Document
Werbung

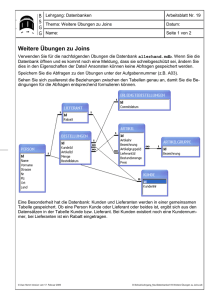
3. Datenbanken Begriffe: Eine Datenbank ist eine Menge zu verwaltender Daten. Die Verwaltungssoftware nennt sich Datenbankmanagementsystem (DBMS). Anforderungen an ein DBMS: Einziger Prozess, der direkt auf Daten zugreift und diese verändert Andere Programme laufen über DBMS Muss Mehrbenutzer ausgelegt sein (Nutzerrechte, Zugriffsrechte) Unterstützung der Datenkonsistenz (Datensicherung, Wiederherstellung) Mehrfachspeicherung verringern und kontrollieren Führt Konsistenzprüfung durch Datenbankmodelle: Grundlage für die Strukturierung der Daten und ihrer Beziehungen zueinander ist das Datenbankmodell, das durch den DBMS-Hersteller festgelegt wird. Je nach Datenbankmodell muss das Datenmodell an bestimmte Strukturierungsmöglichkeiten angepasst werden: hierarchisch: Die Datenobjekte stehen in verdrahteten Eltern-Kind-Beziehungen zueinander. netzwerkartig: Die Datenobjekte werden miteinander in Netzen verdrahtet. relational: Die Datenobjekte stehen in flachen Tabellen, Beziehungen ergeben sich aus Werten der Tabellenspalten. objektorientiert: Die Datenobjekte werden miteinander verdrahtet, sind gegebenenfalls miteinander verwandt und können vom System immer eindeutig identifiziert werden. Es existiert eine Vielzahl von Misch- und Nebenformen, wie zum Beispiel das objektrelationale Modell. Datenbankstruktur: Datenfeld: Zelle innerhalb einer Tabelle Speichert Einzelinfo (Attribut/Eigenschaft) Datensatz: Tupel Zeile der Tabelle Datenfelder, die logischen Zusammenhang haben Einzelinfos, die über Entität gespeichert sind Tabelle: Relation Sammlung von Datensätzen gleicher Struktur Mit logischer Beziehung Datenbank organisierte Sammlung von Daten unterschiedlicher Struktur Ebenen eines Datenbanksystems: Externe Ebene: Anzahl von verschiedenen Schemen oder Benutzerschichten Beschreibt Datenbanksicht einer Gruppe von Nutzern Sicht für Benutzer je nach Rechten und Interesse Konzept. Ebene: Umsetzung von realer Welt in logisches Schema Schema, dass logische Struktur der Datenbank bestimmt Globale Beschreibung der Datenbank, die Details der physischen Speicherstruktur verbirgt Datenschutzkriterien und Zugriffsrechte Interne Ebene: physische Speicherstruktur der Datenbank Physisches Datenbankmodell Datenaufbau, Speicherung und Zugriffspfade Art der Speicherung Verteilung, Zugriff, Speicherung, Kooperation Mit Betriebssystem Komponenten eines Datenbanksystems: Anwendungsprogr. Anwender DB-Admins Kommunikationsschnittstelle Daten-Anfrage-Sprache (DQL) Daten-Definitions-Sprache (DDL) Daten-Manipulations-Sprache (DML) Daten-Steuerungs-Sprache (DCL) SQL DBMS Datenbank Datenspeicherung/Zugriff: Minimaler Speicherbedarf Maximale Geschwindigkeit Art der Speicherung: Unsortiert Sequentiell (aufeinanderfolgend) Indexiert (Verschöagwortung) Datenzugriff: wahlfrei direkt forlaufend Relationale Datenbank: Datenverwaltung in 2 Datentabellen Verknüpfung der Tabellen über Schlüsselfelder zur Realisierung der logischen Beziehungen Datenfelder haben einen Datentyp mit Wertebereich Datenfelder können indexiert werden Bestandteile von ACCESS: Tabelle: Ort der Datenspeicherung Abfrage: Vorschrift zur Auswertung/ÄnderungAuswahl Formular: Maske zur Dateneingabe –ausgabe sowie zur Programmbedienung Bericht: Druckobjekt Makro: Programmablauf Modul: Programme in VBA-Quelltext Seiten: extern zu speichernde Daten-Zugriffsseite im HTML-Format Datenbankentwurf: Ziele: minimale Redundanz Minimaler Speicherbedarf Vermeiden von Problemen bei Datenpflege (Anomalien) Datenbank so gestalten, dass problemlos erweiterbar Vorgehen: Normalisierung (Bottom Up) Entity-Relationship-Modell (Top Down) Normalisierung: 1. Schritt Beseitigen der Wiederholungsgruppen durch bilden von Datensätzen Identifizieren bestehender Datensätze Normalform: wenn in jeder Zeile/Spalte nur atomare Werte existieren Datensätze und Datentabellen eindeutig durch Identifikationsschlüssel identifiziert Identifikationsschlüssel muss eindeutig sein, so klein