Simulation von neuronaler Verarbeitung durch selbstorganisierende
Werbung

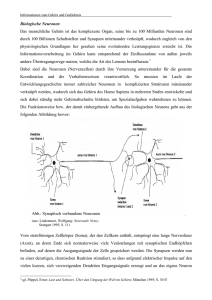
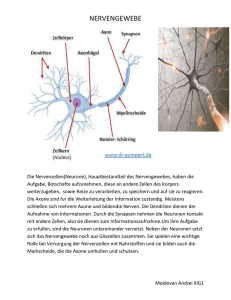
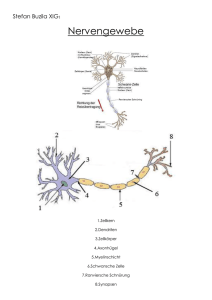
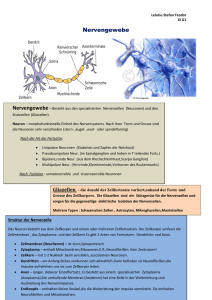
6LPXODWLRQYRQQHXURQDOHU9HUDUEHLWXQJGXUFKVHOEVWRUJDQLVLHUHQGH.DUWHQ Jonas Behr $EVWUDFW Biologische Systeme sind in der Lage, hochkomplexe und stark variierende Situationen in Hinblick auf ein geeignetes Verhalten zu analysieren. Hier bieten sich zwei Chancen: Erstens das Lösen komplexer technischer Probleme durch Modellierung von Systemen, die sich auf biologische Befunde stützen, jedoch aus mathematisch erfassbaren Komponenten bestehen und zweitens das Erlangen eines besseren Verständnisses der biologischen Systeme durch die Modellierung von überschaubaren Systemen und deren Vergleich mit den biologischen Befunden. Diese beiden unterschiedlichen Ansätze erfordern verschiedene Methoden. Um technische Probleme effizient zu lösen ist eine Reduktion der biologischen Systeme auf die notwendigen Komponenten erforderlich. Die mathematische Erfassbarkeit ermöglicht einen Blick in die Zukunft des simulierten Sachverhaltes. Dagegen muss zur Modellierung biologischer Systeme ein vorhandenes Modell schrittweise verfeinert und neuen biologischen Erkenntnissen angepasst werden. Neuronale Netzwerke sind ein Ergebnis dieser Überlegungen. Sie bestehen aus untereinander verknüpften Einheiten, den Neuronen, die über eine spezielle Aktivitätsfunktion aus einem Eingabevektor einen Ausgabewert berechnen, und diesen an eine definierte Menge anderen Neurone weiterleiten (21). Dem Eingabevektor jedes Neurons wird ein Gewichtsvektor gleicher Länge und Dimension zugeordnet, der den Einfluss eines Wertes des Eingabevektors auf die Ausgabe (=Ergebnis der Aktivitätsfunktion) festlegt. Außerdem existiert ein Algorithmus, der die Werte des Gewichtsvektors in vielen Iterationen in eine gezielte Richtung verändert. In jedem dieser Schritte muss ein neues Beispiel eines Eingabevektors vorliegen. Die Anpassung des Gewichtsvektors wird als Lernprozess aufgefasst. Die Summe der Ausgabewerte, die nicht an andere Neurone weitergeleitet werden, wird als Ausgabevektor aufgefasst (18). In diesem Artikel sollen die aktuellen Modelle der selbstorganisierenden Karten vorgestellt werden. Die selbstorganisierenden Karten sind eine Klasse der Neuronalen Netzwerke, die ein besonderes Konzept der neuronalen Verarbeitung im cerebralen Kortex berücksichtigen: Die Topologieerhaltung. Die Topologieerhaltung besagt, dass sich Muster im Eingabevektor auch in der Verarbeitung und der Ausgabe wieder finden. Der Eingabevektor wird als Raum aufgefasst, dementsprechend sind die Neuronen in einem Raum gleicher Dimension angeordnet, wobei sich eindeutig definierte Abstände zwischen den Neuronen angeben lassen. Auch die Ausgabe kann als Raum gleicher oder niedrigerer Dimension aufgefasst werden. Die Topologieerhaltung ist nicht als eins zu eins Abbildung von dem Eingaberaum auf den Verarbeitungsbzw. Ausgaberaum zu verstehen, sondern sie wird der Funktion angepasst. So wird beispielsweise die Hand im cerebralen Kortex trotz geringerer Größe durch einen deutlich größeren Bereich repräsentiert als der Fuß. &5.DWHJRULHQH.1.1 [Systems and Information Theory], D.2.2 [Design Tools and Techniques] .H\ZRUGV: self organizing maps, SOM, self organizing feature maps, SOFM, neural networks, neuron, activity function, learning algorithm, weight vector, best matching unit, perzeptron, cerebral cortex, preservation of topography, supervised SOM (LQIKUXQJ (LQIKUXQJLQGLHELRORJLVFKHQ*UXQGODJHQ Die funktionellen Einheiten des zentralen und peripheren Nervensystems sind die Neuronen. Ihre Morphologie und Größe ist je nach Funktion stark verschieden. Ein gemeinsamer Grundaufbau ist jedoch zu erkennen. Alle Neuronen bestehen aus einem