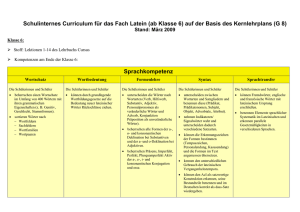
Schaltnetze und Schaltwerke (Rechensysteme A) - E
Werbung
 - E")
Schaltnetze und Schaltwerke
(Rechensysteme A)
Skriptum zur Vorlesung im WS 2005/6
Prof. Dr.-Ing. Werner Grass
Lehrstuhl für Informatik
mit Schwerpunkt Rechnerstrukturen
1 Einführung
1.2
Inhalt der Vorlesung: Erster Teil
Normales Skript
1 Einführung ........................................................................................................................................................... 4
1.1
Information und Datum........................................................................................................................ 4
1.2 Codes und Codierung .................................................................................................................................. 6
1.3
Wichtige Begriffe............................................................................................................................... 14
1.4
Literatur ............................................................................................................................................. 15
Online-Kurs: Formale Grundlagen von Schaltnetzen
Lekion L 1:
I. Grundlegende Begriffe und Notationen
Überblick
2-4: Boolesches Wort, Boolesche Sequenz
5-8: Verhalten und Struktur von Schaltnetzen
9: Notationen
Zusammenfassung
Training
II. Boolesche Funktionen und Schaltfunktionen
Lektion L 2: Verhaltensbeschreibung
Überblick
2: Boolesche Funktionen
3-5: Dualzahlen
6-8: Basiskomponenten von Schaltnetzen
Zusammenfassung
Training
Lektion L 3: Strukturbeschreibung
Überblick
2: Strukturbeschreibung durch Graphen
3-5: Schaltnetzstruktur
6-12: Basisfunktionen für die Schaltnetzstruktur
Zusammenfassung
Training
L 4: Erweiterte Konzepte
Überblick
2-3: Analyse
4-6: Von Booleschen Werten zu Booleschen Wörtern
7: Schaltungsoptimierung
8: Modularer Aufbau
Zusammenfassung
Training
1 Einführung
1.3
III. Boolesche Algebra
Lektion L 5: Termdarstellung
Überblick
2-5: Grundlegende Definitionen
6-10: Def. Boolescher Term
11-13: Termdarstellung - Wertetabelle
14-17: Boolesche Terme über Funktionen
18-20: Operatoren und partielle Ordnung
Zusammenfassung
Training
Gesetze der Booleschen Algebra
Lektion L 6: Grundlegende Gesetze und Definitionen
Überblick
2-5: Grundlegende Definitionen
6-9: Erweiterte Definitionen
Zusammenfassung
Training
Lektion L 7: Darstellung von Booleschen Funktionen als Terme
Überblick
2-3: Einführung 'Entwicklungssatz'
4-7: Anwendung 'Entwicklungssatz'
8: Darstellungstheorem
Zusammenfassung
Training
Lektion L 8: Disjunktive und Konjunktive Normalform
Überblick
2-3: Von Wertetabellen zur Termdarstellung
4-5: Min-Terme, Max-Terme
Zusammenfassung
Training
Normales Skript:
Ergänzung zu Lektion 8: 8a Schaltnetzoptimierung
definiert.
Fehler!
Textmarke
nicht
8a.1 Einführung und Begriffe
Fehler! Textmarke nicht definiert.
8a.2 Methode des Iterativen Consensus zur Bestimmung aller Primimplikanten Fehler!
Textmarke
nicht definiert.
8a.3 Optimale Auswahl von Primimplikanten
Fehler! Textmarke nicht definiert.
8a.4 Grafische Methode zur näherungsweisen Optimierung von Booleschen Funktionen Fehler!
Textmarke nicht definiert.
Wichtige Begriffe Fehler! Textmarke nicht definiert.
1 Einführung
1.4
1 Einführung
1.5
1 Einführung
1.1 Information und Datum
Informatik hat etwas mit Information zu tun. Aber was versteht man unter dem Begriff Information? Beginnen
wir mit Beobachtungen aus unserem täglichen Leben, die im Bezug zum Begriff der Information stehen.
Zwei Menschen telefonieren miteinander. Beim Sprechen werden Schallwellen erzeugt, die durch das im
Telefon eingebaute Mikrofon in elektromagnetische Wellen transformiert werden. Das Telefon des
Gesprächspartners empfängt diese elektromagnetischen Wellen. Der Lautsprecher wandelt sie wieder in
Schallwellen, so dass sie durch das Ohr des Empfängers erfasst werden können.
Wir beobachten an diesem Beispiel, dass Mitteilungen über ein Telefon durch Übertragung physikalischer
Größen erfolgen. Entsprechendes gilt auch bei der Übertragung von Bildern.
