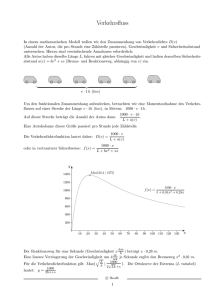
Script Datenmanagement
Werbung

Wintersemester 2009/2010 Script Datenmanagement Jörg Becker Philipp Bergener Patrick Delfmann Milan Karow Lukasz Lis Andrea Malsbender Ralf Plattfaut 03.12.2009 1 Inhaltsverzeichnis Das Script für die Lehrveranstaltung Datenmanagement wurde im Wintersemester 2007/2008 komplett überarbeitet und neu strukturiert. Wir bitten darum, eventuelle Fehler im Script an Ralf Plattfaut ([email protected]) zu melden. Inhaltsverzeichnis 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1.1 Zweck Konzeptioneller Datenmodelle . . . . . . . . . . . . . . . . 1.2 Grundlegende Modellelemente im ERM . . . . . . . . . . . . . . 1.3 Verwendung der Kardinalitäten in der Min-Max-Notation . . . . 1.3.1 Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3.2 Kombinationsmöglichkeiten und deren Interpretation . . . 1.4 Hierarchien und Strukturen im ERM . . . . . . . . . . . . . . . . 1.4.1 Hierarchien und Bäume . . . . . . . . . . . . . . . . . . . 1.4.2 Strukturen und Netze . . . . . . . . . . . . . . . . . . . . 1.5 Attribute im ERM . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5.1 Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5.2 Attribute als Schlüssel . . . . . . . . . . . . . . . . . . . . 1.6 Mehrwertige Relationshiptypen . . . . . . . . . . . . . . . . . . . 1.7 Uminterpretation von Relationshiptypen . . . . . . . . . . . . . . 1.7.1 Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.7.2 Zulässigkeit der Uminterpretation von Relationshiptypen 1.8 Generalisierung und Spezialisierung im ERM . . . . . . . . . . . 1.9 Spezielle Konventionen der ER-Modellierung . . . . . . . . . . . 1.9.1 Benennung von Relationshiptypen . . . . . . . . . . . . . 1.9.2 Das Konzept Zeit“ im Entity-Relationship-Modell . . . . ” 1.9.3 Konventionen zu Kardinalitäten . . . . . . . . . . . . . . 1.9.4 Konventionen zur Generalisierung/Spezialisierung . . . . 1.9.5 Kommentare und zusätzliche Annahmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5 5 5 6 6 8 8 9 11 11 12 13 14 14 16 18 20 21 21 23 23 24 . . . . . . . . . . . . . . 25 25 25 25 26 27 27 29 30 31 32 32 33 34 34 3 Datenbanknormalisierung 3.1 Erste Normalform . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.1 Funktionale Abhängigkeiten . . . . . . . . . . . . . . . . . . . . . . . . . . 37 37 37 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 Überführung von ER-Modellen in Datenbankschemata 2.1 Überführung von Entitytypen . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2 Überführung von Relationshiptypen . . . . . . . . . . . . . . . . . . . . . . 2.2.1 Überführung von (0,n) - (0,n) - Beziehungen . . . . . . . . . . . . . 2.2.2 Überführung von (1,n) - (0,n) - Beziehungen . . . . . . . . . . . . . 2.2.3 Überführung von (1,1) - (0/1,n) - Beziehungen . . . . . . . . . . . . 2.2.4 Überführung von (0,1) - (0/1,n) - Beziehungen . . . . . . . . . . . . 2.2.5 Überführung von (0,1) - (0,1) - Beziehungen . . . . . . . . . . . . . . 2.2.6 Überführung von (0,1) - (1,1) - Beziehungen . . . . . . . . . . . . . . 2.3 Überführung von Generalisierung / Spezialisierung . . . . . . . . . . . . . . 2.3.1 Nichtdisjunkt-Partielle Generalisierung/Spezialisierung . . . . . . . . 2.3.2 Nichtdisjunkt-Totale Generalisierung/Spezialisierung . . . . . . . . . 2.3.3 Disjunkt-Totale Generalisierung/Spezialisierung . . . . . . . . . . . . 2.3.4 Disjunkt-Partielle Generalisierung/Spezialisierung . . . . . . . . . . 2.3.5 Alternative Überführungsmuster für Generalisierung/Spezialisierung 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Inhaltsverzeichnis 3.2 3.3 3.4 3.5 3.1.2 Vorgehen zur Überführung in die 1. Normalform 3.1.3 Beispiel . . . . . . . . . . . . . . . . . . . . . . . Zweite Normalform . . . . . . . . . . . . . . . . . . . . . 3.2.1 Vorgehen zur Überführung in die 2. Normalform 3.2.2 Beispiel . . . . . . . . . . . . . . . . . . . . . . . Dritte Normalform . . . . . . . . . . . . . . . . . . . . . 3.3.1 Vorgehen zur Überführung in die 3. Normalform 3.3.2 Beispiel . . . . . . . . . . . . . . . . . . . . . . . Vierte Normalform . . . . . . . . . . . . . . . . . . . . . 3.4.1 Mehrwertige Abhängigkeiten . . . . . . . . . . . 3.4.2 Beispiel . . . . . . . . . . . . . . . . . . . . . . . Fünfte Normalform . . . . . . . . . . . . . . . . . . . . . 3.5.1 Beispiel . . . . . . . . . . . . . . . . . . . . . . . 3.5.2 Zusammenfassung des Beispiels . . . . . . . . . . 4 Structured Query Language 4.1 SQL als Standard . . . . . . . . . . . . . . . . . . . 4.2 Ziele . . . . . . . . . . . . . . . . . . . . . . . . . . 4.3 Bezeichner . . . . . . . . . . . . . . . . . . . . . . . 4.4 Werte . . . . . . . . . . . . . . . . . . . . . . . . . 4.4.1 Zeichenketten . . . . . . . . . . . . . . . . . 4.4.2 Zahlen . . . . . . . . . . . . . . . . . . . . . 4.4.3 Null-Werte . . . . . . . . . . . . . . . . . . 4.5 Datentypen . . . . . . . . . . . . . . . . . . . . . . 4.5.1 Numerische Datentypen . . . . . . . . . . . 4.5.2 Zeitbezogene Datentypen . . . . . . . . . . 4.5.3 Zeichenkettenbezogene Datentypen . . . . . 4.6 Erstellen von Tabellen (CREATE TABLE) . . . . 4.7 Ändern der Tabellenstruktur (ALTER TABLE) . . 4.8 Entfernen von Tabellen (DROP TABLE) . . . . . 4.9 Einfügen von Daten (INSERT) . . . . . . . . . . . 4.9.1 Direktes Einfügen . . . . . . . . . . . . . . 4.9.2 Einfügen aus anderen Tabellen . . . . . . . 4.10 Abfragen (SELECT) . . . . . . . . . . . . . . . . . 4.10.1 Einfache Abfragen . . . . . . . . . . . . . . 4.10.2 Formulierung von Bedingungen (WHERE) 4.10.3 Sortieren (ORDER BY) . . . . . . . . . . . 4.10.4 JOIN-Syntax . . . . . . . . . . . . . . . . . 4.10.5 Aggregation von Daten . . . . . . . . . . . 4.10.6 Gruppenbildung (GROUP BY) . . . . . . . 4.10.7 Gruppenbedingungen (HAVING) . . . . . . 4.10.8 Reihenfolge bei der Abfragenberechnung . . 4.10.9 Unterabfragen . . . . . . . . . . . . . . . . 4.11 Ändern von Daten (UPDATE) . . . . . . . . . . . 4.12 Löschen von Daten (DELETE) . . . . . . . . . . . 5 Datenbanksnychronisation und Transaktionen 5.1 Synchronisation von Datenbankprozessen 5.2 Transaktionen . . . . . . . . . . . . . . . . 5.2.1 Atomicity (Atomarität) . . . . . . 5.2.2 Consistency (Konsistenz) . . . . . 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 37 40 41 41 42 43 43 44 44 45 46 47 50 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 52 52 52 53 53 54 54 55 55 56 57 58 60 61 61 61 62 62 62 63 65 65 69 70 70 71 72 74 75 . . . . 76 76 76 76 76 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Inhaltsverzeichnis 5.3 5.4 5.2.3 Isolation (Isoliertheit) . . . . . . . . . . . . . . . . 5.2.4 Durability (Dauerhaftigkeit) . . . . . . . . . . . . . Anomalien bei konkurrierenden Zugriffen auf Daten . . . 5.3.1 Dirty Read (Schreib-Lese-Konflikt) . . . . . . . . . 5.3.2 Lost Update (Verlorene Aktualisierung) . . . . . . 5.3.3 Nonrepeatable Read (nicht-wiederholbares Lesen) . 5.3.4 Phantom . . . . . . . . . . . . . . . . . . . . . . . Serialisierbarkeit von Transaktionen . . . . . . . . . . . . 5.4.1 Lese- und Schreibsperren . . . . . . . . . . . . . . 5.4.2 Zwei-Phasen-Protokoll . . . . . . . . . . . . . . . . 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 77 77 77 78 78 79 80 81 82 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1.1 Zweck Konzeptioneller Datenmodelle In einem konzeptionellen Datenmodell sollen die im Betrachtungsgebiet relevanten Daten unabhängig von einem konkreten Datenbankmodell und unabhängig von Funktionen, in denen die Daten verarbeitet werden, dargestellt werden. Ein logisches Datenmodell kann prinzipiell in ein beliebiges Datenbankmodell überführt werden. Das Entity-Relationship-Modell (ERM) ist ein Hilfsmittel zur Darstellung eines konzeptionellen Datenmodells und unabhängig von einem bestimmten Datenbankmodell. Das Datenmodell hält auf konzeptioneller Ebene die im Betrachtungsbereich relevanten Objekte (Entitäten) und Beziehungen (Relationships) zwischen diesen formal fest. Objekte und Beziehungen können durch Eigenschaften (Attribute) näher beschrieben werden. 1.2 Grundlegende Modellelemente im ERM Entity die informationelle Repräsentation eines realen oder künstlichen/abstrakten Objekts (auch: Instanz eines Entitytyps), hat im ERM keine direkte Entsprechung Entitytyp Zusammenfassung bzw. Typisierung gleichartiger Entities zu einer Menge (bzw. einer Klasse), im ERM dargestellt durch ein Rechteck Relation Beziehung zwischen zwei Entities Relationshiptyp Typisiert die Beziehung zwischen zwei Entitytypen, wobei auch ein Entitytyp mit sich selbst in Beziehung gesetzt werden kann (z.B. Hierarchie), im ERM dargestellt durch eine Raute Kante Verbinden Entity- und Relationshiptypen miteinander, Kanten dürfen nicht zwischen gleichartigen Knoten gezogen werden, im ERM dargestellt durch horizontale und vertikale Linien Attribut Weist einem Entity- oder Relationshiptypen typisierte Eigenschaften zu, Attribute können als ellipsenförmige Knoten an Entity- und Relationshiptypen annotiert werden Kardinalität Gibt an, wie oft ein Entity eines Entitytypen A eine Beziehung mit einem Entity eines Entitytypen B eingehen kann, wenn A und B über einen Relationshiptypen in Verbindung gesetzt werden 1.3 Verwendung der Kardinalitäten in der Min-Max-Notation Bei der Min-Max-Notation wird angegeben, wie oft eine Entität mindestens eine Beziehung eingehen muss und wie oft sie maximal eine Beziehung eingehen darf. Um eine Beziehung zwischen zwei Entitytypen zu charakterisieren, sind also zwei (min, max)-Paare notwendig (eins für jeden Entitytyp). Hat die Minimalkardinalität den Wert Eins (oder größer), dann spricht man auch von einer existenziellen Abhängigkeit. 5 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1.3.1 Syntax A (min,max) R (min,max) B Mit min wird angegeben, wie oft ein Entity aus A mindestens eine Beziehung mit einem Entity aus B eingeht bzw. eingehen muss. Übliche Werte für die Minimalkardinalität (also die untere Schranke) sind 0 und 1. Theoretisch - wenn auch selten eingesetzt - sind auch andere nichtnegative Ganzzahlen zulässig. Bei einer Minimalkardinalität von größer als null, ist der Entitytyp existenzabhängig vom verbundenen Entitytyp. Mit max wird angegeben, wie oft ein Entity aus A höchstens eine Beziehung mit B eingehen darf. Die Maximalkardinalität (also die obere Schranke) muss immer größer als 0 sein. Übliche Werte sind 1 oder n (bzw. m), wobei hier die Variable n lediglich angibt, dass die obere Grenze offen ist, d.h. ein A kann Beziehungen mit beliebig vielen Instanzen von B eingehen. Auch für die Maximalkardinalität können bei Bedarf andere natürliche Zahlen als 1 eingesetzt werden. 1.3.2 Kombinationsmöglichkeiten und deren Interpretation Kombinationen ohne Existenzabhängigkeiten: Kombinationen von Kardinalitäten implizieren keine Existenzabhängigkeit, wenn die Minimalkardinalität für alle Entitytypen, die an einer Beziehung teilnehmen, Null ist. Kombination 1.1: (0,n) – (0,m) Vorlesung (0,n) Teilnahme (0,m) Student An einer Vorlesung nehmen null bis beliebig viele Studenten teil, Studenten können an null bis beliebig vielen Vorlesungen Teilnehmen. Kombination 1.2: (0,1) – (0,n) Lehrveranstaltung (0,1) Veranstltgs.ort (0,n) Hörsaal Einer Lehrveranstaltung kann maximal ein Hörsaal zugeordnet werden (muss aber nicht: beispielsweise bei reinen Online-Veranstaltungen). In einem Hörsaal können null bis beliebig viele Vorlesungen stattfinden. Kombination 1.3: (0,1) – (0,1) Mitarbeiter (0,1) Dienstwagen 6 (0,1) Personenkraftwagen 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Mitarbeitern kann jeweils (maximal) ein PKW als Dienstfahrzeug zugeordnet werden. Ein PKW kann der Dienstwagen von (maximal) einem Mitarbeiter sein. Kombinationen mit einseitiger Existenzabhängigkeit: Kombinationen von Kardinalitäten implizieren eine einseitige Existenzabhängigkeit, wenn die Minimalkardinalität für genau einen an der Beziehung teilnehmenden Entitytypen Eins ist. Entities diesen Typs sind abhängig von den Entities, mit denen sie in Beziehung stehen. Kombination 2.1: (0,n) – (1,1) Warengruppe (0,n) Atikel-WG (1,1) Artikel Ein Artikel ist genau einer Warengruppe zugeordnet (d.h. es gibt auch keinen Artikel ohne Warengruppe). Warengruppen können null bis beliebig viele Artikel umfassen. Ein Artikel ist damit existenzabhängig von seiner Warengruppe, die Warengruppe ist jedoch unabhängig von ihren Artikeln. Kombination 2.2: (0,n) – (1,n) Professor (0,n) Dozent (1,n) Vorlesung Ein Professor kann für null bis beliebig viele Vorlesungen als Dozent auftreten. Eine Vorlesung wird von mindestens einem (bis beliebig vielen) Professoren betreut. Vorlesungen sind damit existenzabhängig von Professoren. Kombination 2.3: (0,1) – (1,1) Lehrveranstaltung (0,1) LV-Forum (1,1) Onlineforum Einer Lehrveranstaltung kann ein Online-Forum zugeordnet sein (muss aber nicht), ein Onlineforum ist immer genau einer Veranstaltung zugeordnet. Damit ist das Forum existenzabhängig von der Veranstaltung. Kombination 2.4: (0,1) – (1,n) Die Kombination (0,1) – (1,n) ist theoretisch denkbar, allerdings ist diese ein Spezialfall mit geringer praktischer Relevanz. 7 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Kombinationen mit wechselseitiger Abhängigkeit Wechselseitige Anhängigkeiten entstehen, wenn die Minimalkardinalität einer Beziehung auf beiden Seiten größer als Null ist. Kombination 3.1: (1,n) – (1,1) Rechnung Positionszuordnung (1,n) (1,1) Rechnungsposition Zu einer Rechnung existiert immer mindestens eine Rechnungsposition, eine Rechnungsposition ist genau einer Rechnung zugeordnet. Rechnung und Rechnungsposition sind wechselseitig abhängig voneinander. Kombination 3.2: (1,n) – (1,n) Die Kombination (1,n) – (1,n) ist theoretisch möglich, hat jedoch als Spezialfall geringe praktische Relevanz. Kombination 3.3: (1,1) – (1,1) Die Kombination (1,1) – (1,1) zeigt an, dass eine Beziehung immer zwischen exakt zwei Entities der verbundenen Typen besteht. Eine solche Kombination impliziert in der Regel, dass die beiden beteiligten Entitytypen zu einem Entitytyp zusammengefasst werden sollten. In Ausnahmefällen kann es jedoch fachliche Gründe geben, sie dennoch getrennt zu modellieren. 1.4 Hierarchien und Strukturen im ERM Relationshiptypen müssen nicht zwangsläufig unterschiedliche Entitytypen verbinden, eine Beziehung kann auch zwischen Entities desselben Typs bestehen. Die Minimalkardinalität muss bei solchen Beziehungen in jeder Leserichtung 0 sein, da sonst eine Unendlichschleife typisiert würde. Je nach Maximalkardinalität unterscheidet man zwei Anwendungsfälle: Hierarchien (bzw. Bäume) und Strukturen (bzw. Netze). 1.4.1 Hierarchien und Bäume Hierarchien setzen Entities in eine Über-/Unterordnungsbeziehung. Dabei entsteht eine Baumstruktur, d.h. einem Element darf maximal ein anderes Element (gleichen Typs) übergeordnet werden, einem Element können aber beliebig viele Elemente (gleichen Typs) untergeordnet werden. Die Kardinalität ist also (0,1) – (0,n): Hierarchie (0,1) Elementtyp (0,n) Auf Entityebene lässt sich diese Beziehung wie folgt visualisieren: 8 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Element Element Element Element Element Element Element Element Element Element Aus der Darstellung wird ersichtlich, dass die Hierarchiestruktur mehr als einen Wurzelknoten erlaubt. Es sind darüber hinaus auch Elemente erlaubt, die weder ein über- noch ein untergeordnetes Element haben. Ein zwingend zusammenhängender Baum lässt sich mit Mitteln des ERM nicht darstellen. Beispiele für Hierarchien AntwortHierarchie Hierarchie (0,1) Mitarbeiter (0,1) (0,n) Forumsbeitrag Beispiel 1: Vorgesetzte und untergeordnete Mitarbeiter (0,n) Beispiel 2: Beiträge in einem Internetforum und deren Antworten Insbesondere in Beispiel 2 wird ersichtlich, dass es mehrere Wurzelknoten geben kann: in einem Forum kann entweder eine Antwort auf einen Beitrag, oder aber ein neuer Beitrag verfasst werden. Der neue Beitrag stellt dann einen neuen Wurzelknoten in der Hierarchie dar. 1.4.2 Strukturen und Netze Strukturen bzw. Netze im ERM setzen Entities mit beliebig vielen Entities des gleichen Typs in Verbindung. Potentiell darf jede Instanz eines Entitytyps mit jeder anderen Instanz verbunden sein. Anders als in Hierarchien muss es keine klare Richtung der Beziehung geben, bestimmte Anwendungsfälle können jedoch eine Leserichtung erfordern (siehe Beispiele). Ob eine Strukturbeziehung gerichtet oder ungerichtet ist, lässt sich aus dem ERM nicht direkt ablesen und ist nur aus dem fachlichen Kontext ersichtlich. Die Kardinalität einer Strukturbeziehung ist immer (0,n) - (0,m): 9 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Struktur (0,n) Elementtyp (0,m) Auf Entityebene lässt sich eine Struktur bzw. ein Netz wie folgt visualisieren: Element Element Element Element Element Element Element Element Element Ähnlich den Hierarchien im ERM wird auch bei Strukturen ersichtlich, dass es auf Ebene der Entities unverbundene Teilnetze, sowie damit auch unverbundene Einzelelemente geben darf. Ein zwingend zusammenhängendes Netz lässt sich mit Mitteln des ERMs nicht darstellen. Beispiele für Strukturen Teilstruktur (0,n) Bauteil (0,m) Beispiel 1: Bauteile und ihre Zusammensetzung 10 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode In Beispiel 1 werden Bauteile anderen Bauteilen als Bestandteile zugeordnet. Diese Beziehung ist gerichtet, da ein Bauteil entweder Bestandteil eines verbundenen Bauteils ist, oder aus den verbundenen Bauteilen zusammengesetzt ist. So ist beispielsweise ein Aluminiumrohr Bestandteil eines Fahrradrahmens, jedoch ist der Fahrradrahmen nicht Bestandteil des Rohrs, sondern diesem übergeordnet. Diese Überordnung ist keine (strenge) Hierarchie, da das Rohr potentiell auch in anderen Bauteilen verbaut werden kann (z.B. in der Lenkerkomponente, oder in der Sattelstütze) also nicht genau ein übergeordnetes Element besitzt. Freund (0,n) Mitglied (0,m) Beispiel 2: Freundstrukur von Mitgliedern in einem sozialen Netzwerk Beispiel 2 zeigt ein soziales Netzwerk bei welchem Mitglieder mit anderen Mitgliedern über eine Freundschaftsbeziehung verbunden werden können. Die Beziehung ist im Gegensatz zu Beispiel 1 ungerichtet (bzw. bidirektional oder kommutativ), d.h. wenn Teilnehmer A mit B befreundet ist, so ist auch B mit A befreundet. Reale Beispiele für Implementationen solcher Netzwerke sind Internetplattformen wie bspw. StudiVZ, Facebook, XING, MySpace etc. 1.5 Attribute im ERM Attribute beschreiben Entitytypen näher, in dem deren jeweilige Eigenschaften festgelegt werden. Auch Relationshiptypen können durch die Annotierung von Attributen näher definiert werden. 