wie möglich gestalten, aus einem oder mehreren Datenfeldern Bestehend, natürliche o. künstliche Merkmale der Gespeicherten Entität Nach 1. Schritt sind Daten grundsätzlich in relationaler Datenbank speicherbar, aber Problem der Anomalien besteht Anomalien Infos, die vom tatsächlichen Sachverhalt abweichen Entstehen durch Einfügen (Insert-Anomalien) Entstehen durch Ändern (Update-Anomalien) Entstehen durch Löschen (Delete-Anomalien) 2. Schritt Felder, die nur von Teilen des zusammengesetzten Schlüssels abhängig sind, werden in eine gesonderte Tabelle ausgelagert 2 neue Tabellen, Teile des zusammengesetzten Schlüssels sind Primärschlüssel (in Ursprungstabelle Fremdschlüssel) 3. Schritt Felder, die von Feldern abhängig sind, die nicht Bestandteil eines Primärschlüssels sind können in eine neue Tabelle (funktionale Abhängigkeit) 2 weitere Tabellen, siehe 2. Schritt Beziehungstypen: 1:1 1 Dastensatz der Tabelle 1 ist genau ein Datensatz der Tabelle 2 zugeordnet 1:n 1 Datensatz der Tabelle 1 sind mehrere Datensätze der Tabelle 2 zugeordnet n:m mehrere Datensätze der Tabelle 1 sind mehreren Datensätzen der Tabelle 2 zugeordnet letzter Schritt Relationenmodell erstellt mit referentieller Integrität (gegenseitiger Bedingungsprüfung) ERM: Darstellung der realen Welt in einem Entity-Relationship-Diagramm Einhaltung einer Schrittfolge ist wichtig: 1) Zeichnen des ERD durch: a) Finden der Entitätsmengen b) Finden der Beziehungsmengen c) Festlegen der Identifikationsschlüssel d) Eliminieren der nicht-hierarchischen Beziehungen (globale Normalisierung) e) Festlegen der weiteren Attribute 2) Zeichnen des Relationenmodells 3) (Festlegen der Transaktionen) Entitäten Individuum, reales Objekt, abstraktes Konzept, Vorgang/Ereignis Entity-Set Entitätsmengen (ähnlich, zusammengehörig, vergleichbar) Zu d) beseitigen der n:m Beziehung durch erstellen einer Hilfstabelle, Primärschlüssel Der zugehörigen Entity-Sets werden zu Fremdschlüsseln in der neuen Tabelle Auflösen einer 1:n Beziehung: Primärschlüssel der 1-Seite wird zum Fremdschlüssel auf der n-Seite Abfragen: Vorschriften zur Auswahl oder/und Auswertung, Änderung von Daten einer Datenbank Folge von SQL Anweisungen, die logisch zusammen gehören Befehle zur Datenmanipulation: Select (Auswahl von Daten) Update (ändern von Daten) Delete (löschen von Daten) Insert (einfügen von Daten) Operationen der Relationentheorie: Selektion Auswahl des Datensatzes der Tabelle, die Slektionskriterium erfüllt Projektion Auswahl von Datenfeldern einer Datentabelle Mengenoperation Vereinigung U Menge der Datensätze die in DT 1 oder DT 2 vorkommen Durchschnitt Menge der Datensätze, die in DT 1 und DT 2 vorkommen Differenz Menge der Datensätze die in DT 1 aber nicht in DT 2 vorkommen Verbund (Joining) Das Kreuprodukt ist Kombination jedes Datensatzes der DT 1 mit jedem Datensatz der DT 2, Joining reduziert die Anzahl der Datensätze auf tatsächlich vorhandene Erstellen mit Hilfe von ACCESS: QBE Neues Dokument erstellen Links auf „Abfrage“ Oben auf „Neu“ Tabellen wählen, aus denen die DS gebraucht werden Nach Auswahl „Schließen“ Mit Doppelklick die DS aus der Tabellenübersicht auswählen Häkchen bedeutet „wird angezeigt“ „Sortierung“ frei wählbar „Kriterien“ auch frei wählbar (z. B. „d“; >100 Und <200; Zwischen 9:00 Und 10:00; Am 9809-21) Struktur einer Abfrage: SELECT… Wahl der Tabelle, des Datenfeldes FROM… aus welcher Tabelle, aus welchem Datenfeld WHERE… Kriterium unter dem ausgewählt/angezeigt werden soll ORDER BY… Ergebnisse ordnen nach Kriterium (optional) Bsp.: SELECT TANKEN.Fahrerkürzel, TANKEN.Datum, TANKEN.Uhrzeit FROM TANKEN WHERE TANKEN.Treibstoffart = „d“ ORDER BY TANKEN.Uhrzeit; Fahrerkürzel, Datum und Uhrzeit aller Tankvorgänge bei denen Diesel getankt wurde, sortiert nach Uhrzeit Joining: Inner Join zeigt alle Datensätze, die in beiden Tabellen vorhanden sind Left Join zeigt alle Datensätze der DT 1 und die zugehörigen Infos aus DT 2 Right Join zeigt alle Datensätze der DT 2 und die zugehörigen Infos aus DT 1