Definition: Signal, Signalübertragung
Die Darstellung einer Mitteilung durch zeitliche Veränderungen einer physikalischen Größe
heißt Signal. Eine Weitergabe einer Mitteilung erfolgt durch Signalübertragung.
Die Herstellung einer Verbindung zum Gesprächspartner gelingt nicht immer. Dann ist ein Anrufbeantworter
eine gute Möglichkeit, ein Sprachsignal zu speichern. Text speichert man auf Papier, Plattenspeicher (disk), CD
ROM u.ä. Bei all diesen Trägern bezeichnet man den Speichervorgang als "schreiben" oder "aufzeichnen".
Definition: Inschrift, Schriftträger
Eine dauerhafte Darstellung einer Mitteilung bezeichnen wir als Inschrift. Das benutzte
Medium nennen wir Schriftträger.
Die Informatik erzeugt und verarbeitet Signale und Inschriften. Dabei genügt es oftmals, von der physikalischen
Darstellung von Mitteilungen zu abstrahieren. Bei Text interessiert beispielsweise die Zeichenfolge und nicht, ob
sie gesprochen oder geschrieben wurde und welches Medium benutzt wurde.
Definition: Nachricht, Repräsentation von Nachrichten
Abstraktionen von Inschriften und Signalen nennen wir Nachrichten. Wir repräsentieren
Nachrichten in Form von endlichen Zeichenfolgen.
Beispiel: "Position" ist eine endliche Zeichenfolge.
Beispiel: Ein Bild aus roten und weißen Punkten kann beispielsweise durch folgende
Zeichenkette beschrieben werden:
rrrwwrrwwwrwrwwwwwrwwwwwr.
Dabei bezeichne w ein weißes Feld, r ein rotes Feld und eine neue Zeile.
1 Einführung
1.6
r
r
r
w
w
r
r
w
w
w
r
w
r
w
w
w
w
w
r
w
w
w
w
w
r
Nachrichten sind Gegenstände der Informatik. Signale und Inschriften sind Mittel zur Übertragung bzw.
Speicherung von Nachrichten. In diesem Kapitel beschäftigen wir uns mit Nachrichten und solchen Zeichen, die
zur Repräsentation von Nachrichten in der Informatik eingesetzt werden.
Nun können wir uns dem Begriff Information zuwenden.
Definition: Information, Kontext, Interpretationsvorschrift
Information ist die einer Nachricht zugeordnete Bedeutung. Damit eine solche Zuordnung
möglich ist, muss man den Kontext der Nachricht kennen. Die kontextabhängige Ermittlung
der Information aus einer Nachricht nennen wir Interpretationsvorschrift.
Interpretationsvorschrift
Nachricht
→ Information
Die gleiche Nachricht wird unter verschiedenen Kontexten unterschiedlich interpretiert.
Beispiel: Die Zeichenfolge "Passat" kann je nach Kontext ein Autotyp oder ein Wind sein.
Gleiche Nachrichten können aber auch im gleichen Kontext unterschiedlich interpretiert werden. Solche
Nachrichten heißen mehrdeutig.
Beispiel: Die Zeichenfolge "Position einer Person" kann die Aufgabenstellung in einem Betrieb
kennzeichnen oder den Ort, an dem sich ein Mitarbeiter des Betriebs aufhält. Hier kann nicht
immer garantiert werden, dass der Kontext eine eindeutige Interpretation erzwingt.
Wir kennen auch inkonsistente Nachrichten, das sind solche, denen sich in einem Kontext keine Information
zuordnen lässt.
Beispiel: Ein Kreter sagt: "Alle Kreter lügen"
Die Informatik hat u.a. die Aufgabe, Nachrichten zu interpretieren. Hierzu muss ein Kontext und eine damit
verbundene Interpretationsvorschrift festgelegt werden. Mehrdeutigkeiten sind zu klären und Inkonsistenzen zu
vermeiden.
Jeder Nachricht kann dann im entsprechenden Kontext eine Bedeutung zugeordnet werden.
Definition: Daten
Das Paar
Nachricht, zugeordnete Information
nennen wir Datum.
Ein Datum ist also eine bedeutungstragende Nachricht.
Definition: Datenverarbeitung
Eine bedeutungstreue Verarbeitung von Nachrichten nennen wir Datenverarbeitung.
1 Einführung
1.7
Beispiel: Nachricht: "Dies ist ein Satz."
Das Ergebnis einer Verarbeitung kann beispielsweise das Sortieren der Buchstaben, Satz- und
Leerzeichen sein: "aDeeiiinSsttz. "
Bei einer Interpretationsvorschrift "Deutsche Sprache" ist diese Verarbeitung natürlich nicht
bedeutungstreu, da das Ergebnis im Kontext der deutschen Sprache keinen Sinn ergibt.
