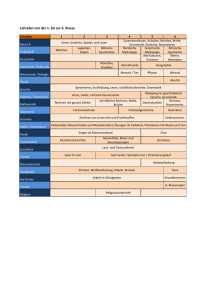
Folien zur Vorlesung - IMN/HTWK
Werbung

Theoretische Grundlagen der Informatik Prof. Dr. Sibylle Schwarz Hochschule für Technik, Wirtschaft und Kultur Leipzig Fakultät Informatik, Mathematik und Naturwissenschaften Gustav-Freytag-Str. 42a, 04277 Leipzig Zimmer Z 411 (Zuse-Bau), http://www.imn.htwk-leipzig.de/~schwarz [email protected] WS 2013/2014 1 Informatik Informatik Lehre von der Darstellung und Verarbeitung von Information durch Algorithmen Teilgebiete der Informatik: theoretisch technisch Sprachen zur Formulierung von Information und Algorithmen, I Möglichkeiten und Grenzen der Berechenbarkeit durch Algorithmen, I Grundlagen für technische und praktische (und angewandte) Informatik I maschinelle Darstellung von Information Mittel zur Ausführung von Algorithmen (Rechnerarchitektur, Hardware-Entwurf, Netzwerk, . . . ) I I praktisch Entwurf und Implementierung von Algorithmen (Betriebssysteme, Compilerbau, SE, . . . ) angewandt Anwendung von Algorithmen (Text- und Bildverarbeitung, Datenbanken, KI, Medizin-, Bio-, Wirtschafts-, Medieninformatik, . . . ) 2 Inhalt der Lehrveranstaltung Theoretische Grundlagen der Informatik Einführung in formale Methoden in der Informatik, insbesondere Modellierung von Daten durch I Mengen I Wörter und formale Sprachen I Terme Abläufen durch I Zustandübergangssysteme I Abstrakte Maschinen I Berechnungsmodelle Eigenschaften (von Daten und Abläufen) durch Logiken I klassische Aussagenlogik I klassische Prädikatenlogik (der 1. Stufe) 3 Modellierung von Daten Beispiel Skatkarten Farben: Karo, Herz, Pik, Kreuz Menge F = {♦, ♥, ♠, ♣} Werte: Zahlen: 7, 8, 9, 10 Menge Z = {7, 8, 9, 10} I Bilder: Bube, Dame, König, As Menge B = {B, D, K , A} Menge aller Werte: Z ∪ B I Menge aller Karten: F × (Z ∪ B) Spielkarten sind die Elemente dieser Menge, (♠, 9) ∈ F × (Z ∪ B) z.B. (♥, B) ∈ F × (Z ∪ B), wichtiges Ziel der Modellierung in der Informatik: Repräsentation von Daten in einer Form, die maschinell dargestellt und verarbeitet werden kann Datentypen (abstrakte und konkrete) 4 Modellierung Modelle sind Abstraktionen realer Dinge, Eigenschaften, Beziehungen, Vorgänge I Auswahl von (für den Anwendungsbereich, zur Problemlösung) wichtigem Wissen I Vernachlässigung unwichtiger Details Beispiele: I Liniennetzplan I Grundriss I Stundenplan I Kostenplan spezielle Form der Modelle abhängig von I Problembereich I geplante Verwendung 5 Logik Beispiel: 1. Tom besucht heute das Kino oder das Konzert. Tom ist nicht im Kino. Also besucht Tom das Konzert. √ 2. √2 ist eine rationale oder eine irrationale Zahl. 2 6∈ .√ Also ist 2 irrational. Q gemeinsames Schema: Aus (P oder Q) und (nicht P) lässt sich Q schließen. formal: {P ∨ Q, ¬P} |= Q maschinelle Verarbeitung logischer Formelmengen z.B. durch SAT-Solver, Inferenzsysteme, Prolog-Interpreter 6 Formale Sprachen Modellierung von Daten, Abläufen und Systemen I Zeichen (Alphabet) z.B. {A,E,O,M,T}, {0, 1} I Folgen von Zeichen (Zeichenketten, Wörter) z.B. TOMATE, 10100 I Mengen von Wörtern (Sprachen) z.B. Menge aller Wörter, die das Teilwort OMA enthalten Menge aller Wörter, die auf 00 enden I Mengen von Sprachen (Sprachklassen) z.B. alle Sprachen, die nur endliche viele Wörter enthalten endliche Darstellung unendlicher Sprachen, z.B. durch reguläre Ausdrücke, Grammatiken Eignung verschiedener Sprachklassen zur maschinellen Darstellung von Daten und Abläufen 7 Zustandsübergangssysteme Münzenspiel: Startzustand : 6 Münzen auf einem Stapel Spielzug : zwei Münzen von einem Stapel nehmen und auf jeden Nachbarstapel je eine Münze legen I In welchen Zuständen sind gar keine Züge möglich? I Welche Zustände sind aus dem Startzustand erreichbar? I Wieviele Züge können (mindestens / höchstens) gespielt werden, bis kein Zug mehr möglich ist? I Verliert (kann nicht mehr ziehen) der erste oder der zweite Spieler, wenn zwei Spieler abwechselnd ziehen? Startzustand: ... 6 ... 8 Vorteile der formalen Darstellung Abstraktion von unwichtigen Details (Entwicklung und Verwendung von Modellen) Präzisierung der relevanten Aussagen (eindeutige Semantik) Systematisches Lösen (auch maschinell) von formal dargestellten Problemen möglich Struktureigenschaften formaler Beschreibungen Schlussweisen unabhängig von Bedeutung der Aussagen 9 Einordnung der LV in Teilgebiete der Informatik theoretisch Eigenschaften formaler Beschreibungs- und Programmiersprachen I Möglichkeiten und Grenzen der Berechenbarkeit durch Algorithmen, I Logik als Modellierung-Sprache (Formulierung von Information und Algorithmen) I Grundlagen für technische und praktische (und angewandte) Informatik I technisch Mathematische Grundlagen der digitalen Informationsverarbeitung (maschinelle Darstellung, Übermittlung und Verarbeitung von Information) praktisch Modellierung, Darstellung, Spezifikation von Algorithmen und Daten Grundlagen der Softwareentwicklung Anwendung logischer Verfahren zur Verifikation der Korrektheit von Programmen angewandt Anwendung der in der Softwareentwicklung, Wissensverarbeitung, KI 10 Lernziele I Fähigkeit zur Abstraktion I Grundkenntnisse in Modellbildung I Grundverständnis der Logik als Sprache der Informatik I Beweisverfahren I Zusammenhänge zu anderen Gebieten der Informatik und Mathematik 11 Literatur Folien zur Vorlesung, jeweils nach der Vorlesung veröffentlicht unter www.imn.htwk-leipzig.de/~schwarz/lehre/ws13/tgi/ empfohlene Bücher: Formale Sprachen und Berechnungsmodelle I zur Modellierung: I Uwe Kastens, Hans Kleine Büning: Modellierung - Grundlagen und formale Methoden, Hanser 2008 I zur Logik I Michael Huth, Mark Ryan: Logic in Computer Schience, Cambridge University Press 2010 I Uwe Schöning: Logik für Informatiker, Spektrum, 1995 I Martin Kreuzer, Stefan Kühling: Logik für Informatiker, Pearson Studium, 2006 I zu formalen Sprachen und Berechnungsmodellen: I Uwe Schöning: Theoretische Informatik - kurzgefasst, Spektrum 2001 I John E. Hopcroft, Jeffrey D. Ullman: Einführung in die Automatentheorie, Formale Sprachen und Komplexitätstheorie, Addison-Wesley 1990 12 Informatik studieren Selbstudium: Vor- und Nachbereitung jeder Lehrveranstaltung (Vorlesung, Seminar, Praktikum, ...) Unterlagen zu den Lehrveranstaltungen (eigene Mitschrift, Skript, Folien, Zusatzmaterial, Übungsaufgaben) durcharbeiten Übungsaufgaben regelmäßig und rechtzeitig lösen, (Aufgaben vom Typ der) Übungsaufgaben gehören zum Stoff der LV und werden geprüft Bücher benutzen (Bibliothek), enthalten oft zusätzliche Übungsaufgaben, Informationen aus dem Internet sind oft unzuverlässig Lerngruppen bilden und gemeinsam lernen Nachfragen bei Dozenten (E-Mail, Sprechzeit, nach der Lehrveranstaltung,. . . ), Mitstudenten, älteren Studenten, . . . 13 Organisation der Lehrveranstaltung Folien, Übungsserien, Termine, Änderungen, ... unter www.imn.htwk-leipzig.de/~schwarz/lehre/ws13/tgi/ Modulbeschreibung INB-TGI: portal.imn.htwk-leipzig.de/studium/ ordnungen-und-modulkataloge 90 h für Präsenzstudium + 120 für Selbststudium Lehrveranstaltungen für jeden Studenten: I wöchentlich zwei Vorlesungen (60 SWS) I wöchentlich eine Übung (30 SWS) Vor- und Nachbereitung: schriftliche Aufgaben (ÜS) praktische Aufgaben (Autotool) Literaturstudium Selbststudium: Vor- und Nachbereitung (90 h) Prüfungsvorbereitung (30 h) 14 Schriftliche Hausaufgaben – Seminar schriftliche Übungsserien wöchentlich unter www.imn.htwk-leipzig.de/~schwarz/lehre/ws13/tgi Lernziele bei der Bearbeitung der Übungsserien: I Nachbereitung der letzten Vorlesung anhand der Vorlesungsfolien und (der angegebenen) Literatur I Vorbereitung der nächsten Vorlesung I Vorbereitung der Seminarvorträge zu jeder Aufgabe Übungen: I Besprechung der Lösungen der schriftlichen Hausaufgaben (Vorrechnen durch Studenten, Prüfungszulassung) I Fragen zum aktuellen Vorlesungsstoff und zu den neuen schriftlichen und praktischen Hausaufgaben 15 Praktische Hausaufgaben – Autotool https: //autotool.imn.htwk-leipzig.de/cgi-bin/Super.cgi Account anlegen: 1. Click „HTWK “ 2. Daten eintragen (korrekte Matrikelnummer, Email [email protected]) 3. Click „absenden“ Passwort wird an die angegebene Email-Adresse geschickt (Geduld, kann dauern). Account benutzen: I Anmeldung mit Matrikelnummer (Click „Login“) I Passwort ändern (Click „update“) I „Einschreiben“ in Übungsgruppe I Aufgabe ansehen und lösen (Click „Solve“) 16 Prüfung Klausur Aufgabentypen aus den Übungsserien Zulassungsvoraussetzungen: regelmäßige erfolgreiche Lösung der Hausaufgaben, d.h.: I mindestens dreimal richtiges „Vorrechnen“ von Übungsaufgaben in den Übungen I 50 % aller Punkte für praktische Pflichtaufgaben (Autotool) 17 Was bisher geschah Inhalt und Organisation der Lehrveranstaltung Modellierungsbeispiele: I Modellierung von Daten: Skatkarten, Spielzustände I Modellierung von Abläufen: Münzenspiel, ÜA lineares Solitaire I Modellierung von Eigenschaften: ÜA Landsleute 18 Syntax und Semantik Semantik (Bedeutung) Was wird dargestellt? Syntax (Darstellungsform) Wie wird es dargestellt? (meist viele verschiedene Möglichkeiten) Beispiele: I Lineares Solitaire (Zustände) Semantik: Spielzustand im linearen Solitaire Syntax: Möglichkeiten, z.B. Z ∈ {0, 1}∗ , Z ∈ {S, K }∗ , Z ∈ {, ◦}∗ I Lineares Solitaire (Ablauf) Semantik: möglicher Verlauf eines Spieles Syntax: Möglichkeiten, z.B. I I I Folge von Spielzuständen Modellierung der Spielzüge (als Regeln) und Folge der angewendeten Regeln Weg in der graphischen Darstellung des Spieles 19 Prozess beim Lösen von Aufgaben (Problemen) Analyse der (informalen) Aufgabe, Identifikation von I Aufgabenbereich (Kontext) I Eingabedaten (Typ, mögliche Werte) I gewünschte Lösung (Typ, Eigenschaften, Zusammenhang mit Eingabe) Modellierung (Spezifikation, formale Darstellung) von I Aufgabenbereich (Kontext) I Eingaben I Lösungen Modellierung von Daten und deren Eigenschaften Entwurf einer Lösungsstrategie für die modellierte Aufgabe (mit vorhandenen oder neuen Methoden) Modellierung von Berechnungen und deren Eigenschaften Realisierung der Lösestrategie im Modellbereich Ausführung der Lösestrategie im Modellbereich Übertragung der Lösung vom Modellbereich in die Realität 20 Beispiel (informale Aufgabe) Gesucht sind alle Skatkarten, die von einer gegebenen Skatkarte in einem Null-Spiel (also ohne Trümpfe) gestochen werden. 21 Analyse der Aufgabe (Aufgabenbereich) Worum geht es? Unterscheidung der für die reale Aufgabe wichtigen bzw. unwichtigen Eigenschaften, z.B.: I Blatt für welches Spiel (z.B. Skat, Doppelkopf)? im Beispiel: Skatblatt, d.h. Jede Karte hat genau eine der Farben ♦, ♥, ♠, ♣ , und ist eine Zahl zwischen 7 und 10 oder ein Bild B,D,K,A I deutsches oder französisches Blatt? I Stichregeln innerhalb einer Farbe? Ordnung zwischen Karten derselben Farbe I Trumpfregeln? 22 Analyse der Aufgabe: Ein- und Ausgabedaten Eingaben: Welche Art Daten sind gegeben? (Typen, Bereiche) Eingabe im Beispiel: eine Karte aus einem Skatblatt, beschrieben durch ein Paar (Farbe, Wert) Was sind die gewünschten Lösungen? Typ: z.B. ja/nein (evtl. mit Begründung), Plan, Gewinnstrategie, Typ der Lösung im Beispiel: Menge von Karten Eigenschaften Zusammenhang zwischen Ein- und Ausgaben Eigenschaften der Lösung im Beispiel: Menge aller Karten mit 1. derselben Farbe wie die gegebene Karte 2. kleinerem Wert als die gegebene Karte 23 Modellierung (Spezifikation, formale Darstellung) Aufgabenbereich (Kontext): Skatblatt, d.h. Menge aller Karten: K = F × {Z ∪ B} mit F = {♦, ♥, ♠, ♣} , Z = {7, 8, 9, 10} und B = {B, D, K , A} Ordnung der Karten derselben Farbe (also auf Z ∪ B): 7 < 8 < 9 < 10 < B < D < K < A Karten unterschiedlicher Farben stechen einander nicht Eingabedaten: eine Karte e ∈ K Lösung: Typ: Menge von Karten, d.h. M ⊆ K Eigenschaften Zusammenhang zwischen Ein- und Ausgaben: für jede Karte k ∈ K gilt genau dann k ∈ M, wenn 1. Farbe(k ) = Farbe(e) und 2. Wert(k ) < Wert(e) 24 Modellierung von Daten Darstellung der Objekte und ihrer Beziehungen zueinander I Spielzustände im linearen Solitaire (Z ∈ {0, 1}∗ ), Eigenschaften, Beziehungen dazwischen z.B. Eigenschaft „Endzustand“, Relation „geht über zu“ I Skatkarten (k ∈ F × (Z ∪ B)), Eigenschaften, Beziehungen dazwischen z.B. Eigenschaften „Lusche“,„Trumpf“, Relation „sticht“ I N, mit Eigenschaften, Beziehungen, Operationen z.B. Eigenschaften „gerade“, „prim“, Relationen ≤, =, |, Operationen +, −, ·, mod, div, Nachfolger I R, mit Eigenschaften, Beziehungen, Operationen z.B. Eigenschaft „rational“, Relationen ≤, =, Operationen +, −, ·, allgemein: (algebraische) Struktur (M, R, F ) M Menge von Daten (Trägermenge) R Eigenschaften, Relationen auf M F Operationen auf M 25 (Konkrete) Datentypen (konkreter) Datentyp: I Trägermenge (nichtleer, Menge aller Werte) I Eigenschaften von und Relationen zwischen den Elementen der Trägermenge I Operationen auf der Trägermenge = (algebraische) Struktur Beispiele: I integer mit +,-,*,/ I string mit ++, reverse I boolean mit And, Or, Not I string ∪ integer mit length 26 Einfache und zusammengesetzte (konkrete) Datentypen einfache Datentypen, z.B. int, bool, float, ... zusammengesetzte Datentypen Konstruktion durch die Operationen I Vereinigung ∪ von Datentypen Beispiel Skat: W = Z ∪ B I kartesisches Produkt × von Datentypen: Beispiel Skat: K = F × W mehrfaches Produkt desselben Typs, z.B. Tupel Beispiel Skat: Blatt in der Hand nach dem Austeilen ∈ K 10 I rekursive Datentypen, z.B. Listen I Abbildung zwischen Datentypen (Funktionen) 27 Zusammengesetzte Datentypen (konkreter) Datentyp: I Menge von Werten (Daten) I Menge von Relationen und Operationen auf diesen Werten Beispiele: I Daten: Telefonnummern, Namen Operationen: Suchen der Telefonnummer zu einem Namen I Daten: Studentendaten Operationen: Sortieren nach Name, Matrikelnummer, Noten Gruppen einteilen, zusammenlegen I Daten: Bestellungen Operationen: Einfügen, Löschen, Dringlichste finden, nach Betrag sortieren I Daten: Orte mit Verbindungen Operationen: kürzeste Verbindung suchen I Daten: arithmetische Ausdrücke Operationen: Teilausdrücke ersetzen, Wert berechnen 28 Zusammengesetzter Datentyp: Papierstapel I Trägermengen: I I Typ Blatt (oben einseitig bedruckt) Typ Stapel (von Blättern) I Eigenschaft: „ist leer“ I Operationen: top : Stapel → Blatt oberes Blatt auf dem Stapel pop : Stapel → Stapel oberes Blatt vom Stapel entfernen push : (Blatt × Stapel) → Stapel Blatt oben auf den Stapel legen 29 Eigenschaften der Stapel-Operationen Operationen: top : Stapel → Blatt pop : Stapel → Stapel push : (Blatt × Stapel) → Stapel einige Zusammenhänge zwischen den Stapel-Operationen: für alle Blätter (Stapelelemente) e und alle Stapel s gilt: I Wird zuerst ein Blatt e auf einen Stapel s gelegt und dann von diesem Stapel das obere Blatt weggenommen, enthält man den ursprünglichen Stapel s pop(push(e, s)) = s I top(push(e, s)) = e I push(top(s), pop(s)) = s Beobachtung: Dieselben Eigenschaften gelten auch für Bücher-, Teller- und andere Stapel, sind also unabhängig vom Typ der Stapelelemente 30 Abstrakte Datentypen Abstraktion von der Realisierung (Trägermenge, Implementierung der Operationen) Abstrakter Datentyp (ist Beschreibung einer ganzen Klasse konkreter Datentypen): Signatur enthält Typ- und Funktionsdeklarationen (Syntax) im Stapel-Beispiel: top : Stapel → Blatt pop : Stapel → Stapel push : (Blatt × Stapel) → Stapel Axiome: formale Definition der Eigenschaften und Zusammenhänge zwischen Operationen (Semantik) im Stapel-Beispiel: I pop(push(e, s)) = s I top(push(e, s)) = e I push(top(s), pop(s)) = s Ein Konkreter Datentyp (algebraische Stuktur) (M, R, F ) ist Instanz (Implementierung, Realisierung) eines abstrakten Datentypes gdw. alle Relationen aus R und Operationen aus F alle im ADT definierten Bedingungen erfüllen 31 Was bisher geschah I Beziehung zwischen Realität und Modell I Semantik (Bedeutung) und Syntax (Darstellungsform) I Schritte zum Lösen von Aufgaben (Problemen) I Analyse und formale Darstellung informal gegebener Aufgaben I algebraische Strukturen (M, F , R) mit M Menge von Daten (Trägermenge) F Funktionen auf M R Eigenschaften, Relationen auf M I einfache und zusammengesetzte Datentypen I konkrete und abstrakte Datentypen 32 Mathematische Grundlagen Relationen und Operationen auf Mengen (mehr dazu in LV Mathe) I Element-Beziehung x ∈ M zwischen Individuen und Mengen I Teilmengen-Relation zwischen Mengen A ⊆ B gdw. : für alle x ∈ A gilt auch x ∈ B I Operationen auf Mengen: I I I Vereinigung: A ∪ B = {x | x ∈ A oder x ∈ B} (kartesisches) Produkt: A × B = {(x, y ) | x ∈ A und y ∈ B} Folgen (mehrfaches Produkt über S derselben Menge): Ai = A × · · · × A, Notation A∗ = i∈N Ai | {z } i−mal I I N Für jedes i ∈ gilt Ai+1 = A × Ai , wobei A1 = A Potenzmenge (Menge aller Teilmengen) einer Menge A: 2A = {M ⊆ A} Menge aller Funktionen von Menge A in Menge B: B A = {f : A → B} (Potenzmenge ist Spezialfall mit B = {0, 1}) 33 Algebraische Strukturen – Beispiele I Menge aller Menschen Relationen: älter-als, Geschwister (zweistellig) einstellige Relationen (Eigenschaften): blond Funktion (einstellig): Mutter I Menge aller natürlichen Zahlen Relationen: ≥ (zweistellig), | (teilt, zweistellig) einstellige Relationen (Eigenschaften): prim, gerade Funktion: Nachfolger (einstellig), + (zweistellig) I Menge 2 aller Punkte der Ebene Relationen: kleinerer-Abstand-von-0 (zweistellig), bilden-gleichseitiges-Dreieck (dreistellig) Funktionen: verschieben (einstellig), Mittelpunkt (zweistellig) I Menge A∗ aller endlichen Wörter (Vektoren) über Alphabet A Relation: Anfangswort (zweistellig), lexikographische Ordnung Funktionen: Spiegelung (einstellig), Verkettung (zweistellig) N R 34 Algebraische Strukturen desselben Types A Menge {0, 1} mit I Konstanten 0, 1 I Funktionen min, max (zweistellig) I Eigenschaft gerade I Relation ≤ (zweistellig) B Menge aller Studenten im Raum mit I Konstanten Anton, Berta I Funktionen Älterer, kleinere-Matrikelnummer(zweistellig) I Eigenschaft blond I Relation befreundet (zweistellig) C Menge 2N mit I Konstanten ∅, I Funktionen ∩, ∪ (zweistellig) I Eigenschaft endlich I Relation ⊆ (zweistellig) N 35 Signaturen Gemeinsamkeiten der Strukturen A, B, C: I I I I zwei Konstanten (nullstellige Funktionen) zwei zweistellige Funktionen eine Eigenschaft (einstellige Relation) eine zweistellige Relation Bezeichnung der Relationen und Funktionen durch Symbole (mit zugeordneter Stelligkeit): Signatur Σ = (ΣF , ΣR ) mit Mengen ΣF = {(f , n) | n ∈ } von Funktionssymbolen (mit Stelligkeit) ΣR = {(R, n) | n ∈ } von Relationssymbolen (mit Stelligkeit) (nullstellige Funktionssymbole heißen Konstantensymbole) Signatur definiert einen Typ von Strukturen Strukturen mit derselben Signatur können sich unterscheiden in N N I I Trägermenge Bedeutung der Funktions- und Relationssymbole 36 Beispiele für Signaturen I Signatur für arithmetische Ausdrücke über natürlichen, rationalen, reellen, . . . Zahlen ΣF = {(+, 2), (−, 2), (·, 2), (/, 2)}∪ je ein nullstelliges Symbol für jede Zahl aus der Trägermenge ΣR = {(=, 2), (≤, 2)} I Signatur für aussagenlogische Formeln ΣF = {(∨, 2), (∧, 2), (→, 2), (¬, 1), (f, 0), (t, 0)}, ΣR = ∅ I Signatur für alle drei Strukturen A, B, C auf früherer Folie: ΣF = {(apfel, 0), (banane, 0), (kirsche, 2), (pflaume, 2)} ΣR = {(zwiebel, 1), (tomate, 2)} 37 Terme gegeben: N I funktionale Signatur ΣF = {(f , n) | n ∈ } (Relationssysmbole kommen in Termen nicht vor) I Menge X von Individuenvariablen Definition (induktiv) X Die Menge Term(ΣF , ) aller Terme über der (funktionalen) Signatur ΣF mit Variablen aus der Menge ist definiert durch: IA Jede Variable x ∈ X X ist ein Term. (X ⊆ Term(ΣF , X)) IS Sind (f , n) ∈ ΣF (f ist n-stelliges Funktionssymbol) und t1 , . . . , tn Terme aus Term(ΣF , ), dann ist f (t1 , . . . , tn ) ein Term aus Term(ΣF , ). X X Terme haben Baumstruktur verschiedene Darstellungen möglich, z.B. Infix-, Präfix-, Postfixform Terme ohne Variablen heißen Grundterme. Menge aller Grundterme: Term (ΣF , ∅) 38 Terme – Beispiele I X für ΣF = {(f , 1), (g, 2), (h, 2), (c, 0)} und = {x, y , z} gilt z.B. c ∈ Term(ΣF , ∅) ⊆ Term(ΣF , ) (Grundterm) z ∈ Term(ΣF , ), aber z 6∈ Term(ΣF , ∅) (kein Grundterm) f (c) ∈ Term(ΣF , ∅) ⊆ Term(ΣF , ), h(f (x), c) ∈ Term(ΣF , ), aber h(f (x), c) 6∈ Term(ΣF , ∅) f 6∈ Term(ΣF , ), h(c) 6∈ Term(ΣF , ), x(c) 6∈ Term(ΣF , ) X X X X X X Q X I für ΣF = {(+, 2), (−, 2), (·, 2), (/ 2)} ∪ {(q, 0) | q ∈ } ist Term(ΣF , ∅) die Menge aller arithmetischen Ausdrücke (Terme) mit rationalen Zahlen (z.B. 3/5+1/4), Term(ΣF , {a, b, c}) die Menge aller arithmetischen Ausdrücke (Terme) mit rationalen Zahlen und Variablen aus der Menge {a, b, c} (z.B. 3a+2b/c), I ΣF = {(apfel, 0), (banane, 0), (kirsche, 2), (pflaume, 2)} I apfel ∈ Term(Σ , ∅), Grundterm F I kirsche (x, pflaume(y , banane)) ∈ Term(Σ , {x, y , z}) F kein Grundterm I banane(apfel(pflaume, kirsche(pflaume))) 6∈ Term(Σ , F I pflaume(apfel, kirsche(banane, apfel)) ∈ Term(Σ , ∅) F X) 39 Was bisher geschah I Beziehung zwischen Realität und formalem Modell I Semantik (Bedeutung) und Syntax (Darstellungsform) I algebraische Strukturen (M, F , R) mit M Menge von Daten (Trägermenge) F Funktionen auf M R Eigenschaften, Relationen auf M I Signaturen Σ = (ΣF , ΣR ) I Menge aller Terme Term(ΣF , ) über der funktionalen Signatur ΣF und der Variablenmenge X X 40 Wiederholung Terme Definition (induktiv) X Die Menge Term(ΣF , ) aller Terme über der (funktionalen) Signatur ΣF mit Variablen aus der Menge ist definiert durch: IA Jede Variable x ∈ X X ist ein Term. (X ⊆ Term(ΣF , X)) IS Sind (f , n) ∈ ΣF (f ist n-stelliges Funktionssymbol) und t1 , . . . , tn Terme aus Term(ΣF , ), dann ist f (t1 , . . . , tn ) ein Term aus Term(ΣF , ). X X Beispiele: I Für die Signatur ΣF = {(f , 2), (g, 1), (a, 0)} und die Variablenmenge = {x, y , z} gilt f (g(x), f (y , g(f (a, z)))) ∈ Term(ΣF , ), a(f (a, f (x, b(c)))) 6∈ Term(ΣF , ) X X I X Für die Signatur ΣF = {(z, 0), (s, 1)} gilt z ∈ Term(ΣF , ∅), s(s(z)) ∈ Term(ΣF , ∅), allgemein: Term(ΣF , ∅) = {s(. . . (s(z)) . . .) | i ∈ | {z } N} i−mal 41 Menge aller Variablen in einem Term Definition (induktiv): X Für jeden Term t ∈ Term(ΣF , ) ist die Menge var(t) aller in t vorkommenden Variablen definiert durch: IA: falls t = x ∈ X (Variable), dann var(t) = {x} IS: falls t = f (t1 , . . . , tn ) mit (f , n) ∈ ΣF , dann var(t) = var(t1 ) ∪ · · · ∪ var(tn ) Beispiel: Für t = f (g(x, a), g(f (a, y ), x)) gilt var(t) = {x, y } 42 Anzahl der Variablenvorkommen in einem Term Definition (induktiv): X Für jeden Term t ∈ Term(ΣF , ) ist die Anzahl varcount(t) aller Variablenvorkommen in t definiert durch: IA: falls t = x ∈ X (Variable), dann varcount(t) = 1 IS: falls t = f (t1 , . . . , tn ) mit (f , n) ∈ ΣF , dann varcount(t) = varcount(t1 ) + · · · + varcount(tn ) Beispiel: Für t = f (g(x, a), g(f (a, y ), x)) gilt varcount(t) = 3 varcount(t) ist die Anzahl aller mit Variablen markierten Blätter im Termbaum von t Allgemein gilt varcount(t) ≥ |var(t)| 43 Tiefe des Terms Definition (induktiv): Für jeden Term t ∈ Term(ΣF , durch: IA: falls t = x ∈ X) ist seine Tiefe tiefe(t) definiert X (Variable), dann tiefe(t) = 0 IS: falls t = f (t1 , . . . , tn ) mit (f , n) ∈ ΣF , dann tiefe(t) = 1 + max{tiefe(t1 ), . . . , tiefe(tn )} (wobei max(∅) = 0) Beispiel: Für t = f (g(x, a), g(f (a, y ), x)) gilt tiefe(t) = . . . 44 Postorder-Folge des Terms Definition (induktiv): Für jeden Term t ∈ Term(ΣF , postorder(t) definiert durch: IA: falls t = x ∈ X) ist seine Postorder-Folge X (Variable), dann postorder(t) = x IS: falls t = f (t1 , . . . , tn ) mit (f , n) ∈ ΣF , dann postorder(t) = postorder(t1 ) ◦ · · · ◦ postorder(tn ) ◦ f (◦ Verkettung) Beispiel: Für t = f (g(x, a), g(f (a, y ), x)) gilt postorder(t) = . . . 45 Menge aller Teilterme eines Terms Definition (induktiv): Für jeden Term t ∈ Term(ΣF , Teilterme t definiert durch: IA: falls t = x ∈ X) ist die Menge TT(t) aller X (Variable), dann TT(t) = {x} IS: falls t = f (t1 , . . . , tn ) mit (f , n) ∈ ΣF , dann TT(t) = {t} ∪ TT(t1 ) ∪ · · · ∪ TT(tn ) Beispiel: Für t = g(f (a, x), x) gilt TT(t) = . . . 46 Prinzip der strukturellen Induktion Beobachtung: Bestimmung von Variablenmenge, Anzahl der Variablenvorkommen, Menge der Teilterme, Tiefe eines Terms, Postorder-Folge geschah nach demselben Schema: Definition einer Funktion f : Term(ΣF , X) → M durch Induktion über die Struktur des Terms Für jeden Terme t ∈ Term(ΣF , definiert durch: X) ist der Funktionswert f (t) IA: Definition des Funktionswertes f (t) für Variablen t = x ∈ (Blätter im Termbaum) X IS: Definition des Funktionswertes f (t) für zusammengesetzten Terme t = f (t1 , . . . , tn ) durch eine Kombination der Funktionswerte der direkten Teilterme von t (also t1 , . . . , tn ) 47 Beweise durch strukturelle Induktion Nachweis, dass eine Eigenschaft E für alle Terme t ∈ Term(ΣF , ) gilt durch X Induktion über die Struktur des Terms X Die Eigenschaft E ist für jeden Term t ∈ Term(ΣF , ) erfüllt, wenn man die folgenden beiden Aussagen nachweisen kann: IA: E gilt für jede Variable t = x ∈ X (Blätter im Termbaum) IS: Falls E für n Terme t1 , . . . , tn gilt und (f , n) ∈ ΣF , dann gilt E auch für t = f (t1 , . . . , tn ) IV : E gilt für die Terme t1 , . . . , tn IH : E gilt für f (t1 , . . . , tn ) (mit (f , n) ∈ ΣF ) IB : Nachweis, dass IH aus IV folgt. prominenter Spezialfall: Beweise durch vollständige Induktion (für (mehr dazu in den Mathematik-LV) N) 48 Σ-Strukturen (Semantik) Definition Zu einer Signatur Σ = (ΣF , ΣR ) heißt A = (A, J·KA ) genau dann Σ-Struktur, wenn I A 6= ∅ Trägermenge (Universum) I für jedes (f , n) ∈ ΣF gilt Jf KA : An → A (Jf KA ist eine n-stellige Funktion auf A) I für jedes (R, n) ∈ ΣR gilt JRKA ⊆ An (JRKA ist eine n-stellige Relation auf A) Für jedes Symbol s aus der Signatur Σ bezeichnet JsKA die Bedeutung (Semantik) von s in der Struktur A. Beispiel: Für die Signatur Σ = (ΣF , ΣR ) mit ΣF = {(c, 0)} und ΣR = {(b, 1), (f , 2)} ist die Struktur A = (A, J·KA ) mit A = Menge aller Studenten in diesem Raum, JcKA = Student links hinten, JbKA = blond, Jf KA = befreundet eine Σ-Struktur 49 Beispiele für Σ-Strukturen I für die Signatur Σ = (ΣF , ΣR ) mit ΣF = {(+, 2), (1, 0)} und ΣR = {(≤, 2)} sind z.B. ( , {+, 1}, {≤}) und ( , {+, 1}, {≤}) Σ-Strukturen für die Signatur Σ = (ΣF , ΣR ) mit ΣF = {(f , 2), (c, 0)} und ΣR = {(R, 2)} sind z.B. ( , {+, 0}, {|}) und ( , {, 2}, {≤}) Σ-Strukturen Für die Signatur Σ = (ΣF , ΣR ) mit ΣF = {(apfel, 0), (banane, 0), (kirsche, 2), (pflaume, 2)} ΣR = {(zwiebel, 1), (tomate, 2)} sind z.B. die folgenden Strukturen Σ-Strukturen: N I Q N I I I Q A = ({0, 1}, J·KA ) mit JapfelKA = 0, JbananeKA = 1 JkirscheKA = min, JpflaumeKA = max JzwiebelKA = {0}, JtomateKA = ≤ B = ( , J·KB ) mit JapfelKB = 3, JbananeKB = −1 JkirscheKB (x, y ) = x y , JpflaumeKB (x, y ) = x − y JzwiebelKB = 2 (gerade), JtomateKB = {(x, y ) | x < y } R Z 50 Wert von Grundtermen in Strukturen gegeben: funktionale Signatur ΣF = {(f , n) | n ∈ ΣF -Struktur A = (A, J·KA ) N} Definition (induktiv) Der Wert des ΣF -Grundtermes t = f (t1 , . . . , tn ) ∈ Term(ΣF , ∅) in der ΣF -Struktur A = (A, J·KA ) ist JtKA = Jf KA (Jt1 KA , . . . , Jtn KA ) Fehlt hier der Induktionsanfang? nein, als Spezialfall enthalten: Für t = c mit (c, 0) ∈ ΣF (Konstante) gilt JtKA = JcKA (Bedeutung der Konstante c in A, gegeben in Definition von A) 51 Beispiel Signatur Σ = (ΣF , ΣR ) mit ΣF = {(apfel, 0), (banane, 0), (kirsche, 2), (pflaume, 2)} ΣR = {(zwiebel, 1), (tomate, 2)} s = apfel t = pflaume(apfel, kirsche(banane, apfel)) Σ-Struktur A = (A, J·KA ) mit A = N JapfelKA = 5 JbananeKA = 3 für alle a, b ∈ A: JkirscheKA (a, b) = a + b für alle a, b ∈ A: JpflaumeKA (a, b) = a · b JzwiebelKA = {0, . . . , 10} JtomateKA = {(2n, n) | n ∈ JsKA = 5 JtKA = . . . N} 52 Weiteres Beispiel s = apfel t = pflaume(apfel, kirsche(banane, apfel)) Σ-Struktur B = (B, J·KB ) mit B = {0, 1} JapfelKB = 0 JbananeKB = 1 für alle a, b ∈ B: JkirscheKB (a, b) = min(a, b) für alle a, b ∈ B: JpflaumeKB (a, b) = max(a, b) JzwiebelKB = {0} JtomateKB = {(0, 0), (0, 1), (1, 1)} JsKB = JapfelKB = 0, JtKB = . . . 