1.5.1 Syntax Attribute werden im ERM durch eine Ellipse dargestellt, welche über eine Kante mit dem näher zu beschreibenden Knoten verbunden wird. Für eine kompaktere Darstellung der Attribute im ERM ist es auch erlaubt, die Attribute eines Typs in einer Ellipse zusammenzufassen. Die einzelnen Attribute werden dann durch Kommata getrennt: Entitytyp Attribut1 Entitytyp Attribut1, Attribut2, Attribut3 Attribut2 11 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Durch die Attribute eines Knotens wird bestimmt, welche Informationen über eine Entität oder eine Beziehung im zu entwickelnden Datenbanksystem abgelegt werden sollen. Grundsätzlich ist die Wahl der Attribute für einen Entity- oder Relationshiptypen vom jeweiligen Anwendungskontext abhängig: Personenkraftwagen Personenkraftwagen Modell, Erstzulassung, Kilometerstand, Unfallstatus, Farbe, TÜV-Status, Verkaufspreis Modell, Risikoklasse, Stellplatz Schadenfreiheitsrabatt Beispiel 1: Attributierung eines PKW für eine Anwendung im Gebrauchtwagenhandel (Auszug) Beispiel 2: Attributierung eines PKW für eine Anwendung eines KFZVersicherungsanbieters (Auszug) Neben Entitytypen können auch Relationshiptypen mit Attributen versehen werden, wenn den Beziehungen spezifische Eigenschaften zugeordnet werden sollen. Sinnvoll ist eine solche Attributierung in der Regel nur dann, wenn eine N-zu-M-Beziehung besteht, da sich in diesem Fall die Beziehungsattribute nicht einem an der Beziehung beteiligten Entitytyp zuordnen lassen: Prüfung (0,m) Prüfungsteilnahme (0,n) Student Note Beispiel: Attributierung einer Beziehung 1.5.2 Attribute als Schlüssel Attribute werden nicht nur dazu eingesetzt, Entities oder Beziehungen näher zu beschreiben, sondern können darüber hinaus dazu dienen, solche Elemente eindeutig zu identifizieren. Folgende Begrifflichkeiten werden unterschieden: Schlüsselkandidat: Ein Schlüsselkandidat ist eine Menge an Attributen, die die Tupel einer Relation eindeutig identifiziert. Diese Menge muss minimal sein, dass heißt alle Attribute in der Menge müssen für die Eindeutigkeit notwendig sein. Eine Relation kann mehrere Schlüsselkandidaten besitzen. 12 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Primärschlüssel: Ein Primärschlüssel ist der Schlüsselkandidat, der zur eindeutigen Identifikation der Tupel einer Relation ausgewählt wurde. Im ERM werden Primärschlüsselattribute durch Unterstreichung gekennzeichnet: Entitytyp Entitytyp Schlüsselattribut1, Schlüsselattribut2, Attribut3, Attribut4 Schlüssel Attribut2 Fremdschlüssel: Der Fremdschlüssel ist eine Menge von Attributen einer Relation, welche auf einen Primärschlüssel einer anderen oder der gleichen Relation verweist. Ein Fremdschlüssel kann theoretisch auch auf einen anderen Schlüsselkandidaten als den Primärschlüssel verweisen. Fremdschlüssel entstehen bei der Überführung des ERM in ein Tabellenschema in Abhängigkeit der Beziehungen und ihrer Kardinalitäten (siehe Abschnitt 1.2: Überführung des ERM in ein Datenbankschema). Im ERM selbst werden Fremdschlüssel daher nicht dargestellt. 1.6 Mehrwertige Relationshiptypen In den bisherigen Beispielen wurden Relationshiptypen dazu eingesetzt entweder zwei Entitytypen, oder einen Entitytypen mit sich selbst in Beziehung zu setzen. Grundsätzlich ist es jedoch möglich, drei oder mehr Entitytypen über einen Relationshiptypen zu verbinden. Ein Beispiel: In einem Serviceunternehmen ist eine Kundenfahrt dadurch definiert, dass ein Mitarbeiter mit einem Fahrzeug des Fuhrparks für einen spezifischen Kundenauftrag fährt. Ein Kundenauftrag kann jedoch mehrere Fahrten erfordern. Jedes Fahrzeug des Fuhrparks kann von jedem Mitarbeiter verwendet werden - ein Mitarbeiter, der eine Fahrt zu erledigen hat, reserviert sich aus dem Fuhrpark ein beliebiges freies Fahrzeug. Für Versicherungs- und Abrechnungszwecke soll festgehalten werden, welcher Mitarbeiter welches Fahrzeug im Rahmen welches Kundenauftrags verwendet hat. Diese Anforderungen lassen sich mit einem trinären Relationshiptypen elegant abbilden: 13 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Kraftfahrzeug (0,n) Fahrzeugnr Kundenauftrag (0,n) Fahrt Auftragsnr Mitarbeiter (0,n) Personalnr Es sind darüber hinaus natürlich auch Relationshiptypen möglich, die mehr als drei Entitytypen verbinden. 1.7 Uminterpretation von Relationshiptypen Relationshiptypen beschreiben Beziehungen zwischen Instanzen zweier oder mehrerer Entities. Bestimmte fachliche Fälle können es erfordern, dass ein Relationshiptyp wiederum mit einem Entitytypen eine Beziehung eingehen muss. Da Relationshiptypen nicht direkt mit Relationshiptypen verbunden werden dürfen, muss der betreffende Relationshiptyp uminterpretiert werden. 1.7.1 Syntax Im ERM wird zur Uminterpretation eines Relationshiptypen ein Rechteck um das Rautensymbol gezogen, um die Entity-Rolle des Knotens zu kennzeichnen. Wichtig dabei ist, dass die jeweiligen Kanten je nach eingenommener Rolle entweder an die Seiten des Rechtecks, oder an die Eckpunkte der Raute gezogen werden: 14 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode E-Typ 1 (0,n) E-Typen docken an R-Typ-Eckpunkt an Uminterpretierter R-Typ (0,n) R-Typ (1,1) E-Typ 3 R-Typ dockt an E-Typ-Seite an (0,m) E-Typ 2 Beispiel Ein Handelsunternehmen bezieht Artikel von unterschiedlichen Lieferanten und nimmt Bestellungen von Kunden entgegen. Dabei kann ein Artikel im Sortiment von mehreren Lieferanten bezogen werden, Lieferanten liefern in der Regel mehrere verschiedene Artikel. Für Nachweiszwecke ist es erforderlich, dass für jeden vom Kunden bestellten Artikel nachvollzogen werden kann, von welchem Lieferanten der Artikel jeweils stammt. Folgende Lösungsvarianten stehen zur Disposition: Lieferant Variante 1: Die Beziehung wird mit einem ternären R-Typ dargestellt. Problem: Es kann kein Artikel seinem Lieferanten zugeordnet werden (Liefernachweis), wenn dieser Artikel noch nicht von einem Kunden bestellt wurde. Artikel Kunde 15 (0,n) (0,n) (0,n) Bestellung 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode (0,n) Lieferant Variante 2: Ein zusätzlicher R-Typ bildet den Liefernachweis ab. Problem: Diese Variante ermöglicht Inkonsistenzen zwischen den Beziehungstypen Bestellung und Liefernachweis: so könnte ein Bestellartikel einem Lieferanten zugeordnet werden, der diesen laut Liefernachweis gar nicht liefert. Variante 3: Der R-Typ Liefernachweis wird uminterpretiert. Dadurch können nur Bestellungen erzeugt werden, die sich auf einen konkret von einem Lieferanten gelieferten Artikel beziehen. Die Lieferung ist aber von der Kundenbestellung unabhängig. Variante 3 löst das fachliche Problem. (0,n) Liefernachweis (0,n) Artikel Kunde Lieferant (0,n) Bestellung (0,n) (0,n) Liefernachweis Artikel (0,n) (0,n) Bestellung Kunde (0,n) 1.7.2 Zulässigkeit der Uminterpretation von Relationshiptypen Die Uminterpretation von Relationshiptypen ist in solchen Fällen sinnvoll, in denen der Beziehungstyp bei weitergehender fachlicher Betrachtung selbst Entity-Merkmale aufweist. Formal ausgedrückt ergibt sich folgende Definition: Definition: Für die Uminterpretation eines Relationshiptypen müssen zwei Bedingungen erfüllt sein: • der Relationshiptyp beschreibt Beziehungen, die aus Sicht von mindestens zwei beteiligten Entitytypen nicht-eindeutig sind, und • die Instanzen des Relationshiptypen gehen nicht-eindeutige Beziehungen mit Instanzen von Entitytypen ein, die nicht an der ursprünglichen Beziehung beteiligt waren. Als nicht-eindeutige Beziehungen werden solche Beziehungen bezeichnet, deren Minimalkardinalität und/oder Maximalkardinalität von 1 abweicht. D.h. eine Beziehung ist aus Sicht eines Entitytypen dann eindeutig, wenn die Kardinalität für diesen Typen (1,1) beträgt. 16 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Beispiel Folgende fachliche Beschreibung ist gegeben: In einem Computerpool wird den Nutzern eine ” Anzahl von Rechnern zur Verfügung gestellt. Auf Grund von technischen und lizenzrechtlichen Einschränkungen, werden auf den Rechnern verschiedene Pakete an Softwareprodukten installiert.“ Aus diesen Anforderungen lässt sich zunächst eine typische M-N-Beziehung interpretieren1 : Es gibt einen Entitytyp Softwareprodukt dessen Instanzen beliebig (genauer: unbestimmt) viele Beziehungen mit Instanzen des Typen Rechner eingehen können. Wiederum können auf den Rechnern beliebig viele Produkte installiert sein. Den ursprünglichen Anforderung wird nun folgende Information hinzugefügt: Eine datenbank” gestützte Anwendung soll nun protokollieren, welche Nutzer die verschiedenen Produkte auf welchen Rechnern nutzen. Jede Nutzung soll protokolliert werden“ Der Text verleiht dem ursprünglich als Beziehung modellierten Konzept Installierte Software nun eine entity-artige“ Qualität. Die Nutzung bezieht sich nicht auf eine beliebige Konstel” lation von Rechner und Softwareprodukt, sondern auf die konkrete Kombination die durch den Relationshiptyp Installierte Software repräsentiert wird. Da Nutzer dasselbe Softwareprodukt auf demselben Rechner beliebig oft nutzen können, ist die Beziehung des Konzepts Installierte Sofware zum Nutzer nicht-eindeutig (0,n-Kardinalität). Der Relationshiptyp Installierte Software muss daher uminterpretiert werden. Softwareprodukt (0,n) Installierte Software Rechner (0,n) Nutzung (0,n) Nutzer (0,n) Wird eine der beiden oben genannten formalen Bedingungen verletzt, ist eine Uminterpretation nicht zulässig. 1 Da keine näheren Angaben vorliegen, wird von der genauen Gestalt der technischen und lizenzrechtlichen ” Einschränkungen“ abstrahiert. 17 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1.8 Generalisierung und Spezialisierung im ERM Die Generalisierung und Spezialisierung von Entitytypen dient dazu, gemeinsame Eigenschaften ähnlicher Entitytypen zusammenzufassen. Die gemeinsamen Attribute und Beziehungen aller ähnlichen Typen gehen dabei auf den generalisierten Typ über, spezifische Attribute und Beziehungen verbleiben in den spezialisierten Typen: (1,1) (0,n) Kundenbetreuer (0,n) Betreuung (1,1) Kunde PersonalNr, Telefonnr, Büro Gehaltsklasse (0,n) (1,1) Abteilungsleiter PersonalNr, Telefonnr, Büro, Dienstwagen Kundenbetreuer Gehaltsklasse (0,n) (1,1) Mitarbeiter (0,n) Betreuung (1,1) Kunde D,P Abteilungsleiter PersonalNr, Telefonnr, Büro Dienstwagen Unterschieden werden Generalisierung und Spezialisierung hinsichtlich ihrer Dimensionen Zerlegung und Vollständigkeit: 18 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode D - disjunkt Ein Entity darf nur maximal einem Spezialfall angehören T - total Jedes Entity muss mindestens einem Spezialfall angehören N,T D,T Disjunkt-Total: Jedes Entity gehört immer genau einem Spezialfall an P - partiell Ein Entity darf einem Spezialfall angehören, muss aber nicht N - nicht disjunkt Ein Entity darf beliebig vielen Spezialfällen angehören Nichtdisjunkt-Total: Jedes Entity gehört immer mindestens einem Spezialfall an. N,P D,P Disjunkt-Partiell: Jedes Entity kann maximal einem Spezialfall angehören. Nichtdisjunkt-Partiell: Jedes Entity kann einem oder mehreren Spezialfällen angehören Beispiele Disjunkt-total: Ein Student ist entweder als Fern- oder als Direktstudent eingeschrieben. Direktstudent Student D,T Fernstudent 19 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Disjunkt-partiell: Ein Mitarbeiter kann Programmierer oder Kundenbetreuer sein (aber nicht beides). Es gibt jedoch Mitarbeiter, die weder das eine noch das andere sind. Programmierer Mitarbeiter D,P Kundenbetreuer Nichtdisjunkt-total: Ein Geschäftspartner eines Handelsunternehmens kann ein Lieferant oder ein Kunde sein. Es kann aber auch beides zutreffen, wenn ein Lieferant bei dem Handelsunternehmen Artikel bestellt - beispielsweise könnte ein Produzent und Lieferant von Kugelschreibern bei einem Händler für Büroartikel seine Druckertoner bestellen. Geschäftspartner, die weder Lieferant noch Kunde sind, gibt es nicht. Lieferant Geschäftspartner N,T Kunde Nichtdisjunkt-partiell: An einer Tagung können verschiedene Personen teilnehmen. Einige Teilnehmer sind Redner, d.h. sie halten auf der Tagung einen Vortrag. Veranstalter sind Teilnehmer, die an der Gestaltung der Tagung mitwirken. Veranstalter können auch selbst Vorträge halten, also Redner sein. Es gibt Teilnehmer, die weder Redner noch Veranstalter sind. Redner Tagungsteilnehmer N,P Veranstalter 1.9 Spezielle Konventionen der ER-Modellierung Bei der Erstellung konzeptioneller Modelle nach dem konstruktivistischen Modellbild der Wirtschaftsinformatik bestehen grundsätzliche Freiheitsgrade, wie bestimmte Sachverhalte im Modell darzustellen sind. Im Rahmen der Modellierung realweltlicher Zusammenhänge zur Konstruktion von Datenstrukturen äußern sich solche Freiheiten beispielsweise in der Frage, ob ein Konzept im ERM als Entity- oder als Relationshiptyp, oder welche Kardinalitäten für eine spezifische Beziehung modelliert werden sollen. Nicht selten lassen Modellierungssprachen wie das ERM mehrere Modellierungsvarianten für semantisch gleichartige Strukturen zu. Ein weiteres Problem stellen unterschiedliche Versionen gleicher Sprachen dar, so werden Modellierungssprachen wie das ERM von unterschiedlichen Autoren erweitert und modifiziert, implementierungsnahe Standards wie SQL werden von Herstellerfirmen für entsprechende Systeme unterschiedlich interpretiert oder ergänzt. 20 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1.9.1 Benennung von Relationshiptypen Eine häufig gestellte Frage betrifft die Benennung von Relationshiptypen. In der Literatur existieren dafür verschiedene Ansätze, wie Verbenbeschreibungen (z. B. Student - nimmt teil Vorlesung) oder Wortketten (Artikel - Artikel-Lieferant-Zuordnung - Lieferant). Beide Varianten haben Nachteile: • Verbenbezeichnungen lassen häufig nur eine Leserichtung zu: Student - nimmt Teil (an) - Vorlesung ist sinnvoll, aber: Vorlesung - nimmt Teil (an) - Student ergibt keinen Sinn • Verbenbezeichnungen führen dazu, dass resultierende Tabellen keinen fachlich sinnvollen Namen haben (z. B. Tabelle hat oder ist zugeordnet) • die Verkettung mit dem Wort Zuordnung ergibt bei einer Uminterpretation unschöne Ausdrücke (z.B. Lieferanten-Artikel-Zuordnung-Kunden-Zuordnung) Aus diesem Grund gilt folgende Konvention: Konvention: Relationshiptypen sind (wenn möglich) mit sinnvollen Substantivbezeichnungen zu versehen! Beispiele: statt Mitarbeiter-Projekt-Zuordnung eher Projektmitglied statt Kunde-Bearbeiter-Zuordnung eher Betreuer statt (Professor) hält (Vorlesung), eher Dozent Die Einschränkung ’wenn möglich’ bezieht sich insbesondere auf Beziehungstypen, die in einer (1,1)-Kardinalität stehen. Bei solchen Beziehungen ist eine sinnvolle Bezeichnung teilweise kaum zu finden. Auch resultieren diese Relationshiptypen bei der Überführung in das Datenbankschema nicht in eigenen Tabellen. Deshalb gilt: Konvention: Relationshiptypen, die in einer (1,1)-Beziehung stehen, müssen nicht benannt werden, wenn sich keine sinnvolle Bezeichnung finden lässt. 1.9.2 Das Konzept Zeit“ im Entity-Relationship-Modell ” In Datenmodellen können häufig Beziehungen auftreten, die einen Zeitbezug haben und sich über diesen Zeitbezug definieren. Modelliert man an solche Relationshiptypen einen Entitytyp Zeit, so drückt man aus, dass die Beziehung zeitabpunkthängig und die Zeit Primärschlüsselbestandteil ist. Der Entitytyp Zeit nimmt jedoch bei der Überführung in das Datenbankschema eine Sonderrolle ein, da aus ihm keine Tabelle resultiert. Beispiel Kunden können Artikel bestellen. Um sicherstellen zu können, dass derselbe Kunde denselben Artikel zu einem späteren Zeitpunkt wieder bestellen kann, wird der Zeitpunktbezug in das Modell aufgenommen. Die Abbildung zeigt, wie das Zeitkonstrukt im ERM dargestellt wird und welche Tabellen resultieren. Es wird sichtbar, dass der Entitytyp Zeit nur noch als Attribut 21 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode und Primärschlüsselbestandteil in der Relation Bestellung auftaucht, jedoch in keiner eigenen Relation: Artikel (0,n) Artikelnr (0,n) Bestellung Relation Kunde Relation Artikel Kundennr Name Artikelnr Name ... ... ... ... ... ... ... ... Zeit Relation Bestellung Menge Kunde Zeitpunkt (0,n) #Kundennr #Artikelnr Zeitpunkt Menge ... ... ... ... ... ... ... ... Kundennr Beziehungen können sich neben Zeitpunkten auch auf Zeitspannen beziehen. Konzeptionell ist eine Zeitspanne nichts anderes als eine Paarung von zwei Zeitpunkten. Dies lässt sich im ERM einfach durch eine Struktur über dem Entitytyp Zeit darstellen. Soll sich nun ein Relationshiptyp auf eine Zeitspanne beziehen, wird die Struktur uminterpretiert. Beispiel: Ein Vermieter vermietet Wohnungen an Mieter. Das Mietverhältnis ist gekennzeichnet durch eine Zeitspanne (also einen Start- und Endzeitpunkt). Die Abbildung zeigt die Zeitspanne als Struktur über Zeitpunkten und die resultierenden Relationen: Wohnung Wohnungsnr Mieter (0,n) Mietverhältnis (0,n) (0,n) Zeitspanne (0,n) Zeit Relation Mieter Relation Wohnung Mieternr Name Wohnungsnr Name ... ... ... ... ... ... ... ... #Mieternr #Wohnungsnr Anfangszp Endzp ... ... ... ... ... ... ... ... Relation Mietverhältnis (0,n) Mieternr Zeitpunkt Als Konvention gilt: Konvention: Zeitpunkte und Zeitspannen sind im ERM mit eigenen Entitytypen bzw. Strukturen zu modellieren, wenn sich Beziehungen zur eindeutigen Identifikation auf Zeitpunkte oder Zeitspannen beziehen. Anders ausgedrückt: ist die Zeit in irgendeiner Form Bestandteil des Primärschlüssels eines Relationshiptypen, dann ist sie explizit zu modellieren. 22 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode 1.9.3 Konventionen zu Kardinalitäten Kardinalitäten beschreiben einen Beziehungstypen näher bzw. drücken aus, wie oft ein Entity eines Typs eine bestimmte Beziehung eingehen kann. Da die Kardinalitäten ein wesentlicher Bestandteil eines Beziehungstyps sind, kann auf deren Angabe nicht verzichtet werden. Daher gilt: Konvention: Kardinalitäten sind immer zu explizieren, zwischen Entitytypen, Relationshiptypen und uminterpretierten Relationshiptypen gibt es keine Kanten ohne Kardinalitätsangaben! Teilweise lassen sich Aufgabentexte oder fachliche Beschreibungen hinsichtlich der Kardinalitäten unterschiedlich interpretieren. Für die untere Grenze (Minimalkardinalität) gilt daher folgende Konvention: Konvention: Bei unterschiedlichen Interpretationen hinsichtlich der Kardinalitäten sollte immer so wenig restriktiv wie möglich modelliert werden. Das heißt konkret: wenn die textliche Beschreibung nichts anderes vorgibt, ist als untere Grenze 0 und als obere Grenze n zu modellieren. Impliziert der Aufgabentext klar eine 1 als Minimum (z.B.: ein X hat genau/mindestens ein Y“) oder Maximum (z.B.: ein X hat genau/höchstens ” ” ein Y“), ist das im Modell natürlich zu berücksichtigen. Für die Schreibweise der Kardinalitäten gilt: Konvention: Die vorgeschriebene Schreibweise für Kardinalitäten ist: (0,1), (1,1), (0,n), (1,n). Andere Schreibweisen von bestimmten Autoren verzichten auf die Klammern, geben statt einem Buchstaben einen Stern (*) als Symbol für beliebig an, oder trennen Min und Max nicht durch Komma, sondern mit zwei Punkten. Aus Gründen der einheitlichen Darstellung ist im Rahmen der Lehrveranstaltung nur die obere Schreibweise zugelassen. Häufig wird bei Beziehungen, deren Maximum auf beiden Seiten n ist, die Schreibweise mit wechselnden Buchstaben n“ und m“ [z.B.: (0,n) - (0,m)] verwendet. Damit soll angezeigt ” ” werden, dass die tatsächliche Kardinalität auf Entity-Ebene auf der einen Seite von der auf der anderen Seite unabhängig ist. Da eine solche Abhängigkeit praktisch nie besteht, kann auf wechselnde Buchstaben als Anzeige beliebiger Maxima verzichtet werden (im anderen Fall dürfte sonst im ganzen Modell kein Buchstabe doppelt vorkommen). 