IS20041KlausurVorb
Werbung

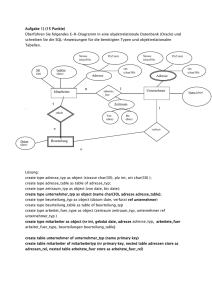
F A C H H O C H S C H U L E F Ü R D I E W I R T S C H A F T F H D W , H A N N O V E R I N FORM ATI ON S S Y TE M E K L AUS URVO RBE RE IT UN G (16. M Ä RZ 2004) Studiengang: Informatik/Wirtschaftsinformatik Studienquartal: III. Theoriequartal Prüfungsumfang: Vorlesungen. Dozent: Löwe Termin: 26. März 2004 Dauer: 90 Minuten 40 Punkte zu erreichen: Wissen 16, Anwendung 16 und Transfer 8 Punkte. TEIL I: WISSEN (25 MINUTEN) Aufgabe 1 (2 Punkte): Sei folgende Tabellendefinition in Oracle gegeben: create table t (c1 number, c2 number); Dann führen die Statements insert into t values (1,2); insert into t values (1,2); auf der Basis einer zunächst leeren Tabelle zu zwei Zeilen. Warum stimmt das eigentlich nicht mit der relationalen Semantik überein? Was muss man tun, damit eine Tabelle t mit identischen zwei Zeilen als Inhalt unmöglich wird? Aufgabe 2 (1 Punkt): Mit Standard-SQL kann man nicht jede beliebige Funktion (z. B. wie in LOMF) definieren! Welches programmiersprachliche Feature fehlt dazu? Aufgabe 3 (1 Punkt): Kann man mit PL/SQL jede beliebige Funktion (z. B. wie in LOMF) definieren? Aufgabe 4 (3 Punkte): In jedem Select-Statement (Syntax) der allgemeinen Form select an1.sn1, an2.sn2, ... anm.snm from t1 a1, ... tk ak where “condition”; werden gleichzeitig drei semantische Operationen angewendet: (a) Die Bildung eines kartesischen Produkts, (b) eine mengenmäßige Aussonderung und (c) eine Projektion aus einem Produkt. Welche syntaktischen Teile des Select-Statements formulieren diese drei semantischen Operationen? Aufgabe 5 (1 Punkt): Was ist ein Primary Key? Aufgabe 6 (2 Punkte): Was ist ein Index? Aufgabe 7 (1 Punkt): Warum legt Oracle für jedes Unique Constraint (also auch für jeden Primary Key) automatisch einen Index an? Aufgabe 8 (2 Punkt): Was ist ein Foreign Key? Aufgabe 9 (2 Punkte): Warum sollen Key’s immer nur aus einem Feld von numerischem Typ bestehen? Aufgabe 10 (2 Punkte): Warum sind Sequencer in Oracle das einzig probate Mittel, um in einem Mehrbenutzerbetrieb die eindeutige Vergabe von Primärschlüsseln zu regeln? Aufgabe 11 (3 Punkte): Angenommen die Tabelle create table t (id number primary key, value number not null); hat 5 Zeilen. Wie viele Zeilen erzeugen dann folgende Select-Statement’s? (a) select * from t a1, t a2; (b) select a1.id, a2.id from t a1, t a2; (c) select distinct a1.value, a2.value from t a1, t a2; (d) select * from t a1, t a2 where a1.id = a2.id; (e) select * from (select a1.id a1id, a2.id a2id from t a1, t a2), t a4; (f) select count(*) from (select a1.id a1id, a2.id a2id from t a1, t a2), t a4; Aufgabe 12 (1 Punkt): Je normalisierter ein relationales Schema ist, umso weniger ????? enthalten die Daten in diesem Schema. Aufgabe 13 (2 Punkte): Normalisierung von relationalen Schemata beseitigt viele Probleme bei ????? der Tabellen, erhöht aber den Aufwand bei ????? Aufgabe 14 (2 Punkte): Was ist ein View? Aufgabe 15 (2 Punkte): Transaktionen sind ein Abstraktionskonzept. Wovon wird abstrahiert? Aufgabe 16 (2 Punkte): Der Nutzer von Datenbanksystemen hat zwei Möglichkeiten, Transaktionen zu beenden. Welche? Erläutern Sie den jeweiligen Effekt! Aufgabe 17 (4 Punkte): Transaktionen sollten die ACID-Eigenschaften besitzen. Erläutern sie die vier Eigenschaften kurz! Aufgabe 18 (1 Punkt): Welche Eigenschaft von Transaktionen macht ein besonderes Verfahren beim Wiederanlaufen eines Transaktions-gesicherten Systems nach einem Totalausfall nötig? Aufgabe 19 (1 Punkt): Welche Eigenschaft von Transaktionen ist insbesondere für den Multi-UserBetrieb erforderlich? Aufgabe 