Blätter zur Vorlesung - Institut für Verteilte Systeme
Werbung

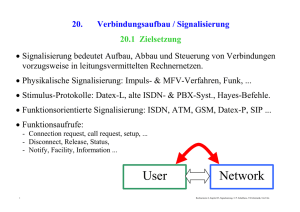
16. System Area Networks - SAN 16.1 Grid- und Cluster Computing SAN - System Area Networks mit 10-300m Radius: - SCI, Infiniband, Quadrics, Myrinet, Gigabit-Ethernet …, - Grid-Computing auch über grössere Distanzen. Supercomputing Alternativen: - Sonderanfertigung der Prozessorelemente und des Verbindungsschaltwerkes, - Hochleistungsrechner aus Serienfertigung, verbunden über ein "System Area Netz", - Kopplung von lokalen Clusters über Weitbereichsnetz (Grid-Computing). Sportlicher Wettstreit um den schnellsten Computer weltweit: - Kostenvorteile beim Einsatz von "Commodity Hardware". - Das "Interconnection Network" spielt ebenfalls eine entscheidende Rolle. Einsatzbereiche: 1 Simulation nuklearer Explosionen & Prozesse, Simulation intra- & interzellulärer Prozesse, Strömungsmechanische Simulationen, Wetter und Umweltprozesse, Militärische Aufklärung, Genomanalysen ... Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.2 Schnellste 10 Supercomputer weltweit (Nov. 2005) Rechenleistung in Teraflops für Linpack Benchmark. http://www.top500.org/lists/2005/11/ (November 2005) Autoren: Hans Meuer, E. Strohmaier, Jack Dongarra, Horst D. Simon 2 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.2.1 Rang 1: BlueGene/L, IBM Geplant sind 380 Teraflops. 131072 Power PC Prozessoren. 3 verschiedene Interconnects: - Ethernet für E/A, Diagnose & Start, - Baumstruktur für kurze Latenzzeiten, - 3D-Torus für Nachbarschaftsrouting (mit Wrap-Around). Lawrence Livermore …. 3 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.2.2 Rang 4: Columbia von SGI Gemeinsamer verteilter Speicher: - http://www.sgi.com/products/servers/altix/memory.html, - Linux Betriebssystem, - NumaLink-tm. 20 supercluster Schränke, enthaltend je: - 512 Itanium CPUs mit 1,5 oder 1,6 GHz, - 1 Terabyte Speicher pro 512 Prozessoren. Verbindung zwischen den Schränken: - SGI® NUMAlink™ InfiniBand network 10 gigabit Ethernet 1 gigabit Ethernet. Militärische Anwendungen etc. 4 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.2.3 Rang 7: Earth Simulator: War im Sommer 2004 noch auf Rang 1 plaziert. "Japanese 'Computenik' Earth Simulator shatters US supercomputer hegemony". 5120 Vektorprozessoren in 640 Racks und 640*640 Crossbar Vernetzung. Forschungsschwerpunkte: - Atmosphere and Ocean Simulation Group Advanced Perception Research Group Holistic Simulation Research Group Solid Earth Simulation Group Keine militärischen Ziele … 36 Teraflops. 5 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.2.4 Rang 18: ASCI Q, erster Teilabschnitt von 3: 14 Teraflops, 8192 Alpha CPUs, Quadrics System Area Network. 2 von 3 geplanten Sektionen installiert. 6 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.2.5 Rang 20: "SuperMac" am Virginia Institute of Polytechnic ~1100 Dual G5 Macintosh Computers (Power PC CPUs), Infiniband System Area Netzwerk. Aufrüstung auf 12 Teraflops. Video on #3: http://a772.g.akamai.net/5/772/51/9f7e36e61b692c/1a1a1aaa2198c6279 70773d80669d84574a8d80d3cb12453c02589f25382e353c32f94c32a5fb e3495f468cd3098f764db4eb4134575a5d9/va_tech_480.mov 7 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.3 Lokale Peripherieschnittstelle für "System Area Networks": 16.3.1 Hierarchie der Datenpfade in PC Systemen - PCI insbesondere: PCI-X-533: derzeit maximal 4,3 GBytes/sec, 64 Bit Übertragungsbreite, Taktrate 533 MHz, Fehlerkorrektur CPU PCI Express: - Adaptec, Intel, HP, - IBM, Microsoft, - AMD, TI … 8 ... Netz-Adapter PCI-SIG: Device Adapter Geplant bis zu 20 GigaBytes/sec, 2,5 Gigatransfers/sec (8b/10b Codierung), Host Bridge Skalierbar: 1, 2, 4, 8, 16, 32 Bit/Takt, Speicherkohärenz