Anders ist die Situation, wenn die Interpretationsvorschrift "Zeichenfolge" lautet, etwa mit
dem Ziel Zeichenfolgen zu analysieren (z.B.: Häufigkeitsverteilung der Buchstaben). Dann ist
das Ergebnis der Berechnung durchaus bedeutungstreu, da "aDeeiiinSsttz. " eine Zeichenfolge
darstellt.
1.2 Codes und Codierung
Notation:
` 0 = {0,1, 2,3, 4,…} :
` = {1, 2,3, 4,…} :
\:
Menge der natürlichen Zahlen einschließlich der 0
Menge der natürlichen Zahlen
Menge der reellen Zahlen
B = {O, L} :
Menge der Booleschen Werte
B = B
×
B
× " ×
B :
n
Menge der n-stelligen Booleschen Wörter
n mal
B* :
bn bn −1 " b1 :
Menge beliebiger, endlich langer Boolescher Wörter
n-stelliges Wort über B = {O, L} , d.h. bi ∈ B für 1 ≤ i ≤ n
B 2 = B × B = { OO , OL , LO , LL
A, E :
A*, E * :
Menge der zweistelligen Booleschen Wörter; die Klammerung
kann auch entfallen
endliche, linear geordnete Zeichenvorräte
Menge beliebiger, endlich langer Wörter über den Alphabeten
A bzw. E
Sei x ∈ \; x ∈ ] : x ≤ x < x + 1 :
A:
}:
größte ganze Zahl ≤ x
Anzahl der Element in einer Menge A
In diesem Abschnitt betrachten wir die Darstellung von Nachrichten in Form von Zeichenfolgen über einem
endlichen, linear geordneten Zeichenvorrat A , auch Alphabet genannt.
Beispiel: Sei A = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}. Wegen 0 < 1 < 2 < 3 < 4 < 5 < 6 < 7 < 8 < 9 ist
dieser Zeichenvorrat linear geordnet. Für jedes Paar von unterschiedlichen Zeichen aus A
kann nämlich gesagt werden, welches größer und welches kleiner ist. Auch die Zeichen des
Schriftalphabets sind linear geordnet: a < b < c < d < .......
Aus technischen Gründen spielt der Zeichenvorrat B = {O, L} in der Rechnertechnik eine besondere Rolle. Wir
werden später genauer darauf eingehen, jetzt legen wir einfach fest: O < L. Die Werte O und L bezeichnen wir
auch als Boolesche Werte (nach dem Mathematiker George Boole 1815-1864).
1 Einführung
1.8
Ein Element der Menge B nennen wir Binärzeichen oder Bit (binary digit).
Aus den Elementen eines Zeichenvorrats lassen sich endliche Zeichenfolgen bilden, die wir Wörter nennen.
Werden die Elemente eines Zeichenvorrats als Ziffern interpretiert, sprechen wir auch von Zahlen anstatt von
Wörtern. Wörter fügen wir häufig in spitze Klammern, Zahlen dagegen grundsätzlich nicht.
Beispiel: wort , 7384
Die Menge A * der endlichen Zeichenfolgen über einem Zeichenvorrat A nennen wir Menge der Wörter über
A . Dabei ist die Länge der Wörter in A* beliebig, aber endlich.
Beispiel: Sei A = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}. Wir betrachten endliche Zeichenfolgen der
maximalen Länge 2, dann sind unter anderem alle Zahlen von 0, 1, ..., 98, 99 Elemente der
Menge A *.
Bei der Menge B* = {O, L} * sprechen wir von Binärwörtern. Häufig betrachten wir Mengen von Binärwörtern
einer festen Stellenzahl n ∈ ` : B n = {O, L} ; man spricht in diesem Fall auch von n-Bit-Wörtern.
n
Beispiel: Menge aller 2-Bit-Wörter:
B2 = {O, L} = { OO , OL , LO , LL } .
2
Abbildungen zwischen Zeichenvorräten A → E und zwischen den Wörtern von Zeichenvorräten A* → E *
heißen Codes (oder Codierung).
Ein Code ist also im Allgemeinen eine (injektive) Abbildung der Form:
c: A* → E *
Wichtige Spezialfälle entstehen durch die Einschränkung auf feste Stellenzahlen und damit auf die Teilmengen
A n ⊂ A * und E m ⊂ E * :
mit n, m ∈ `
c: A n → E m
oder auf andere spezifische Teilmengen von A * und E * .
c: A ' → E '
mit A ' ⊆ A * und E ' ⊆ E *
Bei Spezialisierungen auf Mengen Boolescher Wörter schreiben wir B statt A bzw. E
Beispiel:
Seien: n = 1, m = 2, A = {0,1, 2,3} , B2 = { OO , OL , LO , LL } ⊂ B * und c1 : A → B 2
mit c1(0) = ⟨OO⟩, c1(1) = ⟨OL⟩, c1(2) = ⟨LO⟩, c1(3) = ⟨LL⟩.