1.9.4 Konventionen zur Generalisierung/Spezialisierung Für Generalisierungen/Spezialisierungen gilt: Konvention: Entitytypen sollten nach Möglichkeit sinnvoll generalisiert bzw. spezialisiert werden. 23 1 Konzeptionelle Datenmodelle mit der Entity-Relationship-Methode Ob eine Generalisierung sinnvoll ist, kann im konkreten Fall Ermessenssache sein. Generalisierungen empfehlen vor allem dann, wenn dadurch Attribute und Beziehungskanten nicht redundant modelliert werden müssen. Spezialisierungen empfehlen sich, wenn bestimmte Attribute oder Beziehungen eines Entitytyps nur für eine abgrenzbare Gruppe von Instanzen eine Bedeutung haben. Darüber hinaus gilt: Konvention: Generalisierungen sind immer hinsichtlich ihrer Zerlegung (disjunkt/nichtdisjunkt) und ihrer Vollständigkeit (total/partiell) zu kennzeichnen. 1.9.5 Kommentare und zusätzliche Annahmen Textliche Beschreibungen fachlicher Sachverhalte sind in der Regel in natürlicher Sprache verfasst - das Gleiche gilt für Klausur- und Übungsaufgaben. Alle natürlichen Sprachen (z.B. Deutsch, Englisch, aber auch Fachsprachen) teilen die Eigenschaft potentiell mehrdeutig und damit unterschiedlich interpretierbar zu sein. Sprachen wie das ERM verwenden natürlich- / bzw. fachsprachliche Ausdrücke und erben als semiformale Sprachen diesen Defekt. Aus diesem Grund kann es sinnvoll sein, Modellelemente mit Kommentaren zu annotieren, um so das Modellverständnis zu verbessern. Auch Annahmen, welche der Modellerstellung zu Grunde gelegt werden, weil bestimmte fachliche Informationen fehlen oder unklar sind, sollten expliziert werden. Ein weiterer Anwendungsfall für Kommentare sind Informationen oder Einschränkungen, die sich in der gewählten Modellierungssprache nicht ausdrücken lassen. Für die Lehrveranstaltung Datenmanagement gelten folgende Konventionen: Konvention: Zusätzliche Annahmen können getroffen werden, sollten jedoch deutlich und explizit am Modell annotiert werden. Die Annahmen dürfen Aufgaben jedoch nicht im Kern verändern (so können zwar ergänzende Annahmen getroffen werden, eine Vereinfachung durch Weglassen von Aufgabenteilen durch Annahmen ist unzulässig). 24 2 Überführung von ER-Modellen in Datenbankschemata 2 Überführung von ER-Modellen in Datenbankschemata Im letzten Kapitel wurde erläutert, wie auf fachkonzeptioneller Ebene mit Hilfe der EntityRelationship-Notation Datenmodelle erstellt werden, die als Vorlage für die Umsetzung in Datenbankschemata dienen können. In diesem Abschnitt wird der Übergang vom Fachkonzept auf die Ebene der Datenverarbeitung beschrieben. Dazu werden in einem ersten Schritt Tabellenstrukturen aus den grafischen Modellen abgeleitet und anschließend Anomalien und Inkonsistenzprobleme durch den Prozess der Normalisierung behoben. 2.1 Überführung von Entitytypen Die Überführung von Entitytypen in Relationen ist vergleichsweise einfach. Grundsätzlich gilt: aus einem Entitytyp resultiert eine Tabelle bzw. Relation, Primär- und Nichtschlüsselattribute werden in Spalten überführt: Kunde Kundennr Name PLZ Vorname Straße Ort Hausnr Tabelle Kunde Kundennr Name Vorname Straße Hausnr Ort PLZ ... ... ... ... ... ... ... ... ... ... ... ... ... ... Alternative Schreibweise: Kunde (Kundennr, Name, Vorname, Straße, Hausnr, Ort, PLZ) 2.2 Überführung von Relationshiptypen Die Überführung der Relationshiptypen ist abhängig von den jeweiligen Kardinalitäten der beteiligten Entitytypen. Dabei können für bestimmte Kombinationen auch verschiedene Entwurfslösungen möglich sein. Im Folgenden werden die einzelnen Überführungen dargestellt. 2.2.1 Überführung von (0,n) - (0,n) - Beziehungen Grundsätzlich gilt: Bei Beziehungen die auf beiden Seiten eine offene Maximalkardinalität besitzen, resultiert aus dem Relationshiptyp eine eigene Tabelle. Dabei werden die Primärschlüssel der beteiligten Entitytypen als Fremdschlüssel referenziert. Der Primärschlüssel der aus dem Relationshiptyp resultierenden Tabelle setzt sich aus diesen Fremdschlüsseln zusammen: 25 2 Überführung von ER-Modellen in Datenbankschemata (0,n) Kunde KundenID Name (0,n) Kauf Menge Artikel ArtikelID Name Relation Kunde Relation Kauf KundenID Name #Kunde.KundenID #Artikel.ArtikelID Menge Relation Artikel ArtikelID Name ... ... ... ... ... ... ... ... ... ... ... ... ... ... Kunde (Kunde.KundenID, Name) Kauf (#Kunde.KundenID, #Artikel.ArtikelID, Menge)2 Artikel (Artikel.ArtikelID, Name) 2.2.2 Überführung von (1,n) - (0,n) - Beziehungen Die Überführung von (1,n) - (0,n) - Beziehungen unterscheidet sich von den vorangegangenen Beziehungen mit 0 als Minimalkardinalität auf beiden Seiten auf DV-Ebene nicht. Es muss jedoch auf Implementierungsebene dafür gesorgt werden, dass das Anlegen eines Datensatzes des Entitytyps auf der (1,n)-Seite in einer atomaren Transaktion zum Anlegen eines Datensatzes in der R-Typ-Tabelle führt: Student StudentID 2 Name (1,n) Studium (0,n) Fachsemester Das Rautesymbol (#) dient zur Kennzeichnung des Fremdschlüssels. 26 Studiengang StudiengangID Name 2 Überführung von ER-Modellen in Datenbankschemata Relation Student Relation Studium StudentID Name #Student.StudentID #Studiengang.StudiengangID Fachsemester Relation Artikel StudiengangID Name 1 Ronny 1 1 2 1 Kunstgeschichte 2 Silvio 2 3 16 2 Hauswirtschaftslehre 3 Rocco 3 2 5 3 Ökotrophologie 4 Kevin 3 3 5 ... ... ... ... 4 3 1 ... ... ... Da eine (1,n)-Zuordnung besteht, müssen die Datensätze in einer atomaren Transaktion angelegt werden 2.2.3 Überführung von (1,1) - (0/1,n) - Beziehungen Die Überführung von Relationshiptypen mit einer (1,1)-Kardinalität resultiert nicht in einer eigenen Relation. Stattdessen referenziert die Relation des Entitytyps auf der (1,1)-Seite die Relation des Entitytypen auf der (0,n)- bzw. (1,n)-Seite mit über einen Fremdschlüssel. Der Fremdschlüssel wird nicht Bestandteil des Primärschlüssels: ArtikelArtikelmerkmalZuO (1,1) Artikelmerkmal (0,n) Artikel ArtikelmerkmalID ArtikelID Relation Artikelmerkmal Relation Artikel ArtikelmerkmalID Name #Artikel.ArtikelID ArtikelID Name ... ... ... ... ... ... ... ... ... ... Für wechselseitig abhängige Entitytypen gilt: Für jeden Datensatz auf der (1,n)-Seite ist ein Datensatz auf der (1,1)-Seite in einer atomaren Transformation anzulegen. 2.2.4 Überführung von (0,1) - (0/1,n) - Beziehungen Für Beziehungen mit einer (0,1)-Kardinalität auf einer Seite entstehen grundsätzlich zwei Varianten der Auflösung: Zubehör ZubehörID (0,1) Ausstattung Name (0,n) Artikel ArtikelID 27 Name 2 Überführung von ER-Modellen in Datenbankschemata Variante 1 Variante 2 Relation Zubehör Relation Zubehör Relation Artikel ZubehörID Name #Artikel.ArtikelID ZubehörID Name ArtikelID Name 1 Spikereifen 1 1 Spikereifen 1 Mountainbike 2 Rennlenkeraufsatz 2 2 Rennlenkeraufsatz 2 Rennrad 3 Rennhelm NULL 3 Rennhelm ... ... ... ... ... ... ... Relation Artikel Relation Ausstattung ArtikelID Name #Zubehör.ZubehörID #Artikel.ArtikelID 1 Mountainbike 1 1 2 Rennrad 2 2 ... ... ... ... In Variante 1 resultiert aus dem Relationshiptyp keine eigene Tabelle. Es wird vorgegangen wie bei (1,1) - (0—1,n) - Beziehungen. Der einzige Unterschied besteht darin, dass auf Datensatzebene Null-Einträge für den Fremdschlüssel zulässig sind, da die Zuordnung optional ist. In Variante 2 wird der Relationshiptyp in eine eigene Tabelle überführt. Der Vorteil dieser Variante ist die Vermeidung der Null-Einträge, ein Nachteil ist die gesteigerte Komplexität durch eine zusätzliche Tabelle. Analoge Varianten entstehen auch bei der Überführung von Hierarchien: Baugruppenhierarchie (0,1) (0,n) Teil TeilID Name 28 2 Überführung von ER-Modellen in Datenbankschemata Variante 1 Variante 2 Relation Teil Relation Teil Relation Baugruppenhierarchie TeilID Name ÜG:#Teil.TeilID TeilID Name UG:#Teil.TeilID ÜG#Teil.TeilID 1 Fahrrad NULL 1 Fahrrad 2 1 2 Rad 1 2 Rad 3 1 3 Rahmen 1 3 Rahmen 4 1 4 Kette 1 4 Kette ... ... ... ... ... ... ... 2.2.5 Überführung von (0,1) - (0,1) - Beziehungen Auch bei (0,1) - (0,1) - Beziehungen bestehen die beiden Möglichkeiten, den Relationshiptypen entweder in eine eigene Tabelle zu überführen, oder die Referenz über einen Fremdschlüssel in der Entitytabelle zu realisieren. Da beide Entitytypen in ihrer Beziehung gleichberechtigt sind, kann der Fremdschlüssel entweder in der einen, oder der anderen Tabelle abgelegt werden. Wird eine eigene Tabelle für den Beziehungstypen angelegt muss entschieden werden, welcher Fremdschlüssel zum Primärschlüssel wird. Es entstehen also insgesamt vier Möglichkeiten der Überführung: Im Beispiel kann ein Rechner innerhalb eines Netzwerks eine IP-Adresse erhalten. Eine IPAdresse kann nur einem Rechner zugeordnet werden, nicht jede Adresse ist jedoch vergeben. Das dargestellte Modell bildet nur den aktuellen Zustand ab (keine Zuordnungshistorie): Rechner RechnerID (0,1) Adressierung (0,1) Name IP-Adresse IP-Adresse URL Im Überführungsvariante 1 wird Adressierung nicht in eine eigene Tabelle überführt. Stattdessen verweist die Tabelle IP-Adresse per Fremdschlüssel auf den zugewiesenen Rechner: Variante 1 Relation Rechner Relation IP-Adresse RechnerID Name IP-Adresse URL #Rechner.RechnerID (UNIQUE) 1 PCWI6056 128.176.234.112 www.wi.uni-muenster.de 1 2 WI-LS 128.176.124.25 www.ercis.de NULL 3 ZIVUNIX 128.176.0.12 www.uni-muenster.de 3 ... ... ... ... ... 29 2 Überführung von ER-Modellen in Datenbankschemata In Variante 2 wird ähnlich vorgegangen, jedoch verweist hier die Tabelle Rechner auf die zugewiesene IP-Adresse: Variante 2 Relation Rechner Relation IP-Adresse RechnerID Name #IP-Adresse.IP-Adresse (UNIQUE) IP-Adresse URL 1 PCWI6056 128.176.234.112 128.176.234.112 www.wi…. 2 WI-LS 128.176.0.12 128.176.124.25 www.er... 3 ZIVUNIX NULL 128.176.0.12 www.uni... ... ... ... ... ... In den Varianten 3 und 4 wird der Relationshiptyp Adressierung in eine eigene Tabelle überführt. Als Primärschlüssel dieser Tabelle wird entweder der Schlüssel von Rechner (Variante 3) oder der Schlüssel von IP-Adresse verwendet. Ein zusammengesetzter Schlüssel ist hier nicht zulässig, da dieser eine N-zu-M-Zuordnung erlauben würde: Variante 3 Relation Rechner Relation Adressierung RechnerID Name #Rechner.RechnerID #IP-Adresse.IP-Adresse (UNIQUE) Relation IP-Adresse IP-Adresse URL 1 PCWI6056 1 128.176.234.112 128.176.234.112 www.wi…. 2 WI-LS 2 128.176.0.12 128.176.124.25 www.er... 3 ZIVUNIX ... ... 128.176.0.12 www.uni... ... ... ... ... Variante 4 Relation Rechner Relation Adressierung RechnerID Name #Rechner.RechnerID (UNIQUE) #IP-Adresse.IP-Adresse Relation IP-Adresse IP-Adresse URL 1 PCWI6056 1 128.176.234.112 128.176.234.112 www.wi…. 2 WI-LS 2 128.176.0.12 128.176.124.25 www.er... 3 ZIVUNIX ... ... 128.176.0.12 www.uni... ... ... ... ... Allen Varianten gemeinsam ist, dass die jeweils verwendeten Fremdschlüsselattribute eindeutig (UNIQUE) sein müssen, auch wenn sie nicht als Primärschlüssel verwendet werden. Nur so kann die Maximalkardinalität von 1 umgesetzt werden. 2.2.6 Überführung von (0,1) - (1,1) - Beziehungen Die Varianten für solche Beziehungen sind zunächst analog zu denen bei (0,1) - (0,1) - Beziehungen. Der zentrale Unterschied ist, dass für die Gewährleistung der Minimalkardinalität 1 spezielle Spaltenrestriktionen oder Trigger notwendig sind. Darüber hinaus ist es bei (0,1) (1,1) - Beziehungen nicht sinnvoll, den Beziehungstyp in eine eigene Tabelle zu überführen. 30 2 Überführung von ER-Modellen in Datenbankschemata (0,1) Person PersonID (1,1) Fahrerlaubnis Name Führerschein FührerscheinID Datum Variante 1 Relation Person Relation Führerschein PersonID Name FührerscheinID Datum 1 Ronny 123456789 01.01.2007 1 2 Silvio 987654321 29.04.1999 3 3 Rocco 111111111 10.12.1967 4 4 Kevin ... ... ... ... #Person.PersonID (UNIQUE, NOT NULL) ... In Variante 1 verweist die Relation auf der (1,1)-Seite über einen Fremdschlüssel auf die zugeordnete Relation. Die Fremdschlüsselspalte darf in diesem Fall nicht NULL sein, um die Minimalkardinalität von eins nicht zu verletzen. Variante 2 Relation Person Relation Führerschein PersonID Name #Führerschein.FührerscheinID (UNIQUE) FührerscheinID Datum 1 Ronny 123456789 123456789 01.01.2007 2 Silvio NULL 987654321 29.04.1999 3 Rocco 987654321 111111111 10.12.1967 4 Kevin 111111111 ... ... ... ... ... 265419873 14.11.2007 265419873 Bei neuen Einträgen in die Tabelle Führerschein muss ein Trigger dafür sorgen, dass in der selben Transaktion entweder eine neue Person angelegt wird, oder eine bestehende Person mit #Führerschein.FührerscheinID = NULL den neuen Datensatz zugeordnet bekommt In Variante 2 verweist die Relation auf (0,1)-Seite auf die zugeordnete Relation. Hier muss ein Trigger gewährleisten, dass für jeden neuen Datensatz auf (1,1)-Seite eine Zuordnung existiert. 2.3 Überführung von Generalisierung / Spezialisierung Die Generalisierung bzw. Spezialisierung ist als objektorientiertes Konzept nicht unmittelbar in das relationale Schema zu überführen. Daher wird das Konstrukt zunächst in ein EntitytypRelationshiptyp-Muster überführt um anschließend die oben beschriebenen Überführungsregeln anwenden zu können. Teilweise müssen dabei jedoch zusätzliche Einschränkungen (Constraints) expliziert werden, um die jeweilige Kombination aus Vollständigkeit und Zerlegung korrekt umzusetzen. 31 2 Überführung von ER-Modellen in Datenbankschemata 2.3.1 Nichtdisjunkt-Partielle Generalisierung/Spezialisierung Die nichtdisjunkt-partielle Generalisierung/Spezialisierung ist in der Überführung am wenigsten problematisch, da diese sich 1:1 in ein Entitytyp-Relationshiptyp-Muster überführen lässt, ohne dass zusätzliche Annahmen oder Einschränkungen notwendig sind: Person PersonID N,P Doktorand ist Person Doktorand Name DoktorandID (0,1) Kumulativ (1,1) Doktorand DoktorandID Kumulativ StudentID Fachsemester PersonID Person Name Student (0,1) StudentID Student ist Person Fachsemester (1,1) Student Die entstehenden (0,1) - (1,1) - Beziehungen können überführt werden, wie in Abschnitt 2.2.6 in Variante 2 beschrieben: Relation Student Relation Doktorand StudentID Fachsemester DoktorandID Kumulativ S1 3 D1 TRUE S2 6 D2 FALSE S3 15 ... ... ... ... Relation Person PersonID Name #Doktorand.DoktorandID (UNIQUE) #Student.StudentID (UNIQUE) 1 Ronny D1 NULL 2 Silvio NULL S1 3 Rocco D2 S3 4 Kevin NULL NULL ... ... ... ... 2.3.2 Nichtdisjunkt-Totale Generalisierung/Spezialisierung Bei der nichtdisjunkt-totalen Generalisierung/Spezialisierung entsteht bei der Überführung ein Constraint. Da jedes Entity mindestens einer Spezialisierung angehören muss, ist gilt für die Fremdschlüssel der generalisierten Tabelle, dass mindestens einer nicht mit Null belegt ist: Geschäftspartner N,T Kunde ist GP Kunde eingeschränkt Kontakt.ID Name (1,1) (0,1) KNr Kunde KNr KontaktID Geschäftspartner Name Lieferant LNr (0,1) Lieferant ist GP LNr 32 (1,1) Lieferant 2 Überführung von ER-Modellen in Datenbankschemata Relation Geschäftspartner KontaktID Name #Lieferant.LNr (UNIQUE) #Kunde.KNr (UNIQUE) 1 C&A NULL K1 2 IBM L1 NULL 3 Apple L2 K3 ... ... ... ... 4 XXXXX NULL NULL Verboten! Constraint: „Pro Eintrag ist entweder #Lieferant.LNr oder #Kunde.KNr ausgeprägt, oder beide!“ (inklusives ODER) Relation Lieferant Relation Kunde LNr ... KNr ... L1 ... K1 ... L2 ... K2 ... ... ... K3 ... ... ... 2.3.3 Disjunkt-Totale Generalisierung/Spezialisierung Bei der disjunkt-totalen Generalisierung/Spezialisierung muss jedes Entity genau einer Spezialisierung angehören. Für die Fremdschlüssel der generalisierten Tabelle gilt, dass genau einer nicht mit Null belegt ist: (1,1) ist Student D,T Direktstudent Direktstudent eingeschränkt (0,1) Matrikelnr Name DSID Matrikelnr DSID Student Name FSID (0,1) Fernstudent (1,1) ist Fernstudent FSID Relation Student Relation Direktstudent Matrikelnr Name #Direktstudent.DSID (UNIQUE) #Fernstudent.FSID (UNIQUE) DSID ... 232123 Ronny DS1 NULL DS1 ... 232146 Silvio DS2 NULL DS2 ... 232155 Chantalle NULL FS1 ... ... ... ... ... ... 232200 XXXXX NULL NULL FSID ... 232209 XXXXX DS1 FS1 FS1 ... FS2 ... ... ... Relation Fernstudent Verboten! Constraint: „Pro Eintrag ist entweder #Direktstudent.DSID oder #Fernstudent.FSID ausgeprägt!“ (exklusives ODER) 33 2 Überführung von ER-Modellen in Datenbankschemata 2.3.4 Disjunkt-Partielle Generalisierung/Spezialisierung Bei der disjunkt-partiellen Generalisierung/Spezialisierung gehört ein Entity zu maximal einer Spezialisierung, kann aber auch nur zum generalisierten Typ zählen. Für die Fremdschlüssel der generalisierten Tabelle gilt, dass immer höchsten einer nicht mit Null belegt ist. (1,1) ist Mitarbeiter D,P Programmierer Programmierer eingeschränkt (0,1) Personalnr Name PrID Personalnr PrID Mitarbeiter Name BeID (0,1) Berater (1,1) ist Berater BeID Relation Mitarbeiter Relation Programmierer Personalnr Name #Programmierer.PrID (UNIQUE) #Berater.BeID (UNIQUE) PrID ... 1 Ronny P1 NULL P1 ... 2 Silvio NULL NULL P2 ... 3 Chantalle NULL B1 ... ... ... ... ... ... 5 XXXXX P1 B1 Relation Berater Verboten! Constraint: „Pro Eintrag ist entweder #Berater.BeID oder #Programmierer.PrID ausgeprägt, oder keins von beiden!“ (NICHT UND) BeID ... B1 ... B2 ... ... ... 2.3.5 Alternative Überführungsmuster für Generalisierung/Spezialisierung Universaltabelle: Bei der Universaltabelle werden der generalisierte und seine spezialisierten in einer Tabelle zusammengeführt (umgangssprachlich wird die Hierarchie flachgeklopft“, wes” wegen in der Literatur für die Universaltabelle teilweise auch der Begriff flat table“ gebraucht ” wird). Bei der Universaltabelle gelten für die unterschiedlichen Kombinationen die gleichen Constraints, wie bisher beschrieben, allerdings beziehen sich diese nicht auf einzelne Fremdschlüssel, sondern auf die jeweiligen Attributgruppen der speziellen Typen. 