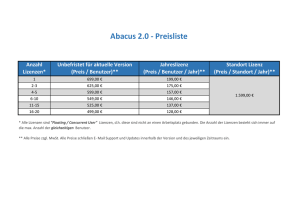
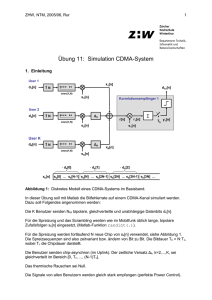
Kapitel 5 Das System IDEE
Werbung

IDEE Ein System zur intelligenten und flexiblen Dateneingabe bei internetbasierten Beratungssystemen Diplomarbeit im Fach Informatik vorgelegt von cand. Inform. Frank Lierler Betreuer: Prof. Dr. Frank Puppe Dipl.-Inform. Mitchel Berberich Lehrstuhl für Künstliche Intelligenz und Angewandte Informatik Informatik VI Universität Würzburg ERKÄRUNG Ich erkläre hiermit, die vorliegende Diplomarbeit selbständig verfasst und keinen anderen als die angegebenen Quellen und Hilfsmittel benutzt zu haben. …………………………………….. Würzburg, den 07.01.2003 2 Inhalt Kapitel 1 Einleitung ..........................................................................................................................5 Kapitel 2 Theoretische Grundlagen zur Dateneingabe .....................................................................7 2.1 Dateneingabe bei bestehenden Systemen ...............................................................................7 2.1.1 ALBIS Praxis-Dialog ......................................................................................................7 2.1.2 StudiBot (Universität Karlsruhe) .....................................................................................9 2.1.3 SAP Jobberater ..............................................................................................................10 2.1.4 1882direkt Kontoeröffnungs-Beratung..........................................................................11 2.1.5 Neckermann Produktberatung .......................................................................................12 2.1.6 Porsche Produktberater ..................................................................................................13 2.1.7 Ask Jeeves .....................................................................................................................15 2.1.8 Law Expert System ........................................................................................................16 2.1.9 Jano Consult ..................................................................................................................17 2.1.10 LegalCity Ratgeber Recht ...........................................................................................19 2.2.11 d3web ..........................................................................................................................20 2.2.12 PEN-Ivory....................................................................................................................22 2.2.13 Zusammenfassender Überblick über die vorgestellten Systeme .................................24 2.2 Varianten der Benutzeroberfläche von Dialogen .................................................................25 2.2.1 Dialogarten ....................................................................................................................25 2.2.2 Darstellungsmöglichkeiten ............................................................................................28 2.2.3 Fragearten ......................................................................................................................30 2.2.4 Verwendete Techniken zur Eingabe von Daten in Dialogen ........................................31 2.3 Spezifikation einer Dialogoberfläche für IDEE ...................................................................35 2.3.1 Auswahl der Dialogart ...................................................................................................36 2.3.2 Auswahl der Darstellungsart .........................................................................................37 2.3.3 Auswahl der Elemente zur Dateneingabe und Position im Dialog ...............................39 2.3.4 Entwurf eines Beispieldialoges .....................................................................................41 Kapitel 3 Computerlinguistische Grundlagen der Verarbeitung von natürlichsprachlichem Text in Computersystemen (Text Processing) ...............................................................................42 3.1 Einsatzgebiete computerlinguistischer Verfahren (ANWENDUNGEN).............................42 3.1.1 Indexieren und Abruf von textuellen Datenbanken / Volltextsuche (TextMining).......43 3.1.2 Maschinelle Übersetzung .............................................................................................43 3.1.3 Automatische Textproduktion .......................................................................................44 3.1.4 Automatische Textüberprüfung / Fehlerkorrektur ........................................................44 3.1.5 Automatische Inhaltsanalyse /Textklassifikation ..........................................................44 3.1.6 Abschnittserkennung .....................................................................................................45 3.1.7 Informations-Extraktion (IE) .........................................................................................45 3.1.8 Automatisierter Unterricht .............................................................................................46 3.1.9 Dialogsysteme und automatisierte Auskunft .................................................................46 3.1.10 Textzusammenfassung ................................................................................................46 3.3 Wiederkehrende Problemfelder in der Computerlinguistik..................................................46 3.2.1 Bisheriges Indexieren und Finden in textuellen Textdatenbanken ................................47 3.2.2 Einsatz von grammatischem Wissen .............................................................................48 3.2.3 Zusammenfassung: Anwendung auf IDEE ...................................................................51 3.3 Methoden der computerlinguistischen Textverarbeitung .....................................................52 3.3.1 Parsing 1: Lexikalische Analyse (Scanner) ..................................................................52 3.3.2 Parsing 2: Syntaktische Analyse (Parser) .....................................................................54 3 3.3.3 Morphologische Analyse (Stemmer) ........................................................................... 55 3.3.4 Semantische Analyse..................................................................................................... 57 3.3.5 Pragmatik POS-Zweideutigkeit (?) ............................... Error! Bookmark not defined. 3.4 Das Lexikon als Hilfsmittel in der Computerlinguistik ....................................................... 57 3.4.1 Wörterbuch .................................................................................................................... 58 3.4.2 Terminologieserver ....................................................................................................... 58 3.4.3 Ontologieserver ............................................................................................................. 59 3.4.4 Fehlerkorrektur .............................................................................................................. 60 Kapitel 4 Architektur von IDEE..................................................................................................... 62 4.1 Apache Jakarta Lucene als Grundgerüst des Systems ......................................................... 62 4.2 Indexierung........................................................................................................................... 64 4.3 Suche mit Lucene ................................................................................................................. 66 4.4 Bewertungsfunktion in Lucene und Verwendung in IDEE ................................................. 67 4.5 Erweiterung 1: Einführung einer Grammatik für Arztbriefe ............................................... 69 4.5.1 Übersicht ....................................................................................................................... 69 4.5.2 Zielsetzung für die IDEE Grammatik (Beispiel eines Arztbriefes im Anhang) ........... 70 4.5.3 Beschreibung der Grammatik (Regeln im Anhang) ...................................................... 71 4.6 Erweiterung 2: Aufbau und Einsatz eines Wörterbuchs (Lexikon) ..................................... 72 4.6.1 Zielsetzung .................................................................................................................... 72 4.6.2 Aufbau ........................................................................................................................... 73 Kapitel 5 Das System IDEE ........................................................................................................... 75 5.1 KnowME Plugin ................................................................................................................... 75 5.2 XML Dialogoberfläche ........................................................................................................ 76 Kapitel 6 Evaluation ....................................................................................................................... 78 6.1 Beschreibung von Evaluationsarten und Eingrenzung (Diss Tina)Error! Bookmark not defined. 6.2 Beispiele von Suchanfragen ................................................................................................. 78 6.2.1 Gemeinsamkeiten der Evaluationsschritte hinsichtlich der Systemfunktionalität ........ 78 6.2.2 Erster Prototyp............................................................................................................... 79 6.2.3 Einführung einer automatischen Erweiterung des Suchstirngs ..................................... 80 6.2.4 Einführung eines Scalers ............................................................................................... 81 6.2.5 Einführung einer Grammatik für Arztbriefe ................................................................. 81 6.3 Stärken und Schwächen von IDEE ...................................................................................... 90 Kapitel 7 Erweiterungen und Ausblick .......................................................................................... 94 7.1 Stemming und morphologische Analyse.............................................................................. 94 7.2 Wörterbuch ........................................................................................................................... 95 7.3 Behandlung von Folgefragen ............................................................................................... 95 7.4 Eingabekorrektur .................................................................................................................. 96 7.5 Eingabeergänzung ................................................................................................................ 96 7.6 Semantische Analyse............................................................................................................ 97 Kapitel 8 Anhang ........................................................................................................................... 98 Literatur .......................................................................................................................................... 99 4 Kapitel 1 Einleitung Wissensbasierte Diagnose- und Informationssysteme finden in der heutigen Zeit in immer mehr Gebieten eine zunehmende Verbreitung. Dies liegt sicherlich auch daran, dass sich durch die stetige Weiterentwicklung von entsprechenden Anwendungen, die Generierung und Pflege solcher wissensbasierter Systeme wesentlich vereinfacht hat. Ein bekanntes und umfassendes Werkzeug für die Erstellung von wissensbasierten Diagnose- und Informationssystemen ist der an der Universität Würzburg entwickelte Shellbaukasten D3. In seiner neuen, JAVA-basierten Version d3web bietet er auch die Möglichkeit neben der reinen Entwicklung eines Beratungssystems, dieses im Internet verfügbar zu machen. Dazu stellt d3web eine webbasierte Benutzeroberfläche bereit. Die Erweiterung um dieses Front-End liegt durchaus im Trend der Zeit. Durch die stark zunehmende Benutzung des Internets im letzen Jahrzehnt finden sich auch in dieser Domäne immer mehr wissensbasierte Systeme, die den Benutzer beratend zur Seite stehen und manchmal auch eine Diagnosefunktion aufweisen. Die Dateneingabe in diesen internetbasierten wie auch herkömmlichen Beratungssystemen ist jedoch in vielen Fällen bisher gegenüber dem Benutzer sehr restriktiv. Daraus ergibt sich der Wunsch nach einer flexiblen Möglichkeit der Dateneingabe, welche die Wünsche und Vorlieben des Benutzers berücksichtigen und entsprechend angepasst werden kann. Der Vergleich verschiedener Eingabemöglichkeiten und der auf den dabei gewonnenen Erkenntnissen aufbauende Entwurf einer benutzerfreundlichen flexiblen Schnittstelle zur Dateneingabe sind Grundlage der vorliegenden Diplomarbeit. Im Hauptteil der Arbeit wurde das System IDEE (Intelligent Data Entry Environment) zur intelligenten und flexiblen Dateneingabe entwickelt, das eine Freitexteingabe für das oben vorgestellte d3web implementiert. Die vorliegende Arbeit gliedert sich in drei Hauptteile. Im ersten Teil werden bereits existierende internetbasierte und herkömmliche Beratungssysteme untersucht und hinsichtlich der Art und Flexibilität ihrer Dateneingabe miteinander verglichen. Auf den gewonnenen Erkenntnissen aufbauend wird eine intelligente und flexible Dateneingabe für d3web entworfen, die u.a. eine Freitexteingabe beinhaltet. Die für eine Freitexteingabe notwendigen theoretischen Grundlagen werden im zweiten Teil der Arbeit erläutert und hinsichtlich der Anwendbarkeit auf das entwickelte System IDEE betrachtet. 5 Im dritten Hauptteil wird die Architektur von IDEE dargestellt und die Benutzerschnittstelle des Systems beschrieben. Dieser Teil schließt mit einer Evaluation des entwickelten Systems IDEE und einem Ausblick auf Erweiterungsmöglichkeiten. 6 Kapitel 2 Theoretische Grundlagen zur Dateneingabe Im ersten Kapitel sollen die theoretischen Grundlagen zur Eingabe von Daten in Computersystemen, besonders im Hinblick auf Beratungs- und Informationssysteme erläutert werden. Dazu werden in Abschnitt 2.2 zunächst aktuelle Systeme betrachtet und anschließend hinsichtlich ihrer Dateneingabe miteinander verglichen. Aufbauend darauf werden im Abschnitt 2.3 verschiedene Varianten der Benutzeroberfläche von Dialogen erläutert und diese anhand verschiedener Gesichtspunkte klassifiziert. Im abschließenden Abschnitt 2.4 werden die gewonnenen Erkenntnisse gegeneinander abgewogen und daraus resultierend ein beispielhafter Dialog entworfen, der als Grundlage für die Benutzerschnittstelle des implementierten Systems IDEE zur intelligenten Dateneingabe dient. 2.1 Dateneingabe bei bestehenden Systemen Ziel dieses Abschnitts ist die Betrachtung einiger aktueller Beratungs- und Informationssysteme hinsichtlich deren Möglichkeiten zur Eingabe von Daten durch den Benutzer. Betrachtet werden u. a. bestehende Systeme zur reinen Datenverwaltung, wie Software für die Arztpraxis und Elektronischen Patientenakte (EPA), sowie Systeme mit Beratungsfunktion (Diagnosefunktion), wie D3, LegalCity, Rechtsberatungs-Software... Zur heutigen Zeit befinden sich eine Vielzahl von Beratungs- und Informationssystemen auf dem Markt. Sie unterscheiden sich vor allem in ihrer Funktionalität, wie auch in den verschiedenen Möglichkeiten, mit der der Benutzer seine Daten und Anfragen in das System eingeben kann. Im folgenden Kapitel werden verschiedene Systeme kurz vorgestellt und ihre Varianten der Eingabe von Daten beschrieben. 2.1.1 ALBIS Praxis-Dialog Der Praxis-Dialog von ALBIS [Albis] stellt ein umfangreiches Softwareprodukt für Arztpraxen dar. Es beinhaltet u. a. die elektronische Verwaltung von Patientendaten, aber auch zahlreiche andere Funktionalitäten, wie z.B. Funktionen zur automatisierten Abrechnung. Für jeden Patienten verwaltet das System neben den jeweiligen Stammdaten eine medizini- 7 sche Dokumentation. Hier werden alle Befunde, Diagnosen, Verordnungen, Briefwechsel etc. eingetragen. Abb. 2.1: ALBIS Demoversion. Patientenkartei mit Eingabemaske für Patientendaten. Hier stehen u. a. folgende Eingabemöglichkeiten zur Verfügung: textuelle Eingabe von Kürzeln, durch eine automatische Eingabeergänzung unterstützt. Textuelle Eingabe, durch Auswahllisten unterstützt. Button für OC-Antwort. PullDown-Menü. Freitexteingabe. Numerisches Eingabefeld. Checkbox für Ja/Nein-Antwort Die Eingabe der Patienten Stammdaten erfolgt mittels eines Formulars, das vom Benutzer ausgefüllt wird. Das Formular beinhaltet Felder für die Eingabe von Text (Name, Adresse, …) oder numerischen Daten (Alter, Größe,...), Pull-Down-Menüs, sowie Checkboxen für One Choice (OC-Antworten) wie z.B. männlich/weiblich, und Ja/Nein Antworten (Gebührenbefreiung). Die Darstellung der medizinischen Dokumentation lehnt sich an das im bisherigen Praxisbetrieb verwendete System der Dateikarten an. Der Albis Praxis Dialog stellt hier Textfelder zur Freitexteingabe zur Verfügung. Durch ein Kürzel wird zunächst angegeben, um welche Art von Dokumentation es sich handelt (z.B. „dia“ für Diagnose). Das System bietet dabei je nach bisheriger Eingabe eine automatische Ergänzung an, so dass im geeigneten Fall das Kürzel nicht ganz ausgeschrieben werden muss. Nach dem Kürzel folgt die eigentliche Dokumentation in einem Textfeld. Hier kann der Benutzer 8 Freitext eingeben. Das System bietet zusätzlich jedoch eine Unterstützung zur standardisierten und vereinfachten Eingabe. Es werden Übersichts-Tabellen zur Verfügung gestellt, die z.B. alle nach ICD-10 aufgeschlüsselten Krankheiten oder Medikamente der Gelben Liste enthalten. Der Benutzer kann hier die geeignete Auswahl durch Anklicken treffen. 2.1.2 StudiBot (Universität Karlsruhe) Der StudiBot der Universität Karlsruhe (TH) [Uni KA] beantwortet Fragen zum dortigen Informatik-Studium. Der Benutzer hat die Möglichkeit, Fragen in ein Textfeld einzugeben oder Links durch Anklicken auszuwählen. Übersichtlich ist hierbei, dass sowohl die zuletzt eingegebenen Fragen (gelb unterlegt) wie auch die dazu gefundenen Antworten und Links angezeigt werden. Es macht allerdings den Anschein, dass sich die Antworten des StudiBots auf wenige vordefinierte Antwortsätze beziehen. Abb. 2.2: StudiBot der Universität Karlsruhe (TH). In dem Textfeld kann der Benutzer seine Frage eingeben. Das System zeigt daraufhin die eingegebene Frage nochmals an, gibt eine Antwort aus und stellt Links zu anderen Fragen zur Verfügung. Gelegentlich gibt es Schwierigkeiten, mehrere wichtige Begriffe aus einer Frage zu erkennen. Im unteren Beispiel wird z.B. auf die Frage „Welche Vorlesungen gibt es im Hauptstudium?“ nur eine Unterteilung des Hauptstudiums in 3 Phasen erklärt und ein Link zu den jeweiligen Phasen angeboten. Auch bei weiterer Verfolgung dieser Links erfährt man 9 nichts über das Vorlesungsangebot. Bei Eingabe des Begriffes „Vorlesungen“ erhält man allerdings einen Link auf das aktuelle Vorlesungsverzeichnis. Die gesamte Navigation beschränkt sich auf Eingeben neuer Fragen und Verfolgen der in den Antworten angebotenen Links. Ein Zurückspringen zu vorherigen Fragen ist nicht möglich. 2.1.3 SAP Jobberater Der SAP Jobberater wird auf der Webseite der Firma SAP [SAP] angeboten und soll Interessenten Fragen über Jobs und Karriere bei SAP beantworten. Er basiert auf dem Lingubot System der Firma KiwiLogic [KiwiLogic]. Dies ist ein Softwareprodukt zur einfachen Erstellung und Pflege von virtuellen Kundenberatern. Die Eingabe einer Frage beim SAP Jobberater erfolgt über ein Textfeld, in das der Benutzer nach Möglichkeit einen kurzen, vollständigen Satz eingeben soll. Gemäß seinem Zwecke beschränkt sich das „Verstehen“ des Jobberaters hauptsächlich auf Fragen bezüglich Jobs und Karriere bei SAP. Hier erkennt er allerdings eine Vielzahl von Anfragen. Die Antworten fallen meist sehr ausführlich aus, allerdings gibt es keine Links zu anderen Seiten, so dass die Navigation nur über die Eingabezeile erfolgt. Auch ein Zurückspringen zu vorherigen Fragen ist nicht möglich. Abb. 2.3: SAP Jobberater. In einem Textfeld (2) kann der Benutzer seine Frage formulieren. Das System gibt daraufhin die gefundenen Antworten in dem darüber liegenden Ausgabefeld (2) aus. 10 2.1.4 1882direkt Kontoeröffnungs-Beratung „MiA“ (Meine interaktive Assistentin) heißt die virtuelle Beraterin zur Kontoeröffnung bei der 1822direkt [1822direkt]. Sie wurde von der Firma Smart Bot Technologies [SBT] entwickelt, die Standardlösungen für kommunizierende Roboter, so genannte Smart Bots, entwickelt und vertreibt. Diese Roboter sollen Fragen von Benutzern automatisch richtig beantworten. Das Dialogfenster ist in zwei Bereiche aufgeteilt. Auf der linken Seite wird zu jeder Zeit ein Text ausgegeben, der dem Benutzer seine Eingabemöglichkeiten und weitere Schritte kurz erklärt. Darunter befindet sich ein Textfeld zur Freitexteingabe. Im rechten Bereich werden (je nach Beratungsschritt) die Fragen und Auswahlmöglichkeiten sowie Erklärungen hierzu präsentiert. Abb. 2.4: 1822direkt Kontoeröffnungs-Beratung. Der Benutzer kann im rechten Bereich eine Frage (1) durch Anklicken auswählen (OC-Antwortalternative). Alternativ kann die Nummer der Frage in das Textfeld (2) eingegeben werden. In das Textfeld können auch frei formulierte Fragen eingegeben werden. Oberhalb des Textfeldes gibt das System eine kurze Erklärung, wie der Benutzer mit dem System interagieren kann. Die Navigation ist zu Beginn der Beratung sehr einfach gehalten. Dem Benutzer werden jeweils verschiedene nummerierte Fragen angeboten, aus denen er eine durch Anklicken auswählen kann (OC-Antwort). Somit gelangt er zur nächsten Seite. Alternativ kann der Benutzer auch die Nummer der Frage in ein Textfeld eingeben. Es gibt allerdings keine Möglichkeit, zu vorherigen Seiten zurückzukehren. Die Beratung muss immer von neuem begonnen werden. Neben der oben beschriebenen Navigation bietet das System die Mög- 11 lichkeit, Fragen in das Textfeld einzugeben. Bei einer kurzen Evaluation des Systems zeigte sich, dass nur wenige der eingegebenen Begriffe erkannt werden und das System immer wieder auf die vordefinierten Fragen verweist, zwischen denen der Benutzer auswählen soll. In einigen Folgefenstern bietet das System auch die Möglichkeit, Checkboxen für OCAntworten sowie MC-Antworten anzuklicken. Numerische Angaben können mittels eines Schiebereglers geändert werden. Auch Auswahlmöglichkeiten durch Pull-Down-Menüs sind im Dialog vorhanden. Des Weiteren werden innerhalb des Erklärungstextes, den das System in jedem Schritt ausgibt, Links zu anderen Seiten angeboten, die dann in einem neuen Fenster geöffnet werden. Gelegentlich werden im Erklärungstext auch konkrete Fragen an den Benutzer gestellt. Daraufhin erscheinen unterhalb des Textfeldes zwei Schaltflächen mit „ja“ und „nein“, mit denen der Benutzer die Frage beantworten kann. Abb. 2.5: Folgefenster des Beratungsassistenten von 1822direct: Es finden u. a. sich folgende Elemente: 1. Erklärungstext, 2. Links zu anderen Seiten, 3. Ja/Nein Auswahl mittels Schaltflächen, 4. Pull-Down-Menü, 5. OC-Antwortalternativen, 6. Ja/Nein Auswahl mittels Checkbox, 7. Eingabe von numerischen Werten mittels Schiebereglers. 