Röntgenphotonen und Materie. Die Streustrahlung ist umso größer, je höher die Röhrenspannung und je Größer das Volumen des durchstrahlten Objekts ist. Um die Streustrahlung zu reduzieren wird einmal vor den Primärstrahl eine Blende gesetzt, um das Volumen der durchstrahlten Fläche so klein wie möglich zu halten. Des Weiteren wird vor den Detektor ein Lamellenraster positioniert, das aus Bleilamellen und strahlungsdurchlässigen Stoffen besteht (siehe Abbildung 1.10). So werden Sekundärstrahlen absorbiert. Wichtig ist, dass das Raster richtig fokussiert und positioniert ist, weil sonst zu viel Bildinformation verloren gehen kann. 3. Filmmaterial 1.5.2 Schärfe Ein Bild ist scharf, wenn die Ränder einzelner, kleiner Details gut zu erkennen sind. Subjektiv hängt die Schärfe auch von dem Kontrast im Bild ab. Faktoren die die Schärfe im Bild beeinflussen: 1. Größe des Brennflecks (Fokus): 1.6 Weitere röntgenologische Verfahren 9 B Fokus F OA PSfrag replacements Objekt OF A Filmmaterial G G Abbildung 1.11: geometrische Unschärfe wird durch die Leistung der Röhre, das Anodenmaterial und die Anodenkonstruktion bestimmt. 2. Gesetzmäßigleiten der Zentralprojektion: Wie man in Abbildung 1.11(geometrische Unschärfe) erkennt, hängt die geometrische Unschärfe G von drei Faktoren ab: dem Fokus-Objekt-Abstand F OA, dem Objekt-Film-Abstand OF A und dem Fokus B. Um eine möglichst kleine geometrische Unschärfe zu erhalten, wählt man den F OA möglichst groß (mindestens 5-mal so groß wie Objektdicke) und der F OA möglichst klein. G= B ∗ F OA F OA 3. Anwendung von Verstärkerfolie: Das Verwenden von Verstärkerfolie ermöglicht eine geringere Strahlenbelastung beim Patienten und erzeugt subjektiv schärfere und kontrastreichere Bilder. Da Röntgenstrahlen nicht im Frequenzbereich von Licht liegen würden sehr hohe Dosen zum Belichten eines Filmes benötigt werden. Mit der fluoriszierende Verstärkerfolie wird daher die Röntgenstrahlung in Licht umgewandelt (aus einem Photon entstehen mehrere Lichtquanten), das den Film dann belichten kann. 4. Minimierung von Bewegungsunschärfe: Um die Bewegungsunschärfe zu Minimieren ist eine kurze Belichtung und eine genaue Geräteeinstellung wichtig. Ausserdem sollte der Patient gut fixiert sein. 1.6 Weitere röntgenologische Verfahren 1.6.1 Durchleuchtung Bei der Durchleuchtung will der Arzt Bewegungsabläufe wie z.B. die Ausbreitung eines Kontrastmittels beobachten. Früher stand der Arzt dazu neben dem fluoreszie- 10 Bildgebende Verfahren in der Medizin Abbildung 1.12: Mammographie der weiblichen Brust renden Leuchtschirm. Dies führte allerdings zu einer erheblichen Strahlenbelastung. Heute wird ein so genannter Röntgenbildverstärker benutzt. Die geschwächten Röntgenstrahlen treffen auf einen fluoreszierenden Eingangsschirm des Röntgenbildverstärkers. Die dabei ausgelösten Elektronen werden durch eine Spannung zum Ausgangsschirm hin beschleunigt und fokussiert. Dies wird über eine Fernsehkamera auf einem Monitor beobachtet. Das entstehende Bild ist allerdings helligkeits-invertiert, da die stark absorbierte Strahlung ja am wenigsten Licht freisetzt und somit dunkel dargestellt wird. 1.6.2 Mammographie Die Mammographie ist die röntgenologische Untersuchung der Brust (lat. Mamma = Brustdrüse)(siehe Abbildung 1.12). Da die Brust aus Weichgewebe besteht, ist nur eine weiche Röntgenstrahlung notwendig. Auf eine Anode aus Molybdän werden Elektronen mit einer Spannung von 28 kV bis 35 kV beschleunigt, so dass hauptsächlich charakteristische Strahlung entsteht. Die Strahlenexposition der Patientin ist daher relativ hoch. 1.6.3 Angiographie Angiographie ist die röntgenologische Untersuchung von Venen und Arterien (lat. Angio = Gefäß). Damit sich die Gefäße von dem restlichen Gewebe unterscheiden wird ein Kontrastmittel verabreicht. Nun wird vor der Einnahme ein Maskenbild erzeugt. Nach der Einnahme des Kontrastmittels ein so genanntes Füllbild. Durch Subtraktion (DSA1 ) der beiden Bilder erhält man ein Differenzbild, welches nur das vom Kontrastmittel durchsetztes Gewebe zeigt (siehe Abbildung 1.13). Oft werden die Bilder aus Sequenzen gemittelt, um eine Besserung des Signal/Rauschverhältnisses zu erreichen. 1.6.4 Röntgencomputertomographie Unter Tomographie versteht man die Abbildung einer zweidimensionalen Schicht. (lat. Tomos = Schicht) eines dreidimensionalen Objekts. Die Röntgencomputertomographie funktioniert im Prinzip wie die klassische Röntgenaufnahme (siehe Abbildung 1 Digital Substraction Angiography 1.6 Weitere röntgenologische Verfahren 11 Abbildung 1.13: angiographische Aufnahme der menschlichen Lunge nach dem Subtraktionsverfahren Abbildung 1.14: Röntgencomputertomographie: Schichtaufnahme des menschlichen Unterleibs 12 Bildgebende Verfahren in der Medizin −100 0 PSfrag replacements +1000 +100 +1000 0 −1000 Abbildung 1.15: Fensterung: Der Bereich zwischen 0 HU und 100 HU wird auf die Grauwerte aufgeteilt, sodass ein optischer Unterschied zwischen den betrachteten Gewebearten sichtbar ist. 2.1), allerdings wird durch einen Kollimator (Blende, die den Strahl bündelt) nur ein einziger Strahl (Fächerstrahl) ausgesandt, der den Körper passiert und auf der anderen Seite von einem Detektor aufgenommen wird. Dieser Strahl wird linear in der Schichtebene bewegt. So ergibt sich ein herkömmliches Röntgenbild. Allerdings ist die Auflösung besser, da es nicht zu Störungen aufgrund von Halbschattenbildung kommt. Nun dreht sich die Röntgenröhre um einen bestimmten Winkel und erzeugt eine Projektion aus diesem Winkel. Wenn die Röhre das Objekt einmal komplett umrundet hat, lässt sich aus den vielen Projektionen durch algebraische Rekonstruktion, Fourier-Transformation, gefilterte Rückprojektion ein Bild erzeugen (vgl. 2.1). Zur Verdeutlichung einige typische Daten eines aktuellen Tomographen: • Röhrenspannung 120 bis 150 kV (Kilovolt) • 500 bis 1000 Detektoren • Drehwinkel pro Schritt 0,5 bis 1 Grad (d.h. 360 bis 720 Projektionen) • Schichtdicke wählbar zwischen 1mm und 8mm. 1.6.5 Fenstertechnik mit der Hounsfiledskala Wegen sehr ähnlichen Schwächungskoeffizienten können manche Organe oder Gewebetypen nur aufgrund der Lage und nicht der Helligkeit eindeutig identifiziert werden. Abhilfe schafft die so genannte Fenstertechnik mit Hilfe der Hounsfieldskala. Die Hounsfileldskala zeigt den relativen Absorptionsunterschiede im Vergleich zu Wasser 1.7 Weitere tomographische Verfahren 13 Abbildung 1.16: Kernspintomographie des menschlichen Knies in Promille. Wobei −1000 HU (Hounsfield-Unit) der Absorption von Luft bzw. im Vakuum ausdrückt. 0 HU entspricht der Absorptionstärke von Wasser. Nach oben ist die Skala offen. Das Absorptionsvermögen von dichten Knochen liegt bei ca. 3000 HU. Das Auge kann unter normalen Bedingungen nur ca. 30 Graustufen unterscheiden. Verteilt man diese 30 Stufen gleichmäßig auf einen Bereich von mehreren tausend HU, so erscheinen Bereiche mit leicht unterschiedlichem Schwächungsvermögen ununterscheidbar in derselben Graustufe auf dem Monitor. Um dennoch etwas erkennen zu können, teilt man die Graustufen einfach auf einen kleineren Bereich die so genannten Fenster auf (siehe Abbildung 1.15). 1.7 Weitere tomographische Verfahren 1.7.1 Kernspintomographie Der menschliche Körper besteht zum größten Teil aus Waserstoff. Die positiv geladenen Kerne der Wasserstoffatome im Organismus, die Protonen, verhalten sich unter einem starken Magnetfeld genau so wie Eisenspäne unter einem gewöhnlichen Magneten: Sie orientieren sich alle in eine Richtung. Richtet man nun eine Art von Radiowellen auf die so in Reih und Glied gebrachten Protonen, nehmen sie die Energie auf und werden dadurch etwas von ihrer Ausrichtungsachse abgelenkt. Nach Abschalten der Radiowellen kehren die Protonen in ihre alte Lage zurück und geben dabei die aufgenommene Energie in Form von schwachen Radiowellen wieder ab. Diese Signale werden von einer Antenne aufgefangen und durch ein computergestütztes Rechenverfahren in ein Bild umgesetzt. Je lockerer ein Körpergewebe ist, desto mehr Wasser und Wasserstoff enthält es. Weichgewebe sind besonders wasserstoffreich, Knochen bsonders wasserstoffarm. Umgekehrt wie bei Röntgenuntersuchungen lassen sich mit der Magnetresonanztomographie Weichteile je nach ihrem Wassergehalt besonders gut voneinander abgrenzen (siehe Abbildung 1.16). Sie werden entsprechend ihrem Wasserstoffgehalt in verschiedenen Graustufen dargestellt. Die Methode ist daher besonders aussagekräftig in Körperregionen, in denen viel Weichgewebe vorhanden ist. Knochen und Luft stellen sich im Gegensatz hierzu gar nicht dar und erscheinen auf dem 14 Bildgebende Verfahren in der Medizin Abbildung 1.17: SPECT des menschlichen Gehirns kernspintomographischen Bild schwarz, im Röntgenbild dagegen weiß. Die Kernspintomographie hat den Vorteil gegenüber der Röntgentomographie, dass sie den Patienten nicht belastet. Allerdings sind nur Aufnahmen von wasserstoffreichen Geweben möglich. 1.7.2 Emissioncomputertomographie: SPECT/PET Positronen sind Elementarteilchen, die im Atomkern entstehen, wenn dieser mit Energie beschickt wird oder radioaktiv zerfällt. Obwohl sich der Atomkern dabei zunächst nicht verändert, bewirkt die aufgenommene Energie die Bildung eines Zwillingspaares von Elementarteilchen, die sich nur in ihrer Ladung unterscheiden, nämlich eines Elektrons und eines Positrons (positiv geladenes Teilchen mit Eigenschaften eines Elektrons). Stabil ist diese Bildung nicht: Da die Positronen physikalisch zur Antimaterie gehören, verschwinden sie auch sofort wieder, hinterlassen aber eine Spur: Die anfänglich hineingesteckte Energie wird als schwache, aber meßbare Strahlung wieder frei. Diese Strahlung wird gemessen und erzeugt ein Bild (siehe Abbildung 1.17). 1.7.3 Weitere tomographische Verfahren Als weitere tomographische Verfahren sind die optische Tomographie, die Quantentomographie und die Impendenztomographie zu nennen. 1.8 Weitere bildgebende Verfahren 1.8.1 Szintigraphie Bei der Szintigraphie (von Szintillation = Flackern, Aufblitzen, Funkeln) wird ein radioaktives Isotop intravenös injiziert und anschließend die Verteilung des Isotops mit einer Kamera, die radioaktive γ-Strahlen messen kann, aufgezeichnet. Um ein zweidimensionales Bild zu bekommen, wird der Körper oder das untersuchte Organ zentimeterweise abgetastet und die Stärke der gemessenen γ-Strahlung als Helligkeits- oder Farbpunkt in ein Bild übertragen (siehe Abbildung 1.18). 1.9 Ausblick 15 Abbildung 1.18: Schilddrüsen-Szintigraphie Abbildung 1.19: Sonographie bei der pränatalen Diagnostik 1.8.2 Sonographie Die Ultraschall-Untersuchung ist ein Verfahren zur bildlichen Darstellung verschiedener Körperregionen mit Hilfe von Ultraschallwellen (siehe Abbildung 1.19). Der Arzt benötigt für die Sonographie einen Schallkopf. Dabei handelt es sich um einen piezoelektrischen Kristall. Piezo-elektrisch heißt elektrisch durch Druck. Dieser Kristall wird durch bestimmte Hochfrequenzen zur Aussendung von Ultraschallwellen angeregt. Die Schallwellen werden im Körper des Patienten je nach Gewebeart absorbiert oder reflektiert. Der Schallkopf kann die reflektierten Schallwellen wiederum empfangen. Er wirkt also gleichzeitig als Schallsender und Schallempfänger. Die reflektierten Schallwellen werden in elektrische Impulse verwandelt, mit einem bestimmten Gerät verstärkt und auf einem Bildschirm dargestellt. Der Arzt erhält dadurch zweidimensionale Bilder, die ihm eine räumliche Vorstellung von Größe, Form und Struktur der untersuchten Organe, Weichteilgewebe und Gefäße vermitteln. Mit den besonderen Verfahren der Doppler-Sonographie und der Farb-Doppler-Sonographie erhält der Arzt zusätzlich Informationen über die Strömungsrichtung, -geschwindigkeit und -stärke des Blutflusses in den Gefäßen (siehe Abbildung 1.20). 1.9 Ausblick Wo jetzt ein Einblick in die Entstehung und die Problematik der Bildaufnahme gegeben wurde, wird nun auf die Weiterverarbeitung der Bilder eingegangen: gefilterte Rückprojektion, Einsatz von Filtern, Segmentierung, Registrierungsverfahren etc. 16 Bildgebende Verfahren in der Medizin Abbildung 1.20: Dopplersonographie Literaturverzeichnis [Ber99] Roland Berger. Moderne Bildgebende Verfahren der medizinischen Diagnostik. Logos Verlag, Berlin, 1999. [Bie80] Helmold Biel. Röntgenstrahlen ihre Anwendung in Medizin und Technik. Teubner Verlag, Leipzig, 1980. [Dös00] Olaf Dössel. Bildgebende Verfahren in der Medizin- Von der Technik zur medizinischen Anwendung. Springer Verlag, Heidelberg, 2000. [LOPR97] Thomas Lehmann, Walter Oberschelp, Erich Pelikan, and Rudolf Repges. Bildverarbeitung in der Medizin. Springer Verlag, Heidelberg, 1997. 18 LITERATURVERZEICHNIS Kapitel 2 Röntgen CT: gefilterte Rückprojektion Thomas Lempa 15 Mai 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼tommyboy 20 Röntgen CT: gefilterte Rückprojektion 2.1 Problemstellung In dem Kapitel 1.1 wurde erklärt wie ein Röntgen CT funktioniert. Im folgenden Kapitel wird auf die Nutzung des Röngen CT in der Medizin eingegangen und deren Zusammenhänge mit der Bildverarbeitung beschrieben. Im Jahre 1972 wurde die Computertomographie von Hounsfield und Cormack entwickelt. Diese Entwicklung wurde dann im Jahr 1979 mit einem Nobelpreis belohnt. CT ist ein Röntgen-Schichtbildverfahren, das die überlagerungsfreie Darstellung aller Körperregionen in Querschnitten erlaubt. In den ersten Jahren dauertr die Anfertigung einer Schichtbildaufnahme fast 5 minuten, durch die Weiterentwicklung der technik verkürzte sich die Zeit auf 1 Sekunde pro Aufnahme. Diese Entwicklung erleichter es den Ärzten Tumore und andere Anomalitäten im Körper zu erkennen. Die Problemtik dabei ist wie man ein Bild aus der Projektion eines Körpers wiederherstellen kann. Im folgendem Kapitel wird näher auf die Problematik der Projektion und der Rekonstruktion des Bildes aus der projektion mit Hilfe der inversen Radontransformation eingegangen. Hierbei gibt es zwei Möglichkeiten: Fourier - Scheiben - Theorem und Gefilterte Rückprojektion. Aber dazu später. 2.2 Röntgen Computertomographie Ein Körper, der sich im Röntgen CT befindet wird durch einen fächerartigen Röntgenstrahl durchdringt (vgl. 2.1. Abbildung 2.1: Bestrahlung eines Körpers im Röntgen CT Diese Röntgenstrahlen werden innnerhalb des Körpers durch die verschiedenen Strukturen (Knochen, Organe, Fett, Muskeln) unterschiedlich stark abgeschwächt. Auf der anderen Seite befinden sich mehrere Detektoren, die die Röntgenstrahlung messen und an einen leistungsstarken Computer weiter leiten. Da die Röngenröhre und die Detektoren sich um den Patienten, bzw. Körper um den Winkel θ drehen entstehen ganz viele Projektionen, welche dann in ein Bild umgewandelt werden. 2.3 Definition einer Projektion 21 Abbildung 2.2: Beispiel eines entstandenen Bildes 2.3 Definition einer Projektion Im folgendem Kapitel wird erklärt, was eine Projektion ist und wie diese entsteht. Ich werde mich dabei auf die parallele Projektion (vgl. Bild 2.3) beschränken. 2.3.1 Projektionsarten Es gibt drei unterschiedliche Projektionsarten. Die parallele, gleichwinklig gefächerte und gleichräumig gefächerte Projektion. Bei der parallelen Projektion (vgl. Bild 2.3) wird linear über die Länge der Projektion gescannt, dann um einen bestimmten Winkle gedreht und wieder über die Länge der Projektion gescannt. Dies führt dazu, daß man mehr Zeit braucht um die Meßwerte zu verabeiten. Die Rekonstruktion der Projektion ist jedoch sehr einfach. Die gefächerte Projektion (vgl. Bild 2.5)ist schneller, jedoch benötigt man einen komplizierteren Algorithmus für die Rekonstruktion. Bei der gefächrten Projektion gibt es zwei Varianten , die gleichwinklig gefächerte (Bild 2.4) und die gleichräumig gefächerte (Bild 2.5). Bei der ersten Variante haben die Detektoren unterschiedlichen abstand zu einander, die Röntgenstrahlen haben jedoch gleichen Winkel. Bei der zweiten Variante haben die Detektoren den gleichen Abstand zu einander, aber die Röntgenstrahlen werden unter unterschiedlichen Winkel an die Detektoren weiter geleitet. Die rekonstruktionsverfahren sind hier auch unterschiedlich. Mehr darüber kann man bei [SHJ88] nachlesen. Pθ2 t Pθ 1 t PSfrag replacements y f (x, y) θ1 θ2 x Abbildung 2.3: Parallele Projektion (parallel projection) PSfrag replacements y 22 x t θ1 θ2 PSfrag replacements f (x, y) Pθy1 Pθx2 t θ1 θ2 f (x, y) P θ1 P θ2 y Röntgen CT: gefilterte Rückprojektion y Pθ Pθ 2 1 t t f (x, y) x x β1 β2 t s1 β1 s2 β2 f (x, y) Abbildung 2.4: Gleichwinklige gefächerte Projektion (equingular fanbeam projection) P θ1 P θ2 s1 y s2 Pθ 2 1 Pθ t t f (x, y) x β2 s2 β1 s1 Abbildung 2.5: Gleichräumig gefächerte Projektion (equispaced fanbeam projection) 2.3.2 Prjektion einer Bleikugel (einfaches Beispiel) Damit man eine bessere Vorstellung bekommt was eine Projektion ist und wie diese funktioniert, betrachten wir eine Bleikugel im CT (vgl. 2.6). Im Bild 2.6 wird eine Bleikugel mit Röntgenstrahlen bestrahlt. Eine Bleikugel ist ein einfaches Objekt mit homogänen Intensität und homogenen Material. Wie schon im Kapitel 1.1 bereits erwähnt, ist das Absorbtionsvermögen eines Objektes durch ihren Abschwächungskoeffizienten µ spezifiziert. Die Röntgenquelle strahlt eine Intensitäe I0 aus, die beim durchdringen der Bleikugel entlang eines Strahles s geschwächt wird. Die Abschwächung wird durch eine exponentielle Funktion modelliert [Tof96]: I(ρ, θ) = I0 e−µ1 s1 wobei s den gesamten Strahl bezeichnet. Die Röntgenstrahlen können hier als Linien angesehen werden. Jede Linie, welche durch das Objekt durchgeht kann mit zwei Parametern beschrieben werden. Der Abstand vom Ursprung zur Linie ρ und der Winkel θ relativ zu der x-Achse. s ist dann die Länge der Linie zum betrachtenden Punkt. Um den Punkt auf der Linie berechnen zu können, muß man vom xy Koodrinatensystem in das ρθ Koordinatensystem umgewandelt werden. β1 β2 f (x, y) P θ1 P θ2 s1 s2 y x t β1 β2 f (x, y) P θ1 PSfrag replacements P θ2 y s1 x s2 t θ1 θ2 f (x, y) P θ1 P θ2 y 2.3 Definition einer Projektion 23 t y ρ θ s x Röntgenquelle x t β 1 Abbildung 2.6: Projektion einer Bleikugel β2 f (x, y) P θ1 Pθ2 ρ cos θ − sin θ x (2.1) s1 = s sin θ cos θ y s2 Man ermittelt also für yjeden Punkt ρs entlang P der Linie die Abschwächung und summiert diese auf I(ρ, θ) x= I0 e−µ1 s1 = I0 e− i µi si . Somit ergibt sich die projektion des Objektes. Da die Bleikugel aus einem homogänen material besteht, entsteht t β1 als Projektion eine Halbkugel. β2 f (x, y) 2.3.3 Projektion eines Körpers (allgemein) P θ1 Der menschliche KörperPbesteht jedoch aus unterschiedlichen Materialien, wie Knoθ2 chen, Organe, Fett, Muskeln s1 etc, aus diesem Grund gibt es auch unterschiedliche Abschwächungen. s2 y Im Bild 2.7 wird ein Körper mit den Röntgenstrahlen gescannt. Der Körper ist hier nicht homogen. Es enthält unterschidliche Materialien. x t θ ρ Röntgenquelle s y ρ θ s x Röntgenquelle Abbildung 2.7: Linienintegral durch einen Körper Bild ?? zeigt drei unterschieliche Körper. Im Beispiel (a) ist die Intensität des Körpers homogen wie bei der Bleikugel θ ρ Röntgenquelle 24 Röntgen CT: gefilterte Rückprojektion (a) µ1 (b) µ1 µ2 (c) µ1 µ2 µ3µ4 µ5 µ6 s1 s2 s3 s4 s5 s6 s Abbildung 2.8: Drei unterschiedliche Körper mit Abschwächungskoeffizienten µ und der Größe s I(ρ, θ) = I0 e−µ1 s1 (2.2) Wenn es zwei unterschiedlich homogene Körper wie im Beispiel (b) sind wird die Intensität wie folgt dargestellt I(ρ, θ) = I0 e−µ1 s1 −µ2 s2 (2.3) Bei mehreren unterschiedlichen homogenen Körpern wie im Beispiel (c), werden die intensitäten aufsummiert I(ρ, θ) = I0 e− P i µi s i (2.4) Somit kann man die Projektion eines Strahles als ein Linienintegral beschreiben I(ρ, θ) = I0 e− R µ(x,yds (2.5) Mit der Formel 2.5 erhalten wir die Projektion des gescannten Körpers, können damit jedoch nicht weiter rechnen. Um mit der Projektion weiter arbeiten zu können, müssen wir erst die Grundsätze der Radon Transformation erfahren. 