53 Noch ein Beispiel s = apfel t = pflaume(apfel, kirsche(banane, apfel)) Σ-Struktur D = (D, J·KD ) mit D = 2N JapfelKD = ∅ JbananeKD = N für alle M, N ∈ D: JkirscheKD (M, N) = M ∩ N für alle M, N ∈ D: JpflaumeKD (M, N) = M ∪ N JzwiebelKD = {M ⊆ N | |M| ∈ N} JtomateKD = {(M, N) ∈ D 2 | M ⊆ N} JsKD = JapfelKD = ∅, JtKD = . . . 54 Äquivalenz von Grundtermen in einer Struktur Definition ΣF -Grundterme s, t ∈ Term(ΣF , ∅) mit JsKA = JtKA heißen äquivalent in A (s ≡A t). In den Beispielen oben gilt s ≡B t, aber s 6≡A t. aus dem Mathematik-Unterricht (Schule): Äquivalenz von Termen lässt sich oft durch syntaktische Umformungen (Termersetzung) testen z.B. Ausklammern, Ausmultiplizieren, Summanden vertauschen usw. 55 Was bisher geschah I Beziehung zwischen Realität und formalem Modell I Semantik (Bedeutung) und Syntax (Darstellungsform) von Daten Syntax (Terme): I Signaturen Σ = (ΣF , ΣR ) I Term(ΣF , I strukturelle Induktion über Terme (für Funktionen, Beweise) X): Menge aller Terme über ΣF und X Semantik von Termen: I algebraische Strukturen (M, F , R) I Σ-Strukturen A = (A, J·KA ) mit I I I A 6= ∅ Trägermenge (Universum) für jedes (f , n) ∈ ΣF gilt Jf KA : An → A für jedes (R, n) ∈ ΣR gilt JRKA ⊆ An I Werte von Grundtermen in Σ-Strukturen (induktiv definiert) I Äquivalenz von Grundtermen in Σ-Strukturen 56 Interpretationen für Terme mit Variablen gegeben: Signatur Σ = (ΣF , ΣR ), Variablenmenge Σ-Struktur A = (A, J·KA ) Term t ∈ Term(ΣF , ) X X Problem: Welchen Wert in A repräsentieren Variablen x ∈ X X? Lösung: Belegung β : → A der Individuenvariablen (ordnet jeder Variablen einen Wert aus der Trägermenge von A zu) Definition Eine (Σ-)Interpretation für einen Term t ∈ Term(ΣF , Paar (A, β) aus I I X) ist ein einer Σ-Struktur A = (A, J·KA ) und einer Belegung β : X → A. 57 Beispiele Signatur Σ = {(f , 2), (g, 2), (a, 0)}, Variablenmenge I N Interpretation (A, α) mit Σ-Struktur A = ( , J·KA ), wobei ∀m, n ∈ ∀m, n ∈ N: N: JaKA = 1 Jf KA (m, n) = m + n JgKA (m, n) = m · n und Variablenbelegung α : {x, y } → α(x) = 2 und α(y ) = 1 I X = {x, y } N, wobei Interpretation (B, β) mit Σ-Struktur B = (2{a,b,c} , J·KB ): 2{a,b,c} ∀M, N ∈ ∀M, N ∈ 2{a,b,c} JaKB = {b, c} : Jf KB (M, N) = M \ N : JgKB (M, N) = M ∪ N und Variablenbelegung β : {x, y } → 2{a,b,c} , wobei β(x) = ∅ und β(y ) = {b} 58 Interpretation von Termen mit Variablen Definition (induktiv) Für jede Signatur Σ = (ΣF , ΣR ), jede Interpretation (A, β) mit A = (A, J·KA ) und β : → A ist der Wert des Termes t ∈ Term(ΣF , ) in (A, β) definiert durch X X IA falls t = x ∈ X, dann JtK(A,β) = β(x) IS falls t = f (t1 , . . . , tn ), dann JtKA = Jf KA Jt1 K(A,β) , . . . , Jtn K(A,β) Der Wert eines Termes in einer Interpretation ((A, J·KA ), α) ist ein Element aus A. 59 Beispiele Signatur Σ = (ΣF , ΣR ) mit ΣF = {(a, 0), (b, 0), (f , 1), (g, 2), (h, 2)} und ΣR = ∅ Variablenmenge = {x, y } X Σ-Struktur S = (S, J·KS ) mit S JaKS JbKS ∀d ∈ S : Jf KS (d) ∀d, e ∈ S : JgKS (d, e) ∀d, e ∈ S : JhKS (a, b) Variablenbelegungen β : {x, y } → γ : {x, y } → = = = = = = N 5 3 1+d d +e d ·e N mit β(x) = 0, β(y ) = 1 N mit γ(x) = 2, γ(y ) = 0 Terme s = g(h(f (a), x), h(x, y )) und t = h(f (x), g(y , a)) JsK(S,β) = . . . , JtK(S,β) = . . . , JsK(S,γ) = . . . , JtK(S,γ) = . . . (Tafel) 60 Mehrsortige Signaturen S mehrsortige Signatur (mit Sorten aus einer Menge ) enthält Relationssymbole mit Argumenttypen (s ⊆ ∗ ) Funktionssymbole mit Argument-und Ergebnistypen (f : ∗ → ) S S S mehrsortige Signatur Σ mit Sorten S = {Si | i ∈ I} Beispiel: Bücher mit Autoren und Erscheinungsjahr I Sorten: B (Bücher), P (Personen), J (Jahreszahlen), 2B (Mengen von Büchern), I Funktionssymbole (mit Argument-und Ergebnistypen): erscheinungsjahr :B →J erstesBuch :P →B gemeinsameBücher : P × P → 2B Relationen (mit Argumenttypen): Autor ⊆B×P Coautor ⊆ P × P I 61 Terme über mehrsortigen Signaturen S gegeben: mehrsortige Signatur Σ mit Menge von Sorten Variablenmenge 0 = × (jede Variable mit einer zugeordneter Sorte aus ) X X S S Definition (induktiv) S X Für jede Sorte S ∈ ist die Menge TermS (Σ, 0 ) aller Terme der Sorte S mit Variablen aus der Menge 0 definiert durch: IA: {x | (x : S) ∈ X X0 } ⊆ TermS (ΣF , X0 ) IS: Für alle f mit (f : S1 × · · · × Sn → S) ∈ Σ und alle Tupel (t1 , . . . , tn ), wobei für alle k ∈ {1, . . . , n} gilt tk ∈ TermSk (Σ, 0 ), ist f (t1 , . . . , tn ) ∈ TermS (Σ, 0 ) X X Spezialfall: Jede Konstante f : S ∈ Σ ist Σ-Term der Sorte S. Beispiele: t = erscheinungsjahr(erstesBuch(x)) mit (x : P) ∈ 0 ist ein Term in TermJ (Σ, 0 ) erstesBuch(erscheinungsjahr(x)) ist kein Term X X 62 Mehrsortige Σ-Strukturen S gegeben: -sortige Signatur Σ S Σ-Struktur A = ({AS | S ∈ }, J·KA ) mit S I für jede Sorte S ∈ eine nichtleere Menge AS (Trägermenge, Universum der Sorte) I für jedes Funktionssymbol f : S1 . . . Sn → S eine Funktion Jf KA : AS1 × . . . × ASn → AS I für jedes Relationssymbol R : S1 × . . . × Sn eine Relation JRKA ⊆ AS1 × . . . × ASn S S Wert von Termen mit -sortiger Signatur Σ in der -sortigen Struktur A = ({AS | S ∈ }, J·KA ) analog zur Definition für einsortige Signaturen und Strukturen S 63 Relationen als mehrsortige Funktionen Beispiel: (einsortiges) Relationssymbol (r , 2) Signatur Σ = (ΣF , ΣR ) mit ΣF = ∅ und ΣR = {(r , 2)} Interpretation in einer einsortigen Σ-Struktur A mit Träger |A| und Jr KA ⊆ |A| × |A| Einführung der Sorten S (für Trägermenge) und B = {f, t} (für Wahrheitswerte) Definition der Funktion fr : S × S → B mit ∀(x, y ) ∈ S 2 : (x, y ) ∈ r gdw. fR (x, y ) = t 64 Relationen als mehrsortige Funktionen für beliebige Stelligkeit n: Übersetzung jedes Relationssymbols (r , n) ∈ ΣR in ein Funktionssymbol fr : S n → , so dass B ∀(x1 , . . . , xn ) ∈ S n : (x1 , . . . , xn ) ∈ r gdw. fr (x1 , . . . , xn ) = t Jeder relationalen (einsortigen) Signatur ΣR läßt sich eine zweisortige funktionale Signatur Σ0 = Σ0F ∪ Σ0R zuordnen: Σ0F = {f : S n → S | (f , n) ∈ ΣF } Σ0R = {fr : S n → B | (r , n) ∈ ΣR } Analog lassen sich mehrsortige Relationen durch mehrsortige Funktionen ersetzen. Es genügt also, mehrsortige Strukturen ohne Relationen zu betrachten. 65 Abstrakter Datentyp (Interface) – Beispiel Aufgabe: Verwaltung einer Menge ganzer Zahlen (z.B. ID-Nummern), so dass festgestellt werden kann, ob eine Zahl darin enthalten ist und Zahlen hinzugefügt und entfernt werden können. B Sorten (Wertebereiche): Zahl, Menge, Wahrheitswert ( ) Signatur: Funktionen zum Finden, Hinzufügen, Entfernen B B contains : Menge × Zahl → add, remove : Menge × Zahl → Menge isempty : Menge → emptyset : Menge Axiome (definieren die Semantik der Operationen): ∀n ∈ Zahl ∀s ∈ Menge ∀n ∈ ∀s ∈ Menge ∀n ∈ ∀s ∈ Menge ∀m, n ∈ ∀s ∈ Menge ∀n ∈ N N N N : : : : : isempty((emptyset) = t, contains(emptyset, n) = f, contains(add(s, n), n) = t, contains(remove(s, n), n) = f, add(add(s, n), m) = add(add(s, m), n), add(add(s, n), n) = add(s, n), . . . 66 Konkreter Datentyp (Implementierung) – Beispiel verschiedene Möglichkeiten zur Darstellung der Sorten: 1. Wahrheitswerte z.B. als {0, 1}, {−1, 0} 2. Zahlen in verschiedenen Zahlendarstellungen, z.B. dezimal, binär, zu anderer Basis, Maschinenzahlen (eingeschränkter Bereich) 3. Mengen als (sortierte) Folgen (mit / ohne Wiederholungen) von Zahlen 4. Zuordnung Zahl → {f, t} mit t, falls Zahl in der Menge, f sonst (charakteristische Funktion) 5. {0, 1}-Folgen abstrakter Datentyp: Signatur Σ und Axiome Φ, exakte Formulierung der Aufgabe, Spezifikation konkreter Datentyp: Σ-Struktur, welche Φ erfüllt (Modell für Φ) Umsetzung, Implementierung (mehr dazu in LV Algorithmen und Datenstrukturen) 67 Wiederholung ADT Stack (Stapel, Keller) Sorten E: Elementtyp, S: Stapel von Elementen vom Typ E, (Wahrheitswerte) B Signatur Σ: top pop push new isEmpty Axiome , z.B. ∀s ∀s ∀s ∀s ∈S ∈S ∈S ∈S :S :S :E ×S : :S ∀e ∈ E ∀e ∈ E ∀e ∈ E ∀e ∈ E : : : : →E →S →S S → B isEmpty(new) isEmpty(push(e, s)) top(push(e, s)) pop(push(e, s)) push(top(s), pop(s)) = = = = = t f e s s 68 Was bisher geschah: Modellierung von Daten I Beziehung zwischen Realität und formalem Modell I Semantik (Bedeutung) und Syntax (Darstellungsform) von Daten I Beispiel (ÜA) lineares Solitaire Syntax: I Signaturen Σ = (ΣF , ΣR ) I Terme in Term(ΣF , I strukturelle Induktion über Terme (für Funktionen, Beweise) X) Semantik: I algebraische Strukturen (M, F , R) I Interpretationen (A, β) mit I I I Σ-Struktur A = (A, J·KA ) Belegung der Individuenvariablen β : X→A Werte von Termen in Interpretationen 69 Wörter – Beispiele banane ist ein Wort (Zeichenkette) mit Symbolen aus der Menge {a, b, e, n}, neben und abbbeeeab auch, ananas und ab + bea nicht 2009 ist ein Wort mit Symbolen aus der Menge {0, 2, 9}, 90 und 09020090 auch, −2090 nicht (x + y ) · (z − x) ist ein Wort mit Symbolen aus der Menge {x, y , z, (, ), +, −, ·}, ()xz(xy + − auch, x + 3 · z nicht (¬p ∧ p) → q ist ein Wort mit Symbolen aus der Menge {p, q, ∧, ¬, →, (, )}, q → (p → q) und ∧)(¬p∧ auch, p ↔ q nicht otto holt obst. ist ein Wort mit Symbolen aus der Menge {otto, obst, holt, ., }, .otto..otto auch, los otto nicht 70 Begriffe Notationen: Für eine Menge A heißt An = A · · × A} = {w1 · · · wn | ∀i : wi ∈ A} | × ·{z n Menge aller Wörter der Länge n über A (n-Tupel, Vektoren, Listen, Zeichenketten) S ∗ A = {n∈N} An Menge aller Wörter über A A0 = {ε} mit leerem Wort ε Alphabet (endliche) Menge A von Symbolen Wort endliche Folge von Symbolen w = w1 · · · wn mit ∀i ∈ {1, . . . , n} : wi ∈ A Länge eines Wortes |w| = Anzahl der Symbole in w Anzahl der Vorkommen eines Symboles in einem Wort |w|a = Anzahl der a in w (für a ∈ A) Sprache Menge von Wörtern L ⊆ A∗ 71 Beispiele für Sprachen I Menge aller englischen Wörter L1 ⊂ {a, . . . , z}∗ I Menge aller deutschen Wörter L2 ⊂ {a, . . . , z, ß,ä,ö,ü}∗ I Menge aller möglichen DNA L3 ⊆ {A, T , G, C}∗ I Menge aller natürlichen Zahlen in Dezimaldarstellung L4 ⊆ {0, . . . , 9}∗ (evtl. mit führenden Nullen) I Menge aller natürlichen Zahlen in Binärdarstellung (Bitfolgen beliebiger Länge) L5 ⊆ {0, 1}∗ I Menge aller deutschen Sätze L6 ⊂ (L2 ∪ {., , , !, ?, (, ), −})∗ Problem: Für die automatische Verarbeitung von Sprachen ist eine endliche Darstellung notwendig (auch für unendliche Sprachen). 72 Verkettung von Wörtern Verkettung ◦ von Wörtern: ◦ : A∗ × A∗ → A∗ , wobei für alle Wörter u = u1 · · · um ∈ A∗ , v = v1 · · · vn ∈ A∗ gilt u ◦ v = u1 · · · um v1 · · · vn Beispiel: anne ◦ marie = annemarie Eigenschaften der Operation ◦: I ◦ ist assoziativ, d.h. ∀u, v , w ∈ A∗ : (u ◦ v ) ◦ w = u ◦ (v ◦ w) I Das leere Wort ε ist neutrales Element für ◦, d.h. ∀w ∈ A∗ : ε ◦ w = w ◦ ε = w ◦ ist nicht kommutativ. Gegenbeispiel: u = marie, v = anne u ◦ v = marieanne 6= annemarie = v ◦ u 73 Umkehrung (gespiegeltes Wort) Umkehrung von w = w1 · · · wn : w R = wn · · · w1 Beispiele: marieR = eiram, 2013R = 3102, 101R = 101 to ◦ m ◦ (ate)R Fakt Für jedes Wort w ∈ A∗ gilt w R R R R !R ◦n = ... = w. Fakt Für zwei beliebige Wörter u, v ∈ A∗ gilt (u ◦ v )R = v R ◦ u R . 74 Palindrome Palindrom: Wort w mit w = w R B: anna, neben, ε, jedes Wort der Länge 1 Die Menge aller Palindrome über dem Alphabet A ist Lpal = {w ∈ A∗ | w = w R } = {w ◦ w R | w ∈ A∗ } ∪ {w ◦ a ◦ w R | w ∈ A∗ ∧ a ∈ A} | {z } | {z } Lpal0 Lpal1 Beispiele für Wörter aus Lpal : I otto = ot ◦ to = ot ◦ (ot)R für w = ot ∈ A∗ = {a, . . . , z}∗ I reliefpfeiler = relief ◦ p ◦ feiler = relief ◦ p ◦ (relief )R für w = relief ∈ A∗ = {a, . . . , z}∗ I 1 = ε ◦ 1 ◦ ε = ε ◦ 1 ◦ εR I ε=ε◦ε=ε◦ für A = {0, 1} εR 75 Relationen auf Wörtern (binäre Relation = Menge geordneter Paare) Präfix-Relation (Anfangswort): v ⊆ A∗ × A∗ Für zwei Wörter u = u1 · · · um ∈ A∗ , v = v1 · · · vn ∈ A∗ gilt u v v genau dann, wenn ein Wort w ∈ A∗ existiert, so dass u ◦ w = v gilt. Beispiele: I an v anna (mit w = na) I n 6v anna I tom v tomate (mit w = ate) I oma 6v tomate I für jedes Wort u ∈ A∗ gilt ε v u (mit w = u) I für jedes Wort u ∈ A∗ gilt u v u (mit w = ε) 76 Postfix- und Infix-Relation auf Wörtern Postfix-Relation: Für zwei Wörter u = u1 · · · um ∈ A∗ , v = v1 · · · vn ∈ A∗ heißt u genau dann Postfix (Suffix) von v , wenn ein Wort w ∈ A∗ existiert, so dass w ◦ u = v gilt. Beispiel: enten ist Postfix von studenten Infix-Relation (Teilwort, Faktor): Für zwei Wörter u = u1 · · · um ∈ A∗ , v = v1 · · · vn ∈ A∗ heißt u genau dann Infix von v , wenn zwei Wörter w, w 0 ∈ A∗ existieren, so dass w ◦ u ◦ w 0 = v gilt. Beispiel: uwe ist Infix von sauwetter satt ist kein Infix von sauwetter 77 Sprachen als Mengen Sprachen L ⊆ A∗ sind Mengen von Wörtern Mengenrelationen auf Sprachen: L ⊆ L0 gdw. ∀w ∈ A∗ : w ∈ L → w ∈ L0 L = L0 gdw. ∀w ∈ A∗ : w ∈ L ↔ w ∈ L0 Mengenoperationen auf Sprachen: L ∪ L0 = {w | w ∈ L ∨ w ∈ L0 } L ∩ L0 = {w | w ∈ L ∧ w ∈ L0 } L \ L0 = {w | w ∈ L ∧ w 6∈ L0 } Komplement einer Sprache L ⊆ A∗ : L = A∗ \ L Beispiel: [ [ L= An L= An ∪ N n∈3 N n∈{3i+1|i∈ } [ N An n∈{3i+2|i∈ } 78 Was bisher geschah I I Alphabet, Wort, Sprache Operationen auf Wörtern: I I Spiegelung R Verkettung ◦ I Palindrome I Relationen zwischen Wörtern: Präfix, Infix, Postfix I Mengenoperationen und -relationen auf Sprachen: ∪, ∩, , \, ⊆, = 79 Weitere Operationen auf Sprachen Verkettung ◦ von Sprachen: L1 ◦ L2 = {u ◦ v | u ∈ L1 ∧ v ∈ L2 } Beispiel: L1 = {111, 1, 10} L2 = {00, 0} L1 ◦ L2 = {111, 1, 10} ◦ {00, 0} = {1110, 11100, 10, 100, 1000} Spiegelung LR = {w R | w ∈ L} Beispiel: L = {a, ab, aba, abab} LR = {a, ba, aba, baba} 80 Iterierte Verkettung I für Sprachen L ⊆ A∗ L0 = {ε} ∀n ∈ N: Ln+1 = Ln ◦ L = L · · ◦ L} | ◦ ·{z n+1−mal L∗ = [ n∈ I N Ln L+ = [ N Ln n∈ \{0} für Wörter u ∈ A∗ : ∈ A∗ , u ∗ = {u}∗ = {u n | n ∈ un = u · · u} | ·{z u+ = u ∗ \ {ε} = {u}+ = {u n | n ∈ n−mal N \ {0}} N} ⊆ A∗ ⊆ A∗ Beispiele: (101)3 a∗ ∗ (ab) = 101101101 und 1013 = 10111 N} = {ε, a, aa, aaa, . . .} | i ∈ N} = {ε, ab, abab, ababab, . . .} = {ai | i ∈ = {(ab) i 81 Mehr Beispiele für Sprachen I {aa, b}∗ N ∧ ∀i ∈ {1, . . . , n} : ui ∈ {aa, b}} = {u1 ◦ · · · ◦ un | n ∈ = {ε, b, aa, bb, aab, baa, bbb, aaaa, aabb, baab, bbaa, bbbb, . . .} I ∅ ◦ {aba, bb} = . . . I {ε} ◦ {aba, bb} = . . . I {bb}∗ = {w ∈ b∗ | |w| ∈ 2 } = . . . {0}∗ )∗ N = {w ∈ {0, 1}∗ | w1 = 1} ∪ {ε} I ({1} ◦ I ({a} ∪ {b, ab})∗ = . . . 82 Reguläre Ausdrücke – Syntax Die Menge RegExp(A) aller regulären Ausdrücke über einem Alphabet A ist (induktiv) definiert durch: IA: ∅ ∈ RegExp(A), ε ∈ RegExp(A) und für jedes Symbol a ∈ A gilt a ∈ RegExp(A) IS: für alle E ∈ RegExp(A) und F ∈ RegExp(A) gilt (E + F ), EF , (E)∗ ∈ RegExp(A). Beispiele: ε + a, ε + ∅, (a + ∅)∗ , ε + ((ab)∗ a)∗ dieselbe Definition kürzer: RegExp(A) = Term(ΣF , ∅) für die Signatur ΣF = {(∅, 0), (ε, 0), (∗ , 1), (+, 2), (·, 2)} ∪ {(a, 0) | a ∈ A} (Baumdarstellung) 83 Beispiele (ohne überflüssige Klammern) I Für A = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} gilt 0+(1+2+3+4+5+6+7+8+9)(0+1+2+3+4+5+6+7+8+9)∗ ∈ RegExp(A) I Für A = {0, 1} gilt I I (1 + ε)∗ + (10)∗ ∈ RegExp(A) (0 + 11)∗ + ((0 + (1)∗ )0)∗ ∈ RegExp(A) Oft werden A E + = EE ∗ En = E · · E} | ·{z n−mal ∗ E n∗ = E · · E} | ·{z n−mal für n ∈ N als Kurzbezeichnungen verwendet. 84 Reguläre Ausdrücke – Semantik Jeder reguläre Ausdruck E ∈ RegExp(A) repräsentiert eine Sprache L(E) ⊆ A∗ . L(∅) L(ε) ∀a ∈ A : L(a) ∀E, F ∈ RegExp(A) : L(E + F ) ∀E, F ∈ RegExp(A) : L(EF ) ∀E, F ∈ RegExp(A) : L(E ∗ ) = ∅ = {ε} = {a} = L(E) ∪ L(F ) = L(E) ◦ L(F ) ∗ = (L(E)) Eine Sprache L ⊆ A∗ heißt genau dann regulär, wenn ein regulärer Ausdruck E ∈ RegExp(A) existiert, so dass L = L(E). Beispiel: Die Menge L aller Dezimaldarstellungen natürlicher Zahlen ist regulär wegen L = L (0 + (1 + 2 + · · · + 9)(0 + 1 + · · · + 9)∗ ) 85 Beispiele Für A = {a, b} gilt N} | i ∈ N} L(ab∗ ) = {a, ab, abb, abbb, abbbb, . . .} = {abi | i ∈ ∗ L((ab) ) = {ε, ab, abab, ababab, . . .} = {(ab) L((a + b)∗ ) = {a, b}∗ i L(a∗ b∗ ) = {u ◦ v | u ∈ a∗ ∧ v ∈ b∗ } L((a∗ b∗ )∗ ) = {a, b}∗ L(A∗ aba) = {u ◦ aba | u ∈ A∗ }∗ Reguläre Ausdrücke ermöglichen eine endliche Darstellung unendlicher Sprachen. 86 Beispiele regulärer Sprachen I L1 = ∅, wegen ∅ ∈ RegExp(A) und L(∅) = ∅ = L1 I L2 = {a, bab}, wegen a + bab ∈ RegExp(A) und L(a + bab) = L2 I L3 = {w ∈ {a, b, c}∗ | abba v w}, wegen abba(a + b + c)∗ ∈ RegExp(A) und L(abba(a + b + c)∗ ) = L3 I {w ∈ {a, b, c}∗ | aa oder bbb sind Infix von w} I I I N {w ∈ {a, b}∗ | |w|a ∈ 2N} {w ∈ {a, b}∗ | |w| ∈ 2 } alle möglichen HTWK-Email-Adressen 87 Äquivalenz regulärer Ausdrücke Zwei reguläre Ausdrücke E, F ∈ RegExp(A) heißen genau dann äquivalent, wenn L(E) = L(F ) gilt. Beispiele: I (a + b)∗ , (a∗ + b∗ )∗ und a∗ (ba∗ )∗ sind äquivalent I ab∗ und (ab)∗ sind nicht äquivalent I (11 + 0 + 110 + 011)∗ und (11 + 0)∗ sind . . . 88 Was bisher geschah Alphabet, Wort, Sprache Wörter: I Operationen auf Wörtern: Verkettung ◦, Spiegelung I Relationen auf Wörtern: Palindrom (Eigenschaft), Präfix (v), Infix, Postfix R Sprachen (Mengen von Wörtern) I Operationen auf Sprachen: Mengenoperationen ∪, ∩, , \ Verkettung ◦ und Spiegelung R von Sprachen iterierte Verkettung ∗ I Relationen zwischen Sprachen: Mengenrelationen ⊆, = Reguläre Ausdrücke, reguläre Sprachen 89 Weitere Relationen auf A∗ (Halb-)Ordnungen (Definition in Mathe-LV) Präfix-, Postfix-, Infix-Relation auf A∗ bei gegebener Reihenfolge < auf dem Alphabet A: lexikographische Ordnung auf A∗ : ∀u, v ∈ A∗ : u ≤lex v gdw. 1. u v v oder 2. ∃w ∈ A∗ ∃a, b ∈ A : a < b ∧ wa v u ∧ wb v v quasi-lexikographische Ordnung auf A∗ : ∀u, v ∈ A∗ : u ≤qlex v gdw. 1. |u| ≤ |v | oder 2. |u| = |v | ∧ u ≤lex v Beispiele: für A = {a, b} mit a < b I ab v aba, ab ≤lex aba, ab ≤qlex aba I abab 6v abba, aber abab ≤lex abba und abab ≤qlex abba, I aaa ≤lex ab, aber aaa 6≤qlex ab I ab 6≤lex aaba, aber ab ≤qlex aaba 90 Interessante Fragen für Sprachen I Ist ein gegebenes Wort w ∈ A∗ in der Sprache L ⊆ A∗ enthalten? (Wortproblem) I Enthält die Sprache L ⊆ A∗ nur endlich viele Wörter? I Gilt L1 ⊆ L2 für zwei Sprachen L1 , L2 ⊆ A∗ ? I Gilt L1 = L2 für zwei Sprachen L1 , L2 ⊆ A∗ ? I Ist eine gegebene Sprache L ⊆ A∗ regulär? (d.h. L = L(E) für einen regulären Ausdruck E ∈ RegExp(A)) I Woran erkennt man, dass eine Sprache nicht regulär ist? Alle Antworten sind für endliche Sprachen einfach, aber für unendliche Sprachen in endlicher Darstellung (z.B. durch reguläre Ausdrücke) meist schwierig. 91 Interessante Fragen für reguläre Ausdrücke I Ist für einen gegebenen regulären Ausdruck E ∈ RegExp(A) ein gegebenes Wort w ∈ A∗ in der Sprache L(E) enthalten? (Wortproblem) I Gilt L(E) = ∅ für einen gegebenen regulären Ausdruck E ∈ RegExp(A)? I Gilt L(E) = A∗ für einen gegebenen regulären Ausdruck E ∈ RegExp(A)? I Sind zwei gegebene reguläre Ausdrücke E ∈ RegExp(A) und F ∈ RegExp(A) äquivalent? (also L(E) = L(F )) I Gilt L(E) ⊆ L(F ) für zwei gegebene reguläre Ausdrücke E ∈ RegExp(A) und F ∈ RegExp(A)? I Existiert für zwei gegebene reguläre Ausdrücke E ∈ RegExp(A) und F ∈ RegExp(A) ein Wort w ∈ A∗ mit w ∈ L(E) \ L(F )? 92 Wortproblem praktisch – Beispiele Eingabe : Sprache L ⊆ A∗ , z.B. durch regulären Ausdruck E mit L = L(E), Wort w ∈ A∗ Frage: Gilt w ∈ L? Ausgabe: ja oder nein (evtl. mit Begründung) I Syntaktische Tests: I Ist die gegebene Zeichenkette die Dezimaldarstellung einer ganzen Zahl? (Sprache: Menge aller gültigen Dezimaldarstellungen) I Ist die gegebene Zeichenkette eine korrekt geformte Email-Adresse (der HTWK)? I Ist der gegebene Quelltext ein syntaktisch korrektes Java-Programm? I Ist die gegebene Zeichenkette die Binärdarstellung einer geraden Zahl? (durch drei teilbaren Zahl, usw.) I Folgen von Aktionen: I An- und Ausziehen (in umgekehrter Reihenfolge) I Ist eine Folge von Aktionen möglich / zulässig ? I Führt eine Folge von Nutzereingaben zu einem Fehler? 93 Wiederholung: Lineares Solitaire Startkonfiguration : n Spielsteine nebeneinander (oder andere Ausgangsposition) Spielzug : Münze springt über einen benachbarten Stein auf dahinterliegendes leeres Feld formale Modellierung: Konfiguration (Spielzustand): w ∈ {0, 1}∗ Startkonfiguration: 0 . . . 0 |1 .{z . . 1} 0 . . . 0 ∈ {0, 1}∗ n−mal (oder anderes Wort w ∈ {0, 1}∗ ) mögliche Züge: an beliebiger passender Position 110 → 001 011 → 100 (Paare (l, r ) ∈ {0, 1}∗ × {0, 1}∗ , notiert l → r ) 94 Wortersetzungssysteme (Semi-Thue-Systeme, Axel Thue, 1914). Alphabet A Wortersetzungsregel (l, r ) ∈ A∗ × A∗ (notiert l → r ) Wortersetzungssystem (SRS) endliche Menge von Wortersetzungsregeln Beispiele: I A = {0, 1} I I I Regel 110 → 001, SRS S = {110 → 001, 011 → 100} A = {a, b, c} I I Regel ba → ab, SRS S = {a → ab, ba → c, abc → ε} 95 Anwendung von Wortersetzungsregeln Eine Regel l → r ist auf ein Wort w ∈ A∗ anwendbar, falls l ein Infix von w ist. Beispiel: Regel ma → ε ist I auf tomate anwendbar, u = to, v = te, I auf am, motte und meta nicht anwendbar. Eine Anwendung der Regel l → r auf ein Wort w = u ◦ l ◦ v ∈ ergibt das Wort u ◦ r ◦ v . (Ersetzung des Teilwortes l durch r ) Beispiel: ab → a angewendet auf baababa = u ◦ l ◦ v I mit u = ba und v = aba ergibt baaaba I mit u = baab und v = a ergibt baabaa 96 Ableitungsschritt Ableitungsschritt (u, (l → r ), p, v ) im Wortersetzungssystem S mit u ∈ A∗ : Ausgangswort l → r ∈ S: auf u anwendbare Regel p ∈ {1, . . . , |u|}: Position im Wort u, an der der (gewählte) Infix l beginnt v ∈ A∗ : nach Anwendung der Regel l → r an Position p auf u entstandenes Wort Beispiel: S = {ab → ba, a → b}, u = aba mögliche Ableitungsschritte in S (aba, (ab → ba), 1, baa) (aba, (a → b), 3, abb) (aba, (a → b), 1, bba) 97 Ein-Schritt-Ableitungsrelation Jedes Wortersetzungssystem S ⊆ A∗ × A∗ definiert eine Relation →S ⊆ A∗ × A∗ , wobei genau dann u →S v gilt, wenn ein Ableitungsschritt (u, (l → r ), p, v ) mit (l → r ) ∈ S existiert. Beispiel: Für S = {ab → ba, a → b} gilt I aba →S baa wegen (aba, (ab → ba), 1, bba) I aba →S bba wegen (aba, (a → b), 1, bba) I aba →S abb wegen (aba, (a → b), 3, abb) I aba 6→S bbb 98 Ableitungen Eine Folge von Ableitungsschritten (u, (l1 → r1 ), p1 , u2 ), (u2 , (l2 → r2 ), p2 , u3 ), · · · , (un−1 , (ln−1 → rn−1 , pn−1 , v ) im Wortersetzungssystem S heißt Ableitung von u nach v in S. v heißt in S aus v ableitbar gdw. eine Ableitung von u nach v in S existiert. Beispiel: S = {ab → ba, a → b}, u = aba Folge von Ableitungsschritten (aba, (ab → ba), 1, baa), (baa, (a → b), 3, bab), (bab, (a → b), 2, bbb) ab→ba a→b a→b aba −→ baa −→ bab −→ bbb Länge der Ableitung = Anzahl der Ableitungsschritte In jedem System S existiert für jedes u ∈ A∗ die leere Ableitung (der Länge 0) von u nach u. 99 Beispiele S1 = {||| → |} mit u = ||||||| und v = |||| Was wird hier „berechnet“? Anderes Wortersetzungssystem mit derselben Wirkung? S2 = {11 → 1, 00 → 1, 01 → 0, 10 → 0} und u = 1101001 Wirkung verschiedener Ableitungreihenfolgen? S3 = {c → aca, c → bcb, c → a, c → b, c → ε} und u = c Menge aller in S3 ableitbaren Wörter, die kein c enthalten? 100 Ersetzungsrelation Jedes Wortersetzungssystem S ⊆ (A∗ × A∗ ) definiert die Ersetzungsrelation →∗S ⊆ (A∗ × A∗ ), wobei genau dann u →∗S v gilt, wenn eine Ableitung von u nach v existiert. Beispiel: S = {a → aa}, I für jedes n ≥ 1 gilt ba →∗S b |a ·{z · · a} n wegen ba →S baa →S baaa →S · · · →S b |a ·{z · · a} n I b →∗S b, aber für kein Wort w 6= b gilt b →∗S w (→∗S ist die reflexive transitive Hülle von →S ) 101 Sprachen aus Wortersetzungssystemen Jedes Paar (Wortersetzungssystem S, Anfangswort w ∈ A∗ ) über einem Alphabet A definiert die Sprache L(S, w) = {v ∈ A∗ | w →∗S v } (alle Wörter v , die von w durch eine Ableitung in S erreicht werden) Beispiel: S = {c → aca, c → bcb, c → ε}, w = c L(S, w) = {w ◦ c ◦ w R } (Menge aller Palindrome über {a, b, c}, die höchstens an der mittleren Position ein c enthalten) Jedes Paar (Wortersetzungssystem S, Menge M ⊆ A∗ ) über einem Alphabet A definiert die Sprache [ L(S, M) = L(S, w) w∈L (alle Wörter v , die von irgendeinem w ∈ M durch eine Ableitung in S erreicht werden) 102 Ausdrucksstärke von Wortersetzungssystemen Wortersetzungssysteme (SRS) I ermöglichen eine endliche Darstellung unendlicher Sprachen. (als Erzeugungsvorschrift für alle Wörter der Sprache) Beispiele: L ({ε → aaa}, ε) = {a3n | n ∈ } = L((aaa)∗ ) L ({2 → 020, 2 → 121}, 2) = {w2w R | w ∈ {0, 1}∗ } N I können zur Modellierung von Zuständen und Übergängen dazwischen verwendet werden z.B. Spiele, Ausführung von Programmen, Programmverifikation Beispiel: lineares Solitaire I können Berechnungen simulieren (Bestimmung von erreichbaren Wörtern ohne Nachfolger) Beispiel: ε ∈ L ({||| → |}, ||||||) 103 Was bisher geschah I Alphabet, Wort, Sprache I Operationen und Relationen auf Wörtern und Sprachen I interessante Fragen für Sprachen und Wörter (Wortproblem) Reguläre Ausdrücke I Syntax, Semantik I endliche Darstellung evtl. unendlicher Sprachen Wortersetzungssysteme S ⊆ A∗ × A∗ I Wortersetzungssregel l → r mit l, r ∈ A∗ I Ersetzungsschritt in S I Ableitung in S: endliche Folge von Ersetzungsschritten I von Wortersetzungssystem S ⊆ A∗ × A∗ und Startwort w ∈ A∗ definierte Sprache L(S, w) ⊆ A∗ 104 Wortproblem für durch reguläre Ausdrücke definierte Sprachen ∗ Wortproblem (L, w) ∈ 2(A ) × A∗ ist definiert durch: I Wort w ∈ A∗ I Sprache L ⊆ A∗ und bedeutet: Gilt w ∈ L? durch reguläre Ausdrücke definierte Sprachen L = L(E) sind definiert durch I regulären Ausdruck E ∈ RegExp(A) Wortproblem (L(E), w) für durch reguläre Ausdrücke definierte Sprache L(E) ist definiert durch: I Wort w ∈ A∗ I regulären Ausdruck E ∈ RegExp(A∗ ) und bedeutet: Gilt w ∈ L(E)? Beispiele: I Wortproblem (L(a∗ b∗ ), ab) (Gilt ab ∈ L(a∗ b∗ )?) I Wortproblem (L(a∗ b∗ ), ba) (Gilt ba ∈ L(a∗ b∗ )?) 