Im genetischen Code steht ein bestimmtes Triplett von Nucleotiden
Werbung

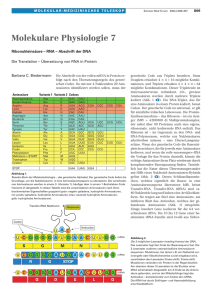
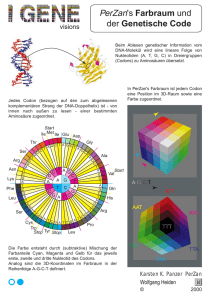
Im genetischen Code steht ein bestimmtes Triplett von Nucleotiden für eine bestimmte Aminosäure: Eine nähere Betrachtung Als den Biologen dämmerte, dass die Anweisungen für die Proteinsynthese in der DNA codiert sind, erkannten sie sofort das Problem: Es gibt nur vier verschiedene Nucleo-tide, um 20 Aminosäuren zu codieren. Daher kann der genetische Code nicht der chinesischen Sprache ähnlich sein, bei der jedes Zeichen einem einzelnen Wort entspricht. Wenn nämlich jede Nucleotidbase in eine Aminosäure übersetzt würde, so könnten nur 4 der 20 Aminosäuren codiert werden. Würde eine Sprache mit einem Zweibuchstaben-Code ausreichen? Die Basensequenz AG könnte eine Aminosäure codieren und GT eine andere. Da es vier Basen sind, würde dies 16 (4 2) mögliche Kombinationen zulassen - nicht genug, um alle 20 Aminosäuren zu codieren. Tripletts von Nucleotidbasen sind die kleinsten Codewörter, durch die alle Aminosäuren codiert werden können. (b) eukarvotische Zelle Wenn nämlich drei aufeinanderfolgende Basen eine Aminosäure codieren, so gibt es 64 (4 3) mögliche Codeworte -mehr als genug für die Codierung aller Aminosäuren. Experimente zum Informationsfluss vom Gen zum Protein bewiesen tatsächlich die Existenz eines Triplett-Codes: Die genetische Anweisung für die Synthese eines Polypeptids ist in der DNA durch eine Serie von Drei-Nucleotid-Wörtern niedergeschrieben. So codiert beispielsweise das Triplett AGT in der DNA die Aminosäure Serin, die dann an der entsprechenden Position in das wachsende Polypeptid eingebaut wird. Eine Zelle kann die Basentripletts eines Gens nicht direkt in Aminosäuren übersetzen. Der Zwischenschritt ist die Transkription, bei der das Gen die Folge der Basentripletts auf dem mRNA-Molekül bestimmt. Bei jedem Gen wird nur einer der beiden DNA-Stränge transkribiert. Dieser Strang wird als Matrizenstrang bezeichnet, weil er die Vorlage (Matrize) für die Anordnung der Basen im RNA-Transkript darstellt. Der komplementäre Strang, also der „Nichtmatrizenstrang", besitzt die gleiche Basensequenz wie das RNA-Transkript. In einem DNA-Molekül kann abwechselnd der eine oder der andere Einzelstrang als Matrize für eine RNA-Synthese dienen; für ein bestimmtes Gen sind jedoch Matrizenstrang und Nichtmatrizenstrang klar festgelegt. Ein mRNA-Molekül ist komplementär zur DNA-Vorlage und nicht identisch mit dieser, weil auch die RNA-Basen nach den Gesetzen der Basenpaarung aneinandergereiht werden (Abbildung 16.4). Das Prinzip ist dasselbe wie bei der spezifischen Basenpaarung während der DNA-Replikation. Wird ein DNA-Strang transkribiert, so bildet das Basentriplett CCG in der DNA die Vorlage für das komplementäre Triplett GGC in der mRNA. Die Basentripletts der mRNA werden als Codons bezeichnet. Wie in Abbildung 16.4 zu sehen ist, paart sich U, die dem T in der DNA entsprechende Base, mit A. Daher wird das DNA-Triplett AGT in der mRNA als das Codon UCA erscheinen und in die Aminosäure Serin übersetzt werden. Bei der Translation wird die Abfolge der Codons auf der mRNA in die Sequenz der Aminosäuren übersetzt oder translatiert, die dann eine Polypeptidkette bilden. Jedes Codon der mRNA bedingt den Einbau einer der 20 Aminosäuren an der richtigen Position im Polypeptid. Da Codons Basentripletts sind, beträgt die Zahl der Nucleotide einer mRNA ein Dreifaches der Zahl der Aminosäuren des Proteinproduktes. In einer 300 Nucleotide langen mRNA kann ein Protein von 100 Aminosäuren codiert sein. Wie der genetische Code entschlüsselt wurde Der genetische Code wurde von Molekularbiologen in den frühen 60er