Beispiel:
Seien: A = {0,1, 2,3} , B ' = { O , LO , LLO , LLL } ⊂ B * und c2 : A → B ' mit c2(0) =
⟨O⟩, c2(1) = ⟨LO⟩, c2(2) = ⟨LLO⟩, c2(3) = ⟨LLL⟩. Die Codewörter entstehen durch
Anwendung einer speziellen Konstruktionsvorschrift, auf die hier nicht eingegangen werden
kann.
In dieser Einführung sehen wir vor, dass die Abbildungen umkehrbar eindeutig sind. Die Umkehrabbildung zum
Code c nennen wir Decodierungs-Abbildung oder kurz Decodierung d.
d : {c(a ) : a ∈ A '} → A ' ,
dabei bedeutet {c(a ) : a ∈ A '} die Menge aller Wörter, die durch Anwendung der Funktion c auf die Menge der
Elemente aus A ' entstehen. Da die Abbildungen umkehrbar eindeutig sein sollen, gilt für jedes Element a ∈ A ' :
1 Einführung
1.9
d (c ( a )) = a
Beispiel: A = {0,1, 2,3} , B ' = { O , LO , LLO , LLL } ⊂ B * und c2 : A → B ' mit c2(0) =
⟨O⟩, c2(1) = ⟨LO⟩, c2(2) = ⟨LLO⟩, c2(3) = ⟨LLL⟩.
Außerdem sei d 2 : B → A ' mit d2(⟨O⟩) = 0, d2(⟨LO⟩) = 1, d2(⟨LLO⟩) = 2, d2(⟨LLL⟩) = 3.
Damit gilt:
d(c(0)) = d(⟨O⟩) = 0, d(c(1)) = d(⟨LO⟩) = 1, d(c(2)) = d(⟨LLO⟩) = 2, d(c(3)) = , d(⟨LLL⟩) = 3.
1.2.1 Beispiele für Codes
Wir betrachten Binärcodes, die jedes zu codierende Zeichen a ∈ A auf ein n-Bit-Wort aus B n abbilden:
c:A → E
mit E ⊆ B n
(erlaubt partielle Abbildungen)
Ein weit verbreiteter Code mit der Länge n = 7 ist der ASCII – Code (ASCII: American Standard Code for
Information Interchange), der in Bild 1.1 dargestellt ist. Jedem Zeichen auf der Tastatur ist ein rechnerinterner
Code zugewiesen.
c7 c6 c5
c4 c3 c2c1
OOO
OOL
OOOO
NUL
DLE
OOOL
SOH
DC1
OOLO
STX
OOLL1
OLO
OLL
LOO
LOL
LLO
LLL
0
@
P
`
p
!
1
A
Q
a
q
DC2
"
2
B
R
b
r
ETX
DC3
#
3
C
S
c
s
OLOO
EOT
DC4
$
4
D
T
d
t
OLOL
ENQ
NAK
%
5
E
U
e
u
OLLO
ACK
SYN
&
6
F
V
f
v
OLLL
BEL
ETB
´
7
G
W
g
w
LOOO
BS
CAN
(
8
H
X
h
x
LOOL
HT
EM
)
9
I
Y
I
y
LOLO
LF
SUB
*
:
J
Z
j
z
LOLL
VT
ESC
+
;
K
[
k
{
LLOO
FF
FS
,
<
L
\
l
|
LLOL
CR
QS
-
=
M
]
m
}
LLLO
SO
RS
.
>
N
^
n
LLLL
SI
US
/
?
O
_
o
DEL
Bild 1.1: ASCII-Code; Beispiele cASCII(A) = ⟨LOO OOOL⟩
Die sieben Stellen reichen zur Darstellung von 52 Groß- und Kleinbuchstaben, 10 Ziffern sowie 66 Steuer- und
Sonderzeichen. Insgesamt kann man mit n-stelligen Binärwörtern 2n unterschiedliche Binärwörter (Elemente der
Menge B n ) bilden. Bei n = 7 also 27 = 128 unterschiedliche Binärwörter.
1 Einführung
1.10
Für die Beurteilung von Codes im Zusammenhang verschiedener Anwendungen spielt der Hammingabstand eine
bedeutende Rolle.