rezeptiven Bereich, den Dendriten, und einem effektiven Bereich, dem Axon. In der Lage davon unabhängig besitzen sie einen Zellkörper (Soma) für die notwendigen Stoffwechselprozesse. Die Dendriten sind meist stark verzweigt und werden deshalb häufig als Dendritenbaum bezeichnet. Mit anderen Nervenzellen, Rezeptor- und Effektorzellen sind die Nervenzellen durch Synapsen verbunden (15). Jegliche Information wird über elektrochemische Gradienten über der Membran der Neuronen übermittelt. Der elektrochemische Gradient über einer Membran wird auch als Membranpotential bezeichnet. Dieses Membran-potential wird durch den gerichteten und energie-abhängigen Transport von Ionen durch spezifische Ionenkanäle aufrechterhalten. Eine Reizweiterleitung über größere Distanz erfolgt nur in den Axonen durch eine Kettenreaktion von Veränderungen der Durchlässigkeit von Ionenkanälen für bestimmte Ionen (3). Diese Weiterleitung ist nicht analog, sondern erfolgt entweder ganz oder gar nicht. Somit lassen sich einzelne Ereignisse der Weiterleitung als so genannte ‚Spikes’ erfassen. Die Intensität des Signals wird nur über die Frequenz der Spikes übertragen. Gelangt ein Spike an die Synapsen an den Enden eines Axons werden so genannte Neurotransmitter ausgeschüttet, die den wenige Nanometer breiten Spalt zum nächsten Neuron oder der Effektorzelle überwinden und dort eine Veränderung des Membranpotentials bewirken (3). Dies kann das Membranpotential entweder erhöhen oder verringern. Sinkt das Membranpotential an der Stelle des Neurons, an der das Axon abgeht, dem ‚Axonhügel’, unter einen bestimmten Schwellenwert, wird ein Spike ausgelöst. Das Membranpotential entspricht der Summe der eingehenden Reize, wobei für die Summation entscheidend ist, wie weit die eingehende Synapse von Axonhügel entfernt ist. Der Grund dafür ist der Widerstand, der sich der Bewegung der Neuronen entgegenstellt und eine nicht absolute Undurchlässigkeit der Membran für Ionen. :LHUHSUlVHQWLHUWGDVNQVWOLFKH1HXURQGLH5HDOLWlW Künstliche Neuronen können entweder als funktionelle Einheiten eines Computerprogramms oder tatsächlich als Hardware realisiert sein. Ich werde mich in diesem Artikel auf die Beschreibung des Ersteren beschränken. Somit sind künstliche Neuronen Einheiten die folgende Komponenten enthalten (18, 20, 21): 1. 2. 3. 4. 5. 6. die Variablen für eingehende ‚Signale’ eine Variable für das ausgehende ‚Signal’ Variablen für die Gewichtung der unterschiedlichen Eingänge eine Variable für den Schwellenwert (Bias) eine Funktion für die Berechnung des ausgehenden Signals eine Funktion für die Anpassung der Gewichte Die Gewichtung der Eingänge entspricht physiologisch deren Abstand zum Axonhügel. Da ein Axon über viele Synapsen mit einer weiteren Nervenzelle verbunden sein kann, ist es auch möglich, die Anzahl der Synapsen mit in das Gewicht einzubeziehen, und diese als einen Eingang zusammenzufassen, da die Aktivität dieser Synapsen immer gleich ist. Der Bias entspricht dem Schwellenwert, ab dem am Axonhügel ein Spike gefeuert wird. In einigen Fällen bewirkt die Einführung und Adaption des Schwellenwertes eine Beschleunigung des Lernprozesses (18), häufig jedoch wird darauf verzichtet. Die Berechnung des Ausgangswertes erfolgt genau so wie in der Natur. Dort ist einfach die Summe der Ionen innerhalb und außerhalb der Zelle für das Membranpotential am Axonhügel entscheidend. Aus oben genannten Gründen ist das Membranpotential am Axonhügel schon die ‚gewichtete’ Summe über den Eingängen. Das Training der künstlichen neuronalen Netzwerke funktioniert über Beispiele entspricht somit grundsätzlich dem der natürlichen Neuronalen Netzwerke. Psychologische Untersuchungen bestätigen die Ähnlichkeit des Lernverhaltens beider Systeme. So konnten Toiviainen et al. (1998) Zusammenhänge zwischen der Reaktionsweise des menschlichen Gehirns auf