105 Wortproblem für durch SRS erzeugte Sprachen Wortproblem (L, w) ist definiert durch: I Wort w ∈ A∗ I Sprache L ⊆ A∗ und bedeutet: Gilt w ∈ L? durch SRS erzeugte Sprache L = L(S, u) ist definiert durch I Wortersetzungssystem S ⊆ A∗ × A∗ I Startwort u ∈ A∗ Wortproblem (L(S, u), w) für eine durch ein SRS erzeugte Sprache ist definiert durch: I Wort w ∈ A∗ I Wortersetzungssystem S ⊆ A∗ × A∗ I Startwort u ∈ A∗ und bedeutet: Gilt w ∈ L(S, u)? Beispiele: I Wortproblem (L({a → aa, a → bb, ba → ab}, a), abab) I Wortproblem (L({aa → a, bb → ε}, abba), ε) 106 SRS-Wortproblem und Ableitbarkeit Wortproblem (L(S, u), w) mit I Wort w ∈ A∗ I Wortersetzungssystem S ⊆ A∗ × A∗ I Startwort u ∈ A∗ bedeutet: Gilt w ∈ L(S, u)? alternative Formulierung: Gilt u →∗S w? Darstellung der Ableitungsrelation →S als (unendlicher) gerichteter Graph GS = (V , E) mit Knoten: V = A∗ Kanten: E = {(u, v ) ∈ A∗ | u →S v } ⊆ V 2 u →∗S w gilt genau dann, wenn in GS ein Pfad (zusammenhängende Folge von Kanten) von u nach w existiert. Beispiel: (Tafel) S = {ab → ba}, abab →∗S baba, aber abab 6→∗S abaa, abab 6→∗S aabb 107 Lösungsverfahren für SRS-Wortprobleme Lösung des Wortproblems und anderer Fragen zu Sprachen ist für endliche Sprachen einfach, für unendliche Sprachen oft nicht. Darstellung der Sprache durch ein Wortersetzungssystem kann helfen. Idee: Lösung des Wortproblem w ∈ L(S, u) durch Standardverfahren: Suche eines Pfades von u nach w im Ableitungsgraphen des Wortersetzungssystems S Problem: I Pfadsuche ist Standardverfahren für endliche Graphen. (mehr dazu in LV Algorithmen und Datenstrukturen) I Ableitungsgraphen von Wortersetzungssystemen sind meist unendlich. Standardverfahren anwendbar, wenn Suche in einer endlichen Menge von Wörtern (endlichem Teilgraphen) genügt 108 Nichtverlängernde Wortersetzungssysteme Ein Wortersetzungssystem S heißt genau dann nichtverlängernd, wenn für jede Regel (l → r ) ∈ S gilt: |l| ≥ |r |. Wortproblem (L, w): Eingabe : Sprache L ⊆ A∗ , Wort w ∈ A∗ Frage: Gilt w ∈ L? Ausgabe: ja oder nein Beispiel: S = {ab → ba, ac → a}, u = abcac, w = aacb Satz Für jedes nichtverlängernde Wortersetzungssystem S ⊆ A∗ × A∗ und beliebige Wörter u, w ∈ A∗ ist das Wortproblem (L(S, u), w) in endlicher Zeit maschinell korrekt lösbar. Idee: Pfadsuche im endlichen Teilgraphen aller Wörter v ∈ A∗ mit |v | ≤ |u| 109 Nichtverkürzende Wortersetzungssysteme Ein Wortersetzungssystem S heißt genau dann nichtverkürzend, wenn für jede Regel (l → r ) ∈ S gilt: |l| ≤ |r |. Beispiel: S = {a → ba, b → a}, u = ba, w = bba, w 0 = aab Satz Für jedes nichtverkürzende Wortersetzungssystem S ⊆ A∗ × A∗ und beliebige Wörter u, w ∈ A∗ ist das Wortproblem (L(S, u), w) in endlicher Zeit maschinell korrekt lösbar. Idee: Pfaduche im endlichen Teilgraphen aller Wörter v ∈ A∗ mit |u| ≤ |v | ≤ |w| 110 Wortersetzungssysteme mit verlängernden und verkürzenden Regeln Beispiel: c c c aca S= bcb ada bdb → → → → → → → baaca, aacba, bbcabb, d, d, d, d Für Wortersetzungssysteme S mit verlängernden und verkürzenden Regeln existiert im Allgemeinen kein maschinelles Verfahren, welches für beliebige Wörter u, w ∈ A∗ feststellt, ob u →∗s w gilt. 111 Ableitbare Wörter über Teilalphabet Beispiele: A = {a, b, c}, c → c → c → S= c → c → aca, bcb, ε, a, b L(S, c) = {u ◦ d ◦ u R | u ∈ {a, b}∗ ∧ d ∈ {a, b, c, ε}} Menge aller Wörter in L(S, c) ∩ {a, b}∗ : Palindrome über {a, b} c ist Hilfssymbol zur Erzeugung der Palindrome 112 Natürliche Sprache Wortersetzungssystem S enthält die Regeln: Satz → Subjekt Prädikat . Subjekt → mArtikel mSubstantiv Subjekt → wArtikel wSubstantiv mArtikel → Der wArtikel → Die mSubstantiv → Hund wSubstantiv → Sonne Prädikat → bellt Prädikat → scheint Alphabet A = {Der, Die, Hund, Sonne, bellt, scheint, .}∪ { Satz, Subjekt, Prädikat, nArtikel, mArtikel, nSubstantiv, mSubstantiv} Ableitbare Wörter in L(S, Satz ) ohne Hilfssymbole aus der Menge {Satz, Subjekt, Prädikat, mArtikel, wArtikel, mSubstantiv, wSubstantiv}: Menge korrekter deutscher Sätze (dieser einfachen Form mit ausschließlich den Worten Der, Die, Hund, Sonne, bellt, scheint). 113 Aussagenlogik Wortersetzungssystem S enthält die Regeln: Formel → Variable Formel → Konstante Formel → ( ¬ Formel ) Formel → ( Formel ∨ Formel ) Formel → ( Formel ∧ Formel ) Variable → p Variable → q Konstante → t Konstante → f Alphabet A = {t, f, p, q, ¬, ∨, ∧, (, )} ∪{ Formel,Variable, Konstante} Wörter in L(S, Formel ) ∩ {t, f, p, q, ¬, ∨, ∧, (, )}∗ : Menge AL({p, q}) aller aussagenlogischen Formeln mit Aussagenvariablen aus der Menge {p, q} 114 Dezimaldarstellung natürlicher Zahlen Wortersetzungssystem S enthält die Regeln Zahl → 0 Zahl → 1Ziffernfolge .. . Zahl Ziffernfolge → → .. . 9Ziffernfolge 0Ziffernfolge Ziffernfolge Ziffernfolge → → 9Ziffernfolge ε Alphabet {0, . . . , 9} ∪ { Zahl, Ziffernfolge } Wörter in L(S, Zahl ) ∩ {0, . . . , 9}∗ : Menge aller Dezimaldarstellungen natürlicher Zahlen 115 Programmiersprachen Java-Syntax (Ausschnitt) in Backus-Naur Form (BNF) (John Backus, Peter Naur) a → r1 |r2 | . . . |rn statt mehrerer Regeln a → r1 , . . . , a → rn ::= statt → (in ASCII darstellbar) Hilfssymbole markiert durch < und > 116 Definition Grammatik Grammatik G = (N, T , P, S) mit Nichtterminalsymbole endliche Menge N (Hilfssymbole) Terminalsymbole endliche Menge T (Alphabet der erzeugten Sprache) Wortersetzungssystem P ⊆ (N ∪ T )+ × (N ∪ T )∗ (Produktionen) Startsymbol S ∈ N Beispiel: G = (N, T , P, S) mit N = {S}, = {0, 1}, S → 0S1 P = S → ε T 117 Grammatiken: Beispiele I G = (N, T , P, E) mit N = {E, F , G}, T = {(, ), a, +, ·} und E → G, E → E + G, G → F, P= G → G · F, F → a, F → (E) I G = (N, T , P, S) mit N = {S, A, B, C}, T S → aSBC, S → aBC, CB → BC, aB → ab, P= bB → bb, bC → bc, cC → cc = {a, b, c} 118 Ableitungen in Grammatiken Ableitung in Grammatik G = (N, T , P, S): Ableitung im Ersetzungssystem P mit Startwort S Beispiel: G = (N, T , P, S) mit N = {S, A, B} = {0, 1} S S P = A B T → → → → 0SA 0A 1 A Ableitung: S → 0SA → 0S1 → 00A1 → 0011 119 Durch Grammatiken definierte Sprachen Grammatik G = (N, T , P, S) definiert die Sprache L(G) = {w ∈ T ∗ | S →∗P w} = L(P, S) ∩ T ∗ Beispiel: G = (N, T , P, S) mit N = {S, Z } = {0, 1} S S Z P = Z Z T → → → → → 1Z , 0, 0Z , 1Z , ε definiert die Sprache L(G) = . . . 120 Äquivalenz von Grammatiken Zwei Grammatiken G1 und G2 heißen genau dann äquivalent, wenn L(G1 ) = L(G2 ) gilt. Beispiel: G1 = (N1 , {0, 1}, P1 , S) mit N1 = {S, A, B} und S → 0SA S → 0A P1 = A → 1 B → A und G2 = (N2 , {0, 1}, P2 , S 0 ) mit N2 = {S 0 } und P2 = S 0 → 0S 0 1, S 0 → 01 sind äquivalent wegen L(G1 ) = L(G2 ) = . . . 121 Chomsky-Hierarchie (Noam Chomsky, 1956) Eine Grammatik G = (N, T , P, S) ist vom Chomsky-Typ 0 immer, 1 falls für jede Regel (l → r ) ∈ P gilt: |l| ≤ |r | (monoton, kontextsensitiv) 2 falls Typ 1 und für jede Regel (l → r ) ∈ P gilt: l ∈ N (kontextfrei) 3 falls Typ 2 und für jede Regel (l → r ) ∈ P gilt: r ∈ (T ∪ TN) (regulär) Eine Sprache L ⊆ T ∗ heißt vom Typ i für i ∈ {0, . . . , 3}, falls L \ {ε} = L(G) für eine Grammatik G vom Typ i. Li bezeichnet die Menge aller Sprachen vom Typ i. Es gibt Sprachen, die durch keine Grammatik erzeugt werden, also keinen Chomsky-Typ haben (Begründung später). 122 Beispiele I G = ({S}, {a, b}, P, S) mit P = {S → aSb, S → ab, S → a, S → b} ist vom Typ 2 I G = ({S, A, B}, {a, b}, P, S) mit P = {S → aA, A → aB, B → bB, B → b} ist vom Typ 3 I G = ({A, B, C}, {a, b, c}, P, A) mit A → aABC, A → aBC, CB → BC, aB → ab, P= bB → bb, bC → bc, cC → cc ist vom Typ 1 erzeugt die Sprache L(G) = . . . 123 Was bisher geschah I Alphabet, Wort, Sprache I Operationen und Relationen auf Wörtern und Sprachen I interessante Fragen für Sprachen und Wörter z.B. Wortproblem endliche Darstellungen von (möglicherweise unendlichen) Sprachen: I Reguläre Ausdrücke (Terme, Syntax) und durch sie beschriebene Sprachen (Semantik) I Wortersetzungssysteme (Konstruktionsanleitung) und durch sie erzeugte Sprachen Grammatiken (Konstruktionsanleitung) I I I I I I Terminal-, Nichtterminalsymbole Ableitungen in Grammatiken durch Grammatiken erzeugte Sprachen Äquivalenz von Grammatiken Chomsky-Hierarchie für Grammatiken und Sprachen 124 Dyck-Sprache Klammerpaar (, ) Dyck-Sprache: Menge aller korrekt geklammerten Ausdrücke erzeugt durch Grammatik G = ({S}, {(, )}, P, S) mit S → ε S → SS P = S → (S) Beispiele: I ()(()()) ∈ L(G) I ())(6∈ L(G) 125 Allgemeine Dyck-Sprachen Menge aller korrekt geklammerten Ausdrücke mit n Paaren von Klammern: (i , )i für i ∈ {1, . . . , n} erzeugt durch Grammatik G = ({S}, {(i , )i | i ∈ {1, . . . , n}}, P, S) mit S → ε P = ∪ {S → (i S)i | i ∈ {1, . . . , n}} S → SS Symbole müssen nicht notwendig Klammern sein, z.B. aacdacababdbbcabdb ∈ Dyck-Sprache mit a statt (1 , b statt )1 , c statt (2 und d statt )2 126 Beispiel G = ({A, B, C}, {a, b, c}, P, A) mit A → A → CB → aB → P= bB → bC → cC → aABC, aBC, BC, ab, bb, bc, cc erzeugt die Sprache L(G) = . . . 127 Beispiel G = ({Z , F }, {ab}, P, Z ) mit Z Z F P= F F → → → → → 0, 1F , ε 0F , 1F erzeugt die Sprache L(G) = . . . 128 Wiederholung Chomsky-Hierarchie Eine Grammatik G = (N, T , P, S) ist vom Chomsky-Typ 0 immer, 1 falls für jede Regel (l → r ) ∈ P gilt: |l| ≤ |r | (monoton, kontextsensitiv) 2 falls Typ 1 und für jede Regel (l → r ) ∈ P gilt: l ∈ N (kontextfrei) 3 falls Typ 2 und für jede Regel (l → r ) ∈ P gilt: r ∈ (T ∪ TN) (regulär) Eine Sprache L ⊆ T ∗ heißt vom Typ i für i ∈ {0, . . . , 3}, falls L \ {ε} = L(G) für eine Grammatik G vom Typ i. Li bezeichnet die Menge aller Sprachen vom Typ i. Es gibt Sprachen, die durch keine Grammatik erzeugt werden, also keinen Chomsky-Typ haben (Begründung später). 129 Grammatiken mit ε-Regeln ε-Regel : Wortersetzungsregel der Form l → ε Beispiele: I G1 = ({A, B}, {0, 1}, P1 , A) mit P1 = {A → 1B0, B → 1B0, B → ε} ist äquivalent zu G2 = ({A}, {0, 1}, P2 , A) mit P2 = {A → 1A0, A → 10} (ohne ε-Regel) I G = ({A}, {0, 1}, P, A) mit P = {A → 1A0, A → ε} ist nicht äquivalent zu einer Grammatik ohne ε-Regel, weil ε ∈ L(G) Aber: L(G) \ {ε} wird von einer Grammatik ohne ε-Regel erzeugt (L(G) \ {ε} = L(G2 )) 130 ε-Sonderregel in kontextfreien Grammatiken Wiederholung: Sprache L ⊆ T ∗ heißt kontextfrei (Typ 2), wenn eine kontextfreie Grammatik G mit L(G) = L \ ε existiert. ästhetischer wäre: L(G) = L, deshalb kontextfreie Grammatik G = (N, X , P, S) mit ε-Sonderregel: Regel S → ε erlaubt (aber nicht benötigt), falls S in keiner rechten Regelseite in P vorkommt. Fakt Zu jeder kontextfreien Sprache L existiert eine kontextfreie Grammatik mit ε-Sonderregel, so dass L = L(G) gilt. (neues Startsymbol S 0 und Regeln S 0 → ε, S 0 → S hinzufügen) Folgerung Zu jeder regulären Sprache L existiert eine reguläre Grammatik mit ε-Sonderregel, so dass L = L(G) gilt. 131 Eliminierung der ε-Regeln – Beispiel G = ({A, B, S}, {0, 1}, P, S) mit P = {S → AB, A → 1AB, A → ε, B → 0, B → ε, } 1. (schrittweise) Berechnung der Menge aller NT A mit A →∗P ε (löschbare NT): hier: M = {A, B, S} 2. Hinzufügen modifizierter Kopien jeder Regel, die NT aus M auf der rechten Seite enthält. Modifikation: Weglassen des NT rechts, auch Kombinationen hier neu: S → A, S → B, S → ε, A → 1A, A → 1B, A → 1 3. Löschen aller ε-Regeln bis auf ε-Sonderregel Die so konstruierte Grammatik ist kontextfrei, enthält höchstens die ε-Sonderregel und ist äquivalent zu G. 132 Reguläre Sprachen Jede reguläre Sprache L ⊆ A∗ I ist definiert durch einen regulären Ausdruck E ∈ RegExpA I wird erzeugt von einer regulären Grammatik G = (N, T , P, S) mit T = A Beispiel: Die Sprache aller Binärdarstellungen natürlicher Zahlen ohne führende Nullen L(G) = {0} ∪ {1} ◦ {0, 1}∗ I ist definiert durch den regulären Ausdruck 0 + 1(0 + 1)∗ I wird erzeugt von der regulären Grammatik G = ({Z , F }, {ab}, P, Z ) mit P = {Z → 0, Z → 1F , F → ε, F → 0F , F → 1F } oder nur mit ε-Sonderregel (Tafel) 133 Ableitungsbäume für kontextfreie Grammatiken Beispiel: Grammatik G = (N, T , P, E) mit N = {E, F }, T = {a, b, c, (, ), +, ∗}, P = {E → (E + E), E → F ∗ F , F → E, E → a, E → b, E → c} Ableitung für w = (c ∗ a + (b + a ∗ a)) allgemein: Grammatik G = (N, T , P, S) Ableitung S →P w1 →P w2 →P · · · →P wn = w für w in G Ableitungsbaum zu einem Wort w in der kontextfreien Grammatik G (induktive Definition): I Wurzel mit Markierung S I für jeder Anwendung einer Regel A →P r1 · · · rn : Verzweigung bei Symbol A in n Kinder mit Markierungen r1 . . . , rn I Markierung der Blätter (von links nach rechts): Wort w Ein Ableitungsbaum repräsentiert i.A. mehrere Ableitungen. 134 Rechts- und Linksableitungen Eine Ableitung für w in einer kontextfreien Grammatik G heißt Linksableitung , falls in jedem Schritt das am weitesten links stehende Nichtterminal Rechtsableitung , falls in jedem Schritt das am weitesten rechts stehende Nichtterminal ersetzt wird. Zu jedem Ableitungsbaum für w in G existieren I genau eine Linksableitung für w in G und I genau eine Rechtsableitung für w in G. 135 Mehrdeutige kontextfreie Grammatiken Grammatik G heißt eindeutig , falls für jedes Wort w ∈ L(G) genau ein Ableitungsbaum in G existiert. mehrdeutig , sonst. Beispiel: Grammatik G = (N, T , P, E) mit N = {S}, T = {a} und P = {S → SS, S → a} für w = aaa Eindeutigkeit von Grammatiken ist z.B. beim Entwurf von Programmiersprachen (Syntax) wichtig. „dangling else“-Problem (z.B. in C, Java): <Anw> ::= if <Ausdr> then <Anw> <Anw> ::= if <Ausdr> then <Anw> else <Anw> Was bedeutet: if C1 then if C2 then A else B 136 Inhärent mehrdeutige Sprachen Sprachen L, für die keine eindeutige Grammatik G mit L = L(G) existiert, heißen inhärent mehrdeutig. Beispiel: L = {al bm c n | l, m, n > 0 ∧ (l = m ∨ m = n)} ist inhärent mehrdeutig. L = L1 ∪ L2 mit L1 = {al bm c n | l, m, n > 0 ∧ l = m} = {al bl c n | l, n > 0} L2 = {al bm c n | l, m, n > 0 ∧ m = n} = {al bn c n | l, n > 0} Für jedes Wort in L1 ∩ L2 existieren in jeder Grammatik, die L erzeugt, zwei Ableitungsbäume. 137 Was bisher geschah Alphabet, Wort, Sprache Operationen und Relationen auf Wörtern und Sprachen I interessante Fragen für Sprachen und Wörter z.B. Wortproblem endliche Darstellungen von (möglicherweise unendlichen) Sprachen: I Reguläre Ausdrücke (Terme, Syntax) und durch sie beschriebene Sprachen (Semantik) I Wortersetzungssysteme (Konstruktionsanleitung) und durch sie erzeugte Sprachen I Grammatiken (Konstruktionsanleitung) und durch sie erzeugte Sprachen I reguläre Sprachen I I I I I beschrieben durch reguläre Ausdrücke erzeugt von regulären Grammatiken kontextfreie Sprachen I I Ableitungsbäume Mehrdeutigkeit 138 Mächtigkeitsvergleich unendlicher Mengen Eine Menge M heißt genau dann höchstens so mächtig wie die Menge N, wenn eine surjektive Funktion f : N → M existiert. (f : N → M ist surjektiv, gdw. ∀x ∈ M∃n ∈ N : f (n) = x) Beispiele: I I M = {1, 2, 3} ist höchstens so mächtig wie N = {a, b, c, d} N ist höchstens so mächtig wie 3N Zwei Mengen M und N heißen genau dann gleichmächtig, wenn I M höchstens so mächtig wie N und I N höchstens so mächtig wie M ist. (genau dann, wenn eine bijektive Funktion f : N → M existiert) Beispiele: I I M = {1, 2, 3, 4} und N = {a, b, c, d} sind gleichmächtig N und 3N sind gleichmächtig. 139 Abzählbarkeit Eine Menge M heißt genau dann abzählbar, wenn sie höchstens so mächtig wie ist. (also eine surjektive Funktion f : → M existiert) N N (Unendliche) Mengen, die nicht abzählbar sind, heißen überabzählbar. Beispiele: I N, Menge aller geraden Zahlen, Menge aller Primzahlen, jede endliche Menge, Menge aller Paare natürlicher Zahlen, sind abzählbar, I Q R ist überabzählbar. 140 Erstes Diagonalverfahren von Cantor (z.B. zum Nachweis der Abzählbarkeit einer Menge) Satz Die Menge alle Paare natürlicher Zahlen ist abzählbar. Beweisidee (Tafel): zweidimensionale (unendliche) Darstellung diagonale Durchquerung Dovetailing: analoge Idee zur sequentiellen Simulation paralleler Berechnungen I Für jedes endliche Alphabet A ist die Menge A∗ abzählbar. I Für jedes endliche Alphabet A ist jede Sprache L ⊆ A∗ abzählbar. 141 Zweites Diagonalverfahren von Cantor (z.B. zum Nachweis der Überabzählbarkeit einer Menge) Satz Es existieren überabzählbar viele unendliche 01-Folgen. ({0, 1}ω ist überabzählbar.) Beweisidee: indirekt (Tafel) allgemeinere Aussage: Satz (Cantor) Für jede Menge M ist ihre Potenzmenge 2M von M mächtiger als M. 142 Beispiele überabzählbarer Mengen R N [0, 1) ⊂ ist mächtiger als . Es gibt überabzählbar viele reelle Zahlen im Intervall [0, 1]. ist mächtiger als . Es gibt überabzählbar viele reelle Zahlen. N 2 (Menge aller Mengen natürlicher Zahlen) ist mächtiger als . (Überabzählbarkeit der Menge M = 2N ) Es gibt überabzählbar viele Mengen natürlicher Zahlen. ∗ {0,1} 2 Menge aller Sprachen L ⊆ {0, 1}∗ ist mächtiger als {0, 1}∗ . Es gibt überabzählbar viele Sprachen über dem Alphabet {0, 1}. ∗ A 2 für beliebiges endliches Alphabet A Für jedes endliche Alphabet A ist die Menge aller Sprachen über A überabzählbar. R N N 143 Lässt sich jede Sprache durch eine Grammatik repräsentieren? Existiert zu jeder Sprache L ⊆ A∗ eine Grammatik G mit L = L(G)? Nein (Gegenbeispiel später) Begründung: (Aussage für A = {0, 1} zu zeigen, genügt) 1. Wieviele Grammatiken über dem endlichen Alphabet A gibt es? abzählbar viele (weil Grammatiken endliche Beschreibungen sind, nach erstem Diagonalverfahren von Cantor) 2. Wieviele Sprachen L ⊆ A∗ gibt es? überabzählbar viele (zweites Diagonalverfahren von Cantor) Damit existieren sogar sehr viel mehr (überabzählbar viele) Sprachen, die nicht durch Grammatiken beschrieben werden können. Warum sind Grammatiken trotzdem wichtig / interessant? 144 Wortproblem für von Grammatiken erzeugte Sprachen Wortproblem (L, w) ist definiert durch: Wort w ∈ A∗ I Sprache L ⊆ A∗ I und bedeutet: Gilt w ∈ L? Jede durch eine Grammatik G erzeugte Sprache L = L(G) ist definiert durch die Grammatik G = (N, T , P, S) mit I I endliche Mengen N, T , S ∈ N Wortersetzungssystem P ⊆ (N ∪ T )+ × (N ∪ T )∗ Wortproblem (L(G), w) für von einer Grammatik erzeugten Sprache ist definiert durch: Wort w ∈ A∗ I Grammatik G = (N, T , P, S) I und bedeutet: Gilt w ∈ L(G)? Satz Für jede monotone Grammatik G (Chomsky-Typ 1) ist das Wortproblem (L(G), w) in endlicher Zeit maschinell korrekt lösbar. (folgt aus entsprechendem Satz für nichtverkürzende Wortersetzungssysteme) 145 Anwendung bei der Übersetzung von Programmen Höhere Programmiersprachen (z.B. C, Java) erfordern Übersetzung von Quell- in Maschinen- oder Byte-Code Quellcode ↓ Zwischendarstellung ↓ Java-Bytecode Übersetzung in zwei Phasen: 1. Analyse-Phase (Front-End): Transformation des Quellcodes in eine Zwischendarstellung 2. Synthese-Phase (Back-End): Transformation der Zwischendarstellung in Java-Bytecode 146 Analyse-Phase Quellcode Scanner Parser −→ Folge von Token −→ Syntaxbaum lexikalische Analyse (Scanner) lineare Analyse des Quelltextes, Aufteilung in Einheiten (Token) z.B. Schlüsselwörter, Bezeichner, Operatorsymbole, Zahlen reguläre Sprachen (reguläre Ausdrücke, reguläre Grammatiken, . . . ) Syntaxnalyse (Parser) hierarchische Struktur des Quelltextes z.B. Ausdrücke, Verzweigungen, Schleifen kontextfreie Sprachen (kontextfrie Grammatiken, . . . ) semantische Analyse Annotationen im Syntaxbaum, z.B. Typprüfungen 147 Einsatz ähnlicher Analyse-Methoden I Übersetzung von Daten zwischen verschiedenen Formaten I Verarbeitung von Domain-spezifischen Sprachen I Textformatierung I kontextabhängige Hilfe in Entwicklungsumgebungen I statische Analyse zur Fehlersuche in Programmen I Interpreter I graphische Editoren (z.B. für UML-Diagramme) mit automatischer Programmgenerierung 148 Darstellung von Termmengen durch kontextfreie Grammatiken X Wiederholung: induktive Definition für Term(ΣF , ) Die Menge Term(ΣF , ) aller Terme über der (funktionalen) Signatur ΣF mit Variablen aus der Menge ist definiert durch: X IA Jede Variable x ∈ X X ist ein Term. (X ⊆ Term(ΣF , X)) IS Sind (f , n) ∈ ΣF (f ist n-stelliges Funktionssymbol) und t1 , . . . , tn Terme aus Term(ΣF , ), dann ist f (t1 , . . . , tn ) ein Term aus Term(ΣF , ). X X kontextfreie Grammatik für Term(ΣF , ∅) in Präfixform: G = ({S}, T , P, S) mit T = {s | ∃n : (s, n) ∈ ΣF } ∪ P = {S → s | (s, 0) ∈ Σ} X ∪ {(, ), , } ∪{S → s(S) | (s, 1) ∈ Σ} ∪{S → s(S, S) | (s, 2) ∈ Σ} . ∪ .. ∪{S → x | x ∈ X} 149 Beispiel funktionale Signatur ΣF = {(a, 0), (b, 0), (f , 1), (g, 2), (h, 3))}, Variablenmenge {x, y } kontextfreie Grammatik für Term(ΣF , ) in Präfixform: G = ({S}, {a, b, f , g, h, x, y , (, ), , }, P, S) mit S → a S → b S → f (S) S → g(S, S) P= S → h(S, S, S) S → x S → y X Ableitung des Terms f (h(g(a, x), b, y ): S → f (S) → f (h(S, S, S)) → f (h(S, b, S)) → f (h(S, b, y )) → f (h(g(S, S), b, y )) → f (h(g(a, S), b, y )) → f (h(g(a, x), b, y )) ähnlich für Postfix- und Infixform (ggf. Operatorpräferenzen beachten) 150 Beispiel: HTML-Tabellen von der Homepage zu dieser LV: <table> <tr><td> <td> <td> <tr><td> <td> <td> <tr><td> <td> <td> <tr><td> <td> <td> </table> ungerade Woche: </td><td>Montag</td> 9:30 - 11:00 </td><td> Uhr </td> in LNW006 </td></tr> </td><td>Dienstag </td> 15:30 - 17:00 </td><td> Uhr </td> in G327</td></tr> gerade Woche: </td><td>Dienstag</td> 9:30 - 11:00 </td><td> Uhr </td> in LNW006 </td></tr> </td><td> Mittwoch</td> 11:15 - 12:45 </td><td> Uhr </td> in LNW006</td></tr> 151 Grammatik für HTML-Tabellen Grammatik G = ({T , R, C, S}, ASCII, P, T ) mit Beispiel-Ableitung (Linksableitung): T → <table> R </table> → <table> <tr> C </tr> R </table> → <table> <tr> <td> S </td> C </tr> R </table> →∗ <table> <tr> <td> ungerade Woche: </td> C </tr> R </table> → <table> <tr> <td> ungerade Woche: </td> <td> S </td> C </tr> R </table> →∗ <table> <tr> <td> ungerade Woche: </td> <td> Montag </td> C </tr> R </table> → ... Jedes in G ableitbare Wort ist Quelltext einer HTML-Tabelle. 152 Formale Sprachen – Zusammenfassung I Alphabet, Wort, Sprache I Operationen und Relationen auf Wörtern und Sprachen I interessante Fragen für Sprachen und Wörter z.B. Wortproblem endliche Darstellungen von (möglicherweise unendlichen) Sprachen: I Reguläre Ausdrücke (Terme, Syntax) und durch sie beschriebene Sprachen (Semantik) I Wortersetzungssysteme (Konstruktionsanleitung) und durch sie erzeugte Sprachen I Grammatiken (Konstruktionsanleitung) und durch sie erzeugte Sprachen (Chmosky-Hierarchie) I Äquivalenz 153 Formale Sprachen – Spezialfälle kontextfreie Sprachen (Chomsky-Typ 2) erzeugt von kontextfreien Grammatiken Ableitungsbäume, Mehrdeutigkeit schnelle Verfahren zur Lösung des Wortproblems Anwendungen z.B. in Parsern für Programmtransformationen (z.B. Compiler), Verarbeitung natürlicher Sprache reguläre Sprachen (Chomsky-Typ 3) definiert durch reguläre Ausdrücke, erzeugt von regulären Grammatiken sehr schnelle Verfahren zur Lösung des Wortproblems Anwendungen z.B. in Scannern für Programmtransformationen (z.B. Compiler), Suche in Texten 154 Logik in der Informatik theoretische Informatik, Grundlagen: Beschreibung von formalen Sprachen und Berechnungsmodellen (klassische Prädikatenlogik) technische Informatik, z.B. Digitaltechnik: Logikgatter / Schaltnetze (klassische Aussagenlogik) Spezifikation: Definition der Anforderungen an Hardware Verifikation der Korrektheit von Hardware praktische Informatik, z.B. Programmierung: Spezifikation: Definition der Anforderungen an Software Verifikation der Korrektheit von Software Datentypen: definiert durch Eigenschaften (statt Realisierung) (klassische Prädikatenlogik, modale und temporale Logiken) angewandte Informatik, z.B. Datenbanken, künstliche Intelligenz: Wissensrepräsentation / Expertensysteme Problemlösen / automatischen Beweisen (klassische und nichtklassische Logiken, Fuzzy-Logik) allgemein: Logik als Sprache zur Formulierung und Manipulation geeigneter formaler Modelle der Realität 155 Logik – Geschichte I Logik in Philosophie, Rhetorik (Syllogismen) Aristoteles (384 - 322 v.Chr.) I Grundlagen der Rechentechnik Aussagenlogik George Boole (1815 - 1864) I Mathematische Logik Formalisierung des Beweisens (Begriffe und Schlußregeln) Gottfried Wilhelm Leibniz (1646 - 1716) Gottlob Frege (1848 - 1925) David Hilbert (1862 - 1943) Kurt Gödel (1906 - 1978) Unvollständigkeitssatz I formale Grundlagen der (theoretischen) Informatik Alonzo Church (1903 - 1995) Alan Turing (1912 - 1954) 156 Aussagen Aussage = Behauptung Beispiele: I Es regnet. I Die Straße ist naß. I I 9 ist eine Primzahl. √ 2∈ I 3<5 I x < 5 (hängt von x ab, keine Aussage) I Ist x < 5? (keine Aussage) I Sei x < 5. (keine Aussage) I Morgen regnet es. I Es ist nicht alles Gold, was glänzt. Q 157 Wahrheitswerte Prinzipien der klassischen Logik: Zweiwertigkeit Jede Aussage ist wahr oder falsch. ausgeschlossener Widerspruch Keine Aussage ist sowohl wahr als auch falsch. Wahrheitswerte 1 (wahr) oder 0 (falsch) Jede Aussage p hat genau einen Wahrheitswert W(p) ∈ {0, 1}. Beispiele: I W(Es regnet.) = ? I W(Die Straße ist naß.) = ? I I W(9 ist eine Primzahl.) = 0 √ W( 2 ∈ ) = 0 I W(3 < 5) = 1 I W(Morgen regnet es.) = ? I W(Es ist nicht alles Gold, was glänzt.)=1 Q 158 Zusammengesetzte Ausdrücke – Junktoren Junktor (mit zugeordneter Stelligkeit): Symbol (Syntax) für Verknüpfung von Aussagen z.B. „und“ (zweistellig), „nicht“ (einstellig) Gottlob Frege: Die Bedeutung des Ganzen ist eine Funktion der Bedeutung seiner Teile. Wahrheitswert eines zusammengesetzten Ausdruckes lässt sich aus dem Wahrheitswert seiner Teilausdrücke berechnen. Semantik (Bedeutung) eines n-stelligen Junktors ∗: [∗] : {0, 1}n −→ {0, 1} (n-stellige Funktion auf der Menge {0, 1}) Wahrheitswertkonstanten (nullstellige Junktoren): t mit [t] = 1 f mit [f] = 0 159 Konjunktion ∧ Es regnet und 9 ist eine Primzahl. I W(9 ist eine Primzahl.)= 0 I W(Es regnet.)=? I W(Es regnet und 9 ist eine Primzahl.)=0 p ∧ q ist genau dann wahr, wenn beide Aussagen p und q wahr sind. W(p) W(q) W(p ∧ q) 0 0 0 0 1 0 1 0 0 1 1 1 W(p ∧ q) = min(W(p), W(q)) [∧] = min ist kommutativ, assoziativ n ^ pi = p1 ∧ p2 ∧ · · · ∧ pn i=1 160 Disjunktion ∨ (inklusiv) Es regnet oder 3 < 5. I W(3 < 5) = 1 I W(Es regnet)=? I W(Es regnet oder 3 < 5.)=1 p ∨ q ist genau dann wahr, wenn wenigstens eine der Aussagen p und q wahr ist. W(p) W(q) W(p ∨ q) 0 0 0 0 1 1 1 0 1 1 1 1 W(p ∨ q) = max(W(p), W(q)) [∨] = max ist kommutativ, assoziativ n _ pi = p1 ∨ p2 ∨ · · · ∨ pn i=1 161 Negation ¬ √ √ (meist 2 6∈ ¬( 2 ∈ ) √ I W( 2 ∈ )=0 √ I W(¬( 2 ∈ )) = 1 Q Q Q) Q ¬p ist genau dann wahr, wenn p falsch ist. W(p) W(¬p) 0 1 1 0 W(¬p) = 1 − W(p) 162 Implikation → Wenn es regnet, dann ist die Straße naß. I W(Es regnet.)=? I W(Die Straße ist naß.)=? I W(Wenn es regnet, dann ist die Straße naß.)=1 p → q ist genau dann wahr, wenn die Aussage p falsch oder die Aussage q wahr ist. W(p) W(q) W(p → q) 0 0 1 0 1 1 0 0 1 1 1 1 W(p → q) = 1 falls W(p) ≤ W(q) 0 sonst 163 Äquivalenz ↔ 3 < 5 gilt genau dann, wenn 0 < 5 − 3 gilt. I W(3 < 5) = 1 I W(0 < 5 − 3) = 1 I W(3 < 5 gilt genau dann, wenn 0 < 5 − 3 gilt.)