20 (1 Punkt): Welche Eigenschaft von Transaktionen kann ein erfolgreiches „Commit“ verhindern, obwohl keinerlei Schreib- oder Lesekonflikte mit anderen Transaktionen vorliegen? Aufgabe 21 (1 Punkt): Warum machen die ACI-Eigenschaften von Transaktionen ohne die DEigenschaft wenig Sinn? Aufgabe 22 (2 Punkte): Was sind Save Points? Aufgabe 23 (4 Punkte): Erläutern Sie den Unterschied zwischen geschachtelten und verteilten Transaktionen! Aufgabe 24 (2 Punkte): Warum sind geschachtelte Transaktionen nötig, wenn man jede Prozedur und Funktion einer Anwendung transaktionsgesichert durchführen möchte? Aufgabe 25 (2 Punkte): Was hat Serialisierung von Transaktionen mit Isolation zu tun? Aufgabe 26 (2 Punkte): Warum kann der Isolationslevel Committed Read in Datenbanksystemen zu Effekten im Multi-User-Betrieb führen, die man mit den selben Transaktionen im Single-User-Betrieb nicht erreichen kann? Aufgabe 27 (2 Punkte): Was unterscheidet die Isolationslevel Dirty Read und Committed Read? Aufgabe 28 (2 Punkte): Warum haben Transaktionen im Isolationslevel Dirty Read nur noch die ACD-Eigenschaften? Aufgabe 29 (4 Punkte): Was sind optimistische und pessimistische Sperren? Welche Probleme treten bei den beiden Arten von Sperren jeweils auf? Aufgabe 30 (3 Punkte): Was ist ein Deadlock? Welches Sperrkonzept führt zu Deadlocks? Geben Sie ein Beispiel! 2 Aufgabe 31 (2 Punkte): Geben Sie eine Deadlock-Situation an, in der eine Transaktion an zwei verschiedenen Deadlocks beteiligt ist! Aufgabe 32 (2 Punkte): Sei T die Menge der Offenen Transaktionen zu einem Zeitpunkt t in einem Datenbanksystem und W T T die Wartet-auf-Relation, i. e. falls (t1, t2) W, dann wartet t1 auf t2. Wann liegt zum Zeitpunkt t ein Deadlock vor, wann nicht? Aufgabe 33 (3 Punkte): Was ist Starvation? Welches Sperrkonzept führt zu Starvation? Geben Sie ein Beispiel! Aufgabe 34 (2 Punkte): Warum sollten Datenbanktransaktionen kurz sein? Aufgabe 35 (1 Punkt): Welches typisch objektorientierte Modellierungskonzept ist nur schwer auf relationale Tabellenschemata abzubilden? Aufgabe 36 (1 Punkt): Grob gesprochen verhält sich Klasse zu Objekt zu Attribute zu Wert in der Objektorientierung wie Tabelle zu ????? zu ????? zu ????? in relationalen Datenbanken. Aufgabe 37 (2 Punkte): Nennen und erläutern Sie kurz zwei der Probleme, die man erhält, wenn man Klassenmodelle so in relationale Schemata abbildet, dass für jede Klasse eine Tabelle entworfen wird und Vererbung zwischen Klassen über Fremdschlüssel zwischen entsprechenden Tabellen realisiert wird! Aufgabe 38 (2 Punkte): Nennen und erläutern Sie kurz zwei der Probleme, die man erhält, wenn man Klassenmodelle so in relationale Schemata abbildet, dass für jede Klasse eine Tabelle entworfen wird und vererbte Attribute direkt in der Tabelle der erbenden Klasse realisiert werden! Aufgabe 39 (6 Punkte): Erläutern sie die beiden Methoden, Klassenmodelle in relationale Schemata umzusetzen, indem für jede Klasse (konkret oder abstrakt) eine Tabelle vorgesehen wird. Nennen sie einen wesentlichen Vorteil und einen wesentlichen Nachteil für jede Methode!1 Aufgabe 40 (6 Punkte): Beschreiben Sie die Methode Eine-Tabelle-pro-Klassenhierarchie zur Umsetzung von Klassenmodellen in relationale Schemata! Nennen Sie zwei Vorteile, den dieses Verfahren gegenüber den beiden Varianten Eine-Tabelle-pro-Klasse hat! Aufgabe 41 (2 Punkte): Welche Vorteile hat man, wenn man alle Fehlerkonstanten für eine OraclePL/SQL-Anwendung in einem eigenen Package zusammenfasst? Aufgabe 42 (2 Punkte): Warum ist es sinnvoll, alle Fehler und Ausnahmen einer Oracle-PL/SQLAnwendung ausschließlich mit