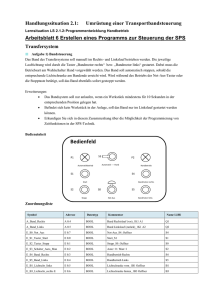
Praktikum Funktionale Programmierung - Goethe
Werbung

Anleitung zum Praktikum Funktionale Programmierung Sommersemester 2011 Dr. David Sabel Institut für Informatik Fachbereich Informatik und Mathematik Goethe-Universität Frankfurt am Main Postfach 11 19 32 D-60054 Frankfurt am Main Email: [email protected] Stand: 9. Juli 2011 Inhaltsverzeichnis 1 2 3 4 Allgemeines 1.1 Organisatorisches . . . . . . . 1.1.1 Webseite . . . . . . . . 1.1.2 Regelmäßiges Treffen 1.1.3 Modulprüfung . . . . 1.2 Haskell . . . . . . . . . . . . . 1.2.1 Material zu Haskell . 1.2.2 GHC . . . . . . . . . . 1.2.3 Haskell Platform . . . 1.2.4 Cabal, Hackage . . . . 1.3 Quellcode . . . . . . . . . . . 1.4 Dokumentation . . . . . . . . 1.5 Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2 2 3 3 4 4 4 5 6 6 6 7 . . . . . . 8 8 11 11 11 14 16 . . . . 17 17 21 22 26 Teil 2: Type-Check und Transformation in einfachere Syntax 4.1 Das Typsystem . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 34 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Kurzübersicht über das Projekt 2.1 Das Softwareprojekt . . . . . . . . . 2.1.1 Präsentation der Ergebnisse . 2.2 Die Sprache CHF . . . . . . . . . . . 2.2.1 Die Syntax von Ausdrücken 2.2.2 Typisierung von Ausdrücken 2.2.3 Beispiele . . . . . . . . . . . . Teil 1: Lexen und Parsen 3.1 Quelltext lexen . . . . . . . 3.2 Parsen mit Happy . . . . . . 3.2.1 Ausgabe des Parsers 3.2.2 Die Parserdefinition D. Sabel, FP-PR, SoSe 2011 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Stand: 9. Juli 2011 Inhaltsverzeichnis . . . . 40 43 47 47 Teil 3: Abstrakte Maschinen 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme . . . . . . . . . . . . . . . . . . . . . . . . . . 5.1.1 Implementierung . . . . . . . . . . . . . . . . . . . . . . 5.2 Die IO-Mark 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2.1 Implementierung . . . . . . . . . . . . . . . . . . . . . . 5.3 Die Nebenläufige Maschine – Concurrent Mark 1 . . . . . . . 5.4 Der Interpreter . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 4.2 5 4.1.1 Gleichungen mit Unifikation lösen . 4.1.2 Implementierung des Typchecks . . Transformation in eine vereinfachte Syntax 4.2.1 Transformation in MExpr . . . . . . . Bibliography D. Sabel, FP-PR, SoSe 2011 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 56 62 68 70 76 78 1 Stand: 9. Juli 2011 1 Allgemeines 1.1 Organisatorisches 1.1.1 Webseite Die Webseite zum Praktikum ist unter http://www.ki.informatik.uni-frankfurt.de/lehre/SS2011/FP-PR/ zu finden. Neben dieser Anleitung und Aufgabenstellungen sind dort Verweise auf weiteres Material sowie aktuelle Informationen zu finden. Insbesondere ist dort ein Skript namens „Begleitmaterial zum Praktikum Funktionale Programmierung“ zu finden, dass einige kurze Kapitel zu notwendigem Hintergrundwissen zum Praktikum enthält: Neben der Bedienung von CVS, Hinweisen zum Debuggen in Haskell, werden dort die Werkzeuge Haddock zur Dokumentation und Happy zum Erstellen von Parsern erörtert. Außerdem werden einzelne Konstrukte von Haskell dort erläutert: Datentypdefinitionen insbesondere die Verwendung der sog. Record-Syntax, Typklassen, das hierarchische Modulsystem sowie monadisches Programmieren und Concurrent Haskell. Das Skript kann als Nachschlagewerk benutzt werden, wenn es die Aufgaben dieser Anleitung erfordern. D. Sabel, FP-PR, SoSe 2011 Stand: 9. Juli 2011 1.1 Organisatorisches 1.1.2 Regelmäßiges Treffen Dienstags, um 14 c.t. findet in Seminarraum 9 ein regelmäßiges Treffen aller Praktikumsteilnehmer statt. Hier sollen Fragen und Probleme diskutiert werden, die Anwesenheit ist somit i.A. erforderlich. Genaue Termine bzw. ob das regelmäßiges Treffen ausfällt usw. finden sich auf der Webseite zum Praktikum. 1.1.3 Modulprüfung Die Modulprüfung für Masterstudierende wird für die korrekte und vollständige Bearbeitung der Aufgaben vergeben. Die Benotung findet aufgrund der abgegebenen Programme und Dokumentation statt. Hierfür sollte zusätzlich ein selbst verfasstes Protokoll (maximal 2 Seiten) über die selbst erbrachten Leistungen abgegeben werden. Es sollen je 2–3 Teilnehmer für das Praktikum eine Gruppe bilden. Zur Erfüllung der Aufgaben gehört die Abgabe und Präsentation eines hier auf den Rechnern der RBI laufenden, kommentierten Programms, sowie eine schriftliche Ausarbeitung, die folgendes enthält: • eine kurze Erläuterung der Grundlagen, die zur Lösung der Aufgabe notwendig waren. • eine kurze Beschreibung der Lösung selbst. • ein Protokoll, das den Prozess der Problemlösung dokumentiert. Hierbei sollte insbesondere erfasst werden, wieviel Zeit für die einzelnen Tätigkeiten benötigt wurden, und wie die Arbeiten innerhalb der Gruppe aufgeteilt wurden. • die Dokumentation der durchgeführten Tests. Es gibt drei Zeitpunkte zu denen (Zwischen-)ergebnisse präsentiert werden sollen. Gleichzeitig soll zu diesen Zeitpunkten der aktuelle Stand der schriftlichen Ausarbeitung und der implementierten Programmme abgegeben werden! Der erste Teil ist in Kapitel 3 beschrieben, für ihn (Aufgaben 1, 2, 3 und 4) sind 3 Wochen Bearbeitungszeit vorgesehen. Die Beschreibung der anderen beiden Teile (Teil 2: Typcheck und Transformation in einfachere Syntax, Teil 3: Abstrakte Maschinen) fehlen noch in dieser Anleitung und werden nachgeliefert. Außerdem sei erwähnt, dass die Beteiligung bzw. das Stellen von Fragen bei den Besprechungen ausdrücklich erwünscht ist. D. Sabel, FP-PR, SoSe 2011 3 Stand: 9. Juli 2011 1 Allgemeines 1.2 Haskell Die Implementierung der Programme soll in Haskell erfolgen. Kenntnisse in Haskell oder anderen Funktionalen Programmiersprachen sind für die Teilnahme am Praktikum notwendig. 1.2.1 Material zu Haskell Haskell1 ist eine der zur Zeit wohl bedeutendsten, nicht-strikten, funktionalen Programmiersprachen. Wer sich eingehender in Haskell vertiefen möchte, sei auf den Haskell-Report (Jones, 2003) verwiesen, in dem die Sprache definiert wird. Zur Einarbeitung in Haskell sind das deutsche Buch (Chakravarty & Keller, 2004), die Bücher (Thompson, 1999), (Bird, 1998), (O’Sullivan et al., 2008) sowie (Hudak et al., 2000) und auch die Skripte (Sabel, 2011b; SchmidtSchauß, 2010a; Schmidt-Schauß, 2010b) empfehlenswert. Für Haskell gibt es mittlerweile eine recht große Anzahl von Standardbibliotheken, die hierarchisch organisiert sind. Die Dokumentation der Bibliotheken ist online unter http://www.haskell.org/ghc/docs/latest/html/libraries/index.html zu finden. Zum Haskell-Programmieren verwenden wir den GHC2 . 1.2.2 GHC Der Glasgow Haskell Compiler3 (GHC) hält sich an den Haskell-Report. Im GHC gibt es Erweiterungen, die z.B. die Typklassen betreffen. Der GHC ist fast vollständig in Haskell geschrieben und erzeugt C-Code als Zwischencode, der dann von einem auf dem System verfügbaren C-Compiler in ein ausführbares Programm übersetzt wird. Diese Tatsache macht den GHC äußerst portierbar. Für einige Plattformen gibt es zusätzlich einen Code-Erzeuger. GHC bietet zusätzlich noch den GHCi, der eine interaktive Version des GHC darstellt und als Interpreter zum schnellen Programmieren und Testen verwendet werden kann. Der GHCi wird in einer Konsole mit dem Kommando ghci Die offizielle Homepage zu Haskell ist http://haskell.org. Ein vollständige Liste aller Haskell-Implementierungen http://www.haskell.org/haskellwiki/Implementations zu finden. 3 Die Homepage des GHC ist http://haskell.org/ghc. 1 2 Stand: 9. Juli 2011 4 ist unter D. Sabel, FP-PR, SoSe 2011 1.2 Haskell gestartet (dafür muss der Pfad zur GHC-Installation im Suchpfad der Konsole eingetragen sein). Im Interpreter bietet das Kommando :help eine Hilfe und eine Übersicht über die Interpreterkommandos an. Mit :load kann eine Quelldatei geladen werden. Alternativ kann dies auch direkt beim Starten des GHCi als Parameter durchgeführt werden mit ghci "Dateiname" Haskell Quellcode-Dateien haben die Endung .hs oder für Dateien im Literate-Style mit .lhs: Im „normalen“ Stil sind alle Zeilen Programme, außer solchen die explizit als Kommentar gekennzeichnet sind (mit „-- “ wird ein Zeilenkommentar markiert, mit „{-“ und „-}“ ein geklammerter Kommentar). Hingegen werden im „Literate Haskell“-Stil alle Text-Zeilen als Kommentar interpretiert, es sei denn sie werden explizit als Programm gekennzeichnet. Programmzeilen beginnen mit einen Größerzeichen und einem Leerzeichen (“> ”), zusätzlich muss sich zwischen Kommentar und Codezeilen immer eine Leerzeile befinden, ansonsten bekommen wir eine Fehlermeldung: .... line 8: unlit: Program line next to comment phase ‘Literate pre-processor’ failed (exitcode = 1) Zum Compilieren eines Programms mit dem GHC muss i.A. ein Modul namens Main definiert werden, welches eine Funktion main vom Typ IO () enthält (diese Funktion wird beim Programmstart ausgeführt). Ein solches Modul kann dann compiliert werden durch den Aufruf: ghc --make -o "OutputName" Main.hs Dieser Aufruf compiliert die Datei namens Main.hs und deren Importe (hierfür dient u.a. der Parameter --make) und erstellt eine ausführbare Datei namens OutputName. 1.2.3 Haskell Platform Sofern verfügbar empfiehlt es sich die Haskell Platform http://hackage.haskell.org/platform/ zu installieren. Diese beinhaltet neben dem GHC noch weitere Werkzeuge, wie den Lexer-Generator Alex und den Parser-Generator Happy, sowie einige zusätzliche Programmbibliotheken. D. Sabel, FP-PR, SoSe 2011 5 Stand: 9. Juli 2011 1 Allgemeines 1.2.4 Cabal, Hackage Neben den Standardbibliotheken gibt es unter http://hackage.haskell.org eine große Sammlung weiterer Pakete, die in einem standardisierten Format vorliegen (so genannte Cabal-Packages). Unter http://www.haskell.org/haskellwiki/Cabal/How_to_install_a_Cabal_package kann man nachlesen, wie diese installiert werden. 1.3 Quellcode Der Quellcode sollte wartbar sein, und dementsprechend aufgebaut, dokumentiert und kommentiert werden. Es empfiehlt sich die Dateien mithilfe der hierarchischen Modulstruktur zu strukturieren. Der vorgegebene Quellcode ist hierarchisch angelegt und sämtlicher neuer Quellcode sollte in diese Struktur eingefügt werden. Zudem sollte durch geeignete Import- und Export-Listen in den Moduldeklarationen eine geeignete Kapselung erfolgen. Damit der ghci das Modul auch findet, muss das oberste Verzeichnis der Modulstruktur für ihn auffindbar sein. Dafür gibt es beim ghci den Parameter -i<dir> Search for imported modules in the directory <dir>. Wenn wir z.B. gerade im Verzeichnis CHF/Parse/ sind und wollen das Modul mit Dateinamen Lexer.lhs laden, so sollten wir ghci wie folgt aufrufen: ghci -i:../../ Lexer.lhs Nahezu sämtliche vorgegebenen Quellcode-Dateien sind im „Literate Haskell“-Stil verfasst. Im Praktikum wird der Quellcode mittels CVS4 verwaltet werden (siehe (Sabel, 2011a)). 1.4 Dokumentation Die erstellten Programme sollten ausführlich kommentiert werden, so dass ein „Leser“ des Programms dieses nachvollziehen kann. Zusätzlich soll für die Module eine HTML-Dokumentation mit Hilfe des Tools Haddock5 erstellt werden (siehe (Sabel, 2011a)). Es sei jedoch angemerkt, dass eine reine 4 5 Concurrent Versions System, http://www.nongnu.org/cvs/ http://haskell.org/haddock Stand: 9. Juli 2011 6 D. Sabel, FP-PR, SoSe 2011 1.5 Tests Haddock-Dokumentation nicht ausreicht, da mit Haddock nur die exportierten Funktionen und Datentypen dokumentiert werden und zudem eher deren Verwendung und nicht deren Implementierung erklärt wird. 1.5 Tests Sämtliche implementierten Funktionen, Datenstrukturen und Module müssen getestet werden. Teilweise sind Testdaten bzw. Testaufrufe vorgegeben. Diese müssen durchgeführt und im Idealfall auch bestanden werden. Es ist aber auch notwendig eigene Tests mit sinnvoll überlegten Testaufrufen durchzuführen. Sämtliche Tests sind zu dokumentieren und derart zu gestalten, dass sie leicht erneut durchgeführt, d.h. reproduziert, werden können. Zum Testen bietet sich eventuell auch die QuickCheck-Bibliothek (http://hackage.haskell.org/cgi-bin/hackage-scripts/package/QuickCheck) an. D. Sabel, FP-PR, SoSe 2011 7 Stand: 9. Juli 2011 2 Kurzübersicht über das Projekt 2.1 Das Softwareprojekt Ziel des Praktikums ist es, einen Interpreter für die nebenläufige funktionale Programmiersprache CHF zu entwickelt. In (Sabel & Schmidt-Schauß, 2011) wurde CHF definiert und eine kontextuelle Semantik dafür untersucht. CHF wertet verzögert aus und verfügt zusätzlich über Konstrukte zur imperativen und zur nebenläufigen Programmierung: • MVars sind Speicherzellen in denen Werte abgelegt und gelesen werden können. Eine MVar ist entweder leer oder gefüllt. Will ein nebenläufiger Thread aus einer leeren MVar einen Wert lesen, so wird der Thread so lange warten, bis ein anderer Thread die MVar füllt. Umgekehrt führt der Versuch des Schreibens in eine bereits gefüllte MVar dazu, dass der entsprechende Thread solange blockiert ist, bis ein anderer Thread die MVar entleert hat. Bei mehreren Threads die gleichzeitig auf eine MVar zugreifen möchten, darf stets nur ein Thread zugreifen, die anderen Threads werden blockiert. • Futures sind nebenläufige Threads, die als Ergebnis einen Wert zurückliefern können. Sie können daher benutzt werden, um nebenläufig (oder auch parallel) einen Wert zu ermitteln. In CHF wird durch D. Sabel, FP-PR, SoSe 2011 Stand: 9. Juli 2011 2.1 Das Softwareprojekt eine Future eine sogenannte monadische Berechnung durchgeführt, die daher auch imperativ sein darf (d.h. auf MVars zugreifen darf). Man kann CHF als eine Kernsprache für Concurrent Haskell ansehen, wobei nebenläufige Threads durch nebenläufige Futures ersetzt wurden. Im Praktikum sollen die wesentlichen Phasen des Kompilierens für CHF implementiert werden, und eine abstrakte Maschine zur Ausführung von CHFProgrammen erstellt werden. Ohne die Sprache CHF im Detail darzustellen, geben wir an dieser Stelle einen Überblick über das Projekt. Wir beschreiben zunächst allgemein die Phasen eines Compilers Lexikalische Analyse, Scanning Hierbei wird der Quelltext in einen Strom von Token transformiert, Leerzeichen, Umbrüche, Kommentare usw. werden dabei entfernt. Ein Token ist eine syntaktische Einheit, wie z.B. Schlüsselwörter (letrec, case, in,. . . ) oder Zahlen. Der Lexer sollte dabei den Eingabestring nur einmal durchlaufen und somit lineare Zeit (in der Anzahl der Zeichen) verbrauchen. Die Ausgabe des Lexers wird an den Parser übergeben. Syntaktische Analyse, Parsing Hier wird geprüft, ob der Tokenstrom von der kontextfreien Grammatik hergeleitet wird, d.h. das Programm syntaktisch korrekt ist. Es gibt hierfür verschiedene Parse-Methoden, wir werden einen sog. Shift-Reduce-Parser automatisch mithilfe eines Parsergenerators erzeugen. Die Ausgabe des Parsers ist i.A. ein Syntaxbaum, wir werden den Syntaxbaum mittels eines Haskell-Datentyps darstellen. Semantische Analyse Hierbei wird das Programm auf semantische Fehler überprüft. Z.B. wird bei manchen imperativen Programmen geprüft, ob alle benutzten Variablen auch deklariert sind, oder auch ein Typcheck durchgeführt. Zwischencodeerzeugung Hier wird Code für eine abstrakte Maschine erzeugt. Codeoptimierung Der erzeugte Zwischencode wir optimiert. Codeerzeugung Erzeugung eines Programms für eine reale Maschine. Wir werden die wesentlichen Phasen des Compilierens für die Sprache CHF implementieren, wobei wir im Gegensatz zu einem Compiler, die letzten beiden Phasen (wenn überhaupt) vermutlich nur rudimentär implemen- D. Sabel, FP-PR, SoSe 2011 9 Stand: 9. Juli 2011 2 Kurzübersicht über das Projekt tieren werden. Daher entwicklen wir eher einen Interpreter, der den Quelltext nimmt die ersten 4 Phasen durchläuft und anschließend das Programm auf einer abstrakten Maschine ausführt. Ein großer Teil des Praktikums wird sich der Implementierung solcher abstrakter Maschinen widmen. Abbildung 2.1 gibt einen ungefähren Überblick über die einzelnen Teilschritte unseres Interpretes (CHFi), welchen wir im Praktikum implementieren werden. Abbildung 2.1: Projektübersicht Neben den einzelnen Phasen des Compilers wird im Praktikum, wird eine abstrakte Maschine implementiert. Basierend auf der abstrakten Maschine von Sestoft (Sestoft, 1997) (Mark 1) für funktionale Ausdrücke werden wir eine Maschine implementieren die monadisches IO (den Zugriff auf die MVars) ausführen kann (IO-Mark 1). Diese Maschine wird letztendlich um nebenläufige Futures erweitert (Concurrent Mark 1). Der rechte Teil von Abbildung 2.1 zeigt die einzelnen Maschinen. Das Praktikum ist in 3 Teile eingeteilt: • In Teil 1 wird der Lexer und der Parser implementiert. Da wir in diesem Teil nicht allzuviel Zeit verlieren möchten, ist hier schon ein Großteil des Parsers vorgegeben. • In Teil 2 wird die semantische Analyse durchgeführt daher ein Typchecker für CHF-Ausdrücke implementiert. • In Teil 3 werden die abstrakten Maschinen implementiert. Stand: 9. Juli 2011 10 D. Sabel, FP-PR, SoSe 2011 2.2 Die Sprache CHF 2.1.1 Präsentation der Ergebnisse Ergebnisse sollen dreimal präsentiert werden: • Nach Abschluss von Teil 1 • Nach Abschluss von Teil 2 • Nach Abschluss aller Teile. Zu diesen drei Zeitpunkten soll auch der aktuelle Stand der Ausarbeitung sowie die bis dahin vorhandenen Programme abgegeben werden. 