Töne verschiedener Klangfarben und der Reaktion eines neuronalen Netzwerkes nach Kohonen auf diese Töne aufzeigen (1). ‚supervised neural Networks’. Schon sehr kleine Perzeptrons mit nur einem Neuron können einfache logische Operationen wie die ‚und’, ‚oder’ oder ‚nicht’ Verknüpfung erlernen und nach einer gewissen Anzahl an Lerndurchgängen mit praktisch einhundertprozentiger Sicherheit durchführen. Komplexere Vorgänge und beispielsweise die logische Operation ‚exklusiv oder’ können mit zwei oder mehrstufigen Perzeptrons gelöst werden (18, 20). Es konnte bewiesen werden, dass ein Perzeptron alle Probleme, die es prinzipiell lösen kann durch oben genanntes Lernverfahren auch löst (18). Ein Beispiel für die Anwendung eines komplexeren Perzeptrons ist die Berechnung der Korrekturkraft nach Eingabe des Winkels eines nur in einer Ebene beweglichen Stabes, der immer im Gleichgewicht gehalten werden soll. 1.3. Abb. 2: Zweidimensionales inverses Pendel (18) Struktur und Konzepte Neuronaler Netzwerke 1.3.1. Perzeptrons Ein typisches Neuron eines Perzeptrons ist folgendermaßen aufgebaut. Es besitzt zu jedem Eingang eine Gewichtsvariable, die Werte zwischen minus eins und eins annehmen kann. Dabei repräsentieren negative Werte hemmende und positive Werte erregende Synapsen. Der Wert eins beziehungsweise minus eins steht für eine maximale erregende beziehungsweise hemmende Wirkung einer Synapse (18). Die Aktivitätsfunktion summiert die mit dem jeweiligen Gewicht multiplizierten Eingänge auf und zieht davon den Bias ab. Im einfachsten Fall ist die Aktivitätsfunktion wie unten dargestellt nicht stetig und gibt für alle Werte kleiner gleich null eine null und für alle Werte größer null eine eins aus. Der Erfolg des Netzwerkes kann immer direkt durch die Veränderung des Winkels überprüft werden. Die Gewichte werden so verschoben, dass die Größe des Winkels minimiert wird. 6HOEVWRUJDQLVLHUHQGH1HW]ZHUNH Selbstorganisierende neuronale Netzwerke besitzen eine vorgegebene räumliche Anordnung der Neuronen, weshalb sie auch als selbstorganisierende Karten (SOM, englisch: Self Organizing Maps) bezeichnet werden. Sie bekommen keine Rückmeldung von einem übergeordneten System, ob ihre Arbeit erfolgreich ist oder nicht. Dennoch benötigen sie eine übergeordnete Struktur, die Operationen auf der Menge der Neuronen ausführen kann (7). Als Beispiel sind hier die Bestimmung des ‚Abstandes’ zweier Neuronen und die Ermittlung des so genannten ‚Gewinnerneurons’, die in vielen Algorithmen nötig ist, zu nennen. Abb.1: Aufbau eines Neuron aus ‚Perzeptron Lernverfahren’ Perzeptrons sind ein oder mehrschichtige Anordnungen von künstlichen Neuronen. Diese Neuronalen Netzwerke berechnen nach ihrer Initialisierung beliebige Werte und bekommen nach der Berechnung des Wertes eine Rückmeldung von einer übergeordneten Einheit, ob der Wert gut oder schlecht war (18). Die Gewichte und der Bias werden algorithmisch so verändert, dass die Wahrscheinlichkeit steigt, dass bei der nächsten vergleichbaren Eingabe ein besseres Ergebnis erzielt wird. Je nach Aufgabe und Menge der Daten kann die Anpassung der Gewichte sehr komplex sein. Aufgrund der benötigten Rückmeldung gehören die Perzeptrons zu der Klasse der (LJHQVFKDIWHQ1HXURQDOHU1HW]ZHUNH Neuronale Netzwerke sind im Gegensatz zu von Neumann Rechnern in der Lage bestimmte Funktionen zu erlernen. Das ist nur dann ein Vorteil, wenn genügend Beispieldaten vorhanden sind, da direkt nach der Initialisierung der Netzwerke keine sinnvolle Funktion vorhanden ist. Die Generierung sinnvoller Beispieldaten kann in vielen Fällen das größte Problem sein. Ein großer Vorteil neuronaler Netzwerke bietet sich, wenn ein gewisser Anteil an Eingabedaten vollkommen anders (falsch) strukturiert ist, oder ganz andere Wertebereiche aufweist als der typische Datensatz. In Programmen mit festen Algorithmen sind solche fehlerhaften Daten nur schwer abzufangen und es droht ein Ausfall des Systems. Neuronale Netzwerke können solche Daten problemlos verarbeiten, da sie keine feste Struktur in der Eingabe benötigen. einzelnen Gewichte können Werte zwischen eins und minus eins annehmen, wobei positive Werte für erregende und negative Werte für hemmende Synapsen stehen. 