2.1.5 Neckermann Produktberatung Der Neckermann Produktberater soll einen Kunden, der ein Produkt über das Internet bei Neckermann kaufen möchte, bei der Auswahl des gewünschten und auf die Bedürfnisse des Kunden zugeschnittenen Produkts unterstützen. Der Produktberater basiert dabei auf 12 der Software empolis orenge der Softwarefirma Empolis, einer umfangreichen Softwarelösung für den Bereich Wissensmanagement und Information Retrieval [Empolis]. Die Produktberatung wird durch einen Mehrfragendialog realisiert, bei dem alle Fragen gleichzeitig gestellt werden. Der Benutzer kann in einem Formular Angaben zu den Anforderungen eines Produktes machen und auch die Priorität der einzelnen Anforderungen angeben. Dies geschieht durch Auswahl von Checkboxen (bei MC-Fragen) sowie über Pull-Down-Menüs (bei OC-Fragen). Gemäß den Angaben werden dann geeignete Produkte gesucht und präsentiert. Mittels Links können dann weitere Informationen angezeigt oder das Produkt in den Einkaufskorb übernommen werden. Abb. 2.6: Neckermann Produktberatung, Eingabemaske. Innerhalb dieses Mehrfrage-Dialogs hat der Benutzer folgende Eingabemöglichkeiten: 1. Checkboxen für MC-Antworten, 2. Pull-Down-Menüs für OCAntworten. Neben den Angaben zu den Anforderungen des gesuchten Produktes kann der Benutzer zu jeder Anforderung auch deren Wichtigkeit angeben (3). 2.1.6 Porsche Produktberater Der Porsche Produktberater ist auf der Webseite für Gebrauchtwagen bei der Firma Porsche zu finden. Er ist dafür konzipiert, einen Kunden bei der Suche nach einem Porsche Gebrauchtwagen zu unterstützen und aus den Angeboten jene Automobile herauszusuchen, die den Kundenwünschen entsprechen. 13 Die Eingabe der gewünschten Spezifikationen des Porsche erfolgt über ein Feld zur Texteingabe. Hier kann der Benutzer verschiedene natürlichsprachliche Merkmale wie Modell, Farbe oder Preis eingeben. Mittels eines Pull-Down-Menüs kann noch ein Land für den momentanen Standort des Wagens ausgewählt werden. Außerdem gibt es im Dialog noch eine Checkbox, die den Wunsch nach der ausweisbaren Mehrwertsteuer bei der Suche berücksichtigt. Abb. 2.7: Porsche Produktberater, Anfragefenster. In einem Textfeld (1) kann der Benutzer seine Suchkriterien als Freitext formulieren. In einem Pull-Down-Menü (2) kann der aktuelle Standort des Fahrzeugs gewählt werden. Außerdem findet sich eine Checkbox (3) für die Option der ausweisbaren Mehrwertsteuer. Nach dem Ausführen der Suche präsentiert der Produktberater die gefundenen Automobile übersichtlich in einer Liste. Dabei wird eine Übersicht über die wichtigsten Daten zu den jeweiligen Autos angegeben. Die Ergebnisliste kann nach allen präsentierten Daten sortiert werden. Durch Auswahl eines einzelnen Suchergebnisses gelangt man mittels eines Links zur vollständigen Beschreibung des entsprechenden Porsche. Wichtig ist zu erwähnen, dass bei der Ergebnispräsentation auch eine Bewertung jedes Suchergebnisses mittels der prozentualen Überdeckung der Anfrage mit dem Suchergebnis angegeben ist. Eine kurze Evaluation hat allerdings gezeigt, dass diese Bewertung nicht immer korrekt ist. So wurden in manchen Fällen eine 100%-ige Überdeckung angegeben, obwohl Begriffe der Suchanfrage nicht im Ergebnis enthalten waren. Die Suche erfolgt hauptsächlich über Schlüsselwörter, 14 die z.B. das Modell oder eine Farbe bezeichnen. An welcher Stelle des Suchergebnisses diese Wörter vorkommen, spielt erfahrungsgemäß eine untergeordnete Rolle. Manche Begriffe werden auch nicht richtig erkannt. So lieferte beispielsweise die Suche nach "über 50 000 Euro" nur Automobile, deren Preis unter diesem Wert lag. Abb. 2.8 Porsche Produktberater, Ergebnispräsentation. Die gefundenen Automobile werden in einer Liste präsentiert, die neben den wichtigsten Spezifikationen der Autos auch eine Gewichtung jedes Treffers enthält. 2.1.7 Ask Jeeves "Ask Jeeves" [Ask] ist eine Internet Suchmaschine, die im Vergleich zu anderen Suchmaschinen neben der einer Auflistung von Suchbegriffen auch Suchanfragen in Phrasen- oder Frageform verarbeiten kann. Die Eingabe der Anfrage erfolgt dabei, wie bei den meisten Suchmaschinen, über eine Zeile für Texteingabe. Laut Dokumentation [Ask Doku] unterstützt Ask Jeeves eine automatische Korrektur zur Verbesserung vieler Schreibfehler. Außerdem schlägt es alternative Suchbegriffe zu eingegebenen Begriffen vor. Die Reihenfolge spielt bei der Sucheingabe ebenfalls eine Rolle. Daraus kann geschlossen werden, dass Ask Jeeves den eingegebenen Suchstring zumindest in einfacher Weise analysiert, um weitergehende Informationen zu gewinnen, die eine Suche präzisieren. Die dazu eingesetzten Verfahren sind allerdings in der genannten Doku- 15 mentation nicht erwähnt. Die Generierung der Suchergebnisse geschieht dabei in erster Line mit Hilfe der Teoma Suchtechnologie [Teoma]. Das Teoma Suchverfahren verwendet dabei die themenbezogene Popularität von Webseiten zur Bewertung ihrer Relevanz. Die themenbezogene Popularität einer Seite wird dadurch bestimmt, wie viele andere Webseiten mit dem gleichen Themengebiet diese Seite referenzieren. Abb. 2.9: Ask Jeeves Suchmaschine. In dem Textfeld zur Eingabe kann der Benutzer seine Suchanfrage stellen. Das System verarbeitet neben einzelnen Schlagwörtern auch Eingaben in Phrasen- oder Frageform. 2.1.8 Law Expert System Bei diesem System handelt es sich um ein regelbasiertes Expertensystem zum Steuerrecht für steuerliche Online-Berechnungen [LawExpert]. Es wurde von Michael Lang, Wissenschaftlicher Mitarbeiter am Lehrstuhl für Betriebswirtschaftliche Steuerlehre der Universität Augsburg, entwickelt. Die Eingabe durch den Benutzer ist formularbasiert und sehr einfach gehalten. Zunächst wählt der Benutzer aus einer Liste ein Gebiet aus, zu dem er Auskünfte benötigt und bekommt daraufhin ein Formular präsentiert. Die Dialogart, die in diesem Formular verwendet wird, ist ein Mehrfragendialog, bei dem alle Fragen gleichzeitig gestellt werden. Es handelt sich dabei grundsätzlich um OC-Fragen. Der Benutzer kann innerhalb des Formulars Checkboxen auszuwählen (Ja/Nein-Antwort) und numerische Eingaben in Textfeldern zu machen. Nichtnumerische Eingaben werden mit NaN (Not a 16 Number) erkannt, bei gemischten Eingaben extrahiert das System den numerischen Anteil der Eingabe. Die Ausgabe der Antworten erfolgt zeitgleich zur Eingabe in speziell (blau) gekennzeichneten Feldern des Formulars. Dabei werden, analog zur Eingabe, entweder Checkboxen aktiviert oder numerische Werte ausgegeben. Da die gesamte Ein-/Ausgabe in nur einem Formular stattfindet, sind Änderungen und Korrekturen der eingegebenen Werte jederzeit ohne Probleme möglich. Zudem kann der Benutzer dadurch eintretende Änderungen bei der Ausgabe sofort verfolgen. Abb. 2.10 Mehrfragedialog von Law-Expert-System. Der Benutzer kann die OC-Fragen durch Anklicken von Checkboxen (1) oder durch numerische Angaben in Textfeldern (2) beantworten. Die Ausgabe der Antworten erfolgt simultan in den blau gekennzeichneten Feldern (3). 2.1.9 Jano consult Jano consult ist eine Software-Architektur zur standardisierten Beantwortung juristischer Probleme und wurde von der Firma janolaw AG entwickelt [JanoLaw]. Der Benutzer wählt zunächst aus einer großen Anzahl von Problembereichen die auf sein Problem zu- 17 treffende Anfrage aus. Die Problembereiche sind übersichtlich in einer Baumstruktur geordnet, in der man durch Verfolgen von Links zur gewünschten Anfrage gelangt. Nach Spezifizierung der Anfrage stellt das System nun nacheinander alle zur Lösungsfindung wichtigen Fragen an den Benutzer. Es handelt sich hierbei also um einen Einfrage-Dialog. Zu jeder Frage wird eine detaillierte Erklärung gegeben, die den juristischen Sachverhalt beschreibt und somit eine Beantwortung wesentlich erleichtert. Bei den zu beantwortenden Fragen handelt sich um One-Choice-Fragen, die der Benutzer durch Anklicken von „ja“ oder „nein“ beantwortet. Bei komplexer Fragestellung bietet das System auch die Antwortalternative „mehr Details“. Durch diese wird eine Frage in einfachere Unterfangen aufgespaltet. Abb. 2.11: jano consult Rechtsberatung. Dieser Einfragendialog stellt jeweils OC-Fragen (1), die durch Anklicken von „ja“ oder „nein“ beantwortet werden (2). Zu jeder Frage gibt es eine ausführliche Erklärung (3). Bei schwieriger Fragestellung kann die Frage auch in Einzelfragen aufgespaltet werden (4). Auf der Webseite von janolaw findet sich folgende Beschreibung des Systems: „Die Datenbank-Architektur orientiert sich an den Fragestellungen, die in der juristischen Beratungspraxis typisch und gängig sind. Ausgehend von seinem individuellen Grundproblem wird der Anwender systematisch durch die Alternativen der juristischen Problemlö- 18 sung geführt. Im Ergebnis erhält er ein auf seine Fragestellung bezogenes Prüfungsprotokoll. Die Struktur der Software wurzelt in der Entscheidungsbaum-Methodik. Der juristische Kontext wird so aufgearbeitet, dass die Voraussetzungen für die Beantwortung der gestellten Frage vollständig abgeprüft und in die nächste logische Frage überführt werden. Für Kunden von janolaw bedeutet dies: Sie werden über die Beantwortung lösbarer Fragen zu ihrem Ergebnis geführt. Ist die Fragestellung komplexer, steht neben den StandardAntworten "ja" oder "nein" die Antwortalternative "mehr Details" zur Verfügung, mit der die Frage in einfache Unterfragen aufgebrochen wird. Auf dem Weg zur passenden Antwort liefert janolaw die notwendigen Formulare.“ [JanoConsult] 2.1.10 LegalCity Ratgeber Recht Dieser Ratgeber zu Rechtsfragen wurde an der Universität Würzburg entwickelt und stützt sich auf den Shellbaukasten für Expertensysteme D3, welches ebenfalls dort entwickelt wird. Der Benutzer wird während der Beratung mittels eines Einfrage-Dialogs geführt. Es werden nacheinander Fragen gestellt, die durch Anklicken von Antwortalternativen (Checkboxen) beantwortet werden. Das System generiert daraufhin Folgefragen, so lange bis eine Lösung gefunden wurde. Zu jeder Frage und ihren Antwortalternativen gibt es eine kurze genauere Erklärung, die Unklarheiten bei der richtigen Beantwortung der Frage vermeiden soll. Ferner gibt das System jederzeit Auskunft über die bisherigen Ergebnisse und verdächtigten Diagnosen. Der Benutzer kann somit auch jederzeit die Beratung beenden und sich ein Ergebnis mit Erklärungen ausgeben lassen. Die Navigation ist ebenfalls sehr übersichtlich gestaltet. Es besteht die Möglichkeit, schrittweise zu vorherigen Fragen zurückzukehren, um Änderungen vorzunehmen, sowie auch Beratungen zu unterbrechen und Fälle abzuspeichern. 19 Abb. 2.12: LegalCity, Beratung zum Mietrecht. Die Eingabe bei diesem Einfragendialog erfolgt mittels Checkboxen. Ferner werden Schaltflächen zur Navigation, zum Abspeichern und zum Unterbrechen bereitgestellt. 2.2.11 d3web d3web ist der Java-basierte Nachfolger von D3, eines an der Universität Würzburg entwickelten umfangreichen Shellbaukastens für wissensbasierte Diagnose und Informationssysteme. Mit D3 können z.B. auf schnelle und einfache Weise verteilte Wissensbasierte Systeme erstellt werden. Der Nachfolger d3web kann sowohl als Front-End bestehender Wissensbasierter Systeme verwendet oder zum Einbinden von Wissensbasierten Systemen in andere Anwendungen herangezogen werden. Im Folgenden sind nun die Weboberfläche von d3web zur Dateneingabe dargestellt und die Eingabemöglichkeiten beschrieben. 20 Abb. 2.13 d3web, Web Front-End. Auf der linken Seite wird die aktuell geladene Wissensbasis dargestellt, und ermöglicht dadurch einen leichten Zugriff auf alle Fragen. Die rechte Seite gibt Auskunft über verdächtigte oder bereits etablierte Diagnosen. In der Mitte findet sich der eigentliche Dialog zur Dateneingabe. Für die Dateneingabe stehen Textfelder (1), Checkboxen (2) sowie Options-Buttons (3) zur Verfügung. Die Weboberfläche ist in 3 Hauptfelder eingeteilt. Auf der linken Seite sind alle Frageklassen und Fragen der aktuell geladenen Wissensbasis in einer Baumstruktur verfügbar. Ist eine Frage schon beantwortet, wird die Antwort bei der jeweiligen Frage mit angezeigt. Mit Hilfe der hier angezeigten Baumstruktur ist es möglich, auf einfache Weise auf eine beliebige Frage der Wissensbasis zuzugreifen um diese beispielsweise zu beantworten oder bisherige Antworten zu überprüfen. Auf der rechten Seite finden sich u. a. Angaben zu den bisher verdächtigten oder bereits etablierten Diagnosen. In der Mitte der Weboberfläche befindet sich der eigentliche Dialog für die Präsentation von zu beantwortenden Fragen und die Auswahl bzw. eine Eingabe einer Antwortalternative. Im gezeigten Beispiel können mehrere Fragen gleichzeitig dargestellt werden, es handelt sich also um einen Mehrfragendialog. Zur Eingabe von Daten für die Beantwortung von Fragen stehen verschiedene Möglichkeiten zur Verfügung. Es gibt Textfelder für die Eingabe von textuellen oder numerischen Eingaben, Checkboxen für die Beantwortung von MC-Fragen und OptionsButtons für die Auswahl der Antwortalternative bei OC- Fragen. Die Navigation innerhalb 21 des Dialogs wird normalerweise vom System geführt, d.h., das System steuert, welche Fragen als nächste gestellt werden. Allerdings kann der Benutzer jederzeit durch Browsen innerhalb der Wissensbasis (diese ist, wie erwähnt, als Baumstruktur auf der linken Seite der Weboberfläche von d3web dargestellt) in die Navigation innerhalb der Wissensbasis eingreifen. 2.2.12 PEN-Ivory PEN-Ivory [PenIvory] wurde an der Stanford University School of Medicine entwickelt und ist ein Computersystem zur Verwaltung von Krankheitsverläufen bei Patienten. Das Ziel des PEN-Ivory Projektes war es, ein System zu entwickeln, welches folgende zwei Vorteile miteinander verbindet: die Vorzüge der einfachen, schnellen und gebräuchlichen Datenerfassung mittels Papier und Stift, und einer strukturierten und maschinell verarbeitbaren Dateneingabe. Es wurde ein System geschaffen, bei dem der Benutzer seine Daten mittels eines Stiftes auf einem drucksensitiven Display (Touch-Screen) eingibt. Dabei macht der Benutzer nur einfache Markierungen: er kann Begriffe entweder einkreisen oder durchstreichen sowie, eine bereits gemachte Eingabe mittels Ausstreichen wieder rückgängig machen. Zur einfachen Dateneingabe wurden verschiedene Prototypen von grafischen Benutzeroberflächen (GUIs) entwickelt und miteinander verglichen. Bei allen Benutzeroberflächen ist das Display vertikal in zwei Bereiche unterteilt. Im linken Teil sind die Begriffe für medizinische Befunde aufgelistet (Befund-Formular). Der rechte Teil repräsentiert eine Attribut-Palette mit Modifikatoren, mit denen die Befunde genauer spezifiziert werden können. Die einzelnen Benutzeroberflächen unterscheiden sich nun dadurch, wie die Befunde und die Attribut-Palette dargestellt werden. Dabei gibt es drei Unterscheidungsmerkmale: 1. Das Befund-Formular kann entweder als lange Liste von Befunden dargestellt werden, in der man mittels einer Scrollbar navigieren kann. Oder die Befunde sind in einer Serie von „Karteikarten“ zusammengefasst, wobei jeweils nur eine Karteikarte angezeigt wird und zu anderen Karteikarten durch Anklicken ihres „Reiters“ gewechselt werden kann. 2. Es werden entweder zu jeder Zeit alle in der Wissensbasis vorhandenen Befunde angezeigt und diejenigen optisch hervorgehoben, welche die Beschwerden des Pa- 22 tienten betreffen. Oder es werden nur die Befunde angezeigt, die mit den Beschwerden des Patienten in Verbindung stehen. 3. Die Attribut-Palette wird immer vollständig angezeigt, d.h. es werden zu jeder Zeit alle Attribut-Kategorien angezeigt, auch diejenigen, die für den gerade ausgewählten Befund irrelevant sind. In diesem Fall werden dann in der irrelevanten Kategorie keine Modifikatoren angezeigt. Alternativ wird die Attribut-Palette dynamisch generiert. Sie wird nur bei Bedarf angezeigt (Pop-Up Fenster) und enthält nur diejenigen Attribut-Kategorien, die für den jeweiligen Befund relevant sind. Dadurch ist auch die Position der Kategorien innerhalb der Attribut-Palette variabel. Abb. 2.14: PEN-Ivory Benutzeroberfläche. Im linken Bereich befinden sich die gruppierten Namen von Befunden. Die rechte Seite repräsentiert die Attribut-Palette. Sie wird benutzt, um die Befunde mittels Modifikatoren genauer zu spezifizieren. Um herauszufinden, welches Eingabeformat die einfachste und schnellste Dateneingabe ermöglicht, wurden nun verschiedene Benutzeroberflächen generiert, die sich jeweils in einem der drei oben beschriebenen Merkmale unterscheiden. Anschließend wurden die verschiedenen Systeme hinsichtlich der benötigten Zeit für die Eingabe von Testfällen untersucht. Der Test bestätigte die Vermutung, dass ein Karteikartensystem im Zusammenhang mit einer fixierten und vollständigen Darstellung sowohl der Befunde wie auch der Attribut-Palette, die schnellste Dateneingabe ermöglicht. Zur Erklärung dieses Ergebnisses wird angegeben, dass bei dieser Benutzeroberfläche die Befunde und Attribute im- 23 mer an derselben Position dargestellt werden. Der Benutzer kann sich diese Position merken und Befunde und Attribute somit schneller wiederfinden. 2.2.13 Zusammenfassender Überblick über die vorgestellten Systeme In der folgenden Tabelle werden die verschiedenen Eingabeformate der vorgestellten Sys- Text X X X Diagnosen Numerische Eingabe X Navigation zurück Pull-Down-Menü (OC) X Links Checkboxen (MC) Mehrfrage Dialog Praxis- Buttons (OC) ALBIS Einfrage Dialog Name des Systems teme zusammengefasst: Dialog Studi Bot X X X X X SAP Jobberater X X X 1822direkt Kon- X X X X toeröffnung Neckermann X X X X X X X X Produktberatung Porsche Pro- X X X X X X duktberater Ask Jeeves X Law Expert Sys- X X X X tem Legal City Rat- X X X X X X X X X X geber Recht D3 Web X Pen Ivory X X X Abb. 2.15: Übersicht der verwendeten Eingabeformate und Dialogarten in den vorgestellten Systemen 24 2.2 Varianten der Benutzeroberfläche von Dialogen 2.2.1 Dialogarten Im folgenden Abschnitt werden einige Varianten von Dialogen betrachtet, die sich für eine Benutzeroberfläche eignen. Dieser Abschnitt lehnt sich an einen Text von Mitchel Berberich [Berberich 01] an, in dem diese Thematik übersichtlich beschrieben wird. 2.2.1.1 Einfragendialog Bei einem Einfragendialog wird dem Benutzer zu jeder Zeit immer nur eine Frage präsentiert. Nach Beantwortung einer Frage erscheint dann die nächste Frage. Der Einfragendialog stellt also eine sehr einfache Dialogform dar. Seine Darstellung der Fragen ist auch für unerfahrene Benutzer leicht verständlich, da sie der gebräuchlichen Darstellung von Fragen in gedruckten Fragebögen gleicht. Abb. 2.16: Einfragendialog: Es wird nur eine Frage präsentiert. Nach deren Beantwortung (hier durch Klicken des OK-Buttons) erscheint die nächste Frage. 2.2.1.2 Mehrfragendialog Beim Mehrfragendialog werden, wie der Name schon sagt, mehrere Fragen gleichzeitig an den Benutzer gestellt. Dies hat zum Vorteil, dass die Reihenfolge der Beantwortung der Fragen variabel ist. Der Benutzer hat beim Mehrfragendialog auch eine besser Übersicht darüber, welche Fragen er noch zu beantworten hat und welche bereits beantwortet sind. Der Mehrfragendialog bietet darüber hinaus besonders bei internetbasierten Dialogen eine effizientere Abarbeitung der Fragen, da neue Fragen nicht immer erst geladen werden müssen, was zu einer erheblichen Zeitverzögerung führen kann. Die Behandlung von Fol25 gefragen erfordert beim Mehrfragendialog jedoch besondere Beachtung. Zunächst stellt sich bezüglich des Layouts die Frage, ob Folgefragen von Anfang an dargestellt werden sollen (ggf. bis zur Erfüllung ihrer Vorbedingungen deaktiviert) oder erst nach Beantwortung ihrer Vorbedingungen (vorhergehenden Fragen) eingeblendet werden. Bei internetbasierten Dialogen stellt sich außerdem die Frage, zu welchem Zeitpunkt die Vorbedingungen überprüft werden sollen. Es besteht zum einen die Möglichkeit, Vorbedingungen zusammen mit den Folgefragen zu übertragen und Client-seitig zu überprüfen. Auf der anderen Seite kann die Überprüfung auch durch den Server erfolgen, wodurch jedoch eine bidirektionale Datenübertragung zwischen Client und Server stattfinden muss, was wiederum zu einer zeitlichen Verzögerung führt. Abb. 2.17: Mehrfragendialog: Es werden gleichzeitig mehrere Fragen präsentiert. Der Benutzer kann die Fragen in einer beliebigen Reihenfolge bearbeiten. Folgefragen (hier eingerückt dargestellt) sind deaktiviert, falls ihre Vorbedingung nicht erfüllt ist. Ist der Benutzer mit der Beantwortung aller Fragen fertig, bestätigt er dies durch Anklicken des OK-Buttons. 2.2.1.3 Klappdialog Bei einem Klappdialog werden einzelne Fragen gruppiert und zu Fragebögen (Frageklassen) zusammengefasst. Die Frageklassen können wiederum Frageklassenoberbegriffen 26 untergeordnet sein usw., wodurch eine beliebig verschachtelte Baumstruktur („Symptomhierarchie“) entsteht. In dieser Baumstruktur können die einzelnen Äste bei Bedarf „ausgeklappt“ werden. Die Antworten zu den einzelnen Fragen werden dann mittels Popup-Menüs realisiert. Der Klappdialog hat den Vorteil, dass erfahrene Benutzer die Fragen durch die Baumstruktur schnell und effektiv finden können. Außerdem ist die Reihenfolge, in der die Fragen beantwortet werden, vollständig dem Benutzer überlassen und nicht vom System vorgegeben. Für unerfahrene Benutzer ist ein Klappdialog eher ungeeignet, da ihnen diese Dialogform fremd ist und auch Orientierungshilfen wie Antwortalternativen und Bilder in der normalen Ansicht fehlen. Diese werden erst bei Auswahl einer Frage in einem Popup-Menü angezeigt. Abb. 2.18: Klappdialog. 