34 2 Überführung von ER-Modellen in Datenbankschemata Person PersonID N,P Doktorand Kumulativ Name Student Fachsemester Relation Person PersonID Name Kumulativ Fachsemester 1 Ronny TRUE NULL 2 Silvio NULL 3 3 Rocco FALSE 15 4 Kevin NULL NULL ... ... ... ... Verwerfen des generalisierten Typs: Bei totalen Spezialisierungen ist es möglich, die allgemeinen Attribute in die spezialisierten Typen zu ziehen und den generellen Typen zu verwerfen. Vorteil dieses Musters ist, dass für die Auflösung der totalen Generalisierung/Spezialisierung keine zunächst keine Constraints notwendig sind: (0,1) Geschäftspartner N,T Kunde Kunde KontaktID, Name, Kundennr KontaktID Name Kundennr ist KontaktID, Name, Lieferantennr Lieferant (0,1) Lieferantennr 35 Lieferant 2 Überführung von ER-Modellen in Datenbankschemata Direktstudent Student D,T Direktstudent Matrikelnr, Name, DSID Matrikelnr Name DSID Matrikelnr, Name, FSID Fernstudent Fernstudent FSID Problem: Nachteilige Komplexitäten entstehen, wenn der generalisierte Typ Beziehungen eingeht. Sind das mehr als eine Beziehung, erfordert das Verwerfen des generalisierten Typs mehr zusätzliche Constraints als die oben vorgestellten Überführungsmuster: Prüfungsleistung (1,1) (0,n) Student Matrikelnr D,T Direktstudent Name DSID Fernstudent FSID (0,n) Direktstudent (0,1) Hier ist ein XOR-Constraint notwendig – die Prüfungsleistung ist entweder einem Direktstudenten, oder einem Fernstudenten zuzuordnen! Matrikelnr, Name, DSID Prüfungsleistung Matrikelnr, Name, FSID (0,1) (0,n) Fernstudent Das Verwerfen des generalisierten Typs ist daher nur dann sinnvoll, wenn dieser keine eigenen Beziehungen eingeht. Bei partiellen Generalisierungen/Spezialisierungen darf grundsätzlich nicht nach diesem Muster verfahren werden. 36 3 Datenbanknormalisierung 3 Datenbanknormalisierung Es existieren Regeln, um Daten zu strukturieren, bevor sie dann in eine Datenbank überführt werden. Dieser Prozess stellt sicher, dass keine Inkonsistenzen auftreten. Er wird Normalisierung genannt. Ziel der Normalisierung ist es, Redundanzen in Nicht-Schlüsselattributen zu vermeiden. Die Konsistenz der Datenbank soll bei Änderungen erhalten bleiben. 3.1 Erste Normalform Eine Relation befindet sich in erster Normalform, wenn jede Attributausprägung atomar ist. Damit darf eine Relation keine Wiederholungsgruppen enthalten. Eine Wiederholungsgruppe ist eine Gruppe von Attributen, die für einen Datensatz mehrfach belegt sind. Anders ausgedrückt: Eine Wiederholungsgruppe liegt dann vor, wenn nicht dem Schlüssel angehörende Attribute nicht vom Schlüssel funktional abhängig sind, d.h. dass die Ausprägung einer Spalte mit dem Schlüssel nicht eindeutig identifiziert werden können. Definition: Eine Relation befindet sich in erster Normalform, wenn jede Attributausprägung atomar ist. 3.1.1 Funktionale Abhängigkeiten Funktionale Abhängigkeit: Seien A und B Attributmengen einer Relation R, dann ist B funktional abhängig von A, wenn jedem Wert von A genau ein Wert von B zugeordnet ist. Vollfunktionale Abhängigkeit: Seien A und B Attributmengen einer Relation R, dann ist B vollfunktional abhängig von A, wenn B funktional abhängig ist von A, jedoch nicht von irgendeiner Teilmenge von A. 3.1.2 Vorgehen zur Überführung in die 1. Normalform Um eine Tabelle in die erste Normalform zu überführen, sind sämtliche nicht-atomare Attributausprägungen aufzulösen. 1. Nicht-atomare Attributausprägungen identifizieren 2. Nicht-atomare Datensätze auflösen (Auffüllen der Zeilen) 3. Primärschlüssel identifizieren 3.1.3 Beispiel Als Ausgangspunkt für die Normalisierung ist die folgende Relation Skieigenschaften gegeben, die Daten über Hersteller, Ski und Eigenschaften enthält. 37 3 Datenbanknormalisierung HNR F0012 S0001 S0002 Hersteller SkiNr SkiName FRC4R RC4 Race FRC4W RC4 Worldcup SR Rocker ST Threat SS Sinox Fischer Salomon Stöckli GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut 1. Nicht-atomare Attributausprägungen identifizieren: In der Relation existieren mehrere nicht-atomare Attribute: HNR und Hersteller sowie SkiNr und SkiName. HNR F0012 S0001 S0002 Hersteller SkiNr SkiName FRC4R RC4 Race FRC4W RC4 Worldcup SR Rocker ST Threat SS Sinox Fischer Salomon Stöckli GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut 2. Nicht-atomare Datensätze auflösen (Auffüllen der Zeilen): Die markierten Spalten werden Schritt für Schritt aufgefüllt. 38 3 Datenbanknormalisierung HNR Hersteller SkiNr SkiName F0012 Fischer FRC4R RC4 Race F0012 Fischer FRC4W RC4 Worldcup S0001 Salomon SR Rocker S0001 Salomon ST Threat S0002 Stöckli SS Sinox GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut Dadurch entsteht nach und nach eine Relation, in der jeder Datensatz atomar ist. Hinweis: Unter Umständen existieren hier weiterhin leere“ Zellen. Diese sind dann mit null zu füllen. ” HNR F0012 F0012 F0012 F0012 F0012 F0012 F0012 F0012 S0001 S0001 S0001 S0001 S0001 S0001 S0002 S0002 Hersteller Fischer Fischer Fischer Fischer Fischer Fischer Fischer Fischer Salomon Salomon Salomon Salomon Salomon Salomon Stöckli Stöckli SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS SkiName RC4 Race RC4 Race RC4 Race RC4 Race RC4 Worldcup RC4 Worldcup RC4 Worldcup RC4 Worldcup Rocker Rocker Rocker Threat Threat Threat Sinox Sinox GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut 3. Primärschlüssel identifizieren: In der entstandenen Relation, die aus vollständig atomaren Datensätzen besteht, wird nun ein Primärschlüssel identifiziert. Dieser identifiziert jeden Datensatz eindeutig. Hinweis: Durch die Auflösung von nicht-atomaren Datensätzen muss der Primärschlüssel häufig zusammengesetzt sein. 39 3 Datenbanknormalisierung HNR F0012 F0012 F0012 F0012 F0012 F0012 F0012 F0012 S0001 S0001 S0001 S0001 S0001 S0001 S0002 S0002 Hersteller Fischer Fischer Fischer Fischer Fischer Fischer Fischer Fischer Salomon Salomon Salomon Salomon Salomon Salomon Stöckli Stöckli SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS SkiName RC4 Race RC4 Race RC4 Race RC4 Race RC4 Worldcup RC4 Worldcup RC4 Worldcup RC4 Worldcup Rocker Rocker Rocker Threat Threat Threat Sinox Sinox GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut Ergebnis ist eine Relation, die in erster Normalform vorliegt. Jeder Datensatz wird durch den Primärschlüssel, der sich aus SkiNr, GenreID und EID zusammensetzt, identifiziert. Hinweis: Sollte ein Attribut, welches in einem Datensatz null annimmt, als Teil des Primärschlüssels gewählt werden, so müssen die null-Werte durch künstliche Daten ersetzt werden. HNR F0012 F0012 F0012 F0012 F0012 F0012 F0012 F0012 S0001 S0001 S0001 S0001 S0001 S0001 S0002 S0002 Hersteller Fischer Fischer Fischer Fischer Fischer Fischer Fischer Fischer Salomon Salomon Salomon Salomon Salomon Salomon Stöckli Stöckli SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS SkiName RC4 Race RC4 Race RC4 Race RC4 Race RC4 Worldcup RC4 Worldcup RC4 Worldcup RC4 Worldcup Rocker Rocker Rocker Threat Threat Threat Sinox Sinox GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut 3.2 Zweite Normalform Definition: Eine Relation befindet sich in zweiter Normalform, wenn sie sich in erster Normalform befindet und alle Nichtschlüsselattribute vollfunktional vom Primärschlüssel abhängig sind. Damit dürfen keine Nichtschlüsselattribute existieren, die nur von einem Teil des Primärschlüssels abhängen. Um eine Relation von der ersten in die zweite Normalform zu überführen, sind solche Attributgruppen in eigene Relationen auszulagern. 40 3 Datenbanknormalisierung 3.2.1 Vorgehen zur Überführung in die 2. Normalform 1. Alle Relationen, deren Primärschlüssel aus nur einem Attribut besteht, sind bereits in zweiter Normalform. 2. Alle Relationen, die keine Nichtschlüsselattribute enthalten, sind bereits in zweiter Normalform. 3. Alle übrigen Relationen sind wie folgt zu untersuchen: Alle Gruppen von Nichtschlüsselattributen identifizieren, die jeweils von einem Teil des Schlüssels funktional abhängig sind und diese jeweils mit dem Schlüsselteil in eine eigene Tabelle überführen. Der ausgegliederte Schlüsselteil wird Schlüssel der neuen Tabelle. Die ausgegliederten Nichtschlüsselattribute werden aus der Ursprungstabelle entfernt. 3.2.2 Beispiel Prüfung ob bereits zweite Normalform vorliegt: Der Primärschlüssel der Beispielrelation besteht aus mehr als einem Attribut (Bedingung 1 ist nicht erfüllt). Die Relation enthält ein oder mehr Nichtschlüsselattribute (Bedingung 2 ist nicht erfüllt). Deshalb muss nun überprüft werden, ob Nichtschlüsselattribute nur von einem Teil des Schlüssels abhängen. HNR F0012 F0012 F0012 F0012 F0012 F0012 F0012 F0012 S0001 S0001 S0001 S0001 S0001 S0001 S0002 S0002 Hersteller Fischer Fischer Fischer Fischer Fischer Fischer Fischer Fischer Salomon Salomon Salomon Salomon Salomon Salomon Stöckli Stöckli SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS SkiName RC4 Race RC4 Race RC4 Race RC4 Race RC4 Worldcup RC4 Worldcup RC4 Worldcup RC4 Worldcup Rocker Rocker Rocker Threat Threat Threat Sinox Sinox GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut So sind in der Relation die Attribute HNR, Hersteller und SkiName nur von SkiNr, das Attribut Genre nur von GenreID und das Attribut Eignung nur von EID abhängig. Deshalb werden einige Relationen ausgegliedert. Dabei wird der Schlüssel aus der Ursprungsrelation übernommen und doppelte Eitnräge aus der neuen Relation entfernt. Auf diese Art entstehen die neuen Relationen Eignung, Genre und Ski. EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 Eignung gut gut mittel sehr gut sehr gut sehr gut gut sehr gut sehr gut sehr gut gut sehr gut mittel mangelhaft gut gut EID 1 2 3 5 41 Eignung sehr gut gut mittel mangelhaft 3 Datenbanknormalisierung GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 HNR F0012 F0012 F0012 F0012 F0012 F0012 F0012 F0012 S0001 S0001 S0001 S0001 S0001 S0001 S0002 S0002 Hersteller Fischer Fischer Fischer Fischer Fischer Fischer Fischer Fischer Salomon Salomon Salomon Salomon Salomon Salomon Stöckli Stöckli Genre Kurzschwung Carving Carving Freeride Kurzschwung Carving Freeride Freeride Freeride Buckelpiste Buckelpiste Freestyle Freeride Kurzschwung Kurzschwung Carving SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS GenreID 001 002 003 004 005 SkiName RC4 Race RC4 Race RC4 Race RC4 Race RC4 Worldcup RC4 Worldcup RC4 Worldcup RC4 Worldcup Rocker Rocker Rocker Threat Threat Threat Sinox Sinox SkiNr FRC4R FRC4W SR ST SS Genre Kurzschwung Carving Freeride Buckelpiste Freestyle SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox HNR F0012 F0012 S0001 S0001 S0002 Hersteller Fischer Fischer Salomon Salomon Stöckli Ergebnis Nach der Überführung in die 2. Normalform existieren die folgenden 4 Tabellen. SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 SkiNr FRC4R FRC4W SR ST SS SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox GenreID 001 002 003 004 005 Genre Kurzschwung Carving Freeride Buckelpiste Freestyle HNR F0012 F0012 S0001 S0001 S0002 EID 1 2 3 5 Hersteller Fischer Fischer Salomon Salomon Stöckli Eignung sehr gut gut mittel mangelhaft 3.3 Dritte Normalform Definition: Eine Relation befindet sich in dritter Normalform, wenn sie sich in zweiter Normalform befindet und kein Nichtschlüsselattribut transitiv vom Primärschlüssel abhängig ist. Damit dürfen keine Nichtschlüsselattribute existieren, die indirekt über andere Nichtschlüsselattribute vom Primärschlüssel abhängen. Um eine Relation von der zweiten in die dritte Normalform zu überführen, sind solche Attributgruppen in eigene Relationen auszulagern. 42 3 Datenbanknormalisierung 3.3.1 Vorgehen zur Überführung in die 3. Normalform 1. Alle Tabellen, die keine Nichtschlüsselattribute oder nur ein Nichtschlüsselattribut enthalten, sind bereits in dritter Normalform 2. Alle übrigen Tabellen sind wie folgt zu untersuchen: Alle Gruppen von Nichtschlüsselattributen identifizieren, die vom Schlüssel transitiv (d. h. indirekt über ein anderes Nichtschlüsselattribut - die sog. Determinante) abhängig sind. Diese Nichtschlüsselattribute werden in eigene Tabellen ausgegliedert. Die Determinante wird zum Primärschlüssel der neuen Tabelle. Die transitiv abhängigen Nichtschlüsselattribute werden aus der Ursprungstabelle entfernt. Die Determinante verbleibt hingegen in der Ursprungstabelle als Nichtschlüsselattribut. Hinweis: Nach Überführung in die 3. Normalform müssen eventuelle künstliche Werte wieder durch null ersetzt werden. Ist dann ein Attribut, welches Teil des Primärschlüssels ist, null, so muss der entsprechende Datensatz entfernt werden. Im Prinzip sind null-Werte natürlich erlaubt, allerdings dürfen sie nicht Teil des Schlüssels sein. 3.3.2 Beispiel 1. Tabellen mit einem oder keine Nichtschlüsselattribut: Da sie nur ein bzw. kein Nichtschlüsselattribut haben, sind Genre, Eignung und Ski-Genre-Eignung bereits in dritter Normalform. SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 GenreID 001 002 003 004 005 EID 1 2 3 5 Genre Kurzschwung Carving Freeride Buckelpiste Freestyle Eignung sehr gut gut mittel mangelhaft 2. Übrige Tabellen: In der Tabelle Ski ist das Attribut Hersteller direkt vom Attribut HNR und damit nur transitiv vom Primärschlüssel SkiNr abhängig. SkiNr FRC4R FRC4W SR ST SS SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox HNR F0012 F0012 S0001 S0001 S0002 Hersteller Fischer Fischer Salomon Salomon Stöckli Das Attribut wird daher zusammen mit einer Kopie von HNR in eine eigene Tabelle ausgegliedert. 43 3 Datenbanknormalisierung SkiNr FRC4R FRC4W SR ST SS SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox HNR F0012 F0012 S0001 S0001 S0002 SkiNr FRC4R FRC4W SR ST SS SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox HNR F0012 S0001 S0002 Hersteller Fischer Salomon Stöckli HNR F0012 F0012 S0001 S0001 S0002 Hersteller Fischer Fischer Salomon Salomon Stöckli Damit ergeben sich im Ergebnis die folgenden 5 Tabellen: SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 SkiNr FRC4R FRC4W SR ST SS EID 1 2 3 5 SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox Eignung sehr gut gut mittel mangelhaft HNR F0012 F0012 S0001 S0001 S0002 HNR F0012 S0001 S0002 GenreID 001 002 003 004 005 Genre Kurzschwung Carving Freeride Buckelpiste Freestyle Hersteller Fischer Salomon Stöckli 3.4 Vierte Normalform Definition: Eine Relation befindet sich in 4. Normalform, wenn sie sich in 3. Normalform befindet und keine mehrwertigen Abhängigkeiten enthält. Eine Relation mit weniger als 3 Attributen hat keine mehrwertigen Abhängigkeiten (ist also immer in 4. NF, wenn sie sich in 1. NF befindet). Eine Relation, die Nichtschlüsselattribute besitzt und sich in der 3. NF befindet, ist automatisch in 4. NF 3.4.1 Mehrwertige Abhängigkeiten In einer Relation R (A, B, C) ist das Attribut C mehrwertig abhängig von Attribut A, falls zu einem A-Wert, für jede Kombination dieses A-Wertes mit einem B-Wert, eine identische Menge von C-Werten erscheint. Alternativ: Eine mehrwertige Abhängigkeit repräsentiert eine Abhängigkeit zwischen Attributen A, B und C einer Relation, so dass es für jeden Wert von A eine Menge von Werten von B und eine Menge von Werten von C gibt. Die Mengen der Werte von C und von B sind dabei jedoch unabhängig voneinander. Wenn in einer Relation R (A, B, C) dass Attribut C mehrwertig abhängig ist von A, so ist auch B mehrwertig abhängig von A. 44 3 Datenbanknormalisierung 3.4.2 Beispiel Die einzige Tabelle, die im bisherigen Beispiel auf die 4. Normalform überprüft werden muss, ist die Relation Ski-Genre-Eignung, da nur sie 3 Schlüssel- und keine Nichtschlüsselattribute enthält. Die Überprüfung der einzelnen Attribute auf mehrwertige Abhängigkeit, zeigt allerdings, dass die Tabelle die 4. Normalform nicht verletzt. Die ersten Widersprüche sind grau hervorgehoben. SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 GenreID 001 001 001 001 002 002 002 002 003 003 003 003 003 004 004 005 SkiNr ST SS FRC4W FRC4R SS FRC4R FRC4R FRC4W FRC4W FRC4R ST FRC4W SR SR SR ST EID 5 2 1 2 2 2 3 1 2 1 3 1 1 1 2 1 EID 1 1 1 1 1 1 1 2 2 2 2 2 2 3 3 5 SkiNr FRC4R FRC4W FRC4W FRC4W SR SR ST FRC4R FRC4R SS SS FRC4W SR ST FRC4R ST GenreID 003 001 002 003 003 004 005 001 002 001 002 003 004 003 002 001 Da sich obige Tabelle in 4. Normalform befindet, betrachten wir ein weiteres Beispiel: ALTZuordnung Hier zeigt die Analyse, dass zwar TeilNr und ArbGangID nicht mehrwertig von LPlatzID abhängig sind (Unterschiedliche Ausprägungen für LPlatzID = LPA 3). Allerdings sind LPlatzID und ArbGangID mehrwertig abhängig von TeilNr. ALTZuordnung ALTZuordnung Die Tabelle befindet sich daher nicht in 4. Normalform und kann in die folgenden zwei Tabellen zerlegt werden. 45 3 Datenbanknormalisierung Bedeutung der 4. Normalform Mehrwertige Abhängigkeiten, wie sie im obigen Beispiel vorkommen, stellen sich im ERM als von einander unabhängige n:m-Beziehungen dar. So sind im gegebenen Beispiel der Lagerort eines Teils und seine Verwendung in Arbeitsgängen völlig unabhängig von einander und sollten daher in getrennten Relationen gespeichert werden. Dadurch können Redundanzen vermieden werden. Wenn man auf diese Aufspaltung verzichtet, müssten z. B. für denn Fall, dass T01 jetzt auch an LPA 2 gelagert werden kann, drei Spalten in der Relationen ALTZuordnung hinzugefügt werden: Eine für jeden Arbeitsgang in dem das Teil verwendet wird. Tabellen, die gegen die 4. Normalform verstoßen, entstehen häufig bei der Eliminierung von Wiederholungsgruppen zum Erstellen der ersten Normalform. 3.5 Fünfte Normalform Die fünfte Normalform überprüft Relationen auf so genannte Lossles-Join-Abhängigkeiten. Eine Relation befindet sich dann in 5. Normalform, wenn sie sich in 4. Normalform befindet und sich nicht verlustfrei in Einzelrelationen zerlegen lässt. Eine Relation in 1. NF mit weniger als 3 Attributen ist automatisch in 5. NF, da sie sich nicht weiter zerlegen lässt. Eine Relation, die mindestens ein Nichtschlüsselattribut besitzt und sich in der 3. NF befindet, ist automatisch in 5. NF Hinweise zum Natural Join Beim Natural Join zweier Tabellen werden Datensätze über ein gemeinsames Attribut verbunden. Im folgenden Beispiel wurden die Relationen A-B und A-C über das gemeinsame Attribut AID gejoint. Dabei wird für jede AID das Kreuzprodukt aus den Kombinationen von BID und CID entsprechend den Ursprungstabellen gebildet: 46 3 Datenbanknormalisierung Relation A-B-C (A) Relation A-B Relation A-C AID BID AID CID AID BID CID A1 B1 A1 C1 A1 B1 C1 A1 B2 C1 A1 B2 A1 A2 B2 A2 C4 A1 B1 C4 C1 A1 B2 C4 A4 B3 A2 C3 A2 B2 C1 A4 C4 A2 B2 C3 A4 B3 C4 (über AID) Für die Überprüfung der fünften Normalform einer Relation mit 3 Schlüsselattributen (A, B, C) ist jedoch der Natural Join von drei Einzeltabellen notwendig: A-B mit A-C mit B-C. Dazu wird zunächst der Natural Join zwischen zwei der Tabellen vorgenommen (z.B. über AID siehe oben). Das Ergebnis wird dann über den gesamten Schlüssel der verbleibenden Tabelle (hier BID, CID) gejoined. Dabei fallen in Relation A-B-C (a) alle Datensätze weg, deren Kombination von BID und CID nicht in der Relation B-C vorkommen: Relation A-B-C (A) Relation B-C AID BID CID BID CID A1 B1 C1 B1 C2 A1 B2 C1 B1 C4 A1 B1 C4 B2 C1 A1 B2 B2 C4 A2 B2 B3 C4 A2 A4 Relation A-B-C (voll) (über BID,CID) AID BID CID A1 B2 C1 A1 B1 C4 C4 A1 B2 C4 C1 A2 B2 C1 B2 C3 A4 B3 C4 B3 C4 Die Reihenfolge der Joins (also ob der Join zuerst über AID, BID, oder CID durchgeführt wird) ist dabei beliebig. 