Statistik I im Sommersemester 2007
Werbung

Statistik I im Sommersemester 2007
Themen am 21.5.07:
Wahrscheinlichkeitstheorie III
• Zufallsvariablen und Wahrscheinlichkeitsverteilungen
• Stichprobenkennwerte, Kennwerteverteilungen und Populationsparameter
• Statistische Modellierung und Realität
• Stichprobenziehung in der Umfrageforsschung
• Wahrscheinlichkeitsverteilungen von Häufigkeiten und Anteilen bei einfachen
Zufallsauswahlen
Lernziele:
1. Gemeinsamkeiten u. Unterschiede von empirischen Variablen und Zufallsvariablen
2. Bedeutung der frequentistischen Wahrscheinlichkeitsdefinition und des Gesetzes der
großen Zahl
3. Auswirkung von Schichtung, Klumpung und Ausfällen auf Kennwerteverteilungen
4. Anwendung von Binomialverteilung und hypergeometrischer Verteilung
Wiederholung: Wahrscheinlichkeitstheorie
Apriori-Wahrscheinlichkeit eines Ereignisses
=: Anzahl der Elementarereignisse, die zusammen das Ereignis bilden, geteilt durch die
Summe der Elementarereignisse im Ereignisraum insgesamt.
Axiomatische Wahrscheinlichkeitstheorie:
A1: 0 ≤ Pr(A) ≤ 1; A2: Pr(Ω) = 1; A3: Pr(A∪B) = Pr(A) + Pr(B) wenn A∩B = {}
Bedingte Wahrscheinlichkeit: Pr(A|B) = Pr(A∩B) / Pr(B)
Statistische Unabhängigkeit: Pr(A|B) = Pr(A) bzw. Pr(B|A) = Pr(B)
Additionstheorem:
Multiplikationstheorem:
Satz von Bayes:
Pr(A∪B) = Pr(A) + Pr(B) – Pr(A∩B)
Pr(A∩B) = Pr(A|B) · Pr(B) = Pr(B|A) · Pr(A)
Pr ( A B ) =
Pr ( B A ) ⋅ Pr ( A )
Pr ( B )
=
Pr ( B A ) ⋅ Pr ( A )
Pr ( B A ) ⋅ Pr ( A ) + Pr ( B ¬A ) ⋅ Pr ( ¬A )
Zufallsexperiment Urnenmodell als Basis für:
- einfache Zufallsauswahl ohne Zurücklegen
- einfache Zufallsauswahl mit Zurücklegen
Vorlesung Statistik I
1
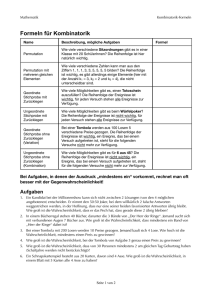
Wiederholung: Kombinatorik
Anzahl der möglichen unterscheidbaren Anordnungen von N Elementen (Permutationen):
PN = N ⋅ ( N − 1) ⋅ (N − 2) ⋅…3 ⋅ 2 ⋅1 = N!
Produkt aus N Faktoren
Anzahl von möglichen unterscheidbaren Anordnungen von n Elementen aus N Elementen ohne
Zurücklegen (Variationen) :
n
N
Vn = N ⋅ (N − 1) ⋅ (N − 2) ⋅… (N − n + 2) ⋅ (N − n + 1) = ∏ ( N − i + 1)
Produkt aus n Faktoren
i =1
Anzahl von unterscheidbaren Möglichkeiten, n Elementen aus N Elementen ohne Berücksichtigung der Anordnung auszuwählen (Kombinationen):
N!
( N − n )! =
N!
N ⋅ (N − 1) ⋅… ⋅ (N − n + 1) ⎛ N ⎞
N Vn
K
=
=
=
=⎜ ⎟
N
n
Pn
n!
N
−
n
!
⋅
n!
n
⋅
(n
−
1)
⋅
⋅
2
⋅
1
…
(
)
⎝n⎠
Wenn n von N Elementen ohne Berücksichtigung der Anordnung ausgewählt werden, bleiben
notwendigerweise N–n Elemente übrig.
Daher gibt NKn auch die Anzahl der Möglichkeiten an, eine Menge N in zwei Teilmengen der
Umfänge n und N–n aufzuteilen.
Vorlesung Statistik I
2
Wiederholung: Kombinatorik und Zufallsvariablen
Variationen mit Zurücklegen
Anzahl der Anordnungen von n Elementen aus N Elementen wobei jedes Element mehrfach vorkommen kann: Nn
Kombinationen mit Zurücklegen
Anzahl von Möglichkeiten n Elementen aus N Elementen ohne Berücksichtigung der Anordnung auszuwählen:
⎛ N + n − 1⎞
⎜
⎟
n
⎝
⎠
Auftretenswahrscheinlichkeit einer Stichprobe:
a) bei Berücksichtigung der Anordnung:
Kehrwert aus der Zahl der möglichen Stichproben bei Berücksichtigung der Reihenfolge,
b) ohne Berücksichtigung der Anordnung:
Kehrwert aus der Zahl der möglichen Stichproben bei Berücksichtigung der Reihenfolge
mal Anzahl der möglichen Anordnungen der jeweils ausgewählten Stichprobenelemente.
⇒ Bei Auswahlen mit Zurücklegen gibt es unterschiedliche Auftretenswahrcsheinlichkeiten in Abhängigkeit von den jeweils mehrfach ausgewählten Elementen.
Vorlesung Statistik I
3
Haushaltsnummer der zweiten
Befragung
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
6
5
4
3
2
1
0
0
1
2
3
4
5
6
Haushaltsnummer der ersten Befragung
Die Berechnung der Ziehungswahrscheinlichkeit einer Stichprobe ist nur der erste Schritt bei der
Abschätzung der Risiken von Fehlentscheidungen bei Induktionsschlüssen von einer Stichprobe
auf die Population, aus der die Stichprobe kommt.
So kann das Ausgangsbeispiel der zweimaligen Befragung von jeweils einem von 6 Haushalten
eines Dorfes als eine einfache Zufallsauswahl von n=2 aus N=6 Elementen mit Zurücklegen
aufgefasst werden.
Von Interesse sind i.a. nicht die Stichproben an sich, sondern Kennwerte, die aus den resultierenden Verteilungen in einer Stichprobe berechnen und als Schätzung entsprechender Kennwerte in der Population herangezogen werden.
Für jede Stichprobe lässt sich z.B. das mittlere Haushaltseinkommen berechnen.
Vorlesung Statistik I
4
Haushaltsnummer der zweiten
Befragung
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
6
Elemente in RealisierungswahrMittleres
Stichprobe
scheinlichkeit
Einkommen
{1,1}
1/36
1000 €
{2,1}
2/36
1500 €
{3,1}{2,2}
3/36
2000 €
{4,1}{3,2}
4/36
2500 €
{5,1}{4,2}{3,3}
5/36
3000 €
{6,1}{5,2}{4,3}
6/36
3500 €
{6,2}{5,3}{4,4}
5/36
4000 €
{6,3}{5,4}
4/36
4500 €
{6,4}{5,5}
3/36
5000 €
{6,5}
2/36
5500 €
{6,6}
1/36
6000 €
Summe:
36/36
Die bei Berücksichtigung der Anordnung unterscheidbaren 36 Stichproben ergeben 11 unterschiedliche Werte, wenn in jeder Stichprobe der Stichprobenmittelwert des Haushaltseinkommens über die beiden ausgewählten Haushalte (Fälle) berechnet wird.
Da jede Stichprobe eine angebbare Auswahlwahrscheinlichkeit hat, lassen sich auch für die unterscheidbaren Werte der mittleren Haushaltseinkommen Realisierungswahrscheinlichkeiten berechnen. Sie ergeben sich jeweils aus der Summe der Auswahlwahrscheinlichkeiten der Stichproben, die zum gleichen mittleren Einkommen führen.
Vorlesung Statistik I
5
Haushaltsnummer der zweiten
Befragung
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
6
Elemente in RealisierungswahrMittleres
Stichprobe
scheinlichkeit
Einkommen
{1,1}
1/36
1000 €
{2,1}
2/36
1500 €
{3,1}{2,2}
3/36
2000 €
{4,1}{3,2}
4/36
2500 €
{5,1}{4,2}{3,3}
5/36
3000 €
{6,1}{5,2}{4,3}
6/36
3500 €
{6,2}{5,3}{4,4}
5/36
4000 €
{6,3}{5,4}
4/36
4500 €
{6,4}{5,5}
3/36
5000 €
{6,5}
2/36
5500 €
{6,6}
1/36
6000 €
Summe:
36/36
Variablen, deren Ausprägungen mit (im Prinzip berechenbaren) Auftretenswahrscheinlichkeiten
realisiert werden, heißen Zufallsvariablen.
