AND Menge
Werbung

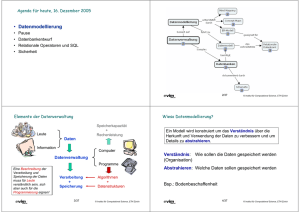
Agenda für heute, 15. Dezember 2006 • Datenmodellierung • • • • Pause Datenbankentwurf Relationale Operatoren und SQL Sicherheitsaspekte 2/35 © Institut für Computational Science, ETH Zürich Elemente der Datenverwaltung Leute Daten Speicherkapazität + Rechenleistung Information Computer Datenverwaltung Programme Eine Beschreibung der Verarbeitung und Speicherung der Daten muss für Leute verständlich sein, sich aber auch für die Programmierung eignen! Verarbeitung + Speicherung 3/35 Algorithmen + Datenstrukturen © Institut für Computational Science, ETH Zürich Wieso Datenmodellierung? • Verständnis über Herkunft und Verwendung der Daten • Details abstrahieren Verständnis: Wie sollen die Daten gespeichert werden (Organisation) Abstrahieren: Welche Daten sollen gespeichert werden Bsp.: Bodenbeschaffenheit 4/35 © Institut für Computational Science, ETH Zürich Hilfsmittel für die Modellierung von Daten Methode Unterstützt Mind mapping Gedanken assoziativ spontan darstellen Concept Maps Wissen kontextabhängig organisieren und darstellen Entity-Relationship Modell Datenbankgerechte Darstellung von Objekten, deren Merkmale und Beziehungen zueinander 5/35 © Institut für Computational Science, ETH Zürich Mind mapping 6/35 © Institut für Computational Science, ETH Zürich Concept maps 7/35 © Institut für Computational Science, ETH Zürich Entity-Relationship-Diagramm Beziehungstyp Name Nahrungsmittel Quantität m m Name Rezept Nährstoff Zutaten Entitätsmenge Beziehung (Relationship) m Verluste 8/35 1 Warencode Lebensmittel Nährstoff Entitätsmenge Merkmal (Attribut) © Institut für Computational Science, ETH Zürich Tabellarische Darstellung von Entitätsmengen Nahrungsmittel Entitätsmenge Name Aprikose Bürli Paranuss CH-Code 18.1.2.1 12.1.2.Z.2 18.1.6.6 0.8 8.618 13 g g g 86.79 39.632 5.929 g g g Kalium 315 159.927 680 Masseinheit mg mg mg Kohlehydrate 12.1 48.802 11.8 Masseinheit g g g Vitamin E 0.7 0.411 7 Masseinheit mg mg mg Protein Masseinheit Wasser Masseinheit Attributname Attribut Entität 9/35 © Institut für Computational Science, ETH Zürich Entflechten von Information Nahrungsmittel Name Aprikose Aprikose Aprikose Bürli Bürli Bürli CH-Code 18.1.2.1 18.1.2.1 18.1.2.1 12.1.2.Z.2 12.1.2.Z.2 12.1.2.Z.2 180 84 57 180 84 57 86.79 12.1 0.4 39.632 48.802 2.032 Nährstoff_id Menge Nährstoffe Nährstoff_id 57 84 180 178 Name_d Eisen Kohlehydrate Wasser Vitamin K Name_f Fer Hydrate de carbon Eau Vitamine K Name_i Ferro Carboidrati Acqua Vitamina K mg g g mg Masseinheit = Schlüssel: stellt Verbindung zwischen Tabellen her 10/35 © Institut für Computational Science, ETH Zürich Festhalten von Beziehungen (Relationships) Nahrungsmittel Analyse m NMittel_id 1000842 1001511 Name_d Aprikose Bürli Name_f Abricot Bürli Name_i Albicocca Bürli 18.1.2.1 12.1.2.Z.2 CH-Code 1 2 NMittel_id 1000842 1001511 m Nährstoff_id 180 84 Quelle CIQUAL Inst. f. LMW Menge 86.79 48.802 Methode unbekannt Summenwert Person M. Racher S. Jacob 1 1 Nährstoffe Nährstoff_id Analyse_id 180 84 57 178 Name_d Wasser Kohlehydrat Eisen Vitamin K Name_f Eau Hydrate de carbon Fer Vitamine K Name_i Acqua Carboidrati Ferro Vitamina K g g mg mg Masseinheit 11/35 © Institut für Computational Science, ETH Zürich • Datenmodellierung • Datenbankentwurf • Relationale Operatoren und SQL • Sicherheitsaspekte © Institut für Computational Science, ETH Zürich Modelle vs. Schemata Modellierung der Daten aus der realen Welt Entity-Relationship-Modell