Hilfe einer zentralen Operation raiseApplicationError zu erzeugen. Aufgabe 43 (2 Punkte): Warum soll man in einem Package für jede Operation sämtliche Ausnahmen, die die Methode für die Operation erzeugen kann, innerhalb des Operationskommentars dokumentieren? Aufgabe 44 (2 Punkte): „Stored Procedures“ Abstraktionsmittel! Wovon wird abstrahiert! in Datenbankmanagementsystemen sind ein Aufgabe 45 (4 Punkte): Welches Konzept kann man anwenden, um als Ergebnis einer Stored-Procedure eine ganze Menge homogen strukturierter Resultate abzuliefern? Erläutern sie das Konzept anhand eines schlagenden Beispiels! Aufgabe 46 (2 Punkte): Warum sind „Stored Procedures“ ein probates Mittel, um mit den Problemen wenig normalisierter Schemata fertig zu werden? Aufgabe 47 (2 Punkte): Wieso kann es beim Entwurf von Oracle-Packages vorkommen, dass man dieselbe Operation einmal transaktionsgesichert und einmal nicht transaktionsgesichert benötigt. Aufgabe 48 (1 Punkt): Vergleichen wir das Package-Konzept von Oracle-PL/SQL objektorientierten Konzepten, so verhält sich „Package Body“ zu Klasse wie „Package“ zu ??? 1 mit Diskutieren Sie nur das entstehende Schema, nicht etwaige Schnittstellen auf der Datenbank- oder der Nutzerseite! 3 Aufgabe 49 (2 Punkte): Warum ist es von Vorteil, den Zugriff von Klienten auf relationale Datenbanken über eine Schnittstelle aus Stored Procedures zu regeln. Nennen Sie zwei verschiedene Gründe! Aufgabe 50 (2 Punkte): Warum sollten alle (in SQL formulierten) Zugriffe einer „Client“-Software auf einen Datenbank-„Server“ an einer Stelle konzentriert werden, selbst wenn keine „Stored Procedures“ benutzt werden? Aufgabe 51 (2 Punkte): Warum soll man null-Werte zur Repräsentation vernünftiger Daten möglichst vermeiden? Aufgabe 52 (2 Punkte): Für Oracle stimmt die leere Zeichenkette mit dem null-Wert überein. Warum ist das ein schwerer Entwurfsfehler? Aufgabe 53 (2 Punkte): Warum ist das Proxi-Pattern bei dem Entwurf eines objektorientierten Klients für ein relationales Datenbanksystem nützlich? Aufgabe 54 (2 Punkte): Warum muss man in der Persistenzschicht eines objektorientierten Klients für ein relationales Datenbanksystem alle bereits aus der Datenbank entnommenen Objekte in einem ObjektCache zwischenspeichern? TEIL II: ANWENDUNG ( 40 MINUTEN) Aufgabe 55 (4 Punkte): Wie werden Assoziationen aus Klassenmodellen in Relationenschemata umgesetzt? Geben Sie jeweils ein Beispiel für eine gerichtete Assoziation mit (a) Quellkardinalität 0..1 und Zielkardinalität 1, (b) Quellkardinalität 0..1 und Zielkardinalität *, (c) Quellkardinalität * und Zielkardinalität 1 und (d) Quellkardinalität * und Zielkardinalität * mit samt der relationalen Umsetzung in Form „create-table-Anweisungen“ in SQL an! Aufgabe 56 (4 Punkte): Die umgesetzten Assoziationen im Relationenschema sind dann gar nicht mehr gerichtet, denn man kann jetzt sowohl bei vorgegebenem Quellobjekt die assoziierten Zielobjekte als auch bei vorgegebenem Zielobjekt die assoziierten Quellobjekte gleich gut ermitteln. Schreiben Sie die entsprechenden acht Abfragen zu ihren Beispielen aus Aufgabe 55 (nennen sie das vorgegebene Objekt jeweils x)! Aufgabe 57 (8 Punkte): Bei gestiegenen Benzinpreisen wird Fahrradfahren attraktiver. Deswegen scheint ein Bike-Sharing-Unternehmen in Hannover ein erfolgversprechendes Start-up, das unter intensiver Nutzung des Internets aufgezogen werden soll. Sie sollen ein Relationenmodell für eine zentrale Datenhaltung entwickeln, dass folgende geplanten Prozesse des neuen Unternehmens unterstützt. Kunden sollen über das Internet ermitteln können welcher Radtyp (zunächst sind geplant Lastenrad, Tourenrad und Rennrad) an welchem Standort (festzulegende Plätze im Stadtgebiet, an denen man Räder ausleihen und zurückgeben kann) verfügbar ist. Reservierungen für verfügbare Räder und Vorbestellungen für Rädertypen, die derzeit an einem Standort nicht verfügbar sind, können auch über das Internet gemacht werden. Bei der Reservierung erhält der Kunde eine Reservierungsnummer, die gleichzeitig für die nächsten 3 Stunden der Kode zum Öffnen des Fahrradschlosses ist (wird über Funk an das reservierte Fahrrad übertragen). 