2.4 Radon Transformation Schon 1917 hat Johann Radon in seinem Artikel “ Über die Bestimmung von Funktionen durch Integralwerte längs gewisser Manigfaltigkeiten ” theoretisch demonstriert, dass man ein Objekt aus seiner Projektionen rekonstruieren kann. Bei der Radon Transformation geht es darum, dass man eine beliebige intergrierbare Funktion f (x, y) durch alle Linienintegrale über das Definitionsgebiet f (x, y) beschreibt. Die Projektion wird also durch die Vereinignung einer Reihe von Linienintegralen kreiert. Diese Erkenntniss bekam ihre Praktische Anwendung erst ca. 55 Jahre später. [Ber99] Die enstprechende Formel sieht wie folgt aus ǧ(ρ, θ) = Z ∞ µ (ρ cos θ − s sin θ, ρ sin θ + s cos θ) ds −∞ (2.6) 2.5 Anwendung der Radon Transformation 25 2.5 Anwendung der Radon Transformation Die Radon Transformation wird in der Mathematik für die Berechnung der Linienintegrale verwendet. Mit Hilfe der Radon Transformation kann die Projektion anscließend in ein Bild umgewandelt werden. Diese erkenntnis wurde dann seit 1973 in der Medizin angewandt. Die von uns betrachtete Integralfunktion muß nun umgewandelt werden, damit man mit der Rekonstruktion fortfahren kann. Wir betrachten erneut die Integralfunktion für die Projektion I(ρ, θ) = I0 e− R µ(x,yds (2.7) Diese muß so umgestellt werden, damit keine Exponentialfunktion mehr vorhanden ist. Erster Schritt R∞ I(ρ, θ) = I0 e− −∞ µ(x,y)ds R∞ I(ρ, θ) − −∞ µ(x,y)ds e = I0 R∞ I0 µ(x,y)ds −∞ e = I(ρ, θ) durch diese Umformung bekommen wir eine Integralfunktion Z ∞ I0 log = µ(x, y)ds I(ρ, θ) −∞ (2.8) Wie oben erwähnt muß man, um den betrachtenden Punkt auf der Linie berechnen zu können, vom xy Koordinatensystem in das ρθ Koordinatensystem umwandeln. Dies passiert mit einer Rotationsmatrix x cos θ − sin θ ρ (2.9) = y sin θ cos θ s Nachdem man die Formel 2.5 in die Formel 2.8 eingesetzt hat erhält man die Radon Transformation Z ∞ ǧ(ρ, θ) = µ (ρ cos θ − s sin θ, ρ sin θ + s cos θ) ds (2.10) −∞ Mit Hilfe der Dirac Delta Funktion kann man die Formel wie folgt schreiben ǧ(ρ, θ) = Z ∞ −∞ Z ∞ µ(x, y)δ(ρ − x cos θ − y cos θ)dxdy (2.11) −∞ Die Umwandlung mit der Dirac Delta Funktion ist deswegen von Vorteil, weil alle Werte, die außerhalb des betrachtenden Bereichs liegen mal null multipliziert und alle Wert, die betrachtet werden mal eins multipliziert. Somit werden nur relevante Werte zu Weiterverarbeitung abgespeichert. Durch die ganze Umformung sehen wir, daß man die Formel der Projektion in Form der Radon Transformation darstellen kann. Mit Hilfe der Radon Transformation kann man nun das Bild aus der Projektion rekonstruieren. 26 Röntgen CT: gefilterte Rückprojektion 2.6 Rekonstruktion Im Folgenden Abschnitt wird erklärt, welche Möglichkeiten es gibt aus den gegebenen Projektionen ein Bild zu rekonstruieren. Da die Projektionen mit Hilfe der Radon Transformation beschrieben wird, würde es nahe liegen durch die inverse Radon Transformation das Bild rekonstruieren zu können. Es gibt zwei Möglichkeiten die Radon Transformation zu invertieren. Einmal mit Hilfe des Fourier - Scheiben - Theorems (fourier slice theorem) und der gefilterten Rückprojektion (filtered backprojection). 2.6.1 Fourier-Scheiben-Theorem (fourier slice theorem) Das Fourier-Scheiben-Theorem ist eine Möglichkeit die Radontransformation zu invertieren. Die Invertierung wird mit Hilfe der 2D - Fouriertransdormation (vgl. Formel ??) durchgeführt. G(kx , ky ) = Z ∞ −∞ Z ∞ µ(x, y)e−j(kx x+ky y) dxdy (2.12) −∞ Im ersten Schritt werden die Polarkoordinaten in die Transformation eingeführt, damit man besser rechnen kann x cos θ =ν y sin θ (2.13) Die Formel wird nun mit der Dirac Delta Funktion, wie in der Formel 2.10 erklärt, optimiert G(ν cos θ, ν sin θ) = = Z Z ∞ −∞ ∞ −∞ Z Z ∞ −∞ ∞ −∞ Z Z ∞ g(x, y)δ(ρ − x cos θ − y sin θ)e −∞ ∞ −∞ −jρν dxdy dρ g(x, y)δ(ρ − x cos θ − y sin θ)dxdy e−jρν (2.14) dρ Nach dem ausmultiplizieren und vereinfachen erhalten wir dies G(ν cos θ, ν sin θ) = Z ∞ ǧ(ρ, θ)e−jρν dρ (2.15) −∞ Hier sieht man durch die Umwandlung der 2D - Fouriertransformation und einführung der Polarkoordintaen erhalten wir auf der rechten Seite die 1D Fouriertransformation der Radontransformation (vgl. Formel 2.15). Durch einführung der inversen Fouriertransformation µ(x, y) = Z ∞ −∞ Z ∞ G(kx , ky )ej(kx x+ky y) dkx dky (2.16) −∞ kann man die Radontransformation, also die Projektion, invertieren und somit das Bild rekonstruieren. Im Bild 2.9 wird es bildlich verdeutlicht. P θ1 P θ2 s1 s2 y (b) (c) µ1 µ2 µ3 x t β1 µ6 β2 s1 2.6 Rekonstruktion f (x, y) s2 P θ1 s3 P θ2 s4 t ion y ekt s5 Proj s1 s6 s2 y µ4 µ5 x t θ ρ Röntgenquelle 27 Fouriertransformation θ y x θ x Objekt s y Frequenzraum x θ ρAbbildung 2.9: Fourier Transformation Röntgenquelle Ortsraum s (a) 2.6.2 Zusammenfassung (b) (c) Körpers erhalten wir Messwerte mit einer Projektion des KörNachdem scannen eines pers. Diese Projektionµ1kann mit Hilfe der Radontransformation beschrieben werden. µ2 Hierbei nehmen wir die 2D Fouriertransformation hinzu, führen Polarkoordinaten ein, 3 und stellen fest, daß in µder geänderten Formel die 1D Fouriertransformation der Radonµ4 transformation (also Projektion) enthalten ist. Somit kann man mit Hilfe der inversen 5 Fouriertransformation µdie Radontransformation (Projektion) invertieren und erhält somit das digitale Bild. µ6 s1 s2 2.6.3 Interpolation s3 s4 Bei einer geringen anzahl von Projektionen erhalten wir in dem Frequenraum relativ s5 wenige Informationen. Im Bild 2.10 erkennt man Lücken zwischen den einzelnen s6 Bildpunkten. Die fehlende y Information wird durch eine Interpolation der benachbarten Punkte ersetzt. x t θ Projektion Objekt Ortsraum Fouriertransformation Frequenzraum y x s θ f (x, y) Projektion Abbildung 2.10: Interpolation der inversen Fourier Transformation 28 Röntgen CT: gefilterte Rückprojektion 2.6.4 Vor- und Nachteile Dieser Algorithmus ist sehr schnell, jedoch durch den ständigen wechsel zwischen Fourierraum und Ortraum kann es zu Instabilitäten und dadurch zu Verlangsamung kommen. 2.7 Gefilterte Rückprojektion (filtered backprojection) Diese Methode wird am häufigsten in den medizinischen Scannern aufgrund der numerischen Stabilität verwendet, obwohl der algorithmus etwas langsamer ist. Bei der gefilterten Rückprojektion müssen wir wieder auf die inverse Fouriertransformation zurückgraeifen (vgl. 2.17) µ(x, y) = Z ∞ −∞ Z ∞ G(kx , ky )ej(kx x+ky y) dkx dky (2.17) −∞ Wie schon bei dem Fourier Slice Theorem müssen wieder Polarkoordinat eingeführt werden, welche die bearbeitung des Algorithmus vereinfacht. Anschließend wird die Formel umgeformt. µ(x, y) = = = Z Z 2π 0 π Z Z ∞ νG(ν cos θ, ν sin θ)ej(x cos θ+y sin θ) dνdθ 0 ∞ |ν|G(ν cos θ, ν sin θ)ej(x cos θ+y sin θ) dνdθ Z ∞ Z πZ ∞Z ∞ −jρν ǧ(ρ̃, θ)e dρ̃ ej(x cos θ+y sin θ) dνdθ (2.18) |ν| 0 0 0 0 −∞ −∞ Die Formel 2.18 kann nun in 2 Teile aufgeschlüsselt werden. • Die Rückprojektion g(x, y) = Z π ǧ¯(ρ, θ)dθ 0 • Die Filterung der Rückprojektion ǧ¯(ρ, θ) = Z ∞ |ν| −∞ Z ∞ −∞ ǧ(ρ̃, θ)e−jρν dρ̃ ejρν dν 2.7.1 Rückprojektion (backprojection) Wie man in Bild 2.11 zu sehen ist wird in dem ersten Teil der sehen kann, kann man die Projektion mit Hilfe der inversen Fouriertransformation wieder in ein Bild uwandeln. Das komplette Bild wird dann wiederhergestellt in dem man um den Winkel θ alle Projektionen rückprojeziert (vgl. Bild 2.12). s2 (c) s3 µ1 s4 µ2 s5 µ3 s6 µ4 y µ5 x µ6 t s1 2.7 Gefilterte Rückprojektion (filtered backprojection) θ s2 Objekt s4 Ortsraum s5 Fouriertransformation s6 29 s Projektion s3 y y x x t s θ θProjektion f (x, y) Objekt y Pr oj ek tio n Frequenzraum f (x, y) x ProjektionOrtsraum Fouriertransformation Frequenzraum y x s θ f (x, y) Abbildung 2.11: Rückprojektion Projektion y x s f (x, y) Projektion Pθ1 y Pθ2 Pθ3 Pθ6 Pθ4 x Pθ5 Abbildung 2.12: Rückprojektion um den Winkel θ Interpolation Bei der Rückprojektion trifft der Projektionsstrahl meistens nicht auf die quadratischen Pixel. Aus diesem Grund verwendet man die Interpolation. Bei der Interpolation geht man “rückwärts” vor. Man zielt von dem Zentrum eines Pixels unter dem Winkel θ auf die Projektion. Im allgemeinen trifft man nicht auf einen Ort, an dem sich bei der Messung ein Detektor befand, somit interpoliert man linear zwischen den benachbarten Meßwerten und man addiert den Projektionswert zum betrachteten Pixel dazu. 2.7.2 Filterung Die Filterung ist nicht unbedint notwendig, verbessert jedoch die Qualität der Bilder. Diese werden weniger verrauscht. In den Bildern 2.13 und 2.14 sieht man den unterschied ganz deutlich. In diesem θ Objekt f (x, y) Ortsraum Projektion y x y s x f (x, y) Projektions yθ 30 f (x, xy) Projektion Pθ1 Pθ2 y P θ 3x Pθ4 s f (x, Pθy) 5 Projektion Pθ6 y x Pθ1 Pθ2 Pθ3 Pθ4 Pθ5 Pθ6 y x Fouriertransformation Frequenzraum Röntgen CT: gefilterte Rückprojektion y y x y x x Abbildung 2.13: Ungefilterte Projektion y y y x x x Abbildung 2.14: Gefilterte Projektion Beispiel betrachten wir eine Puntbildfunktion. Bei der ungefilterten Projektion verschmiert das Ergebnisbild. Bei der gefilterten Projektion entstehen links und rechts des Peaks negative Werte, die bei der Rückprojektion als nnegative Grauwerteïn das Bild eingetragen werden. Die negativen Werte gleichen die zuviel eingetragenen Werte rechts und links von dem Pink aus, somit entsteht ein Schärfere Bild. Die bekanntesten Filter die hierbei verwendet werden sind von Shepp und Logan und von Ramachandran und Lakshminarayanan. Weitere Informationen können in der Fachliteratur nachgelesen werden. Implementierung des Filters Bei der Implementierung des Filters entstehen jedoch Probleme. Mathematisch funktioniert das wunderbar, jedoch bei der Implementation gibt es Probleme mit der Frequenz. Aus diesem Grund muß die Projektion bandbegrenzt werden, damit das Abtastheorem eingehaltet werden kann. Dabei gibt es eine größte Frequenz. Bevor jedoch die größte Frequenz (bei einer Bandbegrenzung wird eine festgelegt) erreicht wird kann sein daß schon da das Spektrum vom rauschen dominiert wird. Dies kann nur durch eine geeignete Bandbreite verhindert werden. 2.7.3 Vor- und Nachteile Bei dieser Möglichkeit ein Bild zu rekonstruieren gibt es gravierende Vorteile. Man kann mit der Rekonstruktion schon beginnen, sobald die erste Projektion gemessen wurde, dies beschleunigt das Rekonstruktionsverfahren und reduzier die Menge an Daten. Außerdem kann die Rekonstruktion parallelisiert werden. Das heißt es können hierbei auch mehrere Prozesse bzw. Rechner parallel die Rekonstruktion verarbeiten. Literaturverzeichnis [Ber99] Roland Berger. Moderne bildgebende Verfahren der medizinischen Diagnostik - Ein Weg zu interessanterem Physikuntericht. Logos Verlag Berlin, 1999. [Feu02] Johannes Feulner. Facharbeit: http://www.feulnercaps.de/Facharbeit/Facharbeit.pdf. Technical report, 2002. Tomographie mit Röntgenstrahlen und Bau eines Computertomographen. [KS88] A.C. Kak and Malcolm Slaney. Principles of Computerized Tomographic Imaging. IEEE Press, 1988. Eine elektronische Kopie findet man unter: http://slaney.org/pct/pct-toc.html. [SHJ88] J.L.C. Sanz, E.B. Hinkle, and A.K. Jain. Radon and Projection TransformBased Computer Vision. Springer Series in Information sciences, 1988. [Tof96] Peter Toft. The Radon Transform - Theory and implementation. Ph.D. thesis. Department of Mathematical Modelling, Technical University of Denmark, 1996. Eine elektronische Kopie findet man unter: http://pto.linux.dk/PhD/. 32 LITERATURVERZEICHNIS Kapitel 3 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter Diana Wald 22.Mai 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼ladydie 34 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter 3.1 Einleitung Seit dem man versucht, die Umwelt zu reflektieren, Informationen darüber zu sammeln, auszutauschen und zu verarbeiten steht man vor einem fundamentalen Problem: Die Unzulänglichkeit und Fehleranfälligkeit aller künstlich erschaffenen Modelle und Darstellungsformen. Moderne Untersuchungsmethoden in der Medizin liefern vielfach Daten in Form von 2- und 3D Bildern. Beispiele solcher Verfahren sind die Röntgenaufnahmen, Ultraschallbilder, CT oder MRI (s. Kapitel [Wür03]). In der Regel sind die gewonnenen Daten fehlerbehaftet. Es ensteht das Problem, aus den beobachteten Bildern, die wesentliche, zugrunde liegende Struktur herauszufiltern. Der Grund für die Fehleranfälligkeit liegt darin, dass in der digitalen Bildverarbeitung eine Vielzahl von möglichen Störquellen die Korrektheit der aufgenommenen Informationen gefährden. Ein Teil dieser Störungen wird durch die Natur des Aufnahmeprozesses selbst verursacht (z.B. durch Ablenkung, Absorption und Interferenzen von Röntgenstrahlen). Andere Ursachen liegen in der Unzulänglichkeit des aufnehmenden Systems (z.B. Linsenfehler oder eine unzureichende Auflösung bei der Bilddigitalisierung). Außerdem können noch andere Störungen auftreten wie z.B. Verwacklung bei der Bildaufnahme. Die Frage ist, was kann man tun wenn eine solche fehlerhafte Version vorliegt? Die Lösung, man versucht die im Bild vorhandenen Informationen dahingegend zu nutzen eine möglichst genaue Abschätzung des Originalbildes zu leisten. Für diesen Vorgang, der in der Bildverarbeitung als Filterung bezeichnet wird, wurden in den letzen Jahren zahlreiche Ansätze entwickelt. In dieser Arbeit wird besonders auf den adaptiven Wiener und den anisotropischen adaptiven Filter eingegangen. 3.2 Bildaufnahmeprozess Der Bildaufnahmeprozess kann in zwei Schritte gegliedert werden. Einmal der Weg zum digitalisierten Bild und anschließend die Weiterverarbeitung durch einen Filter. Diese beiden Schritte werden kurz erläutert, da sie zum Verständnis der Filterung beitragen. 3.2.1 Der Weg zum digitalisierten Bild Als Eingabe dient ein Objekt aus der natürlichen Umgebung. Dieses Objekt wird durch ein optisches System (Kamara, Linse etc.) zur digitalen Verarbeitung aufgenommen und liegt als 2D Bild vor (Bildaufnahme ). An dieser Stelle können bereits erste Beeinträchtigungen des Bildes auftreten (z.B. Verwischen, Bewegung). Das optisch aufgenommene Bild wird digitalisiert. Das bedeutet, die in analoger Form vorliegenden Informationen werden in digitale Daten umgesetzt. Dieser Prozess lässt sich in zwei Schritten modellieren. Zuerst wird, aufgrund des CCD Chips, ein Raster der Größe N x M über das Bild gelegt. Dessen Größe hängt von der gewünschten Detailierung bzw. Auflösung ab (Abtastung ). Anschließend wird für jedes der N x M Rasterflächenstücke ein digital codierter Wert eingetragen, der die gemessene (Licht-)Intensität des Originalbildes innerhalb des Stückes repräsentiert (Quantisierung ). Zu dem digitalisierten Bild wird ein Rauschen addiert. Das Rauschen kann durch die Digitalisierung und aus externen Faktoren entstanden sein. Wir nehmen ein additives Rausch Modell an. Als Ausgabe erhalten wir ein verrauschtes Bild g. Dieses Bild liegt als N x M - Matrix 3.3 Filter 35 PSfrag replacements im Rechner für die Bearbeitung vor. Es gilt g = f + n. Das Bild 3.1 schildert den Entstehungsprozess. 3D - Welt Bildaufnahme 2D - Bild Digitalisierung + verrauschtes Bild g Rauschen externe Faktoren n Abbildung 3.1: Prozess der Bildentstehung mit Integration von Rauschen Wobei das Ideale Bild f das aufzunehmende Objekt ist. Dieses Objekt könnte z.B. ein Teil der Erdoberfläche sein, die von der Kamera aufgenommen wird. Das bedeutet also, f ist das Originalbild, welches kein Rauschen bzw. keine Fehler enthält. 3.2.2 Die Weiterverarbeitung durch einen Filter Als Eingabe erhält man das digitalisierte Bild g, dass als Grundlage für die Weiterverarbeitung dient. Das Bild g wird nun mit einem Filter bearbeitet. Wie der Filter funktioniert und aus welchen Komponenten er sich im Einzelnen zusammensetzt, hängt von der gewählten Methode ab. Durch die Anwendung des Filters auf das digitalisierte Bild g erhält man als Ergebnis eine Abschätzung. Diese Abschätzung stellt das verbesserte PSfrag replacements Bild fˆ dar, wobei die Schätzung die ideale Information f annähert, sprich fˆ → f . Das Bild 3.2 schildert die Weiterverarbeitung. verrauschtes Bild Filter g h verbessertes Bild fˆ Abbildung 3.2: Prozess der Weiterverarbeitung durch Filterung 3.3 Filter Filter sind Verfahren die ein Bild in ein Bild transformieren. Digitale Filter gehören zu den wirkungsvollsten Verfahren der Bildverarbeitung. Wir können damit relevante Inhalte hervorheben, Störungen beseitigen und visuelle Beurteilung erleichtern. Das Ziel von Filtern ist, die digitalen Bilder zu verbessern ohne dabei wichtige Informationen zu verlieren. Es gibt verschiedene Arten von Filter [Pau03]. 3.3.1 Lineare Filter: Lineare Filter verwenden eine Maske mit Gewichtsfaktoren. Die Maske berechnet zu jedem Bildpunkt eine Linearkombination aus den Gewichtsfaktoren und den Pixelwerten in der Umgebung des Quell-Punktes. Wenn die Filtermaske für alle Bildpunkte gleich bleibt, spricht man von einem homogenen Filter. Mathematisch ist ein linearer 36 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter Filter im Ortsraum eine Faltung des Bildes g mit einer Maske h (fˆ = h ∗ g) Beispiel: Mittelwertfilter, Tief- und Hochpassfilter, Wiener Filter. 3.3.2 Nichtlineare Filter Nichtlineare Filter lassen sich nicht als Faltung beschreiben. Die Beschreibung besteht aus verschiedenen deterministische oder statistische Verfahren. Nichtlineare Filter ermöglichen häufig gegenüber linearen Filtern eine Verarbeitung bei deutlich gesteigerter Bildqualität. Beispiel: Medianfilter, Morphologische Filter, anisotropischer adaptiver Filter. 3.3.3 Adaptive Filter Bei adaptiven Filtern ist das Ergebnis der Filteroperation abhängig von der Umgebung der Pixel. Adaptive Filter können das Rauschen in Bildern verringern, ohne andere Bildinformationen zu verwischen, d.h. die Kanten bleiben im Bild erhalten. Man kann auch sagen, ein adaptiver Filter passt seine Impulsantwort dem Signal an. Deswegen kann man ihn auch Anpassungsfähigen Filter nennen. 3.4 Wiener Filter Der Wiener Filter wurde nach dem Mathematiker und Kybernetiker Norbert Wiener (1894 - 1964) benannt. Er gehört zu den am häufigsten, bei der Bildverarbeitung, verwendeten Klassen der Linearen Filter. Die Eigenschaften des Wiener Filters sind: optische Bildverbesserung basierend auf dem stochastischen Mittel. Der Filter ist effizient gegen jegliche Art von Bildstörungen wie z.B. verwischen, Rauschen oder Verzerrung. Der Wiener Filter arbeitet im Fourierraum, da dort der Rechenaufwand niedriger ist. 3.4.1 Mathematische Herleitung Bei der mathematischen Herleitung des Wiener Filters arbeiten wir im eindimensionalen Signalraum. Der Ansatz für die mathematische Herleitung, ist die Faltung des Bildes g mit einer Maske h: fˆ = h ∗ g (3.1) Das Problem dabei ist, der Filter h (in unserem Beispiel der Wiener Filter) ist unbekannt. Das heißt, man muss einen Rechenweg finden der h errechnet. Die Idee für den Wiener Filter ist, den Fehler zwischen dem Originalbild f und dem gefilterten Bild fˆ zu minimieren. Dies geschieht durch die Minimierung des Erwartungswert vom quadratischen Abstandes zwischen f und fˆ zu jedem diskreten Zeitpunkt, k ≥ 0. E(fˆ(k) − f (k))2 → min für alle k≥0 (3.2) Bei der mathematischen Herleitung des Wiener Filters wird wie folgt vorgegangen. Zuerst wird der Erwartungswert umgeformt und nach h(i) abgeleitet, wobei h(i) der Wiener Filter h im Zeitraum an einer bestimmten Stelle i ist. Anschließend wird die Ableitung auf null gesetzt (Minimierungsanforderung) und eingesetzt, so dass man den Filter h bzw. deren Fouriertransformierte H erhält. Unser Ziel ist es, h zu errechnen so das fˆ (k) → f (k) ∀k ≥ 0 gilt. 3.4 Wiener Filter 37 Erwartungswert Bei der Umformung des Erwartungswertes, sei A der Erwartungswert. A = E(fˆ(k) − f (k))2 ,∀k ≥ 0 (3.3) ˆ = g(k) ∗ h(k) ist, kann man die Gleichung auch als da f(k) E(g(k) ∗ h(k) − f (k))2 ,∀k ≥ 0 (3.4) schreiben. Ausgehend vonP der Formel der diskreten Faltung 1 folgt: =∞ g(k) ∗ h(k) = =−∞ g(k − )h(). Setzt man dieses in die Gleichung(3.4) ein, so erhält man den umgeformten Erwartungswert in der Gleichung(3.5) E( =∞ X g(k − )h() − f (k))2 (3.5) =−∞ Bei der Ableitung des Erwartungswertes wird nach h(i) abgeleitet, wobei i in dem Fall eine Laufvariable über die diskreten Stellen der Funktion ist. Das bedeutet, für die d(A) und wird wie folgt berechnet. mathematische Schreibweise gilt d(h(i)) P=∞ d E{( =−∞ g(k − )h() − f (k))2 } d(A) = d(h(i)) d(h(i)) (3.6) Die allgemeine Ableitungsregel solcher Funktionen lautet [a(b(e)) n ]0 = na(b(e))n−1 d(b(e)) de , P=∞ 2 wobei a = b , b = =−∞ g(k − )h() − f (k))2 und e = h(i) ist. Damit ergibt sich für die Ableitung von A, unter Berücksichtigung der Eigenschaft vom Erwartungswert, folgende Gleichung: E{2 " =∞ X =−∞ # g(k − )h() − f (k) g(k − i)} (3.7) wobei g(k−i) die Ableitung von d(b(e)) darstellt. Dies berechnet sich folgendermaßen: de Die Summe wird aufgelöst und man wählt den Faktor der von h(i) Pabhängig ist. Im vorliegenden Fall ist dies g(k − i), denn aus der Summe folgt: = · · · + g(k + 2)h(2) + g(k + 1)h(1) + g(k)h(0) + · · · + g(k − i)h(i) + · · · . Die Gleichung aus (3.7) kann man wie folgt umstellen: 2E{ = 2E{ =∞ X g(k − )h()g(k − i) − f (k)g(k − i)} = =−∞ =∞ X (g(k − )g(k − i))h()} − 2E{f (k)g(k − i)} =−∞ R kontinuierlich: g(t) ∗ h(t) = ∞ −∞ g(τ )h(t − τ )dτ P=∞ diskret: g(k) ∗ h(k) = =−∞ g(k − )h() 1 Faltung: (3.8) 38 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter Gleichung(3.8) beinhaltet die Ausdrücke g(k − )g(k − i) und f (k)g(k − i), die nichts anderes sind als die Autokorrelation 2 vom Signal g: ϕgg und die Kreuzkorrelation von den Signalen f und g : ϕgf . Dadurch ergibt sich die Gleichung(3.9) 2 =∞ X ϕgg ( − i)h() − 2ϕgf (−i) (3.9) =−∞ Aufgrund der Kommutativität der Korrelations Gleichung folgt: 2 =∞ X ϕgg (i − )h() − 2ϕgf (i) (3.10) =−∞ Wenn man die Gleichung(3.10) genauer betrachtet, erkennt man die diskrete Faltungsgleichung in der Formel wieder. 