Die Auftretenswahrscheinlichkeiten der Ausprägungen definieren die Wahrscheinlichkeitsfunktion Pr(X), oft auch als f(x) symbolisiert, einer Zufallsvariablen X, die jeder Ausprägung
ihre Realisierungswahrscheinlichkeit zuordnet.
Die Wahrscheinlichkeitsfunktion der Ausprägungen einer Zufallsvariablen entspricht den
relativen Auftretenshäufigkeiten der Ausprägungen einer empirischen Verteilung.
Vorlesung Statistik I
6
Haushaltsnummer der zweiten
Befragung
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
6
X (mittleres
Wahrscheinlich- VerteilungsEinkomen in €) keitsfunktion
funktion
1000
1/36
1/36
1500
2/36
3/36
2000
3/36
6/36
2500
4/36
10/36
3000
5/36
15/36
3500
6/36
21/36
4000
5/36
26/36
4500
4/36
30/36
5000
3/36
33/36
5500
2/36
35/36
6000
1/36
36/36
Summe:
36/36
Die Aufsummierung der Wahrscheinlichkeitsfunktion ergibt die Verteilungsfunktion F(X),
die für jede Ausprägung einer Zufallsvariablen X die Wahrscheinlichkeit angibt, dass eine
Realisierung kleiner oder gleich dieser Ausprägung ist:
F(X = x) = Pr(X ≤ x)
Die Verteilungsfunktion von Zufallsvariablen entspricht der empirischen Verteilungsfunktion
empirischer Variablen, also der Aufsummierung der relativen Häufigkeiten, mit denen eine
Ausprägung vorkommt.
Vorlesung Statistik I
7
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
X (mittleres
Einkomen in €)
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
Summe:
Wahrscheinlichkeitsfunktion
1/36 = 0.0278
2/36 = 0.0555
3/36 = 0.0833
4/36 = 0.1111
5/36 = 0.1389
6/36 = 0.1667
5/36 = 0.1389
4/36 = 0.1111
3/36 = 0.0833
2/36 = 0.0555
1/36 = 0.0278
36/36 = 1.0000
Verteilungsfunktion
1/36 = 0.0278
3/36 = 0.0833
6/36 = 0.1667
10/36 = 0.2778
15/36 = 0.4167
21/36 = 0.5833
26/36 = 0.7222
30/36 = 0.8333
33/36 = 0.9167
35/36 = 0.9722
36/36 = 1.0000
Quantile
10%
25%
50%
75%
90%
X · Pr(X)
X2 · Pr(X)
1000/36
1000000/36
3000/36
4500000/36
6000/36
12000000/36
10000/36
25000000/36
15000/36
45000000/36
21000/36
73500000/36
20000/36
80000000/36
18000/36
81000000/36
15000/36
75000000/36
11000/36
60500000/36
6000/36 36000000/36
126000/36 493500000/36
3500
13708333.33
Analog zu empirischen Verteilungsfunktionen lassen sich auch für Zufallsvariablen aus der
Umkehrung der Verteilungsfunktion Quantilwerte berechnen.
So ist das z.B. das 10%-Quantil der Wert, bei dem die Verteilungsfunktion erstmals den Anteil
0.1 erreicht oder überschreitet.
Das 50%-Quantil ist bei Zufallsvariablen immer gleichzeitig der Median, da bei Wahrscheinlichkeiten nicht zwischen geraden und ungeraden Fallzahlen unterschieden werden kann.
Im Beispiel beträgt der Median 3500 €.
Vorlesung Statistik I
8
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
X (mittleres
Einkomen in €)
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
Summe:
Wahrscheinlichkeitsfunktion
1/36 = 0.0278
2/36 = 0.0555
3/36 = 0.0833
4/36 = 0.1111
5/36 = 0.1389
6/36 = 0.1667
5/36 = 0.1389
4/36 = 0.1111
3/36 = 0.0833
2/36 = 0.0555
1/36 = 0.0278
36/36 = 1.0000
Verteilungsfunktion
1/36 = 0.0278
3/36 = 0.0833
6/36 = 0.1667
10/36 = 0.2778
15/36 = 0.4167
21/36 = 0.5833
26/36 = 0.7222
30/36 = 0.8333
33/36 = 0.9167
35/36 = 0.9722
36/36 = 1.0000
Quantile
10%
25%
50%
75%
90%
X · Pr(X)
X2 · Pr(X)
1000/36
1000000/36
3000/36
4500000/36
6000/36
12000000/36
10000/36
25000000/36
15000/36
45000000/36
21000/36
73500000/36
20000/36
80000000/36
18000/36
81000000/36
15000/36
75000000/36
11000/36
60500000/36
6000/36 36000000/36
126000/36 493500000/36
3500
13708333.33
Analog zu empirischen Verteilungen lassen sich auch für Zufallsvariablen weitere Kennwerte
berechnen. Das arithmetische Mittel heißt bei Zufallsvariablen Erwartungswert µX („mü von
X“) und ist die Summe aus den Ausprägungen mal deren Auftretenswahrscheinlichkeiten:
μ(X) = μ X = ∑ Pr ( x (k ) ) ⋅ x (k )
K
k =1
Im Beispiel ergibt sich ein Erwartungswert von 3500 €.
Vorlesung Statistik I
9
Zufallsvariablen und Wahrscheinlichkeitsverteilungen
X (mittleres
Einkomen in €)
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
Summe:
Wahrscheinlichkeitsfunktion
1/36 = 0.0278
2/36 = 0.0555
3/36 = 0.0833
4/36 = 0.1111
5/36 = 0.1389
6/36 = 0.1667
5/36 = 0.1389
4/36 = 0.1111
3/36 = 0.0833
2/36 = 0.0555
1/36 = 0.0278
36/36 = 1.0000
Verteilungsfunktion
1/36 = 0.0278
3/36 = 0.0833
6/36 = 0.1667
10/36 = 0.2778
15/36 = 0.4167
21/36 = 0.5833
26/36 = 0.7222
30/36 = 0.8333
33/36 = 0.9167
35/36 = 0.9722
36/36 = 1.0000
Quantile
10%
25%
50%
75%
90%
X · Pr(X)
X2 · Pr(X)
1000/36
1000000/36
3000/36
4500000/36
6000/36
12000000/36
10000/36
25000000/36
15000/36
45000000/36
21000/36
73500000/36
20000/36
80000000/36
18000/36
81000000/36
15000/36
75000000/36
11000/36
60500000/36
6000/36 36000000/36
126000/36 493500000/36
3500
13708333.33
Die Varianz σ2X (ausgesprochen „sigma-quadrat von X“) ist der Erwartungswert der quadrierten
Abweichungen vom Mittelwert:
2
2
σ (X) = σ = ∑ Pr ( x (k ) ) ⋅ ( x (k ) − μ X ) = ∑ Pr ( x (k ) ) ⋅ x (k
) − μX
K
2
2
X
k =1
2
K
k =1
Im Beispiel beträgt die Varianz 1 458 333.33 €2 (=13708333.33–35002) und die Standardabweichung 1207.61 €.
Vorlesung Statistik I
10
Stichprobenkennwerte, Kennwerteverteilungen und
Populationsparameter
Bezogen auf eine konkrete Stichprobe ist das durchschnittliche Haushaltseinkommen in dieser
Stichprobe ein Kennwert der empirischen Einkommensverteilung in der Stichprobe,
bezogen auf die Wahrscheinlichkeitsverteilung der durchschnittlichen Haushaltseinkommen in
den möglichen Stichproben dagegen eine Realisierung einer Zufallsvariablen.
Ziel der Berechnung eines Stichprobenmittelwerts ist i.a. die Schätzung eines Populationskennwertes, im Beispiel des durchschnittlichen Haushaltseinkommen in der Population. Kennwerte
einer Population heißen auch Populationsparameter. Die Werte von Populationsparametern sind
in der Regel unbekannt und werden daher mit Hilfe von Stichprobendaten geschätzt.
Der zum Schätzen oder Testens eines Populationsparameters berechnete Kennwert einer Stichprobe wird auch als Statistik bezeichnet.
Über alle möglichen Stichproben hinweg ist die Statistik eine Zufallsvariable, deren Wahrscheinlichkeitsverteilung auch als Kennwerteverteilung bezeichnet wird, da es sich um die
(Wahrscheinlichkeits-) Verteilung von Stichprobenkennwerten über verschiedene Stichproben
handelt.