2.2 Die Sprache CHF In diesem Abschnitt wird die Programmiersprache CHF vorgestellt. 2.2.1 Die Syntax von Ausdrücken Abbildung 2.2 zeigt die Syntax von Ausdrücken Expr der Sprache CHF. Diese benutzen als Unterausdrücke monadische Ausdrücke MExpr. e, ei ∈ Expr ::= x | me | (λx → e) | (e1 e2 ) | (c e1 . . . ear(c) ) | (seq e1 e2 ) | (caseT e of {((cT,1 x1 . . . xar(cT,1 ) ) → eT,1 ); ... ((cT,|T | x1 . . . xar(cT,|T | ) ) → eT,|T | ))} | (letrec x1 = e1 ; . . . ; xn = en in e) wobei n ≥ 1 me ∈ MExpr ::= (return e) | (e1 >>= e2 ) | (forkIO e) | (takeMVar e) | (newMVar e) | (putMVar e1 e2 ) Abbildung 2.2: Vollgeklammerte Syntax der Sprache CHF Die Sprache CHF verfügt über • Variablen x aus einer Menge von Variablen Var • Abstraktionen λx → e, die anonyme Funktionen darstellen. Durch λx wird der formale Parameter x im Rumpf e gebunden. Man kann den Ausdruck λx → e auffassen, wie die mathematische Definition einer D. Sabel, FP-PR, SoSe 2011 11 Stand: 9. Juli 2011 2 Kurzübersicht über das Projekt Funktion f (x) = e, wobei der Name f nicht definiert wird. In Ausdrücken, die die Funktion verwenden möchten, steht daher anstelle von f die Definition λx → e selbst. • Anwendungen (e1 e2 ), um Funktionen (oder sogar beliebige Ausdrücke) auf Argumente anzuwenden. • rekursive letrec-Ausdrücke: In letrec x1 = e1 , . . . , xn = en in e, werden die Werte der Variablen xi definiert. Da das letrec rekursiv ist, dürfen die xi sowohl in allen ei als auch in e verwendet werden (sie sind dort gebunden). Beachte, dass alle Variablennamen x1 , . . . , xn verschieden sein müssen und das „leere letrecs“ der Form letrec in e nicht erlaubt sind. • seq-Ausdrücke zur sequentiellen Auswertung: Die Auswertung von (seq e1 e2 ) wertet zunächst e1 und danach e2 aus. Sind beide Auswertungen erfolgreich so ist der Wert von (seq e1 e2 ) der Wert von e2 . • Kontruktoranwendungen (ci e1 . . . en ), wobei ci ein Datenkonstruktor ist und n die Stelligkeit des Konstruktors ist (die wir mit ar(ci ) bezeichnen). Wir nehmen an, dass eine bestimmte Menge von Datenkonstruktoren samt ihrer Stelligkeit bereits definiert ist. Diese Menge ist partitioniert, wobei jede Partition die Datenkonstruktoren eines Typs festlegt. Z.B. könnten wir annehmen, dass die Konstruktoren True und False eine Partition für den Typ Bool bilden. True und False sind nullstellige Konstruktoren (ar(False) = 0 = ar(True) = 0), die man daher auch Konstanten nennt. Als weiteres Beispiel betrachten wir Listen, die durch die Konstante Nil (für die leere Liste) und den zweistelligen Konstruktor Cons beschrieben werden können. Dies sind nur Beispiele, später werden wir auf die Definition der Datenkonstruktoren noch genauer eingehen. • case-Ausdrücke um Datenkonstruktoren zu zerlegen. Hier kommen die Typen wieder ins Spiel: Die Alternativen in den case-Ausdrücken müssen formal alle Konstruktoren deselben Typs abdecken. Z.B. wäre case x of {Nil → y, True → z} verboten, da Nil und True zu unterschiedlichen Typen gehören. Beachte, dass in CHF nur Variablen in Pattern einer case-Alternative erlaubt sind, d.h. es gibt keine sog. verschachtelten Pattern wie z.B. (Cons True Nil) (welches genau die Stand: 9. Juli 2011 12 D. Sabel, FP-PR, SoSe 2011 2.2 Die Sprache CHF Liste [True] matchen würde). Die gezeigte Syntax erfordert, dass es genau eine Alternative pro Konstruktor des jeweiligen Typs gibt. Wir werden dies in der Implementierung etwas lockerer handhaben: Fehlende Alternativen sind (genau wie in Haskell) erlaubt und führen möglicherweise zu einem Laufzeitfehler. • Monadische Ausdrücke Wir beschreiben die einzelnen Konstrukte der monadischen Ausdrücke: • return e verpackt einen beliebigen Ausdruck e in eine monadische Aktion (die nichts tut außer e zurück zu liefern). • newMVar e erzeugt eine neue MVar mit Inhalt e. Das Ergebnis ist return y, wobei y der Name der MVar ist. • takeMVar e wertet zunächst e solange aus, bis dort der Name einer MVar steht, anschließend wird der Wert aus der MVar gelesen und die MVar leer hinterlassen. Ist die MVar jedoch vorher schon leer, so wird der Thread solange warten, bis ein anderer Thread die MVar füllt. Das Ergebnis der Ausführung von takeMVar x ist return e0 , falls die MVar namens x den Wert e0 beinhaltete. • putMVar e1 e2 wertet zunächst e1 solange aus, bis dort der Name einer MVar steht. Anschließend wird in die MVar der Ausdruck e1 abgelegt, falls diese leer ist. Ist die MVar gefüllt, muss der Thread warten, bis ein anderer Thread die MVar entleert. Das Ergebnis einer putMVar-Aktion ist (return Unit). Hierbei ist Unit ein Datenkonstruktor des Typs Unit. Dieser besteht gerade einzig und allein aus dem Wert Unit. Unit ist daher ein Nullwert, der zurückgegeben wird, wenn man eigentlich gar nichts zurückgeben will. • forkIO e erzeugt eine Future für e, wobei e eine monadische Aktion ist. D.h. es wird ein nebenläufiger Thread erzeugt, der e ausführt. Der aufrufende Thread erhält sofort nach Ausführen von forkIO e das Ergebnis return y, wobei y der Name der erzeugten Future für e ist. Das Besondere daran ist, dass der aufrufende Thread sofort weiterrechnen kann. Erst wenn dieser den Wert von y benötigt, muss er u.U. warten, bis der nebenläufige Thread für e seine Berechnung beendet hat. Wie wir später sehen werden, geschieht diese Synchronisation völlig automatisch ohne weiteres Zutun des Programmierers. D. Sabel, FP-PR, SoSe 2011 13 Stand: 9. Juli 2011 2 Kurzübersicht über das Projekt • Der „bind“-Operator >>= dient der sequentiellen Ausführung von zwei monadischen Aktionen. In e1 >>= e2 muss e1 eine monadische Aktion sein und e2 ist eine Funktion die das Ergebnis der monadischen Aktion e1 verwendet, um eine neue monadische Aktion zu erstellen. Z.B. kann man mit >>= die folgende Aktion zusammenbauen: (takeMVar x) >>= (λy → putMVar y True). Diese liest zunächst aus der MVar namen sx den Namen einer anderen MVar und schreibt anschließend in diese MVar den Wert True. Beachte, dass monadische Aktionen nur auf oberster Ebene ausgeführt werden und ansonsten (als Unterausdruck) wie Werte (genauer: genauso wie Konstruktoranwendungen) behandelt werden. 2.2.2 Typisierung von Ausdrücken CHF ist eine monomorph typisierte Sprache1 , d.h. es gibt (im Gegensatz) zu Haskell keine Typvariablen in den Typen2 . Das Typsystem unterscheidet zwischen „normalen“ funktionalen Ausdrücken, monadischen Aktionen und Typen der MVars. Monadische Aktionen sind stets vom Typ IO τ , wobei τ ein beliebiger Typ ist, MVar haben den Typ MVar τ , wobei τ der Typ ist, den der Ausdruck in der MVar besitzt. Typen können daher anhand der folgenden Syntax geformt werden: τ, τi ∈ Type ::= IO τ | T | MVar τ | τ1 → τ2 Hierbei ist T ein Typkonstruktor. Diese werden anhand der vorhanden Datentypen vorgegeben. Z.B. ist Bool ein solcher Typkonstruktor. Für einen Ausdruck e schreiben wir e :: τ , wenn e den Typ τ hat. Die Datenkonstruktoren haben alle einen fest vorgegebenen Typ, wobei rekursive Typen erlaubt sind. Wir werden (ähnlich wie in Haskell) Benutzerdefinierte Datentypen erlauben, die am Anfang des Quelltextes mithilfe einer data-Anweisung definiert werden. Z.B. dürfen wir schreiben: data Bool = True | False Der Parser wird uns daraus extrahieren, dass der Typ Bool die beiden Datenkonstruktoren True und False beinhaltet, wobei beide genau den Typ 1 Im Gegensatz zum Typsystem in (Sabel & Schmidt-Schauß, 2011), ist die hier betrachtete Typisierung noch „monomorpher“. 2 trotzdem werden wir für die Implementierung des Typchecks auch Typvariablen verwenden Stand: 9. Juli 2011 14 D. Sabel, FP-PR, SoSe 2011 2.2 Die Sprache CHF Bool haben. Als Beispiel für einen rekursiven Typ betrachten wir den Typ ListBool, der Listen von Booleschen Werten darstellen kann3 data ListBool = NilBool | ConsBool Bool ListBool Der Parser wird dies interpretieren als: Der Typ ListBool beinhaltet die Datenkonstruktoren NilBool und ConsBool, wobei diese die folgenden Typen haben: NilBool :: ListBool ConsBool :: Bool → ListBool → ListBool Beachte, dass man anhand der Typen der Konstruktoren auch direkt deren Stelligkeit ablesen kann: NilBool erwartet keine Eingaben und ist daher 0-stellig, ConsBool erwartet zwei Eingaben und ist daher 2-stellig. Wir werden das genaue Typsystem später kennenlernen, an dieser Stelle wollen wir lediglich die Typen einiger Konstrukte angeben und erläutern: • return hat den Typ τ → IO τ , d.h. das Argument von return kann beliebigen Typs sein und insgesamt stellt (return e) (für passendes e) eine monadische Aktion vom Typ (IO τ ) dar. • forkIO hat den Typ IO τ → IO τ , d.h. in (forkIO e) muss e eine monadische Aktion sein. Diese wird nebenläufig als Future ausgeführt. Insgesamt stellt (forkIO e) eine monadische Aktion dar, die als Ergebnis den Wert der Futureberechnung liefert. • takeMVar hat den Typ MVar τ → IO τ , d.h. in (takeMVar e) muss e ein Ausdruck sein, der zu einem Namen einer MVar auswertet und (takeMVar e) stellt eine monadische Aktion dar, die als Ergebnis den Inhalt der MVar (vom Typ τ ) liefert. • putMVar hat den Typ MVar τ → τ → IO Unit, d.h. in (putMVar e1 e2 ) muss e1 ein Ausdruck sein, der zu einem Namen einer MVar auswertet und (putMVar e1 e2 ) stellt eine monadische Aktion dar, die als Ergebnis den Nullwert Unit liefert (da putMVar nur in die MVar schreibt, genügt dieses Ergebnis). • newMVar hat den Typ τ → IO(MVar τ ), was dazu passt, dass (newMVar e) eine monadische Aktion darstellt, die eine MVar mit Inhalt e erstellt und den Namen der MVar als Ergebnis liefert. 3 Beachte: Da wir kein polymorphes Typsystem zur Verfügung haben, können wir keinen Typ für beliebige Listen definieren. D. Sabel, FP-PR, SoSe 2011 15 Stand: 9. Juli 2011 2 Kurzübersicht über das Projekt • >>= hat den Typ IO τ1 → (τ1 → IO τ2 ) → IO τ2 , da das linke Argument von >>= eine monadische Aktion sein muss, deren Ergebnis vom rechten Argument verwendet wird, und daraus eine neue monadische Aktion erstellt wird. Desweiteren ist erwähnswert, dass das Typsystem bestimmte seqAusdrücke verbietet: In seq a b muss a einen funktionalen Typ haben, d.h. der Typ von a darf weder IO τ noch (MVar τ ) sein. Diese Beschränkung stellt u.a. sicher, dass die monadischen Gesetze in CHF gelten (siehe (Sabel & Schmidt-Schauß, 2011)). 2.2.3 Beispiele Wir geben noch einige Beispiel-Ausdrücke an, um zu verdeutlichen, wie in CHF programmiert wird. Beispiel 2.2.1. Die Identitätsfunktion kann in CHF durch \x -> x implementiert werden. Beachte, dass wir im Quelltext \ statt λ und -> statt → verwenden. Die Funktion \x -> \y -> x erwartet zwei Argumente und bildet stets auf das erste Argument ab. Der Ausdruck case b of {True -> e1; False -> e2} verhält sich wie Haskell’s if-then-else-Ausdruck: if b then e1 else e2. Beispiel 2.2.2. Ein Ausdruck, der die Liste [True, False, False] von booleschen Werten umdreht, kann in CHF programmiert werden als letrec reverse = \xs -> case xs of { NilBool -> NilBool; (ConsBool y ys) -> append (reverse ys) (ConsBool y NilBool) }; append = \xs -> \ys -> case xs of { NilBool -> ys; (ConsBool u us) -> ConsBool u (append us ys) } in reverse (ConsBool True (ConsBool False (ConsBool False NilBool))) Vorher müssen natürlich die Typen Bool und ListBool definiert sein. Stand: 9. Juli 2011 16 D. Sabel, FP-PR, SoSe 2011 3 Teil 1: Lexen und Parsen In diesem ersten Teil geht es darum, das CHF-Programm vom Quelltext (als String) in einen Haskell-Datentyp zu überführen, der Programme (im Grunde als Baum) darstellt. Dieser Prozess ist im allgemeinen zweistufig: In der ersten Phasen wird die lexikalische Analyse durchgeführt, die Kommentare und Leerzeichen werden aus dem Quelltext entfernt, und syntaktische Einheiten werden zu sog. Token zusammenfasst. In der zweiten Phase wird die syntaktische Analyse durchgeführt, die den Tokenstrom des Lexers erhält und anhand einer (kontextfreien) Grammatik den Parsebaum (bzw. Syntaxbaum) erzeugt. 3.1 Quelltext lexen Das Format für den Quelltext ist folgendermaßen: Der Quelltext ist in zwei Abschnitte aufgeteilt: • Im ersten Abschnitt können (u.U. mehrere) Datentyp-Definitionen stehen. Der Abschnitt darf jedoch auch leer sein. Jede Datentypdefinition wird mit dem Schlüsselwort data eingeleitet und definiert einen Typ. Die Syntax ist allgemein: data Typname = Konstruktordefinition1 | . . . | Konstruktordefinitionn Stand: 9. Juli 2011 D. Sabel, FP-PR, SoSe 2011 3 Teil 1: Lexen und Parsen wobei eine Konstruktordefinition von der Form KonstruktorName1 Argumenttyp1 . . . Argumenttypm ist. Sowohl KonstruktorName als auch Typname müssen mit einem Großbuchstaben beginnen und dürfen nur Buchstaben enthalten. Weiterhin muss gelten, dass alle Konstruktornamen verschieden sind (dies wird jedoch erst beim Parsen überprüft). Argumenttypen sind aufgebaut entsprechend der Grammatik: Typ ::= (Typ -> Typ) | Typname D.h. Argumenttypen bestehen aus Funktionstypen und Typkonstruktoren. Insgesamt müssen alle verwendeten Typnamen in den Argumenttypen definiert sein (was vom Parser geprüft wird). Eine Ausnahme ist der Typ Unit, dieser wird durch den Parser automatisch hinzugefügt, mit der Definition data Unit = Unit • Im zweiten Abschnitt (nicht optional, sondern dieser muss vorhanden sein), muss ein CHF-Ausdruck stehen. Der zweite Teil wird mit dem Schlüsselwort expression eingeleitet. Für CHF-Ausdrücke verwenden wird \ statt λ und -> statt →. Ausdrücke dürfen beliebig viele Klammern ( und ) benutzen, während geschweifte Klammern { und } nur für die Abgrenzung der case-Alternativen benutzt werden dürfen. Die Einrückung von Ausdrücken ist im Gegensatz zu Haskell-Quellcode egal, dafür müssen die Semikolons zwischen letrec-Bindungen und case-Alternativen stets vorhanden sein. Variablennamen müssen mit einem Kleinbuchstaben beginnen, wobei bel. Buchstaben und Zahlen anschließend folgen dürfen. Konstruktornamen folgen der Konvention in den Typdefinitionen: Sie beginnen mit einem Großbuchstaben gefolgt von bel. anderen Buchstaben. Für case-Ausdrücke wird im Quelltext kein Index T für den Typ verwendet, sondern einfach nur case. Zudem erlauben wir im Quelltext Zeilenkommentare: Diese werden mit -eingeleitet und bewirken, dass der Rest der Zeile als Kommentar und nicht als Quellcode erkannt wird. Stand: 9. Juli 2011 18 D. Sabel, FP-PR, SoSe 2011 3.1 Quelltext lexen Mögliche Schlüsselwörter im Quelltext sind daher: expression, data, case, of, letrec, in, seq, newMVar, putMVar, takeMVar, return und forkIO sowie die Symbole \, >>=, ;, =, ->, |, (, ), { und }. Die Ausgabe des Lexers ist eine Liste von Token. Für die Token soll der folgende Typ verwendet werden, der im Modul CHF.Parse.Lexer definiert ist: > data Token label = > TokenKeyword String label > | TokenSymbol String label > | TokenVar String label > | TokenCons String label > | TokenUnknown Char label > deriving(Eq,Show) Der Typ Token ist polymorph über der Variable label definiert, und alle verschiedenen Token können als zweites Argument einen Wert für label speichern. Desweiteren hat der Typ Token fünf verschiedene Konstruktoren: • TokenKeyword zeigt ein gefundenes Schlüsselwort im Text an, das erste Argument ist das Schlüsselwort. • TokenSymbol zeigt ein gefundenes Symbol im Text an, das erste Argument ist das Symbol (als String). • TokenVar zeigt eine gefundene Variable im Text an, das erste Argument ist der Name der Variablen. • TokenCons zeigt einen gefundenen Daten- oder Typkonstruktor