Jahren geknackt. Sie führten eine Reihe eleganter Experimente durch, welche die Aminosäurebedeutung jedes RNA-Codons enträtselten. Das erste Codon wurde im Jahre 1961 durch den Amerikaner Marshall Nirenberg entschlüsselt. Nirenberg hatte eine synthetische mRNA hergestellt, indem er lauter RNA-Nucleotide mit der Stickstoffbase Uracil aneinanderhängte. Wo auch immer auf dieser RNA die Translation begann, es war immer nur ein einziges Codon in vielfacher Wiederholung: UUU. Nirenberg gab diese „Poly(U)-RNA" in ein Reagenzglas mit einer Mischung von Aminosäuren, Ribosomen und anderen für die Proteinsynthese nötigen Komponenten. Sein artifizielles System translatierte Poly(U) in ein Polypeptid, das nur eine einzige Sorte von Aminosäure enthielt, nämlich Phenylala-nin (Phe), viele Male aneinandergereiht (Polyphenylalanin). Daraus leitete Nirenberg ab, das mRNA-Codon UUU müsse die Aminosäure Phenylalanin codieren. Bald danach wurden die Aminosäuren identifiziert, die durch die Codons AAA, GGG und CCC codiert werden. Obwohl kompliziertere Techniken eingesetzt werden mussten, um gemischte Tripletts wie AUA und CGA zu decodieren, waren alle 64 Codons in der Mitte der 60er Jahre entschlüsselt. Wie aus Abbildung 16.5 zu ersehen ist, codieren nur 61 Tripletts Aminosäuren. Bemerkenswerterweise besitzt das Codon AUG eine Doppelfunktion: Es codiert nicht nur die Aminosäure Methionin (Met), sondern dient auch als Startcodon oder „Initiationscodon". Die genetische Botschaft beginnt auf der mRNA stets mit AUG, das der Proteinsynthese-Maschinerie signalisiert, die Translation an diesem Codon zu beginnen. (Da AUG auch Methio-nin bedeutet, tragen alle neu gebildeten Polypeptide als erste Aminosäure Methionin. Es existiert jedoch ein Enzym, welches die Startaminosäure gegebenenfalls wieder vom Poly-peptid entfernt.) Die verbleibenden drei Codons haben keine Aminosäurebedeutung, sondern dienen ausschließlich als „Satzzeichen". Sie wirken als Stopcodons oder „Terminationscodons" und signalisieren das Ende der genetischen Botschaft. Wie Sie in Abbildung 16.5 sehen, ist der genetische Code redundant, aber eindeutig. Obwohl die Codons GAA und GAG beide für Glutaminsäure stehen (Redundanz), codiert keines von ihnen eine andere Aminosäure (Eindeutigkeit). Die Redundanz des Codes ist nicht zufällig verteilt. In vielen Fällen gibt es für eine bestimmte Aminosäure „synonyme" Codons, die sich nur an der dritten Position des Tripletts unterscheiden. Wir werden später in diesem Kapitel eine Konsequenz dieser Redundanz diskutieren. Anstelle von „Redundanz" spricht man auch von „Degeneration" des genetischen Codes. Die Chance, den Sinn einer geschriebenen Botschaft zu begreifen, hängt von unserer Fähigkeit ab, die Symbole in ihrer richtigen Reihenfolge und Gruppierung zu lesen. Dieses Ordnungsprinzip wird als Leseraster bezeichnet (englisch: reading frame). Betrachten wir den Satz: „Der Bär mag den Aal". Vertauscht man die Worte in diesem Satz, so entsteht unerwartet ein anderer Sinn, „Der Aal mag den Bär". Wenn man die Buchstaben nicht richtig in Worte gliedert, wie zum Beispiel „Derbärmagdenaal", so könnte man annehmen, das erste Wort wäre „Derb". Das Leseraster ist also wichtig für die molekulare Sprache der Zelle. Die Aminosäuren in Abbildung 16.4 können nur in der richtigen Anordnung translatiert werden, wenn die mRNA-Codons UGG UUU GGC UCA von Anfang bis Ende in der richtigen Reihenfolge und in Dreiergruppen gelesen werden. Obwohl die Basen in der mRNA kontinuierlich aneinanderhängen, liest die Proteinsynthese-Maschinerie der Zelle die Botschaft im richtigen Leseraster als eine Folge von nichtüberlappenden dreibuchstabigen Codewörtern. Die Botschaft wird nicht als eine Folge überlappender