Es gilt daher, drei verschiedene Verteilungen zu unterscheiden:
1. die Verteilung in einer Population,
2. die Verteilung in einer Stichprobe und
3. die Kennwerteverteilung über alle möglichen Stichproben.
Vorlesung Statistik I
11
Stichprobenkennwerte, Kennwerteverteilungen und Populationsparameter
Populationsverteilung:
Haush.
einkom. nk pk cpk
1000
1 1/6 1/6
2000
1 1/6 2/6
3000
1 1/6 3/6
4000
1 1/6 4/6
5000
1 1/6 5/6
6000
1 1/6 6/6
Summe: 6 6/6
Stichprobenverteilung 1
Haush. {1,1}
einkom. nk pk cpk
1000
1 0.5 0.5
1000
1 0.5 1.0
Summe: 2 1.0
Stichprobenverteilung 2
Haush. {1,2}
einkom. nk pk cpk
1000
1 0.5 0.5
2000
1 0.5 1.0
Summe: 2 1.0
Auf die Populationsverteilung bzw. deren Parameter ist das Forschungsinteresse gerichtet;
sie ist jedoch der direkten Beobachtung nicht (oder nur mit sehr großem Aufwand) zugänglich.
Beobachtet werden kann dagegen die Verteilung in einer Stichprobe. Von den aus den Stichprobendaten berechneten empirischen Kennwerten wird in einem Induktionsschluss auf die
Werte der Populationsparameter geschlossen.
Vorlesung Statistik I
12
Stichprobenkennwerte, Kennwerteverteilungen und Populationsparameter
Populationsverteilung:
Haush.
einkom. nk pk cpk
1000
1 1/6 1/6
2000
1 1/6 2/6
3000
1 1/6 3/6
4000
1 1/6 4/6
5000
1 1/6 5/6
6000
1 1/6 6/6
Summe: 6 6/6
Kennwerteverteilung:
X (mittleres
Wahrscheinlich- VerteilungsEinkomen in €) keitsfunktion
funktion
1000
1/36
1/36
1500
2/36
3/36
2000
3/36
6/36
2500
4/36
10/36
3000
5/36
15/36
3500
6/36 =1/3 2/3 21/36
4000
5/36
26/36
4500
4/36
30/36
5000
3/36
33/36
5500
2/36
35/36
6000
1/36
36/36
Summe:
36/36
}
Stichprobenverteilung 1
Haush. {1,1}
einkom. nk pk cpk
1000
1 0.5 0.5
1000
1 0.5 1.0
Summe: 2 1.0
Stichprobenverteilung 2
Haush. {1,2}
einkom. nk pk cpk
1000
1 0.5 0.5
2000
1 0.5 1.0
Summe: 2 1.0
Die Kennwerteverteilung ist das Verbindungsglied zwischen Stichprobe und Population.
Sie ermöglicht Aussagen über die Risiken des Induktionsschlusses.
Im Beispiel lässt sich so aus der Kennwerteverteilung ablesen, dass mit einer Wahrscheinlichkeit von 1/6 ein Stichprobenmittelwert genau mit dem Populationsmittelwert (3500 €) übereinstimmt und mit einer Wahrscheinlichkeit von 2/3 der Stichprobenmittelwert um maximal 1000 €
vom Populationsmittelwert abweicht.
Vorlesung Statistik I
13
Stichprobenkennwerte, Kennwerteverteilungen und Populationsparameter
Populationsverteilung:
Haush.
einkom. nk pk cpk
1000
1 1/6 1/6
2000
1 1/6 2/6
3000
1 1/6 3/6
4000
1 1/6 4/6
5000
1 1/6 5/6
6000
1 1/6 6/6
Summe: 6 6/6
Kennwerteverteilung:
X (mittleres
Wahrscheinlich- VerteilungsEinkomen in €) keitsfunktion
funktion
1000
1/36
1/36
1500
2/36
3/36
2000
3/36
6/36
2500
4/36
10/36
3000
5/36
15/36
3500
6/36
21/36
4000
5/36
26/36
4500
4/36
30/36
5000
3/36
33/36
5500
2/36
35/36
6000
1/36
36/36
Summe:
36/36
Stichprobenverteilung 1
Haush. {1,1}
einkom. nk pk cpk
1000
1 0.5 0.5
1000
1 0.5 1.0
Summe: 2 1.0
Stichprobenverteilung 2
Haush. {1,2}
einkom. nk pk cpk
1000
1 0.5 0.5
2000
1 0.5 1.0
Summe: 2 1.0
Aussagen über die Stichprobengüte beziehen sich in der Statistik also stets auf die Kennwerteverteilung.
Ein konkreter Stichprobenmittelwert kann vom gesuchten Populationsparameter trotz hoher
Stichprobengüte sehr stark abweichen.
So sind in den beiden rechts wiedergegebenen Stichproben die Stichprobenmittewerte mit
Werten von 1000€ und 1500€ deutlich vom Populationsmittelwert mit 3500€ entfernt.
Vorlesung Statistik I
14
Statistische Modellierung und Realität
Wahrscheinlichkeitsverteilungen unterscheiden sich von empirisch erhobenen Verteilungen
darin, dass anstelle der relativen Häufigkeiten von Realisierungen Realisierungswahrscheinlichkeiten stehen.
Es scheint also eine Ähnlichkeit zwischen relativen Häufigkeiten und Wahrscheinlichkeiten zu
geben.
Diese Ähnlichkeit wird in der frequentistischen Definition der Wahrscheinlichkeit (auch als
A-posteriori-Definition von Wahrscheinlichkeit bezeichnet) explizit formuliert:
Die Wahrscheinlichkeit Pr(A) eines Ereignisses A ist gleich dem Grenzwert
der relativen Auftretenshäufigkeit nA / n dieses Ereignisses, wenn die Zahl der
Wiederholungen n des Zufallsexperiments, zu dessen Ereignissen A gehört,
über alle Grenzen wächst:
⎛n ⎞
lim ⎜ A ⎟ = Pr ( A )
n →∞
⎝ n ⎠
Die frequentistische Wahrscheinlichkeitsdefinition führt zu einem scheinbar empirischen Wahrscheinlichkeitsbegriff, da Wahrscheinlichkeiten nach dieser Definition relative Häufigkeiten
sind.
Da es aber empirisch unmöglich ist, Zufallsexperimente tatsächlich unendlich oft zu wiederholen, können sie nicht direkt beobachtet werden.
Vorlesung Statistik I
15
Das Gesetz der großen Zahl
Begründet wird die frequentistische Sicht auf Wahrscheinlichkeit durch das Gesetz der großen
Zahl:
Wenn die Zahl n der Wiederholungen eines Zufallsexperiments über alle Grenzen steigt,
dann nähert sich die Wahrscheinlichkeit, dass der Abstand der relativen Häufigkeit nA/n
eines Ereignisses A von der Wahrscheinlichkeit Pr(A) dieses Ereignisses im einfachen
Zufallsexperiment kleiner oder gleich einer beliebig kleinen positiven Zahl ist, dem Wert
Eins an.
⎛ ⎛n
⎞⎞
lim ⎜ Pr ⎜ A − Pr ( A ) < ε ⎟ ⎟ = 1
n →∞
⎠⎠
⎝ ⎝ n
Das Gesetz der großen Zahl lässt sich formal beweisen.
Eine Idee, wieso das Gesetz funktioniert, zeigt das Beispiel des wiederholten Werfens einer
Münze. Ein solcher Münzwurf lässt sich als Zufallsexperiment mit zwei möglichen Ergebnissen
„Kopf“ und „Zahl“auffassen, die im folgenden durch die Buchstaben A für „Kopf“ und B für
„Zahl“ symbolisiert werden.
Entsprechend der klassischen Wahrscheinlichkeitsdefinition wird unterstellt, dass die Realisierungswahrscheinlichkeit jedes der beiden Ereignisse 0.5 beträgt. Denkbar sind aber auch beliebige andere Werte, die sich zu 1.0 summieren.
Da die Wiederholungen eines Zufallsexperiments unter gleichen Bedingungen zu voneinander
statistisch unabhängigen Ereignissen führen, ist bei n Wiederholungen des Experiments die
Wahrscheinlichkeit des Auftretens einer beliebigen Folge der möglichen Ereignisse 0.5n, da in
jedem Experiment ein Ereignis mit Wahrscheinlichkeit 0.5 auftritt.