3.5.1 Beispiel Im Beispiel muss wiederum nur die Relation Ski-Genre-Eignung überprüft werden, denn sie ist die einzige ohne Nichtschlüsselattribute und mit mindestens drei Schlüsselattributen. Es zeigt sich aber, dass die Zerlegung in drei einzelne Relationen nicht verlustfrei ist. SkiNr FRC4R FRC4R FRC4R FRC4W FRC4W SR SR ST ST ST SS EID 1 2 3 1 2 1 2 1 3 5 2 GenreID 001 001 001 002 002 002 003 003 004 004 005 EID 1 2 5 1 2 3 1 3 1 2 1 SkiNr FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W SR SR ST ST ST SS SS GenreID 001 002 003 001 002 003 003 004 001 003 005 001 002 Bei der Zusammenführung dieser drei Relationen ergibt nicht wieder die ursprüngliche Relation. Stattdessen taucht zum Beispiel der folgende Eintrag auf. 47 3 Datenbanknormalisierung SkiNr FRC4R GenreID EID 003 3 Da sich obiges Beispiel in 5. Normalform befindet, betrachten wir ein weiteres Beispiel, dass angibt welche Menschen mit welchem Werkzeug welches Material bearbeiten können. Zerlegt man diese Relation in 3 einzelne Tabellen und führt sie über Natural Joins wieder zusammen, erhält man wieder die Ursprungstabelle. Diese verletzt daher die 5. Normalform und muss in die 3 einzelnen Tabellen zerlegt werden, um sie zu erfüllen. Werkzeug Material Mensch Werkzeug Mensch Material A1 W1 A1 M1 W1 M1 A1 W2 A1 M2 W2 M2 A2 W1 A2 M1 W2 M1 Mensch Werkzeug Material A1 W1 M2 A1 W1 M1 A1 W2 M2 A1 W2 M1 A2 W1 M1 Mensch Werkzeug Material A1 W1 M1 A1 W2 M2 A1 W2 M1 A2 W1 M1 Bedeutung der 5. Normalform Die Zerlegung obiger Tabelle in 3 Einzeltabellen bedeutet, dass hier drei von einander unabhängige Relationen existieren. So kann ein Mensch bestimmte Materialien (unabhängig vom Werkzeug bearbeiten) und bestimmte Werkzeuge (unabhängig vom Material) bedienen. Genauso eigenen sich bestimmte Werkzeuge zur Bearbeitung von Materialien (unabhängig vom Bediener). In einem ERM stellt sich dies folgendermaßen dar. 48 3 Datenbanknormalisierung (0,n) (0,m) (0,m) (0,n) (0,n) (0,m) Befände sich die Tabelle dagegen in 5. Normalform und würde nicht zerlegt, ergäbe sich folgendes ERM: (0,n) (0,n) (0,n) Wird eine Relation nicht in die 5. Normalform überführt, so kann es beim Einfügen in die und Löschen aus der Datenbank zu Inkonsistenzen kommen. Löschen: In der realen Welt geht die Beziehung A1 - W2 aus der Relation Mensch Werkzeug verloren. Der entsprechende Datensatz wird gelöscht. Wird in der Relation Mensch-WerkzeugMaterial, die sich nicht in 5. NF befindet, ebenfalls nur ein Satz gestrichen, z.B. der zweite Datensatz, dann ist im dritten Satz durch A1-W2-M1 eine Beziehung zwischen A1 und W2 erhalten geblieben, wodurch die Datenbank nicht mehr konsistent ist. Einfügen: In der realen Welt kommt die Beziehung A3 - W2 hinzu, da Mensch 3 jetzt auch Werkzeug 2 bedienen kann. In der Relation Mensch-Werkzeug-Material muss ein Satz eingefügt werden z.B.: A3 - W2 - M2, um dieses darstellen zu können. Dieser kann aber durch Natural Join nicht erzeugt werden, da dann in der Relation Mensch-Material auch eine Beziehung zwischen A3 und M2 vorhanden sein müsste. Damit befindet sich die Datenbank in einem inkonsistenten Zustand. Die Beziehung zwischen A3 und W2 kann somit in der Relation Mensch-WerkzeugMaterial nicht ohne zusätzliche Materialzuordnung vorgenommen werden. Achtung: Bei der fünften Normalform muss die mögliche Zerlegung auch immer inhaltlich betrachtet werden. Es ist nämlich möglich das die Zerlegung in unabhängige Relationen inhaltlich nicht korrekt ist und der Verstoß gegen die 5. Normaform nur existiert, weil die betrachtete Tabelle insgesamt nur wenige Datensätze enthält. Fügt man z. B. in die Ursprungsrelation den Datensatz (A2, W2, D2) ein, zeigt sich, dass sich die Relation schon in 5. Normalform befindet und keine Zerlegung mehr möglich ist. 49 3 Datenbanknormalisierung Werkzeug Material Mensch Werkzeug Mensch Material A1 W1 A1 M1 W1 M1 A1 W2 A1 M2 W2 M2 A2 W1 A2 M1 W2 M1 A2 W2 A2 M2 Mensch Werkzeug Material A1 W1 M2 A1 W1 M1 A1 W2 M2 A1 W2 M1 A2 W1 M2 A2 W1 M1 A2 W2 M2 A2 W2 M1 Mensch Werkzeug Material Mensch Werkzeug Material A1 W1 M1 A1 W1 M1 A1 W2 M2 A1 W2 M2 A1 W2 M1 A1 W2 M1 A2 W1 M1 A2 W1 M1 A2 W2 M2 A2 W2 M2 A2 W2 M1 3.5.2 Zusammenfassung des Beispiels In unserem durchgängigen Beispiel erhält man also nach Normalisierung die folgenden fünf Tabellen: SkiNr FRC4R FRC4R FRC4R FRC4R FRC4W FRC4W FRC4W FRC4W SR SR SR ST ST ST SS SS GenreID 001 002 002 003 001 002 003 003 003 004 004 005 003 001 001 002 EID 2 2 3 1 1 1 2 1 1 1 2 1 3 5 2 2 SkiNr FRC4R FRC4W SR ST SS EID 1 2 3 5 SkiName RC4 Race RC4 Worldcup Rocker Threat Sinox Eignung sehr gut gut mittel mangelhaft Ein zugehöriges ERM könnte wie folgt aussehen: 50 HNR F0012 F0012 S0001 S0001 S0002 HNR F0012 S0001 S0002 GenreID 001 002 003 004 005 Hersteller Fischer Salomon Stöckli Genre Kurzschwung Carving Freeride Buckelpiste Freestyle 3 Datenbanknormalisierung Genre (0,n) Skieignung für Genre (0,n) Ski (1,1) (0,n) Eignung 51 Skihersteller (0,n) Hersteller 4 Structured Query Language 4 Structured Query Language 4.1 SQL als Standard Die Structured Query Language (SQL) ist eine Sprache zur Definition, Abfrage und Manipulation von Daten in relationalen Datenbanken. Sie wurde erstmals vom American National Standards Institute (ANSI) 1986 und ein Jahr später von der International Organisation for Standardization (ISO) standardisiert. 1992 wurde von der ISO die nächste Version des Standards veröffentlicht, die unter den Namen SQL-92 oder SQL2 bekannt ist. Alle aktuellen (relationalen) Datenbankmanagementsysteme ((R)DBMS) halten sich im Wesentlichen an diese Standardversion. Auch dieses Skript orientiert sich an SQL-92. Hersteller von DBMS implementieren in ihren Produkten häufig zusätzliche Funktionalitäten oder weichen geringfügig von dem Standard ab. Eine konkrete produktspezifische Variante der SQL-Sprache wird SQL-Dialekt genannt. In diesem Skript wird aus Gründen der Nachvollziehbarkeit und Praxistauglichkeit der Dialekt des MySQL Community Server 5.0 mit InnoDBEngine verwendet. Selbstverständlich wird hier der Dialekt und Funktionsumfang von MySQL nicht vollständig beschrieben. Weiterführende Informationen findet der interessierte Leser im MySQL Referenzhandbuch.3 Viele durch die unterschiedlichen Hersteller im Laufe der Zeit eingebrachte Erweiterungen zu SQL-92 wurden auch von ISO 1999 und 2003 standardisiert. Einige der Themenbereiche, die dort angesprochen werden, sind Objektorientierung, XML-Einbindung und rekursive Anfragen. Diese Themen sind jedoch nicht Gegenstand dieses Skripts. 4.2 Ziele SQL wurde entwickelt, um die Benutzer von DBMS bei folgenden Aufgaben zu unterstützen: • Erstellen von Datenbank- und Relationsstrukturen • Erstellen von Datenbank- und Relationsstrukturen Durchführung grundlegender Datenmanagementaufgaben, wie z.B. Hinzufügen, Modifikation und Löschen von Daten innerhalb der Datenbank • Ausführen von einfachen und komplexen Anfragen SQL hat eine relativ einfache Syntax und ist semantisch an die englische Sprache angelehnt. Es besteht hauptsächlich aus zwei Teilen: • Data Definition Language (DDL) - zum Definieren von Datenbankstrukturen und Steuerung der Datenzugriffsrechte • Data Manipulation Language (DML) - zum Auslesen und Aktualisieren von Daten SQL ist generell eine deklarative Sprache (im Gegensatz zu imperativen Sprachen, wie den Programmiersprachen C oder Java). Der Benutzer formuliert also im Code, welche Information (was) benötigt wird und nicht wie diese zu extrahieren und berechnen ist. 4.3 Bezeichner Bezeichner werden in SQL benutzt, um Objekte (wie z.B. Datenbanken, Tabellen, Spalten und Alias) innerhalb des DBMS zu identifizieren. Ein Standardbezeichner kann aus großen und kleinen lateinischen Buchstaben, Ziffern und dem Unterstrichzeichen bestehen und muss mit einem 3 MySQL Referenzhandbuch ist in verschiedenen Varianten unter http://dev.mysql.com/doc/ zu finden. 52 4 Structured Query Language Buchstaben anfangen. Darüber hinaus ist es in MySQL möglich, auch andere Zeichen zu verwenden, allerdings muss der Bezeichner in diesem Fall stets in Anführungszeichen gesetzt werden. Das Anführungszeichen ist hier der Backtick (zu finden eine Taste rechts vom ß, mit Umschalttaste). Das Anführungszeichen muss auch benutzt werden, wenn ein reserviertes Wort als Bezeichner genutzt werden soll. Reservierte Wörter sind solche, die in der Sprache SQL eine besondere Bedeutung haben (wie z.B. Befehlsklauseln, Datentypen, Funktionen und Operatoren)4 . Beispiele von Bezeichnerverwendung sind: EineTabelle Tabelle332 ‘Eine schöne Tabelle‘ ‘Lieferant/Artikel‘ MySQL unterstützt Namen, die aus einem oder mehreren Bezeichnern bestehen. Die Bestandteile eines mehrteiligen Namens müssen durch Punkte getrennt werden. Die ersten Bestandteile eines mehrteiligen Namens agieren als Qualifikationsmerkmal, das den Kontext beeinflusst, in dem der endgültige Bezeichner interpretiert wird. Spaltenreferenzierung col name tbl name.col name db name.tbl name.col name Bedeutung Die Spalte col name einer in der Anweisung verwendeten Tabelle hat diesen Namen. Die Spalte col name der Tabelle tbl name aus der Standarddatenbank. Die Spalte col name der Tabelle tbl name aus der Datenbank db name. Das Präfix tbl name oder db name.tbl name muss für eine Spaltenreferenzierung in einer Anweisung nicht angeben werden, sofern die Referenzierung eindeutig ist. Die Unterscheidung von Groß- und Kleinschreibung bei Bezeichnern ist generell vom Betriebssystem abhängig. Unter Microsoft Windows kann man annehmen, dass nicht zwischen Großund Kleinschreibung unterschieden wird. Allerdings sollte innerhalb eines Befehls eine durchgehend einheitliche und konsequente Schreibweise verwendet werden. 4.4 Werte 4.4.1 Zeichenketten Eine Zeichenkette (String) ist eine Abfolge von Zeichen, die in einfache Anführungszeichen gesetzt ist 5 . Innerhalb eines Strings haben bestimmte Sequenzen jeweils eine spezielle Bedeutung. Jede dieser Sequenzen beginnt mit einem Backslash. Dieser wird häufig als Escape-Zeichen bezeichnet. Es stehen unter anderem folgende Escape-Sequenzen zu Verfügung: 4 MySQL gestattet auch die Verwendung bestimmter Schlüsselwörter als Bezeichner ohne Anführungszeichen, da viele Benutzer sie in der Vergangenheit bereits eingesetzt haben. Beispiel: DATE, ENUM, TEXT, TIME 5 Doppelte Anführungszeichen können unter Umständen auch angewendet werden. 53 4 Structured Query Language \’ \“ \n \r \t \n \\ einfaches Anführungszeichen (’) doppeltes Anführungszeichen (“) Zeilenwechsel bzw. -vorschub Absatzschaltung Tabulator Zeilenwechsel bzw. -vorschub Backslash (umgekehrter Schrägstrich) Beispiel: ’Das ist eine Zeichenkette’ ’Ein \n \’String\’ \n ist auch eine Zeichenkette.’ 4.4.2 Zahlen Ganze Zahlen werden als Abfolge von Ziffern dargestellt. Fest- und Gleitkommazahlen verwenden den Punkt als Dezimaltrennzeichen. Bei allen Zahlentypen werden durch ein vorangestelltes Plusoder Minuszeichen negative bzw. positive Werte angezeigt. 4.4.3 Null-Werte Der Wert Null bedeutet keine Daten“. Die Groß-/Kleinschreibung wird bei Null nicht unter” schieden. Ein Null-Wert unterscheidet sich maßgeblich von Werten wie 0 für numerische Typen oder vom Leer-String ’ ’ für String-Typen: • In Spalten, die zum Primärschlüssel gehören, werden Null-Werte automatisch verboten. • Null-Werte können in jeder Spalte manuell verboten werden, in dem der Zusatz Not Null bei der Spaltendefinition verwendet wird. • Der Wert eines Ausdrucks der Form p ⊕ q, wobei ⊕ für ein Element der Operatormenge {<, >, =, <>, +, −, ∗, /} steht, beträgt dann Null, wenn mindestens eines der Argumente p oder q Null ist. Aus diesem Grund exisitieren mit IS NULL und IS NOT NULL in SQL spezielle Vergleichsfunktionen, welche einen Vergleich mit Null ermöglichen. • Die Gruppierungs- und Sortierfunktionen DISTINCT, GROUP BY und ORDER BY betrachten alle Null-Werte als gleich. • SQL benutzt eine dreiwertige Logik mit den Werten True, False und Null. Der logische Wert von zusammengesetzten logischen Ausdrücken wird dabei – wie in folgenden Tabellen dargestellt – bestimmt: p true true true false false false Null Null Null q true false Null true false Null true false Null p∧q true false Null false false false Null false Null p∨q true true true true false Null true Null Null 54 p true false Null NOT p false true Null 4 Structured Query Language • Aggregationsfunktionen wie COUNT(), MIN() und SUM() ignorieren Null-Werte. Eine Ausnahme bildet die Funktion COUNT(*), die Zeilen und nicht einzelne Spaltenwerte zählt. • MySQL behandelt Null-Werte für manche Datentypen abweichend. Wird beispielsweise Null in eine Integer-Spalte eingefügt, welche das AUTO INCREMENT-Attribut gesetzt hat, wird stattdessen die nächste Folgenummer eingesetzt. 4.5 Datentypen Jeder Spalte innerhalb einer Tabelle muss ein Datentyp zugewiesen werden. Es gibt grundsätzlich numerische, zeitbezogene und zeichenkettenbezogene Datentypen. 4.5.1 Numerische Datentypen Bei numerischen Datentypen wird weiter zwischen exakten Datentypen (ganze Zahlen, Festkommazahlen) und gerundeten Datentypen (Gleitkommazahlen) unterschieden. Exakte Datentypen haben eine feste Repräsentation. Sie bestehen aus Ziffern, einem optionalen Komma und einem optionalen Vorzeichen. Alle Berechnungen werden exakt durchgeführt und es gibt keine Rundungsfehler. Gleitkommazahlen dienen dagegen einer approximativen Darstellung reeller Zahlen. Sie stellen einen viel größeren Wertebereich zur Verfügung, haben dafür aber nur eine begrenzte Genauigkeit. Dadurch können bei Berechnungen Rundungsfehler entstehen und einige wichtige mathematische Rechenregeln werden außer Kraft gesetzt. Exakte Datentypen BOOLEAN: Dieser Datentyp dient der Darstellung zweier möglicher Wahrheitswerte (TRUE und FALSE).6 SMALLINT [UNSIGNED]: Repräsentiert einen verkürzten Bereich bereich von Ganzzahlen (Integer). Der vorzeichenbehaftete Bereich liegt zwischen -32768 und 32767. Der vorzeichenlose Bereich liegt zwischen 0 und 65535. INTEGER [UNSIGNED], INT [UNSIGNED]: Repräsentiert einen Ganzzahlenbereich zwischen -2147483648 und 2147483647 (vorzeichenbehaftet), bzw. zwischen 0 und 4294967295 (vorzeichenlos). {DECIMAL | NUMERIC}[(M[,D])] [UNSIGNED]: Exakte Festkommazahl. M ist die Gesamtzahl der Dezimalstellen (Genauigkeit), D die Anzahl der Stellen hinter dem Dezimalpunkt. Der Dezimalpunkt sowie das Zeichen ’-’ (für negative Zahlen) werden bei der Zählung für M nicht berücksichtigt. Wenn D 0 ist, haben die Werte keinen Dezimalpunkt und keine Nachkommastellen. Die maximale Anzahl der Stellen (M) beträgt bei DECIMAL 65, die maximale Anzahl unterstützter Dezimalstellen (D) 30. Wird D weggelassen, wird als Vorgabe 0 verwendet; fehlt die Angabe M, ist 10 der Standardwert. Sofern angegeben, verbietet UNSIGNED negative Werte. Berechnungen in den Grundrechenarten (+, -, *, /) erfolgen bei DECIMAL-Spalten stets mit einer Genauigkeit von 65 Stellen. Gerundete Datentypen 6 MySQL interpretiert BOOLEAN (auch BOOL) als TINYINT(1). Dabei sind TRUE und FALSE Aliase für 1 und 0. Aus diesem Grund wird BOOLEAN den numerischen Datentypen zugeordnet. 55 4 Structured Query Language FLOAT[(M,D)] [UNSIGNED] Kleine Gleitkommazahl (mit einfacher Genauigkeit). Darstellbar sind Werte aus der Menge [−3, 40 · 1038 ; −1, 18 · 10−38 ] ∪ {0} ∪ [1, 18 · 10−38 ; 3, 40 · 1038 ]. M ist die Gesamtzahl von Dezimalstellen, D die Anzahl der Stellen hinter dem Dezimalpunkt. Wenn M und D nicht angegeben werden, werden die Werte in diesem Rahmen gespeichert, was hardwareseitig unterstützt wird. Eine Gleitkommazahl mit einfacher Genauigkeit ist auf bis zu sieben Dezimalstellen genau. Sofern angegeben, verbietet UNSIGNED negative Werte. {DOUBLE PRECISION| DOUBLE | REAL}[(M,D)] [UNSIGNED] Gleitkommazahl normaler Größe (mit doppelter Genauigkeit). Darstellbar sind Werte aus der Menge [−1, 80 · 10308 ; −2, 23 · 10−308 ] ∪ {0} ∪ [2, 23 · 10−308 ; 1, 80 · 10308 ]. M ist die Gesamtzahl von Dezimalstellen, D die Anzahl der Stellen hinter dem Dezimalpunkt. Wenn M und D nicht angegeben werden, werden die Werte im Rahmen dessen gespeichert, was hardwareseitig unterstützt wird. Eine Gleitkommazahl mit einfacher Genauigkeit ist auf bis zu 15 Dezimalstellen genau. Sofern angegeben, verbietet UNSIGNED negative Werte. 4.5.2 Zeitbezogene Datentypen Zur Darstellung zeitbezogener Daten dienen die Datentypen DATETIME, DATE und TIME. DATETIME DATETIME dient der Repräsentation von Zeitpunkten, welche sowohl das Datum als auch die Uhrzeit umfasst. Der unterstützte Bereich liegt zwischen 1000-01-01 00:00:00 und 9999-12-31 23:59:59. Die Werte können u.a. in einem der folgenden Formate angegeben werden: • als String im Format ’YYYY-MM-DD HH:MM:SS’ • als String im Format ’YYYY-MM-DD’; für die Uhrzeit wird 00:00:00 angenommen • als Zahl in den Formaten YYYYMMDDHHMMSS oder YYMMDDHHMMSS • als Zahl in den Formaten YYYYMMDD oder YYMMDD; für die Uhrzeit wird 00:00:00 angenommen • als Ergebnis einer Funktion, die einen in entsprechenden Zeitwert zurückgibt, z.B. NOW() oder CURRENT DATE. DATE Dient der Repräsentation von Zeitpunkten, die nur durch ein Datum beschrieben werden. Der unterstützte Bereich liegt zwischen 1000-01-01 und 9999-12-31. Die Werte können u.a. in einem der folgenden Formate angegeben werden: • als String im Format ’YYYY-MM-DD’ • als Zahl in den Formaten YYYYMMDD oder YYMMDD • als Ergebnis einer Funktion, die einen in entsprechenden Zeitwert zurückgibt, z.B. NOW() oder CURRENT DATE. TIME Dient der Repräsentation von Zeitwerten, die entweder einen Zeitpunkt oder einen Zeitintervall in der Form HH:MM:SS beschreiben. Unterstützt wird der Bereich zwischen -838:59:59 und 838:59:59. Die Werte können u.a. in einem der folgenden Formate angegeben werden: • als String im Format ’D HH:MM:SS’, ’HH:MM:SS’, ’HH:MM’, ’D HH:MM’, ’D HH’ oder ’SS’. Dabei steht D für Tage und kann einen Wert zwischen 0 und 34 haben 56 4 Structured Query Language • als Zahl im Format HHMMSS • als Ergebnis einer Funktion, die einen Zeitwert zurückgibt, z.B. CURRENT TIME. 4.5.3 Zeichenkettenbezogene Datentypen Zeichenketten (Strings) sind Folgen von Zeichen, die grundsätzlich mit einem bestimmten Zeichensatz7 kodiert sind. Es stehen folgende Datentypen zur Verfügung: CHAR[(M)] Die Länge einer CHAR-Spalte ist auf den beim Anlegen der Tabelle deklarierten Wert M beschränkt. Dieser kann zwischen 0 und 255 liegen. Wenn CHAR-Werte gespeichert werden, werden sie nach rechts mit Leerzeichen bis auf die angegebene Länge aufgefüllt. Beim Abrufen von CHAR-Werten werden die am Ende stehenden Leerzeichen entfernt. Wird kein M angegeben, wird standardmäßig die Länge von einem Zeichen (M=1) angenommen. VARCHAR[(M)] Werte in VARCHAR-Spalten sind Strings variabler Länge M. Diese kann zwischen 0 und 65.535 liegen. Im Gegensatz zu CHAR werden VARCHAR-Werte nur mit so vielen Zeichen wie erforderlich zuzüglich 1-2 Bytes, welche die Länge angeben. Die folgende Tabelle veranschaulicht die Unterschiede zwischen den Typen CHAR und VARCHAR. Hierzu wird das jeweilige Ergebnis der Speicherung verschiedener String-Werte in CHAR(4)- und VARCHAR(4)-Spalten angezeigt: Wert ’’ ’ab’ ’abcd’ ’abcdefgh’ CHAR(4) ’ ’ ’ab ’ ’abcd’ ’abcd’ Speicherbedarf 4 Byte 4 Byte 4 Byte 4 Byte VARCHAR(4) ’’ ’ab’ ’abcd’ ’abcd’ Speicherbedarf 1 Byte 3 Byte 5 Byte 5 Byte TEXT Repräsentiert lange Zeichenketten, die mit einem bestimmten Zeichensatz kodiert sind. Die maximale Länge der Zeichenkette beträgt dabei 216 − 1. Wie viel Speicherplatz tatsächlich in Anspruch genommen wird, hängt von dem verwendeten Zeichensatz ab. Beispielsweise ist bei Verwendung des utf8-Unicode-Zeichensatzes darauf zu achten, dass einige Zeichen mehr als ein Byte Speicherplatz benötigen. BLOB Die Abkürzung BLOB steht für Binary Large Object und dient der Speicherung langer Zeichenketten, die keinen Zeichensatz zugewiesen haben. In diesem Fall spricht man von binären Strings (Byte-Strings), da ein Zeichen einem Byte gleichgestellt wird. Die Sortierung basiert auf den numerischen Werten der Bytes in den Spaltenwerten. In manchen Fällen kann es wünschenswert sein, Binärdaten – wie bspw. Mediendateien – in BLOB-Spalten zu speichern. ENUM(’value1’ [,’value2’] ...) ENUM8 (Enumeration) ist ein Datentyp, der nur solche String-Werte erlaubt, die beim Erstellen der Tabelle explizit in der Spaltendefinition aufgelistet wurden. Als Werte kommen unter bestimmten Umständen auch der Leer-String (’’) oder Null in Frage. Jeder Wert in der Auflistung bekommt einen mit 1 beginnenden nummerierten Index. Der Indexwert des als Fehlerwert verwendeten Leer-Strings ’’ ist 0. Es kann also bspw. folgende SELECT-Anweisung verwendet werden, um Datensätze zu ermitteln, bei denen ungültige ENUM-Werte zugewiesen wurden: 7 8 Ein Zeichensatz ist eine Zuordnung zwischen alphanumerischen Zeichen und Zahlen. Der Datentyp ENUM ist MySQL-spezifisch und ist nicht Bestandteil des ISO-Standards. 