Wörter - UGGUUU, und so fort - gelesen, wodurch ein ganz anderer Sinn entstünde. Fassen wir zusammen, was Sie gerade gelernt haben. Die genetische Information ist in der Folge nichtüberlappender Basentripletts oder Codons verschlüsselt, von denen jedes bei der Proteinsynthese in eine bestimmte Aminosäure übersetzt wird. Die evolutionäre Bedeutung einer gemeinsamen genetischen Sprache Der genetische Code ist nahezu universell und wird von so verschiedenen Organismen wie Bakterien und Menschen benutzt. Das RNA-Codon CCG zum Beispiel wird von allen untersuchten Organismen in die Aminosäure Prolin translatiert. Im Labor können Gene auch nach Übertragung von einer Art auf die andere korrekt transkribiert und translatiert werden (Abbildung 16.6). Als eine wichtige Anwendung dieser Universalität kann man Bakterien durch Einbau des menschlichen Insulingens dazu bringen, Insulin zu synthetisieren, ein Produkt, das Zuckerkranke benötigen. Solche Anwendungsmöglichkeiten haben zu einer aufregenden Entwicklung der Biotechnologie geführt, über die Sie in Kapitel 19 noch Einzelheiten erfahren werden. Es gibt aber einige interessante Ausnahmen von der Universalität des genetischen Codes. In einigen einzelligen Eukaryoten, den Ciliaten (zu ihnen gehört auch das bereits erwähnte Pantoffeltierchen Paramecium, siehe Abbildung 7.23b), fanden Biologen eine Variante des StandardCodes. In diesen Organismen werden die Basentripletts UAA und UAG nicht als Stopsignale gelesen wie in anderen Organismen, sondern als Glutamin-Codon. Forscher haben in der DNA von Mitochondrien und Chloroplasten noch weitere Abweichungen vom StandardCode entdeckt; diese extra-chromosomale DNA codiert für eine Reihe von Proteinen der betreffenden Organellen. Obwohl die Biologen noch nicht verstehen, wie sich diese Variationen des genetische Codes im Laufe der Evolution entwickelt haben, steht für sie die evolutionäre Bedeutung des fast universellen Charakters des genetischen Codes außer Frage. Eine gemeinsame Sprache, die heute von allen lebenden Organismen benutzt wird, muss sehr dicht am Ursprung des Lebens entstanden sein - früh genug, um von jenen Urformen verwendet zu werden, welche die Vorfahren aller heute existierender Lebewesen sind, angefangen von den einfachsten Bakterien bis hin zu den kompliziertesten Pflanzen und Tieren. Das gemeinsame genetische Vokabular belegt die Verwandtschaft aller Organismen auf dieser Erde. Wir haben nun die Entschlüsselung und die evolutionäre Bedeutung des genetischen Codes besprochen und können uns jetzt ausführlicher den Vorgängen während der Transkription und der Translation zuwenden. 16.5 Das Wörterbuch des genetischen Codes. Die drei Basen eines mRNA-Codons werden hier als die erste, zweite und dritte Base bezeichnet. Üben Sie den Gebrauch des Code-Wörterbuches, indem Sie die vier Codons aus Abbildung 16.4 suchen. Das erste, UGG, ist das einzige Codon für die Aminosäure Tryptophan. Die meisten Aminosäuren werden jedoch durch zwei oder mehr Codons verschlüsselt. So stehen die beiden Codons UUU und UUC für die Aminosäure Phenylala-nin (Phe). Wird eines dieser beiden Codons auf dem mRNA-Molekül gelesen, so wird Phenylalanin in die wachsende Polypeptidkette eingebaut. Die beiden Codons UUU und UUC sind also im genetischen Code gleichbedeutend (synonym). Als Besonderheit steht das Codon AUG nicht nur für die Aminosäure Methionin (Met), sondern dient auch als Startsignal der Translation. Die Ribosomen sind die Orte der Proteinsynthese: Sie beginnen am AUG-Codon mit der Translation der mRNA. Drei der 64 Codons dienen als Stopsignale. Jedes der drei Stopcodons signalisiert das Ende der genetischen Botschaft, und die fertige Polypeptidkette wird vom Ribosom gelöst.