Konzeptionelles Schema Relationales Datenmodell Modellierung der Daten im Rechner 12/35 © Institut für Computational Science, ETH Zürich Grundlagen für den Datenbankentwurf Selektive Abfrage Basisdaten Datenbank Konzeptionelles Schema Internes Schema • Datenstrukturen • Datentypen • Zugriffsmechanismen • Logische Gesamtstruktur • Eigenschaften der Daten • Beziehungen unter den Daten Datenmodell 13/35 Externes Schema • Anwendungsspezifische Sicht auf die Daten © Institut für Computational Science, ETH Zürich Das Verbreitetste: Das Relationenmodell • Tabellen in denen Einträge (Tupel) eingefügt, gelöscht oder geändert werden können (Mutationen) • Verteilen von Daten auf mehrere Tabellen (Normalisieren) reduziert Redundanz, d.h. die wiederholte Speicherung gleicher Werte • Verknüpfen von Daten aus den individuellen Tabellen mit relationalen Operatoren stellt die ursprüngliche Information wieder her 14/35 © Institut für Computational Science, ETH Zürich Elemente einer Relation Relation Attributname Attribut Nahrungsmittel Name Aprikose Bürli CH-Code Wasser Massein h Kohlehyd Massein h Eisen Massein h 18.1.2.1 86.79 g 12.1 g 0.4 mg 12.1.2.Z.2 39.632 g 39.632 g 2.032 mg Tupel Attributwert 15/35 © Institut für Computational Science, ETH Zürich Verteilen von Daten auf mehrere Tabellen Nahrungsmittel Name Aprikose Bürli CH-Code Wasser 18.1.2.1 86.79 g 12.1 g 0.4 mg 12.1.2.Z.2 39.632 g 39.632 g 2.032 mg Nahrungsmittel Masseinh Kohlehyd Massein h Name CH-Code Eisen Massein h Nährstoff_id Menge Aprikose 18.1.2.1 180 86.79 Aprikose 18.1.2.1 84 12.1 Aprikose 18.1.2.1 57 0.4 Bürli 12.1.2.Z.2 180 39.632 Bürli 12.1.2.Z.2 84 48.802 Bürli 12.1.2.Z.2 57 2.032 Nährstoffe Nährstoff_id Name_d Name_f Name_i Masseinh . 57 Eisen Fer Ferro mg 84 Kohlehydrate Hydrate de carbon Carboidrate g 180 Wasser Eau 16/35 Acqua g © Institut für Computational Science, ETH Zürich Daten zusammenführen: Nährwerte von Bürli Nahrungsmittel Name CH-Code Nährstoff_id Menge Aprikose 18.1.2.1 180 86.79 Aprikose 18.1.2.1 84 12.1 Aprikose 18.1.2.1 57 0.4 Bürli 12.1.2.Z.2 180 39.632 Bürli 12.1.2.Z.2 84 48.802 Bürli 12.1.2.Z.2 57 2.032 Nährwerte Nam e Name_d Menge Bürli Wasser 39.632 Bürli Kohlehydrate 48.802 Nährstoffe Id_Nr 57 84 180 Name_d Eisen Name_f Name_i Fer Kohlehydrate Hydrate de carbon Wasser Masseinh . Ferro mg Carboidrate g Acqua g Eau 17/35 © Institut für Computational Science, ETH Zürich • Datenmodellierung • Datenbankentwurf • Relationale Operatoren und SQL • Sicherheitsaspekte Relationale Operatoren Die drei wichtigsten Operatoren der relationalen Algebra für das Manipulieren von Tabellen sind: a) Selection Wählt diejenigen Tupel einer Relation aus, welche bestimmte Bedingungen erfüllen. b) Projection Wählt eine oder mehrere Spalten einer Relation aus. c) Join Paart selektiv Spalten aus verschiedenen Relationen. 18/35 © Institut für Computational Science, ETH Zürich Datenbanken abfragen: SQL "Wieviele Nahrungsmittel enthalten weniger als 50 g Kohlehydrate ?" Natürlichsprachlich formulierte Frage Abfragesprache für Datenbanken z.B. SQL SELECT Menge FROM Nährstoffe WHERE Nährstoff_id = 84 AND Menge < 50 (Structured Query Language) Nährstoffe Tabellarische Ausgabe (Relation) 19/35 © Institut für Computational Science, ETH Zürich Projection mit dem SQL-Befehl SELECT Attribut Relation SELECT CH-Code FROM Nahrungsmittel Nahrungsmittel Name CH-Code Nährstoff_id Menge Aprikose 18.1.2.1 180 86.79 Aprikose 18.1.2.1 84 12.1 Resultat: Paranuss 18.1.6.6 