4 Die Rückgabe eines Rads wird über Funk durch das Anschließen des Rades an einem der Standorte in die Zentrale gemeldet. Bei vorhandener Vorbestellung wird die Vorbestellung zu einer Reservierung und der entsprechende Kunde per E-Mail (inkl. Reservierungsnummer) unterrichtet. Die Zentrale des Unternehmens benötigt jederzeit eine Übersicht darüber, welcher Kunde welches Rad benutzt sowie welche Reservierungen und Vorbestellungen vorliegen. Rechnungen werden monatlich erstellt. Sie stellen alle abgeschlossenen Ausleihvorgänge des Monats einzeln dar. Der Preis pro Ausleihe ergibt sich aus Radtyp und Nutzungsdauer in Stunden. (a) Entwickeln sie zunächst ein Fachklassenmodell für die beschriebene Anwendung in UML-Notation! (b) Setzen Sie das Klassenmodell dann in ein relationales Schema um! Dokumentieren Sie die resultierenden Tabellen in Form von „create-table-Anweisungen“ in SQL! Aufgabe 58 (8 Punkte): Entwickeln Sie ein Relationenschema für ein Datenbanksystem, das die Verwaltung und Durchführung von Lehrveranstaltungen an der FHDW unterstützt. (a) Modellieren Sie zumindest die Konzepte Lehrveranstaltung, Student, Dozent, Raum, Studienquartal, Durchführungszeit, Klausur und Note (in der Klausur) als Klassenmodell in UML-Notation. (b) Setzen Sie das Klassenmodell dann in ein relationales Schema um! Dokumentieren Sie die resultierenden Tabellen in Form von „create-table-Anweisungen“ in SQL! Aufgabe 59 (8 Punkte): Es soll ein System zur Verteilung von Gemeinkosten auf Kostenstellen entwickelt werden. Wir unterscheiden elementare Kostenstellen, die auf sie gebuchte Gemeinkosten vollständig aufnehmen und nicht weiter verteilen können. Strukturierte Kostenstellen, hingegen, bestehen aus einer Gruppe von anderen Kostenstellen, auf die anfallende Gemeinkosten vollständig verteilt werden. Die Weiterverteilung von gebuchten Gemeinkosten soll entlang eines Verteilplans auf die enthaltenen Kostenstellen erfolgen. (a) Geben Sie ein Klassenmodell in UML-Notation an, dass diese Struktur von sich rekursiv enthaltenden Kostenstellen mit prozentuale Verteilplänen beschreibt. Das bisher erarbeitete Modell gestattet die Verteilung nach nur einem festen Verteilplan pro Kostenstelle für alle Buchungen. (b) Verändern Sie das Klassenmodell so, dass verschiedene Verteilpläne für unterschiedliche Kostenarten möglich sind. (c) Setzen Sie Ihr Klassenmodell in ein Relationenschema um! Dokumentieren Sie die resultierenden Tabellen in Form von „create-table-Anweisungen“ in SQL! Aufgabe 60 (4 Punkte): Wie muss man das folgende Schema verändern, um das null-Werte-Problem aus Aufgabe 52 zu vermeiden und zwar ohne jegliche Verwendung von null-Werten? create table NullTrouble (id number primary key, value varchar2(200)) Wie werden jetzt die zuvor fehlerhaften insert insert select select into NullTrouble values (1, ‘’); into NullTrouble values (2, null); id from NullTrouble where value = ‘’; id from NullTrouble where value is null; formuliert? Aufgabe 61 (4 Punkte): Partielle Ordnungen oder Hierarchische Relationen (z. B. die Vererbungshierarchie) können auf zwei