an, das erste Argument ist der Name des Konstruktors. • TokenUnknown wird benutzt um unbekannte Zeichen im Quelltext als Token darzustellen. Eine Alternative wäre es, direkt eine Fehlermeldung auszugeben, wenn ein solches Zeichen gefunden wird. Wir überlassen die Fehlerausgabe jedoch dem Parser, der anhand dieses Tokens eine Fehlermeldung ausgeben wird. Das label-Argument werden wir verwenden, um die Position des Tokens im Quelltext zu speichern. Hierfür benutzen wir ein Paar aus zwei Ganzzahlen, dass die Zeile und die Spalte des Tokens im Quelltext angibt. Daher ist die Ausgabe des Lexer eine Liste von Elementen vom Typ TokenType, wobei: D. Sabel, FP-PR, SoSe 2011 19 Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen > type TokenType = Token SourceMark > type SourceMark = (Int,Int) I Aufgabe 1. Implementieren Sie im Modul CHF.Parse.Lexer eine Funktion lexCHF :: String -> [TokenType], welche die lexikalische Analyse für CHF-Quellcode durchführt, d.h. syntaktische Einheiten erkennt, Leerzeichen und Umbrüche entfernt, Zeilenkommentare entfernt und als Ausgabe eine Liste von Tokens liefert, wobei die Token mit ihrer Position im Quelltext markiert sind. Versuchen Sie den Lexer so zu implementieren, dass er die Eingabe genau einmal durchläuft. Hinweise: • In der Bibliothek Data.List finden sich einige hilfreiche Funktionen, die Sie für die Implementierung des Lexers verwenden können. • Sie müssen nicht genau eine Funktion implementieren, d.h. Sie können auch weitere Funktionen als Hilfsfunktionen definieren. Einige Beispielaufrufe sind: *CHF.Parse.Lexer> lexCHF "data Bool = True | False expression \\x -> x" [TokenKeyword "data" (1,1),TokenCons "Bool" (1,6),TokenSymbol "=" (1,11), TokenCons "True" (1,13),TokenSymbol "|" (1,18),TokenCons "False" (1,20), TokenKeyword "expression" (1,26),TokenSymbol "\\" (1,37), TokenVar "x" (1,38),TokenSymbol "->" (1,40),TokenVar "x" (1,43)] *CHF.Parse.Lexer> lexCHF "expression 1+1" [TokenKeyword "expression" (1,1),TokenUnknown ’1’ (1,12), TokenUnknown ’+’ (1,13),TokenUnknown ’1’ (1,14)] *CHF.Parse.Lexer> lexCHF "data L = L P expression (case x of {True -> (x True)})" [TokenKeyword "data" (1,1),TokenCons "L" (1,6),TokenSymbol "=" (1,8), TokenCons "L" (1,10), TokenCons "P" (1,12),TokenKeyword "expression" (1,14), TokenSymbol "(" (1,25),TokenKeyword "case" (1,26),TokenVar "x" (1,31), TokenKeyword "of" (1,33),TokenSymbol "{" (1,36),TokenCons "True" (1,37), TokenSymbol "->" (1,42),TokenSymbol "(" (1,45),TokenVar "x" (1,46), TokenCons "True" (1,48),TokenSymbol ")" (1,52),TokenSymbol "}" (1,53), TokenSymbol ")" (1,54)] *CHF.Parse.Lexer> lexCHF "expression (return True) >>= \\x -> putMVar x True" [TokenKeyword "expression" (1,1),TokenSymbol "(" (1,12), TokenKeyword "return" (1,13),TokenCons "True" (1,20),TokenSymbol ")" (1,24), TokenSymbol ">>=" (1,26),TokenSymbol "\\" (1,30),TokenVar "x" (1,31), Stand: 9. Juli 2011 20 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy TokenSymbol "->" (1,33),TokenKeyword "putMVar" (1,36),TokenVar "x" (1,44), TokenCons "True" (1,46)] Implementieren Sie Funktionen getLabel :: Token label -> label, die den Label eines Tokens extrahiert und showToken :: Token label -> String, die den zum Token passenden ursprünglichen Text anzeigt. Einige Beipspielaufrufe sind: *CHF.Parse.Lexer> (1,38) *CHF.Parse.Lexer> "x" *CHF.Parse.Lexer> "letrec" *CHF.Parse.Lexer> (20,20) getLabel (TokenVar "x" (1,38)) showToken (TokenVar "x" (1,38)) showToken (TokenKeyword "letrec" (20,20)) getLabel (TokenKeyword "letrec" (20,20)) J 3.2 Parsen mit Happy Ziel des Parsens ist es, anhand einer Grammatik die Gültigkeit der Eingaben (Datentypdefinitionen und Ausdruck) zu erkennen und diese als Syntax- bzw. Parsebaum darzustellen. Einen Parser per Hand zu implementieren ist eher kompliziert. Daher bietet es sich an, einen Parsergenerator zu verwenden. Dieser erstellt anhand einer Parserdefinitionsdatei automatisch einen Parser. In Haskell ist happy1 der wohl bekannteste Parsergenerator. In der Datei CHF/Parse/Parser.ly befindet sich die Parserdefinition aus der happy die Datei CHF/Parse/Parser.hs erstellen wird, die das Modul CHF.Parse.Parser darstellt und insbesondere die Funktionen parseCHF :: String -> ParserOutput parse :: [TokenType] -> ParserOutput exportieren. Die Funktion parse ist der eigentliche Parser, der die Ausgabe des Lexers als Eingabe erhält und ein Parseergebnis liefert (den Typ ParserOutput erläutern wir im Anschluss). Die Funktion parseCHF verknüpft schon den Parser mit dem Lexer und erwartet daher den Quelltext als Eingabe. Die Implementierung von parseCHF ist: > parseCHF inp = parse $ (lexCHF "data Unit = Unit\n") ++ lexCHF inp Neben dem eigentlich Quelltext wird an dieser Stelle die Datentypdefintion für Unit hinein „geschmuggelt“. 1 http://haskell.org/happy D. Sabel, FP-PR, SoSe 2011 21 Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen 3.2.1 Ausgabe des Parsers Wir betrachten nun zunächst die Ausgabe des Parsers, also den Haskelldatentyp, der das Parseergebnis bei erfolgreichem Parsen darstellen soll (diese Definitionen befinden sich in Parser.ly): > type ParserOutput = ParseTree () ConsName VarName > data ParseTree a cname vname = > ParseTree [TDef cname cname] (Expr a cname vname) > deriving(Eq,Show) > type ConsName = (SourceMark,String) > type VarName = (SourceMark,String) ParserOutput ist ein ParseTree, wobei ein ParseTree im Grunde ein Paar ist, bestehend aus einer Liste von Typdefinitionen und einem Audruck (das passt gerade zum Quelltext). Für Konstrukturnamen wird dabei der Typ ConsName verwendet, der neben dem eigentlichen Namen noch die Markierung im Quelltext (Zeile,Spalte) mit abspeichert, für Variablennamen wird der Typ VarName verwendet, der neben dem Variablennamen noch die Position im Quelltext speichert. Der Sinn dabei ist, auch später noch nach dem Parsen einigermaßen sinnvolle Fehlermeldungen ausgeben zu können. Es fehlt noch die Defintion der Typen TDef und Expr. Diese sind im Modul CHF.CoreL.Expression definiert. Wir erörtern zunächst den Expr-Typ: > data Expr label cname v = > Var v > | Lam v (Expr label cname v) > | App (Expr label cname v) (Expr label cname v) > | Seq (Expr label cname v) (Expr label cname v) > | Cons (Either MAction cname) [Expr label cname v] > | Case (Expr label cname v) [CAlt label cname v] > | Letrec [Binding label cname v] (Expr label cname v) > | Label label (Expr label cname v) > deriving(Eq,Show) > data MAction = Fork | Return | Take | Put | New | Bind > deriving(Eq,Show) Stand: 9. Juli 2011 22 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy > data CAlt label cname v = > CAlt cname [v] (Expr label cname v) > deriving(Eq,Show) > data Binding label cname v = > v :=: (Expr label cname v) > deriving(Eq,Show) Der Datentyp Expr ist polymorph über einer beliebigen Markierung label, dem Typ der Konstruktornamen consname und dem Typ der Variablennamen v definiert. Wir erörtern, wie CHF-Ausdrücke mithilfe der einzelnen Konstruktoren dargestellt werden. • Var v dient zur Darstellung einer Variablen, z.B. soll x später durch Var "x", bzw. mit Positionsmarkierung als Var ((1,1),"x") dargestellt werden. • Lam v e stellt eine Abstraktion dar, d.h. λx → e wird zu Lam "x" e. • App e1 e2 stellt eine Anwendung dar, d.h. (e1 e2 ) wird dargestellt durch App e1 e2 . • Seq e1 e2 stellt einen seq-Ausdruck dar, d.h. seq e1 e2 wird dargestellt durch Seq e1 e2 • Cons c [args] stellt entweder eine Konstruktorapplikation oder einen (gesättigten) monadischen Operator dar. Diese Doppelt-Verwendung wird später nützlich sein, da in der abstrakten Maschine die monadischen Operationen teilweise wie Konstruktoren behandelt werden. Zur Unterscheidung, zwischen Datenkonstruktoren und Monadischen Operatoren wird der Datentyp Either verwendet2 . Normale Konstruktoranwendungen werden durch Right dargestellt, d.h. (ci e1 . . . en ) wird dargestellt durch Cons (Right "c_i") [e1,...,en], wobei wir am Anfang anstelle von "c_i" den Konstruktornamen zusammen mit seiner Position speichern, also z.B. ((1,4),"c_i"). Monadische Aktionen werden durch Left angewendet auf die entsprechende Aktion dargestellt. Für die Aktionen ist der Datentyp MAction vordefiniert, wobei Fork gerade forkIO, Return gerade return, Take gerade takeMVar, Put gerade putMVar, New gerade 2 Dieser ist in Haskell vordefiniert als data Either a b = Left a | Right b D. Sabel, FP-PR, SoSe 2011 23 Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen newMVar und Bind gerade >>= darstellt. Z.B. wird e1 >>= e2 dargestellt als Cons (Right Bind) [e1,e2] und putMVar e1 e2 wird dargestellt als Cons (Right Put) [e1,e2]. • Case e [alt] stellt gerade einen case-Ausdruck dar, wobei [alt] die Liste der case-Alternativen ist. Diese werden durch den Typ CAlt dargestellt. Eine Alternative ((c x1 . . . xn ) → e) wird daher dargestellt durch CAlt "c" [x1,...,xn] e. Wir betrachten zwei Beispiele: Der Ausdruck case e of {True → False; False → True} wird dargestellt durch (ohne Positionsmarkierungen): Case e [CAlt "True" [] (Cons (Right "False") []) ,CAlt "False" [] (Cons (Right "True") [])] Der Ausdruck case e of {(ConsBool y ys) → return ys; NilBool → return e} wird dargestellt durch: (Case e [CAlt "ConsBool" ["y","ys"] (Cons (Left Return) ["ys"]) ,CAlt "NilBool" [] (Cons (Left Return) [e]]) • Letrec binds e dient zur Darstellung von letrec-Ausdrücken. Hierbei ist binds eine Liste von Bindungen, wobei eine Bindung durch den Typ Binding implementiert ist, die einen infix-Konstruktor :=: zur Verfügung stellt. z.B. wird letrec x1 = e1 , . . . , xn = en in e dargestellt als: (Letrec ["x1" :=: e1, ..., "xn" :=: en] e) • Label label e dient dazu einen beliebigen Unterausdruck mit einer Markierung zu versehen. Während des Parsens werden wir dieses Konstrukt nicht benutzen, allerdings später während dem Typcheck, um Typen von Unterausdrücken zu speichern. Die erste Komponente von ParseTree ist eine Liste von Datentypdefinitionen vom Typ TDef, der Parser übersetzt die data-Anweisungen in diese Liste. Der Typ TDef ist definiert als: Stand: 9. Juli 2011 24 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy > data TDef tname cname = TDef tname [(cname,Type tname)] > > deriving(Eq,Show) > data Type tname = > TC tname > | (Type tname) :->: (Type tname) > | TVar String > | TIO (Type tname) > | TMVar (Type tname) > deriving(Ord,Eq,Show) TDef ist polymorph über den Namen der Typkonstruktoren tname und den Namen der Datenkonstruktoren cname definiert. Ein Objekt vom Typ TDef stellt genau eine komplette data-Anweisung dar. Das erste Argument ist der definierte Typ, anschließend folgt eine Liste mit Elementen der Form (Konstruktorname, Typ des Konstruktors). Der Typ ist dabei durch den Datentyp Type dargestellt: • TC tname stellt einen Typkonstruktor dar, z.B wird Bool als TC "Bool" dargestellt. • t1 :->: t2 stellt einen Funktionstypen dar, d.h. den Typ t1 → t2 . • TIO t stellt einen IO-Typen dar. z.B, wird IO Bool als TIO (TC "Bool") dargestellt. • TMVar stellt einen MVar-Typen dar, z.B. wird MVar (Bool -> ListBool) durch TMVar (TC "Bool" :->: TC "ListBool") dargestellt. • TVar stellt eine Typvariable dar. Diese können im Quelltext nicht auftreten, werden aber beim Typcheck benötigt. Wir geben noch ein vollständiges Beispiel an: Wenn die Eingabe ist data Bool = True | False data ListBool = NilBool | ConsBool Bool ListBool expression (seq True True) D. Sabel, FP-PR, SoSe 2011 25 Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen So liefert der Parser (mit allen Markierungen): ParseTree [TDef ((1,6),"Bool") [(((1,13),"True"),TC ((1,6),"Bool")), (((2,13),"False"),TC ((1,6),"Bool"))], TDef ((3,6),"ListBool") [(((3,17),"NilBool"),TC ((3,6),"ListBool")), (((4,17),"ConsBool"), TC ((4,26),"Bool") :->: (TC ((4,31),"ListBool") :->: TC ((3,6),"ListBool")))], TDef ((1,6),"Unit") [(((1,13),"Unit"),TC ((1,6),"Unit"))] ] (Seq (Cons (Right ((7,6),"True")) []) (Cons (Right ((7,11),"True")) []) ) Beachte, dass die Typdefinition für Unit automatisch hinzugefügt wurde. 3.2.2 Die Parserdefinition Die Parserdefinition ist größtenteils in der Datei Parser.ly vorgegeben, da es ziemlich aufwändig ist, eine Grammatik zu finden, die frei von Konflikten3 ist. Allerdings müssen beim Parsen noch einige zusätzliche Überprüfungen durchgeführt werden, die noch implementiert werden müssen. Wir betrachten zunächst die Tokendefinition des Parsers, diese bildet einzelnen Token auf „interne Symbole“ ab. Diese internen Symbole werden dann in der eigentlichen kontextfreien Grammatik verwendet: > > > > > > > > > > > 3 %token var cons ’|’ ’\\’ ’>>=’ ’;’ ’=’ ’->’ ’(’ ’{’ { { { { { { { { { { TokenVar _ _ } TokenCons _ _ } TokenSymbol "|" _ } TokenSymbol "\\" _ } TokenSymbol ">>=" _ } TokenSymbol ";" _ } TokenSymbol "=" _ } TokenSymbol "->" _ } TokenSymbol "(" _ } TokenSymbol "{" _ } Genauer gesagt: eine Grammatik die eindeutig und nicht mehrdeutig ist. Stand: 9. Juli 2011 26 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy > > > > > > > > > > > > > > ’)’ ’}’ ’case’ ’of’ ’letrec’ ’in’ ’seq’ ’newMVar’ ’putMVar’ ’takeMVar’ ’forkIO’ ’return’ ’data’ ’expr’ { { { { { { { { { { { { { { TokenSymbol TokenSymbol TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword TokenKeyword ")" _ } "}" _ } "case" _ } "of" _ } "letrec" _ } "in" _ } "seq" _ } "newMVar" _ } "putMVar" _ } "takeMVar" _ } "forkIO" _} "return" _ } "data" _ } "expression" _ } Beachte, dass das TokenUnknown nicht abgebildet wird, da es in der Grammatik nicht vorkommt, und daher immer zu einem Fehler führt. Anschließend folgt eine Liste der Assoziativitäten und Prioritäten der Konstrukte, wobei sich die Prioritäten durch die Reihenfolge in der Aufzählung ergeben: > > > > > > > > > > > > > %right ’->’ %right ’>>=’ %left ’seq’ %nonassoc ’in’ %nonassoc ’of’ %nonassoc ’case’ %nonassoc ’letrec’ %nonassoc ’forkIO’ %nonassoc ’takeMVar’ %nonassoc ’putMVar’ %nonassoc ’return’ %nonassoc ’newMVar’ %% Schließlich folgt die eigentliche Grammatik. Beachte, dass diese “so kompliziert” ist, damit der Programmierer nicht alle Klammern angeben muss, z.B. wird (\x -> \y -> x y) (\z -> z) True erkannt, obwohl nicht alle Anwendungen explizit geklammert sind. Das Startsymbol der Grammatik D. Sabel, FP-PR, SoSe 2011 27 Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen ist SOURCECODE, in geschweiften Klammern steht hinter jeder Produktion, was mit dem Ergebnis gemacht werden soll. Z.B. wird nach dem Parsen der Typdefinitionen (Nichtterminal TDEFS), das Ergebnis an die Funktion checkTDEFS übergeben, um weitere Tests auszuführen. > SOURCECODE :: {ParserOutput} > SOURCECODE : EXPR { checkParseTree $ ParseTree [] $1 } > | TDEFS EXPR { checkParseTree $ ParseTree $1 $2 } Grammatik f"ur die Datentypdefinitionen: > > > > > > > > > > > > TDEFS : TDEFSIT TDEFSIT : TDEF | TDEF TDEFSIT TDEF : ’data’ cons ’=’ CDEFS { { { { CDEFS { { { { { { CDEF TYPE > TK > : | : | : | CDEF CDEF ’|’ CDEFS cons cons TYPE TK TK TYPE : cons | ’(’ TK ’->’ TK ’)’ checkTDEFS $1 } [$1] } $1:$2 } (TDef (mkCons $2) (listsToTypes $4 (TC $ mkCons $2))) } [$1] } $1:$3 } (mkCons $1,[]) } (mkCons $1,$2) } [$1] } $1:$2 } { TC $ mkCons $1 } { $2 :->: $4 } Grammatik f"ur Ausdr"ucke: > EXPR > EXPR > REXPR > > > :: {Expr () ConsName VarName} : ’expr’ REXPR : ’letrec’ BINDS ’in’ REXPR | ’\\’ var ’->’ REXPR | REXPR ’>>=’ REXPR | AEXPR { { { { { $2 } checkBinds $4 $2 $1 } Lam (mkVar $2) $4 } Cons (Left Bind) [$1,$3] } $1 } > AEXPR > > > : | | | { { { { $1 } Cons (Right (mkCons $1)) $2 } mkAPP $1 $2} Cons (Right (mkCons $1)) [] } > BINDS > : BIND | BIND ’;’ BINDS Stand: 9. Juli 2011 IEXPR cons CONSARGS IEXPR CONSARGS cons { [$1] } { $1:$3 } 28 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy > BIND : var ’=’ REXPR > IEXPR : > | > > > | > | > > > | > | > > > | > > > | > | > > > | > | > > > | > | > > > | > | > | > ALTS : > | > ALT : > > > PAT : > | > VARARGS > > > > > { (mkVar $1) :=: $3 } ’seq’ IEXPR IEXPR ’(’ ’seq’ cons cons ’)’ { Seq $2 $3} { Seq (Cons (Right (mkCons $3)) []) (Cons (Right (mkCons $4)) [])} ’newMVar’ IEXPR { Cons (Left New) [$2] } ’(’ ’newMVar’ cons ’)’ { Cons (Left New) [(Cons (Right (mkCons $3)) [])] } ’putMVar’ IEXPR IEXPR { Cons (Left Put) [$2,$3] } ’(’ ’putMVar’ cons IEXPR ’)’ { Cons (Left Put) [(Cons (Right (mkCons $3)) []),$4] } ’(’ ’putMVar’ IEXPR cons’)’ { Cons (Left Put) [$3,(Cons (Right (mkCons $4)) [])] } ’takeMVar’ IEXPR { Cons (Left Take) [$2] } ’(’ ’takeMVar’ cons ’)’ { Cons (Left Take) [(Cons (Right (mkCons $3)) [])] } ’return’ IEXPR { Cons (Left Return) [$2] } ’(’ ’return’ cons ’)’ { Cons (Left Return) [(Cons (Right (mkCons $3)) [])] } ’forkIO’ IEXPR { Cons (Left Fork) [$2] } ’(’ ’forkIO’ cons ’)’ { Cons (Left Fork) [(Cons (Right (mkCons $3)) [])] } ’(’ REXPR ’)’ { $2 } var { Var (mkVar $1) } ’case’ REXPR ’of’ ’{’ ALTS ’}’ { checkAlts $1 $2 $5 } ALT { [$1] } ALT ’;’ ALTS { $1:$3 } PAT ’->’ REXPR { checkAlt $2 (CAlt (fst $1) (snd $1) $3) } cons { (mkCons $1,[]) } ’(’ cons VARARGS ’)’ { (mkCons $2,$3) } : var { [mkVar $1] } | var VARARGS { (mkVar $1):$2} CONSARGS : | | | IEXPR IEXPR CONSARGS cons CONSARGS cons D. Sabel, FP-PR, SoSe 2011 { { { { 29 [$1] } $1:$2} Cons (Right $ mkCons $1) []:$2} [Cons (Right $ mkCons $1) []]} Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen Die Funktion checkTDEFS prüft, ob alle geparsten Typkonstruktoren und Datenkonstruktoren in den data-Definitionen stimmig sind: Typen und Datenkonstruktoren werden nur einmal definiert, verwendete Datenkonstruktoren und Typen sind auch definiert. Die Konstruktion der Typen aus der Definition heraus, wird durch die Funktion listToTypes erledigt. Diese Funktionen sind bereits vorgegeben in Parser.ly. Beispiele, für checkTDEFS einen Fehler während des Parsens generiert, sind z.B. parseCHF "data ListBool = NilBool | ConsBool Bool ListBool expression NilBool" *** Exception: type "Bool" not defined Zeile :1 Spalte: 36 parseCHF "data Bool = True | False data NochmalBool = True | False expression True" ParseTree *** Exception: data constructor False already used Zeile: 1 Spalte: 53 Die Funktionen mkCons und mkVar erstellen aus dem Token einen entsprechenden Konstruktor oder eine Variable vom Expr-Typ, wobei diese mit Positionsmarkierungen versehen sind. Beim Parsen einer case-Alternative, eines case-Ausdrucks und eines letrec-Ausdrucks sind weitere Tests nötig (die Funktionen checkAlt, checkAlts und checkBinds, diese sollen in der nächsten Aufgabe implementiert werden.) I Aufgabe 2. Implementieren Sie im vierten Teil der Parser-Spezifikation in der Datei Parser.ly die folgenden Funktionen: • checkAlt :: TokenType -> CAlt () ConsName VarName -> CAlt () ConsName VarName Die das Token einer case-Alternative, und die case-Alternative selbst erhält, und prüft, ob alle Variablen des Patterns verschieden sind. Ist dies nicht der Fall, so wird mittels error eine Fehlermeldung ausgedruckt, die möglichst genau angibt, wo und warum der Fehler aufgetreten ist (diese Information finden Sie z.B. im Token). Sind alle Variablen verschieden, so wird die Alternative als Ausgabe zurück geliefert. Ein Beispiel ist die Eingabe data Bool = True | False data ListBool = NilBool | ConsBool Bool ListBool expression case NilBool of {(ConsBool y y) -> True; NilBool -> False} Wendet man parseCHF auf diese Eingabe an, so sollte durch checkAlt der Fehler bemerkt werden, dass y doppelt verwendet wird, und eine Fehlermeldung der Form Stand: 9. Juli 2011 30 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy *** Exception: repeated variable "y"in a pattern of a case alternative before Zeile: 4 Spalte: 34 generiert werden. • checkAlts :: TokenType -> (Expr () ConsName VarName) -> [CAlt () ConsName VarName] -> (Expr () ConsName VarName) die das Token zu einem case-Ausdruck, einen Ausdruck e und caseAlternativen alts erhält. Daraus konstruiert checkAlts den case-Ausdruck case e of alts, wobei vorher geprüft werden muss, ob doppelte Alternativen (also Alternativen für den gleichen Konstruktor) vorhanden sind. Ist dies der Fall, so soll mittels error eine aussagekräftige Fehlermeldung ausgegeben werden. Ein Beispielprogramm ist data Bool = True | False expression case True of {False -> True; False -> True} Der Aufruf von parseCHF soll mittels checkAlts die folgende Fehlermeldung generieren: *** Exception: multiple case-alternatives for constructor "False" Zeile: 3 Spalte: 2 • checkBinds :: Expr () ConsName VarName -> [Binding () ConsName VarName] -> TokenType -> Expr () ConsName VarName die einen Ausdruck e, letrec-Bindungen Env und das Token des zugehörigen letrec-Ausdrucks erhält und den Ausdruck letrec Env in e erzeugt, wobei zuvor überprüft werden muss, ob alle Bindungsvariablen der Bindungen verschieden sind. Ist dies der Fall, so soll mit error ein aussagekräftiger Fehler erzeugt werden. Ein Beispiel ist: parseCHF "expression letrec x = x; x = y in x" *** Exception: multiple bindings in letrec expression for variable ’x’ Zeile: 1 Spalte: 12 J D. Sabel, FP-PR, SoSe 2011 31 Stand: 9. Juli 2011 3 Teil 1: Lexen und Parsen Die Parserdefinition enthält noch einige weitere nützliche Funktionen, wie z.B. happyError, die immer aufgerufen wird, sobald ein Parse-Fehler auftritt. Wir gehen nicht weiter auf diese Funktion ein. Der so vom Parser gelieferte Syntaxbaum ist unter Umständen immer noch nicht syntaktisch richtig. Dies liegt daran, dass manche syntaktische Bedingung nicht mehr mit einer kontextfreien Grammatik ausgedrückt werden kann. Zwei wesentliche Fehler, die noch nach dem Parsen in Ausdrücken vorhanden sein können, sind: • Im Ausdruck wird ein Konstruktor verwendet, der in den DatentypDefinitionen nicht definiert wurde. Betrachte z.B. den Quelltext expression case True of {True -> False; False -> True} Die Konstruktoren True und False werden verwendet, obwohl sie gar nicht definiert wurden. Man kann diesen Test jedoch nicht mit der kontextfreien Grammatik des Parser ausdrücken, da die dataAnweisungen selbst Teil der Grammatik sind. • Im Ausdruck können die Konstruktoren mit falscher Stelligkeit verwendet werden, z.B. könnte im Ausdruck (True False) stehen, obwohl True ein nullstelliger Konstruktor ist und daher keine Argumente erwartet Der zweite Fehler wird im Rahmen des Typchecks im nächsten Teil erkannt. Der erste Fehler wird in der nächsten Aufgabe bearbeitet: I Aufgabe 3. Implementieren Sie in der Parser-Definition Parser.ly eine Funktion: checkParseTree :: ParserOutput -> ParserOutput, die den geparsten Ausdruck rekursiv durchläuft und für alle dort auftretenden Konstruktoren (auch in den Pattern der case-Alternativen) prüft, ob die Konstruktornamen in den Typdefinitionen (erste Komponente von ParseTree) definiert werden. Ist dies der Fall, so wird der ParseTree unverändert zurückgegeben. Anderenfalls soll eine aussagekräftige Fehlermeldung (mit Position des falschen Namens) generiert werden. Ein Beispiel ist: parseCHF "expression True" *** Exception: Constructor "True" not defined Zeile: 1 Spalte: 12 J Stand: 9. Juli 2011 32 D. Sabel, FP-PR, SoSe 2011 3.2 Parsen mit Happy I Aufgabe 4. Erstellen Sie mit happy den Parser, indem Sie happy -iinfo.txt Parser.ly aufrufen. Dies erstellt die Haskell-Quelltext-Datei Parser.hs sowie eine Datei info.txt die Auskunft über die Zustände des erstellten Shift-Reduce-Parsers gibt. Schauen Sie sich den Inhalt von info.txt an, um die Wirkungsweise des Parsers (etwas) zu verstehen. Testen Sie anschließend den Parser mit einigen Eingaben. Welche Ausdrücke können geparst werden? Welche Klammern kann der Benutzer weglassen, welche J nicht? D. Sabel, FP-PR, SoSe 2011 33 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax 4.1 Das Typsystem Für einen CHF-Ausdruck e schreiben wir e :: τ , wenn e den Typ τ hat. In Abbildung 4.1 sind Typisierungsregeln für CHF angegeben. Hierbei ist Γ eine Typumgebung, die die Typen von Variablen festhält, d.h. Γ ist eine Menge der Form {x1 :: τ1 , . . . , xn :: τn }. Die Notation Γ ∪ S meint, dass wir zu Γ neue Typen für neue Variablen hinzufügen, d.h. die Mengen der Variablen in Γ und S sind stets disjunkt. Die Notation Γ ` e :: τ bedeutet, dass man den Ausdruck e mit dem Typ τ für die Typumgebung Γ typisieren kann. Die Bruchstrichnotation in den Regeln ist so zu deuten: Voraussetzung Konsequenz D.h. man muss stets die Voraussetzung zeigen, um die Konsequenz schließen zu dürfen. Umgekehrt kann man daraus auch mehr oder weniger direkt den Algorithmus zum Type-Checking ablesen: Um einen Ausdruck zu typisieren, zerlegt man diesen stückweise anhand seiner Syntax und baut damit implizit den Herleitungsbaum von unten nach oben auf. D. Sabel, FP-PR, SoSe 2011 Stand: 9. Juli 2011 4.1 Das Typsystem Γ ` e :: τ Γ ` e1 :: IO τ1 , Γ ` return e :: IO τ Γ ` e :: MVar τ Γ ` e2 :: τ1 → IO τ2 Γ ` e1 >>= e2 :: IO τ2 Γ ` e1 :: MVar τ, Γ ` takeMVar e :: IO τ Γ ` forkIO e :: IO τ Γ ` e2 :: τ Γ ` e :: τ Γ ` putMVar e1 e2 :: IO () ∀i : Γ ` ei :: τi und c :: τ1 → . . . → τn → τn+1 Γ ` newMVar e :: IO (MVar τ ) Γ ` e1 :: τ1 → τ2 , Γ ` (c e1 . . . ear(c) ) :: τn+1 Γ ` e2 :: τ1 Γ ` (e1 e2 ) :: τ2 Γ ` e1 :: τ1 , Γ ` e2 :: τ2 τ1 = τ3 → τ4 oder τ1 = T Γ ∪ {x :: τ1 } ` e :: τ2 Γ ` (λx → e) :: τ1 → τ2 Γ ` e :: IO τ Γ ∪ {x :: τ } ` x :: τ Γ ` (seq e1 e2 ) :: τ2 Γ ` e :: T, ∀i : Γ ∪ {x1,i :: τ1,i , . . . xni ,i :: τni ,i } ` (ci x1,i . . . xni ,i ) :: T, ∀i : Γ ∪ {x1,i :: τ1,i , . . . xni ,i :: τni ,i } ` ei :: τ2 Γ ` (caseT e of(c1 x1,1 . . . xn1 ,1 → e1 ) . . . (cm x1,m . . . xnm ,m → em )) :: τ2 ∀i : Γ ∪ {x1 :: τ1 , . . . xn :: τn } ` ei :: τi , Γ ∪ {x1 :: τ1 , . . . xn :: τn } ` e :: τ Γ ` (letrec x1 = e1 , . . . xn = en in e) :: τ Abbildung 4.1: Typisierungsregeln Wir beschreiben kurz die Regeln: • Die ersten sechs Regeln dienen der Typisierung von monadischen Ausdrücken. • Die siebte Regel dient der Typisierung einer Konstruktoranwendung. Hierbei muss man den Typ des Konstruktors (also τ1 → . . . → τn ) bereits kennen. Für unseren Typcheck ist dies kein Problem, da der Parsebaum bereits die Typen der durch die data-Anweisungen definierten Konstruktoren kennt. • Die achte Regel dient der Typisierung von Anwendungen. • Abstraktionen werden mit der neunten Regel typisiert. Will man λx → e typisieren, so muss man (rekursiv) den Rumpf von e typisieren. In e kann x als freie Variable vorkommen. Deshalb wird in die Typumgebung Γ ein Typ für x hinzugefügt. D. Sabel, FP-PR, SoSe 2011 35 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax • Die zehnte Regel ist ein Axiom (die Voraussetzung ist leer). Sie dient der Typisierung von Variablen, wobei diese geschieht, indem einfach der entsprechende Typ in der Typumgebung nachgeschaut wird. • Die elfte Regel dient der Typisierung von seq-Ausdrücken, wobei die beiden Beschränkungen τ1 = τ3 → τ4 oder τ1 = T gerade ausdrücken, dass der Typ τ1 des ersten Arguments von seq kein IO-Typ und auch kein MVar-Typ sein darf. • Die zwölfte Regel dient der Typisierung von case-Ausdrücken. Wir erläutern die drei Zeilen in der Voraussetzung: Die erste Zeile besagt, dass der T -Index in caseT gerade zum Typ des Ausdrucks e passen muss und dass e selbst typisierbar sein muss. In der Implementierung werden wir den Abgleich zwischem dem Index und dem Typ von e nicht durchführen, da wir keinen T -Index in case-Ausdrücken verwenden. Für die zweite und die dritte Zeile wird Γ jeweils um Typen für die Pattern-Variablen einer case-Alternativen erweitert und schließlich werden die Pattern (Zeile 2) und die rechten Seiten der Alternativen getypt. Durch Verwendung der gleichen Symbole (Pattern müssen alle den Typ T erhalten, die rechten Seite müssen alle den Typ τ2 erhalten) wird sichergestellt, dass alle rechten Seiten den gleichen Typ haben, und dass alle Pattern den selben Typ wie e haben. • Die letzte Regel dient der Typisierung letrec-Ausdrücken. Hierbei ist die Behandlung der Variablen zu beachten: Da das letrec rekursiv sein darf, können die Variablen x1 , . . . , xn in e1 , . . . , en und e auftauchen. Da Γ für die Typisierung all dieser Unterausdrücke um die gleichen Typannahmen für alle xi erweitert wird, wird sichergestellt, dass jedes xi stets mit dem gleichen Typ typisiert wird. Für den eigentlichen Typisierungsalgorithmus wird mit der Annahme Γ = ∅ gestartet, da wir nur geschlossene Ausdrücke als Programme betrachten. Der Parser prüft allerdings nicht, ob ein Ausdruck keine freien Variablen enthält. Typisiert man einen Ausdruck der freie Variablen enthält (z.B. λx → y) beginnend mit Γ = ∅, so stößt man während der Typisierung auf die freie Variable, d.h. man möchte das Axiom für Variablen anwenden, aber für die Variable befindet sich kein Eintrag in Γ. In diesem Fall soll der Typchecker eine Fehlermeldung liefern, die die Position der freien Variablen ausgibt und erläutert, dass es sich um eine freie Variable handelt. Wir geben einige Beispiele für Typisierungen an. Stand: 9. Juli 2011 36 D. Sabel, FP-PR, SoSe 2011 4.1 Das Typsystem Beispiel 4.1.1. Wir nehmen an, dass die Datentypen Bool und ListBool wie vorher definiert sind. Der Ausdruck λx → x lässt sich z.B. mit Bool → Bool typisieren: x :: Bool ` x :: Bool ∅ ` λx → x :: Bool → Bool Der Ausdruck λx → x lässt sich ebenso mit ListBool → ListBool typisieren: x :: ListBool ` x :: ListBool ∅ ` λx → x :: ListBool → ListBool Der Ausdruck ((λx → λy → x) True False) lässt sich mit Bool typisieren: {x :: Bool, y :: Bool} ` y :: Bool {x :: Bool} ` (λy → x) :: Bool → Bool True :: Bool ∅ ` (λx → λy → x) :: Bool → Bool → Bool ∅ ` True :: Bool ∅ ` ((λx → λy → x) True) :: Bool → Bool False :: Bool ∅ ` False :: Bool ∅ ` ((λx → λy → x) True False) :: Bool Der Ausdruck ConsBool True NilBool lässt sich mit ListBool typisieren: True :: Bool ∅ ` True :: Bool NilBool :: ListBool ∅ ` NilBool :: ListBool und ConsBool :: Bool → ListBool → ListBool ∅ ` (ConsBool True NilBool) :: ListBool Die Typisierung der Identitätsfunktion λx → x zeigt ein Problem, das entsteht, wenn man die so formulierten Typisierungsregeln automatisieren will. Man muss den Typ für x raten, um mit der Voraussetzung ∅ ∪ {x :: ?} ` x . . . weiter rechnen zu können. Der Ausweg ist, Typvariablen – also Variablen, die für Typen stehen – zu benutzen. Man nimmt für den Typ von x zunächst eine Variable an und löst später die Bedingungen an die Variable, die entstehen können. D. Sabel, FP-PR, SoSe 2011 37 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax Um dies formal zu fassen erweiteren wir die Typregeln, um eine weitere Komponente E: Hierbei handelt es sich um Gleichungen zwischen Typen (mit Typvariablen). Diese werden bei der Typisierung aufgesammelt und später gelöst. Wir schreiben Γ ` e :: τ, E und meinen damit: In der Typumgebung Γ kann für den Ausdruck e der Typ σ(τ ) hergeleitet werden, wenn σ die Lösung der Gleichungen aus E ist. Da wir nun Typvariablen erlauben, können wir nicht mehr einfach fordern, dass in einer Voraussetzung ein bestimmter Typ stehen muss, dort kann nun stets auch eine Typvariable entstehen, die noch gelöst werden muss. Betrachte, z.B. die Regel für die Anwendung: Ohne Typvariablen konnten wir schreiben: Γ ` e1 :: τ1 → τ2 , Γ ` e2 :: τ1 Γ ` (e1 e2 ) :: τ2 Mit Typvariablen kann nun allerdings der Fall aufreteten, dass der Typ von e1 nicht τ1 → τ2 ist, sondern eine Typvariable ist (die man mit τ1 → τ2 instantiieren dürfte). Dieses Problem wird in den Typregeln durch Verwendung von Typgleichungen umgangen: Γ ` e1 :: τ1 , E1 und Γ ` e2 :: τ2 , E2 . Γ ` (e1 e2 ) :: α, E1 ∪ E2 ∪ {τ1 = τ2 → α} Die Anforderung, dass e1 einen Funktionstyp haben muss, wird nun mit . der neu entstandenen Gleichung τ1 = τ2 → α ausgedrückt. In Abbildung 4.2 sind die Typregeln mit dieser Erweiterung angegeben. Zum Beispiel wird die Identitätsfunktion mit diesen Typregeln wie folgt typisiert: {x :: α} ` x :: α, ∅ ∅ ` λx → x :: α → α, ∅ Dies ergibt einen polymorphen Typ für die Identitätsfunktion, den wir nun mit einer beliebigen Grundsubstitution in einen monomorphen Typ umwandeln können. Für dieses Beispiel entstehen allerdings keine Gleichungen. Wir betrachten als weiteres Beispiel die Typisierung von ((λx → λy → x) True False): Stand: 9. Juli 2011 38 D. Sabel, FP-PR, SoSe 2011 4.1 Das Typsystem Γ ` e :: τ, E Γ ` e1 :: τ1 , E1 und Γ ` e2 :: τ2 , E2 . . Γ ` e1 >>= e2 :: IO α2 , E1 ∪ E2 ∪ {τ1 = IO α, τ2 = α → IO α2 } Γ ` return e :: IO τ, E Γ ` e :: τ, E Γ ` e :: τ, E . Γ ` forkIO e :: τ, E ∪ {τ = IO α} . Γ ` takeMVar e :: IO α, E ∪ {τ = MVar α} Γ ` e1 :: τ1 , E1 und Γ ` e2 :: τ2 , E2 . Γ ` putMVar e1 e2 :: IO (), E1 ∪ E2 ∪ {τ1 = MVar τ2 } Γ ` e :: τ, E Γ ` newMVar e :: IO (MVar τ ), E ∀i : Γ ` ei :: τi , Ei [ . Γ ` (c e1 . . . ear(c) ) :: τn+1 , Ei ∪ {Typ(c) = τ1 → . . . → τn → τn+1 } i Γ ` e1 :: τ1 , E1 und Γ ` e2 :: τ2 , E2 . Γ ` (e1 e2 ) :: α, E1 ∪ E2 ∪ {τ1 = τ2 → α} Γ ` e1 :: τ1 , Γ ` e2 :: τ2 , E . . τ1 = τ3 → τ4 oder τ1 = T Γ ∪ {x :: α} ` e :: τ, E Γ ` (λx → e) :: α → τ, E Γ ∪ {x :: τ } ` x :: τ, ∅ Γ ` (seq e1 e2 ) :: τ2 , E Γ ` e :: τ, E ∀i : Γ ∪ {x1,i :: α1,i , . . . xni ,i :: αni ,i } ` (ci x1,i . . . xni ,i ) :: τi , Ei ∀i : Γ ∪ {x1,i :: α1,i , . . . xni ,i :: αni ,i } ` ei :: τi0 , Ei0 case e of(c1 x1,1 . . . xn1 ,1 → e1 ) [ [ [ . [ . :: α, E ∪ Ei ∪ Ei0 ∪ α = ... Γ` τi ∪ τ = τi0 i i i i (cm x1,m . . . xnm ,m → em ) ∀i : Γ ∪ {x1 :: α1 , . . . xn :: αn } ` ei :: τi , Ei Γ ∪ {x1 :: α1 , . . . xn :: αn } ` e :: τ, E [ [ . Γ ` (letrec x1 = e1 , . . . xn = en in e) :: τ, E ∪ Ei ∪ {αi = τi } i i Abbildung 4.2: Typisierungsregeln mit Gleichungen D. Sabel, FP-PR, SoSe 2011 39 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax {x :: α2 , y :: α3 } ` x :: α2 , ∅ {x :: α2 } ` λy → x :: α3 → α2 , ∅ , ∅ ` (λx → λy → x) :: α2 → α3 → α2 , ∅ ∅ ` True :: Bool, ∅ , . ∅ ` ((λx → λy → x) True) :: α1 , {α2 → α3 → α2 = Bool → α1 } ∅ ` False :: Bool, ∅ . ∅ ` ((λx → λy → x) True False) :: α0 , {α2 → α3 → α2 = Bool → α1 , α1 = Bool → α0 } Nun müsste man die Gleichungen . {α2 → α3 → α2 = Bool → α1 , α1 = Bool → α0 } lösen. Durch Hinschauen erkennt man, dass α2 α3 α0 α1 = Bool = Bool = Bool = Bool → Bool eine Lösung der Gleichungen ist. Wir führen noch die folgende Regel ein, um Typen wirklich herzuleiten: Γ ` e :: τ, E Typherleitung Γ ` σ(e) wenn σ Lösung von E Für unser Beispiel können wir daher schließen . . ∅ ` ((λx → λy → x) True False) :: α0 , {α2 → α3 → α2 = Bool → α1 , α1 = Bool → α0 } ((λx → λy → x) True False) :: Bool 4.1.1 Gleichungen mit Unifikation lösen Um einen Typ mit den eben vorgestellten Typregeln herzuleiten, benötigen wir noch ein Verfahren, um die entstandenen Typgleichungen zu lösen. Dies liefert die sogenannte Unifikation. Sie operiert auf zwei Gleichungsmengen Eg und Eu . Hierbei sind Eu die ungelösten Gleichungen und Eg die gelösten Gleichungen. Der Unifikationsalgorithmus startet mit leerem Eg und mit den zu lösenden Gleichungen in Eu . Der Algorithmus ist beendet, sobald Eu leer ist, oder f ail auftritt. Hierbei bedeutet f ail, dass das Gleichungssystem nicht lösbar ist (die Typisierung daher ebenso fehlschlägt). In jedem Stand: 9. Juli 2011 40 D. Sabel, FP-PR, SoSe 2011 4.1 Das Typsystem Schritt wendet der Algorithmus eine der im folgenden aufgezählten Regeln an. Hierbei bezeichnet E[τ /a], die Gleichungsmenge E in der in allen Gleichungen (in allen Untertermen der linken und rechten Seiten) die Variable α durch den Typ τ ersetzt wurde. Die Unifikationsregeln sind im folgenden aufgelistet, wobei α stets eine Typvariable ist und T, T1 , T2 Typkonstruktoren bezeichnen: • Elim . Eg , {α = α} ∪ Eu Eg , Eu . Eg , {α = τ } ∪ Eu • Solve , falls α nicht in τ vorkommt. . Eg [τ /α] ∪ {α = τ }, Eu [τ /α] • Occ.Check • Orient f ail . , falls α in τ vorkommt und τ 6= α . Eg , {τ = α} ∪ Eu , wenn τ keine Typvariable ist . Eg , {α = τ } ∪ Eu • Decomp.T • FailT . Eg , {α = τ } ∪ Eu . Eg , {T = T } ∪ Eu Eg , Eu . Eg , {T1 = τ } ∪ Eu f ail , falls τ = T2 und T1 6= T2 , τ = IO τ 0 , τ = MVar τ 0 oder τ = τ1 → τ2 . Eg , {IO τ1 = IO τ2 } ∪ Eu • Decomp.IO . Eg , {τ1 = τ2 } ∪ Eu • FailIO . Eg , {IO τ1 = τ2 } ∪ Eu f ail • Decomp.MVar • FailMVar , falls τ2 = T , τ2 = MVar τ 0 oder τ2 = τ1 → τ2 . Eg , {MVar τ1 = MVar τ2 } ∪ Eu . Eg , {τ1 = τ2 } ∪ Eu . Eg , {MVar τ1 = τ2 } ∪ Eu D. Sabel, FP-PR, SoSe 2011 f ail , falls τ2 = T , τ2 = IO τ 0 oder τ2 = τ1 → τ2 41 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax . Eg , {τ1 → τ2 = τ10 → τ20 } ∪ Eu • Decomp.Fn . . Eg , {τ1 = τ10 , τ2 = τ20 } ∪ Eu • FailFn . Eg , {τ1 → τ2 = τ } ∪ Eu f ail , falls τ = T , τ = IO τ 0 oder τ = MVar τ 0 Beispiel 4.1.2. Wir unifzieren die Gleichungen: . . . . {b → c = c → a, b = d → MVar Bool, c = Bool → MVar d, e = a → Bool} Eg = ∅, . . Eu = {b → c = c → a, b = d → MVar Bool, . . c = Bool → MVar d, e = a → Bool} Eg = ∅, . . . Eu = {b = c, c = a, b = d → MVar Bool, . . c = Bool → MVar d, e = a → Bool} . Eg = {b = c}, . . . . Eu = {c = a, c = d → MVar Bool, c = Bool → MVar d, e = a → Bool} . . Eg = {b = a, c = a}, . . . Eu = {a = d → MVar Bool, a = Bool → MVar d, e = a → Bool} . . . Eg = {b = d → MVar Bool, c = d → MVar Bool, a = d → MVar Bool}, . . Eu = {d → MVar Bool = Bool → MVar d, e = (d → MVar Bool) → Bool} . . . Eg = {b = d → MVar Bool, c = d → MVar Bool, a = d → MVar Bool}, . . . Eu = {d = Bool, MVar Bool = MVar d, e = (d → MVar Bool) → Bool} . . . Eg = {b = Bool → MVar Bool, c = Bool → MVar Bool, a = Bool → MVar . . Eu = {MVar Bool = MVar Bool, e = (Bool → MVar Bool) → Bool} . . . Eg = {b = Bool → MVar Bool, c = Bool → MVar Bool, a = Bool → MVar . . Eu = {Bool = Bool, e = (Bool → MVar Bool) → Bool} . . . Eg = {b = Bool → MVar Bool, c = Bool → MVar Bool, a = Bool → MVar . Eu = {e = (Bool → MVar Bool) → Bool} . . . Eg = {b = Bool → MVar Bool, c = Bool → MVar Bool, a = Bool → MVar . e = (Bool → MVar Bool) → Bool}, Eu = ∅ . Bool, d = Bool}, . Bool, d = Bool}, . Bool, d = Bool}, . Bool, d = Bool, Die Substitution (genannt: der Unifikator) lässt sich nun ablesen als {b 7→ Bool → MVar Bool, c 7→ Bool → MVar Bool, a 7→ Bool → MVar Bool, d 7→ Bool, e 7→ (Bool → MVar Bool) → Bool}, I Aufgabe 5. Im Modul CHF.SemAna.TypeCheck ist der Typ TypeEquation für Stand: 9. Juli 2011 42 D. Sabel, FP-PR, SoSe 2011 4.1 Das Typsystem Typgleichungen definiert als Paar von Typen: > type TypeEquation tname = (Type tname, Type tname) Der Typ Type wurde bereits im Modul CHF.CoreL.Language definiert. Implementieren Sie in diesem Modul die Unifikation auf Typgleichungen: Implementieren Sie eine Funktion unify :: [TypeEquation ConsName] -> Either String [TypeEquation ConsName] die Typgleichungen als Eingabe erhält und die Gleichungen unifiziert und entweder Right loesung liefert, wobei loesung die gelösten Gleichungen sind, oder Left fehler liefert, wobei fehler ein String ist, der Auskunft über den bei der Unifikation aufgetretenen Fehler gibt. Zur Implementierung von unify ist es hilfreich einige Hilfsfunkion zu definieren: • Eine Variante von unify, die als Eingaben die gelösten und die ungelösten Gleichungen erhält. • Eine Funktion, die die Substitution E[τ /α] auf Typgleichungen durchführt. • Eine Funktion, die testet, ob eine Typvariable α in einem Typ τ vorkommt. J 4.1.2 Implementierung des Typchecks In der nächsten Aufgabe soll der Typcheck entsprechend den Typisierungsregeln aus Abbildung 4.2 implementiert werden. Die Eingabe des Typcheckers ist ein Ausdruck vom Typ Expr. Da wir uns zwischendrin die Typen von Unterausdrücken „merken“ müssen, verwenden wir den Konstruktor Label, um dort die Typen der Unterausdrücke zu speichern, d.h. in einem ein voll typisierten Ausdruck, ist jede „Stufe“ des Ausdrucks durch ein Label verpackt. Z.B. erhält der Ausdruck Lam ((1,13),"x") (Var ((1,18),"x")) mit Typen versehen die Form Label (TVar "t1" :->: TVar "t1") (Lam ((1,13),"x") (Label (TVar "t1") (Var ((1,18),"x")))) D. Sabel, FP-PR, SoSe 2011 43 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax Die Idee des Typisierungsalgorithmus folgt zunächst genau den Typisierungsregeln: Der Ausdruck wird rekursiv abgearbeitet und typisiert, die Gleichungen werden erzeugt und aufgesammelt, anschließend werden die Gleichungen unifiziert und die entstande Lösung wird auf den markierten Ausdruck angewendet (bzw. eine Fehlermeldung wird erzeugt, falls ein Fehler auftritt). Im Modul CHF.SemAna.TypeCheck ist der Typ TypeOfCons definiert als > type TypeOfCons = [(String, Type ConsName)] Er stellt die Abbildung (als Liste von Paaren) von Konstruktornamen auf den Typ des Konstruktors dar. Zusätzlich sind bereits zwei Hilfsfunktionen definiert: • mkTypeOfConsList :: [TDef ConsName ConsName] -> TypeOfCons erstellt aus der TDef-Liste die TypeOfCons-Liste • getTypeOfCons :: TypeOfCons -> String -> Maybe (Type ConsName) schaut den Typ eines Konstruktors in der TypeOfCons-Liste nach. Falls er existiert wird Just t zurück gegeben, wobei t der Typ des Konstruktors ist. Existiert der Konstruktor nicht (sollte nicht vorkommen), so wird Nothing zurück gegeben. Diese Funktion kann in der Typisierungsregel für Konstruktoranwendungen verwendet werden, um Typ(c) zu berechnen. I Aufgabe 6. Im Modul CHF.SemAna.TypeCheck ist der Typ TypeEnvironment zur Darstellung von Γ definiert als: > type TypeEnvironment = [(String,Type ConsName)] Er stellt Γ als Liste von Paaren (Variablenname, Typ der Variablen) dar. Implementieren Sie dort die Funktion typecheck: > typecheck :: > TypeOfCons -> -> [String] -> -> TypeEnvironment -> -> (Expr () ConsName VarName) -> -> ([String], > [TypeEquation ConsName], > Expr (Type ConsName) ConsName Stand: 9. Juli 2011 44 Liste der Konstruktortypen frische Namen Gamma Ausdruck -- verbleibende Namen -- Gleichungen E VarName) -- Ausdruck mit Typmarkierungen D. Sabel, FP-PR, SoSe 2011 4.1 Das Typsystem die die Typisierungsregeln entsprechend Abbildung 4.2 auf einen Ausdruck (rekursiv) anwendet. Die Eingaben sind: • Die TypeOfCons-Liste zum Nachschlagen der Typen der Datenkonstruktoren • Eine Liste von Strings, die als neue Namen dienen. Diese Namen werden verwendet, um Namen für neue Typvariablen parat zu haben. • Der Ausdruck. Die Ausgabe der Funktion typecheck ist ein Drei-Tupel bestehend aus: • Den verbleibenden neuen Namen (jene, die doch nicht benutzt wurden) • Den Gleichungen E • Dem Ausdruck, der nun mit Typmarkierungen (mithilfe des LabelKonstruktors) versehen ist. Benutzen Sie hierbei die folgende Variante der Regel zur Typisierung von seqAusdrücken: Γ ` e1 :: τ1 , Γ ` e2 :: τ2 , E Γ ` (seq e1 e2 ) :: τ2 , E Im Gegensatz zur Regel in Abbildung 4.2, prüft diese Regel nicht, ob der Typ des ersten Arguments von seq weder ein IO- noch ein MVar-Typ ist. Diesen Test werden wir erst später durchführen. Beachten Sie den Fall, dass der Typcheck eine freie Variable entdeckt, und geben Sie in diesem Fall eine Fehlermeldung mit der Position und dem Namen der freien Variablen aus. Ein Variable ist frei, wenn sie nicht im Geltungsbereich eines Binders steht. Binder in CHF sind λx, die Pattern in case-Ausdrücken und die letrec-Bindungen. Die Typisierungsregeln finden freie Variablen dadurch, dass eine Variable x typisiert werden soll, diese jedoch nicht in der Typumgebung Γ enthalten ist. J In der nächsten Aufgabe fügen wir den Typcheck und die Unifikation zu einem Algorithmus zusammen. I Aufgabe 7. Implementieren Sie im Modul CHF.SemAna.TypeCheck die Funktion tCheck :: ParseTree () ConsName VarName -> Expr (Type ConsName) ConsName VarName D. Sabel, FP-PR, SoSe 2011 45 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax Die Funktion erwartet die Ausgabe des Parsers als Eingabe und führt anschließend den wie folgt den Typcheck durch: 1. Zunächst wird typecheck für den Ausdruck aufgerufen, wobei mittels mkTypeOfConsList vorher die TypeOfCons-Liste erstellt werden muss. Für die benötigten neuen Namen, können Sie z.B. die Liste ["t" ++ show i | i <- [1..]] verwenden. 2. Anschließend werden die erhaltenen Typgleichungen unifiziert (hierfür können Sie unify verwenden). 3. War die Unifikation nicht erfolgreich, so wird der Typcheck mit einer Fehlermeldung abgebrochen. Anderenfalls wenden Sie den erhaltenen Unifikator auf alle Typmarkierungen des Ausdrucks an, den Sie nach Schritt 1 erhalten haben. 4. Schließlich durchlaufen Sie den aus dem letzten Schritt erhaltenen Ausdruck erneut rekursiv und überprüfen, ob jeder seq-Ausdruck richtig getypt ist: Das erste Argument darf keinen IO- oder MVar-Typen erhalten haben. Wird ein fehlerhafter seq-Ausdruck gefunden, so wird eine Fehlermeldung ausgegeben, anderenfalls wird der typisierte Ausdruck als Ergebnis zurück gegeben. J Der so implementierte Typcheck ist noch etwas unkomfortabel bei der Generierung von Fehlermeldungen, da die Fehler erst bei der entgültigen Unifikation festgestellt werden. Um Fehler früher zu entdecken (und dadurch auch bessere Fehlermeldungen generieren zu können), kann man folgende Zusatzregel einführen: Γ ` e :: τ, E Γ, ` e :: σ(τ ), Eσ , wenn σ Lösung von E Hierbei ist Eσ das Gleichungssystem E, wobei der Unifikator σ auf alle Gleichungen angewendet wird. Diese Regel erlaubt es, jederzeit zwischendrin schon einmal zu unifizieren. I Aufgabe 8. Passen Sie die Funktion typecheck so an, dass nach jeder Regelanwendung bereits einmal unifiziert wird (mit der eben beschriebenen Regel). Tritt bei dieser Unifikation ein Fehler auf, so soll sofort eine Fehlermeldung ausgegeben werden, die möglichst genau angibt, wo der Typfehler aufgetreten ist. J Stand: 9. Juli 2011 46 D. Sabel, FP-PR, SoSe 2011 4.2 Transformation in eine vereinfachte Syntax 4.2 Transformation in eine vereinfachte Syntax Wir sorgen zunächst dafür, dass Ausdrücke die sogenannte „Distinct Variable Convention“ erfüllen. Diese besagt, dass sämtliche Variablennamen unterschiedlich sind, wenn sie zu unterschiedlichen Bindern gehören. Am einfachsten kann man die DVC erfüllen, indem man den Ausdruck komplett mit neuen Namen von oben nach unten umbenennt. I Aufgabe 9. Implementieren Sie im Modul CHF.Transformation.Renamer die Funktion > renameAndClean :: Expr (Type ConsName) ConsName VarName > -> [String] > -> (Expr () String String, [String]) Diese erhält den typisierten Ausdruck und eine Liste von neuen Variablennamen und • benennt sämtliche gebundene Namen mit frischen Namen um. Die wesentliche Idee des Algorithmus dabei ist es, sich am Binder (z.B. Lam x e) die Umbenennung von x zu merken, um sie dann beim Umbenennen von Variablen im Rumpf e nachzuschauen. Zum Merken kann eine Liste von Paaren der Form (alter Name, neuer Name) verwendet werden, effizienter ist allerdings die Verwendung anderer Datenstrukturen, z.B. eine Map aus der Bibliothek Data.Map • stellt sämtliche Variablen und Konstruktoren nicht mehr mit ihrer Positionsmarkierung dar, sondern ausschließlich als String. • die Typinformation komplett wegwirft, indem sämtliche Label entfernt werden. Die Ausgabe ist das Paar bestehend aus dem umbenannten und vereinfachten AusJ druck sowie der Liste der noch verbleibenden neuen Namen. 