2{ϕgg (i) ∗ h(i) − ϕgf (i)} (3.11) In Gleichung(3.11) ist der Ableitungsprozess an einer bestimmten Stelle i abgeschlossen. Minimierungsanforderung Um den Minimierungsanforderungen gerecht zu werden, wird die Ableitung gleich null gesetzt. 2{ϕgg (i) ∗ h(i) − ϕgf (i)} = 0 ϕgg (i) ∗ h(i) = ϕgf (i) (3.12) Da eine Faltung nicht ausmultiplizierbar ist, wechselt man in den Fourierraum, um dort nach dem Filter H auflösen zu können. Φgg (w)H(w) H(w) = Φgf (w) Φgf (w) = Φgg (w) (3.13) wobei w für die Frequenz im Fourierraum steht. 2 Korrelation: Korrelation basiert auf zwei Signalen. Sie errechnet die lineare Abhängigkeit zu einander. Das heißt ϕ = 1 → maximale abhängigkeit und ϕ = 0 → keine Korrelation (nicht linear abhängig, sie können dennoch statistisch abhängig sein) Autokorrelation: Signal wird mit sich selbst verglichen, in dem es, unter allen möglichen verschiebungen, mit sich selbst multipliziert wird. ϕxx (t) = E{X(τ )X(τ + t)} Kreuzkorrelation: Zwei unterschiedliche Signale werden mit einander verglichen ϕ xy (t) = E {X(τ )Y (τ + t)} {z } | τ +t−τ =t 3.4 Wiener Filter 39 Umrechnungen Zur Erinnerung, das verrauschte Bild g entsteht aus der Addition des optimalen Bildes f und dem additiven Rauschen n, so das gilt g = f + n bzw. deren Fouriertransformierte G = F + N . Um H berechnen zu können, muss man die unbekannten Φ gf (f ) und Φgg (f ) mit Hilfe der Korrelation umformen bzw. ersetzen. Φgf = GF = (F + N )F = F F + N F = Φf f Φgg = (F + N )(F + N ) = F F + N N + F N + N F = Φf f + Φnn Φf f = Φgg − Φnn (3.14) (3.15) (3.16) wobei man annimmt, dass N F und F N statistisch unabhängig sind. Das bedeutet wieder rum, sie sind unkorreliert und werden gleich 0 gesetzt. Außerdem steht F für konjungiert und d.h. das Vorzeichen des imaginären Teils wird umgekehrt. Frequenzantwort des Wiener Filters Setzt man die Umformungen aus 3.4.1 in H ein, so erhält man die Frequenzantwort des Wiener Filters: Φgf Φf f Φgg − Φnn = = Φgg Φgg Φgg Φnn (3.17) H =1− Φgg Wenn Φnn = 0 ist, d.h. wenn keine Störungen vorhanden sind, dann lässt der Filter alle Signale, ohne diese zu verarbeiten, durch. Wenn aber Φ nn sehr groß ist, d.h. das Rauschen ist an dieser Stelle sehr stark vorhanden, dann tendiert H gegen 0 und das Signal wird nicht durchgelassen. H= Rechenvorschrift für F̂ Abschließend erhält man folgende Rechenvorschrift, um aus dem Digitalbild, mittels klassischer Wiener Filterung, das gefilterte Bild zu errechnen: F̂ = H ∗ G = (1 − Φnn )∗G Φgg (3.18) Hier ist es wichtig zu erläutern, dass n für das gesamte Bild abgeschätzt wird. Das bedeutet, der Wiener Filter ist hier ein homogener Filter. 3.4.2 Adaptiver Wiener Filter Die meisten Rauschfilter beruhen auf einem Glättungsverfahren. Dabei wird neben dem Rauschen auch Kanten, Linien oder selbst kleine Details geglättet. Wenn dann z.B. auf ein gefiltertes Bild später eine Kantensegmentierung angewendet werden soll, so bereitet die durch die Glättung verloren gegangenen Bildinformation erhebliche Schwierigkeiten. Der Hauptgrund für das verwischen ist, dass ein homogener Filter für das gesamte Bild verwendet wird. Das heißt, der Filter ist unveränderlich. Eine Lösung wäre, die Stärke der Filterung an die lokalen Bildgegebenheiten zu adaptieren bzw. anpassen. Es gibt mehrere Möglichkeiten um den Wiener Filter zu erweitern. Hier wurde sich nur auf den adaptiven Wiener Filter per lokale Anpassung beschränkt. 40 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter Lokale Anpassung Der Wiener Filter beschreibt einen unveränderlichen Filter, der für das gesamte Bild verwendet wird. Ein Weg, den Filter flexibel zu machen ist, man verwendet eine lokale Variable für den Rauschparameter n H =1− Φnn (x) Φgg (3.19) PSfrag replacements Hier wird n an jeder Stelle x abgeschätzt (= addaptiv). Das Problem hierbei ist jedoch, dass die Berechnung sehr kostspielig ist, da sich der Filter von Pixel zu Pixel verändert. 3.4.3 Schema des Wiener Filters Die nachfolgende Abbildung zeigt noch einmal abschließend das komplette Schema von der Verarbeitung des Wiener Filters. Impulsantwort unbekannte Impulsantwort Autokorrelation des verrauschten Bildes Φgg von g bestimmen h Rauschanalyse Digitalbild Rauschen n aus dem Digitalbild extrahieren Digitalbild g g n Φgg FT FT FT Frequenzantwort des Wiener Filters bestimmen Φnn G x F̂ H IFT fˆ FT = Fouriertransformation IFT = Inverse FT 3.4.4 Beispiel Zum Abschluß wird der Effekt des Wiener Filters, anhand eines Beispieles noch einmal verdeutlicht. Beispiel anhand eines Bildes Als Eingabe erhalten wir ein verrauschtes Bild g (1.Abbildung). Da wir im Frequenz Bereich arbeiten, benötigen wir das Spektrum des Bildes g (siehe Abbildung 2.). Anschließend berechnen wir, nach der Beschreibung aus Abschnit 3.4.1, den Wiener Filter (3. Abbildung) und multiplizieren diesen mit dem Spektrum des Bildes g (4. Abbildung). Transformiert man dieses Spektrum zurück, so erhält man das verbesserte Bild fˆ (5. Abbildung). Wenn man dieses mit dem Originalbild f , bzw. mit dem Ausgangsbild vergleicht, erkennt man die Wirkungsweise des Wiener Filters. 3.5 Anisotropischer adaptiver Filter 1. verrauschtes Bild g 2. Spektrum des Bildes g 4. multiplikation zwischen g und H 5. gefiltertes Bild fˆ 41 3. Frequenzantwort des Wiener Filters H 6. Originalbild f Beispiel aus der Elektrotechnik Der Wiener Filter stammt ursprünglich aus der Elektrotechnik. Im Internet existiert ein Beispiel für den Wiener Filter, das die Arbeitsweise mittels Geräuschen verdeutlicht. Bei diesem Beispiel kann man hören und auch sehen, dass der Filter sich von Geräusch zu Geräusch oder Rauschstärke verändert. Das Beispiel ist auf der Internetseite http://www.nt.e-technik.uni-erlangen.de/∼rabe/SYSTOOL/SYSTOOL2.02/HTTP/wien.htm zu finden. 3.5 Anisotropischer adaptiver Filter Anisotrop bedeutet, nicht in alle Richtungen hin gleiche Eigenschaften aufweisend. Der Anisotropische adaptive Filter gehört zu der Filterklasse der nicht linearen Filter. Der Filter ist entwickelt worden, um ein Bild zu glätten bzw. seine hochfrequenten Störungen zu entfernen. Sein Interesse liegt jedoch im Erhalt der Struktur. Der anisotropischen adaptiven Filter wird anhand von mehreren Beispielen visualisiert bzw. seine Wirkung erklärt. Auf die mathematische Herleitung wird nicht eingangen. 3.5.1 Eigenschaften Der Anisotropische Filter entzieht den Informationen das Rauschen ohne dabei die Struktur im Bild zu zerstören. Nebenbei hat er noch die Eigentschaft, kleine Gegenstandsunstimmigkeiten bzw. kleine Details zu schärfen. Der Filter hat also die Fähigkeit, Kanten bzw. Ränder im Bild zu erkennen und kann somit dort eine Filterung verhindern. Das hat dann zur Folge, dass die Gefahr der Kantenverschemmung verhindert wird. Durch die Arbeitsweise des Filter, dessen Eigenschaften in alle Richtungen hin unterschiedlich sind, ist es möglich die Filterung in die eine Richtung (orthogonal zu den Kanten) durchzuführen bzw. zu glätten und andererseits in die andere Richtung (entlang Kanten) diese Glättung zu verhindern. 42 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter 3.5.2 Beispiele Wie schon erwähnt, wird in dieser Ausarbeitung der anisotropischen Filter anhand mehreren Beispielen erklärt. Kantenerhaltung Bei diesem Beispiel, wird das Prinzip der Kantenerhaltung visualisiert. Man sieht, dass der linke Filter die Kante glättet. Das heißt die Sequenz wird bei der Kante abgerundet. Da hingegen, spürt der rechte Filter, der nichtlineare Filter, die Kante auf und verschärft diese dazu. Die Sequenz wird zu einer eindeutigen Kante. Filter der eine Kante glättet nichtlinearen Filter, der eine Kante aufspürt Wobei die durchgezogene Linie die Sequenz des Ausgangsbildes und die gestrichelte Linie die Sequenz des gefiltereten Bildes ist. Kantenerkennung In diesem Beispiel wird gezeigen, das man den anisotropischen adaptiven Filter so anpassen kann, das er bestimmte Bereiche aus einem Bild erkennen kann. Wir haben als Eingabe ein MRI Bild von einem Schädelinneren (Bild 1). Wir möchten den Filter so anpassen, dass er das Gehirngewebe bzw. deren Ränder und Kanten aufspürt. Bei dem ersten Durchlauf (Bild 2) scheint der Filter das Gehirngewebe aufzuspüren, jedoch ist das Ergebnis noch nicht zufriedenstellend. Durch Wiederholungen und Anpassungen des Filters bzw. Anpassung deren Konstante, erreichen wir in Bild 3 das der Filter das Gehirngewebe erkennt. In Bild 4 erhalten wir ein optimales Ergebnis. Durch das Aufspüren, verhindert der Filter dort eine Glättung und es sind weitere Verarbeitungen (z.B. Segmentierung) möglich. Bild 1 Bild 2 Bild 3 Bild 4 3.6 Schlusswort 43 Kontrasterhöhung Als Eingabe erhalten wir ein MRI Bild der Kopfes (links). Über dieses kontrastarme Bild werden wir den anisotropischen Filter anwenden. Als Ergebnis erhalten wir das Bild rechts. Man sieht den Unterschied beider Bilder sofort. Das rechte Bild hat einen deutlich höheren Kontrast. Vorallem werden die kleinen Details am Halswirbel besser erkennbar. Links: Originales Bild. Rechts: gefiltertes Bild Rauschentfernung und Kantenerhaltung Als Eingabe haben wir ein Ultraschallbild des Herzens. Man sieht, dass das Originalbild (oben), stark verrauscht ist. Das untere Bild ist das gefilterte Bild. Das Rauschen wurde komplett entfernt, wobei die Konturen ihren Kontrast und Schärfe beibehalten, nicht sogar verschärft haben. Oben: Originale Bildreihenfolge. Unten: Ergebnis nach der Filterrung 3.6 Schlusswort Wir haben erfahren, das dem Mediziner, für eine Diagnose, eine Reihe von bildgebenden Verfahren zur Verfügung steht. Diese Geräte erzeugen Bilder vom Menschen, die es erlauben, sie von innen zu betrachten (siehe Kapitel [Wür03]). Leider wissen wir 44 Vorverarbeitung: adaptive Wiener Filter und anisotropische adaptive Filter auch, dass derartiges Bildmaterial nicht immer so klar ist, wie man es sich wünscht. Es befinden sich in den erzeugten Bildern oft Störungen verschiedenen Ursprungs. Jedoch ist es für den Mediziner besonders wichtig, dass das vorliegende Bild möglichst gut das tatsächlich aufgenommene Objekt repräsentiert. In vielen Fällen passiert es nämlich, dass das bildgebende System Strukturen erzeugt, und somit das resultierende Bild vom realen Objekt abweicht. Außerdem treten oft Störungen in Form von Unschärfe oder Rauschen im Bildmaterial auf. All dies gilt zu vermeiden bzw. nachträglich zu entfernen oder zu mindern, da sonst falsche Diagnosen von dem Mediziner erstellt werden können. Deswegen ist es sehr wichtig, das Verfahren entwickelt werden, die diese Störungen so perfekt wie es geht entfernt, ohne dabei die Struktur des Bildes zu verändern. In meiner Arbeit, wurden zwei solcher Verfahren vorgestellt, den adaptiven Wiener (Kapitel 3.4) sowie den anisotropischen adaptiven Filter (Kapitel 3.5). Die Effektivität beider Filter wurde anhand zahlreicher Beispiele gezeigt. Durch solche Verfahren, wird dem Mediziner die Diagnose vereinfacht und Fehldiagnosen verhindert. Das bedeutet also, die Bildverarbeitung ist nicht nur in der Informatik sondern auch im Bereich der Medizin ein nicht mehr weg zu denkendes Element. Aus diesem Grund wird die Forschung nach neuen Bildverarbeitungs-Verfahren immer weiter gehen. Literaturverzeichnis [Ban02] L.N. Bankman. Handbook of Medical Imaging Processing and Analysis. academic Press series in Biomedical Engeneering, 2002. [GM00] M.Hofbauer G. Moschytz. Adaptive Filter. Springer, Berlin, Heidelberg, 2000. [Ham87] Richard W. Hamming. Digitale Filter. VCH, 1987. [Neu72] Edgar Neuburger. Einführung in die Theorie des linearen Optimalfiters. R. Oldenbourg München Wien, 1972. [Neu98] Eschmann Neunzert. Analysis 1 + 2. Springer, 3.auflage edition, 1998. [Pau03] D. Paulus. Vorlesung bildverarbeitung, 2003. Computervisualistik. [Wür03] Verena Würbel. Bildgebende verfahren. Technical report, Universität Koblenz, 2003. Hauptseminar: Medizinische Bildverarbeitung. 46 LITERATURVERZEICHNIS Kapitel 4 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen Natalie Menk 05. Juni 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼nmenk 48 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen 4.1 Motivation Modellfreie Segmentierungsverfahren wie zum Beispiel Schwellwertverfahren, Regionenwachstum, Kantendetektion oder morphologische Operatoren sind teilweise sehr zeitaufwändig, wenn man nur bestimmte Objekte im Bild segmentieren will. Deformierbare Modelle liefern hier schnellere Ergebnisse und bieten außerdem die Möglichkeit zur Automatisierung der Segmentierung. In der medizinischen Bildverarbeitung liegen oft mit Artefakten wie zum Beispiel Rauschen oder Lücken behaftete Bilder vor. Deformierbare Modelle eignen sich zur Segmentierung dieser Bilder. Die bekanntesten unter den deformierbaren Modellen sind Snakes. Sie sind planare deformierbare Kurven, die dazu benutzt werden, Objektgrenzen in Bildern zu finden. Snakes zählen zu den energieminimierenden deformierbaren Modellen. Abbildung 4.1: Snake (weiß) eine Zellwand segmentierend. [MT96] 4.2 Das klassische Snake-Modell [MT02] 4.2.1 Mathematische Grundlagen Eine Snake ist, geometrisch gesehen, eine parametrisierte Kurve in R 2 . Die Kontur wird durch v(s) = ((x(s), y(s))T repräsentiert, wobei x und y die Koordinatenfunktion und s ∈ [0, 1] ist. Die Form der Kurve wird durch ihre Energie beschrieben: Esnake (v) = Einnen (v) + Eauen (v) (4.1) Die Energie der Snake ist also eine Zusammensetzung ihrer inneren und äußeren Energie. Während die innere Energie eine Kraft in Richtung Konturzentrum ausübt, zeigt die externe Energie vom Objektzentrum weg. Innere Bedingungen (wie z.B. die erste Ableitung) lassen sich aus der Kontur selbst ableiten und repräsentieren a-priori Information über den Verlauf und das Aussehen der gesuchten Objektkontur. Die am häufigsten verwendete Funktion für die innere Energie lautet: 2 2 2 Z 1 ∂ v ∂v (4.2) Einnen (v) = w1 (s) + w2 (s) 2 ds ∂s ∂s 0 4.2 Das klassische Snake-Modell 49 2 ∂ v Dabei ist ∂v ∂s die erste und ∂s2 die zweite partielle Ableitung nach s. Durch eine unterschiedliche Festlegung der Parameter w1 und w2 , kann man die Ausprägung der Krümmungen oder der Glattheit der Kurve bestimmen: Wenn w1 (s) erhöht wird, ist die Spannung der Kurve größer; große Schleifen und Auswölbungen werden eliminiert, indem die Länge der Snake reduziert wird. Somit können Ecken und starke Krümmungen sehr gut segmentiert werden. Erhöht man hingegen w2 (s), wird damit die Starrheit erhöht. Die Kontur wird stärker geglättet und ist weniger flexibel d.h. glatte Strukturen werden besser segmentiert. Der zweite Term in (1) repräsentiert die externe Energie: Abbildung 4.2: Links: w1 (s) > w2 (s). Ecken und starke Krümmungen können sehr gut segmentiert werden. Rechts: w2 (s) > w1 (s). Glattere Strukturen werden besser segmentiert. Eauen (v) = Z 1 (P (v(s))ds (4.3) 0 P (x, y) ist eine skalare Potentialfunktion, die vom Benutzer gewählt werden muss. Die Definition dieser Potentialfunktion ist abhängig von den Bildeigenschaften, die von der parametrisierten Kontur erkannt werden sollen, da die externe Energie zur Führung durch die Punkte, die Bestandteile von Kanten sind, dient. Bei der Wahl wird also der Bildinhalt, wie beispielsweise die Gradientenstärke, berücksichtigt. Sehr häufig wählt man P (x, y) = −c|∇[Gσ ∗ I(x, y)]|. Durch Faltung des Bildes I(x, y) mit einem Gaußfilter Gσ wird das in medizinischen Bildern oft vorhandene Rauschen reduziert. Mit der Konstante c wird die Größe der Potentialfunktion kontrolliert. 4.2.2 Energieminimierungsverfahren Die Form der Snake ist gefunden, wenn die Gesamtenergie der Snake minimiert ist. Im folgenden werden 2 Methoden zur Energieminimierung vorgestellt: Die erste stammt aus der Physik, während die zweite eher heuristisch ist. Euler-Lagrange Gleichung [MT02] Die Funktion der Gesamtenergie der Snake lautet zusammengefasst: Esnake (v) = Z |0 1 2 2 2 Z 1 Z 1 ∂ v ∂v (P (v(s))ds = w1 (s) + w2 (s) 2 ds + F (s, v, v 0 , v 00 )ds ∂s ∂s 0 0 {z } | {z } {z } | interneEnergie externeEnergie Gesamtenergie 50 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen Dabei ist v 0 die erste Ableitung und v 00 die zweite Ableitung. Die Gesamtenergie gilt es nun durch Auffinden eines globalen Enegieminimums für die aktive Kontur zu minimieren. Eine Methode zur Energieminimierung ist die Verwendung der aus der Physik stammenden Euler-Lagrange Gleichung: − ∂ 2 ∂F ∂F ∂ ∂F ( 0 ) + 2 ( 00 ) + =0 ∂s ∂v ∂s ∂v ∂v Einsetztung der Funktion für die Gesamtenergie der Snake ergibt: ∂ ∂2v ∂v ∂2 − w1 + 2 w2 2 + ∇P (v(s, t)) = 0 ∂s ∂s ∂s ∂s (4.4) (4.5) Da die Kontur v(s), welche die Gesamtenergie Esnake (v) minimiert, gesucht ist, wird diese Gleichung durch numerische Algorithmen zur Lösung von Differentialgleichungen nach v(s) aufgelöst. (Siehe [MT02], [Coh91], [MT96].) Greedy-Algorithmus Ein Greedy-Algorithmus kann immer dann verwendet werden, wenn es um ein Optimierungsproblem geht; es soll sukzessiv eine optimale Lösung gefunden werden. Der Name Greedy=gefräßig erklärt sich dadurch, dass ein Greedy-Algorithmus nach der Methode ’Nimm immer das größte Stück’ vorgeht. Der im folgenden gezeigte Greedy-Algorithmus ist ein iterativer Ansatz zur Energieminimierung und wurde erstmals von [WS90] vorgestellt. Hier wird immer ’das kleinste Stück’, also die kleinste Energie genommen, da die Energie minimiert werden soll. Greedy Algorithmus: • Zuerst initialisiert der Benutzer die Snake, indem er n Konturpunkte nahe an der zu segmentierenden Struktur manuell auswählt. Die Kontur ist geschlossen, wenn v(o) = v(1). v1 PSfrag replacementsv(0) = v(1) v2 v0 = v n vn−1 Abbildung 4.3: Initialisierung einer geschlossenen Kontur • Als nächstes wird die Energie des ersten Konturpunktes v0 und dessen acht Nachbarpixeln berechnet. Der erste Konturpunkt v0 wird auf die Koordinaten des Pixels mit der niedrigsten Energie gesetzt. Mit den anderen Konturpunkten v1 bis vn verfährt man genauso. Das heißt: Von jedem Konturpunkt v i , i ∈ [1, n] wird seine Energie und jeweils die Energie seiner 8 Nachberpixel berechnet und dort wo von diesen Pixeln die Energie am niedrigsten ist, setzt man die neue Position des Konturpunktes vi . 4.2 Das klassische Snake-Modell 51 • Durch die Berechnung von vn wird die Position des ersten Konturpunktes v0 nochmals ermittelt, da v0 = vn . Dies ist notwendig, da bei der ersten Berechnung die alte Position des Konturpunktes vn−1 miteingeflossen ist. Nachdem die Koordinaten des Konturpunktes vn ermittelt wurden, ist der erste Iterationsschritt beendet. • Diese Positionsberechnung der einzelnen Konturpunkte wird solange wiederholt, bis eine vorgegebene Anzahl von Punkten ihre Position nicht mehr ändert. Ein Abbruch nach n Iterationsschritten ist auch möglich, garantiert aber nicht immer eine optimale Energieminimierung der Snake. Abbildung 4.4: Energieminimierung durch Greedy-Algorithmus. Leider führt der Greedy-Algorithmus nicht immer zu einer optimalen Lösung. Er liefert aber dennoch in der Praxis häufig gute Ergebnisse. 