verschiedene Weisen in Relationenschemata abgebildet werden: (1) Normalisiert durch Ablegen nur der erzeugenden Relation oder (2) denormalisiert, indem der transitive 5 und reflexive Abschluss der erzeugenden Relation abgelegt und bei Veränderungen konsistent gehalten wird. Das Schema ist dabei gleich: create sequencer SEQSet; create table Set(id number primary key); create table PartialOrder(ancestor number foreign key references Set(id), descendant number foreign key references Set(id)); (a) (b) (c) (d) Unter welchen Umständen wählen Sie die erste Abbildung? Unter welchen Umständen bevorzugen Sie die zweite? Geben Sie das Select-Statement an, dass aus der Darstellung (2) die erzeugende Relation herausfiltert! Geben Sie das Select-Statement an, dass auf Basis der erzeugenden Relation den transitiven und reflexiven Abschluss liefert! (Achtung!!!) Aufgabe 62 (1 Punkt): Schreiben Sie die Lösung aus Aufgabe 61 (c) als View in Oracle-SQL! Aufgabe 63 (4 Punkte): Es seien folgende beiden Tabellen gegeben: create table Set (id number primary key); create table Equivalence(left number not null foreign key references Set(id), right number not null foreign key references Set(id), constraint Relation unique (left,right)); Die zweite Tabelle sei, wie der Name schon sagt, eine Äquivalenzrelation, also reflexiv, symmetrisch und transitiv. Formulieren Sie ein Select-Statement, das die Zeilen ermittelt, die in die Äquivalenztabelle eingefügt werden müssen, wenn ein neues Paar (l,r) in die Relation aufgenommen werden und die Relation ihre drei Eigenschaften behalten soll! Aufgabe 64 (6 Punkte): Es sei folgendes Schema gegeben: create sequence SEQSet nocache; create table Set (id number primary key, value varchar2(200) not null); create table TotalOrder(left number not null foreign key references Set(id), right number not null foreign key references Set(id), constraint Relation unique (left,right)); Die zweite Tabelle soll eine totale Ordnung der Einträge in der ersten Tabelle darstellen (ohne reflexiven und transitiven Abschluss).2 Schreiben Sie einen Oracle-Package-Body für folgendes Package: Create or replace package OrderedSet is function insertEntry(value varchar2, behind number) return number; function insertEntry(value varchar2, inFrontOf number) return number; procedure shiftOnePlaceBackward(entryId number); procedure shiftOnePlaceForward(entryId number); procedure removeEntry(entryId number); end; (Hinweis: Beachten Sie die Sonderbedingungen beim Einfügen des ersten Elements, beim Löschen des letzten Elements und beim Einfügen, Löschen sowie Verschieben am Anfang und Ende der Liste!) Aufgabe 65 (6 Punkte): Realisieren Sie das Package aus Aufgabe 64 auf der Basis folgenden Schemas: create sequence SEQSet nocache; create table Set (id number primary key, value varchar2(200) not null, position number not null, constraint PositionConstraint unique (position)); 2 Kann z. B. als Sortierreihenfolge für die Anzeige eines Klienten nützlich sein! 6 Hier wird die Ordnung der Einträge durch die Positionsnummer angegeben. Das heißt, dass ein Eintrag vor einem anderen Eintrag steht, wenn seine Position kleiner ist. Aufgabe 66 (5 Punkte): Übersetzen Sie folgendes Klassendiagramm in relationale Tabellenstrukturen und zwar nach der Methode „Eine Tabelle pro Klasse“ mit Fremdschlüsselbeziehungen als Realisierung der Vererbung! Dokumentieren Sie die resultierenden Tabellen in Form von „create-table-Anweisungen“ in SQL! * Person Kommunikationskanal name: String Natürliche Person Juristische Person vorname: String Adresse Telefon postleitzahl: Integer ort: String vorwahl: Integer durchwahl: Integer art: Integer Postfachadresse Straßenadresse nummer: Integer straßenname: String nummer: Integer Aufgabe 67 (2 Punkte): Schreiben Sie für die Tabellenstruktur aus Aufgabe 66 eine Abfrage, die die Namen der natürlichen Personen mit einer Postfachadresse ermittelt! Aufgabe 68 (5 Punkte): Übersetzen Sie das Klassendiagramm aus Aufgabe 66 in relationale Tabellenstrukturen und zwar nach der Methode „Eine Tabelle pro Klasse“ mit „ausmultiplizierten“ ererbten Attributen! Dokumentieren Sie die resultierenden Tabellen in Form von „create-tableAnweisungen“ in SQL! Aufgabe 69 (2 Punkte): Schreiben Sie für die Tabellenstruktur aus Aufgabe 68 eine Abfrage, die die Namen der natürlichen Personen mit einer Postfachadresse ermittelt! Aufgabe 70 (5 Punkte): Übersetzen Sie das Klassendiagramm aus Aufgabe 66 in relationale Tabellenstrukturen und zwar nach der Methode „Eine Tabelle pro Vererbungshierarchie“! Dokumentieren Sie die resultierenden Tabellen in Form von „create-table-Anweisungen“ in SQL! Aufgabe 71 (2 Punkte): Schreiben Sie für die Tabellenstruktur aus Aufgabe 70 eine Abfrage, die die Namen der natürlichen Personen mit einer Postfachadresse ermittelt! TEIL III: TRANSFER (25 MINUTEN) Aufgabe 72 (5 Punkte): Aufgabe 51 empfiehlt, null-Werte völlig zu vermeiden! Das bedeutet aber in voller Konsequenz, dass alle Spalten im gesamten Schema das Constraint „not null“ erhalten. (a) Wie muss man das folgende Schema verändern, wenn man null-Werte vollständig vermeiden will, aber dieselbe Information darstellen möchte? create table t1 (id number primary key, val1 number, val2 number); (b) Wie müssen folgende Select’s auf das neue Schema umgesetzt werden: 7 select id from t where val1 is null; select id from t where val2 = 2; (c) Wie geht man mit partiellen Fremdschlüsseln um? Das heißt, wie verändern Sie das folgende Schema, um null-Werte zu vermeiden: create table t1 (id number primary key, val1 number, val2 number); craete table t2 (id number primary key, t1ref number foreign key references t1(id), t2ref number foreign key references t2(id)); (d) Wie muss man jetzt den folgenden Join umgestalten: select x.val1,z.id from t1 x, t2 y, t2 z where z.t2ref = y.id and y.t1ref = x.id; Aufgabe 73 (4 Punkte): Beschreiben Sie das allgemeine Verfahren zur kompletten Vermeidung von Null-Werten, das bereits in Aufgabe 60 und Aufgabe 72 beispielhaft angewendet wurde! Mit welchem objektorientierten Entwurfsmuster hat das Verfahren Gemeinsamkeiten? Aufgabe 74 (3Punkte): Betrachten Sie folgende Tabellendefinitionen: create table Set (id number primary key); create table Relation(left number not null foreign key references Set(id), right number not null foreign key references Set(id), constraint Relation unique (left,right)); Aufgabe 75 Geben sie ein Select-Statement an, das eine minimale Menge von Paaren ermittelt, die aus der Tabelle Relation entfernt werden müssen, damit der Inhalt antisymmetrisch ist! (Achtung schwer, nutzen Sie auch die Eigenschaften der Elemente von Set!) Aufgabe 76 (5 Punkte): Wir kommen auf Aufgabe 63 zurück! Geben sie ein Select-Statement an, das die Tabelle Equivalence auf eine erzeugende Relation einschränkt. Das Ergebnis des Select’s soll also unter allen Relationen, deren reflexiver, symmetrischer und transitiver Abschluss genau den Inhalt der Ausgangstabelle ergibt, eine minimale3 Relation ermitteln. (Achtung schwer, nutzen Sie auch die Eigenschaften der Elemente von Set!) Aufgabe 77 (3 Punkte): Was hat ein Cursor in Oracle mit einem Iterator in Java gemein? Welchen Unterschied gibt es? Aufgabe 78 (2 Punkte): Warum reichen Write Locks (wie z. B. bei