4.2.1 Transformation in MExpr Die abstrakten Maschinen erfordern eine leicht veränderte (bzw. vereinfachte) Syntax innerhalb der Ausdrücke. Kurz gesagt, erlauben die Maschinen nur Variablen als Argumente in Anwendungen und Konstruktoranwendungen. Auch das zweite Argument von seq darf nur eine Variable sein. Da die D. Sabel, FP-PR, SoSe 2011 47 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax monadischen Operatoren zum Teil wie Konstruktoranwendungen behandelt werden, müssen auch deren Argumente stets Variablen sein. Formal ist die Syntax von Maschinenausdrücken: e, ei ∈ Expr M ::= x | me | (λx → e) | (e x) | (c x1 . . . xar(c) ) | (seq e1 x) | (caseT e of {((cT,1 x1 . . . xar(cT,1 ) ) → eT,1 ); ... ((cT,|T | x1 . . . xar(cT,|T | ) ) → eT,|T | ))} | (letrec x1 = e1 ; . . . ; xn = en in e) wobei n ≥ 1 me ∈ MExprM ::= (return x) | (x1 >>= x2 ) | (forkIO x) | (takeMVar x) | (newMVar x) | (putMVar x1 x2 ) Die Transformation von ursprünglichen Ausdrücken in Maschinenausdrücke ist relativ einfach zu bewerkstelligen, indem man neue letrecAusdrücke einführt. Sei e ein Ausdruck, dann bezeichnen wir mit JeK den Maschinenausdruck zu e. Die wesentlichen Regeln zur Übersetzung sind: • J(e1 e2 )K = letrec x = Je2 K in (Je1 K x), wobei x eine neue Variable ist. • J(c e1 . . . en )K = letrec x1 = Je1 K, . . . , xn = Jen K in (c x1 . . . xn ), wobei x1 , . . . , xn neue Variablen sind. • Jseq e1 e2 K = letrec x = Je2 K in (seq Je2 K x), wobei x eine neue Variable ist. • Jreturn eK = letrec x = JeK in return x, wobei x eine neue Variable ist. • Je1 >>= e2 K = letrec x1 = Je1 K, x2 = Je2 K in x1 >>= x2 , wobei x1 , x2 neue Variablen sind. • JforkIO eK = letrec x = JeK in forkIO x, wobei x eine neue Variable ist. • JtakeMVar eK = letrec x = JeK in takeMVar x, wobei x eine neue Variable ist. • JnewMVar eK = letrec x = JeK in newMVar x, wobei x eine neue Variable ist. Stand: 9. Juli 2011 48 D. Sabel, FP-PR, SoSe 2011 4.2 Transformation in eine vereinfachte Syntax • JputMVar e1 e2 K = letrec x1 = Je1 K, x2 = Je2 K in putMVar x1 x2 , wobei x1 , x2 neue Variablen sind. Für alle anderen Konstrukte wird J·K homomorph über die Termstruktur gezogen: • JxK = x • Jλx → eK = λx.JeK • Jletrec x1 = e1 , . . . , xn = en in eK = letrec x1 = Je1 K, . . . , xn = Jen K in JeK • JcaseT e of {pat1 → e1 ; . . . ; pat|T | → eT }K = caseT JeK of {pat1 → Je1 K; . . . ; pat|T | → JeT K} Im Modul CHF.CoreL.MachineLanguage ist der Datentyp MExpr für Maschinenausdrücke definiert als: > data MExpr cname v = > VarM v > | LamM v (MExpr cname v) > | AppM (MExpr cname v) v > | SeqM (MExpr cname v) v > | ConsM (Either MAction cname) [v] > | CaseM (MExpr cname v) [MCAlt cname v] > | LetrecM [MBinding cname v] (MExpr cname v) > deriving(Eq,Show) > data MCAlt cname v = > CAltM cname [v] (MExpr cname v) > deriving(Eq,Show) > data MBinding cname v = > v := (MExpr cname v) > deriving(Eq,Show) I Aufgabe 10. Definieren Sie im Modul CHF.Transformation.Core2Machine die Funktion > normalize :: [String] > -> Expr () String String > -> ([String], MExpr String String) D. Sabel, FP-PR, SoSe 2011 49 Stand: 9. Juli 2011 4 Teil 2: Type-Check und Transformation in einfachere Syntax die als Eingaben eine Liste von neuen Namen und einen Ausdruck erhält und diesen entsprechend der Übersetzuung J·K in einen Maschinenausdruck konvertiert und das Paar bestehend aus den verbleibenden frischen Namen und dem Maschinenausdruck liefert. J I Aufgabe 11. Definieren Sie im Modul CHF.Transformation.Core2Machine eine Funktion toMachineExpr :: String -> MExpr String String, die ein Quellprogramm erhält, die lexikalische und die syntaktische Analyse durchführt, anschließend den Typcheck durchführt und nach der Umbenennung den Maschinenausdruck liefert. Für die Liste der frischen Namen können Sie hierbei z.B. die Liste ["_x" ++ show i | i <- [1..]] verwenden. J Stand: 9. Juli 2011 50 D. Sabel, FP-PR, SoSe 2011 5 Teil 3: Abstrakte Maschinen 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme Eine einfache abstrakte Maschine zur call-by-need Auswertung von letrecSprachen ist die Mark 1 aus (Sestoft, 1997). Die in (Sestoft, 1997) beschriebenen Maschinen passen zu unserer Sprache bis auf die nebenläufige Auswertung und den monadischen Operationen. Deshalb werden wir später die Mark 1-Maschine zunächst um monadische Berechnungen (IO-Mark 1) und anschließend um nebenläufige Auswertung (Concurrent Mark 1) erweitern. Die Mark 1-Maschine, die wir zunächst betrachten, behandelt alle monadischen Operationen genauso wie Konstruktoranwendungen. Da keine case-Ausdrücke existieren, die solche „Konstruktoranwendungen“ (wie z.B. takeMVar x) zerlegen können, ist diese Behandlung sehr einfach. Auch die Nichtexistenz der Nebenläufigkeit passt dazu: Ein Ausdruck forkIO e wird wie eine Konstruktoranwendung behandelt und daher ist es einfach nicht möglich, auf der Mark 1-Maschine einen neuen Thread zu erzeugen. Wir benötigen noch die Definition der Werte, welche jene Ausdrücke sind, zu denen wir unsere Programme auswerten möchten. Für die Mark 1Maschine erklären wir auch die monadischen Operationen zu Werten: Definition 5.1.1. Ein MExpr-Ausdruck ist ein Mark 1-Wert, wenn er eine Abstraktion, eine Konstruktorapplikation, oder ein monadischer Ausdruck ist. Ein MExpr- Stand: 9. Juli 2011 D. Sabel, FP-PR, SoSe 2011 5 Teil 3: Abstrakte Maschinen Ausdruck ist in WHNF (weak head normal form, schwache Kopfnormalform), wenn er eine der folgenden Formen besitzt: • \x → e, oder • (c y1 . . . yar(c) ), wobei c ein Konstruktor, oder ein monadischer Operator ist. • letrec x1 = e1 , . . . , xn = en in v, wobei v ein Mark 1-Wert ist. Der Zustand der Mark 1-Maschine ist ein 3-Tupel (H, e, S). Hierbei gilt: • H ist ein Heap. Ein Heap ist eine Menge von Heapbindungen. Eine Heapbindung p 7→ e besteht aus einer Heapvariablen p und einem Ausdruck e. Für jede Heapvariable darf nur eine Bindung im Heap vorkommen, d.h. der Heap ist eine Abbildung von Heapvariablen auf · 2 für die disjunkte Vereinigung der Ausdrücke. Wir schreiben H1 ∪H Heaps H1 und H2 . • e ist der aktuell auszuwertende Ausdruck. Wir nennen diese Komponente auch Control, da sie die Auswertung (d.h. den Ablauf der Maschine) steuert. • S ein Stack ist. Auf dem Stack merkt man sich den Teil des Ausdrucks, den man erst später auswerten möchte. Will man z.B. eine Applikation (e x) auswerten, so merkt man sich zunächst x auf dem Stack, wertet e (zu einer Abstraktion) aus, und schaut danach auf dem Stack nach, wie man weiter machen muss (x als Argument im Rumpf der Abstraktion einsetzen). Elemente im Stack können sein: – #app (x) zum Merken des Arguments x einer Applikation; – #seq (x) zum Merken des zweiten Argumentes eines seqAusdrucks; – #case (alts) zum Merken der Alternativen eines case-Ausdrucks; – #heap (x) zum Merken eines zu aktualisierenden Heapeintrags. Abbildung 5.1 zeigt die Übergangsrelation à (auch Maschinentransition genannt) der Mark 1-Maschine, d.h. à gibt an, wie man aus einem Zustand den darauf folgenden Zustand berechnet. Dies ist eine operationale Semantik, genauer eine sog. small-step Semantik, da die Regeln die Auswertung in vielen kleinen Schritten festlegen. Die ersten Regeln (pushApp), (pushSeq), (pushAlts) dienen dazu, die richtige Position zum „weitermachen“ zu finden: Für eine Anwendung und M1 M1 Stand: 9. Juli 2011 52 D. Sabel, FP-PR, SoSe 2011 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme (pushApp) (H, (e x), S) à (H, e, #app (x) : S) (pushSeq) (H, (seq e x), S) à (H, e, #seq (x) : S) (pushAlts) (H, (case e of alts), S) à (H, e, #case (alts) : S) (takeApp) (H, λx → e, #app (y) : S) à (H, e[y/x], S) (takeSeq) (H, v, #seq (y) : S) à (H, y, S), falls v ein Mark 1-Wert ist (branch) (H, (c x1 . . . xn ), #case (. . . (c y1 . . . yn ) → e; . . .) : S) à (H, e[xi /yi ]ni=1 , S) M1 M1 M1 M1 M1 M1 (nobranch) (enter) (update) (mkBinds) (H, (c x1 . . . xn ), #case (alts) : S) à Laufzeitfehler, falls alts keine Alternative für Konstruktor c enthält M1 · 7→ e}, y, S) à (H, e, #heap (y) : S) (H∪{y M1 · 7→ v}, v, S) (H, v, #heap (y) : S) à (H∪{y falls v ein Mark 1-Wert ist M1 (H, letrec x1 = e1 ; . . . ; xn = en in e, S) · 1 7→ e1 [yi /xi ]ni=1 , . . . , yn 7→ en [yi /xi ]ni=1 }, e[yi /xi ]ni=1 , S) à (H∪{y wobei yi frische Variablen sind M1 (blackhole) (H, y, S) → (H, y, S), falls keine Bindung für y im Heap Abbildung 5.1: Zustandübergangsregeln der Mark 1 einen seq-Ausdruck wird in das erste Argument gesprungen, beim caseAusdruck rutscht der zu unterscheidende Ausdruck in den Fokus. Bei allen drei Regeln, wird sich auf dem Stack gemerkt, wie später weiter gemacht werden muss: Für die Anwendung wird das Argument (eine Variable) auf den Stack gelegt, für seq-Ausdrücke wird das zweite Argument auf dem Stack gesichert und für case-Ausdrücke werden die Alternativen auf dem Stack abgelegt. Die nächsten vier Regeln (takeApp), (takeSeq), (branch) und (nobranch) sind genau dafür da, dass eine mit den ersten drei Regeln begonnene Unterauswertung beendet ist: Für eine Anwendung muss diese Unterauswertung mit einer Abstraktion enden, anschließend wird das Argument vom Stack genommen und eine β-Reduktion durchgeführt, indem das Argument im Rumpf der Abstraktion den formalen Parameter ersetzt (Regel (takeApp)). Für die seq-Auswertung genügt es, dass das erste Argument zu einem Wert, d.h. zu einer Abstraktion, zu einer Konstruktoranwendung oder einem mo- D. Sabel, FP-PR, SoSe 2011 53 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen nadischen Ausdruck ausgewertet wurde. In diesem Fall wird das zweite Argument vom Stack genommen und als Resultat des seq-Ausdrucks weiter verwendet (Regel (takeSeq)). Für case-Ausdrücke muss der zu unterscheidende Ausdruck zu einer Konstruktoranwendung ausgewertet werden. Ist dies geschehen, so werden die case-Alternativen vom Stack genommen und die passende Alternative wird gewählt, wobei die aktuellen Paramter die formalen Parameter (die Patternvariablen) ersetzen, hierbei meint e[xi /yi ]ni=1 die Ersetzung aller Variablen y1 , . . . , yn in e durch die Variablen x1 , . . . , xn (Regel (branch)). Existiert keine passende Alternative, so wird ein Laufzeitfehler gemeldet (Regel (nobranch)). Die Regeln (update) und (enter) werden benutzt, um die Auswertung von Heap-gebundenen Variablen zu steuern: Wird der Wert einer solchen Variablen benötigt, so wird die entsprechende Bindung vom Heap entnommen und auf dem Stack wird sich gemerkt, welche Variable gerade ausgewertet wird (Regel (enter)). Ist die Auswertung erfolgreich beendet (d.h. mit einem Wert (Abstraktion, Konstruktoranwendung oder monadischer Ausdruck), so wird die entsprechende aktualisierte Bindung in den Heap zurück geschrieben und die entsprechende Markierung vom Stack entfernt (Regel (update)). Die vorletzte Regel (die Regel (mkBinds)) verarbeitet einen letrecAusdruck: Sämtliche letrec-Bindungen werden in den Heap geschoben, wobei diese (wie auch der „in“-Ausdruck) mit neuen Namen umbenannt werden. Schließlich gibt es noch die Regel (blackhole), die angewendet wird, falls eine Variable ausgewertet werden soll, die nicht im Heap vorhanden ist. Dieser Fall tritt z.B. auf, wenn eine rekursive letrec-Bindung sich selbst referenziert, z.B. letrec x = x in x: Die ersten zwei Schritt der Auswertung sind: (∅, letrec x = x in x, []) à ({p 7→ p}, p, []) à (∅, p, [#heap (p)]). Jetzt ist Control die Variable p, die jedoch nicht im Heap liegt. Die Regel (blackhole) kann nun beliebig oft angwendet werden. (∅, p, [#heap (p)]) à (∅, p, [#heap (p)]) à (∅, p, [#heap (p)]) à . . ., d.h. die Maschine ist in einer Endlosschleife. M1 M1 M1 M1 M1 Beachte, dass ungetypte Fälle nicht auftreten können (z.B. der Ausdruck ist eine Abstraktion, aber auf dem Stack liegt ein #case (alts)-Eintrag als oberstes Element), da der Typcheck diese Ausdrücke aussortiert. Es fehlen jetzt noch Angaben, mit welchem Zustand man beginnt und wann man aufhört: Sei e ein MExpr-Ausdruck, so startet die Maschine mit dem Zustand Stand: 9. Juli 2011 54 D. Sabel, FP-PR, SoSe 2011 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme (∅, e, []), d.h. mit leerem Heap und leerem Stack. Die Maschine stoppt, wenn keine Regel mehr anwendbar ist. In diesem Fall ist der aktuelle Ausdruck (Control) ein Mark 1-Wert und der Stack ist leer, genauer: Definition 5.1.2. Ein Zustand der Mark 1-Maschine ist ein Endzustand, wenn er von der Form (H, v, []) ist, wobei v ein Wert ist. Diese Definition passt gerade zu den WHNFs, wobei das äußere letrec durch den Heap H dargestellt ist. Wir betrachten zunächst zwei Beispielausführungen der Maschine: Beispiel 5.1.3. Der Ausdruck letrec x = (λy → y) z, z = True in x wird auf der Mark 1-Maschine wie folgt ausgewertet: Heap ∅ Control Stack letrec [] x = (λy → y) z; z = True in x Regel à {p1 7→ (λy → y) p2 , p1 p2 7→ True} [] (mkBinds) à {p2 7→ True} (λy → y) p2 [#heap (p1 )] (enter) à {p2 7→ True} (λy → y) [#app (p2 ), #heap (p1 )] (pushApp) à {p2 7→ True} p2 [#heap (p1 )] (takeApp) à {} True [#heap (p2 ), #heap (p1 )] (enter) à {p2 7→ True} True [#heap (p1 )] (update) à {p2 7→ True, p1 7→ True} True [] (update) M1 M1 M1 M1 M1 M1 M1 Beispiel 5.1.4. Der Ausdruck letrec i = Cons x1 i; x1 = True in case i of { (Cons x xs) → xs; Nil → Nil} D. Sabel, FP-PR, SoSe 2011 55 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen wird auf der Mark 1-Maschine wie folgt ausgewertet: Heap ∅ Control Stack letrec [] i = Cons x1 i, x1 = True in case i of { (Cons x xs) → xs; Nil → Nil} Regel à {p1 7→ Cons p2 p1 , case p1 of { p2 7→ True} (Cons x xs) → xs; Nil → Nil} [] (mkBinds) à {p1 7→ Cons p2 p1 , p1 (Cons x xs) → xs; )] [#case (Nil → Nil (pushAlts) [#heap (p1 ), (enter) M1 M1 p2 7→ True} à {p2 7→ True} M1 Cons p2 p1 (Cons x xs) → xs; )] #case (Nil → Nil à {p1 7→ Cons p2 p1 , Cons p2 p1 (Cons x xs) → xs; )] [#case (Nil → Nil (update) à {p1 7→ Cons p2 p1 , p1 p2 7→ True} [] (branch) à {p1 7→ True} [#heap (p1 )] (enter) [] (update) M1 p2 7→ True} M1 M1 Cons p2 p1 à {p1 7→ Cons p2 p1 , Cons p2 p1 p2 7→ True} M1 5.1.1 Implementierung Zur Implementierung der Maschine werden wir nun genauer untersuchen, welche Datenstrukturen und welche Operationen benötigt werden. Für die Darstellung der Maschinenausdrücke definieren wir als Abkürzungen: > type Mark1Expr = MExpr Mark1Cons Mark1Var > type Mark1Var = String > type Mark1Cons = String Stand: 9. Juli 2011 56 D. Sabel, FP-PR, SoSe 2011 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme Wir benötigen drei Datenstrukturen: Control: Hier ist die Datenstruktur bereits durch Mark1Expr implementiert, allerdings brauchen wir eine zusätzliche Operation: In den Regeln (takeApp), (mkBinds) und (branch) werden Variablen durch Variablen substituiert. D.h. es fehlt eine Funktion substitute :: Mark1Expr -> Mark1Var -> Mark1Var -> Mark1Expr, die einen Ausdruck und zwei Variablen erhält und im Ausdruck die erste durch die zweite Variable ersetzt. Heap: Heapeinträge sind Paare vom Typ (String,Mark1Expr). Da der Heap eine Abbildung von Variablen auf Ausdrücke ist, bietet es sich an den Datentyp Map aus der Standardbibliothek Data.Map zu verwenden, d.h. wir könnten den Typ Heap definieren als type Heap = Map Mark1Var Mark1Expr Wir benötigen die folgenden Operationen auf dem Heap: • Für die Regeln (enter) und (blackhole): lookupHeap : Mark1Var -> Heap -> Maybe (Mark1Var,Heap), die eine Heapvariable und einen Heap erhält, und – falls eine Bindung für die Heapvariable existiert, die Bindung aus dem Heap entfernt und das Paar bestehend aus dem Ausdruck und dem modifizierten Heap liefert, – Nothing liefert, falls keine Bindung existiert. • Für die Regeln (update) und (mkBinds): insertHeap : Mark1Var -> Mark1Expr -> Heap -> Heap, die eine Variable, einen Ausdruck und einen Heap erhält und eine neue Bindung auf dem Heap anlegt, und schließlich den geänderten Heap zurückgibt. • emptyHeap :: Heap zum Erstellen eines leeren Heaps. Stack: Stackelemente können Variablen aus einer Applikation #app (x), Variablen aus dem Heap #heap (x), case-Alternativen #case (alts), oder rechte Ausdrücke von seq-Ausdrücken #seq (x) sein. D.h. die Elemente könnten durch den Datentypen data StackElem D. Sabel, FP-PR, SoSe 2011 = RetApp Mark1Var | RetHeap Mark1Var 57 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen | RetCase [MCAlt Mark1Cons Mark1Var] | RetSeq Mark1Var repräsentiert werden. Der Stack selbst kann dann durch eine Liste von StackElem-Elementen dargestellt werden, d.h. type Stack = [StackElem] Operationen auf dem Stack sind: • Für die Regeln (pushApp), (pushSeq), (pushAlts) und (enter): push :: StackElem -> Stack -> Stack, welche ein StackElement oben auf den Stack legt. • Für die Regeln (takeApp), (takeAlts), (takeSeq) und (update): pop :: Stack -> (StackElem,Stack), welche das oberste Element des Stacks entnimmt und das Paar bestehend aus dem obersten Stackelement und dem verbleibenden Stack liefert. • isEmptyStack :: Stack -> Bool, die prüft, ob der Stack leer ist. • emptyStack :: Stack, die einen neuen leeren Stack anlegt. Zusätzlich werden Operationen auf dem StackElem-Typ benötigt. Wir könnten nun direkt loslegen und die Datenstrukturen wie eben analysiert implementieren. Allerdings benötigen die anderen Maschinen auch andere Elemente im Stack und im Heap. Deswegen werden diese Datenstrukturen in der folgenden Aufgabe polymorph über den Elementtypen definiert und implementiert. I Aufgabe 12. Das Modul CHF.AbsM.Heap definiert einen Datentypen für den Heap, der polymorph über den Heapvariablen und den rechten Seiten der Bindungen ist, d.h. > import qualified Data.Map as Map > type Heap p e = (Map.Map) p e Implementieren Sie im gleichen Modul die folgenden Operationen auf dem Datentypen • emptyHeap :: Heap p e zum Erstellen eines leeren Heaps. Stand: 9. Juli 2011 58 D. Sabel, FP-PR, SoSe 2011 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme • lookupHeap :: p -> Heap p e -> Maybe (e, Heap p e), die wie oben beschrieben im Heap nach dem Eintrag für p sucht und die rechte Seite der Bindung, sowie den modifizierten Heap liefert. Eventuell müssen Sie an den Typ p weitere Typklassen-Anforderungen stellen. • insertHeap :: p -> e -> Heap p e -> Heap p e, die wie oben beschrieben eine Heapvariable vom Typ p und eine rechte Seite vom Typ e sowie einen Heap erhält und die entsprechende neue Bindung im Heap anlegt und schließlich den modifizierten Heap zurück liefert. Auch hier ist es möglich, dass an p weitere Typklassen-Anforderungen