Vorlesung Statistik I
16
Das Gesetz der großen Zahl
Bei z.B. 3 Wiederholungen sind 8 (= 2·2·2) Ergebnisse möglich:
{A,A,A}, {A,A,B}, {A,B,A}, {B,A,A}, {A,B,B}, {B,A,B}, {B,B,A} und {B,B,B}
Soll die relative Häufigkeit des Ereignisses A („Kopf“) berechnet werden, interessiert allerdings
nicht die Reihenfolge sondern nur die Anzahl des Auftretens von A in allen Stichproben.
Bei n Wiederholungen kann die Zahl nA der möglichen Ereignisse zwischen 0 (niemals „Kopf“)
und n (immer „Kopf“ variieren).
Von den 2n möglichen Ergebnissen ist die Zahl der Ergebnisse, in denen insgesamt nA mal Ereignis A realisiert werden kann, gleich der Zahl der Variationen ohne Zurücklegen von nA Elementen aus n Elementen also „n über nA“.
Somit beträgt die Wahrscheinlichkeit nA:
⎛ n ⎞
n!
Pr ( n A ) = ⎜ ⎟ ⋅ 0.5n =
⋅ 0.5n
( n − n A )!⋅ n!
⎝ nA ⎠
Da die relative Auftretenshäufigkeit pA von A der Quotient nA/n ist, lassen sich alle realisierbaren relativen Häufigkeiten von A über diese Formel berechnen.
Bei n=3 Wiederholungen ergibt sich z.B.:
⎛ 3⎞
⎛ 3⎞
Pr ( 0 / 3) = ⎜ ⎟ 0.53 = 0.125 , Pr (1/ 3) = ⎜ ⎟ 0.53 = 0.375 ,
⎝0⎠
⎝1⎠
⎛ 3⎞
⎛ 3⎞
Pr ( 2 / 3) = ⎜ ⎟ 0.53 = 0.375 , Pr ( 3/ 3) = ⎜ ⎟ 0.53 = 0.125
⎝ 2⎠
⎝ 3⎠
Vorlesung Statistik I
17
Das Gesetz der großen Zahl
n Pr(0.3 ≤ pA ≤ 0.7)
1
0.00
2
0.50
3
0.75
4
0.38
5
0.63
6
0.78
n Pr(0.3 ≤ pA ≤ 0.7)
7
0.55
8
0.71
9
0.82
10
0.66
11
0.77
12
0.85
n Pr(0.3 ≤ pA ≤ 0.7)
13
0.91
14
0.82
15
0.88
16
0.92
17
0.86
18
0.90
n
10
100
500
1000
5000
10000
50000
pA
.200
.500
.524
.474
.495
.507
.504
pA–0.5
–.300
.000
.024
–.026
–.005
.007
.004
Über die Wahrscheinlichkeiten der Anteile lässt sich auch ausrechnen, wie wahrscheinlich es
ist, dass die realisierte relative Häufigkeit innerhalb eines Intervalls liegt.
So kann z.B. berechnet werden, wie wahrscheinlich es ist, dass die relative Häufigkeit des
Ereignisses A („Kopf“) beim mehrmaligen Werfen einer Münze zwischen 0.3 und 0.7 liegt,
wenn die Wahrscheinlichkeit beim einmaligen Werfen 0.5 beträgt.
Es zeigt sich, dass diese Wahrscheinlichkeit, wie es das Gesetz der großen Zahl behauptet, – mit
gewissen Schwankungen – immer mehr ansteigt.
Ein ähnliches Egebnis ergibt der empirische Versuch.
So zeigt die Tabelle rechts den Anteil des Ereignisses A, wenn tatsächlich wiederholt eine
Münze geworfen wird.
Vorlesung Statistik I
18
Das Gesetz der großen Zahl
Obwohl es also eine Beziehung zwischen empirischen relativen Häufigkeiten und Wahrscheinlichkeiten zu geben scheint, sollte doch klar sein, dass der Begriff „Wahrscheinlichkeit“ eine
theoretische Modellvorstellung ist und kein reales empirisches Phänomen.
Tatsächlich beruht der frequentistische Wahrscheinlichkeitsbegriff auf einen (fehlerhaften)
Zirkelschluss, falls er mit dem Gesetz der großen Zahl begründet wird. Im Gesetz der großen
Zahl taucht ja bereits der Begriff der Wahrscheinlichkeit auf, der erst durch die frequentistische
Vorstellung definiert werden soll.
Die frequentistische Definition wäre erst dann nicht zirkulär, wenn es gelänge, die Forderung
der „Wiederholung eines Zufallsexperiments unter gleichen Bedingungen“ unabhängig vom
Begriff der statistischen Unabhängigkeit zweier Ereignisse zu definieren.
Ungeachtet dieses logischen Problems führt der frequentistische Wahrscheinlichkeitsbegriff
jedoch zu einer intuitiven und hilfreichen Vorstellung der Bedeutung des Wortes „Wahrscheinlichkeit“.
Ein Vorteil gegenüber dem klassischen Wahrscheinlichkeistbegriff liegt insbesondere auch darin, dass nicht unterstellt werden muss, dass Elementarereignisse mit gleicher Wahrscheinlichkeit auftreten müssen. Stattdessen kann durch Wiederholen empirisch „geprüft“ werden, ob z.B.
eine Münze oder ein Würfel ausgewogen ist, d.h. zu gleichwahrscheinlichen Ergebnissen führt.
Vorlesung Statistik I
19
Stichprobenziehung in der Umfrageforschung
Bei Anwendungen der Wahrscheinlichkeitstheorie sollte stets überlegt werden, welches
Zufallsexperiment zu den beobachtbaren Ereignissen geführt haben mag und ob die hierbei
getroffenen Annahmen zutreffen.
So folgen z.B. sozialwissenschaftliche Wahrscheinlichkeitsauswahlen oft nicht dem Lotteriemodell, wie es die einfache Zufallsauswahl unterstellt.
Stattdessen werden in der Umfrageforschung meist geschichtete (stratifizierte, engl. stratified)
und/oder (mehrstufigen) Klumpenstichproben (engl. cluster sampling) gezogen.
In beiden Situationen ist die Grundgesamtheit in eine (große) Zahl von Teilgruppen (Subpopulationen) zerteilt.
In einer geklumpten Stichprobe wird in einem mehrstufigen Auswahlverfahren zunächst eine
Anzahl von Teilgruppen (Cluster) zufällig ausgewählt. Innerhalb dieser Teilgruppen werden
dann in einer weiteren zufälligen Auswahl die eigentlich interessierenden Elemente ausgewählt.
Dieses Vorgehen kann sich sogar über mehr als zwei Stufen erstrecken. So werden bei persönlichen Interviews oft in einem ersten Schritt Orte ausgewählt, innerhalb derer im zweiten Schritt
Haushalte ausgewählt werden, innerhalb derer dann im dritten Schritt eine „Zielperson“ ausgewählt wird.
Bei geschichteten Stichproben wird die Population ebenfalls in Teilgruppen aufgeteilt, die hier
als „Schichten“ bezeichnet werden. In jeder Schicht werden dann Zufallsauswahlen gezogen.
In der Praxis werden mehrstufige geklumpte Stichproben innerhalb von Schichten gezogen.
Vorlesung Statistik I
20
Haushaltsnummer der zweiten
Befragung
Geklumpte und geschichtete Stichproben
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
6
X (mittleres
Wahrscheinlich- VerteilungsEinkomen in €) keitsfunktion
funktion
1000
1/36
1/36
1500
2/36
3/36
2000
3/36
6/36
2500
4/36
10/36
3000
5/36
15/36
3500
6/36
21/36
4000
5/36
26/36
4500
4/36
30/36
5000
3/36
33/36
5500
2/36
35/36
6000
1/36
36/36
Summe:
36/36
Die Auswirkungen von geklumpten und geschichteten Stichproben lassen sich an dem Beispiel
der einfachen Zufallsauswahl von n=2 aus N=6 Haushalten verdeutlichen.
Die Haushaltsnummern geben wieder das Einkommen des Haushalts in 1000€ pro Monat
wieder.
Bei einer einfachen Zufallsauswahl gibt es genau 36 mögliche Ereignisse, die mit gleicher
Wahrscheinlichkeit auftreten und zu 11 Stichproben mit unterschiedlichem Stichprobenmittelwert des Einkommens führen.
Vorlesung Statistik I
21
Haushaltsnummer der zweiten
Befragung
Geklumpte und geschichtete Stichproben
Einfache Zufallsauswahl
n=2 aus N=6:
Erwartungswert: 3500 €
Standardabw. 1207.615€:
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
Die Population kann in zwei Teilgruppen zerlegt
werden, wobei die ersten drei Haushalte die erste
und die letzten drei die zweite Gruppe bilden.