2.2.1.4 Freitexteingabe Eine Freitexteingabe1 gewährt dem Benutzer eine große Flexibilität bei der Eingabe von Daten und der Beantwortung der Fragen. Die Reihenfolge, in der die Fragen beantwortet Unter „Freitexteingabe“ ist im Folgenden keine natürlichsprachliche Eingabe gemeint. Vielmehr kann der Benutzer eine Menge von Wörtern eingeben. Diese werden anschließend mit den in der Wissensbasis ver1 27 werden, ist vollkommen frei. Der Benutzer muss, im Gegensatz zu den oben vorgestellten Dialogen, die interne Struktur der Wissensbasis nicht mehr kennen und muss die Fragen in dieser Struktur auch nicht mehr suchen, um sie zu beantworten. Besonders nützlich ist eine schnelle Dateneingabe in beliebiger Reihenfolge dann, wenn der Benutzer schon am Anfang wichtige Beobachtungen macht, die auf eine bestimmte Diagnose hinweisen. Die schnelle Eingabe einer für eine Diagnose typischen Beobachtung kann in diesem Fall, eine wesentlich schnellere Diagnosefindung durch das System bewirken, als bei einer Abarbeitung von Fragen in einer Reihenfolge, die vom System vorgeschlagen wird. Hier können nämlich unter Umständen zunächst Fragen gestellt werden, die für den aktuellen Fall weniger von Bedeutung sind. Bei der Freitexteingabe kann der Benutzer Text nach einer vorher definierten Syntax in ein Textfeld eingeben. Die Syntax könnte z.B. aus Paaren Frage/Wert bestehen, wobei die einzelnen Frage/Wert-Paare durch Trennzeichen (z.B. Semikolons) separiert sind. Ein Beispiel für eine Eingabe wäre z.B.: „Alter 30; männlich, Leber sonographisch vergrößert“. Das Diagnosesystem versucht nun, die eingegebenen Begriffen in den Fragen und Fragewerten der Wissensbasis wiederzufinden und auf die internen Objekte der Wissensbasis abzubilden. Daraufhin wird ein Fragebogen generiert, der mit den erkannten Werten ausgefüllt ist und vom Benutzer verifiziert und validiert werden soll. 2.2.2 Darstellungsmöglichkeiten In diesem Abschnitt werden verschiedene Möglichkeiten zur Darstellung der Fragen und Antwortalternativen innerhalb eines Dialogs beschrieben und ihre Vor- und Nachteile gegenübergestellt. 2.2.2.1 Fixierte Darstellung Eine fixierte Darstellung hat zum Ziel, Fragen und Antwortalternativen immer an derselben Position auf dem Bildschirm darzustellen. Dies hat den Vorteil, dass sich der Benutzer die Position einer Frage und die Position einer Antwortalternative merken und sie somit schneller wiederfinden kann. Die Dateneingabe ist somit für erfahrene Benutzer, die mit dem System vertraut sind, schneller möglich. In der Wissensbasis sind jedoch so gut wie immer mehr Fragen vorhanden, als gleichzeitig auf dem Bildschirm dargestellt werden wendeten Begriffen und deren Synonymen verglichen und anschließend den Objekten der Wissensbasis zugeordnet. 28 können. Eine Lösung für dieses Problem ist die seitenweise Darstellung der Fragen. Fragen werden dabei zu Seiten (Karteikarten) zusammengefasst. Zwischen den einzelnen Karteikarten kann dann durch Anklicken ihres Reiters gewechselt werden. Sind die Antwortalternativen direkt bei den Fragen angegeben, werden auch sie automatisch an einer fixen Position zusammen mit der Frage angezeigt. Eine weitere Möglichkeit besteht jedoch darin, die Antwortalternativen von den Fragen zu trennen und in einem eigenen Bereich des Bildschirms darzustellen. Dazu werden alle Antwortalternativen sämtlicher Fragen der Wissensbasis zu Gruppen (Kategorien) zusammengefasst. Diese Kategorien können dann, ähnlich wie bei den Fragen, seitenweise mittels Karteikarten dargestellt werden. Da die Antwortalternativen in ihrer Anzahl jedoch meist geringer sind als die Fragen einer Wissensbasis, können alle Kategorien oft auch permanent angezeigt werden. Beim Beantworten einer speziellen Frage werden dann nur diejenigen Antwortalternativen aktiviert, die für die entsprechende Frage zur Verfügung stehen. Ein Nachteil einer fixierten Darstellung liegt im erhöhten Platzbedarf, den sie auf dem Bildschirm benötigt. Es werden unter Umständen irrelevante Fragen und nicht auswählbare Antwortalternativen angezeigt. Dies hat zur Folge, dass eine geringere Anzahl von relevanten Fragen gleichzeitig dargestellt werden kann, was zu einer Verschlechterung der Übersicht über die Zusammenhänge der Fragen untereinander führen kann. 2.2.2.2 Dynamische Darstellung Eine dynamische Darstellung legt keinen Wert auf die Darstellung von Fragen und Antwortalternativen an festgelegten Positionen. Sie verfolgt vielmehr das Ziel, die für den Benutzer relevante Informationen übersichtlich darzustellen. So können beispielsweise nur genau diejenigen Fragen dargestellt werden, die zum jeweiligen Zeitpunkt gerade wichtig sind. Dadurch wird die Menge der Information, die der Benutzer gleichzeitig betrachten muss, wesentlich reduziert. So werden Folgefragen z.B. erst nach Beantwortung ihrer Vorbedingungen angezeigt (Klappdialog). Antwortalternativen können mittels Popup-Menüs realisiert werden, die erst dann angezeigt werden, wenn man eine Frage ausgewählt hat. So bleibt mehr Platz für die Darstellung von Fragen. Übersteigt die Anzahl der Fragen die Menge der gleichzeitig auf dem Monitor anzeigbaren Information, können bei einer dynamischen Darstellung Scrollbalken verwendet werden. Man ist also nicht an eine seitenweise Darstellung (wie bei der fixierten Darstellung beschrieben) gebunden. Werden sämtliche Fragen in einer Liste mit Scrollfunktion aufgelis- 29 tet, sind sie für unerfahrene Benutzer leichter zu finden, als bei einer seitenweisen Darstellung. Der Benutzer muss nicht alle Karteikarten durchsuchen, um eine gewisse Frage zu finden. 2.2.3 Fragearten Fragen, die an den Benutzer gestellt werden, unterscheiden sich in der Art der Antworten, die der Benutzer geben kann. Manchmal ist z.B. nur eine Antwort möglich, wobei bei anderen Fragen mehrere Antwortalternativen zutreffen können. Im Folgenden werden verschiedene Fragetypen kurz beschrieben. 2.2.3.1 One-Choice Fragen (Eine Antwort) Bei One-Choice Fragen (OC-Fragen) kann der Benutzer genau eine Antwort auswählen. Die Frage ist vollständig beantwortet, sobald diese eine Antwort gegeben wurde. Somit ist hier keine Bestätigung durch den Benutzer notwendig, mit der er anzeigt, dass er die Beantwortung der Frage abgeschlossen hat. Ein Beispiel für eine OC-Frage wäre z.B. die Frage nach dem Geschlecht eines Patienten mit den Antwortalternativen „männlich“ und „weiblich“. 2.2.3.2 Multiple-Choice Fragen Multiple-Choice Fragen bieten dem Benutzer die gleichzeitige Auswahl mehrerer Antwortalternativen zur Beantwortung der Frage. Hier tritt das Problem auf, dass das System nicht automatisch erkennen kann, wann die Beantwortung der Frage beendet ist. Der Benutzer muss deshalb die Beendigung der Beantwortung explizit bestätigen. Ein Beispiel für eine MC-Frage ist die Frage nach der Lokalität von Gelenkschmerzen mit Angabe aller Gelenke als Antwortalternativen. 2.2.3.3 Ja/Nein Fragen Die wohl einfachste Frageart sind Ja/Nein Fragen. Es wird direkt nach einer Tatsache gefragt. Der Benutzer kann die Frage nur mit „Ja“ oder „Nein“ beantworten, je nachdem ob das Faktum zutrifft oder nicht. Ja/Nein Fragen sind somit ein Spezialfall von One-Choice 30 Fragen mit nur zwei Antwortalternativen. Mit der Angabe einer Antwort ist die Frage vollständig beantwortet, eine Bestätigung des Eingabe-Endes ist nicht notwendig. Ein Beispiel ist die Frage: „Rauchen Sie?“ mit den Antwortalternativen „ja“ und „nein“. 2.2.3.4 Numerische Fragen Bei numerischen Fragen ist die vom Benutzer gegebene Antwort ein numerischer Wert. Dieser wird entweder direkt in ein (numerisches) Textfeld eingegeben oder auch beispielsweise durch einen Schieberegler festgelegt. Im Unterschied zu den Fragen mit einer festen Anzahl von Antwortalternativen ist hier die Anzahl der möglichen Antwortalternativen zunächst unbeschränkt. Es müssen deshalb Einschränkungen gemacht werden. Dies geschieht meist in der Angabe eines zulässigen Wertebereiches. Ein Beispiel für eine numerische Frage ist die Frage nach dem Alter des Patienten. 2.2.3.5 Bild Fragen Bei Bildfragen wird die Beantwortung einer Frage mittels Anklicken eines bestimmten Bereiches eines präsentierten Bildes getroffen. Es können jedoch auch mehrere Bilder zur Auswahl stehen, beispielsweise je ein Bild pro Antwortalternative. Je nachdem, ob mehrere Bilder oder Bildbereiche gleichzeitig ausgewählt werden können sollen, werden Bildfragen intern auf One-Choice oder Multiple-Choice Fragen abgebildet. 2.2.4 Verwendete Techniken zur Eingabe von Daten in Dialogen Es gibt verschiedenen Möglichkeiten, Daten in Dialogen einzugeben. Dazu gibt es standardisierte Techniken, die je nach Fragetyp zum Einsatz kommen. Diese Eingabevarianten werden hier beschrieben: 2.2.4.1 Checkbox (bei MC-Fragen) Checkboxen sind quadratische Schaltflächen, die durch Anklicken aktiviert bzw. wieder deaktiviert werden können. Mit ihnen hat der Benutzer die Möglichkeit z.B. zwischen zutreffend / nicht zutreffend auszuwählen. Checkboxen werden deshalb für Multiple-Choice 31 Fragen verwendet. Trifft eine Antwortalternative zu, markiert der Benutzer die entsprechende Checkbox dieser Antwortalternative. Wichtig ist, dass Checkboxen voneinander unabhängig sind und somit beliebig viele Checkboxen gleichzeitig aktiviert werden können. Abb. 2.19: Checkboxen: Der Benutzer kann durch Anklicken mehrere Checkboxen aktivieren und so alle zutreffenden Antwortalternativen auswählen. Die Beendigung der Eingabe muss durch Anklicken des OK Buttons bestätigt werden. 2.2.4.2 Options-Button (bei OC-Fragen ja/nein) Options-Buttons sind runde Schaltknöpfe, die ebenfalls durch Anklicken aktiviert werden. Der Unterschied zu Checkboxen ist, dass Options-Buttons voneinander abhängig sind. Options-Buttons sind in Gruppen vereint. Alle Antwortalternativen zu einer Frage bilden beispielsweise eine Gruppe. Innerhalb einer Gruppe kann nur ein Options-Button aktiviert sein. Bei Auswahl eines Options-Buttons werden alle anderen Options-Buttons derselben Gruppe automatisch deaktiviert. Options-Buttons finden deshalb bei One-Choice Fragen und Ja/Nein-Fragen Verwendung. Hier kann nur eine Antwort gegeben werden. Abb. 2.20: Options-Buttons: Zum Beantworten der Frage kann der Benutzer eine Antwort durch Anklicken des Options- Buttons auswählen. Andere Options-Buttons werden dabei automatisch deaktiviert. 2.2.4.3 Pull-Down-Menüs (bei OC-Fragen) Bei einem Pull-Down-Menü werden die Antwortalternativen in einem Menü aufgelistet, das sich erst bei Bedarf (z.B. Anklicken einer Frage) öffnet. Es stellt eine Platz sparende 32 Alternative zur permanenten Darstellung der Antwortalternativen dar. Pull-Down-Menüs finden bei One-Choice Fragen Verwendung. Der Benutzer kann nach Aufklappen des Menüs aus der Liste eine Antwortalternative auswählen. Meist befindet sich oberhalb des Pull-Down-Menüs noch eine Text-Box, die dauerhaft angezeigt wird und in welcher die ausgewählte Antwort dargestellt wird. Abb. 2.21: Pull-Down-Menü: Beim Anklicken des Pull-Down-Buttons wird das Menü geöffnet. Hier kann der Benutzer eine der aufgelisteten Antwortalternativen auswählen. 2.2.4.4 Listen-Box (List von Elementen, ggf. mit Scrollbalken) Eine Listen-Box ist eine mehrzeilige Text-Box, in der verschiedenen Antwortalternativen dargestellt werden. Übersteigt die Anzahl der möglichen Antwortalternativen die Zeilen in der Listen-Box, wird eine Scroll-Funktion angeboten. Der Benutzer kann von den Antwortalternativen genau eine durch Anklicken auswählen. Diese wird dann (farblich) markiert. Listen-Boxen eignen sich hervorragend für One-Choice Fragen, bei denen es Standard-Antworten und weniger häufige Antworten gibt. Die oft verwendeten Antworten werden dann permanent in der Listbox dargestellt und sind somit übersichtlich und schnell auszuwählen. Selten verwendete Antwortalternativen können durch Scrollen erreicht werden. Im Vergleich zu einem normalen Pull-Down-Menü wird die Übersichtlichkeit und schnelle Auswahlmöglichkeit von (Standard-) Antworten erhöht. Dies geht allerdings zu Lasten des Platzbedarfs. 33 Abb. 2.22: Listen-Box: Die Antwortalternativen sind in einer Liste aufgelistet. Von dieser Liste werden aber nur eine gewisse Anzahl von Elementen in der Listen-Box gleichzeitig dargestellt. Dabei ist es sinnvoll, häufig gewählte Antwortalternativen oben in der Liste zu halten, da sie dann standardmäßig angezeigt werden. Zu den anderen Antwortalternativen kann mittels der Scroll-Leiste gescrollt werden. 2.2.4.5 Text-Box (Freitexteingabe) Die Text-Box bietet dem Benutzer die Möglichkeit zur Freitexteingabe seiner Antwort. In einem Textfeld kann er Eingaben in numerischer oder textueller Form machen. Die Antwortalternativen werden also vom System nicht zur Auswahl vorgegeben. Es können zwar Hinweise zur vom System unterstützten Syntax der Eingabe gegeben werden, für die syntaktische Korrektheit der Eingabe trägt der Benutzer allerdings die alleinige Verantwortung. Nicht zulässige Eingaben können vom System zurückgewiesen werden. Im Gegensatz zu einer Auswahl von Antwortalternativen durch Anklicken, muss bei einer Freitexteingabe die Eingabe zunächst analysiert werden um sie anschließend auf intern vorhandene Antwortalternativen des Systems abzubilden. Abb. 2.23: Text-Box: In eine Text-Box kann der Benutzer eine beliebige Zeichenfolge eingeben. Die syntaktische Richtigkeit muss vom System überprüft werden. Das Ende der Eingabe muss bestätigt werden. 34 2.2.4.6 Schieberegler Numerische Daten können auch mittels eines Schiebereglers eingegeben werden. Mit Hilfe der Maus kann ein Knopf auf einer Laufleiste verschoben werden. Je nach Position des Knopfes auf dem Regler ergibt sich dann ein numerischer Wert. Der Vorteil gegenüber einer numerischen Eingabe in einem Textfeld liegt in der festgelegten Anzahl der möglichen Werte. Abb. 2.24: Schieberegler: Durch Verschieben des Regler kann der Benutzer einen numerischen Werte aus dem vorgegebenen Wertebereich des Schiebereglers auswählen. 2.3 Spezifikation einer Dialogoberfläche für IDEE Im folgenden Abschnitt wird ein Dialog für eine flexible Dateneingabe für die an der Universität Würzburg entwickelte Umgebung für Diagnosesysteme d3web [d3web] entworfen. Dieser Dialog soll neben der bereits verwendeten formularbasierten Eingabe die Möglichkeit einer Freitexteingabe bieten und beide Eingabemethoden möglichst gut verbinden. Dabei werden die in den vorhergehenden Abschnitten vorgestellten Möglichkeiten zur Dialoggestaltung und hinsichtlich der Eignung für den zu entwerfenden Dialog betrachtet und die entsprechenden Elemente und Varianten ausgewählt. Ziel ist es, eine Dialogoberfläche zu entwerfen, die dem Benutzer eine möglichst einfache, schnelle und verständliche Eingabe seiner Daten gewährleistet. Hierzu ist es u. a. notwendig, die Fragen und Antwortalternativen übersichtlich zu präsentieren, Eingaben einfach zu halten und den Benutzer bei der Eingabe möglichst gut zu unterstützen. Wichtiges Ziel bei der hier beschriebenen Dialogentwicklung ist aber auch, dem Benutzer die Kontrolle über 35 die Art und Reihenfolge seiner Eingabe zu überlassen und ihn dabei nicht durch strikte Vorgaben des Beratungssystems zu bevormunden. Bei der Entwicklung des Dialogs werden die im vorhergehenden Kapitel beschriebenen Möglichkeiten zur Eingabe betrachtet und versucht, eine bestmögliche Kombination zu finden. 2.3.1 Auswahl der Dialogart Wie im vorhergehenden Abschnitt beschrieben, gibt es verschiedene Arten von Dialogen, wie z.B. den Einfragendialog, Mehrfragendialog, Klappdialog oder die Freitexteingabe. Jeder dieser Dialoge hat seine Vor- und Nachteile. In Hinblick auf die Entwicklung einer flexiblen Dateneingabe erwies es sich als vielversprechend, sich nicht auf eine dieser bisherigen Dialogarten festzulegen, sondern die jeweiligen Vorteile miteinander in einem neuen Dialog zu vereinen. Die einfachste oben vorgestellte Dialogart bildet der Einfragendialog, bei dem jeweils nur eine Frage präsentiert wird. Diese Dialogart ist zwar für unerfahrene Benutzer die wohl verständlichste Dialogform, da sie den Benutzer vollständig in der Reihenfolge der Dateneingabe führt. Dies widerspricht jedoch dem Wunsch nach einer flexiblen Dateneingabe grundlegend, weshalb auf diese Dialogart verzichtet wurde. Eine Verbesserung hinsichtlich der gerade beschriebenen Einschränkungen des Einfragendialogs bezüglich einer flexiblen Dateneingabe wird im Mehrfragendialog durch die gleichzeitige Darstellung mehrere Fragen gegeben. Der Benutzer kann die Reihenfolge der Beantwortung dieser dargestellten Fragen frei entscheiden. Allerdings ergibt sich immer noch die Einschränkung, dass der Benutzer auf die nicht dargestellten Fragen keinen Zugriff hat, diese also nicht beantworten kann. Ein Zugriff auf alle Fragen der Wissensbasis wird erst durch hinzufügen einer Navigationsmöglichkeit innerhalb der Wissensbasis erzielt. Dieser Ansatz ist bereits im Klappdialog realisiert, der einzelnen Fragen zu Frageklassen zusammenfasst und diese in einer Baumstruktur gliedert, auf die jederzeit zugegriffen werden kann. Allerdings wird bei dem beschriebenen Klappdialog die Darstellung der Antwortalternativen jeweils durch ein PopUp Fenster bei der jeweiligen Frage dargestellt. Diese Vorgehensweise erweist sich jedoch als äußerst unübersichtlich, da z.B. die Werte der beantworteten Fragen nur durch aufklappen des Pop-Up Fensters eingesehen werden können. 36 Durch Kombination der Navigationsmöglichkeit in der Wissensbasis und der vorteilhaften Darstellung der Fragen und Antworten im Mehrfragendialog wurde eine erweitere Dialogform entworfen. Dieser Ansatz ist auch schon beim Dialogsystem d3web verfolgt worden. Wie beim Klappdialog beschrieben, werden die Fragen einer Wissensbasis zu Frageklassen zusammengefasst, die wiederum in eine übergreifende Struktur eingeordnet werden können. Die Navigation zwischen diesen Frageklassen wird innerhalb eines separaten Fensters gewährleistet. In diesem Fenster sind alle Frageklassen einer Wissensbasis in einer übersichtlichen Baumstruktur dargestellt. Der Benutzer kann somit in einfacher und übersichtlicher Weise durch die Wissensbasis browsen und die gewünschten Frageklassen auswählen. Die Darstellung der Fragen einer Frageklasse wird dann im Hauptfenster des Dialoges realisiert. Hier werden in der Form eines Mehrfragendialoges alle Fragen einer Frageklasse gleichzeitig dargestellt. Der Benutzer hat somit einerseits eine Gesamtübersicht über die Fragen einer Frageklasse und deren Werte und kann anderseits die Fragen in beliebiger Reihenfolge beantworten. Die entscheidende Neuerung bei der Entwicklung des Dialoges zur flexiblen Dateneingabe stellt jedoch die Kombination einer Freitexteingabe mit der im vorhergehenden Absatz beschriebenen erweiterten Dialogform dar. Dies wird durch Bereitstellen eines Fensters für die Eingabe von Freitext realisiert. Hier kann der Benutzer seine Daten, wie z.B. Symptome, eingeben und diese werden dann automatisch auf die entsprechenden Fragen und deren Antwortalternativen abgebildet. Der Benutzer muss in diesem Fall nicht die Wissensbasis durchforsten um eine spezielle Frage zu beantworten. Bei der so entstandenen Dialogform zur flexiblen Dateneingabe, kann der Benutzer die beiden Ansätze der herkömmlichen Dateneingabe mittels direkter Fragebeantwortung im Mehrfragendialog mit der Freitexteingabe nach seinen Wünschen und Bedürfnissen kombinieren. 2.3.2 Auswahl der Darstellungsart Das Ziel einer großen Flexibilität bei der Dateneingabe und der Dialogoberfläche findet sich auch bei der Darstellungsart wieder. So wurden z.B. verschiedene Ansätze vorgesehen, die der Benutzer nach seinen Wünschen oder Anforderungen anpassen kann. Oft ist 37 auch in Abhängigkeit vom Aufbau der verwendeten Wissensbasis eine bestimmte Darstellungsart vorteilhaft. Eines der größten Probleme bei der Entwicklung einer Benutzeroberfläche ist eine übersichtliche Präsentation aller wichtigen Daten auf dem beschränkten Platz des Monitors. Es ist so gut wie nie möglich, alle Informationen gleichzeitig darzustellen ohne aufgrund der Informationsmenge die Übersicht zu verlieren. Folgedessen muss eine Auswahl getroffen werden, welche Daten zu einem Zeitpunkt dargestellt werden sollen und wie diese Daten präsentiert werden. Um möglichst viel relevante Information gleichzeitig übersichtlich auf dem Bildschirm zu präsentieren, wird als einfachster Schritt einen flexible Skalierung der Position der ausgegebenen Daten angewandt. Dabei wird in Abhängigkeit der Daten automatisch ein übersichtliches Layout generiert. So kann beispielsweise anhand der Länge der Antworten ein Raster berechnet werden, mit dem sich eine maximale Anzahl der Fragen übersichtlich und platzsparend darstellen lässt. Ein weiterer Schritt zur möglichst kompakten vollständigen Darstellung relevanter Information ist, die zu einem Zeitpunkt nicht relevanten Daten auszublenden. Diese werden erst dargestellt, wenn sie benötigt werden. Im entworfenen Dialog gibt es deshalb z.B. die Möglichkeit Folgefragen zunächst auszublenden. Sie werden dann erst beim Erreichen von notwendigen Vorbedingungen (d.h. entsprechende Beantwortung anderer Fragen) aktiviert. Dies ist besonders dann sinnvoll, falls in der Wissensbasis viele Folgefragen enthalten sind die nur in (seltenen) Spezialfällen gestellt werden. Eine permanente Darstellung aller dieser Folgefragen würde die Übersicht über die relevanten Daten wesentlich verringern. Das Ausblenden von Daten hat auf der anderen Seite allerdings den Nachteil, dass sich der Zugriff auf die nicht dargestellten Daten erschwert, falls diese in der Wissensbasis gefunden werden sollen. Beim Entwurf des Dialogs wurde auch versucht, die Vorteile einer fixierten Darstellung mit Einfließen zu lassen. So hat sich bezüglich der Widerauffindbarkeit von Daten gezeigt, dass man sich hier die menschliche Fähigkeit zum Erinnern von Positionen zur Hilfe nehmen kann. Werden dieselben Daten immer wieder an der gleichen Position auf dem Bildschirm dargestellt, ist es für den Benutzer wesentlich einfacher, diese Daten schnell wie38 derzufinden. Im Gegensatz dazu muss der Benutzer bei variabler Darstellung von Daten, wie sie beispielsweise bei Scroll-Listen auftritt, Daten möglicherweise auf dem ganzen Bildschirm suchen. Eine weitestgehend fixierte Darstellung der Daten wird im Dialog z.B. durch die dort vorhandene seitenweise Darstellung der Frageklassen ermöglicht. In diesen sind, wie bekannt, zusammengehörende Daten zu Einheiten zusammengefasst. Diese Daten können aufgrund ihrer kompakten Größe oft gleichzeitig und übersichtliche dargestellt werde. Zwischen den einzelnen Seiten wird, wie bereits beschrieben, mittels einer Navigationsleiste gewechselt. 