8QWHUVFKLHGHYRQNQVWOLFKHQ1HXURQHQ]XU5HDOLWlW Die Struktur der meisten künstlichen neuronalen Netzwerke ist schon bei der Initialisierung festgelegt. Natürliche Neuronale Netzwerke durchlaufen eine Entwicklung, in der die Struktur und die Funktion gleichzeitig angepasst beziehungsweise erlernt wird. Dieser Lern- und Entwicklungsprozess ist extrem komplex und kann nicht vollständig simuliert werden. Deshalb müssen einige Vereinfachungen in künstlichen neuronalen Netzwerken vorgenommen werden. Dazu gehört zum Beispiel, dass Gewichte für Eingänge vom positiven in den negativen Bereich und umgekehrt wechseln können. In der Natur sind hemmende und erregende Synapsen physiologisch unterscheidbar und können nicht ineinander überführt werden. Natürlich kann auch der Umfang der Vernetzung und die Masse an Neuronen mit heutigen Mitteln nicht nachgeahmt werden. 5HDOLVLHUXQJGHU0RGHOOH Die Modelle, die in diesem Artikel besprochen werden, lassen sich alle durch objektorientierte Programmiersprachen implementieren und auf einem von Neumann Rechner testen. Dies führt allerdings schnell zu Problemen, da ein von Neumann Rechner nur eine CPU besitzt, und die Berechnungen der Masse der Neuronen sequenziell abarbeiten muss. Die Effizienz der Modelle geht dabei verloren. Um dieses Problem zu beheben muss das Modell als Hardware realisiert werden. 6HOEVWRUJDQLVLHUHQGH.DUWHQ *HPHLQVDPNHLWHQLP$XIEDXYRQ VHOEVWRUJDQLVLHUHQGHQ.DUWHQ Selbstorganisierende Karten besitzen folgende essentielle Elemente: Jedes Neuron besitzt eine definierte Anzahl von Eingängen. Auf der Menge der Eingänge wird eine Reihenfolge festgelegt, so dass diese als ‚Eingabevektor’ aufgefasst werden kann. Jedem Eingabevektor wird ein ‚Gewichtsvektor’ zugeordnet, der den einzelnen Eingängen Werte zuordnet. Daher muss der Gewichtsvektor die gleiche Dimension wie der Eingabevektor besitzen. Einem Raum von Neuronen (Neuronengitter) wird eine Nachbarschaftsstruktur zugeordnet, so dass ein klar definierter Abstand zwischen je zwei Neuronen angegeben werden kann. Die Nachbarschaftsstruktur ermöglicht die Definition einer Nachbarschaftsfunktion g, die eine gegenseitige Beeinflussung der Neuronen erfasst. Es existiert eine Aktivitätsfunktion A(v,r,g) die jedem Neuron r zu jedem Eingabevektor v bei gegebener Nachbarschaftsfunktion g eine Aktivität bzw. einen Ausgabewert zuweist. Die Menge der Ausgabewerte wird als Ausgangsraum aufgefasst und hat dieselbe Nachbarschaftsstruktur wie das Neuronengitter (14, 16). 6WUXNWXUGHU.RKRQHQ.DUWHQ Der Lernalgorithmus nach Kohonen baut darauf auf, dass ein ‚Gewinnerneuron’ r’ ermittelt wird, das unter allen Neuronen r den maximalen Ausgabewert besitzt. Dieses Neuron ist das Neuron, das nach Subtraktion des Eingabevektors die minimale euklidische Norm aufweist (1, 5, 14). ||wr’-v|| = minr||wr-v|| Wobei wr der Gewichtsvektor des Neuron r ist und v den Eingabevektor bezeichnet. Die euklidische Norm berechnet sich folgendermaßen (5, 14): ||v|| = sqUW d k=1 (vk)2) Diese Beziehung gilt, da die euklidische Norm der Gewichtsvektoren konstant gehalten wird und bei allen Neuronen identisch ist. Die Aktivität der Neuronen berechnet sich nach folgender Formel (5, 14, 17): ArY H d k=1 (wr,k vk) + g (d(r,r’)) Ar’(v) - S) Dabei ist e eine sigmoide Funktion, die gegen plus Unendlich zur eins und gegen minus Unendlich zur null strebt. Ein Beispiel für eine solche sigmoide Funktion ist folgende: e(x) = 1- 1/(1+EXP(x)) Abb.3: Sigmoide Funktion nach F. Acs Der sigmoide Verlauf der