In einer geklumpten Auswahl wird zunächst mit
gleicher Wahrscheinlichkeit eine der beiden
Teilgruppen ausgewählt und innerhalb der
Teilgruppen zwei Haushalte.
Vorlesung Statistik I
6
Geklumpte Auswahl
n=2 aus Nm=3 in m=1 von M=2 Cluster
Stichprobe
Einkommen Wahrscheinl.
{1,1}
1000 €
1/18
{2,1}
1500 €
2/18
{3,1}{2,2}
2000 €
3/18
{3,2}
2500 €
2/18
{3,3}
3000 €
1/18
{4,4}
4000 €
1/18
{5,4}
4500 €
2/18
{6,4}{5,5}
5000 €
3/18
{6,5}
5500 €
2/18
{6,6}
6000 €
1/18
Erwartungswert: 3500 €
Standardabw. 1607.28€:
Die Anzahl der möglichen Stichproben
reduziert sich dann auf 18, die zu 10
unterschiedlichen Stichprobenmittelwerten führen.
22
Haushaltsnummer der zweiten
Befragung
Geklumpte und geschichtete Stichproben
Einfache Zufallsauswahl
n=2 aus N=6:
Erwartungswert: 3500 €
Standardabw. 1207.615€:
6
5
4
3
2
1
0
0
1
2
3
4
5
6
Haushaltsnummer der ersten Befragung
Stratifizierte Auswahl
n=1 aus Nm=3 in jeder von M=2 Schichten:
Stichprobe
Einkommen Wahrscheinl.
{4,1}
2500 €
1/9
{5,1}{4,2}
3000 €
2/9
{6,1}{5,2}{4,3} 3500 €
3/9
{6,2}{5,3}
4000 €
2/9
{6,3}
4500 €
1/9
Erwartungswert: 3500 €
Standardabw.
577.35€:
Bei einer geschichteten Auswahl wird aus jeder der
beiden Teilgruppen jeweils ein Element zufällig
ausgewählt.
Die Anzahl der möglichen Stichproben reduziert sich wiederum auf 18, die zu 5 unterschiedlichen Stichprobenmittelwerten führen.
Die drei Auswahlverfahren führen zu drei Kennwerteverteilungen mit gleichem Erwartungswert
aber unterschiedlicher Standardabweichung.
Vorlesung Statistik I
23
Haushaltsnummer der zweiten
Befragung
Geklumpte und geschichtete Stichproben
Einfache Zufallsauswahl
n=2 aus N=6:
Erwartungswert: 3500 €
Standardabw. 1207.615€:
6
5
Geklumpte Auswahl
n=2 aus Nm=3 in m=1 von M=2 Cluster
Stichprobe
Einkommen Wahrscheinl.
Erwartungswert: 3500 €
Standardabw. 1607.28€:
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
6
Stratifizierte Auswahl
n=1 aus Nm=3 in jeder von M=2 Schichten:
Erwartungswert: 3500 €
Standardabw.
577.35€:
Wenn sich – wie in dem Beispiel – die Elemente innerhalb einer Teilgruppe ähnlicher sind als
die Elemente in unterschiedlichen Teilgruppen, dann führen geschichtete Stichproben dazu,
dass die Standardabweichung der Kennwerteverteilung kleiner ist als die Standardabweichung
bei einer einfachen Zufallsauswahl.
Umgekehrt ist in dieser Situation die Standardabweichung bei einer geklumpten Stichprobe
größer als bei einer einfachen Zufallsauswahl.
Falls die interessierenden Eigenschaften der Elemente einer Population unabhängig von der Zugehörigkeit zu einer Teilgruppe variieren, unterscheiden sich die Standardabweichungen nicht.
Vorlesung Statistik I
24
Haushaltsnummer der zweiten
Befragung
Unterschiedliche Ausfallwahrscheinlichkeiten
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
Ausfallwahrscheinlichkeit
0.10
0.64
6
Einkom- Wahrscheinlichkeiten
men (X) Auswahl Ausfall Pr(X)
1000
1/36 1/10 .025
1500
2/36 1/10 .050
2000
3/36 1/10 .075
2500
4/36 1/10 .100
3000
5/36 1/10 .125
3500
6/36 1/10 .150
4000
5/36 16/25 .050
4500
4/36 16/25 .040
5000
3/36 16/25 .030
5500
2/36 16/25 .020
6000
1/36 16/25 .010
Summe:
36/36
.675
Missing
.325
In der Realität lassen sich Auswahlpläne aufgrund von Ausfällen nicht vollständig realisieren.
Im Beispiel wird angenommen, dass die Ausfallwahrscheinlichkeit Pr(A) bei einem Stichprobenmittelwert von max. 3500€ 0.10 und bei höheren Einkommen 0.64 beträgt.
Bei einer einfachen Zufallsauswahl von n=2 aus N=6 mit Zurücklegen ist dann die Realisierungswahrscheinlichkeit einer Stichprobe k die Wahrscheinlichkeit, die Stichprobe entsprechend der Auswahlwahrscheinlichkeit der Zufallsauswahl (d.h. nach dem Stichprobenplan)
auszuwählen, mal der Wahrscheinlichkeit, nicht auszufallen:
Pr ( Sk ) = Pr ( X k ) ⋅ Pr ( ¬A k ) = Pr ( X k ) ⋅ (1 − Pr ( A k ) )
Vorlesung Statistik I
25
Haushaltsnummer der zweiten
Befragung
Unterschiedliche Ausfallwahrscheinlichkeiten
6
5
4
3
2
1
0
0
1
2
3
4
5
Haushaltsnummer der ersten Befragung
Ausfallwahrscheinlichkeit
0.10
0.64
6
Einkom- Wahrscheinlichkeiten ohne Miss.
men (X) Auswahl Ausfall Pr(X) Pr(X)
1000
1/36
1/10 .025
.037
1500
2/36
1/10 .050
.074
2000
3/36
1/10 .075
.111
2500
4/36 1/10 .100
.148
3000
5/36 1/10 .125
.185
3500
6/36 1/10 .150
.222
4000
5/36 16/25 .050
.074
4500
4/36 16/25 .040
.059
5000
3/36 16/25 .030
.044
5500
2/36 16/25 .020
.030
6000
1/36 16/25 .010
.015
Summe:
36/36
.675
.999
Missing
.325
Die Wahrscheinlichkeit, dass eine Stichprobe nicht ausfällt, beträgt 0.675. Entsprechend ist die
Wahrscheinlichkeit eines Ausfalls 0.325.
Da nur bei realisierten Stichproben Stichprobenmittelwerte berechnet werden können, reduziert
sich die Kennwerteverteilung auf die bedingten Wahrscheinlichkeiten, dass eine Stichprobe
realisiert wird:
Pr ( X ) ⋅ (1 − Pr ( A k ) )
Pr ( S ¬A ) =
K
∑ (1 − Pr ( A k ) )
k =1
Vorlesung Statistik I
26
Haushaltsnummer der zweiten
Befragung
Unterschiedliche Ausfallwahrscheinlichkeiten
6
5
4
3
2
1
0
0
1
2
3
4
5
6
Haushaltsnummer der ersten Befragung
Ausfallwahrscheinlichkeit
0.10
0.64
Der Erwartungswert der Kennwerteverteilung beträgt dann 3111.11€ und die Standardabweichung
ist 1099.94€
Einkom- Wahrscheinlichkeiten ohne Miss.
men (X) Auswahl Ausfall Pr(X) Pr(X)
1000
1/36
1/10 .025
.037
1500
2/36
1/10 .050
.074
2000
3/36
1/10 .075
.111
2500
4/36 1/10 .100
.148
3000
5/36 1/10 .125
.185
3500
6/36 1/10 .150
.222
4000
5/36 16/25 .050
.074
4500
4/36 16/25 .040
.059
5000
3/36 16/25 .030
.044
5500
2/36 16/25 .020
.030
6000
1/36 16/25 .010
.015
Summe:
36/36
.675
.999
Missing
.325
Einfache Zufallsauswahl mit Ausfällen
n=2 aus N=6:
Erwartungswert: 3111.11 €
Standardabw. 1099.94 €:
Bei systematischen Ausfällen, d.h. Ausfallwahrscheinlichkeiten, die mit der interessierenden
Eigenschaft der Elemente in der Population zusamenhängen, kann also der Erwartungswert der
Kennwerteverteilung vom zu schätzenden Populationsparameter abweichen.
Die Schätzung ist dann verzerrt.