Oracle) nicht aus, um die volle Serialisierung von Transaktionen zu erreichen? Aufgabe 79 (2 Punkte): Welche Operation eines Oracle-Sequencer muss als Kritischer Abschnitt (Mutex) ausgeführt werden? Aufgabe 80 (2 Punkte): Was hat Isolation von Transaktionen mit dem Konzept Kritischer Abschnitte (Mutex) zu tun? Aufgabe 81 (2 Punkte): Sind Transaktionen kritische Abschnitte (Mutex)? Begründen Sie Ihre Antwort! Aufgabe 82 (2 Punkte): Sind kritische Abschnitte (Mutex) Transaktionen? Begründen Sie Ihre Antwort! Aufgabe 83 (3 Punkte): Transaktionen und kritische Abschnitte (Mutex) sind Hilfsmittel zur Beherrschung von Parallelität oder Multi-User-Betrieb. Was haben beide Konzepte (in ihrer Reinform) gemeinsam? Wo liegen die Unterschiede? 3 Bzgl. Mengeninklusion. 8 Aufgabe 84 (4 Punkte): Warum sind Oracle-Transaktionen auch im höchsten Isolationslevel nicht automatisch kritische Abschnitte (Mutex) für alle benutzten Ressourcen? Was muss der Entwickler von Transaktionen zusätzlich tun, um wirklich Kritische Abschnitte zu erhalten? Aufgabe 85 (2 Punkte): Kann man mit geschachtelten Transaktionen Save Points simulieren? Begründen Sie Ihre Antwort! Aufgabe 86 (2 Punkte): Kann man mit Save Points geschachtelten Transaktionen simulieren? Begründen Sie Ihre Antwort! Aufgabe 87 (1 Punkt): Warum kann man Save Points nicht benutzen, um Undo-Funktionalität wie z. B. in Word zu realisieren? Aufgabe 88 (2 Punkte): Mindert die Herabsetzung des Isolationslevels von Serializable auf Committed Read in Oracle Starvation- oder Deadlock-Probleme? Begründen Sie Ihre Antwort! Aufgabe 89 (2 Punkte): Mindert die Ersetzung von select ... for update-Klauseln in Oracle durch einfache select-Klauseln Starvation- oder Deadlock-Probleme? Begründen Sie Ihre Antwort! Aufgabe 90 (2 Punkte): Warum steigt der Transaktionsdurchsatz in einem Datenbanksystem, wenn der Isolationslevel gesenkt wird? Aufgabe 91 (2 Punkte): Warum sinkt der Transaktionsdurchsatz in einem Datenbanksystem, wenn die Grundeinheit für Sperren von Feldern über Zeilen über Gruppen von Zeilen (physische „Pages“) bis hin zu ganzen Tabellen vergröbert wird. Aufgabe 92 (2 Punkte): Sei T die Menge der Offenen Transaktionen zu einem Zeitpunkt t in einem Datenbanksystem und W T T die Wartet-auf-Relation, i. e. falls (t1, t2) W, dann wartet t1 auf t2. (a) Viele Elemente muss W mindestens haben, wenn ein Deadlock existiert? (b) Wieviele Elemente kann W höchstens haben, ohne dass ein Deadlock vorliegt? Aufgabe 93 (3 Punkte): Deadlocks können vollständig vermieden werden, wenn es gelingt, alle Ressourcen total zu ordnen, und sämtliche Transaktionen alle benötigten Ressourcen in der Reihenfolge ihrer Ordnungskennziffer (z. B. aufsteigend) sperren. (a) Warum kann es dann keine Deadlocks mehr geben? Kennt also jede Datenbanktransaktion zu Beginn ihrer Ausführung alle Ressourcen, die sie sperren möchte, sind Deadlocks Schnee von gestern. (b) Warum kann eine Datenbanktransaktion im Allgemeinen nicht zu Beginn alle Ressourcen kennen, die sie sperren möchte? Wir retten das Verfahren im allgemeinen Fall dadurch, dass jede Transaktion, die eine Ressource mit der Ordnungszahl x sperren möchte, zuvor alle bereits gesperrten Ressourcen mit größerer Ordnungskennzahl freigibt und nach der erfolgreichen Sperre auf x wieder versucht zu sperren. (c) Gibt es jetzt ein Starvationproblem? Aufgabe 94 (4 Punkte): Innerhalb von offenen Transaktionen arbeitet man normalerweise nicht auf den Originaldaten sondern auf Kopien. Wenn der dafür nötige Platz nicht zur Verfügung steht, kann man die ACID-Eigenschaften von Transaktionen auch bei der direkten Manipulation der Originaldaten gewährleisten, wenn alle elementaren Schritte, die in einer Transaktion ausgeführt werden können, eine bestimmten Eigenschaft besitzen. Welche Eigenschaft ist das? Welches Sperrverfahren (bzgl. Schreib- und Lesezugriffen) muss man dann anwenden? Warum? Aufgabe 95 (2 Punkte): Welches grundsätzliche Problem ergibt sich, wenn zwei der „fetten“ JavaKlienten, wie wir sie in der Vorlesung kennen gelernt haben, parallel auf dasselbe Schema im selben Oracle-Server zugreifen? 