nicht beabsichtigt, Peripheral Connect wenig Anschlussleitungen, Serielle Übertragung, Packet Betrieb South Bridge - Host Connect Device Adapter - Hypertransport, Pentium FSB … Speicher PCI, PCI-X, PCI-Express Ethernet, Infiniband, Myrinet, Quadrics … Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.4 Aktuelle "System Area Netze" Cut-through switching. Rundspruch im "Switching Fabric". Protokollverarbeitung im Hostadapter. Protokollelemente für Barriers und Locks. Full-duplex und Tandem Betrieb möglich. Direkter Speicherzugriff in der Partnermaschine. Split transactions für schnellen Zugriff zum Hostspeicher. Latenzzeit [ μsec ] Übertragungsrate Mbytes/sec Besonderes 1,4 1333 Vert. Gem. Speicher Quadrics/Qs Net II 3 900 Split Transactions MyriNet 5 250 RDMA InfiniBand 6 860 ARDMA 1Gigabit Ethernet 17 90 WAN SCI 9 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.5 Durchsatzverhalten Am Beispiel von InfiniBand, MyriNet, GigabitEthernet. Hoher Durchsatz erst für längere Pakete. 10 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.6 Quadrics Übliche Gruppenkommunikationsoperationen in wenigen Mikrosekunden: - Split-transaktionen verstecken die Speicherlatenzen, - barrier, broadcast, reduce. Link Geschwindigkeit ist 1,3 Gbytes/sec in jeder Richtung. Adapterkarte im im Rechner: - Standard PCI-Express interface - RDMA Operationen zwischen User spaces in 64 bit Architecturen. - 64 bit virtuelle Adressierung, Spec für 8er Switch: - Andauernde Datenrate ist 900Mbytes/s - Übertragungsbreite ist 10 bits Verzögerungsbilanz am PCI-X bus für total 530 ns zwischen PCI-X: - 100 ns im sendenden Adapter, - 300 ns für einen 128 node Switch mit 20 m Kabel, - 130 ns durch den empfangenden Adapter. 11 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.7 InfiniBand: Übertragungsleistung: - Maximum Transfer Unit (MTU or payload) zwischen 256 und 4096 bytes - Aggregate Switch Bandwidth - 160Gb/sec - Maximum PCI Bus Bandwidth - 2Gb/sec InfiniBand Switch Attribute: - Blockierungsfreie Durchschaltung 8 Ports für 4X (10Gb/sec) InfiniBand, Ports konfigurierbar als 1X or 4X Cut Through Switching Standard IBTA 1.0a. CPU, PCI and Other Bus Interfaces: - 2.5 or 10 Gb/s Kupfer oder Glasfaseranschlüsse. 32-bit/66MHz PCI v2.2 Compatible Interface General Purpose IO Pins I2C Compatible Bus Durch das Netzprotokoll unterstützte Speicheroperationen: - Send/Receive über Warteschlangenpuffer. - RDMA-Write: Remote Direct Memory Access, schreibend. - RDMA-Read: Remote Direct Memory Access, lesend, 12 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess - Receive Pufferbereitstellung. Atomare RDMA Operationen: - Compare & Swap - Fetch Add atomic Transport-Service Typen: - 13 Reliable Connection (RC) , Unreliable Connection (UC), Reliable Datagram (RD), Unreliable Datagram (UD), Raw Datagram. Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.8 Myrinet: Voll-duplex 2+2 Gigabit/sec links, switch ports, interface ports. Die Firmware im Adapter kommuniziert direkt mit dem Hostprozess und überspringt die Protokollstacks im Betriebssystem. Nachrichten: - < 4 Mikroskunden zwischen Unix-Prozessen, - kontinuierliche Datenraten von 2 Gbits/s. - zuverlässige und geordnete Übertragung. Softwareschnittstellen und Bibliotheken: - MPI, VI, Sockets, and TCP/IP 14 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess 16.9 Scalable Coherent Interface (SCI) Akzeptierter ISO/ANSI/IEEE Standard, 1596-1992 Voll-Duplex mit 2*667 Mbytes/sec über Punkt-zu-Punkt Verbindungen. Garantierte Übertragung und niedrige Latenzzeiten (<1,4 mikrosec). Netzprotokoll für feingranulare Speicherkonsistenz. Implementierung als Ring- oder als Sternnetz. 15 Rechnernetze II, Sommer 2006, VS Informatik, Uni Ulm, P. Schulthess