2.3.3 Auswahl der Elemente zur Dateneingabe und Position im Dialog Um auch bei der Auswahl der Elemente zur Dateneingabe flexibel zu sein, wurden im entworfenen Dialog verschiedene dieser Elemente vorgesehen zwischen denen der Benutzer je nach seinen Anforderung die geeigneten auswählen kann. In engem Zusammenhang mit der Auswahl der Elemente steht auch die Position dieser Elemente im Dialog. Beide Aspekte werden hier erläutert. Im Dialog wurden folgende beiden Möglichkeiten der Dateneingabe vorgesehen: die bisherige Dateneingabe durch Beantwortung von Fragen mittels Auswahl einer Antwortalternative und die Freitexteingabe. Die Freitexteingabe wird durch ein Fenster fester Größe realisiert, in dem der entsprechende Text eingegeben werden kann. Eine weiterführende Beschreibung dieser StandardEingabeform findet an dieser Stelle nicht statt. Bei der herkömmlichen Dateneingabe werden zu jeder Frage alle Antwortalternativen präsentiert aus denen dann eine (bei OC-Fragen) oder mehrere (bei MC-Fragen) ausgewählt werden. Zur Markierung der Auswahl sind im Dialog standardmäßig Options-Buttons bzw. Checkboxen vorgesehen. Nach den individuellen Bedürfnissen bzw. den Gegebenheiten der Wissensbasis können diese nun auf verschiedener Weise im Dialog angeordnet werden: 39 Anordnung nebeneinander: Eine Anordnung der Antwortalternativen nebeneinander gewährleistet eine kompakte Darstellung und somit die Möglichkeit, mehr Information gleichzeitig auf einer Seite darzustellen. Sie beeinträchtigt jedoch unter Umständen den Ansatz einer fixierten Darstellung, die ein Element immer an der gleichen Stelle des Dialoges darstellen will um somit ein schnelleres Wiederfinden zu ermöglichen. Eine Darstellung der Antwortalternativen nebeneinander beispielsweise ist dann vorteilhaft, wenn es zu Fragen viele Antwortalternativen gibt, besonders wenn diese eine kurze Länge aufweisen. Anordnung untereinander: Die andere Möglichkeit besteht in der Anordnung der Antwortalternativen untereinander. Sie beansprucht mehr Platz zur Darstellung, zielt allerdings auf eine fixierte Darstellungsart hin. Diese Anordnung ist beispielsweise bei Fragen mit Antwortalternativen von sehr großer oder unterschiedlicher Länge übersichtlicher. Hier hätte eine Darstellung nebeneinander ohnehin kaum Vorteile im geringeren Platzbedarf. Pop-Up Menü: Alternativ können die Antworten als Pop-Up Menü dargestellt werden. Dies vereinigt die Vorteile des geringen Platzbedarfs und der Tendenz zur fixierten Darstellung der Fragen. Die Auswahl der Fragen ist allerdings dadurch aufwendiger. Außerdem geht die Übersicht über bereits aktivierte Fragen (zumindest bei MC-Fragen) verloren. Pop-Up Menüs zeigen ihren Vorteil deshalb hauptsächlich dann, wenn eine große Menge an Information auf einer Seite fix dargestellt werden soll. 40 2.3.4 Entwurf eines Beispieldialoges Hier ist der Entwurf eines Beispieldialoges dargestellt, dem die oben beschriebene Struktur und Element der Dialogspezifikation zugrunde liegt. Er ist als eine von vielen möglichen Dialogrealisationen zu sehen und soll nur als Anregung dienen. Abb. 2.25: Entwurf eines Dialoges für IDEE. Der Dialog ist als seitenweiser Mehrfragendialog realisiert. Auf der linken Seite findet sich eine Leiste zur Navigation zwischen den einzelnen Seiten. Innerhalb einer Seite sind die einzelnen Fragen durch einen farblich anderen Hintergrund voneinander abgehoben. Bei den Fragen finden sich unterschiedliche Darstellungsmöglichkeiten der Antwortalternativen: Anordnung untereinander, Anordnung nebeneinander Pop-Up Menüs sowie Listen-Boxen. Ebenso ist ein Eingabefeld für eine Freitexteingabe vorhanden. 41 Kapitel 3 Computerlinguistische Grundlagen der Verarbeitung von natürlichsprachlichem Text in Computersystemen Neben den oben beschriebenen Eingabemöglichkeiten von Daten durch Formulare, in denen der Benutzer verschiedene Antwortalternativen zu einer Frage auswählen kann, soll das System auch die Möglichkeit einer Freitexteingabe zur Verfügung stellen. Diese Möglichkeit der Dateneingabe Diagnosesystemen wurde auch schon bei [Berberich 1999] vorgeschlagen. Bei der Freitexteingabe soll der Benutzer in einem Textfeld alternativ zur formularbasierten Eingabe alle für ihn wichtigen Beobachtungen einfach und schnell eingeben können. Dies hat u. a. den Vorteil, dass er nicht an die Vorgaben der Formulare gebunden ist und seine Eingaben in beliebiger Reihenfolge machen kann. Ferner wird eine schnelle Dateneingabe ermöglicht, da sich der Benutzer weder mit Lesen von Fragen noch Antwortalternativen befassen muss. Möchte der Benutzer spezielle Fragen beantworten, muss er diese auch nicht mehr in der Wissensbasis suchen, was ebenfalls zu einem Zeitgewinn führt. Die Freitexteingabe ist somit besonders zur schnellen Eingabe von Daten, die dem Benutzer wichtig erscheinen, gut geeignet. Die durch den Benutzer mittels Freitext eingegebenen Daten müssen vom System weiterverarbeitet werden und auf die Wissensbasis des Systems abgebildet werden. Um dies zu gewährleisten, muss das System die Eingaben richtig erkennen und zuordnen können. Hierbei kommt die computerlinguistische Sprachverarbeitung zum Einsatz. Im Folgenden soll zunächst ein Überblick über die üblichen Verfahren und Anwendungsgebiete der computerlinguistischen Sprachverarbeitung gegeben werden. Darauf aufbauend werden die Besonderheiten bei der Freitexteingabe aufgezeigt und die diesbezügliche Anwendbarkeit der zuvor genannten Verfahren untersucht. 3.1 Einsatzgebiete computerlinguistischer Verfahren Der Einsatz von grammatischem Wissen und computerlinguistischen Verfahren stellt bei Computeranwendungen in den unterschiedlichsten Gebieten einen großen Nutzen dar und 42 ermöglicht eine Vielzahl von Verbesserungen. Im Folgenden sollen einige Anwendungsgebiete der Computerlinguistik kurz aufgegriffen werden. 3.1.1 Indexieren und Abruf von textuellen Datenbanken / Volltextsuche (TextMining) In einer textuellen Datenbank werden Texte in elektronischer Form gespeichert. Dabei handelt es sich meist um große bis sehr große Datenbestände, wie z.B. alle Ausgaben einer Zeitschrift. Ebenso kann man das World Wide Web als eine extrem große, unstrukturierte und sich schnell ändernde textuelle Datenbank auffassen, die Unmengen von Information enthält. Ziel bei der Benutzung einer textuellen Datenbank ist es, zu einer spezifischen Fragestellung sämtliche relevanten Objekte (Dokumente) und Textstellen zu finden. Je größer allerdings eine solche Datenbank ist, desto schwieriger gestaltet sich die effiziente Suche nach relevanter und nützlicher Information. Einfache wortbasierte Methoden (diese Vergleichen lediglich die Zeichen der Suchanfrage mit denjenigen in der Datenbank) haben dabei oft nur eingeschränkten Erfolg. Bessere Suchergebnisse erhält man durch den Einsatz verschiedener computerlinguistischer Verfahren, wie sie in den folgenden Abschnitten näher beschrieben werden. 3.1.2 Maschinelle Übersetzung Die Überwindung von Sprachbarrieren spielt in unserer Zeit der zunehmenden Globalisierung eine wichtige Rolle. Der Nutzen von maschinellen Übersetzungsprogrammen die Texte von einer Quellsprache in eine andere Zielsprache überführen ist unübersehbar. Bei der Übersetzung ist es wichtig, die Intention und Bedeutung beizubehalten. Dies erfordert allerdings ein großes Wissen über den inhaltlichen und kulturellen Kontext. Die große Herausforderung der maschinellen Übersetzung liegt deshalb in der Erfassung der Bedeutung und des Kontextes eines Textes. Dazu ist eine präzise computerlinguistische Analyse wie auch eine hochwertige Generierung des Zieltextes erforderlich. Für ein tiefgehendes Verständnis der meisten Texte ist allerdings auch ein großer Anteil an „Weltwissen“ erforderlich, um z.B. Mehrdeutigkeiten aufzulösen oder Referenzen herzustellen. Dieses Weltwissen ist jedoch leider oft nicht formal beschreibbar und somit i. a. nicht berechenbar. Menschliche Übersetzungen werden sich somit wohl in naher Zukunft nicht durch den Computer ersetzten lassen. 43 3.1.3 Automatische Textproduktion Es gibt eine Vielzahl von Fällen in denen sich automatisierte Textproduktion vorteilhaft einsetzen lässt. Denken wir z.B. an Produktionsfirmen, die immer wieder Produktbeschreibungen oder Bedienungsanleitungen erstellen müssen, oder den Büro-Bereich, wo ein Großteil der Korrespondenz aus Briefen besteht, die sich nur in genau definierten Bereichen unterscheiden. Die Methoden in der Computerlinguistik zur automatischen Textproduktion reichen von einfachen Schablonen bis hin zu flexiblen interaktiven Systemen, die sich linguistisches Wissen zunutze machen. 3.1.4 Automatische Textüberprüfung / Fehlerkorrektur Die automatisierte Textüberprüfung ist schon in einer Vielzahl von standard (Office)Softwareprodukten vertreten. Einfache Ansätze zur orthographischen Überprüfung eines Textes greifen auf vordefinierte Wortformenlisten zurück. Andere Systeme ermöglichen auch die Überprüfung der Syntax mit Erkennung von Fehlern in Wortstellung, Zeichensetzung etc. Eine genauere Erläuterung über die Verfahren der automatisierten Fehlererkennung findet sich in Abschnitt XXXXXXXXX. 3.1.5 Automatische Inhaltsanalyse /Textklassifikation Durch die immer weiter wachsende Flut an (gedruckter) Information gewinnt eine automatische Inhaltsanalyse und Klassifikation von Texten immer mehr an Bedeutung. Die automatische Inhaltsanalyse stellt auch eine wichtige Voraussetzung für weiterführende Anwendungen in der Computerlinguistik dar, wie z.B. für eine konzeptbasierte Indexierung (s. u.), oder eine leistungsfähige maschinelle Übersetzung. Ein klassisches Beispiel der automatischen Textklassifikation ist die Einordnung von (Zeitungs-) Nachrichten in verschiedene Rubriken. Die daraus resultierenden klassifizierten Textbestände ermöglichen einen wesentlich leichteren Zugang zur gewünschten Information. Dies wird besonders dann deutlich, wenn bei der Suche nicht genau feststeht, was genau gesucht wird, sondern ein Überblick über ein unbekanntes Suchgebiet geschaffen werden soll. Eine ausführliche Beschreibung der symbolischen Wissensextraktion im WWW findet sich bei [Carven, Freitag et al.]. 44 3.1.6 Abschnittserkennung Bei der Abschnittserkennung kommt es darauf an, in einem Text Abschnitte zu unterschiedlichen Themengebieten zu finden. Dazu ist es notwendig, dass Änderungen der Thematik sicher erkannt werden. Diese Anwendungen sind beispielsweise beim Erkennen und Verfolgen von Nachrichten äußerst nützlich, wobei natürlich auch das Gebiet der Textklassifikation mit einfließt. Ansätze zur dieser Thematik sind z.B. in [Yang et al.] beschrieben, die sich mit Lernverfahren zur Erkennung und Verfolgen von Nachrichten beschäftigten. 3.1.7 Informations-Extraktion (IE) Das oben bereits erwähnte Phänomen der Informationsüberflutung macht es immer schwieriger relevante Information zu finden und zu extrahieren um sie schließlich in kompakter Form darzustellen. Systeme zur Informationsextraktion sollen nun aus freien Texten gezielt domänenspezifisches Wissen aufspüren und strukturieren können. Dabei soll unwichtige Information „überlesen“ werden. Die Systeme zur Informations- Extraktion haben nicht zum Ziel, eine vollständige Analyse von Texten zu liefern, sie sollen vielmehr Textpassagen mit relevanter Information analysieren und „verstehen“. Ein sehr modular aufgebautes und damit äußerst flexibles System zur Informations- Extraktion für die deutsche Sprache ist SMES (Saarbrücker Message Extraction System) [SMES 1, SMES 2]. Bei diesem kommen so genannte „flache Textverarbeitungsmethoden“ zum Einsatz, die bestimmte generische Sprachregularitäten, die bekanntermaßen zu Komplexitätsproblemen führen, nicht oder nur pragmatisch behandeln. Dazu wird nach der lexikalischen und morphologischen Analyse keine vollständige syntaktische Analyse des Eingabetextes durchgeführt, sondern diese nur auf Textfragmente beschränkt. Beim Parsen erfolgt dabei eine strikte Trennung zwischen der Phrasen- und der Satzstruktur: zunächst werden einzelne Phrasen erkannt, die dann in einem weiteren Schritt zu einer komplexeren Satzstruktur zusammengesetzt werden. Durch diese modulare Vorgehensweise wird ermöglicht, eine domänenunabhängige Phrasenanalyse durchzuführen und diese mit sehr domänenspezifischen Regeln zur Erkennung von komplexen Satzeinheiten zu koppeln. 45 SMES soll im Folgenden als kleines Beispiel verwendet werden um die konkrete Realisierung von computerlinguistischen Techniken, wie sie in den folgenden Abschnitten beschrieben werden, näher zu erläutern. 3.1.8 Automatisierter Unterricht Das Erlernen einer Fremdsprache ist ein treffendes Beispiel für die Einsatzmöglichkeiten von computerlinguistischen Verfahren beim automatisierten Unterricht. Herkömmliche Systeme bieten meist nur Multiple-Choice Aufgaben, Lückentexte oder die Möglichkeit zur Eingabe einzelner Wörter an. Äußerst wichtig sind jedoch auch die Verarbeitung von Eingaben komplexer Sätze oder beispielsweise eine leistungsfähige und sinnvolle Fehlererkennung, die erst durch NLP-Ansätze zu realisieren sind. 3.1.9 Dialogsysteme und automatisierte Auskunft Dialogsysteme finden sich in einer Vielzahl von Bereichen, wie wir in Kapitel 1 gesehen haben. Einfache Systeme sind z.B. eine automatisierte Reiseauskunft über Datenbankabfragen. Sie reichen bis hin zu komplexen Expertensystemen, wie sie z.B. die Grundlage dieser Diplomarbeit bilden. Einige der vielen Vorteile einer natürlichsprachlichen Schnittstelle in Dialogen sind die Möglichkeit einer einfacheren, schnelleren und verständlicheren Dateneingabe, wie auch die flexiblere und präzisere Ergebnispräsentation bis hin zur Sprachausgabe . Sie trägt im Idealfall zu einer Reduktion der Barrieren der MenschMaschine-Kommunikation bei. 3.1.10 Textzusammenfassung 3.3 Wiederkehrende Problemfelder in der Computerlinguistik Im folgenden Abschnitt sollen Grenzen bei der Sprachverarbeitung aufgezeigt werden und die Überwindung dieser Restriktionen mit Hilfe von grammatischem Wissen beschrieben werden. Als Beispiel wird hierbei die sehr häufig auftretende Indexierung und Suche in textuellen Datenbanken hergenommen, wie sie im vorhergehenden Abschnitt beschrieben wurde. 46 3.2.1 Bisheriges Indexieren und Finden in textuellen Textdatenbanken In einer textuellen Datenbank ist eine beliebige Sammlung von Texten elektronisch gespeichert, wobei im Vergleich zu einer klassischen tabellarischen Datenbank keinerlei Strukturbeschränkungen vorliegen. Um eine Suche nach Texten oder Textstellen in dieser Datenbank zu ermöglichen, wird ein wortbasierter Index aufgebaut. Dieser verwendet die Buchstaben des Alphabets als Schlüsselwörter und referenziert alle deren Vorkommen im Text. Eine bestimmte Zeichenfolge kann deshalb durch Berechnung der Schnittmenge der Positionen der einzelnen Buchstaben im Text wiedergefunden werden. Aus Benutzersicht gestaltet sich die Sucheingabe allerdings auf wortvektorbasierter Ebene. Er gibt alle ihm wichtig erscheinenden Wörter als Suchanfrage ein. Die Suche liefert daraufhin den Text oder Textabschnitt, in dem alle diese Wörter vorkommen. Die Qualität einer Suchanfrage in textuellen Datenbanken wird dabei über die Parameter Recall und Precision gemessen. Recall misst, wieviel Prozent der relevanten Texte einer Datenbank gefunden wurden. Precision misst, wieviele relevante Texte im Suchergebnis enthalten sind. Die Praxis hat gezeigt, dass diese Parameter nicht unabhängig voneinander sind, sondern sich in etwa umgekehrt proportional zueinander verhalten. Diese Wortvektorbasierte Suche auf Grundlage von indexierten Datenbanken kommen in sehr vielen heutigen Computeranwendungen vor. Denke man nur an die Suchmaschinen im Internet, ohne die eine das Auffinden von wichtigen Informationen undenkbar wäre, Bibliothekskataloge, oder natürlich auch die in dieser Arbeit entwickelte Dateneingabe IDEE. Bei der Suche auf Grundlage eines buchstabenbasierten Indexes kommt es allerdings sehr schnell zu Einschränkungen und Problemen, die erst durch Einsatz computerlinguistischer Verfahren gelöst werden können. Diese Einschränkungen und ihre Lösungsansätze werden nun im Folgenden beschrieben. 47 3.2.2 Einsatz von grammatischem Wissen In diesem Abschnitt werden zunächst textuelle Phänomene beschrieben, die durch reine buchstabenbasierte Verfahren nicht gelöst werden können. Sie werden in Verbindung mit den grammatikalischen Komponenten der Computerlinguistik in Beziehung gesetzt, die eine Lösungsmöglichkeit anbieten. Im zweiten Teil werden Optimierungsmethoden aus der Computerlinguistik erläutert, die ebenfalls zu einer Verbesserung des Suchergebnisses führen. 3.2.2.1 Phänomene die linguistisch Lösungen erfordern - Morphologie Mit einer buchstabenorientierten Suche können keine Wortformen erkannt werden. Die Suche nach „Haus“ liefert deshalb keine Treffer für die Wortform „Häuser“. Es können nur exakte Übereinstimmungen erkannt werden. Eine Lösung für dieses Problem würde ein morphologisches Analyseprogramm bieten, welches automatisch Wortformen erkennt und alle zugehörigen Wörter auf eine gemeinsame Grundform abbildet. Dieses „Stemming“-Programm ist der oft angewandten einfachen Methode des Weglassens von Wortendungen („Truncation“) mit Abstand überlegen. Der wohl bekannteste Stemming-Algorithmus für die englische Sprache ist der Algorithmus von Porter [Porter]. Da die morphologische Analyse für das Deutsche weit schwieriger ist, existieren hier oft nur eingeschränkte Verfahren. Auch vom Porter-Alogrithmus gibt es eine Abwandlung für die deutsche Sprache [Porter deutsch]. Eine erwähnenswerte Implementierung findet sich in Jakarta Lucene [Lucene]. - Lexikon Bei einer buchstabenorientierten Suche können keine semantischen Korrelationen zwischen Wörtern erkannt werden. Die Suche nach „Mensch“ liefert somit keine Treffer für relevante Vorkommen von Unterbegriffen wie z.B. „Kind“. Eine Lösung liefert hierbei eine Lexikonstruktur, die für jedes Wort seine zugehörigen Synonyme (gleichbedeutende Wörter), Hyperonyme (Oberbegriffe) und Hyponyme (Unterbegriffe) verwaltet. Das Lexikon kann dann beispielsweise zu einer Erweiterung der Suchanfrage herangezogen werden. Eine ausführliche Betrachtung zu Lexika als Hilfsmittel der Computerlinguistik folgt in 2.5. 48 - Syntax Syntaktische Strukturen können mit einer buchstabenorientierten Suchmethode ebenfalls nicht erkannt werden. Die Anfrage „Geprelltes Handgelenk und gebrochener Unterarm“ liefert dasselbe Suchergebnis wie „gebrochenes Handgelenk und geprellter Unterarm“. Ein syntaktischer Parser liefert hierfür eine Lösung indem er den grammatikalischen Zusammenhang zwischen dem jeweiligen Adjektiv und zugehörigen Substantiv erkennt. Die verschiedenen Arten von Parsern und ihre Funktionsweise werden bei den Techniken der Computerlinguistik näher erläutert. REFERENZ - Semantik Buchstabenorientierte Suchverfahren können keine semantischen Zusammenhänge wie z.B. Äquivalenzen zwischen verschiedenen Beschreibungen desselben Sachverhalts darzustellen (z.B. aktive und passive Darstellung). Diese Problematik kann durch eine semantische Analyse gelöst werden, die auf den syntaktischen Parser und eine geeignete Lexikonstruktur aufbaut. - Pragmatik Allein mit der semantischen Analyse kann die eigentliche Bedeutung eines Satzes manchmal nicht abgeleitet werden. So ist zielt beispielsweise die Frage: „Wissen sie die Uhrzeit?“ nicht auf die Antwort „Ja“ oder „Nein“. Vielmehr möchte der Fragesteller die Uhrzeit erfahren. Kontextabhängige Formulierungen in Texten oder auch Verwenden von allgemeinen Begriffen wie „Problem oder Situation“ verschlechtern das Suchergebnis in wortbasierten Suchen erheblich. Diese Phänomene treten sehr häufig auf und erfordern für ihre Behandlung eine erfolgreiche theoretische und praktische Durchdringung der Pragmatik. 3.2.2.2 Linguistische Methoden der Optimierung Linguistisches Wissen kann an verschiedenen Stellen einer Datenbankstruktur angewandt werden um das Suchergebnis zu verbessern. Diese Möglichkeiten werden nun genauer erläutert. 49 - Verarbeitung der Anfrage Um das Suchergebnis zu verbessern kann zunächst die Suchanfrage optimiert werden. Dazu bieten sich folgenden Möglichkeiten: a) automatische Anfrage Expansion (Query Expansion) Hierbei wird die ursprüngliche Anfrage erweitert. Dies kann einerseits durch Hinzufügen von Flexionsformen erfolgen, wodurch verschiedene Wortformen abgedeckt werden. Ferner können Synonyme, Ober- und Unterbegriffe hinzugefügt werden. Eine wegen ihres Aufwandes seltener verwendetet Expansionsmöglichkeit ist die Hinzunahme von syntaktisch äquivalenten Formulierungen (z.B. gebrochener Arm -> Arm, der gebrochen ist). b) interaktive Anfrageoptimierung Die automatische erweiterte Anfrage wird dem Benutzer vor der eigentlichen Suche noch einmal zur Verifikation präsentiert. Dies hat den Vorteil, dass falsche oder irrelevante Expansionen gestrichen werden können und die Suchanfrage somit vereinfacht wird. -Differenzierung der Indexierung Die Qualität des Suchergebnisses kann auch durch eine Verfeinerung bei der Indexierung verbessert werden. Dabei gibt es verschiedene Ansätze der Indexierung: a) Buchstaben-Orientierte Indexierung Diese einfache Standardmethode wurde oben ausführlich beschrieben. Sie ermöglicht das Auffinden aller Vorkommen einer Buchstabenfolge in einer Datenbank. b) Morphologie-Basierte Indexierung Dabei werden Wortformen analysiert und auf eine Grundform abgebildet. Es wird dadurch eine Suche nach allen Textstellen mit derselben Grundform ermöglicht. c) Syntax-Basierte Indexierung 50 Durch Analyse der Syntax durch einen Parser wird die so gewonnene Information in den Index aufgenommen. Er ermöglicht somit das Auffinden aller syntaktisch äquivalenten Konstruktionen eines Textes. d) Konzept-Basierte Indexierung Beim Einlesen wird der Text semantisch und pragmatisch analysiert. Semantische Mehrdeutigkeiten werden dadurch eliminiert und kontextabhängiger Sprachgebrauch erschlossen. Somit können alle Vorkommen eines bestimmten Konzepts gefunden werden. - Nachbearbeitung der gefundenen Daten Auch eine nachträgliche Bearbeitung der „Rohdaten“ einer Suche bringt Vorteile mit sich. So ist beispielsweise die Textmenge nach der Suche wesentlich reduziert, was die Weiterverarbeitung erleichtert. Aus den Suchergebnissen können so relevante Informationen leichter herausgefiltert werden. 3.2.3 Zusammenfassung: Anwendung auf IDEE Auch in der hier entwickelten Dateneingabe IDEE ist eine Vielzahl der oben diskutierten Lösungsmöglichkeiten für auftretende Probleme in der Computerlinguistik mit eingeflossen und implementiert worden: Bei der Indexierung der Fragen- und Antworttexte aus der Wissensbasis wird eine morphologiebasierte Indexierung verwendet. Dabei kommt der in Jakarta Lucene enthaltene deutsche Stemmer zum Einsatz, der die Morphologie der Texte analysiert und Wortformen auf eine gemeinsame Grundform abbildet. In gleicher Weise werden auch die Wörter der Suchanfrage morphologisch analysiert und vereinheitlicht. Aus allen Wörtern der gerade aktuellen Wissensbasis wird automatisch ein Lexikon konstruiert. Dies enthält zu jedem Wort alle in der Wissesbasis vorhandenen Teilwörter und Komposita, an denen es beteiligt ist. Alle enthaltenen Einträge liegen natürlich in ihrer gestemmten morphologischen Grundform vor. Das Lexikon wird für die automatische 51 Erweiterung der Suchanfrage verwendet. Dadurch enthält das Suchergebnis alle Synonyme, Ober- und Teilwörter. In Anlehnung an vorliegende aktuelle Arztbriefe ist ein syntaktischer Parser implementiert. Dieser ermöglicht die Erkennung eines Kontextes in denen Symptome stehen und erweitert die Suchanfrage automatisch um diesen Kontext. Des Weiteren werden Wertangaben (Zahl + Maßeinheit) erkannt, welche dann speziell verarbeitet werden können. Zur Verfeinerung des Suchergebnisses erfolgt einen nachträglich Filterung der Treffer anhand einer internen Bewertungsfunktion. Diese skaliert die einzelnen Suchtreffer untereinander und filtert nur die besten Ergebnisse heraus. 