9 Aufgabe 96 (2 Punkte): Warum kann man das Problem aus Aufgabe 95 nicht einfach dadurch entschärfen, dass alle Select’s grundsätzlich mit der „...for update“-Klausel ausgeführt werden? Aufgabe 97 (4 Punkte): Interfaces oder Mehrfachvererbung machen das Verfahren zur Übersetzung von Klassenmodellen in relationale Schemata nach dem Muster „Eine Tabelle pro Klassenhierarchie“ deutlich komplizierter. Warum? Aufgabe 98 (2 Punkte): Wie repräsentiert man den Datenhaushalt eines Observer-Patterns in einem Relationenschema? Aufgabe 99 (3 Punkte): Mit Hilfe von Views kann man in gewisser Weise die abstrakte Summe t1 ++ t2 zweier verschiedener Tabellen t1 und t2 bilden. Wie? Was muss man dann für die Sequencer der beiden zugrunde liegenden Tabellen beachten? Warum ist diese Summenbildung gegenüber der Objektorientierten eingeschränkt? Aufgabe 100 (6 Punkte):Wir betrachten eine weitere Variante zur Speicherung spezieller Hierarchien, sogenannter Wälder. Wälder sind Hierarchien, in denen jeder Knoten höchsten einen direkten Vaterknoten besitzt.4 Knoten ohne Vater sind Wurzeln, Knoten ohne Söhne Blätter. Die Knoten mit derselben Wurzel bilden einen Baum im Wald. Ein Beispiel dieser Variante wird durch folgendes Schema dargestellt: create sequencer SEQSet nocache; create table Set (id number primary key, root number foreign key references set(id)); create table Wood (father number foreign key references set(id), son number foreign key references set(id)); Die erste Tabelle enthält die Objekte des Waldes. Die zweite Tabelle enthält die erzeugende Relation für die partielle Ordnung, die den Wald definiert. Über den root-Verweis der ersten Tabelle wird dabei zusätzlich für jeden Knoten x stets der Knoten bezeichnet, der die Wurzel in dem Baum darstellt, zu dem x gehört. Dadurch ist der Zugriff auf ganze Bäume des Waldes sehr performant. (a) Schreiben Sie ein Select-Statement, dass alle Objekte in Set ermittelt, die im selben Baum wie ein vorgegebener Knoten mit id x sind. (b) Schreiben Sie ein Select-Statement, dass alle Paare aus Wood ermittelt, die an der Definition der Struktur des Baumes beteiligt sind, in dem ein vorgegebener Knoten mit id x liegt. (c) Welche der Operationen im folgenden Package, die die redundante Information (root) konsistent halten sollen, sind einfach und sehr performant zu realisieren, welche erfordern erheblich mehr Rechenaufwand? Warum? create or replace package Root is function checkInsertPossible(father number, son number) return boolean; /* Prüft, ob <son> direkter Unterknoten von <father> werden kann. */ function insertNewNode return number; /* Fügt einen neuen Knoten in <Set> ein. */ procedure insertRelation(father number, son number); /* Macht, falls möglich, <son> zum direkten Unterknoten von <father> */ procedure deleteRelation(father number, son number); /* Trennt einen Baum zwischen <father> und <son> auf. <father> ist danach Blatt und <son> ist danach Wurzel */ end; (d) Warum hat diese Variante Probleme mit allgemeinen partiellen Ordnungen (Dschungeln)? 4 Einfach-Vererbung ist von dieser Art. Und die Komposition (existenzabhängige Aggregation) sollte so sein. 10