4.2.3 Dynamisch deformierbare Modelle [MT02] Bisher wurden hier nur statische Snakes vorgestellt. Es ist jedoch sinnvoll ein dynamisches System, welches in den Gleichgewichtszustand streben kann, zu betrachten. Bei dynamisch deformierbaren Modellen wird auch die Formentwicklung im Laufe der Zeit berücksichtigt. Dazu wird ein weiterer Parameter t für die Zeit eingeführt. Die parametrische Darstellung der zeitvariierenden Kontur lautet nun: v(s, t) = ((x(s, t), y(s, t))T . Zusätzlich wird eine Masse µ(s) der Snake und eine Dämpfungskraft γ(s) verwendet, um ein realistischeres physikalisches Verhalten der Snake zu erhalten. Neu zu der Euler-Lagrange Gleichung (5) kommen also die erste und die zweite partielle Ableitung nach t, eine Masse µ(s) und eine Dämpfungskraft γ(s). Dies ergibt die Lagrange-Bewegungsgleichung: ∂v ∂ ∂ 2v ∂v ∂2 ∂2v − µ 2 +γ w1 + 2 w2 2 = −∇P (v(s, t)) (4.6) ∂t ∂t ∂s ∂s ∂s ∂s Gesucht ist hier die Snake v(s, t), bei der die Energiefunktion (1) minimal wird. Der Gleichgewichtszustand ist erreicht, wenn die internen und externen Kräfte die Balance 2 halten und die Kontur ruht (z.B. ∂∂t2v = ∂v ∂t = 0). 4.2.4 Nachteile klassischer Snakes Nachteile klassischer Snakes und ähnlichen deformierbaren Konturmodellen nach [MT02]und [MT00]: 52 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen • Snakes sind als interaktive Modelle entwickelt worden. In nichtinteraktiven Modellen müssen sie nahe an der zu segmentierenden Struktur initialisiert werden, um eine gute Performanz zu gewährleisten. • Die feste geometrische Parametrisierung der Kontur in Verbindung mit der internen Verformungsenergie der Snake schränken ihre geometrische Flexibilität ein und halten sie davon ab, lange röhrenförmige oder sich gabelnden Strukturen zu segmentieren. • Die Topologie der zu segmentierenden Struktur muss schon vorher bekannt sein, weil klassische deformierbare Konturmodelle fest geometrisch parametrisiert sind und deshalb topologische Transformationen nicht ohne zusätzliche Maschinerie durchführen können. Das heißt, dass klassische Snakes topologisch unflexibel sind: Sie können nur Objekte mit einer sehr einfachen Struktur (Ei-ähnliche Form) segmentieren. Es gibt diverse Ansätze, um diese Nachteile zu beseitigen, einer davon ist der der T-Snakes (Topologically Adaptable Snakes) von T. McInerney und D. Terzopoulos [MT95]. 4.3 T-Snakes [MT95], [MT00] 4.3.1 Eigenschaften Abbildung 4.5: Segmentierung mittels T-Snake Die Initialisierung der T-Snake erfolgt als geschlossene 2D Kontur irgendwo innerhalb oder ausserhalb der zu segmentierenden Struktur. Eine wichtige Eigenschaft der T-Snakes ist, dass die Knoten der Kontur durch adjustierbare Kanten verbunden sind. Diese Konturkanten werden T-Snake Elemente genannt. Da die Menge der Knoten und Elemente während des Entwicklungsprozesses nicht konstant bleibt, sind die T-Snakes elastisch und können sich auch langen röhrenförmigen oder sich gabelnden Strukturen anpassen. 4.3.2 Komponenten der T-Snake Eine T-Snake besteht aud zwei Komponenten: Die erste Komponente ist die diskrete Darstellung der Lagrange-Bewegungsgleichung 4.3 T-Snakes 53 (6): µi v̈i + γi v̇i + αi + βi = fi (4.7) v̈i ist die Beschleunigung und v̇i Geschwindigkeitder Snake. αi + βi ist die interne Energie, wobei αi die Spannung und βi die Starrheit definiert. fi ist die externe Energie. Genaueres dazu in [MT95]. Da diese Darstellung eine diskrete Approximation des klassischen Snake Modells ist, behält die T-Snake viele Eigenschaften dieser. Die zweite Komponente ist die Simplexzerlegung (Triangulierung) des Bildraumes durch die Coxeter-Freudenthal Triangulierung.(siehe bild ??.) Mithilfe dieser Zerlegung kann eine Unterscheidung in innere Region und äußere Re- Abbildung 4.6: Simplexzerlegung des Bildraums. Die Schnittpunkte mit der Kontur sind markiert. gion der T-Snake erfolgen: Simplexecken innerhalb der T-Snake erhalten eine positive Markierung und Simplexecken außerhalb eine negative Markierung. Simplexe, durch die die Kontur verläuft, heißen Grenzzellen. Sie haben Ecken mit verschiedenen Markierungen. ?? Die Berechnung der geometrischen Parameter, also die Bestimmung der Grenzzellen und Ausmachen der T-Snake Knoten und Elemente, nennt man simplizite Approximation der T-Snake. Sie kann jeden beliebigen Genauigkeitsgrad erreichen, da die Größe der Simplizes variiert werden kann. − − + − + + + + − Abbildung 4.7: Klassifikation eines Simplex. 4.3.3 Iterative Neubestimmung der geometrischen Parameter [MT00] Eine iterative Neubestimmung der geometrischen Parameter der T-Snake erfolgt alle M ∈ (5, 10] Zeitschritte, wobei M durch den Benutzer festgelegt wird. Es wird vom Benutzer außerdem bestimmt, ob die T-Snake expandieren oder schrumpfen soll. Am Ende eines Verformungsschrittes haben sich die Konturknoten relativ zu den Simplexkanten bewegt. ??. 54 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen Deshalb müssen nun die neuen geometrischen Parameter der deformierten T-Snake berechnet werden. Diese Berechnung der neuen simpliziten Approximation der Kontur geschieht durch einen 2-Phasen Reparametrisierungsalgorithmus: Phase 1: Zunächst erfolgt ein Schnittpunkttest der Snake mit den Kanten der Grenzzellen. ??. Ein so gefundener Schnittpunkt ist ein potentieller T-Snake Knoten und wird in einer Datenstruktur, die mit der geschnittenen Simplexkante assoziiert wird, abgelegt. Jedem Schnittpunkt wird ein Vorzeichen gegeben, um zu bestimmen, welcher Simplexkantenteil sich in der inneren Halbseite des T-Snake-Elements und welcher sich in der äußeren Halbseite des T-Snake-Elements befindet. Dies wird mithilfe der Normalen des die Simplexkante schneidenden T-Snake-Elements bestimmt: In positiver Richtung der Normalen ist Außen und in negativer Richtung Innen. Ein Spezialfall tritt auf, wenn es mehrere Schnittpunkte der Kontur mit einer Simplexkante gibt. Diese Situation kann entstehen, wenn die T-Snake sich selber oder mit einer anderen T-Snake schneidet. In diesem Fall wird das kleiner nummerierte Ende der Simlexkante genommen und mit Hilfe der Normalen des die Simplexkante schneidenden T-Snake-Elements bestimmt, auf welcher Seite der T-Snake diese Simplexecke liegt. Nun wird jeder Schnittpunkt mit dem unter Umständen noch aus der vorherigen Iteration existierenden Schnittpunkt verglichen. Wenn sie gegensätzliche Vorzeichen haben schließen sie sich gegenseitig aus und werden gelöscht. Wenn sie dagegen dasselbe Vorzeichen haben, ersetzt der neue Schnittpunkt den alten. Falls es vorher noch keinen Schnittpunkt für diese Simplexkante gab, wird der neue Schnittpunkt in der Simplexkantendatenstruktur abgelegt. Alle noch existierenden Schnittpunkte definieren die neuen T-Snake Knoten und ihre Verbindungen die neuen T-Snake Elemente. Wenn eine Gitterecke im Inneren der T-Snake liegt, und noch eine negative Markierung hat, wird diese in einer Schlange (queue) für Phase 2 gespeichert. Phase 2: Wenn die T-Snake expandiert ist, sind einige Simplexecken, die vorher außerhalb der T-Snake lagen, nun innerhalb dieser. (Siehe ??.) Sie müssen diese nun eine positive Markierung erhalten, damit es möglich ist, die innere Region der T-Snake zu erkennen. Dies geschieht, indem die Warteschlange (von Simplexecken, die zwar im Inneren der T-Snake liegen, aber noch eine negative Markierung haben sind), welche in Phase 1 angelegt wurde, abgearbeitet wird. Wenn ein Schnittpunkt in einer Datenstruktur abgelegt wurde und die zugehörige (im Inneren der T-Snake liegende) Simplexecke noch eine negative Markierung hat, muß sie eine positive Markierung erhalten. Diese Simplexecke wirkt als ’Saat’ für die Nachbarsimplexecken, welche durch einen Regionenfüllalgorithmus auch eine positive Markierung bekommen, falls die dazwischenliegende Simplexkante keine Schnittpunkte mit der Kontur hat. 4.3.4 T-Snake Algorithmus T-Snake Algorithmus nach [MT00]: 4.3 T-Snakes 55 -. SST QR 4 /0 21 343 56 78 9 9: ;< => + +, ?@ !! %)%& '( )* AB "" #$ %%& MOP MN KL IJ HG FE HG FE CD WX ©ª ¨§ ¨§ UV ¥¦ ZkY klZY ^] [\ ^] __` dc ab dc ef oop mn i i gh qqr st uuv wx zy ~} jzy {| ~} j yz yz ¢¡ £¤ ¢¡ Abbildung 4.8: T-Snake vor (innen) und nach (außen) Verformungsschritten. Die Knoten der T-Snake haben sich relativ zu den Simplexkanten bewegt. Aktuelle Schnittpunkte: grau Für jeden Deformationschritt (M Zeitschritte): 1. Für (M ∈ (5, 10) Zeitschritte): a) Berechne die externen und internen Kräfte, die auf die T-Snake Konten und Elemente wirken. b) Update der Knotenpositionen durch Verwendung der Euler Methode, welche in MT00, S.76 beschrieben wird. 2. Führe Phase 1 aus. 3. Führe Phase 2 aus. 4. Überprüfe für alle T-Snake Elemente, ob sie noch gültig sind. Ein T-Snake Element heißt gültig, falls sein zugehöriges Simplex noch immer eine Grenzzelle ist. Verwerfe ungültige T-snake Elemente und unbenutzte Knoten. 5. Benutze die Simplexecken, die in Phase 2 eine positive Markierung erhielten, um neue Grenzzellen zu bestimmen und neue T-Snake Knoten und Elemente auszumachen. Der Gleichgewichtszustand ist erreicht, wenn alle T-Snake Elemente für eine durch den Benutzer bestimmte Anzahl von Deformationsschritten inaktiv waren. Die T-Snake Aktivität wird durch das Gitter gemessen, indem eine Flammenverbreitungsanalogie verwendet wird. Den Konturelementen wird eine ’Temperatur’ zugewiesen, die auf der Anzahl der Deformationsschritte, in denen das Element gültig geblieben ist, basiert. Ein T-Snake Element wird deaktiviert, wenn seine Temperatur unter einen vorher festgesetzten ’Gefrierpunkt’ fällt. Wenn der Gleichgewichtszustand erreicht ist, kann das Gitter deaktiviert werden und die Kontur wird als klassische parametrisierte Snake weitergeführt. Die internen Energiepunkte erzeugen nun gleichmässiger verteilte Konturpunkte. 4.3.5 Interaktive Kontrolle [MT00] Die Simplexzerlegung des Bildraumes erlaubt es T-Snakes, die intuitiven interaktiven Kapazitäten der klassischen Snakes zu unterstützten: Benutzer können auf die Snake anziehende oder abstoßende Kräfte ausüben, indem sie z.B. Quellen oder Vulkane verwenden. Quellen (springs) sind Stellen mit besonders niedriger Energie und ziehen die Kontur wegen der Energieminimierung an. Vulkane (volcano) sind dagegen Stellen mit besonders hoher Energie und wirken somit auf die 56 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen Abbildung 4.9: Beispiel interaktiver Kräfte. Links: Eine CT-Aufname der linken Herzkammer. Rechts: Eine deformierbare Kontur bewegt sich zu großen Gradienten in dem durch Edge detection bearbeiteten Bild, beeinflusst durch gesetzte Punktbedingungen und einer Quelle, welche die Kontur zu einer Kante rechts unten im Bild zieht. [XPP00] Kontur abstoßend. Ein anderer nützlicher T-Snake Interaktionsmechanismus sind geometrische Punktbedingungen. Dabei werden Punkte gesetzt, durch die die Snake verlaufen muss. Sie gehören zu den harten Bedingungen, die immer erfüllt sein müssen. Mit ihnen kann der Benutzer die T-Snake zwingen, eine bestimmte Form anzunehmen. Weiche Punktbedingungen wie zum Beispiel verankerte Quellen müssen nur einigermaßen erfüllt werden und betreffen deshalb nur eine definierte Nachbarschaft. Abbildung 4.10: T-Snake, neuronale Zellen segmentierend. Sie muss die vom Benutzer festgelegten Punkte durchlaufen. 4.3.6 Beurteilung der T-Snakes Die Initialisierung der T-Snake ist flexibel: Sie muss nicht mehr nahe an der zu segmentierenden Struktur initialisiert werden und kann anfangs sowohl außerhalb als auch innerhalb platziert werden, was ein klarer Vorteil gegenüber den klassischen Snakes ist. ([MT00]) Die Zellzerlegung des Bildraumes ermöglicht topologische Transformationen wie z.B. lange, röhrenförmige oder sich gabelnde Strukturen wie in ??. Durch die topologisch angepassten aktiven Konturen wird das Verschmelzen oder Trennen von Snakes möglich. Deshalb können auch mehrere T-Snakes in der inneren Region der zu segmentierenden Struktur initialisiert werden.([MT00]) T-Snakes haben eine verbesserte Effizienz und eine Automatisierung des Segmentierungsprozesses ist möglich.([MT95]) Komplexe anatomische Strukturen sind ohne addititionelle Maschinerie segmentierbar.([MT02]) Nachteilig zu bemerken ist, dass Rauschen und andere Bildartefakte noch immer das T-Snake Verhalten und somit auch das Ergebnis der Seg- 4.4 Zusammenfassung 57 Abbildung 4.11: T-Snake bei der Erkennung von retinalen Blutgefäßen. mentierung störend beeinflussen können. Das Problem bei deformierbaren Modellen ist aber die recht komplizierte Bestimmung der Energien. 4.4 Zusammenfassung Snakes sind dazu geeignet, mit Artefakten behaftete Bilder zu segmentieren und werden deshalb in der die medizinischen Bildverarbeitung eingesetzt. Snakes sind energieminimierende deformierbare Modelle, die sowohl als parametrische Kurve (klassische Snakes), als auch als diskrete Kurve (T-Snakes) dargestellt werden können. Das Prinzip funktioniert folgendermaßen: Zuerst wird aus einem Bild eine Energiefunktion, bestehend aus interner und externer Energie erzeugt. Dann initialisiert der Benutzer die Snake. Als nächstes wird versucht, die Energie zu minimieren. In Abhängigkeit von der gewählten Energie paßt sich die Snake in Folge der Energieminimierung unterschiedlichen Merkmalen im Bild, wie zum Beispiel Kanten und Linien an. Benutzer können auch interagieren indem sie beispielsweise Energieminima oder -maxima im Bild festlegen, die die Kontur anziehen bzw. abstoßen oder es gibt auch die Möglichkeit, Punkte, durch die die Snake laufen muss, zu bestimmen. Die Erweiterung des klassischen Snake Modells (T-Snakes) birgt Vorteile wie Unempfindlichkeit gegenüber der initialisierten Position und eine höhere Flexibilität der Kontur. Das hier vorgestellte 2D-Snake-Modell lässt sich übrigens auch auf 3D erweitern. ([MT00].) 58 2D Segmentierung medizinischer Bilder: Segmentierung mit deformierbaren Modellen Literaturverzeichnis [Coh91] L. D. Cohen. On active contour models and balloons. Computer Vision, Graphics, and Image Processing. Image Understanding, 53(2):211–218, 1991. [KWT87] M. Kass, A. Witkin, and D. Terzopoulos. Snakes: Active contour models. Vis. Comput., 1:321–331, 1987. [MA99] T. McInerney and D. And. Topology adaptive deformable surfaces for medical image volume segmentation, 1999. [MT95] T. McInerney and D. Terzopoulos. Topologically adaptable snakes. In ICCV, pages 840–845, 1995. [MT96] T. McInerney and D. Terzopoulos. Deformable models in medical images analysis: A survey, 1996. [MT00] T. McInerney and D. Terzopoulos. T-snakes: Topology adaptive snakes, 2000. [MT02] T. McInerney and D. Terzopoulos. Deformable models. In I.N. Bankman. Handbook of Medical Imaging Processing and Analysis. Academic Press, page 127ff, 2002. [WS90] D.J. Williams and M. Shah. A fast algorithm for active contours. In Proc. 3rd Int.Conf. on Computer Vision (ICCV), pages 592–595, 1990. [XP98] C. Xu and J. Prince. Snakes, shapes, and gradient vector flow, 1998. [XPP00] Chenyang Xu, Dzung L. Pham, and Jerry L. Prince. Image segmentation using deformable models, 2000. 60 LITERATURVERZEICHNIS Kapitel 5 Registrierungsverfahren Rebecca Hoffmann 03. Juli 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼rebhoff 62 Registrierungsverfahren Registrierungsverfahren finden einen hohen Nutzen in der heutigen Medizin. Sie werden an vielen verschiedenen Stellen gebraucht und eingesetzt. In diesem Zusammenhang soll die Anwendung und der Nutzen von Registrierung in der Medizin deutlich gemacht werden, außerdem wird die Registrierung medizinischer Daten näher erläutert und eine Klassifikation der Vorgehensweise vorgestellt. Anschließend wird ein konkretes Beispiel für eine 2D/3D Registrierung inklusive Verwendung von Ähnlichkeitsmaßen dargestellt. 5.1 Motivation und Nutzen in der Medizin Registrierungsverfahren haben sich in der Medizin als notwendig erwiesen. Dies hat folgende Gründe. Auf der einen Seite gibt es unterschiedliche bildgebende Verfahren und deren Zweckmäßigkeiten: Ein CT Volumen wird meist dann verwendet, wenn man Informationen über dichtes Gewebe eines Patienten wie z.B. Knochen erhalten möchte, da bei CTs Knochendetails sehr gut zu erkennen sind. Zudem eignen sich CT-Datensätze besser zur Strahlentherapieplanung. Auf MR-Bildern ist meist weiches Gewebe besser zu sehen. Daher wird diese Methode meist angewendet, wenn man es darum geht, Information über weiches Gewebe wie zum Beispiel einen Tumor zu erhalten. Positron Emission Tomography (PET-)Aufnahmen hingegen zeigen eher die funktionalen als die anatomischen Information. Sie werden zum Beispiel gebraucht, wenn man die aktiven funktionalen Gebiete des Gehirns finden möchte. Abbildung 5.1 zeigt Beispiele von 3D-Aufnahmen des Kopfes durch die erwähnten Bildgebenden Verfahren. Damit man die gewonnenen Informationen aus den unterschiedlichen Verfahren miteinander vergleichen und die Bilder fusionieren kann, um somit den höchstmöglichen Informationsstand zu erlangen, ist die Registrierung der vorhandenen Daten notwendig. Nur so können alle wichtigen Eigenschaften für beispielsweise eine Operation erkannt werden. Auf der anderen Seite werden oft zeitlich versetze Aufnahmen eines Patienten gemacht. Die Bilder einer Person werden zu einem unterschiedlichen Zeitpunkt aufgenommen. Dies kann zum Beispiel vor, während oder nach einer Operation geschehen. Vor einem Eingriff ist meist sicher zu stellen, wo sich der zu operierende Bereich befindet und ob sich durch die festgestellte Position Komplikationen ergeben könnten. Daher werden zeitlich früher gemachte Bilder mit Bildern während der Operation verglichen. Nach dem Eingriff will der Arzt wissen, ob er operativ erfolgreich war. Da die Lage des Patienten vor, während und nach der OP nie exakt identisch ist, liegen zwar Aufnahmen des gleichen Objektes vor, allerdings ist die Position und die Bildmodalität unterschiedlich, so dass eine Registrierung der Datensätze zum Vergleichen angewendet werden muss. Zudem liegen oft Daten von mehren Patienten vor. Auch hier müssen die Bilder registriert werden, damit man sie gegenübergestellt werden können. Anwendung findet Registrierung unter anderem in der bildgesteuerten Chirugie (image guided surgery). Hier liegen die Anforderungen vor allem in der hohen Genauigkeit und in der kurzen Rechenzeit der einzelnen Verfahren. Im Folgenden werden einige Beispiele von Bilddatensätze nach ihrer Registierung mit anschließender Fusion vorgestellt. Abbildung 5.2[Bor] zeigt ein CT und ein PET Bild eines Querschnittes durch die Brust, erkennbar an der abgebildetet Wirbelsäule und den daneben gelegenen Nieren. Der Pfeil im CT-Datensatz weißt auf einen Tumor in der Milzgegend hin, der operativ entfernt werden soll. Um den Erfolg der Resektion zu garantieren, dürfen gesunde und aktive Regionen in der Gegend des Tumors nicht beschädigt werden. Hierzu wird eine PET Aufname gemacht, um zu sehen, wo sich 5.1 Motivation und Nutzen in der Medizin CT MR 63 PET Abbildung 5.1: 3D Abbildungen vom Kopf, stammend aus unterschiedlichen bildgebenden Verfahren die funktionalen Aktivitäten in dem betroffenen Bereich befinden. Sie liegen bei dieser Aufnahme im Darm und in den Nieren (siehe grüne Pfeile). Nach der Berechnung der Registrierung bekommt man das fusionierte Bild. Links CT, Rechts PET Fusion von CT und PET Abbildung 5.2: Beispiel einer Registrierung von einem CT und PET Volumen eines Querschnitts durch die Brust Ein weiteres Beispiel für eine Registrierung mit anschließender Fusion der registrierten Bilddaten zeigt Bild 5.3. Es stellt verschiedene Aufnahmen einer 66jährigen Frau mit einem rechts parietalem1 Glioblastom2 dar. In der ersten Reihe sind MRAufnahmen des Schädels zu verschiedenen Zeitpunkten zu sehen. Die zweite Reihe zeigt korrespondierende PET-Daten nach der Registrierung. Während die dritte und die vierte Reihe die Fusion der registrieten Schichten zur Planung der Operation enthalten. Die Fusion der MR-Daten mit der PET-Darstellung des sensomotorisch aktivierten Areal der Großhirnrinde zeigt, dass das aktivierte Areal das perifokale Ödem nur tangiert und daher bei der geplanten operativen Entfernung nicht gefährdet ist [LzB02]. 1 seitlich, scheitelwärts gelegen Gehirntumor 2 bösartiger 64 Registrierungsverfahren Abbildung 5.3: Fusion von MR und PET 5.2 Registrierungsverfahren 5.2.1 Definition Unter dem Begriff Registrierung versteht man nach [LzB02] allgemein die Berechnung einer Transformation, die zwei korrespondierende Bildinhalte in zwei verschiedenen Koordinatensystemen aufeinander abbildet. Hier liegt zunächst ein Korrespondenzproblem vor, da man als erstes die übereinstimmenden Bildinhalte gefunden werden müssen. Daher spricht man auch oft von ’Matching’ von Bildern. Diese Bildinhalte können ganze Objekte, Regionen oder auch einzelne Bildpunkte sein. Ziel ist es, zwischen den verschiedenen Bildrepräsentationen eine maximal mögliche Übereinstimmung zu finden bzw. herzustellen. Verschiedene Ähnlichkeitsmaße werden im Abschnitt 5.4.4 vorgestellt. Außerdem sagt die Definition noch nichts über die Dimensionen der beiden Koordinatensysteme und die Spezifikation der Transformation aus. Letzteres wird in Abschnitt 5.3.8 näher erläutert. Im nächsten Abschnitt werden zusätzliche Faktoren erwähnt, die diese Definition erweitern und ein Registrierungsverfahren spezifizieren. 