3.3 Methoden der computerlinguistischen Textverarbeitung Die linguistische Textverarbeitung zielt im Idealfall auf das „Verstehen“ eines Textes durch den Computer hin. Je mehr die Bedeutung eines Textes und seiner Textteile und Sätze erschlossen ist, umso größer ist der Nutzen der aus diesen Zusatzinformationen gezogen werden kann und umso umfassender und präziser kann ein Text weiterverarbeitet werden. Vorteile linguistischer Zusatzinformation wurden im vorhergehenden Abschnitt bereits erläutert. Die Gewinnung linguistischer Zusatzinformation aus einem Text bis hin zum (vollständigen) Verständnis eines Textes durch den Computer ist ein langer und nicht trivialer Weg. Seit Jahrzehnten beschäftigen sich eine Vielzahl von Computerexperten mit dieser Thematik der natürlichen Sprachverarbeitung (Natrual Language Processing, NLP) und sind noch lange nicht am Ziel des vollständigen Verständnisses von Texten angekommen. Im Folgenden Abschnitt werden die einzelnen Schritte der computerlinguistischen Textverarbeitung erläutert. 3.3.1 Parsing 1: Lexikalische Analyse (Scanner) Zu Beginn stellt sich jeder Text für den Computer zunächst als lange Kette (String) von aneinander gereiten Zeichen dar, aus der in dieser Form keine Bedeutung abgeleitet wer- 52 den kann. Deshalb ist es das erste Ziel, diesen String in einzelne Symbole (engl. Tokens) zu unterteilen. Ein Token ist dabei eine Folge von Zeichen, die zusammen eine bestimmte Bedeutung haben. Das Zerlegen eines Eingabestrings in Symbole durch einen sogenannten Scanner wird als lexikalische Analyse bezeichnet. Die Hauptaufgabe des Scanners besteht also darin, Textzeichen zu lesen und daraus eine Folge von Symbolen zu erzeugen die dann in einem weiteren Schritt von einem Parser (s. 2.4.2) syntaktisch analysiert werden können. Man kann einen Scanner in zwei Arbeitsschritte unterteilen. In einem ersten Schritt wird die Eingabe lediglich gelesen und einzelne Wörter (Lexeme) extrahiert. Im zweiten Schritt, der eigentlichen lexikalischen Analyse, wird die Bedeutung dieser Wörter erkannt. Der Scanner kann die einfache Zerlegung des Textes in Wörter (Lexeme) mit einer internen Liste von Trennzeichen, sogenannten Delimetern, realisieren. Dies sind spezielle Zeichen, wie z.B. Leerzeichen, Zeilenumbruch, Satzzeichen etc., die das Ende eines Tokens signalisieren. Dabei können diese Zeichen entweder überlesen und somit aus der Ausgabe entfernt werden, oder sie werden als eigenes Token behandelt. Die viel wichtigere Aufgabe des Scanners ist jedoch die eigentliche lexikalische Analyse, welche die Bedeutung von Tokens ergründet. So können z.B. Datumsangaben, Schlüsselwörter, Operatoren aber auch Absätze etc. erkannt werden. Dazu muss allerdings spezifiziert werden, welche Zeichenfolgen letztendlich auf ein entsprechendes Symbol (bei der Ausgabe) abgebildet werden. Dies wird durch eine zum Symbol gehörende Regel, dem sogenannten Muster beschrieben. Entsprechen verschiedene Lexeme (wie z.B. Mo, Di, Mi, Do, Fr, Sa, So für das Symbol Wochentag) demselben Muster und werden somit auf dasselbe Symbol abgebildet, muss der Scanner neben dem Symbol zusätzliche Informationen liefern. Dies wird durch eine Attribut Werte Struktur realisiert (z.B. (Wochentag, Mo)). Heute gibt es schon eine Vielzahl von Hilfsprogrammen, die das Generieren von Scannern erleichtern. Eines der bekanntesten ist der Scannergenerator lex, ein wohl bekanntes UNIX-Tool. Ihm werden die Regeln für den Scanner in Form von regulären Ausdrücken übergeben und er erzeugt daraus den gewünschten Scanner. Das Ergebnis der lexikalischen Analyse ist eine lineare Struktur aus einzelnen Symbolen, die zwar für sich selbst, aber untereinander noch keine Bedeutung haben. Die lexikalische 53 Analyse ist die Voraussetzung für jegliche weitere Textverarbeitung und findet deshalb in allen Anwendungen, die Text verarbeiten Verwendung. 3.3.2 Parsing 2: Syntaktische Analyse (Parser) In der syntaktischen Analyse wird mit Hilfe eines Parsers versucht, syntaktische Strukturen in einem Text/Satz zu erkennen. Für syntaktische Strukturen gibt es dabei in der Linguistik zwei Betrachtungsweisen. Die erste sieht syntaktische Strukturen als Relationen zwischen Wörtern (Dependenz-Syntax). Bei der anderen Betrachtungsweise gibt es neben Wörtern auch komplexere Strukturen, so genannte Konstituenten oder Phrasen. So setzt sich hier ein Satz „Der Hund hat gebellt“ beispielsweise aus einer Nominalphase (NP: der Hund) und einer Verbalphrase (VP: hat gellt) zusammen Diese Betrachtungsweise hat sich in den letzen Jahrzehnten in der Computerlinguistik stärker etabliert. In beiden Betrachtungsweisen werden die syntaktischen Strukturen mittels Baumgraphen dargestellt. Es gibt eine Vielzahl verschiedener Parsing-Techniken deren genaue Beschreibung den Rahmen dieser Arbeit sprengen würde. Hierzu sei auf die zahlreiche Literatur über die Computerlinguistik, wie z.B. [Carstensen] verwiesen. Es soll hier nur eine kurze Klassifikation verschiedener Ansätze erfolgen. Die Regeln, die alle gültigen semantischen Konstrukte einer Sprache festlegen, sind in einer Grammatik beschrieben. Dabei gibt es verschiedene Klassen von Grammatiken [Carstensen], wobei die in der Computerlinguistik meist kontextfreie Grammatiken verwendet werden, da hierfür effiziente Parser existieren. (Beim Parsen wird nun versucht, einen für eine Folge von Symbolen eines Textes eine entsprechende Regel in der Grammatik zu finden, um daraus die syntaktische Struktur abzuleiten. Der Analyseprozess besteht dabei zu einem nicht unwesentlichen Teil aus Suchprozessen. Parser lassen sich anhand von verschiedenen Kriterien klassifizieren, wie z.B. die Verarbeitungsrichtung der Eingabe, der Analyserichtung und ihrer Suchstrategie. Eines der Unterscheidungsmerkmale von Parsern ist ihre Analyserichtung. Es gibt die TopDown-Verarbeitung und die Bottom-Up-Verarbeitung. Bei der Top-Down-Analyse werden von dem Start-Symbol der Grammatik aus schrittweise Regeln expandiert, bis man zu Blättern (Terminal-Symbolen) im Parse-Baum gelangt. Umgekehrt wird bei der Bottom- 54 Up-Analyse von der Kette der eingegebenen Symbole selbst ausgegangen und die Anwendung der Grammatikregeln erfolgt als Reduktion der Symbole. Dies wird solange durchgeführt, bis die Eingabe vollständig auf das Startsymbol reduziert wurde. Ferner existieren auch Parser, die beide dieser Techniken ineinander vereinen. Eine andere Art der Klassifikation von Parsern lässt sich auf der Ebene der verwendeten Suchstrategien treffen. Die wichtigsten Suchstrategien sind hier Tiefensuche und Breitensuche. Bei der Tiefensuche wird ein eingeschlagener Suchpfad bei der Suche solange verfolgt, bis er nicht mehr fortgesetzt werden kann. Erst dann werden alternative Pfade durchlaufen. Bei der Breitensuche werden alle Suchpfade um einen Schritt fortgesetzt, bevor eine der Alternativen weiterverfolgt wird. Ist eine Bewertungsfunktion für die Pfade des Suchraums vorhanden, kann ein bewertetes Suchverfahren angewandt werden, wie z.B. die Best-First suche, bei der jeweils der erfolgsversprechendste Pfad weiterverfolgt wird. Heute werden Parser für die syntaktische Analyse meist mit Hilfsprogrammen entwickelt. Ein sehr bekanntes kommt aus dem UNIX-Feld und ist der Parser Generator Yacc (Yet Another Compiler Compiler) der C-Code erzeugt. Es gibt Parsergeneratoren aber auch für viele andere Programmiersprachen, wie z.B. javacc für JAVA. Das Grundprinzip dieser Generatoren ist immer gleich. Der Benutzer definiert die gewünschten syntaktischen Regeln seiner Sprache, woraus der Parser-Generator einen ausführbaren Parser erzeugt. Parser Generatoren arbeiten dabei meist nach dem Bottom-Up-Verfahren. 3.3.3 Morphologische Analyse (Stemmer) Wörter erscheinen in den meisten Sprachen in vielen verschiedenen Formen (Singular, Plural, Adjektiv ...) und sind auch Ausgangspunkt für neue Wortbildungen. Durch eine morphologische Analyse wird nun versucht, die vorhandenen systematischen Zusammenhänge zwischen den Wörtern und Wortformen zu erkennen und Wörter morphologisch zu klassifizieren. Ein einfacher und sehr verbreiteter Ansatz ist die Verwendung von endlichen Automaten. Dabei sind die morphologischen Regeln durch endliche Automaten definiert, die die zulässigen Übergänge beschrieben sind. Damit kann allerdings nur überprüft werden, ob einen Wortform wohlgeformt ist. Um eine Analyse der Wortform zu ermöglichen, werden zu den 55 Übergängen im endlichen Automaten zusätzliche Informationen z.B. über Tempus oder Casus hinzugefügt. Man erhält dadurch einen sogenannten Finite State Transducer FST (Endlichen Automaten). Ein anderer Ansatz ist die Verwendung von Analyselexika. Dabei kann man die Lexika darin unterscheiden, ob das Analyselexikon aus Wortformen, Morphemen oder Allomorphen besteht. Bei der Wortformen-Methode ist eine Möglichkeit, mit einfachen Mitteln eine simple und funktionierende Wortformenerkennung zu realisieren. Sind alle Wortformen einer Sprache einzeln aufgelistet, nimmt das Lexikon u. U. enorme Ausmaße an. Die Pflege eines Wörterbuchs ist somit aufwendig. Ein großer Nachteil ist, dass diese Methode nur Wortformen erkennen kann, die im Lexikon verzeichnet sind. Neologismen können somit nicht zur Laufzeit erkannt werden. Die Morphem-Methode verwendet ein Analyselexikon aus analysierten Morphemen. Sie hat den Vorteil eines kleinen Lexikons und dass Neologismen zur Laufzeit erkannt werden können. Der entscheidende Nachteil ist allerdings der extrem komplexe Erkennungsalgorithmus[Hauser]. Bei der dritten Methode sind Allomorphe als Schlüsselwörter. Sie verbindet die Vorteile der beiden vorhergehenden Methoden: die Möglichkeit der Neologismen Erkennung zur Laufzeit, ein kleines Lexikon sowie einen einfachen Erkennungsalgorithmus. Die Morphologische Analyse dient also zum Erkennen von Flexionen und zusammengesetzten Wörtern. Besonders in der deutschen Sprache ist ein sicheres und präzises Erkennen von Zusammensetzungen für die Sprachverarbeitung sehr wichtig, da sie sehr häufig im Deutschen vorkommen. Anwendungen für die morphologische Analyse sind zahlreich. Durch das Abbilden von Wortformen auf eine Grundform und Aufteilung zusammengesetzter Wörter wird zunächst einmal Redundanz verringert was somit auch zur Steigerung des Informationsgewinns führt. Beim Beispiel der Suche in einer Datenbank lässt sich z.B. durch Suche nach einer morphologischen Grundform das Suchergebnis wesentlich verbessern, da sämtliche Wortformen des Suchbegriffes in der Datenbank erkannt werden. Eine morphologische Analyse ist hier dem einfachen Abschneiden von Endungen (Truncation), die ebenfalls zu einer Reduktion an Wortformen führen soll, in Präzision und Effektivität weit überlegen. 56 Die morphologische Analyse ist auch ein Grundstein für viele weiterführende Anwendungen, wie z.B. die semantische Analyse. Auch Parser setzen oft schon eine morphologische Analyse voraus, da ihre Komplexität sonst erheblich zunehmen würde. 3.3.4 Semantische Analyse Als eine Teildisziplin der Linguistik beschäftigt sich die Semantik mit der Bedeutung natürlichsprachlicher Ausdrücke. Dabei geht es einerseits um die Bedeutung von Worten (lexikalische Semantik), Sätzen (Satzsemantik) wie auch um die Bedeutung von ganzen Texten (Diskurssemantik). In der Semantik sollen die Prozesse analysiert werden, die es einem Zuhörer ermöglichen, die Ideen und Gedanken hinter einer Äußerung zu verstehen. Semantik ist also auf die Interpretation von Äußerungen ausgerichtet, nicht auf die Erzeugung von Äußerungen. Der Prozess der Interpretation darf jedoch nicht mit dem gesamten Verstehensprozess gleichgesetzt werden. Ein Satz kann (in verschiedenen Kontexten) auf verschiedene Arten verstanden werden. Der Satz „Die Tür geht auf“ kann z.B. ein Deklarativsatz (gibt einen Sachverhalt wieder) oder auch Ausdruck einer einfachen Wahrnehmung sein. Diese Analyse liegt außerhalb der Semantik sondern gehört auf das Gebiet der Pragmatik. In der Semantik werden also verschiedene situative Parameter bewusst ausgeblendet. (siehe auch [Carsensen], Kap. 3.4). Allgemein betrachte wird bei der semantischen Analyse versucht, zwischen der syntaktisch analysierten Oberfläche einer Sprache und einer Ebene semantischer Objekte eine Zuordnung zu finden [Hausser]. So soll z.B. für einen syntaktisch analysierten Satz dessen Bedeutung (auch im Kontext) erschlossen werden. 3.4 Das Lexikon als Hilfsmittel in der Computerlinguistik Das Lexikon spielt eine zentrale Rolle in der Computerlinguistik. Es bildet den unverzichtbaren Kern jedes Sprachverarbeitungssystems. Unter einem Lexikon wird formal ein "nach 57 Stichwörtern alphabetisch geordnetes Nachschlagewerk für alle Wissensgebiete od. für ein bestimmtes Sachgebiet" [Duden] verstanden. Dabei gibt es viele verschiedene Möglichkeiten im Aufbau von Lexika und der Menge und Art der darin verzeichneten Informationen. Abhängig von Aufbau und Inhalt eines Lexikons ist dann auch seine Verwendungsmöglichkeit in der Computerlinguistik. Im Folgenden werden einige mögliche Arten von Lexika anhand ihrer Anwendbarkeit in der Computerlinguistik dargestellt. 3.4.1 Wörterbuch Ein Wörterbuch ist die wohl einfachste Form eines Lexikons. Es ist im grundlegenden Sinne ein einfaches Verzeichnis von Wörtern, das ggf. als Erweiterung zu jedem in ihm enthaltenen Wort weiterführende Informationen enthält. So können beispielsweise syntaktische oder semantische Informationen angegeben sein. Ein Wörterbuch kann je nach Aufbau in den verschiedenartigsten Anwendungen eingesetzt werden. So reicht zur primitiven Erkennung von Schreibfehlern ein Wörterbuch, das alle Wörter einer Sprache verzeichnet. Hierbei können jedoch nur so genannte Nicht-Wörter, also Zeichenfolgen, die in dieser Form nicht in der Sprache vorkommen, erkannt werden. Näheres hierzu in Abschnitt 2.5.4. Sind im Wörterbuch beispielsweise syntaktische Informationen (wie z.B. Angaben zur Wortart) zu den Wörtern angegeben, kann es in Verbindung mit Syntaxregeln zu einer syntaktischen Analyse eingesetzt werden. In ähnlicher Weise kann ein Wörterbuch zur semantischen Analyse herangezogen werden, wenn entsprechende semantische Informationen verzeichnet sind. Erkennen von Teilworten und Oberbegriffen 3.4.2 Terminologieserver In dem gerade beschriebenen Wörterbuch sind lediglich weiterführende Informationen zu einem Wort an sich angegeben. Es ist jedoch auch oft erforderlich, Informationen über Gemeinsamkeiten von verschiedenen Wörtern zu verzeichnen. 58 Betrachten wir beispielsweise die Terminologie in der Medizin. Unter Terminologie versteht man die "Gesamtheit der in einem Fachgebiet üblichen Fachwörter u. –ausdrücke" [Duden]. Hier gibt es z.B. für die eindeutige Klassifikation von Krankheiten verschiedene Begriffssysteme, die Krankheiten in unterschiedlicher Weise darstellen. So gibt es für dieselbe Krankheit in jedem Begriffssystem eine spezifische Codierung. Man kann dies mit Wörtern aus verschiedenen Sprachen vergleichen, die für denselben Begriff nur eine andere Darstellungsweise liefern (z.B. deutsch: "Baum" und engl:"tree") oder analog mit Synonymen einer Sprache. Mit Hilfe eines Lexikons in dem nun weiterführende Angaben zur Terminologie enthalten, wie z.B. die Angabe von Synonymen, Schreibweisen oder Bezeichnungen in unterschiedlichen Begriffsystemen zu jedem Wort, ist es möglich, die Beziehungen zwischen diesen Bezeichnungen herzustellen. Lexika dieser Art finden deshalb beispielsweise Anwendung in Übersetzungssystemen oder Terminologieservern. Terminologieserver verwalten verschiedene Begriffssysteme einer Terminologie und setzten diese zueinander in Verbindung. Sie können deshalb quasi als "Übersetzer" zwischen verschiedenen Begriffsystemen einer Terminologie verstanden werden. Näheres zu Terminologieservern in der Medizin findet sich bei [Ingenerf]. Neben der Anwendung in Terminologieservern und bei der Übersetzung gibt es aber für derart aufgebaute Lexika eine Vielzahl weiterer Anwendungen. Ein Lexikon, welches beispielsweise Synonyme enthält, kann auch gut bei jeder Anwendung die eine wortbasierte Suche durchführt, eingesetzt werden. Es kann hier zur automatischen Erweiterung der Anfrage um Synonyme eingesetzt werden. Somit werden nicht nur die explizit eingegebene Wörter, sondern auch bedeutungsgleiche gefunden. 3.4.3 Ontologieserver Keine der beiden bisher vorgestellten Lexikonformen verzeichnet semantische Beziehungen von verschiedenen Worten untereinander. Betrachten wir z.B. die beiden Worte „Tier“ und „Hund“, so ist „Hund“ ein semantischer Unterbegriff (Hyponym) von „Tier“, beide Wörter sind jedoch nicht synonym. In zentrales Computersystem, das diese Beziehungen wiedergeben kann, wird oft als Terminologieserver bezeichnet. Terminologieserver können bei der Analyse von semantischen Zusammenhängen äußerst hilfreich sein. Ein mögliches Einsatzgebiet in der Medizin ist beispielsweise bei der Diagnosefindung vorstellbar. Hier sind die Erkennung semantischer Zusammenhänge oft entscheidend. So trägt hier z.B. oft 59 ein spezielles Symptom (z.B. „gebrochener Finger“) oft zu allgemeineren Diagnosen bei (z.B. „eingeschränkte Benutzung der Hand“). 3.4.4 Fehlerkorrektur In der Computerlinguistik werden heutzutage drei Arten von Fehlern unterschieden, bei denen unterschiedliche Anforderungen an die Methoden zur Korrektur gestellt werden. Diese werden hier kurz vorgestellt. 3.4.4.1 Korrektur von Nicht-Wörtern Die Art von Fehlern, bei denen das falsch geschriebenen Wort in einem "Nicht-Wort" resultiert, kann am einfachsten korrigiert werden. Unter "Nicht-Wort" versteht man dabei eine Zeichenfolge, die in dieser Weise nicht in der Sprache vorkommt. Die Erkennung von Nicht-Wörtern kann mit Hilfe eines Wörterbuchs der Sprache durchgeführt werden, das alle Wörter dieser Sprache auflistet. Nicht-Wort kann dadurch erkannt werden, dass es nicht im Wörterbuch vorkommt. Zur Korrektur dieses Nicht-Wortes wird versucht, die im Lexikon enthalten Wörter zu finden, die zum Nicht-Wort am ähnlichsten sind. Dazu verwendet man meist die sogenannte Minimal-Edit-Distance, eine Funktion, welche die minimale Zahl von Änderungen angibt, um das Nicht-Wort in ein gültiges Wort des Wörterbuchs zu überführen. 3.4.4.2 Kontextabhängige Korrektur Es gibt auch Eingabefehler, die zu einem anderen gültigen Wort führen. Ein Typischer Fehler hierfür ist z.B. mir obwohl das Wort mit eingegeben werden sollte. Diese Fehler lassen sich mit einem einfachen Wörterbuch, welches nur alle Wörter einer Sprache verzeichnet, nicht finden. Es werden also Verfahren eingesetzt, die den lokalen Kontext eines Wortes mit berücksichtigen. Eine ausführliche Beschreibung dieser Verfahren findet sich in [Kukich], sie seien hier nur kurz erwähnt. Es gibt heuristische Ansätze auf sogenannten "Verwechslungsmengen". In diesen Mengen sind Wörter zusammengefasst, die häufig verwechselt werden. Kommt nun eines dieser Wörter im Text vor, werden auf dieses Wort zugeschnittene Heuristiken angewandt um 60 mögliche Schreibfehler zu entdecken. Dieses Verfahren kann allerdings nur Fehler korrigieren, bei denen das falsch geschriebene Wort in der Verwechslungsmenge auftritt. Ein anderer, statistikbasierter Ansatz arbeitet mit Hilfe von Trigram-Wahrscheinlichkeiten, die bestimmen, mit welcher Wahrscheinlichkeit 3 benachbarte Worte vorkommen. Diese Wahrscheinlichkeiten werden anhand großer Textkorpora ermittelt. Ein eingegebener Satz wird nun durch systematisches Verändern von Wörtern in Alternativsätze überführt. Hat einer der Alternativsätze eine höhere Wahrscheinlichkeit als der ursprüngliche Satz, wird eine Korrektur vorgeschlagen. 3.4.4.3 Grammatikkorrektur Es kommen auch solche Fehler vor, zu dessen Korrektur nicht die Analyse des lokalen Kontextes sondern die Analyse eines ganzen Satzes oder sogar eines ganzen Textabschnittes notwendig ist. Typische Fehler dieser Art sind Grammatikfehler. Ein Problem bei der Korrektur von Grammatikfehlern ist allerdings, dass NLP-Systeme die syntaktische Analyse von fehlerhaften Sätzen ablehnen. Ein Ansatz ist nun die sogenannte "Constraint Relaxion". Hier werden bestimmte Bedingungen an die Grammatik so lange gelockert, bis eine Analyse des eingegebenen Satzes möglich ist. Sobald dies gelingt, ist dann auch bekannt, welche Bedingung verletzt wurde und es kann eine Korrektur vorgeschlagen werden. [s. Carstensen et al] 61 Kapitel 4 Architektur von IDEE Freitexteingabe In diesem Kapitel wird der interne Aufbau der in dieser Diplomarbeit entwickelten IDEEFreitexteingabe (IDEE = Intelligent Data Entry Environment) zur intelligenten und textuellen Dateneingabe bei internetbasierten Beratungssystemen beschrieben. Das Grundgerüst für das System liefert die Suchmaschine Jakarta Lucene der Apache Software Foundation. Mit Hilfe von Lucene wird zunächst ein Index über die Elemente der Wissensbasis des Beratungssystems aufgebaut. Unter Verwendung dieses Indexes wird dann die spätere Suche durchgeführt, welche die Dateneingabe auf die Elemente der Wissensbasis abbildet. Um neben einfachen Suchanfragen auch gesamte Arztbriefe durch IDEE verarbeiten zu können, wurde ein Parser entwickelt, der die komplexe Eingabe in einzelne Suchanfragen zerlegt. Durch Einbinden eines anhand der Wissensbasis aufgebauten Lexikons, werden die ursprünglichen Suchanfragen so erweitert, dass automatisch auch nach Teilworten und zusammengesetzten Worten gesucht wird. Die Architektur und die genaue Verfahrensweise von IDEE, um eine komplexe Benutzereingabe auf die entsprechenden Elemente der Wissensbasis abzubilden und diese zurückzuliefern, werden nun ausführlich beschrieben. 