Vorlesung Statistik I
27
Wahrscheinlichkeitsverteilungen von Häufigkeiten und Anteilen
Binomialverteilung
Im Zusammenhang mit dem Gesetz der großen Zahl wurde die Wahrscheinlichkeit berechnet,
mit der bei n Würfen einer Münze nA bzw pA mal das Ereignis A („Kopf“) auftritt.
Dabei wurde unterstellt, dass die Wahrscheinlichkeit von „Kopf“ wie „Zahl“ jeweils 0.5 beträgt.
Es ist auch möglich, die Wahrscheinlichkeit von nA bzw pA zu berechnen, wenn die Auftretenswahrscheinlichkeit Pr(A) nicht 0.5 sondern eine beliebige Zahl πA zwischen 0 und 1 ist.
Wenn z.B. die Wahrscheinlichkeit von A Pr(A) = πA = 0.4 beträgt, dann muss die Wahrscheinlichkeit des komplementären Ereignisses B = ¬A offenbar Pr(B) = πB = 1 – 0.4 = 0.6 betragen.
Da bei n Wiederholungen nA mal A auftritt, muss entsprechend nB = n – nA mal B auftreten.
Die n Wiederholungen sind statistisch unabhängig voneinander. Somit ist die Wahrscheinlichkeit bei Berücksichtigung der Reihenfolge (Anordnung), in der A bzw. B ausgewählt werden:
Pr ( n A ) = Pr ( n − n A ) = Pr ( n B ) = 0.4n A ⋅ 0.6n B = πAn A ⋅ πBn B = πAn A ⋅ (1 − π A )
n −nA
Solange nur die Häufigkeiten nA und nB interessieren, ist die Reihenfolge der Ziehung der Elemente irrelevant. Die Zahl der ununterscheidbaren Stichproben ist dann gleich der Zahl der
Möglichkeiten, die insgesamt n Element in zwei Gruppen der Größe nA und nB = n – nA aufzuteilen. Aus den Regeln der Kombinatorik ergibt sich diese Anzahl der jeweils ununterscheidbaren Stichproben als „n über nA“ bzw. was zum gleichen Ergebnis führt „n über nB“.
Vorlesung Statistik I
28
Binomialverteilung
Für die Wahrscheinlichkeit der Häufigkeiten nA und nB ohne Berücksichtigung der
Auswahlreihenfolge gilt somit:
⎛ n ⎞ nA
⎛ n ⎞ nA
nB
Pr ( n A ) = Pr ( n − n A ) = Pr ( n B ) = ⎜ ⎟ 0.4 ⋅ 0.6 = ⎜ ⎟ 0.4 ⋅ 0.6n B
⎝ nA ⎠
⎝ nB ⎠
Die so berechneten Wahrscheinlichkeiten folgen der sogenannten Binomialverteilung, die sich
ergibt, wenn die Wahrscheinlichkeit der Auftretenshäufigkeit eines Ereignisses A bei n statistisch unabhängigen Wiederholungen eines Zufallsexperiments interessiert.
In der generelleren Darstellung wird folgende Notation verwendet:
π1 ist die Wahrscheinlichkeit, mit der das interessierende Ereignis (A) im Zufallsexperiment auftritt,
n ist die Zahl der unabhängigen Wiederholungen des Zufallsexperiments,
n1 ist die Häufigkeit, mit der das interessierende Ereignis A in diesen n Wiederholungen
auftritt,
X ist eine Zufallsvariable, die die Werte 0, 1, ..., n1, ..., n annehmen kann.
Die Wahrscheinlichkeitsverteilung von X ist dann binomialverteilt mit den Parametern π1
und n, symbolisiert durch b(X; n, π1)
⎛n⎞
n!
n −n
n −n
Pr(X = n1 ) = ⎜ ⎟ ⋅ π1n1 ⋅ (1 − π1 ) 1 =
⋅ π1n1 ⋅ (1 − π1 ) 1 = b ( X;n, π1 )
(n − n1 )!⋅ n!
⎝ n1 ⎠
Vorlesung Statistik I
29
Binomialverteilung
Pr(X) = b(X;5,0.5)
0.3125
0.3125
0.1563
0.1563
0.0313
0.0313
0
1
2
3
4
5
X
Pr(X) = b(X;10,0.5)
0.2461
0.2051
0.1172
0.2051
0.1172
0.0439
0.0098
0.0439
0.0098
0.001
0
0.001
1
2
3
4
5
6
7
8
9
10
X
Pr(X) = b(X;10,0.4)
0.2508
0.1115
0.0425
0.0106
0.0016
0.0001
0.1209
0.0403
0.006
1
2
3
Aus der Wahrscheinlichkeitsverteilung lässt sich durch Aufsummieren die Verteilungsfunktion berechnen:
n1
⎛n⎞ j
n− j
F(X = n1 ) = Pr(X ≤ n1 ) = ∑ ⎜ ⎟ ⋅ π1 ⋅ (1 − π1 )
j= 0 ⎝ j ⎠
0.2007
0.215
0
Die Verteilungsform der Binomialverteilung variiert mit den
Verteilungsparametern π1 und n. Ist π1 = 0.5, ist die Verteilung symmetrisch, bei π1 < 0.5, ist sie linkssteil bzw. rechtsschief und bei π1 > 0.5, ist sie rechtssteil bzw. linksschief.
Mit steigendem n nimmt die Schiefe dadurch faktisch ab,
dass an einem Ende der Verteilung die Auftetenswahrcheinlichkeiten schnell gegen null gehen.
4
5
6
7
8
9
10
X
Pr(X) = b(X;10,0.7)
0.2668
0.2001
0.2335
0.1029
0.0368
0.1211
0.009
0.0014
0.0281
0.0001
Es lässt sich zeigen, dass der Erwartungswert und die
Varianz der Binomialverteilung Funktionen der beiden
Parameter π1 und n sind:
μ X = n ⋅ π1
σ 2X = n ⋅ π1 ⋅ (1 − π1 )
0
0
1
2
3
4
5
6
7
8
9
10
X
Vorlesung Statistik I
30
Bernoulli-Verteilung und Summen voneinander unabhängiger Binomialverteilungen
Ein Spezialfall der Binomialverteilung ergibt sich, wenn n=1 ist. Die Verteilung wird dann auch
Punkt-Binomialverteilung oder Bernoulli-Verteilung genannt.
Für die Wahrscheinlichkeitsverteilung gilt dann:
P ( X = 1) = π1 und P(X = 0) = π0 = 1 − π1
Erwartungswert und die Varianz sind:
μ X = π1 und σ X2 = π1 ⋅ (1 − π1 )
Eine Binomialverteilung mit den Parametern π1 und n kann als Summe statistisch unabhängiger
Bernoulli-Verteilungen mit jeweils gleichen Parameterwert π1 aufgefasst werden.
Generell gilt:
Wenn X1 binomialverteilt ist mit b(X1; m1, π1) und X2 binomialverteilt mit
b(X2; m2, π1), und X1 und X2 statistisch unabhängig voneinander sind,
dann ist die Summe Y = X1 + X2 ebenfalls binomialverteilt mit b(Y; m1+m2, π1).
Für den Erwartungswert und die Varianz gilt dann:
μ ( X1 ) = m1 ⋅ π1 ; σ 2 ( X1 ) = m1 ⋅ π1 ⋅ (1 − π1 )
μ ( X 2 ) = m 2 ⋅ π1 ; σ 2 ( X1 ) = m 2 ⋅ π1 ⋅ (1 − π1 )
μ ( Y ) = ( m1 + m 2 ) ⋅ π1 ; σ 2 ( X1 ) = ( m1 + m 2 ) ⋅ π1 ⋅ (1 − π1 )
Vorlesung Statistik I
31
Erwartungswert und Varianz von Linearkombinationen unabhängiger Zufallsvariablen
Die Berechnung von Erwartungswerten und Varianzen von Summen aus den Erwartungswerten
und Varianzen der Summanden gilt nicht nur für die Binomialverteilung, sondern generell und
lässt sich auf beliebige Linearkombinationen von unabhängigen Zufallsvariablen verallgemeinern.