57 4 Structured Query Language SELECT ∗ FROM tbl_name WHERE enum_col = 0 ; Eine Spalte, die als ENUM(’ja’, ’nein’, ’vielleicht’) definiert ist, kann jeden der nachfolgend angegebenen Werte annehmen. Auch die Indizes der einzelnen Werte werden in der Tabelle angezeigt: Wert Null ’’ ’ja’ ’nein’ ’vielleicht’ Index Null 0 1 2 3 Eine Auflistung der erlaubten Werte darf maximal 65.535 Elemente enthalten. 4.6 Erstellen von Tabellen (CREATE TABLE) Relationen werden in einer relationalen Datenbank in Tabellen gespeichert. Um eine Tabelle zu erstellen und ihre Struktur zu definieren, wird der Befehl CREATE TABLE mit folgender Syntax verwendet: CREATE TABLE tbl_name ( create_definition , . . . ) −−c r e a t e d e f i n i t i o n : col_name data_type [ NOT NULL | NULL ] [ DEFAULT default_value ] [ AUTO_INCREMENT ] [ UNIQUE | PRIMARY KEY ] | PRIMARY KEY ( col_name , . . . ) | UNIQUE ( col_name , . . . ) | FOREIGN KEY ( col_name , . . . ) REFERENCES tbl_name ( col_name , . . . ) [ ON DELETE reference_option ] [ ON UPDATE reference_option ] −−r e f e r e n c e o p t i o n : CASCADE | SET NULL | NO ACTION Nach dem Schlüsselwort CREATE TABLE folgt der Bezeichner für die neue Tabelle und (in Klammern gesetzt) eine Liste von Spalten, gefolgt von zusätzlichen optionalen Definitionen von Primär- oder Fremdschlüsseln sowie UNIQUE-Indizes. Ein UNIQUE-Index verbietet wiederholende Werte innerhalb einer Spalte oder Spalten. Beispiel 1 CREATE TABLE Kategorie ( KategorieNr INT AUTO_INCREMENT PRIMARY KEY , Kategoriename VARCHAR ( 2 0 ) NOT NULL UNIQUE , Beschreibung TEXT , Abbildung BLOB ); In diesem Beispiel wird eine Tabelle mit der Bezeichnung Kategorie erstellt. Die neue Tabelle hat vier Spalten. Die Spalte KategorieNr ist vom Typ INT und wird zum Primärschlüssel 58 4 Structured Query Language deklariert. Der Zusatz AUTO INCREMENT9 schaltet eine zusätzliche Funktionalität ein, die beim Einfügen neuer Datensätze dafür sorgt, dass die Kategorienummer automatisch fortlaufend nummeriert wird. Der Kategoriename ist ein String mit variabler Länge, jedoch nicht größer als 20 Zeichen. Der Zusatz NOT NULL bewirkt, dass das Feld erforderlich ist, d.h. es dürfen keine Null-Werte eingetragen werden. Auf dieser Spalte wird auch ein UNIQUE-Index deklariert, der wiederholende Werte verbietet. Die Beschreibung ist eine große nicht-binäre Zeichenkette. In der Spalte Abbildung werden dagegen digitale Grafiken der Artikel in Form binärer Zeichenketten (Byte-Strings) gespeichert.10 Die letzten beiden Felder sind optional (da kein NOT NULL angegeben wurde). Beispiel 2 CREATE TABLE Artikel ( ArtikelNr INT NOT NULL AUTO_INCREMENT , Artikelname VARCHAR ( 4 0 ) DEFAULT NULL , KategorieNr INT NOT NULL , Einzelpreis DECIMAL ( 1 9 , 4 ) DEFAULT NULL , Lagerbestand SMALLINT DEFAULT NULL , PRIMARY KEY ( ArtikelNr ) , FOREIGN KEY ( KategorieNr ) REFERENCES Kategorie ( KategorieNr ) ON DELETE NO ACTION ON UPDATE NO ACTION ); In Beispiel 2 werden mit dem Zusatz DEFAULT Standardwerte für bestimmte Spalten definiert. Sie werden beim Einfügen neuer Datensätze dann angewendet, wenn kein expliziter Wert für diese Spalte angegeben wird. Zur Primärschlüssel-Definition wird hier eine andere Syntax als zuvor verwendet. Die Definition geschieht gesondert nach der Angabe aller Spalten mit dem Schlüsselwort PRIMARY KEY, gefolgt von einer Liste der Schlüsselspalten in Klammern. Diese Syntaxvariante muss verwendet werden, wenn der Primärschlüssel aus mehr als einer Spalte besteht. Nach der Definition des Primärschlüssels wird ein Fremdschlüssel definiert, was für sogenannte referentielle Integrität sorgt. In diesem Beispiel referenziert die Spalte KategorieNr die gleichnamige Spalte aus der Elterntabelle Kategorie. Es besteht noch zusätzlich die Möglichkeit, bestimmte Regeln zu definieren, die das Systemverhalten im Hinblick auf die FremdschlüsselBeziehung steuern. Es kann angegeben werden, was bei einem Versuch passieren soll, einen referenzierten Wert aus der Elterntabelle zu löschen (ON DELETE) oder einen solchen Wert zu ändern (ON UPDATE). Dabei gibt es grundsätzlich drei Möglichkeiten: 9 10 AUTO INCREMENT ist eine MySQL-Erweiterung zum Standard-SQL. Zu beachten ist, dass das Speichern von Grafikdaten in der Datenbank nicht unbedingt sinnvoll sein muss. In der Regel werden in Datenbanken lediglich Referenzen auf die Dateien im Dateisystem gespeichert, um die Größe der Datenbank im Rahmen zu halten. 59 4 Structured Query Language Option NO ACTION (Voreinstellung) CASCADE SET NULL Wirkung Ändern/Löschen referenzierter Datensätze in der Elterntabelle nicht möglich. Änderungen in der referenzierten Tabelle werden in dem referenzierenden Datensatz automatisch übernommen. Wird ein referenzierter Datensatz in der Elterntabelle gelöscht, so werden alle ihn referenzierenden Datensätze aus der Tabelle automatisch gelöscht. Wird ein referenzierter Datensatz in der Elterntabelle gelöscht oder geändert, so werden alle ihn referenzierende Werte aus der Tabelle mit Null-Werten ersetzt. Diese Option ergibt nur dann Sinn, wenn die Spaltendefinition Null-Werte zulässt. Wenn keine Option zur referentiellen Integrität angegeben wird, wird standardmäßig NO ACTION angewendet. 4.7 Ändern der Tabellenstruktur (ALTER TABLE) Wenn die Struktur einer bereits angelegten Tabelle geändert werden soll, wird dazu der Befehl ALTER TABLE mit folgender Syntax verwendet: ALTER TABLE tbl_name alter_specification [ , alter_specification ] ... −− a l t e r s p e c i f i c a t i o n : ADD [ COLUMN ] column_definition [ FIRST | AFTER col_name ] | ADD PRIMARY KEY ( col_name , . . . ) | ADD UNIQUE ( col_name , . . . ) | ADD FOREIGN KEY ( col_name , . . . ) REFERENCES tbl_name ( col_name , . . . ) [ ON DELETE reference_option ] [ ON UPDATE reference_option ] | CHANGE [ COLUMN ] old_col_name column_definition [ FIRST | AFTER col_name ] | DROP [ COLUMN ] col_name | DROP PRIMARY KEY | DROP FOREIGN KEY fk_symbol | DROP INDEX index_name | RENAME TO new_tbl_name Nach dem Schlüsselwort ALTER TABLE und dem Tabellennamen folgt eine Liste von durch Kommata getrennten Änderungsanweisungen. Beispiel ALTER TABLE Artikel ADD COLUMN Artikelbeschreibung TEXT AFTER Artikelname , CHANGE COLUMN Lagerbestand Lagerbestand SMALLINT NOT NULL , DROP COLUMN Einzelpreis ; Im Beispiel wird die Struktur der Tabelle Artikel geändert, indem eine neue Spalte Artikelbeschreibung des Typs TEXT hinzugefügt wird. Mit der Option FIRST bzw. AFTER col name hat man die Möglichkeit, die Position der neuen Spalte in der Tabelle anzugeben. Mit CHANGE 60 4 Structured Query Language COLUMN werden bestehende Spaltendefinitionen geändert. Hierbei ist anzumerken, dass direkt nach dem Namen der zu ändernden Spalte der neue Spaltenname und weitere Bestandteile einer vollständigen Spaltendefinition folgen. Wird der Spaltenname nicht geändert, so muss er zweimal hintereinander angegeben werden. Die Anweisung DROP COLUMN ermöglicht das Löschen von Spalten. Des Weiteren besteht die Möglichkeit Primär-, Fremdschlüssel und UNIQUE-Indices zu definieren sowie diese zu löschen. In den zwei letzteren Fällen muss der Name der entsprechenden Bedingung angegeben werden, der mit dem Befehl SHOW CREATE TABLE tbl name herauszufinden ist. Mit der Anweisung RENAME TO besteht die Möglichkeit, eine Tabelle umzubenennen. 4.8 Entfernen von Tabellen (DROP TABLE) Das Schema einer Relation und alle bereits eingegebenen Daten können mit dem DROP TABLEBefehl gelöscht werden. Somit wird eine Tabelle aus der Datenbank vollständig und endgültig entfernt: DROP TABLE tbl_name Beispiel DROP TABLE Kunde ; Im Beispiel wird die Tabelle Kunde vollständig aus dem System entfernt. Dabei gehen alle darin enthaltenen Daten verloren! exploits_of_a_mom.png (PNG-Grafik, 666x205 Pixel) http://imgs.xkcd.com/comics/exploits_of_a_mom.png xkcd.com 4.9 Einfügen von Daten (INSERT) Das Einfügen von Datensätzen in eine Tabelle geschieht unter Verwendung des INSERT-Befehls. Der Vorgang kann entweder durch direkte Angabe der einzufügenden Datensätze oder durch Einfügen von Datensätzen aus einer anderen Tabelle geschehen. 4.9.1 Direktes Einfügen Syntax INSERT INTO tbl_name [ ( col_name , . . . ) ] VALUES ( { expr | DEFAULT } , . . . ) , ( . . . ) , . . . 61 4 Structured Query Language Werden Spaltennamen (col name,...) angegeben, so werden Werte nur in die entsprechenden Spalten der Tabelle eingefügt. Dies ist nur möglich, wenn die nicht angegebenen Spalten einen Standardwert haben. Der Standardwert kann entweder explizit durch die DEFAULT-Option angegeben werden oder es wird bei Spalten, die Null-Werte zulassen, Null als Standardwert angenommen. Werden keine Spaltennamen angegeben, so bezieht sich das INSERT auf alle Spalten der Tabelle. Soll in eine Spalte, die nicht als NOT NULL definiert wurde, ein Null-Wert eingefügt werden, so geschieht das durch Eingabe des Wertes Null. Wenn mehrere Datensätze mit einem Befehl hinzugefügt werden sollen, so können die einzelnen VALUES-Gruppen durch Kommata getrennt angegeben werden. 4.9.2 Einfügen aus anderen Tabellen Syntax INSERT INTO tbl_name [ ( col_name , . . . ) ] SELECT . . . Mit dieser Syntaxvariante besteht die Möglichkeit, sich die hinzufügenden Werte von einer beliebigen SELECT-Anfrage liefern zu lassen. Natürlich müssen dabei die Spalten des Abfrageergebnisses den angegebenen (oder allen - wenn kein (col name,...) vorhanden) Spalten hinsichtlich der Tabellendefinition entsprechen. D.h. die Tabelle muss das SELECT-Ergebnis aufnehmen können. 4.10 Abfragen (SELECT) Um die in den Relationen gespeicherten Daten abzurufen, werden an das DBMS Abfragen (Queries) gestellt. Nach der Bearbeitung der Abfrage, liefert das System ein Ergebnis zurück. Das Ergebnis hat die Form einer Tabelle, d.h. es besteht aus benannten Spalten und in Zeilen organisierten Datensätzen. Jeder Spalte ist dabei auch ein bestimmter Typ zugewiesen. Die Durchführung der Abfragen ermöglicht der SELECT-Befehl. Syntax SELECT [ ALL | DISTINCT ] select_expr , . . . [ FROM table_references [ WHERE where_condition ] [ GROUP BY { col_name | expr } , . . . ] [ HAVING where_condition ] [ ORDER BY { col_name | expr } , . . . ] .. 4.10.1 Einfache Abfragen Die Grundform einer Abfrage in SQL wird durch die ’SELECT...FROM...WHERE’-Klausel gebildet. Hinter dem Schlüsselwort SELECT werden die Ergebnisspalten spezifiziert, die ausgegeben werden sollen (Projektion). Hinter dem Schlüsselwort FROM müssen die Namen aller Tabellen angegeben werden, deren Spalten ausgegeben werden sollen oder zur Formulierung der Bedingungen benötigt werden. Auf das Schlüsselwort WHERE folgend können Bedingungen angegeben 62 4 Structured Query Language werden, denen die Elemente der beteiligten Relationen genügen müssen, um Bestandteil der Lösungsmenge zu werden (Selektion). Da es möglich ist, dass nach Projektion und Selektion in der Lösungsmenge gleiche Datensätze mehrmals vorkommen, bietet SQL die Möglichkeit, durch die Angabe von DISTINCT hinter SELECT nur verschiedene Datensätze anzuzeigen. Wird ALL (oder nichts) anstatt DISTINCT angegeben, so bleibt die Lösungsmenge unverändert. Beispiel 1 SELECT Artikelname , Einzelpreis FROM Artikel WHERE ArtikelNr =1234; In Beispiel 1 werden solche Datensätze in der Tabelle Artikel gesucht, die den Wert 1234 in der Spalte ArtikelNr haben. Da in diesem Fall ArtikelNr Primärschlüssel ist, dürfen sich dessen Werte nicht wiederholen, es wird also nach genau einem Datensatz gesucht. Dabei wird hier nicht der vollständige Datensatz zurückgeliefert, sondern nur die Werte der Spalten Artikelname und Einzelpreis. Wird als select expr, ... ein * (Sternchen) angegeben, so werden alle verfügbaren Spalten des Ergebnisses zurückgeliefert. Sollen alle Datensätze (Zeilen) einer Tabelle ohne Einschränkung ausgegeben werden, kann auf die WHERE-Klausel verzichtet werden.11 In Beispiel 2 wird eine Abfrage gezeigt, die uneingeschränkt alle Daten aus der Tabelle Artikel zurück gibt. Beispiel 2 SELECT ∗ FROM Artikel ; select expr kann auch ein Ausdruck sein, der Tabellenspalten verwendet oder sogar ein solcher, der ohne Referenzierung einer Tabelle berechnet wird. Es kann sich als praktisch erweisen, dem Ausdruck einen Namen (sogenannten Alias) zu geben. Diese Möglichkeiten werden in Beispiel 3 gezeigt. Beispiel 3 SELECT Einzelpreis ∗2 AS ‘ Doppelter Preis ‘ , 2∗2+3 AS Berechnung FROM Artikel ; Auf das Schlüsselwort AS kann verzichtet werden. Wenn nur Tabellen-unabhängige Ausdrücke berechnet werden, kann die FROM-Klausel ebenfalls weggelassen werden. Beispiel 4 SELECT 1 Eins ; Das Ergebnis der Abfrage aus dem Beispiel 4 hat eine Spalte mit dem Namen Eins und einen Datensatz. Es wird einfach die Zahl 1 ausgegeben. 4.10.2 Formulierung von Bedingungen (WHERE) Hinter dem Schlüsselwort WHERE können Bedingungen in Form von Ausdrücken angegeben werden. Diese bestimmen die vorzunehmende Selektion und können unterschiedlicher Art sein. Zum einen sind einfache Vergleiche möglich, zum anderen besteht die Möglichkeit, neue Abfragen (sogenannte Unterabfragen oder Subqueries) in die Bedingungen zu integrieren. Solche Ausdrücke 11 Es kann auch eine Bedingung gesetzt werden, die immer erfühlt ist, wie z.B. WHERE 1=1. Dies kann z.B. bei dynamischer SQL-Generierung praktisch sein. 63 4 Structured Query Language sind auch an anderen Stellen zulässig, wie z.B. hinter dem SELECT-Schlüsselwort oder (in beschränkter Form) in der HAVING-Klausel. In den folgenden Beispielen wird von der Relation Kunde mit den Attributen KundenCode, Firma und PLZ (Postleitzahl des Kundenwohnorts) ausgegangen. Für die Formulierung von Bedingungen gibt es in SQL unter anderem folgende Möglichkeiten: • einfacher Vergleich (=, <, >, <>, <=, >=) – WHERE Firma=’BAKER AG ’ – WHERE PLZ<>’48161 ’ • Verknüpfung von Bedingungen mit AND, OR oder NOT – WHERE ( PLZ=’48161 ’ OR PLZ=’48149 ’ ) AND Firma<>’ERCIS ’ • der BETWEEN-Operator zur Definition eines Suchbereiches – WHERE Firma BETWEEN ’BAKER AG ’ AND ’ERCIS ’} Statt mit BETWEEN zu arbeiten kann auch die Ober- und Untergrenze des Bereichs separat überprüft werden: – WHERE Firma>=’BAKER AG ’ AND Firma<=’ERCIS ’ • der LIKE-Operator – WHERE Firma LIKE ’B_ker ’} Mit dem LIKE-Operator kann eine Ähnlichkeitsabfrage für alphanumerische Konstanten durchgeführt werden. Als Wildcards dienen der Unterstrich ( ) als Platzhalter für ein Zeichen und das Prozentzeichen (%) als Platzhalter für n Zeichen (n >= 0). Beispiel SELECT ∗ FROM Kunde WHERE Firma LIKE ’M%’ ; Es werden alle Kunden ausgegeben, deren Namen mit ’M’ beginnen. • die Operatoren IS NULL und IS NOT NULL – WHERE Firma IS NULL – WHERE PLZ IS NOT NULL • der IN-Operator – WHERE PLZ IN ( ’48149 ’ , ’48161 ’ , ’48143 ’ ) Es werden solche Datensätze in die Ergebnismenge übernommen, die einem der Einträge in der Liste entsprechen. – Als Liste für den IN-Operator kann auch eine SELECT-Query dienen: WHERE PLZ IN ( SELECT PLZ FROM Postleitzahlen WHERE Bundesland=’NRW ’ ) • der EXISTS-Operator in Verbindung mit einer Unterabfrage 64 4 Structured Query Language – WHERE EXISTS ( SELECT . . . FROM . . . WHERE . . . ) Diese Bedingung prüft, ob es für einen Datensatz ein Ergebnis in der Subquery gibt. • verschiedene String-Funktionen, z.B. CONCAT() – SELECT CONCAT ( ’Kundennummer : ’ , KundenCode , ’, Firma : ’ , Firma ) AS ‘ Kundencode und Firma ‘ FROM Kunde ; CONCAT(str1,str2,...) gibt den String zurück, der aus der Verkettung der Argumente entsteht. • verschiedene mathematische Funktionen, z.B. ROUND() – SELECT Artikelname , ROUND ( Einzelpreis ) FROM Artikel WHERE ROUND ( Einzelpreis ) >20; ROUND(X) gibt das Argument X gerundet auf den nächstgelegenen Integer zurück. • verschiedene Datumsfunktionen, z.B. YEAR() – SELECT BestellNr , YEAR ( Bestelldatum ) FROM Bestellung WHERE YEAR ( Bestelldatum )=2001; YEAR(date) gibt für ein Datum im Bereich zwischen 1000 und 9999 das Jahr als Zahl zurück. 4.10.3 Sortieren (ORDER BY) Wird eine Abfrage durch eine ORDER BY-Klausel abgeschlossen, so bewirkt dies eine Sortierung der Lösungsmenge anhand der Werte einer oder mehrerer vorgegebener Spalten. Für jeden Spaltennamen hinter ORDER BY kann angegeben werden, ob anhand dieser Spalte aufsteigend (ASC) oder absteigend (DESC) sortiert werden soll. Wird weder ASC noch DESC angegeben, so wird automatisch ASC, also aufsteigende Sortierung, angenommen. In dieser Klausel ist es möglich, die in der SELECT-Klausel definierten Aliase zu verwenden. Beispiel 6 SELECT Firma , PLZ FROM Kunde ORDER BY PLZ DESC , Firma ; In Beispiel 6 wird eine Kundenliste nach Postleitzahlen absteigend geordnet ausgegeben. Wohnen mehrere Kunden im gleichen Ort, werden sie namentlich aufsteigend geordnet ausgegeben. 