180 5.929 CH-Code Bürli 12.1.2.Z.2 180 39.632 18.1.2.1 Bürli 12.1.2.Z.2 84 48.802 18.1.2.1 Bürli 12.1.2.Z.2 57 2.032 18.1.6.6 12.1.2.Z.2 12.1.2.Z.2 12.1.2.Z.2 20/35 © Institut für Computational Science, ETH Zürich Selection mit dem SQL-Befehl SELECT SELECT * FROM Nahrungsmittel WHERE Menge < 15 Nahrungsmittel Resultat: Name CH-Code Nährstoff_id Menge Aprikose 18.1.2.1 180 86.79 Aprikose 18.1.2.1 84 12.1 Paranuss 18.1.6.6 180 5.929 Bürli 12.1.2.Z.2 180 39.632 Bürli 12.1.2.Z.2 84 48.802 Bürli 12.1.2.Z.2 57 2.032 Name CH-Code Attributwert Nährstoff_id Menge Aprikose 18.1.2.1 84 12.1 Paranuss 18.1.6.6 180 5.929 Bürli 12.1.2.Z.2 57 2.032 21/35 © Institut für Computational Science, ETH Zürich Selection + Projection mit dem SQL-Befehl SELECT SELECT Nährstoff_id, Menge FROM Nahrungsmittel WHERE Nährstoff_id = 84 Nahrungsmittel Name CH-Code Nährstoff_id Menge Aprikose 18.1.2.1 180 86.79 Aprikose 18.1.2.1 84 12.1 Paranuss 18.1.6.6 180 5.929 Bürli 12.1.2.Z.2 180 39.632 Bürli 12.1.2.Z.2 84 48.802 Bürli 12.1.2.Z.2 57 2.032 Nährstoff_id Menge 84 12.1 84 48.802 Resultat: 22/35 © Institut für Computational Science, ETH Zürich Hinweis SELECT Nährstoff_id, Menge FROM Nahrungsmittel WHERE Nährstoff_id = 84 • Im Allgemeinen versteht man eine SELECT-FROM-WHERE Abfrage am schnellsten, indem man zuerst die FROM-Klausel betrachtet um zu sehen, welche Relationen involviert sind (Nahrungsmittel). • Anschliessend betrachtet man die WHERE-Klausel um zu sehen, welche Attribute eines Tupels für die Abfrage wichtig sind (Nährstoff_id). • Am Schluss sieht man der SELECT-Klausel an, was die Ausgabe ist (Nährstoff_id, Menge). 23/35 © Institut für Computational Science, ETH Zürich Selection + Projection + Join mit dem SQL-Befehl SELECT SELECT Name, Name_d, Menge FROM NM, NS WHERE Name = Bürli AND Menge > 30 NM Name CH-Code Nährstoff_id Menge Resultat: NM.Name NS.Name_d NM.Menge Aprikose 18.1.2.1 180 86.79 Aprikose 18.1.2.1 84 12.1 Bürli Wasser 39.632 Aprikose 18.1.2.1 57 0.4 Bürli Kohlehydrate 48.802 Bürli 12.1.2.Z.2 180 39.632 Bürli 12.1.2.Z.2 84 48.802 Bürli 12.1.2.Z.2 57 2.032 NS Id_Nr 57 84 180 Name_d Eisen Name_f Name_i Fer Kohlehydrate Hydrate de carbon Wasser Eau Masseinh . Hauptkomp. Ferro mg ja Carboidrate g ja g ja 24/35 Acqua © Institut für Computational Science, ETH Zürich Funktionen in SQL SQL stellt verschiedene andere Operatoren zur Verfügung, so unter Anderem die folgenden fünf Aggregations-Operatoren : SUM Berechnet die Summe der numerischen Werte einer Spalte AVG Berechnet den Durchschnitt der Werte einer Spalte MIN Gibt den kleinsten Wert einer Spalte zurück MAX Gibt den grössten Wert einer Spalte zurück COUNT Gibt die Anzahl Zeilen einer Tabelle zurück 25/35 © Institut für Computational Science, ETH Zürich • Datenmodellierung • Datenbankentwurf • Relationale Operatoren und SQL • Sicherheitsaspekte Statistische Datenbanken • Vertrauliche Daten • Abfragen beschränkt auf statistische Operationen (Aggregationen): COUNT SUM MEAN MIN MAX 26/35 © Institut für Computational Science, ETH Zürich Statistische Datenbanken Abfragen an Datenbanken werden als logischer Ausdruck formuliert Beispiel Suche: "weiblich AND Professor OR (Gehalt ≥ CHF 80000)" Bei statistischen Datenbanken sind Antworten Resultate von Aggregations-Operatoren • Somit stehen nur statistische Daten zur Verfügung • Es werden empfindliche Daten nicht preisgegeben Trotzdem kann es leicht sein, bestimmte vertrauliche Daten durch geeignete statistische Abfragen, die Rückschlüsse zulassen, herzuleiten! 