Seien a, b Binärwörter gleicher Länge n: a = an an −1 " a1 , b = bn bn −1 " b1 ,
Die Anzahl der Stellen, in denen sich die Wörter a und b unterscheiden, nennen wir ihren Hammingabstand
(nach dem Mathematiker Richard Wesley Hamming 1915 -1998).
Definition: Hammingabstand zweier Binärwörter
Der Hammingabstand zweier Binärwörter kann damit wie folgt definiert werden:
Ham_abst: A × A → ` mit A ⊆ Bn
mit Ham_abst ( an an −1 " a1 , bn bn −1 " b1
n
) = ∑d
i =1
i
,
1, falls ai ≠ bi
wobei di =
0 sonst
Beispiel: Seien a = OLLOL und b = OOLLL , dann sind d5 = 0, d4 = 1, d3 = 0, d2 = 1, d1
= 0 und
Ham_abst ( OLLOL , OOLLL
5
) = ∑d
i =1
i
= 0 +1+ 0 +1+ 0 = 2 .
Definition: Hammingabstand einer Codierungsabbildung
Der Hammingabstand einer Codierungsabbildung c
c:A → E
mit E ⊆ B n
ist durch den kleinsten Hammingabstand zwischen je zwei unterschiedlichen Binärwörtern aus
E gegeben (a, b ∈ A , c(a), c(b) ∈ E , aus a ≠ b folgt c(a) ≠ c(b)).
Ham_abst(c) = min{Ham_abst(c(a), c(b)): (a, b ∈ A ) ∧ a ( a ≠ b ) ).
Bei vielen Codes ist der Hammingabstand der Codierungsabbildung 1. Ein großer Hammingabstand ist dann
erforderlich, wenn man Fehler, wie sei etwa bei der Übertragung von Zeichenketten oder deren Abspeicherung
entstehen können, mit großer Wahrscheinlichkeit als solche erkennen oder sogar korrigieren will.
Beispiel: Seien A = {⊕, ⊗} , E ' = { OOO , LLL
} , d.h.
E ' ⊆ B3 . Obwohl wir also
zur Codierung der zwei Zeichen nur einstellige Binärwörter brauchen, wählen wir
Binärwörter, die jeweils aus drei gleichen Binärzeichen bestehen.
Sei c ( ⊕ ) = OOO und c ( ⊗ ) = LLL .
Dann ist Ham_abst(c) = min{Ham_abst(c ( ⊕ ) , c ( ⊗ ) ) = 3. Nehmen wir an, dass wir
die Binärwörter Bit für Bit über eine Leitung übertragen und dass Störungen auftreten
können. Sie machen sich dadurch bemerkbar, dass einzelne Stellen unvorhersehbar
von O nach L bzw. L nach O verfälscht werden. Der Empfänger erhält bei einer solchen Störung ein Binärwort, für das gilt: e ∈ B3 aber e ∉ E ' . Das empfangene Codewort ist also nicht zulässig.
1 Einführung
1.11
Nehmen wir an, dass wir bei einer bestimmten Übertragung das Wort OOO
sen-
den, der Empfänger aber OLO empfängt. Der Empfänger kennt das empfangene
Wort und die Menge zulässiger Codewörter E ' = { OOO , LLL
} . Er weiß daher
mit Sicherheit, dass ein Fehler bei der Sendung aufgetreten ist. Dies nennt man
Fehlererkennung.
Kann der Empfänger darüber hinaus ermitteln, welche der drei Stellen mit höchster
Wahrscheinlichkeit gestört sind, spricht man von Fehlerkorrektur. Sind die Stellen
bekannt, muss man bei Binärwörtern nur den jeweils anderen Wert einsetzen, also O
für L oder L für O.
Im Beispiel gelingt dies tatsächlich, wenn wir annehmen, dass die Wahrscheinlichkeit
für die Verfälschung einer Stelle höher ist als die Wahrscheinlichkeit für eine
Verfälschung von zwei Stellen und die wiederum höher als die Wahrscheinlichkeit für
die Verfälschung von drei Stellen usw.
Fehlerkorrektur:
Der Empfänger bildet den Hammingabstand des empfangenen Codewortes zu allen
Codewörtern der Menge E ' = { OOO , LLL } . Es werde OLO empfangen.
Ham_abst ( OLO , OOO
Wenn OOO
) =1;
gesendet und die zweite Stelle verfälscht wurde, dann wird OLO
empfangen.
Ham_abst ( OLO , LLL
)=2
Wenn LLL gesendet und die Stellen eins und drei verfälscht wurden, dann wird
ebenfalls OLO empfangen.