4.10.4 JOIN-Syntax Da sich Informationen in stark normalisierten Datenbanken auf verschiedene Tabellen verteilen, ist es bei der Abfragen meist notwendig, diese wieder zu verknüpfen. Das wird durch einen Verbund (Join) erreicht, der die Tabellen temporär (d.h. für die Dauer der Anfrage) verbindet. Das Ergebnis eines Joins ist wie eine neue vollständige Tabelle anzusehen. Als Beispiel sind folgende zwei Tabellen gegeben: 65 4 Structured Query Language Tabelle Servicepunkt SPID VERTRID ---------- ---------1 1 2 1 3 2 4 NULL BEZEICH ------Punkt 1 Punkt 2 Punkt 3 Punkt 4 Tabelle Vertriebsregion VERTRID SUPERVERTRID ---------- -----------1 NULL 2 1 3 1 NAME ---------Region 1 Region 2 Region 3 Wenn mehrere Tabellen verknüpft werden, kann es vorkommen, dass sich gleichnamige Spalten in verschiedenen Tabellen befinden. Werden solche Spalten in einem Befehl referenziert, müssen qualifizierte Namen der Form tbl name.col name benutzt werden, um Eindeutigkeit zu gewährleisten. In solchen Fällen ist es oft nützlich, den Tabellen (kürzere) Aliasnamen zu vergeben. Dies geschieht durch Angabe des Aliases mit dem optionalen Wort AS hinter dem Tabellennamen in der FROM-Klausel, wie im folgenden Beispiel. . . . FROM servicepunkt AS alias_s , vertriebsregion alias_v CROSS JOIN Ein Cross Join bildet das kartesische Produkt (=Kreuzprodukt) zweier Tabellen. Es wird jede Zeile der ersten Tabelle mit jeder Zeile der zweiten Tabelle kombiniert. Eine praktische Anwendung gibt es dafür jedoch eher selten. Es ist folgende Syntax zugelassen: SELECT ∗ FROM servicepunkt s CROSS JOIN vertriebsregion v ; #oder : SELECT ∗ FROM servicepunkt s , vertriebsregion v ; Ausgabe: SPID VERTRID BEZEICH VERTRID SUPERVERTRID NAME ---------- ---------- ------- ---------- ------------ -------1 1 Punkt 1 1 NULL Region 1 1 1 Punkt 1 2 1 Region 2 1 1 Punkt 1 3 1 Region 3 2 1 Punkt 2 1 NULL Region 1 2 1 Punkt 2 2 1 Region 2 2 1 Punkt 2 3 1 Region 3 3 2 Punkt 3 1 NULL Region 1 3 2 Punkt 3 2 1 Region 2 3 2 Punkt 3 3 1 Region 3 4 NULL Punkt 4 1 NULL Region 1 4 NULL Punkt 4 2 1 Region 2 4 NULL Punkt 4 3 1 Region 3 66 4 Structured Query Language INNER JOIN Ein Inner Join verbindet genau die Zeilen von zwei Tabellen miteinander, für die eine explizit angegebene Bedingung erfüllt wird. Sollen mehrere Bedingungen gleichzeitig angewendet werden, werden diese mittels logischer Operatoren (AND, OR) verknüpft. Folgende Syntax ist zulässig: SELECT ∗ FROM servicepunkt s INNER JOIN vertriebsregion v ON s . VERTRID=v . VERTRID ; Die Bedingung im Teil hinter ON muss keine Äquivalenz sein - auch bspw. “größer als“oder “kleiner als“sind als Bedingung zulässig. Alternativ kann der Join über die WHERE-Klausel erfolgen: SELECT ∗ FROM servicepunkt s , vertriebsregion v WHERE s . VERTRID=v . VERTRID ; Ausgabe: SPID VERTRID BEZEICH VERTRID SUPERVERTRID NAME ---------- ---------- ------- ---------- ------------ -------1 1 Punkt 1 1 NULL Region 1 2 1 Punkt 2 1 NULL Region 1 3 2 Punkt 3 2 1 Region 2 Wenn als Bedingung die Äquivalenz bzgl. eines oder mehrerer Attribute definiert werden soll (also bspw. “’kunde.kundenID=bestellung.kundenID’) und die entsprechenden Spalten in beiden Tabellen den gleichen Namen und Datentyp besitzen, kann auch folgende Syntax verwendet werden: SELECT ∗ FROM servicepunkt s INNER JOIN vertriebsregion v USING ( VERTRID ) ; mit der Ausgabe: VERTRID SPID BEZEICH SUPERVERTRID NAME ---------- ---------- ------- ------------ -------1 1 Punkt 1 NULL Region 1 1 2 Punkt 2 NULL Region 1 2 3 Punkt 3 1 Region 2 Wie zu sehen ist, besteht der Unterschied darin, dass die (gleichnamigen) Spalten nicht doppelt zurückgegeben werden. NATURAL JOIN Wenn die JOIN-Bedingungen Äquivalenzen sind und die entsprechenden Spalten in beiden Tabellen den gleichen Namen und Datentyp besitzen und es keine anderen Spalten (also solche, die nicht Bestandteil der Bedingung des Joins sein sollen) gibt, die in beiden Tabellen die den gleichen Namen und Datentyp besitzen, so kann der obige INNER JOIN mit USING durch einen NATURAL JOIN ersetzt werden: 67 4 Structured Query Language SELECT ∗ FROM servicepunkt s NATURAL JOIN vertriebsregion v ; ergibt VERTRID SPID BEZEICH SUPERVERTRID NAME ---------- ---------- ------- ------------ -------1 1 Punkt 1 NULL Region 1 1 2 Punkt 2 NULL Region 1 2 3 Punkt 3 1 Region 2 LEFT OUTER JOIN = LEFT JOIN Außer INNER JOINs gibt es auch so genannte OUTER JOINs. Ein LEFT (OUTER) JOIN kombiniert jede Zeile der ersten Tabelle mit den Zeilen der zweiten Tabelle, die die Bedingungen erfüllen oder mit Null-Werten, wenn keine passenden Zeilen der zweiten Tabelle vorhanden sind. So gibt es im Beispiel eine Vertriebsregion, in der sich keine Servicepunkte befinden. Wird eine Liste aller Regionen benötigt, auf der zusätzlich entsprechende Servicepunkte annotiert sind, so ist folgende Anfrage hilfreich: SELECT ∗ FROM vertriebsregion v LEFT JOIN servicepunkt s ON v . VERTRID=s . VERTRID ; Ausgabe: VERTRID SUPERVERTRID NAME SPID VERTRID BEZEICH ---------- ------------ -------- ---------- ---------- ------1 NULL Region 1 1 1 Punkt 1 1 NULL Region 1 2 1 Punkt 2 2 1 Region 2 3 2 Punkt 3 3 1 Region 3 NULL NULL NULL Sind nur die Regionen zu ermitteln, in der sich keine Servicepunkte befinden, liefert folgende Anfrage das gewünschte Ergebnis: SELECT ∗ FROM vertriebsregion v LEFT JOIN servicepunkt s ON v . VERTRID=s . VERTRID WHERE s . VERTRID IS NULL ; Ausgabe: VERTRID SUPERVERTRID NAME SPID VERTRID BEZEICH ---------- ------------ -------- ---------- ---------- ------3 1 Region 3 NULL NULL NULL RIGHT OUTER JOIN = RIGHT JOIN 68 4 Structured Query Language Ein RIGHT (OUTER) JOIN funktioniert genauso wie LEFT (OUTER) JOIN, nur werden hier alle Zeilen der zweiten (rechten) Tabelle mit passenden Zeilen der ersten (linken) Tabelle oder Null-Werten kombiniert. FULL OUTER JOIN = FULL JOIN12 Ein vollständiger Außenverbund kombiniert die Funktionsweise der beiden LEFT und RIGHT JOINs. Es werden die Zeilen der linken Tabelle mit denen der rechten verknüpft, die die angegebenen Bedingungen erfüllen. Außerdem werden die verbleibenden Zeilen sowohl der linken als auch der rechten mit Null-Werten verknüpft. Folgende Anfrage erstellt uns eine Liste von allen Vertriebsregionen und allen Servicepunkten mit ihrer Zuordnung, sofern vorhanden. SELECT ∗ FROM vertriebsregion v FULL JOIN servicepunkt s ON v . VERTRID=s . VERTRID ; Ausgabe: VERTRID SUPERVERTRID NAME SPID VERTRID BEZEICH ---------- ------------ -------- ---------- ---------- ------1 Region 1 1 1 Punkt 1 1 Region 1 2 1 Punkt 2 2 1 Region 2 3 2 Punkt 3 3 1 Region 3 NULL NULL NULL NULL NULL NULL 4 NULL Punkt 4 JOINS von mehreren Tabellen Wenn ein Verbund von mehr als zwei Tabellen gebildet wird, werden die Tabellen normalerweise von links nach rechts verknüpft. Da dies bei Outer Joins eine Rolle spielen kann, kann man diese Reihenfolge durch Setzen von Klammern verändern. Beim Ausführen von komplexeren Anfragen sorgt das DBMS (der Optimierer) dafür, dass der Vorgang möglichst kurz dauert. Es werden beispielsweise zuerst die Bedingungen betrachtet, die die Menge der Zeilen aus einer (oder aus mehreren) Tabelle(n) am meisten begrenzen. Dies hat zur Folge, dass später wesentlich weniger Zeilen in der Join-Phase verbunden werden. Eine Ausnahme von dieser Vorgehensweise bilden hier z.B. die Bedingungen, die sich im HAVINGTeil befinden. Diese werden erst nach der Verbunderstellung und Gruppenbildung angewendet. Aus diesem Grund sollten nur solche Ausdrücke in den HAVING-Teil gesetzt werden, die nicht innerhalb der WHERE-Klausel formuliert werden können, da sonst Performance-Nachteile entstehen. 4.10.5 Aggregation von Daten In manchen Situationen sind nicht die Werte der einzelnen Datensätze von Interesse, sondern solche, die eine Gruppe von Datensätzen zusammenfassend beschreiben. Um sie zu ermitteln, gibt es in SQL die folgenden fünf speziellen Aggregationsfunktionen: 12 FULL (OUTER) JOIN wird von MySQL nicht unterstützt. 69 4 Structured Query Language COUNT([DISTINCT] expr) COUNT(*) MIN(expr) MAX(expr) SUM(expr) AVG(expr) Ermittelt die Anzahl der gültigen Werte innerhalb einer Gruppe. Wird die Option DISTINCT verwendet, werden gleiche Werte nur einmal gezählt. Ermittelt die Anzahl der Datensätze im Ergebnis. Ermittelt den kleinsten Wert einer Gruppe von Werten. Ermittelt den größten Wert einer Gruppe von Werten. Ermittelt die Summe der Werte einer Gruppe von Werten. Ermittelt das arithmetische Mittel einer Gruppe von Werten. Grundsätzlich gilt die Regel, dass Null-Werte durch die Aggregationsfunktionen ignoriert werden. Eine Ausnahme ist COUNT(*), das alle Datensätze in der Gruppe – unabhängig der darin enthaltenen Werte – zählt. Beispiel 7 SELECT MAX ( Einzelpreis ) FROM Artikel ; In Beispiel 7 wird der höchste Preis aller Artikel gesucht. Beispiel 8 SELECT COUNT ( DISTINCT PLZ ) FROM Kunde ; In Beispiel 8 wird die Anzahl unterschiedlicher Postleitzahlen aller Kunden gesucht. 4.10.6 Gruppenbildung (GROUP BY) Mit der GROUP BY-Klausel können die Zeilen eines (Zwischen-)Ergebnisses anhand der Werte einer oder mehrerer Spalten gruppiert werden. Die Gruppierung erfolgt so, dass die Spalten, nach denen die Gruppierung erfolgt, keine doppelten Werte mehr enthalten. Hinter GROUP BY erfolgt die Angabe eines oder mehrerer Spaltennamen. Wenn Gruppierung angewendet wird, dürfen hinter SELECT nur solche Spalten stehen, über die gruppiert wird, oder Ausdrücke, die genau einen Wert pro Gruppe liefern (s. Aggregationsfunktionen). Der Sinn hinter der Gruppenbildung liegt in der Anwendung von Aggregationsfunktionen, die nach Ausführung genau einen Wert pro Gruppe liefern. Beispiel 9 SELECT Land , COUNT ( ∗ ) FROM Kunde GROUP BY Land ; In Beispiel 9 wird eine Liste von Ländern, in denen Kunden angesiedelt sind, mit der Anzahl von Kunden in dem jeweiligen Land ausgegeben. 4.10.7 Gruppenbedingungen (HAVING) Durch die HAVING-Komponente erfolgt nach der Bildung der Gruppen mittels GROUP BY eine Auswahl der Gruppen, die den durch die HAVING-Bedingung gegebenen Anforderungen genügen. Der Unterschied zur Auswahl durch die Bedingungen hinter WHERE liegt darin, dass Tabellenzeilen, 70 4 Structured Query Language die den Bedingungen hinter WHERE nicht genügen, bei der Gruppenbildung durch GROUP BY nicht berücksichtigt werden, während durch die HAVING-Bedingung bereits gebildete Gruppen aus der Lösungsmenge ausgeschlossen werden können. In der HAVING-Bedingung werden im Allgemeinen Aggregationsfunktionen angewendet. Beispiel 10 SELECT PLZ , COUNT ( Firma ) as KundenProPLZ FROM Kunde WHERE NOT ( ( Firma=’Baker AG ’ ) AND ( PLZ=’48149 ’ ) ) GROUP BY PLZ HAVING KundenProPLZ >1; In Beispiel 10 werden Kunden, die die gleiche Postleitzahl haben, zusammengruppiert. Pro Postleitzahl wird anschließend die Anzahl der dazugehörigen Kunden ausgegeben. Bei der Abfrage wird der Kunde Maier aus 48149 (Münster) nicht berücksichtigt. 3.2.8 Reihenfolge der Abfragenberechnung 4.10.8 Reihenfolge bei derbei Abfragenberechnung Die Bearbeitung Bearbeitung von konzeptionell immer in einer bestimmten Reihenfolge abgeDie von Abfragen Abfragenwird wird konzeptionell immer in einer bestimmten Reihenfolge wickelt. Diese wird auf folgender Abbildung dargestellt: abgewickelt. Diese wird auf folgender Abbildung dargestellt. FROM: WHERE: Definiert die Ausgangstabellen Selektiert die Reihen, die der Bedingung genügen GROUP BY: Gruppiert Reihen auf der Basis gleicher Werte in Spalten HAVING: Selektiert Gruppen, die der Bedingung genügen SELECT: Selektiert Spalten ORDER BY: Sortiert Reihen auf der Basis von Spalten Zuerst werden die zu verknüpfenden Tabellen verbunden. Anschließend werden die WHEREBedingungen angewendet, die das Ergebnis beschränken. Danach werden Gruppen gebildet, in dem Datensätze mit gleichen Wertekombinationen der GROUP BY-Spalten zusammengefasst 71 werden. Die HAVING-Klausel bewirkt als nächstes, dass unerwünschte Gruppen aussortiert werden. Danach werden nur die im SELECT-Teil ausgewählten Spalten aus dem Ergebnis 4 Structured Query Language Zuerst werden die zu verknüpfenden Tabellen verbunden. Anschließend werden die WHEREBedingungen angewendet, die das Ergebnis beschränken. Danach werden Gruppen gebildet, in dem Datensätze mit gleichen Wertekombinationen der GROUP BY-Spalten zusammengefasst werden. Die HAVING-Klausel bewirkt als nächstes, dass unerwünschte Gruppen aussortiert werden. Danach werden nur die im SELECT-Teil ausgewählten Spalten aus dem Ergebnis ausgewählt und anschließend erfolgt eine Sortierung anhand angegebener Kriterien. 4.10.9 Unterabfragen Innerhalb eines SELECT-Befehls können sich weitere Abfragen befinden (d. h. es werden mehrere SELECT...FROM...WHERE-Statements ineinandergeschachtelt). Bei den inneren Abfragen spricht man von Unterabfragen (Subqueries). Die äußere Abfrage wird dabei als Hauptabfrage bezeichnet. Jede Unterabfrage selbst kann als Hauptabfrage angesehen werden, wenn sie Unterabfragen besitzt. Subqueries erlauben es, komplexe Abfragen strukturiert aufzubauen und eigenständige Lösungsteile zu isolieren. Grundsätzlich gibt es vier Arten von Unterabfragen bezüglich des Ergebnistyps: • Eine Skalarunterabfrage liefert genau eine Spalte und genau eine Zeile, d.h. einen einzelnen Wert zurück. Grundsätzlich kann eine solche Unterabfrage an allen Stellen verwendet werden, an denen einzelne Werte zulässig sind (Beispiele 11, 12 und 18 ). • Eine Spaltenunterabfrage liefert genau eine Spalte, aber mehrere Zeilen zurück. Diese Unterabfragen werden vor allem dort verwendet, wo ein Vergleich mit einer Liste von Werten durchgeführt wird, z.B. mit dem IN-Operator (Beispiel 13 ). • Eine Zeilenunterabfrage liefert mehrere Spalten, aber genau eine Zeile zurück. Sie findet in einfachen Vergleichen Anwendung, in denen mehrere Spalten involviert sind (zeilenbasierter Vergleich) (Beispiele 14 und 15 ). • Eine Tabellenunterabfrage liefert mehr als eine Spalte und mehr als eine Zeile zurück. Sie kann zum einen in einem zeilenbasierten Vergleich mit einer Liste von Zeilen (z.B. mit dem IN-Operator) eingesetzt werden, zum anderen können solche Unterabfragen in der FROM-Klausel an Stelle von Tabellen verwendet werden (Beispiele 16 und 17 ). Beispiel 11 SELECT ArtikelNr , LieferantenNr , Einkaufspreis FROM Liefernachweis WHERE Einkaufspreis=(SELECT MAX ( Einkaufspreis ) FROM Liefernachweis ) ; In Beispiel 11 werden Artikelnummer, Lieferantennummer und Preis von dem am teuersten eingekauften Artikel ausgegeben. Gibt es mehrere solche Artikel, werden alle ausgegeben. Hier wird eine Skalarunterabfrage im WHERE-Teil angewendet. Wie zu sehen ist, werden Unterabfragen stets in Klammern gesetzt. Beispiel 12 SELECT ArtikelNr , Einkaufspreis − ( SELECT AVG ( Einkaufspreis ) FROM Liefernachweis ) AS ‘ Abweichung vom Durchschnittspreis ‘ FROM Liefernachweis ; 72 4 Structured Query Language In Beispiel 12 werden für jeden Artikel seine Nummer und die Abweichung vom Durchschnittspreis aller Artikel ausgegeben. Es ist ein Beispiel einer Skalarunterabfrage im SELECT-Teil. Beispiel 13 SELECT ∗ FROM Artikel WHERE ArtikelNr IN ( SELECT ArtikelNr FROM Liefernachweis WHERE Einkaufspreis <10); Beispiel 13 stellt die Verwendung einer Spaltenunterabfrage mit dem IN-Operator dar. In der Unterabfrage werden zuerst die Nummern von denjenigen Artikeln ermittelt, deren Einkaufspreis weniger als 10 beträgt. Somit wird eine Liste von Werten gebildet. In der Hauptabfrage werden alle Informationen zu den Artikeln ausgegeben, deren Nummern sich in der Liste befinden. Beispiel 14 SELECT ArtikelNr FROM Artikel WHERE ( Einzelpreis , Lagerbestand )=( SELECT MAX ( Einzelpreis ) , MIN ( Lagerbestand ) FROM Artikel ) ; In Beispiel 14 wird eine Zeilenunterabfrage in einem einfachen Vergleich verwendet. In der Unterabfrage werden zuerst der maximale Einzelpreis und der minimale Lagerbestand von allen Artikeln ermittelt. In der Hauptabfrage wird dann überprüft, ob es Artikel gibt, die gleichzeitig den maximalen Preis und minimalen Lagerbestand haben. Sind solche vorhanden, werden ihre Nummern ausgegeben. Die Unterabfrage liefert hier genau eine Zeile mit zwei Spalten. Der Vergleich erfolgt zeilenbasiert, da Einzelpreis und Lagerbestand hinter dem durch die Klammern zu einer Zeile zusammengefasst werden. Beispiel 14 ist somit semantisch äquivalent zum Beispiel 15: Beispiel 15 SELECT ArtikelNr FROM Artikel WHERE Einzelpreis=(SELECT MAX ( Einzelpreis ) FROM Artikel ) AND Lagerbestand=(SELECT MIN ( Lagerbestand ) FROM Artikel ) ; Beispiel 16 SELECT ∗ FROM Bestellposition WHERE ( ArtikelNr , LieferantenNr ) IN ( SELECT ArtikelNr , LieferantenNr FROM Liefernachweis WHERE Einkaufspreis <10 ); Beispiel 16 stellt die Verwendung einer Tabellenunterabfrage mit dem IN-Operator dar. In der Unterabfrage werden zuerst die Kombinationen von Artikeln und Lieferanten ermittelt, denen ein Einkaufspreis von weniger als 10 entspricht. Somit wird eine Liste von Zeilen gebildet. In der Hauptabfrage werden dann die Bestellpositionen ausgegeben, die den Kombinationen von Artikeln und Lieferanten aus der Liste entsprechen. Beispiel 17 73 4 Structured Query Language SELECT AVG ( Summe ) , COUNT ( KategorieNr ) FROM ( SELECT SUM ( Lagerbestand ) AS Summe , KategorieNr FROM Artikel GROUP BY KategorieNr ) AS Summen ; Im Beispiel 17 wird eine Tabellenunterabfrage in der FROM-Klausel an Stelle einer Tabelle verwendet. In der Unterabfrage werden Artikel aus der gleichen Kategorie zusammengefasst, wobei die Summe der Lagerbestände pro Kategorie berechnet wird. In der Hauptabfrage wird dieses Zwischenergebnis noch einmal aggregiert, in dem der Durschnitt aller Summen und die Anzahl der Kategorien berechnet werden. Somit gibt es in einer Abfrage zwei aufeinander aufbauende Aggregationsstufen. Unterabfragen im FROM-Teil müssen einen Alias zugewiesen haben und können wie normale Tabellen verwendet werden, z.B. als Bestandteil eines Joins. Beispiel 18 SELECT ArtikelNr , LieferantenNr , Einkaufspreis FROM Liefernachweis ln1 WHERE Einkaufspreis=( SELECT MAX ( ln2 . Einkaufspreis ) FROM Liefernachweis ln2 WHERE ln1 . ArtikelNr = ln2 . ArtikelNr ); Im Beispiel 18 wird für jeden Artikel der Lieferant (oder Lieferanten) gesucht, der diesen Artikel zum höchsten Preis verkauft. Hier wird diese Aufgabe mit einer korrelierten Unterabfrage gelöst. Korrelierte Unterabfragen sind solche, die Tabellen aus der Hauptabfrage referenzieren. In einer Unterabfrage können alle Tabellen (oder Tabellenaliasse) der übergeordneten Abfragen verwendet werden. Im Beispiel 18 referenzieren beide Aliasse ln1 und ln2 die gleiche Tabelle Liefernachweis. Allerdings verwendet die Unterabfrage auch den Alias ln1, welcher in der Hauptabfrage vergeben wird. Korrelierte Unterabfragen sind aber mit Vorsicht zu verwenden, da sie oft sehr ineffizient und recht langsam sind. Insbesondere muss grundsätzlich eine solche Unterabfrage für jede Zeile der Hauptabfrage einzeln berechnet werden. Das Umschreiben der Abfrage als Join kann die Leistung unter Umständen verbessern. 