5.3 Klassifikation der Verfahren Um die vorhandenen Registierungsverfahren besser charakterisieren zu können, wird im Folgenden eine Klassifikation nach [LzB02] und [MV98] beschrieben, die neun verschiedene Kriterien beinhaltet. 5.3 Klassifikation der Verfahren 65 5.3.1 Modalität Die Modaliät bezieht sich auf die Art der verwendeten Bildgebenden Verfahren, um die zu registrierenden Bilder zu bekommen. Es werden vier Modalitätsklassen unterschieden: Bei unimodaler (oder auch monomodaler) Registrierung gehören die Bilder derselben Modalität an (Bsp.: CT-CT, MR-MR), es handelt sich folglich um dasselbe bildgebende Verfahren. Im Gegensatz dazu liegen unterschiedliche Modalitäten bei der multimodalen Registierung vor (Bsp.: CT-PET, CT-Röntgenbild, SPECT-MR). Sowohl beim Modalität – Modell als auch beim Patient – Modalität Verfahren liegt jeweils nur eine Abbildung vor. Die andere ’Modalität’ ist entweder ein Modell oder der Patient selber. Ein Modell kann ein anatomischer Atlas (s. Abschnitt 5.3.3) oder auch ein mathematisches Modell der Physiologie sein. Zur vierten Kategorie zählen solche Verfahren, die auf den aktuellen Koordinaten des Patienten beruhen. Zwar wird auch hier zwischen zwei Bildern eine Transformation gesucht, allerdings ist diese stark von der Position des Patienten abhängig (Bsp.: Tumorprojektion aus dem CT auf den aktuellen Situs) 5.3.2 Dimensionalität Ein weitere Möglichkeit der Charakterisierung der Verfahren liegt schon in der allgemeinen Definition erwähnten Dimension beider Bilder. Zunächst einmal wird differenziert, ob alle Dimensionen nur räumlich sind oder ob die Zeit eine zusätzliche Dimension darstellt, wenn Zeitserien, d.h. mehr als zwei Bilder, vorliegen. Im Allgemeinen kann man von n-dimensionalen auf m-dimensionale Registrierungsproblemen sprechen, wobei n und m den jeweiligen Grad der Dimension angeben. Als Beispiel für ein 2D-2D Verfahren ist u.a. die Registrierung von Röntgenbildern zu nennen. Die Registrierung zweier CT-Datensätze oder eines CT und MR Datensatzes benötigt ein 3D-3D Verfahren, während eine 2D-3D Registrierung hauptsächlich bei der Abbildung von räumlichen Daten auf projektive Daten gebraucht wird (z.B. die Registrierung eines prä-operatives CT-Volumen zu einer intra-operativen Röntgenaufnahme (siehe auch Abschnitt 5.4)). Die Registrierung von Volumendaten auf Kamerabilder benötigt im allgemeinen ein 3D-2D Verfahren. Die Zeit spielt in einigen Fällen eine große Rolle. Wenn man den wachsenden Knochenaufbau eines Kindes verfolgen möchte, sind Aufnahmen über ein langes Zeitintervall notwendig. Genauso ist der Zeitfaktor im Allgemeinen wichtig, wenn man die Veränderung eines bestimmten Körperorgans verfolgen möchte. Vergleichsweise ist hier auch das Wachsen eines Tumors zu nennen. Unter der Betrachtung der Zeit können ebenfalls wie bei der räumlichen Aufteilung drei Möglichkeiten gehen, nämlich 2D-2D, 3D-3D oder 2D-3D Datensätze. 5.3.3 Subjekt Wenn nur Aufnahmen eines Patienten vorliegen, spricht man von Intrasubjektregistrierung. Die Registierung von Daten verschiender Patienten bezeichnet man hingegen als Intersubjektregistrierung. Die letzte Kategorie stellt die Atlas/Patient-Registrierungdar. Dabei wird eine Aufnahme des Patienten und ein konstruiertes Bild verwendet. Unter Atlas versteht man meist einen Datensatz, der durch Mittelung von Daten verschiedener Patienten errechnet wird. D.h. der Atlas ist eine künstlich hergestellte Aufnahme, die darstellt, wie der gesunde Körperaufbau des Menschen aussehen müsste und anhanddessen können Aufnahmen kranker Regionen mit dem ’Ideal’-Bild überprüft wer- 66 Registrierungsverfahren den. Der Gebrauch liegt hier meist beim Aufstellen von Statistiken über Informationen wie Größe und Form bestimmter Strukturen. Außerdem wird die Atlas/PatientRegistrierung oft beim Auffinden von anormalen sprich kranken Regionen im Körper gebraucht. 5.3.4 Objekt Das Objekt ist das, was meist registriert wird. Es kennzeichnet bestimmte Organe oder Körperregionen: • Kopf (Schädel, Gehirn, Augen, Zähne) • Thorax (ganz, Nieren, Leber) • Becken • Gliedmaße (Oberschenkelknochen, Oberarmknochen, Hand) • Wirbelsäule, Wirbel • etc. An dieser Stelle sollte erwähnt werden, dass in der Bildverarbeitung vorallem die Registrieung des Kopfes (Schädel und Gehirn) sehr verbreitet ist. Da es sich meist um Knochenstrukturen und wenig bewegte weiche Materie handelt, ist die zur Registrierung notwendige Transformation oft leichter zu finden, da man von starren Körperteilen ausgehen kann. (siehe auch Abschnitt 5.3.7) 5.3.5 Interaktion Registrierungsverfahren werden nach dem Grad ihrer Selbstständigkeit bzw. ihrer Automatisierung unterschieden. Manuelle Algorithmen liegen vor, wenn die Steuerung der Registrierung durch den Benutzer erforderlich ist. Der für den manuellen Eingriff notwendige aktuelle Status der Transformatin wird dem Benutzer von der vorhandenen Software mitgeteilt. Bei semiautomatischen Algorithmen liegt entweder die Initalisierung (z.B. Segmentierung bestimmter Objekte) oder die Steuerung (z.B. Akzeptanz oder Rückweisung einer vorgeschlagenen Registrierung) beim Benutzer, während bei den automatischen Algorithmen nur die Bilddaten bereitgestellt werden und die Registrierung ohne jegliches Eingreifen stattfindet. Diskussionswürdig ist bestimmt, inwieweit der Benutzer in die Verfahren eingreifen sollte und wo darin die Nützlichkeit liegt. Auf der einen Seite könnten durch menschliche ’Überwachung’ die Robustheit und Effizienz eines Algorithmus gesteigert werden. Auf der anderen Seite nimmt der größte Teil der Registrierung, das Finden der geeigneten Transformation, einen Bereich ein, in dem das Eingreifen weniger Sinn macht. 5.3.6 Basis Das Festlegen einer Basis ist abhängig von den Eigenschaften der vorhandenen Datensätze. Sie dient dazu, so wenig Daten wie möglich registrieren zu müssen. Zur Extraktion einer Registrierungsbasis sind i.d.R. Vorverarbeitungsschritte wie Filterung, Segmentierung oder 3D-Rekonstruktion erforderlich ( [LzB02]). Die gesuchte Basis soll 5.3 Klassifikation der Verfahren 67 auf den charakteristischen Merkmalen der wesentlichen Bildinhalte der zu registrierenden Struktur beruhen, damit die Originaldaten auf ihre wichtigsten Bestandteile reduziert werden können. Es gibt unterschiedliche Arten der Registrierungsbasis. Die drei wichtigsten Gruppen sind zunächst extrinsischen, intrinsischen und nicht-bildbasierten Verfahren. Extrinsische Basen können noch einmal in invasive 3 und nicht-invasive unterteilt werden. Unter ersteren versteht man unter anderem Stereotaktische Rahmen oder Schraubenmarker. Zu nicht-invasiven Basen gehören unter anderem Abdrücke, Bezugsrahmen, Zahnadapter oder auch Hautmarker. Beruht die Registrierung auf einer intrinsische Basis, kann sie sich auf verschiedene Verfahren beziehen. Landmark basierende Verfahren können zum Beispiel anatomische oder geometrische Landmarken sein. Segmentierungsbasierte Verfahren unterscheiden sich in starren und deformierbaren Modellen. Zu nennen sind hier Punkte, Kurven und Oberflächen (starr) sowie Snakes und Netze (deformierbar). Verfahren, die auf Voxeleigenschaften basieren, nutzen beispielsweise Eigenschaften wie Grauwerte, beziehen sich auf den gesamten Bildinhalt, der oft zu Skalaren oder Vektoren reduziert wird. An dieser Stelle sei noch erwähnt, dass der erste merkmalsbasierte Algorithmus 1990 entwickelte wurde. Erst vier Jahre später folgte ein intensitätsbasierte Algorithmus. Extrinsische Basen enthalten Objekte, die ’künstlich’ in den Bildraum eingebracht worden sind. Im Gegensatz dazu beruhen intrinsische Basen meist auf Bilddaten, die nur aufgrund der Anatomie des Patienten vorhanden sind. Zuletzt sind noch die nicht-bildbasierten Verfahren zu nennen. Ihnen liegt meist ein kalibriertes Koordinatensystem zugrunde, d.h. A-priori statt A-posteriori Registrierung. 5.3.7 Transformation (modellbasiert) Wie bereits erwähnt ist das Ziel eines Registrierungsverfahren die Bedingungen der Transformation, die beide vorliegende Bilder miteinander in Übereinstimmung bringt. Bei der Modell basierten Transformation liegt eine endliche Anzahl an Modellparametern vor, im Gegensatz zur einer vollständig elastischen Transformation. Entspricht die gesuchte Transformation nur einer Verschiebung des einen Punktes zu seinem korrespondierenden Punkt aus dem anderen Datensatz, dann kann sie durch eine Translation modelliert werden. Hingegen kommt zu einer starren Transformation noch die Möglichkeit der Rotation hinzu. Liegt eine affine Transformation vor, dann kann die Transformation eine Rotation, Skalierung, Translation, Spiegelung und Scherung beinhalten. Projektive Transformationen werden zum Beispiel bei der Röntgenprojektion verwendet. Je mehr Freiheitsgrade (Parameter) eine Transformation besitzt, desto höher ist ihre Elastizität (siehe auch Tabelle 5.1). Das Finden der jeweils geeigneten Transformation für die Registrierung hängt von den Randbedingungen des Problems ab. Beispielsweise kann für die Registrierung von knöchernen Strukturen meist eine starre Transformation verwendet werden, während Weichteile aufgrund ihrer Elastizität meist eine Transformation mit vielen Freiheitsgraden benötigen. 3 med. eindringend 68 Registrierungsverfahren 5.3.8 Transformationsbereich Wendet man die Transformation global an, dann wirkt das Änderen eines Transformationsparameters auf das gesamte Bild. Möchten man verschiedene Transformationen für unterschiedliche Regionen verwenden, spricht man von einemlokalen Transformationsbereich. Es existieren somit zusätzliche Parametersätze. Tabelle 5.1 zeigt eine Übersicht über die Transformationen und ihren Wirkungsbereiche. Original Global Lokal Tabelle 5.1: Beispiele für 2-D Transformationen Erste Reihe: starre Transformationen, Zweite Reiche: affine Transformationen, Dritte Reihe: projektive Transformationen, Vierte Reihe: kurvige Transformationen 5.3.9 Optimierungsverfahren Optimierungsverfahren werden benutzt um die Ähnlichkeitsfunktion im u.U. hochdimensionalen Parameterraum der Transformation mit Hilfe von Ähnlichkeitsmaßen global zu minimieren (siehe auch Abschnitt 5.4.4). Erschöpfende Suchverfahren gehen alle möglichen Kombinationen der Transformationsparametersätze durch, um das globale Optimum zu finden. Da dies ziemlich aufwendig ist, ist ein solches Verfahren nur bei wenigen Freiheitsgraden möglich, da der Aufwand sonst zu hoch wäre. Man stelle sich vor, wie viele Optionen allein bei einer starren Transformation vorliegen, mit jeweils drei Translationen und drei Rotationen (jeweils x-, y-, z-Achse). Heuristische Strategien versuchen den Suchraum mit Hilfe verschiedener Verfahren einzuschränken. Hierzu werden zum Beispiel das Gradientenabstiegsverfahren oder die Levenberg-Marquardt-Methode verwendet. Iterative Verfahren berechnen das Ähnlichkeitsmaß abhängig vom aktuell erreichten Zustand der Registrierung jeweils neu, bis das Optimum gefunden ist. 5.4 Registierungsverfahren von Penney 69 5.4 Registierungsverfahren von Penney 5.4.1 Klassifikation des Registrierungsverfahren Basierend auf die Klassifikation vom letzten Abschnitt soll im Folgenden ein konkretes Beispiel für eine multimodale 2D-3D Registrierung vorgestellt werden. Beim Verfahren von Penney [Pen99] wird ein prä-operatives CT Volumen der (Lenden-) Wirbelsäule mit einem intra-operativen Röntgenbild des selben Objektes registriert. Es handelt sich hierbei um eine Intrasubjektregistrierung, da Aufnahmen eines Patienten vorliegen. Die Registrierung erfolgt ausschließlich anhand der Bilddaten, die vom Patienten stammten, d.h. es liegt eine intrinsische Basis vor, die auf den Voxelintensitäten der Datensätze basiert. Zudem wird eine starre Transformation mit perspektivischer Projektion angewendet, d.h. es existieren zehn Freiheitsgrade, wobei sechs extrinsische und vier intrinische Parameter vorliegen. Der Transformationsbereich bezieht sich auf das ganze Bild, ist also folglich global. Zur Optimierung der Registrierung verwendet Penney zudem heuristische Verfahren. Die Grundidee liegt bei der Herstellung eines Digitally Reconstructed Radiograph (DRR). Nachdem man dieses aus dem CT Volumen berechnet hat, wird es mit Hilfe von Ähnlichkeitsmaßen mit dem Röntgenbild verglichen. Somit liegt im Endeffekt eine 2D-2D Registrierung vor. In den nächsten Abschnitten wird nun auf einzelnen Punkte näher eingegangen. 5.4.2 Digitally Reconstructed Radiograph Ein DRR ist die Erzeugung einer künstlichen Projektion des 3D CT-Volumen. Hierzu wird von der bekannten Position der Röntgenquelle Röntgenstrahlen durch das CTVolumen gesendet (Abbildung 5.4). Die Werte der getroffenen Voxelwerte werden anhand des Röntgenschwächungsgesetz aufaddiert. Falls die Strahlen keine Voxelzentren treffen, muss zwischen diesen interpoliert werden. Dies geschieht durch eine bilineare Interpolation. Wichtig ist hierbei, dass truncation4 vermieden wird. Truncation tritt dann auf, wenn Strahlen oben oder unten durch das CT-Volumen gebrochen werden und somit unvollständig sind. Um dies zu verhindern, wird meist eine ROI (Region of Interest) definiert, damit Truncation während der Projektion vermieden werden kann. IDRR IF L PSfrag replacements CT-Volumen X-ray Source Abbildung 5.4: Erzeugung eines DRR 4 Abbrechen, Abschneiden 70 Registrierungsverfahren Die Erzeugung des DRR erfolgt anhand der Abbildungsmatrix M, die Projektion vom 3D-Raum auf die 2D-Bildebene beschreibt: Die Abbildungsmatrix M vom 3D-Raum auf die 2D-Bildebene besteht aus folgenden Parametern: M = P(cs , ls , k1 , k2 )T(X, Y, Z)R(θx , θy , θz ) (5.1) Wobei P die projektive Transformation bekannt als Kalibrierungsmatrix ist. c s , ls geben die Position an, wo die Normale zur Bildebene durch die Röntgenstrahlquelle geht. k1 und k2 gleichen die Pixelgrößen in horizontaler (xpix ) und vertikaler (ypix ) Richypix xpix und k2 = f ocallength . T beinhaltet die Translationen um die tung an. k1 = f ocallength x-,y- und z-Achse und R steht für die Rotationen um die jeweiligen Achsen Die Transformationen werden im projektiven Raum P 2 gegeben: 1 0 0 X 0 1 0 Y (5.2) T= 0 0 1 Z 0 0 0 1 cos θz cos θy − sin θz cos θy R= sin θy 0 sin θz cos θx + cos θz sin θy sin θx cos θz cos θx − sin θz sin θy sin θx − cos θy sin θz 0 sin θz sin θx − cos θz sin θy cos θz cos θz sin θx + sin θz sin θy cos θz cos θy cos θx 0 (5.3) 5.4.3 Registrierungsverfahren als Optimierungsproblem Die Abbildung des Volumens zu einem DRR wird durch die Lage der Kamera (externe Parameter) und ihre internen Parameter spezifiziert. Die internen Parameter werden durch einen Kalibrierungsschritt bestimmt, während nach den externen Parametern gesucht werden muss. Der Transformationsbereich ist 6-dimensional, er besteht aus drei Translationen und drei Rotationen (starre Transformation). Die beste Transformation ist diejenige, für die der Abstand zwischen DRR und dem aktuellen Röntgenbild am kleinsten ist: dist{DRR, F L} −→ 0 (5.4) Dieser Abstand misst die Ähnlichkeit zwischen beiden Bildern und ist die zu optimierende Funktion. Um nicht den gesamten Suchraum durch eine erschöpfende Suche abzutasten, werden heuristische Strategien eingesetzt (s. Abschnitt 5.3.9). Beispiele hier für sind u.a. Downhill Simplex, der Gradientabstieg oder der Levenberg-Marquardt Algorithmus. 5.4.4 Ähnlichkeitsmaße Wie bereits in Abschnitt 5.3.9 erwähnt, gibt es unterschiedliche Ähnlichkeitsmaße, die die Güte- Verfahren der Registrierung verbessern [PWL+ 98][HBHH01]. Wichtig ist, dass die Maße korrekt arbeiten und gegenüber weichem Gewebe (soft tissue structures) 0 0 0 1 5.4 Registierungsverfahren von Penney 71 und intra-operativen Instrumenten5(interventional instruments), die bei Penney auftreten, unempfindlich, sprich robust sind. Penney verwendet u.a. folgende intensitätsbasierte Ähnlichkeitsmaße: Normierte Kreuzkorrelation P ¯ ¯ (i,j)∈T (If l (i, j) − If l )(IDRR (i, j) − IDRR ) qP R = qP 2 ¯ 2 ¯ (i,j)∈T (If l (i, j) − If l ) (i,j)∈T (IDRR (i, j) − IDRR ) (5.5) Kreuzkorrelation ist ein Maß aus der Statistik, welches die Ähnlichkeit zwischen zwei Bildern mißt, hierzu werden die Abstände der Grauwerte der beiden Eingabebilder I f l und IDRR zu ihren jeweiligen Mittelwerten I¯f l und I¯DRR in einer bestimmten Region T berechnet. Da dieser Maß sehr von den Pixelintensitäten abhängig ist, kann eine kleine Anzahl von Fehlpixel schnell zu einem schlechten Ergebniss bei der Ähnlichkeitsmessung und somit zu einer schlechten Registrierung führen. Dies kann vor allem auftreten, wenn im CT und damit auch im DRR interventional instruments vorkommen, da diese eine kleine Anzahl an Pixeln bzw. deren Intensität stark verändern (vlg. [PWL+ 98]). Gradientenkorrelation Gradientenkorrelation ist ein auf der Normierten Kreuzkorrelation basierendes AbdI dI , dIDRR mittels horistandsmaß. Es werden die Gradietenbilder dif l , djf l , dIDRR di dj zontalem und vertikalem Sobel erzeugt. Danach berechnet man die Normierte KreuzdI dI und zwischen djf l und dIDRR korrelation zwischen dif l und dIDRR di dj . Das Ergebnis ist der Mittelwert aus beiden Berechnungen. Der Vorteil hierbei liegt darin, dass durch den Sobelfilter (die Gradient Messung) niedrige Frequenzen herausgefiltert werden, die zum Beispiel durch weiches Gewebe auftauchen. Allerdings liegt durch die Verwendung der Normierten Kreuzkorrelation eine Beeinflussung von gering vorkommenden großen Intensitätsunterschieden vor. Die im Vergleich zu der ’reinen’ Normierten Kreuzkorrelation aber relativ gering ist. Pattern Intensity Dieses Ähnlichkeitsmaß beruht auf der Entropie des Differenzbildes von dem Röntgenbild und dem DRR, das wie folgt berechnet wird. Idif f (i, j) = If l (i, j) − sIDRR (i, j) (5.6) Wobei s ein Skalierungsfaktor ist. Man beginnt mit dem Wert 0 und erhört s, bis man das Minimum von der Entropie H erreicht hat. Die Berechnung der Entropie H von Idif f ist gegeben durch: H(Idif f ) = − X p(x) log p(x) (5.7) x Da die Entropie ein Maß für den Informationsgehalt eines Bildes ist, ist das Ziel das Minimum von H zu finden, weil dann so wenig Information in I Dif f enthalten ist. 5 Lineal, Stent, etc. 72 Registrierungsverfahren Dabei geht man davon aus, dass bei einer hohen Ähnlichkeit von I f l und IDRR die Bilder nahezu identisch sein müssten. Das Verfahren basiert auf dem Histogramm des IDif f -Bildes. Die Werte vom Differenzbild werden in 64 gleich große Kästen (Bins) unterteilt, um das Histogramm zu erstellen und p(x) gibt an, mit welcher Wahrscheinlichkeit ein Pixel vom Differenzbild IDif f zu dem Bin x gehört. Jeder Pixel erhält die gleiche Gewichtung unabhängig von seiner Intensität. Deshalb ist dieses Maß robust gegenüber großen Unterschieden der Pixelintensitäten in einer kleinen Anzahl von Pixel, die u.a. beim Vorkommen von intra-operativen Instrumenten auftreten. Allerdings treten Fehlerquoten auf, wenn weiches Gewebe in den Bildern auftritt. 