Dieser zweite Fall mit zwei gestörten Stellen ist laut Annahme aber unwahrscheinlicher als der erste Fall. Daher kann der Empfänger das Wort OLO zum Wort
OOO korrigieren und hat damit mit großer Wahrscheinlichkeit das tatsächlich ge-
sendete Wort ermittelt.
Hinweis: Das Aneinanderreihen von drei gleichen Wörtern ist keine gute Methode,
um mit Fehlern umzugehen. Sie dient hier nur zur Erklärung der Begriffe Fehlererkennung und Fehlerkorrektur.
Aufgabe: Schreiben Sie die drei Binärwörter auf, die nicht Element von
E ' = { OOO , LLL } sind, und die der Empfänger in das Wort OOO korrigiert.
Die zwei Zeichen der Menge A = {⊕, ⊗} könnte man mit den einstelligen Binärwörtern O und L codieren.
Im Beispiel haben wir drei Stellen verwendet. Man nennt eine solche Codierung stellen-redundant. Redundanz
ist immer erforderlich, um Fehler zu erkennen. Mehr Redundanz ist erforderlich, um Fehler sogar zu korrigieren.
Definition: Stellen-redundante Codierung
Ein Code
c:A → E
mit E ⊆ B n
1 Einführung
1.12
heißt stellen-redundant, wenn gilt n > log 2 A , wobei log 2 den Logarithmus zur Basis 2, A
die Anzahl der Elemente in A und : Rundung auf die nächst größere ganze Zahl bedeutet.
Beispiel: Sei A = {⊕, ⊗, :} . Dann gilt: A = 3,
log 2 A = 2 , jeder Code mit n > 2 ist
stellen-redundant.
Beispiel: 2.7 = 3 , 3 = 3
Ist ein n-stelliger Code stellen-redundanzfrei, dann schreiben wir:
c : A → Bn ,
auch dann, wenn A keine Zweierpotenz darstellt und damit 2n - A Wörter der Menge B n nicht genutzt
werden.
Im Falle n-stelliger stellen-redundanter Codes schreiben wir:
c:A → E
mit E ⊆ B n ,
da jetzt höchstens die Hälfte der Wörter der Menge B n genutzt werden, wir codieren ja mit mindestens einer
Stelle mehr als unbedingt notwendig wäre.
Eine systematische Methode zur Einführung nützlicher Redundanz mit der Möglichkeit der Fehlererkennung ist
das Anketten eines Paritäts-Bits an die Wörter der Bildmenge eines redundanzfreien Codes.
Sei ein stellen-redundanzfreier Code
c1 : A → B n
gegeben. Wir konstruieren dazu einen stellen-redundanten Code:
c2 : A → E
mit E ⊆ B n +1
durch Ankettung eines Paritätsbits. Hierzu definieren wir eine Funktion pb zur Bestimmung des Wertes des
Paritätsbits. Für jedes Element a ∈ A legen wir fest:
c2 ( a ) = c1 ( a ) pb ( c1 ( a ) ) .
Dabei bezeichnet der Operator "| " die Konkatenation, d.h. das nebeneinander Anordnen von Binärwörtern.
c1 ( a ) bezeichnet ein n-stelliges Binärwort e = en en −1 " e1 und pb ( c1 ( a ) ) ∈ {O, L}
Es gilt:
pb: B n → B mit:
O, falls qs ( e ) gerade
pb ( e ) =
L, falls qs ( e ) ungerade
und
qs: B n → `
mit
qs ( en en −1 " e1
n
) = ∑d
i =1
i
,
1, falls ei = L
wobei di =
0 sonst
qs(e) bezeichnet also die Anzahl der Zeichen L in e (Quersumme).
1 Einführung
1.13
Beispiel: Seien A = {⊕, ⊗, :} und c1 ( ⊕ ) = OO , c1 ( ⊗ ) = OL , c1 ( : ) = LO .
Dann gilt:
da qs ( OO
) =0
c2 ( ⊕ ) = OO
O =
OOO ,
c2 ( ⊗ ) = OL
L =
OLL ,
da qs ( OL
) =1
(ungerade Anzahl)
c2 ( ⊗ ) = LO
L =
LOL ,
da qs ( LO ) = 1.
(ungerade Anzahl)
(gerade Anzahl)
Jedes Binärwort aus E = { OOO , OLL , LOL } besitzt eine gerade Anzahl von
Zeichen L. Bei Verfälschung von genau einem Wert entsteht eine ungerade Anzahl
von Zeichen L in dem verfälschten Wort. Wird also ein Wort mit ungerader Anzahl
von Zeichen L empfangen, dann ist sicher eine Verfälschung aufgetreten.
Bei Einsatz von Paritätsbits kann man daher einen Teil der möglichen Verfälschungen erkennen.