Wenn (1) Y = b0 + b1 · X1 + b2 · X2 + ... + bK · XK,
(2) alle Xk statistisch unabhängig voneinander sind,
dann gilt für den Erwartungswert und die Varianz von Y:
K
μ Y = μ ( Y ) = b 0 + b1 ⋅ μ ( X1 ) + b 2 ⋅ μ ( X 2 ) + … + b K ⋅ μ ( X k ) = b 0 + ∑ b k ⋅ μ ( X k )
k =1
K
σ = σ ( Y ) = b ⋅ σ ( X1 ) + b ⋅ σ ( X 2 ) + … + b ⋅ σ ( X K ) = ∑ b k2 ⋅ σ 2 ( X k )
2
Y
2
2
1
2
2
2
2
2
K
2
k
Zwei Zufallsvariablen X und W sind statistisch unabhängig voneinander, wenn die Wahrscheinlichkeit des gemeinsamen Auftretens gerade das Produkt der Wahrscheinlichkeitsfunktionen ist: Pr ( X = x ∩ W = w ) = Pr ( X = x ) ⋅ Pr ( W = w ) für alle x und w
Diese Regel kann als Verallgemeinerung der Berechnung von Mittelwert und Varianz einer
Lineartransformation einer Variablen aufgefasst werden.
Tatsächlich gilt die Aussage auch entsprechend für die Verteilungen empirischer Variablen,
falls diese unkorreliert sind.
Auch für Zufallsvariablen gilt genaugenommen die schwächere Formulierung, dass die sog.
Produktmomentkorrelation zwischen allen Summanden null betragen muss.
Vorlesung Statistik I
32
Hypergeometrische Verteilung
Die Binimialverteilung gibt die Häufigkeit des Auftretens eines Ereignisses an, wenn ein Zufallsexperiment wiederholt wird. Diese Situation trifft auf eine einfache Zufallsauswahl mit
Zurücklegen zu. Die Binomialverteilung gibt also auch die Wahrscheinlichkeit der Häufigkeit
wieder, mit der ein beliebiges Populationsmerkmal A in einer Stichprobe vorkommt, die über
eine einfache Zufallsauswahl mit Zurücklegen gewonnen wurde.
Wenn es aber darum geht, mittels einer Stichprobe Informationen über eine Population zu gewinnen, warum sollte dann ein Element mehrfach ausgewählt werden? Realistischer ist eine
einfache Zufallsauswahl ohne Zurücklegen.
Wenn eine Population insgesamt N Elemente umfasst, von denen N1 eine interessierende Eigenschaft haben, dann können entsprechend N0 = N – N1 diese Eigenschaft nicht aufweisen.
In einer Stichprobe von n Elementen, die mit einer einfachen Zufallsauswahl ohne Zurücklegen
aus der Population gezogen wurden, weisen n1 Elemente die interessierende Eigenschaft auf,
wobei n1 entweder zwischen 0 und n oder zwischen 0 und N1 variieren kann, je nachdem, ob
n < N1 oder ob n > N1.
Entsprechend haben dann n0 = n – n1 der ausgewählten Elemente die interessierende Eigenschaft nicht.
Da in der Stichprobe n1 von maximal N1 Elementen die interessierende Eigenschaft A aufweisen können, gibt es „N1 über n1“ Möglichkeiten (Anordnungen), die n1 Elemente aus den N1
Elementen auszuwählen.
Vorlesung Statistik I
33
Hypergeometrische Verteilung
Analog gibt es „N0 über n0“ Möglichkeiten (Anordnungen), die n0 Elemente aus N0 ohne die
Eigenschaft A auszuwählen.
Die einfache Zufallsauswahl führt dazu, dass die Auswahl der n1 Elemente aus N1 mit der interessierenden Eigenschaft A unabhängig von der Auswahl der n0 Elemente aus N0 ohne diese
Eigenschaft erfolgt. Die Gesamtzahl der Anordnungen der n1 und n0 Elemente ist daher das
Produkt der beiden Möglichkeiten also „N1 über n1“ mal „N0 über n0“.
Insgesamt gibt es bei einer einfachen Zufallsauswahl ohne Zurücklegen „N über n“ Möglichkeiten, ohne Berücksichtigung der Anordnung n von N Elementen (egal ob mit oder ohne der
interessirenden Eigenschaft A!) auszuwählen.
Die Realisierungswahrscheinlichkeit einer einzelnen Stichprobe ist der Kehrwert dieser Zahl.
Die Wahrscheinlichkeit, dass von einer Stichprobe mit n Elementen genau n1 die interessierenden Eigenschaft A aufweisen, ist dann der Quotient aus den beiden Anzahlen:
⎛ N1 ⎞ ⎛ N 0 ⎞ ⎛ N1 ⎞ ⎛ N − N1 ⎞
⎜ n ⎟⋅⎜ n ⎟ ⎜ n ⎟⋅⎜ N − n ⎟
1 ⎠
Pr ( n1 ) = ⎝ 1 ⎠ ⎝ 0 ⎠ = ⎝ 1 ⎠ ⎝
⎛ N⎞
⎛ N⎞
⎜n⎟
⎜n⎟
⎝ ⎠
⎝ ⎠
Eine Zufallsvariable mit den möglichen Ausprägungen 0, 1, ..., n1 ist hypergeometrisch verteilt,
wenn die Wahrscheinlichkeitsfunktion dieser Formel folgt.
Vorlesung Statistik I
34
Hypergeometrische Verteilung
Die hypergeometrische Verteilung hat die drei Parameter n, N und N1.
Ist X hypergeometrisch verteilt, wird hierfür das Symbol h(X; n, N, N1) verwendet:
⎛ N1 ⎞ ⎛ N − N1 ⎞
( N − N1 )!
N1 !
⋅
⋅
⎜ n ⎟ ⎜ N − n ⎟ n !⋅ N − n ! n − n !⋅ N − N − n + n !
( 1 1) (
1) (
1
1)
1 ⎠
⎝
Pr ( X = n1 ) = h ( X = n1;n, N, N1 ) = 1 ⎠ ⎝
= 1
N!
⎛ N⎞
⎜n⎟
n!⋅ ( N − n )!
⎝ ⎠
Die Verteilungsfunktion ergibt sich über Aufsummieren:
⎛ N1 ⎞ ⎛ N − N1 ⎞
⎟⋅⎜ n − j ⎟
n1 ⎜
j
⎠
F ( X = n1 ) = Pr ( X ≤ n1 ) = ∑ ⎝ ⎠ ⎝
⎛ N⎞
j= 0
⎜n⎟
⎝ ⎠
Der Erwartungswert und die Varianz betragen:
μX = n ⋅
Vorlesung Statistik I
N1
N ⎛ N ⎞ N−n
und σ X2 = n ⋅ 1 ⋅ ⎜1 − 1 ⎟ ⋅
N
N ⎝
N ⎠ N −1
35
Hypergeometrische Verteilung
Pr(X) = h(X;5,20,10)
0.3483
0.3483
0.1354
0.1354
0.0163
0.0163
0
1
2
3
4
5
X
Pr(X) = h(X;10,20,10)
0.3437
0.2387
0.2387
0.0779
0.0779
0.011
0.011
0.0005
0.0005 0
0
0
1
Die Form der hypergeometrischen Verteilung hängt von den
Parametern ab. Sind die Häufigkeiten N1 und N0 in der Population gleich groß, d.h. N1/N = 0.5, dann ist die Verteilung
symmetrisch. Ist N1/N < 0.5, dann ist die Verteilung rechtsschief bzw. linkssteil, ist N1/N > 0.5, dann ist die Verteilung
linksschief bzw. rechtssteil. Mit steigender Stichprobengröße
nimmt die Schiefe ab, der Verlauf wird immer symmetrischer.
2
3
4
5
6
7
8
9
10
X
Pr(X) = h(X;5,20,7)
0.3874
0.3228
0.1761
0.083
0.0293
0
1
2
3
0.0014
4
5
X
Pr(X) = h(X;10,20,7)
0.3251 0.3251
0.1463
0.1463
0.0271
0.0015
0.0271
0.0015
0
1
2
3
4
5
6
7
0
0
0
8
9
10
X
Vorlesung Statistik I
36
Beziehung zwischen hypergeometrischer Verteilung und Binomialverteilung
b(X,10,0.5) und h(X,10,20,10) im Vergleich
b(X;10,0.5)
h(X;10,20,10)
0
1
2
3
4
5
6
7
8
9 10
X
Auch wenn in der Realität eher Zufallsauswahlen ohne Zurücklegen als mit Zurücklegen vorkommen, werden Wahrscheinlichkeiten häufiger über die Binomialverteilung berechnet, da die
Binomialverteilung einen Parameter weniger aufweist und einfacher zu berechnen ist.
Begründet wird dies mit der Ähnlichkeit der beiden Verteilungen. Die Abbildung zeigt aber
auch, dass bei gleichem n und gleichen Populationsanteilen π1 = N1/N die hypergeometrische
Verteilung enger um den Erwartungswert streut. Ursache ist die geringere Varianz.