5.4.5 Bewertung des Verfahrens von Penney Der große Vorteil des Verfahrens von Penney liegt sicherlich darin, dass es sich um eine intensitätsbasierte Registrierung handelt. Somit werden Korrespondenzprobleme und Segmentierung vermieden. Zudem ist durch die Konstruktion eines ’Phantom’Röntgenbildes (DRR) aus dem CT-Volumen die Registrierung zwischen DRR und dem inter-operativen Röntgenbild effizienter und effektiver. Außerdem benutzt Penney zusätzlich Optimierungs- und Ähnlichkeitsverfahren, die eine Registrierung exakter und robuster machen sollen. Allerdings liegt hierbei das Problem, dass man nicht weiß, welches Verfahren man zur Optimierung benutzen soll. Literaturverzeichnis [Bor] www.bocaradiology.com/Procedures/PET.html. [HBHH01] Derek L.G. Hill, Philipp G. Batchelor, Mark Holden, and David J. Hawkes. Medical image registration. Phys. Med. Biol., 46:1–45, 2001. [LzB02] Thomas M. Lehman and Erdmuthe Meyer zu Bexten. Handbuch der Medizinischen Informatik. Hanser, Muenchen, 2002. [MV98] Antoine J.B. Maintz and Max A. Viergever. A survey of medical image registration. Medical Image Analysis, 2:1–36, 1998. [Pen99] Graeme P. Penney. Registration of tomographic images to X-ray projections for use in image guided interventions. PhD thesis, Computational Imaging Science Group, Dvision of Radiological Sciences and Medical Engineering, King’s College, London, 1999. [PWL+ 98] Graeme P. Penney, Juergen Weese, John A. Little, Paul Desmedt, Derek L.G. Hill, and David J. Hawkes. A comparison of similarity measures for use in 2-d–3-d medical image registration. IEEE Transactions on Medical Imaging, 17:586–595, 1998. [SNC90] George W. Sherouse, Kevin Novins, and Edward L. Chaney. Computation of digitally reconstructed radiography for use in radiotherapy treatment design. International Journal of Radiation Oncology, Biology, Physics, 18:651–658, 1990. 74 LITERATURVERZEICHNIS Kapitel 6 Bayes Netze Regine Wolff ??.April 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼reginew 76 Bayes Netze 6.1 Motivation In medizinischen Anwendungen fehlen oft die Möglichkeiten einer eindeutigen Zuordnung zwischen den Fakten, sprich den Symptomen, und der Schlussfolgerung, der Diagnose. Das kommt daher, dass die Fakten meist nicht exakt abgrenzbar sind, sie sind schlecht (diffus) strukturiert und oft komplexer Natur. Außerdem sind die meisten Fakten unterschiedlich interpretierbar. Es ist daher nur selten möglich, aus bestimmten Symptome eindeutig auf eine, bzw. auf die Diagnose zu schließen. Eine Lösung bieten hier die Bayes-Netze. Bayes-Netze sind graphische Modelle, welche die Graphentheorie und Wahrscheinlichkeitstheorie miteinander kombinieren. Hierauf wird jedoch später noch im Einzelnen eingegangen. Es werden den Aussagen für das Auftreten bestimmter Symptome bei vorliegenden Diagnose Wahrscheinlichkeiten zugeordnet. Beispielsweise die Wahrscheinlichkeit, dass jemand der eine Grippe hat auch Fieber hat. Diese können dann mit Hilfe der Bayes - Netze visualisiert werden und es kann damit im umgekehrten von dem Symptom Fieber auf die Wahrscheinlichkeit der Diagnose Grippe geschlossen werden. Es können durch die Bayes-Netze Probleme behandelt werden, die durch andere Methoden wegen ihrer Komplexität oder wegen fehlender Daten nicht erfasst werden können. Mit ihnen kann Wissen als Ansammlung von Wahrscheinlichkeiten ausgedrückt werden und somit können Folgerungsprozesse gut simuliert werden. Die Bayesche Wahrscheinlichkeitsrechnung erlaubt überdies Formulierung rein subjektiver Wahrscheinlichkeiten und kann somit menschliche Intuition, Erfahrung und Fachwissen mit einbeziehen. So kann also durch Experten formuliertes Wissen berücksichtigt werden. Zudem ist es mit den Bayes-Netze einfach verschiedene Modellannahmen auszuprobieren und Wahrscheinlichkeitsannahmen zu verändern. Die Auswirkungen hiervon lassen sich dann wieder direkt am Graphen (Netz) ablesen. Die ursprünglichen Wahrscheinlichkeiten werden aus Beobachtungen einer großen Zahl von Fällen statistisch ermittelt. 6.2 Statistischer Grundlagen Wahrscheinlichkeiten Eine Zufallsvariable X kann alle Werte des Wertebereiches W B = {x1 , . . . , xn }n ∈ N annehmen Jeder dieser Werte tritt mit einer bestimmten Wahrscheinlichkeit P (X = xi ) mit i = {1, . . . , n}n ∈ N auf. Das Auftreten eines bestimmten Wertes einer Zufallsvariablen A = (X = xi ) nennt man Ereignis. P(A) ist die unbedingte (a priori) Wahrscheinlichkeit Dieses ist die Wahrscheinlichkeit, dass Ereignis A eintreten wird in dem Fall, dass 6.2 Statistischer Grundlagen 77 keine zusätzliche Information verfügbar ist Beispiel : X = W eather , xi = {Sunny, Rain, Cloudy, Snow} P (W eather = Sunny) = 0.7 P (W eather = Rain) = 0.2 P (W eather = Cloudy) = 0.08 P (W eather = Snow) = 0.02 P (X) ist der Vektor der Wahrscheinlichkeiten für den Wertebereich der Zufallsvariable X: also in dem vorliegendem Beispiel P (W eather) = h0.7, 0.2, 0.08, 0.02i Die Summe des Vektors P (X) muss immer 1 ergeben n X P (X = xi ) = 1 i=1 Liegen nun zusätzliche Informationen vor, kann nicht mehr mit der a priori Wahrscheinlichkeiten gerechnet werden, sondern mit der: P(A|B) bedingte (a posteriori) Wahrscheinlichkeit Dieses ist die Wahrscheinlichkeit des Ereignisses A unter der Bedingung B. Es ist also die Wahrscheinlichkeit, dass A eintritt nachdem B bereits eingetreten ist. P (X|Y ) ist die Tabelle aller bedingten Wahrscheinlichkeiten über alle Werte der Vektoren X und Y . Die bedingte Wahrscheinlichkeiten ergeben sich aus den unbedingten Wahrscheinlichkeiten (falls P (B) > 0) per Definition folgendermaßen : P (A|B) = P (A ∧ B) P (B) Umgekehrt lässt sich dann auch die absolute Wahrscheinlichkeit von P (A) aus den bedingten Wahrscheinlichkeiten von P (A|B) und der absolute Wahrscheinlichkeit von P (B) berechnen: X P (A) = P (A|Bi )P (Bi ) i Das Produktgesetz lautet: P (A ∧ B) = P (A|B)P (B) und P (A ∧ B) = P (B|A)P (A) 78 Bayes Netze Beispiel P (Sunny ∧ Headache) = P (Sunny|Headache)P (Headache) Das Summengesetz lautet: P (A ∨ B) = P (A) + P (B) − P (A ∧ B) außerdem gilt P (¬A) = 1 − P (A) 6.3 Aufbau Bayes-Netze Die Basis der Bayes-Netze bildet das Theorem von Bayes. Die Herleitung von diesem erfolgt über das Produktgesetz: Es gilt P (A ∧ B) = P (A|B)P (B) und P (A ∧ B) = P (B|A)P (A) Durch Gleichsetzen der rechten Seite folgt P (A|B)P (B) = P (B|A)P (A) −→ P (A|B) = P (B|A)P (A) P (B) Voraussetzung für das Bayes-Theorem ist die Kenntnis folgender Wahrscheinlichkeitswerte: 1. die a-priori-Wahrscheinlichkeiten P (A) und P (B) und 2. die a-posteriori Wahrscheinlichkeit P (B|A). Mit dem Bayes - Theorem können also unbekannte a-posteriori Wahrscheinlichkeiten aus bekannten Wahrscheinlichkeiten berechnet werden Beispiel: Wie hoch ist Wahrscheinlichkeit einer Bronchitis bei Husten P (Bronchitis) = 0.05 P (Husten) = 0.2 P (Husten|Bronchitis) = 0.8 daraus folgt: P (Bronchitis|Husten) = = P (Husten|Bronchitis) ∗ P (Bronchitis) (6.1) P (Husten) 0.8 ∗ 0.05 = 0.2 (6.2) 0.2 Jetzt stellt sich die Frage, warum man dann nicht gleich die Wahrscheinlichkeit einer Bronchitis bei Husten P (Bronchitis|Husten) schätzt? Das hat folgende Gründe: 6.3 Aufbau Bayes-Netze 79 Das Husten bei einer Bronchitis vorhanden ist P (Husten|Bronchitis), ist kausal und somit robuster, die Wahrscheinlichkeit ändert sich nicht so schnell. Das man aber auch eine Bronchitis hat, wenn man Husten hat P (Bronchitis|Husten) ist diagnostisch. Es ist von den a priori Wahrscheinlichkeiten abhängig : Tritt verhäuft eine Bronchitis P (Bronchitis) auf, so bleibt die Wahrscheinlichkeit von Husten bei einer Bronchitis P (Husten|Bronchitis) unverändert, jedoch nehmen Husten P (Husten) und Bronchitis bei Husten P (Bronchitis|Husten) proportional zu. Der Aufbau der Bayes-Netze ist nun folgendermaßen: • die Knoten sind die Merkmale (Zufallsvariablen) und • die Kanten repräsentieren die Abhängigkeiten • in/an den Knoten steht jeweils eine vollständige Tabelle bedingter Wahrscheinlichkeiten Der Graph ist azyklisch. (DAG) A B PSfrag replacements C D E Abbildung 6.1: Graph Anhand des Graphen in Abbildung 6.1 kann man erkennen, dass C von A und B abhängt, D jedoch nur von C. Daher lässt sich folgende Unabhängigkeitsannahme machen: P (D|C, B, A) = P (D|C) Mit den Knoten X1 , . . . , Xn und den Werten der Variablen x1 , . . . , xn gilt nach der Kettenregel P (x1 , . . . xn ) = P (xn |xn−1 , . . . , x1 ) ∗ . . . ∗ P (x2 |x1 ) ∗ P (x1 ) n Y = P (xi |xi−1 , . . . , x1 ) (6.3) (6.4) i=1 Durch die Unabhängigkeitsannahmen ist dies auch zur einfacheren Schreibweise P (x1 , . . . xn ) = n Y P (xi |parents(xi )) i=1 äquivalent, was bedeutet, dass jeder Knoten nur von seinen direkten Eltern abhängt. PSfrag replacements 80 Bayes Netze P(A)= 0.6/0.4 P(B)= 0.5/0.5 A B P(C|A=t,B=t)= 0.95/0.05 P(C|A=t,B=f)= 0.96/0.04 C P(C|A=f,B=t)= 0.26/0.74 P(C|A=f,B=f)= 0.01/0.99 P(D|C=f)= 0.05/0.95 D E P(D|C=f)= 0.10/0.99 P(D|C=t)= 0.90/0.10 P(D|C=t)=0.90/0.10 P(D|C=f)=0.05/0.95 P(E|C=t)=0.70/0.3 P(E|C=f)=0.01/0.99 P(E|C=t)= 0.70/0.30 Abbildung 6.2: Bayes-Netz Anhand des Graphen in Abbildung 6.2 lässt sich dann z.B. folgende Wahrscheinlichkeit berechnen: P (D, E, C, ¬B, ¬A) = P (D|C) ∗ P (E|C) ∗ P (C|¬B, ¬A) ∗ P (¬A) ∗ P (¬B) (6.5) = 0.90 ∗ 0.70 ∗ 0.01 ∗ 0.4 ∗ 0.5 (6.6) = 0.00126 (6.7) Wahrscheinlichkeitswerte gewinnt man Idealerweise aus aussagekräftigen statistischen Studien - oftmals wird man sie aber auch auf die Erfahrung basierend schätzen müssen 6.4 Diagnose mit Hilfe von Bayes-Netze Die Darstellung der Merkmale und ihrer Abhängigkeiten untereinander mit Hilfe der Bayes - Netze bietet zwei wesentliche Vorteile: Zum einen eine übersichtliche Form zur Erstellung und zur Darstellung einer Wissensbasis. Zum anderen bietet sie aber auch eine vorteilhafte Repräsentationsform für Computerbasierte Anwendungen. Hiermit können Knoten und Kanten nämlich leicht in einer formalisierten Datenstruktur gespeichert werden und außerdem kann die Bayes-Formeln für die Kanten vorberechnet werden. Damit entspricht eine Anfrage an ein Bayes - Netz lediglich noch einem Suchvorgang. Dass heißt, man setzt die Bayes-Netze dann ein, wenn man die Beurteilung von Abhängigkeiten zwischen Fakten möchte; wenn man also die Berechnung der wahrscheinlichste Diagnose Di für eine bestimmte, vorliegende Symptomkombination S1 . . . Sn will. Voraussetzungen sind allerdings die Kenntnis folgender Wahrscheinlichkeitswerte: 1. die a-priori-Wahrscheinlichkeiten P (Di ) einer Menge von n Diagnosen 2. den bedingten Wahrscheinlichkeiten P (Sj /Di ), d.h. der statistischen Häufigkeit des Auftretens der Symptome bei gegebener Diagnose Di . 6.4 Diagnose mit Hilfe von Bayes-Netze 81 das Bayes - Theorem lautet dann folgendermaßen: P (Di )P (S1 |Di ) ∗ P (S2 |Di ) ∗ . . . ∗ P (Sn |Di ) P (Di |S1 , . . . , Sn ) = Pn j=1 P (Dj )P (S1 |Dj ) ∗ P (S2 |Dj ) ∗ . . . ∗ P (Sn |Dj ) Damit kann man für verschiedenen Symptomen oder Symptomkombinationen die Wahrscheinlichste Diagnose berechnen. Beispiel : Wie hoch die Wahrscheinlichkeit einer Bronchitis(B) = Di oder eines Bronchialkarzinom (CA) = Dj bei den Symptomen Husten (Hu), Auswurf(A) und Heiserkeit(Hei)? P (B) ∗ P (Hu|B) ∗ P (A|B) ∗ P (Hei|B) (6.8) P (B) ∗ P (Hu|B) ∗ P (A|B) ∗ P (Hei|B) + P (CA) ∗ P (Hu|CA) ∗ P (A|CA) ∗ P (Hei|CA) 0.05 ∗ 0.8 ∗ 0.7 ∗ 0.4) = (6.9) 0.05 ∗ 0.8 ∗ 0.7 ∗ 0.4 + 0.001 ∗ 0.6 ∗ 0.5 ∗ 0.1 = 0.97 (6.10) P (B|Hu, A, Hei) = P (CA) ∗ P (Hu|CA) ∗ P (A|CA) ∗ P (Hei|CA) (6.11) P (B) ∗ P (Hu|B) ∗ P (A|B) ∗ P (Hei|B) + P (CA) ∗ P (Hu|CA) ∗ P (A|CA) ∗ P (Hei|CA) 0.001 ∗ 0.6 ∗ 0.5 ∗ 0.1 = (6.12) 0.0115 = 0.03 (6.13) P (Ca|Hu, A, Hei) = Wie man sieht ist die Wahrscheinlichkeit einer Bronchitis bei den vorliegenden Symptomen wesentlich höher, als die Wahrscheinlichkeit eines Bronchialkarzinom. Die Symptomkombinationen lassen sich im Bayes - Netz visualisieren. Auf diese Art wird die Abhängigkeit der Symptome übersichtlicht. Anhand des Graphen in Abbildung 6.3 lässt sich unschwer erkennen, dass A eine (mögliche) direkte Ursache für B und C darstellt. Somit würde eine Bestätigung von A also die Wahrscheinlichkeit, dass sowohl B als auch C wahr sind erhöhen. B und C werden wiederum als (mögliche) direkte Ursache für D angesehen, während nur C E auslösen kann. Beispiel: Wie hoch ist die Wahrscheinlichkeit von Krebsmetastasen bei erhöhtem Calciumspiegel ? Man sieht die Wahrscheinlichkeit einer Krebsmetastase beträgt 20%, die Wahrscheinlichkeit eines erhöhten Calciumspiegels bei Krebsmetastasen beträgt 80%, die eines normalen 20% Die absolute Wahrscheinlichkeit eines erhöhten Calciumspiegels beträgt: P (b̄) = P (b̄|a) ∗ P (a) + P (b̄|ā) ∗ P (ā) (6.14) = 0.20 ∗ 0.80 + 0.20 ∗ 0.80 (6.15) = 0.32 (6.16) Hiermit hat man alle Kenntnisse zusammen, die man benötigt um die Bayes - Regel anwenden zu können. Es ergibt sich also eine Wahrscheinlichkeit von Krebsmetastasen PSfrag replacements 82 Bayes Netze A Krebsmetastasen A : a = nein / ā = ja P (a)0.80/0.20 Calciumspiegel B : b =normal / b̄ = erhöht P (b|a) = 0.80 / 0.20 P (b|ā) = 0.20 / 0.80 Gehirntumor C : c = nein / c̄ = ja P (c|a) = 0.95 / 0.05 P (c|ā = 0.80 / 0.20 Koma D : d = nicht im Koma / d¯ = komatös P (d|b, c) = 0.95 / 0.05 P (d|b, c̄) = 0.80 / 0.20 P (d|b̄, c) = 0.80 / 0.20 P (d|b̄, c̄) = 0.80 / 0.20 Kopfschmerzen E : e = keine , ē = starke P (e|c) = 0.40 /0.60 P (e|c̄) = 0.20 / 0.80 B C D E P(a,b,c,d,e)=P(a)*P(b|a)*P(c|a)*P(d|b,c)*P(e|c) Abbildung 6.3: Bayes-Netz mit Krankheitssymptomen bei erhöhtem Calciumspiegel : P (b̄|ā) ∗ P (ā) P (b̄) 0.80 ∗ 0.20 = 0.32 = 0.50 P (ā|b̄) = (6.17) (6.18) (6.19) Gibt es nun neue Informationen über eine Variable, weil sie sich z.B. als wahr herausgestellt hat, hat das Auswirkungen auf die Wahrscheinlichkeiten der Zustände der anderen Variablen. Diese werden dann neu berechnet. Jedoch werden immer nur die absoluten Wahrscheinlichkeiten neu berechnet, nie die in den Tabellen gespeicherten bedingten Variablen. Ändert sich z.B. die Wahrscheinlichkeit von einem erhöhten Calciumspiegel P ( b̄) von den bisher 32% auf 100% ( weil er festgestellt wurde ) erhöht sich auch die Wahrscheinlichkeit von P (ā), den Krebsmetastasen Die genaue Berechnung der Änderungen kann in [Pea88] nachgelesen werden. Ein Beispiel für so ein Expertensystem ist MEDIKUS. Das steht für Modellbildung, Erklärung und Diagnose bei komplexen unsicheren Sachverhalten und ist ein Projekt der Universität - Oldenburg.[MED] Dieses Projekt hat zum Ziel hat ëin wissensbasiertes Werkzeug zu entwickeln, welches die Bildung von Erklärungsmodellen sowie diagnostische Strategien in Wissensbereichen unterstützt soll, die komplex, vernetzt und mit Unsicherheit behaftet sind.D̈abei liegt der Exemplarische Wissensbereiche in der Umweltmedizin und der Humangenetik. Das System soll später mal für Dienstleistungen, z.B. als Werkzeug zur Entscheidungsunterstützung eingesetzt werden. Der Implementationsstand zurzeit ist folgender: 6.5 Klassifikation mit Bayes-Netzen 83 • linguistischen Modelleditor: macht eine vereinfachte natürlichsprachliche Darstellung von Wissen möglich • graphischen Modelleditor: hier kann ein Erklärungsmodell direkt als BayesNetz aufgebaut werden • Übersetzer zur automatischen Umsetzung natürlichsprachlich formulierter Wissensinhalte in graphische Darstellung eines Bayes-Netzes. Das System wird mit diesem Beispiel vorgestellt: Beispiel : Chorea Huntington Die Chorea Huntington ist eine Erbkrankheit, die auf dem Untergang von Nervengewebe in verschiedenen Gehirnbezirken beruht. Dieses führt zu ungewollten, ausfahrenden und schleudernden Bewegungen; insbesondere die Arme und die Schultermuskeln sind betroffen. Anhand dieses Graphen kann man sehen, welche Faktoren einen Alter Alage beim Vater PSfrag replacements Anlage beim Vater Anlage beim Sohn Manifestation Abbildung 6.4: Bayes-Netz für Chorea Huntington Einfluss auf das Vorhandensein dieser Krankheit haben und wie sie sich gegenseitig beeinflussen. Die Knoten haben folgende Merkmalsvektoren Anlage beim Vater: ja, nein Alter: 0-10, 10-20, 20-30, 30-40, 40-50, 50-60, 60-70, 70-80 (Jahre) Manifestation: ja, nein Anlage beim Sohn: ja, nein Für die einzelnen Faktoren lassen sich absolute und bedingte Wahrscheinlichkeiten angeben. Beispielsweise p(AnlagebeimV ater(nein)) = 0.5 (6.20) p(Alter(20 − 30)) = 0.125 (6.21) p(M anif estation(nein)|Alter(50 − 60), AnlagebeimV ater(ja)) p(AnlagebeimSohn(nein)|AnlagebeimV ater(ja)) = 0.04 (6.22) = 0.5 (6.23) Dazu gibt es dann das in Abbildung ?? dargestellte Interface: In dem sich in der Mitte das Modell als Bayes-Netz befindet. Über, bzw. unter den Knoten befinden sich die zugehörige Evidenz (Beobachtung), sowie die berechneten Wahrscheinlichkeiten für die entsprechende Evidenz. 6.5 Klassifikation mit Bayes-Netzen Die Klassifikation in den medizinischen Bildanalyse - und Erkennungssystemen bedeutet die computergestüzte Entscheidung welche Segmente diagnostisch bzw. the- 84 Bayes Netze Abbildung 6.5: MEDIKUS rapeutisch relevant sind. Hierzu zählen z.B. z.B. Tumore oder Läsionen. Die Klassifikation ist zur Verarbeitung und Interpretation einer Vielzahl bildobjektspezifischer Merkmale und ihre Kombinationen notwendig. Sie soll, die mittels Segmentierung bestimmten Regionen vorgegebenen Klassen zuordnen, um Aussagen darüber treffen zu können was für Regionen das sind. In der Abbildung 6.6 repräsentiert x ein Merkmal, p(g) Luft Knochen PSfrag replacements wenig dichtes Gewebe dichtes Gewebe g Abbildung 6.6: Histogramm eines z.B. CT-Bildes in diesem Fall einen Grauwert gi und K1 . . . Kn die repräsentieren die verschiedenen Klassen. Aus dem Histogramm kann die Wahrscheinlichkeitsverteilungen geschätzt werden und wodurch die a-priori Wahrscheinlichkeit P (x ∈ Ki ) bekannt wird. Außerdem kann die bedingte Wahrscheinlichkeit P (x = gi |x ∈ Ki ) , dass x den Grauwert gi besitzt wenn es einer bestimmten Klasse angehört, abgelesen werden. Bei der Klassifikation wird nun nach der Klassenzugehörigkeit gesucht: P (x ∈ Ki |x = gi ) = P (x ∈ Ki )P (x = gi |x ∈ Ki ) P (x = gi ) 6.6 Zusammenfassung 85 Man sieht, dass x zu mehreren Klassen zugehören kann. Daher wird sich für die Klasse k entschieden, die die höchste a posteriori Wahrscheinlichkeit besitzt: k = arg max P (x ∈ Ki |x = gi ) i 6.6 Zusammenfassung Die Bayes-Netze sind gut zur Darstellung unsicheren oder komplexen Wissens geeignet. Jedoch ist einer ihrer großen Nachteile die Beschaffung dieses Wissens. Dieses nur von Experten schätzen zu lassen ist zu unsicher, daher muss das Netz oft mit Testdaten trainiert werden. Bayes-Netze werden bisher so gut wie gar nicht in der klinischen Praxis eingesetzt, da neben der fehlenden Integration in die Gesamt-EDV-Infrastruktur eines Krankenhauses und weiteren Problemen vor allem ein Problem dagegen spricht: Der Aufbau und die ständige Aktualisierung der Wissensbasis. Hier seien einige Systeme als Beispiele für den Umfang bisher realisierter medizinischer Wissensbasen genannt, nachzulesen unter [?]: • MYCIN: 450 Produktionsregeln • Internist-1 / QMR: 500 Krankheitsprofile • Iliad: 1.700 Krankheitsprofile • Dxplain: 2.100 Krankheitsprofile • HELP: 5.000 Wissensbankregeln • RMRS / CARE: 1.400 Wissensbankregeln Es wurden 10-20 Jahre als Zeiträume für die Entwicklung dieser Wissensbasen von jeweiligen Entwickler angegeben. Und trotzdem beinhalten diese Wissensbasen zusammen höchstenfalls 5%(!) (vermutlich noch deutlich weniger) des medizinischen Wissens. Daran sieht man, dass eine wirkliche Verwendung der Systeme in der Praxis noch lange nicht wirklich realisiert werden kann. 86 Bayes Netze Literaturverzeichnis [GSL01] C. Gelli, G. Schucan, and M. Leu. Expertensysteme. Technical report, Universität Zürich, 2000/2001. Seminar : Wissensmanagement. [Koc00] K.R Koch. Einführung in die Bayes-Statistik. Springer, Berlin [u.a.], 2000. [MED] Medikus. Technical report, Universität Oldenburg. Projekt : MEDIKUS. [Pea88] J. Pearl. Probalistic Reasoning in Intelligent Systems. Morgan Kaufmann, San Francisco,Calif, 1988. [Skra] http://www.imise.uni-leipzig.de/lehre/medinf/MMB/Skripte/Bayes/Bayes1.pdf. [Skrb] http://isgwww.cs.uni-magdeburg.de/bv/skript/mba/VL07.pdf. 88 LITERATURVERZEICHNIS Kapitel 7 Retina Ola Danysz 17.Juli 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼danysz 90 Retina Literaturverzeichnis 92 LITERATURVERZEICHNIS Kapitel 8 Endoskopie Philipp Schaer 24. Juli 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼schaer 94 Endoskopie 8.1 Motivation In der Medizin hat sich die Endoskopie zu einer hochtechnisierten Methode entwickelt, die in vielen Fachrichtungen eingesetzt wird. Leicht philosophisch betrachtet verwirklicht die Endoskopie zwei Grundbedürfnisse des Menschen (und der Ärzte im besonderen): Licht ins Dunkel zu bringen und das Sehen und Erkennen mit dem eigenen Auge [Kra02]. So stammt der Begriff der Endoskopie aus dem Griechischen und setzt sich zusammen aus den Wörter endo: innen, innerhalb und skopein: betrachten. Im Inneren des Körpers bieten sich vielseitige Möglichkeiten, die Offensichtlichste ist die der Inspektion innerer Organe (Coloskopie, Gastroskopie, etc). Aber auch für therapeutische (z.B. Zysten- oder Gallenblassenentfernungen unter minimal invasiven Operationsbedingungen) oder diagnostische Maßnahmen (Biopsien) kann die Endoskopie eingesetzt werden. Im allgemeinen bringt der Einsatz von Bildverarbeitung