Aufgabe: Geben Sie ein Beispiel für die Verfälschung mehrerer Stellen an, die mit
dieser Methode nicht erkannt werden kann.
Will man Fehler nicht nur erkennen, sondern möglichst auch korrigieren, dann benötigt man mehr redundante
Stellen. Wir haben weiter oben schon die Möglichkeit kennen gelernt, ein Codewort einfach dreimal zu verschicken.
Sei ein stellen-redundanzfreier Code
c1 : A → B n
gegeben. Wir konstruieren dazu einen stellen-redundanten Code:
c2 : A → E
mit E ⊆ B3n
mit c2 ( a ) = c1 ( a ) c1 ( a ) c1 ( a )
Wird dann eine Stelle verfälscht, dann betrifft dies nur eines der drei Wörter. Die beiden übrigen Wörter bleiben
korrekt. Vergleicht man daher die drei empfangenen Wörter, und bestimmt die beiden gleichen Wörter, dann
kann man c1 ( a ) daraus ermitteln.
Beispiel: Es werde c2 ' ( a ) = c1 ( a ) c1 ' ( a ) c1 ( a ) empfangen. Das erste und dritte Wort sind
gleich und bestimmen das als korrekt angesehenen Wort c1 ( a ) .
Die geschilderte Methode ist sehr aufwändig, da man 2n redundante Stellen benötigt. Mit einer einfachen
Modifikation erreicht man das gleiche Ziel mit weniger redundanten Stellen.
Sei ein stellen-redundanzfreier Code
c1 : A → Bn
gegeben. Wir konstruieren zu jedem Codewort c1(a) die Paritätsstelle und verdoppeln das so geschaffene und um
eine Stelle verlängerte Wort:
c2 : A → E
mit E ⊆ B
2⋅( n +1)
mit c2 ( a ) = c1 ( a ) pb ( c1 ( a ) ) c1 ( a ) pb ( c1 ( a ) )
1 Einführung
1.14
Wird dann eine Stelle verfälscht, dann betrifft dies nur eines der beiden Wörter c1 ( a ) pb ( c1 ( a ) ) . Durch Auswertung der Paritätsstelle können wir erkennen, welches der beiden Wörter gestört wurde, das andere ist korrekt.
Beispiel: Es werde c2 ' ( a ) = c1 ' ( a ) pb ( c1 ( a ) ) c1 ( a ) pb ( c1 ( a ) ) empfangen. Im ersten Wort
erkennen wir einen Fehler bei der Überprüfung des Paritätsbits. Das zweite Teilwort liefert uns
das gewünschte Wort c1 ( a ) .
Die modifizierte Methode ist immer noch sehr aufwändig. Man benötigt zwar nur noch n + 2 redundante Stellen,
doch gibt es "intelligentere Verfahren" die weit weniger Stellen benötigen und das gleiche leisten. Um solche
Verfahren zu beschreiben, fehlen uns hier die Zeit und mathematische Grundkenntnisse.
Solche Verfahren haben eine große Bedeutung im Internet und bei der Abspeicherung von Binärwörtern im
Arbeitsspeicher und auf dem Plattenspeicher eines Rechners.
1.2.2 Zahlendarstellung
Wir werden uns in einem späteren Kapitel ausführlicher mit Zahlendarstellungen im Rechner und Rechenoperationen beschäftigen. Hier wollen wir lediglich einige einfache Grundlagen legen.
Das Dezimalzahlenssystem ist uns so vertraut, dass wir keinen Unterschied mehr machen zwischen der Zahl,
einem Wort über der Menge der Ziffern {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} und ihrem Wert. So hat die Zahl 287 den
Wert 2*102 + 8*101 + 7*100. Der Zahl 10 kommt hier eine Sonderrolle zu, man nennt sie die Basis B. Ziffern
sind alle Werte aus ` 0 im Bereich 0 bis B – 1.
Einen solchen systematischen Zusammenhang zwischen Zahl und Wert nennt man Stellenwertsystem. Zur Darstellung führen wir eine Funktion wertB ein. Sie liefert zu einer Zahl mit der Basis B den zugehörigen Wert. Wir
konkretisieren dies gleich für die Basen B = 10 und B = 2:
wert10: {0,1, 2,3, 4,5, 6, 7,8,9} → ` 0
n
n
mit wert10 ( zn zn −1 " z1 ) = ∑ zi *10i −1
i =1
Wie allgemein üblich verzichten wir auf die Klammerung von Zahlen, die wir bei Wörtern eingeführt haben.