27/35 © Institut für Computational Science, ETH Zürich Gewisses Vorwissen erlaubt Rückschlüsse: Beispiel 1 Die Daten sind erfunden, Ähnlichkeiten mit lebenden Personen sind rein zufällig! Von Urs Schmied (im Bild rechts) wissen wir, dass er • zwischen 34 und 36 Jahre alt ist • Jus studierte • bei der UBS eine Position als Vizepräsident inne hat 28/35 © Institut für Computational Science, ETH Zürich Gewisses Vorwissen erlaubt Rückschlüsse: Beispiel 1 Wir wissen auch, dass er im Spital ist, aber nicht wieso. Weil wir Zugang zur statistischen Datenbank des Spitals haben, formulieren wir folgende Frage: Wie viele Patienten haben folgende Eigenschaften? Männlich Alter 34 – 36 Verheiratet Zwei Kinder Lic.jur. Bank-Vizepräsident Antwort: 1 Wir gehen davon aus, dass es sich um Urs handelt und erhalten somit vertrauliche Informationen über ihn mit der folgenden Abfrage: 29/35 © Institut für Computational Science, ETH Zürich Gewisses Vorwissen erlaubt Rückschlüsse: Beispiel 1 Frage: Wie viele Patienten haben folgende Eigenschaften? Männlich Alter 34 – 36 Verheiratet Zwei Kinder Lic.jur. Bank-Vizepräsident Nehmen Antidepressiva Das System wird mit "1" antworten, falls Schmied Antidepressiva erhält, sonst mit "0" 30/35 © Institut für Computational Science, ETH Zürich Lassen sich solche Rückschlüsse verhindern? Einfaches Prinzip der "Blossstellung" • Eine Abfrage deren Antwortgrösse 1 ist. • Die Antwortgrösse der Abfrage AND X. Verhinderung durch minimale Antwortgrösse: Antworte auf keine Abfrage, die weniger als k oder mehr als n-k Datensätze in der Antwort hat. n = totale Anzahl Datensätze in der Datenbank Diese Kontrolle ist leider nicht wirksam 31/35 © Institut für Computational Science, ETH Zürich Gewisses Vorwissen erlaubt Rückschlüsse: Beispiel 2 Geheime Wahlspenden Name Geschlecht Beruf Spende (CHF) Schamanski M Journalist 3000 Staub M Journalist 500 Bertolli M Unternehmer Ott W Journalist 5000 Zwahlen W Wissenschaftler 1000 Koller M Wissenschaftler 20000 Waser W Arzt 2000 Schmid M Anwalt 10000 1 n = 8; bei k =2: min. Antwortgrösse = 2, max. Antwortgrösse = 6 32/35 © Institut für Computational Science, ETH Zürich Rückschlüsse mittels "Tracker" Angenommen, die Frage: (Journalist AND W) identifiziert Ott eindeutig Kontrolle Die minimale Anwortgrösse verhindert direkte Abfragen über Ott Umgehung Kleine Antwortmengen "füttern", damit sie die minimale Antwortgrösse erreichen Danach wird der Effekt der zusätzlichen Datensätze subtrahiert Die Formel, welche die zusätzlichen Datensätze identifiziert, wird "Tracker" genannt (To "track down" additional characteristics of an individual) 33/35 © Institut für Computational Science, ETH Zürich Tracker anwenden Frage: Wie viele Personen sind Journalist? Antwort: 3 Frage: Wie viele Personen sind Journalist AND M? Antwort: 2 Rückschluss: (Journalist AND W) identifiziert 1 Individuum (Ott) Frage: Summe der Spenden der Journalisten? Antwort: CHF 8500 Frage: Summe der Spenden Journalist AND M? Antwort: CHF 3500 Rückschluss: Spende der einzigen Journalistin = CHF 5000! 34/35 © Institut für Computational Science, ETH Zürich Kontrolle ist schwierig Abfragen tragen unweigerlich Information aus einer Datenbank Man kann deshalb nicht annehmen, dass sich ein System nie Blossstellen lässt Deshalb Zugriffe aufzeichnen (threat monitoring) Notwendiger Aufwand für Blossstellungen hoch halten 35/35 © Institut für Computational Science, ETH Zürich Wir wünschen Ihnen ein schönes Wochenende!