mehrere naheliegende Vorteile oder Verbesserungen mit sich. Zum einen wird versucht die Operations- oder Behandlungsbedingungen zu verbessern und dadurch eine Verbesserung der Ergebnisse zu erreichen. Wünschenswert sind natürlich auch eine Reduzierung des Risikos für die Patienten und der damit zusammenhängenden Komplikationen. Abbildung 8.1: Erste endoskopische Untersuchung 1868 von Dr. Kußmaul, durchgeführt an einem Schwertschlucker 8.2 Verschiedene Endoskope und Funktionsweisen 95 8.2 Verschiedene Endoskope und Funktionsweisen 8.2.1 Entwicklung des Endoskops Die erste endoskopische Untersuchung wurde bereits 1868 von Dr. Kußmaul 1 an einem Schwertschlucker durchgeführt (vergl. Abb. 8.1). Damals noch mit einem einfachen starren Rohr, als Beleuchtungsquelle mußte eine gewöhnliche Kerze herhalten. Später wurden zur Ausleuchtung glühende Platindrähte, Miniaturlampen und Spiegelund Linsensysteme verwendet, woher auch der im Deutschen oft benutze Begriff der “Spiegelung” stammt. Moderne Endoskope arbeiten mit lichtleitenden Glasfasern zur Lichtübertragung. Eine starke Beleuchtungsquelle sitzt ausserhalb des Endoskops und leitet das erzeugte Licht ins Innere des Körpers. Der Vorteil liegt darin, dass die immense Wärmeentwicklung nicht im Inneren des Körpers vorliegt und so dem Patienten ggf. verletzen könnte. Prinzipiell wird zwischen starren und flexiblen Endoskopen unterschieden (vergl. Abb. 8.3). Starre Endoskope finden häufig ihren Einsatz in der minimal invasiven Chirugie. Flexible Endoskope werden mehr zu diagnostischen Zwecken eingesetzt. Am bekanntesten sind wohl die Gastro- und Coloskopie (Darm- und Magenspiegelung). Flexible Endoskope Starre Endoskope Speiseröhre, Magen, Dünn-, Dickdarm Bauchhöhle Atemwege Atemwege, Brusthöhle Gallenwege Harnwege Harnblase Gynäkologische Eingriffe Blutgefäße Gelenke, Neurochirogische OP Abbildung 8.2: Verschiedene typische Einsatzgebiete für flexible und starre Endoskope Abbildung 8.3: Nachteile der Glasfaserendoskope 8.2.2 Aufbau eines Endoskops Die bis vor kurzem noch übliche Bildübertragungstechnik bei endoskopischen Maßnahmen war die Glasfaserbildübertragung [Kra02]. Zur Bildübertragung wird ein kohärentes Glasfaserbündel aus bis zu 50.000 Einzelfasern eingesetzt. Dies entspricht einer Bildauflösung von ca. 220*200 Bildpunkten. Das Bild wird aufgerastert und über die Glasfasern zum Okularobjektiv gespiegelt und dort wieder zu einem Bild zusammengesetzt. Das so übertragene Bild kann entweder direkt durch das Okular betrachtet werden oder über eine externe aufgesetzte Videokamera auf einen Monitor übertragen werden. In diesem Fall spricht man von einer indirekten Videoendoskopie [Kra02]. Auf Abbildung 8.3 sehen wir allerdings die Nachteile, die diese Art der Bildübertragung mit sich bringen. Ein aufgerastertes Objekt kann durch schlechte Auflösung, 1 Dr. Adolf Kußmaul, prakt. Arzt aus Freiburg 96 Endoskopie ungeordnete, ungleichmäßige oder schlichtweg zu dicke Fasern nicht mehr korrekt erkannt werden. Der Arzt kann mit den so erlangten Bildern nur sehr schwer arbeiten. 8.2.3 Der Schritt zur digitalen Verarbeitung Eine direkte digitale Aufnahme mittels eines CCD Chips liegt nahe, da sich all diese Probleme durch den Einsatz verhindern, bzw. ausbessern lassen. Die Möglichkeit zum Einsatz von CCD-Technologie ist allerdings noch beschränkt auf eine Mindestdicke des verwendeten Endoskops von ca. 4-5 mm. Ausgeschlossen sind damit zur Zeit noch ein Einsatz im Bereich der Endoskopie von Blutgefäßen, Harn-, Gallen- oder Atemwegen. 8.3 Verfahren am Beispiel der laparoskopische Gallenblasenentfernung Abbildung 8.4: links: Schematische Darstellung einer Laparoskopie, rechts: Aufnahme während einer Operation Auch wenn die direkte digitale Aufnahme der Bilder viele Probleme der klassischen Videoendoskpie löst bleiben doch noch viele weitere Probleme bestehen. Exemplarisch wurde hier eine Laparoskopie2 ausgewählt, um einige typische Probleme zu erläutern und Lösungsansätze aus dem Bereich der Bildverarbeitung zu präsentieren. Unser spezielles Beispiel ist eine laparoskopische Cholezystektomie 3. Bei dieser Operationsmethode werden mehrere endoskopische Intrumente durch kleine, ca. 2 cm große Schnitte in der Bauchdecke, in den Bauchraum eingeführt. Der Bauchraum wird mit CO2 gefüllt und aufgebläht, um den benötigten Platz für die Operation im Bauchinnenraum zu schaffen. Eine Videoendoskopie ist hier zwangsläufig notwendig, da mehrere Personen gleichzeitig den Operationsraum begutachten müssen, so z.B. der operierende Arzt und weitere Assistenten, etc. Es handelt sich hierbei um eine sogenannte minimalinvasive Operation (vgl. Abb. 8.4). 2 Endoskopie des Bauchraums 3 Gallenblasenentfernung 8.3 Verfahren am Beispiel der laparoskopische Gallenblasenentfernung 97 8.3.1 Typische Probleme einer Laparoskopie Bei der Endoskopie des Bauchraums entstehen charakteristische Bildstörungen, wie z.B. Glanzlichter, Verzerrungen, Farbfehler oder eventuell vorhandene Schwebepartikel. Glanzlichter entstehen durch Reflexionen der Beleuchtungsquelle an feuchten Organoberflächen. Sie erzeugen starke Kontraste im Bild, die die Bildqualität beeinträchtigen. Durch die eingesetzten Kameraoptiken, die häufig mit Weitwinkeln arbeiten kommt es häufig zu Verzerrungen im Bild. Der Operationsraum Bauch birgt weiterhin die Gefahr von freien Schwebepartikeln. Diese entstehen bei der Verbrennung von Gewebe, was z.B. bei der Präparation von Wunden vorkommt. Die Schwebepartikel verschlechtern die Sicht und machen im schlimmsten Falle einen kompletten Austausch des CO2 nötig. Letztendlich kommt es häufig zu Farbfehlern in den Bildaufnahmen. Diese sind bedingt durch die vorwiegend rötliche Farbe im Bauchinneraum (z.B. Blut und Gewebe). Abbildung 8.5 zeigt einige Beispiele für solche Störungen. Abbildung 8.5: Typische Bildstörungen, links: Farbfehler, mitte: Schwebepartikel, rechts: Glanzlichter und Farbfehler 8.3.2 Das Problem der Glanzlichter Als Glanzlichter bezeichnen wir überbelichtete Stellen im Bild. Dabei handelt es sich um Gewebe, das orthogonal zur Blickrichtung ausgerichtet ist und dadurch überbelichtet wird. Bei der Endoskopie wird das Problem noch dadurch verschärft, dass die Lichtquelle direkt neben der Kamera sitzt. Durch die Überbelichtung hat der Arzt keine Möglichkeit das darunterliegende Gewebe zu erkennen, weder die Farbe, noch die Struktur. Im Folgenden werden einige Lösungsansätze präsentiert um die Glanzlichter zuverlässig zu detektieren und ggf. durch korrekte Farbwerte zu ersetzen. einfallendes Licht reflektierender Anteil diffuser Anteil Abbildung 8.6: links: Glanzlichter in einer endoskopischen Aufnahme des Bauchraums, rechts: Schema des Dichromatischen Reflexionsmodells 98 Endoskopie Dichromatisches Reflexionsmodell Das Dichromatische Relexionsmodell ist eine Erweiterung des allgemeinen, gebräuchlichen Monochromatischen Reflexionsmodells [Sha85]. Es gibt hierbei nicht nur eine Reflexionsfarbe, sondern der reflektierte Teil spaltet sich auf in eine sogenannte Oberflächen- und Körperreflexion (vgl. Abb. 8.6). Dies bedeutet, dass ein Bestandteil der einfallenden Lichtwellen unter die Oberfläche dringt, von den Pigmenten absorbiert, gestreut und schließlich diffus das Objekt wieder verläßt. Dies ist die Körperreflexion. Ein anderer Teil der Lichtwellen wird allerdings direkt an der Oberfläche gespiegelt, dringt nicht unter die Oberfläche und ist daher auch invariant bzgl. der Körperfarbe. Die Farbe der Oberflächenreflexion ist also relativ konstant bzgl. der Wellenlänge des einfallenden Lichtes. Es wird angenommen, dass es sich bei diesem Teil der Reflexion um den glanzlichtproduzierenden Teil handelt. Mathematisch läßt sich das Dichromatische Reflexionsmodell wie folgt durch die Formel von Shafer [Sha85] darstellen: C = mb (n, s) Z fC (λ)e(λ)cb (λ)dλ + ms (n, s, v) λ Z fC (λ)e(λ)cs (λ)dλ(8.1) λ Die Wellenlänge ist λ, n die Oberflächennormale, s die Ausrichtung der Belichtungsquelle (Source) und v die Blickrichtung des Betrachters. Die Reflexionseigenschaften und das Rückstrahlvermögen des Körpers (Body) und der Oberfläche (Surface) werden in cb (λ) und cs (λ) festgehalten. Bezeichnen durch mb , ms werden die geometrische Abhängigkeit der Körper- und Oberflächenreflexion. Das einfallende Licht wird durch e(λ) repräsentiert. Die gesamte Formel liefert also einen von den Sensoren des CCD-Chips aufgenommen Farbwert. Farbräume nach Grever und Stokman Grevers und Stokman stellen in [GS00] folgende Vereinfachung vor. Die Überlegungen zu dieser Vereinfachungen beruhen auf einer NIR (neutral interface reflection) und einer vollständig weißen Beleuchtungsquelle. Die NIR besagt, dass c s (λ) und e(λ) und unabhängig von λ sind, also von der Wellenlänge des einfallenden Lichtes. Dies macht Sinn vor dem Hintergrund der Vorüberlegungen aus Abschnitt 8.3.2. Es ergibt sich also e(λ) = e und cs (λ) R = cs . Desweiteren sei kC = λ fC (λ)cb (λ)dλ. Dies fasst die Abhängigkeit von Sensoren und Oberflächenreflexion zusammen. Es ergibt sich folgende vereinfachte Form: Cw = emb (n, s)kC + ems (n, s, v)cs Z fC (λ)dλ (8.2) λ Cw kann nun interpretiert werden als: “Gesehene Farbe unter der Annahme einer weißen Beleuchtung”. Stokman und Grevers Rvereinfachen weiterhin, immerRnoch unter der Annahme eiR ner weißen Beleuchtung, λ fR (λ)dλ = λ fG (λ)dλ = λ fB (λ)dλ = f . Da wir im RGB-Raum arbeiten gehen wir also bei einer weißen Beleuchtung von gleichmäßigen hohen werten für alle Kanäle aus. Schlußendlich ergibt sich folgende, kompakte Formel: Cw = emb (n, s)kC + ems (n, s, v)cs f {z } | {z } | Cb Cs (8.3) 8.3 Verfahren am Beispiel der laparoskopische Gallenblasenentfernung 99 Basierend auf dieser vereinfachten Form des Dichromatischen Reflexionsmodelles werden zwei neue Farbräume definiert. In ihren Versuchen haben Stokman und Grevers photometrische Invarianzen dieser Farbmodelle gezeigt. Ihre Versuche bezogen sich dabei auf Bildererkennungsalgorithmen, die mit den unterschiedlichen Farbräumen getestet wurden. Zuerst wird der Farbraum c1 c2 c3 vorgestellt. Aus den vorhandenen RGB Werten werden die c1 c2 c3 Farbwerte errechnet. c1 c2 c3 R ) max{G, B} G = arctan( ) max{R, B} B ) = arctan( max{R, G} = arctan( (8.4) (8.5) (8.6) cn stellt dabei die Winkel der Körperreflexion dar, welche konsequenterweise invariant für matte Oberflächen sind. In unserer Annahme gingen wir von einer diffusen Körperreflexion aus. Formel 8.7 zeigt, dass c1 nur abhängig von Sensoren- und Oberflächeneigenschaften ist. Gleiches gilt für c2 und c3 . emb (n, s)kR ) max{emb (n, s)kG , emb (n, s)kB } kR = arctan( ) max{kG , kb } c1 (Rb , Gb , Gb ) = arctan( (8.7) (8.8) Bei dem zweiten neuen Farbraum l1 l2 l3 handelt es sich um normalisierte Farbabstände. |R − G| |R − G| + |R − B| + |G − B| |R − B| l2 = |R − G| + |R − B| + |G − B| |G − B| l3 = |R − G| + |R − B| + |G − B| l1 = (8.9) (8.10) (8.11) Anwendung zur Glanzlichtdetektion Ausgehend von den schon beschriebenen Versuchen zur Objekterkennung zeigten sich besondere Eigenschaften der neuen Farbräume. Tabelle 8.7 zeigt die entsprechenden Sensitivitäten und Invarianzen gegenüber bestimmten Bildeigenschaften. In den entsprechenden Farbraumbildern werden Kantendetektionen durchgeführt. Im normalen RGB-Bild werden Kanten sowohl bei Objektformänderungen, Schatten, Glanzlichtern und Materialveränderungen beobachtet. Die neu definierten Farbräume zeigen nur zu bestimmten Bildeigenschaften eine Kante an. Diese Eigenschaften werden ausgenutzt um gezielt nur Glanzlichtkanten zu detektieren. Folgender kleiner “Algorithmus” ermöglicht es gefundene Kanten im Bild klassifizieren zu können [GS00]. • KanteRGB − Kantec1 c2 c3 ⇒ Schatten- oder Objektkante • Kantec1 c2 c3 − Kantel1 l2 l3 ⇒ Glanzlichtkante • Kantel1 l2 l3 ⇒ Materialübergangskante 100 Endoskopie RBG c1 c2 c3 l1 l2 l3 Objektform + - Schatten + - Glanzlichter + + - Materialveränd. + + + Abbildung 8.7: Eigenschaften der unterschiedlichen Farbräume: (+) Sensitivität für Bildeigenschaft, (-) Invarianz und Robustheit gegenüber Bildeigenschaft Ergebnisse Die Abbildungen 8.8 und 8.9 zeigen zwei Beispielergebnisse für das zuvor beschriebene Verfahren. Das künstliche Beispiel (Abb. 8.8) veranschaulicht die einzelnen Schritte zur Detektion der einzelnen Glanzregionen. Da durch das Verfahren nur Glanzlichtkanten detektiert werden, allerdings keine Glanzlichtregionen wird nachträglich noch ein Füllalgorithmus (z.B. mit Schwellwerten) eingesetzt. Abbildung 8.8: Künstliches Beispiel, obere Reihe: Kanten im RGB-, c1 c2 c3 und l1 l2 l3 -Farbraum, rechts-unten: klassifizierte Glanzlichtkante Abbildung 8.9: Beispielbild aus Endoskopieaufnahme, nach Anwendung eines Füll-Algorithmus HSV-Modell als Alternative Speziell bei endoskopischen Aufnahmen des Bauchinnenraums zeigt das Dichromatische Reflexionsmodell einige Schwächen. Die Annahme des vorherigen Verfahrens sah eine konstante weiße Beleuchtung voraus. Bei der Beleuchtung des vorwiegend roten Gewebes kann der rote reflektierte Farbanteil wiederrum als Beleuchtungsquelle für benachbartes Gewebe gerechnet werden. So stimmen die Voraussetzungen für die ab Abschnitt 8.3.2 vorgenommenen Vereinfachungen und Umformungen nicht mehr. Alternativ hat sich ein Schwellwertverfahren im HSV -Raum bewährt. Glanzlichter sind charakterisiert durch eine geringe Sättigung S und eine hohe Intensität V . Die Annahme dass durch solch ein Schwellwertverfahren auch einfache, weiße helle Flächen detektiert werden könnten, ist nur begrenzt richtig, da solche Flächen im Bauchraum nicht vorkommen. Anschließend an das Schwellwertverfahren wird noch eine Dilatation mit z.B. der Maskengröße 3x3 angewendet, um eine geschlossene Glanzlichtregion zu erhalten. Ergebnissbilder dieses Verfahren sieht man auf der Abbildung 8.10. 8.4 Ausblick 101 Abbildung 8.10: Glanzlichterkennung mit Hilfe des HSV-Modells, von links: 1. Orginalbild, 2. Nach Schwellwertverfahren, 3. Nach zusätzlich einer Dilatation, 4. Nach insgesamt 3 Dilatationen Glanzlichtsubstitution durch Lichtfelder Die Glanzlichterkennung alleine ist nicht ausreichend. Wünschenswert ist eine Ersetzung der Glanzlichter durch möglichst korrekte Farbwerte, dies fasst man unter dem Begriff Glanzlichtsubstitution zusammen. Eine Möglichtkeit zur Glanzlichsubstitution bietet der Einsatz von Lichtfeldern. Lichtfelder ermöglichen es aus einer Sequenz von aufgenommenen Kamerabildern unbekannte Kamerapositionen zu errechnen. Hierfür wird versucht aus der Sequenz 3D-Informationen zu gewinnen und ein 3D-Modell der Szene zu berechen. Für eine korrekte Konstruktion eines Lichtfeldes aus einer realen Szene müssen große Ansprüche an die Kalibrierung der intrinsischen (z.B. Brennweite) und extrinsischen (Position und Orientierung) Kameraparameter, sowie an eine robuste Punktverfolgung gesetzt werden. Dies ist nötig um bei einem niedrigen Signal-zu-Rausch Verhältnis noch korrekt kalibrieren zu können und mit Ausreissern und Ungenauigkeiten zurecht zu kommen [VPS+ 02]. Um eine Unterscheidung zwischen Pixeln, die nicht rekonstruiert werden können oder sollen und solchen, auf die eine Rekonstruktion angewendet werden soll, zu ermöglichen wird eine sogenannte Vertrauenskarte eingeführt. Diese Vertrauenskarte besitzt die gleichen Bilddimensionen wie das Ursprungsbild und besteht aus Werten zwischen 0 und 1. Die Vertrauenskarte wird auf 1 gesetzt, falls genug 3D-Informationen vorliegen; sie wird auf 0 gesetzt, falls keine 3D-Informationen verfügbar sind. Auf das Beispiel der Glanzlichter bezogen bedeutet dies, dass Glanzlichtstellen einen Wert von 0 auf der Vertrauenskarte erlangen. Dies sind folglich die Gebiete, die durch Informationen aus anderen Bildern der Sequenz ergänzt, bzw. ersetzt werden sollen um ein korrektes Bild zu erhalten. Ein Wert 0 in der Vertrauenskarte bedeutet, dass die Farbinformationen an dieser Stelle durch Interpolation von benachbarten Punkten im Lichtfeld ermittelt werden. Das Ergebnis ist ein Lichtfeld, in dem korrekte Bildinformationen anstelle der unbrauchbaren Glanzlichter zu sehen sind (siehe Abbildung 8.11). Das Unsichtbare wird sichtbar gemacht [VPS+ 02]. 8.4 Ausblick Auch wenn eine Endoskopie heutzutage nicht mehr so barbarisch anmutet wie zu Dr. Kußmauls Zeiten (vgl. Abbildung 8.1), ist eine solche Untersuchung, speziell in der Diagnostik, für den Patienten eine unangenehme und teilsweise schmerzliche Situation. Als Ausblick werden zwei zukunftsträchtige Technologien vorgestellt, die erstmals den Begriff minimalinvasiv nicht nur in Bezug zu einer Operation setzen, sondern auch zur 102 Endoskopie unbekannte Kamerasicht bekannte Kamerasicht Orginalbild Abbildung 8.11: Glanzlichtsubstitution mit Hilfe von Lichtfeldern, von links: 1. Schematische Darstellung, 2. Gerendertes Gallenblasenbild (ohne Vertrauenskarte), 3. Gerendertes Gallenblasenbild (mit Vertrauenskarte), 4. Differenzbild Diagnostik. 8.4.1 Virtuelle Endoskopie Die Virtuelle Endoskopie stellt eine effiziente Methode dar um große Bilddatenmengen aus Elektronenstrahl- und Spiralröntgentomographen zu verarbeiten. Die Ergebnisse dieser Aufnahmen werden nicht mehr als Schichtenbilder präsentiert, sondern werden als 3D Modell visualisiert. Dies kann nicht nur zur interoperativen Unterstützung genutzt werden, sondern auch zur Therapiekontrolle [ESB+ 00]. Ein Beispiel sei hier die VR-Bronchoskopie. Die klassische Bronchoskopie wird häufig im Zusammenhang mit Bronchoskarzinomen (Lungenkrebs, häufigste krebsbedingte Todesursache) durchgeführt. Dieser klassiche Weg birgt allerdings einige gravierende Nachteile. Die Eindringtiefe mit dem Bronchoskop ist, bedingt durch die Instrumentendicke und die extremen Verschachtelungen in den Bronchien, begrenzt. Die Invasivität des Verfahrens ist sehr unangenehm. Desweiteren existieren hohe Komplikationsrisiken, wie z.B. Infektionen oder Perforationen des feinen Lungengewebes. Starre Endoskopien an den Bronchien verlangen sogar eine Vollnarkose, die weitere Probleme mit sich bringt. Abbildung 8.12: links: Virtuelle Endoskopie mit Dastellung implantierter Stents, mitte und rechts: Endoskopiekapsel der Firma Given Image Die Vorteile der Virtuellen Endoskopie liegen klar in der minimalen Invasivität und den neuen Zugänge zur visuellen Exploration großer Bilddatenmengen. 8.4.2 Kamerakapseln Herkömmliche Endoskope können nicht alle Regionen des Körpers erreichen und sichtbar machen. So ist der Dünndarm nur unter sehr schweren Bedingungen erreichbar. Zur Untersuchung spezieller Krankheiten (Morbus-Crohn) und Symptome (okkulte 8.5 Zusammenfassung und Ergebnis 103 Blutungen) ist eine Endoskopie des Dünndarm allerdings zur genauen Diagnose notwendig. Die israelische Firma Given Imaging Ltd.4 hat eine Kapsel entwickelt, die eine vollständige CCD-Kamera enthält und bis zu acht Stunden Bilder aus dem inneren des Körpers senden kann. Die Kapsel wird vom Patienten geschluckt und durchläuft den normalen Verdauungsweg. Ein einfaches Schlucken ist möglich, da die Kapsel mit ihren Ausmassen von nur 26mm Länge und 11mm Durchmesser nicht größer ist als ein normales Hustenbonbon. Die Kapsel wird durch die natürliche Darmtätigkeit passiv weiterbewegt. Bei der Kapsel handelt es sich um ein “Wegspül”-Produkt, dass heisst, sie muss nicht nach dem Ausscheiden ausgelesen werden. Die aufgenommenen Daten werden direkt aus dem Körper gesendet und durch ein Sensorenarray, dass der Patient am Körper trägt aufgezeichnet. Diese Sensoren zeichnen gleichzeitig die Position der Kapsel auf. Eine spezielle Software sorgt dafür, dass der diagnostizierende Arzt nicht alle acht Stunden des aufgezeichneten Videomaterials betrachten muss, sondern schneidet die Videodaten direkt zusammen und filtert Sequenzen mit wenigen oder keinen Änderungen heraus, so dass ein zu betrachtendes Video von 30-40 Minuten Länge entsteht. Bisher beschränkt sich diese Art der Untersuchung noch auf den Dünndarm, da die Batterieleistung noch auf maximal acht Stunden gegrenzt ist. Ein Erkennen von z.B. Krebs oder Zysten im Dickdarm ist dadurch leider noch nicht möglich. 