In der rechnerinternen Darstellung verwendet man u.a. das Dualzahlensystem, eine spezielle Form eines binären
Zahlensystems. (Es gibt eine Vielzahl anderer binärer Zahlensysteme). Dualzahlen besitzen die Basis 2 und können als Wort über der Menge der Ziffern {0, 1} dargestellt werden.
wert2: {0,1}n → ` 0
n
mit wert2 ( an an −1 " a1 ) = ∑ ai * 2i −1
i =1
Um Dualzahlen von Dezimalzahlen zu unterscheiden, fügen wir in Zweifelsfällen die Indizes 2 bzw. 10 an.
Beispiel: Wir betrachten die Zahlen 1110 und 112
wert10 (1110 ) = 1*101 + 1*100
wert2 (112 ) = 1*21 + 1*20
Bei Einhaltung der angegebenen Randbedingungen ist jeder Zahl in einem Stellenwertsystem umkehrbar eindeutig ein Wert zugeordnet. Zahlen verschiedener Basen lassen sich ineinander umrechnen.
1 Einführung
1.15
Die Wandlung einer Dualzahl in eine Dezimalzahl ist sehr einfach: Da die Ziffern 0 und 1 und die Basis 2 auch
n
im Dezimalzahlensystem gültig sind, berechnet man einfach die Summe
∑a *2
i =1
i −1
i
unter Anwendung der
Rechenregeln im Dezimalzahlensystem.
Beispiel: 100102 = 1*24 + 0*23 + 0*22 + 1*21 + 0*20
1.3
10
= 1610 + 2 10 = 1810
Wichtige Begriffe
In diesem Abschnitt geben wir Begriffe an, die im Text besprochen wurden. An Hand dieser Liste können Sie
überprüfen, ob Sie alle wichtigen Begriffe beherrschen. Ausnahmsweise geben wir in diesem Kapitel auch
Kurzantworten:
Bit: Ein Element der Menge B = {O, L}
Binärzeichen = Bit
Code: (nicht unbedingt eindeutige)
Abbildung der Form:
c: A* → E *
A * und E * Wörter aus Zeichenvorräten A bzw. E
Codierung = Code
Codewort:
endliche Zeichenfolgen aus beliebigem Zeichenvorrat
Daten: Ein Datum ist eine bedeutungstragende Nachricht
Datenverarbeitung: bedeutungstreue Verarbeitung von Nachrichten
Decodierung: Umkehrabbildung zum Code c nennen wir Decodierung d
d : {c(a ) : a ∈ A '} → A ' ,
Dualzahl: Zahl im Stellenwertsystem mit der Basis 2
Fehlererkennung: empfangenes Codewort gehört nicht zu den vereinbarten;
Paritybit
kann
erkennen,
wenn
eine
ungerade
Zahl
von
Stellenverfälschungen aufgetreten ist.
1-Fehlerkorrektur: Bestimmung
der
Stelle
eines
Codewortes,
die
am
wahrscheinlichsten gestört wurde und Veränderung dieser Stelle von O
nach L oder von L nach O.
Hammingabstand: Anzahl der Stellen, in denen sich zwei Binärwörter a und
b unterscheiden
Inschrift: dauerhafte
Darstellung
einer
Mitteilung
(Beispiel
auf
Magnetplattenspeicher)
Interpretationsvorschrift: kontextabhängige
einer Nachricht
Ermittlung
der
Information
aus
1 Einführung
Konkatenation von Wörtern: a1a2 ....am
1.16
b1b2 ....bn = a1a2 ....am b1b2 ....bn
Nachricht: Abstraktionen von Inschriften und Signalen
Bn → B
Paritätsbit: Berechnungsvorschrift: pb:
O, falls qs ( e ) gerade
pb ( e ) =
L, falls qs ( e ) ungerade
mit:
Repräsentation von Nachrichten: endliche Zeichenfolgen
Schriftträger: Medium zur dauerhafte Darstellung einer Mitteilung
Signal: zeitliche Veränderungen einer physikalischen Größe
Stellenredundanz: Ein Code c : A → E
mit E ⊆ B n heißt stellen-redundant, wenn
gilt n > log 2 A
Wert von Zahlen in Stellenwertsystemen: Beispiel Dezimalzahl:
1.4
( zn
n
zn −1 " z1 ) = ∑ zi *10i −1
i =1
Literatur
Dieses Kapitel 1 orientiert sich an:
Broy, Manfred: Informatik; Eine grundlegende Einführung, Teil II; Berlin: Springer Verlag
Richter, Reinhard; Sander, Peter; Stucky Wolffried: Der Rechner als System: Organisation, Daten, Programme:
Stuttgart: Teubner-Verlag
Zimmermann, Wolf: Signale, Datum, Information;
http://www.informatik.uni-halle.de/swt/Teaching/info1/folien/signal.pdf
1 Einführung
1.17