4.1 Apache Jakarta Lucene als Grundgerüst des Systems Jakarta Lucene ist eine leistungsstarke, komplett in Java geschriebene Suchmaschine. Sie stammt aus dem Jakarta Projekt der Apache Software Foundation. Dieses open-source Projekt hat zum Ziel, hochwertige Server Software für die Java Plattform zu entwickeln, die kommerziellen Produkten in nichts nachsteht. Jakarta Lucene ist nicht als fertiges outof-the-box Softwareprodukt zu verstehen, ermöglicht aber eine äußerst flexible und einfache Einbindung in fast jede Java-Anwendung und lässt sich auch leicht an individuelle Anforderungen anpassen. Jakarta Lucene stellt das Grundgerüst für das entwickelte System IDEE zur intelligenten textuellen Dateneingabe bereit. Lucene ist ein mächtiges, flexibles und einfach zu benutzendes Werkzeug zur Indexierung und Suche in Texten. In IDEE wird es einerseits zur Indexierung der Texte von Fragen und Antworten der aktuellen Wissensbasis verwendet. Anderseits stellt Lucene auch die Funktionalität einer effektiven Suche auf dem aufgebauten Index bereit, mit deren Hilfe die vom Benutzer eingegebenen Symptome auf die Fragen 62 und Antworten der Wissensbasis abgebildet werden können. Im Folgenden soll die Funktionalität von Lucene kurz beschrieben werden. Wie bei Suchmaschinen üblich, löst auch Lucene seine Aufgabe in zwei Hauptschritten: Erstellung eines Indexes über die Elemente des Suchraums und die anschließende eigentliche Suche. Der Aufbau und die Pflege (Konsistenzhaltung) eines Indexes ist ein zentrales Problem beim Aufbau einer effizienten Suchmaschine. Zunächst muss eine Liste aller Vorkommen der Wörter des Textes erstellt werden. Daraufhin wird ein inverser Index aufgebaut, der zu jedem Wort die Positionen im Text verzeichnet, an denen es vorkommt. In den meisten Suchmaschinen wird dieser Index mit Binärbäumen implementiert. Lucene hingegen arbeitet mit mehreren Index-Segmenten, die es intern immer wieder zu größeren Segmenten zusammenführt. Dieser Ansatz wirkt sich sowohl bei der Erstellung und Pflege wie auch bei der Suche positiv auf die Performanz aus [Goetz]. Bei der Suche ermöglicht Lucene auch die Behandlung von anspruchsvollen Anfragen, die z.B. durch logische Operatoren verknüpft sind oder Wildcards enthalten. Um diese Anfragen in ein von Lucene geeignetes Format für die Suche zu überführen, ist ein so genannter Query-Parser vorhanden. Dieser wird im Abschnitt zur Suche noch genauer beschrieben. Ferner hat Lucene eine interne Bewertungsfunktion. Diese kann die gefundenen Treffer bewerten. Die Bewertungsfunktion kann durch so genannte Scores (Gewichten) den jeweiligen Bedürfnissen des Benutzers angepasst werden. So kann er z.B. durch Angabe eines Faktors bei einem Wort der Suchanfrage angeben, wie relevante dieses Wort bei der Bewertung der Treffer ist. Neben den beschriebenen Methoden zur Indexierung und Suche gibt es in Jakarta Lucene auch Anwendung von computerlinguistischen Methoden wie sie im letzen Kapitel beschrieben wurden. Zunächst muss sowohl der zu indexierende Text wie auch die jeweilige Suchanfrage zur Verarbeitung durch das System vorbereitet werden. Dies geschieht mittels eines Scanners, der die lexikalische Analyse vornimmt. Lucene bietet in einer Java-Klasse „Analysis“ einen Tokenizer (Scanner) an, der zusammenhängende Folgen von Characters (char im Sinne der Java Definition) zu einem Token zusammenfasst. Des Weiteren gibt es verschie63 dene Filterfunktionen (z.B. einen „Lower-Case“ Filter, der alle Großbuchstaben in die jeweilige Kleinschreibung umwandelt oder einen „Stopp-Wort-Filter, der definierte Wörter aus dem Eingabestrom herausfiltert) die beliebig kombiniert werden können. Zur Abbildung von Wortformen auf eine Grundform stellt Lucene einen Stemmer für die englische Sprache bereit, der sich an dem bekannten Porter Stemmer [Porter] orientiert. Auch für die deutsche Sprache ist ein einfacher Stemmer in Lucene implementiert. In den folgenden Abschnitten wird nun die Verwendung der Funktionalität von Lucene in der intelligenten Dateneingabe IDEE beschrieben und die darauf aufbauende Implementierung des Systems beschrieben. 4.2 Indexierung Eine wesentliche Aufgabe von IDEE besteht darin, zu einer vom Benutzer gemachten Eingabe von Symptomen die entsprechenden Fragen und Antworten der Wissensbasis zu finden. Dies kann mit einer leistungsfähigen Suchmaschine realisiert werden. Der zentrale Schritt beim Aufbau einer Suchmaschine ist die Erstellung eines Indexes, welcher zu einem Suchbegriff die entsprechenden Referenzen im Suchraum (hier die Wissensbasis) enthält. Die Indexierung gliedert sich dabei in zwei Schritte, die im Folgenden beschrieben werden. 4.2.1 Aufbereitung des Suchraums: Bevor ein Index über die zu suchenden Elemente erstellt werden kann, müssen die Elemente des Suchraums in ein für die Indexierung durch Lucene geeignetes Format überführt werden. Die grundlegende Datenstruktur die hierfür in Lucene verwendet wird, besteht aus sogenannten Dokumenten. Ein Dokument ist dabei ein Objekt das aus einer beliebigen Anzahl von Feldern, mit jeweils einem Namen und einem Wert besteht. Zu jedem Feld können dabei Parameter angegeben werden, die spezifizieren, ob und wie dieses Feld später für die Suche indexiert wird. Des Weiteren kann zu jedem Feld noch ein Gewicht (Boost-Faktor) angegeben werden, das spezifiziert, wie stark ein Suchtreffer in diesem Feld später gewichtet werden soll. 64 Um nun ein für die Indexierung in IDEE geeignetes Format zu definieren, wurden folgende Überlegungen angestellt. Wie wir wissen ist es das Ziel, zu einer Benutzereingabe eine zutreffende Frage-Antwort Kombination in der Wissensbasis zu finden. Für die Indexierung sind somit die Texte der Frage und Antwortalternativen entscheidend. Um die Indexierung der Wissensbasis durch Lucene zu gewährleisten wird deshalb ein Dokument erstellt, welches in einem Feld den Text einer Frage in Kombination mit genau einer ihrer Antwortalternativen enthält. Neben den Texten der Fragen und Antworten wird jeweils in einem separaten Feld die (in der Wissensbasis definierte) eindeutige ID der Frage und Antwort gespeichert. Dies ermöglicht später einen einfachen Zugriff auf das Frageobjekt und dessen Antwortalternative in der Wissensbasis. Angaben zu einer Bewertungsfunktion (s. U.). 4.2.2 Indexierung: Nachdem das Format der Dokumente festgelegt wurde, kann der Index erstellt werden. Da wir für den zu indexierenden Inhalt der Wissensbasis im vorhergehenden Schritt Dokumente in einem Lucene konformen Format definiert haben, können die standardmäßig in Lucene implementierten Methoden zur Indexierung anwenden. Bei der Indexierung werden die Texte der Fragen und Antworten der Wissensbasis durch einen von Jakarta Lucene bereitgestellten Tokenizer (Scanner) zunächst in einzelne Tokens zerlegt. Auf dem erhaltenen Tokenstrom werden anschließend verschiedene Bereinigungen vorgenommen, wie z.B. die Vereinheitlichung von Groß- und Kleinschreibung und das Entfernen von Füllworten, so genannten Stop-Words. Eine für die Entfernung von Füllworten erforderliche Liste an Stop-Words ist in Lucene bereits enthalten. Sie enthält z.B. Artikel, Pronomen und Präpositionen. Diese Liste kann leicht erweitert und modifiziert werden. Zu der erwähnten Bereinigung des Tokenstroms werden verschiedene, von Jakarta Lucene bereitgestellte Filter verwendet, welche die gewünschte Funktionalität liefern. Ferner kommt bei der Indexierung der Wissensbasis auch der in Lucene vorhandene Stemmer für die deutsche Sprache zum Einsatz. Dieser lehnt sich an den Porter Stemming-Algorithmus [Porter deutsch] an, der mit Hilfe von definierten Regeln versucht, Wörter mit demselben Wortstamm auf eine gemeinsame Grundform (engl. Stem) abzubilden. Dabei werden hauptsächlich die Wortendungen anhand der Regeln verändert oder abgeschnitten, sowie Umlaute ersetzt. Eine vollständige Auflistung der verwendeten Regeln findet sich im Anhang. Da in 65 IDEE die Indexierung über die vom Stemmer generierte Grundform eines Wortes erfolgt, werden somit alle Wörter der Wissensbasis mit derselben Grundform gleich indexiert. Dies hat bei der späteren Suche den Vorteil, dass sämtliche Wortformen mit derselben Grundform gefunden werden können. Dazu muss allerdings dann auch bei der Generierung der Suchanfrage nach dieser Grundform gesucht werden. Sämtliche Filter können durch den modularen Aufbau von IDEE und Lucene leicht ersetzt werden. 4.3 Suche mit Lucene Zu Beginn der Suche mit Lucene steht die Formulierung einer Anfrage. Lucene bietet dafür einen sogenannten Query-Parser an, der einen Eingabestring parst und in ein internes Format überführt, mit dem dann die eigentliche Suche durchgeführt wird. Dem QueryParser liegt dabei eine durchaus mächtige Anfragesprache zugrunde. Diese ermöglicht es dem Benutzer, einzelne Suchbegriffe durch Boolesche Operatoren zu verknüpfen (AND, OR, NOT) sowie Begriffe durch Klammerung zu gruppieren. Weitere Features sind z.B. die Unterstützung von Wildcard-Suche und die Bestimmung der Vorkommensreihenfolge („Leber FOLLOWED BY Werte“). Eine ausführliche Beschreibung aller Möglichkeiten der Anfragesprache findet sich bei [Lucene]. Des Weiteren bietet Lucene die Möglichkeit, jeden Term der Suchanfrage mit einem sogenannten "Boost-Faktor" zu versehen, der die relative Gewichtung dieses Terms bei der Suche angibt. Dies geschieht durch Angabe des Faktors nach dem Term (z.B. Leber^2.5). Eine genaue Erläuterung der in Lucene verwendeten internen Bewertungsfunktion wird im nachfolgenden Abschnitt gegeben. Ein erster Entwurf von IDEE verwendete bei der Generierung einer Anfrage direkt den in Lucene vorhandenen Query-Parser. Der Benutzer konnte dabei die oben beschriebene Syntax bei der Eingabe seines Suchstrings verwenden (Gruppierung von Suchbegriffen und Angabe Boolescher Operatoren und Boost-Faktoren...). Im Laufe der Entwicklung von IDEE und der Erweiterung deren Funktionalität wurde sowohl ein Lexikon zur automatischen Anfrageerweiterung wie auch ein Parser zur Verarbeitung von Arztbriefen implementiert (siehe Abschnitt XXXX und XXXX). Beide Erweiterungen wurden als Zwischenschritt zwischen der Eingabe des Suchstrings durch den Benutzer und der Generierung der Anfrage durch den Lucene Query-Parser realisiert. Dabei wurde die ursprüngliche Funkti- 66 score(q,d) = Σ termFreq(t in d) * inAllDocsFreq(t) * fieldBoost(t.field in d) * * lengthNorm(t.field in d) * overlap(q,d) * queryNorm(q) onalität der direkten Verwendung des Query-Parser und seiner Anfragesprache durch den Parser für Arztbriefe und die automatische intelligente Anfrageerweiterung ersetzt. Diese Erweiterungen ermöglichen nun neben der Verarbeitung komplizierterer Eingaben (Arztbriefe statt nur einzelne Suchstrings) eine Suche nach verwandten Begriffen (Synonymen, Teilwörtern) sowie einer daraufhin abgestimmten internen Bewertung der Suchergebnisse. Im späteren Verlauf des Kapitels findet sich eine ausführliche Beschreibung der genannten Erweiterungen. Nachdem nun eine Anfrage durch den Lucene Query-Parser generiert wurde, kann die eigentliche Suche auf dem erstellten Index erfolgen. Die Suche liefert alle Dokumente des Indexes zurück, welche die Bedingungen der Anfrage erfüllen. Im Falle von IDEE wird auf dem Feld der Texte von Frage und Antwort gesucht. Bei IDEE liefert die Suche alle Fragen mit Antwortalternative zurück, bei der mindestens einer der Suchbegriffe im Text der Frage oder Antwortalternative vorkommt. Jedem Treffer ist dabei eine Bewertung (Score) zugewiesen, die durch die Bewertungsfunktion von Lucene bestimmt ist (siehe nächsten Abschnitt). 4.4 Bewertungsfunktion in Lucene und Verwendung in IDEE Eine Bewertungsfunktion für Suchergebnisse bietet entscheidende Vorteile gegenüber einer Suche ohne Gewichtung der Ergebnisse. So kann die Güte eines Treffers bestimmt werden und außerdem die einzelnen Treffer der Suche untereinander verglichen werden. Dies ist z.B. für das Herausfiltern relevanter Treffer notwendig. Die in Lucene enthaltene Bewertungsfunktion ist von vielen Parametern abhängig. Diese werden nun kurz beschrieben. Die Grundfunktion für die Berechung der Gewichtung eines Anfrage q für ein Dokument d ist folgende: 67 t in q termFreq(t in d) = Häufigkeit eines Terms t in einem Dokument d inAllDocsFreq(t) = Häufigkeit eines Terms t in allen Dokumenten d filedBoost(t.field in d) = Boost Faktor des Feldes des Index, in dem der Term t vokommt lengthNorm(t.field in d) = Normierung über die Länge des Feldes, in dem der Term t vorkommt overlap(d, q) = Überdeckung eines Dokumentes d durch die Anfrage q queryNorm(q) = Normierung für die gesamte Query q. (Verändert nicht die Reihenfolge der Treffer einer Query sondern dient vielmehr dem Vergleich mehrer Querys untereinander. In diese Funktion fließen also u. a. für jeden Term der Suchanfrage ein, wie gut dieser Term das Dokument überdeckt und wie eindeutig er auf dieses eine Dokument hinweist oder ob er noch in vielen anderen Dokumenten vorkommt. Es wird jedoch nicht nur jeder Term einzeln für sich betrachtet, sonder auch, wie alle Terme der Suchanfrage zusammen das Dokument charakterisieren. Neben dieser Grundfunktion für die Berechnung eines Gewichtes für ein bei einer Suche gefundenes Dokument, bietet Lucene noch die Möglichkeit, Gewichte durch Angabe von Faktoren, so genannte Boosts, anzupassen. Ein Boost kann zunächst beim Festlegen der Dokumentenstruktur für die Indexierung für jedes Feld des Indexes angegeben werden. Dies hat zur Folge, dass das Gewicht aller Terme, die in diesem Index-Feld gefunden werden, durch den Boost-Faktor verändert wird. Beim konkreten Anlegen und Indexieren eines Dokuments kann außerdem ein Boost Faktor für dieses Dokument angegeben werden. Eine weitere Möglichkeit einen Boost-Faktor anzugeben ist bei der Generierung der Anfrage. Hier kann man jeden Term der Suchanfrage einen Boost zuweisen. In IDEE wurde von der Grundfunktion der Bewertung von Treffern die Lucene bereitstellt gebrauch gemacht. Ferner kommen in IDEE verschiedene der oben beschriebenen Möglichkeiten des Boostings zum Einsatz. So wurden beispielsweise Boost-Faktoren dazu verwendet, um die bei der automatischen Anfrageerweiterung generierten Suchstrings zu normieren. Die genaue Beschreibung der Bestimmung der dort verwendeten BoostFaktoren findet sich im entsprechenden Abschnitt zur automatischen Anfrageerweiterung. 68 4.5 Erweiterung 1: Einführung einer Grammatik für Arztbriefe 4.5.1 Übersicht Beim ersten Entwurf der textuellen Dateneingabe mit IDEE wurde zunächst die von Lucene bereitgestellte Anfragesprache als Grundlage genommen. Diese ermöglichte neben der simplen Eingabe der Suchbegriffe beispielsweise auch eine Gruppierung von Suchbegriffen, Angabe von Booleschen Operatoren oder direkte Angabe eines Boost-Faktors für einen Suchbegriff. Es war aber jeweils nur die Eingabe eines einzigen Anfragestrings für eine Suche möglich. Ferner mussten bei diesem Anfragestring alle der relevanten Suchbegriffe eingegeben werden. Dies hatte zur Einschränkung, dass es mit dieser einfachen Eingabemöglichkeit der Suchstrings nicht möglich war, eine komplexere syntaktische Struktur, wie sie beispielsweise in Arztbriefen vorkommt, zu verarbeiten. In besagten Arztbriefen werden z.B. zu einem Kontext (z.B. Leber) in Gruppen zusammengefasste Symptome angegeben (z.B.: „Leber: Oberfläche glatt, Durchmesser 12 cm.“) Jede Gruppe von Symptomen bildet dabei eine Aussage innerhalb dieses Kontextes (hier: eine Aussage zur Oberfläche, eine Aussage zur Größe). Zur Erweiterung des Systems wurde deshalb eine Grammatik spezifiziert und ein Parser entwickelt, der die syntaktische Struktur von Arztbriefen verarbeiten kann. Als Grundlage dazu dienten automatisch generierte Arztbriefe aus der Universitätsklinik Berlin Köpenick. Ein Beispiel eines solchen Arztbriefes findet sich im Anhang. Zum Erzeugen des Parsers wurde der Pasergenerator JavaCC (Java Compiler Compiler) [javacc] eingesetzt. Der erzeugte Parser vereinigt dann in sich eine lexikalische Analyse, d.h. Aufteilung des Eingabestrings in einzelne Wörter (Tokens) sowie die syntaktische Analyse (zuweisen einer Bedeutung zu jedem Wort). Um eine Parser mit JavaCC zu generieren wird für die lexikalische Analyse zunächst eine Stop-Word Liste spezifiziert, die einerseits die Zeichen festlegt, welche Wörter trennen und außerdem Zeichen oder Zeichenfolgen enthalten kann, welche aus dem Eingabestring entfernt werden sollen. Für den Parser zur Verarbeitung von Arztbriefe in IDEE wurde dabei die deutsche Stop-WordListe aus Lucene übernommen, schon alleine aus dem Grund, die Kompatibilität zum restlichen System von IDEE, das ja auf Lucene aufbaut, zu garantieren. Für die syntaktische 69 Analyse wird dem Parsergenerator JavaCC die zuvor definierte Grammatik in einem JavaCC eigenen Format übergeben. Die Beschreibung dieses Eingabeformates findet sich bei einer Vielzahl von Beschreibungen zu JavaCC (z.B. [javacc]). JavaCC generiert daraufhin Java Klassen für einen adäquaten Parser. Die Hauptaufgabe bei der Entwicklung des Parsers für Arztbriefe lag also in der Spezifikation der Grammatik, wie sie in den beiden nächsten Abschnitt beschrieben wird. 4.5.2 Zielsetzung für die IDEE Grammatik (Beispiel eines Arztbriefes im Anhang) Die Erweiterung des Systems durch einen Parser für die Behandlung von Arztbriefen hatte zum Ziel, die eingeschränkte Möglichkeit der Eingabe von einzelnen Suchstrings, die alle Suchbegriffe enthalten muss, durch eine leistungsfähigere Eingabevariante zu ersetzen, die ganze Texte im Format eines Arztbriefes verarbeiten kann. Für die Definition einer Grammatik wurden dabei Arztbriefe aus der Universitätsklinik Berlin Köpenick verwendet. Bei der Analyse dieser Briefe wurde u. a. folgende wichtige Struktur erkannt: Der Text ist in Absätze unterteilt, welche jeweils mit der Definition eines Kontextes beginnen, der für den gesamten folgenden Absatz relevant ist. Innerhalb eines Absatzes können allerdings auch Unterkontexte vorkommen, die den ursprünglichen Kontext noch näher spezifizieren. Nach der Definition eines Kontextes folgt eine beliebige Anzahl von Symptomen, die sich auf diesen Kontext beziehen. Innerhalb eines Symptoms können dabei sowohl einfache textuelle Angaben stehen, wie auch numerische Angaben (ggf. mit zugehöriger Einheit), die eine Wertangabe zu einem Symptom darstellen. Bei der Entwicklung der Grammatik für den Parser wurde auf eine vollständige syntaktische Analyse der Arztbriefe verzichtet. Diese ist für die deutsche Sprache sehr komplex und nur mit großem Aufwand zu realisieren. Vielmehr wurde Wert darauf gelegt, den Arztbrief in einzelne Absätze zu unterteilen und den zugehörigen Kontext und ggf. auch die Unterkontexte dieses Abschnittes zu erkennen. Innerhalb eines Kontextes werden dann die einzelnen Symptomangaben isoliert (z.B. „Oberfläche glatt“). Dabei sollen auch sämtliche Wertangaben, die aus einem numerischen Wert und ggf. einer zugehörigen Einheit bestehen, erkannt werden. 70 Das eigentliche Ziel das durch das Parsen der Arztbriefe verfolgt wird ist, aus dem Arztbrief einzelne Anfragen für die in IDEE implementierte Suche zu erzeugen. Eine Suchanfrage besteht dabei aus den Wörtern einer Symptomangabe erweitert um den jeweiligen aktuellen Kontext in dem diese Symptomangabe gemacht wurde. Eine Sonderbehandlung erfahren dabei Wertangaben. Der numerische Wert wird nicht in die Sucheanfrage mit übernommen, da er aufgrund der Vielzahl seiner möglichen Ausprägungen so gut wie nie einen Sinnvollen Treffer bei der Suche liefern würde. Feste numerische Werte sind in der Wissensbasis außerdem eher selten vorhanden. Die Einheit die einem Wert zugeordnet ist, kann jedoch sehr wohl sinnvoll bei der Suchanfrage eingesetzt werden. 4.5.3 Beschreibung der Grammatik (Regeln im Anhang) Eine vollständige Auflistung aller in der entworfenen Grammatik vorhandenen Regeln findet sich im Anhang. Hier soll nur ein kurzer Überblick über die wichtigsten Definitionen gegeben werden. Absätze innerhalb des Arztbriefes werden durch einen Zeilenumbruch erkannt. Ein Absatz kann mit einem Kontext beginnen, der für den gesamten Absatz gilt. Die Definition eines Kontextes wird durch einen Doppelpunkt abgeschlossen. Daraufhin folgen Symptomangaben, die jeweils mittels eines Satzzeichens (Punkt, Komma, Semikolon) voneinander getrennt sind. Innerhalb einer Symptomangabe kann eine Wertangabe vorkommen. Diese besteht aus einem numerischen Wert und optional einer Einheit. Zur Erkennung der Einheiten wird eine vorgegebene Liste gebräuchlicher Einheiten verwendet. Die spezifizierte Grammatik ist stark den zugrunde liegenden Arztbriefen angepasst um ihrem Ziel der hohen Anwendbarkeit auf diese Arztbriefe gerecht zu werden. Dies schränkt natürlich die Anwendbarkeit auf Texte ein, die in einem wesentlich anderen Format vorliegen. Für Texte in anderen Formaten kann die Grammatik jedoch leicht verändert und angepasst werden oder es besteht die Möglichkeit eine neue Grammatik zu entwerfen, die dann auf eine einfache Weise in das System mit eingebunden werden kann. 71 Zusammenfassend kann man sagen, dass die Einführung einer Grammatik für die Behandlung von Arztbriefen die Eingabemöglichkeiten des Systems wesentlich erweitert hat. Es können nun nicht nur einzelne Anfragen gestellt werden die sämtliche Suchbegriffe enthalten müssen, sondern gleichzeitig mehrere Eingaben gemacht werden, die untereinander in gemeinsamen Kontexten stehen. Durch die syntaktische Analyse können verschiedne der in Kaptitel 2 erläuterten Vorteile des Einsatzes eines Parsers realisiert werden. So bietet das System nun z.B. die Erkennung von Absätzen, Kontexten, Symptomangaben und Wertangaben. Dies alles ermöglicht eine Präzisierung der Suchanfrage und steigert somit die Chancen die Qualität der Treffer zu erhöhen. 4.6 Erweiterung 2: Aufbau und Einsatz eines Wörterbuchs (Lexikon) Die bei der ursprünglichen Implementierung bei IDEE verwendete Eingabeverarbeitung durch den in Lucene vorhandenen Query-Parser ermöglichte weder die Suche nach Synonymen noch eine zuverlässige Suche nach Teilwörtern bzw. zusammengesetzten Wörtern. Lediglich die explizite Angabe von Synonymen im Suchstring sowie die Verwendung von Wildcards konnte eine geringfügige Verringerung des Problems schaffen. Diese Art der Eingabe ist allerdings sehr Aufwändig und erfordert vom Benutzer einen (zumindest ungefähren) Überblick über die in der Wissensbasis verwendete Terminologie um die gewünschten Treffer zu erzielen. Ist ein Term der Suchanfrage (abgesehen vom Stemming) nicht genau wie angegeben in der Wissensbasis verzeichnet, wird für ihn kein Treffer gefunden. Zum Lösen dieser Problematik wurde ein Lexikon aufgebaut. Zielsetzung und Aufbau werden im Folgenden beschrieben. 