=1 p ↔ q ist genau dann wahr, wenn entweder beide Aussagen p und q gelten oder beide nicht gelten. W(p) W(q) W(p ↔ q) 0 0 1 0 1 0 1 0 0 1 1 1 W(p ↔ q) = 1 falls W(p) = W(q) 0 sonst 164 Übersicht Junktoren und ihre Bedeutung wahr falsch Konjunktion Disjunktion Negation Implikation Äquivalenz Stelligkeit Syntax Symbol Semantik Wahrheitswertfunktion 0 0 2 2 1 2 2 t f ∧ ∨ ¬ → ↔ 1 0 min max x 7→ 1 − x ≤ = 165 Aussagenlogische Formeln (Syntax) Definition (induktiv) Die Menge AL(P) aller (aussagenlogischen) Formeln mit Aussagenvariablen aus der Menge P ist definiert durch: IA: Jede Aussagenvariable p ∈ P ist eine Formel. (P ⊆ AL(P)). I t und f sind Formeln. IS: I I Ist ϕ eine Formel, dann ist auch ¬ϕ eine Formel. Sind ϕ und ψ Formeln, dann sind auch ϕ ∨ ψ, ϕ ∧ ψ, ϕ → ψ und ϕ ↔ ψ Formeln. IS’: (Zusammenfassung aller Unterpunkte zu IS) Sind j ein n-stelliger Junktor und ϕ1 , . . . , ϕn Formeln, dann ist auch j(ϕ1 , . . . , ϕn ) eine Formel. (Aus {ϕ1 , . . . , ϕn } ⊆ AL(P) folgt j(ϕ1 , . . . , ϕn ) ∈ AL(P).) dieselbe Definition kürzer: AL(P) = Term(ΣF , P) mit der Signatur ΣF = {(t, 0), (f, 0), (¬, 1), (∨, 2), (∧, 2), (→, 2), (↔, 2)} (Baumdarstellung) 166 Menge aller Aussagenvariablen einer Formel Definition (induktiv über Formelaufbau): Für jede aussagenlogische Formel ϕ ∈ AL(P) ist die Menge var(ϕ) aller in ϕ vorkommenden Aussagenvariablen definiert durch: IA: falls ϕ = p (Atom), dann var(ϕ) = {p} I nullstellige Junktoren (t, f): IS: I I für ϕ = t oder ϕ = f gilt var(ϕ) = ∅ einstellige Junktoren (¬): für ϕ = ¬ϕ1 gilt var(ϕ) = var(ϕ1 ) zweistellige Junktoren (∗ ∈ {∨, ∧, →, ↔}): für ϕ = ϕ1 ∗ ϕ2 gilt var(ϕ) = var(ϕ1 ) ∪ var(ϕ2 ) Beispiel: Für ϕ = p → ((q ↔ t) ∨ (r → q)) gilt var(ϕ) = {p, q, r } 167 Aussagenlogische Interpretationen (Belegungen der Aussagenvariablen mit Wahrheitswerten) Interpretation (für Formeln ϕ ∈ AL(P)) Funktion W : P −→ {0, 1} Beispiel: P = {p, q} und W mit W (p) = 1 und W (q) = 0 Menge aller Interpretationen für Formeln ϕ ∈ AL(P) W(P) = {W : P −→ {0, 1}} = 2P Notation: für P = {p, q} ist W(P) = {W00 , W01 , W10 , W11 } mit W00 (p) = W00 (q) = 0, W01 (p) = 0 und W01 (q) = 1, W10 (p) = 1 und W10 (q) = 0, W11 (p) = W11 (q) = 1. 168 Wahrheitswerte für Formeln Erweiterung der Interpretation W : P −→ {0, 1} zu einer Funktion W : AL(P) −→ {0, 1} Der Wert W (ϕ) der Formel ϕ in der Interpretation W wird induktiv mit den Wahrheitswertfunktionen der Junktoren aus den Werten der Teilformeln von ϕ bestimmt: IA: falls ϕ = p ∈ P (Atom), dann W (ϕ) = W (p) IS: I I I nullstellige Junktoren t, f: W (t) = 1 , W (f) = 0 einstelliger Junktor ¬: für ϕ = ¬ψ gilt W (¬ψ) = [¬]W (ψ) = 1 − W (ψ) zweistellige Junktoren ∨, ∧: W (ψ1 ∧ ψ2 ) = W (ψ1 )[∧]W (ψ2 ) = min (W (ψ1 ), W (ψ2 )) W (ψ1 ∨ ψ2 ) = W (ψ1 )[∨]W (ψ2 ) = max (W (ψ1 ), W (ψ2 )) W (ψ1 → ψ2 ) = W (ψ1 )[→]W (ψ2 ) = 1 gdw. W (ψ1 ) ≤ W (ψ2 ) W (ψ1 ↔ ψ2 ) = W (ψ1 )[↔]W (ψ2 ) = 1 gdw. W (ψ1 ) = W (ψ2 ) Beispiel: ϕ = ((p ∧ ¬q) → (¬r ∨ (p ↔ q))) W (p) = 0, W (q) = 1, W (r ) = 0, W (ϕ) =? 169 Wahrheitswerttabellen Untersuchung der Werte einer Formel ϕ ∈ AL(P) in allen möglichen Interpretationen W ∈ (P) Darstellung in einer Tabelle mit Zeilen – Interpretationen W : var(ϕ) :→ {0, 1} Spalten – Teilformeln von ϕ W W (p1 ) · · · 0 ··· .. . 1 ··· W (pn ) W (ψ) für Teilformeln ψ von ϕ W (ϕ) 0 ··· .. . 1 ··· Beispiel: ϕ = p → ((q ↔ t) ∨ (r → q)) Wertetabelle einer n-stelligen Booleschen Funktion fϕ : {0, 1}n −→ {0, 1}. Die Semantik jeder aussagenlogischen Formel mit n Aussagenvariablen ist eine n-stellige Boolesche Funktion. 170 Modellmenge einer Formel Menge aller Interpretationen (Belegungen) für Formeln aus AL(P) W(P) = {W : P −→ {0, 1}} = 2P Die Belegung W : P → {0, 1} erfüllt die Formel ϕ ∈ AL(P) genau dann, wenn W (ϕ) = 1. Beispiel: erfüllende Belegungen für p ∨ (q ∧ ¬p): W10 , W01 , W11 Definition Jede aussagenlogische Interpretation W : P → {0, 1} mit W (ϕ) = 1 heißt Modell (erfüllende Belegung der Aussagenvariablen) für ϕ. Menge aller Modelle von ϕ ∈ AL(P): Mod(ϕ) = {W : P −→ {0, 1} | W (ϕ) = 1} Beispiele: Mod(p ∨ (q ∧ ¬p)) = . . ., Mod(p → p) = W({p}), Mod(p ∧ ¬p) = ∅ 171 Erfüllbarkeit und Allgemeingültigkeit Definition Eine Formel ϕ ∈ AL(P) heißt erfüllbar , wenn sie ein Modell hat (Mod(ϕ) 6= ∅) Beispiel: ¬p → p unerfüllbar (Widerspruch), wenn sie kein Modell hat (Mod(ϕ) = ∅, für jede Interpretation W gilt W (ϕ) = 0), Beispiel: p ∧ ¬p allgemeingültig (Tautologie), wenn jede Belegung ein Modell für ϕ ∈ AL(P) ist (Mod(ϕ) = (P), für jede Interpretation W gilt W (ϕ) = 1). Beispiel: p ∨ ¬p W Fakt Eine Formel ϕ ∈ AL(P) ist genau dann allgemeingültig, wenn die Formel ¬ϕ unerfüllbar ist. 172 Semantische Äquivalenz aussagenlogischer Formeln Definition Zwei Formeln ϕ und ψ mit Mod(ϕ) = Mod(ψ) heißen (semantisch) äquivalent (ϕ ≡ ψ). Äquivalente Formeln haben dieselbe Wahrheitswertfunktion (Semantik). Nachweis z.B. durch I Wahrheitswerttabellen I Äquivalente Umformung der Modellmengen Beispiele: I p → q ≡ ¬p ∨ q I p ∨ q ≡ ¬p → q I p ∧ q ≡ ¬(p → ¬q) I p ↔ q ≡ (p → q) ∧ (q → p) Achtung: Das Symbol ≡ ist kein Junktor (Syntax), sondern ein Symbol für eine Relation zwischen Formeln (Semantik), 173 Wichtige Äquivalenzen Für alle aussagenlogischen Formeln ϕ, ψ, η gilt: I ϕ ∨ ϕ ≡ ϕ, I ϕ ∨ ψ ≡ ψ ∨ ϕ, ϕ ∧ ψ ≡ ψ ∧ ϕ (Kommutativität von ∧ und ∨) I ϕ ∨ (ψ ∨ η) ≡ (ϕ ∨ ψ) ∨ η ϕ ∧ (ψ ∧ η) ≡ (ϕ ∧ ψ) ∧ η (Assoziativität von ∧ und ∨) I ϕ ∧ (ψ ∨ η) ≡ (ϕ ∧ ψ) ∨ (ϕ ∧ η) ϕ ∨ (ψ ∧ η) ≡ (ϕ ∨ ψ) ∧ (ϕ ∨ η) (Distributivgesetze) I ¬¬ϕ ≡ ϕ (Doppelnegation) I ¬(ϕ ∨ ψ) ≡ ¬ϕ ∧ ¬ψ, ¬(ϕ ∧ ψ) ≡ ¬ϕ ∨ ¬ψ (DeMorgansche Regeln) I ϕ ∨ ψ ≡ ¬(¬ϕ ∧ ¬ψ), ϕ ∧ ψ ≡ ¬(¬ϕ ∨ ¬ψ) (Dualität von ∧ und ∨) I ϕ → ψ ≡ ¬ψ → ¬ϕ (Kontraposition) I (ϕ ∧ ψ) ∨ (¬ϕ ∧ ψ) ≡ ψ (Fallunterscheidung) ϕ ∧ ϕ ≡ ϕ, ϕ ∨ f ≡ ϕ, ϕ∧t≡ϕ 174 Umformen von Formeln Satz (Ersetzbarkeitstheorem) Für drei Formeln ϕ, ψ, η ∈ AL(P), wobei ψ ≡ η und ψ eine Teilformel von ϕ ist, gilt ϕ ≡ ϕ0 , wobei ϕ0 entsteht, indem in ϕ ein Vorkommen von ψ durch η ersetzt wird. (Nachweis durch strukturelle Induktion) Formeln können also durch Ersetzung äquivalenter Teilformeln in semantisch äquivalente Formeln umgeformt werden. (Änderung der Syntax bei unveränderter Semantik) 175 Junktorbasen (vollständige Operatorensysteme) Eine Menge J von Junktoren heißt genau dann Junktorbasis, wenn zu jeder aussagenlogische Formel ϕ eine äquivalente aussagenlogische Formel ψ (d.h. ϕ ≡ ψ) existiert, wobei ψ nur Junktoren aus der Menge J enthält. Beispiele: Die Mengen I {¬, ∨, ∧} I {¬, ∨} I {¬, ∧} I {¬, →} I {f, →} I {NAND} I {NOR} (x NAND y ≡ ¬(x ∧ y )) (x NOR y ≡ ¬(x ∨ y )) sind Junktorbasen. Die Mengen {∨, ∧} und {∨, ∧, →} sind keine Junktorbasen. 176 Normalformen spezielle Formeln: Literal Atom oder negiertes Atom NNF Formeln, in denen das Negationssymbol ¬ höchstens auf Atome angewendet wird, heißen in Negations-Normalform. Beispiel: ¬p ∨ ((¬q ∨ p) ∧ q), ¬p, p W V mi CNF Formeln der Form ni=1 l i,j j=1 mit Literalen li,j heißen in konjunktiver Normalform. Beispiel: (¬p ∨ ¬q) ∧ (p ∨ q) ∧ ¬q, p ∨ q, p ∧ ¬q, ¬p V W mi DNF Formeln der Form ni=1 l j=1 i,j mit Literalen li,j heißen in disjunktiver Normalform. Beispiel: ¬p ∨ (¬q ∧ p) ∨ (p ∧ q), p ∨ q, p ∧ ¬q, ¬p 177 Satz über Normalformen Satz Zu jeder Formel ϕ ∈ AL(P) existieren I eine äquivalente Formel ϕ1 ∈ AL(P) in NNF, I eine äquivalente Formel ϕ2 ∈ AL(P) in CNF und I eine äquivalente Formel ϕ3 ∈ AL(P) in DNF. Transformation beliebiger Formeln in Normalformen: 1. Formeln mit Junktoren →, ↔, t, f schrittweise durch Formeln mit ausschließlich ∨, ∧, ¬ ersetzen 2. Konstruktion einer NNF durch (mehrmalige) Anwendung der deMorganschen Regeln 3. Konstruktion der CNF und DNF durch (mehrmalige) Anwendung der Distributivgesetze auf die NNF Beispiel: p ↔ q , (a → b) → c 178 Modelle von Formelmengen Menge aller Modelle einer Menge Φ ⊆ AL(P) von Formeln: ^ \ ϕ Mod(Φ) = Mod(ϕ) = Mod ϕ∈Φ ϕ∈Φ (Eine Belegung W : P −→ {0, 1} ist genau dann Modell für eine Menge Φ ⊆ AL(P) von Formeln, wenn W Modell für jede Formel ϕ ∈ Φ ist.) Beispiele: I Mod({p, p → q}) = {W11 } I Mod(∅) = {W : P → {0, 1}} (Jede Belegung ist ein Modell für die Formelmenge ∅.) I Beschreibung einer Situation (Menge von Aussagen): I I Anna geht zur Party, wenn Tom oder Paul hingehen. Tom geht zur Party, wenn Paul nicht hingeht. als Formelmenge: Φ = {(T ∨ P) → A, ¬P → T } Mod(Φ) = . . . 179 Was bisher geschah Wiederholung: klassische Aussagenlogik Syntax: I AL(P) = Term(ΣF , P) mit der Signatur ΣF = {(t, 0), (f, 0), (¬, 1), (∨, 2), (∧, 2), (→, 2), (↔, 2)} (Baumstruktur) I Menge der vorkommenden Variablen Semantik: I Belegungen W : P → {0, 1} I Menge (P) = {W : P → {0, 1}} = 2P aller Belegungen I Wert W (ϕ) einer Formel ϕ ∈ AL(P) unter einer Belegung W : P → {0, 1} I Modelle von Formeln, Mod(ϕ) I Semantik einer Formel: Boolesche Funktion W I I I I (Un-)Erfüllbarkeit, Allgemeingültigkeit Äquivalenz von Formeln äquivalente Umformungen von Formeln Normalformen 180 Zusammenhang: logische Junktoren – Mengenoperationen zur Erinnerung: Mod(ϕ) = {W : P −→ {0, 1} | W (ϕ) = 1} Fakt Für alle Formeln ϕ, ψ ∈ AL(P) gilt Mod(¬ϕ) = W(P) \ Mod(ϕ) (1) Mod(ϕ ∨ ψ) = Mod(ϕ) ∪ Mod(ψ) (2) Mod(ϕ ∧ ψ) = Mod(ϕ) ∩ Mod(ψ) (3) 181 Wiederholung: Modelle von Formelmengen Menge aller Modelle einer Menge Φ ⊆ AL(P) von Formeln: ^ \ ϕ Mod(Φ) = Mod(ϕ) = Mod ϕ∈Φ ϕ∈Φ (Eine Belegung W : P −→ {0, 1} ist genau dann Modell für eine Menge Φ ⊆ AL(P) von Formeln, wenn W Modell für jede Formel ϕ ∈ Φ ist.) Beispiele: I Mod({p, p → q}) = {W11 } I Mod(∅) = {W : P → {0, 1}} (Jede Belegung ist ein Modell für die Formelmenge ∅.) I Beschreibung einer Situation (Menge von Aussagen): I I Anna geht zur Party, wenn Tom oder Paul hingehen. Tom geht zur Party, wenn Paul nicht hingeht. als Formelmenge: Φ = {(T ∨ P) → A, ¬P → T } Mod(Φ) = . . . 182 Modellierung durch aussagenlogische Formelmengen Aussagen: 1. Es wird nicht mehr viel Eis gekauft, wenn es kalt ist. 2. Der Eisverkäufer ist traurig, wenn nicht viel Eis gekauft wird. 3. Es ist kalt. Darstellung als Formelmenge Φ ⊆ AL({k , t, v }): Φ = {k → ¬v , ¬v → t, k } Menge aller Modelle von Φ: Mod(Φ) = . . . neue zusätzliche Aussage: 4. Der Eisverkäufer ist nicht traurig. Erweiterung der Formelmenge Φ zu Φ0 = Φ ∩ {¬t} = {k → ¬v , ¬v → t, k , ¬t} Menge aller Modelle von Φ0 : Mod(Φ0 ) = . . . Fakt Für alle Formelmengen Φ, Ψ ⊆ AL(P) gilt: Aus Φ ⊆ Ψ folgt Mod(Φ) ⊇ Mod(Ψ). 183 Semantisches Folgern Definition Eine Formel ψ ∈ AL(P) heißt (semantische) Folgerung aus der Menge Φ ⊆ AL(P) von Formeln (Φ |= ψ), falls Mod(Φ) ⊆ Mod(ψ) gilt. Beispiele: I {p, p → q} |= q I {p, ¬(q ∧ p)} |= ¬q I {p} |= q → p I ∅ |= p ∨ ¬p Folgerungsrelation: zweistellige Relation |= ⊆ 2AL(P) × AL(P) Spezialfälle der Notation: für Φ = {ϕ}: ϕ |= ψ (statt {ϕ} |= ψ) für Φ = ∅: |= ψ (statt ∅ |= ψ) 184 Modellierungsbeispiel Party Beschreibung der Situation (Menge von Aussagen): I Anna geht zur Party, wenn Tom oder Paul hingehen. I Tom geht zur Party, wenn Paul nicht hingeht. Folgt aus diesen Aussagen, dass Anna die Party besucht? Modellierung der Aussagen: Φ = {(T ∨ P) → A, ¬P → T } Modellierung der Frage: I Formulierung als Behauptung (Aussage): ψ = A I Frage umformuliert: Gilt Φ |= ψ ? 185 Sätze über das Folgern I Für endliche Formelmengen Φ = {ϕ1 , . . . , ϕn } gilt Φ |= ψ gdw. n ^ ϕi |= ψ i=1 I |= ϕ gdw. ϕ allgemeingültig ist. I Zwei Formeln ϕ und ψ sind genau dann äquivalent (ϕ ≡ ψ), wenn ϕ |= ψ und ψ |= ϕ gilt. Für jede Formelmenge Φ ⊆ AL(P) und jede Formel ψ ∈ AL(P) gilt: I falls ψ ∈ Φ, dann gilt Φ |= ψ. I Φ |= ψ gdw. Mod(Φ) = Mod(Φ ∪ {ψ}) I Φ |= ψ gdw. Φ ∪ {¬ψ} unerfüllbar I Φ |= ψ gdw. Φ ∪ {¬ψ} |= f 186 Was bisher geschah (klassische Aussagenlogik) Syntax: I AL(P) = Term(ΣF , P) mit der Signatur ΣF = {(t, 0), (f, 0), (¬, 1), (∨, 2), (∧, 2), (→, 2), (↔, 2)} ∪{(p, 0) | p ∈ P} (Baumstruktur) I Menge der vorkommenden Variablen Semantik: I Belegungen W : P → {0, 1} I Menge (P) = {W : P → {0, 1}} = 2P aller Belegungen I Wert W (ϕ) einer Formel ϕ ∈ AL(P) unter einer Belegung W : P → {0, 1} I Modelle von Formeln, W ∈ Mod(ϕ) gdw. W (ϕ) = 1 I Semantik einer Formel ϕ: Modellmenge Mod(ϕ) für ϕ ∈ AL(P): Mod(ϕ) beschreibt Boolesche Funktion W 187 Was bisher geschah (Logiken allgemein) I (Un-)Erfüllbarkeit, Allgemeingültigkeit I I I ϕ unerfüllbar gdw. Mod(ϕ) = ∅ ϕ erfüllbar gdw. Mod(ϕ) 6= ∅ ϕ allgemeingültg gdw. Mod(ϕ) = Menge aller Interpretationen für ϕ I Äquivalenz von Formeln ≡ ⊆ AL(P) × AL(P), wobei ϕ ≡ ψ gdw. Mod(ϕ) = Mod(ψ) I Semantische Folgerung |= ⊆ 2AL(P) × AL(P), wobei Φ |= ψ gdw. Mod(Φ) ⊆ Mod(ψ) 188 Typische Fragen für Formeln und Formelmengen gegeben: Formelmenge Φ ⊆ AL(P) (oder Formel ϕ ∈ AL(P)) Frage: ... Antwort: ja / nein (Wahrheitswert), evtl. mit Begründung Frage beim Erfüllbarkeitsproblem : Ist Φ erfüllbar? Gültigkeitsproblem : Ist Φ allgemeingültig? (effiziente) maschinelle Lösungsverfahren erwünscht Diese Fragen sind für alle Logiken interessant. (AL(P) dient hier nur als Beispiel.) 189 Darstellung der Eingaben als Wörter Wiederholung: Jede endliche Formelmenge Φ V ⊆ AL(P) hat dieselbe Semantik (Modellmenge) wie die Formel ϕ∈Φ ϕ ∈ AL(P). Dies ermöglicht die Darstellung jeder Eingabe als Wort über dem Alphabet A = P ∪ {¬, ∨, ∧, →, (, )}: I Jede Formel ϕ ∈ AL(P) ist ein Wort ∈ A∗ I Darstellung Vendlicher Formelmengen Φ ⊆ AL(P) als ∗ Formeln ϕ∈Φ ϕ ∈ AL(P), also auch als Wort ∈ A Menge aller möglichen (syntaktisch korrekten) Eingaben ist eine Sprache ⊆ A∗ (nämlich genau AL(P)). Lässt sich diese Sprache durch eine Grammatik erzeugen? Wenn ja, welchen Chomsky-Typ hat diese Sprache? 190 Darstellung der Probleme als formale Sprachen Darstellung der Probleme als formale Sprachen (Mengen von Wörtern): Erfüllbarkeitsproblem : E = {ϕ ∈ AL(P) | ϕ erfüllbar} ⊆ AL(P) Gültigkeitsproblem : A = {ϕ ∈ AL(P) | ϕ allgemeingültig} ⊆ AL(P) Erfüllbarkeits- bzw. Gültigkeitsproblem sind Wortprobleme: ? Erfüllbarkeitsproblem : ϕ ∈ E ? Gültigkeitsproblem : ϕ ∈ A 191 Folgerungsproblem gegeben: Paar (Φ, ψ) mit Formelmenge Φ ⊆ AL(P) und Formel ψ ∈ AL(P) Frage: Gilt Φ |= ψ Antwort: ja / nein (Wahrheitswert), evtl. mit Begründung Wiederholung: Endliche Formelmenge Φ ⊆ AL(P) V hat dieselbe Semantik (Modellmenge) wie die Formel ϕ∈Φ ϕ. Folgerungsproblem als formale Sprache: n o F = (Φ, ψ) ∈ 2AL(P) × AL(P) | Φ |= ψ ^ ^ ¬ψ ∧ = ϕ ∈ AL(P) | ¬ψ ∧ ϕ unerfüllbar ϕ∈Φ ϕ∈Φ 192 Zusammenhänge zwischen Erfüllbarkeits-, Allgemeingültigkeits- und Folgerungsproblemen Erfüllbarkeits-, Gültigkeits- und Folgerungsproblem sind aufeinander reduzierbar (ineinander übersetzbar): ? Erfüllbarkeitsproblem ϕ ∈ E (Ist ϕ erfüllbar?) äquivalentes Folgerungsproblem: ϕ ∈ E gdw. (ϕ, f) 6∈ F (ϕ 6|= f) ? Allgemeingültigkeitsproblem ϕ ∈ A (Ist ϕ allgemeingültig?) äquivalentes Erfüllbarkeitsproblem: ϕ ∈ A gdw. ¬ϕ 6∈ E (¬ϕ unerfüllbar) äquivalentes Folgerungsproblem: ϕ ∈ E gdw. (t, ϕ) ∈ F (|= ϕ) ? Folgerungsproblem (Φ, ψ) ∈ F (Gilt Φ |= ψ ?) äquivalentes Erfüllbarkeitsproblem: V (Φ, ψ) ∈ F gdw. ¬ψ ∧ ϕ∈Φ 6∈ E V (¬ψ ∧ ϕ∈Φ unerfüllbar) Hat man ein Lösungsverfahren für eins dieser Probleme, dann kann man damit auch die beiden anderen Probleme lösen. 193 Syntaktisches Ableiten – Ziel gegeben: Formelmenge Φ Formel ψ Frage : Gilt Φ |= ψ ? Ziel: Verfahren zur Beantwortung dieser Frage durch syntaktische Operationen (ohne Verwendung der Semantik, Modellmengen) Syntaktische Ableitungsrelation ` ⊆ 2AL(P) × AL(P) passend zur semantischen Folgerungsrelation |= ⊆ 2AL(P) × AL(P) ` passt zu |= gdw. für jede Formelmenge Φ ∈ AL(P) und jede Formel ψ ∈ AL(P): Φ`ψ gdw. Φ |= ψ 194 Kalküle – Motivation Formale Methode zur schrittweisen syntaktischen Ableitung von sematischen Folgerungen (Formeln) aus einer Menge von Formeln (Hypothesen) Definition von Schlussregeln zur syntaktischen Ableitung von Folgerungen aus Formelmengen (Hypothesen) oft mehrere Voraussetzungen und eine Folgerung (analog Spielregeln, Grammatik-Regeln) Ableitungen : geeignete Kombinationen von Schlussregeln (Baumstruktur) 195 Kalküle - Definition Kalkül Menge von Axiomenschemata , d.h. Schema für Formeln, deren Gültigkeit vorausgesetzt wird, Regelschemata zur syntaktischen Ableitung weiterer gültiger Formeln aus Formelmengen (Axiomen und Hypothesen) häufige Darstellung von Regelschemata: ··· An B I Voraussetzungen (oben): A1 , . . . , An I Folgerung (unten): B Beispiel: Regelschema (Modus Ponens) mit Variablen A, B für Formeln A1 A A → B (MP) B 196 Kalküle - Instanziierung Variablen in Axiomenschemata und Regelschemata müssen vor der Anwendung instanziiert (durch Formeln substituiert) werden. Axiom: instanziiertes Axiomenschema Schlussregel: instanziiertes Regelschema Beispiel: A A → B (MP) B mit Instanziierung A 7→ (p → q), B 7→ ¬q p→q (p → q) → (¬q) (MP) ¬q 197 Ableitungen in Kalkülen gegeben: Kalkül K = (A, R), Formelmenge Φ (Hypothesen, Annahmen) Definition (induktiv): Ableitung der Formel ψ aus Φ in K IA: Ist ψ eine Hypothese (also ψ ∈ Φ) oder ein Axiom (instanziiertes Axiomenschema), dann ist ψ eine Ableitung für ψ aus Φ in K . IS: Sind ϕ1 ··· ψ ϕn eine Schlussregel in K und B1 , . . . , Bn Ableitungen für ϕ1 , . . . , ϕn aus Φ in K , dann ist B1 ··· ψ Bn eine Ableitung für ψ aus Φ in K . 198 Vollständigkeit und Korrekheit von Kalkülen Ableitbarkeit von Formeln aus Formelmengen im Kalkül K : Syntax: Sequenz ϕ1 , . . . , ϕn `K ψ Semantik: Es gibt eine Ableitung von ψ aus der Formelmenge {ϕ1 , . . . , ϕn } im Kalkül K . Ein Kalkül K ist nur dann sinnvoll, wenn gilt: Korrektheit: Aus ϕ1 , . . . , ϕn `K ψ folgt {ϕ1 , . . . , ϕn } |= ψ. Vollständigkeit: Aus {ϕ1 , . . . , ϕn } |= ψ folgt ϕ1 , . . . , ϕn `K ψ. Nachweis über induktiven Aufbau der Ableitungen möglich: IA: Jedes Axiom in K ist eine allgemeingültige Formel. IS: Für jede Schlussregel ϕ1 ··· ψ in K gilt {ϕ1 , . . . , ϕn } |= ψ ϕn 199 Beweise in Kalkülen Möglichkeiten zum Nachweis der Allgemeingültigkeit einer Formel ψ: semantisch: I I syntaktisch: I I Spezialfall Φ = ∅: ψ allgemeingültig WW-Tabellen, Modellmengen Nachweis, dass ∅ |= ψ (|= ψ) äquivalente Umformung von t zu ψ (oder von ψ zu t), Nachweis von ∅ `K ψ (`K ψ) in einem vollständigen und korrekten Kalkül K gdw. |= ψ gdw. `K ψ Beweis für (Allgemeingültigkeit von) ψ in K : Ableitung von ψ aus ∅ in K 200 Beispiel: Kalkül des natürlichen Schließens (Gerhard Gentzen, 1935) Idee: formale Beschreibung des menschlichen Vorgehens beim logischen Schließen und Beweisen Für jeden Junktor ∗ I eine Einführungsregel (∗I) Junktor in der Folgerung (unten), aber in keiner Voraussetzung (oben) des Regelschemas, I eine Eliminierungsregel (∗E) Junktor in einer Voraussetzung (oben), aber nicht in der Folgerung (unten) des Regelschemas, Beispiel: Modus Ponens eliminiert → A A → B (→E) B 201 Kalkül des natürlichen Schließens: Regeln für ∧ A B (∧I) A∧B A ∧ B (∧E) A A ∧ B (∧E) B Schlussregeln korrekt, weil ∀ϕ, ψ: {ϕ, ψ} |= ϕ ∧ ψ {ϕ ∧ ψ} |= ϕ {ϕ ∧ ψ} |= ψ Beispiel: Ableitung für p ∧ q, r `N q ∧ r p∧q (∧E) q q∧r r (∧I) (∧I) Um A ∧ B abzuleiten, muss man sowohl A als auch B ableiten. (∧E) Falls A ∧ B schon abgeleitet wurde, lassen sich daraus auch A und B ableiten. 202 Kalkül des natürlichen Schließens: Regeln für ¬¬ A (¬¬I) ¬¬A ¬¬A (¬¬E) A Schlussregeln korrekt , weil ∀ϕ: {ϕ} |= ¬¬ϕ {¬¬ϕ} |= ϕ Beispiel: Ableitung für p, ¬¬(q ∧ r ) `N ¬¬p ∧ r (Tafel) (¬¬I) Um ¬¬A abzuleiten, muss man A ableiten. (¬¬E) Falls ¬¬A schon abgeleitet wurde, lässt sich daraus auch A ableiten. 203 Kalkül des natürlichen Schließens: Regeln für ∨ A (∨I) A∨B B (∨I) A∨B A∨B [A] .. . C C [B] .. . C (∨E) Schlussregeln korrekt, weil ∀ϕ, ψ, η: {ϕ} |= ϕ∨ψ {ψ} |= ϕ∨ψ {ϕ∨ψ, ϕ → η, ψ → η} |= η Beispiel: Ableitung für p ∨ q `N q ∨ p (Tafel) (∨I) Um A ∨ B abzuleiten, genügt es, eine der Aussagen A oder B ableiten. (∨E) (Fallunterscheidung) Wenn man A ∨ B schon abgeleitet hat und C ableiten möchte, kann man für die Bedingungen A und B einzeln zeigen, dass C unter dieser Bedingung gilt. 204 Kalkül des natürlichen Schließens: Regeln für → [A] .. . B (→I) A→B A A → B (→E) B Schlussregeln korrekt, weil ∀ϕ, ψ: {ϕ → ψ} |= ϕ → ψ {ϕ, ϕ → ψ} |= ψ Beispiel: Ableitung für (p ∧ q) → r `N p → (q → r ) (Tafel) (→I) A → B lässt sich ableiten, indem man zeigt, dass sich B ableiten lässt, wenn A als Annahme hinzugefügt wird. (→E) Modus Ponens 205 Kalkül des natürlichen Schließens: Regeln für ¬ [A] .. . f (¬I) ¬A A f ¬A (¬E) f (fE) A Schlussregeln korrekt, weil ∀ϕ: ϕ → f |= ¬ϕ {ϕ, ¬ϕ} |= f f |= ϕ Beispiel: Ableitung für (p ∧ q) → r `N p → (q → r ) (Tafel) (¬I) ¬A lässt sich ableiten, indem man zeigt, dass sich f ableiten lässt, wenn A angenommen wird. (Spezialfall A = ¬ϕ: Beweis durch Widerspruch) (¬E) Falls A und ¬A schon abgeleitet wurde, lässt sich daraus f ableiten. 206 Was bisher geschah Wiederholung: klassische Aussagenlogik I Syntax: AL(P) = Term(ΣF , P) mit der Signatur ΣF = {(t, 0), (f, 0), (¬, 1), (∨, 2), (∧, 2), (→, 2), (↔, 2)} ∪{(p, 0) | p ∈ P} I Semantik: Modellmenge Mod(ϕ) ⊆ {W : P → {0, 1}}, WW-Tabelle, Boolesche Funktion I Äquivalenz von Formeln ϕ ≡ ψ I Semantisches Folgern Φ |= ψ I Darstellung von Erfüllbarkeits-, Gültigkeits- und Folgerungsproblem als formale Sprachen I Syntaktisches Schließen Φ `K ψ I Kalkül des natürlichen Schließens 207 Modellierung in Aussagenlogik – Beispiel I Wenn der Zug zu spät kommt und kein Taxi am Bahnhof steht, ist Tom nicht pünktlich. I Der Zug kam zu spät und Tom ist pünktlich. Frage: Stand ein Taxi am Bahnhof? Modellierung der Aussagen: Φ = {(z ∧ ¬t) → ¬p, z ∧ p} Modellierung der Frage (als Behauptung): ψ = t Folgerungsproblem (Φ, ψ) ∈ F (Gilt Φ |= ψ ? ) Lösungsansätze semantisch: WW-Tabellen, Bestimmung der Modellmengen syntaktisch: Ableitung Φ `N t 208 Typische praktische Probleme kombinatorische Probleme, z.B. Planungsprobleme (Registerzuweisung, Zeitplanung), Graphfärbung I Verifikation digitaler Schaltungen: I gegeben: Schaltung: (Ausgabe-Verhalten als boolesche Funktion, Formel ϕ) Spezifikation (logische Formel ψ) Frage: Erfüllt die Schaltung die Spezifikation? (Folgt ψ aus ϕ?) Gegenbeispiel bei negativer Antwort: Belegung W : P → {0, 1} mit W (ϕ ∧ ¬ψ) = 1 I Verifikation von Programmen: gegeben: Programm (Ausgabe-Verhalten als Formelmenge Φ) Spezifikation (logische Formel ψ) Frage: Erfüllt das Programm die Spezifikation? (Folgt ψ aus Φ?) Gegenbeispiel bei negativer Antwort: Belegung W : P → {0, 1} mit W ∈ Mod(Φ ∪ {¬ψ}) 209 DNF-SAT Problem DNF-SAT: W Vki gegeben: DNF ϕ = m i=1 j=1 li,j Frage: Ist ϕ erfüllbar? Lösungsidee: I ϕ ist genau dann erfüllbar, wenn (wenigstens) eine der m Vi Konjunktionen kj=1 li,j erfüllbar ist. Vki I Konjunktion j=1 li,j ist genau dann unerfüllbar, wenn für eine Aussagenvariable x ∈ var(ϕ) gilt: {x, ¬x} ⊆ {li,j | j ∈ {1, . . . , ki }} (Widerspruch). W Vki Lösungsverfahren: ϕ = m i=1 j=1 li,j ist genau dann Vi erfüllbar , wenn eine der m Konjunktionen kj=1 li,j widerspruchsfrei ist, unerfüllbar , wenn alle m Konjunktionen einen Widerspruch enthalten. Problem DNF-SAT ist einfach (schnell) zu lösen. 210 CNF-SAT Problem CNF-SAT: V Wki gegeben: CNF ϕ = m i=1 j=1 li,j Frage: Ist ϕ erfüllbar? Lösungsansätze: I Test aller möglichen Belegungen (aufwendig) für große Anzahl an Aussagenvariablen ineffizient I Umformung in eine zu ϕ äquivalente DNF ψ (aufwendig) Test von ψ auf Erfüllbarkeit (einfach) für große Anzahl an Aussagenvariablen ineffizient Konstruktion einer Formel ψ mit I 1. ψ und ϕ erfüllbarkeitsäquivalent (also ψ erfüllbar gdw. ϕ erfüllbar) und 2. Erfüllbarkeit für ψ einfach zu testen Problem CNF-SAT ist schwierig (zeitaufwendig) zu lösen. 211 Erfüllbarkeitsäquivalenz Definition Zwei Formeln ϕ, ψ heißen erfüllbarkeitsäquivalent, wenn gilt: ϕ ist genau dann erfüllbar, wenn ψ erfüllbar ist. Achtung: Erfüllbarkeitsäquivalenz ist schwächer als semantische Äquivalenz. Beispiel: p ∨ q und r sind erfüllbarkeitsäquivalent, aber nicht äquivalent. Erfüllbarkeitsäquivalenz bleibt beim Einsetzen in Formeln nicht erhalten. Beispiel: p und q sind erfüllbarkeitsäquivalent, aber p ∧ ¬p und p ∧ ¬q nicht. 212 Spezialfall 2-SAT 2-CNF: Formel der Form ϕ= ki m _ ^ li,j mit ∀i ∈ {1, . . . , m} : ki ≤ 2 i=1 j=1 Problem 2-SAT: gegeben: 2-CNF ϕ Frage: Ist ϕ erfüllbar? Problem 2-SAT ist einfach (schnell) zu lösen. (Lösung als Graphproblem) Aber: Nicht zu jeder Formel ϕ ∈ AL(P) existiert eine erfüllbarkeitsäquivalente 2-CNF. 213 3-CNF 3-CNF: Formel der Form ϕ= ki m _ ^ li,j mit ∀i ∈ {1, . . . , m} : ki ≤ 3 i=1 j=1 Satz Zu jeder Formel ϕ ∈ AL(P) existiert eine erfüllbarkeitsäquivalente 3-CNF ψ. gegeben: CNF ϕ Wk Konstruktion von ψ durch Ersetzen jeder Konjunktion j=1 lj durch (l1 ∨ q1 ) ∧ k^ −1 (¬qh−1 ∨ lh ∨ qh ) ∧ (¬qk −1 ∨ lk −1 ∨ lk ) h=2 mit neuen Aussagevariablen {q1 , . . . , qn } (für Teilformeln) Beispiel: (a ∨ b ∨ c ∨ d) erfüllbarkeitsäquivalent zu (a ∨ q1 ) ∧ (¬q1 ∨ b ∨ q2 ) ∧ (¬q2 ∨ c ∨ d) 214 Spezialfall 3-SAT Problem 3-SAT: gegeben: 3-CNF ϕ Frage: Ist ϕ erfüllbar? Problem 3-SAT ist schwierig zu lösen. (genauso aufwendig wie CNF-SAT) 215 SAT-Solver SAT-Solver: Werkzeug zum Lösen von CNF-SAT-Instanzen Problem CNF-SAT schwierig (in ungünstigen Fällen) SAT-Solver I benutzen heuristische Verfahren, I finden für praktische Probleme oft schnell eine Lösung, I meist Ausgabe einer erfüllenden Belegung möglich (wenn eine existiert) aktive Forschung auf diesem Gebiet: jährlich Wettbewerbe (www.satcompetition.org) typische Anwendung von SAT-Solvern: 1. Modellierung des ursprünglichen Problems P als CNF-SAT-Instanz P 0 (Darstellung als CNF ϕ) 2. Lösung von P 0 mit SAT-Solver 3. Übersetzung erfüllender Belegung für ϕ in Lösung für P 216 Modellierungsbeispiel: n-Damen Frage: Lassen sich n Damen so auf einem n × n-Schachbrett anordnen, dass keine Dame eine andere bedroht? Lösung: Anordnung, falls möglich Bedingungen: I n Damen auf dem Feld I keine Zeilenbedrohung I keine Spaltenbedrohung I keine diagonale Bedrohung 217 Repräsentation des 3-Damen-Problems 9 Felder – Aussagenvariablen {x1 , . . . , x9 } Bedingungen: I I I I n Damen auf dem Feld, (in jeder Zeile eine Dame) x1 ∨ x2 ∨ x3 , x4 ∨ x5 ∨ x6 , x7 ∨ x8 ∨ x9 keine Zeilenbedrohung x1 → ¬x2 , x4 → ¬x5 , x7 → ¬x8 , x1 → ¬x3 , x4 → ¬x6 , x7 → ¬x9 , x2 → ¬x3 x5 → ¬x6 x8 → ¬x9 keine Spaltenbedrohung x1 → ¬x4 , x2 → ¬x5 , x3 → ¬x6 , x1 → ¬x7 , x2 → ¬x8 , x3 → ¬x9 , x4 → ¬x7 x5 → ¬x8 x6 → ¬x9 keine diagonale Bedrohung x1 → ¬x5 , x1 → ¬x9 , x2 → ¬x6 , x3 → ¬x5 , x3 → ¬x7 , x2 → ¬x4 , x5 x4 x5 x6 → ¬x9 → ¬x8 → ¬x7 → ¬x8 Lösung: Modell (erfüllende Belegung) 218 Lösung mit SAT-Solver DIMACS-Format für CNF (ASCII): erste Zeile enthält Typ (cnf), Anzahl der Klauseln und Aussagenvariablen (z.B. p cnf 5 3) I Aussagenvariablen {1, . . . , n} I jede Klausel eine Zeile, - statt ¬, Literale durch Leerzeichen getrennt, 0 markiert Ende der Klausel I 3-Damen-Problem hat keine Lösung (unerfüllbar) eine Lösung für das 4-Damen-Problem: ¬1 ∧ ¬2 ∧ 3 ∧ ¬4 ∧5 ∧ ¬6 ∧ ¬7 ∧ ¬8 ∧ ¬9 ∧¬10 ∧ ¬11 ∧ 12 ∧¬13 ∧ 14 ∧ ¬15 ∧ ¬16 × × × × typische Anwendungen für SAT-Solver: Schaltkreisverifikation Model-Checking I Planen I Constraint-Lösen I kombinatorische Suchprobleme, z.B. Sudoku I I 219 Zusammenfassung klassische Aussagenlogik Syntax: AL(P) = Term(ΣF , P) mit der Signatur ΣF = {(t, 0), (f, 0), (¬, 1), (∨, 2), (∧, 2), (→, 2), (↔, 2)} ∪ {(p, 0) | p ∈ P} Semantik: Modellmenge Mod(ϕ) ⊆ {W : P → {0, 1}}, WW-Tabelle, Boolesche Funktion semantische Äquivalenz von Formeln ϕ ≡ ψ Semantisches Folgern Φ |= ψ I Syntaktisches Ableiten Φ `N ψ, Kalküle (Kalkül des natürlichen Schließens) I Anwendungen: I Erfüllbarkeitsprobleme, z.B. kombinatorische Suche: n-Damen, Planen I Allgemeingültigkeitsprobleme, z.B. Schaltungsentwurf I Unerfüllbarkeitsprobleme, z.B. Hardware-Verifikation (Nachweis der Korrektkeit) I Folgerungsprobleme, z.B. automatisches Beweisen Darstellung als formale Sprachen, Wortprobleme I CNF und SAT-Solver I I 220 Algorithmische Entscheidbarkeit der Aussagenlogik Es existieren Verfahren, welche I für jede Formel ϕ ∈ AL(P) entscheiden, ob I ϕ erfüllbar ist, z.B. semantisch Modellmengen, WW-Tabelle I ϕ unerfüllbar ist, z.B. semantisch Modellmengen, WW-Tabelle syntaktisch Ableitung für ϕ `K f, äquivalente Umformung von ϕ zu f, I ϕ allgemeingültig ist, z.B. semantisch Modellmengen, WW-Tabelle syntaktisch Ableitung für `K ϕ, äquivalente Umformung zu ϕ ≡ t, I für jedes Paar von Formeln ϕ, ψ ∈ AL(P) entscheiden, ob ϕ ≡ ψ semantisch Modellmengen, WW-Tabelle syntaktisch äquivalente Umformungen I für jede Formelmenge Φ ⊆ AL(P) und jede Formel ψ ∈ AL(P) entscheiden, ob Φ |= ψ (ob ψ aus Φ folgt) semantisch Modellmengen, WW-Tabelle V syntaktisch Ableitung für Φ `K ψ, Umformung ¬ψ ∧ ϕ∈Φ ϕ ≡ f 221 Beschränkte Ausdrucksstärke der Aussagenlogik I Aussagen immer zweiwertig (nur wahr oder falsch, keine Zwischenwerte), z.B.: Die Rose ist rot. Das Bier ist kalt. Der Student ist fleißig. (Erweiterung zu mehrwertigen Logiken, fuzzy logic) I Aussagen immer absolut (keine Abhängigkeit vom Kontext, z.B. Ort, Zeitpunkt), z.B.: Es regnet. x > 3 (Erweiterung zur Modal- und Temporallogiken) I Aussagen über alle Elemente „großer“ Mengen aufwendig (Erstellung, Platzbedarf), z.B. n-Damen-Problem I keine Aussagen über Elemente einer unendlichen Mengen oder Mengen unbestimmter Mächtigkeit möglich, z.B. I Jede durch 4 teilbare Zahl ist gerade. I In jedem zusammenhängenden Graphen mit ≥ 2 Knoten hat jeder Knoten einen Nachbarn. I Es ist nicht alles Gold was glänzt. (Erweiterung zur Prädikatenlogik) 222 Modellierung in Prädikatenlogik Grundannahme: Die zu modellierende Welt besteht aus Individuen, die Eigenschaften haben und zueinander in Beziehungen (Relationen, Funktionen) stehen. Prädikatenlogik zur Formalisierung von Aussagen über Eigenschaften oder Beziehungen von Individuen aus algebraischen Strukturen 223 Prädikatenlogische Aussagen – Beispiele Personen sind genau dann Geschwister, wenn sie dieselbe Mutter oder denselben Vater haben. I A ist genau dann Nachfahre von B, wenn B A’s Vater oder A’s Mutter ist oder ein Elternteil von A Nachfahre von B ist. I Nachfahren derselben Person sind verwandt. Individuenbereich: Menge von Personen Beziehungen: Nachfahre, verwandt, Geschwister Funktionen: Mutter, Vater I Primzahlen sind genau diejenigen natürlichen Zahlen, die genau zwei verschiedene Teiler haben. I Gerade Zahlen sind genau diejenigen natürlichen Zahlen, die durch 2 teilbar sind. I Es existieren gerade Primzahlen. I Nachfolger ungerader Primzahlen sind nicht prim. I Das Quadrat jeder geraden Zahl ist gerade. Individuenbereich: Menge aller natürlichen Zahlen Eigenschaft: prim, gerade Beziehung: teilt Funktion: Nachfolger, Quadrat I N 224 Signaturen und Terme (Wiederholung) Syntax: Signatur Σ = (ΣF , ΣR ), Menge von Variablen Terme Term(Σ, ) (nur ΣF relevant), Grundterme Term(Σ, ∅) X X Semantik: I I I I I Σ-Struktur A = (A, J·KA ): I nichtleere Trägermenge A I für jedes (f , n) ∈ Σ eine Funktion Jf KA : An → A F n I für jedes (R, n) ∈ Σ eine Relation JRK A ⊆A R Σ-Interpretation (A, α) mit Σ-Struktur A = (A, J·KA ) und Belegung der Individuenvariablen α : X→A Wert JtKA des Grundtermes t ∈ Term(Σ, ∅) in Σ-Struktur A, Äquivalenz von Grundtermen s, t ∈ Term(Σ, ∅) in Struktur A: s ≡A t gdw. JsKA = JtKA Wert JtK(A,α) des Termes t ∈ Term(Σ, (A, α) X) in Σ-Interpretation 225 Beispiele (Wiederholung) Signatur Σ = (ΣF , ΣR ) mit ΣF = {(a, 0), (f , 1)} und ΣR = {(P, 1), (R, 2)}, Variablenmenge = {x, y } Σ-Struktur S = (S, J·KS ) mit X S = {0, 1, 2} JaKS = 1 JPKS = {0, 2} für alle d ∈ S: Jf KS (d) = 2 − d JRKS = {(1, 0), (1, 2), (2, 2)} Belegung β : {x, y } → {0, 1, 2}: β(x) = 0, β(y ) = 1 Werte der folgenden Terme aus Term(Σ, ) in der Interpretation (S, β): JaK(S,β) = . . ., Jy K(S,β) = . . ., Jf (a)K(S,β) = . . ., Jf (f (x))K(S,β) = . . . f (f (a)) ≡S f (a) ≡S a X 226 Atome (elementare Aussagen) Aussagenlogik : Aussagenvariable, bekommt festen Wahrheitswert durch Belegung Prädikatenlogik : (parametrisierte) Aussage über Eigenschaften von oder Beziehungen zwischen Individuen Wahrheitswert abhängig von beteiligten Individuen z.B. nebeneinander(x, y ),gerade(n) , x < 3, x < y , geschwister(x, mutter(y )) 227 Atome – Syntax Atom elementare Formel, repräsentiert Eigenschaften von oder Beziehungen zwischen Individuen Signatur Σ = (ΣF , ΣR ) mit I Menge ΣF von Funktionssymbolen mit Stelligkeit (f , n) I Menge ΣR von Relationssymbolen mit Stelligkeit (R, n) Definition Menge aller Σ-Atome mit Variablen aus der Menge Atom(Σ, X: X) = {R(t1 , . . . , tn ) | (R, n) ∈ ΣR und t1 , . . . , tn ∈ Term(ΣF , X)} Atome ohne Individuenvariablen heißen Grundatome. Menge aller Grundatome: Atom(Σ, ∅) 228 Atome – Beispiele I Signatur Σ = (ΣF , ΣR√) mit ΣF = {(1, 0), (2, 0), ( , 1), (+, 2)} ΣR = {(=, 2), (≤, 2)} Variablenmenge = {x, y , z} X I I I I X X √ √ √x = 2 ∈ Atom(Σ, ) ) (aber x + 2 ∈ Term(ΣF , px + 2√ 6∈ Atom(Σ, p√ 1+ 2≤ 2 ∈ Atom(Σ, ∅) X)) Signatur Σ = (ΣF , ΣR ) mit ΣF = {(a, 0), (b, 0), (k , 2), (d, 2)} ΣR = {(P, 1), (Q, 2)} Variablenmenge = {x, y } X I I I I I X y 6∈ Atom(Σ, ) P(x) ∈ Atom(Σ, ) P(a) ∈ Atom(Σ, ∅) P(Q(P(a), k (x, y ))) 6∈ Atom(Σ, ) Q(k (a, d(y , a)), x) ∈ Atom(Σ, ) X X X 229 Atome – Semantik X Signatur Σ = (ΣF , ΣR ), Variablenmenge Menge Atom(Σ, ) aller Atome mit Variablen aus Σ-Interpretation (A, α) mit X I X Σ-Struktur A = (A, J·KA ) X→A Wert des Atomes a = P(t1 , . . . , tn ) ∈ Atom(Σ, X) in der Interpretation I Belegung der Individuenvariablen α : (A, α): JaK(A,α) = JP(t1 , . . . , tn )K(A,α) = JPKA Jt1 K(A,α) , . . . , Jtn K(A,α) 1 falls Jt1 K(A,α) , . . . , Jtn K(A,α) ∈ JPKA = 0 sonst (Spezialfall Atom a mit (a, 0) ∈ ΣF : JaK(A,α) = JaKA ) Der Wert eines Atomes in einer Interpretation (A, α) ist ein Wahrheitswert. Der Wert von Grundatomen in einer Interpretation (A, α) hängt nicht von der Belegung α ab. 230 Semantik von Atomen – Beispiele Signatur Σ = (ΣF , ΣR ) mit ΣF = {(a, 0), (f , 1)} und ΣR = {(P, 1), (R, 2)}, Variablenmenge = {x, y } Σ-Struktur S = (S, J·KS ) mit X S = {0, 1, 2} JaKS = 1 JPKS = {0, 2} für alle d ∈ S: Jf KS (d) = 2 − d JRKS = {(1, 0), (1, 2), (2, 2)} Belegung β : {x, y } → {0, 1, 2}: β(x) = 0, β(y ) = 1 Wert der folgenden Atome aus Atom(Σ, ) in der Interpretation (S, β) (Tafel): JP(x)K(S,β) = . . . , JP(a)K(S,β) = . . ., JP(f (a))K(S,β) = . . . , JP(f (f (x)))K(S,β) = . . ., JR(x, a)K(S,β) = . . ., JR(f (y ), x)K(S,β) = . . . X 231 Prädikatenlogik (der ersten Stufe) – Syntax bekannt: aussagenlogische Junktoren t, f, ¬, ∨, ∧, →, ↔ neu: Σ-Atome, Quantoren ∀, ∃ Definition (induktiv) X Die Menge FOL(Σ, ) aller Formeln der Prädikatenlogik (der ersten Stufe, first order logic) über der Signatur Σ mit (Individuen-)Variablen aus der Menge ist definiert durch: X X X IA: Atom(Σ, ) ⊆ FOL(Σ, ) (alle Atome sind Formeln) IS: I I X Aus {ϕ1 , . . . , ϕn } ⊆ FOL(Σ, ) folgt für jeden n-stelligen Junktor ∗: ∗(ϕ1 , . . . , ϕn ) ∈ FOL(Σ, ) Aus ϕ ∈ FOL(Σ, ) und x ∈ folgt {∀xϕ, ∃xϕ} ⊆ FOL(Σ, ) X X X X Baumstruktur der Formeln (analog zur Definition von Termen) FOL(Σ, ) ist eine formale Sprache (Welcher Chomsky-Typ?)) X 232 Beispiele I Signatur Σ = (ΣF , ΣR ) mit ΣF = {(a, 0), (f , 1)} und ΣR = {(P, 1), (R, 2)} Variablenmenge = {x, y } Formeln aus FOL(Σ, ): X I X ϕ1 = P(f (x)) ϕ2 = (P(x) ↔ (¬P(f (x)) ∧ (∀x∃y ((P(x) ↔ P(y )) ∧ R(x, y ))))) ϕ3 = ∀x∀y ϕ2 Σ = (∅, ΣR ) mit ΣR = {(p, 0), (q, 0)}, X=∅ Formeln aus FOL(Σ, ∅): ψ1 = p∨q ψ2 = ¬p ∨ ¬(q ∨ p) (Syntax der Aussagenlogik ist Spezialfall der FOL-Syntax) 233 Variablen in Formeln Eine Individuenvariablen x ∈ X kommt vor in Term t, falls t = x oder t = f (t1 , . . . , tn ) und x in einem ti vorkommt Atom a = p(t1 , . . . , tn ), falls x in einem ti vorkommt Formel ϕ, falls x in einem Atom in ϕ (Teilformel von ϕ, die Atom ist) vorkommt. var(ϕ) Menge aller in ϕ vorkommenden Indiviuenvariablen Ein Vorkommen der Indiviuenvariablen x in ϕ heißt gebunden , falls x in einer Teilformel von ϕ der Form ∃xψ oder ∀xψ vorkommt, bvar(ϕ) Menge aller in ϕ gebundenen vorkommenden Variablen frei , sonst fvar(ϕ) Menge aller in ϕ frei vorkommenden Variablen var(ϕ) = fvar(ϕ) ∪ bvar(ϕ) gilt immer. fvar(ϕ) ∩ bvar(ϕ) 6= ∅ ist möglich. 234 Beispiele ϕ1 = R(x, a) ϕ2 = ∃xR(x, f (y , x)) bvar(ϕ1 ) = ∅, fvar(ϕ1 ) = {x} bvar(ϕ2 ) = {x}, fvar(ϕ2 ) = {y } ϕ3 = (P(x) ↔ (¬P(f (x)) ∧ (∀x∃y ((P(x) ↔ P(y )) ∧ R(x, y ))))) bvar(ϕ3 ) = {x, y }, fvar(ϕ3 ) = {x} ϕ4 = ∀x∀y ϕ3 bvar(ϕ4 ) = {x, y }, fvar(ϕ4 ) = ∅ 235 Was bisher geschah klassische Prädikatenlogik (der ersten Stufe) FOL(Σ, X) Syntax: I Wiederholung: I I I I I Signaturen Σ = (ΣF , ΣR ) Terme Term(Σ, ) X X) Formeln in FOL(Σ, X) Atome in FOL(Σ, Variablenvorkommen in einer Formel ϕ ∈ FOL(Σ, freie (fvar(ϕ)), gebundene (bvar(ϕ)) Vorkommen X): Semantik: I Wiederholung: I I I I Σ-Strukturen S = (S, J·KS ), Belegungen der Individuenvariablen, Σ-Interpretationen Wert von Termen in Σ-Interpretationen Wert von Atomen in Σ-Interpretationen 236 Modifizierte Interpretationen Signature Σ, Variablenmenge X Σ-Struktur S = (S, J·KS ) X → S der Variablen aus X in S modifizierte Belegung β[x 7→ a] : X → S mit Belegung β : β[x 7→ a](y ) = a für y = x β(y ) sonst Σ-Interpretation (S, β) mit I I Σ-Struktur S = (S, J·KS ) Variablenbelegung β : X→S modifizierte Interpretation (S, β[x 7→ a]) 237 Wert in Interpretationen Wert in Σ-Interpretation (S, β) mit S = (S, J·KS ) I I I I X: JxK(S,β) = β(x) ∈ S eines Termes t = f (t1 , . . . , tn ) ∈ Term(Σ F , X): einer Individuenvariable x ∈ JtK(S,β) = Jf KS Jt1 K(S,β) , . . . , Jtn K(S,β) ∈ S X eines Atomes a = p(t1 , . . . , tn ) ∈ Atom(Σ, ): JaK(S,β) = JpKS (Jt1 K(S,β) , . . . , Jtn K(S,β) ) ∈ {0, 1} einer Formel ϕ ∈ FOL(Σ, X): JϕK(S,β) ∈ {0, 1} J¬ϕK(S,β) = 1 − JϕK(S,β) Jϕ ∨ ψK(S,β) = max(JϕK(S,β) , JψK(S,β) ) Jϕ ∧ ψK(S,β) = min(JϕK(S,β) , JψK(S,β) ) J∃xϕK(S,β) = max{JϕK(S,β[x7→a]) | a ∈ S} J∀xϕK(S,β) = min{JϕK(S,β[x7→a]) | a ∈ S} 238 Beispiele Σ = (ΣR , ΣF ) mit ΣF = {(f , 1)},ΣR = {(R, 2)}, ϕ = ¬R(x, y ) ∧ ∃zR(z, z) I I X = {x, y , z} ψ = ∀x∃yR(x, f (y )) Σ-Struktur A = (A, J·KA ) mit A = {a, b, c} Jf KA (a) = Jf KA (b) = c, Jf KA (c) = a JRKA = {(a, a), (b, a), (a, c)} Belegung α(x) = b, α(y ) = a , α(z) = b JϕK(A,α) = . . . JψK(A,α) = . . . Z Σ-Struktur B = (B, J·KB ) mit B = Jf KB (d) = −d, JRKB =≤ Belegung β(x) = 5, β(y ) = 3, β(z) = −1, JϕK(B,β) = . . . JψK(B,β) = . . . 239 Spezialfall Aussagenlogik – Semantik Σ = (ΣF , ΣR ) mit ΣR = {(p, 0) | p ∈ P} (Aussagenvariablen) Σ-Struktur S = (S, J·KS ) definiert für jedes p ∈ P : JpKS ∈ {0, 1} (Trägermenge S irrelevant) Struktur S definiert also eine Belegung WS : P → {0, 1} der Aussagenvariablen mit Wahrheitswerten durch für alle Atome p ∈ P: WS (p) := JpKS Dann gilt auch für alle Formeln ϕ ∈ FOL(Σ, ∅) (= AL(P)): JϕKS = WS (ϕ) Beispiel: Σ = (ΣF , ΣR ) mit ΣF = ∅, ΣR = {(a, 0), (b, 0), (c, 0)} ϕ = a ∧ (¬c ∨ b) Σ-Struktur S = (S, J·KS ) mit JaKS = JcKS = 1 und JbKS = 0 WS (a) = WS (c) = 1 und WS (b) = 0 (aussagenlogischer) Wert WS (ϕ) = 0 (= JϕKS ) 240 Modelle für Formeln (analog zu Aussagenlogik) Σ-Interpretation (S, β) erfüllt (ist Modell für) die Formel ϕ ∈ FOL(Σ, ) genau dann, wenn JϕK(S,β) = 1. X X Menge aller Modelle der Formel ϕ ∈ FOL(Σ, ) S = (S, J·KS ) ist Σ-Struktur und β : Mod(ϕ) = (S, β) und JϕK(S,β) = 1 Formel ϕ ∈ FOL(Σ, X→S X) heißt erfüllbar gdw. Mod(ϕ) 6= ∅ (z.B. ∀x (P(x) ∨ Q(x))) unerfüllbar gdw. Mod(ϕ) = ∅ (z.B. ∀xP(x) ∧ ∃x¬P(x) ) allgemeingültig gdw. Mod(ϕ) = {(S, β) | S = (S, J·KS ) ist Σ-Struktur und β : X → S} (Menge aller Σ-Interpretationen) 241 Beispiele ϕ = R(x) ∧ ∃y ((¬R(y )) ∧ E(y , x)) I Struktur G = ({1, . . . , 4}, J·KG ) mit JRKG = {1, 2, 4}, JEKG = {(1, 2), (3, 2)} und Belegung α : {x, y } → {1, . . . , 4} mit α(x) = 2, α(y ) = 2 (G, α) ∈ Mod(ϕ) I Struktur H = ({a, b}, J·KH ) mit JRKH = {a}, JEKH = {(a, a), (b, b)}, Belegung β : {x, y } → {a, b} mit β(x) = a, β(y ) = a (H, β) 6∈ Mod(ϕ) I Struktur J = ( , J·KJ ) mit JRKJ = 2 (Menge aller geraden Zahlen), JEKJ = {(i, i + 1) | i ∈ } und Belegung γ : {x, y } → mit γ(x) = γ(y ) = 0 (J , γ) ∈ Mod(ϕ) Z Z Z Z 242 Semantische Äquivalenz von Formeln (analog Aussagenlogik) Für ϕ, ψ ∈ FOL(Σ, X ) gilt ϕ≡ψ gdw. Mod(ϕ) = Mod(ψ) Beispiele: I ¬∀xP(x) ≡ ∃x¬P(x) I ∀x∃yR(x, y ) 6≡ ∀x∃yR(y , x) I ∀x∃yR(x, y ) 6≡ ∃x∀yR(x, y ) 243 Wichtige Äquivalenzen mit Quantoren ¬∀xϕ ≡ ∃x¬ϕ ¬∃xϕ ≡ ∀x¬ϕ ∀xϕ ∧ ∀xψ ≡ ∀x(ϕ ∧ ψ) ∃xϕ ∨ ∃xψ ≡ ∃x(ϕ ∨ ψ) ∀x∀y ϕ = ∀y ∀xϕ ∃x∃y ϕ = ∃y ∃xϕ für x 6∈ fvar(ψ) und ∗ ∈ {∨, ∧} gilt außerdem ∀xϕ ∗ ψ ≡ ∀x(ϕ ∗ ψ) ∃xϕ ∗ ψ ≡ ∃x(ϕ ∗ ψ) ∃y ϕ ≡ ∃xϕy 7→x (gebundene Umbenennung) ∀y ϕ ≡ ∀xϕy 7→x (gebundene Umbenennung) 244 Was bisher geschah X klassische Prädikatenlogik (der ersten Stufe) FOL(Σ, ) FOL(Σ, )-Syntax: I Wiederholung: Signaturen, Terme I Atome, Formeln in FOL(Σ, ) I Variablenvorkommen in einer Formel ϕ ∈ FOL(Σ, ): frei (fvar(ϕ)), gebunden (bvar(ϕ)) FOL(Σ, )-Semantik: I Wiederholung: X X X X I I I I Σ-Interpretationen Werte von Termen in Σ-Interpretationen Werte von Atomen, Formeln in Σ-Interpretationen analog Aussagenlogik: I I I Modellmengen (Un-)Erfüllbarkeit, Allgemeingültigkeit Äquivalenz von Formeln AL(P) als Spezialfall (Syntax und Semantik): AL(P) = FOL(Σ, ∅) mit ΣR = {(p, 0) | p ∈ P} (Fragment der Prädikatenlogik FOL(Σ, )) X 245 Modelle von Formelmengen Menge aller Modelle der Formelmenge Φ ⊆ FOL(Σ, \ Mod(Φ) = Mod(ϕ) X): ϕ∈Φ Beispiele: Signatur Σ = (ΣF , ΣR ) mit ΣF = {(f , 1)}, ΣR = {(P, 1), (R, 2)}, Φ = {P(x), ∀x∃yR(x, f (y ))} I Für Σ-Interpretation (A, α) mit Struktur A = ({1, 2, 3}, J·KA ) mit Jf KA (1) = Jf KA (3) = 2, Jf KA (2) = 3, JPKA = {1, 2}, JRKA = {(1, 3), (2, 2), (3, 2)}, und Belegung α : {x, y } → {a, b, c}, wobei α(x) = α(y ) = 2 gilt (A, α) ∈ Mod(Φ) I Für Σ-Interpretation (B, β) mit Struktur B = ( , J·KB ) mit ∀n ∈ : Jf KB (n) = 3n, JPKB = 3 , JRKB = ≤ und Belegung β : {x, y } → mit β(x) = 2, β(y ) = 0 gilt (B, β) 6∈ Mod(Φ) N N N N 246 Mehr Modelle von Formelmengen Φ = {∀x(P(x) ∨ P(y )), ∀x∀y ((P(x) ∧ E(x, y )) → ¬P(y )))} I Für (A, α) mit A = ({0, . . . , 5}, J·KA ), wobei JPKA = {0, 2} und JEKA = {(i, i + 1) | i ∈ {0, . . . , 4}} und α(x) = 1, α(y ) = 2 gilt (A, α) ∈ Mod(Φ) I Für (B, β) mit B = ( , J·KB ), wobei JPKB = 2 und JEKB = {(i, i + 1) | i ∈ } und α(x) = α(y ) = 0 gilt (B, β) ∈ Mod(Φ) Z Z Z 247 Semantische Folgerung (analog Aussagenlogik) Für Φ ⊆ FOL(Σ, X ) und ψ ∈ FOL(Σ, X ) gilt Φ |= ψ gdw. Mod(Φ) ⊆ Mod(ψ) Beispiele: I {∀x(P(x) ∨ Q(x)), ¬P(y )} |= Q(y ) I {∀x(P(x) ∨ Q(x)), ¬P(x)} |= Q(x) I {∀x(P(x) ∨ Q(x)), ∀x¬P(x)} |= ∀xQ(x) I {∀x(P(x) ∨ Q(x)), ∃x¬P(x)} 6|= ∀xQ(x) 248 Allgemeingültigkeit, Erfüllbarkeit, Folgerungen analog zur Aussagenlogik gelten auch in FOL(Σ, Zusammenhänge wie X) X I Eine Formel ϕ ∈ FOL(Σ, ) ist genau dann allgemeingültig, wenn die Formel ¬ϕ unerfüllbar ist. I Φ |= ψ gdw. Φ ∪ {¬ψ} unerfüllbar. I ϕ ≡ ψ gdw. ϕ |= ψ und ψ |= ϕ. I Für jede Formelmenge Φ und jede Formel ψ ∈ Φ gilt Φ |= ψ. I Für jede unerfüllbare Formelmenge Φ und jede Formel ψ gilt Φ |= ψ. Für Formeln ohne Quantoren gilt außerdem: I Zu jeder Formel ϕ ∈ AL(P) ohne Quantoren existieren I I I eine äquivalente Formel ϕ1 ∈ AL(P) in NNF, eine äquivalente Formel ϕ2 ∈ AL(P) in CNF und eine äquivalente Formel ϕ3 ∈ AL(P) in DNF. 249 Sätze Jede Formel ϕ ∈ FOL(Σ, X) mit fvar(ϕ) = ∅ heißt Satz. Beispiele: I ∀x∀y (R(x, y ) → R(y , x)) ist ein Satz. I R(x, y ) → R(y , x), ∀x(R(x, y ) → R(y , x)), ∃y (R(x, y ) → R(y , x)), ∀x(R(x, y ) → ∃yR(y , x)) sind keine Sätze. für ϕ ∈ FOL(Σ, X) mit fvar(ϕ) = {x1, . . . , xn }: universeller Abschluß ∀ϕ := ∀x1 · · · ∀xn ϕ existentieller Abschluß ∃ϕ := ∃x1 · · · ∃xn ϕ Fakt Für jede Formel ϕ ∈ FOL(Σ, X) sind ∀ϕ und ∃ϕ Sätze. 250 Modelle von Sätzen X Auf den Wert eines Satzes ϕ ∈ FOL(Σ, ) in einer Interpretation I = (S, β) hat die Belegung β keinen Einfluss, d.h. für beliebige Belegungen α, β : → S gilt X JϕK(S,α) = JϕK(S,β) Beispiel: ϕ = ∀x∃y (P(x) ∧ E(x, y ) → ¬P(y )) X Für Sätze ϕ ∈ FOL(Σ, ) genügt es also, den Wert in Strukturen (statt in Interpretationen) zu betrachten: JϕKS := JϕK(S,β) für eine beliebige Belegung β : Menge aller Modelle des Satzes ϕ ∈ FOL(Σ, X→S X): Mod(ϕ) = {S | S = (S, J·KS ) ist Σ-Struktur und JϕKS = 1} 251 Modelle von Satzmengen Signatur Σ = (∅, ΣR ) mit ΣR = {(R, 2)} ∀x R(x, x), ∀x∀y (R(x, y ) → R(y , x)) , Φ= ∀x∀y ∀z ((R(x, y ) ∧ R(y , z)) → R(x, z)) I I I Für Σ-Struktur A = ({a, b, c}, J·KA ) mit JRKA = {(a, a), (a, c), (b, b), (c, a), (c, c)} gilt A ∈ Mod(Φ) N Für Σ-Struktur B = ( , J·KB ) mit JRKB = ≤ gilt B 6∈ Mod(Φ) Mod(Φ) = Menge aller Σ-Strukturen S, in denen JRKS eine Äquivalenzrelation ist. 252 Charakterisierung von Strukturen durch Sätze Beispiel: Graphen mit Knotenfärbung Signatur Σ = (∅, ΣR ) mit ΣR = {(R, 1), (G, 1), (B, 1), (E, 2)} ∀x¬E(x, x), ∀x∀y (E(x, y ) → E(y , x)), ∀x(R(x) ∨ G(x) ∨ B(x)), Φ= ∀x(R(x) → ¬(G(x) ∨ B(x)), ∀x(G(x) → ¬(R(x) ∨ B(x)), ∀x(B(x) → ¬(G(x) ∨ R(x)) (jeder Knoten mit genau einer Farbe aus {R, G, B} gefärbt) Mod(Φ) = Menge aller ungerichteten schlingenfreien Graphen mit Knotenfärbung mit Farben aus {R, G, B} 253 Mehr Beispiele Σ = (ΣF , ΣR ) mit ΣR = {(=, 2), (R, 2), (P, 1)} Vereinbarung: Bedeutung von = fest, Identität auf Trägermenge I Strukturen mit mindestens zwei Elementen in der Trägermenge, ∃x∃y ¬(x = y ) I Strukturen mit unendlicher Trägermenge, ∀x¬R(x, x), ∀x∀y ∀z (R(x, y ) ∧ R(y , z) → R(x, z)) , Φ= ∀x∃y (R(x, y )) I 2-färbbare (bipartite) Graphen ∀x∀y (R(x, y ) → (P(x) ↔ ¬P(y )) 254 Charakterisierung algebraischer Strukturen I Signatur Σ = (ΣF , ΣR ) mit ΣF = ∅, ΣR = {(R, 2), (=, 2)} ∀x R(x, x), ∀x∀y ((R(x, y ) ∧ R(y , x)) → x = y ) , ΦPO = ∀x∀y ∀z ((R(x, y ) ∧ R(y , z)) → R(x, z)) Mod(ΦPO ) = alle Mengen mit partieller Ordnung R, z.B. ( , ≤), ( , |), (2X , ⊆) N I Z Signatur Σ = (ΣF , ΣR ) mit ΣF = {(◦, 2)}, ΣR = {(=, 2)} ΦH = {∀x ∀y ∀z (x ◦ (y ◦ z) = (x ◦ y ) ◦ z)} N Z Mod(ΦH ) = alle Halbgruppen, z.B. ( , +), (2 , ·), (A∗ , ◦) I Signatur Σ = (ΣF , ΣR ) mit ΣF = {(◦, 2), (e, 0)}, ΣR = {(=, 2)} ΦM = {∀x ∀y ∀z (x ◦ (y ◦ z) = (x ◦ y ) ◦ z) , ∀x(x ◦ e = x)} ∗ Mod(ΦM ) = alle Monoide, z.B. ( , ·, 1), (A∗ , ◦, ε), 2A , ∪, ∅ Z I Signatur Σ = (ΣF , ΣR ) mit ΣF = {(◦, 2), (e, 0)}, ΣR = {(=, 2)} ∀x ∀y ∀z (x ◦ (y ◦ z) = (x ◦ y ) ◦ z) , ΦKG = ∀x(x ◦ e = x), ∀x∃y (x ◦ y = e), ∀x∀y (x ◦ y = y ◦ x) N Q Mod(ΦKG ) = alle kommutativen Gruppen, z.B. (2 , +, 0), ( , ·, 1) 255 Was bisher geschah klassische Prädikatenlogik (der ersten Stufe) FOL(Σ, FOL(Σ, )-Syntax: X I Signaturen, Terme, Atome, Formeln in FOL(Σ, I freie und gebundene Variablenvorkommen in Formeln und Formelmengen FOL(Σ, X) X) X)-Semantik: I Σ-Strukturen, Σ-Interpretationen I Werte von Termen, Atomen, Formeln in Σ-Interpretationen analog Aussagenlogik: I I I I I Modellmengen (Un-)Erfüllbarkeit, Allgemeingültigkeit Äquivalenz von Formeln semantische Folgerungen Sätze und Satzmengen (Syntax, Semantik) Charakterisierung von Strukturen durch Satzmengen z.B. Äquivalenzrelationen, Graphenklassen, Halbgruppen usw. 256 Wiederholung: Abstrakte Datentypen (ADT) Sorten (Typen) Signatur Σ = (ΣF , ΣR ) definiert die Darstellungsform, Typdeklarationen (Syntax) Axiome: Menge Φ ⊆ FOL(Σ, ) von Sätzen oft (∀-quantifizierte) Gleichungen zwischen Termen, beschreibt die gewünschten Eigenschaften von und Zusammenhänge zwischen den Symbolen, definiert die Bedeutung der Symbole (Semantik) X Spezifikation von Software-Schnittstellen (Interface): Darstellung der Anforderungen an jede Implementierung (oft durch Formelmengen ⊆ FOL(Σ, ), Axiome) X Abstraktion von konkreten Repräsentationen der Daten (Trägermengen) und konkrete Implementierung der Operationen 257 Wiederholung: Konkrete Datentypen konkreter Datentyp (= Σ-Struktur) S = (S, J·KS ) mit I Menge S von Daten (Trägermengen) I für jedes Symbol s in Σ die Bedeutung JsKS (Implementierung) Jeder ADT repräsentiert eine Menge konkreter Datentypen: genau alle Implementierungen (Σ-Strukturen), die alle Axiome des ADT erfüllen 258 Abstrakter Datentyp (Beispiel) ADT für (Blickrichtung in) Himmelsrichtungen Norden, Osten, Süden, Westen mit Operationen für Rechts- und Linksabbiegen und Umlenken ADT Himmelsrichtungen (Spezifikation): Sorten: Himmelsrichtung (HR) = {N, O, S, W} Signatur: N, O, S, W : HR rechts, links, um : HR → HR Axiome: rechts(N) = O, links(N) = W, um(N) = S, . . . ∀h ∈ HR : rechts(links(h)) = h, ∀h ∈ HR : links(rechts(h)) = h, ∀h ∈ HR : rechts(rechts(h)) = um(h), . . . 259 Konkreter Datentyp (Beispiele) Implementierung des ADT Himmelsrichtungen, z.B.: cos ϕ − sin ϕ I als Punkte im 2 mit Drehmatrizen sin ϕ cos ϕ 0 1 0 −1 ϕ = −π/2 : R = ϕ = π/2 : L = −1 0 1 0 R A = ({(0, 1), (1, 0), (0, −1), (−1, 0)}, J·KA ) mit JNKA = (0, 1), JOKA = (1, 0), JSKA = (0, −1), JWKA = (−1, 0), x x ∀(x, y ) : JrechtsKA (x, y ) = R ∧ JlinksKA (x, y ) = L y y ∀(x, y ) : JumKA (x, y ) = (−x, −y ) Ist diese Implementierung korrekt (d.h. Modell aller Axiome)? I B = ({0, 1, 2, 3}, J·KB ) mit JNKB = 0, JOKB = 1, JSKB = 2, JWKB = 3, ∀x : JrechtsKB (x) = (x + 1) mod 4 ∀x : JlinksKB (x) = (x − 1) mod 4, ∀x : JumKB (x) = (x + 2) mod 4 Ist diese Implementierung korrekt? 260 Spezifikation und Verifikation Jeder ADT spezifiziert eine Menge konkreter Datentypen: genau alle Implementierungen (Σ-Strukturen), die alle Axiome des ADT erfüllen Menge aller korrekten Implementierungen des ADT = Modellmenge der Menge Φ der Axiome des ADT Verifikation: formaler Nachweis der Korrektheit von Implementierungen bzgl. der Spezifikation (ADT) oft durch Ableitungen in geeigneten Kalkülen (maschinelle Unterstützung durch Werkzeuge wie z.B. Coq, pvs, Isabelle, KIV, KeY) (mehr dazu in LV im Master-Studium) 261 Prädikatenlogisches Ableiten Aussagen wie z.B. die folgende lassen sich i.A. nicht durch Nachprüfen aller Interpretationen zeigen: In jeder Menge mit einer Äquivalenzrelation R gilt ϕ = ∀x∀y ∀z (R(x, y ) ∧ R(x, z) → R(y , z)) d. h. ∀x R(x, x) ∀x∀y (R(x, y ) → R(y , x)) |= ϕ ∀x∀y ∀z (R(x, y ) ∧ R(y , z) → R(x, z)) Syntaktische Methoden sind daher in Prädikatenlogik noch viel wichtiger als in Aussagenlogik 262 Gültigkeitsproblem Wiederholung: (Allgemein)-Gültigkeitsproblem in einer Logik gegeben: Formel ϕ in dieser Logik Frage: Ist ϕ allgemeingültig? als formale Sprache (Wortproblem): G = {ϕ | Mod(¬ϕ) = ∅} Erfüllbarkeits- und Folgerungsproblem sind darauf reduzierbar. für jede Logik interessant: Gibt es automatische Verfahren (Algorithmen), die dieses Problem entscheidet, also zu jeder gegebenen Formel dieser Logik die Frage korrekt mit ja oder nein beantwortet? Logiken, für die es solche Algorithmen gibt, heißen entscheidbar. 263 Wiederholung: Kalkül des natürlichen Schließens Kalkül: Menge von Axiomenschemata , d.h. Schema für Formeln, deren Gültigkeit vorausgesetzt wird, Regelschemata zur syntaktischen Ableitung weiterer gültiger Formeln aus Formelmengen (Axiomen und Hypothesen) Kalkül des natürlichen Schließens: Für jeden Junktor ∗ eine Einführungsregel (∗I) Junktor in der Folgerung (unten), aber in keiner Voraussetzung (oben) des Regelschemas, I eine Eliminierungsregel (∗E) Junktor in einer Voraussetzung (oben), aber nicht in der Folgerung (unten) des Regelschemas, I Ableitungsschritt: Anwendung einer geeignet instanziierten Regel auf schon Hypothesen und abgeleitete Formeln Ableitung (Beweis): Kombination von Ableitungsschritten (Baumform) 264 Kalkül des natürlichen Schließens: Junktoren A B (∧I) A∧B A ∧ B (∧E) A A (∨I) A∨B B (∨I) A∨B [A] .. . B (→I) A→B f (fE) A A A ∧ B (∧E) B [A] [B] .. .. . . A∨B C C (∨E) C A → B (→E) B [A] .. . f (¬I) ¬A A f ¬A (¬E) 265 Kalkül des natürlichen Schließens: Regeln für ∀ für neu eingeführte Konstante a (repräsentiert „beliebiges“ Element): A[x 7→ a] (∀I) ∀xA für beliebigen Term t, in welchem keine Variable durch Einsetzen für x in A gebunden wird: ∀xA (∀E) A[x 7→ t] Schlussregeln korrekt , weil ∀ϕ: {ϕ[x 7→ a]} |= ∀xϕ {∀xϕ} |= ϕ[x 7→ t] (∀I) Um ∀xA abzuleiten, muss man zeigen, dass A[x 7→ a] für eine neu eingeführte Konstante a (repräsentiert beliebiges Element) gilt. (∀E) Falls ∀xA abgeleitet, gilt auch für jeden beliebigen Term t, in dem keine Variable durch Einsetzen in A gebunden wird, A[x 7→ t]. 266 Beispiele für Ableitungen mit ∀-Regeln I Alle Hunde bellen. Max ist ein Hund. Also bellt Max. ∀x(H(x) → B(x)), H(m) `N B(m) I ∀x(H(x) → B(x)) (∀E) H(m) → B(m) H(m) (→E) B(m) Jede nichtnegative Zahl ist gleich ihrem Betrag. ∀x(x ≥ 0 → x = |x|), ∀x(x ≥ 0) `N ∀x(x = |x|) ∀x(x ≥ 0 → x = |x|) (∀E) n ≥ 0 → n = |n| (→E) n = |n| (∀I mit „beliebiger“ Zahl n) ∀x(x = |x|) ∀x(P(x) ∧ Q(x)) `N ∀xP(x) ∧ ∀xQ(x) ∀x(x ≥ 0) (∀E) n≥0 I 267 Kalkül des natürlichen Schließens: Regeln für ∃ für beliebigen Term t, in welchem keine Variable durch Einsetzen für x in A gebunden wird: für neu eingeführte Konstante a: ∃xA A[x 7→ t] (∃I) ∃xA [A[x 7→ a]] .. . B (∃E) B Schlussregeln korrekt , weil ∀ϕ: {ϕ[x 7→ t]} |= ∃xϕ {∃xϕ, ϕ[x 7→ a] → ψ} |= ψ (∃I) Hat man für einen Term t gezeigt, dass A[x 7→ t] gilt, kann man daraus ∃xA ableiten. (∃E) Falls ∃xA schon abgeleitet wurde und B für eine neu eingeführte Konstante a aus der Annahme A[x 7→ a] abgeleitet werden kann, dann ist damit auch B abgeleitet. (Bei jeder Anwendung von (∃E) muss eine eigene neue Konstante eingeführt werden) 268 Beispiele für Ableitungen mit ∃-Regeln I 2 ist gerade. 2 ist eine Primzahl. Also gibt es gerade Primzahlen. G(2), P(2) `N ∃x(G(x) ∧ P(x)) I G(2) P(2) (∧I) G(2) ∧ P(2) (∃I) ∃x(G(x) ∧ P(x)) Manche Studenten sind klug und fleißig. Also sind manche klug und manche fleißig. ∃x(K (x) ∧ F (X )) `N ∃xK (x) ∧ ∃xF (x)) [K (a) ∧ F (a)] K (a) ∃x(K (x) ∧ F (x)) ∃xK (x) ∃xK (x) (∃I) (∃E mit a) ∃xK (x) ∧ ∃xF (x) I [K (b) ∧ F (b)] (∧E) F (b) ∃x(K (x) ∧ F (x)) ∃xF (x) ∃xF (x) (∧E) (∃I) (∃E mit b) (∧I) ∃x(P(x) ∧ ¬Q(x)), ∀x(P(x) → R(x)) `N ∃x(R(x) ∧ ¬Q(x)) 269 Aufzählbarkeit Ableitungsrelation z.B. durch Erweiterung des Kalkül des natürlichen Schließens auf Prädikatenlogik Mit Hilfe logischer Kalküle (z.B. des natürlichen Schließens) lassen sich alle allgemeingültigen Formeln ϕ ∈ FOL(Σ, ) algorithmisch aufzählen (nacheinander angeben). X Idee: Alle Formeln „gleichzeitig“ ableiten (dove tailing) Bei jedem erfolgreichen Versuch Formel ausgeben und diese Berechnung für diese Formel abbrechen. Es gibt aber kein Verfahren, welches algorithmisch entscheidet (d.h. für jede beliebige Formel ϕ ∈ FOL(Σ, ) in endlicher Zeit die Antwort ja/nein berechnet), ob eine gegebene Formel allgemeingültig ist (in der Aufzählung vorkommt). X 270 Unentscheidbarkeit der Prädikatenlogik der ersten Stufe FOL(Σ, X) Satz Es existiert kein Algorithmus, der für jede beliebige Formel ϕ ∈ FOL(Σ, X ) entscheidet, ob ϕ allgemeingültig ist. (Das Gültigkeitsproblem in) FOL(Σ, X) ist also unentscheidbar. Im Gegensatz dazu gilt für die Aussagenlogik AL(P): Satz Es existiert (wenigstens) ein Algorithmus, der für jede beliebige Formel ϕ ∈ AL(P) entscheidet, ob ϕ allgemeingültig ist. (Test endlich vieler endlicher Strukturen genügt, z.B. Wahrheitswerttabellen, Modellmengen, Kalküle,. . . ) (Das Gültigkeitsproblem in) AL(P) ist also entscheidbar. 271 Zusammenfassung: Logik(en) in der Informatik einige prominente Anwendungen: I Digitaltechnik (AL) I Abstrakte Datentypen (FOL) (mehr dazu in LV Algorithmen und Datenstrukturen) I Wissensrepräsentation und -verarbeitung (AL, FOL, nichtklassische Logiken) mehr dazu in LV Künstliche Intelligenz I Semantic Web (FOL, Beschreibungslogiken, OWL) I Problemlösen, Planung (AL, FOL) I Multiagentensysteme (FOL, Epistemische Logik) I deklarative Programmierung (AL, FOL) (logische Programmierung, Constraint-Programmierung) I Beschreibung von Abläufen (FOL, temporale Logiken) I Spezifikation des Verhaltens von Software und Systemen (AL, FOL, Temporale Logiken, Prozesslogiken) (mehr dazu in LV zu Verifikationstechniken) 272 Anwendung: Wissensrepräsentation und -verarbeitung I Entscheidungstabellen, - Bäume, -Diagramme I Regelbasiertes Schließen I unvollständiges Wissen, nichtmonotones Schließen I unscharfes Wissen, fuzzy logic, probabilistische Logik I Klassifizierung, Diagnose I Zusammenhänge zwischen Begriffen, Ontologien I Darstellung von Wissen im Semantic Web I Planen, z.B. Stundenpläne, Ablaufpläne 273 Anwendung: logische Programmierung Prolog-Programm P: liest(paul,krimi). liest(tina,arztroman). liest(bob,X). mag(tina,X) :- liest(X,krimi). repräsentiert die Formelmenge liest(paul, krimi), liest(tina, arztroman), ∀x(liest(bob, x)), P= ∀x(liest(x, krimi) → mag(tina, x)) Anfrage: ?