Funktion ermöglicht eine präzisere Anpassung der Gewichte als der für die Perzeptrons (siehe Oben) beschriebene unstetige Verlauf. Die Funktion g ist die Nachbarschaftsfunktion und spiegelt die laterale Wechselwirkung unter den Neuronen wieder. Diese wird von der Distanz zwischen dem Neuron r und dem Gewinnerneuron r’ bestimmt, die von der Funktion d wiedergegeben wird. g zeigt typischerweise den Verlauf der Differenz zweier Gaußglocken ((5) Seite 27 (‚Die Funktion entspricht auch einer negativen Laplace-Funktion’)). Für Eingaben, die kleiner einer Konstante a sind erhält man positive Werte. In dem Intervall zwischen a und einer weiteren Konstante b negative Werte und sonst null. Für r = r’ also bei 0 besitzt die Funktion ihr Maximum. Der Sinn dieser Funktion liegt darin, dass Neuronen, die dem Gewinnerneuron benachbart sind, ihre Aktivität steigern und welche, die weiter als a entfernt sind weniger aktiv sind. Dadurch werden Strukturen hervorgehoben. S steht für einen Schwellenwert, der die Aktivierbarkeit eines Neuron regelt. Kohonen schlägt für diesen Zweck folgende Funktion von: gr,r’= exp(-d(r’-r)/2a²) 6HOEVWRUJDQLVLHUHQGH.DUWHQQDFK.RKRQHQ T. Kohonen legte in den 60. Jahren den Grundstein für das heute am weitesten verbreitete Modell selbstorganisierender Karten. Er betrachtet eine zweidimensionale Neuronenschicht, die von einer Rezeptorebene mit Eingaben versorgt wird. Jedes Neuron des Layers empfängt von allen Kanälen der Rezeptorebene Signale (11). Dementsprechend haben die Gewichtsvektoren aller Neuronen die gleiche Dimension. Die Wobei a als Reichweite der lateralen Beeinflussung aufgefasst werden kann. Der Faktor a sollte im Verlauf des Lernprozesses verringert werden. Es besteht auch die Möglichkeit die laterale Wechselwirkung nur über eine Gaußglocke zu realisieren. Die Auswahl des jeweiligen Verfahrens und der Konstante a ist von der Zielstellung abhängig. Durch einen niedrigen Wert für a ist eine hohe Auflösung zu erreichen, ein hoher Wert führ a bewirkt eine schnellere Mustererkennung. Wirkt die Funktion g nur als Gaußkurve wird keine Verdeutlichung vorhandener Strukturen erreicht. Die Anpassung des Gewichtsvektors aller Neuronen erfolgt ebenfalls nach einer von der Distanz zum Gewinnerneuron abhängigen Formel. Für das Maß der Veränderung der Gewichte wird wiederum die Funktion g(d(r,r’)) verwendet, da auch hier die Strukturen der Eingabe verdeutlicht werden sollen. Des Weiteren wird ein Faktor s eingeführt, der die Lerngeschwindigkeit festlegt. Dieser Faktor besitzt entscheidende Bedeutung, da er bestimmt wie schnell sich das Netzwerk an eine bestimmte Art von Eingaben anpasst. Bei stark variierenden Eingaben muss er sehr klein gewählt werden, um Informationen aus vorherigen Eingaben nicht zu schnell wieder zu verlieren. Daraus resultiert auch eine große Zahl an Iterationen des Lernalgorithmus, um stark variable Informationen zu verarbeiten. Außerdem sollte der Faktor s zu Beginn des Lernvorgangs größer gewählt und dann schrittweise verkleinert werden. Dies ermöglicht eine Zeitersparnis zu Beginn und eine bessere Feineinstellung des Netzwerkes zu einem späteren Zeitpunkt. Für die Anpassung der Gewichte wird folgende Formel vorgeschlagen (5, 14): nur schwach gehemmt. Die Bipolarzellen des schwach erregten Bereichs, werden von benachbarten stark erregten Lichtsinneszellen stark gehemmt. Durch diesen Mechanismus werden vorhandene Kontraste verstärkt und Konturen hervorgehoben (15). Die laterale Inhibition entspricht einer einfachen Realisierung einer Nachbarschaftsfunktion einer selbstorganisierenden Karte. Der Reichweitenparameter der Nachbarschaftsfunktion wird durch die Verschaltung der Horizontalzelle festgelegt. ¨Zr,k= s(g(d(r,r’))(vk-wr,k)) Nach der Anpassung der einzelnen Werte des Gewichtsvektors wird dieser normiert um ||w|| konstant zu halten. Für die Auswertung der erlernten Strukturen des Neuronalen Netzwerkes wird der Begriff des rezeptiven Feldes eingeführt (5). Das rezeptive Feld eines Neurons r* ist eine Teilmenge des Eingangsraumes. Diese Teilmenge enthält alle Eingangsvektoren, deren Gewinnerneuron r* ist. Dies ermöglicht eine strenge Klassifizierung der Eingaben. Der Trainingsalgorithmus nach Kohonen sieht folgender-maßen aus: 1. 