4.11 Ändern von Daten (UPDATE) Das Ändern bestehender Datensätze geschieht mit dem UPDATE-Befehl. Es können die Werte einer oder mehrerer Spalten gleichzeitig geändert werden. Während des Änderungsvorgangs sind die alten Werte zugänglich; so ist es beispielsweise in der Tabelle Artikel möglich, die Preise aller Artikel um 1 zu erhöhen, ohne die Preise explizit angeben zu müssen. Es können Bedingungen an die Zeilen der Tabelle gestellt werden, für die Änderungen stattfinden sollen. Änderungen finden immer für alle Zeilen statt, die den Bedingungen hinter dem Schlüsselwort WHERE genügen. Wird keine WHERE-Klausel verwendet, so werden alle Datensätze der Tabelle geändert! Syntax: UPDATE tbl_name SET col_name1=expr1 [ , col_name2=expr2 . . . ] [ WHERE where_condition ] 74 4 Structured Query Language Beispiel 1 UPDATE Artikel SET Einzelpreis=Einzelpreis +1; In Beispiel 1 werden die Preise aller Artikel um 1 erhöht. Beispiel 2 UPDATE Kunde SET PLZ = ’48149 ’ , Straße = ’Leonardo - Campus 3’ , Region = ’Münsterland ’ , Ort = ’Münster ’ , Land = ’Deutschland ’ WHERE Firma = ’ERCIS ’ ; Im Beispiel 2 werden über mehrere Spalten verteilte Adressdaten des Kunden ERCIS aktualisiert. 4.12 Löschen von Daten (DELETE) Das Löschen von Datensätzen geschieht durch den DELETE-Befehl. Es können nur ganze Zeilen gelöscht werden. Es kann eine Bedingung angegeben werden, die die zu löschenden Zeilen erfüllen müssen. Wird keine Bedingung angegeben, so werden alle Datensätze aus einer Tabelle gelöscht! Die Tabellenstruktur bleibt dabei noch erhalten. Syntax: DELETE FROM tbl_name [ WHERE where_condition ] Beispiel 1 DELETE FROM Kunde WHERE Ort=’Münster ’ ; In Beispiel 1 werden alle Kunden, die in Münster ansässig sind, gelöscht. Beispiel 2 DELETE FROM Artikel ; In Beispiel 2 werden sämtliche Datensätze aus der Tabelle Artikel entfernt. Die Tabellenstruktur bleibt dabei noch erhalten, sodass neue Datensätze hinzugefügt werden können. Die Struktur kann jedoch mit dem Befehl DROP TABLE entfernt werden. 75 5 Datenbanksnychronisation und Transaktionen 5 Datenbanksnychronisation und Transaktionen 5.1 Synchronisation von Datenbankprozessen Bei der Datenbanksynchronisation geht es um die Möglichkeit, mit mehreren Nutzern gleichzeitig auf einer Datenbank zu arbeiten. Beim parallelen Zugriff auf Daten kann es zu Konkurrenzsituationen kommen, die im ungünstigsten Fall die Konsistenz der Daten gefährden. 5.2 Transaktionen Operationen auf Datenbanksystemen werden in so genannten Transaktionen durchgeführt. Transaktionen sind Operationen, die eine Datenbank von einem konsistenten Zustand in einen anderen konsistenten Zustand versetzen. Eine Transaktion ist dabei eine vom Benutzer definierte Folge von Aktionen, die bestimmte Eigenschaften erfüllen soll. Die erwünschten Eigenschaften von Transaktionen werden unter dem Akronym ACID zusammengefasst. ACID steht für Atomicity (Atomarität), Consistency (Konsistenz), Isolation (Isoliertheit) und Durability (Dauerhaftigkeit). 5.2.1 Atomicity (Atomarität) Die Atomarität von Transaktionen beschreibt deren Eigenschaft der Unteilbarkeit. Eine Transaktion wird nach diesem Prinzip entweder vollständig oder gar nicht auf einem Datenbestand wirksam. Eine Transaktion die erfolgreich vollständig durchgeführt wurde und deren Effekt auf den Datenbestand gesichert werden soll, bestätigt diese Persistierung durch den so genannten commit. Kann eine Transaktion nicht erfolgreich durchgeführt werden, gilt diese als abgebrochen (abort). Das DBMS muss nun dafür sorgen, dass alle Änderungen im Datenbestand, die durch die Transaktion hervorgerufen wurden, wieder rückgängig gemacht werden. Man spricht dabei von einem roll back. 5.2.2 Consistency (Konsistenz) Die Eigenschaft der Konsistenz von Transaktionen bezeichnen, dass das Ergebnis einer Transaktion eine Datenbank in einen konsistenten Zustand versetzen muss, vorausgesetzt, die Datenbank befand sich vor der Transaktion in einem solchen Zustand. Konsistent bedeutet in diesem Zusammenhang die fachliche Korrektheit (Integrität) der Daten. Beispielsweise darf in einem doppischen Buchhaltungssystem keine Buchung ohne Gegenbuchung erfolgen. Oder werden in einem System Daten redundant gehalten, so müssen diese bei Änderung konsistent (identisch) gehalten werden. 5.2.3 Isolation (Isoliertheit) Die Isoliertheit von Transaktionen sorgt dafür, dass eine Transaktion, welche noch nicht vollständig ausgeführt wurde, keinen Einfluss auf die Ergebnisse einer parallel ausgeführten Transaktion haben darf. Die Ergebnisse der Transaktion werden also erst nach dem commit für andere Transaktionen sichtbar. 76 5 Datenbanksnychronisation und Transaktionen Die einfachste Möglichkeit, Isoliertheit von Transaktionen zu gewährleisten ist deren streng serielle Abarbeitung. Da dies bei größeren Mengen konkurrierender Zugriffe zu nicht akzeptablen Wartezeiten führen würde, ist diese Lösung in vielen Fällen nicht praktikabel. Isoliertheit heißt also, dass die Ergebnismenge von konkurrent (bzw. parallelisiert) ausgeführten Transaktionen identisch mit der Ergebnismenge ist, wären die Transaktionen seriell ausgeführt worden. 5.2.4 Durability (Dauerhaftigkeit) Die Dauerhaftigkeit von Transaktionen bezeichnet die Eigenschaft des Datenbankmanagementsystems, dass, sobald eine Transaktion durch commit bestätigt wurde, deren Effekt in der Datenbank wirksam bleibt. Im Gegensatz zu den übrigen Eigenschaften richtet sich die Dauerhaftigkeit weniger an die Sicherung der (fachlichen) Integrität der Daten, als vielmehr die Sicherung der Daten vor Systemausfällen, Hardwarefehlern und anderen externen Risiken. 5.3 Anomalien bei konkurrierenden Zugriffen auf Daten Verstößt eine Transaktion gegen eine oder mehrere der oben genannten Eigenschaften, kann es bei konkurrierenden Zugriffen auf gleiche Datenobjekte zu unterschiedlichen Anomalien kommen. 5.3.1 Dirty Read (Schreib-Lese-Konflikt) Der Dirty Read bezeichnet grundsätzlich eine Situation, in der eine Transaktion A einen Wert liest, welcher von einer Transaktion B verändert (geschrieben) wurde, Transaktion B jedoch noch nicht via commit bestätigt wurde. Beispiel 1: Dirty Read A = 100 Transaktion 1 read a1<-A a1 = a1 - 10 write a1->A Transaktion 2 read a2<-A a2 = a2 + 50 write a2->A commit a1 = 100 a1 = 90 A = 90 a2 = 90 a2 = 140 A = 140 rollback T2 liest einen Wert für A, der von T1 überschrieben wurde. T2 ändert diesen Wert und überschreibt A erneut. T2 bestätigt mit commit, wogegen T1 abgebrochen wird. Das Ergebnis von T2 ist somit nicht konsistent, da die Transaktion einen Dirty Read für A durchgeführt hat. Die Anomalie kommt zustande, da die Transaktionen die Eigenschaft der Isoliertheit nicht erfüllen. Beispiel 2: Inconsistent Analysis Integritätsbedingung: A + B = 0 Ziel: Umbuchung von 1,- EUR 77 5 Datenbanksnychronisation und Transaktionen Transaktion 1 read a1<-A a1 = a1 - 1 write a1->A Transaktion 2 read a2<-A read b2<-B read b1<-B b1 = b1 + 1 write b1->B commit a1 = 0 a1 = -1 A = -1 a2 = -1 b2 = 0 b1 = 0 b1 = 1 B = 1 Wird die Transaktion 2 zum angegebenen Zeitpunkt ausgeführt, d.h. während die Transaktion 1 noch läuft, so erhält sie eine inkonsistente Sicht auf die Werte A und B (A wurde bereits geschrieben, B noch nicht). Die inkonsistente Sicht (Inconsistent Analysis) ist ein Spezialfall des Dirty Reads. Die Anomalie kommt zustande, da die Transaktionen ebenfalls die Eigenschaft der Isoliertheit nicht erfüllen. 5.3.2 Lost Update (Verlorene Aktualisierung) Das Lost Update bezeichnet eine Situation, in der eine Transaktion einen Wert schreibt, eine andere Transaktion denselben Wert wieder überschreibt, ohne dass die Aktualisierung der ersten Transaktion berücksichtigt wird. Im Unterschied zum Dirty Read lesen beide Transaktionen das Datum in einem konsistenten Zustand. Beispiel 3: Lost Update Beide Transaktionen wollen A um 10 erhöhen, A habe einen Wert von 20. Transaktion 1 read a1<-A Transaktion 2 read a2<-A a1 = a1 + 10 write a1->A a2 = a2 + 10 write a2->A a1 = 20 a2 = 20 a1 = 30 A = 30 a2 = 30 A = 30 Auswertung: A hat jetzt den Wert 30. Bei einzelnen Betrachtungen der Transaktionen hat es den Anschein, als wären sie korrekt durchgeführt worden. Bei Betrachtung beider Transaktionen ergibt sich ein Fehler (A hätte 40 betragen müssen, die Auswirkung einer Transaktion ging verloren), der nicht genau lokalisiert werden kann und nur schwer für den einzelnen Benutzer zu erkennen ist, da dieser nur seine Transaktion isoliert sieht. Ein Problem des Lost Updates ist, dass es nicht zu einem inkonsistenten Zustand der Datenbank führen muss und daher bei Überprüfung der Konsistenzbedingungen der Datenbank nicht unbedingt entdeckt wird. Er sollte deshalb von vornherein durch geeignete Mechanismen vermieden werden. 5.3.3 Nonrepeatable Read (nicht-wiederholbares Lesen) Der Nonrepeatable Read bezeichnet eine Situation, in der eine Transaktion ein Datum mehrmals liest, dieses Datum in der Zwischenzeit jedoch durch eine andere Transaktion geändert wurde. 78 5 Datenbanksnychronisation und Transaktionen Der Unterschied zum Dirty Read ist, dass die lesende Transaktion bei jedem Zugriff auf einen konsistenten Zustand der Datenbank zugreift, jedoch im Laufe ihrer Abarbeitung unterschiedliche Zustände vorfindet. Der Unterschied zur inkonsistenten Sicht liegt darin, dass es sich hier bei allen Lesezugriffen um das gleiche Datum handelt. Bei der Inconsistent Analysis werden dagegen unterschiedliche Daten gelesen, welche aber gemeinsam (fälschlicherweise als konsistent) betrachtet werden. Beispiel 4: Nonrepeatable Read L = 200, B = 100, R = 100, E = 50 Konsistenzregel: L − R > 0 Transaktion 1 read l1<-L read r1<-R read b1<-B l1 = l1 - r1 - b1 Transaktion 2 read l2<-L read r2<-R read e2<-E l2 = l2 - r2 - e2 read l2<-L l2 = l2 - 50 write l2->L commit read l1<-L l1 = l1 - b1 write l1->L commit l1 = 200 r1 = 100 b1 = 0 l1 = 0 l2 = 200 r2 = 100 e2 = 50 l2 = 50 l2 = 200 l2 = 150 L = 150 l1 = 150 l1 = 50 L = 50 Im diesem Beispiel steht L für einen Lagerbestand, R für Reservierungen auf den Bestand, B für eine aktuelle Bestellung und E für eine Entnahme für die Produktion. Transaktion 1 überprüft zunächst, ob der Lagerbestand L abzüglich der Reservierung R groß genug ist, um Bestellung B zu bedienen. Da l1=0, kann die Bestellung durchgeführt werden. Transaktion 1 liest nun den Lagerbestand erneut und zieht die bestellte Menge ab. In Zwischenzeit hat jedoch Transaktion 2 den Lagerbestand um eine Entnahme E verringert, so dass Transaktion 1 nun eine Operation durchführt, die auf Grundlage veralteter Daten entschieden wurde. Das Ergebnis ist ein inkonsistenter Zustand des Systems, da nun die Reservierungen den Lagerbestand überschreiten. 5.3.4 Phantom Phantome sind ein Problem, welches bei Transaktionen entsteht, die sich auf mehrere Tupel beziehen. Das Problem ähnelt dem Nonrepeatable Read mit dem Unterschied, dass sich das wiederholte Lesen nicht auf ein Datum, sondern auf eine Menge von Daten einer (oder mehrerer) Tabellen bezieht. Beispiel 5: Phantom Transaktion 1 soll den durchschnittlichen Umsatz pro Kunde berechnen. 79 5 Datenbanksnychronisation und Transaktionen Transaktion 1 read a1<-count(Kunde) Transaktion 2 a1 = 110 insert into Kunde commit read u1<-sum(Umsatz) du1 = u1 / a1 write du1->DU commit u1 = 220 du1 = 2 DU = 2 Der Wert DU, den die Transaktion 1 berechnet, ist zum Zeitpunkt des commits der Transaktion bereits nicht mehr gültig. Transaktion 2 hat in der Zwischenzeit einen zusätzlichen Datensatz in die Tabelle Kunde eingetragen, der in der Durchschnittsberechnung nicht berücksichtigt wird. Ein solcher Datensatz wird als Phantom bezeichnet. Der korrekte Wert für DU wäre 1,982. 5.4 Serialisierbarkeit von Transaktionen Eine Menge von Ausführungen von Transaktionen führt immer zu einem konsistenten Zustand der Datenbank, wenn alle Transaktionen der Reihe nach (seriell) abgearbeitet werden. Die Reihenfolge der Transaktionen ist dabei egal. Würde das Datenmanagement nur jeweils die Ausführung einer Transaktion gleichzeitig zulassen, so wäre damit die Konsistenz der Datenbank gewährleistet. Diese Einschränkung durch das DBMS führt jedoch zu einer geringen Effizienz des Datenbanksystems, da auch Transaktionen, die überhaupt nicht auf gemeinsame Teile der Datenbank zugreifen, nicht parallel ausgeführt werden dürfen. Das DBMS soll einen möglichst hohen Grad an paralleler Abarbeitung von Transaktionen zulassen, ohne dass Fehler in der Datenbank auftreten. Dies ist immer dann der Fall, wenn die Wirkung der parallel ausgeführten Transaktionen der Wirkung irgendeiner seriellen Ausführung der gleichen Transaktionen entspricht. Das System paralleler Transaktionen heißt dann serialisierbar. Definition: Ein System von parallelen Transaktionen ist dann korrekt synchronisiert, wenn es serialisierbar ist, d.h. wenn mindestens eine (gedachte) serielle Ausführung derselben Transaktionen existiert, die das Datenbanksystem in denselben Zustand überführt, wie die parallele Ausführung. Anders ausgedrückt ist ein System von parallelen Transaktionen genau dann nicht serialisierbar, wenn es die Datenbank in einen Zustand versetzt, der mit keiner der möglichen seriellen Reihenfolgen der beteiligten Transaktionen reproduzierbar wäre (ausgehend vom jeweils gleichen Vorzustand). Zur Gewährleistung der Serialisierbarkeit eines Systems paralleler Transaktionen werden Synchronisationsverfahren angewendet. Man unterscheidet zwei Arten solcher Verfahren: • Verifizierende Verfahren: Zu bestimmten Zeitpunkten wird getestet, ob die Serialisierbarkeit noch gegeben ist. Liegt eine Verletzung der Serialisierbarkeit vor, so wird eine geeignete Transaktion zurückgesetzt und neu gestartet. • Präventive Verfahren: Es wird verhindert, dass nicht-serialisierbare Folgen von Transaktionsausführungen überhaupt entstehen. In diese Kategorie fallen insbesondere die Sperrverfahren. 80 5 Datenbanksnychronisation und Transaktionen 5.4.1 Lese- und Schreibsperren Die Synchronisation eines Systems paralleler Transaktionen kann geschehen, indem jede Transaktion die Objekte in der Datenbank sperrt, die für ihre Abarbeitung benötigt werden. Möchte eine Transaktion ein Objekt nur lesen, so kann sie eine sog. Lesesperre (RLOCK) für das entsprechende Objekt anfordern. Auf einem Objekt dürfen gleichzeitig beliebig viele Lesesperren gesetzt sein. Soll das Objekt auch verändert werden, so ist eine exklusive Sperre (oder auch Schreibsperre, WLOCK) anzufordern. Alternativ kann eine Lesesperre in eine Schreibsperre umgewandelt werden, sofern keine weitere Lesesperre auf diesem Objekt gesetzt ist. Bei der Anforderung von Sperren sind bestimmte Protokolle zu beachten, da durch den Gebrauch von Sperren alleine keine Serialisierbarkeit garantiert wird: Beispiel 6: Inkonsistenzen trotz Sperren Transaktion 1 read a1<-A a1 = a1 + 1 write a1->A read b1<-B b1 = a1 write b1->B Transaktion 2 read b2<-B b2 + 2 write b2->B read a2<-A a2 = b2 write a2->A a1 = 1 a1 = 2 A = 2 b1 = 1 b1 = 2 B = 2 b2 = 2 b2 = 4 B = 4 a2 = 2 a2 = 4 A = 4 Haben A und B vor der Ausführung von t1 und t2 beide den Wert 1, so führt sowohl die Hintereinanderausführung t1-¿t2 als auch die Hintereinanderausführung t2-¿t1 zu dem Endwert 4 für A und B. Eine parallele Ausführung von t1 und t2 ist somit nur dann korrekt, wenn sie ebenfalls zu dem Wert 4 für die Objekte A und B führt: 81 5 Datenbanksnychronisation und Transaktionen Transaktion 1 wlock A Transaktion 2 wlock B read a1<-A read b2<-B a1 = a1 + 1 b2 + 2 write a1->A write b2->B a1 = 1 b2 = 1 a1 = 2 b2 = 3 A = 2 B = 3 unlock A unlock B wlock B wlock A read b1<-B read a2<-A b1 = a1 a2 = b2 write b1->B write a2->A b1 = 3 a2 = 2 b1 = 2 a2 = 3 B = 2 A = 3 unlock B unlock A Die Datenbank hat nach dieser parallelen Ausführung den Wert 3 für A und den Wert 2 für B. Es gibt keinen äquivalenten seriellen Ablauf von t1 und t2, obwohl Sperren verwendet wurden. 5.4.2 Zwei-Phasen-Protokoll Das Zwei-Phasen-Protokoll ist ein Sperrprotokoll, das Serialisierbarkeit garantiert. Das Protokoll fordert, dass die Anforderung und die Freigabe von Sperren durch eine Transaktion in zwei getrennten Phasen erfolgen. Nachdem eine Transaktion eine Sperre freigegeben hat, darf sie keine weiteren Sperren mehr anfordern. Beispiel 7: Vorheriges Beispiel mit Zwei-Phasen-Protokoll Transaktion 1 rlock A Transaktion 2 rlock B read a1<-A read b2<-B a1 = a1 + 1 b2 + 2 a1 b2 a1 b2 = = = = wlock A 1 1 2 3 wlock B write a1->A write b2->B rlock B: Muss warten, da B gesperrt rlock A: Muss warten, da A gesperrt --- DEADLOCK --- 82 A = 2 B = 3 5 Datenbanksnychronisation und Transaktionen t1 und t2 befinden sich in einem Deadlock, da beide Transaktionen auf die Freigabe einer Sperre warten, die durch die jeweils andere Transaktion gehalten wird. Die Deadlock-Situation wird durch das DBMS erkannt und aufgehoben, indem eine der beiden Transaktionen (hier beispielhaft t2) zurückgesetzt wird. Transaktion 1 Transaktion 2 rollback: zurücksetzen der Transaktion, B wird frei und auf den Wert 1 gesetzt. rlock B (Sperre kann jetzt gesetzt werden) read b1<-B b1 = a1 wlock B B = 1 b1 = 1 b1 = 2 b1 = 2 rlock B: muss warten write b1->B unlock B B = 2 read b2<-B b2 = 2 b2 + 2 wlock B write b2->B rlock A read a2<-A a2 = b2 wlock A write a2->A unlock A unlock B b2 = 4 unlock A B = 4 a2 = 2 a2 = 4 A = 4 A und B haben beide den Wert 4. Der parallele Ablauf von t1 und t2 ist somit serialisierbar. Würde an dieser Stelle die Transaktion t2 mit einem rlock B erneut gestartet werden, dann käme es zu einem späteren Zeitpunkt zu einem erneuten Deadlock. Dieser müsste dann ebenfalls durch rollback aufgelöst werden. Daher wurde in diesem Beispiel der Neustart von t2 verzögert. Es gibt zwei besondere Formen des Zwei-Phasen-Protokolls: Preclaiming und Sperren bis Ende der Transaktion (EOT) Preclaiming: Beim Preclaiming müssen zu Beginn einer Transaktion vor der eigentlichen Verarbeitung alle gewünschten Sperren angefordert werden. Dies hat den Vorteil, dass jede Transaktion, die in die Verarbeitungsphase kommt, Sperren für alle zur Verarbeitung notwendigen Objekte besitzt. Die Transaktion kann somit nicht mehr an einem Deadlock beteiligt sein. Tritt der Deadlock bereits vor der Verarbeitung beim Anfordern der Sperren auf, so ist das Zurücksetzen der Transaktion problemlos möglich, da sie noch keine Objekte in der Datenbank verändert hat. Preclaiming ist nur dann möglich, wenn schon vor Beginn der Verarbeitung alle an der Verarbeitung beteiligten Objekte bekannt sind. Weiterhin schränkt Preclaiming die mögliche Parallelität bei der Abarbeitung von Transaktionen ein, da Sperren länger als notwendig gesetzt sind. 83 5 Datenbanksnychronisation und Transaktionen Sperren bis EOT: Beim Sperren bis EOT (End of Transaction) werden alle Sperren bis zum Ende einer Transaktion gehalten. Dies hat den Vorteil, dass keine andere Transaktion Werte gelesen haben kann, wenn eine Transaktion zurückgesetzt werden muss. Durch Sperren bis EOT wird der mögliche Parallelitätsgrad bei der Ausführung von Transaktionen eingeschränkt, da Sperren länger als notwendig gehalten werden. Ein Deadlock kann durch Sperren bis EOT nicht verhindert werden. 84