gestellt werden müssen. J I Aufgabe 13. Implementieren Sie im Modul CHF.AbsM.Stack einen Datentypen für den Stack, der polymorph über den Einträgen im Stack ist type Stack a = ... Implementieren Sie im gleichen Modul die folgenden Operationen auf dem Stack: • emptyStack :: Stack a zum Erzeugen eines leeren Stacks. • isEmptyStack :: Stack a -> Bool, die prüft ob der Stack leer ist. • push :: a -> Stack a -> Stack a, die ein Element und einen Stack erhält und das Element oben auf den Stack legt. • pop :: Stack a -> (a, Stack a), die das oberste Element vom Stack nimmt und das Paar bestehend aus diesem Element und dem Reststack zurück gibt. J I Aufgabe 14. Im Modul CHF.AbsM.Stack.StackElem ist der gleichnamige Datentyp definiert als > data StackElem v a = RetApp v | RetHeap v > deriving (Eq,Show) | RetCase a | RetSeq v D.h. Stack-Elemente sind polymorph über den Variablen v und den Alternativen a. Sie können entweder Variablen aus einer Anwendung, Variablen aus dem Heap, Variablen von seq-Ausdrücken oder case-Alternativen sein. Implementieren Sie die folgenden Funktionen in diesem Modul: D. Sabel, FP-PR, SoSe 2011 59 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen • isRetApp :: StackElem v a von der Form RetApp ... ist. -> Bool, die testet, ob ein Stack-Element • isRetHeap :: StackElem v a von der Form RetHeap ... ist. -> Bool, die testet, ob ein Stack-Element • isRetCase :: StackElem v a von der Form RetCase ... ist. -> Bool, die testet, ob ein Stack-Element • isRetSeq :: StackElem v a von der Form RetSeq ... ist. -> Bool, die testet, ob ein Stack-Element • mkRetHeap :: v -> StackElem v a, die aus einer Variablen ein RetHeapObjekt erstellt. • mkRetApp :: v -> StackElem v a, die aus einer Variablen ein RetAppObjekt erstellt. • mkRetCase :: a -> StackElem v a, die aus case-Alternativen ein RetCase-Objekt erstellt. • mkRetSeq :: v -> StackElem v a, die ein RetSeq-Objekt erstellt. • fromVar :: StackElem v a -> v, die aus einem RetApp-, RetSeq-, oder RetHeap-Objekt die Variable extrahiert. • fromRetCase :: StackElem v a die Alternativen extrahiert. -> a, die aus einem RetCase-Objekt J I Aufgabe 15. Implementieren Sie im Modul CHF.CoreL.MachineLanguage eine Funktion > substitute :: Mark1Expr -> Mark1Var -> Mark1Var -> Mark1Expr die einen Ausdruck und zwei Variablen erhält und alle Vorkommen der ersten J Variablen durch die zweite ersetzt. Nachdem nun alle notwendigen Datenstrukturen und Operationen vorhanden sind, können wir die Mark 1-Maschine implementieren. Im Modul CHF.AbsM.Mark1 wird der Datentyp für den Zustand der Mark 1 definiert (unter Benutzung der Record-Syntax (siehe (Sabel, 2011a)): Stand: 9. Juli 2011 60 D. Sabel, FP-PR, SoSe 2011 5.1 Die Abstrakte Maschine Mark 1 zur Ausführung funktionaler CHF-Programme > data Mark1State = > Mark1State { > heap :: Heap Mark1Var Mark1Expr , > control :: Mark1Expr, > stack :: (Stack (StackElem Mark1Var [MCAlt Mark1Cons Mark1Var])) > } Der Zustand besteht somit aus den 3 Komponenten: • dem Heap vom Typ (Heap Mark1Var Mark1Expr), d.h. einer Abbildung von Variablen auf Mark1Expr-Ausdrücke; • Control, als Ausdruck vom Typ Mark1Expr; • dem Stack vom Typ Stack (StackElem Mark1Var [MCAlt Mark1Cons Mark1Var])) D.h. für die Variablen setzen wir den Typ Mark1Var und für die Alternativen den Typ [MCAlt Mark1Cons Mark1Var] ein. I Aufgabe 16. Implementieren Sie im Modul LFPC.AbsM.Mark1 die folgenden Funktionen: • startState :: Mark1Expr -> Mark1State, die einen Mark1ExprAusdruck erhält und den Startzustand der Maschine für diesen Ausdruck berechnet. • nextState :: Mark1State -> [Mark1Var] -> (Mark1State,[Mark1Var]), die einen Zustand der Mark 1 sowie eine Liste (neuer) Variablen erhält, und entsprechend der Übergangsrelation den Folgezustand berechnet und zusätzlich die nicht benutzten neuen Variablen zurück gibt. • finalState :: Mark1State -> [Mark1Var] -> (Mark1State, [Mark1Var]), die einen Zustand der Mark 1 sowie eine Liste (neuer) Variablen erhält, und entsprechend den Endzustand der Maschine berechnet und zusätzlich die nicht benutzten neuen Variablen zurück gibt. • exec :: Mark1Expr -> [Mark1Var] -> String, die einen Ausdruck vom Typ Mark1Expr und eine Liste neuer Variablennamen erhält, anschließend die Mark 1-Maschine für diesen Ausdruck ausführt und schließlich das Ergebnis als String wie folgt ausdruckt: D. Sabel, FP-PR, SoSe 2011 61 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen – Für Abstraktionen soll einfach der Text <<<Function>>> gedruckt werden – Für Konstruktoranwendungen (c x1 . . . xn ) soll der Konstruktor c gedruckt werden, anschließend sollen rekursiv x1 bis xn mit der Maschine ausgewertet und deren Wert gedruckt werden. Dafür müssen Sie die Maschine erneut anwerfen: Wenn (H, (c x1 , . . . , xn ), []) der Endzustand war, so soll zunächst (H, x1 , []) zur Berechnung des Strings für x1 angewendet werden, der dadurch veränderte Heap soll benutzt werden, um x2 auszuwerten usw. Beachten Sie: Die Hintereinander-Auswertung von (H, x1 , []), . . . (H, xn , []) ist eher als falsch anzusehen, da sie den gleichen Heap H verdoppelt und dadurch Doppelauswertungen ermöglicht. – Monadische Operationen sollen wie Konstruktoranwendungen beim Drucken behandelt werden. J I Aufgabe 17. Implementieren Sie im Modul CHF.Run eine Funktion runMark1, die ein CHF-Programm erwartet, dann das Programm lext, parst, der semantischen Analyse unterzieht, in eine Mark1Expr umwandelt, schließlich auf der Mark 1Maschine laufen lässt und das Ergebnis als String zurück liefert. Für die neuen Variablen, die Sie brauchen werden, verwenden Sie interne Variablen, z.B. die Liste ["_internal" ++ show x | x <- [1..]]. J 5.2 Die IO-Mark 1 In diesem Abschnitt werden wir die Mark 1-Maschine erweitern, sodass monadische Operationen, wie das Anlegen und der Zugriff auf MVars, ausgeführt werden können. Die Operation forkIO kann diese Maschine noch nicht verarbeiten, da wir erst im nächsten Abschnitt nebenläufige Threads hinzufügen werden. Um mit der Mark 1-Maschine auch die monadischen Aktionen ausführen zu können, muss der Maschinenzustand zunächst um eine weitere Komponente erweitert werden: Die Speicherzellen, d.h. die MVars, müssen zusätzlich gespeichert werden. Die Auswertung folgt nun der Idee: Werte zunächst wie auf der Mark 1 Maschine aus. Wenn der Mark 1-Endzustand eine monadische Aktion ist, dann führe diese durch: Stand: 9. Juli 2011 62 D. Sabel, FP-PR, SoSe 2011 5.2 Die IO-Mark 1 • Die Operation newMVar x legt eine neue MVar mit Inhalt x an, und gibt als Resultat return y, wobei y der Name der MVar ist. • Die Operation takeMVar y liest den Wert aus der MVar namens y aus, entleert die MVar und gibt return v zurück, wenn v der Inhalt der MVar war. • Die Operation putMVar y z schreibt den Wert z in die MVar y und liefert return Unit zurück. • Die Operation e1 >>= e2 führt zunächst e1 , bis diese von der Form return x ist, anschließend wird das erste monadische Gesetz angwendet um fortzufahren: return x >>= e2 wird in die Anwendung (e2 x) überführt. Damit dies richtig funktioniert, muss man sich dafür wieder die Rücksprung-Operationen merken (z.B. e2 im obigen Beispiel für die >>= Operation). Dieses Merken wird durch einen weiteren Stack realisiert – den IO-Stack. Auch die Operatoren takeMVar und putMVar haben noch ein Problem: Zur Ausführung muss das jeweils erste Argument wirklich eine MVarReferenz sein, damit man die zugehörige MVar kennt. Auch dieses Problem wird der IO-Stack lösen. Insgesamt definieren wir daher: Definition 5.2.1. Der Zustand der IO-Mark 1-Maschine ist ein 5-Tupel (H, M, e, S, I) wobei: • H ist ein Heap, der eine Abbildung von Variablen auf Ausdrücke darstellt. • M ist eine Menge von MVars. Auch hier kann man von einer Abbildung von Variablen auf Ausdrücken sprechen, wobei es Variablen gibt, die auf „leer“ abgebildet werden. Wir notieren eine MVar namens x mit Inhalt y als x m y und eine leere MVar namens x als x m •. • e ist der aktuell auszuwertende Ausdruck. • S ist der Mark 1-Stack • I ist der IO-Stack. Dieser kann als Elemente enthalten: – #take : Damit wird sich gemerkt, dass eine takeMVar-Operation noch ausgeführt werden muss. – #put (x): Es wird sich gemerkt, dass eine putMVar-Operation durchgeführt werden muss, die x in die MVar schreiben will. D. Sabel, FP-PR, SoSe 2011 63 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen – # >>= (y): Es muss noch eine >>= -Operation durchgeführt werden, deren zweites Argument y ist. Für einen Ausdruck e startet die Maschine mit leerem Heap, ohne MVars und mit leeren Stacks. Ein Endzustand ist erreicht, wenn die beiden Stacks leer sind und der auszuwertende Ausdruck von der Form (return x), eine Abstraktion, eine Konstruktoranwendung oder der Name einer MVar ist. Definition 5.2.2. Für einen Ausdruck e ist der Startzustand der IO-Mark 1Maschine das 5-Tupel (∅, ∅, e, [], []). Ein Zustand der IO-Mark 1-Maschine ist ein Endzustand, wenn er von der Form (H, M, return x, [], []), oder von der Form (H, M, v, [], []) ist, wobei v eine Abstraktion, eine Konstruktoranwendung oder der Name einer MVar ist. Die Übergangsregeln (die Relation à ) der IO-Mark 1-Maschine sind in Abbildung 5.2 angegeben. Wir gehen kurz auf diese ein: IM1 • Die ersten neun Regeln sind direkt von der Mark 1-Maschine übernommen, und auf das 5-Tupel angepasst, wobei die neuen Komponenten – MVars und IO-Stack – keine Rolle spielen • Die (update)-Regel ist leicht angepasst, für den Fall, dass eine Variable ausgewertet werden soll, die den Namen einer MVar darstellt, in diesem Fall wird die Variable einfach zurück in den Heap geschrieben. • Sämtliche anderen Regeln (außer (blackhole)) werden nur ausgeführt, wenn der normale Stack leer ist. • Die Regel (newMVar) führt eine newMVar-Operation durch: Es wird eine neue MVar mit entsprechendem Inhalt erzeugt und return y ist der neue auszuwertende Ausdruck, wobei y der Name der erzeugten MVar ist. • Die Regel (takeMVar) führt eine takeMVar-Operation durch: Hierfür muss der aktuell auzuwertende Ausdruck der Name einer (gefüllten) MVar sein und der IO-Stack enthält als oberstes Element einen #take Eintrag. • Die Regel (emptyTake) ist das Gegenstück zu (takeMVar), für den Fall, dass die MVar leer ist. In diesem Fall blockiert die Berechnung eigentlich. Der Einfachheit halber geben wir an dieser Stelle einfach den Stand: 9. Juli 2011 64 D. Sabel, FP-PR, SoSe 2011 5.2 Die IO-Mark 1 vorherigen Zustand zurück. Da die IO-Mark 1 noch keine nebenläufigen Threads unterstützt, bedeutet dies, dass sich die Maschine in einer Endlosschleife befindet. • Die Regeln (putMVar) und (fullPut) dienen zur Verarbeitung einer putMVar-Operation: Diese liegt bereits auf dem IO-Stack und der aktuelle Ausdruck ist der Name einer MVar. Ist diese leer, so kann die Operation durchgeführt werden (die MVar wird gefüllt, und return Unit ist das Resultat). Ist die MVar voll, so wird blockiert, d.h. der aktuelle Zustand ist auch der Nachfolgezustand. • Die Regeln (pushTake) und (pushPut) werden durchgeführt, wenn die Maschine zum ersten Mal eine takeMVar- bzw. eine putMVar- Operation sieht: In diesem Fall muss das jeweils erste Argument ausgewertet werden, bis es ein Name einer MVar ist. Um sich den Rücksprung zu merken, wird ein entsprechendes Element auf den IO-Stack gelegt. • Die Regel (pushBind) wird durchgeführt, um in einem >>= -Operator zunächst die linke Aktion durchzuführen (auf dem IO-Stack wird sich gemerkt, dass man danach nach rechts springen muss). Ist die Auswertung der linken Aktion beendet, so ist der aktuelle Ausdruck von der Form return x, in diesem Fall wird die (lunit)-Regel verwendet, um die Auswertung des >>= -Operators zu vollenden. • Schließlich gibt es noch die (blackhole)-Regel, die Anwendung findet, wenn eine Variable ausgewertet werden soll, die weder im Heap vorkommt, noch eine MVar repräsentiert. Wir betrachten ein Beispiel: Beispiel 5.2.3. Wir werten den Ausdruck letrec x1 = True, x2 = (newMVar x1 ); x3 = (λx.takeMVar x) in x2 >>= x3 auf der IO-Mark 1 aus: (∅, ∅, letrec . . . in x2 >>= x3 , [], []) p 7 → True, 1 mkBinds , ∅, p2 >>= p3 , [], [] à p2 → 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 D. Sabel, FP-PR, SoSe 2011 65 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen (pushApp) (H, M, (e x), S, I) à (H, M, e, #app (x) : S, I) (pushSeq) (H, M, (seq e x), S, I) à (H, M, e, #seq (x) : S, I) (pushAlts) (H, M, (case e of alts), S, I) à (H, M, e, #case (alts) : S, I) (takeApp) (H, M, λx → e, #app (y) : S, I) à (H, M, e[y/x], S, I) (takeSeq) (H, M, v, #seq (y) : S, I) à (H, M, y, S, I), falls v ein Mark 1-Wert ist (branch) (H, M, (c x1 . . . xn ), #case (. . . (c y1 . . . yn ) → e; . . .) : S, I) à (H, M, e[xi /yi ]ni=1 , S, I) IM1 IM1 IM1 IM1 IM1 IM1 (nobranch) (H, M, (c x1 . . . xn ), #case (alts) : S, I) à Laufzeitfehler, falls alts keine Alternative für Konstruktor c enthält IM1 · 7→ e}, M, y, S, I) à (H, M, e, #heap (y) : S, I) (H∪{y (enter) IM1 (H, M, letrec x1 = e1 ; . . . ; xn = en in e, S, I) · 1 7→ e1 [yi /xi ]ni=1 , . . . , yn 7→ en [yi /xi ]ni=1 }, M, e[yi /xi ]ni=1 , S, I) à (H∪{y wobei yi frische Variablen sind (mkBinds) IM1 (update) (newMVar) · 7→ v}, M, v, S, I) (H, M, v, #heap (y) : S, I) à (H∪{y falls v ein Mark 1-Wert ist; oder v m z oder v m • in M enthalten ist IM1 · m x}, return y, [], I) (H, M, newMVar x, [], I) à (H, M∪{y wobei y eine neue Variable ist IM1 (takeMVar) · m y}, x, [], #take : I) à (H, M∪{x · m •}, return y, [], I) (H, M∪{x (emptyTake) · m •}, x, [], #take : I) à (H, M∪{x · m •}, x, [], #take : I) (H, M∪{x (putMVar) IM1 IM1 · m •}, x, [], #put (y) : I) (H, M∪{x · m y}, return Unit, [], I) à (H, M∪{x IM1 (fullPut) · m z}, x, [], #put (y) : I) (H, M∪{x · m z}, x, [], #put (y) : I) à (H, M∪{x IM1 (pushTake) (H, M, takeMVar x, [], I) à (H, M, x, [], #take : I) (pushPut) (H, M, putMVar x y, [], I) à (H, M, x, [], #put (y) : I) (pushBind) (H, M, x >>= y, [], I) à (H, M, x, [], # >>= (y) : I) (lunit) (H, M, return x, [], # >>= (y) : I) à (H, M, (y x), [], I) (blackhole) (H, M, x, S, I) à (H, M, x, S, I) falls x weder im Heap H noch in M vorkommt. IM1 IM1 IM1 IM1 IM1 Abbildung 5.2: Zustandübergangsregeln der IO-Mark 1 Stand: 9. Juli 2011 66 D. Sabel, FP-PR, SoSe 2011 5.2 Die IO-Mark 1 p1 → 7 True, pushBind , ∅, p2 , [], [# >>= (p3 )] à p2 → 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 Ã( ) ! p1 → 7 True, à , ∅, (newMVar p1 ), [#heap (p2 )], [# >>= (p3 )] p3 → 7 (λx.takeMVar x) enter IM1 p 7 → True, 1 update à p2 → , ∅, (newMVar p1 ), [], [# >>= (p3 )] 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 7 True, p1 → newMVar à p2 → , {q m p1 }, (return q), [], [# >>= (p3 )] 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 7 True, p1 → lunit , {q m p1 }, (p3 q), [], [] à p2 → 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 p1 → 7 True, pushApp à p2 → , {q m p1 }, p3 , [#app (q)], [] 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 Ã( ) ! p1 → 7 True, à , {q m p1 }, (λx.takeMVar x), [#heap (p3 ), #app (q)], [] p2 → 7 (newMVar p1 ) enter IM1 p1 → 7 True, update à p2 → , {q m p1 }, (λx.takeMVar x), [#app (q)], [] 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 p1 → 7 True, takeApp , {q m p1 }, takeMVar q, [], [] à p2 → 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 D. Sabel, FP-PR, SoSe 2011 67 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen p1 → 7 True, pushTake , {q m p1 }, q, [], [#take ] à p2 → 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 7 True, p1 → takeMVar à p2 → , {q m •}, (return p1 ), [], [] 7 (newMVar p1 ), p3 7→ (λx.takeMVar x) IM1 5.2.1 Implementierung Durch die Implementierung der Mark 1-Maschine können wir einiges wiederverwenden: Der Heap und der Stack können direkt verwendet werden. Für den IO-Stack, genügt es, ein passendes Modul für die Elemente des IO-Stacks zu implementieren: I Aufgabe 18. Im Modul CHF.AbsM.Stack.IOStackElem ist der Datentyp für Elemente des IO-Stacks definiert als: > data IOStackElem v = RetTake | RetPut v | RetBind v > deriving (Eq,Show) Implementieren Sie dort die Funktionen: • isRetTake :: IOStackElem v -> Bool, die ein IOStackElem-Element erhält und prüft, ob dieses ein RetTake-Element ist. • isRetPut :: IOStackElem v -> Bool, die ein IOStackElem-Element erhält und prüft, ob dieses ein RetPut-Element ist. • isRetBind :: IOStackElem v -> Bool, die ein IOStackElem-Element erhält und prüft, ob dieses ein RetBind-Element ist. • mkRetTake :: IOStackElem v, die ein RetTake-Element erstellt. • mkRetPut :: v -> IOStackElem v, die eine Variable erhält und daraus ein RetPut-Element erstellt. • mkRetBind :: v -> IOStackElem v, die eine Variable erhält und daraus ein RetBind-Element erstellt. • fromVarIOStack :: IOStackElem v -> v, die ein RetPutRetBind-Element erhält und die Variable heraus extrahiert. Stand: 9. Juli 2011 68 oder D. Sabel, FP-PR, SoSe 2011 5.2 Die IO-Mark 1 J Für die Menge der MVars verwenden wir ebenfalls den Heap-Datentyp, wobei die rechten Seiten der Bindungen vom Typ Maybe Mark1Var sind, d.h. entweder eine Variable (dargestellt als Just var) oder Nothing, was gerade bedeutet, dass die MVar leer ist. Insgesamt definieren wir daher den Zustand der IO-Mark 1-Maschine im Modul CHF.AbsM.IOMark1 als: > data IOMark1State = IOMark1State > {heap :: Heap Mark1Var Mark1Expr , > mvars :: Heap Mark1Var (Maybe Mark1Var), > control :: Mark1Expr, > stack :: (Stack (StackElem Mark1Var [MCAlt Mark1Cons Mark1Var])), > ioStack :: Stack (IOStackElem Mark1Var) > } I Aufgabe 19. Implementieren Sie im Modul CHF.AbsM.IOMark1: • Eine Funktion startState :: Mark1Expr -> IOMark1State, die für einen Ausdruck den Startzustand der IO-Mark 1-Maschine berechnet. • Eine Funktion nextState :: IOMark1State -> [Mark1Var] -> (IOMark1State,[Mark1Var]) die als Eingaben einen Zustand der IO-Mark 1-Maschine und eine Liste von neuen Variablen erhält und den entsprechenden Nachfolgezustand sowie die verbleibenden Variablen liefert, indem sie eine der Transitionen aus Abbildung 5.2 auf den Eingabezustand anwendet. • Eine Funktion finalState :: IOMark1State -> [Mark1Var] -> (IOMark1State, [Mark1Var]) die für einen IO-Mark 1-Zustand und eine Liste neuer Variablen, versucht den Endzustand der Maschine zu berechnen (und die Liste der nicht benötigten Variablen ebenfalls zurück liefert). D. Sabel, FP-PR, SoSe 2011 69 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen J Eine Funktion exec :: Mark1Expr -> [Mark1Var] -> String, die für einen Ausdruck und eine Liste neuer Variablen das Ergebnis der Auswertung als String berechnet, wird im Modul CHF.AbsM.IOMark1 bereit gestellt. Beim Ausdrucken ist darauf zu achten, dass tieferliegende monadische Aktionen nicht durch das Ausdrucken ausgeführt werden. Der Trick, den die Funktion exec hierfür verwendet, besteht darin, zunächst die IO-Mark 1Maschine laufen zu lassen, aber anschließend für die Argumentauswertung die Mark 1-Maschine zu verwenden. I Aufgabe 20. Implementieren Sie im Modul CHF.Run eine Funktion runIOMark1, die ein CHF-Programm erwartet, dann das Programm lext, parst, der semantischen Analyse unterzieht, in eine Mark1Expr umwandelt, schließlich auf der IO-Mark 1-Maschine laufen lässt und das Ergebnis als String zurück liefert. J 5.3 Die Nebenläufige Maschine – Concurrent Mark 1 Für die nebenläufige Maschine Concurrent Mark 1 können wir große Teile der IO-Mark 1-Maschine wiederverwenden, da sie nahezu perfekt dazu passt einen einzelnen Thread auszuwerten. Im Grunde besteht der Schritt von der IO-Mark 1 zur Concurrent Mark 1 aus den folgenden Teilschritten: • Statt einem Ausdruck werden nun mehrere Ausdrücken(in Form einer Menge von Threads) nebenläufig ausgewertet. Den Heap H und die MVars M teilen sich dabei alle Threads. Jeder Thread hat jedoch: einen Ausdruck, einen eigenen Stack und einen eigenen IO-Stack • Es gibt einen ausgezeichneten Thread: Wenn dieser Thread terminiert, dann terminiert das gesamte Programm. Um dies zu verwalten, werden wir den Threads Namen geben. Dies ist auch nötig, damit die Threads zu Futures werden, die (von anderen Threads) referenziert werden können. Der ausgzeichnete Thread erhält den Namen _main_. • Wenn ein Thread (sagen wir namens y) seine Auswertung beendet hat (also der aktuelle Thread die Form (return x) besitzt und beide Stacks leer sind), dann wird der Thread entfernt und das Ergebnis wird als normale Heap-Bindung in den Heap eingefügt (also die Bindung y 7→ x). Diese Regel wird für alle Threads außer dem ausgezeichneten Thread verwendet. Stand: 9. Juli 2011 70 D. Sabel, FP-PR, SoSe 2011 5.3 Die Nebenläufige Maschine – Concurrent Mark 1 • Die Regel für das Erzeugen einer Future (die forkIO-Operation) muss hinzugefügt werden. • Die Auswertung ist interleaved: Es wird ein Thread ausgewählt, dieser darf einen Transitionschritt machen, anschließend wird erneut gewählt usw. • Für die Wahl des nächsten Threads, sollte eine Art von Fairness implementiert werden, sodass jeder Thread nach endlich vielen Schritten der gesamten Maschine auch selbst ein eigenen Schritt gemacht hat. Hierfür werden wir die Threads mit Ressourcen markieren (soviele Schritte darf der Thread noch ausführen, bis der nächste an der Reihe ist), und zudem eine Queue der Threads verwalten. Formal definieren wir: Definition 5.3.1. Eine Future (ein Thread) der Concurrent Mark 1-Maschine ist ein 4-Tupel (x, e, S, I) wobei • x ein Variablenname ist. Wir nennen x den Namen der Future, bzw. sagen wir manchmal auch einfach „Future x“. • e ist der durch die Future auszuwertende Ausdruck (Control). • S ist ein Stack. • I ist ein IO-Stack. Der Zustand der Concurrent Mark 1-Maschine ist ein 4-Tupel (H, M, T , Q), wobei • H ist ein Heap. • M ist eine Menge von MVars. • T ist eine Menge von Futures. • Q ist eine FIFO-Queue, die die Reihenfolge der Futures verwaltet und für jede Future aus T eine Ressource (eine natürliche Zahl) enthält. Ein Zustand ist gültig genau dann, wenn • alle Namen der Futures in T verschieden sind, und • T enthält eine Future namens _main_ D. Sabel, FP-PR, SoSe 2011 71 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen Im Modul CHF.AbsM.CMark1 ist der Datentyp für Threads der Concurrent Mark 1-Maschine definiert als > data CMark1Thread = CMark1Thread { > name :: Mark1Var, > control :: Mark1Expr, > stack :: (Stack (StackElem Mark1Var [MCAlt Mark1Cons Mark1Var])), > ioStack :: Stack (IOStackElem Mark1Var) > } Der Datentyp für den Zustand der Maschine ist definiert als > data CMark1State = CMark1State { > heap :: Heap Mark1Var Mark1Expr, > mvars :: Heap Mark1Var (Maybe Mark1Var), > threads :: Heap Mark1Var CMark1Thread, > queue :: [(Int,Mark1Var)] > } Für die Menge der Threads wird hier erneut die Heap-Datenstruktur benutzt, damit man einen bestimmten Thread effizient in der Menge der Threads suchen kann. Aals Schlüssel für die Einträge werden dabei die Namen der Threads benutzt. Die Queue wird dargestellt als Liste von Paaren, wobei ein Paar gerade aus einer Ressource (ganze Zahl) und dem Namen der Future besteht. Definition 5.3.2. Sei e ein Ausdruck, dann ist der Startzustand der Concurrent Mark 1-Maschine (∅, ∅, T , Q), wobei • T = {(_main_, e, [], [])} • Q enthält nur einen Eintrag: (1,_main_) Ein Zustand der Concurrent Mark 1-Maschine ist ein Endzustand, wenn der Thread namens _main_ von der Form (_main_, return x, [], []) oder von der Form (_main_, v, [], []) ist, wobei v eine Abstraktion, eine Konstruktoranwendung, oder der Name einer MVar ist. In Abbildung 5.3 wird die Übergangsrelation à für die Concurrent Mark 1-Maschine definiert. Dabei darf stets derjenige Thread einen Schritt machen, der in der Queue Q ganz vorne steht. Im Wesentlichen sind hierbei drei Fälle zu unterscheiden: CM1 Stand: 9. Juli 2011 72 D. Sabel, FP-PR, SoSe 2011 5.3 Die Nebenläufige Maschine – Concurrent Mark 1 • Die Regel (unIO) wird verwendet, wenn eine nebenläufige Future ihre Berechnung beendet hat. In diesem Fall wird der Thread entfernt und eine Bindung im Heap für das Resultat erzeugt. • Die Regel (forkIO) wird angewendet, wenn ein neuer Thread mithilfe einer forkIO-Operation erzeugt werden soll. Hierbei wird eine neue Future angelegt: Es entsteht ein neuer Thread, der hinten mit einer zufällig gezogenen Ressource in die Queue Q eingefügt wird. Der erzeugende Thread erhält den Namen der Future als Rückgabe. • Die Regel (liftIOM) liftet die Regeln der IO-Mark 1-Maschine für die Concurrent Mark 1-Maschine: Für den ausgewählten Thread wird eine IO-Mark 1-Transition angewendet. Die letzten beiden Regeln passen dabei die Ressourcen des auswertenden Threads an: War die Ressource echt größer 1, so wird sie um 1 erniedrigt, der Thread verbleibt jedoch vorne in der Queue. War die Ressource 1, so muss sich der Thread ganz hinten in die Queue einreihen. Er erhält dabei eine neue Ressource, die zufällig aus den natürlichen Zahlen gewählt wird. Diese Ressourcen-Verfahren entspricht gerade dem Round-Robin-Verfahren mit „Zeitscheiben“: Ein Thread darf eine zeitlang rechnen, wird dann inaktiv und erhält erst dann wieder Rechenzeit, wenn alle anderen Threads rechnen durften. Man kann sich überlegen, dass diese Strategie fair in der Hinsicht ist, dass jeder Thread nach endlich vielen Schritten rechnen darf. Eine Verbesserung wäre es, zusätzlich FIFO-Queues für jede MVar einzuführen, damit jeder Thread (der es möchte) auch nach endlich vielen Schritt auf eine MVar zugreifen darf (wenn dies überhaupt möglich ist). I Aufgabe 21. Implementieren Sie im Modul CHF.AbsM.CMark1: • Eine Funktion startState :: Mark1Expr -> CMark1State, die einen Ausdruck erhält und den Startzustand der Concurrent Mark 1-Maschine für diesen Ausdruck berechnet. • Eine Funktion setSchedule :: CMark1State -> Int -> CMark1State, die einen Zustand der Concurrent Mark 1-Maschine und eine Zahl m erhält (für den schon ein Schritt gemacht wurde) und das Scheduling nach dem Schritt durchführt: – Der erste Eintrag der Queue Q wird betrachtet. Sei dieser (n, x) – Falls n > 1 ist, so ändere den Eintrag ab auf (n − 1, x) D. Sabel, FP-PR, SoSe 2011 73 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen · (H, M, T ∪{(x, (return y), [], [])}, (n, x) : Q) · à (H∪{x 7→ y}, M, T , Q) x 6= _main_ (unIO) CM1 · (H, M, T ∪{(x, (forkIO y), [], I)}, (n, x) : Q) (fork) · ∪{(x, (return z), [], I), (z, y, [], [])}, Q0 ) à (H, M, T½ (n − 1, x) : Q++[(m, z)] falls n > 1 wobei Q0 := Q++[(m, z), (n0 , x)] falls n = 1. 0 Hierbei sind m, n zufällig gewählte natürliche Zahlen; z ist eine neue Variable. CM1 (liftIOM) · (H, M, T ∪{(x, e, S, I)}, (n, x) : Q) 0 0 · à (H , M , T ∪{(x, e0 , S 0 , I 0 )}, Q0 ) CM1 falls (H, M, e, S, I) à (H0 , M0 , e0 , S 0 , I 0 ) wobei Q0 := (n − 1, x) : Q falls n > 1 und Q0 := Q++[(n0 , x)] falls n = 1. Hierbei ist n0 eine zufällig gewählte natürliche Zahl. Die Regel darf nur dann angewendet werden, wenn weder (fork) noch (unIO) anwendbar sind. IM1 Abbildung 5.3: Zustandübergangsregeln der Concurrent Mark 1 Stand: 9. Juli 2011 74 D. Sabel, FP-PR, SoSe 2011 5.3 Die Nebenläufige Maschine – Concurrent Mark 1 – Falls n = 1 ist, so setze den Eintrag auf (m, x) und verschiebe m von der Front der Queue an die letzte Position in der Queue. • Eine Funktion nextState :: CMark1State -> [Mark1Var] -> [Int] -> (CMark1State, [Mark1Var],[Int]) die einen Concurrent Mark 1-Zustand, eine Liste neuer Variablennamen und eine Liste von Zahlen (für die Ressourcen) erhält, den Nachfolgezustand der Concurrent Mark 1-Maschine berechnet und das 3-Tupel bestehend aus – Nachfolgezustand – verbleibende neue Namen – verbleibende (nicht verwendete) Ressourcenzahlen liefert. • Eine Funktion finalState :: CMark1State -> [Mark1Var] -> [Int] -> (CMark1State, [Mark1Var],[Int]) die einen Concurrent Mark 1-Zustand, eine Liste neuer Variablennamen und eine Liste von Zahlen (für die Ressourcen) erhält, den Endzustand der Concurrent Mark 1-Maschine berechnet und das 3-Tupel bestehend aus – Endzustand – verbleibende neue Namen – verbleibende (nicht verwendete) Ressourcenzahlen liefert. J Im Modul CHF.AbsM.CMark1 ist die Funktion exec :: Mark1Expr -> [Mark1Var] -> [Int] -> String D. Sabel, FP-PR, SoSe 2011 75 Stand: 9. Juli 2011 5 Teil 3: Abstrakte Maschinen bereits vorgegeben, die das Ergebnis der Concurrent Mark 1-Maschine ausdruckt. Hierbei geht sie wie folgt vor: Monadische Unterausdrücke des _main_-Threads werden nicht mehr ausgeführt, sondern gedruckt (dieser Thread wird wie in der Mark 1-Maschine behandelt), nebenläufige Threads dürfen beim Drucken weiter Aktionen ausführen und werden daher wie in der IO-Mark 1-Maschine behandelt. I Aufgabe 22. Implementieren Sie im Modul CHF.Run eine Funktion runCMark1, die ein CHF-Programm erwartet, dann das Programm lext, parst, der semantischen Analyse unterzieht, in eine Mark1Expr umwandelt, schließlich auf der Concurrent Mark 1-Maschine laufen lässt und das Ergebnis als String zurück liefert. Testen Sie verschiedene Implementierungen für die Wahl der Liste von Ressourcen. Beispielsweise könnte man die Liste (repeat 1) verwenden (allerdings sind die Zahlen dann nicht zufällig). Eine andere Möglichkeit besteht darin mit den Funktionen aus der Bibliothek System.Random eine Liste von Pseudo-Zufallszahlen zu erzeugen. Implementieren Sie im Modul CHF.Run eine Funktion runCM1 :: String -> IO (), die wie runCMark1 ein Eingabeprogramm analysiert und auf der Concurrent Mark 1-Maschine laufen lässt und das Ergebnis ausdruckt. Sorgen Sie für einen nichtdeterministischen Ablauf, indem Sie die Ressourcenzahlen (zufällig) in Abhängigkeit von der Systemzeit erzeugen. Verwenden J Sie hierfür die Bibliothek System.CPUTime. 5.4 Der Interpreter I Aufgabe 23. Implementieren Sie in der Datei Main.hs ein Modul Main, dass einen interaktiven Interpreter für CHF bereitstellt. Hierbei soll ähnlich wie im GHCi agiert werden können. Die Minimalanforderungen sind: • CHF-Ausdrücke können eingeben und ausgewertet werden • Sind die Ausdrücke syntaktisch oder typfalsch, wird eine Fehlermeldung ausgegeben, der Interpreter wird aber nicht beendet. • Datentypdefinitionen können mit :define Typdefinition hinzugefügt werden, d.h. der Interpreter „merkt“ sich, welche Datentypen eingegeben wurden. • Mit :quit kann der Interpreter verlassen werden. • Ein Quellprogramm kann aus einer Datei geladen und ausgeführt werden. Stand: 9. Juli 2011 76 D. Sabel, FP-PR, SoSe 2011 5.4 Der Interpreter Hinweise: • Zum Speichern der aktuellen Datentypdefinition empfiehlt es sich eine IORef aus dem Modul Data.IORef zu verwenden. • Zum Abfangen der Fehler sind die Funktionen try (oder auch catch) und evaluate aus der Bibliothek Control.Exception hilfreich. Compilieren Sie den Interpreter und testen Sie ihn ausgiebig. D. Sabel, FP-PR, SoSe 2011 77 J Stand: 9. Juli 2011 Literatur Bird, R. S. (1998). Introduction to Functional Programming Using Haskell. Prentice-Hall. Chakravarty, M. M. T. & Keller, G. C. (2004). Einführung in die Programmierung mit Haskell. Pearson Studium. Hudak, P., Peterson, J., & Fasel, J. H. (2000). A Gentle Introduction to Haskell. Online verfügbar unter http://haskell.org/tutorial/. Jones, S. P., editor (2003). Haskell 98 Language and Libraries. Cambridge University Press. Auch online verfügbar unter http://haskell.org/definition. O’Sullivan, B., Stewart, D., & Goerzen, J. (2008). Real World Haskell. O’Reilly Media, Inc. Webseite zum Buch: http://book.realworldhaskell.org/read/. Sabel, D. (2011a). Begleitmaterial tionale Programmierung. frankfurt.de/lehre/SS2011/FP-PR/. zum Praktikum „Funkhttp://www.ki.informatik.uni- Sabel, D. (2011b). Skript zur Vorlesung „Einführung in die Funktionale Programmierung“ (Wintersemester 2010 / 2011). http://www.ki.informatik.uni-frankfurt.de/lehre/WS2010/EFP/. Sabel, D. & Schmidt-Schauß, M. (2011). A contextual semantics for concurrent Haskell with futures. Frank report 44, Institut für Informatik. Fachbereich Informatik und Mathematik. J. W. Goethe-Universität Frankfurt am Main. http://www.ki.informatik.unifrankfurt.de/papers/frank/frank-44.pdf. Schmidt-Schauß, M. (2010a). Skript zur Vorlesung „Einführung in die Funktionale Programmierung“ (Wintersemester 2009 / 2010). http://www.ki.informatik.uni-frankfurt.de/lehre/WS2009/EFP/. Schmidt-Schauß, M. (2010b). Skript lagen der Programmierung 2“ D. Sabel, FP-PR, SoSe 2011 zur Vorlesung „Grund(Sommersemester 2010). Stand: 9. Juli 2011 LITERATUR http://www.informatik.uni-frankfurt.de/∼prg2/SS2010/index.html. Sestoft, P. (1997). Deriving a lazy abstract machine. J. Funct. Programming, 7(3):231–264. Thompson, S. (1999). Haskell – The Craft of Functional Programming. Addison-Wesley. D. Sabel, FP-PR, SoSe 2011 79 Stand: 9. Juli 2011