- mag(tina,X). repräsentiert die Formel ψ = mag(tina,X) (Wen mag Tina?) Paar (Programm, Anfrage) repräsentiert das Problem: Für welche Belegungen β gilt P |= β(ψ)? Lösung durch SLD-Resolution (Kalkül zum Schließen in einem geeigneten FOL(Σ, )-Fragment) X 274 Anwendung: Wortmodelle Alphabet A: (endliche) Menge von Symbolen) Wort w = w1 · · · wn ∈ A∗ als I Funktion w : {1, . . . , n} → A (von Positionen auf Symbole) mit ∀i ∈ {1, . . . , n} : w(i) = wi I Für Σ = (ΣF , ΣR ) mit ΣR = {(≤, 2)} ∪ {(a, 1) | a ∈ A} Σ-Struktur w = ({1, . . . , n}, J·Kw ) mit J≤Kw =≤ ∀a ∈ A : JaKw = {i ∈ {1, . . . , n} | wi = a} Beispiel: A = {a, b, c}, logische Beschreibung der Mengen aller Wörter, I die kein a enthalten: ¬∃x a(x) I die mindestens ein a und ein b enthalten: ∃x a(x) ∧ ∃x b(x) I die mit a beginnen: ∀x (∀y (x ≤ y ) → a(x)) I in denen nach jedem a ein b steht (nicht notwendig direkt): ∀x (a(x) → ∃y (x ≤ y ∧ b(y ))) 275 Anwendung: Korrektheit von Systemen Modellierung des Verhaltens von Systemen (zeitliche Abläufe, Zeitpunkte in ), z.B. N I ∀n∃m(n ≤ m ∧ P(n) → Q(m)) I ∃n∀m(m > n → ¬P(n))) Spezifikation (Anforderungen), z.B.: I Ein Fehlerzustand wird nie erreicht. ¬∃n Fehler(n) I Jeder Fehler wird sofort nach dem Auftreten behoben. ∀n (Fehler(n) → ¬Fehler(n + 1))) I Jeder einmal gestellte Auftrag a wird irgendwann erledigt. ∀a∀n ( gestellt(a, n) → ∃m(n ≤ m ∧ erledigt(a, m))) 276 Zustandsübergangssysteme Zustandsübergangssystem (Q, X , δ) Q (endliche) Menge von Zuständen X endliche Menge von Aktionen δ : X → (Q × Q) Übergangsrelationen δ ordnet jeder Aktion a ∈ X eine Relation δ(a) ⊆ Q × Q zu (Graph mit Kantenfärbung, Farben: Aktionen) Ziel: Spezifikation (formale Beschreibung von Anforderungen) von Zustandsübergangssystemen Prädikatenlogik zur Darstellung der Eigenschaften von I Zuständen I (zulässigen) Aktionen I Wirkung der Aktionen (Zustandsübergänge) 277 Beispiel: lineares Solitaire Q = {0, 1}∗ Zustände (mögliche Spielkonfigurationen) X = {(011 → 100), (110 → 001)} Aktionen (zulässige Spielzüge) δ : {(011 → 100), (110 → 001)} → {0, 1}∗ × {0, 1}∗ (z.B. (101101, 110001) ∈ δ(011 → 100)) Zustandsübergänge bei Ausführung von Zügen, (u, v ) ∈ δ(011 → 100) gdw. |u| = |v | ∧ i ∈ {2, . . . , |u| − 1} ∧ui−1 = 0 ∧ ui = 1 ∧ ui−1 = 1 ∃i ∧vi−1 = 1 ∧ vi = 0 ∧ vi−1 = 0 ∧∀j (j 6= i − 1 ∧ j 6= i ∧ j 6= i + 1) → uj = vj 278 Beispiel: Münzschließfach Aktionen: A aufschließen Eigenschaften: g bezahlt Z zuschließen o offen O Tür öffnen b belegt S Tür schließen G Geld einwerfen Beispiele für Anforderungen (Spezifikation): Am Münzschließfach sollen nur Abläufe (Wort w ∈ {A, Z , O, S, G}∗ ) möglich sein, die folgende Anforderungen (Eigenschaften) erfüllen: I Offene Fächer können nicht zugeschlossen werden. ∀x(o(x) → ¬∃yZ (x, y )) I In belegte Fächer kann kein Geld eingeworfen werden. ∀x(b(x) → ¬∃yG(x, y )) I Kein nicht bezahltes Fach kann zugeschlossen werden. ¬∃x(¬g(x) ∧ ∃yZ (x, y )) Dazu werden auch häufig nichtklassische Logiken verwendet. (z.B. Temporallogiken: (entscheidbare) FOL-Fragmente) 279 Beispiel Münzschließfach {b} ∅ Entwurf des Systems: S O {o} G A S {g, o} Z {g} O Beispiele für mögliche Abläufe (während eines Tages) w ∈ {A, Z , O, S, G}∗ : I OGSZAGSZA: zwei Belegungszyklen I OSOSOS: Tür wiederholt öffnen und schließen I ε I OSOGSOSZASOSOGSZASO Jeder mögliche Ablauf erfüllt die Spezifikation (Anforderungen): ∀x(o(x) → ¬∃yZ (x, y )), ∀x(b(x) → ¬∃yG(x, y )), Φ= ¬∃x(¬g(x) ∧ ∃yZ (x, y )) 280 Berechnungen als Zustandsübergangssysteme imperative Programmierung (von-Neumann-Modell): Ausführungsmodell: abstrakte Maschine Berechnung eines imperativen Programmes p: Ausführung des Programmes p mit Eingabe i, d.h. (endliche oder unendliche) Folge von Zuständen einer abstrakten Maschine Zustand: Speicherbelegung Modellierung einer Berechnung (Ausführung eines Programmes) durch Folge von Zustandsübergängen (Rechenschritte) formale Beschreibung der Semantik (Wirkung) eines imperativen Programmes p: Abbildung (partielle Funktion) von Eingaben auf Ausgaben (und Nebenwirkungen) 281 Beispiel: Vertauschen Aufgabe: Vertauschen zweier Zahlen Zustände (x, y , z) ∈ N3, wobei x = Wert der Variable (Speicherplatz) a y = Wert der Variable (Speicherplatz) b z = Wert der Variable (Speicherplatz) c Programm: c := a a := b b := c Zustandsübergangssystem der Berechnung für a = 3, b = 5: (3, 5, ?) start c := a (3, 5, 3) a := b (5, 5, 3) b := c (5, 3, 3) 282 Eigenschaften von Berechnungen Spezifikation (formale Beschreibung des Verhaltens) eines Vorbedingung: ϕ Programmes p: Nachbedingung: ψ Bedeutung: Beginnt die Ausführung des Programmes in einem Zustand, der die Vorbedingung ϕ erfüllt, dann gilt im Zustand nach Programmende die Nachbedingung ψ. Verifikation: Nachweis, dass ein imperatives Programm korrekt ist (also seine Spezifikation erfüllt) Idee: Induktion über die Programmstruktur (Baum) aus IA: elementaren Anweisungen (Zuweisungen, Unterprogrammaufrufe) und IS: Operationen zur Kombination von Anweisungen: Nacheinanderausführung, Verzweigung, Wiederholung 283 Nachweis der Eigenschaften von Berechnungen Spezifikation durch Hoare-Tripel: {ϕ} p {ψ} Beispiel Vertauschen: {a = x ∧ b = y }c := a; a := b; b := c{a = y ∧ b = x} einige Ableitungsregeln im Hoare-Kalkül: {ϕ} c1 {ψ} {ψ} c2 {η} (Nacheinanderausführung) {ϕ} c1 ; c2 {η} ϕ → ϕ0 {ϕ0 } c {ψ 0 } {ϕ} c {ψ} ψ0 → ψ (Abschwächung) {ϕ ∧ B}c{ϕ} (Wiederholung) {ϕ} while B c {ϕ ∧ ¬B} Axiom: {ϕ[x 7→ t]} x := t {ϕ} (Zuweisung) 284 Zustandsübergangssystem Münzschließfach 0 S 4 A O Z S 1 G 3 2 O Aktionen: A aufschließen Eigenschaften: g bezahlt (2, 3) Z zuschließen o offen (1, 2) O Tür öffnen b belegt (4) S Tür schließen G Geld einwerfen 285 Endliche Automaten – Definition NFA (nondeterministic finite automaton) A = (X , Q, δ, I, F ) mit X endliches Alphabet, Q endliche Menge von Zuständen, δ Übergangsrelationen δ : X → (Q × Q), I ⊆ Q Startzustände, F ⊆ Q akzeptierende Zustände. 286 NFA: Beispiel A = (X , Q, δ, {0, 3}, {2, 3, 4}) mit X = {a, b, c} Q = {0, 1, 2, 3, 4} δ(a) = {(0, 0), (0, 1), (1, 3)} δ(b) = {(0, 0), (1, 2)} δ(c) = {(0, 3), (3, 3), (4, 1)} a,b a 0 c 3 b 1 a 2 c c 4 287 Eigenschaften endlicher Automaten NFA A = (X , Q, δ, I, F ) heißt vollständig , falls ∀a ∈ X ∀p ∈ Q : |{q | (p, q) ∈ δ(a)}| ≥ 1 deterministisch (DFA) , falls 1. |I| = 1 und 2. ∀a ∈ X ∀p ∈ Q : |{q | (p, q) ∈ δ(a)}| ≤ 1 Beispiele: a,b b b 0 1 a vollständig nicht deterministisch b a 0 b a b b 0 1 nicht vollständig deterministisch 1 a vollständig deterministisch 288 Pfade in endlichen Automaten Für einen NFA A = (X , Q, δ, I, F ) und ein Wort w ∈ X ∗ heißt eine Folge von Zuständen p = (p0 , p1 , . . . , pn ) ∈ Q ∗ genau dann Pfad für w in A, wenn gilt: 1. p0 ∈ I und 2. ∀i ∈ {1, . . . , n} : (pi−1 , pi ) ∈ δ(wi ) akzeptierender Pfad für w in A, wenn zusätzlich gilt: 3. pn ∈ F 289 Beispiel b NFA A = ({a, b}, {0, 1}, δ, {0}, {0}) mit δ(a) = {(0, 1)} und δ(b) = {(0, 0), (0, 1), (1, 0)} a,b 0 1 b Pfade für I abbb: a b b b 0 → 1 → 0 → 0 → 0 ∈ F (akzeptierend) a b b b 0 → 1 → 0 → 0 → 1 6∈ F (nicht akzeptierend) a b b b 0 → 1 → 0 → 1 → 0 ∈ F (akzeptierend) I aba: a b a 0 → 1 → 0 → 1 6∈ F (nicht akzeptierend) I aa existieren nicht: 0 → 1 → ? a a 290 Akzeptanz durch endliche Automaten NFA A akzeptiert ein Wort w gdw. ein akzeptierender Pfad für w in A existiert. Beispiel: NFA A aus vorigem Beispiel (Tafel) I akzeptiert das Wort abbb (z.B.) über den akzeptierenden Pfad a b b b 0→1→0→1→0∈F I akzeptiert das Wort aba nicht, weil 0 → 1 → 0 → 1 der einzige Pfad für aba in A ist und im Zustand 1 6∈ F endet, I akzeptiert das Wort aa nicht, weil dafür kein Pfad in A existiert. a b a A akzeptiert genau alle Wörter, in denen auf jedes a sofort ein b folgt, also genau die Wörter in der Sprache L(b + ab)∗ . 291 NFA-akzeptierbare Sprachen NFA A = (X , Q, δ, I, F ) akzeptiert die Sprache L(A) = {w ∈ X ∗ | ∃ akzeptierender Pfad für w in A} ∃(p0 , . . . , p|w| ) ∈ Q ∗ : p0 ∈ I ∧ p|w| ∈ F = w ∈ X ∗ ∧ ∀i ∈ {1, . . . , |w|} : (pi−1 , pi ) ∈ δ(wi ) Sprache L(A) beschreibt das Verhalten (Semantik) des NFA Beispiel: A = ({a, b}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 0), (2, 2)} und δ(b) = {(0, 0), (0, 1), (1, 2), (2, 2)} akzeptiert L(A) = . . . Eine Sprache L ⊆ X ∗ heißt genau dann NFA-akzeptierbar, wenn ein NFA A mit L = L(A) existiert. Menge aller NFA-akzeptierbaren Sprachen: REC(NFA) Beispiel: L = {w | w enthält ein Infix aa oder bba} ist NFA-akzeptierbar. 292 Beispiele NFA-akzeptierbarer Sprachen I L1 = {w ∈ {0, 1}∗ | |w|0 ist ungerade } I L2 = {w ∈ {a, b}∗ | w beginnt mit ab und endet mit ba} I L3 = L(G) mit G = ({S, T }, {0, 1}, P, S) mit P = {S → 11T , T → 0S, T → 0} I L4 = L(E) mit E = (a + b)∗ ab∗ I L5 = L(F ) mit F = ((a + b)c)∗ Beobachtung: Diese Sprachen lassen sich alle durch reguläre Ausdrücke repräsentieren. 293 Was bisher geschah I I Modellierung durch Zustandsübergangssysteme NFA A = (X , Q, δ, I, F ) I I vollständig deterministisch (DFA) I Akzeptanz von Wörtern durch NFA I von einem NFA A akzeptierte Sprache L(A) Verhalten von A, Semantik I NFA-akzeptierbare Sprachen REC(NFA) I Operationen auf Sprachen: I I Mengenoperationen ∪, ∩, , \ Sprachoperationen ◦, ∗ , R I reguläre Ausdrücke E ∈ RegExp(X ), repräsentierte Sprache L(E) ⊆ X ∗ I Grammatiken G = (N, X , P, S) erzeugte Sprache L(G) ⊆ X ∗ 294 Isomorphie endlicher Automaten Zwei NFA A = (X , Q, δ, I, F ) und B = (X , Q 0 , δ 0 , I 0 , F 0 ) sind genau dann isomorph, wenn eine bijektive Funktion h : Q → Q 0 existiert, so daß I genau dann s ∈ I , wenn h(s) ∈ I 0 , I genau dann f ∈ F , wenn h(f ) ∈ F 0 und I für jedes a ∈ X : genau dann (p, q) ∈ δ(a), wenn (h(p), h(q)) ∈ δ 0 (a). Beispiel: A = ({a, b}, {0, 1, 2}, δ, {0}, {0}) mit δ(a) = {(0, 1), (1, 2), (2, 0)} und δ(b) = {(0, 2), (1, 0), (2, 1)} und B = ({a, b}, {α, β, γ}, δ, {β}, {β}) mit δ(a) = {(α, β), (β, γ), (γ, α)} und δ(b) = {(α, γ), (β, α), (γ, β)} sind isomorph mit h(0) = β, h(1) = γ, h(2) = α. (Graphisomorphie zwischen gerichteten Graphen mit markierten Kanten) Fakt Isomorphie von NFA ist eine Äquivalenzrelation. 295 Äquivalenz endlicher Automaten Zwei NFA A, B heißen genau dann äquivalent, wenn L(A) = L(B) gilt. Beispiel: Der NFA A = ({a, b}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 1), (1, 1)} und δ(b) = {(1, 1), (1, 2)} und der NFA B = ({a, b}, {0, 1, 2, 3}, δ, {0}, {2}) mit δ(a) = {(0, 1), (1, 1), (2, 1), (3, 3)} und δ(b) = {(0, 3), (1, 2), (2, 2), (3, 3)} sind äquivalent. Warum? Fakt Äquivalenz endlicher Automaten ist eine Äquivalenzrelation. Fakt Isomorphe endliche Automaten sind äquivalent. Also: Umbenennung der Zustände eines NFA ändert die Semantik (akzeptierte Sprache) nicht. 296 Vervollständigung von NFA Motivation: In vollständigen NFA existiert zu jedem Wort wenigstens ein Weg, Akzeptanz des Wortes durch Menge der mit dem letzten Symbol erreichten Zustände auf allen Wegen feststellbar. Satz Zu jedem NFA existiert ein äquivalenter vollständiger NFA. (Hinzufügen eines zusätzlichen nichtakzeptierenden Zustandes, falls notwendig) Beispiel: A = ({a, b}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 0), (1, 2)} und δ(b) = {(0, 1)} äquivalenter vollständiger NFA B = ({a, b}, {0, 1, 2, 3}, δ, {0}, {2}) mit δ(a) = {(0, 0), (1, 2), (2, 3), (3, 3)} und δ(b) = {(0, 1), (1, 3), (2, 3), (3, 3)} 297 Wiederholung: Pfade in NFA b NFA A = ({a, b}, {0, 1}, δ, {0}, {0}) mit δ(a) = {(0, 1)} und δ(b) = {(0, 0), (0, 1), (1, 0)} a,b 0 1 b Pfade für I abbb: a b b b 0 → 1 → 0 → 0 → 0 ∈ F (akzeptierend) a b b b 0 → 1 → 0 → 0 → 1 6∈ F (nicht akzeptierend) a b b b 0 → 1 → 0 → 1 → 0 ∈ F (akzeptierend) I aba: a b a 0 → 1 → 0 → 1 6∈ F (nicht akzeptierend) I aa existieren nicht: 0 → 1 → ? a a Alle Pfade für ein Wort w in einem NFA A lassen sich in einem Baum zusammenfassen. (Tafel) 298 Vorteil deterministischer Automaten a,b Beispiele: 0 b a,b a 1 0 a,b b 1 Akzeptanz der Wörter aab, bba ? Zu jedem DFA A = (X , Q, δ, I, F ) und jedem Wort w ∈ X ∗ I existiert in A höchstens ein Pfad für w, I lässt sich in höchstens |w| Schritten feststellen, ob A das Wort w akzeptiert, I lässt sich in höchstens |w| Schritten feststellen, ob A das Wort w nicht akzeptiert. Existiert zu jedem NFA ein äquivalenter DFA? 299 Nachfolgermengen in NFA Nachfolgermengen im NFA A = (X , Q, δ, I, F ): NA (a, p) = {q ∈ Q | (p, q) ∈ δ(a)} (a-Nachfolger von p ∈ Q) Menge aller Zustände, die über eine a-Kante aus dem Zustand p erreichbar sind S NA (a, M) = p∈M NA (a, p) (a-Nachfolger von M ⊆ Q) Menge aller Zustände, die über eine a-Kante aus einem Zustand aus M erreichbar sind b a,b Beispiel: 0 1 b Nachfolgermengen der Zustände: NA (a, 0) = {1} NA (a, 1) = ∅ NA (b, 0) = {0, 1} NA (b, 1) = {1} Nachfolgermengen aller Mengen von Zuständen: NA (a, {0}) = {1} NA (b, {0}) = {0, 1} NA (a, ∅) = ∅ NA (a, {1}) = ∅ NA (b, {1}) = {0} NA (b, ∅) = ∅ NA (a, {0, 1}) = {1} NA (b, {0, 1}) = {0, 1} 300 Konstruktion von DFA aus NFA allgemeines Verfahren: gegeben: NFA A = (X , Q, δ, I, F ) gesucht: DFA B = (X , QB , δB , IB , FB ) mit L(A) = L(B) Konstruktion: (Potenzmengen-Konstruktion) Automat B = (X , QB , δB , IB , FB ) mit Q B = 2Q IB = {I} FB = {M ⊆ Q | F ∩ M 6= ∅} für jedes a ∈ X : δB (a) = {(M, NA (a, M)) | M ⊆ Q} Beispiel: Konstruktion eines DFA B äquivalent zum NFA A aus dem vorigen Beispiel häufige Variante: Einschränkung auf von IB erreichbare Zustände 301 Korrektheit der Konstruktion Fakt Der nach der Potenzmengenkonstruktion aus dem Automaten A = (X , Q, δ, I, F ) konstruierte Automat B = (X , QB , δB , IB , FB ) ist ein endlicher Automat, vollständig, deterministisch und äquivalent zu A. Begründungen für Endlichkeit: Weil Q endlich, ist auch 2Q = QB endlich. Vollständigkeit: Für jedes Symbol a ∈ X und jeden Zustand M ∈ QB existiert in B genau ein (also mindestens ein) a-Nachfolger von M, nämlich NA (a, M). Determinismus: 1. Startzustand IB = I ist eindeutig bestimmt, 2. Für jedes Symbol a ∈ X und jeden Zustand M ∈ QB existiert in B genau ein (also höchstens ein) a-Nachfolger von M, nämlich NA (a, M). Äquivalenz: Nachweis von L(A) ⊆ L(B) und L(B) ⊆ L(A) durch „Übersetzung“ der akzeptierenden Pfade 302 Praktische Bedeutung Ob ein Wort w in einer regulären Sprache L enthalten ist, lässt sich mit einem DFA A mit L(A) = L schnell bestimmen (O(|w|)) aber: (evtl. aufwendige) Vorbereitung notwendig (Konstruktion des DFA A mit L(A) = L) Vorbereitung lohnt sich für häufige Anwendung, z.B. in I Übersetzerbau einmal Konstruktion der DFA für Schlüsselwörter und Konstantendarstellungen (z.B. Gleitkomma-Darstellungen) Syntaxcheck und -analyse für viele Programme I Suchmaschinen einmal Konstruktion des DFA für Suchwort / Suchwörter Durchsuchen vieler Texte (schnell) 303 Ausblick Transformation von NFA in äquivalente DFA (Potenzmengenkonstruktion) ist Grundlage für I Automatenkonstruktionen für Sprachoperationen (Komplement, Schnitt) I eindeutige Darstellung regulärer Sprachen (Minimalautomat) notwendig zur algorithmischen Feststellung der Gleichheit zweier regulärer Sprachen I Transformation von DFA in reguläre Ausdrücke später: Grundideen der Potenzmengen-Konstruktion: I Zusammenfassung der Nachfolgermengen garantiert I Determinismus (und Vollständigkeit) und I Äquivalenz der Automaten I Endlichkeit der Menge aller möglichen Zustände Funktionieren ähnliche Ideen auch für andere Maschinenmodelle? Antworten (Vorschau): I nein für Kellerautomaten I ja für Turing-Maschinen 304 NFA für Komplement NFA-akzeptierbarer Sprachen Beispiel: vollständiger DFA A = ({a, b}, {0, 1, 2, 3}, δ, {0}, {2}) mit δ(a) = {(0, 1), (1, 3), (2, 2), (3, 3)} und δ(b) = {(0, 3), (1, 2), (2, 2), (3, 3)} allgemeines Verfahren: gegeben: vollständiger DFA A = (X , Q, δ, I, F ) gesucht: NFA B mit L(B) = L(A) Konstruktion: DFA B = (X , Q, δ, I, Q \ F ) Fakt Der oben definierte NFA B akzeptiert die Sprache L(A). 305 NFA für Vereinigung NFA-akzeptierbarer Sprachen Beispiel: NFA A = ({a, b}, {0, 1}, δA , {0}, {0}) mit δA (a) = {(0, 1), (1, 0)} und δA (b) = ∅ NFA B = ({a, b}, {2, 3, 4}, δB , {2}, {4}) mit δB (a) = {(2, 3), (4, 3)} und δB (b) = {(3, 4)} allgemeines Verfahren: gegeben: NFA A = (X , QA , δA , IA , FA ) und NFA B = (X , QB , δB , IB , FB ) mit QA ∩ QB = ∅ (Zustände umbenennen, falls notwendig) gesucht: NFA C mit L(C) = L(A) ∪ L(B) Konstruktion: NFA C = (X , QA ∪ QB , δC , IA ∪ IB , FA ∪ FB ) mit ∀a ∈ X : δC (a) = δA (a) ∪ δB (a) Fakt Der oben definierte NFA C akzeptiert die Sprache L(A) ∪ L(B). Zu gegebenen Automaten A und B lässt sich damit auch ein Automat C mit L(C) = L(A) ∩ L(B) = L(A) ∪ L(B) (deMorgan) konstruieren. (Dazu existieren aber auch effektivere Methoden.) 306 NFA mit ε-Übergängen ε-NFA: NFA ohne Einschränkung δ(ε) = IQ , stattdessen δ(ε) ⊇ IQ (zusätzliche Kanten im Automatengraphen mit Beschriftung ε) ε-NFA vereinfachen oft die Modellierung von Sprachen und Abläufen. Beispiel: A = ({a, b, c}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 0)}, δ(b) = {(1, 1)}, δ(c) = {(2, 2)} und δ(ε) = {(0, 1), (1, 2)} Akzeptanz von Wörtern analog zu NFA: ε-NFA A = (X , Q, δ, I, F ) akzeptiert ein Wort w ∈ X ∗ genau dann, wenn δ ∗ (w) ∩ (I × F ) 6= ∅. δ ∗ (w) = δ ∗ (ε) ◦ δ(w1 ) ◦ δ ∗ (ε) ◦ · · · ◦ δ ∗ (ε) ◦ δ(wn ) ◦ δ ∗ (ε) ε-NFA A im Beispiel oben akzeptiert die Sprache L(A) = a∗ b∗ c ∗ Fakt Zu jedem NFA A existiert ein äquivalenter ε-NFA B mit genau einem Startzustand und genau einem akzeptierenden Zustand. 307 NFA für Verkettung NFA-akzeptierbarer Sprachen Beispiel: NFA A = ({a, b}, {0}, δA , {0}, {0}) mit δA (a) = ∅ und δA (b) = {(0, 0)} NFA B = ({a, b}, {1, 2, 3}, δB , {1, 3}, {2}) mit δB (a) = {(3, 2), (3, 3)} und δB (b) = {(1, 2)} allgemeines Verfahren: gegeben: NFA A = (X , QA , δA , IA , FA ) und NFA B = (X , QB , δB , IB , FB ) mit QA ∩ QB = ∅ gesucht: NFA C mit L(C) = L(A) ◦ L(B) Konstruktion: 1. (A0 ≡ A ∧ |FA0 | = 1): ε-NFA A0 = (X , QA ∪ {fA }, δA0 , IA , {fA }) mit ∀a ∈ X : δA0 (a) = δA (a) und δA0 (ε) = δA (ε) ∪ {(q, fA ) | q ∈ FA } 2. (B 0 ≡ B ∧ |IB 0 | = 1): ε-NFA B 0 = (X , QB ∪ {sB }, δB0 , {sB }, FB ) mit ∀a ∈ X : δB0 (a) = δB (a) und δB0 (ε) = δB (ε) ∪ {(sB , q) | q ∈ IB } 3. (◦): ε-NFA C = (X , QA ∪ QB ∪ {fA , sB }, δC , IA , FB ) mit ∀a ∈ X : δC (a) = δA0 (a) ∪ δB0 (a) und δC (ε) = δA0 (ε) ∪ δB0 (ε) ∪ {(fA , sB )} Fakt Der oben definierte ε-NFA C akzeptiert die Sprache L(A) ◦ L(B). 308 NFA für iterierte Verkettung Beispiel: NFA A = ({a, b}, {0, 1, 2, 3}, δA , {0}, {3}) mit δA (a) = {(0, 1), (2, 3)} und δA (b) = {(1, 2)} allgemeines Verfahren: gegeben: NFA A = (X , Q, δA , I, F ) gesucht: NFA B mit L(B) = L(A)∗ Konstruktion: 1. (A0 ≡ A ∧ |IA0 | = 1 ∧ |FA0 | = 1): ε-NFA A0 = (X , QA ∪ {sA , fA }, δA0 , {sA }, {fA }) mit ∀a ∈ X : δA0 (a) = δA (a) und δA0 (ε) = {(sA , q) | q ∈ IA } ∪ {(q, fA ) | q ∈ FA } 2. (∗ ): ε-NFA B = (X , QA ∪ {sA , fA }, δB , {sA }, {fA }) mit ∀a ∈ X : δB (a) = δA0 (a) und δB (ε) = δA0 (ε) ∪ {(sA , fA ), (fA , sA )} Fakt Der oben definierte ε-NFA B akzeptiert die Sprache L(A)∗ . 309 Abschlusseigenschaften von REC(NFA) Satz Sind L und L0 NFA-akzeptierbare Sprachen, dann sind auch die Sprachen I L ∪ L0 (Vereinigung) I L (Komplement) I L ∩ L0 (Schnitt) I L ◦ L0 (Verkettung) I Ln , L∗ (iterierte Verkettung) I LR (Spiegelung) NFA-akzeptierbar. dieselbe Aussage kürzer: Die Menge REC(NFA) ist abgeschlossen unter I Mengenoperationen: ∪, I Sprachoperationen ◦, ∗ , (und damit auch ∩ und \) R 310 Reguläre Ausdrücke und NFA Satz Eine Sprache L ⊆ X ∗ ist genau dann durch einen regulären Ausdruck definiert, wenn sie NFA-akzeptierbar ist. zu zeigen ist: 1. Jede durch einen regulären Ausdruck definierte Sprache ist NFA-akzeptierbar. (Für jeden regulären Ausdruck E existiert ein NFA A mit L(E) = L(A).) 2. Jede NFA-akzeptierbare Sprache ist durch einen regulären Ausdruck definiert. (Für jeden NFA A existiert ein regulärer Ausdruck E mit L(E) = L(A).) 311 Konstruktion: Regulärer Ausdruck → NFA zu zeigen: Für jeden regulären Ausdruck E existiert ein NFA A mit L(E) = L(A). Beispiel: E = ab∗ + b Induktive Konstruktion des NFA A (Induktion über die Struktur des regulären Ausdruckes E): IA L(∅), L(ε) und L(a) für alle a ∈ X sind NFA-akzeptierbar (Tafel) IS sind L(E) und L(F ) NFA-akzeptierbar, dann sind auch I I I L(E + F ) = L(E) ∪ L(F ), L(EF ) = L(E) ◦ L(F ) und L(E ∗ ) = L(E)∗ NFA-akzeptierbar (wegen Abgeschlossenheit von REC(NFA) unter ∪, ◦, ∗ ) 312 NFA und reguläre Grammatiken Beispiel: NFA A = ({a, b}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 1)} und δ(b) = {(1, 0), (1, 2)} reguläre Grammatik G = ({S, B}, {a, b}, P, S) mit P = {S → aB, B → bS, B → b} definieren beide die Sprache L(A) = L(G) = (ab)+ Satz Eine Sprache L ⊆ X ∗ ist genau dann NFA-akzeptierbar, wenn L \ {ε} von einer regulären Grammatik (Chomsky-Typ 3) erzeugt wird. 313 Konstruktion: reguläre Grammatik → NFA gegeben: reguläre Grammatik G = (N, X , P, S) (Chomsky 3) Konstruktion: NFA A = (X , Q, δ, I, F ) mit Q = N ∪ {f } mit f 6∈ N I = {S} F = {f } für jedes a ∈ X : δ(a) = {(A, B) | (A → aB) ∈ P} ∪{(A, f ) | (A → a) ∈ P} Beispiel: Zur regulären Grammatik G = ({S, B}, {0, 1}, P, S) mit P = {S → 0B, B → 0B, B → 1S, B → 0} wird der NFA A = ({0, 1}, {S, B, f }, δ, {S}, {f }) mit δ(0) = {(S, B), (B, B), (B, f )} und δ(1) = {(B, S)} konstruiert. Fakt Für den wie oben zur Grammatik G konstruierten NFA A gilt L(G) = L(A). 314 Konstruktion: NFA → reguläre Grammatik gegeben: NFA A = (X , Q, δ, I, F ) Konstruktion: reguläre Grammatik G = (N, X , P, S) mit N = Q ∪ {S} mit S 6∈ Q [ {p → aq | (p, q) ∈ δ(a)} P = a∈X ∪ [ {S → aq | ∃s ∈ I : (s, q) ∈ δ(a)} a∈X ∪ [ {p → a | ∃f ∈ F : (p, f ) ∈ δ(a)} a∈X Beispiel: A = ({a, b}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 1), (1, 2)} und δ(b) = {(1, 1), (2, 1)} konstruierte Grammatik G = ({S, 0, 1, 2}, {a, b}, P, S) mit P = {0 → a1, 1 → b1, 1 → a2, 2 → b1, S → a1, 1 → a} Fakt Für die wie oben aus dem NFA A konstruierte Grammatik G gilt L(G) = L(A) \ {ε}. 315 Was bisher geschah I I Modellierung durch Zustandsübergangssysteme, z.B. Münzschließfach, Fahrkartenautomat, lineares Solitaire NFA A = (X , Q, δ, I, F ) (endlicher Automat) I I vollständig, Vervollständigung deterministisch (DFA), Potenzmengenkonstruktion I Akzeptanz von Wörtern durch NFA I von einem NFA A akzeptierte Sprache L(A) Verhalten, Semantik des NFA A I NFA-akzeptierbare Sprachen REC(NFA) REC(NFA) ist abgeschlossen unter den Operationen ∪, ∩, , ◦, ∗ , R 316 Algorithmische Lösungen für reguläre Sprachen alle Sprachen in Eingaben endlich beschrieben, z.B. als NFA Wortproblem Eingabe: (L, w), Ausgabe: ja, falls w ∈ L, sonst nein (Suche nach mit w markiertem Pfad im Automatengraphen) Leerheit Eingabe: L, Ausgabe: ja, falls L = ∅, sonst nein (Erreichbarkeit akzeptierender Zustände in NFA für L) Vollständigkeit Eingabe: L, Ausgabe: ja, falls L = X ∗ (also L = ∅), sonst nein (Erreichbarkeit im Automaten für L) Endlichkeit Eingabe: L, Ausgabe: ja, falls L endlich, sonst nein (Suche nach akzeptierendem Weg mit Schleife) Disjunktheit Eingabe: L1 , L2 , Ausgabe: ja, falls L1 ∩ L2 = ∅, sonst nein Inklusion Eingabe: L1 , L2 , Ausgabe: ja, falls L1 ⊆ L2 , sonst nein ? (Test L1 ∩ L2 = ∅) Gleichheit Eingabe: L1 , L2 , Ausgabe: ja, falls L1 = L2 , sonst nein ? (Test (L1 ∩ L2 ) ∪ (L2 ∩ L1 ) = ∅) 317 Wiederholung: Chomsky-Hierarchie Eine Grammatik G = (N, T , P, S) ist vom Chomsky-Typ 0 immer, 1 falls für jede Regel (l → r ) ∈ P gilt: |l| ≤ |r | (monoton, kontextsensitiv) 2 falls Typ 1 und für jede Regel (l → r ) ∈ P gilt: l ∈ N (kontextfrei) 3 falls Typ 2 und für jede Regel (l → r ) ∈ P gilt: r ∈ (T ∪ TN) (regulär) Eine Sprache L ⊆ T ∗ heißt vom Typ i für i ∈ {0, . . . , 3}, falls L \ {ε} = L(G) für eine Grammatik G vom Typ i. Li bezeichnet die Menge aller Sprachen vom Typ i. Es gibt Sprachen, die durch keine Grammatik erzeugt werden, also keinen Chomsky-Typ haben. Warum? Für jedes endliche Alphabet X ist I die Menge aller Grammatiken G = (N, X , P, S) abzählbar, I die Menge 2(X ∗ ) aller Sprachen über X überabzählbar. 318 Charakterisierungen regulärer Sprachen Für jede Sprache L ⊆ X ∗ über einem endlichen Alphabet X sind die folgenden Aussagen äquivalent: I L ist regulär, I es existiert ein regulärer Ausdruck E ∈ RegExp(X ) mit L = L(E), I L ∈ L3 (L hat Chomsky-Typ 3), I es existiert eine reguläre Grammatik G = (N, X , P, S) mit L \ {ε} = L(G), I es existiert ein NFA A = (X , QA , δA , IA , FA ) mit L = L(A), I es existiert ein DFA B = (X , QB , δB , IB , FB ) mit L = L(B). Die Menge L3 aller regulären Sprachen ist abgeschlossen unter den Operationen ∪, ∩, , ◦, ∗ , R 319 Wiederholung: Kontextfreie Grammatiken Grammatik G = (N, T , P, S) vom Chomsky-Typ 2 Alle Regeln in P haben die Form l → r mit l ∈ N und r ∈ (N ∪ T )+ Grammatik G = (N, T , P, S) erzeugt die Sprache L(G) = {w ∈ T ∗ | S →∗P w} I Syntax regulärer (arithmetischer, logischer) Ausdrücke I Syntax von Programmiersprachen (zusammengesetzte Ausdrücke und Anweisungen) 320 Wiederholung: Beispiele kontextfreier Sprachen Dyck-Sprache: Menge aller korrekt geklammerten Ausdrücke, a für ( und b für ) erzeugt durch die Grammatik GD = ({S}, {a, b}, PD , S) mit PD = {S → ε, S → SS, S → aSb} (Chomsky-Typ 2 mit ε-Sonderregel) Palindrom-Sprache (über X = {a, b}) erzeugt durch Grammatik GP = ({S}, {a, b}, PP , S) mit PP = {S → ε, S → a, S → b, S → aSa, S → bSb} (Chomsky-Typ 2 mit ε-Sonderregel) Łukasiewicz-Sprache: Menge aller Preorder-Durchquerungen von Binärbäumen mit Markierungen der Blätter mit a und inneren Knoten mit b erzeugt durch Grammatik GL = ({S}, {a, b}, PL , S) mit PL = {S → b, S → aSS} Warum sind diese Sprachen nicht NFA-akzepzierbar? 