2. 3. 4. 5. initialisiere alle Gewichtsvektoren mit zufälligen Werten präsentiere einen Eingabevektor bestimme das Gewinnerneuron adaptiere die Gewichte aller Neuronen gehe zu Schritt 2 Mit Kohonen Karten lassen sich zahlreiche physiologische Übereinstimmungen finden. An dieser Stelle möchte ich auf ein besonders anschauliches Beispiel eingehen: Erstens ist hier die Abbildung von den Lichtsinneszellen der Retina (Netzhaut) auf das Tectum Opticum (Sehzentrum des Gehirns) zu nennen. Zwischen den Lichtsinneszellen und dem Gehirn sind 4 Ebenen von Nervenzellen geschaltet. Die unterste Ebene ist die der Ganglienzellen, deren Axone direkt in das Tectum Opticum reichen. Je nach Region in der Retina werden eine (in der Fovea centralis (=gelber Fleck)) bis einhundertdreißig Lichtsinneszellen auf eine Ganglienzelle abgebildet (15). Zwischen den Ganglienzellen und den Lichtsinneszellen befinden sich die Bipolarzellen. An beiden Verbindungen der Bipolarzellen, also den Synapsen der Lichtsinneszellen auf die Bipolarzellen und denen der Bipolarzellen auf die Ganglienzellen, befinden sich horizontal verschaltete Zellen (Horizontalzellen und Amakrine), die regulierend auf die Synapsen einwirken und so laterale Wechselwirkungen bewirken können. Eine leicht zu demonstrierende Art der lateralen Wechselwirkung ist die laterale Inhibition. Das Konzept der lateralen Inhibition ist folgendes. Jede Lichtsinneszelle erregt eine Bipolarzelle und hemmt proportional zur erregenden Wirkung über Horizontalzellen die benachbarten Bipolarzellen. Dadurch wird die Bipolarzelle einer stark erregten Lichtsinneszelle an der Grenze zu einem Bereich schwach erregter Zellen von diesen Abb. 4: Zuordnung der Körperregionen zum Schnitt durch den cerebralen Kortex +LHUDUFKLVFKH1HXURQDOH1HW]ZHUNH Die Neuronen eines hierarchischen neuronalen Netzwerks sind in einer Baumstruktur angeordnet. Verbindungen unter den Neuronen existieren nur zwischen Kinder- und Elternneuronen. Das einzige Neuron das kein Elternneuron besitzt ist das ‚Wurzelneuron’. Nur die Neuronen auf der untersten Ebene des Baumes besitzen keine Kinder (1). Diese Verbindungen zwischen den Neuronen sind nun für die Lernalgorithmen von ausschlaggebender Bedeutung. Prinzipiell wird immer ein Gewinnerneuron auf einer Ebene gesucht, dessen Gewichtsvektor die geringste euklidische Distanz zu dem aktuellen Trainingsmuster aufweist. Ist ein Gewinnerneuron ermittelt, so werden dessen Gewichte und alle Gewichte der Neuronen, die in einer Verwandtschaftsbeziehung darunter liegen aktualisiert. Sind also zwei Trainingsmuster ähnlich, dann ist es sehr wahrscheinlich, dass die jeweiligen Gewinnerneurone auf der untersten Ebene das selbe Elternneuron besitzen (1). Hierarchische neuronale Netzwerke sind also in der Lage Trainingsmuster zu gruppieren und verschiedene Abstraktionsstufen der Gruppierung von Trainingsmustern wiederzugeben. 9HUJOHLFK]ZLVFKHQGHQEHLGHQ$UFKLWHNWXUHQ Kohonen strebt mit seiner Architektur eine möglichst hohe physiologische Übereinstimmung an, wobei physiologische Übereinstimmungen mit hierarchischen neuronalen Netzwerken zwar denkbar aber noch nicht bewiesen sind. Wenn auch die Lernalgorithmen dieser Modelle sich unterscheiden, ist doch jede Ebene eines Hierarchischen Netzwerks ist mit einer Kohonen-Karte vergleichbar. Zwei unterschiedliche Gruppen von Trainingsmustern sind in einer Ebene durch die ihnen jeweils entsprechenden Bereiche zu unterscheiden. Der Vorteil des hierarchischen