4.6.1 Zielsetzung Wie bereits in Kapitel 2 beschrieben, kann ein Lexikon in der Computerlinguistik für viele verschiedene Aufgaben herangezogen werden. Für den Einsatz in IDEE wird ein Lexikon aus Teil- und zusammengesetzten Wörtern der Wissensbasis aufgebaut. Die Generierung des Lexikons erfolgt dabei beim Laden und Indexieren der Wissensbasis. Dies hat zum Vorteil, dass es exakt auf die aktuelle Wissensbasis abgestimmt ist und somit alle in der Wissensbasis vorhandenen Komposita und Teilwörter zu einem Begriff enthält. Das so aufgebaute Lexikon wird in IDEE dann zur automatischen Erweiterung eines eingegebenen 72 Suchstrings bei der Generierung einer Suchanfrage eingesetzt. Dabei wird die Suchanfrage um sämtliche in der Wissensbasis enthaltene Komposita und Teilwörter jedes einzelnen Wortes des ursprünglichen Suchstrings erweitert. Da allerdings die Expansion des eingegebenen Suchstrings zu einer Verschiebung der von Lucene bereitgestellten Gewichtung eines Treffers führt, wurde bei der Anfragegenerierung zu jedem Term ein Boost-Faktor hinzugefügt. Dieser Berechnet sich aus der Anzahl der Expansionen eines Terms. Ziel war es, die Summe der Gewichte eines Terms und seiner Expansionen mit seinem ursprünglichen Gewicht gleichzusetzen. Zusätzlich wurde auch die Funktionalität vorgesehen, die ursprünglichen Terme mittels eines Boost-Faktors separat zu gewichten. 4.6.2 Aufbau Das Lexikon wird wie bereits erwähnt direkt beim Einlesen und Indexieren der Wissensbasis rekursiv aufgebaut. Es enthält zu jedem (gestemmten) Wort, das in den Fragen und Antworten der Wissensbasis vorkommt, einen Eintrag. Das Lexikon ist intern als TreeMap-Struktur implementiert. Als Schlüssel wird allerdings nicht das Wort selber eingesetzt., sondern die unter Zuhilfenahmen des deutschen Stemmers von Lucene gestemmte Form. Die Verwendung der gestemmten Form verringert einerseits die Anzahl der Lexikoneinträge und ermöglicht andererseits eine optimale Einbindung in IDEE, bei welcher der Suchindex auch über den gestemmten Wörtern aufgebaut ist. Der Lexikoneintrag zu einem Wort enthält als Hauptbestandteile jeweils eine Liste aus allen Oberbegriffen und allen Teilwörtern dieses Wortes die im Lexikon verzeichnet sind, ihrerseits also einen eigenen Lexikoneintrag aufweisen (zusätzlich ist die Möglichkeit für die Angabe von Synonymen vorgesehen, die allerdings nicht automatisch Als Teilwort ist jedes andere Wort definiert, das in der Wissensbasis als echter Substring dieses ursprünglichen Wortes vorkommt. Simultan versteht man hier unter einem Kompositum jedes andere Wort der Wissensbasis, für das das ursprüngliche Wort ein echter Substring ist. Neben den oben beschriebenen Bestandteilen enthält jeder Lexikoneintrag zusätzliche Informationen wie z.B. die gestemmten Wortformen der in im Lexikoneintrag enthaltenen 73 Komposita und Teilwörter. Diese zusätzliche Information wird zur Konsistenzhaltung des Lexikons herangezogen und wird deshalb hier nicht näher erläutert. Das gesamte Lexikon kann in ein XML-Format überführt und in diesem abgespeichert werden. Dieses moderne, flexible und weit verbreitete Format hat entscheidende Vorteile. Es ist in jedem XML Browser anzeigbar und lesbar. Außerdem ist das Lexikon dadurch leicht zu editieren. Ein Auszug aus dem Lexikon findet sich im Anhang. 74 Kapitel 5 Das System IDEE Im folgenden Kapitel wird das in dieser Arbeit entwickelte System IDEE (Intelligent Data Entry Environment) aus der Benutzersicht beschrieben. Bei der Entwicklung von IDEE wurden zwei verschiedene Benutzeroberflächen entworfen, die eine Interaktion mit dem System ermöglichen. Die erste Benutzerfläche wurde als Plug-In für den WissensbasisEditor KnowME implementiert und diente bei der gesamten Entwicklung des Systems als Benutzerschnittstelle. Für die Einbindung in den d3web-Dialog wurde dann allerdings eine Schittstelle zu diesem Dialog entworfen und der Dialog angepasst. Im Folgenden sind beide Benutzerschittstellen kurz beschrieben. 5.1 KnowME Plugin Abb. xx: KnowME mit IDEE-Plugin: Im linken Teil findet sich die Funktionalität die von KnowME bereitgestellt wird. Das Plugin beschränkt sich auf je ein Feld zur Dateneingabe und zur Ergebnisausgabe, sowie einen Button zur Bestätigung der Eingabe. 75 Die erste Benutzerschnittstelle wurde als Plugin für KnowME implementiert. Die Realisierung als Plugin ermöglichte eine einfache und schnelle Generierung dieser Benutzeroberfläche. Das KnowME Plugin diente während der gesamten Entwicklung des Systems als Interface und spielte für die ersten Evaluationen eine entscheidende Rolle. Die Oberfläche diese Interface ist sehr einfach gehalten. Es gibt lediglich ein Texteingabefenster, in das der Benutzer Suchanfragen eingeben kann. Mittels eines OK-Buttons wird die Eingabe bestätigt und die Suche bei IDEE gestartet. Die Suchergebnisse werden dann in einem Ausgabefenster ausgegeben. Die gesamte restliche für die Bedienung von IDEE notwendige Funktionalität (wie z.B. Auswahl der zu ladenden Wissesbasis) wird von der eigentlichen Oberfläche des Wissesbasiseditors KnowME übernommen. 5.2 XML Dialogoberfläche Zur Einbindung in den vorhandenen webbasierten Dialog von d3web wurde eine Schnittstelle zum bisherigen XML Dialog spezifiziert und durch Modifizierung der bisherigen Oberfläche eine vorläufige Benutzerschnittstelle für IDEE entworfen. Ähnlich zum Aufbau der Oberfäche des KnowME-Plugins gibt es ein Fenster für die Eingabe der Suchanfrage und einen Button zur Bestätigung der Eingabe. Die Ausgabe wird in einem Ausgabefenster mittels bereits vorhandenen xsl Stylesheets, die jedoch zur Ausgabe der Treffergewichtung modifiziert wurden, zur Laufzeit generiert. Der Benutzer gibt seine Suchanfrage in das Eingabefeld ein und bestätigt das Ende der Eingabe durch drücken des OK-Buttons. Die Anfrage wird nun an den Server übermittelt, der mit IDEE die Suchanfrage bearbeitet und das Ergebnis an den Client zurückschickt. Hier wird das Suchergebnis im Ausgabefenster präsentiert. Der Benutzer hat nun die Möglichkeit, bei den präsentierten Fragen die Antwortalternativen zu ändern bzw. zu ergänzen und in das System zu übernehmen. Wird eine Frage nicht explizit bestätigt, wird sie auch nicht in das System übernommen. 76 Abb. 6.xx: d3web Dialog mit Ein und Ausgabe für IDEE. Im Mittelteil findet sich die für IDEE entscheidende Funktionalität. Es existiert ein Feld zur Dateneingabe, Felder für Übernehmen oder Verwerfen der Eingabe und ein Ausgabefeld für die gefundenen Fragen. Die Antworten der Fragen können modifiziert und ergänzt werden. Danach können die richtig erkannten Frage in das System übernommen werden. 77 Kapitel 6 Evaluation Im folgenden Kapitel wird die Evaluation des einwickelten Systems IDEE beschrieben. Im ersten Teil werden die Tests zu verschiedenen Zeitpunkten der Systementwicklung erläutert und die jeweils gewonnenen Erkenntnisse aufgezeigt. Im zweiten Teil folgt die Beschreibung der quantitativen Evaluation des Systems, wie sie zum Abschluss der Diplomarbeit durchgeführt wurde. Ferner wird eine Beispielanfrage beschreiben, welche die genaue Vorgehensweise des Systems bei der Suche beschreibt. Das Kapitel schließt mit einer kurzen Zusammenfassung der Stärken und Schwächen von IDEE. 6.1 Tests während der Entwicklungsphase Während der gesamten Zeit der Entwicklung von IDEE wurden immer wieder Tests durchgeführt, die den aktuellen Stand und die Fähigkeiten des Systems in der jeweiligen Ausbaustufe mit unterschiedlichen Mengen von Zusatzwissen ergründen sollten. Aufbauend auf den erkannten Schwächen und Einschränkungen wurden dann Konzepte für die Verbesserung erarbeitet und nach deren Einbindung in das System erneute Tests durchgeführt. Bei einem Test wurden jeweils verschiedene Symptome in IDEE eingegeben. Die Auswahl der Symptome erfolgte dabei anhand von vorliegenden Arztbriefen der Universitätsklinik Berlin Köpenick. Die bei der Suche gefundenen Fragen und Antworten der Wissensbasis und das Gewicht der gefundenen Treffer wurden anschließend analysiert. Im Folgenden sollen einige Suchanfragen und die daraus gewonnenen Erkenntnisse näher beschrieben werden. Dabei wird auch die Entwicklung des Systems beleuchtet 6.1.1 Gemeinsamkeiten der Evaluationsschritte hinsichtlich der Systemfunktionalität Alle in den nächsten Abschnitten beschriebenen Evaluationen bauen auf einer Grundfunktionalität von IDEE auf. Diese ist die folgende: Der zur Suche eingesetzte Index wurde, wie in Kapitel 3 beschrieben, mit Hilfe von Jakarta Lucene aufgebaut. Dabei wurde u. a. der in Lucene enthaltene deutsche Stemmer verwendet. Die Suche erfolgt innerhalb des Indexes auf einem Feld, welches jeweils den Text einer Frage in Kombination mit den Text einer Antwortalternative dieser Frage enthält. 78 Die Gewichtung der Suchergebnisse erfolgt durch die in Jakarta Lucene implementiert Gewichtung ohne Verwendung von Boost-Faktoren 6.1.2 Erster Prototyp Beim ersten untersuchten Prototyp von IDEE ist nur die in 5.2.1 erläuterte Grundfunktionalität implementiert. Der Eingabestring besteht aus einer durch Leerzeichen getrennten Abfolge von Symptomen (z.B. "Leberoberfläche sonographisch glatt"). Der eingegebene Suchstring wird durch den Jakarta Lucene Query-Parser unter Verwendung des deutschen Stemmers in einen Anfrage überführt mit dem dann die Suche ausgeführt wird. Die Suche liefert alle Fragen-Antwort Kombinationen zurück, bei denen mindestens eines der eingegebenen Symptome im Text der Frage oder der zugehörigen Antwort vorkommt. Bei Hinzufügen neuer Symptome zum Suchstring erhöht sich deshalb die Trefferzahl. Es liefern allerdings nur solche Terme in der Wissensbasis Treffer, deren gestemmte Form exakt mit der gestemmten Form des Suchbegriffes übereinstimmt. So liefern z.B. "Leber", "Lebers", "Lebern", Leberns" und "Leb" dieselben Treffer, da alle dieser Wortformen auf denselben Stem abgebildet werden. Hingegen liefern "sonographisch" und "sonografisch" nicht dieselben Treffer, da sie keinen gemeinsamen Stem haben. Das grundlegende Problem liegt aber nicht beim verwendeten Stemmer sondern daran, dass die verwendete Suche nur exakte Übereinstimmungen von Termen der Suchanfrage (nicht zu verwechseln mit dem eingegebenen Suchstring!) mit den Termen im Index als Treffer erkennt. Ein Ansatz zur Lösung dieses Problems ist die Erweiterung der Suchanfrage um Terme mit lexikalischer oder semantischer Ähnlichkeit (Teilworte bzw. Synonyme oder andere Schreibweisen). Die Gewichtung der Suchergebnisse richtet sich nach der Anzahl der erkannten Worte im Verhältnis zur Gesamtanzahl der Worte in der Frage-Antwort Kombination. Dadurch werden, bei gleicher Anzahl der gefundenen Terme, Fragen-Antwort-Kombinationen mit einer geringeren Gesamtanzahl von Termen bevorzugt. 79 6.1.3 Einführung einer automatischen Erweiterung des Suchstrings Der eingegebenen Suchstring wird nun, bevor aus ihm durch den Lucene Query-Parser eine Anfrage generiert wird, automatisch um Teil- und zusammengesetzte Wörter sowie Synonyme (falls im Wörterbuch vorhanden) erweitert. Dazu wird ein Lexikon verwendet, das zu einem Begriff der Wissensbasis alle seine Teilwörter und Komposita, die als eigenständiger Term in der Wissensbasis vorkommen, verzeichnet. Um eine sinnvolle Gewichtung des erweiterten Suchstrings zu erhalten, wird bei jedem hinzugefügten Term ein Boost-Faktor angegeben. Der Boost-Faktor wird so berechnet, dass die Summe der BoostFaktoren aller Erweiterungen zu einem Begriff einen festgesetzten Wert (Standard: 1,0) ergibt. Die Suche mit dem erweiterten Suchstring liefert in jedem Fall mehr Treffer. Voraussetzung der Möglichkeit einer Erweiterung bei dem hier verwendeten Lexikon ist allerdings, dass der Begriff in der eingegebenen Weise in der Wissensbasis vorkommt. Das liegt allerdings nur am Inhalt des Lexikons. Da es automatisch aus allen Begriffen der Wissensbasis erstellt wird, hat es folgedessen nur Einträge zu Begriffen, die in der Wissensbasis vorkommen. Ersetzt man das Lexikon durch ein umfangreicheres, werden auch andere Begriffe erkannt. Es werden nun auch Fragen und Antwortalternativen gefunden, die nur Teilwörter oder Komposita der ursprünglich eingegebenen Begriffe enthalten. Dies erhöht die Trefferwahrscheinlichkeit, insbesondere für die Fragen, in denen ein Teil des eingegebenen Begriffes in der Frage und der andere Teil in der Antwort vorkommt. So wird z.B. bei der Eingabe des Suchbegriffes "Leberform" auch die Frage "Laparoskopischer Befund an der Leber" mit der Antwort "Form auffällig" gefunden. Die Evaluation hat gezeigt, dass ein zusammengesetzter Suchbegriff oft andere Suchergebnisse liefert, als die Suche mit den Teilwörtern dieses Begriffes. Dies liegt u. a. an der Menge der Erweiterungen, die für einen Begriff erfolgen. So wird das Kompositum "Leberform" nur durch seine Teilwörter "Leber" und "Form" expandiert. Die Eingabe von "Leber Form" resultiert allerdings in der Erweiterung um 13 zusätzliche Begriffe, da sowohl Leber wie auch Form sehr häufig bei der Bildung von Komposita beteiligt sind. Dies liegt an dem Phänomen, dass die deutsche Sprache viele Wörter durch Komposition (Zusammensetzung) bildet. 80 Durch die unterschiedlichen Suchergebnisse bei der Suche nach zusammengesetzten Wörtern oder ihrer einzelnen Wörter ergibt sich auch eine Verschiebung der Gewichtung der gefundenen Frage-Antwort-Kombinationen. In vielen Fällen stimmen jedoch die am besten gewichteten Treffer überein. Sicherlich ist aber eine genauere Analyse und Anpassung der Boost-Faktoren für die erweiterten Begriffe sinnvoll. 6.1.4 Einführung eines Scalers Um die oft enorme Anzahl an Treffern untereinander zu vergleichen und einzugrenzen wird ein Scaler eingeführt, der die bei jedem Treffer angegebene Bewertung beurteilt. Dazu wird die Bewertung des besten Treffers als Referenz genommen und alle Treffer, die außerhalb eines (konfigurierbaren) zum besten Treffer liegen, verworfen. Dieses Verfahren ändert nichts an der Reihenfolge der Treffer, sondern schließt als irrelevant betrachtete Treffer von der Präsentation aus. Die Evaluation hat gezeigt, dass dies eine durchaus sinnvolle Methode ist. Voraussetzung ist natürlich ein geeigneter Scaling Faktor. Der Standardwert wurde aufgrund von Erfahrungen auf 1,2 festgelegt. Er kann jedoch jederzeit leicht angepasst werden. 6.1.5 Einführung einer Grammatik für Arztbriefe Die Einführung eines Parsers für die Verarbeitung von Arztbriefen (nach der Vorlage der Universitätsklinik Berlin Köpenick) ändert nichts an der eigentlichen Suche. Vielmehr erstellt der Parser aus dem Arztbrief lediglich einzelne Suchstrings, die dann für aufeinander folgende Suchen verwendet werden. Durch Einführung dieses Parsers vor der eigentlichen Suche wird nun ermöglicht, neben der Eingabe von einzelnen Suchstrings ganze Texte im entsprechenden Arztbriefformat zu verarbeiten. Beim Entwurf einer Grammatik des Parsers anhand der vorliegenden Arztbriefe der Universität Berlin Köpenick wurde festgestellt, dass diese Arztbriefe an verschiedenen Stellen keine eindeutige übergreifende Syntax aufweisen. Da für den Parser aber eine eindeutige Syntax notwendig ist, wurde an diesen uneindeutigen Stellen ein Kompromiss gesucht und eine Syntax definiert. 81 Die Evaluation des Parsers hat gezeigt, dass er in der Lage ist, auch mehrere Absätze eines Arztbriefes mit allen seinen Kontexten und dazugehörigen Symptomangaben zu verarbeiten, falls sich der Arztbrief strikt an die definierte Syntax des Parsers hält. Kontexte und Wertangaben werden dabei zuverlässig erkannt. 6.2 Abschließende quantitative Evaluation Zum Abschluss der Diplomarbeit wurde eine quantitative Evaluation durchgeführt, die aufzeigen sollte, wie gut das System eingegebene Suchanfragen auf die Fragen und Antwortalternativen der SonoConsult Wissensbasis von D3 abbilden kann. Zur Evaluation lagen 10 Arztbriefe vor, die automatisch mittels eines Templates (Schablone) aus Testfällen von D3 generiert worden waren. Ferner lagen die Daten des Falles vor, die zur Generierung des jeweiligen Arztbriefes herangezogen wurden. Die vorliegenden Daten zu einem Fall sind dabei die Menge aller bereits beantworteten oder hergeleiteten Fragen und Symptominterpretationen in diesem Fall. Es wurde nun nach einer Möglichkeit gesucht, aus den vorliegenden Daten (Falldaten, Schablone und generierter Arztbrief) eine möglichst aussagekräftige Evaluation zu gestalten. Dabei wurden zwei verschiedene Ansätze verfolgt. Bei beiden Ansätzen wurden die Arztbriefe als Eingabe für IDEE verwendet und damit eine Suche in der Wissensbasis durchgeführt. Beim ersten Ansatz wurde evaluiert, wie viele der Falldaten durch die Suchtreffer überdeckt werden. Der zweite Ansatz ermittelte, wie gut der eingegebene Arztbrief vom System bei der Suche erkannt wurde. Die beiden Evaluations-Ansätze werden im Folgenden näher erläutert. 6.2.1. Überdeckung der Falldaten Im ersten Schritt der Evaluation wurde ermittelt, wie viele der Fragen und Symptominterpretationen aus den Falldaten durch die von IDEE gefundenen Elemente der Wissensbasis wieder rekonstruiert werden können. Dazu wurde pro Testlauf ein Arztbrief in das System eingegeben und eine Suche durchgeführt. Die gefundenen Elemente der Wissensbasis 82 wurden daraufhin mit den Falldaten verglichen. Dabei wurde ermittelt, wie viele Elemente der Falldaten durch die Suche erkannt wurden. Bei diesem Evaluations-Ansatz treten jedoch einige Einschränkungen auf. Zunächst werden bei der Erstellung des Arztbriefes nicht alle Elemente aus den Falldaten verwendet. Es gibt also Elemente in den Falldaten, deren Wert für die Schablone und somit für die Generierung des Arztbriefes irrelevant ist. Der Wert dieser Elemente hat also keinen Einfluss auf den Text des Arztbriefes. Somit kann umgekehrt auch nicht anhand des Arztbriefes auf den Wert eines dieser Elemente geschlossen werden. Diese Elemente würde also das Ergebnis der Evaluation verfälschen. Deshalb wurden zu Beginn jedes Testlaufes die Elemente der Falldaten mit allen Einträgen der Schablone abgeglichen, und irrelevante Elemente aus den Falldaten zur Evaluation entfernt. Zurück blieben die Elemente der Falldaten, die Auswirkungen auf den generierten Arztbrief haben können (nicht müssen!). Ein weiteres, schwerwiegenderes Problem bei diesem Evaluationsansatz ist, dass bei der Generierung einer bestimmten Ausgabe im Arztbrief mehrere Elemente aus den Falldaten mitbestimmend sein können. Selbst das Nichtvorhandensein von Elementen (Werten) in den Falldaten kann eine bestimmte Ausgabe generieren. Dies hat zur Folge, dass für eine Ausgabe sowohl mehrer Elemente verantwortlich sind oder unter Umständen ein Element gar nicht vorhanden sein muss um eine Ausgabe zu generieren. Dies widerspricht dem Ziel der Freitexteingabe, eine Eingabe gezielt auf ein vollständiges Element der Wissensbasis abzubilden. Somit ist eine reine Untersuchung der Überdeckung der Falldaten durch die Ergebnisse einer Suchanfrage, für die Ermittlung der Qualität von IDEE hinsichtlich der Erkennung von Freitexteingaben, eingeschränkt aussagekräftig. Dies spiegelt sich auch schon in der Tatsache wieder, dass die Anzahl der aus einem Arztbrief generierten Suchanfragen in allen Testfällen stets stark kleiner war als die Anzahl der Elemente der Falldaten. Für eine vergleichende Evaluation von IDEE hinsichtlich der Steigerung der Treffermenge durch Hinzunahme des Wörterbuches oder Berücksichtigung von verschiedenen Treffertiefen oder Gewichten, ist dieses Evaluationsverfahren ausreichend gut geeignet. Zusammenfassend kann man die bei diesem Evaluationsansatz gewonnenen Daten formal folgendermaßen beschreiben: Sei G die Menge aller Elemente (der Wissensbasis), die am Arztbriefgenerator beteiligt sind. Sei n die Anzahl der in einem Fall F vorhandenen Elemente. Sei x die Anzahl aller Elemente f aus F für die gilt: f ist nicht in G. 83 Dann ist n – x die Anzahl der Elemente f aus F, die auch in G sind und somit auf die Generierung des Arztbriefes Einfluss nehmen können. Sei t die Anzahl der Treffer einer Suche von IDEE (d.h. t ist in F) Bei dieser Evaluation wird untersucht: Überdeckung der Falldaten = t / n-x Es wurden nun mit diesem Evaluationsansatz verschiedene Testläufe durchgeführt, bei denen zunächst ermittelt wurde, wie hoch die Trefferquote von IDEE ist, wenn nur die besten Suchtreffer gewertet werden. Anschließend wurde schrittweise die zulässige Tiefe der Suchtreffer erhöht, also auch die zweitbesten, drittbesten usw. Treffer in die Evaluation miteinbezogen. Derselbe Test wurde sowohl ohne Verwendung des in IDEE vorhandenen Lexikons durchgeführt. Bei Verwendung des Lexikons werden die Wörter der Suchanfragen automatisch um ihre Komposita und Teilwörter erweitert. Die Erwartungen bei der Evaluation lagen darin, dass eine Steigerung der Trefferquote sowohl bei der Erweiterung der Treffertiefe wie auch die Hinzunahme des Lexikons angenommen wurde. Die einzelnen Evaluationsergebnisse finden sich in folgenden Tabellen und Diagrammen. Durchschnittliche Überdeckung ohne Lexikon Fall 1 2 3 4 5 6 7 8 9 10 Elemente Suchim Fall anfragen 60 40 78 46 53 34 79 47 41 17 94 50 74 44 49 20 46 34 62 27 1 Treffer 19 30 18 26 8 18 25 14 16 18 2 Treffer 22 34 19 31 12 36 31 16 18 22 3 Treffer 25 36 20 35 13 40 32 17 18 24 4 Treffer 26 38 20 37 13 42 35 17 19 27 5 10 Treffer Treffer 29 35 39 46 23 30 38 48 13 15 45 54 37 44 19 27 21 25 27 29 Abb. 6.1 Rohdaten für die Evaluation der Überdeckung der Falldaten durch die Suchanfrage OHNE LEXIKON. Die Anzahl der Elemente im Fall bezieht sich dabei auf die Elemente, die auch in der Schablone für die Arztbriefgenerierung vorkommen. Unter Suchanfragen ist die Anzahl der von IDEE generierten Suchanfragen zu diesem Fall verzeichnet. Die restlichen Spalten geben an, wie viele Treffer einer Suchanfrage für die Ermittlung der Überdeckung der Falldaten herangezogen wurden (z.B. bei 4 Treffer werden die besten vier Treffer der Suchanfrage betrachtet). Durchschnittliche Überdeckung mit Lexikon 84 Fall 1 2 3 4 5 6 7 8 9 10 Elemente Suchin Fall anfragen 60 40 78 46 53 34 79 47 41 17 94 50 74 44 49 20 46 34 62 27 1 Treffer 22 30 18 27 10 32 27 13 16 18 2 Treffer 25 35 21 34 14 41 35 17 19 22 3 Treffer 25 37 22 37 15 43 35 18 19 25 4 Treffer 27 40 23 40 15 45 40 18 21 28 5 Treffer 32 43 28 45 15 50 44 19 26 28 10 Treffer 39 49 33 54 15 60 48 26 28 34 Abb. 6.1 Rohdaten für die Evaluation der Überdeckung der Falldaten durch die Suchanfrage MIT LEXIKON. 0,600 0,500 0,400 0,300 0,200 0,100 0,000 1 2 3 4 5 10 Treffertiefe 1 2 3 4 5 10 ohne Lexikon 0,302 0,372 0,400 0,420 0,447 0,544 mit Lexikon 0,329 0,406 0,425 0,456 0,508 0,592 Abb. 6.2: Durchschnittliche Überdeckung der Falldaten durch die Treffer der Suchanfrage. Die Treffertiefe gibt an, wie viele Treffer bei der Evaluation der Überdeckung berücksichtigt wurden. Anhand der graphischen Repräsentation kann man sehr schön die Steigerung der Überdeckung der Falldaten durch Vergrößerung der Treffertiefe erkennen. Daraus kann abgeleitet werden, dass auch Treffer, die von IDEE nicht als bester Treffer gewertet werden wichtige Informationen enthalten können, die zu einer Überdeckungssteigerung beitragen. Wichtiger ist sicherlich jedoch die Verbesserung der Überdeckung durch Hinzunahme der Anfrageerweiterung mittels eines Lexikons. 