Während die Erwartungswerte gleich sind, ist die Varianz der hypergeometrischen Verteilung
um den Faktor (N-n)/(N-1) geringer als die Varianz der Binomialverteilung.
Vorlesung Statistik I
37
Beziehung zwischen hypergeometrischer Verteilung und Binomialverteilung
0.4
Pr(X)
0.3
0.2
0.1
0
0
h(X;10,20,10)
1
2
3
4
h(X;10,100,50)
5
6
7
X
h(X;10,200,100)
8
9
10
b(X;10,0.5)
Wenn der Populationsumfang N relativ zum Stichprobenumfang n ansteigt, dann nähert sich
der Faktor (N–n)/(N–1)immer mehr den Wert eins an.
Tatsächlich nähern sich auch die Wahrscheinlichkeiten der Ausprägungen von Binomialverteilung und hypergeometrischer Verteilung immer mehr an.
Die Abbildung zeigt exemplarisch die Auftretetenswahrscheinlichkeiten von hypergeometrischen Verteilungen mit den Parametern h(X;10,20,10), h(X;10,100,50) und h(X;10,200,100)
sowie die Binomialverteilung mit den Parametern b(X,10,0.5). Gemeinsam ist allen Verteilungen, dass der Populationsanteil des betrachteten Merkmals A stets π1=N1/N=0.5 beträgt. Je
größer der Populationsumfang, desto ähnlicher sind sich die Verteilungen.
Vorlesung Statistik I
38
Beziehung zwischen hypergeometrischer Verteilung und Binomialverteilung
Für praktische Zwecke ist die Annäherung hinreichend genau, wenn das
Verhältnis von Populationsgröße zur
Stichprobengröße größer 20 ist:
N
> 20
n
Pr(X)
0.4
0.3
0.2
0.1
Diese Bedingung ist in der Umfrageforschung praktisch immer erfüllt.
0
0
1
2
3
4
5
6
7
8
9
10
X
h(X;10,20,10)
h(X;10,100,50)
h(X;10,200,100)
b(X;10,0.5)
Im Extremfall einer unendlich großen Population sind die beiden Verteilungen identisch.
Wenn eine Wahrscheinlichkeitsverteilung einer anderen unter bestimmten Bedingungen immer
ähnlicher wird, spricht man von einer asymptotischen Annäherung.
Die hypergeometrische Verteilung nähert sich der Binomialverteilung asymptotisch an, wenn
der Populationsumfang N über alle Grenzen ansteigt und dabei der betrachtete Populationsanteil
N1/N konstant bleibt:
N ⎞
⎛
lim ( h ( X, n, N, N1 ) ) = b ⎜ X;n, 1 ⎟
N →∞
N⎠
⎝
Vorlesung Statistik I
39
Wahrscheinlichkeiten von Anteilen bei einfachen Zufallsauswahlen mit Zurücklegen
Die hypergeometrische Verteilung bzw. die Binomialverteilung kann genutzt werden, um die
Wahrscheinlichkeitsverteilungen von (absoluten) Häufigkeiten eines Merkmals A in einer
Stichprobe bei einfachen Zufallsauswahlen mit bzw. ohne Zurücklegen zu berechnen.
Über diese Wahrscheinlichkeitsverteilungen können aber auch die relative Häufgkeiten in der
Stichprobe berechnet werden.
Die Wahrscheinlichkeitsverteilung einer relative Häufigkeit p1 = n1/n lässt sich aus der Verteilung der absoluten Häufigkeit berechnen, da es sich um eine Lineartransformation handelt:
p1 = 0 + 1/n ·n1
Ausgangspunkt ist eine Population mit insgesamt N Elementen, von denen N1 eine interessierende Eigenschaft aufweisen. Wenn zufällig n=1 Element aus dieser Population ausgewählt
wird, beträgt die Wahrscheinlichkeit, dass das Element die interessierende Eigenschaft aufweist
π1 = N1/N. Die Wahrscheinlichkeitsverteilung ist dann bernoulliverteilt. Bei einer größeren
Fallzahl mit n > 1 Elementen ist dann die Häufigkeit bei einer einfachen Zufallsauswahl mit
Zurücklegen binomialverteilt mit den Parametern n und π1 = N1/N.
Bei einfachen Zufallsauswahlen mit Zurücklegen berechnet sich daher die Wahrscheinlichkeit
einer relative Häufigkeit p1 = n1/n über die Binomialverteilung nach:
p ⋅n
n ⋅(1− p1 )
N1 ⎞ ⎛ n ⎞ ⎛ N1 ⎞ 1 ⎛ N1 ⎞
⎛
⋅ ⎜ ⎟ ⋅ ⎜1 −
Pr ( p1 ) = b ⎜ X = n ⋅ p1;n, ⎟ = ⎜
⎟
⎟
N ⎠ ⎝ p1 ⋅ n ⎠ ⎝ N ⎠
N⎠
⎝
⎝
Vorlesung Statistik I
40
Wahrscheinlichkeiten von Anteilen bei einfachen Zufallsauswahlen mit Zurücklegen
Die Binomialverteilung kann annäherungsweise auch bei einer einfachen Zufallsauswahl ohne
Zurücklegen verwendet werden, wenn der Populationsumfang N relativ zur Stichprobengröße n
sehr groß ist: N/n >20.
Ist diese Bedingung nicht erfüllt, berechnet sich die Wahrscheinlichkeit einer relative Häufigkeit
p1 = n1/n bei einer einfachen Zufallsauswahle ohne Zurücklegen über die hypergeometrische
Verteilung nach:
⎛ N1 ⎞ ⎛ N − N1 ⎞
⎜n ⋅p ⎟⋅⎜n − n ⋅p ⎟
1⎠ ⎝
1⎠
Pr ( p1 ) = b ( X = n ⋅ p1;n, N, N1 ) = ⎝
⎛n⎞
⎜ N⎟
⎝ ⎠
Die Gleichungen gelten jeweils nur unter der Bedingung p1 = n1/n. Bei anderen Werte p1 ≠ n1/n
sind die Auftretenswahrscheinlichkeiten stets null.
Für den Erwartungswert und die Varianz der Kennwerteverteilung eines Anteils folgt aus der
Regel für Linearkombinationen
• bei einer einfachen Zufallsauswahl mit Zurücklegen:
N
1 N ⎛ N ⎞
μ ( p1 ) = 1 und σ 2 ( p1 ) = ⋅ 1 ⋅ ⎜ 1 − 1 ⎟
N
n N ⎝
N⎠
• bei einer einfachen Zufallsauswahl ohne Zurücklegen:
N
1 N ⎛ N ⎞ N−n
μ ( p1 ) = 1 und σ 2 ( p1 ) = ⋅ 1 ⋅ ⎜1 − 1 ⎟ ⋅
N
n N ⎝
N ⎠ N −1
Vorlesung Statistik I
41
Haushaltsnummer der zweiten
Befragung
Anwendungsbeispiel
0
⎛2⎞ 4
⋅⎜ ⎟ =
⎝3⎠ 9
1
⎛2⎞ 4
⋅⎜ ⎟ =
⎝3⎠ 9
2
⎛2⎞ 1
⋅⎜ ⎟ =
⎝3⎠ 9
2! ⎛ 1 ⎞
Pr(p1 = 0.0) =
⋅⎜ ⎟
0!⋅ 2! ⎝ 3 ⎠
6
5
2
Pr(p1=0.0)
4
2! ⎛ 1 ⎞
Pr(p1 = 0.5) =
⋅⎜ ⎟
1!⋅1! ⎝ 3 ⎠
3
2
Pr(p1=1.0)
1
Pr(p1=0.5)
0
0
1
2
3
4
5
6
2! ⎛ 1 ⎞
Pr(p1 = 1.0) =
⋅⎜ ⎟
2!⋅ 0! ⎝ 3 ⎠
1
0
Haushaltsnummer der ersten Befragung
Wie wahrscheinlich ist es, dass bei der einfachen Zufallsauswahl mit Zurücklegen von n=2 aus
N=6 Haushalten der Anteil der ausgewählten Haushalte, die maximal 2000 € Monatseinkommen haben, 0.0, 0.5 bzw. 1.0 beträgt.
Der Anteil der Haushalte mit einem Einkommen von maximal 2000 € beträgt in der Population
2/6 = 1/3.
Dann gilt für die gesuchten Wahrscheinlichkeiten:
Pr(0.0) = 16/36 = b(X=0; 2, 1/3) = 4/9,
Pr(0.5) = 16/36 = b(X=1; 2, 1/3) = 4/9,
Pr(1.0) = 4/36 = b(X=2; 2, 1/3) = 1/9.
Vorlesung Statistik I
42