Netzwerks ist, das ein Neuron, das einem dieser Bereiche übergeordnet ist, genau die entscheidende Eigenschaft dieses Bereichs enthält, und so die Gruppen der Trainingsmuster besser greifbar sind. :HLWHUH%HLVSLHOHVHOEVWRUJDQLVLHUHQGHU .DUWHQ VHOEVWRUJDQLVLHUHQGH VXSHUYLVHG620 .DUWHQ PLW )HHGEDFN Diese Klasse neuronaler Netzwerke entstand aus der biologischen Motivation heraus, dass die topologieerhaltenden Karten doch einer Erfolgskontrolle unterliegen. So wird zum Beispiel der Erfolg des Lichtsinnesorgans durch andere Sinnesorgane wie den Tastsinn kontrolliert. Eine Anpassung der selbstorganisierenden Karten an diese Kontrolle ist zumindest während der Entwicklung eines Organismus anzunehmen. 1HXURQHQJDV0RGHOO Das Neuronengas-Modell geht einen anderen Weg zur Konstruktion topologieerhaltender Karten als die bisher betrachteten Modelle. Der Neuronenraum wird nur als eine Menge von Neuronen ohne Nachbarschaftsbeziehung aufgefasst. Der Gewichtsvektor eines Neurons wird als Position in Raum gedeutet. Bei der Präsentation eines Eingangsvektors v werden die Neurone bestimmt, deren Gewichtsvektoren einen Abstand von v besitzen, der geringer als eine Konstante k ist. Diese Neurone werden gemäß dieser Distanz sortiert, und von der Reihenfolge abhängig werden die Gewichte angepasst. Die tatsächliche Distanz spielt dabei keine Rolle mehr. Dadurch wird das Modell leichter mathematisch handhabbar (14). Durch das Neuronengas-Modell entsteht keine nachbarschaftserhaltende Abbildung, da die Neuronen nur als Menge betrachtet werden und keine Nachbarschaftsbeziehung zwischen ihnen existiert. Es ist jedoch möglich eine Nachbarschaftsbeziehung zwischen den Neuronen im Anschluss an einen Lernprozess einzuführen. Dazu wird das rezeptive Feld eines Neurons r so definiert, dass es alle Eingangsvektoren enthält, deren erstes Neuron in der oben definierten Reihenfolge das Neuron r ist. Auf diese weise lässt sich der Eingangsraum in Felder gliedern. Zwei Neuronen werden jetzt gemäß einer Nachbarschaftsstruktur über dem Eingangsraum als benachbart bezeichnet, wenn ihre rezeptiven Felder aneinander Grenzen. Die Bestimmung dieser Nachbarschaftsstruktur kann iterativ erfolgen. Abb. 5: Entwicklung der Nachbarschaftsbeziehung einer Implementierung eines Neuronengas-Modells (14) 9LVXDOLVLHUXQJVHOEVWRUJDQLVLHUHQGHU.DUWHQ Da selbstorganisierende Karten eine räumliche Struktur aufweisen bieten sich einfache Darstellungsmöglichkeiten durch die Zuordnung von Objekten zu bereichen der Karte (vergleiche Abb.4) oder durch Darstellung der Werte der Gewichtsvektoren in einem entsprechenden Raum. Abb. 6: Kohonen-Karte zur Visualisierung von Lernalgorithmen Darstellung der Gewichtsvektoren nach 0, 50,200,10000 Lernschritten (14) Diese Implementierung einer Kohonen-Karte (Abbildung 6) wird ausschließlich zur Visualisierung der Lernalgorithmen verwendet. Der Eingaberaum des Netzwerks ist zweidimensional, somit sind auch die Gewichtsvektoren zweidimensional. Dargestellt sind die Gewichtsvektoren der Neuronen, die als Punkte in einer Ebene interpretiert werden. Die eingezeichneten Gewichtsvektoren benachbarter Neurone werden durch Linien miteinander verbunden. Der Eingaberaum ist durch den als Quadrat dargestellten Bereich beschränkt. Die Initialisierung der Gewichtsvektoren wurde zufällig, aber in einem beschränkten Wertebereich vorgenommen (14). Ein ähnliches Netzwerk wird im folgenden Beispiel verwendet. Die Koordinaten des Raumes werden hier jedoch nicht direkt an das Netzwerk übergeben, sondern müssen vom Netzwerk ermittelt werden. In diesem Versuch wird eine sensorische Karte eines realen Raumes mittels einer beweglichen Schallquelle und der Messung der Schallintensität an zwei Sensoren erstellt: Abb. 7: erstellen einer sensorischen zweidimensionalen Raumes (18) Karte eines (LQVDW]VHOEVWRUJDQLVLHUHQGHU.DUWHQIUSUDNWLVFKH 