321 Maschinenmodelle Definition (endliche Beschreibung) durch I interne Steuerung (z.B. endliche Menge von Zuständen) I externen Speicher mit speziellen Zugriffsmöglichkeiten I Typ des Speicherinhaltes (z.B. endliches Wort über endlichem Alphabet) I Zugriffsmethode (z.B. Lesen / Schreiben, einmal / wiederholt, feste Reihenfolge) Konfigurationen (Momentaufnahmen) und endlich beschriebene Menge zulässiger Übergänge zwischen Konfigurationen schrittweise Berechnung : Folge von Konfigurationen von einer Startkonfiguration über zulässige Konfigurationsübergänge Akzeptanz einer Eingabe durch akzeptierende Berechnung: endliche Konfigurationenfolge zu einer akzeptierenden Konfiguration 322 NFA als Maschinenmodell algorithmische Lösung des Wortproblems w ∈ L für reguläre Sprachen L (gegeben durch NFA A mit L = L(A)) NFA A = (X , Q, δ, I, F ) als abstrakte Maschine: externer Speicher Eingabeband aus einzelnen Speicherzellen (enthält ein Wort w ∈ X ∗ ) interner Speicher enthält einen Zustand aus Q Steuerelement Zugriff auf I Eingabeband (externer Speicher): Lesen Bewegung in jedem Schritt eine Zelle nach rechts I Zustand (interner Speicher): Lesen und Schreiben 323 Arbeitsweise des Maschinenmodells NFA Start Steuerelement (Lesekopf) in einem Startzustand über der ersten Zelle des Eingabewortes Schritt I I I NFA liest Zeichen in der Zelle unter dem Lesekopf Zustandsübergang im Steuerelement (entsprechend Übergangsrelation und gelesenem Symbol) Lesekopf bewegt sich zur rechten Nachbarzelle Ende Lesekopf auf Zelle ohne Eingabesymbol NFA akzeptiert das Eingabewort, falls akzeptierender Zustand im internen Speicher 324 Konfigurationen eines NFA NFA A = (X , Q, δ, I, F ) Konfiguration (q, w) mit aktuellem Zustand q ∈ Q und ungelesenem Teil des Eingabewortes w ∈ X ∗ Startkonfiguration (s, u) mit Startzustand s ∈ I und Eingabewort u ∈ X ∗ Akzeptierende Konfiguration (f , ε) mit akzeptierendem Zustand f ∈ F Folgekonfiguration zur Konfiguration (p, aw) mit a ∈ X und w ∈ X ∗ : Konfiguration (q, w) mit (p, q) ∈ δ(a) Notation: (p, aw) ` (q, w) Berechnung für Eingabewort w ∈ X ∗ in A: Folge ((q0 , u0 ), . . . , (qn , un )) von Konfigurationen, wobei für alle i ∈ {0, . . . , n − 1} gilt (qi , ui ) ` (qi+1 , ui+1 ) akzeptierende Berechnung für Eingabewort w ∈ X ∗ in A: Berechnung für w mit Endkonfiguration (qn , vn ) = (f , ε) (analog zu akzeptierendem Pfad für w in A) 325 Beispiel A = ({a, b}, {0, 1, 2}, δ, {0}, {2}) mit δ(a) = {(0, 0), (1, 2)} und δ(b) = {(0, 1), (2, 2)} b a b 0 1 a 2 Eingabewort aabab Startkonfiguration (0, aabab) Endkonfiguration (2, ε) akzeptierende Berechnung für Eingabewort aabab in A: (0, aabab) ` (0, abab) ` (0, bab) ` (1, ab) ` (2, b) ` (2, ε) Man bemerke die Analogie zum akzeptierenden Pfad a a b a b 0→0→0→1→2→2 für aabab in A 326 Maschinenmodelle und Algorithmen Algorithmus: in Schritte geordnete Arbeitsvorschrift I endliche Beschreibung I eines schrittweise ausgeführten Verfahrens I in einer formalen Beschreibungssprache. Arbeitsweise abstrakter Maschinen: I endliche Beschreibung in einer formalen Sprache (Übergangsrelation, Programm) I schrittweise Bearbeitung I (Ergebnis nach endlich vielen Schritten) Jede abstrakte Maschine führt einen Algorithmus aus. (z.B. zur Lösung des Wortproblems (L, w) für reguläre Sprachen L) 327 Parameter abstrakter Maschinenmodelle Verschiedene Maschinenmodelle unterscheiden sich in I Art (Datentyp) und Kapazität des internen und externen Speichers I Art des Zugriffs auf internen und externen Speicher I Reihenfolge der Zugriffe (einmalig, wiederholt) I Determinismus Maschinen definieren (akzeptieren) Sprachen: Menge aller Eingaben mit akzeptierenden Berechnungen Maschinenmodelle definieren Sprachklassen: Menge aller durch eine solche Maschine definierten Sprachen 328 Kellerautomaten – Motivation L = {wcw R | w ∈ {a, b}∗ } ist kontextfrei, aber nicht regulär (NFA-akzeptierbar). gesucht: (einfaches) Maschinenmodell, welches die Sprache L akzeptiert Maschine benötigt Speicher für Folge von Symbolen, um auf diese in umgekehrter Reihenfolge zugreifen zu können passender ADT für den internen Speicher mit dieser Eigenschaft: Stack (Keller) mit seinen Operationen zum I Einfügen (push) I Lesen des „oberen “ Symbols (top) I Entfernen des „oberen “ Symbols (pop) Kellerautomat (pushdown automaton, PDA): Erweiterung von NFA (mit ε-Übergängen) um internen Speicher (Keller, Stack) 329 Kellerautomaten – Definition nichtdeterministischer Kellerautomat (PDA) A = (X , Q, Γ, δ, q0 , F , ⊥) mit X Alphabet (endlich, nichtleer) Q Menge von Zuständen (endlich, nichtleer) Γ Kelleralphabet (endlich, nichtleer) q0 ∈ Q Startzustand F ⊆ Q Menge der akzeptierenden Zustände δ : (X ∪ {ε}) → (Q × Q × Γ × Γ∗ ) Übergangsrelationen mit Änderung des Kellerinhaltes ⊥ ∈ Γ Kellerboden-Symbol 330 PDA – Beispiel PDA A = ({a, b, c}, {q0 , p, q}, {⊥, A, B}, δ, q0 , {q}, ⊥) mit δ(a) = {(q0 , q0 , K , AK ), (p, p, A, ε)} mit K ∈ {⊥, A, B} δ(b) = {(q0 , q0 , K , BK ), (p, p, B, ε)} mit K ∈ {⊥, A, B} δ(c) = {(q0 , p, K , K )} mit K ∈ {⊥, A, B} δ(ε) = {(p, q, ⊥, ⊥)} a: b: K | AK K | BK q0 a: b: c:K |K A|ε B|ε p ε:⊥|⊥ q mit K ∈ {⊥, A, B} 331 PDA – Konfigurationen Konfiguration (q, w, k ) ∈ Q × X ∗ × Γ∗ mit I Zustand q ∈ Q I (noch zu lesendes) Eingabewort w ∈ X ∗ I Kellerinhalt k ∈ Γ∗ I Startkonfigurationen (q0 , w, ⊥) mit w ∈ X ∗ beliebig I Übergang zwischen Konfigurationen: (p, aw, Gk ) ` (q, w, k 0 k ) mit (p, q, G, k 0 ) ∈ δ(a) für k ∈ Γ∗ und (p, w, Gk ) ` (q, w, k 0 k ) mit (p, q, G, k 0 ) ∈ δ(ε) für k ∈ Γ∗ I akzeptierende Konfigurationen (q, ε, k ) mit q ∈ F , k ∈ Γ∗ akzeptierende Berechnung (Konfigurationenfolge) für w in A: Folge (q0 , w0 , k0 ) ` · · · ` (qn , wn , kn ) von Konfigurationen mit 1. (q0 , w0 , k0 ) ist eine Startkonfiguration mit w0 = w. 2. (qn , wn , kn ) ist eine akzeptierende Konfiguration mit wn = ε. 3. Für jedes i ∈ {1, . . . , n} gilt (qi−1 , wi−1 , ki−1 ) ` (qi , wi , ki ). 332 Von PDA akzeptierte Sprachen PDA A = (X , Q, Γ, δ, q0 , F , ⊥) akzeptiert das Wort w ∈ X ∗ gdw. eine akzeptierende Berechnung (Konfigurationenfolge) mit der Startkonfiguration (q0 , w, ⊥) existiert. PDA A = (X , Q, Γ, δ, q0 , F , ⊥) akzeptiert die Sprache L(A) = {w ∈ X ∗ | A akzeptiert w} Sprache L heißt PDA-akzeptierbar gdw. ein PDA A mit L = L(A) existiert. PDA A und B heißen äquivalent gdw. L(A) = L(B) 333 PDA-Akzeptanz – Beispiel PDA A = ({a, b}, {q0 , p, q}, {⊥, x}, δ, q0 , {q}, ⊥) mit δ(a) = {(q0 , q0 , K , xK )} für K ∈ {x, ⊥} δ(b) = {(p, p, x, ε)} δ(ε) = {(q0 , p, K , K ), (p, q, ⊥, ⊥)} mit K ∈ {x, ⊥} a : K | xK q0 b:x |ε ε:K |K p ε:⊥|⊥ q für K ∈ {x, ⊥} A akzeptiert das Wort aabb über die Konfigurationenfolge (q0 , aabb, ⊥) ` (q0 , abb, x⊥) ` (q0 , bb, xx⊥) ` (p, bb, xx⊥) ` (p, b, x⊥) ` (p, ε, ⊥) ` (q, ε, ⊥) und ε über die Konfigurationenfolge (q0 , ε, ⊥) ` (p, ε, ⊥) ` (q, ε, ⊥) aber nicht abb, aba Es gilt L(A) = {an bn | n ∈ } Damit ist die Sprache {an bn | n ∈ } PDA-akzeptierbar. N N 334 Deterministische PDA PDA A = (X , Q, Γ, δ, q0 , F , ⊥) heißt deterministisch (DPDA) gdw. ∀a ∈ X ∀q ∈ Q ∀K ∈ Γ : |{(p, B) | (q, p, K , B) ∈ δ(a) ∪ δ(ε)}| ≤ 1 Sprache L heißt deterministisch kontextfrei gdw. ein deterministischer PDA A mit L = L(A) existiert. Beispiele: N} ist deterministisch kontextfrei, I L = {an bn | n ∈ I L0 = {wcw R ∈ {a, b}∗ | w ∈ {a, b}∗ } ist deterministisch kontextfrei, I L00 = {waw R ∈ {a, b}∗ | w ∈ {a, b}∗ } nicht. Die Menge aller durch deterministische PDA akzeptierbaren Sprachen ist eine echte Teilmenge der Menge aller durch PDA akzeptierbaren Sprachen. 335 Was bisher geschah abstrakte Maschinenmodelle: I Definition: I I I Steuerelement externer Speicher (Ein- und Ausgabe) interner Speicher I Konfiguration (Start-, akzeptierend, Übergänge) I Berechnung I akzeptierte Sprache einer Maschine I akzeptierte Sprachklasse eines Maschinenmodells PDA (Kellerautomat) A = (X , Q, Γ, δ, q0 , F , ⊥) I nichtdeterministisch (PDA) I deterministisch (DPDA) Menge aller durch DPDA akzeptierbaren Sprachen ist eine echte Teilmenge der Menge aller durch PDA akzeptierbaren Sprachen. Beispiel: L = {waw R | w ∈ {a, b}∗ } ∈ REC(PDA) \ REC(DPDA) 336 Schnitt PDA-akzeptierbarer mit regulären Sprachen Satz I Sind L eine PDA-akzeptierbare und L0 eine reguläre Sprache, dann ist die Sprache L ∩ L0 PDA-akzeptierbar. I Sind L eine durch einen DPDA-akzeptierbare und L0 eine reguläre Sprache, dann ist die Sprache L ∩ L0 durch einen DPDA akzeptierbar. gegeben: PDA A = (X , QA , Γ, δA , iA , FA , ⊥) mit L = L(A) DFA B = (X , QB , δB , {iB }, FB ) mit L0 = L(B) N Beispiel: Dyck-Sprache ∩ a∗ b∗ = {an bn | n ∈ } Produktkonstruktion: PDA C = (X , QA × QB , Γ, δ, (iA , iB ), FA × Fb , ⊥) mit (pA , qA , G, k ) ∈ δA (a) ∀a ∈ X : δ(a) = ((pA , pB ), (qA , qB ), G, k ) | ∧(pB , qB ) ∈ δB (a) δ(ε) = {((pA , pB ), (qA , pB ), G, k ) | (pA , qA , G, k ) ∈ δA (ε)} Für den oben konstruierten PDA C gilt L(C) = L(A) ∩ L(B). 337 Spezialfall: Schnitt regulärer Sprachen schon bekannt: REC(NFA) ist unter ∩ abgeschlossen. gegeben: DFA A = (X , QA , δA , {iA }, FA ) DFA B = (X , QB , δB , {iB }, FB ) Beispiel: (ab)∗ ∩ a∗ b∗ a∗ Produktkonstruktion: DFA C = (X , QA × QB , δ, {(iA , iB )}, FA × Fb ) mit (pA , qA ) ∈ δA (a) ∀a ∈ X : δ(a) = ((pA , pB ), (qA , qB )) | ∧(pB , qB ) ∈ δB (a) Für den oben konstruierten DFA C gilt L(C) = L(A) ∩ L(B). 338 PDA – Akzeptanz durch leeren Keller alternative Akzeptanzbedingung akzeptierende Konfigurationen: (q, ε, ε) mit q ∈ Q beliebig Angabe akzeptierender Zustände überflüssig Beispiel: L = {an bn | n ∈ } ist PDA-akzeptierbar durch PDA A = ({a, b}, {q0 , p}, {⊥, x}, δ, q0 , ⊥) mit δ(a) = {(q0 , q0 , K , xK )} für K ∈ Γ δ(b) = {(p, p, x, ε)} δ(ε) = {(q0 , p, K , K ), (q0 , p, ⊥, ε), (p, p, ⊥, ε)} für K ∈ {x, ⊥} N b: ε: a : K | xK q0 ε: ε: K |K ⊥|ε x |ε ⊥|ε p für K ∈ {x, ⊥} 339 Akzeptanzbedingungen für PDA zwei Möglichkeiten zur Definition akzeptierender Konfigurationen: 1. Akzeptanz durch akzeptierenden Zustand (analog NFA): (q, ε, k ) mit q ∈ F und k ∈ Γ∗ beliebig 2. Akzeptanz durch leeren Keller: (q, ε, ε) mit q ∈ Q beliebig Beispiel: Die Sprache L = {an bn | n ∈ durch akzeptierende Zustände akzeptiert durch den PDA A = ({a, b}, {q0 , p, q}, {⊥, x}, δ, q0 , {q}, ⊥) mit a : K | xK q0 b:x |ε ε:K |K p ε:⊥|⊥ q N} wird mit leerem Keller akzeptiert durch den PDA B = ({a, b}, {q0 , p, q}, {⊥, x}, δ, q0 , ⊥) mit a : K | xK ε: ε: q0 b: ε: K |K ⊥|ε x |ε ⊥|ε p für K ∈ {x, ⊥} 340 Äquivalenz beider Akzeptanzbedingungen Satz 1. Zu jedem PDA mit akzeptierenden Zuständen existiert ein äquivalenter PDA, der mit leerem Keller akzeptiert. 2. Zu jedem PDA, der mit leerem Keller akzeptiert, existiert ein äquivalenter PDA mit akzeptierenden Zuständen. Idee (PDA-Transformationen): 1. PDA mit akzeptierenden Zuständen → PDA mit leerem Keller: neues Kellerboden-Symbol und neuen Endzustand hinzufügen, ursprünglicher Automat arbeitet „darüber“, nach Übergang in einen akzeptierenden Zustand ε-Übergänge in diesem akzeptierenden Zustand zum Entfernen aller restlichen Kellersymbole 2. PDA mit leerem Keller → PDA mit akzeptierenden Zuständen: neuen (einzigen) akzeptierenden Zustand hinzufügen, für jeden Übergang in eine Konfiguration mit leerem Keller einen Übergang in diesen akzeptierenden Zustand hinzufügen. 341 Kontextfreie Grammatiken und PDA schon bekannt: L3 = REC(NFA) Die Menge aller regulären (Chomsky-Typ 3) Sprachen ist genau die Menge aller NFA-akzeptierbaren Sprachen. Nachweis durch Übersetzungen I reguläre Grammatik G → NFA A mit L(A) = L(G) I NFA A → reguläre Grammatik G mit L(A) = L(G) Satz L2 = REC(PDA) Die Menge aller kontextfreien (Chomsky-Typ 2) Sprachen ist genau die Menge aller PDA-akzeptierbaren Sprachen. 342 Kontextfreie Grammatik → PDA Lemma Zu jeder kontextfreien Grammatik G existiert ein PDA A mit L(A) = L(G). Beispiel: Łukasiewicz-Sprache erzeugt durch die Grammatik G = ({S}, {a, b}, P, S) mit P = {S → b, S → aSS} gegeben: kontextfreie Grammatik G = (N, X , P, S) Idee: Tiefensuche im Ableitungsbaum (Linksableitung) PDA A = (X , {q}, N ∪ X , δ, q, S) mit δ(ε) ∀a ∈ X : δ(a) = {(q, q, B, w) | B → w ∈ P} = {(q, q, a, ε)} akzeptiert mit leerem Keller Für den so konstruierten PDA A gilt L(A) = L(G). Nachweis: Eindeutige Zuordnung zwischen Linksableitungen S → u 1 A1 v 1 → u 1 u 2 A2 v 2 → · · · → u 1 . . . u m−1 Am−1 v m−1 → w = u 1 . . . u m und akzeptierenden Berechnungen für w = u 1 . . . u m (q, w, S) ` (q, u 1 . . . u m , u 1 A1 v 1 ) ` · · · ` (q, u 2 . . . u m , A1 v 1 ) ` (q, u 2 . . . u m , u 2 A2 v 2 ) ` · · · ` (q, u m , u m ) ` · · · ` (q, ε, ε) 343 PDA → kontextfreie Grammatik Beispiel: PDA A = ({a, b}, {q}, {X , ⊥}, δ, q, ⊥} (LK-Akzeptanz) mit δ(a) = {(q, q, X , XX )(q, q, ⊥, X ⊥)}, δ(b) = {(q, q, X , ε)} und δ(ε) = {(q, q, ⊥, ε)} Lemma Zu jedem PDA A existiert eine kontextfreie Grammatik G mit L(A) = L(G). Nacheinanderausführung der Konstruktionen PDA → kontextfreie Grammatik → PDA führt zur folgenden Aussage: Folgerung Zu jedem PDA existiert ein äquivalenter PDA mit einem Zustand, der mit leerem Keller akzeptiert. 344 PDA → kontextfreie Grammatik (Vorbereitung) Fakt Jeder PDA A = (X , Q, Γ, δ, q0 , ⊥) (LK-Akzeptanz) ist äquivalent zu einem PDA B = (X , Q 0 , Γ0 , δ 0 , q00 , ⊥0 ) (LK-Akzeptanz) mit der Eigenschaft ∀a ∈ X ∪ {ε} ∀(p, q, G, w) ∈ δ 0 (a) : |w| ≤ 2 Konstruktion: für jedes a ∈ x ∪ {ε} Ersetzung jedes Überganges (p, q, G, w) ∈ δ(a) für w = w1 . . . wn mit n > 2 durch die Regeln (p, p1 , G, wn−1 wn ) ∈ δ(a) (p1 , p2 , wn−1 , wn−2 wn−1 ) ∈ δ(ε) .. . (pn−1 , q, w2 , w1 w2 ) ∈ δ(ε) mit neu hinzugefügten Zuständen p1 , . . . , pn−1 345 PDA → kontextfreie Grammatik (Idee) gegeben: PDA A = (X , Q, Γ, δ, q0 , ⊥) (LK-Akzeptanz) mit ∀a ∈ X ∪ {ε} ∀(p, q, G, w) ∈ δ(a) : |w| ≤ 2 Ziel: Konstruktion einer kontextfreien Grammatik G = (N, X , P, S), so dass die Linksableitungen in G genau den akzeptierenden Berechnungen in A entsprechen. akzeptierende Berechnung für w in A: (q0 , w, ⊥) ` · · · ` (q, ε, ε) mögliche Konfigurationsübergänge in A: I oberes Kellersymbol löschen (p, q, A, ε) ∈ δ(a) für a ∈ X ∪ {ε} entspricht Grammatikregel (p, A, q) → a I oberes Kellersymbol durch genau ein neues ersetzen (p, q, A, B) ∈ δ(a) für a ∈ x ∪ {ε} entspricht Grammatikregel (p, A, q 0 ) → a(q, B, q 0 ) für alle q 0 ∈ Q I oberes Kellersymbol durch genau zwei neue ersetzen (p, q, A, BC) ∈ δ(a) für a ∈ x ∪ {ε} entspricht Grammatikregel (p, A, q 0 ) → a(q, B, r )(r , C, q 0 ) für alle q0, r ∈ Q 346 PDA → kontextfreie Grammatik (Konstruktion) gegeben: PDA A = (X , Q, Γ, δ, q0 , ⊥) (LK-Akzeptanz) mit ∀a ∈ X ∪ {ε} ∀(p, q, G, w) ∈ δ(a) : |w| ≤ 2 Konstruktion kontextfreier Grammatik G = (N, X , P, S) mit N = (Q × Γ × Q) ∪ {S} P = {S → (q0 , ⊥, q) | q ∈ Q} ∪ {(p, B, q) → a | (p, q, B, ε) ∈ δ(a)} ∪ {(p, B, q) → a(p0 , C, q) | (p, p0 , B, C) ∈ δ(a) ∧ q ∈ Q} ∪ {(p, B, q) → a(p0 , C, q)(q, D, q 0 ) | (p, p0 , B, CD) ∈ δ(a) ∧ q, q 0 ∈ Q} Für die so konstruierte Grammatik G gilt L(A) = L(G). 347 PDA → kontextfreie Grammatik (Beispiel) PDA A = ({a, b}, {q}, {X , ⊥}, δ, q, ⊥} (LK-Akzeptanz) mit δ(a) = {(q, q, X , XX )(q, q, ⊥, X ⊥)}, δ(b) = {(q, q, X , ε)}, δ(ε) = {(q, q, ⊥, ε)} G = (N, X , P, S) zu A mit N = {S, (q, ⊥, q), (q, X , q)} S → (q, ⊥, q) (q, X , q) → b (q, ⊥, q) → ε P = (q, X , q) → a(q, X , q)(q, X , q) (q, ⊥, q) → a(q, X , q)(q, ⊥, q) wegen (q, q, X , ε) ∈ δ(b) wegen (q, q, ⊥, ε) ∈ δ(ε) wegen (q, q, X , XX ) ∈ δ(a) wegen (q, q, ⊥, X ⊥) ∈ δ(a) 348 Abschlusseigenschaften von CF Sind L1 und L2 kontextfreie Sprachen, dann sind auch I L1 ∪ L2 I L1 ◦ L2 I L∗1 I L1 ∩ L0 für jede reguläre Sprache L0 kontextfreie Sprachen. Die Menge aller kontextfreien Sprachen ist nicht abgeschlossen unter I Schnitt Beispiel: L1 = {ai bi c k | i, k > 0} ∈ CF und L2 = {ai bk c k | i, k > 0} ∈ CF, aber L1 ∩ L2 = {ai bi c i | i > 0} 6∈ CF nicht. I Komplement (Warum ?) 349 Algorithmische Lösungen für kontextfreie Sprachen algorithmisch entscheidbar sind Wortproblem: Eingabe (L, w) (durch PDA A mit L = L(A)) Ausgabe: ja, falls w ∈ L, sonst nein (Akzeptanz durch A) I Leerheit: Eingabe L (durch CFG G mit L = L(G)), Ausgabe: ja, falls L(G) = ∅, sonst nein (ja, falls Startsymbol der Grammatik kein Terminalwort erzeugt) I Endlichkeit: Eingabe L, Ausgabe: ja, falls L endlich, sonst nein (Pumping-Lemma, hier nicht gezeigt) I nicht algorithmisch entscheidbar sind Inklusion: Eingabe L1 , L2 , Ausgabe: ja, falls L1 ⊆ L2 , sonst nein I Gleichheit: Eingabe L1 , L2 , Ausgabe: ja, falls L1 = L2 , sonst nein I Disjunktheit: Eingabe L1 , L2 , Ausgabe: ja, falls L1 ∩ L2 = ∅, sonst nein I Kontextfreiheit des Schnittes: Eingabe L1 , L2 , Ausgabe: ja, falls L1 ∩ L2 kontextfrei, sonst nein I 350 Was bisher geschah Reguläre Sprachen (REG): erzeugt durch reguläre Grammatik (Chomsky-Typ 3), akzeptiert von NFA, DFA abgeschlossen unter ∪, ∩, , ◦, ∗ , R Anwendungen z.B. Suchen von Zeichenketten in Texten, Darstellung von Bezeichnern, Konstanten nicht-reguläre Sprachen , z.B. {an bn | n ∈ }, Dyck-Sprachen, 2 {w ∈ {a, b}∗ | w = w R }, {an | n ∈ } N N Kontextfreie Sprachen (CF): erzeugt durch kontextfreie Grammatik (Chomsky-Typ 2) akzeptiert von PDA abgeschlossen unter ∪, ◦, ∗ , R Anwendungen z.B. Syntax regulärer und arithmetischer Ausdrücke, Formeln, Programmier- und Beschreibungssprachen, (natürlichen Sprachen), nicht-kontextfreie Sprachen , z.B. {an bn c n | n ∈ }, 2 {ww | w ∈ {a, b}∗ }, {an | n ∈ } N N 351 Wiederholung: Maschinenmodelle Definition (endliche Beschreibung) durch I interne Steuerung (z.B. endliche Menge von Zuständen) I externen und internen Speicher mit speziellen Zugriffsmöglichkeiten I Typ des Speicherinhaltes (z.B. endliches Wort über endlichem Alphabet) I Zugriffsmethode (z.B. Lesen / Schreiben, einmal / wiederholt, feste Reihenfolge) Konfigurationen (Momentaufnahmen) und endliche Menge zulässiger lokaler Übergänge zwischen Konfigurationen schrittweise Berechnung : Folge von Konfigurationen von einer Startkonfiguration über zulässige Konfigurationsübergänge Akzeptanz einer Eingabe durch akzeptierende Berechnung: endliche Konfigurationenfolge zu einer akzeptierenden Konfiguration 352 Unendliche Konfigurationsfolgen Jede Instanz eines Maschinenmodells (gegebener NFA, DFA, PDA, DPDA, TM) definiert ein Zustandsübergangssystem (gerichteter Graph): Knoten: Konfigurationen (Zustände) darunter Start- und akzeptierende Konfigurationen Kanten: zulässige Konfigurationsübergänge Beispiel: PDA B = ({a}, {0, 1}, {⊥, X }, δB , 0, {0}, ⊥) mit δA (a) = {(0, 1, ⊥, ⊥), (0, 1, X , X )}, δA (ε) = {(0, 1, ⊥, X ⊥), (1, 0, X , ε)} Beobachtung: In PDA mit ε-Übergängen können unendliche Konfigurationsfolgen existieren. Aber: Akzeptierende Konfigurationsfolgen für endliche Wörter sind immer endlich. Deshalb sind unendliche Konfigurationsfolgen für die Definition von Sprachen und Sprachklassen endlicher Wörter irrelevant. 353 Wiederholung – Sprachen vom Chomsky-Typ 0 Regeln der Form l → r mit l ∈ (N ∪ T )+ und r ∈ (N ∪ T )∗ Beispiel: G = ({A, B, C}, {a, b, c}, P, A) mit A → aABC A → aBC CB → BC aB → ab P= bB → bb bC → bc cC → cc (sogar Chomsky-Typ 1) definiert die Sprache L(G) = {an bn c n | n ∈ N \ {0}} 354 Turing-Maschine – Idee Ziel: Maschinenmodell für Sprachen vom Chomsky-Typ 0 (und 1) Komponenten des Maschinenmodells: I Steuereinheit: Lese/Schreib-Kopf I interner Speicher: 1. endliche Menge von Zuständen (Lesen / Schreiben) 2. beidseitig unendliches Arbeitsband aus Zellen I I I Typ des Speicherinhaltes: endliches Wort über endlichem Alphabet (Arbeitsalphabet) Zugriffsmethode: Lesen / Schreiben Bewegung des Lese/Schreib-Kopfes auf ein Nachbarfeld externer Speicher: 3. beidseitig unendliches Eingabeband aus Zellen I I Typ des Speicherinhaltes: endliches Wort über endlichem Alphabet (Eingabealphabet) Zugriffsmethode: Lesen Bewegung des Lese-Kopfes auf ein Nachbarfeld übliche Vereinfachung der Struktur: Zusammenfassen der Bänder im internen und externen Speicher zu einem Eingabe- und Arbeitsband (2,3) mit Lese/Schreib-Zugriff 355 Turing-Maschine – Definition Turing-Maschine (TM) M = (X , Q, Γ, δ, q0 , F , ) mit X endliches Eingabealphabet Q endliche Menge von Zuständen Γ ⊃ X endliches Arbeitsalphabet δ ⊆ (Γ × Q × Γ × Q × {L, R, N}) Übergangsrelation q0 Startzustand F akzeptierende Zustände ∈ Γ \ X Leere-Zelle-Symbol TM M heißt deterministisch gdw. ∀a ∈ Γ∀q ∈ Q : | {(a, q, b, p, x) | p ∈ Q, b ∈ Γ, x ∈ {L, R, N}}∩δ| ≤ 1 356 Beispiele für Turing-Maschinen I TM M1 = ({a, b}, {q0 , f }, {a, b, }, δ, q0 , {f }, ) mit δ = {(a, q0 , a, q0 , L), (b, q0 , b, q0 , L), (, q0 , , f , R)} I TM M2 = ({a, b}, {q0 , qa , qb , f }, {a, b, }, δ, q0 , {f }, ) mit (a, q0 , , qa , R), (b, q0 , , qb , R), (a, qa , a, qa , R), (b, qa , b, qa , R), δ= (a, qb , a, qb , R), (b, qb , b, qb , R), (, q0 , , f , R), (, qa , a, f , R), (, qb , b, f , R) I TM M3 = ({1}, {q0 , q1 , q2 , q3 , q4 , f }, {1, x, }, δ, q0 , {f }, ) mit δ = {(1, q0 , 1, q1 , R), (1, q1 , x, q2 , R), (1, q2 , 1, q3 , R)} ∪ {(1, q3 , x, q2 , R), (1, q4 , 1, q4 , L), (x, q1 , x, q1 , R)} ∪ {(x, q2 , x, q2 , R), (x, q3 , x, q3 , R), (x, q4 , x, q4 , L)} ∪ {(, q1 , , f , L), (, q2 , , q4 , L), (, q4 , , q0 , R)} 357 Konfigurationen einer TM TM M = (X , Q, Γ, δ, q0 , F , ) Konfiguration (u, q, v ) ∈ (Γ∗ × q × Γ∗ ) bedeutet: I I I aktueller Bandinhalt: w = uv aktueller Zustand der TM: q Schreib-/Lesekopf der TM zeigt auf erstes Symbol von v (Leere-Zelle-Symbol, falls v = ε) Startkonfigurationen (, q0 , w) mit w ∈ X ∗ akzeptierende Konfigurationen (u, q, v ) mit q ∈ F Konfigurationsübergänge von (ua, p, bv ): für (b, p, c, q, R) ∈ δ : (ua, p, bv ) ` (uac, q, v ) für (b, p, c, q, L) ∈ δ : (ua, p, bv ) ` (u, q, acv ) für (b, p, c, q, N) ∈ δ : (ua, p, bv ) ` (ua, q, cv ) 358 Akzeptanz durch TM TM M = (X , Q, Γ, δ, q0 , F , ) M akzeptiert das Wort w ∈ X ∗ gdw. eine Folge k0 , . . . , kn von Konfigurationen ki ∈ Γ∗ × Q × Γ∗ exisiert, so dass gilt: 1. k0 = (, q0 , w) ist die Startkonfiguration mit Eingabe w 2. kn ∈ Γ∗ × F × Γ∗ ist eine akzeptierende Konfiguration 3. für jedes i ∈ {1, . . . , n} ist ki−1 ` ki ein zulässiger Konfigurationsübergang Beispiele: n L(M1 ) = L(M2 ) = {a, b}∗ , L(M3 ) = {1(2 ) | n ∈ N} M akzeptiert die Sprache L(M) = {w ∈ X ∗ | M akzeptiert w} L ⊆ X ∗ heißt Turing-akzeptierbar gdw. eine TM M mit L = L(M) existiert. 359 Was bisher geschah Maschinenmodelle: endliche Automaten: alle regulären Sprachen (Chomsky-Typ 3) durch nichtdeterministisches (NFA) und deterministisches (DFA) Maschinenmodell akzeptierbar. (Transformation von NFA in äquivalente DFA möglich.) REC(NFA) = REG abgeschlossen unter ∪, ∩, , ◦, ∗ , R PDA : alle kontextfreien Sprachen (Chomsky-Typ 2) durch nichtdeterministisches Maschinenmodell (PDA) akzeptierbar, aber nicht durch deterministisches Maschinenmodell (keine Transformation möglich) REC(PDA) = CF abgeschlossen unter ∪, ◦, ∗ , R und Schnitt mit REG, aber nicht unter ∩, TM : REC(TM) entspricht Chomsky-Typ ? akzeptieren deterministisches und nichtdeterministisches Modell dieselbe Sprachklasse ? abgeschlossen unter ? 360 NFA (X , Q, δ, I, F ) I I Eingabeband (externer Speicher) enthält w ∈ X ∗ Zugriff durch Lesekopf auf einer Zelle des Eingabebandes, Bewegung auf rechte Nachbarzelle interner Speicher: q ∈ Q, Zugriff Lesen / Schreiben PDA (X , Q, Γ, δ, q0 , F , ⊥) I I Eingabeband (externer Speicher) enthält w ∈ X ∗ Zugriff durch Lesekopf auf einer Zelle des Eingabebandes keine Bewegung oder Bewegung auf rechte Nachbarzelle interner Speicher: I I q ∈ Q, Zugriff Lesen / Schreiben Stack k ∈ Γ∗ (Zugriff mit push, pop, top) TM (X , Q, Γ, δ, q0 , F , ) I I (Eingabe- und Arbeits-)Band (externer und interner Speicher) enthält zu Beginn w ∈ X ∗ Zugriff durch Lese/Schreibkopf auf eine Zelle keine, Rechts- oder Links-Bewegung auf Nachbarzelle interner Speicher: q ∈ Q, Zugriff Lesen / Schreiben 361 Turing-Maschine – Beispiel TM M = ({a, b, c}, {q0 , q1 , q2 , q3 , f }, {a, b, x, }, δ, q0 , {f }, ) mit (, q0 , , f , N), (, q3 , , q0 , R), (a, q , x, q , R), 0 1 (a, q , a, q , R), 1 1 (a, q , a, q , L), 3 3 (b, q1 , x, q2 , R), (b, q2 , b, q2 , R), δ= (b, q3 , b, q3 , L), (c, q , x, q , L), 2 3 (x, q , x, q , R), 0 0 (x, q , x, q , R), 1 1 (x, q , x, q , R), 2 2 (x, q3 , x, q3 , L) akzeptiert L(M) = {an bn c n | n ∈ N} 362 Berechnung einer Turing-Maschine Möglichkeiten für Berechnungen einer TM M für ein Eingabewort w: 1. Berechnung endet in einer akzeptierenden Konfiguration (u, p, v ) (d.h. p ∈ F ), 2. Berechnung endet in einer nicht-akzeptierenden Konfiguration (u, p, v ) (d.h. p 6∈ F ), 3. Berechnung endet nicht (unendliche Berechnung). Im Fall 1 akzeptiert M das Eingabewort w, in Fall 2 und 3 nicht. Zu jeder TM M existiert eine TM M 0 , so dass L(M) = L(M 0 ) und in M 0 jede endliche nicht-fortsetzbare Berechnung in einer akzeptierenden Konfiguration endet. (d.h. Fall 2 kommt in M 0 nicht vor) 363 Alternative Akzeptanzbedingung für TM TM M = (X , Q, Γ, δ, q0 , F , ) hält in einer Konfiguration (u, q, v ) ∈ Γ∗ × Q × Γ∗ gdw. aus (u, q, v ) kein Konfigurationsübergang in M möglich ist. Zu jeder TM M existiert eine TM M 0 mit L(M) = L(M 0 ) ohne Nachfolgekonfigurationen aus akzeptierenden Konfigurationen. (evtl. neuen akzeptierenden Zustand hinzufügen) Fakt Zu jeder TM M existiert eine TM M 0 mit L(M) = L(M 0 ), die nur in akzeptierenden Konfigurationen hält. (Schleifen in nicht-akzeptierenden Zuständen hinzufügen) Fakt Zu jeder TM M existiert eine TM M 0 , so dass für jedes w ∈ M akzeptiert w gdw. M 0 bei Eingabe von w hält. X∗ : Akzeptierende Zustände sind bei Akzeptanz durch Halt irrelevant (analog PDA-Akzeptanz durch leeren Keller). 364 TM für Verschiebung TM M = ({0, •, 1}, {q0 , q1 , q2 , q3 , q4 , q5 , f }, {0, 1, •, }, δ, q0 , {f }, ) mit (, q1 , , q4 , L), (0, q0 , 0, q0 , R), (0, q , •, q , L), 1 2 (1, q , 1, q , R), 0 0 (1, q1 , •, q3 , L), δ= (•, q0 , •, q1 , R), (•, q , 0, q , R), 5 2 (•, q , 1, q , R), 5 3 (•, q4 , , f , N), (•, q5 , •, q1 , R) akzeptiert jedes Eingabewort aus (0 + 1)∗ • (0 + 1)∗ , verschiebt dabei den Teil nach dem • um eine Zelle nach links 365 Operationen auf TM-akzeptierbaren Sprachen gegeben: TM A, TM B (Akzeptanz durch Halt) gesucht: TM C mit ∩: L(C) = L(A) ∩ L(B) ∪: L(C) = L(A) ∪ L(B) ◦: L(C) = L(A) ◦ L(B) ∗: L(C) = L(A)∗ R: L(C) = L(A)R Skizzen zu Konstruktionen der TM C (Tafel) mit Turing-Maschinen für „Hilfsarbeiten“, z.B. Verschieben, Kopieren, Zerlegen von Wörtern, Steuerung der abwechselnden Ausführung mehrerer TM 366 Was bisher geschah Turing-Maschine (X , Q, Γ, δ, q0 , F , ) I akzeptiert Sprache L ⊆ X ∗ (durch akzeptierende Zustände oder Halt) I ändert i.A. während der Berechnung den Inhalt (w ∈ Γ∗ ) des Arbeitsbandes I Menge REC(TM) der TM-akzeptierbaren Sprachen ist abgeschlossen unter ∪, ∩, ◦,∗ ,R , aber nicht unter I Akzeptieren deterministische und nichtdeterministische TM dieselbe Sprachklasse? I REC(TM) entspricht Chomsky-Typ ? 367 Nichtdeterministische TM TM M = ({0, 1}, {p, q, f }, {0, 1, }, δ, p, {f }, ) mit (0, p, 1, p, R), (1, p, 1, p, R), (1, p, 1, q, R), δ= (1, q, 1, q, R), (, q, , f , N) akzeptiert z.B. das Wort 11011 mit (u.A.) folgender Berechnung (, p, 11011) ` (1, p, 1011) ` (11, p, 011) ` (111, p, 11) ` (1111, q, 1) ` (11111, q, ) ` (11111, f , ) 368 Simulation nichtdeterministischer TM Satz Zu jeder nichtdeterministischen TM M existiert eine deterministische TM M 0 mit L(M) = L(M 0 ). Beweisidee: Menge aller möglichen Berechnungen von M für Eingabe w bilden einen Baum (evtl. mit unendlichen Pfaden): Knoten : Konfigurationen Wurzel : Startkonfiguration (Startzustand, Eingabewort) Blätter : akzeptierende Konfigurationen Kanten : zulässige Konfigurationsübergänge in M M0 führt Breitensuche in diesem Baum durch (simuliert parallele Berechnung aller Möglichkeiten), Bandinhalt von M 0 sind Konfigurationen aus M M 0 akzeptiert, sobald eine akzeptierende Konfiguration von M auf dem Band steht. 