8.5 Zusammenfassung und Ergebnis Die Endoskopie bietet viele Möglichkeiten Verborgenes im Körper des Menschen sichtbar zu machen. Doch das sichtbargemachte Verborgene selbst birgt noch Verborgenes in sich, dass der Bildverarbeitung weite Betätigungsfelder bietet um diese Bildinformationen weiter zu verbessern oder erst zum Vorschein zu bringen. Interdisziplinäre Methoden, wie die Virtuelle Endoskopie, die viel mit den Verfahren der Computergrafik arbeiten zeigen, dass auf dem Gebiet der Endoskopie vorerst kein Ende der technischen Entwicklung zu sehen ist. Da es sich bei Endoskopieaufnahmen in der Regel um bewegte Bilder und keine Standaufnahmen handelt, sind die hier im Text präsentierten Bilder, z.B. zum Phänomen der Glanzlichter, nicht immer perfekt geeignet um das Problem zu veranschaulichen. Das wirkliche Problem, die Aufnahmen nicht richtig erkennen zu können sieht man nur in tatsächlichen bewegten Aufnahmen. Zu diesem Zweck habe ich unter der URL http://www.schaer.de/studium/medbv einige Videoaufnahmen verschiedener Endoskopieverfahren zum Download bereitgestellt. 4 http://www.givenimaging.com 104 Endoskopie Literaturverzeichnis [ESB+ 00] K.-H. Englmeier, M. Siebert, R. Brüning, J. Scheidler, and M. Reiser]. Prinzipien and derzeitige möglichkeiten der virtuellen endoskopie. CEUR Workshop - Bildverarbeitung für die Medizin, 2000. [GS00] Th. Grevers and H. M. G. Stokman. Classifying color transitions into shadow-geometry, illumination highlight or material edges. Proceedings of the International Conference on Image Processing (ICIP), 2000. [Kra02] Rüdiger Kramme. Medizintechnik - Verfahren, Systeme, Informationsverarbeitung. Springer Verlag Berlin, 2002. [Sha85] S. A. Shafer. Using color to seperate reflection components. COLOR research an application, pages 210–218, 1985. [VKP+ 00] F. Vogt, C. Klimowicz, D. Paulus, W. Hohenberger, H. Niemann, and C.H. Schick. Bildverarbeitung in der endoskopie des bauchraums. 2000. [VPS+ 02] F. Vogt, D. Paulus, I. Scholz, H. Niemann, and C. Schick. Glanzlichsubstitution durch lichtfelder - unsichtbares wird sichtbar. -, 2002. 106 LITERATURVERZEICHNIS Kapitel 9 Dermatologie Christian Bauer 31.Juli 2003 Institut für Computer Visualistik Universität Koblenz-Landau Universitätsstraße 1, 56070 Koblenz [email protected] http://www.uni-koblenz.de/∼chrbauer 108 Dermatologie Abbildung 9.1: Zwei Beispiele maligner Melanome. 9.1 Einleitung Diese Ausarbeitung behandelt die Erkennung von schwarzem Hautkrebs mit Hilfe der medizinischen Bildverarbeitung und basiert auf der Doktorarbeit von René Pompl [Pom00]. Sie ist das dritte und abschließende praktische Beispiel dieses Seminars. 9.2 Motivation Das maligne Melanom1 ist die bösartigste beim Menschen auftretende Hautkrankheit (siehe Abbildung 9.1). 10% der Hautkrebsfälle aber 75% der Hautkrebstoten in den USA sind ein eindeutiges Indiz für die Aggressivität dieser Krankheit. Der Tumor geht von den Melanozyten2 aus und ist ein bösartiges Geschwulst der Schleimhäute und der Haut. Das Wachstum erfolgt zuerst an der Hautoberfläche und geht später in die Tiefe. Hier kommt es zur Metastasierung 3 . Aus diesem Grund sinken mit der Eindringtiefe des malignen Melanoms die Überlebenschancen rapide. Für eine effektive Behandlung mittels Entfernen des befallenen Gewebes ist eine möglichst frühe Diagnose von Nöten. Die richtige Einschätzung einer Läsion ist jedoch sehr schwierig. Nur Dermatologen mit sehr viel Erfahrung auf diesem Gebiet erreichen mit Hilfe der Dermatoskopie eine zu 90% korrekte Diagnose. Ein Analysesystem, dass Dermatologen bei der Diagnose unterstützt und dabei transparent und in seinen Einzelschritten nachvollziehbar bleibt, erscheint deswegen sinnvoll. In den folgenden Abschnitten soll zu so einem Analysesystem ein kleiner Einblick vorgenommen werden. In Abschnitt 3 wird auf die Dermatoskopie eingegangen. Darauf folgt Abschnitt 4 über die Merkmale einer Läsion und die dermatoskopische ABCD-Regel. In Abschnitt 5 werden die Haardetektion, die Segmentierung, zwei Merkmalsanalysen und der Klassifikator vorgestellt. In Abschnitt 6 folgt die abschließende Zusammenfassung. 1 Medizinische Bezeichnung für „schwarzer Hautkrebs“. Das Gegenstück ist ein unschädlicher Hautfleck und trägt die medizinische Bezeichnung „benigne melanozytäre Hautveränderung“. 2 Pigmentbildenende Zellen der Haut. 3 Verteilung von Tumorzellen über Blut- und Lympfgefäße im Körper. 9.3 Dermatoskopie 109 Abbildung 9.2: Zwei Dermatoskope: Links: Ein Dermatoskop wie es für die Dermatoskopie von Dermatologen verwendet wird. Rechts: Ein Dermatoskop mit aufmontierter Digitalkamera. 9.3 Dermatoskopie Ausgangspunkt für dieses Vorhaben ist die Dermatoskopie oder auch Auflichtmikroskopie. Das Dermatoskop (Abbildung 9.2) ähnelt einer Handlupe mit zehnfacher Vergrößerung und einer Beleuchtungsvorrichtung. Desweiteren hat das Dermatoskop einen Vorbau mit Glasplatte. Durch den Vorbau wird ein gleichbleibender Abstand eingehalten. Mit der Glasplatte wird die Haut durch Druck geglättet und fehlerverursachende Unebenheiten minimiert. Die Verwendung einer Kontaktflüssigkeit verbessert die Erkennbarkeit von Farben und Strukturen der betrachteten Läsion und tiefere Strukturen werden sichtbar. Geringe Veränderungen machen das Dermatoskop für das Analysesystem nutzbar. Die Verwendung einer Digitalkamera mit einem Vorbau der dem Dermatoskop entspricht, ermöglicht standardisierte Aufnahmen von den Läsionen, die dann vom Analysesystem ausgewertet werden. Die Bilder haben eine Auflösung von 44 Pixel/mm und eine Größe von 512 × 512 Pixel. Der verwendete Farbraum ist RGB mit 8bit/Kanal. Ein Dermatoskop mit Digitalkamera ist in Abbildung 9.2 dargestellt. 9.4 Merkmale Die Bilder der Läsionen werden vom Analysesystem auf Merkmale untersucht, an denen eine Unterscheidung von malignen Melanomen zu benignen melanozytären Hautveränderungen vorgenommen werden kann. Zur Auswahl stehen grundsätzlich sämtliche visuellen Eigenschaften, die eine Läsion ausmachen und in der Bildverarbeitung verarbeitet werden können wie zum Beispiel Farb-, Form- und Struktureigenschaften. Für die Effektivität des Analysesystems ist es entscheidend, welche Merkmale gewählt werden. Eine möglichst eindeutige Klassifikation von malign zu benign ist hier erwünscht. In diesem Fall wird zusätzlich verlangt, dass das System für den Dermatologen in der Diagnose verständlich und nachvollziehbar ist. Dadurch fallen Merkmale weg, deren Eigenschaften zwar von einem Computer errechnet, aber vom menschlichen Auge nicht verarbeitet werden können. Deswegen erscheint es ratsam, sich bei der Auswahl der Merkmale an der von Dermatologen verwendeten Methode zu orientieren. Der Dermatologe wird in dem von ihm praktizierten Verfahren wirklich unterstützt. 110 Dermatologie 9.4.1 dermatoskopische ABCD-Regel Das von Dermatologen verwendete Verfahren heißt dermatoskopische ABCD-Regel. Hierbei finden vier Merkmale Anwendung: Asymmetrie An zwei imaginären Linien wird kontrolliert, in wie fern die Läsion asymmetrische Eigenschaften aufweißt. Die Überprüfung erfolgt anhand Geometrie, Farbe und Strukturvielfalt. Begrenzung Es wird beurteilt, wie sehr der Übergang von der Läsion zur umgebenden Haut eine scharfe Kante aufweißt bzw. wie fließend dieser ist. Farbtöne Die Anzahl der in der Läsion auftretenden Farbtöne wird gezählt. Typische auftretende Farben sind weiß, rot, hellbraun, dunkelbraun, blaugrau und schwarz. Differentialstruktur In Läsionen können strukturelle Formen wie Streifen, Schollen, Netzwerke und Punkte auftreten. Die Anzahl der Strukturformen wird hier bewertet. Die einzelnen Merkmale werden bewertet und mit einer festgelegten Gewichtung aufsummiert. Daraus ergibt sich der sogenannte Dermatoskopie-Punktewert. Umso höher dieser ist, desto größer ist das Risiko eines malignen Melanoms. Problematisch ist, dass die Merkmale objektiv definiert sind, aber vom Dermatologen anhand seiner Erfahrungen subjektiv bewertet werden. Ein Analysesystem ist hier im Vorteil, da es objektiv ist. 9.4.2 Verwendete Merkmale Die sich für das Analysesystem qualitativ durchgesetzte Merkmalskombinaton ist von den Merkmalen her denen der dermatoskopischen ABCD-Regel sehr ähnlich und besteht aus den folgenden sechs: • Die Asymmetrie der Farbverteilung • Die Asymmetrie der Strukturverteilung • Die Krümmung der Kontur • Die Vielfalt der Farben • Die Vielfalt der Strukturen • Die Größe der Läsion 9.5 Verfahren zur Merkmalsanaylse Der folgende Abschnitt befaßt sich mit einem Überblick über die Vorverarbeitung (Haardetektion, Segmentierung), einer genaueren Vorstellung zweier Verfahren zur Merkmalsextraktion und abschließend mit dem Klassifikator. 9.5 Verfahren zur Merkmalsanaylse 111 Abbildung 9.3: Aus [Pom00] Seite 96 Beispiel zur Haardetektion. Links sind detektierte Haare weiß hervorgehoben. 9.5.1 Haardetektion Haare erscheinen wie die zu untersuchenden Läsionen dunkler als die Haut. Deswegen können durch sie die Segmentierung der Läsion und die spätere Merkmalsanalyse beeinflußt und verfälscht werden. Auf ein Grauwertbild der Läsionsaufnahme wird wegen der länglichen und dünnen Struktur von Haaren ein Liniendetektionsverfahren angewandt. Stücke länger als 125 Pixel4 werden als Haar angesehen. Abbildung 9.3 zeigt eine durchgeführte Haardetektion. 9.5.2 Segmentierung Hier wird die dunklere Läsion von der Haut mittels eines Schwellwertbasierten Verfahrens getrennt. Zuerst wird ein Grauwerthistogramm des Blaukanals 5 erstellt, ohne die Pixel der Haare zu berücksichtigen. Ein solches Grauwerthistogramm ist in Abbildung 9.4 zu sehen. Der gesuchte Schwellwert befindet sich im Minimum zwischen Abbildung 9.4: Aus [Pom00] Seite 97 Grauwerthistogramm des Blaukanals einer Läsionsaufnahme. den dunklen (Läsion) und den hellen Grauwerten (Haut 6 ). Nachdem das Histogramm 4 Dieser Wert wurde in Versuchen ermittelt. Hautveränderungen enthalten im Gegensatz zur Haut einen Blauanteil. Dadurch wird das Verfahren auch bei dunkelhäutigen Patienten anwendbar. 6 Ergibt aufgrund der gleichmäßigen Struktur eine gaußähnliche Verteilung im Bereich heller Grauwerte. 5 Melanozytäre 112 Dermatologie Abbildung 9.5: Aus [Pom00] Seite 98, Links: Darstellung der Pixel, die den ermittelten Schwellwert unterschreiten. Rechts: Die fertige Läsionsmaske. Die Kontur ist weiß dargestellt. mit einem Mittelwertfilter (Breite 5) geglättet wurde, wird iterativ das Minimum ermittelt, dieser Wert etwas Richtung Haut verschoben7 und die Auflösung verfeinert, bis das Histogramm eine bimodale8 Form annimmt. Alle Pixel kleiner als der Schwellwert werden in einem Binärbild auf 1 gesetzt. Haarpixel werden entfernt und Lücken mittels Dilatation geschlossen. Ein Medianfilter (Größe 9 × 9) verhindert einen unregelmäßigen Rand. Wurden mehrere Flächen markiert, so wird die größte als Läsion gewertet, die anderen werden entfernt. Als Läsionsmaske werden die Pixel definiert, die sich innerhalb der Kontur der Fläche befinden (Abbildung 9.5). Dieses Ergebnis wird dem Dermatologen zur Korrektur vorgelegt. Er kann entweder den Schwellwert verändern oder Regionen zur Maske hinzufügen bzw. entfernen. Diese Kontrolle ist aufgrund der teilweise komplexen Strukturen von Läsionen notwendig. 9.5.3 Asymmetrie der Farbverteilung Dieses Verfahren erstellt seine Diagnose, indem die Farbwerte achsensymmetrischer Pixel verglichen werden. Typische Farben, die beim malignen Melanom auftreten können, sind schwarz, stahlblau, rot und weiß. Durch das unregelmäßige Wachstum ist eine Klassifikation durch die Position der Farben innerhalb der Läsion möglich. Verfahren Symmetrie der Pixel Für den Symmetrievergleich der Pixel werden zuerst der geometrische Schwerpunkt und die Symmetrieachsen ermittelt. Das Pixel i wird durch die Koordinaten (xi , yi ) dargestellt. Der geometrische Schwerpunkt S der Läsion wird über die Mittelwerte aller x- und y-Koordinaten ermittelt: n x̄ = 1X xi n i=1 n ȳ = 1X yi → S = (x̄, ȳ) n i=1 Mit dem geometrischen Schwerpunkt werden die Symmetrieachsen ermittelt, indem zunächst die empirische Kovarianz Cov(X, Y ) gebildet und damit dann die Kovari7 Verbessert 8 Ein das Ergebnis in den Randbereichen. Histogramm bestehend aus zwei Maxima und einem breiten dazwischenliegendem Minimum. 9.5 Verfahren zur Merkmalsanaylse 113 Abbildung 9.6: Überprüfung der Achsensymmetrie von Pixeln. Beim oberen Beispiel liegt das achsensymmetrische Pixel außerhalb der Maske. Somit gibt es kein Pixelpaar. Beim unteren Beispiel liegen beide Pixel innerhalb der Maske, folglich ist hier ein Pixelpaar vorhanden. anzmatrix C bestimmt wird: Cov(X, Y ) = C= 1X (xi − x̄)(yi − ȳ) n i Cov(X, X) Cov(X, Y ) Cov(Y, X) Cov(Y, Y ) Die Eigenwerte λi und Eigenvektoren υ~i werden so bestimmt, dass gilt: C υ~i = λi υ~i Der Eigenvektor mit dem größten dazugehörigen Eigenwert beschreibt die Richtung der Hauptsymmetrieachse9 während der andere Eigenvektor orthogonal zu diesem liegt. Mit dem geometrischen Schwerpunkt S als Schnittpunkt bilden sie die Symmetrieachsen g1 (Hauptachse) und g2 (Nebenachse). Für alle Objektpixel wird geprüft, ob ein Pixel p bezüglich g1 ein achsensymmetrisches Pendant p0 besitzt10 (siehe Abbildung 9.6). Ein solches Pixelpaar wird zur Menge P 111 hinzugefügt. Ungenauigkeiten beim Finden des achsensymmetrischen Pixels werden mit dem Nearest-Neighbour-Verfahren behoben. Der selbe Vorgang wird mit der Nebenachse g2 wiederholt. Achsensymmetrische Punktepaare werden hier zur Menge P 212 hinzugefügt. Vergleich der Farben Es folgt der Vergleich der Farbwerte der Pixelpaare in den Mengen P 1 und P 2 . Nach dem Wechsel in den HLS-Farbraum13 werden die FarbdifferenzMittelwerte der Pixelpaare aus den Mengen P 1 und P 2 gebildet: CSi = 1 X d(p) (i = 1, 2) |P i | i p∈P 9 Gerade durch die größte Varianz der Objektpixel. an Position p0 hat den Wert 1. 11 Menge achsensymmetrischer Pixelpaare bezüglich g . 1 12 Menge achsensymmetrischer Pixelpaare bezüglich g . 2 13 Farbe wird mit den Werten Hue, Lightness und Saturation beschrieben und ähnelt der menschlichen Farbwahrnehmung 10 Läsionsmaske 114 Dermatologie Abbildung 9.7: Aus [Pom00] Seite 107 ROC-Kurve zur Farbasymmetrie. Der markierte Punkt ist der Schwellwert mir den besten Separierungseigenschaften. d(p) beschreibt den Farbabstand zwischen p und p0 : d(p) = q (wh min({|hp − hp0 |, 360 − |hp − hp0 |}))2 + (wl (lp − lp0 ))2 + (ws (sp − sp0 ))2 wh = 1 wl = 120 ws = 120 Mit hp , lp und sp werden die hue-, lightness- und saturation-Werte des Pixels bezeichnet. Mit den Gewichten (wh , wl , ws ) können Unterschiede der Größenskalen und der Einfluss der Farb-Koordinatenachsen ausgeglichen werden14 . Der Gesamtscore CS ergibt sich nun aus dem größeren der beiden Werte, da die größere Farbdifferenz für die Diagnose entscheidend ist: CS = max({CS1 , CS2 }) Ergebnisse Die Qualität eines Verfahrens wird anhand einer Stichprobe aus 120 zufällig gewählten Bildern aus einem Pool von 560 benignen melanozytären Hautveränderungen und 189 malignen Melanomen ermittelt. Für die verschiedenen Verfahren besitzen die Scores jeweils einen eigenen Wertebereich, für den es gilt, einen Schwellwert für die Klassifikation zu finden. Anhand der Stichprobe gibt es je nach Schwellwert unterschiedliche Werte für Sensitivität15 und Spezifität16 . Trägt man diese in ein Diagramm mit den Achsen Sensitivität und FPR (Falsch-Positiv-Rate: 1 − Spezif ität) ein, so erhält man eine ROC-Kurve (Receiver Operating Characteristic), wie in Abbildung 9.7 zu sehen. Es ist möglich, einen Schwellwert zu wählen, der eine Sensitivität von 100% aufweißt, jedoch auf Kosten der Spezifität. Der optimale Schwellwert klassifiziert malign und benign möglichst gut, hat also eine hohe Sensitivität und Spezifität, und gehört in der ROC-Kurve zu dem Punkt, der am dichtesten am Optimum (Sensitivität = Spezif ität = 1) liegt. Bei der Asymmetrie der Farbverteilung wird mit dem passenden Schwellwert eine Sensitivität von 88,4% bei einer Spezifität von 87,5% erreicht. Diese Werte kann man in der ROC-Kurve (Abbildung 9.7) an der markierten Stelle wiederfinden. 9.5 Verfahren zur Merkmalsanaylse 115 Abbildung 9.8: Aus [Pom00] Seite 107 Visualisierung der Farbasymmetrie: Drei Beispiele mit von links nach rechts zunehmender Asymmetrie. Oben das Original. Unten die dazugehörige Visualisierung Visualisierung Die Farbunterschiede zwischen den achsensymmetrischen Pixeln sollen dargestellt werden. Hierzu werden die Farbabstände in einer Look-up-Tabelle farbcodiert, von blau (geringer Abstand) über grün zu rot (großer Abstand). Pixel ohne Pendant werden schwarz dargestellt. Drei Beispiele sind in Abbildung 9.8 abgebildet. 9.5.4 Vielfalt der Farben Dieses Verfahren erstellt seine Diagnose anhand der Anzahl der unterschiedlichen Farben und deren Häufigkeit in der Läsion, da die Farbvielfalt einer benignen melanozytären Hautveränderung geringer ist als die eines malignen Melanoms. Verfahren Zuerst wird der Farbraum diskretisiert, indem die drei Farbachsen in 100 gleichgroße Abschnitte17 unterteilt werden. Auf Basis dieser Partitionierung wird die relative dreidimensionale Häufigkeitsverteilung phls 18 berechnet. Nun wird die Entropie der Farbhäufigkeitsverteilung bestimmt: XXX CV = − phls log(phls ) (∀phls ≥ 0) h l s Mit der Anzahl der Farben und der Homogenität der Farbhäufigkeitsverteilung steigt der Score CV monoton an. Ergebnisse Mit dem richtig gewählten Schwellwert erreicht das Verfahren der Farbvielfal eine Sensitivität von 85,7% bei einer Spezifität von 83,0%. Abbildung 9.9 zeigt die dazugehö14 Hier verwendete Werte wurden empirisch ermittelt. der als malign klassifizierten maligner Melanome. 16 Anzahl der als benign klassifizierten benigner melanozytärer Hautveränderungen. 17 Homogene Partition. Unterschiedliche Wertebereiche resultieren in verschieden große Intervallgrößen. 18 relative Häufigkeit von Pixeln an den entsprechenden Koordinaten im HLS-Farbraum. 15 Anzahl 116 Dermatologie Abbildung 9.9: Aus [Pom00] Seite 131 ROC-Kurve zur Farbvielfalt. Der markierte Punkt entspricht dem Schwellwert mit dem besten Sensitivität/Spezifität-Verhältnis. Abbildung 9.10: Aus [Pom00] Seite 132 Visualisierung der Farbvielfalt: Drei Beispiele mit zunehmender Farbvielfalt. Oben das Original. Unten die dazugehörige Visualisierung. rige ROC-Kurve. Visualisierung Bei der Visualisierung wird die Vielfalt der vorhandenen Farben erkennbar dargestellt. Ein malignes Melanom beansprucht nur einen geringen Anteil der hue-Achse. Für das menschliche Auge nicht sichtbare feine Farbunterschiede werden durch eine Falschfarbendarstellung mittels einer Look-up-Tabelle erkennbar. Zwecks Nachvollziehbarkeit wird nur die hue-Komponente betrachtet. Abbildung 9.10 zeigt drei Beispiele für die Farbvielfalt. Rechts ist gut erkennbar, wie kaum sichtbare Farbunterschiede in der Visualisierung mit kontrastreichen Farben dargestellt werden. 9.5.5 Klassifikator Beim Klassifikator werden die Ergebnisse aller sechs Merkmalsanalysen zu einer einzelnen Diagnose zusammengefaßt. 9.6 Zusammenfassung 117 Verfahren Um aus den sechs Einzelergebnissen ein einzelnes zu erhalten, werden zuerst die Einzelscores der Merkmale auf [0, 1] skaliert. Danach wird eine Lineare Diskriminanzfunktion ([Pom00], S.80) aufgestellt: lda(~x) = 3.4(Asymmetrie, F arbe) + 2.8(Asymmetrie, Struktur) +2.9(Kontur, Krümmung) + 5.3(F arbvielf alt) +1.6(Strukturvielf alt) + 1.4(Grösse) Als letztes wird die Klassifikation vorgenommen: malign f alls lda(~x) ≥ 5.1 class(~x) = benign sonst Ergebnisse Die geschätzte Klassifikationsleistung für unbekannte Muster liegt mit einer Sensitivität von 91,5% bei einer Spezifität von 93,4% sehr hoch. Insgesamt werden 93% der Läsionen richtig klassifiziert (Korrektheit). Somit entspricht das Verfahren den Fähigkeiten von einem der seltenen Spezialisten auf diesem Gebiet. Hierzu auch die ROC-Kurve in Abbildung 9.11. Abbildung 9.11: Aus [Pom00] Seite 148 ROC-Kurve des Gesamtscores. 9.6 Zusammenfassung Die Vielfalt an möglichen Merkmalen zur Melanomdiagnostik ist enorm. Da stellt sich bei diesem Verfaren aber die Frage, ob bei einer Krankheit wie dem schwarzen Hautkrebs es nicht effektivere Merkmale gibt, die der Forderung nach Transparenz nicht folgen. Auch wurden oft Werte empirisch ermittelt, was die Möglichkeit offen läßt, dass diese Werte nicht die optimalen sind. Die Reproduzierbarkeit der Ergebnisse wird sich auch noch herausstellen müssen. Das Feld der Melanomerkennung bietet also noch viel Platz um neue, bessere Verfahren zu finden, genau wie andere Bereiche der Dermatologie. 118 Dermatologie Literaturverzeichnis [Pom00] René Pompl. Quantitative Bildverarbeitung und ihre Anwendung auf melanozytäre Hautveränderungen. PhD thesis, Technische Universität München, 2000.