3UREOHPH Selbstorganisierende Karten finden häufig dann Anwendung, wenn hochdimensionale Daten unter Einbeziehung von Ähnlichkeiten auf niederdimensionale Räume abgebildet werden sollen. Als Beispiel für eine solche Abbildung wird eine Tabelle von Tiereigenschaften betrachtet, die durch eine selbstorganisierende Karte unter Erhaltung der Nachbarschaft ähnlicher Eigenschaften auf ein zweidimensionales Feld abgebildet wird. Abb. 8: Hochdimensionale Eingaben (18) (6) Extended .RKRQHQ Maps :URL: http://odur.let.rug.nl/~kleiweg/kohonen/kohonen.html [13.05.04] (7) Fausett, L. (1994): )XQGDPHQWDOVRI1HXUDO1HWZRUNV, Prentice HallNew York (8) Jänich, K. (1991): /LQHDUH$OJHEUD, 4. Auflage, Berlin, Heidelberg, Springer Verlag (9) Kohonen, T. (2001): 6HOI2UJDQL]LQJ0DSV, 3.Auflage,Springer Verlag, Berlin Abb. 9: Merkmale der Tiere werden an Eingänge angelegt; Tiername steht im Bereich höchster Aktivität der Karte. (Die Lesbarkeit der Daten ist nicht relevant)(18) Solche Probleme stellen sich beispielsweise bei der Schriftanalyse, der visuellen Personenidentifikation und der Sprachanalyse. (10) Kohonen Networks URL: http://www.cs.bham.ac.uk/resources/courses/SEM2A2/We b/Kohonen.htm [13.05.04] (11) .RKRQHQ V Self Organizing Networks URL: http://www.rocksolidimages.com/pdf/kohonen.pdf [20.04.2004] (12) Teuvo Kohonen URL: http://www.cis.hut.fi/research/som- 5HVPHH research/teuvo.html [13.05.04] Zur Erforschung neuronaler Verarbeitung in lebenden Organismen sind künstliche neuronale Netzwerke ein hervorragendes Mittel. Lernprozesse können in Systemen von überschaubarer Komplexität simuliert werden und aus dem Vergleich der Ergebnisse mit den natürlichen Befunden können wertvolle Rückschlüsse gezogen werden. Das größte Hindernis in der Forschung mit künstlichen neuronalen Netzwerken ist die mangelhafte Repräsentation derselben auf sequenziell arbeitenden Rechnern. Die Entwicklung von Hardwarerealisierungen neuronaler Netzwerke wird jedoch vorangetrieben und es ist vermutlich bald mit kostengünstigen Lösungen zu rechnen. Die besprochenen Modelle werden auch in vielen Bereichen der Technik praktische Anwendung finden. (13) Toiviainen, P. et al. (1998): 7LPEUHVLPLODULW\ &RQYHUJHQFHRIQHXUDOEHKDYLRUDODQGFRPSXWDWLRQDO DSSURDFKHVZeitschrift für Psychologie, 204: 281-303 (14) Villmann, T. (1996): 7RSRORJLHHUKDOWXQJLQ VHOEVWRUJDQLVLHUHQGHQ.DUWHQ Harri Deutsch Verlag, Frankfurt (15) Wehner, R. & Gehring, W. (1995): =RRORJLH, 23. Auflage, Thieme Verlag, Stuttgart (16) Wiemer, Jan C. (2000): /HDUQLQJ7RSRJUDSK\LQ1HXUDO 1HWZRUNV, http://deposit.ddb.de/cgibin/dokserv?idn=962378798 http://www-brs.ub.ruhr-uni- /LWHUDWXU bochum.de/netahtml/HSS/Diss/WiemerJanC/diss.pdf (1) Acs, F. (2000): +LHUDUFKLVFKH1HXURQDOH1HW]H (QWZLFNOXQJHLQHV3URJUDPPV\VWHPV]XU6LPXODWLRQ HLQHUQHXHQ.ODVVHYRQNQVWOLFKHQ1HXURQDOHQ1HW]HQ URL: http://www.psychologie.uni- [20.04.2004] (17) Wienholt, W. (1996): (QWZXUIQHXURQDOHU1HW]H Harri Deutsch Verlag, Frankfurt (18) 3HU]HSWURQ/HUQYHUIDKUHQURL: regensburg.de/Greenlee/team/Acs/DIPLOM.PDF KWWSZZZDJULQIRUPDWLNXQLNOGHIRUVFKXQJPRELV [02.06.2004] [12.05.04] (2) +6B)RUVFKXQJB1HXURQDOHB1HW]H http://www.psychologie.uniwuerzburg.de/methoden/lehre/skripten/HS_Meth_Forschun g/HS_Forschung_Neuronale%20Netze.pdf [04.06.2004] (3) Alberts, B. (2001): /HKUEXFK GHU 0ROHNXODUHQ =HOOELRORJLH, 2.Auflage, Wiley-VCH, Weinheim (4) Allison, N.& Yin, H. (2001): $GYDQFHVLQ6HOI 2UJDQLVLQJ0DSV, Springer Verlag, London (5) Born, C. (1996): (LQG\QDPLVFKHV0RGHOO]XUYLVXHOOHQ FRUWLNDOHQ,QIRUPDWLRQVYHUDUEHLWXQJ, Harri Deutsch Verlag, Frankfurt (19) Publikationen von Günter Bachelier URL: http://www.vianec.de/Literatur/Inhalt_B98d.html (20) 1HXUDO1HWZRUNV URL: KWWSZZZVWDWVRIWLQNFRPWH[WERRNVWQHXQHWKWPO [3.5.2004] (21) (LQIKUXQJLQ1HXURQDOH1HW]H, URL: http://wwwmath.unimuenster.de/SoftComputing/lehre/material/wwwnnscript/pr in.html [20.04.2004]