369 Beispiel - Sprache vom Chomsky-Typ 0 Regeln l → r mit l ∈ (T ∪ N)+ , r ∈ (T ∪ N)∗ G = ({S, T , }, {0, 1}, P, S) mit S → 1S101 S → 01S00 S → 110S11 0S0 → T P= 0T 0 → T 1S1 → T 1T 1 → T T → ε Gilt ε ∈ L(G) ? S → 110S11 → 11001S0011 → 11001110S110011 → 110011101S101110011 → 11001110T 01110011 →∗ 110T 011 → 11T 11 → 1T 1 → T → ε 370 TM und Sprachen vom Chomsky-Typ 0 Satz Die Menge aller Sprachen, die von einer TM akzeptiert werden, ist genau die Menge aller Sprachen vom Chomsky-Typ 0. Idee der Konstruktionen: I Grammatik → TM: M berechnet für das Eingabewort w (letztes Wort einer Ableitung) eine Ableitung in der Grammatik „rückwärts“. (Evtl. wird dabei der Bandinhalt geeignet verschoben.) TM akzeptiert, wenn Bandinhalt = Startsymbol I TM → Grammatik: Grammatik erzeugt für jedes mögliche Eingabewort w einen „Kandidaten“ w 0 (Startkonfiguration der TM mit Eingabe w). Grammatik-Regeln beschreiben die lokalen Änderungen bei Konfigurationsübergängen der TM (Simulation der Berechnung der TM auf w durch Ableitung in der Grammatik). Wird in der Ableitung eine akzeptierende Konfiguration errreicht, „Übersetzung“ des Kandidaten w 0 in Terminalwort w. 371 Beispiel - Sprache vom Chomsky-Typ 1 (monotone, kontextsensitive Grammatik) Regeln l → r mit l, r ∈ (T ∪ N)+ mit |l| ≤ |r | G = ({S, R, T , A, B}, {a, b}, P, S) mit S → RT R → RB BT → AA P= BA → AA RA → ba aA → aa Ableitung für das Wort baaaa S → RT → RBT → RBBT → RBBBT → RBBAA → RBAAA → RAAAA → baAAA → baaAA → baaaA → baaaa 372 TM mit linear beschränktem Band (LBA) TM M = (X , Q, Γ, δ, q0 , F , ) heißt linear beschränkt (LBA) gdw. 1. M nichtdeterministisch und 2. für jede bei Eingabe von w in M erreichbare Konfiguration upv ∈ Γ∗ × Q × Γ∗ gilt |uv | ≤ |w|. Satz Die Menge aller Sprachen, die von einer TM mit linear beschränktem Band akzeptiert werden, ist genau die Menge aller Sprachen vom Chomsky-Typ 1. 373 Abschlusseigenschaften von L0 und L1 Die Menge L0 aller Turing-akzeptierbaren Sprachen (Chomsky-Typ 0) ist abgeschlossen unter: I ∩ (sequentieller Akzeptanztest durch beide TM) I ∪ ((pseudo-)paralleler Akzeptanztest durch beide TM) I ◦, I R ∗ (nichtdeterministische Zerlegung und Test) Die Menge aller Turing-akzeptierbaren Sprachen ist nicht unter Komplement abgeschlossen. (Nachweis durch Gegenbeispiel später) Die Menge L1 aller Sprachen vom Chomsky-Typ 1 ist abgeschlossen unter ∪, ∩, , ◦, ∗ , R Abschluss unter : Immerman, Szelepcsényi (1987) 374 Zusammenfassung: Turing-akzeptierbare Sprachen I Deterministische TM akzeptieren dieselbe Sprachklasse wie nichtdeterministische TM, und zwar genau alle Sprachen vom Chomsky-Typ 0 I Die Menge aller TM-akzeptierbaren Sprachen ist abgeschlossen unter ∪, ∩, ◦, ∗ , aber nicht unter (Gegenbeispiel später) I Wortproblem, Leerheit, Endlichkeit und Gleichheit sind für TM-akzeptierbare Sprachen nicht algorithmisch entscheidbar alternative Bezeichnung: Die Menge aller TM-akzeptierbaren Sprachen ist genau die Menge aller aufzählbaren Sprachen. 375 Zusammenfassung: LBA-akzeptierbare Sprachen I (Nichtdeterministische) linear beschränkte TM (LBA) akzeptieren genau alle Sprachen vom Chomsky-Typ 1 (kontextsensitiv) I Ob deterministische und nichtdeterministische LBA dieselbe Sprachklasse akzeptieren, ist noch unbekannt (LBA-Problem) I Die Menge aller von LBA akzeptierten Sprachen (Chomsky-Typ 1) ist abgeschlossen unter ∪, ∩, , ◦, ∗ , R I Wortproblem ist für LBA-akzeptierbare Sprachen ist algorithmisch entscheidbar. (schon früher gezeigt: Wortproblem für nichtverlängernde Wortersetzungssysteme) I Leerheit, Endlichkeit und Gleichheit kontextsensitiver Sprachen sind nicht algorithmisch entscheidbar. 376 Beispiel - Berechnung einer TM M = ({a, b}, {q0 , q1 , q2 , q3 }, {a, b, }, δ, q0 , ) mit δ = {(a, q0 , , q1 , R), (b, q0 , , q2 , R), (, q0 , , q0 , N)} ∪{(a, q1 , a, q1 , R), (b, q1 , b, q1 , R), (, q1 , a, q3 , N)} ∪{(a, q2 , a, q2 , R), (b, q2 , b, q2 , R), (, q2 , b, q3 , N)} (deterministisch, Akzeptanz durch Halt) akzeptiert die Sprache L(M) = (a + b)+ für Eingabewort I w = aw 0 : Bandinhalt bei Halt w 0 a I w = bw 0 : Bandinhalt bei Halt w 0 b 377 TM zur Berechnung von Funktionen Idee: deterministische TM M berechnet eine Funktion fM : X ∗ → Γ∗ Eingabe w ∈ X ∗ : Inhalt des Arbeitsbandes bei Start der Berechnung (Eingabewort) Ausgabe v ∈ Γ∗ : Inhalt des Arbeitsbandes nach Halt der TM Wenn M bei Eingabe von w nicht hält, ist der Wert fM (w) nicht definiert. TM M berechnet i.A. nur eine partielle Funktion fM : X ∗ → Γ∗ da fM nur für durch Halt akzeptierte Wörter w ∈ X ∗ definiert ist 378 Turing-berechenbare Funktionen Jede deterministische TM M definiert die (partielle) Funktion fM : X ∗ → Γ∗ , wobei ∀w ∈ X ∗ ( v falls Bandinhalt v , nachdem M hält fM (w) = nicht definiert falls M nicht hält Beispiel: M = ({a, b}, {q0 , q1 , q2 , q3 }, {a, b, }, δ, q0 , ) mit δ = {(a, q0 , , q1 , R), (b, q0 , , q2 , R), (, q0 , , q0 , N)} ∪{(a, q1 , a, q1 , R), (b, q1 , b, q1 , R), (, q1 , a, q3 , N)} ∪{(a, q2 , a, q2 , R), (b, q2 , b, q2 , R), (, q2 , b, q3 , N)} definiert die Funktion ( vx falls w = xv mit x ∈ {a, b} und v ∈ {a, b}∗ fM (w) = nicht definiert falls w = ε Eine Funktion f : X ∗ → X ∗ heißt Turing-berechenbar gdw. eine deterministische TM M mit f = fM existiert. 379 Beispiele I I g : {1}∗ → {1}∗ mit g(w) für alle w ∈ {1}∗ undefiniert ist berechenbar durch die TM M = ({1}, {q0 }, {1, }, δ, q0 , ) mit δ = {(q0 , 1, q0 , 1, N), (q0 , , q0 , , N)} f : {a, b}∗ → {a, b}∗ mit für alle w ∈ {a, b}∗ gilt ( am+n falls w = am ban f (w) = nicht definiert sonst ist berechenbar durch die TM M = ({a, b}, {q0 , q1 , q2 , f }, {a, b, }, δ, q0 , ) mit δ = {(a, q0 , a, q0 , R), (b, q0 , a, q1 , R), (, q0 , , q0 , N)} ∪{(a, q1 , a, q1 , R), (b, q1 , b, q1 , N), (, q1 , , q2 , L)} ∪{(a, q2 , , f , N)} 380 Turing-berechenbare Funktionen auf Codierung natürlicher Zahlen, z.B. in I I N N → {1}∗ Binärcodierung c2 : N → {0, 1}∗ Unärcodierung c1 : Beispiele: I M = ({1}, {q0 , q1 }, {1, }, δ, q0 , ) mit δ = {(q0 , 1, q0 , 1, R), (q0 , , q1 , 1, N)} berechnet die Funktion fM (x) = x + 1 in Unärcodierung I M = ({0, 1}, {q0 , q1 , q2 , q3 , f }, {0, 1, }, δ, q0 , ) mit δ = {(0, q0 , 0, q0 , R), (1, q0 , 1, q0 , R), (, q0 , , q1 , L)} ∪{(0, q1 , 1, q3 , L), (1, q1 , 0, q2 , L), (, q1 , , q1 , N)} ∪{(0, q2 , 1, q3 , L), (1, q2 , 0, q2 , L), (, q2 , 1, f , R)} ∪{(0, q3 , 0, q3 , L), (1, q3 , 1, q3 , L), (, q3 , , f , R)} berechnet die Funktion fM (x) = x + 1 in Binärcodierung (ohne führende 0) 381 Was bisher geschah NFA, DFA, PDA und Turing-Maschinen können I Sprachen L ⊆ X ∗ akzeptieren. deterministische Turing-Maschinen können außerdem I (partielle) Funktionen f : X ∗ → X ∗ berechnen (Zahlen, Tupel von Zahlen,. . . codiert als Wörter in X ∗ , z.B. für X = {1} oder X = {0, 1} ) 382 Beispiel: Unärcodierung → Binärcodierung f : {1}∗ → {0, 1}∗ Transformation Unär- → Binärcodierung wird (z.B.) berechnet von TM M = ({1}, {q0 , q1 , q2 , q3 , q4 , f }, {1, 0, x, y , }, δ, q0 , {f }, ) mit (1, q , x, q , R), (, q , , q , L), 0 0 0 1 (x, q , x, q , L), (, q , , q , R), 1 1 1 2 (x, q , y , q , L), (, q , , q , L), 2 3 2 4 (y , q2 , y , q2 , R), (1, q2 , 1, q2 , R), (0, q2 , 0, q2 , R), δ= (, q3 , 1, q2 , R), (0, q3 , 1, q2 , R), (1, q , 0, q , L), (y , q , y , q , L) 3 3 3 3 (y , q4 , , q4 , L), (0, q4 , 0, q4 , L), (1, q4 , 1, q4 , L), (, q4 , , f , R) 383 Mehrstellige Turing-berechenbare Funktionen auf Codierung von Tupeln (x1 , . . . , xk ) ∈ c(x1 ) • c(x2 ) • · · · • c(xk ) N k N durch mit Trennzeichen • Beispiel: TM M = ({1, •}, {q0 , q1 , q2 , f }, {1, •, }, δ, q0 , ) mit δ = {(1, q0 , 1, q0 , R), (•, q0 , 1, q1 , R), (, q0 , , q0 , N)} ∪{(1, q1 , 1, q1 , R), (•, q1 , •, q1 , N), (, q1 , , q2 , L)} ∪{(1, q2 , , f , N)} berechnet die Funktion fM (x, y ) = x + y (in Unärcodierung) N N Eine Funktion f : k → heißt Turing-berechenbar gdw. eine deterministische TM M existiert, so dass für jede Eingabe (x1 , . . . , xk ) ∈ k gilt N f (x1 , . . . , xk ) = y gdw. fM (c(x1 ) • · · · • c(xk )) = c(y ) 384 Codierung von TM (Gödelnummer) (Kurt Gödel 1906 - 1978) Darstellung jeder TM M = (X , Q, Γ, δ, q0 , ) als (endliches) Wort über dem endlichen Alphabet X 0 = X ∪ Γ ∪ Q ∪ {L, R, N}∪ Klammern ∪ Trennzeichen möglich Menge aller Codierungen von TM ist Sprache über X 0 Codierung als {0, 1}-Folge: I Alphabet, Zustände, Richtungen in Unärcodierung (∈ 1∗ ) I Trennzeichen, Klammern als Folgen ∈ 0∗ Gödelnummer einer TM M: Darstellung von M in maschinenlesbarer Form, z.B. ∈ {0, 1}∗ (als Eingabe für eine TM geeignet) Die Menge aller {0, 1}-Folgen, die korrekten Codierungen von TM sind, ist I abzählbar I TM-akzeptierbar (sogar regulär). 385 Beispiel: Gödelnummer einer TM Codierung einer TM als Wort aus {0, 1}∗ Beispiel: TM M = (X , Q, Γ, δ, q1 , ) in {0, 1}∗ mit I X = {1, } mit c(1) = 1, c() = 11 I Q = {q0 , q1 } mit Startzustand q0 : c(q0 ) = 1, c(q1 ) = 11 I B = {L, R, N} mit c(L) = 1, c(R) = 11, c(N) = 111 I δ = {(q0 , , q1 , 1, R), (q1 , , q0 , 1, L), (q0 , 1, q1 , 1, L)} (busy beaver) für jeden Übergang u = (p, a, q, b, r ) ∈ δ: Codierung : c(u) = c(p)0c(a)0c(q)0c(b)0c(r ) c(q0 , , q1 , 1, R) = 101101101011 c(q1 , , q0 , 1, L) = 11011010101 c(q0 , 1, q1 , 1, L) = 1010110101 Codierung der TM M: c(M) = 000c(q0 , , q1 , 1, R)00c(q1 , , q0 , 1, L)00c(q0 , 1, q1 , 1, L)000 386 Nicht Turing-berechenbare Funktionen Ist jede partielle Funktion f : X ∗ → X ∗ (f : X ∗ → Y ∗ , f : → , f : n → ) Turing-berechenbar? N N N N Nein (Gegenbeispiel später) Begründung: (Aussage für X = {0, 1} zu zeigen, genügt) 1. Wieviele Turing-Maschinen über einem endlichen Alphabet gibt es? abzählbar viele (weil TM endlich codiert werden können, nach erstem Diagonalverfahren von Cantor) 2. Wieviele partielle Funktionen f : X ∗ → X ∗ gibt es? überabzählbar viele (zweites Diagonalverfahren von Cantor) Damit existieren sogar sehr viel mehr (überabzählbar viele) partielle Funktionen f : X ∗ → X ∗ (f : X ∗ → Y ∗ , f : → , f : n → ), die nicht von TM berechnet werden können. N N N N Warum sind TM als Berechnungsmodell trotzdem interessant? 387 Intuitiver Berechenbarkeitsbegriff Eine partielle Funktion f : X ∗ → X ∗ ist berechenbar, falls I eine Rechenvorschrift oder I ein Algorithmus oder I ein Programm (in beliebiger Programmiersprache) oder I eine deterministische Turingmaschine N existiert, welche für jedes x ∈ bei Eingabe von x den Wert f (x) ausgibt, falls f (x) definiert ist. weitere Berechnungsmodelle: Registermaschinen, while-Programme, partiell rekursive Funktionen, λ-Kalkül, . . . 388 These von Church (Alonzo Church 1903-1995) Für alle bisher vorgeschlagenen intuitiven Definitionen für berechenbare Funktionen lässt sich beweisen, dass sie dieselbe Klasse von Funktionen bestimmen. These von Church: Die Menge aller Turing-berechenbaren Funktionen ist genau die Menge aller intuitiv berechenbaren Funktionen. (unbeweisbar, weil Definition durch „Intuition“ zu ungenau) 389 Programmierung Bisher: Jede TM löst eine spezielles Problem (Wortproblem für eine Sprache, Berechnung einer Funktion) üblicher Computer kann (theoretisch, bei beliebiger Rechenzeit und Speicherplatz) I beliebige Algorithmen (Programme) ausführen, d.h. I jede berechenbare Funktion berechnen (nach These von Church) I ist also universell (programmierbar). Gibt es programmierbare TM? 390 Universelle TM TM U heißt universelle TM, falls für I jede TM M und I jedes Eingabewort v gilt fU (c(M) • v ) = fM (v ) d.h. falls die TM M bei Eingabe v hält , dann hält auch U bei Eingabe (c(M) • v ) mit Ausgabe fM (v ), nicht hält , dann hält auch U bei Eingabe (c(M) • v ) nicht. TM U kann die Berechnung jeder TM M simulieren. TM U interpretiert die Codierung (das Programm) c(M). U ist also eine programmierbare Turing-Maschine. 391 Arbeitsweise einer universellen TM Universelle TM U speichert die I Codierung der Machine M und I Startkonfiguration q0 w auf dem Arbeitsband und berechnet I die Folge der Konfigurationen von M (durch Zugriff auf die Übergangsrelation von M). Codierung c(M) ist also beides: 1. Beschreibung einer speziellen TM M 2. Programm für eine universelle TM 392 Entscheidbarkeit von Sprachen charakteristische Funktion einer Menge (Sprache) L ⊆ X ∗ : ( 1 falls w ∈ L χL : X ∗ → {0, 1}, wobei ∀w ∈ X ∗ : χL (w) = 0 sonst Sprache (Menge) L ∈ X ∗ heißt entscheidbar gdw. die Funktion χL berechenbar ist. (Entscheidende TM muss also bei jeder Eingabe halten.) Sprache (Menge) L ∈ X ∗ heißt semi-entscheidbar gdw. die „halbe“ charakteristische Funktion χ0L : X ∗ → {0, 1} berechenbar ist: ( 1 falls w ∈ L ∗ 0 ∀w ∈ X : χL (w) = nicht definiert sonst Fakt Eine Sprache ist genau dann semi-entscheidbar, wenn sie Turing-akzeptierbar (aufzählbar) ist. 393 Beispiele entscheidbarer Sprachen I jede endliche Sprache L = {w1 , . . . , wn } (für jedes i nacheinander Test, ob Eingabe = wi ) I jede Sprache vom Chomsky-Typ 1 (Wortproblem für monotone Grammatiken), I {an | n ∈ I Menge aller Primzahlen (z.B. in Unärdarstellung), I Menge aller Primzahlzwillinge, d.h. Paare (p, p + 2) mit Primzahlen p und p + 2 2 N}, {a2 n |n∈ N}, 394 Was bisher geschah Deterministische Turingmaschinen M können (partielle) Funktionen f : X ∗ → X ∗ berechnen, d.h. bei Eingabe w I falls f (w) nicht definiert ist, nicht halten, I falls f (w) = v , mit Bandinhalt v halten. Sprachen L ⊆ X ∗ akzeptieren durch Halt oder durch akzeptierende Zustände, entscheiden , d.h. χL berechnen. I intuitiver Berechenbarkeitsbegriff I These von Church 395 Beispiel TM M = ({0, 1}, {q0 , q1 , q2 , q3 }, {0, 1, }, δ, q0 , {q3 }, ) mit (0, q0 , , q1 , R), (1, q0 , , q2 , R), (, q0 , , q0 , N), (0, q1 , , q1 , R), (1, q1 , , q2 , R), (, q1 , 1, q3 , N), δ= (0, q2 , , q1 , R), (1, q2 , , q2 , R), (, q2 , 0, q3 , N) akzeptiert die Sprache LH (M) = (0 + 1)+ durch Halt (und durch akzeptierende Zustände), berechnet die Funktion fM : ∀x ∈ N → N (binärcodiert) mit N : fM (x) = 1−(x mod 2) = entscheidet die Sprache LE (M) = (0 + 1)∗ 0 1 , falls x gerade 0 , sonst N (Menge 2 ) 396 Menge aller entscheidbaren Sprachen – Abschlusseigenschaften Satz Eine Sprache L ist genau dann entscheidbar, wenn sowohl L als auch L TM-akzeptierbar sind. Idee: „parallele“ Ausführung der Maschinen M mit L(M) = L und N mit L(N) = L auf Eingabe w, genau eine dieser beiden TM hält: M, falls w ∈ L, sonst N Die Menge aller entscheidbaren Sprachen ist abgeschlossen unter Vereinigung wegen χL∪L0 (w) = max(χL (w), χL0 (w)) berechenbar Schnitt wegen χL∩L0 (w) = min(χL (w), χL0 (w)) berechenbar Komplement wegen χL (w) = 1 − χL (w) berechenbar Achtung (Unterschied zu TM-akzeptierbaren Sprachen): Aus der TM-Akzeptierbarkeit von L folgt i.A. nicht die TM-Akzeptierbarkeit von L. 397 Spezielles Halteproblem für TM Wiederholung: Gödelnummer einer TM M: endliche Codierung c(M) von M (z.B. als Binärwort) 1. endliche Beschreibung einer speziellen TM 2. Eingabe (Programm) für eine universelle TM (Simulator) Das spezielle Halteproblem für TM ist die Sprache S = {c(M) | TM M hält bei Eingabe c(M)} Satz Die Sprache S ist Turing-akzeptierbar. Warum? Ist die Sprache S entscheidbar? 398 Unentscheidbarkeit des speziellen Halteproblems Satz Es existiert keine TM, welche das spezielle Halteproblem (die Sprache S) entscheidet, d.h. die folgende Funktion berechnet: 1 falls w = c(M) für eine TM M und M hält bei Eingabe von w χS (w) = 0 sonst indirekter Beweis: (analog Barbier-Problem) Annahme: N ist TM mit fN = χS Konstruktion einer TM N 0 aus N, so dass für jede TM M gilt: ( nicht definiert falls M bei Eingabe von c(M) hält fN 0 (c(M)) = 1 falls M bei Eingabe von c(M) nicht hält Ist fN 0 (c(N 0 )) definiert? Widerspruch, eine solche TM N kann also nicht existieren. 399 Komplement des speziellen Halteproblems Spezielles HP: S = {c(M) | TM M hält bei Eingabe c(M)} Komplement des speziellen HP: w ist keine Codierung einer TM oder S = w| w = c(M) und M hält bei Eingabe c(M) nicht Folgerung Die Sprache S ist nicht Turing-akzeptierbar. Beweisidee (indirekt): I bekannt: 1. S ist TM-akzeptierbar. 2. S ist nicht entscheidbar. 3. S TM-akzeptierbar ∧ S TM-akzeptierbar → S entscheidbar I Annahme: S ist TM-akzeptierbar. dann ist S entscheidbar wegen 1. und 3. Widerspruch zu 2., also Annahme falsch, also S nicht TM-akzeptierbar. 400 Folgerungen aus der Unentscheidbarkeit von S Keine der folgenden Probleme (Sprachen) ist entscheidbar: A = {c(M) • w | M hält bei Eingabe w} allgemeines Halteproblem E = {c(M) | M hält bei Eingabe ε} Halteproblem mit leerer Eingabe T = {c(M) | M hält für jede beliebige Eingabe} Totalitätsproblem I = {c(M) | M hält für irgendeine Eingabe} N = {c(M) | M hält für keine Eingabe} 401 Praktische Bedeutung nach These von Church: Das Halteproblem ist für kein intuitives Berechnungsmodell entscheidbar. Es existiert kein Programm, welches für jedes beliebige Programm P feststellt, ob P immer (für jede Eingabe) hält. (Unentscheidbarkeit des Totalitätsproblems) Es existiert kein Programm, welches für jedes beliebige Paar (P, v ) feststellt, ob das Programm P bei Eingabe von v anhält. (Unentscheidbarkeit des allgemeinen Halteproblems) Solche negativen Aussagen sind nützlich, z.B. um Ressourcenverschwendung (z.B. Arbeitskraft, -zeit) zu vermeiden. 402 Spezialfälle Für spezielle Programme P und Eingaben w lässt sich häufig automatisch feststellen, ob P bei Eingabe von w anhält. realistische Ziele: Anwendung: Programme verwenden, für die Termination für alle (relevanten) Eingaben bewiesen wurde (z.B. als Gerätetreiber) Forschung: möglichst viele und große Klassen von Programmen und Eingaben finden, für die sich Termination (oder Nicht-Termination) beweisen lässt, (Weiter-)Entwicklung von Verfahren zum Nachweis der Termination von Programmen 403 Probleme und Instanzen Problem: Sprache P ⊆ X ∗ (Codierungen einer Klasse von verwandten Aufgaben) Instanz eines Problems: Wort w ∈ X ∗ (Codierung einer speziellen Aufgabe aus dieser Klasse) Lösungsverfahren für das Problem P: Entscheidungsverfahren für P, d.h. Verfahren, welches für jede Instanz (Wort) w ∈ X ∗ bestimmt, ob w ∈ P Beispiel: Wortproblem für reguläre Sprachen Problem: WP-REG = {(c(L), w) | w ∈ L} mit endlicher Darstellung c(L) der Sprache L z.B. c(L) = A für einen NFA A mit L = L(A) Instanz: (c(A), aba) mit A = ({a, b}, {p, q}, δ, {p}, {p, q}) und δ(a) = {(p, p)}, δ(b) = {(p, q), (q, q)} Frage: Gilt (A, aba) ∈ WP-REG? wahr gdw. aba ∈ L(A) Lösungsungsverfahren (Entscheidungsverfahren), z.B. Pfadsuche im Automatengraphen 404 Probleme und Instanzen – Beispiele Enthaltensein in einer Folge (von Elementen des Typs E) Problem: F = {((x1 , . . . , xn ), y ) ∈ E ∗ × E | ∃k ∈ {1, . . . , n} : xk = y } Menge aller Paare ((x1 , . . . , xn ), y ) mit y ∈ {x1 , . . . , xn } Instanz: ((1, 3, 4, 3), 4) (Gilt ((1, 3, 4, 3), 4) ∈ F ? ) Ja, ((1, 3, 4, 3), 4) ∈ F , weil 4 ∈ {1, 3, 4} Lösungsverfahren (Entscheidungsverfahren): (beliebiges) Suchverfahren in Folgen I SAT (Erfüllbarkeitsproblem der Aussagenlogik) Problem: SAT = {ϕ ∈ AL(P) | Mod(ϕ) 6= ∅}, Menge aller erfüllbaren aussagenlogischen Formeln Instanz: ¬a ∧ (a ∨ b ∨ c) ∧ ¬c ∧ ¬b (Gilt (¬a ∧ (a ∨ b ∨ c) ∧ ¬c ∧ ¬b) ∈ SAT ?) Nein, weil Mod(ϕ) = ∅ Lösungsverfahren (Entscheidungsverfahren): I semantisch: Wahrheitswerttabellen I syntaktisch: Kalküle, z.B. natürliches Schließen, äquivalente Umformungen I 405 Probleme und Entscheidungsverfahren Problem P ist unentscheidbar gdw. kein Entscheidungsverfahren (TM, Programm, Algorithmus, . . . ) für P existiert, z.B. spezielles Halteproblem entscheidbar gdw. wenigstens ein Entscheidungsverfahren für P existiert (i.A. existieren mehrere) z.B. SAT, Suche in Folgen, Sortieren von Folgen durch verschiedene Such- und Sortierverfahren (mehr dazu in LV Algorithmen und Datenstrukturen) Entscheidbarkeit eines Problems (Sprache) P wird i.A. durch Angabe eines Entscheidungsverfahrens für P gezeigt. Unentscheidbarkeit eines Problems P wird oft durch Reduktion bekannter unentscheidbarer Probleme (oft HP) auf P gezeigt. 406 Reduktion Reduktion des Problems P auf Problem Q: Transformation der Sprache P ⊆ X ∗ in die Sprache Q ⊆ Y ∗ , d.h. berechenbare Funktion f : X ∗ → Y ∗ mit ∀w ∈ X ∗ : w ∈ P ↔ f (w) ∈ Q (Übersetzung jeder Instanz des Problems P in eine Instanz des Problems Q) Problem P heißt genau dann reduzierbar auf Problem Q (P ≤ Q), wenn eine Reduktion f von P auf Q mit existiert. Reduzierbarkeit zwischen Problemen ist reflexiv , denn Identität ist Reduktion transitiv , denn Nacheinanderausführung zweier Reduktionen ist Reduktion 407 Postsches Korrespondenzproblem (PCP) gegeben: endliche Folge {(xi , yi ) | i ∈ {1, . . . , n}} mit xi , yi ∈ X ∗ Frage: Existiert ein Wort u ∈ {1, . . . , n}∗ mit xu1 · · · xuk = yu1 · · · yuk ? Problem: PCP = {((x1 , y1 ), . . . , (xn , yn )) | ∃w ∈ {1, . . . , n}+ : xw1 ◦ · · · ◦ xw|w| = yw1 ◦ · · · ◦ yw|w| } Menge aller „lösbaren“ PCP-Instanzen Instanz: x1 = 1, y1 = 101, x2 = 10, y2 = 00, x3 = 011, y3 = 11 (Gilt ((1, 101), (10, 00), (011, 11)) ∈ PCP ?) Ja, (((1, 101), (10, 00), (011, 11)), 1321) ∈ PCP, weil w = (1, 3, 2, 3) eine Lösung dieser Instanz ist wegen w = 101110011 = x1 x3 x2 x3 = y1 y3 y2 y3 PCP unentscheidbar, Nachweis durch Reduktion des HP auf PCP Idee: Übersetzung von Berechnungen von TM in PCP, so dass Berechnung nicht haltender TM auf PCP ohne Lösung abgebildet werden. HP unentscheidbar → PCP unentscheidbar 408 Parkettierungsproblem Überdeckung der unendlichen Ebene mit gleichgroßen quadratischen Kacheln (festgelegter Orientierung) mit farbigen Seiten (2-dimensionales Domino) n 2 Problem: Parkett = (D1 , . . . , Dn ) | ∃M ∈ D (Z ) ∀(i, j) ∈ 2 : Z (s(Mi,j ) = n(Mi+1,j ) ∧ o(Mj,i ) = w(Mj+1,i ))} (Menge aller Kachelmengen, mit denen sich die unendliche Ebene korrekt überdecken lässt) Instanz: C = {R, G}, D = {D0 , D1 } mit o(D0 ) = s(D0 ) = R, n(D0 ) = w(D0 ) = G o(D1 ) = s(D1 ) = G, n(D1 ) = w(D1 ) = R Gilt D ∈ Parkett, d.h. lässt sich die unendliche Ebene mit Kacheln aus D überdecken? Ja, ∀(i, j) ∈ 2 : Mj,i = D(i+j) mod 2 Z Parkett unentscheidbar, Nachweis durch Reduktion des HP darauf Idee: Übersetzung von TM in Kachelmengen D, so dass Berechnung nicht haltender TM auf unendliche Parkettierung der Ebene abgebildet werden (Zeile i: Konfiguration zum Zeitpunkt i). HP unentscheidbar → Parkettierungsproblem unentscheidbar 409 Entscheidungsproblem der Prädikatenlogik FOL(Σ, X) klassische Prädikatenlogik (der ersten Stufe) Erfüllbarkeitsproblem Problem: E = {ϕ ∈ FOL(Σ, ) | Mod(ϕ) 6= ∅} Instanz , z.B. ∀x(P(x, f (y ))) Frage: Gilt ∀x(P(x, f (y ))) ∈ E ? X Unerfüllbarkeitsproblem Problem: U = {ϕ ∈ FOL(Σ, ) | Mod(ϕ) = ∅} Instanz , z.B. ∃x(¬p(x) ∧ p(x)) Frage: Gilt ∃x(¬p(x) ∧ p(x)) ∈ U ? X (Allgemein-)Gültigkeitsproblem Problem: A = {ϕ ∈ FOL(Σ, ) | Mod(¬ϕ) = ∅} Instanz , z.B. ∀x(P(x, f (y ))) Frage: Gilt ∀x(P(x, f (y ))) ∈ A ? X Entscheidungsproblem der Prädikatenlogik (Hilbert): algorithmische Lösung eines dieser Probleme 410 Unentscheidbarkeit der Prädikatenlogik Satz Erfüllbarkeits- Unerfüllbarkeits und Gültigkeitsproblem für FOL(Σ, ) sind TM-akzeptierbar. X Beweisidee: Akzeptanz durch Herleitung in einem Beweiskalkül Satz (Gödel, Turing, 1936/37) Erfüllbarkeits- Unerfüllbarkeits und Gültigkeitsproblem für FOL(Σ, ) sind unentscheidbar. X Nachweis durch Reduktion des PCP auf das Gültigkeitsproblem: Konstruktion einer Formel ϕp ∈ FOL(Σ, ) zu jeder PCP-Instanz p, so dass ϕp genau dann allgemeingültig, wenn p lösbar. PCP unentscheidbar → Gültigkeitsproblem für FOL(Σ, ) unentscheidbar X X 411 Organisatorisches Modul Theoretische Grundlagen der Informatik I I vorgesehener Zeitaufwand laut Modulbeschreibung: 90 h für Präsenzstudium als 4+2 SWS = 6h jede Woche + 120 für Selbststudium, verteilt z.B. 90h (= 6h jede Woche) + 30h Prüfungsvorbereitung Bedingung für Prüfungszulassung: I I I Autotool: ≥ 24 Punkte Vorrechnen: ≥ 3 Punkte Auswertung Studentenfragebögen 412 Prüfung Wann? am 11. 2. 2014 um 12:00 - 14:00 Uhr Wo? in den Räumen GuH101, GuH116, LNW006 Treffpunkt zur Raumverteilung (Pläne): vor LNW006 (ab 11:30 Uhr) Wie? Klausur 120 min (einzige) zugelassene Hilfsmittel: ein A4-Blatt handbeschrieben Was? Inhalt der LV Aufgabentypen aus Übungsserien bekannt Viel Erfolg! 413 TGI WS 2013/14 – Lernziele (nach Modulbeschreibung) I theoretischen Grundbegriffe zur der Modellierung praktischer Aufgabenstellungen anwenden I wichtige Klassen formaler Sprachen als Grundlage von Programmier- und Beschreibungssprachen einordnen I die passenden abstrakten Maschinenmodelle zur Darstellung und Lösung praktischer Aufgabenstellungen einsetzen I praktische Aufgabenstellungen durch prädikatenlogische Formeln beschreiben I wissen, dass die Korrektheit von Programmen mit logischen Methoden nachweisbar ist 414 TGI WS 2013/14 – Inhalt I Modellierung: Grundbegriffe und -techniken der Informatik mit praktischen Beispielen I Klassische Logiken: Formalisierung praktischer Aufgabenstellungenstellungen in Aussagen- und Prädikatenlogik (Spezifikation von Algorithmen, abstrakte Datentypen), syntaktische und sematische Lösungsverfahren, Ausdrucksstärke, Grenzen I Terme, strukturelle Induktion I Formale Sprachen: Modellierung durch Wörter und Sprachen, Operationen auf Wörtern und Sprachen, Sprachklassen, Chomsky-Hierarchie, reguläre Ausdrücke I Abstrakte Maschinen: Modellierung durch verschiedene Automatentypen (endliche Automaten, Kellerautomaten, Turing-Maschinen), Operationen auf Automaten, Akzeptanz durch Automaten, Zusammenhang mit formalen Sprachen, Ausdrucksstärke I Berechenbarkeit, These von Church, Entscheidbarkeit, unentscheidbare Probleme 415 Modellierung Ziel: maschinelle Darstellung und Verarbeitung von Informationen Weg: Formalisierung in maschinenlesbaren Sprachen Formalisierung von Daten durch Mengen (mit Mengenoperationen), Folgen Datentypen (abstrakt, konkret) Eigenschaften (Semantik) in klassischer Aussagen und Prädikatenlogik Abläufen als Zustandsübergangssysteme (Graphen mit Knoten- und Kantenmarkierungen) abstrakten Maschinen durch Maschinenmodelle NFA (DFA), PDA (DPDA), TM (LBA) Zusammenhänge mit formalen Sprachen Berechnungen abstrakter Maschinen (Spezialfall von Zustandsübergangssystemen) Beschreibungen von Daten und Abläufen (Syntax) in formalen Sprachen 416 Modellierung von Aufgaben (Problemen) gegeben: informale Aufgabenstellung Identifikation und formale Darstellung von I Menge der Objekte und Typen I Zusammenhänge (Funktionen, Relationen) zwischen Objekten I Typen der Eingaben I Typen der Ausgaben I Eigenschaften der gewünschten Lösung (Zusammenhang zwischen Ein- und Ausgaben) erst danach: Suche nach oder Entwurf von Lösungsverfahren 417 Anwendung: Datentypen Abstrakter Datentyp: Spezifikation von Klassen von (meist mehrsortigen) Σ-Strukturen durch Syntax (Deklaration der Operationen) I I S Menge von Sorten, -sortige Signatur S Semantik Axiome (Menge Φ ∈ FOL(Σ, X ) von Sätzen) (oft allquantifizierte Gleichungen zwischen Termen) beschreiben Eigenschaften und Zusammenhängen der Funktionen und Relationen der Signatur Konkreter Datentyp: I Σ-Stuktur (Menge von Werten mit zugeordneten Operationen), die I Modell der Spezifikation Φ (Axiome) ist Interface: Implementierung: Signatur im abstrakten Datentyp konkreter Datentyp 418 Abstrakter Datentyp – Beispiel stack Sorten E: Elementtyp, ShEi: Stapel (stack) von Elementtyp E, B: {t, f} Signatur Σ: push top pop new empty : ShEi × E : ShEi : ShEi : : ShEi → ShEi →E → ShEi ShEi → SB (Beispiele für) Axiome: ∀s ∈ ShEi∀z ∈ E ∀s ∈ ShEi∀z ∈ E ∀s ∈ ShEi∀z ∈ E empty(new) empty(push(s, z)) top(push(s, z)) pop(push(s, z)) = = = = t 0 z s 419 Diagramme (Tafel) Syntax, Semantik Entscheidbarkeit von FOL und AL Prominente Klassen formaler Sprachen I regulär I (deterministisch) kontextfrei I kontextsensitiv (Chomsky-Typ 1) I Turing-akzeptierbar (aufzählbar) I entscheidbar mit I Inklusionsbeziehungen dazwischen I typische Vertreter der Sprachklasse I Chomsky-Typ I passenden Maschinenmodellen I Abschlusseigenschaften 420