85 6.2.2 Überdeckung des Arztbriefes Zur Qualitativen Evaluation des eigentlichen Zieles von IDEE, nämlich der möglichst guten Erkennung von Freitexteingaben und deren Abbildung auf Element der Wissensbasis, wurde die Überdeckung des Arztbriefes durch die Suchergebnisse betrachtet. Dabei wurde untersucht, wie viele der durch IDEE aus dem Arztbrief generierten Suchanfragen auf richtige (und sinnvolle) Werte der Wissensbasis abgebildet werden. Zur Bestimmung der richtigen Treffer wurden allerdings wieder die vorliegenden Falldaten herangezogen. Sei F der zu untersuchende Fall. Sei T die Menge der von IDEE gefundenen Treffer t. Sei s die Anzahl der von IDEE aus dem Arztbrief generierten Suchanfragen. Sei r die Anzahl der Treffer t, die auch in F enthalten sind. Dann wird definiert: Überdeckung des Arztbriefes = r / s. Falsche Treffer wurden in verschiedene Fehlerkategorien eingeteilt. Die dabei festgelegten Fehlerkategorien sind die folgenden: Grammatik: Durch Differenzen hinsichtlich der Grammatik der Eingabe und der (erwarteten) Grammatik des Systems, werden verschiedene Konstrukte nicht richtig erkannt. Ein Beispiel ist hier z.B. ein aus mehreren Fakten zusammengesetzter Eingabesatz, der nicht richtig in seine Elemente zerlegt wird und somit auch nicht die adäquaten Suchanfragen gestellt werden können. Fehlender Kontext: Dies ist ebenfalls ein Problem der Grammatik. Es tritt beispielsweise dann auf, wenn sich aufeinander folgende Eingaben aufeinander beziehen, der gemeinsame Kontext aber in den einzelnen Suchanfragen nicht mehr zu erkennen ist. Auf der anderen Seite kann der Kontext aber auch in den Fragen der Wissensbasis fehlen. Dies ist bei manchen Folgefragen der Fall, bei denen der übergeordnete Kontext im Fragetext nicht explizit angegeben ist. 86 Lexikon: Erweiterungen Durch die automatische Erweiterung der Suchanfrage durch Teilwörter und Komposita wird das Gewicht der einzelnen Suchwörter so verändert, dass eine unvorteilhafte Gewichtung der Treffer auftreten. Dies ist häufig der Fall, wenn ein Begriff durch eine große Anzahl von Komposita erweitert wird und das zu findende Wort im Fragetext eines dieser Komposita ist. Text ersetzt: Bei der Generierung der Arztbriefe werden manche Begriffe des in der in der Wissesbasis vorhandenen Fragetexte durch andere Begriffe oder Konstrukte ersetzt. Diese neuen Beschreibungen werden also synonym verwendet. Die entsprechende Frage kann dann nur gefunden werden, wenn diese Synonyme oder Konstrukte im Lexikon verzeichnet sind und bei der Generierung der Suchanfrage hinzugenommen werden. Text generiert: Bei der Erstellung der Arztbriefe wird manchmal aus der Kombination von Werten verschiedener Elemente der Falldaten (oder auch dem nicht Vorhandensein von Elementen in den Falldaten) ein Text generiert. Dieser Text weist nicht zwangsweise eine Übereinstimmung mit dem ursprünglichen Fragetexten auf. Somit ist es IDEE nicht möglich, aus dem generierten Text auf die zugrunde liegenden Fragen zu finden. Lucene Gewichtung: Die Gewichtung in Jakarta Lucene berücksichtigt unter anderem die Läge eines Fragetextes für die Gewichtung. Somit werden lange Fragen (die beispielsweise zusätzliche Informationen enthalten) gegenüber kurzen Fragen mit einem geringeren Gewicht versehen. Dies kann in seltenen Fällen allerdings zu einer Verfälschung des Suchergebnisses führen, wenn z.B. die zu findende Frage erklärende Zusatzinformationen hat. Stem: Werden verschiedene Wortformen bei der morphologischen Analyse durch den Stemmer nicht auf dieselbe Grundform abgebildet, kann ihre Verwandtschaft bei der späteren Suche in IDEE nicht berücksichtigt werden. Dieses Problem kann durch Anpassen des Lexikons gelöst werden. 87 Bei der Evaluation wurde ermittelt, wie viele der von IDEE generierte Suchanfragen auf korrekte Werte der Wissensbasis abgebildet werden. Dabei wurden Treffer bis zu einer Treffertiefe von 3 berücksichtigt. Für die Ermittlung der Fehlerhäufigkeiten in den verschiedenen Fehlerkategorien wurden jedoch alle Suchanfragen herangezogen, deren bester Treffer nicht korrekt auf den gewünschten Wert der Wissensbasis abgebildet wurde. Lexikon Text ersetzt 0 5 3 1 6 3 5 0 2 2 48 32 3 1 3 2 1 4 3 4 0 2 3 36 20 1 0 5 3 0 6 4 4 1 2 4 51 27 2 2 4 3 1 6 3 4 1 0 5 19 12 4 0 0 0 0 3 1 2 1 0 6 56 37 4 1 5 3 1 5 3 4 1 0 7 47 27 3 3 3 3 1 5 5 4 1 0 8 20 13 2 0 0 0 0 4 2 1 0 0 9 35 17 1 0 4 4 1 6 3 5 1 2 10 30 20 3 1 2 1 0 4 2 3 0 0 Sinngemäß richtig Stem 1 Text generiert Grammatik 23 Kontext fehlt 3. Treffer 42 Fall 1. Treffer 1 Suchanfragen 2. Treffer Gewichtung Im Folgenden finden sich die Ergebnisse der Evaluation. Abb. 6.3: Rohdaten für die Evaluation der Überdeckung der aus den Arztbriefen generierten Suchanfragen. Prozentuale Erkennung der Suchanfragen 1 0,8 0,6 0,4 0,2 Fall 0 1 2 3 4 5 6 7 8 9 10 3. Treffer 0 0 0 0 0 0 0,1 0 0 0 2. Treffer 0 0,1 0 0 0 0,1 0,2 0,1 0,1 0,1 1. Treffer 0,5 0,7 0,6 0,5 0,6 0,7 0,6 0,7 0,5 0,7 88 Abb. 6.3 Prozentuale Erkennung der Suchanfragen (mit Lexikon). Das Diagramm zeigt, wie viel Prozent der aus den Arztbriefen generierten Suchanfragen durch IDEE richtig erkannt wurden. Dabei werden Treffer bis zu einer Tiefe von 3 berücksichtigt. Anhand des Diagramms kann man sehen, dass bei der Evaluation so gut wie immer mehr als die Hälfte der Suchanfragen sicher im besten Treffer erkannt wurden. Durch Erweiterung der Treffertiefe wurde die Erkennungsleistung nur noch gering gesteigert. Wichtiger Bestandteil der Evaluation war jedoch auch die Einordnung der falsch erkannten Suchanfragen, wie sie im Folgenden gezeigt wird: Verteilung der Fehlerarten Text generiert Text ersetzt Grammatik Kontext fehlt Gewichtung Grammatik Lexikon Stem Kontext fehlt Stem Lexikon Text ersetzt Text generiert Gewichtung Abb. 6.4 Verteilung der Fehlerarten. Das Diagramm zeigt die Verteilung der Fehler in die definierten Kategorien. Die Evaluation hat gezeigt, dass ein Großteil der Fehler durch die übermäßige Erweiterung des Suchstrings durch das Lexikon und die damit zusammenhängende Veränderung der Gewichtung der Treffer verursacht wird. Wird ein Suchbegriff durch das Lexikon stark erweitert, werden die erweiterten Worte mit einem geringen Gewicht versehen, da das Gewicht von der Anzahl der Erweiterungen abhängt. Dieser Fall tritt beispielsweise immer dann auf, wenn das Wort hinsichtlich der Bildung von Komposita sehr produktiv ist. Falls anschließend eines der erweiterten Worte für einen Treffer verantwortlich ist, wird dir Relevanz dieses Wortes aufgrund seines geringen Gewichtes nicht richtig erkannt. Abhilfe würde hier eine andere Gewichtungsfunktion schaffen, die beispielsweise zusammengesetzte Worte, die sich aus mehreren Worten der ursprünglichen Suchanfrage zusammensetzen, stärker gewichtet. 89 Ebenfalls wird noch ein erheblicher Teil der Fehler durch falsches Erkennen von Eingaben durch die Grammatik verursacht. Dies ist in den meisten Fällen dann der Fall, wenn die Eingabe mehrere zusammenhängende Fakten in einem Satz vereint, der dann nicht richtig zerlegt werden kann. Die Trefferquote ist hier wesentlich höher, wenn sich der Benutzer stärker an die Struktur der definierten Grammatik hält und die jedes Fakt einzeln mit allen wichtigen Informationen eingibt, oder diese wichtigen Informationen in einem Kontext vereint (siehe Beschreibung der Grammatik von IDEE). Eine andere Möglichkeit ist der Einsatz einer mächtigeren Grammatik. Die Evaluation hat auch gezeigt, dass das System schon sehr gute Suchergebnisse liefert, falls die Eingabe nicht wesentlich von der Formulierung der Texte in der Wissensbasis abhängt. Werden allerdings dem System unbekannte Synonyme verwendet, können keine geeigneten Treffer gefunden werden. Abhilfe schafft hier die Anpassung des Lexikons hinsichtlich der Synonyme. 6.3 Beispiel einer Suchanfrage Im Folgenden wird die Behandlung einer Suchanfrage mittels eines Arztbriefes von IDEE detailliert beschrieben und daran die Vorgehensweise des Systems erläutert. Als Eingabe erhält das System einen automatisch generierten Arztbrief der hier in Auszügen wiedergegeben ist: LEBER: (Höhe in MCL nicht bestimmt); Form unauffällig; Oberfläche glatt; Unterrand spitz; Verformbarkeit nicht oder kaum vermindert; Binnenstruktur normal; feines Reflexmuster; intrahepatische Gallenwege überall erweitert D. HEPATOCHOLEDOCHUS: Durchmesser 10 mm; unauffällig GALLENBLASE: Z. n. Cholezystektomie MILZ: längs 8 cm, tief 3 cm; Größe, Form und Binnenstruktur unauffällig PFORTADERSYSTEM: unauffällig 6.3.1 Parsen der Eingabe Der Arztbrief wird vom Parser analysiert. Dazu wird er in zunächst in einzelne Absätze unterteilt. Bestimmend für die Unterteilung sind die im Text vorhandenen Zeilenumbrüche. Wir betrachten der Einfachheit halber nur einen Absatz: MILZ: längs 8 cm, tief 3 cm; Größe, Form und Binnenstruktur unauffällig 90 Innerhalb des Absatzes wird nun versucht, ein Kontext zu erkennen, der für den gesamten Absatz gilt. Dieser Kontext ist die Angabe vor dem ersten Doppelpunkt, in unserem Beispiel MILZ. Der erkannte Kontext wird dann später zu jeder Suchanfrage dieses Absatzes hinzugefügt. Es ist auch möglich, einen Unterkontext anzugeben, der dann ebenfalls berücksichtigt wird. Neben dem Kontext wird der Absatz aber auch noch in seine weiteren Bestandteile zerlegt. Dies sind die so genannten Fakten, die jeweils durch ein Satzzeichen voneinander getrennt sind. In unserem Beispiel sind das 4 Fakten: 1) "längs 8 cm", 2) "tief 3 cm", 3) "Größe" und 4) "Form und Binnenstruktur unauffällig". Innerhalb eines Faktes können Wertangaben erkannt werden, die sich aus einer Zahl und ggf. einer Einheit zusammensetzen (z.B. "8 cm"). Aus den erkannten Bestandteilen eines Absatzes wird nun eine Menge von Suchstrings generiert. Ein einzelner Suchstring setzt sich dabei aus seinem jeweiligen Kontext und den Wörtern eines Faktes zusammen. Falls in dem Fakt einen Wertangabe vorkommt, ist auch die Einheit der Wertangabe im Suchstring enthalten. Zwei der generierten Suchanfrage ist z.B. : milz längs cm milz tief cm 6.3.2 Erweitern des Suchstrings Jedes Wort des vorhandenen rudimentäre Suchstring wird nun mit Hilfe des Lexikons um seine Komposita und Teilwörter erweitert. Sind im Lexikon zu einem Wort Synonyme verzeichnet, werden auch dies hinzugefügt. Der Begriff "milz" hat im Lexikon beispielsweise 14 Einträge zu Hyperonymen: milzvergrößerung milzgröße nebenmilz milzinfarkt milzvene milzvenendurchmesser milzdiagnosen milzvenenfluß milzparenchym milzherd milzabszess milzvenenthrombose milzkrankheit milzveränderung Dies werden alle dem Suchstring hinzugefügt. Dabei werden die Erweiterungen jeweils mit einem Gewicht versehen. Dieses ist so definiert, dass die Summe der Gewichte aller Erweiterungen zu einem Begriff einem in IDEE festgelegtes Gewicht (Norm: 1,0) entspricht. Der erweiterte Suchstring in unserem Beispiel ist: cholangiographie^0.07692308 cholangioläres^0.07692308 cholangitis^0.07692308 cm^1.0 flußverlangsamung^0.07692308 langsam^0.07692308 langzeit^0.07692308 längs^1.0 längsausdehnung^0.07692308 91 längsdurchmesser^0.07692308 milz^1.0 milzabszess^0.071428575 6.3.3 Suche Mit diesem Suchstring wird nun die eigentliche Suche durchgeführt. Diese liefert eine Menge von gewichteten Treffern. Das Gewicht wird intern von der verwendeten Suche durch Jakarta Lucene bestimmt. Die Suche liefert in diesem Beispielfall 301 Treffer. Die besten 5 Treffer hierbei sind: 1. (Mf648) 2. (Mf906) 3. (Mf903) 4. (Mf777) 5 (Mf630) Q: milz längs, sonographisch Q: echogener milzherd, durchmesser längs sonographisch Q: echofreier milzherd, durchmesser längs sonographisch Q: leberpunktat, länge sonographisch Q: hufeisenniere, länge sonographisch A: cm S: 0.4932038 A: cm S: 0.24434741 A: cm S: 0.24434741 A: cm S: 0.2077075 A: cm S: 0.2077075 6.3.4 Skalierung der Suchergebnisse Da man nicht alle Suchergebnisse präsentieren will wurde ein Scaler entwickelt, der nur die besten Treffer anzeigt. Die Güte der Treffer wird in Abhängigkeit von der Gewichtung des besten Treffers bestimmt. Hierfür existiert in IDEE ein so genannter Scaling Factor, der festlegt, wie viel Prozent des Gewichtes des besten Treffers erreicht sein muss, damit ein anderer Treffer angezeigt wird. In unserem Beispiel sind die Treffer ab Platz 2 aber so gering gewichtet, dass sie vom Scaler vom ausgegebenen Suchergebnis entfernt werden und somit nur 1 Treffer übrig bleibt. Das Suchergebnis lautet also: 1. (Mf648) Q: milz längs, sonographisch A: cm S: 0.4932038 92 6.4 Stärken und Schwächen von IDEE Die Stärken des bisher implementierten Systems liegt in der umfangreichen Möglichkeit der textuellen Dateneingabe für wissensbasierte Diagnose und Beratungssysteme duch die Wortvektorbasierte Suche und Abbildung der gemachten Eingabe auf die zugrunde liegende Wissensbasis. IDEE ermöglicht: Verarbeitung von Eingabestrings aus mehreren Begriffen Verarbeitung von Texten, die nach einer von IDEE festgelegte Syntax aufgebaut sind Möglichkeit der Suche nach Synonymen und lexikalischen Ober- und Unterbegriffen (abhängig von einem Lexikon) Automatischer, rekursiver Aufbau einen einfachen Lexikons aus Ober- und Unterbegriffen für die Begriffe der Wissensbasis Leichtes Editierbarkeit des bereitgestellten Lexikons durch XML-Format Die Schwächen von IDEE liegen in folgenden Bereichen: automatisch aufgebautes Wörterbuch enthält keine Synonyme bisher keine Suche nach semantischen Ober- und Unterbegriffen (z.B. Fahrzeug – Auto, Fahrrad, Mofa, …). Dies kann aber ebenfalls leicht mittels eines Lexikons gelöst werden. Gewichtung von automatisch erweiterten Suchstrings noch nicht ideal abgestimmt (Anpassung der Boost-Faktoren bzw. Bewertungsfunktion sinnvoll) 93 Kapitel 7 Erweiterungen und Ausblick Im Folgenden Kapitel sollen einige Möglichkeiten zur Erweiterung und Verfeinerung der in dieser Diplomarbeit implementierten intelligenten textuellen Dateneingabe IDEE aufgezeigt werden. 7.1 Stemming und morphologische Analyse Der in IDEE zur Abbildung von Wortformen auf eine Grundform eingesetzte deutsche Stemmer von Jakarta Lucene stellt bereits eine gute Funktionalität bereit und erkennt eine Vielzahl von Wortformen, die in der deutschen Sprache vorkommen. Er ist dabei allerdings durch seinen festen und eingeschränkten Regelsatz nur auf jene Arten der Wortformenbildung ausgelegt, die häufig in der deutschen Sprache vorkommen. Allerdings ist die deutsche Sprache im Vergleich zu vielen anderen Sprachen sehr komplex aufgebaut. So gibt es auch in der Wortformenbildung häufig Ausnahmen und Abweichungen von Produktionsregeln, die sich unter Umständen nicht in einfache Regeln fassen lassen, welche für einen Stemming-Algorithmus geeignet sind. Ein weiteres Problem stellen Wörter aus einer fachbezogenen Terminologie dar, wie sie beispielsweise in einer medizinischen Wissensbasis sehr häufig vorkommen. Sie unterliegen oft nicht den geläufigsten standardisierten Regeln zur Wortformenbildung, wie sie in einem Stemmer (wie beispielsweise von Lucene) enthalten sind. Dies liegt nicht zuletzt daran, da solche Fachtermini oft aus einer anderen Sprache (wie z.B. Latein) übernommen oder abgeleitet wurden. Die Abbildung von Wortformen auf eine Grundform mittels eines Stemming Algorithmus ist also immer gewissen Einschränkungen unterworfen und geht mit einer eingeschränkten Präzision einher. Dies liegt schon in der Natur, wie der Stemming Algorithmus bei der Abbildung einer Wortform auf die zugehörige Grundform vorgeht. Er hat dabei einen festen Regelsatz, der entweder fest definierte Wortendungen abschneidet bzw. reduziert oder bestimmte Zeichen oder Zeichenkombinationen innerhalb eines Wortes ersetzt (z.B. wird „ß“ in „ss“ umgewandelt oder Umlaute ersetzt). Die Morphologie des Wortes bleibt dabei unergründet. 94 Eine Verbesserung der geschilderten Problematik kann durch Einführung einer morphologischen Analyse, wie sie in Kapitel 2 geschildert wurde, erreicht werden. Durch eine morphologische Analyse kann eine präzisere und zuverlässigere Abbildung von Wortformen auf ihre Grundform erfolgen. Dies ermöglicht eine Verringerung falscher oder nicht erkannter Abbildungen und kann dadurch z.B. bei der Suche zu einer Steigerung der Qualität der Treffer führen. Eine vollständige morphologische Analyse ist für die deutsche Sprache allerdings sehr aufwendig. Deshalb wurde sie bisher nicht in IDEE implementiert. Außerdem hat sich gezeigt, dass selbst unter der Verwendung des Stemming-Algorithmus von Lucene eine hohe Trefferquote möglich ist. 7.2 Wörterbuch Eine erstrebenswerte Erweiterung für das in IDEE vorhanden Lexikon aus Synonymen, Komposita und Teilwörtern ist die Implementierung eines leistungsfähigen Editors mit dem der Benutzer z.B. weitere Synonyme angeben kann. Dies ist gerade dann sinnvoll, falls ein globales Lexikon aufgebaut werden soll, das sich nicht nur auf eine Wissensbasis beschränkt. Durch die gewählte Realisierung des Wörterbuchs im XML Format kann dieses aber auch jetzt schon in jedem XML-Browser betrachtet werden und bietet somit auch schon die Möglichkeit der Editierung. Allerdings wird dabei die Konsistenzhaltung vollständig dem Benutzer überlassen, was einerseits zeitaufwändig ist und außerdem eine ungewollte Fehlerquelle darstellt. 7.3 Behandlung von Folgefragen Eine wichtige Erweiterung des Systems liegt in der Behandlung von Folgefragen. In der Wissensbasis können Fragen vorkommen, bei denen Abhängig von ihrer Beantwortung bestimmte Folgefragen gestellt werden. Die Ausgangsfrage bildet somit eine Vorbedingung zur Folgefrage. Somit kann der Text der Ausgangsfrage als Kontext für die entsprechende Folgefrage und deren Antwortalternativen gesehen werden. Hierzu ein Beispiel: Ausgangsfrage: 95 Fragetext: „Oberfläche der Leber auffällig?“ Antwortalternativen: „ja“ / „nein“ Folgefrage, bei Antwort „ja“: Fragetext: „Struktur:“ Antwortalternativen: „glatt“, „bucklig“, „rauh“ Gibt nun der Benutzer als Suchstring „Leberoberfläche glatt“ ein, können die zugehörigen Fragen in der Wissensbasis nicht zuverlässig gefunden werden. Dies liegt daran, dass in dem zur Suche verwendeten Index von IDEE bisher keinerlei Information zwischen den Fragen vorliegt. Ein einfacher Lösungsansatz, der bereits eine Vielzahl der Fälle des oben geschilderten Problems abdecken würde, soll nun aufgezeigt werden. Dabei wird davon ausgegangen, dass in der Wissensbasis Ausgangsfragen, welche eine Folgefrage stellen, oft als Ja-Nein Frage implementiert sind. Eine denkbare Lösung wäre nun die Sonderbehandlung dieser Ja-Nein Fragen bei der Indexierung der Wissensbasis. Dabei würde man sich den Text der Ausgangsfrage als Kontext merken und ihn später zum Indexeintrag aller zugehörigen Folgefragen hinzufügen. Dies sollte allerdings in einem separaten Feld des Indexeintrages erfolgen. Bei der Suche kann dann der Suchstring auch mit dem Inhalt dieses Feldes des Ausgangsfragetextes verglichen werden. Somit ist es möglich, die entsprechende Frage zu finden. 7.4 Eingabekorrektur Als ein weiteres Feature kann eine automatische Fehlerkorrektur der Eingabe erfolgen. Die Techniken zur Fehlerkorrektur wurden bereits in Kapitel 2 erläutert. Eine automatische Fehlerkorrektur ermöglicht, die schlechtere Trefferquote zu eliminieren, die aus einer fehlerbehafteten Eingabe des Suchstrings resultieren würde. 7.5 Eingabeergänzung 96 Eine automatische Eingabeergänzung, wie man sie beispielsweise bereits aus einigen Office-Anwendungen oder Programmierumgebungen (Eclipse) kennt, hat mehrere Vorteile. Zum einen erleichtert sie die Dateneingabe, indem sie den Schreibaufwand reduziert. Ein wesentlich größerer Nutzen kann jedoch daraus gezogen werden, dass bei der automatischen Eingabeergänzung die im Suchraum (hier: der Wissensbasis) verwendete Terminologie eingesetzt werden kann. Der Benutzer wird dabei unterstützt, die richtige Terminologie zu verwenden. Dies ermöglicht eine Steigerung der Trefferquote, da bei Verwendung der Terminologie des Suchraums die Treffer quasi garantiert sind. Zur Realisierung einer automatischen Eingabeergänzung werden standardmäßig Wörterbücher verwendet, welche die gewünschte Terminologie erhalten. Im Falle von IDEE wäre es ideal, das bereits aufgebaute Lexikon für die automatische Eingabeergänzung zu nutzen. 7.6 Semantische Analyse s. o. 97 Kapitel 8 Anhang Grammatik für Parser Auszug aus dem Lexikon Glossar 98 Literatur [1822direkt] 1822direkt, Frankfurt, Germany, (http://www.1822direkt.com) [Albis] ALBIS Ärzteservice Product GmbH & Co KG, Koblenz, Germany, (http://www.albis.de) [Alice] A.L.I.C.E. Artificial Intelligence Foundation, San Francisco, U.S.A. (http://www.alicebot.org) [Ask Jeeves] Interne Suchmaschinen Ask Jeeves (www.ask.com) [Ask Doku] http://static.wc.ask.com/docs/help/help_searchtips.html [Berberich 1999] oder war es doch dein Artikel in [Berberich 01].... [Berberich 01] Berberich, Mitchel: Diagnostik im Internet – Bedarf, Realisierung und Stand der Technik. Kapitel 7 in: Puppe, Frank: Wissensbasierte Diagnosesysteme im Service-Support: Konzepte und Erfahrungen, Springer, 2001, ISBN 3-450-67288-5 [Carstensen] Carstensen, K.-U. et Al. (Hrsg.): Computerlinguistk und Sprachentechnologie. Spektrum Akademischer Verlag, 2001. [Carven et al] Carven M., Freitag D., McCallum A., Mitchell T., Nigam K., Queck CY. : Learning to Extract Symbolic Knowledge from teh World Wide Web. Proceedings of the 14th International Conference on Machine Learning. [Empolis] empolis content managent GmbH, Kaiserslautern, Germany, (http://km.empolis.de) [Hauser] Hauser, Roland: Grundlagen der Computerlinguistik. Springer, 2000. [JanoConsult] https://www2.janolaw.de/jnHomeSub.jsp?id=2&idsub=9 [JanoLaw] janolaw AG, Sulzbach/Ts., Germany, (http://www.janolaw.de) 99 [KiwiLogic] Kiwilogic.com AG, Hamburg, Germany, (http://www.kiwilogic.de) [LawExpert] Law Expert System, (http://www.law-expert-system.net) [Lucene] [LegalCity] Legal City Ratgeber Recht (http://www.legalcity.de) [PenIvory] Poon AD, Fagan LM. PEN-Ivory: The Design and Evaluation of a Pen-Based Computer System for Structured Data Entry. Proceedings of the Annual Symposium on Computer Applications in Medical Care, 447-51, 1994. http://citeseer.nj.nec.com/254342.html [Porter] http://www.tartarus.org/~martin/PorterStemmer/index.html [Porter deutsch] http://snowball.tartarus.org/german/stemmer.html [SAP] SAP Jobberater (http://www.sap-ag.de) [SMES 1] [SMES 2] [SPT] Smart Bot Technologies GmbH, Germany (http://www.smartbot-technologies.de) [Uni KA] Universität Karlsruhe (TH), Germany, (http://www.uni-karlsruhe.de) [Yang et al.] Yang Y., Carbonell J.G., Brown R.D., Pierce T., Archibald B.T., Liu X.: Learning Approaches for Detecting and Tracking Newes Events. IEEE Intelligent Systems 1999 100 [d3web] Umgebung für Diagnosesysteme (http://www.d3web.de) [teoma] Teoma. Search with Autohrity (http://www.teoma.com) 101